

language:
- en
license: cc-by-nc-sa-4.0
size_categories:
- 10K<n<100K
task_categories:
- text-classification
pretty_name: LlamaLens English Dataset
tags:
- Social Media
- News Media
- Sentiment
- Stance
- Emotion
dataset_info:
- config_name: QProp
splits:
- name: train
num_examples: 35986
- name: dev
num_examples: 5125
- name: test
num_examples: 10159
- config_name: Cyberbullying
splits:
- name: train
num_examples: 32551
- name: dev
num_examples: 4751
- name: test
num_examples: 9473
- config_name: clef2024-checkthat-lab
splits:
- name: train
num_examples: 825
- name: dev
num_examples: 219
- name: test
num_examples: 484
- config_name: SemEval23T3-subtask1
splits:
- name: train
num_examples: 302
- name: dev
num_examples: 130
- name: test
num_examples: 83
- config_name: offensive_language_dataset
splits:
- name: train
num_examples: 29216
- name: dev
num_examples: 3653
- name: test
num_examples: 3653
- config_name: xlsum
splits:
- name: train
num_examples: 306493
- name: dev
num_examples: 11535
- name: test
num_examples: 11535
- config_name: claim-detection
splits:
- name: train
num_examples: 23224
- name: dev
num_examples: 5815
- name: test
num_examples: 7267
- config_name: emotion
splits:
- name: train
num_examples: 280551
- name: dev
num_examples: 41429
- name: test
num_examples: 82454
- config_name: Politifact
splits:
- name: train
num_examples: 14799
- name: dev
num_examples: 2116
- name: test
num_examples: 4230
- config_name: News_dataset
splits:
- name: train
num_examples: 28147
- name: dev
num_examples: 4376
- name: test
num_examples: 8616
- config_name: hate-offensive-speech
splits:
- name: train
num_examples: 48944
- name: dev
num_examples: 2802
- name: test
num_examples: 2799
- config_name: CNN_News_Articles_2011-2022
splits:
- name: train
num_examples: 32193
- name: dev
num_examples: 9663
- name: test
num_examples: 5682
- config_name: CT24_checkworthy
splits:
- name: train
num_examples: 22403
- name: dev
num_examples: 318
- name: test
num_examples: 1031
- config_name: News_Category_Dataset
splits:
- name: train
num_examples: 145748
- name: dev
num_examples: 20899
- name: test
num_examples: 41740
- config_name: NewsMTSC-dataset
splits:
- name: train
num_examples: 7739
- name: dev
num_examples: 320
- name: test
num_examples: 747
- config_name: Offensive_Hateful_Dataset_New
splits:
- name: train
num_examples: 42000
- name: dev
num_examples: 5254
- name: test
num_examples: 5252
- config_name: News-Headlines-Dataset-For-Sarcasm-Detection
splits:
- name: train
num_examples: 19965
- name: dev
num_examples: 2858
- name: test
num_examples: 5719
configs:
- config_name: QProp
data_files:
- split: test
path: QProp/test.json
- split: dev
path: QProp/dev.json
- split: train
path: QProp/train.json
- config_name: Cyberbullying
