
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 12,826 | closed | Allow the use of tensorflow datasets having UNKNOWN_CARDINALTY for TFTrainer | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
I am currently working on a project which requires huggingface and tensorflow. I created a huggingface dataset and converted it into tensorflow dataset using `from_generator()`, instead of `from_tensor_slices()` like the example in the docs. The dataset that I am using is very big, hence, it takes a lot of time for it to get converted into a tensor using dictionary comprehension. `from_generator()` handles this well by processing the data on-the-fly. Tensorflow allows training via datasets having UNKNOWN_CARDINALITY. I would like to suggest the same to be implemented in TFTrainer.
| 07-21-2021 09:43:19 | 07-21-2021 09:43:19 | Hi! We're actually trying to deprecate the use of TFTrainer at the moment in favour of Keras - there will be a deprecation warning about this in the next release of Transformers. Using Keras you can train with a generator or tf.data.Dataset without problems.
In addition, we're looking to improve our Tensorflow integration in other ways, such as by making it easier to load huggingface datasets as Tensorflow datasets, which might allow us to retain the cardinality information regardless. This second part is still a work in progress, though!<|||||>> Hi! We're actually trying to deprecate the use of TFTrainer at the moment in favour of Keras - there will be a deprecation warning about this in the next release of Transformers. Using Keras you can train with a generator or tf.data.Dataset without problems.
>
> In addition, we're looking to improve our Tensorflow integration in other ways, such as by making it easier to load huggingface datasets as Tensorflow datasets, which might allow us to retain the cardinality information regardless. This second part is still a work in progress, though!
That's great! Looking forward to the next release!:smile:<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,825 | closed | TFBertModel much slower on GPU than BertModel | ## Environment info
- `transformers` version: 4.8.2
- Platform: Linux-5.8.0-55-generic-x86_64-with-glibc2.31
- Python version: 3.9.5
- PyTorch version (GPU?): 1.9.0 (True)
- Tensorflow version (GPU?): 2.5.0 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik, @Rocketknight1
## Information
Hello,
I have an GPU issue using BertModel with Pytorch 1.9.0 (OK) and Tensorflow 2.5.0 (very slow).
I'm trying to get vectors for each token of a sentence. The following minimal working example takes 15 seconds to process an (identical) sentence 2000 times (on a RTX 3090, cudatoolkit 11.1.74). GPU usage is about 30%
```
text = "this is a very simple sentence for which I need word piece vectors ."
def test_torch():
import torch
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
model = BertModel.from_pretrained("bert-base-multilingual-cased")
model = model.cuda()
start = time.time()
for x in range(2000):
words = tokenizer.cls_token + text + tokenizer.sep_token # add [CLS] and [SEP] around sentence
tokenids = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(words))
#print(tokenids)
token_tensors=torch.tensor([tokenids])
with torch.no_grad():
last_layer_features = model(token_tensors.cuda())[0]
#print(last_layer_features)
end = time.time()
print("%d seconds" % (end-start))
```
whereas using Tensorflow the same takes 130 seconds (and the GPU usage is about 4%):
```
def test_tf2():
import tensorflow as tf
from transformers import TFBertModel, BertTokenizer
with tf.device("/gpu:0"):
tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
model = TFBertModel.from_pretrained("bert-base-multilingual-cased")
#model = model.gpu() # does not exist
start = time.time()
for x in range(2000):
words = tokenizer.cls_token + text + tokenizer.sep_token # add [CLS] and [SEP] around sentence
tokenids = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(words))
token_tensors = tf.convert_to_tensor([tokenids])
#with torch.no_grad():
last_layer_features = model(token_tensors.gpu(), training=False)[0]
end = time.time()
print("%d seconds" % (end-start))
```
So obviously I do not copy things correctly to the GPUs in the Tensorflow example. Does anyone have an idea what is wrong here?
| 07-21-2021 09:04:23 | 07-21-2021 09:04:23 | This is more of a TF issue than a Transformers one - eager TF can be quite inefficient, especially when you're repeatedly calling it with small inputs. In TF you can 'compile' a Python function or model call - this is analogous to using TorchScript in PyTorch, but is much more common and integrated into the main library - e.g. Keras almost always compiles models before running them.
I tested your code with compilation and I got a speedup of 8x-10x, so I'd recommend using that. You can just add `model = tf.function(model)` before the loop, or for even higher performance on recent versions of TF you can use `model = tf.function(model, jit_compile=True)`. Alternatively, all of our models are Keras models, and if you run using the Keras API methods like fit() and predict(), all of the details of compilation and feeding data will be handled for you, and performance will usually be very good.
For more, I wrote a reddit post on the Keras approach with our library [here](https://www.reddit.com/r/MachineLearning/comments/ok81v4/n_tf_keras_and_transformers/), including links to example scripts.
You can also see a guide on using `tf.function` as a call or a decorator [here](https://www.tensorflow.org/guide/function).<|||||>Note that this code is a little bit sloppy - you'll ordinarily want to write the whole function that does what you want, and then call or decorate that function with `tf.function`, as explained in the TF docs. `tf.function(model)` works fine for this small example, but will cause problems if you then later want to use the model object for other things, such as using the Keras API with it.<|||||>Thanks for your reply ! I checked tf.function(model) and it works nicely. However my MWE was too minimal. In reality every sentence is different in wording and length. So I had to add a padding to make sure that all sentences have an equal (maximal) length, and now my "real" code is running as fast as pytorch. Apparently pytorch pads auto-magically, but in Tensorflow I have to do it manually. Anyway, it works! <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,824 | closed | Can't use padding in Wav2Vec2Tokenizer. TypeError: '<' not supported between instances of 'NoneType' and 'int'. | # **Questions & Help**
## Details
I'm trying to get a Tensor of labels from a text in order to train a Wav2Vec2ForCTC from scratch but apparently pad_token_id is set to NoneType, even though I've set a pad_token in my Tokenizer.
This is my code:
```
# Generating the Processor
from transformers import Wav2Vec2CTCTokenizer
from transformers import Wav2Vec2FeatureExtractor
from transformers import Wav2Vec2Processor
tokenizer = Wav2Vec2CTCTokenizer("./vocab.json", unk_token = "[UNK]", pad_token = "[PAD]", word_delimiter_token="|")
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=sampling_rate, padding_value=0.0, do_normalize=True, return_attention_mask=False)
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
with processor.as_target_processor():
batch["labels"] = processor(batch["text"], padding = True, max_length = 1000, return_tensors="pt").input_ids
```
Error message is this:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-8-45831c0137f6> in <module>
9
10 # Processing
---> 11 data = prepare(data)
12 data["input"] = data["input"][0]
13 data["input"] = np.array([inp.T.reshape(12*4096) for inp in data["input"]])
<ipython-input-4-aaba15f24a61> in prepare(batch)
29 # Texts
30 with processor.as_target_processor():
---> 31 batch["labels"] = processor(batch["text"], padding = True, max_length = 1000, return_tensors="pt").input_ids
32
33 return batch
~/anaconda3/lib/python3.8/site-packages/transformers/models/wav2vec2/processing_wav2vec2.py in __call__(self, *args, **kwargs)
115 the above two methods for more information.
116 """
--> 117 return self.current_processor(*args, **kwargs)
118
119 def pad(self, *args, **kwargs):
~/anaconda3/lib/python3.8/site-packages/transformers/tokenization_utils_base.py in __call__(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
2252 if is_batched:
2253 batch_text_or_text_pairs = list(zip(text, text_pair)) if text_pair is not None else text
-> 2254 return self.batch_encode_plus(
2255 batch_text_or_text_pairs=batch_text_or_text_pairs,
2256 add_special_tokens=add_special_tokens,
~/anaconda3/lib/python3.8/site-packages/transformers/tokenization_utils_base.py in batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
2428
2429 # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
-> 2430 padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
2431 padding=padding,
2432 truncation=truncation,
~/anaconda3/lib/python3.8/site-packages/transformers/tokenization_utils_base.py in _get_padding_truncation_strategies(self, padding, truncation, max_length, pad_to_multiple_of, verbose, **kwargs)
2149
2150 # Test if we have a padding token
-> 2151 if padding_strategy != PaddingStrategy.DO_NOT_PAD and (not self.pad_token or self.pad_token_id < 0):
2152 raise ValueError(
2153 "Asking to pad but the tokenizer does not have a padding token. "
TypeError: '<' not supported between instances of 'NoneType' and 'int'
```
I've also tried seting the pad_token with tokenizer.pad_token = "[PAD]". It didn't work.
Does anyone know what I'm doing wrong? Thanks. | 07-21-2021 09:03:14 | 07-21-2021 09:03:14 | @mrcolorblind It's difficult to reproduce your error as many of the variables in your code snippet aren't set and I don't know where `"./vocab.json"` comes from.
However the following code snippet works:
```python
from transformers import Wav2Vec2CTCTokenizer, Wav2Vec2FeatureExtractor, Wav2Vec2Processor
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=False)
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
with processor.as_target_processor():
labels = processor(["hello", "hey", "a"], padding = True, max_length = 1000, return_tensors="pt").input_ids
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@patrickvonplaten @patrickvonplaten I have the same error here, any help?<|||||>@patrickvonplaten me too. any help?<|||||>Could you guys please add a reproducible code snippet that I can debug? :-) Thanks!<|||||>I am getting the same error when I am trying to use gpt2 tokenizer. I am trying to fine tune bert2gpt2 encoder decoder model with your training scripts here: https://huggingface.co/patrickvonplaten/bert2gpt2-cnn_dailymail-fp16
I tried transformers 4.15.0 and 4.6.0 both of them didn't work. |
transformers | 12,823 | closed | Fix generation docstrings regarding input_ids=None | # What does this PR do?
The docstrings incorrectly describe what happens if no input_ids are passed. This PR changes the docstrings so that the actual behavior is described.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
Documentation: @sgugger
| 07-21-2021 08:57:22 | 07-21-2021 08:57:22 | Thanks for reviewing!
The merge conflict has been resolved. |
transformers | 12,822 | closed | label list in MNLI dataset | ## Environment info
- `transformers` version:
- Platform: centos7.2
- Python version: Python3.6.8
- PyTorch version (GPU?): None
- Tensorflow version (GPU?): None
- Using GPU in script?: None
- Using distributed or parallel set-up in script?: None
### Who can help
Models:
- albert, bert, xlm: @LysandreJik
## Information
Model I am using bert-base-uncased-mnli
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: MNLI
* [ ] my own task or dataset:
## To reproduce
When processiong label list for MNLI tasks, I noticed lable_list is defined different in Huggingface transformer and Hugging face dataset.
### label list in datasets
If I load my data via datasets:
```
import datasets
from datasets import load_dataset, load_metric
raw_datasets = load_dataset("glue", 'mnli')
print(raw_datasets['validation_matched'].features['label'].names)
```
It returns:
```
['entailment', 'neutral', 'contradiction']
```
And label is also mentioned in document: https://huggingface.co/datasets/glue.
```
mnli
premise: a string feature.
hypothesis: a string feature.
label: a classification label, with possible values including entailment (0), neutral (1), contradiction (2).
idx: a int32 feature.
```
### label list in transoformers
But in huggingface transformers:
```
processor = transformers.glue_processors['mnli']()
label_list = processor.get_labels()
print(label_list)
```
It returns:
```
['contradiction', 'entailment', 'neutral']
```
### label configs
I checked the config used in datasets which is downloaded from https://raw.githubusercontent.com/huggingface/datasets/1.8.0/datasets/glue/glue.py.
The defination for label_classes is:
```
label_classes=["entailment", "neutral", "contradiction"],
```
And in transformer master, it is defined in function: https://github.com/huggingface/transformers/blob/15d19ecfda5de8c4b50e2cd3129a16de281dbd6d/src/transformers/data/processors/glue.py#L247
It's confusing that same MNLI tasks uses different label order in datasets and transformers. I'm expecting it should be same on both datasets and transformers.
| 07-21-2021 08:46:48 | 07-21-2021 08:46:48 | cc @sgugger @lhoestq, and I think @lewtun was also interested in that at some point.<|||||>Note that the label_list in Transformers is deprecated and should not be used anymore.<|||||>Indeed the order between a model's labels and those in a dataset can differ, which is why we've added a `Dataset.align_labels_with_mapping` function in this PR: https://github.com/huggingface/datasets/pull/2457<|||||>Hi @lewtun , @sgugger . Thanks for the quick reply. So label_list won't be supported in tranformers in future, and should be handled by datasets, right? <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi,
Some of the data in dev_mismatched file doesnt have labels, how should we get accurary from them?
|
transformers | 12,821 | closed | Any example to accelerate BART/MBART model with onnx runtime? | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Transformers.onnx provided a simple way to convert the bart/mbart model to onnx model. But there is no example about how these model could be actually exc by onnx runtime. Bucause some onnx models may occur various of errors. Could you please provide some examples about using onnx runtime to exc these models ?
| 07-21-2021 08:43:59 | 07-21-2021 08:43:59 | The transformer.onnx provides a simple to convert hf models to onnx models. But there is no examples about how to exc them by onnx runtime. Some onnx models actually would meet some errors exc with onnx runtime. Could you please provide some examples and experiments about running them with onnx runtime? |
transformers | 12,820 | closed | fix typo in gradient_checkpointing metadata | help for [ModelArguments.gradient_checkpointing] should be
"If True, use gradient checkpointing to save memory
at the expense of slower backward pass."
not "Whether to freeze the feature extractor layers of the model."
(which is duplicated from [freeze_feature_extractor])
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes Typo
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-21-2021 08:29:09 | 07-21-2021 08:29:09 | |
transformers | 12,819 | closed | Converting a tensor to a python boolean might cause the trace to be incorrect. We can't record the data flow of python values | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: CENTOS 8.
- Python version: 3.7
- PyTorch version (GPU?): 1.9.0 + cuda
- Tensorflow version (GPU?): No
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
@patrickvonplaten, @patil-suraj @LysandreJik
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
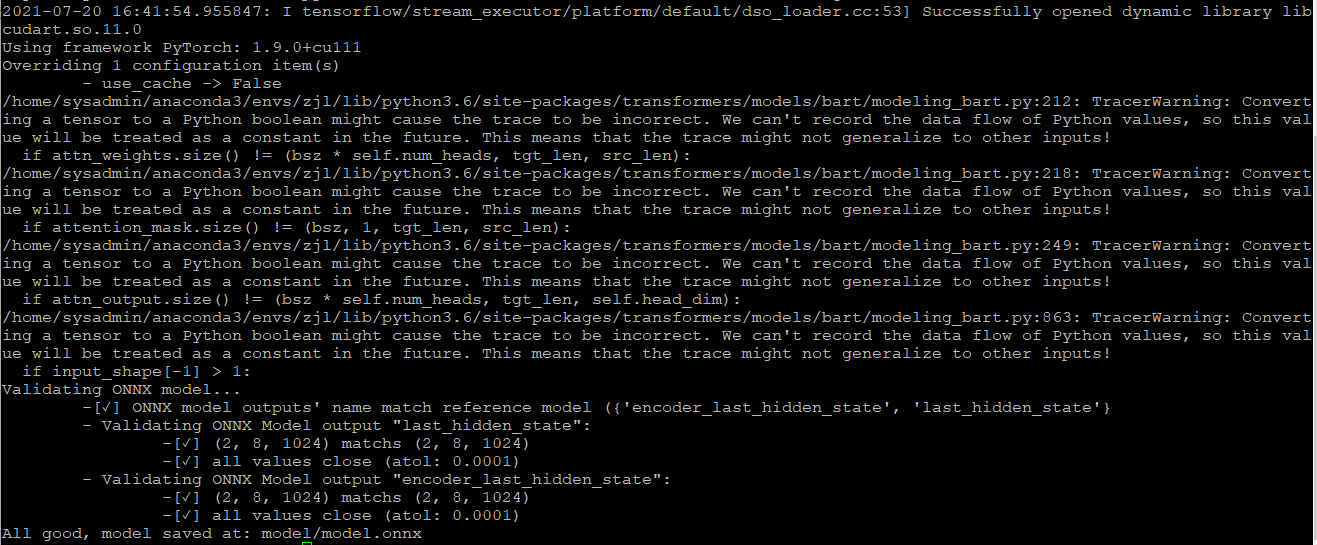
I convert the hugging face bart model to onnx model using transformer.onnx (thanks for the excellent tools). But these warnings occured and they may have a influencec on the performance of model.
| 07-21-2021 06:38:33 | 07-21-2021 06:38:33 | Hi @leoozy, you should safely disregard these warnings. The warnings should only apply to assertions we make to ensure that the input shape passed is correct.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,818 | closed | Refer warmup_ratio when setting warmup_num_steps. | # What does this PR do?
This PR fixes the bug that DeepSpeed schduler does not refer warmup_ratio argument, although DeepSpeed schduler refers warmup_steps argument. This contradicts to the warning message "Both warmup_ratio and warmup_steps given, warmup_steps will override any effect of warmup_ratio during training" defined in training_args.py L.700.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Because this PR relates to DeepSpeed integration, I hope @stas00 may review this. | 07-21-2021 04:19:28 | 07-21-2021 04:19:28 | Thank you for your PR, @tsuchm
I'm trying to understand what you're trying to accomplish and could use some help from you.
Did I understand you correctly that you're saying that Deepspeed integration ignores the `--warmup_ratio` argument and you're proposing how to integrate it? I agree that it could be integrated.
In which case the logic should be the same as in:
https://github.com/huggingface/transformers/blob/cabcc75171650f9131a4cf31c62e1f102589014e/src/transformers/trainer.py#L825-L828
so that `--warmup_steps` takes precedence and we are matching HF Trainer consistently.
The part that I didn't get is what does this have to do with the warning from:
https://github.com/huggingface/transformers/blob/cabcc75171650f9131a4cf31c62e1f102589014e/src/transformers/training_args.py#L724-L727
Thank you.<|||||>> Did I understand you correctly that you're saying that Deepspeed integration ignores the --warmup_ratio argument and you're proposing how to integrate it? I agree that it could be integrated.
Yes, your understanding is correct.
> In which case the logic should be the same as in:
Yes, my PR also aimed to reproduce your pointed code, and I agree that my PR is not exactly equal to your pointed code.
I however think that if you, the development team, hope that these two fragments are exactly same, it is better to abstract them into a function than to copy it. Unfortunately, I do not have enough knowledge to abstract them.
> The part that I didn't get is what does this have to do with the warning from:
I am sorry for my confusing comment. My aim to quote the above warning is simply to indicate that this behavior (DeepSpeed scheduler does not refer warmup_ratio argument) does not match the action that we users expect. I think that no fix for this warning message is necessary. <|||||>I totally agree on all accounts. Thank you for the clarification.
Would you like me to push the changes into your PR branch or would you rather try to do it yourself with my guidance?
Basically this code:
```
warmup_steps = (
self.args.warmup_steps
if self.args.warmup_steps > 0
else math.ceil(num_training_steps * self.args.warmup_ratio)
```
can be made into a method around the same place, e.g. `def get_warmup_steps(self, num_training_steps)`
and then we can call it in both places, in the same way.
Let me know what you prefer.
p.s. may be it best belongs in `TrainingArguments` - let's ask @sgugger where he prefers such wrapper to reside. but for now edit it in place as I suggested if you'd like to try to work it out by yourself.
<|||||>I agree your opinion. I tried to add a new method to get number of warmup steps to TrainingArguments class. Unfortunately, my using environment uses the version 4.8.2, thus, I confirmed my proposal works on the version 4.8.2, and backported it to the main branch.
Could you review my PR?<|||||>a gentle note to reviewers: please don't forget the docs.
Fixed here: https://github.com/huggingface/transformers/pull/12830<|||||>I'm sorry I missed the documentation inside `deepsped`, the main point of the PR was that it was documented a certain way in `training_args.py` and not enforced.<|||||>That's alright, @sgugger. I was just asleep to have a chance to review.
My understanding is that the main intention of this PR was to fix the missing functionality in the Deepspeed integration. And in the process other parts of the ecosystem were touched.<|||||>Thanks to all reviewers. Finally, I have just succeeded to reproduce results of a previous research using warmup strategy. |
transformers | 12,817 | closed | tensor size mismatch in NER.py | Hi,
I am trying to classify tokens for a task similar to NER. I am using the following code:
transformers/examples/pytorch/token-classification/run_ner.py
My input data is in JSON format for both train and test. When I perform classification using BioBERT, it runs without any issue. When I use BERT base (cased or uncased), I get the following error in the middle of the training:
Traceback (most recent call last):
File "/home/tv349/PharmaBERT/transformers/examples/pytorch/token-classification/run_ner.py", line 530, in <module>
main()
File "/home/tv349/PharmaBERT/transformers/examples/pytorch/token-classification/run_ner.py", line 463, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/home/tv349/.conda/envs/HF/lib/python3.8/site-packages/transformers/trainer.py", line 1269, in train
tr_loss += self.training_step(model, inputs)
File "/home/tv349/.conda/envs/HF/lib/python3.8/site-packages/transformers/trainer.py", line 1754, in training_step
loss = self.compute_loss(model, inputs)
File "/home/tv349/.conda/envs/HF/lib/python3.8/site-packages/transformers/trainer.py", line 1786, in compute_loss
outputs = model(**inputs)
File "/home/tv349/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/tv349/.conda/envs/HF/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line 1712, in forward
outputs = self.bert(
File "/home/tv349/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/tv349/.conda/envs/HF/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line 984, in forward
embedding_output = self.embeddings(
File "/home/tv349/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/tv349/.conda/envs/HF/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line 221, in forward
embeddings += position_embeddings
RuntimeError: The size of tensor a (607) must match the size of tensor b (512) at non-singleton dimension 1
Also, this is how I call the function:
python transformers/examples/pytorch/token-classification/run_ner.py \
--model_name_or_path $model_path \
--train_file $train_file \
--validation_file $validation_file \
--output_dir $root_output_dir \
--overwrite_output_dir \
--do_train \
--do_eval
I don't think the problem is in my input data or setting because everything works for BioBERT, but failed for BERT base.
Could you please let me know what can I do to avoid this issue?
Thanks! | 07-21-2021 02:57:35 | 07-21-2021 02:57:35 | cc @sgugger <|||||>Mmm the problem looks like it's coming from the position embedding with an input of size 607, which is larger than 512 (the maximum handled apparently).<|||||>Thanks for the response. But why do you think it works for BioBert and not BERT base?<|||||>Will it help if I provide my training data?<|||||>Anything that could helps us reproduce the issue would help, yes.<|||||>> But why do you think it works for BioBert and not BERT base?
It seems this is happening due to the [`model_max_length`] property in `tokenizer_config.json`. So far I could understand from the [docs], setting this property to a value will trim the tokens while tokenization (please, correct me if I am wrong).
[`tokenizer_config.json` of biobert] sets `model_max_length=512`. But in case of bert-base [cased] or [uncased], `model_max_length` is not specified.
[`model_max_length`]: https://huggingface.co/transformers/internal/tokenization_utils.html?highlight=model_max_length#transformers.tokenization_utils_base.PreTrainedTokenizerBase
[docs]: https://huggingface.co/transformers/internal/tokenization_utils.html?highlight=model_max_length#transformers.tokenization_utils_base.PreTrainedTokenizerBase
[`tokenizer_config.json` of biobert]: https://huggingface.co/dmis-lab/biobert-v1.1/blob/main/tokenizer_config.json
[cased]: https://huggingface.co/bert-base-cased/blob/main/tokenizer_config.json
[uncased]: https://huggingface.co/bert-base-uncased/blob/main/tokenizer_config.json<|||||>Yes, that is very likely the case. I think the script is simply missing a `max_seq_length` parameter (like there is for text classification for instance) that the user should set when the `model_max_length` is either too large or simply missing.
I will add that tomorrow.<|||||>Adding model_max_length=512 to the tokenizer_config.json solved the issue. Thank you very much!<|||||>@sgugger that would be a great idea. I was looking for that option but couldn't find it. Thank you very much for your consideration. |
transformers | 12,816 | closed | [debug] DebugUnderflowOverflow doesn't work with DP | As reported in https://github.com/huggingface/transformers/issues/12815 `DebugUnderflowOverflow` breaks under DP since the model gets new references to model sub-modules/params on replication and the old references are needed to track the model layer names.
It might be possible to think of some workaround, most likely overriding `torch.nn.parallel.data_parallel.replicate` to refresh the model references after the replication, but at the moment this is not required, since DDP works just fine. (or single GPU).
So this PR adds a clean assert when DP is used, instead of a confusing exception. Update docs.
Fixes: https://github.com/huggingface/transformers/issues/12815
@sgugger | 07-21-2021 01:18:58 | 07-21-2021 01:18:58 | |
transformers | 12,815 | closed | DebugUnderflowOverflow crashes with Multi-GPU training | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.8.2
- Platform: Linux-4.15.0-29-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
### Who can help
@stas00
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): Bart (but this is inessential)
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Instantiate a `debug_utils.DebugUnderflowOverflow` for a model (I do this with `debug="underflow_overflow"` to a `TrainingArguments`).
2. Train using multi-GPU setup.
3. the debug hook added by `DebugUnderflowOverflow` to run after `forward()` will crash because of a bad lookup in the class's `module_names` dict.
This does not happen on single-GPU training.
Here's an example that crashes if I run on my (4-GPU) machine, but does **not** crash if I restrict to a single GPU (by calling `export CUDA_VISIBLE_DEVICES=0` before invoking the script):
```
from torch.utils.data import Dataset
from transformers import (BartForConditionalGeneration, BartModel, BartConfig,
Seq2SeqTrainingArguments, Seq2SeqTrainer)
class DummyDataset(Dataset):
def __len__(self):
return 5
def __getitem__(self, idx):
return {'input_ids': list(range(idx, idx+3)),
'labels': list(range(idx, idx+3))}
def main():
train_dataset = DummyDataset()
config = BartConfig(vocab_size=10, max_position_embeddings=10, d_model=8,
encoder_layers=1, decoder_layers=1,
encoder_attention_heads=1, decoder_attention_heads=1,
decoder_ffn_dim=8, encoder_ffn_dim=8)
model = BartForConditionalGeneration(config)
args = Seq2SeqTrainingArguments(output_dir="tmp", do_train=True,
debug="underflow_overflow")
trainer = Seq2SeqTrainer(model=model, args=args, train_dataset=train_dataset)
trainer.train()
if __name__ == '__main__':
main()
```
I get the following stack trace on my multi-GPU machine:
```
Traceback (most recent call last):
File "./kbp_dbg.py", line 29, in <module>
main()
File "./kbp_dbg.py", line 26, in main
trainer.train()
File "[...]/transformers/trainer.py", line 1269, in train
tr_loss += self.training_step(model, inputs)
File "[...]/transformers/trainer.py", line 1762, in training_step
loss = self.compute_loss(model, inputs)
File "[...]/transformers/trainer.py", line 1794, in compute_loss
outputs = model(**inputs)
File "[...]/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "[...]/torch/nn/parallel/data_parallel.py", line 168, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "[...]/torch/nn/parallel/data_parallel.py", line 178, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "[...]/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
output.reraise()
File "[...]/torch/_utils.py", line 425, in reraise
raise self.exc_type(msg)
KeyError: Caught KeyError in replica 0 on device 0.
Original Traceback (most recent call last):
File "[...]/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "[...]/torch/nn/modules/module.py", line 1071, in _call_impl
result = forward_call(*input, **kwargs)
File "[...]/transformers/models/bart/modeling_bart.py", line 1308, in forward
return_dict=return_dict,
File "[...]/torch/nn/modules/module.py", line 1071, in _call_impl
result = forward_call(*input, **kwargs)
File "[...]/transformers/models/bart/modeling_bart.py", line 1173, in forward
return_dict=return_dict,
File "[...]/torch/nn/modules/module.py", line 1071, in _call_impl
result = forward_call(*input, **kwargs)
File "[...]/transformers/models/bart/modeling_bart.py", line 756, in forward
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
File "[...]/torch/nn/modules/module.py", line 1076, in _call_impl
hook_result = hook(self, input, result)
File "[...]/transformers/debug_utils.py", line 246, in forward_hook
self.create_frame(module, input, output)
File "[...]/transformers/debug_utils.py", line 193, in create_frame
self.expand_frame(f"{self.prefix} {self.module_names[module]} {module.__class__.__name__}")
KeyError: Embedding(10, 8, padding_idx=1)
```
And, again, it completes totally fine if you restrict visibility to a single GPU via `CUDA_VISIBLE_DEVICES` before running this.
Having looked into it, I strongly suspect what's happening is the following:
- the `DebugUnderflowOverflow` instantiated in `Trainer.train` populates a `module_names` dict from nn.Modules to names in its constructor [(link)](https://github.com/huggingface/transformers/blob/master/src/transformers/debug_utils.py#L182)
- If multi-gpu training is enabled, `nn.DataParallel` is called (I think [here in trainer.py](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py#L943)).
- this calls `torch.nn.replicate` on its forward pass [(link)](https://github.com/pytorch/pytorch/blob/master/torch/nn/parallel/data_parallel.py#L167), which I believe calls `nn.Module._replicate_for_data_parallel()` [here](https://github.com/pytorch/pytorch/blob/master/torch/nn/parallel/replicate.py#L115), replicating the model once per GPU.
- This results in different `hash()` values for the replicated `nn.Module` objects across different GPUs, in general.
- Finally, the `module_names` lookup in `create_frame()` will crash on the GPUs, since the differently replicated `nn.Module` objects on which the forward-pass hooks are called now have different `hash()` values after multi-GPU replication.
(You can confirm that a module has different hash values after replication via the following snippet):
```
m = torch.nn.Embedding(7, 5)
m2 = m._replicate_for_data_parallel()
print(hash(m))
print(hash(m2))
```
Which will print something like:
```
8730470757753
8730462809617
```
Not sure what the best way to fix this is. If there's a way to instantiate a different `DebugUnderflowOverflow` for each GPU, after replication, that will maybe solve this issue (since per-replica hashes will assumedly be consistent then), but I'm not sure if that's feasible or the best way to do this.
One could also just make the miscreant f-string construction in `create_frame` have a `.get()` with a default as the `module_names` lookup, rather than using square brackets, but this would probably make the debugging traces too uninformative. So I figured I'd just open a bug
## Expected behavior
I'd expect it to either not crash or print a fatal `overflow/underflow debug unsupported for multi-GPU` error or something. I originally thought this was a bug in the model code rather than a multi-GPU thing.
| 07-20-2021 21:59:35 | 07-20-2021 21:59:35 | Thank you for the great report and the analysis of the problem, @kpich.
I will have a look a bit later when I have time to solve this, including your suggestion.
