
language
stringclasses 15
values | src_encoding
stringclasses 34
values | length_bytes
int64 6
7.85M
| score
float64 1.5
5.69
| int_score
int64 2
5
| detected_licenses
listlengths 0
160
| license_type
stringclasses 2
values | text
stringlengths 9
7.85M
|
|---|---|---|---|---|---|---|---|
Go
|
UTF-8
| 2,431 | 2.625 | 3 |
[] |
no_license
|
package mqtt
import (
"errors"
"fmt"
"strings"
"github.com/RedHatInsights/cloud-connector/internal/domain"
)
const (
defaultTopicPrefix string = "redhat"
controlMessageIncomingTopic string = "insights/+/control/out"
controlMessageOutgoingTopic string = "insights/%s/control/in"
dataMessageIncomingTopic string = "insights/+/data/out"
dataMessageOutgoingTopic string = "insights/%s/data/in"
)
type TopicType int8
const (
ControlTopicType TopicType = 0
DataTopicType TopicType = 1
)
type TopicVerifier struct {
prefix string
}
func NewTopicVerifier(prefix string) *TopicVerifier {
topicVerifier := &TopicVerifier{prefix: defaultTopicPrefix}
if prefix != "" {
topicVerifier.prefix = prefix
}
return topicVerifier
}
func (tv *TopicVerifier) VerifyIncomingTopic(topic string) (TopicType, domain.ClientID, error) {
items := strings.Split(topic, "/")
if len(items) != 5 {
return ControlTopicType, "", errors.New("MQTT topic requires 4 sections: " + tv.prefix + ", insights, <clientID>, <type>, in " + topic)
}
if items[0] != tv.prefix || items[1] != "insights" || items[4] != "out" {
return ControlTopicType, "", errors.New("MQTT topic needs to be " + tv.prefix + "/insights/<clientID>/<type>/out")
}
var topicType TopicType
if items[3] == "control" {
topicType = ControlTopicType
} else if items[3] == "data" {
topicType = DataTopicType
} else {
return ControlTopicType, "", errors.New("Invalid topic type")
}
return topicType, domain.ClientID(items[2]), nil
}
func NewTopicBuilder(prefix string) *TopicBuilder {
topicBuilder := &TopicBuilder{prefix: defaultTopicPrefix}
if prefix != "" {
topicBuilder.prefix = prefix
}
return topicBuilder
}
type TopicBuilder struct {
prefix string
}
func (tb *TopicBuilder) BuildOutgoingDataTopic(clientID domain.ClientID) string {
topicStringFmt := tb.prefix + "/" + dataMessageOutgoingTopic
topic := fmt.Sprintf(topicStringFmt, clientID)
return topic
}
func (tb *TopicBuilder) BuildOutgoingControlTopic(clientID domain.ClientID) string {
topicStringFmt := tb.prefix + "/" + controlMessageOutgoingTopic
topic := fmt.Sprintf(topicStringFmt, clientID)
return topic
}
func (tb *TopicBuilder) BuildIncomingWildcardDataTopic() string {
return tb.prefix + "/" + dataMessageIncomingTopic
}
func (tb *TopicBuilder) BuildIncomingWildcardControlTopic() string {
return tb.prefix + "/" + controlMessageIncomingTopic
}
|
C#
|
UTF-8
| 1,232 | 3.46875 | 3 |
[] |
no_license
|
using System;
using System.Linq;
public class IntOrArray
{
public bool IsInt { private set; get; }
public int IValue { private set; get; }
public IntOrArray[] AValue { private set; get; }
public IntOrArray(int i)
{
IsInt = true;
IValue = i;
}
public IntOrArray(IntOrArray[] a)
{
IsInt = false;
AValue = a;
}
}
public class SumAllKlass
{
public static void Main()
{
var l = Construct();
var total = SumAll(l);
Console.WriteLine(total);
}
public static IntOrArray Construct()
{
var innerestTwo = new IntOrArray(2);
var innerestThree = new IntOrArray(3);
var innerestArray = new IntOrArray(new IntOrArray[] { innerestTwo, innerestThree });
var innerOne = new IntOrArray(1);
var innerArray = new IntOrArray(new IntOrArray[] { innerOne, innerestArray });
var outterOne = new IntOrArray(1);
var outterTwo = new IntOrArray(2);
var outterThree = new IntOrArray(3);
return new IntOrArray(new IntOrArray[] { outterOne, outterTwo, outterThree, innerArray });
}
public static int SumAll(IntOrArray l)
{
if (l.IsInt)
{
return l.IValue;
}
else
{
int tempTotal = 0;
foreach(var item in l.AValue)
{
tempTotal += SumAll(item);
}
return tempTotal;
}
}
}
|
Java
|
UTF-8
| 1,727 | 1.84375 | 2 |
[] |
no_license
|
package br.com.wjaa.ranchucrutes.ws.dao;
import br.com.wjaa.ranchucrutes.commons.vo.LocationVo;
import br.com.wjaa.ranchucrutes.framework.dao.GenericDao;
import br.com.wjaa.ranchucrutes.ws.entity.ProfissionalOrigemEntity;
import br.com.wjaa.ranchucrutes.ws.entity.ProfissionalEntity;
import java.util.List;
/**
* Created by wagner on 17/06/15.
*/
public interface ProfissionalDao extends GenericDao<ProfissionalEntity,Long> {
/**
*
* @param idEspecialidade
* @param idConvenio
* @param location
* @param raioPrecisao
* @return
*/
List<ProfissionalEntity> findProfissional(Integer idEspecialidade, Integer idConvenio, LocationVo location, double raioPrecisao);
/**
*
* @param idEspecialidade
* @param location
* @param raioPrecisao
* @return
*/
List<ProfissionalEntity> findProfissionalByEspecialidade(Integer idEspecialidade, LocationVo location,
double raioPrecisao);
/**
*
* @param numeroRegistro
* @return
*/
ProfissionalEntity getProfissionalByNumeroRegistro(String numeroRegistro);
/**
*
* @param email
* @return
*/
ProfissionalEntity getProfissionalByEmail(String email);
ProfissionalEntity getProfissionalByIdAndCategoria(Long idProfissional, Long idClinica, Integer[] idsCategoria);
/**
*
* @param idProfissional
* @param idClinica
* @return
*/
ProfissionalOrigemEntity findProfissionalOrigem(Long idProfissional, Long idClinica);
/**
*
* @param startName
* @return
*/
List<ProfissionalEntity> findProfissionalByStartName(String startName);
}
|
Python
|
UTF-8
| 13,380 | 4.25 | 4 |
[] |
no_license
|
"""
Functions for reading numbers given type
Author: Patrick Kwok (lk2754)
December 21, 2019
"""
import copy
digits = {0: "zero", 1: "one", 2: "two", 3: "three", 4: "four", \
5: "five", 6: "six", 7: "seven", 8: "eight", 9: "nine"}
digits_alt = {0: "oh", 1: "one", 2: "two", 3: "three", 4: "four", \
5: "five", 6: "six", 7: "seven", 8: "eight", 9: "nine"}
teens = {10: "ten", 11: "eleven", 12: "twelve", 13: "thirteen", 14: "fourteen", \
15: "fifteen", 16: "sixteen", 17: "seventeen", 18: "eighteen", 19: "nineteen"}
tens = {10: "ten", 20: "twenty", 30: "thirty", 40: "forty", 50: "fifty", \
60: "sixty", 70: "seventy", 80: "eighty", 90: "ninety"}
multiples = {100: "hundred", 1000: "thousand", 10 ** 6: "million", \
10 ** 9: "billion", 10 ** 12: "trillion"}
ordinals = {"one": "first", "two": "second", "three": "third", "five": "fifth", \
"eight": "eighth", "nine": "ninth", "twelve": "twelfth", "twenty": "twentieth", \
"thirty": "thirtieth", "forty": "fortieth", "fifty": "fiftieth", \
"sixty": "sixtieth", "seventy": "seventieth", "eighty": "eightieth", \
"ninety": "ninetieth"}
def read_by_digit(num):
# Read a number digit by digit (e.g. "342" = "three four two")
# Input: num - string containing the number (can have letters / symbols)
# Output: a dictionary of possible spelt-out forms and probabilities
method1 = ""
method2 = ""
for d in num:
if d.isdigit():
method1 = method1 + digits[int(d)] + " "
method2 = method2 + digits_alt[int(d)] + " "
else:
method1 = method1 + d + " "
method2 = method2 + d + " "
method1 = method1[:-1]
method2 = method2[:-1]
if method1 == method2:
return {method1: 1.0}
return {method1: 0.5, method2: 0.5}
def read_2d(num):
# Read an integer with at most 2 digits
# Input: num - string containing the number
# Output: a string corresponding to the spelt-out form
num = int(num)
if num == 0:
return ""
if num <= 9:
return digits[num]
if num <= 19:
return teens[num]
if num % 10 == 0:
return tens[10*(num//10)]
return tens[10*(num//10)] + " " + digits[num%10]
def read_2d_year(num):
# Helper function for reading years
# Input: num - string containing the number
# Output: a string that is part of the spelt-out form of a year number
num = int(num)
if num == 0:
return "hundred"
if num <= 9:
return "oh " + digits[num]
if num <= 19:
return teens[num]
if num % 10 == 0:
return tens[10*(num//10)]
return tens[10*(num//10)] + " " + digits[num%10]
def read_year(num):
# Read a year number (can have at most 2 letters at beginning or end)
# Input: num - string containing the year number (can have letters)
# Output: a dictionary of possible spelt-out forms and probabilities
bl = ""
el = ""
if num[0].isalpha() and not num[1].isalpha():
bl = num[0] + " "
num = num[1:]
elif num[0].isalpha() and num[1].isalpha() and not num[2].isalpha():
bl = num[0] + " " + num[1] + " "
num = num[2:]
if num[-1].isalpha() and not num[-2].isalpha():
el = " " + num[-1]
num = num[:-1]
elif num[-1].isalpha() and num[-2].isalpha() and not num[-3].isalpha():
el = " " + num[-2] + " " + num[-1]
num = num[:-2]
if not num.isdigit():
return {"NA": 1.0}
if int(num) >= 10000 or int(num) <= 0:
return {"NA": 1.0}
millenium = num[:-3]
century = num[:-2]
year = num[-2:]
if century == "":
return {bl + read_2d(year) + el: 1.0}
if millenium != "" and century[-1] == "0":
if year == "00":
method1 = digits[int(millenium)] + " thousand"
method2 = read_2d(century) + " " + read_2d_year(year)
return {bl + method1 + el: 0.9, bl + method2 + el: 0.1}
else:
method1 = digits[int(millenium)] + " thousand " + read_2d(year)
method2 = digits[int(millenium)] + " thousand and " + read_2d(year)
method3 = read_2d(century) + " " + read_2d_year(year)
return {bl + method1 + el: 0.4, bl + method2 + el: 0.2, bl + method3 + el: 0.4}
method = read_2d(century) + " " + read_2d_year(year)
return {bl + method + el: 1.0}
def read_time(num):
# Read a time of day
# Input: num - string containing the time of day
# Output: a dictionary of possible spelt-out forms and probabilities
num_arr = num.split(":")
hr, m = num_arr[0], num_arr[1]
hr_w = read_2d(hr)
if int(hr) == 0:
hr_w = "zero"
if m == "00":
method1 = hr_w + " " + "o' clock"
method2 = hr_w
return {method1: 0.5, method2: 0.5}
m_w = read_2d(m)
return {hr_w + " " + m_w: 1.0}
def int2words_3d(n):
# Read an integer with at most 3 digits (as array of words)
# Input: n - an integer between 0 and 999
# Output: array of words corresponding to the spelt-out form
if n == 0:
return []
res_arr = []
hundreds = n // 100
rem = n % 100
if hundreds >= 1:
res_arr = res_arr + [digits[hundreds], "hundred"]
ts = (rem // 10) * 10
ones = rem % 10
if rem == 0:
return res_arr
if rem <= 9:
res_arr = res_arr + [digits[rem]]
return res_arr
if rem <= 19:
res_arr = res_arr + [teens[rem]]
return res_arr
if ones == 0:
res_arr = res_arr + [tens[ts]]
return res_arr
res_arr = res_arr + [tens[ts], digits[ones]]
return res_arr
def int2words(num):
# Read an integer with at most 15 digits (as array of words)
# Input: num - an integer between 0 and 10^15-1
# Output: array of words corresponding to the spelt-out form
n = int(num)
if n == 0:
return ["zero"]
part_tn = n // (10 ** 12)
rem_tn = n % (10 ** 12)
part_bn = rem_tn // (10 ** 9)
rem_bn = rem_tn % (10 ** 9)
part_mn = rem_bn // (10 ** 6)
rem_mn = rem_bn % (10 ** 6)
part_ts = rem_mn // 1000
rem_ts = rem_mn % 1000
res_arr = []
if part_tn >= 1:
res_arr = res_arr + int2words_3d(part_tn) + ["trillion"]
if part_bn >= 1:
res_arr = res_arr + int2words_3d(part_bn) + ["billion"]
if part_mn >= 1:
res_arr = res_arr + int2words_3d(part_mn) + ["million"]
if part_ts >= 1:
res_arr = res_arr + int2words_3d(part_ts) + ["thousand"]
res_arr = res_arr + int2words_3d(rem_ts)
return res_arr
def read_by_dig(num):
# Read a number digit by digit (can have letters / symbols, as array of words)
# Input: num - string containing the number
# Output: array of words corresponding to the spelt-out form
res_arr = []
for d in num:
if d.isdigit():
res_arr = res_arr + [digits[int(d)]]
else:
res_arr = res_arr + [d]
return res_arr
def float2words(num):
# Read a number (integer or float, as array of words)
# Input: num - string containing the number
# Output: array of words corresponding to the spelt-out form
res_arr = []
if num[0] == "-":
res_arr = res_arr + ["minus"]
num = num[1:]
num_parts = num.split(".")
if len(num_parts) == 1:
int_part = num_parts[0]
else:
int_part, frac_part = num_parts[0], num_parts[1]
int_part = "".join(int_part.split(","))
res_arr = res_arr + int2words(int_part)
if len(num_parts) >= 2:
res_arr = res_arr + ["point"] + read_by_dig(frac_part)
return res_arr
def num2words(num):
# Read a number (integer, float or fraction)
# Input: num - string containing the number
# Output: a string corresponding to the spelt-out form
res_arr = []
percent = False
if num[-1] == "%":
percent = True
num = num[:-1]
num_parts = num.split("/")
if len(num_parts) == 1:
numer = num_parts[0]
else:
numer, denom = num_parts[0], num_parts[1]
res_arr = res_arr + float2words(numer)
if len(num_parts) >= 2:
res_arr = res_arr + ["over"] + float2words(denom)
if percent:
res_arr.append("percent")
return " ".join(res_arr)
def int2words_4d(num):
# Alternative way for reading 4-digit integers ("1200" = "twelve hundred")
# Input: num - string containing the number (4 digits)
# Output: a string corresponding to the spelt-out form
if len(num) != 4:
return "NA"
hundreds = num[:2]
units = num[2:]
if units[0] == "0":
units = units[1]
if units == "0":
res = num2words(hundreds) + " hundred"
else:
res = num2words(hundreds) + " hundred " + num2words(units)
return res
def ordinal_num(w):
# Convert a cardinal number into ordinal
# Input: w - string containing the spelt-out form of a cardinal number
# Output: a string corresponding to the spelt-out form of the ordinal number
res_arr = w.split(" ")
last = res_arr[-1]
if last in ordinals:
res_arr[-1] = ordinals[last]
else:
res_arr[-1] = last + "th"
return " ".join(res_arr)
def read_num_type(num, t):
# Read a number given a particular type
# Inputs: num - string containing the number
# t - character indicating the type
# Output: a dictionary of possible spelt-out forms and probabilities
if t == "s":
# Serial number, e.g. phone number
return read_by_digit(num)
if t == "y":
# Year number, highway number, house number, room number
return read_year(num)
if t == "t":
# Time
return read_time(num)
# General (cardinal) number or ordinal number
if num[-1] != "%":
cond1 = (len(num) == 4 and eval(num) >= 1000 and eval(num) < 10000)
cond2 = (len(num) == 5 and eval(num) <= -1000 and eval(num) > -10000)
else:
cond1 = False
cond2 = False
if cond1 or cond2:
form1 = num2words(num)
if eval(num) < 0:
form2 = "minus " + int2words_4d(num[1:])
else:
form2 = int2words_4d(num)
if t == "o":
# Ordinal number
form1 = ordinal_num(form1)
form2 = ordinal_num(form2)
if abs(eval(num)) < 2000:
return {form1: 0.5, form2: 0.5}
else:
return {form1: 0.8, form2: 0.2}
if t == "o":
# Ordinal number
return {ordinal_num(num2words(num)): 1.0}
return {num2words(num): 1.0}
def read_num_basic(num, types):
# Read a number based on possible types (basic version)
# Inputs: num - string containing the number
# types - dictionary of probabilities of each type
# Output: a dictionary of possible spelt-out forms and probabilities
res = {}
for t in types:
p = read_num_type(num, t)
for f in p:
if f in res:
res[f] = res[f] + types[t] * p[f]
else:
res[f] = types[t] * p[f]
return res
def split_options(old_p, original, new_option, new_p):
# Reallocate probabilities given a new option and probability
# Inputs: old_p - dictionary of original probabilities
# original - the old option that will see probability decreased
# new_option - the new option
# new_p - the probability (change) for the new option
# Output: dictionary of new probabilities
p = copy.deepcopy(old_p)
p[original] -= new_p
if new_option in p:
p[new_option] += new_p
else:
p[new_option] = new_p
return p
def alternative_one(w):
# Generate alternative spelt-out form if "one" is present (replace by "a")
# Input: w - string containing the spelt-out form of a number
# Output: string corresponding to the new spelt-out form
mult = {"hundred", "thousand", "million", "billion", "trillion"}
old_arr = w.split(" ")
res_arr = []
for i in range(len(old_arr) - 1):
if old_arr[i] == "one" and old_arr[i+1] in mult:
res_arr.append("a")
else:
res_arr.append(old_arr[i])
res_arr.append(old_arr[-1])
return " ".join(res_arr)
def alternative_neg(w):
# Generate alternative spelt-out form if "minus" is present (replace by "negative")
# Input: w - string containing the spelt-out form of a number
# Output: string corresponding to the new spelt-out form
old_arr = w.split(" ")
res_arr = []
for i in range(len(old_arr)):
if old_arr[i] == "minus":
res_arr.append("negative")
else:
res_arr.append(old_arr[i])
return " ".join(res_arr)
def read_num(num, types):
# Read a number based on possible types (final version)
# Inputs: num - string containing the number
# types - dictionary of probabilities of each type
# Output: a dictionary of possible spelt-out forms and probabilities
res = read_num_basic(num, types)
# From basic forms, add alternative forms
for w in res:
alt_one = alternative_one(w)
prob = res[w]
res = split_options(res, w, alt_one, prob / 2)
for w in res:
alt_neg = alternative_neg(w)
prob = res[w]
res = split_options(res, w, alt_neg, prob / 2)
return res
|
C
|
UTF-8
| 5,229 | 2.515625 | 3 |
[
"BSD-2-Clause"
] |
permissive
|
/*
* Copyright (C) Igor Sysoev
* Copyright (C) Nginx, Inc.
*/
#include <ngx_config.h>
#include <ngx_core.h>
#include <ngx_event.h>
/*
实际上,上述问题的解决离不开Nginx的post事件处理机制。这个post事件是什么意思呢?它表示允许事件延后执行。Nginx设计了两个post队列,一
个是由被触发的监听连接的读事件构成的ngx_posted_accept_events队列,另一个是由普通读/写事件构成的ngx_posted_events队列。这样的post事
件可以让用户完成什么样的功能呢?
将epoll_wait产生的一批事件,分到这两个队列中,让存放着新连接事件的ngx_posted_accept_events队列优先执行,存放普通事件的ngx_posted_events队
列最后执行,这是解决“惊群”和负载均衡两个问题的关键。如果在处理一个事件的过程中产生了另一个事件,而我们希望这个事件随后执行(不是立刻执行),
就可以把它放到post队列中。
*/
ngx_queue_t ngx_posted_accept_events; //延后处理的新建连接accept事件
ngx_queue_t ngx_posted_events; //普通延后连接建立成功后的读写事件
/*
post事件队列的操作方法
┏━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓
┃ 方法名 ┃ 参数含义 ┃ 执行意义 ┃
┣━━━━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━┫
┃ ngx_locked_post_event(ev, ┃ ev是要添加到post事件队列 ┃ 向queue事件队列中添加事件ev,注 ┃
┃queue) ┃的事件,queue是post事件队列 ┃意,ev将插入到事件队列的首部 ┃
┣━━━━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━┫
┃ ┃ ┃ 线程安全地向queue事件队列中添加 ┃
┃ ┃ ev是要添加到post队列的事 ┃事件ev。在目前不使用多线程的情况 ┃
┃ngx_post_event(ev, queue) ┃ ┃ ┃
┃ ┃件,queue是post事件队列 ┃下,它与ngx_locked_post_event的功能 ┃
┃ ┃ ┃是相同的 ┃
┣━━━━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━┫
┃ ┃ ev是要从某个post事件队列 ┃ 将事件ev从其所属的post事件队列 ┃
┃ngx_delete_posted_event(ev) ┃ ┃ ┃
┃ ┃移除的事件 ┃中删除 ┃
┣━━━━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━┫
┃ ┃ cycle是进程的核心结构体 ┃ ┃
┃ void ngx_event_process_posted ┃ngx_cycle_t的指针.posted是要 ┃ 谰用posted事件队列中所有事件 ┃
┃(ngx_cycle_t *cycle,ngx_thread_ ┃操作的post事件队列,它的取值 ┃的handler回调方法。每个事件调用完 ┃
┃volatile ngx_event_t **posted); ┃目前仅可以为ngx_posted_events ┃handler方法后,就会从posted事件队列 ┃
┃ I ┃ ┃中删除 ┃
┃ ┃或者ngx_posted_accept_events ┃ ┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━━━━┛
*/
//从posted队列中却出所有ev并执行各个事件的handler
void
ngx_event_process_posted(ngx_cycle_t *cycle, ngx_queue_t *posted)
{
ngx_queue_t *q;
ngx_event_t *ev;
while (!ngx_queue_empty(posted)) {
q = ngx_queue_head(posted);
ev = ngx_queue_data(q, ngx_event_t, queue);
ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0,
"begin to run befor posted event %p", ev);
ngx_delete_posted_event(ev);
ev->handler(ev);
}
}
|
Python
|
UTF-8
| 1,970 | 3.421875 | 3 |
[] |
no_license
|
'''
@author chhattenjr
@date 06/12/2019
@description Given an array of integers representing the color of each sock,
determine how many pair of socks with matching colors there are.
'''
#!/bin/python
import math
import os
import random
import re
import sys
def sockMerchant(n, ar):
numberOfIndividualSocks = n
uniqueColorsNumbers = set(ar)
numberOfIndividualSocksInArray = ar
numberOfIndividualSocksByColor = []
integer = 0
print "Number of Socks: " + str(numberOfIndividualSocks)
if(numberOfIndividualSocks >= 1 or numberOfIndividualSocks <= 100):
print "Colors: " + str(uniqueColorsNumbers)
for i in uniqueColorsNumbers:
count = 0
print "Socks in Array: " + str(numberOfIndividualSocksInArray)
integer = i
print "Integer: " + str(integer)
for j in numberOfIndividualSocksInArray:
if(integer == j):
count += 1
print "Count: " + str(count)
numberOfIndividualSocksByColor.append([integer, count])
else:
SystemExit
print numberOfIndividualSocksByColor
j = 0
numberOfSocks = 0
potentialPairs = []
for i in numberOfIndividualSocksByColor:
numberOfPairs = 0
print "Number of Socks: " + str(i[1])
numberOfSocks = i[1]
if(numberOfSocks > 1):
potentialPairs.append(numberOfSocks)
print "Potential Pairs: " + str(potentialPairs)
totalNumberOfPairs = 0
for i in potentialPairs:
pair = i / 2
print "Pair(s): " + str(pair)
totalNumberOfPairs += pair
print "Total Number of Pairs: " + str(totalNumberOfPairs)
return totalNumberOfPairs
if __name__ == '__main__':
sockNumbers = [6, 5, 2, 3, 5, 2, 2, 1, 1, 5, 1, 3, 3, 3, 5]
sockNumbers2 = [1, 1, 3, 1, 2, 1, 3, 3, 3, 3]
sockMerchant(9, sockNumbers)
#sockMerchant(10, sockNumbers2)
|
Python
|
UTF-8
| 1,758 | 2.53125 | 3 |
[] |
no_license
|
# @Author:Xiran
import torch
import torch.nn as nn
import torch.nn.functional as F
def convbn(in_planes, out_planes, kernel_size, stride, pad, dilation):
return nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size, stride=stride, padding=dilation if dilation > 1 and kernel_size > 1 else pad, dilation=dilation),
nn.BatchNorm2d(out_planes)
)
def deconvbn(in_planes, out_planes, kernel_size, stride, pad, out_pad, dilation):
return nn.Sequential(
nn.ConvTranspose2d(in_planes, out_planes, kernel_size, stride=stride, padding=pad, output_padding=dilation if dilation > 1 else out_pad, dilation=dilation),
# nn.UpsamplingBilinear2d(scale_factor=stride),
# nn.Conv2d(in_planes, out_planes, kernel_size, stride=1, padding=pad),
nn.BatchNorm2d(out_planes)
)
class ResBlock(nn.Module):
def __init__(self, in_planes, out_planes, stride, pad, dilation):
super(ResBlock, self).__init__()
self.in_planes = in_planes,
self.out_planes = out_planes
self.conv1 = nn.Sequential(
convbn(in_planes, out_planes, 3, stride, pad, dilation),
nn.ELU(inplace=True)
)
self.conv2 = convbn(out_planes, out_planes, 3, 1, pad, dilation)
self.downsample_feature = convbn(in_planes, out_planes, 1, stride, 0, dilation)
def forward(self, x):
out = self.conv1(x)
# print('Resblock conv1 size:', out.size())
out = self.conv2(out)
# print('Resblock conv2 size:', out.size())
if self.in_planes != self.out_planes:
x = self.downsample_feature(x)
out += x
# print('addition success')
out = F.elu(out, inplace=True)
return out
|
JavaScript
|
UTF-8
| 3,278 | 3.3125 | 3 |
[] |
no_license
|
/**
*
* 自定义PubSub实现
* var token=PubSub.subscribe(msg,subscriber)-------订阅消息
* PubSub.publish(msg,data)-------发布消息---异步的
* PubSub.publishSync(msg,data)-------发布消息---同步的
* PubSub.unsubscribe(token)--------取消消息订阅
*
* msg-----消息名字-----绑定事件的名字
* subscriber----回调----事件的回调---监听
* data------回调中要用到的数据参数
* token----标识
*
*
*/
(function (window) {
// 定义消息订阅的对象
const PubSub = {}
// 用来存储消息及对应的回调的容器对象
let subscriberContainer = {}
let id = 0 // id值
// 订阅消息
// var token1=PubSub.subscribe('add',回调1)
// var token2=PubSub.subscribe('add',回调2)
// var token3=PubSub.subscribe('del',回调3)
// 大的容器对象==={'add':[回调1,回调2]}
// {'add':{token1:回调1,token2:回调2},'del':{token3:回调3}}
// {'add':{token1:回调}}
// var token1=PubSub.subscribe('add',回调1)
PubSub.subscribe = function (msg, subscriber) {
// 根据消息名字获取的是该消息对应的回调函数的容器(小容器)
let subscribers = subscriberContainer[msg]
// 判断小容器是否存在
if (!subscribers) {
// 没有这个小容器,那么就创建这个小容器对象
subscribers = {}
// 把小容器对象根据msg键,以键值对的方式存储到大容器对象中
subscriberContainer[msg] = subscribers
}
// 创建token
const token = 'id-' + ++id
// 根据标识添加对应的回调
subscribers[token] = subscriber
return token
}
// 发布消息同步
// PbuSub.publish('add')
// {'add':{token1:回调1,token2:回调2},'del':{token3:回调3}}
PubSub.publishSync = function (msg, data) {
const subscribers = subscriberContainer[msg]
// 判断
if (subscribers) {
// 调用----对象转数组,遍历,找到里面的每个函数,直接调用
Object.values(subscribers).forEach(subscriber => {
subscriber(data)
})
}
}
// 发布消息异步
PubSub.publish = function (msg, data) {
const subscribers = subscriberContainer[msg]
setTimeout(() => {
// 判断
if (subscribers) {
// 调用----对象转数组,遍历,找到里面的每个函数,直接调用
Object.values(subscribers).forEach(subscriber => {
subscriber(data)
})
}
}, 1000)
}
// 取消消息订阅
// PubSub.unsubscribe()
// PubSub.unsubscribe('add')
// PubSub.unsubscribe('id-2')
// {'add':{token1:回调1,'id-2':回调2},'del':{token3:回调3}}
// [{token1:回调1,token2:回调2},{token3:回调3}]
PubSub.unsubscribe = function (token) {
// token='add',token='id-2' token--->undefined
// 啥也没有传
if (typeof token === 'undefined') {
subscriberContainer = {}
} else if (token.indexOf('id-') !== -1) {// 传入了token
// 根据token找对应的回调
const subscribers = Object.values(subscriberContainer).find(subscribers => subscribers[token])
subscribers && delete subscribers[token]
} else {// 传入的是名字
delete subscriberContainer[token]
}
}
// 暴露出去
window.PubSub = PubSub
})(window)
|
TypeScript
|
UTF-8
| 1,228 | 2.875 | 3 |
[
"Apache-2.0"
] |
permissive
|
import Big from 'big.js';
const MOJO_PER_FORK = Big(1000000000000);
const BLOCKS_PER_YEAR = 1681920;
export function calculatePoolReward(height: number): Big {
if (height === 0) {
return MOJO_PER_FORK.times(21000000).times(7 / 8);
}
if (height < 3 * BLOCKS_PER_YEAR) {
return MOJO_PER_FORK.times(2).times(7 / 8);
}
if (height < 6 * BLOCKS_PER_YEAR) {
return MOJO_PER_FORK.times(1).times(7 / 8);
}
if (height < 9 * BLOCKS_PER_YEAR) {
return MOJO_PER_FORK.times(0.5).times(7 / 8);
}
if (height < 12 * BLOCKS_PER_YEAR) {
return MOJO_PER_FORK.times(0.25).times(7 / 8);
}
return MOJO_PER_FORK.times(0.125).times(7 / 8);
}
export function calculateBaseFarmerReward(height: number): Big {
if (height === 0) {
return MOJO_PER_FORK.times(21000000).times(1 / 8);
}
if (height < 3 * BLOCKS_PER_YEAR) {
return MOJO_PER_FORK.times(2).times(1 / 8);
}
if (height < 6 * BLOCKS_PER_YEAR) {
return MOJO_PER_FORK.times(1).times(1 / 8);
}
if (height < 9 * BLOCKS_PER_YEAR) {
return MOJO_PER_FORK.times(0.5).times(1 / 8);
}
if (height < 12 * BLOCKS_PER_YEAR) {
return MOJO_PER_FORK.times(0.25).times(1 / 8);
}
return MOJO_PER_FORK.times(0.125).times(1 / 8);
}
|
Java
|
UTF-8
| 7,035 | 3.140625 | 3 |
[] |
no_license
|
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.Scanner;
public class ParseGlucoseData {
// use LinkedHashMap to maintain original ordering of measure values
// map 'm' will have dates (in String format) as key with corresponding ArrayList values which
// will contain Strings that are the measurement values taken on that day
public static LinkedHashMap<String, ArrayList<String>> m;
// store data into a file to prepare for writing-out into new, "cleaned" txt file
public static void toMap(String fileName){
// initialize Scanner to read uncleaned data file
Scanner in = null;
try{
in = new Scanner(new File(fileName));
}
// necessary catch exception
catch (IOException e){
e.printStackTrace();
}
// we will fill local version of map; global map will contain these values by end of method
LinkedHashMap<String, ArrayList<String>> map = new LinkedHashMap<String, ArrayList<String>>();
// while we still have elements in the uncleaned data file left to read
while(in.hasNext()){
// split the line (assuming the line is an entry)
String[] splitDay = in.nextLine().split("}}");
// for each string in the line
for (int i=0; i<splitDay.length; i++){
// in the glucose data this program was based off of, data was given in
// measureName => measureValue format, and the last measureName was "captured_at,"
// and measureValue was the YY-MM-DD for when the measurement was taken
// if the captured_at date we are looking at does not currently exist in the map as a key,
// we put the date in the map as a key, and set its value to an empty ArrayList
// which will contain each of the relevant measurements taken on that day
String key = splitDay[i].substring(splitDay[i].lastIndexOf("=>")+2);
if (!map.containsKey(key)){
map.put(key, new ArrayList<String>());
}
// split the entry/line into the comma-separated measurements
String[] oneDaySplit = splitDay[i].split(",");
// create a map for each date, with the measureName as the key
// and measureValue as the value
// at the end of reading, we will add each of these measureValues to the
// ArrayList value corresponding to the date of this line/entry
LinkedHashMap<String, String> valMap = new LinkedHashMap<String, String>();
// all measureNames will initially have values of '-' as an indicator of missing data
valMap.put("measuredAt1", "-");
valMap.put("mealType1", "-");
valMap.put("beforeMeal1", "-");
valMap.put("notes1", "-");
valMap.put("bloodGlucose1", "-");
valMap.put("measuredAt2", "-");
valMap.put("mealType2", "-");
valMap.put("beforeMeal2", "-");
valMap.put("notes2", "-");
valMap.put("bloodGlucose2", "-");
// in our data, the same variable names appear twice; the first time represents the first
// glucose reading of the day, while the second time represents the second glucose reading
// the variable startAgain will be set equal to the index of the marker ("||") that indicates
// the separation between the first and second glucose readings
int startAgain = 0;
// loop through each measurement in the entry/line
for (int j=0; j<oneDaySplit.length; j++){
// break out of the loop so that we can start looking at second reading measurements
// in the next for loop
if (oneDaySplit[j].substring(0,2).equals("||")){
startAgain = j;
break;
}
String metric = oneDaySplit[j];
if (metric.substring(0, 10).equals("measuredAt")){
valMap.put("measuredAt1", metric.substring(12));
}
if (metric.substring(0, 8).equals("mealType")){
valMap.put("mealType1", metric.substring(10));
}
if (metric.substring(0, 10).equals("beforeMeal")){
valMap.put("beforeMeal1", metric.substring(12));
}
if (metric.substring(0,5).equals("notes")){
valMap.put("notes1", metric.substring(7));
}
if (metric.substring(0, 12).equals("bloodGlucose")){
valMap.put("bloodGlucose1", metric.substring(14));
}
}
// for looping through the second reading measurements
if (startAgain != 0){
for (int k=startAgain; k<oneDaySplit.length; k++){
String metric = oneDaySplit[k];
if (metric.substring(2, 12).equals("measuredAt")){
valMap.put("measuredAt2", metric.substring(14));
}
if (metric.substring(0, 8).equals("mealType")){
valMap.put("mealType2", metric.substring(10));
}
if (metric.substring(0, 10).equals("beforeMeal")){
valMap.put("beforeMeal2", metric.substring(12));
}
if (metric.substring(0,5).equals("notes")){
valMap.put("notes2", metric.substring(7));
}
if (metric.substring(0, 12).equals("bloodGlucose")){
valMap.put("bloodGlucose2", metric.substring(14));
}
}
}
// for each key in the measureName-to-measureValue map for this date,
// add each value to the ArrayList value in the larger map
// (as explained in line 51)
for (String valMapKey : valMap.keySet()){
map.get(key).add(valMap.get(valMapKey));
}
}
}
// fill the global map with teh values from the local map we just created
m = map;
}
public static void writeTo(String fileName){
BufferedWriter bw = null;
FileWriter fw = null;
try{
fw = new FileWriter(fileName);
bw = new BufferedWriter(fw);
// when importing the text file to Excel, we will use '~' as a delimiter
// so we will write the title of all measurement values, separated by '~'s, as the first line in the text file
bw.write("captured_at~measuredAt1~mealType1~beforeMeal1~notes1~bloodGlucose1~measuredAt2~mealType2~beforeMeal2~notes2~bloodGlucose2~");
// new line to prepare to write out data entries
bw.write("\n");
// for each date key in the global map
for (String key : m.keySet()){
// write out the date key (corresponding to "captured_at" we wrote as first column header in line 136)
bw.write(key+"~");
// write out each of the corresponding measurement values
// the LinkedHashMap we used will ensure that we obey the ordering of headers in line 136
for (String val : m.get(key)){
bw.write(val+"~");
}
// new line to prepare for next data entry
bw.write("\n");
}
// necessary catch exception
} catch(IOException e){
e.printStackTrace();
} finally{
// properly close the writers used to write out the cleaned txt file
try{
if (bw != null) bw.close();
if (fw != null) fw.close();
} catch (IOException e){
e.printStackTrace();
}
}
}
public static void main(String[] args) throws FileNotFoundException{
// the text file with the uncleaned data that we want to create a map from
toMap("data/glucoseData.txt");
// the text file we want to write the cleaned data to
writeTo("data/cleanedGlucoseData.txt");
}
}
|
Markdown
|
UTF-8
| 7,556 | 2.75 | 3 |
[] |
no_license
|
---
description: "Recipe of Any-night-of-the-week Cabbage roll stew"
title: "Recipe of Any-night-of-the-week Cabbage roll stew"
slug: 1310-recipe-of-any-night-of-the-week-cabbage-roll-stew
date: 2020-10-02T05:52:37.486Z
image: https://img-global.cpcdn.com/recipes/54799793cefe3b29/751x532cq70/cabbage-roll-stew-recipe-main-photo.jpg
thumbnail: https://img-global.cpcdn.com/recipes/54799793cefe3b29/751x532cq70/cabbage-roll-stew-recipe-main-photo.jpg
cover: https://img-global.cpcdn.com/recipes/54799793cefe3b29/751x532cq70/cabbage-roll-stew-recipe-main-photo.jpg
author: Lou Holland
ratingvalue: 4.7
reviewcount: 34907
recipeingredient:
- "4 carrots diced"
- "1 large onion diced"
- "4 stalks celery diced"
- "3 cloves garlic minced"
- "1 pound lean ground beef"
- "1 pound lean ground pork"
- "1 medium head green cabbage chopped and cored"
- "2 cans diced Italian stewed tomatoes 145 ounce"
- "2 tablespoons tomato paste"
- "6 cups beef broth"
- "1 and one half cups V8 or other vegetable juice"
- "1 teaspoon paprika"
- "1 teaspoon thyme"
- "1 tablespoon Worcestershire sauce"
- "1 bayleaf"
- "to taste salt and pepper"
recipeinstructions:
- "In a large pot Brown ground beef and ground pork then remove and set aside"
- "In the same pot saute onions celery carrots and garlic"
- "Add chop cabbage cook until slightly softened about 3 minutes"
- "Add ground beef and pork back in along with the remaining ingredients. Bring to a boil cover reduce heat to simmer. Simmer about 30 minutes. Add salt and pepper to taste."
categories:
- Recipe
tags:
- cabbage
- roll
- stew
katakunci: cabbage roll stew
nutrition: 291 calories
recipecuisine: American
preptime: "PT26M"
cooktime: "PT32M"
recipeyield: "1"
recipecategory: Lunch
---

Hello everybody, it's John, welcome to my recipe page. Today, I'm gonna show you how to make a special dish, cabbage roll stew. It is one of my favorites food recipes. For mine, I am going to make it a little bit unique. This will be really delicious.
Heat a large pot over medium heat. Add beef and cook until brown, breaking up large pieces of beef. Remove from pot and set aside. Discard the fat, saving two tablespoons in the pot.
Cabbage roll stew is one of the most popular of recent trending meals on earth. It's enjoyed by millions every day. It is easy, it's quick, it tastes yummy. Cabbage roll stew is something that I have loved my whole life. They're nice and they look fantastic.
To begin with this recipe, we have to first prepare a few ingredients. You can cook cabbage roll stew using 16 ingredients and 4 steps. Here is how you cook it.
<!--inarticleads1-->
##### The ingredients needed to make Cabbage roll stew:
1. Take 4 carrots diced
1. Prepare 1 large onion diced
1. Make ready 4 stalks celery diced
1. Make ready 3 cloves garlic minced
1. Get 1 pound lean ground beef
1. Take 1 pound lean ground pork
1. Take 1 medium head green cabbage chopped and cored
1. Get 2 cans diced Italian stewed tomatoes 14.5 ounce
1. Prepare 2 tablespoons tomato paste
1. Get 6 cups beef broth
1. Get 1 and one half cups V8 or other vegetable juice
1. Take 1 teaspoon paprika
1. Get 1 teaspoon thyme
1. Take 1 tablespoon Worcestershire sauce
1. Prepare 1 bayleaf
1. Get to taste salt and pepper
Crumble the raw ground turkey (or beef) and spread along bottom of crock pot. Add the onions, green pepper, garlic, salt, pepper, thyme and cabbage. Lazy Cabbage Roll Stew Growing up in Massachusetts near a large Polish community, I had the pleasure of getting to know cabbage rolls or galumpkis. This stew is a lazy version with the same flavor.
<!--inarticleads2-->
##### Steps to make Cabbage roll stew:
1. In a large pot Brown ground beef and ground pork then remove and set aside
1. In the same pot saute onions celery carrots and garlic
1. Add chop cabbage cook until slightly softened about 3 minutes
1. Add ground beef and pork back in along with the remaining ingredients. Bring to a boil cover reduce heat to simmer. Simmer about 30 minutes. Add salt and pepper to taste.
Lazy Cabbage Roll Stew Growing up in Massachusetts near a large Polish community, I had the pleasure of getting to know cabbage rolls or galumpkis. This stew is a lazy version with the same flavor. Stir in the cabbage and add the tomatoes, stock, vinegar, horseradish, paprika, celery salt, bay leaves and rice and stir. Cover the pot and bring it up to a full simmer. This Paleo Unstuffed Cabbage Stew is made with cabbage, beef, onions & celery with fire-roasted tomatoes.
Turn to Food to Boost Your Mood
For the most part, people have been taught to believe that "comfort" foods are terrible for the body and have to be avoided. However, if your comfort food is candy or junk food this might be true. At times, comfort foods can be very nutritious and good for us to consume. There are a number of foods that actually can boost your moods when you eat them. When you are feeling a little down and are needing an emotional pick-me-up, test out a few of these.
Eggs, would you believe, are fantastic for helping you battle depression. Just be sure that you don't get rid of the yolk. The yolk is the part of the egg that is the most crucial in terms of helping you cheer up. Eggs, particularly the yolks, are rich in B vitamins. B vitamins can be great for raising your mood. This is because they help in improving the function of your neural transmitters, the components of your brain that affect your mood. Eat a couple of eggs to jolly up!
Put together a trail mix from seeds and/or nuts. Peanuts, cashews, sunflower seeds, almonds, pumpkin seeds, etcetera are all fantastic for helping to raise your mood. This is possible as these foods have a bunch of magnesium which increases serotonin production. Serotonin is referred to as the "feel good" substance that our body produces and it tells your brain how you should be feeling at all times. The higher your levels of serotonin, the happier you are going to feel. Not just that, nuts, in particular, are a great source of protein.