data_files:
- split: test
path: Cyberbullying/test.json
- split: dev
path: Cyberbullying/dev.json
- split: train
path: Cyberbullying/train.json
- config_name: clef2024-checkthat-lab
data_files:
- split: test
path: clef2024-checkthat-lab/test.json
- split: dev
path: clef2024-checkthat-lab/dev.json
- split: train
path: clef2024-checkthat-lab/train.json
- config_name: SemEval23T3-subtask1
data_files:
- split: test
path: SemEval23T3-subtask1/test.json
- split: dev
path: SemEval23T3-subtask1/dev.json
- split: train
path: SemEval23T3-subtask1/train.json
- config_name: offensive_language_dataset
data_files:
- split: test
path: offensive_language_dataset/test.json
- split: dev
path: offensive_language_dataset/dev.json
- split: train
path: offensive_language_dataset/train.json
- config_name: xlsum
data_files:
- split: test
path: xlsum/test.json
- split: dev
path: xlsum/dev.json
- split: train
path: xlsum/train.json
- config_name: claim-detection
data_files:
- split: test
path: claim-detection/test.json
- split: dev
path: claim-detection/dev.json
- split: train
path: claim-detection/train.json
- config_name: emotion
data_files:
- split: test
path: emotion/test.json
- split: dev
path: emotion/dev.json
- split: train
path: emotion/train.json
- config_name: Politifact
data_files:
- split: test
path: Politifact/test.json
- split: dev
path: Politifact/dev.json
- split: train
path: Politifact/train.json
- config_name: News_dataset
data_files:
- split: test
path: News_dataset/test.json
- split: dev
path: News_dataset/dev.json
- split: train
path: News_dataset/train.json
- config_name: hate-offensive-speech
data_files:
- split: test
path: hate-offensive-speech/test.json
- split: dev
path: hate-offensive-speech/dev.json
- split: train
path: hate-offensive-speech/train.json
- config_name: CNN_News_Articles_2011-2022
data_files:
- split: test
path: CNN_News_Articles_2011-2022/test.json
- split: dev
path: CNN_News_Articles_2011-2022/dev.json
- split: train
path: CNN_News_Articles_2011-2022/train.json
- config_name: CT24_checkworthy
data_files:
- split: test
path: CT24_checkworthy/test.json
- split: dev
path: CT24_checkworthy/dev.json
- split: train
path: CT24_checkworthy/train.json
- config_name: News_Category_Dataset
data_files:
- split: test
path: News_Category_Dataset/test.json
- split: dev
path: News_Category_Dataset/dev.json
- split: train
path: News_Category_Dataset/train.json
- config_name: NewsMTSC-dataset
data_files:
- split: test
path: NewsMTSC-dataset/test.json
- split: dev
path: NewsMTSC-dataset/dev.json
- split: train
path: NewsMTSC-dataset/train.json
- config_name: Offensive_Hateful_Dataset_New
data_files:
- split: test
path: Offensive_Hateful_Dataset_New/test.json
- split: dev
path: Offensive_Hateful_Dataset_New/dev.json