Meanwhile, any special reason why you're using DP and not DDP (`torch.distributed.launch`)? There each GPU instantiates its own everything and it will work correctly. <|||||>No, only reason I'm using DP rather than DDP is I'm using the `Trainer` framework with its default behaviors on a multi-GPU machine. Using DDP is a good suggestion, thanks!<|||||>DDP is typically faster than DP (as long as the interconnect is fast), please see: https://huggingface.co/transformers/performance.html#dp-vs-ddp<|||||>As a first step, here is a simple reproduction of the OP report with this cmd w/ 2 gpus over DP:
```
export BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0,1 python \
examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --output_dir \
output_dir --adam_eps 1e-06 --do_train --label_smoothing 0.1 --learning_rate 3e-5 \
--logging_first_step --logging_steps 500 --max_source_length 128 --max_target_length 128 \
--val_max_target_length 128 --num_train_epochs 1 --overwrite_output_dir \
--per_device_train_batch_size $BS --predict_with_generate --sortish_sampler --source_lang en \
--target_lang ro --dataset_name wmt16 --dataset_config "ro-en" --source_prefix "translate English to \
Romanian: " --warmup_steps 50 --max_train_samples 50 --debug underflow_overflow
```
gives a similar error.<|||||>Nothing comes to mind as a simple fix at the moment, so for now let's just do a clean assert as you suggested. https://github.com/huggingface/transformers/pull/12816
If someone is stuck and can't use DDP we will revisit this.
And of course, if you or someone would like to work on an actual solution it'd be very welcome. I don't see `nn.DataParallel` having any hooks, so most likely this will require overriding `torch.nn.parallel.data_parallel.replicate` to refresh the model references after the replication. You can see the source code here: https://pytorch.org/docs/stable/_modules/torch/nn/parallel/data_parallel.html#DataParallel So it can be done, but it is not really worth it, IMHO. |
transformers | 12,814 | closed | minor mistake in the documentation of XLMTokenizer | On [this page](https://huggingface.co/transformers/model_doc/xlm.html#xlmtokenizer), the default value of `cls_token` is given as `</s>` whereas it should be `<s>`.
Please fix it.
| 07-20-2021 21:10:38 | 07-20-2021 21:10:38 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,813 | closed | Update pyproject.toml | You don't support Python 3.5, so I've bumped the black `target-version` to `'py36'`. | 07-20-2021 20:12:19 | 07-20-2021 20:12:19 | |
transformers | 12,812 | closed | Expose get_config() on ModelTesters | This exposes the `get_config()`method on `XXXModelTester`s. It makes it accessible in a platform-agnostic way, so that utilities may use that value to obtain a tiny configuration for tests even if `torch` isn't installed.
Part of the pipeline refactor, which needs to have tiny configurations for all models. | 07-20-2021 13:57:39 | 07-20-2021 13:57:39 | |
transformers | 12,811 | closed | Add _CHECKPOINT_FOR_DOC to all models | This adds the `_CHECKPOINT_FOR_DOC` variable for all models that do not have it. This value is used in the pipeline tests refactoring, where all models/tokenizers compatible with a given pipeline are tested. To that end, it is important to have a source of truth as to which checkpoint is well maintained, which should be the case of the `_CHECKPOINT_FOR_DOC` that is used in the documentation. | 07-20-2021 13:46:30 | 07-20-2021 13:46:30 | |
transformers | 12,810 | closed | [CLIP/docs] add and fix examples | # What does this PR do?
Adds examples in PyTorch model docstrings also fixes rendering issues in flax model docstring. | 07-20-2021 12:14:03 | 07-20-2021 12:14:03 | |
transformers | 12,809 | closed | [Longformer] Correct longformer docs | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-20-2021 11:36:01 | 07-20-2021 11:36:01 | |
transformers | 12,808 | closed | https://huggingface.co/facebook/detr-resnet-101-panoptic model has 250 classes ? | coco data has 80 classes.
why the model has 250 classes
id2label: {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2",
"3": "LABEL_3",
"4": "LABEL_4",
"5": "LABEL_5",
"6": "LABEL_6",
"7": "LABEL_7",
"8": "LABEL_8",
"9": "LABEL_9",
"10": "LABEL_10",
"11": "LABEL_11",
"12": "LABEL_12",
"13": "LABEL_13",
"14": "LABEL_14",
"15": "LABEL_15",
"16": "LABEL_16",
"17": "LABEL_17",
"18": "LABEL_18",
"19": "LABEL_19",
"20": "LABEL_20",
"21": "LABEL_21",
"22": "LABEL_22",
"23": "LABEL_23",
"24": "LABEL_24",
"25": "LABEL_25",
"26": "LABEL_26",
"27": "LABEL_27",
"28": "LABEL_28",
"29": "LABEL_29",
"30": "LABEL_30",
"31": "LABEL_31",
"32": "LABEL_32",
"33": "LABEL_33",
"34": "LABEL_34",
"35": "LABEL_35",
"36": "LABEL_36",
"37": "LABEL_37",
"38": "LABEL_38",
"39": "LABEL_39",
"40": "LABEL_40",
"41": "LABEL_41",
"42": "LABEL_42",
"43": "LABEL_43",
"44": "LABEL_44",
"45": "LABEL_45",
"46": "LABEL_46",
"47": "LABEL_47",
"48": "LABEL_48",
"49": "LABEL_49",
"50": "LABEL_50",
"51": "LABEL_51",
"52": "LABEL_52",
"53": "LABEL_53",
"54": "LABEL_54",
"55": "LABEL_55",
"56": "LABEL_56",
"57": "LABEL_57",
"58": "LABEL_58",
"59": "LABEL_59",
"60": "LABEL_60",
"61": "LABEL_61",
"62": "LABEL_62",
"63": "LABEL_63",
"64": "LABEL_64",
"65": "LABEL_65",
"66": "LABEL_66",
"67": "LABEL_67",
"68": "LABEL_68",
"69": "LABEL_69",
"70": "LABEL_70",
"71": "LABEL_71",
"72": "LABEL_72",
"73": "LABEL_73",
"74": "LABEL_74",
"75": "LABEL_75",
"76": "LABEL_76",
"77": "LABEL_77",
"78": "LABEL_78",
"79": "LABEL_79",
"80": "LABEL_80",
"81": "LABEL_81",
"82": "LABEL_82",
"83": "LABEL_83",
"84": "LABEL_84",
"85": "LABEL_85",
"86": "LABEL_86",
"87": "LABEL_87",
"88": "LABEL_88",
"89": "LABEL_89",
"90": "LABEL_90",
"91": "LABEL_91",
"92": "LABEL_92",
"93": "LABEL_93",
"94": "LABEL_94",
"95": "LABEL_95",
"96": "LABEL_96",
"97": "LABEL_97",
"98": "LABEL_98",
"99": "LABEL_99",
"100": "LABEL_100",
"101": "LABEL_101",
"102": "LABEL_102",
"103": "LABEL_103",
"104": "LABEL_104",
"105": "LABEL_105",
"106": "LABEL_106",
"107": "LABEL_107",
"108": "LABEL_108",
"109": "LABEL_109",
"110": "LABEL_110",
"111": "LABEL_111",
"112": "LABEL_112",
"113": "LABEL_113",
"114": "LABEL_114",
"115": "LABEL_115",
"116": "LABEL_116",
"117": "LABEL_117",
"118": "LABEL_118",
"119": "LABEL_119",
"120": "LABEL_120",
"121": "LABEL_121",
"122": "LABEL_122",
"123": "LABEL_123",
"124": "LABEL_124",
"125": "LABEL_125",
"126": "LABEL_126",
"127": "LABEL_127",
"128": "LABEL_128",
"129": "LABEL_129",
"130": "LABEL_130",
"131": "LABEL_131",
"132": "LABEL_132",
"133": "LABEL_133",
"134": "LABEL_134",
"135": "LABEL_135",
"136": "LABEL_136",
"137": "LABEL_137",
"138": "LABEL_138",
"139": "LABEL_139",
"140": "LABEL_140",
"141": "LABEL_141",
"142": "LABEL_142",
"143": "LABEL_143",
"144": "LABEL_144",
"145": "LABEL_145",
"146": "LABEL_146",
"147": "LABEL_147",
"148": "LABEL_148",
"149": "LABEL_149",
"150": "LABEL_150",
"151": "LABEL_151",
"152": "LABEL_152",
"153": "LABEL_153",
"154": "LABEL_154",
"155": "LABEL_155",
"156": "LABEL_156",
"157": "LABEL_157",
"158": "LABEL_158",
"159": "LABEL_159",
"160": "LABEL_160",
"161": "LABEL_161",
"162": "LABEL_162",
"163": "LABEL_163",
"164": "LABEL_164",
"165": "LABEL_165",
"166": "LABEL_166",
"167": "LABEL_167",
"168": "LABEL_168",
"169": "LABEL_169",
"170": "LABEL_170",
"171": "LABEL_171",
"172": "LABEL_172",
"173": "LABEL_173",
"174": "LABEL_174",
"175": "LABEL_175",
"176": "LABEL_176",
"177": "LABEL_177",
"178": "LABEL_178",
"179": "LABEL_179",
"180": "LABEL_180",
"181": "LABEL_181",
"182": "LABEL_182",
"183": "LABEL_183",
"184": "LABEL_184",
"185": "LABEL_185",
"186": "LABEL_186",
"187": "LABEL_187",
"188": "LABEL_188",
"189": "LABEL_189",
"190": "LABEL_190",
"191": "LABEL_191",
"192": "LABEL_192",
"193": "LABEL_193",
"194": "LABEL_194",
"195": "LABEL_195",
"196": "LABEL_196",
"197": "LABEL_197",
"198": "LABEL_198",
"199": "LABEL_199",
"200": "LABEL_200",
"201": "LABEL_201",
"202": "LABEL_202",
"203": "LABEL_203",
"204": "LABEL_204",
"205": "LABEL_205",
"206": "LABEL_206",
"207": "LABEL_207",
"208": "LABEL_208",
"209": "LABEL_209",
"210": "LABEL_210",
"211": "LABEL_211",
"212": "LABEL_212",
"213": "LABEL_213",
"214": "LABEL_214",
"215": "LABEL_215",
"216": "LABEL_216",
"217": "LABEL_217",
"218": "LABEL_218",
"219": "LABEL_219",
"220": "LABEL_220",
"221": "LABEL_221",
"222": "LABEL_222",
"223": "LABEL_223",
"224": "LABEL_224",
"225": "LABEL_225",
"226": "LABEL_226",
"227": "LABEL_227",
"228": "LABEL_228",
"229": "LABEL_229",
"230": "LABEL_230",
"231": "LABEL_231",
"232": "LABEL_232",
"233": "LABEL_233",
"234": "LABEL_234",
"235": "LABEL_235",
"236": "LABEL_236",
"237": "LABEL_237",
"238": "LABEL_238",
"239": "LABEL_239",
"240": "LABEL_240",
"241": "LABEL_241",
"242": "LABEL_242",
"243": "LABEL_243",
"244": "LABEL_244",
"245": "LABEL_245",
"246": "LABEL_246",
"247": "LABEL_247",
"248": "LABEL_248",
"249": "LABEL_249"
}
and what is the trully name of the 250 classes?
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| 07-20-2021 11:28:56 | 07-20-2021 11:28:56 | Yes, the authors just set it to a sufficiently high number to make sure all classes are covered. See https://github.com/facebookresearch/detr/issues/175#issue-672014097
Note that for the panoptic model, one combines the COCO instance classes with stuff classes (background things like trees, streets, sky,...). <|||||>thanks a lot bro.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,807 | open | Model Request: Blenderbot 2.0 | # 🌟 New model addition
## Model description
Facebook released Blenderbot 2.0, a chatbot that builds on RAG and Blenderbot 1.0. It can save interactions for later reference and use web search to find information on the web.
https://parl.ai/projects/blenderbot2/
## Open source status
* [x] the model implementation is available: in Parl.ai
* [x] the model weights are available: https://parl.ai/docs/zoo.html#wizard-of-internet-models
* [ ] who are the authors: (mention them, if possible by @gh-username)
| 07-20-2021 11:21:52 | 07-20-2021 11:21:52 | I am interested to work on this. Can we use RAG-end2end ?<|||||>Is there any news regarding Blenderbot 2.0 with huggingface? <|||||>Any new updates? It's been three months.<|||||>Does anyone want to work together on this?<|||||>I'm interested too. FYI https://github.com/JulesGM/ParlAI_SearchEngine.<|||||>+1<|||||>+1 GitHub - shamanez
On Sat, Nov 20, 2021, 23:30 RM ***@***.***> wrote:
> +1
>
> —
> You are receiving this because you commented.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/12807#issuecomment-974628903>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AEA4FGTW5KWREVEYFQT5PUTUM52EPANCNFSM5AVTBZYQ>
> .
>
<|||||>+1 is there any progress for this?<|||||>Hi @AlafateABULIMITI Yes, we are considering adding this model. But since this is a complex model it might take a couple of weeks to fully integrate it. <|||||>+1 <|||||>Really excited for it! I think even without a search engine implementation people would use it, though examples wouldn't hurt!
Also, btw, someone did a simple search engine implementation already here: https://github.com/JulesGM/ParlAI_SearchEngine<|||||>Thank you for sharing this @Darth-Carrotpie <|||||>Is anyone currently working on this or is it's inclusion just being discussed?<|||||>I have started working on it. Should have a PR soon!<|||||>I should probably also mention that using Newspaper (https://pypi.org/project/newspaper3k/) to extract webpage text is slightly cleaner than the custom solution provided in JulesGM's search server implementation! <|||||>@patil-suraj It has been two months since your last post on Blender 2.0. Do you know when it will be included in Transformers? <|||||>Blenderbot2 is obsolete now. See Seeker https://parl.ai/projects/seeker/
Unfortunately, these conversational AIs seems to be a combination bunch of models and/or APIs, so I understand that they enter with difficulty in Huggingface's transformers.
I wrote something to deploy Seeker and its API on Kubernetes:
https://louis030195.medium.com/deploy-seeker-search-augmented-conversational-ai-on-kubernetes-in-5-minutes-81a61aa4e749<|||||>> Blenderbot2 is obsolete now. See Seeker https://parl.ai/projects/seeker/
>
> Unfortunately, these conversational AIs seems to be a combination bunch of models and/or APIs, so I understand that they enter with difficulty in Huggingface's transformers.
>
> I wrote something to deploy Seeker and its API on Kubernetes: https://louis030195.medium.com/deploy-seeker-search-augmented-conversational-ai-on-kubernetes-in-5-minutes-81a61aa4e749
Blenderbot 2 has memory as well as search engine capabilities, so the potential to remember chat topics between sessions. Unless I'm missing something, SeeKeR doesn't seem to have this feature, so I wouldn't call Blenderbot completely obsolete just yet...<|||||>Blenderbot 3 is out now: https://parl.ai/projects/bb3/#models<|||||>Any progress? With ChatGPT and Sparrow, it seems like chatbots are increasing in both relevance and importance in NLP.<|||||>> I have started working on it. Should have a PR soon!
@patil-suraj Could you please create a draft PR or something so that others can pick up where you left off?<|||||>(It seems like he's switched over to working on `diffusers` in the meantime...)<|||||>@ArthurZucker @younesbelkada (the ML engineers currently in charge of the text models)<|||||>Do we have any updates?<|||||>Patil is no longer working on this issue: he's working on diffusers instead. There don't seem to be any active contributors to this issue at the moment.
I would like to contribute at some point, but I'm swamped with my other to-do items.<|||||>Hey, there has not been any progress here! So currently this is not planned by someone on our team, so if you want to pick it up feel free to do so. Also since the ` BlenderBot` model is already supported, unless the architecture is very different, adding the model should be pretty easy with ` transformers-cli add-new-model-like` 😉
But blenderBot is a pretty complex model, so this is not a good first issue and is better fitted for someone who already added a model! 🚀 In that case we'll gladly support and be there to help!
<|||||>+1<|||||>I guess BlenderBot 3x is also out!
https://twitter.com/ylecun/status/1667196416043925505
It might be a good idea to try porting the dataset over to Huggingface and fine-tuning a better base model... |
transformers | 12,806 | closed | Fix tokenizer saving during training with `Trainer` | **EDIT:** If you have already read this message, you can see the update directly in [this message](https://github.com/huggingface/transformers/pull/12806#issuecomment-899570500)
# What does this PR do?
Fixes #12762.
As shown in this issue, a training launched with the `Trainer` object can fail at the time of the saving of the tokenizer if this last one belongs to a tokenizer class that has a slow version and a fast version but that it was instantiated from a folder containing only the files which permit to initialize the fast version.
I think it is important to solve this problem because this case will happen "more often" with the addition of the new feature to train new tokenizers from a known architecture.
To be even more precise, it does not fail in all cases, it depends on the implementation of the `save_vocabulary` method of the slow version. For example, `BertTokenizer` knows how to generate the slow files but `AlbertTokenizer` copies the files from the files in the folder where the tokenizer was initialized.
My PR proposes to add a test in the trainer tests to test this version that fails.
The fix I propose is really to be discussed because it changes the generated files in some cases (Bert's for example) but it seems to me to be the simplest fix.
If we ever want the behavior not to be modified in the case of the Bert tokenizer, we should find a way to know if the `save_vocabulary` method is able to generate the slow version from the fast version or not. I'm not sure I see a simple way to do this - unless we use a `try/except block. What I see as an alternative would be to add a property to all tokenizer classes that would allow knowing if the `save_vocabulary` method can be executed even without the slow versions present in the initial folder.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. @LysandreJik and @sgugger , I would love to hear your thoughts on this PR even though it is certainly not in its final form.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-20-2021 11:20:46 | 07-20-2021 11:20:46 | I don't think this is the right fix: it just hides the problem as `tokenizer.save_pretrained()` should always work. And it should always save all the possible files, to make it easy for users to share their tokenizer with other users that might not have the `tokenizers` or the `sentencepiece` library installed.
Adding a new class property that tells the tokenizer whether it can save the vocabulary from the fast tokenizer sounds the best fix to me, with the try-excepts blocks in the `save_pretrained` method as the second best option.<|||||>**Update**: I have therefore redone this PR to take into account the return of @sgugger. This time, I propose to add a new `can_save_slow_tokenizer` attribute to all fast tokenizers:
- if the tokenizer fast is able to rebuild the files of the tokenizer slow, the attribute is set to `True`
- otherwise it is set to `False`
I use this attribute in ` _save_pretrained` of `PreTrainedTokenizerFast` so that with the default arguments:
- if possible the slow and fast files are saved
- otherwise only fast files are saved
For information, all slow tokenizers using `spm` have now the `can_save_slow_tokenizer`attribute set to `False`, all other tokenizers have their attribute left at `True`.
Failing tests: I don't think this is related to the current PR but I'll have a closer look :thinking: <|||||>You'll probably need to rebase for the tests to pass.<|||||>@sgugger, @LysandreJik, Thank you very much for your reviews! I have normally applied all your suggestions and after the rebase the tests all pass well :smile: <|||||>In that case, feel free to merge your PR :-) |
transformers | 12,805 | closed | What is the data format of transformers language modeling run_clm.py fine-tuning? | I now use run_clm.py to fine-tune gpt2, the command is as follows:
```
python run_clm.py \\
--model_name_or_path gpt2 \\
--train_file train1.txt \\
--validation_file validation1.txt \\
--do_train \\
--do_eval \\
--output_dir /tmp/test-clm
```
The training data is as follows:
[train1.txt](https://github.com/huggingface/transformers/files/6847229/train1.txt)
[validation1.txt](https://github.com/huggingface/transformers/files/6847234/validation1.txt)
The following error always appears:
```
[INFO|modeling_utils.py:1354] 2021-07-20 17:37:01,399 >> All the weights of GPT2LMHeadModel were initialized from the model checkpoint at gpt2.
If your task is similar to the task the model of the checkpoint was trained on, you can already use GPT2LMHeadModel for predictions without further training.
Running tokenizer on dataset: 100%|██████████| 1/1 [00:00<00:00, 90.89ba/s]
Running tokenizer on dataset: 100%|██████████| 1/1 [00:00<00:00, 333.09ba/s]
Grouping texts in chunks of 1024: 0%| | 0/1 [00:00<?, ?ba/s]
Traceback (most recent call last):
File "D:/NLU/tanka-reminder-suggestion/language_modeling/run_clm.py", line 492, in <module>
main()
File "D:/NLU/tanka-reminder-suggestion/language_modeling/run_clm.py", line 407, in main
desc=f"Grouping texts in chunks of {block_size}",
File "D:\lib\site-packages\datasets\dataset_dict.py", line 489, in map
for k, dataset in self.items()
File "D:\lib\site-packages\datasets\dataset_dict.py", line 489, in <dictcomp>
for k, dataset in self.items()
File "D:\lib\site-packages\datasets\arrow_dataset.py", line 1673, in map
desc=desc,
File "D:\lib\site-packages\datasets\arrow_dataset.py", line 185, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "D:\lib\site-packages\datasets\fingerprint.py", line 397, in wrapper
out = func(self, *args, **kwargs)
File "D:\lib\site-packages\datasets\arrow_dataset.py", line 2024, in _map_single
writer.write_batch(batch)
File "D:\lib\site-packages\datasets\arrow_writer.py", line 388, in write_batch
pa_table = pa.Table.from_pydict(typed_sequence_examples)
File "pyarrow\table.pxi", line 1631, in pyarrow.lib.Table.from_pydict
File "pyarrow\array.pxi", line 332, in pyarrow.lib.asarray
File "pyarrow\array.pxi", line 223, in pyarrow.lib.array
File "pyarrow\array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "D:\lib\site-packages\datasets\arrow_writer.py", line 100, in __arrow_array__
if trying_type and out[0].as_py() != self.data[0]:
File "pyarrow\array.pxi", line 1076, in pyarrow.lib.Array.__getitem__
File "pyarrow\array.pxi", line 551, in pyarrow.lib._normalize_index
IndexError: index out of bounds
```
Is the format of my training data incorrect? Please help me thanks! | 07-20-2021 09:43:30 | 07-20-2021 09:43:30 | The format seems correct. From the [language modeling page](https://github.com/huggingface/transformers/tree/master/examples/pytorch/language-modeling):
> If your dataset is organized with one sample per line, you can use the --line_by_line flag (otherwise the script concatenates all texts and then splits them in blocks of the same length).
So as you're not specifying that flag, it concatenates the text. Perhaps your dataset is just to small to group it into chunks?<|||||>Hi @NielsRogge Thanks for your reply. This `run_clm.py` does not have a `--line_by_line` flag, my `transformers` version is 4.8.2 .
I want to use a function similar to `--line_by_line` in `run_clm.py`, what should I do? Because the length of my training data is not consistent, I don’t want a piece of training data to be divided into two different blocks. Thanks!<|||||>Cc @sgugger: can we add a `line_by_line` option to `run_clm.py`?<|||||>That is the behavior of the script, there is no need to add it. What the script does not support is`line_by_line=False` since it is never used to train causal language models.<|||||>Oh sorry, I just realized I was mistaken: the behavior of the `run_clm` script is to have `line_by_line=False` which is the way masked language models are pretrained. We did not implement the `--line_by_line` option in the run_clm script because GPT-like models are pretrained by concatenating all examples together and then makes blocks of contiguous texts of a given size.
To go back to the initial problem, are you sure you are using the last version of the run_clm script form the master branch? This looks like a bug that was fixed a few days ago for smaller datasets.<|||||>Hi @sgugger Thanks for your reply. My `transformers` version is `4.8.2`. The `run_clm.py` on the `master` branch does not have this bug, but the version on the master has not been officially released yet. The latest version I installed through `pip install transformers` is 4.8.2. By the way, when will the latest version of transformers be released?<|||||>v4.9.0 was released today.<|||||>Thanks a lot!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,804 | closed | [Sequence Feature Extraction] Add truncation | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR adds `truncation` to speech-related feature extractors. It should enable use cases such as: https://github.com/huggingface/transformers/issues/12774
Different to our tokenizers we allow truncation to be just True or False => there is no "truncation strategy". The reason is that for feature extractors the input cannot be a "pair" of input sequences so there is essentially just one use case for truncation that applies to all inputs.
The logic is equivalent to Tokenizers with a small exception in error handling. The differences are shown in example 1. & 2. in the following:
1. truncation=True, no padding, no max_length. IMO this should be an error because it's not clear what should be done here. In Tokenizers we don't throw an error, but simply don't do anything. Throwing an error is better here IMO
```python
from transformers import Wav2Vec2FeatureExtractor, BatchFeature
feat_extractor = Wav2Vec2FeatureExtractor()
dummy_inputs = BatchFeature({"input_values": [[0.1, 0.2, 0.3], [0.1]]})
feat_extractor.pad(dummy_inputs, truncation=True) # -> throws error since `max_length` is not defined
```
2. truncation=True, "longest" padding, no max_length. IMO this should be an error because it doesn't make sense to "truncate" and to pad to the longest tensor in the batch. If we pad to the longest batch, we can't truncate. In Tokenizers we don't throw an error, but simply don't do anything. Throwing an error is better here IMO
```python
from transformers import Wav2Vec2FeatureExtractor, BatchFeature
feat_extractor = Wav2Vec2FeatureExtractor()
dummy_inputs = BatchFeature({"input_values": [[0.1, 0.2, 0.3], [0.1]]})
feat_extractor.pad(dummy_inputs, truncation=True, padding="longest") # -> throws error since `max_length` is not defined and padding not "max_length"
```
3. truncation=True, "max_length" padding. Here the logic is equivalent to tokenizers
```python
from transformers import Wav2Vec2FeatureExtractor, BatchFeature
feat_extractor = Wav2Vec2FeatureExtractor()
dummy_inputs = BatchFeature({"input_values": [[0.1, 0.2, 0.3], [0.1]]})
feat_extractor.pad(dummy_inputs, truncation=True, max_length=2, padding="max_length") # -> output shape is [2, 2]
```
In addition `pad_to_multiple_of` works correctly and equivalent to the Tokenizers. Tests are added to cover all possible use cases.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-20-2021 09:36:59 | 07-20-2021 09:36:59 | |
transformers | 12,803 | closed | Add min and max question length options to TapasTokenizer | # What does this PR do?
Fixes #12790
This PR adds 2 additional attributes to `TapasTokenizer`, namely `min_question_length` and `max_question_length`. These allow the user to skip questions that, when tokenized, are longer or shorter than the specified values. This also better reflects the original implementation (which can be found [here](https://github.com/google-research/tapas/blob/117f3bbed085f1dd0801f9ab3a4d10d2361facd0/tapas/utils/tf_example_utils.py#L941)).
I have also added a corresponding test. | 07-20-2021 08:16:07 | 07-20-2021 08:16:07 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>unstale |
transformers | 12,802 | closed | Very strange Training Data Loss Pattern when fitting MT5 for Summarization | Hi,
I am training a MT5-small summarization model.
On tensorboard the loss function looks like this (see below).
The orange one is with batch size 3 and gradient_accumulation_steps 2 and 10 epochs. It looks normal.
The red one is with the same parameters but gradient_accumulation_steps 3 instead of 2.
The graph looks very strange. After each epoch it makes a huge jump down. Then it seems like it goes up again
between the "jumps".
For me this somehow looks like maybe a bug with gradient_accumulation.
Can someone please check this?
PS: I am using only one GPU.
PPS: The orange line is with default learing rate of 5e-5 the red graph is with learning_rate=5e-4
| 07-20-2021 07:58:30 | 07-20-2021 07:58:30 | Pinging @patil-suraj and @patrickvonplaten for MT5<|||||>PS: I am using only one GPU.<|||||>Hi, @PhilipMay Could please mention which script are you using for this? (Official examples/custom script, Pytrich/TF/FLax ?) <|||||>> Hi, @PhilipMay Could please mention which script are you using for this? (Official examples/custom script, Pytrich/TF/FLax ?)
Oops. Sure @patil-suraj
I am using this: https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization.py<|||||>The params are:
```bash
python run_summarization.py --model_name_or_path "google/mt5-small" --do_train --do_eval \
--source_prefix "summarize: " --output_dir ./checkpoints --per_device_train_batch_size=3 \
--per_device_eval_batch_size=3 --overwrite_output_dir --predict_with_generate --max_source_length 800 \
--max_target_length 96 --save_strategy="epoch" --warmup_ratio=0.3 --dataset_name de_en_mit \
--num_train_epochs 10 --report_to tensorboard --gradient_accumulation_steps=3 --learning_rate=5e-4
```
I modified the script so that `--dataset_name de_en_mit` loads my custom csv dataset.<|||||>PPS: The orange line is with default learing rate of 5e-5 the red graph is with learning_rate=5e-4
Sorry that I had forgotten this info. I have added it again above.<|||||>Small update until the end of the training
<|||||>@patil-suraj so what do you think about this?<|||||>@patil-suraj and news about this?<|||||>Gently pinging @sgugger on this one as well since it's based on the trainer. I'm not really sure it's a bug to be honest<|||||>I'm not sure what bug in the Trainer I should be looking at. What I see is a bumpier training with a higher learning rate, which seems completely normal.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,801 | closed | Add possibility to ignore imports in test_fecther | # What does this PR do?
This PR adds the ability to ignore some imports in the internal mechanism of the tests fetcher. The issue is that a recent PR introduced a dependency on the auto modules for `tokenization_utils_base`, which is a module that often ends up in a dep. Since this is just to grab the tokenizer class and issue an error, the auto module (and then all the models) does not need to be tested if there is a change of tokenization_utils_base.
This is a short-term fix, but a longer term patch is to reduce the the cross-dependencies inside the library.
| 07-20-2021 07:56:34 | 07-20-2021 07:56:34 | |
transformers | 12,800 | closed | I can not find transformers v4.9.0 | 
The doc said the transformer v4.9.0 introduces a new package: transformers.onnx. However I can not find transformers v4.9.0. | 07-20-2021 07:36:42 | 07-20-2021 07:36:42 | v4.9.0 will be out in a few days - for now you can install from source:
```
pip install git+https://github/huggingface/transformers
```<|||||>@LysandreJik Thank you for your repley. I installed the master branch. And tried the BART-large and MBart model (the architecture is totally the same). For Bart-large, I got the following warings:
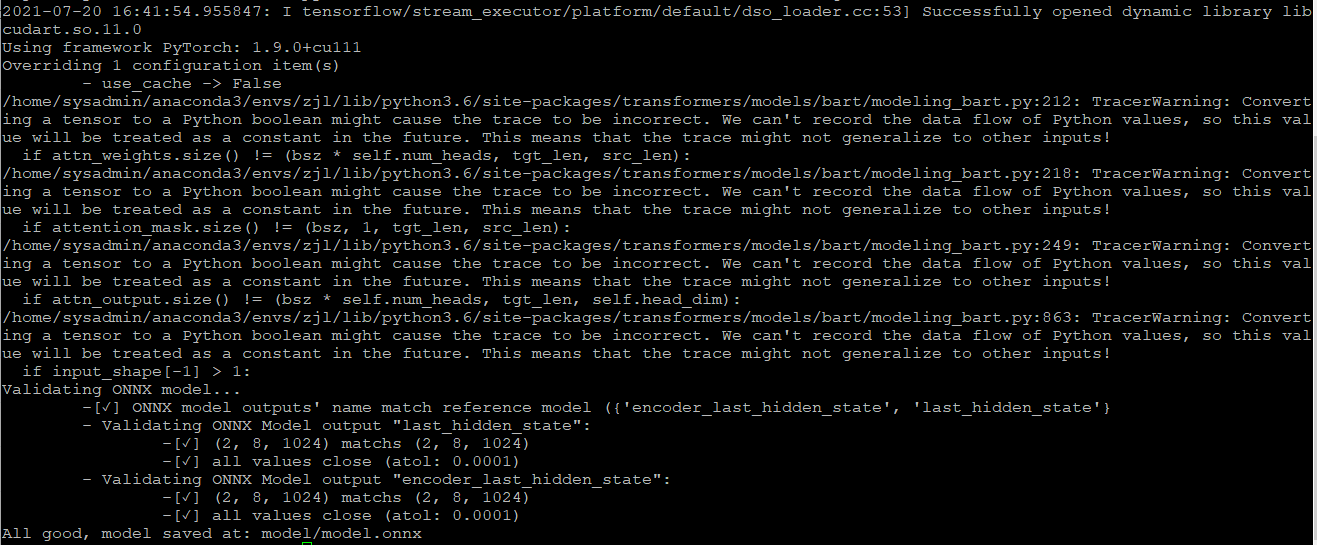
which may have some influences on the performance.
