
blob_id
string | repo_name
string | path
string | length_bytes
int64 | score
float64 | int_score
int64 | text
string |
|---|---|---|---|---|---|---|
f1b3a4323014bd8f78fa1744c04b3b102c888a5c | christina57/lc-python | /lc-python/src/lock/291. Word Pattern II.py | 1,708 | 3.9375 | 4 | """
291. Word Pattern II
Given a pattern and a string str, find if str follows the same pattern.
Here follow means a full match, such that there is a bijection between a letter in pattern and a non-empty substring in str.
Examples:
pattern = "abab", str = "redblueredblue" should return true.
pattern = "aaaa", str = "asdasdasdasd" should return true.
pattern = "aabb", str = "xyzabcxzyabc" should return false.
Notes:
You may assume both pattern and str contains only lowercase letters.
"""
class Solution(object):
def wordPatternMatch(self, pattern, str):
"""
:type pattern: str
:type str: str
:rtype: bool
"""
maps = {}
vset = set()
return self.helper(pattern, 0, str, 0, maps, vset)
def helper(self, pattern, pidx, str, sidx, maps, vset):
if pidx == len(pattern) and sidx == len(str):
return True
elif pidx == len(pattern) or sidx == len(str):
return False
p = pattern[pidx]
if p in maps:
v = maps[p]
if v == str[sidx:sidx+len(v)]:
return self.helper(pattern, pidx+1, str, sidx+len(v), maps, vset)
else:
return False
else:
for i in range(1, len(str)-sidx+2-len(pattern)+pidx):
if str[sidx:sidx+i] in vset:
continue
maps[p] = str[sidx:sidx+i]
vset.add(str[sidx:sidx+i])
if self.helper(pattern, pidx+1, str, sidx+i, maps, vset):
return True
del maps[p]
vset.discard(str[sidx:sidx+i])
return False
|
11d8f281fabaa5b5d44692a71b8004dccaba6b27 | hirenhk15/ga-learner-dst-repo | /basecamp/10_Probability_of_the_Loan_Defaulters/code.py | 1,706 | 3.5625 | 4 | # --------------
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Load the dataframe
df = pd.read_csv(path)
#Code starts here
# TASK 1
# Probability p(A) for the event that fico credit score is greater than 700
p_a = len(df[df['fico'] > 700])/ len(df)
# Probability p(B) for the event that purpose == 'debt_consolidation'
p_b = len(df[df['purpose'] == 'debt_consolidation']) / len(df)
# Probablityp(B|A) for the event purpose == 'debt_consolidation' given 'fico' credit score is greater than 700
df1 = df[df['purpose'] == 'debt_consolidation']
p_b_a = len(df1) / len(df[df['fico'] > 700])
# Independency check
result = p_b_a == p_b
print(result)
# TASK 2
# Probability p(A) for the event that paid.back.loan == Yes
prob_lp = len(df[df['paid.back.loan'] == 'Yes']) / len(df)
# Probability p(B) for the event that credit.policy == Yes
prob_cs = len(df[df['credit.policy'] == 'Yes']) / len(df)
# Probablityp(B|A) for the event paid.back.loan == 'Yes' given credit.policy == 'Yes'
new_df = df['paid.back.loan'] == 'Yes'
new_df1 = df['credit.policy'] == 'Yes'
#print(pd.crosstab(new_df, new_df1)) #, normalize='columns'))
prob_pd_cs = (new_df & new_df1).sum() / new_df.sum()
# Apply bayes theorem
bayes = prob_pd_cs * prob_lp / prob_cs
print(bayes)
# TASK 3
purpose = df['purpose'].value_counts()
purpose.plot.bar()
plt.show()
df1 = df[df['paid.back.loan'] == 'No']
print(df1.shape)
df1['paid.back.loan'].value_counts().plot.bar()
plt.show()
# TASK 4
inst_median = df['installment'].median()
inst_mean = df['installment'].mean()
df['installment'].hist()
plt.show()
df['log.annual.inc'].hist()
plt.show()
|
90ca31e787c0be31675bf6e72e9d984ca3957ba2 | pylinx64/sun_python_14 | /sun_python_14/elka.py | 768 | 3.953125 | 4 | import turtle
t = turtle.Pen()
def star(n):
'''рисует звездочку'''
t.left(90)
t.forward(3*n)
t.color("orange", "yellow") # цвет карандаша, цвет заливки
t.begin_fill() # начало заливка
t.left(126)
for i in range(5):
t.forward(n/5)
t.right(144)
t.forward(n/5)
t.left(72)
t.end_fill() # конец заливки
t.right(126)
def tree(d, s):
'''рисует елочку'''
if d <= 0: return
t.forward(s)
tree(d-1, s*0.8)
t.right(120)
tree(d-3, s*0.5)
t.right(120)
tree(d-3, s*0.5)
t.right(120)
t.backward(s)
t.speed('fastest')
star(100)
t.backward(100*4.8)
t.color('dark green')
tree(20, 100)
turtle.done()
|
87f075deda8f0bf0a7091f4db09ccae8d11f462b | ElderVivot/python-cursoemvideo | /Ex012.py | 167 | 3.6875 | 4 | preco = float(input('Digite o valor produto: '))
desconto = preco * 0.95
print('O valor final do produto após o cálculo do desconto dado é {:.2f}'.format(desconto)) |
6c3ba39b9318806444770ba500bc33a0b0000ff0 | pfreisleben/Blue | /Modulo1/Aula 10 - While/Desafio.py | 1,577 | 4.09375 | 4 | """ Desenvolver um programa para verificar a nota do aluno em uma prova com 10
questões, o programa deve perguntar ao aluno a resposta de cada questão e ao
final comparar com o gabarito da prova assim calcular o total de acertos e a
nota (atribuir 1 ponto por resposta certa). Após cada aluno utilizar o sistema
deve ser feita uma pergunta se outro aluno vai utilizar o sistema.
Após todos os alunos terem respondido informar:
• Maior e Menor Acerto;
• Total de Alunos que utilizaram o sistema;
• A Média das Notas da Turma.
# Gabarito da Prova:
# 01 - A
# 02 - B
# 03 - C
# 04 - D
# 05 - E
# 06 - E
# 07 - D
# 08 - C
# 09 - B
# 10 - A
Após concluir isto você poderia incrementar o programa permitindo que o
professor digite o gabarito da prova # antes dos alunos usarem o programa. """
alunos = []
nota = []
gabarito = ["a", "b", "c", "d", "e", "e", "d", "c", "b", "a"]
continua = True
while continua:
acertos = 0
nome = input("Aluno, digite o seu nome: ")
for questao in range(len(gabarito)):
resposta = input(
f'Digite a resposta para a pergunta {questao + 1}: ').lower()
if resposta == gabarito[questao]:
acertos += 1
alunos.append(nome)
nota.append(acertos)
deveContinuar = input("Outro aluno vai utilizar o sistema? S/N ").lower()
if deveContinuar == 'n':
continua = False
print(f'Maior acerto: {max(nota)}')
print(f'Menor acerto: {min(nota)}')
print(f'Quantidade de alunos que utilizaram: {len(alunos)}')
print(f'A média da sala é: {sum(nota) / len(nota)} ')
|
6ca94d7f14b294ea5da1090e0981cd7c7d1591e9 | Tee1er/ai4all-berkeley-driving | /driving/roadmap.py | 5,401 | 3.515625 | 4 | from math import pi, sin, cos, floor, ceil
import numpy as np
from random import random
from matplotlib.patches import Circle, Rectangle
# all angles in this file are in RADIANS unless otherwise noted
LINEWIDTH = 50.0
def angle_diff(a, b):
"""Calculate the difference in angles between -pi and pi"""
delta = a-b
while delta > pi:
delta -= 2*pi
while delta <= -pi:
delta += 2*pi
return delta
class Tile:
def __init__(self, start, end):
self.start = np.array(start)
self.end = np.array(end)
class StraightTile(Tile):
def distance_angle(self, x, y, theta):
"""Distance and angle from nearest road centerline"""
dist = np.cross(self.vec(), np.array((x,y))-self.start).item()
ang = angle_diff(theta, self.angle())
return dist, ang
def vec(self):
return self.end-self.start
def angle(self):
v = self.vec()
return np.arctan2(v[1], v[0])
def plot(self, ax, xy, linewidth=LINEWIDTH):
p1 = self.start + xy
p2 = self.end + xy
ax.plot([p1[0],p2[0]], [p1[1],p2[1]], linewidth=linewidth, color="gray")
class CurveTile(Tile):
def distance_angle(self, x, y, theta):
"""Distance and angle from nearest road centerline"""
# this is probably more complicated than necessary. Don't stare at it too hard.
c2 = self.center2()
c3 = self.center3()
pos = np.array((x, y))
cpos = pos - c2
cpos3 = np.array((x-c2[0], y-c2[1], 0.0))
if np.linalg.norm(cpos) <= 1e-6:
closest = self.start
else:
closest = c2 + 0.5*cpos/np.linalg.norm(cpos)
# tangent = np.cross((0., 0., c3[2]), cpos3)/np.linalg.norm(cpos3)
closest3 = np.array((closest[0], closest[1], 0.0))
tangent = np.cross((0., 0., c3[2]), closest3-c3)/0.5
assert np.abs(np.linalg.norm(tangent) - 1.0) < 1e-5
dist = np.cross(tangent[0:2], pos-closest).item()
ang = angle_diff(theta, np.arctan2(tangent[1], tangent[0]))
return dist, ang
def center2(self):
"""2d array at the corner the road curves around."""
cx = 1.0 if max(self.start[0], self.end[0]) > 1-1e-5 else 0.0
cy = 1.0 if max(self.start[1], self.end[1]) > 1-1e-5 else 0.0
return np.array((cx, cy))
def center3(self):
"""3d array with x, y at center2. z=-1 if clockwise; z=1 o.w."""
center = self.center2()
relstart = self.start - center
relend = self.end - center
cz = np.cross(relstart, relend).item()
assert cz != 0.0
cz = 1.0 if cz > 0.0 else -1.0
return np.array((center[0], center[1], cz))
def plot(self, ax, xy, linewidth=LINEWIDTH):
c = self.center2() + np.array(xy)
circ = Circle(c, 0.5, linewidth=linewidth, fill=False, edgecolor="gray")
rect = Rectangle(xy, 1.0, 1.0, facecolor="none", edgecolor="none")
ax.add_artist(rect)
ax.add_artist(circ)
circ.set_clip_path(rect)
class RoadMap:
"""Collection of tiles that makes a map. tiles argument is a 2d numpy array of tiles"""
def __init__(self, tiles):
self.tiles = tiles
def distance_angle_deg(self, x, y, theta_deg):
tile = self.get_tile(x, y)
rx, ry = self.tile_relative(x, y)
theta_rad = theta_deg*pi/180
d, a = tile.distance_angle(rx, ry, theta_rad)
return d, a*180/pi
def distance_angle(self, x, y, theta_rad):
tile = self.get_tile(x, y)
rx, ry = self.tile_relative(x, y)
d, a = tile.distance_angle(rx, ry, theta_rad)
return d, a
def get_tile(self, x, y):
"""Return the tile that this falls into"""
row = self.tiles.shape[0]-ceil(y)
row = np.clip(row, 0, self.tiles.shape[0]-1)
col = np.clip(floor(x), 0, self.tiles.shape[1]-1)
return self.tiles[row, col]
def tile_relative(self, x, y):
if x >= self.tiles.shape[1]:
x = x - (self.tiles.shape[1] - 1)
elif x > 0: # within the tiles
x = x%1
if y >= self.tiles.shape[0]:
y = y - (self.tiles.shape[0] - 1)
elif y > 0: # within the tiles
y = y%1
return x, y
def sample(self):
return random()*self.tiles.shape[1], random()*self.tiles.shape[0]
def plot(self, ax, **kwargs):
ax.set_facecolor("lightgreen")
for i in range(self.tiles.shape[0]):
for j in range(self.tiles.shape[1]):
self.tiles[i,j].plot(ax, (j, self.tiles.shape[0]-i-1), **kwargs)
coords = {'left':(0.0, 0.5),
'right':(1.0, 0.5),
'top':(0.5, 1.0),
'bottom':(0.5, 0.0)}
def make_oval():
l = coords['left']
r = coords['right']
t = coords['top']
b = coords['bottom']
rl = StraightTile(r, l)
rb = CurveTile(r, b)
tr = CurveTile(t, r)
lr = StraightTile(l, r)
lt = CurveTile(l, t)
bl = CurveTile(b, l)
return RoadMap(np.array(((rb, rl, bl),
(tr, lr, lt))))
def make_maze():
l = coords['left']
r = coords['right']
t = coords['top']
b = coords['bottom']
rl = StraightTile(r, l)
rb = CurveTile(r, b)
tr = CurveTile(t, r)
lr = StraightTile(l, r)
lt = CurveTile(l, t)
bl = CurveTile(b, l)
tb = StraightTile(t, b)
br = CurveTile(b, r)
lb = CurveTile(l, b)
rt = CurveTile(r, t)
tl = CurveTile(t, l)
bt = StraightTile(b, t)
return RoadMap(np.array([[rb, rl, rl, bl, rb, bl],
[tb, br, lb, rt, tl, bt],
[tb, bt, tr, lr, lr, lt],
[tb, rt, rl, rl, rl, bl],
[tb, br, lb, br, lb, bt],
[tr, lt, tr, lt, tr, lt]]))
|
fc9f6fe10a56bae0da7940787273b420bee73f6f | EoJin-Kim/CodingTest | /이진탐색/정렬된 배열에서 특정 수의 개수 구하기.py | 379 | 3.515625 | 4 | from bisect import bisect_left,bisect_right
def count_by_range(array,left_value,right_value):
right_index=bisect_right(array,right_value)
left_index=bisect_left(array,left_value)
return right_index-left_index
n,x = map(int,input().split())
array = list(map(int,input().split()))
count = count_by_range(array,x,x)
if count ==0:
print(-1)
else:
print(count) |
7b3a791043ddf4841c8da0a767c1044b17df1d49 | Arina-prog/Python_homeworks | /homeworks 5/task_5_10.py | 286 | 3.875 | 4 | # Create a regular expressions to check if string meets some requirements
# #10. stextsel kanonavor artahaytutyun ev stugel te str-um handipum e miqani pahanj
str1 = " es unem %d hat %s " % (2, "shun")
str2 = " es chem sirum voch %s voch %s " % ("katu", "shun")
print(str1)
print(str2) |
87e5cda21d549c3572aff0988f106a58f579876f | joaocmd/Advent-Of-Code-2018 | /5/sol1.py | 1,066 | 3.5625 | 4 | import string
def main():
fp = open("input.txt", "r")
#Remove newline
line = (fp.readline())[:-1]
fp.close()
#Part 1
print(len(reactPolymers(line)))
#Part 2
results = {}
for c in string.ascii_lowercase:
res = removeElement(line, c)
res = reactPolymers(res)
results[c] = res
print(min(len(res) for res in results.values()))
def reactPolymers(original):
res = original[:]
i = 0
while i < len(res)-1:
if ((res[i].isupper() and res[i+1].islower()) or\
(res[i].islower() and res[i+1].isupper())) and\
(res[i].lower() == res[i+1].lower()):
res = res[:i] + res[i+2:]
#Move backwards to see if it created a new possibility
if i != 0: i -= 1
else:
i += 1
return res
def removeElement(original, element):
res = original[:]
i = 0
while i < len(res):
if res[i].lower() == element:
res = res[:i] + res[i+1:]
else:
i += 1
return res |
f51b2e1f73a977298d71152e6d914874f4b4217d | oryband/code-playground | /depth-first-search/tree.py | 291 | 3.578125 | 4 | """This file implements a simple tree node."""
class Node:
"""Tree node simple implentation."""
def __init__(self, v:int, left:'Node'=None, right:'Node'=None):
self.v = v
self.left = left
self.right = right
def __str__(self):
return str(self.v)
|
f29cd6753322209e2de93303aa0debf8417b138a | Vitaliy-Koziak/Homework_6 | /Home work 2_4.py | 876 | 3.703125 | 4 | #Знайти максимальний елемент серед мінімальних елементів стовпців матриці.
import random
m = int(input("Input M:"))
n = int(input("Input N:"))
numbers = [[0] * n for i in range(m)]
for i in range(m):
for j in range(n):
numbers[i][j] = random.randint(1,30)
for i in range(m):
for j in range(n):
print("%4d"%numbers[i][j],end=" ")
print()
array_of_min = []
t = 0
p = 0
min = numbers[t][p]
for j in range(n):
for i in range(m):
if numbers[i][j]< min:
min = numbers[i][j]
if i == m-1 and j < n:
array_of_min.append(min)
min = numbers[p+1][t+1]
print()
for item in array_of_min:
print("%4d "%item,end="")
print()
print()
print(" The maximum element among the minimum elements of the matrix columns is: %d"%max(array_of_min)) |
c62fe5a2808486c363c4a1046203018400e05967 | ANKerD/competitive-programming-constests | /uri/upsolving/1441/code.py | 227 | 3.578125 | 4 | while True:
n = int(raw_input())
if n == 0: break
ans = n
while n != 1:
# print n, i
if n % 2 == 0:
n = n/2
else:
n = 3*n+1
ans = max(ans, n)
print ans |
1d7f90800c6e0e4f102b66901193b3edba74bcc1 | liangrui-online/algori | /水王问题.py | 1,415 | 3.84375 | 4 | """
水王问题:
已知一个数组,找出其中出现次数超过半数的数
"""
def solution_naive(data):
from collections import defaultdict
counter = defaultdict(int)
for item in data:
counter[item] += 1
target, num = None, 0
for char, n in counter.items():
if n > num:
target = char
num = n
if num > len(data) >> 1:
return target
else:
return None
def solution_naive_2(data):
from collections import Counter
counter = Counter(data)
most = counter.most_common(n=1)
target, num = most[0]
if num > len(data) >> 1:
return target
else:
return None
def solution_good(data):
if not data:
return None
target = None
num = 0
for item in data:
if num == 0:
target = item
num += 1
elif target == item:
num += 1
else:
num -= 1
return target if num else None
def test_solution():
import random
import string
# 生成序列
target = random.choice(string.digits)
num = random.randint(5, 50)
data = [target] * num + [random.choice(string.digits) for i in range(num-3)]
random.shuffle(data)
for solution in (solution_naive, solution_naive_2, solution_good):
assert target == solution(data)
if __name__ == '__main__':
test_solution()
|
67345e8527f64bdef3011258ed75f098fdc818f1 | QuantumManiac/cs50 | /pset6/similarities/test.py | 130 | 4.0625 | 4 | string = "hello"
substring = []
n = 3
for i in range(len(string) - n + 1):
substring.append(string[i:n + i])
print(substring)
|
d09e73be564d66863b3e8b745caed6098745a823 | wesselb/ARHC | /arhc/huffman.py | 1,249 | 3.890625 | 4 | from node import Node
import sys
class Huffman:
"""
Construct a symbol code via the Huffman algorithm.