- split: train
path: Offensive_Hateful_Dataset_New/train.json
- config_name: News-Headlines-Dataset-For-Sarcasm-Detection
data_files:
- split: test
path: News-Headlines-Dataset-For-Sarcasm-Detection/test.json
- split: dev
path: News-Headlines-Dataset-For-Sarcasm-Detection/dev.json
- split: train
path: News-Headlines-Dataset-For-Sarcasm-Detection/train.json
LlamaLens: Specialized Multilingual LLM Dataset
This dataset supports the research presented in the paper LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content.
Overview
LlamaLens is a specialized multilingual LLM designed for analyzing news and social media content. It focuses on 18 NLP tasks, leveraging 52 datasets across Arabic, English, and Hindi. This repository contains the English-language portion of the data.
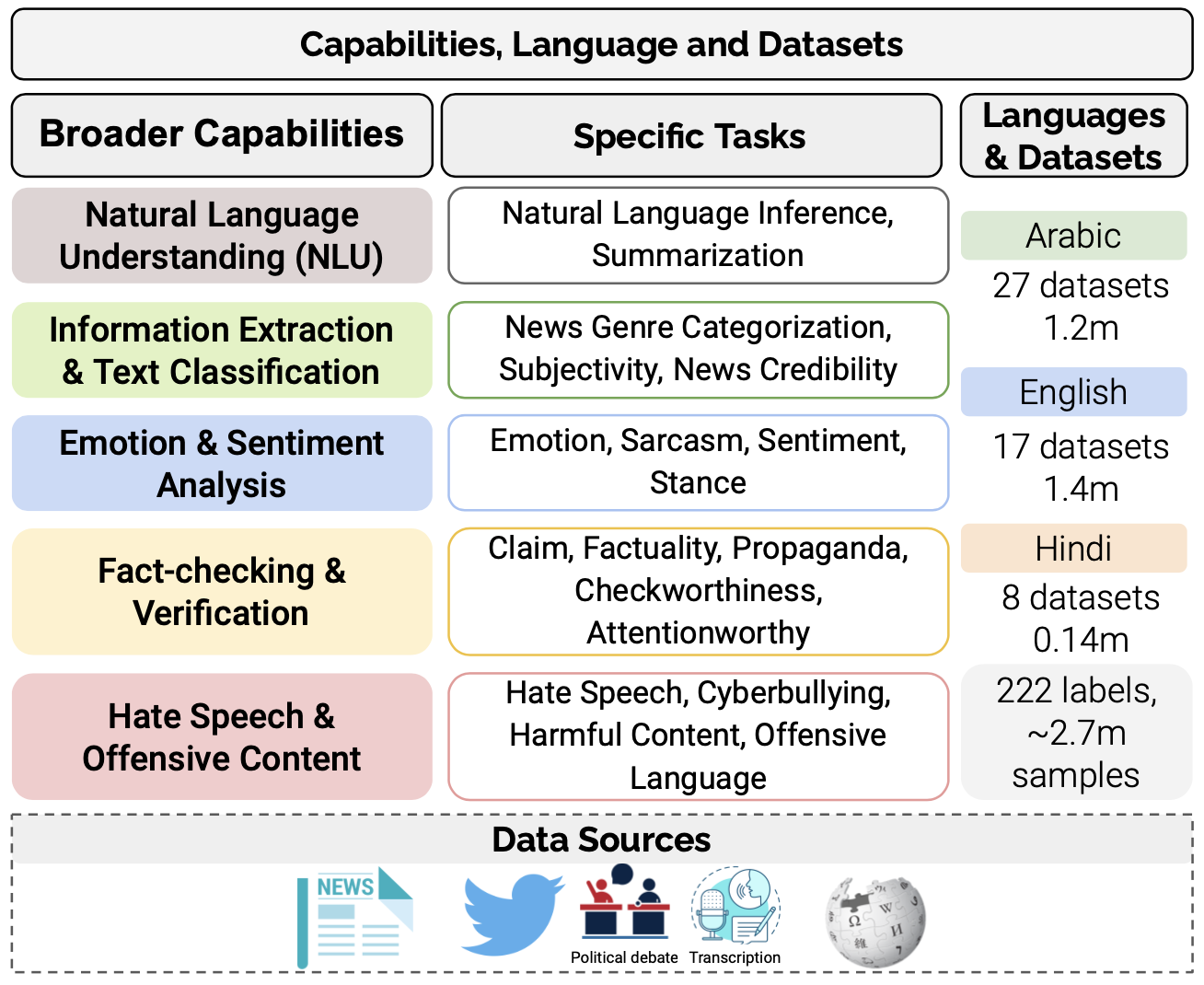
Dataset Details
This dataset comprises various sub-datasets focusing on different text classification tasks related to news and social media analysis. A detailed breakdown of the datasets and their statistics is provided in the metadata section above.
File Format
Each JSONL file in the dataset follows a structured format with the following fields:
id: Unique identifier for each data entry.original_id: Identifier from the original dataset, if available.input: The original text that needs to be analyzed.output: The label assigned to the text after analysis.dataset: Name of the dataset the entry belongs.task: The specific task type.lang: The language of the input text.instructions: A brief set of instructions describing how the text should be labeled.
Example entry in JSONL file:
{
"id": "fb6dd1bb-2ab4-4402-adaa-9be9eea6ca18",
"original_id": null,
"input": "I feel that worldviews that lack the divine tend toward the solipsistic.",
"output": "joy",
"dataset": "Emotion",
"task": "Emotion",
"lang": "en",
"instructions": "Identify if the given text expresses an emotion and specify whether it is joy, love, fear, anger, sadness, or surprise. Return only the label without any explanation, justification, or additional text."
}
Model & Code
- LlamaLens Model on Hugging Face: https://huggingface.co/QCRI/LlamaLens
- LlamaLens GitHub Repository: https://github.com/firojalam/LlamaLens
📢 Citation
If you use this dataset, please cite our paper:
@article{kmainasi2024llamalensspecializedmultilingualllm,
title={LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content},
author={Mohamed Bayan Kmainasi and Ali Ezzat Shahroor and Maram Hasanain and Sahinur Rahman Laskar and Naeemul Hassan and Firoj Alam},
year={2024},
journal={arXiv preprint arXiv:2410.15308},
volume={},
number={},
pages={},
url={https://arxiv.org/abs/2410.15308},
eprint={2410.15308},
archivePrefix={arXiv},
primaryClass={cs.CL}
}