For the Mbart, I got the following error:
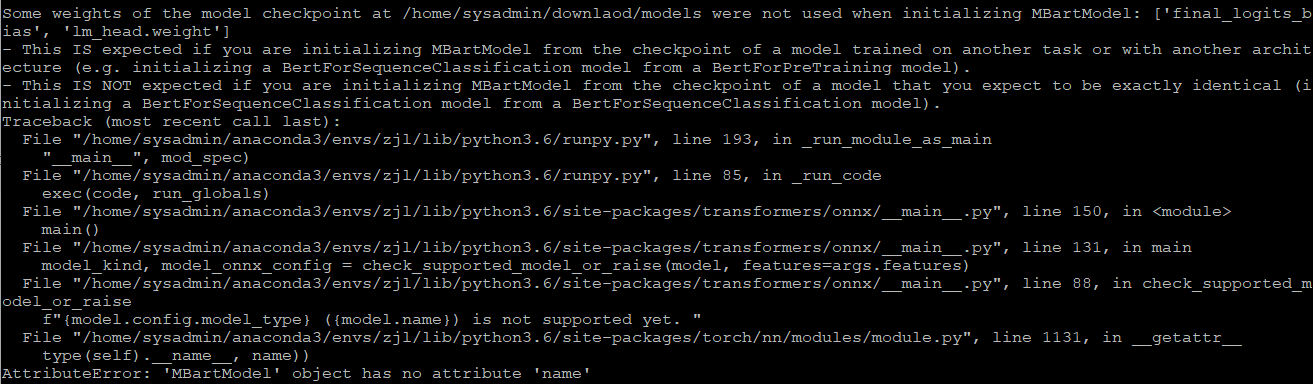
Their archs are the same, so I think the Mbart should work as well. But it seems that it loses some propoerties
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,799 | closed | Jax/Flax Text-Classification Examples are not working... | ## Environment info
- `transformers` version: `pip install -q git+https://github.com/huggingface/transformers.git`
- Platform: Colab | Kaggle Code
- Python version: Python3.6 | Python3.7
- Jax version (TPU): 0.2.17
- Using distributed or parallel set-up in script?: Yes (8 TPUv3 given by Colab or Kaggle)
### Who can help
- jax/flax examples: @patil-suraj @patrickvonplaten
## Information
Model I am using RoBerta, Bert through [jax/flax examples](https://github.com/huggingface/transformers/tree/master/examples/flax#jaxflax-examples) for regression tasks.
The problem arises when using:
* [ ] the python script: [run_flax_glue.py](https://github.com/huggingface/transformers/blob/master/examples/flax/text-classification/run_flax_glue.py)
=> EDIT: `Not working inside colab or kaggle environments`. Please **REPRODUCE** using [colab notebook](https://colab.research.google.com/drive/11-Zj8MRxdgsWIqoX_oixbqk5MdCf4MpW?usp=sharing)
* [ ] the python script: [run_flax_glue.py](https://github.com/huggingface/transformers/blob/master/examples/flax/text-classification/run_flax_glue.py) has a simple bug when used for **custom regression task**
=> EDIT please **REPRODUCE** using [colab notebook](https://colab.research.google.com/drive/1-RCcDgiQ6EGswHaLUOfX_l_0le6naG9B?usp=sharing)
* [ ] the colab notebook: [text_classification_flax.ipynb](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/text_classification_flax.ipynb) => EDIT: This is working fine!
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: Regression task - stsb
EDIT: and Custom regression task.
@patrickvonplaten validated this is working in TPUv3-8 but it is not working in Colab & Kaggle env
## Expected behavior
For python script, it gets stuck with this output:
```
07/19/2021 18:50:23 - INFO - __main__ - ===== Starting training (20 epochs) =====
/usr/local/lib/python3.7/dist-packages/jax/lib/xla_bridge.py:387: UserWarning: jax.host_count has been renamed to jax.process_count. This alias will eventually be removed; please update your code.
"jax.host_count has been renamed to jax.process_count. This alias "
/usr/local/lib/python3.7/dist-packages/jax/lib/xla_bridge.py:374: UserWarning: jax.host_id has been renamed to jax.process_index. This alias will eventually be removed; please update your code.
"jax.host_id has been renamed to jax.process_index. This alias "
07/19/2021 18:50:23 - INFO - __main__ - Epoch 1
07/19/2021 18:50:23 - INFO - __main__ - Training...
2021-07-19 18:53:12.601711: E external/org_tensorflow/tensorflow/compiler/xla/service/slow_operation_alarm.cc:55]
********************************
Very slow compile? If you want to file a bug, run with envvar XLA_FLAGS=--xla_dump_to=/tmp/foo and attach the results.
Compiling module pmap_train_step.64578
********************************
```
For notebook, it gets stuck here:

| 07-20-2021 04:13:54 | 07-20-2021 04:13:54 | There was also a little bug in [python script](https://github.com/huggingface/transformers/blob/master/examples/flax/text-classification/run_flax_glue.py#L358) where label_list is not referenced.
We can declare as None in [L297](https://github.com/huggingface/transformers/blob/master/examples/flax/text-classification/run_flax_glue.py#L297)
Then check if it is assigned in [L357](https://github.com/huggingface/transformers/blob/master/examples/flax/text-classification/run_flax_glue.py#L357)
EDIT:
This error occurred when I don't try with glue task (stsb) but with custom data.<|||||><del>Do you want to open a PR to fix it maybe? :-) </del>
Actually I cannot reproduce the error, when running:
```
python run_flax_glue.py \
--model_name_or_path roberta-base \
--task_name stsb \
--max_length 128 \
--learning_rate 2e-5 \
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--output_dir "./output" \
```
on TPUv3-8 the training finished in ~2 minutes<|||||>@patrickvonplaten
Sorry for the confusion.
For the code getting stuck, Please take a look at this [one](https://colab.research.google.com/drive/11-Zj8MRxdgsWIqoX_oixbqk5MdCf4MpW?usp=sharing)
For the not referenced error, I also confused and it was with the custom data. Please take a look at this [one](https://colab.research.google.com/drive/1-RCcDgiQ6EGswHaLUOfX_l_0le6naG9B?usp=sharing)<|||||>@patrickvonplaten
colab example [text_classification_flax.ipynb](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/text_classification_flax.ipynb) is working fine.
So I am trying to find out why it gets stuck when I use [python script inside colab](https://colab.research.google.com/drive/11-Zj8MRxdgsWIqoX_oixbqk5MdCf4MpW?usp=sharing).<|||||>Hey @bayartsogt-ya,
Note that the Python script is not really made for colab and we recommend using the [text_classification_flax.ipynb](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/text_classification_flax.ipynb) instead.
Could you try using the official text classification notebook instead? <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,798 | closed | Error while converting a RoBERTa TF checkpoint to Pytorch | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: '3.5.1'
- Platform: Linux
- Python version: 3.6.8
- PyTorch version (GPU?): '1.6.0+cu101'
- Tensorflow version (GPU?): '1.14.0'
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik, and @patrickvonplaten may be.
## Information
Model I am using is RoBERTa (finetuned on a custom task). I would like to convert this TF checkpoint to a Pytorch checkpoint that I can further use with the HuggingFace codebase. I tried loading it through with the _from_tf_ flag set but it did not work (shown below).
## To reproduce
Steps to reproduce the behavior:
```
>>> from transformers import RobertaConfig, RobertaForMaskedLM
>>> config = RobertaConfig.from_pretrained('../roberta_config.json')
>>> model = RobertaForMaskedLM.from_pretrained('../model.ckpt-396000.index', from_tf=True, config=config)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/leshekha/.local/lib/python3.6/site-packages/transformers/modeling_utils.py", line 966, in from_pretrained
model = cls.load_tf_weights(model, config, resolved_archive_file[:-6]) # Remove the '.index'
AttributeError: type object 'RobertaForMaskedLM' has no attribute 'load_tf_weights'
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
I expect to get a model object with the parameters initialized from the checkpoint provided. Just like the provided example in the documents page.
```
from transformers import BertConfig, BertModel
>>> # Loading from a TF checkpoint file instead of a PyTorch model (slower, for example purposes, not runnable).
>>> config = BertConfig.from_json_file('./tf_model/my_tf_model_config.json')
>>> model = BertModel.from_pretrained('./tf_model/my_tf_checkpoint.ckpt.index', from_tf=True, config=config)
```
| 07-20-2021 02:26:23 | 07-20-2021 02:26:23 | I solved it. Thanks. <|||||>How did you solve it?<|||||>Hello, how did you solved your problem? |
transformers | 12,797 | closed | [Documentation] Improve docs for hyper-parameter search | # 🚀 Improve documentation for hyper-parameter search
## Motivation
I was recently trying to implement a custom logging callback to use with `Trainer.hyperparameter_search(...)`, but I could not figure out how to access the current run's hyper-parameters to log them. After digging into the source code I discovered that they are available as `TrainerState.trial_params`, which is [currently undocumented](https://huggingface.co/transformers/master/main_classes/callback.html#trainerstate). To make it easier for future users I think the `trial_name` and `trial_params` properties of `TrainerState` should be documented.
## Your contribution
If the maintainers agree that these properties should be documented I'm happy to edit the docstring and submit a PR. Please let me know.
@sgugger
| 07-19-2021 23:49:23 | 07-19-2021 23:49:23 | Yes, please go ahead with a PR, thank you!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,796 | closed | [trainer] sanity checks for `save_steps=0|None` and `logging_steps=0` | This PR deals with combinations of training args that lead to:
```
# --do_eval --evaluation_strategy=steps --logging_steps 0 (no --eval_args)
Traceback (most recent call last):
File "examples/pytorch/translation/run_translation.py", line 617, in <module>
main()
File "examples/pytorch/translation/run_translation.py", line 537, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer.py", line 1340, in train
self.control = self.callback_handler.on_step_end(args, self.state, self.control)
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer_callback.py", line 359, in on_step_end
return self.call_event("on_step_end", args, state, control)
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer_callback.py", line 378, in call_event
result = getattr(callback, event)(
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer_callback.py", line 414, in on_step_end
if args.evaluation_strategy == IntervalStrategy.STEPS and state.global_step % args.eval_steps == 0:
ZeroDivisionError: integer division or modulo by zero
```
and:
```
# --do_eval --evaluation_strategy=steps --logging_steps 0 --eval_args 5
Traceback (most recent call last):
File "examples/pytorch/translation/run_translation.py", line 617, in <module>
main()
File "examples/pytorch/translation/run_translation.py", line 537, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer.py", line 1343, in train
self.control = self.callback_handler.on_step_end(args, self.state, self.control)
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer_callback.py", line 359, in on_step_end
return self.call_event("on_step_end", args, state, control)
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer_callback.py", line 378, in call_event
result = getattr(callback, event)(
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer_callback.py", line 406, in on_step_end
if args.logging_strategy == IntervalStrategy.STEPS and state.global_step % args.logging_steps == 0:
ZeroDivisionError: integer division or modulo by zero
```
(this last one doesn't happen with master, but I reworked things to do the same enforcement in init as for `eval_steps`)
@sgugger
| 07-19-2021 18:49:15 | 07-19-2021 18:49:15 | All good to merge, thanks again! |
transformers | 12,795 | closed | The network does not change if I resume training from checkpoint while also providing custom optimizer and scheduler | ## Environment info
- `transformers` version: 4.3.2
- Platform: Linux-5.4.0-77-generic-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.9.0a0+df837d0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no, 1 gpu
### Who can help
@sgugger
## Information
Model I am using (Bert, XLNet ...):
FlaubertForSequenceClassification
with some serious modifications in the model
The problem arises when using:
* [x] my own modified scripts: (give details below)
Resuming training from a saved checkpoint+scheduler+optimizer with the custom optimizer-scheduler pair
The tasks I am working on is:
* [x] my own task or dataset: (give details below)
Custom sequence classification task.
The model and the script should be working OK, I have been continuously working on the project for a year, and one particular functionality bit of the script stopped working after the upgrade of Transformers 3.0.2 -> 4.3.2
## To reproduce
Here is the essential part of the code:
```
#...
model = FlaubertForMultipleSequenceClassification.from_pretrained(
model_name_or_path, config=config, cache_dir=model_args.cache_dir
)
# 4. Training
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=dev_dataset,
compute_metrics=metrics.compute_multihead_metrics,
# optimizers=optimizers,
data_collator=data_collator,
)
num_training_steps = training_args.num_train_epochs * len(train_dataset) / training_args.per_device_train_batch_size
trainer.create_optimizer_and_scheduler(num_training_steps=int(num_training_steps))
# trainer.optimizer = None
# Check if scheduler and optimizer states should be restored or reinitialized
if model_args.resume_training:
log.info("Resuming training from {}".format(model_name_or_path))
trainer.train(model_name_or_path)
else:
log.info("Starting a new training from {}".format(model_name_or_path))
trainer.train()
```
## Expected behaviour
The network does not change if I resume training from checkpoint (i.e. when loading a saved optimizer and lr_scheduler), while also providing a custom optimizer and scheduler. It means that the weights of the model don't change at all, consecutive saved pytorch_model.bin files match exactly, and so do logged metrics and eval_losses. (The logged learning rate behaves as expected according to the set lr_scheduler.)
I expect the weights of the model to change upon training the model.
## Additional information
In the code above I may resume the entire training run, or simply initialize the model's weight. And it is the former, which does not work.
I know that the manual call to `trainer.create_optimizer_and_scheduler()` is very strange. In my real code, I create an optimizer+scheduler tuple and pass it to `Trainer` constructor as in the commented line above. This manual call is just to emulate bugging behaviour without providing my own functions. I.e. even the default functions behave not like expected.
The main thing is that if I don't provide the optimizer (for example by uncommenting `trainer.optinizer=None`), the training goes on fine. If I don't load the optimizer and just initialize the weights of the model - too. But using custom `lr_scheduler` is required by my code, so I need to specify the optimizer.
Now, one more clue, this approach worked in my previous transformers v3.0.2. The code was the same, modulo some changes due to API upgrade: I defined my tuple of optimizers, initialized `Trainer(optimizers=optimizers)`, then started the training exactly the same way as above, and it worked. I know that 4.3.2 is not the most recent version, so I am sorry if the issue is already solved in newer versions.
Sorry for the long post, I tried to provide all information that I managed to find out myself, but I am giving up. Could someone point me towards the solution to my problem? I would be very grateful for any ideas and hints. Also sorry for not providing a minimal working example. There are a lot of small things to unwind in my model, but I will certainly do this if absolutely necessary.
| 07-19-2021 17:20:09 | 07-19-2021 17:20:09 | Yes, this has been solved since then I believe, as the `Trainer` used to recreate the model when loading a checkpoint (thus disconnecting it from a custom optimizer). This is no longer the case, so I think your code will work if you upgrade to the latest version of Transformers.<|||||>Thank you very much for the reply.
Indeed, this has been corrected and resuming the training works in 4.8.2. |
transformers | 12,794 | closed | add `classifier_dropout` to classification heads | PR for #12781 and maybe a fix for #12792
# Logbook
- added to Electra: `SequenceClassification` and `TokenClassification`
- added to BERT: `SequenceClassification` and `TokenClassification`
- added to RoBERTa: `SequenceClassification` and `TokenClassification`
- added to big_bird: `SequenceClassification` and `TokenClassification`
- added to mobilebert: `SequenceClassification` and `TokenClassification`
- added to reformer: `SequenceClassification` <s>and `TokenClassification`</s>
- added to ConvBERT: `SequenceClassification` and `TokenClassification`
- added to albert: `SequenceClassification` and `TokenClassification` | 07-19-2021 16:37:41 | 07-19-2021 16:37:41 | @sgugger should `classifier_dropout` be only added for `<model_name>ForSequenceClassification`
or also to `<model_name>ForTokenClassification`?<|||||>It should be used for both, yes.<|||||>This is still WIP - I want to add more models. Please do not merge yet ...<|||||>I am done with this PR. It is ready for review.
See logbook above for changed model types. |
transformers | 12,793 | open | Feature Request: El-Attention | # 🚀 Feature request
I've looked into the paper titled "[EL-Attention: Memory Efficient Lossless Attention for Generation](https://arxiv.org/abs/2105.04779)".
It proposes a method for calculating attention that forgoes creating multi-head attention from the hidden state. This saves computational time and frees memory.
## Motivation
El-attention seems to have no downsides, and promises significant memory and performance gains during training and inference.
## Your contribution
The main difficulty may be in that it requires being added directly in to each model's attention mechanism code, or requires a ton of new subclasses for each part of each model. Maybe an easier solution to this would be a pipeline to use custom attention mechanism code. | 07-19-2021 16:35:45 | 07-19-2021 16:35:45 | |
transformers | 12,792 | closed | Declaring `classifier_dropout` in model config but not using it | The PEGASUS model is declaring `classifier_dropout` in the model config:
https://github.com/huggingface/transformers/blob/546dc24e0883e5e9f5eb06ec8060e3e6ccc5f6d7/src/transformers/models/pegasus/configuration_pegasus.py#L128
But the model never uses it. This is a bug IMO.
In contrast mBART defines it:
https://github.com/huggingface/transformers/blob/546dc24e0883e5e9f5eb06ec8060e3e6ccc5f6d7/src/transformers/models/mbart/configuration_mbart.py#L127
and uses it:
https://github.com/huggingface/transformers/blob/546dc24e0883e5e9f5eb06ec8060e3e6ccc5f6d7/src/transformers/models/mbart/modeling_mbart.py#L1395
If wanted I can provide a fix (non breaking) as a PR. | 07-19-2021 16:29:22 | 07-19-2021 16:29:22 | Tagging @NielsRogge<|||||>also see this issue: #12781<|||||>@NielsRogge what do you think?<|||||>Well, since Pegasus does not have SequenceClassification or TokenClassification the `classifier_dropout` could be just removed from the config.<|||||>fixed in PR - closing |
transformers | 12,791 | closed | [CIs] add troubleshooting docs | As discussed in https://github.com/huggingface/transformers/pull/12723#issuecomment-881625490 adding troubleshooting docs for each CI-type.
@LysandreJik | 07-19-2021 15:54:43 | 07-19-2021 15:54:43 | |
transformers | 12,790 | closed | Tapas tokenizer | ## Environment info
- `transformers` version: 4.8.2 and 4.1.1
- Platform: linux-ubuntu 20.04
- Python version: 3.7.5
- PyTorch version (GPU?): 1.9.0+cu111
- Tensorflow version (GPU?): none
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- tapas: @NielsRogge @LysandreJik @sgugger
Library:
- tokenizers: @LysandreJik
-->
## Information
Model I am using : TAPAS
The problem arises when using:
* [ X] my own modified scripts: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. The truncation fails because of maximum length because the truncation is not applied on the query and only on the table.
```python
from transformers import TapasTokenizer
import pandas as pd
tokenizer = TapasTokenizer.from_pretrained(pretrained_model_name_or_path="google/tapas-base-finetuned-tabfact")
large_text: str = '''
The standard Lorem Ipsum passage, used since the 1500s
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."
Section 1.10.32 of "de Finibus Bonorum et Malorum", written by Cicero in 45 BC
"Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo. Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt. Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem. Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur? Quis autem vel eum iure reprehenderit qui in ea voluptate velit esse quam nihil molestiae consequatur, vel illum qui dolorem eum fugiat quo voluptas nulla pariatur?"
1914 translation by H. Rackham
"But I must explain to you how all this mistaken idea of denouncing pleasure and praising pain was born and I will give you a complete account of the system, and expound the actual teachings of the great explorer of the truth, the master-builder of human happiness. No one rejects, dislikes, or avoids pleasure itself, because it is pleasure, but because those who do not know how to pursue pleasure rationally encounter consequences that are extremely painful. Nor again is there anyone who loves or pursues or desires to obtain pain of itself, because it is pain, but because occasionally circumstances occur in which toil and pain can procure him some great pleasure. To take a trivial example, which of us ever undertakes laborious physical exercise, except to obtain some advantage from it? But who has any right to find fault with a man who chooses to enjoy a pleasure that has no annoying consequences, or one who avoids a pain that produces no resultant pleasure?"
Section 1.10.33 of "de Finibus Bonorum et Malorum", written by Cicero in 45 BC
"At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat."
1914 translation by H. Rackham
"On the other hand, we denounce with righteous indignation and dislike men who are so beguiled and demoralized by the charms of pleasure of the moment, so blinded by desire, that they cannot foresee the pain and trouble that are bound to ensue; and equal blame belongs to those who fail in their duty through weakness of will, which is the same as saying through shrinking from toil and pain. These cases are perfectly simple and easy to distinguish. In a free hour, when our power of choice is untrammelled and when nothing prevents our being able to do what we like best, every pleasure is to be welcomed and every pain avoided. But in certain circumstances and owing to the claims of duty or the obligations of business it will frequently occur that pleasures have to be repudiated and annoyances accepted. The wise man therefore always holds in these matters to this principle of selection: he rejects pleasures to secure other greater pleasures, or else he endures pains to avoid worse pains."
'''
tokenized = tokenizer(table=pd.DataFrame(), queries=large_text, max_length=512, truncation=True)
```
This raises the error:
```
~/.pyenv/versions/3.7.5/envs/plop/lib/python3.7/site-packages/transformers/models/tapas/tokenization_tapas.py in __call__(self, table, queries, answer_coordinates, answer_text, add_special_tokens, padding, truncation, max_length, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
633 return_length=return_length,
634 verbose=verbose,
--> 635 **kwargs,
636 )
637
~/.pyenv/versions/3.7.5/envs/plop/lib/python3.7/site-packages/transformers/models/tapas/tokenization_tapas.py in encode_plus(self, table, query, answer_coordinates, answer_text, add_special_tokens, padding, truncation, max_length, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
981 return_length=return_length,
982 verbose=verbose,
--> 983 **kwargs,
984 )
985
~/.pyenv/versions/3.7.5/envs/plop/lib/python3.7/site-packages/transformers/models/tapas/tokenization_tapas.py in _encode_plus(self, table, query, answer_coordinates, answer_text, add_special_tokens, padding, truncation, max_length, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
1036 return_special_tokens_mask=return_special_tokens_mask,
1037 return_length=return_length,
-> 1038 verbose=verbose,
1039 )
1040
~/.pyenv/versions/3.7.5/envs/plop/lib/python3.7/site-packages/transformers/models/tapas/tokenization_tapas.py in prepare_for_model(self, raw_table, raw_query, tokenized_table, query_tokens, answer_coordinates, answer_text, add_special_tokens, padding, truncation, max_length, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, prepend_batch_axis, **kwargs)
1137 if max_length is not None and len(input_ids) > max_length:
1138 raise ValueError(
-> 1139 "Could not encode the query and table header given the maximum length. Encoding the query and table"
1140 f"header results in a length of {len(input_ids)} which is higher than the max_length of {max_length}"
1141 )
ValueError: Could not encode the query and table header given the maximum length. Encoding the query and tableheader results in a length of 1235 which is higher than the max_length of 512
```
## Expected behavior
There should be a parameter to truncate the query as well so as to avoid errors when the query is too large. There are workarounds by changing the model max length but it requires doing the truncation afterwards by hand, so this is defeating the purpose of having truncation parameter.
| 07-19-2021 15:54:25 | 07-19-2021 15:54:25 | Hi,
I have implemented an option which reflects the original implementation. You can initialize `TapasTokenizer` with a `min_question_length` and/or `max_question_length`. If a query is shorter or longer than the specified values, they will be skipped (i.e. the query will be an empty string).<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,789 | closed | Raise exceptions instead of using assertions for control flow | https://github.com/huggingface/transformers/blob/546dc24e0883e5e9f5eb06ec8060e3e6ccc5f6d7/src/transformers/models/gpt2/modeling_gpt2.py#L698
Assertions can't be relied upon for control flow because they can be disabled, as per the following:
```shell
$ python --help
usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ...
...
-O : remove assert and __debug__-dependent statements; add .opt-1 before
.pyc extension; also PYTHONOPTIMIZE=x
...
```
From my understanding, this is why mypy has no qualms about using them to narrow types because you can turn them off at runtime and so they incur zero cost.
Would you be open to me changing these assertions to other appropriate exceptions as I encounter them? | 07-19-2021 14:28:44 | 07-19-2021 14:28:44 | That is an excellent point, and we welcome any PR that changes assert's to proper exception. We have been doing that for long error messages anyway, and I agree with you it's a better choice (as long as we raise the appropriate exception of course).
<|||||>I'm adding the good first issue label, this way if someone wants to take care of one file to remove all asserts and replace them with proper exceptions, they can make a PR with it! The exceptions are examples files or conversion scripts (the convert_xxx.py in some model folder) in which we are fine with asserts.
(Don't try to do all files of the library at one ;-) )<|||||>Hi @sgugger,
I'd like to take up one of the files to start. Should I pick up modelling_gpt2.py and go ahead?<|||||>Any of the files with assert statements is fair game :-)<|||||>Hi @sgugger,
I'd be happy to do this. So I need to change `assert` to 'Exception' type error for only one file?
(Not allowed to do this for every file?)<|||||>Just adding my two cents but I wouldn’t raise bare `Exception`s but instead raise the appropriate type of exception given the error.
> On Aug 19, 2021, at 1:44 AM, Ambesh Shekhar ***@***.***> wrote:
>
>
> Hi @sgugger,
> I'd be happy to do this. So I need to change assert to 'Exception' type error for only one file?
> (Not allowed to do this for every file?)
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub, or unsubscribe.
<|||||>I have created PR #13184 for this issue. Kindly go through it.
Thanks<|||||>@sgugger is this still open ? If so any files with assertion came under the issue right ? Can i join this issue if it's not completed<|||||>@jeffin07 You can pick any file that has not already been treated.<|||||>@sgugger I am also going to pick several files to kill my time. <|||||>I've created PR #13894 . Please take a look.<|||||>I've created PR [#13909](https://github.com/huggingface/transformers/pull/13909) towards this issue. Please take a look<|||||>Hello, I'm new to open source. I wanted to know if this issue is still open and if so how do i check which files have not been edited already and which files require changes still?<|||||>Hello @kushagrabhushan! You can do a search across the repository and look for the `assert` keyword. Here's an example:
https://github.com/huggingface/transformers/blob/3e218523e87002c572f6424d6d24ac656bcc40be/src/transformers/models/bert/modeling_bert.py#L453
I recommend looking only for files in `src/transformers` and in `tests`. In `src/transformers`, it would be nice to replace them by `ValueError`s, and in `tests`, it would be ideal to replace them by unittest assertions. These can be `self.assertEqual`, `self.assertDictEqual`, etc, according to what the assertion is supposed to do.
I would recommend cloning the repository and using a tool to search for these, as the GitHub search isn't ideal for a search like this.<|||||>I would also like to help on this issue. If i understood it right, i should make a separate PR for every single file right? <|||||>Hi, I would like to participate in solving this issue, I will take a look at the files which do not have yet a PR and according to the advices given by the comment of @LysandreJik.<|||||>In cases of assertions being made inside for loops, what would be the best practice?
```py
for sentence in sentences:
if len(sentence["tokens"]) != len(sentence["labels"]):
raise ValueError(f"Number of tokens {len(words)} and labels tokens {len(labels)} mismatch")
```
or
```py
for sentence in sentences:
if len(sentence["tokens"]) != len(sentence["labels"]):
raise ValueError(f"Number of tokens {len(words)} and labels tokens {len(labels)} mismatch in sentence {sentence}")
```
The second approach seems to be a friendly solution for the user since it will show exactly what was the problematic sentence, although, I have seen the first approach used in the PRs. This isn't a critique, I am trying to understand if the first option is better or not.<|||||>The second approach is more informative indeed!<|||||>I am going to tackle on the file [modeling_distilbert.py](\src\transformers\models\distilbert\modeling_distilbert.py) with @Batese2001<|||||>I'd like to work on this file [run_image_captioning_flax.py](https://github.com/huggingface/transformers/blob/main/examples/flax/image-captioning/run_image_captioning_flax.py) <|||||>First time contributing here! I've created PR https://github.com/huggingface/transformers/pull/20478 for this issue. Would appreciate it if anyone could take a look<|||||>I will look and give you a comment after it
Best,
John
Get Outlook for Android<https://aka.ms/AAb9ysg>
________________________________
From: Billy Lee ***@***.***>
Sent: Monday, November 28, 2022 4:10:54 PM
To: huggingface/transformers ***@***.***>
Cc: Chu, John ***@***.***>; Comment ***@***.***>
Subject: Re: [huggingface/transformers] Raise exceptions instead of using assertions for control flow (#12789)
Caution:This email originated from outside of the College. Do not click links or open attachments unless you recognize the sender and know the content is safe. Report anything suspicious to the HelpDesk.
First time contributing here! I've created PR #20478<https://github.com/huggingface/transformers/pull/20478> for this issue. Would appreciate it if anyone could take a look
—
Reply to this email directly, view it on GitHub<https://github.com/huggingface/transformers/issues/12789#issuecomment-1329767859>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AIQLY75OGAN2OSYNWM2WWBTWKUNV5ANCNFSM5AT2I5UA>.
You are receiving this because you commented.Message ID: ***@***.***>
<|||||>First time contributing for me as well! Please have a look at the following PR when you have time! #24757 |
transformers | 12,788 | closed | Add ONNX export for gpt_neo models | ## Status
A recent PR (https://github.com/huggingface/transformers/pull/11786) adds support for exporting a number of models to ONNX.
Among those is the gpt2 model but not gpt_neo.
## Question
I'm wondering whether it wouldn't be sufficient to simply apply the same changes as for gpt2..
Is there any specific reason why gpt_neo was left out?