Cold water fish are excellent if you wish to feel happier. Wild salmon, herring, mackerel, trout, and tuna are all high in omega-3 fats and DHA. These are two substances that boost the quality and function of the gray matter in your brain. It's true: chomping on a tuna fish sandwich can basically help you overcome depression.
Some grains are actually excellent for driving away bad moods. Quinoa, millet, teff and barley are all really wonderful for helping raise your happiness levels. These foods fill you up better and that can help improve your moods too. It's not difficult to feel low when you feel hungry! The reason these grains can improve your mood is that they are not hard to digest. You digest these foods more quickly than other foods which can help increase your blood sugar levels, which, in turn, helps make you feel happier, mood wise.
Green tea is fantastic for moods. You just knew it had to be in here somewhere, right? Green tea is rich in an amino acid called L-theanine. Research has discovered that this amino acid promotes the production of brain waves. This helps raise your mental focus while calming the rest of your body. You already knew green tea could help you become healthier. Now you know that applies to your mood also!
So you see, you don't need to eat junk food or foods that are terrible for you just so to feel better! Try a few of these tips instead.
|
Markdown
|
UTF-8
| 8,727 | 3.03125 | 3 |
[] |
no_license
|
# 前言
`ExtractTextWebpackPlugin`是用来提取公共代码的插件.
比方说把 css 的代码提取到一个文件, 方便单独缓存, css 代码独立加载, 异步加载的模块等等. 但是实际在使用的过程中, 有些疑惑的地方.
- `new ExtractTextWebpackPlugin({allChunk:true})`里面的`allChunk`作用是什么?
- `ExtractTextPlugin.extract`里面的`fallback`什么时候生效?
- `css`或者`less`里面, 碰到`import "./a/v/c.less"`, `background:url(./../a.png)`应该怎么配置打包的路径?
自己对于这几个问题理解不是很到位.
# 安装`ExtractTextWebpackPlugin`
ExtractTextWebpackPlugin 对 webpack 的版本很敏感, 注意安装的版本.
```
# for webpack 4
npm install –save-dev extract-text-webpack-plugin@next
# for webpack 3
npm install --save-dev extract-text-webpack-plugin
# for webpack 2
npm install --save-dev [email protected]
# for webpack 1
npm install --save-dev [email protected]
```
# css 样式提取 ExtractTextWebpackPlugin 基本的配置
这里就简单的说下配置
### wbepack 4.0 以下用`ExtractTextWebpackPlugin`提取 css
webpack4.0 不再使用`ExtractTextWebpackPlugin`来提取公共的 css,而是使用`mini-css-extract-plugin`来提取, 但是 webpack4 的版本要用的话也可以`npm install –save-dev extract-text-webpack-plugin@next`, 需要安装 4.0 版本的`ExtractTextWebpackPlugin`.
> 我当前使用的版本是 webpack-3.12.0
```
const ExtractTextPlugin = require("extract-text-webpack-plugin");
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: "style-loader",
use: "css-loader",
publicPath:"/less/"
})
}
]
},
plugins: [
new ExtractTextPlugin("styles.css"),
]
}
```
##### `ExtractTextPlugin.extract`的一些参数:
- **fallback**: 这个参数是在提取 css 失败的时候,使用的 loader, 异步加载的组件, 通常是包括 css, 而这个 css 的代码是通过`less`转化而来的, 如果该文件的没有提取到单独的`css`文件, 那么就会用`style-loader`处理.
- **use**: 用到的`loader`, 可以是数组, 转化顺序从后往前.所以这样是允许的`use:['css-lodaer','less-loader']`.
- **publicPath**:"/less/", 这是 css 文件路径里面的相对路径部分 , 比如 源码`background:url(./1.jpg)`,打包出来的 css 则是`background:url(./less/[contenthash].jpg)`.
### 实例
在`allChunks:false`的情况下, 公共的代码提取,使用了`fallback:style-loader`来处理没有成功提取的样式.
### webpack.config.js 的配置代码
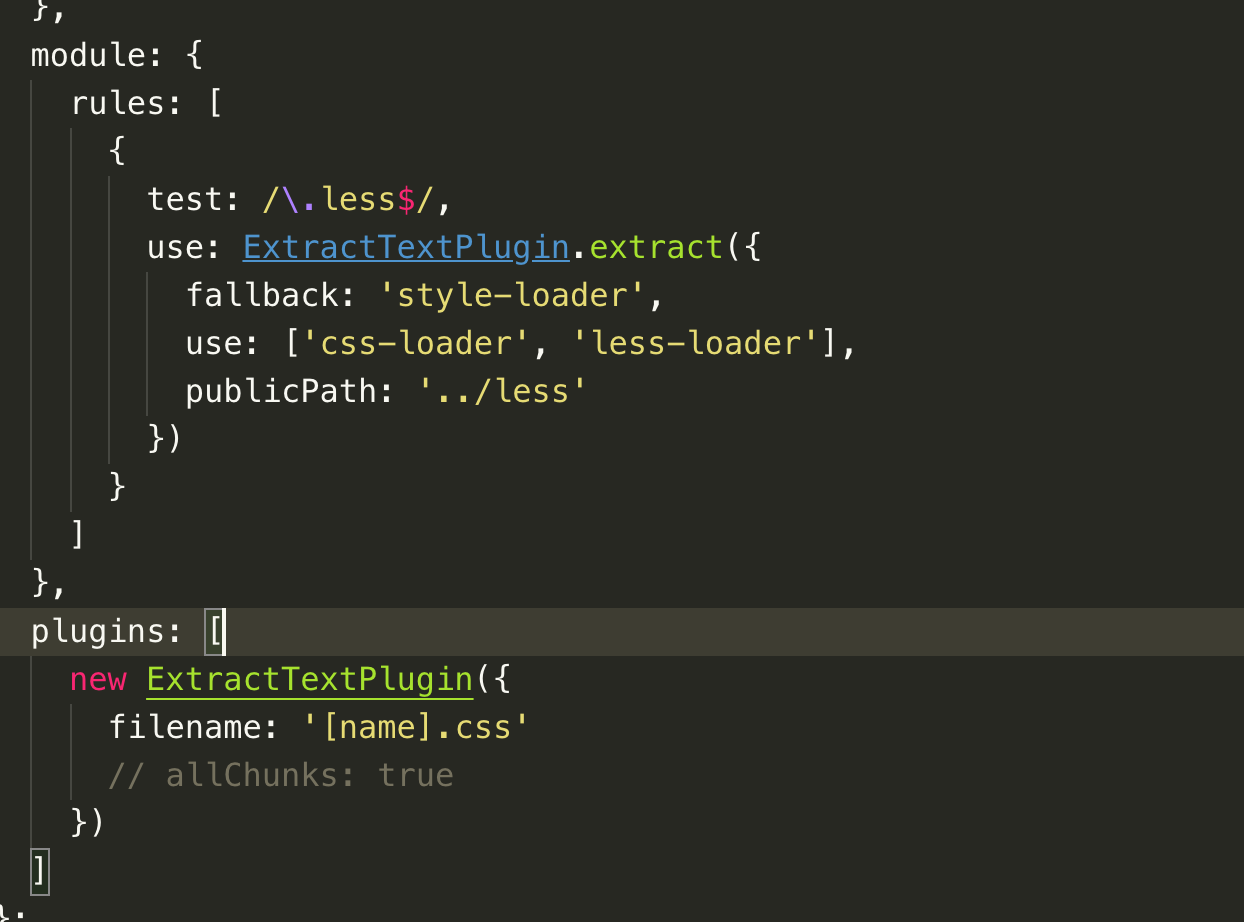
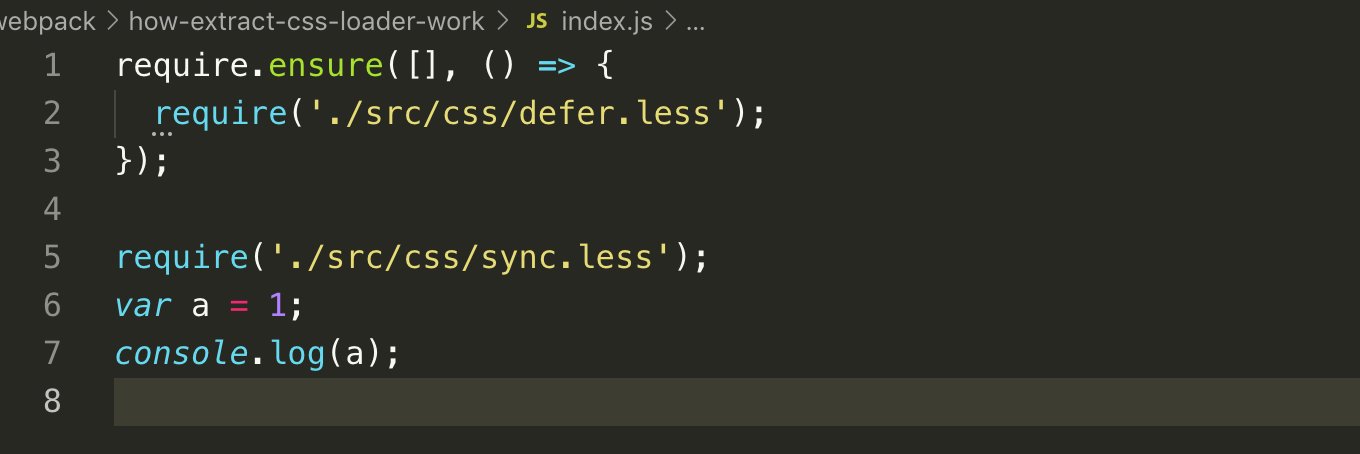
### index.js 入口的 da 打包代码
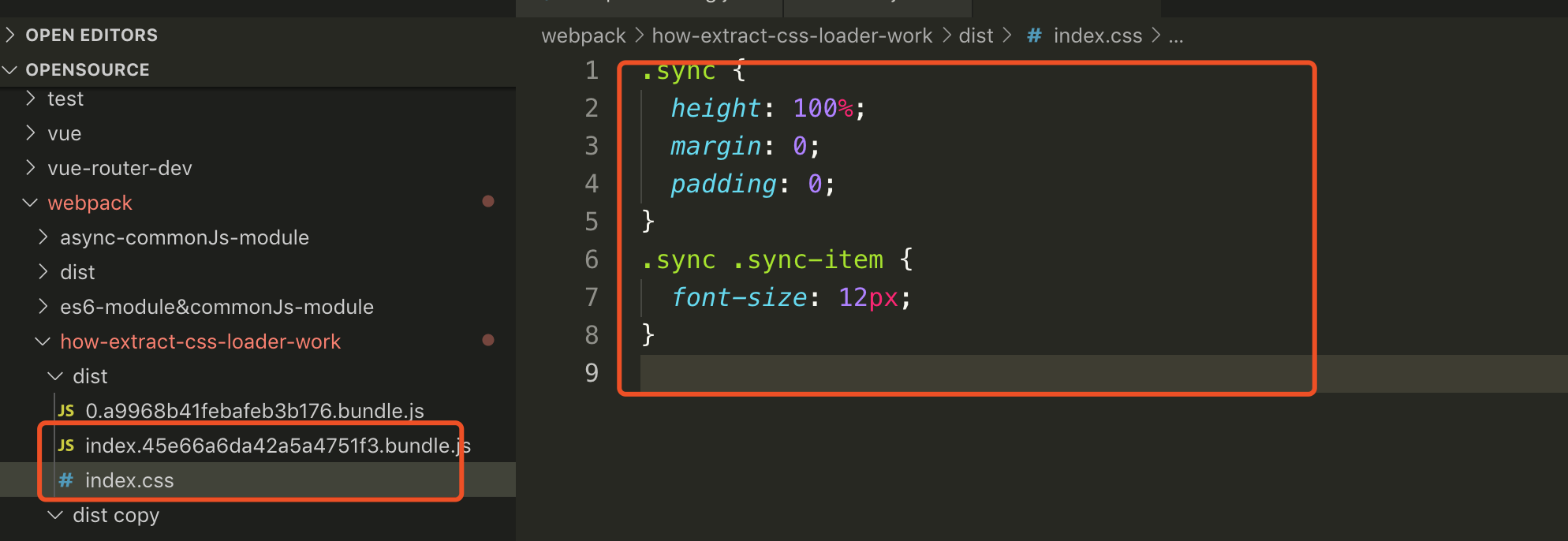
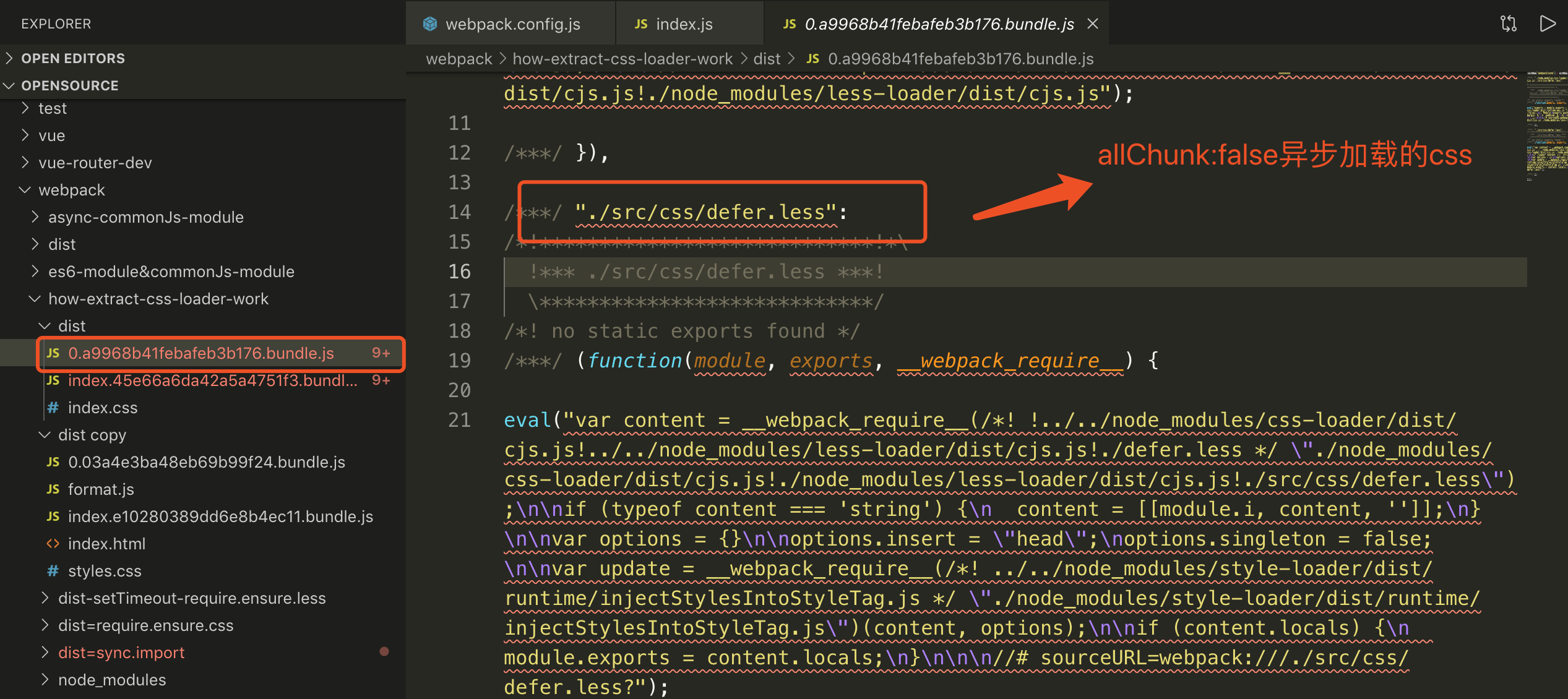
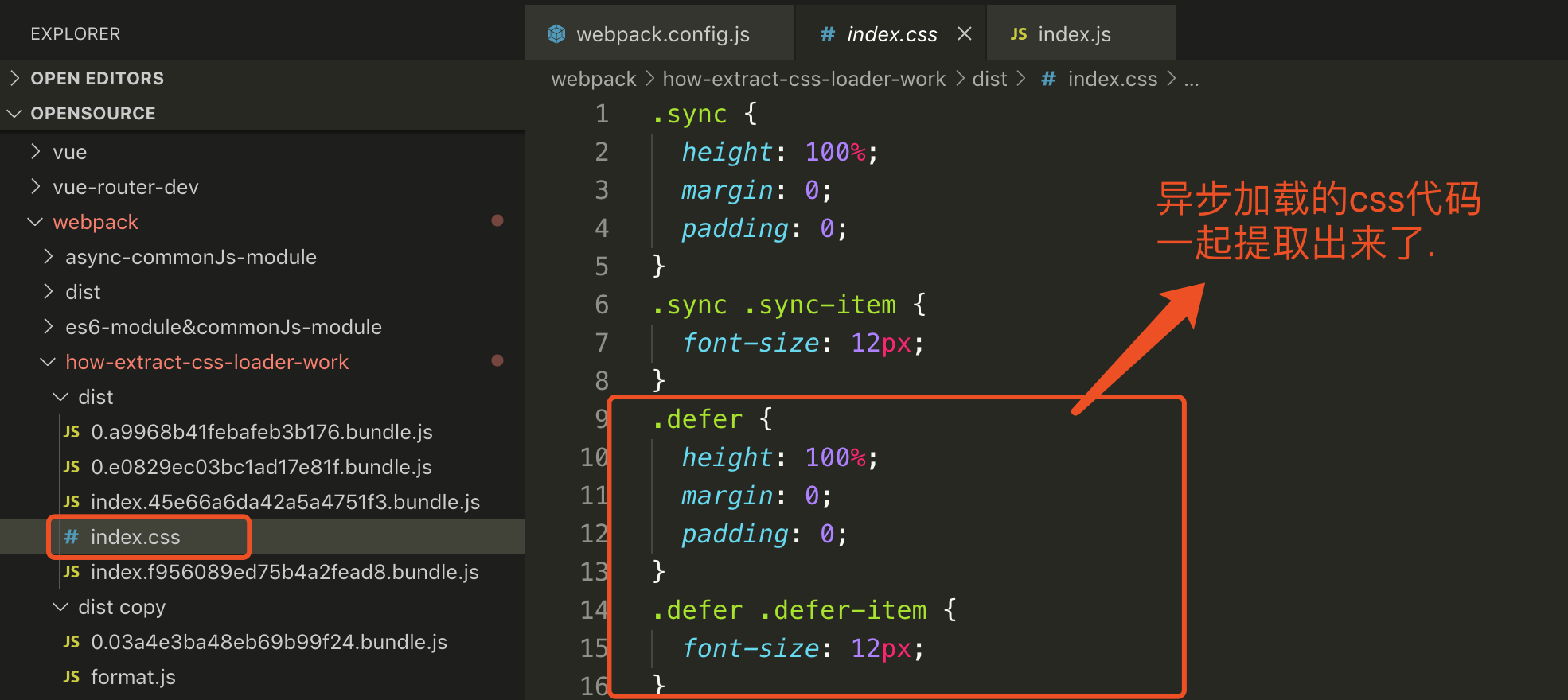
### 打包的结果 allChunks:false
### 打包的结果 allChunks:true
### 小结
> 所以`allChunks:false`为默认值, 默认是从 entry 的入口提取代码,但是不会提取异步加载的代码, `allChunks:true`则是提取所有模块的代码(包括异步加载的模块),到一个文件里面. `fallback`则是在异步代码加载的 css 代码没有被提取的情况下, 以`style-loader`的情况去加载异步组件的样式.
### 提取公共的 css 的插件书写方式
```
new ExtractTextPlugin({
fileName:"[name].css", // [contenthash], [name], [hash]都是允许的
allChunks:true // 是否从所有的chunk中提取
})
```
- allChunks: true, 表示是否从所有的 chunk 中提取代码(意味着异步加载的代码也会被提取).
> CommonsChunkPlugin 的使用是提取多个 entry 的公共代码部分.当提取的代码携带`ExtractTextPlugin.extract`部分的话, 必须设置`allChunks:true`;
### url()
在 css 书写的时候, 经常会携带`background:url(...)`的书写方式, 如果打包输出的图片资源位置修改的时候, 这个时候,应该怎么去配置?
在`css-loader`里面有一个配置
```
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: "style-loader",
use: [{
loader: "css-loader",
options:{ url:true }
}],
publicPath:"/less/"
})
}
```
`url:true`是默认值, 表示在`less`, `css`的代码书写中, 类似以下的写法, 都会自动转化为相对的路径. 除非是类似带`cdn`的绝对路径的除外.
```
import 'style.css' => require("./style.css");
background:url(a.png); => rquire("./a.png");
background:url(http://cnd.quanlincong.com/a.png); => rquire("http://cnd.quanlincong.com/a.png");
```
如果不希望代码的路径有任何变化的转化的话, 可以设置
```
url:false
```
禁止 css 资源转化的时候自动转化.
一般的情况下, 在 css 样式里面的引入的图片, 我想要打包到特定的路径, 比如放到一个目录里面`assets`
```
const ExtractTextPlugin = require('extract-text-webpack-plugin');
module.exports = {
...
module: {
rules: [
{
test: /\.less$/,
use: ExtractTextPlugin.extract({
fallback: 'style-loader',
use: ['css-loader', 'less-loader'],
publicPath: '../images/'
})
},
{
test: /\.(png|jpg|gif)$/i,
use: [
{
loader: 'url-loader',
options: {
fallback: 'file-loader',
limit: 8196,
outputPath: 'images',
publicPath: 'images'
}
}
]
}
]
},
...
}
```
这个时候需要配置`url-loader`, 在图片合适的大小情况下, 打包成 base64, 超出特定的大小, 使用`fallback`配置的`loader`来处理,如果不写默认也是`file-loader`.
关于这个`url-loader`的使用
> url-loader 其实就是 base64 + filr-loader 的处理, 但是 file-loader 的插件需要自己额外安装.
- `fallback: 'file-loader'`代表在文件大小超出 8196 bytes 后, 使用的`file-loader`来加载资源, 此外后面的`outputPath`,`publicPath`配置都是给`file-loader`使用的.
webpack 在介绍这里的时候原话是这样的
> The fallback loader will receive the same configuration options as url-loader.
> 意思就是`url-loader`的配置会传到`file-loader`里面, 所以`file-loader`的配置直接在里面 options 里面写.
- `outputPath:'images'`, 意味这打包的图片资源都输出到`./images`路径下
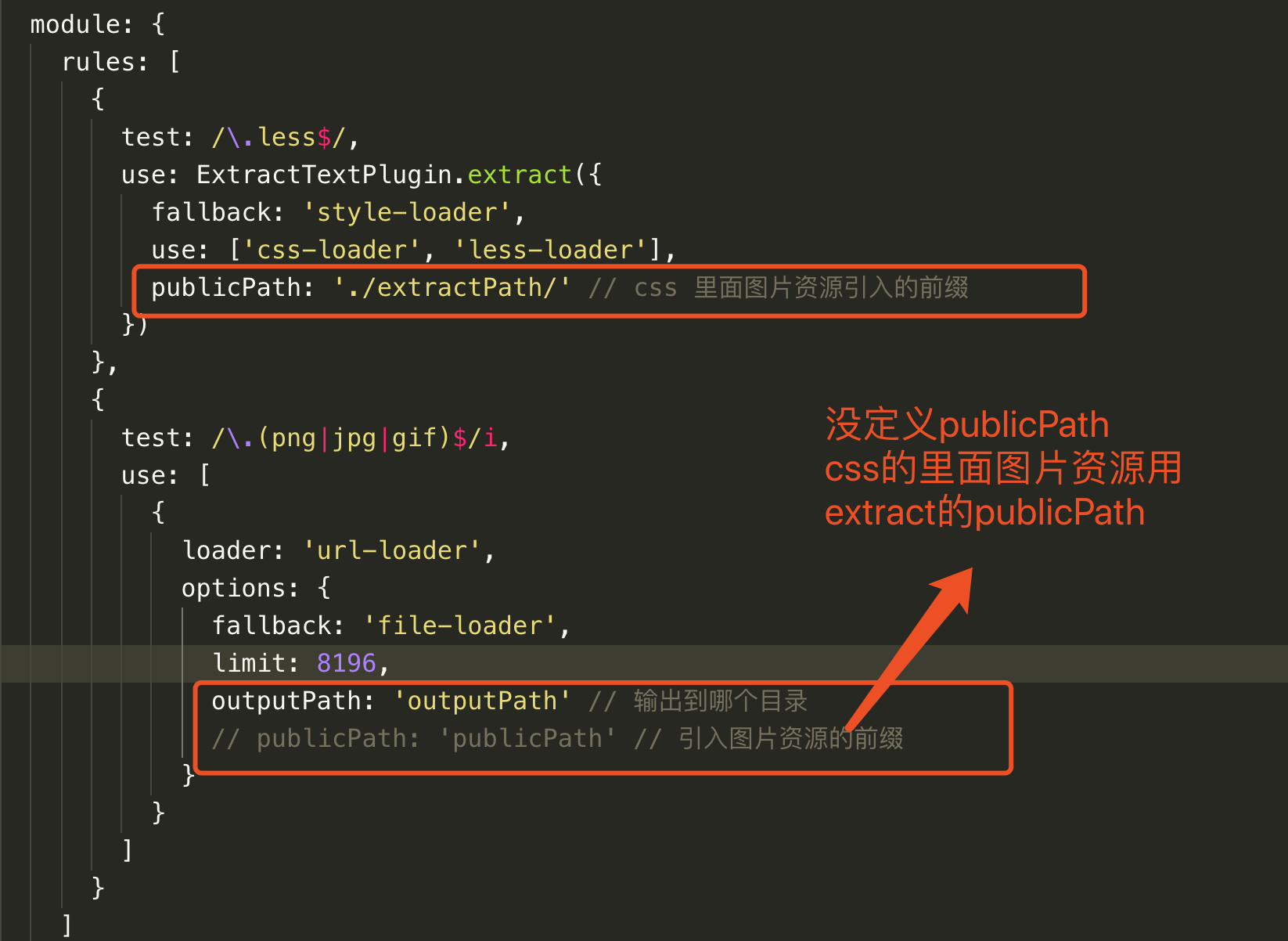
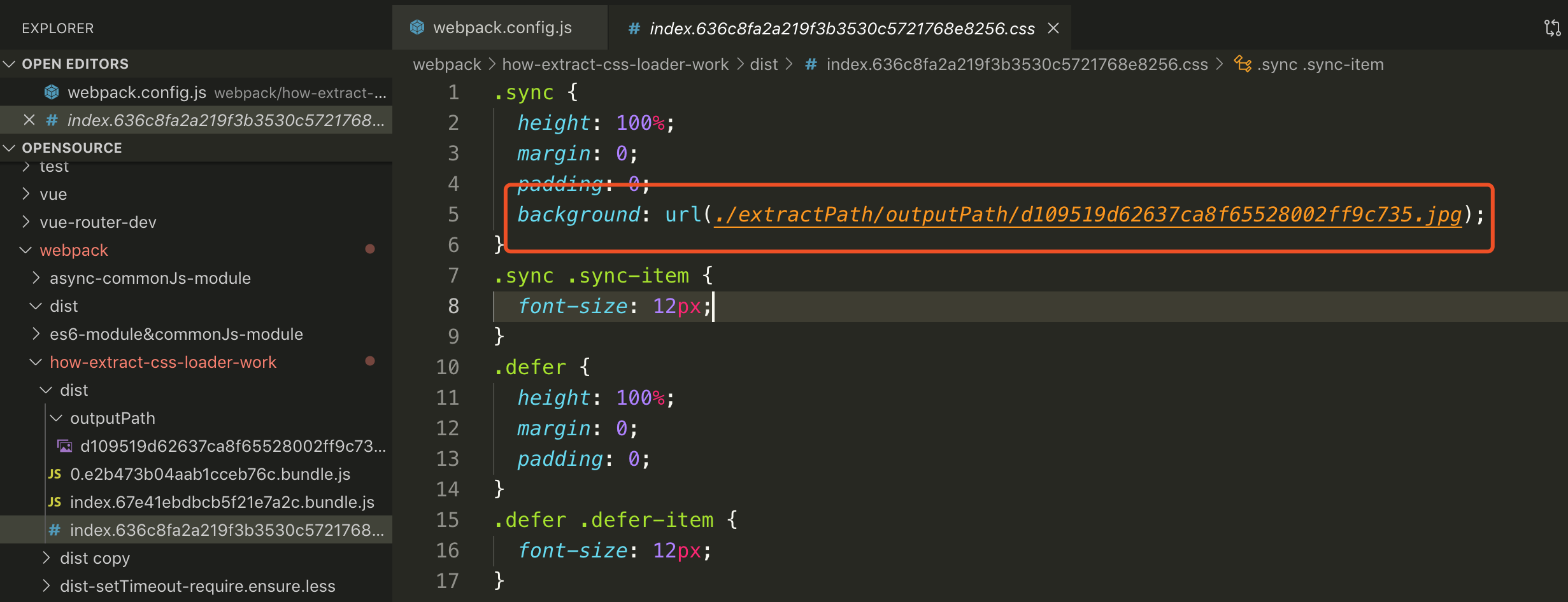
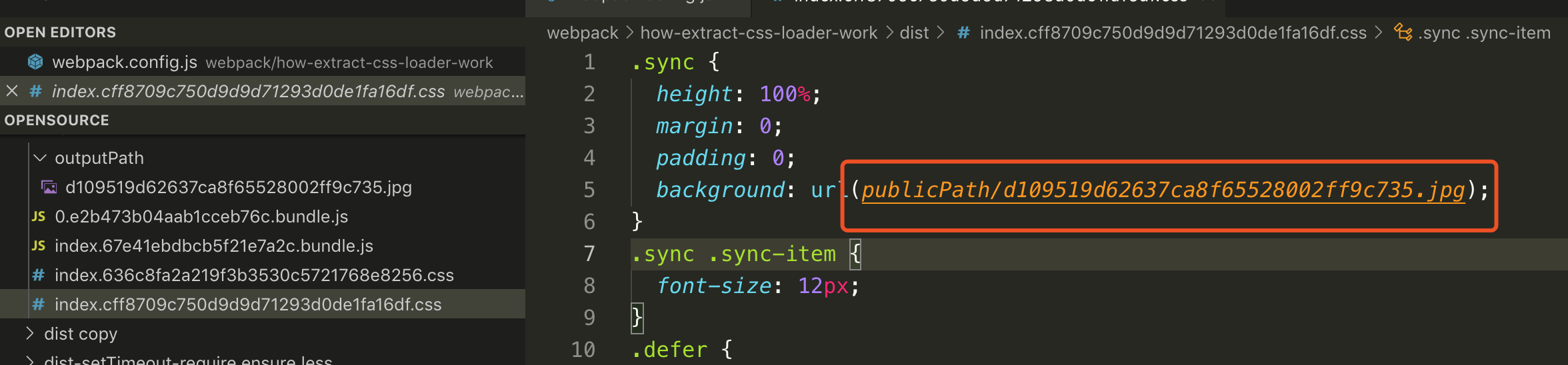
- `publicPath:'images'`, 定义引入图片的时候的路径前缀, 意味着通过`extract-text-webpack-plugin`提取的 css 代码的引入的图片资源, 如果`extract-text-webpack-plugin`里面定义了`publicPath`, 会被`file-loader`里面`publicPath`覆盖; 如果`file-loader`没有定义`publicPath`, 那么普通的图片资源引入的路径为`[outputPath]/filename.png`, 如果在`extract-text-webpack-plugin`定义了`publicPath`, 那么提取出来的图片样式引入的路径则是`[publicPath]/[outputPath]/filename.png`
### `extract-text-webpack-plugin和file-loader的publicPath`例子
### file-loader 没有配置`publicPath`, 使用 extract-text 插件的`publicPath`
### 结果 1,没有配置`file-loader`的 publicPath
### 结果 2,配置了`file-loader`的 publicPath
# 结束
到这里, 终于弄懂了前言说的 3 个问题
- `extract-text-webpack-plugin`的`allChunk:true`, 是提取所有的`chunk`的 css, 包括异步加载的 css
- `fallback`什么时候什么生效? 在异步加载 css 的情况下, 没有成功提取 css 的时候, 会使用`fallback:'style-loader'来处理样式.
- 在 css 里面引用相对的图片资源, 优先使用`extract-text-webpack-plugin`的`publicPath`来添加前缀路径进行加载. 同时如果设置`file-loader`的话, 注意 publicPath 的路径会覆盖`extract-text-webpack-plugin`的`publicPath`;
> https://webpack.js.org/plugins/extract-text-webpack-plugin/#root > https://webpack.js.org/plugins/mini-css-extract-plugin/
|
Python
|
UTF-8
| 1,676 | 3.59375 | 4 |
[] |
no_license
|
class Rectangle:
def __init__(self,width,height):
self.width = width
self.height = height
def __str__ (self):
output = ""
output += ("Rectangle(width="+str(self.width)+", height="+str(self.height)+")")
return output
def set_width(self,new_width):
self.width = new_width
def set_height(self,new_height):
self.height = new_height
def get_area(self):
return (self.width*self.height)
def get_perimeter(self):
return ((2*self.width) + (2*self.height))
def get_diagonal(self):
return ((self.width ** 2 + self.height ** 2) ** .5)
def get_picture(self):
rect=""
if ((self.height>50) or (self.width>50)):
return ("Too big for picture.")
else:
for line in range(self.height):
for column in range (self.width):
rect += "*"
rect += "\n"
return rect
def get_amount_inside(self,shape):
return int(self.get_area()/shape.get_area())
class Square (Rectangle):
def __init__(self,side):
self.side = side
self.width = self.side
self.height = self.side
def __str__ (self):
output = ""
output += ("Square(side="+str(self.side)+")")
return output
def set_side(self,new_side):
self.side = new_side
self.width = self.side
self.height = self.side
def set_width(self,new_side):
self.set_side(new_side)
def set_height(self,new_side):
self.set_side(new_side)
|
Java
|
UTF-8
| 1,528 | 3.03125 | 3 |
[] |
no_license
|
package com.jarqprog.controller;
import com.jarqprog.calculator.OverlapCalc;
import com.jarqprog.calculator.ShapeCoordinatesGenerator;
import com.jarqprog.exceptions.IncorrectCoordinatesException;
import com.jarqprog.view.View;
public class ShapeCalculatorController implements CalculatorController {
private OverlapCalc calc;
private ShapeCoordinatesGenerator generator;
private View view;
public static CalculatorController getInstance(
OverlapCalc calculator, ShapeCoordinatesGenerator generator, View view) {
return new ShapeCalculatorController(calculator, generator, view);
}
private ShapeCalculatorController(OverlapCalc calc, ShapeCoordinatesGenerator generator, View view) {
this.calc = calc;
this.generator = generator;
this.view = view;
}
public void runCalculator() {
String userInput = "";
int[] firstRectangleCoordinates, secondRectangleCoordinates;
while(! userInput.equals("q")) {
firstRectangleCoordinates = generator.generateCoordinates();
secondRectangleCoordinates = generator.generateCoordinates();
try {
calc.calculateOverlapArea(firstRectangleCoordinates, secondRectangleCoordinates);
view.displayObject(calc);
} catch (IncorrectCoordinatesException e) {
view.displayMessage(e.getMessage());
}
userInput = view.getUserInput("To quit press 'q'").toLowerCase();
}
}
}
|
Markdown
|
UTF-8
| 4,610 | 3 | 3 |
[] |
no_license
|
---
wordpress_id: 4691
title: The State of Windows Mobile
date: 2009-01-14T12:57:00+00:00
author: Colin Ramsay
layout: post
wordpress_guid: /blogs/colin_ramsay/archive/2009/01/14/the-state-of-windows-mobile.aspx
categories:
- Compact Framework
- windows mobile
redirect_from: "/blogs/colin_ramsay/archive/2009/01/14/the-state-of-windows-mobile.aspx/"
---
“Have you done any Windows Mobile development?”
“A tiny bit. Isn’t it just like Winforms but on a phone?”
And from such an innocent beginning, a world of pain did explode into my universe. Just like Winforms on a phone is it? What’s the difference between the Compact Framework, Smartphone development, Pocket PC development, Windows Mobile? So many terms! So little time!
Windows Mobile is the operating system, just like Windows Vista. The Compact Framework is just like the .NET Framework on the desktop. As for the difference between a Smartphone and a Pocket PC, well, you’ve got me there. I picked Smartphone because my device had phone functionality and it seems to be working so far. There are separate SDKs for each, so I assume there are some key differences which escape me. With Windows Mobile 6, the Smartphone and Pocket PC SDKs are now Windows Mobile 6 Standard and Windows Mobile 6 Professional, respectively. I think.
Actually I think the real difference in these is the templates for projects you create and the emulators you are provided with. Professional, or Pocket PC, provides emulators for bigger screens. Microsoft has [this to say](http://www.microsoft.com/downloads/details.aspx?familyid=06111A3A-A651-4745-88EF-3D48091A390B&displaylang=en) about the naming kerfuffle:
> With Windows Mobile 6, we are revising our SKU taxonomy and naming to better align our brand and products with the realities of today’s mobile device marketplace. The historical form-factor based distinction between Windows Mobile powered Smartphone and Windows Mobile powered Pocket PC Phone Edition is blurring dramatically. We want our taxonomies and terminology to evolve to better reflect the evolution of the mobile device industry.
So in order to reflect the blurring of the mobile device form factors, they’ve changed from having SDKs named after the types of device to SDKs named “Standard” and “Professional”. Hmm. How about having a single SDK called “Mobile Device SDK” and allow me to pick the device dimensions from within my project on the fly? Back at the start of this tale, I assumed that picking Windows Mobile for development would allow us to target a range of different devices, large and small, and in fact I can do that. I can deploy my application to a Windows Mobile phone with a big screen and to one with a small screen. The SDK split seems pretty artificial with that in mind.
Naming conventions and confusions aside, it is nice to be able to write against a single API and deploy to any Windows Mobile device. Or it would be if it worked.
My bugbear here is with a particular class: CameraCaptureDialog. Take the Samsung Omnia for example. You can certainly pop up the camera using CCD.ShowDialog(), but can you retrieve the filename of the image you took? You cannot. That’s because the Omnia’s camera supports taking multiple images one after the other until you explicitly close it.
How about the HTC Diamond? Well that opens fine, and returns a filename too, but if you try and re-open the camera straight after processing the filename, to allow the user to take another photo, it fails silently and doesn’t show the camera. If you try and do the same thing with the HTC Touch, it freezes.
Part of the issue is that the Compact Framework leaves too much up to the manufacturers and doesn’t give enough control to the developer. We can set the resolution of the camera for example, but we have no shortcut of setting it to the maximum resolution available. If you try and set it to a resolution which is not supported, some devices reset silently to a much lower resolution.
Microsoft need to extend camera support for .NET developers and give a lower level of access. They need to push device manufacturers to adhere to the Windows Mobile APIs and be more precise in how they are specified. And they need to simplify and modernise their mobile development framework so that developers can be fully aware of all the options available to them.
_This post was also published on [my personal blog](http://colinramsay.co.uk/diary/2009/01/14/the-state-of-windows-mobile/ "The State of WIndows Mobile")._
|
Java
|
UTF-8
| 2,425 | 2.75 | 3 |
[] |
no_license
|
package kiwi.sthom.mars;
import android.util.Log;
import com.microsoft.connecteddevices.RemoteSystem;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Static store for {@link RemoteSystem}, since they can not be passed though bundles
*/
class DeviceStorage {
private static Map<String, RemoteSystem> _devices = new HashMap<>();
private static List<OnUpdateListener> _listeners = new ArrayList<>();
static boolean addDevice(RemoteSystem device) {
if (_devices.containsKey(device.getId())) {
return false;
} else {
_devices.put(device.getId(), device);
notifyListeners();
return true;
}
}
static void removeDevice(String id) {
_devices.remove(id);
notifyListeners();
}
static RemoteSystem getDevice(String id) {
if (_devices.containsKey(id)) {
return _devices.get(id);
} else {
return null;
}
}
static List<RemoteSystem> getAll() {
return new ArrayList<>(_devices.values());
}
static void addListener(OnUpdateListener listener) {
if (!_listeners.contains(listener)) {
_listeners.add(listener);
// Give them their first update
listener.onDevicesUpdated(getAll());
}
}
static void removeListener(OnUpdateListener listener) {
if (_listeners.contains(listener)) {
_listeners.remove(listener);
}
}
static void notifyListeners() {
List<RemoteSystem> devices = getAll();
for (OnUpdateListener listener : _listeners) {
listener.onDevicesUpdated(devices);
}
}
static int getDrawableId(RemoteSystem device) {
switch (device.getKind()) {
case DESKTOP:
return R.drawable.ic_desktop_windows_black_24dp;
case PHONE:
return R.drawable.ic_smartphone_black_24dp;
case XBOX:
return R.drawable.ic_xbox_black_24dp;
case HUB:
case HOLOGRAPHIC:
return R.drawable.ic_devices_other_black_24dp;
case UNKNOWN:
default:
return R.drawable.ic_help_circle_black_24dp;
}
}
interface OnUpdateListener {
void onDevicesUpdated(List<RemoteSystem> devices);
}
}
|
Java
|
UTF-8
| 27,122 | 2.1875 | 2 |
[] |
no_license
|
/*
SFLSDE.java
Isaac Triguero Velazquez.
Created by Isaac Triguero Velazquez 23-7-2009
Copyright (c) 2008 __MyCompanyName__. All rights reserved.
*/
package keel.Algorithms.Instance_Generation.SFLSDE;
import keel.Algorithms.Instance_Generation.Basic.PrototypeSet;
import keel.Algorithms.Instance_Generation.Basic.PublicVar;
import keel.Algorithms.Instance_Generation.Basic.PrototypeGenerator;
import keel.Algorithms.Instance_Generation.Basic.Prototype;
import keel.Algorithms.Instance_Generation.Basic.PrototypeGenerationAlgorithm;
import keel.Algorithms.Instance_Generation.Chen.ChenGenerator;
import keel.Algorithms.Instance_Generation.HYB.HYBGenerator;
import keel.Algorithms.Instance_Generation.PSO.PSOGenerator;
import keel.Algorithms.Instance_Generation.*;
import java.util.*;
import keel.Algorithms.Instance_Generation.utilities.*;
import keel.Algorithms.Instance_Generation.utilities.KNN.*;
import org.core.*;
import org.core.*;
import java.util.StringTokenizer;
/**
* @param k Number of neighbors
* @param Population Size.
* @param ParticleSize.
* @param Scaling Factor.
* @param Crossover rate.
* @param Strategy (1-5).
* @param maxEval_IG
* @author Isaac Triguero
* @version 1.0
*/
public class SFLSDEGenerator extends PrototypeGenerator {
/*Own parameters of the algorithm*/
// We need the variable K to use with k-NN rule
private int k;
private int PopulationSize;
private int ParticleSize;
private int maxEval_IG;
private int Strategy;
protected int numberOfClass;
protected int numberOfPrototypes; // Particle size is the percentage
/** Parameters of the initial reduction process. */
private String[] paramsOfInitialReducction = null;
private double tau[] = new double[4];
private double Fl, Fu;
private int iterSFGSS;
private int iterSFHC;
/**
* Build a new SFLSDEGenerator Algorithm
* @param t Original prototype set to be reduced.
* @param perc Reduction percentage of the prototype set.
