
messages
listlengths 3
3
|
|---|
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Trying to git clone via SSH but getting broken pipe error\nI am having some strange issues trying to git clone one of my public GitHub repositories because of a weird issue. I know it's not an issue with my key, because I've taken the same key from another VM and just simply fixed its permissions. This is the error that I get when trying to use SSH:\n[root:kali:~/scripts]# ssh -T [email protected]_write_wait:\nConnection to 192.30.253.112 port 22: Broken pipe\n\nSuggestion 1\nReference: https://gitlab.com/gitlab-com/support-forum/issues/129\nTried to add the following to an /etc/ssh/ssh_config file: \nHost *\nServerAliveInterval 120\nTCPKeepAlive no\n\nand no luck. I've even tried changing TCPKeepAlive to yes, and the same thing happens.\nMy DNS server is set to 8.8.8.8, so not quite sure that's the issue. I can git clone the http URL, just not the SSH URL.\nSuggestion 2\nI also tried to run the ssh command with the verbose option, and according to the output, it looks like it actually authenticates successfully, as shown below:\ndebug1: Server accepts key: pkalg ssh-rsa blen 279\ndebug1: Authentication succeeded (publickey).\nAuthenticated to github.com ([192.30.253.113]:22).\ndebug1: channel 0: new [client-session]\ndebug1: Entering interactive session.\ndebug1: pledge: network\ndebug1: Sending environment.\ndebug1: Sending env LANG = C.UTF-8\ndebug1: Sending env LC_CTYPE = C.UTF-8\npacket_write_wait: Connection to 192.30.253.113 port 22: Broken pipe\n\nAny idea what else could be going wrong here?"
},
{
"role": "assistant",
"content": "I don't know who this guy is, but bless him! This worked for me: https://blog.bchoy.me/post/2018-09-11-vmware-ssh-bug/\nPut this in your ~/.ssh/config\nHost *\n ServerAliveInterval 600\n TCPKeepAlive yes\n IPQoS=throughput\n\nHe has a link to some discussion about the IPQoS parameter -- which fixed it for me."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-rev-list - Lists commit objects in reverse chronological order -E --extended-regexp"
},
{
"role": "assistant",
"content": "Consider the limiting patterns to be extended regular expressions\ninstead of the default basic regular expressions."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker git-ls-files"
},
{
"role": "assistant",
"content": "Show information about files in the index and the working tree"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker"
},
{
"role": "assistant",
"content": "Authors Git was started by Linus Torvalds, and is currently maintained by Junio\nC Hamano. Numerous contributions have come from the Git mailing list\n< [email protected] >. https://openhub.net/p/git/contributors/summary gives you a more complete list of contributors. If you have a clone of git.git itself, the\noutput of git-shortlog and git-blame can show you\nthe authors for specific parts of the project."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Using GitHub Actions to automatically update the repo's submodules\nTitle says it all. I tried using a bunch of different git commands like git submodule update --remote --merge and git submodule foreach git pull origin master which work fine on my computer, but not when it's run on GitHub actions.\nI tried adding git status to the workflow and the status just shows \"Up to date with origin/master, nothing to commit\" or something like that."
},
{
"role": "assistant",
"content": "If you need to auto update references to your submodules via GitHub actions:\nCreate a new workflow in your parent repository that will synchronize references:\nname: 'Submodules Sync'\n\non:\n # Allows you to run this workflow manually from the Actions tab or through HTTP API\n workflow_dispatch:\n\njobs:\n sync:\n name: 'Submodules Sync'\n runs-on: ubuntu-latest\n\n # Use the Bash shell regardless whether the GitHub Actions runner is ubuntu-latest, macos-latest, or windows-latest\n defaults:\n run:\n shell: bash\n\n steps:\n # Checkout the repository to the GitHub Actions runner\n - name: Checkout\n uses: actions/checkout@v2\n with:\n token: ${{ secrets.CI_TOKEN }}\n submodules: true\n\n # Update references\n - name: Git Submodule Update\n run: |\n git pull --recurse-submodules\n git submodule update --remote --recursive\n\n - name: Commit update\n run: |\n git config --global user.name 'Git bot'\n git config --global user.email '[email protected]'\n git remote set-url origin https://x-access-token:${{ secrets.GITHUB_TOKEN }}@github.com/${{ github.repository }}\n git commit -am \"Auto updated submodule references\" && git push || echo \"No changes to commit\"\n\nwhere\n\nCI_TOKEN is a security token variable in GitHub that have 'Read-Write' access to the parent repository, and 'Read' access to submodule repositories.\n\n\nIn the child (submodule) GitHub action notify the parent about changes.\nname: 'Submodule Notify Parent'\n\non:\n push:\n branches:\n - main \n\n # Allows you to run this workflow manually from the Actions tab\n workflow_dispatch:\n\njobs:\n notify:\n name: 'Submodule Notify Parent'\n runs-on: ubuntu-latest\n\n # Use the Bash shell regardless whether the GitHub Actions runner is ubuntu-latest, macos-latest, or windows-latest\n defaults:\n run:\n shell: bash\n\n steps:\n - name: Github REST API Call\n env:\n CI_TOKEN: ${{ secrets.CI_TOKEN }}\n PARENT_REPO: <my_organization/my-app>\n PARENT_BRANCH: develop\n WORKFLOW_ID: <9999999>\n run: |\n curl -fL --retry 3 -X POST -H \"Accept: application/vnd.github.v3+json\" -H \"Authorization: token ${{ env.CI_TOKEN }}\" https://api.github.com/repos/${{ env.PARENT_REPO }}/actions/workflows/${{ env.WORKFLOW_ID }}/dispatches -d '{\"ref\":\"${{ env.PARENT_BRANCH }}\"}'\n\nwhere\n\nPARENT_REPO - name of the parent repository as it is in Github (my_org/my_app or just my_app if there is no organization).\nWORKFLOW_ID - parent Wofklow ID to call via rest API. To find it run curl using your CI_TOKEN:\ncurl -X GET -H \"Authorization: token $CI_TOKEN\" https://api.github.com/repos/$PARENT_REPO/actions/workflows\n\n\n\nRepeat the workflow creation for every submodule.\n\nP.S. For me it works very stable. Please add information about existing github actions with the above logic if there is any."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-svn - Bidirectional operation between a Subversion repository and Git --rmdir"
},
{
"role": "assistant",
"content": "Only used with the dcommit , set-tree and commit-diff commands. Remove directories from the SVN tree if there are no files left\nbehind. SVN can version empty directories, and they are not\nremoved by default if there are no files left in them. Git\ncannot version empty directories. Enabling this flag will make\nthe commit to SVN act like Git. config key: svn.rmdir"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Trigger Gitlab-CI Pipeline only when there is a new tag\n\nI have following gitlab-ci conf. file:\nbefore_script:\n - echo %CI_BUILD_REF%\n - echo %CI_PROJECT_DIR%\n\nstages:\n - createPBLs\n - build\n - package\n\n\ncreate PBLs:\n stage: createPBLs\n script: \n - xcopy /y /s \"%CI_PROJECT_DIR%\" \"C:\\Bauen\\\"\n - cd \"C:\\Bauen\\\"\n - ./run_orcascript.cmd\n\n\nbuild:\n stage: build\n script:\n - cd \"C:\\Bauen\\\"\n - ./run_pbc.cmd\n except:\n - master\n\nbuild_master:\n stage: build\n script:\n - cd \"C:\\Bauen\\\"\n - ./run_pbcm.cmd\n only:\n - master\n\npackage:\n stage: package\n script:\n - cd \"C:\\Bauen\\\"\n - ./cpfiles.cmd\n artifacts:\n expire_in: 1 week\n name: \"%CI_COMMIT_REF_NAME%\"\n paths:\n - GitLab-Build\n\nHow can I add the rule that the pipeline will ONLY trigger if a new tag has been added to a branch? The tag should start with \"Ticket/ticket_\"\nCurrently he is building for every push."
},
{
"role": "assistant",
"content": "You need to use only syntax:\nonly:\n - tags\n\nThis would trigger for any Tag being pushed. If you want to be a bit more specific you can do:\nonly:\n - /Ticket\\/ticket\\_.*/\n\nwhich would build for any push with the Ticket/ticket_ tag."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git push: permission denied (public key)\nI'm trying to push a file to a git repo of a friend but errors on public key.\ngit push origin testbranch\nPermission denied (publickey).\nfatal: Could not read from remote repository.\n\nWhere and how do we define public / private keys? \ngit remote -v returns:\norigin [email protected]:Sesamzaad/NET.git (fetch)\norigin [email protected]:Sesamzaad/NET.git (push)\n\nAny help is appreciated."
},
{
"role": "assistant",
"content": "I was facing same problem and here is what I did that worked for me.\nUse ssh instead of http. Remove origin if its http.\ngit remote rm origin\n\nAdd ssh url\ngit remote add origin [email protected]:<username>/<repo>.git\n\nGenerate ssh key inside .ssh/ folder. It will ask for path and passphrase where you can just press enter and proceed.\ncd ~/.ssh\nssh-keygen\n\nCopy the key. You can view your key using -\ncat ~/.ssh/id_rsa.pub\n\nIf you hadn't specified a different path then this will be the default path.\nAdd this key to your github account.\nNext do -\nssh -T [email protected]\n\nYou will get a welcome message in your console.\ncd into to your project folder. git push -u origin master now works!"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Latex rendering in README.md on Github\n\nIs there any way to render LaTex in README.md in a GitHub repository? I've googled it and searched on stack overflow but none of the related answers seems feasible."
},
{
"role": "assistant",
"content": "For short expresions and not so fancy math you could use the inline HTML to get your latex rendered math on codecogs and then embed the resulting image. Here an example:\n- <img src=\"https://latex.codecogs.com/gif.latex?O_t=\\text { Onset event at time bin } t \" /> \n- <img src=\"https://latex.codecogs.com/gif.latex?s=\\text { sensor reading } \" /> \n- <img src=\"https://latex.codecogs.com/gif.latex?P(s | O_t )=\\text { Probability of a sensor reading value when sleep onset is observed at a time bin } t \" />\n\nWhich should result in something like the next\n\n\n\nUpdate: This works great in eclipse but not in github unfortunately. The only work around is the next:\nTake your latex equation and go to http://www.codecogs.com/latex/eqneditor.php, at the bottom of the area where your equation appears displayed there is a tiny dropdown menu, pick URL encoded and then paste that in your github markdown in the next way:\n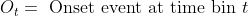\n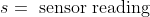 \n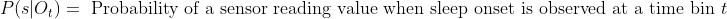"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How to install a bower package using a private git server (SSH)?\nEDIT: this guy do exactly the same with success, can't figure out why it's not working for me.\nI've just installed git and setup permissions/SSH authentication with public/private key (Centos 6.5). I'm able to pull/push without problems using i.e.:\ngit clone [email protected]:projects/boilerplate-template\n\nUsername is git, code placed in /home/git/projects, repository created with git --init --shared boilerplate-template.\nHow can I require boilerplate-template with Bower in another project?\nI've tried with the following bower.json file without luck:\n{\n \"name\": \"my/newproject\",\n \"dependencies\": {\n \"boilerplate-template\": \"git://code.organization.com:projects/boilerplate-template\"\n }\n}\n\n\nECMDERR: Failed to execute \"git ls-remote --tags --heads \n git://code.organization.com:projects/boilerplate-template, exit code\n 128\n unable to lookup code.organization.com (port project)...\n\nSadly it fails because :project is not the port but the path. I've also tried with ssh:// instead of git://:\n\nENOTFOUND: Package\n ssh://code.organization.com:projects/boilerplate-template not found."