@LysandreJik | 07-19-2021 13:28:00 | 07-19-2021 13:28:00 | Hello @softworkz, the documentation for that feature is available here: https://huggingface.co/transformers/master/serialization.html#configuration-based-approach
The goal of #11786 isn't to add support for exporting a number of models to ONNX - it is to add configurations that allow very simple exports to ONNX. If a model (official or unofficial) is unsupported, then adding support for it locally should be as simple as defining a configuration, as is explained in the document linked above. It is perfectly possible that applying the same configuration as GPT-2 to GPT Neo would work out - feel free to give it a try.
If you're having a hard time using the new exporting approach, please let us know, as we're eager for comments. Thank you.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,787 | closed | How to use past_key_values in RAG model? | Hi the team,
Great work on this amazing project! Currently I'm trying to test RAG's performance on some simple QA tasks and I read the document of [RAGforSequenceGeneration](https://huggingface.co/transformers/model_doc/rag.html?highlight=rag#ragsequenceforgeneration). I wonder how exactly to use `past_key_values` to speed up the generation?
I run the following code which is from your example:
```python
model = RagSequenceForGeneration.from_pretrained("facebook/rag-sequence-nq", use_dummy_dataset=True)
# 1. Encode
question_hidden_states = model.question_encoder(input_ids)[0]
# 2. Retrieve
docs_dict = retriever(input_ids.numpy(), question_hidden_states.detach().numpy(), return_tensors="pt")
doc_scores = torch.bmm(question_hidden_states.unsqueeze(1), docs_dict["retrieved_doc_embeds"].float().transpose(1, 2)).squeeze(1)
# 3. Forward to generator
outputs = model(context_input_ids=docs_dict["context_input_ids"], context_attention_mask=docs_dict["context_attention_mask"], doc_scores=doc_scores, decoder_input_ids=labels)
```
and get `outputs` that has five keys:
```python
['logits', 'doc_scores', 'past_key_values', 'context_input_ids', 'generator_enc_last_hidden_state']
```
I then tried to use the model's `generate()` function to get the actual sequence. For the `past_key_values`, what should I plug in here? The document said: "Tuple consists of two elements: `encoder_outputs` of the RAG model (see `encoder_outputs`) and`past_key_values` of the underlying generator. " Thus, I composed a tuple with the `outputs['generator_enc_last_hidden_state']` and the `outputs['past_key_values']` from the latest step generation. It still does not work.
During debugging, I checked the tensor size of the `outputs['past_key_values']`. It is a list of 12 elements (n_layers) and each element is a tuple of four tensors: two of them are of `torch.Size([5, 16, 11, 64])` and two of them are of `torch.Size([5, 16, 300, 64])`. It seems like the later ones are key-value pairs (same size, 300 as hidden), but what are the previous ones (with the size of `torch.Size([5, 16, 11, 64])`)?
I would really appreciate it if you can point me out more references (docs, code) about how to use the RAG model properly!
Many Thanks!
(I think @patrickvonplaten, @lhoestq are the right people who can help.)
| 07-19-2021 13:12:46 | 07-19-2021 13:12:46 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hey @DapangLiu,
I'm very sorry to reply so late here! When doing generation with `RegSequenceForGeneration`, the `past_key_values` are automatically used to speed up generation - so you don't have to do anything ;-)
RAG uses Bart as the decoder and RAG as well as Bart have set `use_cache=True` by default. This then means that `past_key_values` are automatically returned after the first forward pass,
see: https://github.com/huggingface/transformers/blob/1fec32adc6a4840123d5ec5ff5cf419c02342b5a/src/transformers/models/bart/modeling_bart.py#L442
and:
https://github.com/huggingface/transformers/blob/1fec32adc6a4840123d5ec5ff5cf419c02342b5a/src/transformers/models/bart/modeling_bart.py#L1478
Those `past_key_values` are then continuously forwarded during generation :-)<|||||>Hi @patrickvonplaten,
Thanks a lot for your response! The reason why I asked this is because I want to add some noise to the `past_key_values`.
As I mentioned before, I found there were two parts that have different dimensions in the `past_key_values` --- my guess is one is for the cross-attention from the encoder and the other is for the decoder-only key value paris --- but I'm not sure whether it is correct (any docs I can read?).
Or they are both decoder-only key value pairs? Why are they in different dimensions?
Sorry for so many questions. If you could refer me to some docs I can study by myself. Thanks!<|||||>Exactly one are the saved `cross-attention` projections and the second ones are the decoder past key and value projections of all previous steps. You should see that during generation only the tensors of one of the two parts change -> those are the decoder-only past key value pairs :-)<|||||>Thank you! Very helpful! |
transformers | 12,786 | closed | Enforce eval and save strategies are compatible when --load_best_model_at_end | # What does this PR do?
There are multiple reports form users not understanding their `save_strategy` or `save_steps` are overridden by `eval_strategy` and `eval_steps`, so this PR changes the current behavior to raise an error when:
- there is a mismatch between the `save_strategy` and the `eval_strategy`
- in case that common strategy is "steps", `save_steps` is not a round multiple of `eval_steps`.
This way each save happens at the same time as an evaluation and `--load_best_model_at_end` can proceed properly.
Supersedes #12687 | 07-19-2021 12:14:08 | 07-19-2021 12:14:08 | What if we only want to save the best checkpoint during training? Saving a checkpoint every time we do an evaluation will take much space and many checkpoints are unnecessary.<|||||>I see! This should be implemented by setting save_total_limit==1, but it would be great if there's something like a saving strategy called "save_best". |
transformers | 12,785 | closed | Pre training problem, please help me out | ## Environment info
- `transformers` version: 4.8.2
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@sgugger
@LysandreJik
@patrickvonplaten
@patil-suraj
## Information
Model I am using: CodeBert
The problem arises when using:
* [X ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Using the run_mlm.py script from : https://github.com/huggingface/transformers/tree/master/examples/pytorch/language-modeling
2.Inserting the code on terminal:
`python run_mlm.py --model_name_or_path microsoft/codebert-base --train_file /content/TrainingFiles.txt --do_train --do_eval --output_dir /tmp/test-mlm`
3. Getting this error
`python run_mlm.py --model_name_or_path microsoft/codebert-base --train_file /content/TrainingFiles.txt --do_train --do_eval --output_dir /tmp/test-mlm File "run_mlm.py", line 67
model_name_or_path: Optional[str] = field(
^
SyntaxError: invalid syntax`
## Expected behavior
I just want to further pre train my model, any help would be much appreciated
| 07-19-2021 11:35:41 | 07-19-2021 11:35:41 | Are you using the `run_mlm.py` script from master?<|||||>yes sir i am<|||||>Can you create a colab to reproduce?<|||||>I just ran the script on google colab terminal.
`python run_mlm.py --model_name_or_path microsoft/codebert-base --train_file /content/TrainingFiles.txt --do_train --do_eval --output_dir /tmp/test-mlm`
i have attached the training text file here.
[TrainingFiles.txt](https://github.com/huggingface/transformers/files/6841465/TrainingFiles.txt)
<|||||>its definitely a syntax error in the run_mlm.py file, i tried just running it by itself and this is what it throws out
`/content# python /content/run_mlm.py
File "/content/run_mlm.py", line 68
model_name_or_path: Optional[str] = field(
^
SyntaxError: invalid syntax`
<|||||>Ok let me try this, I get back to you in a minute.<|||||>I ran it in a Google Colab notebook, it worked fine for me.
https://colab.research.google.com/drive/1Hqih55xGyVCvNOQKsYOw1mMeULGCR6oQ?usp=sharing
Note that the `run_mlm.py` script checks the minimum version required, which is currently set to 4.9.0 (which will be released soon). I removed that check since it hasn't been released yet.<|||||>Thats interesting, weird that it didn't work for me.
Huge thanks Niels have a wonderful day <|||||>Hi,
I just pre trained my model and it got saved in a directory,
My question is how do i load that model for fine tuning.
I feel like i am not doing something correct here.
These are the files generated after pre training the bert model:
`all_results.json
pytorch_model.bin
tokenizer.json
vocab.json
config.json
runs
trainer_state.json
eval_results.json
special_tokens_map.json
training_args.bin
merges.txt
tokenizer_config.json
train_results.json`
and then i tried to load the model using this,
`model = torch.load('/content/transformers/examples/pytorch/language-modeling/content/tmp/test-mlm/pytorch_model.bin',map_location='cpu')`
Is this correct?
It seems to load it but do i have to load any kind of saved dict or any other sort of files?
A bit confused
Appreciate any help<|||||>Hi,
It's easiest to just load it using the `.from_pretrained(directory_path)` method. Let's say you have trained a BertForMaskedLM model, then you can load it as follows:
```
from transformers import BertForMaskedLM
model = BertForMaskedLM.from_pretrained("path_to_the_directory_with_pytorch_model.bin_and_config.json")
```
<|||||>okay that makes sense, Huge thanks again Niels! :D
Have a wonderful day! |
transformers | 12,784 | closed | Improving pipeline tests | # What does this PR do?
This PR removes `small_models` in favor of random dynamic super small models from tiny_config.
- Main reason, so we can test the pipeline on as much architectures as possible (which is the goal of the pipeline)
- Main drawback, we don't test `fast` vs `non-fast` tokenizers anymore (non fast cannot be learned dynamically on the fly like
the fast tokenizers)
- We cannot test exact values either because the models are random. Introduces ANY help class to make output structure more readable within a test too !
- We don't test explicity TF vs PT outputs on the small tiny config (again random weights), but we will explicitely add those for the slow tests which are going to be much more explicit (with actual values being checked against)
Tl;dr small_models -> random weight with more configs out of the box, large_models, less but check more information within outputs.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@LysandreJik
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
@LysandreJik
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | 07-19-2021 10:17:37 | 07-19-2021 10:17:37 | So let's start to merge those iteratively ?<|||||>Yes :) |
transformers | 12,783 | closed | How to solve the CUDA out of memory | ERROR:
> 07/19/2021 10:04:35 - INFO - __main__ - ***** Running training *****
> 07/19/2021 10:04:35 - INFO - __main__ - Num examples = 23
> 07/19/2021 10:04:35 - INFO - __main__ - Num Epochs = 7██████| 1/1 [00:00<00:00, 4.48ba/s]
> 07/19/2021 10:04:35 - INFO - __main__ - Instantaneous batch size per device = 8 3.76ba/s]
> 07/19/2021 10:04:35 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 8
> 07/19/2021 10:04:35 - INFO - __main__ - Gradient Accumulation steps = 1
> 07/19/2021 10:04:35 - INFO - __main__ - Total optimization steps = 21
> 0%| | 0/21 [00:00<?, ?it/s]Traceback (most recent call last):
> File "./run_clm_no_trainer.py", line 496, in <module>
> main()
> File "./run_clm_no_trainer.py", line 460, in main
> accelerator.backward(loss)
> File "/usr/local/lib/python3.6/dist-packages/accelerate/accelerator.py", line 251, in backward
> loss.backward()
> File "/usr/local/lib/python3.6/dist-packages/torch/tensor.py", line 245, in backward
> torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
> File "/usr/local/lib/python3.6/dist-packages/torch/autograd/__init__.py", line 147, in backward
> allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
> RuntimeError: CUDA out of memory. Tried to allocate 1.53 GiB (GPU 0; 31.75 GiB total capacity; 30.16 GiB already allocated; 221.75 MiB free; 30.22 GiB reserved in total by PyTorch)
> 0%| | 0/21 [00:00<?, ?it/s]
I use the official example of finetuning gpt2 from https://github.com/huggingface/transformers/blob/master/examples/pytorch/language-modeling/run_clm_no_trainer.py
No modifications on this code.
```
CUDA_VISIBLE_DEVICES=1 python ./run_clm_no_trainer.py \
--num_train_epochs 7 \
--model_name_or_path gpt2 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--output_dir ./finetune_cache \
--preprocessing_num_workers 8
```
My GPU device 1 is of 32510M CUDA memory, V100.
How can I solve the memory error, without degrading the performance of the finetuned gpt2 ? | 07-19-2021 10:12:18 | 07-19-2021 10:12:18 | I changed the param of block_size to 512, it solves the memory error. Will this change have effects on the performance of gpt2 ?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,782 | closed | [Flax] Correct flax docs | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Lots of Flax models had incorrect or missing documentation. In this PR I went through the docs of all Flax models and corrected the docstrings so that they:
- run correctly
- show the correct use case (some MBart examples didn't make sense)
- link to the correct output types
@LysandreJik @sgugger - it would be great if we could re-enable the examples tests to make sure they all run correctly. Happy to help on it this week!
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| 07-19-2021 10:04:07 | 07-19-2021 10:04:07 | |
transformers | 12,781 | closed | Set dropout for ClassificationHead | When I train a classification task I want to be able to set a dropout value for the prediction head.
This dropout value should be independent of the other dropout values of the language model.
Now the issue is: If I want to set a dropout for the ClassificationHead of Electra (and other models) I have to set the
`hidden_dropout_prob`. See here:
https://github.com/huggingface/transformers/blob/546dc24e0883e5e9f5eb06ec8060e3e6ccc5f6d7/src/transformers/models/electra/modeling_electra.py#L903
But this sets (changes) the dropout of many other layers too. IMO that should not be the case.
IMO there should be an dedicated dropout for the head which is defaulted by `hidden_dropout_prob` but can be changed by
the user.
@sgugger and @LysandreJik what do you think?
PS: I can provide a PR if wanted... | 07-19-2021 09:42:24 | 07-19-2021 09:42:24 | Valid point, some models (like mBART, DETR, PEGASUS) have a `classifier_dropout` in their config.
It should ideally be the case for all models.<|||||>Agreed with Niels. If you want to make a PR @PhilipMay, please go ahead. Just make sure to use the same attribute name ( `classifier_dropout`) as in the existing models, and make sure there is no breaking change (which should be the case with your proposition).<|||||>> and make sure there is no breaking change (which should be the case with your proposition).
@sgugger I am confused - sorry.
You mean my suggestion:
> IMO there should be an dedicated dropout for the head which is defaulted by hidden_dropout_prob but can be changed by
the user.
Adds no breaking change and is ok? Or do you say it adds a breaking change?<|||||>Well - I just started with Electra: #12794
@sgugger can you please check that if it follows the right pattern? If yes I can add the other models.<|||||>This is closed by the PR merge. |
transformers | 12,780 | closed | Documentation of longformer model is confusinng | ### Who can help
#Documentation: @sgugger
Models:
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
## Information
Model I am using longformer:
The problem arises when using:
* [ ] the official example scripts: (give details below)
```
>>> import torch
>>> from transformers import LongformerModel, LongformerTokenizer
>>> model = LongformerModel.from_pretrained('allenai/longformer-base-4096')
>>> tokenizer = LongformerTokenizer.from_pretrained('allenai/longformer-base-4096')
>>> SAMPLE_TEXT = ' '.join(['Hello world! '] * 1000) # long input document
>>> input_ids = torch.tensor(tokenizer.encode(SAMPLE_TEXT)).unsqueeze(0) # batch of size 1
>>> # Attention mask values -- 0: no attention, 1: local attention, 2: global attention
>>> attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to local attention
>>> global_attention_mask = torch.zeros(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to global attention to be deactivated for all tokens
>>> global_attention_mask[:, [1, 4, 21,]] = 1 # Set global attention to random tokens for the sake of this example
... # Usually, set global attention based on the task. For example,
... # classification: the <s> token
... # QA: question tokens
... # LM: potentially on the beginning of sentences and paragraphs
>>> outputs = model(input_ids, attention_mask=attention_mask, global_attention_mask=global_attention_mask)
>>> sequence_output = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output
```
In the documentation https://huggingface.co/transformers/model_doc/longformer.html#transformers.models.longformer.modeling_longformer.LongformerMaskedLMOutput it's saying
Mask values selected in [0, 1]:
0 for local attention (a sliding window attention),
1 for global attention (tokens that attend to all other tokens, and all other tokens attend to them).
But in the code and in comment section :
# Attention mask values -- 0: no attention, 1: local attention, 2: global attention
**Why 3 sets of values here??**
`attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to local attention`
Here all are set to Global attention ( Setting it to 1)
global_attention_mask = torch.zeros(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to global attention to be deactivated for all tokens
| 07-19-2021 09:12:56 | 07-19-2021 09:12:56 | Thanks for the issue! This PR: https://github.com/huggingface/transformers/pull/12809/files fixes the outdated comment. |
transformers | 12,779 | closed | Longer timeout for slow tests | About 50 slow tests go over to 5 minutes mark and currently get killed by the timeout. I don't have time to fix them right now so putting the timeout to 10 minutes so that we still have coverage on those tests. Will get back to it when I have a free cycle. | 07-19-2021 08:55:28 | 07-19-2021 08:55:28 | |
transformers | 12,778 | closed | Unable to finetune RAG end2end due to error in finetune_rag.py file | ## Environment info
- `transformers` version: 4.8.2
- Platform: Ubuntu 20.04
- Python version: 3.8.10
- PyTorch version (GPU?): 1.10.0.dev20210717+cu111
- Tensorflow version (GPU?): none
- Using GPU in script?: yes, 8 A6000s
- Using distributed or parallel set-up in script?: yes, ray 2.0.0.dev0
### Who can help
Quentin Lhoest (@lhoestq), Patrick von Platen (@patrickvonplaten)
## Information
Model I am using (Bert, XLNet ...): RAG
The problem arises when using:
* [ ] the official example scripts: I used the finetune_rag_ray_end2end.sh script, but it doesn't run in my env with either ray or pytorch as distributed retriever mode.
* [ ] my own modified scripts: I only modified the args to finetune_rag.py
``` python finetune_rag.py \
--data_dir squad-training \
--output_dir model_checkpoints \
--model_name_or_path facebook/rag-token-base \
--model_type rag_token \
--fp16 \
--gpus 8 \
--profile \
--do_train \
--end2end \
--do_predict \
--n_val -1 \
--train_batch_size 8 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 10 \
--warmup_steps 500 \
--gradient_accumulation_steps 8 \
--distributed_retriever pytorch \
--num_retrieval_workers 4 \
--passages_path SQUAD-KB/my_knowledge_dataset \
--index_path SQUAD-KB/my_knowledge_dataset_hnsw_index.faiss \
--index_name custom \
--context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
--csv_path SQUAD-KB/squad-kb.csv \
--index_gpus 1 \
--gpu_order [5,6,7,8,9,0,1,2,3,4] \
--shard_dir test_dir/kb-shards \
--indexing_freq 500
```
The tasks I am working on is:
* [ ] my own task or dataset: I'm working with different datasets, but for now I've only tested on the data made available by @shamanez [here](https://drive.google.com/drive/folders/1qyzV-PaEARWvaU_jjpnU_NUS3U_dSjtG?usp=sharing)
## To reproduce
Steps to reproduce the behavior:
0. pip install torch, transformers, pytorch_lightning, ray[default]
1. Download the data from [here](https://drive.google.com/drive/folders/1qyzV-PaEARWvaU_jjpnU_NUS3U_dSjtG?usp=sharing) and put the SQUAD-KB and squad-training directories in the same directory of the script
2. Change the args to finetune_rag.py
3. testing with ‘distributed_retriever pytorch‘ I get this error
```
INFO:__main__:please use RAY as the distributed retrieval method
Traceback (most recent call last):
File "finetune_rag.py", line 793, in <module>
main(args)
File "finetune_rag.py", line 730, in main
model: GenerativeQAModule = GenerativeQAModule(args)
File "finetune_rag.py", line 138, in __init__
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
UnboundLocalError: local variable 'retriever' referenced before assignment
Stopped all 12 Ray processes.
```
4. testing with ‘distributed_retriever ray‘ I get this error
```
Global seed set to 42
initializing ddp: GLOBAL_RANK: 0, MEMBER: 1/8
test_dir/kb-shards
2021-07-18 10:38:55,472 INFO worker.py:805 -- Connecting to existing Ray cluster at address: 135.181.63.142:6379
INFO:__main__:Getting named actors for NODE_RANK 0, LOCAL_RANK 7
Traceback (most recent call last):
File "/root/Retr_Exp/transformers/examples/research_projects/rag-end2end-retriever/finetune_rag.py", line 793, in <module>
main(args)
File "/root/Retr_Exp/transformers/examples/research_projects/rag-end2end-retriever/finetune_rag.py", line 725, in main
named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
File "/root/Retr_Exp/transformers/examples/research_projects/rag-end2end-retriever/finetune_rag.py", line 725, in <listcomp>
named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
File "/root/CS-Env/lib/python3.8/site-packages/ray-2.0.0.dev0-py3.8-linux-x86_64.egg/ray/_private/client_mode_hook.py", line 82, in wrapper
return func(*args, **kwargs)
File "/root/CS-Env/lib/python3.8/site-packages/ray-2.0.0.dev0-py3.8-linux-x86_64.egg/ray/worker.py", line 1746, in get_actor
return worker.core_worker.get_named_actor_handle(name)
File "python/ray/_raylet.pyx", line 1565, in ray._raylet.CoreWorker.get_named_actor_handle
File "python/ray/_raylet.pyx", line 158, in ray._raylet.check_status
ValueError: Failed to look up actor with name 'retrieval_worker_0'. You are either trying to look up a named actor you didn't create, the named actor died, or the actor hasn't been created because named actor creation is asynchronous.
```
## Expected behavior
The expected behaviour consist in being able to finetune RAG without errors
| 07-19-2021 08:28:45 | 07-19-2021 08:28:45 | Hi,
1. first, the RAG-end2end cannot get a train with pytorch_retriever, since it's not enabled and you have to use ray_retriever (Since it is very slow and hard to update the indexed KB).
2. The second issue is related you your distributed system and we have discussed it in [this issue](https://github.com/huggingface/transformers/issues/12050#issuecomment-856646135).
For a quick fix, change the [line](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag-end2end-retriever/finetune_rag.py#L707) as follows (change the variables in to int) :
**if ("LOCAL_RANK" not in os.environ or int(os.environ["LOCAL_RANK"]) == 0) and (
"NODE_RANK" not in os.environ or int(os.environ["NODE_RANK"]) == 0
):**
<|||||>The error persists for me even after the quick fix. I've tried to run the script using a single GPU, a single A6000, to verify that everything else works and it does but the projections for how long a single epoch should take are a bit worrying.
```
Epoch 0: 0%| | 157/257383819 [01:12<33135:48:12, 2.16it/s, loss=nan, v_num=7
```
On previous attempts I have let it run for longer but the projected time doesn't lower significantly, is this reasonable or am I getting something else wrong?
Btw for reference I'm using the instances from https://datacrunch.io/ they might have gpus running on different nodes so the ray issues could be caused by the setup. Any suggestion on how I could proceed? Is it a problem with Pytorch Lightning, should I use an older version of ray? And is a single A6000 not enough to conclude the Squad pretraining?
Thank you very much for any help!
Edit: The scripts in the test_run folder are able to do training and validation on a single GPU in a reasonable amount of time<|||||>@AntonioLopardo ,
Oh yeah sorry :) , I thought I fixed this issue during the PR. It is basically a problem with PL's parameter naming. Comment the following [line](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag-end2end-retriever/lightning_base.py#L405) in the lightning-base.
_"Btw for reference I'm using the instances from https://datacrunch.io/ they might have gpus running on different nodes so the ray issues could be caused by the setup. Any suggestion on how I could proceed? Is it a problem with Pytorch Lightning, should I use an older version of ray? "_
No there's no problem with PL or RAY. It is just how you set up your cluster. Basically, when using RAY, we only create processes in the master process, and then during the other processes, we use these actors. So what is happening is the "if" condition gets messed up with different naming of nodes and master processes. To solve this, play around with these environmental variables.
**LOCAL_RANK" not in os.environ or os.environ["LOCAL_RANK"**
<|||||>On your second question, @Dopaminezsy solved it as follows.

<|||||>I'm still having issues running the code on more than one GPU, but it runs in about 3 hours for each epoch on one now, thank you very much for your help @shamanez! I'll continue to try to run on more GPUs, but I've already tried many variations of the "LOCAL_RANK" and "NODE_RANK" lines without much success.
Btw do you think it would be possible to run the retriever with a different encoder, say the "facebook/dpr-ctx_encoder-single-nq-base" or another one finetuned on a specific domain? <|||||>Happy to help you. Well the GPU problem is very hard to solve without having access to a server. But I hope you get the logic! where you need to make sure the "if" condition is true in the main process. Try to add the node parameter to the trainer from [here](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag-end2end-retriever/lightning_base.py#L401). Anyways you can also check how to execute codes in node architecture.
Yeah, it is possible. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@AntonioLopardo @shamanez Hi!
I think the problem is the version of the ray library. I had the same problem with version 2.0. In version 1.3, the error doesn't appear.<|||||>I believe part of the reason that the code runs slowly is, because the validation step is run after every training step. See [this](https://github.com/huggingface/transformers/blob/main/examples/research_projects/rag-end2end-retriever/lightning_base.py#L404). @shamanez is my understanding correct, and is it necessary for the validation step to be run after every training step?
P.S. Thank you for updating the implementation with the newer Ray and PL versions, it's very helpful 😄 <|||||>@aidansan Thanks a pointing this out. Seems like PL lightning document has changed.
Please read this - https://pytorch-lightning.readthedocs.io/en/stable/common/trainer.html#val-check-interval
seems like now we need to change it to a float.
<|||||>> I'm still having issues running the code on more than one GPU, but it runs in about 3 hours for each epoch on one now, thank you very much for your help @shamanez! I'll continue to try to run on more GPUs, but I've already tried many variations of the "LOCAL_RANK" and "NODE_RANK" lines without much success. Btw do you think it would be possible to run the retriever with a different encoder, say the "facebook/dpr-ctx_encoder-single-nq-base" or another one finetuned on a specific domain?
yes it is possible.<|||||>https://pytorch-lightning.readthedocs.io/en/stable/common/trainer.html#check-val-every-n-epoch check-val-every-n-epoch might work as well?<|||||>yeah I think so
|
transformers | 12,777 | closed | Error in the model card page | https://huggingface.co/facebook/bart-large-mnli
this page is about the
> facebook/bart-large-mnli model.
However, in the section of
> With manual PyTorch
the example show the loaded model is joeddav/xlm-roberta-large-xnli, which is not
> facebook/bart-large-mnli
I suppose that this is an error . | 07-19-2021 07:34:04 | 07-19-2021 07:34:04 | Thank you for the report, I have updated the modelcard in [`hf.co#c626438`](https://huggingface.co/facebook/bart-large-mnli/commit/c626438eeca63a93bd6024b0a0fbf8b3c0c30d7b) |
transformers | 12,776 | closed | How to use the transformers pre-training model to calculate the probability of a sentence instead of PPL? | I now want to use the pre-trained language model of transformers to calculate the probability of a sentence (a value between 0 and 1) instead of PPL. What should I do? Thanks! | 07-19-2021 06:28:17 | 07-19-2021 06:28:17 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,775 | closed | Adding m2m100 12B | # 🌟 New model addition
Hi!
I was wondering if there's been any work on adding the 12B version of m2m100 model to huggingface.
Given libraries such as fairscale or parallelformers, inference with these relatively big models should be possible now.
Are there any model changes needed to accommodate the 12B version? And does the current m2m100 [conversion script](https://github.com/huggingface/transformers/blob/master/src/transformers/models/m2m_100/convert_m2m100_original_checkpoint_to_pytorch.py) work for it?
## Open source status
* [X] the model weights are available: [link](https://github.com/pytorch/fairseq/blob/master/examples/m2m_100/README.md#12b-model)
Tagging @patil-suraj who added m2m100.
| 07-19-2021 06:12:49 | 07-19-2021 06:12:49 | And also please add:
1. flores101_mm100_615M | 12 | 1024 | 4096 | 256,000 | 615M | https://dl.fbaipublicfiles.com/flores101/pretrained_models/flores101_mm100_615M.tar.gz
2. flores101_mm100_175M | 6 | 512 | 2048 | 256,000 | 175M | https://dl.fbaipublicfiles.com/flores101/pretrained_models/flores101_mm100_175M.tar.gz
from http://www.statmt.org/wmt21/large-scale-multilingual-translation-task.html
> These models are trained similar to M2M-100 with additional support for the languages that are part of the WMT Large-Scale Multilingual Machine Translation track. (paper https://arxiv.org/pdf/2106.03193.pdf)
<|||||>@Mehrad0711
> I was wondering if there's been any work on adding the 12B version of m2m100 model to huggingface.
Supporting such large model inference in Transformers is under work now, so it should be possible to add the 12B model in near future, I will post an update once it's ready :)
> And does the current m2m100 conversion script work for it?
The current conversion script might not work for the 12B model, as the module structure seems a bit different.
@Fikavec
Thank you for sharing these links, I will add those models.<|||||>Hi @patil-suraj,
Just wanted to check if there's any news/ progress for adding the new models.
Thanks.<|||||>Hey @Mehrad0711 !
The 12B checkpoints are now available on the hub:
https://huggingface.co/models?other=m2m100-12B<|||||>Hi @patil-suraj,
Thanks a lot for your work!<|||||>Hi @patil-suraj ! Thank you for a bigger [models](https://huggingface.co/models?other=m2m100-12B) ! Please tell me why "max_length" and "num_beams" parameters not presented in [config.json](https://huggingface.co/facebook/m2m100-12B-last-ckpt/blob/main/config.json)? Without "max_length" parameter models to much truncates translation results by default. What is the maximum best value of "max_length" and best value of "num_beams" for this models? In older [config](https://huggingface.co/facebook/m2m100_1.2B/blob/main/config.json) i'm saw: "max_length": 200, "num_beams": 5. In the [paper](https://arxiv.org/pdf/2010.11125.pdf) i'm found 'The length filtering removes sentences that are too long—more than 250 subwords after segmentation with SPM—or with a length mismatch between the sentence and its translation—if the length ratio is greater than 3×. ' and 'We use a beam search with beam of size 5'. Maybe add max_length and num_beams into example of using models in huggingface pages? |
transformers | 12,774 | closed | max_length parameter in Wav2Vec2FeatureExtractor doesn't affect | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.8.2
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.5
- PyTorch version (GPU?): 1.9.0+cpu (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?:no
### Who can help
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
I'm attempting to receive a features vector of short wav (audio) files using wav2vec by using Hugging Face Transformers.
The problem arises when using:
* [ X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ X] my own task or dataset: (give details below)
## To reproduce
I ask a question about that in [StackOverflow](https://stackoverflow.com/questions/68430210/how-to-limit-the-size-of-the-features-vector-in-wav2vec)
Steps to reproduce the behavior:
1. Two wav files for example are in this [drive ](https://drive.google.com/drive/folders/1j-BNp8D8yN16exgoacgDtDrnMF-jQP91?usp=sharing)
2. extract the feature vector of any file by using a pre-trained wav2vec model with a size limit parameter
3. measure the size of the output vector
4. surprise...
minimal code example:
```
import librose
import numpy as np
from transformers import Wav2Vec2FeatureExtractor
input_audio, _ = librosa.load(file,
sr=16000)
features_with_padding = feature_extractor(input_audio, sampling_rate=16000,
return_tensors="np", padding="max_length", max_length=60000).input_values
features_without_padding = feature_extractor(input_audio, sampling_rate=16000,
return_tensors="np", max_length=60000).input_values
print(features_with_padding.shape, features_without_padding.shape)
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
The expected behavior is to get only 60K vector size and not 80-90K vector.