:param symbols: List of symbols that represents the alphabet.
"""
def __init__(self, symbols):
self.build(symbols)
def build(self, symbols):
""" Build a tree of symbols according to the Huffman algorithm. """
while len(symbols) > 1:
self.mergeTwoLowestProbSymbols(symbols)
self.root = symbols[0]
self.encoding = dict(self.root.getEncoding())
def mergeTwoLowestProbSymbols(self, symbols):
""" Merge the two lowest probability symbols. """
symbols.sort(key=lambda symbol: symbol.getProb())
symbols.insert(0, Node(symbols.pop(0), symbols.pop(0)))
def encode(self, stream):
""" Encode the first symbol encountered in a stream by the code symbol
generated by the Huffman algorithm. """
symbol = ''
while not (symbol in self.encoding):
symbol += stream.read()
return self.encoding[symbol]
def decode(self, stream):
""" Decode the first code symbol encountered in a stream by its symbol
in string representation. """
return self.root.decode(stream)
|
da5529cb8578aa547e05f3821426ede8add05590 | Swathi-16-oss/python- | /sales tax.py | 265 | 3.8125 | 4 | '''calculating sales tax:
cost of item*sales tax of rate in decimal part=sales tax
calculating price of an item:
cost of item+sales tax=total cost of item'''
itemcost=60
salestax=7.5
salestax=7.5/100
total=itemcost*salestax
print("%.2f"%total)
#o/p:4.50
|
ef4ccf21d7229ecec425e906e1faa9f78ca24fcf | bagusdewantoro/zedshaw | /ex43test.py | 6,198 | 3.671875 | 4 | from sys import exit
from random import randint
from textwrap import dedent
class Adegan(object):
def masuk(self):
print("Adegan ini belum di-set")
print("Subclass it and implement enter().")
exit(1)
class Mesin(object):
def __init__(self, peta_adegan):
self.peta_adegan = peta_adegan
def main(self):
adegan_sekarang = self.peta_adegan.adegan_pembuka()
adegan_terakhir = self.peta_adegan.adegan_next('selesai')
while adegan_sekarang != adegan_terakhir:
nama_adegan_next = adegan_sekarang.masuk()
adegan_sekarang = self.peta_adegan.adegan_next(nama_adegan_next)
#Pastikan untuk print out adegan terakhir:
adegan_sekarang.masuk()
class Kalah(Adegan):
ejekan = [
"Kamu mati.., bener-bener payah",
"Seandainya kamu lebih pintar..",
"Pecundang..",
"Bahkan anjing kecil saya lebih pintar.."
"Kalah totalll"
]
def masuk(self):
print(Kalah.ejekan[randint(0, len(self.ejekan)-1)])
exit(1)
class KoridorUtama(Adegan):
def masuk(self):
print(dedent("""
Gothon dari Planet Percal menyerang dan
menghancurkan pasukanmu. Kamu adalah anggota
terakhir dan misimu adalah mendapat bom nuklir
dari persenjataan, dan hancurkan kapalnya
setelah berhasil kabur.
Kamu lari di koridor utama menuju gudang
persenjataan ketika Gothon datang. Dia
menghalangi pintu persenjataan dan hampir
menembakmu."""))
aksi = input("> ('tembak', 'hindari', 'bercanda'): ")
if aksi == "tembak":
print(dedent("""
Dengan cepat kostumnya hancur, dia sangat
marah dan langsung menembakmu berkali-kali.
Kemudian dia memakanmu."""))
return 'mati'
elif aksi == "hindari":
print(dedent("""
Kamu menghindar dengan tangkas, tapi malah
terpeleset, dia dengan cepat menginjak dan
memakanmu."""))
return 'mati'
elif aksi == "bercanda":
print(dedent("""
Beruntung, dia suka bercanda, lalu dia ketawa,
dan kemudian kamu bisa tembak dia, lalu langsung
menuju pintu gudang senjata."""))
return 'gudang_senjata'
else:
print("Salah Ngetik!")
return 'koridor_utama'
class SenjataLaser(Adegan):
def masuk(self):
print(dedent("""
Kamu masuk gudang senjata, ngecek barangkali ada
Gothon lain. Kamu menemukan bom neutron. Perlu
memasukkan kode max 10 kali, kodenya 3 digit,
jika salah, bomnya failed selamanya"""))
kode = f"{randint(1,9)}{randint(1,9)}{randint(1,9)}"
tebak = int(input("[keypad]> "))
tebakan = 0
while tebak != kode and tebakan < 10:
# DUA BARIS DI BAWAH INI ADALAH CHEAT TAMBAHAN DARI BAGUS:
if tebak == 777:
return 'jembatan'
# DI BAWAH INI SUDAH SESUAI ASLINYA:
print("BZZZZDDD")
tebakan += 1
tebak = int(input("[keypad]> "))
if tebak == kode:
print(dedent("""
Kotaknya terbuka, kamu ambil bom, lari
secepat mungkin ke jembatan dan harus
meletakkan di tempat yang tepat."""))
return 'jembatan'
else:
print(dedent("""
Kotaknya terkunci, kamu cuman bisa terdiam.
Gothon meledakkan kapa dan kamu mati."""))
return 'mati'
class Jembatan(Adegan):
def masuk(self):
print(dedent("""
Kamu lari menuju jembatan membawa bom neutron
dan hendak menaruhnya di sana dengan tepat.
5 Gothon kaget dan mereka ngga mau menembakmu
karena kamu bawa bom itu."""))
aksi = input("> ('buru-buru taruh', 'taruh perlahan') : ")
if aksi == "buru-buru taruh":
print(dedent("""
Kamu tidak menaruh di tempat yang tepat.
Bom gagal meledak, lalu Gothon menembakmu."""))
return 'mati'
elif aksi == "taruh perlahan":
print(dedent("""
Bom terpasang dengan benar. Para Gothon takut.
Kamu berlari menuju pintu dan menguncinya. Lalu
kamu lari ke tempat melarikan diri."""))
return 'alat_kabur'
else:
print("SALAH KETIK!")
return 'jembatan'
class Alat_Kabur(Adegan):
def masuk(self):
print(dedent("""
Kamu buru-buru masuk ke kapal mencoba kabur dengan alat
untuk melarikan diri. Ada 5 alat, pilih yang mana?"""))
alat_bener = randint(1,5)
tebak = input("[alat #]> ")
if int(tebak) == 777:
print(dedent("""
Kamu berhasil kabur dan para Gothon meledakk!!!"""))
return 'tamat'
elif int(tebak) != alat_bener:
print(dedent(f"""
Kamu pilih alat nomor {tebak} dan mengancurkan
seluruh kapal."""))
return 'mati'
elif int(tebak) == alat_bener:
print(dedent("""
Kamu berhasil kabur dan para Gothon meledakk!!!"""))
return 'tamat'
class Tamat(Adegan):
def masuk(self):
print("Kamu menang! Selamat!")
# return 'tamat' ##--> Ini kode asli ZED
# DI BAWAH INI MODIFIKASI BAGUS:
return exit(1)
class Peta(object):
adegan_adegan = {
'koridor_utama' : KoridorUtama(),
'gudang_senjata' : SenjataLaser(),
'jembatan' : Jembatan(),
'alat_kabur' : Alat_Kabur(),
'mati' : Kalah(),
'tamat' : Tamat()
}
def __init__(self, adegan_awal):
self.adegan_awal = adegan_awal
def adegan_next(self, nama_adegan):
val = Peta.adegan_adegan.get(nama_adegan)
return val
def adegan_pembuka(self):
return self.adegan_next(self.adegan_awal)
a_map = Peta('koridor_utama')
a_game = Mesin(a_map)
a_game.main()
|
a7a70c1fab0030337ff929f3565d584679db6d16 | tlfhmy/PythonStudy | /Tkinter/Entry.py | 754 | 3.625 | 4 | import tkinter as tk
from tkinter import ttk
win = tk.Tk()
win.geometry("800x600")
win.title("Entry")
win.resizable(0, 0)
aLable = ttk.Label(win, text="A Lable")
aLable.grid(column=0, row=0)
def clickMe():
#action.configure(text="** I have been Clicked! **")
#aLable.configure(foreground='red')
action.configure(text='Hello ' + name.get())
action = ttk.Button(win, text="Click Me!", command=clickMe)
action.grid(column=1, row=0)
#action.configure(state='disable')
ttk.Label(win, text="Enter a name: ").grid(column=0, row=0)
name = tk.StringVar()
nameEntered = ttk.Entry(win, width=12, textvariable=name)
nameEntered.grid(column=0, row=1)
nameEntered.focus()
ttk.Label(win, text="Choose a number:").grid(column=2, row=0)
win.mainloop() |
fd6ab0f62eb49e328cef63372005bde1d7151bff | sfitzsimmons/Exercises | /NumberRange.py | 361 | 4.3125 | 4 | # this exercise wants me to test whether a number is within 100 of 1000 or 2000.
given_number = int(input("Enter number: "))
if 900 < given_number < 1100:
print("Your number is within 100 of 1000.")
elif 1900 < given_number < 2100:
print("Your number is within 100 of 2000")
else:
print("Your number is not within 100 of 1000 or 2000.")
|
7b359ce76cc5e39a8f837d5726370bd5b7db025b | Hassan6678/Image_processing | /MLP.py | 2,358 | 3.859375 | 4 | from sklearn.neural_network import MLPClassifier
import Data
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
d = Data.load_my_dataset()
X, y = d.data, d.target
train_X, test_X, train_y, test_y = train_test_split(X, y,
train_size=0.7,
random_state=3,
stratify=y)
mlp = MLPClassifier(random_state=0)
mlp.fit(train_X, train_y)
print("Accuracy on training set: {:.2f}".format(mlp.score(train_X, train_y)))
print("Accuracy on test set: {:.2f}".format(mlp.score(test_X, test_y)))
# compute the mean value per feature on the training set
mean_on_train = train_X.mean(axis=0)
# compute the standard deviation of each feature on the training set
std_on_train = train_X.std(axis=0)
# subtract the mean, and scale by inverse standard deviation
# afterward, mean=0 and std=1
X_train_scaled = (train_X - mean_on_train) / std_on_train
# use THE SAME transformation (using training mean and std) on the test set
X_test_scaled = (test_X - mean_on_train) / std_on_train
mlp = MLPClassifier(random_state=0)
mlp.fit(X_train_scaled, train_y)
print("Accuracy on training set: {:.3f}".format(
mlp.score(X_train_scaled, train_y)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, test_y)))
mlp = MLPClassifier(max_iter=1000, random_state=0)
mlp.fit(X_train_scaled, train_y)
print("Accuracy on training set: {:.3f}".format(
mlp.score(X_train_scaled, train_y)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, test_y)))
training_accuracy = []
test_accuracy = []
n_iter = [200,400,600,800,1000,1200,1400,1600,1800,2000]
ran = 20
for n in n_iter:
# build the model
clf = MLPClassifier(max_iter=n, random_state=ran)
clf.fit(train_X, train_y)
# record training set accuracy
training_accuracy.append(clf.score(train_X, train_y))
# record generalization accuracy
test_accuracy.append(clf.score(test_X, test_y))
ran = ran + 20
print("Test Accuracy: ", test_accuracy)
print("Train Accuracy: ", training_accuracy)
plt.plot(n_iter, training_accuracy, label="training accuracy")
plt.plot(n_iter, test_accuracy, label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_iteration")
plt.legend()
plt.show() |
05cc5dfaba953171d908446cf9b487d3803147e8 | FelixOpolka/Statistical-Learning-Algorithms | /common/Tester.py | 2,989 | 3.96875 | 4 | """Tester for various predictors. Given a data set file (csv)
the tester loads the data sets, separates it into training and
test set and performs the training and subsequent testing."""
# Currently, only classification tests supported
import csv
from random import shuffle
def __parse(string):
"""Parses a given string into a float if it contains a dot, into
integer otherwise.
:param string: Given string to parse.
:return: Integer or float representation of the given string. """
if "." in string:
return float(string)
return int(string)
def __load_data_set(path, test_set_length):
"""Loads the data set specified by its path (pointing to a csv file),
shuffles it and returns the resulting training and test set.
:param path: Path pointing to the data set's csv file. Output variable
must be the last column.
:param test_set_length: Length of the resulting test set in number
of tuples. The rest of the data set will make up the training set.
:return: Training and test set resulting from data set."""
with open(path) as file:
data = [tuple([__parse(x) for x in line]) for line in csv.reader(file)]
shuffle(data)
test_set = data[:test_set_length]
training_set = data[test_set_length:]
return training_set, test_set
def __get_accuracy(predictor, test_set, evaluate):
"""Calculates the accuracy of a given classification predictor using
the given test set.
:param predictor: Predictor to test.
:param test_set: Test set to use for testing.
:param evaluate: Function that is used to evaluate the predictor.
Should take as arguments the predictor to evaluate and the input
and returns corresponding prediction.
:return: Measured accuracy of the predictor."""
correct_count = 0
for point in test_set:
input = point[0:-1]
output = point[-1]
prediction = evaluate(predictor, input)
if prediction == output:
correct_count += 1
return correct_count/len(test_set)
def test(path, test_set_length, train, evaluate):
"""Tests a classification predictor on a given data sets and
returns its accuracy.
:param data-set: Path pointing to the data set's csv file. Output
variable must be the last column. Output must be discrete variable.
:param test_set_length: Length of the test set constructed from the
data set in tuples. The rest of the data set will make up the training
set.
:param train: Method for training the predictor that should be
tested. Given a training set should return a trained predictor.
:param evaluate: Method for evaluating the predictor that should be
tested. Given a predictor and an input should return corresponding
prediction.
:return: Measured accuracy of the predictor."""
training_set, test_set = __load_data_set(path, test_set_length)
predictor = train(training_set)
return __get_accuracy(predictor, test_set, evaluate)
|
b461e31da1b8d04215671e9b827ab89f106fce24 | mattshakespeare/pythonPractise | /random.py | 3,243 | 4.03125 | 4 | #outputs random int between 1 - 100
import random
print(random.randint(1,100))
print()
#outputs random entity from a list of fruit
fruit = ["Grapes", "Orange", "Banana", "Grapefruit", "Honeydew Melon", "Strawberry", "Watermelon"]
print(random.choice(fruit))
print()
#user and computer choose heads or tails
#if user == computer "You win"
#if user != computer "Bad luck"
y = "y"
while y == "y":
x = ["Heads", "Tails"]
comp = random.choice(x)
user = input("Lets play heads or tails, what do you choose: ")
user = user.title()
if user == "Heads" or user == "Tails":
if user == comp:
print("You win, the computer picked", comp,".")
y = input("Press y to play again, press x to end the game: ")
else:
if user != comp:
print("Bad luck!!!!!!, the computer picked ", comp,".")
y = input("Press y to play again, press x to end the game: ")
else:
print("You must choose heads or tails.")
print()
#reads random int
#user has two attempts to guess the int
#before second attempt output "Too high" or "Too low"
comp = random.randint(1, 5)
user = int(input("The computer has a number between 1 and 5. Can you guess: "))
if user == comp:
print("Correct, you win.")
else:
if user > comp:
user = int(input("Too high, try agian: "))
elif user < comp:
user = int(input("Too low, try again: "))
if user == comp:
print("Correct, second time lucky!!!")
else:
print("Unlcuky, you lose the computers number was", comp)
print()
#reads random int between 1 and 10
#while user int != comp int, loop continues
comp = random.randint(1,10)
user = int(input("The computer has a number between 1 and 10, can you guess the computers number: "))
if user != comp:
while user != comp:
if user > comp:
print("Too high.")
if user < comp:
print("Too low.")
user = int(input("Try again: "))
print(user, " is correct the game is over.")
print()
#math quiz, reads two random int *5 and user answers each sum.