},
{
"role": "assistant",
"content": "Ok, found the solution here: Using Bower as the Package Management tool for Internal, Private Libraries. Simply remove git:// or ssh:// and add .git suffix:\n\"[email protected]:projects/boilerplate-template.git#~1\""
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-log - Show commit logs off, none"
},
{
"role": "assistant",
"content": "Disable output of diffs for merge commits. Useful to override\nimplied value."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How can I find the N largest files in a Git repository?\nI wanted to find the 10 largest files in my repository. The script I came up with is as follows:\nREP_HOME_DIR=<top level git directory>\nmax_huge_files=10\n\ncd ${REP_HOME_DIR}\ngit verify-pack -v ${REP_HOME_DIR}/.git/objects/pack/pack-*.idx | \\\n grep blob | \\\n sort -r -k 3 -n | \\\n head -${max_huge_files} | \\\n awk '{ system(\"printf \\\"%-80s \\\" `git rev-list --objects --all | grep \" $1 \" | cut -d\\\" \\\" -f2`\"); printf \"Size:%5d MB Size in pack file:%5d MB\\n\", $3/1048576, $4/1048576; }'\ncd -\n\nIs there a better/more elegant way to do the same?\nBy \"files\" I mean the files that have been checked into the repository."
},
{
"role": "assistant",
"content": "This Bash \"one-liner\" displays the 10 largest blobs in the repository, sorted from smallest to largest. In contrast to the other answers, this includes all files tracked by the repository, even those not present in any branch tip.\nIt's very fast, easy to copy & paste and only requires standard GNU utilities.\ngit rev-list --objects --all \\\n| git cat-file --batch-check='%(objecttype) %(objectname) %(objectsize) %(rest)' \\\n| sed -n 's/^blob //p' \\\n| sort --numeric-sort --key=2 \\\n| tail -n 10 \\\n| cut -c 1-12,41- \\\n| $(command -v gnumfmt || echo numfmt) --field=2 --to=iec-i --suffix=B --padding=7 --round=nearest\n\nThe first four lines implement the core functionality, the fifth limits the number of results, while the last two lines provide the nice human-readable output that looks like this:\n...\n0d99bb931299 530KiB path/to/some-image.jpg\n2ba44098e28f 12MiB path/to/hires-image.png\nbd1741ddce0d 63MiB path/to/some-video-1080p.mp4\n\nFor more information, including further filtering use cases and an output format more suitable for script processing, see my original answer to a similar question.\nmacOS users: Since numfmt is not available on macOS, you can either omit the last line and deal with raw byte sizes or brew install coreutils."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Jenkins - abort running build if new one is started\nI use Jenkins and Multibranch Pipeline. I have a job for each active git branch.\nNew build is triggered by push in git repository. What I want is to abort running builds in current branch if new one appears in same branch. \nFor example: I commit and push to branch feature1. Then BUILD_1 started in Jenkins. I make another commit and push to branch feature1 while BUILD_1 is still running. I want BUILD_1 to be aborted and to start BUILD_2. \nI tried to use stage concurrency=x option, and stage-lock-milestone feature, but didn't manage to solve my problem.\nAlso I've read this thread Stopping Jenkins job in case newer one is started, but there is no solution for my problem.\nDo you know any solution to this?"
},
{
"role": "assistant",
"content": "With Jenkins script security many of the solutions here become difficult since they are using non-whitelisted methods.\nWith these milestone steps at the start of the Jenkinsfile, this is working for me:\ndef buildNumber = env.BUILD_NUMBER as int\nif (buildNumber > 1) milestone(buildNumber - 1)\nmilestone(buildNumber)\n\nThe result here would be:\n\nBuild 1 runs and creates milestone 1\nWhile build 1 is running, build 2 fires. It has milestone 1 and milestone 2. It passes milestone 1, which causes build #1 to abort."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How to quickly disable / enable stages in Gitlab CI\n\nWhen you work on your .gitlab-ci.yml for a big project, for example having a time consuming testing stage causes a lot of delay. Is there an easy way to disable that stage, as just removing it from the stages definition, will make the YAML invalid from Gitlab's point of view (since there's a defined but unused stage), and in my case results in:\ntest job: chosen stage does not exist; available stages are .pre, build, deploy, .post\n\nSince YAML does not support block comments, you'd need to comment out every line of the offending stage.\nAre there quicker ways?"
},
{
"role": "assistant",
"content": "You could disable all the jobs from your stage using this trick of starting the job name with a dot ('.'). See https://docs.gitlab.com/ee/ci/jobs/index.html#hide-jobs for more details.\n.hidden_job:\n script:\n - run test"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-log - Show commit logs ignore-all-space"
},
{
"role": "assistant",
"content": "Ignore whitespace when comparing lines. This ignores differences\neven if one line has whitespace where the other line has none."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Untrack files from git temporarily\nI have setup a local git on my machine. When I initialized git, I added pre-compiled libs and binaries. However, now during my development I don't want to check in those files intermittently. I dont want to remove these files from repo. Is there any way to not keep a track of these files till I complete my development. (I think I can not use .gitignore as it works only for those files which are not in git. I want to temporarily disable tracking of files.)"
},
{
"role": "assistant",
"content": "git update-index should do what you want\nThis will tell git you want to start ignoring the changes to the file\ngit update-index --assume-unchanged path/to/file\nWhen you want to start keeping track again\ngit update-index --no-assume-unchanged path/to/file\nGithub Documentation: update-index"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-log - Show commit logs %aL"
},
{
"role": "assistant",
"content": "author local-part (see %al ) respecting .mailmap, see git-shortlog or git-blame )"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-ls-files - Show information about files in the index and the working tree"
},
{
"role": "assistant",
"content": "SYNOPSIS git ls-files [-z] [-t] [-v] [-f]\n\t\t[-c|--cached] [-d|--deleted] [-o|--others] [-i|--ignored]\n\t\t[-s|--stage] [-u|--unmerged] [-k|--killed] [-m|--modified]\n\t\t[--resolve-undo]\n\t\t[--directory [--no-empty-directory]] [--eol]\n\t\t[--deduplicate]\n\t\t[-x <pattern>|--exclude=<pattern>]\n\t\t[-X <file>|--exclude-from=<file>]\n\t\t[--exclude-per-directory=<file>]\n\t\t[--exclude-standard]\n\t\t[--error-unmatch] [--with-tree=<tree-ish>]\n\t\t[--full-name] [--recurse-submodules]\n\t\t[--abbrev[=<n>]] [--format=<format>] [--] [<file>…]"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git push heroku master says \"Everything up-to-date\", but the app is not current\n\nI have an app on Heroku that is running old code. I've made a small change and committed the change. I then ran\ngit push heroku master\n\nIt'll say\nFetching repository, done.\nEverything up-to-date\n\nBut if I go and look at the app, it's all old code. I did revert the site back to another version in Heroku about 15 days ago, but pushed updates to it since then and they worked.\nWhy is heroku not getting the most current files from my github repository? Is there a way to just reset the app and push the files from github again? I have production data in the database so I do NOT want to touch it."
},
{
"role": "assistant",
"content": "Kindly confirm your current branch is master. \n git branch \n\nIf the pointer is not pointing the master, then check out to master branch\ngit checkout master\n\nCommit your changes and try to push to heroku\ngit commit -am \"xxxyyzzz\" \ngit push heroku master"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "master branch and 'origin/master' have diverged, how to 'undiverge' branches'?\nSomehow my master and my origin/master branch have diverged.\nI actually don't want them to diverge.\nHow can I view these differences and merge them?"
},
{
"role": "assistant",
"content": "You can review the differences with a:\ngit log HEAD..origin/main\n\n# old repositories\ngit log HEAD..origin/master\n\nbefore pulling it (fetch + merge) (see also \"How do you get git to always pull from a specific branch?\")\nNote: since Git 2.28 (Q3 2020), the default branch is configurable, and now (2021+) set to main, no longer master.\nThe rest of the answer reflects that more recent convention.\n\nWhen you have a message like:\n\n\"Your branch and 'origin/main' have diverged, # and have 1 and 1 different commit(s) each, respectively.\"\n\nCheck if you need to update origin.\nIf origin is up-to-date, then some commits have been pushed to origin from another repo while you made your own commits locally.\n... o ---- o ---- A ---- B origin/main (upstream work)\n \\\n C main(your work)\n\nYou based commit C on commit A because that was the latest work you had fetched from upstream at the time.\nHowever, before you tried to push back to origin, someone else pushed the commit B.\nDevelopment history has diverged into separate paths.\nYou can then merge or rebase. See Pro Git: Git Branching - Rebasing for details.\nMerge\nUse the git merge command:\n$ git merge origin/main\n\n# old repositories\n$ git merge origin/master\n\nThis tells Git to integrate the changes from origin/main into your work and create a merge commit.\nThe graph of history now looks like this:\n... o ---- o ---- A ---- B origin/main (upstream work)\n \\ \\\n C ---- M main (your work)\n\nThe new merge, commit M, has two parents, each representing one path of development that led to the content stored in that commit.\nNote that the history behind M is now non-linear.\nRebase\nUse the git rebase command:\n$ git rebase origin/main\n\n# old repositories\n$ git rebase origin/master\n\nThis tells Git to replay commit C (your work) as if you had based it on commit B instead of A.\nCVS and Subversion users routinely rebase their local changes on top of upstream work when they update before commit.\nGit just adds explicit separation between the commit and rebase steps.\nThe graph of history now looks like this:\n... o ---- o ---- A ---- B origin/main (upstream work)\n \\\n C' main (your work)\n\nCommit C' is a new commit created by the git rebase command.\nIt is different from C in two ways:\n\nIt has a different history: B instead of A.\nIts content accounts for changes in both B and C; it is the same as M from the merge example.\n\nNote that the history behind C' is still linear.\nWe have chosen (for now) to allow only linear history in cmake.org/cmake.git.\nThis approach preserves the CVS-based workflow used previously and may ease the transition.\nAn attempt to push C' into our repository will work (assuming you have permissions and no one has pushed while you were rebasing).\nThe git pull command provides a shorthand way to fetch from origin and rebase local work on it:\n$ git pull --rebase\n\nThis combines the above fetch and rebase steps into one command."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Reset all changes after last commit in git\nHow can I undo every change made to my directory after the last commit, including deleting added files, resetting modified files, and adding back deleted files?"
},
{
"role": "assistant",
"content": "First, reset any changes\nThis will undo any changes you've made to tracked files and restore deleted files:\ngit reset HEAD --hard\n\nSecond, remove new files\nThis will delete any new files that were added since the last commit:\ngit clean -fd\n\nFiles that are not tracked due to .gitignore are preserved; they will not be removed\nWarning: using -x instead of -fd would delete ignored files. You probably don't want to do this."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff - Show changes between commits, commit and working tree, etc -G<regex>"
},
{
"role": "assistant",
"content": "Look for differences whose patch text contains added/removed\nlines that match <regex>. To illustrate the difference between -S<regex> --pickaxe-regex and -G<regex> , consider a commit with the following diff in the same\nfile: + return frotz(nitfol, two->ptr, 1, 0);\n...\n- hit = frotz(nitfol, mf2.ptr, 1, 0); While git log -G\"frotz\\(nitfol\" will show this commit, git log\n-S\"frotz\\(nitfol\" --pickaxe-regex will not (because the number of\noccurrences of that string did not change). Unless --text is supplied patches of binary files without a textconv\nfilter will be ignored. See the pickaxe entry in gitdiffcore for more\ninformation."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker"
},
{
"role": "assistant",
"content": "FURTHER DOCUMENTATION See the references in the \"description\" section to get started\nusing Git. The following is probably more detail than necessary\nfor a first-time user. The Git concepts chapter of the\nuser-manual and gitcore-tutorial both provide\nintroductions to the underlying Git architecture. See gitworkflows for an overview of recommended workflows. See also the howto documents for some useful\nexamples. The internals are documented in the Git API documentation . Users migrating from CVS may also want to\nread gitcvs-migration ."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How to apply unmerged upstream pull requests from other forks into my fork?\n\nA project on GitHub that I have a fork of has a new pull requests that I want to pull into my fork that the author has not pulled in yet.\nIs there a simple way to apply pull request from other forks into my fork? Is there something else here that I am missing?"