Ideally, I want to get the same size vectors but I don't think that it's possible.
<!-- A clear and concise description of what you would expect to happen. -->
Thanks! | 07-18-2021 20:54:41 | 07-18-2021 20:54:41 | cc @patrickvonplaten and @patil-suraj <|||||>@yanirmr - thanks a lot for you issue! The problem is that we currently don't support "truncation" in Transformers which means that when one wants to pad to a length that is shorter than the `max_length` nothing is changed. However, `truncation` is a very important feature so I will work on adding this functionality! |
transformers | 12,773 | closed | Can't load config for [community model] : DeepESP/gpt2-spanish | ## Environment info
- `transformers` version: 3.3.1
- Platform: Linux-4.15.0-135-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
-
### Who can help
@julien-c
@mfuntowicz
## Information
`DeepESP/gpt2-spanish` is not recognized as a community model.
Same issue as #6226 and #6688.
As you can see from previous issues, this was supposedly fixed past year but for some reason this bug is back again.
## To reproduce
```
from transformers import AutoConfig
config = AutoConfig.from_pretrained("DeepESP/gpt2-spanish")
```
This will result in the following error message:
```
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/transformers/configuration_utils.py", line 359, in get_config_dict
raise EnvironmentError
OSError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/dist-packages/transformers/configuration_auto.py", line 310, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/configuration_utils.py", line 368, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'DeepESP/gpt2-spanish'. Make sure that:
- 'DeepESP/gpt2-spanish' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'DeepESP/gpt2-spanish' is the correct path to a directory containing a config.json file
```
## Expected behavior
`DeepESP/gpt2-spanish` should be recognized as a community model on `AutoConfig`. | 07-18-2021 15:13:30 | 07-18-2021 15:13:30 | Solved by upgrading `transformers` to a higher version. |
transformers | 12,772 | closed | We made a toolkit can parallelize almost all the Hugging Face models. But we have some question ! | We recently developed an opensource called `parallelformers,` (https://github.com/tunib-ai/parallelformers) and have a few questions, so we write an issue here.
Q. As a logo, an image homage to the hugging face was used. Not exactly the same CI, but from Unicode. Will it be a problem?
Q. What do you think about collaboration? We can include model parallelization for all models in hugging face transformers.
---
The following is what I posted on Reddit to promote our opensource.
Hello, I am writing to inform you about the release of Parallelformers (https://github.com/tunib-ai/parallelformers), a model parallelization library at TUNiB. Parallelformers is a toolkit that supports inference parallelism for 68 models in Huggingface Transformers with 1 line of code.
Previously, DeepSpeed-Inference was used as a parallelization toolkit for model inference.
(1) It was impossible to deploy to the web server due to the process flow,
(2) Lack of integration with Huggingface Transformers, which has now become the de facto standard for natural language processing tools. (DeepSpeed-Inference only supports 3 models)
(3) Also, since parallelization starts in the GPU state, there was a problem that all parameters of the model had to be put on the GPU before parallelization.
Parallelformers solved a number of problems in DeepSpeed-Inference. Using this toolkit internally, we were able to easily deploy a large model to our web server, reducing the cost of deployment by up to 3-5x. More detailed information and source code can be found on GitHub. Thanks !
| 07-18-2021 04:00:58 | 07-18-2021 04:00:58 | Hello @hyunwoongko, thanks a lot for sharing, this is a really cool project! No problem at all regarding the image homage (really cool logo by the way!)
I'm pinging @stas00 who has led the efforts of model parallelization and DeepSpeed integration on our side and would probably be interested. Also pinging @sgugger as he has done some similar work.<|||||>Thank you for implementing and sharing your project, @hyunwoongko,
I haven't had a chance to study your project closely yet, but is it correct that you implemented tensor parallelism from Megatron?
In other words this outstanding feature: https://github.com/huggingface/transformers/issues/10321 except for inference-only?
(There are many types of model parallelism and it is much easier to understand things when the generic MP term is not used, but an explicit type is described. Here is my initial attempt to map out the distinctions https://huggingface.co/transformers/master/parallelism.html)<|||||>@stas00
I'll write a blog post about the architecture of our tools soon and share them.<|||||>Oh, but why have you deleted all the detailed comments you posted earlier? I was looking forward to studying those and now they are all gone. I'm puzzled.
My plan was to do a feasibility study and then see if we can integrate your work into HF transformers. Just very busy with other projects to respond quickly at the moment.<|||||>Because the article was written too hastily and too long, I decided that it would be more helpful for you to understand it by organizing it more neatly and accurately than explaining it in the issue comments. (I was going to blog soon, maybe within this week.)<|||||>at the end I was able to cheat since github sent me all the comments ;) So I have just read those comments you deleted.
It wasn't long at all, on the contrary I'd say it could use more details in places. Some images were great and some weren't super clear. So adding some words would help.
And I'm very appreciating you wanted to merge this into HF transformers! That would be an amazing contribution!
So bottom line, beside the leaner launcher, the core of your project is Tensor Parallel from built upon Megatron-LM, correct? this is exactly what I was planning to work on when I had free time, so your timing is perfect.
Let's discuss the training side of it. I think to most users of HF transformers that would be the most important application of Tensor parallelism. So in the deleted note you mentioned that DDP-support needs to be integrated to make it work in training. That's the MPU part, right? And we probably should think about Pipeline too while building the MPU, while not implementing it just yet.
Also do you think it'd be a good idea to invite @RezaYazdaniAminabadi into this process, so that gradually we can use your project's flexibility and add Deepspeed CUDA kernels speeds where possible. i.e. work together with the Deepspeed project. That's of course if Reza is interested and his superiors support the effort. We already discussed with Deepspeed to start deploying some of their kernels in the transformers (but haven't done anything yet).
How do you propose we work on integrating this? Perhaps pick a few models first and work on a PR that integrates those and then in a subsequent PR work on other models? Probably leaving the optional launcher out at first and then considering it next?
On a personal note: we are about to launch the first training of the Big Science project https://github.com/bigscience-workshop/ so my availability depends on that, if when we launch it all goes well, I will have more time, if not please bear with me, but I will do my best to support this integration process at least a bit at a time.
If you have any questions or concerns please don't hesitate to ask. I will try to address those.<|||||>I have sent my thoughts about collaboration to your email ([email protected]) !<|||||>Thank you for emailing me your notes, @hyunwoongko
We need to discuss it here and not in private, since this is not my personal project. Therefore please re-paste all or just the parts that you feel are open to the public and we will continue the discussion here. <|||||>Okay. First of all, I'm very happy to have your positive comments. Here are my thoughts.
1. The basic architecture of Parallelformers is similar to that of DeepSpeed. Now that the integration of HuggingFace Transformers and DeepSpeed is in progress, I think it would be the best if we all could cooperate together. A day ago I received such a proposal (working with DeepSpeed team) from @RezaYazdaniAminabadi, an MS engineer.
2. Probably I should be working on the implementation of model parallelization through tensor slicing. Currently Parallelformers supports almost all models in HuggingFace without fused CUDA kernels. If we work together on this project, which I really hope to do, I plan to find a way to integrate the current mechanism to the fused CUDA kernel. I believe if this works out, we can obtain both the speed of the fused CUDA kernel and the scalabilities of Parallelformers.
3. I also think training parallelization is an important issue. In my opinion, it is necessary to consider integrating Tensor MP with DP and DDP. I hope ultimately all the models in Transformers support 3D parallelization through ZeRO + Pipeline with Tensor MP.
4. Currently it is not possible to deploy a model on the web server with DeepSpeed, which I think a critical issue. Obviously, Parallelformers started to tackle it, but I'm open to any cooperation to find a better solution.<|||||>Everything you shared sounds good to me, @hyunwoongko.
With regards to 3D parallelism. currently the main obstacle in HF Transformers to support Pipeline Parallelism (PP) is the presence of multiple optional features that prevent the model from being convertable to `nn.Sequential` which is the prerequisite for implementing PP. Though Sagemaker docs claim that they are able to use PP without a model being converted to `nn.Sequential`. So it's possible that to get to PP we may have to make alternative versions stripped of the optional features. But we can discuss this when we are done with TP (tensor parallelism).
I posted this earlier, could you please address this?
> Let's discuss the training side of it. I think to most users of HF transformers that would be the most important application of Tensor parallelism. So in the deleted note you mentioned that DDP-support needs to be integrated to make it work in training. That's the MPU part, right? And we probably should think about Pipeline too while building the MPU, while not implementing it just yet.
Practically, since you understand your code the best, please let's discuss how to approach the integration of it.
Also let me add a reference to your project at https://huggingface.co/transformers/master/parallelism.html#tensor-parallelism<|||||>> With regards to 3D parallelism. currently the main obstacle in HF Transformers to support Pipeline Parallelism (PP) is the presence of multiple optional features that prevent the model from being convertable to nn.Sequential which is the prerequisite for implementing PP. Though Sagemaker docs claim that they are able to use PP without a model being converted to nn.Sequential. So it's possible that to get to PP we may have to make alternative versions stripped of the optional features. But we can discuss this when we are done with TP (tensor parallelism).
I totally agree with your opinion. An interesting thing is that my former colleague was the first to implement PP on a torch. ([torchgpipe](https://github.com/kakaobrain/torchgpipe)) He first implemented it in a way that uses `nn.Sequential`. So, if possible, I'll try to ask him for advice.
One thing I'm considering is to utilize `nn.ModuleList` in PP. Currently, most of the Transformers models are implemented as `nn.ModuleList`. I think it would be good to use it for PP. the fact that Sagemaker can parallelize Huggingface's models easily means there's something we haven't been able to figure out. I hope that in the future we will continue to work together to find such a scalable way.
> Let's discuss the training side of it. I think to most users of HF transformers that would be the most important application of Tensor parallelism. So in the deleted note you mentioned that DDP-support needs to be integrated to make it work in training. That's the MPU part, right? And we probably should think about Pipeline too while building the MPU, while not implementing it just yet.
Yes, we need to implement training side of it. However, it seems a little difficult to use NVIDIA's mpu implementation in transformers. My idea is to leverage the mechanism of parallelformers again. It is to utilize the most of existing transformers code. When I was implementing parallelformers, I was able to successfully parallelize most models `forward` by changing only a few `nn.Linear` layers while utilize existing transformers codes. And I think this can be applied to `backward` as well. However, combining this with the fused CUDA kernel on DeepSpeed side can be quite difficult. I think `forward` is ok, but `backward` is hard. Because backward is not implemented in their Tensor MP kernel.
Combining DP and DDP probably requires minor changes to the existing torch implementation. As you know, with DP and DDP, same model parameters are broadcast to all GPU. And, each piece of data is sent to each GPUs.
e.g.
- if bsz=16, n_gpus=2
- gpu1=batch 0-7
- gpu2=batch 8-15
This needs to be partitioned. If Tensor MP size is 2, we should create two partitions.
e.g.
- mp_group1=gpu 0, 1
- mp_group2=gpu 2, 3
And I think that the data should be split by each partition, not by each GPU.
e.g.
- if bsz=16, n_gpus=4, mp_size=2
- mp_group1(gpu0,1)=batch 0-7
- mp_group2(gpu2,3)=batch 8-15 <|||||>I wrote it with a little help from a translator. If you can't understand, please tell me :)
---
Here is a first draft of the collaboration plan. Please feel free to comment. Everyone involved in the collaboration will be able to modify this plan depending on the circumstances.
### Step 1. Collaborate DeepSpeed and TUNiB to move Paralleformers Tensor MP
The method of replacing the existing layer uses the scalable method of parallelformers. This does not change the entire transformer layer, but a method to replace a few linear layers with a sliced linear layer or a sliced all-reduce linear layer. Since DeepSpeed's Tensor MP replaced the entire Transformer layer, it could not reflect the specific mechanism of each model.
Firstly, I will implement this method and PR to DeepSpeed. (And this is what the DeepSpeed team wants me to do. refer to [here](https://github.com/microsoft/DeepSpeed/issues/1161#issuecomment-883739436)) Ultimately, it's a good idea to archive parallelformers after most of the mechanisms of parallelformers are moved in DeepSpeed. It's a pity that our toolkit will be archived, but I think user accessibility is much more important because I want more people to easily use the large model. Parallelformers are less accessible compared to HF Transformers and MS DeepSpeed.
### Step 2. Collaborate DeepSpeed and TUNiB about fused CUDA kernel
However, it is quite challenging to combine it with the CUDA kernel in the training process. In my opinion, it would not be difficult to implement forward pass, but the problem is backward. There is currently no backward pass implementation in the Tensor MP kernel in DeepSpeed. Because currently, Tensor MP is provided as inferences, DeepSpeed team didn't need to implement backward pass. Unfortunately, since I do not understand the CUDA code at a high level, it will be difficult for me to write the CUDA backward code myself.
Therefore, collaboration with DeepSpeed should be made in this part. It would be nice if we could collaborate with DeepSpeed and discuss about backward implementation of the DeepSpeed Tensor MP kernel. If this is impossible, it may be difficult to use the CUDA kernel during the training process.
### Step 3. Collaborate Huggingface and TUNiB about transformers
In this step, we will add the newly implemented Tensor MP kernel by DeepSpeed and TUNiB into the HuggingFace. I think it will be similar to the [Policy](https://github.com/tunib-ai/parallelformers/tree/main/parallelformers/policies) I implemented in parallelformers.
There are two methods to add to HuggingFace side.
1) Like `modeling_MODEL.py` and `tokenization_MODEL.py` in each model directory, we can create `parallel_MODEL.py` about the parallelization policy.
2) Alternatively, it is also worth considering about utilizing config.json. However, this can also be a fairly large work because every config.json files uploaded to hub needs to be changed.
### Step 4. Collaborate Huggingface and TUNiB about DP, DDP, PP
Once Tensor MP is done, we will be able to proceed with combining it with DP and DDP. At the same time, It would be good to consider about implementing PP using `nn.ModuleList`. In my opinion, the existing PP based on `nn.Sequntial` is not suitable for HF transformers. I will to ask a former colleague for their opinion on a PP implementation based on `nn.ModuleList`.<|||||>We probably should discuss PP elsewhere and focus in this thread on what's already working in your project. So I will give a brief overview only:
> I totally agree with your opinion. An interesting thing is that my former colleague was the first to implement PP on a torch. ([torchgpipe](https://github.com/kakaobrain/torchgpipe)) He first implemented it in a way that uses `nn.Sequential`. So, if possible, I'll try to ask him for advice.
Great!
> One thing I'm considering is to utilize `nn.ModuleList` in PP. Currently, most of the Transformers models are implemented as `nn.ModuleList`. I think it would be good to use it for PP. the fact that Sagemaker can parallelize Huggingface's models easily means there's something we haven't been able to figure out. I hope that in the future we will continue to work together to find such a scalable way.
The 3 frameworks that currently provide PP as an API that I know of are fairscale, deepspeed and pytorch's recent versions - these all require `nn.Sequential`. So unless we implements a custom PP, `nn.ModuleList` won't do. Moreover you have other modules before and after the block list with very different inputs/outputs.
Actually, the main complication of the current models, is the inputs/outputs. PP requires simple tensor variables that can be sliced at the batch dimension. HF models have a gazillion of variables that aren't tensors and thus can't be sliced. Some variables are tuples of tuples and are used as aggregates.
If you'd like to see the sort of jumps through the hoops I had to go through to make it work for t5, please see:
- https://github.com/huggingface/transformers/pull/9765 (because of the conditional encoder, I had to implement this as 2 pipes. And the way I managed to make it work was super-inefficient, that's why it was never merged).
- https://github.com/huggingface/transformers/pull/9940 (I tried a different approach and this attempt I didn't even bother finishing as Deepspeed zero3 came out and it was a way easier to use to solve the same problem)
Note that over the spring pytorch has developed a much more user-friendlier PP API, which now allows passing non-tensor variables, which should make things much easier.
Most likely we will have to make stripped versions of the current models which support only the features that PP can accommodate.
<|||||>> Yes, we need to implement training side of it. However, it seems a little difficult to use NVIDIA's mpu implementation in transformers.
I wasn't referring to a specific MPU implementation. Deepspeed has one too. It's basically the manager of all dimensions of parallelism. The only reason I mentioned it so that we consider the future PP dimension as we develop the manager.
> My idea is to leverage the mechanism of parallelformers again. It is to utilize the most of existing transformers code. When I was implementing parallelformers, I was able to successfully parallelize most models `forward` by changing only a few `nn.Linear` layers while utilize existing transformers codes. And I think this can be applied to `backward` as well. However, combining this with the fused CUDA kernel on DeepSpeed side can be quite difficult. I think `forward` is ok, but `backward` is hard. Because backward is not implemented in their Tensor MP kernel.
Then we start with just that.
> Combining DP and DDP probably requires minor changes to the existing torch implementation. As you know, with DP and DDP, same model parameters are broadcast to all GPU. And, each piece of data is sent to each GPUs.
>
> e.g.
>
> * if bsz=16, n_gpus=2
>
> * gpu1=batch 0-7
>
> * gpu2=batch 8-15
>
>
> This needs to be partitioned. If Tensor MP size is 2, we should create two partitions.
>
> e.g.
>
> * mp_group1=gpu 0, 1
>
> * mp_group2=gpu 2, 3
>
>
> And I think that the data should be split by each partition, not by each GPU.
>
> e.g.
>
> * if bsz=16, n_gpus=4, mp_size=2
>
> * mp_group1(gpu0,1)=batch 0-7
>
> * mp_group2(gpu2,3)=batch 8-15
Yes, that's the whole point of MPU. DP doesn't even need to know about TP, it just sees gpu0 and gpu2 - it has no idea there are more GPUs in the pipe. Each parallel dimension typically hides its existence from other dimensions, which allows things to keep simple.
<|||||>Your collaboration plans is very clear, @hyunwoongko.
Thank you for your inspiration to share your work for the good of all! It's true that being part of a "bigger pie" will make your work accessible to a lot more users.
Wrt step2, you know that Deepspeed has a full TP implementation, except not in CUDA kernels - perhaps this can be utilized instead for `backward`?
Otherwise please ping or tag me when you need my input here or on the Deepspeed github.
Looking forward to this inspiring collaboration, @hyunwoongko <|||||>First of all, we need to discuss this collaborative process with @RezaYazdaniAminabadi.
Can we discuss it here? I'm curious about your opinion.<|||||>> Wrt step2, you know that Deepspeed has a full TP implementation, except not in CUDA kernels - perhaps this can be utilized instead for backward?
I'll review the code soon. Thank you.
<|||||>https://tunib.notion.site/TECH-2021-07-26-Parallelformers-Journey-to-deploying-big-models-32b19a599c38497abaad2a98727f6dc8
Here is the English version of the blog post!<|||||>@stas00 Sorry for the delay this work. We are also making a public large-scale model that can cover Asian languages. I've been very busy these days, so I haven't had much time to contribute to Hugging Face. I will work on it as soon as possible.<|||||>Also pinging @siddk whose team also has been working on improving `transformers` to support TP https://github.com/stanford-crfm/mistral.
For context, while your team was on a summer break, @hyunwoongko implemented Parallelformers and we started discussing how to integrate their work, while planning integration of Deepspeed CUDA kernels for TP.
So now that your team is getting back let's discuss how to best collaborate.<|||||>Oh this is awesome, thanks @stas00 and nice to meet you @hyunwoongko. Let me get up to speed on this thread, but this looks like amazing work!<|||||>@siddk Hello. Could you please explain so I can get the context? :)<|||||>I will resume this work from this weekend. Since my company is so busy now, most of the open source work will probably be done on weekends. I will working on deepspeed this week. I had an offline meeting with them and we are discussing how to combine. (Probably integration with Huggingface transformers will not take place soon because it is steps 3 and 4.)
<|||||>It's really cool to see this collaboration in the pipeline! I'm not affiliated with any of the frameworks/organizations here at stake, but I do come from HF BigScience side of things where I've briefly discussed things with @stas00. If there's grunt work or anything else that has to be done, I'd be more than happy to contribute in ways that I can. <|||||>@jaketae I already know you by KoClip project. nice to meet you. Your work would be of great help. :)
@stas00 Currenlty, we need to talk more with the DeepSpeed team. I will first integrate the parallelformers features into deepspeed. However, what deepspeed and transformers currently want is slightly different, so we need to adjust it.
1) deepspeed wants to improve deepspeed-inference, maybe they are not considering training features.
2) transformers want to improve training features with 3D parallelization. (and as we said before, we have to consider a megatron-lm style mpu if we implement training features with pp and dp. The problem is I don't know if it's okay for me to implement this in deepspeed).<|||||>As I commented in another issue:
HF transformers wants both training and inference. It's just that we have a lot more users using the library for training. So there is definitely not misalignment between the two.
Remember that Deepspeed already has PP, so they are just missing TP and inference.
HF Transformers doesn't have those yet, hence the difference.
(thanks to @hyunwoongko for correcting me that DS doesn't have TP)
<|||||>> @siddk Hello. Could you please explain so I can get the context? :)
https://twitter.com/siddkaramcheti/status/1430195543301492744<|||||>> If there's grunt work or anything else that has to be done, I'd be more than happy to contribute in ways that I can.
@jaketae, the idea is to first pick one model and port it to TP and later PP. Then we will have to replicate this for all models (or at least models that will support this), so there will be a ton of work for quite a few people to contribute.<|||||>I will close this issue. lets discuss in https://github.com/huggingface/transformers/issues/13690 |
transformers | 12,771 | closed | GPTNeo Flax - crashes - n> sizes_size | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.0.dev0
- Platform: Linux-5.4.0-1043-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.3.4 (cpu)
- Jax version: 0.2.17
- JaxLib version: 0.1.68
### Who can help
@patrickvonplaten
## Information
Trying to run the experimental GPTNeo Flax script. Are getting the following error:
```
07/17/2021 16:08:11 - INFO - __main__ - ***** Running training *****
07/17/2021 16:08:11 - INFO - __main__ - Num examples = 2852257
07/17/2021 16:08:11 - INFO - __main__ - Num Epochs = 10
07/17/2021 16:08:11 - INFO - __main__ - Instantaneous batch size per device = 3
07/17/2021 16:08:11 - INFO - __main__ - Total train batch size (w. parallel & distributed) = 24
07/17/2021 16:08:11 - INFO - __main__ - Total optimization steps = 1188440
Epoch ... (1/10): 0%| | 0/10 [00:00<?, ?it/sF0717 16:08:46.411695 76098 array.h:414] Check failed: n < sizes_size | 0/118844 [00:00<?, ?it/s]
*** Check failure stack trace: ***
@ 0x7f4a22c7f347 (unknown)
@ 0x7f4a22c7ded4 (unknown)
@ 0x7f4a22c7d9c3 (unknown)
@ 0x7f4a22c7fcc9 (unknown)
@ 0x7f4a1e8e7eee (unknown)
@ 0x7f4a1e87ab2f (unknown)
@ 0x7f4a1e878cc2 (unknown)
@ 0x7f4a223fddb4 (unknown)
@ 0x7f4a223ff212 (unknown)
@ 0x7f4a223fce23 (unknown)
@ 0x7f4a1885856f (unknown)
@ 0x7f4a1e8a3248 (unknown)
@ 0x7f4a1e8a4d2b (unknown)
@ 0x7f4a1e3f202b (unknown)
@ 0x7f4a1e8e3001 (unknown)
@ 0x7f4a1e8e0d6a (unknown)
@ 0x7f4a1e8e08bd (unknown)
@ 0x7f4a1e8e3001 (unknown)
@ 0x7f4a1e8e0d6a (unknown)
@ 0x7f4a1e8e08bd (unknown)
@ 0x7f4a1df5f13f (unknown)
@ 0x7f4a1df5a52e (unknown)
@ 0x7f4a1df64292 (unknown)
@ 0x7f4a1df71ffd (unknown)
@ 0x7f4a1db5c6b6 (unknown)
@ 0x7f4a1db5c014 TpuCompiler_Compile
@ 0x7f4a28dcf956 xla::(anonymous namespace)::TpuCompiler::Compile()
@ 0x7f4a2657f0d4 xla::Service::BuildExecutables()
@ 0x7f4a265751a0 xla::LocalService::CompileExecutables()
@ 0x7f4a264b9e07 xla::LocalClient::Compile()
@ 0x7f4a264942a0 xla::PjRtStreamExecutorClient::Compile()
@ 0x7f4a2408f152 xla::PyClient::Compile()
@ 0x7f4a23e095e2 pybind11::detail::argument_loader<>::call_impl<>()
@ 0x7f4a23e09a51 pybind11::cpp_function::initialize<>()::{lambda()#3}::operator()()
@ 0x7f4a23df0460 pybind11::cpp_function::dispatcher()
@ 0x5f2cc9 PyCFunction_Call
https://symbolize.stripped_domain/r/?trace=7f4a22c7f347,7f4a22c7ded3,7f4a22c7d9c2,7f4a22c7fcc8,7f4a1e8e7eed,7f4a1e87ab2e,7f4a1e878cc1,7f4a223fddb3,7f4a223ff211,7f4a223fce22,7f4a1885856e,7f4a1e8a3247,7f4a1e8a4d2a,7f4a1e3f202a,7f4a1e8e3000,7f4a1e8e0d69,7f4a1e8e08bc,7f4a1e8e3000,7f4a1e8e0d69,7f4a1e8e08bc,7f4a1df5f13e,7f4a1df5a52d,7f4a1df64291,7f4a1df71ffc,7f4a1db5c6b5,7f4a1db5c013,7f4a28dcf955,7f4a2657f0d3,7f4a2657519f,7f4a264b9e06,7f4a2649429f,7f4a2408f151,7f4a23e095e1,7f4a23e09a50,7f4a23df045f,5f2cc8&map=20957999b35a518f734e5552ed1ebec946aa0e35:7f4a2378b000-7f4a2a67dfc0,2a762cd764e70bc90ae4c7f9747c08d7:7f4a15d2d000-7f4a22fae280
https://symbolize.stripped_domain/r/?trace=7f4acedc218b,7f4acedc220f,7f4a22c7f487,7f4a22c7ded3,7f4a22c7d9c2,7f4a22c7fcc8,7f4a1e8e7eed,7f4a1e87ab2e,7f4a1e878cc1,7f4a223fddb3,7f4a223ff211,7f4a223fce22,7f4a1885856e,7f4a1e8a3247,7f4a1e8a4d2a,7f4a1e3f202a,7f4a1e8e3000,7f4a1e8e0d69,7f4a1e8e08bc,7f4a1e8e3000,7f4a1e8e0d69,7f4a1e8e08bc,7f4a1df5f13e,7f4a1df5a52d,7f4a1df64291,7f4a1df71ffc,7f4a1db5c6b5,7f4a1db5c013,7f4a28dcf955,7f4a2657f0d3,7f4a2657519f,7f4a264b9e06,7f4a2649429f&map=20957999b35a518f734e5552ed1ebec946aa0e35:7f4a2378b000-7f4a2a67dfc0,2a762cd764e70bc90ae4c7f9747c08d7:7f4a15d2d000-7f4a22fae280
*** SIGABRT received by PID 76098 (TID 76098) on cpu 46 from PID 76098; ***
E0717 16:08:46.484046 76098 coredump_hook.cc:292] RAW: Remote crash data gathering hook invoked.
E0717 16:08:46.484074 76098 coredump_hook.cc:384] RAW: Skipping coredump since rlimit was 0 at process start.
E0717 16:08:46.484099 76098 client.cc:222] RAW: Coroner client retries enabled (b/136286901), will retry for up to 30 sec.
E0717 16:08:46.484107 76098 coredump_hook.cc:447] RAW: Sending fingerprint to remote end.
E0717 16:08:46.484121 76098 coredump_socket.cc:124] RAW: Stat failed errno=2 on socket /var/google/services/logmanagerd/remote_coredump.socket
E0717 16:08:46.484133 76098 coredump_hook.cc:451] RAW: Cannot send fingerprint to Coroner: [NOT_FOUND] Missing crash reporting socket. Is the listener running?
E0717 16:08:46.484139 76098 coredump_hook.cc:525] RAW: Discarding core.
F0717 16:08:46.411695 76098 array.h:414] Check failed: n < sizes_size
E0717 16:08:46.761921 76098 process_state.cc:771] RAW: Raising signal 6 with default behavior
``` | 07-17-2021 16:24:26 | 07-17-2021 16:24:26 | Hey @peregilk,
could you please provide the exact command that you ran to reproduce the error?<|||||>I am using the default script. I have the data stored on an attached disk to the VM. The data is in json-format. I have a gpt-tokenizer with the correct number of tokens that is stored in the model directory. Here are the paramters I am running:
```
python run_clm_mp.py \
--model_name_or_path /mnt/disks/flaxdisk/norwegian-gptneo-red/ \
--tokenizer_name /mnt/disks/flaxdisk/norwegian-gptneo-red/ \
--train_file /mnt/disks/flaxdisk/corpus/social_train.json \
--validation_file /mnt/disks/flaxdisk/corpus/social_validation.json \
--do_train \
--do_eval \
--block_size 1024 \
--num_train_epochs 10 \
--learning_rate 4e-6 \
--per_device_train_batch_size 3 \
--per_device_eval_batch_size 3 \
--overwrite_output_dir \
--output_dir /mnt/disks/flaxdisk/norwegian-gptneo-red \
--cache_dir /mnt/disks/flaxdisk/cache/ \
--dtype bfloat16 \
--logging_steps 97 \
--eval_steps 96\
--push_to_hub
```
<|||||>Hi @patrickvonplaten,
I have tried running the script also with the gpt2-tokenizer and the example wikipedia text. Here are my current settings:
```
python run_clm_mp.py \
--model_name_or_path /mnt/disks/flaxdisk/norwegian-gptneo-red/ \
--tokenizer_name gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train \
--do_eval \
--block_size 1024 \
--num_train_epochs 5 \
--learning_rate 4e-6 \
--per_device_train_batch_size 3 \
--per_device_eval_batch_size 3 \
--overwrite_output_dir \
--output_dir /mnt/disks/flaxdisk/output/ \
--cache_dir /mnt/disks/flaxdisk/cache/ \
--dtype bfloat16 \
--logging_steps 97 \
--eval_steps 96\
--push_to_hub
```
I am getting exactly the same error. I have also checked in my code here: https://huggingface.co/pere/norwegian-gptneo-red/tree/main. With the current command in run.sh.<|||||>@patrickvonplaten <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Think we might have solved this by limiting the list size of TPU tensors to `eval_steps`...but @patil-suraj will take a deeper look into large model pretraining in JAX in the following weeks so stay tuned for more robust notebooks on large GPT model pretraining :-)<|||||>This link might be useful as well: https://github.com/huggingface/transformers/issues/12505#issuecomment-873988017
Not sure if this solves the problem - but with @patil-suraj we're looking into making GPT2 more useable on TPU with Flax anyway at the moment. So we should have an answer in like 1,2 weeks<|||||>Thanks, Patrick. Ill wait a couple of weeks and see that @patil-suraj finds out.
