
url
stringlengths 53
56
| repository_url
stringclasses 1
value | labels_url
stringlengths 67
70
| comments_url
stringlengths 62
65
| events_url
stringlengths 60
63
| html_url
stringlengths 41
46
| id
int64 450k
1.69B
| node_id
stringlengths 18
32
| number
int64 1
2.72k
| title
stringlengths 1
209
| user
dict | labels
list | state
stringclasses 1
value | locked
bool 2
classes | assignee
null | assignees
list | milestone
null | comments
list | created_at
timestamp[s] | updated_at
timestamp[s] | closed_at
timestamp[s] | author_association
stringclasses 3
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
104k
⌀ | reactions
dict | timeline_url
stringlengths 62
65
| performed_via_github_app
null | state_reason
stringclasses 2
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/coleifer/peewee/issues/2118
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2118/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2118/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2118/events
|
https://github.com/coleifer/peewee/issues/2118
| 573,608,441 |
MDU6SXNzdWU1NzM2MDg0NDE=
| 2,118 |
How works count subquery?
|
{
"login": "EugeneRymarev",
"id": 6260309,
"node_id": "MDQ6VXNlcjYyNjAzMDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6260309?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/EugeneRymarev",
"html_url": "https://github.com/EugeneRymarev",
"followers_url": "https://api.github.com/users/EugeneRymarev/followers",
"following_url": "https://api.github.com/users/EugeneRymarev/following{/other_user}",
"gists_url": "https://api.github.com/users/EugeneRymarev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/EugeneRymarev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/EugeneRymarev/subscriptions",
"organizations_url": "https://api.github.com/users/EugeneRymarev/orgs",
"repos_url": "https://api.github.com/users/EugeneRymarev/repos",
"events_url": "https://api.github.com/users/EugeneRymarev/events{/privacy}",
"received_events_url": "https://api.github.com/users/EugeneRymarev/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Fixed. As a workaround until I tag a new release, you can use:\r\n\r\n```python\r\nExpression(subquery, OP.EQ, 0)\r\n```\r\n\r\nInstead of `subquery == 0`."
] | 2020-03-01T20:20:35 | 2020-04-01T13:30:31 | 2020-03-01T21:52:33 |
NONE
| null |
I need count in subquery. Example at http://docs.peewee-orm.com/en/latest/peewee/hacks.html#other-methods
My code:
```
subquery_condition = (UserSurvey.user == User.id) & (UserSurvey.is_current == False)
subquery = (UserSurvey.select(fn.COUNT(UserSurvey.id)).where(subquery_condition))
condition = User.next_notify & (User.next_notify <= dt_now) & (subquery == 0)
```
I receive error:
> Traceback (most recent call last):
> File "/mnt/d/projects/venvs/survey_bot/lib/python3.8/site-packages/click/core.py", line 717, in main
> rv = self.invoke(ctx)
> File "/mnt/d/projects/venvs/survey_bot/lib/python3.8/site-packages/click/core.py", line 1137, in invoke
> return _process_result(sub_ctx.command.invoke(sub_ctx))
> File "/mnt/d/projects/venvs/survey_bot/lib/python3.8/site-packages/click/core.py", line 956, in invoke
> return ctx.invoke(self.callback, **ctx.params)
> File "/mnt/d/projects/venvs/survey_bot/lib/python3.8/site-packages/click/core.py", line 555, in invoke
> return callback(*args, **kwargs)
> File "/mnt/d/projects/survey_bot/project/tlgrm.py", line 37, in notifications
> dialog_bot.send_notifications()
> File "/mnt/d/projects/survey_bot/project/telegram_dialog/bot.py", line 280, in send_notifications
> users = get_user_for_notifications()
> File "/mnt/d/projects/survey_bot/project/views/user.py", line 103, in get_user_for_notifications
> condition = User.next_notify & (User.next_notify <= dt_now) & (subquery == 0)
> File "/mnt/d/projects/venvs/survey_bot/lib/python3.8/site-packages/peewee.py", line 817, in __eq__
> return self._hash == other._hash
> AttributeError: 'int' object has no attribute '_hash'
>
> Process finished with exit code 1
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2118/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2118/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2117
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2117/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2117/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2117/events
|
https://github.com/coleifer/peewee/pull/2117
| 573,007,845 |
MDExOlB1bGxSZXF1ZXN0MzgxNTk3ODU5
| 2,117 |
Update sqliteq.py
|
{
"login": "dev-dsp",
"id": 4235552,
"node_id": "MDQ6VXNlcjQyMzU1NTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4235552?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dev-dsp",
"html_url": "https://github.com/dev-dsp",
"followers_url": "https://api.github.com/users/dev-dsp/followers",
"following_url": "https://api.github.com/users/dev-dsp/following{/other_user}",
"gists_url": "https://api.github.com/users/dev-dsp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dev-dsp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dev-dsp/subscriptions",
"organizations_url": "https://api.github.com/users/dev-dsp/orgs",
"repos_url": "https://api.github.com/users/dev-dsp/repos",
"events_url": "https://api.github.com/users/dev-dsp/events{/privacy}",
"received_events_url": "https://api.github.com/users/dev-dsp/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2020-02-28T21:13:46 | 2020-02-28T23:00:57 | 2020-02-28T23:00:57 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2117/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2117/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2117",
"html_url": "https://github.com/coleifer/peewee/pull/2117",
"diff_url": "https://github.com/coleifer/peewee/pull/2117.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2117.patch",
"merged_at": "2020-02-28T23:00:57"
}
|
|
https://api.github.com/repos/coleifer/peewee/issues/2116
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2116/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2116/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2116/events
|
https://github.com/coleifer/peewee/pull/2116
| 572,999,914 |
MDExOlB1bGxSZXF1ZXN0MzgxNTkxMjU3
| 2,116 |
add jsonb array oid
|
{
"login": "james-lawrence",
"id": 2835871,
"node_id": "MDQ6VXNlcjI4MzU4NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2835871?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/james-lawrence",
"html_url": "https://github.com/james-lawrence",
"followers_url": "https://api.github.com/users/james-lawrence/followers",
"following_url": "https://api.github.com/users/james-lawrence/following{/other_user}",
"gists_url": "https://api.github.com/users/james-lawrence/gists{/gist_id}",
"starred_url": "https://api.github.com/users/james-lawrence/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/james-lawrence/subscriptions",
"organizations_url": "https://api.github.com/users/james-lawrence/orgs",
"repos_url": "https://api.github.com/users/james-lawrence/repos",
"events_url": "https://api.github.com/users/james-lawrence/events{/privacy}",
"received_events_url": "https://api.github.com/users/james-lawrence/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I don't think using arrays with jsonb is a sensible thing for anyone to do, since json has a native list type already. Going to pass on this.",
"whether you think it is sensible is immaterial, postgresql allows it. and clearly some people have usecases for it.\r\n"
] | 2020-02-28T20:56:16 | 2020-03-04T12:45:30 | 2020-02-28T21:11:09 |
CONTRIBUTOR
| null |
attempts to add JSONB array column to postgresql.
however unsure of how to use it. the generated code looks correct
however these fail:
```python
Model.update(array=[{}]).where(Model.id == 1).execute()
Model.create(array=[{}])
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2116/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2116/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2116",
"html_url": "https://github.com/coleifer/peewee/pull/2116",
"diff_url": "https://github.com/coleifer/peewee/pull/2116.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2116.patch",
"merged_at": null
}
|
https://api.github.com/repos/coleifer/peewee/issues/2115
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2115/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2115/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2115/events
|
https://github.com/coleifer/peewee/issues/2115
| 572,379,320 |
MDU6SXNzdWU1NzIzNzkzMjA=
| 2,115 |
Fix for #1991 causes DoesNotExist error during row iteration
|
{
"login": "brandond",
"id": 370103,
"node_id": "MDQ6VXNlcjM3MDEwMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/370103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brandond",
"html_url": "https://github.com/brandond",
"followers_url": "https://api.github.com/users/brandond/followers",
"following_url": "https://api.github.com/users/brandond/following{/other_user}",
"gists_url": "https://api.github.com/users/brandond/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brandond/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brandond/subscriptions",
"organizations_url": "https://api.github.com/users/brandond/orgs",
"repos_url": "https://api.github.com/users/brandond/repos",
"events_url": "https://api.github.com/users/brandond/events{/privacy}",
"received_events_url": "https://api.github.com/users/brandond/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"```sql\r\nSELECT\r\n COALESCE(\"t1\".\"guid\", \"t2\".\"guid\") AS \"guid\",\r\n COALESCE(\"t1\".\"remedy_group\", ?) AS \"name\",\r\n \"t3\".\"id\",\r\n COUNT(\"t2\".\"host_id\") AS \"count\",\r\n JSON_GROUP_ARRAY(\"t2\".\"host_id\") AS \"host_ids\" \r\nFROM \"vulnerability\" AS \"t2\" \r\nINNER JOIN \"plugin\" AS \"t3\" ON (\"t2\".\"plugin_id\" = \"t3\".\"id\") \r\nINNER JOIN \"query\" AS \"t4\" ON (\"t2\".\"query_id\" = \"t4\".\"id\") \r\nINNER JOIN \"host\" AS \"t5\" ON (\"t2\".\"host_id\" = \"t5\".\"ip_address\") \r\nLEFT OUTER JOIN \"team\" AS \"t1\" ON (\"t1\".\"name\" = (\r\n SELECT \"t1\".\"name\" FROM \"team\" AS \"t1\" \r\n WHERE (\r\n (\"t1\".\"name\" = TRIM(json_extract(\"t5\".\"tags\", ?))) OR \r\n (\"t1\".\"remedy_group\" = TRIM(json_extract(\"t5\".\"tags\", ?)))) LIMIT ?\r\n)) \r\nWHERE ((\r\n (\"t2\".\"remediation_group_id\" = ?) AND \r\n (\"t4\".\"process\" IN (?, ?))) AND\r\n (\"t5\".\"state\" != ?)) \r\nGROUP BY \r\n COALESCE(\"t1\".\"guid\", \"t2\".\"guid\"), \r\n COALESCE(\"t1\".\"remedy_group\", ?), \r\n \"t3\".\"id\" \r\nORDER BY COALESCE(\"t1\".\"guid\", \"t2\".\"guid\"), COALESCE(\"t1\".\"remedy_group\", ?), \"t3\".\"id\"\r\n```",
"Does one of those models have a primary key that is a foreign-key to a different table?\r\n\r\nIs there any way you can provide a *minimal* way to reproduce this issue? At the very least subtract from this example until you can isolate the minimal query that reproduces the problem?",
">I am guessing I somehow have a Vulnerability with a host_id set to a value that doesn't have a corresponding PK in the Host table\r\n\r\nHow would this happen? The whole thing with referential integrity is that this should not occur.",
"Going through the stack trace, I'll show you my thoughts:\r\n\r\nWe're checking if an instance belongs to a set/dict, so we need its hash, which consists of the class and primary-key value:\r\n\r\n```\r\n File \"/var/task/peewee.py\", line 6483, in __hash__\r\n return hash((self.__class__, self._pk))\r\n```\r\n\r\nThe `_pk` accessor is a property that gets the value of the primary-key field. Note that it uses `primary_key.safe_name`. When the primary-key is *also* a foreign-key, this accessor will the be \"object_id_name\", which allows us to access the raw value of the foreign-key, rather than potentially issuing a query to resolve the foreign-key to an instance.\r\n\r\n```\r\n File \"/var/task/peewee.py\", line 6374, in get_id\r\n return getattr(self, self._meta.primary_key.safe_name)\r\n```\r\n\r\nIt looks like you've got a composite primary-key...Why do people do this?!\r\n\r\n```\r\n File \"/var/task/peewee.py\", line 5382, in __get__\r\n for field_name in self.field_names])\r\n```\r\n\r\nOne part of the composite pk is also a foreign-key?\r\n\r\n```\r\n File \"/var/task/peewee.py\", line 4332, in __get__\r\n return self.get_rel_instance(instance)\r\n```\r\n\r\nMissing the part we need:\r\n\r\n```\r\n File \"/var/task/peewee.py\", line 4327, in get_rel_instance\r\n raise self.rel_model.DoesNotExist\r\n```",
"In your composite primary-key that also contains a foreign-key, try changing the foreign-key part to be the \"safe-name\" of the FK rather than the FK field itself:\r\n\r\n```python\r\n\r\n# Change this:\r\nprimary_key = CompositeKey('host', 'other_field')\r\n\r\n# To this:\r\nprimary_key = CompositeKey('host_id', 'other_field')\r\n```\r\n\r\nTry that out and let me know if it fixes the problem and works.\r\n\r\n>using composite primary keys ever\r\n\r\nActive record ORMs do not work well with composite pks. Try using a regular autoincrement / uuid in the future and just put a unique constraint on the columns you need to guarantee are unique. You'll have a much better time.",
"@brandond - can you please take a look at my latest comment and provide additional info?",
"I have been able to reproduce the issue by adding the following code to tests/models.py:\r\n\r\n```python\r\nclass Neighbourhood(TestModel):\r\n name = CharField()\r\n city = ForeignKeyField(City)\r\n class Meta:\r\n primary_key = CompositeKey('name', 'city')\r\n\r\nclass TestCompositePKwithFK(ModelTestCase):\r\n @requires_models(City, Neighbourhood)\r\n def test_join_query(self):\r\n city = City.create(name='city')\r\n neighbourhood = Neighbourhood.create(name='n1',city=city)\r\n\r\n query = (Neighbourhood\r\n .select(\r\n Neighbourhood.name,\r\n City.name\r\n )\r\n .join(City).where(\r\n Neighbourhood.name == 'n1'\r\n ) )\r\n \r\n res = query.get()\r\n self.assertEqual(res.name,'n1')\r\n self.assertEqual(res.city.name, 'city')\r\n```\r\nI am not sure of what you mean with the safe-name of the FK. Replacing \"city\" by \"city_id\" in the CompositeKey declaration causes a KeyError at database creation time",
"You're probably going to hate me for this, but here's a subsection of the model code. I have the business logic in a subclass of RemediationGroupBase, so self.vulnerabilities hits the backref to the Vulnerability model which does indeed have a composite pk.\r\n\r\n```python\r\n\r\nclass RemediationGroupBase(ModelBase):\r\n \"\"\"Peewee model class representing persistent data associated with a Tenable asset group\"\"\"\r\n id = IntegerField(verbose_name='Group ID', primary_key=True)\r\n name = CharField(verbose_name='Group Name')\r\n guid = CharField(verbose_name='Template GUID')\r\n mid_tier = CharField(verbose_name='Remedy Mid-Tier')\r\n process = CharField(verbose_name='Process')\r\n\r\n class Meta:\r\n without_rowid = True\r\n table_name = 'remediation_group'\r\n\r\nclass Vulnerability(ModelBase):\r\n \"\"\"Peewee model class representing a single Vulnerability finding\"\"\"\r\n last_seen = DateTimeField(verbose_name='Last Seen Date')\r\n first_seen = DateTimeField(verbose_name='First Seen Date')\r\n plugin_text = CompressedField(verbose_name='Plugin Text', compression_level=9)\r\n netbios_name = CharField(verbose_name='NetBIOS Name')\r\n mac_address = CharField(verbose_name='MAC Address')\r\n repository = CharField(verbose_name='Repository')\r\n port = IntegerField(verbose_name='Port')\r\n dns_name = CharField(verbose_name='DNS Name')\r\n protocol = CharField(verbose_name='Protocol')\r\n host = ForeignKeyField(verbose_name='Host', model=Host, backref='vulnerabilities')\r\n plugin = ForeignKeyField(verbose_name='Plugin', model=Plugin, backref='vulnerabilities')\r\n remediation_group = ForeignKeyField(verbose_name='Remediation Group', model=RemediationGroupBase, backref='vulnerabilities')\r\n query = ForeignKeyField(verbose_name='Query ID', model=Query, backref='vulnerabilities')\r\n guid = CharField(verbose_name='Query Template GUID')\r\n patched = BooleanField(verbose_name='Patched', default=False)\r\n\r\n class Meta:\r\n without_rowid = True\r\n primary_key = CompositeKey('host', 'port', 'protocol', 'plugin', 'first_seen')\r\n```\r\n\r\nI'm using a composite PK because I'm bulk-loading denormalized data from a 3rd party API and just use insert().on_conflict_replace() to deduplicate rows.\r\n\r\nI'll try replacing 'host' with 'host_id', etc in the CompositeKey and see if that makes it happier.",
"As @Nurbel mentioned, using the safe name causes a KeyError on table creation:\r\n\r\n```\r\n File \"/home/ec2-user/.local/lib/python2.7/site-packages/ticketlib/models.py\", line 178, in <module>\r\n Vulnerability.create_table(safe=True)\r\n File \"/home/ec2-user/.local/lib/python2.7/site-packages/peewee.py\", line 6529, in create_table\r\n cls._schema.create_all(safe, **options)\r\n File \"/home/ec2-user/.local/lib/python2.7/site-packages/peewee.py\", line 5679, in create_all\r\n self.create_table(safe, **table_options)\r\n File \"/home/ec2-user/.local/lib/python2.7/site-packages/peewee.py\", line 5534, in create_table\r\n self.database.execute(self._create_table(safe=safe, **options))\r\n File \"/home/ec2-user/.local/lib/python2.7/site-packages/peewee.py\", line 5492, in _create_table\r\n for field_name in meta.primary_key.field_names]\r\nKeyError: 'plugin_id'\r\n```",
"Thanks for the info - I'll get to the bottom of this.",
"I'll give that change a try, but the tests have all failed?",
"I'll fix the tests, thanks."
] | 2020-02-27T21:44:37 | 2020-03-02T22:16:34 | 2020-03-02T20:42:57 |
NONE
| null |
I have a rather large cross-model join query that started throwing an exception after updating from 3.9.6 to 3.13.1. This appears to be caused by the fix for #1991 .
The query is:
```python
for inc in (self.vulnerabilities
.select(fn.COALESCE(Team.guid, Vulnerability.guid).alias('guid'),
fn.COALESCE(Team.remedy_group, self.name).alias('name'),
Plugin.id,
fn.COUNT(Vulnerability.host_id).alias('count'),
fn.JSON_GROUP_ARRAY(Vulnerability.host_id).python_value(str).alias('host_ids'))
.join(Plugin, src=Vulnerability)
.join(Query, src=Vulnerability)
.join(Host, src=Vulnerability)
.join(Team, join_type=JOIN.LEFT_OUTER, on=(Team.name == team_name), src=Host)
.where(Query.process << INCIDENT_PROCESS_PLUGIN)
.where(Host.state != HOST_STATE_TERMINATED)
.group_by(fn.COALESCE(Team.guid, Vulnerability.guid),
fn.COALESCE(Team.remedy_group, self.name),
Plugin.id)
.order_by(fn.COALESCE(Team.guid, Vulnerability.guid),
fn.COALESCE(Team.remedy_group, self.name),
Plugin.id)):
# do something
```
The resulting query SQL that gets logged is:
```
('SELECT COALESCE("t1"."guid", "t2"."guid") AS "guid", COALESCE("t1"."remedy_group", ?) AS "name", "t3"."id", COUNT("t2"."host_id") AS "count", JSON_GROUP_ARRAY("t2"."host_id") AS "host_ids" FROM "vulnerability" AS "t2" INNER JOIN "plugin" AS "t3" ON ("t2"."plugin_id" = "t3"."id") INNER JOIN "query" AS "t4" ON ("t2"."query_id" = "t4"."id") INNER JOIN "host" AS "t5" ON ("t2"."host_id" = "t5"."ip_address") LEFT OUTER JOIN "team" AS "t1" ON ("t1"."name" = (SELECT "t1"."name" FROM "team" AS "t1" WHERE (("t1"."name" = TRIM(json_extract("t5"."tags", ?))) OR ("t1"."remedy_group" = TRIM(json_extract("t5"."tags", ?)))) LIMIT ?)) WHERE ((("t2"."remediation_group_id" = ?) AND ("t4"."process" IN (?, ?))) AND ("t5"."state" != ?)) GROUP BY COALESCE("t1"."guid", "t2"."guid"), COALESCE("t1"."remedy_group", ?), "t3"."id" ORDER BY COALESCE("t1"."guid", "t2"."guid"), COALESCE("t1"."remedy_group", ?), "t3"."id"', [u'Server Operations', u'$.TechOwnerName', u'$.RemedyGroup', 1, 764, u'standard', u'compliance', u'terminated', u'Server Operations', u'Server Operations'])
```
The exception is:
```
File "/var/task/ticketlib/remediation.py", line 232, in get_known_tickets
Plugin.id)):
File "/var/task/peewee.py", line 4287, in next
self.cursor_wrapper.iterate()
File "/var/task/peewee.py", line 4206, in iterate
result = self.process_row(row)
File "/var/task/peewee.py", line 7450, in process_row
if instance not in set_keys and dest not in set_keys \
File "/var/task/peewee.py", line 6483, in __hash__
return hash((self.__class__, self._pk))
File "/var/task/peewee.py", line 6374, in get_id
return getattr(self, self._meta.primary_key.safe_name)
File "/var/task/peewee.py", line 5382, in __get__
for field_name in self.field_names])
File "/var/task/peewee.py", line 4332, in __get__
return self.get_rel_instance(instance)
File "/var/task/peewee.py", line 4327, in get_rel_instance
raise self.rel_model.DoesNotExist
HostDoesNotExist
```
It's failing in the iterator, without any iterations of the for loop running. I am guessing I somehow have a Vulnerability with a host_id set to a value that doesn't have a corresponding PK in the Host table, but I can't even try to track that down because it's blowing up the iterator immediately.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2115/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2115/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2114
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2114/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2114/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2114/events
|
https://github.com/coleifer/peewee/issues/2114
| 569,523,683 |
MDU6SXNzdWU1Njk1MjM2ODM=
| 2,114 |
generate_models on SQLite database throws KeyError when database contains invalid foreign keys
|
{
"login": "kohavytank",
"id": 46892817,
"node_id": "MDQ6VXNlcjQ2ODkyODE3",
"avatar_url": "https://avatars.githubusercontent.com/u/46892817?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kohavytank",
"html_url": "https://github.com/kohavytank",
"followers_url": "https://api.github.com/users/kohavytank/followers",
"following_url": "https://api.github.com/users/kohavytank/following{/other_user}",
"gists_url": "https://api.github.com/users/kohavytank/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kohavytank/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kohavytank/subscriptions",
"organizations_url": "https://api.github.com/users/kohavytank/orgs",
"repos_url": "https://api.github.com/users/kohavytank/repos",
"events_url": "https://api.github.com/users/kohavytank/events{/privacy}",
"received_events_url": "https://api.github.com/users/kohavytank/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Ehhh, man that's a really quite badly-broken schema. Not using constraints is one thing, but using constraints and then having them be extremely broken is not really something I intend to support.\r\n\r\nIf you need a workaround, just use pwiz' \"-t\" option to explicitly specify the list of un-broken tables, and then enter in the others by hand."
] | 2020-02-23T16:49:03 | 2020-02-23T20:34:09 | 2020-02-23T20:34:08 |
NONE
| null |
Because foreign key constraints in SQLite can be disabled (and is disabled by default), it is possible to create a table with an invalid foreign key, like this:
```python
from peewee import SqliteDatabase
sqlite_db = SqliteDatabase(':memory:')
sqlite_db.execute_sql("""CREATE TABLE IF NOT EXISTS "table1" ("_id" INTEGER PRIMARY KEY,"name" TEXT,"value" INTEGER REFERENCES "non-existent-table"("non-existent-column"))""")
```
When running generate_models on such databases a KeyError is thrown.
```
>>> from playhouse.reflection import generate_models
>>> generate_models(sqlite_db)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\kohavy\.virtualenvs\dtu--X-W94Eo\lib\site-packages\playhouse\reflection.py", line 775, in generate_models
return introspector.generate_models(**options)
File "C:\Users\kohavy\.virtualenvs\dtu--X-W94Eo\lib\site-packages\playhouse\reflection.py", line 674, in generate_models
include_views)
File "C:\Users\kohavy\.virtualenvs\dtu--X-W94Eo\lib\site-packages\playhouse\reflection.py", line 661, in introspect
related_name=related_names.get(src))
File "C:\Users\kohavy\.virtualenvs\dtu--X-W94Eo\lib\site-packages\playhouse\reflection.py", line 130, in set_foreign_key
self.rel_model = model_names[foreign_key.dest_table]
KeyError: 'non-existent-table'
```
Is there a way to generate models for a database without the foreign key constraints? or a way to hook a callback to generate the appropriate field (IntegerField in the above case) when a foreign key is missing?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2114/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2114/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2113
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2113/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2113/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2113/events
|
https://github.com/coleifer/peewee/issues/2113
| 568,820,837 |
MDU6SXNzdWU1Njg4MjA4Mzc=
| 2,113 |
Update record through foreign key
|
{
"login": "albireox",
"id": 568775,
"node_id": "MDQ6VXNlcjU2ODc3NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/568775?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albireox",
"html_url": "https://github.com/albireox",
"followers_url": "https://api.github.com/users/albireox/followers",
"following_url": "https://api.github.com/users/albireox/following{/other_user}",
"gists_url": "https://api.github.com/users/albireox/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albireox/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albireox/subscriptions",
"organizations_url": "https://api.github.com/users/albireox/orgs",
"repos_url": "https://api.github.com/users/albireox/repos",
"events_url": "https://api.github.com/users/albireox/events{/privacy}",
"received_events_url": "https://api.github.com/users/albireox/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Peewee is an active record ORM, so you would need to `save()` any instances you modify."
] | 2020-02-21T08:56:33 | 2020-02-21T16:29:21 | 2020-02-21T16:29:21 |
NONE
| null |
If I have two tables, say `User` and `Tweet` related via a foreign key, and I try to do
```python
tweet = Tweet.select().first()
tweet.user.name = 'John Smith'
tweet.save()
```
The new name for the user is not saved (although no error is raised and `tweet.save()` returns `1`). The same is true if I do `tweet.user.save()`.
Is is possible to update the related record in peewee? I know I can do the query on `User` and join with `Tweet`, but sometimes it'd be convenient to update it through the foreign key.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2113/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2113/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2112
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2112/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2112/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2112/events
|
https://github.com/coleifer/peewee/issues/2112
| 567,168,858 |
MDU6SXNzdWU1NjcxNjg4NTg=
| 2,112 |
playhouse.reflection.generate_models does not reflect field constraints
|
{
"login": "gregspurrier",
"id": 5880,
"node_id": "MDQ6VXNlcjU4ODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/5880?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gregspurrier",
"html_url": "https://github.com/gregspurrier",
"followers_url": "https://api.github.com/users/gregspurrier/followers",
"following_url": "https://api.github.com/users/gregspurrier/following{/other_user}",
"gists_url": "https://api.github.com/users/gregspurrier/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gregspurrier/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gregspurrier/subscriptions",
"organizations_url": "https://api.github.com/users/gregspurrier/orgs",
"repos_url": "https://api.github.com/users/gregspurrier/repos",
"events_url": "https://api.github.com/users/gregspurrier/events{/privacy}",
"received_events_url": "https://api.github.com/users/gregspurrier/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"We don't currently support inspecting constraints besides \"NOT NULL\" and an implied \"UNIQUE\"."
] | 2020-02-18T21:27:31 | 2020-02-18T21:30:04 | 2020-02-18T21:30:04 |
NONE
| null |
Using peewee 3.13.1 with PostgreSQL 9.6.15 and psycopg2 2.8.2, I noticed that a model class generated with `generate_models()` had a column that did not reflect its specified `constraints`:
```python
from peewee import TextField, Check
from playhouse.reflection import generate_models
class TestModel(db.Model):
a_field = TextField(constraints=[Check("a_field != ''")])
TestModel.create_table()
TestModel.a_field.constraints
#>
models = generate_models(db.database)
models["testmodel"]._meta.columns["a_field"].constraints
#> None
```
Here is the table definition:
```
# \d testmodel
Table "public.testmodel"
Column | Type | Collation | Nullable | Default
---------+---------+-----------+----------+---------------------------------------
id | integer | | not null | nextval('testmodel_id_seq'::regclass)
a_field | text | | not null |
Indexes:
"testmodel_pkey" PRIMARY KEY, btree (id)
Check constraints:
"testmodel_a_field_check" CHECK (a_field <> ''::text)
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2112/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2112/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2111
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2111/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2111/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2111/events
|
https://github.com/coleifer/peewee/issues/2111
| 567,161,372 |
MDU6SXNzdWU1NjcxNjEzNzI=
| 2,111 |
playhouse.reflection.generate_models does not reflect index_type
|
{
"login": "gregspurrier",
"id": 5880,
"node_id": "MDQ6VXNlcjU4ODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/5880?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gregspurrier",
"html_url": "https://github.com/gregspurrier",
"followers_url": "https://api.github.com/users/gregspurrier/followers",
"following_url": "https://api.github.com/users/gregspurrier/following{/other_user}",
"gists_url": "https://api.github.com/users/gregspurrier/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gregspurrier/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gregspurrier/subscriptions",
"organizations_url": "https://api.github.com/users/gregspurrier/orgs",
"repos_url": "https://api.github.com/users/gregspurrier/repos",
"events_url": "https://api.github.com/users/gregspurrier/events{/privacy}",
"received_events_url": "https://api.github.com/users/gregspurrier/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Currently we don't support detection of special index-types."
] | 2020-02-18T21:12:53 | 2020-02-18T21:30:28 | 2020-02-18T21:30:28 |
NONE
| null |
Using peewee 3.13.1 with PostgreSQL 9.6.15 and psycopg2 2.8.2, I noticed that a model class generated with generate_models() had a column that did not reflect its specified `index_type`:
```python
# db is a FlaskDB object
class TestModel(db.Model):
a_field = TextField(index=True, index_type="BRIN")
TestModel.create_table()
models = generate_models(db.database)
models["testmodel"].a_field.index
#> True
models["testmodel"].a_field.index_type
#> None
```
Here is the table definition:
```
# \d testmodel
Table "public.testmodel"
Column | Type | Collation | Nullable | Default
---------+---------+-----------+----------+---------------------------------------
id | integer | | not null | nextval('testmodel_id_seq'::regclass)
a_field | text | | not null |
Indexes:
"testmodel_pkey" PRIMARY KEY, btree (id)
"testmodel_a_field" brin (a_field)
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2111/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2111/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2110
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2110/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2110/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2110/events
|
https://github.com/coleifer/peewee/pull/2110
| 565,960,340 |
MDExOlB1bGxSZXF1ZXN0Mzc1ODY1NzMy
| 2,110 |
Fix tests for UTC >=+ 4 timezones
|
{
"login": "felixonmars",
"id": 1006477,
"node_id": "MDQ6VXNlcjEwMDY0Nzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1006477?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/felixonmars",
"html_url": "https://github.com/felixonmars",
"followers_url": "https://api.github.com/users/felixonmars/followers",
"following_url": "https://api.github.com/users/felixonmars/following{/other_user}",
"gists_url": "https://api.github.com/users/felixonmars/gists{/gist_id}",
"starred_url": "https://api.github.com/users/felixonmars/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/felixonmars/subscriptions",
"organizations_url": "https://api.github.com/users/felixonmars/orgs",
"repos_url": "https://api.github.com/users/felixonmars/repos",
"events_url": "https://api.github.com/users/felixonmars/events{/privacy}",
"received_events_url": "https://api.github.com/users/felixonmars/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Thanks!"
] | 2020-02-16T19:59:54 | 2020-02-17T01:24:45 | 2020-02-17T00:40:10 |
CONTRIBUTOR
| null |
Currently test_timestamp_field_from_ts assumes the timezone to be less than +4 so it remains the same day. This would fail when running with for example UTC+8:
```
======================================================================
FAIL: test_timestamp_field_parts (tests.fields.TestTimestampField)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/build/python-peewee/src/peewee-3.13.1/tests/fields.py", line 1066, in test_timestamp_field_parts
self.assertEqual(d, 2)
AssertionError: 1 != 2
----------------------------------------------------------------------
Ran 859 tests in 3.450s
FAILED (failures=1, skipped=102)
```
Just comparing it with dt_utc.day fixes the failure.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2110/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2110/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2110",
"html_url": "https://github.com/coleifer/peewee/pull/2110",
"diff_url": "https://github.com/coleifer/peewee/pull/2110.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2110.patch",
"merged_at": "2020-02-17T00:40:09"
}
|
https://api.github.com/repos/coleifer/peewee/issues/2109
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2109/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2109/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2109/events
|
https://github.com/coleifer/peewee/pull/2109
| 565,950,202 |
MDExOlB1bGxSZXF1ZXN0Mzc1ODU4NzIx
| 2,109 |
postgres/introspector: fix query to find capitalized table
|
{
"login": "fmarcolino",
"id": 19367970,
"node_id": "MDQ6VXNlcjE5MzY3OTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/19367970?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fmarcolino",
"html_url": "https://github.com/fmarcolino",
"followers_url": "https://api.github.com/users/fmarcolino/followers",
"following_url": "https://api.github.com/users/fmarcolino/following{/other_user}",
"gists_url": "https://api.github.com/users/fmarcolino/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fmarcolino/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fmarcolino/subscriptions",
"organizations_url": "https://api.github.com/users/fmarcolino/orgs",
"repos_url": "https://api.github.com/users/fmarcolino/repos",
"events_url": "https://api.github.com/users/fmarcolino/events{/privacy}",
"received_events_url": "https://api.github.com/users/fmarcolino/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2020-02-16T18:48:10 | 2020-02-17T00:37:39 | 2020-02-17T00:37:39 |
CONTRIBUTOR
| null |
Fixes #2108
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2109/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2109/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2109",
"html_url": "https://github.com/coleifer/peewee/pull/2109",
"diff_url": "https://github.com/coleifer/peewee/pull/2109.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2109.patch",
"merged_at": "2020-02-17T00:37:38"
}
|
https://api.github.com/repos/coleifer/peewee/issues/2108
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2108/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2108/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2108/events
|
https://github.com/coleifer/peewee/issues/2108
| 565,949,595 |
MDU6SXNzdWU1NjU5NDk1OTU=
| 2,108 |
playhouse/introspector: doesn't work with capitalized table names (Postgres DB)
|
{
"login": "fmarcolino",
"id": 19367970,
"node_id": "MDQ6VXNlcjE5MzY3OTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/19367970?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fmarcolino",
"html_url": "https://github.com/fmarcolino",
"followers_url": "https://api.github.com/users/fmarcolino/followers",
"following_url": "https://api.github.com/users/fmarcolino/following{/other_user}",
"gists_url": "https://api.github.com/users/fmarcolino/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fmarcolino/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fmarcolino/subscriptions",
"organizations_url": "https://api.github.com/users/fmarcolino/orgs",
"repos_url": "https://api.github.com/users/fmarcolino/repos",
"events_url": "https://api.github.com/users/fmarcolino/events{/privacy}",
"received_events_url": "https://api.github.com/users/fmarcolino/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Thanks, I've merged your patch."
] | 2020-02-16T18:43:53 | 2020-02-17T00:37:52 | 2020-02-17T00:37:38 |
CONTRIBUTOR
| null |
Hello, I'm trying inspect a table, but he doesn't find her. A exception is raised: UndefinedTable. I think that there is a bug in the query. When we don't put the double quotes in the table name, the postgres database consider name table as lower case.

I did here fixing the identifier table, in the PostgresqlMetadata Class and he works now.
What is the best solution?
Vlw flw
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2108/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2108/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2107
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2107/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2107/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2107/events
|
https://github.com/coleifer/peewee/pull/2107
| 565,387,506 |
MDExOlB1bGxSZXF1ZXN0Mzc1NDM2MjYw
| 2,107 |
Add UUID array to array types for postgresql.
|
{
"login": "james-lawrence",
"id": 2835871,
"node_id": "MDQ6VXNlcjI4MzU4NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2835871?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/james-lawrence",
"html_url": "https://github.com/james-lawrence",
"followers_url": "https://api.github.com/users/james-lawrence/followers",
"following_url": "https://api.github.com/users/james-lawrence/following{/other_user}",
"gists_url": "https://api.github.com/users/james-lawrence/gists{/gist_id}",
"starred_url": "https://api.github.com/users/james-lawrence/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/james-lawrence/subscriptions",
"organizations_url": "https://api.github.com/users/james-lawrence/orgs",
"repos_url": "https://api.github.com/users/james-lawrence/repos",
"events_url": "https://api.github.com/users/james-lawrence/events{/privacy}",
"received_events_url": "https://api.github.com/users/james-lawrence/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2020-02-14T15:14:03 | 2020-02-18T13:20:53 | 2020-02-14T22:04:35 |
CONTRIBUTOR
| null |
not sure if this is the entirety of the change needed to support uuid arrays.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2107/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2107/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2107",
"html_url": "https://github.com/coleifer/peewee/pull/2107",
"diff_url": "https://github.com/coleifer/peewee/pull/2107.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2107.patch",
"merged_at": "2020-02-14T22:04:35"
}
|
https://api.github.com/repos/coleifer/peewee/issues/2106
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2106/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2106/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2106/events
|
https://github.com/coleifer/peewee/issues/2106
| 565,385,695 |
MDU6SXNzdWU1NjUzODU2OTU=
| 2,106 |
postgresql: missing support for arrays of uuid's and jsonb
|
{
"login": "james-lawrence",
"id": 2835871,
"node_id": "MDQ6VXNlcjI4MzU4NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2835871?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/james-lawrence",
"html_url": "https://github.com/james-lawrence",
"followers_url": "https://api.github.com/users/james-lawrence/followers",
"following_url": "https://api.github.com/users/james-lawrence/following{/other_user}",
"gists_url": "https://api.github.com/users/james-lawrence/gists{/gist_id}",
"starred_url": "https://api.github.com/users/james-lawrence/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/james-lawrence/subscriptions",
"organizations_url": "https://api.github.com/users/james-lawrence/orgs",
"repos_url": "https://api.github.com/users/james-lawrence/repos",
"events_url": "https://api.github.com/users/james-lawrence/events{/privacy}",
"received_events_url": "https://api.github.com/users/james-lawrence/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Merged patch for UUID array.\r\n\r\nAn array of json doesn't make sense to me, since json supports lists as a fundamental data type."