},
{
"role": "assistant",
"content": "Update: Via Webpage\nYou can also do this via the github webpage.\nI assume, you should have already a fork (MyFork) of the common repo (BaseRepo) which has the pending pull request from a fork (OtherFork) you are interested in.\n\nNavigate to the fork (OtherFork) which has initiated the pull request which you like to get into your fork (MyFork)\nGo to the pull requests page of OtherFork\nClick new pull request\nThe pending pull request(s) should be offered. Remember to select proper OtherFork branch too. Select on the left side as the base fork your fork (MyFork) (IMPORTANT).\nNow the option of View pull request should change to Create pull request. Click this.\n\nNow you should have a pending pull request in your fork (MyFork), which you can simply accept."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git rebase without changing commit timestamps\nWould it make sense to perform git rebase while preserving the commit timestamps?\nI believe a consequence would be that the new branch will not necessarily have commit dates chronologically. Is that theoretically possible at all? (e.g. using plumbing commands; just curious here)\nIf it is theoretically possible, then is it possible in practice with rebase, not to change the timestamps?\nFor example, assume I have the following tree:\nmaster <jun 2010>\n |\n :\n :\n : oldbranch <feb 1984>\n : /\noldcommit <jan 1984>\n\nNow, if I rebase oldbranch on master, the date of the commit changes from feb 1984 to jun 2010. Is it possible to change that behaviour so that the commit timestamp is not changed? In the end I would thus obtain:\n oldbranch <feb 1984>\n /\n master <jun 2010>\n |\n :\n\nWould that make sense at all? Is it even allowed in git to have a history where an old commit has a more recent commit as a parent?"
},
{
"role": "assistant",
"content": "Update June 2014: David Fraser mentions in the comments a solution also detailed in \"Change timestamps while rebasing git branch\", using the option --committer-date-is-author-date (introduced initially in Jan. 2009 in commit 3f01ad6\n\nNote that the --committer-date-is-author-date option seems to leave the author timestamp, and set the committer timestamp to be the same as the original author timestamp, which is what the OP Olivier Verdier wanted.\nI found the last commit with the correct date and did:\ngit rebase --committer-date-is-author-date SHA\n\n\nSee git am:\n\n--committer-date-is-author-date\n\nBy default the command records the date from the e-mail message as the commit author date, and uses the time of commit creation as the committer date.\nThis allows the user to lie about the committer date by using the same value as the author date.\n\nNote: with Git 2.29 (Q4 2020), git rebase --committer-date-is-author-date or --ignore-date will also work with:\n\ninteractive rebase (rebase -i/rebase --interactive)\nfor the root commit (git rebase --root)\n\nSee \"Change timestamps while rebasing git branch\".\n\n(Original answer, June 2012)\nYou could try, for a non-interactive rebase\n(see just above: with Git 2.29, Q4 2020, that will work with an interactive rebase as well)\ngit rebase --ignore-date\n\n(from this SO answer)\nThis is passed to git am, which mentions:\n --ignore-date\n\n\nBy default the command records the date from the e-mail message as the commit author date, and uses the time of commit creation as the committer date.\nThis allows the user to lie about the author date by using the same value as the committer date.\n\nFor git rebase, this option is \"Incompatible with the --interactive option.\"\nSince you can change at will the timestamp of old commit date (with git filter-branch), I suppose you can organize your Git history with whatever commit date order you want/need, even set it to the future!.\n\nAs Olivier mentions in his question, the author date is never changed by a rebase;\nFrom the Pro Git Book:\n\n\nThe author is the person who originally wrote the work,\nwhereas the committer is the person who last applied the work.\n\nSo, if you send in a patch to a project and one of the core members applies the patch, both of you get credit.\n\nTo be extra clear, in this instance, as Olivier comments:\n\nthe --ignore-date does the opposite of what I was trying to achieve!\nNamely, it erases the author's timestamp and replace them with the commits timestamps!\nSo the right answer to my question is:\nDo not do anything, since git rebase does actually not change authors' timestamps by default.\n\n\nAs DylanYoung adds in the comments, using \"How to identify conflicting commits by hash during git rebase?\":\n\nUsing the SEQUENCE_EDITOR variable and rebase interactive, you would just loop over the current todo list and add a command setting the GIT_COMMITER_DATE to the date of the original commit before each commit in the todo.\nIt's a bit less fiddly because you have the list of original commits to start with (you don't have to hack into git internals to find it), but a bit more work because you have to handle the entire list at once. –\nOnce you're able to identify the original commit you can do something like:\ngit rebase -x 'GIT_COMMITTER_DATE=\"git show -s --format=%ci ``get_current_commit``\" git commit --amend --no-edit"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-log - Show commit logs --pickaxe-regex"
},
{
"role": "assistant",
"content": "Treat the <string> given to -S as an extended POSIX regular\nexpression to match."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-log - Show commit logs %al"
},
{
"role": "assistant",
"content": "author email local-part (the part before the @ sign)"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-rebase - Reapply commits on top of another base tip --root"
},
{
"role": "assistant",
"content": "Rebase all commits reachable from <branch> , instead of\nlimiting them with an <upstream> . This allows you to rebase\nthe root commit(s) on a branch. See also INCOMPATIBLE OPTIONS below."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff - Show changes between commits, commit and working tree, etc --diff-filter=[(A|C|D|M|R|T|U|X|B)…[*]]"
},
{
"role": "assistant",
"content": "Select only files that are Added ( A ), Copied ( C ),\nDeleted ( D ), Modified ( M ), Renamed ( R ), have their\ntype (i.e. regular file, symlink, submodule, …) changed ( T ),\nare Unmerged ( U ), are\nUnknown ( X ), or have had their pairing Broken ( B ).\nAny combination of the filter characters (including none) can be used.\nWhen * (All-or-none) is added to the combination, all\npaths are selected if there is any file that matches\nother criteria in the comparison; if there is no file\nthat matches other criteria, nothing is selected. Also, these upper-case letters can be downcased to exclude. E.g. --diff-filter=ad excludes added and deleted paths. Note that not all diffs can feature all types. For instance, copied and\nrenamed entries cannot appear if detection for those types is disabled."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Merging: Hg/Git vs. SVN\nI often read that Hg (and Git and...) are better at merging than SVN but I have never seen practical examples of where Hg/Git can merge something where SVN fails (or where SVN needs manual intervention). Could you post a few step-by-step lists of branch/modify/commit/...-operations that show where SVN would fail while Hg/Git happily moves on? Practical, not highly exceptional cases please...\nSome background: we have a few dozen developers working on projects using SVN, with each project (or group of similar projects) in its own repository. We know how to apply release- and feature-branches so we don't run into problems very often (i.e., we've been there, but we've learned to overcome Joel's problems of \"one programmer causing trauma to the whole team\" or \"needing six developers for two weeks to reintegrate a branch\"). We have release-branches that are very stable and only used to apply bugfixes. We have trunks that should be stable enough to be able to create a release within one week. And we have feature-branches that single developers or groups of developers can work on. Yes, they are deleted after reintegration so they don't clutter up the repository. ;)\nSo I'm still trying to find the advantages of Hg/Git over SVN. I'd love to get some hands-on experience, but there aren't any bigger projects we could move to Hg/Git yet, so I'm stuck with playing with small artificial projects that only contain a few made up files. And I'm looking for a few cases where you can feel the impressive power of Hg/Git, since so far I have often read about them but failed to find them myself."
},
{
"role": "assistant",
"content": "I too have been looking for a case where, say, Subversion fails to merge a branch and Mercurial (and Git, Bazaar, ...) does the right thing.\nThe SVN Book describes how renamed files are merged incorrectly. This applies to Subversion 1.5, 1.6, 1.7, and 1.8! I have tried to recreate the situation below:\n\ncd /tmp\nrm -rf svn-repo svn-checkout\nsvnadmin create svn-repo\nsvn checkout file:///tmp/svn-repo svn-checkout\ncd svn-checkout\nmkdir trunk branches\necho 'Goodbye, World!' > trunk/hello.txt\nsvn add trunk branches\nsvn commit -m 'Initial import.'\nsvn copy '^/trunk' '^/branches/rename' -m 'Create branch.'\nsvn switch '^/trunk' .\necho 'Hello, World!' > hello.txt\nsvn commit -m 'Update on trunk.'\nsvn switch '^/branches/rename' .\nsvn rename hello.txt hello.en.txt\nsvn commit -m 'Rename on branch.'\nsvn switch '^/trunk' .\nsvn merge --reintegrate '^/branches/rename'\n\nAccording to the book, the merge should finish cleanly, but with wrong data in the renamed file since the update on trunk is forgotten. Instead I get a tree conflict (this is with Subversion 1.6.17, the newest version in Debian at the time of writing):\n\n--- Merging differences between repository URLs into '.':\nA hello.en.txt\n C hello.txt\nSummary of conflicts:\n Tree conflicts: 1\n\nThere shouldn't be any conflict at all — the update should be merged into the new name of the file. While Subversion fails, Mercurial handles this correctly:\nrm -rf /tmp/hg-repo\nhg init /tmp/hg-repo\ncd /tmp/hg-repo\necho 'Goodbye, World!' > hello.txt\nhg add hello.txt\nhg commit -m 'Initial import.'\necho 'Hello, World!' > hello.txt\nhg commit -m 'Update.'\nhg update 0\nhg rename hello.txt hello.en.txt\nhg commit -m 'Rename.'\nhg merge\n\nBefore the merge, the repository looks like this (from hg glog):\n\n@ changeset: 2:6502899164cc\n| tag: tip\n| parent: 0:d08bcebadd9e\n| user: Martin Geisler \n| date: Thu Apr 01 12:29:19 2010 +0200\n| summary: Rename.\n|\n| o changeset: 1:9d06fa155634\n|/ user: Martin Geisler \n| date: Thu Apr 01 12:29:18 2010 +0200\n| summary: Update.\n|\no changeset: 0:d08bcebadd9e\n user: Martin Geisler \n date: Thu Apr 01 12:29:18 2010 +0200\n summary: Initial import.\n\nThe output of the merge is:\n\nmerging hello.en.txt and hello.txt to hello.en.txt\n0 files updated, 1 files merged, 0 files removed, 0 files unresolved\n(branch merge, don't forget to commit)\n\nIn other words: Mercurial took the change from revision 1 and merged it into the new file name from revision 2 (hello.en.txt). Handling this case is of course essential in order to support refactoring and refactoring is exactly the kind of thing you will want to do on a branch."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-switch - Switch branches <start-point>"
},
{
"role": "assistant",
"content": "The starting point for the new branch. Specifying a <start-point> allows you to create a branch based on some\nother point in history than where HEAD currently points. (Or,\nin the case of --detach , allows you to inspect and detach\nfrom some other point.) You can use the @{-N} syntax to refer to the N-th last\nbranch/commit switched to using \"git switch\" or \"git checkout\"\noperation. You may also specify - which is synonymous to @{-1} .\nThis is often used to switch quickly between two branches, or to undo\na branch switch by mistake. As a special case, you may use A...B as a shortcut for the merge\nbase of A and B if there is exactly one merge base. You can leave\nout at most one of A and B , in which case it defaults to HEAD ."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker git-var"
},
{
"role": "assistant",
"content": "Show a Git logical variable"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Is there a way to make git remember the password for WebDAV remotes?\nI'm working with Git pushing changes to a repository shared over HTTP / WebDAV, and Git prompts for a password for every operation that accesses the HTTP remote. Is there any way to make Git cache the password / have the remote server not prompt me?\nThe remote webserver should be an Apache and could possibly be reconfigured if necessary."