*/
public SFLSDEGenerator(PrototypeSet _trainingDataSet, int neigbors,int poblacion, int perc, int iteraciones, double F, double CR, int strg)
{
super(_trainingDataSet);
algorithmName="SFLSDE";
this.k = neigbors;
this.PopulationSize = poblacion;
this.ParticleSize = perc;
this.maxEval_IG = iteraciones;
this.numberOfPrototypes = getSetSizeFromPercentage(perc);
int dimensions = trainingDataSet.get(0).numberOfInputs();
this.maxEval_IG = (int) (trainingDataSet.size() * dimensions*PublicVar.EvalWeight);
}
/**
* Build a new SFLSDEGenerator Algorithm
* @param t Original prototype set to be reduced.
* @param params Parameters of the algorithm (only % of reduced set).
*/
public SFLSDEGenerator(PrototypeSet t, Parameters parameters)
{
super(t, parameters);
algorithmName="SFLSDE";
this.k = parameters.getNextAsInt();
this.PopulationSize = parameters.getNextAsInt();
this.ParticleSize = parameters.getNextAsInt();
this.maxEval_IG = parameters.getNextAsInt();
this.iterSFGSS = parameters.getNextAsInt();
this.iterSFHC = parameters.getNextAsInt();
this.Fl = parameters.getNextAsDouble();
this.Fu = parameters.getNextAsDouble();
this.tau[0] = parameters.getNextAsDouble();
this.tau[1] = parameters.getNextAsDouble();
this.tau[2] = parameters.getNextAsDouble();
this.tau[3] = parameters.getNextAsDouble();
this.Strategy = parameters.getNextAsInt();
int dimensions = trainingDataSet.get(0).numberOfInputs();
this.maxEval_IG = (int) (trainingDataSet.size() * dimensions*PublicVar.EvalWeight);
this.numberOfPrototypes = getSetSizeFromPercentage(ParticleSize);
this.numberOfClass = trainingDataSet.getPosibleValuesOfOutput().size();
System.out.print("\nPsxhll: " + "Evaluation weight used: " + PublicVar.EvalWeight + " Swar= "+PopulationSize+ " Particle= "+ ParticleSize + " maxEval_IG= "+ maxEval_IG+" tau4= "+this.tau[3]+ " CrossverType = "+"\n");
//numberOfPrototypes = getSetSizeFromPercentage(parameters.getNextAsDouble());
}
public PrototypeSet mutant(PrototypeSet population[], int actual, int mejor, double SFi){
PrototypeSet mutant = new PrototypeSet(population.length);
PrototypeSet r1,r2,r3,r4,r5, resta, producto, resta2, producto2, result, producto3, resta3;
//We need three differents solutions of actual
int lista[] = new int[population.length];
inic_vector_sin(lista,actual);
desordenar_vector_sin(lista);
// System.out.println("Lista = "+lista[0]+","+ lista[1]+","+lista[2]);
r1 = population[lista[0]];
r2 = population[lista[1]];
r3 = population[lista[2]];
r4 = population[lista[3]];
r5 = population[lista[4]];
switch(this.Strategy){
case 1: // ViG = Xr1,G + F(Xr2,G - Xr3,G) De rand 1
resta = r2.restar(r3);
producto = resta.mulEscalar(SFi);
mutant = producto.sumar(r1);
break;
case 2: // Vig = Xbest,G + F(Xr2,G - Xr3,G) De best 1
resta = r2.restar(r3);
producto = resta.mulEscalar(SFi);
mutant = population[mejor].sumar(producto);
break;
case 3: // Vig = ... De rand to best 1
resta = r1.restar(r2);
resta2 = population[mejor].restar(population[actual]);
producto = resta.mulEscalar(SFi);
producto2 = resta2.mulEscalar(SFi);
result = population[actual].sumar(producto);
mutant = result.sumar(producto2);
break;
case 4: // DE best 2
resta = r1.restar(r2);
resta2 = r3.restar(r4);
producto = resta.mulEscalar(SFi);
producto2 = resta2.mulEscalar(SFi);
result = population[mejor].sumar(producto);
mutant = result.sumar(producto2);
break;
case 5: //DE rand 2
resta = r2.restar(r3);
resta2 = r4.restar(r5);
producto = resta.mulEscalar(SFi);
producto2 = resta2.mulEscalar(SFi);
result = r1.sumar(producto);
mutant = result.sumar(producto2);
break;
case 6: //DE rand to best 2
resta = r1.restar(r2);
resta2 = r3.restar(r4);
resta3 = population[mejor].restar(population[actual]);
producto = resta.mulEscalar(SFi);
producto2 = resta2.mulEscalar(SFi);
producto3 = resta3.mulEscalar(SFi);
result = population[actual].sumar(producto);
result = result.sumar(producto2);
mutant = result.sumar(producto3);
break;
/*// Para hacer esta estrat�gia, lo que hay que elegir es CrossoverType = Arithmetic
* case 7: //DE current to rand 1
resta = r1.restar(population[actual]);
resta2 = r2.restar(r3);
producto = resta.mulEscalar(RandomGenerator.Randdouble(0, 1));
producto2 = resta2.mulEscalar(this.ScalingFactor);
result = population[actual].sumar(producto);
mutant = result.sumar(producto2);
break;
*/
}
// System.out.println("********Mutante**********");
// mutant.print();
mutant.applyThresholds();
return mutant;
}
/**
* Local Search Fitness Function
* @param Fi
* @param xt
* @param xr
* @param xs
* @param actual
*/
public double lsff(double Fi, double CRi, PrototypeSet population[], int actual, int mejor){
PrototypeSet resta, producto, mutant;
PrototypeSet crossover;
double FitnessFi = 0;
//Mutation:
mutant = new PrototypeSet(population[actual].size());
mutant = mutant(population, actual, mejor, Fi);
//Crossover
crossover =new PrototypeSet(population[actual]);
for(int j=0; j< population[actual].size(); j++){ // For each part of the solution
double randNumber = RandomGenerator.Randdouble(0, 1);
if(randNumber< CRi){
crossover.set(j, mutant.get(j)); // Overwrite.
}
}
// Compute fitness
PrototypeSet nominalPopulation = new PrototypeSet();
nominalPopulation.formatear(crossover);
FitnessFi = accuracy(nominalPopulation,trainingDataSet);
return FitnessFi;
}
/**
* SFGSS local Search.
* @param population
* @return
*/
public PrototypeSet SFGSS(PrototypeSet population[], int actual, int mejor, double CRi){
double a=0.1, b=1;
double fi1=0, fi2=0, fitnessFi1=0, fitnessFi2=0;
double phi = (1+ Math.sqrt(5))/5;
double scaling;
PrototypeSet crossover, resta, producto, mutant;
for (int i=0; i<this.iterSFGSS; i++){ // Computation budjet
fi1 = b - (b-a)/phi;
fi2 = a + (b-a)/phi;
fitnessFi1 = lsff(fi1, CRi, population,actual,mejor);
fitnessFi2 = lsff(fi2, CRi,population,actual,mejor);
if(fitnessFi1> fitnessFi2){
b = fi2;
}else{
a = fi1;
}
} // End While
if(fitnessFi1> fitnessFi2){
scaling = fi1;
}else{
scaling = fi2;
}
//Mutation:
mutant = new PrototypeSet(population[actual].size());
mutant = mutant(population, actual, mejor, scaling);
//Crossover
crossover =new PrototypeSet(population[actual]);
for(int j=0; j< population[actual].size(); j++){ // For each part of the solution
double randNumber = RandomGenerator.Randdouble(0, 1);
if(randNumber< CRi){
crossover.set(j, mutant.get(j)); // Overwrite.
}
}
return crossover;
}
/**
* SFHC local search
* @param xt
* @param xr
* @param xs
* @param actual
* @param SFi
* @return
*/
public PrototypeSet SFHC(PrototypeSet population[], int actual, int mejor, double SFi, double CRi){
double fitnessFi1, fitnessFi2, fitnessFi3, bestFi;
PrototypeSet crossover, resta, producto, mutant;
double h= 0.5;
for (int i=0; i<this.iterSFHC; i++){ // Computation budjet
fitnessFi1 = lsff(SFi-h, CRi, population,actual,mejor);
fitnessFi2 = lsff(SFi, CRi, population,actual,mejor);
fitnessFi3 = lsff(SFi+h, CRi, population,actual,mejor);
if(fitnessFi1 >= fitnessFi2 && fitnessFi1 >= fitnessFi3){
bestFi = SFi-h;
}else if(fitnessFi2 >= fitnessFi1 && fitnessFi2 >= fitnessFi3){
bestFi = SFi;
h = h/2; // H is halved.
}else{
bestFi = SFi;
}
SFi = bestFi;
}
//Mutation:
mutant = new PrototypeSet(population[actual].size());
mutant = mutant(population, actual, mejor, SFi);
//Crossover
crossover = new PrototypeSet(population[actual]);
for(int j=0; j< population[actual].size(); j++){ // For each part of the solution
double randNumber = RandomGenerator.Randdouble(0, 1);
if(randNumber< CRi){
crossover.set(j, mutant.get(j)); // Overwrite.
}
}
return crossover;
}
/**
* Generate a reduced prototype set by the SFLSDEGenerator method.
* @return Reduced set by SFLSDEGenerator's method.
*/
public PrototypeSet reduceSet()
{
System.out.print("\nThe algorithm SFLSDE is starting...\n Computing...\n");
System.out.println("Reduction %, result set = "+((trainingDataSet.size()-numberOfPrototypes)*100)/trainingDataSet.size()+ "\n");
if(numberOfPrototypes < trainingDataSet.getPosibleValuesOfOutput().size()){
System.out.println("Number of prototypes less than the number of clases");
numberOfPrototypes = trainingDataSet.getPosibleValuesOfOutput().size();
}
//Algorithm
// First, we create the population, with PopulationSize.
// like a prototypeSet's vector.
PrototypeSet nominalPopulation;
PrototypeSet population [] = new PrototypeSet [PopulationSize];
PrototypeSet mutation[] = new PrototypeSet[PopulationSize];
PrototypeSet crossover[] = new PrototypeSet[PopulationSize];
double ScalingFactor[] = new double[this.PopulationSize];
double CrossOverRate[] = new double[this.PopulationSize]; // Inside of the Optimization process.
double fitness[] = new double[PopulationSize];
// First Stage, Initialization.
population[0]=selecRandomSet(numberOfPrototypes,true).clone() ;
// Aseguro que al menos hay un representante de cada clase.
PrototypeSet clases[] = new PrototypeSet [this.numberOfClass];
for(int i=0; i< this.numberOfClass; i++){
clases[i] = new PrototypeSet(trainingDataSet.getFromClass(i));
System.out.println("Clase "+i+", size= "+ clases[i].size());
}
for(int i=0; i< population[0].size(); i++){
for(int j=0; j< this.numberOfClass; j++){
if(population[0].getFromClass(j).size() ==0 && clases[j].size()!=0){
population[0].add(clases[j].getRandom());
}
}
}
/* for(int i=0; i< this.numberOfClass; i++){
System.out.println("Solucion clase "+i+", size= "+ population[0].getFromClass(i).size());
}
*/
//population[0].print();
fitness[0] = accuracy(population[0],trainingDataSet);
// population[0].print();
for(int i=1; i< PopulationSize; i++){
population[i] = new PrototypeSet();
for(int j=0; j< population[0].size(); j++){
population[i].add(trainingDataSet.getFromClass(population[0].get(j).getOutput(0)).getRandom());
}
fitness[i] = accuracy(population[i],trainingDataSet); // SFLSDE fitness, no hace falta formatear porque son aleatorios!
}
//We select the best initial particle
double bestFitness=fitness[0];
int bestFitnessIndex=0;
for(int i=1; i< PopulationSize;i++){
if(fitness[i]>bestFitness){
bestFitness = fitness[i];
bestFitnessIndex=i;
}
}
for(int j=0;j<PopulationSize;j++){
//Now, I establish the index of each prototype.
for(int i=0; i<population[j].size(); ++i)
population[j].get(i).setIndex(i);
}
boolean cruceExp [] = new boolean[PopulationSize];
// Initially the Scaling Factor and crossover for each Individual are randomly generated between 0 and 1.
for(int i=0; i< this.PopulationSize; i++){
ScalingFactor[i] = RandomGenerator.Randdouble(0, 1);
CrossOverRate[i] = RandomGenerator.Randdouble(0, 1);
}
double randj[] = new double[5];
//for(int iter=0; iter< MaxIter; iter++){ // Main loop
int ev = 0;
while (ev < maxEval_IG)// Main loop
{
for(int i=0; i<PopulationSize; i++){
// Generate randj for j=1 to 5.
for(int j=0; j<5; j++){
randj[j] = RandomGenerator.Randdouble(0, 1);
}
if(i==bestFitnessIndex && randj[4] < tau[2]){
System.out.println("SFGSS applied");
//SFGSS
crossover[i] = SFGSS(population, i, bestFitnessIndex, CrossOverRate[i]);
ev+= this.iterSFGSS *2; //Psxhll: Two evaluations are called within for-loop of iterSFGSS times in method SFGSS
}else if(i==bestFitnessIndex && tau[2] <= randj[4] && randj[4] < tau[3]){
//SFHC
System.out.println("SFHC applied");
crossover[i] = SFHC(population, i, bestFitnessIndex, ScalingFactor[i], CrossOverRate[i]);
ev+= this.iterSFHC *3; //Psxhll: Three evaluations are called within for-loop of iterSFHC times in method SFHC
}else {
// Fi update
if(randj[1] < tau[0]){
ScalingFactor[i] = this.Fl + this.Fu*randj[0];
}
// CRi update
if(randj[3] < tau[1]){
CrossOverRate[i] = randj[2];
}
// Mutation Operation.
mutation[i] = new PrototypeSet(population[i].size());
//Mutation:
mutation[i] = mutant(population, i, bestFitnessIndex, ScalingFactor[i]);
// Crossver Operation.
crossover[i] = new PrototypeSet(population[i]);
for(int j=0; j< population[i].size(); j++){ // For each part of the solution
double randNumber = RandomGenerator.Randdouble(0, 1);
if(randNumber<CrossOverRate[i]){
crossover[i].set(j, mutation[i].get(j)); // Overwrite.
}
}
}
// Fourth: Selection Operation.
//nominalPopulation = new PrototypeSet();
//nominalPopulation.formatear(population[i]);
// fitness[i] = accuracy(nominalPopulation,trainingDataSet);
//ev++;
nominalPopulation = new PrototypeSet();
nominalPopulation.formatear(crossover[i]);
double trialVector = accuracy(nominalPopulation,trainingDataSet);
ev++;
if(trialVector > fitness[i]){
population[i] = new PrototypeSet(crossover[i]);
fitness[i] = trialVector;
}
if(fitness[i]>bestFitness){
bestFitness = fitness[i];
bestFitnessIndex=i;
}
}//End for loop
//System.out.println("Acc= "+ bestFitness);
} //End main while-loop
nominalPopulation = new PrototypeSet();
nominalPopulation.formatear(population[bestFitnessIndex]);
System.err.println("\n% de acierto en training Nominal " + KNN.classficationAccuracy(nominalPopulation,trainingDataSet,1)*100./trainingDataSet.size() );
// nominalPopulation.print();
return nominalPopulation;
}
public PrototypeSet reduceSet_OriginalSetting()
{
System.out.print("\nThe algorithm SFLSDE is starting...\n Computing...\n");
System.out.println("Reduction %, result set = "+((trainingDataSet.size()-numberOfPrototypes)*100)/trainingDataSet.size()+ "\n");
if(numberOfPrototypes < trainingDataSet.getPosibleValuesOfOutput().size()){
System.out.println("Number of prototypes less than the number of clases");
numberOfPrototypes = trainingDataSet.getPosibleValuesOfOutput().size();
}
//Algorithm
// First, we create the population, with PopulationSize.
// like a prototypeSet's vector.
PrototypeSet nominalPopulation;
PrototypeSet population [] = new PrototypeSet [PopulationSize];
PrototypeSet mutation[] = new PrototypeSet[PopulationSize];
PrototypeSet crossover[] = new PrototypeSet[PopulationSize];
double ScalingFactor[] = new double[this.PopulationSize];
double CrossOverRate[] = new double[this.PopulationSize]; // Inside of the Optimization process.
double fitness[] = new double[PopulationSize];
// First Stage, Initialization.
population[0]=selecRandomSet(numberOfPrototypes,true).clone() ;
// Aseguro que al menos hay un representante de cada clase.
PrototypeSet clases[] = new PrototypeSet [this.numberOfClass];
for(int i=0; i< this.numberOfClass; i++){
clases[i] = new PrototypeSet(trainingDataSet.getFromClass(i));
System.out.println("Clase "+i+", size= "+ clases[i].size());
}
for(int i=0; i< population[0].size(); i++){
for(int j=0; j< this.numberOfClass; j++){
if(population[0].getFromClass(j).size() ==0 && clases[j].size()!=0){
population[0].add(clases[j].getRandom());
}
}
}
/* for(int i=0; i< this.numberOfClass; i++){
System.out.println("Solucion clase "+i+", size= "+ population[0].getFromClass(i).size());
}
*/
//population[0].print();
fitness[0] = accuracy(population[0],trainingDataSet);
// population[0].print();
for(int i=1; i< PopulationSize; i++){
population[i] = new PrototypeSet();
for(int j=0; j< population[0].size(); j++){
population[i].add(trainingDataSet.getFromClass(population[0].get(j).getOutput(0)).getRandom());
}
fitness[i] = accuracy(population[i],trainingDataSet); // SFLSDE fitness, no hace falta formatear porque son aleatorios!
}
//We select the best initial particle
double bestFitness=fitness[0];
int bestFitnessIndex=0;
for(int i=1; i< PopulationSize;i++){
if(fitness[i]>bestFitness){
bestFitness = fitness[i];
bestFitnessIndex=i;
}
}
for(int j=0;j<PopulationSize;j++){
//Now, I establish the index of each prototype.
for(int i=0; i<population[j].size(); ++i)
population[j].get(i).setIndex(i);
}
boolean cruceExp [] = new boolean[PopulationSize];
// Initially the Scaling Factor and crossover for each Individual are randomly generated between 0 and 1.
for(int i=0; i< this.PopulationSize; i++){
ScalingFactor[i] = RandomGenerator.Randdouble(0, 1);
CrossOverRate[i] = RandomGenerator.Randdouble(0, 1);
}
double randj[] = new double[5];
for(int iter=0; iter< 500; iter++){ // Main loop
//int ev = 0;
//while (ev < maxEval_IG)// Main loop
//{
for(int i=0; i<PopulationSize; i++){
// Generate randj for j=1 to 5.
for(int j=0; j<5; j++){
randj[j] = RandomGenerator.Randdouble(0, 1);
}
if(i==bestFitnessIndex && randj[4] < tau[2]){
System.out.println("SFGSS applied");
//SFGSS
crossover[i] = SFGSS(population, i, bestFitnessIndex, CrossOverRate[i]);
}else if(i==bestFitnessIndex && tau[2] <= randj[4] && randj[4] < tau[3]){
//SFHC
System.out.println("SFHC applied");
crossover[i] = SFHC(population, i, bestFitnessIndex, ScalingFactor[i], CrossOverRate[i]);
}else {
// Fi update
if(randj[1] < tau[0]){
ScalingFactor[i] = this.Fl + this.Fu*randj[0];
}
// CRi update
if(randj[3] < tau[1]){
CrossOverRate[i] = randj[2];
}
// Mutation Operation.
mutation[i] = new PrototypeSet(population[i].size());
//Mutation:
mutation[i] = mutant(population, i, bestFitnessIndex, ScalingFactor[i]);
// Crossver Operation.
crossover[i] = new PrototypeSet(population[i]);
for(int j=0; j< population[i].size(); j++){ // For each part of the solution
double randNumber = RandomGenerator.Randdouble(0, 1);
if(randNumber<CrossOverRate[i]){
crossover[i].set(j, mutation[i].get(j)); // Overwrite.
}
}
}
// Fourth: Selection Operation.
//nominalPopulation = new PrototypeSet();
//nominalPopulation.formatear(population[i]);
//fitness[i] = accuracy(nominalPopulation,trainingDataSet);
nominalPopulation = new PrototypeSet();
nominalPopulation.formatear(crossover[i]);
double trialVector = accuracy(nominalPopulation,trainingDataSet);
if(trialVector > fitness[i]){
population[i] = new PrototypeSet(crossover[i]);
fitness[i] = trialVector;
}
if(fitness[i]>bestFitness){
bestFitness = fitness[i];
bestFitnessIndex=i;
}
}//End for loop
//System.out.println("Acc= "+ bestFitness);
} //End main while-loop
nominalPopulation = new PrototypeSet();
nominalPopulation.formatear(population[bestFitnessIndex]);
System.err.println("\n% de acierto en training Nominal " + KNN.classficationAccuracy(nominalPopulation,trainingDataSet,1)*100./trainingDataSet.size() );
// nominalPopulation.print();
return nominalPopulation;
}
/**
* General main for all the prototoype generators
* Arguments:
* 0: Filename with the training data set to be condensed.
* 1: Filename which contains the test data set.
* 3: Seed of the random number generator. Always.
* **************************
* 4: .Number of neighbors
* 5: Swarm Size
* 6: Particle Size
* 7: Max Iter
* 8: C1
* 9: c2
* 10: vmax
* 11: wstart
* 12: wend
* @param args Arguments of the main function.
* @throws Exception
*/
public static void main(String[] args) throws Exception
{
Parameters.setUse("SFLSDE", "<seed> <Number of neighbors>\n<Swarm size>\n<Particle Size>\n<maxEval_IG>\n<DistanceFunction>");
Parameters.assertBasicArgs(args);
PrototypeSet training = PrototypeGenerationAlgorithm.readPrototypeSet(args[0]);
PrototypeSet test = PrototypeGenerationAlgorithm.readPrototypeSet(args[1]);
long seed = Parameters.assertExtendedArgAsInt(args,2,"seed",0,Long.MAX_VALUE);
SFLSDEGenerator.setSeed(seed);
int k = Parameters.assertExtendedArgAsInt(args,3,"number of neighbors", 1, Integer.MAX_VALUE);
int swarm = Parameters.assertExtendedArgAsInt(args,4,"swarm size", 1, Integer.MAX_VALUE);
int particle = Parameters.assertExtendedArgAsInt(args,5,"particle size", 1, Integer.MAX_VALUE);
int iter = Parameters.assertExtendedArgAsInt(args,6,"max iter", 1, Integer.MAX_VALUE);
double c1 = Parameters.assertExtendedArgAsInt(args,7,"c1", 1, Double.MAX_VALUE);
double c2 =Parameters.assertExtendedArgAsInt(args,8,"c2", 1, Double.MAX_VALUE);
double vmax =Parameters.assertExtendedArgAsInt(args,9,"vmax", 1, Double.MAX_VALUE);
double wstart = Parameters.assertExtendedArgAsInt(args,10,"wstart", 1, Double.MAX_VALUE);
double wend =Parameters.assertExtendedArgAsInt(args,11,"wend", 1, Double.MAX_VALUE);
//String[] parametersOfInitialReduction = Arrays.copyOfRange(args, 4, args.length);
//System.out.print(" swarm ="+swarm+"\n");
SFLSDEGenerator generator = new SFLSDEGenerator(training, k,swarm,particle,iter, 0.5,0.5,1);
PrototypeSet resultingSet = generator.execute();
//resultingSet.save(args[1]);
//int accuracyKNN = KNN.classficationAccuracy(resultingSet, test, k);
int accuracy1NN = KNN.classficationAccuracy(resultingSet, test);
generator.showResultsOfAccuracy(Parameters.getFileName(), accuracy1NN, test);
}
}
|
Java
|
UTF-8
| 759 | 2.046875 | 2 |
[] |
no_license
|
package com.wb.repository;
import com.wb.entity.Task;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
/**
* <p>文件名称:TaskRepo </p>
* <p>文件描述:</p>
* <p>版权所有:版权所有(C)2011-2099 </p>
* <p>公 司:口袋购物 </p>
* <p>内容摘要:</p>
* <p>其他说明:</p>
* <p>完成日期:2016/10/29 </p>
*
* @author wubin
*/
@Repository
public interface TaskRepo extends CrudRepository<Task, Long>{
List<Task> findByCntGreaterThan(int cnt);
@Query("select task from com.wb.entity.Task task order by task.gmtCreate desc")
List<Task> findOrderByGmtCreateDesc();
}
|
Markdown
|
UTF-8
| 9,372 | 3.40625 | 3 |
[] |
no_license
|
## iOS 单例
>单例模式可能是设计模式中最简单的形式了,这一模式的意图就是使得类中的一个对象成为系统中的唯一实例。它提供了对类的对象所提供的资源的全局访问点。因此需要用一种只允许生成对象类的唯一实例的机制。
下面让我们来看下单例的作用:
- 可以保证的程序运行过程,一个类只有一个示例,而且该实例易于供外界访问
- 从而方便地控制了实例个数,并节约系统资源。
### 方法一(误)
```
+ (instancetype)sharedInstance
{
static Singleton *instance = nil;
if (!instance) {
instance = [[Singleton alloc] init];
}
return instance;
}
```
这种方式的单例不是线程安全的。
假设此时有两条线程:线程1和线程2,都在调用shareInstance方法来创建单例,那么线程1运行到if (instance == nil)出发现instance = nil,那么就会初始化一个instance,假设此时线程2也运行到if的判断处了,此时线程1还没有创建完成实例instance,所以此时instance = nil还是成立的,那么线程2又会创建一个instace。
为了解决线程安全问题,可以使用dispatch_once、互斥锁。
### 方法二 (误)
```
static Singleton *instance = nil;
+ (instancetype)sharedInstance
{
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
instance = [[Singleton alloc] init];
});
return instance;
}
```
或
```
static Singleton *instance = nil;
+ (instancetype)sharedInstance
{
@synchronized (self) {
if (!instance) {
instance = [[Singleton alloc] init];
}
}
return instance;
}
```
上面的两个方法保证了线程安全,但是不够全面。如果使用其他方式创建,能创建出不同的对象,违背了单例的设计原则。
```
Singleton *s = nil;
s = [Singleton sharedInstance];
NSLog(@"%@", s);
s = [[Singleton alloc] init];
NSLog(@"%@", s);
s = [Singleton new];
NSLog(@"%@", s);
```
打印出三个不同的地址
```
2016-12-21 20:46:30.414 Singleton[28843:2198096] <Singleton: 0x6000000168c0>
2016-12-21 20:46:30.415 Singleton[28843:2198096] <Singleton: 0x610000016340>
2016-12-21 20:46:30.415 Singleton[28843:2198096] <Singleton: 0x6180000164a0>
```
### 方法三(误)
为了防止别人不小心利用alloc/init方式创建示例,也为了防止别人故意为之,我们要保证不管用什么方式创建都只能是同一个实例对象,这就得重写另一个方法。
在方法二的基础上增加重写下面的方法:
```
+ (instancetype)allocWithZone:(struct _NSZone *)zone
{
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
instance = [super allocWithZone:zone];
});
return instance;
}
```
再测试,发现打印出来的地址都一样了。
但是,还没结束。
我们添加一些属性,并在-init方法中进行初始化:
```
@property (assign, nonatomic)int height;
@property (strong, nonatomic)NSObject *object;
@property (strong, nonatomic)NSMutableArray *array;
```
然后重写-description方法:
```
- (NSString *)description
{
NSString *result = @"";
result = [result stringByAppendingFormat:@"<%@: %p>",[self class], self];
result = [result stringByAppendingFormat:@" height = %d,",self.height];
result = [result stringByAppendingFormat:@" array = %p,",self.array];
result = [result stringByAppendingFormat:@" object = %p,",self.object];
return result;
}
```
还用上面的方法,打印结果:
```
2016-12-21 20:58:03.523 Singleton[29239:2252268] <Singleton: 0x608000039d00> height = 10, arrayM = 0x60800005b150, object = 0x60800000b3e0,
2016-12-21 20:58:03.523 Singleton[29239:2252268] <Singleton: 0x608000039d00> height = 10, arrayM = 0x618000052540, object = 0x61800000b430,
2016-12-21 20:58:03.524 Singleton[29239:2252268] <Singleton: 0x608000039d00> height = 10, arrayM = 0x60800004ae00, object = 0x60800000b3e0,
```
可以看到,尽管使用的是同一个示例,可是他们的属性却不一样。
因为尽管没有为示例重新分配内存空间,但是因为又执行了init方法,会导致property被重新初始化。
### 方法四
为了保证属性的初始化只执行一次,可以将属性的初始化或者默认值设置也限制只执行一次。我们这里加上dispatch_once。
```
+ (instancetype)sharedInstance
{
return [[Singleton alloc] init];
}
+ (instancetype)allocWithZone:(struct _NSZone *)zone
{
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
instance = [super allocWithZone:zone];
});
return instance;
}
- (instancetype)init
{
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
instance = [super init];
if (instance) {
instance.height = 10;
instance.object = [[NSObject alloc] init];
instance.array = [[NSMutableArray alloc] init];
}
});
return instance;
}
```
这种方式保证了单例的唯一,也保证了属性初始化的唯一。
### 关于线程安全
**GCD的dispatch_once方式:**保证程序在运行过程中只会被运行一次,那么假设此时线程1先执行shareInstance方法,创建了一个实例对象,线程2就不会再去执行dispatch_once的代码了。从而保证了只会创建一个实例对象。
**互斥锁方式:**会把锁内的代码当做一个任务,这个任务执行完毕前,不会被其他线程访问。
但是这种简单的互斥锁方式在每次调用单例时都会锁一次,很影响性能,单例使用越频繁,影响越大。
### 优化互斥锁方式
**DCL(double check lock):**双重检查模式是优化了的互斥锁方式,过程就是check-lock-check,是对静态变量instance的两次判空。第一次判空避免了不必要的同步,第二次判空是为了创建实例。
将上面的简单互斥锁方式修改一下:
```
if (!instance) {
@synchronized (self) {
if (!instance) {
instance = [super allocWithZone:zone];
}
}
}
return instance;
```
DCL优点是资源利用率高,第一次执行时单例对象才被实例化,效率高。缺点是第一次加载时反应稍慢一些,在高并发环境下也有一定的缺陷,虽然发生的概率很小。
效率:
GCD > DCL > 简单互斥锁
### 使用+load或+initialize
load方法与initialize方法都会被Runtime自动调用一次,并且在Runtime情况下,这两个方法都是线程安全的。
根据这种特性,来实现单例类。
```
+ (void)initialize
{
if ([self class] == [Singleton class] && instance == nil) {
instance = [[Singleton alloc] init];
instance.height = 10;
instance.object = [[NSObject alloc] init];
instance.array = [[NSMutableArray alloc] init];
}
}
+ (instancetype)sharedInstance
{
return instance;
}
+ (instancetype)allocWithZone:(struct _NSZone *)zone
{
if (instance == nil) {
instance = [super allocWithZone:zone];
}
return instance;
}
```
1. `if([self class] == [Singleton class]...)` 是为了保证 initialize方法只有在本类而非subclass时才执行单例初始化方法。
2. ` if (... && instance == nil)` 是为了防止+initialize多次调用而产生多个实例(除了Runtime调用,我们也可以显示调用+initialize方法)。经过测试,当我们将+initialize方法本身作为class的第一个方法执行时,Runtime的+initialize会被先调用(这保证了线程安全),然后我们自己显示调用的+initialize函数再被调用。 由于+initialize方法的第一次调用一定是Runtime调用,而Runtime又保证了线程安全性,因此这里只简单的检测 singalObject == nil即可。
最好不用+load来做单例是因为它是在程序被装载时调用的,可能单例所依赖的环境尚未形成,它比较适合对Class做设置。(更多关于+load和+initialize的知识,[看这里](load_initialize.md))
### 使用宏
如果我们需要在程序中创建多个单例,那么需要在每个类中都写上一次上述代码,非常繁琐。
我们可以使用宏来封装单例的创建,这样任何类需要创建单例,只需要一行代码就搞定了。
```
#define SingletonH(name) + (instancetype)shared##name;
#define SingletonM(name) \
static id instance = nil; \
+ (instancetype)sharedInstance \
{ \
static dispatch_once_t onceToken; \
dispatch_once(&onceToken, ^{ \
instance = [[[self class] alloc] init]; \
}); \
return instance; \
} \
```
### 其他
当然单例如果实现了NSCopying和NSMutableCopying协议,可以补充下面的方法:
```
- (id)copyWithZone:(NSZone *)zone
{
return instance;
}
- (id)mutableCopyWithZone:(NSZone *)zone
{
return instance;
}
```
#### 结束语
全部代码在这里[demo](https://github.com/liuyanhongwl/ios-design-patterns)
#### 参考
- [iOS中的单例你用对了么?](http://www.cocoachina.com/ios/20160713/17017.html)
- [iOS单例详解](http://www.jianshu.com/p/5226bc8ed784)
- [单例模式虽好但请不要滥用](http://www.nowamagic.net/librarys/veda/detail/921)
- [NSObject的load与initialize方法](http://blog.csdn.net/u013378438/article/details/52060925)
|
JavaScript
|
UTF-8
| 1,790 | 2.515625 | 3 |
[] |
no_license
|
import React from 'react';
import './styles/App.css'
import { FaPen } from "react-icons/fa";
import {GiDoctorFace} from 'react-icons/gi'
import {chirpData} from './data';
import {useState} from 'react'
const App = () =>{
var [chirps, setChirps] = useState(chirpData)
var [thought,setThought] = useState('')
var [name,setName] = useState('')
const addChirp = () =>{
setChirps([...chirps,{"name":name,"thought":thought}])
setName('')
setThought('')
}
return(
<div className="formdiv mt-4 container">
<div className="row">
<div lassName="col-4">
<div className="inputchirps">
<div className="mb-3">
<div style={{position:"relative"}}><label for="exampleFormControlInput1" className="form-label"><div style={{position:"absolute",left:"10px",top:"4px"}}><GiDoctorFace/></div></label>
<input type="email" onChange={(e)=>{setName(e.target.value)}} className="form-control inputs" id="exampleFormControlInput1" placeholder=" Username" value={name} /></div>
</div>
<div className="mb-3">
<div style={{position:"relative"}}><label for="exampleFormControlInput1" className="form-label"><div style={{position:"absolute",left:"10px",top:"4px"}}><FaPen/></div></label>
<textarea className="form-control inputs" id="exampleFormControlTextarea1" rows="3" onChange={(e)=>{setThought(e.target.value)}} value = {thought} placeholder=" Enter your text here"></textarea>
</div>
</div>
</div>
<button type="button" class="btn btn-primary" onClick={addChirp}>Chirp it</button>
</div>
<div className="col-4"></div>
<div className="my-chirps col-4">
{
chirps.map(val=>{
return (
<><h1>{val.name}</h1>
<p>{val.thought}</p> <hr/></>)
})
}
</div>
</div>
</div>
)
}
export default App;
|
PHP
|
UTF-8
| 735 | 2.5625 | 3 |
[] |
no_license
|
<?
class session {
private $db = null;
private $sessionid = null;
function __construct($user_id = false) {
if (isset($_SESSION['prva_database'])) $this->db = unserialize($_SESSION['prva_database']);
else $this->db = new database();
if(isset($_SESSION['prva_sid'])) $this->sessionid = $_SESSION['prva_sid'];
if(!$user_id) {
}
}
function check_session() {
}
function create_session($user_id) {
}
private function make_key() {
$m = new misc();
$key = $m->get_key(15);
$chk_key = $this->db->query("SELECT `session_id` FROM `prva_sessions` WHERE `session_key` = '$key'");
if(!empty($chk_key)) {
$key = $this->make_key();
}
return $key;
}
}
?>
|
C++
|
UTF-8
| 1,400 | 2.9375 | 3 |
[] |
no_license
|
/**
* @author Quickgrid ( Asif Ahmed )
* @link https://quickgrid.wordpress.com
* Problem: UVA
*/
#include<cstdio>
#include<climits>
#include<iostream>
#include<sstream>
static unsigned A[1000001], L[500001], R[500001];
static char inBuffer[10000001], outBuffer[10000001];
static unsigned long long c;
void Merge(unsigned front, unsigned mid, unsigned rear){
unsigned n1 = mid-front+1;
unsigned n2 = rear - mid;
unsigned i = 0;
for(; i < n1; ++i)
L[i] = A[front + i];
unsigned j = 0;
for(; j < n2; ++j)
R[j] = A[mid + 1 + j];
L[n1] = INT_MAX;
R[n2] = INT_MAX;
i = j = 0;
unsigned k = front;
for(; k <= rear; ++k){
if(L[i] <= R[j]){
A[k] = L[i++];
c += j;
}
else
A[k] = R[j++];
}
}
void Mergesort(unsigned front, unsigned rear){
if(front < rear){
unsigned mid = (rear + front) >> 1;
Mergesort(front, mid);
Mergesort(mid + 1, rear);
Merge(front, mid, rear);
}
}
int main(){
unsigned n, i;
fread(inBuffer, 1, sizeof inBuffer, stdin);
std::istringstream sin(inBuffer);
std::ostringstream sout(outBuffer);
while(sin >> n){
c = i = 0;
for(; i < n; ++i)
sin >> A[i];
Mergesort(0, n - 1);
sout << c;
sout << "\n";
}
std::cout << sout.str();
return 0;
}
|
Markdown
|
UTF-8
| 659 | 3.40625 | 3 |
[] |
no_license
|
## Solution 1
`for (char cur : s.toCharArray())` is faster than `for (int i = 0; i < s.length(); i++) { char cur = s.charAt(i);}`
Time complexity: O(n)
Space complexity: O(1)
```java
class Solution {
public int minAddToMakeValid(String s) {
int left = 0;
int result = 0;
for (char cur : s.toCharArray()) {
if (cur == '(') {
left++;
}
else if (cur == ')') {
if (left > 0) {
left--;
}
else {
result++;
}
}
}
return result + left;
}
}
```
|
Markdown
|
UTF-8
| 838 | 3.0625 | 3 |
[
"LicenseRef-scancode-unknown-license-reference",
"Apache-2.0"
] |
permissive
|
# GitHub Integration
If you plan on using GitHub with your bot, you'll need to configure a few details
## Personal Access Token
The GitHub [Personal Access Token](https://help.github.com/articles/creating-an-access-token-for-command-line-use/) is what will enable the bot to execute actions on your behalf. You can configure the level of permissions that you want to give to this token as part of the token creation. At a minimum, it should have the `repo` scope selected, so that issues can be created and deployments can be triggered.
Be sure to record the token after it is generated for you. Once you navigate away from this page, you will not be able to view the token again.
## Domain (Optional)
By default, the public GitHub repository is used. If you're using GitHub Enterprise, you can configure the domain with this input.
|
Python
|
UTF-8
| 1,260 | 4.53125 | 5 |
[] |
no_license
|
'''
Write a function called reverse_vowels. This function should reverse the vowels in a string. Any characters which are not vowels should
remain in their original position. You should not consider "y" to be a vowel.
reverse_vowels("Hello!") # "Holle!"
reverse_vowels("Tomatoes") # "Temotaos"
reverse_vowels("Reverse Vowels In A String") # "RivArsI Vewols en e Streng"
reverse_vowels("aeiou") # "uoiea"
reverse_vowels("why try, shy fly?") # "why try, shy fly?"