#var stores users score and outputs score
score = 0
x = input("Let's have a math quiz, press x to take part, press anything else to skip: ")
if x == "x":
for i in range(1, 6):
num1 = random.randint(0, 100)
num2 = random.randint(0, 100)
ans = num1 + num2
print("Question", i," : ", num1, " + ", num2)
user = int(input("= "))
if user == ans:
print("Correct!")
score += 1
else:
print("Incorrect. The answer is ", ans)
print("You scored: ", score,"/5")
print()
#stores list of five colours, user has two attempts to guess compters choice
col = ["Red", "Yellow", "Orange", "Blue", "Green"]
comp = random.choice(col)
print(col)
user = input("What colour do you think the computer is thinking of: ")
user = user.title()
if user == comp:
print("Well done, you guessed correctly.")
elif user != comp:
print("Wrong, you must be ", comp, "with envy.")
user = input("Try again: ")
user = user.title()
if user == comp:
print("Second time lucky!!!")
else:
print("Unlucky, the computers colour was ", comp, ".")
|
f0f0d8e4a4d18ef2a0eb28e43d62bc8cb14cc7c1 | masuda350/hangman | /Problems/Checking email/main.py | 386 | 3.8125 | 4 | def check_email(string):
length_string = len(string)
at = string.find('@')
if length_string == len(string.replace(' ', '')):
return string.find('.', at, length_string) > at + 1
return False
# Another solution 1
# if '@' in string and ' ' not in string and '@.' not in string:
# return string.rfind('.') > string.find('@') + 1
# return False
|
642cf30ccfb6a00ef74b187f9864ed7c0d964da7 | beccam/tournament-results_2 | /tournament.py | 4,447 | 3.625 | 4 | #!/usr/bin/env python
#
# tournament.py -- implementation of a Swiss-system tournament
#
import psycopg2
def connect():
"""Connect to the PostgreSQL database. Returns a database connection."""
""" Will connect with the tournament database. """
return psycopg2.connect("dbname=tournament")
def deleteMatches():
"""Remove all the match records from the database."""
""" Will clear out the matches table in the database. """
conn = connect()
c = conn.cursor()
c.execute("DELETE FROM matches")
conn.commit()
conn.close()
def deletePlayers():
"""Remove all the player records from the database."""
"""Will remove the players from the players table in the database."""
conn = connect()
c = conn.cursor()
c.execute("DELETE FROM players")
conn.commit()
conn.close()
def countPlayers():
"""Returns the number of players currently registered."""
"""Will return number of players in the players table. """
conn = connect()
c = conn.cursor()
c.execute("SELECT count(*) AS num_players FROM players;")
num_players = c.fetchone()
conn.close()
return num_players[0]
def registerPlayer(name):
"""Adds a player to the tournament database.
The database assigns a unique serial id number for the player. (This
should be handled by your SQL database schema, not in your Python code.)
Args:
name: the player's full name (need not be unique).
"""
""" Adds a player to the players table."""
conn = connect()
c = conn.cursor()
c.execute("INSERT INTO players (name) VALUES (%s)", (name,))
conn.commit()
conn.close()
def playerStandings():
"""Returns a list of the players and their win records, sorted by wins.
The first entry in the list should be the player in first place, or a player
tied for first place if there is currently a tie.
Returns:
A list of tuples, each of which contains (id, name, wins, matches):
id: the player's unique id (assigned by the database)
name: the player's full name (as registered)
wins: the number of matches the player has won
matches: the number of matches the player has played
"""
"""Will return a list of players and wins, sorted by most wins."""
conn = connect()
c = conn.cursor()
c.execute("""
SELECT x0.id as id, x0.name as name, COALESCE(win, 0) wins, COALESCE(matches_played, 0) as matches
FROM
(SELECT id, name from players) x0
LEFT OUTER JOIN
(SELECT p1.id as id1, p1.name as name, count(m1.id) as matches_played
FROM players as p1, matches as m1
WHERE p1.id = m1.player_one_id OR p1.id = m1.player_two_id
GROUP BY p1.id) x1
ON (x0.id = x1.id1)
LEFT OUTER JOIN
(SELECT count(*) as win, p2.id as id2
FROM matches as m2, players as p2
WHERE (p2.id = m2.winner_id)
GROUP BY p2.id) x2
ON (x1.id1 = x2.id2)
ORDER BY wins DESC, matches DESC;""")
return c.fetchall()
def reportMatch(winner, loser):
"""Records the outcome of a single match between two players.
Args:
winner: the id number of the player who won
loser: the id number of the player who lost
"""
"""Will return the result of a single match between two players."""
conn = connect()
c = conn.cursor()
sql = '''
INSERT INTO matches(player_one_id,player_two_id,winner_id)
VALUES( %s , %s , %s );''' % ( str(winner) , str(loser) , str(winner))
c.execute(sql)
conn.commit()
conn.close()
def swissPairings():
"""Returns a list of pairs of players for the next round of a match.
Assuming that there are an even number of players registered, each player
appears exactly once in the pairings. Each player is paired with another
player with an equal or nearly-equal win record, that is, a player adjacent
to him or her in the standings.
Returns:
A list of tuples, each of which contains (id1, name1, id2, name2)
id1: the first player's unique id
name1: the first player's name
id2: the second player's unique id
name2: the second player's name
"""
"""Will return a list of players for the next round according to the Swiss
pairing style."""
rows = playerStandings()
pairs = []
for (i, j) in zip(rows, rows[1::])[::2]:
pair = (i[0], i[1], j[0], j[1])
pairs.append(pair)
return pairs
|
14e7622a487ae12f73725f2edff16dbf77c3f42a | Priyankavad/Python-Programs | /Hcf.py | 531 | 4.1875 | 4 | # defining a function to calculate HCF
def calculate_hcf(h, p):
# selecting the smaller number
if h > p:
smaller = p
else:
smaller = h
for i in range(1,smaller + 1):
if((h % i == 0) and (p % i == 0)):
hcf = i
return hcf
# taking input from users
num1 = int(input("Enter first number: "))
num2 = int(input("Enter second number: "))
# printing the result for the users
print("The H.C.F. of", num1,"and", num2,"is", calculate_hcf(num1, num2))
|
fc46870652eb4c2e095ae5f753e5ab703f28359e | MasumTech/URI-Online-Judge-Solution-in-Python | /URI-1013.py | 128 | 3.53125 | 4 | row_input = input().split(" ")
a, b, c = row_input
greatest = max(int(a), int(b), int(c))
print(str(greatest) + ' eh o maior') |
ccd6b8b35096bbf3522de9fa7973055264a30e69 | zhangjh12492/python_used | /head_first/chapter5/class_used_1.py | 1,200 | 3.625 | 4 | from head_first.chapter5.filter_speed_2 import sanitize
class Athlete:
name = ''
dob = ''
times = []
filename = ''
def __init__(self, filename=''):
self.filename = filename
def top3(self):
return sorted(set([sanitize(t) for t in self.times]))[0:3]
def get_coach_data(self):
try:
with open(self.filename) as file:
data = file.readline()
templ = data.strip().split(",")
self.name = templ.pop(0)
self.dob = templ.pop(0)
self.times = templ
return self
except IOError as ioerr:
print('File error:' + str(ioerr))
return None
def add_time(self,time_value):
self.times.append(time_value)
def add_times(self,list_of_times):
self.times.extend(list_of_times)
sarah = Athlete('sarah.txt')
james = Athlete('James Jones')
print(type(sarah))
print(type(james))
print(sarah.get_coach_data().top3())
print(sarah.get_coach_data().name + "'s fastest times are: " +
str(sarah.get_coach_data().top3()))
sarah.add_time('1.24')
print(sorted(sarah.times))
sarah.add_times(['1.35','2.45'])
print(sorted(sarah.times)) |
4971419f604f342ea8c09943c7069a3cf3e93288 | tanzoniteblack/Hangman | /src/loadDic.py | 523 | 3.75 | 4 | def loadDic(lang = "en"):
"""Load file lang_dict.txt and pick a word from it at random"""
# import random library to make choice
from random import choice
# Read dictionary line by line and turn into list
dictionary = open(lang+"_dict.txt").readlines()
# return random entry with \n (new line) character stripped and made lower-case (this could be changed if dictionary is double checked for desired case, or case is made non-important by letter guesser aspect of program)
return choice(dictionary).rstrip().lower()
|
19503ae16969204cebd1c69e94206fcbc48669d3 | Ujjal-Baniya/CompetitiveProgramming-python | /Youtube tricks for competitive/stack_implementation.py | 1,488 | 3.953125 | 4 | ### write your solution below this line ###
class Stack:
def __init__(self, size):
self.size = size
self.data = [None]* self.size
self.top = -1
def push(self,val):
if not self.isFull():
self.data.append(val)
self.top += 1
def isFull(self):
if self.top >= self.size-1:
return 1
return 0
def pop(self):
poped = None
if not self.isEmpty():
poped = self.data.pop()
self.top -= 1
return poped
def peek(self):
return self.data[-1]
def isEmpty(self):
if self.top <= -1:
return 1
return 0
if __name__ == "__main__":
test_cases=int(input()) # number of test cases
size=int(input()) # size of Stack
stack=Stack(size) # creating new stack object
while(test_cases>0):
instruction=input().split()
val=0
if len(instruction)>1:
val=int(instruction[1])
instruction=int(instruction[0])
if(instruction==1):
print(f'push:{val}')
stack.push(val)
elif (instruction==2):
print(f'pop:{stack.pop()}')
elif (instruction==3):
print(f'peek:{stack.peek()}')
elif(instruction==4):
print(f'isEmpty:{stack.isEmpty()}')
elif(instruction==5):
print(f'isFull:{stack.isFull()}')
test_cases=test_cases-1 |
8bfcf06865e2cf7b23bc7c58435ca81250b7930f | Tonaay/Learning-Python | /Python Files/prac02.py | 3,296 | 4.125 | 4 | #Tony Van
#UP821148
import math
def circumferenceOfCircle():
radius = eval(input("Enter Radius :"))
circumference = 2 * math.pi * radius
print("The circumference is", circumference)
def areaofCircle():
radius = eval(input("Enter Radius :"))
Area = math.pi * radius**2
print("The area is", Area)
def costOfPizza():
diameter = float(input("Enter diameter :"))
radius2 = diameter/2
area2 = math.pi * radius2**2
cost = area2*1.5/100
print("Pizza will cost £",round(cost,2))
#Exercise 5 and 6 - distanceBetweenPoints
def slopeOfLine():
x1 = eval(input("Enter x1: "))
y1 = eval(input("Enter y1: "))
x2 = eval(input("Enter x2: "))
y2 = eval(input("Enter y2: "))
slope = (y2-y1) / (x2-x1)
distance = math.sqrt((x2 - x1)**2 + (y2 - y1)**2)
print("Slope is =", slope ,"Distance is =",distance)
def travelStatistics():
averageSpeed = eval(input("Input average speed in km/hour: "))
duration = eval(input("Enter duration in hours: "))
distance2 = averageSpeed * duration
litreUsed = 0.2*distance2
print("Distance travelled =" , distance2 , " || Fuel used in litres =" , litreUsed)
def sumOfNumbers():
numberInput = int(input("Enter number: "))
numberAddition = range(numberInput+1)
sumOfRange = sum(numberAddition)
print(sumOfRange)
def sumNum2():
numInput = eval(input("Enter number : "))
for i in range(1, numInput+1):
sum = 0
for i2 in range(1, i+1):
sum = sum + i2
print(str(sum))
def volL():
radius4 = eval(input("enter radius"))
volume = math.pi/3*4*radius4**3
print(volume)
def averageOfNumbers():
amountNo = eval(input("How many numbers to input: "))
total = 0
for i in range(amountNo):
total = total + eval(input("Enter numbers"))
average = total/amountNo
print("Average number is ", average)
def selectCoins():
startingCoin = eval(input("Enter starting amount"))
amountRemaining = startingCoin
twoPound = startingCoin // 200
amountRemaining -= twoPound * 200
onePound = amountRemaining // 100
amountRemaining -= onePound * 100
pence50 = amountRemaining // 50
amountRemaining -= pence50 * 50
pence20 = amountRemaining // 20
amountRemaining -= pence20 * 20
pence10 = amountRemaining // 10
amountRemaining -= pence10 * 10
pence5 = amountRemaining // 5
amountRemaining -= pence5 * 5
pence2 = amountRemaining // 2
amountRemaining -= pence2 * 2
pence1 = amountRemaining // 1
amountRemaining -= pence1 * 1
print("£2 x ", twoPound,"|| £1 x ", onePound, "|| 50p x ", pence50, "|| 20p x ", pence20, "|| 10p x ", pence10, "|| 5p x ", pence5, "|| 2p x ", pence2, "|| 1p x ", pence1)
def selectCoins2():
startingCoin = eval(input("Enter starting amount: "))
coinType = [200,100,50,20,10,5,2,1]
nextCoin = [0,0,0,0,0,0,0,0]
amountRemaining = startingCoin
for i in range(8):
nextCoin[i] = amountRemaining // coinType[i]
amountRemaining -= nextCoin[i] * coinType[i]
pounds = 100
pennyList = ["2.00","1.00",50,10,5,2,1]
print("£ :", pennyList, "Minimum coin amount :", nextCoin)
|
4857c78c79f8f566b79dda8d6115e17ea9920391 | hernandez87v/Zookeeper | /Problems/Sum/task.py | 100 | 3.578125 | 4 | # put your python code here
n = int(input())
n2 = int(input())
n3 = int(input())
print(n + n2 + n3)
|
880a4e2fe9147fca7fbd91b954a30790832db9c0 | renukadeshmukh/Leetcode_Solutions | /helpers/linked_list_helper.py | 513 | 3.828125 | 4 |
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
class LinkedList:
@staticmethod
def printLinkedList(head):
cur = head
while cur != None:
print(cur.val, '-->>')
cur = cur.next
@staticmethod
def array_to_linkedlist(nums):
head = ListNode(nums[0])
cur = head
for n in nums[1:]:
node = ListNode(n)
cur.next = node
cur = cur.next
return head |
6857220bc1479c12da478462c80709b2233b8d90 | RachelMurt/Python | /Ice cream.py | 316 | 4.125 | 4 | flavour = input("What is your favourite ice cream flavour?: ")
if flavour == 'mint chocolate chip':
print ("The best flavour! You have great taste!")
elif flavour == 'cookie dough':
print ("A good choice!")
elif flavour == 'cherry':
print ("Why?")
else:
print ("That's alright, I guess.")
|
dc0b060b1dd8892a93ecf8cdbff479b475f4b56e | rohith2506/Algo-world | /interviewbit/bin_search/search2d.py | 378 | 3.625 | 4 | '''
Start at top-right
1) top - bottom by checking with the last element of each row in the array
2) Then go right - left until you find the element
elegant solution
'''
class Solution:
def searchMatrix(self, A, B):
m, n = len(A), len(A[0])
i, j = 0, n - 1
while i < m and j >= 0:
if A[i][j] == B: return 1
if A[i][j] > B: j = j - 1
else: i = i + 1
return 0
|
fffed9df6ff0926e463c160ce427dbcc597e929e | vovakpro13/PythonLabs | /Lab_3/task_1.py | 421 | 3.640625 | 4 | N = int(input('Enter N:'))
if 0 <= N <= 10:
for row in range(1, N + 1):
res = ''
for col in range(1, row + 1):
res += ' ' + str(N - row + col)
print(' ' * (N - 1) + res)
for row in range(1, N + 1):
res = ''
for col in range(1, row + 1):
res += ' ' + str(row - col + 1)
print(' ' * (N - row) + res)
else:
print('N is not correct!') |
99709c7a255a960957ebae16230e877bb71cf94b | ericfourrier/scikit-learn | /examples/mixture/plot_gmm_sin.py | 3,242 | 3.6875 | 4 | """
=================================
Gaussian Mixture Model Sine Curve
=================================
This example highlights the advantages of the Dirichlet Process:
complexity control and dealing with sparse data. The dataset is formed
by 100 points loosely spaced following a noisy sine curve. The fit by
the GMM class, using the expectation-maximization algorithm to fit a
mixture of 10 Gaussian components, finds too-small components and very
little structure. The fits by the Dirichlet process, however, show
that the model can either learn a global structure for the data (small
alpha) or easily interpolate to finding relevant local structure
(large alpha), never falling into the problems shown by the GMM class.
"""
import itertools
import numpy as np
from scipy import linalg
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import mixture
color_iter = itertools.cycle(['navy', 'c', 'cornflowerblue', 'gold',
'darkorange'])
def plot_results(X, Y_, means, covariances, index, title):
splot = plt.subplot(3, 1, 1 + index)
for i, (mean, covar, color) in enumerate(zip(
means, covariances, color_iter)):
v, w = linalg.eigh(covar)
v = 2. * np.sqrt(2.) * np.sqrt(v)
u = w[0] / linalg.norm(w[0])
# as the DP will not use every component it has access to
# unless it needs it, we shouldn't plot the redundant
# components.
if not np.any(Y_ == i):
continue
plt.scatter(X[Y_ == i, 0], X[Y_ == i, 1], .8, color=color)
# Plot an ellipse to show the Gaussian component
angle = np.arctan(u[1] / u[0])
angle = 180. * angle / np.pi # convert to degrees
ell = mpl.patches.Ellipse(mean, v[0], v[1], 180. + angle, color=color)
ell.set_clip_box(splot.bbox)
ell.set_alpha(0.5)
splot.add_artist(ell)
plt.xlim(-6., 4. * np.pi - 6.)
plt.ylim(-5., 5.)
plt.title(title)
plt.xticks(())
plt.yticks(())
# Number of samples per component
n_samples = 100
# Generate random sample following a sine curve
np.random.seed(0)
X = np.zeros((n_samples, 2))
step = 4. * np.pi / n_samples
for i in range(X.shape[0]):
x = i * step - 6.