},
{
"role": "assistant",
"content": "The way is to use ~/.netrc as outlined in step 3 of this Git documentation:\n\nThen, add the following to your $HOME/.netrc (you can do without, but will be\n asked to input your password a lot of times):\nmachine <servername>\nlogin <username>\npassword <password>\n\n...and set permissions:\nchmod 600 ~/.netrc\n\n\nUPDATE:\nAs of git 1.7.9, it seems the way to go would be the native credential helper API. Git comes with a plaintext credential store or a less convenient but more secure temporary credential cache. It's also possible to use third-party credential helpers. So far I'm aware of a helper for the native Windows Credential Store, and one that integrates with the OS X keychain. (The Git build shipped by Homebrew has a binary for it, as might other OS X Git distributions. Github also provides a standalone binary.)\nGenerally, it should be sufficient to set up the a credential helper once:\ngit config --global credential.helper wincred\n\nOr instead of wincred, use whichever helper is appropriate for your platform. (If the name of the helper executable is git-credential-wincred, the value you set the option to will be wincred, etc.)\nThe credential helpers also support the need to have separate sets of credentials for different repositories on the same host."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - fatal: Unknown index entry format\n\nWhen I'm trying use git status or git checkout master or git pull, \nI'm getting an error :- \n\n\"fatal: Unknown index entry format 61740000\".\n\nI've tried to Reinitialize existing Git repository. But it did not fix the problem.\nI'm new to git, and I have just made a first branch and make some changes and trying to commit the changes.\nTried searching on Google but can't find the right solution for the code 61740000.\nEdit: Deleted the whole local repository and then again cloned from remote repository (git status worked), created a branch (git status worked) and made changes to files (git status error).\nPlease help."
},
{
"role": "assistant",
"content": "When your index is broken you can normally delete the index file and reset it.\nrm -f .git/index\ngit reset\n\nor you clone the repo again."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-rev-list - Lists commit objects in reverse chronological order"
},
{
"role": "assistant",
"content": "NAME git-rev-list - Lists commit objects in reverse chronological order"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-format-patch - Prepare patches for e-mail submission --filename-max-length=<n>"
},
{
"role": "assistant",
"content": "Instead of the standard 64 bytes, chomp the generated output\nfilenames at around <n> bytes (too short a value will be\nsilently raised to a reasonable length). Defaults to the\nvalue of the format.filenameMaxLength configuration\nvariable, or 64 if unconfigured."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Images corrupt after git push\nI added some .png images to my git repo and then pushed them to my remote repository. I noticed that the images are in the remote repository, but they are broken. \nIn order to verify this, I compared the binary data for the images on my local and my remote repos. I also ran the file command on images in both repos.\nImage on local repository\nFirst 10 Lines of Binary data:\n\n8950 4e47 0d0a 1a0a 0000 000d 4948 4452\n 0000 0019 0000 0014 0806 0000 0078 7796\n bd00 0000 1974 4558 7453 6f66 7477 6172\n 6500 4164 6f62 6520 496d 6167 6552 6561\n 6479 71c9 653c 0000 0373 6954 5874 584d\n 4c3a 636f 6d2e 6164 6f62 652e 786d 7000\n 0000 0000 3c3f 7870 6163 6b65 7420 6265\n 6769 6e3d 22ef bbbf 2220 6964 3d22 5735\n 4d30 4d70 4365 6869 487a 7265 537a 4e54\n 637a 6b63 3964 223f 3e20 3c78 3a78 6d70\n\nResult of file command: \n\nbundles/admin/public/images/messages-icon.png: PNG image data, 24 x 16, 8-bit/color RGBA, non-interlaced\n\nImage pushed to remote repository\nFirst 10 Lines of Binary data:\n\n8950 4e47 0a1a 0a00 0000 0d49 4844 5200\n 0000 1900 0000 1408 0600 0000 7877 96bd\n 0000 0019 7445 5874 536f 6674 7761 7265\n 0041 646f 6265 2049 6d61 6765 5265 6164\n 7971 c965 3c00 0003 7369 5458 7458 4d4c\n 3a63 6f6d 2e61 646f 6265 2e78 6d70 0000\n 0000 003c 3f78 7061 636b 6574 2062 6567\n 696e 3d22 efbb bf22 2069 643d 2257 354d\n 304d 7043 6568 6948 7a72 6553 7a4e 5463\n 7a6b 6339 6422 3f3e 203c 783a 786d 706d\n\nResult of file command: \n\nbundles/admin/public/images/notifications-icon.png: data\n\nWhy would this be happening? I searched all over google and this site for answers but have found none."
},
{
"role": "assistant",
"content": "I had this issue too - here's a generic .gitattributes that looks generally safe for php web repos that worked for me: https://github.com/Danimoth/gitattributes/blob/master/Web.gitattributes\nrunning git check-attr --all -- path/to/png before and after adding the new gitattributes showed that the image file was originally treated as a text file, and now it's binary (note I had to commit/push the .gitattributes file for it to take effect on remote)\nIn case the link goes dead:\n# These settings are for any web project\n\n# Handle line endings automatically for files detected as text\n# and leave all files detected as binary untouched.\n# * text=auto\n# NOTE - originally I had the above line un-commented. it caused me a lot of grief related to line endings because I was dealing with WordPress plugins and the website changing line endings out if a user modified a plugin through the web interface. commenting this line out seems to have alleviated the git chaos where simply switching to a branch caused it to believe 500 files were modified.\n\n#\n# The above will handle all files NOT found below\n#\n\n#\n## These files are text and should be normalized (Convert crlf => lf)\n#\n\n# source code\n*.php text\n*.css text\n*.sass text\n*.scss text\n*.less text\n*.styl text\n*.js text\n*.coffee text\n*.json text\n*.htm text\n*.html text\n*.xml text\n*.svg text\n*.txt text\n*.ini text\n*.inc text\n*.pl text\n*.rb text\n*.py text\n*.scm text\n*.sql text\n*.sh text\n*.bat text\n\n# templates\n*.ejs text\n*.hbt text\n*.jade text\n*.haml text\n*.hbs text\n*.dot text\n*.tmpl text\n*.phtml text\n\n# server config\n.htaccess text\n\n# git config\n.gitattributes text\n.gitignore text\n.gitconfig text\n\n# code analysis config\n.jshintrc text\n.jscsrc text\n.jshintignore text\n.csslintrc text\n\n# misc config\n*.yaml text\n*.yml text\n.editorconfig text\n\n# build config\n*.npmignore text\n*.bowerrc text\n\n# Heroku\nProcfile text\n.slugignore text\n\n# Documentation\n*.md text\nLICENSE text\nAUTHORS text\n\n\n#\n## These files are binary and should be left untouched\n#\n\n# (binary is a macro for -text -diff)\n*.png binary\n*.jpg binary\n*.jpeg binary\n*.gif binary\n*.ico binary\n*.mov binary\n*.mp4 binary\n*.mp3 binary\n*.flv binary\n*.fla binary\n*.swf binary\n*.gz binary\n*.zip binary\n*.7z binary\n*.ttf binary\n*.eot binary\n*.woff binary\n*.pyc binary\n*.pdf binary"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker GIT_AUTHOR_DATE"
},
{
"role": "assistant",
"content": "The date used for the author identity when creating commit or tag objects, or\nwhen writing reflogs. See git-commit for valid formats."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff - Show changes between commits, commit and working tree, etc --patience"
},
{
"role": "assistant",
"content": "Generate a diff using the \"patience diff\" algorithm."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What would I use git-worktree for?\nI read Github's post on git-worktree. They write:\n\nSuppose you're working in a Git repository on a branch called feature, when a user reports a high-urgency bug in master. First you create a linked working tree with a new branch, hotfix, checked out relative to master […] You can fix the bug, push hotfix, and create a pull request.\n\nWhen I'm working on a branch called feature and some high-urgency bug in master is reported, I usually stash away whatever I'm working on and create a new branch. When I'm done, I can continue working. This is a very simple model, I've been working like that for years.\nOn the other hand, using git-worktree has its own limitations:\n\nFor example, it's not allowed to have the same branch checked out in two linked working trees at the same time, because that would allow changes committed in one working tree to bring the other one out of sync.\n\nWhy would I choose a more complicated workflow for a problem that's already been solved?\nIs there anything about git-worktree that couldn't be done beforehand and that justifies this whole new, complex feature?"
},
{
"role": "assistant",
"content": "For me, git worktree is the biggest improvement since a long time. I'm working in enterprise software development. There, it is very common that you have to maintain old versions like what you released 3 years ago. Of course you have a branch for each version so that you can easily switch to it and fix a bug. However, switching is expensive, because in the meantime you completely restructured the repository and maybe build system. If you switch, your IDE will run mad trying to adapt the project settings.\nWith worktree, you can avoid that constant reconfiguration. Checkout those old branches in separate folders using worktree. For each branch, you got an independent IDE project.\nOf course this could have been done in the past by cloning the repo several times and this has been my approach so far. However, that also meant wasting hardrive space and worse needing to fetching the same changes from the repo several times."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Git pre-commit hook : changed/added files\nI am writing a pre-commit hook. I want to run php -l against all files with .php extension. However I am stuck.\nI need to obtain a list of new/changed files that are staged. deleted files should be excluded.\nI have tried using git diff and git ls-files, but I think I need a hand here."
},
{
"role": "assistant",
"content": "A slightly neater way of obtaining the same list is: \ngit diff --cached --name-only --diff-filter=ACM\n\nThis will return the list of files that need to be checked. \nBut just running php -l on your working copy may not be the right thing to do. If you are doing a partial commit i.e. just selecting a subset of the differences between your current working set and the HEAD for the commit, then the test will be run on your working set, but will be certifying a commit that has never existed on your disk.\nTo do it right you should extract the whole staged image to a temp area and perform the test there .\nrm -rf $TEMPDIR\nmkdir -p $TEMPDIR\ngit checkout-index --prefix=$TEMPDIR/ -af\ngit diff --cached --name-only --diff-filter=ACM | xargs -n 1 -I '{}' \\bin\\echo TEMPDIR/'{}' | grep \\\\.php | xargs -n 1 php -l\n\nSee Building a better pre-commit hook for Git for another implementation."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-push - Update remote refs along with associated objects"
},
{
"role": "assistant",
"content": "GIT URLS In general, URLs contain information about the transport protocol, the\naddress of the remote server, and the path to the repository.\nDepending on the transport protocol, some of this information may be\nabsent. Git supports ssh, git, http, and https protocols (in addition, ftp\nand ftps can be used for fetching, but this is inefficient and\ndeprecated; do not use them). The native transport (i.e. git:// URL) does no authentication and\nshould be used with caution on unsecured networks. The following syntaxes may be used with them: ssh:// [ <user> @ ] <host> [ : <port> ] / <path-to-git-repo> git:// <host> [: <port> ] / <path-to-git-repo> http [ s ] :// <host> [ : <port> ] / <path-to-git-repo> ftp [ s ] :// <host> [ : <port> ] / <path-to-git-repo> An alternative scp-like syntax may also be used with the ssh protocol: [ <user> @ ] <host> :/ <path-to-git-repo> This syntax is only recognized if there are no slashes before the\nfirst colon. This helps differentiate a local path that contains a\ncolon. For example the local path foo:bar could be specified as an\nabsolute path or ./foo:bar to avoid being misinterpreted as an ssh\nurl. The ssh and git protocols additionally support ~ <username> expansion: ssh:// [ <user> @ ] <host> [ : <port> ] /~ <user> / <path-to-git-repo> git:// <host> [ : <port> ] /~ <user> / <path-to-git-repo> [ <user> @ ] <host> :~ <user> / <path-to-git-repo> For local repositories, also supported by Git natively, the following\nsyntaxes may be used: /path/to/repo.git/ file:///path/to/repo.git/ These two syntaxes are mostly equivalent, except when cloning, when\nthe former implies --local option. See git-clone for\ndetails. git clone , git fetch and git pull , but not git push , will also\naccept a suitable bundle file. See git-bundle . When Git doesn’t know how to handle a certain transport protocol, it\nattempts to use the remote- <transport> remote helper, if one\nexists. To explicitly request a remote helper, the following syntax\nmay be used: <transport> :: <address> where <address> may be a path, a server and path, or an arbitrary\nURL-like string recognized by the specific remote helper being\ninvoked. See gitremote-helpers for details. If there are a large number of similarly-named remote repositories and\nyou want to use a different format for them (such that the URLs you\nuse will be rewritten into URLs that work), you can create a\nconfiguration section of the form: [url \" <actual-url-base> \"]\n\t\tinsteadOf = <other-url-base> For example, with this: [url \"git://git.host.xz/\"]\n\t\tinsteadOf = host.xz:/path/to/\n\t\tinsteadOf = work: a URL like \"work:repo.git\" or like \"host.xz:/path/to/repo.git\" will be\nrewritten in any context that takes a URL to be \"git://git.host.xz/repo.git\". If you want to rewrite URLs for push only, you can create a\nconfiguration section of the form: [url \" <actual-url-base> \"]\n\t\tpushInsteadOf = <other-url-base> For example, with this: [url \"ssh://example.org/\"]\n\t\tpushInsteadOf = git://example.org/ a URL like \"git://example.org/path/to/repo.git\" will be rewritten to\n\"ssh://example.org/path/to/repo.git\" for pushes, but pulls will still\nuse the original URL."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Show git contributions from GitLab account on my GitHub\n\nI worked a summer job as a software developer for which I was given a git account to use (my own email on the company's domain), and that repository was saved on GitLab. I had TONS of contributions on that which I would like to be shown on my GitHub account. Is it possible to show that?\nI have tried adding the git email to my GitHub account, but that did not help (waited >24hrs).\nPlease let me know if there is a possibility of me being able to do this. Thanks in advance."