] | 2020-02-14T15:10:58 | 2020-02-14T22:05:16 | 2020-02-14T22:05:16 |
CONTRIBUTOR
| null |
see #1470 for related PR.
relevant oids:
UUID array OID: 2951
JSONB array OID: 3807
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2106/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2105
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2105/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2105/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2105/events
|
https://github.com/coleifer/peewee/issues/2105
| 563,793,733 |
MDU6SXNzdWU1NjM3OTM3MzM=
| 2,105 |
Can't convert string to float
|
{
"login": "vkachhawa",
"id": 40148937,
"node_id": "MDQ6VXNlcjQwMTQ4OTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/40148937?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vkachhawa",
"html_url": "https://github.com/vkachhawa",
"followers_url": "https://api.github.com/users/vkachhawa/followers",
"following_url": "https://api.github.com/users/vkachhawa/following{/other_user}",
"gists_url": "https://api.github.com/users/vkachhawa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vkachhawa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vkachhawa/subscriptions",
"organizations_url": "https://api.github.com/users/vkachhawa/orgs",
"repos_url": "https://api.github.com/users/vkachhawa/repos",
"events_url": "https://api.github.com/users/vkachhawa/events{/privacy}",
"received_events_url": "https://api.github.com/users/vkachhawa/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"This is not your personal \"help\" message board. Use stackoverflow if you need help. Also you contacted me directly via my website in addition to posting here. Please don't spam.\r\n\r\nAs I said in my email response to you, your data is fucked. You're storing lat/lon in a string field like `[1.234, 2.345]`. Just process your data and separate them out into two separate numeric columns, and your life will be easier *plus* your queries will execute dramatically faster.",
"`the_string_expression.cast('numeric')` should do it, by the way."
] | 2020-02-12T06:58:52 | 2020-02-12T13:58:35 | 2020-02-12T13:57:41 |
NONE
| null |
I have a database which has the column "loc" which has latitude and longitude data stored in a string:like this " [36.166540711883776,-115.14080871936427]" it's a complete string now i am able to get values of latitude and longitude using query like this: "36.166540711883776".Now how do i convert them to a float value in the query so i can use them in the great circle distance formula My code looks like this:
radius = 10
query_lat = (new_table.select(fn.substr(new_table.loc, fn.instr(new_table.loc, "[") + 1, fn.instr(new_table.loc, ",") - 2)))
query_long = (new_table.select(fn.substr(new_table.loc, fn.instr(new_table.loc, ",") + 2,(fn.instr(new_table.loc, "]") - fn.instr(new_table.loc, ",") - 2))))
output_query = (new_table.select(new_table.id, new_table.loc, new_table.userId, new_table.description, new_table.price, new_table.status).where(
(fn.acos(
fn.cos(fn.radians(36.166540711883776)) * fn.cos(
query_lat) * fn.cos(fn.radians(-115.14080871936427) - query_long)
+ fn.sin(fn.radians(36.166540711883776)) * fn.sin(query_lat)) * 3969) <= radius))
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2105/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2105/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2104
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2104/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2104/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2104/events
|
https://github.com/coleifer/peewee/issues/2104
| 563,589,182 |
MDU6SXNzdWU1NjM1ODkxODI=
| 2,104 |
playhouse.reflection.generate_models reorders compound index keys
|
{
"login": "gregspurrier",
"id": 5880,
"node_id": "MDQ6VXNlcjU4ODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/5880?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gregspurrier",
"html_url": "https://github.com/gregspurrier",
"followers_url": "https://api.github.com/users/gregspurrier/followers",
"following_url": "https://api.github.com/users/gregspurrier/following{/other_user}",
"gists_url": "https://api.github.com/users/gregspurrier/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gregspurrier/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gregspurrier/subscriptions",
"organizations_url": "https://api.github.com/users/gregspurrier/orgs",
"repos_url": "https://api.github.com/users/gregspurrier/repos",
"events_url": "https://api.github.com/users/gregspurrier/events{/privacy}",
"received_events_url": "https://api.github.com/users/gregspurrier/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Verified on Postgres 12 as well. Thanks for the report.",
"Fixed. Thanks again for the report!"
] | 2020-02-11T23:16:07 | 2020-02-12T03:46:35 | 2020-02-12T03:32:44 |
NONE
| null |
Using peewee 3.13.1 with PostgreSQL 9.6.15 and psycopg2 2.8.2, I noticed that a model class generated with `generate_models()` had the incorrect order for the keys of a reflected compound index:
```
# \d typicaluser
Table "public.typicaluser"
Column | Type | Collation | Nullable | Default
------------+---------+-----------+----------+-----------------------------------------
id | integer | | not null | nextval('typicaluser_id_seq'::regclass)
first_name | text | | not null |
last_name | text | | not null |
email | text | | not null |
Indexes:
"typicaluser_pkey" PRIMARY KEY, btree (id)
"typicaluser_last_name_first_name" btree (last_name, first_name)
```
vs.
```
>>> from playhouse.reflection import generate_models
>>> models = generate_models(database)
>>> models["typicaluser"]._meta.indexes
[(['first_name', 'last_name'], False)]
```
Note that the generated model has `['first_name', 'last_name']` vs the `(last_name, first_name)` order in the database.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2104/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2104/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2103
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2103/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2103/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2103/events
|
https://github.com/coleifer/peewee/issues/2103
| 563,252,971 |
MDU6SXNzdWU1NjMyNTI5NzE=
| 2,103 |
ForeignKeyFields out of sync?
|
{
"login": "oz123",
"id": 1083045,
"node_id": "MDQ6VXNlcjEwODMwNDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1083045?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oz123",
"html_url": "https://github.com/oz123",
"followers_url": "https://api.github.com/users/oz123/followers",
"following_url": "https://api.github.com/users/oz123/following{/other_user}",
"gists_url": "https://api.github.com/users/oz123/gists{/gist_id}",
"starred_url": "https://api.github.com/users/oz123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/oz123/subscriptions",
"organizations_url": "https://api.github.com/users/oz123/orgs",
"repos_url": "https://api.github.com/users/oz123/repos",
"events_url": "https://api.github.com/users/oz123/events{/privacy}",
"received_events_url": "https://api.github.com/users/oz123/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"usermessage is not user? I think you have problems with your schema. Peewee is not fundamentally broken, if that's what you're suggesting.\r\n\r\nTry stackoverflow for questions like these in the future.",
"I am not suggesting peewee is broken. I am just trying to figure what is going on here. \r\nI being bugged by these issue for quite a while and I have no clue how to figure this out. Maybe I need to fix my schema. But I don't where to start. Is this really because I have a table called user?",
"Your schema is messed up is what I'm trying to suggest. Why would the usermessage's id be the same as the user's id? There's not even a foreign-key to the user table anywhere in your schema.\r\n\r\n>because I have a table called user\r\n\r\nNo.",
"I dumped the database and re-imported it with an ID 1 instead of 9 (after editing the sql file). I don't know if it is a good idea. Maybe it's a patchy solution. \r\nBy saying the schema is messed up you mean that the data was corrupt? Could it be because I made some changes without peewee?\r\nAlternatively, by saying `Your schema is messed up` do you mean I need to change my models in Python?\r\nI am sorry if these are trivial questions for you. This project is the first project I did with peewee so it's not trivial for me. \r\n"
] | 2020-02-11T14:41:42 | 2020-02-11T19:07:59 | 2020-02-11T17:54:15 |
NONE
| null |
At the risk of sounding stupid, I don't know how to give this issue a title.
I have the following database schema:
```python
class UserMessage(BaseModel):
uuid = UUIDField(index=True)
link = UUIDField(index=True)
email = CharField()
name = CharField()
message = CharField()
timestamp = DateTimeField(default=datetime.datetime.utcnow)
# files attribute is a foriegnkey on UploadedEncryptedFile
@property
def full_message(self):
message = "Hi you got the following message from "
message += self.name + ":\n"
message += self.message
logg.info("found %d files", self.files.count())
if self.files.count():
message += "\n\nAttched files:\n"
url = "{APP_URL}/files/{link}".format(
**{"APP_URL": APP_URL, 'link': self.link})
message += url
return message
class UploadedEncryptedFile(BaseModel):
name = CharField()
file_content = BlobField()
user = ForeignKeyField(UserMessage, backref='files', on_delete='CASCADE')
class User(BaseModel):
name = CharField(unique=True) # adding unique true creates an index
email = CharField(255)
password = BlobField(255)
```
When a UserMessage is created it gets the wrong id:
```sql
sqlite> SELECT id from usermessage;
id
9
sqlite> SELECT user_id FROM uploadedencryptedfile;
user_id
1
sqlite>
```
Could peewee doing something wrong here because there is a table called user?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2103/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2102
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2102/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2102/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2102/events
|
https://github.com/coleifer/peewee/pull/2102
| 562,803,993 |
MDExOlB1bGxSZXF1ZXN0MzczMzMzNDEw
| 2,102 |
Add `.union` to the CTE class
|
{
"login": "aconz2",
"id": 3137597,
"node_id": "MDQ6VXNlcjMxMzc1OTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/3137597?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aconz2",
"html_url": "https://github.com/aconz2",
"followers_url": "https://api.github.com/users/aconz2/followers",
"following_url": "https://api.github.com/users/aconz2/following{/other_user}",
"gists_url": "https://api.github.com/users/aconz2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aconz2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aconz2/subscriptions",
"organizations_url": "https://api.github.com/users/aconz2/orgs",
"repos_url": "https://api.github.com/users/aconz2/repos",
"events_url": "https://api.github.com/users/aconz2/events{/privacy}",
"received_events_url": "https://api.github.com/users/aconz2/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"UNION ALL is provided because it is needed for writing recursive queries, so the omission was somewhat intentional.",
"And UNION is required for writing other recursive queries. I added another small example to further illustrate the difference [here](https://github.com/aconz2/peewee/blob/feature/cte-union/tests/models.py#L2829-L2839) \r\n\r\n",
"Thanks, I've merged an equivalent patch.",
"Awesome, much appreciated"
] | 2020-02-10T20:19:41 | 2020-02-12T17:40:29 | 2020-02-12T17:19:43 |
CONTRIBUTOR
| null |
This complements the existing `union_all` method for CTE's.
`tests/sql.py` is purely syntactic b/c the following are identical
```
echo 'WITH RECURSIVE "fibonacci" AS (SELECT 1 AS "n", 0 AS "fib_n", 1 AS "next_fib_n" UNION ALL SELECT ("fibonacci"."n" + 1) AS "n", "fibonacci"."next_fib_n", ("fibonacci"."fib_n" + "fibonacci"."next_fib_n") FROM "fibonacci" WHERE ("n" < 10)) SELECT "fibonacci"."n", "fibonacci"."fib_n" FROM "fibonacci";' | sqlite3
```
```
echo 'WITH RECURSIVE "fibonacci" AS (SELECT 1 AS "n", 0 AS "fib_n", 1 AS "next_fib_n" UNION SELECT ("fibonacci"."n" + 1) AS "n", "fibonacci"."next_fib_n", ("fibonacci"."fib_n" + "fibonacci"."next_fib_n") FROM "fibonacci" WHERE ("n" < 10)) SELECT "fibonacci"."n", "fibonacci"."fib_n" FROM "fibonacci";' | sqlite3
```
`tests/models.py` adds a semantic test on the transitive closure of a directed graph. I tried to stay within the existing test models but needed a non-tree to be able to test properly.
Let me know if you'd like anything else from this
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2102/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2102/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2102",
"html_url": "https://github.com/coleifer/peewee/pull/2102",
"diff_url": "https://github.com/coleifer/peewee/pull/2102.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2102.patch",
"merged_at": null
}
|
https://api.github.com/repos/coleifer/peewee/issues/2101
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2101/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2101/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2101/events
|
https://github.com/coleifer/peewee/issues/2101
| 562,225,544 |
MDU6SXNzdWU1NjIyMjU1NDQ=
| 2,101 |
inserting silently fails
|
{
"login": "DavHau",
"id": 42246742,
"node_id": "MDQ6VXNlcjQyMjQ2NzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/42246742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DavHau",
"html_url": "https://github.com/DavHau",
"followers_url": "https://api.github.com/users/DavHau/followers",
"following_url": "https://api.github.com/users/DavHau/following{/other_user}",
"gists_url": "https://api.github.com/users/DavHau/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DavHau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DavHau/subscriptions",
"organizations_url": "https://api.github.com/users/DavHau/orgs",
"repos_url": "https://api.github.com/users/DavHau/repos",
"events_url": "https://api.github.com/users/DavHau/events{/privacy}",
"received_events_url": "https://api.github.com/users/DavHau/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"When you have a primary key that is not autogenerated, you need to specify `force_insert=True` when saving.\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/models.html#id4\r\n\r\nHere's my advice: don't use composite keys. Just use the standard autoinc primary key and use a multi-column unique constraint. You'll have a **much** better time.\r\n\r\nPeewee doesn't support foreign keys to composite primary keys, either, which sometimes trips people up.\r\n\r\nLastly, Google before you post, because this is heavily traveled ground"
] | 2020-02-09T19:23:42 | 2020-02-09T20:26:18 | 2020-02-09T20:26:18 |
NONE
| null |
python: 3.7
peewee: 3.13.1
The following code fails to insert without any notice:
```python
from peewee import *
db = SqliteDatabase(f'test.db')
class BaseModel(Model):
class Meta:
database = db
class Script(BaseModel):
name = CharField()
version = CharField()
script = TextField(null=True)
class Meta:
primary_key = CompositeKey('name', 'version')
db.connect()
db.create_tables([Script])
Script(name="test", version="1.1.1", script="test script").save()
print(Script.select().exists())
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2101/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2101/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2100
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2100/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2100/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2100/events
|
https://github.com/coleifer/peewee/issues/2100
| 562,024,451 |
MDU6SXNzdWU1NjIwMjQ0NTE=
| 2,100 |
on_conflict(update) doesn't return count of changed rows
|
{
"login": "vladiscripts",
"id": 6325118,
"node_id": "MDQ6VXNlcjYzMjUxMTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/6325118?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vladiscripts",
"html_url": "https://github.com/vladiscripts",
"followers_url": "https://api.github.com/users/vladiscripts/followers",
"following_url": "https://api.github.com/users/vladiscripts/following{/other_user}",
"gists_url": "https://api.github.com/users/vladiscripts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vladiscripts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vladiscripts/subscriptions",
"organizations_url": "https://api.github.com/users/vladiscripts/orgs",
"repos_url": "https://api.github.com/users/vladiscripts/repos",
"events_url": "https://api.github.com/users/vladiscripts/events{/privacy}",
"received_events_url": "https://api.github.com/users/vladiscripts/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"In this minimal test, using an auto-increment primary key, Peewee is returning the PK of the modified row:\r\n\r\n```python\r\n\r\ndb = SqliteDatabase(':memory:')\r\n# Or use postgres\r\n# db = PostgresqlDatabase('peewee_test')\r\n\r\nclass Register(Model):\r\n key = TextField(unique=True)\r\n value = IntegerField()\r\n class Meta:\r\n database = db\r\n\r\ndb.create_tables([Register])\r\n\r\nRegister.create(key='k0', value=0)\r\niq = (Register\r\n .insert(key='k1', value=1)\r\n .on_conflict(conflict_target=[Register.key],\r\n update={Register.value: Register.value + 1}))\r\n\r\nprint(iq.execute())\r\nprint(iq.execute())\r\n\r\nfor r in Register.select():\r\n print(r.key, r.value)\r\n```\r\n\r\nPrints the following for both Sqlite and Postgres:\r\n\r\n```\r\n2\r\n2\r\nk0 0\r\nk1 2\r\n```\r\n\r\nWhich is what I'd expect.",
"On same schema:\r\n\r\n```python\r\ndata = {'k0':0, 'k1':1, 'k2':2}\r\n\r\nfor k, v in data.items():\r\n iq = (Register\r\n .insert(key=k, value=v)\r\n .on_conflict_ignore()\r\n .execute())\r\n print(f'on_conflict_ignore change = {iq}')\r\n\r\nprint('table contains:')\r\nfor r in Register.select():\r\n print(r.key, r.value)\r\n\r\nfor k, v in data.items():\r\n iq = (Register\r\n .insert(key=k, value=v)\r\n .on_conflict(conflict_target=[Register.key],\r\n update={Register.value: Register.value + 1})\r\n .execute())\r\n print(f'on_conflict_update change = {iq}')\r\n\r\nprint('table contains:')\r\nfor r in Register.select():\r\n print(r.key, r.value)\r\n```\r\n\r\noutput:\r\n```\r\non_conflict_ignore change = 1\r\non_conflict_ignore change = 2\r\non_conflict_ignore change = 3\r\ntable contains:\r\nk0 0\r\nk1 1\r\nk2 2\r\non_conflict_update change = 3\r\non_conflict_update change = 3\r\non_conflict_update change = 3\r\ntable contains:\r\nk0 1\r\nk1 2\r\nk2 3\r\n```\r\nAll rows was changed. But return of `insert.on_conflict(update = ...).execute()` are alway 3 (`change = 3`). ",
"Sqlite is reporting the last insert rowid (3). These examples are not triggering the rows-modified branch, but the last-insert-rowid branch.",
"Sorry, I don't understand. How to get a sign that UPDATE has been done? In my case, it doesn’t matter if the return is the number of rows changed as stated in the `.update` documentation, or the PK of the modified row as you said above.",
"You mean how to differentiate between inserting a new row and updating an existing one?",
"Yes. In my case, tens of thousands of rows are regularly loaded into the table. And need to check if any rows have been updated. This is the trigger for executing a following program code.",
"You'll have to experiment with it -- as it is, I believe even if peewee returned you the `rows_affected`, it would still just be the total number of rows you insert/update.",
"That is, Peewee hasn't and haven't expect support for returning count_updated or last_modified_rowid for the `.on_conflict(update=)` method. It returns only the rowid of the last execution of insert. While [`Model.update()` returns](http://docs.peewee-orm.com/en/latest/peewee/api.html#Model.update) the number of rows changed. Do I understand correctly?",
"There's no such thing as a last-modified rowid in Sqlite. Sqlite has last inserted id, and rows affected."
] | 2020-02-08T14:15:44 | 2021-03-08T12:11:44 | 2020-02-09T17:14:04 |
NONE
| null |
The `Insert.execute()` and `Update.execute()` methods, when making changes, return non-zero values, according to the [help](http://docs.peewee-orm.com/en/latest/peewee/api.html#Model.update).
The `Insert.on_conflict().execute()` method works same.
But `Insert.on_conflict(update = ...).execute()` makes changes always returning zero. Example:
```python
changed = (Data
.insert(date=date, pid=pid, value=value)
.on_conflict(
conflict_target=[Data.date, Data.pid],
update={Data.value: 7})
.execute())
```
Peewee 3.13.1, SQLite, Python 3.7
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2100/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2099
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2099/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2099/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2099/events
|
https://github.com/coleifer/peewee/issues/2099
| 559,567,176 |
MDU6SXNzdWU1NTk1NjcxNzY=
| 2,099 |
LATERAL join without on=
|
{
"login": "albireox",
"id": 568775,
"node_id": "MDQ6VXNlcjU2ODc3NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/568775?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albireox",
"html_url": "https://github.com/albireox",
"followers_url": "https://api.github.com/users/albireox/followers",
"following_url": "https://api.github.com/users/albireox/following{/other_user}",
"gists_url": "https://api.github.com/users/albireox/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albireox/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albireox/subscriptions",
"organizations_url": "https://api.github.com/users/albireox/orgs",
"repos_url": "https://api.github.com/users/albireox/repos",
"events_url": "https://api.github.com/users/albireox/events{/privacy}",
"received_events_url": "https://api.github.com/users/albireox/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Can you share your desired SQL?",
"Possibly there's some quirk in Postgresql's query grammar that requires the \"ON true\" clause. That's rather annoying that it's so particular about it -- but for now I'll suggest using `SQL('true')` until I can look into this a bit more.",
"The desired SQL would be \r\n\r\n```\r\nWITH \"sample\" AS (\r\n SELECT \"t1\".\"pk\", \"t1\".\"ra\", \"t1\".\"dec\" FROM \"sky\" AS \"t1\" WHERE (\"t1\".\"pk\" > 200000)) \r\nSELECT \"sample\".\"pk\", \"t2\".\"pk\" FROM \"sample\" LEFT JOIN LATERAL (\r\n SELECT \"sample\".\"pk\" FROM \"sky\" AS \"t3\" WHERE ((\"t3\".\"pk\" IN (SELECT * FROM \"sample\")) AND q3c_join(\"sample\".\"ra\", \"sample\".\"dec\", \"t3\".\"ra\", \"t3\".\"dec\", 0.0016666666666666668)) ORDER BY q3c_dist(\"sample\".\"ra\", \"sample\".\"dec\", \"t3\".\"ra\", \"t3\".\"dec\") ASC LIMIT 1 OFFSET 1) \r\nAS \"t2\" ON true WHERE (\"t2\".\"pk\" IS NULL)\r\n```\r\n\r\nThe only think that doesn't seem to be output is the `ON true`.\r\n\r\nI agree that using `SQL('true')` is better than the `'true'` string and it fixes the problem for me. ",
"Ahhh, I think I know what the issue is!\r\n\r\nThis was only fixed recently, in 8829c948 -- which will automatically add the \"on true\" expression whenever you use a lateral join. So you might try upgrading to 3.13 or newer."
] | 2020-02-04T08:43:01 | 2020-02-04T12:47:45 | 2020-02-04T12:47:45 |
NONE
| null |
I'm trying to do the following query
```python
class Sky(peewee.Model):
pk = peewee.PrimaryKeyField()
ra = peewee.FloatField()
dec = peewee.FloatField()
class Meta:
db_table = 'sky'
database = database
# Select a sample here. For now use just a filter on pk for testing.
sample = (Sky
.select()
.where(Sky.pk > 200000)
.cte('sample'))
subq = (Sky
.select(sample.c.pk)
.where(
peewee.fn.q3c_join(sample.c.ra, sample.c.dec, Sky.ra, Sky.dec, 1. / 600))
.order_by(
peewee.fn.q3c_dist(sample.c.ra, sample.c.dec, Sky.ra, Sky.dec).asc())
.limit(1)
.offset(1))
ss = (sample
.select_from(sample.c.pk, subq.c.pk)
.join(subq, peewee.JOIN.LEFT_LATERAL)
.where(subq.c.pk.is_null())
.with_cte(sample))
ss.execute()
```
This query fails with
```
peewee.ProgrammingError: syntax error at or near "WHERE"
LINE 1: ..."."ra", "t3"."dec") ASC LIMIT 1 OFFSET 1) AS "t2" WHERE ("t2...
```
If I add an `on=true` to the left lateral join, that translates into an `ON 1` in the SQL query which fails with
```
ERROR: argument of JOIN/ON must be type boolean, not type integer
LINE 1: ...ra", "t3"."dec") ASC LIMIT 1 OFFSET 1) AS "t2" ON 1 WHERE ("...
```
If I do something like `on='true'` that works, I assume because it's always evaluated as true. I wonder if there's a better way of doing this or if peewee should add the `ON true` automatically.
Also, I'm not sure if the example [here](http://docs.peewee-orm.com/en/latest/peewee/hacks.html#postgres-lateral-joins) is incomplete since it does not include an `on=` clause.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2099/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2098
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2098/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2098/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2098/events
|
https://github.com/coleifer/peewee/issues/2098
| 558,627,057 |
MDU6SXNzdWU1NTg2MjcwNTc=
| 2,098 |
Recursive save
|
{
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"It's pretty simple - check out: https://github.com/coleifer/flask-peewee/blob/master/flask_peewee/rest.py#L419 for an example of how flask-peewee's REST module handles it.\r\n\r\nYou could also write something recursive. To get the relations, just look at the `model._meta.refs` dict, which maps field instances to related models.\r\n\r\nUntested:\r\n\r\n```python\r\n\r\naccum = [obj]\r\nwhile accum:\r\n curr = accum.pop()\r\n curr.save()\r\n for fk in curr._meta.refs:\r\n rel_obj = getattr(curr, fk.name, None)\r\n if rel_obj is not None:\r\n accum.append(rel_obj)\r\n```",
"It looks like this does successfully save all the objects, but it doesn't seem to properly save the foreign key relations in the database. Do you know why that is?",
"You probably aren't setting things properly, I have no idea - check your code."
] | 2020-02-02T01:42:43 | 2020-02-03T12:33:58 | 2020-02-02T12:08:40 |
NONE
| null |
Is there a convenient function to recursively save a nested object? I'm using [`dict_to_model`](http://docs.peewee-orm.com/en/latest/peewee/playhouse.html#dict_to_model) that produces a nested object, and calling `save` on the returned object seems to only save the top-level one.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2098/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2098/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2097
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2097/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2097/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2097/events
|
https://github.com/coleifer/peewee/issues/2097
| 557,937,560 |
MDU6SXNzdWU1NTc5Mzc1NjA=
| 2,097 |
About optional field
|
{
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"If a field is optional, use `null=True`. It will default to an empty (NULL) value."
] | 2020-01-31T06:17:53 | 2020-01-31T14:17:07 | 2020-01-31T14:17:07 |
NONE
| null |
If I want to designate some `Field` as being optional, in its `__init__` should I use `null=True`, or set `default` to some value (`"NULL"` or `None`)? Or should I be using both of these two options at the same time?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2097/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2096
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2096/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2096/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2096/events
|
https://github.com/coleifer/peewee/issues/2096
| 555,560,080 |
MDU6SXNzdWU1NTU1NjAwODA=
| 2,096 |
Just the first row can be inserted by insert_many(). The database I uesd is postgresql
|
{
"login": "TraderWithPython",
"id": 45730706,
"node_id": "MDQ6VXNlcjQ1NzMwNzA2",
"avatar_url": "https://avatars.githubusercontent.com/u/45730706?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TraderWithPython",
"html_url": "https://github.com/TraderWithPython",
"followers_url": "https://api.github.com/users/TraderWithPython/followers",
"following_url": "https://api.github.com/users/TraderWithPython/following{/other_user}",
"gists_url": "https://api.github.com/users/TraderWithPython/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TraderWithPython/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TraderWithPython/subscriptions",
"organizations_url": "https://api.github.com/users/TraderWithPython/orgs",
"repos_url": "https://api.github.com/users/TraderWithPython/repos",
"events_url": "https://api.github.com/users/TraderWithPython/events{/privacy}",
"received_events_url": "https://api.github.com/users/TraderWithPython/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I'm not sure what to tell you, but I've added a (passing) unit-test which shows that this is working correctly in my test setup. If you can provide me a minimal failing test-case I will re-examine, but I think the problem is not with Peewee."
] | 2020-01-27T13:04:23 | 2020-01-27T15:06:42 | 2020-01-27T15:06:42 |
NONE
| null |
The model is
class DbTick(Model):
instrument_id: str = CharField()
datetime: datetime = DateTimeField()
bid_price1: float = FloatField()
bid_price2: float = FloatField(null=True)
bid_price3: float = FloatField(null=True)
bid_price4: float = FloatField(null=True)
bid_price5: float = FloatField(null=True)
ask_price1: float = FloatField()
ask_price2: float = FloatField(null=True)
ask_price3: float = FloatField(null=True)
ask_price4: float = FloatField(null=True)
ask_price5: float = FloatField(null=True)
bid_volume1: float = FloatField()
bid_volume2: float = FloatField(null=True)
bid_volume3: float = FloatField(null=True)
bid_volume4: float = FloatField(null=True)
bid_volume5: float = FloatField(null=True)
ask_volume1: float = FloatField()
ask_volume2: float = FloatField(null=True)
ask_volume3: float = FloatField(null=True)
ask_volume4: float = FloatField(null=True)
ask_volume5: float = FloatField(null=True)
last_price: float = FloatField()
highest: float = FloatField()
lowest: float = FloatField()
open: float = FloatField()
close: float = FloatField()
average: float = FloatField()
volume: float = FloatField()
amount: float = FloatField()
open_interest: float = FloatField()
upper_limit: float = FloatField()
lower_limit: float = FloatField()
pre_open_interest: float = FloatField()
pre_settlement: float = FloatField()
pre_close: float = FloatField()
price_tick: float = FloatField()
volume_multiple: int = IntegerField()
ins_class: str = CharField()
expire_datetime: datetime = DateTimeField()
expired: int = IntegerField()
class Meta:
database = db
primary_key = CompositeKey('instrument_id', 'datetime')
And I insert data by the method insert_many(),
with self.db.atomic() as transaction:
for batch in chunked(ticks, 100):
self.DbTick.insert_many(batch).on_conflict_ignore().execute()
The result is that only the first row in the ticks can be inserted. This code is wrapped in a coroutine.
Thanks for helping
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2096/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2096/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2095
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2095/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2095/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2095/events
|
https://github.com/coleifer/peewee/issues/2095
| 554,845,500 |
MDU6SXNzdWU1NTQ4NDU1MDA=
| 2,095 |
Q: How to defer SqliteQueueDatabase?
|
{
"login": "BoboTiG",
"id": 2033598,
"node_id": "MDQ6VXNlcjIwMzM1OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2033598?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BoboTiG",
"html_url": "https://github.com/BoboTiG",
"followers_url": "https://api.github.com/users/BoboTiG/followers",
"following_url": "https://api.github.com/users/BoboTiG/following{/other_user}",
"gists_url": "https://api.github.com/users/BoboTiG/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BoboTiG/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BoboTiG/subscriptions",
"organizations_url": "https://api.github.com/users/BoboTiG/orgs",
"repos_url": "https://api.github.com/users/BoboTiG/repos",
"events_url": "https://api.github.com/users/BoboTiG/events{/privacy}",
"received_events_url": "https://api.github.com/users/BoboTiG/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The tables *are* created, but since this multi-threaded, their creation may be deferred for a moment.\r\n\r\nFor example:\r\n\r\n```python\r\n\r\ndb = SqliteQueueDatabase(None)\r\n\r\nclass Reg(Model):\r\n key = TextField()\r\n value = IntegerField()\r\n class Meta:\r\n database = db\r\n\r\ndb.init('foo.db')\r\ndb.start()\r\ndb.connect()\r\ndb.create_tables([Reg])\r\n\r\nprint(db.database)\r\nprint(db.get_tables())\r\n```\r\n\r\nThe above code may print:\r\n\r\n```\r\nfoo.db\r\n[]\r\n```\r\n\r\nWhich indicates that the tables aren't created immediately (though they *are* created as soon as the running thread switches). It seems you have forgotten, maybe, that python is single-threaded?\r\n\r\nTo force a context-switch, you can introduce a tiny sleep(), which will switch contexts and then show you the expected output:\r\n\r\n```python\r\n\r\nprint(db.database)\r\nimport time; time.sleep(0.01)\r\nprint(db.get_tables())\r\n```\r\n\r\nThis prints the expected:\r\n\r\n```\r\nfoo.db\r\n['reg']\r\n```",
"I think it does not work because the parent's thread is a QThread.\r\nI also tried those snippets (just before the `time.sleep()` trick) without luck:\r\n\r\n```python\r\nfrom PyQt5.QtCore import QCoreApplication\r\nQCoreApplication.processEvents()\r\n```\r\n```python\r\nfrom PyQt5.QtCore import QTimer\r\ntimer = QTimer()\r\ntimer.timeout.connect(lambda: None)\r\ntimer.start(100)\r\n```\r\n\r\nDo you know some workaround?",
"how other resolve this question?\r\n\r\nimport time; time.sleep(0.01)\r\n\r\n\r\n\r\n",
"this is my code:\r\n\r\nit is ok, `sleep()` is primary code.\r\n\r\n```python\r\n# -*- coding: utf-8 -*-\r\nimport time\r\n\r\nfrom peewee import TextField, AutoField, Model\r\nfrom playhouse.sqliteq import SqliteQueueDatabase\r\n\r\ndb = SqliteQueueDatabase(database='database.db')\r\n\r\n\r\nclass UserModel(Model):\r\n id = AutoField()\r\n name = TextField()\r\n\r\n class Meta:\r\n database = db\r\n\r\n table_name = 'tb_user'\r\n\r\n\r\n# cerate\r\ndb.create_tables([UserModel])\r\n\r\n# wait\r\ntime.sleep(0.01)\r\n\r\n# query\r\nrow = UserModel.select('id').where(\r\n UserModel.id, '=', 1\r\n).get_or_none()\r\n\r\nprint(row)\r\n# None\r\n\r\n```",
"You could try using a barrier or an event. See https://docs.python.org/3/library/threading.html"
] | 2020-01-24T16:52:31 | 2022-11-04T13:10:29 | 2020-01-24T21:24:01 |
NONE
| null |
Hello,
This is a very great module, thanks for that :muscle:
I am trying to defer `SqliteQueueDatabase` initalization as the database filename is only known at run-time. This is the code:
```python
# models.py
PRAGMAS = (("foreign_keys", 1), ("journal_mode", "wal"), ("synchronous", 3))
DATABASE = SqliteQueueDatabase(None, autostart=False, pragmas=PRAGMAS)
class BaseModel(Model):
class Meta:
database = DATABASE
only_save_dirty = True
```
And elsewhere I set the real database file:
```python
# file.py
db = "my-file.db"
DATABASE.init(db, pragmas=PRAGMAS) # I am not sure if pragmas is useful?
DATABASE.start()
DATABASE.connect()
DATABASE.create_tables(MODELS)
```
Unfortunately, I cannot manage to make the code works: tables are not created.
Note that the same code (minus `DATABASE.start()`) works like a charm if I use `SqliteDatabase`.
Do you have a clue what I am doing wrong?
Thanks a lot :)
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2095/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2094
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2094/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2094/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2094/events
|
https://github.com/coleifer/peewee/issues/2094
| 554,773,212 |
MDU6SXNzdWU1NTQ3NzMyMTI=
| 2,094 |
Array aggregate with ORDER BY clause
|
{
"login": "iksteen",
"id": 1001206,
"node_id": "MDQ6VXNlcjEwMDEyMDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1001206?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iksteen",
"html_url": "https://github.com/iksteen",
"followers_url": "https://api.github.com/users/iksteen/followers",
"following_url": "https://api.github.com/users/iksteen/following{/other_user}",
"gists_url": "https://api.github.com/users/iksteen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iksteen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iksteen/subscriptions",
"organizations_url": "https://api.github.com/users/iksteen/orgs",
"repos_url": "https://api.github.com/users/iksteen/repos",
"events_url": "https://api.github.com/users/iksteen/events{/privacy}",
"received_events_url": "https://api.github.com/users/iksteen/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The method you're describing is an acceptable way of handling this. I'm going to pass on implementing a fix right now, but may reconsider it later.",
"Actual fix is now in: fe84246980d0b68290db9566b40dad446eefd600",
"That's awesome! Thanks for the quick response (and implementing the feature!)."
] | 2020-01-24T14:39:05 | 2020-01-25T15:07:27 | 2020-01-24T21:15:17 |
NONE
| null |
Postgresql supports ordered array aggregation in the form of:
`ARRAY_AGG(expression [ORDER BY [sort_expression {ASC | DESC}], [...])`
The way I currently implement it:
```
fn.array_agg(NodeList([
subscriptions_q.c.topic_id,
SQL("ORDER BY"),
popularity_q.c.popularity.asc(),
]))
```
Do you happen to know a nicer way of implementing array_agg's order by clause using peewee? If not, would you be willing to accept a PR that adds a function that adds this functionality to f.e. playhouse.postgres_ext?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2094/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2094/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2093
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2093/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2093/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2093/events
|
https://github.com/coleifer/peewee/issues/2093
| 554,259,022 |
MDU6SXNzdWU1NTQyNTkwMjI=
| 2,093 |
join model with prefetched another model
|
{
"login": "senya96",
"id": 11079921,
"node_id": "MDQ6VXNlcjExMDc5OTIx",
"avatar_url": "https://avatars.githubusercontent.com/u/11079921?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/senya96",
"html_url": "https://github.com/senya96",
"followers_url": "https://api.github.com/users/senya96/followers",
"following_url": "https://api.github.com/users/senya96/following{/other_user}",
"gists_url": "https://api.github.com/users/senya96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/senya96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/senya96/subscriptions",
"organizations_url": "https://api.github.com/users/senya96/orgs",
"repos_url": "https://api.github.com/users/senya96/repos",
"events_url": "https://api.github.com/users/senya96/events{/privacy}",
"received_events_url": "https://api.github.com/users/senya96/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2020-01-23T16:16:11 | 2020-01-24T12:24:59 | 2020-01-24T12:24:59 |
NONE
| null |
Hello.
I have 3 models.
```python
class Model1(peewee.Model):
model2 = ForeignKeyField(Model2)
class Model2(peewee.Model):
pass
class Model3(peewee.Model):
model2 = ForeignKeyField(Model2)
```
I want to select all data from **Model1** joined with **Model2** and prefetch all **Model3-objects** to every **Model2-object**.
I don't understand how I can do it.