However, I am not sure if this is related to the OOM issues with GPT2. The current issue is really a duplicate of [https://github.com/huggingface/transformers/issues/12761](https://github.com/huggingface/transformers/issues/12761). Mem is OK both on VM and TPU. Script crashes because a failed check (n> sizes_size) in array.h:414. <|||||>I've been meaning to look into this -- it shouldn't be possible to crash jax like this. Sorry for the continued delay! I'm about to be on vacation, but I think I can finally look at this when I get back the week after next.<|||||>Can someone try running this with the latest jax[tpu] install? At least one crash has been resolved since this was posted, and I wonder if this one was as well.<|||||>Hey @skye !
I just ran this script with latest jax[tpu] install and it runs without any issues. <|||||>Just documenting my experiences publicly here. I am getting this error running JaxLib version: 0.1.68. Upgrading to JaxLib 0.1.72 solves the issue. The script now runs without any issues.
Please also see the issue: https://github.com/huggingface/transformers/issues/12761. Here @arampacha is reporting the same error while using JaxLib 0.1.68.<|||||>This and #12761 look like different issues actually, they just both crash in JAX's C++ backend so have similar-looking output. I think this can be closed.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,770 | closed | Fix push_to_hub docstring and make it appear in doc | # What does this PR do?
As pointed out in #12700, the documentation of `psuh_to_hub` was not appearing in the objects like `PretrainedConfig`, `PreTrainedModel` or `PreTrainedTokenzier`. This PR addresses that. It also customizes the documentation for each object (in particular the example) but since I didn't want to make (and maintain) five copies of the docstring, I'm reusing the technique we use for Flax docstrings (copy the method and then adapt its docstring). I think it's okay to have a refactored approach here since it's for the internals of the lib but let me know.
This PR also simplifies the doc page of the tokenizer by using the `special_members` keyword for the methods we want to force to appear even if they are not redefined in the subclass, instead of naming everything in `members`.
Fixes #12700
| 07-17-2021 09:03:53 | 07-17-2021 09:03:53 | |
transformers | 12,769 | closed | Seq2SeqTrainer Model parallelism with AWS Sagemaker - not enough values to unpack error | ## Environment info
- `transformers` version: 4.6
- Platform: 'ml.p3.16xlarge' AWS DLC container
- Python version: 3.6
- PyTorch version (GPU?): 1.7 (True)
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: Yes
### Who can help
@philschmid @patrickvonplaten
## Information
Model I am using (Bert, XLNet ...): allenai/led-base-16384
The problem arises when using:
* [ ] my own modified scripts: (give details below)
I am trying to use AWS Sagemaker DLC container to train LED-base in a model parallel way using Seq2SeqTrainer on an 'ml.p3.16xlarge' instance on a custom dataset for the task of summarization. I am getting a 'not enough values to unpack error'.

## To reproduce
Here are the settings used
```python
from sagemaker.huggingface import HuggingFace
hyperparameters = {
'model_name': 'allenai/led-base-16384',
'train_batch_size': 4,
'eval_batch_size': 4,
'num_train_epochs': 1
}
instance_count = 1
mpi_options = {
'enabled': True,
'processes_per_host': 8
}
smp_options = {
'enabled': True,
'parameters': {
'microbatches': 4,
'placement_strategy': 'spread',
'pipeline': 'interleaved',
'optimize': 'speed',
'partitions': 4,
'ddp': True
}
}
distribution = {
'smdistributed': {'modelparallel': smp_options},
'mpi': mpi_options
}
```
```python
huggingface_estimator = HuggingFace(entry_point='led_train.py',
source_dir='./scripts',
instance_type='ml.p3.16xlarge',
instance_count=instance_count,
role=role,
transformers_version='4.6',
pytorch_version='1.7',
py_version='py36',
hyperparameters=hyperparameters,
distribution=distribution
)
```
Using this in the training script led_train.py
```python
from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainer, Seq2SeqTrainingArguments, AutoTokenizer
```
## Expected behavior
Expected model parallel training to happen smoothly
| 07-17-2021 08:50:30 | 07-17-2021 08:50:30 | cc @sgugger<|||||>@suneelmatham do you need to run the LED-base in model parallel? Shouldn't the `base` version easily fit into memory? From the [hub](https://huggingface.co/allenai/led-base-16384) It only seems to be around 700MB. You could go with data parallelism to speed up your training. https://huggingface.co/docs/sagemaker/train#advanced-features<|||||>What is this `led_train.py` script? The error is not linked to the distributed training at first glance: it's just that the `input_ids` are not a 2d tensor (`batch_size` by `sequence_length`).<|||||>Thanks for the checking the issue out!
@philschmid I was doing a trial run with LED-base to test model parallel trng with Seq2SeqTrainer since the example notebook was with SageMakerTrainer. I plan to use LED-large for full run. I wanted to try model parallel since the dataset instances are long transcripts and hence was getting Out of memory error even with a really small batch size.
@sgugger led_train.py script is the training script which runs in an AWS DLC container and is triggered by the rest of the code which is being run from a sagemaker jupyter notebook. The same training script is running fine on a single AWS instance without using distributed options. I suspect the issue might be with using Seq2SeqTrainer with distributed options set. Specifically, the example notebook was using SageMakerTrainer as the trainer. I have read in HF release of 4.6 that Trainer itself can directly be used instead of SageMakerTrainer. So, I assumed that Seq2SeqTrainer will work fine too with model parallelism
I am using this fn for tokenization
```python
def tokenize(batch):
inputs = tokenizer(batch['src'], padding='max_length', truncation=True)
outputs = tokenizer(batch['tgt'], padding='max_length', truncation=True, max_length=max_output_length)
batch['input_ids'] = inputs.input_ids
batch['attention_mask'] = inputs.attention_mask
batch["global_attention_mask"] = len(batch["input_ids"]) * [[0 for _ in range(len(batch["input_ids"][0]))]]
batch['global_attention_mask'][0][0] = 1
batch['labels'] = outputs.input_ids
batch['labels'] = [
[-100 if token == tokenizer.pad_token_id else token for token in labels]
for labels in batch['labels']
]
return batch
```
and the following for Seq2SeqTrainer
```python
training_args = Seq2SeqTrainingArguments(
predict_with_generate=True,
evaluation_strategy='steps',
per_device_train_batch_size=args.train_batch_size,
per_device_eval_batch_size=args.eval_batch_size,
fp16=True,
output_dir=args.model_dir,
logging_steps=5,
eval_steps=10,
save_steps=10,
save_total_limit=2,
# gradient_accumulation_steps=4,
num_train_epochs=args.num_train_epochs,
report_to='wandb',
run_name='ml2xlarge model parallel',
# max_grad_norm= 0
)
trainer = Seq2SeqTrainer(
model=led,
tokenizer=tokenizer,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=val_dataset
)
```
I assumed that Seq2SeqTrainer will handle batching of input_ids to pass to the model and it worked out fine when running on a single instance. Should I modify the tokenization fn. to fix this. Please let me know.<|||||>> @philschmid I was doing a trial run with LED-base to test model parallel trng with Seq2SeqTrainer since the example notebook was with SageMakerTrainer. I plan to use LED-large for full run. I wanted to try model parallel since the dataset instances are long transcripts and hence was getting Out of memory error even with a really small batch size.
I think data-parallel is definitely well more suited for this. The [allenai/led-large-16384](https://huggingface.co/allenai/led-large-16384) is only around 2GB and will be fast and scale better with only using data-parallel. The small batch sizes then can we scaled with scaling to multiple GPUs or even multiple nodes. We have a blog post [here](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq) about how to do it or you can go to https://huggingface.co/docs/sagemaker/train#advanced-features and replace your `distribution` config to
```bash
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
```<|||||>Thanks. Will try with data parallel<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,768 | open | Alphafold 2.0 | # 🌟 New model addition
It would be so amazing to have Alphafold model in huggingface. 😍
I don't know if there is any plan to add these kind of models to huggingface repo.
<!-- Important information -->
## Model description
## Open source status
* [x] the model implementation is available: ([github](https://github.com/deepmind/alphafold))
* [] the model weights are available: ([github](https://github.com/deepmind/alphafold))
* [x] who are the authors: (@deepmind) | 07-17-2021 07:55:01 | 07-17-2021 07:55:01 | cc @Rocketknight1 :)<|||||>cc @Narsil too, this is something we've been looking at internally!<|||||>Any updates? <|||||>We roughly looked into it, but alphafold requires quite a bit of data to work with (other known proteins configurations), and it seems just transposing the model would be not super relevant on its own.
Feel free to take a look on your own, I think it would be a great addition if we could make it work, but it seemed the overall `alphafold` thing would be quite the undertaking and require a lot of other dependencies, which is why we haven't started a proper integration. |
transformers | 12,767 | closed | How to override model.generate() function in GenerationMixin class? | Hi, I want to override `_generate_no_beam_search`, `_generate_beam_search` methods in `GenerationMixin` class to adjust `next_token_logits`.
I tried it by adding adjusted methods in my custom model code but seems not working.
I'd appreciate any help. Thanks! | 07-17-2021 05:13:08 | 07-17-2021 05:13:08 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discuss.huggingface.co) instead?
Thanks!<|||||>Hi, have you found the solutions? I'm facing the same issue.<|||||>@rxlian Hi, I failed to override `model.generate()` function, but in my case overriding `_prepare_encoder_decoder_kwargs_for_generation` function in the model definition was successful! |
transformers | 12,766 | closed | Log Azure ML metrics only for rank 0 | Collect only the loss values reported in the log file on 0th process from a multi GPU experiment into the Metrics table/chart.
Fixes # (issue)
The loss values displayed in the metrics from from all devices which does not reflect the correct total loss for distributed runs.
| 07-17-2021 01:01:48 | 07-17-2021 01:01:48 | |
transformers | 12,765 | closed | Error in HuggingFace Course "Fine-tuning a pretrained model" | New to huggingface and just going through your newly posted course.
## To reproduce
Open a google collab notebook.
Run
```
!pip install transformers[sentencepiece]
!pip install datasets
```
Then follow the steps in this chapter of the huggingface course https://huggingface.co/course/chapter3/3?fw=pt
At the step where you are told to call `trainer.train()` you see this error
```
***** Running training *****
Num examples = 3668
Num Epochs = 3
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 1377
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py in convert_to_tensors(self, tensor_type, prepend_batch_axis)
698 if not is_tensor(value):
--> 699 tensor = as_tensor(value)
700
ValueError: too many dimensions 'str'
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
8 frames
<ipython-input-50-3435b262f1ae> in <module>()
----> 1 trainer.train()
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, **kwargs)
1241 self.control = self.callback_handler.on_epoch_begin(args, self.state, self.control)
1242
-> 1243 for step, inputs in enumerate(epoch_iterator):
1244
1245 # Skip past any already trained steps if resuming training
/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py in __next__(self)
519 if self._sampler_iter is None:
520 self._reset()
--> 521 data = self._next_data()
522 self._num_yielded += 1
523 if self._dataset_kind == _DatasetKind.Iterable and \
/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py in _next_data(self)
559 def _next_data(self):
560 index = self._next_index() # may raise StopIteration
--> 561 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
562 if self._pin_memory:
563 data = _utils.pin_memory.pin_memory(data)
/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/fetch.py in fetch(self, possibly_batched_index)
45 else:
46 data = self.dataset[possibly_batched_index]
---> 47 return self.collate_fn(data)
/usr/local/lib/python3.7/dist-packages/transformers/data/data_collator.py in __call__(self, features)
121 max_length=self.max_length,
122 pad_to_multiple_of=self.pad_to_multiple_of,
--> 123 return_tensors="pt",
124 )
125 if "label" in batch:
/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py in pad(self, encoded_inputs, padding, max_length, pad_to_multiple_of, return_attention_mask, return_tensors, verbose)
2700 batch_outputs[key].append(value)
2701
-> 2702 return BatchEncoding(batch_outputs, tensor_type=return_tensors)
2703
2704 def create_token_type_ids_from_sequences(
/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py in __init__(self, data, encoding, tensor_type, prepend_batch_axis, n_sequences)
202 self._n_sequences = n_sequences
203
--> 204 self.convert_to_tensors(tensor_type=tensor_type, prepend_batch_axis=prepend_batch_axis)
205
206 @property
/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py in convert_to_tensors(self, tensor_type, prepend_batch_axis)
714 )
715 raise ValueError(
--> 716 "Unable to create tensor, you should probably activate truncation and/or padding "
717 "with 'padding=True' 'truncation=True' to have batched tensors with the same length."
718 )
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.
```
## Expected behavior
I guess I expected it to start training? The error message seems incorrect since padding and truncation are already set to True.
| 07-16-2021 20:09:20 | 07-16-2021 20:09:20 | cc @sgugger <|||||>I am unable to reproduce. Are you sure you don't have an old version of transformers in your Colab runtime for some reason? Could you run
```
! transformers-cli env
```
in a cell and paste the output here?<|||||>My apologies for the spurious issue. I did a factory reset of my runtime today and was unable to replicate the error. Thanks for the awesome library!<|||||>I get the same error described above. Doing a factory reset does not help.
The tensorflow version works fine though.
>
> `transformers` version: 4.16.0
> - Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
> - Python version: 3.7.12
> - PyTorch version (GPU?): 1.10.0+cu111 (False)
> - Tensorflow version (GPU?): 2.7.0 (False)
> - Flax version (CPU?/GPU?/TPU?): not installed (NA)
> - Jax version: not installed
> - JaxLib version: not installed
> - Using GPU in script?: Yes
> - Using distributed or parallel set-up in script?: No<|||||>> I am unable to reproduce. Are you sure you don't have an old version of transformers in your Colab runtime for some reason? Could you run
>
> ```
> ! transformers-cli env
> ```
>
> in a cell and paste the output here?
@sgugger
This is the ouput
```
- `transformers` version: 4.18.0
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- Huggingface_hub version: 0.6.0
- PyTorch version (GPU?): 1.11.0+cu113 (True)
- Tensorflow version (GPU?): 2.8.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
i am trying to use 'bert-base-cased' for text classificationn, and i got the same error as OP |
transformers | 12,764 | closed | [Wav2Vec2] Padded vectors should not allowed to be sampled | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Correct negative sampling for Wav2Vec2ForPreTraining. Previously padded feature vectors could be sampled which would give the model bad signals during pretraining. This PR makes sure that a padded feature vector cannot be sampled as a "negative" vector.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-16-2021 16:55:42 | 07-16-2021 16:55:42 | PR is tested on Wav2Vec2 PreTraining in Flax |
transformers | 12,763 | closed | IndexError: index out of range in self | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.6.1
- Platform: Ubuntu Linux
- Python version:3.88
- PyTorch version (GPU?):1.8.1
- Tensorflow version (GPU?):N/A
- Using GPU in script?:No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik
@patrickvonplaten
@patil-suraj
## Information
Model I am using (Bert, XLNet ...):
BERT
The problem arises when using:
my own modified scripts
The tasks I am working on is:
word sense disambiguation
## To reproduce
Steps to reproduce the behavior:
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
class my_BERT(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config)
self.dropout = torch.nn.Dropout(config.hidden_dropout_prob)
self.ranking_linear = torch.nn.Linear(config.hidden_size, 1)
self.init_weights()
...
model_dir = "... bert_base-augmented-batch_size=128-lr=2e-5-max_gloss=6"
model = my_Bert.from_pretrained(model_dir)
tokenizer = BertTokenizer.from_pretrained(model_dir)
...
model.bert(
input_ids=torch.tensor(bert_input.input_ids, dtype=torch.long).unsqueeze(0).to(DEVICE),
attention_mask=torch.tensor(bert_input.input_mask, dtype=torch.long).unsqueeze(0).to(DEVICE),
token_type_ids=torch.tensor(bert_input.segment_ids, dtype=torch.long).unsqueeze(0).to(DEVICE)
)[1]
)
```
```
Traceback (most recent call last):
File "... my_bert.py", line 605, in <module>
print(my_match.matching())
File "... my_bert.py", line 595, in matching
best_sense = get_sense(modified_sentence)
File "..my_bert.py", line 565, in get_sense
model.bert(
File "... my_env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "... my_env/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line 964, in forward
embedding_output = self.embeddings(
File "... my_env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "... my_env/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line 201, in forward
inputs_embeds = self.word_embeddings(input_ids)
File "... my_env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "... my_env/lib/python3.8/site-packages/torch/nn/modules/sparse.py", line 156, in forward
return F.embedding(
File "... my_env/lib/python3.8/site-packages/torch/nn/functional.py", line 1916, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self
```
## Expected behavior
When I run my code with transformers==2.9.0, there is no problem, but when I upgrade to the newer version (4.6.1), this error appears.
Here is the [url ](https://entuedu-my.sharepoint.com/personal/boonpeng001_e_ntu_edu_sg/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fboonpeng001%5Fe%5Fntu%5Fedu%5Fsg%2FDocuments%2FBERT%2DWSD%2Fmodel%2Fbert%5Fbase%2Daugmented%2Dbatch%5Fsize%3D128%2Dlr%3D2e%2D5%2Dmax%5Fgloss%3D6&originalPath=aHR0cHM6Ly9lbnR1ZWR1LW15LnNoYXJlcG9pbnQuY29tLzpmOi9nL3BlcnNvbmFsL2Jvb25wZW5nMDAxX2VfbnR1X2VkdV9zZy9FaVd6YmxPeXlPQkR0dU8za2xVYlhvQUIzVEhGemtlLTJNTFdndUlYckRvcFdnP3J0aW1lPTZaYVhQYzVLMlVn)where I got the word sense disambiguation model:
Here is its GitHub [repo](https://github.com/BPYap/BERT-WSD):
This problem seems to be similar to this other [issue](https://github.com/huggingface/transformers/issues/5611), but I don't know what value I need to specify for the 'vocab_size' (the library said the vocab_size was 30523, but specifying this didn't change anything).
Also, I tried using a really small input sequence, but this error still came.
Thank you to anyone who is able to help! | 07-16-2021 16:19:23 | 07-16-2021 16:19:23 | Hello! Could you print `model.config.vocab_size` and `len(tokenizer)`? These two should be the same, as otherwise your tokenizer will generate IDs that the model cannot understand (which seems to be the case here)<|||||>@LysandreJik
```model.config.vocab_size``` returns 30523, and ```len(tokenizer)``` returns 30524
I tried adding ```vocab_size=30524``` as a parameter to ```model = my_Bert.from_pretrained(model_dir)```, but then I got the following error:
```
RuntimeError: Error(s) in loading state_dict for BertWSD:
size mismatch for bert.embeddings.word_embeddings.weight: copying a param with shape torch.Size([30523, 768]) from checkpoint, the shape in current model is torch.Size([30524, 768]).
```
<|||||>Before trying to resize your model, we should understand why your tokenizer is suddenly bigger than it was in version v2.9.0. Resizing the model embedding is possible, but it implies initializing randomly the embeddings linked to the last token that your tokenizer can generate - which isn't ideal.
Would it be possible for you to upload your model and tokenizer on the hub, so that I may take a look? You can see a guide of how to do it here: https://huggingface.co/docs/hub/adding-a-model<|||||>Thank you for your reponse @LysandreJik
I am using a model and tokenizer from the following github [repo ](https://github.com/BPYap/BERT-WSD/tree/master/model) and the model and tokenizer themselves are in this microsoft sharepoint [folder](https://entuedu-my.sharepoint.com/:f:/g/personal/boonpeng001_e_ntu_edu_sg/EiWzblOyyOBDtuO3klUbXoAB3THFzke-2MLWguIXrDopWg?e=08umXD). If the link to the sharepoint folder doesn't work, please look at "bert_base-augmented-batch_size=128-lr=2e-5-max_gloss=6" under the github repo's models folder. Please let me know if this is sufficient, or whether I should still upload this model to the hugging face hub.<|||||>@LysandreJik
It appears that in the ```config.json``` (I am pretty sure this is for the model), the ```vocab_size``` is 30523, which matches the results from above. The ```tokenizer_config.json``` doesn't include a ```vocab_size``` key in the json object. When I go to the ```vocab.txt```, it shows that there are 30522 tokens (line 30523 is blank). However, this doesn't match the results from above, where len(tokenizer) returned 30524. Do you think this may be impacting why the model works for transformers==2.9.0, but doesn't work for transformers==4.6.1?
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>I have added custom tokens using tokenizer.add_tokens and ran train(), got the same error. I found out that, need to resize model like this model.resize_token_embeddings(len(tokenizer)) and it worked.
So, every call of add_token should be followed by resize model.
Check if it's the case with yours as well. |
transformers | 12,762 | closed | t5 fast tokenizer save_vocabulary fails without sentencepiece file | ## Environment info
- `transformers` version: 4.9.0.dev0
- Platform: Linux-5.4.0-1043-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.3.4 (tpu)
- Jax version: 0.2.16
- JaxLib version: 0.1.68
- Using GPU in script?: no (tpu)
- Using distributed or parallel set-up in script?: I guess data parallel
### Who can help
Models:
- t5: @patrickvonplaten
Library:
- tokenizers: @LysandreJik
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [] my own task or dataset: (give details below)
Task is summarization
## To reproduce
Steps to reproduce the behavior:
1. Use the [summarization example code](https://github.com/huggingface/transformers/blob/3cd15c1dd62c5c9a9202fae9f00b8eba3eb2b95d/examples/pytorch/summarization/run_summarization.py) and fine tune a pre-trained t5 tokenizer and model created according to the flax mlm example scripts and [t5 tokenizer](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/t5_tokenizer_model.py) -- for instance [t5-base-norwegian](https://huggingface.co/patrickvonplaten/t5-base-norwegian/tree/main)
When the finetuning-summary-trainer saves the model, it will also attempt to save the vocabulary. This will fail with the following stack trace, because the tokenizers `self.vocab_file` is None, where it is expected to point at a sentencepiece file:
```
Traceback (most recent call last):
File "/home/yeb/Developer/yhavinga/t5-base-dutch-summarization/run_summarization.py", line 620, in <module>
main()
File "/home/yeb/Developer/yhavinga/t5-base-dutch-summarization/run_summarization.py", line 545, in main
trainer.save_model() # Saves the tokenizer too for easy upload
File "/home/yeb/Developer/yhavinga/t5-base-dutch-summarization/transformers/src/transformers/trainer.py", line 1883, in save_model
self._save(output_dir)
File "/home/yeb/Developer/yhavinga/t5-base-dutch-summarization/transformers/src/transformers/trainer.py", line 1933, in _save
self.tokenizer.save_pretrained(output_dir)
File "/home/yeb/Developer/yhavinga/t5-base-dutch-summarization/transformers/src/transformers/tokenization_utils_base.py", line 1958, in save_pretrained
save_files = self._save_pretrained(
File "/home/yeb/Developer/yhavinga/t5-base-dutch-summarization/transformers/src/transformers/tokenization_utils_fast.py", line 567, in _save_pretrained
vocab_files = self.save_vocabulary(save_directory, filename_prefix=filename_prefix)
File "/home/yeb/Developer/yhavinga/t5-base-dutch-summarization/transformers/src/transformers/models/t5/tokenization_t5_fast.py", line 150, in save_vocabulary
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
File "/usr/lib/python3.8/posixpath.py", line 374, in abspath
path = os.fspath(path)
TypeError: expected str, bytes or os.PathLike object, not NoneType
Process finished with exit code 1
```
The following hack works around the problem:
```
diff --git a/src/transformers/models/t5/tokenization_t5_fast.py b/src/transformers/models/t5/tokenization_t5_fast.py
index 3f972b006..cc238a119 100644
--- a/src/transformers/models/t5/tokenization_t5_fast.py
+++ b/src/transformers/models/t5/tokenization_t5_fast.py
@@ -147,9 +147,10 @@ class T5TokenizerFast(PreTrainedTokenizerFast):
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
- if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
- copyfile(self.vocab_file, out_vocab_file)
- logger.info(f"Copy vocab file to {out_vocab_file}")
+ if self.vocab_file:
+ if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
+ copyfile(self.vocab_file, out_vocab_file)
+ logger.info(f"Copy vocab file to {out_vocab_file}")
return (out_vocab_file,)
```
## Expected behavior
No error.
| 07-16-2021 14:37:42 | 07-16-2021 14:37:42 | Maybe of interest to @SaulLu :)<|||||>Thank you very much for sharing this error! I share your opinion.
I have opened a PR #12806 to solve this problem. :slightly_smiling_face: <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>unstale<|||||>Stumbled upon the same issue as I was using an old version of transformers -- Thanks a bunch for your PR @SaulLu ! Once I upgraded the transformers version, it got fixed. |
transformers | 12,761 | closed | Unable to run model parallel training using jax on TPU-VM | ## Environment info
- `transformers` version: 4.9.0.dev0
- Platform: Linux-5.4.0-1043-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.9.0+cpu (False)
- Tensorflow version (GPU?): 2.7.0-dev20210705 (False)
- Flax version: 0.3.4 (tpu)
- Jax version: 0.2.16
- JaxLib version: 0.1.68
- Using distributed or parallel set-up in script?: Yes
### Who can help
examples/research_projects/jax/model_parallel
@patil-suraj
## Information
Model I am using GPTNeo-1.3B (for instance the one with resized to multiple of 8 embedding can be found [here](https://huggingface.co/flax-community/gpt-neo-1.3B-resized-embed))
The problem arises when using:
- the official example scripts
- my own modified scripts:
Same error is observed with [customized script](https://github.com/ncoop57/gpt-code-clippy/blob/main/run_clm_mp_apps.py)
## To reproduce
Run the command below in `examples/research_projects/jax-projects/model parallel` folder in cloned tarnsformers repo:
```
python run_clm_mp.py \
--model_name_or_path flax-community/gpt-neo-1.3B-resized-embed \
--tokenizer_name gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --do_eval \
--block_size 1024 \
--num_train_epochs 5 \
--learning_rate 4e-6 \
--per_device_train_batch_size 3 --per_device_eval_batch_size 3 \
--overwrite_output_dir --output_dir ~/tmp/flax-clm \
--cache_dir ~/datasets_cache/wikitext --dtype bfloat16 \
--logging_steps 96 --eval_steps 96
```
Stack trace:
```
07/16/2021 13:59:13 - INFO - absl - A polynomial schedule was set with a non-positive `transition_steps` value; this results in a constant schedule with value `init_value`.
/home/arto/jenv/lib/python3.8/site-packages/jax/experimental/pjit.py:160: UserWarning: pjit is an experimental feature and probably has bugs!
warn("pjit is an experimental feature and probably has bugs!")
07/16/2021 13:59:21 - INFO - __main__ - ***** Running training *****
07/16/2021 13:59:21 - INFO - __main__ - Num examples = 2318
07/16/2021 13:59:21 - INFO - __main__ - Num Epochs = 5
07/16/2021 13:59:21 - INFO - __main__ - Instantaneous batch size per device = 3
07/16/2021 13:59:21 - INFO - __main__ - Total train batch size (w. parallel & distributed) = 24
07/16/2021 13:59:21 - INFO - __main__ - Total optimization steps = 480
Epoch ... (1/5): 0%| | 0/5 [00:00<?, ?it/sF0716 13:59:49.611617 14290 array.h:414] Check failed: n < sizes_size | 0/96 [00:00<?, ?it/s]
*** Check failure stack trace: ***
@ 0x7efd6d030347 (unknown)
@ 0x7efd6d02eed4 (unknown)
@ 0x7efd6d02e9c3 (unknown)
@ 0x7efd6d030cc9 (unknown)
@ 0x7efd68c98eee (unknown)
@ 0x7efd68c2bb2f (unknown)
@ 0x7efd68c29cc2 (unknown)
@ 0x7efd6c7aedb4 (unknown)
@ 0x7efd6c7b0212 (unknown)
@ 0x7efd6c7ade23 (unknown)
@ 0x7efd62c0956f (unknown)
@ 0x7efd68c54248 (unknown)
@ 0x7efd68c55d2b (unknown)
@ 0x7efd687a302b (unknown)
@ 0x7efd68c94001 (unknown)
@ 0x7efd68c91d6a (unknown)
@ 0x7efd68c918bd (unknown)
@ 0x7efd68c94001 (unknown)
@ 0x7efd68c91d6a (unknown)
@ 0x7efd68c918bd (unknown)
@ 0x7efd6831013f (unknown)
@ 0x7efd6830b52e (unknown)
@ 0x7efd68315292 (unknown)
@ 0x7efd68322ffd (unknown)
@ 0x7efd67f0d6b6 (unknown)
@ 0x7efd67f0d014 TpuCompiler_Compile
@ 0x7efd73180956 xla::(anonymous namespace)::TpuCompiler::Compile()
@ 0x7efd709300d4 xla::Service::BuildExecutables()
@ 0x7efd709261a0 xla::LocalService::CompileExecutables()
@ 0x7efd7086ae07 xla::LocalClient::Compile()
@ 0x7efd708452a0 xla::PjRtStreamExecutorClient::Compile()
@ 0x7efd6e440152 xla::PyClient::Compile()
@ 0x7efd6e1ba5e2 pybind11::detail::argument_loader<>::call_impl<>()
@ 0x7efd6e1baa51 pybind11::cpp_function::initialize<>()::{lambda()#3}::operator()()
@ 0x7efd6e1a1460 pybind11::cpp_function::dispatcher()
@ 0x5f2cc9 PyCFunction_Call
https://symbolize.stripped_domain/r/?trace=7efd6d030347,7efd6d02eed3,7efd6d02e9c2,7efd6d030cc8,7efd68c98eed,7efd68c2bb2e,7efd68c29cc1,7efd6c7aedb3,7efd6c7b0211,7efd6c7ade22,7efd62c0956e,7efd68c54247,7efd68c55d2a,7efd687a302a,7efd68c94000,7efd68c91d69,7efd68c918bc,7efd68c94000,7efd68c91d69,7efd68c918bc,7efd6831013e,7efd6830b52d,7efd68315291,7efd68322ffc,7efd67f0d6b5,7efd67f0d013,7efd73180955,7efd709300d3,7efd7092619f,7efd7086ae06,7efd7084529f,7efd6e440151,7efd6e1ba5e1,7efd6e1baa50,7efd6e1a145f,5f2cc8&map=20957999b35a518f734e5552ed1ebec946aa0e35:7efd6db3c000-7efd74a2efc0,2a762cd764e70bc90ae4c7f9747c08d7:7efd600de000-7efd6d35f280
https://symbolize.stripped_domain/r/?trace=7eff9cd0b18b,7eff9cd0b20f,7efd6d030487,7efd6d02eed3,7efd6d02e9c2,7efd6d030cc8,7efd68c98eed,7efd68c2bb2e,7efd68c29cc1,7efd6c7aedb3,7efd6c7b0211,7efd6c7ade22,7efd62c0956e,7efd68c54247,7efd68c55d2a,7efd687a302a,7efd68c94000,7efd68c91d69,7efd68c918bc,7efd68c94000,7efd68c91d69,7efd68c918bc,7efd6831013e,7efd6830b52d,7efd68315291,7efd68322ffc,7efd67f0d6b5,7efd67f0d013,7efd73180955,7efd709300d3,7efd7092619f,7efd7086ae06,7efd7084529f&map=20957999b35a518f734e5552ed1ebec946aa0e35:7efd6db3c000-7efd74a2efc0,2a762cd764e70bc90ae4c7f9747c08d7:7efd600de000-7efd6d35f280
*** SIGABRT received by PID 14290 (TID 14290) on cpu 89 from PID 14290; ***
E0716 13:59:49.681807 14290 coredump_hook.cc:292] RAW: Remote crash data gathering hook invoked.
