
text
stringlengths 7
328k
| id
stringlengths 14
166
| metadata
dict | __index_level_0__
int64 0
459
|
|---|---|---|---|
use super::with_tracing::{linear, linear_no_bias, Embedding, Linear};
use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::{layer_norm, LayerNorm, Module, VarBuilder};
use serde::Deserialize;
pub const DTYPE: DType = DType::F32;
#[derive(Debug, Clone, Copy, PartialEq, Eq, Deserialize)]
#[serde(rename_all = "lowercase")]
pub enum PositionEmbeddingType {
Absolute,
Alibi,
}
// https://huggingface.co/jinaai/jina-bert-implementation/blob/main/configuration_bert.py
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
pub vocab_size: usize,
pub hidden_size: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub intermediate_size: usize,
pub hidden_act: candle_nn::Activation,
pub max_position_embeddings: usize,
pub type_vocab_size: usize,
pub initializer_range: f64,
pub layer_norm_eps: f64,
pub pad_token_id: usize,
pub position_embedding_type: PositionEmbeddingType,
}
impl Config {
pub fn v2_base() -> Self {
// https://huggingface.co/jinaai/jina-embeddings-v2-base-en/blob/main/config.json
Self {
vocab_size: 30528,
hidden_size: 768,
num_hidden_layers: 12,
num_attention_heads: 12,
intermediate_size: 3072,
hidden_act: candle_nn::Activation::Gelu,
max_position_embeddings: 8192,
type_vocab_size: 2,
initializer_range: 0.02,
layer_norm_eps: 1e-12,
pad_token_id: 0,
position_embedding_type: PositionEmbeddingType::Alibi,
}
}
}
#[derive(Clone, Debug)]
struct BertEmbeddings {
word_embeddings: Embedding,
// no position_embeddings as we only support alibi.
token_type_embeddings: Embedding,
layer_norm: LayerNorm,
span: tracing::Span,
}
impl BertEmbeddings {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let word_embeddings =
Embedding::new(cfg.vocab_size, cfg.hidden_size, vb.pp("word_embeddings"))?;
let token_type_embeddings = Embedding::new(
cfg.type_vocab_size,
cfg.hidden_size,
vb.pp("token_type_embeddings"),
)?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self {
word_embeddings,
token_type_embeddings,
layer_norm,
span: tracing::span!(tracing::Level::TRACE, "embeddings"),
})
}
}
impl Module for BertEmbeddings {
fn forward(&self, input_ids: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_size, seq_len) = input_ids.dims2()?;
let input_embeddings = self.word_embeddings.forward(input_ids)?;
let token_type_embeddings = Tensor::zeros(seq_len, DType::U32, input_ids.device())?
.broadcast_left(b_size)?
.apply(&self.token_type_embeddings)?;
let embeddings = (&input_embeddings + token_type_embeddings)?;
let embeddings = self.layer_norm.forward(&embeddings)?;
Ok(embeddings)
}
}
#[derive(Clone, Debug)]
struct BertSelfAttention {
query: Linear,
key: Linear,
value: Linear,
num_attention_heads: usize,
attention_head_size: usize,
span: tracing::Span,
span_softmax: tracing::Span,
}
impl BertSelfAttention {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let attention_head_size = cfg.hidden_size / cfg.num_attention_heads;
let all_head_size = cfg.num_attention_heads * attention_head_size;
let hidden_size = cfg.hidden_size;
let query = linear(hidden_size, all_head_size, vb.pp("query"))?;
let value = linear(hidden_size, all_head_size, vb.pp("value"))?;
let key = linear(hidden_size, all_head_size, vb.pp("key"))?;
Ok(Self {
query,
key,
value,
num_attention_heads: cfg.num_attention_heads,
attention_head_size,
span: tracing::span!(tracing::Level::TRACE, "self-attn"),
span_softmax: tracing::span!(tracing::Level::TRACE, "softmax"),
})
}
fn transpose_for_scores(&self, xs: &Tensor) -> Result<Tensor> {
let mut x_shape = xs.dims().to_vec();
x_shape.pop();
x_shape.push(self.num_attention_heads);
x_shape.push(self.attention_head_size);
xs.reshape(x_shape)?.transpose(1, 2)?.contiguous()
}
fn forward(&self, xs: &Tensor, bias: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let query_layer = self.query.forward(xs)?;
let key_layer = self.key.forward(xs)?;
let value_layer = self.value.forward(xs)?;
let query_layer = self.transpose_for_scores(&query_layer)?;
let key_layer = self.transpose_for_scores(&key_layer)?;
let value_layer = self.transpose_for_scores(&value_layer)?;
let attention_scores = query_layer.matmul(&key_layer.t()?)?;
let attention_scores = (attention_scores / (self.attention_head_size as f64).sqrt())?;
let attention_scores = attention_scores.broadcast_add(bias)?;
let attention_probs = {
let _enter_sm = self.span_softmax.enter();
candle_nn::ops::softmax_last_dim(&attention_scores)?
};
let context_layer = attention_probs.matmul(&value_layer)?;
let context_layer = context_layer.transpose(1, 2)?.contiguous()?;
let context_layer = context_layer.flatten_from(D::Minus2)?;
Ok(context_layer)
}
}
#[derive(Clone, Debug)]
struct BertSelfOutput {
dense: Linear,
layer_norm: LayerNorm,
span: tracing::Span,
}
impl BertSelfOutput {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("dense"))?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self {
dense,
layer_norm,
span: tracing::span!(tracing::Level::TRACE, "self-out"),
})
}
fn forward(&self, xs: &Tensor, input_tensor: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = self.dense.forward(xs)?;
self.layer_norm.forward(&(xs + input_tensor)?)
}
}
#[derive(Clone, Debug)]
struct BertAttention {
self_attention: BertSelfAttention,
self_output: BertSelfOutput,
span: tracing::Span,
}
impl BertAttention {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let self_attention = BertSelfAttention::new(vb.pp("self"), cfg)?;
let self_output = BertSelfOutput::new(vb.pp("output"), cfg)?;
Ok(Self {
self_attention,
self_output,
span: tracing::span!(tracing::Level::TRACE, "attn"),
})
}
fn forward(&self, xs: &Tensor, bias: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let self_outputs = self.self_attention.forward(xs, bias)?;
let attention_output = self.self_output.forward(&self_outputs, xs)?;
Ok(attention_output)
}
}
#[derive(Clone, Debug)]
struct BertGLUMLP {
gated_layers: Linear,
act: candle_nn::Activation,
wo: Linear,
layernorm: LayerNorm,
intermediate_size: usize,
}
impl BertGLUMLP {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let gated_layers = linear_no_bias(
cfg.hidden_size,
cfg.intermediate_size * 2,
vb.pp("gated_layers"),
)?;
let act = candle_nn::Activation::Gelu; // geglu
let wo = linear(cfg.intermediate_size, cfg.hidden_size, vb.pp("wo"))?;
let layernorm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("layernorm"))?;
Ok(Self {
gated_layers,
act,
wo,
layernorm,
intermediate_size: cfg.intermediate_size,
})
}
}
impl Module for BertGLUMLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let residual = xs;
let xs = xs.apply(&self.gated_layers)?;
let gated = xs.narrow(D::Minus1, 0, self.intermediate_size)?;
let non_gated = xs.narrow(D::Minus1, self.intermediate_size, self.intermediate_size)?;
let xs = (gated.apply(&self.act) * non_gated)?.apply(&self.wo);
(xs + residual)?.apply(&self.layernorm)
}
}
#[derive(Clone, Debug)]
struct BertLayer {
attention: BertAttention,
mlp: BertGLUMLP,
span: tracing::Span,
}
impl BertLayer {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let attention = BertAttention::new(vb.pp("attention"), cfg)?;
let mlp = BertGLUMLP::new(vb.pp("mlp"), cfg)?;
Ok(Self {
attention,
mlp,
span: tracing::span!(tracing::Level::TRACE, "layer"),
})
}
fn forward(&self, xs: &Tensor, bias: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
self.attention.forward(xs, bias)?.apply(&self.mlp)
}
}
fn build_alibi_bias(cfg: &Config) -> Result<Tensor> {
let n_heads = cfg.num_attention_heads;
let seq_len = cfg.max_position_embeddings;
let alibi_bias = Tensor::arange(0, seq_len as i64, &Device::Cpu)?.to_dtype(DType::F32)?;
let alibi_bias = {
let a1 = alibi_bias.reshape((1, seq_len))?;
let a2 = alibi_bias.reshape((seq_len, 1))?;
a1.broadcast_sub(&a2)?.abs()?.broadcast_left(n_heads)?
};
let mut n_heads2 = 1;
while n_heads2 < n_heads {
n_heads2 *= 2
}
let slopes = (1..=n_heads2)
.map(|v| -1f32 / 2f32.powf((v * 8) as f32 / n_heads2 as f32))
.collect::<Vec<_>>();
let slopes = if n_heads2 == n_heads {
slopes
} else {
slopes
.iter()
.skip(1)
.step_by(2)
.chain(slopes.iter().step_by(2))
.take(n_heads)
.cloned()
.collect::<Vec<f32>>()
};
let slopes = Tensor::new(slopes, &Device::Cpu)?.reshape((1, (), 1, 1))?;
alibi_bias.to_dtype(DType::F32)?.broadcast_mul(&slopes)
}
#[derive(Clone, Debug)]
struct BertEncoder {
alibi: Tensor,
layers: Vec<BertLayer>,
span: tracing::Span,
}
impl BertEncoder {
fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
if cfg.position_embedding_type != PositionEmbeddingType::Alibi {
candle::bail!("only alibi is supported as a position-embedding-type")
}
let layers = (0..cfg.num_hidden_layers)
.map(|index| BertLayer::new(vb.pp(&format!("layer.{index}")), cfg))
.collect::<Result<Vec<_>>>()?;
let span = tracing::span!(tracing::Level::TRACE, "encoder");
let alibi = build_alibi_bias(cfg)?.to_device(vb.device())?;
Ok(Self {
alibi,
layers,
span,
})
}
}
impl Module for BertEncoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let seq_len = xs.dim(1)?;
let alibi_bias = self.alibi.i((.., .., ..seq_len, ..seq_len))?;
let mut xs = xs.clone();
for layer in self.layers.iter() {
xs = layer.forward(&xs, &alibi_bias)?
}
Ok(xs)
}
}
#[derive(Clone, Debug)]
pub struct BertModel {
embeddings: BertEmbeddings,
encoder: BertEncoder,
pub device: Device,
span: tracing::Span,
}
impl BertModel {
pub fn new(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let embeddings = BertEmbeddings::new(vb.pp("embeddings"), cfg)?;
let encoder = BertEncoder::new(vb.pp("encoder"), cfg)?;
Ok(Self {
embeddings,
encoder,
device: vb.device().clone(),
span: tracing::span!(tracing::Level::TRACE, "model"),
})
}
}
impl Module for BertModel {
fn forward(&self, input_ids: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let embedding_output = self.embeddings.forward(input_ids)?;
let sequence_output = self.encoder.forward(&embedding_output)?;
Ok(sequence_output)
}
}
|
candle/candle-transformers/src/models/jina_bert.rs/0
|
{
"file_path": "candle/candle-transformers/src/models/jina_bert.rs",
"repo_id": "candle",
"token_count": 5806
}
| 35 |
use crate::models::with_tracing::QMatMul;
use crate::quantized_nn::{layer_norm, linear, Embedding, Linear};
pub use crate::quantized_var_builder::VarBuilder;
use candle::{Module, Result, Tensor, D};
use candle_nn::LayerNorm;
pub type Config = super::blip_text::Config;
#[derive(Debug, Clone)]
struct TextEmbeddings {
word_embedddings: Embedding,
position_embeddings: Embedding,
layer_norm: LayerNorm,
position_ids: Tensor,
}
impl TextEmbeddings {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let word_embedddings =
Embedding::new(cfg.vocab_size, cfg.hidden_size, vb.pp("word_embeddings"))?;
let position_embeddings = Embedding::new(
cfg.max_position_embeddings,
cfg.hidden_size,
vb.pp("position_embeddings"),
)?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
let position_ids =
Tensor::arange(0, cfg.max_position_embeddings as u32, vb.device())?.unsqueeze(0)?;
Ok(Self {
word_embedddings,
position_embeddings,
layer_norm,
position_ids,
})
}
fn forward(&self, xs: &Tensor, past_kv_len: usize) -> Result<Tensor> {
let seq_len = xs.dim(1)?;
let position_ids = self.position_ids.narrow(1, past_kv_len, seq_len)?;
let embeddings = self.word_embedddings.forward(xs)?;
let position_embeddings = self.position_embeddings.forward(&position_ids)?;
(embeddings + position_embeddings)?.apply(&self.layer_norm)
}
}
#[derive(Debug, Clone)]
struct TextSelfAttention {
query: Linear,
key: Linear,
value: Linear,
attention_head_size: usize,
num_attention_heads: usize,
attention_scale: f64,
kv_cache: Option<(Tensor, Tensor)>,
}
impl TextSelfAttention {
fn new(cfg: &Config, is_cross_attention: bool, vb: VarBuilder) -> Result<Self> {
let num_attention_heads = cfg.num_attention_heads;
let attention_head_size = cfg.hidden_size / num_attention_heads;
let all_head_size = cfg.num_attention_heads * attention_head_size;
let query = linear(cfg.hidden_size, all_head_size, vb.pp("query"))?;
let in_size = if is_cross_attention {
cfg.encoder_hidden_size
} else {
cfg.hidden_size
};
let key = linear(in_size, all_head_size, vb.pp("key"))?;
let value = linear(in_size, all_head_size, vb.pp("value"))?;
let attention_scale = 1f64 / (attention_head_size as f64).sqrt();
Ok(Self {
query,
key,
value,
attention_head_size,
num_attention_heads,
attention_scale,
kv_cache: None,
})
}
fn transpose_for_scores(&self, xs: &Tensor) -> Result<Tensor> {
let (b_size, seq_len, _) = xs.dims3()?;
xs.reshape((
b_size,
seq_len,
self.num_attention_heads,
self.attention_head_size,
))?
.permute((0, 2, 1, 3))
}
fn reset_kv_cache(&mut self) {
self.kv_cache = None
}
fn forward(
&mut self,
xs: &Tensor,
encoder_hidden_states: Option<&Tensor>,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let query = self
.transpose_for_scores(&self.query.forward(xs)?)?
.contiguous()?;
let (key, value) = match encoder_hidden_states {
None => {
let key = self.transpose_for_scores(&self.key.forward(xs)?)?;
let value = self.transpose_for_scores(&self.value.forward(xs)?)?;
let (key, value) = match &self.kv_cache {
None => (key, value),
Some((prev_key, prev_value)) => {
let key = Tensor::cat(&[prev_key, &key], 2)?;
let value = Tensor::cat(&[prev_value, &value], 2)?;
(key, value)
}
};
self.kv_cache = Some((key.clone(), value.clone()));
(key, value)
}
Some(xs) => {
let key = self.transpose_for_scores(&self.key.forward(xs)?)?;
let value = self.transpose_for_scores(&self.value.forward(xs)?)?;
// no kv-cache in this case, but the results could probably be memoized.
(key, value)
}
};
let key = key.contiguous()?;
let value = value.contiguous()?;
let attention_scores = query.matmul(&key.t()?)?;
let attention_scores = (attention_scores * self.attention_scale)?;
let attention_scores = match attention_mask {
Some(mask) => attention_scores.broadcast_add(mask)?,
None => attention_scores,
};
let attention_probs = candle_nn::ops::softmax_last_dim(&attention_scores)?;
attention_probs
.matmul(&value)?
.permute((0, 2, 1, 3))?
.flatten_from(D::Minus2)
}
}
#[derive(Debug, Clone)]
struct TextSelfOutput {
dense: Linear,
layer_norm: LayerNorm,
}
impl TextSelfOutput {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("dense"))?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self { dense, layer_norm })
}
fn forward(&self, xs: &Tensor, input_tensor: &Tensor) -> Result<Tensor> {
(xs.apply(&self.dense) + input_tensor)?.apply(&self.layer_norm)
}
}
#[derive(Debug, Clone)]
struct TextAttention {
self_: TextSelfAttention,
output: TextSelfOutput,
}
impl TextAttention {
fn new(cfg: &Config, is_cross_attention: bool, vb: VarBuilder) -> Result<Self> {
let self_ = TextSelfAttention::new(cfg, is_cross_attention, vb.pp("self"))?;
let output = TextSelfOutput::new(cfg, vb.pp("output"))?;
Ok(Self { self_, output })
}
fn reset_kv_cache(&mut self) {
self.self_.reset_kv_cache()
}
fn forward(
&mut self,
xs: &Tensor,
encoder_hidden_states: Option<&Tensor>,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let self_outputs = self
.self_
.forward(xs, encoder_hidden_states, attention_mask)?;
self.output.forward(&self_outputs, xs)
}
}
#[derive(Debug, Clone)]
struct TextIntermediate {
dense: Linear,
intermediate_act_fn: candle_nn::Activation,
}
impl TextIntermediate {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.intermediate_size, vb.pp("dense"))?;
Ok(Self {
dense,
intermediate_act_fn: cfg.hidden_act,
})
}
}
impl Module for TextIntermediate {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.dense)?.apply(&self.intermediate_act_fn)
}
}
#[derive(Debug, Clone)]
struct TextOutput {
dense: Linear,
layer_norm: LayerNorm,
}
impl TextOutput {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.intermediate_size, cfg.hidden_size, vb.pp("dense"))?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self { dense, layer_norm })
}
fn forward(&self, xs: &Tensor, input_tensor: &Tensor) -> Result<Tensor> {
(xs.apply(&self.dense)? + input_tensor)?.apply(&self.layer_norm)
}
}
#[derive(Debug, Clone)]
struct TextLayer {
attention: TextAttention,
cross_attention: Option<TextAttention>,
intermediate: TextIntermediate,
output: TextOutput,
}
impl TextLayer {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let attention = TextAttention::new(cfg, false, vb.pp("attention"))?;
let cross_attention = if cfg.is_decoder {
Some(TextAttention::new(cfg, true, vb.pp("crossattention"))?)
} else {
None
};
let intermediate = TextIntermediate::new(cfg, vb.pp("intermediate"))?;
let output = TextOutput::new(cfg, vb.pp("output"))?;
Ok(Self {
attention,
cross_attention,
intermediate,
output,
})
}
fn reset_kv_cache(&mut self) {
self.attention.reset_kv_cache();
if let Some(ca) = &mut self.cross_attention {
ca.reset_kv_cache()
}
}
fn forward(
&mut self,
xs: &Tensor,
encoder_hidden_states: &Tensor,
attention_mask: &Tensor,
) -> Result<Tensor> {
let attention_output = self.attention.forward(xs, None, Some(attention_mask))?;
let attention_output = match &mut self.cross_attention {
Some(ca) => ca.forward(&attention_output, Some(encoder_hidden_states), None)?,
None => candle::bail!("expected some cross-attn"),
};
let intermediate_output = self.intermediate.forward(&attention_output)?;
self.output.forward(&intermediate_output, &attention_output)
}
}
#[derive(Debug, Clone)]
struct TextEncoder {
layers: Vec<TextLayer>,
}
impl TextEncoder {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb = vb.pp("layer");
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
for i in 0..cfg.num_hidden_layers {
let layer = TextLayer::new(cfg, vb.pp(i))?;
layers.push(layer)
}
Ok(Self { layers })
}
fn reset_kv_cache(&mut self) {
self.layers.iter_mut().for_each(|l| l.reset_kv_cache())
}
fn forward(
&mut self,
xs: &Tensor,
encoder_hidden_states: &Tensor,
attention_mask: &Tensor,
) -> Result<Tensor> {
let mut xs = xs.clone();
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, encoder_hidden_states, attention_mask)?
}
Ok(xs)
}
}
#[derive(Debug, Clone)]
pub struct TextPooler {
dense: Linear,
}
impl TextPooler {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("dense"))?;
Ok(Self { dense })
}
}
impl Module for TextPooler {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.narrow(D::Minus1, 0, 1)?
.squeeze(D::Minus1)?
.apply(&self.dense)?
.tanh()
}
}
#[derive(Debug, Clone)]
struct TextPredictionHeadTransform {
dense: Linear,
transform_act_fn: candle_nn::Activation,
layer_norm: LayerNorm,
}
impl TextPredictionHeadTransform {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("dense"))?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self {
dense,
transform_act_fn: cfg.hidden_act,
layer_norm,
})
}
}
impl Module for TextPredictionHeadTransform {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.dense)?
.apply(&self.transform_act_fn)?
.apply(&self.layer_norm)
}
}
#[derive(Debug, Clone)]
struct TextLMPredictionHead {
transform: TextPredictionHeadTransform,
decoder: Linear,
}
impl TextLMPredictionHead {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let transform = TextPredictionHeadTransform::new(cfg, vb.pp("transform"))?;
let weight = QMatMul::new(cfg.hidden_size, cfg.vocab_size, vb.pp("decoder"))?;
let bias = vb.get(cfg.vocab_size, "bias")?.dequantize(vb.device())?;
let decoder = Linear::from_weights(weight, Some(bias));
Ok(Self { transform, decoder })
}
}
impl Module for TextLMPredictionHead {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.transform)?.apply(&self.decoder)
}
}
#[derive(Debug, Clone)]
struct TextOnlyMLMHead {
predictions: TextLMPredictionHead,
}
impl TextOnlyMLMHead {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let predictions = TextLMPredictionHead::new(cfg, vb.pp("predictions"))?;
Ok(Self { predictions })
}
}
impl Module for TextOnlyMLMHead {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
self.predictions.forward(xs)
}
}
#[derive(Debug, Clone)]
struct TextModel {
embeddings: TextEmbeddings,
encoder: TextEncoder,
past_kv_len: usize,
// We do not need the pooler for caption generation
}
impl TextModel {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let embeddings = TextEmbeddings::new(cfg, vb.pp("embeddings"))?;
let encoder = TextEncoder::new(cfg, vb.pp("encoder"))?;
Ok(Self {
embeddings,
encoder,
past_kv_len: 0,
})
}
fn forward(
&mut self,
input_ids: &Tensor,
encoder_hidden_states: &Tensor,
attention_mask: &Tensor,
) -> Result<Tensor> {
let (_b_sz, seq_len) = input_ids.dims2()?;
let embedding_output = self.embeddings.forward(input_ids, self.past_kv_len)?;
let sequence_output =
self.encoder
.forward(&embedding_output, encoder_hidden_states, attention_mask)?;
self.past_kv_len += seq_len;
// We're interested in the sequence-output rather than the pooled-output.
Ok(sequence_output)
}
fn reset_kv_cache(&mut self) {
self.past_kv_len = 0;
self.encoder.reset_kv_cache();
}
}
#[derive(Debug, Clone)]
pub struct TextLMHeadModel {
bert: TextModel,
cls: TextOnlyMLMHead,
}
impl TextLMHeadModel {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let bert = TextModel::new(cfg, vb.pp("bert"))?;
let cls = TextOnlyMLMHead::new(cfg, vb.pp("cls"))?;
Ok(Self { bert, cls })
}
pub fn forward(
&mut self,
input_ids: &Tensor,
encoder_hidden_states: &Tensor,
) -> Result<Tensor> {
let seq_len = input_ids.dim(1)?;
let mask: Vec<_> = (0..seq_len)
.flat_map(|i| (0..seq_len).map(move |j| if j > i { f32::NEG_INFINITY } else { 0f32 }))
.collect();
let mask = Tensor::from_vec(mask, (seq_len, seq_len), input_ids.device())?;
let sequence_output = self.bert.forward(input_ids, encoder_hidden_states, &mask)?;
let prediction_scores = self.cls.forward(&sequence_output)?;
// return_logits is false so we don't discard the last sequence element.
Ok(prediction_scores)
}
pub fn reset_kv_cache(&mut self) {
self.bert.reset_kv_cache()
}
}
|
candle/candle-transformers/src/models/quantized_blip_text.rs/0
|
{
"file_path": "candle/candle-transformers/src/models/quantized_blip_text.rs",
"repo_id": "candle",
"token_count": 7022
}
| 36 |
use crate::models::with_tracing::{conv2d, linear, Conv2d, Linear};
use candle::{Module, ModuleT, Result, Tensor, D};
use candle_nn::{conv2d_no_bias, layer_norm, Activation, Conv2dConfig, VarBuilder};
use serde::Deserialize;
use std::collections::HashMap;
// https://github.com/huggingface/transformers/blob/main/src/transformers/models/segformer/configuration_segformer.py
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
#[serde(default)]
pub id2label: HashMap<String, String>,
pub num_channels: usize,
pub num_encoder_blocks: usize,
pub depths: Vec<usize>,
pub sr_ratios: Vec<usize>,
pub hidden_sizes: Vec<usize>,
pub patch_sizes: Vec<usize>,
pub strides: Vec<usize>,
pub num_attention_heads: Vec<usize>,
pub mlp_ratios: Vec<usize>,
pub hidden_act: candle_nn::Activation,
pub layer_norm_eps: f64,
pub decoder_hidden_size: usize,
}
#[derive(Debug, Clone)]
struct SegformerOverlapPatchEmbeddings {
projection: Conv2d,
layer_norm: candle_nn::LayerNorm,
}
impl SegformerOverlapPatchEmbeddings {
fn new(
config: &Config,
patch_size: usize,
stride: usize,
num_channels: usize,
hidden_size: usize,
vb: VarBuilder,
) -> Result<Self> {
let projection = conv2d(
num_channels,
hidden_size,
patch_size,
Conv2dConfig {
stride,
padding: patch_size / 2,
..Default::default()
},
vb.pp("proj"),
)?;
let layer_norm =
candle_nn::layer_norm(hidden_size, config.layer_norm_eps, vb.pp("layer_norm"))?;
Ok(Self {
projection,
layer_norm,
})
}
}
impl Module for SegformerOverlapPatchEmbeddings {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let embeddings = self.projection.forward(x)?;
let shape = embeddings.shape();
// [B, C, H, W] -> [B, H * W, C]
let embeddings = embeddings.flatten_from(2)?.transpose(1, 2)?;
let embeddings = self.layer_norm.forward(&embeddings)?;
// [B, H * W, C] -> [B, C, H, W]
let embeddings = embeddings.transpose(1, 2)?.reshape(shape)?;
Ok(embeddings)
}
}
#[derive(Debug, Clone)]
struct SegformerEfficientSelfAttention {
num_attention_heads: usize,
attention_head_size: usize,
query: Linear,
key: Linear,
value: Linear,
sr: Option<Conv2d>,
layer_norm: Option<layer_norm::LayerNorm>,
}
impl SegformerEfficientSelfAttention {
fn new(
config: &Config,
hidden_size: usize,
num_attention_heads: usize,
sequence_reduction_ratio: usize,
vb: VarBuilder,
) -> Result<Self> {
if hidden_size % num_attention_heads != 0 {
candle::bail!(
"The hidden size {} is not a multiple of the number of attention heads {}",
hidden_size,
num_attention_heads
)
}
let attention_head_size = hidden_size / num_attention_heads;
let all_head_size = num_attention_heads * attention_head_size;
let query = linear(hidden_size, all_head_size, vb.pp("query"))?;
let key = linear(hidden_size, all_head_size, vb.pp("key"))?;
let value = linear(hidden_size, all_head_size, vb.pp("value"))?;
let (sr, layer_norm) = if sequence_reduction_ratio > 1 {
(
Some(conv2d(
hidden_size,
hidden_size,
sequence_reduction_ratio,
Conv2dConfig {
stride: sequence_reduction_ratio,
..Default::default()
},
vb.pp("sr"),
)?),
Some(candle_nn::layer_norm(
hidden_size,
config.layer_norm_eps,
vb.pp("layer_norm"),
)?),
)
} else {
(None, None)
};
Ok(Self {
num_attention_heads,
attention_head_size,
query,
key,
value,
sr,
layer_norm,
})
}
fn transpose_for_scores(&self, hidden_states: Tensor) -> Result<Tensor> {
let (batch, seq_length, _) = hidden_states.shape().dims3()?;
let new_shape = &[
batch,
seq_length,
self.num_attention_heads,
self.attention_head_size,
];
let hidden_states = hidden_states.reshape(new_shape)?;
let hidden_states = hidden_states.permute((0, 2, 1, 3))?;
Ok(hidden_states)
}
}
impl Module for SegformerEfficientSelfAttention {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
// [B, C, H, W] -> [B, H * W, C]
let hidden_states = x.flatten_from(2)?.permute((0, 2, 1))?;
let query = self
.transpose_for_scores(self.query.forward(&hidden_states)?)?
.contiguous()?;
let hidden_states = if let (Some(sr), Some(layer_norm)) = (&self.sr, &self.layer_norm) {
let hidden_states = sr.forward(x)?;
// [B, C, H, W] -> [B, H * W, C]
let hidden_states = hidden_states.flatten_from(2)?.permute((0, 2, 1))?;
layer_norm.forward(&hidden_states)?
} else {
// already [B, H * W, C]
hidden_states
};
// standard self-attention
let key = self
.transpose_for_scores(self.key.forward(&hidden_states)?)?
.contiguous()?;
let value = self
.transpose_for_scores(self.value.forward(&hidden_states)?)?
.contiguous()?;
let attention_scores =
(query.matmul(&key.t()?)? / f64::sqrt(self.attention_head_size as f64))?;
let attention_scores = candle_nn::ops::softmax_last_dim(&attention_scores)?;
let result = attention_scores.matmul(&value)?;
let result = result.permute((0, 2, 1, 3))?.contiguous()?;
result.flatten_from(D::Minus2)
}
}
#[derive(Debug, Clone)]
struct SegformerSelfOutput {
dense: Linear,
}
impl SegformerSelfOutput {
fn new(hidden_size: usize, vb: VarBuilder) -> Result<Self> {
let dense = linear(hidden_size, hidden_size, vb.pp("dense"))?;
Ok(Self { dense })
}
}
impl Module for SegformerSelfOutput {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
self.dense.forward(x)
}
}
#[derive(Debug, Clone)]
struct SegformerAttention {
attention: SegformerEfficientSelfAttention,
output: SegformerSelfOutput,
}
impl SegformerAttention {
fn new(
config: &Config,
hidden_size: usize,
num_attention_heads: usize,
sequence_reduction_ratio: usize,
vb: VarBuilder,
) -> Result<Self> {
let attention = SegformerEfficientSelfAttention::new(
config,
hidden_size,
num_attention_heads,
sequence_reduction_ratio,
vb.pp("self"),
)?;
let output = SegformerSelfOutput::new(hidden_size, vb.pp("output"))?;
Ok(Self { attention, output })
}
}
impl Module for SegformerAttention {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let attention_output = self.attention.forward(x)?;
self.output.forward(&attention_output)
}
}
#[derive(Debug, Clone)]
struct SegformerDWConv {
dw_conv: Conv2d,
}
impl SegformerDWConv {
fn new(dim: usize, vb: VarBuilder) -> Result<Self> {
let dw_conv = conv2d(
dim,
dim,
3,
Conv2dConfig {
stride: 1,
padding: 1,
groups: dim,
..Default::default()
},
vb.pp("dwconv"),
)?;
Ok(Self { dw_conv })
}
}
impl Module for SegformerDWConv {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
self.dw_conv.forward(x)
}
}
#[derive(Debug, Clone)]
struct SegformerMixFFN {
dense1: Linear,
dw_conv: SegformerDWConv,
act: Activation,
dense2: Linear,
}
impl SegformerMixFFN {
fn new(
config: &Config,
in_features: usize,
hidden_features: usize,
out_features: usize,
vb: VarBuilder,
) -> Result<Self> {
let dense1 = linear(in_features, hidden_features, vb.pp("dense1"))?;
let dw_conv = SegformerDWConv::new(hidden_features, vb.pp("dwconv"))?;
let act = config.hidden_act;
let dense2 = linear(hidden_features, out_features, vb.pp("dense2"))?;
Ok(Self {
dense1,
dw_conv,
act,
dense2,
})
}
}
impl Module for SegformerMixFFN {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let (batch, _, height, width) = x.shape().dims4()?;
let hidden_states = self
.dense1
.forward(&x.flatten_from(2)?.permute((0, 2, 1))?)?;
let channels = hidden_states.dim(2)?;
let hidden_states = self.dw_conv.forward(
&hidden_states
.permute((0, 2, 1))?
.reshape((batch, channels, height, width))?,
)?;
let hidden_states = self.act.forward(&hidden_states)?;
let hidden_states = self
.dense2
.forward(&hidden_states.flatten_from(2)?.permute((0, 2, 1))?)?;
let channels = hidden_states.dim(2)?;
hidden_states
.permute((0, 2, 1))?
.reshape((batch, channels, height, width))
}
}
#[derive(Debug, Clone)]
struct SegformerLayer {
layer_norm_1: candle_nn::LayerNorm,
attention: SegformerAttention,
layer_norm_2: candle_nn::LayerNorm,
mlp: SegformerMixFFN,
}
impl SegformerLayer {
fn new(
config: &Config,
hidden_size: usize,
num_attention_heads: usize,
sequence_reduction_ratio: usize,
mlp_ratio: usize,
vb: VarBuilder,
) -> Result<Self> {
let layer_norm_1 = layer_norm(hidden_size, config.layer_norm_eps, vb.pp("layer_norm_1"))?;
let attention = SegformerAttention::new(
config,
hidden_size,
num_attention_heads,
sequence_reduction_ratio,
vb.pp("attention"),
)?;
let layer_norm_2 = layer_norm(hidden_size, config.layer_norm_eps, vb.pp("layer_norm_2"))?;
let mlp = SegformerMixFFN::new(
config,
hidden_size,
hidden_size * mlp_ratio,
hidden_size,
vb.pp("mlp"),
)?;
Ok(Self {
layer_norm_1,
attention,
layer_norm_2,
mlp,
})
}
}
impl Module for SegformerLayer {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let shape = x.shape().dims4()?;
// [B, C, H, W] -> [B, H * W, C]
let hidden_states = x.flatten_from(2)?.permute((0, 2, 1))?;
let layer_norm_output = self.layer_norm_1.forward(&hidden_states)?;
let layer_norm_output = layer_norm_output.permute((0, 2, 1))?.reshape(shape)?;
// attention takes in [B, C, H, W] in order to properly do conv2d (and output [B, H * W, C])
let attention_output = self.attention.forward(&layer_norm_output)?;
let hidden_states = (attention_output + hidden_states)?;
let layer_norm_output = self.layer_norm_2.forward(&hidden_states)?;
let mlp_output = self
.mlp
.forward(&layer_norm_output.permute((0, 2, 1))?.reshape(shape)?)?;
hidden_states.permute((0, 2, 1))?.reshape(shape)? + mlp_output
}
}
#[derive(Debug, Clone)]
struct SegformerEncoder {
/// config file
config: Config,
/// a list of embeddings
patch_embeddings: Vec<SegformerOverlapPatchEmbeddings>,
/// a list of attention blocks, each consisting of layers
blocks: Vec<Vec<SegformerLayer>>,
/// a final list of layer norms
layer_norms: Vec<candle_nn::LayerNorm>,
}
impl SegformerEncoder {
fn new(config: Config, vb: VarBuilder) -> Result<Self> {
let mut patch_embeddings = Vec::with_capacity(config.num_encoder_blocks);
let mut blocks = Vec::with_capacity(config.num_encoder_blocks);
let mut layer_norms = Vec::with_capacity(config.num_encoder_blocks);
for i in 0..config.num_encoder_blocks {
let patch_size = config.patch_sizes[i];
let stride = config.strides[i];
let hidden_size = config.hidden_sizes[i];
let num_channels = if i == 0 {
config.num_channels
} else {
config.hidden_sizes[i - 1]
};
patch_embeddings.push(SegformerOverlapPatchEmbeddings::new(
&config,
patch_size,
stride,
num_channels,
hidden_size,
vb.pp(&format!("patch_embeddings.{}", i)),
)?);
let mut layers = Vec::with_capacity(config.depths[i]);
for j in 0..config.depths[i] {
let sequence_reduction_ratio = config.sr_ratios[i];
let num_attention_heads = config.num_attention_heads[i];
let mlp_ratio = config.mlp_ratios[i];
layers.push(SegformerLayer::new(
&config,
hidden_size,
num_attention_heads,
sequence_reduction_ratio,
mlp_ratio,
vb.pp(&format!("block.{}.{}", i, j)),
)?);
}
blocks.push(layers);
layer_norms.push(layer_norm(
hidden_size,
config.layer_norm_eps,
vb.pp(&format!("layer_norm.{}", i)),
)?);
}
Ok(Self {
config,
patch_embeddings,
blocks,
layer_norms,
})
}
}
impl ModuleWithHiddenStates for SegformerEncoder {
fn forward(&self, x: &Tensor) -> Result<Vec<Tensor>> {
let mut all_hidden_states = Vec::with_capacity(self.config.num_encoder_blocks);
let mut hidden_states = x.clone();
for i in 0..self.config.num_encoder_blocks {
hidden_states = self.patch_embeddings[i].forward(&hidden_states)?;
for layer in &self.blocks[i] {
hidden_states = layer.forward(&hidden_states)?;
}
let shape = hidden_states.shape().dims4()?;
hidden_states =
self.layer_norms[i].forward(&hidden_states.flatten_from(2)?.permute((0, 2, 1))?)?;
hidden_states = hidden_states.permute((0, 2, 1))?.reshape(shape)?;
all_hidden_states.push(hidden_states.clone());
}
Ok(all_hidden_states)
}
}
#[derive(Debug, Clone)]
struct SegformerModel {
encoder: SegformerEncoder,
}
impl SegformerModel {
fn new(config: &Config, vb: VarBuilder) -> Result<Self> {
let encoder = SegformerEncoder::new(config.clone(), vb.pp("encoder"))?;
Ok(Self { encoder })
}
}
impl ModuleWithHiddenStates for SegformerModel {
fn forward(&self, x: &Tensor) -> Result<Vec<Tensor>> {
self.encoder.forward(x)
}
}
#[derive(Debug, Clone)]
struct SegformerMLP {
proj: Linear,
}
impl SegformerMLP {
fn new(config: &Config, input_dim: usize, vb: VarBuilder) -> Result<Self> {
let proj = linear(input_dim, config.decoder_hidden_size, vb.pp("proj"))?;
Ok(Self { proj })
}
}
impl Module for SegformerMLP {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
self.proj.forward(x)
}
}
#[derive(Debug, Clone)]
struct SegformerDecodeHead {
linear_c: Vec<SegformerMLP>,
linear_fuse: candle_nn::Conv2d,
batch_norm: candle_nn::BatchNorm,
classifier: candle_nn::Conv2d,
}
impl SegformerDecodeHead {
fn new(config: &Config, num_labels: usize, vb: VarBuilder) -> Result<Self> {
let mut linear_c = Vec::with_capacity(config.num_encoder_blocks);
for i in 0..config.num_encoder_blocks {
let hidden_size = config.hidden_sizes[i];
linear_c.push(SegformerMLP::new(
config,
hidden_size,
vb.pp(&format!("linear_c.{}", i)),
)?);
}
let linear_fuse = conv2d_no_bias(
config.decoder_hidden_size * config.num_encoder_blocks,
config.decoder_hidden_size,
1,
Conv2dConfig::default(),
vb.pp("linear_fuse"),
)?;
let batch_norm = candle_nn::batch_norm(
config.decoder_hidden_size,
config.layer_norm_eps,
vb.pp("batch_norm"),
)?;
let classifier = conv2d_no_bias(
config.decoder_hidden_size,
num_labels,
1,
Conv2dConfig::default(),
vb.pp("classifier"),
)?;
Ok(Self {
linear_c,
linear_fuse,
batch_norm,
classifier,
})
}
fn forward(&self, encoder_hidden_states: &[Tensor]) -> Result<Tensor> {
if encoder_hidden_states.len() != self.linear_c.len() {
candle::bail!(
"The number of encoder hidden states {} is not equal to the number of linear layers {}",
encoder_hidden_states.len(),
self.linear_c.len()
)
}
// most fine layer
let (_, _, upsample_height, upsample_width) = encoder_hidden_states[0].shape().dims4()?;
let mut hidden_states = Vec::with_capacity(self.linear_c.len());
for (hidden_state, mlp) in encoder_hidden_states.iter().zip(&self.linear_c) {
let (batch, _, height, width) = hidden_state.shape().dims4()?;
let hidden_state = mlp.forward(&hidden_state.flatten_from(2)?.permute((0, 2, 1))?)?;
let hidden_state = hidden_state.permute((0, 2, 1))?.reshape((
batch,
hidden_state.dim(2)?,
height,
width,
))?;
let hidden_state = hidden_state.upsample_nearest2d(upsample_height, upsample_width)?;
hidden_states.push(hidden_state);
}
hidden_states.reverse();
let hidden_states = Tensor::cat(&hidden_states, 1)?;
let hidden_states = self.linear_fuse.forward(&hidden_states)?;
let hidden_states = self.batch_norm.forward_t(&hidden_states, false)?;
let hidden_states = hidden_states.relu()?;
self.classifier.forward(&hidden_states)
}
}
trait ModuleWithHiddenStates {
fn forward(&self, xs: &Tensor) -> Result<Vec<Tensor>>;
}
#[derive(Debug, Clone)]
pub struct SemanticSegmentationModel {
segformer: SegformerModel,
decode_head: SegformerDecodeHead,
}
impl SemanticSegmentationModel {
pub fn new(config: &Config, num_labels: usize, vb: VarBuilder) -> Result<Self> {
let segformer = SegformerModel::new(config, vb.pp("segformer"))?;
let decode_head = SegformerDecodeHead::new(config, num_labels, vb.pp("decode_head"))?;
Ok(Self {
segformer,
decode_head,
})
}
}
impl Module for SemanticSegmentationModel {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let hidden_states = self.segformer.forward(x)?;
self.decode_head.forward(&hidden_states)
}
}
#[derive(Debug, Clone)]
pub struct ImageClassificationModel {
segformer: SegformerModel,
classifier: Linear,
}
impl ImageClassificationModel {
pub fn new(config: &Config, num_labels: usize, vb: VarBuilder) -> Result<Self> {
let segformer = SegformerModel::new(config, vb.pp("segformer"))?;
let classifier = linear(config.decoder_hidden_size, num_labels, vb.pp("classifier"))?;
Ok(Self {
segformer,
classifier,
})
}
}
impl Module for ImageClassificationModel {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let all_hidden_states = self.segformer.forward(x)?;
let hidden_states = all_hidden_states.last().unwrap();
let hidden_states = hidden_states.flatten_from(2)?.permute((0, 2, 1))?;
let mean = hidden_states.mean(1)?;
self.classifier.forward(&mean)
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_config_json_load() {
let raw_json = r#"{
"architectures": [
"SegformerForImageClassification"
],
"attention_probs_dropout_prob": 0.0,
"classifier_dropout_prob": 0.1,
"decoder_hidden_size": 256,
"depths": [
2,
2,
2,
2
],
"downsampling_rates": [
1,
4,
8,
16
],
"drop_path_rate": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_sizes": [
32,
64,
160,
256
],
"image_size": 224,
"initializer_range": 0.02,
"layer_norm_eps": 1e-06,
"mlp_ratios": [
4,
4,
4,
4
],
"model_type": "segformer",
"num_attention_heads": [
1,
2,
5,
8
],
"num_channels": 3,
"num_encoder_blocks": 4,
"patch_sizes": [
7,
3,
3,
3
],
"sr_ratios": [
8,
4,
2,
1
],
"strides": [
4,
2,
2,
2
],
"torch_dtype": "float32",
"transformers_version": "4.12.0.dev0"
}"#;
let config: Config = serde_json::from_str(raw_json).unwrap();
assert_eq!(vec![4, 2, 2, 2], config.strides);
assert_eq!(1e-6, config.layer_norm_eps);
}
}
|
candle/candle-transformers/src/models/segformer.rs/0
|
{
"file_path": "candle/candle-transformers/src/models/segformer.rs",
"repo_id": "candle",
"token_count": 11365
}
| 37 |
#![allow(dead_code)]
//! # Diffusion pipelines and models
//!
//! Noise schedulers can be used to set the trade-off between
//! inference speed and quality.
use candle::{Result, Tensor};
pub trait SchedulerConfig: std::fmt::Debug {
fn build(&self, inference_steps: usize) -> Result<Box<dyn Scheduler>>;
}
/// This trait represents a scheduler for the diffusion process.
pub trait Scheduler {
fn timesteps(&self) -> &[usize];
fn add_noise(&self, original: &Tensor, noise: Tensor, timestep: usize) -> Result<Tensor>;
fn init_noise_sigma(&self) -> f64;
fn scale_model_input(&self, sample: Tensor, _timestep: usize) -> Result<Tensor>;
fn step(&self, model_output: &Tensor, timestep: usize, sample: &Tensor) -> Result<Tensor>;
}
/// This represents how beta ranges from its minimum value to the maximum
/// during training.
#[derive(Debug, Clone, Copy)]
pub enum BetaSchedule {
/// Linear interpolation.
Linear,
/// Linear interpolation of the square root of beta.
ScaledLinear,
/// Glide cosine schedule
SquaredcosCapV2,
}
#[derive(Debug, Clone, Copy)]
pub enum PredictionType {
Epsilon,
VPrediction,
Sample,
}
/// Time step spacing for the diffusion process.
///
/// "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
#[derive(Debug, Clone, Copy)]
pub enum TimestepSpacing {
Leading,
Linspace,
Trailing,
}
impl Default for TimestepSpacing {
fn default() -> Self {
Self::Leading
}
}
/// Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
/// `(1-beta)` over time from `t = [0,1]`.
///
/// Contains a function `alpha_bar` that takes an argument `t` and transforms it to the cumulative product of `(1-beta)`
/// up to that part of the diffusion process.
pub(crate) fn betas_for_alpha_bar(num_diffusion_timesteps: usize, max_beta: f64) -> Result<Tensor> {
let alpha_bar = |time_step: usize| {
f64::cos((time_step as f64 + 0.008) / 1.008 * std::f64::consts::FRAC_PI_2).powi(2)
};
let mut betas = Vec::with_capacity(num_diffusion_timesteps);
for i in 0..num_diffusion_timesteps {
let t1 = i / num_diffusion_timesteps;
let t2 = (i + 1) / num_diffusion_timesteps;
betas.push((1.0 - alpha_bar(t2) / alpha_bar(t1)).min(max_beta));
}
let betas_len = betas.len();
Tensor::from_vec(betas, betas_len, &candle::Device::Cpu)
}
|
candle/candle-transformers/src/models/stable_diffusion/schedulers.rs/0
|
{
"file_path": "candle/candle-transformers/src/models/stable_diffusion/schedulers.rs",
"repo_id": "candle",
"token_count": 930
}
| 38 |
use candle::{Module, Result, Tensor};
use candle_nn::{linear, Linear, VarBuilder};
// A simplified version of:
// https://github.com/huggingface/diffusers/blob/119ad2c3dc8a8fb8446a83f4bf6f20929487b47f/src/diffusers/models/attention_processor.py#L38
#[derive(Debug)]
pub struct Attention {
to_q: Linear,
to_k: Linear,
to_v: Linear,
to_out: Linear,
heads: usize,
scale: f64,
use_flash_attn: bool,
}
#[cfg(feature = "flash-attn")]
fn flash_attn(
q: &Tensor,
k: &Tensor,
v: &Tensor,
softmax_scale: f32,
causal: bool,
) -> Result<Tensor> {
candle_flash_attn::flash_attn(q, k, v, softmax_scale, causal)
}
#[cfg(not(feature = "flash-attn"))]
fn flash_attn(_: &Tensor, _: &Tensor, _: &Tensor, _: f32, _: bool) -> Result<Tensor> {
unimplemented!("compile with '--features flash-attn'")
}
impl Attention {
pub fn new(
query_dim: usize,
heads: usize,
dim_head: usize,
use_flash_attn: bool,
vb: VarBuilder,
) -> Result<Self> {
let inner_dim = dim_head * heads;
let scale = 1.0 / f64::sqrt(dim_head as f64);
let to_q = linear(query_dim, inner_dim, vb.pp("to_q"))?;
let to_k = linear(query_dim, inner_dim, vb.pp("to_k"))?;
let to_v = linear(query_dim, inner_dim, vb.pp("to_v"))?;
let to_out = linear(inner_dim, query_dim, vb.pp("to_out.0"))?;
Ok(Self {
to_q,
to_k,
to_v,
to_out,
scale,
heads,
use_flash_attn,
})
}
fn batch_to_head_dim(&self, xs: &Tensor) -> Result<Tensor> {
let (b_size, seq_len, dim) = xs.dims3()?;
xs.reshape((b_size / self.heads, self.heads, seq_len, dim))?
.permute((0, 2, 1, 3))?
.reshape((b_size / self.heads, seq_len, dim * self.heads))
}
fn head_to_batch_dim(&self, xs: &Tensor) -> Result<Tensor> {
let (b_size, seq_len, dim) = xs.dims3()?;
xs.reshape((b_size, seq_len, self.heads, dim / self.heads))?
.permute((0, 2, 1, 3))?
.reshape((b_size * self.heads, seq_len, dim / self.heads))
}
fn get_attention_scores(&self, query: &Tensor, key: &Tensor) -> Result<Tensor> {
let attn_probs = (query.matmul(&key.t()?)? * self.scale)?;
candle_nn::ops::softmax_last_dim(&attn_probs)
}
pub fn forward(&self, xs: &Tensor, encoder_hidden_states: &Tensor) -> Result<Tensor> {
let (b_size, channel, h, w) = xs.dims4()?;
let xs = xs.reshape((b_size, channel, h * w))?.t()?;
let query = self.to_q.forward(&xs)?;
let key = self.to_k.forward(encoder_hidden_states)?;
let value = self.to_v.forward(encoder_hidden_states)?;
let query = self.head_to_batch_dim(&query)?;
let key = self.head_to_batch_dim(&key)?;
let value = self.head_to_batch_dim(&value)?;
let xs = if self.use_flash_attn {
let init_dtype = query.dtype();
let q = query
.to_dtype(candle::DType::F16)?
.unsqueeze(0)?
.transpose(1, 2)?;
let k = key
.to_dtype(candle::DType::F16)?
.unsqueeze(0)?
.transpose(1, 2)?;
let v = value
.to_dtype(candle::DType::F16)?
.unsqueeze(0)?
.transpose(1, 2)?;
flash_attn(&q, &k, &v, self.scale as f32, false)?
.transpose(1, 2)?
.squeeze(0)?
.to_dtype(init_dtype)?
} else {
let attn_prs = self.get_attention_scores(&query, &key)?;
attn_prs.matmul(&value)?
};
let xs = self.batch_to_head_dim(&xs)?;
self.to_out
.forward(&xs)?
.t()?
.reshape((b_size, channel, h, w))
}
}
|
candle/candle-transformers/src/models/wuerstchen/attention_processor.rs/0
|
{
"file_path": "candle/candle-transformers/src/models/wuerstchen/attention_processor.rs",
"repo_id": "candle",
"token_count": 2076
}
| 39 |
## Running [llama2.c](https://github.com/karpathy/llama2.c) Examples
Here, we provide two examples of how to run [llama2.c](https://github.com/karpathy/llama2.c) written in Rust using a Candle-compiled WASM binary and runtimes.
### Pure Rust UI
To build and test the UI made in Rust you will need [Trunk](https://trunkrs.dev/#install)
From the `candle-wasm-examples/llama2-c` directory run:
Download assets:
```bash
# Model and tokenizer
wget -c https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget -c https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
```
Run hot reload server:
```bash
trunk serve --release --public-url / --port 8080
```
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model } from "./build/m.js";
```
The full example can be found under `./lib-example.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/lib-example.html` in your browser.
|
candle/candle-wasm-examples/llama2-c/README.md/0
|
{
"file_path": "candle/candle-wasm-examples/llama2-c/README.md",
"repo_id": "candle",
"token_count": 449
}
| 40 |
import init, { Model } from "./build/m.js";
async function fetchArrayBuffer(url) {
const cacheName = "phi-mixformer-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
async function concatenateArrayBuffers(urls) {
const arrayBuffers = await Promise.all(urls.map(url => fetchArrayBuffer(url)));
let totalLength = arrayBuffers.reduce((acc, arrayBuffer) => acc + arrayBuffer.byteLength, 0);
let concatenatedBuffer = new Uint8Array(totalLength);
let offset = 0;
arrayBuffers.forEach(buffer => {
concatenatedBuffer.set(new Uint8Array(buffer), offset);
offset += buffer.byteLength;
});
return concatenatedBuffer;
}
class Phi {
static instance = {};
static async getInstance(
weightsURL,
modelID,
tokenizerURL,
configURL,
quantized
) {
// load individual modelID only once
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: "loading", message: "Loading Model" });
const [weightsArrayU8, tokenizerArrayU8, configArrayU8] =
await Promise.all([
weightsURL instanceof Array ? concatenateArrayBuffers(weightsURL) : fetchArrayBuffer(weightsURL),
fetchArrayBuffer(tokenizerURL),
fetchArrayBuffer(configURL),
]);
this.instance[modelID] = new Model(
weightsArrayU8,
tokenizerArrayU8,
configArrayU8,
quantized
);
}
return this.instance[modelID];
}
}
let controller = null;
self.addEventListener("message", (event) => {
if (event.data.command === "start") {
controller = new AbortController();
generate(event.data);
} else if (event.data.command === "abort") {
controller.abort();
}
});
async function generate(data) {
const {
weightsURL,
modelID,
tokenizerURL,
configURL,
quantized,
prompt,
temp,
top_p,
repeatPenalty,
seed,
maxSeqLen,
} = data;
try {
self.postMessage({ status: "loading", message: "Starting Phi" });
const model = await Phi.getInstance(
weightsURL,
modelID,
tokenizerURL,
configURL,
quantized
);
self.postMessage({ status: "loading", message: "Initializing model" });
const firstToken = model.init_with_prompt(
prompt,
temp,
top_p,
repeatPenalty,
64,
BigInt(seed)
);
const seq_len = 2048;
let sentence = firstToken;
let maxTokens = maxSeqLen ? maxSeqLen : seq_len - prompt.length - 1;
let startTime = performance.now();
let tokensCount = 0;
while (tokensCount < maxTokens) {
await new Promise(async (resolve) => {
if (controller && controller.signal.aborted) {
self.postMessage({
status: "aborted",
message: "Aborted",
output: prompt + sentence,
});
return;
}
const token = await model.next_token();
if (token === "<|endoftext|>") {
self.postMessage({
status: "complete",
message: "complete",
output: prompt + sentence,
});
return;
}
const tokensSec =
((tokensCount + 1) / (performance.now() - startTime)) * 1000;
sentence += token;
self.postMessage({
status: "generating",
message: "Generating token",
token: token,
sentence: sentence,
totalTime: performance.now() - startTime,
tokensSec,
prompt: prompt,
});
setTimeout(resolve, 0);
});
tokensCount++;
}
self.postMessage({
status: "complete",
message: "complete",
output: prompt + sentence,
});
} catch (e) {
self.postMessage({ error: e });
}
}
|
candle/candle-wasm-examples/phi/phiWorker.js/0
|
{
"file_path": "candle/candle-wasm-examples/phi/phiWorker.js",
"repo_id": "candle",
"token_count": 1667
}
| 41 |
use candle::{Device, Tensor};
use candle_transformers::generation::LogitsProcessor;
pub use candle_transformers::models::quantized_t5::{
Config, T5EncoderModel, T5ForConditionalGeneration, VarBuilder,
};
use candle_wasm_example_t5::console_log;
use tokenizers::Tokenizer;
use wasm_bindgen::prelude::*;
const DEVICE: Device = Device::Cpu;
#[wasm_bindgen]
pub struct ModelEncoder {
model: T5EncoderModel,
tokenizer: Tokenizer,
}
#[wasm_bindgen]
pub struct ModelConditionalGeneration {
model: T5ForConditionalGeneration,
tokenizer: Tokenizer,
config: Config,
}
#[wasm_bindgen]
impl ModelConditionalGeneration {
#[wasm_bindgen(constructor)]
pub fn load(
weights: Vec<u8>,
tokenizer: Vec<u8>,
config: Vec<u8>,
) -> Result<ModelConditionalGeneration, JsError> {
console_error_panic_hook::set_once();
console_log!("loading model");
let vb = VarBuilder::from_gguf_buffer(&weights, &DEVICE)?;
let mut config: Config = serde_json::from_slice(&config)?;
let tokenizer =
Tokenizer::from_bytes(&tokenizer).map_err(|m| JsError::new(&m.to_string()))?;
let model = T5ForConditionalGeneration::load(vb, &config)?;
config.use_cache = false;
Ok(Self {
model,
tokenizer,
config,
})
}
pub fn decode(&mut self, input: JsValue) -> Result<JsValue, JsError> {
let input: ConditionalGenerationParams =
serde_wasm_bindgen::from_value(input).map_err(|m| JsError::new(&m.to_string()))?;
let device = &DEVICE;
self.model.clear_kv_cache();
let mut output_token_ids = [self.config.pad_token_id as u32].to_vec();
let prompt = input.prompt;
let repeat_penalty = input.repeat_penalty;
let repeat_last_n = input.repeat_last_n;
let seed = input.seed;
let max_length = usize::clamp(input.max_length.unwrap_or(512), 0, 512);
let temperature = if input.temperature <= 0. {
None
} else {
Some(input.temperature)
};
let top_p = if input.top_p <= 0. || input.top_p >= 1. {
None
} else {
Some(input.top_p)
};
let mut logits_processor = LogitsProcessor::new(seed, temperature, top_p);
let tokens = self
.tokenizer
.encode(prompt, true)
.map_err(|m| JsError::new(&m.to_string()))?
.get_ids()
.to_vec();
let input_token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?;
let encoder_output = self.model.encode(&input_token_ids)?;
let mut decoded = String::new();
for index in 0.. {
if output_token_ids.len() > max_length {
break;
}
let decoder_token_ids = if index == 0 {
Tensor::new(output_token_ids.as_slice(), device)?.unsqueeze(0)?
} else {
let last_token = *output_token_ids.last().unwrap();
Tensor::new(&[last_token], device)?.unsqueeze(0)?
};
let logits = self
.model
.decode(&decoder_token_ids, &encoder_output)?
.squeeze(0)?;
let logits = if repeat_penalty == 1. {
logits
} else {
let start_at = output_token_ids.len().saturating_sub(repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
repeat_penalty,
&output_token_ids[start_at..],
)?
};
let next_token_id = logits_processor.sample(&logits)?;
if next_token_id as usize == self.config.eos_token_id {
break;
}
output_token_ids.push(next_token_id);
if let Some(text) = self.tokenizer.id_to_token(next_token_id) {
let text = text.replace('▁', " ").replace("<0x0A>", "\n");
decoded += &text;
}
}
Ok(serde_wasm_bindgen::to_value(
&ConditionalGenerationOutput {
generation: decoded,
},
)?)
}
}
#[wasm_bindgen]
impl ModelEncoder {
#[wasm_bindgen(constructor)]
pub fn load(
weights: Vec<u8>,
tokenizer: Vec<u8>,
config: Vec<u8>,
) -> Result<ModelEncoder, JsError> {
console_error_panic_hook::set_once();
console_log!("loading model");
let vb = VarBuilder::from_gguf_buffer(&weights, &DEVICE)?;
let mut config: Config = serde_json::from_slice(&config)?;
config.use_cache = false;
let tokenizer =
Tokenizer::from_bytes(&tokenizer).map_err(|m| JsError::new(&m.to_string()))?;
let model = T5EncoderModel::load(vb, &config)?;
Ok(Self { model, tokenizer })
}
pub fn decode(&mut self, input: JsValue) -> Result<JsValue, JsError> {
let device = &DEVICE;
let input: DecoderParams =
serde_wasm_bindgen::from_value(input).map_err(|m| JsError::new(&m.to_string()))?;
self.model.clear_kv_cache();
let sentences = input.sentences;
let normalize_embeddings = input.normalize_embeddings;
let n_sentences = sentences.len();
let mut all_embeddings = Vec::with_capacity(n_sentences);
for sentence in sentences {
let tokens = self
.tokenizer
.encode(sentence, true)
.map_err(|m| JsError::new(&m.to_string()))?
.get_ids()
.to_vec();
let token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?;
let embeddings = self.model.forward(&token_ids)?;
console_log!("generated embeddings {:?}", embeddings.shape());
// Apply some avg-pooling by taking the mean embedding value for all tokens (including padding)
let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?;
let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?;
let embeddings = if normalize_embeddings {
embeddings.broadcast_div(&embeddings.sqr()?.sum_keepdim(1)?.sqrt()?)?
} else {
embeddings
};
console_log!("{:?}", embeddings.shape());
all_embeddings.push(embeddings.squeeze(0)?.to_vec1::<f32>()?);
}
Ok(serde_wasm_bindgen::to_value(&DecoderOutput {
embeddings: all_embeddings,
})?)
}
}
#[derive(serde::Serialize, serde::Deserialize)]
struct ConditionalGenerationOutput {
generation: String,
}
#[derive(serde::Serialize, serde::Deserialize)]
struct DecoderOutput {
embeddings: Vec<Vec<f32>>,
}
#[derive(serde::Serialize, serde::Deserialize)]
pub struct DecoderParams {
sentences: Vec<String>,
normalize_embeddings: bool,
}
#[derive(serde::Serialize, serde::Deserialize)]
pub struct ConditionalGenerationParams {
prompt: String,
temperature: f64,
seed: u64,
top_p: f64,
repeat_penalty: f32,
repeat_last_n: usize,
max_length: Option<usize>,
}
fn main() {
console_error_panic_hook::set_once();
}
|
candle/candle-wasm-examples/t5/src/bin/m-quantized.rs/0
|
{
"file_path": "candle/candle-wasm-examples/t5/src/bin/m-quantized.rs",
"repo_id": "candle",
"token_count": 3555
}
| 42 |
pub const WITH_TIMER: bool = true;
struct Timer {
label: &'static str,
}
// impl Timer {
// fn new(label: &'static str) -> Self {
// if WITH_TIMER {
// web_sys::console::time_with_label(label);
// }
// Self { label }
// }
// }
impl Drop for Timer {
fn drop(&mut self) {
if WITH_TIMER {
web_sys::console::time_end_with_label(self.label)
}
}
}
mod app;
mod audio;
pub mod languages;
pub mod worker;
pub use app::App;
pub use worker::Worker;
|
candle/candle-wasm-examples/whisper/src/lib.rs/0
|
{
"file_path": "candle/candle-wasm-examples/whisper/src/lib.rs",
"repo_id": "candle",
"token_count": 252
}
| 43 |
//load the candle yolo wasm module
import init, { Model, ModelPose } from "./build/m.js";
async function fetchArrayBuffer(url) {
const cacheName = "yolo-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
class Yolo {
static instance = {};
// Retrieve the YOLO model. When called for the first time,
// this will load the model and save it for future use.
static async getInstance(modelID, modelURL, modelSize) {
// load individual modelID only once
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: `loading model ${modelID}:${modelSize}` });
const weightsArrayU8 = await fetchArrayBuffer(modelURL);
if (/pose/.test(modelID)) {
// if pose model, use ModelPose
this.instance[modelID] = new ModelPose(weightsArrayU8, modelSize);
} else {
this.instance[modelID] = new Model(weightsArrayU8, modelSize);
}
} else {
self.postMessage({ status: "model already loaded" });
}
return this.instance[modelID];
}
}
self.addEventListener("message", async (event) => {
const { imageURL, modelID, modelURL, modelSize, confidence, iou_threshold } =
event.data;
try {
self.postMessage({ status: "detecting" });
const yolo = await Yolo.getInstance(modelID, modelURL, modelSize);
self.postMessage({ status: "loading image" });
const imgRes = await fetch(imageURL);
const imgData = await imgRes.arrayBuffer();
const imageArrayU8 = new Uint8Array(imgData);
self.postMessage({ status: `running inference ${modelID}:${modelSize}` });
const bboxes = yolo.run(imageArrayU8, confidence, iou_threshold);
// Send the output back to the main thread as JSON
self.postMessage({
status: "complete",
output: JSON.parse(bboxes),
});
} catch (e) {
self.postMessage({ error: e });
}
});
|
candle/candle-wasm-examples/yolo/yoloWorker.js/0
|
{
"file_path": "candle/candle-wasm-examples/yolo/yoloWorker.js",
"repo_id": "candle",
"token_count": 756
}
| 44 |
# syntax=docker/dockerfile:1
# read the doc: https://huggingface.co/docs/hub/spaces-sdks-docker
# you will also find guides on how best to write your Dockerfile
FROM node:20 as builder-production
WORKDIR /app
COPY --link --chown=1000 package-lock.json package.json ./
RUN --mount=type=cache,target=/app/.npm \
npm set cache /app/.npm && \
npm ci --omit=dev
FROM builder-production as builder
RUN --mount=type=cache,target=/app/.npm \
npm set cache /app/.npm && \
npm ci
COPY --link --chown=1000 . .
RUN --mount=type=secret,id=DOTENV_LOCAL,dst=.env.local \
npm run build
FROM node:20-slim
RUN npm install -g pm2
COPY --from=builder-production /app/node_modules /app/node_modules
COPY --link --chown=1000 package.json /app/package.json
COPY --from=builder /app/build /app/build
CMD pm2 start /app/build/index.js -i $CPU_CORES --no-daemon
|
chat-ui/Dockerfile/0
|
{
"file_path": "chat-ui/Dockerfile",
"repo_id": "chat-ui",
"token_count": 351
}
| 45 |
import {
ADMIN_API_SECRET,
COOKIE_NAME,
EXPOSE_API,
MESSAGES_BEFORE_LOGIN,
PARQUET_EXPORT_SECRET,
} from "$env/static/private";
import type { Handle } from "@sveltejs/kit";
import {
PUBLIC_GOOGLE_ANALYTICS_ID,
PUBLIC_ORIGIN,
PUBLIC_APP_DISCLAIMER,
} from "$env/static/public";
import { collections } from "$lib/server/database";
import { base } from "$app/paths";
import { findUser, refreshSessionCookie, requiresUser } from "$lib/server/auth";
import { ERROR_MESSAGES } from "$lib/stores/errors";
import { sha256 } from "$lib/utils/sha256";
import { addWeeks } from "date-fns";
import { checkAndRunMigrations } from "$lib/migrations/migrations";
import { building } from "$app/environment";
if (!building) {
await checkAndRunMigrations();
}
export const handle: Handle = async ({ event, resolve }) => {
if (event.url.pathname.startsWith(`${base}/api/`) && EXPOSE_API !== "true") {
return new Response("API is disabled", { status: 403 });
}
function errorResponse(status: number, message: string) {
const sendJson =
event.request.headers.get("accept")?.includes("application/json") ||
event.request.headers.get("content-type")?.includes("application/json");
return new Response(sendJson ? JSON.stringify({ error: message }) : message, {
status,
headers: {
"content-type": sendJson ? "application/json" : "text/plain",
},
});
}
if (event.url.pathname.startsWith(`${base}/admin/`) || event.url.pathname === `${base}/admin`) {
const ADMIN_SECRET = ADMIN_API_SECRET || PARQUET_EXPORT_SECRET;
if (!ADMIN_SECRET) {
return errorResponse(500, "Admin API is not configured");
}
if (event.request.headers.get("Authorization") !== `Bearer ${ADMIN_SECRET}`) {
return errorResponse(401, "Unauthorized");
}
}
const token = event.cookies.get(COOKIE_NAME);
let secretSessionId: string;
let sessionId: string;
if (token) {
secretSessionId = token;
sessionId = await sha256(token);
const user = await findUser(sessionId);
if (user) {
event.locals.user = user;
}
} else {
// if the user doesn't have any cookie, we generate one for him
secretSessionId = crypto.randomUUID();
sessionId = await sha256(secretSessionId);
if (await collections.sessions.findOne({ sessionId })) {
return errorResponse(500, "Session ID collision");
}
}
event.locals.sessionId = sessionId;
// CSRF protection
const requestContentType = event.request.headers.get("content-type")?.split(";")[0] ?? "";
/** https://developer.mozilla.org/en-US/docs/Web/HTML/Element/form#attr-enctype */
const nativeFormContentTypes = [
"multipart/form-data",
"application/x-www-form-urlencoded",
"text/plain",
];
if (event.request.method === "POST") {
refreshSessionCookie(event.cookies, event.locals.sessionId);
if (nativeFormContentTypes.includes(requestContentType)) {
const referer = event.request.headers.get("referer");
if (!referer) {
return errorResponse(403, "Non-JSON form requests need to have a referer");
}
const validOrigins = [
new URL(event.request.url).origin,
...(PUBLIC_ORIGIN ? [new URL(PUBLIC_ORIGIN).origin] : []),
];
if (!validOrigins.includes(new URL(referer).origin)) {
return errorResponse(403, "Invalid referer for POST request");
}
}
}
if (event.request.method === "POST") {
// if the request is a POST request we refresh the cookie
refreshSessionCookie(event.cookies, secretSessionId);
await collections.sessions.updateOne(
{ sessionId },
{ $set: { updatedAt: new Date(), expiresAt: addWeeks(new Date(), 2) } }
);
}
if (
!event.url.pathname.startsWith(`${base}/login`) &&
!event.url.pathname.startsWith(`${base}/admin`) &&
!["GET", "OPTIONS", "HEAD"].includes(event.request.method)
) {
if (
!event.locals.user &&
requiresUser &&
!((MESSAGES_BEFORE_LOGIN ? parseInt(MESSAGES_BEFORE_LOGIN) : 0) > 0)
) {
return errorResponse(401, ERROR_MESSAGES.authOnly);
}
// if login is not required and the call is not from /settings and we display the ethics modal with PUBLIC_APP_DISCLAIMER
// we check if the user has accepted the ethics modal first.
// If login is required, `ethicsModalAcceptedAt` is already true at this point, so do not pass this condition. This saves a DB call.
if (
!requiresUser &&
!event.url.pathname.startsWith(`${base}/settings`) &&
!!PUBLIC_APP_DISCLAIMER
) {
const hasAcceptedEthicsModal = await collections.settings.countDocuments({
sessionId: event.locals.sessionId,
ethicsModalAcceptedAt: { $exists: true },
});
if (!hasAcceptedEthicsModal) {
return errorResponse(405, "You need to accept the welcome modal first");
}
}
}
let replaced = false;
const response = await resolve(event, {
transformPageChunk: (chunk) => {
// For some reason, Sveltekit doesn't let us load env variables from .env in the app.html template
if (replaced || !chunk.html.includes("%gaId%")) {
return chunk.html;
}
replaced = true;
return chunk.html.replace("%gaId%", PUBLIC_GOOGLE_ANALYTICS_ID);
},
});
return response;
};
|
chat-ui/src/hooks.server.ts/0
|
{
"file_path": "chat-ui/src/hooks.server.ts",
"repo_id": "chat-ui",
"token_count": 1879
}
| 46 |
<script lang="ts">
import { base } from "$app/paths";
import Logo from "$lib/components/icons/Logo.svelte";
import { switchTheme } from "$lib/switchTheme";
import { isAborted } from "$lib/stores/isAborted";
import { PUBLIC_APP_NAME, PUBLIC_ORIGIN } from "$env/static/public";
import NavConversationItem from "./NavConversationItem.svelte";
import type { LayoutData } from "../../routes/$types";
import type { ConvSidebar } from "$lib/types/ConvSidebar";
import type { Model } from "$lib/types/Model";
import { page } from "$app/stores";
export let conversations: ConvSidebar[] = [];
export let canLogin: boolean;
export let user: LayoutData["user"];
function handleNewChatClick() {
isAborted.set(true);
}
const dateRanges = [
new Date().setDate(new Date().getDate() - 1),
new Date().setDate(new Date().getDate() - 7),
new Date().setMonth(new Date().getMonth() - 1),
];
$: groupedConversations = {
today: conversations.filter(({ updatedAt }) => updatedAt.getTime() > dateRanges[0]),
week: conversations.filter(
({ updatedAt }) => updatedAt.getTime() > dateRanges[1] && updatedAt.getTime() < dateRanges[0]
),
month: conversations.filter(
({ updatedAt }) => updatedAt.getTime() > dateRanges[2] && updatedAt.getTime() < dateRanges[1]
),
older: conversations.filter(({ updatedAt }) => updatedAt.getTime() < dateRanges[2]),
};
const titles: { [key: string]: string } = {
today: "Today",
week: "This week",
month: "This month",
older: "Older",
} as const;
const nModels: number = $page.data.models.filter((el: Model) => !el.unlisted).length;
</script>
<div class="sticky top-0 flex flex-none items-center justify-between px-3 py-3.5 max-sm:pt-0">
<a class="flex items-center rounded-xl text-lg font-semibold" href="{PUBLIC_ORIGIN}{base}/">
<Logo classNames="mr-1" />
{PUBLIC_APP_NAME}
</a>
<a
href={`${base}/`}
on:click={handleNewChatClick}
class="flex rounded-lg border bg-white px-2 py-0.5 text-center shadow-sm hover:shadow-none dark:border-gray-600 dark:bg-gray-700"
>
New Chat
</a>
</div>
<div
class="scrollbar-custom flex flex-col gap-1 overflow-y-auto rounded-r-xl from-gray-50 px-3 pb-3 pt-2 max-sm:bg-gradient-to-t md:bg-gradient-to-l dark:from-gray-800/30"
>
{#each Object.entries(groupedConversations) as [group, convs]}
{#if convs.length}
<h4 class="mb-1.5 mt-4 pl-0.5 text-sm text-gray-400 first:mt-0 dark:text-gray-500">
{titles[group]}
</h4>
{#each convs as conv}
<NavConversationItem on:editConversationTitle on:deleteConversation {conv} />
{/each}
{/if}
{/each}
</div>
<div
class="mt-0.5 flex flex-col gap-1 rounded-r-xl p-3 text-sm md:bg-gradient-to-l md:from-gray-50 md:dark:from-gray-800/30"
>
{#if user?.username || user?.email}
<form
action="{base}/logout"
method="post"
class="group flex items-center gap-1.5 rounded-lg pl-2.5 pr-2 hover:bg-gray-100 dark:hover:bg-gray-700"
>
<span
class="flex h-9 flex-none shrink items-center gap-1.5 truncate pr-2 text-gray-500 dark:text-gray-400"
>{user?.username || user?.email}</span
>
<button
type="submit"
class="ml-auto h-6 flex-none items-center gap-1.5 rounded-md border bg-white px-2 text-gray-700 shadow-sm group-hover:flex hover:shadow-none md:hidden dark:border-gray-600 dark:bg-gray-600 dark:text-gray-400 dark:hover:text-gray-300"
>
Sign Out
</button>
</form>
{/if}
{#if canLogin}
<form action="{base}/login" method="POST" target="_parent">
<button
type="submit"
class="flex h-9 w-full flex-none items-center gap-1.5 rounded-lg pl-2.5 pr-2 text-gray-500 hover:bg-gray-100 dark:text-gray-400 dark:hover:bg-gray-700"
>
Login
</button>
</form>
{/if}
<button
on:click={switchTheme}
type="button"
class="flex h-9 flex-none items-center gap-1.5 rounded-lg pl-2.5 pr-2 text-gray-500 hover:bg-gray-100 dark:text-gray-400 dark:hover:bg-gray-700"
>
Theme
</button>
{#if nModels > 1}
<a
href="{base}/models"
class="flex h-9 flex-none items-center gap-1.5 rounded-lg pl-2.5 pr-2 text-gray-500 hover:bg-gray-100 dark:text-gray-400 dark:hover:bg-gray-700"
>
Models
<span
class="ml-auto rounded-full border border-gray-300 px-2 py-0.5 text-xs text-gray-500 dark:border-gray-500 dark:text-gray-400"
>{nModels}</span
>
</a>
{/if}
{#if $page.data.enableAssistants}
<a
href="{base}/assistants"
class="flex h-9 flex-none items-center gap-1.5 rounded-lg pl-2.5 pr-2 text-gray-500 hover:bg-gray-100 dark:text-gray-400 dark:hover:bg-gray-700"
>
Assistants
<span
class="ml-auto rounded-full border border-gray-300 px-2 py-0.5 text-xs text-gray-500 dark:border-gray-500 dark:text-gray-400"
>New</span
>
</a>
{/if}
<a
href="{base}/settings"
class="flex h-9 flex-none items-center gap-1.5 rounded-lg pl-2.5 pr-2 text-gray-500 hover:bg-gray-100 dark:text-gray-400 dark:hover:bg-gray-700"
>
Settings
</a>
{#if PUBLIC_APP_NAME === "HuggingChat"}
<a
href="{base}/privacy"
class="flex h-9 flex-none items-center gap-1.5 rounded-lg pl-2.5 pr-2 text-gray-500 hover:bg-gray-100 dark:text-gray-400 dark:hover:bg-gray-700"
>
About & Privacy
</a>
{/if}
</div>
|
chat-ui/src/lib/components/NavMenu.svelte/0
|
{
"file_path": "chat-ui/src/lib/components/NavMenu.svelte",
"repo_id": "chat-ui",
"token_count": 2177
}
| 47 |
<script lang="ts">
import { PUBLIC_APP_NAME, PUBLIC_VERSION } from "$env/static/public";
import { PUBLIC_ANNOUNCEMENT_BANNERS } from "$env/static/public";
import { PUBLIC_APP_DESCRIPTION } from "$env/static/public";
import Logo from "$lib/components/icons/Logo.svelte";
import { createEventDispatcher } from "svelte";
import IconGear from "~icons/bi/gear-fill";
import AnnouncementBanner from "../AnnouncementBanner.svelte";
import type { Model } from "$lib/types/Model";
import ModelCardMetadata from "../ModelCardMetadata.svelte";
import { findCurrentModel } from "$lib/utils/models";
import { base } from "$app/paths";
import { useSettingsStore } from "$lib/stores/settings";
import JSON5 from "json5";
export let currentModel: Model;
export let models: Model[];
const settings = useSettingsStore();
$: currentModelMetadata = findCurrentModel(models, $settings.activeModel);
const announcementBanners = PUBLIC_ANNOUNCEMENT_BANNERS
? JSON5.parse(PUBLIC_ANNOUNCEMENT_BANNERS)
: [];
const dispatch = createEventDispatcher<{ message: string }>();
</script>
<div class="my-auto grid gap-8 lg:grid-cols-3">
<div class="lg:col-span-1">
<div>
<div class="mb-3 flex items-center text-2xl font-semibold">
<Logo classNames="mr-1 flex-none" />
{PUBLIC_APP_NAME}
<div
class="ml-3 flex h-6 items-center rounded-lg border border-gray-100 bg-gray-50 px-2 text-base text-gray-400 dark:border-gray-700/60 dark:bg-gray-800"
>
v{PUBLIC_VERSION}
</div>
</div>
<p class="text-base text-gray-600 dark:text-gray-400">
{PUBLIC_APP_DESCRIPTION ||
"Making the community's best AI chat models available to everyone."}
</p>
</div>
</div>
<div class="lg:col-span-2 lg:pl-24">
{#each announcementBanners as banner}
<AnnouncementBanner classNames="mb-4" title={banner.title}>
<a
target="_blank"
href={banner.linkHref}
class="mr-2 flex items-center underline hover:no-underline">{banner.linkTitle}</a
>
</AnnouncementBanner>
{/each}
<div class="overflow-hidden rounded-xl border dark:border-gray-800">
<div class="flex p-3">
<div>
<div class="text-sm text-gray-600 dark:text-gray-400">Current Model</div>
<div class="flex items-center gap-1.5 font-semibold max-sm:text-smd">
{#if currentModel.logoUrl}
<img
class=" overflown aspect-square size-4 rounded border dark:border-gray-700"
src={currentModel.logoUrl}
alt=""
/>
{:else}
<div class="size-4 rounded border border-transparent bg-gray-300 dark:bg-gray-800" />
{/if}
{currentModel.displayName}
</div>
</div>
<a
href="{base}/settings/{currentModel.id}"
class="btn ml-auto flex h-7 w-7 self-start rounded-full bg-gray-100 p-1 text-xs hover:bg-gray-100 dark:border-gray-600 dark:bg-gray-800 dark:hover:bg-gray-600"
><IconGear /></a
>
</div>
<ModelCardMetadata variant="dark" model={currentModel} />
</div>
</div>
{#if currentModelMetadata.promptExamples}
<div class="lg:col-span-3 lg:mt-6">
<p class="mb-3 text-gray-600 dark:text-gray-300">Examples</p>
<div class="grid gap-3 lg:grid-cols-3 lg:gap-5">
{#each currentModelMetadata.promptExamples as example}
<button
type="button"
class="rounded-xl border bg-gray-50 p-3 text-gray-600 hover:bg-gray-100 max-xl:text-sm xl:p-3.5 dark:border-gray-800 dark:bg-gray-800 dark:text-gray-300 dark:hover:bg-gray-700"
on:click={() => dispatch("message", example.prompt)}
>
{example.title}
</button>
{/each}
</div>
</div>{/if}
<div class="h-40 sm:h-24" />
</div>
|
chat-ui/src/lib/components/chat/ChatIntroduction.svelte/0
|
{
"file_path": "chat-ui/src/lib/components/chat/ChatIntroduction.svelte",
"repo_id": "chat-ui",
"token_count": 1525
}
| 48 |
import type { Migration } from ".";
import { getCollections } from "$lib/server/database";
import { ObjectId, type AnyBulkWriteOperation } from "mongodb";
import type { Assistant } from "$lib/types/Assistant";
import { generateSearchTokens } from "$lib/utils/searchTokens";
const migration: Migration = {
_id: new ObjectId("5f9f3e3e3e3e3e3e3e3e3e3e"),
name: "Update search assistants",
up: async (client) => {
const { assistants } = getCollections(client);
let ops: AnyBulkWriteOperation<Assistant>[] = [];
for await (const assistant of assistants
.find()
.project<Pick<Assistant, "_id" | "name">>({ _id: 1, name: 1 })) {
ops.push({
updateOne: {
filter: {
_id: assistant._id,
},
update: {
$set: {
searchTokens: generateSearchTokens(assistant.name),
},
},
},
});
if (ops.length >= 1000) {
process.stdout.write(".");
await assistants.bulkWrite(ops, { ordered: false });
ops = [];
}
}
if (ops.length) {
await assistants.bulkWrite(ops, { ordered: false });
}
return true;
},
down: async (client) => {
const { assistants } = getCollections(client);
await assistants.updateMany({}, { $unset: { searchTokens: "" } });
return true;
},
};
export default migration;
|
chat-ui/src/lib/migrations/routines/01-update-search-assistants.ts/0
|
{
"file_path": "chat-ui/src/lib/migrations/routines/01-update-search-assistants.ts",
"repo_id": "chat-ui",
"token_count": 497
}
| 49 |
import type { TextGenerationStreamOutput } from "@huggingface/inference";
import type OpenAI from "openai";
import type { Stream } from "openai/streaming";
/**
* Transform a stream of OpenAI.Chat.ChatCompletion into a stream of TextGenerationStreamOutput
*/
export async function* openAIChatToTextGenerationStream(
completionStream: Stream<OpenAI.Chat.Completions.ChatCompletionChunk>
) {
let generatedText = "";
let tokenId = 0;
for await (const completion of completionStream) {
const { choices } = completion;
const content = choices[0]?.delta?.content ?? "";
const last = choices[0]?.finish_reason === "stop";
if (content) {
generatedText = generatedText + content;
}
const output: TextGenerationStreamOutput = {
token: {
id: tokenId++,
text: content ?? "",
logprob: 0,
special: last,
},
generated_text: last ? generatedText : null,
details: null,
};
yield output;
}
}
|
chat-ui/src/lib/server/endpoints/openai/openAIChatToTextGenerationStream.ts/0
|
{
"file_path": "chat-ui/src/lib/server/endpoints/openai/openAIChatToTextGenerationStream.ts",
"repo_id": "chat-ui",
"token_count": 320
}
| 50 |
import { SEARXNG_QUERY_URL } from "$env/static/private";
export async function searchSearxng(query: string) {
const abortController = new AbortController();
setTimeout(() => abortController.abort(), 10000);
// Insert the query into the URL template
let url = SEARXNG_QUERY_URL.replace("<query>", query);
// Check if "&format=json" already exists in the URL
if (!url.includes("&format=json")) {
url += "&format=json";
}
// Call the URL to return JSON data
const jsonResponse = await fetch(url, {
signal: abortController.signal,
})
.then((response) => response.json() as Promise<{ results: { url: string }[] }>)
.catch((error) => {
console.error("Failed to fetch or parse JSON", error);
throw new Error("Failed to fetch or parse JSON");
});
// Extract 'url' elements from the JSON response and trim to the top 5 URLs
const urls = jsonResponse.results.slice(0, 5).map((item) => item.url);
if (!urls.length) {
throw new Error(`Response doesn't contain any "url" elements`);
}
// Map URLs to the correct object shape
return { organic_results: urls.map((link) => ({ link })) };
}
|
chat-ui/src/lib/server/websearch/searchSearxng.ts/0
|
{
"file_path": "chat-ui/src/lib/server/websearch/searchSearxng.ts",
"repo_id": "chat-ui",
"token_count": 362
}
| 51 |
import type { Timestamps } from "./Timestamps";
export interface ConversationStats extends Timestamps {
date: {
at: Date;
span: "day" | "week" | "month";
field: "updatedAt" | "createdAt";
};
type: "conversation" | "message";
/** _id => number of conversations/messages in the month */
distinct: "sessionId" | "userId" | "userOrSessionId" | "_id";
count: number;
}
|
chat-ui/src/lib/types/ConversationStats.ts/0
|
{
"file_path": "chat-ui/src/lib/types/ConversationStats.ts",
"repo_id": "chat-ui",
"token_count": 134
}
| 52 |
export interface GAEvent {
hitType: "event";
eventCategory: string;
eventAction: string;
eventLabel?: string;
eventValue?: number;
}
// Send a Google Analytics event
export function sendAnalyticsEvent({
eventCategory,
eventAction,
eventLabel,
eventValue,
}: Omit<GAEvent, "hitType">): void {
// Mandatory fields
const event: GAEvent = {
hitType: "event",
eventCategory,
eventAction,
};
// Optional fields
if (eventLabel) {
event.eventLabel = eventLabel;
}
if (eventValue) {
event.eventValue = eventValue;
}
// @ts-expect-error typescript doesn't know gtag is on the window object
if (!!window?.gtag && typeof window?.gtag === "function") {
// @ts-expect-error typescript doesn't know gtag is on the window object
window?.gtag("event", eventAction, {
event_category: event.eventCategory,
event_label: event.eventLabel,
value: event.eventValue,
});
}
}
|
chat-ui/src/lib/utils/analytics.ts/0
|
{
"file_path": "chat-ui/src/lib/utils/analytics.ts",
"repo_id": "chat-ui",
"token_count": 313
}
| 53 |
type UUID = ReturnType<typeof crypto.randomUUID>;
export function randomUUID(): UUID {
// Only on old safari / ios
if (!("randomUUID" in crypto)) {
return "10000000-1000-4000-8000-100000000000".replace(/[018]/g, (c) =>
(
Number(c) ^
(crypto.getRandomValues(new Uint8Array(1))[0] & (15 >> (Number(c) / 4)))
).toString(16)
) as UUID;
}
return crypto.randomUUID();
}
|
chat-ui/src/lib/utils/randomUuid.ts/0
|
{
"file_path": "chat-ui/src/lib/utils/randomUuid.ts",
"repo_id": "chat-ui",
"token_count": 166
}
| 54 |
import { describe, expect, it } from "vitest";
import { isMessageId } from "./isMessageId";
import { v4 } from "uuid";
describe("isMessageId", () => {
it("should return true for a valid message id", () => {
expect(isMessageId(v4())).toBe(true);
});
it("should return false for an invalid message id", () => {
expect(isMessageId("1-2-3-4")).toBe(false);
});
it("should return false for an empty string", () => {
expect(isMessageId("")).toBe(false);
});
});
|
chat-ui/src/lib/utils/tree/isMessageId.spec.ts/0
|
{
"file_path": "chat-ui/src/lib/utils/tree/isMessageId.spec.ts",
"repo_id": "chat-ui",
"token_count": 170
}
| 55 |
<script lang="ts">
export let name: string;
export let description: string = "";
export let createdByName: string | undefined;
export let avatar: string | undefined;
import logo from "../../../../../static/huggingchat/logo.svg?raw";
</script>
<div class="flex h-full w-full flex-col items-center justify-center bg-black p-2">
<div class="flex w-full max-w-[540px] items-start justify-center text-white">
{#if avatar}
<img class="h-64 w-64 rounded-full" style="object-fit: cover;" src={avatar} alt="avatar" />
{/if}
<div class="ml-10 flex flex-col items-start">
<p class="mb-2 mt-0 text-3xl font-normal text-gray-400">
<span class="mr-1.5 h-8 w-8">
<!-- eslint-disable-next-line -->
{@html logo}
</span>
AI assistant
</p>
<h1 class="m-0 {name.length < 38 ? 'text-5xl' : 'text-4xl'} font-black">
{name}
</h1>
<p class="mb-8 text-2xl">
{description.slice(0, 160)}
{#if description.length > 160}...{/if}
</p>
<div class="rounded-full bg-[#FFA800] px-8 py-3 text-3xl font-semibold text-black">
Start chatting
</div>
</div>
</div>
{#if createdByName}
<p class="absolute bottom-4 right-8 text-2xl text-gray-400">
An AI assistant created by {createdByName}
</p>
{/if}
</div>
|
chat-ui/src/routes/assistant/[assistantId]/thumbnail.png/ChatThumbnail.svelte/0
|
{
"file_path": "chat-ui/src/routes/assistant/[assistantId]/thumbnail.png/ChatThumbnail.svelte",
"repo_id": "chat-ui",
"token_count": 545
}
| 56 |
import { refreshSessionCookie } from "$lib/server/auth";
import { collections } from "$lib/server/database";
import { ObjectId } from "mongodb";
import { DEFAULT_SETTINGS } from "$lib/types/Settings";
import { z } from "zod";
import type { UserinfoResponse } from "openid-client";
import { error, type Cookies } from "@sveltejs/kit";
import crypto from "crypto";
import { sha256 } from "$lib/utils/sha256";
import { addWeeks } from "date-fns";
export async function updateUser(params: {
userData: UserinfoResponse;
locals: App.Locals;
cookies: Cookies;
userAgent?: string;
ip?: string;
}) {
const { userData, locals, cookies, userAgent, ip } = params;
// Microsoft Entra v1 tokens do not provide preferred_username, instead the username is provided in the upn
// claim. See https://learn.microsoft.com/en-us/entra/identity-platform/access-token-claims-reference
if (!userData.preferred_username && userData.upn) {
userData.preferred_username = userData.upn as string;
}
const {
preferred_username: username,
name,
email,
picture: avatarUrl,
sub: hfUserId,
} = z
.object({
preferred_username: z.string().optional(),
name: z.string(),
picture: z.string().optional(),
sub: z.string(),
email: z.string().email().optional(),
})
.refine((data) => data.preferred_username || data.email, {
message: "Either preferred_username or email must be provided by the provider.",
})
.parse(userData);
// check if user already exists
const existingUser = await collections.users.findOne({ hfUserId });
let userId = existingUser?._id;
// update session cookie on login
const previousSessionId = locals.sessionId;
const secretSessionId = crypto.randomUUID();
const sessionId = await sha256(secretSessionId);
if (await collections.sessions.findOne({ sessionId })) {
throw error(500, "Session ID collision");
}
locals.sessionId = sessionId;
if (existingUser) {
// update existing user if any
await collections.users.updateOne(
{ _id: existingUser._id },
{ $set: { username, name, avatarUrl } }
);
// remove previous session if it exists and add new one
await collections.sessions.deleteOne({ sessionId: previousSessionId });
await collections.sessions.insertOne({
_id: new ObjectId(),
sessionId: locals.sessionId,
userId: existingUser._id,
createdAt: new Date(),
updatedAt: new Date(),
userAgent,
ip,
expiresAt: addWeeks(new Date(), 2),
});
// refresh session cookie
refreshSessionCookie(cookies, secretSessionId);
} else {
// user doesn't exist yet, create a new one
const { insertedId } = await collections.users.insertOne({
_id: new ObjectId(),
createdAt: new Date(),
updatedAt: new Date(),
username,
name,
email,
avatarUrl,
hfUserId,
});
userId = insertedId;
await collections.sessions.insertOne({
_id: new ObjectId(),
sessionId: locals.sessionId,
userId,
createdAt: new Date(),
updatedAt: new Date(),
userAgent,
ip,
expiresAt: addWeeks(new Date(), 2),
});
// move pre-existing settings to new user
const { matchedCount } = await collections.settings.updateOne(
{ sessionId: previousSessionId },
{
$set: { userId, updatedAt: new Date() },
$unset: { sessionId: "" },
}
);
if (!matchedCount) {
// if no settings found for user, create default settings
await collections.settings.insertOne({
userId,
ethicsModalAcceptedAt: new Date(),
updatedAt: new Date(),
createdAt: new Date(),
...DEFAULT_SETTINGS,
});
}
}
// migrate pre-existing conversations
await collections.conversations.updateMany(
{ sessionId: previousSessionId },
{
$set: { userId },
$unset: { sessionId: "" },
}
);
}
|
chat-ui/src/routes/login/callback/updateUser.ts/0
|
{
"file_path": "chat-ui/src/routes/login/callback/updateUser.ts",
"repo_id": "chat-ui",
"token_count": 1318
}
| 57 |
import { base } from "$app/paths";
import { redirect } from "@sveltejs/kit";
export async function load({ parent, params }) {
const data = await parent();
const assistant = data.settings.assistants.find((id) => id === params.assistantId);
if (!assistant) {
throw redirect(302, `${base}/assistant/${params.assistantId}`);
}
return data;
}
|
chat-ui/src/routes/settings/(nav)/assistants/[assistantId]/+page.ts/0
|
{
"file_path": "chat-ui/src/routes/settings/(nav)/assistants/[assistantId]/+page.ts",
"repo_id": "chat-ui",
"token_count": 115
}
| 58 |
# How to contribute to Datasets?
[](CODE_OF_CONDUCT.md)
Datasets is an open source project, so all contributions and suggestions are welcome.
You can contribute in many different ways: giving ideas, answering questions, reporting bugs, proposing enhancements,
improving the documentation, fixing bugs,...
Many thanks in advance to every contributor.
In order to facilitate healthy, constructive behavior in an open and inclusive community, we all respect and abide by
our [code of conduct](CODE_OF_CONDUCT.md).
## How to work on an open Issue?
You have the list of open Issues at: https://github.com/huggingface/datasets/issues
Some of them may have the label `help wanted`: that means that any contributor is welcomed!
If you would like to work on any of the open Issues:
1. Make sure it is not already assigned to someone else. You have the assignee (if any) on the top of the right column of the Issue page.
2. You can self-assign it by commenting on the Issue page with the keyword: `#self-assign`.
3. Work on your self-assigned issue and eventually create a Pull Request.
## How to create a Pull Request?
If you want to add a dataset see specific instructions in the section [*How to add a dataset*](#how-to-add-a-dataset).
1. Fork the [repository](https://github.com/huggingface/datasets) by clicking on the 'Fork' button on the repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone [email protected]:<your Github handle>/datasets.git
cd datasets
git remote add upstream https://github.com/huggingface/datasets.git
```
3. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
**do not** work on the `main` branch.
4. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e ".[dev]"
```
(If datasets was already installed in the virtual environment, remove
it with `pip uninstall datasets` before reinstalling it in editable
mode with the `-e` flag.)
5. Develop the features on your branch.
6. Format your code. Run `black` and `ruff` so that your newly added files look nice with the following command:
```bash
make style
```
7. _(Optional)_ You can also use [`pre-commit`](https://pre-commit.com/) to format your code automatically each time run `git commit`, instead of running `make style` manually.
To do this, install `pre-commit` via `pip install pre-commit` and then run `pre-commit install` in the project's root directory to set up the hooks.
Note that if any files were formatted by `pre-commit` hooks during committing, you have to run `git commit` again .
8. Once you're happy with your contribution, add your changed files and make a commit to record your changes locally:
```bash
git add -u
git commit
```
It is a good idea to sync your copy of the code with the original
repository regularly. This way you can quickly account for changes:
```bash
git fetch upstream
git rebase upstream/main
```
9. Once you are satisfied, push the changes to your fork repo using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
Go the webpage of your fork on GitHub. Click on "Pull request" to send your to the project maintainers for review.
## How to add a dataset
You can share your dataset on https://huggingface.co/datasets directly using your account, see the documentation:
* [Create a dataset and upload files on the website](https://huggingface.co/docs/datasets/upload_dataset)
* [Advanced guide using the CLI](https://huggingface.co/docs/datasets/share)
## How to contribute to the dataset cards
Improving the documentation of datasets is an ever-increasing effort, and we invite users to contribute by sharing their insights with the community in the `README.md` dataset cards provided for each dataset.
If you see that a dataset card is missing information that you are in a position to provide (as an author of the dataset or as an experienced user), the best thing you can do is to open a Pull Request on the Hugging Face Hub. To do, go to the "Files and versions" tab of the dataset page and edit the `README.md` file. We provide:
* a [template](https://github.com/huggingface/datasets/blob/main/templates/README.md)
* a [guide](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md) describing what information should go into each of the paragraphs
* and if you need inspiration, we recommend looking through a [completed example](https://huggingface.co/datasets/eli5/blob/main/README.md)
If you are a **dataset author**... you know what to do, it is your dataset after all ;) ! We would especially appreciate if you could help us fill in information about the process of creating the dataset, and take a moment to reflect on its social impact and possible limitations if you haven't already done so in the dataset paper or in another data statement.
If you are a **user of a dataset**, the main source of information should be the dataset paper if it is available: we recommend pulling information from there into the relevant paragraphs of the template. We also eagerly welcome discussions on the [Considerations for Using the Data](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md#considerations-for-using-the-data) based on existing scholarship or personal experience that would benefit the whole community.
Finally, if you want more information on the how and why of dataset cards, we strongly recommend reading the foundational works [Datasheets for Datasets](https://arxiv.org/abs/1803.09010) and [Data Statements for NLP](https://www.aclweb.org/anthology/Q18-1041/).
Thank you for your contribution!
## Code of conduct
This project adheres to the HuggingFace [code of conduct](CODE_OF_CONDUCT.md).
By participating, you are expected to abide by this code.
|
datasets/CONTRIBUTING.md/0
|
{
"file_path": "datasets/CONTRIBUTING.md",
"repo_id": "datasets",
"token_count": 1715
}
| 59 |
# Load audio data
You can load an audio dataset using the [`Audio`] feature that automatically decodes and resamples the audio files when you access the examples.
Audio decoding is based on the [`soundfile`](https://github.com/bastibe/python-soundfile) python package, which uses the [`libsndfile`](https://github.com/libsndfile/libsndfile) C library under the hood.
## Installation
To work with audio datasets, you need to have the `audio` dependencies installed.
Check out the [installation](./installation#audio) guide to learn how to install it.
## Local files
You can load your own dataset using the paths to your audio files. Use the [`~Dataset.cast_column`] function to take a column of audio file paths, and cast it to the [`Audio`] feature:
```py
>>> audio_dataset = Dataset.from_dict({"audio": ["path/to/audio_1", "path/to/audio_2", ..., "path/to/audio_n"]}).cast_column("audio", Audio())
>>> audio_dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': 'path/to/audio_1',
'sampling_rate': 16000}
```
## AudioFolder
You can also load a dataset with an `AudioFolder` dataset builder. It does not require writing a custom dataloader, making it useful for quickly creating and loading audio datasets with several thousand audio files.
## AudioFolder with metadata
To link your audio files with metadata information, make sure your dataset has a `metadata.csv` file. Your dataset structure might look like:
```
folder/train/metadata.csv
folder/train/first_audio_file.mp3
folder/train/second_audio_file.mp3
folder/train/third_audio_file.mp3
```
Your `metadata.csv` file must have a `file_name` column which links audio files with their metadata. An example `metadata.csv` file might look like:
```text
file_name,transcription
first_audio_file.mp3,znowu się duch z ciałem zrośnie w młodocianej wstaniesz wiosnie i możesz skutkiem tych leków umierać wstawać wiek wieków dalej tam były przestrogi jak siekać głowę jak nogi
second_audio_file.mp3,już u źwierzyńca podwojów król zasiada przy nim książęta i panowie rada a gdzie wzniosły krążył ganek rycerze obok kochanek król skinął palcem zaczęto igrzysko
third_audio_file.mp3,pewnie kędyś w obłędzie ubite minęły szlaki zaczekajmy dzień jaki poślemy szukać wszędzie dziś jutro pewnie będzie posłali wszędzie sługi czekali dzień i drugi gdy nic nie doczekali z płaczem chcą jechać dali
```
`AudioFolder` will load audio data and create a `transcription` column containing texts from `metadata.csv`:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder")
>>> # OR by specifying the list of files
>>> dataset = load_dataset("audiofolder", data_files=["path/to/audio_1", "path/to/audio_2", ..., "path/to/audio_n"])
```
You can load remote datasets from their URLs with the data_files parameter:
```py
>>> dataset = load_dataset("audiofolder", data_files=["https://foo.bar/audio_1", "https://foo.bar/audio_2", ..., "https://foo.bar/audio_n"]
>>> # for example, pass SpeechCommands archive:
>>> dataset = load_dataset("audiofolder", data_files="https://s3.amazonaws.com/datasets.huggingface.co/SpeechCommands/v0.01/v0.01_test.tar.gz")
```
Metadata can also be specified as JSON Lines, in which case use `metadata.jsonl` as the name of the metadata file. This format is helpful in scenarios when one of the columns is complex, e.g. a list of floats, to avoid parsing errors or reading the complex values as strings.
To ignore the information in the metadata file, set `drop_metadata=True` in [`load_dataset`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder", drop_metadata=True)
```
If you don't have a metadata file, `AudioFolder` automatically infers the label name from the directory name.
If you want to drop automatically created labels, set `drop_labels=True`.
In this case, your dataset will only contain an audio column:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder_without_metadata", drop_labels=True)
```
<Tip>
For more information about creating your own `AudioFolder` dataset, take a look at the [Create an audio dataset](./audio_dataset) guide.
</Tip>
For a guide on how to load any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="./loading">general loading guide</a>.
|
datasets/docs/source/audio_load.mdx/0
|
{
"file_path": "datasets/docs/source/audio_load.mdx",
"repo_id": "datasets",
"token_count": 1529
}
| 60 |
# Process
🤗 Datasets provides many tools for modifying the structure and content of a dataset. These tools are important for tidying up a dataset, creating additional columns, converting between features and formats, and much more.
This guide will show you how to:
- Reorder rows and split the dataset.
- Rename and remove columns, and other common column operations.
- Apply processing functions to each example in a dataset.
- Concatenate datasets.
- Apply a custom formatting transform.
- Save and export processed datasets.
For more details specific to processing other dataset modalities, take a look at the <a class="underline decoration-pink-400 decoration-2 font-semibold" href="./audio_process">process audio dataset guide</a>, the <a class="underline decoration-yellow-400 decoration-2 font-semibold" href="./image_process">process image dataset guide</a>, or the <a class="underline decoration-green-400 decoration-2 font-semibold" href="./nlp_process">process text dataset guide</a>.
The examples in this guide use the MRPC dataset, but feel free to load any dataset of your choice and follow along!
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("glue", "mrpc", split="train")
```
<Tip warning={true}>
All processing methods in this guide return a new [`Dataset`] object. Modification is not done in-place. Be careful about overriding your previous dataset!
</Tip>
## Sort, shuffle, select, split, and shard
There are several functions for rearranging the structure of a dataset.
These functions are useful for selecting only the rows you want, creating train and test splits, and sharding very large datasets into smaller chunks.
### Sort
Use [`~Dataset.sort`] to sort column values according to their numerical values. The provided column must be NumPy compatible.
```py
>>> dataset["label"][:10]
[1, 0, 1, 0, 1, 1, 0, 1, 0, 0]
>>> sorted_dataset = dataset.sort("label")
>>> sorted_dataset["label"][:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
>>> sorted_dataset["label"][-10:]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
Under the hood, this creates a list of indices that is sorted according to values of the column.
This indices mapping is then used to access the right rows in the underlying Arrow table.
### Shuffle
The [`~Dataset.shuffle`] function randomly rearranges the column values. You can specify the `generator` parameter in this function to use a different `numpy.random.Generator` if you want more control over the algorithm used to shuffle the dataset.
```py
>>> shuffled_dataset = sorted_dataset.shuffle(seed=42)
>>> shuffled_dataset["label"][:10]
[1, 1, 1, 0, 1, 1, 1, 1, 1, 0]
```
Shuffling takes the list of indices `[0:len(my_dataset)]` and shuffles it to create an indices mapping.
However as soon as your [`Dataset`] has an indices mapping, the speed can become 10x slower.
This is because there is an extra step to get the row index to read using the indices mapping, and most importantly, you aren't reading contiguous chunks of data anymore.
To restore the speed, you'd need to rewrite the entire dataset on your disk again using [`Dataset.flatten_indices`], which removes the indices mapping.
Alternatively, you can switch to an [`IterableDataset`] and leverage its fast approximate shuffling [`IterableDataset.shuffle`]:
```py
>>> iterable_dataset = dataset.to_iterable_dataset(num_shards=128)
>>> shuffled_iterable_dataset = iterable_dataset.shuffle(seed=42, buffer_size=1000)
```
### Select and Filter
There are two options for filtering rows in a dataset: [`~Dataset.select`] and [`~Dataset.filter`].
- [`~Dataset.select`] returns rows according to a list of indices:
```py
>>> small_dataset = dataset.select([0, 10, 20, 30, 40, 50])
>>> len(small_dataset)
6
```
- [`~Dataset.filter`] returns rows that match a specified condition:
```py
>>> start_with_ar = dataset.filter(lambda example: example["sentence1"].startswith("Ar"))
>>> len(start_with_ar)
6
>>> start_with_ar["sentence1"]
['Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
'Arison said Mann may have been one of the pioneers of the world music movement and he had a deep love of Brazilian music .',
'Arts helped coach the youth on an eighth-grade football team at Lombardi Middle School in Green Bay .',
'Around 9 : 00 a.m. EDT ( 1300 GMT ) , the euro was at $ 1.1566 against the dollar , up 0.07 percent on the day .',
"Arguing that the case was an isolated example , Canada has threatened a trade backlash if Tokyo 's ban is not justified on scientific grounds .",
'Artists are worried the plan would harm those who need help most - performers who have a difficult time lining up shows .'
]
```
[`~Dataset.filter`] can also filter by indices if you set `with_indices=True`:
```py
>>> even_dataset = dataset.filter(lambda example, idx: idx % 2 == 0, with_indices=True)
>>> len(even_dataset)
1834
>>> len(dataset) / 2
1834.0
```
Unless the list of indices to keep is contiguous, those methods also create an indices mapping under the hood.
### Split
The [`~Dataset.train_test_split`] function creates train and test splits if your dataset doesn't already have them. This allows you to adjust the relative proportions or an absolute number of samples in each split. In the example below, use the `test_size` parameter to create a test split that is 10% of the original dataset:
```py
>>> dataset.train_test_split(test_size=0.1)
{'train': Dataset(schema: {'sentence1': 'string', 'sentence2': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 3301),
'test': Dataset(schema: {'sentence1': 'string', 'sentence2': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 367)}
>>> 0.1 * len(dataset)
366.8
```
The splits are shuffled by default, but you can set `shuffle=False` to prevent shuffling.
### Shard
🤗 Datasets supports sharding to divide a very large dataset into a predefined number of chunks. Specify the `num_shards` parameter in [`~Dataset.shard`] to determine the number of shards to split the dataset into. You'll also need to provide the shard you want to return with the `index` parameter.
For example, the [imdb](https://huggingface.co/datasets/imdb) dataset has 25000 examples:
```py
>>> from datasets import load_dataset
>>> datasets = load_dataset("imdb", split="train")
>>> print(dataset)
Dataset({
features: ['text', 'label'],
num_rows: 25000
})
```
After sharding the dataset into four chunks, the first shard will only have 6250 examples:
```py
>>> dataset.shard(num_shards=4, index=0)
Dataset({
features: ['text', 'label'],
num_rows: 6250
})
>>> print(25000/4)
6250.0
```
## Rename, remove, cast, and flatten
The following functions allow you to modify the columns of a dataset. These functions are useful for renaming or removing columns, changing columns to a new set of features, and flattening nested column structures.
### Rename
Use [`~Dataset.rename_column`] when you need to rename a column in your dataset. Features associated with the original column are actually moved under the new column name, instead of just replacing the original column in-place.
Provide [`~Dataset.rename_column`] with the name of the original column, and the new column name:
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.rename_column("sentence1", "sentenceA")
>>> dataset = dataset.rename_column("sentence2", "sentenceB")
>>> dataset
Dataset({
features: ['sentenceA', 'sentenceB', 'label', 'idx'],
num_rows: 3668
})
```
### Remove
When you need to remove one or more columns, provide the column name to remove to the [`~Dataset.remove_columns`] function. Remove more than one column by providing a list of column names:
```py
>>> dataset = dataset.remove_columns("label")
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.remove_columns(["sentence1", "sentence2"])
>>> dataset
Dataset({
features: ['idx'],
num_rows: 3668
})
```
Conversely, [`~Dataset.select_columns`] selects one or more columns to keep and removes the rest. This function takes either one or a list of column names:
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.select_columns(['sentence1', 'sentence2', 'idx'])
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.select_columns('idx')
>>> dataset
Dataset({
features: ['idx'],
num_rows: 3668
})
```
### Cast
The [`~Dataset.cast`] function transforms the feature type of one or more columns. This function accepts your new [`Features`] as its argument. The example below demonstrates how to change the [`ClassLabel`] and [`Value`] features:
```py
>>> dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
>>> from datasets import ClassLabel, Value
>>> new_features = dataset.features.copy()
>>> new_features["label"] = ClassLabel(names=["negative", "positive"])
>>> new_features["idx"] = Value("int64")
>>> dataset = dataset.cast(new_features)
>>> dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['negative', 'positive'], names_file=None, id=None),
'idx': Value(dtype='int64', id=None)}
```
<Tip>
Casting only works if the original feature type and new feature type are compatible. For example, you can cast a column with the feature type `Value("int32")` to `Value("bool")` if the original column only contains ones and zeros.
</Tip>
Use the [`~Dataset.cast_column`] function to change the feature type of a single column. Pass the column name and its new feature type as arguments:
```py
>>> dataset.features
{'audio': Audio(sampling_rate=44100, mono=True, id=None)}
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> dataset.features
{'audio': Audio(sampling_rate=16000, mono=True, id=None)}
```
### Flatten
Sometimes a column can be a nested structure of several types. Take a look at the nested structure below from the SQuAD dataset:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("squad", split="train")
>>> dataset.features
{'answers': Sequence(feature={'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None),
'context': Value(dtype='string', id=None),
'id': Value(dtype='string', id=None),
'question': Value(dtype='string', id=None),
'title': Value(dtype='string', id=None)}
```
The `answers` field contains two subfields: `text` and `answer_start`. Use the [`~Dataset.flatten`] function to extract the subfields into their own separate columns:
```py
>>> flat_dataset = dataset.flatten()
>>> flat_dataset
Dataset({
features: ['id', 'title', 'context', 'question', 'answers.text', 'answers.answer_start'],
num_rows: 87599
})
```
Notice how the subfields are now their own independent columns: `answers.text` and `answers.answer_start`.