Thank you.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2093/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2092
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2092/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2092/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2092/events
|
https://github.com/coleifer/peewee/issues/2092
| 553,178,196 |
MDU6SXNzdWU1NTMxNzgxOTY=
| 2,092 |
Select the nth element of an array created dynamically in a query
|
{
"login": "bdoms",
"id": 126839,
"node_id": "MDQ6VXNlcjEyNjgzOQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/126839?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bdoms",
"html_url": "https://github.com/bdoms",
"followers_url": "https://api.github.com/users/bdoms/followers",
"following_url": "https://api.github.com/users/bdoms/following{/other_user}",
"gists_url": "https://api.github.com/users/bdoms/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bdoms/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bdoms/subscriptions",
"organizations_url": "https://api.github.com/users/bdoms/orgs",
"repos_url": "https://api.github.com/users/bdoms/repos",
"events_url": "https://api.github.com/users/bdoms/events{/privacy}",
"received_events_url": "https://api.github.com/users/bdoms/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"You need a couple things. It seems postgres *requires* the additional parentheses around the function invocation -- which is annoying but workable.\r\n\r\n```python\r\n\r\nfrom peewee import EnclosedNodeList\r\nfrom playhouse.postgres_ext import ObjectSlice\r\n\r\n# Function invocation - nothing weird here.\r\nf = fn.string_to_array(Page.url, '/')\r\n\r\n# Wrap function invocation in additional parentheses.\r\nfp = EnclosedNodeList([f])\r\n\r\n# Indexing operation. Postgres uses 1-based indexes, so 1->2.\r\n# This addition happens in Peewee to allow Python code to emulate\r\n# python's 0-based indexing.\r\nitem = ObjectSlice(fp, [1])\r\n\r\nquery = Page.select(item.alias('url_part'))\r\n```"
] | 2020-01-21T22:26:49 | 2020-01-21T23:57:18 | 2020-01-21T23:57:17 |
NONE
| null |
Love peewee, using the most recent version (3.13.1) and I've run into a situation causing an error. I may not have the right syntax, but after scouring the web and the docs and the source code I can't find it if it exists.
I'm trying to mimic this SQL, which works in Postgres:
```sql
select (string_to_array(page.url, '/'))[2] from page;
```
Getting array elements from fields using the `ArrayField` extension works, but when the arrays are created with `string_to_array` the way to access a specific element is not obvious.
Here's the setup:
```python
from peewee import Model, fn, CharField
from playhouse.postgres_ext import PostgresqlExtDatabase
peewee_db = PostgresqlExtDatabase('mydbname')
class Page(Model):
url = CharField(null=True)
class Meta:
database = peewee_db
peewee_db.connect()
Page.select(fn.STRING_TO_ARRAY(Page.url, '/')[2]).execute()
```
And it produces this output:
```
peewee.ProgrammingError: operator does not exist: text[] = integer
LINE 1: SELECT (STRING_TO_ARRAY("t1"."url", '/') = 2) FROM "page" A...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.
```
If there is a cast or function that can get the nth item out in a situation like this I would really appreciate the help in figuring it out. The types `text[]` and `integer` look right to me, which I think is where some of the confusion is coming from.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2092/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2092/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2091
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2091/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2091/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2091/events
|
https://github.com/coleifer/peewee/issues/2091
| 552,812,014 |
MDU6SXNzdWU1NTI4MTIwMTQ=
| 2,091 |
prefetch causes fields to be added in dirty_fields
|
{
"login": "navolotsky",
"id": 43314216,
"node_id": "MDQ6VXNlcjQzMzE0MjE2",
"avatar_url": "https://avatars.githubusercontent.com/u/43314216?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/navolotsky",
"html_url": "https://github.com/navolotsky",
"followers_url": "https://api.github.com/users/navolotsky/followers",
"following_url": "https://api.github.com/users/navolotsky/following{/other_user}",
"gists_url": "https://api.github.com/users/navolotsky/gists{/gist_id}",
"starred_url": "https://api.github.com/users/navolotsky/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/navolotsky/subscriptions",
"organizations_url": "https://api.github.com/users/navolotsky/orgs",
"repos_url": "https://api.github.com/users/navolotsky/repos",
"events_url": "https://api.github.com/users/navolotsky/events{/privacy}",
"received_events_url": "https://api.github.com/users/navolotsky/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"@coleifer Please check it. I got this behavior again on Peewee 3.13.3, Python 3.8.2 (tags/v3.8.2:7b3ab59, Feb 25 2020, 23:03:10) [MSC v.1916 64 bit (AMD64)] on win32.",
"The regression test is passing fine for me. If you add a failing test, I will look into this again.",
"```python\r\nfrom peewee import CharField, ForeignKeyField, Model, SqliteDatabase\r\n\r\ndatabase = SqliteDatabase(\":memory:\")\r\n\r\n\r\nclass A(Model):\r\n class Meta:\r\n database = database\r\n only_save_dirty = True\r\n some_str = CharField()\r\n\r\n\r\nclass B(Model):\r\n class Meta:\r\n database = database\r\n only_save_dirty = True\r\n another_str = CharField()\r\n a_instance = ForeignKeyField(model=A)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n database.create_tables(models=[A, B])\r\n a = A.create(some_str='s1')\r\n B.create(another_str='s2', a_instance=a)\r\n b1 = B.select().where(B.another_str == 's2').execute()[0]\r\n print(f\"Without `prefetch`, dirty fields: {b1.dirty_fields}\")\r\n b2 = B.select().where(B.another_str == 's2').prefetch(A)[0]\r\n print(f\"With `prefetch`, dirty fields: {b2.dirty_fields}\")\r\n\r\n```\r\n\r\n",
"OP DELIVERS. Thank you!",
"Hey - I think I see the problem. There's absolutely no reason to use `prefetch` when going from a child-model to a parent-model, as SQL already handles that. Just do:\r\n\r\n```python\r\n\r\nquery = B.select(B, A).join(A).where(B.another_str == 's2')\r\n```"
] | 2020-01-21T11:17:10 | 2020-05-19T14:33:08 | 2020-05-19T14:33:08 |
NONE
| null |
`prefetch` causes fields related to prefetched models to be added in `dirty_fields`.
Could you say why this is so? Is it not possible to make another implementation?
Thanks so much for the answer and excellent ORM.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2091/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2090
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2090/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2090/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2090/events
|
https://github.com/coleifer/peewee/issues/2090
| 552,407,775 |
MDU6SXNzdWU1NTI0MDc3NzU=
| 2,090 |
AttributeError: 'str' object has no attribute 'unwrap'
|
{
"login": "Rizhiy",
"id": 5617397,
"node_id": "MDQ6VXNlcjU2MTczOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5617397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rizhiy",
"html_url": "https://github.com/Rizhiy",
"followers_url": "https://api.github.com/users/Rizhiy/followers",
"following_url": "https://api.github.com/users/Rizhiy/following{/other_user}",
"gists_url": "https://api.github.com/users/Rizhiy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rizhiy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rizhiy/subscriptions",
"organizations_url": "https://api.github.com/users/Rizhiy/orgs",
"repos_url": "https://api.github.com/users/Rizhiy/repos",
"events_url": "https://api.github.com/users/Rizhiy/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rizhiy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Paste the full traceback.",
"Oh, I see - you're using `Decimal` instead of `DecimalField`. That's likely the issue.",
"That's mistake in the code here. In my file it is correct.",
"Then paste the full traceback??",
"```\r\nTraceback (most recent call last):\r\n File \"tmp.py\", line 22, in <module>\r\n for stuff in Post.select('date', 'user', 'number1'):\r\n File \"/home/rizhiy/anaconda3/envs/data/lib/python3.7/site-packages/peewee.py\", line 4287, in next\r\n self.cursor_wrapper.iterate()\r\n File \"/home/rizhiy/anaconda3/envs/data/lib/python3.7/site-packages/peewee.py\", line 4203, in iterate\r\n self.initialize() # Lazy initialization.\r\n File \"/home/rizhiy/anaconda3/envs/data/lib/python3.7/site-packages/peewee.py\", line 7251, in _initialize_columns\r\n node = raw_node.unwrap()\r\nAttributeError: 'str' object has no attribute 'unwrap'\r\n```",
"You need to read the docs. It's nowhere indicated that you pass string field-names into the select() method. You use the field instances themselves.\r\n\r\n```python\r\nPost.select(Post.date, Post.number1, ...)\r\n```\r\n\r\nAlso selecting Post.user will just grab the user_id."
] | 2020-01-20T16:41:28 | 2020-01-20T17:06:04 | 2020-01-20T16:50:45 |
NONE
| null |
I'm trying to retrieve rows from the database and get this error.
My table looks as follows:
```python
class Post(Model):
date = DateField()
user = ForeignKeyField(User, backref='numbers')
number1 = DecimalField(6,2)
number2 = DecimalField(6,2)
class Meta:
database = SqliteDatabase('data.db')
primary_key = CompositeKey('date', 'user')
```
What can be the problem?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2090/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2090/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2089
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2089/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2089/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2089/events
|
https://github.com/coleifer/peewee/issues/2089
| 552,356,262 |
MDU6SXNzdWU1NTIzNTYyNjI=
| 2,089 |
Add backref after foreign key declaration
|
{
"login": "Rizhiy",
"id": 5617397,
"node_id": "MDQ6VXNlcjU2MTczOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5617397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rizhiy",
"html_url": "https://github.com/Rizhiy",
"followers_url": "https://api.github.com/users/Rizhiy/followers",
"following_url": "https://api.github.com/users/Rizhiy/following{/other_user}",
"gists_url": "https://api.github.com/users/Rizhiy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rizhiy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rizhiy/subscriptions",
"organizations_url": "https://api.github.com/users/Rizhiy/orgs",
"repos_url": "https://api.github.com/users/Rizhiy/repos",
"events_url": "https://api.github.com/users/Rizhiy/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rizhiy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"You're going to have a really bad time inheriting foreign-keys. It just doesn't work well.\r\n\r\nFurthermore, composite primary-keys are not well-supported, e.g. Peewee doesn't support foreign-keys to models with composite PKs.\r\n\r\nAlso, having different tables for various \"post\" types is almost guaranteed to be a mistake. If you ever want to combine the results you're forced to do unions and then you will be fighting to get the data you need for each type.\r\n\r\nPlay to the strengths of your database and your tools and use a single table with multiple columns (post_type, text, e.g.). It won't waste space. You know what they say about premature optimization, right?\r\n\r\nDo not use a composite PK (really). Just use an auto-incrementing integer or a UUID if you must. You can add a multi-column unique index on anything you need to constrain."
] | 2020-01-20T15:06:49 | 2020-01-20T16:44:38 | 2020-01-20T16:44:38 |
NONE
| null |
Is it possible to add `backref` after foreign key is declared?
I'm trying to do something like:
```python
class User(Model):
username = CharField(unique=True)
class BasePost(Model):
date = DateField()
user = ForeignKeyField(User)
class Meta:
primary_key = CompositeKey('date', 'ticker')
class ShortPost(BasePost):
text = CharField()
User.add_ref(ShortPost, 'short_posts')
class LongPost(BasePost):
text = TextField()
User.add_ref(LongPost, 'long_posts')
class PicturePost(BasePost):
url = CharField()
User.add_ref(PicturePost, 'pictures')
... other types of posts
```
i.e. I want to have a limit of one type of post per user per day and repeating `CompositeKey('date', 'ticker')` along with the fields is ugly and tiresome.
I don't want to combine all posts into one table, since with many types of posts the table will get very sparse very fast.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2089/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2089/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2088
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2088/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2088/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2088/events
|
https://github.com/coleifer/peewee/issues/2088
| 551,905,400 |
MDU6SXNzdWU1NTE5MDU0MDA=
| 2,088 |
Changing single column primary key to a composite primary key
|
{
"login": "neenuj",
"id": 39304368,
"node_id": "MDQ6VXNlcjM5MzA0MzY4",
"avatar_url": "https://avatars.githubusercontent.com/u/39304368?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/neenuj",
"html_url": "https://github.com/neenuj",
"followers_url": "https://api.github.com/users/neenuj/followers",
"following_url": "https://api.github.com/users/neenuj/following{/other_user}",
"gists_url": "https://api.github.com/users/neenuj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/neenuj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neenuj/subscriptions",
"organizations_url": "https://api.github.com/users/neenuj/orgs",
"repos_url": "https://api.github.com/users/neenuj/repos",
"events_url": "https://api.github.com/users/neenuj/events{/privacy}",
"received_events_url": "https://api.github.com/users/neenuj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I would strongly advise against trying to use a composite primary-key for this, as Peewee provides much better support for scalar primary-keys (integers, uuids, etc). Many things will be harder for you if you switch to a composite primary-key - specifically creating foreign-keys to your \"Person\" table. Peewee **does not support FKs to models with composite PKs**.\r\n\r\nIf you are just trying to enforce the uniqueness of first/last, then create a multi-column UNIQUE index:\r\n\r\n```python\r\n# Specify the table, column names, and whether the index should be\r\n# UNIQUE or not.\r\nmigrate(\r\n # Create a unique index on the first and last name fields:\r\n migrator.add_index('person', ('first', 'last'), True),\r\n)\r\n```\r\n\r\nIf you insist on making your life harder, though, you can consult the Postgresql documentation for instructions on dropping a primary-key and creating a new multi-column PK, as creating/dropping PKs is not supported by the migrations library."
] | 2020-01-19T11:00:52 | 2020-01-19T15:18:19 | 2020-01-19T15:18:18 |
NONE
| null |
I have a 'person' table with auto generated 'id' as the primary key. I want to change this primary key to a composite primary key with first_name and last_name as the columns, using schema migrator. Is it possible to achieve this? Or is executing a SQL my only alternative? I am using PostgreSQL.
def perform_schema_migration(db):
migrator = PostgresqlMigrator(db)
migrate(
migrator.drop_constraint('person', 'person_pkey')
)
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2088/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2088/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2087
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2087/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2087/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2087/events
|
https://github.com/coleifer/peewee/issues/2087
| 551,823,017 |
MDU6SXNzdWU1NTE4MjMwMTc=
| 2,087 |
[Question] Searching through binary data in Postgres
|
{
"login": "its-a-feature",
"id": 5313261,
"node_id": "MDQ6VXNlcjUzMTMyNjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/5313261?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/its-a-feature",
"html_url": "https://github.com/its-a-feature",
"followers_url": "https://api.github.com/users/its-a-feature/followers",
"following_url": "https://api.github.com/users/its-a-feature/following{/other_user}",
"gists_url": "https://api.github.com/users/its-a-feature/gists{/gist_id}",
"starred_url": "https://api.github.com/users/its-a-feature/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/its-a-feature/subscriptions",
"organizations_url": "https://api.github.com/users/its-a-feature/orgs",
"repos_url": "https://api.github.com/users/its-a-feature/repos",
"events_url": "https://api.github.com/users/its-a-feature/events{/privacy}",
"received_events_url": "https://api.github.com/users/its-a-feature/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Got it working with the `fn` hook into the underlying functions."
] | 2020-01-18T20:53:37 | 2020-01-18T22:43:59 | 2020-01-18T22:43:59 |
NONE
| null |
I'm storing user output into a BlobField within my database (instead of a TextField) in case the user's output includes null characters. However, I still want to do regex searching across this data.
From the postgresql command line, I can do a command like:
`select encode(Response.response, 'escape') LIKE 'test%' from Response;`
which escapes the response back to text and then allows me to search like normal. This is a built-in functionality of postgres.
How do I do this from within Peewee? I've tried something like peewee's cast to 'text', but it just uses the hex string representation.
I'm using the latest peewee and python3.6
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2087/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2087/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2086
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2086/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2086/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2086/events
|
https://github.com/coleifer/peewee/issues/2086
| 550,451,753 |
MDU6SXNzdWU1NTA0NTE3NTM=
| 2,086 |
how write one code in peewee for mysql, sqlite
|
{
"login": "TechComet",
"id": 5288136,
"node_id": "MDQ6VXNlcjUyODgxMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5288136?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TechComet",
"html_url": "https://github.com/TechComet",
"followers_url": "https://api.github.com/users/TechComet/followers",
"following_url": "https://api.github.com/users/TechComet/following{/other_user}",
"gists_url": "https://api.github.com/users/TechComet/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TechComet/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TechComet/subscriptions",
"organizations_url": "https://api.github.com/users/TechComet/orgs",
"repos_url": "https://api.github.com/users/TechComet/repos",
"events_url": "https://api.github.com/users/TechComet/events{/privacy}",
"received_events_url": "https://api.github.com/users/TechComet/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"You can specify a custom field type, e.g.\r\n\r\n```python\r\nclass MediumTextField(TextField):\r\n field_type = 'MEDIUMTEXT'\r\n```\r\n\r\nAnd just use that if the db is mysql.\r\n\r\nAlternatively, you can configure MySQL to treat all textfields as MEDIUMTEXT if you wish:\r\n\r\n```python\r\nMySQLDatabase.field_types['TEXT'] = 'MEDIUMTEXT'\r\n```",
"I think something like this is what I was looking for\r\n\r\n```\r\nclass UnknownField(object):\r\n def __init__(self, *_, **__): pass\r\n```\r\n\r\nthank you"
] | 2020-01-15T21:55:45 | 2020-01-23T14:01:02 | 2020-01-15T22:27:30 |
NONE
| null |
Hi,
how write one code in peewee for mysql, sqlite
I use peewee and sqlite on local server but on server use mysql need write one code to use mysql and sqlite
Like
```
database_type = 'mysql'
if database_type == 'mysql':
db = peewee.mysql_connect('localhost', 'root', 'password', 'test1234.db')
else:
db = peewee.sqlite_connect('test123.db')
```
if write MEDIUMTEXT Field and sqlite in database_type use this like TEXT
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2086/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2085
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2085/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2085/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2085/events
|
https://github.com/coleifer/peewee/issues/2085
| 549,109,233 |
MDU6SXNzdWU1NDkxMDkyMzM=
| 2,085 |
Support indexing into array using expression w/postgres
|
{
"login": "coleifer",
"id": 119974,
"node_id": "MDQ6VXNlcjExOTk3NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/119974?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/coleifer",
"html_url": "https://github.com/coleifer",
"followers_url": "https://api.github.com/users/coleifer/followers",
"following_url": "https://api.github.com/users/coleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/coleifer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/coleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/coleifer/subscriptions",
"organizations_url": "https://api.github.com/users/coleifer/orgs",
"repos_url": "https://api.github.com/users/coleifer/repos",
"events_url": "https://api.github.com/users/coleifer/events{/privacy}",
"received_events_url": "https://api.github.com/users/coleifer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Fixed."
] | 2020-01-13T18:35:47 | 2020-01-13T18:51:44 | 2020-01-13T18:51:39 |
OWNER
| null |
Question on SO: https://stackoverflow.com/questions/59708993/how-do-i-access-the-last-index-of-an-arrayfield-in-a-peewee-query-with-postgres
Example:
```python
from peewee import *
from playhouse.postgres_ext import *
db = PostgresqlExtDatabase('peewee_test')
class Test(Model):
value = ArrayField(IntegerField)
class Meta:
database = db
table_name = 'test_1'
db.connect()
db.create_tables([Test])
Test.create(value=[1,2,3,4])
Test.create(value=[2,7,5])
Test.create(value=[5,6,7])
VAL = 6
query = Test.select().where(Test.value[fn.array_length(Test.value) - 1] > VAL)
for row in query:
print(row.value)
```
Error:
```python
Traceback (most recent call last):
File "ww.py", line 22, in <module>
query = Test.select().where(Test.value[fn.array_length(Test.value) - 1] > VAL)
File "/home/charles/pypath/playhouse/postgres_ext.py", line 201, in __getitem__
return ObjectSlice.create(self, value)
File "/home/charles/pypath/playhouse/postgres_ext.py", line 135, in create
parts = map(int, value.split(':'))
AttributeError: 'Expression' object has no attribute 'split'
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2085/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2085/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2084
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2084/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2084/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2084/events
|
https://github.com/coleifer/peewee/issues/2084
| 547,903,492 |
MDU6SXNzdWU1NDc5MDM0OTI=
| 2,084 |
mysql query limit 0
|
{
"login": "hereisok",
"id": 16496811,
"node_id": "MDQ6VXNlcjE2NDk2ODEx",
"avatar_url": "https://avatars.githubusercontent.com/u/16496811?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hereisok",
"html_url": "https://github.com/hereisok",
"followers_url": "https://api.github.com/users/hereisok/followers",
"following_url": "https://api.github.com/users/hereisok/following{/other_user}",
"gists_url": "https://api.github.com/users/hereisok/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hereisok/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hereisok/subscriptions",
"organizations_url": "https://api.github.com/users/hereisok/orgs",
"repos_url": "https://api.github.com/users/hereisok/repos",
"events_url": "https://api.github.com/users/hereisok/events{/privacy}",
"received_events_url": "https://api.github.com/users/hereisok/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2020-01-10T07:05:56 | 2020-01-10T12:15:43 | 2020-01-10T12:15:43 |
NONE
| null |
"limit 0" is a legal operation in [MySQL](https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html)
> LIMIT 0 quickly returns an empty set. This can be useful for checking the validity of a query. It can also be employed to obtain the types of the result columns within applications that use a MySQL API that makes result set metadata available. With the mysql client program, you can use the --column-type-info option to display result column types.
But in peewee,
limit 0 will be converted to LIMIT 2 ** 64-1
https://github.com/coleifer/peewee/blob/fc342ddcfda268a27e40a8178982ddf747de80a8/peewee.py#L2023
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2084/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2083
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2083/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2083/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2083/events
|
https://github.com/coleifer/peewee/issues/2083
| 545,671,916 |
MDU6SXNzdWU1NDU2NzE5MTY=
| 2,083 |
What is wrong about join method?
|
{
"login": "AntmanTmp",
"id": 45066722,
"node_id": "MDQ6VXNlcjQ1MDY2NzIy",
"avatar_url": "https://avatars.githubusercontent.com/u/45066722?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AntmanTmp",
"html_url": "https://github.com/AntmanTmp",
"followers_url": "https://api.github.com/users/AntmanTmp/followers",
"following_url": "https://api.github.com/users/AntmanTmp/following{/other_user}",
"gists_url": "https://api.github.com/users/AntmanTmp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AntmanTmp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AntmanTmp/subscriptions",
"organizations_url": "https://api.github.com/users/AntmanTmp/orgs",
"repos_url": "https://api.github.com/users/AntmanTmp/repos",
"events_url": "https://api.github.com/users/AntmanTmp/events{/privacy}",
"received_events_url": "https://api.github.com/users/AntmanTmp/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Don't alias the good or supplier name in query2. The aliases are confusing you. Query2 returns rows but the repr is empty (none) because of the way you aliases the good name.",
"I strongly suggest you check out the docs on relationships and joins:\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/relationships.html",
"@coleifer Thanks all for you help, i made a mistake and not use the relationship\r\n```\r\n query3 = (Goods.select(\r\n Goods.name.alias('g_name'), Supplier.name.alias('s_name')\r\n ).join(Supplier).where(Goods.name.contains('am')).order_by(Goods.name).limit(10))\r\n for item in query3:\r\n print(f'{item.g_name:>15}:{item.supplier.s_name}')\r\n```\r\n\r\n```\r\nAmaranth Leaves:Joshua\r\nAmaranth Leaves:Georgeann\r\nAmaranth Leaves:Londa\r\nAmaranth Leaves:Lee\r\n Bamboo Shoots:Hubert\r\n Bamboo Shoots:Seymour\r\n Bamboo Shoots:Delmar\r\n Bamboo Shoots:Buster\r\n Bamboo Shoots:Mirella\r\n Edamame:Delmy\r\n```"
] | 2020-01-06T11:09:10 | 2020-01-07T02:28:36 | 2020-01-06T12:26:59 |
NONE
| null |
I have two model and random insert some rows
```
class BaseModel(Model):
created_time = DateTimeField(default=datetime.now)
class Meta:
database = db
class Supplier(BaseModel):
name = CharField(max_length=100, index=True)
address = CharField(max_length=100)
phone = CharField(max_length=20)
@classmethod
def _bulk_create(cls,num:int):
'''
use bulk create, below 2.10.0 not has this attr
:return:
'''
bulk=[]
g=Generic(locales.EN)
for _ in range(num):
bulk.append(
Supplier(
name=g.person.name(),
address=g.address.address(),
phone=g.person.telephone()
)
)
with db.atomic():
Supplier.bulk_create(bulk)
@classmethod
def _create_many(cls,num:int):
'''
use create many, insert num*100 count row
:param num:
:return:
'''
def gen_supplier():
'''yield 100 count of supplier'''
field=Field(locales.EN)
supplier=(
lambda : {
'name':field('name'),
'address':field('address'),
'phone':field('telephone')
}
)
yield Schema(schema=supplier).create(iterations=100)
for _ in range(num):
supplier=next(gen_supplier())
with db.atomic():
Supplier.insert_many(supplier).execute()
class Meta:
database = db
table_name = 'supplier'
class Goods(BaseModel):
supplier = ForeignKeyField(Supplier, related_name='goods')
name = CharField(max_length=100, index=True)
click_num = IntegerField(default=0, )
goods_num = IntegerField(default=0, )
price = FloatField(default=0.00, )
brief = TextField()
@classmethod
def _bulk_create(cls,num:int):
query=Supplier.select()
count=query.count()
bulk=[]
g=Generic(locales.EN)
food_keys=['vegetables','drinks','fruits']
for _ in range(num):
bulk.append(
Goods(
supplier=query[randint(0,count-1)],
name=g.food._choice_from(food_keys[randint(0,2)]),
click_num=randint(1,1000),
goods_num=randint(0,10000),
price=round(uniform(20.5,200.5),2),
brief=g.text.text()
)
)
with db.atomic():
Goods.bulk_create(bulk)
@classmethod
def _create_many(cls,num:int):
field = Field(locales.EN)
goods = (
lambda: {
'supplier_id': randint(1,1000), #supplier must hit db
'name':field('food.vegetable'),
'click_num':randint(1, 1000),
'goods_num':randint(0, 10000),
'price' : round(uniform(20.5, 200.5), 2),
'brief':field('text')
}
)
goods=Schema(schema=goods).create(iterations=num)
with db.atomic():
Goods.insert_many(goods).execute()
class Meta:
table_name = 'goods'
```
When I try to use join method, I found some doubts, so maybe there is wrong about my code or some flaws of this lib
```
def query_data():
'''
http://docs.peewee-orm.com/en/latest/peewee/query_examples.html#
:return:
'''
print('-'*20+'case,limit,order,distinct'+'-'*20)
cost = Case(None, [(Goods.price > 100, 'expensive')], 'cheap')
query1=(Goods.select(Goods.name,cost.alias('cost')).order_by(Goods.name).limit(10).distinct())
for item in query1:
print(f'{item.name:>15}:{item.cost}')
print('-' * 20 + 'join' + '-' * 20)
query2=(Goods.select(
Goods.name.alias('g_name'), Supplier.name.alias('s_name')
).join(Supplier).where(Goods.name.contains('am')).order_by(Goods.name).limit(10))
for item in query2:
print(item)
```
when i call query_data func, get this result
```
--------------------case,limit,order,distinct--------------------
Amaranth Leaves:expensive
Artichoke:expensive
Artichoke:cheap
Arugula:expensive
Arugula:cheap
Asparagus:expensive
Asparagus:cheap
Aubergine:cheap
Aubergine:expensive
Avocado:expensive
--------------------join--------------------
None
None
None
None
None
None
None
None
None
None
```
But I print sql of query2, and it is ok when run script in mysql
```
SELECT `t1`.`name` AS `g_name`, `t2`.`name` AS `s_name` FROM `goods` AS `t1` INNER JOIN `supplier` AS `t2` ON (`t1`.`supplier_id` = `t2`.`id`) WHERE (`t1`.`name` LIKE '%am%') ORDER BY `t1`.`name` LIMIT 10;
```
result below:
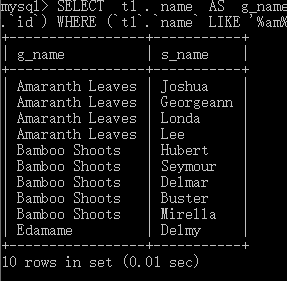
__Q: why all the item in query2 is None?__
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2083/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2083/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2082
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2082/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2082/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2082/events
|
https://github.com/coleifer/peewee/issues/2082
| 542,485,906 |
MDU6SXNzdWU1NDI0ODU5MDY=
| 2,082 |
ambiguous column error on update query
|
{
"login": "ydelibasi",
"id": 10705144,
"node_id": "MDQ6VXNlcjEwNzA1MTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/10705144?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydelibasi",
"html_url": "https://github.com/ydelibasi",
"followers_url": "https://api.github.com/users/ydelibasi/followers",
"following_url": "https://api.github.com/users/ydelibasi/following{/other_user}",
"gists_url": "https://api.github.com/users/ydelibasi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydelibasi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydelibasi/subscriptions",
"organizations_url": "https://api.github.com/users/ydelibasi/orgs",
"repos_url": "https://api.github.com/users/ydelibasi/repos",
"events_url": "https://api.github.com/users/ydelibasi/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydelibasi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Can you share the generated SQL for your query? I tried to replicate a minimal example and the generated SQL contains qualified names that would seem to resolve any ambiguity.\r\n\r\nAlso, what version of Peewee are you using?",
"generated SQL:\r\n`\r\n('UPDATE \"user_data\".\"user_file_rows\" SET \"location_ids\" = \"parent_ids\" FROM \"r_data\".\"location\" AS \"t1\" WHERE ((st_intersects(\"geom\", \"geom\") AND (\"fileid_id\" = %s)) AND (\"location_level_id\" = %s))', ['6f3697c3-****', 4])\r\n`\r\n\r\nI use peewee 3.6.4\r\nThanks",
"Upgrade to a newer version - that should resolve the problem with the SQL generation.",
"I upgraded version. It works.\r\n\r\nThanks"
] | 2019-12-26T08:49:34 | 2019-12-26T15:09:49 | 2019-12-26T14:52:22 |
NONE
| null |
I have two geometry columns with same name. I would like execute update query but I get "peewee.ProgrammingError: column reference "geom" is ambiguous" error.
How to use alias for this columns ?
```
UserFileRows.update(
location_ids=Location.parent_ids
)
.from_(Location)
.where((fn.st_intersects(UserFileRows.geom, Location.geom)) &
(UserFileRows.fileid == file_id) &
(Location.location_level_id == 4)).execute()
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2082/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2082/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2081
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2081/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2081/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2081/events
|
https://github.com/coleifer/peewee/issues/2081
| 542,453,955 |
MDU6SXNzdWU1NDI0NTM5NTU=
| 2,081 |
on_conflict update is not evaluating the WHERE clause correctly
|
{
"login": "neenuj",
"id": 39304368,
"node_id": "MDQ6VXNlcjM5MzA0MzY4",
"avatar_url": "https://avatars.githubusercontent.com/u/39304368?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/neenuj",
"html_url": "https://github.com/neenuj",
"followers_url": "https://api.github.com/users/neenuj/followers",
"following_url": "https://api.github.com/users/neenuj/following{/other_user}",
"gists_url": "https://api.github.com/users/neenuj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/neenuj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neenuj/subscriptions",
"organizations_url": "https://api.github.com/users/neenuj/orgs",
"repos_url": "https://api.github.com/users/neenuj/repos",
"events_url": "https://api.github.com/users/neenuj/events{/privacy}",
"received_events_url": "https://api.github.com/users/neenuj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The docs are very clear, you cannot use python \"or\", \"and\" or \"not\" to combine expressions.\r\n\r\nRewrite\r\n\r\n```python\r\nPerson.fname != EXCLUDED.fname or Person.lname != EXCLUDED.lname\r\n```\r\n\r\nAs\r\n\r\n```python\r\n(Person.fname != EXCLUDED.fname) | (Person.lname != EXCLUDED.lname)\r\n```",
"Thank you! This worked for me. I am struggling to find the documentation on this. Could you point me to the link if you have it handy, please?",
"https://docs.peewee-orm.com/en/latest/peewee/query_operators.html#"
] | 2019-12-26T06:46:05 | 2022-12-03T14:39:16 | 2019-12-26T13:48:58 |
NONE
| null |
Thank you for creating Peewee and for being active on addressing issues and on answering questions.
I encountered issues while upserting data using on_conflict() method. So i faked a scenario to identify the root cause and here is what i could find.
I created a Person model using Peewee inserted a record using the below dict:
personDict = {'id':'11011', 'fname':'Jane', 'lname':'Austin', 'age':28}
Then i tried updating the record using on_conflict() method. The below code should have updated the age of the above record to 30, since the id is the same and since the condition (fname != 'Jane' or lname != 'Austin') evaluates to true. But 'age' did not get updated.
It seems like when we have a WHERE clause with an 'or' condition, if the first condition is evaluated to false, the remaining conditions in the where clause are not evaluated. In the below code, if i switch the order of the two conditions, to make it (Person.lname != EXCLUDED.lname or Person.lname != EXCLUDED.lname), then the update works. Is there a workaround to address this issue?
personDict = {'id':'11011', 'fname':'Jane', 'lname':'Brown', 'age':30}
upsert(personDict )
def upsert(personDict ):
query = Person.insert(personDict)
query.on_conflict(conflict_target=[Person.id],
update={Person.age: EXCLUDED.age},
where=(Person.fname != EXCLUDED.fname or
Person.lname != EXCLUDED.lname)).execute()
If i run the below PostgreSQL statement, the 'age'does get updated to 30 as expected.
INSERT INTO person (id, fname, lname, age)
VALUES (11011, 'Jane', 'Brown', 30)
ON CONFLICT (id)
DO UPDATE
SET age = EXCLUDED.age
WHERE (person.fname <> EXCLUDED.fname OR person.lname <> EXCLUDED.lname);
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2081/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2081/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2080
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2080/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2080/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2080/events
|
https://github.com/coleifer/peewee/issues/2080
| 541,352,797 |
MDU6SXNzdWU1NDEzNTI3OTc=
| 2,080 |
something is wrong with proxy
|
{
"login": "viponedream",
"id": 16624529,
"node_id": "MDQ6VXNlcjE2NjI0NTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/16624529?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/viponedream",
"html_url": "https://github.com/viponedream",
"followers_url": "https://api.github.com/users/viponedream/followers",
"following_url": "https://api.github.com/users/viponedream/following{/other_user}",
"gists_url": "https://api.github.com/users/viponedream/gists{/gist_id}",
"starred_url": "https://api.github.com/users/viponedream/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/viponedream/subscriptions",
"organizations_url": "https://api.github.com/users/viponedream/orgs",
"repos_url": "https://api.github.com/users/viponedream/repos",
"events_url": "https://api.github.com/users/viponedream/events{/privacy}",
"received_events_url": "https://api.github.com/users/viponedream/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Please edit your issue to format your code and I will reopen."
] | 2019-12-21T17:51:31 | 2019-12-21T22:34:41 | 2019-12-21T22:34:40 |
NONE
| null |
in one app, i want to use two database, but it only save to the last database.
1, define model
database_proxy = Proxy()
class Item_DB(Model):
user = CharField(null=True, unique=False)
class Meta:
database = database_proxy # Use proxy for our DB.
2, define my own class the use peewee.
class Database:
def __init__(self, table_name: str, orm_mapping = None, db = None):
self.table_name = table_name
self.table = None
self.db = db if db is not None else sqlite_database
database_proxy.initialize(self.db)
self.orm_mapping = orm_mapping if orm_mapping is not None else Item_DB
def get_table(self):
table = type(self.table_name, (self.orm_mapping,), {})
self.db.connect(reuse_if_open=True)
if not table.table_exists():
try:
table.create_table()
except BaseException:
print(f'建立表{table}不成功!')
return table
def update(self, item: Item):
table = self.get_table()
with self.db.atomic() as transaction:
try:
table.replace(item.__dict__).execute()
except:
transaction.rollback()
3, use it now
DB_NAME = "all_account.db"
DB_PATH = os.path.join(ROOT_PATH, DB_NAME)
_db = SqliteDatabase(str(DB_PATH))
all_db = Database(table_name=app_name, orm_mapping=Item_DB, db=_db)
DB_NAME = "account.db"
DB_PATH = os.path.join(ROOT_PATH, DB_NAME)
_db = SqliteDatabase(str(DB_PATH))
main_db = Database(table_name=app_name, orm_mapping=Item_DB, db=_db)
item=something
all_db.update(item)
i want to save the data to the first db(all_db), but in fact it save to the last one.
it seems it can not change the database.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2080/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2080/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2079
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2079/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2079/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2079/events
|
https://github.com/coleifer/peewee/issues/2079
| 541,161,215 |
MDU6SXNzdWU1NDExNjEyMTU=
| 2,079 |
create_tables with safe=True doesn't work for indexes
|
{
"login": "miguelglopes",
"id": 23117662,
"node_id": "MDQ6VXNlcjIzMTE3NjYy",
"avatar_url": "https://avatars.githubusercontent.com/u/23117662?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/miguelglopes",
"html_url": "https://github.com/miguelglopes",
"followers_url": "https://api.github.com/users/miguelglopes/followers",
"following_url": "https://api.github.com/users/miguelglopes/following{/other_user}",
"gists_url": "https://api.github.com/users/miguelglopes/gists{/gist_id}",
"starred_url": "https://api.github.com/users/miguelglopes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/miguelglopes/subscriptions",
"organizations_url": "https://api.github.com/users/miguelglopes/orgs",
"repos_url": "https://api.github.com/users/miguelglopes/repos",
"events_url": "https://api.github.com/users/miguelglopes/events{/privacy}",
"received_events_url": "https://api.github.com/users/miguelglopes/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"MySQL does not support \"IF NOT EXISTS\" for indexes for some reason.\r\n\r\nSo what peewee does when you're using MySQL is to first check if the table exists -- and if it does -- then it's a no-op. So I think something weird may be going on in your setup.",
"Ok, I think I found the problem.\r\n\r\nI capitalized the first letter in the name of the table. But on mysql workbench it showed as all lower letters. I did some tests:\r\ntable._meta.table_name returned 'Show'\r\ndb.table_exists(\"Show\") returned false \r\ndb.table_exists(\"show\") returned true\r\n\r\nIf I capitalize the first letter of the name of the table, it doesn't detect the table exists and does the create table operation.\r\n\r\nIf i don't capitalize, everything works as expected.",
"I think by default mysql uses case insensitive tables in windows, which I'm running.\r\n\r\nPeewee should, somehow, read this behaviour from the mysql lower_case_table_names variable."