E0716 13:59:49.681854 14290 coredump_hook.cc:384] RAW: Skipping coredump since rlimit was 0 at process start.
E0716 13:59:49.681862 14290 client.cc:222] RAW: Coroner client retries enabled (b/136286901), will retry for up to 30 sec.
E0716 13:59:49.681870 14290 coredump_hook.cc:447] RAW: Sending fingerprint to remote end.
E0716 13:59:49.681876 14290 coredump_socket.cc:124] RAW: Stat failed errno=2 on socket /var/google/services/logmanagerd/remote_coredump.socket
E0716 13:59:49.681886 14290 coredump_hook.cc:451] RAW: Cannot send fingerprint to Coroner: [NOT_FOUND] Missing crash reporting socket. Is the listener running?
E0716 13:59:49.681891 14290 coredump_hook.cc:525] RAW: Discarding core.
F0716 13:59:49.611617 14290 array.h:414] Check failed: n < sizes_size
E0716 13:59:49.953522 14290 process_state.cc:771] RAW: Raising signal 6 with default behavior
Aborted (core dumped)
```
## Expected behavior
Training in model parallel mode.
| 07-16-2021 14:29:58 | 07-16-2021 14:29:58 | @arampacha @patil-suraj Just confirming that I have the exact same problems. I do also get the error when running the example code on a fresh install. Please note that this is a duplicate of the report posted here: https://github.com/huggingface/transformers/issues/12771<|||||>Thanks for the very clear and detailed report!
This looks like a JAX bug, JAX should never abort like this. This line:
`F0716 13:59:49.611617 14290 array.h:414] Check failed: n < sizes_size `
indicates that this CHECK is failing:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/xla/array.h#L414
I'll try the repro and see if I can figure out what's going on here.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>This is on me, I haven't had a chance to debug this yet.<|||||>Apologies again for the delay. I finally took a look at this, and it appears to work on a fresh VM. Here are the exact commands I used:
Create and ssh to a new VM:
```
gcloud alpha compute tpus tpu-vm create skyewm-tmp --accelerator-type v3-8 --version v2-alpha --zone us-central1-a
gcloud alpha compute tpus tpu-vm ssh skyewm-tmp
```
Then on the VM:
```
pip install "jax[tpu]>=0.2.16" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
pip install tensorflow-cpu
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
pip install flax optax datasets
cd examples/research_projects/jax-projects/model_parallel/
USE_TORCH=0 python3 run_clm_mp.py --model_name_or_path flax-community/gpt-neo-1.3B-resized-embed --tokenizer_name gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train --do_eval --block_size 1024 --num_train_epochs 5 --learning_rate 4e-6 --per_device_train_batch_size 3 --per_device_eval_batch_size 3 --overwrite_output_dir --output_dir ~/tmp/flax-clm --cache_dir ~/datasets_cache/wikitext --dtype bfloat16 --logging_steps 96 --eval_steps 96
```
Note that I had to install `tensorflow-cpu` and use `USE_TORCH=0` to make the script run (different errors than what you were seeing though, issues for another day...).
Am I doing something wrong, or perhaps this magically fixed itself?<|||||>Thanks @skye!
Isnt it awesome when you leave for vacation and the bugs magically solves themselves when you are gone...;)
I am not able to run your code on my old TPU VM. However, it runs perfectly when creating a new VM!
Seems like the new VM is running JaxLib 0.1.71, while the old is using JaxLib 0.1.68.
I did the following update my old server:
```
pip install "jaxlib>=0.1.71"
```
This does however lead to an "TpuExecutable_Serialize not available in this library."-error. However reinstalling jax-tpu fixes this issue as well:
```
pip install "jax[tpu]>=0.2.16" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
```
I am now able to run the scripts without getting the "n < sizes_size"-error. Thanks a lot for the help. Maybe update the requirements.txt?
<|||||>Glad to hear it's working for you! And thanks for describing your upgrade journey, this is useful feedback. Just upgrading jaxlib causes that error because there's a jaxlib-libtpu version mismatch (libtpu is the low-level library jax uses to access the TPU). Specifying the `[tpu]` extra when installing/upgrading jax makes sure the latest compatible `jaxlib` and `libtpu-nightly` versions are pulled in.
We should improve that error message, and also clarify our install instructions to explain this all better. Please lemme know if you have specific ideas for things that would have helped you.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,760 | closed | Embedding layer Pruning implementation | I want to use a multilingual model (in my case MT5) to train it for two languages (English and German).
These models have a very high vocab size because they are multilingual.
This large embedding needs a lot of RAM on GPU.
My idea is: Tokenize a large English and German corpus and find out which tokens are needed.
Then remove all tokens that are not needed. I call this pruning...
This removal needs to be done on the model embedding layer
and on the tokenizer (in my case a sentencepiece tokenizer).
Did anybody ever implement something like that? Is there maybe some example code?
@sgugger @LysandreJik
If I manage to implement I might provide the functionality as a PR.
| 07-16-2021 14:16:52 | 07-16-2021 14:16:52 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,759 | closed | Preserve `list` type of `additional_special_tokens` in `special_token_map` | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #12598
As shown in the issue, the value associated with the `additional_special_tokens` key in the `special_tokens_map` attribute of a tokenizer was of type string while its content is rather a list. This PR proposes a fix to keep the list type and adds tests.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. @LysandreJik and @sgugger, I would love to have a second look if there was ever a reason I missed that required the list to become a string.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-16-2021 13:20:51 | 07-16-2021 13:20:51 | |
transformers | 12,758 | closed | Turn on eval mode when exporting to ONNX | Disabling T5 as it has an export issue we need to address first. | 07-16-2021 12:48:44 | 07-16-2021 12:48:44 | @LysandreJik sorry I can't see what you're referring to 🧐 🙈 |
transformers | 12,757 | closed | [flax/model_parallel] fix typos | # What does this PR do?
This PR fixes some typos in the readme and directory name | 07-16-2021 11:14:25 | 07-16-2021 11:14:25 | |
transformers | 12,756 | closed | unk_id is missing for SentencepieceTokenizer | Trained sentencepiece tokenizer from Tokenizer library with some added tokens
```
"added_tokens": [
{
"id": 0,
"special": true,
"content": "<unk>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
},
{
"id": 1,
"special": true,
"content": "<s>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
},
{
"id": 2,
"special": true,
"content": "</s>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
},
{
"id": 3,
"special": true,
"content": "<cls>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
},
{
"id": 4,
"special": true,
"content": "<sep>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
},
{
"id": 5,
"special": true,
"content": "<pad>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
},
{
"id": 6,
"special": true,
"content": "<mask>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
},
{
"id": 7,
"special": true,
"content": "<eod>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
},
{
"id": 8,
"special": true,
"content": "<eop>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false
}
],
```
When this tokenizer encounters unknown words, it throws unk_id is missing error.
`Exception: Encountered an unknown token but `unk_id` is missing`
How do I set unk_id for this tokenizer?
This is how I load my tokenizer
```
tokenizer = Tokenizer.from_file('./unigram.json')
tokenizer = XLNetTokenizerFast(tokenizer_object=tokenizer, unk_token="<unk>")
``` | 07-16-2021 09:30:30 | 07-16-2021 09:30:30 | Maybe of interest to @SaulLu <|||||>I have an idea where the problem might come from.
To be sure that this is the source of the error, @darwinharianto, could you share with me your `unigram.json` file or, if you can't, the content of the `model` key and the `unk_id` subkey in your `unigram.json` file? :slightly_smiling_face: <|||||>Sorry for the late reply, here is my unigram.json
[unigram.json.zip](https://github.com/huggingface/transformers/files/6837202/unigram.json.zip)
Edit:
This is how I used the tokenizer
```
def tokenize_function(examples):
token_res = tokenizer(examples["text"], truncation=True, max_length=MAX_LENGTH)
for i, item in enumerate(token_res["input_ids"]):
if len(item) % 2 != 0:
token_res["input_ids"][i].insert(-2,5)
token_res["attention_mask"][i].insert(-2,0)
token_res["token_type_ids"][i].insert(-2,1)
return token_res
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorForPermutationLanguageModeling(
tokenizer=tokenizer,
plm_probability = 0.16666666666666666,
max_span_length = 6
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset
)
```
I don't know why, but for `DataCollatorForPermutationLanguageModeling` it needs even number of words, so I pad the content in tokenize function<|||||>Thanks for the document, I think the error comes from the fact that the value associated to the `model` key and the `unk_id` subkey in your `unigram.json` file is `null` instead of `0` (`"<unk>"` is the first token of your vocabulary).
If you have used the training script of `SentencePieceUnigramTokenizer` provided in :hugs: tokenizers library, I've opened a PR [here](https://github.com/huggingface/tokenizers/pull/762) to solve this missing information for the future trainings - as the `unk_token` need to be pass to the `Trainer` and currently you haven't the opportunity to do it. :slightly_smiling_face:
However, I guess you don't want to re-train your tokenizer. In this case, the simplest is to change by hand the value in the `unigram.json` file associated to the `unk_id` key so that it matches the id of the unknown token (in your case `0`).
I would be happy to know if this indeed solves the error you had :relaxed:
<|||||>Thanks!
Manually changing unk_id to 0 make it works |
transformers | 12,755 | closed | ValueError: cannot reshape array of size ... in run_t5_mlm_flax.py data_collator | ## Environment info
- `transformers` version: 4.9.0.dev0
- Platform: Linux-5.4.0-1043-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.3.4 (tpu)
- Jax version: 0.2.16
- JaxLib version: 0.1.68
- Using GPU in script?: no (tpu)
- Using distributed or parallel set-up in script?: I guess data parallel
### Who can help
Models:
t5: @patrickvonplaten, @patil-suraj
## Information
When pre-training t5-base or t5_v1_1-base on Dutch c4 or oscar, a long time into the training the following error is raised on the [line 305 of the t5 mlm flax script](https://huggingface.co/yhavinga/t5-base-dutch-oscar-fail/blob/main/run_t5_mlm_flax.py#L305)
```
Traceback (most recent call last):
File "./run_t5_mlm_flax.py", line 750, in <module>
model_inputs = data_collator(samples)
File "./run_t5_mlm_flax.py", line 262, in __call__
batch["input_ids"] = self.filter_input_ids(input_ids, input_ids_sentinel)
File "./run_t5_mlm_flax.py", line 305, in filter_input_ids
input_ids = input_ids_full[input_ids_full > 0].reshape((batch_size, -1))
ValueError: cannot reshape array of size 98111 into shape (192,newaxis)
```
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts:
The scripts and training state are uploaded to the model hub at [yhavinga/t5-base-dutch-oscar-fail](https://huggingface.co/yhavinga/t5-base-dutch-oscar-fail/tree/main)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
Pre-training t5-v1-1-base on Dutch oscar and/or c4.
The error seems to persist over multiple datasets used, and at least two projects in the Flax/Jax Community week:
This is a grep of this error in my training runs:
```
cannot reshape array of size 130815 into shape (256,newaxis)
cannot reshape array of size 32703 into shape (64,newaxis)
cannot reshape array of size 392447 into shape (768,newaxis)
cannot reshape array of size 523263 into shape (1024,newaxis)
cannot reshape array of size 130815 into shape (256,newaxis)
cannot reshape array of size 28927 into shape (256,newaxis)
```
and another user replied in the flax-jax channel "we also struggled with this issue while T5 pre-training. Since there are not too many corrupted samples you can simply avoid them by wrapping data_collator calls into a try/catch block."
## To reproduce
Steps to reproduce the behavior:
1. Clone the repo [yhavinga/t5-base-dutch-oscar-fail](https://huggingface.co/yhavinga/t5-base-dutch-oscar-fail/tree/main) on a TPU-v3-8 vm
2. Run the script `run_t5.sh` and wait
## Expected behavior
No reshape errors. | 07-16-2021 08:15:08 | 07-16-2021 08:15:08 | Thanks for the issue! I'll try to look into it today :-)
By `".. and wait"`, how long does it take on your machine? Also do you think it might be possible to get the error on a much smaller dataset then the whole dutch oscar dataset (which is quite large)?
Also note that `batch_size` should ideally be set to a power of 2 (8, 16, 32) especially on TPU. Also is the `run_t5_mlm_flax.py` the most current T5 pretraining script from master (date 16.07.2021)?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@patrickvonplaten is it resolved now?<|||||>Hey @patil-suraj , I've seen this error now during model training. I've used a batch size of 8 (both for training and evaluating) and it only happens for one certain corpus (other pre-trainings were good).
I will try to find the problematic sentence in that batch now!
<|||||>Code snippet that throws the error is:
https://github.com/huggingface/transformers/blob/e65bfc09718f132c76558d591be08c9751dd3ff2/examples/flax/language-modeling/run_t5_mlm_flax.py#L363-L375
I dill'ed/pickled `input_ids` (argument, before it is getting re-shaped):
```bash
array([ 8, 2451, 91, 1655, 23, 7212, 6, 73, 4590,
10, 7, 3, 17053, 11, 1839, 10, 2587, 5,
1458, 2799, 7, 3, 22434, 10, 3, 5409, 152,
3, 12, 9326, 108, 107, 2740, 23, 130, 22409,
504, 353, 152, 3, 12, 1954, 2652, 132, 7,
21751, 23, 1881, 152, 3, 12, 21870, 23, 1881,
4, 1, 178, 3, 15334, 5, 59, 385, 8,
1760, 42, 604, 4, 1, 39, 332, 14, 25,
8, 81, 372, 20, 1606, 747, 101, 5, 3,
2007, 81, 2934, 4615, 7, 3, 5481, 745, 769,
9, 4603, 1513, 8, 928, 4, 1, 143, 1515,
22, 3, 19, 60, 442, 5, 63, 215, 3,
4536, 5, 5367, 3433, 17, 6538, 6, 7, 198,
17, 3, 16011, 4, 1, 9812, 14025, 4, 1,
13, 20, 3, 1880, 641, 8, 492, 61, 5,
1, 6837, 23, 2452, 10670, 7, 1031, 5203, 29,
746, 2138, 8822, 42, 37, 397, 8, 2822, 5,
1336, 7, 11851, 71, 112, 4, 1, 246, 12361,
50, 1342, 6, 23, 11098, 72, 3, 24, 67,
1124, 351, 1582, 5, 268, 8868, 25, 3, 24,
54, 1124, 351, 2349, 4, 1, 5596, 20595, 3,
5022, 13, 8, 394, 2599, 8, 272, 1976, 1184,
4653, 73, 10541, 2545, 113, 7613, 16, 3, 54,
5, 48, 62, 15, 5, 48, 1, 83, 2405,
10, 174, 6, 3, 2733, 32, 61, 8, 4433,
5, 9, 88, 26, 16396, 3, 11363, 78, 1,
3, 395, 174, 2454, 3, 14552, 3, 22308, 22,
38, 3561, 12, 7, 5348, 11, 6240, 29, 3,
12429, 6, 2743, 21, 1126, 13, 8, 16481, 112,
2657, 4086, 4, 1, 89, 3, 18, 15, 5,
54, 2136, 427, 11511, 3, 701, 23, 3, 19641,
42, 7420, 91, 105, 12674, 1022, 749, 3, 6809,
36, 105, 12674, 1022, 11, 73, 180, 4596, 2459,
7, 5719, 11, 10, 2459, 61, 5291, 11, 12674,
4, 1, 172, 147, 3, 5984, 6, 15164, 16,
5, 6659, 7078, 11, 9829, 5, 2462, 7078, 11,
9829, 5, 1243, 5764, 5, 1078, 9795, 7, 6003,
22795, 2812, 31, 2023, 21, 3, 13112, 5, 101,
247, 210, 11, 386, 401, 21, 9746, 6, 7,
3, 7738, 9280, 6, 1925, 16891, 6, 78, 78,
78, 1, 143, 232, 195, 6, 57, 2308, 29,
32, 198, 5, 29, 28, 682, 3, 92, 7,
29, 9, 928, 2687, 4, 1, 5412, 6614, 7969,
16, 12, 10973, 11238, 327, 4717, 3, 18, 54,
12, 24, 48, 139, 3, 23392, 3, 18, 48,
15, 3, 34, 34, 3, 12, 3, 23392, 3,
24, 48, 15, 3, 34, 34, 3, 5, 6614,
7969, 16, 12, 10973, 11238, 327, 4717, 3, 18,
54, 12, 24, 48, 139, 3, 23392, 3, 18,
48, 15, 3, 34, 34, 3, 12, 3, 23392,
3, 24, 48, 15, 3, 34, 34, 3, 458,
2891, 3236, 5, 5412, 6614, 14491, 16, 16, 327,
4717, 3, 18, 15, 12, 24, 48, 139, 3,
23392, 3, 18, 48, 15, 3, 34, 34, 3,
5, 5412, 6614, 7969, 16, 12, 10973, 11238, 327,
4717, 3, 18, 54, 12, 18, 48, 139, 5,
3, 23392, 3, 24, 47, 15, 3, 34, 34,
3, 5, 5412, 6614, 14491, 16, 16, 327, 4717,
3, 18, 54, 12, 18, 48, 139, 5, 3,
23392, 3, 24, 47, 15, 3, 34, 34, 7,
13642, 2891, 3, 5, 5412, 6614, 14491, 16, 16,
327, 4717, 3, 18, 54, 12, 18, 48, 897,
454, 5, 3, 23392, 3, 24, 47, 15, 3,
34])
```
And `input_ids_full` is:
```bash
array([ 8, 32102, -1, 1655, 23, 7212, 6, 73, 4590,
32101, -1, -1, -1, 11, 1839, 10, 2587, 5,
1458, 2799, 7, 3, 22434, 10, 3, 5409, 32100,
-1, 12, 9326, 108, 107, 2740, 23, 130, 22409,
504, 353, 152, 3, 12, 1954, 2652, 132, 7,
21751, 23, 32099, 152, 3, 12, 21870, 23, 1881,
4, 1, 178, 3, 15334, 5, 59, 385, 8,
1760, 42, 604, 4, 1, 39, 332, 14, 25,
8, 81, 372, 20, 1606, 747, 101, 5, 3,
2007, 81, 2934, 4615, 7, 3, 5481, 745, 769,
9, 4603, 1513, 8, 928, 4, 1, 143, 1515,
32098, -1, -1, -1, -1, 5, 63, 215, 3,
4536, 5, 5367, 3433, 17, 6538, 6, 7, 198,
17, 3, 16011, 4, 1, 9812, 14025, 4, 32097,
13, 20, 3, 1880, 641, 8, 492, 61, 5,
1, 6837, 32096, -1, -1, 7, 1031, 5203, 29,
746, 2138, 8822, 42, 37, 397, 8, 2822, 5,
1336, 7, 11851, 71, 112, 4, 1, 246, 12361,
50, 1342, 6, 23, 11098, 72, 3, 24, 67,
1124, 351, 1582, 5, 268, 8868, 25, 3, 24,
54, 1124, 351, 2349, 4, 1, 5596, 20595, 3,
5022, 13, 8, 394, 2599, 8, 272, 1976, 32095,
4653, 73, 10541, 2545, 113, 7613, 16, 3, 54,
5, 48, 62, 15, 32094, -1, -1, -1, -1,
-1, -1, -1, 3, 2733, 32, 61, 8, 4433,
5, 9, 88, 26, 16396, 3, 11363, 78, 1,
3, 395, 174, 2454, 3, 14552, 3, 22308, 22,
32093, -1, 12, 32092, -1, -1, 6240, 29, 3,
12429, 6, 2743, 32091, -1, -1, -1, -1, 112,
2657, 4086, 4, 1, 89, 3, 18, 15, 5,
54, 2136, 427, 11511, 3, 701, 23, 3, 19641,
42, 7420, 91, 105, 12674, 32090, -1, -1, 6809,
32089, -1, -1, -1, 11, 73, 180, 4596, 2459,
7, 5719, 11, 10, 32088, -1, 5291, 11, 12674,
4, 1, 172, 147, 3, 32087, -1, -1, 16,
5, 6659, 7078, 11, 9829, 5, 2462, 7078, 11,
9829, 5, 1243, 5764, 5, 1078, 9795, 7, 6003,
22795, 2812, 31, 2023, 21, 3, 13112, 5, 101,
247, 210, 32086, 386, 401, 21, 9746, 6, 7,
3, 7738, 9280, 6, 1925, 16891, 6, 78, 78,
78, 1, 143, 232, 195, 6, 57, 2308, 29,
32, 198, 5, 29, 28, 682, 3, 92, 7,
29, 9, 928, 2687, 4, 1, 5412, 6614, 7969,
16, 12, 10973, 11238, 327, 4717, 3, 18, 54,
12, 24, 48, 139, 3, 23392, 3, 18, 48,
15, 32085, -1, -1, -1, -1, -1, 23392, 3,
32084, -1, 15, 3, 34, 34, 3, 5, 6614,
7969, 16, 12, 10973, 32083, -1, -1, -1, -1,
54, 12, 24, 48, 139, 3, 23392, 32082, 18,
48, 15, 3, 34, 34, 3, 32081, -1, -1,
3, 24, 48, 15, 3, 34, 34, 3, 458,
2891, 3236, 5, 5412, 6614, 14491, 16, 16, 327,
4717, 3, 18, 15, 12, 24, 48, 139, 3,
23392, 3, 18, 48, 15, 32080, -1, -1, -1,
-1, -1, 6614, 7969, 16, 12, 10973, 11238, 327,
4717, 3, 32079, -1, -1, -1, -1, -1, 5,
3, 23392, 3, 24, 32078, 15, 3, 34, 34,
3, 5, 5412, 6614, 14491, 16, 16, 327, 4717,
3, 18, 54, 12, 18, 48, 139, 5, 3,
23392, 3, 24, 47, 15, 3, 34, 32077, -1,
13642, 2891, 3, 5, 5412, 6614, 14491, 16, 16,
327, 4717, 3, 18, 54, 12, 18, 48, 897,
454, 5, 32076, -1, 3, 24, 47, 15, 3,
32075])
```<|||||>The `input_ids` can be back translated into the following text:
```text
Out[5]: 'der Gelegenheit zum Abschluss von Verträgen über Grundstücke und grundstücksgleiche Rechte, Wohnräume und gewerbliche Räume; -Planung uns Ausführung von Bauvorhaben aller Art; -Erwerb und Veräußerung von Immobilien; -Verwaltung von Immobilien.</s> Er schildert, wie dort der Alltag aussieht.</s> Sie sichern auf der einen Seite den Risikoschutz ab, bilden einen Sparanteil und decken darüber hinaus die Verwaltungskosten der Gesellschaft.</s> Darum ist es so wichtig, dass Ihr lernt, Eure Texte zu beurteilen und selbst zu reparieren.</s> Angebotsdetails.</s> in den kommenden Wochen der Frage nach,</s> Vermittlung von Sprachfiguren und Texttypen für verschiedene Kommunikationsprozesse aus dem Bereich der Wissenschaft, Technik und Journalistik.</s> Tagsüber werden Temperaturen von circa 28°C erwartet, welche nachts auf 24°C fallen.</s> Korneuburg schlägt in der letzten Runde der ersten Klasse Weinviertel überforderte Zistersdorfer 4,5/0,5</s> Das Fiepen richtet sich nach der Spannung, die durch das Netzteil fließt!</s> steptext dance project ist eine Produktions- und Präsentationsplattform für zeitgenössischen Tanz mit Sitz in der Schwankhalle Bremen.</s> Der 10,4 Kilometer lange Wanderweg führt von Kreuzberg aus parallel zum Sahrbachweg nördlich des Sahrbachs über Krälingen und Häselingen nach Kirchsahr.</s> An alle verliebten Veganer, Rohköstler, Urköstler, Umweltfreunde, Tierliebhaber und Green Wedding Fans: Schluss mit verstecken, ab jetzt gehts richtig rund mit veganen und rohköstlichen Traumhochzeiten!!!</s> Dabei sollen sie Verantwortung für sich selbst, für ein Projekt – und für die Gesellschaft übernehmen.</s> Fein Winkel Schleifer-Polierer WPO 14-25 E Ø 150 mm - Ø 250 mm, Winkel Schleifer-Polierer WPO 14-25 E Ø 150 mm - Ø 250 mm + Set Edelstahl, Fein Winkel Polierer WPO 10-25 E Ø 150 mm, Fein Winkel Schleifer-Polierer WPO 14-15 E, Ø 230 mm, Fein Winkel Polierer WPO 14-15 E, Ø 230 mm und Marine Set, Fein Winkel Polierer WPO 14-15 XE, Ø 230 m'
```
So `</s>` is missing at the end?<|||||>@stefan-it thanks for diving into this!
@patrickvonplaten apologies for not responding earlier, the flax/jax week was pretty hectic & time constrained. To answer your question: the error doesn't occur often and takes in the order of hours to occur.
The reshape error I got is caused by a single special token (0) in the input_ids, which causes filter_input_ids() to remove one token too many, resulting in a faulty shape.
I put the input_ids and label_ids that triggered it into a self-contained testfile (need to rename to .py to run).
[testcase.txt](https://github.com/huggingface/transformers/files/7932459/testcase.txt)
The faulty text decodes to a text containing <pad>.:
`alleen op de standaardlocaties bijgewerkt. Pak de update (KB) uit door gebruik te maken van de opdracht KB /x:<pad>. Kopieer Msrdp.cab van <locatie> naar het aangepaste pad. * Dit scenario is van toepassing als u RDC 6.0 of later op de clientcomputer (werkstation) hebt geïnstalleerd. Vraag Nadat ik de beveiligingsupdate heb geïnstalleerd, wordt het ActiveX-onderdeel door Internet Explorer 6 en Internet Explorer 7 niet op mijn computer geïnstalleerd. Hoe komt dat? Vanaf de Windows Update-website: Windows Update biedt de bijgewerkte versie van het bestand Msrdp.ocx echter automatisch aan als het kwetsbare Msrdp.ocx-bestand zich bevindt in %Windir%\Download Program Files op de client. Door de update te installeren vanaf de Terminal Services Web-server. Deze update vervangt het bestand Msrdp.cab file echter alleen op de standaardlocaties. Kopieer het bestand Msrdp.cab vanaf <locatie> naar het aangepaste pad. Vraag Het bestand Msrdp.ocx is niet aanwezig nadat ik de update heb geïnstalleerd. Hoe komt dat? Antwoord Deze update werkt alleen de bestanden bij die op de computer aanwezig zijn voordat u deze update installeert. Als het bestand Msrdp.ocx dus niet aanwezig was op de op Windows XP SP2 gebaseerde computer voordat u deze update hebt geïnstalleerd, wordt het bestand Msrdp.ocx niet gedownload en niet op de computer geïnstalleerd. Wanneer het bestand Msrdp.ocx op de client wordt geïnstalleerd, biedt Windows Update de update opnieuw aan de clientcomputer aan. Vraag Hoe kan ik controleren of het bestand Msrdp.ocx op mijn systeem staat? dir "%windir%\downloaded program files" Vraag Het bestand Msrdp.cab is niet aanwezig nadat ik de update heb geïnstalleerd. Hoe komt dat? Antwoord Deze update werkt alleen de bestanden bij die op de computer aanwezig zijn voordat u deze update installeert. Als het bestand Msrdp.cab niet aanwezig was op de op Windows XP SP2 gebaseerde computer voordat u de update hebt geïnstalleerd, wordt het bestand Msrdp.cab niet op de clientcomputer geïnstalleerd. Vraag`
In the dataset this text can be found with the `<pad>` string as well.