'''
def reverse_vowels(msg):
vowels = 'aeiouAEIOU'
vowel_indexes = []
for i, cha in enumerate(msg):
if cha in vowels:
vowel_indexes.append(i)
i = 0
count = len(vowel_indexes) - 1
msg_list = list(msg)
while i < len(vowel_indexes)/2:
temp = msg_list[vowel_indexes[count]]
msg_list[vowel_indexes[count]] = msg_list[vowel_indexes[i]]
msg_list[vowel_indexes[i]] = temp
count -= 1
i += 1
return "".join(msg_list)
print(reverse_vowels("Hello!")) # "Holle!"
print(reverse_vowels("Tomatoes")) # "Temotaos"
print(reverse_vowels("Reverse Vowels In A String")) # "RivArsI Vewols en e Streng"
print(reverse_vowels("aeiou")) # "uoiea"
print(reverse_vowels("why try, shy fly?")) # "why try, shy fly?"
|
Java
|
UTF-8
| 543 | 1.640625 | 2 |
[] |
no_license
|
package com.foo.web;
import com.foo.domain.Patient;
import org.springframework.roo.addon.web.mvc.controller.annotations.ControllerType;
import org.springframework.roo.addon.web.mvc.controller.annotations.RooController;
import org.springframework.roo.addon.web.mvc.thymeleaf.annotations.RooThymeleaf;
/**
* = PatientsCollectionThymeleafController
*
* TODO Auto-generated class documentation
*
*/
@RooController(entity = Patient.class, type = ControllerType.COLLECTION)
@RooThymeleaf
public class PatientsCollectionThymeleafController {
}
|
Ruby
|
UTF-8
| 6,793 | 3.421875 | 3 |
[] |
no_license
|
class Node
attr_accessor :value, :left, :right
def initialize(value=nil, left=nil, right=nil)
@value = value
@left = left
@right = right
end
end
class Tree
attr_accessor :root
def initialize(ary)
@array = ary.uniq.sort
end
def build_tree
len = @array.length
mid = len/2
arleft = Tree.new(@array[0..mid-1]).build_tree unless mid==0
arright = Tree.new(@array[mid+1..len-1]).build_tree unless len==mid+1
@root = Node.new(@array[mid],arleft,arright)
return @root
end
def insert(value)
temp = @root
while temp != nil do
return 'Value exists!' if value == temp.value
if value < temp.value
prev = temp
temp = temp.left
l = true
else
prev = temp
temp = temp.right
l = false
end
end
@array = @array.push(value).sort
temp = Node.new(value)
l ? prev.left = temp : prev.right = temp
return 'Value inserted.'
end
def delete(value)
exist = @array.index(value)
if exist
@array = @array - [value]
temp = Tree.new(@array)
root = temp.build_tree
@root.value = root.value
@root.left = root.left
@root.right = root.right
p "#{value} is deleted and tree is rebalanced"
else
p 'Node does not exist'
end
end
def find(value)
temp = @root
while temp != nil do
if value == temp.value
return temp
elsif value < temp.value
temp = temp.left
elsif value > temp.value
temp = temp.right
end
end
return nil
end
def level_order(currentRoot=@root)
if currentRoot==nil
return
end
if currentRoot==@root
@queue = [@root]
@levelorder = []
end
while [email protected]? do
temp = @queue.shift
@levelorder.push(temp.value)
@queue.push(temp.left) unless temp.left == nil
@queue.push(temp.right) unless temp.right == nil
end
return @levelorder
end
def inorder(currentRoot=@root)
if currentRoot==nil
return
end
if currentRoot==@root
@inorder = []
end
inorder(currentRoot.left)
@inorder.push(currentRoot.value)
inorder(currentRoot.right)
return @inorder
end
def preorder(currentRoot=@root)
if currentRoot==nil
return
end
if currentRoot==@root
@preorder = []
end
@preorder.push(currentRoot.value)
preorder(currentRoot.left)
preorder(currentRoot.right)
return @preorder
end
def postorder(currentRoot=@root)
if currentRoot==nil
return
end
if currentRoot==@root
@postorder = []
end
postorder(currentRoot.left)
postorder(currentRoot.right)
@postorder.push(currentRoot.value)
return @postorder
end
def height(node=@root)
temp = @root
value = node.value
while temp != node do
if temp == nil
return 'Node does not exist'
elsif value < temp.value
temp = temp.left
elsif value > temp.value
temp = temp.right
end
end
height = 1
level = [temp]
levelCopy = []
while !level.empty? do
level.each do |n|
levelCopy.push(n.left) unless n.left == nil
levelCopy.push(n.right) unless n.right == nil
end
return height if levelCopy.empty?
height += 1
level = levelCopy
levelCopy = []
end
end
def depth(node=@root)
depth = 1
temp = @root
value = node.value
while temp != node do
if temp == nil
return 'Node does not exist'
elsif value < temp.value
temp = temp.left
elsif value > temp.value
temp = temp.right
elsif node.value == temp.value
return 'Same value but different node'
end
depth += 1
end
return depth
end
def balanced?(node=@root)
if node==nil
return
end
if node==@root
@queue = [@root]
end
while [email protected]? do
temp = @queue.shift
temp.left != nil ? hl = height(temp.left) : hl = 0
temp.right != nil ? hr = height(temp.right) : hr = 0
delta = hl - hr
return false if delta > 1 || delta < -1
@queue.push(temp.left) unless temp.left == nil
@queue.push(temp.right) unless temp.right == nil
end
return true
end
def rebalance
temp = Tree.new(@array)
root = temp.build_tree
@root.value = root.value
@root.left = root.left
@root.right = root.right
end
def pretty_print(node = @root, prefix = '', is_left = true)
pretty_print(node.right, "#{prefix}#{is_left ? '│ ' : ' '}", false) if node.right
puts "#{prefix}#{is_left ? '└── ' : '┌── '}#{node.value}"
pretty_print(node.left, "#{prefix}#{is_left ? ' ' : '│ '}", true) if node.left
end
end
ary = Array.new(15) { rand(1..100) }
tree = Tree.new(ary)
root = tree.build_tree
p tree.balanced?
p tree.level_order
p tree.preorder
p tree.inorder
p tree.postorder
tree.insert(110)
tree.insert(120)
tree.insert(130)
p tree.balanced?
tree.rebalance
p tree.balanced?
p tree.level_order
p tree.preorder
p tree.inorder
p tree.postorder
tree.delete(110)
p tree.inorder
tree.pretty_print
=begin all test
ary1 = [1,4,8,3,7,1,5,2] #1 2 4 5
p ary1.uniq.sort
tree1 = Tree.new(ary1)
root = tree1.build_tree
#=begin
p root.left.left.value
p root.left.value
p root.left.right.value
p root.value
p root.right.value
##################
p '-----------insert test------------'
tree1.insert(6)
nod1 = tree1.find(4)
p root.value #4
#p root.right.value
#p root.right.left.value
p root.right.left.right.value #6
#p root.right.left.right.left.value
p '---here==='
tree1.insert(9.0)
p root.value #4
p root.right.right.right.value #9
#=end
p '===check me==='
#tree1.insert(2.5)
ary2 = [2,5,8,15,25,35]
tree2 = Tree.new(ary2)
root = tree2.build_tree
p root.value
p root.left.value
p root.left.right.value
p root.left.right.left
tree2.insert(6)
tree2.insert(20)
tree2.insert(21)
tree2.insert(22)
p root.value #15
p root.right.left.left.right.right.value #22
p tree2.insert(21)
qnode = tree2.find(21)
p qnode.value
p qnode.right.value
#=end
p '----levelorder----'
ary3 = [2,5,8,15,25,30,35]
#ary3 = [1,2,3]
tree3 = Tree.new(ary3)
root = tree3.build_tree
p tree3.level_order
p tree3.level_order
p '----inorder----'
p tree3.inorder
p tree3.inorder
p tree3.preorder
p tree3.preorder
p tree3.postorder
p tree3.postorder
p '====height===='
nod = tree3.find(30)
p tree3.height(nod)
#p root.right.left.left
p tree3.insert(21)
#p root.right.left.left.right
p tree3.height(nod)
p tree3.depth(nod)
nod = tree3.find(21)
p tree3.depth(nod)
p '--------------------'
p nod1.value
p tree3.depth(nod1)
p tree3.balanced?
p tree3.insert(22)
p tree3.balanced?
p '*********************'
tree3.rebalance
p root.value
p root.right.left.left.value
=end
|
C#
|
UTF-8
| 1,964 | 2.859375 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace MarsRover
{
public interface IPlatformCommand
{
string Execute(Platform platform);
}
public class PlatformInitializeCommand : IPlatformCommand
{
private Position maxPosition;
public PlatformInitializeCommand(Position maxPosition)
{
this.maxPosition = maxPosition;
}
public string Execute(Platform platform)
{
platform.Initialize(maxPosition);
return string.Empty;
}
}
public class NewRoverCommand : IPlatformCommand
{
private Position position;
private Heading heading;
public NewRoverCommand(Position position, Heading heading)
{
this.position = position;
this.heading = heading;
}
public string Execute(Platform platform)
{
new Rover(position, heading, platform);
return string.Empty;
}
}
public class RotateRoverCommand : IPlatformCommand
{
private Rotation rotation;
public RotateRoverCommand(Rotation rotation)
{
this.rotation = rotation;
}
public string Execute(Platform platform)
{
var rover = platform.GetRover();
rover.Turn(rotation);
return string.Empty;
}
}
public class MoveRoverCommand : IPlatformCommand
{
public string Execute(Platform platform)
{
var rover = platform.GetRover();
rover.Move();
return string.Empty;
}
}
public class PrintPositionAndHeadingRoverCommand : IPlatformCommand
{
public string Execute(Platform platform)
{
var rover = platform.GetRover();
return rover.PrintPositionAndHeading();
}
}
}
|
Python
|
UTF-8
| 576 | 4.53125 | 5 |
[] |
no_license
|
# dice_game.py
from random import randint
sides = input("Enter dice sides: ")
sides = int(sides)
player1 = input("Enter player 1 name: ")
player2 = input("Enter player 2 name: ")
player1_diceroll = randint(1, sides)
player2_diceroll = randint(1, sides)
print(player1 + " rolls " + str(player1_diceroll))
print(player2 + " rolls " + str(player2_diceroll))
if player1_diceroll == player2_diceroll:
print("Tie")
elif player1_diceroll > player2_diceroll:
print(player1 + " " + "wins!")
elif player1_diceroll < player2_diceroll:
print(player2 + " " + "wins!")
|
JavaScript
|
UTF-8
| 2,309 | 3.296875 | 3 |
[] |
no_license
|
// FORK this starter file and save it to your own Repl.it account.
// Declare and initialize the 12 variables here:
const input = require('readline-sync');
let numOfAstronauts = input.question("How many Astronauts are going on this mission? ");
let date = "Monday 2019-03-18";
let time = "10:05:34 AM";
// let astronautCount = 7; was used before attempting the bonus mission.
let astronautStatus = "ready";
let averageAstronautMassKg = 80.7;
let crewMassKg = numOfAstronauts * averageAstronautMassKg;
let fuelMassKg = 760000;
let shuttleMassKg = 74842.31;
let totalMassKg = crewMassKg + fuelMassKg + shuttleMassKg;
let fuelTempCelsius = -225;
let fuelLevel = 1; // dont make a string, make a 1 so we can use it in the future 1 * 100 is 100% EG 0.9 = 90%
let weatherStatus = "clear";
let lineBar = "-------------------------------------";
let takeOffStatus = "YES";
// Write code to generate the LC04 report here:
console.log(lineBar);
console.log("> LC04 - LAUNCH CHECKLIST");
console.log(lineBar);
console.log("Date: " + date);
console.log("Time: " + time);
console.log("\n");
console.log(lineBar);
console.log("> ASTRONAUT INFO");
console.log(lineBar);
console.log("* count: " + numOfAstronauts);
console.log("* status: " + astronautStatus);
console.log("\n");
console.log(lineBar);
console.log("> FUEL DATA");
console.log(lineBar);
console.log("* Fuel temp celsius: " + fuelTempCelsius +" C");
console.log("* Fuel level: " + (fuelLevel * 100) + "%");
console.log("\n");
console.log(lineBar);
console.log("> Mass DATA");
console.log(lineBar);
console.log("* Crew mass: " + crewMassKg + " kg")
console.log("* Fuel mass: " + fuelMassKg +" kg")
console.log("* Shuttle mass: " + shuttleMassKg +" kg")
console.log("* Total mass: " + totalMassKg +" kg")
console.log("\n");
console.log(lineBar);
console.log("> FLIGHT PLAN");
console.log(lineBar);
console.log("Weather: " + weatherStatus)
console.log("\n");
console.log(lineBar);
console.log("> OVERALL STATUS");
console.log(lineBar);
console.log("Clear for takeoff: " + takeOffStatus);
// instead of using "string (space) + variable. you can use just a comma "," which will add a space and append it.
// When done, have your TA check your code.
// BONUS: Use readline-sync to prompt the user to enter the number of astronauts going on the mission.
|
C++
|
UTF-8
| 4,452 | 2.9375 | 3 |
[
"MIT"
] |
permissive
|
#ifndef MD5_HPP
#define MD5_HPP
#include<iostream>
#include<string>
using namespace std;
#define shift(x, n) (((x) << (n)) | ((x) >> (32-(n))))//右移的时候,高位一定要补零,而不是补充符号位
#define F(x, y, z) (((x) & (y)) | ((~x) & (z)))
#define G(x, y, z) (((x) & (z)) | ((y) & (~z)))
#define H(x, y, z) ((x) ^ (y) ^ (z))
#define I(x, y, z) ((y) ^ ((x) | (~z)))
#define A 0x67452301
#define B 0xefcdab89
#define C 0x98badcfe
#define D 0x10325476
//strBaye的长度
unsigned int strlength;
//A,B,C,D的临时变量
unsigned int atemp;
unsigned int btemp;
unsigned int ctemp;
unsigned int dtemp;
//常量ti unsigned int(abs(sin(i+1))*(2pow32))
const unsigned int k[]={
0xd76aa478,0xe8c7b756,0x242070db,0xc1bdceee,
0xf57c0faf,0x4787c62a,0xa8304613,0xfd469501,0x698098d8,
0x8b44f7af,0xffff5bb1,0x895cd7be,0x6b901122,0xfd987193,
0xa679438e,0x49b40821,0xf61e2562,0xc040b340,0x265e5a51,
0xe9b6c7aa,0xd62f105d,0x02441453,0xd8a1e681,0xe7d3fbc8,
0x21e1cde6,0xc33707d6,0xf4d50d87,0x455a14ed,0xa9e3e905,
0xfcefa3f8,0x676f02d9,0x8d2a4c8a,0xfffa3942,0x8771f681,
0x6d9d6122,0xfde5380c,0xa4beea44,0x4bdecfa9,0xf6bb4b60,
0xbebfbc70,0x289b7ec6,0xeaa127fa,0xd4ef3085,0x04881d05,
0xd9d4d039,0xe6db99e5,0x1fa27cf8,0xc4ac5665,0xf4292244,
0x432aff97,0xab9423a7,0xfc93a039,0x655b59c3,0x8f0ccc92,
0xffeff47d,0x85845dd1,0x6fa87e4f,0xfe2ce6e0,0xa3014314,
0x4e0811a1,0xf7537e82,0xbd3af235,0x2ad7d2bb,0xeb86d391};
//向左位移数
const unsigned int s[]={
7,12,17,22,7,12,17,22,7,12,17,22,7,
12,17,22,5,9,14,20,5,9,14,20,5,9,14,20,5,9,14,20,
4,11,16,23,4,11,16,23,4,11,16,23,4,11,16,23,6,10,
15,21,6,10,15,21,6,10,15,21,6,10,15,21};
const char str16[]="0123456789abcdef";
void mainLoop(unsigned int M[])
{
unsigned int f,g;
unsigned int a=atemp;
unsigned int b=btemp;
unsigned int c=ctemp;
unsigned int d=dtemp;
for (unsigned int i = 0; i < 64; i++)
{
if(i<16){
f=F(b,c,d);
g=i;
}else if (i<32)
{
f=G(b,c,d);
g=(5*i+1)%16;
}else if(i<48){
f=H(b,c,d);
g=(3*i+5)%16;
}else{
f=I(b,c,d);
g=(7*i)%16;
}
unsigned int tmp=d;
d=c;
c=b;
b=b+shift((a+f+k[i]+M[g]),s[i]);
a=tmp;
}
atemp=a+atemp;
btemp=b+btemp;
ctemp=c+ctemp;
dtemp=d+dtemp;
}
/*
*填充函数
*处理后应满足bits≡448(mod512),字节就是bytes≡56(mode64)
*填充方式为先加一个1,其它位补零
*最后加上64位的原来长度
*/
unsigned int* add(string str)
{
unsigned int num=((str.length()+8)/64)+1;//以512位,64个字节为一组
unsigned int *strByte=new unsigned int[num*16]; //64/4=16,所以有16个整数
strlength=num*16;
for (unsigned int i = 0; i < num*16; i++)
strByte[i]=0;
for (unsigned int i=0; i <str.length(); i++)
{
strByte[i>>2]|=(str[i])<<((i%4)*8);//一个整数存储四个字节,i>>2表示i/4 一个unsigned int对应4个字节,保存4个字符信息
}
strByte[str.length()>>2]|=0x80<<(((str.length()%4))*8);//尾部添加1 一个unsigned int保存4个字符信息,所以用128左移
/*
*添加原长度,长度指位的长度,所以要乘8,然后是小端序,所以放在倒数第二个,这里长度只用了32位
*/
strByte[num*16-2]=str.length()*8;
return strByte;
}
string changeHex(int a)
{
int b;
string str1;
string str="";
for(int i=0;i<4;i++)
{
str1="";
b=((a>>i*8)%(1<<8))&0xff; //逆序处理每个字节
for (int j = 0; j < 2; j++)
{
str1.insert(0,1,str16[b%16]);
b=b/16;
}
str+=str1;
}
return str;
}
string getMD5(string source)
{
atemp=A; //初始化
btemp=B;
ctemp=C;
dtemp=D;
unsigned int *strByte=add(source);
for(unsigned int i=0;i<strlength/16;i++)
{
unsigned int num[16];
for(unsigned int j=0;j<16;j++)
num[j]=strByte[i*16+j];
mainLoop(num);
}
return changeHex(atemp).append(changeHex(btemp)).append(changeHex(ctemp)).append(changeHex(dtemp));
}
#endif // MD5_HPP
/*
int main()
{
string ss;
// cin>>ss;
string s=getMD5("admin");//21232f297a57a5a743894a0e4a801fc3
cout<<s;
return 0;
}
//*/
|
PHP
|
UTF-8
| 2,907 | 2.65625 | 3 |
[] |
no_license
|
<?php
$validqualification = true;
$validcourse = true;
$validlevel = true;
$validgrade = true;
$validgradeset = true;
$fullinput = true;
$setcourse = true;
$setlevel = true;
$setgrade = true;
include(dirname(__FILE__) . "/../core/connection.php");
if ( isset($_POST['course']) && isset($_POST['level']) && isset($_POST['grade']) ) {
$course = mysqli_real_escape_string($link, $_POST['course']);
$level = mysqli_real_escape_string($link, $_POST['level']);
$grade = mysqli_real_escape_string($link, $_POST['grade']);
$checkCourse = mysqli_stmt_init($link);
mysqli_stmt_prepare($checkCourse, "SELECT count(*) FROM courses WHERE Course = ?");
mysqli_stmt_bind_param($checkCourse, 's', $course);
mysqli_stmt_execute($checkCourse);
$result = mysqli_stmt_get_result($checkCourse);
$courseresult = $result -> fetch_row();
$checkLevel = mysqli_stmt_init($link);
mysqli_stmt_prepare($checkLevel, "SELECT count(*) FROM levels WHERE Level = ?");
mysqli_stmt_bind_param($checkLevel, 's', $level);
mysqli_stmt_execute($checkLevel);
$result = mysqli_stmt_get_result($checkLevel);
$levelresult = $result -> fetch_row();
$checkGrade = mysqli_stmt_init($link);
mysqli_stmt_prepare($checkGrade, "SELECT count(*) FROM grades WHERE Grade = ?");
mysqli_stmt_bind_param($checkGrade, 's', $grade);
mysqli_stmt_execute($checkGrade);
$result = mysqli_stmt_get_result($checkGrade);
$graderesult = $result -> fetch_row();
$checkGrade = mysqli_stmt_init($link);
mysqli_stmt_prepare($checkGrade, "SELECT count(*) FROM grades INNER JOIN levels ON grades.GradeSetID = levels.GradeSet
WHERE levels.Level = ? and grades.Grade = ?");
mysqli_stmt_bind_param($checkGrade, 'ss', $level, $grade);
mysqli_stmt_execute($checkGrade);
$result = mysqli_stmt_get_result($checkGrade);
$gradesetresult = $result -> fetch_row();
if ($courseresult[0] == 0){
$validcourse = false;
$validqualification = false;
}
if ($levelresult[0] == 0){
$validlevel = false;
$validqualification = false;
}
if ($graderesult[0] == 0){
$validgrade = false;
$validqualification = false;
}
if ($gradesetresult[0] == 0){
$validgradeset = false;
$validqualification = false;
}
echo json_encode(array("completeinput"=>$fullinput, "qualificationvalid"=>$validqualification, "coursevalid"=>$validcourse, "levelvalid"=>$validlevel,
"gradevalid"=>$validgrade, "gradesetvalid"=>$validgradeset));
}
else
{
if (!isset($_POST['course'])){
$setcourse = false;
$validqualification = false;
}
if (!isset($_POST['level'])){
$setlevel = false;
$validqualification = false;
}
if (!isset($_POST['grade'])){
$setgrade = false;
$validqualification = false;
}
$fullinput= false;
echo json_encode(array("completeinput"=>$fullinput, "qualificationvalid"=>$validqualification, "courseSet"=>$setcourse, "levelSet"=>$setlevel,
"gradeSet"=>$setgrade));
}
mysqli_close($link);
?>
|
Markdown
|
UTF-8
| 793 | 2.546875 | 3 |
[] |
no_license
|
EQ Works Coding Challange
### Prerequisites
You'll need to have git and node installed in your system.
### Build and Run the project
Please note that you will need to set environment variables before running the nodejs server
Follow these steps as following:
1. Create .env file in server folder.
2. Copy all environment variables in this file and save it.
Note that these environment variables are same as provided in the challange.
As per the requirements, I am not adding them in this repository.
I have provided the contents of .env file in the email. If you do not have it, please feel free to contact me.
* Run development server:
```
cd server
npm install
npm run dev
```
* Run development client:
```
npm install
npm start
```
Open the web browser to http://localhost:3000//
|
C++
|
UTF-8
| 5,499 | 3.1875 | 3 |
[] |
no_license
|
#include <algorithm>
#include <iostream>
#include <iterator>
#include <set>
#include <tuple>
#include <unordered_map>
#include <vector>
using namespace std;
// 58. Length of Last Word
class Solution {
public:
int lengthOfLastWord(string s) {
istringstream iss(s);
vector<string> tokens;
copy(istream_iterator<string>(iss), istream_iterator<string>(),
back_inserter(tokens));
if (tokens.empty()) return 0;
return rbegin(tokens)->size();
}
};
// 13. Roman to Integer
class Solution {
public:
int romanToInt(string s) {
unordered_map<char, int> code_map = {{'I', 1}, {'V', 5}, {'X', 10},
{'L', 50}, {'C', 100}, {'D', 500},
{'M', 1000}};
int result = code_map[s[s.size() - 1]];
for (int i = s.size() - 2; i >= 0; --i) {
if (code_map[s[i]] >= code_map[s[i + 1]]) {
result += code_map[s[i]];
} else {
result -= code_map[s[i]];
}
}
return result;
}
};
// 97. Interleaving String
class Solution {
public:
bool isInterleave(string s1, string s2, string s3) {
int m = s1.size();
int n = s2.size();
int l = s3.size();
if (m + n != l) return false;
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
dp[0][0] = true; // initialization
for (int i = 1; i <= m; i++)
dp[i][0] = dp[i - 1][0] && s1[i - 1] == s3[i - 1]; // s2 = empty; s1 = s3
for (int j = 1; j <= n; j++)
dp[0][j] =
dp[0][j - 1] && s2[j - 1] == s3[j - 1]; // s1 = empty; s2 = s3;
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// any way from s1 and s2; if they are true -> get next
dp[i][j] = (dp[i - 1][j] && s3[i + j - 1] == s1[i - 1]) ||
(dp[i][j - 1] && s3[i + j - 1] == s2[j - 1]);
}
}
return dp[m][n];
}
};
// 97. Interleaving String
// path compressed
class Solution {
public:
bool isInterleave(string s1, string s2, string s3) {
int m = s1.size();
int n = s2.size();
int l = s3.size();
if (m + n != l) return false;
if (m < n) return isInterleave(s2, s1, s3);
vector<bool> dp(n + 1, false);
dp[0] = true; // initialization
for (int j = 1; j <= n; j++)
dp[j] = dp[j - 1] && s2[j - 1] == s3[j - 1]; // s1 = empty; s2 = s3;
int i, j;
for (int i = 1; i <= m; i++) {
dp[0] = dp[0] && s1[i - 1] == s3[i - 1];
for (int j = 1; j <= n; j++) {
// any way from s1 and s2; if they are true -> get next
dp[j] = (dp[j - 1] && s3[i + j - 1] == s2[j - 1]) ||
(dp[j] && s3[i + j - 1] == s1[i - 1]);
}
}
return dp[n];
}
};
// 14. Longest Common Prefix
// do not use the range based for
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
int idx = 0;
if (strs.empty()) return "";
while (idx < strs[0].size()) {
for (int i = 1; i < strs.size(); i++) {
if (idx < strs[i].size() && strs[0][idx] == strs[i][idx]) {
continue;
} else {
return strs[0].substr(0, idx);
}
}
idx++;
}
return strs[0].substr(0, idx);
}
};
// 49. Group Anagrams
// use dictionary store the keys of the group
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> res;
unordered_map<string, vector<string>> str_map;
for (string s : strs) {
string t = s;
sort(t.begin(), t.end());
if (str_map.count(t) == 0)
str_map.insert({t, vector<string>(1, s)});
else
str_map[t].push_back(s);
}
for (auto p : str_map) {
res.push_back(p.second);
}
return res;
}
};
// 38. Count and Say
// pay attention to the while if loop, don't forget increment
class Solution {
public:
string countAndSay(int n) {
string temp = "1";
string next;
for (int i = 1; i < n; i++) {
string next;
for (int j = 0; j < temp.size(); j++) {
int counter = 1;
while (j + 1 < temp.size() && temp[j] == temp[j + 1]) {
counter++;
j++;
}
next += to_string(counter);
next.push_back(temp[j]);
}
temp = next;
}
return temp;
}
};
// 67. Add Binary
// swap to make the code concise
// add result
class Solution {
public:
string addBinary(string a, string b) {
// swap a and b
if (a.size() > b.size()) return addBinary(b, a);
reverse(a.begin(), a.end());
reverse(b.begin(), b.end());
a += string(b.size() - a.size(), '0');
string ans;
// add bit by bit
int c_0 = 0;
int i;
for (int i = 0; i < a.size() && i < b.size(); i++) {
int a_0 = a[i] - '0', b_0 = b[i] - '0';
int bit = c_0 + a_0 + b_0;
c_0 = bit >= 2 ? 1 : 0;
bit = bit >= 2 ? bit - 2 : bit;
ans.push_back((bit + '0'));
}
if (c_0 == 1) ans.push_back('1');
reverse(ans.begin(), ans.end());
return ans;
}
};
//22. Generate Parentheses
//use dfs and number of ) and ( as backtracking
class Solution {
public:
vector<string> generateParenthesis(int n) {
vector<string> res;
addParaenthesis(res, "", n, 0);
return res;
}
void addParaenthesis(vector<string> res, string s, int l, int r) {
if (l == 0 && r == 0) {
res.push_back(s);
}
if (l > 0) addParaenthesis(res, s + "(", l - 1, r + 1);
if (r > 0) addParaenthesis(res, s + ")", l - 1, r - 1);
}
};
|
Markdown
|
UTF-8
| 25,798 | 2.71875 | 3 |
[
"Apache-2.0"
] |
permissive
|
# Textured Cube Tutorial
| <pre><b>Windows (DirectX 12) </pre></b> | <pre><b>Linux (Vulkan) </pre></b> | <pre><b>MacOS (Metal) </pre></b> | <pre><b>iOS (Metal)</pre></b> |
|-----------------------------------------------------------------------|------------------------------------------------------------------|-----------------------------------------------------------------|---------------------------------------------------------------|
|  |  |  |  |
This tutorial demonstrates textured cube rendering using Methane Kit:
- [TexturedCubeApp.h](TexturedCubeApp.h)
- [TexturedCubeApp.cpp](TexturedCubeApp.cpp)
- [Shaders/TexturedCubeUniforms.h](Shaders/TexturedCubeUniforms.h)
- [Shaders/TexturedCube.hlsl](Shaders/TexturedCube.hlsl)
Tutorial demonstrates the following Methane Kit features additionally to demonstrated in [Hello Cube](../02-HelloCube):
- Use base user interface application for graphics UI overlay rendering
- Create 2D textures with data loaded data from images and creating samplers
- Bind buffers and textures to program arguments and configure argument access modifiers
- SRGB gamma-correction support in textures loader and color transformation in pixel shaders
## Application Controls
Common keyboard controls are enabled by the `Platform`, `Graphics` and `UserInterface` application controllers:
- [Methane::Platform::AppController](/Modules/Platform/App/README.md#platform-application-controller)
- [Methane::Graphics::AppController, AppContextController](/Modules/Graphics/App/README.md#graphics-application-controllers)
- [Methane::UserInterface::AppController](/Modules/UserInterface/App/README.md#user-interface-application-controllers)
## Application and Frame Class Definitions
Let's start from the application header file [TexturedCubeApp.h](TexturedCubeApp.h) which declares
application class `TexturedCubeApp` derived from the base class `UserInterface::App<TexturedCubeFrame>`
and frame class `TexturedCubeFrame` derived from the base class `Graphics::AppFrame`
similar to how it was done in [HelloCube](../02-HelloCube) tutorial.
The difference here is the [UserInterface::App](../../Modules/UserInterface/App) base class used instead of
[Graphics::App](../../Modules/Graphics/App) class for visualization of optional UI elements and rendering it in screen overlay.
```cpp
#pragma once
#include <Methane/Kit.h>
#include <Methane/UserInterface/App.hpp>
namespace Methane::Tutorials
{
...
namespace gfx = Methane::Graphics;
namespace rhi = Methane::Graphics::Rhi;
struct TexturedCubeFrame final : gfx::AppFrame
{
// Volatile frame-dependent resources for rendering to dedicated frame-buffer in swap-chain
...
using gfx::AppFrame::AppFrame;
};
using UserInterfaceApp = UserInterface::App<TexturedCubeFrame>;
class TexturedCubeApp final : public UserInterfaceApp
{
public:
TexturedCubeApp();
~TexturedCubeApp() override;
// GraphicsApp overrides
void Init() override;
bool Resize(const gfx::FrameSize& frame_size, bool is_minimized) override;
bool Update() override;
bool Render() override;
protected:
// IContextCallback override
void OnContextReleased(rhi::IContext& context) override;
private:
bool Animate(double elapsed_seconds, double delta_seconds);
// Global state members, rendering primitives and graphics resources
...
};
} // namespace Methane::Tutorials
```
Methane Kit is designed to use [deferred rendering approach](https://docs.microsoft.com/en-us/windows/win32/direct3d11/overviews-direct3d-11-render-multi-thread-render)
with triple buffering for minimized waiting of frame-buffer release in swap-chain.
In order to prepare graphics resource states ahead of next frames rendering, `TexturedCubeFrame` structure keeps
volatile frame dependent resources used for rendering to dedicated frame-buffer. It includes uniforms buffer and
program bindings objects as well as render command list for render commands encoding
and a set of command lists submitted for execution on GPU via command queue.
```cpp
struct TexturedCubeFrame final : Graphics::AppFrame
{
rhi::Buffer uniforms_buffer;
rhi::ProgramBindings program_bindings;
rhi::RenderCommandList render_cmd_list;
rhi::CommandListSet execute_cmd_list_set;
using gfx::AppFrame::AppFrame;
};
```
[Shaders/TexturedCubeUniforms.h](Shaders/TexturedCubeUniforms.h) header contains declaration of `Constants` and `Uniforms`
structures with data saved in constants buffer `m_const_buffer` field of `TexturedCubeApp` class below and uniforms buffer
`uniforms_buffer` field of `TexturedCubeFrame` structure above.
Structures from this header are reused in [HLSL shader code](#textured-cube-shaders) and 16-byte packing in C++ is used
gor common memory layout in HLSL and C++.
Uniform structures in [Shaders/TexturedCubeUniforms.h](Shaders/TexturedCubeUniforms.h):
```hlsl
struct Constants
{
float4 light_color;
float light_power;
float light_ambient_factor;
float light_specular_factor;
};
struct Uniforms
{
float3 eye_position;
float3 light_position;
float4x4 mvp_matrix;
float4x4 model_matrix;
};
```
```cpp
namespace hlslpp
{
#pragma pack(push, 16)
#include "Shaders/TexturedCubeUniforms.h"
#pragma pack(pop)
}
class TexturedCubeApp final : public UserInterfaceApp
{
...
private:
const float m_cube_scale = 15.F;
const hlslpp::Constants m_shader_constants{
{ 1.F, 1.F, 0.74F, 1.F }, // - light_color
700.F, // - light_power
0.04F, // - light_ambient_factor
30.F // - light_specular_factor
};
hlslpp::Uniforms m_shader_uniforms { };
gfx::Camera m_camera;
rhi::RenderState m_render_state;
rhi::BufferSet m_vertex_buffer_set;
rhi::Buffer m_index_buffer;
rhi::Buffer m_const_buffer;
rhi::Texture m_cube_texture;
rhi::Sampler m_texture_sampler;
const gfx::SubResources m_shader_uniforms_subresources{
{ reinterpret_cast<Data::ConstRawPtr>(&m_shader_uniforms), sizeof(hlslpp::Uniforms) }
};
};
```
## Application Construction and Initialization
Application is created with constructor defined in [TexturedCubeApp.cpp](TexturedCubeApp.cpp).
Graphics application settings are generated by utility function `GetGraphicsTutorialAppSettings(...)`
defined in [Methane/Tutorials/AppSettings.hpp](../../Common/Include/Methane/Tutorials/AppSettings.hpp).
Camera orientation is reset to the default state. Camera and light rotating animation is added to the animation pool bound to
`TexturedCubeApp::Animate` function described below.
```cpp
TexturedCubeApp::TexturedCubeApp()
: UserInterfaceApp(
GetGraphicsTutorialAppSettings("Methane Textured Cube", AppOptions::GetDefaultWithColorOnlyAndAnim()),
GetUserInterfaceTutorialAppSettings(AppOptions::GetDefaultWithColorOnlyAndAnim()),
"Methane tutorial of textured cube rendering")
{
m_shader_uniforms.light_position = hlslpp::float3(0.F, 20.F, -25.F);
m_camera.ResetOrientation({ { 13.0F, 13.0F, -13.0F }, { 0.0F, 0.0F, 0.0F }, { 0.0F, 1.0F, 0.0F } });
m_shader_uniforms.model_matrix = hlslpp::float4x4::scale(m_cube_scale);
// Setup animations
GetAnimations().emplace_back(std::make_shared<Data::TimeAnimation>(std::bind(&TexturedCubeApp::Animate, this, std::placeholders::_1, std::placeholders::_2)));
}
```
## Graphics Resources Initialization
Cube vertex structure is defined with fields for position, normal and texture coordinates, as well auxiliary
layout description used for automatic mesh vertex data generation.
```cpp
struct CubeVertex
{
gfx::Mesh::Position position;
gfx::Mesh::Normal normal;
gfx::Mesh::TexCoord texcoord;
inline static const gfx::Mesh::VertexLayout layout{
gfx::Mesh::VertexField::Position,
gfx::Mesh::VertexField::Normal,
gfx::Mesh::VertexField::TexCoord,
};
};
```
Initialization of the `UserInterface::App` resources is done with base class `UserInterface::Init()` method.
Initial camera projection size is set with `m_camera.Resize(...)` call by passing frame size from the context settings,
initialized in the base class `Graphics::App::InitContext(...)`.
Vertices and indices data of the cube mesh are generated with `Graphics::CubeMesh<CubeVertex>` template class defined
using vertex structure with layout description defined above. Vertex and index buffers are created with
`GetRenderContext().CreateBuffer(...)` factory method using `rhi::BufferSettings::ForVertexBuffer(...)` and
`rhi::BufferSettings::ForIndexBuffer(...)` settings. Generated data is copied to buffers with `Rhi::Buffer::SetData(...)` call,
which is taking a sub-resource derived from `Data::Chunk` class describing continuous memory range and holding its data.
Similarly, constants buffer is created with `GetRenderContext().CreateBuffer(rhi::BufferSettings::ForConstantBuffer(...))`
and filled with data from member variable `m_shader_constants`.
```cpp
void TexturedCubeApp::Init()
{
UserInterfaceApp::Init();
const rhi::CommandQueue render_cmd_queue = GetRenderContext().GetRenderCommandKit().GetQueue();
m_camera.Resize(GetRenderContext().GetSettings().frame_size);
// Create vertex buffer for cube mesh
const gfx::CubeMesh<CubeVertex> cube_mesh(CubeVertex::layout);
const Data::Size vertex_data_size = cube_mesh.GetVertexDataSize();
const Data::Size vertex_size = cube_mesh.GetVertexSize();
rhi::Buffer vertex_buffer = GetRenderContext().CreateBuffer(rhi::BufferSettings::ForVertexBuffer(vertex_data_size, vertex_size));
vertex_buffer.SetData(render_cmd_queue, {
reinterpret_cast<Data::ConstRawPtr>(cube_mesh.GetVertices().data()),
vertex_data_size
});
m_vertex_buffer_set = rhi::BufferSet(rhi::BufferType::Vertex, { vertex_buffer });
// Create index buffer for cube mesh
const Data::Size index_data_size = cube_mesh.GetIndexDataSize();
const gfx::PixelFormat index_format = gfx::GetIndexFormat(cube_mesh.GetIndex(0));
m_index_buffer = GetRenderContext().CreateBuffer(rhi::BufferSettings::ForIndexBuffer(index_data_size, index_format));
m_index_buffer.SetData(render_cmd_queue, {
reinterpret_cast<Data::ConstRawPtr>(cube_mesh.GetIndices().data()),
index_data_size
});
// Create constants buffer for frame rendering
const auto constants_data_size = static_cast<Data::Size>(sizeof(m_shader_constants));
m_const_buffer = GetRenderContext().CreateBuffer(rhi::BufferSettings::ForConstantBuffer(constants_data_size));
m_const_buffer.SetData(render_cmd_queue, {
reinterpret_cast<Data::ConstRawPtr>(&m_shader_constants),
constants_data_size
});
...
}
```
Cube face texture is created using `Graphics::ImageLoader` class available via `Graphics::App::GetImageLoader()` function.
Texture is loaded from JPEG image embedded in application resources by path in embedded file system `MethaneBubbles.jpg`.
Image is added to application resources in build time and [configured in CMakeLists.txt](#cmake-build-configuration).
`Graphics::ImageOptionMask` is passed to image loader function to request mipmaps generation and use SRGB color format.
`Rhi::Sampler` object is created with `GetRenderContext().CreateSampler(...)` function which defines
parameters of texture sampling from shader.
```cpp
void TexturedCubeApp::Init()
{
...
// Load texture image from file
constexpr gfx::ImageOptionMask image_options({ gfx::ImageOption::Mipmapped, gfx::ImageOption::SrgbColorSpace });
m_cube_texture = GetImageLoader().LoadImageToTexture2D(render_cmd_queue, "MethaneBubbles.jpg", image_options, "Cube Face Texture");
// Create sampler for image texture
m_texture_sampler = GetRenderContext().CreateSampler(
rhi::Sampler::Settings
{
rhi::Sampler::Filter { rhi::Sampler::Filter::MinMag::Linear },
rhi::Sampler::Address { rhi::Sampler::Address::Mode::ClampToEdge }
}
);
...
}
```
`Rhi::Program` object is created in `Rhi::Program::Settings` structure using `GetRenderContext().CreateProgram(...)` factory method.
Vertex and Pixel shaders are created and loaded from embedded resources as pre-compiled byte-code.
Program settings also include additional description `Rhi::ProgramArgumentAccessors` of program arguments bound to graphics resources.
Argument description defines specific access modifiers for program arguments used in `Rhi::ProgramBindings` object.
Also, it is important to note that render state settings enables depth testing for correct rendering of cube faces.
Finally, render state is created using settings structure via `GetRenderContext().CreateRenderState(...)` factory method.
```cpp
void TexturedCubeApp::Init()
{
...
// Create render state with program
m_render_state = GetRenderContext().CreateRenderState(
rhi::RenderState::Settings
{
GetRenderContext().CreateProgram(
rhi::Program::Settings
{
rhi::Program::ShaderSet
{
{ rhi::ShaderType::Vertex, { Data::ShaderProvider::Get(), { "TexturedCube", "CubeVS" } } },
{ rhi::ShaderType::Pixel, { Data::ShaderProvider::Get(), { "TexturedCube", "CubePS" } } },
},
rhi::ProgramInputBufferLayouts
{
rhi::Program::InputBufferLayout
{
rhi::Program::InputBufferLayout::ArgumentSemantics { cube_mesh.GetVertexLayout().GetSemantics() }
}
},
rhi::ProgramArgumentAccessors
{
{ { rhi::ShaderType::All, "g_uniforms" }, rhi::ProgramArgumentAccessor::Type::FrameConstant },
{ { rhi::ShaderType::Pixel, "g_constants" }, rhi::ProgramArgumentAccessor::Type::Constant },
{ { rhi::ShaderType::Pixel, "g_texture" }, rhi::ProgramArgumentAccessor::Type::Constant },
{ { rhi::ShaderType::Pixel, "g_sampler" }, rhi::ProgramArgumentAccessor::Type::Constant },
},
GetScreenRenderPattern().GetAttachmentFormats()
}
),
GetScreenRenderPattern()
}
);
...
}
```
Final part of initialization is related to frame-dependent resources, creating independent resource objects for each frame in swap-chain:
- Create uniforms buffer with `GetRenderContext().CreateBuffer(rhi::BufferSettings::ForConstantBuffer(...))` method.
- Create program arguments to resources bindings with `m_render_state.GetProgram().CreateBindings(..)` function.
- Create rendering command list with `render_cmd_queue.CreateRenderCommandList(...)` and
create set of command lists with `rhi::CommandListSet(...)` for execution in command queue.
Finally at the end of `Init()` function `App::CompleteInitialization()` is called to complete graphics
resources initialization to prepare for rendering. It uploads graphics resources to GPU and initializes shader bindings on GPU.
```cpp
void TexturedCubeApp::Init()
{
...
// Create frame buffer resources
const auto uniforms_data_size = static_cast<Data::Size>(sizeof(m_shader_uniforms));
for(TexturedCubeFrame& frame : GetFrames())
{
// Create uniforms buffer with volatile parameters for frame rendering
frame.uniforms_buffer = GetRenderContext().CreateBuffer(rhi::BufferSettings::ForConstantBuffer(uniforms_data_size, false, true));
// Configure program resource bindings
frame.program_bindings = m_render_state.GetProgram().CreateBindings({
{ { rhi::ShaderType::All, "g_uniforms" }, { { frame.uniforms_buffer.GetInterface() } } },
{ { rhi::ShaderType::Pixel, "g_constants" }, { { m_const_buffer.GetInterface() } } },
{ { rhi::ShaderType::Pixel, "g_texture" }, { { m_cube_texture.GetInterface() } } },
{ { rhi::ShaderType::Pixel, "g_sampler" }, { { m_texture_sampler.GetInterface() } } },
}, frame.index);
// Create command list for rendering
frame.render_cmd_list = render_cmd_queue.CreateRenderCommandList(frame.screen_pass);
frame.execute_cmd_list_set = rhi::CommandListSet({ frame.render_cmd_list.GetInterface() }, frame.index);
}
UserInterfaceApp::CompleteInitialization();
}
```
`TexturedCubeApp::OnContextReleased` callback method releases all graphics resources before graphics context is released,
which is necessary when graphics device is switched via [Graphics::AppContextController](../../Modules/Graphics/App/README.md#graphicsappcontextcontrollerincludemethanegraphicsappcontextcontrollerh)
with `LCtrl + X` shortcut.
```cpp
void TexturedCubeApp::OnContextReleased(gfx::Context& context)
{
m_texture_sampler = {};
m_cube_texture = {};
m_const_buffer = {};
m_index_buffer = {};
m_vertex_buffer_set = {};
m_render_state = {};
UserInterfaceApp::OnContextReleased(context);
}
```
## Frame Rendering Cycle
Animation function bound to time-animation is called automatically as a part of every render cycle, just before `App::Update` function call.
This function rotates light position and camera in opposite directions.
```cpp
bool TexturedCubeApp::Animate(double, double delta_seconds)
{
const float rotation_angle_rad = static_cast<float>(delta_seconds * 360.F / 4.F) * gfx::ConstFloat::RadPerDeg;
hlslpp::float3x3 light_rotate_matrix = hlslpp::float3x3::rotation_axis(m_camera.GetOrientation().up, rotation_angle_rad);
m_shader_uniforms.light_position = hlslpp::mul(m_shader_uniforms.light_position, light_rotate_matrix);
m_camera.Rotate(m_camera.GetOrientation().up, static_cast<float>(delta_seconds * 360.F / 8.F));
return true;
}
```
`TexturedCubeApp::Update()` function is called before `App::Render()` call to update shader uniforms with model-view-project (MVP)
matrices and eye position based on current camera orientation, updated in animation.
```cpp
bool TexturedCubeApp::Update()
{
if (!UserInterfaceApp::Update())
return false;
// Update Model, View, Projection matrices based on camera location
m_shader_uniforms.mvp_matrix = hlslpp::transpose(hlslpp::mul(m_shader_uniforms.model_matrix, m_camera.GetViewProjMatrix()));
m_shader_uniforms.eye_position = m_camera.GetOrientation().eye;
return true;
}
```
`TexturedCubeApp::Render()` method is called after all. Initial base method `UserInterfaceApp::Render()` call waits for
previously current frame buffer presenting is completed. When frame buffer is free, new frame rendering can be started:
1. Uniforms buffer is filled with new shader uniforms data updated in calls above.
2. Render command list encoding starts with `IRenderCommandList::Reset(...)` call taking render state object and optional debug group,
which is defining named region in commands sequence.
1. View state is set with viewports and scissor rects
2. Program bindings are set
3. Vertex buffers set is set
4. Indexed draw call is issued
3. `UserInterface::App::RenderOverlay(...)` is called to record UI drawing command in render command list.
4. Render command list is committed and passed to `Graphics::ICommandQueue::Execute` call for execution on GPU.
5. `RenderContext::Present()` is called to schedule frame buffer presenting to screen.