] | 2019-12-20T19:30:37 | 2019-12-21T01:14:08 | 2019-12-20T20:37:12 |
NONE
| null |
When running the following code:
```
import peewee
db = peewee.MySQLDatabase(
config["database"]["db"],
user=config["database"]["user"],
password=config["database"]["pwd"],
host=config["database"]["host"],
port=config["database"]["port"],
)
db.connect()
class Show(peewee.Model):
showid = peewee.PrimaryKeyField()
year = peewee.IntegerField(null=True)
class Meta:
db_table = "Show"
database = db
class LatestEpisode(peewee.Model):
show = peewee.ForeignKeyField(Show, backref="latestEpisodes")
season = peewee.IntegerField()
episode = peewee.IntegerField()
class Meta:
db_table = "LatestEpisode"
database = db
db.create_tables([Show, LatestEpisode], safe=True)
```
Everything runs as expected if the tables don't exist.
However, if they exist, i got the following error:
peewee.InternalError: (1061, "Duplicate key name 'latestepisode_show_id'")
The problem is that, although the tables are created with "IF NOT EXISTS", due to the safe=True, the indexes are not:
('CREATE INDEX `latestepisode_show_id` ON `LatestEpisode` (`show_id`)', [])
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2079/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2079/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2078
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2078/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2078/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2078/events
|
https://github.com/coleifer/peewee/issues/2078
| 539,442,526 |
MDU6SXNzdWU1Mzk0NDI1MjY=
| 2,078 |
Get the SQL output of count?
|
{
"login": "ztj1993",
"id": 13493380,
"node_id": "MDQ6VXNlcjEzNDkzMzgw",
"avatar_url": "https://avatars.githubusercontent.com/u/13493380?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ztj1993",
"html_url": "https://github.com/ztj1993",
"followers_url": "https://api.github.com/users/ztj1993/followers",
"following_url": "https://api.github.com/users/ztj1993/following{/other_user}",
"gists_url": "https://api.github.com/users/ztj1993/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ztj1993/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ztj1993/subscriptions",
"organizations_url": "https://api.github.com/users/ztj1993/orgs",
"repos_url": "https://api.github.com/users/ztj1993/repos",
"events_url": "https://api.github.com/users/ztj1993/events{/privacy}",
"received_events_url": "https://api.github.com/users/ztj1993/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
">I want to get SQL output\r\n\r\nI don't know what this means? The above function will query the database and return the count of rows in the select query.",
"You can use `.scalar()` to obtain the result of a scalar aggregate query.\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/querying.html#retrieving-scalar-values\r\n\r\nPlease note that the issue tracker is not for \"how do I...\" questions. Post those on stackoverflow or ask in the #peewee IRC channel or mailing list. This is for tracking issues with the software."
] | 2019-12-18T04:21:21 | 2019-12-18T14:24:40 | 2019-12-18T14:23:56 |
NONE
| null |
Suppose I have a query
```
OrderModel.select().count()
```
I want to get SQL output, Because I only use the model, not the database.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2078/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2078/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2077
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2077/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2077/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2077/events
|
https://github.com/coleifer/peewee/issues/2077
| 539,054,275 |
MDU6SXNzdWU1MzkwNTQyNzU=
| 2,077 |
Suggestions for moving from SQLIte to PostgreSQL ?
|
{
"login": "nhi-vanye",
"id": 17260552,
"node_id": "MDQ6VXNlcjE3MjYwNTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/17260552?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nhi-vanye",
"html_url": "https://github.com/nhi-vanye",
"followers_url": "https://api.github.com/users/nhi-vanye/followers",
"following_url": "https://api.github.com/users/nhi-vanye/following{/other_user}",
"gists_url": "https://api.github.com/users/nhi-vanye/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nhi-vanye/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nhi-vanye/subscriptions",
"organizations_url": "https://api.github.com/users/nhi-vanye/orgs",
"repos_url": "https://api.github.com/users/nhi-vanye/repos",
"events_url": "https://api.github.com/users/nhi-vanye/events{/privacy}",
"received_events_url": "https://api.github.com/users/nhi-vanye/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"This is more appropriate for stack-overflow, as the issue tracker is used for tracking issues with the library."
] | 2019-12-17T13:05:56 | 2019-12-18T14:19:02 | 2019-12-18T14:19:02 |
NONE
| null |
I'm currently using SQLite as the backend for a simulation program and am interested in supporting the use of PostgreSQL to allow for multiple independent simulations to be run in parallel.
The blocker is a user-defined function.
SQLite has no SQL functions so I wrote it in python
PostgreSQL might be able to use PL/python - but its unclear how to integrate that with peewee.
I suppose I could have two implementations (python, SQL), but that would be less than optimal (and how do I get configuration data into a SQL function - plus one reason I wrote it in python was that I couldn't get my head around it in SQL).
The function is doing set math and returning a bool that is used in the parent query.
What have other people done in tis area ?
```
allowed = False
try:
relatives_1 = set()
relatives_2 = set()
# TODO - make the "relationship limit" configurable
common_ancestor = censere.models.RelationshipEnum.great_great_great_grandparent
for r1 in censere.models.Relationship.select(censere.models.Relationship.second).where(
( censere.models.Relationship.first == id_1 ) &
( censere.models.Relationship.relationship <= common_ancestor )
).tuples():
relatives_1.add( str(r1[0]) )
for r2 in censere.models.Relationship.select(censere.models.Relationship.second).where(
( censere.models.Relationship.first == id_2 ) &
( censere.models.Relationship.relationship <= common_ancestor )
).tuples():
relatives_2.add( str(r2[0]) )
if relatives_1 == relatives_2:
allowed = False
if len(relatives_1 & relatives_2) == 0:
allowed = True
except Exception as e:
logging.log( logging.ERROR, 'Caught exception %s', str(e) )
return allowed
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2077/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2076
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2076/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2076/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2076/events
|
https://github.com/coleifer/peewee/issues/2076
| 538,994,670 |
MDU6SXNzdWU1Mzg5OTQ2NzA=
| 2,076 |
[Question] Query database output
|
{
"login": "zaee-k",
"id": 51817794,
"node_id": "MDQ6VXNlcjUxODE3Nzk0",
"avatar_url": "https://avatars.githubusercontent.com/u/51817794?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zaee-k",
"html_url": "https://github.com/zaee-k",
"followers_url": "https://api.github.com/users/zaee-k/followers",
"following_url": "https://api.github.com/users/zaee-k/following{/other_user}",
"gists_url": "https://api.github.com/users/zaee-k/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zaee-k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zaee-k/subscriptions",
"organizations_url": "https://api.github.com/users/zaee-k/orgs",
"repos_url": "https://api.github.com/users/zaee-k/repos",
"events_url": "https://api.github.com/users/zaee-k/events{/privacy}",
"received_events_url": "https://api.github.com/users/zaee-k/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
">What I get now:\r\n\r\nThat is *not* returned by executing a `select()` query. That is metadata on the model instance. By default, issuing a `select()` will return a cursor that yields model instances for each row of the result set.\r\n\r\nMy guess is that you want something like `.dicts()`, which should give you exactly what you want. Just modify your query:\r\n\r\n```python\r\n\r\nquery = MyModel.select()\r\nfor obj in query:\r\n # obj is a MyModel instance.\r\n ...\r\n\r\n# This is probably what you want:\r\nfor row in query.dicts():\r\n # row is a dict of just the field data.\r\n ...\r\n```\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/querying.html#retrieving-row-tuples-dictionaries-namedtuples",
"Yes! That was the thing I've thought to do. All is good now, thanks! :)"
] | 2019-12-17T11:03:34 | 2019-12-19T14:18:19 | 2019-12-18T14:22:02 |
NONE
| null |
Hey there!
First of all a big big thank you for creating peewee, it's a nice module to work with PostgreSQL and SQLite!
I have one silly question in regard of querying database. Currently I'm playing with peewee and FastAPI. One thing I've noticed is upon executing select(), data is of course queried and returned BUT together with some metadata like "__data__", "_dirty" and "__rel__".
How can I get only the data which is stored in db EXCEPT that metadata? I might of course just read "__data__" value from the output, but when using aliases, my alias and value is outside "__data__". Here example to visualize:
What I get now:
```
[
{
"__data__":{
"id":25052,
"l":"abc",
"asd":"bbd",
"ip":"218.1.1.1",
"timestamp":"2019-12-17T11:57:46.790299"
},
"_dirty":[
],
"__rel__":{
}
}
]
```
What I want to get:
```
[
{
"id":25052,
"l":"abc",
"zxc":"def",
"ip":"218.1.1.1",
"timestamp":"2019-12-17T11:57:46.790299"
}
]
```
TL;DR: How to hide "_dirty", "_rel" and remove "__data__" as key for actual data?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2076/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2076/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2075
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2075/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2075/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2075/events
|
https://github.com/coleifer/peewee/issues/2075
| 538,174,286 |
MDU6SXNzdWU1MzgxNzQyODY=
| 2,075 |
pwiz incorrectly generates a composite unique index
|
{
"login": "navolotsky",
"id": 43314216,
"node_id": "MDQ6VXNlcjQzMzE0MjE2",
"avatar_url": "https://avatars.githubusercontent.com/u/43314216?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/navolotsky",
"html_url": "https://github.com/navolotsky",
"followers_url": "https://api.github.com/users/navolotsky/followers",
"following_url": "https://api.github.com/users/navolotsky/following{/other_user}",
"gists_url": "https://api.github.com/users/navolotsky/gists{/gist_id}",
"starred_url": "https://api.github.com/users/navolotsky/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/navolotsky/subscriptions",
"organizations_url": "https://api.github.com/users/navolotsky/orgs",
"repos_url": "https://api.github.com/users/navolotsky/repos",
"events_url": "https://api.github.com/users/navolotsky/events{/privacy}",
"received_events_url": "https://api.github.com/users/navolotsky/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Yes, `pwiz` is intended to provide a reasonable best-effort at converting the schema into the db into models, but it is not 100% perfect. As the docs say, it's purpose is to produce some basic skeleton code that should handle correct column types and foreign-keys. Things like constraints across columns with arbitrary SQL functions are not introspected currently.\r\n\r\nThat being said, constraints are not enforced on the Python side at all -- so the fact that peewee models may not reflect the constraint will not have any impact on the actual constraint that exists in the database.",
"Ok, I agree. But I think in that case it would be better, if pwiz just do nothing (the non-text field is assigned unique), because it’s easy to overlook and it’s confusing later when you look at the models while develop. I understand that this can be difficult to fix. This is just a wish =)",
"Thanks, I will look into it some more.",
"So unfortunately this is a limitation of the data returned by postgresql when introspecting the set of indexes on a table. Peewee uses a rather complex query to ask postgres for metadata about the index, which includes an aggregation of the columns used in that index. Because the unique comprises a column and a function, our query only returns the column which was matched.\r\n\r\nFor now I don't think we can do much better and this will just have to be a known limitation.\r\n\r\nAlternatives might be to try and parse the index sql to extract the columns, but in that case we still wouldn't be likely to get an accurate reflection of the actual schema since we'd also have to capture the functions being applied."
] | 2019-12-16T04:12:05 | 2019-12-18T14:49:51 | 2019-12-18T14:49:50 |
NONE
| null |
### Issue
There is the problem with pwiz: if there is a unique index across two fields, one of which is `text` or `varchar` and a value of the `lower()` function from a value of such field is taken into the unique index, then a composite unique index is not generated. Instead, the non-text field is assigned unique.
### Examples
Tables definition in PostgreSQL dialect:
```SQL
CREATE TABLE test_table
(
id SERIAL PRIMARY KEY,
some_field INTEGER,
some_text_field TEXT
);
CREATE UNIQUE INDEX test_table_somes_uniq
ON test_table (some_field, lower(some_text_field));
CREATE TABLE test_table2
(
id SERIAL PRIMARY KEY,
some_field INTEGER,
some_varchar_field VARCHAR(255)
);
CREATE UNIQUE INDEX test_table2_somes_uniq
ON test_table2 (some_field, lower(some_varchar_field));
```
peewee models generated by pwiz:
```python
class TestTable(BaseModel):
some_field = IntegerField(null=True, unique=True)
some_text_field = TextField(null=True)
class Meta:
table_name = 'test_table'
class TestTable2(BaseModel):
some_field = IntegerField(null=True, unique=True)
some_varchar_field = CharField(null=True)
class Meta:
table_name = 'test_table2'
```
### Versions
* peewee: 3.12.0
* PostgreSQL: 11.3
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2075/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2075/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2074
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2074/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2074/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2074/events
|
https://github.com/coleifer/peewee/issues/2074
| 538,032,222 |
MDU6SXNzdWU1MzgwMzIyMjI=
| 2,074 |
Update from values
|
{
"login": "eternalflow",
"id": 9920174,
"node_id": "MDQ6VXNlcjk5MjAxNzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9920174?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eternalflow",
"html_url": "https://github.com/eternalflow",
"followers_url": "https://api.github.com/users/eternalflow/followers",
"following_url": "https://api.github.com/users/eternalflow/following{/other_user}",
"gists_url": "https://api.github.com/users/eternalflow/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eternalflow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eternalflow/subscriptions",
"organizations_url": "https://api.github.com/users/eternalflow/orgs",
"repos_url": "https://api.github.com/users/eternalflow/repos",
"events_url": "https://api.github.com/users/eternalflow/events{/privacy}",
"received_events_url": "https://api.github.com/users/eternalflow/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Yes:\r\n\r\n```python\r\n# let's say we want to update two rows.\r\nvl = ValuesList([\r\n (1, 'huey-x'),\r\n (2, 'zaizee-x')], columns=['id', 'username'], alias='vl')\r\nquery = (User\r\n .update({'username': vl.c.username})\r\n .from_(vl)\r\n .where(User.id == vl.c.id))\r\n```",
"Also you can look at the tests:\r\n\r\nhttps://github.com/coleifer/peewee/blob/fc342ddcfda268a27e40a8178982ddf747de80a8/tests/models.py#L4120-L4162"
] | 2019-12-15T10:37:24 | 2019-12-16T12:47:31 | 2019-12-16T12:46:49 |
NONE
| null |
Is there a way to create following query for batch updating rows from given values?
```sql
UPDATE mytable m
SET
field1 = v.field1,
field2 = v.field2
FROM (SELECT * FROM (VALUES %s) as t (id, field1, field2)) v
WHERE m.id = v.id
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2074/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2074/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2073
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2073/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2073/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2073/events
|
https://github.com/coleifer/peewee/issues/2073
| 534,737,220 |
MDU6SXNzdWU1MzQ3MzcyMjA=
| 2,073 |
Should there be an All expression?
|
{
"login": "toppk",
"id": 6306634,
"node_id": "MDQ6VXNlcjYzMDY2MzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6306634?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/toppk",
"html_url": "https://github.com/toppk",
"followers_url": "https://api.github.com/users/toppk/followers",
"following_url": "https://api.github.com/users/toppk/following{/other_user}",
"gists_url": "https://api.github.com/users/toppk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/toppk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/toppk/subscriptions",
"organizations_url": "https://api.github.com/users/toppk/orgs",
"repos_url": "https://api.github.com/users/toppk/repos",
"events_url": "https://api.github.com/users/toppk/events{/privacy}",
"received_events_url": "https://api.github.com/users/toppk/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Just append to a list and use `reduce` to combine the list elements (expressions).",
"https://stackoverflow.com/questions/22238194/python-peewee-dynamically-or-clauses?r=SearchResults",
"That still has the same issue with an empty clauses array. you need to have one element for this to work.",
"```python\r\nclauses = [\r\n (User.username == 'something'),\r\n (User.something == 'another thing'),\r\n ...\r\n]\r\nquery = User.select()\r\nif clauses:\r\n query = query.where(reduce(operator.or_, clauses))\r\n```"
] | 2019-12-09T07:17:03 | 2019-12-09T15:42:42 | 2019-12-09T12:13:35 |
NONE
| null |
Just getting started with peewee, and I was looking at this pattern , to dynamically control the "where " clause.
```
where = Expression(1,"=",1) # All
if some_condition1():
where &= (Users.group_id != 1)
if some_condition2():
where &= (Users.name % "%en%")
query = Users.select().where(where)
```
It seems this pattern is the best way to accomplish a dynamic where condition. If so, it would be nice to have an "All" expression instance inside peewee, so I wouldn't have to define it myself.
Something like:
`All = Expression(1,"=",1)`
Of course, if there's an better way to control which expressions are used in a query, I'd like to know what it is, I've looked at the examples, and didn't see anything offhand.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2073/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2072
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2072/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2072/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2072/events
|
https://github.com/coleifer/peewee/pull/2072
| 534,182,902 |
MDExOlB1bGxSZXF1ZXN0MzUwMTM3Nzcx
| 2,072 |
Use contextvars when available, to support async frameworks
|
{
"login": "tiangolo",
"id": 1326112,
"node_id": "MDQ6VXNlcjEzMjYxMTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1326112?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tiangolo",
"html_url": "https://github.com/tiangolo",
"followers_url": "https://api.github.com/users/tiangolo/followers",
"following_url": "https://api.github.com/users/tiangolo/following{/other_user}",
"gists_url": "https://api.github.com/users/tiangolo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tiangolo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tiangolo/subscriptions",
"organizations_url": "https://api.github.com/users/tiangolo/orgs",
"repos_url": "https://api.github.com/users/tiangolo/repos",
"events_url": "https://api.github.com/users/tiangolo/events{/privacy}",
"received_events_url": "https://api.github.com/users/tiangolo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I'm going to pass on this implementation. I think a more correct approach would be to create a standalone connection-state manager for asyncio usage. This could be provided by a mixin that overrides the `Database.__init__()` method and assigns compatible values to `_state` and `_lock` (also note that this patch does not handle `_lock`).",
"I see. Would you be willing to accept a mixin like that as part of Peewee?\r\n\r\nAbout `_lock`, its job is to bock _all_ the other threads that want to use the same lock. In an async framework, Peewee interactions would/should run in a threadpool with `run_in_executor`, and `threading.lock` would still be blocking any other thread that tries to use the same lock. So it would behave the same and achieve the same.\r\n\r\nIn contrast, `contextvars` are needed because the same connection data would be used in more than one thread, so it needs to be shareable. And the same thread could end up handling different connections, so they need to be dependent on their async context, not the thread.",
"> Would you be willing to accept a mixin like that as part of Peewee?\r\n\r\nI'm not sure yet. Peewee isn't async internally; doesn't use async idioms, doesn't use async drivers, etc. At the same this is a legit issue for people trying to use Peewee with asyncio. That said, the solution is 3.7+ only, which I guess is a very small number of users.\r\n\r\nHowever I think most people who want to use Peewee with asyncio just use [peewee-async](https://github.com/05bit/peewee-async). So I'm not sure if there's an actual need for this change.\r\n\r\nAt the end of the day I'm always in favor of playing to pythons dynamism and using gevent, which just works.",
"Get it. Thanks for the feedback. I'll document it accordingly in FastAPI.",
"Just chiming in: I have a FastAPI+Peewee project going, mostly because I enjoy each project's simplicity. I didn't choose FastAPI because it's async, I choose it because it was a quick and easy way to build a project.\r\n\r\nI think some better support between the two projects would be worthwhile, even if Peewee will never be async-ready. FastAPI is asyncio-based, but is _so much more than just for async_, so I'd urge you to consider the mixin."
] | 2019-12-06T18:02:16 | 2020-04-10T10:58:04 | 2019-12-08T13:29:53 |
NONE
| null |
## Summary
This is a backwards-compatible change to use [`contextvars`](https://docs.python.org/3/library/contextvars.html) instead of [`threading.local`](https://docs.python.org/3/library/threading.html#thread-local-data) when available.
`contextvars` is only available in Python 3.7 and above, so the implementation falls back to `threading.local` when not available.
This fixes errors for async frameworks (like FastAPI) when used with a load that requires more than one single request concurrently.
## Description
`threading.local` creates a value exclusive to the current thread, but an async framework would run all the "tasks" in the same thread, and possibly not in order. On top of that, an async framework could run some sync code in a threadpool (`run_in_executor`), but belonging to the same "task".
This means that, with the current implementation, multiple tasks could be using the same `threading.local` variable, and at the same time, if they execute sync IO-blocking code in a threadpool (`run_in_executor`), that code won't have access to the variable, even while it's part of the same "task" and it should be able to get access to that.
## Reproducing the error
To demonstrate the error, take this example FastAPI application:
```Python
from datetime import date
import time
from fastapi import FastAPI, Depends
import peewee
db = peewee.SqliteDatabase("my_app.db", check_same_thread=False)
class Person(peewee.Model):
name = peewee.CharField()
birthday = peewee.DateField()
class Meta:
database = db
db.connect()
db.create_tables([Person])
if not Person.select().first():
uncle_bob = Person(name="Bob", birthday=date(1960, 1, 15))
uncle_bob.save()
db.close()
app = FastAPI()
def get_db():
db.connect()
try:
yield db
finally:
if not db.is_closed():
db.close()
@app.get("/", dependencies=[Depends(get_db)])
def read_root():
# Simulate a potentially long task to make it easy to
# demonstrate the error
time.sleep(15)
return Person.select().get()
```
Run it with:
```bash
uvicorn main:app
```
Open the browser at http://127.0.0.1:8000/docs in 5 tabs at the same time.
Use the "Try it out" button and the "Execute" button for the single `/` endpoint, in each one of the tabs. With a small time difference between each one (1 sec).
After 15 seconds, one (or more) of the tabs will show the response, while the rest will show a 500 error.
And the console will show an error like:
```
peewee.OperationalError: Connection already opened
```
What happens is that:
* The first tab starts a request
* The application opens the database connection to handle the first request
* Meanwhile, another tab starts another request
* The application tries to open the database connection to handle the second request
* It currently expects to handle that second request in a different thread, but as it is on the same thread, it's accessing the same object, with the connection already opened by the previous request. And more importantly, the *same* connection object.
## Note
An equivalent error would occur when using a middleware, with an example comparable to the one in the docs.
Although the current example in the docs starts a connection at application startup and closes it right before terminating the application. It doesn't really create a connection per-request, that would be achieved with a middleware (or better, with a dependency, as in the example above).
## Proposed fix
The proposed fix uses tries to import [`contextvars`](https://docs.python.org/3/library/contextvars.html) (Python 3.7+) and updates the `_ConnectionLocal` class to keep behaving as normal, but use `contextvars` underneath when available. When not, fall back to `threading.local`. It keeps the interface of `_ConnectionLocal` the same to simplify any external code using it.
`contextvars` is backward-compatible. In Python 3.7+, with synchronous code, it will provide the same behavior that `threading.local` would have.
https://www.python.org/dev/peps/pep-0567/#backwards-compatibility
> This proposal preserves 100% backwards compatibility.
>
> Libraries that use threading.local() to store context-related values, currently work correctly only for synchronous code. Switching them to use the proposed API will keep their behavior for synchronous code unmodified, but will automatically enable support for asynchronous code.
Running the same example from above, using this branch, should return the responses without errors.
## Updated docs
I also updated the docs for FastAPI, to use normal `def` functions and a dependency, as that would probably be the best way to structure it in FastAPI.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2072/reactions",
"total_count": 6,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2072/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2072",
"html_url": "https://github.com/coleifer/peewee/pull/2072",
"diff_url": "https://github.com/coleifer/peewee/pull/2072.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2072.patch",
"merged_at": null
}
|
https://api.github.com/repos/coleifer/peewee/issues/2071
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2071/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2071/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2071/events
|
https://github.com/coleifer/peewee/issues/2071
| 533,907,588 |
MDU6SXNzdWU1MzM5MDc1ODg=
| 2,071 |
atomic() does not seem to have lock_type argument on 3.13.0
|
{
"login": "JeanBarriere",
"id": 11390722,
"node_id": "MDQ6VXNlcjExMzkwNzIy",
"avatar_url": "https://avatars.githubusercontent.com/u/11390722?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JeanBarriere",
"html_url": "https://github.com/JeanBarriere",
"followers_url": "https://api.github.com/users/JeanBarriere/followers",
"following_url": "https://api.github.com/users/JeanBarriere/following{/other_user}",
"gists_url": "https://api.github.com/users/JeanBarriere/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JeanBarriere/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JeanBarriere/subscriptions",
"organizations_url": "https://api.github.com/users/JeanBarriere/orgs",
"repos_url": "https://api.github.com/users/JeanBarriere/repos",
"events_url": "https://api.github.com/users/JeanBarriere/events{/privacy}",
"received_events_url": "https://api.github.com/users/JeanBarriere/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Looks like a breaking change made here: https://github.com/coleifer/peewee/commit/36f5b4a0fef0bd236f25bf99f92f74852f219103",
"For now try removing the keyword (lock_type) and just pass the string 'immediate'. I will put together a fix, in any case.",
"I'm tagging a new release once the build passes. Thanks for reporting this so quickly.",
"https://github.com/coleifer/peewee/releases/tag/3.13.1",
"Thank you for the fast update"
] | 2019-12-06T11:27:42 | 2019-12-06T15:49:38 | 2019-12-06T15:28:58 |
NONE
| null |
Hi !
We're using peewee on our project and we are using it with an IMMEDIATE lock type, as:
`db.atomic(lock_type="IMMEDIATE")`
Everything was working fine on the 3.12.0, but now we have this error:
`TypeError: atomic() got an unexpected keyword argument 'lock_type'`
Any idea why ?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2071/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2071/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2070
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2070/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2070/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2070/events
|
https://github.com/coleifer/peewee/issues/2070
| 532,480,049 |
MDU6SXNzdWU1MzI0ODAwNDk=
| 2,070 |
Regression in 3.12.0 with regard to saving model with JSONField
|
{
"login": "arel",
"id": 153497,
"node_id": "MDQ6VXNlcjE1MzQ5Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/153497?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arel",
"html_url": "https://github.com/arel",
"followers_url": "https://api.github.com/users/arel/followers",
"following_url": "https://api.github.com/users/arel/following{/other_user}",
"gists_url": "https://api.github.com/users/arel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arel/subscriptions",
"organizations_url": "https://api.github.com/users/arel/orgs",
"repos_url": "https://api.github.com/users/arel/repos",
"events_url": "https://api.github.com/users/arel/events{/privacy}",
"received_events_url": "https://api.github.com/users/arel/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Thanks for reporting, this is now fixed in master."
] | 2019-12-04T06:34:28 | 2019-12-04T14:10:48 | 2019-12-04T14:10:41 |
NONE
| null |
A change between 3.11.2 and 3.12.0 broke support for JSONFields. This seems related to #2034, but I don't think this is a duplicate.
I'm using mysql as the database.
To reproduce:
```python
import os
import json
from peewee import Model, TextField
from playhouse.db_url import connect
uri = os.environ.get('DATABASE')
db = connect(uri)
class JSONField(TextField):
def db_value(self, value):
json_string = json.dumps(value)
return json_string
def python_value(self, value):
if value is not None:
return json.loads(value)
class BaseModel(Model):
class Meta:
database = db
class Example(BaseModel):
data = JSONField()
e = Example.create(data=['abc', 'def'])
e.save() # FAILS for version 3.12.0; works for 3.11.2.
```
I get the following exception:
```
...
~/.local/share/virtualenvs/acm-api-UVOmdwT4/lib/python3.7/site-packages/pymysql/err.py in raise_mysql_exception(data)
107 errval = data[3:].decode('utf-8', 'replace')
108 errorclass = error_map.get(errno, InternalError)
--> 109 raise errorclass(errno, errval)
InternalError: (1241, 'Operand should contain 1 column(s)')
```
And, if I debug, I see the problem is with the JSONField's SQL representation:
```mysql
UPDATE `example` SET `data` = ('\"abc\"', '\"def\"') WHERE (`example`.`id` = 2)
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2070/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2070/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2069
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2069/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2069/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2069/events
|
https://github.com/coleifer/peewee/issues/2069
| 532,019,357 |
MDU6SXNzdWU1MzIwMTkzNTc=
| 2,069 |
Mixing hybrid properties with relationships
|
{
"login": "LVerneyPEReN",
"id": 58298410,
"node_id": "MDQ6VXNlcjU4Mjk4NDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/58298410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LVerneyPEReN",
"html_url": "https://github.com/LVerneyPEReN",
"followers_url": "https://api.github.com/users/LVerneyPEReN/followers",
"following_url": "https://api.github.com/users/LVerneyPEReN/following{/other_user}",
"gists_url": "https://api.github.com/users/LVerneyPEReN/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LVerneyPEReN/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LVerneyPEReN/subscriptions",
"organizations_url": "https://api.github.com/users/LVerneyPEReN/orgs",
"repos_url": "https://api.github.com/users/LVerneyPEReN/repos",
"events_url": "https://api.github.com/users/LVerneyPEReN/events{/privacy}",
"received_events_url": "https://api.github.com/users/LVerneyPEReN/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"It's pretty simple, I added a test-case showing how to do it:\r\n\r\n```python\r\nclass Order(TestModel):\r\n name = TextField()\r\n\r\n @hybrid_property\r\n def quantity(self):\r\n return sum([item.qt for item in self.items])\r\n\r\n @quantity.expression\r\n def quantity(cls):\r\n return fn.SUM(Item.qt).alias('quantity')\r\n\r\nclass Item(TestModel):\r\n order = ForeignKeyField(Order, backref='items')\r\n qt = IntegerField()\r\n\r\ndata = (\r\n ('a', (4, 3, 2, 1)),\r\n ('b', (1000, 300, 30, 7)),\r\n ('c', ()))\r\nfor name, qts in data:\r\n o = Order.create(name=name)\r\n for qt in qts:\r\n Item.create(order=o, qt=qt)\r\n\r\nquery = Order.select().order_by(Order.name)\r\n# NOTE: this loop issues an additional query for each order in the loop\r\n# because it has to gather up all the order's items and count the quantities.\r\nself.assertEqual([o.quantity for o in query], [10, 1337, 0])\r\n\r\nquery = (Order\r\n .select(Order.name, Order.quantity.alias('sql_qt'))\r\n .join(Item, JOIN.LEFT_OUTER)\r\n .group_by(Order.name)\r\n .order_by(Order.quantity.desc()))\r\nself.assertEqual([o.sql_qt for o in query], [None, 1337, 10])\r\n```\r\n\r\nYou probably omitted the join / group-by when using it in a query.\r\n\r\nNote in case it is not obvious, but resolving the property on an order instance will issue a query to grab all that order's items and sum them in python. **It's hugely inefficient and should never be done.**",
"Thanks for the (very!) quick answer on this, this solves perfectly my need!\r\n\r\nIt would probably be a nice addition to http://docs.peewee-orm.com/en/latest/peewee/hacks.html (or any better place in the doc), as it deserves more emphasis from within the doc, in my opinion!\r\n\r\nThanks!",
"Glad to help. This is not something I would encourage simply because it can imply additional queries in a non-obvious way."
] | 2019-12-03T14:20:43 | 2019-12-04T14:12:36 | 2019-12-03T17:09:42 |
NONE
| null |
Hi,
I'd like to have something similar to SQLAlchemy's hybrid with relationships example in Peewee. Typically, given the following simple models,
```
class Housing(BaseModel):
id = peewee.AutoField()
@hybrid_property
def nb_nights(self):
return sum(x.nb_nuitees for x in self.nuitees)
@nb_nights.expression
def nb_nights(cls):
return peewee.fn.SUM(Nuitees.nb_nights)
class Nights(BaseModel):
nb_nights = peewee.IntegerField()
housing = peewee.ForeignKeyField(
Housing, backref='nights'
)
```
I'd like to be able to do queries such as `Housing.select().where(Housing.nb_nights == 2)` which would ideally result in a SQL query such as
```
SELECT housing.id, SUM(nights.nb_nights) AS nb_nights FROM housing JOIN nights ON nights.housing_id=housing.id WHERE nb_nights = 2 GROUP BY housing.id
```
I cannot find a way to do it with Peewee currently, not sure whether I am missing something or this is a bug somewhere. Is it achievable with Peewee?
Thanks!
EDIT: Note that the `@nb_nights.expression` is just provided here as a hint of what I'm expecting to find. I tried a couple of variations, including running subqueries etc without being able to come up with anything working fine.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2069/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2069/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2068
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2068/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2068/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2068/events
|
https://github.com/coleifer/peewee/pull/2068
| 532,008,525 |
MDExOlB1bGxSZXF1ZXN0MzQ4MzQ4MjAy
| 2,068 |
BL-536
|
{
"login": "rafae1",
"id": 31249932,
"node_id": "MDQ6VXNlcjMxMjQ5OTMy",
"avatar_url": "https://avatars.githubusercontent.com/u/31249932?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rafae1",
"html_url": "https://github.com/rafae1",
"followers_url": "https://api.github.com/users/rafae1/followers",
"following_url": "https://api.github.com/users/rafae1/following{/other_user}",
"gists_url": "https://api.github.com/users/rafae1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rafae1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rafae1/subscriptions",
"organizations_url": "https://api.github.com/users/rafae1/orgs",
"repos_url": "https://api.github.com/users/rafae1/repos",
"events_url": "https://api.github.com/users/rafae1/events{/privacy}",
"received_events_url": "https://api.github.com/users/rafae1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hey, there's some cool stuff in here. I'll look to maybe integrate some of this. Can you tell me more about some of the changes I'm looking at? I understand the reasoning for certain of them, but others aren't clear exactly what the intent is.",
"* e5ad248db24210e62a2a3829ea78627202aa0d3d\r\n* 99921b9b3d8444eec1daf58d4ce06b6210e3aefd\r\n* 8829c9483fef222e844a092c7720c8e5f6ee1a07"
] | 2019-12-03T14:04:41 | 2019-12-03T16:58:06 | 2019-12-03T14:05:19 |
NONE
| null |
imporve JSONLookUp contains method
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2068/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2068/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2068",
"html_url": "https://github.com/coleifer/peewee/pull/2068",
"diff_url": "https://github.com/coleifer/peewee/pull/2068.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2068.patch",
"merged_at": null
}
|
https://api.github.com/repos/coleifer/peewee/issues/2067
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2067/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2067/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2067/events
|
https://github.com/coleifer/peewee/issues/2067
| 531,994,408 |
MDU6SXNzdWU1MzE5OTQ0MDg=
| 2,067 |
Support for SuperSQLite
|
{
"login": "lllama",
"id": 598411,
"node_id": "MDQ6VXNlcjU5ODQxMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/598411?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lllama",
"html_url": "https://github.com/lllama",
"followers_url": "https://api.github.com/users/lllama/followers",
"following_url": "https://api.github.com/users/lllama/following{/other_user}",
"gists_url": "https://api.github.com/users/lllama/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lllama/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lllama/subscriptions",
"organizations_url": "https://api.github.com/users/lllama/orgs",
"repos_url": "https://api.github.com/users/lllama/repos",
"events_url": "https://api.github.com/users/lllama/events{/privacy}",
"received_events_url": "https://api.github.com/users/lllama/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"You have *got* to be kidding me, this is absolute garbage. It is incredibly easy to build your own SQLite, which the default Python driver should pick up.\r\n\r\nThis should contain all the information you might need:\r\n\r\nhttp://charlesleifer.com/blog/compiling-sqlite-for-use-with-python-applications/",
"Not seeing a single thing about Windows on there, plus specifying a single dependency with pre-built binaries would make cross-platform distribution a lot easier but thanks for the quick response, I guess?",
"Sorry - I don't know the first thing about how to do this on Windows.",
"Okay, I'll investigate what I need to do for that and how to bundle it up with my app. Given that I'll struggle to then get a Windows build working with gitlab CI, would implementing my own backend be the best way forward should I want to use that other lib? Or is some sort of monkey patch possible to get the existing one working?",
"You can look at the apsw playhouse extension for an example, since it looks like supersqlite is a wrapper on apsw."
] | 2019-12-03T13:43:25 | 2019-12-03T14:40:04 | 2019-12-03T14:11:25 |
NONE
| null |
Is it possible to swap out the default sqlite driver with SuperSQLite? (https://github.com/plasticityai/supersqlite). The library provides an up to date version of sqlite and adds a number of extensions which would be useful for my app.