## Map
Some of the more powerful applications of 🤗 Datasets come from using the [`~Dataset.map`] function. The primary purpose of [`~Dataset.map`] is to speed up processing functions. It allows you to apply a processing function to each example in a dataset, independently or in batches. This function can even create new rows and columns.
In the following example, prefix each `sentence1` value in the dataset with `'My sentence: '`.
Start by creating a function that adds `'My sentence: '` to the beginning of each sentence. The function needs to accept and output a `dict`:
```py
>>> def add_prefix(example):
... example["sentence1"] = 'My sentence: ' + example["sentence1"]
... return example
```
Now use [`~Dataset.map`] to apply the `add_prefix` function to the entire dataset:
```py
>>> updated_dataset = small_dataset.map(add_prefix)
>>> updated_dataset["sentence1"][:5]
['My sentence: Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
"My sentence: Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'My sentence: They had published an advertisement on the Internet on June 10 , offering the cargo for sale , he added .',
'My sentence: Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
]
```
Let's take a look at another example, except this time, you'll remove a column with [`~Dataset.map`]. When you remove a column, it is only removed after the example has been provided to the mapped function. This allows the mapped function to use the content of the columns before they are removed.
Specify the column to remove with the `remove_columns` parameter in [`~Dataset.map`]:
```py
>>> updated_dataset = dataset.map(lambda example: {"new_sentence": example["sentence1"]}, remove_columns=["sentence1"])
>>> updated_dataset.column_names
['sentence2', 'label', 'idx', 'new_sentence']
```
<Tip>
🤗 Datasets also has a [`~Dataset.remove_columns`] function which is faster because it doesn't copy the data of the remaining columns.
</Tip>
You can also use [`~Dataset.map`] with indices if you set `with_indices=True`. The example below adds the index to the beginning of each sentence:
```py
>>> updated_dataset = dataset.map(lambda example, idx: {"sentence2": f"{idx}: " + example["sentence2"]}, with_indices=True)
>>> updated_dataset["sentence2"][:5]
['0: Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
"1: Yucaipa bought Dominick 's in 1995 for $ 693 million and sold it to Safeway for $ 1.8 billion in 1998 .",
"2: On June 10 , the ship 's owners had published an advertisement on the Internet , offering the explosives for sale .",
'3: Tab shares jumped 20 cents , or 4.6 % , to set a record closing high at A $ 4.57 .',
'4: PG & E Corp. shares jumped $ 1.63 or 8 percent to $ 21.03 on the New York Stock Exchange on Friday .'
]
```
### Multiprocessing
Multiprocessing significantly speeds up processing by parallelizing processes on the CPU. Set the `num_proc` parameter in [`~Dataset.map`] to set the number of processes to use:
```py
>>> updated_dataset = dataset.map(lambda example, idx: {"sentence2": f"{idx}: " + example["sentence2"]}, num_proc=4)
```
The [`~Dataset.map`] also works with the rank of the process if you set `with_rank=True`. This is analogous to the `with_indices` parameter. The `with_rank` parameter in the mapped function goes after the `index` one if it is already present.
```py
>>> import torch
>>> from multiprocess import set_start_method
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> from datasets import load_dataset
>>>
>>> # Get an example dataset
>>> dataset = load_dataset("fka/awesome-chatgpt-prompts", split="train")
>>>
>>> # Get an example model and its tokenizer
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-0.5B-Chat").eval()
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-0.5B-Chat")
>>>
>>> def gpu_computation(batch, rank):
... # Move the model on the right GPU if it's not there already
... device = f"cuda:{(rank or 0) % torch.cuda.device_count()}"
... model.to(device)
...
... # Your big GPU call goes here, for example:
... chats = [[
... {"role": "system", "content": "You are a helpful assistant."},
... {"role": "user", "content": prompt}
... ] for prompt in batch["prompt"]]
... texts = [tokenizer.apply_chat_template(
... chat,
... tokenize=False,
... add_generation_prompt=True
... ) for chat in chats]
... model_inputs = tokenizer(texts, padding=True, return_tensors="pt").to(device)
... with torch.no_grad():
... outputs = model.generate(**model_inputs, max_new_tokens=512)
... batch["output"] = tokenizer.batch_decode(outputs, skip_special_tokens=True)
... return batch
>>>
>>> if __name__ == "__main__":
... set_start_method("spawn")
... updated_dataset = dataset.map(
... gpu_computation,
... batched=True,
... batch_size=16,
... with_rank=True,
... num_proc=torch.cuda.device_count(), # one process per GPU
... )
```
The main use-case for rank is to parallelize computation across several GPUs. This requires setting `multiprocess.set_start_method("spawn")`. If you don't you'll receive the following CUDA error:
```bash
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method.
```
### Batch processing
The [`~Dataset.map`] function supports working with batches of examples. Operate on batches by setting `batched=True`. The default batch size is 1000, but you can adjust it with the `batch_size` parameter. Batch processing enables interesting applications such as splitting long sentences into shorter chunks and data augmentation.
#### Split long examples
When examples are too long, you may want to split them into several smaller chunks. Begin by creating a function that:
1. Splits the `sentence1` field into chunks of 50 characters.
2. Stacks all the chunks together to create the new dataset.
```py
>>> def chunk_examples(examples):
... chunks = []
... for sentence in examples["sentence1"]:
... chunks += [sentence[i:i + 50] for i in range(0, len(sentence), 50)]
... return {"chunks": chunks}
```
Apply the function with [`~Dataset.map`]:
```py
>>> chunked_dataset = dataset.map(chunk_examples, batched=True, remove_columns=dataset.column_names)
>>> chunked_dataset[:10]
{'chunks': ['Amrozi accused his brother , whom he called " the ',
'witness " , of deliberately distorting his evidenc',
'e .',
"Yucaipa owned Dominick 's before selling the chain",
' to Safeway in 1998 for $ 2.5 billion .',
'They had published an advertisement on the Interne',
't on June 10 , offering the cargo for sale , he ad',
'ded .',
'Around 0335 GMT , Tab shares were up 19 cents , or',
' 4.4 % , at A $ 4.56 , having earlier set a record']}
```
Notice how the sentences are split into shorter chunks now, and there are more rows in the dataset.
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> chunked_dataset
Dataset({
features: ['chunks'],
num_rows: 10470
})
```
#### Data augmentation
The [`~Dataset.map`] function could also be used for data augmentation. The following example generates additional words for a masked token in a sentence.
Load and use the [RoBERTA](https://huggingface.co/roberta-base) model in 🤗 Transformers' [FillMaskPipeline](https://huggingface.co/transformers/main_classes/pipelines#transformers.FillMaskPipeline):
```py
>>> from random import randint
>>> from transformers import pipeline
>>> fillmask = pipeline("fill-mask", model="roberta-base")
>>> mask_token = fillmask.tokenizer.mask_token
>>> smaller_dataset = dataset.filter(lambda e, i: i<100, with_indices=True)
```
Create a function to randomly select a word to mask in the sentence. The function should also return the original sentence and the top two replacements generated by RoBERTA.
```py
>>> def augment_data(examples):
... outputs = []
... for sentence in examples["sentence1"]:
... words = sentence.split(' ')
... K = randint(1, len(words)-1)
... masked_sentence = " ".join(words[:K] + [mask_token] + words[K+1:])
... predictions = fillmask(masked_sentence)
... augmented_sequences = [predictions[i]["sequence"] for i in range(3)]
... outputs += [sentence] + augmented_sequences
...
... return {"data": outputs}
```
Use [`~Dataset.map`] to apply the function over the whole dataset:
```py
>>> augmented_dataset = smaller_dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, batch_size=8)
>>> augmented_dataset[:9]["data"]
['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'Amrozi accused his brother, whom he called " the witness ", of deliberately withholding his evidence.',
'Amrozi accused his brother, whom he called " the witness ", of deliberately suppressing his evidence.',
'Amrozi accused his brother, whom he called " the witness ", of deliberately destroying his evidence.',
"Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'Yucaipa owned Dominick Stores before selling the chain to Safeway in 1998 for $ 2.5 billion.',
"Yucaipa owned Dominick's before selling the chain to Safeway in 1998 for $ 2.5 billion.",
'Yucaipa owned Dominick Pizza before selling the chain to Safeway in 1998 for $ 2.5 billion.'
]
```
For each original sentence, RoBERTA augmented a random word with three alternatives. The original word `distorting` is supplemented by `withholding`, `suppressing`, and `destroying`.
### Process multiple splits
Many datasets have splits that can be processed simultaneously with [`DatasetDict.map`]. For example, tokenize the `sentence1` field in the train and test split by:
```py
>>> from datasets import load_dataset
# load all the splits
>>> dataset = load_dataset('glue', 'mrpc')
>>> encoded_dataset = dataset.map(lambda examples: tokenizer(examples["sentence1"]), batched=True)
>>> encoded_dataset["train"][0]
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0,
'input_ids': [ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
```
### Distributed usage
When you use [`~Dataset.map`] in a distributed setting, you should also use [torch.distributed.barrier](https://pytorch.org/docs/stable/distributed?highlight=barrier#torch.distributed.barrier). This ensures the main process performs the mapping, while the other processes load the results, thereby avoiding duplicate work.
The following example shows how you can use `torch.distributed.barrier` to synchronize the processes:
```py
>>> from datasets import Dataset
>>> import torch.distributed
>>> dataset1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> if training_args.local_rank > 0:
... print("Waiting for main process to perform the mapping")
... torch.distributed.barrier()
>>> dataset2 = dataset1.map(lambda x: {"a": x["a"] + 1})
>>> if training_args.local_rank == 0:
... print("Loading results from main process")
... torch.distributed.barrier()
```
## Concatenate
Separate datasets can be concatenated if they share the same column types. Concatenate datasets with [`concatenate_datasets`]:
```py
>>> from datasets import concatenate_datasets, load_dataset
>>> bookcorpus = load_dataset("bookcorpus", split="train")
>>> wiki = load_dataset("wikipedia", "20220301.en", split="train")
>>> wiki = wiki.remove_columns([col for col in wiki.column_names if col != "text"]) # only keep the 'text' column
>>> assert bookcorpus.features.type == wiki.features.type
>>> bert_dataset = concatenate_datasets([bookcorpus, wiki])
```
You can also concatenate two datasets horizontally by setting `axis=1` as long as the datasets have the same number of rows:
```py
>>> from datasets import Dataset
>>> bookcorpus_ids = Dataset.from_dict({"ids": list(range(len(bookcorpus)))})
>>> bookcorpus_with_ids = concatenate_datasets([bookcorpus, bookcorpus_ids], axis=1)
```
### Interleave
You can also mix several datasets together by taking alternating examples from each one to create a new dataset. This is known as *interleaving*, which is enabled by the [`interleave_datasets`] function. Both [`interleave_datasets`] and [`concatenate_datasets`] work with regular [`Dataset`] and [`IterableDataset`] objects.
Refer to the [Stream](./stream#interleave) guide for an example of how to interleave [`IterableDataset`] objects.
You can define sampling probabilities for each of the original datasets to specify how to interleave the datasets.
In this case, the new dataset is constructed by getting examples one by one from a random dataset until one of the datasets runs out of samples.
```py
>>> seed = 42
>>> probabilities = [0.3, 0.5, 0.2]
>>> d1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
>>> d3 = Dataset.from_dict({"a": [20, 21, 22]})
>>> dataset = interleave_datasets([d1, d2, d3], probabilities=probabilities, seed=seed)
>>> dataset["a"]
[10, 11, 20, 12, 0, 21, 13]
```
You can also specify the `stopping_strategy`. The default strategy, `first_exhausted`, is a subsampling strategy, i.e the dataset construction is stopped as soon one of the dataset runs out of samples.
You can specify `stopping_strategy=all_exhausted` to execute an oversampling strategy. In this case, the dataset construction is stopped as soon as every samples in every dataset has been added at least once. In practice, it means that if a dataset is exhausted, it will return to the beginning of this dataset until the stop criterion has been reached.
Note that if no sampling probabilities are specified, the new dataset will have `max_length_datasets*nb_dataset samples`.
```py
>>> d1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
>>> d3 = Dataset.from_dict({"a": [20, 21, 22]})
>>> dataset = interleave_datasets([d1, d2, d3], stopping_strategy="all_exhausted")
>>> dataset["a"]
[0, 10, 20, 1, 11, 21, 2, 12, 22, 0, 13, 20]
```
## Format
The [`~Dataset.set_format`] function changes the format of a column to be compatible with some common data formats. Specify the output you'd like in the `type` parameter and the columns you want to format. Formatting is applied on-the-fly.
For example, create PyTorch tensors by setting `type="torch"`:
```py
>>> import torch
>>> dataset.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])
```
The [`~Dataset.with_format`] function also changes the format of a column, except it returns a new [`Dataset`] object:
```py
>>> dataset = dataset.with_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])
```
<Tip>
🤗 Datasets also provides support for other common data formats such as NumPy, Pandas, and JAX. Check out the [Using Datasets with TensorFlow](https://huggingface.co/docs/datasets/master/en/use_with_tensorflow#using-totfdataset) guide for more details on how to efficiently create a TensorFlow dataset.
</Tip>
If you need to reset the dataset to its original format, use the [`~Dataset.reset_format`] function:
```py
>>> dataset.format
{'type': 'torch', 'format_kwargs': {}, 'columns': ['label'], 'output_all_columns': False}
>>> dataset.reset_format()
>>> dataset.format
{'type': 'python', 'format_kwargs': {}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}
```
### Format transform
The [`~Dataset.set_transform`] function applies a custom formatting transform on-the-fly. This function replaces any previously specified format. For example, you can use this function to tokenize and pad tokens on-the-fly. Tokenization is only applied when examples are accessed:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> def encode(batch):
... return tokenizer(batch["sentence1"], padding="longest", truncation=True, max_length=512, return_tensors="pt")
>>> dataset.set_transform(encode)
>>> dataset.format
{'type': 'custom', 'format_kwargs': {'transform': <function __main__.encode(batch)>}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}
```
You can also use the [`~Dataset.set_transform`] function to decode formats not supported by [`Features`]. For example, the [`Audio`] feature uses [`soundfile`](https://python-soundfile.readthedocs.io/en/0.11.0/) - a fast and simple library to install - but it does not provide support for less common audio formats. Here is where you can use [`~Dataset.set_transform`] to apply a custom decoding transform on the fly. You're free to use any library you like to decode the audio files.
The example below uses the [`pydub`](http://pydub.com/) package to open an audio format not supported by `soundfile`:
```py
>>> import numpy as np
>>> from pydub import AudioSegment
>>> audio_dataset_amr = Dataset.from_dict({"audio": ["audio_samples/audio.amr"]})
>>> def decode_audio_with_pydub(batch, sampling_rate=16_000):
... def pydub_decode_file(audio_path):
... sound = AudioSegment.from_file(audio_path)
... if sound.frame_rate != sampling_rate:
... sound = sound.set_frame_rate(sampling_rate)
... channel_sounds = sound.split_to_mono()
... samples = [s.get_array_of_samples() for s in channel_sounds]
... fp_arr = np.array(samples).T.astype(np.float32)
... fp_arr /= np.iinfo(samples[0].typecode).max
... return fp_arr
...
... batch["audio"] = [pydub_decode_file(audio_path) for audio_path in batch["audio"]]
... return batch
>>> audio_dataset_amr.set_transform(decode_audio_with_pydub)
```
## Save
Once you are done processing your dataset, you can save and reuse it later with [`~Dataset.save_to_disk`].
Save your dataset by providing the path to the directory you wish to save it to:
```py
>>> encoded_dataset.save_to_disk("path/of/my/dataset/directory")
```
Use the [`load_from_disk`] function to reload the dataset:
```py
>>> from datasets import load_from_disk
>>> reloaded_dataset = load_from_disk("path/of/my/dataset/directory")
```
<Tip>
Want to save your dataset to a cloud storage provider? Read our [Cloud Storage](./filesystems) guide to learn how to save your dataset to AWS or Google Cloud Storage.
</Tip>
## Export
🤗 Datasets supports exporting as well so you can work with your dataset in other applications. The following table shows currently supported file formats you can export to:
| File type | Export method |
|-------------------------|----------------------------------------------------------------|
| CSV | [`Dataset.to_csv`] |
| JSON | [`Dataset.to_json`] |
| Parquet | [`Dataset.to_parquet`] |
| SQL | [`Dataset.to_sql`] |
| In-memory Python object | [`Dataset.to_pandas`] or [`Dataset.to_dict`] |
For example, export your dataset to a CSV file like this:
```py
>>> encoded_dataset.to_csv("path/of/my/dataset.csv")
```
|
datasets/docs/source/process.mdx/0
|
{
"file_path": "datasets/docs/source/process.mdx",
"repo_id": "datasets",
"token_count": 10400
}
| 61 |
# Metric Card for Accuracy
## Metric Description
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'accuracy': 1.0}
```
### Inputs
- **predictions** (`list` of `int`): Predicted labels.
- **references** (`list` of `int`): Ground truth labels.
- **normalize** (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.
- **sample_weight** (`list` of `float`): Sample weights Defaults to None.
### Output Values
- **accuracy**(`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.
Output Example(s):
```python
{'accuracy': 1.0}
```
This metric outputs a dictionary, containing the accuracy score.
#### Values from Popular Papers
Top-1 or top-5 accuracy is often used to report performance on supervised classification tasks such as image classification (e.g. on [ImageNet](https://paperswithcode.com/sota/image-classification-on-imagenet)) or sentiment analysis (e.g. on [IMDB](https://paperswithcode.com/sota/text-classification-on-imdb)).
### Examples
Example 1-A simple example
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
>>> print(results)
{'accuracy': 0.5}
```
Example 2-The same as Example 1, except with `normalize` set to `False`.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)
>>> print(results)
{'accuracy': 3.0}
```
Example 3-The same as Example 1, except with `sample_weight` set.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])
>>> print(results)
{'accuracy': 0.8778625954198473}
```
## Limitations and Bias
This metric can be easily misleading, especially in the case of unbalanced classes. For example, a high accuracy might be because a model is doing well, but if the data is unbalanced, it might also be because the model is only accurately labeling the high-frequency class. In such cases, a more detailed analysis of the model's behavior, or the use of a different metric entirely, is necessary to determine how well the model is actually performing.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
|
datasets/metrics/accuracy/README.md/0
|
{
"file_path": "datasets/metrics/accuracy/README.md",
"repo_id": "datasets",
"token_count": 1120
}
| 62 |
# Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""COMET metric.
Requirements:
pip install unbabel-comet
Usage:
```python
from datasets import load_metric
comet_metric = load_metric('metrics/comet/comet.py')
#comet_metric = load_metric('comet')
#comet_metric = load_metric('comet', 'wmt-large-hter-estimator')
source = ["Dem Feuer konnte Einhalt geboten werden", "Schulen und Kindergärten wurden eröffnet."]
hypothesis = ["The fire could be stopped", "Schools and kindergartens were open"]
reference = ["They were able to control the fire.", "Schools and kindergartens opened"]
predictions = comet_metric.compute(predictions=hypothesis, references=reference, sources=source)
predictions['scores']
```
"""
import comet # From: unbabel-comet
import torch
import datasets
logger = datasets.logging.get_logger(__name__)
_CITATION = """\
@inproceedings{rei-EtAl:2020:WMT,
author = {Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon},
title = {Unbabel's Participation in the WMT20 Metrics Shared Task},
booktitle = {Proceedings of the Fifth Conference on Machine Translation},
month = {November},
year = {2020},
address = {Online},
publisher = {Association for Computational Linguistics},
pages = {909--918},
}
@inproceedings{rei-etal-2020-comet,
title = "{COMET}: A Neural Framework for {MT} Evaluation",
author = "Rei, Ricardo and
Stewart, Craig and
Farinha, Ana C and
Lavie, Alon",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.213",
pages = "2685--2702",
}
"""
_DESCRIPTION = """\
Crosslingual Optimized Metric for Evaluation of Translation (COMET) is an open-source framework used to train Machine Translation metrics that achieve high levels of correlation with different types of human judgments (HTER, DA's or MQM).
With the release of the framework the authors also released fully trained models that were used to compete in the WMT20 Metrics Shared Task achieving SOTA in that years competition.
See the [README.md] file at https://unbabel.github.io/COMET/html/models.html for more information.
"""
_KWARGS_DESCRIPTION = """
COMET score.
Args:
`sources` (list of str): Source sentences
`predictions` (list of str): candidate translations
`references` (list of str): reference translations
`cuda` (bool): If set to True, runs COMET using GPU
`show_progress` (bool): Shows progress
`model`: COMET model to be used. Will default to `wmt-large-da-estimator-1719` if None.
Returns:
`samples`: List of dictionaries with `src`, `mt`, `ref` and `score`.
`scores`: List of scores.
Examples:
>>> comet_metric = datasets.load_metric('comet')
>>> # comet_metric = load_metric('comet', 'wmt20-comet-da') # you can also choose which model to use
>>> source = ["Dem Feuer konnte Einhalt geboten werden", "Schulen und Kindergärten wurden eröffnet."]
>>> hypothesis = ["The fire could be stopped", "Schools and kindergartens were open"]
>>> reference = ["They were able to control the fire.", "Schools and kindergartens opened"]
>>> results = comet_metric.compute(predictions=hypothesis, references=reference, sources=source)
>>> print([round(v, 2) for v in results["scores"]])
[0.19, 0.92]
"""
@datasets.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class COMET(datasets.Metric):
def _info(self):
return datasets.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
homepage="https://unbabel.github.io/COMET/html/index.html",
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"sources": datasets.Value("string", id="sequence"),
"predictions": datasets.Value("string", id="sequence"),
"references": datasets.Value("string", id="sequence"),
}
),
codebase_urls=["https://github.com/Unbabel/COMET"],
reference_urls=[
"https://github.com/Unbabel/COMET",
"https://www.aclweb.org/anthology/2020.emnlp-main.213/",
"http://www.statmt.org/wmt20/pdf/2020.wmt-1.101.pdf6",
],
)
def _download_and_prepare(self, dl_manager):
if self.config_name == "default":
self.scorer = comet.load_from_checkpoint(comet.download_model("wmt20-comet-da"))
else:
self.scorer = comet.load_from_checkpoint(comet.download_model(self.config_name))
def _compute(self, sources, predictions, references, gpus=None, progress_bar=False):
if gpus is None:
gpus = 1 if torch.cuda.is_available() else 0
data = {"src": sources, "mt": predictions, "ref": references}
data = [dict(zip(data, t)) for t in zip(*data.values())]
scores, mean_score = self.scorer.predict(data, gpus=gpus, progress_bar=progress_bar)
return {"mean_score": mean_score, "scores": scores}
|
datasets/metrics/comet/comet.py/0
|
{
"file_path": "datasets/metrics/comet/comet.py",
"repo_id": "datasets",
"token_count": 2168
}
| 63 |
# Metric Card for Google BLEU (GLEU)
## Metric Description
The BLEU score has some undesirable properties when used for single
sentences, as it was designed to be a corpus measure. The Google BLEU score, also known as GLEU score, is designed to limit these undesirable properties when used for single sentences.
To calculate this score, all sub-sequences of 1, 2, 3 or 4 tokens in output and target sequence (n-grams) are recorded. The precision and recall, described below, are then computed.
- **precision:** the ratio of the number of matching n-grams to the number of total n-grams in the generated output sequence
- **recall:** the ratio of the number of matching n-grams to the number of total n-grams in the target (ground truth) sequence
The minimum value of precision and recall is then returned as the score.
## Intended Uses
This metric is generally used to evaluate machine translation models. It is especially used when scores of individual (prediction, reference) sentence pairs are needed, as opposed to when averaging over the (prediction, reference) scores for a whole corpus. That being said, it can also be used when averaging over the scores for a whole corpus.
Because it performs better on individual sentence pairs as compared to BLEU, Google BLEU has also been used in RL experiments.
## How to Use
At minimum, this metric takes predictions and references:
```python
>>> sentence1 = "the cat sat on the mat".split()
>>> sentence2 = "the cat ate the mat".split()
>>> google_bleu = datasets.load_metric("google_bleu")
>>> result = google_bleu.compute(predictions=[sentence1], references=[[sentence2]])
>>> print(result)
{'google_bleu': 0.3333333333333333}
```
### Inputs
- **predictions** (list of list of str): list of translations to score. Each translation should be tokenized into a list of tokens.
- **references** (list of list of list of str): list of lists of references for each translation. Each reference should be tokenized into a list of tokens.
- **min_len** (int): The minimum order of n-gram this function should extract. Defaults to 1.
- **max_len** (int): The maximum order of n-gram this function should extract. Defaults to 4.
### Output Values
This metric returns the following in a dict:
- **google_bleu** (float): google_bleu score
The output format is as follows:
```python
{'google_bleu': google_bleu score}
```
This metric can take on values from 0 to 1, inclusive. Higher scores are better, with 0 indicating no matches, and 1 indicating a perfect match.
Note that this score is symmetrical when switching output and target. This means that, given two sentences, `sentence1` and `sentence2`, whatever score is output when `sentence1` is the predicted sentence and `sencence2` is the reference sentence will be the same as when the sentences are swapped and `sentence2` is the predicted sentence while `sentence1` is the reference sentence. In code, this looks like:
```python
sentence1 = "the cat sat on the mat".split()
sentence2 = "the cat ate the mat".split()
google_bleu = datasets.load_metric("google_bleu")
result_a = google_bleu.compute(predictions=[sentence1], references=[[sentence2]])
result_b = google_bleu.compute(predictions=[sentence2], references=[[sentence1]])
print(result_a == result_b)
>>> True
```
#### Values from Popular Papers
### Examples
Example with one reference per sample:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references)
>>> print(round(results["google_bleu"], 2))
0.44
```
Example with multiple references for the first sample:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references)
>>> print(round(results["google_bleu"], 2))
0.61
```
Example with multiple references for the first sample, and with `min_len` adjusted to `2`, instead of the default `1`:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references, min_len=2)
>>> print(round(results["google_bleu"], 2))
0.53
```
Example with multiple references for the first sample, with `min_len` adjusted to `2`, instead of the default `1`, and `max_len` adjusted to `6` instead of the default `4`:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses,references=list_of_references, min_len=2, max_len=6)
>>> print(round(results["google_bleu"], 2))
0.4
```
## Limitations and Bias
## Citation
```bibtex
@misc{wu2016googles,
title={Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation},
author={Yonghui Wu and Mike Schuster and Zhifeng Chen and Quoc V. Le and Mohammad Norouzi and Wolfgang Macherey and Maxim Krikun and Yuan Cao and Qin Gao and Klaus Macherey and Jeff Klingner and Apurva Shah and Melvin Johnson and Xiaobing Liu and Łukasz Kaiser and Stephan Gouws and Yoshikiyo Kato and Taku Kudo and Hideto Kazawa and Keith Stevens and George Kurian and Nishant Patil and Wei Wang and Cliff Young and Jason Smith and Jason Riesa and Alex Rudnick and Oriol Vinyals and Greg Corrado and Macduff Hughes and Jeffrey Dean},
year={2016},
eprint={1609.08144},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Further References
- This Hugging Face implementation uses the [nltk.translate.gleu_score implementation](https://www.nltk.org/_modules/nltk/translate/gleu_score.html)
|
datasets/metrics/google_bleu/README.md/0
|
{
"file_path": "datasets/metrics/google_bleu/README.md",
"repo_id": "datasets",
"token_count": 3361
}
| 64 |
# Metric Card for MSE
## Metric Description
Mean Squared Error(MSE) represents the average of the squares of errors -- i.e. the average squared difference between the estimated values and the actual values.
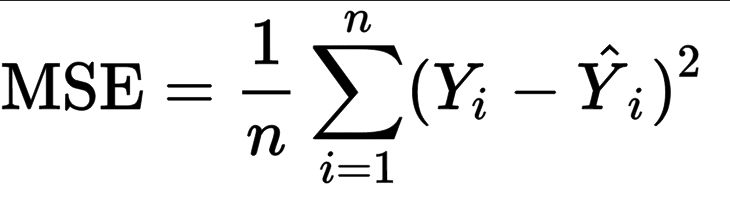
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> mse_metric = datasets.load_metric("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mse_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
- `squared` (`bool`): If `True` returns MSE value, if `False` returns RMSE (Root Mean Squared Error). The default value is `True`.
### Output Values
This metric outputs a dictionary, containing the mean squared error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MSE `float` value ranges from `0.0` to `1.0`, with the best value being `0.0`.
Output Example(s):
```python
{'mse': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mse': array([0.41666667, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> from datasets import load_metric
>>> mse_metric = load_metric("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mse_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mse': 0.375}
```
Example with `squared = True`, which returns the RMSE:
```python
>>> from datasets import load_metric
>>> mse_metric = load_metric("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> rmse_result = mse_metric.compute(predictions=predictions, references=references, squared=False)
>>> print(rmse_result)
{'mse': 0.6123724356957945}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> from datasets import load_metric
>>> mse_metric = load_metric("mse", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0, 2], [-1, 2], [8, -5]]
>>> results = mse_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'mse': array([0.41666667, 1. ])}
"""
```
## Limitations and Bias
MSE has the disadvantage of heavily weighting outliers -- given that it squares them, this results in large errors weighing more heavily than small ones. It can be used alongside [MAE](https://huggingface.co/metrics/mae), which is complementary given that it does not square the errors.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
```bibtex
@article{willmott2005advantages,
title={Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance},
author={Willmott, Cort J and Matsuura, Kenji},
journal={Climate research},
volume={30},
number={1},
pages={79--82},
year={2005}
}
```
## Further References
- [Mean Squared Error - Wikipedia](https://en.wikipedia.org/wiki/Mean_squared_error)
|
datasets/metrics/mse/README.md/0
|
{
"file_path": "datasets/metrics/mse/README.md",
"repo_id": "datasets",
"token_count": 1554
}
| 65 |
# Metric Card for SARI
## Metric description
SARI (***s**ystem output **a**gainst **r**eferences and against the **i**nput sentence*) is a metric used for evaluating automatic text simplification systems.
The metric compares the predicted simplified sentences against the reference and the source sentences. It explicitly measures the goodness of words that are added, deleted and kept by the system.
SARI can be computed as:
`sari = ( F1_add + F1_keep + P_del) / 3`
where
`F1_add` is the n-gram F1 score for add operations
`F1_keep` is the n-gram F1 score for keep operations
`P_del` is the n-gram precision score for delete operations
The number of n grams, `n`, is equal to 4, as in the original paper.
This implementation is adapted from [Tensorflow's tensor2tensor implementation](https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/sari_hook.py).
It has two differences with the [original GitHub implementation](https://github.com/cocoxu/simplification/blob/master/SARI.py):
1) It defines 0/0=1 instead of 0 to give higher scores for predictions that match a target exactly.
2) It fixes an [alleged bug](https://github.com/cocoxu/simplification/issues/6) in the keep score computation.
## How to use
The metric takes 3 inputs: sources (a list of source sentence strings), predictions (a list of predicted sentence strings) and references (a list of lists of reference sentence strings)
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted."]
predictions=["About 95 you now get in."]
references=[["About 95 species are currently known.","About 95 species are now accepted.","95 species are now accepted."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary with the SARI score:
```
print(sari_score)
{'sari': 26.953601953601954}
```
The range of values for the SARI score is between 0 and 100 -- the higher the value, the better the performance of the model being evaluated, with a SARI of 100 being a perfect score.
### Values from popular papers
The [original paper that proposes the SARI metric](https://aclanthology.org/Q16-1029.pdf) reports scores ranging from 26 to 43 for different simplification systems and different datasets. They also find that the metric ranks all of the simplification systems and human references in the same order as the human assessment used as a comparison, and that it correlates reasonably with human judgments.
More recent SARI scores for text simplification can be found on leaderboards for datasets such as [TurkCorpus](https://paperswithcode.com/sota/text-simplification-on-turkcorpus) and [Newsela](https://paperswithcode.com/sota/text-simplification-on-newsela).
## Examples
Perfect match between prediction and reference:
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted ."]
predictions=["About 95 species are currently accepted ."]
references=[["About 95 species are currently accepted ."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
print(sari_score)
{'sari': 100.0}
```
Partial match between prediction and reference:
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted ."]
predictions=["About 95 you now get in ."]
references=[["About 95 species are currently known .","About 95 species are now accepted .","95 species are now accepted ."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
print(sari_score)
{'sari': 26.953601953601954}
```
## Limitations and bias
SARI is a valuable measure for comparing different text simplification systems as well as one that can assist the iterative development of a system.
However, while the [original paper presenting SARI](https://aclanthology.org/Q16-1029.pdf) states that it captures "the notion of grammaticality and meaning preservation", this is a difficult claim to empirically validate.
## Citation
```bibtex
@inproceedings{xu-etal-2016-optimizing,
title = {Optimizing Statistical Machine Translation for Text Simplification},
authors={Xu, Wei and Napoles, Courtney and Pavlick, Ellie and Chen, Quanze and Callison-Burch, Chris},
journal = {Transactions of the Association for Computational Linguistics},
volume = {4},
year={2016},
url = {https://www.aclweb.org/anthology/Q16-1029},
pages = {401--415},
}
```
## Further References
- [NLP Progress -- Text Simplification](http://nlpprogress.com/english/simplification.html)
- [Hugging Face Hub -- Text Simplification Models](https://huggingface.co/datasets?filter=task_ids:text-simplification)
|
datasets/metrics/sari/README.md/0
|
{
"file_path": "datasets/metrics/sari/README.md",
"repo_id": "datasets",
"token_count": 1355
}
| 66 |
# Copyright 2021 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""TER metric as available in sacrebleu."""
import sacrebleu as scb
from packaging import version
from sacrebleu import TER
import datasets
_CITATION = """\
@inproceedings{snover-etal-2006-study,
title = "A Study of Translation Edit Rate with Targeted Human Annotation",
author = "Snover, Matthew and
Dorr, Bonnie and
Schwartz, Rich and
Micciulla, Linnea and
Makhoul, John",
booktitle = "Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers",
month = aug # " 8-12",
year = "2006",
address = "Cambridge, Massachusetts, USA",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2006.amta-papers.25",
pages = "223--231",
}
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
"""
_DESCRIPTION = """\
TER (Translation Edit Rate, also called Translation Error Rate) is a metric to quantify the edit operations that a
hypothesis requires to match a reference translation. We use the implementation that is already present in sacrebleu
(https://github.com/mjpost/sacreBLEU#ter), which in turn is inspired by the TERCOM implementation, which can be found
here: https://github.com/jhclark/tercom.
The implementation here is slightly different from sacrebleu in terms of the required input format. The length of
the references and hypotheses lists need to be the same, so you may need to transpose your references compared to
sacrebleu's required input format. See https://github.com/huggingface/datasets/issues/3154#issuecomment-950746534
See the README.md file at https://github.com/mjpost/sacreBLEU#ter for more information.
"""
_KWARGS_DESCRIPTION = """
Produces TER scores alongside the number of edits and reference length.
Args:
predictions (list of str): The system stream (a sequence of segments).
references (list of list of str): A list of one or more reference streams (each a sequence of segments).
normalized (boolean): If `True`, applies basic tokenization and normalization to sentences. Defaults to `False`.
ignore_punct (boolean): If `True`, applies basic tokenization and normalization to sentences. Defaults to `False`.
support_zh_ja_chars (boolean): If `True`, tokenization/normalization supports processing of Chinese characters,
as well as Japanese Kanji, Hiragana, Katakana, and Phonetic Extensions of Katakana.
Only applies if `normalized = True`. Defaults to `False`.
case_sensitive (boolean): If `False`, makes all predictions and references lowercase to ignore differences in case. Defaults to `False`.
Returns:
'score' (float): TER score (num_edits / sum_ref_lengths * 100)
'num_edits' (int): The cumulative number of edits
'ref_length' (float): The cumulative average reference length
Examples:
Example 1:
>>> predictions = ["does this sentence match??",
... "what about this sentence?",
... "What did the TER metric user say to the developer?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"],
... ["Your jokes are...", "...TERrible"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... case_sensitive=True)
>>> print(results)
{'score': 150.0, 'num_edits': 15, 'ref_length': 10.0}
Example 2:
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... case_sensitive=True)
>>> print(results)
{'score': 62.5, 'num_edits': 5, 'ref_length': 8.0}
Example 3:
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... normalized=True,
... case_sensitive=True)
>>> print(results)
{'score': 57.14285714285714, 'num_edits': 6, 'ref_length': 10.5}
Example 4:
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... ignore_punct=True,
... case_sensitive=False)
>>> print(results)
{'score': 0.0, 'num_edits': 0, 'ref_length': 8.0}
Example 5:
>>> predictions = ["does this sentence match??",
... "what about this sentence?",
... "What did the TER metric user say to the developer?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"],
... ["Your jokes are...", "...TERrible"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... ignore_punct=True,
... case_sensitive=False)
>>> print(results)
{'score': 100.0, 'num_edits': 10, 'ref_length': 10.0}
"""
@datasets.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class Ter(datasets.Metric):
def _info(self):
if version.parse(scb.__version__) < version.parse("1.4.12"):
raise ImportWarning(
"To use `sacrebleu`, the module `sacrebleu>=1.4.12` is required, and the current version of `sacrebleu` doesn't match this condition.\n"
'You can install it with `pip install "sacrebleu>=1.4.12"`.'
)
return datasets.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
homepage="http://www.cs.umd.edu/~snover/tercom/",
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"predictions": datasets.Value("string", id="sequence"),
"references": datasets.Sequence(datasets.Value("string", id="sequence"), id="references"),
}
),
codebase_urls=["https://github.com/mjpost/sacreBLEU#ter"],
reference_urls=[
"https://github.com/jhclark/tercom",
],
)
def _compute(
self,
predictions,
references,
normalized: bool = False,
ignore_punct: bool = False,
support_zh_ja_chars: bool = False,
case_sensitive: bool = False,
):
references_per_prediction = len(references[0])
if any(len(refs) != references_per_prediction for refs in references):
raise ValueError("Sacrebleu requires the same number of references for each prediction")
transformed_references = [[refs[i] for refs in references] for i in range(references_per_prediction)]
sb_ter = TER(
normalized=normalized,
no_punct=ignore_punct,
asian_support=support_zh_ja_chars,
case_sensitive=case_sensitive,
)
output = sb_ter.corpus_score(predictions, transformed_references)
return {"score": output.score, "num_edits": output.num_edits, "ref_length": output.ref_length}
|
datasets/metrics/ter/ter.py/0
|
{
"file_path": "datasets/metrics/ter/ter.py",
"repo_id": "datasets",
"token_count": 3967
}
| 67 |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""To write records into Parquet files."""
import errno
import json
import os
import sys
from pathlib import Path
from typing import Any, Dict, Iterable, List, Optional, Tuple, Union
import fsspec
import numpy as np
import pyarrow as pa
import pyarrow.parquet as pq
from fsspec.core import url_to_fs
from . import config
from .features import Features, Image, Value
from .features.features import (
FeatureType,
_ArrayXDExtensionType,
cast_to_python_objects,
generate_from_arrow_type,
get_nested_type,
list_of_np_array_to_pyarrow_listarray,
numpy_to_pyarrow_listarray,
to_pyarrow_listarray,
)
from .filesystems import is_remote_filesystem
from .info import DatasetInfo
from .keyhash import DuplicatedKeysError, KeyHasher
from .table import array_cast, cast_array_to_feature, embed_table_storage, table_cast
from .utils import logging
from .utils import tqdm as hf_tqdm
from .utils.file_utils import hash_url_to_filename
from .utils.py_utils import asdict, first_non_null_value
logger = logging.get_logger(__name__)
type_ = type # keep python's type function
class SchemaInferenceError(ValueError):
pass
class TypedSequence:
"""
This data container generalizes the typing when instantiating pyarrow arrays, tables or batches.
More specifically it adds several features:
- Support extension types like ``datasets.features.Array2DExtensionType``:
By default pyarrow arrays don't return extension arrays. One has to call
``pa.ExtensionArray.from_storage(type, pa.array(data, type.storage_type))``
in order to get an extension array.
- Support for ``try_type`` parameter that can be used instead of ``type``:
When an array is transformed, we like to keep the same type as before if possible.
For example when calling :func:`datasets.Dataset.map`, we don't want to change the type
of each column by default.
- Better error message when a pyarrow array overflows.
Example::
from datasets.features import Array2D, Array2DExtensionType, Value
from datasets.arrow_writer import TypedSequence
import pyarrow as pa
arr = pa.array(TypedSequence([1, 2, 3], type=Value("int32")))
assert arr.type == pa.int32()
arr = pa.array(TypedSequence([1, 2, 3], try_type=Value("int32")))
assert arr.type == pa.int32()
arr = pa.array(TypedSequence(["foo", "bar"], try_type=Value("int32")))
assert arr.type == pa.string()
arr = pa.array(TypedSequence([[[1, 2, 3]]], type=Array2D((1, 3), "int64")))
assert arr.type == Array2DExtensionType((1, 3), "int64")
table = pa.Table.from_pydict({
"image": TypedSequence([[[1, 2, 3]]], type=Array2D((1, 3), "int64"))
})
assert table["image"].type == Array2DExtensionType((1, 3), "int64")
"""
def __init__(
self,
data: Iterable,
type: Optional[FeatureType] = None,
try_type: Optional[FeatureType] = None,
optimized_int_type: Optional[FeatureType] = None,
):
# assert type is None or try_type is None,
if type is not None and try_type is not None:
raise ValueError("You cannot specify both type and try_type")
# set attributes
self.data = data
self.type = type
self.try_type = try_type # is ignored if it doesn't match the data
self.optimized_int_type = optimized_int_type
# when trying a type (is ignored if data is not compatible)
self.trying_type = self.try_type is not None
self.trying_int_optimization = optimized_int_type is not None and type is None and try_type is None
# used to get back the inferred type after __arrow_array__() is called once
self._inferred_type = None
def get_inferred_type(self) -> FeatureType:
"""Return the inferred feature type.
This is done by converting the sequence to an Arrow array, and getting the corresponding
feature type.
Since building the Arrow array can be expensive, the value of the inferred type is cached
as soon as pa.array is called on the typed sequence.
Returns:
FeatureType: inferred feature type of the sequence.
"""
if self._inferred_type is None:
self._inferred_type = generate_from_arrow_type(pa.array(self).type)
return self._inferred_type
@staticmethod
def _infer_custom_type_and_encode(data: Iterable) -> Tuple[Iterable, Optional[FeatureType]]:
"""Implement type inference for custom objects like PIL.Image.Image -> Image type.
This function is only used for custom python objects that can't be direclty passed to build
an Arrow array. In such cases is infers the feature type to use, and it encodes the data so
that they can be passed to an Arrow array.
Args:
data (Iterable): array of data to infer the type, e.g. a list of PIL images.
Returns:
Tuple[Iterable, Optional[FeatureType]]: a tuple with:
- the (possibly encoded) array, if the inferred feature type requires encoding
- the inferred feature type if the array is made of supported custom objects like
PIL images, else None.
"""
if config.PIL_AVAILABLE and "PIL" in sys.modules:
import PIL.Image
non_null_idx, non_null_value = first_non_null_value(data)
if isinstance(non_null_value, PIL.Image.Image):
return [Image().encode_example(value) if value is not None else None for value in data], Image()
return data, None
def __arrow_array__(self, type: Optional[pa.DataType] = None):
"""This function is called when calling pa.array(typed_sequence)"""
if type is not None:
raise ValueError("TypedSequence is supposed to be used with pa.array(typed_sequence, type=None)")
del type # make sure we don't use it
data = self.data
# automatic type inference for custom objects
if self.type is None and self.try_type is None:
data, self._inferred_type = self._infer_custom_type_and_encode(data)
if self._inferred_type is None:
type = self.try_type if self.trying_type else self.type
else:
type = self._inferred_type
pa_type = get_nested_type(type) if type is not None else None
optimized_int_pa_type = (
get_nested_type(self.optimized_int_type) if self.optimized_int_type is not None else None
)
trying_cast_to_python_objects = False
try:
# custom pyarrow types
if isinstance(pa_type, _ArrayXDExtensionType):
storage = to_pyarrow_listarray(data, pa_type)
return pa.ExtensionArray.from_storage(pa_type, storage)
# efficient np array to pyarrow array
if isinstance(data, np.ndarray):
out = numpy_to_pyarrow_listarray(data)
elif isinstance(data, list) and data and isinstance(first_non_null_value(data)[1], np.ndarray):
out = list_of_np_array_to_pyarrow_listarray(data)
else:
trying_cast_to_python_objects = True
out = pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))
# use smaller integer precisions if possible
if self.trying_int_optimization:
if pa.types.is_int64(out.type):
out = out.cast(optimized_int_pa_type)
elif pa.types.is_list(out.type):
if pa.types.is_int64(out.type.value_type):
out = array_cast(out, pa.list_(optimized_int_pa_type))
elif pa.types.is_list(out.type.value_type) and pa.types.is_int64(out.type.value_type.value_type):
out = array_cast(out, pa.list_(pa.list_(optimized_int_pa_type)))
# otherwise we can finally use the user's type
elif type is not None:
# We use cast_array_to_feature to support casting to custom types like Audio and Image
# Also, when trying type "string", we don't want to convert integers or floats to "string".
# We only do it if trying_type is False - since this is what the user asks for.
out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
return out
except (
TypeError,
pa.lib.ArrowInvalid,
pa.lib.ArrowNotImplementedError,
) as e: # handle type errors and overflows
# Ignore ArrowNotImplementedError caused by trying type, otherwise re-raise
if not self.trying_type and isinstance(e, pa.lib.ArrowNotImplementedError):
raise
if self.trying_type:
try: # second chance
if isinstance(data, np.ndarray):
return numpy_to_pyarrow_listarray(data)
elif isinstance(data, list) and data and any(isinstance(value, np.ndarray) for value in data):
return list_of_np_array_to_pyarrow_listarray(data)
else:
trying_cast_to_python_objects = True
return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))
except pa.lib.ArrowInvalid as e:
if "overflow" in str(e):
raise OverflowError(
f"There was an overflow with type {type_(data)}. Try to reduce writer_batch_size to have batches smaller than 2GB.\n({e})"
) from None
elif self.trying_int_optimization and "not in range" in str(e):
optimized_int_pa_type_str = np.dtype(optimized_int_pa_type.to_pandas_dtype()).name
logger.info(
f"Failed to cast a sequence to {optimized_int_pa_type_str}. Falling back to int64."
)
return out
elif trying_cast_to_python_objects and "Could not convert" in str(e):
out = pa.array(
cast_to_python_objects(data, only_1d_for_numpy=True, optimize_list_casting=False)
)
if type is not None:
out = cast_array_to_feature(out, type, allow_number_to_str=True)
return out
else:
raise
elif "overflow" in str(e):
raise OverflowError(
f"There was an overflow with type {type_(data)}. Try to reduce writer_batch_size to have batches smaller than 2GB.\n({e})"
) from None
elif self.trying_int_optimization and "not in range" in str(e):
optimized_int_pa_type_str = np.dtype(optimized_int_pa_type.to_pandas_dtype()).name
logger.info(f"Failed to cast a sequence to {optimized_int_pa_type_str}. Falling back to int64.")
return out
elif trying_cast_to_python_objects and "Could not convert" in str(e):
out = pa.array(cast_to_python_objects(data, only_1d_for_numpy=True, optimize_list_casting=False))
if type is not None:
out = cast_array_to_feature(out, type, allow_number_to_str=True)
return out
else:
raise
class OptimizedTypedSequence(TypedSequence):
def __init__(
self,
data,
type: Optional[FeatureType] = None,
try_type: Optional[FeatureType] = None,
col: Optional[str] = None,
optimized_int_type: Optional[FeatureType] = None,
):
optimized_int_type_by_col = {
"attention_mask": Value("int8"), # binary tensor
"special_tokens_mask": Value("int8"),
"input_ids": Value("int32"), # typical vocab size: 0-50k (max ~500k, never > 1M)
"token_type_ids": Value(
"int8"
), # binary mask; some (XLNetModel) use an additional token represented by a 2
}
if type is None and try_type is None:
optimized_int_type = optimized_int_type_by_col.get(col, None)
super().__init__(data, type=type, try_type=try_type, optimized_int_type=optimized_int_type)
class ArrowWriter:
"""Shuffles and writes Examples to Arrow files."""
_WRITER_CLASS = pa.RecordBatchStreamWriter
def __init__(
self,
schema: Optional[pa.Schema] = None,
features: Optional[Features] = None,
path: Optional[str] = None,
stream: Optional[pa.NativeFile] = None,
fingerprint: Optional[str] = None,
writer_batch_size: Optional[int] = None,
hash_salt: Optional[str] = None,
check_duplicates: Optional[bool] = False,
disable_nullable: bool = False,
update_features: bool = False,
with_metadata: bool = True,
unit: str = "examples",
embed_local_files: bool = False,
storage_options: Optional[dict] = None,
):
if path is None and stream is None:
raise ValueError("At least one of path and stream must be provided.")
if features is not None:
self._features = features
self._schema = None
elif schema is not None:
self._schema: pa.Schema = schema
self._features = Features.from_arrow_schema(self._schema)
else:
self._features = None
self._schema = None
if hash_salt is not None:
# Create KeyHasher instance using split name as hash salt
self._hasher = KeyHasher(hash_salt)
else:
self._hasher = KeyHasher("")
self._check_duplicates = check_duplicates
self._disable_nullable = disable_nullable
if stream is None:
fs, path = url_to_fs(path, **(storage_options or {}))
self._fs: fsspec.AbstractFileSystem = fs
self._path = path if not is_remote_filesystem(self._fs) else self._fs.unstrip_protocol(path)
self.stream = self._fs.open(path, "wb")
self._closable_stream = True
else:
self._fs = None
self._path = None
self.stream = stream
self._closable_stream = False
self.fingerprint = fingerprint
self.disable_nullable = disable_nullable
self.writer_batch_size = writer_batch_size or config.DEFAULT_MAX_BATCH_SIZE
self.update_features = update_features
self.with_metadata = with_metadata
self.unit = unit
self.embed_local_files = embed_local_files
self._num_examples = 0
self._num_bytes = 0
self.current_examples: List[Tuple[Dict[str, Any], str]] = []
self.current_rows: List[pa.Table] = []
self.pa_writer: Optional[pa.RecordBatchStreamWriter] = None
self.hkey_record = []
def __len__(self):
"""Return the number of writed and staged examples"""
return self._num_examples + len(self.current_examples) + len(self.current_rows)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.close()
def close(self):
# Try closing if opened; if closed: pyarrow.lib.ArrowInvalid: Invalid operation on closed file
if self.pa_writer: # it might be None
try:
self.pa_writer.close()
except Exception: # pyarrow.lib.ArrowInvalid, OSError
pass
if self._closable_stream and not self.stream.closed:
self.stream.close() # This also closes self.pa_writer if it is opened
def _build_writer(self, inferred_schema: pa.Schema):
schema = self.schema
inferred_features = Features.from_arrow_schema(inferred_schema)
if self._features is not None:
if self.update_features: # keep original features it they match, or update them
fields = {field.name: field for field in self._features.type}
for inferred_field in inferred_features.type:
name = inferred_field.name
if name in fields:
if inferred_field == fields[name]:
inferred_features[name] = self._features[name]
self._features = inferred_features
schema: pa.Schema = inferred_schema
else:
self._features = inferred_features
schema: pa.Schema = inferred_features.arrow_schema
if self.disable_nullable:
schema = pa.schema(pa.field(field.name, field.type, nullable=False) for field in schema)
if self.with_metadata:
schema = schema.with_metadata(self._build_metadata(DatasetInfo(features=self._features), self.fingerprint))
else:
schema = schema.with_metadata({})
self._schema = schema
self.pa_writer = self._WRITER_CLASS(self.stream, schema)
@property
def schema(self):
_schema = (
self._schema
if self._schema is not None
else (pa.schema(self._features.type) if self._features is not None else None)
)
if self._disable_nullable and _schema is not None:
_schema = pa.schema(pa.field(field.name, field.type, nullable=False) for field in _schema)
return _schema if _schema is not None else []
@staticmethod
def _build_metadata(info: DatasetInfo, fingerprint: Optional[str] = None) -> Dict[str, str]:
info_keys = ["features"] # we can add support for more DatasetInfo keys in the future
info_as_dict = asdict(info)
metadata = {}
metadata["info"] = {key: info_as_dict[key] for key in info_keys}
if fingerprint is not None:
metadata["fingerprint"] = fingerprint
return {"huggingface": json.dumps(metadata)}
def write_examples_on_file(self):
"""Write stored examples from the write-pool of examples. It makes a table out of the examples and write it."""
if not self.current_examples:
return
# preserve the order the columns
if self.schema:
schema_cols = set(self.schema.names)
examples_cols = self.current_examples[0][0].keys() # .keys() preserves the order (unlike set)
common_cols = [col for col in self.schema.names if col in examples_cols]
extra_cols = [col for col in examples_cols if col not in schema_cols]
cols = common_cols + extra_cols
else:
cols = list(self.current_examples[0][0])
batch_examples = {}
for col in cols:
# We use row[0][col] since current_examples contains (example, key) tuples.
# Morever, examples could be Arrow arrays of 1 element.
# This can happen in `.map()` when we want to re-write the same Arrow data
if all(isinstance(row[0][col], (pa.Array, pa.ChunkedArray)) for row in self.current_examples):
arrays = [row[0][col] for row in self.current_examples]
arrays = [
chunk
for array in arrays
for chunk in (array.chunks if isinstance(array, pa.ChunkedArray) else [array])
]
batch_examples[col] = pa.concat_arrays(arrays)
else:
batch_examples[col] = [
row[0][col].to_pylist()[0] if isinstance(row[0][col], (pa.Array, pa.ChunkedArray)) else row[0][col]
for row in self.current_examples
]
self.write_batch(batch_examples=batch_examples)
self.current_examples = []
def write_rows_on_file(self):
"""Write stored rows from the write-pool of rows. It concatenates the single-row tables and it writes the resulting table."""
if not self.current_rows:
return
table = pa.concat_tables(self.current_rows)
self.write_table(table)
self.current_rows = []
def write(
self,
example: Dict[str, Any],
key: Optional[Union[str, int, bytes]] = None,
writer_batch_size: Optional[int] = None,
):
"""Add a given (Example,Key) pair to the write-pool of examples which is written to file.
Args:
example: the Example to add.
key: Optional, a unique identifier(str, int or bytes) associated with each example
"""
# Utilize the keys and duplicate checking when `self._check_duplicates` is passed True
if self._check_duplicates:
# Create unique hash from key and store as (key, example) pairs
hash = self._hasher.hash(key)
self.current_examples.append((example, hash))
# Maintain record of keys and their respective hashes for checking duplicates
self.hkey_record.append((hash, key))
else:
# Store example as a tuple so as to keep the structure of `self.current_examples` uniform
self.current_examples.append((example, ""))
if writer_batch_size is None:
writer_batch_size = self.writer_batch_size
if writer_batch_size is not None and len(self.current_examples) >= writer_batch_size:
if self._check_duplicates:
self.check_duplicate_keys()
# Re-intializing to empty list for next batch
self.hkey_record = []
self.write_examples_on_file()
def check_duplicate_keys(self):
"""Raises error if duplicates found in a batch"""
tmp_record = set()
for hash, key in self.hkey_record:
if hash in tmp_record:
duplicate_key_indices = [
str(self._num_examples + index)
for index, (duplicate_hash, _) in enumerate(self.hkey_record)
if duplicate_hash == hash
]
raise DuplicatedKeysError(key, duplicate_key_indices)
else:
tmp_record.add(hash)
def write_row(self, row: pa.Table, writer_batch_size: Optional[int] = None):
"""Add a given single-row Table to the write-pool of rows which is written to file.
Args:
row: the row to add.
"""
if len(row) != 1:
raise ValueError(f"Only single-row pyarrow tables are allowed but got table with {len(row)} rows.")
self.current_rows.append(row)
if writer_batch_size is None:
writer_batch_size = self.writer_batch_size
if writer_batch_size is not None and len(self.current_rows) >= writer_batch_size:
self.write_rows_on_file()
def write_batch(
self,
batch_examples: Dict[str, List],
writer_batch_size: Optional[int] = None,
):
"""Write a batch of Example to file.
Ignores the batch if it appears to be empty,
preventing a potential schema update of unknown types.
Args:
batch_examples: the batch of examples to add.
"""
if batch_examples and len(next(iter(batch_examples.values()))) == 0:
return
features = None if self.pa_writer is None and self.update_features else self._features
try_features = self._features if self.pa_writer is None and self.update_features else None
arrays = []
inferred_features = Features()
# preserve the order the columns
if self.schema:
schema_cols = set(self.schema.names)
batch_cols = batch_examples.keys() # .keys() preserves the order (unlike set)
common_cols = [col for col in self.schema.names if col in batch_cols]
extra_cols = [col for col in batch_cols if col not in schema_cols]
cols = common_cols + extra_cols
else:
cols = list(batch_examples)
for col in cols:
col_values = batch_examples[col]
col_type = features[col] if features else None
if isinstance(col_values, (pa.Array, pa.ChunkedArray)):
array = cast_array_to_feature(col_values, col_type) if col_type is not None else col_values
arrays.append(array)
inferred_features[col] = generate_from_arrow_type(col_values.type)
else:
col_try_type = try_features[col] if try_features is not None and col in try_features else None
typed_sequence = OptimizedTypedSequence(col_values, type=col_type, try_type=col_try_type, col=col)
arrays.append(pa.array(typed_sequence))
inferred_features[col] = typed_sequence.get_inferred_type()
schema = inferred_features.arrow_schema if self.pa_writer is None else self.schema
pa_table = pa.Table.from_arrays(arrays, schema=schema)
self.write_table(pa_table, writer_batch_size)
def write_table(self, pa_table: pa.Table, writer_batch_size: Optional[int] = None):
"""Write a Table to file.
Args:
example: the Table to add.
"""
if writer_batch_size is None:
writer_batch_size = self.writer_batch_size
if self.pa_writer is None:
self._build_writer(inferred_schema=pa_table.schema)
pa_table = pa_table.combine_chunks()
pa_table = table_cast(pa_table, self._schema)
if self.embed_local_files:
pa_table = embed_table_storage(pa_table)
self._num_bytes += pa_table.nbytes
self._num_examples += pa_table.num_rows
self.pa_writer.write_table(pa_table, writer_batch_size)
def finalize(self, close_stream=True):
self.write_rows_on_file()
# In case current_examples < writer_batch_size, but user uses finalize()
if self._check_duplicates:
self.check_duplicate_keys()
# Re-intializing to empty list for next batch
self.hkey_record = []
self.write_examples_on_file()
# If schema is known, infer features even if no examples were written
if self.pa_writer is None and self.schema:
self._build_writer(self.schema)
if self.pa_writer is not None:
self.pa_writer.close()
self.pa_writer = None
if close_stream:
self.stream.close()
else:
if close_stream:
self.stream.close()
raise SchemaInferenceError("Please pass `features` or at least one example when writing data")
logger.debug(
f"Done writing {self._num_examples} {self.unit} in {self._num_bytes} bytes {self._path if self._path else ''}."
)
return self._num_examples, self._num_bytes
class ParquetWriter(ArrowWriter):
_WRITER_CLASS = pq.ParquetWriter
class BeamWriter:
"""
Shuffles and writes Examples to Arrow files.
The Arrow files are converted from Parquet files that are the output of Apache Beam pipelines.
"""
def __init__(
self,
features: Optional[Features] = None,
schema: Optional[pa.Schema] = None,
path: Optional[str] = None,
namespace: Optional[str] = None,
cache_dir: Optional[str] = None,
):
if features is None and schema is None:
raise ValueError("At least one of features and schema must be provided.")
if path is None:
raise ValueError("Path must be provided.")
if features is not None:
self._features: Features = features
self._schema: pa.Schema = features.arrow_schema
else:
self._schema: pa.Schema = schema
self._features: Features = Features.from_arrow_schema(schema)
self._path = path
self._parquet_path = os.path.splitext(path)[0] # remove extension
self._namespace = namespace or "default"
self._num_examples = None
self._cache_dir = cache_dir or config.HF_DATASETS_CACHE
def write_from_pcollection(self, pcoll_examples):
"""Add the final steps of the beam pipeline: write to parquet files."""
import apache_beam as beam
def inc_num_examples(example):
beam.metrics.Metrics.counter(self._namespace, "num_examples").inc()
# count examples
_ = pcoll_examples | "Count N. Examples" >> beam.Map(inc_num_examples)
# save dataset
return (
pcoll_examples
| "Get values" >> beam.Values()
| "Save to parquet"
>> beam.io.parquetio.WriteToParquet(
self._parquet_path, self._schema, shard_name_template="-SSSSS-of-NNNNN.parquet"
)
)
def finalize(self, metrics_query_result: dict):
"""
Run after the pipeline has finished.
It converts the resulting parquet files to arrow and it completes the info from the pipeline metrics.
Args:
metrics_query_result: `dict` obtained from pipeline_results.metrics().query(m_filter). Make sure
that the filter keeps only the metrics for the considered split, under the namespace `split_name`.
"""
# Beam FileSystems require the system's path separator in the older versions
fs, parquet_path = url_to_fs(self._parquet_path)
parquet_path = str(Path(parquet_path)) if not is_remote_filesystem(fs) else fs.unstrip_protocol(parquet_path)
shards = fs.glob(parquet_path + "*.parquet")
num_bytes = sum(fs.sizes(shards))
shard_lengths = get_parquet_lengths(shards)
# Convert to arrow
if self._path.endswith(".arrow"):
logger.info(f"Converting parquet files {self._parquet_path} to arrow {self._path}")
try: # stream conversion
num_bytes = 0
for shard in hf_tqdm(shards, unit="shards"):
with fs.open(shard, "rb") as source:
with fs.open(shard.replace(".parquet", ".arrow"), "wb") as destination:
shard_num_bytes, _ = parquet_to_arrow(source, destination)
num_bytes += shard_num_bytes
except OSError as e: # broken pipe can happen if the connection is unstable, do local conversion instead
if e.errno != errno.EPIPE: # not a broken pipe
raise
logger.warning(
"Broken Pipe during stream conversion from parquet to arrow. Using local convert instead"
)
local_convert_dir = os.path.join(self._cache_dir, "beam_convert")
os.makedirs(local_convert_dir, exist_ok=True)
num_bytes = 0
for shard in hf_tqdm(shards, unit="shards"):
local_parquet_path = os.path.join(local_convert_dir, hash_url_to_filename(shard) + ".parquet")
fs.download(shard, local_parquet_path)
local_arrow_path = local_parquet_path.replace(".parquet", ".arrow")
shard_num_bytes, _ = parquet_to_arrow(local_parquet_path, local_arrow_path)
num_bytes += shard_num_bytes
remote_arrow_path = shard.replace(".parquet", ".arrow")
fs.upload(local_arrow_path, remote_arrow_path)
# Save metrics
counters_dict = {metric.key.metric.name: metric.result for metric in metrics_query_result["counters"]}
self._num_examples = counters_dict["num_examples"]
self._num_bytes = num_bytes
self._shard_lengths = shard_lengths
return self._num_examples, self._num_bytes
def get_parquet_lengths(sources) -> List[int]:
shard_lengths = []
for source in hf_tqdm(sources, unit="parquet files"):
parquet_file = pa.parquet.ParquetFile(source)
shard_lengths.append(parquet_file.metadata.num_rows)
return shard_lengths
def parquet_to_arrow(source, destination) -> List[int]:
"""Convert parquet file to arrow file. Inputs can be str paths or file-like objects"""
stream = None if isinstance(destination, str) else destination
parquet_file = pa.parquet.ParquetFile(source)
# Beam can create empty Parquet files, so we need to pass the source Parquet file's schema
with ArrowWriter(schema=parquet_file.schema_arrow, path=destination, stream=stream) as writer:
for record_batch in parquet_file.iter_batches():
pa_table = pa.Table.from_batches([record_batch])
writer.write_table(pa_table)
num_bytes, num_examples = writer.finalize()
return num_bytes, num_examples
|
datasets/src/datasets/arrow_writer.py/0
|
{
"file_path": "datasets/src/datasets/arrow_writer.py",
"repo_id": "datasets",
"token_count": 14687
}
| 68 |
# Copyright 2020 The TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""Download manager interface."""
import enum
import io
import os
import posixpath
import tarfile
import warnings
import zipfile
from datetime import datetime
from functools import partial
from itertools import chain
from typing import Callable, Dict, Generator, List, Optional, Tuple, Union
from .. import config
from ..utils import tqdm as hf_tqdm
from ..utils.deprecation_utils import DeprecatedEnum, deprecated
from ..utils.file_utils import (
cached_path,
get_from_cache,
hash_url_to_filename,
is_relative_path,
stack_multiprocessing_download_progress_bars,
url_or_path_join,
)
from ..utils.info_utils import get_size_checksum_dict
from ..utils.logging import get_logger
from ..utils.py_utils import NestedDataStructure, map_nested, size_str
from ..utils.track import TrackedIterable, tracked_str
from .download_config import DownloadConfig
logger = get_logger(__name__)
BASE_KNOWN_EXTENSIONS = [
"txt",
"csv",
"json",
"jsonl",
"tsv",
"conll",
"conllu",
"orig",
"parquet",
"pkl",
"pickle",
"rel",
"xml",
]
MAGIC_NUMBER_TO_COMPRESSION_PROTOCOL = {
bytes.fromhex("504B0304"): "zip",
bytes.fromhex("504B0506"): "zip", # empty archive
bytes.fromhex("504B0708"): "zip", # spanned archive
bytes.fromhex("425A68"): "bz2",
bytes.fromhex("1F8B"): "gzip",
bytes.fromhex("FD377A585A00"): "xz",
bytes.fromhex("04224D18"): "lz4",
bytes.fromhex("28B52FFD"): "zstd",
}
MAGIC_NUMBER_TO_UNSUPPORTED_COMPRESSION_PROTOCOL = {
b"Rar!": "rar",
}
MAGIC_NUMBER_MAX_LENGTH = max(
len(magic_number)
for magic_number in chain(MAGIC_NUMBER_TO_COMPRESSION_PROTOCOL, MAGIC_NUMBER_TO_UNSUPPORTED_COMPRESSION_PROTOCOL)
)
class DownloadMode(enum.Enum):
"""`Enum` for how to treat pre-existing downloads and data.
The default mode is `REUSE_DATASET_IF_EXISTS`, which will reuse both
raw downloads and the prepared dataset if they exist.
The generations modes:
| | Downloads | Dataset |
|-------------------------------------|-----------|---------|
| `REUSE_DATASET_IF_EXISTS` (default) | Reuse | Reuse |
| `REUSE_CACHE_IF_EXISTS` | Reuse | Fresh |
| `FORCE_REDOWNLOAD` | Fresh | Fresh |
"""
REUSE_DATASET_IF_EXISTS = "reuse_dataset_if_exists"
REUSE_CACHE_IF_EXISTS = "reuse_cache_if_exists"
FORCE_REDOWNLOAD = "force_redownload"
class GenerateMode(DeprecatedEnum):
REUSE_DATASET_IF_EXISTS = "reuse_dataset_if_exists"
REUSE_CACHE_IF_EXISTS = "reuse_cache_if_exists"
FORCE_REDOWNLOAD = "force_redownload"
@property
def help_message(self):
return "Use 'DownloadMode' instead."
def _get_path_extension(path: str) -> str:
# Get extension: train.json.gz -> gz
extension = path.split(".")[-1]
# Remove query params ("dl=1", "raw=true"): gz?dl=1 -> gz
# Remove shards infos (".txt_1", ".txt-00000-of-00100"): txt_1 -> txt
for symb in "?-_":
extension = extension.split(symb)[0]
return extension
def _get_extraction_protocol_with_magic_number(f) -> Optional[str]:
"""read the magic number from a file-like object and return the compression protocol"""
# Check if the file object is seekable even before reading the magic number (to avoid https://bugs.python.org/issue26440)
try:
f.seek(0)
except (AttributeError, io.UnsupportedOperation):
return None
magic_number = f.read(MAGIC_NUMBER_MAX_LENGTH)
f.seek(0)
for i in range(MAGIC_NUMBER_MAX_LENGTH):
compression = MAGIC_NUMBER_TO_COMPRESSION_PROTOCOL.get(magic_number[: MAGIC_NUMBER_MAX_LENGTH - i])
if compression is not None:
return compression
compression = MAGIC_NUMBER_TO_UNSUPPORTED_COMPRESSION_PROTOCOL.get(magic_number[: MAGIC_NUMBER_MAX_LENGTH - i])
if compression is not None:
raise NotImplementedError(f"Compression protocol '{compression}' not implemented.")
def _get_extraction_protocol(path: str) -> Optional[str]:
path = str(path)
extension = _get_path_extension(path)
# TODO(mariosasko): The below check will be useful once we can preserve the original extension in the new cache layout (use the `filename` parameter of `hf_hub_download`)
if (
extension in BASE_KNOWN_EXTENSIONS
or extension in ["tgz", "tar"]
or path.endswith((".tar.gz", ".tar.bz2", ".tar.xz"))
):
return None
with open(path, "rb") as f:
return _get_extraction_protocol_with_magic_number(f)
class _IterableFromGenerator(TrackedIterable):
"""Utility class to create an iterable from a generator function, in order to reset the generator when needed."""
def __init__(self, generator: Callable, *args, **kwargs):
super().__init__()
self.generator = generator
self.args = args
self.kwargs = kwargs
def __iter__(self):
for x in self.generator(*self.args, **self.kwargs):
self.last_item = x
yield x
self.last_item = None
class ArchiveIterable(_IterableFromGenerator):
"""An iterable of (path, fileobj) from a TAR archive, used by `iter_archive`"""
@staticmethod
def _iter_tar(f):
stream = tarfile.open(fileobj=f, mode="r|*")
for tarinfo in stream:
file_path = tarinfo.name
if not tarinfo.isreg():
continue
if file_path is None:
continue
if os.path.basename(file_path).startswith((".", "__")):
# skipping hidden files
continue
file_obj = stream.extractfile(tarinfo)
yield file_path, file_obj
stream.members = []
del stream
@staticmethod
def _iter_zip(f):
zipf = zipfile.ZipFile(f)
for member in zipf.infolist():
file_path = member.filename
if member.is_dir():
continue
if file_path is None:
continue
if os.path.basename(file_path).startswith((".", "__")):
# skipping hidden files
continue
file_obj = zipf.open(member)
yield file_path, file_obj
@classmethod
def _iter_from_fileobj(cls, f) -> Generator[Tuple, None, None]:
compression = _get_extraction_protocol_with_magic_number(f)
if compression == "zip":
yield from cls._iter_zip(f)
else:
yield from cls._iter_tar(f)
@classmethod
def _iter_from_path(cls, urlpath: str) -> Generator[Tuple, None, None]:
compression = _get_extraction_protocol(urlpath)
with open(urlpath, "rb") as f:
if compression == "zip":
yield from cls._iter_zip(f)
else:
yield from cls._iter_tar(f)
@classmethod
def from_buf(cls, fileobj) -> "ArchiveIterable":
return cls(cls._iter_from_fileobj, fileobj)
@classmethod
def from_path(cls, urlpath_or_buf) -> "ArchiveIterable":
return cls(cls._iter_from_path, urlpath_or_buf)
class FilesIterable(_IterableFromGenerator):
"""An iterable of paths from a list of directories or files"""
@classmethod
def _iter_from_paths(cls, urlpaths: Union[str, List[str]]) -> Generator[str, None, None]:
if not isinstance(urlpaths, list):
urlpaths = [urlpaths]
for urlpath in urlpaths:
if os.path.isfile(urlpath):
yield urlpath
else:
for dirpath, dirnames, filenames in os.walk(urlpath):
# in-place modification to prune the search
dirnames[:] = sorted([dirname for dirname in dirnames if not dirname.startswith((".", "__"))])
if os.path.basename(dirpath).startswith((".", "__")):
# skipping hidden directories
continue
for filename in sorted(filenames):
if filename.startswith((".", "__")):
# skipping hidden files
continue
yield os.path.join(dirpath, filename)
@classmethod
def from_paths(cls, urlpaths) -> "FilesIterable":
return cls(cls._iter_from_paths, urlpaths)
class DownloadManager:
is_streaming = False
def __init__(
self,
dataset_name: Optional[str] = None,
data_dir: Optional[str] = None,
download_config: Optional[DownloadConfig] = None,
base_path: Optional[str] = None,
record_checksums=True,
):
"""Download manager constructor.
Args:
data_dir:
can be used to specify a manual directory to get the files from.
dataset_name (`str`):
name of dataset this instance will be used for. If
provided, downloads will contain which datasets they were used for.
download_config (`DownloadConfig`):
to specify the cache directory and other
download options
base_path (`str`):
base path that is used when relative paths are used to
download files. This can be a remote url.
record_checksums (`bool`, defaults to `True`):
Whether to record the checksums of the downloaded files. If None, the value is inferred from the builder.
"""
self._dataset_name = dataset_name
self._data_dir = data_dir
self._base_path = base_path or os.path.abspath(".")
# To record what is being used: {url: {num_bytes: int, checksum: str}}
self._recorded_sizes_checksums: Dict[str, Dict[str, Optional[Union[int, str]]]] = {}
self.record_checksums = record_checksums
self.download_config = download_config or DownloadConfig()
self.downloaded_paths = {}
self.extracted_paths = {}
@property
def manual_dir(self):
return self._data_dir
@property
def downloaded_size(self):
"""Returns the total size of downloaded files."""
return sum(checksums_dict["num_bytes"] for checksums_dict in self._recorded_sizes_checksums.values())
@staticmethod
def ship_files_with_pipeline(downloaded_path_or_paths, pipeline):
"""Ship the files using Beam FileSystems to the pipeline temp dir.
Args:
downloaded_path_or_paths (`str` or `list[str]` or `dict[str, str]`):
Nested structure containing the
downloaded path(s).
pipeline ([`utils.beam_utils.BeamPipeline`]):
Apache Beam Pipeline.
Returns:
`str` or `list[str]` or `dict[str, str]`
"""
from ..utils.beam_utils import upload_local_to_remote
remote_dir = pipeline._options.get_all_options().get("temp_location")
if remote_dir is None:
raise ValueError("You need to specify 'temp_location' in PipelineOptions to upload files")
def upload(local_file_path):
remote_file_path = posixpath.join(
remote_dir, config.DOWNLOADED_DATASETS_DIR, os.path.basename(local_file_path)
)
logger.info(
f"Uploading {local_file_path} ({size_str(os.path.getsize(local_file_path))}) to {remote_file_path}."
)
upload_local_to_remote(local_file_path, remote_file_path)
return remote_file_path
uploaded_path_or_paths = map_nested(
lambda local_file_path: upload(local_file_path),
downloaded_path_or_paths,
)
return uploaded_path_or_paths
def _record_sizes_checksums(self, url_or_urls: NestedDataStructure, downloaded_path_or_paths: NestedDataStructure):
"""Record size/checksum of downloaded files."""
delay = 5
for url, path in hf_tqdm(
list(zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten())),
delay=delay,
desc="Computing checksums",
):
# call str to support PathLike objects
self._recorded_sizes_checksums[str(url)] = get_size_checksum_dict(
path, record_checksum=self.record_checksums
)
@deprecated("Use `.download`/`.download_and_extract` with `fsspec` URLs instead.")
def download_custom(self, url_or_urls, custom_download):
"""
Download given urls(s) by calling `custom_download`.
Args:
url_or_urls (`str` or `list` or `dict`):
URL or `list` or `dict` of URLs to download and extract. Each URL is a `str`.
custom_download (`Callable[src_url, dst_path]`):
The source URL and destination path. For example
`tf.io.gfile.copy`, that lets you download from Google storage.
Returns:
downloaded_path(s): `str`, The downloaded paths matching the given input
`url_or_urls`.
Example:
```py
>>> downloaded_files = dl_manager.download_custom('s3://my-bucket/data.zip', custom_download_for_my_private_bucket)
```
"""
cache_dir = self.download_config.cache_dir or config.DOWNLOADED_DATASETS_PATH
max_retries = self.download_config.max_retries
def url_to_downloaded_path(url):
return os.path.join(cache_dir, hash_url_to_filename(url))
downloaded_path_or_paths = map_nested(url_to_downloaded_path, url_or_urls)
url_or_urls = NestedDataStructure(url_or_urls)
downloaded_path_or_paths = NestedDataStructure(downloaded_path_or_paths)
for url, path in zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten()):
try:
get_from_cache(
url, cache_dir=cache_dir, local_files_only=True, use_etag=False, max_retries=max_retries
)
cached = True
except FileNotFoundError:
cached = False
if not cached or self.download_config.force_download:
custom_download(url, path)
get_from_cache(
url, cache_dir=cache_dir, local_files_only=True, use_etag=False, max_retries=max_retries
)
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
return downloaded_path_or_paths.data
def download(self, url_or_urls):
"""Download given URL(s).
By default, only one process is used for download. Pass customized `download_config.num_proc` to change this behavior.
Args:
url_or_urls (`str` or `list` or `dict`):
URL or `list` or `dict` of URLs to download. Each URL is a `str`.
Returns:
`str` or `list` or `dict`:
The downloaded paths matching the given input `url_or_urls`.
Example:
```py
>>> downloaded_files = dl_manager.download('https://storage.googleapis.com/seldon-datasets/sentence_polarity_v1/rt-polaritydata.tar.gz')
```
"""
download_config = self.download_config.copy()
download_config.extract_compressed_file = False
if download_config.download_desc is None:
download_config.download_desc = "Downloading data"
download_func = partial(self._download, download_config=download_config)
start_time = datetime.now()
with stack_multiprocessing_download_progress_bars():
downloaded_path_or_paths = map_nested(
download_func,
url_or_urls,
map_tuple=True,
num_proc=download_config.num_proc,
desc="Downloading data files",
)
duration = datetime.now() - start_time
logger.info(f"Downloading took {duration.total_seconds() // 60} min")
url_or_urls = NestedDataStructure(url_or_urls)
downloaded_path_or_paths = NestedDataStructure(downloaded_path_or_paths)
self.downloaded_paths.update(dict(zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten())))
start_time = datetime.now()
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
duration = datetime.now() - start_time
logger.info(f"Checksum Computation took {duration.total_seconds() // 60} min")
return downloaded_path_or_paths.data
def _download(self, url_or_filename: str, download_config: DownloadConfig) -> str:
url_or_filename = str(url_or_filename)
if is_relative_path(url_or_filename):
# append the relative path to the base_path
url_or_filename = url_or_path_join(self._base_path, url_or_filename)
out = cached_path(url_or_filename, download_config=download_config)
out = tracked_str(out)
out.set_origin(url_or_filename)
return out
def iter_archive(self, path_or_buf: Union[str, io.BufferedReader]):
"""Iterate over files within an archive.
Args:
path_or_buf (`str` or `io.BufferedReader`):
Archive path or archive binary file object.
Yields:
`tuple[str, io.BufferedReader]`:
2-tuple (path_within_archive, file_object).
File object is opened in binary mode.
Example:
```py
>>> archive = dl_manager.download('https://storage.googleapis.com/seldon-datasets/sentence_polarity_v1/rt-polaritydata.tar.gz')
>>> files = dl_manager.iter_archive(archive)
```
"""
if hasattr(path_or_buf, "read"):
return ArchiveIterable.from_buf(path_or_buf)
else:
return ArchiveIterable.from_path(path_or_buf)
def iter_files(self, paths: Union[str, List[str]]):
"""Iterate over file paths.
Args:
paths (`str` or `list` of `str`):
Root paths.
Yields:
`str`: File path.
Example:
```py
>>> files = dl_manager.download_and_extract('https://huggingface.co/datasets/beans/resolve/main/data/train.zip')
>>> files = dl_manager.iter_files(files)
```
"""
return FilesIterable.from_paths(paths)
def extract(self, path_or_paths, num_proc="deprecated"):
"""Extract given path(s).
Args:
path_or_paths (path or `list` or `dict`):
Path of file to extract. Each path is a `str`.
num_proc (`int`):
Use multi-processing if `num_proc` > 1 and the length of
`path_or_paths` is larger than `num_proc`.
<Deprecated version="2.6.2">
Pass `DownloadConfig(num_proc=<num_proc>)` to the initializer instead.
</Deprecated>
Returns:
extracted_path(s): `str`, The extracted paths matching the given input
path_or_paths.
Example:
```py
>>> downloaded_files = dl_manager.download('https://storage.googleapis.com/seldon-datasets/sentence_polarity_v1/rt-polaritydata.tar.gz')
>>> extracted_files = dl_manager.extract(downloaded_files)
```
"""
if num_proc != "deprecated":
warnings.warn(
"'num_proc' was deprecated in version 2.6.2 and will be removed in 3.0.0. Pass `DownloadConfig(num_proc=<num_proc>)` to the initializer instead.",
FutureWarning,
)
download_config = self.download_config.copy()
download_config.extract_compressed_file = True
extract_func = partial(self._download, download_config=download_config)
extracted_paths = map_nested(
extract_func,
path_or_paths,
num_proc=download_config.num_proc,
desc="Extracting data files",
)
path_or_paths = NestedDataStructure(path_or_paths)
extracted_paths = NestedDataStructure(extracted_paths)
self.extracted_paths.update(dict(zip(path_or_paths.flatten(), extracted_paths.flatten())))
return extracted_paths.data
def download_and_extract(self, url_or_urls):
"""Download and extract given `url_or_urls`.
Is roughly equivalent to:
```
extracted_paths = dl_manager.extract(dl_manager.download(url_or_urls))
```
Args:
url_or_urls (`str` or `list` or `dict`):
URL or `list` or `dict` of URLs to download and extract. Each URL is a `str`.
Returns:
extracted_path(s): `str`, extracted paths of given URL(s).
"""
return self.extract(self.download(url_or_urls))
def get_recorded_sizes_checksums(self):
return self._recorded_sizes_checksums.copy()
def delete_extracted_files(self):
paths_to_delete = set(self.extracted_paths.values()) - set(self.downloaded_paths.values())
for key, path in list(self.extracted_paths.items()):
if path in paths_to_delete and os.path.isfile(path):
os.remove(path)
del self.extracted_paths[key]
def manage_extracted_files(self):
if self.download_config.delete_extracted:
self.delete_extracted_files()
|
datasets/src/datasets/download/download_manager.py/0
|
{
"file_path": "datasets/src/datasets/download/download_manager.py",
"repo_id": "datasets",
"token_count": 9779
}
| 69 |
# Copyright 2020 The HuggingFace Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import sys
from collections.abc import Mapping
import numpy as np
import pyarrow as pa
from .. import config
from ..utils.py_utils import map_nested
from .formatting import TensorFormatter
class NumpyFormatter(TensorFormatter[Mapping, np.ndarray, Mapping]):
def __init__(self, features=None, **np_array_kwargs):
super().__init__(features=features)
self.np_array_kwargs = np_array_kwargs
def _consolidate(self, column):
if isinstance(column, list):
if column and all(
isinstance(x, np.ndarray) and x.shape == column[0].shape and x.dtype == column[0].dtype for x in column
):
return np.stack(column)
else:
# don't use np.array(column, dtype=object)
# since it fails in certain cases
# see https://stackoverflow.com/q/51005699
out = np.empty(len(column), dtype=object)
out[:] = column
return out
return column
def _tensorize(self, value):
if isinstance(value, (str, bytes, type(None))):
return value
elif isinstance(value, (np.character, np.ndarray)) and np.issubdtype(value.dtype, np.character):
return value
elif isinstance(value, np.number):
return value
default_dtype = {}
if isinstance(value, np.ndarray) and np.issubdtype(value.dtype, np.integer):
default_dtype = {"dtype": np.int64}
elif isinstance(value, np.ndarray) and np.issubdtype(value.dtype, np.floating):
default_dtype = {"dtype": np.float32}
elif config.PIL_AVAILABLE and "PIL" in sys.modules:
import PIL.Image
if isinstance(value, PIL.Image.Image):
return np.asarray(value, **self.np_array_kwargs)
return np.asarray(value, **{**default_dtype, **self.np_array_kwargs})
def _recursive_tensorize(self, data_struct):
# support for torch, tf, jax etc.
if config.TORCH_AVAILABLE and "torch" in sys.modules:
import torch
if isinstance(data_struct, torch.Tensor):
return self._tensorize(data_struct.detach().cpu().numpy()[()])
if hasattr(data_struct, "__array__") and not isinstance(data_struct, (np.ndarray, np.character, np.number)):
data_struct = data_struct.__array__()
# support for nested types like struct of list of struct
if isinstance(data_struct, np.ndarray):
if data_struct.dtype == object:
return self._consolidate([self.recursive_tensorize(substruct) for substruct in data_struct])
if isinstance(data_struct, (list, tuple)):
return self._consolidate([self.recursive_tensorize(substruct) for substruct in data_struct])
return self._tensorize(data_struct)
def recursive_tensorize(self, data_struct: dict):
return map_nested(self._recursive_tensorize, data_struct, map_list=False)
def format_row(self, pa_table: pa.Table) -> Mapping:
row = self.numpy_arrow_extractor().extract_row(pa_table)
row = self.python_features_decoder.decode_row(row)
return self.recursive_tensorize(row)
def format_column(self, pa_table: pa.Table) -> np.ndarray:
column = self.numpy_arrow_extractor().extract_column(pa_table)
column = self.python_features_decoder.decode_column(column, pa_table.column_names[0])
column = self.recursive_tensorize(column)
column = self._consolidate(column)
return column
def format_batch(self, pa_table: pa.Table) -> Mapping:
batch = self.numpy_arrow_extractor().extract_batch(pa_table)
batch = self.python_features_decoder.decode_batch(batch)
batch = self.recursive_tensorize(batch)
for column_name in batch:
batch[column_name] = self._consolidate(batch[column_name])
return batch
|
datasets/src/datasets/formatting/np_formatter.py/0
|
{
"file_path": "datasets/src/datasets/formatting/np_formatter.py",
"repo_id": "datasets",
"token_count": 1871
}
| 70 |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""
Hashing function for dataset keys using `hashlib.md5`
Requirements for the hash function:
- Provides a uniformly distributed hash from random space
- Adequately fast speed
- Working with multiple input types (in this case, `str`, `int` or `bytes`)
- Should be platform independent (generates same hash on different OS and systems)
The hashing function provides a unique 128-bit integer hash of the key provided.
The split name is being used here as the hash salt to avoid having same hashes
in different splits due to same keys
"""
from typing import Union
from huggingface_hub.utils import insecure_hashlib
def _as_bytes(hash_data: Union[str, int, bytes]) -> bytes:
"""
Returns the input hash_data in its bytes form
Args:
hash_data: the hash salt/key to be converted to bytes
"""
if isinstance(hash_data, bytes):
# Data already in bytes, returns as it as
return hash_data
elif isinstance(hash_data, str):
# We keep the data as it as for it ot be later encoded to UTF-8
# However replace `\\` with `/` for Windows compatibility
hash_data = hash_data.replace("\\", "/")
elif isinstance(hash_data, int):
hash_data = str(hash_data)
else:
# If data is not of the required type, raise error
raise InvalidKeyError(hash_data)
return hash_data.encode("utf-8")
class InvalidKeyError(Exception):
"""Raises an error when given key is of invalid datatype."""
def __init__(self, hash_data):
self.prefix = "\nFAILURE TO GENERATE DATASET: Invalid key type detected"
self.err_msg = f"\nFound Key {hash_data} of type {type(hash_data)}"
self.suffix = "\nKeys should be either str, int or bytes type"
super().__init__(f"{self.prefix}{self.err_msg}{self.suffix}")
class DuplicatedKeysError(Exception):
"""Raise an error when duplicate key found."""
def __init__(self, key, duplicate_key_indices, fix_msg=""):
self.key = key
self.duplicate_key_indices = duplicate_key_indices
self.fix_msg = fix_msg
self.prefix = "Found multiple examples generated with the same key"
if len(duplicate_key_indices) <= 20:
self.err_msg = f"\nThe examples at index {', '.join(duplicate_key_indices)} have the key {key}"
else:
self.err_msg = f"\nThe examples at index {', '.join(duplicate_key_indices[:20])}... ({len(duplicate_key_indices) - 20} more) have the key {key}"
self.suffix = "\n" + fix_msg if fix_msg else ""
super().__init__(f"{self.prefix}{self.err_msg}{self.suffix}")
class KeyHasher:
"""KeyHasher class for providing hash using md5"""
def __init__(self, hash_salt: str):
self._split_md5 = insecure_hashlib.md5(_as_bytes(hash_salt))
def hash(self, key: Union[str, int, bytes]) -> int:
"""Returns 128-bits unique hash of input key
Args:
key: the input key to be hashed (should be str, int or bytes)
Returns: 128-bit int hash key"""
md5 = self._split_md5.copy()
byte_key = _as_bytes(key)
md5.update(byte_key)
# Convert to integer with hexadecimal conversion
return int(md5.hexdigest(), 16)
|
datasets/src/datasets/keyhash.py/0
|
{
"file_path": "datasets/src/datasets/keyhash.py",
"repo_id": "datasets",
"token_count": 1378
}
| 71 |
from dataclasses import dataclass
from typing import Callable, Optional
import datasets
@dataclass
class GeneratorConfig(datasets.BuilderConfig):
generator: Optional[Callable] = None
gen_kwargs: Optional[dict] = None
features: Optional[datasets.Features] = None
def __post_init__(self):
assert self.generator is not None, "generator must be specified"
if self.gen_kwargs is None:
self.gen_kwargs = {}
class Generator(datasets.GeneratorBasedBuilder):
BUILDER_CONFIG_CLASS = GeneratorConfig
def _info(self):
return datasets.DatasetInfo(features=self.config.features)
def _split_generators(self, dl_manager):
return [datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs=self.config.gen_kwargs)]
def _generate_examples(self, **gen_kwargs):
for idx, ex in enumerate(self.config.generator(**gen_kwargs)):
yield idx, ex
|
datasets/src/datasets/packaged_modules/generator/generator.py/0
|
{
"file_path": "datasets/src/datasets/packaged_modules/generator/generator.py",
"repo_id": "datasets",
"token_count": 351
}
| 72 |
#
# Copyright (c) 2017-2021 NVIDIA CORPORATION. All rights reserved.
# This file coems from the WebDataset library.
# See the LICENSE file for licensing terms (BSD-style).
#
"""
Binary tensor encodings for PyTorch and NumPy.
This defines efficient binary encodings for tensors. The format is 8 byte
aligned and can be used directly for computations when transmitted, say,
via RDMA. The format is supported by WebDataset with the `.ten` filename
extension. It is also used by Tensorcom, Tensorcom RDMA, and can be used
for fast tensor storage with LMDB and in disk files (which can be memory
mapped)
Data is encoded as a series of chunks:
- magic number (int64)
- length in bytes (int64)
- bytes (multiple of 64 bytes long)
Arrays are a header chunk followed by a data chunk.
Header chunks have the following structure:
- dtype (int64)
- 8 byte array name
- ndim (int64)
- dim[0]
- dim[1]
- ...
"""
import struct
import sys
import numpy as np
def bytelen(a):
"""Determine the length of a in bytes."""
if hasattr(a, "nbytes"):
return a.nbytes
elif isinstance(a, (bytearray, bytes)):
return len(a)
else:
raise ValueError(a, "cannot determine nbytes")
def bytedata(a):
"""Return a the raw data corresponding to a."""
if isinstance(a, (bytearray, bytes, memoryview)):
return a
elif hasattr(a, "data"):
return a.data
else:
raise ValueError(a, "cannot return bytedata")
# tables for converting between long/short NumPy dtypes
long_to_short = """
float16 f2
float32 f4
float64 f8
int8 i1
int16 i2
int32 i4
int64 i8
uint8 u1
uint16 u2
unit32 u4
uint64 u8
""".strip()
long_to_short = [x.split() for x in long_to_short.split("\n")]
long_to_short = {x[0]: x[1] for x in long_to_short}
short_to_long = {v: k for k, v in long_to_short.items()}
def check_acceptable_input_type(data, allow64):
"""Check that the data has an acceptable type for tensor encoding.
:param data: array
:param allow64: allow 64 bit types
"""
for a in data:
if a.dtype.name not in long_to_short:
raise ValueError("unsupported dataypte")
if not allow64 and a.dtype.name not in ["float64", "int64", "uint64"]:
raise ValueError("64 bit datatypes not allowed unless explicitly enabled")
def str64(s):
"""Convert a string to an int64."""
s = s + "\0" * (8 - len(s))
s = s.encode("ascii")
return struct.unpack("@q", s)[0]
def unstr64(i):
"""Convert an int64 to a string."""
b = struct.pack("@q", i)
return b.decode("ascii").strip("\0")
def check_infos(data, infos, required_infos=None):
"""Verify the info strings."""
if required_infos is False or required_infos is None:
return data
if required_infos is True:
return data, infos
if not isinstance(required_infos, (tuple, list)):
raise ValueError("required_infos must be tuple or list")
for required, actual in zip(required_infos, infos):
raise ValueError(f"actual info {actual} doesn't match required info {required}")
return data
def encode_header(a, info=""):
"""Encode an array header as a byte array."""
if a.ndim >= 10:
raise ValueError("too many dimensions")
if a.nbytes != np.prod(a.shape) * a.itemsize:
raise ValueError("mismatch between size and shape")
if a.dtype.name not in long_to_short:
raise ValueError("unsupported array type")
header = [str64(long_to_short[a.dtype.name]), str64(info), len(a.shape)] + list(a.shape)
return bytedata(np.array(header, dtype="i8"))
def decode_header(h):
"""Decode a byte array into an array header."""
h = np.frombuffer(h, dtype="i8")
if unstr64(h[0]) not in short_to_long:
raise ValueError("unsupported array type")
dtype = np.dtype(short_to_long[unstr64(h[0])])
info = unstr64(h[1])
rank = int(h[2])
shape = tuple(h[3 : 3 + rank])
return shape, dtype, info
def encode_list(l, infos=None): # noqa: E741
"""Given a list of arrays, encode them into a list of byte arrays."""
if infos is None:
infos = [""]
else:
if len(l) != len(infos):
raise ValueError(f"length of list {l} must muatch length of infos {infos}")
result = []
for i, a in enumerate(l):
header = encode_header(a, infos[i % len(infos)])
result += [header, bytedata(a)]
return result
def decode_list(l, infos=False): # noqa: E741
"""Given a list of byte arrays, decode them into arrays."""
result = []
infos0 = []
for header, data in zip(l[::2], l[1::2]):
shape, dtype, info = decode_header(header)
a = np.frombuffer(data, dtype=dtype, count=np.prod(shape)).reshape(*shape)
result += [a]
infos0 += [info]
return check_infos(result, infos0, infos)
magic_str = "~TenBin~"
magic = str64(magic_str)
magic_bytes = unstr64(magic).encode("ascii")
def roundup(n, k=64):
"""Round up to the next multiple of 64."""
return k * ((n + k - 1) // k)
def encode_chunks(l): # noqa: E741
"""Encode a list of chunks into a single byte array, with lengths and magics.."""
size = sum(16 + roundup(b.nbytes) for b in l)
result = bytearray(size)
offset = 0
for b in l:
result[offset : offset + 8] = magic_bytes
offset += 8
result[offset : offset + 8] = struct.pack("@q", b.nbytes)
offset += 8
result[offset : offset + bytelen(b)] = b
offset += roundup(bytelen(b))
return result
def decode_chunks(buf):
"""Decode a byte array into a list of chunks."""
result = []
offset = 0
total = bytelen(buf)
while offset < total:
if magic_bytes != buf[offset : offset + 8]:
raise ValueError("magic bytes mismatch")
offset += 8
nbytes = struct.unpack("@q", buf[offset : offset + 8])[0]
offset += 8
b = buf[offset : offset + nbytes]
offset += roundup(nbytes)
result.append(b)
return result
def encode_buffer(l, infos=None): # noqa: E741
"""Encode a list of arrays into a single byte array."""
if not isinstance(l, list):
raise ValueError("requires list")
return encode_chunks(encode_list(l, infos=infos))
def decode_buffer(buf, infos=False):
"""Decode a byte array into a list of arrays."""
return decode_list(decode_chunks(buf), infos=infos)
def write_chunk(stream, buf):
"""Write a byte chunk to the stream with magics, length, and padding."""
nbytes = bytelen(buf)
stream.write(magic_bytes)
stream.write(struct.pack("@q", nbytes))
stream.write(bytedata(buf))
padding = roundup(nbytes) - nbytes
if padding > 0:
stream.write(b"\0" * padding)
def read_chunk(stream):
"""Read a byte chunk from a stream with magics, length, and padding."""
magic = stream.read(8)
if magic == b"":
return None
if magic != magic_bytes:
raise ValueError("magic number does not match")
nbytes = stream.read(8)
nbytes = struct.unpack("@q", nbytes)[0]
if nbytes < 0:
raise ValueError("negative nbytes")
data = stream.read(nbytes)
padding = roundup(nbytes) - nbytes
if padding > 0:
stream.read(padding)
return data
def write(stream, l, infos=None): # noqa: E741
"""Write a list of arrays to a stream, with magics, length, and padding."""
for chunk in encode_list(l, infos=infos):
write_chunk(stream, chunk)
def read(stream, n=sys.maxsize, infos=False):
"""Read a list of arrays from a stream, with magics, length, and padding."""
chunks = []
for _ in range(n):
header = read_chunk(stream)
if header is None:
break
data = read_chunk(stream)
if data is None:
raise ValueError("premature EOF")
chunks += [header, data]
return decode_list(chunks, infos=infos)
def save(fname, *args, infos=None, nocheck=False):
"""Save a list of arrays to a file, with magics, length, and padding."""
if not nocheck and not fname.endswith(".ten"):
raise ValueError("file name should end in .ten")
with open(fname, "wb") as stream:
write(stream, args, infos=infos)
def load(fname, infos=False, nocheck=False):
"""Read a list of arrays from a file, with magics, length, and padding."""
if not nocheck and not fname.endswith(".ten"):
raise ValueError("file name should end in .ten")
with open(fname, "rb") as stream:
return read(stream, infos=infos)
|
datasets/src/datasets/packaged_modules/webdataset/_tenbin.py/0
|
{
"file_path": "datasets/src/datasets/packaged_modules/webdataset/_tenbin.py",
"repo_id": "datasets",
"token_count": 3409
}
| 73 |
import copy
from dataclasses import dataclass, field
from typing import ClassVar, Dict
from ..features import ClassLabel, Features, Value
from .base import TaskTemplate
@dataclass(frozen=True)
class TextClassification(TaskTemplate):
# `task` is not a ClassVar since we want it to be part of the `asdict` output for JSON serialization
task: str = field(default="text-classification", metadata={"include_in_asdict_even_if_is_default": True})
input_schema: ClassVar[Features] = Features({"text": Value("string")})
label_schema: ClassVar[Features] = Features({"labels": ClassLabel})
text_column: str = "text"
label_column: str = "labels"
def align_with_features(self, features):
if self.label_column not in features:
raise ValueError(f"Column {self.label_column} is not present in features.")
if not isinstance(features[self.label_column], ClassLabel):
raise ValueError(f"Column {self.label_column} is not a ClassLabel.")
task_template = copy.deepcopy(self)
label_schema = self.label_schema.copy()
label_schema["labels"] = features[self.label_column]
task_template.__dict__["label_schema"] = label_schema
return task_template
@property
def column_mapping(self) -> Dict[str, str]:
return {
self.text_column: "text",
self.label_column: "labels",
}
|
datasets/src/datasets/tasks/text_classification.py/0
|
{
"file_path": "datasets/src/datasets/tasks/text_classification.py",
"repo_id": "datasets",
"token_count": 520
}
| 74 |
import re
import textwrap
from collections import Counter
from itertools import groupby
from operator import itemgetter
from pathlib import Path
from typing import Any, ClassVar, Dict, List, Optional, Tuple, Union
import yaml
from huggingface_hub import DatasetCardData
from ..config import METADATA_CONFIGS_FIELD
from ..info import DatasetInfo, DatasetInfosDict
from ..naming import _split_re
from ..utils.logging import get_logger
from .deprecation_utils import deprecated
logger = get_logger(__name__)
class _NoDuplicateSafeLoader(yaml.SafeLoader):
def _check_no_duplicates_on_constructed_node(self, node):
keys = [self.constructed_objects[key_node] for key_node, _ in node.value]
keys = [tuple(key) if isinstance(key, list) else key for key in keys]
counter = Counter(keys)
duplicate_keys = [key for key in counter if counter[key] > 1]
if duplicate_keys:
raise TypeError(f"Got duplicate yaml keys: {duplicate_keys}")
def construct_mapping(self, node, deep=False):
mapping = super().construct_mapping(node, deep=deep)
self._check_no_duplicates_on_constructed_node(node)
return mapping
def _split_yaml_from_readme(readme_content: str) -> Tuple[Optional[str], str]:
full_content = list(readme_content.splitlines())
if full_content and full_content[0] == "---" and "---" in full_content[1:]:
sep_idx = full_content[1:].index("---") + 1
yamlblock = "\n".join(full_content[1:sep_idx])
return yamlblock, "\n".join(full_content[sep_idx + 1 :])
return None, "\n".join(full_content)
@deprecated("Use `huggingface_hub.DatasetCardData` instead.")
class DatasetMetadata(dict):
# class attributes
_FIELDS_WITH_DASHES = {"train_eval_index"} # train-eval-index in the YAML metadata
@classmethod
def from_readme(cls, path: Union[Path, str]) -> "DatasetMetadata":
"""Loads and validates the dataset metadata from its dataset card (README.md)
Args:
path (:obj:`Path`): Path to the dataset card (its README.md file)
Returns:
:class:`DatasetMetadata`: The dataset's metadata
Raises:
:obj:`TypeError`: If the dataset's metadata is invalid
"""
with open(path, encoding="utf-8") as readme_file:
yaml_string, _ = _split_yaml_from_readme(readme_file.read())
if yaml_string is not None:
return cls.from_yaml_string(yaml_string)
else:
return cls()
def to_readme(self, path: Path):
if path.exists():
with open(path, encoding="utf-8") as readme_file:
readme_content = readme_file.read()
else:
readme_content = None
updated_readme_content = self._to_readme(readme_content)
with open(path, "w", encoding="utf-8") as readme_file:
readme_file.write(updated_readme_content)
def _to_readme(self, readme_content: Optional[str] = None) -> str:
if readme_content is not None:
_, content = _split_yaml_from_readme(readme_content)
full_content = "---\n" + self.to_yaml_string() + "---\n" + content
else:
full_content = "---\n" + self.to_yaml_string() + "---\n"
return full_content
@classmethod
def from_yaml_string(cls, string: str) -> "DatasetMetadata":
"""Loads and validates the dataset metadata from a YAML string
Args:
string (:obj:`str`): The YAML string
Returns:
:class:`DatasetMetadata`: The dataset's metadata
Raises:
:obj:`TypeError`: If the dataset's metadata is invalid
"""
metadata_dict = yaml.load(string, Loader=_NoDuplicateSafeLoader) or {}
# Convert the YAML keys to DatasetMetadata fields
metadata_dict = {
(key.replace("-", "_") if key.replace("-", "_") in cls._FIELDS_WITH_DASHES else key): value
for key, value in metadata_dict.items()
}
return cls(**metadata_dict)
def to_yaml_string(self) -> str:
return yaml.safe_dump(
{
(key.replace("_", "-") if key in self._FIELDS_WITH_DASHES else key): value
for key, value in self.items()
},
sort_keys=False,
allow_unicode=True,
encoding="utf-8",
).decode("utf-8")
class MetadataConfigs(Dict[str, Dict[str, Any]]):
"""Should be in format {config_name: {**config_params}}."""
FIELD_NAME: ClassVar[str] = METADATA_CONFIGS_FIELD
@staticmethod
def _raise_if_data_files_field_not_valid(metadata_config: dict):
yaml_data_files = metadata_config.get("data_files")
if yaml_data_files is not None:
yaml_error_message = textwrap.dedent(
f"""
Expected data_files in YAML to be either a string or a list of strings
or a list of dicts with two keys: 'split' and 'path', but got {yaml_data_files}
Examples of data_files in YAML:
data_files: data.csv
data_files: data/*.png
data_files:
- part0/*
- part1/*
data_files:
- split: train
path: train/*
- split: test
path: test/*
data_files:
- split: train
path:
- train/part1/*
- train/part2/*
- split: test
path: test/*
PS: some symbols like dashes '-' are not allowed in split names
"""
)
if not isinstance(yaml_data_files, (list, str)):
raise ValueError(yaml_error_message)
if isinstance(yaml_data_files, list):
for yaml_data_files_item in yaml_data_files:
if (
not isinstance(yaml_data_files_item, (str, dict))
or isinstance(yaml_data_files_item, dict)
and not (
len(yaml_data_files_item) == 2
and "split" in yaml_data_files_item
and re.match(_split_re, yaml_data_files_item["split"])
and isinstance(yaml_data_files_item.get("path"), (str, list))
)
):
raise ValueError(yaml_error_message)
@classmethod
def _from_exported_parquet_files_and_dataset_infos(
cls,
revision: str,
exported_parquet_files: List[Dict[str, Any]],
dataset_infos: DatasetInfosDict,
) -> "MetadataConfigs":
metadata_configs = {
config_name: {
"data_files": [
{
"split": split_name,
"path": [
parquet_file["url"].replace("refs%2Fconvert%2Fparquet", revision)
for parquet_file in parquet_files_for_split
],
}
for split_name, parquet_files_for_split in groupby(parquet_files_for_config, itemgetter("split"))
],
"version": str(dataset_infos.get(config_name, DatasetInfo()).version or "0.0.0"),
}
for config_name, parquet_files_for_config in groupby(exported_parquet_files, itemgetter("config"))
}
if dataset_infos:
# Preserve order of configs and splits
metadata_configs = {
config_name: {
"data_files": [
data_file
for split_name in dataset_info.splits
for data_file in metadata_configs[config_name]["data_files"]
if data_file["split"] == split_name
],
"version": metadata_configs[config_name]["version"],
}
for config_name, dataset_info in dataset_infos.items()
}
return cls(metadata_configs)
@classmethod
def from_dataset_card_data(cls, dataset_card_data: DatasetCardData) -> "MetadataConfigs":
if dataset_card_data.get(cls.FIELD_NAME):
metadata_configs = dataset_card_data[cls.FIELD_NAME]
if not isinstance(metadata_configs, list):
raise ValueError(f"Expected {cls.FIELD_NAME} to be a list, but got '{metadata_configs}'")
for metadata_config in metadata_configs:
if "config_name" not in metadata_config:
raise ValueError(
f"Each config must include `config_name` field with a string name of a config, "
f"but got {metadata_config}. "
)
cls._raise_if_data_files_field_not_valid(metadata_config)
return cls(
{
config["config_name"]: {param: value for param, value in config.items() if param != "config_name"}
for config in metadata_configs
}
)
return cls()
def to_dataset_card_data(self, dataset_card_data: DatasetCardData) -> None:
if self:
for metadata_config in self.values():
self._raise_if_data_files_field_not_valid(metadata_config)
current_metadata_configs = self.from_dataset_card_data(dataset_card_data)
total_metadata_configs = dict(sorted({**current_metadata_configs, **self}.items()))
for config_name, config_metadata in total_metadata_configs.items():
config_metadata.pop("config_name", None)
dataset_card_data[self.FIELD_NAME] = [
{"config_name": config_name, **config_metadata}
for config_name, config_metadata in total_metadata_configs.items()
]
def get_default_config_name(self) -> Optional[str]:
default_config_name = None
for config_name, metadata_config in self.items():
if len(self) == 1 or config_name == "default" or metadata_config.get("default"):
if default_config_name is None:
default_config_name = config_name
else:
raise ValueError(
f"Dataset has several default configs: '{default_config_name}' and '{config_name}'."
)
return default_config_name
# DEPRECATED - just here to support old versions of evaluate like 0.2.2
# To support new tasks on the Hugging Face Hub, please open a PR for this file:
# https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/pipelines.ts
known_task_ids = {
"image-classification": [],
"translation": [],
"image-segmentation": [],
"fill-mask": [],
"automatic-speech-recognition": [],
"token-classification": [],
"sentence-similarity": [],
"audio-classification": [],
"question-answering": [],
"summarization": [],
"zero-shot-classification": [],
"table-to-text": [],
"feature-extraction": [],
"other": [],
"multiple-choice": [],
"text-classification": [],
"text-to-image": [],
"text2text-generation": [],
"zero-shot-image-classification": [],
"tabular-classification": [],
"tabular-regression": [],
"image-to-image": [],
"tabular-to-text": [],
"unconditional-image-generation": [],
"text-retrieval": [],
"text-to-speech": [],
"object-detection": [],
"audio-to-audio": [],
"text-generation": [],
"conversational": [],
"table-question-answering": [],
"visual-question-answering": [],
"image-to-text": [],
"reinforcement-learning": [],
"voice-activity-detection": [],
"time-series-forecasting": [],
"document-question-answering": [],
}
if __name__ == "__main__":
from argparse import ArgumentParser
ap = ArgumentParser(usage="Validate the yaml metadata block of a README.md file.")
ap.add_argument("readme_filepath")
args = ap.parse_args()
readme_filepath = Path(args.readme_filepath)
dataset_metadata = DatasetMetadata.from_readme(readme_filepath)
print(dataset_metadata)
dataset_metadata.to_readme(readme_filepath)
|
datasets/src/datasets/utils/metadata.py/0
|
{
"file_path": "datasets/src/datasets/utils/metadata.py",
"repo_id": "datasets",
"token_count": 6000
}
| 75 |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""Version utils."""
import dataclasses
import re
from dataclasses import dataclass
from functools import total_ordering
from typing import Optional, Union
_VERSION_REG = re.compile(r"^(?P<major>\d+)" r"\.(?P<minor>\d+)" r"\.(?P<patch>\d+)$")
@total_ordering
@dataclass
class Version:
"""Dataset version `MAJOR.MINOR.PATCH`.