X[i, 0] = x + np.random.normal(0, 0.1)
X[i, 1] = 3. * (np.sin(x) + np.random.normal(0, .2))
# Fit a Gaussian mixture with EM using ten components
gmm = mixture.GaussianMixture(n_components=10, covariance_type='full',
max_iter=100).fit(X)
plot_results(X, gmm.predict(X), gmm.means_, gmm.covariances_, 0,
'Expectation-maximization')
# Fit a Dirichlet process Gaussian mixture using ten components
dpgmm = mixture.DPGMM(n_components=10, covariance_type='full', alpha=0.01,
n_iter=100).fit(X)
plot_results(X, dpgmm.predict(X), dpgmm.means_, dpgmm._get_covars(), 1,
'Dirichlet Process,alpha=0.01')
# Fit a Dirichlet process Gaussian mixture using ten components
dpgmm = mixture.DPGMM(n_components=10, covariance_type='diag', alpha=100.,
n_iter=100).fit(X)
plot_results(X, dpgmm.predict(X), dpgmm.means_, dpgmm._get_covars(), 2,
'Dirichlet Process,alpha=100.')
plt.show()
|
30fbc3ca908882c11ca9584c7006c7bb3b0c1931 | amit4tech/DG-Python | /Session 1-6/linear_search.py | 350 | 3.734375 | 4 | n = int(input("Enter your number:"))
l = [1, 23,34,6,23,3,123,12,-23, 123, 82, 928,100,6,9,324,2,2,34,23,4,2,12,42]
if n in l:
print("Yes found")
else:
print("Not found")
# i = 0
# while i < len(l):
# if l[i] == n:
# print("Yes at index:", i)
# break
# i = i + 1
# if i >= len(l):
# print("Not found")
|
b862c409d237fa858a3ce9df33ec4f8f6b3ff4e3 | rafaelperazzo/programacao-web | /moodledata/vpl_data/22/usersdata/130/11991/submittedfiles/av1_2.py | 377 | 4 | 4 | # -*- coding: utf-8 -*-
from __future__ import division
import math
a=input('Digite o valor de a:')
b=input('Digite o valor de b:')
c=input('Digite o valor de c:')
d=input('Digite o valor de d:')
if a==c or b==d:
if b!=d or a!=c:
if a!=b or b!=c or c!=d:
print('V')
else:
print('F')
else:
print('F')
else:
print('F')
|
06a9f84cd999dd240c01897d89882f96a500fc4e | techiethrive/mad_libs_generator | /main.py | 552 | 4.21875 | 4 | """ Mad Libs Generator
----------------------------------------
"""
//Loop back to this point once code finishes
loop = 1
while (loop < 10):
// All the questions that the program asks the user
noun = input("Choose a noun: ")
p_nou = input("Choose a noun: ")
// Displays the story based on the users input
print ("------------------------------------------")
print ("Be kind to your",noun,"- footed", p_noun)
print ("For a duck
print ("------------------------------------------")
// Loop back to "loop = 1"
loop = loop + 1
|
11110aef1bc7307757c98c4eb8fa860f7939cb49 | RaulNinoSalas/Programacion-practicas | /Practica5/P5E5.py | 562 | 4.125 | 4 | """RAUL NIO SALAS, DAW 1. PRACTICA 5 EJERCICIO 5
Escriu un programa que te demani dos nombres cada vegada ms grans i els guardi en una llista.
Per a terminar d'escriure els nombres, escriu un nombre que no sigui major a l'anterior. El
programa termina escribint la llista de nombres.."""
numeros=[ ]
n1=raw_input("Escribe un numero ")
n2=raw_input("Escribe uno mayor que "+n1+": ")
numeros.append(n1)
while n1<n2:
numeros.append(n2)
n2=raw_input("Escribe uno mayor que "+n2+", por favor ")
print "Los numeros que has escrito son",numeros
|
0d3ceceb1ff8a9bc62a2749191e6409a1ecbbf42 | GuilhermeOS/JovemProgramadorSENAC | /atividadeAvaliativa/ex07.py | 241 | 4.15625 | 4 | numero = int(input("Informe um número inteiro e positivo: "))
soma = 1
if type(numero) == int and numero > 0:
for n in range(1, numero + 1):
soma += 1/n
print(soma)
else:
print("Digite um número inteiro e positivo!") |
d6cf11e4ae7e0425e8989f5a3f5208dcfed261d9 | spake/perl2python | /perl2python.py | 783 | 3.59375 | 4 | # perl2python python module
# by george caley!
# has a few functions that come in handy
import sys
ARGV = sys.argv[1:]
def num(s):
"""Converts a variable to the appropriate number type."""
if type(s) == str:
if len(s) == 0:
return 0
elif "." in s:
return float(s)
else:
return int(s)
elif type(s) == list:
return len(s)
else:
return s
def string(s):
"""Converts something to a string, Perl style."""
if type(s) == list:
return "".join(map(string, s))
else:
return str(s)
def fopen(s):
"""Functions the same as Python's open function, except that trying to open '-' will return stdin."""
if s == "-":
return sys.stdin
return open(s)
def chomp(s):
"""Removes a single newline from a string."""
if s.endswith("\n"):
return s[:-1]
else:
return s |
49ecf060a318b20c43265038b2e4e23e0052022f | hanyang7427/study | /machine_learning/83/lemma.py | 415 | 3.609375 | 4 | import nltk.stem as ns
words=['table', 'probably', 'wolves', 'playing', 'is', 'dog',
'the ', 'beeches', 'grounded', 'dreamt', 'envision']
lemmatizer = ns.WordNetLemmatizer()
for word in words:
lemma = lemmatizer.lemmatize(word, pos='n')
print(lemma)
print('-' * 80)
lemmatizer = ns.WordNetLemmatizer()
for word in words:
lemma = lemmatizer.lemmatize(word, pos='v')
print(lemma)
print('-' * 80)
|
051180f7a152b0dad1e5d475d2688d17bf80856e | Undersent/Algorithms | /Lista6/PrimAlg.py | 1,957 | 3.75 | 4 | from Lista6 import Queue
def shortestPath(graph, start):
# cost, start_vertex , parent
priorityQueue = Queue.BinHeap()
priorityQueue.insert([0,['0',-1,0]])
mstTree = []
#print("abc", priorityQueue.delMin())
# visited set
seen = set()
while True:
_, info = priorityQueue.delMin()
vertex = info[0]
parent_vertex = info[1]
cost = info[2]
if vertex not in seen:
# vertex is not in visited list , add it
seen.add(vertex)
mstTree.append((vertex, parent_vertex,cost))
if len(seen) == len(graph):
break
#Update min heap with all adjacent vertex cost,vertex,parent
for (next_vertex, cost_vertex) in graph[vertex].items():
priorityQueue.insert([cost_vertex,[next_vertex, vertex, cost_vertex]])
return mstTree
"""G = {'0': {'1':10, '2':6, '3':5},
'1': {'0':10,'3':15},
'2': {'0': 6, '3':4},
'3':{'4':105,'1':15, '2':4, '0' : 5},
'4':{'3':105}}
print(shortestPath(G, '0'))
print("length :" + str(len(G)))"""
with open('input.txt') as f:
polyShape = []
for line in f:
line = line.split() # to deal with blank
if line: # lines (ie skip them)
line = [i for i in line]
polyShape.append(line)
verticles = int(polyShape[0][0])
Gx = {}
for i in range(0,verticles):
Gx[str(i)] = None
polyShape.pop(0)
polyShape.pop(0)
#print(polyShape)
for index in range(0,verticles):
Gy = {}
for item in polyShape:
if item[0] == index:
Gy[str(item[1])] = item[2]
if index == item[1]:
Gy[str(item[0])] = item[2]
#print("gy ",Gy)
Gx[str(index)] = Gy
mst = (shortestPath(Gx, '0'))
sum =0
mst.pop(0)
for item in mst:
sum += item[2]
print ("From ", item[0], " To ",item[1], " weight ", item[2])
print("Minimal spanning tree ", sum)
print("length :" + str(len(Gx)-1))
#647 |
2a0f8ed434e0fcab731bd05a5c6e7fe31fcb7409 | hmoshabbar/python_oops_concept-program- | /python oops concept.py | 551 | 3.9375 | 4 | # define a class with name
class student:
def __init__(self,name,roll_no,email): # define initialization that class
self.name=name
self.roll_no=roll_no
self.email=email
def display_student(self):
print "Student Name:",self.name
print "Student Roll_no:",self.roll_no
print "Student email:",self.email
d1= student("Rahul",56,"[email protected]")
d1.display_student()
if __name__=="__main__":
Main()
O/P:
Student Name: Rahul
Student Roll_no: 56
Student email: [email protected]
|
59c1756642006d0ed131b2209d19baa4fcb6cb94 | mrshu/wiki-corpora-generator | /wikilangs.py | 1,256 | 3.53125 | 4 | #!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import print_function
import wikipedia
import click
import Queue
def clean_title(title):
return title.encode('ascii', 'ignore').lower()\
.replace('/', '_').replace(' ', '_')
def dump_page(title, lang, path):
wikipedia.set_lang(lang)
page = wikipedia.page(title)
real_path = '{}/{}/{}.txt'.format(path, lang, clean_title(title))
summary = page.summary.encode('utf-8').replace('\n', ' ')
if len(summary) < 1:
print("Empty summary, skipping ({}) {}".format(limit, page))
else:
with open(real_path, 'w+') as f:
f.write(summary + '\n')
print("Dumped {} ({})".format(page, lang))
@click.command()
@click.option('--title', help='The title to start dumping with')
@click.option('--langs', default='en',
help='The comma separated languages of the wikis')
@click.option('--path',
default='dumps/',
help='The default prefix for path where the data will be dumped')
def main(title, langs, path):
"""Simple script for generating clean text corpora from wiki sites."""
for lang in langs.split(','):
dump_page(title, lang, path)
if __name__ == "__main__":
main()
|
a511caeabf5f97fadcf638a71416754ad5283c31 | mikaylakonst/ExampleCode | /loopsandvariables.py | 556 | 4.1875 | 4 | # Function definitions go at the top of your file
# returns the total of all the numbers from 1 to n
def numbers(n):
total = 0
for i in range(1, n + 1):
total = total + i
return total
# returns a string with all the numbers from 1 to n
def numbersString(n):
wholeString = ""
for i in range(1, n + 1):
wholeString = wholeString + str(i) + " "
return wholeString
# Your main code goes down here
user_input = int(input("Pick a number"))
total = numbers(user_input)
print(total)
bigString = numbersString(user_input)
print(bigString)
|
a4bc901203f790fbeb2e42df1c1a05bad7087b3a | uchenna-j-edeh/dailly_problems | /after_twittr/max_consec_sum.py | 1,128 | 3.96875 | 4 | """
Good morning! Here's your coding interview problem for today.
This problem was asked by Amazon.
Given an array of numbers, find the maximum sum of any contiguous subarray of the array.
For example, given the array [34, -50, 42, 14, -5, 86], the maximum sum would be 137, since we would take elements 42, 14, -5, and 86.
Given the array [-5, -1, -8, -9], the maximum sum would be 0, since we would not take any elements.
Do this in O(N) time.
"""
def max_sum_array(arr):
# iterate through array
# set the max array to be the first int
# then start comparing from first
# if you find something bigger update varaibale, store index, otherwise start at new index
# max_sum = arr[0]
# val = arr[0]
max_so_far = arr[0]
max_ending_here = 0
for a in arr:
max_ending_here = max_ending_here + a
if max_so_far < max_ending_here:
max_so_far = max_ending_here
if max_ending_here < 0:
max_ending_here = 0
return max_so_far
print(max_sum_array([34, -50, 42, 14, -5, 86]))
print(max_sum_array([-34, -1, -42, -14, -5, -86]))
|
65ffdbca9ee9f0f96989791fc7c99bdc78b584a7 | FelipeDreissig/Prog-em-Py---CursoEmVideo | /Mundo 3/02 - Listas - p1/Ex081.py | 662 | 3.71875 | 4 | ## listtinha boba
cond = 's'
c = 1
quant = 0
l = []
while cond=='s':
if c == 1:
n_aux = int(input(f'Digite o 1º número:'))
l.append(n_aux)
else:
n = int(input(f'Digite o {c}º valor:'))
l.append(n)
c = c + 1
quant = quant + 1
cond = str(input('Deseja continuar? [S/N]')).strip().lower()[0]
print(f'Foram digitados {quant} número(s).')
j = 0
for c in range(0, len(l)):
if 5 == l[c]:
j = j + 1
print(f'O valor cinco aparece {j} vezes, na posição', end=' ')
print(f'{c+1}')
if j == 0:
print('O valor cinco não aparece.')
l.sort(reverse=True)
print(f'Os valores são: {l}')
|
ec58bb7ad75f30ca3e08e76cf77a14456b4b5ca4 | luliyucoordinate/Leetcode | /src/0932-Beautiful-Array/0932.py | 369 | 3.703125 | 4 | class Solution:
def beautifulArray(self, N):
"""
:type N: int
:rtype: List[int]
"""
result = [1]
while len(result) < N:
result = [i * 2 - 1 for i in result] + [i * 2 for i in result]
return [i for i in result if i <= N]
if __name__ == "__main__":
N = 4
print(Solution().beautifulArray(N)) |
1910b96f9fac61161d5a2d29343375353e62c648 | yunxifeng/pythonstudy | /03python--高级语法/08--p12.py | 1,044 | 3.984375 | 4 | # 死锁问题案例
import threading
import time
lock_1 = threading.Lock()
lock_2 = threading.Lock()
def func_1():
print("func_1 starting")
lock_1.acquire()
print("func_1 申请了lock_1")
time.sleep(2)
print("func_1 等待申请 lock_2")
lock_2.acquire()
print("func_1 申请了lock_2")
lock_1.release()
print("func_1 释放了 lock_1")
lock_2.release()
print("func_1 释放了 lock_2")
def func_2():
print("func_2 starting")
lock_2.acquire()
print("func_2 申请了lock_2")
time.sleep(4)
print("func_2 等待申请 lock_1")
lock_1.acquire()
print("func_2 申请了lock_1")
lock_2.release()
print("func_2 释放了 lock_2")
lock_1.release()
print("func_2 释放了 lock_1")
def main():
print("主进程启动")
t1 = threading.Thread(target=func_1, args=())
t2 = threading.Thread(target=func_2, args=())
t1.start()
t2.start()
t1.join()
t2.join()
print("主线程结束")
if __name__ == "__main__":
main() |
2416975b15f0904217d4aad238e17507a59e623e | adityacd/StatisticalCalculator | /Statistics/Proportion.py | 245 | 3.578125 | 4 | from Calculator.Division import division
from Calculator.Addition import addition
def proportion(lst):
t = 0
for n in lst:
if (n % 2) == 0:
t = addition(t, 1)
value = division(len(lst), t)
return value
|
50f4cdd5b497adfcb37422fb3ff235f0c5f4a219 | BradyBassett/Simple-ATM | /main.py | 6,805 | 4.09375 | 4 | # Use snake cases from now on instead of camel cases when writing python
# PROTOTYPE VERSION
import random
import time
class Accounts:
# Defining Account instance variables.
def __init__(self, pin, balance, annualInterestRate=3.4):
self.pin = pin
self.balance = balance
self.annualInterestRate = annualInterestRate
# Class function to return the monthly interest rate.
def getMonthlyInterestRate(self):
return self.annualInterestRate / 12
# class function to calculate difference between the balance and the amount withdrawn.
def withdraw(self, amount):
self.balance -= amount
# class function to calculate the sum between the balance and the amount deposited.
def deposit(self, amount):
self.balance += amount
# Class function to calculate the product of the balance and the annual interest rate.
def getAnnualInterest(self):
return self.balance * self.annualInterestRate
# Class function to calculate the product of the balance and the monthly interest rate.
def getMonthlyInterest(self):
return self.balance * self.getMonthlyInterestRate()
# Revieves pin from user input and validates input.
def getAccountPin():
while True:
pin = input("\nEnter four digit account pin: ")
try:
pin = int(pin)
if 1000 <= pin <= 9999:
return pin
else:
print(f"\n{pin} is not a valid pin... Try again")
except ValueError:
print(f"\n{pin} is not a vaild pin... Try again")
# Recieves user input for option selection and validates selection.
def getSelection():
while True:
selection = input("\nEnter your selection: ")
try:
selection = int(selection)
if 1 <= selection <= 4:
return selection
else:
print(f"{selection} is not a valid choice... Try again")
except ValueError:
print(f"{selection} is not a valid choice... Try again")
# Recieves user input and validates if input is either yes, y, no, or n.
def correctAmount(amount):
while True:
answer = input(f"Is ${amount} the correct ammount, Yes or No? ")
try:
answer = answer.lower()
if answer == "y" or answer == "yes":
return True
elif answer == "n" or answer == "no":
return False
else:
print("Please enter a valid response")
except AttributeError:
print("Please enter a valid response")
# Recieves user input on amount to withdraw and validates inputed value.
def withdraw(workingAccount):
while True:
try:
amount = float(input("\nEnter amount you want to withdraw: "))
amount = round(amount, 2)
if amount > 0 and ((workingAccount.balance) - amount) > 0:
answer = correctAmount(amount)
if answer == True:
print("Verifying withdraw")
time.sleep(random.randint(1, 2))
return amount
elif (((workingAccount.balance) - amount) < 0):
print("\nYour balance is less than the withdraw amount")
elif amount == 0:
answer = correctAmount(amount)
if answer == True:
print("Canceling withdraw")
time.sleep(random.randint(1, 2))
return amount
else:
print("\nPlease enter an amount greater than or equal to 0")
except (ValueError, TypeError):
print("\nAmount entered is invalid... Try again")
# Recieves user input on amount to deposit and validates inputed value.
def deposit():
while True:
try:
amount = float(input("\nEnter amount you want to deposit: "))
amount = round(amount, 2)
if amount > 0:
answer = correctAmount(amount)
if answer == True:
print("Verifying deposit")
time.sleep(random.randint(1, 2))
return amount
elif amount == 0:
answer = correctAmount(amount)
if answer == True:
print("Canceling deposit")
time.sleep(random.randint(1, 2))
return amount
else:
print("\nPlease enter an amount greater than or equal to 0")
except (ValueError, TypeError):
print("\nAmount entered is invalid... Try again")
# End of program to print out account information and return false to end main loop
def exitATM(workingAccount):
print("\nTransaction is now complete.")