Can I swap the underlying lib, or would it require its own backend?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2067/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2067/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2066
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2066/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2066/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2066/events
|
https://github.com/coleifer/peewee/issues/2066
| 531,948,641 |
MDU6SXNzdWU1MzE5NDg2NDE=
| 2,066 |
delete_instance causes error if tables are not created
|
{
"login": "JuleBert",
"id": 26938997,
"node_id": "MDQ6VXNlcjI2OTM4OTk3",
"avatar_url": "https://avatars.githubusercontent.com/u/26938997?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JuleBert",
"html_url": "https://github.com/JuleBert",
"followers_url": "https://api.github.com/users/JuleBert/followers",
"following_url": "https://api.github.com/users/JuleBert/following{/other_user}",
"gists_url": "https://api.github.com/users/JuleBert/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JuleBert/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JuleBert/subscriptions",
"organizations_url": "https://api.github.com/users/JuleBert/orgs",
"repos_url": "https://api.github.com/users/JuleBert/repos",
"events_url": "https://api.github.com/users/JuleBert/events{/privacy}",
"received_events_url": "https://api.github.com/users/JuleBert/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Peewee should only be traversing the graph of tables related by foreign-key, so my guess is that you have some weird stuff going on in your foreign-key inheritance because Peewee will not traverse subclasses blindly. If you can provide a minimal example showing a bug I will reopen.",
"A minimal example is no problem. \r\nAs you will see the class `Child` is not created as a table and is only used as a template to be inherited from.\r\n\r\n```\r\n# docker run --name postgres -e POSTGRES_DB=postgres -e POSTGRES_PASSWORD=postgres -e POSTGRES_USER=postgres -d -p 5432:5432 postgres\r\n\r\nfrom peewee import *\r\n\r\npg_db = PostgresqlDatabase('postgres', user='postgres', password='postgres',\r\n host='localhost', port=5432)\r\n\r\nclass Parent(Model):\r\n name = CharField()\r\n class Meta:\r\n database = pg_db\r\n\r\nclass Child(Model):\r\n parent = ForeignKeyField(Parent)\r\n class Meta:\r\n database = pg_db\r\n\r\nclass Son(Child):\r\n boys_name = CharField()\r\n\r\nclass Daughter(Child):\r\n girls_name = CharField()\r\n\r\nif __name__ == '__main__':\r\n pg_db.create_tables([Parent, Son, Daughter])\r\n parent = Parent.create(name='dad')\r\n Son.create(boys_name='jim', parent=parent)\r\n Daughter.create(girls_name='jane', parent=parent)\r\n parent.delete_instance(recursive=True)\r\n```",
"Oh, I see what you mean - thank you, you are correct this does produce an error due to the missing Child table. Unfortunately, this is not something I am planning to fix, as inheritance + foreign-keys has always been rather fraught territory. Peewee models maintain an in-memory graph of their relations and there is no way to differentiate between a model that is used as a simple \"base-class\" only.\r\n\r\nMy recommendation would be to put the foreign-keys on the base-classes *OR* declare your foreign-keys such that they specify the appropriate on_delete/on_update behavior and then avoid using recursive delete-instance.\r\n\r\n```python\r\nparent = ForeignKeyField(Parent, on_delete='cascade')\r\n```\r\n\r\nPutting FKs on base-classes is also problematic because of the way backrefs are set-up. It's truly better to just put them where they live."
] | 2019-12-03T12:25:47 | 2019-12-04T15:27:36 | 2019-12-03T14:06:08 |
NONE
| null |
Hi there,
we are using peewee to create a medium complex data structur. We are using inheritance since a lot of table are similar to each other. We do this by creating template classes which are not created as tables later on. These classes are picked up by delete_instance although they are created as tables. Which causes an error.
Is this a bug and can be fixed by checking whether a table is created? Or is there a workaroud / hint for me to make this work without creating my template classes as tables?
Thanks a lot in advance
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2066/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2066/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2065
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2065/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2065/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2065/events
|
https://github.com/coleifer/peewee/issues/2065
| 531,530,509 |
MDU6SXNzdWU1MzE1MzA1MDk=
| 2,065 |
fn.IF returning True instead of values
|
{
"login": "mikemill",
"id": 1652125,
"node_id": "MDQ6VXNlcjE2NTIxMjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1652125?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mikemill",
"html_url": "https://github.com/mikemill",
"followers_url": "https://api.github.com/users/mikemill/followers",
"following_url": "https://api.github.com/users/mikemill/following{/other_user}",
"gists_url": "https://api.github.com/users/mikemill/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mikemill/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mikemill/subscriptions",
"organizations_url": "https://api.github.com/users/mikemill/orgs",
"repos_url": "https://api.github.com/users/mikemill/repos",
"events_url": "https://api.github.com/users/mikemill/events{/privacy}",
"received_events_url": "https://api.github.com/users/mikemill/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Peewee uses a heuristic for function calls when the first argument is a field, where peewee applies that field's conversion method to the value returned by the database. This usually works, but you've found a case where it is problematic. To avoid coercing the function output, specify `coerce=False`:\r\n\r\n```python\r\n# Note you don't need TestModel.flag == True\r\nfn.IF(TestModel.flag, 'hello', 'goodbye', coerce=False)\r\n```",
"Confirmed. Thanks!"
] | 2019-12-02T20:49:49 | 2019-12-02T21:35:46 | 2019-12-02T21:09:32 |
NONE
| null |
I'm trying to use `fn.IF` to pick a value to use. However, if using a model property it is returning `True` as the value instead of the proper value and this is happening even if that property is `False`.
Example script (note: this is a greatly simplified version of what I'm actually trying to do):
```python
from peewee import BooleanField, fn, Model
from playhouse.pool import PooledMySQLDatabase
db_conn = PooledMySQLDatabase(
user='',
password='',
database='',
stale_timeout=5 * 60
)
class TestModel(Model):
flag = BooleanField()
class Meta:
database = db_conn
TestModel.create_table(safe=True)
TestModel.create(flag=True)
TestModel.create(flag=False)
query = (
TestModel.select(
TestModel.id,
fn.IF(
TestModel.flag,
'Hello',
'GoodBye'
).alias('test')
)
).dicts()
print(query)
for record in query:
print(record)
```
The output I get is:
```
SELECT `t1`.`id`, IF(`t1`.`flag`, 'Hello', 'GoodBye') AS `test` FROM `testmodel` AS `t1`
{'id': 1, 'test': True}
{'id': 2, 'test': True}
```
And if I run that query inside MySQL I get the following results:
```
mysql> SELECT `t1`.`id`, IF(`t1`.`flag`, 'Hello', 'GoodBye') AS `test` FROM `testmodel` AS `t1`;
+----+---------+
| id | test |
+----+---------+
| 1 | Hello |
| 2 | GoodBye |
+----+---------+
```
which is what I'd expect to get.
I can modify the query slightly to:
```python
query = (
TestModel.select(
TestModel.id,
fn.IF(
TestModel.flag == True,
'Hello',
'GoodBye'
).alias('test')
)
).dicts()
```
And that does appear to work but it seems unnecessary to require the comparison on a boolean field.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2065/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2065/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2064
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2064/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2064/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2064/events
|
https://github.com/coleifer/peewee/issues/2064
| 530,233,802 |
MDU6SXNzdWU1MzAyMzM4MDI=
| 2,064 |
How to print raw sql for Blog.select().where(Blog.id == 1)
|
{
"login": "jet10000",
"id": 2258120,
"node_id": "MDQ6VXNlcjIyNTgxMjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2258120?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jet10000",
"html_url": "https://github.com/jet10000",
"followers_url": "https://api.github.com/users/jet10000/followers",
"following_url": "https://api.github.com/users/jet10000/following{/other_user}",
"gists_url": "https://api.github.com/users/jet10000/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jet10000/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jet10000/subscriptions",
"organizations_url": "https://api.github.com/users/jet10000/orgs",
"repos_url": "https://api.github.com/users/jet10000/repos",
"events_url": "https://api.github.com/users/jet10000/events{/privacy}",
"received_events_url": "https://api.github.com/users/jet10000/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Peewee returns a parameterized query, a 2-tuple of SQL string and parameters. This is to save people doing crazy stuff and getting SQL injection vulnerabilities. The driver accepts this 2-tuple and does the right thing.",
"What about for DB API (PEP-249) v2.0 drivers? How can I tell peewee to not add double quotes on everything? \r\nex:\r\nfrom: SELECT \"t1\".\"item1\", \"t1\".\"item2\", \"t1\".\"item3\" FROM \"trex_inventory_recipe_material\" AS t1\r\nto: SELECT t1.item1, t1.item2, t1.item3 FROM trex_inventory_recipe_material AS t1",
"Why would you want to do that? Lots of times people unwittingly (or intentionally) use reserved words for column-names, e.g. \"count\". Peewee adds quotes to ensure that identifiers are always treated as-such.",
"I'm using Impyla which is fully DB API v2.0 compiant. And the HiveServer2 (Hive) gives an error when it sees double quoted column-names.",
"On your database class, just set the quote attribute to be an empty string.\r\n\r\n```python\r\n\r\nclass HiveDatabase(...)\r\n quote = ''\r\n```\r\n\r\nDoes that address the issue?",
"No change - using peewee 2.9.0\r\nI'm still getting double quotes when doing a select() on the Model,\r\n\r\n<class 'model.dbo.item_table.ItemTable'> SELECT \"t1\".\"rname\", \"t1\".\"mrole\", \"t1\".\"rmaterial\" FROM \"db1\".\"item_table\" AS t1 []\r\n",
">peewee 2.9.0\r\n\r\nThat's a very old version, from March 2017. For peewee 3.0, I think you would actually set `quote = ('', '')` instead of empty string, but since you're on such an old version I'm not sure what to advise.",
"Thanks @coleifer - appreciate it. Thanks for pointing me in the right path - using `quote = ''`\r\nAlso, you reminded me that I forgot to change the version on the documentation. I was looking at the \"latest\". Older versions (like 2.9.0) use `quote_char = ''` \r\nYup; I will be upgrading it and fix any breaks along the way. Thank you!"
] | 2019-11-29T09:11:10 | 2020-07-06T19:33:37 | 2019-11-29T17:43:18 |
NONE
| null |
```
q = Blog.select().where(Blog.id == 1)
print(q.sql())
```
I want to compile to raw sql .
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2064/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2064/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2063
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2063/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2063/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2063/events
|
https://github.com/coleifer/peewee/issues/2063
| 529,769,075 |
MDU6SXNzdWU1Mjk3NjkwNzU=
| 2,063 |
Model.filter not generating correct SQL for join clause
|
{
"login": "yifeikong",
"id": 1035487,
"node_id": "MDQ6VXNlcjEwMzU0ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1035487?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yifeikong",
"html_url": "https://github.com/yifeikong",
"followers_url": "https://api.github.com/users/yifeikong/followers",
"following_url": "https://api.github.com/users/yifeikong/following{/other_user}",
"gists_url": "https://api.github.com/users/yifeikong/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yifeikong/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yifeikong/subscriptions",
"organizations_url": "https://api.github.com/users/yifeikong/orgs",
"repos_url": "https://api.github.com/users/yifeikong/repos",
"events_url": "https://api.github.com/users/yifeikong/events{/privacy}",
"received_events_url": "https://api.github.com/users/yifeikong/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Sorry, 3.12.0 seems to work, closing. I was using 3.10",
"OK, It's not fixed. Actually it randomly happens each time you restart the flask server.",
"I think the reason is in function of peewee.ModelSelect.filter().\r\ntarget code is:\r\n```python\r\n dq_joins = set()\r\n while q:\r\n curr = q.popleft()\r\n if not isinstance(curr, Expression):\r\n continue\r\n for side, piece in (('lhs', curr.lhs), ('rhs', curr.rhs)):\r\n if isinstance(piece, DQ):\r\n query, joins = self.convert_dict_to_node(piece.query)\r\n dq_joins.update(joins)\r\n```\r\n\r\nI can't understand why you use set() to define dq_joins? if use list(), this error will disappear.",
"Thanks for the analysis. Yeah, it looks like the use of `set` is causing problems with the ordering of the joins. I will take a look!",
"Fixed.",
"Thanks! peewee has the lowest open-issue/star ratio in all the repositories I have seen on GitHub. ^_^"
] | 2019-11-28T08:43:23 | 2019-11-29T02:26:20 | 2019-11-28T15:01:03 |
NONE
| null |
I have three models in a heritical order:
```python
class CrawlProject(Model):
name = CharField()
class CrawlGroup(Model):
name = CharField()
project = ForeignKeyField(CrawlProject)
class CrawlRule(Model):
name = CharField()
group = ForeignKeyField(CrawlGroup)
```
Given the following code:
```python
CrawlRule.filter(group__project__id=47)
```
Then I got the following error:
```
File "/home/tiger/repos/baelish/.venv/lib/python3.6/site-packages/MySQLdb/cursors.py", line 378, in _query
db.query(q)
File "/home/tiger/repos/baelish/.venv/lib/python3.6/site-packages/MySQLdb/connections.py", line 280, in query
_mysql.connection.query(self, query)
eewee.OperationalError: (1054, "Unknown column 't3.project_id' in 'on clause'")
```
The generated SQL is like:
```SQL
SELECT `t1`.`id` FROM `crawl_rule` AS `t1`
INNER JOIN `crawl_project` AS `t2`ON (`t3`.`project_id` = `t2`.`id`)
INNER JOIN `crawl_group` AS `t3` ON (`t1`.`group_id` = `t3`.`id`)
WHERE ((`t3`.`project_id` = 47)) LIMIT 20 OFFSET 0
```
It seems that `t3` was referenced before defined.
actually, simply swapping the inner joins works:
```SQL
SELECT `t1`.`id` FROM `crawl_rule` AS `t1`
INNER JOIN `crawl_group` AS `t3` ON (`t1`.`group_id` = `t3`.`id`)
INNER JOIN `crawl_project` AS `t2`ON (`t3`.`project_id` = `t2`.`id`)
WHERE ((`t3`.`project_id` = 47)) LIMIT 20 OFFSET 0
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2063/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2062
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2062/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2062/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2062/events
|
https://github.com/coleifer/peewee/issues/2062
| 529,756,395 |
MDU6SXNzdWU1Mjk3NTYzOTU=
| 2,062 |
Dealys with multiprocessing
|
{
"login": "codez266",
"id": 7484906,
"node_id": "MDQ6VXNlcjc0ODQ5MDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/7484906?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/codez266",
"html_url": "https://github.com/codez266",
"followers_url": "https://api.github.com/users/codez266/followers",
"following_url": "https://api.github.com/users/codez266/following{/other_user}",
"gists_url": "https://api.github.com/users/codez266/gists{/gist_id}",
"starred_url": "https://api.github.com/users/codez266/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codez266/subscriptions",
"organizations_url": "https://api.github.com/users/codez266/orgs",
"repos_url": "https://api.github.com/users/codez266/repos",
"events_url": "https://api.github.com/users/codez266/events{/privacy}",
"received_events_url": "https://api.github.com/users/codez266/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I'm sorry, this is not something I can help with. No code, extremely vague description, no information about where things are stuck.\r\n\r\nYou might just make sure that before you fork new processes you are creating a new database connection, as an open connection in the parent-process might get inherited by the child process which could be buggy / problematic.",
"filter.py:\r\n\r\n```\r\nfrom mwapilib import get_qual_samples, get_mwapi_session,\\\r\n get_page_revs_with_quals,get_user_info, chunkify, main_header,\\\r\n talk_header, user_header, get_page_edits_from_db\r\nfrom revscoring.utilities.util import dump_observation, read_observations\r\nfrom concurrent.futures import ThreadPoolExecutor\r\n\r\ndef get_all_page_revs(labelings, workers = 5):\r\n all_edits = pd.DataFrame([], columns = main_header)\r\n executor = ThreadPoolExecutor(max_workers=workers)\r\n session = get_mwapi_session()\r\n partial_get_page_revs = partial(get_page_revs_with_quals, session)\r\n #edits_from_db = get_page_edits_from_db(labelings)\r\n for edits in executor.map(partial_get_page_revs, labelings):\r\n for labeling in labelings:\r\n edits = partial_get_page_revs(labeling)\r\n all_edits = all_edits.append(edits, sort = False)\r\n pdb.set_trace()\r\n return all_edits\r\n```\r\n\r\n\r\nmwapilib:\r\n\r\n\r\n```\r\nimport mwapi\r\nimport traceback\r\nimport numpy as np\r\nimport sys\r\nimport pdb\r\nfrom itertools import islice\r\nimport pandas as pd\r\nimport random\r\nimport mwreverts.api\r\nfrom mw.lib import title as mwtitle\r\nimport traceback\r\nfrom multiprocessing import Pool\r\nfrom models import Page, Quality, Revision, User\r\nfrom models import database as db\r\nfrom functools import partial\r\nfrom revscoring.utilities.util import dump_observation, read_observations\r\nimport peewee\r\nimport json\r\nimport re\r\n\r\ndef get_page_edits(session, labeling):\r\n pageid = labeling['pageid']\r\n page_revs_arr = []\r\n # First, try to look for the pageid in the database\r\n page_present = Revision.select().where(Revision.rev_page ==\r\n pageid).count()\r\n page_present = 0\r\n #if False:\r\n if page_present > 0:\r\n page_revs = []\r\n # get results\r\n revs = (Page\r\n .select(Page, Revision)\r\n .join(Revision, on=(Page.page_id==Revision.rev_page).alias('rev'))\r\n .where(Page.page_id == pageid\r\n ))\r\n for page in revs:\r\n rev = page.rev\r\n page_revs.append([rev.rev_id, rev.rev_page, rev.rev_comment,\r\n rev.rev_user, rev.rev_user_text, rev.rev_timestamp,\r\n rev.rev_minor_edit, rev.rev_len,\r\n rev.rev_sha1, rev.rev_quality, page.page_title])\r\n\r\n return pd.DataFrame(page_revs, columns = main_header)\r\n\r\n elif page_present == 0:\r\n page_revs = []\r\n doc = session.get(\r\n action='query', prop='revisions', formatversion=2,\r\n pageids = pageid, rvprop=['ids', 'timestamp', 'user', 'size', 'comment',\r\n 'sha1', 'flags', 'userid'],\r\n continuation=True, rvlimit=500, rvslots='main', rvdir='newer')\r\n title = ''\r\n for result in doc:\r\n pages = result['query']['pages']\r\n for page in pages:\r\n if 'revisions' not in page:\r\n continue\r\n for rev in page['revisions']:\r\n revid = rev['revid']\r\n pageid = page['pageid']\r\n title = mwtitle.normalize(page['title'])\r\n ts = pd.Timestamp(rev.get('timestamp', ''))\r\n\r\n rev = (\r\n revid,\r\n pageid,\r\n rev.get('comment', ''),\r\n rev.get('userid'),\r\n rev.get('user'),\r\n rev.get('timestamp', ''),\r\n 1 if rev.get('minor', False) else 0,\r\n rev.get('size', 0),\r\n rev.get('sha1', '')\r\n )\r\n page_revs.append(rev)\r\n\r\n talk_id = labeling['talk_page_id']\r\n talk_edits = get_page_qualities(session, talk_id)\r\n page_revs_with_quals = []\r\n for rev in page_revs:\r\n ts = rev[5]\r\n t_filter = talk_edits['rev_timestamp'] < ts\r\n rev_new = list(rev)\r\n rev_new[5] = pd.Timestamp(ts).strftime('%Y%m%d%H%M%S')\r\n try:\r\n max_ts = talk_edits.where(t_filter)['rev_timestamp'].idxmax()\r\n quals.append(talk_edits.loc[max_ts, 'quality'])\r\n rev_new = list(rev)\r\n rev_new[5] = pd.Timestamp(ts).strftime('%Y%m%d%H%M%S')\r\n page_revs_with_quals.append(tuple(rev_new) + (class_map[quals[-1]],))\r\n except:\r\n sys.stderr.write('#')\r\n sys.stderr.flush()\r\n page_revs_with_quals.append(tuple(rev_new) + (0,))\r\n quals.append('non-def')\r\n\r\n Revision.insert_many(page_revs_with_quals,fields=['rev_id', 'rev_page',\r\n 'rev_comment', 'rev_user', 'rev_user_text', 'rev_timestamp',\r\n 'rev_minor_edit', 'rev_len', 'rev_sha1' ,'rev_quality']).execute()\r\n Page.insert(page_id = pageid, page_namespace = 0, page_title =\r\n title).execute()\r\n edits = pd.DataFrame([rev+(title,) for rev in page_revs_with_quals], columns = main_header)\r\n return edits\r\n```\r\n\r\nthe filter class creates multiple processes and calls the get_page_revs from mwapilib.py in each of them. The get_page_revs function uses the Page, and Revision db models to query existing data and inserts new data after fetching from api.\r\n\r\nThe processes are getting stuck in deadlock in the get_page_edits function.\r\n\r\nModels:\r\n```\r\nfrom peewee import *\r\n\r\ndatabase = MySQLDatabase(....})\r\n\r\nclass UnknownField(object):\r\n def __init__(self, *_, **__): pass\r\n\r\nclass BaseModel(Model):\r\n class Meta:\r\n database = database\r\n\r\nclass Page(BaseModel):\r\n page_id = IntegerField()\r\n page_namespace = IntegerField()\r\n page_title = CharField()\r\n\r\n class Meta:\r\n table_name = 'page'\r\n primary_key = False\r\n\r\nclass Revision(BaseModel):\r\n rev_comment = CharField()\r\n rev_id = IntegerField()\r\n rev_len = IntegerField(null=True)\r\n rev_minor_edit = IntegerField()\r\n rev_page = IntegerField()\r\n rev_quality = IntegerField()\r\n rev_sha1 = CharField(null=True)\r\n rev_timestamp = CharField()\r\n rev_user = IntegerField()\r\n rev_user_text = CharField(null=True)\r\n\r\n class Meta:\r\n table_name = 'revision'\r\n primary_key = False\r\n```",
"It's called \"**Thread**PoolExecutor\" - meaning threads, not processes.",
"> The processes are getting stuck in deadlock in the get_page_edits function.\r\n\r\nWhere exactly?",
"@codez266 you fell into a trap that many Python noobs are falling into.\r\nThreads in Python are not CPU threads, but rather execution threads internal to the CPython interpreter. All your threads are running on a single CPU. Running alot of threads with IO will\r\ncause a lot of context switching and slow execution. \r\nConsider re-designing your software in such way that you delegate the heavy processing to the database, not the Python client. If you have no other choice, consider using \r\n```\r\nfrom multiprocessing import Pool\r\n```\r\nBut this comes with some caveats. "
] | 2019-11-28T08:13:41 | 2019-11-30T05:02:37 | 2019-11-28T15:04:39 |
NONE
| null |
Hi, I have a code that uses peewee to access a MySQL backend. The code needs to look for the data related to a bunch of wikipedia pages first in the MySQL table, and if not present fetch it from the internet using an API. I'm multiprocessing to fetch data for multiple pages simultaneously. Each process handles one page. My database access just contains read and join operations. However, with peewee, the processes seem to be stuck waiting for each other, even though i'm doing no writes at all. I'm not sure what underlying locking it uses.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2062/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2061
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2061/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2061/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2061/events
|
https://github.com/coleifer/peewee/issues/2061
| 528,416,379 |
MDU6SXNzdWU1Mjg0MTYzNzk=
| 2,061 |
Join attr does get added with left outer join (3.11 ... 3.12)
|
{
"login": "nad2000",
"id": 177266,
"node_id": "MDQ6VXNlcjE3NzI2Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/177266?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nad2000",
"html_url": "https://github.com/nad2000",
"followers_url": "https://api.github.com/users/nad2000/followers",
"following_url": "https://api.github.com/users/nad2000/following{/other_user}",
"gists_url": "https://api.github.com/users/nad2000/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nad2000/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nad2000/subscriptions",
"organizations_url": "https://api.github.com/users/nad2000/orgs",
"repos_url": "https://api.github.com/users/nad2000/repos",
"events_url": "https://api.github.com/users/nad2000/events{/privacy}",
"received_events_url": "https://api.github.com/users/nad2000/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"It seems you included two versions in the issue title -- are you indicating this is a regression?",
"At any rate -- when you are using a left outer join, all rows from the left-hand table (Tweet) are included, along with any matching from the right-hand (User). This means you can have Tweet without a User.\r\n\r\nWhen you manually patch a related object onto a user-defined attribute, currently peewee does not set the join attribute when there is no data/related-object to set.\r\n\r\nYou can work around this for now by just using the regular `user` attr, or you can use `hasattr(tweet, 'author')` / `getattr(tweet, 'author', None)` instead.",
"> It seems you included two versions in the issue title -- are you indicating this is a regression?\r\n\r\nI have seen this behaviour with both versions. \r\n\r\nyes, it's, in a way, a regression. With version 2.x (it used to be defined with an **alias** of the join condition) it was working. The value of the property was None, eg, the test was `twee.author is None`",
"This is probably worth documenting as I was expecting a null result. (Thinking about it, I suspect the null result would be rather difficult to implement -- so docs would be great)"
] | 2019-11-26T00:33:15 | 2020-11-23T05:21:15 | 2019-11-26T02:47:52 |
NONE
| null |
http://docs.peewee-orm.com/en/latest/peewee/relationships.html#selecting-from-multiple-sources shows how to user **attr** with joins. It works with inner join fine. The query fails with the outer join.
```python
>>> class User(Model):
... name = CharField()
... class Meta:
... database = db
>>> class Tweet(Model):
... user = ForeignKeyField(User, null=True)
... message = TextField(null=True)
... class Meta:
... database = db
>>> for r in Tweet.select(Tweet, User).join(User, JOIN.LEFT_OUTER, attr="author"): print(r.author)
2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Tweet' object has no attribute 'author'
'Tweet' object has no attribute 'author'
>>> for r in Tweet.select(Tweet, User).join(User, attr="author"): print(r.author)
2
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2061/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2061/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2060
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2060/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2060/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2060/events
|
https://github.com/coleifer/peewee/issues/2060
| 528,070,489 |
MDU6SXNzdWU1MjgwNzA0ODk=
| 2,060 |
dynamic table name support
|
{
"login": "TaylorChen",
"id": 2860840,
"node_id": "MDQ6VXNlcjI4NjA4NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2860840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TaylorChen",
"html_url": "https://github.com/TaylorChen",
"followers_url": "https://api.github.com/users/TaylorChen/followers",
"following_url": "https://api.github.com/users/TaylorChen/following{/other_user}",
"gists_url": "https://api.github.com/users/TaylorChen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TaylorChen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TaylorChen/subscriptions",
"organizations_url": "https://api.github.com/users/TaylorChen/orgs",
"repos_url": "https://api.github.com/users/TaylorChen/repos",
"events_url": "https://api.github.com/users/TaylorChen/events{/privacy}",
"received_events_url": "https://api.github.com/users/TaylorChen/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"It's right there in the docs.\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/models.html#table-names\r\n\r\n> If you wish to implement your own naming convention\r\n\r\nIt has example code."
] | 2019-11-25T12:59:14 | 2019-11-25T17:04:57 | 2019-11-25T17:04:57 |
NONE
| null |
In my business, some tables are divided according to time, such as table table_20191214, table_20191215, how can I do it in the current orm framework?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2060/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2059
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2059/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2059/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2059/events
|
https://github.com/coleifer/peewee/pull/2059
| 527,726,849 |
MDExOlB1bGxSZXF1ZXN0MzQ0OTI3NDA3
| 2,059 |
Typo in example.rst doc
|
{
"login": "maghniem",
"id": 16522435,
"node_id": "MDQ6VXNlcjE2NTIyNDM1",
"avatar_url": "https://avatars.githubusercontent.com/u/16522435?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maghniem",
"html_url": "https://github.com/maghniem",
"followers_url": "https://api.github.com/users/maghniem/followers",
"following_url": "https://api.github.com/users/maghniem/following{/other_user}",
"gists_url": "https://api.github.com/users/maghniem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maghniem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maghniem/subscriptions",
"organizations_url": "https://api.github.com/users/maghniem/orgs",
"repos_url": "https://api.github.com/users/maghniem/repos",
"events_url": "https://api.github.com/users/maghniem/events{/privacy}",
"received_events_url": "https://api.github.com/users/maghniem/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2019-11-24T17:04:48 | 2019-11-24T23:18:20 | 2019-11-24T23:18:20 |
CONTRIBUTOR
| null |
Adding fields after the table has been created will required you to
either drop the table and re-create it or manually add the columns
using an *ALTER TABLE* query.
To
Adding fields after the table has been created will require you to
either drop the table and re-create it or manually add the columns
using an *ALTER TABLE* query.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2059/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2059",
"html_url": "https://github.com/coleifer/peewee/pull/2059",
"diff_url": "https://github.com/coleifer/peewee/pull/2059.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2059.patch",
"merged_at": "2019-11-24T23:18:20"
}
|
https://api.github.com/repos/coleifer/peewee/issues/2058
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2058/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2058/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2058/events
|
https://github.com/coleifer/peewee/pull/2058
| 527,655,107 |
MDExOlB1bGxSZXF1ZXN0MzQ0ODc2ODg5
| 2,058 |
Support for FastAPI
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Lovely!"
] | 2019-11-24T06:08:10 | 2019-11-29T04:59:04 | 2019-11-24T23:17:52 |
NONE
| null |
Update docs with connection management in FastAPI framework
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2058/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2058",
"html_url": "https://github.com/coleifer/peewee/pull/2058",
"diff_url": "https://github.com/coleifer/peewee/pull/2058.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2058.patch",
"merged_at": "2019-11-24T23:17:52"
}
|
https://api.github.com/repos/coleifer/peewee/issues/2057
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2057/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2057/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2057/events
|
https://github.com/coleifer/peewee/pull/2057
| 527,654,756 |
MDExOlB1bGxSZXF1ZXN0MzQ0ODc2NjQz
| 2,057 |
FastAPI support in Docs
|
{
"login": "aniljaiswal",
"id": 43805107,
"node_id": "MDQ6VXNlcjQzODA1MTA3",
"avatar_url": "https://avatars.githubusercontent.com/u/43805107?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aniljaiswal",
"html_url": "https://github.com/aniljaiswal",
"followers_url": "https://api.github.com/users/aniljaiswal/followers",
"following_url": "https://api.github.com/users/aniljaiswal/following{/other_user}",
"gists_url": "https://api.github.com/users/aniljaiswal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aniljaiswal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aniljaiswal/subscriptions",
"organizations_url": "https://api.github.com/users/aniljaiswal/orgs",
"repos_url": "https://api.github.com/users/aniljaiswal/repos",
"events_url": "https://api.github.com/users/aniljaiswal/events{/privacy}",
"received_events_url": "https://api.github.com/users/aniljaiswal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2019-11-24T06:03:35 | 2019-11-24T06:04:40 | 2019-11-24T06:04:33 |
NONE
| null |
Add docs for connection management in FastAPI
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2057/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2057",
"html_url": "https://github.com/coleifer/peewee/pull/2057",
"diff_url": "https://github.com/coleifer/peewee/pull/2057.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2057.patch",
"merged_at": null
}
|
https://api.github.com/repos/coleifer/peewee/issues/2056
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2056/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2056/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2056/events
|
https://github.com/coleifer/peewee/issues/2056
| 527,641,515 |
MDU6SXNzdWU1Mjc2NDE1MTU=
| 2,056 |
BloomFilter add from_buffer function
|
{
"login": "winterxc",
"id": 633342,
"node_id": "MDQ6VXNlcjYzMzM0Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/633342?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/winterxc",
"html_url": "https://github.com/winterxc",
"followers_url": "https://api.github.com/users/winterxc/followers",
"following_url": "https://api.github.com/users/winterxc/following{/other_user}",
"gists_url": "https://api.github.com/users/winterxc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/winterxc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/winterxc/subscriptions",
"organizations_url": "https://api.github.com/users/winterxc/orgs",
"repos_url": "https://api.github.com/users/winterxc/repos",
"events_url": "https://api.github.com/users/winterxc/events{/privacy}",
"received_events_url": "https://api.github.com/users/winterxc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Done.\r\n\r\n```python\r\nnew_bf = BloomFilter.from_buffer(buf)\r\n```",
"Thank you!"
] | 2019-11-24T02:59:07 | 2019-12-01T02:01:44 | 2019-11-24T23:46:22 |
NONE
| null |
Hi, for rebuild Bloomfilter from cache, can add a from_buffer function to BloomFilter?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2056/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2056/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2055
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2055/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2055/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2055/events
|
https://github.com/coleifer/peewee/issues/2055
| 527,475,367 |
MDU6SXNzdWU1Mjc0NzUzNjc=
| 2,055 |
Peewee and Postgres HA: load balancer or master/master fail-over?
|
{
"login": "Andrei-Pozolotin",
"id": 1622151,
"node_id": "MDQ6VXNlcjE2MjIxNTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1622151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Andrei-Pozolotin",
"html_url": "https://github.com/Andrei-Pozolotin",
"followers_url": "https://api.github.com/users/Andrei-Pozolotin/followers",
"following_url": "https://api.github.com/users/Andrei-Pozolotin/following{/other_user}",
"gists_url": "https://api.github.com/users/Andrei-Pozolotin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Andrei-Pozolotin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Andrei-Pozolotin/subscriptions",
"organizations_url": "https://api.github.com/users/Andrei-Pozolotin/orgs",
"repos_url": "https://api.github.com/users/Andrei-Pozolotin/repos",
"events_url": "https://api.github.com/users/Andrei-Pozolotin/events{/privacy}",
"received_events_url": "https://api.github.com/users/Andrei-Pozolotin/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I'm not familiar with that project, but I think I get the jist of your question and hopefully can provide some pointers.\r\n\r\nPeewee implements a simple connection-per-thread model internally. The connection pool simply plugs into the connect / close steps of the usual peewee workflow to recycle connections. So it provides pooling, but not load-balancing or master/slave or anything of that nature. The pool's `_connect()` method shows how you can insert your own logic for actually creating connections.\r\n\r\nMaybe the simplest thing you could do would be to skip the pool for now and just subclass `PostgresqlDatabase` and override the `_connect()` method (the method responsible for actually creating the psycopg2 connection). You could pass in a list of hosts and then, when the method is called, open a connection on the appropriate host. You could also add your failover logic here, e.g.:\r\n\r\n```python\r\n\r\nclass ExampleDatabase(PostgresqlDatabase):\r\n def __init__(self, database, conn_info_list, **kwargs):\r\n # e.g., [{'host': '10.8.0.1'}, {'host': '10.8.1.1'}, ...]\r\n self.conn_info_list = conn_info_list\r\n self.conns = itertools.cycle(self.conn_info_list)\r\n super(ExampleDatabase, self).__init__(database, **kwargs)\r\n\r\n def _connect(self):\r\n while self.conn_info_list:\r\n conn_kwargs = next(self.conns) # load balancing\r\n try:\r\n kwargs = self.connect_params.copy() # Get a copy of anything specified in __init__()\r\n kwargs.update(conn_kwargs) # Add in args specific for the next conn in list.\r\n conn = psycopg2.connect(database=self.database, **kwargs)\r\n except SomeException:\r\n # failover\r\n self.conn_info_list.remove(conn_kwargs) # Remove the bad conn from list\r\n self.conns = itertools.cycle(self.conn_info_list)\r\n else:\r\n return conn\r\n raise Exception('out of connections to try! everything failed!')\r\n```\r\n\r\nHopefully this gives you some ideas, though I think stuff like this might be better handled in a dedicated connection proxy, e.g. pgbouncer or something that sits between peewee and your database cluster.",
"1. Thank you for the code snippet - that is what I had in mind. Though hoped `peewee` had more hidden treasures right in the play box :-)\r\n\r\n2. `PgPool` and `PgBouncer` both add needless complexity, while their fail-over modes are rather limited/inflexible.\r\n\r\n3. Thanks again!\r\n\r\n"
] | 2019-11-23T00:18:40 | 2019-11-23T01:58:56 | 2019-11-23T01:20:47 |
NONE
| null |
@coleifer Charles:
1. say, there is a master/master replication cluster based on `pglogical`:
https://www.2ndquadrant.com/en/resources/pglogical/pglogical-docs/
2. question: is there an easy way to reuse [PooledPostgresqlExtDatabase](http://docs.peewee-orm.com/en/latest/peewee/playhouse.html#PooledPostgresqlExtDatabase)
so that it can serve as:
* a round robin load balancer for the cluster
* a transparent master/master fail-over manager
* ?
3. any ideas are much appreciated, thank you.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2055/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2054
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2054/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2054/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2054/events
|
https://github.com/coleifer/peewee/issues/2054
| 526,765,954 |
MDU6SXNzdWU1MjY3NjU5NTQ=
| 2,054 |
Proxy for Metadata's `schema` field?
|
{
"login": "rmoretto",
"id": 12282955,
"node_id": "MDQ6VXNlcjEyMjgyOTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/12282955?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rmoretto",
"html_url": "https://github.com/rmoretto",
"followers_url": "https://api.github.com/users/rmoretto/followers",
"following_url": "https://api.github.com/users/rmoretto/following{/other_user}",
"gists_url": "https://api.github.com/users/rmoretto/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rmoretto/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rmoretto/subscriptions",
"organizations_url": "https://api.github.com/users/rmoretto/orgs",
"repos_url": "https://api.github.com/users/rmoretto/repos",
"events_url": "https://api.github.com/users/rmoretto/events{/privacy}",
"received_events_url": "https://api.github.com/users/rmoretto/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Well, I think you could probably get rid of your `get_base_model()` function, as it seems redundant given that you're already using a proxy for your database. That doesn't address the issue, but in your example it's really not doing anything but adding an unnecessary layer of misdirection.\r\n\r\nNow to the crux of the issue: certain model metadata attributes *are* inheritable ([see table in [documentation](http://docs.peewee-orm.com/en/latest/peewee/models.html#model-options-and-table-metadata)). However, model metadata is set at class-creation time and after that, the attributes on one model instance are not connected to the \"parent\" metadata.\r\n\r\nSo what you would need to do is apply the schema across all your models. For a more advanced usage, you can specify a custom model metadata implementation -- and then use the built-in `SubclassAwareMetadata` -- which tracks subclasses. You could then override the `schema` setter to propagate to all subclasses. This is a fairly advanced usage, though, but it is do-able.\r\n\r\n```python\r\n\r\nclass SchemaPropagateMetadata(SubclassAwareMetadata):\r\n @property\r\n def schema(self):\r\n return self._schema\r\n @schema.setter\r\n def schema(self, value):\r\n # self.models is essentially a singleton shared by all models\r\n # that use this metadata class.\r\n for model in self.models:\r\n model._meta._schema = value\r\n\r\nclass BaseModel(Model):\r\n class Meta:\r\n database = db\r\n model_metadata_class = SchemaPropagateMetadata\r\n\r\n# Now settings SomeModel._meta.schema will propagate the changes\r\n# to every model that inherits from BaseModel.\r\n```",
"Thank you very much, it worked like a charm!"