Args:
version_str (`str`):
The dataset version.
description (`str`):
A description of what is new in this version.
major (`str`):
minor (`str`):
patch (`str`):
Example:
```py
>>> VERSION = datasets.Version("1.0.0")
```
"""
version_str: str
description: Optional[str] = None
major: Optional[Union[str, int]] = None
minor: Optional[Union[str, int]] = None
patch: Optional[Union[str, int]] = None
def __post_init__(self):
self.major, self.minor, self.patch = _str_to_version_tuple(self.version_str)
def __repr__(self):
return f"{self.tuple[0]}.{self.tuple[1]}.{self.tuple[2]}"
@property
def tuple(self):
return self.major, self.minor, self.patch
def _validate_operand(self, other):
if isinstance(other, str):
return Version(other)
elif isinstance(other, Version):
return other
raise TypeError(f"{other} (type {type(other)}) cannot be compared to version.")
def __eq__(self, other):
try:
other = self._validate_operand(other)
except (TypeError, ValueError):
return False
else:
return self.tuple == other.tuple
def __lt__(self, other):
other = self._validate_operand(other)
return self.tuple < other.tuple
def __hash__(self):
return hash(_version_tuple_to_str(self.tuple))
@classmethod
def from_dict(cls, dic):
field_names = {f.name for f in dataclasses.fields(cls)}
return cls(**{k: v for k, v in dic.items() if k in field_names})
def _to_yaml_string(self) -> str:
return self.version_str
def _str_to_version_tuple(version_str):
"""Return the tuple (major, minor, patch) version extracted from the str."""
res = _VERSION_REG.match(version_str)
if not res:
raise ValueError(f"Invalid version '{version_str}'. Format should be x.y.z with {{x,y,z}} being digits.")
return tuple(int(v) for v in [res.group("major"), res.group("minor"), res.group("patch")])
def _version_tuple_to_str(version_tuple):
"""Return the str version from the version tuple (major, minor, patch)."""
return ".".join(str(v) for v in version_tuple)
|
datasets/src/datasets/utils/version.py/0
|
{
"file_path": "datasets/src/datasets/utils/version.py",
"repo_id": "datasets",
"token_count": 1291
}
| 76 |
import contextlib
import copy
import itertools
import json
import os
import pickle
import re
import sys
import tempfile
from functools import partial
from pathlib import Path
from unittest import TestCase
from unittest.mock import MagicMock, patch
import numpy as np
import numpy.testing as npt
import pandas as pd
import pyarrow as pa
import pytest
from absl.testing import parameterized
from fsspec.core import strip_protocol
from packaging import version
import datasets.arrow_dataset
from datasets import concatenate_datasets, interleave_datasets, load_from_disk
from datasets.arrow_dataset import Dataset, transmit_format, update_metadata_with_features
from datasets.dataset_dict import DatasetDict
from datasets.features import (
Array2D,
Array3D,
Audio,
ClassLabel,
Features,
Image,
Sequence,
Translation,
TranslationVariableLanguages,
Value,
)
from datasets.info import DatasetInfo
from datasets.iterable_dataset import IterableDataset
from datasets.splits import NamedSplit
from datasets.table import ConcatenationTable, InMemoryTable, MemoryMappedTable
from datasets.tasks import (
AutomaticSpeechRecognition,
LanguageModeling,
QuestionAnsweringExtractive,
Summarization,
TextClassification,
)
from datasets.utils.logging import INFO, get_logger
from datasets.utils.py_utils import temp_seed
from .utils import (
assert_arrow_memory_doesnt_increase,
assert_arrow_memory_increases,
require_dill_gt_0_3_2,
require_jax,
require_not_windows,
require_pil,
require_polars,
require_pyspark,
require_sqlalchemy,
require_tf,
require_torch,
require_transformers,
set_current_working_directory_to_temp_dir,
)
class PickableMagicMock(MagicMock):
def __reduce__(self):
return MagicMock, ()
class Unpicklable:
def __init__(self, **kwargs):
for key, value in kwargs.items():
setattr(self, key, value)
def __getstate__(self):
raise pickle.PicklingError()
def picklable_map_function(x):
return {"id": int(x["filename"].split("_")[-1])}
def picklable_map_function_with_indices(x, i):
return {"id": i}
def picklable_map_function_with_rank(x, r):
return {"rank": r}
def picklable_map_function_with_indices_and_rank(x, i, r):
return {"id": i, "rank": r}
def picklable_filter_function(x):
return int(x["filename"].split("_")[-1]) < 10
def picklable_filter_function_with_rank(x, r):
return r == 0
def assert_arrow_metadata_are_synced_with_dataset_features(dataset: Dataset):
assert dataset.data.schema.metadata is not None
assert b"huggingface" in dataset.data.schema.metadata
metadata = json.loads(dataset.data.schema.metadata[b"huggingface"].decode())
assert "info" in metadata
features = DatasetInfo.from_dict(metadata["info"]).features
assert features is not None
assert features == dataset.features
assert features == Features.from_arrow_schema(dataset.data.schema)
assert list(features) == dataset.data.column_names
assert list(features) == list(dataset.features)
IN_MEMORY_PARAMETERS = [
{"testcase_name": name, "in_memory": im} for im, name in [(True, "in_memory"), (False, "on_disk")]
]
@parameterized.named_parameters(IN_MEMORY_PARAMETERS)
class BaseDatasetTest(TestCase):
@pytest.fixture(autouse=True)
def inject_fixtures(self, caplog, set_sqlalchemy_silence_uber_warning):
self._caplog = caplog
def _create_dummy_dataset(
self, in_memory: bool, tmp_dir: str, multiple_columns=False, array_features=False, nested_features=False
) -> Dataset:
assert int(multiple_columns) + int(array_features) + int(nested_features) < 2
if multiple_columns:
data = {"col_1": [3, 2, 1, 0], "col_2": ["a", "b", "c", "d"], "col_3": [False, True, False, True]}
dset = Dataset.from_dict(data)
elif array_features:
data = {
"col_1": [[[True, False], [False, True]]] * 4, # 2D
"col_2": [[[["a", "b"], ["c", "d"]], [["e", "f"], ["g", "h"]]]] * 4, # 3D array
"col_3": [[3, 2, 1, 0]] * 4, # Sequence
}
features = Features(
{
"col_1": Array2D(shape=(2, 2), dtype="bool"),
"col_2": Array3D(shape=(2, 2, 2), dtype="string"),
"col_3": Sequence(feature=Value("int64")),
}
)
dset = Dataset.from_dict(data, features=features)
elif nested_features:
data = {"nested": [{"a": i, "x": i * 10, "c": i * 100} for i in range(1, 11)]}
features = Features({"nested": {"a": Value("int64"), "x": Value("int64"), "c": Value("int64")}})
dset = Dataset.from_dict(data, features=features)
else:
dset = Dataset.from_dict({"filename": ["my_name-train" + "_" + str(x) for x in np.arange(30).tolist()]})
if not in_memory:
dset = self._to(in_memory, tmp_dir, dset)
return dset
def _to(self, in_memory, tmp_dir, *datasets):
if in_memory:
datasets = [dataset.map(keep_in_memory=True) for dataset in datasets]
else:
start = 0
while os.path.isfile(os.path.join(tmp_dir, f"dataset{start}.arrow")):
start += 1
datasets = [
dataset.map(cache_file_name=os.path.join(tmp_dir, f"dataset{start + i}.arrow"))
for i, dataset in enumerate(datasets)
]
return datasets if len(datasets) > 1 else datasets[0]
def test_dummy_dataset(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertEqual(dset[0]["filename"], "my_name-train_0")
self.assertEqual(dset["filename"][0], "my_name-train_0")
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
self.assertDictEqual(
dset.features,
Features({"col_1": Value("int64"), "col_2": Value("string"), "col_3": Value("bool")}),
)
self.assertEqual(dset[0]["col_1"], 3)
self.assertEqual(dset["col_1"][0], 3)
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, array_features=True) as dset:
self.assertDictEqual(
dset.features,
Features(
{
"col_1": Array2D(shape=(2, 2), dtype="bool"),
"col_2": Array3D(shape=(2, 2, 2), dtype="string"),
"col_3": Sequence(feature=Value("int64")),
}
),
)
self.assertEqual(dset[0]["col_2"], [[["a", "b"], ["c", "d"]], [["e", "f"], ["g", "h"]]])
self.assertEqual(dset["col_2"][0], [[["a", "b"], ["c", "d"]], [["e", "f"], ["g", "h"]]])
def test_dataset_getitem(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertEqual(dset[0]["filename"], "my_name-train_0")
self.assertEqual(dset["filename"][0], "my_name-train_0")
self.assertEqual(dset[-1]["filename"], "my_name-train_29")
self.assertEqual(dset["filename"][-1], "my_name-train_29")
self.assertListEqual(dset[:2]["filename"], ["my_name-train_0", "my_name-train_1"])
self.assertListEqual(dset["filename"][:2], ["my_name-train_0", "my_name-train_1"])
self.assertEqual(dset[:-1]["filename"][-1], "my_name-train_28")
self.assertEqual(dset["filename"][:-1][-1], "my_name-train_28")
self.assertListEqual(dset[[0, -1]]["filename"], ["my_name-train_0", "my_name-train_29"])
self.assertListEqual(dset[range(0, -2, -1)]["filename"], ["my_name-train_0", "my_name-train_29"])
self.assertListEqual(dset[np.array([0, -1])]["filename"], ["my_name-train_0", "my_name-train_29"])
self.assertListEqual(dset[pd.Series([0, -1])]["filename"], ["my_name-train_0", "my_name-train_29"])
with dset.select(range(2)) as dset_subset:
self.assertListEqual(dset_subset[-1:]["filename"], ["my_name-train_1"])
self.assertListEqual(dset_subset["filename"][-1:], ["my_name-train_1"])
def test_dummy_dataset_deepcopy(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(10)) as dset:
with assert_arrow_memory_doesnt_increase():
dset2 = copy.deepcopy(dset)
# don't copy the underlying arrow data using memory
self.assertEqual(len(dset2), 10)
self.assertDictEqual(dset2.features, Features({"filename": Value("string")}))
self.assertEqual(dset2[0]["filename"], "my_name-train_0")
self.assertEqual(dset2["filename"][0], "my_name-train_0")
del dset2
def test_dummy_dataset_pickle(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
tmp_file = os.path.join(tmp_dir, "dset.pt")
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(0, 10, 2)) as dset:
with open(tmp_file, "wb") as f:
pickle.dump(dset, f)
with open(tmp_file, "rb") as f:
with pickle.load(f) as dset:
self.assertEqual(len(dset), 5)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertEqual(dset[0]["filename"], "my_name-train_0")
self.assertEqual(dset["filename"][0], "my_name-train_0")
with self._create_dummy_dataset(in_memory, tmp_dir).select(
range(0, 10, 2), indices_cache_file_name=os.path.join(tmp_dir, "ind.arrow")
) as dset:
if not in_memory:
dset._data.table = Unpicklable()
dset._indices.table = Unpicklable()
with open(tmp_file, "wb") as f:
pickle.dump(dset, f)
with open(tmp_file, "rb") as f:
with pickle.load(f) as dset:
self.assertEqual(len(dset), 5)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertEqual(dset[0]["filename"], "my_name-train_0")
self.assertEqual(dset["filename"][0], "my_name-train_0")
def test_dummy_dataset_serialize(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with set_current_working_directory_to_temp_dir():
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(10)) as dset:
dataset_path = "my_dataset" # rel path
dset.save_to_disk(dataset_path)
with Dataset.load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertEqual(dset[0]["filename"], "my_name-train_0")
self.assertEqual(dset["filename"][0], "my_name-train_0")
expected = dset.to_dict()
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(10)) as dset:
dataset_path = os.path.join(tmp_dir, "my_dataset") # abs path
dset.save_to_disk(dataset_path)
with Dataset.load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertEqual(dset[0]["filename"], "my_name-train_0")
self.assertEqual(dset["filename"][0], "my_name-train_0")
with self._create_dummy_dataset(in_memory, tmp_dir).select(
range(10), indices_cache_file_name=os.path.join(tmp_dir, "ind.arrow")
) as dset:
with assert_arrow_memory_doesnt_increase():
dset.save_to_disk(dataset_path)
with Dataset.load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertEqual(dset[0]["filename"], "my_name-train_0")
self.assertEqual(dset["filename"][0], "my_name-train_0")
with self._create_dummy_dataset(in_memory, tmp_dir, nested_features=True) as dset:
with assert_arrow_memory_doesnt_increase():
dset.save_to_disk(dataset_path)
with Dataset.load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(
dset.features,
Features({"nested": {"a": Value("int64"), "x": Value("int64"), "c": Value("int64")}}),
)
self.assertDictEqual(dset[0]["nested"], {"a": 1, "c": 100, "x": 10})
self.assertDictEqual(dset["nested"][0], {"a": 1, "c": 100, "x": 10})
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(10)) as dset:
with assert_arrow_memory_doesnt_increase():
dset.save_to_disk(dataset_path, num_shards=4)
with Dataset.load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset.to_dict(), expected)
self.assertEqual(len(dset.cache_files), 4)
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(10)) as dset:
with assert_arrow_memory_doesnt_increase():
dset.save_to_disk(dataset_path, num_proc=2)
with Dataset.load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset.to_dict(), expected)
self.assertEqual(len(dset.cache_files), 2)
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(10)) as dset:
with assert_arrow_memory_doesnt_increase():
dset.save_to_disk(dataset_path, num_shards=7, num_proc=2)
with Dataset.load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset.to_dict(), expected)
self.assertEqual(len(dset.cache_files), 7)
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(10)) as dset:
with assert_arrow_memory_doesnt_increase():
max_shard_size = dset._estimate_nbytes() // 2 + 1
dset.save_to_disk(dataset_path, max_shard_size=max_shard_size)
with Dataset.load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset.to_dict(), expected)
self.assertEqual(len(dset.cache_files), 2)
def test_dummy_dataset_load_from_disk(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir).select(range(10)) as dset:
dataset_path = os.path.join(tmp_dir, "my_dataset")
dset.save_to_disk(dataset_path)
with load_from_disk(dataset_path) as dset:
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertEqual(dset[0]["filename"], "my_name-train_0")
self.assertEqual(dset["filename"][0], "my_name-train_0")
def test_restore_saved_format(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_format(type="numpy", columns=["col_1"], output_all_columns=True)
dataset_path = os.path.join(tmp_dir, "my_dataset")
dset.save_to_disk(dataset_path)
with load_from_disk(dataset_path) as loaded_dset:
self.assertEqual(dset.format, loaded_dset.format)
def test_set_format_numpy_multiple_columns(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
fingerprint = dset._fingerprint
dset.set_format(type="numpy", columns=["col_1"])
self.assertEqual(len(dset[0]), 1)
self.assertIsInstance(dset[0]["col_1"], np.int64)
self.assertEqual(dset[0]["col_1"].item(), 3)
self.assertIsInstance(dset["col_1"], np.ndarray)
self.assertListEqual(list(dset["col_1"].shape), [4])
np.testing.assert_array_equal(dset["col_1"], np.array([3, 2, 1, 0]))
self.assertNotEqual(dset._fingerprint, fingerprint)
dset.reset_format()
with dset.formatted_as(type="numpy", columns=["col_1"]):
self.assertEqual(len(dset[0]), 1)
self.assertIsInstance(dset[0]["col_1"], np.int64)
self.assertEqual(dset[0]["col_1"].item(), 3)
self.assertIsInstance(dset["col_1"], np.ndarray)
self.assertListEqual(list(dset["col_1"].shape), [4])
np.testing.assert_array_equal(dset["col_1"], np.array([3, 2, 1, 0]))
self.assertEqual(dset.format["type"], None)
self.assertEqual(dset.format["format_kwargs"], {})
self.assertEqual(dset.format["columns"], dset.column_names)
self.assertEqual(dset.format["output_all_columns"], False)
dset.set_format(type="numpy", columns=["col_1"], output_all_columns=True)
self.assertEqual(len(dset[0]), 3)
self.assertIsInstance(dset[0]["col_2"], str)
self.assertEqual(dset[0]["col_2"], "a")
dset.set_format(type="numpy", columns=["col_1", "col_2"])
self.assertEqual(len(dset[0]), 2)
self.assertIsInstance(dset[0]["col_2"], np.str_)
self.assertEqual(dset[0]["col_2"].item(), "a")
@require_torch
def test_set_format_torch(self, in_memory):
import torch
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_format(type="torch", columns=["col_1"])
self.assertEqual(len(dset[0]), 1)
self.assertIsInstance(dset[0]["col_1"], torch.Tensor)
self.assertIsInstance(dset["col_1"], torch.Tensor)
self.assertListEqual(list(dset[0]["col_1"].shape), [])
self.assertEqual(dset[0]["col_1"].item(), 3)
dset.set_format(type="torch", columns=["col_1"], output_all_columns=True)
self.assertEqual(len(dset[0]), 3)
self.assertIsInstance(dset[0]["col_2"], str)
self.assertEqual(dset[0]["col_2"], "a")
dset.set_format(type="torch")
self.assertEqual(len(dset[0]), 3)
self.assertIsInstance(dset[0]["col_1"], torch.Tensor)
self.assertIsInstance(dset["col_1"], torch.Tensor)
self.assertListEqual(list(dset[0]["col_1"].shape), [])
self.assertEqual(dset[0]["col_1"].item(), 3)
self.assertIsInstance(dset[0]["col_2"], str)
self.assertEqual(dset[0]["col_2"], "a")
self.assertIsInstance(dset[0]["col_3"], torch.Tensor)
self.assertIsInstance(dset["col_3"], torch.Tensor)
self.assertListEqual(list(dset[0]["col_3"].shape), [])
@require_tf
def test_set_format_tf(self, in_memory):
import tensorflow as tf
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_format(type="tensorflow", columns=["col_1"])
self.assertEqual(len(dset[0]), 1)
self.assertIsInstance(dset[0]["col_1"], tf.Tensor)
self.assertListEqual(list(dset[0]["col_1"].shape), [])
self.assertEqual(dset[0]["col_1"].numpy().item(), 3)
dset.set_format(type="tensorflow", columns=["col_1"], output_all_columns=True)
self.assertEqual(len(dset[0]), 3)
self.assertIsInstance(dset[0]["col_2"], str)
self.assertEqual(dset[0]["col_2"], "a")
dset.set_format(type="tensorflow", columns=["col_1", "col_2"])
self.assertEqual(len(dset[0]), 2)
self.assertEqual(dset[0]["col_2"].numpy().decode("utf-8"), "a")
def test_set_format_pandas(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_format(type="pandas", columns=["col_1"])
self.assertEqual(len(dset[0].columns), 1)
self.assertIsInstance(dset[0], pd.DataFrame)
self.assertListEqual(list(dset[0].shape), [1, 1])
self.assertEqual(dset[0]["col_1"].item(), 3)
dset.set_format(type="pandas", columns=["col_1", "col_2"])
self.assertEqual(len(dset[0].columns), 2)
self.assertEqual(dset[0]["col_2"].item(), "a")
@require_polars
def test_set_format_polars(self, in_memory):
import polars as pl
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_format(type="polars", columns=["col_1"])
self.assertEqual(len(dset[0].columns), 1)
self.assertIsInstance(dset[0], pl.DataFrame)
self.assertListEqual(list(dset[0].shape), [1, 1])
self.assertEqual(dset[0]["col_1"].item(), 3)
dset.set_format(type="polars", columns=["col_1", "col_2"])
self.assertEqual(len(dset[0].columns), 2)
self.assertEqual(dset[0]["col_2"].item(), "a")
def test_set_transform(self, in_memory):
def transform(batch):
return {k: [str(i).upper() for i in v] for k, v in batch.items()}
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_transform(transform=transform, columns=["col_1"])
self.assertEqual(dset.format["type"], "custom")
self.assertEqual(len(dset[0].keys()), 1)
self.assertEqual(dset[0]["col_1"], "3")
self.assertEqual(dset[:2]["col_1"], ["3", "2"])
self.assertEqual(dset["col_1"][:2], ["3", "2"])
prev_format = dset.format
dset.set_format(**dset.format)
self.assertEqual(prev_format, dset.format)
dset.set_transform(transform=transform, columns=["col_1", "col_2"])
self.assertEqual(len(dset[0].keys()), 2)
self.assertEqual(dset[0]["col_2"], "A")
def test_transmit_format(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
transform = datasets.arrow_dataset.transmit_format(lambda x: x)
# make sure identity transform doesn't apply unnecessary format
self.assertEqual(dset._fingerprint, transform(dset)._fingerprint)
dset.set_format(**dset.format)
self.assertEqual(dset._fingerprint, transform(dset)._fingerprint)
# check lists comparisons
dset.set_format(columns=["col_1"])
self.assertEqual(dset._fingerprint, transform(dset)._fingerprint)
dset.set_format(columns=["col_1", "col_2"])
self.assertEqual(dset._fingerprint, transform(dset)._fingerprint)
dset.set_format("numpy", columns=["col_1", "col_2"])
self.assertEqual(dset._fingerprint, transform(dset)._fingerprint)
def test_cast(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
features = dset.features
features["col_1"] = Value("float64")
features = Features({k: features[k] for k in list(features)[::-1]})
fingerprint = dset._fingerprint
# TODO: with assert_arrow_memory_increases() if in_memory else assert_arrow_memory_doesnt_increase():
with dset.cast(features) as casted_dset:
self.assertEqual(casted_dset.num_columns, 3)
self.assertEqual(casted_dset.features["col_1"], Value("float64"))
self.assertIsInstance(casted_dset[0]["col_1"], float)
self.assertNotEqual(casted_dset._fingerprint, fingerprint)
self.assertNotEqual(casted_dset, dset)
assert_arrow_metadata_are_synced_with_dataset_features(casted_dset)
def test_class_encode_column(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
with self.assertRaises(ValueError):
dset.class_encode_column(column="does not exist")
with dset.class_encode_column("col_1") as casted_dset:
self.assertIsInstance(casted_dset.features["col_1"], ClassLabel)
self.assertListEqual(casted_dset.features["col_1"].names, ["0", "1", "2", "3"])
self.assertListEqual(casted_dset["col_1"], [3, 2, 1, 0])
self.assertNotEqual(casted_dset._fingerprint, dset._fingerprint)
self.assertNotEqual(casted_dset, dset)
assert_arrow_metadata_are_synced_with_dataset_features(casted_dset)
with dset.class_encode_column("col_2") as casted_dset:
self.assertIsInstance(casted_dset.features["col_2"], ClassLabel)
self.assertListEqual(casted_dset.features["col_2"].names, ["a", "b", "c", "d"])
self.assertListEqual(casted_dset["col_2"], [0, 1, 2, 3])
self.assertNotEqual(casted_dset._fingerprint, dset._fingerprint)
self.assertNotEqual(casted_dset, dset)
assert_arrow_metadata_are_synced_with_dataset_features(casted_dset)
with dset.class_encode_column("col_3") as casted_dset:
self.assertIsInstance(casted_dset.features["col_3"], ClassLabel)
self.assertListEqual(casted_dset.features["col_3"].names, ["False", "True"])
self.assertListEqual(casted_dset["col_3"], [0, 1, 0, 1])
self.assertNotEqual(casted_dset._fingerprint, dset._fingerprint)
self.assertNotEqual(casted_dset, dset)
assert_arrow_metadata_are_synced_with_dataset_features(casted_dset)
# Test raises if feature is an array / sequence
with self._create_dummy_dataset(in_memory, tmp_dir, array_features=True) as dset:
for column in dset.column_names:
with self.assertRaises(ValueError):
dset.class_encode_column(column)
def test_remove_columns(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
fingerprint = dset._fingerprint
with dset.remove_columns(column_names="col_1") as new_dset:
self.assertEqual(new_dset.num_columns, 2)
self.assertListEqual(list(new_dset.column_names), ["col_2", "col_3"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
with dset.remove_columns(column_names=["col_1", "col_2", "col_3"]) as new_dset:
self.assertEqual(new_dset.num_columns, 0)
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset._format_columns = ["col_1", "col_2", "col_3"]
with dset.remove_columns(column_names=["col_1"]) as new_dset:
self.assertListEqual(new_dset._format_columns, ["col_2", "col_3"])
self.assertEqual(new_dset.num_columns, 2)
self.assertListEqual(list(new_dset.column_names), ["col_2", "col_3"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
def test_rename_column(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
fingerprint = dset._fingerprint
with dset.rename_column(original_column_name="col_1", new_column_name="new_name") as new_dset:
self.assertEqual(new_dset.num_columns, 3)
self.assertListEqual(list(new_dset.column_names), ["new_name", "col_2", "col_3"])
self.assertListEqual(list(dset.column_names), ["col_1", "col_2", "col_3"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
def test_rename_columns(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
fingerprint = dset._fingerprint
with dset.rename_columns({"col_1": "new_name"}) as new_dset:
self.assertEqual(new_dset.num_columns, 3)
self.assertListEqual(list(new_dset.column_names), ["new_name", "col_2", "col_3"])
self.assertListEqual(list(dset.column_names), ["col_1", "col_2", "col_3"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
with dset.rename_columns({"col_1": "new_name", "col_2": "new_name2"}) as new_dset:
self.assertEqual(new_dset.num_columns, 3)
self.assertListEqual(list(new_dset.column_names), ["new_name", "new_name2", "col_3"])
self.assertListEqual(list(dset.column_names), ["col_1", "col_2", "col_3"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
# Original column not in dataset
with self.assertRaises(ValueError):
dset.rename_columns({"not_there": "new_name"})
# Empty new name
with self.assertRaises(ValueError):
dset.rename_columns({"col_1": ""})
# Duplicates
with self.assertRaises(ValueError):
dset.rename_columns({"col_1": "new_name", "col_2": "new_name"})
def test_select_columns(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
fingerprint = dset._fingerprint
with dset.select_columns(column_names=[]) as new_dset:
self.assertEqual(new_dset.num_columns, 0)
self.assertListEqual(list(new_dset.column_names), [])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
fingerprint = dset._fingerprint
with dset.select_columns(column_names="col_1") as new_dset:
self.assertEqual(new_dset.num_columns, 1)
self.assertListEqual(list(new_dset.column_names), ["col_1"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
with dset.select_columns(column_names=["col_1", "col_2", "col_3"]) as new_dset:
self.assertEqual(new_dset.num_columns, 3)
self.assertListEqual(list(new_dset.column_names), ["col_1", "col_2", "col_3"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
with dset.select_columns(column_names=["col_3", "col_2", "col_1"]) as new_dset:
self.assertEqual(new_dset.num_columns, 3)
self.assertListEqual(list(new_dset.column_names), ["col_3", "col_2", "col_1"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset._format_columns = ["col_1", "col_2", "col_3"]
with dset.select_columns(column_names=["col_1"]) as new_dset:
self.assertListEqual(new_dset._format_columns, ["col_1"])
self.assertEqual(new_dset.num_columns, 1)
self.assertListEqual(list(new_dset.column_names), ["col_1"])
self.assertNotEqual(new_dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(new_dset)
def test_concatenate(self, in_memory):
data1, data2, data3 = {"id": [0, 1, 2]}, {"id": [3, 4, 5]}, {"id": [6, 7]}
info1 = DatasetInfo(description="Dataset1")
info2 = DatasetInfo(description="Dataset2")
with tempfile.TemporaryDirectory() as tmp_dir:
dset1, dset2, dset3 = (
Dataset.from_dict(data1, info=info1),
Dataset.from_dict(data2, info=info2),
Dataset.from_dict(data3),
)
dset1, dset2, dset3 = self._to(in_memory, tmp_dir, dset1, dset2, dset3)
with concatenate_datasets([dset1, dset2, dset3]) as dset_concat:
self.assertTupleEqual((len(dset1), len(dset2), len(dset3)), (3, 3, 2))
self.assertEqual(len(dset_concat), len(dset1) + len(dset2) + len(dset3))
self.assertListEqual(dset_concat["id"], [0, 1, 2, 3, 4, 5, 6, 7])
self.assertEqual(len(dset_concat.cache_files), 0 if in_memory else 3)
self.assertEqual(dset_concat.info.description, "Dataset1\n\nDataset2")
del dset1, dset2, dset3
def test_concatenate_formatted(self, in_memory):
data1, data2, data3 = {"id": [0, 1, 2]}, {"id": [3, 4, 5]}, {"id": [6, 7]}
info1 = DatasetInfo(description="Dataset1")
info2 = DatasetInfo(description="Dataset2")
with tempfile.TemporaryDirectory() as tmp_dir:
dset1, dset2, dset3 = (
Dataset.from_dict(data1, info=info1),
Dataset.from_dict(data2, info=info2),
Dataset.from_dict(data3),
)
dset1, dset2, dset3 = self._to(in_memory, tmp_dir, dset1, dset2, dset3)
dset1.set_format("numpy")
with concatenate_datasets([dset1, dset2, dset3]) as dset_concat:
self.assertEqual(dset_concat.format["type"], None)
dset2.set_format("numpy")
dset3.set_format("numpy")
with concatenate_datasets([dset1, dset2, dset3]) as dset_concat:
self.assertEqual(dset_concat.format["type"], "numpy")
del dset1, dset2, dset3
def test_concatenate_with_indices(self, in_memory):
data1, data2, data3 = {"id": [0, 1, 2] * 2}, {"id": [3, 4, 5] * 2}, {"id": [6, 7, 8]}
info1 = DatasetInfo(description="Dataset1")
info2 = DatasetInfo(description="Dataset2")
with tempfile.TemporaryDirectory() as tmp_dir:
dset1, dset2, dset3 = (
Dataset.from_dict(data1, info=info1),
Dataset.from_dict(data2, info=info2),
Dataset.from_dict(data3),
)
dset1, dset2, dset3 = self._to(in_memory, tmp_dir, dset1, dset2, dset3)
dset1, dset2, dset3 = dset1.select([2, 1, 0]), dset2.select([2, 1, 0]), dset3
with concatenate_datasets([dset3, dset2, dset1]) as dset_concat:
self.assertTupleEqual((len(dset1), len(dset2), len(dset3)), (3, 3, 3))
self.assertEqual(len(dset_concat), len(dset1) + len(dset2) + len(dset3))
self.assertListEqual(dset_concat["id"], [6, 7, 8, 5, 4, 3, 2, 1, 0])
# in_memory = False:
# 3 cache files for the dset_concat._data table
# no cache file for the indices because it's in memory
# in_memory = True:
# no cache files since both dset_concat._data and dset_concat._indices are in memory
self.assertEqual(len(dset_concat.cache_files), 0 if in_memory else 3)
self.assertEqual(dset_concat.info.description, "Dataset2\n\nDataset1")
dset1 = dset1.rename_columns({"id": "id1"})
dset2 = dset2.rename_columns({"id": "id2"})
dset3 = dset3.rename_columns({"id": "id3"})
with concatenate_datasets([dset1, dset2, dset3], axis=1) as dset_concat:
self.assertTupleEqual((len(dset1), len(dset2), len(dset3)), (3, 3, 3))
self.assertEqual(len(dset_concat), len(dset1))
self.assertListEqual(dset_concat["id1"], [2, 1, 0])
self.assertListEqual(dset_concat["id2"], [5, 4, 3])
self.assertListEqual(dset_concat["id3"], [6, 7, 8])
# in_memory = False:
# 3 cache files for the dset_concat._data table
# no cache file for the indices because it's None
# in_memory = True:
# no cache files since dset_concat._data is in memory and dset_concat._indices is None
self.assertEqual(len(dset_concat.cache_files), 0 if in_memory else 3)
self.assertIsNone(dset_concat._indices)
self.assertEqual(dset_concat.info.description, "Dataset1\n\nDataset2")
with concatenate_datasets([dset1], axis=1) as dset_concat:
self.assertEqual(len(dset_concat), len(dset1))
self.assertListEqual(dset_concat["id1"], [2, 1, 0])
# in_memory = False:
# 1 cache file for the dset_concat._data table
# no cache file for the indices because it's in memory
# in_memory = True:
# no cache files since both dset_concat._data and dset_concat._indices are in memory
self.assertEqual(len(dset_concat.cache_files), 0 if in_memory else 1)
self.assertTrue(dset_concat._indices == dset1._indices)
self.assertEqual(dset_concat.info.description, "Dataset1")
del dset1, dset2, dset3
def test_concatenate_with_indices_from_disk(self, in_memory):
data1, data2, data3 = {"id": [0, 1, 2] * 2}, {"id": [3, 4, 5] * 2}, {"id": [6, 7]}
info1 = DatasetInfo(description="Dataset1")
info2 = DatasetInfo(description="Dataset2")
with tempfile.TemporaryDirectory() as tmp_dir:
dset1, dset2, dset3 = (
Dataset.from_dict(data1, info=info1),
Dataset.from_dict(data2, info=info2),
Dataset.from_dict(data3),
)
dset1, dset2, dset3 = self._to(in_memory, tmp_dir, dset1, dset2, dset3)
dset1, dset2, dset3 = (
dset1.select([2, 1, 0], indices_cache_file_name=os.path.join(tmp_dir, "i1.arrow")),
dset2.select([2, 1, 0], indices_cache_file_name=os.path.join(tmp_dir, "i2.arrow")),
dset3.select([1, 0], indices_cache_file_name=os.path.join(tmp_dir, "i3.arrow")),
)
with concatenate_datasets([dset3, dset2, dset1]) as dset_concat:
self.assertTupleEqual((len(dset1), len(dset2), len(dset3)), (3, 3, 2))
self.assertEqual(len(dset_concat), len(dset1) + len(dset2) + len(dset3))
self.assertListEqual(dset_concat["id"], [7, 6, 5, 4, 3, 2, 1, 0])
# in_memory = False:
# 3 cache files for the dset_concat._data table, and 1 for the dset_concat._indices_table
# There is only 1 for the indices tables (i1.arrow)
# Indeed, the others are brought to memory since an offset is applied to them.
# in_memory = True:
# 1 cache file for i1.arrow since both dset_concat._data and dset_concat._indices are in memory
self.assertEqual(len(dset_concat.cache_files), 1 if in_memory else 3 + 1)
self.assertEqual(dset_concat.info.description, "Dataset2\n\nDataset1")
del dset1, dset2, dset3
def test_concatenate_pickle(self, in_memory):
data1, data2, data3 = {"id": [0, 1, 2] * 2}, {"id": [3, 4, 5] * 2}, {"id": [6, 7], "foo": ["bar", "bar"]}
info1 = DatasetInfo(description="Dataset1")
info2 = DatasetInfo(description="Dataset2")
with tempfile.TemporaryDirectory() as tmp_dir:
dset1, dset2, dset3 = (
Dataset.from_dict(data1, info=info1),
Dataset.from_dict(data2, info=info2),
Dataset.from_dict(data3),
)
schema = dset1.data.schema
# mix from in-memory and on-disk datasets
dset1, dset2 = self._to(in_memory, tmp_dir, dset1, dset2)
dset3 = self._to(not in_memory, tmp_dir, dset3)
dset1, dset2, dset3 = (
dset1.select(
[2, 1, 0],
keep_in_memory=in_memory,
indices_cache_file_name=os.path.join(tmp_dir, "i1.arrow") if not in_memory else None,
),
dset2.select(
[2, 1, 0],
keep_in_memory=in_memory,
indices_cache_file_name=os.path.join(tmp_dir, "i2.arrow") if not in_memory else None,
),
dset3.select(
[1, 0],
keep_in_memory=in_memory,
indices_cache_file_name=os.path.join(tmp_dir, "i3.arrow") if not in_memory else None,
),
)
dset3 = dset3.rename_column("foo", "new_foo")
dset3 = dset3.remove_columns("new_foo")
if in_memory:
dset3._data.table = Unpicklable(schema=schema)
else:
dset1._data.table, dset2._data.table = Unpicklable(schema=schema), Unpicklable(schema=schema)
dset1, dset2, dset3 = (pickle.loads(pickle.dumps(d)) for d in (dset1, dset2, dset3))
with concatenate_datasets([dset3, dset2, dset1]) as dset_concat:
if not in_memory:
dset_concat._data.table = Unpicklable(schema=schema)
with pickle.loads(pickle.dumps(dset_concat)) as dset_concat:
self.assertTupleEqual((len(dset1), len(dset2), len(dset3)), (3, 3, 2))
self.assertEqual(len(dset_concat), len(dset1) + len(dset2) + len(dset3))
self.assertListEqual(dset_concat["id"], [7, 6, 5, 4, 3, 2, 1, 0])
# in_memory = True: 1 cache file for dset3
# in_memory = False: 2 caches files for dset1 and dset2, and 1 cache file for i1.arrow
self.assertEqual(len(dset_concat.cache_files), 1 if in_memory else 2 + 1)
self.assertEqual(dset_concat.info.description, "Dataset2\n\nDataset1")
del dset1, dset2, dset3
def test_flatten(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"a": [{"b": {"c": ["text"]}}] * 10, "foo": [1] * 10},
features=Features({"a": {"b": Sequence({"c": Value("string")})}, "foo": Value("int64")}),
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fingerprint = dset._fingerprint
with dset.flatten() as dset:
self.assertListEqual(sorted(dset.column_names), ["a.b.c", "foo"])
self.assertListEqual(sorted(dset.features.keys()), ["a.b.c", "foo"])
self.assertDictEqual(
dset.features, Features({"a.b.c": Sequence(Value("string")), "foo": Value("int64")})
)
self.assertNotEqual(dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset)
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"a": [{"en": "Thank you", "fr": "Merci"}] * 10, "foo": [1] * 10},
features=Features({"a": Translation(languages=["en", "fr"]), "foo": Value("int64")}),
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fingerprint = dset._fingerprint
with dset.flatten() as dset:
self.assertListEqual(sorted(dset.column_names), ["a.en", "a.fr", "foo"])
self.assertListEqual(sorted(dset.features.keys()), ["a.en", "a.fr", "foo"])
self.assertDictEqual(
dset.features,
Features({"a.en": Value("string"), "a.fr": Value("string"), "foo": Value("int64")}),
)
self.assertNotEqual(dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset)
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"a": [{"en": "the cat", "fr": ["le chat", "la chatte"], "de": "die katze"}] * 10, "foo": [1] * 10},
features=Features(
{"a": TranslationVariableLanguages(languages=["en", "fr", "de"]), "foo": Value("int64")}
),
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fingerprint = dset._fingerprint
with dset.flatten() as dset:
self.assertListEqual(sorted(dset.column_names), ["a.language", "a.translation", "foo"])
self.assertListEqual(sorted(dset.features.keys()), ["a.language", "a.translation", "foo"])
self.assertDictEqual(
dset.features,
Features(
{
"a.language": Sequence(Value("string")),
"a.translation": Sequence(Value("string")),
"foo": Value("int64"),
}
),
)
self.assertNotEqual(dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset)
@require_pil
def test_flatten_complex_image(self, in_memory):
# decoding turned on
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"a": [np.arange(4 * 4 * 3, dtype=np.uint8).reshape(4, 4, 3)] * 10, "foo": [1] * 10},
features=Features({"a": Image(), "foo": Value("int64")}),
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fingerprint = dset._fingerprint
with dset.flatten() as dset:
self.assertListEqual(sorted(dset.column_names), ["a", "foo"])
self.assertListEqual(sorted(dset.features.keys()), ["a", "foo"])
self.assertDictEqual(dset.features, Features({"a": Image(), "foo": Value("int64")}))
self.assertNotEqual(dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset)
# decoding turned on + nesting
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"a": [{"b": np.arange(4 * 4 * 3, dtype=np.uint8).reshape(4, 4, 3)}] * 10, "foo": [1] * 10},
features=Features({"a": {"b": Image()}, "foo": Value("int64")}),
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fingerprint = dset._fingerprint
with dset.flatten() as dset:
self.assertListEqual(sorted(dset.column_names), ["a.b", "foo"])
self.assertListEqual(sorted(dset.features.keys()), ["a.b", "foo"])
self.assertDictEqual(dset.features, Features({"a.b": Image(), "foo": Value("int64")}))
self.assertNotEqual(dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset)
# decoding turned off
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"a": [np.arange(4 * 4 * 3, dtype=np.uint8).reshape(4, 4, 3)] * 10, "foo": [1] * 10},
features=Features({"a": Image(decode=False), "foo": Value("int64")}),
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fingerprint = dset._fingerprint
with dset.flatten() as dset:
self.assertListEqual(sorted(dset.column_names), ["a.bytes", "a.path", "foo"])
self.assertListEqual(sorted(dset.features.keys()), ["a.bytes", "a.path", "foo"])
self.assertDictEqual(
dset.features,
Features({"a.bytes": Value("binary"), "a.path": Value("string"), "foo": Value("int64")}),
)
self.assertNotEqual(dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset)
# decoding turned off + nesting
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"a": [{"b": np.arange(4 * 4 * 3, dtype=np.uint8).reshape(4, 4, 3)}] * 10, "foo": [1] * 10},
features=Features({"a": {"b": Image(decode=False)}, "foo": Value("int64")}),
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fingerprint = dset._fingerprint
with dset.flatten() as dset:
self.assertListEqual(sorted(dset.column_names), ["a.b.bytes", "a.b.path", "foo"])
self.assertListEqual(sorted(dset.features.keys()), ["a.b.bytes", "a.b.path", "foo"])
self.assertDictEqual(
dset.features,
Features(
{"a.b.bytes": Value("binary"), "a.b.path": Value("string"), "foo": Value("int64")}
),
)
self.assertNotEqual(dset._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset)
def test_map(self, in_memory):
# standard
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
fingerprint = dset._fingerprint
with dset.map(
lambda x: {"name": x["filename"][:-2], "id": int(x["filename"].split("_")[-1])}
) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "name": Value("string"), "id": Value("int64")}),
)
self.assertListEqual(dset_test["id"], list(range(30)))
self.assertNotEqual(dset_test._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
# no transform
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
with dset.map(lambda x: None) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertEqual(dset_test._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
# with indices
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(
lambda x, i: {"name": x["filename"][:-2], "id": i}, with_indices=True
) as dset_test_with_indices:
self.assertEqual(len(dset_test_with_indices), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test_with_indices.features,
Features({"filename": Value("string"), "name": Value("string"), "id": Value("int64")}),
)
self.assertListEqual(dset_test_with_indices["id"], list(range(30)))
assert_arrow_metadata_are_synced_with_dataset_features(dset_test_with_indices)
# interrupted
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
def func(x, i):
if i == 4:
raise KeyboardInterrupt()
return {"name": x["filename"][:-2], "id": i}
tmp_file = os.path.join(tmp_dir, "test.arrow")
self.assertRaises(
KeyboardInterrupt,
dset.map,
function=func,
with_indices=True,
cache_file_name=tmp_file,
writer_batch_size=2,
)
self.assertFalse(os.path.exists(tmp_file))
with dset.map(
lambda x, i: {"name": x["filename"][:-2], "id": i},
with_indices=True,
cache_file_name=tmp_file,
writer_batch_size=2,
) as dset_test_with_indices:
self.assertTrue(os.path.exists(tmp_file))
self.assertEqual(len(dset_test_with_indices), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test_with_indices.features,
Features({"filename": Value("string"), "name": Value("string"), "id": Value("int64")}),
)
self.assertListEqual(dset_test_with_indices["id"], list(range(30)))
assert_arrow_metadata_are_synced_with_dataset_features(dset_test_with_indices)
# formatted
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_format("numpy", columns=["col_1"])
with dset.map(lambda x: {"col_1_plus_one": x["col_1"] + 1}) as dset_test:
self.assertEqual(len(dset_test), 4)
self.assertEqual(dset_test.format["type"], "numpy")
self.assertIsInstance(dset_test["col_1"], np.ndarray)
self.assertIsInstance(dset_test["col_1_plus_one"], np.ndarray)
self.assertListEqual(sorted(dset_test[0].keys()), ["col_1", "col_1_plus_one"])
self.assertListEqual(sorted(dset_test.column_names), ["col_1", "col_1_plus_one", "col_2", "col_3"])
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
def test_map_multiprocessing(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir: # standard
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
fingerprint = dset._fingerprint
with dset.map(picklable_map_function, num_proc=2) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "id": Value("int64")}),
)
self.assertEqual(len(dset_test.cache_files), 0 if in_memory else 2)
if not in_memory:
self.assertIn("_of_00002.arrow", dset_test.cache_files[0]["filename"])
self.assertListEqual(dset_test["id"], list(range(30)))
self.assertNotEqual(dset_test._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
with tempfile.TemporaryDirectory() as tmp_dir: # num_proc > num rows
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
fingerprint = dset._fingerprint
with dset.select([0, 1], keep_in_memory=True).map(picklable_map_function, num_proc=10) as dset_test:
self.assertEqual(len(dset_test), 2)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "id": Value("int64")}),
)
self.assertEqual(len(dset_test.cache_files), 0 if in_memory else 2)
self.assertListEqual(dset_test["id"], list(range(2)))
self.assertNotEqual(dset_test._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
with tempfile.TemporaryDirectory() as tmp_dir: # with_indices
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
with dset.map(picklable_map_function_with_indices, num_proc=3, with_indices=True) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "id": Value("int64")}),
)
self.assertEqual(len(dset_test.cache_files), 0 if in_memory else 3)
self.assertListEqual(dset_test["id"], list(range(30)))
self.assertNotEqual(dset_test._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
with tempfile.TemporaryDirectory() as tmp_dir: # with_rank
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
with dset.map(picklable_map_function_with_rank, num_proc=3, with_rank=True) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "rank": Value("int64")}),
)
self.assertEqual(len(dset_test.cache_files), 0 if in_memory else 3)
self.assertListEqual(dset_test["rank"], [0] * 10 + [1] * 10 + [2] * 10)
self.assertNotEqual(dset_test._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
with tempfile.TemporaryDirectory() as tmp_dir: # with_indices AND with_rank
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
with dset.map(
picklable_map_function_with_indices_and_rank, num_proc=3, with_indices=True, with_rank=True
) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "id": Value("int64"), "rank": Value("int64")}),
)
self.assertEqual(len(dset_test.cache_files), 0 if in_memory else 3)
self.assertListEqual(dset_test["id"], list(range(30)))
self.assertListEqual(dset_test["rank"], [0] * 10 + [1] * 10 + [2] * 10)
self.assertNotEqual(dset_test._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
with tempfile.TemporaryDirectory() as tmp_dir: # new_fingerprint
new_fingerprint = "foobar"
invalid_new_fingerprint = "foobar/hey"
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
self.assertRaises(
ValueError, dset.map, picklable_map_function, num_proc=2, new_fingerprint=invalid_new_fingerprint
)
with dset.map(picklable_map_function, num_proc=2, new_fingerprint=new_fingerprint) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "id": Value("int64")}),
)
self.assertEqual(len(dset_test.cache_files), 0 if in_memory else 2)
self.assertListEqual(dset_test["id"], list(range(30)))
self.assertNotEqual(dset_test._fingerprint, fingerprint)
self.assertEqual(dset_test._fingerprint, new_fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
file_names = sorted(Path(cache_file["filename"]).name for cache_file in dset_test.cache_files)
for i, file_name in enumerate(file_names):
self.assertIn(new_fingerprint + f"_{i:05d}", file_name)
with tempfile.TemporaryDirectory() as tmp_dir: # lambda (requires multiprocess from pathos)
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
with dset.map(lambda x: {"id": int(x["filename"].split("_")[-1])}, num_proc=2) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "id": Value("int64")}),
)
self.assertEqual(len(dset_test.cache_files), 0 if in_memory else 2)
self.assertListEqual(dset_test["id"], list(range(30)))
self.assertNotEqual(dset_test._fingerprint, fingerprint)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test)
def test_map_new_features(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
features = Features({"filename": Value("string"), "label": ClassLabel(names=["positive", "negative"])})
with dset.map(
lambda x, i: {"label": i % 2}, with_indices=True, features=features
) as dset_test_with_indices:
self.assertEqual(len(dset_test_with_indices), 30)
self.assertDictEqual(
dset_test_with_indices.features,
features,
)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test_with_indices)
def test_map_batched(self, in_memory):
def map_batched(example):
return {"filename_new": [x + "_extension" for x in example["filename"]]}
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(map_batched, batched=True) as dset_test_batched:
self.assertEqual(len(dset_test_batched), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test_batched.features,
Features({"filename": Value("string"), "filename_new": Value("string")}),
)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test_batched)
# change batch size and drop the last batch
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
batch_size = 4
with dset.map(
map_batched, batched=True, batch_size=batch_size, drop_last_batch=True
) as dset_test_batched:
self.assertEqual(len(dset_test_batched), 30 // batch_size * batch_size)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test_batched.features,
Features({"filename": Value("string"), "filename_new": Value("string")}),
)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test_batched)
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.formatted_as("numpy", columns=["filename"]):
with dset.map(map_batched, batched=True) as dset_test_batched:
self.assertEqual(len(dset_test_batched), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test_batched.features,
Features({"filename": Value("string"), "filename_new": Value("string")}),
)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test_batched)
def map_batched_with_indices(example, idx):
return {"filename_new": [x + "_extension_" + str(idx) for x in example["filename"]]}
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(
map_batched_with_indices, batched=True, with_indices=True
) as dset_test_with_indices_batched:
self.assertEqual(len(dset_test_with_indices_batched), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test_with_indices_batched.features,
Features({"filename": Value("string"), "filename_new": Value("string")}),
)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test_with_indices_batched)
# check remove columns for even if the function modifies input in-place
def map_batched_modifying_inputs_inplace(example):
result = {"filename_new": [x + "_extension" for x in example["filename"]]}
del example["filename"]
return result
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(
map_batched_modifying_inputs_inplace, batched=True, remove_columns="filename"
) as dset_test_modifying_inputs_inplace:
self.assertEqual(len(dset_test_modifying_inputs_inplace), 30)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(
dset_test_modifying_inputs_inplace.features,
Features({"filename_new": Value("string")}),
)
assert_arrow_metadata_are_synced_with_dataset_features(dset_test_modifying_inputs_inplace)
def test_map_nested(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict({"field": ["a", "b"]}) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.map(lambda example: {"otherfield": {"capital": example["field"].capitalize()}}) as dset:
with dset.map(lambda example: {"otherfield": {"append_x": example["field"] + "x"}}) as dset:
self.assertEqual(dset[0], {"field": "a", "otherfield": {"append_x": "ax"}})
def test_map_return_example_as_dict_value(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict({"en": ["aa", "bb"], "fr": ["cc", "dd"]}) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.map(lambda example: {"translation": example}) as dset:
self.assertEqual(dset[0], {"en": "aa", "fr": "cc", "translation": {"en": "aa", "fr": "cc"}})
def test_map_fn_kwargs(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict({"id": range(10)}) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fn_kwargs = {"offset": 3}
with dset.map(
lambda example, offset: {"id+offset": example["id"] + offset}, fn_kwargs=fn_kwargs
) as mapped_dset:
assert mapped_dset["id+offset"] == list(range(3, 13))
with dset.map(
lambda id, offset: {"id+offset": id + offset}, fn_kwargs=fn_kwargs, input_columns="id"
) as mapped_dset:
assert mapped_dset["id+offset"] == list(range(3, 13))
with dset.map(
lambda id, i, offset: {"id+offset": i + offset},
fn_kwargs=fn_kwargs,
input_columns="id",
with_indices=True,
) as mapped_dset:
assert mapped_dset["id+offset"] == list(range(3, 13))
def test_map_caching(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
self._caplog.clear()
with self._caplog.at_level(INFO, logger=get_logger().name):
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with patch(
"datasets.arrow_dataset.Dataset._map_single",
autospec=Dataset._map_single,
side_effect=Dataset._map_single,
) as mock_map_single:
with dset.map(lambda x: {"foo": "bar"}) as dset_test1:
dset_test1_data_files = list(dset_test1.cache_files)
self.assertEqual(mock_map_single.call_count, 1)
with dset.map(lambda x: {"foo": "bar"}) as dset_test2:
self.assertEqual(dset_test1_data_files, dset_test2.cache_files)
self.assertEqual(len(dset_test2.cache_files), 1 - int(in_memory))
self.assertTrue(("Loading cached processed dataset" in self._caplog.text) ^ in_memory)
self.assertEqual(mock_map_single.call_count, 2 if in_memory else 1)
with tempfile.TemporaryDirectory() as tmp_dir:
self._caplog.clear()
with self._caplog.at_level(INFO, logger=get_logger().name):
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(lambda x: {"foo": "bar"}) as dset_test1:
dset_test1_data_files = list(dset_test1.cache_files)
with dset.map(lambda x: {"foo": "bar"}, load_from_cache_file=False) as dset_test2:
self.assertEqual(dset_test1_data_files, dset_test2.cache_files)
self.assertEqual(len(dset_test2.cache_files), 1 - int(in_memory))
self.assertNotIn("Loading cached processed dataset", self._caplog.text)
with tempfile.TemporaryDirectory() as tmp_dir:
self._caplog.clear()
with self._caplog.at_level(INFO, logger=get_logger().name):
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with patch(
"datasets.arrow_dataset.Pool",
new_callable=PickableMagicMock,
side_effect=datasets.arrow_dataset.Pool,
) as mock_pool:
with dset.map(lambda x: {"foo": "bar"}, num_proc=2) as dset_test1:
dset_test1_data_files = list(dset_test1.cache_files)
self.assertEqual(mock_pool.call_count, 1)
with dset.map(lambda x: {"foo": "bar"}, num_proc=2) as dset_test2:
self.assertEqual(dset_test1_data_files, dset_test2.cache_files)
self.assertTrue(
(len(re.findall("Loading cached processed dataset", self._caplog.text)) == 1)
^ in_memory
)
self.assertEqual(mock_pool.call_count, 2 if in_memory else 1)
with tempfile.TemporaryDirectory() as tmp_dir:
self._caplog.clear()
with self._caplog.at_level(INFO, logger=get_logger().name):
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(lambda x: {"foo": "bar"}, num_proc=2) as dset_test1:
dset_test1_data_files = list(dset_test1.cache_files)
with dset.map(lambda x: {"foo": "bar"}, num_proc=2, load_from_cache_file=False) as dset_test2:
self.assertEqual(dset_test1_data_files, dset_test2.cache_files)
self.assertEqual(len(dset_test2.cache_files), (1 - int(in_memory)) * 2)
self.assertNotIn("Loading cached processed dataset", self._caplog.text)
if not in_memory:
try:
self._caplog.clear()
with tempfile.TemporaryDirectory() as tmp_dir:
with self._caplog.at_level(INFO, logger=get_logger().name):
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
datasets.disable_caching()
with dset.map(lambda x: {"foo": "bar"}) as dset_test1:
with dset.map(lambda x: {"foo": "bar"}) as dset_test2:
self.assertNotEqual(dset_test1.cache_files, dset_test2.cache_files)
self.assertEqual(len(dset_test1.cache_files), 1)
self.assertEqual(len(dset_test2.cache_files), 1)
self.assertNotIn("Loading cached processed dataset", self._caplog.text)
# make sure the arrow files are going to be removed
self.assertIn(
Path(tempfile.gettempdir()),
Path(dset_test1.cache_files[0]["filename"]).parents,
)
self.assertIn(
Path(tempfile.gettempdir()),
Path(dset_test2.cache_files[0]["filename"]).parents,
)
finally:
datasets.enable_caching()
def test_map_return_pa_table(self, in_memory):
def func_return_single_row_pa_table(x):
return pa.table({"id": [0], "text": ["a"]})
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func_return_single_row_pa_table) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"id": Value("int64"), "text": Value("string")}),
)
self.assertEqual(dset_test[0]["id"], 0)
self.assertEqual(dset_test[0]["text"], "a")
# Batched
def func_return_single_row_pa_table_batched(x):
batch_size = len(x[next(iter(x))])
return pa.table({"id": [0] * batch_size, "text": ["a"] * batch_size})
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func_return_single_row_pa_table_batched, batched=True) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"id": Value("int64"), "text": Value("string")}),
)
self.assertEqual(dset_test[0]["id"], 0)
self.assertEqual(dset_test[0]["text"], "a")
# Error when returning a table with more than one row in the non-batched mode
def func_return_multi_row_pa_table(x):
return pa.table({"id": [0, 1], "text": ["a", "b"]})
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertRaises(ValueError, dset.map, func_return_multi_row_pa_table)
# arrow formatted dataset
def func_return_table_from_expression(t):
import pyarrow.dataset as pds
return pds.dataset(t).to_table(
columns={"new_column": pds.field("")._call("ascii_capitalize", [pds.field("filename")])}
)
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.with_format("arrow").map(func_return_table_from_expression, batched=True) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"new_column": Value("string")}),
)
self.assertEqual(dset_test.with_format(None)[0]["new_column"], dset[0]["filename"].capitalize())
def test_map_return_pd_dataframe(self, in_memory):
def func_return_single_row_pd_dataframe(x):
return pd.DataFrame({"id": [0], "text": ["a"]})
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func_return_single_row_pd_dataframe) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"id": Value("int64"), "text": Value("string")}),
)
self.assertEqual(dset_test[0]["id"], 0)
self.assertEqual(dset_test[0]["text"], "a")
# Batched
def func_return_single_row_pd_dataframe_batched(x):
batch_size = len(x[next(iter(x))])
return pd.DataFrame({"id": [0] * batch_size, "text": ["a"] * batch_size})
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func_return_single_row_pd_dataframe_batched, batched=True) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"id": Value("int64"), "text": Value("string")}),
)
self.assertEqual(dset_test[0]["id"], 0)
self.assertEqual(dset_test[0]["text"], "a")
# Error when returning a table with more than one row in the non-batched mode
def func_return_multi_row_pd_dataframe(x):
return pd.DataFrame({"id": [0, 1], "text": ["a", "b"]})
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertRaises(ValueError, dset.map, func_return_multi_row_pd_dataframe)
@require_torch
def test_map_torch(self, in_memory):
import torch
def func(example):
return {"tensor": torch.tensor([1.0, 2, 3])}
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "tensor": Sequence(Value("float32"))}),
)
self.assertListEqual(dset_test[0]["tensor"], [1, 2, 3])
@require_tf
def test_map_tf(self, in_memory):
import tensorflow as tf
def func(example):
return {"tensor": tf.constant([1.0, 2, 3])}
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "tensor": Sequence(Value("float32"))}),
)
self.assertListEqual(dset_test[0]["tensor"], [1, 2, 3])
@require_jax
def test_map_jax(self, in_memory):
import jax.numpy as jnp
def func(example):
return {"tensor": jnp.asarray([1.0, 2, 3])}
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "tensor": Sequence(Value("float32"))}),
)
self.assertListEqual(dset_test[0]["tensor"], [1, 2, 3])
def test_map_numpy(self, in_memory):
def func(example):
return {"tensor": np.array([1.0, 2, 3])}
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "tensor": Sequence(Value("float64"))}),
)
self.assertListEqual(dset_test[0]["tensor"], [1, 2, 3])
@require_torch
def test_map_tensor_batched(self, in_memory):
import torch
def func(batch):
return {"tensor": torch.tensor([[1.0, 2, 3]] * len(batch["filename"]))}
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(func, batched=True) as dset_test:
self.assertEqual(len(dset_test), 30)
self.assertDictEqual(
dset_test.features,
Features({"filename": Value("string"), "tensor": Sequence(Value("float32"))}),
)
self.assertListEqual(dset_test[0]["tensor"], [1, 2, 3])
def test_map_input_columns(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
with dset.map(lambda col_1: {"label": col_1 % 2}, input_columns="col_1") as mapped_dset:
self.assertEqual(mapped_dset[0].keys(), {"col_1", "col_2", "col_3", "label"})
self.assertEqual(
mapped_dset.features,
Features(
{
"col_1": Value("int64"),
"col_2": Value("string"),
"col_3": Value("bool"),
"label": Value("int64"),
}
),
)
def test_map_remove_columns(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.map(lambda x, i: {"name": x["filename"][:-2], "id": i}, with_indices=True) as dset:
self.assertTrue("id" in dset[0])
self.assertDictEqual(
dset.features,
Features({"filename": Value("string"), "name": Value("string"), "id": Value("int64")}),
)
assert_arrow_metadata_are_synced_with_dataset_features(dset)
with dset.map(lambda x: x, remove_columns=["id"]) as mapped_dset:
self.assertTrue("id" not in mapped_dset[0])
self.assertDictEqual(
mapped_dset.features, Features({"filename": Value("string"), "name": Value("string")})
)
assert_arrow_metadata_are_synced_with_dataset_features(mapped_dset)
with mapped_dset.with_format("numpy", columns=mapped_dset.column_names) as mapped_dset:
with mapped_dset.map(
lambda x: {"name": 1}, remove_columns=mapped_dset.column_names
) as mapped_dset:
self.assertTrue("filename" not in mapped_dset[0])
self.assertTrue("name" in mapped_dset[0])
self.assertDictEqual(mapped_dset.features, Features({"name": Value(dtype="int64")}))
assert_arrow_metadata_are_synced_with_dataset_features(mapped_dset)
# empty dataset
columns_names = dset.column_names
with dset.select([]) as empty_dset:
self.assertEqual(len(empty_dset), 0)
with empty_dset.map(lambda x: {}, remove_columns=columns_names[0]) as mapped_dset:
self.assertListEqual(columns_names[1:], mapped_dset.column_names)
assert_arrow_metadata_are_synced_with_dataset_features(mapped_dset)
def test_map_stateful_callable(self, in_memory):
# be sure that the state of the map callable is unaffected
# before processing the dataset examples
class ExampleCounter:
def __init__(self, batched=False):
self.batched = batched
# state
self.cnt = 0
def __call__(self, example):
if self.batched:
self.cnt += len(example)
else:
self.cnt += 1
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
ex_cnt = ExampleCounter()
dset.map(ex_cnt)
self.assertEqual(ex_cnt.cnt, len(dset))
ex_cnt = ExampleCounter(batched=True)
dset.map(ex_cnt)
self.assertEqual(ex_cnt.cnt, len(dset))
@require_not_windows
def test_map_crash_subprocess(self, in_memory):
# be sure that a crash in one of the subprocess will not
# hang dataset.map() call forever
def do_crash(row):
import os
os.kill(os.getpid(), 9)
return row
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with pytest.raises(RuntimeError) as excinfo:
dset.map(do_crash, num_proc=2)
assert str(excinfo.value) == (
"One of the subprocesses has abruptly died during map operation."
"To debug the error, disable multiprocessing."
)
def test_filter(self, in_memory):
# keep only first five examples
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
with dset.filter(lambda x, i: i < 5, with_indices=True) as dset_filter_first_five:
self.assertEqual(len(dset_filter_first_five), 5)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_filter_first_five.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_filter_first_five._fingerprint, fingerprint)
# filter filenames with even id at the end + formatted
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
dset.set_format("numpy")
fingerprint = dset._fingerprint
with dset.filter(lambda x: (int(x["filename"][-1]) % 2 == 0)) as dset_filter_even_num:
self.assertEqual(len(dset_filter_even_num), 15)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_filter_even_num.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_filter_even_num._fingerprint, fingerprint)
self.assertEqual(dset_filter_even_num.format["type"], "numpy")
def test_filter_with_indices_mapping(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
dset = Dataset.from_dict({"col": [0, 1, 2]})
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.filter(lambda x: x["col"] > 0) as dset:
self.assertListEqual(dset["col"], [1, 2])
with dset.filter(lambda x: x["col"] < 2) as dset:
self.assertListEqual(dset["col"], [1])
def test_filter_empty(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertIsNone(dset._indices, None)
tmp_file = os.path.join(tmp_dir, "test.arrow")
with dset.filter(lambda _: False, cache_file_name=tmp_file) as dset:
self.assertEqual(len(dset), 0)
self.assertIsNotNone(dset._indices, None)
tmp_file_2 = os.path.join(tmp_dir, "test_2.arrow")
with dset.filter(lambda _: False, cache_file_name=tmp_file_2) as dset2:
self.assertEqual(len(dset2), 0)
self.assertEqual(dset._indices, dset2._indices)
def test_filter_batched(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
dset = Dataset.from_dict({"col": [0, 1, 2]})
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.filter(lambda x: [i > 0 for i in x["col"]], batched=True) as dset:
self.assertListEqual(dset["col"], [1, 2])
with dset.filter(lambda x: [i < 2 for i in x["col"]], batched=True) as dset:
self.assertListEqual(dset["col"], [1])
def test_filter_input_columns(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
dset = Dataset.from_dict({"col_1": [0, 1, 2], "col_2": ["a", "b", "c"]})
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.filter(lambda x: x > 0, input_columns=["col_1"]) as filtered_dset:
self.assertListEqual(filtered_dset.column_names, dset.column_names)
self.assertListEqual(filtered_dset["col_1"], [1, 2])
self.assertListEqual(filtered_dset["col_2"], ["b", "c"])
def test_filter_fn_kwargs(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict({"id": range(10)}) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
fn_kwargs = {"max_offset": 3}
with dset.filter(
lambda example, max_offset: example["id"] < max_offset, fn_kwargs=fn_kwargs
) as filtered_dset:
assert len(filtered_dset) == 3
with dset.filter(
lambda id, max_offset: id < max_offset, fn_kwargs=fn_kwargs, input_columns="id"
) as filtered_dset:
assert len(filtered_dset) == 3
with dset.filter(
lambda id, i, max_offset: i < max_offset,
fn_kwargs=fn_kwargs,
input_columns="id",
with_indices=True,
) as filtered_dset:
assert len(filtered_dset) == 3
def test_filter_multiprocessing(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
with dset.filter(picklable_filter_function, num_proc=2) as dset_filter_first_ten:
self.assertEqual(len(dset_filter_first_ten), 10)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_filter_first_ten.features, Features({"filename": Value("string")}))
self.assertEqual(len(dset_filter_first_ten.cache_files), 0 if in_memory else 2)
self.assertNotEqual(dset_filter_first_ten._fingerprint, fingerprint)
with tempfile.TemporaryDirectory() as tmp_dir: # with_rank
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
with dset.filter(
picklable_filter_function_with_rank, num_proc=2, with_rank=True
) as dset_filter_first_rank:
self.assertEqual(len(dset_filter_first_rank), min(len(dset) // 2, len(dset)))
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_filter_first_rank.features, Features({"filename": Value("string")}))
self.assertEqual(len(dset_filter_first_rank.cache_files), 0 if in_memory else 2)
self.assertNotEqual(dset_filter_first_rank._fingerprint, fingerprint)
def test_filter_caching(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
self._caplog.clear()
with self._caplog.at_level(INFO, logger=get_logger().name):
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.filter(lambda x, i: i < 5, with_indices=True) as dset_filter_first_five1:
dset_test1_data_files = list(dset_filter_first_five1.cache_files)
with dset.filter(lambda x, i: i < 5, with_indices=True) as dset_filter_first_five2:
self.assertEqual(dset_test1_data_files, dset_filter_first_five2.cache_files)
self.assertEqual(len(dset_filter_first_five2.cache_files), 0 if in_memory else 2)
self.assertTrue(("Loading cached processed dataset" in self._caplog.text) ^ in_memory)
def test_keep_features_after_transform_specified(self, in_memory):
features = Features(
{"tokens": Sequence(Value("string")), "labels": Sequence(ClassLabel(names=["negative", "positive"]))}
)
def invert_labels(x):
return {"labels": [(1 - label) for label in x["labels"]]}
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"tokens": [["foo"] * 5] * 10, "labels": [[1] * 5] * 10}, features=features
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.map(invert_labels, features=features) as inverted_dset:
self.assertEqual(inverted_dset.features.type, features.type)
self.assertDictEqual(inverted_dset.features, features)
assert_arrow_metadata_are_synced_with_dataset_features(inverted_dset)
def test_keep_features_after_transform_unspecified(self, in_memory):
features = Features(
{"tokens": Sequence(Value("string")), "labels": Sequence(ClassLabel(names=["negative", "positive"]))}
)
def invert_labels(x):
return {"labels": [(1 - label) for label in x["labels"]]}
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"tokens": [["foo"] * 5] * 10, "labels": [[1] * 5] * 10}, features=features
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.map(invert_labels) as inverted_dset:
self.assertEqual(inverted_dset.features.type, features.type)
self.assertDictEqual(inverted_dset.features, features)
assert_arrow_metadata_are_synced_with_dataset_features(inverted_dset)
def test_keep_features_after_transform_to_file(self, in_memory):
features = Features(
{"tokens": Sequence(Value("string")), "labels": Sequence(ClassLabel(names=["negative", "positive"]))}
)
def invert_labels(x):
return {"labels": [(1 - label) for label in x["labels"]]}
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"tokens": [["foo"] * 5] * 10, "labels": [[1] * 5] * 10}, features=features
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
tmp_file = os.path.join(tmp_dir, "test.arrow")
dset.map(invert_labels, cache_file_name=tmp_file)
with Dataset.from_file(tmp_file) as inverted_dset:
self.assertEqual(inverted_dset.features.type, features.type)
self.assertDictEqual(inverted_dset.features, features)
def test_keep_features_after_transform_to_memory(self, in_memory):
features = Features(
{"tokens": Sequence(Value("string")), "labels": Sequence(ClassLabel(names=["negative", "positive"]))}
)
def invert_labels(x):
return {"labels": [(1 - label) for label in x["labels"]]}
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"tokens": [["foo"] * 5] * 10, "labels": [[1] * 5] * 10}, features=features
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.map(invert_labels, keep_in_memory=True) as inverted_dset:
self.assertEqual(inverted_dset.features.type, features.type)
self.assertDictEqual(inverted_dset.features, features)
def test_keep_features_after_loading_from_cache(self, in_memory):
features = Features(
{"tokens": Sequence(Value("string")), "labels": Sequence(ClassLabel(names=["negative", "positive"]))}
)
def invert_labels(x):
return {"labels": [(1 - label) for label in x["labels"]]}
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"tokens": [["foo"] * 5] * 10, "labels": [[1] * 5] * 10}, features=features
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
tmp_file1 = os.path.join(tmp_dir, "test1.arrow")
tmp_file2 = os.path.join(tmp_dir, "test2.arrow")
# TODO: Why mapped twice?
inverted_dset = dset.map(invert_labels, cache_file_name=tmp_file1)
inverted_dset = dset.map(invert_labels, cache_file_name=tmp_file2)
self.assertGreater(len(inverted_dset.cache_files), 0)
self.assertEqual(inverted_dset.features.type, features.type)
self.assertDictEqual(inverted_dset.features, features)
del inverted_dset
def test_keep_features_with_new_features(self, in_memory):
features = Features(
{"tokens": Sequence(Value("string")), "labels": Sequence(ClassLabel(names=["negative", "positive"]))}
)
def invert_labels(x):
return {"labels": [(1 - label) for label in x["labels"]], "labels2": x["labels"]}
expected_features = Features(
{
"tokens": Sequence(Value("string")),
"labels": Sequence(ClassLabel(names=["negative", "positive"])),
"labels2": Sequence(Value("int64")),
}
)
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(
{"tokens": [["foo"] * 5] * 10, "labels": [[1] * 5] * 10}, features=features
) as dset:
with self._to(in_memory, tmp_dir, dset) as dset:
with dset.map(invert_labels) as inverted_dset:
self.assertEqual(inverted_dset.features.type, expected_features.type)
self.assertDictEqual(inverted_dset.features, expected_features)
assert_arrow_metadata_are_synced_with_dataset_features(inverted_dset)
def test_select(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
# select every two example
indices = list(range(0, len(dset), 2))
tmp_file = os.path.join(tmp_dir, "test.arrow")
fingerprint = dset._fingerprint
with dset.select(indices, indices_cache_file_name=tmp_file) as dset_select_even:
self.assertIsNotNone(dset_select_even._indices) # an indices mapping is created
self.assertTrue(os.path.exists(tmp_file))
self.assertEqual(len(dset_select_even), 15)
for row in dset_select_even:
self.assertEqual(int(row["filename"][-1]) % 2, 0)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_select_even.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_select_even._fingerprint, fingerprint)
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
indices = list(range(0, len(dset)))
with dset.select(indices) as dset_select_all:
# no indices mapping, since the indices are contiguous
# (in this case the arrow table is simply sliced, which is more efficient)
self.assertIsNone(dset_select_all._indices)
self.assertEqual(len(dset_select_all), len(dset))
self.assertListEqual(list(dset_select_all), list(dset))
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_select_all.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_select_all._fingerprint, fingerprint)
indices = range(0, len(dset))
with dset.select(indices) as dset_select_all:
# same but with range
self.assertIsNone(dset_select_all._indices)
self.assertEqual(len(dset_select_all), len(dset))
self.assertListEqual(list(dset_select_all), list(dset))
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_select_all.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_select_all._fingerprint, fingerprint)
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
bad_indices = list(range(5))
bad_indices[-1] = len(dset) + 10 # out of bounds
tmp_file = os.path.join(tmp_dir, "test.arrow")
self.assertRaises(
Exception,
dset.select,
indices=bad_indices,
indices_cache_file_name=tmp_file,
writer_batch_size=2,
)
self.assertFalse(os.path.exists(tmp_file))
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
indices = iter(range(len(dset))) # iterator of contiguous indices
with dset.select(indices) as dset_select_all:
# no indices mapping, since the indices are contiguous
self.assertIsNone(dset_select_all._indices)
self.assertEqual(len(dset_select_all), len(dset))
indices = reversed(range(len(dset))) # iterator of not contiguous indices
tmp_file = os.path.join(tmp_dir, "test.arrow")
with dset.select(indices, indices_cache_file_name=tmp_file) as dset_select_all:
# new indices mapping, since the indices are not contiguous
self.assertIsNotNone(dset_select_all._indices)
self.assertEqual(len(dset_select_all), len(dset))
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
bad_indices = list(range(5))
bad_indices[3] = "foo" # wrong type
tmp_file = os.path.join(tmp_dir, "test.arrow")
self.assertRaises(
Exception,
dset.select,
indices=bad_indices,
indices_cache_file_name=tmp_file,
writer_batch_size=2,
)
self.assertFalse(os.path.exists(tmp_file))
dset.set_format("numpy")
with dset.select(
range(5),
indices_cache_file_name=tmp_file,
writer_batch_size=2,
) as dset_select_five:
self.assertIsNone(dset_select_five._indices)
self.assertEqual(len(dset_select_five), 5)
self.assertEqual(dset_select_five.format["type"], "numpy")
for i, row in enumerate(dset_select_five):
self.assertEqual(int(row["filename"][-1]), i)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_select_five.features, Features({"filename": Value("string")}))
def test_select_then_map(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.select([0]) as d1:
with d1.map(lambda x: {"id": int(x["filename"].split("_")[-1])}) as d1:
self.assertEqual(d1[0]["id"], 0)
with dset.select([1]) as d2:
with d2.map(lambda x: {"id": int(x["filename"].split("_")[-1])}) as d2:
self.assertEqual(d2[0]["id"], 1)
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
with dset.select([0], indices_cache_file_name=os.path.join(tmp_dir, "i1.arrow")) as d1:
with d1.map(lambda x: {"id": int(x["filename"].split("_")[-1])}) as d1:
self.assertEqual(d1[0]["id"], 0)
with dset.select([1], indices_cache_file_name=os.path.join(tmp_dir, "i2.arrow")) as d2:
with d2.map(lambda x: {"id": int(x["filename"].split("_")[-1])}) as d2:
self.assertEqual(d2[0]["id"], 1)
def test_pickle_after_many_transforms_on_disk(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertEqual(len(dset.cache_files), 0 if in_memory else 1)
with dset.rename_column("filename", "file") as dset:
self.assertListEqual(dset.column_names, ["file"])
with dset.select(range(5)) as dset:
self.assertEqual(len(dset), 5)
with dset.map(lambda x: {"id": int(x["file"][-1])}) as dset:
self.assertListEqual(sorted(dset.column_names), ["file", "id"])
with dset.rename_column("id", "number") as dset:
self.assertListEqual(sorted(dset.column_names), ["file", "number"])
with dset.select([1, 0]) as dset:
self.assertEqual(dset[0]["file"], "my_name-train_1")
self.assertEqual(dset[0]["number"], 1)
self.assertEqual(dset._indices["indices"].to_pylist(), [1, 0])
if not in_memory:
self.assertIn(
("rename_columns", (["file", "number"],), {}),
dset._data.replays,
)
if not in_memory:
dset._data.table = Unpicklable() # check that we don't pickle the entire table
pickled = pickle.dumps(dset)
with pickle.loads(pickled) as loaded:
self.assertEqual(loaded[0]["file"], "my_name-train_1")
self.assertEqual(loaded[0]["number"], 1)
def test_shuffle(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
tmp_file = os.path.join(tmp_dir, "test.arrow")
fingerprint = dset._fingerprint
with dset.shuffle(seed=1234, keep_in_memory=True) as dset_shuffled:
self.assertEqual(len(dset_shuffled), 30)
self.assertEqual(dset_shuffled[0]["filename"], "my_name-train_28")
self.assertEqual(dset_shuffled[2]["filename"], "my_name-train_10")
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_shuffled.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_shuffled._fingerprint, fingerprint)
with dset.shuffle(seed=1234, indices_cache_file_name=tmp_file) as dset_shuffled:
self.assertEqual(len(dset_shuffled), 30)
self.assertEqual(dset_shuffled[0]["filename"], "my_name-train_28")
self.assertEqual(dset_shuffled[2]["filename"], "my_name-train_10")
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_shuffled.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_shuffled._fingerprint, fingerprint)
# Reproducibility
tmp_file = os.path.join(tmp_dir, "test_2.arrow")
with dset.shuffle(seed=1234, indices_cache_file_name=tmp_file) as dset_shuffled_2:
self.assertListEqual(dset_shuffled["filename"], dset_shuffled_2["filename"])
# Compatible with temp_seed
with temp_seed(42), dset.shuffle() as d1:
with temp_seed(42), dset.shuffle() as d2, dset.shuffle() as d3:
self.assertListEqual(d1["filename"], d2["filename"])
self.assertEqual(d1._fingerprint, d2._fingerprint)
self.assertNotEqual(d3["filename"], d2["filename"])
self.assertNotEqual(d3._fingerprint, d2._fingerprint)
def test_sort(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
# Sort on a single key
with self._create_dummy_dataset(in_memory=in_memory, tmp_dir=tmp_dir) as dset:
# Keep only 10 examples
tmp_file = os.path.join(tmp_dir, "test.arrow")
with dset.select(range(10), indices_cache_file_name=tmp_file) as dset:
tmp_file = os.path.join(tmp_dir, "test_2.arrow")
with dset.shuffle(seed=1234, indices_cache_file_name=tmp_file) as dset:
self.assertEqual(len(dset), 10)
self.assertEqual(dset[0]["filename"], "my_name-train_8")
self.assertEqual(dset[1]["filename"], "my_name-train_9")
# Sort
tmp_file = os.path.join(tmp_dir, "test_3.arrow")
fingerprint = dset._fingerprint
with dset.sort("filename", indices_cache_file_name=tmp_file) as dset_sorted:
for i, row in enumerate(dset_sorted):
self.assertEqual(int(row["filename"][-1]), i)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_sorted.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_sorted._fingerprint, fingerprint)
# Sort reversed
tmp_file = os.path.join(tmp_dir, "test_4.arrow")
fingerprint = dset._fingerprint
with dset.sort("filename", indices_cache_file_name=tmp_file, reverse=True) as dset_sorted:
for i, row in enumerate(dset_sorted):
self.assertEqual(int(row["filename"][-1]), len(dset_sorted) - 1 - i)
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_sorted.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_sorted._fingerprint, fingerprint)
# formatted
dset.set_format("numpy")
with dset.sort("filename") as dset_sorted_formatted:
self.assertEqual(dset_sorted_formatted.format["type"], "numpy")
# Sort on multiple keys
with self._create_dummy_dataset(in_memory=in_memory, tmp_dir=tmp_dir, multiple_columns=True) as dset:
tmp_file = os.path.join(tmp_dir, "test_5.arrow")
fingerprint = dset._fingerprint
# Throw error when reverse is a list of bools that does not match the length of column_names
with pytest.raises(ValueError):
dset.sort(["col_1", "col_2", "col_3"], reverse=[False])
with dset.shuffle(seed=1234, indices_cache_file_name=tmp_file) as dset:
# Sort
with dset.sort(["col_1", "col_2", "col_3"], reverse=[False, True, False]) as dset_sorted:
for i, row in enumerate(dset_sorted):
self.assertEqual(row["col_1"], i)
self.assertDictEqual(
dset.features,
Features(
{
"col_1": Value("int64"),
"col_2": Value("string"),
"col_3": Value("bool"),
}
),
)
self.assertDictEqual(
dset_sorted.features,
Features(
{
"col_1": Value("int64"),
"col_2": Value("string"),
"col_3": Value("bool"),
}
),
)
self.assertNotEqual(dset_sorted._fingerprint, fingerprint)
# Sort reversed
with dset.sort(["col_1", "col_2", "col_3"], reverse=[True, False, True]) as dset_sorted:
for i, row in enumerate(dset_sorted):
self.assertEqual(row["col_1"], len(dset_sorted) - 1 - i)
self.assertDictEqual(
dset.features,
Features(
{
"col_1": Value("int64"),
"col_2": Value("string"),
"col_3": Value("bool"),
}
),
)
self.assertDictEqual(
dset_sorted.features,
Features(
{
"col_1": Value("int64"),
"col_2": Value("string"),
"col_3": Value("bool"),
}
),
)
self.assertNotEqual(dset_sorted._fingerprint, fingerprint)
# formatted
dset.set_format("numpy")
with dset.sort(
["col_1", "col_2", "col_3"], reverse=[False, True, False]
) as dset_sorted_formatted:
self.assertEqual(dset_sorted_formatted.format["type"], "numpy")
@require_tf
def test_export(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
# Export the data
tfrecord_path = os.path.join(tmp_dir, "test.tfrecord")
with dset.map(
lambda ex, i: {
"id": i,
"question": f"Question {i}",
"answers": {"text": [f"Answer {i}-0", f"Answer {i}-1"], "answer_start": [0, 1]},
},
with_indices=True,
remove_columns=["filename"],
) as formatted_dset:
with formatted_dset.flatten() as formatted_dset:
formatted_dset.set_format("numpy")
formatted_dset.export(filename=tfrecord_path, format="tfrecord")
# Import the data
import tensorflow as tf
tf_dset = tf.data.TFRecordDataset([tfrecord_path])
feature_description = {
"id": tf.io.FixedLenFeature([], tf.int64),
"question": tf.io.FixedLenFeature([], tf.string),
"answers.text": tf.io.VarLenFeature(tf.string),
"answers.answer_start": tf.io.VarLenFeature(tf.int64),
}
tf_parsed_dset = tf_dset.map(
lambda example_proto: tf.io.parse_single_example(example_proto, feature_description)
)
# Test that keys match original dataset
for i, ex in enumerate(tf_parsed_dset):
self.assertEqual(ex.keys(), formatted_dset[i].keys())
# Test for equal number of elements
self.assertEqual(i, len(formatted_dset) - 1)
def test_to_csv(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
# File path argument
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
file_path = os.path.join(tmp_dir, "test_path.csv")
bytes_written = dset.to_csv(path_or_buf=file_path)
self.assertTrue(os.path.isfile(file_path))
self.assertEqual(bytes_written, os.path.getsize(file_path))
csv_dset = pd.read_csv(file_path)
self.assertEqual(csv_dset.shape, dset.shape)
self.assertListEqual(list(csv_dset.columns), list(dset.column_names))
# File buffer argument
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
file_path = os.path.join(tmp_dir, "test_buffer.csv")
with open(file_path, "wb+") as buffer:
bytes_written = dset.to_csv(path_or_buf=buffer)
self.assertTrue(os.path.isfile(file_path))
self.assertEqual(bytes_written, os.path.getsize(file_path))
csv_dset = pd.read_csv(file_path)
self.assertEqual(csv_dset.shape, dset.shape)
self.assertListEqual(list(csv_dset.columns), list(dset.column_names))
# After a select/shuffle transform
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset = dset.select(range(0, len(dset), 2)).shuffle()
file_path = os.path.join(tmp_dir, "test_path.csv")
bytes_written = dset.to_csv(path_or_buf=file_path)
self.assertTrue(os.path.isfile(file_path))
self.assertEqual(bytes_written, os.path.getsize(file_path))
csv_dset = pd.read_csv(file_path)
self.assertEqual(csv_dset.shape, dset.shape)
self.assertListEqual(list(csv_dset.columns), list(dset.column_names))
# With array features
with self._create_dummy_dataset(in_memory, tmp_dir, array_features=True) as dset:
file_path = os.path.join(tmp_dir, "test_path.csv")
bytes_written = dset.to_csv(path_or_buf=file_path)
self.assertTrue(os.path.isfile(file_path))
self.assertEqual(bytes_written, os.path.getsize(file_path))
csv_dset = pd.read_csv(file_path)
self.assertEqual(csv_dset.shape, dset.shape)
self.assertListEqual(list(csv_dset.columns), list(dset.column_names))
def test_to_dict(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
# Full
dset_to_dict = dset.to_dict()
self.assertIsInstance(dset_to_dict, dict)
self.assertListEqual(sorted(dset_to_dict.keys()), sorted(dset.column_names))
for col_name in dset.column_names:
self.assertLessEqual(len(dset_to_dict[col_name]), len(dset))
# With index mapping
with dset.select([1, 0, 3]) as dset:
dset_to_dict = dset.to_dict()
self.assertIsInstance(dset_to_dict, dict)
self.assertEqual(len(dset_to_dict), 3)
self.assertListEqual(sorted(dset_to_dict.keys()), sorted(dset.column_names))
for col_name in dset.column_names:
self.assertIsInstance(dset_to_dict[col_name], list)
self.assertEqual(len(dset_to_dict[col_name]), len(dset))
def test_to_list(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset_to_list = dset.to_list()
self.assertIsInstance(dset_to_list, list)
for row in dset_to_list:
self.assertIsInstance(row, dict)
self.assertListEqual(sorted(row.keys()), sorted(dset.column_names))
# With index mapping
with dset.select([1, 0, 3]) as dset:
dset_to_list = dset.to_list()
self.assertIsInstance(dset_to_list, list)
self.assertEqual(len(dset_to_list), 3)
for row in dset_to_list:
self.assertIsInstance(row, dict)
self.assertListEqual(sorted(row.keys()), sorted(dset.column_names))
def test_to_pandas(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
# Batched
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
batch_size = dset.num_rows - 1
to_pandas_generator = dset.to_pandas(batched=True, batch_size=batch_size)
for batch in to_pandas_generator:
self.assertIsInstance(batch, pd.DataFrame)
self.assertListEqual(sorted(batch.columns), sorted(dset.column_names))
for col_name in dset.column_names:
self.assertLessEqual(len(batch[col_name]), batch_size)
# Full
dset_to_pandas = dset.to_pandas()
self.assertIsInstance(dset_to_pandas, pd.DataFrame)
self.assertListEqual(sorted(dset_to_pandas.columns), sorted(dset.column_names))
for col_name in dset.column_names:
self.assertEqual(len(dset_to_pandas[col_name]), len(dset))
# With index mapping
with dset.select([1, 0, 3]) as dset:
dset_to_pandas = dset.to_pandas()
self.assertIsInstance(dset_to_pandas, pd.DataFrame)
self.assertEqual(len(dset_to_pandas), 3)
self.assertListEqual(sorted(dset_to_pandas.columns), sorted(dset.column_names))
for col_name in dset.column_names:
self.assertEqual(len(dset_to_pandas[col_name]), dset.num_rows)
@require_polars
def test_to_polars(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
# Batched
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
batch_size = dset.num_rows - 1
to_polars_generator = dset.to_polars(batched=True, batch_size=batch_size)
for batch in to_polars_generator:
self.assertIsInstance(batch, sys.modules["polars"].DataFrame)
self.assertListEqual(sorted(batch.columns), sorted(dset.column_names))
for col_name in dset.column_names:
self.assertLessEqual(len(batch[col_name]), batch_size)
del batch
# Full
dset_to_polars = dset.to_polars()
self.assertIsInstance(dset_to_polars, sys.modules["polars"].DataFrame)
self.assertListEqual(sorted(dset_to_polars.columns), sorted(dset.column_names))
for col_name in dset.column_names:
self.assertEqual(len(dset_to_polars[col_name]), len(dset))
# With index mapping
with dset.select([1, 0, 3]) as dset:
dset_to_polars = dset.to_polars()
self.assertIsInstance(dset_to_polars, sys.modules["polars"].DataFrame)
self.assertEqual(len(dset_to_polars), 3)
self.assertListEqual(sorted(dset_to_polars.columns), sorted(dset.column_names))
for col_name in dset.column_names:
self.assertEqual(len(dset_to_polars[col_name]), dset.num_rows)
def test_to_parquet(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
# File path argument
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
file_path = os.path.join(tmp_dir, "test_path.parquet")
dset.to_parquet(path_or_buf=file_path)
self.assertTrue(os.path.isfile(file_path))
# self.assertEqual(bytes_written, os.path.getsize(file_path)) # because of compression, the number of bytes doesn't match
parquet_dset = pd.read_parquet(file_path)
self.assertEqual(parquet_dset.shape, dset.shape)
self.assertListEqual(list(parquet_dset.columns), list(dset.column_names))
# File buffer argument
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
file_path = os.path.join(tmp_dir, "test_buffer.parquet")
with open(file_path, "wb+") as buffer:
dset.to_parquet(path_or_buf=buffer)
self.assertTrue(os.path.isfile(file_path))
# self.assertEqual(bytes_written, os.path.getsize(file_path)) # because of compression, the number of bytes doesn't match
parquet_dset = pd.read_parquet(file_path)
self.assertEqual(parquet_dset.shape, dset.shape)
self.assertListEqual(list(parquet_dset.columns), list(dset.column_names))
# After a select/shuffle transform
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset = dset.select(range(0, len(dset), 2)).shuffle()
file_path = os.path.join(tmp_dir, "test_path.parquet")
dset.to_parquet(path_or_buf=file_path)
self.assertTrue(os.path.isfile(file_path))
# self.assertEqual(bytes_written, os.path.getsize(file_path)) # because of compression, the number of bytes doesn't match
parquet_dset = pd.read_parquet(file_path)
self.assertEqual(parquet_dset.shape, dset.shape)
self.assertListEqual(list(parquet_dset.columns), list(dset.column_names))
# With array features
with self._create_dummy_dataset(in_memory, tmp_dir, array_features=True) as dset:
file_path = os.path.join(tmp_dir, "test_path.parquet")
dset.to_parquet(path_or_buf=file_path)
self.assertTrue(os.path.isfile(file_path))
# self.assertEqual(bytes_written, os.path.getsize(file_path)) # because of compression, the number of bytes doesn't match
parquet_dset = pd.read_parquet(file_path)
self.assertEqual(parquet_dset.shape, dset.shape)
self.assertListEqual(list(parquet_dset.columns), list(dset.column_names))
@require_sqlalchemy
def test_to_sql(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
# Destionation specified as database URI string
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
file_path = os.path.join(tmp_dir, "test_path.sqlite")
_ = dset.to_sql("data", "sqlite:///" + file_path)
self.assertTrue(os.path.isfile(file_path))
sql_dset = pd.read_sql("data", "sqlite:///" + file_path)
self.assertEqual(sql_dset.shape, dset.shape)
self.assertListEqual(list(sql_dset.columns), list(dset.column_names))
# Destionation specified as sqlite3 connection
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
import sqlite3
file_path = os.path.join(tmp_dir, "test_path.sqlite")
with contextlib.closing(sqlite3.connect(file_path)) as con:
_ = dset.to_sql("data", con, if_exists="replace")
self.assertTrue(os.path.isfile(file_path))
sql_dset = pd.read_sql("data", "sqlite:///" + file_path)
self.assertEqual(sql_dset.shape, dset.shape)
self.assertListEqual(list(sql_dset.columns), list(dset.column_names))
# Test writing to a database in chunks
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
file_path = os.path.join(tmp_dir, "test_path.sqlite")
_ = dset.to_sql("data", "sqlite:///" + file_path, batch_size=1, if_exists="replace")
self.assertTrue(os.path.isfile(file_path))
sql_dset = pd.read_sql("data", "sqlite:///" + file_path)
self.assertEqual(sql_dset.shape, dset.shape)
self.assertListEqual(list(sql_dset.columns), list(dset.column_names))
# After a select/shuffle transform
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset = dset.select(range(0, len(dset), 2)).shuffle()
file_path = os.path.join(tmp_dir, "test_path.sqlite")
_ = dset.to_sql("data", "sqlite:///" + file_path, if_exists="replace")
self.assertTrue(os.path.isfile(file_path))
sql_dset = pd.read_sql("data", "sqlite:///" + file_path)
self.assertEqual(sql_dset.shape, dset.shape)
self.assertListEqual(list(sql_dset.columns), list(dset.column_names))
# With array features
with self._create_dummy_dataset(in_memory, tmp_dir, array_features=True) as dset:
file_path = os.path.join(tmp_dir, "test_path.sqlite")
_ = dset.to_sql("data", "sqlite:///" + file_path, if_exists="replace")
self.assertTrue(os.path.isfile(file_path))
sql_dset = pd.read_sql("data", "sqlite:///" + file_path)
self.assertEqual(sql_dset.shape, dset.shape)
self.assertListEqual(list(sql_dset.columns), list(dset.column_names))
def test_train_test_split(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
fingerprint = dset._fingerprint
dset_dict = dset.train_test_split(test_size=10, shuffle=False)
self.assertListEqual(list(dset_dict.keys()), ["train", "test"])
dset_train = dset_dict["train"]
dset_test = dset_dict["test"]
self.assertEqual(len(dset_train), 20)
self.assertEqual(len(dset_test), 10)
self.assertEqual(dset_train[0]["filename"], "my_name-train_0")
self.assertEqual(dset_train[-1]["filename"], "my_name-train_19")
self.assertEqual(dset_test[0]["filename"], "my_name-train_20")
self.assertEqual(dset_test[-1]["filename"], "my_name-train_29")
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_train.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_test.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_train._fingerprint, fingerprint)
self.assertNotEqual(dset_test._fingerprint, fingerprint)
self.assertNotEqual(dset_train._fingerprint, dset_test._fingerprint)
dset_dict = dset.train_test_split(test_size=0.5, shuffle=False)
self.assertListEqual(list(dset_dict.keys()), ["train", "test"])
dset_train = dset_dict["train"]
dset_test = dset_dict["test"]
self.assertEqual(len(dset_train), 15)
self.assertEqual(len(dset_test), 15)
self.assertEqual(dset_train[0]["filename"], "my_name-train_0")
self.assertEqual(dset_train[-1]["filename"], "my_name-train_14")
self.assertEqual(dset_test[0]["filename"], "my_name-train_15")
self.assertEqual(dset_test[-1]["filename"], "my_name-train_29")
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_train.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_test.features, Features({"filename": Value("string")}))
dset_dict = dset.train_test_split(train_size=10, shuffle=False)
self.assertListEqual(list(dset_dict.keys()), ["train", "test"])
dset_train = dset_dict["train"]
dset_test = dset_dict["test"]
self.assertEqual(len(dset_train), 10)
self.assertEqual(len(dset_test), 20)
self.assertEqual(dset_train[0]["filename"], "my_name-train_0")
self.assertEqual(dset_train[-1]["filename"], "my_name-train_9")
self.assertEqual(dset_test[0]["filename"], "my_name-train_10")
self.assertEqual(dset_test[-1]["filename"], "my_name-train_29")
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_train.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_test.features, Features({"filename": Value("string")}))
dset.set_format("numpy")
dset_dict = dset.train_test_split(train_size=10, seed=42)
self.assertListEqual(list(dset_dict.keys()), ["train", "test"])
dset_train = dset_dict["train"]
dset_test = dset_dict["test"]
self.assertEqual(len(dset_train), 10)
self.assertEqual(len(dset_test), 20)
self.assertEqual(dset_train.format["type"], "numpy")
self.assertEqual(dset_test.format["type"], "numpy")
self.assertNotEqual(dset_train[0]["filename"].item(), "my_name-train_0")
self.assertNotEqual(dset_train[-1]["filename"].item(), "my_name-train_9")
self.assertNotEqual(dset_test[0]["filename"].item(), "my_name-train_10")
self.assertNotEqual(dset_test[-1]["filename"].item(), "my_name-train_29")
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_train.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_test.features, Features({"filename": Value("string")}))
del dset_test, dset_train, dset_dict # DatasetDict
def test_shard(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir, self._create_dummy_dataset(in_memory, tmp_dir) as dset:
tmp_file = os.path.join(tmp_dir, "test.arrow")
with dset.select(range(10), indices_cache_file_name=tmp_file) as dset:
self.assertEqual(len(dset), 10)
# Shard
tmp_file_1 = os.path.join(tmp_dir, "test_1.arrow")
fingerprint = dset._fingerprint
with dset.shard(num_shards=8, index=1, indices_cache_file_name=tmp_file_1) as dset_sharded:
self.assertEqual(2, len(dset_sharded))
self.assertEqual(["my_name-train_1", "my_name-train_9"], dset_sharded["filename"])
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_sharded.features, Features({"filename": Value("string")}))
self.assertNotEqual(dset_sharded._fingerprint, fingerprint)
# Shard contiguous
tmp_file_2 = os.path.join(tmp_dir, "test_2.arrow")
with dset.shard(
num_shards=3, index=0, contiguous=True, indices_cache_file_name=tmp_file_2
) as dset_sharded_contiguous:
self.assertEqual([f"my_name-train_{i}" for i in (0, 1, 2, 3)], dset_sharded_contiguous["filename"])
self.assertDictEqual(dset.features, Features({"filename": Value("string")}))
self.assertDictEqual(dset_sharded_contiguous.features, Features({"filename": Value("string")}))
# Test lengths of sharded contiguous
self.assertEqual(
[4, 3, 3],
[
len(dset.shard(3, index=i, contiguous=True, indices_cache_file_name=tmp_file_2 + str(i)))
for i in range(3)
],
)
# formatted
dset.set_format("numpy")
with dset.shard(num_shards=3, index=0) as dset_sharded_formatted:
self.assertEqual(dset_sharded_formatted.format["type"], "numpy")
def test_flatten_indices(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertIsNone(dset._indices)
tmp_file = os.path.join(tmp_dir, "test.arrow")
with dset.select(range(0, 10, 2), indices_cache_file_name=tmp_file) as dset:
self.assertEqual(len(dset), 5)
self.assertIsNotNone(dset._indices)
tmp_file_2 = os.path.join(tmp_dir, "test_2.arrow")
fingerprint = dset._fingerprint
dset.set_format("numpy")
with dset.flatten_indices(cache_file_name=tmp_file_2) as dset:
self.assertEqual(len(dset), 5)
self.assertEqual(len(dset.data), len(dset))
self.assertIsNone(dset._indices)
self.assertNotEqual(dset._fingerprint, fingerprint)
self.assertEqual(dset.format["type"], "numpy")
# Test unique works
dset.unique(dset.column_names[0])
assert_arrow_metadata_are_synced_with_dataset_features(dset)
# Empty indices mapping
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir) as dset:
self.assertIsNone(dset._indices, None)
tmp_file = os.path.join(tmp_dir, "test.arrow")
with dset.filter(lambda _: False, cache_file_name=tmp_file) as dset:
self.assertEqual(len(dset), 0)
self.assertIsNotNone(dset._indices, None)
tmp_file_2 = os.path.join(tmp_dir, "test_2.arrow")
fingerprint = dset._fingerprint
dset.set_format("numpy")
with dset.flatten_indices(cache_file_name=tmp_file_2) as dset:
self.assertEqual(len(dset), 0)
self.assertEqual(len(dset.data), len(dset))
self.assertIsNone(dset._indices, None)
self.assertNotEqual(dset._fingerprint, fingerprint)
self.assertEqual(dset.format["type"], "numpy")
# Test unique works
dset.unique(dset.column_names[0])
assert_arrow_metadata_are_synced_with_dataset_features(dset)
@require_tf
@require_torch
def test_format_vectors(self, in_memory):
import numpy as np
import tensorflow as tf
import torch
with tempfile.TemporaryDirectory() as tmp_dir, self._create_dummy_dataset(
in_memory, tmp_dir
) as dset, dset.map(lambda ex, i: {"vec": np.ones(3) * i}, with_indices=True) as dset:
columns = dset.column_names
self.assertIsNotNone(dset[0])
self.assertIsNotNone(dset[:2])
for col in columns:
self.assertIsInstance(dset[0][col], (str, list))
self.assertIsInstance(dset[:2][col], list)
self.assertDictEqual(
dset.features, Features({"filename": Value("string"), "vec": Sequence(Value("float64"))})
)
dset.set_format("tensorflow")
self.assertIsNotNone(dset[0])
self.assertIsNotNone(dset[:2])
for col in columns:
self.assertIsInstance(dset[0][col], (tf.Tensor, tf.RaggedTensor))
self.assertIsInstance(dset[:2][col], (tf.Tensor, tf.RaggedTensor))
self.assertIsInstance(dset[col], (tf.Tensor, tf.RaggedTensor))
self.assertTupleEqual(tuple(dset[:2]["vec"].shape), (2, 3))
self.assertTupleEqual(tuple(dset["vec"][:2].shape), (2, 3))
dset.set_format("numpy")
self.assertIsNotNone(dset[0])
self.assertIsNotNone(dset[:2])
self.assertIsInstance(dset[0]["filename"], np.str_)
self.assertIsInstance(dset[:2]["filename"], np.ndarray)
self.assertIsInstance(dset["filename"], np.ndarray)
self.assertIsInstance(dset[0]["vec"], np.ndarray)
self.assertIsInstance(dset[:2]["vec"], np.ndarray)
self.assertIsInstance(dset["vec"], np.ndarray)
self.assertTupleEqual(dset[:2]["vec"].shape, (2, 3))
self.assertTupleEqual(dset["vec"][:2].shape, (2, 3))
dset.set_format("torch", columns=["vec"])
self.assertIsNotNone(dset[0])
self.assertIsNotNone(dset[:2])
# torch.Tensor is only for numerical columns
self.assertIsInstance(dset[0]["vec"], torch.Tensor)
self.assertIsInstance(dset[:2]["vec"], torch.Tensor)
self.assertIsInstance(dset["vec"][:2], torch.Tensor)
self.assertTupleEqual(dset[:2]["vec"].shape, (2, 3))
self.assertTupleEqual(dset["vec"][:2].shape, (2, 3))
@require_tf
@require_torch
def test_format_ragged_vectors(self, in_memory):
import numpy as np
import tensorflow as tf
import torch
with tempfile.TemporaryDirectory() as tmp_dir, self._create_dummy_dataset(
in_memory, tmp_dir
) as dset, dset.map(lambda ex, i: {"vec": np.ones(3 + i) * i}, with_indices=True) as dset:
columns = dset.column_names
self.assertIsNotNone(dset[0])
self.assertIsNotNone(dset[:2])
for col in columns:
self.assertIsInstance(dset[0][col], (str, list))
self.assertIsInstance(dset[:2][col], list)
self.assertDictEqual(
dset.features, Features({"filename": Value("string"), "vec": Sequence(Value("float64"))})
)
dset.set_format("tensorflow")
self.assertIsNotNone(dset[0])
self.assertIsNotNone(dset[:2])
for col in columns:
self.assertIsInstance(dset[0][col], tf.Tensor)
self.assertIsInstance(dset[:2][col], tf.RaggedTensor if col == "vec" else tf.Tensor)
self.assertIsInstance(dset[col], tf.RaggedTensor if col == "vec" else tf.Tensor)
# dim is None for ragged vectors in tensorflow
self.assertListEqual(dset[:2]["vec"].shape.as_list(), [2, None])
self.assertListEqual(dset["vec"][:2].shape.as_list(), [2, None])
dset.set_format("numpy")
self.assertIsNotNone(dset[0])
self.assertIsNotNone(dset[:2])
self.assertIsInstance(dset[0]["filename"], np.str_)
self.assertIsInstance(dset[:2]["filename"], np.ndarray)
self.assertIsInstance(dset["filename"], np.ndarray)
self.assertIsInstance(dset[0]["vec"], np.ndarray)
self.assertIsInstance(dset[:2]["vec"], np.ndarray)
self.assertIsInstance(dset["vec"], np.ndarray)
# array is flat for ragged vectors in numpy
self.assertTupleEqual(dset[:2]["vec"].shape, (2,))
self.assertTupleEqual(dset["vec"][:2].shape, (2,))
dset.set_format("torch")
self.assertIsNotNone(dset[0])
self.assertIsNotNone(dset[:2])
self.assertIsInstance(dset[0]["filename"], str)
self.assertIsInstance(dset[:2]["filename"], list)
self.assertIsInstance(dset["filename"], list)
self.assertIsInstance(dset[0]["vec"], torch.Tensor)
self.assertIsInstance(dset[:2]["vec"][0], torch.Tensor)
self.assertIsInstance(dset["vec"][0], torch.Tensor)
# pytorch doesn't support ragged tensors, so we should have lists
self.assertIsInstance(dset[:2]["vec"], list)
self.assertIsInstance(dset[:2]["vec"][0], torch.Tensor)
self.assertIsInstance(dset["vec"][:2], list)
self.assertIsInstance(dset["vec"][0], torch.Tensor)
@require_tf
@require_torch
def test_format_nested(self, in_memory):
import numpy as np
import tensorflow as tf
import torch
with tempfile.TemporaryDirectory() as tmp_dir, self._create_dummy_dataset(
in_memory, tmp_dir
) as dset, dset.map(lambda ex: {"nested": [{"foo": np.ones(3)}] * len(ex["filename"])}, batched=True) as dset:
self.assertDictEqual(
dset.features, Features({"filename": Value("string"), "nested": {"foo": Sequence(Value("float64"))}})
)
dset.set_format("tensorflow")
self.assertIsNotNone(dset[0])
self.assertIsInstance(dset[0]["nested"]["foo"], (tf.Tensor, tf.RaggedTensor))
self.assertIsNotNone(dset[:2])
self.assertIsInstance(dset[:2]["nested"][0]["foo"], (tf.Tensor, tf.RaggedTensor))
self.assertIsInstance(dset["nested"][0]["foo"], (tf.Tensor, tf.RaggedTensor))
dset.set_format("numpy")
self.assertIsNotNone(dset[0])
self.assertIsInstance(dset[0]["nested"]["foo"], np.ndarray)
self.assertIsNotNone(dset[:2])
self.assertIsInstance(dset[:2]["nested"][0]["foo"], np.ndarray)
self.assertIsInstance(dset["nested"][0]["foo"], np.ndarray)
dset.set_format("torch", columns="nested")
self.assertIsNotNone(dset[0])
self.assertIsInstance(dset[0]["nested"]["foo"], torch.Tensor)
self.assertIsNotNone(dset[:2])
self.assertIsInstance(dset[:2]["nested"][0]["foo"], torch.Tensor)
self.assertIsInstance(dset["nested"][0]["foo"], torch.Tensor)
def test_format_pandas(self, in_memory):
import pandas as pd
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_format("pandas")
self.assertIsInstance(dset[0], pd.DataFrame)
self.assertIsInstance(dset[:2], pd.DataFrame)
self.assertIsInstance(dset["col_1"], pd.Series)
@require_polars
def test_format_polars(self, in_memory):
import polars as pl
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
dset.set_format("polars")
self.assertIsInstance(dset[0], pl.DataFrame)
self.assertIsInstance(dset[:2], pl.DataFrame)
self.assertIsInstance(dset["col_1"], pl.Series)
def test_transmit_format_single(self, in_memory):
@transmit_format
def my_single_transform(self, return_factory, *args, **kwargs):
return return_factory()
with tempfile.TemporaryDirectory() as tmp_dir:
return_factory = partial(
self._create_dummy_dataset, in_memory=in_memory, tmp_dir=tmp_dir, multiple_columns=True
)
with return_factory() as dset:
dset.set_format("numpy", columns=["col_1"])
prev_format = dset.format
with my_single_transform(dset, return_factory) as transformed_dset:
self.assertDictEqual(transformed_dset.format, prev_format)
def test_transmit_format_dict(self, in_memory):
@transmit_format
def my_split_transform(self, return_factory, *args, **kwargs):
return DatasetDict({"train": return_factory()})
with tempfile.TemporaryDirectory() as tmp_dir:
return_factory = partial(
self._create_dummy_dataset, in_memory=in_memory, tmp_dir=tmp_dir, multiple_columns=True
)
with return_factory() as dset:
dset.set_format("numpy", columns=["col_1"])
prev_format = dset.format
transformed_dset = my_split_transform(dset, return_factory)["train"]
self.assertDictEqual(transformed_dset.format, prev_format)
del transformed_dset # DatasetDict
def test_with_format(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
with dset.with_format("numpy", columns=["col_1"]) as dset2:
dset.set_format("numpy", columns=["col_1"])
self.assertDictEqual(dset.format, dset2.format)
self.assertEqual(dset._fingerprint, dset2._fingerprint)
# dset.reset_format()
# self.assertNotEqual(dset.format, dset2.format)
# self.assertNotEqual(dset._fingerprint, dset2._fingerprint)
def test_with_transform(self, in_memory):
with tempfile.TemporaryDirectory() as tmp_dir:
with self._create_dummy_dataset(in_memory, tmp_dir, multiple_columns=True) as dset:
transform = lambda x: {"foo": x["col_1"]} # noqa: E731
with dset.with_transform(transform, columns=["col_1"]) as dset2:
dset.set_transform(transform, columns=["col_1"])
self.assertDictEqual(dset.format, dset2.format)
self.assertEqual(dset._fingerprint, dset2._fingerprint)
dset.reset_format()
self.assertNotEqual(dset.format, dset2.format)
self.assertNotEqual(dset._fingerprint, dset2._fingerprint)
@require_tf
def test_tf_dataset_conversion(self, in_memory):
tmp_dir = tempfile.TemporaryDirectory()
for num_workers in [0, 1, 2]:
if num_workers > 0 and sys.platform == "win32" and not in_memory:
continue # This test hangs on the Py3.10 test worker, but it runs fine locally on my Windows machine
with self._create_dummy_dataset(in_memory, tmp_dir.name, array_features=True) as dset:
tf_dataset = dset.to_tf_dataset(columns="col_3", batch_size=2, num_workers=num_workers)
batch = next(iter(tf_dataset))
self.assertEqual(batch.shape.as_list(), [2, 4])
self.assertEqual(batch.dtype.name, "int64")
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
tf_dataset = dset.to_tf_dataset(columns="col_1", batch_size=2, num_workers=num_workers)
batch = next(iter(tf_dataset))
self.assertEqual(batch.shape.as_list(), [2])
self.assertEqual(batch.dtype.name, "int64")
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
# Check that it works with all default options (except batch_size because the dummy dataset only has 4)
tf_dataset = dset.to_tf_dataset(batch_size=2, num_workers=num_workers)
batch = next(iter(tf_dataset))
self.assertEqual(batch["col_1"].shape.as_list(), [2])
self.assertEqual(batch["col_2"].shape.as_list(), [2])
self.assertEqual(batch["col_1"].dtype.name, "int64")
self.assertEqual(batch["col_2"].dtype.name, "string") # Assert that we're converting strings properly
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
# Check that when we use a transform that creates a new column from existing column values
# but don't load the old columns that the new column depends on in the final dataset,
# that they're still kept around long enough to be used in the transform
transform_dset = dset.with_transform(
lambda x: {"new_col": [val * 2 for val in x["col_1"]], "col_1": x["col_1"]}
)
tf_dataset = transform_dset.to_tf_dataset(columns="new_col", batch_size=2, num_workers=num_workers)
batch = next(iter(tf_dataset))
self.assertEqual(batch.shape.as_list(), [2])
self.assertEqual(batch.dtype.name, "int64")
del transform_dset
del tf_dataset # For correct cleanup
@require_tf
def test_tf_index_reshuffling(self, in_memory):
# This test checks that when we do two epochs over a tf.data.Dataset from to_tf_dataset
# that we get a different shuffle order each time
# It also checks that when we aren't shuffling, that the dataset order is fully preserved
# even when loading is split across multiple workers
data = {"col_1": list(range(20))}
for num_workers in [0, 1, 2, 3]:
with Dataset.from_dict(data) as dset:
tf_dataset = dset.to_tf_dataset(batch_size=10, shuffle=True, num_workers=num_workers)
indices = []
for batch in tf_dataset:
indices.append(batch["col_1"])
indices = np.concatenate([arr.numpy() for arr in indices])
second_indices = []
for batch in tf_dataset:
second_indices.append(batch["col_1"])
second_indices = np.concatenate([arr.numpy() for arr in second_indices])
self.assertFalse(np.array_equal(indices, second_indices))
self.assertEqual(len(indices), len(np.unique(indices)))
self.assertEqual(len(second_indices), len(np.unique(second_indices)))
tf_dataset = dset.to_tf_dataset(batch_size=1, shuffle=False, num_workers=num_workers)
for i, batch in enumerate(tf_dataset):
# Assert that the unshuffled order is fully preserved even when multiprocessing
self.assertEqual(i, batch["col_1"].numpy())
@require_tf
def test_tf_label_renaming(self, in_memory):
# Protect TF-specific imports in here
import tensorflow as tf
from datasets.utils.tf_utils import minimal_tf_collate_fn_with_renaming
tmp_dir = tempfile.TemporaryDirectory()
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
with dset.rename_columns({"col_1": "features", "col_2": "label"}) as new_dset:
tf_dataset = new_dset.to_tf_dataset(collate_fn=minimal_tf_collate_fn_with_renaming, batch_size=4)
batch = next(iter(tf_dataset))
self.assertTrue("labels" in batch and "features" in batch)