```cpp
bool TexturedCubeApp::Render()
{
if (!UserInterfaceApp::Render())
return false;
// Update uniforms buffer related to current frame
const TexturedCubeFrame& frame = GetCurrentFrame();
const rhi::CommandQueue& render_cmd_queue = GetRenderContext().GetRenderCommandKit().GetQueue();
frame.uniforms_buffer.SetData(render_cmd_queue, m_shader_uniforms_subresources);
// Issue commands for cube rendering
META_DEBUG_GROUP_VAR(s_debug_group, "Cube Rendering");
frame.render_cmd_list.ResetWithState(m_render_state, &s_debug_group);
frame.render_cmd_list.SetViewState(GetViewState());
frame.render_cmd_list.SetProgramBindings(frame.program_bindings);
frame.render_cmd_list.SetVertexBuffers(m_vertex_buffer_set);
frame.render_cmd_list.SetIndexBuffer(m_index_buffer);
frame.render_cmd_list.DrawIndexed(rhi::RenderPrimitive::Triangle);
RenderOverlay(frame.render_cmd_list);
// Execute command list on render queue and present frame to screen
frame.render_cmd_list.Commit();
render_cmd_queue.Execute(frame.execute_cmd_list_set);
GetRenderContext().Present();
return true;
}
```
Graphics render loop is started from `main(...)` entry function using `GraphicsApp::Run(...)` method which is also parsing command line arguments.
```cpp
int main(int argc, const char* argv[])
{
return TexturedCubeApp().Run({ argc, argv });
}
```
## Textured Cube Shaders
HLSL 6 shaders [Shaders/Cube.hlsl](Shaders/Cube.hlsl) implement Phong shading with texturing.
SRGB gamma-correction is implemented with `ColorLinearToSrgb(...)` function from [Common/Shaders/Primitives.hlsl](../Common/Shaders/Primitives.hlsl)
which is converting final color from linear-space to SRGB color-space.
```cpp
#include "TexturedCubeUniforms.h"
#include "..\..\..\Common\Shaders\Primitives.hlsl"
struct VSInput
{
float3 position : POSITION;
float3 normal : NORMAL;
float2 texcoord : TEXCOORD;
};
struct PSInput
{
float4 position : SV_POSITION;
float3 world_position : POSITION;
float3 world_normal : NORMAL;
float2 texcoord : TEXCOORD;
};
ConstantBuffer<Constants> g_constants : register(b0);
ConstantBuffer<Uniforms> g_uniforms : register(b1);
Texture2D g_texture : register(t0);
SamplerState g_sampler : register(s0);
PSInput CubeVS(VSInput input)
{
const float4 position = float4(input.position, 1.F);
PSInput output;
output.position = mul(position, g_uniforms.mvp_matrix);
output.world_position = mul(position, g_uniforms.model_matrix).xyz;
output.world_normal = normalize(mul(float4(input.normal, 0.F), g_uniforms.model_matrix).xyz);
output.texcoord = input.texcoord;
return output;
}
float4 CubePS(PSInput input) : SV_TARGET
{
const float3 fragment_to_light = normalize(g_uniforms.light_position - input.world_position);
const float3 fragment_to_eye = normalize(g_uniforms.eye_position.xyz - input.world_position);
const float3 light_reflected_from_fragment = reflect(-fragment_to_light, input.world_normal);
const float4 texel_color = g_texture.Sample(g_sampler, input.texcoord);
const float4 ambient_color = texel_color * g_constants.light_ambient_factor;
const float4 base_color = texel_color * g_constants.light_color * g_constants.light_power;
const float distance = length(g_uniforms.light_position - input.world_position);
const float diffuse_part = clamp(dot(fragment_to_light, input.world_normal), 0.0, 1.0);
const float4 diffuse_color = base_color * diffuse_part / (distance * distance);
const float specular_part = pow(clamp(dot(fragment_to_eye, light_reflected_from_fragment), 0.0, 1.0), g_constants.light_specular_factor);
const float4 specular_color = base_color * specular_part / (distance * distance);;
return ColorLinearToSrgb(ambient_color + diffuse_color + specular_color);
}
```
## CMake Build Configuration
CMake build configuration [CMakeLists.txt](CMakeLists.txt) of the application
is powered by the included Methane CMake modules:
- [MethaneApplications.cmake](../../CMake/MethaneApplications.cmake) - defines function `add_methane_application`
- [MethaneShaders.cmake](../../CMake/MethaneShaders.cmake) - defines function `add_methane_shaders`
- [MethaneResources.cmake](../../CMake/MethaneResources.cmake) - defines functions `add_methane_embedded_textures` and `add_methane_copy_textures`
Shaders are compiled in build time and added as byte code to the application embedded resources.
Texture images are added to the application embedded resources too.
```cmake
include(MethaneApplications)
include(MethaneShaders)
include(MethaneResources)
add_methane_application(
TARGET MethaneTexturedCube
NAME "Methane Textured Cube"
DESCRIPTION "Tutorial demonstrating textured rotating cube rendering with Methane Kit."
INSTALL_DIR "Apps"
SOURCES
TexturedCubeApp.h
TexturedCubeApp.cpp
Shaders/TexturedCubeUniforms.h
)
set(TEXTURES_DIR ${RESOURCES_DIR}/Textures)
set(TEXTURES ${TEXTURES_DIR}/MethaneBubbles.jpg)
add_methane_embedded_textures(MethaneTexturedCube "${TEXTURES_DIR}" "${TEXTURES}")
add_methane_shaders_source(
TARGET MethaneTexturedCube
SOURCE Shaders/TexturedCube.hlsl
VERSION 6_0
TYPES
frag=CubePS
vert=CubeVS
)
add_methane_shaders_library(MethaneTexturedCube)
target_link_libraries(MethaneTexturedCube
PRIVATE
MethaneAppsCommon
)
```
## Continue learning
Continue learning Methane Graphics programming in the next tutorial [Shadow Cube](../04-ShadowCube),
which is demonstrating multi-pass rendering for drawing simple shadows.
|
Ruby
|
UTF-8
| 296 | 3.390625 | 3 |
[] |
no_license
|
class Phrase
attr_reader :sentence
def initialize(sentence)
@sentence = sentence
end
def word_count
results = Hash.new(0)
words.each { |word| results[word] += 1 }
results
end
private
def words
sentence.gsub(/[\W_]+/, ' ').downcase.split(/[\s,]+/)
end
end
|
Markdown
|
UTF-8
| 1,059 | 2.6875 | 3 |
[] |
no_license
|
# Article 27
Les personnes titulaires d'un diplôme de docteur en médecine bénéficient, à compter du 31 décembre 2004, d'une dispense totale d'enseignement théorique, sous réserve de suivre, dans la limite des places disponibles, dans un institut de formation en soins infirmiers de leur choix, un enseignement de deux semaines portant sur la démarche de soins et d'effectuer un stage à temps complet de soins infirmiers d'une durée de deux mois. Les modalités du stage sont fixées, après avis du conseil technique, par le directeur de l'institut de formation en soins infirmiers choisi par le candidat.
Pour être autorisé à se présenter aux épreuves prévues aux articles 13 et 14 ci-dessus, le candidat doit avoir obtenu une note de stage au moins égale à 10 sur 20. Cette note est étayée d'une appréciation précise et motivée. La personne responsable du stage communique celle-ci au candidat au cours d'un entretien. Si la moyenne n'est pas obtenue, le candidat est autorisé à recommencer une seule fois le stage de deux mois.
|
JavaScript
|
UTF-8
| 188 | 3.125 | 3 |
[] |
no_license
|
const removeElements = function (head, val) {
if (head == null)
return head;
head.next = removeElements(head.next, val);
return head.val === val ? head.next : head;
};
|
PHP
|
UTF-8
| 5,560 | 3.359375 | 3 |
[] |
no_license
|
<?php
/**
* Class PDO MySQL for manipulate SQL
* SELECT, INSERT, UPDATE, DELETE
*/
class MysqlAdapter {
public $db;
public $id;
public $bind;
/**
* default array fetch mode
*/
protected $_fetchMode = PDO::FETCH_ASSOC;
/**
* constructor connect pdo mysql
*
* @param string $host
* @param string $user
* @param string $password
* @param string $database
*/
public function __construct($host, $user, $password, $database) {
try {
$this->db = new PDO('mysql:host=' . $host . ';dbname=' . $database, $user, $password);
$this->db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
} catch (PDOException $e) {
print 'Kesalahan : ' . $e->getMessage() . '<br/>';
die();
}
}
/**
* get table
*
*/
public function getDb() {
return $this->db;
}
public function getBind() {
return $this->bind;
}
public function clearBind() {
unset($this->bind);
}
/**
* set bind param
*
* @param string $quote
* @param mixed $value
* @return string
*/
public function quote($query, $value, $key = 'col') {
$ph = ':' . $key;
$query = str_replace('?', $ph, $query);
$this->bind[$key] = $value;
return $query;
}
/**
* query execute sql
*
* @param string $sql
* @param array $bind
* @return object
*/
public function query($sql, $bind = array()) {
if ($sql instanceof Mysql_Select) {
if (empty($bind))
$bind = $sql->getBind();
$sql = $sql->getSql();
}
else {
if (empty($bind))
$bind = $this->bind;
}
if (!is_array($bind))
$bind = array($bind);
$stmt = $this->db->prepare($sql);
$stmt->execute($bind);
$stmt->setFetchMode($this->_fetchMode);
$this->clearBind();
return $stmt;
}
/**
* insert data
*
* @param string $table
* @param array $row
* @return int
*/
public function insert($table, $bind) {
$vals = array();
foreach ($bind as $k => $v) {
$vals[] = ':' . $k;
}
$query = sprintf('INSERT INTO %s (%s) VALUES (%s)', $table, implode(',', array_keys($bind)), implode(', ', $vals)
);
$stmt = $this->query($query, $bind);
$result = $stmt->rowCount();
$this->id = $this->db->lastInsertId();
return $result;
}
/**
* get last id
*
* @return int
*/
public function lastInsertId() {
return $this->id;
}
/**
* update data
*
* @param string $table
* @param array $row
* @param string $where
* @return int
*/
public function update($table, $data, $where) {
$vals = array();
foreach ($data as $k => $v) {
$vals[] = $k . ' = :' . $k;
$this->bind[$k] = $v;
}
if (is_array($where))
$where = implode(' AND ', $where);
$query = sprintf('UPDATE %s SET %s WHERE %s', $table, implode(',', $vals), $where
);
$stmt = $this->query($query);
$result = $stmt->rowCount();
return $result;
}
/**
* delete data
*
* @param string $table
* @param string $where
* @return int
*/
public function delete($table, $where) {
if (is_array($where))
$where = implode(' AND ', $where);
$query = sprintf('DELETE FROM %s WHERE %s', $table, $where
);
$stmt = $this->query($query);
$result = $stmt->rowCount();
return $result;
}
/**
* query select sql
*
* @return Mysql_Select
*/
public function select() {
return new Mysql_Select($this);
}
/**
* fetch data, optional fetch mode. defailt array
*
* @param string $query
* @param array $bind
* @param string $fetchMode
* @return array/object
*/
public function fetchAll($query, $bind = array(), $fetchMode = null) {
if ($fetchMode === null)
$fetchMode = $this->_fetchMode;
$stmt = $this->query($query, $bind);
return $stmt->fetchAll($fetchMode);
}
/**
* fetch data array
*
* @param string $query
* @param array $bind
* @return array
*/
public function fetchAssoc($query, $bind = array()) {
$stmt = $this->query($query, $bind);
return $stmt->fetchAll(PDO::FETCH_ASSOC);
}
/**
* fetch data object
*
* @param string $query
* @param array $bind
* @return object
*/
public function fetchObj($query, $bind = array()) {
$stmt = $this->query($query, $bind);
return $stmt->fetchAll(PDO::FETCH_OBJ);
}
public function fetchNum($sql, $bind = array()) {
$stmt = $this->query($sql, $bind);
return $stmt->fetchAll(PDO::FETCH_NUM);
}
public function fetchPairs($sql, $bind = array()) {
$stmt = $this->query($sql, $bind);
$data = array();
while ($row = $stmt->fetch(PDO::FETCH_NUM)) {
$data[$row[0]] = $row[1];
}
return $data;
}
public function fetchOne($sql, $bind = array()) {
$stmt = $this->query($sql, $bind);
return $stmt->fetchColumn(0);
}
public function __destruct() {
;
}
}
|
Python
|
UTF-8
| 661 | 3.15625 | 3 |
[] |
no_license
|
#file handling
file=open("C:\\Users\\fawwa\\OneDrive\\Desktop\\file\\example1.txt", "r")
#print(dir(f))
#print(f.read())
#f.seek(0)
#print(f.read())
#f.seek(1)
#print(f.read())
#a=file.readlines()
#file.seek(0)
#print(file.readline())
#print(file.readline())
#for f in a:
# print(f)
print("a")
print("b")
for f in file:
print(f,end="")
file.close()
file1=open("C:\\Users\\fawwa\\OneDrive\\Desktop\\file\\contohappend.txt", "a")
file1.write("testing")
file2=open("C:\\Users\\fawwa\\OneDrive\\Desktop\\file\\contohwrite.txt.txt", "w")
file2.write("testing2")
file2.writelines(("nama saya fawwaz ", "saya suka main PC"))
file1.close()
file2.close()
|
Markdown
|
UTF-8
| 8,224 | 2.578125 | 3 |
[
"MIT"
] |
permissive
|
# Autograder Manual
The purpose of this document is to outline the functionality, use, and rules of
the cs3210 autograder.
In cs3210 this semester we will be using an interactive autograder to help
evaluate your lab solutions. The autograder will download your submissions from
[GaTech's GitHub](https://github.gatech.edu), and then run a series of tests on
your code, delivering the results to you as it runs (usually).
The goal of the autograder is to help you ensure you've implemented the project
correctly, and have a good idea of the credit you will receive. It is not
intended for debugging your project, and will not deliver particularly useful
feedback (it will only tell you if you pass or fail a test, not what that test
was, or why you failed).
## Autograder Policies
The autograder is intended to help you throughout this course, and give you some
confidence as to where you stand with your lab submissions. However, the
autograder doesn't have infinite resources, and needs to ensure submissions are
kept safe. As a result, the autograder has several specific policies it will
require you to adhere to.
### Feedback Submissions
If students were to all submit their lab frequently (and last minute), the
autograder queue would become very long, potentially causing students to wait
many hours before their submission is graded, resulting in poor grades and late
submissions. This issue is caused by students attempting to use the autograder
as a last-minute debugging tool instead of its true intention -- an automatic
grading and feedback mechanism. To help alleviate this issue, the autograder
will only provide students with a limited amount of feedback per day by limiting
the number of submissions it provides feedback for.
To be more precise, when you run the autograder with a feedback-enabled
submission, the autograder will tell you what test number it's running, if you
passed that test, then ultimately the total number of tests you've passed. This
will give you a good idea of how well your submission did. Once you've expended
all of your available feedback enabled submissions, the autograder will only
tell you that it has run your submission, and provide no graded feedback.
The policy on feedback-enabled submissions is that students get one-per-day
(a day starts at midnight, and ends at midnight). These "feedbacks" cannot be
stockpiled (it goes away at midnight). However, we understand that sometimes
students are working hard and don't want to wait until the next day to submit,
so we provide 3 extra graded feedbacks per project, which the student may use at
any point in place of a non-feedback submission (e.g. at your 2nd+ submission
for that day). These extra feedbacks do not transition between projects.
### Malicious Submissions
All submissions to the autograder will be logged both locally (on the
autograder) and remotely (off the autograder), and may be audited. Any
unauthorized attempt to subvert the autograder, either by gaining control of the
autograder machine, exposing autograder testcases, or generally using the
autograder for any purpose other than its intended one (to grade your code),
will be considered a violation of Georgia Tech's honor code and will be
severely punished. The autograder has many safety checks and fail-safes in
place. Do not attempt to attack the autograder!
### Autograder-Specific Requirements
The autograder does place some specific restrictions on how you modify your
code and construct your labs. You may add any source files you like to the
bootloader, kernel, or user files, but the autograder will not respect any
changes to CMakeLists.txt (that would allow students to run arbitrary code).
Instead, you must specify any changes in the list within the Sources.cmake
directory.
Additionally, the autograder will ignore any changes made to any of the scripts
run to create the kernel. The files the autograder will ignore or overwrite
includes:
- CMakeLists.txt
- user/CMakeLists.txt
- kernel/CMakeLists.txt
- bootblock/CMakeLists.txt
- tools/CMakeLists.txt
- scripts/xv6-qemu
- tools/mkfs
- tools/cuth
- tools/printpcs
- tools/pr.pl
- tools/runoff
- tools/runoff1
- tools/runoff.list
- tools/runoff.spec
- tools/show1
- tools/spinp
- tools/toc.ftr
- tools/toc.hdr
- kernel/tools/mksym.sh
- kernel/tools/vectors.pl
Furthermore, the autograder restricts the changes you are allowed to make to your
Sources.cmake (`kernel/Sources.cmake`, `user/Sources.cmake`, and
`bootblock/Sources.cmake`). You are only allowed to modify the lists present in
those files.
Finally, when the autograder runs your code, it will do so in Release mode (with
the option `-DCMAKE_BUILD_TYPE=Release`). Ensure your code works in Release
mode before submitting it to the autograder!
### Misc Autograder Rules
- You may only have one submission queued at a time (if you have a submission
queued, but not yet graded, the autograder will reject additional submission
requests until your submission is graded).
## Autograder Use
To use the autograder, visit the [autograder page][autograder], and click the
authenticate button. NOTE: You'll have to be logged into the campus VPN to access
it. This will bring you to a GitHub login page, where you will
give the autograder permission to know your identity and checkout your private
repositories. Once you've completed the authentication, you will be taken back
to the autograder, where the autograder will display the available labs. From
here the operation of the autograder should be mostly self-explanatory. We'll
outline a few important details about lab submission now.
### Submission Confirmation
Once you choose to submit your lab, the autograder will show you a confirmation
page, containing a series of information looking somewhat like this:
```
Grade request for lab: lab1
Request has locked in timestamp: 06-23-2020 11:43
github commit hash to be graded: d6f55858a1945baaf1e1925eddbf8fe29dc3fe14
Your request will do the following:
Original Due Date (before late days): 09-02-2020 23:59
Previous Due Date (after previously applied late days): 09-02-2020 23:59
New Due Date (after late days applied for this request): 09-02-2020 23:59
Late Days applied for this request: 0
Late Penalty (if you're out of late days): 0%
Late Days remaining: 3
Feedback Given: True
Extra Feedback Used: False
Extra Feedback Remaining (after submission): 0
You have 5 minutes to confirm this submission, afterwards a resubmission is
required.
Continue with this submission? (resources will only be used after confirm)
```
Here is a quick breakdown of the fields in this confirmation message:
- **Grade request for lab** -- What lab are we grading?
- **Request has locked in timestamp** -- If you hit confirm within the next 5
minutes, this is the timestamp that will be used for the purposes of grading
your lab (and determining late-ness).
- **github commit hash to be graded** -- This is the GitHub hash that will be
checked out and graded by the autograder. Ensure it matches the hash you've
last commited and pushed to your GitHub repository (e.g. with `git log`).
- **Original Due Date** -- If you were to never use late-days on this lab, when
would it be due?
- **Previous Due Date** -- Before this submission, what was your due date (any
late days you've used as a part of prior submissions will be reflected here)?
- **New Due Date** -- After this submission, this is your new due date (after
late day application).
- **Late Days applied...** -- The number of late-days that will be used as a
part of this request (remember, you only get 3 for the entire semester).
- **Late Penalty** -- What penalty to your score will you get from this
submission due to it being late?
- **Late Days Remaining** -- The number of late days you have remaining for the
semester (after any late days in this request are used)
- **Feedback Given** -- Will this request give you feedback?
- **Extra Feedback Used** -- Will this request use one of your extra feedbacks?
(you get 3 per lab)
- **Extra Feedback Remaining** -- How many extra feedbacks will you have after this
submission?
[autograder]:https://cs3210-autograder.cc.gatech.edu/index.html
|
Java
|
UTF-8
| 1,802 | 3.171875 | 3 |
[] |
no_license
|
package Model;
import java.io.File;
import java.io.IOException;
import javax.sound.sampled.AudioInputStream;
import javax.sound.sampled.AudioSystem;
import javax.sound.sampled.Clip;
import javax.sound.sampled.LineUnavailableException;
import javax.sound.sampled.UnsupportedAudioFileException;
/**
* @author Brandon Blaschke
* Class to control and play Audio.
*/
public class AudioPlayer {
/**
* Clip of audio to play from
*/
Clip clip;
/**
* Audio input stream.
*/
AudioInputStream audioInputStream;
/**
* Status of the audio
*/
AudioStatus audioStatus;
/**
* Create a AudioPlayer for a single piece of audio.
* @param filePath Path to file.
* @throws UnsupportedAudioFileException
* @throws IOException
* @throws LineUnavailableException
*/
public AudioPlayer(String filePath) throws UnsupportedAudioFileException, IOException, LineUnavailableException
{
audioInputStream = AudioSystem.getAudioInputStream(new File(filePath).getAbsoluteFile());
clip = AudioSystem.getClip();
clip.open(audioInputStream);
clip.loop(Clip.LOOP_CONTINUOUSLY);
clip.stop();
audioStatus = AudioStatus.STOPPED;
}
/**
* Play the audio.
*/
public void play() {
if (audioStatus != AudioStatus.PLAYING)
clip.loop(Clip.LOOP_CONTINUOUSLY);
audioStatus = AudioStatus.PLAYING;
}
/**
* Pause the Audio.
*/
public void pause() {
if (audioStatus == AudioStatus.PLAYING && audioStatus != AudioStatus.STOPPED)
clip.stop();
audioStatus = AudioStatus.PAUSED;
}
/**
* Stop audio and close stream.
*/
public void stop() {
if (audioStatus != AudioStatus.STOPPED) {
clip.stop();
clip.close();
audioStatus = AudioStatus.STOPPED;
}
}
}
/**
* Enum for the current status of the audio.
*/
enum AudioStatus {
PLAYING, STOPPED, PAUSED;
}
|
Python
|
UTF-8
| 1,605 | 3.296875 | 3 |
[] |
no_license
|
#-*- coding: utf-8 -*-
from matplotlib import pyplot as plt
import numpy as np
import math
import scipy as sc #funciones cientificas
class AdalineGD(object):
def __init__(self, eta = 0.1, n_iter = 50):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, Y):
self.w_ = np.zeros(1+X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
output = self.net_input(X)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
cost = (errors ** 2).sum() / 2.0
self.cost_.append(cost)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0])
def activation(self, X):
return self.net_input(X)
def predict(self, X):
return np.where(self.activation(X) >= 0.0, 1, -1)
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(8,4))
adal = AdalineGD(n_iter = 10, eta = 0.01,).fit(X, y)
ax[0].plot(range(1, len(adal.cost_) + 1), np.log10(adal.cost_), marker = 'o')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('log(Sum-squared-error)')
ax[0].set_title('Adaline - Learning rate 0.01')
ada2 = AdalineGD(n_iter = 10, eta = 0.0001).fit(X, y)
ax[1].plot(range(1, len(ada2.cost_) + 1), ada2.cost_, marker = 'o')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Sum- squared error')
ax[1].set_title('Adaline learning rate 0.0001')
plt.show()
'''
array_puntos = np.array([[0,0],[1,0],[0,1],[1,1]])
for i in range(4):
plt.plot(array_puntos[i][0], array_puntos[i][1], "o", c = "red")
plt.show()
'''
|
Java
|
UTF-8
| 466 | 2.90625 | 3 |
[] |
no_license
|
package Calc;
public class RomanToArabic {
public static int rTA (String arabic) {
int result = 0;
int[] decimal = {10, 9, 5, 4, 1};
String[] roman = {"X", "IX", "V", "IV", "I"};
for (int i = 0; i < decimal.length; i++) {
while (arabic.indexOf(roman[i]) == 0) {
result += decimal[i];
arabic = arabic.substring(roman[i].length());
}
}
return result;
}
}
|
Java
|
UTF-8
| 606 | 2.3125 | 2 |
[
"Apache-2.0"
] |
permissive
|
package com.eden.sdk.unluac.decompile.expression;
import com.eden.sdk.unluac.decompile.Declaration;
import com.eden.sdk.unluac.decompile.Output;
public class LocalVariable
extends Expression
{
private final Declaration decl;
public LocalVariable(Declaration paramDeclaration)
{
super(9);
this.decl = paramDeclaration;
}
public int getConstantIndex()
{
return -1;
}
public boolean isBrief()
{
return true;
}
public boolean isDotChain()
{
return true;
}
public void print(Output paramOutput)
{
paramOutput.print(this.decl.name);
}
}
|
Python
|
UTF-8
| 4,689 | 2.78125 | 3 |
[
"MIT"
] |
permissive
|
import tensorflow as tf
import numpy as np
from datetime import datetime
from tqdm import tqdm
class QueueRunner(object):
def __init__(self, filename_list, Model, batch_size=32, image_size=256, image_channels=3):
#We create a tf variable to hold the global step, this has the effect
#that when a checkpoint is created this value is saved.
#Making the plots in tensorboard being continued when the model is restored.
global_step = tf.Variable(0)
increment_step = global_step.assign_add(1)
#Create a queue that will be automatically fill by another thread
#as we read batches out of it
batch = self.batch_queue(filename_list, batch_size, image_size, image_channels)
# Create the graph, etc.
m = Model(batch)
init_op = tf.initialize_all_variables()
#This is required to intialize num_epochs for the filename_queue
init_local = tf.initialize_local_variables()
# Create a saver.
saver = tf.train.Saver(keep_checkpoint_every_n_hours=1)
# Create a session for running operations in the Graph.
sess = tf.Session(config=tf.ConfigProto(
gpu_options = tf.GPUOptions(allow_growth=True),
log_device_placement=False,
allow_soft_placement=True))
# Create a summary writer, add the 'graph' to the event file.
log_datetime = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
writer = tf.train.SummaryWriter('./logs/'+log_datetime,
sess.graph, flush_secs=30, max_queue=2)
# Initialize the variables (like the epoch counter).
sess.run([init_op,init_local])
# Start input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
progress = tqdm()
while not coord.should_stop():
# Run training steps or whatever
global_step = sess.run(increment_step)
progress.update()
m.step(sess)
if global_step % 10 == 0:
m.summarize(sess, writer, global_step)
if global_step % 2000 == 0:
# Append the step number to the checkpoint name:
saver.save(sess, './logs/'+log_datetime, global_step=global_step)
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
# When done, ask the threads to stop.
coord.request_stop()
# Wait for threads to finish.
coord.join(threads)
sess.close()
def read_png(self,filename_queue, image_size=256, image_channels=3):
reader = tf.WholeFileReader()
_ , value = reader.read(filename_queue)
raw_int_image = tf.image.decode_png(value, channels=image_channels)
center_cropped_image = tf.image.resize_image_with_crop_or_pad(raw_int_image, image_size, image_size)
float_image = tf.cast(center_cropped_image,tf.float32)
float_image = tf.sub(tf.div(float_image, 127.5), 1.0)
#required for graph shape inference
float_image.set_shape((image_size,image_size,image_channels))
return float_image
def batch_queue(self,filenames, batch_size, image_size, image_channels, num_epochs=None):
with tf.variable_scope("batch_queue"):
filename_queue = tf.train.string_input_producer(
filenames, num_epochs=num_epochs, shuffle=True)
image_node = self.read_png(filename_queue, image_size, image_channels)
# min_after_dequeue defines how big a buffer we will randomly sample
# from -- bigger means better shuffling but slower start up and more
# memory used.
# capacity must be larger than min_after_dequeue and the amount larger
# determines the maximum we will prefetch. Recommendation:
# min_after_dequeue + (num_threads + a small safety margin) * batch_size
min_after_dequeue = 1000
capacity = min_after_dequeue + 3 * batch_size
example_batch = tf.train.shuffle_batch(
[image_node], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch
class QueueRunner3D(QueueRunner):
def read_png(self,filename_queue, image_size=32, image_channels=1):
reader = tf.WholeFileReader()
_ , value = reader.read(filename_queue)
raw_int_image = tf.image.decode_png(value, channels=image_channels)
center_cropped_image = tf.image.resize_image_with_crop_or_pad(raw_int_image, image_size * image_size, image_size)
float_image = tf.cast(center_cropped_image,tf.float32)
float_image = tf.sub(tf.div(float_image, 127.5), 1.0)
float_image = tf.reshape(float_image, shape=(32,32,32))
#required for graph shape inference
float_image.set_shape((image_size,image_size,image_size))
return float_image
|
Go
|
UTF-8
| 723 | 2.984375 | 3 |
[] |
no_license
|
package env
import (
"flag"
"os"
)
var (
Hostname string // hostname
Mode string // run mode
)
const (
DEBUG = "debug" // 开发
TEST = "test" // 测试
GRAY = "gray" // 灰度
RELEASE = "release" // 生产
)
func init() {
var err error
if Hostname, err = os.Hostname(); err != nil || Hostname == "" {
Hostname = os.Getenv("HOSTNAME")
}
addFlag(flag.CommandLine)
}
func defaultString(env, value string) string {
v := os.Getenv(env)
if v == "" {
return value
}
return v
}
// 优先级从低到高 default < goenv < command
func addFlag(f *flag.FlagSet) {
f.StringVar(&Mode, "mode", defaultString("MODE", DEBUG), "run mode,default debug mode.value:[debug,test,gray,release]")
}
|
Java
|
UTF-8
| 1,051 | 2.703125 | 3 |
[] |
no_license
|
package db;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
/**
* Entity Manager Provider for working with JPA
*
* @author Michal Siron
*/
public class EntityManagerProvider {
private static final String PERSISTENCE_UNIT_NAME = "bookshelf";
/**
* Entity manager factory for creating EntityManager
* can be created just once for all app scope
*/
private static final EntityManagerFactory ENTITY_MANAGER_FACTORY = Persistence.createEntityManagerFactory(PERSISTENCE_UNIT_NAME);
/**
* Empty private constructor to avoid instantiation.
*/
private EntityManagerProvider(){}
/**
* Creates new entity manager from Entity manager factory
*
* @return new EntityManager
*/
static EntityManager getEntityManager(){
return ENTITY_MANAGER_FACTORY.createEntityManager();
}
/**
* Close EntityManagerFactory
*/
static void close(){
ENTITY_MANAGER_FACTORY.close();
}
}
|
SQL
|
UTF-8
| 2,934 | 3.125 | 3 |
[] |
no_license
|
CREATE DATABASE IF NOT EXISTS db_place_holder default charset utf8mb4 COLLATE utf8mb4_general_ci;
GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER ON db_place_holder.* TO user_place_holder@"%" IDENTIFIED BY 'password_place_holder';
flush privileges;
use db_place_holder;
CREATE TABLE `merchant_api_info` (
`id` int(11) NOT NULL AUTO_INCREMENT
COMMENT 'id',
`app_name` varchar(20) NOT NULL
COMMENT '应用名',
`app_key` varchar(128) NOT NULL
COMMENT '应用key',
`contact_person` varchar(20) NOT NULL
COMMENT '应用联系人',
`contact_phone` varchar(11) NOT NULL
COMMENT '应用联系电话',
`org` varchar(11) NOT NULL
COMMENT '所属组织',
`secret` varchar(128) NOT NULL
COMMENT 'msp注册使用的密码',
`app_user_obj` text COMMENT 'appUser对象序列化',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_app_name` (`app_name`) USING BTREE
)
ENGINE = InnoDB
COMMENT ='商户应用授权表';
CREATE TABLE `retry_spot` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` varchar(20) NOT NULL COMMENT '名称',
`description` varchar(1024) DEFAULT NULL COMMENT '描述',
`creation_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
`class_name` varchar(256) NOT NULL COMMENT '调用类全名',
`invoked_method_name` varchar(256) NOT NULL COMMENT '调用类方法名',
`invoked_method_parameters` text NOT NULL COMMENT '调用类方法参数',
`recover_method_name` varchar(256) NOT NULL COMMENT '恢复调用方法',
`recover_parameters` mediumblob NOT NULL COMMENT '恢复调用参数',
`exception` text NOT NULL COMMENT '异常',
`status` int(1) NOT NULL DEFAULT '0' COMMENT '0-创建,1-再次执行成功',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=gbk COMMENT='retry spot 现场记录表';
CREATE TABLE `file_record` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`biz_id` varchar(256) NOT NULL COMMENT 'biz id',
`owner` varchar(256) DEFAULT NULL COMMENT 'owner',
`creation_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
`file_name` varchar(1024) NOT NULL COMMENT '文件名',
`file_type` varchar(256) NOT NULL COMMENT '文件类型',
`status` int(1) NOT NULL DEFAULT '0' COMMENT '0-创建,1-归档',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=gbk COMMENT='file 记录表';
INSERT INTO `merchant_api_info` (`id`, `app_name`, `app_key`, `contact_person`, `contact_phone`, `org`, `secret`, `app_user_obj`) VALUES (1, 'test_app_oneKey', 'VfZ0ff8x+621NhpaFCn3e83Jqoqofjk/i79DTw37K9P9JSvxy+OjnXqAb8FG3+p6h63W+SfVw5TfWWKAyuacxlrkGFyeXacv6Bmke1chEWYhrAdm2mdIX4Fk2tXjWVg7', 'foy', '13333333333', 'org1', '', NULL);
INSERT INTO `merchant_api_info` (`id`, `app_name`, `app_key`, `contact_person`, `contact_phone`, `org`, `secret`, `app_user_obj`) VALUES (2, 'acunetix_scanner', 'OjnXqAb8FG3wdttdd', 'acunetix_scanner', '13333333333', 'org1', '', NULL);
|
Java
|
UTF-8
| 1,313 | 3.40625 | 3 |
[] |
no_license
|
package multiThread;
import java.util.Arrays;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinClass extends RecursiveTask<Integer> {
public int[] intArr;
public ForkJoinClass(int[] src) {
this.intArr = src;
}
@Override
protected Integer compute() {
if(intArr.length <= 2) {
int count = 0;
for(int i: intArr) {
count += i;
}
return count;
} else {
int mid = intArr.length/2;
ForkJoinClass leftTask = new ForkJoinClass(Arrays.copyOfRange(intArr, 0, mid));
ForkJoinClass rightTask = new ForkJoinClass(Arrays.copyOfRange(intArr, mid, intArr.length));
invokeAll(leftTask,rightTask);
return leftTask.join() + rightTask.join();
}
}
public static void main(String[] args) {
int[] intArr = new int[10000];
for(int i = 0; i < intArr.length; i++) {
intArr[i] = i;
}
System.out.println("makeArr size = " + intArr.length);
ForkJoinClass sumTask = new ForkJoinClass(intArr);
ForkJoinPool pool = new ForkJoinPool();
pool.invoke(sumTask);
System.out.println("执行结果:" + sumTask.join());
}
}
|
Java
|
UTF-8
| 23,816 | 2.390625 | 2 |
[] |
no_license
|
/*
* Copyright (C) 2016 jkhome
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA.
*/
package picbrowserj;
import java.awt.Color;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import static java.nio.file.StandardCopyOption.REPLACE_EXISTING;
import java.util.ArrayList;
import java.sql.*;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
/**
*
* @author jkhome
*/
interface ModelListener {
void EventPics_added(DatPicture Picture); //Picture loaded for browsing
void EventPics_moved(DatPicture Picture);
void EventPics_viewed(DatPicture Picture); //Picture selected for viewing
void EventPics_new(DatPicture Picture);
}
public class ModelPictures extends picbrowserj.Observable<ModelListener>{
private static ModelPictures s_Instance;
private static Connection s_DBConn;
private static ArrayList<DatTag> s_Tags;
private static DatTagRel s_TagsRelation;
private static ArrayList<DatPicture> s_Pictures;
private static ArrayList<DatPicture> s_PicturesNew;
private ModelPictures() {
s_Tags = new ArrayList<DatTag>();
s_TagsRelation = new DatTagRel();
s_Pictures = new ArrayList<DatPicture>();
s_PicturesNew = new ArrayList<DatPicture>();
InitDB();
LoadTags();
LoadPictures();
}
public static boolean init() {
if (s_Instance==null) {
s_Instance= new ModelPictures();
return true;
} else {
return false;
}
}
public static boolean shutdown () {
return true;
}
public static ModelPictures getInstance() {
if (s_Instance==null) {
//Todo throw exception
}
return s_Instance;
}
private void InitDB() {
Statement stmt = null;
Boolean Init =true;
try {
Class.forName("org.sqlite.JDBC");
s_DBConn = DriverManager.getConnection("jdbc:sqlite:PicBowser.db");
stmt = s_DBConn.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT count(*) FROM sqlite_master WHERE type='table' AND name='Config' COLLATE NOCASE" );
while ( rs.next() ) {
Init=(rs.getInt(1)==0);
}
rs.close();
stmt.close();
if (Init) {
stmt = s_DBConn.createStatement();
String sql = "CREATE TABLE Config " +
"(ID INTEGER PRIMARY KEY AUTOINCREMENT," +
" Name TEXT NOT NULL, " +
" ValueInt INT , " +
" ValueText TEXT )";
stmt.executeUpdate(sql);
stmt.close();
stmt = s_DBConn.createStatement();
sql = "CREATE TABLE Pictures " + //definition of all pictures
"(ID INTEGER PRIMARY KEY AUTOINCREMENT," +
" Path TEXT NOT NULL, " +
" Name CHAR(50), " +
" Status INT, " +
" Rating REAL)";
stmt.executeUpdate(sql);
stmt.close();
stmt = s_DBConn.createStatement();
sql = "CREATE TABLE TagDef " + //definition of a Tag
"(ID INTEGER PRIMARY KEY AUTOINCREMENT," +
" Color INT, " +
" Status INT, " +
" Tag CHAR(50)) " ;
stmt.executeUpdate(sql);
stmt.close();
stmt = s_DBConn.createStatement();
sql = "CREATE TABLE TagRel " + //definition how one Tag relates to another
"(ID INTEGER PRIMARY KEY AUTOINCREMENT," +
" Status INT, " +
" ParentID INT, " +
" SubID INT ) " ;
stmt.executeUpdate(sql);
stmt.close();
stmt = s_DBConn.createStatement();
sql = "CREATE TABLE Tags " + //definition what tags a picture has
"(ID INTEGER PRIMARY KEY AUTOINCREMENT," +
" Status INT, " +
" IDListTags INT NOT NULL, " +
"IDPicture INT NOT NULL )" ;
stmt.executeUpdate(sql);
stmt.close();
}
UpdateConfig("Version","",100);
createTestData();
//////////////////////////////////////////////////////////////////
} catch ( Exception e ) {
HandleDBError( e);
}
}
private void createTestData(){
// Todo set on FirstRun
UpdateConfig("Store","d:/temp",0);
int v= GetConfigInt("Version");
//Todo DB init goes here //////////////////////////////////////
DatTag Tag;
Tag= new DatTag();
Tag.Text ="Animal";
Tag.BGColor=Color.cyan;
UpdateTags(Tag);
Tag= new DatTag();
Tag.Text ="Deer";
Tag.BGColor=Color.LIGHT_GRAY;
UpdateTags(Tag);
Tag= new DatTag();
Tag.Text ="Fox";
Tag.BGColor=Color.LIGHT_GRAY;
UpdateTags(Tag);
DatPicture pic= new DatPicture();
pic.Name ="20150628_115213.jpg";
pic.Path="D:/temp/artists/artists3/20150628_115213.jpg";
pic.addTag(new DatTag("Deer",Color.GREEN));
UpdatePictures(pic);
pic = new DatPicture();
pic.Name ="TPhoto_00001.jpg";
pic.Path="D:/temp/artists/artists3/TPhoto_00001.jpg";
pic.addTag(new DatTag("Fox",Color.GREEN));
UpdatePictures(pic);
}
private void HandleDBError( Exception e) {
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
System.exit(0);
}
private int GetConfigInt(String Name) {
Statement stmt = null;
String sql;
int Return=0;
Boolean Exists=false;
try {
stmt = s_DBConn.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT ID,Name,ValueText,ValueInt FROM Config;" );
while ( rs.next() ) {
//Todo fix non exist
Exists=true;
Return = rs.getInt("ValueInt");
}
rs.close();
stmt.close();
}catch ( Exception e ) {
HandleDBError( e);
}
return Return;
}
private String GetConfigString(String Name) {
Statement stmt = null;
String sql;
String Return="";
Boolean Exists=false;
try {
stmt = s_DBConn.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT ID,Name,ValueText,ValueInt FROM Config;" );
while ( rs.next() ) {
//Todo fix non exist
Exists=true;
Return = rs.getString("ValueString");
}
rs.close();
stmt.close();
}catch ( Exception e ) {
HandleDBError( e);
}
return Return;
}
private Boolean RefreshTagListID(DatTag Tag ) {
Statement stmt = null;
Boolean Update=false;
ResultSet rs;
try {
stmt = s_DBConn.createStatement();
rs = stmt.executeQuery( "SELECT ID,Color,Tag FROM TagDef where Tag='"+Tag.Text+"';" );
while ( rs.next() ) {
Update=true;
Tag.IDListTags = rs.getInt("ID");
Tag.BGColor= new Color(rs.getInt("Color"));
}
rs.close();
stmt.close();
} catch ( Exception e ) {
HandleDBError( e);
}
return Update;
}
//updates/creates entry in Tag-Dictionary
private void UpdateTags(DatTag Tag) {
Statement stmt = null;
String sql="";
Boolean Update=false;
int id = -1;
try {
Update = RefreshTagListID(Tag);
s_DBConn.setAutoCommit(false);
stmt = s_DBConn.createStatement();
if(Update) {
sql = "Update TagDef Set Tag='"+Tag.Text+"',Color="+
String.format("%d",Tag.BGColor.getRGB()) +
",Status="+String.format("%d",Tag.Status)+
" where ID="+String.format("%d",Tag.IDListTags)+";";
} else {
sql = "INSERT INTO TagDef (Tag,Color,Status) " +
"VALUES ( '"+Tag.Text+
"',"+String.format("%d",Tag.BGColor.getRGB())+
", "+String.format("%d",Tag.Status)+
");";
}
stmt.executeUpdate(sql);
stmt.close();
s_DBConn.commit();
CleanupDeadLinks();
} catch ( Exception e ) {
HandleDBError( e);
}
if(!Update) { //tag is new, add them to local collection
RefreshTagListID(Tag); //fetch ID after Insert
s_Tags.add(Tag);
}
}
//Todo delete entrys with IDs pointing nowhere
private void CleanupDeadLinks() {
Statement stmt = null;
String sql="";
Boolean Update=false;
int id = -1;
try {
s_DBConn.setAutoCommit(false);
stmt = s_DBConn.createStatement();
sql = "Delete from TagDef where Status=1;"; //TODO also remove Relations to pictures and childtags:
stmt.executeUpdate(sql);
stmt.close();
s_DBConn.commit();
} catch ( Exception e ) {
HandleDBError( e);
}
}
private Boolean RefreshPictureID(DatPicture Pic ) {
Statement stmt = null;
Boolean Update=false;
ResultSet rs;
try {
stmt = s_DBConn.createStatement();
rs = stmt.executeQuery( "SELECT ID FROM Pictures where Path='"+Pic.Path+"';" );
while ( rs.next() ) {
Update=true;
Pic.ID = rs.getInt("ID");
}
rs.close();
stmt.close();
} catch ( Exception e ) {
HandleDBError( e);
}
return Update;
}
//updates/creates entry in Tag-Dictionary
private void UpdateTagRelation( ) {
Statement stmt = null;
String sql="";
Boolean Update=false;
int id = -1;
try {
s_DBConn.setAutoCommit(false);
stmt = s_DBConn.createStatement();
for(DatTagRel.Value e:s_TagsRelation) {
/*UPDATE tableName SET VALUE='newValue' WHERE COLUMN='identifier'
IF @@ROWCOUNT=0
INSERT INTO tableName VALUES (...)*/
sql = "INSERT OR REPLACE INTO TagRel (ParentID,SubID,Status) " +
"VALUES ("+ String.format("%d",e.TagParent.IDListTags)+
", "+String.format("%d",e.TagChild.IDListTags)+
", "+String.format("%d",e.Status)+
");";
stmt.executeUpdate(sql);
}
sql = "Delete from TagRel where Status=1;";
stmt.executeUpdate(sql);
stmt.close();
s_DBConn.commit();
} catch ( Exception e ) {
HandleDBError( e);
}
}
//updates/creates Picture-Entry
private void UpdatePictures(DatPicture Pic) {
Statement stmt = null;
String sql="";
Boolean Update=false;
ResultSet rs;
Update = RefreshPictureID(Pic);
try {
s_DBConn.setAutoCommit(false);
stmt = s_DBConn.createStatement();
if(Update) {
sql = "Update Pictures Set Path='"+Pic.Path+
"',Name='"+Pic.Name+
"',Rating="+String.format("%d",Pic.Rating)+
" where ID="+String.format("%d",Pic.ID)+";";
} else {
sql = "INSERT INTO Pictures (Path,Name,Rating) " +
"VALUES ( '"+Pic.Path+"','"+Pic.Name +"',"+
String.format("%d",Pic.Rating)+");";
}
stmt.executeUpdate(sql);
stmt.close();
s_DBConn.commit();
} catch ( Exception e ) {
HandleDBError( e);
}
Update = RefreshPictureID(Pic);
if (Pic.RequiresTagUpload()) UpdatePictureTags(Pic);
}
private Boolean RefreshTagID(DatTag Tag, DatPicture Pic ) {
Statement stmt = null;
Boolean Update=false;
ResultSet rs;
try {
stmt = s_DBConn.createStatement();
rs = stmt.executeQuery( "SELECT ID FROM Tags where IDListTags="+Tag.IDListTags+
" and IDPicture="+ Pic.ID +";" );
while ( rs.next() ) {
//Update=true;
Tag.IDTags = rs.getInt("ID");
}
rs.close();
stmt.close();
} catch ( Exception e ) {
HandleDBError( e);
}
return Update;
}
//updates the tags of a picture, creates tags if necessary
private void UpdatePictureTags(DatPicture Pic) {
Statement stmt = null;
String sql="";
int TagID;
int PicID;
ResultSet rs;
try {
//PicID should already be set
PicID = Pic.ID;
assert(PicID>=0);
//stmt = s_DBConn.createStatement();
for(int i=0; i< Pic.Tags.size();i++) {
UpdateTags(Pic.Tags.get(i));
TagID = Pic.Tags.get(i).IDListTags; // should now have ID
assert(TagID>=0);
RefreshTagID(Pic.Tags.get(i),Pic);
/* rs = stmt.executeQuery( "SELECT ID FROM Tags where IDListTags="+TagID+
" and IDPicture="+ PicID +";" );
while ( rs.next() ) {
//Update=true;
Pic.Tags.get(i).IDTags = rs.getInt("ID");
}
rs.close();*/
}
//stmt.close();
s_DBConn.setAutoCommit(false);
stmt = s_DBConn.createStatement();
for(int i=0; i< Pic.Tags.size();i++) {
TagID = Pic.Tags.get(i).IDTags;
if(TagID>=0) {
sql = "Update Tags Set IDPicture="+String.format("%d",Pic.ID)+
",IDListTags=" +String.format("%d",Pic.Tags.get(i).IDListTags)+
" where ID="+String.format("%d",TagID)+";";
} else {
sql = "INSERT INTO Tags (IDListTags,IDPicture) " +
"VALUES ("+
String.format("%d",Pic.Tags.get(i).IDListTags)+","+
String.format("%d",Pic.ID)+");";
}
stmt.executeUpdate(sql);
}
stmt.close();
s_DBConn.commit();
for(int i=0; i< Pic.Tags.size();i++) {
RefreshTagID(Pic.Tags.get(i),Pic);
}
} catch ( Exception e ) {
HandleDBError( e);
}
}
private void UpdateConfig(String Name, String ValueString, int ValueInt) {
Statement stmt = null;
String sql="";
Boolean Update=false;
try {
stmt = s_DBConn.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT ID,Name,ValueText,ValueInt FROM Config;" );
while ( rs.next() ) {
Update=true;
int id = rs.getInt("ID");
String name = rs.getString("Name");
}
rs.close();
stmt.close();
s_DBConn.setAutoCommit(false);
stmt = s_DBConn.createStatement();
if(Update) {
sql = "Update Config Set ValueText='"+ValueString+
"',ValueInt="+String.format("%d",ValueInt)+
" where Name='"+Name+"';";
} else {
sql = "INSERT INTO Config (Name,ValueText,ValueInt) " +
"VALUES ( '"+Name+"','"+ValueString +"',"+
String.format("%d",ValueInt)+");";
}
stmt.executeUpdate(sql);
stmt.close();
s_DBConn.commit();
} catch ( Exception e ) {
HandleDBError( e);
}
}
private void LoadPictures() {
s_Pictures = new ArrayList<DatPicture>();
Statement stmt = null;
String sql="";
DatPicture Pic;
DatTag Tag;
try {
stmt = s_DBConn.createStatement();
//loading pictures
ResultSet rs = stmt.executeQuery( "SELECT ID,Path,Name,Rating From Pictures;" );
while ( rs.next() ) {
Pic= new DatPicture();
Pic.ID= rs.getInt("ID");
Pic.Name =rs.getString("Name");
Pic.Path=rs.getString("Path");
Pic.Rating = rs.getInt("Rating");
s_Pictures.add(Pic);
}
rs.close();
//loading tags for pictures
for(int i=0; i< s_Pictures.size();i++) {
rs = stmt.executeQuery( "SELECT Tags.ID,Tags.IDListTags,Tag "+
"From Tags inner join TagDef on Tags.IDListTags=TagDef.ID where Tags.IDPicture="+
s_Pictures.get(i).ID +";" );
while ( rs.next() ) {
Tag = new DatTag();
Tag.IDListTags = rs.getInt("IDListTags");
Tag.IDTags = rs.getInt("ID");
Tag.Text = rs.getString("Tag");
s_Pictures.get(i).Tags.add(Tag);
}
rs.close();
}
stmt.close();
} catch ( Exception e ) {
HandleDBError( e);
}
}
public void SavePicture(DatPicture Pic) {
UpdatePictures(Pic);
}
public ArrayList<DatPicture> getAllPicture() {
return s_Pictures;
}
public ArrayList<DatPicture> getNewPictures() {
return s_PicturesNew;
}
//Moves a picture physically to a directory
//if the picture exists in DB - updates the data in DB
//fires eventPics_moved when done
public void MovePicture(DatPicture Pic, Path NewPath) throws IOException {
//we cannot assume that Pic is already in DB ! Only path might be set.