] | 2019-11-21T18:26:21 | 2019-11-22T16:28:31 | 2019-11-22T02:14:45 |
NONE
| null |
Hello,
I'm trying to replicate the `DatabaseProxy` behavior but with the `Model._meta.schema` property. I need to define the name of the schema with the `DatabaseProxy` initialization, but I'm failing miserably.
I basically have a factory for base models that go basically like:
```python
# util.py
import peewee
def base_model_factory(model_database):
class BaseModel(peewee.Model):
class Meta:
database = model_database
return BaseModel
```
The models definitions:
```python
# models.py
import peewee
db_proxy = peewee.DatabaseProxy()
BaseModel = base_model_factory(db_proxy)
def initialize_database(database, schema):
db_proxy.initialize(database)
BaseModel._meta.schema = schema
class MyModel(BaseModel):
id = peewee.AutoField()
```
And the usage:
```python
# app.py
import util
import models
import peewee
def main():
db = peewee.PostgresqlDatabase("my_db")
schema = "my_schema"
models.initialize_database(db, schema)
print(models.MyModel._meta.schema) # None
```
When I import the `utils` module the `MyModel` is defined with no schema, so the line `BaseModel._meta.schema = schema` has basically no effect, as the `MyModel` was already defined.
I could on the `initialize_database` add a line with the `MyModel._meta.schema = schema` but I would need to do that for all my models, and some of those models are divided into multiple modules, which I believe could bring some problems(?).
Is there any way of doing this initialization in a less stupid way? Or should I just bite the bullet and define explicitly the schema for all my models in the `initialize_database` function?
Thank in advance.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2054/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2054/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2053
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2053/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2053/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2053/events
|
https://github.com/coleifer/peewee/issues/2053
| 522,012,914 |
MDU6SXNzdWU1MjIwMTI5MTQ=
| 2,053 |
Iterating through a ManyToManyField with a DeferredThroughModel gives back Expression objects
|
{
"login": "seanballais",
"id": 7175885,
"node_id": "MDQ6VXNlcjcxNzU4ODU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7175885?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/seanballais",
"html_url": "https://github.com/seanballais",
"followers_url": "https://api.github.com/users/seanballais/followers",
"following_url": "https://api.github.com/users/seanballais/following{/other_user}",
"gists_url": "https://api.github.com/users/seanballais/gists{/gist_id}",
"starred_url": "https://api.github.com/users/seanballais/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/seanballais/subscriptions",
"organizations_url": "https://api.github.com/users/seanballais/orgs",
"repos_url": "https://api.github.com/users/seanballais/repos",
"events_url": "https://api.github.com/users/seanballais/events{/privacy}",
"received_events_url": "https://api.github.com/users/seanballais/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Eureka! I solved the problem.\r\n\r\nI did not perform `.set_model()` to the `DeferredThroughModel` instance I was using for `Class`. It was only being used inside a function that only gets called during creation of the database file causing the field to be unbounded and causing my problem when the database file was not being created. Using `.set_model()` outside the function and during the initialization of the module all of my models reside in fixed the issue.\r\n\r\n**TL;DR to those folks who might come across the same problem:** Make sure `.set_model()` for all `DeferredThroughModel` instances gets called before using the model the `DeferredThroughModel` is used in."
] | 2019-11-13T07:31:36 | 2019-11-13T14:02:38 | 2019-11-13T14:02:38 |
NONE
| null |
I have a two models, `Class` and `TimeSlot`. `Class` has a many-to-many field, `timeslots`, to `TimeSlot`. The field uses a `DeferredThroughModel`.
Now, say I have an instance of `Class` in a variable called `class`. I want to iterate through the `timeslots` of `class`, so let's do:
for timeslot in class.timeslots:
print(type(timeslot))
However, the type of `timeslot` is `Expression` and not `TimeSlot`. `class.timeslots` also gives back a `ManyToManyField: (unbound)` instead of `ManyToManyQuery`. This problem only affects `Class`. Other classes that use a `ManyToManyField` without a `DeferredThroughModel` just do fine.
How do you fix this problem?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2053/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2053/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2052
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2052/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2052/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2052/events
|
https://github.com/coleifer/peewee/issues/2052
| 517,733,263 |
MDU6SXNzdWU1MTc3MzMyNjM=
| 2,052 |
How to get last day of month
|
{
"login": "Maheshkumar094",
"id": 39484115,
"node_id": "MDQ6VXNlcjM5NDg0MTE1",
"avatar_url": "https://avatars.githubusercontent.com/u/39484115?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Maheshkumar094",
"html_url": "https://github.com/Maheshkumar094",
"followers_url": "https://api.github.com/users/Maheshkumar094/followers",
"following_url": "https://api.github.com/users/Maheshkumar094/following{/other_user}",
"gists_url": "https://api.github.com/users/Maheshkumar094/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Maheshkumar094/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Maheshkumar094/subscriptions",
"organizations_url": "https://api.github.com/users/Maheshkumar094/orgs",
"repos_url": "https://api.github.com/users/Maheshkumar094/repos",
"events_url": "https://api.github.com/users/Maheshkumar094/events{/privacy}",
"received_events_url": "https://api.github.com/users/Maheshkumar094/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Couple ways, this way worked for me just now:\r\n\r\n```python\r\n\r\nfrom peewee import *\r\nfrom peewee import NodeList # Grab this explicitly.\r\n\r\nclass Foo(BaseModel):\r\n timestamp = DateTimeField()\r\n\r\nts_month = fn.date_trunc('month', Foo.timestamp)\r\neom = NodeList((SQL('INTERVAL'), '1 MONTH - 1 DAY'))\r\n\r\n# For each timestamp we have stored, grab the last day of the month\r\n# for the given timestamp.\r\nquery = Foo.select(ts_month + eom)\r\nfor row in query.tuples():\r\n print(row)\r\n\r\n# Alternatively, if you just want the end of the current month:\r\nts_month = fn.date_trunc('month', fn.now())\r\neom = NodeList((SQL('INTERVAL'), '1 MONTH - 1 DAY'))\r\nexpr = ts_month + eom\r\n```\r\n\r\nThere's probably a better way to do it, but the above should work.",
"@coleifer \r\nThanks a lot, work for me."
] | 2019-11-05T12:06:48 | 2019-11-06T06:33:00 | 2019-11-05T15:02:37 |
NONE
| null |
I am trying to get last day of the month for that I can find out the sql query
`SELECT (date_trunc('MONTH', now()::date) + INTERVAL '1 MONTH - 1 day')::DATE;`
but I am unable formate into peewee query can you please help me doing this.
Your comment and suggestion really appreciate.
Thank You
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2052/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2052/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2051
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2051/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2051/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2051/events
|
https://github.com/coleifer/peewee/pull/2051
| 515,176,648 |
MDExOlB1bGxSZXF1ZXN0MzM0Njc5NDY1
| 2,051 |
Update querying.rst
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2019-10-31T05:31:57 | 2019-10-31T14:53:31 | 2019-10-31T14:53:31 |
NONE
| null |
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2051/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2051/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2051",
"html_url": "https://github.com/coleifer/peewee/pull/2051",
"diff_url": "https://github.com/coleifer/peewee/pull/2051.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2051.patch",
"merged_at": "2019-10-31T14:53:31"
}
|
|
https://api.github.com/repos/coleifer/peewee/issues/2050
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2050/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2050/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2050/events
|
https://github.com/coleifer/peewee/issues/2050
| 514,745,880 |
MDU6SXNzdWU1MTQ3NDU4ODA=
| 2,050 |
how to create multiple tables with one class ?
|
{
"login": "wongzhichao",
"id": 19945110,
"node_id": "MDQ6VXNlcjE5OTQ1MTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/19945110?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wongzhichao",
"html_url": "https://github.com/wongzhichao",
"followers_url": "https://api.github.com/users/wongzhichao/followers",
"following_url": "https://api.github.com/users/wongzhichao/following{/other_user}",
"gists_url": "https://api.github.com/users/wongzhichao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wongzhichao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wongzhichao/subscriptions",
"organizations_url": "https://api.github.com/users/wongzhichao/orgs",
"repos_url": "https://api.github.com/users/wongzhichao/repos",
"events_url": "https://api.github.com/users/wongzhichao/events{/privacy}",
"received_events_url": "https://api.github.com/users/wongzhichao/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Really depends on what you're trying to do, but there are APIs for setting the table name, or you can use inheritance or dynamic class-creation to create additional classes."
] | 2019-10-30T15:05:38 | 2019-10-30T15:17:25 | 2019-10-30T15:17:25 |
NONE
| null |
I need to create multiple tables with one class, but i cannot find a way to implement it!
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2050/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2050/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2049
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2049/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2049/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2049/events
|
https://github.com/coleifer/peewee/issues/2049
| 514,303,792 |
MDU6SXNzdWU1MTQzMDM3OTI=
| 2,049 |
BlobField not converted to bytes on Python 3.3+ and Postgresql
|
{
"login": "PatTheMav",
"id": 9436503,
"node_id": "MDQ6VXNlcjk0MzY1MDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9436503?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PatTheMav",
"html_url": "https://github.com/PatTheMav",
"followers_url": "https://api.github.com/users/PatTheMav/followers",
"following_url": "https://api.github.com/users/PatTheMav/following{/other_user}",
"gists_url": "https://api.github.com/users/PatTheMav/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PatTheMav/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PatTheMav/subscriptions",
"organizations_url": "https://api.github.com/users/PatTheMav/orgs",
"repos_url": "https://api.github.com/users/PatTheMav/repos",
"events_url": "https://api.github.com/users/PatTheMav/events{/privacy}",
"received_events_url": "https://api.github.com/users/PatTheMav/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"A `memoryview` is just a pointer to a buffer of bytes. It can be indexed, sliced, etc without incurring an allocation and copy. This is a very important optimization to retain when the database-driver supports it (eg psycopg2). Your example field is exactly how I would work-around this if your code depends on having a `bytes` object instead.\r\n\r\nFor what it's worth, most APIs support using `memoryview` just as they would `bytes` or `bytearray`...you can write them to a file, etc., so if you are running into some kind of compatibility issue you might consider addressing it upstream.",
"> For what it's worth, most APIs support using memoryview just as they would bytes or bytearray...you can write them to a file, etc., so if you are running into some kind of compatibility issue you might consider addressing it upstream.\r\n \r\nYeah fair enough - hopefully the next person switching from Py2 to Py3 will find this issue and understands how to solve it without having to change lots of application logic.. 😁",
"Many python 2.x drivers return `buffer` type. Python 2.7 also has memoryview and bytearray, so it really just depends on the driver you're using."
] | 2019-10-29T23:55:04 | 2019-10-30T16:18:58 | 2019-10-30T13:25:21 |
NONE
| null |
Due to psycopg2 converting Postgres' `bytea` data to `memoryview` objects starting with Python 3.3, models with `BlobField`s require special care:
Data needs to be converted to bytes via `tobytes()` to achieve expected behavior.
Right now Peewee's core implementation doesn't seem to take this into account (the tests seem to check for this and apply `tobytes` themselves), which would require a project to either implement a Postgres-only conversion step _or_ create a custom field that handles the conversion, à la:
```
class Py3Blob(BlobField):
def python_value(self, value):
if isinstance(value, memoryview):
return value.tobytes()
else:
return super().python_value(value)
```
IIRC the motivation behind using `memoryview` was to use a more memory-efficient data type for actually big blobs (e.g. image data) that wouldn't require copying that data around, which is a valid concern and might make automatically converting this data to bytes a no-go.
Is there a chance for Peewee nevertheless converting to bytes itself to align Py3 behavior for `BlobField`s with Py2, especially as the Model wouldn't return different types based on backend _and_ Python version or maybe a "watch out for this, fix with custom field" warning in the docs?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2049/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2049/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2048
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2048/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2048/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2048/events
|
https://github.com/coleifer/peewee/issues/2048
| 510,609,438 |
MDU6SXNzdWU1MTA2MDk0Mzg=
| 2,048 |
Difficulty in accessing joined-on attribute
|
{
"login": "esztermarton",
"id": 35615910,
"node_id": "MDQ6VXNlcjM1NjE1OTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/35615910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/esztermarton",
"html_url": "https://github.com/esztermarton",
"followers_url": "https://api.github.com/users/esztermarton/followers",
"following_url": "https://api.github.com/users/esztermarton/following{/other_user}",
"gists_url": "https://api.github.com/users/esztermarton/gists{/gist_id}",
"starred_url": "https://api.github.com/users/esztermarton/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/esztermarton/subscriptions",
"organizations_url": "https://api.github.com/users/esztermarton/orgs",
"repos_url": "https://api.github.com/users/esztermarton/repos",
"events_url": "https://api.github.com/users/esztermarton/events{/privacy}",
"received_events_url": "https://api.github.com/users/esztermarton/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"You need to explicitly select the columns from Tweet which you want to retain.\r\n\r\nUsing `self.users` is a bit yuck. In fact using that many-to-many is extremely yuck because it serves no purpose and adds needless tables/joins. All you really need is a table containing two foreign keys to User to serve as your method of relating one user to another:\r\n\r\n```python\r\nclass Relationship(BaseModel):\r\n from_user = ForeignKeyField(User, backref='relationships')\r\n to_user = ForeignKeyField(User, backref='related_to')\r\n```\r\n\r\nThis is from the twitter example code, by the way: https://github.com/coleifer/peewee/blob/master/examples/twitter/app.py",
"Thanks for reading through my essay of an issue :)\r\n\r\n> You need to explicitly select the columns from Tweet which you want to retain.\r\n\r\nVery helpful thanks - I assume you mean this for the one that uses the .is_null()\r\n\r\n> Using self.users is a bit yuck. In fact using that many-to-many is extremely yuck because it serves no purpose and adds needless tables/joins. All you really need is a table containing two foreign keys to User to serve as your method of relating one user to another:\r\n\r\nYes, I don't really like it that much either. Does it not add to efficiency though, because it is then joining things on to a handful of users instead of hundreds of thousands? Would be happy to join on User instead if self.users adds nothing but complexity.\r\n\r\nI do really like your Relationship table solution to avoid the many-to-many. Unless I'm misunderstanding though, the many to many is kind of needed in my usecase, it is a pretty important object that allows me to do lots of things to those UserCollections and to each User within it (here I just implemented the same thing with the Twitter example and needed to include it in case the ManyToMany was the cause of my problems...)\r\n",
"The Relationship table is basically the \"through table\" of a many-to-many right?",
"I don't get the sense that you're very familiar with SQL, though I may be mistaken. However, at the end of the day you should keep in mind that everything gets translated into a sql query which returns rows of columns.\r\n\r\nDocumentation on selecting from multiple sources:\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/relationships.html#selecting-from-multiple-sources\r\n\r\n> Unless I'm misunderstanding though, the many to many is kind of needed in my usecase, it is a pretty important object that allows me to do lots of things to those UserCollections and to each User within it\r\n\r\nIf a given collection has a semantic meaning, then yeah, using the schema you've described does make sense. In your example, though, the table was empty except for the many-to-many relationship, which makes the whole construction inefficient and overly complex.\r\n\r\nI'd suggest stackoverflow, but honestly, I really don't know how much I can help because you really need a firm grasp on SQL to be able to use it efficiently.",
"Hey @coleifer - just so you know, changing my code to the equivalent of the following (what I understood by \"explicitly select columns from Tweets\") didn't work:\r\n```\r\ndef get_users_with_latest_tweets(self):\r\n Latest = Tweet.alias()\r\n latest_tweet_id = (\r\n Latest.select(\r\n Latest.user.alias(\"user\"), fn.MAX(Latest.id).alias(\"id\")\r\n )\r\n .group_by(Latest.user)\r\n )\r\n tweet_ids = [l.id for l in latest_tweet_id]\r\n\r\n return (\r\n self.users.join(\r\n Tweet,\r\n on=(User.id == Tweet.user),\r\n join_type=JOIN.LEFT_OUTER,\r\n ).select(User.id, User.name, Tweet.id)\r\n .where(\r\n Tweet.id.is_null()\r\n | (Tweet.id.in_(tweet_ids))\r\n )\r\n )\r\n\r\nusers_with_latest_tweets = user_collection.get_users_with_latest_tweets()\r\n```\r\n\r\nI also kind of think that if one is able to query like `.where(Tweet.id.in_(tweet_ids))`, I'd also expect to be able to query like `.where(Tweet.id.is_null())` on a joined on column without having to specify columns specifically. I'm still not quite sure if this, and/or the other issue I had, are due to what you would classify as bugs or missing features, but if so and theres plans to change it, I'd maybe be happy to help out and have a look at it?\r\n\r\nOtherwise I've worked around it in my code now. Thanks for all your help."
] | 2019-10-22T12:02:59 | 2019-10-24T09:56:30 | 2019-10-22T15:43:32 |
NONE
| null |
Using version 3.9.2.
Attempting to create a query for the following usecase (quite similar to [an example with tweets in the documentation](http://docs.peewee-orm.com/en/latest/peewee/relationships.html#common-table-expressions)):
- Fetch a subset of users with their latest tweet (if it exists)
- Be able to access both user and tweet objects after the query for further `where` clauses in different functions (for example to query for the language of the tweet or the nationality of the user)
The User, Tweet and UserCollection objects look something like this:
```
class User(Model):
name = CharField()
class Tweet(Model):
user = ForeignKeyField(
column_name="user_id",
field="id",
model=User,
backref="tweets",
)
class UserCollection(Model):
users = ManyToManyField(User, backref="collections")
```
I tried two different approaches, and in both I have hit walls.
**First approach:**
- Groupby query to fetch latest tweet ids per user
- join this on to users
- join tweets on to this
Problems:
- I can't seem to access the tweet objects from the user.
Code:
```
def get_users_with_latest_tweets(self):
Latest = Tweet.alias()
latest_tweet_id = (
Latest.select(
Latest.user.alias("user"), fn.MAX(Latest.id).alias("id")
)
.group_by(Latest.user)
.alias("latest_tweet_id")
)
return (
self.users
.join(
latest_tweet_id,
on=(latest_tweet_id.c.user == User.id),
join_type=JOIN.LEFT_OUTER,
)
.switch(User)
.join(
Tweet,
on=(Tweet.id == latest_tweet_id.c.id),
join_type=JOIN.LEFT_OUTER,
# attr="t",
)
)
users_with_latest_tweets = user_collection.get_users_with_latest_tweets()
```
- When I iterate through users_with_latest_tweets they are user objects, as expected.
- However, if on the user object I access the tweets attribute, it seems to contain not just the ones that I joined on in the first join, but also all other tweets belonging to the user too. This is despite the fact that the query itself does work as expected, as shown by the fact that if I iterate through users_with_latest_tweets.tuples()
- When I explicitly set attr, it seemed to ignore it: when i iterate through the objects, they did not have the attribute that I would have wanted the tweets to be found in. On the other hand, from looking at source code I might have expected it to raise an error, but it also didn't do that. I wonder if it is because it was joining it on to not the User objects, but rather the Tweet alias object? I'm not sure.
**Second approach:**
- Groupby query to fetch latest tweet ids per user
- join tweets on to users and add a where clause to limit it to certain tweet ids plus those with no tweet id joined
Problems:
- On the where clause, it doesn't include those where tweet id is null
Code:
```
def get_users_with_latest_tweets(self):
Latest = Tweet.alias()
latest_tweet_id = (
Latest.select(
Latest.user.alias("user"), fn.MAX(Latest.id).alias("id")
)
.group_by(Latest.user)
)
tweet_ids = [l.id for l in latest_tweet_id]
return (
self.users.join(
Tweet,
on=(User.id == Tweet.user),
join_type=JOIN.LEFT_OUTER,
).where(
Tweet.id.is_null()
| (Tweet.id.in_(tweet_ids))
)
)
users_with_latest_tweets = user_collection.get_users_with_latest_tweets()
```
I would expect users_with_latest_tweets to have the same length as self.users (since it is a left outer join). However, when there are users with no tweets, those users are not returned.
I tried the second approach to simplify the first syntactically, I'm not sure if there is significant difference in efficiency between the two.
Could you please help with either one or both of these?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2048/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2048/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2047
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2047/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2047/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2047/events
|
https://github.com/coleifer/peewee/issues/2047
| 509,702,302 |
MDU6SXNzdWU1MDk3MDIzMDI=
| 2,047 |
ModuleNotFoundError: No module named 'peewee'
|
{
"login": "52lemon",
"id": 13587459,
"node_id": "MDQ6VXNlcjEzNTg3NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/13587459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/52lemon",
"html_url": "https://github.com/52lemon",
"followers_url": "https://api.github.com/users/52lemon/followers",
"following_url": "https://api.github.com/users/52lemon/following{/other_user}",
"gists_url": "https://api.github.com/users/52lemon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/52lemon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/52lemon/subscriptions",
"organizations_url": "https://api.github.com/users/52lemon/orgs",
"repos_url": "https://api.github.com/users/52lemon/repos",
"events_url": "https://api.github.com/users/52lemon/events{/privacy}",
"received_events_url": "https://api.github.com/users/52lemon/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"You must have some problem in your imports. This is definitely not the appropriate place for questions like this. Try stackoverflow."
] | 2019-10-21T02:51:28 | 2019-10-21T02:54:22 | 2019-10-21T02:54:22 |
NONE
| null |
i install peewee with pip3, and i got the error below
`
(logpress-tornado) F:\Projects\logpress-tornado>python3 manager.py --cmd=syncdb
Traceback (most recent call last):
File "manager.py", line 17, in <module>
from core import jinja_environment, smtp_server
File "F:\Projects\logpress-tornado\core.py", line 7, in <module>
from lib.database import Database
File "F:\Projects\logpress-tornado\lib\database.py", line 8, in <module>
import peewee
ModuleNotFoundError: No module named 'peewee'
`
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2047/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2047/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2046
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2046/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2046/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2046/events
|
https://github.com/coleifer/peewee/issues/2046
| 509,644,235 |
MDU6SXNzdWU1MDk2NDQyMzU=
| 2,046 |
Query.returning() wrong alias implementation
|
{
"login": "dmkulazhenko",
"id": 13505031,
"node_id": "MDQ6VXNlcjEzNTA1MDMx",
"avatar_url": "https://avatars.githubusercontent.com/u/13505031?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dmkulazhenko",
"html_url": "https://github.com/dmkulazhenko",
"followers_url": "https://api.github.com/users/dmkulazhenko/followers",
"following_url": "https://api.github.com/users/dmkulazhenko/following{/other_user}",
"gists_url": "https://api.github.com/users/dmkulazhenko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dmkulazhenko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dmkulazhenko/subscriptions",
"organizations_url": "https://api.github.com/users/dmkulazhenko/orgs",
"repos_url": "https://api.github.com/users/dmkulazhenko/repos",
"events_url": "https://api.github.com/users/dmkulazhenko/events{/privacy}",
"received_events_url": "https://api.github.com/users/dmkulazhenko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"peewee==3.11.2\r\npsycopg2-binary==2.8.4\r\n(PostgreSQL)\r\n\r\n\r\n",
"@coleifer, any reply?)",
"Fixed in c2dc7ca7caaafc0840b771de6e5dfc5cbabe83a0",
"@coleifer, thx, have a nice day!"
] | 2019-10-20T20:00:09 | 2019-10-20T21:52:13 | 2019-10-20T21:46:00 |
NONE
| null |
Hi there!
I tried to use peewee as SQLGenerator (yeah, I know that it's very strange and ... know, I just have a reason of doing this shit :trollface:)
That's OK:
```
c = User.insert(username='Petr').returning(User.username)
c.sql()
[stdout]: ('INSERT INTO "user" ("username", "password", "last_activity") VALUES (%s, %s, %s) RETURNING "user"."username"', ['Petr', 'password', 1571594114])
```
But if I will try to use alias in returning section:
```
c = User.insert(username='Petr').returning(User.username.alias('u'))
c.sql()
[stdout]: ('INSERT INTO "user" ("username", "password", "last_activity") VALUES (%s, %s, %s) RETURNING "u"', ['Petr', 'password', 1571594114])
```
That isn't OK, because I want something like:
```
('INSERT INTO "user" ("username", "password", "last_activity") VALUES (%s, %s, %s) RETURNING "user"."username" AS "u"', ['Petr', 'password', 1571594114])
```
idk, if that problem reproduces with other queries (not insert)...
Maybe, I just cannot find method, that do this staff, btw I can't find anything about this [here](http://docs.peewee-orm.com/en/latest/peewee/querying.html#returning-clause).
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2046/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2046/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2045
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2045/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2045/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2045/events
|
https://github.com/coleifer/peewee/issues/2045
| 509,517,955 |
MDU6SXNzdWU1MDk1MTc5NTU=
| 2,045 |
BinaryJSONField unescaped JSON text
|
{
"login": "DucChau",
"id": 1124271,
"node_id": "MDQ6VXNlcjExMjQyNzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1124271?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DucChau",
"html_url": "https://github.com/DucChau",
"followers_url": "https://api.github.com/users/DucChau/followers",
"following_url": "https://api.github.com/users/DucChau/following{/other_user}",
"gists_url": "https://api.github.com/users/DucChau/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DucChau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DucChau/subscriptions",
"organizations_url": "https://api.github.com/users/DucChau/orgs",
"repos_url": "https://api.github.com/users/DucChau/repos",
"events_url": "https://api.github.com/users/DucChau/events{/privacy}",
"received_events_url": "https://api.github.com/users/DucChau/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I'm not clear on why you used a text-field in the first place or whether that is in any way related to the problem. Or, for that matter, what the underlying actual column type is on your table? The peewee `playhouse.postgres_ext.BinaryJSONField` will store and retrieve data as JSON. So you can store `dict`, `list`, and string/scalar values.\r\n\r\nThe docs should give you clear examples on usage:\r\n\r\n* http://docs.peewee-orm.com/en/latest/peewee/playhouse.html#JSONField\r\n* http://docs.peewee-orm.com/en/latest/peewee/playhouse.html#BinaryJSONField"
] | 2019-10-19T22:34:11 | 2019-10-19T23:01:35 | 2019-10-19T23:01:35 |
NONE
| null |
Hello,
I'm using `PostgresqlExtDatabase` for the `JSONBField` types.
I currently have a JSONB text field in a Postgres table. When I set the field type to `TextField` in the PeeWee model, saving data in the table looks like valid JSON. Example of JSON value I'm saving to the table below.
``` {"query": "select \n count(*) as count \nfrom\n foo\n", "value": [21950367]}```
However when I switch the field type out to `BinaryJSONField` all values in the field becomes escaped. This makes it a pain to use the JSON parsing functions in Postgres.
```"{\"query\": \"select \\n count(*) as count \\nfrom\\n foo\\n\", \"value\": [21950367]}"```
Is there a way to not escape values going into the `BinaryJSONField` field when saving via a model in peewee?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2045/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2045/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2044
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2044/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2044/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2044/events
|
https://github.com/coleifer/peewee/issues/2044
| 508,824,500 |
MDU6SXNzdWU1MDg4MjQ1MDA=
| 2,044 |
Confusing @db.atomic() behavior - transactions don't wrap entire method?
|
{
"login": "brandond",
"id": 370103,
"node_id": "MDQ6VXNlcjM3MDEwMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/370103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brandond",
"html_url": "https://github.com/brandond",
"followers_url": "https://api.github.com/users/brandond/followers",
"following_url": "https://api.github.com/users/brandond/following{/other_user}",
"gists_url": "https://api.github.com/users/brandond/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brandond/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brandond/subscriptions",
"organizations_url": "https://api.github.com/users/brandond/orgs",
"repos_url": "https://api.github.com/users/brandond/repos",
"events_url": "https://api.github.com/users/brandond/events{/privacy}",
"received_events_url": "https://api.github.com/users/brandond/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"FWIW, if I switch APSWDatabase out for SqliteDatabase I do see it starting an exclusive transaction when populate_forum is entered, but it does not appear to be committed when the function returns? But it is getting committed somehow.\r\n\r\n```\r\nINFO:__main__:About to call populate\r\nDEBUG:peewee:('BEGIN EXCLUSIVE', None)\r\nINFO:__main__:Creating post 1\r\nDEBUG:peewee:('SAVEPOINT \"s86e3fbb27555458bb1c03c846eabf2e6\";', None)\r\nDEBUG:peewee:('SELECT \"t1\".\"id\", \"t1\".\"name\" FROM \"forum\" AS \"t1\" WHERE (\"t1\".\"name\" = ?) LIMIT ? OFFSET ?', [u'Foo Forum', 1, 0])\r\nDEBUG:peewee:('SAVEPOINT \"s78555c6a162b49209a8963c41b3d2809\";', None)\r\nDEBUG:peewee:('INSERT INTO \"forum\" (\"name\") VALUES (?)', [u'Foo Forum'])\r\nDEBUG:peewee:('RELEASE SAVEPOINT \"s78555c6a162b49209a8963c41b3d2809\";', None)\r\nDEBUG:peewee:('SELECT \"t1\".\"id\", \"t1\".\"name\", \"t1\".\"forum_id\" FROM \"thread\" AS \"t1\" WHERE ((\"t1\".\"name\" = ?) AND (\"t1\".\"forum_id\" = ?)) LIMIT ? OFFSET ?', [u'Foo Thread One', 1, 1, 0])\r\nDEBUG:peewee:('SAVEPOINT \"sf31da5dd91c9409da6de4481f2f98954\";', None)\r\nDEBUG:peewee:('INSERT INTO \"thread\" (\"name\", \"forum_id\") VALUES (?, ?)', [u'Foo Thread One', 1])\r\nDEBUG:peewee:('RELEASE SAVEPOINT \"sf31da5dd91c9409da6de4481f2f98954\";', None)\r\nDEBUG:peewee:('INSERT INTO \"post\" (\"title\", \"body\", \"thread_id\") VALUES (?, ?, ?)', [u'Test Post 1', u'Question?', 1])\r\nDEBUG:peewee:('RELEASE SAVEPOINT \"s86e3fbb27555458bb1c03c846eabf2e6\";', None)\r\nINFO:__main__:Creating post 2\r\nDEBUG:peewee:('SAVEPOINT \"sb2f8f9f353cd4e0994a2515d4742e5cc\";', None)\r\nDEBUG:peewee:('SELECT \"t1\".\"id\", \"t1\".\"name\" FROM \"forum\" AS \"t1\" WHERE (\"t1\".\"name\" = ?) LIMIT ? OFFSET ?', [u'Bar Forum', 1, 0])\r\nDEBUG:peewee:('SAVEPOINT \"s0c3e9fc230d349daa357b53735d23382\";', None)\r\nDEBUG:peewee:('INSERT INTO \"forum\" (\"name\") VALUES (?)', [u'Bar Forum'])\r\nDEBUG:peewee:('RELEASE SAVEPOINT \"s0c3e9fc230d349daa357b53735d23382\";', None)\r\nDEBUG:peewee:('SELECT \"t1\".\"id\", \"t1\".\"name\", \"t1\".\"forum_id\" FROM \"thread\" AS \"t1\" WHERE ((\"t1\".\"name\" = ?) AND (\"t1\".\"forum_id\" = ?)) LIMIT ? OFFSET ?', [u'Bar Thread One', 2, 1, 0])\r\nDEBUG:peewee:('SAVEPOINT \"sa0af313a8f544b4cb9eb4908c97334ab\";', None)\r\nDEBUG:peewee:('INSERT INTO \"thread\" (\"name\", \"forum_id\") VALUES (?, ?)', [u'Bar Thread One', 2])\r\nDEBUG:peewee:('RELEASE SAVEPOINT \"sa0af313a8f544b4cb9eb4908c97334ab\";', None)\r\nDEBUG:peewee:('INSERT INTO \"post\" (\"title\", \"body\", \"thread_id\") VALUES (?, ?, ?)', [u'Off-Topic', u'Rant, Rave...', 2])\r\nDEBUG:peewee:('RELEASE SAVEPOINT \"sb2f8f9f353cd4e0994a2515d4742e5cc\";', None)\r\nINFO:__main__:Creating post 3\r\nDEBUG:peewee:('SAVEPOINT \"s03d90b12912e49028a73c6cf390b1659\";', None)\r\nDEBUG:peewee:('SELECT \"t1\".\"id\", \"t1\".\"name\" FROM \"forum\" AS \"t1\" WHERE (\"t1\".\"name\" = ?) LIMIT ? OFFSET ?', [u'Foo Forum', 1, 0])\r\nDEBUG:peewee:('SELECT \"t1\".\"id\", \"t1\".\"name\", \"t1\".\"forum_id\" FROM \"thread\" AS \"t1\" WHERE ((\"t1\".\"name\" = ?) AND (\"t1\".\"forum_id\" = ?)) LIMIT ? OFFSET ?', [u'Foo Thread One', 1, 1, 0])\r\nDEBUG:peewee:('INSERT INTO \"post\" (\"title\", \"body\", \"thread_id\") VALUES (?, ?, ?)', [u'Re: Test Post 1', u'Answer.', 1])\r\nDEBUG:peewee:('RELEASE SAVEPOINT \"s03d90b12912e49028a73c6cf390b1659\";', None)\r\nINFO:__main__:Done creating all posts\r\nINFO:__main__:Populate returned\r\n```",
"I think that one source of my confusion is that APSWDatabase executes the transaction BEGIN and COMMIT statements directly, bypassing the normal logging that execute_sql does. So it's doing what it should, but I can't tell that from looking at the logs.\r\n\r\nhttps://github.com/coleifer/peewee/blob/master/playhouse/apsw_ext.py#L106",
"> I think that one source of my confusion is that APSWDatabase executes the transaction BEGIN and COMMIT statements directly, bypassing the normal logging that execute_sql does. So it's doing what it should, but I can't tell that from looking at the logs.\r\n\r\nYes that is the reason you weren't seeing `begin` or `commit` being logged with apsw."
] | 2019-10-18T02:55:34 | 2019-10-18T12:27:39 | 2019-10-18T12:27:38 |
NONE
| null |
I have some code that does a bunch of batch importing from another system. This takes a while and creates/deletes/modifies a bunch of rows across multiple tables. I'd like to do this all in a single transaction so that I can serve read requests while the batch process is running without getting odd partially-processed data.
I have tried wrapping the batch functions in `@atomic()` decorators, or using `with atomic() as transaction`, but neither seem to do what I want. Even when I use immediate or exclusive locks, it still only wraps individual model operations in transactions.
Here's a sample:
```python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import logging
from peewee import Model
from playhouse.apsw_ext import APSWDatabase, CharField, ForeignKeyField, AutoField
logging.basicConfig(level='DEBUG')
logger = logging.getLogger(__name__)
db = APSWDatabase('test.db',
pragmas=(('foreign_keys', 'on'),
('auto_vacuum', 'NONE'),
('journal_mode', 'WAL'),
('locking_mode', 'NORMAL'),
('synchronous', 'NORMAL')))
class BaseModel(Model):
class Meta:
database = db
without_rowid = True
only_save_dirty = True
class Forum(BaseModel):
id = AutoField()
name = CharField()
class Thread(BaseModel):
id = AutoField()
name = CharField()
description = CharField
forum = ForeignKeyField(model=Forum, backref='threads', on_update='CASCADE', on_delete='CASCADE')
class Post(BaseModel):
id = AutoField()
title = CharField()
body = CharField()
thread = ForeignKeyField(model=Thread, backref='posts', on_update='CASCADE', on_delete='CASCADE')
with db.connection_context():
db.create_tables([Forum, Thread, Post], fail_silently=True)
@db.atomic('EXCLUSIVE')
def populate_forum():
logger.info('Creating post 1')
save_post('Foo Forum', 'Foo Thread One', 'Test Post 1', 'Question?')
logger.info('Creating post 2')
save_post('Bar Forum', 'Bar Thread One', 'Off-Topic', 'Rant, Rave...')
logger.info('Creating post 3')
save_post('Foo Forum', 'Foo Thread One', 'Re: Test Post 1', 'Answer.')
logger.info('Done creating all posts')
@db.atomic('IMMEDIATE')
def save_post(forum_name, thread_name, title, body):
forum, _ = Forum.get_or_create(name=forum_name)
thread, _ = Thread.get_or_create(forum=forum, name=thread_name)
return Post.create(thread=thread, title=title, body=body)
if __name__ == '__main__':
logger.info('About to call populate')
populate_forum()
logger.info('Populate returned')
```
I'm working off the docs here: http://docs.peewee-orm.com/en/latest/peewee/database.html#set-locking-mode-for-transaction
Given the decorators on both `populate_forum` and `save_post`, I would expect to see transactions and/or savepoints created and committed at the start and end of each call, but that's not happening.
