Datasets:

license: apache-2.0
task_categories:
- visual-question-answering
language:
- en
tags:
- spatial-reasoning
- multimodal
pretty_name: Spatial457
size_categories:
- 10K<n<100K
Spatial457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models
Xingrui Wang1, Wufei Ma1, Tiezheng Zhang1, Celso M. de Melo2, Jieneng Chen1, Alan Yuille1
1 Johns Hopkins University 2 DEVCOM Army Research Laboratory
🌐 Project Page • 📄 Paper • 🤗 Dataset • 💻 Code
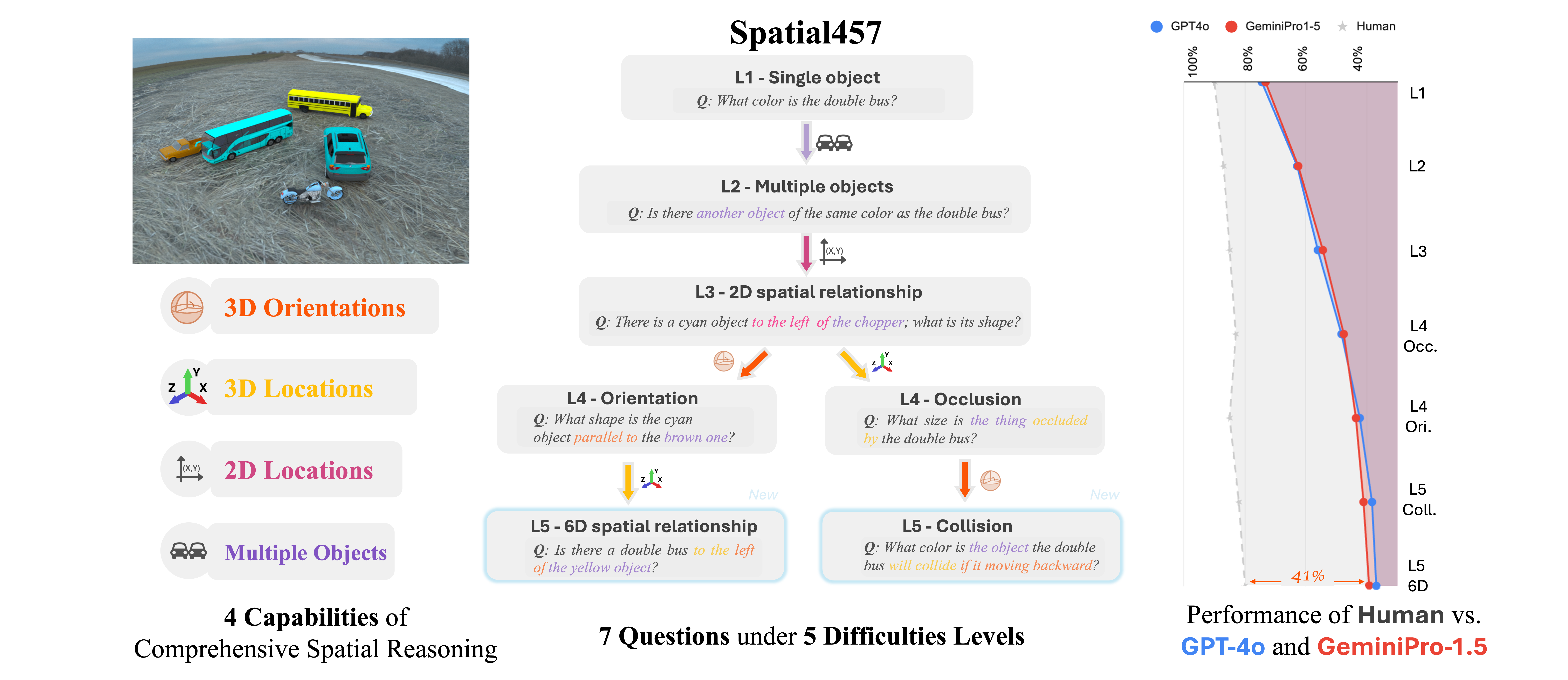
🧠 Introduction
Spatial457 is a diagnostic benchmark designed to evaluate 6D spatial reasoning in large multimodal models (LMMs). It systematically introduces four core spatial capabilities:
- 🧱 Multi-object understanding
- 🧭 2D spatial localization
- 📦 3D spatial localization
- 🔄 3D orientation estimation
These are assessed across five difficulty levels and seven diverse question types, ranging from simple object queries to complex reasoning about physical interactions.
📂 Dataset Structure
The dataset is organized as follows:
Spatial457/
├── images/ # RGB images used in VQA tasks
├── questions/ # JSONs for each subtask
│ ├── L1_single.json
│ ├── L2_objects.json
│ ├── L3_2d_spatial.json
│ ├── L4_occ.json
│ └── ...
├── Spatial457.py # Hugging Face dataset loader script
├── README.md # Documentation
Each JSON file contains a list of VQA examples, where each item includes:
- "image_filename": image file name used in the question
- "question": natural language question
- "answer": boolean, string, or number
- "program": symbolic program (optional)
- "question_index": unique identifier
This modular structure supports scalable multi-task evaluation across levels and reasoning types.
🛠️ Dataset Usage
You can load the dataset directly using the Hugging Face 🤗 datasets library:
🔹 Load a specific subtask (e.g., L1_single)
from datasets import load_dataset
dataset = load_dataset("RyanWW/Spatial457", name="L5_6d_spatial", split="validation", data_dir=".")
Each example is a dictionary like:
{
'image': <PIL.Image.Image>,
'image_filename': 'superCLEVR_new_000001.png',
'question': 'Is the large red object in front of the yellow car?',
'answer': 'True',
'program': [...],
'question_index': 100001
}
🔹 Other available configurations
[
"L1_single", "L2_objects", "L3_2d_spatial",
"L4_occ", "L4_pose", "L5_6d_spatial", "L5_collision"
]
You can swap name="..." in load_dataset(...) to evaluate different spatial reasoning capabilities.
📚 Citation
@inproceedings{wang2025spatial457,
title = {Spatial457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models},
author = {Wang, Xingrui and Ma, Wufei and Zhang, Tiezheng and de Melo, Celso M and Chen, Jieneng and Yuille, Alan},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
url = {https://arxiv.org/abs/2502.08636}
}