print("Transaction number: ", random.randint(10000, 1000000))
print("Current Interest Rate: ", workingAccount.annualInterestRate)
print("Monthly Interest Rate: ", workingAccount.annualInterestRate / 12)
print("Thanks for using this ATM")
return False
def main():
# Creating all accounts possible, could be stored or read from a file/database instead for better functionality overall.
accounts = []
for i in range(1000, 9999):
account = Accounts(i, 0)
accounts.append(account)
# ATM Processes loop
loop = True
while loop:
pin = getAccountPin()
print(pin)
# Account session loop
while loop:
# Menu Selection
print("\n1 - View Balance \t 2 - Withdraw \t 3 - Deposit \t 4 - Exit ")
selection = getSelection()
# Getting working account object by comparing pins
for acc in accounts:
# Comparing user inputted pin to pins created
if acc.pin == pin:
workingAccount = acc
break
# View Balance
if selection == 1:
print(f"\nYour balance is ${workingAccount.balance}")
# Withdraw
elif selection == 2:
workingAccount.withdraw(withdraw(workingAccount))
print(f"\nUpdated Balance: ${workingAccount.balance}")
# Deposit
elif selection == 3:
workingAccount.deposit(deposit())
print(f"\nUpdated Balance: ${workingAccount.balance}")
# Exit
elif selection == 4:
loop = exitATM(workingAccount)
# Invalid input
else:
print("Enter a valid choice")
if __name__ == "__main__":
main()
|
d032ef1a11c3f3b671ce09004efe9f7a0706c635 | James-Rouse/Number-Guessing-Game | /guessing_game.py | 2,199 | 4.15625 | 4 | # Going for the "exceeds" grade. Pls reject me if I don't meet that bar.
import random
print("Welcome to the Number Guessing Game!")
print("There is no HIGHSCORE. This should be easy for you.")
answer_number = random.randrange(1, 11)
player_trys = 1
high_score = "placeholder"
while True:
try:
player_guess = input("Pick a number between 1 and 10: ")
player_guess = int(player_guess)
if player_guess < 1 or player_guess > 10:
print("Please enter a number within the given range.")
continue
except ValueError:
print("Please enter a number.")
continue
if player_guess < answer_number:
print("It is higher!")
player_trys += 1
continue
elif player_guess > answer_number:
print("It is lower!")
player_trys += 1
continue
else:
print("You got it! It took you {} tries!".format(player_trys))
if high_score == "placeholder":
print("You achieved the HIGHSCORE! Congrats!")
elif player_trys == 1 and high_score != 1:
print("Not only did you achieve the HIGHSCORE, but you achieved the best HIGHSCORE possible! Congrats!")
elif player_trys == 1 and high_score == 1:
print("You matched the HIGHSCORE! I'd say to try to beat it, but you can't!")
elif player_trys == high_score:
print("You matched the HIGHSCORE! Now try to beat it!")
elif player_trys < high_score:
print("You achieved the HIGHSCORE! Congrats!")
while True:
play_again = input("Would you like to play again? Yes or no?: ")
play_again = play_again.lower()
if play_again == "yes":
break
elif play_again == "no":
break
else:
print("Please enter only yes or no!")
continue
if play_again == "yes":
answer_number = random.randrange(1, 11)
if high_score == "placeholder" or high_score > player_trys:
high_score = player_trys
print("The HIGHSCORE is {}.".format(high_score))
player_trys = 1
continue
else:
print("We hope you had fun!")
break
|
6a53f844836a2f878b3840f5ebcc8a738d0d17c3 | matheuscordeiro/HackerRank | /Random Problems/Grading Students/solution.py | 1,669 | 4.40625 | 4 | #!/usr/local/bin/python3
"""Task
HackerLand University has the following grading policy:
- Every student receives a grade in the inclusive range from 0 to 100.
- Any grade less than 40 is a failing grade.
Sam is a professor at the university and likes to round each student's grade according to these rules:
- If the difference between the grade and the next multiple of 5 is less than 3, round grade up to the next multiple of 5.
- If the value of grade is less than 38, no rounding occurs as the result will still be a failing grade.
For example, grade=84 will be rounded to 85 but grade=29 will not be rounded because the rounding would result in a number that is less than 40.
Given the initial value of 40 for each of Sam's n students, write code to automate the rounding process.
"""
#
# Complete the 'gradingStudents' function below.
#
# The function is expected to return an INTEGER_ARRAY.
# The function accepts INTEGER_ARRAY grades as parameter.
#
def gradingStudents(grades):
result = []
for grade in grades:
if grade < 38:
result.append(grade)
else:
difference = 5 - (grade % 5)
if difference < 3:
result.append(grade + difference)
else:
result.append(grade)
return result
if __name__ == '__main__':
fptr = open(os.environ['OUTPUT_PATH'], 'w')
grades_count = int(input().strip())
grades = []
for _ in range(grades_count):
grades_item = int(input().strip())
grades.append(grades_item)
result = gradingStudents(grades)
fptr.write('\n'.join(map(str, result)))
fptr.write('\n')
fptr.close()
|
bac32ba211c0c82d4fa164db4c821ce3fbd01516 | robjamesd220/kairos_gpt3 | /Programming_with_GPT-3/GPT-3_Python/semantic_search.py | 1,879 | 3.625 | 4 | # Importing Dependencies
from chronological import read_prompt, fetch_max_search_doc, main
# Creates a seamntic search over the given document 'animal.txt' to fetch the top_most response
async def fetch_top_animal(query):
# function read_prompt takes in the text file animals.txt and split on ',' -- similar to what you might do with a csv file
prompt_animals = read_prompt('animals').split(',')
# Return the top most response
# Default Config: engine="ada" (Fast and efficient for semantic search)
return await fetch_max_search_doc(query, prompt_animals, engine="ada")
# Creates a seamntic search over the given document 'animal.txt' to fetch the top-3 responses
async def fetch_three_top_animals(query, n):
# function read_prompt takes in the text file animals.txt and split on ',' -- similar to what you might do with a csv file
prompt_animals = read_prompt('animals').split(',')
# Return the top-3 responses
# Default Config: engine="ada" (Fast and efficient for semantic search), n=number of responses to be returned
return await fetch_max_search_doc(query, prompt_animals, engine="ada", n=n)
# Designing the end-to-end async workflow, capable of running multiple prompts in parallel
async def workflow():
# Making async call to the search functions
fetch_top_animal_res = await fetch_top_animal("monkey")
fetch_top_three_animals_res = await fetch_three_top_animals("monkey", 3)
# Printing the result in console
print('-------------------------')
print('Top Most Match for given Animal: {0}'.format(fetch_top_animal_res))
print('-------------------------')
print('Top Three Match for given Animal: {0}'.format(fetch_top_three_animals_res))
print('-------------------------')
# invoke Chronology by using the main function to run the async workflow
main(workflow) |
4abfc0fd0ff3888828df98572a6ddf44e20731a5 | rogerroxbr/Treinamento-Analytics | /Trabalhos/Pedro Thiago/14_9/ex4.8.py | 440 | 4.15625 | 4 | num1 = float(input('Digite o primeiro número:\n'))
num2 = float(input('Digite o segundo número:\n'))
operation = input('Qual operação você deseja fazer? (+ , -, /)\n')
if operation[0] == '+':
var = num1 + num2
elif operation[0] == '-':
var = num1 - num2
elif operation[0] == '/':
var = num1 / num2
elif operation[0] == '*':
var = num1 * num2
else:
print('Operação inválida!')
print(f'seu resultado é: {var}') |
1c48ba5001da1481a317415ce19de53263f310c4 | AndreeaMihaelaP/Python | /Lab_1/Ex_1.py | 467 | 3.5 | 4 | # Find The largest common divisor of multiple numbers. Define a function with variable number of parameters to resolve this.
def cmmdc(*multipleNumbers):
result = multipleNumbers[0]
for x in multipleNumbers[1:]:
if result < x:
temp = result
result = x
x = temp
while x != 0:
temp = x
x = result % x
result = temp
return result
print(cmmdc(2,4,16)) |
4d0d9bf07a707079f8253629258c1c19677306cc | je-castelan/Algorithms_Python | /Leetcode/reverse_number.py | 925 | 3.828125 | 4 | # https://leetcode.com/problems/reverse-integer/
# Reverse digits of an integer.
# Example1: x = 123, return 321
# Example2: x = -123, return -321
# Solucion O(n)
def reverse_number(number):
sign = 1 if number >= 0 else -1
number = abs(number)
position = len(str(number))
new_number = 0
while position > 0:
next_number = number % 10
number = number // 10
new_number += (next_number * (10**(position-1)))
position -= 1
return new_number * sign
if __name__ == "__main__":
print(reverse_number(123))
print(reverse_number(-123))
print(reverse_number(321))
print(reverse_number(-321))
print(reverse_number(46921))
print(reverse_number(-56472))
print(reverse_number(0))
print(reverse_number(1000))
print(reverse_number(59000))
print(reverse_number(-2143847412))
print(reverse_number(1534236469))
|
94ca45b5bb76251b1368ef346b974c8b226e7c2e | GreatEki/site_blocker | /site_blocker.py | 1,603 | 3.546875 | 4 | import time
from datetime import datetime as dt
# Creating a custom variable of datetime - 'dt'
host_test = "hosts"
host_path = r"C:\Windows\System32\drivers\etc\hosts"
redirect = '127.0.0.1'
website_list = ["www.facebook.com", "facebook.com", "www.instagram.com", "instagram.com"]
while True:
if dt (dt.now().year, dt.now().month, dt.now().day,8) < dt.now() < dt(dt.now().year, dt.now().month, dt.now().day,16):
with open(host_path, 'r+') as file:
content = file.read()
# print(content)
# Check to see if the sites to be blocked are in the host file
# First we iterate throught the list of websites
for website in website_list:
# Check to see if each website is in the content of the host file.
if website in content:
pass
else:
# If site is not in the content of the host file we write the website to the host file
file.write(redirect + " " + website + " \n")
print('Cannot access webiste during working hours')
else:
#
with open(host_path, 'r+') as file:
# read the content of the file line by line and store each line in a list - 'content'
content = file.readlines()
file.seek(0)
for line in content:
if not any(website in line for website in website_list):
file.write(line)
file.truncate()
print('Site Blocker relaxed, Enjoy browsing')
time.sleep(5)
|
b83a63103d131da09062db6e828ea5cbb153e02f | Sandip-Dhakal/Python_class_files | /tutorial2.py | 194 | 3.921875 | 4 | a=2
b=3
c=b/a
print(c)
print(int(c))
print(str(c))
t ="23.4"
f=float(t)
print("The number is", f+1)
print("The number is "+ t)
print("The number is", t)
print("The number is {:.3f}".format(f))
|
b3a241c032ba5a41d061809dc7f2f45de3e4663e | Anjalipatil18/Function-Questions-From-Saral-In-python | /list_change.py | 265 | 3.96875 | 4 | def list_change(list1, list2):
new_list=[]
i=0
while i<len(list1):
if i<list1[i] :
multiply=list1[i]*list2[i]
new_list.append(multiply)
i=i+1
return new_list
multiple_list=list_change([5, 10, 50, 20], [2, 20, 3, 5])
print multiple_list
|
9a2da9b8853060473a93083843ced7d89eaf0df9 | pzy636588/jfsdkjfkj | /截取字符串.py | 508 | 3.59375 | 4 | # _*_coding: UTF-8_*_
# 开发团队: 彭大工程师
# 开发人员: penghong
# 开发时间: 2020/10/12 21:29
# 文件名称: 截取字符串
# 开发工具: PyCharm
str2='人生苦短,我用python!'
sub1=str2[1]
sub2=str2[2:5]
sub3=str2[:5] #从左边开始截取5个字符
sub4=str2[5:] #从第6个字符截取
print('原字符串',str2)
print(sub1+'\n'+sub2+'\n'+sub3+'\n'+sub4+'\n')
try:
sub1=str2[15]
except IndexError:
print('指定的索引不存在') |
7908e4fde4bac55b1a62392e52be77fb30ee9072 | lixiang2017/leetcode | /problems/1328.0_Break_a_Palindrome.py | 730 | 3.734375 | 4 | '''
T: O(N)
S: O(N)
Runtime: 51 ms, faster than 55.08% of Python3 online submissions for Break a Palindrome.
Memory Usage: 13.8 MB, less than 61.62% of Python3 online submissions for Break a Palindrome.
'''
class Solution:
def breakPalindrome(self, palindrome: str) -> str:
p = palindrome
if len(p) == 1:
return ''
pl = list(p)
n = len(p)
all_a = True
for i, ch in enumerate(pl):
if ch != 'a' and not (n % 2 == 1 and n // 2 == i):
pl[i] = 'a'
all_a = False
break
if not all_a:
return ''.join(pl)
else:
pl[-1] = 'b'
return ''.join(pl)
|
d425e6c299197f754249ab6f5b7021363bd1a8c2 | Styrkar1/HR_PY1_Commits | /Hopaverk10/addtolist.py | 429 | 4.28125 | 4 | def triple_list(x):
x = []
y = []
z = []
a = []
newchar = ""
while newchar.upper() != "EXIT":
newchar = input("Enter value to be added to list: ")
x.append(newchar)
y.append(newchar)
z.append(newchar)
a.extend(x)
a.extend(y)
a.extend(z)
return a
initial_list = []
new_list = triple_list(initial_list)
for items in new_list:
print(items)
|
06702fd88feac0beb117f68733f814e33a7da6d0 | bog287/Student_Lab_Management | /UI/printeaza.py | 1,960 | 3.625 | 4 | def printMainMenu():
"""
Afiseaza meniul principal
"""
print("\n")
print("####MENIU PRINCIPAL####")
print("[1] - Meniu studenti")
print("[2] - Meniu probleme")
print("[3] - Meniu asignari")
print("[4] - Meniu statistici")
print("[0] - Exit")
def printStudMenu():
"""
Afiseaza meniul de studenti
"""
print("\n")
print("####MENIU STUDENTI####")
print("[1] - Adauga student")
print("[2] - Afiseaza lista studenti")
print("[3] - Modifica student")
print("[4] - Gaseste student dupa id")
print("[5] - Sterge un student")
print("[6] - Genereaza studenti random")
print("[0] - Inapoi la meniul principal")
def printProblemeMenu():
"""
Afiseaza meniul de probleme
"""
print("\n")
print("####MENIU PROBLEME####")
print("[1] - Adauga problema")
print("[2] - Afiseaza lista probleme")
print("[3] - Modifica problema")
print("[4] - Gaseste problema dupa nrLab_nrPb")
print("[5] - Sterge o problema")
print("[6] - Genereaza probleme random")
print("[0] - Inapoi la meniul principal")
def printAsignariMenu():
"""
Afiseaza meniul de asignari
"""
print("\n")
print("####MENIU ASIGNARI####")
print("[1] - Adauga asignare")
print("[2] - Afiseaza lista asignari")
print("[0] - Inapoi la meniul principal")
def printStatisticiMenu():
"""
Afiseaza meniul de statistici
"""
print("\n")
print("####MENIU STATISTICI####")
print("[1] - Lista de studenți și notele lor la o problema de laborator dat, ordonat: alfabetic după nume")
print("[2] - Lista de studenți și notele lor la o problema de laborator dat, ordonat: alfabetic după notă")
print("[3] - Toți studenții cu media notelor de laborator mai mica decât 5")
print("[4] - Numărul de studenți notați și „media laboratorului” pentru un laborator dat")
print("[0] - Inapoi la meniul principal")
|
1a5b5ce5db4fbd13fbdf3bf5bb0cc4ba5f7ce97f | XuLongjia/DataStructure-Algorithm | /数据结构(python)/11 insertSort.py | 684 | 3.875 | 4 | #!usr/bin/python
# -*- coding:utf-8 -*-
def insertSort(ls):
'''插入排序,时间复杂度为n方,属于稳定排序'''
n = len(ls)
for j in range(1,n):
i = j #i代表内层
#从右边取出一个元素,然后插入到左边正确的位置中
while i >0:
if ls[i] < ls[i-1]:
ls[i],ls[i-1] = ls[i-1],ls[i]
else:
break #如果上面的if语句没有执行说明序列已经有序啦,就不需要再往右边走了,相当于做了一个优化
i -= 1
return ls
if __name__ =='__main__':
ls = [9,8,7,6,5,4,3,2,1,0]
print(insertSort(ls)) |
e088c6e707733b152f6dcb0f0549f48c53edf1aa | freesoul84/python_codes | /other_python_codes/perfect_.py | 344 | 3.78125 | 4 | test=int(input())
def fact(n):
if n<2:
f=1
else:
f=n*fact(n-1)
return f
for _ in range(test):
number=int(input())
sum1=0
temp=number
while number>0:
r=number%10
sum1+=fact(r)
number=number//10
if sum1==temp:
print("Perfect")
else:
print("Not Perfect")
|
4cab7cfe068117dfb18b1b96b598b080594ccdef | wesley-998/Python-Exercicies | /030_impar-par.py | 155 | 3.84375 | 4 | n = int(input('Digite um valor: '))
n1 = n%2
print(n1)
if n1 == 0:
print('{} é Par!'.format(n))
else:
print('{} é Impar!'.format(n))
|
8ed6b103d45d0cd67fb566fa743c6c75c6527c58 | kaharkapil/Python-Programs | /marks.py | 527 | 3.84375 | 4 | # input of 5 subjects marks
hin=int(input("Enter marks of hindi:"))
eng=int(input("Enter marks of english:"))
maths=int(input("Enter marks of maths:"))
sci=int(input("Enter marks of science:"))
san=int(input("Enter marks of sanscrit:"))
count=0
if hin<33:
count=count+1
if eng<33:
count=count+1
if maths<33:
count=count+1
if sci<33:
count=count+1
if san<33:
count=count+1
print("no.of subjects having <33",count)
if count==0:
print("pass")
elif count<3:
print("Supplementry")
else:
print("fail")
|
f7482f9cb1a98b868ee834e510aa774d6ac44b35 | meethu/LeetCode | /solutions/0098.validate-binary-search-tree/validate-binary-search-tree.py | 1,242 | 3.890625 | 4 | # Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def isValidBST(self, root: TreeNode) -> bool:
inorder = self.inorder(root)
return inorder == list(sorted(set(inorder)))
def inorder(self, root): # 中序遍历,递增
if root is None:
return []
return self.inorder(root.left) + [root.val] + self.inorder(root.right)
# class Solution:
# def isValidBST(self, root):
# """
# :type root: TreeNode
# :rtype: bool
# """
# def helper(node, lower = float('-inf'), upper = float('inf')):
# if not node:
# return True
# val = node.val
# if val <= lower or val >= upper:
# return False
# if not helper(node.right, val, upper):
# return False
# if not helper(node.left, lower, val):
# return False
# return True
# return helper(root)
# 作者:LeetCode
# 链接:https://leetcode-cn.com/problems/validate-binary-search-tree/solution/yan-zheng-er-cha-sou-suo-shu-by-leetcode/ |
133c8348115f6f383ddb90e49c354efeaf97cc28 | rg3915/python-experience | /others/redundancy/redundancia2.py | 4,293 | 3.765625 | 4 | # -*- coding: utf-8 -*-
from redundancia import redun_palavra_palavra, redun_palavra_frase, redun_frase_frase
def remover_aspas(texto):
'''
Remove aspas, caso o texto contenha aspas no começo e no final da frase.