tf_dataset = new_dset.to_tf_dataset(
columns=["features", "labels"], collate_fn=minimal_tf_collate_fn_with_renaming, batch_size=4
)
batch = next(iter(tf_dataset))
self.assertTrue("labels" in batch and "features" in batch)
tf_dataset = new_dset.to_tf_dataset(
columns=["features", "label"], collate_fn=minimal_tf_collate_fn_with_renaming, batch_size=4
)
batch = next(iter(tf_dataset))
self.assertTrue("labels" in batch and "features" in batch) # Assert renaming was handled correctly
tf_dataset = new_dset.to_tf_dataset(
columns=["features"],
label_cols=["labels"],
collate_fn=minimal_tf_collate_fn_with_renaming,
batch_size=4,
)
batch = next(iter(tf_dataset))
self.assertEqual(len(batch), 2)
# Assert that we don't have any empty entries here
self.assertTrue(isinstance(batch[0], tf.Tensor) and isinstance(batch[1], tf.Tensor))
tf_dataset = new_dset.to_tf_dataset(
columns=["features"],
label_cols=["label"],
collate_fn=minimal_tf_collate_fn_with_renaming,
batch_size=4,
)
batch = next(iter(tf_dataset))
self.assertEqual(len(batch), 2)
# Assert that we don't have any empty entries here
self.assertTrue(isinstance(batch[0], tf.Tensor) and isinstance(batch[1], tf.Tensor))
tf_dataset = new_dset.to_tf_dataset(
columns=["features"],
collate_fn=minimal_tf_collate_fn_with_renaming,
batch_size=4,
)
batch = next(iter(tf_dataset))
# Assert that labels didn't creep in when we don't ask for them
# just because the collate_fn added them
self.assertTrue(isinstance(batch, tf.Tensor))
del tf_dataset # For correct cleanup
@require_tf
def test_tf_dataset_options(self, in_memory):
tmp_dir = tempfile.TemporaryDirectory()
# Test that batch_size option works as expected
with self._create_dummy_dataset(in_memory, tmp_dir.name, array_features=True) as dset:
tf_dataset = dset.to_tf_dataset(columns="col_3", batch_size=2)
batch = next(iter(tf_dataset))
self.assertEqual(batch.shape.as_list(), [2, 4])
self.assertEqual(batch.dtype.name, "int64")
# Test that batch_size=None (optional) works as expected
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
tf_dataset = dset.to_tf_dataset(columns="col_3", batch_size=None)
single_example = next(iter(tf_dataset))
self.assertEqual(single_example.shape.as_list(), [])
self.assertEqual(single_example.dtype.name, "int64")
# Assert that we can batch it with `tf.data.Dataset.batch` method
batched_dataset = tf_dataset.batch(batch_size=2)
batch = next(iter(batched_dataset))
self.assertEqual(batch.shape.as_list(), [2])
self.assertEqual(batch.dtype.name, "int64")
# Test that batching a batch_size=None dataset produces the same results as using batch_size arg
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
batch_size = 2
tf_dataset_no_batch = dset.to_tf_dataset(columns="col_3")
tf_dataset_batch = dset.to_tf_dataset(columns="col_3", batch_size=batch_size)
self.assertEqual(tf_dataset_no_batch.element_spec, tf_dataset_batch.unbatch().element_spec)
self.assertEqual(tf_dataset_no_batch.cardinality(), tf_dataset_batch.cardinality() * batch_size)
for batch_1, batch_2 in zip(tf_dataset_no_batch.batch(batch_size=batch_size), tf_dataset_batch):
self.assertEqual(batch_1.shape, batch_2.shape)
self.assertEqual(batch_1.dtype, batch_2.dtype)
self.assertListEqual(batch_1.numpy().tolist(), batch_2.numpy().tolist())
# Test that requesting label_cols works as expected
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
tf_dataset = dset.to_tf_dataset(columns="col_1", label_cols=["col_2", "col_3"], batch_size=4)
batch = next(iter(tf_dataset))
self.assertEqual(len(batch), 2)
self.assertEqual(set(batch[1].keys()), {"col_2", "col_3"})
self.assertEqual(batch[0].dtype.name, "int64")
# Assert data comes out as expected and isn't shuffled
self.assertEqual(batch[0].numpy().tolist(), [3, 2, 1, 0])
self.assertEqual(batch[1]["col_2"].numpy().tolist(), [b"a", b"b", b"c", b"d"])
self.assertEqual(batch[1]["col_3"].numpy().tolist(), [0, 1, 0, 1])
# Check that incomplete batches are dropped if requested
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
tf_dataset = dset.to_tf_dataset(columns="col_1", batch_size=3)
tf_dataset_with_drop = dset.to_tf_dataset(columns="col_1", batch_size=3, drop_remainder=True)
self.assertEqual(len(tf_dataset), 2) # One batch of 3 and one batch of 1
self.assertEqual(len(tf_dataset_with_drop), 1) # Incomplete batch of 1 is dropped
# Test that `NotImplementedError` is raised `batch_size` is None and `num_workers` is > 0
if sys.version_info >= (3, 8):
with self._create_dummy_dataset(in_memory, tmp_dir.name, multiple_columns=True) as dset:
with self.assertRaisesRegex(
NotImplementedError, "`batch_size` must be specified when using multiple workers"
):
dset.to_tf_dataset(columns="col_1", batch_size=None, num_workers=2)
del tf_dataset # For correct cleanup
del tf_dataset_with_drop
class MiscellaneousDatasetTest(TestCase):
def test_from_pandas(self):
data = {"col_1": [3, 2, 1, 0], "col_2": ["a", "b", "c", "d"]}
df = pd.DataFrame.from_dict(data)
with Dataset.from_pandas(df) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2"])
self.assertDictEqual(dset.features, Features({"col_1": Value("int64"), "col_2": Value("string")}))
features = Features({"col_1": Value("int64"), "col_2": Value("string")})
with Dataset.from_pandas(df, features=features) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2"])
self.assertDictEqual(dset.features, Features({"col_1": Value("int64"), "col_2": Value("string")}))
features = Features({"col_1": Value("int64"), "col_2": Value("string")})
with Dataset.from_pandas(df, features=features, info=DatasetInfo(features=features)) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2"])
self.assertDictEqual(dset.features, Features({"col_1": Value("int64"), "col_2": Value("string")}))
features = Features({"col_1": Sequence(Value("string")), "col_2": Value("string")})
self.assertRaises(TypeError, Dataset.from_pandas, df, features=features)
@require_polars
def test_from_polars(self):
import polars as pl
data = {"col_1": [3, 2, 1, 0], "col_2": ["a", "b", "c", "d"]}
df = pl.from_dict(data)
with Dataset.from_polars(df) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2"])
self.assertDictEqual(dset.features, Features({"col_1": Value("int64"), "col_2": Value("large_string")}))
features = Features({"col_1": Value("int64"), "col_2": Value("large_string")})
with Dataset.from_polars(df, features=features) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2"])
self.assertDictEqual(dset.features, Features({"col_1": Value("int64"), "col_2": Value("large_string")}))
features = Features({"col_1": Value("int64"), "col_2": Value("large_string")})
with Dataset.from_polars(df, features=features, info=DatasetInfo(features=features)) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2"])
self.assertDictEqual(dset.features, Features({"col_1": Value("int64"), "col_2": Value("large_string")}))
features = Features({"col_1": Sequence(Value("string")), "col_2": Value("large_string")})
self.assertRaises(TypeError, Dataset.from_polars, df, features=features)
def test_from_dict(self):
data = {"col_1": [3, 2, 1, 0], "col_2": ["a", "b", "c", "d"], "col_3": pa.array([True, False, True, False])}
with Dataset.from_dict(data) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(dset["col_3"], data["col_3"].to_pylist())
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2", "col_3"])
self.assertDictEqual(
dset.features, Features({"col_1": Value("int64"), "col_2": Value("string"), "col_3": Value("bool")})
)
features = Features({"col_1": Value("int64"), "col_2": Value("string"), "col_3": Value("bool")})
with Dataset.from_dict(data, features=features) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(dset["col_3"], data["col_3"].to_pylist())
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2", "col_3"])
self.assertDictEqual(
dset.features, Features({"col_1": Value("int64"), "col_2": Value("string"), "col_3": Value("bool")})
)
features = Features({"col_1": Value("int64"), "col_2": Value("string"), "col_3": Value("bool")})
with Dataset.from_dict(data, features=features, info=DatasetInfo(features=features)) as dset:
self.assertListEqual(dset["col_1"], data["col_1"])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(dset["col_3"], data["col_3"].to_pylist())
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2", "col_3"])
self.assertDictEqual(
dset.features, Features({"col_1": Value("int64"), "col_2": Value("string"), "col_3": Value("bool")})
)
features = Features({"col_1": Value("string"), "col_2": Value("string"), "col_3": Value("int32")})
with Dataset.from_dict(data, features=features) as dset:
# the integers are converted to strings
self.assertListEqual(dset["col_1"], [str(x) for x in data["col_1"]])
self.assertListEqual(dset["col_2"], data["col_2"])
self.assertListEqual(dset["col_3"], [int(x) for x in data["col_3"].to_pylist()])
self.assertListEqual(list(dset.features.keys()), ["col_1", "col_2", "col_3"])
self.assertDictEqual(
dset.features, Features({"col_1": Value("string"), "col_2": Value("string"), "col_3": Value("int32")})
)
features = Features({"col_1": Value("int64"), "col_2": Value("int64"), "col_3": Value("bool")})
self.assertRaises(ValueError, Dataset.from_dict, data, features=features)
def test_concatenate_mixed_memory_and_disk(self):
data1, data2, data3 = {"id": [0, 1, 2]}, {"id": [3, 4, 5]}, {"id": [6, 7]}
info1 = DatasetInfo(description="Dataset1")
info2 = DatasetInfo(description="Dataset2")
with tempfile.TemporaryDirectory() as tmp_dir:
with Dataset.from_dict(data1, info=info1).map(
cache_file_name=os.path.join(tmp_dir, "d1.arrow")
) as dset1, Dataset.from_dict(data2, info=info2).map(
cache_file_name=os.path.join(tmp_dir, "d2.arrow")
) as dset2, Dataset.from_dict(data3) as dset3:
with concatenate_datasets([dset1, dset2, dset3]) as concatenated_dset:
self.assertEqual(len(concatenated_dset), len(dset1) + len(dset2) + len(dset3))
self.assertListEqual(concatenated_dset["id"], dset1["id"] + dset2["id"] + dset3["id"])
@require_transformers
@pytest.mark.integration
def test_set_format_encode(self):
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
def encode(batch):
return tokenizer(batch["text"], padding="longest", return_tensors="np")
with Dataset.from_dict({"text": ["hello there", "foo"]}) as dset:
dset.set_transform(transform=encode)
self.assertEqual(str(dset[:2]), str(encode({"text": ["hello there", "foo"]})))
@require_tf
def test_tf_string_encoding(self):
data = {"col_1": ["á", "é", "í", "ó", "ú"], "col_2": ["à", "è", "ì", "ò", "ù"]}
with Dataset.from_dict(data) as dset:
tf_dset_wo_batch = dset.to_tf_dataset(columns=["col_1", "col_2"])
for tf_row, row in zip(tf_dset_wo_batch, dset):
self.assertEqual(tf_row["col_1"].numpy().decode("utf-8"), row["col_1"])
self.assertEqual(tf_row["col_2"].numpy().decode("utf-8"), row["col_2"])
tf_dset_w_batch = dset.to_tf_dataset(columns=["col_1", "col_2"], batch_size=2)
for tf_row, row in zip(tf_dset_w_batch.unbatch(), dset):
self.assertEqual(tf_row["col_1"].numpy().decode("utf-8"), row["col_1"])
self.assertEqual(tf_row["col_2"].numpy().decode("utf-8"), row["col_2"])
self.assertEqual(tf_dset_w_batch.unbatch().element_spec, tf_dset_wo_batch.element_spec)
self.assertEqual(tf_dset_w_batch.element_spec, tf_dset_wo_batch.batch(2).element_spec)
def test_cast_with_sliced_list():
old_features = Features({"foo": Sequence(Value("int64"))})
new_features = Features({"foo": Sequence(Value("int32"))})
dataset = Dataset.from_dict({"foo": [[i] * (i % 3) for i in range(20)]}, features=old_features)
casted_dataset = dataset.cast(new_features, batch_size=2) # small batch size to slice the ListArray
assert dataset["foo"] == casted_dataset["foo"]
assert casted_dataset.features == new_features
@pytest.mark.parametrize("include_nulls", [False, True])
def test_class_encode_column_with_none(include_nulls):
dataset = Dataset.from_dict({"col_1": ["a", "b", "c", None, "d", None]})
dataset = dataset.class_encode_column("col_1", include_nulls=include_nulls)
class_names = ["a", "b", "c", "d"]
if include_nulls:
class_names += ["None"]
assert isinstance(dataset.features["col_1"], ClassLabel)
assert set(dataset.features["col_1"].names) == set(class_names)
assert (None in dataset.unique("col_1")) == (not include_nulls)
@pytest.mark.parametrize("null_placement", ["first", "last"])
def test_sort_with_none(null_placement):
dataset = Dataset.from_dict({"col_1": ["item_2", "item_3", "item_1", None, "item_4", None]})
dataset = dataset.sort("col_1", null_placement=null_placement)
if null_placement == "first":
assert dataset["col_1"] == [None, None, "item_1", "item_2", "item_3", "item_4"]
else:
assert dataset["col_1"] == ["item_1", "item_2", "item_3", "item_4", None, None]
def test_update_metadata_with_features(dataset_dict):
table1 = pa.Table.from_pydict(dataset_dict)
features1 = Features.from_arrow_schema(table1.schema)
features2 = features1.copy()
features2["col_2"] = ClassLabel(num_classes=len(table1))
assert features1 != features2
table2 = update_metadata_with_features(table1, features2)
metadata = json.loads(table2.schema.metadata[b"huggingface"].decode())
assert features2 == Features.from_dict(metadata["info"]["features"])
with Dataset(table1) as dset1, Dataset(table2) as dset2:
assert dset1.features == features1
assert dset2.features == features2
@pytest.mark.parametrize("dataset_type", ["in_memory", "memory_mapped", "mixed"])
@pytest.mark.parametrize("axis, expected_shape", [(0, (4, 3)), (1, (2, 6))])
def test_concatenate_datasets(dataset_type, axis, expected_shape, dataset_dict, arrow_path):
table = {
"in_memory": InMemoryTable.from_pydict(dataset_dict),
"memory_mapped": MemoryMappedTable.from_file(arrow_path),
}
tables = [
table[dataset_type if dataset_type != "mixed" else "memory_mapped"].slice(0, 2), # shape = (2, 3)
table[dataset_type if dataset_type != "mixed" else "in_memory"].slice(2, 4), # shape = (2, 3)
]
if axis == 1: # don't duplicate columns
tables[1] = tables[1].rename_columns([col + "_bis" for col in tables[1].column_names])
datasets = [Dataset(table) for table in tables]
dataset = concatenate_datasets(datasets, axis=axis)
assert dataset.shape == expected_shape
assert_arrow_metadata_are_synced_with_dataset_features(dataset)
def test_concatenate_datasets_new_columns():
dataset1 = Dataset.from_dict({"col_1": ["a", "b", "c"]})
dataset2 = Dataset.from_dict({"col_1": ["d", "e", "f"], "col_2": [True, False, True]})
dataset = concatenate_datasets([dataset1, dataset2])
assert dataset.data.shape == (6, 2)
assert dataset.features == Features({"col_1": Value("string"), "col_2": Value("bool")})
assert dataset[:] == {"col_1": ["a", "b", "c", "d", "e", "f"], "col_2": [None, None, None, True, False, True]}
dataset3 = Dataset.from_dict({"col_3": ["a_1"]})
dataset = concatenate_datasets([dataset, dataset3])
assert dataset.data.shape == (7, 3)
assert dataset.features == Features({"col_1": Value("string"), "col_2": Value("bool"), "col_3": Value("string")})
assert dataset[:] == {
"col_1": ["a", "b", "c", "d", "e", "f", None],
"col_2": [None, None, None, True, False, True, None],
"col_3": [None, None, None, None, None, None, "a_1"],
}
@pytest.mark.parametrize("axis", [0, 1])
def test_concatenate_datasets_complex_features(axis):
n = 5
dataset1 = Dataset.from_dict(
{"col_1": [0] * n, "col_2": list(range(n))},
features=Features({"col_1": Value("int32"), "col_2": ClassLabel(num_classes=n)}),
)
if axis == 1:
dataset2 = dataset1.rename_columns({col: col + "_" for col in dataset1.column_names})
expected_features = Features({**dataset1.features, **dataset2.features})
else:
dataset2 = dataset1
expected_features = dataset1.features
assert concatenate_datasets([dataset1, dataset2], axis=axis).features == expected_features
@pytest.mark.parametrize("other_dataset_type", ["in_memory", "memory_mapped", "concatenation"])
@pytest.mark.parametrize("axis, expected_shape", [(0, (8, 3)), (1, (4, 6))])
def test_concatenate_datasets_with_concatenation_tables(
axis, expected_shape, other_dataset_type, dataset_dict, arrow_path
):
def _create_concatenation_table(axis):
if axis == 0: # shape: (4, 3) = (4, 1) + (4, 2)
concatenation_table = ConcatenationTable.from_blocks(
[
[
InMemoryTable.from_pydict({"col_1": dataset_dict["col_1"]}),
MemoryMappedTable.from_file(arrow_path).remove_column(0),
]
]
)
elif axis == 1: # shape: (4, 3) = (1, 3) + (3, 3)
concatenation_table = ConcatenationTable.from_blocks(
[
[InMemoryTable.from_pydict(dataset_dict).slice(0, 1)],
[MemoryMappedTable.from_file(arrow_path).slice(1, 4)],
]
)
return concatenation_table
concatenation_table = _create_concatenation_table(axis)
assert concatenation_table.shape == (4, 3)
if other_dataset_type == "in_memory":
other_table = InMemoryTable.from_pydict(dataset_dict)
elif other_dataset_type == "memory_mapped":
other_table = MemoryMappedTable.from_file(arrow_path)
elif other_dataset_type == "concatenation":
other_table = _create_concatenation_table(axis)
assert other_table.shape == (4, 3)
tables = [concatenation_table, other_table]
if axis == 1: # don't duplicate columns
tables[1] = tables[1].rename_columns([col + "_bis" for col in tables[1].column_names])
for tables in [tables, reversed(tables)]:
datasets = [Dataset(table) for table in tables]
dataset = concatenate_datasets(datasets, axis=axis)
assert dataset.shape == expected_shape
def test_concatenate_datasets_duplicate_columns(dataset):
with pytest.raises(ValueError) as excinfo:
concatenate_datasets([dataset, dataset], axis=1)
assert "duplicated" in str(excinfo.value)
def test_interleave_datasets():
d1 = Dataset.from_dict({"a": [0, 1, 2]})
d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
d3 = Dataset.from_dict({"a": [22, 21, 20]}).select([2, 1, 0])
dataset = interleave_datasets([d1, d2, d3])
expected_length = 3 * min(len(d1), len(d2), len(d3))
expected_values = [x["a"] for x in itertools.chain(*zip(d1, d2, d3))]
assert isinstance(dataset, Dataset)
assert len(dataset) == expected_length
assert dataset["a"] == expected_values
assert dataset._fingerprint == interleave_datasets([d1, d2, d3])._fingerprint
def test_interleave_datasets_probabilities():
seed = 42
probabilities = [0.3, 0.5, 0.2]
d1 = Dataset.from_dict({"a": [0, 1, 2]})
d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
d3 = Dataset.from_dict({"a": [22, 21, 20]}).select([2, 1, 0])
dataset = interleave_datasets([d1, d2, d3], probabilities=probabilities, seed=seed)
expected_length = 7 # hardcoded
expected_values = [10, 11, 20, 12, 0, 21, 13] # hardcoded
assert isinstance(dataset, Dataset)
assert len(dataset) == expected_length
assert dataset["a"] == expected_values
assert (
dataset._fingerprint == interleave_datasets([d1, d2, d3], probabilities=probabilities, seed=seed)._fingerprint
)
def test_interleave_datasets_oversampling_strategy():
d1 = Dataset.from_dict({"a": [0, 1, 2]})
d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
d3 = Dataset.from_dict({"a": [22, 21, 20]}).select([2, 1, 0])
dataset = interleave_datasets([d1, d2, d3], stopping_strategy="all_exhausted")
expected_length = 3 * max(len(d1), len(d2), len(d3))
expected_values = [0, 10, 20, 1, 11, 21, 2, 12, 22, 0, 13, 20] # hardcoded
assert isinstance(dataset, Dataset)
assert len(dataset) == expected_length
assert dataset["a"] == expected_values
assert dataset._fingerprint == interleave_datasets([d1, d2, d3], stopping_strategy="all_exhausted")._fingerprint
def test_interleave_datasets_probabilities_oversampling_strategy():
seed = 42
probabilities = [0.3, 0.5, 0.2]
d1 = Dataset.from_dict({"a": [0, 1, 2]})
d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
d3 = Dataset.from_dict({"a": [22, 21, 20]}).select([2, 1, 0])
dataset = interleave_datasets(
[d1, d2, d3], stopping_strategy="all_exhausted", probabilities=probabilities, seed=seed
)
expected_length = 16 # hardcoded
expected_values = [10, 11, 20, 12, 0, 21, 13, 10, 1, 11, 12, 22, 13, 20, 10, 2] # hardcoded
assert isinstance(dataset, Dataset)
assert len(dataset) == expected_length
assert dataset["a"] == expected_values
assert (
dataset._fingerprint
== interleave_datasets(
[d1, d2, d3], stopping_strategy="all_exhausted", probabilities=probabilities, seed=seed
)._fingerprint
)
@pytest.mark.parametrize("batch_size", [4, 5])
@pytest.mark.parametrize("drop_last_batch", [False, True])
def test_dataset_iter_batch(batch_size, drop_last_batch):
n = 25
dset = Dataset.from_dict({"i": list(range(n))})
all_col_values = list(range(n))
batches = []
for i, batch in enumerate(dset.iter(batch_size, drop_last_batch=drop_last_batch)):
assert batch == {"i": all_col_values[i * batch_size : (i + 1) * batch_size]}
batches.append(batch)
if drop_last_batch:
assert all(len(batch["i"]) == batch_size for batch in batches)
else:
assert all(len(batch["i"]) == batch_size for batch in batches[:-1])
assert len(batches[-1]["i"]) <= batch_size
@pytest.mark.parametrize(
"column, expected_dtype",
[(["a", "b", "c", "d"], "string"), ([1, 2, 3, 4], "int64"), ([1.0, 2.0, 3.0, 4.0], "float64")],
)
@pytest.mark.parametrize("in_memory", [False, True])
@pytest.mark.parametrize(
"transform",
[
None,
("shuffle", (42,), {}),
("with_format", ("pandas",), {}),
("class_encode_column", ("col_2",), {}),
("select", (range(3),), {}),
],
)
def test_dataset_add_column(column, expected_dtype, in_memory, transform, dataset_dict, arrow_path):
column_name = "col_4"
original_dataset = (
Dataset(InMemoryTable.from_pydict(dataset_dict))
if in_memory
else Dataset(MemoryMappedTable.from_file(arrow_path))
)
if transform is not None:
transform_name, args, kwargs = transform
original_dataset: Dataset = getattr(original_dataset, transform_name)(*args, **kwargs)
column = column[:3] if transform is not None and transform_name == "select" else column
dataset = original_dataset.add_column(column_name, column)
assert dataset.data.shape == (3, 4) if transform is not None and transform_name == "select" else (4, 4)
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
# Sort expected features as in the original dataset
expected_features = {feature: expected_features[feature] for feature in original_dataset.features}
# Add new column feature
expected_features[column_name] = expected_dtype
assert dataset.data.column_names == list(expected_features.keys())
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
assert len(dataset.data.blocks) == 1 if in_memory else 2 # multiple InMemoryTables are consolidated as one
assert dataset.format["type"] == original_dataset.format["type"]
assert dataset._fingerprint != original_dataset._fingerprint
dataset.reset_format()
original_dataset.reset_format()
assert all(dataset[col] == original_dataset[col] for col in original_dataset.column_names)
assert set(dataset["col_4"]) == set(column)
if dataset._indices is not None:
dataset_indices = dataset._indices["indices"].to_pylist()
expected_dataset_indices = original_dataset._indices["indices"].to_pylist()
assert dataset_indices == expected_dataset_indices
assert_arrow_metadata_are_synced_with_dataset_features(dataset)
@pytest.mark.parametrize(
"transform",
[None, ("shuffle", (42,), {}), ("with_format", ("pandas",), {}), ("class_encode_column", ("col_2",), {})],
)
@pytest.mark.parametrize("in_memory", [False, True])
@pytest.mark.parametrize(
"item",
[
{"col_1": "2", "col_2": 2, "col_3": 2.0},
{"col_1": "2", "col_2": "2", "col_3": "2"},
{"col_1": 2, "col_2": 2, "col_3": 2},
{"col_1": 2.0, "col_2": 2.0, "col_3": 2.0},
],
)
def test_dataset_add_item(item, in_memory, dataset_dict, arrow_path, transform):
dataset_to_test = (
Dataset(InMemoryTable.from_pydict(dataset_dict))
if in_memory
else Dataset(MemoryMappedTable.from_file(arrow_path))
)
if transform is not None:
transform_name, args, kwargs = transform
dataset_to_test: Dataset = getattr(dataset_to_test, transform_name)(*args, **kwargs)
dataset = dataset_to_test.add_item(item)
assert dataset.data.shape == (5, 3)
expected_features = dataset_to_test.features
assert sorted(dataset.data.column_names) == sorted(expected_features.keys())
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature] == expected_dtype
assert len(dataset.data.blocks) == 1 if in_memory else 2 # multiple InMemoryTables are consolidated as one
assert dataset.format["type"] == dataset_to_test.format["type"]
assert dataset._fingerprint != dataset_to_test._fingerprint
dataset.reset_format()
dataset_to_test.reset_format()
assert dataset[:-1] == dataset_to_test[:]
assert {k: int(v) for k, v in dataset[-1].items()} == {k: int(v) for k, v in item.items()}
if dataset._indices is not None:
dataset_indices = dataset._indices["indices"].to_pylist()
dataset_to_test_indices = dataset_to_test._indices["indices"].to_pylist()
assert dataset_indices == dataset_to_test_indices + [len(dataset_to_test._data)]
def test_dataset_add_item_new_columns():
dataset = Dataset.from_dict({"col_1": [0, 1, 2]}, features=Features({"col_1": Value("uint8")}))
dataset = dataset.add_item({"col_1": 3, "col_2": "a"})
assert dataset.data.shape == (4, 2)
assert dataset.features == Features({"col_1": Value("uint8"), "col_2": Value("string")})
assert dataset[:] == {"col_1": [0, 1, 2, 3], "col_2": [None, None, None, "a"]}
dataset = dataset.add_item({"col_3": True})
assert dataset.data.shape == (5, 3)
assert dataset.features == Features({"col_1": Value("uint8"), "col_2": Value("string"), "col_3": Value("bool")})
assert dataset[:] == {
"col_1": [0, 1, 2, 3, None],
"col_2": [None, None, None, "a", None],
"col_3": [None, None, None, None, True],
}
def test_dataset_add_item_introduce_feature_type():
dataset = Dataset.from_dict({"col_1": [None, None, None]})
dataset = dataset.add_item({"col_1": "a"})
assert dataset.data.shape == (4, 1)
assert dataset.features == Features({"col_1": Value("string")})
assert dataset[:] == {"col_1": [None, None, None, "a"]}
def test_dataset_filter_batched_indices():
ds = Dataset.from_dict({"num": [0, 1, 2, 3]})
ds = ds.filter(lambda num: num % 2 == 0, input_columns="num", batch_size=2)
assert all(item["num"] % 2 == 0 for item in ds)
@pytest.mark.parametrize("in_memory", [False, True])
def test_dataset_from_file(in_memory, dataset, arrow_file):
filename = arrow_file
with assert_arrow_memory_increases() if in_memory else assert_arrow_memory_doesnt_increase():
dataset_from_file = Dataset.from_file(filename, in_memory=in_memory)
assert dataset_from_file.features.type == dataset.features.type
assert dataset_from_file.features == dataset.features
assert dataset_from_file.cache_files == ([{"filename": filename}] if not in_memory else [])
def _check_csv_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_dataset_from_csv_keep_in_memory(keep_in_memory, csv_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = Dataset.from_csv(csv_path, cache_dir=cache_dir, keep_in_memory=keep_in_memory)
_check_csv_dataset(dataset, expected_features)
@pytest.mark.parametrize(
"features",
[
None,
{"col_1": "string", "col_2": "int64", "col_3": "float64"},
{"col_1": "string", "col_2": "string", "col_3": "string"},
{"col_1": "int32", "col_2": "int32", "col_3": "int32"},
{"col_1": "float32", "col_2": "float32", "col_3": "float32"},
],
)
def test_dataset_from_csv_features(features, csv_path, tmp_path):
cache_dir = tmp_path / "cache"
# CSV file loses col_1 string dtype information: default now is "int64" instead of "string"
default_expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = Dataset.from_csv(csv_path, features=features, cache_dir=cache_dir)
_check_csv_dataset(dataset, expected_features)
@pytest.mark.parametrize("split", [None, NamedSplit("train"), "train", "test"])
def test_dataset_from_csv_split(split, csv_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
dataset = Dataset.from_csv(csv_path, cache_dir=cache_dir, split=split)
_check_csv_dataset(dataset, expected_features)
assert dataset.split == split if split else "train"
@pytest.mark.parametrize("path_type", [str, list])
def test_dataset_from_csv_path_type(path_type, csv_path, tmp_path):
if issubclass(path_type, str):
path = csv_path
elif issubclass(path_type, list):
path = [csv_path]
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
dataset = Dataset.from_csv(path, cache_dir=cache_dir)
_check_csv_dataset(dataset, expected_features)
def _check_json_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_dataset_from_json_keep_in_memory(keep_in_memory, jsonl_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = Dataset.from_json(jsonl_path, cache_dir=cache_dir, keep_in_memory=keep_in_memory)
_check_json_dataset(dataset, expected_features)
@pytest.mark.parametrize(
"features",
[
None,
{"col_1": "string", "col_2": "int64", "col_3": "float64"},
{"col_1": "string", "col_2": "string", "col_3": "string"},
{"col_1": "int32", "col_2": "int32", "col_3": "int32"},
{"col_1": "float32", "col_2": "float32", "col_3": "float32"},
],
)
def test_dataset_from_json_features(features, jsonl_path, tmp_path):
cache_dir = tmp_path / "cache"
default_expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = Dataset.from_json(jsonl_path, features=features, cache_dir=cache_dir)
_check_json_dataset(dataset, expected_features)
def test_dataset_from_json_with_class_label_feature(jsonl_str_path, tmp_path):
features = Features(
{"col_1": ClassLabel(names=["s0", "s1", "s2", "s3"]), "col_2": Value("int64"), "col_3": Value("float64")}
)
cache_dir = tmp_path / "cache"
dataset = Dataset.from_json(jsonl_str_path, features=features, cache_dir=cache_dir)
assert dataset.features["col_1"].dtype == "int64"
@pytest.mark.parametrize("split", [None, NamedSplit("train"), "train", "test"])
def test_dataset_from_json_split(split, jsonl_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
dataset = Dataset.from_json(jsonl_path, cache_dir=cache_dir, split=split)
_check_json_dataset(dataset, expected_features)
assert dataset.split == split if split else "train"
@pytest.mark.parametrize("path_type", [str, list])
def test_dataset_from_json_path_type(path_type, jsonl_path, tmp_path):
if issubclass(path_type, str):
path = jsonl_path
elif issubclass(path_type, list):
path = [jsonl_path]
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
dataset = Dataset.from_json(path, cache_dir=cache_dir)
_check_json_dataset(dataset, expected_features)
def _check_parquet_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_dataset_from_parquet_keep_in_memory(keep_in_memory, parquet_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = Dataset.from_parquet(parquet_path, cache_dir=cache_dir, keep_in_memory=keep_in_memory)
_check_parquet_dataset(dataset, expected_features)
@pytest.mark.parametrize(
"features",
[
None,
{"col_1": "string", "col_2": "int64", "col_3": "float64"},
{"col_1": "string", "col_2": "string", "col_3": "string"},
{"col_1": "int32", "col_2": "int32", "col_3": "int32"},
{"col_1": "float32", "col_2": "float32", "col_3": "float32"},
],
)
def test_dataset_from_parquet_features(features, parquet_path, tmp_path):
cache_dir = tmp_path / "cache"
default_expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = Dataset.from_parquet(parquet_path, features=features, cache_dir=cache_dir)
_check_parquet_dataset(dataset, expected_features)
@pytest.mark.parametrize("split", [None, NamedSplit("train"), "train", "test"])
def test_dataset_from_parquet_split(split, parquet_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
dataset = Dataset.from_parquet(parquet_path, cache_dir=cache_dir, split=split)
_check_parquet_dataset(dataset, expected_features)
assert dataset.split == split if split else "train"
@pytest.mark.parametrize("path_type", [str, list])
def test_dataset_from_parquet_path_type(path_type, parquet_path, tmp_path):
if issubclass(path_type, str):
path = parquet_path
elif issubclass(path_type, list):
path = [parquet_path]
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
dataset = Dataset.from_parquet(path, cache_dir=cache_dir)
_check_parquet_dataset(dataset, expected_features)
def _check_text_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 1
assert dataset.column_names == ["text"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_dataset_from_text_keep_in_memory(keep_in_memory, text_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"text": "string"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = Dataset.from_text(text_path, cache_dir=cache_dir, keep_in_memory=keep_in_memory)
_check_text_dataset(dataset, expected_features)
@pytest.mark.parametrize(
"features",
[
None,
{"text": "string"},
{"text": "int32"},
{"text": "float32"},
],
)
def test_dataset_from_text_features(features, text_path, tmp_path):
cache_dir = tmp_path / "cache"
default_expected_features = {"text": "string"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = Dataset.from_text(text_path, features=features, cache_dir=cache_dir)
_check_text_dataset(dataset, expected_features)
@pytest.mark.parametrize("split", [None, NamedSplit("train"), "train", "test"])
def test_dataset_from_text_split(split, text_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"text": "string"}
dataset = Dataset.from_text(text_path, cache_dir=cache_dir, split=split)
_check_text_dataset(dataset, expected_features)
assert dataset.split == split if split else "train"
@pytest.mark.parametrize("path_type", [str, list])
def test_dataset_from_text_path_type(path_type, text_path, tmp_path):
if issubclass(path_type, str):
path = text_path
elif issubclass(path_type, list):
path = [text_path]
cache_dir = tmp_path / "cache"
expected_features = {"text": "string"}
dataset = Dataset.from_text(path, cache_dir=cache_dir)
_check_text_dataset(dataset, expected_features)
@pytest.fixture
def data_generator():
def _gen():
data = [
{"col_1": "0", "col_2": 0, "col_3": 0.0},
{"col_1": "1", "col_2": 1, "col_3": 1.0},
{"col_1": "2", "col_2": 2, "col_3": 2.0},
{"col_1": "3", "col_2": 3, "col_3": 3.0},
]
for item in data:
yield item
return _gen
def _check_generator_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_dataset_from_generator_keep_in_memory(keep_in_memory, data_generator, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = Dataset.from_generator(data_generator, cache_dir=cache_dir, keep_in_memory=keep_in_memory)
_check_generator_dataset(dataset, expected_features)
@pytest.mark.parametrize(
"features",
[
None,
{"col_1": "string", "col_2": "int64", "col_3": "float64"},
{"col_1": "string", "col_2": "string", "col_3": "string"},
{"col_1": "int32", "col_2": "int32", "col_3": "int32"},
{"col_1": "float32", "col_2": "float32", "col_3": "float32"},
],
)
def test_dataset_from_generator_features(features, data_generator, tmp_path):
cache_dir = tmp_path / "cache"
default_expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = Dataset.from_generator(data_generator, features=features, cache_dir=cache_dir)
_check_generator_dataset(dataset, expected_features)
@require_not_windows
@require_dill_gt_0_3_2
@require_pyspark
def test_from_spark():
import pyspark
spark = pyspark.sql.SparkSession.builder.master("local[*]").appName("pyspark").getOrCreate()
data = [
("0", 0, 0.0),
("1", 1, 1.0),
("2", 2, 2.0),
("3", 3, 3.0),
]
df = spark.createDataFrame(data, "col_1: string, col_2: int, col_3: float")
dataset = Dataset.from_spark(df)
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
@require_not_windows
@require_dill_gt_0_3_2
@require_pyspark
def test_from_spark_features():
import PIL.Image
import pyspark
spark = pyspark.sql.SparkSession.builder.master("local[*]").appName("pyspark").getOrCreate()
data = [(0, np.arange(4 * 4 * 3).reshape(4, 4, 3).tolist())]
df = spark.createDataFrame(data, "idx: int, image: array<array<array<int>>>")
features = Features({"idx": Value("int64"), "image": Image()})
dataset = Dataset.from_spark(
df,
features=features,
)
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 1
assert dataset.num_columns == 2
assert dataset.column_names == ["idx", "image"]
assert isinstance(dataset[0]["image"], PIL.Image.Image)
assert dataset.features == features
assert_arrow_metadata_are_synced_with_dataset_features(dataset)
@require_not_windows
@require_dill_gt_0_3_2
@require_pyspark
def test_from_spark_different_cache():
import pyspark
spark = pyspark.sql.SparkSession.builder.master("local[*]").appName("pyspark").getOrCreate()
df = spark.createDataFrame([("0", 0)], "col_1: string, col_2: int")
dataset = Dataset.from_spark(df)
assert isinstance(dataset, Dataset)
different_df = spark.createDataFrame([("1", 1)], "col_1: string, col_2: int")
different_dataset = Dataset.from_spark(different_df)
assert isinstance(different_dataset, Dataset)
assert dataset[0]["col_1"] == "0"
# Check to make sure that the second dataset wasn't read from the cache.
assert different_dataset[0]["col_1"] == "1"
def _check_sql_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@require_sqlalchemy
@pytest.mark.parametrize("con_type", ["string", "engine"])
def test_dataset_from_sql_con_type(con_type, sqlite_path, tmp_path, set_sqlalchemy_silence_uber_warning):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
if con_type == "string":
con = "sqlite:///" + sqlite_path
elif con_type == "engine":
import sqlalchemy
con = sqlalchemy.create_engine("sqlite:///" + sqlite_path)
# # https://github.com/huggingface/datasets/issues/2832 needs to be fixed first for this to work
# with caplog.at_level(INFO):
# dataset = Dataset.from_sql(
# "dataset",
# con,
# cache_dir=cache_dir,
# )
# if con_type == "string":
# assert "couldn't be hashed properly" not in caplog.text
# elif con_type == "engine":
# assert "couldn't be hashed properly" in caplog.text
dataset = Dataset.from_sql(
"dataset",
con,
cache_dir=cache_dir,
)
_check_sql_dataset(dataset, expected_features)
@require_sqlalchemy
@pytest.mark.parametrize(
"features",
[
None,
{"col_1": "string", "col_2": "int64", "col_3": "float64"},
{"col_1": "string", "col_2": "string", "col_3": "string"},
{"col_1": "int32", "col_2": "int32", "col_3": "int32"},
{"col_1": "float32", "col_2": "float32", "col_3": "float32"},
],
)
def test_dataset_from_sql_features(features, sqlite_path, tmp_path, set_sqlalchemy_silence_uber_warning):
cache_dir = tmp_path / "cache"
default_expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = Dataset.from_sql("dataset", "sqlite:///" + sqlite_path, features=features, cache_dir=cache_dir)
_check_sql_dataset(dataset, expected_features)
@require_sqlalchemy
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_dataset_from_sql_keep_in_memory(keep_in_memory, sqlite_path, tmp_path, set_sqlalchemy_silence_uber_warning):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = Dataset.from_sql(
"dataset", "sqlite:///" + sqlite_path, cache_dir=cache_dir, keep_in_memory=keep_in_memory
)
_check_sql_dataset(dataset, expected_features)
def test_dataset_to_json(dataset, tmp_path):
file_path = tmp_path / "test_path.jsonl"
bytes_written = dataset.to_json(path_or_buf=file_path)
assert file_path.is_file()
assert bytes_written == file_path.stat().st_size
df = pd.read_json(file_path, orient="records", lines=True)
assert df.shape == dataset.shape
assert list(df.columns) == list(dataset.column_names)
@pytest.mark.parametrize("in_memory", [False, True])
@pytest.mark.parametrize(
"method_and_params",
[
("rename_column", (), {"original_column_name": "labels", "new_column_name": "label"}),
("remove_columns", (), {"column_names": "labels"}),
(
"cast",
(),
{
"features": Features(
{
"tokens": Sequence(Value("string")),
"labels": Sequence(Value("int16")),
"answers": Sequence(
{
"text": Value("string"),
"answer_start": Value("int32"),
}
),
"id": Value("int32"),
}
)
},
),
("flatten", (), {}),
],
)
def test_pickle_dataset_after_transforming_the_table(in_memory, method_and_params, arrow_file):
method, args, kwargs = method_and_params
with Dataset.from_file(arrow_file, in_memory=in_memory) as dataset, Dataset.from_file(
arrow_file, in_memory=in_memory
) as reference_dataset:
out = getattr(dataset, method)(*args, **kwargs)
dataset = out if out is not None else dataset
pickled_dataset = pickle.dumps(dataset)
reloaded_dataset = pickle.loads(pickled_dataset)
assert dataset._data != reference_dataset._data
assert dataset._data.table == reloaded_dataset._data.table
def test_dummy_dataset_serialize_fs(dataset, mockfs):
dataset_path = "mock://my_dataset"
dataset.save_to_disk(dataset_path, storage_options=mockfs.storage_options)
assert mockfs.isdir(dataset_path)
assert mockfs.glob(dataset_path + "/*")
reloaded = dataset.load_from_disk(dataset_path, storage_options=mockfs.storage_options)
assert len(reloaded) == len(dataset)
assert reloaded.features == dataset.features
assert reloaded.to_dict() == dataset.to_dict()
@pytest.mark.parametrize(
"uri_or_path",
[
"relative/path",
"/absolute/path",
"s3://bucket/relative/path",
"hdfs://relative/path",
"hdfs:///absolute/path",
],
)
def test_build_local_temp_path(uri_or_path):
extracted_path = strip_protocol(uri_or_path)
local_temp_path = Dataset._build_local_temp_path(extracted_path).as_posix()
extracted_path_without_anchor = Path(extracted_path).relative_to(Path(extracted_path).anchor).as_posix()
# Check that the local temp path is relative to the system temp dir
path_relative_to_tmp_dir = Path(local_temp_path).relative_to(Path(tempfile.gettempdir())).as_posix()
assert (
"hdfs://" not in path_relative_to_tmp_dir
and "s3://" not in path_relative_to_tmp_dir
and not local_temp_path.startswith(extracted_path_without_anchor)
and local_temp_path.endswith(extracted_path_without_anchor)
), f"Local temp path: {local_temp_path}"
class TaskTemplatesTest(TestCase):
def test_task_text_classification(self):
labels = sorted(["pos", "neg"])
features_before_cast = Features(
{
"input_text": Value("string"),
"input_labels": ClassLabel(names=labels),
}
)
# Labels are cast to tuple during `TextClassification.__post_init_`, so we do the same here
features_after_cast = Features(
{
"text": Value("string"),
"labels": ClassLabel(names=labels),
}
)
# Label names are added in `DatasetInfo.__post_init__` so not needed here
task_without_labels = TextClassification(text_column="input_text", label_column="input_labels")
info1 = DatasetInfo(
features=features_before_cast,
task_templates=task_without_labels,
)
# Label names are required when passing a TextClassification template directly to `Dataset.prepare_for_task`
# However they also can be used to define `DatasetInfo` so we include a test for this too
task_with_labels = TextClassification(text_column="input_text", label_column="input_labels")
info2 = DatasetInfo(
features=features_before_cast,
task_templates=task_with_labels,
)
data = {"input_text": ["i love transformers!"], "input_labels": [1]}
# Test we can load from task name when label names not included in template (default behaviour)
with Dataset.from_dict(data, info=info1) as dset:
self.assertSetEqual({"input_text", "input_labels"}, set(dset.column_names))
self.assertDictEqual(features_before_cast, dset.features)
with dset.prepare_for_task(task="text-classification") as dset:
self.assertSetEqual({"labels", "text"}, set(dset.column_names))
self.assertDictEqual(features_after_cast, dset.features)
# Test we can load from task name when label names included in template
with Dataset.from_dict(data, info=info2) as dset:
self.assertSetEqual({"input_text", "input_labels"}, set(dset.column_names))
self.assertDictEqual(features_before_cast, dset.features)
with dset.prepare_for_task(task="text-classification") as dset:
self.assertSetEqual({"labels", "text"}, set(dset.column_names))
self.assertDictEqual(features_after_cast, dset.features)
# Test we can load from TextClassification template
info1.task_templates = None
with Dataset.from_dict(data, info=info1) as dset:
with dset.prepare_for_task(task=task_with_labels) as dset:
self.assertSetEqual({"labels", "text"}, set(dset.column_names))
self.assertDictEqual(features_after_cast, dset.features)
def test_task_question_answering(self):
features_before_cast = Features(
{
"input_context": Value("string"),
"input_question": Value("string"),
"input_answers": Sequence(
{
"text": Value("string"),
"answer_start": Value("int32"),
}
),
}
)
features_after_cast = Features(
{
"context": Value("string"),
"question": Value("string"),
"answers": Sequence(
{
"text": Value("string"),
"answer_start": Value("int32"),
}
),
}
)
task = QuestionAnsweringExtractive(
context_column="input_context", question_column="input_question", answers_column="input_answers"
)
info = DatasetInfo(features=features_before_cast, task_templates=task)
data = {
"input_context": ["huggingface is going to the moon!"],
"input_question": ["where is huggingface going?"],
"input_answers": [{"text": ["to the moon!"], "answer_start": [2]}],
}
# Test we can load from task name
with Dataset.from_dict(data, info=info) as dset:
self.assertSetEqual(
{"input_context", "input_question", "input_answers.text", "input_answers.answer_start"},
set(dset.flatten().column_names),
)
self.assertDictEqual(features_before_cast, dset.features)
with dset.prepare_for_task(task="question-answering-extractive") as dset:
self.assertSetEqual(
{"context", "question", "answers.text", "answers.answer_start"},
set(dset.flatten().column_names),
)
self.assertDictEqual(features_after_cast, dset.features)
# Test we can load from QuestionAnsweringExtractive template
info.task_templates = None
with Dataset.from_dict(data, info=info) as dset:
with dset.prepare_for_task(task=task) as dset:
self.assertSetEqual(
{"context", "question", "answers.text", "answers.answer_start"},
set(dset.flatten().column_names),
)
self.assertDictEqual(features_after_cast, dset.features)
def test_task_summarization(self):
# Include a dummy extra column `dummy` to test we drop it correctly
features_before_cast = Features(
{"input_text": Value("string"), "input_summary": Value("string"), "dummy": Value("string")}
)
features_after_cast = Features({"text": Value("string"), "summary": Value("string")})
task = Summarization(text_column="input_text", summary_column="input_summary")
info = DatasetInfo(features=features_before_cast, task_templates=task)
data = {
"input_text": ["jack and jill took a taxi to attend a super duper party in the city."],
"input_summary": ["jack and jill attend party"],
"dummy": ["123456"],
}
# Test we can load from task name
with Dataset.from_dict(data, info=info) as dset:
with dset.prepare_for_task(task="summarization") as dset:
self.assertSetEqual(
{"text", "summary"},
set(dset.column_names),
)
self.assertDictEqual(features_after_cast, dset.features)
# Test we can load from Summarization template
info.task_templates = None
with Dataset.from_dict(data, info=info) as dset:
with dset.prepare_for_task(task=task) as dset:
self.assertSetEqual(
{"text", "summary"},
set(dset.column_names),
)
self.assertDictEqual(features_after_cast, dset.features)
def test_task_automatic_speech_recognition(self):
# Include a dummy extra column `dummy` to test we drop it correctly
features_before_cast = Features(
{
"input_audio": Audio(sampling_rate=16_000),
"input_transcription": Value("string"),
"dummy": Value("string"),
}
)
features_after_cast = Features({"audio": Audio(sampling_rate=16_000), "transcription": Value("string")})
task = AutomaticSpeechRecognition(audio_column="input_audio", transcription_column="input_transcription")
info = DatasetInfo(features=features_before_cast, task_templates=task)
data = {
"input_audio": [{"bytes": None, "path": "path/to/some/audio/file.wav"}],
"input_transcription": ["hello, my name is bob!"],
"dummy": ["123456"],
}
# Test we can load from task name
with Dataset.from_dict(data, info=info) as dset:
with dset.prepare_for_task(task="automatic-speech-recognition") as dset:
self.assertSetEqual(
{"audio", "transcription"},
set(dset.column_names),
)
self.assertDictEqual(features_after_cast, dset.features)
# Test we can load from Summarization template
info.task_templates = None
with Dataset.from_dict(data, info=info) as dset:
with dset.prepare_for_task(task=task) as dset:
self.assertSetEqual(
{"audio", "transcription"},
set(dset.column_names),
)
self.assertDictEqual(features_after_cast, dset.features)
def test_task_with_no_template(self):
data = {"input_text": ["i love transformers!"], "input_labels": [1]}
with Dataset.from_dict(data) as dset:
with self.assertRaises(ValueError):
dset.prepare_for_task("text-classification")
def test_task_with_incompatible_templates(self):
labels = sorted(["pos", "neg"])
features = Features(
{
"input_text": Value("string"),
"input_labels": ClassLabel(names=labels),
}
)
task = TextClassification(text_column="input_text", label_column="input_labels")
info = DatasetInfo(
features=features,
task_templates=task,
)
data = {"input_text": ["i love transformers!"], "input_labels": [1]}
with Dataset.from_dict(data, info=info) as dset:
# Invalid task name
self.assertRaises(ValueError, dset.prepare_for_task, "this-task-does-not-exist")
# Invalid task type
self.assertRaises(ValueError, dset.prepare_for_task, 1)
def test_task_with_multiple_compatible_task_templates(self):
features = Features(
{
"text1": Value("string"),
"text2": Value("string"),
}
)
task1 = LanguageModeling(text_column="text1")
task2 = LanguageModeling(text_column="text2")
info = DatasetInfo(
features=features,
task_templates=[task1, task2],
)
data = {"text1": ["i love transformers!"], "text2": ["i love datasets!"]}
with Dataset.from_dict(data, info=info) as dset:
self.assertRaises(ValueError, dset.prepare_for_task, "language-modeling", id=3)
with dset.prepare_for_task("language-modeling") as dset1:
self.assertEqual(dset1[0]["text"], "i love transformers!")
with dset.prepare_for_task("language-modeling", id=1) as dset2:
self.assertEqual(dset2[0]["text"], "i love datasets!")
def test_task_templates_empty_after_preparation(self):
features = Features(
{
"input_text": Value("string"),
"input_labels": ClassLabel(names=["pos", "neg"]),
}
)
task = TextClassification(text_column="input_text", label_column="input_labels")
info = DatasetInfo(
features=features,
task_templates=task,
)
data = {"input_text": ["i love transformers!"], "input_labels": [1]}
with Dataset.from_dict(data, info=info) as dset:
with dset.prepare_for_task(task="text-classification") as dset:
self.assertIsNone(dset.info.task_templates)
def test_align_labels_with_mapping_classification(self):
features = Features(
{
"input_text": Value("string"),
"input_labels": ClassLabel(num_classes=3, names=["entailment", "neutral", "contradiction"]),
}
)
data = {"input_text": ["a", "a", "b", "b", "c", "c"], "input_labels": [0, 0, 1, 1, 2, 2]}
label2id = {"CONTRADICTION": 0, "ENTAILMENT": 2, "NEUTRAL": 1}
id2label = {v: k for k, v in label2id.items()}
expected_labels = [2, 2, 1, 1, 0, 0]
expected_label_names = [id2label[idx] for idx in expected_labels]
with Dataset.from_dict(data, features=features) as dset:
with dset.align_labels_with_mapping(label2id, "input_labels") as dset:
self.assertListEqual(expected_labels, dset["input_labels"])
aligned_label_names = [dset.features["input_labels"].int2str(idx) for idx in dset["input_labels"]]
self.assertListEqual(expected_label_names, aligned_label_names)
def test_align_labels_with_mapping_ner(self):
features = Features(
{
"input_text": Value("string"),
"input_labels": Sequence(
ClassLabel(
names=[
"b-per",
"i-per",
"o",
]
)
),
}
)
data = {"input_text": [["Optimus", "Prime", "is", "a", "Transformer"]], "input_labels": [[0, 1, 2, 2, 2]]}
label2id = {"B-PER": 2, "I-PER": 1, "O": 0}
id2label = {v: k for k, v in label2id.items()}
expected_labels = [[2, 1, 0, 0, 0]]
expected_label_names = [[id2label[idx] for idx in seq] for seq in expected_labels]
with Dataset.from_dict(data, features=features) as dset:
with dset.align_labels_with_mapping(label2id, "input_labels") as dset:
self.assertListEqual(expected_labels, dset["input_labels"])
aligned_label_names = [
dset.features["input_labels"].feature.int2str(idx) for idx in dset["input_labels"]
]
self.assertListEqual(expected_label_names, aligned_label_names)
def test_concatenate_with_no_task_templates(self):
info = DatasetInfo(task_templates=None)
data = {"text": ["i love transformers!"], "labels": [1]}
with Dataset.from_dict(data, info=info) as dset1, Dataset.from_dict(
data, info=info
) as dset2, Dataset.from_dict(data, info=info) as dset3:
with concatenate_datasets([dset1, dset2, dset3]) as dset_concat:
self.assertEqual(dset_concat.info.task_templates, None)
def test_concatenate_with_equal_task_templates(self):
labels = ["neg", "pos"]
task_template = TextClassification(text_column="text", label_column="labels")
info = DatasetInfo(
features=Features({"text": Value("string"), "labels": ClassLabel(names=labels)}),
# Label names are added in `DatasetInfo.__post_init__` so not included here
task_templates=TextClassification(text_column="text", label_column="labels"),
)
data = {"text": ["i love transformers!"], "labels": [1]}
with Dataset.from_dict(data, info=info) as dset1, Dataset.from_dict(
data, info=info
) as dset2, Dataset.from_dict(data, info=info) as dset3:
with concatenate_datasets([dset1, dset2, dset3]) as dset_concat:
self.assertListEqual(dset_concat.info.task_templates, [task_template])
def test_concatenate_with_mixed_task_templates_in_common(self):
tc_template = TextClassification(text_column="text", label_column="labels")
qa_template = QuestionAnsweringExtractive(
question_column="question", context_column="context", answers_column="answers"
)
info1 = DatasetInfo(
task_templates=[qa_template],
features=Features(
{
"text": Value("string"),
"labels": ClassLabel(names=["pos", "neg"]),
"context": Value("string"),
"question": Value("string"),
"answers": Sequence(
{
"text": Value("string"),
"answer_start": Value("int32"),
}
),
}
),
)
info2 = DatasetInfo(
task_templates=[qa_template, tc_template],
features=Features(
{
"text": Value("string"),
"labels": ClassLabel(names=["pos", "neg"]),
"context": Value("string"),
"question": Value("string"),
"answers": Sequence(
{
"text": Value("string"),
"answer_start": Value("int32"),
}
),
}
),
)
data = {
"text": ["i love transformers!"],
"labels": [1],
"context": ["huggingface is going to the moon!"],
"question": ["where is huggingface going?"],
"answers": [{"text": ["to the moon!"], "answer_start": [2]}],
}
with Dataset.from_dict(data, info=info1) as dset1, Dataset.from_dict(
data, info=info2
) as dset2, Dataset.from_dict(data, info=info2) as dset3:
with concatenate_datasets([dset1, dset2, dset3]) as dset_concat:
self.assertListEqual(dset_concat.info.task_templates, [qa_template])
def test_concatenate_with_no_mixed_task_templates_in_common(self):
tc_template1 = TextClassification(text_column="text", label_column="labels")
tc_template2 = TextClassification(text_column="text", label_column="sentiment")
qa_template = QuestionAnsweringExtractive(
question_column="question", context_column="context", answers_column="answers"
)
info1 = DatasetInfo(
features=Features(
{
"text": Value("string"),
"labels": ClassLabel(names=["pos", "neg"]),
"sentiment": ClassLabel(names=["pos", "neg", "neutral"]),
"context": Value("string"),
"question": Value("string"),
"answers": Sequence(
{
"text": Value("string"),
"answer_start": Value("int32"),
}
),
}
),
task_templates=[tc_template1],
)
info2 = DatasetInfo(
features=Features(
{
"text": Value("string"),
"labels": ClassLabel(names=["pos", "neg"]),
"sentiment": ClassLabel(names=["pos", "neg", "neutral"]),
"context": Value("string"),
"question": Value("string"),
"answers": Sequence(
{
"text": Value("string"),
"answer_start": Value("int32"),
}
),
}
),
task_templates=[tc_template2],
)
info3 = DatasetInfo(
features=Features(
{
"text": Value("string"),
"labels": ClassLabel(names=["pos", "neg"]),
"sentiment": ClassLabel(names=["pos", "neg", "neutral"]),
"context": Value("string"),
"question": Value("string"),
"answers": Sequence(
{
"text": Value("string"),
"answer_start": Value("int32"),
}
),
}
),
task_templates=[qa_template],
)
data = {
"text": ["i love transformers!"],
"labels": [1],
"sentiment": [0],
"context": ["huggingface is going to the moon!"],
"question": ["where is huggingface going?"],
"answers": [{"text": ["to the moon!"], "answer_start": [2]}],
}
with Dataset.from_dict(data, info=info1) as dset1, Dataset.from_dict(
data, info=info2
) as dset2, Dataset.from_dict(data, info=info3) as dset3:
with concatenate_datasets([dset1, dset2, dset3]) as dset_concat:
self.assertEqual(dset_concat.info.task_templates, None)
def test_task_text_classification_when_columns_removed(self):
labels = sorted(["pos", "neg"])
features_before_map = Features(
{
"input_text": Value("string"),
"input_labels": ClassLabel(names=labels),
}
)
features_after_map = Features({"new_column": Value("int64")})
# Label names are added in `DatasetInfo.__post_init__` so not needed here
task = TextClassification(text_column="input_text", label_column="input_labels")
info = DatasetInfo(
features=features_before_map,
task_templates=task,
)
data = {"input_text": ["i love transformers!"], "input_labels": [1]}
with Dataset.from_dict(data, info=info) as dset:
with dset.map(lambda x: {"new_column": 0}, remove_columns=dset.column_names) as dset:
self.assertDictEqual(dset.features, features_after_map)
class StratifiedTest(TestCase):
def test_errors_train_test_split_stratify(self):
ys = [
np.array([0, 0, 0, 0, 1, 1, 1, 2, 2, 2, 2, 2]),
np.array([0, 1, 1, 1, 2, 2, 2, 3, 3, 3]),
np.array([0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2] * 2),
np.array([0, 0, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5]),
np.array([0, 0, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5]),
]
for i in range(len(ys)):
features = Features({"text": Value("int64"), "label": ClassLabel(len(np.unique(ys[i])))})
data = {"text": np.ones(len(ys[i])), "label": ys[i]}
d1 = Dataset.from_dict(data, features=features)
# For checking stratify_by_column exist as key in self.features.keys()
if i == 0:
self.assertRaises(ValueError, d1.train_test_split, 0.33, stratify_by_column="labl")
# For checking minimum class count error
elif i == 1:
self.assertRaises(ValueError, d1.train_test_split, 0.33, stratify_by_column="label")
# For check typeof label as ClassLabel type
elif i == 2:
d1 = Dataset.from_dict(data)
self.assertRaises(ValueError, d1.train_test_split, 0.33, stratify_by_column="label")
# For checking test_size should be greater than or equal to number of classes
elif i == 3:
self.assertRaises(ValueError, d1.train_test_split, 0.30, stratify_by_column="label")
# For checking train_size should be greater than or equal to number of classes
elif i == 4:
self.assertRaises(ValueError, d1.train_test_split, 0.60, stratify_by_column="label")
def test_train_test_split_startify(self):
ys = [
np.array([0, 0, 0, 0, 1, 1, 1, 2, 2, 2, 2, 2]),
np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3]),
np.array([0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2] * 2),
np.array([0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3]),
np.array([0] * 800 + [1] * 50),
]
for y in ys:
features = Features({"text": Value("int64"), "label": ClassLabel(len(np.unique(y)))})
data = {"text": np.ones(len(y)), "label": y}
d1 = Dataset.from_dict(data, features=features)
d1 = d1.train_test_split(test_size=0.33, stratify_by_column="label")
y = np.asanyarray(y) # To make it indexable for y[train]
test_size = np.ceil(0.33 * len(y))
train_size = len(y) - test_size
npt.assert_array_equal(np.unique(d1["train"]["label"]), np.unique(d1["test"]["label"]))
# checking classes proportion
p_train = np.bincount(np.unique(d1["train"]["label"], return_inverse=True)[1]) / float(
len(d1["train"]["label"])
)
p_test = np.bincount(np.unique(d1["test"]["label"], return_inverse=True)[1]) / float(
len(d1["test"]["label"])
)
npt.assert_array_almost_equal(p_train, p_test, 1)
assert len(d1["train"]["text"]) + len(d1["test"]["text"]) == y.size
assert len(d1["train"]["text"]) == train_size
assert len(d1["test"]["text"]) == test_size
def test_dataset_estimate_nbytes():
ds = Dataset.from_dict({"a": ["0" * 100] * 100})
assert 0.9 * ds._estimate_nbytes() < 100 * 100, "must be smaller than full dataset size"
ds = Dataset.from_dict({"a": ["0" * 100] * 100}).select([0])
assert 0.9 * ds._estimate_nbytes() < 100 * 100, "must be smaller than one chunk"
ds = Dataset.from_dict({"a": ["0" * 100] * 100})
ds = concatenate_datasets([ds] * 100)
assert 0.9 * ds._estimate_nbytes() < 100 * 100 * 100, "must be smaller than full dataset size"
assert 1.1 * ds._estimate_nbytes() > 100 * 100 * 100, "must be bigger than full dataset size"
ds = Dataset.from_dict({"a": ["0" * 100] * 100})
ds = concatenate_datasets([ds] * 100).select([0])
assert 0.9 * ds._estimate_nbytes() < 100 * 100, "must be smaller than one chunk"
def test_dataset_to_iterable_dataset(dataset: Dataset):
iterable_dataset = dataset.to_iterable_dataset()
assert isinstance(iterable_dataset, IterableDataset)
assert list(iterable_dataset) == list(dataset)
assert iterable_dataset.features == dataset.features
iterable_dataset = dataset.to_iterable_dataset(num_shards=3)
assert isinstance(iterable_dataset, IterableDataset)
assert list(iterable_dataset) == list(dataset)
assert iterable_dataset.features == dataset.features
assert iterable_dataset.n_shards == 3
with pytest.raises(ValueError):
dataset.to_iterable_dataset(num_shards=len(dataset) + 1)
with pytest.raises(NotImplementedError):
dataset.with_format("torch").to_iterable_dataset()
@require_pil
def test_dataset_format_with_unformatted_image():
import PIL
ds = Dataset.from_dict(
{"a": [np.arange(4 * 4 * 3).reshape(4, 4, 3)] * 10, "b": [[0, 1]] * 10},
Features({"a": Image(), "b": Sequence(Value("int64"))}),
)
ds.set_format("np", columns=["b"], output_all_columns=True)
assert isinstance(ds[0]["a"], PIL.Image.Image)
assert isinstance(ds[0]["b"], np.ndarray)
@pytest.mark.parametrize("batch_size", [1, 4])
@require_torch
def test_dataset_with_torch_dataloader(dataset, batch_size):
from torch.utils.data import DataLoader
from datasets import config
dataloader = DataLoader(dataset, batch_size=batch_size)
with patch.object(dataset, "_getitem", wraps=dataset._getitem) as mock_getitem:
out = list(dataloader)
getitem_call_count = mock_getitem.call_count
assert len(out) == len(dataset) // batch_size + int(len(dataset) % batch_size > 0)
# calling dataset[list_of_indices] is much more efficient than [dataset[idx] for idx in list of indices]
if config.TORCH_VERSION >= version.parse("1.13.0"):
assert getitem_call_count == len(dataset) // batch_size + int(len(dataset) % batch_size > 0)
@pytest.mark.parametrize("return_lazy_dict", [True, False, "mix"])
def test_map_cases(return_lazy_dict):
def f(x):
"""May return a mix of LazyDict and regular Dict"""
if x["a"] < 2:
x["a"] = -1
return dict(x) if return_lazy_dict is False else x
else:
return x if return_lazy_dict is True else {}
ds = Dataset.from_dict({"a": [0, 1, 2, 3]})
ds = ds.map(f)
outputs = ds[:]
assert outputs == {"a": [-1, -1, 2, 3]}
def f(x):
"""May return a mix of LazyDict and regular Dict, but sometimes with None values"""
if x["a"] < 2:
x["a"] = None
return dict(x) if return_lazy_dict is False else x
else:
return x if return_lazy_dict is True else {}
ds = Dataset.from_dict({"a": [0, 1, 2, 3]})
ds = ds.map(f)
outputs = ds[:]
assert outputs == {"a": [None, None, 2, 3]}
def f(x):
"""Return a LazyDict, but we remove a lazy column and add a new one"""
if x["a"] < 2:
x["b"] = -1
return x
else:
x["b"] = x["a"]
return x
ds = Dataset.from_dict({"a": [0, 1, 2, 3]})
ds = ds.map(f, remove_columns=["a"])
outputs = ds[:]
assert outputs == {"b": [-1, -1, 2, 3]}
# The formatted dataset version removes the lazy column from a different dictionary, hence it should be preserved in the output
ds = Dataset.from_dict({"a": [0, 1, 2, 3]})
ds = ds.with_format("numpy")
ds = ds.map(f, remove_columns=["a"])
ds = ds.with_format(None)
outputs = ds[:]
assert outputs == {"a": [0, 1, 2, 3], "b": [-1, -1, 2, 3]}
def f(x):
"""May return a mix of LazyDict and regular Dict, but we replace a lazy column"""
if x["a"] < 2:
x["a"] = -1
return dict(x) if return_lazy_dict is False else x
else:
x["a"] = x["a"]
return x if return_lazy_dict is True else {"a": x["a"]}
ds = Dataset.from_dict({"a": [0, 1, 2, 3]})
ds = ds.map(f, remove_columns=["a"])
outputs = ds[:]
assert outputs == ({"a": [-1, -1, 2, 3]} if return_lazy_dict is False else {})
def f(x):
"""May return a mix of LazyDict and regular Dict, but we modify a nested lazy column in-place"""
if x["a"]["b"] < 2:
x["a"]["c"] = -1
return dict(x) if return_lazy_dict is False else x
else:
x["a"]["c"] = x["a"]["b"]
return x if return_lazy_dict is True else {}
ds = Dataset.from_dict({"a": [{"b": 0}, {"b": 1}, {"b": 2}, {"b": 3}]})
ds = ds.map(f)
outputs = ds[:]
assert outputs == {"a": [{"b": 0, "c": -1}, {"b": 1, "c": -1}, {"b": 2, "c": 2}, {"b": 3, "c": 3}]}
def f(x):
"""May return a mix of LazyDict and regular Dict, but using an extension type"""
if x["a"][0][0] < 2:
x["a"] = [[-1]]
return dict(x) if return_lazy_dict is False else x
else:
return x if return_lazy_dict is True else {}
features = Features({"a": Array2D(shape=(1, 1), dtype="int32")})
ds = Dataset.from_dict({"a": [[[i]] for i in [0, 1, 2, 3]]}, features=features)
ds = ds.map(f)
outputs = ds[:]
assert outputs == {"a": [[[i]] for i in [-1, -1, 2, 3]]}
def f(x):
"""May return a mix of LazyDict and regular Dict, but using a nested extension type"""
if x["a"]["nested"][0][0] < 2:
x["a"] = {"nested": [[-1]]}
return dict(x) if return_lazy_dict is False else x
else:
return x if return_lazy_dict is True else {}
features = Features({"a": {"nested": Array2D(shape=(1, 1), dtype="int64")}})
ds = Dataset.from_dict({"a": [{"nested": [[i]]} for i in [0, 1, 2, 3]]}, features=features)
ds = ds.map(f)
outputs = ds[:]
assert outputs == {"a": [{"nested": [[i]]} for i in [-1, -1, 2, 3]]}
def test_dataset_getitem_raises():
ds = Dataset.from_dict({"a": [0, 1, 2, 3]})
with pytest.raises(TypeError):
ds[False]
with pytest.raises(TypeError):
ds._getitem(True)
|
datasets/tests/test_arrow_dataset.py/0
|
{
"file_path": "datasets/tests/test_arrow_dataset.py",
"repo_id": "datasets",
"token_count": 126130
}
| 77 |
import datetime
from pathlib import Path
from unittest import TestCase
import numpy as np
import pandas as pd
import pyarrow as pa
import pytest
from datasets import Audio, Features, Image, IterableDataset
from datasets.formatting import NumpyFormatter, PandasFormatter, PythonFormatter, query_table
from datasets.formatting.formatting import (
LazyBatch,
LazyRow,
NumpyArrowExtractor,
PandasArrowExtractor,
PythonArrowExtractor,
)
from datasets.table import InMemoryTable
from .utils import require_jax, require_pil, require_polars, require_sndfile, require_tf, require_torch
class AnyArray:
def __init__(self, data) -> None:
self.data = data
def __array__(self) -> np.ndarray:
return np.asarray(self.data)
def _gen_any_arrays():
for _ in range(10):
yield {"array": AnyArray(list(range(10)))}
@pytest.fixture
def any_arrays_dataset():
return IterableDataset.from_generator(_gen_any_arrays)
_COL_A = [0, 1, 2]
_COL_B = ["foo", "bar", "foobar"]
_COL_C = [[[1.0, 0.0, 0.0]] * 2, [[0.0, 1.0, 0.0]] * 2, [[0.0, 0.0, 1.0]] * 2]
_COL_D = [datetime.datetime(2023, 1, 1, 0, 0, tzinfo=datetime.timezone.utc)] * 3
_INDICES = [1, 0]
IMAGE_PATH_1 = Path(__file__).parent / "features" / "data" / "test_image_rgb.jpg"
IMAGE_PATH_2 = Path(__file__).parent / "features" / "data" / "test_image_rgba.png"
AUDIO_PATH_1 = Path(__file__).parent / "features" / "data" / "test_audio_44100.wav"
class ArrowExtractorTest(TestCase):
def _create_dummy_table(self):
return pa.Table.from_pydict({"a": _COL_A, "b": _COL_B, "c": _COL_C, "d": _COL_D})
def test_python_extractor(self):
pa_table = self._create_dummy_table()
extractor = PythonArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertEqual(row, {"a": _COL_A[0], "b": _COL_B[0], "c": _COL_C[0], "d": _COL_D[0]})
col = extractor.extract_column(pa_table)
self.assertEqual(col, _COL_A)
batch = extractor.extract_batch(pa_table)
self.assertEqual(batch, {"a": _COL_A, "b": _COL_B, "c": _COL_C, "d": _COL_D})
def test_numpy_extractor(self):
pa_table = self._create_dummy_table().drop(["c", "d"])
extractor = NumpyArrowExtractor()
row = extractor.extract_row(pa_table)
np.testing.assert_equal(row, {"a": _COL_A[0], "b": _COL_B[0]})
col = extractor.extract_column(pa_table)
np.testing.assert_equal(col, np.array(_COL_A))
batch = extractor.extract_batch(pa_table)
np.testing.assert_equal(batch, {"a": np.array(_COL_A), "b": np.array(_COL_B)})
def test_numpy_extractor_nested(self):
pa_table = self._create_dummy_table().drop(["a", "b", "d"])
extractor = NumpyArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertEqual(row["c"][0].dtype, np.float64)
self.assertEqual(row["c"].dtype, object)
col = extractor.extract_column(pa_table)
self.assertEqual(col[0][0].dtype, np.float64)
self.assertEqual(col[0].dtype, object)
self.assertEqual(col.dtype, object)
batch = extractor.extract_batch(pa_table)
self.assertEqual(batch["c"][0][0].dtype, np.float64)
self.assertEqual(batch["c"][0].dtype, object)
self.assertEqual(batch["c"].dtype, object)
def test_numpy_extractor_temporal(self):
pa_table = self._create_dummy_table().drop(["a", "b", "c"])
extractor = NumpyArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertTrue(np.issubdtype(row["d"].dtype, np.datetime64))
col = extractor.extract_column(pa_table)
self.assertTrue(np.issubdtype(col[0].dtype, np.datetime64))
self.assertTrue(np.issubdtype(col.dtype, np.datetime64))
batch = extractor.extract_batch(pa_table)
self.assertTrue(np.issubdtype(batch["d"][0].dtype, np.datetime64))
self.assertTrue(np.issubdtype(batch["d"].dtype, np.datetime64))
def test_pandas_extractor(self):
pa_table = self._create_dummy_table()
extractor = PandasArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertIsInstance(row, pd.DataFrame)
pd.testing.assert_series_equal(row["a"], pd.Series(_COL_A, name="a")[:1])
pd.testing.assert_series_equal(row["b"], pd.Series(_COL_B, name="b")[:1])
col = extractor.extract_column(pa_table)
pd.testing.assert_series_equal(col, pd.Series(_COL_A, name="a"))
batch = extractor.extract_batch(pa_table)
self.assertIsInstance(batch, pd.DataFrame)
pd.testing.assert_series_equal(batch["a"], pd.Series(_COL_A, name="a"))
pd.testing.assert_series_equal(batch["b"], pd.Series(_COL_B, name="b"))
def test_pandas_extractor_nested(self):
pa_table = self._create_dummy_table().drop(["a", "b", "d"])
extractor = PandasArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertEqual(row["c"][0][0].dtype, np.float64)
self.assertEqual(row["c"].dtype, object)
col = extractor.extract_column(pa_table)
self.assertEqual(col[0][0].dtype, np.float64)
self.assertEqual(col[0].dtype, object)
self.assertEqual(col.dtype, object)
batch = extractor.extract_batch(pa_table)
self.assertEqual(batch["c"][0][0].dtype, np.float64)
self.assertEqual(batch["c"][0].dtype, object)
self.assertEqual(batch["c"].dtype, object)
def test_pandas_extractor_temporal(self):
pa_table = self._create_dummy_table().drop(["a", "b", "c"])
extractor = PandasArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertTrue(pd.api.types.is_datetime64_any_dtype(row["d"].dtype))
col = extractor.extract_column(pa_table)
self.assertTrue(isinstance(col[0], datetime.datetime))
self.assertTrue(pd.api.types.is_datetime64_any_dtype(col.dtype))
batch = extractor.extract_batch(pa_table)
self.assertTrue(isinstance(batch["d"][0], datetime.datetime))
self.assertTrue(pd.api.types.is_datetime64_any_dtype(batch["d"].dtype))
@require_polars
def test_polars_extractor(self):
import polars as pl
from datasets.formatting.polars_formatter import PolarsArrowExtractor
pa_table = self._create_dummy_table()
extractor = PolarsArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertIsInstance(row, pl.DataFrame)
assert pl.Series.eq(row["a"], pl.Series("a", _COL_A)[:1]).all()
assert pl.Series.eq(row["b"], pl.Series("b", _COL_B)[:1]).all()
col = extractor.extract_column(pa_table)
assert pl.Series.eq(col, pl.Series("a", _COL_A)).all()
batch = extractor.extract_batch(pa_table)
self.assertIsInstance(batch, pl.DataFrame)
assert pl.Series.eq(batch["a"], pl.Series("a", _COL_A)).all()
assert pl.Series.eq(batch["b"], pl.Series("b", _COL_B)).all()
@require_polars
def test_polars_nested(self):
import polars as pl
from datasets.formatting.polars_formatter import PolarsArrowExtractor
pa_table = self._create_dummy_table().drop(["a", "b", "d"])
extractor = PolarsArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertEqual(row["c"][0][0].dtype, pl.Float64)
self.assertEqual(row["c"].dtype, pl.List(pl.List(pl.Float64)))
col = extractor.extract_column(pa_table)
self.assertEqual(col[0][0].dtype, pl.Float64)
self.assertEqual(col[0].dtype, pl.List(pl.Float64))
self.assertEqual(col.dtype, pl.List(pl.List(pl.Float64)))
batch = extractor.extract_batch(pa_table)
self.assertEqual(batch["c"][0][0].dtype, pl.Float64)
self.assertEqual(batch["c"][0].dtype, pl.List(pl.Float64))
self.assertEqual(batch["c"].dtype, pl.List(pl.List(pl.Float64)))
@require_polars
def test_polars_temporal(self):
from datasets.formatting.polars_formatter import PolarsArrowExtractor
pa_table = self._create_dummy_table().drop(["a", "b", "c"])
extractor = PolarsArrowExtractor()
row = extractor.extract_row(pa_table)
self.assertTrue(row["d"].dtype.is_temporal())
col = extractor.extract_column(pa_table)
self.assertTrue(isinstance(col[0], datetime.datetime))
self.assertTrue(col.dtype.is_temporal())
batch = extractor.extract_batch(pa_table)
self.assertTrue(isinstance(batch["d"][0], datetime.datetime))
self.assertTrue(batch["d"].dtype.is_temporal())
class LazyDictTest(TestCase):
def _create_dummy_table(self):
return pa.Table.from_pydict({"a": _COL_A, "b": _COL_B, "c": _COL_C})
def _create_dummy_formatter(self):
return PythonFormatter(lazy=True)
def test_lazy_dict_copy(self):
pa_table = self._create_dummy_table()
formatter = self._create_dummy_formatter()
lazy_batch = formatter.format_batch(pa_table)
lazy_batch_copy = lazy_batch.copy()
self.assertEqual(type(lazy_batch), type(lazy_batch_copy))
self.assertEqual(lazy_batch.items(), lazy_batch_copy.items())
lazy_batch["d"] = [1, 2, 3]
self.assertNotEqual(lazy_batch.items(), lazy_batch_copy.items())
class FormatterTest(TestCase):
def _create_dummy_table(self):
return pa.Table.from_pydict({"a": _COL_A, "b": _COL_B, "c": _COL_C})
def test_python_formatter(self):
pa_table = self._create_dummy_table()
formatter = PythonFormatter()
row = formatter.format_row(pa_table)
self.assertEqual(row, {"a": _COL_A[0], "b": _COL_B[0], "c": _COL_C[0]})
col = formatter.format_column(pa_table)
self.assertEqual(col, _COL_A)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch, {"a": _COL_A, "b": _COL_B, "c": _COL_C})
def test_python_formatter_lazy(self):
pa_table = self._create_dummy_table()
formatter = PythonFormatter(lazy=True)
row = formatter.format_row(pa_table)
self.assertIsInstance(row, LazyRow)
self.assertEqual(row["a"], _COL_A[0])
self.assertEqual(row["b"], _COL_B[0])
self.assertEqual(row["c"], _COL_C[0])
batch = formatter.format_batch(pa_table)
self.assertIsInstance(batch, LazyBatch)
self.assertEqual(batch["a"], _COL_A)
self.assertEqual(batch["b"], _COL_B)
self.assertEqual(batch["c"], _COL_C)
def test_numpy_formatter(self):
pa_table = self._create_dummy_table()
formatter = NumpyFormatter()
row = formatter.format_row(pa_table)
np.testing.assert_equal(row, {"a": _COL_A[0], "b": _COL_B[0], "c": np.array(_COL_C[0])})
col = formatter.format_column(pa_table)
np.testing.assert_equal(col, np.array(_COL_A))
batch = formatter.format_batch(pa_table)
np.testing.assert_equal(batch, {"a": np.array(_COL_A), "b": np.array(_COL_B), "c": np.array(_COL_C)})
assert batch["c"].shape == np.array(_COL_C).shape
def test_numpy_formatter_np_array_kwargs(self):
pa_table = self._create_dummy_table().drop(["b"])
formatter = NumpyFormatter(dtype=np.float16)
row = formatter.format_row(pa_table)
self.assertEqual(row["c"].dtype, np.dtype(np.float16))
col = formatter.format_column(pa_table)
self.assertEqual(col.dtype, np.float16)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["a"].dtype, np.dtype(np.float16))
self.assertEqual(batch["c"].dtype, np.dtype(np.float16))
@require_pil
def test_numpy_formatter_image(self):
# same dimensions
pa_table = pa.table({"image": [{"bytes": None, "path": str(IMAGE_PATH_1)}] * 2})
formatter = NumpyFormatter(features=Features({"image": Image()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["image"].dtype, np.uint8)
self.assertEqual(row["image"].shape, (480, 640, 3))
col = formatter.format_column(pa_table)
self.assertEqual(col.dtype, np.uint8)
self.assertEqual(col.shape, (2, 480, 640, 3))
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["image"].dtype, np.uint8)
self.assertEqual(batch["image"].shape, (2, 480, 640, 3))
# different dimensions
pa_table = pa.table(
{"image": [{"bytes": None, "path": str(IMAGE_PATH_1)}, {"bytes": None, "path": str(IMAGE_PATH_2)}]}
)
formatter = NumpyFormatter(features=Features({"image": Image()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["image"].dtype, np.uint8)
self.assertEqual(row["image"].shape, (480, 640, 3))
col = formatter.format_column(pa_table)
self.assertIsInstance(col, np.ndarray)
self.assertEqual(col.dtype, object)
self.assertEqual(col[0].dtype, np.uint8)
self.assertEqual(col[0].shape, (480, 640, 3))
batch = formatter.format_batch(pa_table)
self.assertIsInstance(batch["image"], np.ndarray)
self.assertEqual(batch["image"].dtype, object)
self.assertEqual(batch["image"][0].dtype, np.uint8)
self.assertEqual(batch["image"][0].shape, (480, 640, 3))
@require_sndfile
def test_numpy_formatter_audio(self):
pa_table = pa.table({"audio": [{"bytes": None, "path": str(AUDIO_PATH_1)}]})
formatter = NumpyFormatter(features=Features({"audio": Audio()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["audio"]["array"].dtype, np.dtype(np.float32))
col = formatter.format_column(pa_table)
self.assertEqual(col[0]["array"].dtype, np.float32)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["audio"][0]["array"].dtype, np.dtype(np.float32))
def test_pandas_formatter(self):
pa_table = self._create_dummy_table()
formatter = PandasFormatter()
row = formatter.format_row(pa_table)
self.assertIsInstance(row, pd.DataFrame)
pd.testing.assert_series_equal(row["a"], pd.Series(_COL_A, name="a")[:1])
pd.testing.assert_series_equal(row["b"], pd.Series(_COL_B, name="b")[:1])
col = formatter.format_column(pa_table)
pd.testing.assert_series_equal(col, pd.Series(_COL_A, name="a"))
batch = formatter.format_batch(pa_table)
self.assertIsInstance(batch, pd.DataFrame)
pd.testing.assert_series_equal(batch["a"], pd.Series(_COL_A, name="a"))
pd.testing.assert_series_equal(batch["b"], pd.Series(_COL_B, name="b"))
@require_polars
def test_polars_formatter(self):
import polars as pl
from datasets.formatting import PolarsFormatter
pa_table = self._create_dummy_table()
formatter = PolarsFormatter()
row = formatter.format_row(pa_table)
self.assertIsInstance(row, pl.DataFrame)
assert pl.Series.eq(row["a"], pl.Series("a", _COL_A)[:1]).all()
assert pl.Series.eq(row["b"], pl.Series("b", _COL_B)[:1]).all()
col = formatter.format_column(pa_table)
assert pl.Series.eq(col, pl.Series("a", _COL_A)).all()
batch = formatter.format_batch(pa_table)
self.assertIsInstance(batch, pl.DataFrame)
assert pl.Series.eq(batch["a"], pl.Series("a", _COL_A)).all()
assert pl.Series.eq(batch["b"], pl.Series("b", _COL_B)).all()
@require_torch
def test_torch_formatter(self):
import torch
from datasets.formatting import TorchFormatter
pa_table = self._create_dummy_table()
formatter = TorchFormatter()
row = formatter.format_row(pa_table)
torch.testing.assert_close(row["a"], torch.tensor(_COL_A, dtype=torch.int64)[0])
assert row["b"] == _COL_B[0]
torch.testing.assert_close(row["c"], torch.tensor(_COL_C, dtype=torch.float32)[0])
col = formatter.format_column(pa_table)
torch.testing.assert_close(col, torch.tensor(_COL_A, dtype=torch.int64))
batch = formatter.format_batch(pa_table)
torch.testing.assert_close(batch["a"], torch.tensor(_COL_A, dtype=torch.int64))
assert batch["b"] == _COL_B
torch.testing.assert_close(batch["c"], torch.tensor(_COL_C, dtype=torch.float32))
assert batch["c"].shape == np.array(_COL_C).shape
@require_torch
def test_torch_formatter_torch_tensor_kwargs(self):
import torch
from datasets.formatting import TorchFormatter
pa_table = self._create_dummy_table().drop(["b"])
formatter = TorchFormatter(dtype=torch.float16)
row = formatter.format_row(pa_table)
self.assertEqual(row["c"].dtype, torch.float16)
col = formatter.format_column(pa_table)
self.assertEqual(col.dtype, torch.float16)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["a"].dtype, torch.float16)
self.assertEqual(batch["c"].dtype, torch.float16)
@require_torch
@require_pil
def test_torch_formatter_image(self):
import torch
from datasets.formatting import TorchFormatter
# same dimensions
pa_table = pa.table({"image": [{"bytes": None, "path": str(IMAGE_PATH_1)}] * 2})
formatter = TorchFormatter(features=Features({"image": Image()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["image"].dtype, torch.uint8)
# torch uses CHW format contrary to numpy which uses HWC
self.assertEqual(row["image"].shape, (3, 480, 640))
col = formatter.format_column(pa_table)
self.assertEqual(col.dtype, torch.uint8)
self.assertEqual(col.shape, (2, 3, 480, 640))
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["image"].dtype, torch.uint8)
self.assertEqual(batch["image"].shape, (2, 3, 480, 640))
# different dimensions
pa_table = pa.table(
{"image": [{"bytes": None, "path": str(IMAGE_PATH_1)}, {"bytes": None, "path": str(IMAGE_PATH_2)}]}
)
formatter = TorchFormatter(features=Features({"image": Image()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["image"].dtype, torch.uint8)
self.assertEqual(row["image"].shape, (3, 480, 640))
col = formatter.format_column(pa_table)
self.assertIsInstance(col, list)
self.assertEqual(col[0].dtype, torch.uint8)
self.assertEqual(col[0].shape, (3, 480, 640))
batch = formatter.format_batch(pa_table)
self.assertIsInstance(batch["image"], list)
self.assertEqual(batch["image"][0].dtype, torch.uint8)
self.assertEqual(batch["image"][0].shape, (3, 480, 640))
@require_torch
@require_sndfile
def test_torch_formatter_audio(self):
import torch
from datasets.formatting import TorchFormatter
pa_table = pa.table({"audio": [{"bytes": None, "path": str(AUDIO_PATH_1)}]})
formatter = TorchFormatter(features=Features({"audio": Audio()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["audio"]["array"].dtype, torch.float32)
col = formatter.format_column(pa_table)
self.assertEqual(col[0]["array"].dtype, torch.float32)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["audio"][0]["array"].dtype, torch.float32)
@require_tf
def test_tf_formatter(self):
import tensorflow as tf
from datasets.formatting import TFFormatter
pa_table = self._create_dummy_table()
formatter = TFFormatter()
row = formatter.format_row(pa_table)
tf.debugging.assert_equal(row["a"], tf.convert_to_tensor(_COL_A, dtype=tf.int64)[0])
tf.debugging.assert_equal(row["b"], tf.convert_to_tensor(_COL_B, dtype=tf.string)[0])
tf.debugging.assert_equal(row["c"], tf.convert_to_tensor(_COL_C, dtype=tf.float32)[0])
col = formatter.format_column(pa_table)
tf.debugging.assert_equal(col, tf.ragged.constant(_COL_A, dtype=tf.int64))
batch = formatter.format_batch(pa_table)
tf.debugging.assert_equal(batch["a"], tf.convert_to_tensor(_COL_A, dtype=tf.int64))
tf.debugging.assert_equal(batch["b"], tf.convert_to_tensor(_COL_B, dtype=tf.string))
self.assertIsInstance(batch["c"], tf.Tensor)
self.assertEqual(batch["c"].dtype, tf.float32)
tf.debugging.assert_equal(
batch["c"].shape.as_list(), tf.convert_to_tensor(_COL_C, dtype=tf.float32).shape.as_list()
)
tf.debugging.assert_equal(tf.convert_to_tensor(batch["c"]), tf.convert_to_tensor(_COL_C, dtype=tf.float32))
@require_tf
def test_tf_formatter_tf_tensor_kwargs(self):
import tensorflow as tf
from datasets.formatting import TFFormatter
pa_table = self._create_dummy_table().drop(["b"])
formatter = TFFormatter(dtype=tf.float16)
row = formatter.format_row(pa_table)
self.assertEqual(row["c"].dtype, tf.float16)
col = formatter.format_column(pa_table)
self.assertEqual(col.dtype, tf.float16)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["a"].dtype, tf.float16)
self.assertEqual(batch["c"].dtype, tf.float16)
@require_tf
@require_pil
def test_tf_formatter_image(self):
import tensorflow as tf
from datasets.formatting import TFFormatter
# same dimensions
pa_table = pa.table({"image": [{"bytes": None, "path": str(IMAGE_PATH_1)}] * 2})
formatter = TFFormatter(features=Features({"image": Image()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["image"].dtype, tf.uint8)
self.assertEqual(row["image"].shape, (480, 640, 3))
col = formatter.format_column(pa_table)
self.assertEqual(col.dtype, tf.uint8)
self.assertEqual(col.shape, (2, 480, 640, 3))
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["image"][0].dtype, tf.uint8)
self.assertEqual(batch["image"].shape, (2, 480, 640, 3))
# different dimensions
pa_table = pa.table(
{"image": [{"bytes": None, "path": str(IMAGE_PATH_1)}, {"bytes": None, "path": str(IMAGE_PATH_2)}]}
)
formatter = TFFormatter(features=Features({"image": Image()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["image"].dtype, tf.uint8)
self.assertEqual(row["image"].shape, (480, 640, 3))
col = formatter.format_column(pa_table)
self.assertIsInstance(col, list)
self.assertEqual(col[0].dtype, tf.uint8)
self.assertEqual(col[0].shape, (480, 640, 3))
batch = formatter.format_batch(pa_table)
self.assertIsInstance(batch["image"], list)
self.assertEqual(batch["image"][0].dtype, tf.uint8)
self.assertEqual(batch["image"][0].shape, (480, 640, 3))
@require_tf
@require_sndfile
def test_tf_formatter_audio(self):
import tensorflow as tf
from datasets.formatting import TFFormatter
pa_table = pa.table({"audio": [{"bytes": None, "path": str(AUDIO_PATH_1)}]})
formatter = TFFormatter(features=Features({"audio": Audio()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["audio"]["array"].dtype, tf.float32)
col = formatter.format_column(pa_table)
self.assertEqual(col[0]["array"].dtype, tf.float32)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["audio"][0]["array"].dtype, tf.float32)
@require_jax
def test_jax_formatter(self):
import jax
import jax.numpy as jnp
from datasets.formatting import JaxFormatter
pa_table = self._create_dummy_table()
formatter = JaxFormatter()
row = formatter.format_row(pa_table)
jnp.allclose(row["a"], jnp.array(_COL_A, dtype=jnp.int64 if jax.config.jax_enable_x64 else jnp.int32)[0])
assert row["b"] == _COL_B[0]
jnp.allclose(row["c"], jnp.array(_COL_C, dtype=jnp.float32)[0])
col = formatter.format_column(pa_table)
jnp.allclose(col, jnp.array(_COL_A, dtype=jnp.int64 if jax.config.jax_enable_x64 else jnp.int32))
batch = formatter.format_batch(pa_table)
jnp.allclose(batch["a"], jnp.array(_COL_A, dtype=jnp.int64 if jax.config.jax_enable_x64 else jnp.int32))
assert batch["b"] == _COL_B
jnp.allclose(batch["c"], jnp.array(_COL_C, dtype=jnp.float32))
assert batch["c"].shape == np.array(_COL_C).shape
@require_jax
def test_jax_formatter_jnp_array_kwargs(self):
import jax.numpy as jnp
from datasets.formatting import JaxFormatter
pa_table = self._create_dummy_table().drop(["b"])
formatter = JaxFormatter(dtype=jnp.float16)
row = formatter.format_row(pa_table)
self.assertEqual(row["c"].dtype, jnp.float16)
col = formatter.format_column(pa_table)
self.assertEqual(col.dtype, jnp.float16)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["a"].dtype, jnp.float16)
self.assertEqual(batch["c"].dtype, jnp.float16)
@require_jax
@require_pil
def test_jax_formatter_image(self):
import jax.numpy as jnp
from datasets.formatting import JaxFormatter
# same dimensions
pa_table = pa.table({"image": [{"bytes": None, "path": str(IMAGE_PATH_1)}] * 2})
formatter = JaxFormatter(features=Features({"image": Image()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["image"].dtype, jnp.uint8)
self.assertEqual(row["image"].shape, (480, 640, 3))
col = formatter.format_column(pa_table)
self.assertEqual(col.dtype, jnp.uint8)
self.assertEqual(col.shape, (2, 480, 640, 3))
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["image"].dtype, jnp.uint8)
self.assertEqual(batch["image"].shape, (2, 480, 640, 3))
# different dimensions
pa_table = pa.table(
{"image": [{"bytes": None, "path": str(IMAGE_PATH_1)}, {"bytes": None, "path": str(IMAGE_PATH_2)}]}
)
formatter = JaxFormatter(features=Features({"image": Image()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["image"].dtype, jnp.uint8)
self.assertEqual(row["image"].shape, (480, 640, 3))
col = formatter.format_column(pa_table)
self.assertIsInstance(col, list)
self.assertEqual(col[0].dtype, jnp.uint8)
self.assertEqual(col[0].shape, (480, 640, 3))
batch = formatter.format_batch(pa_table)
self.assertIsInstance(batch["image"], list)
self.assertEqual(batch["image"][0].dtype, jnp.uint8)
self.assertEqual(batch["image"][0].shape, (480, 640, 3))
@require_jax
@require_sndfile
def test_jax_formatter_audio(self):
import jax.numpy as jnp
from datasets.formatting import JaxFormatter
pa_table = pa.table({"audio": [{"bytes": None, "path": str(AUDIO_PATH_1)}]})
formatter = JaxFormatter(features=Features({"audio": Audio()}))
row = formatter.format_row(pa_table)
self.assertEqual(row["audio"]["array"].dtype, jnp.float32)
col = formatter.format_column(pa_table)
self.assertEqual(col[0]["array"].dtype, jnp.float32)
batch = formatter.format_batch(pa_table)
self.assertEqual(batch["audio"][0]["array"].dtype, jnp.float32)
@require_jax
def test_jax_formatter_device(self):
import jax
from datasets.formatting import JaxFormatter
pa_table = self._create_dummy_table()
device = jax.devices()[0]
formatter = JaxFormatter(device=str(device))
row = formatter.format_row(pa_table)
assert row["a"].device() == device
assert row["c"].device() == device
col = formatter.format_column(pa_table)
assert col.device() == device
batch = formatter.format_batch(pa_table)
assert batch["a"].device() == device
assert batch["c"].device() == device
class QueryTest(TestCase):
def _create_dummy_table(self):
return pa.Table.from_pydict({"a": _COL_A, "b": _COL_B, "c": _COL_C})
def _create_dummy_arrow_indices(self):
return pa.Table.from_arrays([pa.array(_INDICES, type=pa.uint64())], names=["indices"])
def assertTableEqual(self, first: pa.Table, second: pa.Table):
self.assertEqual(first.schema, second.schema)
for first_array, second_array in zip(first, second):
self.assertEqual(first_array, second_array)
self.assertEqual(first, second)
def test_query_table_int(self):
pa_table = self._create_dummy_table()
table = InMemoryTable(pa_table)
n = pa_table.num_rows
# classical usage
subtable = query_table(table, 0)
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A[:1], "b": _COL_B[:1], "c": _COL_C[:1]}))
subtable = query_table(table, 1)
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A[1:2], "b": _COL_B[1:2], "c": _COL_C[1:2]}))
subtable = query_table(table, -1)
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A[-1:], "b": _COL_B[-1:], "c": _COL_C[-1:]}))
# raise an IndexError
with self.assertRaises(IndexError):
query_table(table, n)
with self.assertRaises(IndexError):
query_table(table, -(n + 1))
# with indices
indices = InMemoryTable(self._create_dummy_arrow_indices())
subtable = query_table(table, 0, indices=indices)
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": [_COL_A[_INDICES[0]]], "b": [_COL_B[_INDICES[0]]], "c": [_COL_C[_INDICES[0]]]}),
)
with self.assertRaises(IndexError):
assert len(indices) < n
query_table(table, len(indices), indices=indices)
def test_query_table_slice(self):
pa_table = self._create_dummy_table()
table = InMemoryTable(pa_table)
n = pa_table.num_rows
# classical usage
subtable = query_table(table, slice(0, 1))
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A[:1], "b": _COL_B[:1], "c": _COL_C[:1]}))
subtable = query_table(table, slice(1, 2))
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A[1:2], "b": _COL_B[1:2], "c": _COL_C[1:2]}))
subtable = query_table(table, slice(-2, -1))
self.assertTableEqual(
subtable, pa.Table.from_pydict({"a": _COL_A[-2:-1], "b": _COL_B[-2:-1], "c": _COL_C[-2:-1]})
)
# usage with None
subtable = query_table(table, slice(-1, None))
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A[-1:], "b": _COL_B[-1:], "c": _COL_C[-1:]}))
subtable = query_table(table, slice(None, n + 1))
self.assertTableEqual(
subtable, pa.Table.from_pydict({"a": _COL_A[: n + 1], "b": _COL_B[: n + 1], "c": _COL_C[: n + 1]})
)
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A, "b": _COL_B, "c": _COL_C}))
subtable = query_table(table, slice(-(n + 1), None))
self.assertTableEqual(
subtable, pa.Table.from_pydict({"a": _COL_A[-(n + 1) :], "b": _COL_B[-(n + 1) :], "c": _COL_C[-(n + 1) :]})
)
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A, "b": _COL_B, "c": _COL_C}))
# usage with step
subtable = query_table(table, slice(None, None, 2))
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A[::2], "b": _COL_B[::2], "c": _COL_C[::2]}))
# empty ouput but no errors
subtable = query_table(table, slice(-1, 0)) # usage with both negative and positive idx
assert len(_COL_A[-1:0]) == 0
self.assertTableEqual(subtable, pa_table.slice(0, 0))
subtable = query_table(table, slice(2, 1))
assert len(_COL_A[2:1]) == 0
self.assertTableEqual(subtable, pa_table.slice(0, 0))
subtable = query_table(table, slice(n, n))
assert len(_COL_A[n:n]) == 0
self.assertTableEqual(subtable, pa_table.slice(0, 0))
subtable = query_table(table, slice(n, n + 1))
assert len(_COL_A[n : n + 1]) == 0
self.assertTableEqual(subtable, pa_table.slice(0, 0))
# it's not possible to get an error with a slice
# with indices
indices = InMemoryTable(self._create_dummy_arrow_indices())
subtable = query_table(table, slice(0, 1), indices=indices)
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": [_COL_A[_INDICES[0]]], "b": [_COL_B[_INDICES[0]]], "c": [_COL_C[_INDICES[0]]]}),
)
subtable = query_table(table, slice(n - 1, n), indices=indices)
assert len(indices.column(0).to_pylist()[n - 1 : n]) == 0
self.assertTableEqual(subtable, pa_table.slice(0, 0))
def test_query_table_range(self):
pa_table = self._create_dummy_table()
table = InMemoryTable(pa_table)
n = pa_table.num_rows
np_A, np_B, np_C = np.array(_COL_A, dtype=np.int64), np.array(_COL_B), np.array(_COL_C)
# classical usage
subtable = query_table(table, range(0, 1))
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": np_A[range(0, 1)], "b": np_B[range(0, 1)], "c": np_C[range(0, 1)].tolist()}),
)
subtable = query_table(table, range(1, 2))
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": np_A[range(1, 2)], "b": np_B[range(1, 2)], "c": np_C[range(1, 2)].tolist()}),
)
subtable = query_table(table, range(-2, -1))
self.assertTableEqual(
subtable,
pa.Table.from_pydict(
{"a": np_A[range(-2, -1)], "b": np_B[range(-2, -1)], "c": np_C[range(-2, -1)].tolist()}
),
)
# usage with both negative and positive idx
subtable = query_table(table, range(-1, 0))
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": np_A[range(-1, 0)], "b": np_B[range(-1, 0)], "c": np_C[range(-1, 0)].tolist()}),
)
subtable = query_table(table, range(-1, n))
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": np_A[range(-1, n)], "b": np_B[range(-1, n)], "c": np_C[range(-1, n)].tolist()}),
)
# usage with step
subtable = query_table(table, range(0, n, 2))
self.assertTableEqual(
subtable,
pa.Table.from_pydict(
{"a": np_A[range(0, n, 2)], "b": np_B[range(0, n, 2)], "c": np_C[range(0, n, 2)].tolist()}
),
)
subtable = query_table(table, range(0, n + 1, 2 * n))
self.assertTableEqual(
subtable,
pa.Table.from_pydict(
{
"a": np_A[range(0, n + 1, 2 * n)],
"b": np_B[range(0, n + 1, 2 * n)],
"c": np_C[range(0, n + 1, 2 * n)].tolist(),
}
),
)
# empty ouput but no errors
subtable = query_table(table, range(2, 1))
assert len(np_A[range(2, 1)]) == 0
self.assertTableEqual(subtable, pa.Table.from_batches([], schema=pa_table.schema))
subtable = query_table(table, range(n, n))
assert len(np_A[range(n, n)]) == 0
self.assertTableEqual(subtable, pa.Table.from_batches([], schema=pa_table.schema))
# raise an IndexError
with self.assertRaises(IndexError):
with self.assertRaises(IndexError):
np_A[range(0, n + 1)]
query_table(table, range(0, n + 1))
with self.assertRaises(IndexError):
with self.assertRaises(IndexError):
np_A[range(-(n + 1), -1)]
query_table(table, range(-(n + 1), -1))
with self.assertRaises(IndexError):
with self.assertRaises(IndexError):
np_A[range(n, n + 1)]
query_table(table, range(n, n + 1))
# with indices
indices = InMemoryTable(self._create_dummy_arrow_indices())
subtable = query_table(table, range(0, 1), indices=indices)
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": [_COL_A[_INDICES[0]]], "b": [_COL_B[_INDICES[0]]], "c": [_COL_C[_INDICES[0]]]}),
)
with self.assertRaises(IndexError):
assert len(indices) < n
query_table(table, range(len(indices), len(indices) + 1), indices=indices)
def test_query_table_str(self):
pa_table = self._create_dummy_table()
table = InMemoryTable(pa_table)
subtable = query_table(table, "a")
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": _COL_A}))
with self.assertRaises(KeyError):
query_table(table, "z")
indices = InMemoryTable(self._create_dummy_arrow_indices())
subtable = query_table(table, "a", indices=indices)
self.assertTableEqual(subtable, pa.Table.from_pydict({"a": [_COL_A[i] for i in _INDICES]}))
def test_query_table_iterable(self):
pa_table = self._create_dummy_table()
table = InMemoryTable(pa_table)
n = pa_table.num_rows
np_A, np_B, np_C = np.array(_COL_A, dtype=np.int64), np.array(_COL_B), np.array(_COL_C)
# classical usage
subtable = query_table(table, [0])
self.assertTableEqual(
subtable, pa.Table.from_pydict({"a": np_A[[0]], "b": np_B[[0]], "c": np_C[[0]].tolist()})
)
subtable = query_table(table, [1])
self.assertTableEqual(
subtable, pa.Table.from_pydict({"a": np_A[[1]], "b": np_B[[1]], "c": np_C[[1]].tolist()})
)
subtable = query_table(table, [-1])
self.assertTableEqual(
subtable, pa.Table.from_pydict({"a": np_A[[-1]], "b": np_B[[-1]], "c": np_C[[-1]].tolist()})
)
subtable = query_table(table, [0, -1, 1])
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": np_A[[0, -1, 1]], "b": np_B[[0, -1, 1]], "c": np_C[[0, -1, 1]].tolist()}),
)
# numpy iterable
subtable = query_table(table, np.array([0, -1, 1]))
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": np_A[[0, -1, 1]], "b": np_B[[0, -1, 1]], "c": np_C[[0, -1, 1]].tolist()}),
)
# empty ouput but no errors
subtable = query_table(table, [])
assert len(np_A[[]]) == 0
self.assertTableEqual(subtable, pa.Table.from_batches([], schema=pa_table.schema))
# raise an IndexError
with self.assertRaises(IndexError):
with self.assertRaises(IndexError):
np_A[[n]]
query_table(table, [n])
with self.assertRaises(IndexError):
with self.assertRaises(IndexError):
np_A[[-(n + 1)]]
query_table(table, [-(n + 1)])
# with indices
indices = InMemoryTable(self._create_dummy_arrow_indices())
subtable = query_table(table, [0], indices=indices)
self.assertTableEqual(
subtable,
pa.Table.from_pydict({"a": [_COL_A[_INDICES[0]]], "b": [_COL_B[_INDICES[0]]], "c": [_COL_C[_INDICES[0]]]}),
)
with self.assertRaises(IndexError):
assert len(indices) < n
query_table(table, [len(indices)], indices=indices)
def test_query_table_invalid_key_type(self):
pa_table = self._create_dummy_table()
table = InMemoryTable(pa_table)
with self.assertRaises(TypeError):
query_table(table, 0.0)
with self.assertRaises(TypeError):
query_table(table, [0, "a"])
with self.assertRaises(TypeError):
query_table(table, int)
with self.assertRaises(TypeError):
def iter_to_inf(start=0):
while True:
yield start
start += 1
query_table(table, iter_to_inf())
@pytest.fixture(scope="session")
def arrow_table():
return pa.Table.from_pydict({"col_int": [0, 1, 2], "col_float": [0.0, 1.0, 2.0]})
@require_tf
@pytest.mark.parametrize(
"cast_schema",
[
None,
[("col_int", pa.int64()), ("col_float", pa.float64())],
[("col_int", pa.int32()), ("col_float", pa.float64())],
[("col_int", pa.int64()), ("col_float", pa.float32())],
],
)
def test_tf_formatter_sets_default_dtypes(cast_schema, arrow_table):
import tensorflow as tf
from datasets.formatting import TFFormatter
if cast_schema:
arrow_table = arrow_table.cast(pa.schema(cast_schema))
arrow_table_dict = arrow_table.to_pydict()
list_int = arrow_table_dict["col_int"]
list_float = arrow_table_dict["col_float"]
formatter = TFFormatter()
row = formatter.format_row(arrow_table)
tf.debugging.assert_equal(row["col_int"], tf.ragged.constant(list_int, dtype=tf.int64)[0])
tf.debugging.assert_equal(row["col_float"], tf.ragged.constant(list_float, dtype=tf.float32)[0])
col = formatter.format_column(arrow_table)
tf.debugging.assert_equal(col, tf.ragged.constant(list_int, dtype=tf.int64))
batch = formatter.format_batch(arrow_table)
tf.debugging.assert_equal(batch["col_int"], tf.ragged.constant(list_int, dtype=tf.int64))
tf.debugging.assert_equal(batch["col_float"], tf.ragged.constant(list_float, dtype=tf.float32))
@require_torch
@pytest.mark.parametrize(
"cast_schema",
[
None,
[("col_int", pa.int64()), ("col_float", pa.float64())],
[("col_int", pa.int32()), ("col_float", pa.float64())],
[("col_int", pa.int64()), ("col_float", pa.float32())],
],
)
def test_torch_formatter_sets_default_dtypes(cast_schema, arrow_table):
import torch
from datasets.formatting import TorchFormatter
if cast_schema:
arrow_table = arrow_table.cast(pa.schema(cast_schema))
arrow_table_dict = arrow_table.to_pydict()
list_int = arrow_table_dict["col_int"]
list_float = arrow_table_dict["col_float"]
formatter = TorchFormatter()
row = formatter.format_row(arrow_table)
torch.testing.assert_close(row["col_int"], torch.tensor(list_int, dtype=torch.int64)[0])
torch.testing.assert_close(row["col_float"], torch.tensor(list_float, dtype=torch.float32)[0])
col = formatter.format_column(arrow_table)
torch.testing.assert_close(col, torch.tensor(list_int, dtype=torch.int64))
batch = formatter.format_batch(arrow_table)
torch.testing.assert_close(batch["col_int"], torch.tensor(list_int, dtype=torch.int64))
torch.testing.assert_close(batch["col_float"], torch.tensor(list_float, dtype=torch.float32))
def test_iterable_dataset_of_arrays_format_to_arrow(any_arrays_dataset: IterableDataset):
formatted = any_arrays_dataset.with_format("arrow")
assert all(isinstance(example, pa.Table) for example in formatted)
def test_iterable_dataset_of_arrays_format_to_numpy(any_arrays_dataset: IterableDataset):
formatted = any_arrays_dataset.with_format("np")
assert all(isinstance(example["array"], np.ndarray) for example in formatted)
@require_torch
def test_iterable_dataset_of_arrays_format_to_torch(any_arrays_dataset: IterableDataset):
import torch
formatted = any_arrays_dataset.with_format("torch")
assert all(isinstance(example["array"], torch.Tensor) for example in formatted)
@require_tf
def test_iterable_dataset_of_arrays_format_to_tf(any_arrays_dataset: IterableDataset):
import tensorflow as tf
formatted = any_arrays_dataset.with_format("tf")
assert all(isinstance(example["array"], tf.Tensor) for example in formatted)
@require_jax
def test_iterable_dataset_of_arrays_format_to_jax(any_arrays_dataset: IterableDataset):
import jax.numpy as jnp
formatted = any_arrays_dataset.with_format("jax")
assert all(isinstance(example["array"], jnp.ndarray) for example in formatted)
|
datasets/tests/test_formatting.py/0
|
{
"file_path": "datasets/tests/test_formatting.py",
"repo_id": "datasets",
"token_count": 20610
}
| 78 |
import os
import tempfile
from functools import partial
from unittest import TestCase
from unittest.mock import patch
import numpy as np
import pytest
from datasets.arrow_dataset import Dataset
from datasets.search import ElasticSearchIndex, FaissIndex, MissingIndex
from .utils import require_elasticsearch, require_faiss
pytestmark = pytest.mark.integration
@require_faiss
class IndexableDatasetTest(TestCase):
def _create_dummy_dataset(self):
dset = Dataset.from_dict({"filename": ["my_name-train" + "_" + str(x) for x in np.arange(30).tolist()]})
return dset
def test_add_faiss_index(self):
import faiss
dset: Dataset = self._create_dummy_dataset()
dset = dset.map(
lambda ex, i: {"vecs": i * np.ones(5, dtype=np.float32)}, with_indices=True, keep_in_memory=True
)
dset = dset.add_faiss_index("vecs", batch_size=100, metric_type=faiss.METRIC_INNER_PRODUCT)
scores, examples = dset.get_nearest_examples("vecs", np.ones(5, dtype=np.float32))
self.assertEqual(examples["filename"][0], "my_name-train_29")
dset.drop_index("vecs")
def test_add_faiss_index_from_external_arrays(self):
import faiss
dset: Dataset = self._create_dummy_dataset()
dset.add_faiss_index_from_external_arrays(
external_arrays=np.ones((30, 5)) * np.arange(30).reshape(-1, 1),
index_name="vecs",
batch_size=100,
metric_type=faiss.METRIC_INNER_PRODUCT,
)
scores, examples = dset.get_nearest_examples("vecs", np.ones(5, dtype=np.float32))
self.assertEqual(examples["filename"][0], "my_name-train_29")
def test_serialization(self):
import faiss
dset: Dataset = self._create_dummy_dataset()
dset.add_faiss_index_from_external_arrays(
external_arrays=np.ones((30, 5)) * np.arange(30).reshape(-1, 1),
index_name="vecs",
metric_type=faiss.METRIC_INNER_PRODUCT,
)
# Setting delete=False and unlinking manually is not pretty... but it is required on Windows to
# ensure somewhat stable behaviour. If we don't, we get PermissionErrors. This is an age-old issue.
# see https://bugs.python.org/issue14243 and
# https://stackoverflow.com/questions/23212435/permission-denied-to-write-to-my-temporary-file/23212515
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
dset.save_faiss_index("vecs", tmp_file.name)
dset.load_faiss_index("vecs2", tmp_file.name)
os.unlink(tmp_file.name)
scores, examples = dset.get_nearest_examples("vecs2", np.ones(5, dtype=np.float32))
self.assertEqual(examples["filename"][0], "my_name-train_29")
def test_drop_index(self):
dset: Dataset = self._create_dummy_dataset()
dset.add_faiss_index_from_external_arrays(
external_arrays=np.ones((30, 5)) * np.arange(30).reshape(-1, 1), index_name="vecs"
)
dset.drop_index("vecs")
self.assertRaises(MissingIndex, partial(dset.get_nearest_examples, "vecs2", np.ones(5, dtype=np.float32)))
def test_add_elasticsearch_index(self):
from elasticsearch import Elasticsearch
dset: Dataset = self._create_dummy_dataset()
with patch("elasticsearch.Elasticsearch.search") as mocked_search, patch(
"elasticsearch.client.IndicesClient.create"
) as mocked_index_create, patch("elasticsearch.helpers.streaming_bulk") as mocked_bulk:
mocked_index_create.return_value = {"acknowledged": True}
mocked_bulk.return_value([(True, None)] * 30)
mocked_search.return_value = {"hits": {"hits": [{"_score": 1, "_id": 29}]}}
es_client = Elasticsearch()
dset.add_elasticsearch_index("filename", es_client=es_client)
scores, examples = dset.get_nearest_examples("filename", "my_name-train_29")
self.assertEqual(examples["filename"][0], "my_name-train_29")
@require_faiss
class FaissIndexTest(TestCase):
def test_flat_ip(self):
import faiss
index = FaissIndex(metric_type=faiss.METRIC_INNER_PRODUCT)
# add vectors
index.add_vectors(np.eye(5, dtype=np.float32))
self.assertIsNotNone(index.faiss_index)
self.assertEqual(index.faiss_index.ntotal, 5)
index.add_vectors(np.zeros((5, 5), dtype=np.float32))
self.assertEqual(index.faiss_index.ntotal, 10)
# single query
query = np.zeros(5, dtype=np.float32)
query[1] = 1
scores, indices = index.search(query)
self.assertRaises(ValueError, index.search, query.reshape(-1, 1))
self.assertGreater(scores[0], 0)
self.assertEqual(indices[0], 1)
# batched queries
queries = np.eye(5, dtype=np.float32)[::-1]
total_scores, total_indices = index.search_batch(queries)
self.assertRaises(ValueError, index.search_batch, queries[0])
best_scores = [scores[0] for scores in total_scores]
best_indices = [indices[0] for indices in total_indices]
self.assertGreater(np.min(best_scores), 0)
self.assertListEqual([4, 3, 2, 1, 0], best_indices)
def test_factory(self):
import faiss
index = FaissIndex(string_factory="Flat")
index.add_vectors(np.eye(5, dtype=np.float32))
self.assertIsInstance(index.faiss_index, faiss.IndexFlat)
index = FaissIndex(string_factory="LSH")
index.add_vectors(np.eye(5, dtype=np.float32))
self.assertIsInstance(index.faiss_index, faiss.IndexLSH)
with self.assertRaises(ValueError):
_ = FaissIndex(string_factory="Flat", custom_index=faiss.IndexFlat(5))
def test_custom(self):
import faiss
custom_index = faiss.IndexFlat(5)
index = FaissIndex(custom_index=custom_index)
index.add_vectors(np.eye(5, dtype=np.float32))
self.assertIsInstance(index.faiss_index, faiss.IndexFlat)
def test_serialization(self):
import faiss
index = FaissIndex(metric_type=faiss.METRIC_INNER_PRODUCT)
index.add_vectors(np.eye(5, dtype=np.float32))
# Setting delete=False and unlinking manually is not pretty... but it is required on Windows to
# ensure somewhat stable behaviour. If we don't, we get PermissionErrors. This is an age-old issue.
# see https://bugs.python.org/issue14243 and
# https://stackoverflow.com/questions/23212435/permission-denied-to-write-to-my-temporary-file/23212515
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
index.save(tmp_file.name)
index = FaissIndex.load(tmp_file.name)
os.unlink(tmp_file.name)
query = np.zeros(5, dtype=np.float32)
query[1] = 1
scores, indices = index.search(query)
self.assertGreater(scores[0], 0)
self.assertEqual(indices[0], 1)
@require_faiss
def test_serialization_fs(mockfs):
import faiss
index = FaissIndex(metric_type=faiss.METRIC_INNER_PRODUCT)
index.add_vectors(np.eye(5, dtype=np.float32))
index_name = "index.faiss"
path = f"mock://{index_name}"
index.save(path, storage_options=mockfs.storage_options)
index = FaissIndex.load(path, storage_options=mockfs.storage_options)
query = np.zeros(5, dtype=np.float32)
query[1] = 1
scores, indices = index.search(query)
assert scores[0] > 0
assert indices[0] == 1
@require_elasticsearch
class ElasticSearchIndexTest(TestCase):
def test_elasticsearch(self):
from elasticsearch import Elasticsearch
with patch("elasticsearch.Elasticsearch.search") as mocked_search, patch(
"elasticsearch.client.IndicesClient.create"
) as mocked_index_create, patch("elasticsearch.helpers.streaming_bulk") as mocked_bulk:
es_client = Elasticsearch()
mocked_index_create.return_value = {"acknowledged": True}
index = ElasticSearchIndex(es_client=es_client)
mocked_bulk.return_value([(True, None)] * 3)
index.add_documents(["foo", "bar", "foobar"])
# single query
query = "foo"
mocked_search.return_value = {"hits": {"hits": [{"_score": 1, "_id": 0}]}}
scores, indices = index.search(query)
self.assertEqual(scores[0], 1)
self.assertEqual(indices[0], 0)
# single query with timeout
query = "foo"
mocked_search.return_value = {"hits": {"hits": [{"_score": 1, "_id": 0}]}}
scores, indices = index.search(query, request_timeout=30)
self.assertEqual(scores[0], 1)
self.assertEqual(indices[0], 0)
# batched queries
queries = ["foo", "bar", "foobar"]
mocked_search.return_value = {"hits": {"hits": [{"_score": 1, "_id": 1}]}}
total_scores, total_indices = index.search_batch(queries)
best_scores = [scores[0] for scores in total_scores]
best_indices = [indices[0] for indices in total_indices]
self.assertGreater(np.min(best_scores), 0)
self.assertListEqual([1, 1, 1], best_indices)
# batched queries with timeout
queries = ["foo", "bar", "foobar"]
mocked_search.return_value = {"hits": {"hits": [{"_score": 1, "_id": 1}]}}
total_scores, total_indices = index.search_batch(queries, request_timeout=30)
best_scores = [scores[0] for scores in total_scores]
best_indices = [indices[0] for indices in total_indices]
self.assertGreater(np.min(best_scores), 0)
self.assertListEqual([1, 1, 1], best_indices)
|
datasets/tests/test_search.py/0
|
{
"file_path": "datasets/tests/test_search.py",
"repo_id": "datasets",
"token_count": 4372
}
| 79 |
# Discord 101 [[discord-101]]
Hey there! My name is Huggy, the dog 🐕, and I'm looking forward to train with you during this RL Course!