},
{
"role": "assistant",
"content": "You can upload your GitLab repos to GitHub. Commits with timestamps from previous days will show up on your heatmap. You can do this by creating a repository on GitHub without a README, so that your original repo's .git directory is preserved when you push it upstream. Otherwise, all your timestamps won't be saved, and the entire repo will look like one big commit on the day you upload it.\nFor contributions to GitLab repos you don't own, you could try uploading the fork you've created for it."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff-index - Compare a tree to the working tree or index --dst-prefix=<prefix>"
},
{
"role": "assistant",
"content": "Show the given destination prefix instead of \"b/\"."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff - Show changes between commits, commit and working tree, etc patience"
},
{
"role": "assistant",
"content": "Use \"patience diff\" algorithm when generating patches."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker git-verify-pack"
},
{
"role": "assistant",
"content": "Validate packed Git archive files"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-config - Get and set repository or global options changes"
},
{
"role": "assistant",
"content": "Compute the dirstat numbers by counting the lines that have been\nremoved from the source, or added to the destination. This ignores\nthe amount of pure code movements within a file. In other words,\nrearranging lines in a file is not counted as much as other changes.\nThis is the default behavior when no parameter is given."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How do I update my forked repo using SourceTree?\n\nI am using SourceTree (with BitBucket) to manage my code. I have forked a repo, and the parent repo has been updated.\nHow do I use SourceTree to merge the upstream code into my forked repo?"
},
{
"role": "assistant",
"content": "First, set up the parent repo:\n\nOpen your forked repo in SourceTree.\nSelect Repository ➫ Repository Settings… in the menu (or press ⇧⌘,).\nIn the Remotes pane, press Add.\nEnter any name you like (often upstream or master) and the URL / path to the parent repo.\nPress OK, then OK.\n\nNow, to update:\n\nSelect Pull in the toolbar.\nIn the \"Pull from repository\" drop-down, switch from your fork to the repo you just added.\nPress OK.\n(Optional) Once you pull, you may want to push any new content up to the server."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "GitLab pipeline Docker build gets stuck on apk\n\nTrying to make a simple GitLab pipeline that builds a Docker image for Alpine Linux + Openshift CLI. \nThis is the code:\nFROM frolvlad/alpine-glibc:latest\n\nMAINTAINER Daniel Widerin <[email protected]>\n\nENV OC_VERSION=v3.11.0 \\\n OC_TAG_SHA=0cbc58b \\\n BUILD_DEPS='tar gzip' \\\n RUN_DEPS='curl ca-certificates gettext'\n\nRUN apk --no-cache add $BUILD_DEPS $RUN_DEPS && \\\n curl -sLo /tmp/oc.tar.gz https://github.com/openshift/origin/releases/download/${OC_VERSION}/openshift-origin-client-tools-${OC_VERSION}-${OC_TAG_SHA}-linux-64bit.tar.gz && \\\n tar xzvf /tmp/oc.tar.gz -C /tmp/ && \\\n mv /tmp/openshift-origin-client-tools-${OC_VERSION}-${OC_TAG_SHA}-linux-64bit/oc /usr/local/bin/ && \\\n rm -rf /tmp/oc.tar.gz /tmp/openshift-origin-client-tools-${OC_VERSION}-${OC_TAG_SHA}-linux-64bit && \\\n apk del $BUILD_DEPS\n\nCMD [\"/bin/sh\"]\n\nNow for some reason when running the pipeline it gets stuck on the curl part that downloads the openshift archive.\nStatus: Downloaded newer image for frolvlad/alpine-glibc:latest\n ---> 38dd85a430e8\nStep 2/5 : MAINTAINER Daniel Widerin <[email protected]>\n ---> Running in bdacc7e92e79\nRemoving intermediate container bdacc7e92e79\n ---> c56da0a68f7f\nStep 3/5 : ENV OC_VERSION=v3.11.0 OC_TAG_SHA=0cbc58b BUILD_DEPS='tar gzip' RUN_DEPS='curl ca-certificates gettext'\n ---> Running in cb1e6cdb39ca\nRemoving intermediate container cb1e6cdb39ca\n ---> 727952120e67\nStep 4/5 : RUN apk --no-cache add $BUILD_DEPS $RUN_DEPS && curl -sLo /tmp/oc.tar.gz https://github.com/openshift/origin/releases/download/${OC_VERSION}/openshift-origin-client-tools-${OC_VERSION}-${OC_TAG_SHA}-linux-64bit.tar.gz && tar xzvf /tmp/oc.tar.gz -C /tmp/ && mv /tmp/openshift-origin-client-tools-${OC_VERSION}-${OC_TAG_SHA}-linux-64bit/oc /usr/local/bin/ && rm -rf /tmp/oc.tar.gz /tmp/openshift-origin-client-tools-${OC_VERSION}-${OC_TAG_SHA}-linux-64bit && apk del $BUILD_DEPS\n ---> Running in ef344ef4a96b\nfetch http://dl-cdn.alpinelinux.org/alpine/v3.10/main/x86_64/APKINDEX.tar.gz\n\nIt stays like this for an hour until the pipeline times out.\nTried this same Dockerfile manually and it works fine. \nHow can I diagnose this issue? How can I find any logs for this?"
},
{
"role": "assistant",
"content": "Found that this issue is related to Alpine image having networking issues when run in Docker-in-Docker configuration on Kubernetes/OpenShift based runner. Adding --network host to Docker build helps to fix this issue. \nDocker build --network host .\n\nRelated GitHub issue: github.com/gliderlabs/docker-alpine/issues/307"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How do I revert all local changes in Git managed project to previous state?\nI ran git status which told me everything was up to date and there were no local changes.\nThen I made several consecutive changes and realized I wanted to throw everything away and get back to my original state. Will this command do it for me?\ngit reset --hard HEAD"
},
{
"role": "assistant",
"content": "To revert changes made to your working copy, do this:\ngit checkout .\n\nOr equivalently, for git version >= 2.23:\ngit restore .\n\nTo revert changes made to the index (i.e., that you have added), do this. Warning this will reset all of your unpushed commits to master!:\ngit reset\n\nTo revert a change that you have committed:\ngit revert <commit 1> <commit 2>\n\nTo remove untracked files (e.g., new files, generated files):\ngit clean -f\n\nOr untracked directories (e.g., new or automatically generated directories):\ngit clean -fd"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-config - Get and set repository or global options lines"
},
{
"role": "assistant",
"content": "Compute the dirstat numbers by doing the regular line-based diff\nanalysis, and summing the removed/added line counts. (For binary\nfiles, count 64-byte chunks instead, since binary files have no\nnatural concept of lines). This is a more expensive --dirstat behavior than the changes behavior, but it does count rearranged\nlines within a file as much as other changes. The resulting output\nis consistent with what you get from the other --*stat options."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker GIT_WORK_TREE"
},
{
"role": "assistant",
"content": "Set the path to the root of the working tree.\nThis can also be controlled by the --work-tree command-line\noption and the core.worktree configuration variable."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-daemon - A really simple server for Git repositories --detach"
},
{
"role": "assistant",
"content": "Detach from the shell. Implies --syslog."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How to update local tags to match remote?\nI fixed it for my repo by deleting the local tag and then doing a git fetch. This brought the updated tag. \nIs there are \"right\" way to update tags that may have changed on the remote? This is a simple tag, not signed or anything, created with \"git tag \""
},
{
"role": "assistant",
"content": "Make sure you fetch all the tags (through git fetch --tags), to get all the tags and not just ones referencing commits reachable from the branch heads.\nThose (fetched) tags are annotated ones (and usually not lightweight), and if you add deleted one on the local repo, they will just pop back after the fetch.\nHowever, if you have deleted a lightweight one, then you need to recreate it locally: a lightweight tag isn't usually pushed or fetched to/from a remote repo.\nNote that starting git 1.9/2.0 (Q1 2014), git fetch --tags will fetch everything (like git fetch), plus the tags. See \"Does “git fetch --tags” include “git fetch”?\".\nAgain, fetch \"everything\" means annotated and lightweight (if those lightweight tags were previously pushed).\n\nAs noted below in biocyberman's answer, if you want to fetch tags from all remotes (not just the default remote named 'origin'), you need to add the --all option.\ngit fetch --tags --all"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker gitprotocol-http"
},
{
"role": "assistant",
"content": "Git HTTP-based protocols"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "In plain English, what does \"git reset\" do?\nI have seen interesting posts explaining subtleties about git reset.\nUnfortunately, the more I read about it, the more it appears that I don't understand it fully. I come from a SVN background and Git is a whole new paradigm. I got mercurial easily, but Git is much more technical.\nI think git reset is close to hg revert, but it seems there are differences.\nSo what exactly does git reset do? Please include detailed explanations about:\n\nthe options --hard, --soft and --merge;\nthe strange notation you use with HEAD such as HEAD^ and HEAD~1;\nconcrete use cases and work flows;\nconsequences on the working copy, the HEAD and your global stress level."