Args:
texto (str): Frase.
Returns:
str: Frase corrigida.
'''
return texto.strip('"')
def redundancia(termo, tipo, termos):
'''
Pega a lista de termos, verifica se tem redundancia.
Se sim, retorna a mensagem de erro.
Args:
termo (str): Termo a ser analisado.
tipo (str): Tipo, se 'A' palavra ou 'R' frase.
termos (list): Lista de termos a serem comparados.
Returns:
str: Retorna a mensagem de erro.
'''
lista = []
# Se o termo for uma frase 'R' de uma palavra só, então converte para palavra.
if tipo == 'R':
if len(remover_aspas(termo).split()) == 1:
tipo = 'A'
termo = remover_aspas(termo)
if tipo == 'A':
for i, _termo in enumerate(termos):
meu_termo = remover_aspas(_termo['termos'])
_tipo = _termo['tipo']
# print(i, _termo)
# print(i, meu_termo)
if _tipo == 'A':
# print('caiu no palavra palavra')
resposta = redun_palavra_palavra(termo, meu_termo)
else:
# print('caiu no palavra frase')
resposta = redun_palavra_frase(termo, meu_termo)
# print(i, 'antes', resposta)
if resposta:
lista.append(resposta)
# print(i, 'depois', resposta)
else:
# Se tipo for igual a 'R', considerando a query.
for _termo in termos:
meu_termo = remover_aspas(_termo['termos'])
_tipo = _termo['tipo']
if _tipo == 'R':
resposta = redun_frase_frase(remover_aspas(termo), meu_termo)
else:
# Se for 'A', então troca palavra e frase de lugar
# pra usar a mesma função.
tmp_palavra = meu_termo
tmp_frase = remover_aspas(termo)
resposta = redun_palavra_frase(tmp_palavra, tmp_frase)
if resposta:
lista.append(resposta)
print('\n')
print('lista')
print(lista)
if lista:
msg_error = "O termo '%s' é redundante." % lista[0]['quem']
return msg_error
return
termos = (
# {'termos': 'Ciro', 'id': 20, 'tipo': 'A'},
# {'termos': 'Ciro Gomes', 'id': 20, 'tipo': 'A'},
# {'termos': '"Ciro Gomes Silva Augusto"', 'id': 21, 'tipo': 'R'},
# {'termos': 'Gomes', 'id': 22, 'tipo': 'A'},
# {'termos': 'Silva', 'id': 23, 'tipo': 'A'},
# {'termos': 'Augusto', 'id': 24, 'tipo': 'A'},
# {'termos': '"Antonio Santos"', 'id': 25, 'tipo': 'R'},
# {'termos': 'Antonio', 'id': 26, 'tipo': 'A'},
# {'termos': '"Antonio"', 'id': 27, 'tipo': 'R'},
# {'termos': 'americanas', 'id': 28, 'tipo': 'A'}, # OK
# {'termos': '"americanas teste"', 'id': 29, 'tipo': 'R'}, # OK
# #
# OK {'termos': 'submarino amarelo', 'id': 30, 'tipo': 'A'},
# OK {'termos': '"submarino amarelo"', 'id': 31, 'tipo': 'R'},
# OK {'termos': '"submarino amarelo"', 'id': 32, 'tipo': 'R'},
{'termos': 'submarino amarelo', 'id': 33, 'tipo': 'A'},
# OK {'termos': 'submarino verde amarelo', 'id': 34, 'tipo': 'A'},
# OK {'termos': '"submarino verde amarelo"', 'id': 35, 'tipo': 'R'},
)
# res = redundancia('Ciro', 'A', termos)
# print(res)
# res = redundancia('Antonio', 'R', termos)
# print(res)
# res = redundancia('Pedro', 'A', termos)
# print(res)
# res = redundancia('aaa', 'A', termos)
# print(res)
# res = redundancia('americanas', 'A', termos) # OK
# print(res)
# res = redundancia('"americanas teste"', 'R', termos)
# print(res)
# # 1 OK
# res = redundancia('submarino', 'A', termos)
# print(res)
# # 2 OK
# res = redundancia('"submarino"', 'R', termos)
# print('2 - %s' % res)
# # 3 OK
# res = redundancia('submarino', 'A', termos)
# print('3 - %s' % res)
# # 4 REVER
res = redundancia('"submarino"', 'R', termos)
print('4 - %s' % res)
# # 5 OK
# res = redundancia('"submarino verde"', 'R', termos)
# print('5 - %s' % res)
# # 6 Ok
# res = redundancia('submarino verde', 'A', termos)
# print('6 - %s' % res)
|
d4c4249f54236534e050682374fd068fd1f30928 | vaibhavk1103/hackerrank_30_days_of_code_python | /Day2_30DoC.py | 212 | 3.6875 | 4 | mealcost = float(input())
tippercent = int(input())
taxpercent = int(input())
tip = mealcost * (tippercent/100)
tax = mealcost * (taxpercent/100)
totalcost = mealcost + tip + tax
print(round(totalcost)) |
9374f53a88e2b38f1bebd774ea5ba445cf8f2577 | EricMoura/Aprendendo-Python | /Exercícios de Introdução/Ex011.py | 226 | 3.703125 | 4 | larg = float(input('Qual a largura da parede? '))
alt = float(input('Qual a altura da parede? '))
area = larg*alt
latas = area/2
print(f'A área da parede é {area}m² e é preciso {latas}L de tinta para pintá-la!') |
d1511d4335e3427a9099f3e73321bb485bb19968 | vithuren27/python-bmi-calculator-application | /bmi.py | 2,442 | 3.90625 | 4 | from tkinter import *
root = Tk()
root.title("BMI Calculator")
root.configure(width=100, height=100)
root.configure(bg="black")
def calc():
BMI = BMI_val(mass.get(), height.get())
Stat = getStatus()
stat.set(Stat)
bmi_Val.set(format(BMI, ".2f"))
def BMI_val(mass, height):
return mass/height**2
#def getHeight():
# return height
def clear():
stat.set('')
bmi_Val.set('0.0')
mas.delete(0, 'end')
heigh.delete(0, 'end')
#def getWidth():
# return mass
def getStatus():
if bmi_Val.get() > 40:
return "You are Obese Class 3"
elif bmi_Val.get() > 35 and bmi_Val.get() < 40:
return "You are Obese Class 2"
elif bmi_Val.get() > 30 and bmi_Val.get() < 35:
return "You are Obese Class 1"
elif bmi_Val.get() > 25 and bmi_Val.get() < 30:
return "You are Overweight"
elif bmi_Val.get() > 18.5 and bmi_Val.get() < 25:
return "You are at a Normal weight"
elif bmi_Val.get() > 17 and bmi_Val.get() < 18.5:
return "You are thin"
else:
return "You are very thin"
height = DoubleVar()
h_label = Label(root, text="Height", fg="red", bg="black", font=("Calibri 14 bold"), pady=5, padx=8)
heigh = Entry(root, textvariable=height)
h_label.grid(row=2)
heigh.grid(row=2, column=1, columnspan=2, padx=5)
mass = DoubleVar()
w_label = Label(root, text="Mass", fg="red", bg="black", font=("Calibri 14 bold"), pady=10, padx=2)
mas = Entry(root, textvariable=mass)
w_label.grid(row=4)
mas.grid(row=4, column=1)
bmi_Val = DoubleVar()
stat = StringVar()
bmi = Label(root, text="BMI: ", fg="blue", bg="black", font=("Calibri 14 bold"), pady=10, padx=2, justify=LEFT)
status = Label(root, text="Status", fg="blue", bg="black", font=("Calibri 14 bold"), pady=10, padx=2)
status_msg = Label(root, textvariable=stat, fg="white", bg="black", font=("Calibri 14 bold"), pady=10, padx=2)
BMI_total = Label(root, textvariable=bmi_Val, fg="white", bg="black", font=("Calibri 14 bold"), pady=10, padx=2)
bmi.grid(row=6)
status.grid(row=7)
BMI_total.grid(row=6, column=1)
status_msg.grid(row=7, column=1)
calculate = Button(root, text="Calculate", command=calc, fg="black", bg="white", font=("Calibri 12 bold") )
clear = Button(root, text="Reset", command=clear, fg="black", bg="white", font=("Calibri 14 bold"))
calculate.grid(row=8)
clear.grid(row=8, column=3)
root.mainloop() |
333191daa96b494b6cb28817912aba3f3f9d2254 | saurabh17jan/ds_algo | /sorting_tech/selection_sort.py | 807 | 4.09375 | 4 | # Python program for implementation of Selection Sort
# https://www.geeksforgeeks.org/selection-sort
# Time Complexity: O(n2) as there are two nested loops.
# Auxiliary Space: O(1)
# The good thing about selection sort is it never makes more than O(n) swaps and can be useful when memory write is a costly operation.
# In Place : Yes, it does not require extra space.
import sys
A = [64, 25, 12, 22, 11]
# Traverse through all array elements
for i in range(len(A)):
# Find the minimum element in remaining
# unsorted array
min_idx = i
for j in range(i+1, len(A)):
if A[min_idx] > A[j]:
min_idx = j
# Swap the found minimum element with
# the first element
A[i], A[min_idx] = A[min_idx], A[i]
# Driver code to test above
print ("Sorted array")
for i in range(len(A)):
print("%d" %A[i]),
|
4357811e7d3402a224a28af458b9a2eb581c7d1f | practicewitharjya/wayToPython | /Day 6_File/fileWrite2.py | 137 | 3.6875 | 4 | # Handle the file as read and write mode
f = open("python.txt", "r+")
f.write("I am writing some more line in same file")
print(f.read()) |
96f13b48f31ea1f16f1953459bd74c0c5e503a94 | nayanika2304/DataStructuresPractice | /Practise_linked_list/find_intersection.py | 1,330 | 3.890625 | 4 | '''
Given two (singly) linked lists, determine if the two lists intersect. Return the intersecting
node. Note that the intersection is defined based on reference, not value. That is, if the kth
node of the first linked list is the exact same node (by reference) as the jth node of the second
linked list, then they are intersecting.
1) find the length and tails of both linked list
2) if tails are different, return false
3) set two pointers on each linked list
4) on the longer linked list, advance the pointer by diff in length once
5) traverse on each until pointers are same
'''
class ListNode:
def __init__(self,data,next= None):
self.data = None
self.next = next
class Solution(object):
def getIntersectionNode(self, headA, headB):
curA, curB = headA, headB
lenA, lenB = 0, 0
while curA is not None:
lenA += 1
curA = curA.next
while curB is not None:
lenB += 1
curB = curB.next
curA, curB = headA, headB
if lenA > lenB:
for i in range(lenA - lenB):
curA = curA.next
elif lenB > lenA:
for i in range(lenB - lenA):
curB = curB.next
while curB != curA:
curB = curB.next
curA = curA.next
return curA |
e863c4cf8ce0e3ee3f45f004f7e370255ad5d3b8 | vishnusak/DojoAssignments | /Flask-Login_Registration/MySQLConnect.py | 1,413 | 3.5 | 4 | import MySQLdb as ms
class Sql(object):
""" Sql: Class to provide an abstraction for connecting and querying against MySQL server """
def __init__(self, host, db, user='root', pwd='1979', port=3306):
self.host = host
self.user = user
self.pwd = pwd
self.db = db
self.port = port
self.con = ms.connect(host=self.host, user=self.user, passwd=self.pwd, db=self.db, port=self.port)
self.cur = self.con.cursor()
def get_pwd(self, inp_email):
query = "SELECT password FROM users WHERE email = '{}'".format(inp_email)
result_size = self.cur.execute(query)
if result_size == 1:
result = self.cur.fetchone()[0]
else:
result = False
return result
def get_name(self, inp_email):
query = "SELECT concat(first_name, ' ', last_name) FROM users WHERE email = '{}'".format(inp_email)
result_size = self.cur.execute(query)
if result_size == 1:
result = self.cur.fetchone()[0]
else:
result = False
return result
def register(self, user):
query = "INSERT INTO users (first_name, last_name, email, password, created_at, modified_at) VALUES('{}', '{}', '{}', '{}', NOW(), NOW())".format(user['fname'], user['lname'], user['email'], user['pwd'])
self.cur.execute(query)
self.con.commit()
|
23a640f579748a1ad34d464ad7ee31495b09cca6 | JohnBracken/Monte-Carlo-Simulation-in-Python | /roulette.py | 2,629 | 3.546875 | 4 | #Monte Carlo simulation of roulette wheel
from numpy import random
from matplotlib import pyplot as plt
#Part 1. Outside bets, 5$ bets on red.
#Roulette spins, bet on red, 90 spins a night for a whole year.
land_on_red = list(random.binomial(n=90, p = 18/38, size = 365))
#Gains and losses for each night playing roulette, betting on red.
gains_losses = []
#Calculate the gains/losses for each night of 90 wheel spins.
#Bet $5 on each wheel spin.
for sample in land_on_red:
winnings_or_losses_per_night = 5*sample -5*(90-sample)
gains_losses.append(winnings_or_losses_per_night)
#Histogram of nightly wins/losses for the year.
plt.figure()
plt.hist(gains_losses, bins = 8)
plt.title('Histogram of Nightly Wins/Losses for 1 Year: Betting on Red in Roulette')
plt.xlabel('Nightly Winnings/Losses($)')
plt.ylabel('Counts of Winnings/Losses')
#Part 2a. Inside bets, 5$ bets on a number (35x payout if you win)
land_on_number = list(random.binomial(n=90, p = 1/38, size = 365))
#Gains and losses for each night playing roulette, betting on a number.
gains_losses = []
#Calculate the gains/losses for each night of 90 wheel spins.
#Bet $5 on each wheel spin.
for sample in land_on_number:
winnings_or_losses_per_night = 175*sample -5*(90-sample)
gains_losses.append(winnings_or_losses_per_night)
#Histogram of nightly wins/losses for the year.
plt.figure()
plt.hist(gains_losses, bins = 8)
plt.title('Histogram of Nightly Wins/Losses for 1 Year: Betting on a Number in Roulette')
plt.xlabel('Nightly Winnings/Losses($)')
plt.ylabel('Counts of Winnings/Losses')
##Part 2b (optional): Inside bet, 5$ bet on one number (35x payout) - explicit method one bet at a time.
bet_size = 5
winnings_losses = 0
bets_per_night = 90
count_bets = 0
count_days = 0
winnings_losses_list = []
#Simulate betting on a number and then spinning the wheel for that number.