Path _old = Paths.get(Pic.Path);
//Path _new = Paths.get(NewPath+"/"+_old.getFileName());
//TODO show dialog to ack overwrite/renaming of files
Files.move(_old, NewPath, REPLACE_EXISTING);
Pic.Path=NewPath.toString();
//TODO save picture in DB or update path
this.onEventPics_moved(Pic);
}
/// Adds a newly selected Picture to the unsaved-Picture List
/// If the Picture is already in the list, it is replaced
/// If the Picture is already in DB it is ignored
public void AddNewPicture(DatPicture Pic) {
//Todo ??
s_PicturesNew.add(Pic);
}
public DatPicture getPictureByPath(String Text) {
DatPicture x;
Iterator<DatPicture> it= s_Pictures.iterator();
while (it.hasNext()) {
x=it.next();
if (x.Path.compareTo(Text)==0)
return x;
}
return null;
}
public DatPicture getPictureByID(int ID) {
DatPicture x;
Iterator<DatPicture> it= s_Pictures.iterator();
while (it.hasNext()) {
x=it.next();
if (x.ID==ID)
return x;
}
return null;
}
private void LoadTags() {
s_Tags.clear();//s_Tags = new ArrayList<DatTag>();
//??HashMap<Integer,DatTag> IDList = new HashMap<Integer,DatTag>();
s_TagsRelation.clear(); // = new DatTagRel();
Statement stmt = null;
String sql="";
DatTag Tag;
DatTag Tag2;
try {
stmt = s_DBConn.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT ID,Tag,Color FROM TagDef;" );
while ( rs.next() ) {
Tag= new DatTag();
Tag.IDListTags= rs.getInt("ID");
Tag.BGColor= new Color(rs.getInt("Color"));
Tag.Text =rs.getString("Tag");
s_Tags.add(Tag);
//IDList.put(Tag.IDListTags, Tag);
}
rs.close();
stmt.close();
stmt = s_DBConn.createStatement();
rs = stmt.executeQuery( "SELECT ID,ParentID,SubID FROM TagRel where Status!=1;" );
while ( rs.next() ) {
int ParentID = rs.getInt("ParentID");
int SubID =rs.getInt("SubID");
Tag = getTagByID(ParentID);
Tag2 = getTagByID(SubID);
s_TagsRelation.addRelation(Tag, Tag2);
}
rs.close();
stmt.close();
} catch ( Exception e ) {
HandleDBError( e);
}
}
public DatTag getTagByText(String Text) {
DatTag x;
Iterator<DatTag> it= s_Tags.iterator();
while (it.hasNext()) {
x=it.next();
if (x.Text.compareTo(Text)==0)
return x;
}
return null;
}
public DatTag getTagByID(int ID) {
DatTag x;
Iterator<DatTag> it= s_Tags.iterator();
while (it.hasNext()) {
x=it.next();
if (x.IDListTags==ID)
return x;
}
return null;
}
public DatTag addTag(DatTag Tag) {
UpdateTags(Tag);
return Tag;
}
//TODO
public DatTag deleteTag(DatTag Tag) {
removeRelation(Tag);
return Tag;
}
public void addRelation( DatTag parent,DatTag sub){
s_TagsRelation.addRelation(parent, sub);
UpdateTagRelation();
}
public void removeRelation( DatTag parent, DatTag sub){
s_TagsRelation.removeRelation(parent, sub);
UpdateTagRelation();
}
public void removeRelation( DatTag parent){
s_TagsRelation.removeRelation(parent);
UpdateTagRelation();
}
public List<DatTag> getParentTags(DatTag Me) {
List<DatTag> rel=s_TagsRelation.get(Me,true);
return rel;
}
public List<DatTag> getSubTags(DatTag Me) {
List<DatTag> rel=s_TagsRelation.get(Me,false);
return rel;
}
//returns an unmodifiableList List of all Tags
public List<DatTag> getAllTags() {
return Collections.unmodifiableList(Collections.list(Collections.enumeration(s_Tags)));
}
void onEventPics_added(DatPicture Picture) {
SrvPicManager.getInstance().EventPics_added(Picture);//for(ModelListener l: listeners) l.EventPics_added(Picture);
}
void onEventPics_moved(DatPicture Picture){
SrvPicManager.getInstance().EventPics_moved(Picture);//for(ModelListener l: listeners) l.EventPics_moved(Picture);
}
void onEventPics_viewed(DatPicture Picture){
SrvPicManager.getInstance().EventPics_viewed(Picture);//for(ModelListener l: listeners) l.EventPics_viewed(Picture);
}
void onEventPics_new(DatPicture Picture){
SrvPicManager.getInstance().EventPics_new(Picture);//for(ModelListener l: listeners) l.EventPics_new(Picture);
}
}
|
C#
|
UTF-8
| 1,998 | 2.734375 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.IO;
using zlib;
namespace LitMC.Generator
{
public struct ChunkKey
{
int x, y;
}
public class Chunk
{
public static byte[] generateSimpleChunk(byte sizeX, byte sizeY, byte sizeZ) //real sizes
{
byte[] typeArray = new byte[sizeX * sizeY * sizeZ];
byte[] metadataArray = new byte[sizeX * sizeY * sizeZ / 2];
byte[] lightArray = new byte[sizeX * sizeY * sizeZ / 2];
byte[] skyArray = new byte[sizeX * sizeY * sizeZ / 2];
for (int x = 0; x < sizeX; x++)
{
for (int y = 0; y < sizeY; y++)
{
for (int z = 0; z < sizeZ; z++)
{
int index = y + (z * sizeY) + (x * sizeY * sizeZ);
typeArray[index] = 0x01; //stone
if (index % 2 == 0)
{
metadataArray[index/2] = 0x00;
lightArray[index/2] = 0x00;
skyArray[index/2] = 0x00;
}
}
}
}
using (MemoryStream compressedStream = new MemoryStream())
{
using (ZOutputStream compressionStream = new ZOutputStream(compressedStream, zlibConst.Z_DEFAULT_COMPRESSION))
{
compressionStream.Write(typeArray, 0, typeArray.Length);
compressionStream.Write(metadataArray, 0, metadataArray.Length);
compressionStream.Write(lightArray, 0, lightArray.Length);
compressionStream.Write(skyArray, 0, skyArray.Length);
}
return compressedStream.ToArray();
}
}
}
}
|
C#
|
UTF-8
| 5,059 | 2.75 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace RPG
{
class Skill : Record
{
Cost Cost;
Cooldown Cooldown;
List<Script> Effects;
Bitmap Image;
public Skill()
{
Copy(new Cost(), new Cooldown(), new List<Script>(),null);
}
public Skill(Record type,Cost cost,Cooldown cooldown,List<Script> effects,Bitmap image):base(type)
{
Copy(cost, cooldown, effects,image);
}
public Skill(Skill cloned)
{
Copy(cloned);
}
public bool Copy(Cost cost,Cooldown cooldown,List<Script> effects,Bitmap image)
{
return
Set_Cooldown(cooldown) &&
Set_Cost(cost) &&
Set_Effects(effects)&&
Set_Image(image);
}
public bool Copy(Skill copied)
{
return base.Copy(copied) && Copy(
new Cost(copied.Get_Cost()),
new Cooldown(copied.Get_Cooldown()),
new List<Script>(copied.Get_Effects()),
copied.Get_Image()==null?null:new Bitmap(copied.Get_Image())
);
}
public override ScriptObject Clone()
{
return new Skill(this);
}
public override bool Assign(Record copied)
{
return Copy((Skill)copied);
}
public bool Can_Use(Entity source, Tile target)
{
if (Cost.Can_Pay(source) && Cooldown.Get_Done())
{
return true;
}
return false;
}
public bool Use(Entity source, Tile target)
{
Cost.Pay(source);
Cooldown.Start();
object[] args = { source, target };
for (int i = 0; i < Effects.Count; i++)
{
Effects[i].Execute(args);
}
return true;
}
public bool Try_Use(Entity source, Tile target)
{
if (!Can_Use(source, target))
{
return false;
}
else
{
Use(source, target);
return true;
}
}
public Cooldown Get_Cooldown()
{
return Cooldown;
}
public Cost Get_Cost()
{
return Cost;
}
public List<Script> Get_Effects()
{
return Effects;
}
public double Get_Time_Left()
{
return Cooldown.Get_Time_Left();
}
public Bitmap Get_Image()
{
return Image;
}
public string Get_Details()
{
string text = Get_Identifier() + Environment.NewLine +
Description +Environment.NewLine+"Costs/"+Environment.NewLine+
Cost.ToString() +"Cooldown/"+Environment.NewLine+ Cooldown.ToString();
return text.Replace('_',' ');
}
public bool Set_Cooldown(Cooldown cooldown)
{
Cooldown = cooldown;
return true;
}
public bool Set_Cost( Cost cost)
{
Cost = cost;
return true;
}
public bool Set_Effects(List<Script> effects)
{
Effects = effects;
return true;
}
public bool Set_Image(Bitmap image)
{
Image = image;
return true;
}
public override bool Set_Variable(string name, object value)
{
switch (name)
{
case "Cost": return Set_Cost(
value.GetType()==Cost.GetType() ? (Cost)value:new Cost(new ScriptObject(),Converter.Convert_Array<Cost_Value>(value)));
case "Cooldown": return Set_Cooldown((Cooldown)value);
case "Effects": return Set_Effects(Converter.Convert_Array<Script>(value));
case "Image":return Set_Image((Bitmap)value);
default: return base.Set_Variable(name, value);
}
}
public override object Get_Variable(string name)
{
switch (name)
{
case "Cooldown": return Get_Cooldown();
case "Effects": return Get_Effects();
case "Cost": return Get_Cost();
case "Image":return Get_Image();
default: return base.Get_Variable(name);
}
}
public override object Call_Function(string name, object[] args)
{
switch (name)
{
case "Can_Use": return Can_Use((Entity)args[0], (Tile)args[1]);
case "Try_Use": return Try_Use((Entity)args[0], (Tile)args[1]);
case "Use": return Use((Entity)args[0], (Tile)args[1]);
default: return base.Call_Function(name, args);
}
}
}
}
|
Java
|
UTF-8
| 638 | 1.921875 | 2 |
[] |
no_license
|
package com.example.demo.scheduler;
import com.example.demo.service.SchedulerService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import static com.example.demo.constant.PropertiesConst.PropertiesKeyEL.DB_SCHEDULER_CLEAN_UP_LOGOUT_TOKEN_CRON;
@Component
public class DbScheduler {
@Autowired
private SchedulerService schedulerService;
@Scheduled(cron = DB_SCHEDULER_CLEAN_UP_LOGOUT_TOKEN_CRON)
public void cleanUpLogoutToken() {
schedulerService.cleanUpExpiredLogoutToken();
}
}
|
TypeScript
|
UTF-8
| 4,991 | 2.671875 | 3 |
[
"MIT"
] |
permissive
|
/*
MIT License
Copyright (c) 2019 github0null
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
*/
import * as iconv from 'iconv-lite';
import { File } from '../lib/node-utility/File';
import * as fs from 'fs';
export enum EncodingType {
UTF8 = 'utf8',
UNICODE = 'unicode',
UTF16BE = 'utf16be',
UTF32BE = 'utf32be',
UTF32LE = 'utf32le',
ASCII = 'ascii',
NULL = 'null'
}
export class EncodingConverter {
static trimUtf8BomHeader(str: string | Buffer): string {
if (str instanceof Buffer) {
if (str[0] == 0xef &&
str[1] == 0xbb &&
str[2] == 0xbf) {
str = str.subarray(3);
}
return str.toString();
}
if (str.charCodeAt(0) == 0xef &&
str.charCodeAt(1) == 0xbb &&
str.charCodeAt(2) == 0xbf) {
return str.substr(3);
}
return str;
}
private static getCodeType(bomHead: Buffer): EncodingType {
let codeType: EncodingType;
if (bomHead && bomHead.length === 4) {
switch (bomHead[0]) {
case 0xfe:
if (bomHead[1] === 0xff) {
codeType = EncodingType.UTF16BE;
}
else {
codeType = EncodingType.NULL;
}
break;
case 0xef:
if (bomHead[1] === 0xbb && bomHead[2] === 0xbf) {
codeType = EncodingType.UTF8;
}
else {
codeType = EncodingType.NULL;
}
break;
case 0x00:
if (bomHead[1] === 0x00 && bomHead[2] === 0xfe && bomHead[3] === 0xff) {
codeType = EncodingType.UTF32BE;
}
else {
codeType = EncodingType.NULL;
}
break;
case 0xff:
if (bomHead[1] === 0xfe && bomHead[2] === 0x00 && bomHead[3] === 0x00) {
codeType = EncodingType.UTF32LE;
}
else if (bomHead[1] === 0xfe) {
codeType = EncodingType.UNICODE;
}
else {
codeType = EncodingType.NULL;
}
break;
default:
codeType = EncodingType.ASCII;
break;
}
} else {
codeType = codeType = EncodingType.NULL;
}
return codeType;
}
static getFileCodeType(file: File): Promise<EncodingType> {
return new Promise((resolve) => {
const stream = fs.createReadStream(file.path);
stream.on('readable', () => {
let bomHead: Buffer = stream.read(4);
stream.close();
resolve(EncodingConverter.getCodeType(bomHead));
});
});
}
static getCodeTypeSync(file: File): EncodingType {
const buf = fs.readFileSync(file.path);
return EncodingConverter.getCodeType(buf);
}
static existCode(encoding: string): boolean {
return iconv.encodingExists(encoding);
}
static convertFileToUTF8(file: File, originalEncoding: string, outPath: string) {
fs.createReadStream(file.path)
.pipe(iconv.decodeStream(originalEncoding))
.pipe(iconv.encodeStream('utf8'))
.pipe(fs.createWriteStream(outPath, {
autoClose: true
}));
}
static toTargetCode(str: string, encoding: string): Buffer {
return iconv.encode(iconv.decode(Buffer.from(str), 'utf8'), encoding);
}
static toUtf8Code(buff: Buffer, encoding: string): Buffer {
return iconv.encode(iconv.decode(buff, encoding), 'utf8');
}
}
|
Java
|
UTF-8
| 435 | 1.867188 | 2 |
[] |
no_license
|
package ca.sheridancollege.khoslak.repositories;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import ca.sheridancollege.khoslak.beans.Threadiscussion;
public interface ThreadRepository extends JpaRepository<ca.sheridancollege.khoslak.beans.Threadiscussion,Long> {
public List<Threadiscussion> findAllByOrderByCreateDateDesc();
public List<Threadiscussion> findAllByOrderByCreateDate();
}
|
C++
|
UTF-8
| 351 | 3.65625 | 4 |
[] |
no_license
|
#include <iostream>
using namespace std;
int * fun(int size){
int *p;
p = new int[size];
//setting the array
for(int i =0;i< size;i++){
p[i] = i+1;
}
return p;
}
int main(){
int *ptr, size =7;
ptr = fun(size);
//printing the array
for(int i = 0; i < size; i++){
cout << i <<endl;
}
}
|
Python
|
UTF-8
| 2,459 | 3.03125 | 3 |
[] |
no_license
|
import MySQLdb
db=MySQLdb.connect(user='root',db='mysql',passwd='mysql',host='localhost')
cursor=db.cursor()
cursor.execute("SELECT VERSION()")
data=cursor.fetchone()
print "Database version : %s" % data
db.close()
#Database version : 5.6.21-log
###########Create Table#######################
import MySQLdb
db=MySQLdb.connect(user='root',db='test',passwd='mysql',host='localhost')
cursor=db.cursor()
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
sql="""CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT)"""
cursor.execute(sql)
print "Create table employee done..."
db.close()
###########Insert#######################
import MySQLdb
db=MySQLdb.connect(user='root',db='test',passwd='mysql',host='localhost')
cursor=db.cursor()
sql= """insert into employee (first_name,last_name,age,sex,income) values('John','Smith',20,'M',2000) """
try:
cursor.execute(sql)
db.commit()
print "insert and commit ...."
except:
db.rollback()
print "rollback ...."
db.close()
import MySQLdb
db=MySQLdb.connect(user='root',db='test',passwd='mysql',host='localhost')
cursor=db.cursor()
sql= "insert into employee (first_name,last_name,age,sex,income) values('%s','%s','%d','%c','%d') " % ('John','Smith',20,'M',3000)
try:
cursor.execute(sql)
db.commit()
print "insert and commit ...."
except:
db.rollback()
print "rollback ...."
db.close()
###########Select#######################
import MySQLdb
db=MySQLdb.connect(user='root',db='test',passwd='mysql',host='localhost')
cursor=db.cursor()
sql= "select * from employee where income >%d " % (1000)
try:
cursor.execute(sql)
results=cursor.fetchall()
for row in results:
first_name=row[0]
last_name=row[1]
age=row[2]
sex=row[3]
income=row[4]
print "(first_name=%s,last_name=%s,age=%d,sex=%s,income=%d) " %(first_name,last_name,age,sex,income)
except Exception, e:
print str(e)
print "Error: Unable to fetch data"
db.close()
###########Update#######################
import MySQLdb
db=MySQLdb.connect(user='root',db='test',passwd='mysql',host='localhost')
cursor=db.cursor()
sql= "update employee set age =age+1 where sex ='%c' " % ('M')
try:
cursor.execute(sql)
db.commit()
except Exception, e:
print str(e)
db.rollback()
db.close()
|
C#
|
UTF-8
| 1,718 | 2.6875 | 3 |
[] |
no_license
|
using DependencyInjection_Refactoring_Step2;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Moq;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace DependencyInjection_Refactoring_Step2_Test
{
[TestClass]
public class UnitTest2
{
[TestMethod]
public void AssertPartListCreatorReturnCorrectNumberOfParts()
{
// Arrange
//IDatabaseService databaseService = new DatabaseServiceFourParts();
var databaseServiceMock = new Mock<IDatabaseService>();
databaseServiceMock.Setup(d => d.GetParts())
.Returns(() => new string[] { "PART-1", "PART-2", "PART-3", "PART-4" });
IDatabaseService databaseService = databaseServiceMock.Object;
PartListCreator p = new PartListCreator(databaseService);
// Act
var parts = p.GetParts().ToArray();
// Assert
Assert.IsTrue(parts.Count() == 4);
}
[TestMethod]
public void AssertPartListCreatorReturnCorrectNumberOfPartsWhenPartsAreNotPresents()
{
// Arrange
//IDatabaseService databaseService = new DatabaseServiceEmptyParts();
var databaseServiceMock = new Mock<IDatabaseService>();
databaseServiceMock.Setup(d => d.GetParts())
.Returns(() => null);
IDatabaseService databaseService = databaseServiceMock.Object;
PartListCreator p = new PartListCreator(databaseService);
// Act
var parts = p.GetParts().ToArray();
// Assert
Assert.IsTrue(parts.Count() == 0);
}
}
}
|
Markdown
|
UTF-8
| 12,062 | 3.171875 | 3 |
[] |
no_license
|
## Poker-bots Hit a New Milestone in AI
<center>
<img src="src-poker-bots/cards.jpg" />
</center>
Two separate artificial intelligence (AI) programs recently surpassed humans in a game that was once considered too difficult for artificial intelligence to master. Each one of these events represents a significant milestone in AI by beating professional poker players at Heads-up (two player only) [No-Limit Texas Hold'em](https://www.partypoker.com/how-to-play/school/heads-up.html), one of the more complex variants of poker.
The first reported computer program to outplay human professionals in Heads-up no-limit Texas Hold'em poker came in December 2016, when an AI system called [DeepStack](http://www.sciencemag.org/news/2017/03/artificial-intelligence-goes-deep-beat-humans-poker) played a total of 44,852 hands against 33 professional players. Developed by a team of computer scientists from the University of Alberta along with research collaborators from Charles University in Prague and Czech Technical University, DeepStack beat each of the 11 players who finished their match, 10 of them by statistically significant margins. The team recently published their study in the [March issue of Science](http://science.sciencemag.org/content/early/2017/03/01/science.aam6960).
One month after DeepStack’s publicized victory over human poker players, [Carnegie Mellon University’s poker-bot ‘Libratus’](https://www.cmu.edu/news/stories/archives/2017/january/AI-beats-poker-pros.html) also achieved the feat. In January, Libratus challenged four human poker experts with more than four decades worth of combined experience in a grueling 20-day poker tournament called “Brains vs. Artificial Intelligence: Upping the Ante” held in Pittsburgh. After playing 120,000 hands of heads-up, no-limit Texas Hold’em, Libratus defeated a team of the world’s top-ranked human poker players by 1,776,250 chips. This was a huge accomplishment-- researchers can now say that the victory margin was large enough (at least 99.98 percent was not due to chance) to be considered a statistically significant win.
### Poker: An Incomplete Information Game
Computers have already mastered games like checkers, chess, and Go. Games have long served as tools for measuring the capabilities of AI systems and benchmarking breakthroughs in AI. Last year, [Google's AlphaGo](https://www.theatlantic.com/technology/archive/2016/03/the-invisible-opponent/475611/) famously defeated a legendary champion in the game of Go, a game that has been described as the “Mount Everest of board games.” It was a feat reminiscent of the controversial victory by [IBM’s Deep Blue](https://en.wikipedia.org/wiki/Deep_Blue_versus_Garry_Kasparov) over world chess champion Garry Kasparov.
Checkers, chess, and Go are described as complete information games. Both players are able to observe the full state of the game at any time. While players might keep their strategies secret, what opportunities they have available are commonly known. Texas Hold'em Poker, on the other hand, is an [incomplete information game](https://www.cs.cmu.edu/~sandholm/Solving%20games.Science-2015.pdf). Each player has private information which the other players do not know. Players, therefore, must reason about their opponents probabilistically.
### Playing the Hand
In Heads-Up Texas Hold'em, two players are randomly dealt two face down cards, referred to as the “hole cards.” The hand begins with a betting round called the “pre-flop,” in which players have the options to check, call, raise or fold. Once all the betting in the pre-flop has finished, three community cards called “the flop” are dealt face up in the middle of the table. After the flop, there is a second betting round, and then a single community called “the turn” is dealt, followed by a third betting round. A single final shared card called “the river” is then dealt, followed by the fourth round of betting. All five cards are visible to every player. Due to the random nature of the game and two initial concealed cards, the players’ bets during each of betting round are predicated on guessing what their opponents might do, using intuition.
Once the five cards are laid out, if a player places a bet that forces all other players fold, the remaining player wins the pot. But if two or more players remain after the final betting round, the players enter into the showdown. At this point, each player must make the best poker hand using any combination of their two hole-cards and five community cards. Poker hands must have five cards, and the best poker hand wins the pot.
Given the structure of poker, it is possible for an AI program to calculate the odds and play accordingly, but the approach to betting is less straightforward. For example, if the AI had a pattern of betting high every time it had a good hand, a human player could quickly figure this out and strategize accordingly. For this reason, designing an AI player not only requires the ability to bluff but also correctly interpret ambiguous information to win.
### Variations in Hold’em
It’s also important to note that the no-limit Hold’em poker variation is considerably more complex than limit Hold’em.
In limit Hold’em, bets are structured with betting amounts capped to a fixed sum. Understanding the mathematical principles guiding the game is most important, and being able to calculate the implied odds can help determine an appropriate play. An earlier AI poker-bot developed by the University of Alberta researchers, called [Cepheus](http://poker.srv.ualberta.ca/about)
), [solved Heads Up limit Hold’em using ‘brute force’](http://science.sciencemag.org/content/347/6218/145). According to Cepheus’ developers, there is a “perfect play” that can be determined by running through a massive table of all possible $3 \times 10^{14}$ permutations in limit poker.
On the other hand, in no-limit Hold'em, the minimum bet is equal to the big blind, and players can always bet much more as they want. A player can create situations that could isolate players by raising 4x or 5x the big blind, forcing most players to fold most hands. This pre-flop betting/isolation strategy gives a player a better 'read,' but there are no set moves for each situation. A game between two players in Heads-Up no-limit poker produces 10,160 possible game scenarios (which is on par with the 10,170 possible moves in Go), compared to 1,014 possible situations in limit poker. This takes some degree of brute force to build as close to an optimal strategy as possible.
### No-Limit Poker Bot Strategies
In an incomplete information game like no-limit poker, one way to find the best strategy is to find a [Nash equilibrium](https://en.wikipedia.org/wiki/Nash_equilibrium) for the game, which is exactly what the two AI programs, Libratus and DeepStack, attempt to do. A Nash equilibrium is a pair of strategies for playing the game where neither player can improve their reward by changing their strategy as long as the other player’s strategy remains the same. When playing such a pair of strategies, neither player has any incentive to change strategies. To compute the Nash equilibria of the game, both Libratus and DeepStack use an algorithm called counterfactual regret minimization (CFR).
#### DeepStack's intuition
To determine the best play, DeepStack draws on a set of possible moves by calculating the likelihood of the type of scenario it could encounter-- [something its developers like to compare to intuition](https://arxiv.org/pdf/1701.01724v1.pdf). DeepStack’s researchers train the AI’s intuition using two neural networks: one learns to estimate the counterfactual values after ‘the flop’ cards are dealt, and the second neural network recalculates the values after ‘the turn’ card is dealt. Using the CFR algorithm, DeepStack comes up with the best possible play in a given situation by comparing different possible outcomes using game theory. By itself, CFR would still run into the same problem of trying to calculate all possible possible plays. DeepStack gets around this by only having the CFR algorithm solve for a few moves ahead instead of all possible moves until the end of the game. This simplifies the number of situations and effectively prunes the decision tree it has to compute, thereby making it easier to approximate the Nash equilibrium. Researchers at the University of Alberta and two Czech universities wrote in [Science](https://arxiv.org/pdf/1701.01724.pdf), “DeepStack computes this strategy during play and only for the states of the public tree that actually arise during play.” This means that DeepStack doesn’t have an overarching strategy decided before the game and doesn’t need to keep tabs on all possible abstract situations; therefore, it can computer the decision in seconds. In this case, the DeepStack team trained their AI on the best solutions of the CFR algorithm for random poker situations. That allowed DeepStack’s intuition to become a “fast approximate estimate” of its best solution for the rest of the game without having to actually calculate all the possible moves.
#### How did Libratus win?
Unlike DeepStack, Libratus does not use neural networks and plays with end-game solving, which requires a supercomputer to run 15 million core hours. CMU researchers also claim that Libratus uses faster method to find a Nash equilibria and develops better endgame-solving approach, which are powered by the Pittsburgh Supercomputing Center's Bridges supercomputer. Although the exact details behind Libratus’s mechanism will remain vague until researchers from Carnegie Mellon University publish their work in a paper, Libratus generally relies on three different systems that work together. The first system uses a trial-and-error process known as reinforcement learning, which is what Google’s DeepMind lab used in building AlphaGo. However, there’s a key difference between the two AI programs: instead of learning from the play of human experts, [like AlphaGo did](https://blog.google/topics/machine-learning/alphago-machine-learning-game-go/), Libratus learned from scratch by playing trillions of simulated hands against itself. Using a special variant of Counterfactual Regret Minimization, Libratus was able to learn from its own experiences and play strategies at a complexity in ways humans could not match—playing a much wider range of bets and randomizing and mixing these bets with different bluff ranges and play styles. A second system, called an end-game solver, allows Libratus to learn from games as it was actually playing. With the help of this second system – [detailed in their paper published in March 2017](http://www.cs.cmu.edu/~noamb/papers/17-AAAI-Refinement.pdf) - the first system doesn’t have to run through all the possible scenarios. These two systems together would have been sufficient, but a third system was put in place to prevent the other players from finding patterns in Libratus’ play and exploit them. This third system would run an algorithm overnight to identify patterns and remove them so that Libratus would be pattern-free for play the next day.
So which one is better? It’s hard to compare the abilities of Libratus with DeepStack without them playing against each other. Both poker bots can only play against one other player. Both AIs also played just enough hands to have statistically significant wins. Perhaps the next challenge for both Libratus and DeepStack to tackle would be to play against multiple players all at once.
### Conclusion
Poker involves unique challenges not present in complete information games, and these two poker-bots mark a huge milestone in AI. Game-playing AIs that can understand incomplete information scenarios have important real-life implications. One of the next challenges for AIs is to learn how mimic complex human decision-making to tackle real-world issues with incomplete information.
|
Markdown
|
UTF-8
| 5,121 | 3.1875 | 3 |
[
"Apache-2.0"
] |
permissive
|
# ImageDiff
Tool for image comparison. Features:
* UI console showing differences, allowing user to make captured images a new baseline
* ability to exclude dynamic areas of images that should not be compared
> Note that for now we only support PNG images
## Prerequisites
`node` and `npm` packages have to be installed on the system, they are used by the tool.
Node `8.6.0+` is required, check https://nodejs.org/en/download/package-manager/#debian-and-ubuntu-based-linux-distributions for installation details.
It is recommended to use Git LFS to version images. Download and install the package https://git-lfs.github.com/, then run `git lfs install` in your git project. If you had pulled the changes from LFS before you installed the Git LFS, run `git lfs pull` to download the linked files. From this moment, you're good to go.
## Installation
```
npm install
```
## Usage
### Standalone
You need to capture stdout, stderr and process status code if you need to receive any results from it.
```js
node runner.js <directory with baseline images> <directory with captured images> [UI console port] [mode] [aliasing px] [color delta]
```
### Direct usage from NPM package
```js
const {compareImages, Status, Mode, Default} = require('@showmax/imagediff');
const options = { baselinePath: '/path', capturedPath: '/path', port: 8008, mode: Mode.WITH_CONSOLE, aliasingPx: 4, colorDelta: 75 }
const result = compareImages(options);
if (result.status !== Status.IMAGES_SAME) {
// handle error
}
```
### Options (for standalone / direct usage of imagediff)
* **all paths must be absolute**
* `baselinePath`: directory where all 'template' images are stored or an image path
* `capturedPath`: directory where you save screenshots during a test run or an image path
* `[port]`: port for UI console which opens in case there is a difference between captured and baselined images (default: 8008)
* `[mode]`: default mode `Mode.WITH_CONSOLE` starts a UI console each time a diff is found, the other option is `MODE_NO_CONSOLE` which simply compares images and returns the result
* `[aliasingPx]`: area of surrounding pixels that are treated less strictly then usual, handy when for example browsers render fonts a little bit differently (default: 4)
* `[colorDelta]`: allowed difference of color (in RGB colorspace) that is not considered as image difference (values in range 0-255, default: 75)
Value returned in direct usage is an object with the following properties
* `status`
* `messages`: debug messages for triage
* `errorMessages`: error messages (can be empty)
### Status codes
For most recent status codes, see the source code - `Status` object.
### Results
By default, all results are stored in system's `/tmp/tmp-***********` dir. But for convenience, if there is a `WORKSPACE` env variable, it's used instead and results are stored in `$WORKSPACE/imagediff-results-******`. This may be handy especially when running the comparison on Jenkins with intention to archive artifacts.
### Exclusion of certain parts of an image
This can be handy if your screenshot contains areas that are different every time you take it (time / date / username / ...). In such case you want don't want to include these parts when comparing images.
The configuration is pretty simple. For each test case (e.i. bunch of screenshots for one flow), you create a `excluded-regions.json` file in the directory where image is located (usually the test case directory). The content is as follows:
```json
{
"image-name.png": [
{
"x": 10,
"y": 10,
"width": 50,
"height": 50
}
],
"*": [
{
"x": 10,
"y": 10,
"width": 50,
"height": 50
}
]
}
```
So basically you specify top-left coordinates of a rectangle and its dimensions to create excluded area. You can have as many areas per one image as you want.
In case you have all screenshots with dynamic area in the same place (e.g. part of header, footer, ...) you can use a wildcard character `*` which then applies defined exclusions to all files in the directory (together with exclusions for a particular file).
> If you don't want to configure the coordinates manually in the file, you can use the UI console for it.
## Baseline Recommendations
Even though it's up to you how you store baseline screenshots, the recommended way is to have the following directory structure:
```
baseline
├── < environment name - e.g. browserstack/chrome/... >
│ └── < test case name - e.g. sign_in >
│ ├── 0001-screen1.png
│ ├── 0001-screen2.png
│ └── excluded-regions.json
│
└── chrome
├── adds_recurrent_credit_card_with_new_layout
│ ├── 0001-payment_methods.png
│ └── 0002-cc_form_filled.png
└── adds_recurrent_credit_card_with_old_layout
├── 0001-payment_methods.png
└── 0002-cc_form_filled.png
```
To sum it up, the structure is: `environment -> test case -> screenshots`. Following this recommendation will give you clearer results.
|
C++
|
UTF-8
| 2,703 | 2.8125 | 3 |
[
"LicenseRef-scancode-public-domain"
] |
permissive
|
/*
Dado eletrônico com Franzininho DIY e um módulo matriz de LED 8x8 com MAX7219
by Anderson Costa with ❤ for the Wokwi community
Visit https://wokwi.com to learn about the Wokwi Simulator
Visit https://franzininho.com.br to learn about the Franzininho
*/
#include <LedControl.h>
#include <TinyDebug.h>
#define CLK_PIN PB0
#define CS_PIN PB1
#define DIN_PIN PB2
#define BTN_PIN PB3
#define RND_PIN A0
#define MAX_SEG 1
// Define os padrões binários para cada número do dado (1 a 6) e nenhum
uint8_t dice[7][8] = {
{ B00000000, B00000000, B00000000, B00000000, B00000000, B00000000, B00000000, B00000000 }, // Zero
{ B00000000, B00000000, B00000000, B00011000, B00011000, B00000000, B00000000, B00000000 }, // Um
{ B00000000, B01100000, B01100000, B00000000, B00000000, B00000110, B00000110, B00000000 }, // Dois
{ B11000000, B11000000, B00000000, B00011000, B00011000, B00000000, B00000011, B00000011 }, // Três
{ B00000000, B01100110, B01100110, B00000000, B00000000, B01100110, B01100110, B00000000 }, // Quatro
{ B11000011, B11000011, B00000000, B00011000, B00011000, B00000000, B11000011, B11000011 }, // Cinco
{ B00000000, B11011011, B11011011, B00000000, B00000000, B11011011, B11011011, B00000000 } // Seis
};
// Define os pinos da matriz de LEDs
LedControl led = LedControl(DIN_PIN, CLK_PIN, CS_PIN, MAX_SEG); // MAX7219
bool waitDice = false;
uint8_t numberDice = 0;
void setup() {
Debug.begin();
delay(100);
Debug.println("Clique no botão para jogar o dado...");
pinMode(BTN_PIN, INPUT_PULLUP);
led.shutdown(0, false);
// Para o random não repetir a sequência
randomSeed(analogRead(RND_PIN));
// Ajusta o brilho da matriz de LEDs para intensidade média
led.setIntensity(0, 7);
// Limpa o display
led.clearDisplay(0);
}
void loop() {
// Verifica o pressionamento do botão
if (!digitalRead(BTN_PIN) && !waitDice) {
waitDice = true; // Trava o botão até o final da rolagem
rollsDice(); // Rola o dado
}
}
void showDice(uint8_t number) {
// Percorre a matriz e seta o número
for (uint8_t i = 0; i <= 7; i++) {
led.setRow(0, i, dice[number][i]);
}
}
void rollsDice() {
uint8_t rollingTime = random(10, 15);
for (uint8_t i = 0; i < rollingTime; i++) {
// A variável number vai assumir um valor entre 1 e 6
numberDice = random(1, 7);
showDice(numberDice);
Debug.print(numberDice);
if (i < rollingTime - 1)
Debug.print(", ");
else
Debug.print(" ");
delay(100 + i * 10);
}
showDice(0);
delay(500);
showDice(numberDice);
delay(250);
Debug.print("=> ");
Debug.println(numberDice);
waitDice = false; // Libera o botão para jogar novamente
}
|
Java
|
UTF-8
| 1,231 | 3.5 | 4 |
[] |
no_license
|
package week2.day1;
public class ArraySearchTest {
public static void main(String[] args) {
int[] arr = new int[100_000];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
int number = 2023;
boolean isIn = false;
long startTime;
long endTime;
int countIteration = 0;
// simple search
startTime = System.nanoTime();
// for (int i = 0; i < arr.length; i++) {
// countIteration++;
// if(arr[i] == number) {
// isIn = true;
// break;
// }
// }
int start = 0, end = arr.length - 1;
while (start <= end){
int mid = (start + end) / 2;
countIteration++;
if(arr[mid] == number){
isIn = true;
break;
} else if (arr[mid] > number) {
end = mid -1;
} else {
start = mid + 1;
}
}
endTime = System.nanoTime();
System.out.println("Found - " + isIn);
System.out.println("Iteration - " + countIteration);
System.out.println("Time - " + (endTime - startTime));
}
}
|
Markdown
|
UTF-8
| 397 | 2.65625 | 3 |
[] |
no_license
|
# Vanilla Javascript project
The purpose of this project is to practice some css, html and javascript concepts. The drums, sorting_bands and todo_list was used some info a design inspiration from [this course](https://javascript30.com/).