Although I don't know much about fetching sticks (yet), I know one or two things about Discord. So I wrote this guide to help you learn about it!
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/huggy-logo.jpg" alt="Huggy Logo"/>
Discord is a free chat platform. If you've used Slack, **it's quite similar**. There is a Hugging Face Community Discord server with 50000 members you can <a href="https://discord.gg/ydHrjt3WP5">join with a single click here</a>. So many humans to play with!
Starting in Discord can be a bit intimidating, so let me take you through it.
When you [sign-up to our Discord server](http://hf.co/join/discord), you'll choose your interests. Make sure to **click "Reinforcement Learning,"** and you'll get access to the Reinforcement Learning Category containing all the course-related channels. If you feel like joining even more channels, go for it! 🚀
Then click next, you'll then get to **introduce yourself in the `#introduce-yourself` channel**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/discord2.jpg" alt="Discord"/>
They are in the reinforcement learning category. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
- `rl-announcements`: where we give the **latest information about the course**.
- `rl-discussions`: where you can **exchange about RL and share information**.
- `rl-study-group`: where you can **ask questions and exchange with your classmates**.
- `rl-i-made-this`: where you can **share your projects and models**.
The HF Community Server has a thriving community of human beings interested in many areas, so you can also learn from those. There are paper discussions, events, and many other things.
Was this useful? There are a couple of tips I can share with you:
- There are **voice channels** you can use as well, although most people prefer text chat.
- You can **use markdown style** for text chats. So if you're writing code, you can use that style. Sadly this does not work as well for links.
- You can open threads as well! It's a good idea when **it's a long conversation**.
I hope this is useful! And if you have questions, just ask!
See you later!
Huggy 🐶
|
deep-rl-class/units/en/unit0/discord101.mdx/0
|
{
"file_path": "deep-rl-class/units/en/unit0/discord101.mdx",
"repo_id": "deep-rl-class",
"token_count": 685
}
| 80 |
# Additional Readings [[additional-readings]]
These are **optional readings** if you want to go deeper.
## Monte Carlo and TD Learning [[mc-td]]
To dive deeper into Monte Carlo and Temporal Difference Learning:
- <a href="https://stats.stackexchange.com/questions/355820/why-do-temporal-difference-td-methods-have-lower-variance-than-monte-carlo-met">Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?</a>
- <a href="https://stats.stackexchange.com/questions/336974/when-are-monte-carlo-methods-preferred-over-temporal-difference-ones"> When are Monte Carlo methods preferred over temporal difference ones?</a>
## Q-Learning [[q-learning]]
- <a href="http://incompleteideas.net/book/RLbook2020.pdf">Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 5, 6 and 7</a>
- <a href="https://youtu.be/Psrhxy88zww">Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel</a>
|
deep-rl-class/units/en/unit2/additional-readings.mdx/0
|
{
"file_path": "deep-rl-class/units/en/unit2/additional-readings.mdx",
"repo_id": "deep-rl-class",
"token_count": 297
}
| 81 |
# Conclusion [[conclusion]]
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep Q-Learning agent and shared it on the Hub 🥳.
Take time to really grasp the material before continuing.
Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert, Ms Pac Man). The **best way to learn is to try things on your own!**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari-envs.gif" alt="Environments"/>
In the next unit, **we're going to learn about Optuna**. One of the most critical tasks in Deep Reinforcement Learning is to find a good set of training hyperparameters. Optuna is a library that helps you to automate the search.
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
|
deep-rl-class/units/en/unit3/conclusion.mdx/0
|
{
"file_path": "deep-rl-class/units/en/unit3/conclusion.mdx",
"repo_id": "deep-rl-class",
"token_count": 291
}
| 82 |
# Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: What are the advantages of policy-gradient over value-based methods? (Check all that apply)
<Question
choices={[
{
text: "Policy-gradient methods can learn a stochastic policy",
explain: "",
correct: true,
},
{
text: "Policy-gradient methods are more effective in high-dimensional action spaces and continuous actions spaces",
explain: "",
correct: true,
},
{
text: "Policy-gradient converges most of the time on a global maximum.",
explain: "No, frequently, policy-gradient converges on a local maximum instead of a global optimum.",
},
]}
/>
### Q2: What is the Policy Gradient Theorem?
<details>
<summary>Solution</summary>
*The Policy Gradient Theorem* is a formula that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/policy_gradient_theorem.png" alt="Policy Gradient"/>
</details>
### Q3: What's the difference between policy-based methods and policy-gradient methods? (Check all that apply)
<Question
choices={[
{
text: "Policy-based methods are a subset of policy-gradient methods.",
explain: "",
},
{
text: "Policy-gradient methods are a subset of policy-based methods.",
explain: "",
correct: true,
},
{
text: "In Policy-based methods, we can optimize the parameter θ **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.",
explain: "",
correct: true,
},
{
text: "In Policy-gradient methods, we optimize the parameter θ **directly** by performing the gradient ascent on the performance of the objective function.",
explain: "",
correct: true,
},
]}
/>
### Q4: Why do we use gradient ascent instead of gradient descent to optimize J(θ)?
<Question
choices={[
{
text: "We want to minimize J(θ) and gradient ascent gives us the gives the direction of the steepest increase of J(θ)",
explain: "",
},
{
text: "We want to maximize J(θ) and gradient ascent gives us the gives the direction of the steepest increase of J(θ)",
explain: "",
correct: true
},
]}
/>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
|
deep-rl-class/units/en/unit4/quiz.mdx/0
|
{
"file_path": "deep-rl-class/units/en/unit4/quiz.mdx",
"repo_id": "deep-rl-class",
"token_count": 878
}
| 83 |
# Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: Which of the following interpretations of bias-variance tradeoff is the most accurate in the field of Reinforcement Learning?
<Question
choices={[
{
text: "The bias-variance tradeoff reflects how my model is able to generalize the knowledge to previously tagged data we give to the model during training time.",
explain: "This is the traditional bias-variance tradeoff in Machine Learning. In our specific case of Reinforcement Learning, we don't have previously tagged data, but only a reward signal.",
correct: false,
},
{
text: "The bias-variance tradeoff reflects how well the reinforcement signal reflects the true reward the agent should get from the enviromment",
explain: "",
correct: true,
},
]}
/>
### Q2: Which of the following statements are true, when talking about models with bias and/or variance in RL?
<Question
choices={[
{
text: "An unbiased reward signal returns rewards similar to the real / expected ones from the environment",
explain: "",
correct: true,
},
{
text: "A biased reward signal returns rewards similar to the real / expected ones from the environment",
explain: "If a reward signal is biased, it means the reward signal we get differs from the real reward we should be getting from an environment",
correct: false,
},
{
text: "A reward signal with high variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment",
explain: "",
correct: true,
},
{
text: "A reward signal with low variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment",
explain: "If a reward signal has low variance, then it's less affected by the noise of the environment and produce similar values regardless the random elements in the environment",
correct: false,
},
]}
/>
### Q3: Which of the following statements are true about Monte Carlo method?
<Question
choices={[
{
text: "It's a sampling mechanism, which means we don't analyze all the possible states, but a sample of those",
explain: "",
correct: true,
},
{
text: "It's very resistant to stochasticity (random elements in the trajectory)",
explain: "Monte Carlo randomly estimates everytime a sample of trajectories. However, even same trajectories can have different reward values if they contain stochastic elements",
correct: false,
},
{
text: "To reduce the impact of stochastic elements in Monte Carlo, we take `n` strategies and average them, reducing their individual impact",
explain: "",
correct: true,
},
]}
/>
### Q4: How would you describe, with your own words, the Actor-Critic Method (A2C)?
<details>
<summary>Solution</summary>
The idea behind Actor-Critic is that we learn two function approximations:
1. A `policy` that controls how our agent acts (π)
2. A `value` function to assist the policy update by measuring how good the action taken is (q)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/step2.jpg" alt="Actor-Critic, step 2"/>
</details>
### Q5: Which of the following statements are true about the Actor-Critic Method?
<Question
choices={[
{
text: "The Critic does not learn any function during the training process",
explain: "Both the Actor and the Critic function parameters are updated during training time",
correct: false,
},
{
text: "The Actor learns a policy function, while the Critic learns a value function",
explain: "",
correct: true,
},
{
text: "It adds resistance to stochasticity and reduces high variance",
explain: "",
correct: true,
},
]}
/>
### Q6: What is `Advantage` in the A2C method?
<details>
<summary>Solution</summary>
Instead of using directly the Action-Value function of the Critic as it is, we could use an `Advantage` function. The idea behind an `Advantage` function is that we calculate the relative advantage of an action compared to the others possible at a state, averaging them.
In other words: how taking that action at a state is better compared to the average value of the state
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/advantage1.jpg" alt="Advantage in A2C"/>
</details>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
|
deep-rl-class/units/en/unit6/quiz.mdx/0
|
{
"file_path": "deep-rl-class/units/en/unit6/quiz.mdx",
"repo_id": "deep-rl-class",
"token_count": 1508
}
| 84 |
# Introduction to PPO with Sample-Factory
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/thumbnail2.png" alt="thumbnail"/>
In this second part of Unit 8, we'll get deeper into PPO optimization by using [Sample-Factory](https://samplefactory.dev/), an **asynchronous implementation of the PPO algorithm**, to train our agent to play [vizdoom](https://vizdoom.cs.put.edu.pl/) (an open source version of Doom).
In the notebook, **you'll train your agent to play the Health Gathering level**, where the agent must collect health packs to avoid dying. After that, you can **train your agent to play more complex levels, such as Deathmatch**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/environments.png" alt="Environment"/>
Sound exciting? Let's get started! 🚀
The hands-on is made by [Edward Beeching](https://twitter.com/edwardbeeching), a Machine Learning Research Scientist at Hugging Face. He worked on Godot Reinforcement Learning Agents, an open-source interface for developing environments and agents in the Godot Game Engine.
|
deep-rl-class/units/en/unit8/introduction-sf.mdx/0
|
{
"file_path": "deep-rl-class/units/en/unit8/introduction-sf.mdx",
"repo_id": "deep-rl-class",
"token_count": 328
}
| 85 |
# Godot RL Agents
[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents) is an Open Source package that allows video game creators, AI researchers, and hobbyists the opportunity **to learn complex behaviors for their Non Player Characters or agents**.
The library provides:
- An interface between games created in the [Godot Engine](https://godotengine.org/) and Machine Learning algorithms running in Python
- Wrappers for four well known rl frameworks: [StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/), [CleanRL](https://docs.cleanrl.dev/), [Sample Factory](https://www.samplefactory.dev/) and [Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
- Support for memory-based agents with LSTM or attention based interfaces
- Support for *2D and 3D games*
- A suite of *AI sensors* to augment your agent's capacity to observe the game world
- Godot and Godot RL Agents are **completely free and open source under a very permissive MIT license**. No strings attached, no royalties, nothing.
You can find out more about Godot RL agents on their [GitHub page](https://github.com/edbeeching/godot_rl_agents) or their AAAI-2022 Workshop [paper](https://arxiv.org/abs/2112.03636). The library's creator, [Ed Beeching](https://edbeeching.github.io/), is a Research Scientist here at Hugging Face.
Installation of the library is simple: `pip install godot-rl`
## Create a custom RL environment with Godot RL Agents
In this section, you will **learn how to create a custom environment in the Godot Game Engine** and then implement an AI controller that learns to play with Deep Reinforcement Learning.
The example game we create today is simple, **but shows off many of the features of the Godot Engine and the Godot RL Agents library**. You can then dive into the examples for more complex environments and behaviors.
The environment we will be building today is called Ring Pong, the game of pong but the pitch is a ring and the paddle moves around the ring. The **objective is to keep the ball bouncing inside the ring**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/ringpong.gif" alt="Ring Pong">
### Installing the Godot Game Engine
The [Godot game engine](https://godotengine.org/) is an open source tool for the **creation of video games, tools and user interfaces**.
Godot Engine is a feature-packed, cross-platform game engine designed to create 2D and 3D games from a unified interface. It provides a comprehensive set of common tools, so users **can focus on making games without having to reinvent the wheel**. Games can be exported in one click to a number of platforms, including the major desktop platforms (Linux, macOS, Windows) as well as mobile (Android, iOS) and web-based (HTML5) platforms.
While we will guide you through the steps to implement your agent, you may wish to learn more about the Godot Game Engine. Their [documentation](https://docs.godotengine.org/en/latest/index.html) is thorough, and there are many tutorials on YouTube we would also recommend [GDQuest](https://www.gdquest.com/), [KidsCanCode](https://kidscancode.org/godot_recipes/4.x/) and [Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg) as sources of information.
In order to create games in Godot, **you must first download the editor**. Godot RL Agents supports the latest version of Godot, Godot 4.0.
Which can be downloaded at the following links:
- [Windows](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_win64.exe.zip)
- [Mac](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_macos.universal.zip)
- [Linux](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_linux.x86_64.zip)
### Loading the starter project
We provide two versions of the codebase:
- [A starter project, to download and follow along for this tutorial](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
- [A final version of the project, for comparison and debugging.](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
To load the project, in the Godot Project Manager click **Import**, navigate to where the files are located and load the **project.godot** file.
If you press F5 or play in the editor, you should be able to play the game in human mode. There are several instances of the game running, this is because we want to speed up training our AI agent with many parallel environments.
### Installing the Godot RL Agents plugin
The Godot RL Agents plugin can be installed from the Github repo or with the Godot Asset Lib in the editor.
First click on the AssetLib and search for “rl”
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot1.png" alt="Godot">
Then click on Godot RL Agents, click Download and unselect the LICENSE and README .md files. Then click install.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot2.png" alt="Godot">
The Godot RL Agents plugin is now downloaded to your machine. Now click on Project → Project settings and enable the addon:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot3.png" alt="Godot">
### Adding the AI controller
We now want to add an AI controller to our game. Open the player.tscn scene, on the left you should see a hierarchy of nodes that looks like this:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot4.png" alt="Godot">
Right click the **Player** node and click **Add Child Node.** There are many nodes listed here, search for AIController3D and create it.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot5.png" alt="Godot">
The AI Controller Node should have been added to the scene tree, next to it is a scroll. Click on it to open the script that is attached to the AIController. The Godot game engine uses a scripting language called GDScript, which is syntactically similar to python. The script contains methods that need to be implemented in order to get our AI controller working.
```python
#-- Methods that need implementing using the "extend script" option in Godot --#
func get_obs() -> Dictionary:
assert(false, "the get_obs method is not implemented when extending from ai_controller")
return {"obs":[]}
func get_reward() -> float:
assert(false, "the get_reward method is not implemented when extending from ai_controller")
return 0.0
func get_action_space() -> Dictionary:
assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
return {
"example_actions_continous" : {
"size": 2,
"action_type": "continuous"
},
"example_actions_discrete" : {
"size": 2,
"action_type": "discrete"
},
}
func set_action(action) -> void:
assert(false, "the get set_action method is not implemented when extending from ai_controller")
# -----------------------------------------------------------------------------#
```
In order to implement these methods, we will need to create a class that inherits from AIController3D. This is easy to do in Godot, and is called “extending” a class.
Right click the AIController3D Node and click “Extend Script” and call the new script `controller.gd`. You should now have an almost empty script file that looks like this:
```python
extends AIController3D
# Called when the node enters the scene tree for the first time.
func _ready():
pass # Replace with function body.
# Called every frame. 'delta' is the elapsed time since the previous frame.
func _process(delta):
pass
```
We will now implement the 4 missing methods, delete this code, and replace it with the following:
```python
extends AIController3D
# Stores the action sampled for the agent's policy, running in python
var move_action : float = 0.0
func get_obs() -> Dictionary:
# get the balls position and velocity in the paddle's frame of reference
var ball_pos = to_local(_player.ball.global_position)
var ball_vel = to_local(_player.ball.linear_velocity)
var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
return {"obs":obs}
func get_reward() -> float:
return reward
func get_action_space() -> Dictionary:
return {
"move_action" : {
"size": 1,
"action_type": "continuous"
},
}
func set_action(action) -> void:
move_action = clamp(action["move_action"][0], -1.0, 1.0)
```
We have now defined the agent’s observation, which is the position and velocity of the ball in its local coordinate space. We have also defined the action space of the agent, which is a single continuous value ranging from -1 to +1.
The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following:
```python
extends Node3D
@export var rotation_speed = 3.0
@onready var ball = get_node("../Ball")
@onready var ai_controller = $AIController3D
func _ready():
ai_controller.init(self)
func game_over():
ai_controller.done = true
ai_controller.needs_reset = true
func _physics_process(delta):
if ai_controller.needs_reset:
ai_controller.reset()
ball.reset()
return
var movement : float
if ai_controller.heuristic == "human":
movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
else:
movement = ai_controller.move_action
rotate_y(movement*delta*rotation_speed)
func _on_area_3d_body_entered(body):
ai_controller.reward += 1.0
```
We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node, and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
You can run training live in the editor, by first launching the python training with `gdrl`.
In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene, and you will see there is a “Speed Up” property exposed in the editor:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot6.png" alt="Godot">
Try setting this property up to 8 to speed up training. This can be a great benefit on more complex environments, like the multi-player FPS we will learn about in the next chapter.
### There’s more!
We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
For the ability to export the trained model to .onnx so that you can run inference directly from Godot without the Python server, and other useful training options, take a look at the [advanced SB3 tutorial](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/ADV_STABLE_BASELINES_3.md).
## Author
This section was written by <a href="https://twitter.com/edwardbeeching">Edward Beeching</a>
|
deep-rl-class/units/en/unitbonus3/godotrl.mdx/0
|
{
"file_path": "deep-rl-class/units/en/unitbonus3/godotrl.mdx",
"repo_id": "deep-rl-class",
"token_count": 3416
}
| 86 |
import glob
import sys
import pandas as pd
from huggingface_hub import hf_hub_download, upload_file
from huggingface_hub.utils._errors import EntryNotFoundError
sys.path.append(".")
from utils import BASE_PATH, FINAL_CSV_FILE, GITHUB_SHA, REPO_ID, collate_csv # noqa: E402
def has_previous_benchmark() -> str:
csv_path = None
try:
csv_path = hf_hub_download(repo_id=REPO_ID, repo_type="dataset", filename=FINAL_CSV_FILE)
except EntryNotFoundError:
csv_path = None
return csv_path
def filter_float(value):
if isinstance(value, str):
return float(value.split()[0])
return value
def push_to_hf_dataset():
all_csvs = sorted(glob.glob(f"{BASE_PATH}/*.csv"))
collate_csv(all_csvs, FINAL_CSV_FILE)
# If there's an existing benchmark file, we should report the changes.
csv_path = has_previous_benchmark()
if csv_path is not None:
current_results = pd.read_csv(FINAL_CSV_FILE)
previous_results = pd.read_csv(csv_path)
numeric_columns = current_results.select_dtypes(include=["float64", "int64"]).columns
numeric_columns = [
c for c in numeric_columns if c not in ["batch_size", "num_inference_steps", "actual_gpu_memory (gbs)"]
]
for column in numeric_columns:
previous_results[column] = previous_results[column].map(lambda x: filter_float(x))
# Calculate the percentage change
current_results[column] = current_results[column].astype(float)
previous_results[column] = previous_results[column].astype(float)
percent_change = ((current_results[column] - previous_results[column]) / previous_results[column]) * 100
# Format the values with '+' or '-' sign and append to original values
current_results[column] = current_results[column].map(str) + percent_change.map(
lambda x: f" ({'+' if x > 0 else ''}{x:.2f}%)"
)
# There might be newly added rows. So, filter out the NaNs.
current_results[column] = current_results[column].map(lambda x: x.replace(" (nan%)", ""))
# Overwrite the current result file.
current_results.to_csv(FINAL_CSV_FILE, index=False)
commit_message = f"upload from sha: {GITHUB_SHA}" if GITHUB_SHA is not None else "upload benchmark results"
upload_file(
repo_id=REPO_ID,
path_in_repo=FINAL_CSV_FILE,
path_or_fileobj=FINAL_CSV_FILE,
repo_type="dataset",
commit_message=commit_message,
)
if __name__ == "__main__":
push_to_hf_dataset()
|
diffusers/benchmarks/push_results.py/0
|
{
"file_path": "diffusers/benchmarks/push_results.py",
"repo_id": "diffusers",
"token_count": 1089
}
| 87 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Attention Processor
An attention processor is a class for applying different types of attention mechanisms.
## AttnProcessor
[[autodoc]] models.attention_processor.AttnProcessor
## AttnProcessor2_0
[[autodoc]] models.attention_processor.AttnProcessor2_0
## AttnAddedKVProcessor
[[autodoc]] models.attention_processor.AttnAddedKVProcessor
## AttnAddedKVProcessor2_0
[[autodoc]] models.attention_processor.AttnAddedKVProcessor2_0
## CrossFrameAttnProcessor
[[autodoc]] pipelines.text_to_video_synthesis.pipeline_text_to_video_zero.CrossFrameAttnProcessor
## CustomDiffusionAttnProcessor
[[autodoc]] models.attention_processor.CustomDiffusionAttnProcessor
## CustomDiffusionAttnProcessor2_0
[[autodoc]] models.attention_processor.CustomDiffusionAttnProcessor2_0
## CustomDiffusionXFormersAttnProcessor
[[autodoc]] models.attention_processor.CustomDiffusionXFormersAttnProcessor
## FusedAttnProcessor2_0
[[autodoc]] models.attention_processor.FusedAttnProcessor2_0
## LoRAAttnAddedKVProcessor
[[autodoc]] models.attention_processor.LoRAAttnAddedKVProcessor
## LoRAXFormersAttnProcessor
[[autodoc]] models.attention_processor.LoRAXFormersAttnProcessor
## SlicedAttnProcessor
[[autodoc]] models.attention_processor.SlicedAttnProcessor
## SlicedAttnAddedKVProcessor
[[autodoc]] models.attention_processor.SlicedAttnAddedKVProcessor
## XFormersAttnProcessor
[[autodoc]] models.attention_processor.XFormersAttnProcessor
|
diffusers/docs/source/en/api/attnprocessor.md/0
|
{
"file_path": "diffusers/docs/source/en/api/attnprocessor.md",
"repo_id": "diffusers",
"token_count": 629
}
| 88 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Models
🤗 Diffusers provides pretrained models for popular algorithms and modules to create custom diffusion systems. The primary function of models is to denoise an input sample as modeled by the distribution \\(p_{\theta}(x_{t-1}|x_{t})\\).
All models are built from the base [`ModelMixin`] class which is a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html) providing basic functionality for saving and loading models, locally and from the Hugging Face Hub.
## ModelMixin
[[autodoc]] ModelMixin
## FlaxModelMixin
[[autodoc]] FlaxModelMixin
## PushToHubMixin
[[autodoc]] utils.PushToHubMixin
|
diffusers/docs/source/en/api/models/overview.md/0
|
{
"file_path": "diffusers/docs/source/en/api/models/overview.md",
"repo_id": "diffusers",
"token_count": 336
}
| 89 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Kandinsky 2.2
Kandinsky 2.2 is created by [Arseniy Shakhmatov](https://github.com/cene555), [Anton Razzhigaev](https://github.com/razzant), [Aleksandr Nikolich](https://github.com/AlexWortega), [Vladimir Arkhipkin](https://github.com/oriBetelgeuse), [Igor Pavlov](https://github.com/boomb0om), [Andrey Kuznetsov](https://github.com/kuznetsoffandrey), and [Denis Dimitrov](https://github.com/denndimitrov).
The description from it's GitHub page is:
*Kandinsky 2.2 brings substantial improvements upon its predecessor, Kandinsky 2.1, by introducing a new, more powerful image encoder - CLIP-ViT-G and the ControlNet support. The switch to CLIP-ViT-G as the image encoder significantly increases the model's capability to generate more aesthetic pictures and better understand text, thus enhancing the model's overall performance. The addition of the ControlNet mechanism allows the model to effectively control the process of generating images. This leads to more accurate and visually appealing outputs and opens new possibilities for text-guided image manipulation.*
The original codebase can be found at [ai-forever/Kandinsky-2](https://github.com/ai-forever/Kandinsky-2).
<Tip>
Check out the [Kandinsky Community](https://huggingface.co/kandinsky-community) organization on the Hub for the official model checkpoints for tasks like text-to-image, image-to-image, and inpainting.
</Tip>
<Tip>
Make sure to check out the schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## KandinskyV22PriorPipeline
[[autodoc]] KandinskyV22PriorPipeline
- all
- __call__
- interpolate
## KandinskyV22Pipeline
[[autodoc]] KandinskyV22Pipeline
- all
- __call__
## KandinskyV22CombinedPipeline
[[autodoc]] KandinskyV22CombinedPipeline
- all
- __call__
## KandinskyV22ControlnetPipeline
[[autodoc]] KandinskyV22ControlnetPipeline
- all
- __call__
## KandinskyV22PriorEmb2EmbPipeline
[[autodoc]] KandinskyV22PriorEmb2EmbPipeline
- all
- __call__
- interpolate
## KandinskyV22Img2ImgPipeline
[[autodoc]] KandinskyV22Img2ImgPipeline
- all
- __call__
## KandinskyV22Img2ImgCombinedPipeline
[[autodoc]] KandinskyV22Img2ImgCombinedPipeline
- all
- __call__
## KandinskyV22ControlnetImg2ImgPipeline
[[autodoc]] KandinskyV22ControlnetImg2ImgPipeline
- all
- __call__
## KandinskyV22InpaintPipeline
[[autodoc]] KandinskyV22InpaintPipeline
- all
- __call__
## KandinskyV22InpaintCombinedPipeline
[[autodoc]] KandinskyV22InpaintCombinedPipeline
- all
- __call__
|
diffusers/docs/source/en/api/pipelines/kandinsky_v22.md/0
|
{
"file_path": "diffusers/docs/source/en/api/pipelines/kandinsky_v22.md",
"repo_id": "diffusers",
"token_count": 1050
}
| 90 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Depth-to-image
The Stable Diffusion model can also infer depth based on an image using [MiDaS](https://github.com/isl-org/MiDaS). This allows you to pass a text prompt and an initial image to condition the generation of new images as well as a `depth_map` to preserve the image structure.
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
If you're interested in using one of the official checkpoints for a task, explore the [CompVis](https://huggingface.co/CompVis), [Runway](https://huggingface.co/runwayml), and [Stability AI](https://huggingface.co/stabilityai) Hub organizations!
</Tip>
## StableDiffusionDepth2ImgPipeline
[[autodoc]] StableDiffusionDepth2ImgPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
- load_textual_inversion
- load_lora_weights
- save_lora_weights
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.md/0
|
{
"file_path": "diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.md",
"repo_id": "diffusers",
"token_count": 502
}
| 91 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Habana Gaudi
🤗 Diffusers is compatible with Habana Gaudi through 🤗 [Optimum](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion). Follow the [installation](https://docs.habana.ai/en/latest/Installation_Guide/index.html) guide to install the SynapseAI and Gaudi drivers, and then install Optimum Habana:
```bash
python -m pip install --upgrade-strategy eager optimum[habana]
```
To generate images with Stable Diffusion 1 and 2 on Gaudi, you need to instantiate two instances:
- [`~optimum.habana.diffusers.GaudiStableDiffusionPipeline`], a pipeline for text-to-image generation.
- [`~optimum.habana.diffusers.GaudiDDIMScheduler`], a Gaudi-optimized scheduler.
When you initialize the pipeline, you have to specify `use_habana=True` to deploy it on HPUs and to get the fastest possible generation, you should enable **HPU graphs** with `use_hpu_graphs=True`.
Finally, specify a [`~optimum.habana.GaudiConfig`] which can be downloaded from the [Habana](https://huggingface.co/Habana) organization on the Hub.
```python
from optimum.habana import GaudiConfig
from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
model_name = "stabilityai/stable-diffusion-2-base"
scheduler = GaudiDDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
pipeline = GaudiStableDiffusionPipeline.from_pretrained(
model_name,
scheduler=scheduler,
use_habana=True,
use_hpu_graphs=True,
gaudi_config="Habana/stable-diffusion-2",
)
```
Now you can call the pipeline to generate images by batches from one or several prompts:
```python
outputs = pipeline(
prompt=[
"High quality photo of an astronaut riding a horse in space",
"Face of a yellow cat, high resolution, sitting on a park bench",
],
num_images_per_prompt=10,
batch_size=4,
)
```
For more information, check out 🤗 Optimum Habana's [documentation](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion) and the [example](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) provided in the official GitHub repository.
## Benchmark
We benchmarked Habana's first-generation Gaudi and Gaudi2 with the [Habana/stable-diffusion](https://huggingface.co/Habana/stable-diffusion) and [Habana/stable-diffusion-2](https://huggingface.co/Habana/stable-diffusion-2) Gaudi configurations (mixed precision bf16/fp32) to demonstrate their performance.
For [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) on 512x512 images:
| | Latency (batch size = 1) | Throughput |
| ---------------------- |:------------------------:|:---------------------------:|
| first-generation Gaudi | 3.80s | 0.308 images/s (batch size = 8) |
| Gaudi2 | 1.33s | 1.081 images/s (batch size = 8) |
For [Stable Diffusion v2.1](https://huggingface.co/stabilityai/stable-diffusion-2-1) on 768x768 images:
| | Latency (batch size = 1) | Throughput |
| ---------------------- |:------------------------:|:-------------------------------:|
| first-generation Gaudi | 10.2s | 0.108 images/s (batch size = 4) |
| Gaudi2 | 3.17s | 0.379 images/s (batch size = 8) |
|
diffusers/docs/source/en/optimization/habana.md/0
|
{
"file_path": "diffusers/docs/source/en/optimization/habana.md",
"repo_id": "diffusers",
"token_count": 1399
}
| 92 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Distributed inference with multiple GPUs
On distributed setups, you can run inference across multiple GPUs with 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) or [PyTorch Distributed](https://pytorch.org/tutorials/beginner/dist_overview.html), which is useful for generating with multiple prompts in parallel.
This guide will show you how to use 🤗 Accelerate and PyTorch Distributed for distributed inference.
## 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) is a library designed to make it easy to train or run inference across distributed setups. It simplifies the process of setting up the distributed environment, allowing you to focus on your PyTorch code.
To begin, create a Python file and initialize an [`accelerate.PartialState`] to create a distributed environment; your setup is automatically detected so you don't need to explicitly define the `rank` or `world_size`. Move the [`DiffusionPipeline`] to `distributed_state.device` to assign a GPU to each process.
Now use the [`~accelerate.PartialState.split_between_processes`] utility as a context manager to automatically distribute the prompts between the number of processes.
```py
import torch
from accelerate import PartialState
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
)
distributed_state = PartialState()
pipeline.to(distributed_state.device)
with distributed_state.split_between_processes(["a dog", "a cat"]) as prompt:
result = pipeline(prompt).images[0]
result.save(f"result_{distributed_state.process_index}.png")
```
Use the `--num_processes` argument to specify the number of GPUs to use, and call `accelerate launch` to run the script:
```bash
accelerate launch run_distributed.py --num_processes=2
```
<Tip>
To learn more, take a look at the [Distributed Inference with 🤗 Accelerate](https://huggingface.co/docs/accelerate/en/usage_guides/distributed_inference#distributed-inference-with-accelerate) guide.
</Tip>
## PyTorch Distributed
PyTorch supports [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) which enables data parallelism.
To start, create a Python file and import `torch.distributed` and `torch.multiprocessing` to set up the distributed process group and to spawn the processes for inference on each GPU. You should also initialize a [`DiffusionPipeline`]:
```py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from diffusers import DiffusionPipeline
sd = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
)
```
You'll want to create a function to run inference; [`init_process_group`](https://pytorch.org/docs/stable/distributed.html?highlight=init_process_group#torch.distributed.init_process_group) handles creating a distributed environment with the type of backend to use, the `rank` of the current process, and the `world_size` or the number of processes participating. If you're running inference in parallel over 2 GPUs, then the `world_size` is 2.
Move the [`DiffusionPipeline`] to `rank` and use `get_rank` to assign a GPU to each process, where each process handles a different prompt:
```py
def run_inference(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
sd.to(rank)
if torch.distributed.get_rank() == 0:
prompt = "a dog"
elif torch.distributed.get_rank() == 1:
prompt = "a cat"
image = sd(prompt).images[0]
image.save(f"./{'_'.join(prompt)}.png")
```
To run the distributed inference, call [`mp.spawn`](https://pytorch.org/docs/stable/multiprocessing.html#torch.multiprocessing.spawn) to run the `run_inference` function on the number of GPUs defined in `world_size`:
```py
def main():
world_size = 2
mp.spawn(run_inference, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
main()
```
Once you've completed the inference script, use the `--nproc_per_node` argument to specify the number of GPUs to use and call `torchrun` to run the script:
```bash
torchrun run_distributed.py --nproc_per_node=2
```
|
diffusers/docs/source/en/training/distributed_inference.md/0
|
{
"file_path": "diffusers/docs/source/en/training/distributed_inference.md",
"repo_id": "diffusers",
"token_count": 1499
}
| 93 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
Welcome to 🧨 Diffusers! If you're new to diffusion models and generative AI, and want to learn more, then you've come to the right place. These beginner-friendly tutorials are designed to provide a gentle introduction to diffusion models and help you understand the library fundamentals - the core components and how 🧨 Diffusers is meant to be used.
You'll learn how to use a pipeline for inference to rapidly generate things, and then deconstruct that pipeline to really understand how to use the library as a modular toolbox for building your own diffusion systems. In the next lesson, you'll learn how to train your own diffusion model to generate what you want.
After completing the tutorials, you'll have gained the necessary skills to start exploring the library on your own and see how to use it for your own projects and applications.
Feel free to join our community on [Discord](https://discord.com/invite/JfAtkvEtRb) or the [forums](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) to connect and collaborate with other users and developers!
Let's start diffusing! 🧨
|
diffusers/docs/source/en/tutorials/tutorial_overview.md/0
|
{
"file_path": "diffusers/docs/source/en/tutorials/tutorial_overview.md",
"repo_id": "diffusers",
"token_count": 412
}
| 94 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
[[open-in-colab]]
# Performing inference with LCM-LoRA
Latent Consistency Models (LCM) enable quality image generation in typically 2-4 steps making it possible to use diffusion models in almost real-time settings.
From the [official website](https://latent-consistency-models.github.io/):
> LCMs can be distilled from any pre-trained Stable Diffusion (SD) in only 4,000 training steps (~32 A100 GPU Hours) for generating high quality 768 x 768 resolution images in 2~4 steps or even one step, significantly accelerating text-to-image generation. We employ LCM to distill the Dreamshaper-V7 version of SD in just 4,000 training iterations.
For a more technical overview of LCMs, refer to [the paper](https://huggingface.co/papers/2310.04378).
However, each model needs to be distilled separately for latent consistency distillation. The core idea with LCM-LoRA is to train just a few adapter layers, the adapter being LoRA in this case.
This way, we don't have to train the full model and keep the number of trainable parameters manageable. The resulting LoRAs can then be applied to any fine-tuned version of the model without distilling them separately.
Additionally, the LoRAs can be applied to image-to-image, ControlNet/T2I-Adapter, inpainting, AnimateDiff etc.
The LCM-LoRA can also be combined with other LoRAs to generate styled images in very few steps (4-8).
LCM-LoRAs are available for [stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5), [stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), and the [SSD-1B](https://huggingface.co/segmind/SSD-1B) model. All the checkpoints can be found in this [collection](https://huggingface.co/collections/latent-consistency/latent-consistency-models-loras-654cdd24e111e16f0865fba6).
For more details about LCM-LoRA, refer to [the technical report](https://huggingface.co/papers/2311.05556).
This guide shows how to perform inference with LCM-LoRAs for
- text-to-image
- image-to-image
- combined with styled LoRAs
- ControlNet/T2I-Adapter
- inpainting
- AnimateDiff
Before going through this guide, we'll take a look at the general workflow for performing inference with LCM-LoRAs.
LCM-LoRAs are similar to other Stable Diffusion LoRAs so they can be used with any [`DiffusionPipeline`] that supports LoRAs.
- Load the task specific pipeline and model.
- Set the scheduler to [`LCMScheduler`].
- Load the LCM-LoRA weights for the model.
- Reduce the `guidance_scale` between `[1.0, 2.0]` and set the `num_inference_steps` between [4, 8].
- Perform inference with the pipeline with the usual parameters.
Let's look at how we can perform inference with LCM-LoRAs for different tasks.
First, make sure you have [peft](https://github.com/huggingface/peft) installed, for better LoRA support.
```bash
pip install -U peft
```
## Text-to-image
You'll use the [`StableDiffusionXLPipeline`] with the scheduler: [`LCMScheduler`] and then load the LCM-LoRA. Together with the LCM-LoRA and the scheduler, the pipeline enables a fast inference workflow overcoming the slow iterative nature of diffusion models.
```python
import torch
from diffusers import DiffusionPipeline, LCMScheduler
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
variant="fp16",
torch_dtype=torch.float16
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl")
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
generator = torch.manual_seed(42)
image = pipe(
prompt=prompt, num_inference_steps=4, generator=generator, guidance_scale=1.0
).images[0]
```

Notice that we use only 4 steps for generation which is way less than what's typically used for standard SDXL.
<Tip>
You may have noticed that we set `guidance_scale=1.0`, which disables classifer-free-guidance. This is because the LCM-LoRA is trained with guidance, so the batch size does not have to be doubled in this case. This leads to a faster inference time, with the drawback that negative prompts don't have any effect on the denoising process.
You can also use guidance with LCM-LoRA, but due to the nature of training the model is very sensitve to the `guidance_scale` values, high values can lead to artifacts in the generated images. In our experiments, we found that the best values are in the range of [1.0, 2.0].
</Tip>
### Inference with a fine-tuned model
As mentioned above, the LCM-LoRA can be applied to any fine-tuned version of the model without having to distill them separately. Let's look at how we can perform inference with a fine-tuned model. In this example, we'll use the [animagine-xl](https://huggingface.co/Linaqruf/animagine-xl) model, which is a fine-tuned version of the SDXL model for generating anime.
```python
from diffusers import DiffusionPipeline, LCMScheduler
pipe = DiffusionPipeline.from_pretrained(
"Linaqruf/animagine-xl",
variant="fp16",
torch_dtype=torch.float16
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl")
prompt = "face focus, cute, masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt, num_inference_steps=4, generator=generator, guidance_scale=1.0
).images[0]
```

## Image-to-image
LCM-LoRA can be applied to image-to-image tasks too. Let's look at how we can perform image-to-image generation with LCMs. For this example we'll use the [dreamshaper-7](https://huggingface.co/Lykon/dreamshaper-7) model and the LCM-LoRA for `stable-diffusion-v1-5 `.
```python
import torch
from diffusers import AutoPipelineForImage2Image, LCMScheduler
from diffusers.utils import make_image_grid, load_image
pipe = AutoPipelineForImage2Image.from_pretrained(
"Lykon/dreamshaper-7",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdv1-5")
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronauts in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
generator = torch.manual_seed(0)
image = pipe(
prompt,
image=init_image,
num_inference_steps=4,
guidance_scale=1,
strength=0.6,
generator=generator
).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```

<Tip>
You can get different results based on your prompt and the image you provide. To get the best results, we recommend trying different values for `num_inference_steps`, `strength`, and `guidance_scale` parameters and choose the best one.
</Tip>
## Combine with styled LoRAs
LCM-LoRA can be combined with other LoRAs to generate styled-images in very few steps (4-8). In the following example, we'll use the LCM-LoRA with the [papercut LoRA](TheLastBen/Papercut_SDXL).
To learn more about how to combine LoRAs, refer to [this guide](https://huggingface.co/docs/diffusers/tutorials/using_peft_for_inference#combine-multiple-adapters).
```python
import torch
from diffusers import DiffusionPipeline, LCMScheduler
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
variant="fp16",
torch_dtype=torch.float16
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LoRAs
pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl", adapter_name="lcm")
pipe.load_lora_weights("TheLastBen/Papercut_SDXL", weight_name="papercut.safetensors", adapter_name="papercut")
# Combine LoRAs
pipe.set_adapters(["lcm", "papercut"], adapter_weights=[1.0, 0.8])
prompt = "papercut, a cute fox"
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=4, guidance_scale=1, generator=generator).images[0]
image
```

## ControlNet/T2I-Adapter
Let's look at how we can perform inference with ControlNet/T2I-Adapter and LCM-LoRA.
### ControlNet
For this example, we'll use the SD-v1-5 model and the LCM-LoRA for SD-v1-5 with canny ControlNet.
```python
import torch
import cv2
import numpy as np
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, LCMScheduler
from diffusers.utils import load_image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
).resize((512, 512))
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
controlnet=controlnet,
torch_dtype=torch.float16,
safety_checker=None,
variant="fp16"
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdv1-5")
generator = torch.manual_seed(0)
image = pipe(
"the mona lisa",
image=canny_image,
num_inference_steps=4,
guidance_scale=1.5,
controlnet_conditioning_scale=0.8,
cross_attention_kwargs={"scale": 1},
generator=generator,
).images[0]
make_image_grid([canny_image, image], rows=1, cols=2)
```

<Tip>
The inference parameters in this example might not work for all examples, so we recommend you to try different values for `num_inference_steps`, `guidance_scale`, `controlnet_conditioning_scale` and `cross_attention_kwargs` parameters and choose the best one.
</Tip>
### T2I-Adapter
This example shows how to use the LCM-LoRA with the [Canny T2I-Adapter](TencentARC/t2i-adapter-canny-sdxl-1.0) and SDXL.
```python
import torch
import cv2
import numpy as np
from PIL import Image
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, LCMScheduler
from diffusers.utils import load_image, make_image_grid
# Prepare image
# Detect the canny map in low resolution to avoid high-frequency details
image = load_image(
"https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_canny.jpg"
).resize((384, 384))
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image).resize((1024, 1024))
# load adapter
adapter = T2IAdapter.from_pretrained("TencentARC/t2i-adapter-canny-sdxl-1.0", torch_dtype=torch.float16, varient="fp16").to("cuda")
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
adapter=adapter,
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl")
prompt = "Mystical fairy in real, magic, 4k picture, high quality"
negative_prompt = "extra digit, fewer digits, cropped, worst quality, low quality, glitch, deformed, mutated, ugly, disfigured"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=canny_image,
num_inference_steps=4,
guidance_scale=1.5,
adapter_conditioning_scale=0.8,
adapter_conditioning_factor=1,
generator=generator,
).images[0]
make_image_grid([canny_image, image], rows=1, cols=2)
```

## Inpainting
LCM-LoRA can be used for inpainting as well.
```python
import torch
from diffusers import AutoPipelineForInpainting, LCMScheduler
from diffusers.utils import load_image, make_image_grid
pipe = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdv1-5")
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
# generator = torch.Generator("cuda").manual_seed(92)
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt,
image=init_image,
mask_image=mask_image,
generator=generator,
num_inference_steps=4,
guidance_scale=4,
).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```

## AnimateDiff
[`AnimateDiff`] allows you to animate images using Stable Diffusion models. To get good results, we need to generate multiple frames (16-24), and doing this with standard SD models can be very slow.
LCM-LoRA can be used to speed up the process significantly, as you just need to do 4-8 steps for each frame. Let's look at how we can perform animation with LCM-LoRA and AnimateDiff.
```python
import torch
from diffusers import MotionAdapter, AnimateDiffPipeline, DDIMScheduler, LCMScheduler
from diffusers.utils import export_to_gif
adapter = MotionAdapter.from_pretrained("diffusers/animatediff-motion-adapter-v1-5")
pipe = AnimateDiffPipeline.from_pretrained(
"frankjoshua/toonyou_beta6",
motion_adapter=adapter,
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdv1-5", adapter_name="lcm")
pipe.load_lora_weights("guoyww/animatediff-motion-lora-zoom-in", weight_name="diffusion_pytorch_model.safetensors", adapter_name="motion-lora")
pipe.set_adapters(["lcm", "motion-lora"], adapter_weights=[0.55, 1.2])
prompt = "best quality, masterpiece, 1girl, looking at viewer, blurry background, upper body, contemporary, dress"
generator = torch.manual_seed(0)
frames = pipe(
prompt=prompt,
num_inference_steps=5,
guidance_scale=1.25,
cross_attention_kwargs={"scale": 1},
num_frames=24,
generator=generator
).frames[0]
export_to_gif(frames, "animation.gif")
```

|
diffusers/docs/source/en/using-diffusers/inference_with_lcm_lora.md/0
|
{
"file_path": "diffusers/docs/source/en/using-diffusers/inference_with_lcm_lora.md",
"repo_id": "diffusers",
"token_count": 5693
}
| 95 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable Diffusion XL
[[open-in-colab]]
[Stable Diffusion XL](https://huggingface.co/papers/2307.01952) (SDXL) is a powerful text-to-image generation model that iterates on the previous Stable Diffusion models in three key ways:
1. the UNet is 3x larger and SDXL combines a second text encoder (OpenCLIP ViT-bigG/14) with the original text encoder to significantly increase the number of parameters
2. introduces size and crop-conditioning to preserve training data from being discarded and gain more control over how a generated image should be cropped
3. introduces a two-stage model process; the *base* model (can also be run as a standalone model) generates an image as an input to the *refiner* model which adds additional high-quality details
This guide will show you how to use SDXL for text-to-image, image-to-image, and inpainting.
Before you begin, make sure you have the following libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install -q diffusers transformers accelerate invisible-watermark>=0.2.0
```
<Tip warning={true}>
We recommend installing the [invisible-watermark](https://pypi.org/project/invisible-watermark/) library to help identify images that are generated. If the invisible-watermark library is installed, it is used by default. To disable the watermarker:
```py
pipeline = StableDiffusionXLPipeline.from_pretrained(..., add_watermarker=False)
```
</Tip>
## Load model checkpoints
Model weights may be stored in separate subfolders on the Hub or locally, in which case, you should use the [`~StableDiffusionXLPipeline.from_pretrained`] method:
```py
from diffusers import StableDiffusionXLPipeline, StableDiffusionXLImg2ImgPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
).to("cuda")
```
You can also use the [`~StableDiffusionXLPipeline.from_single_file`] method to load a model checkpoint stored in a single file format (`.ckpt` or `.safetensors`) from the Hub or locally:
```py
from diffusers import StableDiffusionXLPipeline, StableDiffusionXLImg2ImgPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_single_file(
"https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/sd_xl_base_1.0.safetensors",
torch_dtype=torch.float16
).to("cuda")
refiner = StableDiffusionXLImg2ImgPipeline.from_single_file(
"https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/blob/main/sd_xl_refiner_1.0.safetensors", torch_dtype=torch.float16
).to("cuda")
```
## Text-to-image
For text-to-image, pass a text prompt. By default, SDXL generates a 1024x1024 image for the best results. You can try setting the `height` and `width` parameters to 768x768 or 512x512, but anything below 512x512 is not likely to work.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline_text2image = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipeline_text2image(prompt=prompt).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png" alt="generated image of an astronaut in a jungle"/>
</div>
## Image-to-image
For image-to-image, SDXL works especially well with image sizes between 768x768 and 1024x1024. Pass an initial image, and a text prompt to condition the image with:
```py
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image, make_image_grid
# use from_pipe to avoid consuming additional memory when loading a checkpoint
pipeline = AutoPipelineForImage2Image.from_pipe(pipeline_text2image).to("cuda")
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"
init_image = load_image(url)
prompt = "a dog catching a frisbee in the jungle"
image = pipeline(prompt, image=init_image, strength=0.8, guidance_scale=10.5).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-img2img.png" alt="generated image of a dog catching a frisbee in a jungle"/>
</div>
## Inpainting
For inpainting, you'll need the original image and a mask of what you want to replace in the original image. Create a prompt to describe what you want to replace the masked area with.
```py
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
# use from_pipe to avoid consuming additional memory when loading a checkpoint
pipeline = AutoPipelineForInpainting.from_pipe(pipeline_text2image).to("cuda")
img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"
mask_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-inpaint-mask.png"
init_image = load_image(img_url)
mask_image = load_image(mask_url)
prompt = "A deep sea diver floating"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, strength=0.85, guidance_scale=12.5).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-inpaint.png" alt="generated image of a deep sea diver in a jungle"/>
</div>
## Refine image quality
SDXL includes a [refiner model](https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0) specialized in denoising low-noise stage images to generate higher-quality images from the base model. There are two ways to use the refiner:
1. use the base and refiner models together to produce a refined image
2. use the base model to produce an image, and subsequently use the refiner model to add more details to the image (this is how SDXL was originally trained)
### Base + refiner model
When you use the base and refiner model together to generate an image, this is known as an [*ensemble of expert denoisers*](https://research.nvidia.com/labs/dir/eDiff-I/). The ensemble of expert denoisers approach requires fewer overall denoising steps versus passing the base model's output to the refiner model, so it should be significantly faster to run. However, you won't be able to inspect the base model's output because it still contains a large amount of noise.
As an ensemble of expert denoisers, the base model serves as the expert during the high-noise diffusion stage and the refiner model serves as the expert during the low-noise diffusion stage. Load the base and refiner model:
```py
from diffusers import DiffusionPipeline
import torch
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
```
To use this approach, you need to define the number of timesteps for each model to run through their respective stages. For the base model, this is controlled by the [`denoising_end`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_xl#diffusers.StableDiffusionXLPipeline.__call__.denoising_end) parameter and for the refiner model, it is controlled by the [`denoising_start`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_xl#diffusers.StableDiffusionXLImg2ImgPipeline.__call__.denoising_start) parameter.
<Tip>
The `denoising_end` and `denoising_start` parameters should be a float between 0 and 1. These parameters are represented as a proportion of discrete timesteps as defined by the scheduler. If you're also using the `strength` parameter, it'll be ignored because the number of denoising steps is determined by the discrete timesteps the model is trained on and the declared fractional cutoff.
</Tip>
Let's set `denoising_end=0.8` so the base model performs the first 80% of denoising the **high-noise** timesteps and set `denoising_start=0.8` so the refiner model performs the last 20% of denoising the **low-noise** timesteps. The base model output should be in **latent** space instead of a PIL image.
```py
prompt = "A majestic lion jumping from a big stone at night"
image = base(
prompt=prompt,
num_inference_steps=40,
denoising_end=0.8,
output_type="latent",
).images
image = refiner(
prompt=prompt,
num_inference_steps=40,
denoising_start=0.8,
image=image,
).images[0]
image
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/lion_base.png" alt="generated image of a lion on a rock at night" />
<figcaption class="mt-2 text-center text-sm text-gray-500">default base model</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/lion_refined.png" alt="generated image of a lion on a rock at night in higher quality" />
<figcaption class="mt-2 text-center text-sm text-gray-500">ensemble of expert denoisers</figcaption>
</div>
</div>
The refiner model can also be used for inpainting in the [`StableDiffusionXLInpaintPipeline`]:
```py
from diffusers import StableDiffusionXLInpaintPipeline
from diffusers.utils import load_image, make_image_grid
import torch
base = StableDiffusionXLInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = StableDiffusionXLInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = load_image(img_url)
mask_image = load_image(mask_url)
prompt = "A majestic tiger sitting on a bench"
num_inference_steps = 75
high_noise_frac = 0.7
image = base(
prompt=prompt,
image=init_image,
mask_image=mask_image,
num_inference_steps=num_inference_steps,
denoising_end=high_noise_frac,
output_type="latent",
).images
image = refiner(
prompt=prompt,
image=image,
mask_image=mask_image,
num_inference_steps=num_inference_steps,
denoising_start=high_noise_frac,
).images[0]
make_image_grid([init_image, mask_image, image.resize((512, 512))], rows=1, cols=3)
```
This ensemble of expert denoisers method works well for all available schedulers!
### Base to refiner model
SDXL gets a boost in image quality by using the refiner model to add additional high-quality details to the fully-denoised image from the base model, in an image-to-image setting.
Load the base and refiner models:
```py
from diffusers import DiffusionPipeline
import torch
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
```
Generate an image from the base model, and set the model output to **latent** space:
```py
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = base(prompt=prompt, output_type="latent").images[0]
```
Pass the generated image to the refiner model:
```py
image = refiner(prompt=prompt, image=image[None, :]).images[0]
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/sd_xl/init_image.png" alt="generated image of an astronaut riding a green horse on Mars" />
<figcaption class="mt-2 text-center text-sm text-gray-500">base model</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/sd_xl/refined_image.png" alt="higher quality generated image of an astronaut riding a green horse on Mars" />
<figcaption class="mt-2 text-center text-sm text-gray-500">base model + refiner model</figcaption>
</div>
</div>
For inpainting, load the base and the refiner model in the [`StableDiffusionXLInpaintPipeline`], remove the `denoising_end` and `denoising_start` parameters, and choose a smaller number of inference steps for the refiner.
## Micro-conditioning
SDXL training involves several additional conditioning techniques, which are referred to as *micro-conditioning*. These include original image size, target image size, and cropping parameters. The micro-conditionings can be used at inference time to create high-quality, centered images.
<Tip>
You can use both micro-conditioning and negative micro-conditioning parameters thanks to classifier-free guidance. They are available in the [`StableDiffusionXLPipeline`], [`StableDiffusionXLImg2ImgPipeline`], [`StableDiffusionXLInpaintPipeline`], and [`StableDiffusionXLControlNetPipeline`].
</Tip>
### Size conditioning
There are two types of size conditioning:
- [`original_size`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_xl#diffusers.StableDiffusionXLPipeline.__call__.original_size) conditioning comes from upscaled images in the training batch (because it would be wasteful to discard the smaller images which make up almost 40% of the total training data). This way, SDXL learns that upscaling artifacts are not supposed to be present in high-resolution images. During inference, you can use `original_size` to indicate the original image resolution. Using the default value of `(1024, 1024)` produces higher-quality images that resemble the 1024x1024 images in the dataset. If you choose to use a lower resolution, such as `(256, 256)`, the model still generates 1024x1024 images, but they'll look like the low resolution images (simpler patterns, blurring) in the dataset.
- [`target_size`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_xl#diffusers.StableDiffusionXLPipeline.__call__.target_size) conditioning comes from finetuning SDXL to support different image aspect ratios. During inference, if you use the default value of `(1024, 1024)`, you'll get an image that resembles the composition of square images in the dataset. We recommend using the same value for `target_size` and `original_size`, but feel free to experiment with other options!
🤗 Diffusers also lets you specify negative conditions about an image's size to steer generation away from certain image resolutions:
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(
prompt=prompt,
negative_original_size=(512, 512),
negative_target_size=(1024, 1024),
).images[0]
```
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/sd_xl/negative_conditions.png"/>
<figcaption class="text-center">Images negatively conditioned on image resolutions of (128, 128), (256, 256), and (512, 512).</figcaption>
</div>
### Crop conditioning
Images generated by previous Stable Diffusion models may sometimes appear to be cropped. This is because images are actually cropped during training so that all the images in a batch have the same size. By conditioning on crop coordinates, SDXL *learns* that no cropping - coordinates `(0, 0)` - usually correlates with centered subjects and complete faces (this is the default value in 🤗 Diffusers). You can experiment with different coordinates if you want to generate off-centered compositions!
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipeline(prompt=prompt, crops_coords_top_left=(256, 0)).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-cropped.png" alt="generated image of an astronaut in a jungle, slightly cropped"/>
</div>
You can also specify negative cropping coordinates to steer generation away from certain cropping parameters:
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(
prompt=prompt,
negative_original_size=(512, 512),
negative_crops_coords_top_left=(0, 0),
negative_target_size=(1024, 1024),
).images[0]
image
```
## Use a different prompt for each text-encoder
SDXL uses two text-encoders, so it is possible to pass a different prompt to each text-encoder, which can [improve quality](https://github.com/huggingface/diffusers/issues/4004#issuecomment-1627764201). Pass your original prompt to `prompt` and the second prompt to `prompt_2` (use `negative_prompt` and `negative_prompt_2` if you're using negative prompts):
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
# prompt is passed to OAI CLIP-ViT/L-14
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# prompt_2 is passed to OpenCLIP-ViT/bigG-14
prompt_2 = "Van Gogh painting"
image = pipeline(prompt=prompt, prompt_2=prompt_2).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-double-prompt.png" alt="generated image of an astronaut in a jungle in the style of a van gogh painting"/>
</div>
The dual text-encoders also support textual inversion embeddings that need to be loaded separately as explained in the [SDXL textual inversion](textual_inversion_inference#stable-diffusion-xl) section.
## Optimizations
SDXL is a large model, and you may need to optimize memory to get it to run on your hardware. Here are some tips to save memory and speed up inference.
1. Offload the model to the CPU with [`~StableDiffusionXLPipeline.enable_model_cpu_offload`] for out-of-memory errors:
```diff
- base.to("cuda")
- refiner.to("cuda")
+ base.enable_model_cpu_offload()
+ refiner.enable_model_cpu_offload()
```
2. Use `torch.compile` for ~20% speed-up (you need `torch>=2.0`):
```diff
+ base.unet = torch.compile(base.unet, mode="reduce-overhead", fullgraph=True)
+ refiner.unet = torch.compile(refiner.unet, mode="reduce-overhead", fullgraph=True)
```
3. Enable [xFormers](../optimization/xformers) to run SDXL if `torch<2.0`:
```diff
+ base.enable_xformers_memory_efficient_attention()
+ refiner.enable_xformers_memory_efficient_attention()
```
## Other resources
If you're interested in experimenting with a minimal version of the [`UNet2DConditionModel`] used in SDXL, take a look at the [minSDXL](https://github.com/cloneofsimo/minSDXL) implementation which is written in PyTorch and directly compatible with 🤗 Diffusers.
|
diffusers/docs/source/en/using-diffusers/sdxl.md/0
|
{
"file_path": "diffusers/docs/source/en/using-diffusers/sdxl.md",
"repo_id": "diffusers",
"token_count": 6979
}
| 96 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# AutoPipeline
Diffusersは様々なタスクをこなすことができ、テキストから画像、画像から画像、画像の修復など、複数のタスクに対して同じように事前学習された重みを再利用することができます。しかし、ライブラリや拡散モデルに慣れていない場合、どのタスクにどのパイプラインを使えばいいのかがわかりにくいかもしれません。例えば、 [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) チェックポイントをテキストから画像に変換するために使用している場合、それぞれ[`StableDiffusionImg2ImgPipeline`]クラスと[`StableDiffusionInpaintPipeline`]クラスでチェックポイントをロードすることで、画像から画像や画像の修復にも使えることを知らない可能性もあります。
`AutoPipeline` クラスは、🤗 Diffusers の様々なパイプラインをよりシンプルするために設計されています。この汎用的でタスク重視のパイプラインによってタスクそのものに集中することができます。`AutoPipeline` は、使用するべき正しいパイプラインクラスを自動的に検出するため、特定のパイプラインクラス名を知らなくても、タスクのチェックポイントを簡単にロードできます。
<Tip>
どのタスクがサポートされているかは、[AutoPipeline](../api/pipelines/auto_pipeline) のリファレンスをご覧ください。現在、text-to-image、image-to-image、inpaintingをサポートしています。
</Tip>
このチュートリアルでは、`AutoPipeline` を使用して、事前に学習された重みが与えられたときに、特定のタスクを読み込むためのパイプラインクラスを自動的に推測する方法を示します。
## タスクに合わせてAutoPipeline を選択する
まずはチェックポイントを選ぶことから始めましょう。例えば、 [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) チェックポイントでテキストから画像への変換したいなら、[`AutoPipelineForText2Image`]を使います:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
).to("cuda")
prompt = "peasant and dragon combat, wood cutting style, viking era, bevel with rune"
image = pipeline(prompt, num_inference_steps=25).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/autopipeline-text2img.png" alt="generated image of peasant fighting dragon in wood cutting style"/>
</div>
[`AutoPipelineForText2Image`] を具体的に見ていきましょう:
1. [`model_index.json`](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json) ファイルから `"stable-diffusion"` クラスを自動的に検出します。
2. `"stable-diffusion"` のクラス名に基づいて、テキストから画像へ変換する [`StableDiffusionPipeline`] を読み込みます。
同様に、画像から画像へ変換する場合、[`AutoPipelineForImage2Image`] は `model_index.json` ファイルから `"stable-diffusion"` チェックポイントを検出し、対応する [`StableDiffusionImg2ImgPipeline`] を読み込みます。また、入力画像にノイズの量やバリエーションの追加を決めるための強さなど、パイプラインクラスに固有の追加引数を渡すこともできます:
```py
from diffusers import AutoPipelineForImage2Image
import torch
import requests
from PIL import Image
from io import BytesIO
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
).to("cuda")
prompt = "a portrait of a dog wearing a pearl earring"
url = "https://upload.wikimedia.org/wikipedia/commons/thumb/0/0f/1665_Girl_with_a_Pearl_Earring.jpg/800px-1665_Girl_with_a_Pearl_Earring.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
image.thumbnail((768, 768))
image = pipeline(prompt, image, num_inference_steps=200, strength=0.75, guidance_scale=10.5).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/autopipeline-img2img.png" alt="generated image of a vermeer portrait of a dog wearing a pearl earring"/>
</div>
また、画像の修復を行いたい場合は、 [`AutoPipelineForInpainting`] が、同様にベースとなる[`StableDiffusionInpaintPipeline`]クラスを読み込みます:
```py
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image
import torch
pipeline = AutoPipelineForInpainting.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True
).to("cuda")
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = load_image(img_url).convert("RGB")
mask_image = load_image(mask_url).convert("RGB")
prompt = "A majestic tiger sitting on a bench"
image = pipeline(prompt, image=init_image, mask_image=mask_image, num_inference_steps=50, strength=0.80).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/autopipeline-inpaint.png" alt="generated image of a tiger sitting on a bench"/>
</div>
サポートされていないチェックポイントを読み込もうとすると、エラーになります:
```py
from diffusers import AutoPipelineForImage2Image
import torch
pipeline = AutoPipelineForImage2Image.from_pretrained(
"openai/shap-e-img2img", torch_dtype=torch.float16, use_safetensors=True
)
"ValueError: AutoPipeline can't find a pipeline linked to ShapEImg2ImgPipeline for None"
```
## 複数のパイプラインを使用する
いくつかのワークフローや多くのパイプラインを読み込む場合、不要なメモリを使ってしまう再読み込みをするよりも、チェックポイントから同じコンポーネントを再利用する方がメモリ効率が良いです。たとえば、テキストから画像への変換にチェックポイントを使い、画像から画像への変換にまたチェックポイントを使いたい場合、[from_pipe()](https://huggingface.co/docs/diffusers/v0.25.1/en/api/pipelines/auto_pipeline#diffusers.AutoPipelineForImage2Image.from_pipe) メソッドを使用します。このメソッドは、以前読み込まれたパイプラインのコンポーネントを使うことで追加のメモリを消費することなく、新しいパイプラインを作成します。
[from_pipe()](https://huggingface.co/docs/diffusers/v0.25.1/en/api/pipelines/auto_pipeline#diffusers.AutoPipelineForImage2Image.from_pipe) メソッドは、元のパイプラインクラスを検出し、実行したいタスクに対応する新しいパイプラインクラスにマッピングします。例えば、テキストから画像への`"stable-diffusion"` クラスのパイプラインを読み込む場合:
```py
from diffusers import AutoPipelineForText2Image, AutoPipelineForImage2Image
import torch
pipeline_text2img = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
)
print(type(pipeline_text2img))
"<class 'diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline'>"
```
そして、[from_pipe()] (https://huggingface.co/docs/diffusers/v0.25.1/en/api/pipelines/auto_pipeline#diffusers.AutoPipelineForImage2Image.from_pipe)は、もとの`"stable-diffusion"` パイプラインのクラスである [`StableDiffusionImg2ImgPipeline`] にマップします:
```py
pipeline_img2img = AutoPipelineForImage2Image.from_pipe(pipeline_text2img)
print(type(pipeline_img2img))
"<class 'diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline'>"
```
元のパイプラインにオプションとして引数(セーフティチェッカーの無効化など)を渡した場合、この引数も新しいパイプラインに渡されます:
```py
from diffusers import AutoPipelineForText2Image, AutoPipelineForImage2Image
import torch
pipeline_text2img = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
requires_safety_checker=False,
).to("cuda")
pipeline_img2img = AutoPipelineForImage2Image.from_pipe(pipeline_text2img)
print(pipeline_img2img.config.requires_safety_checker)
"False"
```
新しいパイプラインの動作を変更したい場合は、元のパイプラインの引数や設定を上書きすることができます。例えば、セーフティチェッカーをオンに戻し、`strength` 引数を追加します:
```py
pipeline_img2img = AutoPipelineForImage2Image.from_pipe(pipeline_text2img, requires_safety_checker=True, strength=0.3)
print(pipeline_img2img.config.requires_safety_checker)
"True"
```
|
diffusers/docs/source/ja/tutorials/autopipeline.md/0
|
{
"file_path": "diffusers/docs/source/ja/tutorials/autopipeline.md",
"repo_id": "diffusers",
"token_count": 4100
}
| 97 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# xFormers 설치하기
추론과 학습 모두에 [xFormers](https://github.com/facebookresearch/xformers)를 사용하는 것이 좋습니다.
자체 테스트로 어텐션 블록에서 수행된 최적화가 더 빠른 속도와 적은 메모리 소비를 확인했습니다.
2023년 1월에 출시된 xFormers 버전 '0.0.16'부터 사전 빌드된 pip wheel을 사용하여 쉽게 설치할 수 있습니다:
```bash
pip install xformers
```
<Tip>
xFormers PIP 패키지에는 최신 버전의 PyTorch(xFormers 0.0.16에 1.13.1)가 필요합니다. 이전 버전의 PyTorch를 사용해야 하는 경우 [프로젝트 지침](https://github.com/facebookresearch/xformers#installing-xformers)의 소스를 사용해 xFormers를 설치하는 것이 좋습니다.
</Tip>
xFormers를 설치하면, [여기](fp16#memory-efficient-attention)서 설명한 것처럼 'enable_xformers_memory_efficient_attention()'을 사용하여 추론 속도를 높이고 메모리 소비를 줄일 수 있습니다.
<Tip warning={true}>
[이 이슈](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212)에 따르면 xFormers `v0.0.16`에서 GPU를 사용한 학습(파인 튜닝 또는 Dreambooth)을 할 수 없습니다. 해당 문제가 발견되면. 해당 코멘트를 참고해 development 버전을 설치하세요.
</Tip>
|
diffusers/docs/source/ko/optimization/xformers.md/0
|
{
"file_path": "diffusers/docs/source/ko/optimization/xformers.md",
"repo_id": "diffusers",
"token_count": 1049
}
| 98 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
🧨 Diffusers에 오신 걸 환영합니다! 여러분이 diffusion 모델과 생성 AI를 처음 접하고, 더 많은 걸 배우고 싶으셨다면 제대로 찾아오셨습니다. 이 튜토리얼은 diffusion model을 여러분에게 젠틀하게 소개하고, 라이브러리의 기본 사항(핵심 구성요소와 🧨 Diffusers 사용법)을 이해하는 데 도움이 되도록 설계되었습니다.
여러분은 이 튜토리얼을 통해 빠르게 생성하기 위해선 추론 파이프라인을 어떻게 사용해야 하는지, 그리고 라이브러리를 modular toolbox처럼 이용해서 여러분만의 diffusion system을 구축할 수 있도록 파이프라인을 분해하는 법을 배울 수 있습니다. 다음 단원에서는 여러분이 원하는 것을 생성하기 위해 자신만의 diffusion model을 학습하는 방법을 배우게 됩니다.
튜토리얼을 완료한다면 여러분은 라이브러리를 직접 탐색하고, 자신의 프로젝트와 애플리케이션에 적용할 스킬들을 습득할 수 있을 겁니다.
[Discord](https://discord.com/invite/JfAtkvEtRb)나 [포럼](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) 커뮤니티에 자유롭게 참여해서 다른 사용자와 개발자들과 교류하고 협업해 보세요!
자 지금부터 diffusing을 시작해 보겠습니다! 🧨
|
diffusers/docs/source/ko/tutorials/tutorial_overview.md/0
|
{
"file_path": "diffusers/docs/source/ko/tutorials/tutorial_overview.md",
"repo_id": "diffusers",
"token_count": 1210
}
| 99 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 스케줄러
diffusion 파이프라인은 diffusion 모델, 스케줄러 등의 컴포넌트들로 구성됩니다. 그리고 파이프라인 안의 일부 컴포넌트를 다른 컴포넌트로 교체하는 식의 커스터마이징 역시 가능합니다. 이와 같은 컴포넌트 커스터마이징의 가장 대표적인 예시가 바로 [스케줄러](../api/schedulers/overview.md)를 교체하는 것입니다.
스케쥴러는 다음과 같이 diffusion 시스템의 전반적인 디노이징 프로세스를 정의합니다.
- 디노이징 스텝을 얼마나 가져가야 할까?
- 확률적으로(stochastic) 혹은 확정적으로(deterministic)?
- 디노이징 된 샘플을 찾아내기 위해 어떤 알고리즘을 사용해야 할까?
이러한 프로세스는 다소 난해하고, 디노이징 속도와 디노이징 퀄리티 사이의 트레이드 오프를 정의해야 하는 문제가 될 수 있습니다. 주어진 파이프라인에 어떤 스케줄러가 가장 적합한지를 정량적으로 판단하는 것은 매우 어려운 일입니다. 이로 인해 일단 해당 스케줄러를 직접 사용하여, 생성되는 이미지를 직접 눈으로 보며, 정성적으로 성능을 판단해보는 것이 추천되곤 합니다.
## 파이프라인 불러오기
먼저 스테이블 diffusion 파이프라인을 불러오도록 해보겠습니다. 물론 스테이블 diffusion을 사용하기 위해서는, 허깅페이스 허브에 등록된 사용자여야 하며, 관련 [라이센스](https://huggingface.co/runwayml/stable-diffusion-v1-5)에 동의해야 한다는 점을 잊지 말아주세요.
*역자 주: 다만, 현재 신규로 생성한 허깅페이스 계정에 대해서는 라이센스 동의를 요구하지 않는 것으로 보입니다!*
```python
from huggingface_hub import login
from diffusers import DiffusionPipeline
import torch
# first we need to login with our access token
login()
# Now we can download the pipeline
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
```
다음으로, GPU로 이동합니다.
```python
pipeline.to("cuda")
```
## 스케줄러 액세스
스케줄러는 언제나 파이프라인의 컴포넌트로서 존재하며, 일반적으로 파이프라인 인스턴스 내에 `scheduler`라는 이름의 속성(property)으로 정의되어 있습니다.
```python
pipeline.scheduler
```
**Output**:
```
PNDMScheduler {
"_class_name": "PNDMScheduler",
"_diffusers_version": "0.8.0.dev0",
"beta_end": 0.012,
"beta_schedule": "scaled_linear",
"beta_start": 0.00085,
"clip_sample": false,
"num_train_timesteps": 1000,
"set_alpha_to_one": false,
"skip_prk_steps": true,
"steps_offset": 1,
"trained_betas": null
}
```
출력 결과를 통해, 우리는 해당 스케줄러가 [`PNDMScheduler`]의 인스턴스라는 것을 알 수 있습니다. 이제 [`PNDMScheduler`]와 다른 스케줄러들의 성능을 비교해보도록 하겠습니다. 먼저 테스트에 사용할 프롬프트를 다음과 같이 정의해보도록 하겠습니다.
```python
prompt = "A photograph of an astronaut riding a horse on Mars, high resolution, high definition."
```
다음으로 유사한 이미지 생성을 보장하기 위해서, 다음과 같이 랜덤시드를 고정해주도록 하겠습니다.
```python
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_pndm.png" width="400"/>
<br>
</p>
## 스케줄러 교체하기
다음으로 파이프라인의 스케줄러를 다른 스케줄러로 교체하는 방법에 대해 알아보겠습니다. 모든 스케줄러는 [`SchedulerMixin.compatibles`]라는 속성(property)을 갖고 있습니다. 해당 속성은 **호환 가능한** 스케줄러들에 대한 정보를 담고 있습니다.
```python
pipeline.scheduler.compatibles
```
**Output**:
```
[diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
diffusers.schedulers.scheduling_ddim.DDIMScheduler,
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
diffusers.schedulers.scheduling_pndm.PNDMScheduler,
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler]
```
호환되는 스케줄러들을 살펴보면 아래와 같습니다.
- [`LMSDiscreteScheduler`],
- [`DDIMScheduler`],
- [`DPMSolverMultistepScheduler`],
- [`EulerDiscreteScheduler`],
- [`PNDMScheduler`],
- [`DDPMScheduler`],
- [`EulerAncestralDiscreteScheduler`].
앞서 정의했던 프롬프트를 사용해서 각각의 스케줄러들을 비교해보도록 하겠습니다.
먼저 파이프라인 안의 스케줄러를 바꾸기 위해 [`ConfigMixin.config`] 속성과 [`ConfigMixin.from_config`] 메서드를 활용해보려고 합니다.
```python
pipeline.scheduler.config
```
**Output**:
```
FrozenDict([('num_train_timesteps', 1000),
('beta_start', 0.00085),
('beta_end', 0.012),
('beta_schedule', 'scaled_linear'),
('trained_betas', None),
('skip_prk_steps', True),
('set_alpha_to_one', False),
('steps_offset', 1),
('_class_name', 'PNDMScheduler'),
('_diffusers_version', '0.8.0.dev0'),
('clip_sample', False)])
```
기존 스케줄러의 config를 호환 가능한 다른 스케줄러에 이식하는 것 역시 가능합니다.
다음 예시는 기존 스케줄러(`pipeline.scheduler`)를 다른 종류의 스케줄러(`DDIMScheduler`)로 바꾸는 코드입니다. 기존 스케줄러가 갖고 있던 config를 `.from_config` 메서드의 인자로 전달하는 것을 확인할 수 있습니다.
```python
from diffusers import DDIMScheduler
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
```
이제 파이프라인을 실행해서 두 스케줄러 사이의 생성된 이미지의 퀄리티를 비교해봅시다.
```python
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_ddim.png" width="400"/>
<br>
</p>
## 스케줄러들 비교해보기
지금까지는 [`PNDMScheduler`]와 [`DDIMScheduler`] 스케줄러를 실행해보았습니다. 아직 비교해볼 스케줄러들이 더 많이 남아있으니 계속 비교해보도록 하겠습니다.
[`LMSDiscreteScheduler`]을 일반적으로 더 좋은 결과를 보여줍니다.
```python
from diffusers import LMSDiscreteScheduler
pipeline.scheduler = LMSDiscreteScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_lms.png" width="400"/>
<br>
</p>
[`EulerDiscreteScheduler`]와 [`EulerAncestralDiscreteScheduler`] 고작 30번의 inference step만으로도 높은 퀄리티의 이미지를 생성하는 것을 알 수 있습니다.
```python
from diffusers import EulerDiscreteScheduler
pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator, num_inference_steps=30).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_euler_discrete.png" width="400"/>
<br>
</p>
```python
from diffusers import EulerAncestralDiscreteScheduler
pipeline.scheduler = EulerAncestralDiscreteScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator, num_inference_steps=30).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_euler_ancestral.png" width="400"/>
<br>
</p>
지금 이 문서를 작성하는 현시점 기준에선, [`DPMSolverMultistepScheduler`]가 시간 대비 가장 좋은 품질의 이미지를 생성하는 것 같습니다. 20번 정도의 스텝만으로도 실행될 수 있습니다.
```python
from diffusers import DPMSolverMultistepScheduler
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator, num_inference_steps=20).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_dpm.png" width="400"/>
<br>
</p>
보시다시피 생성된 이미지들은 매우 비슷하고, 비슷한 퀄리티를 보이는 것 같습니다. 실제로 어떤 스케줄러를 선택할 것인가는 종종 특정 이용 사례에 기반해서 결정되곤 합니다. 결국 여러 종류의 스케줄러를 직접 실행시켜보고 눈으로 직접 비교해서 판단하는 게 좋은 선택일 것 같습니다.
## Flax에서 스케줄러 교체하기
JAX/Flax 사용자인 경우 기본 파이프라인 스케줄러를 변경할 수도 있습니다. 다음은 Flax Stable Diffusion 파이프라인과 초고속 [DDPM-Solver++ 스케줄러를](../api/schedulers/multistep_dpm_solver) 사용하여 추론을 실행하는 방법에 대한 예시입니다 .
```Python
import jax
import numpy as np
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline, FlaxDPMSolverMultistepScheduler
model_id = "runwayml/stable-diffusion-v1-5"
scheduler, scheduler_state = FlaxDPMSolverMultistepScheduler.from_pretrained(
model_id,
subfolder="scheduler"
)
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
model_id,
scheduler=scheduler,
revision="bf16",
dtype=jax.numpy.bfloat16,
)
params["scheduler"] = scheduler_state
# Generate 1 image per parallel device (8 on TPUv2-8 or TPUv3-8)
prompt = "a photo of an astronaut riding a horse on mars"
num_samples = jax.device_count()
prompt_ids = pipeline.prepare_inputs([prompt] * num_samples)
prng_seed = jax.random.PRNGKey(0)
num_inference_steps = 25
# shard inputs and rng
params = replicate(params)
prng_seed = jax.random.split(prng_seed, jax.device_count())
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
```
<Tip warning={true}>
다음 Flax 스케줄러는 *아직* Flax Stable Diffusion 파이프라인과 호환되지 않습니다.
- `FlaxLMSDiscreteScheduler`
- `FlaxDDPMScheduler`
</Tip>
|
diffusers/docs/source/ko/using-diffusers/schedulers.md/0
|
{
"file_path": "diffusers/docs/source/ko/using-diffusers/schedulers.md",
"repo_id": "diffusers",
"token_count": 6917
}
| 100 |
<!---
Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🧨 Diffusers Examples
Diffusers examples are a collection of scripts to demonstrate how to effectively use the `diffusers` library
for a variety of use cases involving training or fine-tuning.
**Note**: If you are looking for **official** examples on how to use `diffusers` for inference, please have a look at [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
Our examples aspire to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
More specifically, this means:
- **Self-contained**: An example script shall only depend on "pip-install-able" Python packages that can be found in a `requirements.txt` file. Example scripts shall **not** depend on any local files. This means that one can simply download an example script, *e.g.* [train_unconditional.py](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py), install the required dependencies, *e.g.* [requirements.txt](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/requirements.txt) and execute the example script.
- **Easy-to-tweak**: While we strive to present as many use cases as possible, the example scripts are just that - examples. It is expected that they won't work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data and the training loop to allow you to tweak and edit them as required.
- **Beginner-friendly**: We do not aim for providing state-of-the-art training scripts for the newest models, but rather examples that can be used as a way to better understand diffusion models and how to use them with the `diffusers` library. We often purposefully leave out certain state-of-the-art methods if we consider them too complex for beginners.
- **One-purpose-only**: Examples should show one task and one task only. Even if a task is from a modeling point of view very similar, *e.g.* image super-resolution and image modification tend to use the same model and training method, we want examples to showcase only one task to keep them as readable and easy-to-understand as possible.
We provide **official** examples that cover the most popular tasks of diffusion models.
*Official* examples are **actively** maintained by the `diffusers` maintainers and we try to rigorously follow our example philosophy as defined above.
If you feel like another important example should exist, we are more than happy to welcome a [Feature Request](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=) or directly a [Pull Request](https://github.com/huggingface/diffusers/compare) from you!
Training examples show how to pretrain or fine-tune diffusion models for a variety of tasks. Currently we support:
| Task | 🤗 Accelerate | 🤗 Datasets | Colab
|---|---|:---:|:---:|
| [**Unconditional Image Generation**](./unconditional_image_generation) | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
| [**Text-to-Image fine-tuning**](./text_to_image) | ✅ | ✅ |
| [**Textual Inversion**](./textual_inversion) | ✅ | - | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
| [**Dreambooth**](./dreambooth) | ✅ | - | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb)
| [**ControlNet**](./controlnet) | ✅ | ✅ | -
| [**InstructPix2Pix**](./instruct_pix2pix) | ✅ | ✅ | -
| [**Reinforcement Learning for Control**](https://github.com/huggingface/diffusers/blob/main/examples/reinforcement_learning/run_diffusers_locomotion.py) | - | - | coming soon.
## Community
In addition, we provide **community** examples, which are examples added and maintained by our community.
Community examples can consist of both *training* examples or *inference* pipelines.
For such examples, we are more lenient regarding the philosophy defined above and also cannot guarantee to provide maintenance for every issue.
Examples that are useful for the community, but are either not yet deemed popular or not yet following our above philosophy should go into the [community examples](https://github.com/huggingface/diffusers/tree/main/examples/community) folder. The community folder therefore includes training examples and inference pipelines.
**Note**: Community examples can be a [great first contribution](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) to show to the community how you like to use `diffusers` 🪄.
## Research Projects
We also provide **research_projects** examples that are maintained by the community as defined in the respective research project folders. These examples are useful and offer the extended capabilities which are complementary to the official examples. You may refer to [research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects) for details.
## Important note
To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder of your choice and run
```bash
pip install -r requirements.txt
```
|
diffusers/examples/README.md/0
|
{
"file_path": "diffusers/examples/README.md",
"repo_id": "diffusers",
"token_count": 1796
}
| 101 |
from typing import Optional
import torch
from PIL import Image
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DDIMScheduler, DiffusionPipeline, UNet2DConditionModel
from diffusers.image_processor import VaeImageProcessor
from diffusers.utils import (
deprecate,
)
class EDICTPipeline(DiffusionPipeline):
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: DDIMScheduler,
mixing_coeff: float = 0.93,
leapfrog_steps: bool = True,
):
self.mixing_coeff = mixing_coeff
self.leapfrog_steps = leapfrog_steps
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
def _encode_prompt(
self, prompt: str, negative_prompt: Optional[str] = None, do_classifier_free_guidance: bool = False
):
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
prompt_embeds = self.text_encoder(text_inputs.input_ids.to(self.device)).last_hidden_state
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=self.device)
if do_classifier_free_guidance:
uncond_tokens = "" if negative_prompt is None else negative_prompt
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
negative_prompt_embeds = self.text_encoder(uncond_input.input_ids.to(self.device)).last_hidden_state
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def denoise_mixing_layer(self, x: torch.Tensor, y: torch.Tensor):
x = self.mixing_coeff * x + (1 - self.mixing_coeff) * y
y = self.mixing_coeff * y + (1 - self.mixing_coeff) * x
return [x, y]
def noise_mixing_layer(self, x: torch.Tensor, y: torch.Tensor):
y = (y - (1 - self.mixing_coeff) * x) / self.mixing_coeff
x = (x - (1 - self.mixing_coeff) * y) / self.mixing_coeff
return [x, y]
def _get_alpha_and_beta(self, t: torch.Tensor):
# as self.alphas_cumprod is always in cpu
t = int(t)
alpha_prod = self.scheduler.alphas_cumprod[t] if t >= 0 else self.scheduler.final_alpha_cumprod
return alpha_prod, 1 - alpha_prod
def noise_step(
self,
base: torch.Tensor,
model_input: torch.Tensor,
model_output: torch.Tensor,
timestep: torch.Tensor,
):
prev_timestep = timestep - self.scheduler.config.num_train_timesteps / self.scheduler.num_inference_steps
alpha_prod_t, beta_prod_t = self._get_alpha_and_beta(timestep)
alpha_prod_t_prev, beta_prod_t_prev = self._get_alpha_and_beta(prev_timestep)
a_t = (alpha_prod_t_prev / alpha_prod_t) ** 0.5
b_t = -a_t * (beta_prod_t**0.5) + beta_prod_t_prev**0.5
next_model_input = (base - b_t * model_output) / a_t
return model_input, next_model_input.to(base.dtype)
def denoise_step(
self,
base: torch.Tensor,
model_input: torch.Tensor,
model_output: torch.Tensor,
timestep: torch.Tensor,
):
prev_timestep = timestep - self.scheduler.config.num_train_timesteps / self.scheduler.num_inference_steps
alpha_prod_t, beta_prod_t = self._get_alpha_and_beta(timestep)
alpha_prod_t_prev, beta_prod_t_prev = self._get_alpha_and_beta(prev_timestep)
a_t = (alpha_prod_t_prev / alpha_prod_t) ** 0.5
b_t = -a_t * (beta_prod_t**0.5) + beta_prod_t_prev**0.5
next_model_input = a_t * base + b_t * model_output
return model_input, next_model_input.to(base.dtype)
@torch.no_grad()
def decode_latents(self, latents: torch.Tensor):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
return image
@torch.no_grad()
def prepare_latents(
self,
image: Image.Image,
text_embeds: torch.Tensor,
timesteps: torch.Tensor,
guidance_scale: float,
generator: Optional[torch.Generator] = None,
):
do_classifier_free_guidance = guidance_scale > 1.0
image = image.to(device=self.device, dtype=text_embeds.dtype)
latent = self.vae.encode(image).latent_dist.sample(generator)
latent = self.vae.config.scaling_factor * latent
coupled_latents = [latent.clone(), latent.clone()]
for i, t in tqdm(enumerate(timesteps), total=len(timesteps)):
coupled_latents = self.noise_mixing_layer(x=coupled_latents[0], y=coupled_latents[1])
# j - model_input index, k - base index
for j in range(2):
k = j ^ 1
if self.leapfrog_steps:
if i % 2 == 0:
k, j = j, k
model_input = coupled_latents[j]
base = coupled_latents[k]
latent_model_input = torch.cat([model_input] * 2) if do_classifier_free_guidance else model_input
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeds).sample
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
base, model_input = self.noise_step(
base=base,
model_input=model_input,
model_output=noise_pred,
timestep=t,
)
coupled_latents[k] = model_input
return coupled_latents
@torch.no_grad()
def __call__(
self,
base_prompt: str,
target_prompt: str,
image: Image.Image,
guidance_scale: float = 3.0,
num_inference_steps: int = 50,
strength: float = 0.8,
negative_prompt: Optional[str] = None,
generator: Optional[torch.Generator] = None,
output_type: Optional[str] = "pil",
):
do_classifier_free_guidance = guidance_scale > 1.0
image = self.image_processor.preprocess(image)
base_embeds = self._encode_prompt(base_prompt, negative_prompt, do_classifier_free_guidance)
target_embeds = self._encode_prompt(target_prompt, negative_prompt, do_classifier_free_guidance)
self.scheduler.set_timesteps(num_inference_steps, self.device)
t_limit = num_inference_steps - int(num_inference_steps * strength)
fwd_timesteps = self.scheduler.timesteps[t_limit:]
bwd_timesteps = fwd_timesteps.flip(0)
coupled_latents = self.prepare_latents(image, base_embeds, bwd_timesteps, guidance_scale, generator)
for i, t in tqdm(enumerate(fwd_timesteps), total=len(fwd_timesteps)):
# j - model_input index, k - base index
for k in range(2):
j = k ^ 1
if self.leapfrog_steps:
if i % 2 == 1:
k, j = j, k
model_input = coupled_latents[j]
base = coupled_latents[k]
latent_model_input = torch.cat([model_input] * 2) if do_classifier_free_guidance else model_input
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=target_embeds).sample
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
base, model_input = self.denoise_step(
base=base,
model_input=model_input,
model_output=noise_pred,
timestep=t,
)
coupled_latents[k] = model_input
coupled_latents = self.denoise_mixing_layer(x=coupled_latents[0], y=coupled_latents[1])
# either one is fine
final_latent = coupled_latents[0]
if output_type not in ["latent", "pt", "np", "pil"]:
deprecation_message = (
f"the output_type {output_type} is outdated. Please make sure to set it to one of these instead: "
"`pil`, `np`, `pt`, `latent`"
)
deprecate("Unsupported output_type", "1.0.0", deprecation_message, standard_warn=False)
output_type = "np"
if output_type == "latent":
image = final_latent
else:
image = self.decode_latents(final_latent)
image = self.image_processor.postprocess(image, output_type=output_type)
return image
|
diffusers/examples/community/edict_pipeline.py/0
|
{
"file_path": "diffusers/examples/community/edict_pipeline.py",
"repo_id": "diffusers",
"token_count": 4669
}
| 102 |
# Copyright 2024 Bingxin Ke, ETH Zurich and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# --------------------------------------------------------------------------
# If you find this code useful, we kindly ask you to cite our paper in your work.
# Please find bibtex at: https://github.com/prs-eth/Marigold#-citation
# More information about the method can be found at https://marigoldmonodepth.github.io
# --------------------------------------------------------------------------
import math
from typing import Dict, Union
import matplotlib
import numpy as np
import torch
from PIL import Image
from scipy.optimize import minimize
from torch.utils.data import DataLoader, TensorDataset
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
UNet2DConditionModel,
)
from diffusers.utils import BaseOutput, check_min_version
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.28.0.dev0")
class MarigoldDepthOutput(BaseOutput):
"""
Output class for Marigold monocular depth prediction pipeline.
Args:
depth_np (`np.ndarray`):
Predicted depth map, with depth values in the range of [0, 1].
depth_colored (`None` or `PIL.Image.Image`):
Colorized depth map, with the shape of [3, H, W] and values in [0, 1].
uncertainty (`None` or `np.ndarray`):
Uncalibrated uncertainty(MAD, median absolute deviation) coming from ensembling.
"""
depth_np: np.ndarray
depth_colored: Union[None, Image.Image]
uncertainty: Union[None, np.ndarray]
class MarigoldPipeline(DiffusionPipeline):
"""
Pipeline for monocular depth estimation using Marigold: https://marigoldmonodepth.github.io.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
unet (`UNet2DConditionModel`):
Conditional U-Net to denoise the depth latent, conditioned on image latent.
vae (`AutoencoderKL`):
Variational Auto-Encoder (VAE) Model to encode and decode images and depth maps
to and from latent representations.
scheduler (`DDIMScheduler`):
A scheduler to be used in combination with `unet` to denoise the encoded image latents.
text_encoder (`CLIPTextModel`):
Text-encoder, for empty text embedding.
tokenizer (`CLIPTokenizer`):
CLIP tokenizer.
"""
rgb_latent_scale_factor = 0.18215
depth_latent_scale_factor = 0.18215
def __init__(
self,
unet: UNet2DConditionModel,
vae: AutoencoderKL,
scheduler: DDIMScheduler,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
):
super().__init__()
self.register_modules(
unet=unet,
vae=vae,
scheduler=scheduler,
text_encoder=text_encoder,
tokenizer=tokenizer,
)
self.empty_text_embed = None
@torch.no_grad()
def __call__(
self,
input_image: Image,
denoising_steps: int = 10,
ensemble_size: int = 10,
processing_res: int = 768,
match_input_res: bool = True,
batch_size: int = 0,
color_map: str = "Spectral",
show_progress_bar: bool = True,
ensemble_kwargs: Dict = None,
) -> MarigoldDepthOutput:
"""
Function invoked when calling the pipeline.
Args:
input_image (`Image`):
Input RGB (or gray-scale) image.
processing_res (`int`, *optional*, defaults to `768`):
Maximum resolution of processing.
If set to 0: will not resize at all.
match_input_res (`bool`, *optional*, defaults to `True`):
Resize depth prediction to match input resolution.
Only valid if `limit_input_res` is not None.
denoising_steps (`int`, *optional*, defaults to `10`):
Number of diffusion denoising steps (DDIM) during inference.
ensemble_size (`int`, *optional*, defaults to `10`):
Number of predictions to be ensembled.
batch_size (`int`, *optional*, defaults to `0`):
Inference batch size, no bigger than `num_ensemble`.
If set to 0, the script will automatically decide the proper batch size.
show_progress_bar (`bool`, *optional*, defaults to `True`):
Display a progress bar of diffusion denoising.
color_map (`str`, *optional*, defaults to `"Spectral"`, pass `None` to skip colorized depth map generation):
Colormap used to colorize the depth map.
ensemble_kwargs (`dict`, *optional*, defaults to `None`):
Arguments for detailed ensembling settings.
Returns:
`MarigoldDepthOutput`: Output class for Marigold monocular depth prediction pipeline, including:
- **depth_np** (`np.ndarray`) Predicted depth map, with depth values in the range of [0, 1]
- **depth_colored** (`None` or `PIL.Image.Image`) Colorized depth map, with the shape of [3, H, W] and
values in [0, 1]. None if `color_map` is `None`
- **uncertainty** (`None` or `np.ndarray`) Uncalibrated uncertainty(MAD, median absolute deviation)
coming from ensembling. None if `ensemble_size = 1`
"""
device = self.device
input_size = input_image.size
if not match_input_res:
assert processing_res is not None, "Value error: `resize_output_back` is only valid with "
assert processing_res >= 0
assert denoising_steps >= 1
assert ensemble_size >= 1
# ----------------- Image Preprocess -----------------
# Resize image
if processing_res > 0:
input_image = self.resize_max_res(input_image, max_edge_resolution=processing_res)
# Convert the image to RGB, to 1.remove the alpha channel 2.convert B&W to 3-channel
input_image = input_image.convert("RGB")
image = np.asarray(input_image)
# Normalize rgb values
rgb = np.transpose(image, (2, 0, 1)) # [H, W, rgb] -> [rgb, H, W]
rgb_norm = rgb / 255.0 * 2.0 - 1.0 # [0, 255] -> [-1, 1]
rgb_norm = torch.from_numpy(rgb_norm).to(self.dtype)
rgb_norm = rgb_norm.to(device)
assert rgb_norm.min() >= -1.0 and rgb_norm.max() <= 1.0
# ----------------- Predicting depth -----------------
# Batch repeated input image
duplicated_rgb = torch.stack([rgb_norm] * ensemble_size)
single_rgb_dataset = TensorDataset(duplicated_rgb)
if batch_size > 0:
_bs = batch_size
else:
_bs = self._find_batch_size(
ensemble_size=ensemble_size,
input_res=max(rgb_norm.shape[1:]),
dtype=self.dtype,
)
single_rgb_loader = DataLoader(single_rgb_dataset, batch_size=_bs, shuffle=False)
# Predict depth maps (batched)
depth_pred_ls = []
if show_progress_bar:
iterable = tqdm(single_rgb_loader, desc=" " * 2 + "Inference batches", leave=False)
else:
iterable = single_rgb_loader
for batch in iterable:
(batched_img,) = batch
depth_pred_raw = self.single_infer(
rgb_in=batched_img,
num_inference_steps=denoising_steps,
show_pbar=show_progress_bar,
)
depth_pred_ls.append(depth_pred_raw.detach().clone())
depth_preds = torch.concat(depth_pred_ls, axis=0).squeeze()
torch.cuda.empty_cache() # clear vram cache for ensembling
# ----------------- Test-time ensembling -----------------
if ensemble_size > 1:
depth_pred, pred_uncert = self.ensemble_depths(depth_preds, **(ensemble_kwargs or {}))
else:
depth_pred = depth_preds
pred_uncert = None
# ----------------- Post processing -----------------
# Scale prediction to [0, 1]
min_d = torch.min(depth_pred)
max_d = torch.max(depth_pred)
depth_pred = (depth_pred - min_d) / (max_d - min_d)
# Convert to numpy
depth_pred = depth_pred.cpu().numpy().astype(np.float32)
# Resize back to original resolution
if match_input_res:
pred_img = Image.fromarray(depth_pred)
pred_img = pred_img.resize(input_size)
depth_pred = np.asarray(pred_img)
# Clip output range
depth_pred = depth_pred.clip(0, 1)
# Colorize
if color_map is not None:
depth_colored = self.colorize_depth_maps(
depth_pred, 0, 1, cmap=color_map
).squeeze() # [3, H, W], value in (0, 1)
depth_colored = (depth_colored * 255).astype(np.uint8)
depth_colored_hwc = self.chw2hwc(depth_colored)
depth_colored_img = Image.fromarray(depth_colored_hwc)
else:
depth_colored_img = None
return MarigoldDepthOutput(
depth_np=depth_pred,
depth_colored=depth_colored_img,
uncertainty=pred_uncert,
)
def _encode_empty_text(self):
"""
Encode text embedding for empty prompt.
"""
prompt = ""
text_inputs = self.tokenizer(
prompt,
padding="do_not_pad",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids.to(self.text_encoder.device)
self.empty_text_embed = self.text_encoder(text_input_ids)[0].to(self.dtype)
@torch.no_grad()
def single_infer(self, rgb_in: torch.Tensor, num_inference_steps: int, show_pbar: bool) -> torch.Tensor:
"""
Perform an individual depth prediction without ensembling.
Args:
rgb_in (`torch.Tensor`):
Input RGB image.
num_inference_steps (`int`):
Number of diffusion denoisign steps (DDIM) during inference.
show_pbar (`bool`):
Display a progress bar of diffusion denoising.
Returns:
`torch.Tensor`: Predicted depth map.
"""
device = rgb_in.device
# Set timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps # [T]
# Encode image
rgb_latent = self._encode_rgb(rgb_in)
# Initial depth map (noise)
depth_latent = torch.randn(rgb_latent.shape, device=device, dtype=self.dtype) # [B, 4, h, w]
# Batched empty text embedding
if self.empty_text_embed is None:
self._encode_empty_text()
batch_empty_text_embed = self.empty_text_embed.repeat((rgb_latent.shape[0], 1, 1)) # [B, 2, 1024]
# Denoising loop
if show_pbar:
iterable = tqdm(
enumerate(timesteps),
total=len(timesteps),
leave=False,
desc=" " * 4 + "Diffusion denoising",
)
else:
iterable = enumerate(timesteps)
for i, t in iterable:
unet_input = torch.cat([rgb_latent, depth_latent], dim=1) # this order is important
# predict the noise residual
noise_pred = self.unet(unet_input, t, encoder_hidden_states=batch_empty_text_embed).sample # [B, 4, h, w]
# compute the previous noisy sample x_t -> x_t-1
depth_latent = self.scheduler.step(noise_pred, t, depth_latent).prev_sample
torch.cuda.empty_cache()
depth = self._decode_depth(depth_latent)
# clip prediction
depth = torch.clip(depth, -1.0, 1.0)
# shift to [0, 1]
depth = (depth + 1.0) / 2.0
return depth
def _encode_rgb(self, rgb_in: torch.Tensor) -> torch.Tensor:
"""
Encode RGB image into latent.
Args:
rgb_in (`torch.Tensor`):
Input RGB image to be encoded.
Returns:
`torch.Tensor`: Image latent.
"""
# encode
h = self.vae.encoder(rgb_in)
moments = self.vae.quant_conv(h)
mean, logvar = torch.chunk(moments, 2, dim=1)
# scale latent
rgb_latent = mean * self.rgb_latent_scale_factor
return rgb_latent
def _decode_depth(self, depth_latent: torch.Tensor) -> torch.Tensor:
"""
Decode depth latent into depth map.
Args:
depth_latent (`torch.Tensor`):
Depth latent to be decoded.
Returns:
`torch.Tensor`: Decoded depth map.
"""
# scale latent
depth_latent = depth_latent / self.depth_latent_scale_factor
# decode
z = self.vae.post_quant_conv(depth_latent)
stacked = self.vae.decoder(z)
# mean of output channels
depth_mean = stacked.mean(dim=1, keepdim=True)
return depth_mean
@staticmethod
def resize_max_res(img: Image.Image, max_edge_resolution: int) -> Image.Image:
"""
Resize image to limit maximum edge length while keeping aspect ratio.
Args:
img (`Image.Image`):
Image to be resized.
max_edge_resolution (`int`):
Maximum edge length (pixel).
Returns:
`Image.Image`: Resized image.
"""
original_width, original_height = img.size
downscale_factor = min(max_edge_resolution / original_width, max_edge_resolution / original_height)
new_width = int(original_width * downscale_factor)
new_height = int(original_height * downscale_factor)
resized_img = img.resize((new_width, new_height))
return resized_img
@staticmethod
def colorize_depth_maps(depth_map, min_depth, max_depth, cmap="Spectral", valid_mask=None):
"""
Colorize depth maps.
"""
assert len(depth_map.shape) >= 2, "Invalid dimension"
if isinstance(depth_map, torch.Tensor):
depth = depth_map.detach().clone().squeeze().numpy()
elif isinstance(depth_map, np.ndarray):
depth = depth_map.copy().squeeze()
# reshape to [ (B,) H, W ]
if depth.ndim < 3:
depth = depth[np.newaxis, :, :]
# colorize
cm = matplotlib.colormaps[cmap]
depth = ((depth - min_depth) / (max_depth - min_depth)).clip(0, 1)
img_colored_np = cm(depth, bytes=False)[:, :, :, 0:3] # value from 0 to 1
img_colored_np = np.rollaxis(img_colored_np, 3, 1)
if valid_mask is not None:
if isinstance(depth_map, torch.Tensor):
valid_mask = valid_mask.detach().numpy()
valid_mask = valid_mask.squeeze() # [H, W] or [B, H, W]
if valid_mask.ndim < 3:
valid_mask = valid_mask[np.newaxis, np.newaxis, :, :]
else:
valid_mask = valid_mask[:, np.newaxis, :, :]
valid_mask = np.repeat(valid_mask, 3, axis=1)
img_colored_np[~valid_mask] = 0
if isinstance(depth_map, torch.Tensor):
img_colored = torch.from_numpy(img_colored_np).float()
elif isinstance(depth_map, np.ndarray):
img_colored = img_colored_np
return img_colored
@staticmethod
def chw2hwc(chw):
assert 3 == len(chw.shape)
if isinstance(chw, torch.Tensor):
hwc = torch.permute(chw, (1, 2, 0))
elif isinstance(chw, np.ndarray):
hwc = np.moveaxis(chw, 0, -1)
return hwc
@staticmethod
def _find_batch_size(ensemble_size: int, input_res: int, dtype: torch.dtype) -> int:
"""
Automatically search for suitable operating batch size.
Args:
ensemble_size (`int`):
Number of predictions to be ensembled.
input_res (`int`):
Operating resolution of the input image.
Returns:
`int`: Operating batch size.