#90 bets per night for a whole year.
while count_days < 365:
while count_bets < bets_per_night:
land_on_number = random.randint(1, 38)
bet_number = random.randint(1, 38)
if land_on_number == bet_number:
winnings_losses = winnings_losses + bet_size*35
else:
winnings_losses = winnings_losses - bet_size
count_bets += 1
winnings_losses_list.append(winnings_losses)
count_bets = 0
winnings_losses = 0
count_days += 1
plt.figure()
plt.hist(winnings_losses_list, bins = 8)
plt.title('Histogram of Nightly Wins/Losses for 1 Year: Betting on a Number in Roulette')
plt.xlabel('Nightly Winnings/Losses($)')
plt.ylabel('Counts of Winnings/Losses')
plt.show()
|
deccbdb26b8d8f08ebe459fbfe56d9a144b0687b | CeciFerrari16/Esercizi-Python-1 | /es28.py | 701 | 3.59375 | 4 | # Esercizio 28 , Gara studenti
''' Dato un elenco di studenti partecipanti a una gara sportiva di lancio del peso (nome utente, lancio ),
visualizza il valore del lancio del vincitore ( valore massimo)'''
indice = 0
studenti = ["Giacomo", "Gianmarco", "Gianluca", "Gianfranco", "Fausto", "Luigi"]
lancio = [1.2, 1.4, 1.9, 0.9, 2.0, 1.7]
while True:
if indice == 6:
break
else:
print(studenti[indice], lancio[indice])
indice += 1
print("Il valore del lancio del vincitore è", max(lancio))
# oppure con i dizionari
'''
studenti = {
"Giacomo" : 1.2,
"Gianmarco" : 1.4,
"Gianluca" : 1.9,
"Gianfranco" : 0.9,
"Fausto" : 2.0,
"Luigi" : 1.7
}
''' |
3c76359601daef3db963daa6ab41022a515419b6 | utkarshbhardwaj22/TRAINING1 | /venv/Practice107.py | 1,476 | 3.53125 | 4 | """
Random Forest
1. n -> How many decision trees to be used in our model
2. Dataset shall be divided into n number of subsets.
"""
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
"""
data_set = pd.read_csv("covid19-world.csv")
#print(data_set)
india_dataset = data_set[data_set['Country']=='India']
print(india_dataset)
X = india_dataset['Date']
Y = india_dataset['Confirmed']
print("DATE")
print(X)
print("Confirmed Cases")
print(Y)
plt.plot(X, Y)
plt.xlabel("Date")
plt.ylabel("Confirmed Cases")
plt.show()
"""
data_set = pd.read_csv("covid19-world.csv")
#print(data_set)
india_dataset = data_set[data_set['Country']=='India']
print(india_dataset)
X = india_dataset['Date'].values
confirmed_cases = india_dataset['Confirmed'].values
print(X)
days=[]
for date in X:
#print(date)
#print(pd.Period(date,freq='D').dayofyear)
days.append(pd.Period(date,freq='D').dayofyear)
days = np.array(days)
print(days)
#plt.plot(days, confirmed_cases)
#plt.xlabel("Date")
#plt.ylabel("Confirmed Cases")
#plt.show()
model = RandomForestRegressor(n_estimators=100)
days = days[:, np.newaxis]
x_train, x_test, y_train, y_test = train_test_split(days, confirmed_cases, test_size=0.2, random_state=1)
model.fit(x_train,y_train)
y_pred = model.predict(x_test)
print("Original")
print(y_test)
print("Predicted")
print(y_pred)
|
134c88ac472ffef8f3bcac3261cffee27ba65d31 | simonRos/Python | /AssignEight/AssignEight.py | 1,231 | 3.96875 | 4 | #Simon Rosner
#3/21/2016
#This program reads dollar amounts from a text file
#and writes a text file with equivelant pound and euro amounts
#constants
USDperGBP = 0.7 #Dollars per Pound
USDperEUR = 0.89#Dollars per Euro
inFile = "dolla.txt" #name of input file
outFile = "out.txt" #name of output file
def convertToPound(money): #returns equivelant pound amount
return round(float(money)*float(USDperGBP),2) #rounded to 2 dec place
def convertToEuro(money): #returns equivelant euro amount
return round(float(money)*float(USDperEUR),2) #rounded to 2 dec place
f = open(inFile,"r") #opens input file for read
for line in f: #for each line in input file
ou = open(outFile,'a') #opens output file for append
tempString = line #store as tempString
tempString = tempString.rstrip() #strip newline
x = line.replace('$','') #remove dollar sign
tempString += " \u00A3" + str(convertToPound(x)) #append pounds
tempString += " \u20AC" + str(convertToEuro(x)) #append euros
tempString += '\n' #append newline
ou.write(tempString) #write tempString to output file
ou.close() #close output file
f.close() #close input file
|
fc3a8f34596014405d8878c62837507f0799aca2 | mly135/mycode | /PycharmProjects/Test/练习/20170912_函数.py | 706 | 4.03125 | 4 | #coding=utf-8
# 测试函数
def printname(str):
"输出姓名"
print str
# 调用函数
printname("I")
printname(str="love")
# 测试函数
def printNameAndAge(name,age):
print "姓名:",name,"年龄",age
# 调用测试
printNameAndAge(age="23",name="张三")
# 测试函数 缺省参数
def printNameAndAge(name,age="25"):
print "姓名:",name,"年龄",age
# 调用测试
printNameAndAge("李四")
#测试函数 不定长参数
def kebianHs(name,*other):
print name
for var in other:
print var
#调用测试程序
kebianHs("张三","28","男")
#匿名函数
sum = lambda a,b: a+b
#调用匿名函数
print "匿名函数求和",sum(12,22)
|
c0d89e2bffe5bbe841921f4283b4aeda5df76897 | shreyanshu/sudoku_project | /s.py | 716 | 3.59375 | 4 | # -*- coding: utf-8 -*-
''' This module solves a sudoku, This is actually written by Peter Norvig
Code and Explanation can be found here : norvig.com/sudoku.html'''
def cross(A, B):
return [a+b for a in A for b in B]
digits = '123456789'
rows = 'ABCDEFGHI'
cols = digits
squares = cross(rows, cols)
unitlist = ([cross(rows, c) for c in cols] + [cross(r, cols) for r in rows] + [cross(rs, cs) for rs in ('ABC','DEF','GHI') for cs in ('123','456','789')])
units = dict((s, [u for u in unitlist if s in u]) for s in squares)
# print(units)
# print(unitlist)
# peers = dict((s, set(sum(units[s],[]))-set([s])) for s in squares)
peers =dict()
for s in squares:
peers[s] = set(sum(units[s],[]))-set([s])
print(peers)
|
533f34d5e37dc188e2d67343e31e160044ddb0f3 | qmnguyenw/python_py4e | /geeksforgeeks/python/easy/19_19.py | 3,818 | 3.75 | 4 | Generating all possible Subsequences using Recursion
Given an array. The task is to generate and print all of the possible
subsequences of the given array using recursion.
**Examples:**
Input : [1, 2, 3]
Output : [3], [2], [2, 3], [1], [1, 3], [1, 2], [1, 2, 3]
Input : [1, 2]
Output : [2], [1], [1, 2]
Recommended: Please try your approach on _**_{IDE}_**_ first, before moving on
to the solution.
**Approach:** For every element in the array, there are two choices, either
to include it in the subsequence or not include it. Apply this for every
element in the array starting from index 0 until we reach the last index.
Print the subsequence once the last index is reached.
Below diagram shows the recursion tree for array, **arr[] = {1, 2}**.
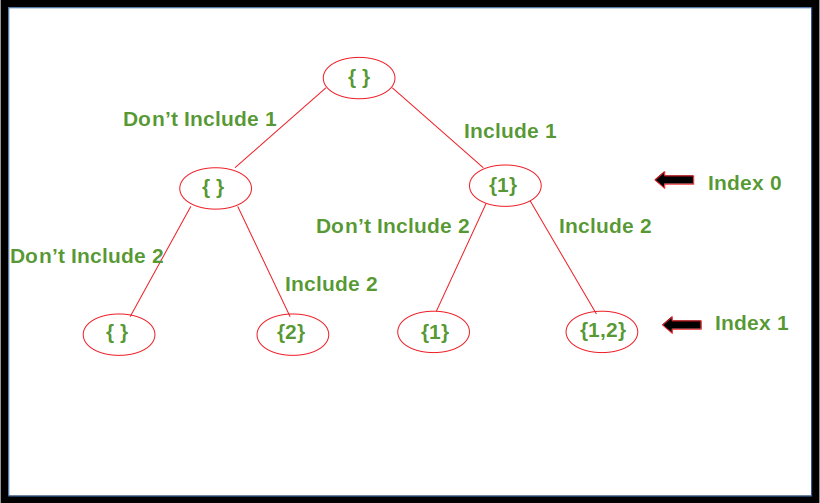
Below is the implementation of the above approach.
## C++
__
__
__
__
__
__
__
// C++ code to print all possible
// subsequences for given array using
// recursion
#include <bits/stdc++.h>
using namespace std;
void printArray(vector<int> arr, int n)
{
for (int i = 0; i < n; i++)
cout << arr[i] << " ";
cout << endl;
}
// Recursive function to print all
// possible subsequences for given array
void printSubsequences(vector<int> arr, int index,
vector<int> subarr)
{
// Print the subsequence when reach
// the leaf of recursion tree
if (index == arr.size())
{
int l = subarr.size();
// Condition to avoid printing
// empty subsequence
if (l != 0)
printArray(subarr, l);
}
else
{
// Subsequence without including
// the element at current index
printSubsequences(arr, index + 1, subarr);
subarr.push_back(arr[index]);
// Subsequence including the element
// at current index
printSubsequences(arr, index + 1, subarr);
}
return;
}
// Driver Code
int main()
{
vector<int> arr{1, 2, 3};
vector<int> b;
printSubsequences(arr, 0, b);
return 0;
}
// This code is contributed by
// sanjeev2552
---
__
__
## Python3
__
__
__
__
__
__
__
# Python3 code to print all possible
# subsequences for given array using
# recursion
# Recursive function to print all
# possible subsequences for given array
def printSubsequences(arr, index, subarr):
# Print the subsequence when reach
# the leaf of recursion tree
if index == len(arr):
# Condition to avoid printing
# empty subsequence
if len(subarr) != 0:
print(subarr)
else:
# Subsequence without including
# the element at current index
printSubsequences(arr, index + 1, subarr)
# Subsequence including the element
# at current index
printSubsequences(arr, index + 1,
subarr+[arr[index]])
return
arr = [1, 2, 3]
printSubsequences(arr, 0, [])
#This code is contributed by Mayank Tyagi
---
__
__
**Output:**
[3]
[2]
[2, 3]
[1]
[1, 3]
[1, 2]
[1, 2, 3]
**Time Complexity:**

Attention geek! Strengthen your foundations with the **Python Programming
Foundation** Course and learn the basics.
To begin with, your interview preparations Enhance your Data Structures
concepts with the **Python DS** Course.
My Personal Notes _arrow_drop_up_
Save
|
ad5d56ffea1d841f2e2664cc54a95fa44847204d | chuma99/Programming | /element.py | 5,052 | 4.1875 | 4 | #11-13-18
#In this assignment, I was able to import a csv file of the elements on the periodic table, and import them into my code. From there,
#I was able to access the elements of the file and complete tasks using them, all through user input.
#Sources: https://www.shanelynn.ie/python-pandas-read_csv-load-data-from-csv-files/
# https://introcs.cs.princeton.edu/python/32class/elements.csv
# https://docs.python.org/2/library/csv.html
# https://www.pythonforbeginners.com/csv/using-the-csv-module-in-python
#On my honor, I have neither given or received unauthorized aid.
import csv #importing libraries that allow us to access csv files
import pandas as pd
class Element:
def __init__(self, name, number, symbol, weight): #constructor
self.name = name
self.number = number
self.symbol = symbol
self.weight = weight
def __str__(self): #print statement
return self.name +" "+ str(self.number) +" "+ self.symbol +" "+ str(self.weight)
def getName(self): #getter to access name
return self.name
def getNumber(self): #getter to access number
return self.number
def getSymbol(self): #getter to access symbol
return self.symbol
def getWeight(self): #getter to access weight
return self.weight
class PeriodicTable:
def __init__(self, table): #constructor
self.names = []
self.numbers = []
self.symbols = []
self.weights = []
self.table = list(csv.reader(open('elements.csv', 'r')))#this imports the csv file as table
self.elementList = []
i = 1
#this next part of the code is a loop that goes through elementlist and adds elements based on the dataset
while i < len(self.table):
self.elementList.append(Element(self.table[i][0], self.table[i][1], self.table[i][2], self.table[i][3]))
if i == 103:
break
i+=1
def __str__(self): #print statement
result = ''
for i in self.elementList:
result += str(i)+'\n'
return result
def findElementNameByWeight(self, weight): #Enter a weight to find an element
for t in self.elementList:
if t.getWeight() == str(weight):
return t.getName()
def findElementNameBySymbol(self, symbol): #Enter a symbol to find an element
for t in self.elementList:
if t.getSymbol() == str(symbol):
return t.getName()
def findElementNameByNumber(self, number): #Enter a number to find an element
for t in self.elementList:
if t.getNumber() == str(number):
return t.getName()
def displayElement(self, name): #Enter element name to display element details.
for t in self.elementList:
if t.getName() == str(name):
return t
def atomicWeightCalculator(self, name1, name2): #Enter two element names and add their atomic weights
weight = 0
for t in self.elementList:
if t.getName() == str(name1):
weight+= float(t.getWeight())
if t.getName() == str(name2):
weight+= float(t.getWeight())
return weight
def getElementList(self): #Returns the element list
return self.elementList
def getTable(self):#Returns the csv file
return self.table
#data = pd.read_csv("elements.csv")
#print(data)
pt = PeriodicTable("elements.csv")
#the following code is the menu that is looped through to complete the tasks mentioned above
print("Hello user, welcome to the periodic table of elements!")
print("What would you like to do here?\n")
x = 1
while x == 1:
print("1. See all elements in the table")
print("2. Find a specific element")
print("3. Display an element's details")
print("4. Calculate the weight of two elements")
print("5. Exit\n")
selection = input("Enter the number of the task you'd like to complete: ")
if selection == "1":
print("Here is the list of elements in order of atomic number.")
print("\n"+pt)
elif selection == "2":
print("How would you like to find this element?\n")
print("1. Using the atomic weight")
print("2. Using its symbol")
print("3. Using the atomic number\n")
choice = input("Enter the number of your choice: ")
if choice == "1":
weight = float(input("Enter the atomic weight of the element you wish to find: "))
print("\n"+pt.findElementNameByWeight(weight))
elif choice == "2":
symbol = str(input("Enter the symbol of the element you wish to find: "))
print("\n"+pt.findElementNameBySymbol(symbol))
elif choice == "3":
number = int(input("Enter the atomic number of the element you wish to find."))
print("\n"+pt.findElementNameByNumber(number))
elif selection == "3":
element = str(input("What is the name of the element who's details you would like to display? "))
print("\n"+pt.displayElement(element))
elif selection == "4":
element1 = str(input("Please enter the first element you would like to add: "))
element2 = str(input("Please enter the second element you would like to add: "))
print("Adding elements atomic weights...")
print("\nThe atomic weights of these elements add up to "+ str(pt.atomicWeightCalculator(element1, element2)) + "!\n")
elif selection == "5":
print("You have exited the periodic table of elements!")
x=2
else:
print("Your input was invalid. Please try again.")
|
3f9b32441b6b1fe1147d380591d0a061e97c5e02 | gabriellee/HackerSchool | /parsedata_keepscores.py | 1,565 | 3.703125 | 4 | #!/usr/bin/env python
'''parse data from csv into people class'''
import numpy as np
import re
def ParseCsv(path):
'''parses data from csv genrated by learning styles survey into student objects with learning style info
Each row is a person, column 1 contains names
the other columns correspond to learning style categories and contain scores
- means the person has the first learning style in the catgory(eg if the column is active v. reflective, a -1 means the person is active)
+ means the person has the second learning style in the category
0 means they are smack dab in the middle!
student_dict is a dictionary with student names mapped to a list containing the student's learning style information
element 1 of the list contains whether the student is active or reflective
2 contains the student's sensing-intuitive number
3 contains the student's visual-verbal number
4 contains sequential or global
'''
#specify file path here
#path = '/home/gabrielle/wkspace/HackerSchool/pseudodata.csv'
n_cols = 5
n_skip_rows = 1
n_name_col = 1
data = np.genfromtxt(path, skip_header = n_skip_rows, delimiter = ",", dtype = None)
student_dict = {}
student_dict = [student[3]*-1 if student[2]=='active' else student[3] for student in data]
student_dict = [student[5]*-1 if student[4]=='sensing' else student[5] for student in data]
student_dict = [student[7]*-1 if student[6]=='visual' else student[7] for student in data]
student_dict = [student[9]*-1 if student[8]=='global' else student[9] for student in data]
return student_dict
|
4a242aa225b0cb4ddec23576702795e55f8db720 | KKosukeee/CodingQuestions | /LeetCode/268_missing_number.py | 910 | 3.765625 | 4 | """
Solution for 268. Missing Number
https://leetcode.com/problems/missing-number/
"""
class Solution:
"""
Runtime: 140 ms, faster than 99.55% of Python3 online submissions for Missing Number.
Memory Usage: 15.1 MB, less than 6.45% of Python3 online submissions for Missing Number.
"""
def missingNumber(self, nums):
"""
Given an array containing n distinct numbers taken from 0, 1, 2, ..., n, find the one that is missing from the array.
Example 1:
Input: [3,0,1]
Output: 2
Example 2:
Input: [9,6,4,2,3,5,7,0,1]
Output: 8
Note:
Your algorithm should run in linear runtime complexity. Could you implement it using only constant extra space complexity?