},
{
"role": "assistant",
"content": "In general, git reset's function is to take the current branch and reset it to point somewhere else, and possibly bring the index and work tree along. More concretely, if your master branch (currently checked out) is like this:\n- A - B - C (HEAD, master)\n\nand you realize you want master to point to B, not C, you will use git reset B to move it there:\n- A - B (HEAD, master) # - C is still here, but there's no branch pointing to it anymore\n\nDigression: This is different from a checkout. If you'd run git checkout B, you'd get this:\n- A - B (HEAD) - C (master)\n\nYou've ended up in a detached HEAD state. HEAD, work tree, index all match B, but the master branch was left behind at C. If you make a new commit D at this point, you'll get this, which is probably not what you want:\n- A - B - C (master)\n \\\n D (HEAD)\n\nRemember, reset doesn't make commits, it just updates a branch (which is a pointer to a commit) to point to a different commit. The rest is just details of what happens to your index and work tree.\nUse cases\nI cover many of the main use cases for git reset within my descriptions of the various options in the next section. It can really be used for a wide variety of things; the common thread is that all of them involve resetting the branch, index, and/or work tree to point to/match a given commit. \nThings to be careful of\n\n--hard can cause you to really lose work. It modifies your work tree.\ngit reset [options] commit can cause you to (sort of) lose commits. In the toy example above, we lost commit C. It's still in the repo, and you can find it by looking at git reflog show HEAD or git reflog show master, but it's not actually accessible from any branch anymore.\nGit permanently deletes such commits after 30 days, but until then you can recover C by pointing a branch at it again (git checkout C; git branch <new branch name>).\n\nArguments\nParaphrasing the man page, most common usage is of the form git reset [<commit>] [paths...], which will reset the given paths to their state from the given commit. If the paths aren't provided, the entire tree is reset, and if the commit isn't provided, it's taken to be HEAD (the current commit). This is a common pattern across git commands (e.g. checkout, diff, log, though the exact semantics vary), so it shouldn't be too surprising.\nFor example, git reset other-branch path/to/foo resets everything in path/to/foo to its state in other-branch, git reset -- . resets the current directory to its state in HEAD, and a simple git reset resets everything to its state in HEAD.\nThe main work tree and index options\nThere are four main options to control what happens to your work tree and index during the reset.\nRemember, the index is git's \"staging area\" - it's where things go when you say git add in preparation to commit.\n\n--hard makes everything match the commit you've reset to. This is the easiest to understand, probably. All of your local changes get clobbered. One primary use is blowing away your work but not switching commits: git reset --hard means git reset --hard HEAD, i.e. don't change the branch but get rid of all local changes. The other is simply moving a branch from one place to another, and keeping index/work tree in sync. This is the one that can really make you lose work, because it modifies your work tree. Be very very sure you want to throw away local work before you run any reset --hard.\n--mixed is the default, i.e. git reset means git reset --mixed. It resets the index, but not the work tree. This means all your files are intact, but any differences between the original commit and the one you reset to will show up as local modifications (or untracked files) with git status. Use this when you realize you made some bad commits, but you want to keep all the work you've done so you can fix it up and recommit. In order to commit, you'll have to add files to the index again (git add ...).\n--soft doesn't touch the index or work tree. All your files are intact as with --mixed, but all the changes show up as changes to be committed with git status (i.e. checked in in preparation for committing). Use this when you realize you've made some bad commits, but the work's all good - all you need to do is recommit it differently. The index is untouched, so you can commit immediately if you want - the resulting commit will have all the same content as where you were before you reset.\n--merge was added recently, and is intended to help you abort a failed merge. This is necessary because git merge will actually let you attempt a merge with a dirty work tree (one with local modifications) as long as those modifications are in files unaffected by the merge. git reset --merge resets the index (like --mixed - all changes show up as local modifications), and resets the files affected by the merge, but leaves the others alone. This will hopefully restore everything to how it was before the bad merge. You'll usually use it as git reset --merge (meaning git reset --merge HEAD) because you only want to reset away the merge, not actually move the branch. (HEAD hasn't been updated yet, since the merge failed)\nTo be more concrete, suppose you've modified files A and B, and you attempt to merge in a branch which modified files C and D. The merge fails for some reason, and you decide to abort it. You use git reset --merge. It brings C and D back to how they were in HEAD, but leaves your modifications to A and B alone, since they weren't part of the attempted merge.\n\nWant to know more?\nI do think man git reset is really quite good for this - perhaps you do need a bit of a sense of the way git works for them to really sink in though. In particular, if you take the time to carefully read them, those tables detailing states of files in index and work tree for all the various options and cases are very very helpful. (But yes, they're very dense - they're conveying an awful lot of the above information in a very concise form.)\nStrange notation\nThe \"strange notation\" (HEAD^ and HEAD~1) you mention is simply a shorthand for specifying commits, without having to use a hash name like 3ebe3f6. It's fully documented in the \"specifying revisions\" section of the man page for git-rev-parse, with lots of examples and related syntax. The caret and the tilde actually mean different things:\n\nHEAD~ is short for HEAD~1 and means the commit's first parent. HEAD~2 means the commit's first parent's first parent. Think of HEAD~n as \"n commits before HEAD\" or \"the nth generation ancestor of HEAD\".\nHEAD^ (or HEAD^1) also means the commit's first parent. HEAD^2 means the commit's second parent. Remember, a normal merge commit has two parents - the first parent is the merged-into commit, and the second parent is the commit that was merged. In general, merges can actually have arbitrarily many parents (octopus merges).\nThe ^ and ~ operators can be strung together, as in HEAD~3^2, the second parent of the third-generation ancestor of HEAD, HEAD^^2, the second parent of the first parent of HEAD, or even HEAD^^^, which is equivalent to HEAD~3."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How can I check write access to a remote Git repository (\"can I push?\")\n\nI am building a (somewhat limited) Git client. To set up a repository, you enter the URL to the remote repo. I want to check whether the user has read+write access to that repository. If not, I present an authentication dialog.\nI check 'read' access with git ls-remote <url>.\nIs there an analogous way to check 'write' access, without cloning the repo first? (I know I could git clone <url> and then git push --dry-run)"
},
{
"role": "assistant",
"content": "If the git repo is in github, open any file in the repo, then click 'edit',\ngithub will show something like this:\n\nYou’re editing a file in a project you don’t have write access to. We’ve created a fork of this project for you to commit your proposed changes \n to. Submitting a change to this file will write it to a new branch in \n your fork, so you can send a pull request.enter code here"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker git-symbolic-ref"
},
{
"role": "assistant",
"content": "Read, modify and delete symbolic refs"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff - Show changes between commits, commit and working tree, etc --ignore-blank-lines"
},
{
"role": "assistant",
"content": "Ignore changes whose lines are all blank."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-config - Get and set repository or global options submoduleMergeConflict"
},
{
"role": "assistant",
"content": "Advice shown when a non-trivial submodule merge conflict is\nencountered."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Git: Compare All Local Commits to Remote Repo Version\nI'm somewhat new to Git and what I'm trying to do seems like it should be possible. Basically I've been working off of clone of a repo and have made quite a few local commits. Is there a way to see the diff of the 'sum' of all my changes and the original repo version? I would assume this would be possible because Git will essentially do this when I do a push.\nHere is an example of what I'm trying to do: in gitk I will see something like this:\n* - [mybranch] Added '42' to end of answers.txt (local commit)\n* - Added 'Hello World' to end of my.txt (local commit)\n* - Added 'C#/.NET' to beginning of my.txt (local commit)\n* - <[RemoteRepo]> (original repo I cloned from)\nHow is it I can view the difference of the sum of all my changes to my.txt and answers.txt when compared to the original version I checked out from RemoteRepo?"
},
{
"role": "assistant",
"content": "There are three ways ( two others from other answers given here )\n1) git diff origin/master master\n2) git diff origin/master..master\n3) git diff origin/master...master\n\nFirst one and second one are same and show changes between the tips of the master and remote master.\nThird one shows changes that occurred on the master since branch last push and I think this is the most appropriate one you are looking for"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker GIT_EXTERNAL_DIFF"
},
{
"role": "assistant",
"content": "When the environment variable GIT_EXTERNAL_DIFF is set, the\nprogram named by it is called to generate diffs, and Git\ndoes not use its builtin diff machinery.\nFor a path that is added, removed, or modified, GIT_EXTERNAL_DIFF is called with 7 parameters: path old-file old-hex old-mode new-file new-hex new-mode where:"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-shortlog - Summarize git log output [--] <path>…"
},
{
"role": "assistant",
"content": "Consider only commits that are enough to explain how the files\nthat match the specified paths came to be. Paths may need to be prefixed with -- to separate them from\noptions or the revision range, when confusion arises."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker GIT_DIFF_OPTS"
},
{
"role": "assistant",
"content": "Only valid setting is \"--unified=??\" or \"-u??\" to set the\nnumber of context lines shown when a unified diff is created.\nThis takes precedence over any \"-U\" or \"--unified\" option\nvalue passed on the Git diff command line."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-config - Get and set repository or global options gc.logExpiry"
},
{
"role": "assistant",
"content": "If the file gc.log exists, then git gc --auto will print\nits content and exit with status zero instead of running\nunless that file is more than gc.logExpiry old. Default is\n\"1.day\". See gc.pruneExpire for more ways to specify its\nvalue."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How can I remove issue reference\n\nI have issue #1 and issue #2 on github.\nI commenting on the issue #1 smthing like this: \"I think that\nissue #2 is associated with this issue\".\nNow in comments of issue #2 the message about referencing issue\n#2 with issue #1 appears.\nI delete my comment on issue #1.\nThe message about referencing issue #2 with issue #1 still\nexists in issue #2 comments.\n\nHow I can remove the message about referencing from issue #2 comments?"
},
{
"role": "assistant",
"content": "It's currently not possible to remove a GitHub Issue reference after it has been created."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Why can't I delete a branch in a remote GitLab repository?\nI'm trying to delete a branch both locally and in a remote GitLab repository. Its name is origin/feat. I tried git push --delete origin feat. Git complains:\nremote: error: By default, deleting the current branch is denied, because the next\nremote: 'git clone' won't result in any file checked out, causing confusion.\nremote: \nremote: You can set 'receive.denyDeleteCurrent' configuration variable to\nremote: 'warn' or 'ignore' in the remote repository to allow deleting the\nremote: current branch, with or without a warning message.\nremote: \nremote: To squelch this message, you can set it to 'refuse'.\nremote: error: refusing to delete the current branch: refs/heads/feat\n\nOK makes sense, so I tried switching to origin/master with git checkout master and it tells me: Already on 'master'. Does the current branch also need to be set in the remote directory? How would I do that?"
},
{
"role": "assistant",
"content": "Try\ngit push origin --delete <branch-name>"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How do you rename a Git commit pushed to GitHub?\nI stupidly pushed a commit to GitHub with a very messed up commit name. How do I change this?\nDoes git commit --amend still work for already pushed commit?"
},
{
"role": "assistant",
"content": "git commit --amend\n\nwhich will bring up your editor, or\ngit commit --amend -m \"Your new message here\"\n\nwhich will allow you to specify the new message on the command line. Also possible, but more useful if you have other commits to reword\ngit rebase -i HEAD^\n# then replace 'pick' with 'r' or 'reword' and save, editor should pop up again to edit the msg\n\nBecause this commit has a new SHA1 due to the change of the contents, you will need to force push the new reference. The force is needed because it tells git to forget about the previous commit. It's a safety measure.\ngit push origin your-branch-name -f"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-config - Get and set repository or global options help.autoCorrect"
},
{
"role": "assistant",
"content": "If git detects typos and can identify exactly one valid command similar\nto the error, git will try to suggest the correct command or even\nrun the suggestion automatically. Possible config values are: 0 (default): show the suggested command. positive number: run the suggested command after specified\ndeciseconds (0.1 sec). \"immediate\": run the suggested command immediately. \"prompt\": show the suggestion and prompt for confirmation to run\nthe command. \"never\": don’t run or show any suggested command."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Pull new updates from original GitHub repository into forked GitHub repository\nI forked someone's repository on GitHub and would like to update my version with commits and updates made in the original repository. These were made after I forked my copy.\nHow can I pull in the changes that were made in the origin and incorporate them into my repository?"