"""
# Search table for suggested max. inference batch size
bs_search_table = [
# tested on A100-PCIE-80GB
{"res": 768, "total_vram": 79, "bs": 35, "dtype": torch.float32},
{"res": 1024, "total_vram": 79, "bs": 20, "dtype": torch.float32},
# tested on A100-PCIE-40GB
{"res": 768, "total_vram": 39, "bs": 15, "dtype": torch.float32},
{"res": 1024, "total_vram": 39, "bs": 8, "dtype": torch.float32},
{"res": 768, "total_vram": 39, "bs": 30, "dtype": torch.float16},
{"res": 1024, "total_vram": 39, "bs": 15, "dtype": torch.float16},
# tested on RTX3090, RTX4090
{"res": 512, "total_vram": 23, "bs": 20, "dtype": torch.float32},
{"res": 768, "total_vram": 23, "bs": 7, "dtype": torch.float32},
{"res": 1024, "total_vram": 23, "bs": 3, "dtype": torch.float32},
{"res": 512, "total_vram": 23, "bs": 40, "dtype": torch.float16},
{"res": 768, "total_vram": 23, "bs": 18, "dtype": torch.float16},
{"res": 1024, "total_vram": 23, "bs": 10, "dtype": torch.float16},
# tested on GTX1080Ti
{"res": 512, "total_vram": 10, "bs": 5, "dtype": torch.float32},
{"res": 768, "total_vram": 10, "bs": 2, "dtype": torch.float32},
{"res": 512, "total_vram": 10, "bs": 10, "dtype": torch.float16},
{"res": 768, "total_vram": 10, "bs": 5, "dtype": torch.float16},
{"res": 1024, "total_vram": 10, "bs": 3, "dtype": torch.float16},
]
if not torch.cuda.is_available():
return 1
total_vram = torch.cuda.mem_get_info()[1] / 1024.0**3
filtered_bs_search_table = [s for s in bs_search_table if s["dtype"] == dtype]
for settings in sorted(
filtered_bs_search_table,
key=lambda k: (k["res"], -k["total_vram"]),
):
if input_res <= settings["res"] and total_vram >= settings["total_vram"]:
bs = settings["bs"]
if bs > ensemble_size:
bs = ensemble_size
elif bs > math.ceil(ensemble_size / 2) and bs < ensemble_size:
bs = math.ceil(ensemble_size / 2)
return bs
return 1
@staticmethod
def ensemble_depths(
input_images: torch.Tensor,
regularizer_strength: float = 0.02,
max_iter: int = 2,
tol: float = 1e-3,
reduction: str = "median",
max_res: int = None,
):
"""
To ensemble multiple affine-invariant depth images (up to scale and shift),
by aligning estimating the scale and shift
"""
def inter_distances(tensors: torch.Tensor):
"""
To calculate the distance between each two depth maps.
"""
distances = []
for i, j in torch.combinations(torch.arange(tensors.shape[0])):
arr1 = tensors[i : i + 1]
arr2 = tensors[j : j + 1]
distances.append(arr1 - arr2)
dist = torch.concatenate(distances, dim=0)
return dist
device = input_images.device
dtype = input_images.dtype
np_dtype = np.float32
original_input = input_images.clone()
n_img = input_images.shape[0]
ori_shape = input_images.shape
if max_res is not None:
scale_factor = torch.min(max_res / torch.tensor(ori_shape[-2:]))
if scale_factor < 1:
downscaler = torch.nn.Upsample(scale_factor=scale_factor, mode="nearest")
input_images = downscaler(torch.from_numpy(input_images)).numpy()
# init guess
_min = np.min(input_images.reshape((n_img, -1)).cpu().numpy(), axis=1)
_max = np.max(input_images.reshape((n_img, -1)).cpu().numpy(), axis=1)
s_init = 1.0 / (_max - _min).reshape((-1, 1, 1))
t_init = (-1 * s_init.flatten() * _min.flatten()).reshape((-1, 1, 1))
x = np.concatenate([s_init, t_init]).reshape(-1).astype(np_dtype)
input_images = input_images.to(device)
# objective function
def closure(x):
l = len(x)
s = x[: int(l / 2)]
t = x[int(l / 2) :]
s = torch.from_numpy(s).to(dtype=dtype).to(device)
t = torch.from_numpy(t).to(dtype=dtype).to(device)
transformed_arrays = input_images * s.view((-1, 1, 1)) + t.view((-1, 1, 1))
dists = inter_distances(transformed_arrays)
sqrt_dist = torch.sqrt(torch.mean(dists**2))
if "mean" == reduction:
pred = torch.mean(transformed_arrays, dim=0)
elif "median" == reduction:
pred = torch.median(transformed_arrays, dim=0).values
else:
raise ValueError
near_err = torch.sqrt((0 - torch.min(pred)) ** 2)
far_err = torch.sqrt((1 - torch.max(pred)) ** 2)
err = sqrt_dist + (near_err + far_err) * regularizer_strength
err = err.detach().cpu().numpy().astype(np_dtype)
return err
res = minimize(
closure,
x,
method="BFGS",
tol=tol,
options={"maxiter": max_iter, "disp": False},
)
x = res.x
l = len(x)
s = x[: int(l / 2)]
t = x[int(l / 2) :]
# Prediction
s = torch.from_numpy(s).to(dtype=dtype).to(device)
t = torch.from_numpy(t).to(dtype=dtype).to(device)
transformed_arrays = original_input * s.view(-1, 1, 1) + t.view(-1, 1, 1)
if "mean" == reduction:
aligned_images = torch.mean(transformed_arrays, dim=0)
std = torch.std(transformed_arrays, dim=0)
uncertainty = std
elif "median" == reduction:
aligned_images = torch.median(transformed_arrays, dim=0).values
# MAD (median absolute deviation) as uncertainty indicator
abs_dev = torch.abs(transformed_arrays - aligned_images)
mad = torch.median(abs_dev, dim=0).values
uncertainty = mad
else:
raise ValueError(f"Unknown reduction method: {reduction}")
# Scale and shift to [0, 1]
_min = torch.min(aligned_images)
_max = torch.max(aligned_images)
aligned_images = (aligned_images - _min) / (_max - _min)
uncertainty /= _max - _min
return aligned_images, uncertainty
|
diffusers/examples/community/marigold_depth_estimation.py/0
|
{
"file_path": "diffusers/examples/community/marigold_depth_estimation.py",
"repo_id": "diffusers",
"token_count": 10952
}
| 103 |
# Copyright 2024 The InstantX Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import cv2
import numpy as np
import PIL.Image
import torch
import torch.nn as nn
from diffusers import StableDiffusionXLControlNetPipeline
from diffusers.image_processor import PipelineImageInput
from diffusers.models import ControlNetModel
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.stable_diffusion_xl import StableDiffusionXLPipelineOutput
from diffusers.utils import (
deprecate,
logging,
replace_example_docstring,
)
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.torch_utils import is_compiled_module, is_torch_version
try:
import xformers
import xformers.ops
xformers_available = True
except Exception:
xformers_available = False
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def FeedForward(dim, mult=4):
inner_dim = int(dim * mult)
return nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, inner_dim, bias=False),
nn.GELU(),
nn.Linear(inner_dim, dim, bias=False),
)
def reshape_tensor(x, heads):
bs, length, width = x.shape
# (bs, length, width) --> (bs, length, n_heads, dim_per_head)
x = x.view(bs, length, heads, -1)
# (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head)
x = x.transpose(1, 2)
# (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head)
x = x.reshape(bs, heads, length, -1)
return x
class PerceiverAttention(nn.Module):
def __init__(self, *, dim, dim_head=64, heads=8):
super().__init__()
self.scale = dim_head**-0.5
self.dim_head = dim_head
self.heads = heads
inner_dim = dim_head * heads
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.to_q = nn.Linear(dim, inner_dim, bias=False)
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
self.to_out = nn.Linear(inner_dim, dim, bias=False)
def forward(self, x, latents):
"""
Args:
x (torch.Tensor): image features
shape (b, n1, D)
latent (torch.Tensor): latent features
shape (b, n2, D)
"""
x = self.norm1(x)
latents = self.norm2(latents)
b, l, _ = latents.shape
q = self.to_q(latents)
kv_input = torch.cat((x, latents), dim=-2)
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
q = reshape_tensor(q, self.heads)
k = reshape_tensor(k, self.heads)
v = reshape_tensor(v, self.heads)
# attention
scale = 1 / math.sqrt(math.sqrt(self.dim_head))
weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
out = weight @ v
out = out.permute(0, 2, 1, 3).reshape(b, l, -1)
return self.to_out(out)
class Resampler(nn.Module):
def __init__(
self,
dim=1024,
depth=8,
dim_head=64,
heads=16,
num_queries=8,
embedding_dim=768,
output_dim=1024,
ff_mult=4,
):
super().__init__()
self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5)
self.proj_in = nn.Linear(embedding_dim, dim)
self.proj_out = nn.Linear(dim, output_dim)
self.norm_out = nn.LayerNorm(output_dim)
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(
nn.ModuleList(
[
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
FeedForward(dim=dim, mult=ff_mult),
]
)
)
def forward(self, x):
latents = self.latents.repeat(x.size(0), 1, 1)
x = self.proj_in(x)
for attn, ff in self.layers:
latents = attn(x, latents) + latents
latents = ff(latents) + latents
latents = self.proj_out(latents)
return self.norm_out(latents)
class AttnProcessor(nn.Module):
r"""
Default processor for performing attention-related computations.
"""
def __init__(
self,
hidden_size=None,
cross_attention_dim=None,
):
super().__init__()
def __call__(
self,
attn,
hidden_states,
encoder_hidden_states=None,
attention_mask=None,
temb=None,
):
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class IPAttnProcessor(nn.Module):
r"""
Attention processor for IP-Adapater.
Args:
hidden_size (`int`):
The hidden size of the attention layer.
cross_attention_dim (`int`):
The number of channels in the `encoder_hidden_states`.
scale (`float`, defaults to 1.0):
the weight scale of image prompt.
num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
The context length of the image features.
"""
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4):
super().__init__()
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
self.scale = scale
self.num_tokens = num_tokens
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
def __call__(
self,
attn,
hidden_states,
encoder_hidden_states=None,
attention_mask=None,
temb=None,
):
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
else:
# get encoder_hidden_states, ip_hidden_states
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
encoder_hidden_states, ip_hidden_states = (
encoder_hidden_states[:, :end_pos, :],
encoder_hidden_states[:, end_pos:, :],
)
if attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
if xformers_available:
hidden_states = self._memory_efficient_attention_xformers(query, key, value, attention_mask)
else:
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# for ip-adapter
ip_key = self.to_k_ip(ip_hidden_states)
ip_value = self.to_v_ip(ip_hidden_states)
ip_key = attn.head_to_batch_dim(ip_key)
ip_value = attn.head_to_batch_dim(ip_value)
if xformers_available:
ip_hidden_states = self._memory_efficient_attention_xformers(query, ip_key, ip_value, None)
else:
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states)
hidden_states = hidden_states + self.scale * ip_hidden_states
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
def _memory_efficient_attention_xformers(self, query, key, value, attention_mask):
# TODO attention_mask
query = query.contiguous()
key = key.contiguous()
value = value.contiguous()
hidden_states = xformers.ops.memory_efficient_attention(query, key, value, attn_bias=attention_mask)
return hidden_states
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> # !pip install opencv-python transformers accelerate insightface
>>> import diffusers
>>> from diffusers.utils import load_image
>>> from diffusers.models import ControlNetModel
>>> import cv2
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> from insightface.app import FaceAnalysis
>>> from pipeline_stable_diffusion_xl_instantid import StableDiffusionXLInstantIDPipeline, draw_kps
>>> # download 'antelopev2' under ./models
>>> app = FaceAnalysis(name='antelopev2', root='./', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
>>> app.prepare(ctx_id=0, det_size=(640, 640))
>>> # download models under ./checkpoints
>>> face_adapter = f'./checkpoints/ip-adapter.bin'
>>> controlnet_path = f'./checkpoints/ControlNetModel'
>>> # load IdentityNet
>>> controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
>>> pipe = StableDiffusionXLInstantIDPipeline.from_pretrained(
... "stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, torch_dtype=torch.float16
... )
>>> pipe.cuda()
>>> # load adapter
>>> pipe.load_ip_adapter_instantid(face_adapter)
>>> prompt = "analog film photo of a man. faded film, desaturated, 35mm photo, grainy, vignette, vintage, Kodachrome, Lomography, stained, highly detailed, found footage, masterpiece, best quality"
>>> negative_prompt = "(lowres, low quality, worst quality:1.2), (text:1.2), watermark, painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured (lowres, low quality, worst quality:1.2), (text:1.2), watermark, painting, drawing, illustration, glitch,deformed, mutated, cross-eyed, ugly, disfigured"
>>> # load an image
>>> image = load_image("your-example.jpg")
>>> face_info = app.get(cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR))[-1]
>>> face_emb = face_info['embedding']
>>> face_kps = draw_kps(face_image, face_info['kps'])
>>> pipe.set_ip_adapter_scale(0.8)
>>> # generate image
>>> image = pipe(
... prompt, image_embeds=face_emb, image=face_kps, controlnet_conditioning_scale=0.8
... ).images[0]
```
"""
def draw_kps(image_pil, kps, color_list=[(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (255, 0, 255)]):
stickwidth = 4
limbSeq = np.array([[0, 2], [1, 2], [3, 2], [4, 2]])
kps = np.array(kps)
w, h = image_pil.size
out_img = np.zeros([h, w, 3])
for i in range(len(limbSeq)):
index = limbSeq[i]
color = color_list[index[0]]
x = kps[index][:, 0]
y = kps[index][:, 1]
length = ((x[0] - x[1]) ** 2 + (y[0] - y[1]) ** 2) ** 0.5
angle = math.degrees(math.atan2(y[0] - y[1], x[0] - x[1]))
polygon = cv2.ellipse2Poly(
(int(np.mean(x)), int(np.mean(y))), (int(length / 2), stickwidth), int(angle), 0, 360, 1
)
out_img = cv2.fillConvexPoly(out_img.copy(), polygon, color)
out_img = (out_img * 0.6).astype(np.uint8)
for idx_kp, kp in enumerate(kps):
color = color_list[idx_kp]
x, y = kp
out_img = cv2.circle(out_img.copy(), (int(x), int(y)), 10, color, -1)
out_img_pil = PIL.Image.fromarray(out_img.astype(np.uint8))
return out_img_pil
class StableDiffusionXLInstantIDPipeline(StableDiffusionXLControlNetPipeline):
def cuda(self, dtype=torch.float16, use_xformers=False):
self.to("cuda", dtype)
if hasattr(self, "image_proj_model"):
self.image_proj_model.to(self.unet.device).to(self.unet.dtype)
if use_xformers:
if is_xformers_available():
import xformers
from packaging import version
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warning(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
self.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
def load_ip_adapter_instantid(self, model_ckpt, image_emb_dim=512, num_tokens=16, scale=0.5):
self.set_image_proj_model(model_ckpt, image_emb_dim, num_tokens)
self.set_ip_adapter(model_ckpt, num_tokens, scale)
def set_image_proj_model(self, model_ckpt, image_emb_dim=512, num_tokens=16):
image_proj_model = Resampler(
dim=1280,
depth=4,
dim_head=64,
heads=20,
num_queries=num_tokens,
embedding_dim=image_emb_dim,
output_dim=self.unet.config.cross_attention_dim,
ff_mult=4,
)
image_proj_model.eval()
self.image_proj_model = image_proj_model.to(self.device, dtype=self.dtype)
state_dict = torch.load(model_ckpt, map_location="cpu")
if "image_proj" in state_dict:
state_dict = state_dict["image_proj"]
self.image_proj_model.load_state_dict(state_dict)
self.image_proj_model_in_features = image_emb_dim
def set_ip_adapter(self, model_ckpt, num_tokens, scale):
unet = self.unet
attn_procs = {}
for name in unet.attn_processors.keys():
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
if name.startswith("mid_block"):
hidden_size = unet.config.block_out_channels[-1]
elif name.startswith("up_blocks"):
block_id = int(name[len("up_blocks.")])
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
elif name.startswith("down_blocks"):
block_id = int(name[len("down_blocks.")])
hidden_size = unet.config.block_out_channels[block_id]
if cross_attention_dim is None:
attn_procs[name] = AttnProcessor().to(unet.device, dtype=unet.dtype)
else:
attn_procs[name] = IPAttnProcessor(
hidden_size=hidden_size,
cross_attention_dim=cross_attention_dim,
scale=scale,
num_tokens=num_tokens,
).to(unet.device, dtype=unet.dtype)
unet.set_attn_processor(attn_procs)
state_dict = torch.load(model_ckpt, map_location="cpu")
ip_layers = torch.nn.ModuleList(self.unet.attn_processors.values())
if "ip_adapter" in state_dict:
state_dict = state_dict["ip_adapter"]
ip_layers.load_state_dict(state_dict)
def set_ip_adapter_scale(self, scale):
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
for attn_processor in unet.attn_processors.values():
if isinstance(attn_processor, IPAttnProcessor):
attn_processor.scale = scale
def _encode_prompt_image_emb(self, prompt_image_emb, device, dtype, do_classifier_free_guidance):
if isinstance(prompt_image_emb, torch.Tensor):
prompt_image_emb = prompt_image_emb.clone().detach()
else:
prompt_image_emb = torch.tensor(prompt_image_emb)
prompt_image_emb = prompt_image_emb.to(device=device, dtype=dtype)
prompt_image_emb = prompt_image_emb.reshape([1, -1, self.image_proj_model_in_features])
if do_classifier_free_guidance:
prompt_image_emb = torch.cat([torch.zeros_like(prompt_image_emb), prompt_image_emb], dim=0)
else:
prompt_image_emb = torch.cat([prompt_image_emb], dim=0)
prompt_image_emb = self.image_proj_model(prompt_image_emb)
return prompt_image_emb
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
prompt_2: Optional[Union[str, List[str]]] = None,
image: PipelineImageInput = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 5.0,
negative_prompt: Optional[Union[str, List[str]]] = None,
negative_prompt_2: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
guess_mode: bool = False,
control_guidance_start: Union[float, List[float]] = 0.0,
control_guidance_end: Union[float, List[float]] = 1.0,
original_size: Tuple[int, int] = None,
crops_coords_top_left: Tuple[int, int] = (0, 0),
target_size: Tuple[int, int] = None,
negative_original_size: Optional[Tuple[int, int]] = None,
negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
negative_target_size: Optional[Tuple[int, int]] = None,
clip_skip: Optional[int] = None,
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
**kwargs,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
`init`, images must be passed as a list such that each element of the list can be correctly batched for
input to a single ControlNet.
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The height in pixels of the generated image. Anything below 512 pixels won't work well for
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
and checkpoints that are not specifically fine-tuned on low resolutions.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image. Anything below 512 pixels won't work well for
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
and checkpoints that are not specifically fine-tuned on low resolutions.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. This is sent to `tokenizer_2`
and `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, pooled text embeddings are generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs (prompt
weighting). If not provided, pooled `negative_prompt_embeds` are generated from `negative_prompt` input
argument.
image_embeds (`torch.FloatTensor`, *optional*):
Pre-generated image embeddings.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the ControlNet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original `unet`. If multiple ControlNets are specified in `init`, you can set
the corresponding scale as a list.
guess_mode (`bool`, *optional*, defaults to `False`):
The ControlNet encoder tries to recognize the content of the input image even if you remove all
prompts. A `guidance_scale` value between 3.0 and 5.0 is recommended.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the ControlNet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
The percentage of total steps at which the ControlNet stops applying.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
`crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
For most cases, `target_size` should be set to the desired height and width of the generated image. If
not specified it will default to `(height, width)`. Part of SDXL's micro-conditioning as explained in
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
To negatively condition the generation process based on a specific image resolution. Part of SDXL's
micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
To negatively condition the generation process based on a target image resolution. It should be as same
as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
callback_on_step_end (`Callable`, *optional*):
A function that calls at the end of each denoising steps during the inference. The function is called
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
`callback_on_step_end_tensor_inputs`.
callback_on_step_end_tensor_inputs (`List`, *optional*):
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
`._callback_tensor_inputs` attribute of your pipeine class.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned containing the output images.
"""
callback = kwargs.pop("callback", None)
callback_steps = kwargs.pop("callback_steps", None)
if callback is not None:
deprecate(
"callback",
"1.0.0",
"Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
)
if callback_steps is not None:
deprecate(
"callback_steps",
"1.0.0",
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
)
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
# align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
prompt_2,
image,
callback_steps,
negative_prompt,
negative_prompt_2,
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
callback_on_step_end_tensor_inputs,
)
self._guidance_scale = guidance_scale
self._clip_skip = clip_skip
self._cross_attention_kwargs = cross_attention_kwargs
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
global_pool_conditions = (
controlnet.config.global_pool_conditions
if isinstance(controlnet, ControlNetModel)
else controlnet.nets[0].config.global_pool_conditions
)
guess_mode = guess_mode or global_pool_conditions
# 3.1 Encode input prompt
text_encoder_lora_scale = (
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
)
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = self.encode_prompt(
prompt,
prompt_2,
device,
num_images_per_prompt,
self.do_classifier_free_guidance,
negative_prompt,
negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
lora_scale=text_encoder_lora_scale,
clip_skip=self.clip_skip,
)
# 3.2 Encode image prompt
prompt_image_emb = self._encode_prompt_image_emb(
image_embeds, device, self.unet.dtype, self.do_classifier_free_guidance
)
bs_embed, seq_len, _ = prompt_image_emb.shape
prompt_image_emb = prompt_image_emb.repeat(1, num_images_per_prompt, 1)
prompt_image_emb = prompt_image_emb.view(bs_embed * num_images_per_prompt, seq_len, -1)
# 4. Prepare image
if isinstance(controlnet, ControlNetModel):
image = self.prepare_image(
image=image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=self.do_classifier_free_guidance,
guess_mode=guess_mode,
)
height, width = image.shape[-2:]
elif isinstance(controlnet, MultiControlNetModel):
images = []
for image_ in image:
image_ = self.prepare_image(
image=image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=self.do_classifier_free_guidance,
guess_mode=guess_mode,
)
images.append(image_)
image = images
height, width = image[0].shape[-2:]
else:
assert False
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
self._num_timesteps = len(timesteps)
# 6. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6.5 Optionally get Guidance Scale Embedding
timestep_cond = None
if self.unet.config.time_cond_proj_dim is not None:
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
timestep_cond = self.get_guidance_scale_embedding(
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
).to(device=device, dtype=latents.dtype)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7.1 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
# 7.2 Prepare added time ids & embeddings
if isinstance(image, list):
original_size = original_size or image[0].shape[-2:]
else:
original_size = original_size or image.shape[-2:]
target_size = target_size or (height, width)
add_text_embeds = pooled_prompt_embeds
if self.text_encoder_2 is None:
text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])
else:
text_encoder_projection_dim = self.text_encoder_2.config.projection_dim
add_time_ids = self._get_add_time_ids(
original_size,
crops_coords_top_left,
target_size,
dtype=prompt_embeds.dtype,
text_encoder_projection_dim=text_encoder_projection_dim,
)
if negative_original_size is not None and negative_target_size is not None:
negative_add_time_ids = self._get_add_time_ids(
negative_original_size,
negative_crops_coords_top_left,
negative_target_size,
dtype=prompt_embeds.dtype,
text_encoder_projection_dim=text_encoder_projection_dim,
)
else:
negative_add_time_ids = add_time_ids
if self.do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
prompt_embeds = prompt_embeds.to(device)
add_text_embeds = add_text_embeds.to(device)
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
encoder_hidden_states = torch.cat([prompt_embeds, prompt_image_emb], dim=1)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
is_unet_compiled = is_compiled_module(self.unet)
is_controlnet_compiled = is_compiled_module(self.controlnet)
is_torch_higher_equal_2_1 = is_torch_version(">=", "2.1")
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# Relevant thread:
# https://dev-discuss.pytorch.org/t/cudagraphs-in-pytorch-2-0/1428
if (is_unet_compiled and is_controlnet_compiled) and is_torch_higher_equal_2_1:
torch._inductor.cudagraph_mark_step_begin()
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
# controlnet(s) inference
if guess_mode and self.do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
controlnet_added_cond_kwargs = {
"text_embeds": add_text_embeds.chunk(2)[1],
"time_ids": add_time_ids.chunk(2)[1],
}
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
controlnet_added_cond_kwargs = added_cond_kwargs
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=prompt_image_emb,
controlnet_cond=image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
added_cond_kwargs=controlnet_added_cond_kwargs,
return_dict=False,
)
if guess_mode and self.do_classifier_free_guidance:
# Infered ControlNet only for the conditional batch.
# To apply the output of ControlNet to both the unconditional and conditional batches,
# add 0 to the unconditional batch to keep it unchanged.
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=encoder_hidden_states,
timestep_cond=timestep_cond,
cross_attention_kwargs=self.cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
# perform guidance
if self.do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
if callback_on_step_end is not None:
callback_kwargs = {}
for k in callback_on_step_end_tensor_inputs:
callback_kwargs[k] = locals()[k]
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
latents = callback_outputs.pop("latents", latents)
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
# make sure the VAE is in float32 mode, as it overflows in float16
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
if needs_upcasting:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
# cast back to fp16 if needed
if needs_upcasting:
self.vae.to(dtype=torch.float16)
else:
image = latents
if not output_type == "latent":
# apply watermark if available
if self.watermark is not None:
image = self.watermark.apply_watermark(image)
image = self.image_processor.postprocess(image, output_type=output_type)
# Offload all models
self.maybe_free_model_hooks()
if not return_dict:
return (image,)
return StableDiffusionXLPipelineOutput(images=image)
|
diffusers/examples/community/pipeline_stable_diffusion_xl_instantid.py/0
|
{
"file_path": "diffusers/examples/community/pipeline_stable_diffusion_xl_instantid.py",
"repo_id": "diffusers",
"token_count": 22649
}
| 104 |
# Inspired by: https://github.com/Mikubill/sd-webui-controlnet/discussions/1236 and https://github.com/Mikubill/sd-webui-controlnet/discussions/1280
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionControlNetPipeline
from diffusers.models import ControlNetModel
from diffusers.models.attention import BasicTransformerBlock
from diffusers.models.unets.unet_2d_blocks import CrossAttnDownBlock2D, CrossAttnUpBlock2D, DownBlock2D, UpBlock2D
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.utils import logging
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import cv2
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> from diffusers import UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
>>> # get canny image
>>> image = cv2.Canny(np.array(input_image), 100, 200)
>>> image = image[:, :, None]
>>> image = np.concatenate([image, image, image], axis=2)
>>> canny_image = Image.fromarray(image)
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetReferencePipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
controlnet=controlnet,
safety_checker=None,
torch_dtype=torch.float16
).to('cuda:0')
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe_controlnet.scheduler.config)
>>> result_img = pipe(ref_image=input_image,
prompt="1girl",
image=canny_image,
num_inference_steps=20,
reference_attn=True,
reference_adain=True).images[0]
>>> result_img.show()
```
"""
def torch_dfs(model: torch.nn.Module):
result = [model]
for child in model.children():
result += torch_dfs(child)
return result
class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeline):
def prepare_ref_latents(self, refimage, batch_size, dtype, device, generator, do_classifier_free_guidance):
refimage = refimage.to(device=device, dtype=dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
ref_image_latents = [
self.vae.encode(refimage[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
ref_image_latents = torch.cat(ref_image_latents, dim=0)
else:
ref_image_latents = self.vae.encode(refimage).latent_dist.sample(generator=generator)
ref_image_latents = self.vae.config.scaling_factor * ref_image_latents
# duplicate mask and ref_image_latents for each generation per prompt, using mps friendly method
if ref_image_latents.shape[0] < batch_size:
if not batch_size % ref_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {ref_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
ref_image_latents = ref_image_latents.repeat(batch_size // ref_image_latents.shape[0], 1, 1, 1)
ref_image_latents = torch.cat([ref_image_latents] * 2) if do_classifier_free_guidance else ref_image_latents
# aligning device to prevent device errors when concating it with the latent model input
ref_image_latents = ref_image_latents.to(device=device, dtype=dtype)
return ref_image_latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
ref_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
guess_mode: bool = False,
attention_auto_machine_weight: float = 1.0,
gn_auto_machine_weight: float = 1.0,
style_fidelity: float = 0.5,
reference_attn: bool = True,
reference_adain: bool = True,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
specified in init, images must be passed as a list such that each element of the list can be correctly
batched for input to a single controlnet.
ref_image (`torch.FloatTensor`, `PIL.Image.Image`):
The Reference Control input condition. Reference Control uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to Reference Control as is. `PIL.Image.Image` can
also be accepted as an image.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
corresponding scale as a list.
guess_mode (`bool`, *optional*, defaults to `False`):
In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
attention_auto_machine_weight (`float`):
Weight of using reference query for self attention's context.
If attention_auto_machine_weight=1.0, use reference query for all self attention's context.
gn_auto_machine_weight (`float`):
Weight of using reference adain. If gn_auto_machine_weight=2.0, use all reference adain plugins.
style_fidelity (`float`):
style fidelity of ref_uncond_xt. If style_fidelity=1.0, control more important,
elif style_fidelity=0.0, prompt more important, else balanced.
reference_attn (`bool`):
Whether to use reference query for self attention's context.
reference_adain (`bool`):
Whether to use reference adain.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
assert reference_attn or reference_adain, "`reference_attn` or `reference_adain` must be True."
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
image,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
controlnet_conditioning_scale,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
global_pool_conditions = (
controlnet.config.global_pool_conditions
if isinstance(controlnet, ControlNetModel)
else controlnet.nets[0].config.global_pool_conditions
)
guess_mode = guess_mode or global_pool_conditions
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 4. Prepare image
if isinstance(controlnet, ControlNetModel):
image = self.prepare_image(
image=image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
height, width = image.shape[-2:]
elif isinstance(controlnet, MultiControlNetModel):
images = []
for image_ in image:
image_ = self.prepare_image(
image=image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
images.append(image_)
image = images
height, width = image[0].shape[-2:]
else:
assert False
# 5. Preprocess reference image
ref_image = self.prepare_image(
image=ref_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=prompt_embeds.dtype,
)
# 6. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 7. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 8. Prepare reference latent variables
ref_image_latents = self.prepare_ref_latents(
ref_image,
batch_size * num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 9. Modify self attention and group norm
MODE = "write"
uc_mask = (
torch.Tensor([1] * batch_size * num_images_per_prompt + [0] * batch_size * num_images_per_prompt)
.type_as(ref_image_latents)
.bool()
)
def hacked_basic_transformer_inner_forward(
self,
hidden_states: torch.FloatTensor,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
timestep: Optional[torch.LongTensor] = None,
cross_attention_kwargs: Dict[str, Any] = None,
class_labels: Optional[torch.LongTensor] = None,
):
if self.use_ada_layer_norm:
norm_hidden_states = self.norm1(hidden_states, timestep)
elif self.use_ada_layer_norm_zero:
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
)
else:
norm_hidden_states = self.norm1(hidden_states)
# 1. Self-Attention
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if self.only_cross_attention:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
else:
if MODE == "write":
self.bank.append(norm_hidden_states.detach().clone())
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if MODE == "read":
if attention_auto_machine_weight > self.attn_weight:
attn_output_uc = self.attn1(
norm_hidden_states,
encoder_hidden_states=torch.cat([norm_hidden_states] + self.bank, dim=1),
# attention_mask=attention_mask,
**cross_attention_kwargs,
)
attn_output_c = attn_output_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
attn_output_c[uc_mask] = self.attn1(
norm_hidden_states[uc_mask],
encoder_hidden_states=norm_hidden_states[uc_mask],
**cross_attention_kwargs,
)
attn_output = style_fidelity * attn_output_c + (1.0 - style_fidelity) * attn_output_uc
self.bank.clear()
else:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if self.use_ada_layer_norm_zero:
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = attn_output + hidden_states
if self.attn2 is not None:
norm_hidden_states = (
self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states)
)
# 2. Cross-Attention
attn_output = self.attn2(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
**cross_attention_kwargs,
)
hidden_states = attn_output + hidden_states
# 3. Feed-forward
norm_hidden_states = self.norm3(hidden_states)
if self.use_ada_layer_norm_zero:
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
ff_output = self.ff(norm_hidden_states)
if self.use_ada_layer_norm_zero:
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = ff_output + hidden_states
return hidden_states
def hacked_mid_forward(self, *args, **kwargs):
eps = 1e-6
x = self.original_forward(*args, **kwargs)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append(mean)
self.var_bank.append(var)
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank) / float(len(self.mean_bank))
var_acc = sum(self.var_bank) / float(len(self.var_bank))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
x_uc = (((x - mean) / std) * std_acc) + mean_acc
x_c = x_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
x_c[uc_mask] = x[uc_mask]
x = style_fidelity * x_c + (1.0 - style_fidelity) * x_uc
self.mean_bank = []
self.var_bank = []
return x
def hack_CrossAttnDownBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
output_states = ()
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_DownBlock2D_forward(self, hidden_states, temb=None, *args, **kwargs):
eps = 1e-6
output_states = ()
for i, resnet in enumerate(self.resnets):
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_CrossAttnUpBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
upsample_size: Optional[int] = None,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
def hacked_UpBlock2D_forward(
self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, *args, **kwargs
):
eps = 1e-6
for i, resnet in enumerate(self.resnets):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
if reference_attn:
attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)]
attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0])
for i, module in enumerate(attn_modules):
module._original_inner_forward = module.forward
module.forward = hacked_basic_transformer_inner_forward.__get__(module, BasicTransformerBlock)
module.bank = []
module.attn_weight = float(i) / float(len(attn_modules))
if reference_adain:
gn_modules = [self.unet.mid_block]
self.unet.mid_block.gn_weight = 0
down_blocks = self.unet.down_blocks
for w, module in enumerate(down_blocks):
module.gn_weight = 1.0 - float(w) / float(len(down_blocks))
gn_modules.append(module)
up_blocks = self.unet.up_blocks
for w, module in enumerate(up_blocks):
module.gn_weight = float(w) / float(len(up_blocks))
gn_modules.append(module)
for i, module in enumerate(gn_modules):
if getattr(module, "original_forward", None) is None:
module.original_forward = module.forward
if i == 0:
# mid_block
module.forward = hacked_mid_forward.__get__(module, torch.nn.Module)
elif isinstance(module, CrossAttnDownBlock2D):
module.forward = hack_CrossAttnDownBlock2D_forward.__get__(module, CrossAttnDownBlock2D)
elif isinstance(module, DownBlock2D):
module.forward = hacked_DownBlock2D_forward.__get__(module, DownBlock2D)
elif isinstance(module, CrossAttnUpBlock2D):
module.forward = hacked_CrossAttnUpBlock2D_forward.__get__(module, CrossAttnUpBlock2D)
elif isinstance(module, UpBlock2D):
module.forward = hacked_UpBlock2D_forward.__get__(module, UpBlock2D)
module.mean_bank = []
module.var_bank = []
module.gn_weight *= 2
# 11. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# controlnet(s) inference
if guess_mode and do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=image,
conditioning_scale=controlnet_conditioning_scale,
guess_mode=guess_mode,
return_dict=False,
)
if guess_mode and do_classifier_free_guidance:
# Infered ControlNet only for the conditional batch.
# To apply the output of ControlNet to both the unconditional and conditional batches,
# add 0 to the unconditional batch to keep it unchanged.
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
# ref only part
noise = randn_tensor(
ref_image_latents.shape, generator=generator, device=device, dtype=ref_image_latents.dtype
)
ref_xt = self.scheduler.add_noise(
ref_image_latents,
noise,
t.reshape(
1,
),
)
ref_xt = self.scheduler.scale_model_input(ref_xt, t)
MODE = "write"
self.unet(
ref_xt,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)
# predict the noise residual
MODE = "read"
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# If we do sequential model offloading, let's offload unet and controlnet
# manually for max memory savings
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.unet.to("cpu")
self.controlnet.to("cpu")
torch.cuda.empty_cache()
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
diffusers/examples/community/stable_diffusion_controlnet_reference.py/0
|
{
"file_path": "diffusers/examples/community/stable_diffusion_controlnet_reference.py",
"repo_id": "diffusers",
"token_count": 21091
}
| 105 |
# Latent Consistency Distillation Example:
[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill stable-diffusion-v1.5 for inference with few timesteps.
## Full model distillation
### Running locally with PyTorch
#### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗 Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
#### Example
The following uses the [Conceptual Captions 12M (CC12M) dataset](https://github.com/google-research-datasets/conceptual-12m) as an example, and for illustrative purposes only. For best results you may consider large and high-quality text-image datasets such as [LAION](https://laion.ai/blog/laion-400-open-dataset/). You may also need to search the hyperparameter space according to the dataset you use.
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_sd_wds.py \
--pretrained_teacher_model=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--learning_rate=1e-6 --loss_type="huber" --ema_decay=0.95 --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub
```
## LCM-LoRA
Instead of fine-tuning the full model, we can also just train a LoRA that can be injected into any SDXL model.
### Example
The following uses the [Conceptual Captions 12M (CC12M) dataset](https://github.com/google-research-datasets/conceptual-12m) as an example. For best results you may consider large and high-quality text-image datasets such as [LAION](https://laion.ai/blog/laion-400-open-dataset/).
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_lora_sd_wds.py \
--pretrained_teacher_model=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--lora_rank=64 \
--learning_rate=1e-4 --loss_type="huber" --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
```
|
diffusers/examples/consistency_distillation/README.md/0
|
{
"file_path": "diffusers/examples/consistency_distillation/README.md",
"repo_id": "diffusers",
"token_count": 1511
}
| 106 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import logging
import math
import os
import random
import time
from pathlib import Path
import jax
import jax.numpy as jnp
import numpy as np
import optax
import torch
import torch.utils.checkpoint
import transformers
from datasets import load_dataset, load_from_disk
from flax import jax_utils
from flax.core.frozen_dict import unfreeze
from flax.training import train_state
from flax.training.common_utils import shard
from huggingface_hub import create_repo, upload_folder
from PIL import Image, PngImagePlugin
from torch.utils.data import IterableDataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTokenizer, FlaxCLIPTextModel, set_seed
from diffusers import (
FlaxAutoencoderKL,
FlaxControlNetModel,
FlaxDDPMScheduler,
FlaxStableDiffusionControlNetPipeline,
FlaxUNet2DConditionModel,
)
from diffusers.utils import check_min_version, is_wandb_available, make_image_grid
from diffusers.utils.hub_utils import load_or_create_model_card, populate_model_card
# To prevent an error that occurs when there are abnormally large compressed data chunk in the png image
# see more https://github.com/python-pillow/Pillow/issues/5610
LARGE_ENOUGH_NUMBER = 100
PngImagePlugin.MAX_TEXT_CHUNK = LARGE_ENOUGH_NUMBER * (1024**2)
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.28.0.dev0")
logger = logging.getLogger(__name__)
def log_validation(pipeline, pipeline_params, controlnet_params, tokenizer, args, rng, weight_dtype):
logger.info("Running validation...")
pipeline_params = pipeline_params.copy()
pipeline_params["controlnet"] = controlnet_params
num_samples = jax.device_count()
prng_seed = jax.random.split(rng, jax.device_count())
if len(args.validation_image) == len(args.validation_prompt):
validation_images = args.validation_image
validation_prompts = args.validation_prompt
elif len(args.validation_image) == 1:
validation_images = args.validation_image * len(args.validation_prompt)
validation_prompts = args.validation_prompt
elif len(args.validation_prompt) == 1:
validation_images = args.validation_image
validation_prompts = args.validation_prompt * len(args.validation_image)
else:
raise ValueError(
"number of `args.validation_image` and `args.validation_prompt` should be checked in `parse_args`"
)
image_logs = []
for validation_prompt, validation_image in zip(validation_prompts, validation_images):
prompts = num_samples * [validation_prompt]
prompt_ids = pipeline.prepare_text_inputs(prompts)
prompt_ids = shard(prompt_ids)
validation_image = Image.open(validation_image).convert("RGB")
processed_image = pipeline.prepare_image_inputs(num_samples * [validation_image])
processed_image = shard(processed_image)
images = pipeline(
prompt_ids=prompt_ids,
image=processed_image,
params=pipeline_params,
prng_seed=prng_seed,
num_inference_steps=50,
jit=True,
).images
images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
image_logs.append(
{"validation_image": validation_image, "images": images, "validation_prompt": validation_prompt}
)
if args.report_to == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
formatted_images.append(wandb.Image(validation_image, caption="Controlnet conditioning"))
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
wandb.log({"validation": formatted_images})
else:
logger.warning(f"image logging not implemented for {args.report_to}")
return image_logs
def save_model_card(repo_id: str, image_logs=None, base_model=str, repo_folder=None):
img_str = ""
if image_logs is not None:
for i, log in enumerate(image_logs):
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
validation_image.save(os.path.join(repo_folder, "image_control.png"))
img_str += f"prompt: {validation_prompt}\n"
images = [validation_image] + images
make_image_grid(images, 1, len(images)).save(os.path.join(repo_folder, f"images_{i}.png"))
img_str += f"\n"
model_description = f"""
# controlnet- {repo_id}
These are controlnet weights trained on {base_model} with new type of conditioning. You can find some example images in the following. \n
{img_str}
"""
model_card = load_or_create_model_card(
repo_id_or_path=repo_id,
from_training=True,
license="creativeml-openrail-m",
base_model=base_model,
model_description=model_description,
inference=True,
)
tags = [
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers",
"controlnet",
"jax-diffusers-event",
"diffusers-training",
]
model_card = populate_model_card(model_card, tags=tags)
model_card.save(os.path.join(repo_folder, "README.md"))
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--controlnet_model_name_or_path",
type=str,
default=None,
help="Path to pretrained controlnet model or model identifier from huggingface.co/models."
" If not specified controlnet weights are initialized from unet.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--from_pt",
action="store_true",
help="Load the pretrained model from a PyTorch checkpoint.",
)
parser.add_argument(
"--controlnet_revision",
type=str,
default=None,
help="Revision of controlnet model identifier from huggingface.co/models.",
)
parser.add_argument(
"--profile_steps",
type=int,
default=0,
help="How many training steps to profile in the beginning.",
)
parser.add_argument(
"--profile_validation",
action="store_true",
help="Whether to profile the (last) validation.",
)
parser.add_argument(
"--profile_memory",
action="store_true",
help="Whether to dump an initial (before training loop) and a final (at program end) memory profile.",
)
parser.add_argument(
"--ccache",
type=str,
default=None,
help="Enables compilation cache.",
)
parser.add_argument(
"--controlnet_from_pt",
action="store_true",
help="Load the controlnet model from a PyTorch checkpoint.",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--output_dir",
type=str,
default="runs/{timestamp}",
help="The output directory where the model predictions and checkpoints will be written. "
"Can contain placeholders: {timestamp}.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=0, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--train_batch_size", type=int, default=1, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=5000,
help=("Save a checkpoint of the training state every X updates."),
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_steps",
type=int,
default=100,
help=("log training metric every X steps to `--report_t`"),
)
parser.add_argument(
"--report_to",
type=str,
default="wandb",
help=('The integration to report the results and logs to. Currently only supported platforms are `"wandb"`'),
)
parser.add_argument(
"--mixed_precision",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument("--streaming", action="store_true", help="To stream a large dataset from Hub.")
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training dataset. By default it will use `load_dataset` method to load a custom dataset from the folder."
"Folder must contain a dataset script as described here https://huggingface.co/docs/datasets/dataset_script) ."
"If `--load_from_disk` flag is passed, it will use `load_from_disk` method instead. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--load_from_disk",
action="store_true",
help=(
"If True, will load a dataset that was previously saved using `save_to_disk` from `--train_data_dir`"
"See more https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.load_from_disk"
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing the target image."
)
parser.add_argument(
"--conditioning_image_column",
type=str,
default="conditioning_image",
help="The column of the dataset containing the controlnet conditioning image.",
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set. Needed if `streaming` is set to True."
),
)
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
nargs="+",
help=(
"A set of prompts evaluated every `--validation_steps` and logged to `--report_to`."
" Provide either a matching number of `--validation_image`s, a single `--validation_image`"
" to be used with all prompts, or a single prompt that will be used with all `--validation_image`s."
),
)
parser.add_argument(
"--validation_image",
type=str,
default=None,
nargs="+",
help=(
"A set of paths to the controlnet conditioning image be evaluated every `--validation_steps`"
" and logged to `--report_to`. Provide either a matching number of `--validation_prompt`s, a"
" a single `--validation_prompt` to be used with all `--validation_image`s, or a single"
" `--validation_image` that will be used with all `--validation_prompt`s."
),
)
parser.add_argument(
"--validation_steps",
type=int,
default=100,
help=(
"Run validation every X steps. Validation consists of running the prompt"
" `args.validation_prompt` and logging the images."
),
)
parser.add_argument("--wandb_entity", type=str, default=None, help=("The wandb entity to use (for teams)."))
parser.add_argument(
"--tracker_project_name",
type=str,
default="train_controlnet_flax",
help=("The `project` argument passed to wandb"),
)
parser.add_argument(
"--gradient_accumulation_steps", type=int, default=1, help="Number of steps to accumulate gradients over"
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
args = parser.parse_args()
args.output_dir = args.output_dir.replace("{timestamp}", time.strftime("%Y%m%d_%H%M%S"))
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
if args.dataset_name is not None and args.train_data_dir is not None:
raise ValueError("Specify only one of `--dataset_name` or `--train_data_dir`")
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
if args.validation_prompt is not None and args.validation_image is None:
raise ValueError("`--validation_image` must be set if `--validation_prompt` is set")
if args.validation_prompt is None and args.validation_image is not None:
raise ValueError("`--validation_prompt` must be set if `--validation_image` is set")
if (
args.validation_image is not None
and args.validation_prompt is not None
and len(args.validation_image) != 1
and len(args.validation_prompt) != 1
and len(args.validation_image) != len(args.validation_prompt)
):
raise ValueError(
"Must provide either 1 `--validation_image`, 1 `--validation_prompt`,"
" or the same number of `--validation_prompt`s and `--validation_image`s"
)
# This idea comes from
# https://github.com/borisdayma/dalle-mini/blob/d2be512d4a6a9cda2d63ba04afc33038f98f705f/src/dalle_mini/data.py#L370
if args.streaming and args.max_train_samples is None:
raise ValueError("You must specify `max_train_samples` when using dataset streaming.")
return args
def make_train_dataset(args, tokenizer, batch_size=None):
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
streaming=args.streaming,
)
else:
if args.train_data_dir is not None:
if args.load_from_disk:
dataset = load_from_disk(
args.train_data_dir,
)
else:
dataset = load_dataset(
args.train_data_dir,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
if isinstance(dataset["train"], IterableDataset):
column_names = next(iter(dataset["train"])).keys()
else:
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
if args.image_column is None:
image_column = column_names[0]
logger.info(f"image column defaulting to {image_column}")
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = column_names[1]
logger.info(f"caption column defaulting to {caption_column}")
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.conditioning_image_column is None:
conditioning_image_column = column_names[2]
logger.info(f"conditioning image column defaulting to {caption_column}")
else:
conditioning_image_column = args.conditioning_image_column
if conditioning_image_column not in column_names:
raise ValueError(
f"`--conditioning_image_column` value '{args.conditioning_image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if random.random() < args.proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
conditioning_image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
images = [image_transforms(image) for image in images]
conditioning_images = [image.convert("RGB") for image in examples[conditioning_image_column]]
conditioning_images = [conditioning_image_transforms(image) for image in conditioning_images]
examples["pixel_values"] = images
examples["conditioning_pixel_values"] = conditioning_images
examples["input_ids"] = tokenize_captions(examples)
return examples
if jax.process_index() == 0:
if args.max_train_samples is not None:
if args.streaming:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).take(args.max_train_samples)
else:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
if args.streaming:
train_dataset = dataset["train"].map(
preprocess_train,
batched=True,
batch_size=batch_size,
remove_columns=list(dataset["train"].features.keys()),
)
else:
train_dataset = dataset["train"].with_transform(preprocess_train)
return train_dataset
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
conditioning_pixel_values = torch.stack([example["conditioning_pixel_values"] for example in examples])
conditioning_pixel_values = conditioning_pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
batch = {
"pixel_values": pixel_values,
"conditioning_pixel_values": conditioning_pixel_values,
"input_ids": input_ids,
}
batch = {k: v.numpy() for k, v in batch.items()}
return batch
def get_params_to_save(params):
return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
def main():
args = parse_args()
if args.report_to == "wandb" and args.hub_token is not None:
raise ValueError(
"You cannot use both --report_to=wandb and --hub_token due to a security risk of exposing your token."
" Please use `huggingface-cli login` to authenticate with the Hub."
)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
transformers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
# wandb init
if jax.process_index() == 0 and args.report_to == "wandb":
wandb.init(
entity=args.wandb_entity,
project=args.tracker_project_name,
job_type="train",
config=args,
)
if args.seed is not None:
set_seed(args.seed)
rng = jax.random.PRNGKey(0)
# Handle the repository creation
if jax.process_index() == 0:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizer and add the placeholder token as a additional special token
if args.tokenizer_name:
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
elif args.pretrained_model_name_or_path:
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
else:
raise NotImplementedError("No tokenizer specified!")
# Get the datasets: you can either provide your own training and evaluation files (see below)
total_train_batch_size = args.train_batch_size * jax.local_device_count() * args.gradient_accumulation_steps
train_dataset = make_train_dataset(args, tokenizer, batch_size=total_train_batch_size)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=not args.streaming,
collate_fn=collate_fn,
batch_size=total_train_batch_size,
num_workers=args.dataloader_num_workers,
drop_last=True,
)
weight_dtype = jnp.float32
if args.mixed_precision == "fp16":
weight_dtype = jnp.float16
elif args.mixed_precision == "bf16":
weight_dtype = jnp.bfloat16
# Load models and create wrapper for stable diffusion
text_encoder = FlaxCLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="text_encoder",
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
vae, vae_params = FlaxAutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path,
revision=args.revision,
subfolder="vae",
dtype=weight_dtype,
from_pt=args.from_pt,
)
unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="unet",
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
if args.controlnet_model_name_or_path:
logger.info("Loading existing controlnet weights")
controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
args.controlnet_model_name_or_path,
revision=args.controlnet_revision,
from_pt=args.controlnet_from_pt,
dtype=jnp.float32,
)
else:
logger.info("Initializing controlnet weights from unet")
rng, rng_params = jax.random.split(rng)
controlnet = FlaxControlNetModel(
in_channels=unet.config.in_channels,
down_block_types=unet.config.down_block_types,
only_cross_attention=unet.config.only_cross_attention,
block_out_channels=unet.config.block_out_channels,
layers_per_block=unet.config.layers_per_block,
attention_head_dim=unet.config.attention_head_dim,
cross_attention_dim=unet.config.cross_attention_dim,
use_linear_projection=unet.config.use_linear_projection,
flip_sin_to_cos=unet.config.flip_sin_to_cos,
freq_shift=unet.config.freq_shift,
)
controlnet_params = controlnet.init_weights(rng=rng_params)
controlnet_params = unfreeze(controlnet_params)
for key in [
"conv_in",
"time_embedding",
"down_blocks_0",
"down_blocks_1",
"down_blocks_2",
"down_blocks_3",
"mid_block",
]:
controlnet_params[key] = unet_params[key]
pipeline, pipeline_params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
args.pretrained_model_name_or_path,
tokenizer=tokenizer,
controlnet=controlnet,
safety_checker=None,
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
pipeline_params = jax_utils.replicate(pipeline_params)
# Optimization
if args.scale_lr:
args.learning_rate = args.learning_rate * total_train_batch_size
constant_scheduler = optax.constant_schedule(args.learning_rate)
adamw = optax.adamw(
learning_rate=constant_scheduler,
b1=args.adam_beta1,
b2=args.adam_beta2,
eps=args.adam_epsilon,
weight_decay=args.adam_weight_decay,
)
optimizer = optax.chain(
optax.clip_by_global_norm(args.max_grad_norm),
adamw,
)
state = train_state.TrainState.create(apply_fn=controlnet.__call__, params=controlnet_params, tx=optimizer)
noise_scheduler, noise_scheduler_state = FlaxDDPMScheduler.from_pretrained(
args.pretrained_model_name_or_path, subfolder="scheduler"
)
# Initialize our training
validation_rng, train_rngs = jax.random.split(rng)
train_rngs = jax.random.split(train_rngs, jax.local_device_count())
def compute_snr(timesteps):
"""
Computes SNR as per https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L847-L849
"""
alphas_cumprod = noise_scheduler_state.common.alphas_cumprod
sqrt_alphas_cumprod = alphas_cumprod**0.5
sqrt_one_minus_alphas_cumprod = (1.0 - alphas_cumprod) ** 0.5
alpha = sqrt_alphas_cumprod[timesteps]
sigma = sqrt_one_minus_alphas_cumprod[timesteps]
# Compute SNR.
snr = (alpha / sigma) ** 2
return snr
def train_step(state, unet_params, text_encoder_params, vae_params, batch, train_rng):
# reshape batch, add grad_step_dim if gradient_accumulation_steps > 1
if args.gradient_accumulation_steps > 1:
grad_steps = args.gradient_accumulation_steps
batch = jax.tree_map(lambda x: x.reshape((grad_steps, x.shape[0] // grad_steps) + x.shape[1:]), batch)
def compute_loss(params, minibatch, sample_rng):
# Convert images to latent space
vae_outputs = vae.apply(
{"params": vae_params}, minibatch["pixel_values"], deterministic=True, method=vae.encode
)
latents = vae_outputs.latent_dist.sample(sample_rng)
# (NHWC) -> (NCHW)
latents = jnp.transpose(latents, (0, 3, 1, 2))
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise_rng, timestep_rng = jax.random.split(sample_rng)
noise = jax.random.normal(noise_rng, latents.shape)
# Sample a random timestep for each image
bsz = latents.shape[0]
timesteps = jax.random.randint(
timestep_rng,
(bsz,),
0,
noise_scheduler.config.num_train_timesteps,
)
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(
minibatch["input_ids"],
params=text_encoder_params,
train=False,
)[0]
controlnet_cond = minibatch["conditioning_pixel_values"]
# Predict the noise residual and compute loss
down_block_res_samples, mid_block_res_sample = controlnet.apply(
{"params": params},
noisy_latents,
timesteps,
encoder_hidden_states,
controlnet_cond,
train=True,
return_dict=False,
)
model_pred = unet.apply(
{"params": unet_params},
noisy_latents,
timesteps,
encoder_hidden_states,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = (target - model_pred) ** 2
if args.snr_gamma is not None:
snr = jnp.array(compute_snr(timesteps))
snr_loss_weights = jnp.where(snr < args.snr_gamma, snr, jnp.ones_like(snr) * args.snr_gamma)
if noise_scheduler.config.prediction_type == "epsilon":
snr_loss_weights = snr_loss_weights / snr
elif noise_scheduler.config.prediction_type == "v_prediction":
snr_loss_weights = snr_loss_weights / (snr + 1)
loss = loss * snr_loss_weights
loss = loss.mean()
return loss
grad_fn = jax.value_and_grad(compute_loss)
# get a minibatch (one gradient accumulation slice)
def get_minibatch(batch, grad_idx):
return jax.tree_util.tree_map(
lambda x: jax.lax.dynamic_index_in_dim(x, grad_idx, keepdims=False),
batch,
)
def loss_and_grad(grad_idx, train_rng):
# create minibatch for the grad step
minibatch = get_minibatch(batch, grad_idx) if grad_idx is not None else batch
sample_rng, train_rng = jax.random.split(train_rng, 2)
loss, grad = grad_fn(state.params, minibatch, sample_rng)
return loss, grad, train_rng
if args.gradient_accumulation_steps == 1:
loss, grad, new_train_rng = loss_and_grad(None, train_rng)
else:
init_loss_grad_rng = (
0.0, # initial value for cumul_loss
jax.tree_map(jnp.zeros_like, state.params), # initial value for cumul_grad
train_rng, # initial value for train_rng
)
def cumul_grad_step(grad_idx, loss_grad_rng):
cumul_loss, cumul_grad, train_rng = loss_grad_rng
loss, grad, new_train_rng = loss_and_grad(grad_idx, train_rng)
cumul_loss, cumul_grad = jax.tree_map(jnp.add, (cumul_loss, cumul_grad), (loss, grad))
return cumul_loss, cumul_grad, new_train_rng
loss, grad, new_train_rng = jax.lax.fori_loop(
0,
args.gradient_accumulation_steps,
cumul_grad_step,
init_loss_grad_rng,
)
loss, grad = jax.tree_map(lambda x: x / args.gradient_accumulation_steps, (loss, grad))
grad = jax.lax.pmean(grad, "batch")
new_state = state.apply_gradients(grads=grad)
metrics = {"loss": loss}
metrics = jax.lax.pmean(metrics, axis_name="batch")
def l2(xs):
return jnp.sqrt(sum([jnp.vdot(x, x) for x in jax.tree_util.tree_leaves(xs)]))
metrics["l2_grads"] = l2(jax.tree_util.tree_leaves(grad))
return new_state, metrics, new_train_rng
# Create parallel version of the train step
p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
# Replicate the train state on each device
state = jax_utils.replicate(state)
unet_params = jax_utils.replicate(unet_params)
text_encoder_params = jax_utils.replicate(text_encoder.params)
vae_params = jax_utils.replicate(vae_params)
# Train!
if args.streaming:
dataset_length = args.max_train_samples
else:
dataset_length = len(train_dataloader)
num_update_steps_per_epoch = math.ceil(dataset_length / args.gradient_accumulation_steps)
# Scheduler and math around the number of training steps.
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
logger.info("***** Running training *****")
logger.info(f" Num examples = {args.max_train_samples if args.streaming else len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
logger.info(f" Total optimization steps = {args.num_train_epochs * num_update_steps_per_epoch}")
if jax.process_index() == 0 and args.report_to == "wandb":
wandb.define_metric("*", step_metric="train/step")
wandb.define_metric("train/step", step_metric="walltime")
wandb.config.update(
{
"num_train_examples": args.max_train_samples if args.streaming else len(train_dataset),
"total_train_batch_size": total_train_batch_size,
"total_optimization_step": args.num_train_epochs * num_update_steps_per_epoch,
"num_devices": jax.device_count(),
"controlnet_params": sum(np.prod(x.shape) for x in jax.tree_util.tree_leaves(state.params)),
}
)
global_step = step0 = 0
epochs = tqdm(
range(args.num_train_epochs),
desc="Epoch ... ",
position=0,
disable=jax.process_index() > 0,
)
if args.profile_memory:
jax.profiler.save_device_memory_profile(os.path.join(args.output_dir, "memory_initial.prof"))
t00 = t0 = time.monotonic()
for epoch in epochs:
# ======================== Training ================================
train_metrics = []
train_metric = None
steps_per_epoch = (
args.max_train_samples // total_train_batch_size
if args.streaming or args.max_train_samples
else len(train_dataset) // total_train_batch_size
)
train_step_progress_bar = tqdm(
total=steps_per_epoch,
desc="Training...",
position=1,
leave=False,
disable=jax.process_index() > 0,
)
# train
for batch in train_dataloader:
if args.profile_steps and global_step == 1:
train_metric["loss"].block_until_ready()
jax.profiler.start_trace(args.output_dir)
if args.profile_steps and global_step == 1 + args.profile_steps:
train_metric["loss"].block_until_ready()
jax.profiler.stop_trace()
batch = shard(batch)
with jax.profiler.StepTraceAnnotation("train", step_num=global_step):
state, train_metric, train_rngs = p_train_step(
state, unet_params, text_encoder_params, vae_params, batch, train_rngs
)
train_metrics.append(train_metric)
train_step_progress_bar.update(1)
global_step += 1
if global_step >= args.max_train_steps:
break
if (
args.validation_prompt is not None
and global_step % args.validation_steps == 0
and jax.process_index() == 0
):
_ = log_validation(
pipeline, pipeline_params, state.params, tokenizer, args, validation_rng, weight_dtype
)
if global_step % args.logging_steps == 0 and jax.process_index() == 0:
if args.report_to == "wandb":
train_metrics = jax_utils.unreplicate(train_metrics)
train_metrics = jax.tree_util.tree_map(lambda *m: jnp.array(m).mean(), *train_metrics)
wandb.log(
{
"walltime": time.monotonic() - t00,
"train/step": global_step,
"train/epoch": global_step / dataset_length,
"train/steps_per_sec": (global_step - step0) / (time.monotonic() - t0),
**{f"train/{k}": v for k, v in train_metrics.items()},
}
)
t0, step0 = time.monotonic(), global_step
train_metrics = []
if global_step % args.checkpointing_steps == 0 and jax.process_index() == 0:
controlnet.save_pretrained(
f"{args.output_dir}/{global_step}",
params=get_params_to_save(state.params),
)
train_metric = jax_utils.unreplicate(train_metric)
train_step_progress_bar.close()
epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
# Final validation & store model.
if jax.process_index() == 0:
if args.validation_prompt is not None:
if args.profile_validation:
jax.profiler.start_trace(args.output_dir)
image_logs = log_validation(
pipeline, pipeline_params, state.params, tokenizer, args, validation_rng, weight_dtype
)
if args.profile_validation:
jax.profiler.stop_trace()
else:
image_logs = None
controlnet.save_pretrained(
args.output_dir,
params=get_params_to_save(state.params),
)
if args.push_to_hub:
save_model_card(
repo_id,
image_logs=image_logs,
base_model=args.pretrained_model_name_or_path,
repo_folder=args.output_dir,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
if args.profile_memory:
jax.profiler.save_device_memory_profile(os.path.join(args.output_dir, "memory_final.prof"))
logger.info("Finished training.")
if __name__ == "__main__":
main()
|
diffusers/examples/controlnet/train_controlnet_flax.py/0
|
{
"file_path": "diffusers/examples/controlnet/train_controlnet_flax.py",
"repo_id": "diffusers",
"token_count": 20114
}
| 107 |
import argparse
import logging
import math
import os
from pathlib import Path
import jax
import jax.numpy as jnp
import numpy as np
import optax
import torch
import torch.utils.checkpoint
import transformers
from flax import jax_utils
from flax.training import train_state
from flax.training.common_utils import shard
from huggingface_hub import create_repo, upload_folder
from huggingface_hub.utils import insecure_hashlib
from jax.experimental.compilation_cache import compilation_cache as cc
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel, set_seed
from diffusers import (
FlaxAutoencoderKL,
FlaxDDPMScheduler,
FlaxPNDMScheduler,
FlaxStableDiffusionPipeline,
FlaxUNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion import FlaxStableDiffusionSafetyChecker
from diffusers.utils import check_min_version
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.28.0.dev0")
# Cache compiled models across invocations of this script.
cc.initialize_cache(os.path.expanduser("~/.cache/jax/compilation_cache"))
logger = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_name_or_path",
type=str,
default=None,
help="Path to pretrained vae or vae identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--instance_data_dir",
type=str,
default=None,
required=True,
help="A folder containing the training data of instance images.",
)
parser.add_argument(
"--class_data_dir",
type=str,
default=None,
required=False,
help="A folder containing the training data of class images.",
)
parser.add_argument(
"--instance_prompt",
type=str,
default=None,
help="The prompt with identifier specifying the instance",
)
parser.add_argument(
"--class_prompt",
type=str,
default=None,
help="The prompt to specify images in the same class as provided instance images.",
)
parser.add_argument(
"--with_prior_preservation",
default=False,
action="store_true",
help="Flag to add prior preservation loss.",
)
parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
parser.add_argument(
"--num_class_images",
type=int,
default=100,
help=(
"Minimal class images for prior preservation loss. If there are not enough images already present in"
" class_data_dir, additional images will be sampled with class_prompt."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="text-inversion-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--save_steps", type=int, default=None, help="Save a checkpoint every X steps.")
parser.add_argument("--seed", type=int, default=0, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument("--train_text_encoder", action="store_true", help="Whether to train the text encoder")
parser.add_argument(
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
)
parser.add_argument(
"--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
)
parser.add_argument("--num_train_epochs", type=int, default=1)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-6,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.instance_data_dir is None:
raise ValueError("You must specify a train data directory.")
if args.with_prior_preservation:
if args.class_data_dir is None:
raise ValueError("You must specify a data directory for class images.")
if args.class_prompt is None:
raise ValueError("You must specify prompt for class images.")
return args
class DreamBoothDataset(Dataset):
"""
A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
It pre-processes the images and the tokenizes prompts.
"""
def __init__(
self,
instance_data_root,
instance_prompt,
tokenizer,
class_data_root=None,
class_prompt=None,
class_num=None,
size=512,
center_crop=False,
):
self.size = size
self.center_crop = center_crop
self.tokenizer = tokenizer
self.instance_data_root = Path(instance_data_root)
if not self.instance_data_root.exists():
raise ValueError("Instance images root doesn't exists.")
self.instance_images_path = list(Path(instance_data_root).iterdir())
self.num_instance_images = len(self.instance_images_path)
self.instance_prompt = instance_prompt
self._length = self.num_instance_images
if class_data_root is not None:
self.class_data_root = Path(class_data_root)
self.class_data_root.mkdir(parents=True, exist_ok=True)
self.class_images_path = list(self.class_data_root.iterdir())
if class_num is not None:
self.num_class_images = min(len(self.class_images_path), class_num)
else:
self.num_class_images = len(self.class_images_path)
self._length = max(self.num_class_images, self.num_instance_images)
self.class_prompt = class_prompt
else:
self.class_data_root = None
self.image_transforms = transforms.Compose(
[
transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def __len__(self):
return self._length
def __getitem__(self, index):
example = {}
instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
if not instance_image.mode == "RGB":
instance_image = instance_image.convert("RGB")
example["instance_images"] = self.image_transforms(instance_image)
example["instance_prompt_ids"] = self.tokenizer(
self.instance_prompt,
padding="do_not_pad",
truncation=True,
max_length=self.tokenizer.model_max_length,
).input_ids
if self.class_data_root:
class_image = Image.open(self.class_images_path[index % self.num_class_images])
if not class_image.mode == "RGB":
class_image = class_image.convert("RGB")
example["class_images"] = self.image_transforms(class_image)
example["class_prompt_ids"] = self.tokenizer(
self.class_prompt,
padding="do_not_pad",
truncation=True,
max_length=self.tokenizer.model_max_length,
).input_ids
return example
class PromptDataset(Dataset):
"A simple dataset to prepare the prompts to generate class images on multiple GPUs."
def __init__(self, prompt, num_samples):
self.prompt = prompt
self.num_samples = num_samples
def __len__(self):
return self.num_samples
def __getitem__(self, index):
example = {}
example["prompt"] = self.prompt
example["index"] = index
return example
def get_params_to_save(params):
return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
def main():
args = parse_args()
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
transformers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
if args.seed is not None:
set_seed(args.seed)
rng = jax.random.PRNGKey(args.seed)
if args.with_prior_preservation:
class_images_dir = Path(args.class_data_dir)
if not class_images_dir.exists():
class_images_dir.mkdir(parents=True)
cur_class_images = len(list(class_images_dir.iterdir()))
if cur_class_images < args.num_class_images:
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path, safety_checker=None, revision=args.revision
)
pipeline.set_progress_bar_config(disable=True)
num_new_images = args.num_class_images - cur_class_images
logger.info(f"Number of class images to sample: {num_new_images}.")
sample_dataset = PromptDataset(args.class_prompt, num_new_images)
total_sample_batch_size = args.sample_batch_size * jax.local_device_count()
sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=total_sample_batch_size)
for example in tqdm(
sample_dataloader, desc="Generating class images", disable=not jax.process_index() == 0
):
prompt_ids = pipeline.prepare_inputs(example["prompt"])
prompt_ids = shard(prompt_ids)
p_params = jax_utils.replicate(params)
rng = jax.random.split(rng)[0]
sample_rng = jax.random.split(rng, jax.device_count())
images = pipeline(prompt_ids, p_params, sample_rng, jit=True).images
images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
images = pipeline.numpy_to_pil(np.array(images))
for i, image in enumerate(images):
hash_image = insecure_hashlib.sha1(image.tobytes()).hexdigest()
image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
image.save(image_filename)
del pipeline
# Handle the repository creation
if jax.process_index() == 0:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizer and add the placeholder token as a additional special token
if args.tokenizer_name:
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
elif args.pretrained_model_name_or_path:
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
else:
raise NotImplementedError("No tokenizer specified!")
train_dataset = DreamBoothDataset(
instance_data_root=args.instance_data_dir,
instance_prompt=args.instance_prompt,
class_data_root=args.class_data_dir if args.with_prior_preservation else None,
class_prompt=args.class_prompt,
class_num=args.num_class_images,
tokenizer=tokenizer,
size=args.resolution,
center_crop=args.center_crop,
)
def collate_fn(examples):
input_ids = [example["instance_prompt_ids"] for example in examples]
pixel_values = [example["instance_images"] for example in examples]
# Concat class and instance examples for prior preservation.
# We do this to avoid doing two forward passes.
if args.with_prior_preservation:
input_ids += [example["class_prompt_ids"] for example in examples]
pixel_values += [example["class_images"] for example in examples]
pixel_values = torch.stack(pixel_values)
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = tokenizer.pad(
{"input_ids": input_ids}, padding="max_length", max_length=tokenizer.model_max_length, return_tensors="pt"
).input_ids
batch = {
"input_ids": input_ids,
"pixel_values": pixel_values,
}
batch = {k: v.numpy() for k, v in batch.items()}
return batch
total_train_batch_size = args.train_batch_size * jax.local_device_count()
if len(train_dataset) < total_train_batch_size:
raise ValueError(
f"Training batch size is {total_train_batch_size}, but your dataset only contains"
f" {len(train_dataset)} images. Please, use a larger dataset or reduce the effective batch size. Note that"
f" there are {jax.local_device_count()} parallel devices, so your batch size can't be smaller than that."
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=total_train_batch_size, shuffle=True, collate_fn=collate_fn, drop_last=True
)
weight_dtype = jnp.float32
if args.mixed_precision == "fp16":
weight_dtype = jnp.float16
elif args.mixed_precision == "bf16":
weight_dtype = jnp.bfloat16
if args.pretrained_vae_name_or_path:
# TODO(patil-suraj): Upload flax weights for the VAE
vae_arg, vae_kwargs = (args.pretrained_vae_name_or_path, {"from_pt": True})
else:
vae_arg, vae_kwargs = (args.pretrained_model_name_or_path, {"subfolder": "vae", "revision": args.revision})
# Load models and create wrapper for stable diffusion
text_encoder = FlaxCLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="text_encoder",
dtype=weight_dtype,
revision=args.revision,
)
vae, vae_params = FlaxAutoencoderKL.from_pretrained(
vae_arg,
dtype=weight_dtype,
**vae_kwargs,
)
unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="unet",
dtype=weight_dtype,
revision=args.revision,
)
# Optimization
if args.scale_lr:
args.learning_rate = args.learning_rate * total_train_batch_size
constant_scheduler = optax.constant_schedule(args.learning_rate)
adamw = optax.adamw(
learning_rate=constant_scheduler,
b1=args.adam_beta1,
b2=args.adam_beta2,
eps=args.adam_epsilon,
weight_decay=args.adam_weight_decay,
)
optimizer = optax.chain(
optax.clip_by_global_norm(args.max_grad_norm),
adamw,
)
unet_state = train_state.TrainState.create(apply_fn=unet.__call__, params=unet_params, tx=optimizer)
text_encoder_state = train_state.TrainState.create(
apply_fn=text_encoder.__call__, params=text_encoder.params, tx=optimizer
)
noise_scheduler = FlaxDDPMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000
)
noise_scheduler_state = noise_scheduler.create_state()
# Initialize our training
train_rngs = jax.random.split(rng, jax.local_device_count())
def train_step(unet_state, text_encoder_state, vae_params, batch, train_rng):
dropout_rng, sample_rng, new_train_rng = jax.random.split(train_rng, 3)
if args.train_text_encoder:
params = {"text_encoder": text_encoder_state.params, "unet": unet_state.params}
else:
params = {"unet": unet_state.params}
def compute_loss(params):
# Convert images to latent space
vae_outputs = vae.apply(
{"params": vae_params}, batch["pixel_values"], deterministic=True, method=vae.encode
)
latents = vae_outputs.latent_dist.sample(sample_rng)
# (NHWC) -> (NCHW)
latents = jnp.transpose(latents, (0, 3, 1, 2))
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise_rng, timestep_rng = jax.random.split(sample_rng)
noise = jax.random.normal(noise_rng, latents.shape)
# Sample a random timestep for each image
bsz = latents.shape[0]
timesteps = jax.random.randint(
timestep_rng,
(bsz,),
0,
noise_scheduler.config.num_train_timesteps,
)
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
# Get the text embedding for conditioning
if args.train_text_encoder:
encoder_hidden_states = text_encoder_state.apply_fn(
batch["input_ids"], params=params["text_encoder"], dropout_rng=dropout_rng, train=True
)[0]
else:
encoder_hidden_states = text_encoder(
batch["input_ids"], params=text_encoder_state.params, train=False
)[0]
# Predict the noise residual
model_pred = unet.apply(
{"params": params["unet"]}, noisy_latents, timesteps, encoder_hidden_states, train=True
).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
if args.with_prior_preservation:
# Chunk the noise and noise_pred into two parts and compute the loss on each part separately.
model_pred, model_pred_prior = jnp.split(model_pred, 2, axis=0)
target, target_prior = jnp.split(target, 2, axis=0)
# Compute instance loss
loss = (target - model_pred) ** 2
loss = loss.mean()
# Compute prior loss
prior_loss = (target_prior - model_pred_prior) ** 2
prior_loss = prior_loss.mean()
# Add the prior loss to the instance loss.
loss = loss + args.prior_loss_weight * prior_loss
else:
loss = (target - model_pred) ** 2
loss = loss.mean()
return loss
grad_fn = jax.value_and_grad(compute_loss)
loss, grad = grad_fn(params)
grad = jax.lax.pmean(grad, "batch")
new_unet_state = unet_state.apply_gradients(grads=grad["unet"])
if args.train_text_encoder:
new_text_encoder_state = text_encoder_state.apply_gradients(grads=grad["text_encoder"])
else:
new_text_encoder_state = text_encoder_state
metrics = {"loss": loss}
metrics = jax.lax.pmean(metrics, axis_name="batch")
return new_unet_state, new_text_encoder_state, metrics, new_train_rng
# Create parallel version of the train step
p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0, 1))
# Replicate the train state on each device
unet_state = jax_utils.replicate(unet_state)
text_encoder_state = jax_utils.replicate(text_encoder_state)
vae_params = jax_utils.replicate(vae_params)
# Train!
num_update_steps_per_epoch = math.ceil(len(train_dataloader))
# Scheduler and math around the number of training steps.
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
def checkpoint(step=None):
# Create the pipeline using the trained modules and save it.
scheduler, _ = FlaxPNDMScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
safety_checker = FlaxStableDiffusionSafetyChecker.from_pretrained(
"CompVis/stable-diffusion-safety-checker", from_pt=True
)
pipeline = FlaxStableDiffusionPipeline(
text_encoder=text_encoder,
vae=vae,
unet=unet,
tokenizer=tokenizer,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch32"),
)
outdir = os.path.join(args.output_dir, str(step)) if step else args.output_dir
pipeline.save_pretrained(
outdir,
params={
"text_encoder": get_params_to_save(text_encoder_state.params),
"vae": get_params_to_save(vae_params),
"unet": get_params_to_save(unet_state.params),
"safety_checker": safety_checker.params,
},
)
if args.push_to_hub:
message = f"checkpoint-{step}" if step is not None else "End of training"
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message=message,
ignore_patterns=["step_*", "epoch_*"],
)
global_step = 0
epochs = tqdm(range(args.num_train_epochs), desc="Epoch ... ", position=0)
for epoch in epochs:
# ======================== Training ================================
train_metrics = []
steps_per_epoch = len(train_dataset) // total_train_batch_size
train_step_progress_bar = tqdm(total=steps_per_epoch, desc="Training...", position=1, leave=False)
# train
for batch in train_dataloader:
batch = shard(batch)
unet_state, text_encoder_state, train_metric, train_rngs = p_train_step(
unet_state, text_encoder_state, vae_params, batch, train_rngs
)
train_metrics.append(train_metric)
train_step_progress_bar.update(jax.local_device_count())
global_step += 1
if jax.process_index() == 0 and args.save_steps and global_step % args.save_steps == 0:
checkpoint(global_step)
if global_step >= args.max_train_steps:
break
train_metric = jax_utils.unreplicate(train_metric)
train_step_progress_bar.close()
epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
if jax.process_index() == 0:
checkpoint()
if __name__ == "__main__":
main()
|
diffusers/examples/dreambooth/train_dreambooth_flax.py/0
|
{
"file_path": "diffusers/examples/dreambooth/train_dreambooth_flax.py",
"repo_id": "diffusers",
"token_count": 11966
}
| 108 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Fine-tuning script for Stable Diffusion for text2image with support for LoRA."""
import argparse
import logging
import math
import os
import random
import shutil
from pathlib import Path
import datasets
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from tqdm import tqdm
from transformers import CLIPImageProcessor, CLIPTextModelWithProjection, CLIPTokenizer, CLIPVisionModelWithProjection
import diffusers
from diffusers import AutoPipelineForText2Image, DDPMScheduler, PriorTransformer
from diffusers.loaders import AttnProcsLayers
from diffusers.models.attention_processor import LoRAAttnProcessor
from diffusers.optimization import get_scheduler
from diffusers.training_utils import compute_snr
from diffusers.utils import check_min_version, is_wandb_available
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.28.0.dev0")
logger = get_logger(__name__, log_level="INFO")
def save_model_card(repo_id: str, images=None, base_model=str, dataset_name=str, repo_folder=None):
img_str = ""
for i, image in enumerate(images):
image.save(os.path.join(repo_folder, f"image_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {base_model}
tags:
- kandinsky
- text-to-image
- diffusers
- diffusers-training
- lora
inference: true
---
"""
model_card = f"""
# LoRA text2image fine-tuning - {repo_id}
These are LoRA adaption weights for {base_model}. The weights were fine-tuned on the {dataset_name} dataset. You can find some example images in the following. \n
{img_str}
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of finetuning Kandinsky 2.2.")
parser.add_argument(
"--pretrained_decoder_model_name_or_path",
type=str,
default="kandinsky-community/kandinsky-2-2-decoder",
required=False,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_prior_model_name_or_path",
type=str,
default="kandinsky-community/kandinsky-2-2-prior",
required=False,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing an image."
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--validation_prompt", type=str, default=None, help="A prompt that is sampled during training for inference."
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_epochs",
type=int,
default=1,
help=(
"Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="kandi_2_2-model-finetuned-lora",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--train_batch_size", type=int, default=1, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="learning rate",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument(
"--adam_weight_decay",
type=float,
default=0.0,
required=False,
help="weight decay_to_use",
)
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--rank",
type=int,
default=4,
help=("The dimension of the LoRA update matrices."),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
return args
DATASET_NAME_MAPPING = {
"lambdalabs/pokemon-blip-captions": ("image", "text"),
}
def main():
args = parse_args()
if args.report_to == "wandb" and args.hub_token is not None:
raise ValueError(
"You cannot use both --report_to=wandb and --hub_token due to a security risk of exposing your token."
" Please use `huggingface-cli login` to authenticate with the Hub."
)
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(
total_limit=args.checkpoints_total_limit, project_dir=args.output_dir, logging_dir=logging_dir
)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load scheduler, image_processor, tokenizer and models.
noise_scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2", prediction_type="sample")
image_processor = CLIPImageProcessor.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_processor"
)
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="tokenizer")
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_encoder"
)
text_encoder = CLIPTextModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="text_encoder"
)
prior = PriorTransformer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="prior")
# freeze parameters of models to save more memory
image_encoder.requires_grad_(False)
prior.requires_grad_(False)
text_encoder.requires_grad_(False)
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move image_encoder, text_encoder and prior to device and cast to weight_dtype
prior.to(accelerator.device, dtype=weight_dtype)
image_encoder.to(accelerator.device, dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
lora_attn_procs = {}
for name in prior.attn_processors.keys():
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=2048, rank=args.rank)
prior.set_attn_processor(lora_attn_procs)
lora_layers = AttnProcsLayers(prior.attn_processors)
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
lora_layers.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
text_input_ids = inputs.input_ids
text_mask = inputs.attention_mask.bool()
return text_input_ids, text_mask
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["clip_pixel_values"] = image_processor(images, return_tensors="pt").pixel_values
examples["text_input_ids"], examples["text_mask"] = tokenize_captions(examples)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
clip_pixel_values = torch.stack([example["clip_pixel_values"] for example in examples])
clip_pixel_values = clip_pixel_values.to(memory_format=torch.contiguous_format).float()
text_input_ids = torch.stack([example["text_input_ids"] for example in examples])
text_mask = torch.stack([example["text_mask"] for example in examples])
return {"clip_pixel_values": clip_pixel_values, "text_input_ids": text_input_ids, "text_mask": text_mask}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
clip_mean = prior.clip_mean.clone()
clip_std = prior.clip_std.clone()
lora_layers, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
lora_layers, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("text2image-fine-tune", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
clip_mean = clip_mean.to(weight_dtype).to(accelerator.device)
clip_std = clip_std.to(weight_dtype).to(accelerator.device)
for epoch in range(first_epoch, args.num_train_epochs):
prior.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(prior):
# Convert images to latent space
text_input_ids, text_mask, clip_images = (
batch["text_input_ids"],
batch["text_mask"],
batch["clip_pixel_values"].to(weight_dtype),
)
with torch.no_grad():
text_encoder_output = text_encoder(text_input_ids)
prompt_embeds = text_encoder_output.text_embeds
text_encoder_hidden_states = text_encoder_output.last_hidden_state
image_embeds = image_encoder(clip_images).image_embeds
# Sample noise that we'll add to the image_embeds
noise = torch.randn_like(image_embeds)
bsz = image_embeds.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=image_embeds.device
)
timesteps = timesteps.long()
image_embeds = (image_embeds - clip_mean) / clip_std
noisy_latents = noise_scheduler.add_noise(image_embeds, noise, timesteps)
target = image_embeds
# Predict the noise residual and compute loss
model_pred = prior(
noisy_latents,
timestep=timesteps,
proj_embedding=prompt_embeds,
encoder_hidden_states=text_encoder_hidden_states,
attention_mask=text_mask,
).predicted_image_embedding
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
mse_loss_weights = torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(
dim=1
)[0]
if noise_scheduler.config.prediction_type == "epsilon":
mse_loss_weights = mse_loss_weights / snr
elif noise_scheduler.config.prediction_type == "v_prediction":
mse_loss_weights = mse_loss_weights / (snr + 1)
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
loss = loss.mean()
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(lora_layers.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
pipeline = AutoPipelineForText2Image.from_pretrained(
args.pretrained_decoder_model_name_or_path,
prior_prior=accelerator.unwrap_model(prior),
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
generator = torch.Generator(device=accelerator.device)
if args.seed is not None:
generator = generator.manual_seed(args.seed)
images = []
for _ in range(args.num_validation_images):
images.append(
pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0]
)
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
del pipeline
torch.cuda.empty_cache()
# Save the lora layers
accelerator.wait_for_everyone()
if accelerator.is_main_process:
prior = prior.to(torch.float32)
prior.save_attn_procs(args.output_dir)
if args.push_to_hub:
save_model_card(
repo_id,
images=images,
base_model=args.pretrained_prior_model_name_or_path,
dataset_name=args.dataset_name,
repo_folder=args.output_dir,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
# Final inference
# Load previous pipeline
pipeline = AutoPipelineForText2Image.from_pretrained(
args.pretrained_decoder_model_name_or_path, torch_dtype=weight_dtype
)
pipeline = pipeline.to(accelerator.device)
# load attention processors
pipeline.prior_prior.load_attn_procs(args.output_dir)
# run inference
generator = torch.Generator(device=accelerator.device)
if args.seed is not None:
generator = generator.manual_seed(args.seed)
images = []
for _ in range(args.num_validation_images):
images.append(pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0])
if accelerator.is_main_process:
for tracker in accelerator.trackers:
if len(images) != 0:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"test": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
accelerator.end_training()
if __name__ == "__main__":
main()
|
diffusers/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_prior.py/0
|
{
"file_path": "diffusers/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_prior.py",
"repo_id": "diffusers",
"token_count": 15579
}
| 109 |
# !pip install opencv-python transformers accelerate
import argparse
import cv2
import numpy as np
import torch
from controlnetxs import ControlNetXSModel
from PIL import Image
from pipeline_controlnet_xs import StableDiffusionControlNetXSPipeline
from diffusers.utils import load_image
parser = argparse.ArgumentParser()
parser.add_argument(
"--prompt", type=str, default="aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
)
parser.add_argument("--negative_prompt", type=str, default="low quality, bad quality, sketches")
parser.add_argument("--controlnet_conditioning_scale", type=float, default=0.7)
parser.add_argument(
"--image_path",
type=str,
default="https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png",
)
parser.add_argument("--num_inference_steps", type=int, default=50)
args = parser.parse_args()
prompt = args.prompt
negative_prompt = args.negative_prompt
# download an image
image = load_image(args.image_path)
# initialize the models and pipeline
controlnet_conditioning_scale = args.controlnet_conditioning_scale
controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SD2.1-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
# get canny image
image = np.array(image)
image = cv2.Canny(image, 100, 200)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
num_inference_steps = args.num_inference_steps
# generate image
image = pipe(
prompt,
controlnet_conditioning_scale=controlnet_conditioning_scale,
image=canny_image,
num_inference_steps=num_inference_steps,
).images[0]
image.save("cnxs_sd.canny.png")
|
diffusers/examples/research_projects/controlnetxs/infer_sd_controlnetxs.py/0
|
{
"file_path": "diffusers/examples/research_projects/controlnetxs/infer_sd_controlnetxs.py",
"repo_id": "diffusers",
"token_count": 646
}
| 110 |
## Textual Inversion fine-tuning example
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Training with Intel Extension for PyTorch
Intel Extension for PyTorch provides the optimizations for faster training and inference on CPUs. You can leverage the training example "textual_inversion.py". Follow the [instructions](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion) to get the model and [dataset](https://huggingface.co/sd-concepts-library/dicoo2) before running the script.
The example supports both single node and multi-node distributed training:
### Single node training
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATA_DIR="path-to-dir-containing-dicoo-images"
python textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<dicoo>" --initializer_token="toy" \
--seed=7 \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--max_train_steps=3000 \
--learning_rate=2.5e-03 --scale_lr \
--output_dir="textual_inversion_dicoo"
```
Note: Bfloat16 is available on Intel Xeon Scalable Processors Cooper Lake or Sapphire Rapids. You may not get performance speedup without Bfloat16 support.
### Multi-node distributed training
Before running the scripts, make sure to install the library's training dependencies successfully:
```bash
python -m pip install oneccl_bind_pt==1.13 -f https://developer.intel.com/ipex-whl-stable-cpu
```
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATA_DIR="path-to-dir-containing-dicoo-images"
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
python -m intel_extension_for_pytorch.cpu.launch --distributed \
--hostfile hostfile --nnodes 2 --nproc_per_node 2 textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<dicoo>" --initializer_token="toy" \
--seed=7 \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--max_train_steps=750 \
--learning_rate=2.5e-03 --scale_lr \
--output_dir="textual_inversion_dicoo"
```
The above is a simple distributed training usage on 2 nodes with 2 processes on each node. Add the right hostname or ip address in the "hostfile" and make sure these 2 nodes are reachable from each other. For more details, please refer to the [user guide](https://github.com/intel/torch-ccl).
### Reference
We publish a [Medium blog](https://medium.com/intel-analytics-software/personalized-stable-diffusion-with-few-shot-fine-tuning-on-a-single-cpu-f01a3316b13) on how to create your own Stable Diffusion model on CPUs using textual inversion. Try it out now, if you have interests.
|
diffusers/examples/research_projects/intel_opts/textual_inversion/README.md/0
|
{
"file_path": "diffusers/examples/research_projects/intel_opts/textual_inversion/README.md",
"repo_id": "diffusers",
"token_count": 1014
}
| 111 |
## [Deprecated] Multi Token Textual Inversion
**IMPORTART: This research project is deprecated. Multi Token Textual Inversion is now supported natively in [the official textual inversion example](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion#running-locally-with-pytorch).**
The author of this project is [Isamu Isozaki](https://github.com/isamu-isozaki) - please make sure to tag the author for issue and PRs as well as @patrickvonplaten.
We add multi token support to textual inversion. I added
1. num_vec_per_token for the number of used to reference that token
2. progressive_tokens for progressively training the token from 1 token to 2 token etc
3. progressive_tokens_max_steps for the max number of steps until we start full training
4. vector_shuffle to shuffle vectors
Feel free to add these options to your training! In practice num_vec_per_token around 10+vector shuffle works great!
## Textual Inversion fine-tuning example
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running on Colab
Colab for training
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
Colab for inference
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
### Cat toy example
You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-5`, so you'll need to visit [its card](https://huggingface.co/runwayml/stable-diffusion-v1-5), read the license and tick the checkbox if you agree.
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
Run the following command to authenticate your token
```bash
huggingface-cli login
```
If you have already cloned the repo, then you won't need to go through these steps.
<br>
Now let's get our dataset.Download 3-4 images from [here](https://drive.google.com/drive/folders/1fmJMs25nxS_rSNqS5hTcRdLem_YQXbq5) and save them in a directory. This will be our training data.
And launch the training using
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="path-to-dir-containing-images"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir="textual_inversion_cat"
```
A full training run takes ~1 hour on one V100 GPU.
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `placeholder_token` in your prompt.
```python
from diffusers import StableDiffusionPipeline
model_id = "path-to-your-trained-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16).to("cuda")
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("cat-backpack.png")
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -U -r requirements_flax.txt
```
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATA_DIR="path-to-dir-containing-images"
python textual_inversion_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 --scale_lr \
--output_dir="textual_inversion_cat"
```
It should be at least 70% faster than the PyTorch script with the same configuration.
### Training with xformers:
You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script. This is not available with the Flax/JAX implementation.
|
diffusers/examples/research_projects/multi_token_textual_inversion/README.md/0
|
{
"file_path": "diffusers/examples/research_projects/multi_token_textual_inversion/README.md",
"repo_id": "diffusers",
"token_count": 1842
}
| 112 |
# PromptDiffusion Pipeline
From the project [page](https://zhendong-wang.github.io/prompt-diffusion.github.io/)
"With a prompt consisting of a task-specific example pair of images and text guidance, and a new query image, Prompt Diffusion can comprehend the desired task and generate the corresponding output image on both seen (trained) and unseen (new) task types."
For any usage questions, please refer to the [paper](https://arxiv.org/abs/2305.01115).
Prepare models by converting them from the [checkpoint](https://huggingface.co/zhendongw/prompt-diffusion)
To convert the controlnet, use cldm_v15.yaml from the [repository](https://github.com/Zhendong-Wang/Prompt-Diffusion/tree/main/models/):
```bash
python convert_original_promptdiffusion_to_diffusers.py --checkpoint_path path-to-network-step04999.ckpt --original_config_file path-to-cldm_v15.yaml --dump_path path-to-output-directory
```
To learn about how to convert the fine-tuned stable diffusion model, see the [Load different Stable Diffusion formats guide](https://huggingface.co/docs/diffusers/main/en/using-diffusers/other-formats).
```py
import torch
from diffusers import UniPCMultistepScheduler
from diffusers.utils import load_image
from promptdiffusioncontrolnet import PromptDiffusionControlNetModel
from pipeline_prompt_diffusion import PromptDiffusionPipeline
from PIL import ImageOps
image_a = ImageOps.invert(load_image("https://github.com/Zhendong-Wang/Prompt-Diffusion/blob/main/images_to_try/house_line.png?raw=true"))
image_b = load_image("https://github.com/Zhendong-Wang/Prompt-Diffusion/blob/main/images_to_try/house.png?raw=true")
query = ImageOps.invert(load_image("https://github.com/Zhendong-Wang/Prompt-Diffusion/blob/main/images_to_try/new_01.png?raw=true"))
# load prompt diffusion controlnet and prompt diffusion
controlnet = PromptDiffusionControlNetModel.from_pretrained("iczaw/prompt-diffusion-diffusers", subfolder="controlnet", torch_dtype=torch.float16)
model_id = "path-to-model"
pipe = PromptDiffusionPipeline.from_pretrained("iczaw/prompt-diffusion-diffusers", subfolder="base", controlnet=controlnet, torch_dtype=torch.float16, variant="fp16")
# speed up diffusion process with faster scheduler and memory optimization
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# remove following line if xformers is not installed
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
# generate image
generator = torch.manual_seed(0)
image = pipe("a tortoise", num_inference_steps=20, generator=generator, image_pair=[image_a,image_b], image=query).images[0]
```
|
diffusers/examples/research_projects/promptdiffusion/README.md/0
|
{
"file_path": "diffusers/examples/research_projects/promptdiffusion/README.md",
"repo_id": "diffusers",
"token_count": 829
}
| 113 |
## Textual Inversion fine-tuning example
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running on Colab
Colab for training
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
Colab for inference
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run:
```bash
pip install -r requirements.txt
```
And initialize an [🤗 Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
### Cat toy example
First, let's login so that we can upload the checkpoint to the Hub during training:
```bash
huggingface-cli login
```
Now let's get our dataset. For this example we will use some cat images: https://huggingface.co/datasets/diffusers/cat_toy_example .
Let's first download it locally:
```py
from huggingface_hub import snapshot_download
local_dir = "./cat"
snapshot_download("diffusers/cat_toy_example", local_dir=local_dir, repo_type="dataset", ignore_patterns=".gitattributes")
```
This will be our training data.
Now we can launch the training using:
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
**___Note: Please follow the [README_sdxl.md](./README_sdxl.md) if you are using the [stable-diffusion-xl](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0).___**
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="./cat"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 \
--scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--push_to_hub \
--output_dir="textual_inversion_cat"
```
A full training run takes ~1 hour on one V100 GPU.
**Note**: As described in [the official paper](https://arxiv.org/abs/2208.01618)
only one embedding vector is used for the placeholder token, *e.g.* `"<cat-toy>"`.
However, one can also add multiple embedding vectors for the placeholder token
to increase the number of fine-tuneable parameters. This can help the model to learn
more complex details. To use multiple embedding vectors, you should define `--num_vectors`
to a number larger than one, *e.g.*:
```bash
--num_vectors 5
```
The saved textual inversion vectors will then be larger in size compared to the default case.
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `placeholder_token` in your prompt.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "path-to-your-trained-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16).to("cuda")
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("cat-backpack.png")
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -U -r requirements_flax.txt
```
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATA_DIR="path-to-dir-containing-images"
python textual_inversion_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 \
--scale_lr \
--output_dir="textual_inversion_cat"
```
It should be at least 70% faster than the PyTorch script with the same configuration.
### Training with xformers:
You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script. This is not available with the Flax/JAX implementation.
|
diffusers/examples/textual_inversion/README.md/0
|
{
"file_path": "diffusers/examples/textual_inversion/README.md",
"repo_id": "diffusers",
"token_count": 1736
}
| 114 |
# Script for converting a Hugging Face Diffusers trained SDXL LoRAs to Kohya format
# This means that you can input your diffusers-trained LoRAs and
# Get the output to work with WebUIs such as AUTOMATIC1111, ComfyUI, SD.Next and others.
# To get started you can find some cool `diffusers` trained LoRAs such as this cute Corgy
# https://huggingface.co/ignasbud/corgy_dog_LoRA/, download its `pytorch_lora_weights.safetensors` file
# and run the script:
# python convert_diffusers_sdxl_lora_to_webui.py --input_lora pytorch_lora_weights.safetensors --output_lora corgy.safetensors
# now you can use corgy.safetensors in your WebUI of choice!
# To train your own, here are some diffusers training scripts and utils that you can use and then convert:
# LoRA Ease - no code SDXL Dreambooth LoRA trainer: https://huggingface.co/spaces/multimodalart/lora-ease
# Dreambooth Advanced Training Script - state of the art techniques such as pivotal tuning and prodigy optimizer:
# - Script: https://github.com/huggingface/diffusers/blob/main/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
# - Colab (only on Pro): https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/SDXL_Dreambooth_LoRA_advanced_example.ipynb
# Canonical diffusers training scripts:
# - Script: https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora_sdxl.py
# - Colab (runs on free tier): https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/SDXL_DreamBooth_LoRA_.ipynb
import argparse
import os
from safetensors.torch import load_file, save_file
from diffusers.utils import convert_all_state_dict_to_peft, convert_state_dict_to_kohya
def convert_and_save(input_lora, output_lora=None):
if output_lora is None:
base_name = os.path.splitext(input_lora)[0]
output_lora = f"{base_name}_webui.safetensors"
diffusers_state_dict = load_file(input_lora)
peft_state_dict = convert_all_state_dict_to_peft(diffusers_state_dict)
kohya_state_dict = convert_state_dict_to_kohya(peft_state_dict)
save_file(kohya_state_dict, output_lora)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Convert LoRA model to PEFT and then to Kohya format.")
parser.add_argument(
"--input_lora",
type=str,
required=True,
help="Path to the input LoRA model file in the diffusers format.",
)
parser.add_argument(
"--output_lora",
type=str,
required=False,
help="Path for the converted LoRA (safetensors format for AUTOMATIC1111, ComfyUI, etc.). Optional, defaults to input name with a _webui suffix.",
)
args = parser.parse_args()
convert_and_save(args.input_lora, args.output_lora)
|
diffusers/scripts/convert_diffusers_sdxl_lora_to_webui.py/0
|
{
"file_path": "diffusers/scripts/convert_diffusers_sdxl_lora_to_webui.py",
"repo_id": "diffusers",
"token_count": 1027
}
| 115 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Conversion script for the NCSNPP checkpoints."""
import argparse
import json
import torch
from diffusers import ScoreSdeVePipeline, ScoreSdeVeScheduler, UNet2DModel
def convert_ncsnpp_checkpoint(checkpoint, config):
"""
Takes a state dict and the path to
"""
new_model_architecture = UNet2DModel(**config)
new_model_architecture.time_proj.W.data = checkpoint["all_modules.0.W"].data
new_model_architecture.time_proj.weight.data = checkpoint["all_modules.0.W"].data
new_model_architecture.time_embedding.linear_1.weight.data = checkpoint["all_modules.1.weight"].data
new_model_architecture.time_embedding.linear_1.bias.data = checkpoint["all_modules.1.bias"].data
new_model_architecture.time_embedding.linear_2.weight.data = checkpoint["all_modules.2.weight"].data
new_model_architecture.time_embedding.linear_2.bias.data = checkpoint["all_modules.2.bias"].data
new_model_architecture.conv_in.weight.data = checkpoint["all_modules.3.weight"].data
new_model_architecture.conv_in.bias.data = checkpoint["all_modules.3.bias"].data
new_model_architecture.conv_norm_out.weight.data = checkpoint[list(checkpoint.keys())[-4]].data
new_model_architecture.conv_norm_out.bias.data = checkpoint[list(checkpoint.keys())[-3]].data
new_model_architecture.conv_out.weight.data = checkpoint[list(checkpoint.keys())[-2]].data
new_model_architecture.conv_out.bias.data = checkpoint[list(checkpoint.keys())[-1]].data
module_index = 4
def set_attention_weights(new_layer, old_checkpoint, index):
new_layer.query.weight.data = old_checkpoint[f"all_modules.{index}.NIN_0.W"].data.T
new_layer.key.weight.data = old_checkpoint[f"all_modules.{index}.NIN_1.W"].data.T
new_layer.value.weight.data = old_checkpoint[f"all_modules.{index}.NIN_2.W"].data.T
new_layer.query.bias.data = old_checkpoint[f"all_modules.{index}.NIN_0.b"].data
new_layer.key.bias.data = old_checkpoint[f"all_modules.{index}.NIN_1.b"].data
new_layer.value.bias.data = old_checkpoint[f"all_modules.{index}.NIN_2.b"].data
new_layer.proj_attn.weight.data = old_checkpoint[f"all_modules.{index}.NIN_3.W"].data.T
new_layer.proj_attn.bias.data = old_checkpoint[f"all_modules.{index}.NIN_3.b"].data
new_layer.group_norm.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.weight"].data
new_layer.group_norm.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.bias"].data
def set_resnet_weights(new_layer, old_checkpoint, index):
new_layer.conv1.weight.data = old_checkpoint[f"all_modules.{index}.Conv_0.weight"].data
new_layer.conv1.bias.data = old_checkpoint[f"all_modules.{index}.Conv_0.bias"].data
new_layer.norm1.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.weight"].data
new_layer.norm1.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.bias"].data
new_layer.conv2.weight.data = old_checkpoint[f"all_modules.{index}.Conv_1.weight"].data
new_layer.conv2.bias.data = old_checkpoint[f"all_modules.{index}.Conv_1.bias"].data
new_layer.norm2.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_1.weight"].data
new_layer.norm2.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_1.bias"].data
new_layer.time_emb_proj.weight.data = old_checkpoint[f"all_modules.{index}.Dense_0.weight"].data
new_layer.time_emb_proj.bias.data = old_checkpoint[f"all_modules.{index}.Dense_0.bias"].data
if new_layer.in_channels != new_layer.out_channels or new_layer.up or new_layer.down:
new_layer.conv_shortcut.weight.data = old_checkpoint[f"all_modules.{index}.Conv_2.weight"].data
new_layer.conv_shortcut.bias.data = old_checkpoint[f"all_modules.{index}.Conv_2.bias"].data
for i, block in enumerate(new_model_architecture.downsample_blocks):
has_attentions = hasattr(block, "attentions")
for j in range(len(block.resnets)):
set_resnet_weights(block.resnets[j], checkpoint, module_index)
module_index += 1
if has_attentions:
set_attention_weights(block.attentions[j], checkpoint, module_index)
module_index += 1
if hasattr(block, "downsamplers") and block.downsamplers is not None:
set_resnet_weights(block.resnet_down, checkpoint, module_index)
module_index += 1
block.skip_conv.weight.data = checkpoint[f"all_modules.{module_index}.Conv_0.weight"].data
block.skip_conv.bias.data = checkpoint[f"all_modules.{module_index}.Conv_0.bias"].data
module_index += 1
set_resnet_weights(new_model_architecture.mid_block.resnets[0], checkpoint, module_index)
module_index += 1
set_attention_weights(new_model_architecture.mid_block.attentions[0], checkpoint, module_index)
module_index += 1
set_resnet_weights(new_model_architecture.mid_block.resnets[1], checkpoint, module_index)
module_index += 1
for i, block in enumerate(new_model_architecture.up_blocks):
has_attentions = hasattr(block, "attentions")
for j in range(len(block.resnets)):
set_resnet_weights(block.resnets[j], checkpoint, module_index)
module_index += 1
if has_attentions:
set_attention_weights(
block.attentions[0], checkpoint, module_index
) # why can there only be a single attention layer for up?
module_index += 1
if hasattr(block, "resnet_up") and block.resnet_up is not None:
block.skip_norm.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
block.skip_norm.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
module_index += 1
block.skip_conv.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
block.skip_conv.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
module_index += 1
set_resnet_weights(block.resnet_up, checkpoint, module_index)
module_index += 1
new_model_architecture.conv_norm_out.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
new_model_architecture.conv_norm_out.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
module_index += 1
new_model_architecture.conv_out.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
new_model_architecture.conv_out.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
return new_model_architecture.state_dict()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--checkpoint_path",
default="/Users/arthurzucker/Work/diffusers/ArthurZ/diffusion_pytorch_model.bin",
type=str,
required=False,
help="Path to the checkpoint to convert.",
)
parser.add_argument(
"--config_file",
default="/Users/arthurzucker/Work/diffusers/ArthurZ/config.json",
type=str,
required=False,
help="The config json file corresponding to the architecture.",
)
parser.add_argument(
"--dump_path",
default="/Users/arthurzucker/Work/diffusers/ArthurZ/diffusion_model_new.pt",
type=str,
required=False,
help="Path to the output model.",
)
args = parser.parse_args()
checkpoint = torch.load(args.checkpoint_path, map_location="cpu")
with open(args.config_file) as f:
config = json.loads(f.read())
converted_checkpoint = convert_ncsnpp_checkpoint(
checkpoint,
config,
)
if "sde" in config:
del config["sde"]
model = UNet2DModel(**config)
model.load_state_dict(converted_checkpoint)
try:
scheduler = ScoreSdeVeScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
pipe = ScoreSdeVePipeline(unet=model, scheduler=scheduler)
pipe.save_pretrained(args.dump_path)
except: # noqa: E722
model.save_pretrained(args.dump_path)
|
diffusers/scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py/0
|
{
"file_path": "diffusers/scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 3608
}
| 116 |
import argparse
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
from diffusers import UnCLIPImageVariationPipeline, UnCLIPPipeline
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
parser.add_argument(
"--txt2img_unclip",
default="kakaobrain/karlo-v1-alpha",
type=str,
required=False,
help="The pretrained txt2img unclip.",
)
args = parser.parse_args()
txt2img = UnCLIPPipeline.from_pretrained(args.txt2img_unclip)
feature_extractor = CLIPImageProcessor()
image_encoder = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
img2img = UnCLIPImageVariationPipeline(
decoder=txt2img.decoder,
text_encoder=txt2img.text_encoder,
tokenizer=txt2img.tokenizer,
text_proj=txt2img.text_proj,
feature_extractor=feature_extractor,
image_encoder=image_encoder,
super_res_first=txt2img.super_res_first,
super_res_last=txt2img.super_res_last,
decoder_scheduler=txt2img.decoder_scheduler,
super_res_scheduler=txt2img.super_res_scheduler,
)
img2img.save_pretrained(args.dump_path)
|
diffusers/scripts/convert_unclip_txt2img_to_image_variation.py/0
|
{
"file_path": "diffusers/scripts/convert_unclip_txt2img_to_image_variation.py",
"repo_id": "diffusers",
"token_count": 554
}
| 117 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""ConfigMixin base class and utilities."""
import dataclasses
import functools
import importlib
import inspect
import json
import os
import re
from collections import OrderedDict
from pathlib import PosixPath
from typing import Any, Dict, Tuple, Union
import numpy as np
from huggingface_hub import create_repo, hf_hub_download
from huggingface_hub.utils import (
EntryNotFoundError,
RepositoryNotFoundError,
RevisionNotFoundError,
validate_hf_hub_args,
)
from requests import HTTPError
from . import __version__
from .utils import (
HUGGINGFACE_CO_RESOLVE_ENDPOINT,
DummyObject,
deprecate,
extract_commit_hash,
http_user_agent,
logging,
)
logger = logging.get_logger(__name__)
_re_configuration_file = re.compile(r"config\.(.*)\.json")
class FrozenDict(OrderedDict):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
for key, value in self.items():
setattr(self, key, value)
self.__frozen = True
def __delitem__(self, *args, **kwargs):
raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
def setdefault(self, *args, **kwargs):
raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
def pop(self, *args, **kwargs):
raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
def update(self, *args, **kwargs):
raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
def __setattr__(self, name, value):
if hasattr(self, "__frozen") and self.__frozen:
raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
super().__setattr__(name, value)
def __setitem__(self, name, value):
if hasattr(self, "__frozen") and self.__frozen:
raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
super().__setitem__(name, value)
class ConfigMixin:
r"""
Base class for all configuration classes. All configuration parameters are stored under `self.config`. Also
provides the [`~ConfigMixin.from_config`] and [`~ConfigMixin.save_config`] methods for loading, downloading, and
saving classes that inherit from [`ConfigMixin`].
Class attributes:
- **config_name** (`str`) -- A filename under which the config should stored when calling
[`~ConfigMixin.save_config`] (should be overridden by parent class).
- **ignore_for_config** (`List[str]`) -- A list of attributes that should not be saved in the config (should be
overridden by subclass).
- **has_compatibles** (`bool`) -- Whether the class has compatible classes (should be overridden by subclass).
- **_deprecated_kwargs** (`List[str]`) -- Keyword arguments that are deprecated. Note that the `init` function
should only have a `kwargs` argument if at least one argument is deprecated (should be overridden by
subclass).
"""
config_name = None
ignore_for_config = []
has_compatibles = False
_deprecated_kwargs = []
def register_to_config(self, **kwargs):
if self.config_name is None:
raise NotImplementedError(f"Make sure that {self.__class__} has defined a class name `config_name`")
# Special case for `kwargs` used in deprecation warning added to schedulers
# TODO: remove this when we remove the deprecation warning, and the `kwargs` argument,
# or solve in a more general way.
kwargs.pop("kwargs", None)
if not hasattr(self, "_internal_dict"):
internal_dict = kwargs
else:
previous_dict = dict(self._internal_dict)
internal_dict = {**self._internal_dict, **kwargs}
logger.debug(f"Updating config from {previous_dict} to {internal_dict}")
self._internal_dict = FrozenDict(internal_dict)
def __getattr__(self, name: str) -> Any:
"""The only reason we overwrite `getattr` here is to gracefully deprecate accessing
config attributes directly. See https://github.com/huggingface/diffusers/pull/3129
This function is mostly copied from PyTorch's __getattr__ overwrite:
https://pytorch.org/docs/stable/_modules/torch/nn/modules/module.html#Module
"""
is_in_config = "_internal_dict" in self.__dict__ and hasattr(self.__dict__["_internal_dict"], name)
is_attribute = name in self.__dict__
if is_in_config and not is_attribute:
deprecation_message = f"Accessing config attribute `{name}` directly via '{type(self).__name__}' object attribute is deprecated. Please access '{name}' over '{type(self).__name__}'s config object instead, e.g. 'scheduler.config.{name}'."
deprecate("direct config name access", "1.0.0", deprecation_message, standard_warn=False)
return self._internal_dict[name]
raise AttributeError(f"'{type(self).__name__}' object has no attribute '{name}'")
def save_config(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
"""
Save a configuration object to the directory specified in `save_directory` so that it can be reloaded using the
[`~ConfigMixin.from_config`] class method.
Args:
save_directory (`str` or `os.PathLike`):
Directory where the configuration JSON file is saved (will be created if it does not exist).
push_to_hub (`bool`, *optional*, defaults to `False`):
Whether or not to push your model to the Hugging Face Hub after saving it. You can specify the
repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
namespace).
kwargs (`Dict[str, Any]`, *optional*):
Additional keyword arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
"""
if os.path.isfile(save_directory):
raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
os.makedirs(save_directory, exist_ok=True)
# If we save using the predefined names, we can load using `from_config`
output_config_file = os.path.join(save_directory, self.config_name)
self.to_json_file(output_config_file)
logger.info(f"Configuration saved in {output_config_file}")
if push_to_hub:
commit_message = kwargs.pop("commit_message", None)
private = kwargs.pop("private", False)
create_pr = kwargs.pop("create_pr", False)
token = kwargs.pop("token", None)
repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
repo_id = create_repo(repo_id, exist_ok=True, private=private, token=token).repo_id
self._upload_folder(
save_directory,
repo_id,
token=token,
commit_message=commit_message,
create_pr=create_pr,
)
@classmethod
def from_config(cls, config: Union[FrozenDict, Dict[str, Any]] = None, return_unused_kwargs=False, **kwargs):
r"""
Instantiate a Python class from a config dictionary.
Parameters:
config (`Dict[str, Any]`):
A config dictionary from which the Python class is instantiated. Make sure to only load configuration
files of compatible classes.
return_unused_kwargs (`bool`, *optional*, defaults to `False`):
Whether kwargs that are not consumed by the Python class should be returned or not.
kwargs (remaining dictionary of keyword arguments, *optional*):
Can be used to update the configuration object (after it is loaded) and initiate the Python class.
`**kwargs` are passed directly to the underlying scheduler/model's `__init__` method and eventually
overwrite the same named arguments in `config`.
Returns:
[`ModelMixin`] or [`SchedulerMixin`]:
A model or scheduler object instantiated from a config dictionary.