Here's what I get:
```
INFO:__main__:About to call populate
INFO:__main__:Creating post 1
DEBUG:peewee:('SAVEPOINT "s937707aee4f546b8b2dcf9fe367dd066";', None)
DEBUG:peewee:('SELECT "t1"."id", "t1"."name" FROM "forum" AS "t1" WHERE ("t1"."name" = ?) LIMIT ? OFFSET ?', [u'Foo Forum', 1, 0])
DEBUG:peewee:('SAVEPOINT "s57afe046777a4d8e83c971ee96dfdabd";', None)
DEBUG:peewee:('INSERT INTO "forum" ("name") VALUES (?)', [u'Foo Forum'])
DEBUG:peewee:('RELEASE SAVEPOINT "s57afe046777a4d8e83c971ee96dfdabd";', None)
DEBUG:peewee:('SELECT "t1"."id", "t1"."name", "t1"."forum_id" FROM "thread" AS "t1" WHERE (("t1"."name" = ?) AND ("t1"."forum_id" = ?)) LIMIT ? OFFSET ?', [u'Foo Thread One', 1, 1, 0])
DEBUG:peewee:('SAVEPOINT "s87d5f1a49c554610bbeb5b1f9ead6a15";', None)
DEBUG:peewee:('INSERT INTO "thread" ("name", "forum_id") VALUES (?, ?)', [u'Foo Thread One', 1])
DEBUG:peewee:('RELEASE SAVEPOINT "s87d5f1a49c554610bbeb5b1f9ead6a15";', None)
DEBUG:peewee:('INSERT INTO "post" ("title", "body", "thread_id") VALUES (?, ?, ?)', [u'Test Post 1', u'Question?', 1])
DEBUG:peewee:('RELEASE SAVEPOINT "s937707aee4f546b8b2dcf9fe367dd066";', None)
INFO:__main__:Creating post 2
DEBUG:peewee:('SAVEPOINT "see2fab7bb9b2445ca3e0d12027e4eddb";', None)
DEBUG:peewee:('SELECT "t1"."id", "t1"."name" FROM "forum" AS "t1" WHERE ("t1"."name" = ?) LIMIT ? OFFSET ?', [u'Bar Forum', 1, 0])
DEBUG:peewee:('SAVEPOINT "s6ae82b0939c9407290ebf66d5ad819eb";', None)
DEBUG:peewee:('INSERT INTO "forum" ("name") VALUES (?)', [u'Bar Forum'])
DEBUG:peewee:('RELEASE SAVEPOINT "s6ae82b0939c9407290ebf66d5ad819eb";', None)
DEBUG:peewee:('SELECT "t1"."id", "t1"."name", "t1"."forum_id" FROM "thread" AS "t1" WHERE (("t1"."name" = ?) AND ("t1"."forum_id" = ?)) LIMIT ? OFFSET ?', [u'Bar Thread One', 2, 1, 0])
DEBUG:peewee:('SAVEPOINT "s65fcebb7fa394bb0ad75af7eedd381f2";', None)
DEBUG:peewee:('INSERT INTO "thread" ("name", "forum_id") VALUES (?, ?)', [u'Bar Thread One', 2])
DEBUG:peewee:('RELEASE SAVEPOINT "s65fcebb7fa394bb0ad75af7eedd381f2";', None)
DEBUG:peewee:('INSERT INTO "post" ("title", "body", "thread_id") VALUES (?, ?, ?)', [u'Off-Topic', u'Rant, Rave...', 2])
DEBUG:peewee:('RELEASE SAVEPOINT "see2fab7bb9b2445ca3e0d12027e4eddb";', None)
INFO:__main__:Creating post 3
DEBUG:peewee:('SAVEPOINT "s4abe0ada7064428bb3715aa6bdab0776";', None)
DEBUG:peewee:('SELECT "t1"."id", "t1"."name" FROM "forum" AS "t1" WHERE ("t1"."name" = ?) LIMIT ? OFFSET ?', [u'Foo Forum', 1, 0])
DEBUG:peewee:('SELECT "t1"."id", "t1"."name", "t1"."forum_id" FROM "thread" AS "t1" WHERE (("t1"."name" = ?) AND ("t1"."forum_id" = ?)) LIMIT ? OFFSET ?', [u'Foo Thread One', 1, 1, 0])
DEBUG:peewee:('INSERT INTO "post" ("title", "body", "thread_id") VALUES (?, ?, ?)', [u'Re: Test Post 1', u'Answer.', 1])
DEBUG:peewee:('RELEASE SAVEPOINT "s4abe0ada7064428bb3715aa6bdab0776";', None)
INFO:__main__:Done creating all posts
INFO:__main__:Populate returned
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2044/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2044/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2043
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2043/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2043/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2043/events
|
https://github.com/coleifer/peewee/issues/2043
| 508,404,864 |
MDU6SXNzdWU1MDg0MDQ4NjQ=
| 2,043 |
How to research peewee code?
|
{
"login": "eebeloglazov",
"id": 29166575,
"node_id": "MDQ6VXNlcjI5MTY2NTc1",
"avatar_url": "https://avatars.githubusercontent.com/u/29166575?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eebeloglazov",
"html_url": "https://github.com/eebeloglazov",
"followers_url": "https://api.github.com/users/eebeloglazov/followers",
"following_url": "https://api.github.com/users/eebeloglazov/following{/other_user}",
"gists_url": "https://api.github.com/users/eebeloglazov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eebeloglazov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eebeloglazov/subscriptions",
"organizations_url": "https://api.github.com/users/eebeloglazov/orgs",
"repos_url": "https://api.github.com/users/eebeloglazov/repos",
"events_url": "https://api.github.com/users/eebeloglazov/events{/privacy}",
"received_events_url": "https://api.github.com/users/eebeloglazov/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The main module should be skimmable in one sitting. The code flows logically, starting at the lower-level and building up. Correlate with the API doc."
] | 2019-10-17T11:14:02 | 2019-10-17T12:31:22 | 2019-10-17T12:31:22 |
NONE
| null |
Hi!
where is the docstrings and comments?
why all code in one file?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2043/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2043/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2042
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2042/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2042/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2042/events
|
https://github.com/coleifer/peewee/issues/2042
| 508,388,059 |
MDU6SXNzdWU1MDgzODgwNTk=
| 2,042 |
Usage example with FastAPI framework
|
{
"login": "aniljaiswal",
"id": 43805107,
"node_id": "MDQ6VXNlcjQzODA1MTA3",
"avatar_url": "https://avatars.githubusercontent.com/u/43805107?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aniljaiswal",
"html_url": "https://github.com/aniljaiswal",
"followers_url": "https://api.github.com/users/aniljaiswal/followers",
"following_url": "https://api.github.com/users/aniljaiswal/following{/other_user}",
"gists_url": "https://api.github.com/users/aniljaiswal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aniljaiswal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aniljaiswal/subscriptions",
"organizations_url": "https://api.github.com/users/aniljaiswal/orgs",
"repos_url": "https://api.github.com/users/aniljaiswal/repos",
"events_url": "https://api.github.com/users/aniljaiswal/events{/privacy}",
"received_events_url": "https://api.github.com/users/aniljaiswal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"http://docs.peewee-orm.com/en/latest/peewee/contributing.html#questions"
] | 2019-10-17T10:39:04 | 2019-10-17T13:24:08 | 2019-10-17T13:24:07 |
NONE
| null |
Hi,
I'm trying to integrate peewee with FastAPI and would be using it with the Serverless lambda framework. Can you provide me an example of how I would structure and use the database in terms of Models? I need to make sure that in a single lambda invocation I'm opening the DB connection, it's closed when the response is sent.
FastAPI documentation only contains SQLAlchemy related things and I love peewee since it's small, efficient and expressive. Any pointers on code structure would be helpful. It would be great if you could share a sample app with MySQL which I can start off with.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2042/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2042/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2041
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2041/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2041/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2041/events
|
https://github.com/coleifer/peewee/pull/2041
| 507,872,844 |
MDExOlB1bGxSZXF1ZXN0MzI4Nzc3NzIx
| 2,041 |
Fix a typo in the doc
|
{
"login": "kipyin",
"id": 28321392,
"node_id": "MDQ6VXNlcjI4MzIxMzky",
"avatar_url": "https://avatars.githubusercontent.com/u/28321392?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kipyin",
"html_url": "https://github.com/kipyin",
"followers_url": "https://api.github.com/users/kipyin/followers",
"following_url": "https://api.github.com/users/kipyin/following{/other_user}",
"gists_url": "https://api.github.com/users/kipyin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kipyin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kipyin/subscriptions",
"organizations_url": "https://api.github.com/users/kipyin/orgs",
"repos_url": "https://api.github.com/users/kipyin/repos",
"events_url": "https://api.github.com/users/kipyin/events{/privacy}",
"received_events_url": "https://api.github.com/users/kipyin/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Thank you."
] | 2019-10-16T14:01:37 | 2019-10-16T14:06:14 | 2019-10-16T14:06:14 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2041/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2041/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2041",
"html_url": "https://github.com/coleifer/peewee/pull/2041",
"diff_url": "https://github.com/coleifer/peewee/pull/2041.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2041.patch",
"merged_at": "2019-10-16T14:06:14"
}
|
|
https://api.github.com/repos/coleifer/peewee/issues/2040
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2040/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2040/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2040/events
|
https://github.com/coleifer/peewee/issues/2040
| 506,574,026 |
MDU6SXNzdWU1MDY1NzQwMjY=
| 2,040 |
sqlite3.Warning: You can only execute one statement at a time.
|
{
"login": "luminousmen",
"id": 9168534,
"node_id": "MDQ6VXNlcjkxNjg1MzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9168534?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/luminousmen",
"html_url": "https://github.com/luminousmen",
"followers_url": "https://api.github.com/users/luminousmen/followers",
"following_url": "https://api.github.com/users/luminousmen/following{/other_user}",
"gists_url": "https://api.github.com/users/luminousmen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/luminousmen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/luminousmen/subscriptions",
"organizations_url": "https://api.github.com/users/luminousmen/orgs",
"repos_url": "https://api.github.com/users/luminousmen/repos",
"events_url": "https://api.github.com/users/luminousmen/events{/privacy}",
"received_events_url": "https://api.github.com/users/luminousmen/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"pysqlite does not like it. Just break it up into multiple statements or use the connection directly and call the `executescript()` method.\r\n\r\nhttps://docs.python.org/2/library/sqlite3.html#sqlite3.Connection.executescript"
] | 2019-10-14T10:41:37 | 2019-10-14T13:22:41 | 2019-10-14T13:22:40 |
NONE
| null |
Hi, I'm trying to execute some SQL scripts on the sqlite database. The SQL scripts example:
```sql
DROP TABLE IF EXISTS t1;
CREATE TABLE t1 (
id integer,
name VARCHAR(100)
);
INSERT INTO t1(id, name) VALUES
(1, 'test');
```
And the code:
```python
from peewee import SqliteDatabase
database = SqliteDatabase(":memory:")
for template in templates:
query = template.format(**args)
database.execute_sql(query)
```
It all crashes on `execute_sql` call because internally the code calls the `execute` method of sqlite and it expects just one particular query.
How to fix that? The same code works with postgres
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2040/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2040/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2039
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2039/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2039/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2039/events
|
https://github.com/coleifer/peewee/issues/2039
| 506,378,203 |
MDU6SXNzdWU1MDYzNzgyMDM=
| 2,039 |
Peewee returns trigger information, but psycopg2 does not
|
{
"login": "phuvp",
"id": 6632710,
"node_id": "MDQ6VXNlcjY2MzI3MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6632710?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/phuvp",
"html_url": "https://github.com/phuvp",
"followers_url": "https://api.github.com/users/phuvp/followers",
"following_url": "https://api.github.com/users/phuvp/following{/other_user}",
"gists_url": "https://api.github.com/users/phuvp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/phuvp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/phuvp/subscriptions",
"organizations_url": "https://api.github.com/users/phuvp/orgs",
"repos_url": "https://api.github.com/users/phuvp/repos",
"events_url": "https://api.github.com/users/phuvp/events{/privacy}",
"received_events_url": "https://api.github.com/users/phuvp/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"This is not a peewee issue. This is a psycopg2 question. Please use the appropriate forum going forward.\r\n\r\nPsycopg2 cursor methods do not return a result. So:\r\n\r\n```\r\ncursor = conn.cursor()\r\ncursor.execute('select ...')\r\nfor row in cursor.fetchall():\r\n ...\r\n```"
] | 2019-10-13T20:33:12 | 2019-10-13T20:57:45 | 2019-10-13T20:57:44 |
NONE
| null |
Hi, I have created a few triggers and am now trying to print their information out. When I run the below, the psyco method errors out since `result=None`, whereas the peewee method returns a list of trigger info shown below. I've already checked that the cursor for psycopg2 is in the right database. I'd like to know what causes this discrepancy.
Output:
`
[('test_db', 'public', 'executortrigger', 'INSERT', 'test_db', 'public', 'executortable', 1, None, 'EXECUTE PROCEDURE test_executor()', 'ROW', 'AFTER', None, None, None, None, None)]
`
`def list_triggers_peewee():
return [i for i in POSTGRES.execute_sql('select * from information_schema.triggers;')]
`
`
def list_triggers_2_psyco():
result = psyco_cursor.execute('select * from information_schema.triggers;')
return [i for i in result.fetchall()]
`
version is peewee 3.10.0
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2039/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2039/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2038
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2038/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2038/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2038/events
|
https://github.com/coleifer/peewee/issues/2038
| 506,193,089 |
MDU6SXNzdWU1MDYxOTMwODk=
| 2,038 |
[Request] field type migrations for playhouse.migrate PostgresqlMigrator
|
{
"login": "mountainash",
"id": 27637,
"node_id": "MDQ6VXNlcjI3NjM3",
"avatar_url": "https://avatars.githubusercontent.com/u/27637?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mountainash",
"html_url": "https://github.com/mountainash",
"followers_url": "https://api.github.com/users/mountainash/followers",
"following_url": "https://api.github.com/users/mountainash/following{/other_user}",
"gists_url": "https://api.github.com/users/mountainash/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mountainash/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mountainash/subscriptions",
"organizations_url": "https://api.github.com/users/mountainash/orgs",
"repos_url": "https://api.github.com/users/mountainash/repos",
"events_url": "https://api.github.com/users/mountainash/events{/privacy}",
"received_events_url": "https://api.github.com/users/mountainash/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Just found this as a possible workaround, but it's a fair bit of \"work\" :-)\r\n\r\nhttps://teamtreehouse.com/community/changing-a-peewee-charfield-to-a-textfield",
"This is a pretty decent request, let me think about what it would entail.",
"Dang - that was fast. Nice work!",
"Thx, I appreciate the suggestion."
] | 2019-10-12T14:21:21 | 2019-10-12T16:05:13 | 2019-10-12T15:59:35 |
NONE
| null |
Can a function be added to PostgresqlMigrator to allow for field types to be changed and logged in a migration? (eg smallint to biginit)
Thank you.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2038/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2038/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2037
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2037/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2037/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2037/events
|
https://github.com/coleifer/peewee/issues/2037
| 505,798,373 |
MDU6SXNzdWU1MDU3OTgzNzM=
| 2,037 |
read from slave, write to master
|
{
"login": "evstratbg",
"id": 10176401,
"node_id": "MDQ6VXNlcjEwMTc2NDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/10176401?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/evstratbg",
"html_url": "https://github.com/evstratbg",
"followers_url": "https://api.github.com/users/evstratbg/followers",
"following_url": "https://api.github.com/users/evstratbg/following{/other_user}",
"gists_url": "https://api.github.com/users/evstratbg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/evstratbg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/evstratbg/subscriptions",
"organizations_url": "https://api.github.com/users/evstratbg/orgs",
"repos_url": "https://api.github.com/users/evstratbg/repos",
"events_url": "https://api.github.com/users/evstratbg/events{/privacy}",
"received_events_url": "https://api.github.com/users/evstratbg/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"You'll have to implement it yourself, which can actually be pretty easy.\r\n\r\nYou probably want to have two database instances (or two pools):\r\n\r\n```python\r\n\r\nmaster = PooledPostgresqlDatabase('master')\r\ndb = PooledPostgresqlDatabase('slave')\r\n```\r\n\r\nThen you can use the `bind_ctx()` context manager to bind your model(s) to the master when you need to do some writes:\r\n\r\n```python\r\n\r\n# Grab connection to master db from pool, and return it after write.\r\nwith master.connection_context():\r\n # Instruct user model (and related models) to use master db for write.\r\n with master.bind_ctx([User]):\r\n User.create(username='huey')\r\n```\r\n\r\nYou can abstract this away in your own context manager:\r\n\r\n```python\r\n\r\n@contextmanager\r\ndef use_master(models):\r\n with master.connection_context():\r\n with master.bind_ctx(models):\r\n yield\r\n```\r\n\r\nDocs: \r\n\r\n* http://docs.peewee-orm.com/en/latest/peewee/api.html#Database.bind_ctx\r\n* http://docs.peewee-orm.com/en/latest/peewee/api.html#Database.connection_context\r\n",
"@coleifer It looks like transaction is not maintained while using `master.bind_ctx(models)`. Can you provide some example where I can maintain transaction while being able to bind the model to specific database?",
"Transactions are specific to a database connection, so there's literally no way to carry the transaction across to another connection..."
] | 2019-10-11T11:32:34 | 2022-10-11T13:20:24 | 2019-10-11T14:08:32 |
NONE
| null |
Hi! I'm using peewee 3.11.2
We have master-slave postgres instances, slave - for reading, master - for writing
https://github.com/coleifer/peewee/blob/fc842eaf54a5d047f9281cf1866f81ce93a98496/docs/peewee/changes.rst
I've found out, that there is no longer `read_slave` extension (link above)
Any possibilities to read from slave and write to master in peewee > 3.0?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2037/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2037/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2036
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2036/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2036/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2036/events
|
https://github.com/coleifer/peewee/issues/2036
| 505,300,673 |
MDU6SXNzdWU1MDUzMDA2NzM=
| 2,036 |
Postgres - server down/up, connect with reuse, but error connection already close
|
{
"login": "wibimaster",
"id": 626666,
"node_id": "MDQ6VXNlcjYyNjY2Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/626666?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wibimaster",
"html_url": "https://github.com/wibimaster",
"followers_url": "https://api.github.com/users/wibimaster/followers",
"following_url": "https://api.github.com/users/wibimaster/following{/other_user}",
"gists_url": "https://api.github.com/users/wibimaster/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wibimaster/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wibimaster/subscriptions",
"organizations_url": "https://api.github.com/users/wibimaster/orgs",
"repos_url": "https://api.github.com/users/wibimaster/repos",
"events_url": "https://api.github.com/users/wibimaster/events{/privacy}",
"received_events_url": "https://api.github.com/users/wibimaster/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"> What's expected\r\n\r\nRead the description of the parameter: http://docs.peewee-orm.com/en/latest/peewee/api.html#Database.connect",
"Sure, I've read it:\r\n\r\nParameters: reuse_if_open (bool) – Do not raise an exception if a connection is already opened.\r\nReturns: whether a new connection was opened.\r\n\r\nIn my case, the connection isn't opened at this time.\r\nIt was, but the connection was lost. So the parameters should returns \"True\" and \"db.connect\" should established a new connection, nop ?\r\n\r\n",
"The connection is actually managed by the database driver, e.g. psycopg2 or pymysql or whatever. Peewee obtains a ref to the connection and keeps it in a threadlocal by default - so the `reuse_if_open` pertains to the internal state of peewee - not the actual socket or whatever managed by the driver.\r\n\r\nBlindly reconnecting has ramifications, e.g. transactional state getting messed up, most importantly. So by default, peewee won't reconnect if the db driver raises an error indicating the socket was closed / etc.\r\n\r\nSee #2007 for some discussion.\r\n\r\nYou could adopt the reconnect stuff from the `playhouse.shortcuts.ReconnectMixin` but I don't recommend it.",
"I have read #2007 ; I forgot to say that I'm using \"PooledPostgresqlExtDatabase()\".\r\nYou said : \r\n\r\n> the pool is slightly different, because that actually checks the \"liveness\" of connections\r\n\r\nNot the case here ? How / When do you check this liveness ?\r\n\r\n**EDIT**\r\n\r\nIf I follow the `playhouse/pool.py`, I see the `_can_reuse()` method that check the transaction status ; if we have an `TRANSACTION_STATUS_INERROR`, the connection object should be `reset()`.\r\nThe `reset()` method seems to make the connection `closed` status to `True`, so the `reuse_if_open` shouldn't return `False` because the Peewee internal state should know that the connection is lost.\r\n\r\nAm I wrong ?",
"Depends on where you get the error. Most likely, if you're following good practices of calling connect() when you start processing and close() when you're done, then the database reset is happening while the connection is sitting in the pool's list of available connections.\r\n\r\nSo if you look at the pool's `_connect` method, you can see that before returning a connection to the application, it checks `if self._is_closed(conn)` to make sure we aren't returning a closed connection. The logic for postgres is:\r\n\r\n```python\r\nclass _PooledPostgresqlDatabase(PooledDatabase):\r\n def _is_closed(self, conn):\r\n if conn.closed:\r\n return True\r\n\r\n txn_status = conn.get_transaction_status()\r\n if txn_status == TRANSACTION_STATUS_UNKNOWN:\r\n return True\r\n elif txn_status != TRANSACTION_STATUS_IDLE:\r\n conn.rollback()\r\n return False\r\n```\r\n\r\nConnections that appear to be closed are simply discarded and garbage-collected, they will not be returned to the user.\r\n\r\nIf you can provide a minimal script to replicate the issue, with a line indicating where you restart the server, that might help indicate where exactly the problem is occurring.\r\n\r\nThat being said, if the connection is checked-out and \"in-use\" by your application during the restart, there's nothing peewee will do about it.",
"Looking into this a bit more,\r\n\r\nIt seems to me that `conn.get_transaction_status()` does not indicate any problems if the connection to the server is severed.\r\n\r\nI put together the following:\r\n\r\n```python\r\nfrom peewee import *\r\nfrom playhouse.pool import PooledPostgresqlDatabase\r\n\r\n\r\ndb = PooledPostgresqlDatabase('peewee_test', user='postgres')\r\n\r\n\r\n# Create a connection in the pool's list of available conns.\r\ndb.connect()\r\ndb.close()\r\n\r\ninput('Restart server now')\r\n\r\ndb.connect()\r\ndb.execute_sql('select 1').fetchall()\r\ndb.close()\r\n```\r\n\r\nAnd it raises the following when attempting to execute the \"select 1\":\r\n\r\n```\r\npsycopg2.errors.AdminShutdown: terminating connection due to unexpected postmaster exit\r\nserver closed the connection unexpectedly\r\n\tThis probably means the server terminated abnormally\r\n\tbefore or while processing the request.\r\n```\r\n\r\nI looked closely, though, and `conn.get_transaction_status()` is returning `0` indicating no problems. So my sense is that psycopg2 just doesn't detect this particular scenario.",
"For what it's worth, it seems that aiopg is using similar logic to peewee: https://github.com/aio-libs/aiopg/blob/master/aiopg/pool.py#L229",
"Thanks for the investigations ; so finally, psycopg2 let the transaction status to Idle even if it's closed :/\r\n\r\nThat's a bad news..\r\n\r\nCan you confirm a last thing for me ?\r\n\r\nIf I run a aiohttp server, but don't start any connection ; when a client comes, I open a connection, do some DB requests, return a result and close the connection.\r\nIf I don't use the pool system, each client creates a new DB connection. That could be massive number of opened connections if I receive a lot of traffic.\r\nBut if I use the pool system, a client could close a connection used by another client at the same time, right ?\r\n\r\nShould I rely on pgpool instead ?\r\n\r\nThanks !\r\n",
"> so finally, psycopg2 let the transaction status to Idle even if it's closed\r\n\r\nThat's what it looked like to me.\r\n\r\nRegarding the pool... The idea is that creating and closing connections has a specific cost. To mitigate that cost, the pool allows you to have some number of connections that will get reused. When you call connect() it will check-out a connection from the pool (creating one if none available). When you're done you close() and the connection returns to the pool of available connections.\r\n\r\nIn a multi-threaded environment it is possible for two separate threads to be running concurrently (~ish cuz gil). Peewee tracks connections using a threadlocal on the database instance, which is in turn what your model instances use to execute queries. So each thread will have its own connection from the pool and it isn't possible for one thread to close the connection of another thread.\r\n\r\nFor asyncio I'm not sure what you should do about this, as I'm not sure the threadlocal model will work. You'll have to test it out.",
"> Should I rely on pgpool instead ?\r\n\r\nDid you have the chance to come up with a solution for your issue? I'm facing the exactly same problem in a asyncio app which calls for peewee pooled... ",
"Peewee database connections are stored in a thread-local and are not async context-aware (unless you use gevent), so you may get unexpected behavior depending on how you use your connections."
] | 2019-10-10T14:14:23 | 2020-12-17T03:14:45 | 2019-10-10T14:45:04 |
NONE
| null |
Hi,
Sorry for the long title, I don't know how to summarize it :x
**Environment:**
* PostgreSQL server
* aiohttp project with Peewee as ORM
* Python 3.7
**How to reproduce**
* Start the aiohttp project, with a "db.connect(reuse=True)" (return True)
* Kill the DB server
* Restart the DB server
* Attempts a request to aiohttp controller
* It systematically try a "db.connect(reuse=True)", that return False (indicates that the DB connection it always established, which indeed is not true)
* It fails to execute a query with "peewee.InterfaceError: connection already closed"
* **EDIT** Sorry I missed: first error that occured is
```
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/peewee.py", line 3005, in execute_sql
cursor.execute(sql, params or ())
psycopg2.OperationalError: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
```
**What's expected**
In case of DB system disconnection, "db.open(reuse=True)" should return True and effectively retry a connection (it doesn't detect the connection close)
Is this an expected behavior ?
Thanks !
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2036/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2036/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2035
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2035/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2035/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2035/events
|
https://github.com/coleifer/peewee/issues/2035
| 505,151,202 |
MDU6SXNzdWU1MDUxNTEyMDI=
| 2,035 |
PostgresqlExtDatabase with RealDictCursor causes KeyError on every select
|
{
"login": "schulzsebastian",
"id": 18170075,
"node_id": "MDQ6VXNlcjE4MTcwMDc1",
"avatar_url": "https://avatars.githubusercontent.com/u/18170075?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/schulzsebastian",
"html_url": "https://github.com/schulzsebastian",
"followers_url": "https://api.github.com/users/schulzsebastian/followers",
"following_url": "https://api.github.com/users/schulzsebastian/following{/other_user}",
"gists_url": "https://api.github.com/users/schulzsebastian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/schulzsebastian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/schulzsebastian/subscriptions",
"organizations_url": "https://api.github.com/users/schulzsebastian/orgs",
"repos_url": "https://api.github.com/users/schulzsebastian/repos",
"events_url": "https://api.github.com/users/schulzsebastian/events{/privacy}",
"received_events_url": "https://api.github.com/users/schulzsebastian/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Yeah, don't use that. If you want dicts, then use the `.dicts()` method. Peewee expects cursors to yield row tuples.\r\n\r\n```python\r\n\r\nq = MyModel.select().dicts()\r\nfor row_dict in q:\r\n # ...\r\n```"
] | 2019-10-10T09:33:41 | 2019-10-10T13:19:33 | 2019-10-10T13:19:32 |
NONE
| null |
Peewee version: 3.11.2
Postgresql version: 11
Db init:
```python
from playhouse.postgres_ext import PostgresqlExtDatabase
from psycopg2.extras import RealDictCursor
database = PostgresqlExtDatabase(
None,
register_hstore=False,
autorollback = True,
cursor_factory=RealDictCursor
)
```
Setting RealDictCursor cursor on PostgresqlExtDatabase database causes KeyError 0 on every select e.g.:
```
project-python | File "/project/app/db/general.py", line 42, in get_all
project-python | for row in cls.select(*fields).dicts():
project-python | File "/root/.local/share/virtualenvs/project-nBADCc5g/lib/python3.6/site-packages/peewee.py", line 4224, in next
project-python | self.cursor_wrapper.iterate()
project-python | File "/root/.local/share/virtualenvs/project-nBADCc5g/lib/python3.6/site-packages/peewee.py", line 4143, in iterate
project-python | result = self.process_row(row)
project-python | File "/root/.local/share/virtualenvs/project-nBADCc5g/lib/python3.6/site-packages/peewee.py", line 7217, in process_row
project-python | result[attr] = converters[i](row[i])
project-python | KeyError: 0
```
Moreover, any use of .create() method returns None without any warnings. I didn't find any information in the documentation or similar error, so I report it as a issue.
My current workaround is to use RealDictCursor only in context manager with raw SQL query, e.g.:
```python
with database.connection().cursor(cursor_factory=RealDictCursor) as cursor:
cursor.execute("select * from table")
print(cursor.fetchall())
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2035/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2035/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2034
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2034/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2034/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2034/events
|
https://github.com/coleifer/peewee/issues/2034
| 504,616,585 |
MDU6SXNzdWU1MDQ2MTY1ODU=
| 2,034 |
JSONFields can't be updated using Model.bulk_update if they're top-level lists
|
{
"login": "KarolTrojanowskiDL",
"id": 55237638,
"node_id": "MDQ6VXNlcjU1MjM3NjM4",
"avatar_url": "https://avatars.githubusercontent.com/u/55237638?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KarolTrojanowskiDL",
"html_url": "https://github.com/KarolTrojanowskiDL",
"followers_url": "https://api.github.com/users/KarolTrojanowskiDL/followers",
"following_url": "https://api.github.com/users/KarolTrojanowskiDL/following{/other_user}",
"gists_url": "https://api.github.com/users/KarolTrojanowskiDL/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KarolTrojanowskiDL/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KarolTrojanowskiDL/subscriptions",
"organizations_url": "https://api.github.com/users/KarolTrojanowskiDL/orgs",
"repos_url": "https://api.github.com/users/KarolTrojanowskiDL/repos",
"events_url": "https://api.github.com/users/KarolTrojanowskiDL/events{/privacy}",
"received_events_url": "https://api.github.com/users/KarolTrojanowskiDL/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Fixed by above commit. Thanks for the report!"
] | 2019-10-09T12:23:18 | 2019-10-09T13:50:40 | 2019-10-09T13:50:40 |
NONE
| null |
DISCLAIMER: I am terribly sorry I didn't read that I should post an issue first. There's already a PR I made for this: #2033
I noticed that using `Model.bulk_update` won't work with `JSONField`s that are top-level lists because by default `Value` will unpack the list into multiple values. Top-level lists are valid JSON objects.
Example:
```python
class Item(Model):
json = JSONField()
item = Item.create(json=['a','b'])
item.json = ['c','d']
Item.bulk_update([item], fields=[Item.json])
```
will raise `OperationalError` because of a malformed update query.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2034/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2034/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2033
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2033/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2033/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2033/events
|
https://github.com/coleifer/peewee/pull/2033
| 504,602,942 |
MDExOlB1bGxSZXF1ZXN0MzI2MjE1MDc1
| 2,033 |
Add ability to update JSON fields that are lists in Model.bulk_update
|
{
"login": "KarolTrojanowskiDL",
"id": 55237638,
"node_id": "MDQ6VXNlcjU1MjM3NjM4",
"avatar_url": "https://avatars.githubusercontent.com/u/55237638?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KarolTrojanowskiDL",
"html_url": "https://github.com/KarolTrojanowskiDL",
"followers_url": "https://api.github.com/users/KarolTrojanowskiDL/followers",
"following_url": "https://api.github.com/users/KarolTrojanowskiDL/following{/other_user}",
"gists_url": "https://api.github.com/users/KarolTrojanowskiDL/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KarolTrojanowskiDL/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KarolTrojanowskiDL/subscriptions",
"organizations_url": "https://api.github.com/users/KarolTrojanowskiDL/orgs",
"repos_url": "https://api.github.com/users/KarolTrojanowskiDL/repos",
"events_url": "https://api.github.com/users/KarolTrojanowskiDL/events{/privacy}",
"received_events_url": "https://api.github.com/users/KarolTrojanowskiDL/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I've patched this in a slightly different way. Am hoping to extend the code elsewhere to use the new `to_value()` interface (as opposed to manually creating Value instances w/the appropriate converter). Thx for the patch, at any rate."
] | 2019-10-09T11:57:22 | 2019-10-09T13:51:58 | 2019-10-09T13:50:23 |
NONE
| null |
I noticed that using `Model.bulk_update` won't work with `JSONField`s that are top-level lists because by default `Value` will unpack the list into multiple values. Top-level lists are valid JSON objects.
Example (before):
```python
class Item(Model):
json = JSONField()
item = Item.create(json=['a','b'])
item.json = ['c','d']
Item.bulk_update([item], fields=[Item.json])
```
will raise `OperationalError` because of a malformed update query.
Example (after):
```python
class Item(Model):
json = JSONField()
item = Item.create(json=['a','b'])
item.json = ['c','d']
Item.bulk_update([item], fields=[Item.json], unpack_values=False)
```
will update the row fine.
This applies to both SQLite and PostgreSQL `JSONField`s.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2033/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2033/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2033",
"html_url": "https://github.com/coleifer/peewee/pull/2033",
"diff_url": "https://github.com/coleifer/peewee/pull/2033.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2033.patch",
"merged_at": null
}
|
https://api.github.com/repos/coleifer/peewee/issues/2032
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2032/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2032/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2032/events
|
https://github.com/coleifer/peewee/issues/2032
| 504,145,894 |
MDU6SXNzdWU1MDQxNDU4OTQ=
| 2,032 |
Install fails if sqlite3 headers not present
|
{
"login": "fungs",
"id": 8776981,
"node_id": "MDQ6VXNlcjg3NzY5ODE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8776981?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fungs",
"html_url": "https://github.com/fungs",
"followers_url": "https://api.github.com/users/fungs/followers",
"following_url": "https://api.github.com/users/fungs/following{/other_user}",
"gists_url": "https://api.github.com/users/fungs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fungs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fungs/subscriptions",
"organizations_url": "https://api.github.com/users/fungs/orgs",
"repos_url": "https://api.github.com/users/fungs/repos",
"events_url": "https://api.github.com/users/fungs/events{/privacy}",
"received_events_url": "https://api.github.com/users/fungs/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Only way around is to install libsqlite3-dev package on Debian based systems, which is not an option in some environments.",
"Looks like you have cython installed, but perhaps it is not compatible with Python 3.5? This error looks to be cython-related rather than anything else (to me).",
"Sqlite does show an error that it couldn't build the sqlite extensions, but it is not a fatal error. The actual error that is causing the install to fail is related to cython:\r\n\r\nhttps://github.com/cython/cython/issues/1507",
"You are probably right about the error being in Cython but it is triggered by peewee install and does not fail if sqlite3 headers are present. Do you know what other Cython extensions are build when installing peewee that might be affected. My logic suggests that the Cython error indirectly results from trying to build the sqlite3 extension which fails. Also the issue you referenced is from 2016 and probably already fixed and has to do with bad combination of Cython and setuptools, which could also be an issue here. I can try to dig into it, any suggestions?",
"What version of Cython are you using? I figured if you're on python 3.5, it might be likely your Cython is also old.",
"I will come back with more details. This is a DataBricks enterprise pre-configured environment using interactive notebooks, so it needs some investigation. That being said, it's not unlikely that there is some kind of misconfiguration.",
"Should be easy to determine the cython version.",
"Cython is 0.24.1 which indeed was released Jul 15, 2016. Likely that this bug is in Cython, but why is it called when I disable C extension building?\r\n",
"> Cython is 0.24.1\r\n\r\nMe:\r\n\r\n> This error looks to be cython-related rather than anything else (to me).\r\n\r\nIf you have cython, peewee tries to cythonize the extensions. It catches a build error, but not this particular cython bug. Just update cython.",
"Ok thanks! This is a legacy environment where I cannot update Cython (it is a static containerized environment). Too bad that the Cython build cannot be disabled in the first place."
] | 2019-10-08T16:22:19 | 2019-10-09T15:35:24 | 2019-10-08T16:57:17 |
NONE
| null |
For latest version 0.11.2 and Python 3.5.2 installing with pip on Linux 64bit does give an exit status of 1 instead of installing without sqlite3 module. On the same system, `import sqlite3` works fine, only development files are missing.
pip install peewee
```
Collecting peewee
Using cached https://files.pythonhosted.org/packages/90/58/04bc705057694cac14c5c9a00dc83a80aafa1de27785227d3ee245cd4165/peewee-3.11.2.tar.gz
Complete output from command python setup.py egg_info:
/tmp/tmp_pw_sqlite3_3umvosqx/test_pw_sqlite3.c:1:21: fatal error: sqlite3.h: No such file or directory
compilation terminated.
/tmp/pip-install-01ifbd7u/peewee/setup.py:100: UserWarning: Could not find libsqlite3, SQLite extensions will not be built.
warnings.warn('Could not find libsqlite3, SQLite extensions will not '
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-install-01ifbd7u/peewee/setup.py", line 162, in <module>
_do_setup(extension_support, sqlite_extension_support)
File "/tmp/pip-install-01ifbd7u/peewee/setup.py", line 157, in _do_setup
ext_modules=cythonize(ext_modules))
File "/databricks/python/lib/python3.5/site-packages/Cython/Build/Dependencies.py", line 799, in cythonize
aliases=aliases)
File "/databricks/python/lib/python3.5/site-packages/Cython/Build/Dependencies.py", line 689, in create_extension_list
raise TypeError(msg)
TypeError: pattern is not of type str nor subclass of Extension (<class 'setuptools.extension.Extension'>) but of type <class 'NoneType'> and class <class 'NoneType'>
unable to compile sqlite3 C extensions - missing headers?
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-install-01ifbd7u/peewee/
```
Similar if you disable sqlite3 detection using `NO_SQLITE=1`
```
Collecting peewee
Using cached https://files.pythonhosted.org/packages/90/58/04bc705057694cac14c5c9a00dc83a80aafa1de27785227d3ee245cd4165/peewee-3.11.2.tar.gz
Complete output from command python setup.py egg_info:
/tmp/pip-install-sdbh8yg2/peewee/setup.py:98: UserWarning: SQLite extensions will not be built at users request.
warnings.warn('SQLite extensions will not be built at users request.')