## Recommended
Want to practice more javascript, css, and html, go to [Wesbos Course](https://javascript30.com/). It is a complete course of those subjects.
|
Markdown
|
UTF-8
| 2,245 | 2.53125 | 3 |
[
"Unlicense"
] |
permissive
|
# У Мукачевому зацвіла «скажена сакура»
Published at: **2019-11-06T12:30:47+00:00**
Author: ****
Original: [ГЛАВКОМ](https://glavcom.ua/country/society/u-mukachevomu-zacvila-skazhena-sakura-638113.html)
У центрі міста Мукачеве знову зацвіла «скажена сакура», що квітне кожного року в листопаді.
Про це повідомив місцевий гід Максим Адаменко, пише Укрінформ.
«У Мукачевому традиційно у листопаді зацвіла «скажена сакура». Це дерево щороку квітне восени. Весною вона також зацвітає однією з перших поміж сакур у місті», - сказав гід.
Гілки сакури, що росте на одній з центральних площ міста — на площі Федорова, на цьому тижні де-не-де вкрилися рожевими квітками.
«Дехто із дослідників пояснює це цвітіння тим, що начебто сакура росте над теплотрасою, але це гіпотеза. Таку аномальну властивість мають іще кілька дерев у місті, які ростуть в інших, нетуристичних, районах і тому не такі примітні. Біологи кажуть, що насправді цвітіння двічі на рік виснажує дерево», - каже Адаменко.
1 з 7на весь екран згорнути
Всі фоторепоратажі
Ця сакура є улюбленицею і у туристів, і у містян: майже усі викладають в соцмережі світлини з рожевими квітками на фоні жовтого листя.
Як повідомлялося, у місті Мукачеві на Закарпатті росте найдовша алея сакур — 1, 3 км. по вулиці Ужгородській. Тут висаджено 252 сакури.
|
Java
|
UTF-8
| 341 | 1.867188 | 2 |
[] |
no_license
|
package com.lzj.Feign;
import com.lzj.bean.Student;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.List;
@FeignClient(name = "provider-service")
public interface ConsumerFeign {
@GetMapping("/student/findAll")
public List<Student> findAll();
}
|
Java
|
UTF-8
| 2,642 | 2.125 | 2 |
[] |
no_license
|
package com.dayanghome.dayangerp.service;
import com.dayanghome.dayangerp.form.AppointmentForm;
import com.dayanghome.dayangerp.form.AppointmentQuery;
import com.dayanghome.dayangerp.form.CustomerQuery;
import com.dayanghome.dayangerp.mapper.AppointmentMapper;
import com.dayanghome.dayangerp.mapper.CustomerMapper;
import com.dayanghome.dayangerp.vo.Appointment;
import com.dayanghome.dayangerp.vo.Customer;
import com.google.common.base.Strings;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import java.util.Set;
@Service
public class AppointmentService {
private static final Logger Log = LoggerFactory.getLogger(AppointmentService.class);
@Autowired AppointmentMapper appointmentMapper;
@Autowired CustomerMapper customerMapper;
@Transactional
public int addAppointment(AppointmentForm form){
Customer customer = form.extractCustomer();
boolean exist = false;
if(!Strings.isNullOrEmpty(form.getMobile())){
List<Customer> existed = customerMapper.findByMobile(form.getMobile());
if(existed != null && existed.size() > 0) {
customer = existed.get(0);
exist = true;
}
}
if(!exist){
customerMapper.insertCustomer(customer);
Log.info("insert new custom id {}, detail {}", customer.getId(), customer);
}
Appointment appointment = form.extractAppointment();
appointment.setCustomerId(customer.getId());
appointment.setCustomerName(customer.getChineseName());
appointmentMapper.insertAppointment(appointment);
return appointment.getId();
}
public List<Appointment> searchAppoint(AppointmentQuery query){
return appointmentMapper.searchAppointment(query);
}
public int countAppointments(AppointmentQuery query){
return appointmentMapper.countByQuery(query);
}
@Transactional
public int updateAppointmentStatus(Integer appointmentId, Integer toStatus){
return appointmentMapper.updateAppointmentStatus(appointmentId, toStatus);
}
@Transactional
public int deleteAppointment(Integer appointmentId){
return appointmentMapper.deleteAppointment(appointmentId);
}
@Transactional
public int addCommentOnAppointment(Integer appointmentId, String comment){
return appointmentMapper.addCommentOnAppointment(appointmentId, comment);
}
}
|
C++
|
UTF-8
| 10,459 | 2.65625 | 3 |
[] |
no_license
|
/*
* AdminIndicesSecundarios.cpp
*
* Created on: 17/11/2014
* Author: joaquin
*/
#include "AdminIndicesSecundarios.h"
#include "../Capa Logica/ArbolBMas/ArbolBMas.h"
#define MODIFICACION 1
AdministradorIndices::AdministradorIndices(){
this->indices = new list<Indice>;
this->indicesCreados = fopen("indicesCreados.txt","r+b");
if(!this->indicesCreados)this->indicesCreados = fopen("indicesCreados.txt","w+");
this->inicializarIndices();
}
AdministradorIndices::~AdministradorIndices(){
list<Indice>::iterator it = this->indices->begin();
while (it != this->indices->end()){
if(it->tipo == ARBOL) delete it->arbol;
else delete it->hash;
++it;
}
fclose(this->indicesCreados);
}
void AdministradorIndices::inicializarIndices(){
Indice* indice = new Indice();
rewind(this->indicesCreados);
char nombreArchivo[LARGO_CADENA];
char nombreEntidad[LARGO_CADENA];
char nombreAtributo[LARGO_CADENA];
int tipoIndice, cantAtributos;
list<string>* nombresAtributos = new list<string>;
while(fscanf(this->indicesCreados,"%s", nombreArchivo) != EOF){
fscanf(this->indicesCreados,"%d", &tipoIndice);
fscanf(this->indicesCreados,"%s %d",nombreEntidad, &cantAtributos);
indice->nombreArchivo = StringUtil::charToString(nombreArchivo);
indice->tipo = tipoIndice;
if(tipoIndice == ARBOL){
indice->arbol = new ArbolBMas(rutaBaseIndiceSec + nombreArchivo);
indice->hash = NULL;
}else{
indice->hash = new Hash(rutaBaseIndiceSec + nombreArchivo + rutaTabla,rutaBaseIndiceSec + nombreArchivo + rutaNodos);
indice->arbol = NULL;
}
indice->nombreEntidad = StringUtil::charToString(nombreEntidad);
for(int i = 0; i < cantAtributos; i++){
fscanf(this->indicesCreados,"%s",nombreAtributo);
nombresAtributos->push_back(nombreAtributo);
}
indice->nombresAtributos = nombresAtributos;
nombresAtributos = new list<string>;
this->indices->push_back(*indice);
indice = new Indice();
}
}
int AdministradorIndices::listar_indices(){
list<Indice>::iterator it = this->indices->begin();
int i = 0;
while (it != this->indices->end()){
cout << i << " - Indice secundario de entidad: "
<< it->nombreEntidad << endl;
cout << "\t \t Ordenado por: ";
list<string>::iterator itNameAtt = it->nombresAtributos->begin();
cout << *itNameAtt;
while (itNameAtt != it->nombresAtributos->end()){
++itNameAtt;
if (itNameAtt != it->nombresAtributos->end()) cout << ", " << *itNameAtt;
}
cout << endl;
++it;
++i;
}
return i;
}
void AdministradorIndices::mostrar_indice(int x){
list<Indice>::iterator it = this->indices->begin();
for (int i = 0; i < x; ++i) {
++it;
}
if (it->tipo == ARBOL) it->arbol->mostrarArbol();
else it->hash->mostrarHash();
}
void AdministradorIndices::eliminar_indice(){
int max = this->listar_indices();
cout << "Elija el indice que desea eliminar:";
int x; cin >> x;
if (x <= max) {
list<Indice>::iterator it = this->indices->begin();
int i;
for (i=0; i < x; ++i ) ++it;
this->indices->erase(it);
this->actualizarIndices();
}
}
void AdministradorIndices::actualizarIndices(){
fclose(this->indicesCreados);
this->indicesCreados = fopen("indicesCreados.txt","w+");
list<Indice>::iterator it = this->indices->begin();
while (it != this->indices->end()) {
Indice indice;
indice.arbol = it->arbol;
indice.nombresAtributos = it->nombresAtributos;
indice.hash = it->hash;
indice.nombreArchivo = it->nombreArchivo;
indice.nombreEntidad = it->nombreEntidad;
indice.tipo = it->tipo;
this->persistirIndice(&indice);
++it;
}
}
void AdministradorIndices::agregar(Instancia* instancia, string nombreEntidad){
list<Indice>::iterator itIndices = this->indices->begin();
string claveNueva;
while (itIndices != this->indices->end()) {
claveNueva = "";
if (itIndices->nombreEntidad == nombreEntidad){
list<string>::iterator itNombresAtributos = itIndices->nombresAtributos->begin();
while (itNombresAtributos != itIndices->nombresAtributos->end()){
list<metaDataAtributo>::iterator itMetaDataNueva = instancia->getListaMetaData()->begin();
int indiceAtributo = 1;
while (itMetaDataNueva != instancia->getListaMetaData()->end()){
if(*itNombresAtributos == itMetaDataNueva->nombre){
//Validar el tipo de atributo devuelto
Atributo* att = instancia->getAtributo(indiceAtributo);
if (itMetaDataNueva->tipo == TEXTO) {
claveNueva += att->texto;
} else {
claveNueva += StringUtil::int2string(att->entero);
}
claveNueva += separadorClaves;
}
++indiceAtributo;
++itMetaDataNueva;
}
++itNombresAtributos;
}
}
if (!claveNueva.empty()){
if(itIndices->tipo == ARBOL) {
itIndices->arbol->agregarValor(*(new Clave(claveNueva)),StringUtil::int2string(instancia->getID()));
} else {
itIndices->hash->insertarElemento(claveNueva,StringUtil::int2string(instancia->getID()));
}
}
++itIndices;
}
}
void AdministradorIndices::eliminar(Instancia* instanciaVieja, string nombreEntidad) {
list<Indice>::iterator itIndices = this->indices->begin();
string claveVieja;
while (itIndices != this->indices->end()) {
claveVieja = "";
if (itIndices->nombreEntidad == nombreEntidad){
list<string>::iterator itNombresAtributos = itIndices->nombresAtributos->begin();
while (itNombresAtributos != itIndices->nombresAtributos->end()){
list<metaDataAtributo>::iterator itMetaDataVieja = instanciaVieja->getListaMetaData()->begin();
int indiceAtributo = 1;
while (itMetaDataVieja != instanciaVieja->getListaMetaData()->end()){
if(*itNombresAtributos == itMetaDataVieja->nombre){
//Validar el tipo de atributo devuelto
Atributo* att = instanciaVieja->getAtributo(indiceAtributo);
if (itMetaDataVieja->tipo == TEXTO) {
claveVieja += att->texto;
} else {
claveVieja += StringUtil::int2string(att->entero);
}
claveVieja += separadorClaves;
}
++indiceAtributo;
++itMetaDataVieja;
}
++itNombresAtributos;
}
}
if (!claveVieja.empty()){
if (itIndices->tipo == ARBOL){
itIndices->arbol->borrarValor(*(new Clave(claveVieja)),StringUtil::int2string(instanciaVieja->getID()));
} else {
itIndices->hash->elminarElemento(claveVieja);
}
}
++itIndices;
}
}
void AdministradorIndices::actualizar(Instancia* instanciaNueva,Instancia* instanciaVieja, string nombreEntidad){
/*
* - Recibo instancia actualizada y el nombre de la entidad a la que pertenece
* - Recorro la lista de indices hasta encontrar un indice cuya entidad coincida
* con la entidad que recibo por parametro
* - Recorro la lista de nombres de atributos del indice y la lista de metadata de la instancia
* - Por cada coincidencia entre el nombreAtrib del indice y el nombre de la lista de metadata,
* hago un getAtributo() y lo agrego a un string
* - agrego el string al arbol
*/
this->eliminar(instanciaVieja,nombreEntidad);
//Luego agrego la clave nueva
this->agregar(instanciaNueva,nombreEntidad);
}
void AdministradorIndices::persistirIndice(Indice* indice){
//[nombreArchivo tipoIndice nombreEntidad cantidadAtributos nombreAtributo+]
fprintf(this->indicesCreados,"%s ",StringUtil::stringToChar(indice->nombreArchivo));
fprintf(this->indicesCreados,"%i %s ", indice->tipo, StringUtil::stringToChar(indice->nombreEntidad));
fprintf(this->indicesCreados,"%zu ",(indice->nombresAtributos)->size());
list<string>::iterator itAtt = indice->nombresAtributos->begin();
while(itAtt != indice->nombresAtributos->end()){
fprintf(this->indicesCreados,"%s ",StringUtil::stringToChar(*itAtt));
++itAtt;
}
fprintf(this->indicesCreados,"\n");
}
void AdministradorIndices::crear_indice(Entidad* entidad){
Indice indice;
indice.nombreEntidad = entidad->getNombre();
cout << "Ingrese el nombre del indice secundario: " << endl;
string nombre; cin >> nombre;
indice.nombreArchivo = nombre;
cout << "Ingrese el tipo de estructura para el indice secundario:" << endl;
cout << " 1). Arbol B+" << endl;
cout << " 2). Hash" << endl;
int tipo, opc; cin >> tipo;
indice.tipo = tipo;
ArbolBMas* arbol = NULL;
Hash* hash = NULL;
metaDataAtributo* dataAtributo;
list<metaDataAtributo>* atts = new list<metaDataAtributo>;
list<int>* numeroAtts = new list<int>;
list<string>* nombresAtributos = new list<string>;
if (tipo==ARBOL)arbol = new ArbolBMas(rutaBaseIndiceSec + nombre);
else hash = new Hash(rutaBaseIndiceSec + nombre + rutaTabla,rutaBaseIndiceSec + nombre + rutaNodos);
cout << "Ingrese los atributos que formaran parte del indice:" << endl;
entidad->listarAtributos();
int x; cin >> x;
dataAtributo = entidad->getAtributo(x);
atts->push_back(*dataAtributo);
nombresAtributos->push_back((*dataAtributo).nombre);
numeroAtts->push_back(x);
//PEDIR MAS ATRIBUTOS
cout << "Desea agregar otro atributo? 1.Si / 2.No: ";
cin >> opc;
while(opc == 1){
entidad->listarAtributos();
cin >> x;
dataAtributo = entidad->getAtributo(x);
atts->push_back(*dataAtributo);
nombresAtributos->push_back((*dataAtributo).nombre);
numeroAtts->push_back(x);
cout << "Desea agregar otro atributo? 1.Si / 2.No: ";
cin >> opc;
}
indice.nombresAtributos = nombresAtributos;
string claveStr = "";
Atributo* atributoInstancia;
for (int i = 1; i <= entidad->getUltimoIDInstancia(); ++i) {//i es el ID de la instancia
bool error;
Instancia* nuevaInstancia = entidad->getInstancia(i,error);
string claveStr = "";
if (!error) {
// CONCATENA CLAVES
list<metaDataAtributo>::iterator itAtt = atts->begin();
list<int>::iterator itNum = numeroAtts->begin();
while(itAtt != atts->end()){
atributoInstancia = nuevaInstancia->getAtributo(*itNum);
if (itAtt->tipo == TEXTO) {
claveStr += atributoInstancia->texto;
} else {
claveStr += StringUtil::int2string(atributoInstancia->entero);
}
++itAtt;
++itNum;
claveStr += separadorClaves;
}
// AGREGA VALOR CON CLAVE CONCATENADA.
if (tipo==ARBOL) {
arbol->agregarValor(*(new Clave(claveStr)),StringUtil::int2string(i));
} else {
hash->insertarElemento(claveStr,StringUtil::int2string(i));
}
}
}
if (tipo == ARBOL){
arbol->persistir();
indice.hash = NULL;
indice.arbol = arbol;
this->indices->push_back(indice);
} else {
indice.arbol = NULL;
indice.hash = hash;
this->indices->push_back(indice);
}
this->persistirIndice(&indice);
}
|
JavaScript
|
UTF-8
| 3,914 | 2.53125 | 3 |
[] |
no_license
|
import * as d3 from 'd3';
import { attrs } from 'd3-selection-multi';
// ================================ aula 28 ================================----
// ================================ [Axis Generator] ================================---
// const dim = {
// width: 600,
// height: 400,
// };
// const svgCanvas = d3.select('body').append('svg').style('background', 'lightgray').attrs(dim);
// let data = [10, 29, 130, 240, 250, 360, 370, 610, 820, 480, 690, 510];
// let months = ['Jan', 'Fev', 'Mar', 'Abr', 'Mai', 'Jun', 'Jul', 'Ago', 'Set', 'Out', 'Nov', 'Dez'];
// const scaleX = d3.scalePoint(months, [50, 550]); // ([domain], [range])
// const scaleY = d3.scaleLinear(d3.extent(data), [350, 50]); // ([domain], [range])
// let axisX = d3.axisBottom(scaleX);
// let axisY = d3.axisLeft(scaleY);
// svgCanvas.append('g').attr('transform', 'translate(0, 350)').call(axisX);
// svgCanvas.append('g').attr('transform', 'translate(50, 0)').call(axisY);
// ================================ aula 29 ================================----
// ================================ [Axis Styling] ================================---
// const dim = {
// width: 600,
// height: 400,
// };
// const svgCanvas = d3.select('body').append('svg').style('background', 'lightgray').attrs(dim);
// let data = [10, 29, 130, 240, 250, 360, 370, 610, 820, 480, 690, 510];
// let months = ['Jan', 'Fev', 'Mar', 'Abr', 'Mai', 'Jun', 'Jul', 'Ago', 'Set', 'Out', 'Nov', 'Dez'];
// const scaleX = d3.scalePoint(months, [50, 550]); // ([domain], [range])
// const scaleY = d3.scaleLinear(d3.extent(data), [350, 50]); // ([domain], [range])
// let axisX = d3.axisBottom(scaleX);
// let axisY = d3.axisLeft(scaleY);
// // axisY.ticks(10);
// axisY.tickValues([40, 100, 300, 500, d3.max(data)]);
// // axisY.tickFormat((d) => '$ ' + d);
// axisX.tickSize(15);
// svgCanvas
// .append('g')
// .attr('transform', 'translate(0, 350)')
// .call(axisX)
// .selectAll('text')
// .attrs({ 'font-size': 12, transform: 'translate(-24, 10), rotate(320)' });
// svgCanvas.append('g').attr('transform', 'translate(50, 0)').call(axisY);
// ================================ aula 30 ================================----
// ================================ [Grid] ================================---
const dim = {
width: 600,
height: 400,
};
const svgCanvas = d3.select('body').append('svg').style('background', 'lightgray').attrs(dim);
let data = [10, 29, 130, 240, 250, 360, 370, 610, 820, 480, 690, 510];
let months = ['Jan', 'Fev', 'Mar', 'Abr', 'Mai', 'Jun', 'Jul', 'Ago', 'Set', 'Out', 'Nov', 'Dez'];
const scaleX = d3.scalePoint(months, [50, 550]); // ([domain], [range])
const scaleY = d3.scaleLinear(d3.extent(data), [350, 50]); // ([domain], [range])
let axisX = d3.axisBottom(scaleX);
let axisY = d3.axisLeft(scaleY);
let gridY = d3.axisLeft(scaleY);
axisY.ticks(10);
// axisY.tickValues([40, 100, 300, 500, d3.max(data)]);
// axisY.tickFormat((d) => '$ ' + d);
gridY.tickSize(-500).tickFormat('').tickSizeOuter(0);
svgCanvas
.append('g')
.attr('transform', 'translate(0, 360)')
.call(axisX)
.selectAll('text')
.attrs({ 'font-size': 12, transform: 'translate(-24, 10), rotate(320)' });
svgCanvas.append('g').attr('transform', 'translate(50, 0)').call(axisY);
svgCanvas.append('g').attr('transform', 'translate(50, 0)').call(gridY).selectAll('line').attrs({
stroke: 'grey',
'stroke-dasharray': '5, 3',
});
// ================================ aula 31 ================================----
// ================================ [Animations] ================================---
// ================================ aula 32 ================================----
// ================================ [] ================================---
// ================================ aula 33 ================================----
// ================================ [] ================================---
|
C#
|
UTF-8
| 1,191 | 2.609375 | 3 |
[
"Apache-2.0"
] |
permissive
|
using System;
using System.Threading;
using System.Threading.Tasks;
namespace CQRSRx.Domain
{
/// <summary>
/// Asynchronous aggregate root repository.
/// </summary>
public interface IAggregateRootRepository<TAggregateRoot> where TAggregateRoot : IAggregateRoot
{
/// <summary>
/// Retrieves the aggregate root asynchronously.
/// </summary>
/// <param name="id">The Id of the aggregate root object.</param>
/// <param name="cancellationToken">The custom cancellation token.</param>
/// <returns>The correspondent task that will yield the aggregate root object.</returns>
Task<TAggregateRoot> LoadAsync(Guid id, CancellationToken cancellationToken);
/// <summary>
/// Atomically commits the pending changes of the aggregate root asynchronously.
/// </summary>
/// <param name="aggregate">The aggregate to commit.</param>
/// <param name="cancellationToken">The custom cancellation token.</param>
/// <returns>The correspondent task for the save operation.</returns>
Task SaveAsync(TAggregateRoot aggregate, CancellationToken cancellationToken);
}
}
|
Java
|
GB18030
| 699 | 2.0625 | 2 |
[] |
no_license
|
package nc.bs.hrwa.allocate.ace.bp;
import nc.impl.pubapp.pattern.data.bill.BillUpdate;
import nc.vo.pub.VOStatus;
import nc.vo.wa.allocate.AggAllocateOutVO;
/**
* ˵BP
*/
public class AceAllocateApproveBP {
/**
* ˶
*
* @param vos
* @param script
* @return
*/
public AggAllocateOutVO[] approve(AggAllocateOutVO[] clientBills, AggAllocateOutVO[] originBills) {
for (AggAllocateOutVO clientBill : clientBills) {
clientBill.getParentVO().setStatus(VOStatus.UPDATED);
}
BillUpdate<AggAllocateOutVO> update = new BillUpdate<AggAllocateOutVO>();
AggAllocateOutVO[] returnVos = update.update(clientBills, originBills);
return returnVos;
}
}
|
JavaScript
|
UTF-8
| 363 | 2.578125 | 3 |
[] |
no_license
|
module.exports = {
name: 'twitch',
description: 'Sends a link to my twitch',
execute(message, args) {
if(!args[0]) {return message.reply("@mention who's twitch link you want")}
let mention = message.mentions.users.first().id;
if(mention === 327261354287431680)
message.author.send('This is my twitch: https://twitch.tv/bowlcakes25');
}
}
|
PHP
|
UTF-8
| 1,525 | 2.71875 | 3 |
[
"BSD-3-Clause"
] |
permissive
|
<?php
namespace app\components;
use GeoIp2\Database\Reader;
class CountryHelper
{
public static function getByIp()
{
$ip = self::getClientIp();
$country = '';
if (!self::isLocalIp($ip)) {
try {
$reader = new Reader(__DIR__ . '/../config/GeoIP2-Country.mmdb');
$record = $reader->country($ip);
if ($record == false) {
//use MaxMind\Db\Reader 修改文件,不会报错导致程序无法进行
} else {
$country = $record->country->isoCode;
}
} catch (ErrorException $e) {
// log
}
}
return $country;
}
private static function isLocalIp($ip)
{
return preg_match('#^(10|172\.16|127\.0|192\.168)\.#', $ip);
}
private static function getClientIp()
{
$ip = $_SERVER['REMOTE_ADDR'];
if (isset($_SERVER['HTTP_CLIENT_IP']) && preg_match('/^([0-9]{1,3}\.){3}[0-9]{1,3}$/', $_SERVER['HTTP_CLIENT_IP'])) {
$ip = $_SERVER['HTTP_CLIENT_IP'];
} elseif(isset($_SERVER['HTTP_X_FORWARDED_FOR']) AND preg_match_all('#\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}#s', $_SERVER['HTTP_X_FORWARDED_FOR'], $matches)) {
foreach ($matches[0] AS $xip) {
if (!preg_match('#^(10|172\.16|192\.168)\.#', $xip)) {
$ip = $xip;
break;
}
}
}
return $ip;
}
}
|
C++
|
UTF-8
| 2,470 | 3.25 | 3 |
[] |
no_license
|
//
// Created by yalavrinenko on 15.01.19.
//
#ifndef XRAY_TRACING_LIB_UTILS_HPP
#define XRAY_TRACING_LIB_UTILS_HPP
#include <vector>
#include <mutex>
#include <cstdio>
template <class TLogData>
class XRTFLogging{
public:
XRTFLogging() = default;
explicit XRTFLogging(std::string const &path):
log_path(path){
open(log_path);
}
void header(std::string const &header_data) {
if (logptr)
std::fprintf(logptr, "%s\n", header_data.c_str());
}
void flush(){
if (logptr) {
for (auto i=0u; i < index; ++i){
auto data = buffer[i].to_string();
fprintf(logptr, "%s\n", data.c_str());
}
index = 0;
}
}
void add_data(TLogData const &data){
if (logptr) {
buffer[index] = data;
++index;
if (buffer.capacity() == index)
flush();
}
}
bool is_open() const {
return logptr != nullptr;
}
~XRTFLogging(){
if (!logptr)
return;
this->flush();
std::fclose(logptr);
}
protected:
void open(std::string const &path){
if (path.empty()) {
logptr = nullptr;
return;
}
logptr = fopen(this->log_path.c_str(), "w");
if (!logptr)
throw std::runtime_error("Unable to open file:" + log_path);
buffer.resize(default_capacity);
index = 0;
}
private:
using xrt_logbuffer = std::vector<TLogData>;
const size_t default_capacity = 1000;
std::string log_path;
FILE* logptr = nullptr;
xrt_logbuffer buffer;
size_t index = 0;
};
template <class TData, class TStorage = std::vector<TData>>
class threadsafe_vector{
public:
threadsafe_vector() = default;
explicit threadsafe_vector(size_t limits = 0):
capacity((limits) ? limits : default_capacity), m_storage(capacity){
}
void add_data(TData const &value){
std::lock_guard<std::mutex> lg(write_mutex);
m_storage[iter] = value;
++iter;
}
void reset() {
std::lock_guard<std::mutex> lg(write_mutex);
iter = 0;
}
TStorage const& container() const{
return m_storage;
}
private:
const size_t default_capacity = 1000;
std::mutex write_mutex;
size_t capacity;
size_t iter{0};
TStorage m_storage;
};
#endif //XRAY_TRACING_LIB_UTILS_HPP
|
Markdown
|
UTF-8
| 5,384 | 2.984375 | 3 |
[] |
no_license
|
# Chapter 02 - Podcast Questions
Podcast Questions
Listen to the Podcast at [https://twit.tv/shows/floss-weekly/episodes/500](https://twit.tv/shows/floss-weekly/episodes/500 "Podcast Interview")
* 7:21 Who is Vicky Brasseur and what does she do?
* Vicky is the director Open Source Strategy for Juniper Networks and former Vice President of the Open Source Initiative. She actively does freelancing to help companies use open source software sustainably.She has more than 20 years experience in the industry and uses open source softwares for almost 30 years.
* 8:45 What has changed the most in regards to the term OpenSource in the last 25+ years?
* Open source software was something people had never heard off 25 years ago to the way we do business. Even if we want to keep the product internal(proprietary),we need a base of open source softwares, such as an open source programming language.
* 10:00 What is assumed to now be the default development pattern for new software?
* The default development of software includes making use of open source software rather than buying proprietary licensed software to build on top off. There are a few companies which are going all in on the open source wave but not as much as we think.
* 13:00 According to Randall, when a company publishes its code as OpenSource, what do they gain?
* Randal suggests that the reason for the number of companies to move to open source are less as the organizations do not know how to leverage advantages of open source .He advices that by uploading the source code. They are not only leveraging the workforce(someone withing the company) but also every user who has interest to use the software.
* 15:57 What do companies struggle with when they decide to opensource their codebase and core-products and how do they solve it?
* When the companies initially decide to move to open software and release thier code to the community,they feared now that thier product is out how will they earn money. Vicky suggests that the problem is with business model rather than the open source philosophy and suggests the organization to have a sound business model before releasing the code. Companies must have a thorough market research to know the demand and then use the open source softwares as a tool to turn profit.
* 19:00 What are some of the OpenSource companies?
* Hortonworks offers an extremely popular distribution of Hadoop, which was 6th on the list of top open source projects and is nearly synonymous with big data.RedHat is the world open source leader.MongoDB is one of the most popular NoSQL databases.
* 19:35 What are the majority of OpenSource companies strategies to make money?
* OpenSource companies focus on the business model to earn money for example support model used by RedHat includes selling of support like deployment and integration services,trainings,paid-certifications,bug-fixes etc.Hosting services like databricks.Open-core is a new model where all bust small peice of source code is proprietary
* 22:40 What do companies need to figure out about Free and OpenSource?
* Companies need to understand what open source software really means .It can be considered a right with reponsiblities. Not just organization but all the employees need to understand the importance of free and open source software and not just reap benefits but contribute back towards the community.
* 24:25 What is the term "Yak-Shaving" mean?
* The term yak shaving refers to all the extraneous tasks we need to get out of the way to actually start the task you were meant to do all along.
* 27:25 Who is Vicky's new book targeting?
* Vicky's book is targeting anybody who ever wanted to contribute to free and open source software but didn’t know how? She wants the audience to understand how important every community member contribution is be it a newbie or a unicorn developer.
* 28:03 What is the book about?
* The book covers topics which are neccecary and helpful to anybody who wants to contribute to Opensource. It gives steps as to how to contribute to the community,selecting project which is beneficial for both the one using the software and the community. The book also covers the history of free software movement.
* 33:25 What is the mistaken impression about contributing to OpenSource Software?
* The biggest mistaken impression about contributing to OpenSource Software is the fear of unable to code hence would not contribute. But this is so wrong . Documentation , Triaging bugs, or a small act like smoke testing is also contribution which is beneficial for the community.
* 37:40 What do you need to read before contributing to an OpenSource project?
* The first thing we must read before contributing to an OpenSource project is the contributing guide .
* 43:00 What does Vicky believe is important for a project to have and to enforce for a community?
* According to Vicky ,It is important for a project to have code of conduct and not just that, enforcing the code of conduct is a must.
* 48:01 What is the myth about users of proprietary operating systems (Windows and MacOS)?
* The myth about users of proprietary operating systems such and Windows and MacOs do not support use of open source software. This is wrong.
* 49:00 Vicky used Linux for 10 years, what drove her away from it?
* Vicky would find making Linux do what she wanted very difficult and time consuming.
|
C#
|
UTF-8
| 2,349 | 3.703125 | 4 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DelegateConsole
{
public class Program
{
static void PrintTitle(Book b)
{
Console.WriteLine("{0}", b.Title);
}
static void Main(string[] args)
{
/*********Simple Delegate*********/
BookDB bookDB = new BookDB();
bookDB.AddBook(new Book("Title 1", "Author1", true, 0.1));
bookDB.AddBook(new Book("Title 2", "Author2", false, 0.2));
bookDB.AddBook(new Book("Title 3", "Author3", true, 0.1));
bookDB.AddBook(new Book("Title 4", "Author4", false, 0.2));
bookDB.AddBook(new Book("Title 5", "Author5", true, 0.1));
PriceCalculator calculator = new PriceCalculator();
bookDB.ProcessPaperbackBooks(new ProcessBookDelegate(calculator.PrintPrice));
bookDB.ProcessPaperbackBooks(new ProcessBookDelegate(PrintTitle));
calculator.PrintPriceTotal();
Console.ReadLine();
/*********Compose Delegate*********/
ComposeDelegate a, b, c, d;
// Create the delegate object a that references
// the method Hello:
a = new ComposeDelegate(Hello);
// Create the delegate object b that references
// the method Goodbye:
b = new ComposeDelegate(Goodbye);
// The two delegates, a and b, are composed to form c:
c = a + b;
// Remove a from the composed delegate, leaving d,
// which calls only the method Goodbye:
d = c - a;
Console.WriteLine("Invoking delegate a:");
a("A");
Console.WriteLine("Invoking delegate b:");
b("B");
Console.WriteLine("Invoking delegate c:");
c("C");
Console.WriteLine("Invoking delegate d:");
d("D");
Console.ReadLine();
}
public static void Hello(string s)
{
Console.WriteLine(" Hello, {0}!", s);
}
public static void Goodbye(string s)
{
Console.WriteLine(" Goodbye, {0}!", s);
}
delegate void ComposeDelegate(string s);
}
}
|
C
|
UTF-8
| 297 | 3.203125 | 3 |
[] |
no_license
|
/**
* @file init.c
* @brief
*
* @author Jeru Sanders
* @date 2/16/2015
*/
#include<stdio.h>
int main()
{
int numbers[1000];
int i;
for (i = 1; i < 1001; i++)
{
numbers[i] = i;
printf("%d\n", numbers[i]);
}
return 0;
}
|
Java
|
UTF-8
| 208 | 1.703125 | 2 |
[] |
no_license
|
package com.wendy.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.wendy.model.Purchase;
public interface PurchaseRepository extends JpaRepository<Purchase,Long> {
}
|
C#
|
UTF-8
| 662 | 2.734375 | 3 |
[] |
no_license
|
namespace Linda.Core.Watch
{
using System;
using System.IO;
public class DefaultWatchBuilder : IWatchBuilder
{
public FileSystemWatcher GetWatcher(string path, Action<object, FileSystemEventArgs> eventMethod, string filter = "*")
{
var watcher = new FileSystemWatcher(path, filter);
watcher.Created += new FileSystemEventHandler(eventMethod);
watcher.Changed += new FileSystemEventHandler(eventMethod);
watcher.Deleted += new FileSystemEventHandler(eventMethod);
watcher.Renamed += new RenamedEventHandler(eventMethod);
return watcher;
}
}
}
|
JavaScript
|
UTF-8
| 1,260 | 2.8125 | 3 |
[] |
no_license
|
const template = document.createElement('template');
template.innerHTML = `
<style>
#messanger {
}
#friend-list{
}
.message-form{
}
#list-of-messages{
display : flex;
flex-direction : column-reverse;
}
</style>
<friend-list></friend-list>
<div id="super-list">
<list-unit></list-unit>
<list-unit></list-unit>
<list-unit></list-unit>
<list-unit></list-unit>
<list-unit></list-unit>
</div>
<my-button></my-button>
`;
class Messanger extends HTMLElement {
constructor() {
super();
this.shadowRoot = this.attachShadow({ mode: 'open' });
this.shadowRoot.appendChild(template.content.cloneNode(true));
this.$message_field = this.shadowRoot.querySelector('message-form');
this.$superButton = this.shadowRoot.querySelector('my-button');
this.$superButton.onclick = this.AddChat;
this.$status = 0;
}
AddChat() {
// потом добавлю открытие меню для создания нового сообщения
const tempDiv = document.createElement('list-unit');
this.shadowRoot.appendChild(tempDiv);
return this.$status;
}
}
customElements.define('my-messanger', Messanger);
|
Python
|
UTF-8
| 5,362 | 3.234375 | 3 |
[
"MIT"
] |
permissive
|
"""Util module that contains the tools to manage input/output files of a control.
Functions:
read_json_file.
read_twf_file.
get_files_path.
Classes:
FileManagerError.
FileManager.
"""
import os
import errno
import csv
import gettext
import logging
import json
def read_json_file(file_name):
"""Read a JSON file.
Args:
file_name: Name of the file.
Returns:
JSON object.
"""
if not file_name:
return None
data = None
if os.path.isfile(file_name):
with open(file_name) as json_data:
data = json.load(json_data)
return data
def read_twf_file(file_name):
"""Read a TWF file.
Args:
file_name: Name of the file.
Returns:
List of six floats.
"""
if not file_name:
return None
if os.path.isfile(file_name):
with open(file_name) as file_data:
try:
return [
float(file_data.readline().rstrip()),
float(file_data.readline().rstrip()),
float(file_data.readline().rstrip()),
float(file_data.readline().rstrip()),
float(file_data.readline().rstrip()),
float(file_data.readline().rstrip())
]
except ValueError:
return None
return None
def get_files_path(start_dir, file_type, recursive=False):
"""Returns the list of files path of a start folder.
Args:
start_dir: Name of the start folder.
recursive: Boolean indicating if it should explore sub folders.
format: Name of the files format.
Returns:
List of files path.
"""
files = []
fext = '.{}'.format(file_type)
if not recursive:
files = [
os.path.join(start_dir, fname) for fname in os.listdir(start_dir)
if os.path.isfile(os.path.join(start_dir, fname)) and fname.endswith(fext)
]
else:
for root, _, dir_files in os.walk(start_dir):
files.extend([os.path.join(root, fname) for fname in dir_files if fname.endswith(fext)])
return files
class FileManagerError(Exception):
"""Exception for FileManager."""
class FileManager:
"""Class to manage input/output files of a control.
Attributes:
output_dir: Folder path for output files.
logger: Logging object.
"""
def __init__(self, output_dir, logger=None):
# parameters
self.output_dir = output_dir
self.logger = logger or logging.getLogger(__name__)
# internal
self._ = gettext.gettext
# check dirs
try:
os.makedirs(self.output_dir)
except OSError as err:
if err.errno != errno.EEXIST:
raise FileExistsError(self._('Cannot create output dir'))
def add_dir(self, dir_name):
"""Add a new folder to the output folder.
Args:
dir_name: Name of the folder to add.
Returns:
Full path of added folder.
Raises:
FileManagerError
"""
path = os.path.join(self.output_dir, dir_name)
try:
os.makedirs(path)
except OSError as err:
if err.errno != errno.EEXIST:
raise FileManagerError(
'{}. {}'.format(self._('Cannot add dir'), self._('Folder already exist'))
)
return path
def get_dir(self, dir_name):
"""Return full path of a folder in output folder.
Args:
dir_name: Name of the folder.
Returns:
Full path of the folder.
"""
return os.path.join(self.output_dir, dir_name)
def _output_file_path(self, dir_name, file_name):
"""Helper method to return full path of a file in the output folder.
Args:
dir_name: Name of the folder.
file_name: Name of the file.
Returns:
Full path of the file.
"""
if dir_name:
return os.path.join(self.get_dir(dir_name), file_name)
return os.path.join(self.output_dir, file_name)
def start_csv_file(self, file_name, hrow, dir_name=None):
"""Initialize a CSV file with the headers.
Args:
file_name: Name of the file.
hrow: Header of the file.
"""
with open(self._output_file_path(dir_name, file_name), 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
if hrow:
writer.writerow(hrow)
def append_csv_file(self, file_name, row, dir_name=None):
"""Append a row to a CSV file.
Args:
file_name: Name of the file.
row: Row to append to the file.
"""
with open(self._output_file_path(dir_name, file_name), 'a', newline='') as csvfile:
writer = csv.writer(csvfile)
if row:
writer.writerow(row)
def write_csv_file(self, dir_name, file_name, hrow, rows):
"""Write a CSV file to a folder in the output folder.
Args:
dir_name: Name of the folder in the output folder.
file_name: Name of the file.
hrow: Header of the file.
rows: Rows of the file.
"""
with open(
self._output_file_path(dir_name, file_name),
'w',
newline='',
encoding='utf-8'
) as csvfile:
writer = csv.writer(csvfile)
if hrow:
writer.writerow(hrow)
if rows:
for row in rows:
writer.writerow(row)
def write_txt_file(self, file_name, data):
"""Write a text file to the output folder.
Args:
file_name: Name of the file.
data: Data of the file.
"""
with open(self._output_file_path(None, file_name), 'w', encoding='utf-8') as txtfile:
if data:
for key, val in data.items():
txtfile.write('{}: {}\n'.format(key, val))
|
Python
|
UTF-8
| 1,235 | 2.53125 | 3 |
[] |
no_license
|
import argparse, os
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('-i',default=os.getcwd(),dest="input")
parser.add_argument('-o',dest="output")
# El threshold para la conversion BW
parser.add_argument('-t', default=150, dest="threshold")
# El ancho en pixels del margen central
parser.add_argument('-w', default=25, dest="sepwidth")
# El numero de paginas que queremos samplear
parser.add_argument('-s', dest="sample")
args = parser.parse_args()
config={}
if args.output is None:
if os.path.isdir(args.input):
config["output"] = os.path.join(args.input,"output")
else:
input_path = os.path.dirname(os.path.abspath(args.input))
config["output"] = os.path.join(input_path,"output")
else:
config["output"] = args.output
if os.path.isdir(args.input):
targets = []
for file in os.listdir(args.input):
if file.endswith(".zip") or file.endswith(".cbz"):
targets.append(os.path.join(args.input,file))
else:
targets = [args.input]
if args.sample is not None:
config['sample'] = int(args.sample)
else:
config['sample'] = None
config['threshold'] = int(args.threshold)
config['sepwidth'] = int(args.sepwidth)
|
C
|
UTF-8
| 318 | 3.1875 | 3 |
[] |
no_license
|
#include <stdio.h>
#include <stdlib.h>
int main() {
int k;
scanf("%d", &k);
int* A = (int*)malloc(sizeof(int) * (k + 1));
if (k < 3)
printf("%d", k);
else {
A[0] = 0;
A[1] = 1;
A[2] = 2;
for (int i = 3; i <= k; i++)
A[i] = (A[i - 1] + A[i - 2])%15746;
printf("%d", A[k]);
}
free(A);
return 0;
}
|
Swift
|
UTF-8
| 2,396 | 2.578125 | 3 |
[] |
no_license
|
//
// BaseScrollViewController.swift
// AppTemplateiOS
//
// Created by Junio Moquiuti on 29/03/20.
// Copyright © 2020 Junio Moquiuti. All rights reserved.
//
import UIKit
import Cartography
class BaseScrollViewController: BaseViewController {
private var scrollViewConstraintGroup = ConstraintGroup()
private let scrollView: UIScrollView = {
let view = UIScrollView()
view.alwaysBounceVertical = false
view.keyboardDismissMode = .onDrag
return view
}()
override func loadView() {
super.loadView()
addScrollView()
}
override func viewDidLoad() {
super.viewDidLoad()
listenToKeyboard()
}
private func addScrollView() {
view.addSubview(scrollView)
constrain(view, scrollView, replace: scrollViewConstraintGroup) { (view, scroll) in
scroll.left == view.left
scroll.right == view.right
scroll.top == view.top
scroll.bottom == view.bottom
}
}
internal func addChildViewToScrollView(childView: UIView, constraintBlock: ((ViewProxy, ViewProxy) -> Void)? = nil) {
scrollView.addSubview(childView)
if let constraintBlock = constraintBlock {
constrain(scrollView, childView, block: constraintBlock)
} else {
constrain(scrollView, childView) { (scroll, subView) in
subView.edges == scroll.edges
subView.width == scroll.width
}
}
}
}
// MARK: - Keyboard Notifications
extension BaseScrollViewController {
override func keyboardWillShow(sender: NSNotification) {
guard let keyboardValue = sender.userInfo?[UIResponder.keyboardFrameEndUserInfoKey] as? NSValue else { return }
let keyboardFrameCG = keyboardValue.cgRectValue
let keyboarFrame = view.convert(keyboardFrameCG, from: view.window)
scrollView.contentInset.bottom = keyboarFrame.height - bottomLayoutGuide.length + 30
scrollView.scrollIndicatorInsets = scrollView.contentInset
scrollView.layoutIfNeeded()
}
override func keyboardWillHide(sender: NSNotification) {
scrollView.contentInset = .zero
scrollView.scrollIndicatorInsets = scrollView.contentInset
scrollView.layoutIfNeeded()
}
}
|
Markdown
|
UTF-8
| 2,904 | 2.640625 | 3 |
[] |
no_license
|
---
title: À propos
published: true
---
### À propos de moi
Je suis un ingénieur civil de Montréal, au Québec, qui se passionne pour la programmation. Bien que mon emploi à temps plein n’ait rien à voir avec la programmation, mon principal passe-temps y touche directement depuis près de 15 ans. En fait, la technologie en général m'a toujours passionnée depuis que j'ai mis la main sur un ordinateur il y a longtemps de cela.