Examples:
```python
>>> from diffusers import DDPMScheduler, DDIMScheduler, PNDMScheduler
>>> # Download scheduler from huggingface.co and cache.
>>> scheduler = DDPMScheduler.from_pretrained("google/ddpm-cifar10-32")
>>> # Instantiate DDIM scheduler class with same config as DDPM
>>> scheduler = DDIMScheduler.from_config(scheduler.config)
>>> # Instantiate PNDM scheduler class with same config as DDPM
>>> scheduler = PNDMScheduler.from_config(scheduler.config)
```
"""
# <===== TO BE REMOVED WITH DEPRECATION
# TODO(Patrick) - make sure to remove the following lines when config=="model_path" is deprecated
if "pretrained_model_name_or_path" in kwargs:
config = kwargs.pop("pretrained_model_name_or_path")
if config is None:
raise ValueError("Please make sure to provide a config as the first positional argument.")
# ======>
if not isinstance(config, dict):
deprecation_message = "It is deprecated to pass a pretrained model name or path to `from_config`."
if "Scheduler" in cls.__name__:
deprecation_message += (
f"If you were trying to load a scheduler, please use {cls}.from_pretrained(...) instead."
" Otherwise, please make sure to pass a configuration dictionary instead. This functionality will"
" be removed in v1.0.0."
)
elif "Model" in cls.__name__:
deprecation_message += (
f"If you were trying to load a model, please use {cls}.load_config(...) followed by"
f" {cls}.from_config(...) instead. Otherwise, please make sure to pass a configuration dictionary"
" instead. This functionality will be removed in v1.0.0."
)
deprecate("config-passed-as-path", "1.0.0", deprecation_message, standard_warn=False)
config, kwargs = cls.load_config(pretrained_model_name_or_path=config, return_unused_kwargs=True, **kwargs)
init_dict, unused_kwargs, hidden_dict = cls.extract_init_dict(config, **kwargs)
# Allow dtype to be specified on initialization
if "dtype" in unused_kwargs:
init_dict["dtype"] = unused_kwargs.pop("dtype")
# add possible deprecated kwargs
for deprecated_kwarg in cls._deprecated_kwargs:
if deprecated_kwarg in unused_kwargs:
init_dict[deprecated_kwarg] = unused_kwargs.pop(deprecated_kwarg)
# Return model and optionally state and/or unused_kwargs
model = cls(**init_dict)
# make sure to also save config parameters that might be used for compatible classes
# update _class_name
if "_class_name" in hidden_dict:
hidden_dict["_class_name"] = cls.__name__
model.register_to_config(**hidden_dict)
# add hidden kwargs of compatible classes to unused_kwargs
unused_kwargs = {**unused_kwargs, **hidden_dict}
if return_unused_kwargs:
return (model, unused_kwargs)
else:
return model
@classmethod
def get_config_dict(cls, *args, **kwargs):
deprecation_message = (
f" The function get_config_dict is deprecated. Please use {cls}.load_config instead. This function will be"
" removed in version v1.0.0"
)
deprecate("get_config_dict", "1.0.0", deprecation_message, standard_warn=False)
return cls.load_config(*args, **kwargs)
@classmethod
@validate_hf_hub_args
def load_config(
cls,
pretrained_model_name_or_path: Union[str, os.PathLike],
return_unused_kwargs=False,
return_commit_hash=False,
**kwargs,
) -> Tuple[Dict[str, Any], Dict[str, Any]]:
r"""
Load a model or scheduler configuration.
Parameters:
pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
Can be either:
- A string, the *model id* (for example `google/ddpm-celebahq-256`) of a pretrained model hosted on
the Hub.
- A path to a *directory* (for example `./my_model_directory`) containing model weights saved with
[`~ConfigMixin.save_config`].
cache_dir (`Union[str, os.PathLike]`, *optional*):
Path to a directory where a downloaded pretrained model configuration is cached if the standard cache
is not used.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download (`bool`, *optional*, defaults to `False`):
Whether or not to resume downloading the model weights and configuration files. If set to `False`, any
incompletely downloaded files are deleted.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, for example, `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only (`bool`, *optional*, defaults to `False`):
Whether to only load local model weights and configuration files or not. If set to `True`, the model
won't be downloaded from the Hub.
token (`str` or *bool*, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, the token generated from
`diffusers-cli login` (stored in `~/.huggingface`) is used.
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, a commit id, or any identifier
allowed by Git.
subfolder (`str`, *optional*, defaults to `""`):
The subfolder location of a model file within a larger model repository on the Hub or locally.
return_unused_kwargs (`bool`, *optional*, defaults to `False):
Whether unused keyword arguments of the config are returned.
return_commit_hash (`bool`, *optional*, defaults to `False):
Whether the `commit_hash` of the loaded configuration are returned.
Returns:
`dict`:
A dictionary of all the parameters stored in a JSON configuration file.
"""
cache_dir = kwargs.pop("cache_dir", None)
force_download = kwargs.pop("force_download", False)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
token = kwargs.pop("token", None)
local_files_only = kwargs.pop("local_files_only", False)
revision = kwargs.pop("revision", None)
_ = kwargs.pop("mirror", None)
subfolder = kwargs.pop("subfolder", None)
user_agent = kwargs.pop("user_agent", {})
user_agent = {**user_agent, "file_type": "config"}
user_agent = http_user_agent(user_agent)
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
if cls.config_name is None:
raise ValueError(
"`self.config_name` is not defined. Note that one should not load a config from "
"`ConfigMixin`. Please make sure to define `config_name` in a class inheriting from `ConfigMixin`"
)
if os.path.isfile(pretrained_model_name_or_path):
config_file = pretrained_model_name_or_path
elif os.path.isdir(pretrained_model_name_or_path):
if os.path.isfile(os.path.join(pretrained_model_name_or_path, cls.config_name)):
# Load from a PyTorch checkpoint
config_file = os.path.join(pretrained_model_name_or_path, cls.config_name)
elif subfolder is not None and os.path.isfile(
os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
):
config_file = os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
else:
raise EnvironmentError(
f"Error no file named {cls.config_name} found in directory {pretrained_model_name_or_path}."
)
else:
try:
# Load from URL or cache if already cached
config_file = hf_hub_download(
pretrained_model_name_or_path,
filename=cls.config_name,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
subfolder=subfolder,
revision=revision,
)
except RepositoryNotFoundError:
raise EnvironmentError(
f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier"
" listed on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a"
" token having permission to this repo with `token` or log in with `huggingface-cli login`."
)
except RevisionNotFoundError:
raise EnvironmentError(
f"{revision} is not a valid git identifier (branch name, tag name or commit id) that exists for"
" this model name. Check the model page at"
f" 'https://huggingface.co/{pretrained_model_name_or_path}' for available revisions."
)
except EntryNotFoundError:
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named {cls.config_name}."
)
except HTTPError as err:
raise EnvironmentError(
"There was a specific connection error when trying to load"
f" {pretrained_model_name_or_path}:\n{err}"
)
except ValueError:
raise EnvironmentError(
f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this model, couldn't find it"
f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
f" directory containing a {cls.config_name} file.\nCheckout your internet connection or see how to"
" run the library in offline mode at"
" 'https://huggingface.co/docs/diffusers/installation#offline-mode'."
)
except EnvironmentError:
raise EnvironmentError(
f"Can't load config for '{pretrained_model_name_or_path}'. If you were trying to load it from "
"'https://huggingface.co/models', make sure you don't have a local directory with the same name. "
f"Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory "
f"containing a {cls.config_name} file"
)
try:
# Load config dict
config_dict = cls._dict_from_json_file(config_file)
commit_hash = extract_commit_hash(config_file)
except (json.JSONDecodeError, UnicodeDecodeError):
raise EnvironmentError(f"It looks like the config file at '{config_file}' is not a valid JSON file.")
if not (return_unused_kwargs or return_commit_hash):
return config_dict
outputs = (config_dict,)
if return_unused_kwargs:
outputs += (kwargs,)
if return_commit_hash:
outputs += (commit_hash,)
return outputs
@staticmethod
def _get_init_keys(cls):
return set(dict(inspect.signature(cls.__init__).parameters).keys())
@classmethod
def extract_init_dict(cls, config_dict, **kwargs):
# Skip keys that were not present in the original config, so default __init__ values were used
used_defaults = config_dict.get("_use_default_values", [])
config_dict = {k: v for k, v in config_dict.items() if k not in used_defaults and k != "_use_default_values"}
# 0. Copy origin config dict
original_dict = dict(config_dict.items())
# 1. Retrieve expected config attributes from __init__ signature
expected_keys = cls._get_init_keys(cls)
expected_keys.remove("self")
# remove general kwargs if present in dict
if "kwargs" in expected_keys:
expected_keys.remove("kwargs")
# remove flax internal keys
if hasattr(cls, "_flax_internal_args"):
for arg in cls._flax_internal_args:
expected_keys.remove(arg)
# 2. Remove attributes that cannot be expected from expected config attributes
# remove keys to be ignored
if len(cls.ignore_for_config) > 0:
expected_keys = expected_keys - set(cls.ignore_for_config)
# load diffusers library to import compatible and original scheduler
diffusers_library = importlib.import_module(__name__.split(".")[0])
if cls.has_compatibles:
compatible_classes = [c for c in cls._get_compatibles() if not isinstance(c, DummyObject)]
else:
compatible_classes = []
expected_keys_comp_cls = set()
for c in compatible_classes:
expected_keys_c = cls._get_init_keys(c)
expected_keys_comp_cls = expected_keys_comp_cls.union(expected_keys_c)
expected_keys_comp_cls = expected_keys_comp_cls - cls._get_init_keys(cls)
config_dict = {k: v for k, v in config_dict.items() if k not in expected_keys_comp_cls}
# remove attributes from orig class that cannot be expected
orig_cls_name = config_dict.pop("_class_name", cls.__name__)
if (
isinstance(orig_cls_name, str)
and orig_cls_name != cls.__name__
and hasattr(diffusers_library, orig_cls_name)
):
orig_cls = getattr(diffusers_library, orig_cls_name)
unexpected_keys_from_orig = cls._get_init_keys(orig_cls) - expected_keys
config_dict = {k: v for k, v in config_dict.items() if k not in unexpected_keys_from_orig}
elif not isinstance(orig_cls_name, str) and not isinstance(orig_cls_name, (list, tuple)):
raise ValueError(
"Make sure that the `_class_name` is of type string or list of string (for custom pipelines)."
)
# remove private attributes
config_dict = {k: v for k, v in config_dict.items() if not k.startswith("_")}
# 3. Create keyword arguments that will be passed to __init__ from expected keyword arguments
init_dict = {}
for key in expected_keys:
# if config param is passed to kwarg and is present in config dict
# it should overwrite existing config dict key
if key in kwargs and key in config_dict:
config_dict[key] = kwargs.pop(key)
if key in kwargs:
# overwrite key
init_dict[key] = kwargs.pop(key)
elif key in config_dict:
# use value from config dict
init_dict[key] = config_dict.pop(key)
# 4. Give nice warning if unexpected values have been passed
if len(config_dict) > 0:
logger.warning(
f"The config attributes {config_dict} were passed to {cls.__name__}, "
"but are not expected and will be ignored. Please verify your "
f"{cls.config_name} configuration file."
)
# 5. Give nice info if config attributes are initialized to default because they have not been passed
passed_keys = set(init_dict.keys())
if len(expected_keys - passed_keys) > 0:
logger.info(
f"{expected_keys - passed_keys} was not found in config. Values will be initialized to default values."
)
# 6. Define unused keyword arguments
unused_kwargs = {**config_dict, **kwargs}
# 7. Define "hidden" config parameters that were saved for compatible classes
hidden_config_dict = {k: v for k, v in original_dict.items() if k not in init_dict}
return init_dict, unused_kwargs, hidden_config_dict
@classmethod
def _dict_from_json_file(cls, json_file: Union[str, os.PathLike]):
with open(json_file, "r", encoding="utf-8") as reader:
text = reader.read()
return json.loads(text)
def __repr__(self):
return f"{self.__class__.__name__} {self.to_json_string()}"
@property
def config(self) -> Dict[str, Any]:
"""
Returns the config of the class as a frozen dictionary
Returns:
`Dict[str, Any]`: Config of the class.
"""
return self._internal_dict
def to_json_string(self) -> str:
"""
Serializes the configuration instance to a JSON string.
Returns:
`str`:
String containing all the attributes that make up the configuration instance in JSON format.
"""
config_dict = self._internal_dict if hasattr(self, "_internal_dict") else {}
config_dict["_class_name"] = self.__class__.__name__
config_dict["_diffusers_version"] = __version__
def to_json_saveable(value):
if isinstance(value, np.ndarray):
value = value.tolist()
elif isinstance(value, PosixPath):
value = str(value)
return value
config_dict = {k: to_json_saveable(v) for k, v in config_dict.items()}
# Don't save "_ignore_files" or "_use_default_values"
config_dict.pop("_ignore_files", None)
config_dict.pop("_use_default_values", None)
return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
def to_json_file(self, json_file_path: Union[str, os.PathLike]):
"""
Save the configuration instance's parameters to a JSON file.
Args:
json_file_path (`str` or `os.PathLike`):
Path to the JSON file to save a configuration instance's parameters.
"""
with open(json_file_path, "w", encoding="utf-8") as writer:
writer.write(self.to_json_string())
def register_to_config(init):
r"""
Decorator to apply on the init of classes inheriting from [`ConfigMixin`] so that all the arguments are
automatically sent to `self.register_for_config`. To ignore a specific argument accepted by the init but that
shouldn't be registered in the config, use the `ignore_for_config` class variable
Warning: Once decorated, all private arguments (beginning with an underscore) are trashed and not sent to the init!
"""
@functools.wraps(init)
def inner_init(self, *args, **kwargs):
# Ignore private kwargs in the init.
init_kwargs = {k: v for k, v in kwargs.items() if not k.startswith("_")}
config_init_kwargs = {k: v for k, v in kwargs.items() if k.startswith("_")}
if not isinstance(self, ConfigMixin):
raise RuntimeError(
f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
"not inherit from `ConfigMixin`."
)
ignore = getattr(self, "ignore_for_config", [])
# Get positional arguments aligned with kwargs
new_kwargs = {}
signature = inspect.signature(init)
parameters = {
name: p.default for i, (name, p) in enumerate(signature.parameters.items()) if i > 0 and name not in ignore
}
for arg, name in zip(args, parameters.keys()):
new_kwargs[name] = arg
# Then add all kwargs
new_kwargs.update(
{
k: init_kwargs.get(k, default)
for k, default in parameters.items()
if k not in ignore and k not in new_kwargs
}
)
# Take note of the parameters that were not present in the loaded config
if len(set(new_kwargs.keys()) - set(init_kwargs)) > 0:
new_kwargs["_use_default_values"] = list(set(new_kwargs.keys()) - set(init_kwargs))
new_kwargs = {**config_init_kwargs, **new_kwargs}
getattr(self, "register_to_config")(**new_kwargs)
init(self, *args, **init_kwargs)
return inner_init
def flax_register_to_config(cls):
original_init = cls.__init__
@functools.wraps(original_init)
def init(self, *args, **kwargs):
if not isinstance(self, ConfigMixin):
raise RuntimeError(
f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
"not inherit from `ConfigMixin`."
)
# Ignore private kwargs in the init. Retrieve all passed attributes
init_kwargs = dict(kwargs.items())
# Retrieve default values
fields = dataclasses.fields(self)
default_kwargs = {}
for field in fields:
# ignore flax specific attributes
if field.name in self._flax_internal_args:
continue
if type(field.default) == dataclasses._MISSING_TYPE:
default_kwargs[field.name] = None
else:
default_kwargs[field.name] = getattr(self, field.name)
# Make sure init_kwargs override default kwargs
new_kwargs = {**default_kwargs, **init_kwargs}
# dtype should be part of `init_kwargs`, but not `new_kwargs`
if "dtype" in new_kwargs:
new_kwargs.pop("dtype")
# Get positional arguments aligned with kwargs
for i, arg in enumerate(args):
name = fields[i].name
new_kwargs[name] = arg
# Take note of the parameters that were not present in the loaded config
if len(set(new_kwargs.keys()) - set(init_kwargs)) > 0:
new_kwargs["_use_default_values"] = list(set(new_kwargs.keys()) - set(init_kwargs))
getattr(self, "register_to_config")(**new_kwargs)
original_init(self, *args, **kwargs)
cls.__init__ = init
return cls
|
diffusers/src/diffusers/configuration_utils.py/0
|
{
"file_path": "diffusers/src/diffusers/configuration_utils.py",
"repo_id": "diffusers",
"token_count": 13540
}
| 118 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Conversion script for the Stable Diffusion checkpoints."""
import os
import re
from contextlib import nullcontext
from io import BytesIO
from urllib.parse import urlparse
import requests
import yaml
from ..models.modeling_utils import load_state_dict
from ..schedulers import (
DDIMScheduler,
DDPMScheduler,
DPMSolverMultistepScheduler,
EDMDPMSolverMultistepScheduler,
EulerAncestralDiscreteScheduler,
EulerDiscreteScheduler,
HeunDiscreteScheduler,
LMSDiscreteScheduler,
PNDMScheduler,
)
from ..utils import is_accelerate_available, is_transformers_available, logging
from ..utils.hub_utils import _get_model_file
if is_transformers_available():
from transformers import (
CLIPTextConfig,
CLIPTextModel,
CLIPTextModelWithProjection,
CLIPTokenizer,
)
if is_accelerate_available():
from accelerate import init_empty_weights
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
CONFIG_URLS = {
"v1": "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml",
"v2": "https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml",
"xl": "https://raw.githubusercontent.com/Stability-AI/generative-models/main/configs/inference/sd_xl_base.yaml",
"xl_refiner": "https://raw.githubusercontent.com/Stability-AI/generative-models/main/configs/inference/sd_xl_refiner.yaml",
"upscale": "https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/x4-upscaling.yaml",
"controlnet": "https://raw.githubusercontent.com/lllyasviel/ControlNet/main/models/cldm_v15.yaml",
}
CHECKPOINT_KEY_NAMES = {
"v2": "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight",
"xl_base": "conditioner.embedders.1.model.transformer.resblocks.9.mlp.c_proj.bias",
"xl_refiner": "conditioner.embedders.0.model.transformer.resblocks.9.mlp.c_proj.bias",
}
SCHEDULER_DEFAULT_CONFIG = {
"beta_schedule": "scaled_linear",
"beta_start": 0.00085,
"beta_end": 0.012,
"interpolation_type": "linear",
"num_train_timesteps": 1000,
"prediction_type": "epsilon",
"sample_max_value": 1.0,
"set_alpha_to_one": False,
"skip_prk_steps": True,
"steps_offset": 1,
"timestep_spacing": "leading",
}
STABLE_CASCADE_DEFAULT_CONFIGS = {
"stage_c": {"pretrained_model_name_or_path": "diffusers/stable-cascade-configs", "subfolder": "prior"},
"stage_c_lite": {"pretrained_model_name_or_path": "diffusers/stable-cascade-configs", "subfolder": "prior_lite"},
"stage_b": {"pretrained_model_name_or_path": "diffusers/stable-cascade-configs", "subfolder": "decoder"},
"stage_b_lite": {"pretrained_model_name_or_path": "diffusers/stable-cascade-configs", "subfolder": "decoder_lite"},
}
def convert_stable_cascade_unet_single_file_to_diffusers(original_state_dict):
is_stage_c = "clip_txt_mapper.weight" in original_state_dict
if is_stage_c:
state_dict = {}
for key in original_state_dict.keys():
if key.endswith("in_proj_weight"):
weights = original_state_dict[key].chunk(3, 0)
state_dict[key.replace("attn.in_proj_weight", "to_q.weight")] = weights[0]
state_dict[key.replace("attn.in_proj_weight", "to_k.weight")] = weights[1]
state_dict[key.replace("attn.in_proj_weight", "to_v.weight")] = weights[2]
elif key.endswith("in_proj_bias"):
weights = original_state_dict[key].chunk(3, 0)
state_dict[key.replace("attn.in_proj_bias", "to_q.bias")] = weights[0]
state_dict[key.replace("attn.in_proj_bias", "to_k.bias")] = weights[1]
state_dict[key.replace("attn.in_proj_bias", "to_v.bias")] = weights[2]
elif key.endswith("out_proj.weight"):
weights = original_state_dict[key]
state_dict[key.replace("attn.out_proj.weight", "to_out.0.weight")] = weights
elif key.endswith("out_proj.bias"):
weights = original_state_dict[key]
state_dict[key.replace("attn.out_proj.bias", "to_out.0.bias")] = weights
else:
state_dict[key] = original_state_dict[key]
else:
state_dict = {}
for key in original_state_dict.keys():
if key.endswith("in_proj_weight"):
weights = original_state_dict[key].chunk(3, 0)
state_dict[key.replace("attn.in_proj_weight", "to_q.weight")] = weights[0]
state_dict[key.replace("attn.in_proj_weight", "to_k.weight")] = weights[1]
state_dict[key.replace("attn.in_proj_weight", "to_v.weight")] = weights[2]
elif key.endswith("in_proj_bias"):
weights = original_state_dict[key].chunk(3, 0)
state_dict[key.replace("attn.in_proj_bias", "to_q.bias")] = weights[0]
state_dict[key.replace("attn.in_proj_bias", "to_k.bias")] = weights[1]
state_dict[key.replace("attn.in_proj_bias", "to_v.bias")] = weights[2]
elif key.endswith("out_proj.weight"):
weights = original_state_dict[key]
state_dict[key.replace("attn.out_proj.weight", "to_out.0.weight")] = weights
elif key.endswith("out_proj.bias"):
weights = original_state_dict[key]
state_dict[key.replace("attn.out_proj.bias", "to_out.0.bias")] = weights
# rename clip_mapper to clip_txt_pooled_mapper
elif key.endswith("clip_mapper.weight"):
weights = original_state_dict[key]
state_dict[key.replace("clip_mapper.weight", "clip_txt_pooled_mapper.weight")] = weights
elif key.endswith("clip_mapper.bias"):
weights = original_state_dict[key]
state_dict[key.replace("clip_mapper.bias", "clip_txt_pooled_mapper.bias")] = weights
else:
state_dict[key] = original_state_dict[key]
return state_dict
def infer_stable_cascade_single_file_config(checkpoint):
is_stage_c = "clip_txt_mapper.weight" in checkpoint
is_stage_b = "down_blocks.1.0.channelwise.0.weight" in checkpoint
if is_stage_c and (checkpoint["clip_txt_mapper.weight"].shape[0] == 1536):
config_type = "stage_c_lite"
elif is_stage_c and (checkpoint["clip_txt_mapper.weight"].shape[0] == 2048):
config_type = "stage_c"
elif is_stage_b and checkpoint["down_blocks.1.0.channelwise.0.weight"].shape[-1] == 576:
config_type = "stage_b_lite"
elif is_stage_b and checkpoint["down_blocks.1.0.channelwise.0.weight"].shape[-1] == 640:
config_type = "stage_b"
return STABLE_CASCADE_DEFAULT_CONFIGS[config_type]
DIFFUSERS_TO_LDM_MAPPING = {
"unet": {
"layers": {
"time_embedding.linear_1.weight": "time_embed.0.weight",
"time_embedding.linear_1.bias": "time_embed.0.bias",
"time_embedding.linear_2.weight": "time_embed.2.weight",
"time_embedding.linear_2.bias": "time_embed.2.bias",
"conv_in.weight": "input_blocks.0.0.weight",
"conv_in.bias": "input_blocks.0.0.bias",
"conv_norm_out.weight": "out.0.weight",
"conv_norm_out.bias": "out.0.bias",
"conv_out.weight": "out.2.weight",
"conv_out.bias": "out.2.bias",
},
"class_embed_type": {
"class_embedding.linear_1.weight": "label_emb.0.0.weight",
"class_embedding.linear_1.bias": "label_emb.0.0.bias",
"class_embedding.linear_2.weight": "label_emb.0.2.weight",
"class_embedding.linear_2.bias": "label_emb.0.2.bias",
},
"addition_embed_type": {
"add_embedding.linear_1.weight": "label_emb.0.0.weight",
"add_embedding.linear_1.bias": "label_emb.0.0.bias",
"add_embedding.linear_2.weight": "label_emb.0.2.weight",
"add_embedding.linear_2.bias": "label_emb.0.2.bias",
},
},
"controlnet": {
"layers": {
"time_embedding.linear_1.weight": "time_embed.0.weight",
"time_embedding.linear_1.bias": "time_embed.0.bias",
"time_embedding.linear_2.weight": "time_embed.2.weight",
"time_embedding.linear_2.bias": "time_embed.2.bias",
"conv_in.weight": "input_blocks.0.0.weight",
"conv_in.bias": "input_blocks.0.0.bias",
"controlnet_cond_embedding.conv_in.weight": "input_hint_block.0.weight",
"controlnet_cond_embedding.conv_in.bias": "input_hint_block.0.bias",
"controlnet_cond_embedding.conv_out.weight": "input_hint_block.14.weight",
"controlnet_cond_embedding.conv_out.bias": "input_hint_block.14.bias",
},
"class_embed_type": {
"class_embedding.linear_1.weight": "label_emb.0.0.weight",
"class_embedding.linear_1.bias": "label_emb.0.0.bias",
"class_embedding.linear_2.weight": "label_emb.0.2.weight",
"class_embedding.linear_2.bias": "label_emb.0.2.bias",
},
"addition_embed_type": {
"add_embedding.linear_1.weight": "label_emb.0.0.weight",
"add_embedding.linear_1.bias": "label_emb.0.0.bias",
"add_embedding.linear_2.weight": "label_emb.0.2.weight",
"add_embedding.linear_2.bias": "label_emb.0.2.bias",
},
},
"vae": {
"encoder.conv_in.weight": "encoder.conv_in.weight",
"encoder.conv_in.bias": "encoder.conv_in.bias",
"encoder.conv_out.weight": "encoder.conv_out.weight",
"encoder.conv_out.bias": "encoder.conv_out.bias",
"encoder.conv_norm_out.weight": "encoder.norm_out.weight",
"encoder.conv_norm_out.bias": "encoder.norm_out.bias",
"decoder.conv_in.weight": "decoder.conv_in.weight",
"decoder.conv_in.bias": "decoder.conv_in.bias",
"decoder.conv_out.weight": "decoder.conv_out.weight",
"decoder.conv_out.bias": "decoder.conv_out.bias",
"decoder.conv_norm_out.weight": "decoder.norm_out.weight",
"decoder.conv_norm_out.bias": "decoder.norm_out.bias",
"quant_conv.weight": "quant_conv.weight",
"quant_conv.bias": "quant_conv.bias",
"post_quant_conv.weight": "post_quant_conv.weight",
"post_quant_conv.bias": "post_quant_conv.bias",
},
"openclip": {
"layers": {
"text_model.embeddings.position_embedding.weight": "positional_embedding",
"text_model.embeddings.token_embedding.weight": "token_embedding.weight",
"text_model.final_layer_norm.weight": "ln_final.weight",
"text_model.final_layer_norm.bias": "ln_final.bias",
"text_projection.weight": "text_projection",
},
"transformer": {
"text_model.encoder.layers.": "resblocks.",
"layer_norm1": "ln_1",
"layer_norm2": "ln_2",
".fc1.": ".c_fc.",
".fc2.": ".c_proj.",
".self_attn": ".attn",
"transformer.text_model.final_layer_norm.": "ln_final.",
"transformer.text_model.embeddings.token_embedding.weight": "token_embedding.weight",
"transformer.text_model.embeddings.position_embedding.weight": "positional_embedding",
},
},
}
LDM_VAE_KEY = "first_stage_model."
LDM_VAE_DEFAULT_SCALING_FACTOR = 0.18215
PLAYGROUND_VAE_SCALING_FACTOR = 0.5
LDM_UNET_KEY = "model.diffusion_model."
LDM_CONTROLNET_KEY = "control_model."
LDM_CLIP_PREFIX_TO_REMOVE = ["cond_stage_model.transformer.", "conditioner.embedders.0.transformer."]
LDM_OPEN_CLIP_TEXT_PROJECTION_DIM = 1024
SD_2_TEXT_ENCODER_KEYS_TO_IGNORE = [
"cond_stage_model.model.transformer.resblocks.23.attn.in_proj_bias",
"cond_stage_model.model.transformer.resblocks.23.attn.in_proj_weight",
"cond_stage_model.model.transformer.resblocks.23.attn.out_proj.bias",
"cond_stage_model.model.transformer.resblocks.23.attn.out_proj.weight",
"cond_stage_model.model.transformer.resblocks.23.ln_1.bias",
"cond_stage_model.model.transformer.resblocks.23.ln_1.weight",
"cond_stage_model.model.transformer.resblocks.23.ln_2.bias",
"cond_stage_model.model.transformer.resblocks.23.ln_2.weight",
"cond_stage_model.model.transformer.resblocks.23.mlp.c_fc.bias",
"cond_stage_model.model.transformer.resblocks.23.mlp.c_fc.weight",
"cond_stage_model.model.transformer.resblocks.23.mlp.c_proj.bias",
"cond_stage_model.model.transformer.resblocks.23.mlp.c_proj.weight",
"cond_stage_model.model.text_projection",
]
VALID_URL_PREFIXES = ["https://huggingface.co/", "huggingface.co/", "hf.co/", "https://hf.co/"]
def _extract_repo_id_and_weights_name(pretrained_model_name_or_path):
pattern = r"([^/]+)/([^/]+)/(?:blob/main/)?(.+)"
weights_name = None
repo_id = (None,)
for prefix in VALID_URL_PREFIXES:
pretrained_model_name_or_path = pretrained_model_name_or_path.replace(prefix, "")
match = re.match(pattern, pretrained_model_name_or_path)
if not match:
return repo_id, weights_name
repo_id = f"{match.group(1)}/{match.group(2)}"
weights_name = match.group(3)
return repo_id, weights_name
def fetch_ldm_config_and_checkpoint(
pretrained_model_link_or_path,
class_name,
original_config_file=None,
resume_download=False,
force_download=False,
proxies=None,
token=None,
cache_dir=None,
local_files_only=None,
revision=None,
):
checkpoint = load_single_file_model_checkpoint(
pretrained_model_link_or_path,
resume_download=resume_download,
force_download=force_download,
proxies=proxies,
token=token,
cache_dir=cache_dir,
local_files_only=local_files_only,
revision=revision,
)
original_config = fetch_original_config(class_name, checkpoint, original_config_file)
return original_config, checkpoint
def load_single_file_model_checkpoint(
pretrained_model_link_or_path,
resume_download=False,
force_download=False,
proxies=None,
token=None,
cache_dir=None,
local_files_only=None,
revision=None,
):
if os.path.isfile(pretrained_model_link_or_path):
checkpoint = load_state_dict(pretrained_model_link_or_path)
else:
repo_id, weights_name = _extract_repo_id_and_weights_name(pretrained_model_link_or_path)
checkpoint_path = _get_model_file(
repo_id,
weights_name=weights_name,
force_download=force_download,
cache_dir=cache_dir,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
)
checkpoint = load_state_dict(checkpoint_path)
# some checkpoints contain the model state dict under a "state_dict" key
while "state_dict" in checkpoint:
checkpoint = checkpoint["state_dict"]
return checkpoint
def infer_original_config_file(class_name, checkpoint):
if CHECKPOINT_KEY_NAMES["v2"] in checkpoint and checkpoint[CHECKPOINT_KEY_NAMES["v2"]].shape[-1] == 1024:
config_url = CONFIG_URLS["v2"]
elif CHECKPOINT_KEY_NAMES["xl_base"] in checkpoint:
config_url = CONFIG_URLS["xl"]
elif CHECKPOINT_KEY_NAMES["xl_refiner"] in checkpoint:
config_url = CONFIG_URLS["xl_refiner"]
elif class_name == "StableDiffusionUpscalePipeline":
config_url = CONFIG_URLS["upscale"]
elif class_name == "ControlNetModel":
config_url = CONFIG_URLS["controlnet"]
else:
config_url = CONFIG_URLS["v1"]
original_config_file = BytesIO(requests.get(config_url).content)
return original_config_file
def fetch_original_config(pipeline_class_name, checkpoint, original_config_file=None):
def is_valid_url(url):
result = urlparse(url)
if result.scheme and result.netloc:
return True
return False
if original_config_file is None:
original_config_file = infer_original_config_file(pipeline_class_name, checkpoint)
elif os.path.isfile(original_config_file):
with open(original_config_file, "r") as fp:
original_config_file = fp.read()
elif is_valid_url(original_config_file):
original_config_file = BytesIO(requests.get(original_config_file).content)
else:
raise ValueError("Invalid `original_config_file` provided. Please set it to a valid file path or URL.")
original_config = yaml.safe_load(original_config_file)
return original_config
def infer_model_type(original_config, checkpoint, model_type=None):
if model_type is not None:
return model_type
has_cond_stage_config = (
"cond_stage_config" in original_config["model"]["params"]
and original_config["model"]["params"]["cond_stage_config"] is not None
)
has_network_config = (
"network_config" in original_config["model"]["params"]
and original_config["model"]["params"]["network_config"] is not None
)
if has_cond_stage_config:
model_type = original_config["model"]["params"]["cond_stage_config"]["target"].split(".")[-1]
elif has_network_config:
context_dim = original_config["model"]["params"]["network_config"]["params"]["context_dim"]
if "edm_mean" in checkpoint and "edm_std" in checkpoint:
model_type = "Playground"
elif context_dim == 2048:
model_type = "SDXL"
else:
model_type = "SDXL-Refiner"
else:
raise ValueError("Unable to infer model type from config")
logger.debug(f"No `model_type` given, `model_type` inferred as: {model_type}")
return model_type
def get_default_scheduler_config():
return SCHEDULER_DEFAULT_CONFIG
def set_image_size(pipeline_class_name, original_config, checkpoint, image_size=None, model_type=None):
if image_size:
return image_size
global_step = checkpoint["global_step"] if "global_step" in checkpoint else None
model_type = infer_model_type(original_config, checkpoint, model_type)
if pipeline_class_name == "StableDiffusionUpscalePipeline":
image_size = original_config["model"]["params"]["unet_config"]["params"]["image_size"]
return image_size
elif model_type in ["SDXL", "SDXL-Refiner", "Playground"]:
image_size = 1024
return image_size
elif (
"parameterization" in original_config["model"]["params"]
and original_config["model"]["params"]["parameterization"] == "v"
):
# NOTE: For stable diffusion 2 base one has to pass `image_size==512`
# as it relies on a brittle global step parameter here
image_size = 512 if global_step == 875000 else 768
return image_size
else:
image_size = 512
return image_size
# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.conv_attn_to_linear
def conv_attn_to_linear(checkpoint):
keys = list(checkpoint.keys())
attn_keys = ["query.weight", "key.weight", "value.weight"]
for key in keys:
if ".".join(key.split(".")[-2:]) in attn_keys:
if checkpoint[key].ndim > 2:
checkpoint[key] = checkpoint[key][:, :, 0, 0]
elif "proj_attn.weight" in key:
if checkpoint[key].ndim > 2:
checkpoint[key] = checkpoint[key][:, :, 0]
def create_unet_diffusers_config(original_config, image_size: int):
"""
Creates a config for the diffusers based on the config of the LDM model.
"""
if (
"unet_config" in original_config["model"]["params"]
and original_config["model"]["params"]["unet_config"] is not None
):
unet_params = original_config["model"]["params"]["unet_config"]["params"]
else:
unet_params = original_config["model"]["params"]["network_config"]["params"]
vae_params = original_config["model"]["params"]["first_stage_config"]["params"]["ddconfig"]
block_out_channels = [unet_params["model_channels"] * mult for mult in unet_params["channel_mult"]]
down_block_types = []
resolution = 1
for i in range(len(block_out_channels)):
block_type = "CrossAttnDownBlock2D" if resolution in unet_params["attention_resolutions"] else "DownBlock2D"
down_block_types.append(block_type)
if i != len(block_out_channels) - 1:
resolution *= 2
up_block_types = []
for i in range(len(block_out_channels)):
block_type = "CrossAttnUpBlock2D" if resolution in unet_params["attention_resolutions"] else "UpBlock2D"
up_block_types.append(block_type)
resolution //= 2
if unet_params["transformer_depth"] is not None:
transformer_layers_per_block = (
unet_params["transformer_depth"]
if isinstance(unet_params["transformer_depth"], int)
else list(unet_params["transformer_depth"])
)
else:
transformer_layers_per_block = 1
vae_scale_factor = 2 ** (len(vae_params["ch_mult"]) - 1)
head_dim = unet_params["num_heads"] if "num_heads" in unet_params else None
use_linear_projection = (
unet_params["use_linear_in_transformer"] if "use_linear_in_transformer" in unet_params else False
)
if use_linear_projection:
# stable diffusion 2-base-512 and 2-768
if head_dim is None:
head_dim_mult = unet_params["model_channels"] // unet_params["num_head_channels"]
head_dim = [head_dim_mult * c for c in list(unet_params["channel_mult"])]
class_embed_type = None
addition_embed_type = None
addition_time_embed_dim = None
projection_class_embeddings_input_dim = None
context_dim = None
if unet_params["context_dim"] is not None:
context_dim = (
unet_params["context_dim"]
if isinstance(unet_params["context_dim"], int)
else unet_params["context_dim"][0]
)
if "num_classes" in unet_params:
if unet_params["num_classes"] == "sequential":
if context_dim in [2048, 1280]:
# SDXL
addition_embed_type = "text_time"
addition_time_embed_dim = 256
else:
class_embed_type = "projection"
assert "adm_in_channels" in unet_params
projection_class_embeddings_input_dim = unet_params["adm_in_channels"]
config = {
"sample_size": image_size // vae_scale_factor,
"in_channels": unet_params["in_channels"],
"down_block_types": down_block_types,
"block_out_channels": block_out_channels,
"layers_per_block": unet_params["num_res_blocks"],
"cross_attention_dim": context_dim,
"attention_head_dim": head_dim,
"use_linear_projection": use_linear_projection,
"class_embed_type": class_embed_type,
"addition_embed_type": addition_embed_type,
"addition_time_embed_dim": addition_time_embed_dim,
"projection_class_embeddings_input_dim": projection_class_embeddings_input_dim,
"transformer_layers_per_block": transformer_layers_per_block,
}
if "disable_self_attentions" in unet_params:
config["only_cross_attention"] = unet_params["disable_self_attentions"]
if "num_classes" in unet_params and isinstance(unet_params["num_classes"], int):
config["num_class_embeds"] = unet_params["num_classes"]
config["out_channels"] = unet_params["out_channels"]
config["up_block_types"] = up_block_types
return config
def create_controlnet_diffusers_config(original_config, image_size: int):
unet_params = original_config["model"]["params"]["control_stage_config"]["params"]
diffusers_unet_config = create_unet_diffusers_config(original_config, image_size=image_size)
controlnet_config = {
"conditioning_channels": unet_params["hint_channels"],
"in_channels": diffusers_unet_config["in_channels"],
"down_block_types": diffusers_unet_config["down_block_types"],
"block_out_channels": diffusers_unet_config["block_out_channels"],
"layers_per_block": diffusers_unet_config["layers_per_block"],
"cross_attention_dim": diffusers_unet_config["cross_attention_dim"],
"attention_head_dim": diffusers_unet_config["attention_head_dim"],
"use_linear_projection": diffusers_unet_config["use_linear_projection"],
"class_embed_type": diffusers_unet_config["class_embed_type"],
"addition_embed_type": diffusers_unet_config["addition_embed_type"],
"addition_time_embed_dim": diffusers_unet_config["addition_time_embed_dim"],
"projection_class_embeddings_input_dim": diffusers_unet_config["projection_class_embeddings_input_dim"],
"transformer_layers_per_block": diffusers_unet_config["transformer_layers_per_block"],
}
return controlnet_config
def create_vae_diffusers_config(original_config, image_size, scaling_factor=None, latents_mean=None, latents_std=None):
"""
Creates a config for the diffusers based on the config of the LDM model.
"""
vae_params = original_config["model"]["params"]["first_stage_config"]["params"]["ddconfig"]
if (scaling_factor is None) and (latents_mean is not None) and (latents_std is not None):
scaling_factor = PLAYGROUND_VAE_SCALING_FACTOR
elif (scaling_factor is None) and ("scale_factor" in original_config["model"]["params"]):
scaling_factor = original_config["model"]["params"]["scale_factor"]
elif scaling_factor is None:
scaling_factor = LDM_VAE_DEFAULT_SCALING_FACTOR
block_out_channels = [vae_params["ch"] * mult for mult in vae_params["ch_mult"]]
down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels)
up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels)
config = {
"sample_size": image_size,
"in_channels": vae_params["in_channels"],
"out_channels": vae_params["out_ch"],
"down_block_types": down_block_types,
"up_block_types": up_block_types,
"block_out_channels": block_out_channels,
"latent_channels": vae_params["z_channels"],
"layers_per_block": vae_params["num_res_blocks"],
"scaling_factor": scaling_factor,
}
if latents_mean is not None and latents_std is not None:
config.update({"latents_mean": latents_mean, "latents_std": latents_std})
return config
def update_unet_resnet_ldm_to_diffusers(ldm_keys, new_checkpoint, checkpoint, mapping=None):
for ldm_key in ldm_keys:
diffusers_key = (
ldm_key.replace("in_layers.0", "norm1")
.replace("in_layers.2", "conv1")
.replace("out_layers.0", "norm2")
.replace("out_layers.3", "conv2")
.replace("emb_layers.1", "time_emb_proj")
.replace("skip_connection", "conv_shortcut")
)
if mapping:
diffusers_key = diffusers_key.replace(mapping["old"], mapping["new"])
new_checkpoint[diffusers_key] = checkpoint.pop(ldm_key)
def update_unet_attention_ldm_to_diffusers(ldm_keys, new_checkpoint, checkpoint, mapping):
for ldm_key in ldm_keys:
diffusers_key = ldm_key.replace(mapping["old"], mapping["new"])
new_checkpoint[diffusers_key] = checkpoint.pop(ldm_key)
def convert_ldm_unet_checkpoint(checkpoint, config, extract_ema=False):
"""
Takes a state dict and a config, and returns a converted checkpoint.
"""
# extract state_dict for UNet
unet_state_dict = {}
keys = list(checkpoint.keys())
unet_key = LDM_UNET_KEY
# at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
logger.warning("Checkpoint has both EMA and non-EMA weights.")
logger.warning(
"In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
" weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
)
for key in keys:
if key.startswith("model.diffusion_model"):
flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
else:
if sum(k.startswith("model_ema") for k in keys) > 100:
logger.warning(
"In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
" weights (usually better for inference), please make sure to add the `--extract_ema` flag."
)
for key in keys:
if key.startswith(unet_key):
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
new_checkpoint = {}
ldm_unet_keys = DIFFUSERS_TO_LDM_MAPPING["unet"]["layers"]
for diffusers_key, ldm_key in ldm_unet_keys.items():
if ldm_key not in unet_state_dict:
continue
new_checkpoint[diffusers_key] = unet_state_dict[ldm_key]
if ("class_embed_type" in config) and (config["class_embed_type"] in ["timestep", "projection"]):
class_embed_keys = DIFFUSERS_TO_LDM_MAPPING["unet"]["class_embed_type"]
for diffusers_key, ldm_key in class_embed_keys.items():
new_checkpoint[diffusers_key] = unet_state_dict[ldm_key]
if ("addition_embed_type" in config) and (config["addition_embed_type"] == "text_time"):
addition_embed_keys = DIFFUSERS_TO_LDM_MAPPING["unet"]["addition_embed_type"]
for diffusers_key, ldm_key in addition_embed_keys.items():
new_checkpoint[diffusers_key] = unet_state_dict[ldm_key]
# Relevant to StableDiffusionUpscalePipeline
if "num_class_embeds" in config:
if (config["num_class_embeds"] is not None) and ("label_emb.weight" in unet_state_dict):
new_checkpoint["class_embedding.weight"] = unet_state_dict["label_emb.weight"]
# Retrieves the keys for the input blocks only
num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
input_blocks = {
layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
for layer_id in range(num_input_blocks)
}
# Retrieves the keys for the middle blocks only
num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
middle_blocks = {
layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
for layer_id in range(num_middle_blocks)
}
# Retrieves the keys for the output blocks only
num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
output_blocks = {
layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
for layer_id in range(num_output_blocks)
}
# Down blocks
for i in range(1, num_input_blocks):
block_id = (i - 1) // (config["layers_per_block"] + 1)
layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
resnets = [
key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
]
update_unet_resnet_ldm_to_diffusers(
resnets,
new_checkpoint,
unet_state_dict,
{"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"},
)
if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
f"input_blocks.{i}.0.op.weight"
)
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
f"input_blocks.{i}.0.op.bias"
)
attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
if attentions:
update_unet_attention_ldm_to_diffusers(
attentions,
new_checkpoint,
unet_state_dict,
{"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"},
)
# Mid blocks
resnet_0 = middle_blocks[0]
attentions = middle_blocks[1]
resnet_1 = middle_blocks[2]
update_unet_resnet_ldm_to_diffusers(
resnet_0, new_checkpoint, unet_state_dict, mapping={"old": "middle_block.0", "new": "mid_block.resnets.0"}
)
update_unet_resnet_ldm_to_diffusers(
resnet_1, new_checkpoint, unet_state_dict, mapping={"old": "middle_block.2", "new": "mid_block.resnets.1"}
)
update_unet_attention_ldm_to_diffusers(
attentions, new_checkpoint, unet_state_dict, mapping={"old": "middle_block.1", "new": "mid_block.attentions.0"}
)
# Up Blocks
for i in range(num_output_blocks):
block_id = i // (config["layers_per_block"] + 1)
layer_in_block_id = i % (config["layers_per_block"] + 1)
resnets = [
key for key in output_blocks[i] if f"output_blocks.{i}.0" in key and f"output_blocks.{i}.0.op" not in key
]
update_unet_resnet_ldm_to_diffusers(
resnets,
new_checkpoint,
unet_state_dict,
{"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"},
)
attentions = [
key for key in output_blocks[i] if f"output_blocks.{i}.1" in key and f"output_blocks.{i}.1.conv" not in key
]
if attentions:
update_unet_attention_ldm_to_diffusers(
attentions,
new_checkpoint,
unet_state_dict,
{"old": f"output_blocks.{i}.1", "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}"},
)
if f"output_blocks.{i}.1.conv.weight" in unet_state_dict:
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
f"output_blocks.{i}.1.conv.weight"
]
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
f"output_blocks.{i}.1.conv.bias"
]
if f"output_blocks.{i}.2.conv.weight" in unet_state_dict:
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
f"output_blocks.{i}.2.conv.weight"
]
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
f"output_blocks.{i}.2.conv.bias"
]
return new_checkpoint
def convert_controlnet_checkpoint(
checkpoint,
config,
):
# Some controlnet ckpt files are distributed independently from the rest of the
# model components i.e. https://huggingface.co/thibaud/controlnet-sd21/
if "time_embed.0.weight" in checkpoint:
controlnet_state_dict = checkpoint
else:
controlnet_state_dict = {}
keys = list(checkpoint.keys())
controlnet_key = LDM_CONTROLNET_KEY
for key in keys:
if key.startswith(controlnet_key):
controlnet_state_dict[key.replace(controlnet_key, "")] = checkpoint.pop(key)
new_checkpoint = {}
ldm_controlnet_keys = DIFFUSERS_TO_LDM_MAPPING["controlnet"]["layers"]
for diffusers_key, ldm_key in ldm_controlnet_keys.items():
if ldm_key not in controlnet_state_dict:
continue
new_checkpoint[diffusers_key] = controlnet_state_dict[ldm_key]
# Retrieves the keys for the input blocks only
num_input_blocks = len(
{".".join(layer.split(".")[:2]) for layer in controlnet_state_dict if "input_blocks" in layer}
)
input_blocks = {
layer_id: [key for key in controlnet_state_dict if f"input_blocks.{layer_id}" in key]
for layer_id in range(num_input_blocks)
}
# Down blocks
for i in range(1, num_input_blocks):
block_id = (i - 1) // (config["layers_per_block"] + 1)
layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
resnets = [
key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
]
update_unet_resnet_ldm_to_diffusers(
resnets,
new_checkpoint,
controlnet_state_dict,
{"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"},
)
if f"input_blocks.{i}.0.op.weight" in controlnet_state_dict:
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = controlnet_state_dict.pop(
f"input_blocks.{i}.0.op.weight"
)
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = controlnet_state_dict.pop(
f"input_blocks.{i}.0.op.bias"
)
attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
if attentions:
update_unet_attention_ldm_to_diffusers(
attentions,
new_checkpoint,
controlnet_state_dict,
{"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"},
)
# controlnet down blocks
for i in range(num_input_blocks):
new_checkpoint[f"controlnet_down_blocks.{i}.weight"] = controlnet_state_dict.pop(f"zero_convs.{i}.0.weight")
new_checkpoint[f"controlnet_down_blocks.{i}.bias"] = controlnet_state_dict.pop(f"zero_convs.{i}.0.bias")
# Retrieves the keys for the middle blocks only
num_middle_blocks = len(
{".".join(layer.split(".")[:2]) for layer in controlnet_state_dict if "middle_block" in layer}
)
middle_blocks = {
layer_id: [key for key in controlnet_state_dict if f"middle_block.{layer_id}" in key]
for layer_id in range(num_middle_blocks)
}
if middle_blocks:
resnet_0 = middle_blocks[0]
attentions = middle_blocks[1]
resnet_1 = middle_blocks[2]
update_unet_resnet_ldm_to_diffusers(
resnet_0,
new_checkpoint,
controlnet_state_dict,
mapping={"old": "middle_block.0", "new": "mid_block.resnets.0"},
)
update_unet_resnet_ldm_to_diffusers(
resnet_1,
new_checkpoint,
controlnet_state_dict,
mapping={"old": "middle_block.2", "new": "mid_block.resnets.1"},
)
update_unet_attention_ldm_to_diffusers(
attentions,
new_checkpoint,
controlnet_state_dict,
mapping={"old": "middle_block.1", "new": "mid_block.attentions.0"},
)
# mid block
new_checkpoint["controlnet_mid_block.weight"] = controlnet_state_dict.pop("middle_block_out.0.weight")
new_checkpoint["controlnet_mid_block.bias"] = controlnet_state_dict.pop("middle_block_out.0.bias")
# controlnet cond embedding blocks
cond_embedding_blocks = {
".".join(layer.split(".")[:2])
for layer in controlnet_state_dict
if "input_hint_block" in layer and ("input_hint_block.0" not in layer) and ("input_hint_block.14" not in layer)
}
num_cond_embedding_blocks = len(cond_embedding_blocks)
for idx in range(1, num_cond_embedding_blocks + 1):
diffusers_idx = idx - 1
cond_block_id = 2 * idx
new_checkpoint[f"controlnet_cond_embedding.blocks.{diffusers_idx}.weight"] = controlnet_state_dict.pop(
f"input_hint_block.{cond_block_id}.weight"
)
new_checkpoint[f"controlnet_cond_embedding.blocks.{diffusers_idx}.bias"] = controlnet_state_dict.pop(
f"input_hint_block.{cond_block_id}.bias"
)
return new_checkpoint
def create_diffusers_controlnet_model_from_ldm(
pipeline_class_name, original_config, checkpoint, upcast_attention=False, image_size=None, torch_dtype=None
):
# import here to avoid circular imports
from ..models import ControlNetModel
image_size = set_image_size(pipeline_class_name, original_config, checkpoint, image_size=image_size)
diffusers_config = create_controlnet_diffusers_config(original_config, image_size=image_size)
diffusers_config["upcast_attention"] = upcast_attention
diffusers_format_controlnet_checkpoint = convert_controlnet_checkpoint(checkpoint, diffusers_config)
ctx = init_empty_weights if is_accelerate_available() else nullcontext
with ctx():
controlnet = ControlNetModel(**diffusers_config)
if is_accelerate_available():
from ..models.modeling_utils import load_model_dict_into_meta
unexpected_keys = load_model_dict_into_meta(
controlnet, diffusers_format_controlnet_checkpoint, dtype=torch_dtype
)
if controlnet._keys_to_ignore_on_load_unexpected is not None:
for pat in controlnet._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the model checkpoint were not used when initializing {controlnet.__name__}: \n {[', '.join(unexpected_keys)]}"
)
else:
controlnet.load_state_dict(diffusers_format_controlnet_checkpoint)
if torch_dtype is not None:
controlnet = controlnet.to(torch_dtype)
return {"controlnet": controlnet}
def update_vae_resnet_ldm_to_diffusers(keys, new_checkpoint, checkpoint, mapping):
for ldm_key in keys:
diffusers_key = ldm_key.replace(mapping["old"], mapping["new"]).replace("nin_shortcut", "conv_shortcut")
new_checkpoint[diffusers_key] = checkpoint.pop(ldm_key)
def update_vae_attentions_ldm_to_diffusers(keys, new_checkpoint, checkpoint, mapping):
for ldm_key in keys:
diffusers_key = (
ldm_key.replace(mapping["old"], mapping["new"])
.replace("norm.weight", "group_norm.weight")
.replace("norm.bias", "group_norm.bias")
.replace("q.weight", "to_q.weight")
.replace("q.bias", "to_q.bias")
.replace("k.weight", "to_k.weight")
.replace("k.bias", "to_k.bias")
.replace("v.weight", "to_v.weight")
.replace("v.bias", "to_v.bias")
.replace("proj_out.weight", "to_out.0.weight")
.replace("proj_out.bias", "to_out.0.bias")
)
new_checkpoint[diffusers_key] = checkpoint.pop(ldm_key)
# proj_attn.weight has to be converted from conv 1D to linear
shape = new_checkpoint[diffusers_key].shape
if len(shape) == 3:
new_checkpoint[diffusers_key] = new_checkpoint[diffusers_key][:, :, 0]
elif len(shape) == 4:
new_checkpoint[diffusers_key] = new_checkpoint[diffusers_key][:, :, 0, 0]
def convert_ldm_vae_checkpoint(checkpoint, config):
# extract state dict for VAE
# remove the LDM_VAE_KEY prefix from the ldm checkpoint keys so that it is easier to map them to diffusers keys
vae_state_dict = {}
keys = list(checkpoint.keys())
vae_key = LDM_VAE_KEY if any(k.startswith(LDM_VAE_KEY) for k in keys) else ""
for key in keys:
if key.startswith(vae_key):
vae_state_dict[key.replace(vae_key, "")] = checkpoint.get(key)
new_checkpoint = {}
vae_diffusers_ldm_map = DIFFUSERS_TO_LDM_MAPPING["vae"]
for diffusers_key, ldm_key in vae_diffusers_ldm_map.items():
if ldm_key not in vae_state_dict:
continue
new_checkpoint[diffusers_key] = vae_state_dict[ldm_key]
# Retrieves the keys for the encoder down blocks only
num_down_blocks = len(config["down_block_types"])
down_blocks = {
layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
}
for i in range(num_down_blocks):
resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
update_vae_resnet_ldm_to_diffusers(
resnets,
new_checkpoint,
vae_state_dict,
mapping={"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"},
)
if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
f"encoder.down.{i}.downsample.conv.weight"
)
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
f"encoder.down.{i}.downsample.conv.bias"
)
mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
num_mid_res_blocks = 2
for i in range(1, num_mid_res_blocks + 1):
resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
update_vae_resnet_ldm_to_diffusers(
resnets,
new_checkpoint,
vae_state_dict,
mapping={"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"},
)
mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
update_vae_attentions_ldm_to_diffusers(
mid_attentions, new_checkpoint, vae_state_dict, mapping={"old": "mid.attn_1", "new": "mid_block.attentions.0"}
)
# Retrieves the keys for the decoder up blocks only
num_up_blocks = len(config["up_block_types"])
up_blocks = {
layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
}
for i in range(num_up_blocks):
block_id = num_up_blocks - 1 - i
resnets = [
key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
]
update_vae_resnet_ldm_to_diffusers(
resnets,
new_checkpoint,
vae_state_dict,
mapping={"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"},
)
if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
f"decoder.up.{block_id}.upsample.conv.weight"
]
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
f"decoder.up.{block_id}.upsample.conv.bias"
]
mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
num_mid_res_blocks = 2
for i in range(1, num_mid_res_blocks + 1):
resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
update_vae_resnet_ldm_to_diffusers(
resnets,
new_checkpoint,
vae_state_dict,
mapping={"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"},
)
mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
update_vae_attentions_ldm_to_diffusers(
mid_attentions, new_checkpoint, vae_state_dict, mapping={"old": "mid.attn_1", "new": "mid_block.attentions.0"}
)
conv_attn_to_linear(new_checkpoint)
return new_checkpoint
def create_text_encoder_from_ldm_clip_checkpoint(config_name, checkpoint, local_files_only=False, torch_dtype=None):
try:
config = CLIPTextConfig.from_pretrained(config_name, local_files_only=local_files_only)
except Exception:
raise ValueError(
f"With local_files_only set to {local_files_only}, you must first locally save the configuration in the following path: 'openai/clip-vit-large-patch14'."
)
ctx = init_empty_weights if is_accelerate_available() else nullcontext
with ctx():
text_model = CLIPTextModel(config)
keys = list(checkpoint.keys())
text_model_dict = {}
remove_prefixes = LDM_CLIP_PREFIX_TO_REMOVE
for key in keys:
for prefix in remove_prefixes:
if key.startswith(prefix):
diffusers_key = key.replace(prefix, "")
text_model_dict[diffusers_key] = checkpoint[key]
if is_accelerate_available():
from ..models.modeling_utils import load_model_dict_into_meta
unexpected_keys = load_model_dict_into_meta(text_model, text_model_dict, dtype=torch_dtype)
if text_model._keys_to_ignore_on_load_unexpected is not None:
for pat in text_model._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the model checkpoint were not used when initializing {text_model.__class__.__name__}: \n {[', '.join(unexpected_keys)]}"
)
else:
if not (hasattr(text_model, "embeddings") and hasattr(text_model.embeddings.position_ids)):
text_model_dict.pop("text_model.embeddings.position_ids", None)
text_model.load_state_dict(text_model_dict)
if torch_dtype is not None:
text_model = text_model.to(torch_dtype)
return text_model
def create_text_encoder_from_open_clip_checkpoint(
config_name,
checkpoint,
prefix="cond_stage_model.model.",
has_projection=False,
local_files_only=False,
torch_dtype=None,
**config_kwargs,
):
try:
config = CLIPTextConfig.from_pretrained(config_name, **config_kwargs, local_files_only=local_files_only)
except Exception:
raise ValueError(
f"With local_files_only set to {local_files_only}, you must first locally save the configuration in the following path: '{config_name}'."
)
ctx = init_empty_weights if is_accelerate_available() else nullcontext
with ctx():
text_model = CLIPTextModelWithProjection(config) if has_projection else CLIPTextModel(config)
text_model_dict = {}
text_proj_key = prefix + "text_projection"
text_proj_dim = (
int(checkpoint[text_proj_key].shape[0]) if text_proj_key in checkpoint else LDM_OPEN_CLIP_TEXT_PROJECTION_DIM
)
text_model_dict["text_model.embeddings.position_ids"] = text_model.text_model.embeddings.get_buffer("position_ids")
keys = list(checkpoint.keys())
keys_to_ignore = SD_2_TEXT_ENCODER_KEYS_TO_IGNORE
openclip_diffusers_ldm_map = DIFFUSERS_TO_LDM_MAPPING["openclip"]["layers"]
for diffusers_key, ldm_key in openclip_diffusers_ldm_map.items():
ldm_key = prefix + ldm_key
if ldm_key not in checkpoint:
continue
if ldm_key in keys_to_ignore:
continue
if ldm_key.endswith("text_projection"):
text_model_dict[diffusers_key] = checkpoint[ldm_key].T.contiguous()
else:
text_model_dict[diffusers_key] = checkpoint[ldm_key]
for key in keys:
if key in keys_to_ignore:
continue
if not key.startswith(prefix + "transformer."):
continue
diffusers_key = key.replace(prefix + "transformer.", "")
transformer_diffusers_to_ldm_map = DIFFUSERS_TO_LDM_MAPPING["openclip"]["transformer"]
for new_key, old_key in transformer_diffusers_to_ldm_map.items():
diffusers_key = (
diffusers_key.replace(old_key, new_key).replace(".in_proj_weight", "").replace(".in_proj_bias", "")
)
if key.endswith(".in_proj_weight"):
weight_value = checkpoint[key]
text_model_dict[diffusers_key + ".q_proj.weight"] = weight_value[:text_proj_dim, :]
text_model_dict[diffusers_key + ".k_proj.weight"] = weight_value[text_proj_dim : text_proj_dim * 2, :]
text_model_dict[diffusers_key + ".v_proj.weight"] = weight_value[text_proj_dim * 2 :, :]
elif key.endswith(".in_proj_bias"):
weight_value = checkpoint[key]
text_model_dict[diffusers_key + ".q_proj.bias"] = weight_value[:text_proj_dim]
text_model_dict[diffusers_key + ".k_proj.bias"] = weight_value[text_proj_dim : text_proj_dim * 2]
text_model_dict[diffusers_key + ".v_proj.bias"] = weight_value[text_proj_dim * 2 :]
else:
text_model_dict[diffusers_key] = checkpoint[key]
if is_accelerate_available():
from ..models.modeling_utils import load_model_dict_into_meta
unexpected_keys = load_model_dict_into_meta(text_model, text_model_dict, dtype=torch_dtype)
if text_model._keys_to_ignore_on_load_unexpected is not None:
for pat in text_model._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the model checkpoint were not used when initializing {text_model.__class__.__name__}: \n {[', '.join(unexpected_keys)]}"
)
else:
if not (hasattr(text_model, "embeddings") and hasattr(text_model.embeddings.position_ids)):
text_model_dict.pop("text_model.embeddings.position_ids", None)
text_model.load_state_dict(text_model_dict)
if torch_dtype is not None:
text_model = text_model.to(torch_dtype)
return text_model
def create_diffusers_unet_model_from_ldm(
pipeline_class_name,
original_config,
checkpoint,
num_in_channels=None,
upcast_attention=None,
extract_ema=False,
image_size=None,
torch_dtype=None,
model_type=None,
):
from ..models import UNet2DConditionModel
if num_in_channels is None:
if pipeline_class_name in [
"StableDiffusionInpaintPipeline",
"StableDiffusionControlNetInpaintPipeline",
"StableDiffusionXLInpaintPipeline",
"StableDiffusionXLControlNetInpaintPipeline",
]:
num_in_channels = 9
elif pipeline_class_name == "StableDiffusionUpscalePipeline":
num_in_channels = 7
else:
num_in_channels = 4
image_size = set_image_size(
pipeline_class_name, original_config, checkpoint, image_size=image_size, model_type=model_type
)
unet_config = create_unet_diffusers_config(original_config, image_size=image_size)
unet_config["in_channels"] = num_in_channels
if upcast_attention is not None:
unet_config["upcast_attention"] = upcast_attention
diffusers_format_unet_checkpoint = convert_ldm_unet_checkpoint(checkpoint, unet_config, extract_ema=extract_ema)
ctx = init_empty_weights if is_accelerate_available() else nullcontext
with ctx():
unet = UNet2DConditionModel(**unet_config)
if is_accelerate_available():
from ..models.modeling_utils import load_model_dict_into_meta
unexpected_keys = load_model_dict_into_meta(unet, diffusers_format_unet_checkpoint, dtype=torch_dtype)
if unet._keys_to_ignore_on_load_unexpected is not None:
for pat in unet._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the model checkpoint were not used when initializing {unet.__name__}: \n {[', '.join(unexpected_keys)]}"
)
else:
unet.load_state_dict(diffusers_format_unet_checkpoint)
if torch_dtype is not None:
unet = unet.to(torch_dtype)
return {"unet": unet}
def create_diffusers_vae_model_from_ldm(
pipeline_class_name,
original_config,
checkpoint,
image_size=None,
scaling_factor=None,
torch_dtype=None,
model_type=None,
):
# import here to avoid circular imports
from ..models import AutoencoderKL
image_size = set_image_size(
pipeline_class_name, original_config, checkpoint, image_size=image_size, model_type=model_type
)
model_type = infer_model_type(original_config, checkpoint, model_type)
if model_type == "Playground":
edm_mean = (
checkpoint["edm_mean"].to(dtype=torch_dtype).tolist() if torch_dtype else checkpoint["edm_mean"].tolist()
)
edm_std = (
checkpoint["edm_std"].to(dtype=torch_dtype).tolist() if torch_dtype else checkpoint["edm_std"].tolist()
)
else:
edm_mean = None
edm_std = None
vae_config = create_vae_diffusers_config(
original_config,
image_size=image_size,
scaling_factor=scaling_factor,
latents_mean=edm_mean,
latents_std=edm_std,
)
diffusers_format_vae_checkpoint = convert_ldm_vae_checkpoint(checkpoint, vae_config)
ctx = init_empty_weights if is_accelerate_available() else nullcontext
with ctx():
vae = AutoencoderKL(**vae_config)
if is_accelerate_available():
from ..models.modeling_utils import load_model_dict_into_meta
unexpected_keys = load_model_dict_into_meta(vae, diffusers_format_vae_checkpoint, dtype=torch_dtype)
if vae._keys_to_ignore_on_load_unexpected is not None:
for pat in vae._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the model checkpoint were not used when initializing {vae.__name__}: \n {[', '.join(unexpected_keys)]}"
)
else:
vae.load_state_dict(diffusers_format_vae_checkpoint)
if torch_dtype is not None:
vae = vae.to(torch_dtype)
return {"vae": vae}
def create_text_encoders_and_tokenizers_from_ldm(
original_config,
checkpoint,
model_type=None,
local_files_only=False,
torch_dtype=None,
):
model_type = infer_model_type(original_config, checkpoint=checkpoint, model_type=model_type)
if model_type == "FrozenOpenCLIPEmbedder":
config_name = "stabilityai/stable-diffusion-2"
config_kwargs = {"subfolder": "text_encoder"}
try:
text_encoder = create_text_encoder_from_open_clip_checkpoint(
config_name, checkpoint, local_files_only=local_files_only, torch_dtype=torch_dtype, **config_kwargs
)
tokenizer = CLIPTokenizer.from_pretrained(
config_name, subfolder="tokenizer", local_files_only=local_files_only
)
except Exception:
raise ValueError(
f"With local_files_only set to {local_files_only}, you must first locally save the text_encoder in the following path: '{config_name}'."
)
else:
return {"text_encoder": text_encoder, "tokenizer": tokenizer}
elif model_type == "FrozenCLIPEmbedder":
try:
config_name = "openai/clip-vit-large-patch14"
text_encoder = create_text_encoder_from_ldm_clip_checkpoint(
config_name,
checkpoint,
local_files_only=local_files_only,
torch_dtype=torch_dtype,
)
tokenizer = CLIPTokenizer.from_pretrained(config_name, local_files_only=local_files_only)
except Exception:
raise ValueError(
f"With local_files_only set to {local_files_only}, you must first locally save the tokenizer in the following path: '{config_name}'."
)
else:
return {"text_encoder": text_encoder, "tokenizer": tokenizer}
elif model_type == "SDXL-Refiner":
config_name = "laion/CLIP-ViT-bigG-14-laion2B-39B-b160k"
config_kwargs = {"projection_dim": 1280}
prefix = "conditioner.embedders.0.model."
try:
tokenizer_2 = CLIPTokenizer.from_pretrained(config_name, pad_token="!", local_files_only=local_files_only)
text_encoder_2 = create_text_encoder_from_open_clip_checkpoint(
config_name,
checkpoint,
prefix=prefix,
has_projection=True,
local_files_only=local_files_only,
torch_dtype=torch_dtype,
**config_kwargs,
)
except Exception:
raise ValueError(
f"With local_files_only set to {local_files_only}, you must first locally save the text_encoder_2 and tokenizer_2 in the following path: {config_name} with `pad_token` set to '!'."
)
else:
return {
"text_encoder": None,
"tokenizer": None,
"tokenizer_2": tokenizer_2,
"text_encoder_2": text_encoder_2,
}
elif model_type in ["SDXL", "Playground"]:
try:
config_name = "openai/clip-vit-large-patch14"
tokenizer = CLIPTokenizer.from_pretrained(config_name, local_files_only=local_files_only)
text_encoder = create_text_encoder_from_ldm_clip_checkpoint(
config_name, checkpoint, local_files_only=local_files_only, torch_dtype=torch_dtype
)
except Exception:
raise ValueError(
f"With local_files_only set to {local_files_only}, you must first locally save the text_encoder and tokenizer in the following path: 'openai/clip-vit-large-patch14'."
)
try:
config_name = "laion/CLIP-ViT-bigG-14-laion2B-39B-b160k"
config_kwargs = {"projection_dim": 1280}
prefix = "conditioner.embedders.1.model."
tokenizer_2 = CLIPTokenizer.from_pretrained(config_name, pad_token="!", local_files_only=local_files_only)
text_encoder_2 = create_text_encoder_from_open_clip_checkpoint(
config_name,
checkpoint,
prefix=prefix,
has_projection=True,
local_files_only=local_files_only,
torch_dtype=torch_dtype,
**config_kwargs,
)
except Exception:
raise ValueError(
f"With local_files_only set to {local_files_only}, you must first locally save the text_encoder_2 and tokenizer_2 in the following path: {config_name} with `pad_token` set to '!'."
)
return {
"tokenizer": tokenizer,
"text_encoder": text_encoder,
"tokenizer_2": tokenizer_2,
"text_encoder_2": text_encoder_2,
}
return
def create_scheduler_from_ldm(
pipeline_class_name,
original_config,
checkpoint,
prediction_type=None,
scheduler_type="ddim",
model_type=None,
):
scheduler_config = get_default_scheduler_config()
model_type = infer_model_type(original_config, checkpoint=checkpoint, model_type=model_type)
global_step = checkpoint["global_step"] if "global_step" in checkpoint else None
num_train_timesteps = getattr(original_config["model"]["params"], "timesteps", None) or 1000
scheduler_config["num_train_timesteps"] = num_train_timesteps
if (
"parameterization" in original_config["model"]["params"]
and original_config["model"]["params"]["parameterization"] == "v"
):
if prediction_type is None:
# NOTE: For stable diffusion 2 base it is recommended to pass `prediction_type=="epsilon"`
# as it relies on a brittle global step parameter here
prediction_type = "epsilon" if global_step == 875000 else "v_prediction"
else:
prediction_type = prediction_type or "epsilon"
scheduler_config["prediction_type"] = prediction_type
if model_type in ["SDXL", "SDXL-Refiner"]:
scheduler_type = "euler"
elif model_type == "Playground":
scheduler_type = "edm_dpm_solver_multistep"
else:
beta_start = original_config["model"]["params"].get("linear_start", 0.02)
beta_end = original_config["model"]["params"].get("linear_end", 0.085)
scheduler_config["beta_start"] = beta_start
scheduler_config["beta_end"] = beta_end
scheduler_config["beta_schedule"] = "scaled_linear"
scheduler_config["clip_sample"] = False
scheduler_config["set_alpha_to_one"] = False
if scheduler_type == "pndm":
scheduler_config["skip_prk_steps"] = True
scheduler = PNDMScheduler.from_config(scheduler_config)
elif scheduler_type == "lms":
scheduler = LMSDiscreteScheduler.from_config(scheduler_config)
elif scheduler_type == "heun":
scheduler = HeunDiscreteScheduler.from_config(scheduler_config)
elif scheduler_type == "euler":
scheduler = EulerDiscreteScheduler.from_config(scheduler_config)
elif scheduler_type == "euler-ancestral":
scheduler = EulerAncestralDiscreteScheduler.from_config(scheduler_config)
elif scheduler_type == "dpm":
scheduler = DPMSolverMultistepScheduler.from_config(scheduler_config)
elif scheduler_type == "ddim":
scheduler = DDIMScheduler.from_config(scheduler_config)
elif scheduler_type == "edm_dpm_solver_multistep":
scheduler_config = {
"algorithm_type": "dpmsolver++",
"dynamic_thresholding_ratio": 0.995,
"euler_at_final": False,
"final_sigmas_type": "zero",
"lower_order_final": True,
"num_train_timesteps": 1000,
"prediction_type": "epsilon",
"rho": 7.0,
"sample_max_value": 1.0,
"sigma_data": 0.5,
"sigma_max": 80.0,
"sigma_min": 0.002,
"solver_order": 2,
"solver_type": "midpoint",
"thresholding": False,
}
scheduler = EDMDPMSolverMultistepScheduler(**scheduler_config)
else:
raise ValueError(f"Scheduler of type {scheduler_type} doesn't exist!")
if pipeline_class_name == "StableDiffusionUpscalePipeline":
scheduler = DDIMScheduler.from_pretrained("stabilityai/stable-diffusion-x4-upscaler", subfolder="scheduler")
low_res_scheduler = DDPMScheduler.from_pretrained(
"stabilityai/stable-diffusion-x4-upscaler", subfolder="low_res_scheduler"
)
return {
"scheduler": scheduler,
"low_res_scheduler": low_res_scheduler,
}
return {"scheduler": scheduler}
|
diffusers/src/diffusers/loaders/single_file_utils.py/0
|
{
"file_path": "diffusers/src/diffusers/loaders/single_file_utils.py",
"repo_id": "diffusers",
"token_count": 30413
}
| 119 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
from typing import Dict, Optional, Tuple, Union
import torch
import torch.nn.functional as F
from torch import nn
from ...configuration_utils import ConfigMixin, register_to_config
from ...schedulers import ConsistencyDecoderScheduler
from ...utils import BaseOutput
from ...utils.accelerate_utils import apply_forward_hook
from ...utils.torch_utils import randn_tensor
from ..attention_processor import (
ADDED_KV_ATTENTION_PROCESSORS,
CROSS_ATTENTION_PROCESSORS,
AttentionProcessor,
AttnAddedKVProcessor,
AttnProcessor,
)
from ..modeling_utils import ModelMixin
from ..unets.unet_2d import UNet2DModel
from .vae import DecoderOutput, DiagonalGaussianDistribution, Encoder
@dataclass
class ConsistencyDecoderVAEOutput(BaseOutput):
"""
Output of encoding method.
Args:
latent_dist (`DiagonalGaussianDistribution`):
Encoded outputs of `Encoder` represented as the mean and logvar of `DiagonalGaussianDistribution`.
`DiagonalGaussianDistribution` allows for sampling latents from the distribution.
"""
latent_dist: "DiagonalGaussianDistribution"
class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
r"""
The consistency decoder used with DALL-E 3.
Examples:
```py
>>> import torch
>>> from diffusers import StableDiffusionPipeline, ConsistencyDecoderVAE
>>> vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
>>> pipe = StableDiffusionPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", vae=vae, torch_dtype=torch.float16
... ).to("cuda")
>>> pipe("horse", generator=torch.manual_seed(0)).images
```
"""
@register_to_config
def __init__(
self,
scaling_factor: float = 0.18215,
latent_channels: int = 4,
encoder_act_fn: str = "silu",
encoder_block_out_channels: Tuple[int, ...] = (128, 256, 512, 512),
encoder_double_z: bool = True,
encoder_down_block_types: Tuple[str, ...] = (
"DownEncoderBlock2D",
"DownEncoderBlock2D",
"DownEncoderBlock2D",
"DownEncoderBlock2D",
),
encoder_in_channels: int = 3,
encoder_layers_per_block: int = 2,
encoder_norm_num_groups: int = 32,
encoder_out_channels: int = 4,
decoder_add_attention: bool = False,
decoder_block_out_channels: Tuple[int, ...] = (320, 640, 1024, 1024),
decoder_down_block_types: Tuple[str, ...] = (
"ResnetDownsampleBlock2D",
"ResnetDownsampleBlock2D",
"ResnetDownsampleBlock2D",
"ResnetDownsampleBlock2D",
),
decoder_downsample_padding: int = 1,
decoder_in_channels: int = 7,
decoder_layers_per_block: int = 3,
decoder_norm_eps: float = 1e-05,
decoder_norm_num_groups: int = 32,
decoder_num_train_timesteps: int = 1024,
decoder_out_channels: int = 6,
decoder_resnet_time_scale_shift: str = "scale_shift",
decoder_time_embedding_type: str = "learned",
decoder_up_block_types: Tuple[str, ...] = (
"ResnetUpsampleBlock2D",
"ResnetUpsampleBlock2D",
"ResnetUpsampleBlock2D",
"ResnetUpsampleBlock2D",
),
):
super().__init__()
self.encoder = Encoder(
act_fn=encoder_act_fn,
block_out_channels=encoder_block_out_channels,
double_z=encoder_double_z,
down_block_types=encoder_down_block_types,
in_channels=encoder_in_channels,
layers_per_block=encoder_layers_per_block,
norm_num_groups=encoder_norm_num_groups,
out_channels=encoder_out_channels,
)
self.decoder_unet = UNet2DModel(
add_attention=decoder_add_attention,
block_out_channels=decoder_block_out_channels,
down_block_types=decoder_down_block_types,
downsample_padding=decoder_downsample_padding,
in_channels=decoder_in_channels,
layers_per_block=decoder_layers_per_block,
norm_eps=decoder_norm_eps,
norm_num_groups=decoder_norm_num_groups,
num_train_timesteps=decoder_num_train_timesteps,
out_channels=decoder_out_channels,
resnet_time_scale_shift=decoder_resnet_time_scale_shift,
time_embedding_type=decoder_time_embedding_type,
up_block_types=decoder_up_block_types,
)
self.decoder_scheduler = ConsistencyDecoderScheduler()
self.register_to_config(block_out_channels=encoder_block_out_channels)
self.register_to_config(force_upcast=False)
self.register_buffer(
"means",
torch.tensor([0.38862467, 0.02253063, 0.07381133, -0.0171294])[None, :, None, None],
persistent=False,
)
self.register_buffer(
"stds", torch.tensor([0.9654121, 1.0440036, 0.76147926, 0.77022034])[None, :, None, None], persistent=False
)
self.quant_conv = nn.Conv2d(2 * latent_channels, 2 * latent_channels, 1)
self.use_slicing = False
self.use_tiling = False
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.enable_tiling
def enable_tiling(self, use_tiling: bool = True):
r"""
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
processing larger images.
"""
self.use_tiling = use_tiling
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.disable_tiling
def disable_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_tiling` was previously enabled, this method will go back to computing
decoding in one step.
"""
self.enable_tiling(False)
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.enable_slicing
def enable_slicing(self):
r"""
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
"""
self.use_slicing = True
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.disable_slicing
def disable_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_slicing` was previously enabled, this method will go back to computing
decoding in one step.
"""
self.use_slicing = False
@property
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.attn_processors
def attn_processors(self) -> Dict[str, AttentionProcessor]:
r"""
Returns:
`dict` of attention processors: A dictionary containing all attention processors used in the model with
indexed by its weight name.
"""
# set recursively
processors = {}
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
if hasattr(module, "get_processor"):
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
for sub_name, child in module.named_children():
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
return processors
for name, module in self.named_children():
fn_recursive_add_processors(name, module, processors)
return processors
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attn_processor
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
r"""
Sets the attention processor to use to compute attention.
Parameters:
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
The instantiated processor class or a dictionary of processor classes that will be set as the processor
for **all** `Attention` layers.
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
processor. This is strongly recommended when setting trainable attention processors.
"""
count = len(self.attn_processors.keys())
if isinstance(processor, dict) and len(processor) != count:
raise ValueError(
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
)
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
if hasattr(module, "set_processor"):
if not isinstance(processor, dict):
module.set_processor(processor)
else:
module.set_processor(processor.pop(f"{name}.processor"))
for sub_name, child in module.named_children():
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
for name, module in self.named_children():
fn_recursive_attn_processor(name, module, processor)
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
def set_default_attn_processor(self):
"""
Disables custom attention processors and sets the default attention implementation.
"""
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
processor = AttnAddedKVProcessor()
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
processor = AttnProcessor()
else:
raise ValueError(
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
)
self.set_attn_processor(processor)
@apply_forward_hook
def encode(
self, x: torch.FloatTensor, return_dict: bool = True
) -> Union[ConsistencyDecoderVAEOutput, Tuple[DiagonalGaussianDistribution]]:
"""
Encode a batch of images into latents.
Args:
x (`torch.FloatTensor`): Input batch of images.
return_dict (`bool`, *optional*, defaults to `True`):
Whether to return a [`~models.consistecy_decoder_vae.ConsistencyDecoderOoutput`] instead of a plain
tuple.
Returns:
The latent representations of the encoded images. If `return_dict` is True, a
[`~models.consistency_decoder_vae.ConsistencyDecoderVAEOutput`] is returned, otherwise a plain `tuple`
is returned.
"""
if self.use_tiling and (x.shape[-1] > self.tile_sample_min_size or x.shape[-2] > self.tile_sample_min_size):
return self.tiled_encode(x, return_dict=return_dict)
if self.use_slicing and x.shape[0] > 1:
encoded_slices = [self.encoder(x_slice) for x_slice in x.split(1)]
h = torch.cat(encoded_slices)
else:
h = self.encoder(x)
moments = self.quant_conv(h)
posterior = DiagonalGaussianDistribution(moments)
if not return_dict:
return (posterior,)
return ConsistencyDecoderVAEOutput(latent_dist=posterior)
@apply_forward_hook
def decode(
self,
z: torch.FloatTensor,
generator: Optional[torch.Generator] = None,
return_dict: bool = True,
num_inference_steps: int = 2,
) -> Union[DecoderOutput, Tuple[torch.FloatTensor]]:
z = (z * self.config.scaling_factor - self.means) / self.stds
scale_factor = 2 ** (len(self.config.block_out_channels) - 1)
z = F.interpolate(z, mode="nearest", scale_factor=scale_factor)
batch_size, _, height, width = z.shape
self.decoder_scheduler.set_timesteps(num_inference_steps, device=self.device)
x_t = self.decoder_scheduler.init_noise_sigma * randn_tensor(
(batch_size, 3, height, width), generator=generator, dtype=z.dtype, device=z.device
)
for t in self.decoder_scheduler.timesteps:
model_input = torch.concat([self.decoder_scheduler.scale_model_input(x_t, t), z], dim=1)
model_output = self.decoder_unet(model_input, t).sample[:, :3, :, :]
prev_sample = self.decoder_scheduler.step(model_output, t, x_t, generator).prev_sample
x_t = prev_sample
x_0 = x_t
if not return_dict:
return (x_0,)
return DecoderOutput(sample=x_0)
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.blend_v
def blend_v(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
blend_extent = min(a.shape[2], b.shape[2], blend_extent)
for y in range(blend_extent):
b[:, :, y, :] = a[:, :, -blend_extent + y, :] * (1 - y / blend_extent) + b[:, :, y, :] * (y / blend_extent)
return b
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.blend_h
def blend_h(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
blend_extent = min(a.shape[3], b.shape[3], blend_extent)
for x in range(blend_extent):
b[:, :, :, x] = a[:, :, :, -blend_extent + x] * (1 - x / blend_extent) + b[:, :, :, x] * (x / blend_extent)
return b
def tiled_encode(self, x: torch.FloatTensor, return_dict: bool = True) -> ConsistencyDecoderVAEOutput:
r"""Encode a batch of images using a tiled encoder.
When this option is enabled, the VAE will split the input tensor into tiles to compute encoding in several
steps. This is useful to keep memory use constant regardless of image size. The end result of tiled encoding is
different from non-tiled encoding because each tile uses a different encoder. To avoid tiling artifacts, the
tiles overlap and are blended together to form a smooth output. You may still see tile-sized changes in the
output, but they should be much less noticeable.
Args:
x (`torch.FloatTensor`): Input batch of images.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~models.consistency_decoder_vae.ConsistencyDecoderVAEOutput`] instead of a
plain tuple.
Returns:
[`~models.consistency_decoder_vae.ConsistencyDecoderVAEOutput`] or `tuple`:
If return_dict is True, a [`~models.consistency_decoder_vae.ConsistencyDecoderVAEOutput`] is returned,
otherwise a plain `tuple` is returned.
"""
overlap_size = int(self.tile_sample_min_size * (1 - self.tile_overlap_factor))
blend_extent = int(self.tile_latent_min_size * self.tile_overlap_factor)
row_limit = self.tile_latent_min_size - blend_extent
# Split the image into 512x512 tiles and encode them separately.
rows = []
for i in range(0, x.shape[2], overlap_size):
row = []
for j in range(0, x.shape[3], overlap_size):
tile = x[:, :, i : i + self.tile_sample_min_size, j : j + self.tile_sample_min_size]
tile = self.encoder(tile)
tile = self.quant_conv(tile)
row.append(tile)
rows.append(row)
result_rows = []
for i, row in enumerate(rows):
result_row = []
for j, tile in enumerate(row):
# blend the above tile and the left tile
# to the current tile and add the current tile to the result row
if i > 0:
tile = self.blend_v(rows[i - 1][j], tile, blend_extent)
if j > 0:
tile = self.blend_h(row[j - 1], tile, blend_extent)
result_row.append(tile[:, :, :row_limit, :row_limit])
result_rows.append(torch.cat(result_row, dim=3))
moments = torch.cat(result_rows, dim=2)
posterior = DiagonalGaussianDistribution(moments)
if not return_dict:
return (posterior,)
return ConsistencyDecoderVAEOutput(latent_dist=posterior)
def forward(
self,
sample: torch.FloatTensor,
sample_posterior: bool = False,
return_dict: bool = True,
generator: Optional[torch.Generator] = None,
) -> Union[DecoderOutput, Tuple[torch.FloatTensor]]:
r"""
Args:
sample (`torch.FloatTensor`): Input sample.
sample_posterior (`bool`, *optional*, defaults to `False`):
Whether to sample from the posterior.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`DecoderOutput`] instead of a plain tuple.
generator (`torch.Generator`, *optional*, defaults to `None`):
Generator to use for sampling.
Returns:
[`DecoderOutput`] or `tuple`:
If return_dict is True, a [`DecoderOutput`] is returned, otherwise a plain `tuple` is returned.
"""
x = sample
posterior = self.encode(x).latent_dist
if sample_posterior:
z = posterior.sample(generator=generator)
else:
z = posterior.mode()
dec = self.decode(z, generator=generator).sample
if not return_dict:
return (dec,)
return DecoderOutput(sample=dec)
|
diffusers/src/diffusers/models/autoencoders/consistency_decoder_vae.py/0
|
{
"file_path": "diffusers/src/diffusers/models/autoencoders/consistency_decoder_vae.py",
"repo_id": "diffusers",
"token_count": 8128
}
| 120 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
# `TemporalConvLayer` Copyright 2024 Alibaba DAMO-VILAB, The ModelScope Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from functools import partial
from typing import Optional, Tuple, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
from ..utils import deprecate
from .activations import get_activation
from .attention_processor import SpatialNorm
from .downsampling import ( # noqa
Downsample1D,
Downsample2D,
FirDownsample2D,
KDownsample2D,
downsample_2d,
)
from .normalization import AdaGroupNorm
from .upsampling import ( # noqa
FirUpsample2D,
KUpsample2D,
Upsample1D,
Upsample2D,
upfirdn2d_native,
upsample_2d,
)
class ResnetBlockCondNorm2D(nn.Module):
r"""
A Resnet block that use normalization layer that incorporate conditioning information.
Parameters:
in_channels (`int`): The number of channels in the input.
out_channels (`int`, *optional*, default to be `None`):
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
groups (`int`, *optional*, default to `32`): The number of groups to use for the first normalization layer.
groups_out (`int`, *optional*, default to None):
The number of groups to use for the second normalization layer. if set to None, same as `groups`.
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
non_linearity (`str`, *optional*, default to `"swish"`): the activation function to use.
time_embedding_norm (`str`, *optional*, default to `"ada_group"` ):
The normalization layer for time embedding `temb`. Currently only support "ada_group" or "spatial".
kernel (`torch.FloatTensor`, optional, default to None): FIR filter, see
[`~models.resnet.FirUpsample2D`] and [`~models.resnet.FirDownsample2D`].
output_scale_factor (`float`, *optional*, default to be `1.0`): the scale factor to use for the output.
use_in_shortcut (`bool`, *optional*, default to `True`):
If `True`, add a 1x1 nn.conv2d layer for skip-connection.
up (`bool`, *optional*, default to `False`): If `True`, add an upsample layer.
down (`bool`, *optional*, default to `False`): If `True`, add a downsample layer.
conv_shortcut_bias (`bool`, *optional*, default to `True`): If `True`, adds a learnable bias to the
`conv_shortcut` output.
conv_2d_out_channels (`int`, *optional*, default to `None`): the number of channels in the output.
If None, same as `out_channels`.
"""
def __init__(
self,
*,
in_channels: int,
out_channels: Optional[int] = None,
conv_shortcut: bool = False,
dropout: float = 0.0,
temb_channels: int = 512,
groups: int = 32,
groups_out: Optional[int] = None,
eps: float = 1e-6,
non_linearity: str = "swish",
time_embedding_norm: str = "ada_group", # ada_group, spatial
output_scale_factor: float = 1.0,
use_in_shortcut: Optional[bool] = None,
up: bool = False,
down: bool = False,
conv_shortcut_bias: bool = True,
conv_2d_out_channels: Optional[int] = None,
):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.up = up
self.down = down
self.output_scale_factor = output_scale_factor
self.time_embedding_norm = time_embedding_norm
conv_cls = nn.Conv2d
if groups_out is None:
groups_out = groups
if self.time_embedding_norm == "ada_group": # ada_group
self.norm1 = AdaGroupNorm(temb_channels, in_channels, groups, eps=eps)
elif self.time_embedding_norm == "spatial":
self.norm1 = SpatialNorm(in_channels, temb_channels)
else:
raise ValueError(f" unsupported time_embedding_norm: {self.time_embedding_norm}")
self.conv1 = conv_cls(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
if self.time_embedding_norm == "ada_group": # ada_group
self.norm2 = AdaGroupNorm(temb_channels, out_channels, groups_out, eps=eps)
elif self.time_embedding_norm == "spatial": # spatial
self.norm2 = SpatialNorm(out_channels, temb_channels)
else:
raise ValueError(f" unsupported time_embedding_norm: {self.time_embedding_norm}")
self.dropout = torch.nn.Dropout(dropout)
conv_2d_out_channels = conv_2d_out_channels or out_channels
self.conv2 = conv_cls(out_channels, conv_2d_out_channels, kernel_size=3, stride=1, padding=1)
self.nonlinearity = get_activation(non_linearity)
self.upsample = self.downsample = None
if self.up:
self.upsample = Upsample2D(in_channels, use_conv=False)
elif self.down:
self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
self.use_in_shortcut = self.in_channels != conv_2d_out_channels if use_in_shortcut is None else use_in_shortcut
self.conv_shortcut = None
if self.use_in_shortcut:
self.conv_shortcut = conv_cls(
in_channels,
conv_2d_out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=conv_shortcut_bias,
)
def forward(self, input_tensor: torch.FloatTensor, temb: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
hidden_states = input_tensor
hidden_states = self.norm1(hidden_states, temb)
hidden_states = self.nonlinearity(hidden_states)
if self.upsample is not None:
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
if hidden_states.shape[0] >= 64:
input_tensor = input_tensor.contiguous()
hidden_states = hidden_states.contiguous()
input_tensor = self.upsample(input_tensor)
hidden_states = self.upsample(hidden_states)
elif self.downsample is not None:
input_tensor = self.downsample(input_tensor)
hidden_states = self.downsample(hidden_states)
hidden_states = self.conv1(hidden_states)
hidden_states = self.norm2(hidden_states, temb)
hidden_states = self.nonlinearity(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.conv2(hidden_states)
if self.conv_shortcut is not None:
input_tensor = self.conv_shortcut(input_tensor)
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
return output_tensor
class ResnetBlock2D(nn.Module):
r"""
A Resnet block.
Parameters:
in_channels (`int`): The number of channels in the input.
out_channels (`int`, *optional*, default to be `None`):
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
groups (`int`, *optional*, default to `32`): The number of groups to use for the first normalization layer.
groups_out (`int`, *optional*, default to None):
The number of groups to use for the second normalization layer. if set to None, same as `groups`.
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
non_linearity (`str`, *optional*, default to `"swish"`): the activation function to use.
time_embedding_norm (`str`, *optional*, default to `"default"` ): Time scale shift config.
By default, apply timestep embedding conditioning with a simple shift mechanism. Choose "scale_shift"
for a stronger conditioning with scale and shift.
kernel (`torch.FloatTensor`, optional, default to None): FIR filter, see
[`~models.resnet.FirUpsample2D`] and [`~models.resnet.FirDownsample2D`].
output_scale_factor (`float`, *optional*, default to be `1.0`): the scale factor to use for the output.
use_in_shortcut (`bool`, *optional*, default to `True`):
If `True`, add a 1x1 nn.conv2d layer for skip-connection.
up (`bool`, *optional*, default to `False`): If `True`, add an upsample layer.
down (`bool`, *optional*, default to `False`): If `True`, add a downsample layer.
conv_shortcut_bias (`bool`, *optional*, default to `True`): If `True`, adds a learnable bias to the
`conv_shortcut` output.
conv_2d_out_channels (`int`, *optional*, default to `None`): the number of channels in the output.
If None, same as `out_channels`.
"""
def __init__(
self,
*,
in_channels: int,
out_channels: Optional[int] = None,
conv_shortcut: bool = False,
dropout: float = 0.0,
temb_channels: int = 512,
groups: int = 32,
groups_out: Optional[int] = None,
pre_norm: bool = True,
eps: float = 1e-6,
non_linearity: str = "swish",
skip_time_act: bool = False,
time_embedding_norm: str = "default", # default, scale_shift,
kernel: Optional[torch.FloatTensor] = None,
output_scale_factor: float = 1.0,
use_in_shortcut: Optional[bool] = None,
up: bool = False,
down: bool = False,
conv_shortcut_bias: bool = True,
conv_2d_out_channels: Optional[int] = None,
):
super().__init__()
if time_embedding_norm == "ada_group":
raise ValueError(
"This class cannot be used with `time_embedding_norm==ada_group`, please use `ResnetBlockCondNorm2D` instead",
)
if time_embedding_norm == "spatial":
raise ValueError(
"This class cannot be used with `time_embedding_norm==spatial`, please use `ResnetBlockCondNorm2D` instead",
)
self.pre_norm = True
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.up = up
self.down = down
self.output_scale_factor = output_scale_factor
self.time_embedding_norm = time_embedding_norm
self.skip_time_act = skip_time_act
linear_cls = nn.Linear
conv_cls = nn.Conv2d
if groups_out is None:
groups_out = groups
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
self.conv1 = conv_cls(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
if temb_channels is not None:
if self.time_embedding_norm == "default":
self.time_emb_proj = linear_cls(temb_channels, out_channels)
elif self.time_embedding_norm == "scale_shift":
self.time_emb_proj = linear_cls(temb_channels, 2 * out_channels)
else:
raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
else:
self.time_emb_proj = None
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
self.dropout = torch.nn.Dropout(dropout)
conv_2d_out_channels = conv_2d_out_channels or out_channels
self.conv2 = conv_cls(out_channels, conv_2d_out_channels, kernel_size=3, stride=1, padding=1)
self.nonlinearity = get_activation(non_linearity)
self.upsample = self.downsample = None
if self.up:
if kernel == "fir":
fir_kernel = (1, 3, 3, 1)
self.upsample = lambda x: upsample_2d(x, kernel=fir_kernel)
elif kernel == "sde_vp":
self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
else:
self.upsample = Upsample2D(in_channels, use_conv=False)
elif self.down:
if kernel == "fir":
fir_kernel = (1, 3, 3, 1)
self.downsample = lambda x: downsample_2d(x, kernel=fir_kernel)
elif kernel == "sde_vp":
self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
else:
self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
self.use_in_shortcut = self.in_channels != conv_2d_out_channels if use_in_shortcut is None else use_in_shortcut
self.conv_shortcut = None
if self.use_in_shortcut:
self.conv_shortcut = conv_cls(
in_channels,
conv_2d_out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=conv_shortcut_bias,
)
def forward(self, input_tensor: torch.FloatTensor, temb: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
hidden_states = input_tensor
hidden_states = self.norm1(hidden_states)
hidden_states = self.nonlinearity(hidden_states)
if self.upsample is not None:
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
if hidden_states.shape[0] >= 64:
input_tensor = input_tensor.contiguous()
hidden_states = hidden_states.contiguous()
input_tensor = self.upsample(input_tensor)
hidden_states = self.upsample(hidden_states)
elif self.downsample is not None:
input_tensor = self.downsample(input_tensor)
hidden_states = self.downsample(hidden_states)
hidden_states = self.conv1(hidden_states)
if self.time_emb_proj is not None:
if not self.skip_time_act:
temb = self.nonlinearity(temb)
temb = self.time_emb_proj(temb)[:, :, None, None]
if self.time_embedding_norm == "default":
if temb is not None:
hidden_states = hidden_states + temb
hidden_states = self.norm2(hidden_states)
elif self.time_embedding_norm == "scale_shift":
if temb is None:
raise ValueError(
f" `temb` should not be None when `time_embedding_norm` is {self.time_embedding_norm}"
)
time_scale, time_shift = torch.chunk(temb, 2, dim=1)
hidden_states = self.norm2(hidden_states)
hidden_states = hidden_states * (1 + time_scale) + time_shift
else:
hidden_states = self.norm2(hidden_states)
hidden_states = self.nonlinearity(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.conv2(hidden_states)
if self.conv_shortcut is not None:
input_tensor = self.conv_shortcut(input_tensor)
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
return output_tensor
# unet_rl.py
def rearrange_dims(tensor: torch.Tensor) -> torch.Tensor:
if len(tensor.shape) == 2:
return tensor[:, :, None]
if len(tensor.shape) == 3:
return tensor[:, :, None, :]
elif len(tensor.shape) == 4:
return tensor[:, :, 0, :]
else:
raise ValueError(f"`len(tensor)`: {len(tensor)} has to be 2, 3 or 4.")
class Conv1dBlock(nn.Module):
"""
Conv1d --> GroupNorm --> Mish
Parameters:
inp_channels (`int`): Number of input channels.
out_channels (`int`): Number of output channels.
kernel_size (`int` or `tuple`): Size of the convolving kernel.
n_groups (`int`, default `8`): Number of groups to separate the channels into.
activation (`str`, defaults to `mish`): Name of the activation function.
"""
def __init__(
self,
inp_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int]],
n_groups: int = 8,
activation: str = "mish",
):
super().__init__()
self.conv1d = nn.Conv1d(inp_channels, out_channels, kernel_size, padding=kernel_size // 2)
self.group_norm = nn.GroupNorm(n_groups, out_channels)
self.mish = get_activation(activation)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
intermediate_repr = self.conv1d(inputs)
intermediate_repr = rearrange_dims(intermediate_repr)
intermediate_repr = self.group_norm(intermediate_repr)
intermediate_repr = rearrange_dims(intermediate_repr)
output = self.mish(intermediate_repr)
return output
# unet_rl.py
class ResidualTemporalBlock1D(nn.Module):
"""
Residual 1D block with temporal convolutions.
Parameters:
inp_channels (`int`): Number of input channels.
out_channels (`int`): Number of output channels.
embed_dim (`int`): Embedding dimension.
kernel_size (`int` or `tuple`): Size of the convolving kernel.
activation (`str`, defaults `mish`): It is possible to choose the right activation function.
"""
def __init__(
self,
inp_channels: int,
out_channels: int,
embed_dim: int,
kernel_size: Union[int, Tuple[int, int]] = 5,
activation: str = "mish",
):
super().__init__()
self.conv_in = Conv1dBlock(inp_channels, out_channels, kernel_size)
self.conv_out = Conv1dBlock(out_channels, out_channels, kernel_size)
self.time_emb_act = get_activation(activation)
self.time_emb = nn.Linear(embed_dim, out_channels)
self.residual_conv = (
nn.Conv1d(inp_channels, out_channels, 1) if inp_channels != out_channels else nn.Identity()
)
def forward(self, inputs: torch.Tensor, t: torch.Tensor) -> torch.Tensor:
"""
Args:
inputs : [ batch_size x inp_channels x horizon ]
t : [ batch_size x embed_dim ]
returns:
out : [ batch_size x out_channels x horizon ]
"""
t = self.time_emb_act(t)
t = self.time_emb(t)
out = self.conv_in(inputs) + rearrange_dims(t)
out = self.conv_out(out)
return out + self.residual_conv(inputs)
class TemporalConvLayer(nn.Module):
"""
Temporal convolutional layer that can be used for video (sequence of images) input Code mostly copied from:
https://github.com/modelscope/modelscope/blob/1509fdb973e5871f37148a4b5e5964cafd43e64d/modelscope/models/multi_modal/video_synthesis/unet_sd.py#L1016
Parameters:
in_dim (`int`): Number of input channels.
out_dim (`int`): Number of output channels.
dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
"""
def __init__(
self,
in_dim: int,
out_dim: Optional[int] = None,
dropout: float = 0.0,
norm_num_groups: int = 32,
):
super().__init__()
out_dim = out_dim or in_dim
self.in_dim = in_dim
self.out_dim = out_dim
# conv layers
self.conv1 = nn.Sequential(
nn.GroupNorm(norm_num_groups, in_dim),
nn.SiLU(),
nn.Conv3d(in_dim, out_dim, (3, 1, 1), padding=(1, 0, 0)),
)
self.conv2 = nn.Sequential(
nn.GroupNorm(norm_num_groups, out_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
)
self.conv3 = nn.Sequential(
nn.GroupNorm(norm_num_groups, out_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
)
self.conv4 = nn.Sequential(
nn.GroupNorm(norm_num_groups, out_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
)
# zero out the last layer params,so the conv block is identity
nn.init.zeros_(self.conv4[-1].weight)
nn.init.zeros_(self.conv4[-1].bias)
def forward(self, hidden_states: torch.Tensor, num_frames: int = 1) -> torch.Tensor:
hidden_states = (
hidden_states[None, :].reshape((-1, num_frames) + hidden_states.shape[1:]).permute(0, 2, 1, 3, 4)
)
identity = hidden_states
hidden_states = self.conv1(hidden_states)
hidden_states = self.conv2(hidden_states)
hidden_states = self.conv3(hidden_states)
hidden_states = self.conv4(hidden_states)
hidden_states = identity + hidden_states
hidden_states = hidden_states.permute(0, 2, 1, 3, 4).reshape(
(hidden_states.shape[0] * hidden_states.shape[2], -1) + hidden_states.shape[3:]
)
return hidden_states
class TemporalResnetBlock(nn.Module):
r"""
A Resnet block.
Parameters:
in_channels (`int`): The number of channels in the input.
out_channels (`int`, *optional*, default to be `None`):
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
"""
def __init__(
self,
in_channels: int,
out_channels: Optional[int] = None,
temb_channels: int = 512,
eps: float = 1e-6,
):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
kernel_size = (3, 1, 1)
padding = [k // 2 for k in kernel_size]
self.norm1 = torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=eps, affine=True)
self.conv1 = nn.Conv3d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=1,
padding=padding,
)
if temb_channels is not None:
self.time_emb_proj = nn.Linear(temb_channels, out_channels)
else:
self.time_emb_proj = None
self.norm2 = torch.nn.GroupNorm(num_groups=32, num_channels=out_channels, eps=eps, affine=True)
self.dropout = torch.nn.Dropout(0.0)
self.conv2 = nn.Conv3d(
out_channels,
out_channels,
kernel_size=kernel_size,
stride=1,
padding=padding,
)
self.nonlinearity = get_activation("silu")
self.use_in_shortcut = self.in_channels != out_channels
self.conv_shortcut = None
if self.use_in_shortcut:
self.conv_shortcut = nn.Conv3d(
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
)
def forward(self, input_tensor: torch.FloatTensor, temb: torch.FloatTensor) -> torch.FloatTensor:
hidden_states = input_tensor
hidden_states = self.norm1(hidden_states)
hidden_states = self.nonlinearity(hidden_states)
hidden_states = self.conv1(hidden_states)
if self.time_emb_proj is not None:
temb = self.nonlinearity(temb)
temb = self.time_emb_proj(temb)[:, :, :, None, None]
temb = temb.permute(0, 2, 1, 3, 4)
hidden_states = hidden_states + temb
hidden_states = self.norm2(hidden_states)
hidden_states = self.nonlinearity(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.conv2(hidden_states)
if self.conv_shortcut is not None:
input_tensor = self.conv_shortcut(input_tensor)
output_tensor = input_tensor + hidden_states
return output_tensor
# VideoResBlock
class SpatioTemporalResBlock(nn.Module):
r"""
A SpatioTemporal Resnet block.
Parameters:
in_channels (`int`): The number of channels in the input.
out_channels (`int`, *optional*, default to be `None`):
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the spatial resenet.
temporal_eps (`float`, *optional*, defaults to `eps`): The epsilon to use for the temporal resnet.
merge_factor (`float`, *optional*, defaults to `0.5`): The merge factor to use for the temporal mixing.
merge_strategy (`str`, *optional*, defaults to `learned_with_images`):
The merge strategy to use for the temporal mixing.
switch_spatial_to_temporal_mix (`bool`, *optional*, defaults to `False`):
If `True`, switch the spatial and temporal mixing.
"""
def __init__(
self,
in_channels: int,
out_channels: Optional[int] = None,
temb_channels: int = 512,
eps: float = 1e-6,
temporal_eps: Optional[float] = None,
merge_factor: float = 0.5,
merge_strategy="learned_with_images",
switch_spatial_to_temporal_mix: bool = False,
):
super().__init__()
self.spatial_res_block = ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=eps,
)
self.temporal_res_block = TemporalResnetBlock(
in_channels=out_channels if out_channels is not None else in_channels,
out_channels=out_channels if out_channels is not None else in_channels,
temb_channels=temb_channels,
eps=temporal_eps if temporal_eps is not None else eps,
)
self.time_mixer = AlphaBlender(
alpha=merge_factor,
merge_strategy=merge_strategy,
switch_spatial_to_temporal_mix=switch_spatial_to_temporal_mix,
)
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
image_only_indicator: Optional[torch.Tensor] = None,
):
num_frames = image_only_indicator.shape[-1]
hidden_states = self.spatial_res_block(hidden_states, temb)
batch_frames, channels, height, width = hidden_states.shape
batch_size = batch_frames // num_frames
hidden_states_mix = (
hidden_states[None, :].reshape(batch_size, num_frames, channels, height, width).permute(0, 2, 1, 3, 4)
)
hidden_states = (
hidden_states[None, :].reshape(batch_size, num_frames, channels, height, width).permute(0, 2, 1, 3, 4)
)
if temb is not None:
temb = temb.reshape(batch_size, num_frames, -1)
hidden_states = self.temporal_res_block(hidden_states, temb)
hidden_states = self.time_mixer(
x_spatial=hidden_states_mix,
x_temporal=hidden_states,
image_only_indicator=image_only_indicator,
)
hidden_states = hidden_states.permute(0, 2, 1, 3, 4).reshape(batch_frames, channels, height, width)
return hidden_states
class AlphaBlender(nn.Module):
r"""
A module to blend spatial and temporal features.
Parameters:
alpha (`float`): The initial value of the blending factor.
merge_strategy (`str`, *optional*, defaults to `learned_with_images`):
The merge strategy to use for the temporal mixing.
switch_spatial_to_temporal_mix (`bool`, *optional*, defaults to `False`):
If `True`, switch the spatial and temporal mixing.
"""
strategies = ["learned", "fixed", "learned_with_images"]
def __init__(
self,
alpha: float,
merge_strategy: str = "learned_with_images",
switch_spatial_to_temporal_mix: bool = False,
):
super().__init__()
self.merge_strategy = merge_strategy
self.switch_spatial_to_temporal_mix = switch_spatial_to_temporal_mix # For TemporalVAE
if merge_strategy not in self.strategies:
raise ValueError(f"merge_strategy needs to be in {self.strategies}")
if self.merge_strategy == "fixed":
self.register_buffer("mix_factor", torch.Tensor([alpha]))
elif self.merge_strategy == "learned" or self.merge_strategy == "learned_with_images":
self.register_parameter("mix_factor", torch.nn.Parameter(torch.Tensor([alpha])))
else:
raise ValueError(f"Unknown merge strategy {self.merge_strategy}")
def get_alpha(self, image_only_indicator: torch.Tensor, ndims: int) -> torch.Tensor:
if self.merge_strategy == "fixed":
alpha = self.mix_factor
elif self.merge_strategy == "learned":
alpha = torch.sigmoid(self.mix_factor)
elif self.merge_strategy == "learned_with_images":
if image_only_indicator is None:
raise ValueError("Please provide image_only_indicator to use learned_with_images merge strategy")
alpha = torch.where(
image_only_indicator.bool(),
torch.ones(1, 1, device=image_only_indicator.device),
torch.sigmoid(self.mix_factor)[..., None],
)
# (batch, channel, frames, height, width)
if ndims == 5:
alpha = alpha[:, None, :, None, None]
# (batch*frames, height*width, channels)
elif ndims == 3:
alpha = alpha.reshape(-1)[:, None, None]
else:
raise ValueError(f"Unexpected ndims {ndims}. Dimensions should be 3 or 5")
else:
raise NotImplementedError
return alpha
def forward(
self,
x_spatial: torch.Tensor,
x_temporal: torch.Tensor,
image_only_indicator: Optional[torch.Tensor] = None,
) -> torch.Tensor:
alpha = self.get_alpha(image_only_indicator, x_spatial.ndim)
alpha = alpha.to(x_spatial.dtype)
if self.switch_spatial_to_temporal_mix:
alpha = 1.0 - alpha
x = alpha * x_spatial + (1.0 - alpha) * x_temporal
return x
|
diffusers/src/diffusers/models/resnet.py/0
|
{
"file_path": "diffusers/src/diffusers/models/resnet.py",
"repo_id": "diffusers",
"token_count": 14494
}
| 121 |
from ...utils import is_flax_available, is_torch_available
if is_torch_available():
from .unet_1d import UNet1DModel
from .unet_2d import UNet2DModel
from .unet_2d_condition import UNet2DConditionModel
from .unet_3d_condition import UNet3DConditionModel
from .unet_i2vgen_xl import I2VGenXLUNet
from .unet_kandinsky3 import Kandinsky3UNet
from .unet_motion_model import MotionAdapter, UNetMotionModel
from .unet_spatio_temporal_condition import UNetSpatioTemporalConditionModel
from .unet_stable_cascade import StableCascadeUNet
from .uvit_2d import UVit2DModel
if is_flax_available():
from .unet_2d_condition_flax import FlaxUNet2DConditionModel
|
diffusers/src/diffusers/models/unets/__init__.py/0
|
{
"file_path": "diffusers/src/diffusers/models/unets/__init__.py",
"repo_id": "diffusers",
"token_count": 265
}
| 122 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from ..utils import deprecate
from .normalization import RMSNorm
class Upsample1D(nn.Module):
"""A 1D upsampling layer with an optional convolution.
Parameters:
channels (`int`):
number of channels in the inputs and outputs.
use_conv (`bool`, default `False`):
option to use a convolution.
use_conv_transpose (`bool`, default `False`):
option to use a convolution transpose.
out_channels (`int`, optional):
number of output channels. Defaults to `channels`.
name (`str`, default `conv`):
name of the upsampling 1D layer.