},
{
"role": "assistant",
"content": "You have to add the original repository (the one you forked) as a remote.\nFrom the GitHub documentation on forking a repository:\n\n\nOnce the clone is complete your repo will have a remote named “origin” that points to your fork on GitHub.\nDon’t let the name confuse you, this does not point to the original repo you forked from. To help you keep track of that repo we will add another remote named “upstream”:\n$ cd PROJECT_NAME\n$ git remote add upstream https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY.git\n$ git fetch upstream\n\n# then: (like \"git pull\" which is fetch + merge)\n$ git merge upstream/master master\n\n# or, better, replay your local work on top of the fetched branch\n# like a \"git pull --rebase\"\n$ git rebase upstream/master\n\n\nThere's also a command-line tool (gh) which can facilitate the operations above.\nHere's a visual of how it works:\n\nSee also \"Are Git forks actually Git clones?\"."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How do you trigger a push when a specific directory in a branch gets an update?\n\nI want my workflow to trigger on a push only if there are changes made to a specific directory. Is this possible, what am I missing? I tried doing something like what you see below, but it didn't fire the trigger.\nname: ABC\n\non:\n push:\n branches: [master/my-directory]\n pull_request:\n branches: [ master ]"
},
{
"role": "assistant",
"content": "push has a property called paths:\nname: ABC\non:\n push:\n branches:\n - master\n paths:\n - my-directory/**\n\nThis will only trigger on pushes to the master branch with changes in the my-directory directory tree. See the filter pattern cheat sheet for all possible filter patterns."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-config - Get and set repository or global options filter.<driver>.clean"
},
{
"role": "assistant",
"content": "The command which is used to convert the content of a worktree\nfile to a blob upon checkin. See gitattributes for\ndetails."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-archive - Create an archive of files from a named tree --prefix=<prefix>/"
},
{
"role": "assistant",
"content": "Prepend <prefix>/ to paths in the archive. Can be repeated; its\nrightmost value is used for all tracked files. See below which\nvalue gets used by --add-file and --add-virtual-file ."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker GIT_SSH_VARIANT"
},
{
"role": "assistant",
"content": "If this environment variable is set, it overrides Git’s autodetection\nwhether GIT_SSH / GIT_SSH_COMMAND / core.sshCommand refer to OpenSSH,\nplink or tortoiseplink. This variable overrides the config setting ssh.variant that serves the same purpose."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What does GIT PUSH do exactly?\nI can't seem to find a good explanation of this.\nI know what git pull does:\n1) a fetch, i.e. all the extra commits from the server are copied into the local repo and the origin/master branch pointer moves to the end of the commit chain\n2) a merge of the origin/master branch into the master branch, the master branch pointer moving to the newly created commit, while the origin/master pointer staying put.\nI assume git push does something very similar, but I don't know for sure. I believe it does one of these, or something similar, or something else (?):\n\ncopies all local commits and makes a merge there (the reverse of what git pull does); but in this case, the server does not have my local master branch, so I can't see what is it merging\n\nOR\n\nmerges my master branch into the origin/master, pushing the resulting commit to the server and linking it next to the existing end-commit, also moving the server's master; this doesn't seem right because then my local origin/master is not in sync with the server's.\n\nI'm currently using git for basic operations so I'm doing fine, but I want to fully understand these internals."
},
{
"role": "assistant",
"content": "Assuming you already understand git's \"objects\" model (your commits and files and so on are all just \"objects in the git database\", with \"loose\" objects—those not packed up to save space—stored in .git/objects/12/34567... and the like)...\nYou are correct: git fetch retrieves objects \"they\" (origin, in this case) have that you don't, and sticks labels on them: origin/master and the like. More specifically, your git calls up theirs on the Internet-phone (or any other suitable transport) and asks: what branches do you have, and what commit IDs are those? They have master and the ID is 1234567..., so your git asks for 1234567... and any other objects needed that you don't already have, and makes your origin/master point to commit object 1234567....\nThe part of git push that is symmetric here is this: your git calls up their git on the same Internet-phone as usual, but this time, instead of just asking them about their branches, your git tells them about your branches and your git repository objects, and then says: \"How about I get you to set your master to 56789ab...?\"\nTheir git takes a look at the objects you sent over (the new commit 56789ab... and whatever other objects you have that they didn't, that they would need to take it). Their git then considers the request to set their master to 56789ab....\nAs Chris K already answered, there is no merging happening here: your git simply proposes that their git overwrite their master with this new commit-ID. It's up to their git to decide whether to allow that.\nIf \"they\" (whoever they are) have not set up any special rules, the default rule that git uses here is very simple: the overwrite is allowed if the change is a \"fast forward\". It has one additional feature: the overwrite is also allowed if the change is done with the \"force\" flag set. It's usually not a good idea to set the force flag here, as the default rule, \"only fast forwards\", is usually the right rule.\nThe obvious question here is: what exactly is a fast forward? We'll get to that in a moment; first I need to expand a bit on labels, or \"references\" to be more formal.\nGit's references\nIn git, a branch, or a tag, or even things like the stash and HEAD are all references. Most of them are found in .git/refs/, a sub-directory of the git repository. (A few top-level references, including HEAD, are right in .git itself.) All a reference is, is a file1 containing an SHA-1 ID like 7452b4b5786778d5d87f5c90a94fab8936502e20. SHA-1 IDs are cumbersome and impossible for people to remember, so we use names, like v2.1.0 (a tag in this case, version 2.1.0 of git itself) to save them for us.\nSome references are—or at least are intended to be—totally static. The tag v2.1.0 should never refer to something other than the SHA-1 ID above. But some references are more dynamic. Specifically, your own local branches, like master, are moving targets. One special case, HEAD, is not even a target of its own: it generally contains the name of the moving-target branch. So there's one exception for \"indirect\" references: HEAD usually contains the string ref: refs/heads/master, or ref: refs/heads/branch, or something along those lines; and git does not (and cannot) enforce a \"never change\" rule for references. Branches in particular change a lot.\nHow do you know if a reference is supposed to change? Well, a lot of this is just by convention: branches move and tags don't. But you should then ask: how do you know if a reference is a branch, or a tag, or what?\nName spaces of references: refs/heads/, refs/tags/, etc.\nOther than the special top-level references, all of git's references are in refs/ as we already noted above. Within the refs/ directory (or \"folder\" if you're on Windows or Mac), though, we can have a whole collection of sub-directories. Git has, at this point, four well-defined subdirectories: refs/heads/ contains all your branches, refs/tags/ contains all your tags, refs/remotes/ contains all your \"remote-tracking branches\", and refs/notes/ contains git's \"notes\" (which I will ignore here as they get a bit complicated).\nSince all your branches are in refs/heads/, git can tell that these should be allowed to change, and since all your tags are in refs/tags/, git can tell that these should not.\nAutomatic motion of branches\nWhen you make a new commit, and are on a branch like master, git will automatically move the reference. Your new commit is created with its \"parent commit\" being the previous branch-tip, and once your new commit is safely saved away, git changes master to contain the ID of the new commit. In other words, it makes sure that the branch name, the reference in the heads sub-directory, always points to the tip-most commit.\n(In fact, the branch, in the sense of a collection of commits that is part of the commit-graph stored in the repository, is a data structure made out of the commits in the repository. Its only connection with the branch name is that the tip commit of the branch itself is stored in the reference label with that name. This is important later, if and when branch names are changed or erased as the repository grows many more commits. For now it's just something to keep in mind: there's a difference between the \"branch tip\", which is where the \"branch name\" points, and the branch-as-a-subset-of-commit-DAG. It's a bit unfortunate that git tends to lump these different concepts under a single name, \"branch\".)\nWhat exactly is a fast forward?\nUsually you see \"fast forward\" in the context of merge, often with the merge done as the second step in a git pull. But in fact, \"fast forwarding\" is actually a property of a label move.\nLet's draw a little bit of a commit graph. The little o nodes represent commits, and each one has an arrow pointing left, left-and-up, or left-and-down (or in one case, two arrows) to its parent (or parents). To be able to refer to three by name I'll give them uppercase letter names instead of o. Also, this character-based artwork doesn't have arrows, so you have to imagine them; just remember that they all point left or left-ish, just like the three names.\n o - A <-- name1\n /\no - o - o - o - B <-- name2\n \\ /\n o - C <-- name3\n\nWhen you ask git to change a reference, you simply ask it to stick a new commit ID into the label. In this case, these labels live in refs/heads/ and are thus branch names, so they are supposed to be able to take on new values.\nIf we tell git to put B into name1, we get this:\n o - A\n /\no - o - o - o - B <-- name1, name2\n \\ /\n o - C <-- name3\n\nNote that commit A now has no name, and the o to the left of it is found only by finding A ... which is hard since A has no name. Commit A has been abandoned, and these two commits have become eligible for \"garbage collection\". (In git, there's a \"ghost name\" left behind in the \"reflog\", that keeps the branch with A around for 30 days in general. But that's a different topic entirely.)\nWhat about telling git to put B into name3? If we do that next, we get this:\n o - A\n /\no - o - o - o - B <-- name1, name2, name3\n \\ /\n o - C\n\nHere, commit C still has a way to find it: start at B and work down-and-left, to its other (second) parent commit, and you find commit C. So commit C is not abandoned.\nUpdating name1 like this is not a fast-forward, but updating name3 is.\nMore specifically, a reference-change is a \"fast forward\" if and only if the object—usually a commit—that the reference used to point-to is still reachable by starting from the new place and working backwards, along all possible backwards paths. In graph terms, it's a fast-forward if the old node is an ancestor of the new one.\nMaking a push be a fast-forward, by merging\nBranch-name fast-forwards occur when the only thing you do is add new commits; but also when, if you've added new commits, you've also merged-in whatever new commits someone else added. That is, suppose your repo has this in it, after you've made one new commit:\n o <-- master\n /\n...- o - o <-- origin/master\n\nAt this point, moving origin/master \"up and right\" would be a fast-forward. However, someone else comes along and updates the other (origin) repo, so you do a git fetch and get a new commit from them. Your git moves your origin/master label (in a fast-forward operation on your repo, as it happens):\n o <-- master\n /\n...- o - o - o <-- origin/master\n\nAt this point, moving origin/master to master would not be a fast-forward, as it would abandon that one new commit.\nYou, however, can do a git merge origin/master operation to make a new commit on your master, with two parent commit IDs. Let's label this one M (for merge):\n o - M <-- master\n / /\n...- o - o - o <-- origin/master\n\nYou can now git push this back to origin and ask them to set their master—which you are calling origin/master—equal to your (new) M, because for them, that's now a fast-forward operation!\nNote that you can also do a git rebase, but let's leave that for a different stackoverflow posting. :-)\n\n1In fact, git references always start out as individual files in various sub-directories, but if a reference doesn't get updated for a long while, it tends to get \"packed\" (along with all the other mostly-static references) into a single file full of packed references. This is just a time-saving optimization, and the key here is not to depend on the exact implementation, but rather to use git's rev-parse and update-ref commands to extract the current SHA-1 from a reference, or update a reference to contain a new SHA-1."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker git-unpack-file"
},
{
"role": "assistant",
"content": "Creates a temporary file with a blob’s contents"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff - Show changes between commits, commit and working tree, etc -D --irreversible-delete"
},
{
"role": "assistant",
"content": "Omit the preimage for deletes, i.e. print only the header but not\nthe diff between the preimage and /dev/null . The resulting patch\nis not meant to be applied with patch or git apply ; this is\nsolely for people who want to just concentrate on reviewing the\ntext after the change. In addition, the output obviously lacks\nenough information to apply such a patch in reverse, even manually,\nhence the name of the option. When used together with -B , omit also the preimage in the deletion part\nof a delete/create pair."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-config - Get and set repository or global options credential.<url>.*"
},
{
"role": "assistant",
"content": "Any of the credential.* options above can be applied selectively to\nsome credentials. For example, \"credential.https://example.com.username\"\nwould set the default username only for https connections to\nexample.com. See gitcredentials for details on how URLs are\nmatched."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Adding your .vim ~/.vimrc to github (aka dot files)\nI have seen a few people that have git repos with their dot files. I'm wondering if they just \ncd ~/\ngit init\ngit add .vimrc\n// etc\n\n? And then that's how they keep it up to date? Or do they probably make copies and sync them?\nWhat strategy do you guys recommend or use? Mostly don't wanna commit and push my entire ~/\nThanks"
},
{
"role": "assistant",
"content": "Making a git repository of your home is probably a bad idea (you would be spending more time creating your .gitignore file than on doing what you really want to do).\nI suggest using a separate git directory for your dotfiles (eg. ~/git/dotfiles) and them making symlinks to your home (eg. ln -s ~/git/dotfiles/.vim ~/.vim, etc.).\nIf you can't be bothered creating symlinks manually each time you want to install your dotfiles somewhere, you can use a script like the following one: https://github.com/gibfahn/dot/blob/master/link."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-apply - Apply a patch to files and/or to the index -q --quiet"
},
{
"role": "assistant",
"content": "Suppress stderr output. Messages about patch status and progress\nwill not be printed."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Cloning an older version of github repo\nI have an Amazon EC2 machine. I would like to clone an older version of github repo on this machine. Normally I use git clone https://linktomyrepo.git How can I clone an older version, say an update from 14 days ago? I can see the exact version I need in the commit history of repository, but do not know how to clone it onto the EC2 machine. Do I need to use the little SHA code next to each commit?"