Du côté programmation, j'ai travaillé sur de nombreux petits projets, où j'ai tout appris par moi-même, avant de m'impliquer dans de plus grands projets. Je suis l’un des principaux développeurs de [SimpsonsCity.com](https://simpsonscity.com), qui est aujourd'hui plus très actif, et l’un des principaux développeurs de [UserFrosting](https://www.userfrosting.com/), un framework de gestion d'utilisateurs _open source_. Les langages de programmation que je connais le plus sont PHP, Javascript et CSS / SCSS, mais j’ai aussi travaillé par le passé avec Java, Swift, ActionScript / Flash (RIP), etc. Ma plus grande force en programmation est le débogage du code source existant en le parcourant et en concevant des tests pour comprendre exactement ce qui ne va pas, même si je ne connais pas le langage dans lequel il est programmé.
Ma plus importante contribution à UserFrosting a été la création du [module de traduction](https://github.com/userfrosting/i18n), un module important pour moi en étant donné que je vis dans un pays bilingue et qu'il peut être important ici de supporter les deux langues officielles, l'anglais et le français, dans une application. J'ai également travaillé avec l'interface de ligne de commande (CLI) de UserFrosting, appelée _Bakery_, et je travaille actuellement à augmenter la couverture des tests automatisés de UserFrosting afin d'atteindre le mythique 100%. Voir la [liste de mes projets](/projects) pour une liste complète de ce sur quoi j'ai travaillé ces derniers temps.
Côté éducation, j'ai un baccalauréat en génie civil de l'École de Technologie Supérieure (ÉTS). J’ai aussi une maîtrise en gestion des infrastructures urbaines, également de l'ÉTS, pour laquelle j'ai travaillé sur un concept de logiciel écrit en PHP dédié à la gestion de projet et au suivi des coûts.
Globalement, j'aime partager mes connaissances en aidant les autres, de la même manière que lorsque j'ai commencé à coder.
### Qu'est-ce que BBQSoftwares?
En un mot, c’est moi. Une de mes premières applications s'appelait _BBQ_. C'était un logiciel de gestion de prêt de petits appareils. Pensez au logiciel qu'une bibliothèque utiliserait pour savoir quel livre a été emprunté par qui, mais pour les petits appareils électroniques tels que des iPhone et des iPad. Ce nom m’a suivi pendant un moment et lorsque j'ai eu besoin d'un nom de domaine... Vous devinez la suite.
|
Java
|
UTF-8
| 859 | 2.625 | 3 |
[] |
no_license
|
package cn.android.demo.apis.ui.widget;
import cn.android.demo.apis.R;
import android.app.Activity;
import android.os.Bundle;
import android.view.View;
import android.widget.TextView;
/**
* 用系统Movie 来显示GIF动画
*
* @author Elroy
*
*/
public class GifViewActivity extends Activity {
TextView tvInfo;
GifView gifView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.ui_widget_gif_movie);
gifView = $id(R.id.movie_gifview);
tvInfo = $id(R.id.movie_gif_textinfo);
String strInfo = "";
strInfo += "Duration:" + gifView.getMovieDuration() + "\n";
strInfo += "W x H" + gifView.getMovieWidth() + " x "
+ gifView.getMovieHeight() + "\n";
tvInfo.setText(strInfo);
}
public <T extends View> T $id(int id) {
return (T) findViewById(id);
}
}
|
C#
|
UTF-8
| 8,156 | 2.796875 | 3 |
[
"MIT"
] |
permissive
|
using System;
using System.Collections.Generic;
using System.Linq;
namespace Connectivity.test
{
public class NaiveConnGraph : IConnGraph
{
private class VertexInfo
{
private bool Equals(VertexInfo other)
{
return Equals(vertex, other.vertex);
}
public override bool Equals(object obj)
{
if (ReferenceEquals(null, obj)) return false;
if (ReferenceEquals(this, obj)) return true;
if (obj.GetType() != this.GetType()) return false;
return Equals((VertexInfo) obj);
}
public readonly ConnVertex vertex;
public readonly HashSet<VertexInfo> edges = new HashSet<VertexInfo>();
public object aug;
public long iteration = 0;
public bool direction = false;
public override int GetHashCode()
{
return vertex.GetHashCode();
}
public VertexInfo(ConnVertex vertex)
{
this.vertex = vertex ?? throw new ArgumentNullException();
}
}
private readonly IAugmentation _augmentation;
private Dictionary<ConnVertex, VertexInfo> _info = new Dictionary<ConnVertex, VertexInfo>();
private VertexInfo EnsureInfo(ConnVertex vertex)
{
if (_info.TryGetValue(vertex, out var existingInfo))
return existingInfo;
var newInfo = new VertexInfo(vertex);
_info[vertex] = newInfo;
return newInfo;
}
public NaiveConnGraph()
{
}
public NaiveConnGraph(IAugmentation augmentation)
{
_augmentation = augmentation;
}
public bool AddEdge(ConnVertex connVertex1, ConnVertex connVertex2)
{
var info1 = EnsureInfo(connVertex1);
var info2 = EnsureInfo(connVertex2);
info1.edges.Add(info2);
return info2.edges.Add(info1);
}
private bool RemoveEdge(VertexInfo u, VertexInfo v)
{
bool result = u.edges.Remove(v);
if (u.edges.Count == 0)
u.iteration = 0;
return result;
}
public bool RemoveEdge(ConnVertex vertex1, ConnVertex vertex2)
{
var info1 = EnsureInfo(vertex1);
var info2 = EnsureInfo(vertex2);
RemoveEdge(info1, info2);
return RemoveEdge(info2, info1);
}
private long _iteration = 0;
public bool IsConnected(ConnVertex vertex1, ConnVertex vertex2)
{
long iteration = ++_iteration;
var info1 = EnsureInfo(vertex1);
var info2 = EnsureInfo(vertex2);
info1.iteration = iteration;
info2.iteration = iteration;
info1.direction = false;
info2.direction = true;
var queue = new Queue<VertexInfo>(new[] {info1, info2});
while (queue.Count > 0)
{
var vert = queue.Dequeue();
foreach (var next in vert.edges)
{
if (next.iteration == iteration)
{
if (next.direction != vert.direction)
return true;
continue;
}
next.direction = vert.direction;
next.iteration = iteration;
queue.Enqueue(next);
}
}
return false;
}
public ICollection<ConnVertex> AdjacentVertices(ConnVertex vertex)
{
if (_info.TryGetValue(vertex, out var info))
{
return info.edges.Select(x => x.vertex).ToArray();
}
else
{
return new ConnVertex[0];
}
}
public object SetVertexAugmentation(ConnVertex connVertex, object vertexAugmentation)
{
var info = EnsureInfo(connVertex);
var old = info.aug;
info.aug = vertexAugmentation;
return old;
}
public object RemoveVertexAugmentation(ConnVertex connVertex)
{
var info = EnsureInfo(connVertex);
var old = info.aug;
info.aug = null;
return old;
}
public object GetVertexAugmentation(ConnVertex vertex)
{
var info = EnsureInfo(vertex);
return info.aug;
}
public ComponentInfo GetComponentInfo(ConnVertex vertex)
{
long iteration = ++_iteration;
var info = EnsureInfo(vertex);
info.iteration = iteration;
int size = 1;
var queue = new Queue<VertexInfo>(new[] {info});
object aug = info.aug;
while (queue.Count > 0)
{
var vert = queue.Dequeue();
foreach (var next in vert.edges)
{
if (next.iteration == iteration)
continue;
size++;
aug = _augmentation.Combine(aug, info.aug);
next.iteration = iteration;
queue.Enqueue(next);
}
}
return new ComponentInfo(vertex, aug, size);
}
public int GetNumberOfComponents()
{
int numberOfComponents = 0;
long iteration = ++_iteration;
var queue = new Queue<VertexInfo>();
foreach (var pair in _info)
{
var info = pair.Value;
if (info.iteration == iteration)
continue;
numberOfComponents++;
queue.Enqueue(info);
while (queue.Count > 0)
{
var vert = queue.Dequeue();
foreach (var next in vert.edges)
{
if (next.iteration == iteration)
continue;
next.iteration = iteration;
queue.Enqueue(next);
}
}
}
return numberOfComponents;
}
public ICollection<ComponentInfo> GetAllComponents()
{
var list = new List<ComponentInfo>();
long iteration = ++_iteration;
var queue = new Queue<VertexInfo>();
foreach (var pair in _info)
{
var info = pair.Value;
if (info.iteration == iteration)
continue;
int size = 1;
var aug = info.aug;
info.iteration = iteration;
queue.Enqueue(info);
while (queue.Count > 0)
{
var vert = queue.Dequeue();
foreach (var next in vert.edges)
{
if (next.iteration == iteration)
continue;
size++;
aug = _augmentation.Combine(aug, next.aug);
next.iteration = iteration;
queue.Enqueue(next);
}
}
list.Add(new ComponentInfo(pair.Key, aug, size));
}
return list;
}
public bool VertexHasAugmentation(ConnVertex vertex)
{
var info = EnsureInfo(vertex);
return info.aug != null;
}
public bool ComponentHasAugmentation(ConnVertex vertex)
{
return this.GetComponentAugmentation(vertex) != null;
}
public void Clear()
{
foreach (var pair in _info)
{
pair.Value.edges.Clear();
pair.Value.iteration = 0;
}
_info.Clear();
}
public void Optimize()
{
}
}
}
|
Java
|
UTF-8
| 325 | 1.671875 | 2 |
[] |
no_license
|
package com.zrt.zenb.controller.vo.jsonMsg;
import com.zrt.zenb.controller.vo.enums.MsgType;
import com.zrt.zenb.controller.vo.jsonMsg.BaseMsg;
import lombok.Data;
/**
* @author intent
*/
@Data
public class SysLog extends BaseMsg {
String logStr;
public SysLog(){
msgType = MsgType.LOG_GET_ACK;
}
}
|
C++
|
UTF-8
| 6,959 | 3.171875 | 3 |
[] |
no_license
|
//
// Created by Michael on 6/21/2015.
//
#include <iostream>
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include "matrix_math.h"
using namespace std;
int inverse_matrix(const double **matrix, double **inverse, int n)
{
bool flag = true;
int i, j, k, ret_val = 1;
double m;
double **augmatrix = NULL;
allocate_2d_array(&augmatrix, n, 2*n);
// Augment input matrix with an identity matrix
for(i = 1; i <= n; i++)
{
for(j = 1; j <= n; j++)
{
augmatrix[i-1][j-1] = matrix[i-1][j-1];
}
augmatrix[i-1][i-1+n] = 1.;
}
// Reduce augmented matrix to upper triangular form
for(k = 1; k <= n-1; k++)
{
if(augmatrix[k-1][k-1] == 0.)
{
flag = false;
for(i = k+1; i <=n; i++)
{
if(augmatrix[i-1][k-1] != 0.)
{
for(j = 1; j <= 2*n; j++)
{
augmatrix[k-1][j-1] += augmatrix[i-1][j-1];
}
flag = true;
break;
}
if (!flag)
{
printf("Matrix is non-invertible due to augmatrix[%d][%d] == 0 and augumatrix[%d][%d] == 0.", k-1, k-1, i-1, k-1);
ret_val = -1;
goto exit_function;
}
}
}
for(j = k+1; j <= n; j++)
{
m = augmatrix[j-1][k-1]/augmatrix[k-1][k-1];
for(i = k; i <= 2*n; i++) augmatrix[j-1][i-1] -= m*augmatrix[k-1][i-1];
}
}
// Test for invertability
for(i = 1; i <= n; i++)
{
if(augmatrix[i-1][i-1] == 0.){
printf("Matrix is non-invertible due to augmatrix[%d][%d] == 0.", i-1, i-1);
ret_val = -2;
goto exit_function;
}
}
// Make diagonal elements as 1
for(i = 1; i <= n; i++)
{
m = augmatrix[i-1][i-1];
for(j = i; j <= 2*n; j++) augmatrix[i-1][j-1] /= m;
}
// Reduced right side half of augmented matrix to identity matrix
for(k = n-1; k >= 1; k--)
{
for(i = 1; i <= k; i++)
{
m = augmatrix[i-1][k];
for(j = k; j <= 2*n; j++) augmatrix[i-1][j-1] -= m*augmatrix[k][j-1];
}
}
// store answer
for (i = 1; i <= n; i++) for(j = 1; j <= n; j++) inverse[i-1][j-1] = augmatrix[i-1][j-1+n];
exit_function:
free_2d_array(&augmatrix, n);
return ret_val;
}
int inverse_matrix2(Array2D<double> *matrix, Array2D<double> *inverse)
{
bool flag = true;
unsigned int i, j, k;
int ret_val = 1;
double m;
unsigned int n = matrix->rows;
Array2D<double> *augmatrix = new Array2D<double>(n, 2*n);
// Augment input matrix with an identity matrix
for(i = 1; i <= n; i++)
{
for(j = 1; j <= n; j++)
{
augmatrix->set_data(i-1, j-1, matrix->get_data(i-1, j-1));
}
augmatrix->set_data(i-1, i-1+n, 1.);
}
// Reduce augmented matrix to upper triangular form
for(k = 1; k <= n-1; k++)
{
if(augmatrix->get_data(k-1, k-1) == 0.)
{
flag = false;
for(i = k+1; i <=n; i++)
{
if(augmatrix->get_data(i-1, k-1) != 0.)
{
for(j = 1; j <= 2*n; j++)
{
augmatrix->increment_data(k-1, j-1, augmatrix->get_data(i-1, j-1));
}
flag = true;
break;
}
if (!flag)
{
printf("Matrix is non-invertible due to augmatrix[%d][%d] == 0 and augumatrix[%d][%d] == 0.\n", k-1, k-1, i-1, k-1);
ret_val = -1;
goto exit_function;
}
}
}
for(j = k+1; j <= n; j++)
{
m = augmatrix->get_data(j-1, k-1)/augmatrix->get_data(k-1, k-1);
for(i = k; i <= 2*n; i++) augmatrix->increment_data(j-1, i-1, -m*augmatrix->get_data(k-1, i-1));
}
}
// Test for invertability
for(i = 1; i <= n; i++)
{
if(augmatrix->get_data(i-1, i-1) == 0.){
printf("Matrix is non-invertible due to augmatrix[%d][%d] == 0.\n", i-1, i-1);
ret_val = -2;
goto exit_function;
}
}
// Make diagonal elements as 1
for(i = 1; i <= n; i++)
{
m = augmatrix->get_data(i-1, i-1);
for(j = i; j <= 2*n; j++) augmatrix->divide_data(i-1, j-1, m);
}
// Reduced right side half of augmented matrix to identity matrix
for(k = n-1; k >= 1; k--)
{
for(i = 1; i <= k; i++)
{
m = augmatrix->get_data(i-1, k);
for(j = k; j <= 2*n; j++) augmatrix->increment_data(i-1, j-1, -m*augmatrix->get_data(k, j-1));
}
}
// store answer
for (i = 1; i <= n; i++) for(j = 1; j <= n; j++) inverse->set_data(i-1, j-1, augmatrix->get_data(i-1, j-1+n));
exit_function:
delete augmatrix;
return ret_val;
}
void multiply_matrix_and_vector(const double **m, const double *v, double *res, int rows, int cols)
{
int i, j;
memset(res, 0, cols*sizeof(double));
for(i = 0; i < rows; i++) for(j = 0; j < cols; j++) res[i] += m[i][j]*v[j];
}
void multiply_matrix_and_vector2(Array2D<double> *m, const double *v, double *res)
{
unsigned int i, j;
memset(res, 0, m->cols*sizeof(double));
for(i = 0; i < m->rows; i++) for(j = 0; j < m->cols; j++) res[i] += m->get_data(i, j)*v[j];
}
void allocate_2d_array(double ***arr, int rows, int cols)
{
int i;
*arr = (double **)calloc((size_t)rows, sizeof(double *));
for(i = 0; i < rows; i++) (*arr)[i] = (double *)calloc((size_t)cols, sizeof(double));
}
void free_2d_array(double ***arr, int rows)
{
int i;
for(i = 0; i < rows; i++)
{
free((*arr)[i]);
(*arr)[i] = NULL;
}
free(*arr);
*arr = NULL;
}
void print_2d_array(double **arr, int rows, int cols)
{
int i, j;
for(i = 0; i < rows; i++)
{
for(j = 0; j < cols; j++) cout << arr[i][j] << ",";
cout << "\n";
}
}
void allocate_3d_array(double ****arr, int i1, int i2, int i3)
{
int i, j;
*arr = (double ***)calloc((size_t)i1, sizeof(double **));
for(i = 0; i < i1; i++)
{
(*arr)[i] = (double **)calloc((size_t)i2, sizeof(double *));
for(j = 0; j < i2; j++)
{
(*arr)[i][j] = (double *)calloc((size_t)i3, sizeof(double));
}
}
}
void free_3d_array(double ****arr, int i1, int i2)
{
int i, j;
for(i = 0; i < i1; i++)
{
for(j = 0; j < i2; j++)
{
free((*arr)[i][j]);
(*arr)[i][j] = NULL;
}
free((*arr)[i]);
(*arr)[i] = NULL;
}
free(*arr);
*arr = NULL;
}
|
Python
|
UTF-8
| 238 | 2.890625 | 3 |
[] |
no_license
|
def checkio(data):
x = len(data)
if x > 0:
count[0] = count[0] + data[x-1]
data2 = data[0:x-1]
return checkio(data2)
else:
return count[0]
count = [0]
print (checkio([1,2,1,2,1]))
|
Markdown
|
UTF-8
| 10,051 | 2.53125 | 3 |
[] |
no_license
|
---
description: "Easiest Way to Prepare Homemade Lemon Layer Cake with Blackberrie Cream Filling and a Lemon Cream Frosting"
title: "Easiest Way to Prepare Homemade Lemon Layer Cake with Blackberrie Cream Filling and a Lemon Cream Frosting"
slug: 1419-easiest-way-to-prepare-homemade-lemon-layer-cake-with-blackberrie-cream-filling-and-a-lemon-cream-frosting
date: 2020-07-16T05:48:53.749Z
image: https://img-global.cpcdn.com/recipes/304cef79a0f0033b/751x532cq70/lemon-layer-cake-with-blackberrie-cream-filling-and-a-lemon-cream-frosting-recipe-main-photo.jpg
thumbnail: https://img-global.cpcdn.com/recipes/304cef79a0f0033b/751x532cq70/lemon-layer-cake-with-blackberrie-cream-filling-and-a-lemon-cream-frosting-recipe-main-photo.jpg
cover: https://img-global.cpcdn.com/recipes/304cef79a0f0033b/751x532cq70/lemon-layer-cake-with-blackberrie-cream-filling-and-a-lemon-cream-frosting-recipe-main-photo.jpg
author: Evelyn Francis
ratingvalue: 4.1
reviewcount: 9
recipeingredient:
- " for the Cake"
- "4 1/2 cups all purpose flour"
- "1 1/2 teaspoons baking powder"
- "1 teaspoon salt"
- "12 ounces (3 sticks) unsalted butter at room temperaturr"
- "2 1/2 cups granulated sugar"
- "6 large eggs at room temperature"
- "2 3/4 cup milk at room temperature"
- "1/4 cup fresh lemon juice"
- "1 1/2 teaspoon vanilla extract"
- " for the blackberry cream filling"
- "1 1/2 cup fresh blackberries"
- "2 tablespoon water"
- "1/8 teaspoon salt"
- "2 teaspoon unflavored gelatin"
- "3 tablespoons cold water"
- "8 ounces marscapone cheese at room temperature"
- "2 cups cold whipping cream"
- "1 1/2 cups confectioners sugar"
- "1 teaspoon vanilla extract"
- " for lemon cream frosting"
- "2 cups cold heavy whipping cream"
- "10 ounces lemon curd homemade or purchased"
- "1 teaspoon vanilla extract"
- "3/4 cup confectioners sugar"
- "1 teaspoon salt"
- " For Garnish"
- "as needed fresh blackberries"
- "as needed yellow and purple sprinkled"
recipeinstructions:
- "Make cake"
- "Preheat the oven to 350, spray 6 - 8 - inch cake pans well with bakers spray."
- "In a bowl whisk together flour, baking powder and salt"
- "In another bowl beat butter and sugar until light and fluffy, about 4 minutes"
- "Beat in eggs, one at a time beating in after each egg, beat in lemon juice and vanilla"
- "Add the flour mixture alternating with the milk in 3 additions, beating until smooth,"
- "Divide the batter evenly in the 6 prepared pans. Bake about 19 to 25 minutes until a toothpick comes put just clean. It will take two batches of cooking, cook 3 cakes at a time."
- "Cool in pans 15 minutes then cool completely on racks befre filling and frosting"
- "Make blackberry cream filling"
- "Place blackberries, water and salt in a small saucepan"
- "Bring to a boil then lower heat, crushing berries with a rubber spatula or spoon and cook until very soft and starting to thicken, stirring to prevent sticking"
- "Strain through a fine mesh strainer to rxtract all juice, discard seeds"
- "Chill juice in refrigerator until cold before adding to cream"
- "Add the 3 tablespoons cold water to a small heat proof bowl. Sprinkle gelatin on the cold water and let sit and soften for 5 minutes"
- "Meanwhile heat some water in a small skillet to a simmer, add softened gelatin and stir until clear and dissolved. Turn off heat and leave gelatin in warm water to stay liquid while beating cream"
- "Beat cream until it holds its shape"
- "In another biwl beat marscapone, confectioner's sugar, vanilla, cold blackberry juice and liquid gelatin until smooth"
- "Fold into whipped cream in 3 additions"
- "Make lemon cream frosting"
- "Whip cream until it has oft peaks"
- "Beat in lemon curd, confectioner's sugar and lemon zest until combined and firm but don't overbeat"
- ""
- ""
- "Assemble Cake"
- "Place one caker layer bottom side up on serving plate"
- "Spread with a layer of blackberrie cream filling"
- "Add second cake layer bottom up and spread with more blackberrieccream"
- "Add third cake layer, bottom up and dpread with more blackberrie cream"
- "Add fourth cake layer and add more blackberrie cream"
- "Add fifth cake layer and add remaining blackberrie cream."
- "Add last sixth layer, then refrigerate at least 1 hour or more to set filling for easy frosting"
- "Frost entire cake with lemon cream frosting"
- "Garnish with fresh blackberries and sprinkles. Chill at least 1 hour before slicing"
- ""
- ""
categories:
- Recipe
tags:
- lemon
- layer
- cake
katakunci: lemon layer cake
nutrition: 166 calories
recipecuisine: American
preptime: "PT28M"
cooktime: "PT35M"
recipeyield: "1"
recipecategory: Dinner
---

Hey everyone, it's me again, Dan, welcome to my recipe site. Today, I will show you a way to prepare a distinctive dish, lemon layer cake with blackberrie cream filling and a lemon cream frosting. One of my favorites. For mine, I'm gonna make it a bit tasty. This is gonna smell and look delicious.
Lemon Layer Cake with Blackberrie Cream Filling and a Lemon Cream Frosting is one of the most popular of current trending meals in the world. It is simple, it is quick, it tastes delicious. It is enjoyed by millions daily. They are nice and they look fantastic. Lemon Layer Cake with Blackberrie Cream Filling and a Lemon Cream Frosting is something that I've loved my whole life.
To get started with this particular recipe, we have to first prepare a few components. You can cook lemon layer cake with blackberrie cream filling and a lemon cream frosting using 29 ingredients and 35 steps. Here is how you cook that.
<!--inarticleads1-->
##### The ingredients needed to make Lemon Layer Cake with Blackberrie Cream Filling and a Lemon Cream Frosting:
1. Prepare for the Cake
1. Prepare 4 1/2 cups all purpose flour
1. Make ready 1 1/2 teaspoons baking powder
1. Prepare 1 teaspoon salt
1. Get 12 ounces (3 sticks) unsalted butter at room temperaturr
1. Take 2 1/2 cups granulated sugar
1. Make ready 6 large eggs at room temperature
1. Take 2 3/4 cup milk, at room temperature
1. Prepare 1/4 cup fresh lemon juice
1. Get 1 1/2 teaspoon vanilla extract
1. Take for the blackberry cream filling
1. Get 1 1/2 cup fresh blackberries
1. Prepare 2 tablespoon water
1. Get 1/8 teaspoon salt
1. Take 2 teaspoon unflavored gelatin
1. Make ready 3 tablespoons cold water
1. Get 8 ounces marscapone cheese, at room temperature
1. Get 2 cups cold whipping cream
1. Get 1 1/2 cups confectioner's sugar
1. Take 1 teaspoon vanilla extract
1. Take for lemon cream frosting
1. Make ready 2 cups cold heavy whipping cream
1. Get 10 ounces lemon curd, homemade or purchased
1. Take 1 teaspoon vanilla extract
1. Get 3/4 cup confectioner's sugar
1. Prepare 1 teaspoon salt
1. Make ready For Garnish
1. Make ready as needed fresh blackberries
1. Prepare as needed yellow and purple sprinkled
<!--inarticleads2-->
##### Instructions to make Lemon Layer Cake with Blackberrie Cream Filling and a Lemon Cream Frosting:
1. Make cake
1. Preheat the oven to 350, spray 6 - 8 - inch cake pans well with bakers spray.
1. In a bowl whisk together flour, baking powder and salt
1. In another bowl beat butter and sugar until light and fluffy, about 4 minutes
1. Beat in eggs, one at a time beating in after each egg, beat in lemon juice and vanilla
1. Add the flour mixture alternating with the milk in 3 additions, beating until smooth,
1. Divide the batter evenly in the 6 prepared pans. Bake about 19 to 25 minutes until a toothpick comes put just clean. It will take two batches of cooking, cook 3 cakes at a time.
1. Cool in pans 15 minutes then cool completely on racks befre filling and frosting
1. Make blackberry cream filling
1. Place blackberries, water and salt in a small saucepan
1. Bring to a boil then lower heat, crushing berries with a rubber spatula or spoon and cook until very soft and starting to thicken, stirring to prevent sticking
1. Strain through a fine mesh strainer to rxtract all juice, discard seeds
1. Chill juice in refrigerator until cold before adding to cream
1. Add the 3 tablespoons cold water to a small heat proof bowl. Sprinkle gelatin on the cold water and let sit and soften for 5 minutes
1. Meanwhile heat some water in a small skillet to a simmer, add softened gelatin and stir until clear and dissolved. Turn off heat and leave gelatin in warm water to stay liquid while beating cream
1. Beat cream until it holds its shape
1. In another biwl beat marscapone, confectioner's sugar, vanilla, cold blackberry juice and liquid gelatin until smooth
1. Fold into whipped cream in 3 additions
1. Make lemon cream frosting
1. Whip cream until it has oft peaks
1. Beat in lemon curd, confectioner's sugar and lemon zest until combined and firm but don't overbeat
1.
1.
1. Assemble Cake
1. Place one caker layer bottom side up on serving plate
1. Spread with a layer of blackberrie cream filling
1. Add second cake layer bottom up and spread with more blackberrieccream
1. Add third cake layer, bottom up and dpread with more blackberrie cream
1. Add fourth cake layer and add more blackberrie cream
1. Add fifth cake layer and add remaining blackberrie cream.
1. Add last sixth layer, then refrigerate at least 1 hour or more to set filling for easy frosting
1. Frost entire cake with lemon cream frosting
1. Garnish with fresh blackberries and sprinkles. Chill at least 1 hour before slicing
1.
1.
So that is going to wrap this up with this special food lemon layer cake with blackberrie cream filling and a lemon cream frosting recipe. Thanks so much for your time. I'm confident you can make this at home. There is gonna be interesting food in home recipes coming up. Don't forget to bookmark this page on your browser, and share it to your loved ones, friends and colleague. Thank you for reading. Go on get cooking!
|
C
|
UTF-8
| 1,337 | 3.265625 | 3 |
[] |
no_license
|
/*
* Filename: printPermissions.c
* Author: Xiaolong Zhou
* Userid: cs30xaeo
* Description: This routine prints out the various rwx permissions for the
* owner, group, and others when the -l flag is set.
* Date: May 25, 2016
* Source of Help: write up, tutors
*/
/*
* Header files include here
*/
#include <sys/stat.h>
#include <stdio.h>
/*
* Function name: printPermissions()
* Function prototype: void printPermissions( const mode_t mode );
* Description: This routine prints out the various rwx permissions for the
* owner, group, and other when the -l flag is set.
* Parameters:
* const mode_t mode -- permission mode.
* Side Effect: None.
* Error Condition: None.
* Return Value: None.
*/
void printPermissions( const mode_t mode ) {
/* print out the various rwx permission for the ugo */
(void)printf("%s", (mode & S_IRUSR) ? "r" : "-");
(void)printf("%s", (mode & S_IWUSR) ? "w" : "-");
(void)printf("%s", (mode & S_IXUSR) ? "x" : "-");
(void)printf("%s", (mode & S_IRGRP) ? "r" : "-");
(void)printf("%s", (mode & S_IWGRP) ? "w" : "-");
(void)printf("%s", (mode & S_IXGRP) ? "x" : "-");
(void)printf("%s", (mode & S_IROTH) ? "r" : "-");
(void)printf("%s", (mode & S_IWOTH) ? "w" : "-");
(void)printf("%s", (mode & S_IXOTH) ? "x" : "-");
}// end of function
|
Markdown
|
UTF-8
| 2,189 | 3.515625 | 4 |
[] |
no_license
|
# lt067
> Given two binary strings, return their sum (also a binary string).
>
> The input strings are both non-empty and contains only characters 1 or 0.
> Example 1:
> Input: a = "11", b = "1"
> Output: "100"
> Example 2:
> Input: a = "1010", b = "1011"
> Output: "10101"
# code
```Java
class Solution {
public String addBinary(String a, String b) {
int[] digitsa = new int[a.length()];
int[] digitsb = new int[b.length()];
int rtnLength = Math.max(digitsa.length, digitsb.length);
int[] rtn = new int[rtnLength];
int carry = 0;
int idxa = a.length() - 1, idxb = b.length() - 1, idxr = rtnLength - 1;
for(int i = 0; i < digitsa.length; i++) { digitsa[i] = a.charAt(i) - '0'; } // attention char int conversion
for(int i = 0; i < digitsb.length; i++) { digitsb[i] = b.charAt(i) - '0'; }
while(idxa >= 0 || idxb >= 0)
{
if ( idxa < 0 )
{
rtn[idxr] = (digitsb[idxb] + 0 + carry) % 2;
carry = (digitsb[idxb] + 0 + carry) / 2;
idxb --;
} else if (idxb < 0) {
rtn[idxr] = (digitsa[idxa] + 0 + carry) % 2;
carry = (digitsa[idxa] + 0 + carry) / 2;
idxa --;
} else {
rtn[idxr] = (digitsa[idxa] + digitsb[idxb] + carry) % 2;
carry = (digitsa[idxa] + digitsb[idxb] + carry) / 2;
idxa --;
idxb --;
}
idxr --;
}
if(carry != 0)
{
char[] rtnc = new char[rtnLength + 1];
rtnc[0] = '1';
for (int i = 1; i < rtnc.length; i++)
{
if(rtn[i-1] == 1) { rtnc[i] = '1'; }
else { rtnc[i] = '0'; }
}
return new String(rtnc);
} else {
char[] rtnc = new char[rtnLength];
for (int i = 0; i < rtnc.length; i++)
{
if(rtn[i] == 1) { rtnc[i] = '1'; }
else { rtnc[i] = '0'; }
}
return new String(rtnc);
}
}
}
```
|
Java
|
UTF-8
| 785 | 3.265625 | 3 |
[] |
no_license
|
package org.yqj.original.demo.lombok;
import lombok.val;
import java.util.ArrayList;
import java.util.HashMap;
/**
* Created by yaoqijun.
* Date:2016-01-23
* Email:[email protected]
* Descirbe:
*/
public class ValTest {
public static void main(String[] args) {
val test = new ArrayList<>(); // 默认final 集合的类型 不做限定
test.add("yaoqijun");
test.add(123);
test.add(Boolean.TRUE);
test.add(123.3123f);
test.forEach(System.out::println);
val map = new HashMap<Integer,String>();
map.put(0, "zero");
map.put(5, "five");
for (val entry : map.entrySet()) {
//System.out.printf("%d: %s\n", entry.getKey(), entry.getValue()); //complie error but run ok cool
}
}
}
|
C++
|
UTF-8
| 2,516 | 2.515625 | 3 |
[] |
no_license
|
#include <windows.h>
#include <psapi.h>
#include <assert.h>
#include "process_stat.h"
static uint64_t file_time_2_utc(const FILETIME* ftime)
{
LARGE_INTEGER li;
assert(ftime);
li.LowPart = ftime->dwLowDateTime;
li.HighPart = ftime->dwHighDateTime;
return li.QuadPart;
}
static int get_processor_number()
{
SYSTEM_INFO info;
GetSystemInfo(&info);
return (int)info.dwNumberOfProcessors;
}
int get_cpu_usage()
{
static int processor_count_ = -1;
static int64_t last_time_ = 0;
static int64_t last_system_time_ = 0;
FILETIME now;
FILETIME creation_time;
FILETIME exit_time;
FILETIME kernel_time;
FILETIME user_time;
int64_t system_time;
int64_t time;
int64_t system_time_delta;
int64_t time_delta;
int cpu = -1;
if (processor_count_ == -1)
{
processor_count_ = get_processor_number();
}
GetSystemTimeAsFileTime(&now);
if (!GetProcessTimes(GetCurrentProcess(), &creation_time, &exit_time,
&kernel_time, &user_time))
{
// We don't assert here because in some cases (such as in the Task Manager)
// we may call this function on a process that has just exited but we have
// not yet received the notification.
return -1;
}
system_time = (file_time_2_utc(&kernel_time) + file_time_2_utc(&user_time))
/
processor_count_;
time = file_time_2_utc(&now);
if ((last_system_time_ == 0) || (last_time_ == 0))
{
// First call, just set the last values.
last_system_time_ = system_time;
last_time_ = time;
return -1;
}
system_time_delta = system_time - last_system_time_;
time_delta = time - last_time_;
assert(time_delta != 0);
if (time_delta == 0)
return -1;
// We add time_delta / 2 so the result is rounded.
cpu = (int)((system_time_delta * 100 + time_delta / 2) / time_delta);
last_system_time_ = system_time;
last_time_ = time;
return cpu;
}
int get_memory_usage(uint64_t* mem, uint64_t* vmem)
{
PROCESS_MEMORY_COUNTERS pmc;
if (GetProcessMemoryInfo(GetCurrentProcess(), &pmc, sizeof(pmc)))
{
if (mem) *mem = pmc.WorkingSetSize;
if (vmem) *vmem = pmc.PagefileUsage;
return 0;
}
return -1;
}
int get_io_bytes(uint64_t* read_bytes, uint64_t* write_bytes)
{
IO_COUNTERS io_counter;
if (GetProcessIoCounters(GetCurrentProcess(), &io_counter))
{
if (read_bytes) *read_bytes = io_counter.ReadTransferCount;
if (write_bytes) *write_bytes = io_counter.WriteTransferCount;
return 0;
}
return -1;
}
|
Python
|
UTF-8
| 1,051 | 2.90625 | 3 |
[] |
no_license
|
import RPi.GPIO as GPIO
import Tkinter as tk
import socket
GPIO.setmode(GPIO.BCM)
pin = 14
GPIO.setup(pin, GPIO.OUT)
HOST = '' # Symbolic name, meaning all available interfaces
PORT = 1338 # Arbitrary non-privileged port
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
print 'Socket created'
try:
s.bind((HOST, PORT))
except socket.error as msg:
print 'Bind failed. Error Code : ' + str(msg[0]) + ' Message ' + msg[1]
sys.exit()
print 'Socket bind complete'
s.listen(10)
print 'Socket now listening'
def clientthread(conn):
print 'Driver connected'
def listenForConnections():
while 1:
#wait to accept a connection - blocking call
conn, addr = s.accept()
print 'Connected with ' + addr[0] + ':' + str(addr[1])
#start new thread takes 1st argument as a function name to be run, second is the tuple of arguments to the function.
start_new_thread(clientthread ,(conn,))
start_new_thread(listenForConnections, ())
s.close()
# GPIO.output(led, GPIO.HIGH)
GPIO.cleanup()
|
C++
|
UTF-8
| 761 | 2.875 | 3 |
[
"MIT"
] |
permissive
|
//
// Created by Karol on 08.09.2016.
//
#define _USE_MATH_DEFINES
#include <cmath>
#include "SDL_helpers.hpp"
int SDL_RenderDrawCircle(SDL_Renderer * renderer, double x, double y, double r, unsigned sides) {
if (sides == 0)
sides = (unsigned)(2.0*M_PI*r / 2.0 + 0.5);
double d_a = 2.0*M_PI/sides;
double angle = d_a;
double x1, y1;
double x2 = r + x;
double y2 = 0.0 + y;
for (unsigned i = 0u; i < sides; ++i) {
x1 = x2; y1 = y2;
x2 = cos(angle) * r + x;
y2 = sin(angle) * r + y;
angle += d_a;
const int result = SDL_RenderDrawLine(renderer, (int)(x1+0.5), (int)(y1+0.5), (int)(x2+0.5), (int)(y2+0.5));
if (result != 0)
return result;
}
return 0;
}
|
C++
|
UTF-8
| 1,296 | 2.640625 | 3 |
[] |
no_license
|
#include <bits/stdc++.h>
#define fi first
#define se second
using namespace std;
typedef long long ll;
const int N = 5e4;
int parent[N], ranks[N];
void initDSU(int n) {
for (int i = 0; i < n; i++) {
parent[i] = i;
ranks[i] = 0;
}
}
int root(int v) {
return v == parent[v] ? v : parent[v] = root(parent[v]);
}
void join(int v, int u) {
v = root(v);
u = root(u);
if (ranks[v] < ranks[u]) {
swap(v, u);
}
parent[u] = v;
if (ranks[v] == ranks[u]) {
ranks[v]++;
}
}
struct Edge {
int u, v, w;
};
int main() {
#if __APPLE__
freopen("input.txt", "r", stdin);
#else
freopen("oil.in", "r", stdin);
freopen("oil.out", "w", stdout);
#endif
int n, k;
scanf("%d%d", &n, &k);
initDSU(n);
vector<Edge> edges(k);
for (int i = 0; i < k; i++) {
scanf("%d%d%d", &edges[i].u, &edges[i].v, &edges[i].w);
--edges[i].u;
--edges[i].v;
}
sort(edges.begin(), edges.end(),
[] (Edge e1, Edge e2) {
return e1.w < e2.w;
});
int ans = 0;
for (int i = 0; i < k; i++) {
if (root(edges[i].v) != root(edges[i].u)) {
ans = edges[i].w;
join(edges[i].v, edges[i].u);
}
}
printf("%d\n", ans);
}
|
TypeScript
|
UTF-8
| 3,739 | 2.6875 | 3 |
[
"MIT"
] |
permissive
|
import { CliBuildError, Type } from '../common/cli-types';
import { ModuleRef } from '../module/module-ref';
import { Injector } from '../dependency-injection/injector';
import { ProviderRef } from '../dependency-injection/provider-refs/provider-ref';
import { EvaluatedOption } from '../parser/options-parser';
import { OptionDefinition, OptionsContainerDefinition} from './option-models';
import { getMetadata, MetadataKey } from '../common/meta-data';
/**
* An internal reference to cli options that can be injected into modules and/or commands, similiar to other providers.
* This ProviderRef implementation also handles the binding of option properties and triggers execution of the afterOptionsInit hook if it
* has been implemented. Different to other providers, an instance of the option needs to be created for each option in the execution path
* regardless of whether it is eventually injected as a dependency into another class
*/
export class OptionsProviderRef<T = any> extends Injector<T> implements ProviderRef<T> {
injectToken: Type<T>;
/**
* Metadata of the option properties for the container class
*/
optionsMetadata: OptionDefinition[];
/**
* Reference to the instantiated options
*/
private instance: T;
singleton = true;
/**
* Creates a new instance of the options provider and reads the options metadata
* @param constructorRef Constructor of the options container
* @param parent Parent injector for the container
* @param globalProviders Reference to global injection scope
*/
constructor(
constructorRef: Type<any>,
parent: ModuleRef,
globalProviders: ProviderRef[],
) {
super(constructorRef, globalProviders, parent);
this.injectToken = constructorRef;
this.optionsMetadata = getMetadata<OptionDefinition[]>(MetadataKey.Option, this.constructorRef) || [];
if (parent) {
this.providers = parent.registerProviders(getMetadata<OptionsContainerDefinition>(MetadataKey.Options, this.constructorRef)?.providers || [], this);
}
}
/**
* Instantiates an instance of the options contructor, injecting dependencies into the constructor if required. Binds the parsed options to
* the decorated option properties, and executed the afterOptionsInit hook if it has been implemented.
* @param moduleRef The module which originated the `injector` call
* @param callstack The dependency injection callstack used to identify circular referencing providers
*/
async init(parsedOptions: EvaluatedOption[]) {
this.instance = await super.resolve();
this.optionsMetadata.forEach(opt => {
const parsedOpt = parsedOptions.find(o => o.definition.name === opt.name || (!!opt.alias && opt.alias === o.definition.alias));
if (parsedOpt) {
this.instance[opt.propertyName] = parsedOpt.value !== undefined ? parsedOpt.value : this.instance[opt.propertyName];
}
});
if ((this.instance as any).afterOptionsInit) {
await (this.instance as any).afterOptionsInit();
}
}
/**
* Returns the options instance. Will throw an error if the init function has not been called prior resolving the value
* @param moduleRef The module which originated the `injector` call
* @param callstack The dependency injection callstack used to identify circular referencing providers
*/
async resolve(): Promise<T> {
if (!this.instance) {
throw new CliBuildError(`Could not resolve options that have not been initialized, ${this.constructorRef.name}`);
}
return this.instance;
}
}
|
Swift
|
UTF-8
| 494 | 2.828125 | 3 |
[
"MIT"
] |
permissive
|
//
// SelectedManager.swift
// HAYO
//
// Created by mono on 8/22/14.
// Copyright (c) 2014 Sheep. All rights reserved.
//
import Foundation
class SelectedManager {
var set = NSMutableSet()
func toggle(obj: AnyObject) -> Bool {
if isSelected(obj) {
set.removeObject(obj)
return false
}
set.addObject(obj)
return true
}
func isSelected(obj: AnyObject) -> Bool {
return set.containsObject(obj)
}
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.