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-install-sdbh8yg2/peewee/setup.py", line 162, in <module>
_do_setup(extension_support, sqlite_extension_support)
File "/tmp/pip-install-sdbh8yg2/peewee/setup.py", line 157, in _do_setup
ext_modules=cythonize(ext_modules))
File "/databricks/python/lib/python3.5/site-packages/Cython/Build/Dependencies.py", line 799, in cythonize
aliases=aliases)
File "/databricks/python/lib/python3.5/site-packages/Cython/Build/Dependencies.py", line 689, in create_extension_list
raise TypeError(msg)
TypeError: pattern is not of type str nor subclass of Extension (<class 'setuptools.extension.Extension'>) but of type <class 'NoneType'> and class <class 'NoneType'>
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-install-sdbh8yg2/peewee/
```
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2032/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2032/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2031
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2031/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2031/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2031/events
|
https://github.com/coleifer/peewee/issues/2031
| 503,583,173 |
MDU6SXNzdWU1MDM1ODMxNzM=
| 2,031 |
Forced default value
|
{
"login": "BukinPK",
"id": 18446718,
"node_id": "MDQ6VXNlcjE4NDQ2NzE4",
"avatar_url": "https://avatars.githubusercontent.com/u/18446718?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BukinPK",
"html_url": "https://github.com/BukinPK",
"followers_url": "https://api.github.com/users/BukinPK/followers",
"following_url": "https://api.github.com/users/BukinPK/following{/other_user}",
"gists_url": "https://api.github.com/users/BukinPK/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BukinPK/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BukinPK/subscriptions",
"organizations_url": "https://api.github.com/users/BukinPK/orgs",
"repos_url": "https://api.github.com/users/BukinPK/repos",
"events_url": "https://api.github.com/users/BukinPK/events{/privacy}",
"received_events_url": "https://api.github.com/users/BukinPK/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I think something is missing in your example, because this code correctly prints \"None\":\r\n\r\n```python\r\n\r\nfrom peewee import *\r\n\r\n\r\ndb = SqliteDatabase(':memory:')\r\n\r\nclass M(Model):\r\n value = IntegerField(null=True)\r\n class Meta:\r\n database = db\r\n\r\ndb.create_tables([M])\r\n\r\nm = M.create()\r\nm_db = M[M.id]\r\n\r\nprint(m_db.value)\r\n# output: None\r\n```",
"I see this.\r\nBut this code correctly throws error and incorrectly prints \"0\":\r\n\r\n```python\r\nfrom peewee import *\r\n\r\n\r\ndb = MySQLDatabase(DB_NAME, user=DB_USER, password=DB_PASSWORD)\r\n\r\nclass M(Model):\r\n value = IntegerField(default=None, null=False)\r\n class Meta:\r\n database = db\r\n\r\ndb.create_tables([M])\r\n\r\nm = M.create()\r\nm_db = M[M.id]\r\n\r\nprint(m_db.value)\r\n\r\n# output:\r\n# /home/bukinpk/.local/lib/python3.7/site-packages/pymysql/cursors.py:170: Warning: (1364, \"Field 'value' doesn't have a default value\")\r\n# result = self._query(query)\r\n# 0\r\n\r\n```",
"On use `SqliteDatabase(':memory:')` such problems I don't observe.",
"Well shyea...you specified your field with null=false, what do you expect?",
"I expect throwing an error on attempt to set value to NULL, same as on use SqliteDatabase(':memory:').",
"Looks like this has to do with the sql_mode setting. If you change it to strict_trans_tables or strict_all_tables it should take care of the problem.",
"Yes, it works! Thanks for the help!\r\n\r\nUPD.:\r\nBut it will broke some string methods, such as:\r\nhttps://github.com/coleifer/peewee/blob/83873b70bcdfb82320f5d3a127e4783c04531b3a/peewee.py#L4563\r\nBecouse you use `||` as concatination operator.\r\nAnd if I change `sql_mode` field, to `STRICT_TRANS_TABLES`, i will turn off actualy setted mode:\r\nhttps://github.com/coleifer/peewee/blob/83873b70bcdfb82320f5d3a127e4783c04531b3a/peewee.py#L3838\r\nAnd operator `||` will not work correctly.\r\nI think, I should set `PIPES_AS_CONCAT,STRICT_TRANS_TABLES`\r\nOr to append `PIPES_AS_CONCAT` mode to all default setted values:\r\n`STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION`."
] | 2019-10-07T17:17:22 | 2019-10-08T00:25:23 | 2019-10-07T21:14:35 |
NONE
| null |
I create a model with a fild:
```
class Map(Model):
size = IntegerField()
```
It is NOT NULL and don't have DEFAULT value by default:
```
pw.IntegerField(
null=False,
default=None,
...
)
```
But when I create new object, with no "size" argument put in automatically generated constructor, a model is created with a value of 0 in the size field, instead of throwing an exception.
```
Map.create()
/home/bukinpk/.local/lib/python3.7/site-packages/pymysql/cursors.py:170: Warning: (1364, "Field 'size' doesn't have a default value")
result = self._query(query)
Out[12]: <Map: 5>
```
How can I deactivate this implicit behavior?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2031/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2031/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2030
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2030/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2030/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2030/events
|
https://github.com/coleifer/peewee/pull/2030
| 501,846,142 |
MDExOlB1bGxSZXF1ZXN0MzI0MDM5MTc2
| 2,030 |
Use the pythonic way to filter with list comprehensions or generator expressions
|
{
"login": "eltonvs",
"id": 8386137,
"node_id": "MDQ6VXNlcjgzODYxMzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8386137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eltonvs",
"html_url": "https://github.com/eltonvs",
"followers_url": "https://api.github.com/users/eltonvs/followers",
"following_url": "https://api.github.com/users/eltonvs/following{/other_user}",
"gists_url": "https://api.github.com/users/eltonvs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eltonvs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eltonvs/subscriptions",
"organizations_url": "https://api.github.com/users/eltonvs/orgs",
"repos_url": "https://api.github.com/users/eltonvs/repos",
"events_url": "https://api.github.com/users/eltonvs/events{/privacy}",
"received_events_url": "https://api.github.com/users/eltonvs/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Gonna pass, thanks though."
] | 2019-10-03T04:32:34 | 2019-10-03T11:11:56 | 2019-10-03T11:11:55 |
NONE
| null |
This is a really small refactor in order to use the pythonic way to filter in python.
References:
- https://www.oreilly.com/library/view/python-cookbook/0596001673/ch01s11.html
- https://www.artima.com/weblogs/viewpost.jsp?thread=98196
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2030/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2030/timeline
| null | null | false |
{
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2030",
"html_url": "https://github.com/coleifer/peewee/pull/2030",
"diff_url": "https://github.com/coleifer/peewee/pull/2030.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2030.patch",
"merged_at": null
}
|
https://api.github.com/repos/coleifer/peewee/issues/2029
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2029/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2029/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2029/events
|
https://github.com/coleifer/peewee/issues/2029
| 500,492,709 |
MDU6SXNzdWU1MDA0OTI3MDk=
| 2,029 |
OpenAPI Specification / SwaggerUI for REST API
|
{
"login": "brandond",
"id": 370103,
"node_id": "MDQ6VXNlcjM3MDEwMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/370103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brandond",
"html_url": "https://github.com/brandond",
"followers_url": "https://api.github.com/users/brandond/followers",
"following_url": "https://api.github.com/users/brandond/following{/other_user}",
"gists_url": "https://api.github.com/users/brandond/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brandond/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brandond/subscriptions",
"organizations_url": "https://api.github.com/users/brandond/orgs",
"repos_url": "https://api.github.com/users/brandond/repos",
"events_url": "https://api.github.com/users/brandond/events{/privacy}",
"received_events_url": "https://api.github.com/users/brandond/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"That's a no then?",
"> flask_peewee\r\n\r\nwrong repo",
"Right, sorry. I mistakenly assumed it was a submodule like the playhouse stuff. I just saw the message that you're not working on it any more. Did you ever get around to breaking out the REST bits into a separate library?"
] | 2019-09-30T20:00:07 | 2019-10-02T07:17:30 | 2019-09-30T20:08:20 |
NONE
| null |
I'd love to have an autogenerated OpenAPI spec with SwaggerUI support that was easy to use with `flask_peewee.rest`. Someone hacked this together as a standalone module but the project appears to be dead:
https://github.com/hapyak/flask-peewee-swagger
I recently hacked together a translation layer to expose PynamoDB models via [Flask-RESTPlus](https://flask-restplus.readthedocs.io), so I considered taking a shot at that for Peewee, but I'd much rather use your built-in REST layer if at all possible.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2029/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2029/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2028
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2028/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2028/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2028/events
|
https://github.com/coleifer/peewee/issues/2028
| 500,486,465 |
MDU6SXNzdWU1MDA0ODY0NjU=
| 2,028 |
Add option tu AutoField
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"If you're using postgresql, `AutoField` will be created as a `SERIAL` column. This automatically creates a sequence for the ID generation and sets up the default nextval. MySQL uses `AUTO_INCREMENT` and Sqlite just uses `INTEGER` (due to the aliasing of the rowid) for auto-incrementing integer fields.\r\n\r\nIt should be possible, if you really need this, to subclass and extend the `AutoField`. An existing example of this is the sqlite `AutoIncrementField` which inserts a special keyword (with special meaning in sqlite).\r\n\r\nAs long as the ordering of the constraints is not important, this should probably work:\r\n\r\n```python\r\nclass IdentityField(AutoField):\r\n def ddl(self, ctx):\r\n node_list = super(IdentityField, self).ddl(ctx)\r\n return NodeList((node_list, SQL('generated by default as identity')))\r\n```",
"I've gone ahead and added an implementation to `playhouse.postgres_ext`. Here is the code for the new field:\r\n\r\n```python\r\n\r\nclass IdentityField(AutoField):\r\n field_type = 'INT'\r\n\r\n def __init__(self, generate_always=False, **kwargs):\r\n self._generate_always = generate_always\r\n super(IdentityField, self).__init__(**kwargs)\r\n\r\n def ddl(self, ctx):\r\n node_list = super(IdentityField, self).ddl(ctx)\r\n sql = SQL('GENERATED %s AS IDENTITY' %\r\n ('ALWAYS' if self._generate_always else 'BY DEFAULT'))\r\n return NodeList((node_list, sql))\r\n```",
"Wow, this is quickly... thanks...\r\n\r\nYes, order is important... with this code it create field correctly\r\n\r\n```python\r\nfrom peewee import *\r\nfrom peewee import Entity, NodeList\r\n\r\nclass FirebirdAutoField(AutoField):\r\n extra = 'generated by default as identity'\r\n\r\n def ddl(self, ctx):\r\n accum = [Entity(self.column_name)]\r\n data_type = self.ddl_datatype(ctx)\r\n if data_type:\r\n accum.append(data_type)\r\n if self.unindexed:\r\n accum.append(SQL('UNINDEXED'))\r\n if self.extra:\r\n accum.append(SQL(self.extra))\r\n if self.primary_key:\r\n accum.append(SQL('PRIMARY KEY'))\r\n if not self.null:\r\n accum.append(SQL('NOT NULL'))\r\n if self.sequence:\r\n accum.append(SQL(\"DEFAULT NEXTVAL('%s')\" % self.sequence))\r\n if self.constraints:\r\n accum.extend(self.constraints)\r\n if self.collation:\r\n accum.append(SQL('COLLATE %s' % self.collation))\r\n return NodeList(accum)\r\n```\r\n\r\nGet\r\n```\r\n30/09/2019 15:43:19 - DEBUG - CREATE TABLE \"person\" (\"id\" INTEGER generated by default as identity PRIMARY KEY NOT NULL, \"name\" VARCHAR(255) NOT NULL, \"last_name\" VARCHAR(255) NOT NULL)\r\n```\r\n\r\nVery thank, best regards\r\n",
"> Yes, order is important... with this code it create field correctly\r\n\r\nIdk, I tested against postgresql with the code I linked and it appears to work correctly. Looking at the postgres syntax diagram it seems to agree that the order of the column constraints isn't important. At any rate, if that works for you, alright.",
"Didn't see that you were trying to use firebird. Makes sense now.",
"Yes, I used Firebird (I preferred Postgres :+1: ) , but not Firebird server, Firebird embedded in Base de LibreOffice. With peewee, now the work it's very funny, many thanks.",
"Well, shoot -- I knew this seemed familiar but I was looking in the wrong modules. I've already implemented `IdentityField` in `peewee.py`. I merged the implementations:\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/api.html#IdentityField",
"It's great, now it's more easy... test with Firebird/Base, work fine, thanks\r\n\r\n```\r\n01/10/2019 11:42:04 - DEBUG - CREATE TABLE \"person\" (\"id\" INT GENERATED BY DEFAULT AS IDENTITY NOT NULL PRIMARY KEY, \"name\" VARCHAR(255) NOT NULL, \"last_name\" VARCHAR(255) NOT NULL, \"birthday\" DATE)\r\n```"
] | 2019-09-30T19:48:53 | 2019-10-01T16:43:29 | 2019-09-30T20:18:03 |
NONE
| null |
Hello...
I need add some extra options in field ID, currently automatic generate in:
```python
class Person(BaseModel):
name = CharField()
last_name = CharField()
```
Field ID generate like: `INTEGER NOT NULL PRIMARY KEY`, it's ok, but, I need:
`INTEGER NOT NULL GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY`
Who to insert: `GENERATED BY DEFAULT AS IDENTITY`
I try with a custom field, but, I not know where.
Thanks in advance.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2028/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2027
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2027/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2027/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2027/events
|
https://github.com/coleifer/peewee/issues/2027
| 499,753,222 |
MDU6SXNzdWU0OTk3NTMyMjI=
| 2,027 |
what does 'backref' really mean in foreign key?
|
{
"login": "bmxbmx3",
"id": 33427015,
"node_id": "MDQ6VXNlcjMzNDI3MDE1",
"avatar_url": "https://avatars.githubusercontent.com/u/33427015?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bmxbmx3",
"html_url": "https://github.com/bmxbmx3",
"followers_url": "https://api.github.com/users/bmxbmx3/followers",
"following_url": "https://api.github.com/users/bmxbmx3/following{/other_user}",
"gists_url": "https://api.github.com/users/bmxbmx3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bmxbmx3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bmxbmx3/subscriptions",
"organizations_url": "https://api.github.com/users/bmxbmx3/orgs",
"repos_url": "https://api.github.com/users/bmxbmx3/repos",
"events_url": "https://api.github.com/users/bmxbmx3/events{/privacy}",
"received_events_url": "https://api.github.com/users/bmxbmx3/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"It's pretty straightforward if you have an understanding of foreign-keys in the first place.\r\n\r\nIf you have a user and tweet model, the tweet has a foreign-key to user to indicate the author of the tweet:\r\n\r\n```python\r\nclass User(Model):\r\n username = TextField()\r\n\r\nclass Tweet(Model):\r\n user = ForeignKeyField(User, backref='tweets')\r\n content = TextField()\r\n```\r\n\r\nSo when you create a tweet, you store the tweet content along with a reference to the user who created it. Thus a tweet has a relationship to *one* user, and a user has an implicit relationship to any number 0..n tweets.\r\n\r\nThe backref provides a way to access the tweets that refer to the given user.\r\n\r\n```python\r\nuser = User.create(username='huey')\r\nTweet.create(user=user, content='huey-1')\r\nTweet.create(user=user, content='huey-2')\r\n\r\n# Get all tweets by huey.\r\nquery = Tweet.select().where(Tweet.user == user)\r\n\r\n# Equivalent to above, using backref:\r\nquery = user.tweets\r\n```",
"> It's pretty straightforward if you have an understanding of foreign-keys in the first place.\r\n> \r\n> If you have a user and tweet model, the tweet has a foreign-key to user to indicate the author of the tweet:\r\n> \r\n> ```python\r\n> class User(Model):\r\n> username = TextField()\r\n> \r\n> class Tweet(Model):\r\n> user = ForeignKeyField(User, backref='tweets')\r\n> content = TextField()\r\n> ```\r\n> \r\n> So when you create a tweet, you store the tweet content along with a reference to the user who created it. Thus a tweet has a relationship to _one_ user, and a user has an implicit relationship to any number 0..n tweets.\r\n> \r\n> The backref provides a way to access the tweets that refer to the given user.\r\n> \r\n> ```python\r\n> user = User.create(username='huey')\r\n> Tweet.create(user=user, content='huey-1')\r\n> Tweet.create(user=user, content='huey-2')\r\n> \r\n> # Get all tweets by huey.\r\n> query = Tweet.select().where(Tweet.user == user)\r\n> \r\n> # Equivalent to above, using backref:\r\n> query = user.tweets\r\n> ```\r\n\r\nIs this feature especially used for NoSQL?",
"> Is this feature especially used for NoSQL?\r\n\r\n",
"> > Is this feature especially used for NoSQL?\r\n> \r\n> \r\n\r\nsorry,it seems that I've made a mistake.It's my fault...anyway,I just don't understand in your toy code why the object `user` could be the class variable of `Tweet` like this:\r\n`Tweet.create(user=**user**, content='huey-1')`\r\nwhy not the basic data types like int,char and so on?I haven't met it before,just seems a bit weird for me.",
"Thank you! This is really useful😋",
"what is the default name for `backref` when we don't specify `backref` parameter?\r\n`<model_name>_set` in django for example.",
"Yes, peewee uses the django convention for the default backref accessor."
] | 2019-09-28T10:15:23 | 2021-01-09T20:32:39 | 2019-09-28T13:47:14 |
NONE
| null |
I have read the documentation and try to understand the meaning of 'backref',which I have found in the word said "Every foreign-key field has an implied back-reference, which is exposed as a pre-filtered Select query using the provided backref attribute."But I still don't know how the back-reference could be exposed as a pre-filtered Select query,can you explain it more clearly please?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2027/reactions",
"total_count": 8,
"+1": 8,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2027/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2026
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2026/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2026/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2026/events
|
https://github.com/coleifer/peewee/issues/2026
| 499,542,877 |
MDU6SXNzdWU0OTk1NDI4Nzc=
| 2,026 |
How best to get inserted row count from Model.insert_many()?
|
{
"login": "grantcox",
"id": 186808,
"node_id": "MDQ6VXNlcjE4NjgwOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/186808?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/grantcox",
"html_url": "https://github.com/grantcox",
"followers_url": "https://api.github.com/users/grantcox/followers",
"following_url": "https://api.github.com/users/grantcox/following{/other_user}",
"gists_url": "https://api.github.com/users/grantcox/gists{/gist_id}",
"starred_url": "https://api.github.com/users/grantcox/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/grantcox/subscriptions",
"organizations_url": "https://api.github.com/users/grantcox/orgs",
"repos_url": "https://api.github.com/users/grantcox/repos",
"events_url": "https://api.github.com/users/grantcox/events{/privacy}",
"received_events_url": "https://api.github.com/users/grantcox/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I hear you -- thanks for mentioning the database you're using. This should work with sqlite as well, though I don't believe it will work for postgres -- but I need to test it out. Let me look into this as I think it's a worthwhile request.",
"ab43376",
"Just a heads-up that this change has been rolled-back in #2556. Going forwards, to obtain the inserted row count, you may use the `Insert.as_rowcount()` chainable query method. Examples:\r\n\r\n```python\r\ndb = MySQLDatabase(...)\r\n\r\nquery = User.insert_many([...])\r\n# Old behavior:\r\n#rowcount = query.execute()\r\n\r\n# Behavior going forwards:\r\nlastid = query.execute()\r\n\r\n# To get the rowcount instead of the last id:\r\nrowcount = query.as_rowcount().execute()\r\n```"
] | 2019-09-27T16:40:45 | 2022-03-28T00:07:11 | 2019-09-30T15:03:08 |
NONE
| null |
I would expect the `Model.insert_many().execute()` return value to the `rowcount` affected, however it appears to always be `0` (presumably it's attempting to get the primary row id inserted?).
I have found that the following approach works, hacking on how the `returning` implementation works. But it doesn't look like the correct way:
```
multi_insert_query = MyModel.insert_many(rows).on_conflict(action='IGNORE')
multi_insert_query._return_cursor = True
cursor = multi_insert_query.execute()
total_inserted = cursor.rowcount
```
Any suggestions for how this is better implemented? I am using MySQL 5.6, although I'm not sure that matters.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2026/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2026/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2025
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2025/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2025/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2025/events
|
https://github.com/coleifer/peewee/issues/2025
| 497,755,435 |
MDU6SXNzdWU0OTc3NTU0MzU=
| 2,025 |
querying jsonfields
|
{
"login": "Nocturem",
"id": 4144490,
"node_id": "MDQ6VXNlcjQxNDQ0OTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/4144490?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nocturem",
"html_url": "https://github.com/Nocturem",
"followers_url": "https://api.github.com/users/Nocturem/followers",
"following_url": "https://api.github.com/users/Nocturem/following{/other_user}",
"gists_url": "https://api.github.com/users/Nocturem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nocturem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nocturem/subscriptions",
"organizations_url": "https://api.github.com/users/Nocturem/orgs",
"repos_url": "https://api.github.com/users/Nocturem/repos",
"events_url": "https://api.github.com/users/Nocturem/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nocturem/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Assuming you're using sqlite, right?",
"yes ",
"This may be related to a change in 3.11.0. If you're using 3.11.0 or newer, can you try using 3.10 and letting me know if it works there?",
"currently on Version: 3.10.0\r\ncan try 3.11.0 if that may help",
"I've just added a test for the `children()` method and it appears passing locally:\r\n\r\nddf4ce32c5ca180b2f93d01f731aaf161be4a2da\r\n\r\nDoes that help at all?",
"Full code for the new test-case:\r\n\r\n```python\r\n def test_children(self):\r\n children = KeyData.data.children().alias('children')\r\n query = (KeyData\r\n .select(KeyData.key, children.c.fullkey.alias('fullkey'))\r\n .from_(KeyData, children)\r\n .where(~children.c.fullkey.contains('k'))\r\n .order_by(KeyData.id, SQL('fullkey')))\r\n accum = [(row.key, row.fullkey) for row in query]\r\n self.assertEqual(accum, [\r\n ('a', '$.x1'),\r\n ('b', '$.x2'),\r\n ('d', '$.x1'),\r\n ('e', '$.l1'), ('e', '$.l2')])\r\n```",
"Maybe try updating to 3.11.1 if you're still experiencing issues? I think I had the versions backwards -- that is, 3.10 had the issue which should be resolved in 3.11.",
"no worries I will try upgrading now and see if that resolves the issue :) \r\nthank you ",
"Oh shit, that test *is* failing on python 3... damn I was accidentally testing on python 2. I need to push a fix for this.",
"tested and working \r\nadditionally may I suggest the addition of \r\n```\r\n def __enter__(self):\r\n return self\r\n\r\n def __exit__(self, *args):\r\n return None\r\n```\r\n\r\non the Alias class \r\nthis allows the convenience of using with statements for context handling \r\n\r\nthus \r\n```\r\nwith User.phone.children().alias('phone_children') as phone:\r\n for row in User.select().from_(User, phone).where(phone.c.value ** '704%'):\r\n ...\r\n```\r\n\r\nI imagine this would probably be handy on the CTE class as well.. ",
"Glad it's fixed. I tagged 3.11.2 release w/the fix.\r\n\r\nI'm not a fan of implementing a context manager that does ... nothing. That is just a slower way of doing a simple assignment.",
"it might allow the garbage collector to recognize the transience of the assignment and toss the disposable variable after as it drops out of scope but mostly its an aesthetic/familiarity case of working similar to the SQL WITH clause where its used for virtual tables and common table expressions.\r\nits not a major thing more a nice to have"
] | 2019-09-24T15:15:44 | 2019-09-24T16:31:58 | 2019-09-24T15:42:26 |
NONE
| null |
Hi there,
Having a little trouble figuring out the children or json_each function in peewee
trying to replicate the basic example
`SELECT DISTINCT user.name
FROM user, json_each(user.phone)
WHERE json_each.value LIKE '704-%';`
however I can't see an example in the documentation
tried mocking up my own effort
```
phone = User.phone.children().alias('phone_children')
query = User.select().from_(User, phone).where(phone.c.value ** '704%')
```
however had some issues trying to execute this getting TypeError: unhashable type: 'Alias'
I am fairly certain I am going about this backwards :(
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2025/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2025/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2024
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2024/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2024/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2024/events
|
https://github.com/coleifer/peewee/issues/2024
| 497,135,438 |
MDU6SXNzdWU0OTcxMzU0Mzg=
| 2,024 |
pip install failed
|
{
"login": "JoanEliot",
"id": 30822817,
"node_id": "MDQ6VXNlcjMwODIyODE3",
"avatar_url": "https://avatars.githubusercontent.com/u/30822817?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JoanEliot",
"html_url": "https://github.com/JoanEliot",
"followers_url": "https://api.github.com/users/JoanEliot/followers",
"following_url": "https://api.github.com/users/JoanEliot/following{/other_user}",
"gists_url": "https://api.github.com/users/JoanEliot/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JoanEliot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JoanEliot/subscriptions",
"organizations_url": "https://api.github.com/users/JoanEliot/orgs",
"repos_url": "https://api.github.com/users/JoanEliot/repos",
"events_url": "https://api.github.com/users/JoanEliot/events{/privacy}",
"received_events_url": "https://api.github.com/users/JoanEliot/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Couldn't tell you. Peewee should be in the main folder, as it installs as a module, not a package."
] | 2019-09-23T14:31:51 | 2019-09-23T14:42:21 | 2019-09-23T14:42:21 |
NONE
| null |
(Windows 10, same experience with global/'main' Python and a venv)
I'm a Python dunderhead so excuse any bad lingo or other evidence of lack.
Installation via pip/pypi gave no errors, but imports failed. Checking \site-packages I find peewee.py and pwiz.py out bare in the main folder, and an egg-info folder but no plain peewee folder. Installation via the peewee git/setup.py produced the expected peewee-3.11.0-py3.7 folder (well, .egg) and imports worked.
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2024/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2024/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2023
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2023/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2023/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2023/events
|
https://github.com/coleifer/peewee/issues/2023
| 497,077,444 |
MDU6SXNzdWU0OTcwNzc0NDQ=
| 2,023 |
Model.filter with alias behaves different from Model.select.where
|
{
"login": "altunyurt",
"id": 126674,
"node_id": "MDQ6VXNlcjEyNjY3NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/126674?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/altunyurt",
"html_url": "https://github.com/altunyurt",
"followers_url": "https://api.github.com/users/altunyurt/followers",
"following_url": "https://api.github.com/users/altunyurt/following{/other_user}",
"gists_url": "https://api.github.com/users/altunyurt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/altunyurt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/altunyurt/subscriptions",
"organizations_url": "https://api.github.com/users/altunyurt/orgs",
"repos_url": "https://api.github.com/users/altunyurt/repos",
"events_url": "https://api.github.com/users/altunyurt/events{/privacy}",
"received_events_url": "https://api.github.com/users/altunyurt/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Why are you using an alias on a plain old select query? Aliases are designed for one reason: to allow you to reference the same table in multiple contexts within a query (e.g. a self-join). There is no reason to alias a model class simply to select from it -- just use the model itself.\r\n\r\nFurthermore, you're using the `filter()` method incorrectly. Why are you passing an expression into the call to `filter()`? Filter is designed solely to provide a django-compatible way of constructing where clauses. You should just chain calls to `.where()` if you're passing in expressions:\r\n\r\n```python\r\n\r\nOI = OrganizationInvitation # no alias!\r\nq = OI.select().where(OI.invitee == '121212121')\r\n\r\n# Or,\r\nq = OI.select().filter(invite='1212121') # Filter uses kwargs, *not* expressions.\r\n```"
] | 2019-09-23T12:49:00 | 2019-09-23T13:42:52 | 2019-09-23T13:42:28 |
NONE
| null |
When alias is used with Model.filter, it somehow adds another table reference to queries.
```
In [5]: oi = OrganizationInvitation.alias()
In [6]: oi.select().where(oi.invitee == "1212121212").sql()
Out[6]:
('SELECT "t1"."id", "t1"."organization_id", "t1"."inviter_id", "t1"."invitee" FROM "organization_invitation" AS "t1" WHERE ("t1"."invitee" = ?)',
['1212121212'])
# Another table reference t2 is added here
In [7]: oi.filter(oi.invitee == "1212121212").sql()
Out[7]:
('SELECT "t1"."id", "t1"."organization_id", "t1"."inviter_id", "t1"."invitee" FROM "organization_invitation" AS "t1" WHERE ("t2"."invitee" = ?)',
['1212121212'])
In [8]: oi.filter(oi.invitee == "1212121212")
Out[8]: <peewee.ModelSelect at 0x7f56290ee748>
In [9]: oi.select().where(oi.invitee == "1212121212")
Out[9]: <peewee.ModelSelect at 0x7f5613fcceb8>
```
I'm using peewee 3.11.0 with apsw 3.28.0 on python 3.7.1
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2023/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2023/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2022
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2022/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2022/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2022/events
|
https://github.com/coleifer/peewee/issues/2022
| 497,038,444 |
MDU6SXNzdWU0OTcwMzg0NDQ=
| 2,022 |
Sybase Database Connection in Peewee.
|
{
"login": "govind-savara",
"id": 13663733,
"node_id": "MDQ6VXNlcjEzNjYzNzMz",
"avatar_url": "https://avatars.githubusercontent.com/u/13663733?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/govind-savara",
"html_url": "https://github.com/govind-savara",
"followers_url": "https://api.github.com/users/govind-savara/followers",
"following_url": "https://api.github.com/users/govind-savara/following{/other_user}",
"gists_url": "https://api.github.com/users/govind-savara/gists{/gist_id}",
"starred_url": "https://api.github.com/users/govind-savara/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/govind-savara/subscriptions",
"organizations_url": "https://api.github.com/users/govind-savara/orgs",
"repos_url": "https://api.github.com/users/govind-savara/repos",
"events_url": "https://api.github.com/users/govind-savara/events{/privacy}",
"received_events_url": "https://api.github.com/users/govind-savara/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"No, but it's easy to add your own database backed.",
"You'll probably want to find a db-api 2.0 driver and then read the docs on adding a new database driver:\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/database.html#adding-a-new-database-driver"
] | 2019-09-23T11:23:26 | 2019-09-23T13:37:27 | 2019-09-23T13:37:27 |
NONE
| null |
Hi, Developers.
Do we have an option to connect to Sybase Database using Peewee ORM?
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2022/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2022/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2021
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2021/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2021/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2021/events
|
https://github.com/coleifer/peewee/issues/2021
| 496,962,491 |
MDU6SXNzdWU0OTY5NjI0OTE=
| 2,021 |
AttributeError: 'bool' object has no attribute 'safe_name' after upgrade 3.10 -> 3.11
|
{
"login": "grandchild",
"id": 770029,
"node_id": "MDQ6VXNlcjc3MDAyOQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/770029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/grandchild",
"html_url": "https://github.com/grandchild",
"followers_url": "https://api.github.com/users/grandchild/followers",
"following_url": "https://api.github.com/users/grandchild/following{/other_user}",
"gists_url": "https://api.github.com/users/grandchild/gists{/gist_id}",
"starred_url": "https://api.github.com/users/grandchild/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/grandchild/subscriptions",
"organizations_url": "https://api.github.com/users/grandchild/orgs",
"repos_url": "https://api.github.com/users/grandchild/repos",
"events_url": "https://api.github.com/users/grandchild/events{/privacy}",
"received_events_url": "https://api.github.com/users/grandchild/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Wow, thanks! So impressed by the quality of your work in general. Thank you for what you do!",
"Pushed 3.11.1 as this seemed like a potentially disruptive regression. Thx for reporting."
] | 2019-09-23T08:36:37 | 2019-09-23T14:03:29 | 2019-09-23T13:35:54 |
NONE
| null |
I updated to peewee to `3.11.0` from `3.10.0` 4 days ago and it presented with the following error. I cannot right now get more detail, because I don't have the time. But I will provide a minimal program reproducing the bug tomorrow. This is just meant as a placeholder, and maybe it'll already point you into the right direction. For now, I downgraded peewee to `3.10.0` and all is well again.
<details><summary>traceback</summary>
<pre>
Traceback (most recent call last):
File "/usr/lib/python3.7/site-packages/flask/app.py", line 2463, in __call__
return self.wsgi_app(environ, start_response)
File "/usr/lib/python3.7/site-packages/flask/app.py", line 2449, in wsgi_app
response = self.handle_exception(e)
File "/usr/lib/python3.7/site-packages/flask/app.py", line 1866, in handle_exception
reraise(exc_type, exc_value, tb)
File "/usr/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/usr/lib/python3.7/site-packages/flask/app.py", line 2446, in wsgi_app
response = self.full_dispatch_request()
File "/usr/lib/python3.7/site-packages/flask/app.py", line 1951, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/usr/lib/python3.7/site-packages/flask/app.py", line 1820, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/usr/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/usr/lib/python3.7/site-packages/flask/app.py", line 1949, in full_dispatch_request
rv = self.dispatch_request()
File "/usr/lib/python3.7/site-packages/flask/app.py", line 1935, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/[...]/app/api.py", line 97, in people
& (EasyContacts.type_id == ContactType.PERSON)
File "/home/[...]/app/api.py", line 88, in <listcomp>
c.referenced_to
File "/usr/lib/python3.7/site-packages/peewee.py", line 4221, in next
self.cursor_wrapper.iterate()
File "/usr/lib/python3.7/site-packages/peewee.py", line 4140, in iterate
result = self.process_row(row)
File "/usr/lib/python3.7/site-packages/peewee.py", line 7364, in process_row
if instance not in set_keys and dest not in set_keys \
File "/usr/lib/python3.7/site-packages/peewee.py", line 6403, in __hash__
return hash((self.__class__, self._pk))
File "/usr/lib/python3.7/site-packages/peewee.py", line 6294, in get_id
return getattr(self, self._meta.primary_key.safe_name)
AttributeError: 'bool' object has no attribute 'safe_name'
</pre>
</details>
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2021/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2021/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2020
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2020/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2020/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2020/events
|
https://github.com/coleifer/peewee/issues/2020
| 496,339,371 |
MDU6SXNzdWU0OTYzMzkzNzE=
| 2,020 |
Is there a way to specify postgresql schema at run time?
|
{
"login": "shon",
"id": 89816,
"node_id": "MDQ6VXNlcjg5ODE2",
"avatar_url": "https://avatars.githubusercontent.com/u/89816?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shon",
"html_url": "https://github.com/shon",
"followers_url": "https://api.github.com/users/shon/followers",
"following_url": "https://api.github.com/users/shon/following{/other_user}",
"gists_url": "https://api.github.com/users/shon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shon/subscriptions",
"organizations_url": "https://api.github.com/users/shon/orgs",
"repos_url": "https://api.github.com/users/shon/repos",
"events_url": "https://api.github.com/users/shon/events{/privacy}",
"received_events_url": "https://api.github.com/users/shon/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Sorry, peewee doesn't support that. I'd suggest writing a context manager that explicitly sets `Model._meta.schema`.\r\n\r\nUntested, but possibly something like this (could be optimized):\r\n\r\n```python\r\n\r\nfrom contextlib import contextmanager\r\n\r\n@contextmanager\r\ndef with_schema(models, schema):\r\n orig = []\r\n for model in models:\r\n orig.append(model._meta.schema)\r\n model._meta.schema = schema\r\n G = model._meta.model_graph(refs=True, backrefs=True) # Traverse all fks.\r\n for _, rel_model, _ in G:\r\n rel_model._meta.schema = schema\r\n yield\r\n for model, schema in zip(models, orig):\r\n model._meta.schema = schema\r\n G = model._meta.model_graph(refs=True, backrefs=True)\r\n for _, rel_model, _ in G:\r\n rel_model._meta.schema = schema\r\n```"
] | 2019-09-20T13:00:28 | 2019-09-20T13:37:01 | 2019-09-20T13:37:01 |
NONE
| null |
Is there any way to specify schema at runtime?
This is specific to postgresql.
**Pseudo code**
```python
class Post(Model):
title = TextField()
class Meta:
def schema_name():
return 'site' + appcontext.tenant_id
```
```python
appcontext.tenant = 13
Post.get(Post.title == 'thanks charles')
# sql: select * from site13.post
```
**Some context**: I am trying to evaluate with different approaches to design a multi-tenant app using postgresql+peewee
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2020/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2020/timeline
| null |
completed
| null | null |
https://api.github.com/repos/coleifer/peewee/issues/2019
|
https://api.github.com/repos/coleifer/peewee
|
https://api.github.com/repos/coleifer/peewee/issues/2019/labels{/name}
|
https://api.github.com/repos/coleifer/peewee/issues/2019/comments
|
https://api.github.com/repos/coleifer/peewee/issues/2019/events
|
https://github.com/coleifer/peewee/issues/2019
| 495,676,074 |
MDU6SXNzdWU0OTU2NzYwNzQ=
| 2,019 |
'autoconnect' unused in 'PostgresqlExtDatabase'
|
{
"login": "wibimaster",
"id": 626666,
"node_id": "MDQ6VXNlcjYyNjY2Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/626666?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wibimaster",
"html_url": "https://github.com/wibimaster",
"followers_url": "https://api.github.com/users/wibimaster/followers",
"following_url": "https://api.github.com/users/wibimaster/following{/other_user}",
"gists_url": "https://api.github.com/users/wibimaster/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wibimaster/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wibimaster/subscriptions",
"organizations_url": "https://api.github.com/users/wibimaster/orgs",
"repos_url": "https://api.github.com/users/wibimaster/repos",
"events_url": "https://api.github.com/users/wibimaster/events{/privacy}",
"received_events_url": "https://api.github.com/users/wibimaster/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Nice find. I need to fix, thanks."
] | 2019-09-19T09:19:09 | 2019-09-19T11:37:52 | 2019-09-19T11:37:52 |
NONE
| null |
Hi !
I'm using Peewee for a Postgres database connection.
The latest documentation says "If you would like to use these awesome features, use the PostgresqlExtDatabase from the playhouse.postgres_ext module", so.. That's what I did :D
But I need the "autoconnect=False" feature, to handle the connection on my own and avoid timeout issues (Peewee never reconnects on its own).
I tried and see that this feature works with "PostgresqlDatabase", but not "PostgresqlExtDatabase" from playhouse..
Is it an oversight or a will?
Thanks !
|
{
"url": "https://api.github.com/repos/coleifer/peewee/issues/2019/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/coleifer/peewee/issues/2019/timeline
| null |
completed
| null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.