Args:
nums(list[int]):
Returns:
int:
"""
return int(len(nums) * (len(nums) + 1) / 2 - sum(nums))
|
4c275951df85b640416457ea779b048c10a82937 | Yuggeo/1.2 | /task1.py | 197 | 3.734375 | 4 | x = list(input())
def funct(x):
ans = None
if int(x[0]) < int(x[1]):
ans = x[1]
if int(x[0]) < int(x[2]):
ans = x[2]
ans = int(x[0])
return ans
print(funct(x)) |
f90f338819308cb0822eab8b590f800dcfd5b31e | VolatileDream/advent-of-code | /2020/day-22/main.py | 3,771 | 3.546875 | 4 | #!/usr/bin/python3
import argparse
import collections
import re
import sys
import typing
def load_file(filename):
contents = []
with open(filename, 'r') as f:
for line in f:
line = line.strip() # remove trailing newline
contents.append(line)
return contents
def load_groups(filename):
# because some files follow this format instead.
contents = []
acc = []
for line in load_file(filename):
if line:
acc.append(line)
else:
contents.append(acc)
acc = []
if acc:
contents.append(acc)
return contents
class SpaceCardDeck:
@staticmethod
def from_lines(lines):
name = int(lines[0].rstrip(":").split(" ")[1])
cards = [int(i) for i in lines[1:]]
return SpaceCardDeck(name, cards)
def __init__(self, player, cards):
self.player = player
self.cards = cards
def __repr__(self):
out = [str(c) for c in self.cards]
out.insert(0, "Player {}:".format(str(self.player)))
return "\n".join(out)
def draw(self):
# return the top card of the deck, removes it from the deck.
return self.cards.pop(0)
def add(self, *cards):
self.cards.extend(cards)
def __len__(self):
return len(self.cards)
def copy(self):
return SpaceCardDeck(self.player, list(self.cards))
def state(self):
# returns a hashable state.
return tuple(self.cards)
def subdeck(self, size):
return SpaceCardDeck(self.player, self.cards[:size])
@staticmethod
def play_combat(deck1, deck2):
previous_states = set()
# outputs (deck1 after game, deck2 after game, pairs)
deck1 = deck1.copy()
deck2 = deck2.copy()
while len(deck1) > 0 and len(deck2) > 0:
state = (deck1.state(), deck2.state())
if state in previous_states:
print("SpaceCardDeck.play_combat non terminating game")
return (deck1.subdeck(0), deck2.subdeck(0))
previous_states.add(state)
c1 = deck1.draw()
c2 = deck2.draw()
if c1 > c2:
deck1.add(c1, c2)
else:
# c1 < c2
deck2.add(c2, c1)
return (deck1, deck2)
@staticmethod
def play_recursive_combat(start1, start2):
previous_states = set()
deck1 = start1.copy()
deck2 = start2.copy()
while len(deck1) > 0 and len(deck2) > 0:
state = (deck1.state(), deck2.state())
if state in previous_states:
return (deck1, deck2.subdeck(0))
previous_states.add(state)
c1 = deck1.draw()
c2 = deck2.draw()
# do sub round?
if len(deck1) >= c1 and len(deck2) >= c2:
win1, win2 = SpaceCardDeck.play_recursive_combat(deck1.subdeck(c1), deck2.subdeck(c2))
if len(win1) > len(win2):
# winner = deck 1
deck1.add(c1, c2)
else:
deck2.add(c2, c1)
else:
# normal round of combat
if c1 > c2:
deck1.add(c1, c2)
else:
# c1 < c2
deck2.add(c2, c1)
return (deck1, deck2)
def deck_score(deck):
cards = list(deck.cards)
cards.reverse()
return sum([(index + 1) * card for index, card in enumerate(cards)])
def part1(things):
d1, d2 = things
result1, result2 = SpaceCardDeck.play_combat(d1, d2)
return max(deck_score(result1), deck_score(result2))
def part2(things):
d1, d2 = things
result1, result2 = SpaceCardDeck.play_recursive_combat(d1, d2)
return max(deck_score(result1), deck_score(result2))
def main(filename):
things = [SpaceCardDeck.from_lines(g) for g in load_groups(filename)]
print("part 1:", part1(things))
print("part 2:", part2(things))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('input', nargs='?', default='/dev/stdin')
args = parser.parse_args(sys.argv[1:])
main(args.input)
|
d326db41baaedaab1a768edd3d117f48824decd0 | AnanthKumarVasamsetti/design_patterns | /chain of responsibility/chain_of_responsibility.py | 1,899 | 3.984375 | 4 | """
Chain of responsibility: In this structural pattern the processing of any given request is handled through a chain of handlers.
Request is passed across the chain of handlers until it is fulfilled.
Example : In following example there will be display of processors which would to take the responsibility of respective numbers
"""
import abc
class Chain:
def __init__(self):
return
@abc.abstractclassmethod
def set_next(self, nextInChain):
pass
@abc.abstractclassmethod
def process(self, numberToProcess):
pass
class NegativeProcessor(Chain):
def __init__(self):
return
def set_next(self, nextInChain):
self.nextInChain = nextInChain
def process(self, numberToProcess):
if numberToProcess < 0:
print("Negative processor: ", numberToProcess)
else:
self.nextInChain.process(numberToProcess)
class PositiveProcessor(Chain):
def __init__(self):
return
def set_next(self, nextInChain):
self.nextInChain = nextInChain
def process(self, numberToProcess):
if numberToProcess > 0:
print("Positive processor: ", numberToProcess)
else:
self.nextInChain.process(numberToProcess)
class ZeroProcessor(Chain):
def __init__(self):
return
def set_next(self, nextInChain):
self.nextInChain = nextInChain
def process(self, numberToProcess):
if numberToProcess == 0:
print("Zero processor: ",numberToProcess)
else:
self.nextInChain.process(numberToProcess)
if __name__ == "__main__":
c1 = NegativeProcessor()
c2 = PositiveProcessor()
c3 = ZeroProcessor()
c1.set_next(c2)
c2.set_next(c3)
c1.process(90)
c1.process(0)
c1.process(-20)
c1.process(50) |
3724d56ee454453cd13c55f6956ce463a54b2e6e | hemerocallis/python-courses | /python_course_week1.py | 2,518 | 4.28125 | 4 |
# coding: utf-8
# In[1]:
# Считать отдельными операторами два целых числа, получить: сумму, разность, результат целочисленного деления,
# частное, остаток от деления, третью степень первого числа и вторую степень второго числа
# и вывести их отдельными операторами вывода.
a = int(input())
b = int(input())
print(a + b) # сумма
print(a - b) # разность
print(a // b) # целочисленное деление
print(a / b) # частное
print(a % b) # остаток от деления
print(a ** 3) # возведение в сепень
print(b ** 2)
# In[5]:
# Считать несколько имен людей одной строкой, записанных латиницей, через пробел, например: «Anna Maria Peter».
# Вывести их одной строкой в порядке возрастания «Anna Maria Peter».
# Вывести их одной строкой в порядке убывания «Peter Maria Anna».
s = str(input())
sorted_list = sorted(s.split())
print(' '.join(sorted_list))
reversed_list = sorted_list[::-1]
print(' '.join(reversed_list))
# In[9]:
# Считать единой строкой без пробелов набор целых чисел (28745623873465386),
# удалить все дубликаты, вывести отдельными операторами вывода в порядке возрастания
# и в порядке убывания в виде кортежей целых чисел (2, 3, 4, 5, 6, 7, 8) и (8, 7, 6, 5, 4, 3, 2).
n = input()
# set может содержать только уникальные значения.
# приводим множество к списку и сортируем его в порядке возрастания
sorted_list = sorted(list(set(n)))
# преобразуем список в кортеж целых чисел и выводим результат
print(tuple(map(int, sorted_list)))
# меняем порядок элементов списка на противоположный
reversed_list = sorted_list[::-1]
# преобразуем перевернутый список в кортеж целых чисел и выводим результат
print(tuple(map(int, reversed_list)))
# In[ ]:
|
0ab33dd1c3bd14c89fae805821b6e3f937404b82 | NotAKernel/python-tutorials | /messages.py | 612 | 3.6875 | 4 | def show_messages(messages):
"""Shows text messages."""
for message in messages:
print(message)
messages = ['Hello, Daniel', 'How are you?']
typed_messages = ['Hello, James', 'I am alright']
def send_messages(typed_messages, delivered_messages):
"""Receives and prints messages."""
while typed_messages:
sent_messages = typed_messages.pop()
print("Your message is sending")
delivered_messages.append(sent_messages)
for delivered_message in delivered_messages:
print(delivered_messages)
delivered_messages = []
send_messages(typed_messages, delivered_messages) |
83bbaa920b062293ffb0265c8a05c9c4d4efa74a | srikarsharan097/Payment-Card-OCR | /Project Code/printing_records.py | 462 | 3.515625 | 4 | import sqlite3 as sqlitedb
print("\nConnecting to database..")
con = sqlitedb.connect('PaymentCards_DB.sqlite')
print("\nConnected.")
print("\nCreating cursor..")
cur = con.cursor()
print("\nCreated.")
print("\nDetails printing..\n")
cur.execute("SELECT * FROM CARDOWNERDETAILS")
col_name_list = [tuple[0] for tuple in cur.description]
print(col_name_list)
result = cur.execute('SELECT * FROM CARDOWNERDETAILS')
for i in result:
print(i) |
3a482bc058088107b91b333869515c854ae8d436 | sarazhan/compiti_inf | /numero29.py | 1,623 | 3.875 | 4 | '''
esercizio pag.73 numero 29: dato un elenco di città con l'indicazione per ciascuna di esse del nome della temperatura massima e minima registrate un giorno
si devono contare quante città hanno superato nel giorno un valore prefissato per l'escursione termica ottenuta per differenza tra temperatura massima e minima
organizza un programma che dopo aver chiesto il valore da controllare dell'escursione termica per ogni città dell'elenco ripeta la richiesta dei dati nome
temperatura massima e minima a calcoli l'escursione termica e controlli se l'escursione è maggiore del valore prefissato in questo caso incrementa il
contatore delle città selezionate alla fine della ripetizione comunica il numero delle città registrato nel contatore
'''
lista_città = input("Scrivi la città poi stccato da uno spazio l'altra città: ").split()
conto = 0
temperatura_max = []
temperatura_min = []
differenze = []
for i in range(len(lista_città)):
tmax = int(input("Quale la temperatura massima registrata in un giorno della città corrispondente? "))
tmin = int(input("Quale la temperatura minima registrata in un giorno della città corrispondente? "))
temperatura_max.append(tmax)
temperatura_min.append(tmin)
valore_fisso = int(input("Inserisce il valore fisso: "))
for n in range(len(temperatura_max)):
differenza = temperatura_max[n] - temperatura_min[n]
print("Le esursioni termiche sono: ", differenza)
differenze.append(differenza)
for n in range(len(temperatura_max)):
val = differenze[n]
if val > valore_fisso:
conto += 1
print("Questo è il conto: ",conto)
|
876ca04bb2e9078610dae49904221814e624bf91 | ashusao/Deep_Learning_Exercises | /Ex_1/hw1_knn.py | 1,498 | 3.8125 | 4 | # -*- coding: utf-8 -*-
"""
Created on
@author: fame
"""
import numpy as np
def compute_euclidean_distances( X, Y ) :
"""
Compute the Euclidean distance between two matricess X and Y
Input:
X: N-by-D numpy array train
Y: M-by-D numpy array test
Should return dist: M-by-N numpy array
"""
num_test = Y.shape[0]
num_train = X.shape[0]
dists = np.zeros((num_test, num_train))
#||v-w||^2 = ||v||^2 + ||w||^2 - 2*dot(v,w)
Y_square = np.reshape((Y**2).sum(axis=1), (-1, 1))
X_square = np.reshape((X**2).sum(axis=1), (1, -1))
dists = np.sqrt( Y_square + X_square - 2*(Y.dot(X.T)))
return dists
def predict_labels( dists, labels, k=2):
"""
Given a Euclidean distance matrix and associated training labels predict a label for each test point.
Input:
dists: M-by-N numpy array
labels: is a N dimensional numpy array
Should return pred_labels: M dimensional numpy array
"""
num_test = dists.shape[0]
pred_labels = np.zeros(num_test)
# loop through all test data
for i in xrange(num_test):
# Calculating labels of k closest neighbours
k_closest = labels[np.argsort(dists[i])][0:k]
#Computing number of occrunce of each label
counts = np.bincount(k_closest.astype(int))
#predicting label with maximum occruence
pred_labels[i] = np.argmax(counts)
return pred_labels
|
8d05e4b76ddde8b398a921f7e561acb03236ad56 | joshsizer/free_code_camp | /algorithms/no_repeats/no_repeats.py | 3,300 | 3.671875 | 4 | """
Created on Sun May 2 2021
Copyright (c) 2021 - Joshua Sizer
This code is licensed under MIT license (see
LICENSE for details)
"""
def perm_alone(str):
"""
Get the permutations of an input string that
don't have consecutive repeat letters.
For example, cbc has permutations: cbc, cbc,
ccb, ccb, bcc, bcc. Only cbc and cbc have no
repeat letters, so 2 is returned.
Runtime is O(n*n!) where n is the length of the
string.
permutations is O(n*n!),
so the total is O(n*n! + n!) which is just
iterating over the permutations is n!,
O(n*n!)
Arguments:
str: The string to compute this special
type of permutation count.
Returns:
the number of permutations containing
no repeat letters.
"""
# Let's get all the permutation for this
# string. This is the difficult part
# of the algorithm
perms = permutations(str)
# Simply count how many of the permutations
# don't contain any repeat characters.
count = 0
for perm in perms:
if not contains_repeats(perm): count += 1
return count
def permutations(str):
"""Generates all the permutations of a given
string.
The runtime is O(n*n!) where n is the length of
the string.
Outer loop runs (n-1).
Middle loop runs (n-1)!
Inner loop runs (n).
(n-1) * (n-1)! * (n) = (n-1) * n!
= n*n! - n! = O(n*n!).
Arguments:
str: The string to find the permutations of
Returns:
An array of permutations of the given string.
"""
# Store all the partial permutations
partial_perms = [str]
# For a 4 length string, the partial
# permutations will be of size 1 -> 2 -> 3
for i in range(len(str) - 1):
# Since we shouldn't modify the length of
# partial_perms while iterating over it,
# create a temporary variable to hold the
# next iteration of partial permutations.
temp = []
# Basically, switch the character in
# position i with the character at
# position k, and this will be a new
# permutation. You have to do this for
# all partial permutations (j).
for j in range(len(partial_perms)):
current_perm = partial_perms[j]
for k in range(i, len(current_perm)):
# To swap characters it's easiest
# to turn the string into an
# array and perform a swap that way.
new_perm = list(current_perm)
temp_char = new_perm[k]
new_perm[k] = new_perm[i]
new_perm[i] = temp_char
temp.append(''.join(new_perm))
partial_perms = temp
return partial_perms
def contains_repeats(str):
"""Determines if a string has repeat letters.
This function is worst case O(n) because it
must at worst check each character in the
string. n is the length of the string.
Arguments:
str: the string to examine for
repeat letters
Returns:
True if the string contains at least
one repeat, False otherwise
"""
for i in range(1, len(str)):
if str[i] == str[i-1]:
return True
return False
print(perm_alone("dabc")) |
1d245a584c81f3f25f059f703eafff8d5c57b8a0 | daminton/code_wars | /python/break_camel_case.py | 312 | 3.90625 | 4 | #Complete the solution so that the function will break up camel casing, using a space between words.
def solution(s):
list = []
for i in s:
if i == i.upper():
list.append(" "),
list.append(i)
else:
list.append(i)
return ''.join(list) |
42bafe600e918fc7634b4ca1738bd92f7798d251 | alex-vegan/100daysofcode-with-python-course | /days/day012/hangman.py | 3,928 | 4.15625 | 4 | import random
WORDLIST_FILENAME = "words.txt"
def loadWords(file=WORDLIST_FILENAME):
"""
Returns a list of valid words. Words are strings of lowercase letters.
"""
print("Loading word list from file...")
inFile = open(file, 'r')
line = inFile.readline()
wordlist = line.split()
print(len(wordlist), "words loaded.")
return wordlist
def chooseWord(wordlist):
"""
wordlist (list): list of words (strings)
Returns a word from wordlist at random
"""
return random.choice(wordlist)
def isWordGuessed(secretWord, lettersGuessed):
'''
secretWord: string, the word the user is guessing
lettersGuessed: list, what letters have been guessed so far
returns: boolean, True if all the letters of secretWord are in lettersGuessed;
False otherwise
'''
for i in secretWord:
if i in lettersGuessed:
continue
else:
return False
return True
def getGuessedWord(secretWord, lettersGuessed):
'''
secretWord: string, the word the user is guessing
lettersGuessed: list, what letters have been guessed so far
returns: string, comprised of letters and underscores that represents
what letters in secretWord have been guessed so far.
'''
guessedWord = ''
for i in secretWord:
if i in lettersGuessed:
guessedWord += i
else:
guessedWord += '.'
return guessedWord
def getAvailableLetters(lettersGuessed):
'''
lettersGuessed: list, what letters have been guessed so far
returns: string, comprised of letters that represents what letters have not
yet been guessed.
'''
availableLetters = ''
for i in 'abcdefghijklmnopqrstuvwxyz':
if not i in lettersGuessed:
availableLetters += i
return availableLetters
def hangman(secretWord):
'''
secretWord: string, the secret word to guess.
Starts up an interactive game of Hangman.
* At the start of the game user knows how many letters the secretWord contains.
* Ask the user to supply one guess (i.e. letter) per round.
* The user receive feedback immediately after each guess about whether their
guess appears in the computers word.
* After each round display to the user the partially guessed word so far,
as well as letters that the user has not yet guessed.
'''
lettersGuessed = []
print('Welcome to the game, Hangman!\n'
'I am thinking of a word that is', len(secretWord),'letters long\n',
getGuessedWord(secretWord, lettersGuessed), end='\n')
mistakesMade = 0
while not isWordGuessed(secretWord, lettersGuessed) and mistakesMade < 8:
letter = (input('-'*50 + '\n'
'You have ' + str(8-mistakesMade) + ' guesses left.\n'
'Available letters: ' + getAvailableLetters(lettersGuessed) + '\n'
'Please guess a letter: ')).lower()
if letter in lettersGuessed:
print("Oops! You've already guessed that letter\n",
getGuessedWord(secretWord, lettersGuessed),end='\n')
else:
lettersGuessed.append(letter)
lettersGuessed = list(set(lettersGuessed))
if letter in secretWord:
print('Good guess:\n',
getGuessedWord(secretWord, lettersGuessed),end='\n')
else:
mistakesMade += 1
print('Oops! That letter is not in my word\n',
getGuessedWord(secretWord, lettersGuessed),end='\n')
print('-'*50)
if mistakesMade == 8:
print('Sorry, you ran out of guesses. The word was "' + secretWord + '"')
else:
print('Congratulations, you won!')
if __name__ == '__main__':
wordlist = loadWords(WORDLIST_FILENAME)
secretWord = chooseWord(wordlist).lower()
hangman(secretWord)
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.