"""
def __init__(
self,
channels: int,
use_conv: bool = False,
use_conv_transpose: bool = False,
out_channels: Optional[int] = None,
name: str = "conv",
):
super().__init__()
self.channels = channels
self.out_channels = out_channels or channels
self.use_conv = use_conv
self.use_conv_transpose = use_conv_transpose
self.name = name
self.conv = None
if use_conv_transpose:
self.conv = nn.ConvTranspose1d(channels, self.out_channels, 4, 2, 1)
elif use_conv:
self.conv = nn.Conv1d(self.channels, self.out_channels, 3, padding=1)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
assert inputs.shape[1] == self.channels
if self.use_conv_transpose:
return self.conv(inputs)
outputs = F.interpolate(inputs, scale_factor=2.0, mode="nearest")
if self.use_conv:
outputs = self.conv(outputs)
return outputs
class Upsample2D(nn.Module):
"""A 2D upsampling layer with an optional convolution.
Parameters:
channels (`int`):
number of channels in the inputs and outputs.
use_conv (`bool`, default `False`):
option to use a convolution.
use_conv_transpose (`bool`, default `False`):
option to use a convolution transpose.
out_channels (`int`, optional):
number of output channels. Defaults to `channels`.
name (`str`, default `conv`):
name of the upsampling 2D layer.
"""
def __init__(
self,
channels: int,
use_conv: bool = False,
use_conv_transpose: bool = False,
out_channels: Optional[int] = None,
name: str = "conv",
kernel_size: Optional[int] = None,
padding=1,
norm_type=None,
eps=None,
elementwise_affine=None,
bias=True,
interpolate=True,
):
super().__init__()
self.channels = channels
self.out_channels = out_channels or channels
self.use_conv = use_conv
self.use_conv_transpose = use_conv_transpose
self.name = name
self.interpolate = interpolate
conv_cls = nn.Conv2d
if norm_type == "ln_norm":
self.norm = nn.LayerNorm(channels, eps, elementwise_affine)
elif norm_type == "rms_norm":
self.norm = RMSNorm(channels, eps, elementwise_affine)
elif norm_type is None:
self.norm = None
else:
raise ValueError(f"unknown norm_type: {norm_type}")
conv = None
if use_conv_transpose:
if kernel_size is None:
kernel_size = 4
conv = nn.ConvTranspose2d(
channels, self.out_channels, kernel_size=kernel_size, stride=2, padding=padding, bias=bias
)
elif use_conv:
if kernel_size is None:
kernel_size = 3
conv = conv_cls(self.channels, self.out_channels, kernel_size=kernel_size, padding=padding, bias=bias)
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
if name == "conv":
self.conv = conv
else:
self.Conv2d_0 = conv
def forward(
self, hidden_states: torch.FloatTensor, output_size: Optional[int] = None, *args, **kwargs
) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
assert hidden_states.shape[1] == self.channels
if self.norm is not None:
hidden_states = self.norm(hidden_states.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
if self.use_conv_transpose:
return self.conv(hidden_states)
# Cast to float32 to as 'upsample_nearest2d_out_frame' op does not support bfloat16
# TODO(Suraj): Remove this cast once the issue is fixed in PyTorch
# https://github.com/pytorch/pytorch/issues/86679
dtype = hidden_states.dtype
if dtype == torch.bfloat16:
hidden_states = hidden_states.to(torch.float32)
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
if hidden_states.shape[0] >= 64:
hidden_states = hidden_states.contiguous()
# if `output_size` is passed we force the interpolation output
# size and do not make use of `scale_factor=2`
if self.interpolate:
if output_size is None:
hidden_states = F.interpolate(hidden_states, scale_factor=2.0, mode="nearest")
else:
hidden_states = F.interpolate(hidden_states, size=output_size, mode="nearest")
# If the input is bfloat16, we cast back to bfloat16
if dtype == torch.bfloat16:
hidden_states = hidden_states.to(dtype)
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
if self.use_conv:
if self.name == "conv":
hidden_states = self.conv(hidden_states)
else:
hidden_states = self.Conv2d_0(hidden_states)
return hidden_states
class FirUpsample2D(nn.Module):
"""A 2D FIR upsampling layer with an optional convolution.
Parameters:
channels (`int`, optional):
number of channels in the inputs and outputs.
use_conv (`bool`, default `False`):
option to use a convolution.
out_channels (`int`, optional):
number of output channels. Defaults to `channels`.
fir_kernel (`tuple`, default `(1, 3, 3, 1)`):
kernel for the FIR filter.
"""
def __init__(
self,
channels: Optional[int] = None,
out_channels: Optional[int] = None,
use_conv: bool = False,
fir_kernel: Tuple[int, int, int, int] = (1, 3, 3, 1),
):
super().__init__()
out_channels = out_channels if out_channels else channels
if use_conv:
self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
self.use_conv = use_conv
self.fir_kernel = fir_kernel
self.out_channels = out_channels
def _upsample_2d(
self,
hidden_states: torch.FloatTensor,
weight: Optional[torch.FloatTensor] = None,
kernel: Optional[torch.FloatTensor] = None,
factor: int = 2,
gain: float = 1,
) -> torch.FloatTensor:
"""Fused `upsample_2d()` followed by `Conv2d()`.
Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of
arbitrary order.
Args:
hidden_states (`torch.FloatTensor`):
Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
weight (`torch.FloatTensor`, *optional*):
Weight tensor of the shape `[filterH, filterW, inChannels, outChannels]`. Grouped convolution can be
performed by `inChannels = x.shape[0] // numGroups`.
kernel (`torch.FloatTensor`, *optional*):
FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] * factor`, which
corresponds to nearest-neighbor upsampling.
factor (`int`, *optional*): Integer upsampling factor (default: 2).
gain (`float`, *optional*): Scaling factor for signal magnitude (default: 1.0).
Returns:
output (`torch.FloatTensor`):
Tensor of the shape `[N, C, H * factor, W * factor]` or `[N, H * factor, W * factor, C]`, and same
datatype as `hidden_states`.
"""
assert isinstance(factor, int) and factor >= 1
# Setup filter kernel.
if kernel is None:
kernel = [1] * factor
# setup kernel
kernel = torch.tensor(kernel, dtype=torch.float32)
if kernel.ndim == 1:
kernel = torch.outer(kernel, kernel)
kernel /= torch.sum(kernel)
kernel = kernel * (gain * (factor**2))
if self.use_conv:
convH = weight.shape[2]
convW = weight.shape[3]
inC = weight.shape[1]
pad_value = (kernel.shape[0] - factor) - (convW - 1)
stride = (factor, factor)
# Determine data dimensions.
output_shape = (
(hidden_states.shape[2] - 1) * factor + convH,
(hidden_states.shape[3] - 1) * factor + convW,
)
output_padding = (
output_shape[0] - (hidden_states.shape[2] - 1) * stride[0] - convH,
output_shape[1] - (hidden_states.shape[3] - 1) * stride[1] - convW,
)
assert output_padding[0] >= 0 and output_padding[1] >= 0
num_groups = hidden_states.shape[1] // inC
# Transpose weights.
weight = torch.reshape(weight, (num_groups, -1, inC, convH, convW))
weight = torch.flip(weight, dims=[3, 4]).permute(0, 2, 1, 3, 4)
weight = torch.reshape(weight, (num_groups * inC, -1, convH, convW))
inverse_conv = F.conv_transpose2d(
hidden_states,
weight,
stride=stride,
output_padding=output_padding,
padding=0,
)
output = upfirdn2d_native(
inverse_conv,
torch.tensor(kernel, device=inverse_conv.device),
pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2 + 1),
)
else:
pad_value = kernel.shape[0] - factor
output = upfirdn2d_native(
hidden_states,
torch.tensor(kernel, device=hidden_states.device),
up=factor,
pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2),
)
return output
def forward(self, hidden_states: torch.FloatTensor) -> torch.FloatTensor:
if self.use_conv:
height = self._upsample_2d(hidden_states, self.Conv2d_0.weight, kernel=self.fir_kernel)
height = height + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
else:
height = self._upsample_2d(hidden_states, kernel=self.fir_kernel, factor=2)
return height
class KUpsample2D(nn.Module):
r"""A 2D K-upsampling layer.
Parameters:
pad_mode (`str`, *optional*, default to `"reflect"`): the padding mode to use.
"""
def __init__(self, pad_mode: str = "reflect"):
super().__init__()
self.pad_mode = pad_mode
kernel_1d = torch.tensor([[1 / 8, 3 / 8, 3 / 8, 1 / 8]]) * 2
self.pad = kernel_1d.shape[1] // 2 - 1
self.register_buffer("kernel", kernel_1d.T @ kernel_1d, persistent=False)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
inputs = F.pad(inputs, ((self.pad + 1) // 2,) * 4, self.pad_mode)
weight = inputs.new_zeros(
[
inputs.shape[1],
inputs.shape[1],
self.kernel.shape[0],
self.kernel.shape[1],
]
)
indices = torch.arange(inputs.shape[1], device=inputs.device)
kernel = self.kernel.to(weight)[None, :].expand(inputs.shape[1], -1, -1)
weight[indices, indices] = kernel
return F.conv_transpose2d(inputs, weight, stride=2, padding=self.pad * 2 + 1)
def upfirdn2d_native(
tensor: torch.Tensor,
kernel: torch.Tensor,
up: int = 1,
down: int = 1,
pad: Tuple[int, int] = (0, 0),
) -> torch.Tensor:
up_x = up_y = up
down_x = down_y = down
pad_x0 = pad_y0 = pad[0]
pad_x1 = pad_y1 = pad[1]
_, channel, in_h, in_w = tensor.shape
tensor = tensor.reshape(-1, in_h, in_w, 1)
_, in_h, in_w, minor = tensor.shape
kernel_h, kernel_w = kernel.shape
out = tensor.view(-1, in_h, 1, in_w, 1, minor)
out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
out = out.view(-1, in_h * up_y, in_w * up_x, minor)
out = F.pad(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
out = out.to(tensor.device) # Move back to mps if necessary
out = out[
:,
max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
:,
]
out = out.permute(0, 3, 1, 2)
out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
out = F.conv2d(out, w)
out = out.reshape(
-1,
minor,
in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
)
out = out.permute(0, 2, 3, 1)
out = out[:, ::down_y, ::down_x, :]
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
return out.view(-1, channel, out_h, out_w)
def upsample_2d(
hidden_states: torch.FloatTensor,
kernel: Optional[torch.FloatTensor] = None,
factor: int = 2,
gain: float = 1,
) -> torch.FloatTensor:
r"""Upsample2D a batch of 2D images with the given filter.
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and upsamples each image with the given
filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the specified
`gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its shape is
a: multiple of the upsampling factor.
Args:
hidden_states (`torch.FloatTensor`):
Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
kernel (`torch.FloatTensor`, *optional*):
FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] * factor`, which
corresponds to nearest-neighbor upsampling.
factor (`int`, *optional*, default to `2`):
Integer upsampling factor.
gain (`float`, *optional*, default to `1.0`):
Scaling factor for signal magnitude (default: 1.0).
Returns:
output (`torch.FloatTensor`):
Tensor of the shape `[N, C, H * factor, W * factor]`
"""
assert isinstance(factor, int) and factor >= 1
if kernel is None:
kernel = [1] * factor
kernel = torch.tensor(kernel, dtype=torch.float32)
if kernel.ndim == 1:
kernel = torch.outer(kernel, kernel)
kernel /= torch.sum(kernel)
kernel = kernel * (gain * (factor**2))
pad_value = kernel.shape[0] - factor
output = upfirdn2d_native(
hidden_states,
kernel.to(device=hidden_states.device),
up=factor,
pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2),
)
return output
|
diffusers/src/diffusers/models/upsampling.py/0
|
{
"file_path": "diffusers/src/diffusers/models/upsampling.py",
"repo_id": "diffusers",
"token_count": 7688
}
| 123 |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
is_transformers_version,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.27.0")):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils import dummy_torch_and_transformers_objects
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
else:
_import_structure["modeling_audioldm2"] = ["AudioLDM2ProjectionModel", "AudioLDM2UNet2DConditionModel"]
_import_structure["pipeline_audioldm2"] = ["AudioLDM2Pipeline"]
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
try:
if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.27.0")):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils.dummy_torch_and_transformers_objects import *
else:
from .modeling_audioldm2 import AudioLDM2ProjectionModel, AudioLDM2UNet2DConditionModel
from .pipeline_audioldm2 import AudioLDM2Pipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
__name__,
globals()["__file__"],
_import_structure,
module_spec=__spec__,
)
for name, value in _dummy_objects.items():
setattr(sys.modules[__name__], name, value)
|
diffusers/src/diffusers/pipelines/audioldm2/__init__.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/audioldm2/__init__.py",
"repo_id": "diffusers",
"token_count": 637
}
| 124 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This model implementation is heavily inspired by https://github.com/haofanwang/ControlNet-for-Diffusers/
import inspect
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
import torch.nn.functional as F
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
from ...image_processor import PipelineImageInput, VaeImageProcessor
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
from ...models import AutoencoderKL, ControlNetModel, ImageProjection, UNet2DConditionModel
from ...models.lora import adjust_lora_scale_text_encoder
from ...schedulers import KarrasDiffusionSchedulers
from ...utils import (
USE_PEFT_BACKEND,
deprecate,
logging,
replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
from ...utils.torch_utils import is_compiled_module, randn_tensor
from ..pipeline_utils import DiffusionPipeline, StableDiffusionMixin
from ..stable_diffusion import StableDiffusionPipelineOutput
from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from .multicontrolnet import MultiControlNetModel
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> # !pip install transformers accelerate
>>> from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel, DDIMScheduler
>>> from diffusers.utils import load_image
>>> import numpy as np
>>> import torch
>>> init_image = load_image(
... "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_inpaint/boy.png"
... )
>>> init_image = init_image.resize((512, 512))
>>> generator = torch.Generator(device="cpu").manual_seed(1)
>>> mask_image = load_image(
... "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_inpaint/boy_mask.png"
... )
>>> mask_image = mask_image.resize((512, 512))
>>> def make_canny_condition(image):
... image = np.array(image)
... image = cv2.Canny(image, 100, 200)
... image = image[:, :, None]
... image = np.concatenate([image, image, image], axis=2)
... image = Image.fromarray(image)
... return image
>>> control_image = make_canny_condition(init_image)
>>> controlnet = ControlNetModel.from_pretrained(
... "lllyasviel/control_v11p_sd15_inpaint", torch_dtype=torch.float16
... )
>>> pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
... )
>>> pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
>>> pipe.enable_model_cpu_offload()
>>> # generate image
>>> image = pipe(
... "a handsome man with ray-ban sunglasses",
... num_inference_steps=20,
... generator=generator,
... eta=1.0,
... image=init_image,
... mask_image=mask_image,
... control_image=control_image,
... ).images[0]
```
"""
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.retrieve_latents
def retrieve_latents(
encoder_output: torch.Tensor, generator: Optional[torch.Generator] = None, sample_mode: str = "sample"
):
if hasattr(encoder_output, "latent_dist") and sample_mode == "sample":
return encoder_output.latent_dist.sample(generator)
elif hasattr(encoder_output, "latent_dist") and sample_mode == "argmax":
return encoder_output.latent_dist.mode()
elif hasattr(encoder_output, "latents"):
return encoder_output.latents
else:
raise AttributeError("Could not access latents of provided encoder_output")
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.prepare_mask_and_masked_image
def prepare_mask_and_masked_image(image, mask, height, width, return_image=False):
"""
Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
``image`` and ``1`` for the ``mask``.
The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
Args:
image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
Raises:
ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
(ot the other way around).
Returns:
tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
dimensions: ``batch x channels x height x width``.
"""
deprecation_message = "The prepare_mask_and_masked_image method is deprecated and will be removed in a future version. Please use VaeImageProcessor.preprocess instead"
deprecate(
"prepare_mask_and_masked_image",
"0.30.0",
deprecation_message,
)
if image is None:
raise ValueError("`image` input cannot be undefined.")
if mask is None:
raise ValueError("`mask_image` input cannot be undefined.")
if isinstance(image, torch.Tensor):
if not isinstance(mask, torch.Tensor):
raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
# Batch single image
if image.ndim == 3:
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
image = image.unsqueeze(0)
# Batch and add channel dim for single mask
if mask.ndim == 2:
mask = mask.unsqueeze(0).unsqueeze(0)
# Batch single mask or add channel dim
if mask.ndim == 3:
# Single batched mask, no channel dim or single mask not batched but channel dim
if mask.shape[0] == 1:
mask = mask.unsqueeze(0)
# Batched masks no channel dim
else:
mask = mask.unsqueeze(1)
assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
# Check image is in [-1, 1]
if image.min() < -1 or image.max() > 1:
raise ValueError("Image should be in [-1, 1] range")
# Check mask is in [0, 1]
if mask.min() < 0 or mask.max() > 1:
raise ValueError("Mask should be in [0, 1] range")
# Binarize mask
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
# Image as float32
image = image.to(dtype=torch.float32)
elif isinstance(mask, torch.Tensor):
raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
# resize all images w.r.t passed height an width
image = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in image]
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
# preprocess mask
if isinstance(mask, (PIL.Image.Image, np.ndarray)):
mask = [mask]
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
mask = mask.astype(np.float32) / 255.0
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
mask = torch.from_numpy(mask)
masked_image = image * (mask < 0.5)
# n.b. ensure backwards compatibility as old function does not return image
if return_image:
return mask, masked_image, image
return mask, masked_image
class StableDiffusionControlNetInpaintPipeline(
DiffusionPipeline,
StableDiffusionMixin,
TextualInversionLoaderMixin,
LoraLoaderMixin,
IPAdapterMixin,
FromSingleFileMixin,
):
r"""
Pipeline for image inpainting using Stable Diffusion with ControlNet guidance.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
The pipeline also inherits the following loading methods:
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
<Tip>
This pipeline can be used with checkpoints that have been specifically fine-tuned for inpainting
([runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting)) as well as
default text-to-image Stable Diffusion checkpoints
([runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)). Default text-to-image
Stable Diffusion checkpoints might be preferable for ControlNets that have been fine-tuned on those, such as
[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint).
</Tip>
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
Provides additional conditioning to the `unet` during the denoising process. If you set multiple
ControlNets as a list, the outputs from each ControlNet are added together to create one combined
additional conditioning.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
"""
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
_exclude_from_cpu_offload = ["safety_checker"]
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
image_encoder: CLIPVisionModelWithProjection = None,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
if isinstance(controlnet, (list, tuple)):
controlnet = MultiControlNetModel(controlnet)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
controlnet=controlnet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
image_encoder=image_encoder,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.mask_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_normalize=False, do_binarize=True, do_convert_grayscale=True
)
self.control_image_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
**kwargs,
):
deprecation_message = "`_encode_prompt()` is deprecated and it will be removed in a future version. Use `encode_prompt()` instead. Also, be aware that the output format changed from a concatenated tensor to a tuple."
deprecate("_encode_prompt()", "1.0.0", deprecation_message, standard_warn=False)
prompt_embeds_tuple = self.encode_prompt(
prompt=prompt,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=lora_scale,
**kwargs,
)
# concatenate for backwards comp
prompt_embeds = torch.cat([prompt_embeds_tuple[1], prompt_embeds_tuple[0]])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_prompt
def encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
lora_scale (`float`, *optional*):
A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
if clip_skip is None:
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
prompt_embeds = prompt_embeds[0]
else:
prompt_embeds = self.text_encoder(
text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
)
# Access the `hidden_states` first, that contains a tuple of
# all the hidden states from the encoder layers. Then index into
# the tuple to access the hidden states from the desired layer.
prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
# We also need to apply the final LayerNorm here to not mess with the
# representations. The `last_hidden_states` that we typically use for
# obtaining the final prompt representations passes through the LayerNorm
# layer.
prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
if isinstance(self, LoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
return prompt_embeds, negative_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_image
def encode_image(self, image, device, num_images_per_prompt, output_hidden_states=None):
dtype = next(self.image_encoder.parameters()).dtype
if not isinstance(image, torch.Tensor):
image = self.feature_extractor(image, return_tensors="pt").pixel_values
image = image.to(device=device, dtype=dtype)
if output_hidden_states:
image_enc_hidden_states = self.image_encoder(image, output_hidden_states=True).hidden_states[-2]
image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
uncond_image_enc_hidden_states = self.image_encoder(
torch.zeros_like(image), output_hidden_states=True
).hidden_states[-2]
uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(
num_images_per_prompt, dim=0
)
return image_enc_hidden_states, uncond_image_enc_hidden_states
else:
image_embeds = self.image_encoder(image).image_embeds
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
uncond_image_embeds = torch.zeros_like(image_embeds)
return image_embeds, uncond_image_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_ip_adapter_image_embeds
def prepare_ip_adapter_image_embeds(
self, ip_adapter_image, ip_adapter_image_embeds, device, num_images_per_prompt, do_classifier_free_guidance
):
if ip_adapter_image_embeds is None:
if not isinstance(ip_adapter_image, list):
ip_adapter_image = [ip_adapter_image]
if len(ip_adapter_image) != len(self.unet.encoder_hid_proj.image_projection_layers):
raise ValueError(
f"`ip_adapter_image` must have same length as the number of IP Adapters. Got {len(ip_adapter_image)} images and {len(self.unet.encoder_hid_proj.image_projection_layers)} IP Adapters."
)
image_embeds = []
for single_ip_adapter_image, image_proj_layer in zip(
ip_adapter_image, self.unet.encoder_hid_proj.image_projection_layers
):
output_hidden_state = not isinstance(image_proj_layer, ImageProjection)
single_image_embeds, single_negative_image_embeds = self.encode_image(
single_ip_adapter_image, device, 1, output_hidden_state
)
single_image_embeds = torch.stack([single_image_embeds] * num_images_per_prompt, dim=0)
single_negative_image_embeds = torch.stack(
[single_negative_image_embeds] * num_images_per_prompt, dim=0
)
if do_classifier_free_guidance:
single_image_embeds = torch.cat([single_negative_image_embeds, single_image_embeds])
single_image_embeds = single_image_embeds.to(device)
image_embeds.append(single_image_embeds)
else:
repeat_dims = [1]
image_embeds = []
for single_image_embeds in ip_adapter_image_embeds:
if do_classifier_free_guidance:
single_negative_image_embeds, single_image_embeds = single_image_embeds.chunk(2)
single_image_embeds = single_image_embeds.repeat(
num_images_per_prompt, *(repeat_dims * len(single_image_embeds.shape[1:]))
)
single_negative_image_embeds = single_negative_image_embeds.repeat(
num_images_per_prompt, *(repeat_dims * len(single_negative_image_embeds.shape[1:]))
)
single_image_embeds = torch.cat([single_negative_image_embeds, single_image_embeds])
else:
single_image_embeds = single_image_embeds.repeat(
num_images_per_prompt, *(repeat_dims * len(single_image_embeds.shape[1:]))
)
image_embeds.append(single_image_embeds)
return image_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
deprecation_message = "The decode_latents method is deprecated and will be removed in 1.0.0. Please use VaeImageProcessor.postprocess(...) instead"
deprecate("decode_latents", "1.0.0", deprecation_message, standard_warn=False)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
if hasattr(self.scheduler, "set_begin_index"):
self.scheduler.set_begin_index(t_start * self.scheduler.order)
return timesteps, num_inference_steps - t_start
def check_inputs(
self,
prompt,
image,
mask_image,
height,
width,
callback_steps,
output_type,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
ip_adapter_image=None,
ip_adapter_image_embeds=None,
controlnet_conditioning_scale=1.0,
control_guidance_start=0.0,
control_guidance_end=1.0,
callback_on_step_end_tensor_inputs=None,
padding_mask_crop=None,
):
if height is not None and height % 8 != 0 or width is not None and width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if padding_mask_crop is not None:
if not isinstance(image, PIL.Image.Image):
raise ValueError(
f"The image should be a PIL image when inpainting mask crop, but is of type" f" {type(image)}."
)
if not isinstance(mask_image, PIL.Image.Image):
raise ValueError(
f"The mask image should be a PIL image when inpainting mask crop, but is of type"
f" {type(mask_image)}."
)
if output_type != "pil":
raise ValueError(f"The output type should be PIL when inpainting mask crop, but is" f" {output_type}.")
# `prompt` needs more sophisticated handling when there are multiple
# conditionings.
if isinstance(self.controlnet, MultiControlNetModel):
if isinstance(prompt, list):
logger.warning(
f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
" prompts. The conditionings will be fixed across the prompts."
)
# Check `image`
is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
self.controlnet, torch._dynamo.eval_frame.OptimizedModule
)
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
self.check_image(image, prompt, prompt_embeds)
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if not isinstance(image, list):
raise TypeError("For multiple controlnets: `image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(image) != len(self.controlnet.nets):
raise ValueError(
f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {len(self.controlnet.nets)} ControlNets."
)
for image_ in image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
self.controlnet.nets
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
if len(control_guidance_start) != len(control_guidance_end):
raise ValueError(
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
)
if isinstance(self.controlnet, MultiControlNetModel):
if len(control_guidance_start) != len(self.controlnet.nets):
raise ValueError(
f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
)
for start, end in zip(control_guidance_start, control_guidance_end):
if start >= end:
raise ValueError(
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
)
if start < 0.0:
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
if end > 1.0:
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
if ip_adapter_image is not None and ip_adapter_image_embeds is not None:
raise ValueError(
"Provide either `ip_adapter_image` or `ip_adapter_image_embeds`. Cannot leave both `ip_adapter_image` and `ip_adapter_image_embeds` defined."
)
if ip_adapter_image_embeds is not None:
if not isinstance(ip_adapter_image_embeds, list):
raise ValueError(
f"`ip_adapter_image_embeds` has to be of type `list` but is {type(ip_adapter_image_embeds)}"
)
elif ip_adapter_image_embeds[0].ndim not in [3, 4]:
raise ValueError(
f"`ip_adapter_image_embeds` has to be a list of 3D or 4D tensors but is {ip_adapter_image_embeds[0].ndim}D"
)
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
def check_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_np = isinstance(image, np.ndarray)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
if (
not image_is_pil
and not image_is_tensor
and not image_is_np
and not image_is_pil_list
and not image_is_tensor_list
and not image_is_np_list
):
raise TypeError(
f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
)
if image_is_pil:
image_batch_size = 1
else:
image_batch_size = len(image)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
def prepare_control_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
crops_coords,
resize_mode,
do_classifier_free_guidance=False,
guess_mode=False,
):
image = self.control_image_processor.preprocess(
image, height=height, width=width, crops_coords=crops_coords, resize_mode=resize_mode
).to(dtype=torch.float32)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline.prepare_latents
def prepare_latents(
self,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
generator,
latents=None,
image=None,
timestep=None,
is_strength_max=True,
return_noise=False,
return_image_latents=False,
):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if (image is None or timestep is None) and not is_strength_max:
raise ValueError(
"Since strength < 1. initial latents are to be initialised as a combination of Image + Noise."
"However, either the image or the noise timestep has not been provided."
)
if return_image_latents or (latents is None and not is_strength_max):
image = image.to(device=device, dtype=dtype)
if image.shape[1] == 4:
image_latents = image
else:
image_latents = self._encode_vae_image(image=image, generator=generator)
image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
if latents is None:
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# if strength is 1. then initialise the latents to noise, else initial to image + noise
latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep)
# if pure noise then scale the initial latents by the Scheduler's init sigma
latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents
else:
noise = latents.to(device)
latents = noise * self.scheduler.init_noise_sigma
outputs = (latents,)
if return_noise:
outputs += (noise,)
if return_image_latents:
outputs += (image_latents,)
return outputs
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline.prepare_mask_latents
def prepare_mask_latents(
self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
):
# resize the mask to latents shape as we concatenate the mask to the latents
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
# and half precision
mask = torch.nn.functional.interpolate(
mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
)
mask = mask.to(device=device, dtype=dtype)
masked_image = masked_image.to(device=device, dtype=dtype)
if masked_image.shape[1] == 4:
masked_image_latents = masked_image
else:
masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
if mask.shape[0] < batch_size:
if not batch_size % mask.shape[0] == 0:
raise ValueError(
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
" of masks that you pass is divisible by the total requested batch size."
)
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
if masked_image_latents.shape[0] < batch_size:
if not batch_size % masked_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
# aligning device to prevent device errors when concating it with the latent model input
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
return mask, masked_image_latents
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline._encode_vae_image
def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
if isinstance(generator, list):
image_latents = [
retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
for i in range(image.shape[0])
]
image_latents = torch.cat(image_latents, dim=0)
else:
image_latents = retrieve_latents(self.vae.encode(image), generator=generator)
image_latents = self.vae.config.scaling_factor * image_latents
return image_latents
@property
def guidance_scale(self):
return self._guidance_scale
@property
def clip_skip(self):
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
return self._guidance_scale > 1
@property
def cross_attention_kwargs(self):
return self._cross_attention_kwargs
@property
def num_timesteps(self):
return self._num_timesteps
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: PipelineImageInput = None,
mask_image: PipelineImageInput = None,
control_image: PipelineImageInput = None,
height: Optional[int] = None,
width: Optional[int] = None,
padding_mask_crop: Optional[int] = None,
strength: float = 1.0,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
ip_adapter_image: Optional[PipelineImageInput] = None,
ip_adapter_image_embeds: Optional[List[torch.FloatTensor]] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 0.5,
guess_mode: bool = False,
control_guidance_start: Union[float, List[float]] = 0.0,
control_guidance_end: Union[float, List[float]] = 1.0,
clip_skip: Optional[int] = None,
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
**kwargs,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`,
`List[PIL.Image.Image]`, or `List[np.ndarray]`):
`Image`, NumPy array or tensor representing an image batch to be used as the starting point. For both
NumPy array and PyTorch tensor, the expected value range is between `[0, 1]`. If it's a tensor or a
list or tensors, the expected shape should be `(B, C, H, W)` or `(C, H, W)`. If it is a NumPy array or
a list of arrays, the expected shape should be `(B, H, W, C)` or `(H, W, C)`. It can also accept image
latents as `image`, but if passing latents directly it is not encoded again.
mask_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`,
`List[PIL.Image.Image]`, or `List[np.ndarray]`):
`Image`, NumPy array or tensor representing an image batch to mask `image`. White pixels in the mask
are repainted while black pixels are preserved. If `mask_image` is a PIL image, it is converted to a
single channel (luminance) before use. If it's a NumPy array or PyTorch tensor, it should contain one
color channel (L) instead of 3, so the expected shape for PyTorch tensor would be `(B, 1, H, W)`, `(B,
H, W)`, `(1, H, W)`, `(H, W)`. And for NumPy array, it would be for `(B, H, W, 1)`, `(B, H, W)`, `(H,
W, 1)`, or `(H, W)`.
control_image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
`List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
`init`, images must be passed as a list such that each element of the list can be correctly batched for
input to a single ControlNet.
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image.
padding_mask_crop (`int`, *optional*, defaults to `None`):
The size of margin in the crop to be applied to the image and masking. If `None`, no crop is applied to image and mask_image. If
`padding_mask_crop` is not `None`, it will first find a rectangular region with the same aspect ration of the image and
contains all masked area, and then expand that area based on `padding_mask_crop`. The image and mask_image will then be cropped based on
the expanded area before resizing to the original image size for inpainting. This is useful when the masked area is small while the image is large
and contain information irrelevant for inpainting, such as background.
strength (`float`, *optional*, defaults to 1.0):
Indicates extent to transform the reference `image`. Must be between 0 and 1. `image` is used as a
starting point and more noise is added the higher the `strength`. The number of denoising steps depends
on the amount of noise initially added. When `strength` is 1, added noise is maximum and the denoising
process runs for the full number of iterations specified in `num_inference_steps`. A value of 1
essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
ip_adapter_image: (`PipelineImageInput`, *optional*): Optional image input to work with IP Adapters.
ip_adapter_image_embeds (`List[torch.FloatTensor]`, *optional*):
Pre-generated image embeddings for IP-Adapter. It should be a list of length same as number of IP-adapters.
Each element should be a tensor of shape `(batch_size, num_images, emb_dim)`. It should contain the negative image embedding
if `do_classifier_free_guidance` is set to `True`.
If not provided, embeddings are computed from the `ip_adapter_image` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 0.5):
The outputs of the ControlNet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original `unet`. If multiple ControlNets are specified in `init`, you can set
the corresponding scale as a list.
guess_mode (`bool`, *optional*, defaults to `False`):
The ControlNet encoder tries to recognize the content of the input image even if you remove all
prompts. A `guidance_scale` value between 3.0 and 5.0 is recommended.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the ControlNet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
The percentage of total steps at which the ControlNet stops applying.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
callback_on_step_end (`Callable`, *optional*):
A function that calls at the end of each denoising steps during the inference. The function is called
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
`callback_on_step_end_tensor_inputs`.
callback_on_step_end_tensor_inputs (`List`, *optional*):
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
`._callback_tensor_inputs` attribute of your pipeine class.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
callback = kwargs.pop("callback", None)
callback_steps = kwargs.pop("callback_steps", None)
if callback is not None:
deprecate(
"callback",
"1.0.0",
"Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
)
if callback_steps is not None:
deprecate(
"callback_steps",
"1.0.0",
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
)
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
# align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
control_image,
mask_image,
height,
width,
callback_steps,
output_type,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
ip_adapter_image,
ip_adapter_image_embeds,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
callback_on_step_end_tensor_inputs,
padding_mask_crop,
)
self._guidance_scale = guidance_scale
self._clip_skip = clip_skip
self._cross_attention_kwargs = cross_attention_kwargs
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if padding_mask_crop is not None:
height, width = self.image_processor.get_default_height_width(image, height, width)
crops_coords = self.mask_processor.get_crop_region(mask_image, width, height, pad=padding_mask_crop)
resize_mode = "fill"
else:
crops_coords = None
resize_mode = "default"
device = self._execution_device
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
global_pool_conditions = (
controlnet.config.global_pool_conditions
if isinstance(controlnet, ControlNetModel)
else controlnet.nets[0].config.global_pool_conditions
)
guess_mode = guess_mode or global_pool_conditions
# 3. Encode input prompt
text_encoder_lora_scale = (
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
)
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
prompt,
device,
num_images_per_prompt,
self.do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
clip_skip=self.clip_skip,
)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if self.do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
if ip_adapter_image is not None or ip_adapter_image_embeds is not None:
image_embeds = self.prepare_ip_adapter_image_embeds(
ip_adapter_image,
ip_adapter_image_embeds,
device,
batch_size * num_images_per_prompt,
self.do_classifier_free_guidance,
)
# 4. Prepare image
if isinstance(controlnet, ControlNetModel):
control_image = self.prepare_control_image(
image=control_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
crops_coords=crops_coords,
resize_mode=resize_mode,
do_classifier_free_guidance=self.do_classifier_free_guidance,
guess_mode=guess_mode,
)
elif isinstance(controlnet, MultiControlNetModel):
control_images = []
for control_image_ in control_image:
control_image_ = self.prepare_control_image(
image=control_image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
crops_coords=crops_coords,
resize_mode=resize_mode,
do_classifier_free_guidance=self.do_classifier_free_guidance,
guess_mode=guess_mode,
)
control_images.append(control_image_)
control_image = control_images
else:
assert False
# 4.1 Preprocess mask and image - resizes image and mask w.r.t height and width
original_image = image
init_image = self.image_processor.preprocess(
image, height=height, width=width, crops_coords=crops_coords, resize_mode=resize_mode
)
init_image = init_image.to(dtype=torch.float32)
mask = self.mask_processor.preprocess(
mask_image, height=height, width=width, resize_mode=resize_mode, crops_coords=crops_coords
)
masked_image = init_image * (mask < 0.5)
_, _, height, width = init_image.shape
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(
num_inference_steps=num_inference_steps, strength=strength, device=device
)
# at which timestep to set the initial noise (n.b. 50% if strength is 0.5)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# create a boolean to check if the strength is set to 1. if so then initialise the latents with pure noise
is_strength_max = strength == 1.0
self._num_timesteps = len(timesteps)
# 6. Prepare latent variables
num_channels_latents = self.vae.config.latent_channels
num_channels_unet = self.unet.config.in_channels
return_image_latents = num_channels_unet == 4
latents_outputs = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
image=init_image,
timestep=latent_timestep,
is_strength_max=is_strength_max,
return_noise=True,
return_image_latents=return_image_latents,
)
if return_image_latents:
latents, noise, image_latents = latents_outputs
else:
latents, noise = latents_outputs
# 7. Prepare mask latent variables
mask, masked_image_latents = self.prepare_mask_latents(
mask,
masked_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
generator,
self.do_classifier_free_guidance,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7.1 Add image embeds for IP-Adapter
added_cond_kwargs = (
{"image_embeds": image_embeds}
if ip_adapter_image is not None or ip_adapter_image_embeds is not None
else None
)
# 7.2 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# controlnet(s) inference
if guess_mode and self.do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=control_image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
return_dict=False,
)
if guess_mode and self.do_classifier_free_guidance:
# Infered ControlNet only for the conditional batch.
# To apply the output of ControlNet to both the unconditional and conditional batches,
# add 0 to the unconditional batch to keep it unchanged.
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
# predict the noise residual
if num_channels_unet == 9:
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=self.cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
# perform guidance
if self.do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
if num_channels_unet == 4:
init_latents_proper = image_latents
if self.do_classifier_free_guidance:
init_mask, _ = mask.chunk(2)
else:
init_mask = mask
if i < len(timesteps) - 1:
noise_timestep = timesteps[i + 1]
init_latents_proper = self.scheduler.add_noise(
init_latents_proper, noise, torch.tensor([noise_timestep])
)
latents = (1 - init_mask) * init_latents_proper + init_mask * latents
if callback_on_step_end is not None:
callback_kwargs = {}
for k in callback_on_step_end_tensor_inputs:
callback_kwargs[k] = locals()[k]
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
latents = callback_outputs.pop("latents", latents)
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# If we do sequential model offloading, let's offload unet and controlnet
# manually for max memory savings
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.unet.to("cpu")
self.controlnet.to("cpu")
torch.cuda.empty_cache()
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False, generator=generator)[
0
]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
if padding_mask_crop is not None:
image = [self.image_processor.apply_overlay(mask_image, original_image, i, crops_coords) for i in image]
# Offload all models
self.maybe_free_model_hooks()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
diffusers/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py",
"repo_id": "diffusers",
"token_count": 36079
}
| 125 |
from typing import TYPE_CHECKING
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
_import_structure = {"pipeline_latent_diffusion_uncond": ["LDMPipeline"]}
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .pipeline_latent_diffusion_uncond import LDMPipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
__name__,
globals()["__file__"],
_import_structure,
module_spec=__spec__,
)
|
diffusers/src/diffusers/pipelines/deprecated/latent_diffusion_uncond/__init__.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/deprecated/latent_diffusion_uncond/__init__.py",
"repo_id": "diffusers",
"token_count": 190
}
| 126 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from packaging import version
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from ....configuration_utils import FrozenDict
from ....image_processor import VaeImageProcessor
from ....loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
from ....models import AutoencoderKL, UNet2DConditionModel
from ....models.lora import adjust_lora_scale_text_encoder
from ....schedulers import KarrasDiffusionSchedulers
from ....utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
from ....utils.torch_utils import randn_tensor
from ...pipeline_utils import DiffusionPipeline
from ...stable_diffusion import StableDiffusionPipelineOutput
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
logger = logging.get_logger(__name__)
def preprocess_image(image, batch_size):
w, h = image.size
w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
image = np.array(image).astype(np.float32) / 255.0
image = np.vstack([image[None].transpose(0, 3, 1, 2)] * batch_size)
image = torch.from_numpy(image)
return 2.0 * image - 1.0
def preprocess_mask(mask, batch_size, scale_factor=8):
if not isinstance(mask, torch.FloatTensor):
mask = mask.convert("L")
w, h = mask.size
w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
mask = mask.resize((w // scale_factor, h // scale_factor), resample=PIL_INTERPOLATION["nearest"])
mask = np.array(mask).astype(np.float32) / 255.0
mask = np.tile(mask, (4, 1, 1))
mask = np.vstack([mask[None]] * batch_size)
mask = 1 - mask # repaint white, keep black
mask = torch.from_numpy(mask)
return mask
else:
valid_mask_channel_sizes = [1, 3]
# if mask channel is fourth tensor dimension, permute dimensions to pytorch standard (B, C, H, W)
if mask.shape[3] in valid_mask_channel_sizes:
mask = mask.permute(0, 3, 1, 2)
elif mask.shape[1] not in valid_mask_channel_sizes:
raise ValueError(
f"Mask channel dimension of size in {valid_mask_channel_sizes} should be second or fourth dimension,"
f" but received mask of shape {tuple(mask.shape)}"
)
# (potentially) reduce mask channel dimension from 3 to 1 for broadcasting to latent shape
mask = mask.mean(dim=1, keepdim=True)
h, w = mask.shape[-2:]
h, w = (x - x % 8 for x in (h, w)) # resize to integer multiple of 8
mask = torch.nn.functional.interpolate(mask, (h // scale_factor, w // scale_factor))
return mask
class StableDiffusionInpaintPipelineLegacy(
DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
):
r"""
Pipeline for text-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
- *LoRA*: [`loaders.LoraLoaderMixin.load_lora_weights`]
- *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
as well as the following saving methods:
- *LoRA*: [`loaders.LoraLoaderMixin.save_lora_weights`]
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
model_cpu_offload_seq = "text_encoder->unet->vae"
_optional_components = ["feature_extractor"]
_exclude_from_cpu_offload = ["safety_checker"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
deprecation_message = (
f"The class {self.__class__} is deprecated and will be removed in v1.0.0. You can achieve exactly the same functionality"
"by loading your model into `StableDiffusionInpaintPipeline` instead. See https://github.com/huggingface/diffusers/pull/3533"
"for more information."
)
deprecate("legacy is outdated", "1.0.0", deprecation_message, standard_warn=False)
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
" `clip_sample` should be set to False in the configuration file. Please make sure to update the"
" config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
" future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
" nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
)
deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["clip_sample"] = False
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
**kwargs,
):
deprecation_message = "`_encode_prompt()` is deprecated and it will be removed in a future version. Use `encode_prompt()` instead. Also, be aware that the output format changed from a concatenated tensor to a tuple."
deprecate("_encode_prompt()", "1.0.0", deprecation_message, standard_warn=False)
prompt_embeds_tuple = self.encode_prompt(
prompt=prompt,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=lora_scale,
**kwargs,
)
# concatenate for backwards comp
prompt_embeds = torch.cat([prompt_embeds_tuple[1], prompt_embeds_tuple[0]])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_prompt
def encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
lora_scale (`float`, *optional*):
A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
if clip_skip is None:
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
prompt_embeds = prompt_embeds[0]
else:
prompt_embeds = self.text_encoder(
text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
)
# Access the `hidden_states` first, that contains a tuple of
# all the hidden states from the encoder layers. Then index into
# the tuple to access the hidden states from the desired layer.
prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
# We also need to apply the final LayerNorm here to not mess with the
# representations. The `last_hidden_states` that we typically use for
# obtaining the final prompt representations passes through the LayerNorm
# layer.
prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
if isinstance(self, LoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
return prompt_embeds, negative_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
deprecation_message = "The decode_latents method is deprecated and will be removed in 1.0.0. Please use VaeImageProcessor.postprocess(...) instead"
deprecate("decode_latents", "1.0.0", deprecation_message, standard_warn=False)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
prompt,
strength,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
callback_on_step_end_tensor_inputs=None,
):
if strength < 0 or strength > 1:
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, num_images_per_prompt, dtype, device, generator):
image = image.to(device=device, dtype=dtype)
init_latent_dist = self.vae.encode(image).latent_dist
init_latents = init_latent_dist.sample(generator=generator)
init_latents = self.vae.config.scaling_factor * init_latents
# Expand init_latents for batch_size and num_images_per_prompt
init_latents = torch.cat([init_latents] * num_images_per_prompt, dim=0)
init_latents_orig = init_latents
# add noise to latents using the timesteps
noise = randn_tensor(init_latents.shape, generator=generator, device=device, dtype=dtype)
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents, init_latents_orig, noise
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
mask_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
add_predicted_noise: Optional[bool] = False,
eta: Optional[float] = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
clip_skip: Optional[int] = None,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.FloatTensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process. This is the image whose masked region will be inpainted.
mask_image (`torch.FloatTensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
PIL image, it will be converted to a single channel (luminance) before use. If mask is a tensor, the
expected shape should be either `(B, H, W, C)` or `(B, C, H, W)`, where C is 1 or 3.
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to inpaint the masked area. Must be between 0 and 1. When `strength`
is 1, the denoising process will be run on the masked area for the full number of iterations specified
in `num_inference_steps`. `image` will be used as a reference for the masked area, adding more noise to
that region the larger the `strength`. If `strength` is 0, no inpainting will occur.
num_inference_steps (`int`, *optional*, defaults to 50):
The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
add_predicted_noise (`bool`, *optional*, defaults to True):
Use predicted noise instead of random noise when constructing noisy versions of the original image in
the reverse diffusion process
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 1. Check inputs
self.check_inputs(prompt, strength, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
clip_skip=clip_skip,
)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
# 4. Preprocess image and mask
if not isinstance(image, torch.FloatTensor):
image = preprocess_image(image, batch_size)
mask_image = preprocess_mask(mask_image, batch_size, self.vae_scale_factor)
# 5. set timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
# encode the init image into latents and scale the latents
latents, init_latents_orig, noise = self.prepare_latents(
image, latent_timestep, num_images_per_prompt, prompt_embeds.dtype, device, generator
)
# 7. Prepare mask latent
mask = mask_image.to(device=device, dtype=latents.dtype)
mask = torch.cat([mask] * num_images_per_prompt)
# 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 9. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# masking
if add_predicted_noise:
init_latents_proper = self.scheduler.add_noise(
init_latents_orig, noise_pred_uncond, torch.tensor([t])
)
else:
init_latents_proper = self.scheduler.add_noise(init_latents_orig, noise, torch.tensor([t]))
latents = (init_latents_proper * mask) + (latents * (1 - mask))
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# use original latents corresponding to unmasked portions of the image
latents = (init_latents_orig * mask) + (latents * (1 - mask))
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# Offload all models
self.maybe_free_model_hooks()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
diffusers/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_inpaint_legacy.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_inpaint_legacy.py",
"repo_id": "diffusers",
"token_count": 18115
}
| 127 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
from typing import Tuple, Union
import torch
import torch.fft as fft
from ..utils.torch_utils import randn_tensor
class FreeInitMixin:
r"""Mixin class for FreeInit."""
def enable_free_init(
self,
num_iters: int = 3,
use_fast_sampling: bool = False,
method: str = "butterworth",
order: int = 4,
spatial_stop_frequency: float = 0.25,
temporal_stop_frequency: float = 0.25,
):
"""Enables the FreeInit mechanism as in https://arxiv.org/abs/2312.07537.
This implementation has been adapted from the [official repository](https://github.com/TianxingWu/FreeInit).
Args:
num_iters (`int`, *optional*, defaults to `3`):
Number of FreeInit noise re-initialization iterations.
use_fast_sampling (`bool`, *optional*, defaults to `False`):
Whether or not to speedup sampling procedure at the cost of probably lower quality results. Enables
the "Coarse-to-Fine Sampling" strategy, as mentioned in the paper, if set to `True`.
method (`str`, *optional*, defaults to `butterworth`):
Must be one of `butterworth`, `ideal` or `gaussian` to use as the filtering method for the
FreeInit low pass filter.
order (`int`, *optional*, defaults to `4`):
Order of the filter used in `butterworth` method. Larger values lead to `ideal` method behaviour
whereas lower values lead to `gaussian` method behaviour.
spatial_stop_frequency (`float`, *optional*, defaults to `0.25`):
Normalized stop frequency for spatial dimensions. Must be between 0 to 1. Referred to as `d_s` in
the original implementation.
temporal_stop_frequency (`float`, *optional*, defaults to `0.25`):
Normalized stop frequency for temporal dimensions. Must be between 0 to 1. Referred to as `d_t` in
the original implementation.
"""
self._free_init_num_iters = num_iters
self._free_init_use_fast_sampling = use_fast_sampling
self._free_init_method = method
self._free_init_order = order
self._free_init_spatial_stop_frequency = spatial_stop_frequency
self._free_init_temporal_stop_frequency = temporal_stop_frequency
def disable_free_init(self):
"""Disables the FreeInit mechanism if enabled."""
self._free_init_num_iters = None
@property
def free_init_enabled(self):
return hasattr(self, "_free_init_num_iters") and self._free_init_num_iters is not None
def _get_free_init_freq_filter(
self,
shape: Tuple[int, ...],
device: Union[str, torch.dtype],
filter_type: str,
order: float,
spatial_stop_frequency: float,
temporal_stop_frequency: float,
) -> torch.Tensor:
r"""Returns the FreeInit filter based on filter type and other input conditions."""
time, height, width = shape[-3], shape[-2], shape[-1]
mask = torch.zeros(shape)
if spatial_stop_frequency == 0 or temporal_stop_frequency == 0:
return mask
if filter_type == "butterworth":
def retrieve_mask(x):
return 1 / (1 + (x / spatial_stop_frequency**2) ** order)
elif filter_type == "gaussian":
def retrieve_mask(x):
return math.exp(-1 / (2 * spatial_stop_frequency**2) * x)
elif filter_type == "ideal":
def retrieve_mask(x):
return 1 if x <= spatial_stop_frequency * 2 else 0
else:
raise NotImplementedError("`filter_type` must be one of gaussian, butterworth or ideal")
for t in range(time):
for h in range(height):
for w in range(width):
d_square = (
((spatial_stop_frequency / temporal_stop_frequency) * (2 * t / time - 1)) ** 2
+ (2 * h / height - 1) ** 2
+ (2 * w / width - 1) ** 2
)
mask[..., t, h, w] = retrieve_mask(d_square)
return mask.to(device)
def _apply_freq_filter(self, x: torch.Tensor, noise: torch.Tensor, low_pass_filter: torch.Tensor) -> torch.Tensor:
r"""Noise reinitialization."""
# FFT
x_freq = fft.fftn(x, dim=(-3, -2, -1))
x_freq = fft.fftshift(x_freq, dim=(-3, -2, -1))
noise_freq = fft.fftn(noise, dim=(-3, -2, -1))
noise_freq = fft.fftshift(noise_freq, dim=(-3, -2, -1))
# frequency mix
high_pass_filter = 1 - low_pass_filter
x_freq_low = x_freq * low_pass_filter
noise_freq_high = noise_freq * high_pass_filter
x_freq_mixed = x_freq_low + noise_freq_high # mix in freq domain
# IFFT
x_freq_mixed = fft.ifftshift(x_freq_mixed, dim=(-3, -2, -1))
x_mixed = fft.ifftn(x_freq_mixed, dim=(-3, -2, -1)).real
return x_mixed
def _apply_free_init(
self,
latents: torch.Tensor,
free_init_iteration: int,
num_inference_steps: int,
device: torch.device,
dtype: torch.dtype,
generator: torch.Generator,
):
if free_init_iteration == 0:
self._free_init_initial_noise = latents.detach().clone()
return latents, self.scheduler.timesteps
latent_shape = latents.shape
free_init_filter_shape = (1, *latent_shape[1:])
free_init_freq_filter = self._get_free_init_freq_filter(
shape=free_init_filter_shape,
device=device,
filter_type=self._free_init_method,
order=self._free_init_order,
spatial_stop_frequency=self._free_init_spatial_stop_frequency,
temporal_stop_frequency=self._free_init_temporal_stop_frequency,
)
current_diffuse_timestep = self.scheduler.config.num_train_timesteps - 1
diffuse_timesteps = torch.full((latent_shape[0],), current_diffuse_timestep).long()
z_t = self.scheduler.add_noise(
original_samples=latents, noise=self._free_init_initial_noise, timesteps=diffuse_timesteps.to(device)
).to(dtype=torch.float32)
z_rand = randn_tensor(
shape=latent_shape,
generator=generator,
device=device,
dtype=torch.float32,
)
latents = self._apply_freq_filter(z_t, z_rand, low_pass_filter=free_init_freq_filter)
latents = latents.to(dtype)
# Coarse-to-Fine Sampling for faster inference (can lead to lower quality)
if self._free_init_use_fast_sampling:
num_inference_steps = int(num_inference_steps / self._free_init_num_iters * (free_init_iteration + 1))
self.scheduler.set_timesteps(num_inference_steps, device=device)
return latents, self.scheduler.timesteps
|
diffusers/src/diffusers/pipelines/free_init_utils.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/free_init_utils.py",
"repo_id": "diffusers",
"token_count": 3339
}
| 128 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from copy import deepcopy
from typing import Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
import torch.nn.functional as F
from packaging import version
from PIL import Image
from ... import __version__
from ...models import UNet2DConditionModel, VQModel
from ...schedulers import DDPMScheduler
from ...utils import deprecate, logging
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> from diffusers import KandinskyV22InpaintPipeline, KandinskyV22PriorPipeline
>>> from diffusers.utils import load_image
>>> import torch
>>> import numpy as np
>>> pipe_prior = KandinskyV22PriorPipeline.from_pretrained(
... "kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16
... )
>>> pipe_prior.to("cuda")
>>> prompt = "a hat"
>>> image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False)
>>> pipe = KandinskyV22InpaintPipeline.from_pretrained(
... "kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16
... )
>>> pipe.to("cuda")
>>> init_image = load_image(
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
... "/kandinsky/cat.png"
... )
>>> mask = np.zeros((768, 768), dtype=np.float32)
>>> mask[:250, 250:-250] = 1
>>> out = pipe(
... image=init_image,
... mask_image=mask,
... image_embeds=image_emb,
... negative_image_embeds=zero_image_emb,
... height=768,
... width=768,
... num_inference_steps=50,
... )
>>> image = out.images[0]
>>> image.save("cat_with_hat.png")
```
"""
# Copied from diffusers.pipelines.kandinsky2_2.pipeline_kandinsky2_2.downscale_height_and_width
def downscale_height_and_width(height, width, scale_factor=8):
new_height = height // scale_factor**2
if height % scale_factor**2 != 0:
new_height += 1
new_width = width // scale_factor**2
if width % scale_factor**2 != 0:
new_width += 1
return new_height * scale_factor, new_width * scale_factor
# Copied from diffusers.pipelines.kandinsky.pipeline_kandinsky_inpaint.prepare_mask
def prepare_mask(masks):
prepared_masks = []
for mask in masks:
old_mask = deepcopy(mask)
for i in range(mask.shape[1]):
for j in range(mask.shape[2]):
if old_mask[0][i][j] == 1:
continue
if i != 0:
mask[:, i - 1, j] = 0
if j != 0:
mask[:, i, j - 1] = 0
if i != 0 and j != 0:
mask[:, i - 1, j - 1] = 0
if i != mask.shape[1] - 1:
mask[:, i + 1, j] = 0
if j != mask.shape[2] - 1:
mask[:, i, j + 1] = 0
if i != mask.shape[1] - 1 and j != mask.shape[2] - 1:
mask[:, i + 1, j + 1] = 0
prepared_masks.append(mask)
return torch.stack(prepared_masks, dim=0)
# Copied from diffusers.pipelines.kandinsky.pipeline_kandinsky_inpaint.prepare_mask_and_masked_image
def prepare_mask_and_masked_image(image, mask, height, width):
r"""
Prepares a pair (mask, image) to be consumed by the Kandinsky inpaint pipeline. This means that those inputs will
be converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for
the ``image`` and ``1`` for the ``mask``.
The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
Args:
image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
Raises:
ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
(ot the other way around).
Returns:
tuple[torch.Tensor]: The pair (mask, image) as ``torch.Tensor`` with 4
dimensions: ``batch x channels x height x width``.
"""
if image is None:
raise ValueError("`image` input cannot be undefined.")
if mask is None:
raise ValueError("`mask_image` input cannot be undefined.")
if isinstance(image, torch.Tensor):
if not isinstance(mask, torch.Tensor):
raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
# Batch single image
if image.ndim == 3:
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
image = image.unsqueeze(0)
# Batch and add channel dim for single mask
if mask.ndim == 2:
mask = mask.unsqueeze(0).unsqueeze(0)
# Batch single mask or add channel dim
if mask.ndim == 3:
# Single batched mask, no channel dim or single mask not batched but channel dim
if mask.shape[0] == 1:
mask = mask.unsqueeze(0)
# Batched masks no channel dim
else:
mask = mask.unsqueeze(1)
assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
# Check image is in [-1, 1]
if image.min() < -1 or image.max() > 1:
raise ValueError("Image should be in [-1, 1] range")
# Check mask is in [0, 1]
if mask.min() < 0 or mask.max() > 1:
raise ValueError("Mask should be in [0, 1] range")
# Binarize mask
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
# Image as float32
image = image.to(dtype=torch.float32)
elif isinstance(mask, torch.Tensor):
raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
# resize all images w.r.t passed height an width
image = [i.resize((width, height), resample=Image.BICUBIC, reducing_gap=1) for i in image]
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
# preprocess mask
if isinstance(mask, (PIL.Image.Image, np.ndarray)):
mask = [mask]
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
mask = mask.astype(np.float32) / 255.0
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
mask = torch.from_numpy(mask)
mask = 1 - mask
return mask, image
class KandinskyV22InpaintPipeline(DiffusionPipeline):
"""
Pipeline for text-guided image inpainting using Kandinsky2.1
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
scheduler ([`DDIMScheduler`]):
A scheduler to be used in combination with `unet` to generate image latents.
unet ([`UNet2DConditionModel`]):
Conditional U-Net architecture to denoise the image embedding.
movq ([`VQModel`]):
MoVQ Decoder to generate the image from the latents.
"""
model_cpu_offload_seq = "unet->movq"
_callback_tensor_inputs = ["latents", "image_embeds", "negative_image_embeds", "masked_image", "mask_image"]
def __init__(
self,
unet: UNet2DConditionModel,
scheduler: DDPMScheduler,
movq: VQModel,
):
super().__init__()
self.register_modules(
unet=unet,
scheduler=scheduler,
movq=movq,
)
self.movq_scale_factor = 2 ** (len(self.movq.config.block_out_channels) - 1)
self._warn_has_been_called = False
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.prepare_latents
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
latents = latents * scheduler.init_noise_sigma
return latents
@property
def guidance_scale(self):
return self._guidance_scale
@property
def do_classifier_free_guidance(self):
return self._guidance_scale > 1
@property
def num_timesteps(self):
return self._num_timesteps
@torch.no_grad()
def __call__(
self,
image_embeds: Union[torch.FloatTensor, List[torch.FloatTensor]],
image: Union[torch.FloatTensor, PIL.Image.Image],
mask_image: Union[torch.FloatTensor, PIL.Image.Image, np.ndarray],
negative_image_embeds: Union[torch.FloatTensor, List[torch.FloatTensor]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 100,
guidance_scale: float = 4.0,
num_images_per_prompt: int = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
**kwargs,
):
"""
Function invoked when calling the pipeline for generation.
Args:
image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
The clip image embeddings for text prompt, that will be used to condition the image generation.
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
mask_image (`np.array`):
Tensor representing an image batch, to mask `image`. White pixels in the mask will be repainted, while
black pixels will be preserved. If `mask_image` is a PIL image, it will be converted to a single
channel (luminance) before use. If it's a tensor, it should contain one color channel (L) instead of 3,
so the expected shape would be `(B, H, W, 1)`.
negative_image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
The clip image embeddings for negative text prompt, will be used to condition the image generation.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
(`np.array`) or `"pt"` (`torch.Tensor`).
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
callback_on_step_end (`Callable`, *optional*):
A function that calls at the end of each denoising steps during the inference. The function is called
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
`callback_on_step_end_tensor_inputs`.
callback_on_step_end_tensor_inputs (`List`, *optional*):
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
`._callback_tensor_inputs` attribute of your pipeline class.
Examples:
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`
"""
if not self._warn_has_been_called and version.parse(version.parse(__version__).base_version) < version.parse(
"0.23.0.dev0"
):
logger.warning(
"Please note that the expected format of `mask_image` has recently been changed. "
"Before diffusers == 0.19.0, Kandinsky Inpainting pipelines repainted black pixels and preserved black pixels. "
"As of diffusers==0.19.0 this behavior has been inverted. Now white pixels are repainted and black pixels are preserved. "
"This way, Kandinsky's masking behavior is aligned with Stable Diffusion. "
"THIS means that you HAVE to invert the input mask to have the same behavior as before as explained in https://github.com/huggingface/diffusers/pull/4207. "
"This warning will be surpressed after the first inference call and will be removed in diffusers>0.23.0"
)
self._warn_has_been_called = True
callback = kwargs.pop("callback", None)
callback_steps = kwargs.pop("callback_steps", None)
if callback is not None:
deprecate(
"callback",
"1.0.0",
"Passing `callback` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
)
if callback_steps is not None:
deprecate(
"callback_steps",
"1.0.0",
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
self._guidance_scale = guidance_scale
device = self._execution_device
if isinstance(image_embeds, list):
image_embeds = torch.cat(image_embeds, dim=0)
batch_size = image_embeds.shape[0] * num_images_per_prompt
if isinstance(negative_image_embeds, list):
negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
if self.do_classifier_free_guidance:
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
negative_image_embeds = negative_image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
image_embeds = torch.cat([negative_image_embeds, image_embeds], dim=0).to(
dtype=self.unet.dtype, device=device
)
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# preprocess image and mask
mask_image, image = prepare_mask_and_masked_image(image, mask_image, height, width)
image = image.to(dtype=image_embeds.dtype, device=device)
image = self.movq.encode(image)["latents"]
mask_image = mask_image.to(dtype=image_embeds.dtype, device=device)
image_shape = tuple(image.shape[-2:])
mask_image = F.interpolate(
mask_image,
image_shape,
mode="nearest",
)
mask_image = prepare_mask(mask_image)
masked_image = image * mask_image
mask_image = mask_image.repeat_interleave(num_images_per_prompt, dim=0)
masked_image = masked_image.repeat_interleave(num_images_per_prompt, dim=0)
if self.do_classifier_free_guidance:
mask_image = mask_image.repeat(2, 1, 1, 1)
masked_image = masked_image.repeat(2, 1, 1, 1)
num_channels_latents = self.movq.config.latent_channels
height, width = downscale_height_and_width(height, width, self.movq_scale_factor)
# create initial latent
latents = self.prepare_latents(
(batch_size, num_channels_latents, height, width),
image_embeds.dtype,
device,
generator,
latents,
self.scheduler,
)
noise = torch.clone(latents)
self._num_timesteps = len(timesteps)
for i, t in enumerate(self.progress_bar(timesteps)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
latent_model_input = torch.cat([latent_model_input, masked_image, mask_image], dim=1)
added_cond_kwargs = {"image_embeds": image_embeds}
noise_pred = self.unet(
sample=latent_model_input,
timestep=t,
encoder_hidden_states=None,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
if self.do_classifier_free_guidance:
noise_pred, variance_pred = noise_pred.split(latents.shape[1], dim=1)
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
_, variance_pred_text = variance_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
noise_pred = torch.cat([noise_pred, variance_pred_text], dim=1)
if not (
hasattr(self.scheduler.config, "variance_type")
and self.scheduler.config.variance_type in ["learned", "learned_range"]
):
noise_pred, _ = noise_pred.split(latents.shape[1], dim=1)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
noise_pred,
t,
latents,
generator=generator,
)[0]
init_latents_proper = image[:1]
init_mask = mask_image[:1]
if i < len(timesteps) - 1:
noise_timestep = timesteps[i + 1]
init_latents_proper = self.scheduler.add_noise(
init_latents_proper, noise, torch.tensor([noise_timestep])
)
latents = init_mask * init_latents_proper + (1 - init_mask) * latents
if callback_on_step_end is not None:
callback_kwargs = {}
for k in callback_on_step_end_tensor_inputs:
callback_kwargs[k] = locals()[k]
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
latents = callback_outputs.pop("latents", latents)
image_embeds = callback_outputs.pop("image_embeds", image_embeds)
negative_image_embeds = callback_outputs.pop("negative_image_embeds", negative_image_embeds)
masked_image = callback_outputs.pop("masked_image", masked_image)
mask_image = callback_outputs.pop("mask_image", mask_image)
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# post-processing
latents = mask_image[:1] * image[:1] + (1 - mask_image[:1]) * latents
if output_type not in ["pt", "np", "pil", "latent"]:
raise ValueError(
f"Only the output types `pt`, `pil`, `np` and `latent` are supported not output_type={output_type}"
)
if not output_type == "latent":
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
if output_type in ["np", "pil"]:
image = image * 0.5 + 0.5
image = image.clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
else:
image = latents
# Offload all models
self.maybe_free_model_hooks()
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
|
diffusers/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_inpainting.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_inpainting.py",
"repo_id": "diffusers",
"token_count": 11058
}
| 129 |
from dataclasses import dataclass
from typing import List, Optional, Union
import numpy as np
import PIL.Image
from ...utils import BaseOutput
@dataclass
class LEditsPPDiffusionPipelineOutput(BaseOutput):
"""
Output class for LEdits++ Diffusion pipelines.
Args:
images (`List[PIL.Image.Image]` or `np.ndarray`)
List of denoised PIL images of length `batch_size` or NumPy array of shape `(batch_size, height, width,
num_channels)`.
nsfw_content_detected (`List[bool]`)
List indicating whether the corresponding generated image contains “not-safe-for-work” (nsfw) content or
`None` if safety checking could not be performed.
"""
images: Union[List[PIL.Image.Image], np.ndarray]
nsfw_content_detected: Optional[List[bool]]
@dataclass
class LEditsPPInversionPipelineOutput(BaseOutput):
"""
Output class for LEdits++ Diffusion pipelines.
Args:
input_images (`List[PIL.Image.Image]` or `np.ndarray`)
List of the cropped and resized input images as PIL images of length `batch_size` or NumPy array of shape `
(batch_size, height, width, num_channels)`.
vae_reconstruction_images (`List[PIL.Image.Image]` or `np.ndarray`)
List of VAE reconstruction of all input images as PIL images of length `batch_size` or NumPy array of shape `
(batch_size, height, width, num_channels)`.
"""
images: Union[List[PIL.Image.Image], np.ndarray]
vae_reconstruction_images: Union[List[PIL.Image.Image], np.ndarray]
|
diffusers/src/diffusers/pipelines/ledits_pp/pipeline_output.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/ledits_pp/pipeline_output.py",
"repo_id": "diffusers",
"token_count": 613
}
| 130 |
import inspect
from itertools import repeat
from typing import Callable, List, Optional, Union
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from ...image_processor import VaeImageProcessor
from ...models import AutoencoderKL, UNet2DConditionModel
from ...pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from ...schedulers import KarrasDiffusionSchedulers
from ...utils import deprecate, logging
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline, StableDiffusionMixin
from .pipeline_output import SemanticStableDiffusionPipelineOutput
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class SemanticStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion with latent editing.
This model inherits from [`DiffusionPipeline`] and builds on the [`StableDiffusionPipeline`]. Check the superclass
documentation for the generic methods implemented for all pipelines (downloading, saving, running on a particular
device, etc.).
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`Q16SafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
"""
model_cpu_offload_seq = "text_encoder->unet->vae"
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
deprecation_message = "The decode_latents method is deprecated and will be removed in 1.0.0. Please use VaeImageProcessor.postprocess(...) instead"
deprecate("decode_latents", "1.0.0", deprecation_message, standard_warn=False)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Copied from diffusers.pipelines.stable_diffusion_k_diffusion.pipeline_stable_diffusion_k_diffusion.StableDiffusionKDiffusionPipeline.check_inputs
def check_inputs(
self,
prompt,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
callback_on_step_end_tensor_inputs=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: int = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
editing_prompt: Optional[Union[str, List[str]]] = None,
editing_prompt_embeddings: Optional[torch.Tensor] = None,
reverse_editing_direction: Optional[Union[bool, List[bool]]] = False,
edit_guidance_scale: Optional[Union[float, List[float]]] = 5,
edit_warmup_steps: Optional[Union[int, List[int]]] = 10,
edit_cooldown_steps: Optional[Union[int, List[int]]] = None,
edit_threshold: Optional[Union[float, List[float]]] = 0.9,
edit_momentum_scale: Optional[float] = 0.1,
edit_mom_beta: Optional[float] = 0.4,
edit_weights: Optional[List[float]] = None,
sem_guidance: Optional[List[torch.Tensor]] = None,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide image generation.
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
editing_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to use for semantic guidance. Semantic guidance is disabled by setting
`editing_prompt = None`. Guidance direction of prompt should be specified via
`reverse_editing_direction`.
editing_prompt_embeddings (`torch.Tensor`, *optional*):
Pre-computed embeddings to use for semantic guidance. Guidance direction of embedding should be
specified via `reverse_editing_direction`.
reverse_editing_direction (`bool` or `List[bool]`, *optional*, defaults to `False`):
Whether the corresponding prompt in `editing_prompt` should be increased or decreased.
edit_guidance_scale (`float` or `List[float]`, *optional*, defaults to 5):
Guidance scale for semantic guidance. If provided as a list, values should correspond to
`editing_prompt`.
edit_warmup_steps (`float` or `List[float]`, *optional*, defaults to 10):
Number of diffusion steps (for each prompt) for which semantic guidance is not applied. Momentum is
calculated for those steps and applied once all warmup periods are over.
edit_cooldown_steps (`float` or `List[float]`, *optional*, defaults to `None`):
Number of diffusion steps (for each prompt) after which semantic guidance is longer applied.
edit_threshold (`float` or `List[float]`, *optional*, defaults to 0.9):
Threshold of semantic guidance.
edit_momentum_scale (`float`, *optional*, defaults to 0.1):
Scale of the momentum to be added to the semantic guidance at each diffusion step. If set to 0.0,
momentum is disabled. Momentum is already built up during warmup (for diffusion steps smaller than
`sld_warmup_steps`). Momentum is only added to latent guidance once all warmup periods are finished.
edit_mom_beta (`float`, *optional*, defaults to 0.4):
Defines how semantic guidance momentum builds up. `edit_mom_beta` indicates how much of the previous
momentum is kept. Momentum is already built up during warmup (for diffusion steps smaller than
`edit_warmup_steps`).
edit_weights (`List[float]`, *optional*, defaults to `None`):
Indicates how much each individual concept should influence the overall guidance. If no weights are
provided all concepts are applied equally.
sem_guidance (`List[torch.Tensor]`, *optional*):
List of pre-generated guidance vectors to be applied at generation. Length of the list has to
correspond to `num_inference_steps`.
Examples:
```py
>>> import torch
>>> from diffusers import SemanticStableDiffusionPipeline
>>> pipe = SemanticStableDiffusionPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
... )
>>> pipe = pipe.to("cuda")
>>> out = pipe(
... prompt="a photo of the face of a woman",
... num_images_per_prompt=1,
... guidance_scale=7,
... editing_prompt=[
... "smiling, smile", # Concepts to apply
... "glasses, wearing glasses",
... "curls, wavy hair, curly hair",
... "beard, full beard, mustache",
... ],
... reverse_editing_direction=[
... False,
... False,
... False,
... False,
... ], # Direction of guidance i.e. increase all concepts
... edit_warmup_steps=[10, 10, 10, 10], # Warmup period for each concept
... edit_guidance_scale=[4, 5, 5, 5.4], # Guidance scale for each concept
... edit_threshold=[
... 0.99,
... 0.975,
... 0.925,
... 0.96,
... ], # Threshold for each concept. Threshold equals the percentile of the latent space that will be discarded. I.e. threshold=0.99 uses 1% of the latent dimensions
... edit_momentum_scale=0.3, # Momentum scale that will be added to the latent guidance
... edit_mom_beta=0.6, # Momentum beta
... edit_weights=[1, 1, 1, 1, 1], # Weights of the individual concepts against each other
... )
>>> image = out.images[0]
```
Returns:
[`~pipelines.semantic_stable_diffusion.SemanticStableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`,
[`~pipelines.semantic_stable_diffusion.SemanticStableDiffusionPipelineOutput`] is returned, otherwise a
`tuple` is returned where the first element is a list with the generated images and the second element
is a list of `bool`s indicating whether the corresponding generated image contains "not-safe-for-work"
(nsfw) content.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(prompt, height, width, callback_steps)
# 2. Define call parameters
batch_size = 1 if isinstance(prompt, str) else len(prompt)
if editing_prompt:
enable_edit_guidance = True
if isinstance(editing_prompt, str):
editing_prompt = [editing_prompt]
enabled_editing_prompts = len(editing_prompt)
elif editing_prompt_embeddings is not None:
enable_edit_guidance = True
enabled_editing_prompts = editing_prompt_embeddings.shape[0]
else:
enabled_editing_prompts = 0
enable_edit_guidance = False
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
if enable_edit_guidance:
# get safety text embeddings
if editing_prompt_embeddings is None:
edit_concepts_input = self.tokenizer(
[x for item in editing_prompt for x in repeat(item, batch_size)],
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
edit_concepts_input_ids = edit_concepts_input.input_ids
if edit_concepts_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(
edit_concepts_input_ids[:, self.tokenizer.model_max_length :]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
edit_concepts_input_ids = edit_concepts_input_ids[:, : self.tokenizer.model_max_length]
edit_concepts = self.text_encoder(edit_concepts_input_ids.to(self.device))[0]
else:
edit_concepts = editing_prompt_embeddings.to(self.device).repeat(batch_size, 1, 1)
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed_edit, seq_len_edit, _ = edit_concepts.shape
edit_concepts = edit_concepts.repeat(1, num_images_per_prompt, 1)
edit_concepts = edit_concepts.view(bs_embed_edit * num_images_per_prompt, seq_len_edit, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if enable_edit_guidance:
text_embeddings = torch.cat([uncond_embeddings, text_embeddings, edit_concepts])
else:
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=self.device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
text_embeddings.dtype,
self.device,
generator,
latents,
)
# 6. Prepare extra step kwargs.
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# Initialize edit_momentum to None
edit_momentum = None
self.uncond_estimates = None
self.text_estimates = None
self.edit_estimates = None
self.sem_guidance = None
for i, t in enumerate(self.progress_bar(timesteps)):
# expand the latents if we are doing classifier free guidance
latent_model_input = (
torch.cat([latents] * (2 + enabled_editing_prompts)) if do_classifier_free_guidance else latents
)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_out = noise_pred.chunk(2 + enabled_editing_prompts) # [b,4, 64, 64]
noise_pred_uncond, noise_pred_text = noise_pred_out[0], noise_pred_out[1]
noise_pred_edit_concepts = noise_pred_out[2:]
# default text guidance
noise_guidance = guidance_scale * (noise_pred_text - noise_pred_uncond)
# noise_guidance = (noise_pred_text - noise_pred_edit_concepts[0])
if self.uncond_estimates is None:
self.uncond_estimates = torch.zeros((num_inference_steps + 1, *noise_pred_uncond.shape))
self.uncond_estimates[i] = noise_pred_uncond.detach().cpu()
if self.text_estimates is None:
self.text_estimates = torch.zeros((num_inference_steps + 1, *noise_pred_text.shape))
self.text_estimates[i] = noise_pred_text.detach().cpu()
if self.edit_estimates is None and enable_edit_guidance:
self.edit_estimates = torch.zeros(
(num_inference_steps + 1, len(noise_pred_edit_concepts), *noise_pred_edit_concepts[0].shape)
)
if self.sem_guidance is None:
self.sem_guidance = torch.zeros((num_inference_steps + 1, *noise_pred_text.shape))
if edit_momentum is None:
edit_momentum = torch.zeros_like(noise_guidance)
if enable_edit_guidance:
concept_weights = torch.zeros(
(len(noise_pred_edit_concepts), noise_guidance.shape[0]),
device=self.device,
dtype=noise_guidance.dtype,
)
noise_guidance_edit = torch.zeros(
(len(noise_pred_edit_concepts), *noise_guidance.shape),
device=self.device,
dtype=noise_guidance.dtype,
)
# noise_guidance_edit = torch.zeros_like(noise_guidance)
warmup_inds = []
for c, noise_pred_edit_concept in enumerate(noise_pred_edit_concepts):
self.edit_estimates[i, c] = noise_pred_edit_concept
if isinstance(edit_guidance_scale, list):
edit_guidance_scale_c = edit_guidance_scale[c]
else:
edit_guidance_scale_c = edit_guidance_scale
if isinstance(edit_threshold, list):
edit_threshold_c = edit_threshold[c]
else:
edit_threshold_c = edit_threshold
if isinstance(reverse_editing_direction, list):
reverse_editing_direction_c = reverse_editing_direction[c]
else:
reverse_editing_direction_c = reverse_editing_direction
if edit_weights:
edit_weight_c = edit_weights[c]
else:
edit_weight_c = 1.0
if isinstance(edit_warmup_steps, list):
edit_warmup_steps_c = edit_warmup_steps[c]
else:
edit_warmup_steps_c = edit_warmup_steps
if isinstance(edit_cooldown_steps, list):
edit_cooldown_steps_c = edit_cooldown_steps[c]
elif edit_cooldown_steps is None:
edit_cooldown_steps_c = i + 1
else:
edit_cooldown_steps_c = edit_cooldown_steps
if i >= edit_warmup_steps_c:
warmup_inds.append(c)
if i >= edit_cooldown_steps_c:
noise_guidance_edit[c, :, :, :, :] = torch.zeros_like(noise_pred_edit_concept)
continue
noise_guidance_edit_tmp = noise_pred_edit_concept - noise_pred_uncond
# tmp_weights = (noise_pred_text - noise_pred_edit_concept).sum(dim=(1, 2, 3))
tmp_weights = (noise_guidance - noise_pred_edit_concept).sum(dim=(1, 2, 3))
tmp_weights = torch.full_like(tmp_weights, edit_weight_c) # * (1 / enabled_editing_prompts)
if reverse_editing_direction_c:
noise_guidance_edit_tmp = noise_guidance_edit_tmp * -1
concept_weights[c, :] = tmp_weights
noise_guidance_edit_tmp = noise_guidance_edit_tmp * edit_guidance_scale_c
# torch.quantile function expects float32
if noise_guidance_edit_tmp.dtype == torch.float32:
tmp = torch.quantile(
torch.abs(noise_guidance_edit_tmp).flatten(start_dim=2),
edit_threshold_c,
dim=2,
keepdim=False,
)
else:
tmp = torch.quantile(
torch.abs(noise_guidance_edit_tmp).flatten(start_dim=2).to(torch.float32),
edit_threshold_c,
dim=2,
keepdim=False,
).to(noise_guidance_edit_tmp.dtype)
noise_guidance_edit_tmp = torch.where(
torch.abs(noise_guidance_edit_tmp) >= tmp[:, :, None, None],
noise_guidance_edit_tmp,
torch.zeros_like(noise_guidance_edit_tmp),
)
noise_guidance_edit[c, :, :, :, :] = noise_guidance_edit_tmp
# noise_guidance_edit = noise_guidance_edit + noise_guidance_edit_tmp
warmup_inds = torch.tensor(warmup_inds).to(self.device)
if len(noise_pred_edit_concepts) > warmup_inds.shape[0] > 0:
concept_weights = concept_weights.to("cpu") # Offload to cpu
noise_guidance_edit = noise_guidance_edit.to("cpu")
concept_weights_tmp = torch.index_select(concept_weights.to(self.device), 0, warmup_inds)
concept_weights_tmp = torch.where(
concept_weights_tmp < 0, torch.zeros_like(concept_weights_tmp), concept_weights_tmp
)
concept_weights_tmp = concept_weights_tmp / concept_weights_tmp.sum(dim=0)
# concept_weights_tmp = torch.nan_to_num(concept_weights_tmp)
noise_guidance_edit_tmp = torch.index_select(
noise_guidance_edit.to(self.device), 0, warmup_inds
)
noise_guidance_edit_tmp = torch.einsum(
"cb,cbijk->bijk", concept_weights_tmp, noise_guidance_edit_tmp
)
noise_guidance_edit_tmp = noise_guidance_edit_tmp
noise_guidance = noise_guidance + noise_guidance_edit_tmp
self.sem_guidance[i] = noise_guidance_edit_tmp.detach().cpu()
del noise_guidance_edit_tmp
del concept_weights_tmp
concept_weights = concept_weights.to(self.device)
noise_guidance_edit = noise_guidance_edit.to(self.device)
concept_weights = torch.where(
concept_weights < 0, torch.zeros_like(concept_weights), concept_weights
)
concept_weights = torch.nan_to_num(concept_weights)
noise_guidance_edit = torch.einsum("cb,cbijk->bijk", concept_weights, noise_guidance_edit)
noise_guidance_edit = noise_guidance_edit + edit_momentum_scale * edit_momentum
edit_momentum = edit_mom_beta * edit_momentum + (1 - edit_mom_beta) * noise_guidance_edit
if warmup_inds.shape[0] == len(noise_pred_edit_concepts):
noise_guidance = noise_guidance + noise_guidance_edit
self.sem_guidance[i] = noise_guidance_edit.detach().cpu()
if sem_guidance is not None:
edit_guidance = sem_guidance[i].to(self.device)
noise_guidance = noise_guidance + edit_guidance
noise_pred = noise_pred_uncond + noise_guidance
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# 8. Post-processing
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, self.device, text_embeddings.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
if not return_dict:
return (image, has_nsfw_concept)
return SemanticStableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
diffusers/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py",
"repo_id": "diffusers",
"token_count": 18046
}
| 131 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import warnings
from functools import partial
from typing import Dict, List, Optional, Union
import jax
import jax.numpy as jnp
import numpy as np
from flax.core.frozen_dict import FrozenDict
from flax.jax_utils import unreplicate
from flax.training.common_utils import shard
from packaging import version
from PIL import Image
from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel
from ...models import FlaxAutoencoderKL, FlaxUNet2DConditionModel
from ...schedulers import (
FlaxDDIMScheduler,
FlaxDPMSolverMultistepScheduler,
FlaxLMSDiscreteScheduler,
FlaxPNDMScheduler,
)
from ...utils import PIL_INTERPOLATION, deprecate, logging, replace_example_docstring
from ..pipeline_flax_utils import FlaxDiffusionPipeline
from .pipeline_output import FlaxStableDiffusionPipelineOutput
from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
# Set to True to use python for loop instead of jax.fori_loop for easier debugging
DEBUG = False
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import jax
>>> import numpy as np
>>> from flax.jax_utils import replicate
>>> from flax.training.common_utils import shard
>>> import PIL
>>> import requests
>>> from io import BytesIO
>>> from diffusers import FlaxStableDiffusionInpaintPipeline
>>> def download_image(url):
... response = requests.get(url)
... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
>>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
>>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
>>> init_image = download_image(img_url).resize((512, 512))
>>> mask_image = download_image(mask_url).resize((512, 512))
>>> pipeline, params = FlaxStableDiffusionInpaintPipeline.from_pretrained(
... "xvjiarui/stable-diffusion-2-inpainting"
... )
>>> prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
>>> prng_seed = jax.random.PRNGKey(0)
>>> num_inference_steps = 50
>>> num_samples = jax.device_count()
>>> prompt = num_samples * [prompt]
>>> init_image = num_samples * [init_image]
>>> mask_image = num_samples * [mask_image]
>>> prompt_ids, processed_masked_images, processed_masks = pipeline.prepare_inputs(
... prompt, init_image, mask_image
... )
# shard inputs and rng
>>> params = replicate(params)
>>> prng_seed = jax.random.split(prng_seed, jax.device_count())
>>> prompt_ids = shard(prompt_ids)
>>> processed_masked_images = shard(processed_masked_images)
>>> processed_masks = shard(processed_masks)
>>> images = pipeline(
... prompt_ids, processed_masks, processed_masked_images, params, prng_seed, num_inference_steps, jit=True
... ).images
>>> images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
```
"""
class FlaxStableDiffusionInpaintPipeline(FlaxDiffusionPipeline):
r"""
Flax-based pipeline for text-guided image inpainting using Stable Diffusion.
<Tip warning={true}>
🧪 This is an experimental feature!
</Tip>
This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
Args:
vae ([`FlaxAutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.FlaxCLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`FlaxUNet2DConditionModel`]):
A `FlaxUNet2DConditionModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
[`FlaxDPMSolverMultistepScheduler`].
safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
"""
def __init__(
self,
vae: FlaxAutoencoderKL,
text_encoder: FlaxCLIPTextModel,
tokenizer: CLIPTokenizer,
unet: FlaxUNet2DConditionModel,
scheduler: Union[
FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
],
safety_checker: FlaxStableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
dtype: jnp.dtype = jnp.float32,
):
super().__init__()
self.dtype = dtype
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
def prepare_inputs(
self,
prompt: Union[str, List[str]],
image: Union[Image.Image, List[Image.Image]],
mask: Union[Image.Image, List[Image.Image]],
):
if not isinstance(prompt, (str, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if not isinstance(image, (Image.Image, list)):
raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
if isinstance(image, Image.Image):
image = [image]
if not isinstance(mask, (Image.Image, list)):
raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
if isinstance(mask, Image.Image):
mask = [mask]
processed_images = jnp.concatenate([preprocess_image(img, jnp.float32) for img in image])
processed_masks = jnp.concatenate([preprocess_mask(m, jnp.float32) for m in mask])
# processed_masks[processed_masks < 0.5] = 0
processed_masks = processed_masks.at[processed_masks < 0.5].set(0)
# processed_masks[processed_masks >= 0.5] = 1
processed_masks = processed_masks.at[processed_masks >= 0.5].set(1)
processed_masked_images = processed_images * (processed_masks < 0.5)
text_input = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
return text_input.input_ids, processed_masked_images, processed_masks
def _get_has_nsfw_concepts(self, features, params):
has_nsfw_concepts = self.safety_checker(features, params)
return has_nsfw_concepts
def _run_safety_checker(self, images, safety_model_params, jit=False):
# safety_model_params should already be replicated when jit is True
pil_images = [Image.fromarray(image) for image in images]
features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
if jit:
features = shard(features)
has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
has_nsfw_concepts = unshard(has_nsfw_concepts)
safety_model_params = unreplicate(safety_model_params)
else:
has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
images_was_copied = False
for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
if has_nsfw_concept:
if not images_was_copied:
images_was_copied = True
images = images.copy()
images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
if any(has_nsfw_concepts):
warnings.warn(
"Potential NSFW content was detected in one or more images. A black image will be returned"
" instead. Try again with a different prompt and/or seed."
)
return images, has_nsfw_concepts
def _generate(
self,
prompt_ids: jnp.ndarray,
mask: jnp.ndarray,
masked_image: jnp.ndarray,
params: Union[Dict, FrozenDict],
prng_seed: jax.Array,
num_inference_steps: int,
height: int,
width: int,
guidance_scale: float,
latents: Optional[jnp.ndarray] = None,
neg_prompt_ids: Optional[jnp.ndarray] = None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
# get prompt text embeddings
prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
# TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
# implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
batch_size = prompt_ids.shape[0]
max_length = prompt_ids.shape[-1]
if neg_prompt_ids is None:
uncond_input = self.tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
).input_ids
else:
uncond_input = neg_prompt_ids
negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
latents_shape = (
batch_size,
self.vae.config.latent_channels,
height // self.vae_scale_factor,
width // self.vae_scale_factor,
)
if latents is None:
latents = jax.random.normal(prng_seed, shape=latents_shape, dtype=self.dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
prng_seed, mask_prng_seed = jax.random.split(prng_seed)
masked_image_latent_dist = self.vae.apply(
{"params": params["vae"]}, masked_image, method=self.vae.encode
).latent_dist
masked_image_latents = masked_image_latent_dist.sample(key=mask_prng_seed).transpose((0, 3, 1, 2))
masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
del mask_prng_seed
mask = jax.image.resize(mask, (*mask.shape[:-2], *masked_image_latents.shape[-2:]), method="nearest")
# 8. Check that sizes of mask, masked image and latents match
num_channels_latents = self.vae.config.latent_channels
num_channels_mask = mask.shape[1]
num_channels_masked_image = masked_image_latents.shape[1]
if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
raise ValueError(
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
" `pipeline.unet` or your `mask_image` or `image` input."
)
def loop_body(step, args):
latents, mask, masked_image_latents, scheduler_state = args
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
latents_input = jnp.concatenate([latents] * 2)
mask_input = jnp.concatenate([mask] * 2)
masked_image_latents_input = jnp.concatenate([masked_image_latents] * 2)
t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
timestep = jnp.broadcast_to(t, latents_input.shape[0])
latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
# concat latents, mask, masked_image_latents in the channel dimension
latents_input = jnp.concatenate([latents_input, mask_input, masked_image_latents_input], axis=1)
# predict the noise residual
noise_pred = self.unet.apply(
{"params": params["unet"]},
jnp.array(latents_input),
jnp.array(timestep, dtype=jnp.int32),
encoder_hidden_states=context,
).sample
# perform guidance
noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
return latents, mask, masked_image_latents, scheduler_state
scheduler_state = self.scheduler.set_timesteps(
params["scheduler"], num_inference_steps=num_inference_steps, shape=latents.shape
)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * params["scheduler"].init_noise_sigma
if DEBUG:
# run with python for loop
for i in range(num_inference_steps):
latents, mask, masked_image_latents, scheduler_state = loop_body(
i, (latents, mask, masked_image_latents, scheduler_state)
)
else:
latents, _, _, _ = jax.lax.fori_loop(
0, num_inference_steps, loop_body, (latents, mask, masked_image_latents, scheduler_state)
)
# scale and decode the image latents with vae
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
return image
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt_ids: jnp.ndarray,
mask: jnp.ndarray,
masked_image: jnp.ndarray,
params: Union[Dict, FrozenDict],
prng_seed: jax.Array,
num_inference_steps: int = 50,
height: Optional[int] = None,
width: Optional[int] = None,
guidance_scale: Union[float, jnp.ndarray] = 7.5,
latents: jnp.ndarray = None,
neg_prompt_ids: jnp.ndarray = None,
return_dict: bool = True,
jit: bool = False,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide image generation.
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter is modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
latents (`jnp.ndarray`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
array is generated by sampling using the supplied random `generator`.
jit (`bool`, defaults to `False`):
Whether to run `pmap` versions of the generation and safety scoring functions.
<Tip warning={true}>
This argument exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a
future release.
</Tip>
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
a plain tuple.
Examples:
Returns:
[`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] is
returned, otherwise a `tuple` is returned where the first element is a list with the generated images
and the second element is a list of `bool`s indicating whether the corresponding generated image
contains "not-safe-for-work" (nsfw) content.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
masked_image = jax.image.resize(masked_image, (*masked_image.shape[:-2], height, width), method="bicubic")
mask = jax.image.resize(mask, (*mask.shape[:-2], height, width), method="nearest")
if isinstance(guidance_scale, float):
# Convert to a tensor so each device gets a copy. Follow the prompt_ids for
# shape information, as they may be sharded (when `jit` is `True`), or not.
guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
if len(prompt_ids.shape) > 2:
# Assume sharded
guidance_scale = guidance_scale[:, None]
if jit:
images = _p_generate(
self,
prompt_ids,
mask,
masked_image,
params,
prng_seed,
num_inference_steps,
height,
width,
guidance_scale,
latents,
neg_prompt_ids,
)
else:
images = self._generate(
prompt_ids,
mask,
masked_image,
params,
prng_seed,
num_inference_steps,
height,
width,
guidance_scale,
latents,
neg_prompt_ids,
)
if self.safety_checker is not None:
safety_params = params["safety_checker"]
images_uint8_casted = (images * 255).round().astype("uint8")
num_devices, batch_size = images.shape[:2]
images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
images = np.asarray(images)
# block images
if any(has_nsfw_concept):
for i, is_nsfw in enumerate(has_nsfw_concept):
if is_nsfw:
images[i] = np.asarray(images_uint8_casted[i])
images = images.reshape(num_devices, batch_size, height, width, 3)
else:
images = np.asarray(images)
has_nsfw_concept = False
if not return_dict:
return (images, has_nsfw_concept)
return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
# Static argnums are pipe, num_inference_steps, height, width. A change would trigger recompilation.
# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
@partial(
jax.pmap,
in_axes=(None, 0, 0, 0, 0, 0, None, None, None, 0, 0, 0),
static_broadcasted_argnums=(0, 6, 7, 8),
)
def _p_generate(
pipe,
prompt_ids,
mask,
masked_image,
params,
prng_seed,
num_inference_steps,
height,
width,
guidance_scale,
latents,
neg_prompt_ids,
):
return pipe._generate(
prompt_ids,
mask,
masked_image,
params,
prng_seed,
num_inference_steps,
height,
width,
guidance_scale,
latents,
neg_prompt_ids,
)
@partial(jax.pmap, static_broadcasted_argnums=(0,))
def _p_get_has_nsfw_concepts(pipe, features, params):
return pipe._get_has_nsfw_concepts(features, params)
def unshard(x: jnp.ndarray):
# einops.rearrange(x, 'd b ... -> (d b) ...')
num_devices, batch_size = x.shape[:2]
rest = x.shape[2:]
return x.reshape(num_devices * batch_size, *rest)
def preprocess_image(image, dtype):
w, h = image.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
image = jnp.array(image).astype(dtype) / 255.0
image = image[None].transpose(0, 3, 1, 2)
return 2.0 * image - 1.0
def preprocess_mask(mask, dtype):
w, h = mask.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
mask = mask.resize((w, h))
mask = jnp.array(mask.convert("L")).astype(dtype) / 255.0
mask = jnp.expand_dims(mask, axis=(0, 1))
return mask
|
diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_inpaint.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_inpaint.py",
"repo_id": "diffusers",
"token_count": 11428
}
| 132 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
import torch
import torch.nn as nn
from transformers import CLIPConfig, CLIPVisionModel, PreTrainedModel
from ...utils import logging
logger = logging.get_logger(__name__)
def cosine_distance(image_embeds, text_embeds):
normalized_image_embeds = nn.functional.normalize(image_embeds)
normalized_text_embeds = nn.functional.normalize(text_embeds)
return torch.mm(normalized_image_embeds, normalized_text_embeds.t())
class StableDiffusionSafetyChecker(PreTrainedModel):
config_class = CLIPConfig
_no_split_modules = ["CLIPEncoderLayer"]
def __init__(self, config: CLIPConfig):
super().__init__(config)
self.vision_model = CLIPVisionModel(config.vision_config)
self.visual_projection = nn.Linear(config.vision_config.hidden_size, config.projection_dim, bias=False)
self.concept_embeds = nn.Parameter(torch.ones(17, config.projection_dim), requires_grad=False)
self.special_care_embeds = nn.Parameter(torch.ones(3, config.projection_dim), requires_grad=False)
self.concept_embeds_weights = nn.Parameter(torch.ones(17), requires_grad=False)
self.special_care_embeds_weights = nn.Parameter(torch.ones(3), requires_grad=False)
@torch.no_grad()
def forward(self, clip_input, images):
pooled_output = self.vision_model(clip_input)[1] # pooled_output
image_embeds = self.visual_projection(pooled_output)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds).cpu().float().numpy()
cos_dist = cosine_distance(image_embeds, self.concept_embeds).cpu().float().numpy()
result = []
batch_size = image_embeds.shape[0]
for i in range(batch_size):
result_img = {"special_scores": {}, "special_care": [], "concept_scores": {}, "bad_concepts": []}
# increase this value to create a stronger `nfsw` filter
# at the cost of increasing the possibility of filtering benign images
adjustment = 0.0
for concept_idx in range(len(special_cos_dist[0])):
concept_cos = special_cos_dist[i][concept_idx]
concept_threshold = self.special_care_embeds_weights[concept_idx].item()
result_img["special_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
if result_img["special_scores"][concept_idx] > 0:
result_img["special_care"].append({concept_idx, result_img["special_scores"][concept_idx]})
adjustment = 0.01
for concept_idx in range(len(cos_dist[0])):
concept_cos = cos_dist[i][concept_idx]
concept_threshold = self.concept_embeds_weights[concept_idx].item()
result_img["concept_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
if result_img["concept_scores"][concept_idx] > 0:
result_img["bad_concepts"].append(concept_idx)
result.append(result_img)
has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result]
for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
if has_nsfw_concept:
if torch.is_tensor(images) or torch.is_tensor(images[0]):
images[idx] = torch.zeros_like(images[idx]) # black image
else:
images[idx] = np.zeros(images[idx].shape) # black image
if any(has_nsfw_concepts):
logger.warning(
"Potential NSFW content was detected in one or more images. A black image will be returned instead."
" Try again with a different prompt and/or seed."
)
return images, has_nsfw_concepts
@torch.no_grad()
def forward_onnx(self, clip_input: torch.FloatTensor, images: torch.FloatTensor):
pooled_output = self.vision_model(clip_input)[1] # pooled_output
image_embeds = self.visual_projection(pooled_output)
special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds)
cos_dist = cosine_distance(image_embeds, self.concept_embeds)
# increase this value to create a stronger `nsfw` filter
# at the cost of increasing the possibility of filtering benign images
adjustment = 0.0
special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment
# special_scores = special_scores.round(decimals=3)
special_care = torch.any(special_scores > 0, dim=1)
special_adjustment = special_care * 0.01
special_adjustment = special_adjustment.unsqueeze(1).expand(-1, cos_dist.shape[1])
concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment
# concept_scores = concept_scores.round(decimals=3)
has_nsfw_concepts = torch.any(concept_scores > 0, dim=1)
images[has_nsfw_concepts] = 0.0 # black image
return images, has_nsfw_concepts
|
diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker.py",
"repo_id": "diffusers",
"token_count": 2300
}
| 133 |
# Copyright 2024 MultiDiffusion Authors and The HuggingFace Team. All rights reserved."
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import inspect
from typing import Any, Callable, Dict, List, Optional, Union
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
from ...image_processor import PipelineImageInput, VaeImageProcessor
from ...loaders import IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
from ...models.lora import adjust_lora_scale_text_encoder
from ...schedulers import DDIMScheduler
from ...utils import (
USE_PEFT_BACKEND,
deprecate,
logging,
replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline, StableDiffusionMixin
from ..stable_diffusion import StableDiffusionPipelineOutput
from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import StableDiffusionPanoramaPipeline, DDIMScheduler
>>> model_ckpt = "stabilityai/stable-diffusion-2-base"
>>> scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
>>> pipe = StableDiffusionPanoramaPipeline.from_pretrained(
... model_ckpt, scheduler=scheduler, torch_dtype=torch.float16
... )
>>> pipe = pipe.to("cuda")
>>> prompt = "a photo of the dolomites"
>>> image = pipe(prompt).images[0]
```
"""
class StableDiffusionPanoramaPipeline(
DiffusionPipeline, StableDiffusionMixin, TextualInversionLoaderMixin, LoraLoaderMixin, IPAdapterMixin
):
r"""
Pipeline for text-to-image generation using MultiDiffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
The pipeline also inherits the following loading methods:
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
"""
model_cpu_offload_seq = "text_encoder->unet->vae"
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
_exclude_from_cpu_offload = ["safety_checker"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: DDIMScheduler,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
image_encoder: Optional[CLIPVisionModelWithProjection] = None,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
image_encoder=image_encoder,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
**kwargs,
):
deprecation_message = "`_encode_prompt()` is deprecated and it will be removed in a future version. Use `encode_prompt()` instead. Also, be aware that the output format changed from a concatenated tensor to a tuple."
deprecate("_encode_prompt()", "1.0.0", deprecation_message, standard_warn=False)
prompt_embeds_tuple = self.encode_prompt(
prompt=prompt,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=lora_scale,
**kwargs,
)
# concatenate for backwards comp
prompt_embeds = torch.cat([prompt_embeds_tuple[1], prompt_embeds_tuple[0]])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_prompt
def encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
lora_scale (`float`, *optional*):
A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
if clip_skip is None:
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
prompt_embeds = prompt_embeds[0]
else:
prompt_embeds = self.text_encoder(
text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
)
# Access the `hidden_states` first, that contains a tuple of
# all the hidden states from the encoder layers. Then index into
# the tuple to access the hidden states from the desired layer.
prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
# We also need to apply the final LayerNorm here to not mess with the
# representations. The `last_hidden_states` that we typically use for
# obtaining the final prompt representations passes through the LayerNorm
# layer.
prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
if isinstance(self, LoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
return prompt_embeds, negative_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_image
def encode_image(self, image, device, num_images_per_prompt, output_hidden_states=None):
dtype = next(self.image_encoder.parameters()).dtype
if not isinstance(image, torch.Tensor):
image = self.feature_extractor(image, return_tensors="pt").pixel_values
image = image.to(device=device, dtype=dtype)
if output_hidden_states:
image_enc_hidden_states = self.image_encoder(image, output_hidden_states=True).hidden_states[-2]
image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
uncond_image_enc_hidden_states = self.image_encoder(
torch.zeros_like(image), output_hidden_states=True
).hidden_states[-2]
uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(
num_images_per_prompt, dim=0
)
return image_enc_hidden_states, uncond_image_enc_hidden_states
else:
image_embeds = self.image_encoder(image).image_embeds
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
uncond_image_embeds = torch.zeros_like(image_embeds)
return image_embeds, uncond_image_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_ip_adapter_image_embeds
def prepare_ip_adapter_image_embeds(
self, ip_adapter_image, ip_adapter_image_embeds, device, num_images_per_prompt, do_classifier_free_guidance
):
if ip_adapter_image_embeds is None:
if not isinstance(ip_adapter_image, list):
ip_adapter_image = [ip_adapter_image]
if len(ip_adapter_image) != len(self.unet.encoder_hid_proj.image_projection_layers):
raise ValueError(
f"`ip_adapter_image` must have same length as the number of IP Adapters. Got {len(ip_adapter_image)} images and {len(self.unet.encoder_hid_proj.image_projection_layers)} IP Adapters."
)
image_embeds = []
for single_ip_adapter_image, image_proj_layer in zip(
ip_adapter_image, self.unet.encoder_hid_proj.image_projection_layers
):
output_hidden_state = not isinstance(image_proj_layer, ImageProjection)
single_image_embeds, single_negative_image_embeds = self.encode_image(
single_ip_adapter_image, device, 1, output_hidden_state
)
single_image_embeds = torch.stack([single_image_embeds] * num_images_per_prompt, dim=0)
single_negative_image_embeds = torch.stack(
[single_negative_image_embeds] * num_images_per_prompt, dim=0
)
if do_classifier_free_guidance:
single_image_embeds = torch.cat([single_negative_image_embeds, single_image_embeds])
single_image_embeds = single_image_embeds.to(device)
image_embeds.append(single_image_embeds)
else:
repeat_dims = [1]
image_embeds = []
for single_image_embeds in ip_adapter_image_embeds:
if do_classifier_free_guidance:
single_negative_image_embeds, single_image_embeds = single_image_embeds.chunk(2)
single_image_embeds = single_image_embeds.repeat(
num_images_per_prompt, *(repeat_dims * len(single_image_embeds.shape[1:]))
)
single_negative_image_embeds = single_negative_image_embeds.repeat(
num_images_per_prompt, *(repeat_dims * len(single_negative_image_embeds.shape[1:]))
)
single_image_embeds = torch.cat([single_negative_image_embeds, single_image_embeds])
else:
single_image_embeds = single_image_embeds.repeat(
num_images_per_prompt, *(repeat_dims * len(single_image_embeds.shape[1:]))
)
image_embeds.append(single_image_embeds)
return image_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
deprecation_message = "The decode_latents method is deprecated and will be removed in 1.0.0. Please use VaeImageProcessor.postprocess(...) instead"
deprecate("decode_latents", "1.0.0", deprecation_message, standard_warn=False)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def decode_latents_with_padding(self, latents, padding=8):
# Add padding to latents for circular inference
# padding is the number of latents to add on each side
# it would slightly increase the memory usage, but remove the boundary artifacts
latents = 1 / self.vae.config.scaling_factor * latents
latents_left = latents[..., :padding]
latents_right = latents[..., -padding:]
latents = torch.cat((latents_right, latents, latents_left), axis=-1)
image = self.vae.decode(latents, return_dict=False)[0]
padding_pix = self.vae_scale_factor * padding
image = image[..., padding_pix:-padding_pix]
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
def check_inputs(
self,
prompt,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
ip_adapter_image=None,
ip_adapter_image_embeds=None,
callback_on_step_end_tensor_inputs=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if ip_adapter_image is not None and ip_adapter_image_embeds is not None:
raise ValueError(
"Provide either `ip_adapter_image` or `ip_adapter_image_embeds`. Cannot leave both `ip_adapter_image` and `ip_adapter_image_embeds` defined."
)
if ip_adapter_image_embeds is not None:
if not isinstance(ip_adapter_image_embeds, list):
raise ValueError(
f"`ip_adapter_image_embeds` has to be of type `list` but is {type(ip_adapter_image_embeds)}"
)
elif ip_adapter_image_embeds[0].ndim not in [3, 4]:
raise ValueError(
f"`ip_adapter_image_embeds` has to be a list of 3D or 4D tensors but is {ip_adapter_image_embeds[0].ndim}D"
)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def get_views(self, panorama_height, panorama_width, window_size=64, stride=8, circular_padding=False):
# Here, we define the mappings F_i (see Eq. 7 in the MultiDiffusion paper https://arxiv.org/abs/2302.08113)
# if panorama's height/width < window_size, num_blocks of height/width should return 1
panorama_height /= 8
panorama_width /= 8
num_blocks_height = (panorama_height - window_size) // stride + 1 if panorama_height > window_size else 1
if circular_padding:
num_blocks_width = panorama_width // stride if panorama_width > window_size else 1
else:
num_blocks_width = (panorama_width - window_size) // stride + 1 if panorama_width > window_size else 1
total_num_blocks = int(num_blocks_height * num_blocks_width)
views = []
for i in range(total_num_blocks):
h_start = int((i // num_blocks_width) * stride)
h_end = h_start + window_size
w_start = int((i % num_blocks_width) * stride)
w_end = w_start + window_size
views.append((h_start, h_end, w_start, w_end))
return views
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
height: Optional[int] = 512,
width: Optional[int] = 2048,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
view_batch_size: int = 1,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
ip_adapter_image: Optional[PipelineImageInput] = None,
ip_adapter_image_embeds: Optional[List[torch.FloatTensor]] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: Optional[int] = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
circular_padding: bool = False,
clip_skip: Optional[int] = None,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 2048):
The width in pixels of the generated image. The width is kept high because the pipeline is supposed
generate panorama-like images.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
view_batch_size (`int`, *optional*, defaults to 1):
The batch size to denoise split views. For some GPUs with high performance, higher view batch size can
speedup the generation and increase the VRAM usage.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
ip_adapter_image: (`PipelineImageInput`, *optional*):
Optional image input to work with IP Adapters.
ip_adapter_image_embeds (`List[torch.FloatTensor]`, *optional*):
Pre-generated image embeddings for IP-Adapter. It should be a list of length same as number of IP-adapters.
Each element should be a tensor of shape `(batch_size, num_images, emb_dim)`. It should contain the negative image embedding
if `do_classifier_free_guidance` is set to `True`.
If not provided, embeddings are computed from the `ip_adapter_image` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
circular_padding (`bool`, *optional*, defaults to `False`):
If set to `True`, circular padding is applied to ensure there are no stitching artifacts. Circular
padding allows the model to seamlessly generate a transition from the rightmost part of the image to
the leftmost part, maintaining consistency in a 360-degree sense.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
height,
width,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
ip_adapter_image,
ip_adapter_image_embeds,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
if ip_adapter_image is not None or ip_adapter_image_embeds is not None:
image_embeds = self.prepare_ip_adapter_image_embeds(
ip_adapter_image,
ip_adapter_image_embeds,
device,
batch_size * num_images_per_prompt,
self.do_classifier_free_guidance,
)
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
clip_skip=clip_skip,
)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Define panorama grid and initialize views for synthesis.
# prepare batch grid
views = self.get_views(height, width, circular_padding=circular_padding)
views_batch = [views[i : i + view_batch_size] for i in range(0, len(views), view_batch_size)]
views_scheduler_status = [copy.deepcopy(self.scheduler.__dict__)] * len(views_batch)
count = torch.zeros_like(latents)
value = torch.zeros_like(latents)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7.1 Add image embeds for IP-Adapter
added_cond_kwargs = (
{"image_embeds": image_embeds}
if ip_adapter_image is not None or ip_adapter_image_embeds is not None
else None
)
# 8. Denoising loop
# Each denoising step also includes refinement of the latents with respect to the
# views.
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
count.zero_()
value.zero_()
# generate views
# Here, we iterate through different spatial crops of the latents and denoise them. These
# denoised (latent) crops are then averaged to produce the final latent
# for the current timestep via MultiDiffusion. Please see Sec. 4.1 in the
# MultiDiffusion paper for more details: https://arxiv.org/abs/2302.08113
# Batch views denoise
for j, batch_view in enumerate(views_batch):
vb_size = len(batch_view)
# get the latents corresponding to the current view coordinates
if circular_padding:
latents_for_view = []
for h_start, h_end, w_start, w_end in batch_view:
if w_end > latents.shape[3]:
# Add circular horizontal padding
latent_view = torch.cat(
(
latents[:, :, h_start:h_end, w_start:],
latents[:, :, h_start:h_end, : w_end - latents.shape[3]],
),
axis=-1,
)
else:
latent_view = latents[:, :, h_start:h_end, w_start:w_end]
latents_for_view.append(latent_view)
latents_for_view = torch.cat(latents_for_view)
else:
latents_for_view = torch.cat(
[
latents[:, :, h_start:h_end, w_start:w_end]
for h_start, h_end, w_start, w_end in batch_view
]
)
# rematch block's scheduler status
self.scheduler.__dict__.update(views_scheduler_status[j])
# expand the latents if we are doing classifier free guidance
latent_model_input = (
latents_for_view.repeat_interleave(2, dim=0)
if do_classifier_free_guidance
else latents_for_view
)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# repeat prompt_embeds for batch
prompt_embeds_input = torch.cat([prompt_embeds] * vb_size)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds_input,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred[::2], noise_pred[1::2]
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents_denoised_batch = self.scheduler.step(
noise_pred, t, latents_for_view, **extra_step_kwargs
).prev_sample
# save views scheduler status after sample
views_scheduler_status[j] = copy.deepcopy(self.scheduler.__dict__)
# extract value from batch
for latents_view_denoised, (h_start, h_end, w_start, w_end) in zip(
latents_denoised_batch.chunk(vb_size), batch_view
):
if circular_padding and w_end > latents.shape[3]:
# Case for circular padding
value[:, :, h_start:h_end, w_start:] += latents_view_denoised[
:, :, h_start:h_end, : latents.shape[3] - w_start
]
value[:, :, h_start:h_end, : w_end - latents.shape[3]] += latents_view_denoised[
:, :, h_start:h_end, latents.shape[3] - w_start :
]
count[:, :, h_start:h_end, w_start:] += 1
count[:, :, h_start:h_end, : w_end - latents.shape[3]] += 1
else:
value[:, :, h_start:h_end, w_start:w_end] += latents_view_denoised
count[:, :, h_start:h_end, w_start:w_end] += 1
# take the MultiDiffusion step. Eq. 5 in MultiDiffusion paper: https://arxiv.org/abs/2302.08113
latents = torch.where(count > 0, value / count, value)
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
if circular_padding:
image = self.decode_latents_with_padding(latents)
else:
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
self.maybe_free_model_hooks()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
diffusers/src/diffusers/pipelines/stable_diffusion_panorama/pipeline_stable_diffusion_panorama.py/0
|
{
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_panorama/pipeline_stable_diffusion_panorama.py",
"repo_id": "diffusers",
"token_count": 22052
}
| 134 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.