},
{
"role": "assistant",
"content": "You can always check out any given state by using a commit hash.\nFor instance, by looking at the log, you identified that 233ab4ef was the state you were interested in: issue a git checkout 233ab4ef to check out that state.\nAnother way to achieve this is by using git checkout @{14.days.ago}"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Set the develop branch as the default for a pull request\n\nI want to make the pull request merge into develop from the feature branch by default.\nI'm advocating the use of git flow, so when a pull request is submitted for a feature, the pull request needs to get merged into develop, and not master.\nSome of the managers commented that being human, there is a possibility that the team leads could overlook that fact and merge the pull request into master by mistake, causing issues with the release later on.\nWe want to mitigate the risks of merge hell so this would go a long way in achieving this goal.\nEdit: I'm using a fork of gitflow called hubflow(http://datasift.github.com/gitflow/). By default, when a feature branch is created git hf feature start [tik-123] the feature branch is created per spec but also gets pushed up to origin. We want this for collaboration. Once the feature is complete, the dev will go to the feature branch in github and issue a pull request. The team leads will then review the pull request and merge the feature into dev if the feature is slated for release in the sprint."
},
{
"role": "assistant",
"content": "Alternatively make develop the default branch that everyone sees when visiting the project. The downside is that anyone who clones it will get an unstable branch by default but all pull requests will go to the develop branch by default too."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "SSL certificate problem: self signed certificate in certificate chain\nI have upgraded my Inteliij IDEA 2019.2 recently and I am getting the following error if I try to pull from using my IDE:\n\nGit Pull Failed: unable to access 'https://github.xxx.com/app-Hello-USD/DGS.git/': SSL certificate problem: self signed certificate in certificate chain.\n\nCould someone help me what option I have to enable?"
},
{
"role": "assistant",
"content": "git config --global http.sslVerify false"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How to perform case insensitive diff in Git\ngit diff does not support a case-insensitive comparison of files. Google shows a very few people asking for that feature, and that too only in combination with some other git diff switch, like with -G or with --color-words.\nI don't care for other switches, as long as git diff can show me the case-insensitive diff.\nSince I didn't see any specific question towards that, and since I found a solution after an hour researching this problem, I am adding this question and the answer."
},
{
"role": "assistant",
"content": "The solution is to use git difftool. With the following config command, I can add a custom diff tool called idiff for Git to use:\ngit config --global difftool.idiff.cmd 'diff -i $LOCAL $REMOTE'\nWith this customization, I can see the case-insensitive comparison like so:\ngit difftool --tool idiff <other diff options> <Git references or files>\nEg.\ngit difftool -t idiff HEAD~1 -- my_schema.sql\nSince git difftool prompts (for yes/no) every time before invoking the the tool, either use -y switch for difftool or add this config option to avoid the prompt:\ngit config --global difftool.prompt 0\nUPDATE (2021/11/26): Here's a consolidated configuration I use, that allows me to use git idiff command that behaves almost identical to how git diff behaves.\ngit config --global difftool.idiff.cmd 'diff --unified=3 --color=always --ignore-case $LOCAL $REMOTE | less --raw-control-chars'\ngit config --global difftool.prompt 0\ngit config --global alias.idiff 'difftool --tool idiff'"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-log - Show commit logs -W --function-context"
},
{
"role": "assistant",
"content": "Show whole function as context lines for each change.\nThe function names are determined in the same way as git diff works out patch hunk headers (see Defining a\ncustom hunk-header in gitattributes )."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-merge - Join two or more development histories together --summary --no-summary"
},
{
"role": "assistant",
"content": "Synonyms to --stat and --no-stat; these are deprecated and will be\nremoved in the future."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git clone with HTTPS or SSH remote?\n\ngit clone supports both HTTPS and SSH remote URLs. Which should I use? What are the advantages of each?\nGitHub's docs don't make a recommendation either way. I recall in 2013 GitHub used to recommend SSH (archive link). Why was that?"
},
{
"role": "assistant",
"content": "GitHub have changed their recommendation several times (example).\nIt appears that they currently recommend HTTPS because it is the easiest to set up on the widest range of networks and platforms, and by users who are new to all this.\nThere is no inherent flaw in SSH (if there was they would disable it) -- in the links below, you will see that they still provide details about SSH connections too:\n\nHTTPS is less likely to be blocked by a firewall.\nhttps://docs.github.com/en/get-started/getting-started-with-git/about-remote-repositories#cloning-with-https-urls\n\nThe https:// clone URLs are available on all repositories, regardless of visibility. https:// clone URLs work even if you are behind a firewall or proxy.\n\n\nAn HTTPS connection allows credential.helper to cache your password.\nhttps://docs.github.com/en/get-started/quickstart/set-up-git#connecting-over-https-recommended\n\nIf you clone with HTTPS, you can cache your GitHub credentials in Git using a credential helper. For more information, see \"Cloning with HTTPS urls\" and \"Caching your GitHub credentials in Git.\""
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff-index - Compare a tree to the working tree or index --skip-to=<file> --rotate-to=<file>"
},
{
"role": "assistant",
"content": "Discard the files before the named <file> from the output\n(i.e. skip to ), or move them to the end of the output\n(i.e. rotate to ). These options were invented primarily for the use\nof the git difftool command, and may not be very useful\notherwise."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Can't push to remote branch, cannot be resolved to branch\n\nI migrated my repos from Bitbucket or Github. I don't think this matters but it's the only thing different. For a little while, I had two remotes set up:\norigin: bitbucket\ngithub: github\n\nThen I removed both and pointed origin to github:\ngit remote remove origin\ngit remote remove github\ngit remote add origin https://github....\n\nTest push of develop branch:\ngit push origin develop\n\nEverything up to date, ok, good.\nCreate a new branch for some work as per usual:\ngit checkout -b Feature/Name\n\nUpdate a file or two. Attempt to push to remote:\ngit push origin Feature/Name\n\nThis results in the error:\n\nfatal: Feature/Name cannot be resolved to branch\n\nSearch online for this issue, find some stuff about ensuring HEAD is correct, others about making sure I've got my branch name case correct (though, at this point the branch doesn't exist on the remote yet). Unable to resolve.\nRan this command:\ngit push --all -u\n\nThis got my Feature/Name branch to github, but still see same behavior as prior:\ngit push origin develop\ngit push origin Feature/Name\n\nThe first works while the second throws the same error. Why?"
},
{
"role": "assistant",
"content": "I was having this issue as well, and it was driving me crazy. I had something like feature/name but git branch -a showed me FEATURE/name. Renaming the branch, deleting and recreating it, nothing worked. What finally fixed it:\nGo into .git/refs/heads\nYou'll see a FEATURE folder. Rename it to feature."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker git-verify-pack"
},
{
"role": "assistant",
"content": "Validate packed Git archive files"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Want to download a Git repository, what do I need (windows machine)?\nI want to download this open source application, and they are using Git. What do I need to download the code base?\nUpdate\nHow do I change the working directory when I am using Git Bash? (I want to download the repo at a certain directory, using pwd tells me I will be downloading the repo where I don't want it."
},
{
"role": "assistant",
"content": "Download Git on Msys. Then:\ngit clone git://project.url.here"
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-show - Show various types of objects --minimal"
},
{
"role": "assistant",
"content": "Spend extra time to make sure the smallest possible\ndiff is produced."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Reverse Apply a commit to working copy\nIn order to investigate the effect introduced by a previous commit, I want to reverse- apply it to my working copy and fiddle around with the code. \nI managed with a workflow around creating and applying a patch, but wonder if this can be done easier.\ngit checkout -b \"tmp-fiddle\"\ngit diff -R -p d9fd2bb^ d9fd2bb > patch_to_examine.patch\n# Manually edit the patch a little\ngit apply patch_to_examine.patch\n\nNote that I am not looking at git revert or git rebase -i since these would either introduce a new commit or change the history: I merely want the changes introduced in d9fd2bb to be un-applied to my current working copy."
},
{
"role": "assistant",
"content": "How about git revert -n?\n\n-n\n--no-commit\n\nUsually the command automatically creates some commits with commit log messages stating which commits were reverted. This flag applies the changes necessary to revert the named commits to your working tree and the index, but does not make the commits. In addition, when this option is used, your index does not have to match the HEAD commit. The revert is done against the beginning state of your index.\nThis is useful when reverting more than one commits' effect to your index in a row."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff - Show changes between commits, commit and working tree, etc --binary"
},
{
"role": "assistant",
"content": "In addition to --full-index , output a binary diff that\ncan be applied with git-apply .\nImplies --patch ."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-show - Show various types of objects --find-copies-harder"
},
{
"role": "assistant",
"content": "For performance reasons, by default, -C option finds copies only\nif the original file of the copy was modified in the same\nchangeset. This flag makes the command\ninspect unmodified files as candidates for the source of\ncopy. This is a very expensive operation for large\nprojects, so use it with caution. Giving more than one -C option has the same effect."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Gitlab - format code automatically upon commit\n\nI'm having some trouble finding info that describes how to update the code base automatically in Gitlab\nScenario\nLet's imagine a developer working on a project commits some code, but forgets to format it before committing. The .gitlab-ci.yml can have a job that will check the formatting, and display an error/warning if found. Is it possible to update the git commit with the code formatted automatically?\nSo the flow would be:\n\nDeveloper commits unformatted code to gitlab\nGit checks the code for formatting\nIf an issue is found, git will run tool X to automatically format the code, and commit it with a git message like \"Automated Git commit -- formatting\"\n.gitlab-ci.yml continues as normal\n\nIs this possible in Gitlab?"
},
{
"role": "assistant",
"content": "Using GitLab 13.09, the answer appears to be \"no\".\nI used this .gitlab-ci.yml:\nimage: python-latest\n\nformat-job:\n script:\n - pip install black\n - black src\n\nAs expected, black echos that my files were reformatted, yet when I check the repo they haven't been fixed.\nMy experience is consistent with this post.\nA potential alternative is to use a pre-commit server hook."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-for-each-ref - Output information on each ref objectname"
},
{
"role": "assistant",
"content": "The object name (aka SHA-1).\nFor a non-ambiguous abbreviation of the object name append :short .\nFor an abbreviation of the object name with desired length append :short=<length> , where the minimum length is MINIMUM_ABBREV. The\nlength may be exceeded to ensure unique object names."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git-diff - Show changes between commits, commit and working tree, etc -p -u --patch"
},
{
"role": "assistant",
"content": "Generate patch (see Generating patch text with -p ).\nThis is the default."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "git - the stupid content tracker GIT_NAMESPACE"
},
{
"role": "assistant",
"content": "Set the Git namespace; see gitnamespaces for details.\nThe --namespace command-line option also sets this value."
}
] |
[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What's the difference between \"git stash save\" and \"git stash push\"?\nWhen should I use git stash save instead of git stash push and vice-versa?"
},
{
"role": "assistant",
"content": "git stash save accepts a single non-option argument — the stash message.\ngit stash push accepts the message with option -m and accepts a list of files to stash as arguments."
}
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.