`
{"text": "Opmerking De bestanden worden uitsluitend bijgewerkt als de bestanden al op de clientcomputer aanwezig waren.\nHoud er rekening mee dat bij specifieke implementaties van de RDC-client de namen van bestanden tijdens de installatie mogelijk worden gewijzigd. De bestandsnamen die worden weergegeven in de sectie Informatie over bestanden, zijn de oorspronkelijke bestandsnamen van voor de installatie.\nVraag Is RDC 5.0 gecorrigeerd voor Windows 2000?\nAntwoord Ja, de Windows 2000-versie van RDC is gecorrigeerd in de upgrade van RDC-versie 5.0 naar 5.1. Dit leidt tot wijzigingen in de gebruikersinterface in de RDC-client. Daarnaast bevat RDC 5.1 nieuwe aanvullende functionaliteit, waaronder mogelijkheden voor omleiding.\nVraag Mijn RDC-client bevindt zich op een aangepaste locatie. Wordt deze bijgewerkt?\nAntwoord Vanwege de eigenschappen van het oudere RDC-installatieprogramma, worden RDC-clients die zich op niet-standaardlocaties bevinden mogelijk niet correct bijgewerkt. Als u dit probleem wilt oplossen, moet u de client verwijderen, vervolgens moet u de client opnieuw installeren met de standaard installatie-eigenschappen en ten slotte installeert u de beveiligingsupdate.\nVraag Waarom moet ik zowel beveiligingsupdate 958471 als beveiligingsupdate 958470 installeren wanneer ik gebruikmaak van Windows 2000 met de zogeheten in-box RDC 5.0-client?\nAntwoord Wanneer u beveiligingsupdate 958471 installeert, wordt er een upgrade van het in-box RDC 5.0-onderdeel naar versie RDC 5.1 uitgevoerd. Deze upgrade maakt deel uit van de installatie van de beveiligingsupdate. Het installeren van beveiligingsupdate 958470 leidt niet tot verdere wijzigingen met betrekking tot binaire bestanden, maar wel tot het implementeren van een killbit om te voorkomen dat het oude ActiveX-besturingelement kan worden geopend vanuit Internet Explorer. Het wordt daarom aangeraden om beide beveiligingsupdates te installeren op Windows 2000-systemen waarop er sprake is van dit probleem.\nOpmerking Remote Desktop Connection 5.0 is ook bekend onder de naam Terminal Services Client en wordt soms aangeduid als RDP omdat het de implementatie van Remote Desktop Protocol op het desbetreffende systeem betreft.\nVraag Na het installeren van de beveiligingsupdates 958470 en 958471 op een Windows 2000-computer is de RDC-gebruikersinterface in belangrijke mate gewijzigd. Hoe komt dat?\nVraag Nadat ik beveiligingsupdate 958471 of 958470 heb ge\u00efnstalleerd in Windows 2000, is er sprake van problemen met oudere toepassingen.\nAntwoord Er kunnen beperkte toepassingsgebonden compatibiliteitsproblemen optreden vanwege gebruikersinterfacewijzigingen die voortvloeien uit de upgrade van RDC 5.0 naar RDC 5.1.\nVraag Nadat ik beveiligingsupdate 958470 of 958471 heb ge\u00efnstalleerd en er een upgrade is uitgevoerd van RDC 5.0 naar RDC 5.1, heb ik RDC 5.0 handmatig opnieuw ge\u00efnstalleerd. Wordt de update opnieuw aangeboden?\nAntwoord De beveiligingsupdates 958470 en 958471 voeren een upgrade van RDC 5.0 naar RDC 5.1 uit. Als u RDC 5.0 uitdrukkelijk opnieuw installeert, wordt deze update niet opnieuw aangeboden. Het wordt echter aangeraden om de beveiligingsupdate handmatig te downloaden en opnieuw te installeren. Houd er rekening mee dat Microsoft RDC 5.0 niet langer beschikbaar stelt voor downloaden.\nVraag Ik heb RDC 5.0 ge\u00efnstalleerd via Terminal Services Advanced Client (TSAC). De beveiligingsupdate 958471 wordt echter niet aangeboden. Hoe komt dat?\nAntwoord De RDC 5.0-versie die wordt ge\u00efnstalleerd via TSAC, wordt bijgewerkt door de beveiligingsupdate 958470. De beveiligingsupdate 958470 wordt daarom niet aangeboden.\nVraag Voordat ik de beveiligingsupdate heb ge\u00efnstalleerd, had ik de RDC 5.1-versie van Msrdp.ocx. Na het installeren van de beveiligingsupdate wordt deze versie van Msrdp.ocx niet meer weergegeven. Waarom is dat?\nAntwoord Wanneer u deze beveiligingsupdate installeert, wordt er een upgrade uitgevoerd van de RDC 5.1-versie van Msrdp.ocx naar de RDC 5.2-versie van Msrdp.ocx.\nVraag Corrigeert deze beveiligingsupdate mijn installatie wanneer ik over een toepassing beschik die de binaire bestanden van Webverbinding met extern bureaublad implementeert op niet-standaardlocaties?\nAntwoord Deze update voor Microsoft Webverbinding met extern bureaublad werkt de binaire bestanden bij op hun standaardlocaties. Als u de binaire bestanden voor Microsoft Webverbinding met extern bureaublad naar een aangepaste locatie hebt gedistribueerd, moet u de aangepaste locatie bijwerken met de bijgewerkte binaire bestanden.\nVraag Ik heb de beveiligingsupdate ge\u00efnstalleerd en nu kan ik geen verbinding maken wanneer ik probeer het ActiveX-onderdeel van MSTSC (Msrdp.ocx) te gebruiken. Hoe komt dat?\nInstalleer de beveiligingsupdate opnieuw op het clientwerkstation, zodat de oudere versie van het bestand Msrdp.ocx dat vanaf de server is gedownload, wordt bijgewerkt.\nOpmerking Het bestand Msrdp.ocx wordt alleen op de standaardlocaties bijgewerkt.\nPak de update (KB) uit door gebruik te maken van de opdracht KB /x:<pad>.\nKopieer Msrdp.cab van <locatie> naar het aangepaste pad.\n* Dit scenario is van toepassing als u RDC 6.0 of later op de clientcomputer (werkstation) hebt ge\u00efnstalleerd.\nVraag Nadat ik de beveiligingsupdate heb ge\u00efnstalleerd, wordt het ActiveX-onderdeel door Internet Explorer 6 en Internet Explorer 7 niet op mijn computer ge\u00efnstalleerd. Hoe komt dat?\nVanaf de Windows Update-website: Windows Update biedt de bijgewerkte versie van het bestand Msrdp.ocx echter automatisch aan als het kwetsbare Msrdp.ocx-bestand zich bevindt in %Windir%\\Download Program Files op de client.\nDoor de update te installeren vanaf de Terminal Services Web-server. Deze update vervangt het bestand Msrdp.cab file echter alleen op de standaardlocaties.\nKopieer het bestand Msrdp.cab vanaf <locatie> naar het aangepaste pad.\nVraag Het bestand Msrdp.ocx is niet aanwezig nadat ik de update heb ge\u00efnstalleerd. Hoe komt dat?\nAntwoord Deze update werkt alleen de bestanden bij die op de computer aanwezig zijn voordat u deze update installeert. Als het bestand Msrdp.ocx dus niet aanwezig was op de op Windows XP SP2 gebaseerde computer voordat u deze update hebt ge\u00efnstalleerd, wordt het bestand Msrdp.ocx niet gedownload en niet op de computer ge\u00efnstalleerd. Wanneer het bestand Msrdp.ocx op de client wordt ge\u00efnstalleerd, biedt Windows Update de update opnieuw aan de clientcomputer aan.\nVraag Hoe kan ik controleren of het bestand Msrdp.ocx op mijn systeem staat?\ndir \"%windir%\\downloaded program files\"\nVraag Het bestand Msrdp.cab is niet aanwezig nadat ik de update heb ge\u00efnstalleerd. Hoe komt dat?\nAntwoord Deze update werkt alleen de bestanden bij die op de computer aanwezig zijn voordat u deze update installeert. Als het bestand Msrdp.cab niet aanwezig was op de op Windows XP SP2 gebaseerde computer voordat u de update hebt ge\u00efnstalleerd, wordt het bestand Msrdp.cab niet op de clientcomputer ge\u00efnstalleerd.\nVraag Ik heb een oude versie van het bestand Msrdp.cab die vanaf mijn Terminal Server Web Server-computer wordt gedistribueerd. Zijn mijn clients kwetsbaar?\nAntwoord De bijgewerkte clientcomputers zijn niet kwetsbaar, ondanks dat de server niet is bijgewerkt. Het wordt echter met klem aangeraden om de update op de Terminal Server Web Server-computer te installeren, zodat het opnieuw distribueren van kwetsbare Msrdp.ocx-bestanden naar clients die niet zijn bijgewerkt, wordt voorkomen.\nVraag Waarom wordt beveiligingsupdate 958470 aangeboden voor mijn computer met Windows 2000, zelfs wanneer RDP niet is ge\u00efnstalleerd?\nAntwoord Beveiligingsupdate 958470 wordt aangeboden voor computers met Windows 2000, ongeacht of RDP is ge\u00efnstalleerd. Als RDP niet is ge\u00efnstalleerd, implementeert beveiligingsupdate 958470 toch killbits om uitzondering van het getroffen RDP ActiveX-besturingselement te voorkomen, maar het zal geen binaire bestanden vervangen.\nOpmerking In deze tabel geldt: x = niet van toepassing.\nOpmerking In deze tabel worden bijna alle gebruikers vertegenwoordigd door de scenario's die in de tabel zijn gemarkeerd met sterretjes (*).", "timestamp": "2017-08-21T21:06:36Z", "url": "https://support.microsoft.com/nl-be/help/958470/ms09-044-description-of-the-security-update-for-remote-desktop-client"}
`
<|||||>Thanks for those examples guys! I'll try to dive into it this week!<|||||>Sorry to be so extremely late here. @stefan-it could you sent me a link to the tokenizer that you used that created this error?<|||||>I think this should fix the problem though: https://github.com/huggingface/transformers/pull/15835 no?
We just need to include 0 here as this is the lowest possible input id. Could you maybe check with this @stefan-it @yhavinga ? |
transformers | 12,754 | closed | Add EncodedInput as an alternative input type of _batch_encode_plus in tokenization_utils_fast | # 🚀 Feature request
The [_batch_encode_plus](https://github.com/huggingface/transformers/blob/6989264963d1f8871404889243d2f15de198ee42/src/transformers/tokenization_utils.py#L483) function in [tokenization_utils](https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_utils.py) supports to use EncodedInput and EncodedInputPair as inputs. I hope the fast tokenizer can also support that in [tokenization_utils_fast](https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_utils_fast.py).
## Motivation
It would be more flexible to add EncodedInput and EncodedInputPair as alternative input types for the default fast tokenizer, meanwhile this feature has been implemented in the original tokenizer.
| 07-16-2021 07:41:56 | 07-16-2021 07:41:56 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,753 | closed | Getting Word Embeddings for Sentences using long-former model? | I am new to **Huggingface** and have few basic queries. This post might be helpful to others as well who are starting to use **longformer** model from **huggingface**.
## Objective:
Create Sentence/document embeddings using **longformer** model. We don't have lables in our data-set, so we want to do clustering on output of embeddings generated. Please let me know if the code is correct?
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` **version:3.0.2**
- Platform:
- Python version: **Python 3.6.12 :: Anaconda, Inc.**
- PyTorch version (GPU?):**1.7.1**
- Tensorflow version (GPU?): **2.3.0**
- Using GPU in script?: **Yes**
- Using distributed or parallel set-up in script?: **parallel**
### Who can help
@patrickvonplaten
##Models:
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
Library:
- benchmarks: @patrickvonplaten
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
## Information
Model I am using longformer:
The problem arises when using:
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] my own task or dataset: (give details below)
## Code:
```
from transformers import LongformerModel, LongformerTokenizer
model = LongformerModel.from_pretrained('allenai/longformer-base-4096',output_hidden_states = True)
tokenizer = LongformerTokenizer.from_pretrained('allenai/longformer-base-4096')
# Put the model in "evaluation" mode, meaning feed-forward operation.
model.eval()
df = pd.read_csv("inshort_news_data-1.csv")
df.head(5)
#**news_article** column is used to generate embedding.
```
```
all_content=list(df['news_article'])
def sentence_bert():
list_of_emb=[]
for i in range(len(all_content)):
SAMPLE_TEXT = all_content[i] # long input document
print("length of string: ",len(SAMPLE_TEXT.split()))
input_ids = torch.tensor(tokenizer.encode(SAMPLE_TEXT)).unsqueeze(0)
# How to include batch of size here?
# Attention mask values -- 0: no attention, 1: local attention, 2: global attention
attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to local attention
attention_mask[:, [0,-1]] = 2
with torch.no_grad():
outputs = model(input_ids, attention_mask=attention_mask)
hidden_states = outputs[2]
token_embeddings = torch.stack(hidden_states, dim=0)
# Remove dimension 1, the "batches".
token_embeddings = torch.squeeze(token_embeddings, dim=1)
# Swap dimensions 0 and 1.
token_embeddings = token_embeddings.permute(1,0,2)
token_vecs_sum = []
# For each token in the sentence...
for token in token_embeddings:
#but preferrable is
sum_vec=torch.sum(token[-4:],dim=0)
# Use `sum_vec` to represent `token`.
token_vecs_sum.append(sum_vec)
h=0
for i in range(len(token_vecs_sum)):
h+=token_vecs_sum[i]
list_of_emb.append(h)
return list_of_emb
f=sentence_bert()
```
## Doubts/Question:
1. If we want to get embeddings in batches, what all changes do I need to make in the above code?
2. If the sentence is " **I am learning longformer model**.". Will the tokenizer function will return ID's of following token in longformer model: **[ 'I', 'am' , 'learning' , 'longformer' , 'model. ']** Is my understanding correct? Can you explain it with minimum reproducible example?
3. Similarly attention mask will return attention weights of following tokens? The part which I didn't understand is its necessary to replace last attention weight of sentence by **2** (in above code)?
4. #outputs[0] gives us sequence_output: torch.Size([768])
#outputs[1] gives us pooled_output torch.Size([1, 512, 768])
#outputs[2]: gives us Hidden_output: torch.Size([13, 512, 768])
Can you talk more about what does each dimension depicts in outputs? Example what does Hidden_output [13, 512, 768]
means ? From where **13, 512 and 768 is coming** ? What does 13, 512 and 768 means in terms of hidden state, embedding dimesion and number of layesr?
5. From which token do we get the sentence embedding in **longformer**? Can you explain it with minimum reproducible example?
6. If I am running the model in linux system, where does pre-trained model get's downloaded or stored? Can you list the complete path?
7. length of string: **15**
**input_ids: tensor([[ 0, 35702, 1437, 3743, 1437, 560, 1437, 48317, 1437, 28884,
20042, 1437, 6968, 241, 1437, 16402, 1437, 463, 1437, 3056,
1437, 48317, 1437, 281, 1437, 16752, 1437, 281, 1437, 1694,
1437, 7424, 4, 2]])**
**input_ids.shape: torch.Size([1, 34])**
My sentence length is **15** then why input_ids and attention_ids are length **34**?
## Expected behavior
Document1: Embeddings
Document2: Embeddings
| 07-16-2021 06:46:20 | 07-16-2021 06:46:20 | Please use the [forums](https://discuss.huggingface.co/) for this kind of questions, we keep the issues for bugs and feature requests only.<|||||>> Please use the [forums](https://discuss.huggingface.co/) for this kind of questions, we keep the issues for bugs and feature requests only.
Thanks for pointing it out. I have posted my question in https://discuss.huggingface.co/
Sorry for confusion.<|||||>It is saying my account is on hold. <|||||>What's your username? You have to read a few posts (that's part of the antispam strategy of discourse) but I can bump your username to avoid that.<|||||>> What's your username? You have to read a few posts (that's part of the antispam strategy of discourse) but I can bump your username to avoid that.
My username is **pchhapolika**<|||||>Ah saw your post and approved it.<|||||>> Ah saw your post and approved it.
Thanks a lot. Closing this request.
Note this question has been moved here: https://discuss.huggingface.co/t/getting-word-embeddings-for-sentences-using-long-former-model/8448 |
transformers | 12,752 | closed | [Flax/run_hybrid_clip] Fix duplicating images when captions_per_image exceeds the number of captions, enable truncation | # What does this PR do?
Do not duplicate images when the number of captions in an example is smaller than `captions_per_image`.
Truncate tokens when number of tokens exceeds `max_length`.
Currently, if an example contains a number of captions smaller than `captions_per_image`, the dataset will get scrambled, because the image paths are going to be duplicated but the number of captions is not.
For example, if an example contains a single caption and `captions_per_image` is equal to 2, one caption will be appended to the captions list, but two image path will be appended to the `image_paths list`. This results in mismatching file_path-caption pairs.
This pull request fixes this issue.
Currently, if a tokenized sentence contains a number of tokens > `max_length`, the dimensions of inputs within a batch won't match.
This pull request fixes this issue by truncating the tokens to max_length.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@patil-suraj
| 07-16-2021 05:23:41 | 07-16-2021 05:23:41 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,751 | closed | add intel-tensorflow-avx512 to the candidates | # What does this PR do?
`intel-tensorflow-avx512` PyPI package is not in the candidates list of transformers.
This PR adds support for detecting `intel-tensorflow-avx512`.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. I think @sgugger could be the right person to review this PR since he has reviewed a similar PR before. | 07-15-2021 22:21:45 | 07-15-2021 22:21:45 | |
transformers | 12,750 | closed | hyperparameter search requirements/gpt2 metric | I am trying to fine tune gpt2 to respond to certain prompts in a specific way, so I am training it on strings like
prompt + "someDivider" + output
I have about 1300 samples of training data, and I wanted to use hyperparameter_search to pick decent hyperparameters. I'm not sure if this requires a validation set, and if it does, what metric do I have to put? Do I even need a metric?
I'm also not sure what to do with the output of hyperparameter_search
I've tried doing research but I haven't really gotten far on this issue. I am relatively new to training AI's.
- ray/raytune: @richardliaw, @amogkam
- gpt2: @patrickvonplaten, @LysandreJik
```
import pandas as pd
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import GPT2Tokenizer, GPT2LMHeadModel, AdamW, get_linear_schedule_with_warmup,AutoTokenizer, DataCollatorForLanguageModeling, AutoConfig, Trainer, TrainingArguments,AutoModelForCausalLM
from tqdm import tqdm, trange
import torch.nn.functional as F
import csv
from datasets import load_dataset,load_metric
import io
from google.colab import files
#version of gpt we use
model_version = 'gpt2-medium'
#create the dataset
raw_datasets = load_dataset('csv', data_files=['train.csv'])
print(raw_datasets)
print(raw_datasets["train"][1])
#initialize tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_version)
tokenizer.pad_token = tokenizer.unk_token #prevents error where there is no token.
#function called by trainer to initialize model. I'm doing it this way so the hyperparameters can be tuned
def model_init():
return GPT2LMHeadModel.from_pretrained(model_version)
#helper for tokenizing everything
def tokenize_function(examples):
return tokenizer(examples["triplet"], truncation=True)
#tokenize all our data
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
#gets rid of original string data
tokenized_datasets=tokenized_datasets.remove_columns(["triplet"])
print(tokenized_datasets)
print(tokenized_datasets["train"]["input_ids"][1])
#collate data
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
#training args (you can control hyperprarameters from here)
training_args = TrainingArguments(output_dir="Finetuned",
overwrite_output_dir=True,
prediction_loss_only=True, #TODO if you are gonna do a validation set and compute metrics, this must be False but since we arent, I set to true
)
trainer = Trainer(
model_init=model_init,
args=training_args,
train_dataset=tokenized_datasets["train"],
data_collator=data_collator,
tokenizer=tokenizer,
)
# Automatically finds good hyperparameters, you can pass arguments into it but idk if I want to mess with them rn
trainer.hyperparameter_search()
trainer.train()
trainer.save_model()
```
| 07-15-2021 22:09:40 | 07-15-2021 22:09:40 | It seems like if I give it an evaluation set from the training set, and no metric, and then set the parameter search to minimize, it will minimize loss?
And then I just initialize a new trainer in the same script using those hyperparamets?
```
best = trainer.hyperparameter_search(direction="minimize", hp_space=my_hp_space_ray)
hyperParameter = best.hyperparameters
print(best)
print(hyperParameter)
#train using best hyperparameters
training_args = TrainingArguments(output_dir="Finetuned",
overwrite_output_dir=True,
eval_steps=100, #steps before we run eval
disable_tqdm=True,
prediction_loss_only = True, #get rid of this if we end up adding metrics
learning_rate = hyperParameter["learning_rate"],
num_train_epochs = hyperParameter["num_train_epochs"],
seed = hyperParameter["seed"],
per_device_train_batch_size =hyperParameter["per_device_train_batch_size"],
)
trainer = Trainer(...)
```
Although that seems that I would be effectively running the whole train loop 21 times
edit: just using validation loss doesn't seem to produce good results<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hey @MarcM0,
Could you please use the [forum](https://discuss.huggingface.co/) for such questions. I think for hyperparameter tuning questions that are not clear bugs the forum is the place to post questions :-) <|||||>Ya I figured it out, thank you<|||||>@MarcM0 have you figured out how to set compute_metrics for hyperparameter search for GPT models?<|||||>I just ended up using the default loss<|||||>Thank you @MarcM0. Do you mean you set compute_metrics=None (None was the default value, unless you provide your implementation)?<|||||>I believe so |
transformers | 12,749 | closed | [ray] Fix `datasets_modules` ImportError with Ray Tune | # What does this PR do?
This PR fixes an ImportError throws due to `datasets_modules` not being loaded on Ray Actors when tuning hyperparamters with Ray, fixing the following issues:
[huggingface/blog#106](https://github.com/huggingface/blog/issues/106)
[huggingface/transformers#11565](https://github.com/huggingface/transformers/issues/11565)
https://discuss.huggingface.co/t/using-hyperparameter-search-in-trainer/785/34
https://discuss.huggingface.co/t/using-hyperparameter-search-in-trainer/785/35
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #11565
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-15-2021 20:45:53 | 07-15-2021 20:45:53 | @richardliaw @pvcastro <|||||>Great! @richardliaw , another approval is still required?<|||||>@sgugger @LysandreJik could you help take a look :) |
transformers | 12,748 | closed | [Wav2Vec2] Correctly pad mask indices for PreTraining | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR makes sure that no mask_indices are predicted for padded tokens and thus ensures that the loss for padded tokens is always ignored.
cc @cceyda
Training run is started for Wav2Vec2 in Flax.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-15-2021 20:22:38 | 07-15-2021 20:22:38 | |
transformers | 12,747 | closed | [WIP] Add classification head for T5 and MT5 | This is an experiment to add a classification head for T5 and MT5 models.
It uses the `T5EncoderModel` and `MT5EncoderModel` without the decoder part. | 07-15-2021 20:15:39 | 07-15-2021 20:15:39 | @LysandreJik or @sgugger
I am trying to add a classification head on top of the T5 and MT5 encoder models.
It works but the performance (metric) of my downstream tasks is very low compared to other models.
Could you maybe do a very quick code review on this PR please?
Maybe you find obvious bugs.
Is the initialization maybe wrong for example?
I am adding a `SequenceSummary` head like XLNet is doing.
This has different values for `summary_type`.
I tried everything: `first`, `last`, `cls_index`. Noting realy works good.
<|||||>PS: T5 and MT5 do not have these `<s>` or `[CLS]` token...
<|||||>Hi @LysandreJik or @sgugger ,
I would be super happy if you could maybe give me some pointers here.<|||||>Maybe @patrickvonplaten will have some ideas, but maybe it's just that those types of models are not really good for sequence classification.<|||||>Hmm, T5 was really made so that every task (including classification tasks) are framed as a text2text task. I don't really see why one would use T5 over BERT for a "Encoder-only" classification task...Could you give a bit more detail on the motivation of this PR? :-) @PhilipMay <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,746 | closed | How to finetune mT5 | I am using mT5 for the task of summarization on a language other than English. But even after training for 30 epochs, the generations are very bad with rouge 1 as 31.5, whereas mBART gives a rouge 1 of 43.1 after training only for 11 epochs.
I wanted to know if mT5's performance is expected to be like this compared to mBART, or am I doing something wrong.
Appreciate any help. Thank you :)
| 07-15-2021 17:04:01 | 07-15-2021 17:04:01 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discuss.huggingface.co) instead?
Thanks!<|||||>> Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
> Could you ask your question on the [forum](https://discuss.huggingface.co) instead?
>
> Thanks!
Alright. Thank you so much!!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,745 | closed | Replace specific tokenizer in log message by AutoTokenizer | # What does this PR do?
As mentioned by @sgugger in PR #12619, I propose with this PR to harmonize the messages in the logs to encourage users to use `AutoTokenizer`.
I've checked that all these tokenizers appear in `TOKENIZER_MAPPING` int the `tokenization_auto.py` file.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. @sgugger since this PR is based on one of your comments, I think you would be interested.
@europeanplaice, I'm just tagging you for your information (I didn't include the change you proposed in your PR).
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-15-2021 16:35:37 | 07-15-2021 16:35:37 | Thank you for accepting my proposal! |
transformers | 12,744 | closed | Blenderbot output logits dimensions mismatch | - `transformers` version: 4.9.0.dev0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.5.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
Models: Blenderbot — @patrickvonplaten, @patil-suraj
Documentation: @sgugger
## Information
The model I am using is `facebook/blenderbot-400M-distill`.
The problem arises when using:
* [x] my own modified scripts
## To reproduce
Steps to reproduce the behaviour:
Run the following code
```python
from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
import torch
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = BlenderbotForConditionalGeneration.from_pretrained('facebook/blenderbot-400M-distill').to(DEVICE)
tokenizer = BlenderbotTokenizer.from_pretrained('facebook/blenderbot-400M-distill')
input_ids = tokenizer.encode("Hello there! My name is Nader", return_tensors="pt").to(DEVICE)
decoder_input_ids = tokenizer.encode("<s>", return_tensors="pt").to(DEVICE)
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
logits = outputs.logits
print(input_ids.shape)
print(logits.shape)
```
## Current output
```
torch.Size([1, 9])
torch.Size([1, 3, 8008])
```
## Expected behaviour
```
torch.Size([1, 9])
torch.Size([1, 9, 8008])
```
According to [the documentation of the `forward()` method,](https://huggingface.co/transformers/model_doc/blenderbot.html?highlight=forward#transformers.BlenderbotForConditionalGeneration.forward) it should return a `Seq2SeqLMOutput` object with a member `logits` having the following properties
> logits (`torch.FloatTensor` of shape (`batch_size`, `sequence_length`, `config.vocab_size`))
and considering that the `input_ids` in this case has dimensions of `(batch_size, sequence_length)` which maps to `(1, 9)` in this case shown in code above, why doesn't the model output logits have dimensions of `(1, 9, 8008)`? Please tell me what does this `3` signify if I'm missing something here. Thanks.
<!-- A clear and concise description of what you would expect to happen. -->
| 07-15-2021 14:21:24 | 07-15-2021 14:21:24 | Seems like a documentation thing. After a little bit of digging, I found out that the output logits have the dimensions of `(batch_size, decoder_sequence_length, config.vocab_size)` not `(batch_size, sequence_length, config.vocab_size)`.<|||||>@naderabdalghani thanks for investigating! Also feel free to open a PR to clarify the docs if you'd like :-) |
transformers | 12,743 | closed | [Debug] wav2vec2 pretraining | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Check https://huggingface.co/patrickvonplaten/debug_repo
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 07-15-2021 13:27:10 | 07-15-2021 13:27:10 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,742 | closed | Patch T5 device test | The input IDs were not cast to the correct device. | 07-15-2021 13:18:53 | 07-15-2021 13:18:53 | Thanks a lot! |
transformers | 12,741 | closed | Change create_model_card to use best eval_results when args.load_best_model_at_end==True | # 🚀 Feature request
When I use Trainer.push_to_hub, the model card that gets generated uses my most recent checkpoint's eval_results. However, if I include load_best_model_at_end=True in my TrainingArguments, then the model that is being pushed can often be from an earlier checkpoint (right?). The suggestion is to change create_model_card (and parse_log_history) to use the best loss when appropriate.
## Motivation
So that the reported evaluation results on the model card match the correct checkpoint of the model pushed to the hub.
## Contribution
Happy to submit a PR, with some guidance on where to make the changes. Would it make sense to pass the trainer as an optional argument to parse_log_history and then use the training args load_best_model_at_end, metric_for_best_model, and greater_is_better to return the best loss as the eval_results if appropriate?
| 07-15-2021 13:14:57 | 07-15-2021 13:14:57 | cc @sgugger <|||||>I don't think there is an easy way to get that loss and metrics. However, note that if you run a last `trainer.evaluate()` (as is done in all the example scripts) the loss and metrics reported will be the ones from the final model, so I would suggest doing this.<|||||>@sgugger that makes sense. Thanks! |
transformers | 12,740 | closed | Skip test while the model is not available | Skip test while the model is not available on the huggingface hub. | 07-15-2021 13:14:06 | 07-15-2021 13:14:06 | |
transformers | 12,739 | closed | Skip test while the model is not available | Skip the test while the model cannot be accessed through the hub. | 07-15-2021 13:06:41 | 07-15-2021 13:06:41 | |
transformers | 12,738 | closed | Doctest Integration | # 🚀 Feature request
It would be nice to add doctest to ensure new additions have working examples in the docstrings and that existing examples do not become outdated with API changes. The feature is already in [pytest](https://docs.pytest.org/en/6.2.x/doctest.html) so adding it should be straightforward.
## Motivation
This will reduce the number of PRs for typos/errors in docstring examples which should allow reviewers to focus on other PRs.
## Your contribution
I wouldn't mind working on this if everyone thinks it is a good idea. | 07-15-2021 12:58:24 | 07-15-2021 12:58:24 | Hi @will-rice! Most of our tests are setup to work with doctest, and we had doctest coverage a few months back. Unfortunately, as the number of model grows, the issue is less of a documentation issue and more of an infrastructure issue :) We're working on setting them back up as we speak.<|||||>ok awesome! I'll go ahead and close this then. |
transformers | 12,737 | closed | Fix MBart failing test | Fixes the failing test by adjusting the expected sentence. The sentence turns from
```
[...] will only worsen the violence and misery of millions.
```
to
```
[...] only make violence and misery worse for millions of people.
```
which seems grammatically correct still. @patrickvonplaten please let me know if you think this is a real issue or not. | 07-15-2021 12:51:58 | 07-15-2021 12:51:58 | Thanks for fixing this test - this was actually failing since a long time and no-one fixed it |
transformers | 12,736 | closed | LXMERT integration test typo | Patches a typo in the LXMERT integration test. | 07-15-2021 12:29:42 | 07-15-2021 12:29:42 | |
transformers | 12,735 | closed | Fix led torchscript | LED can't run on `torchscript`:
```
Failure
Traceback (most recent call last):
File "/home/xxx/transformers/tests/test_modeling_common.py", line 538, in _create_and_check_torchscript
traced_model = torch.jit.trace(
File "/home/xxx/transformers/.env/lib/python3.8/site-packages/torch/jit/_trace.py", line 735, in trace
return trace_module(
File "/home/xxx/transformers/.env/lib/python3.8/site-packages/torch/jit/_trace.py", line 952, in trace_module
module._c._create_method_from_trace(
RuntimeError: 0INTERNAL ASSERT FAILED at "/pytorch/torch/csrc/jit/ir/alias_analysis.cpp":532, please report a bug to PyTorch. We don't have an op for aten::constant_pad_nd but it isn't a special case. Argument types: Tensor, int[], bool,
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/xxx/transformers/tests/test_modeling_led.py", line 284, in test_torchscript
self._create_and_check_torchscript(config, inputs_dict)
File "/home/xxx/transformers/tests/test_modeling_common.py", line 545, in _create_and_check_torchscript
self.fail("Couldn't trace module.")
AssertionError: Couldn't trace module.
``` | 07-15-2021 12:26:10 | 07-15-2021 12:26:10 | |
transformers | 12,734 | closed | Fix DETR integration test | The integration test must be adjusted to reflect DETR's true margin of error. | 07-15-2021 12:22:57 | 07-15-2021 12:22:57 | LGTM! |
transformers | 12,733 | closed | Fix AutoModel tests | Auto model tests were not kept up to date. This patches the following two tests:
```
FAILED tests/test_modeling_auto.py::AutoModelTest::test_model_from_pretrained
FAILED tests/test_modeling_common.py::ModelUtilsTest::test_model_from_pretrained
``` | 07-15-2021 12:22:24 | 07-15-2021 12:22:24 | No worries! |
transformers | 12,732 | closed | Not able to load the custom model after training in Hugging Face | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: colab
### Who can help
@patil-suraj @patrickvonplaten
Models:
Used FlaxGPT2Module as base class and built FlaxGPT2ForMutlipleChoice.After training is done when loading the saved weights in hugging face hub there seems to be an error.
Model hub:
-Hugging Face Hub:https://huggingface.co/Vivek/gpt2-common-sense-reasoning
Error messgae: unpack(b) received extra data.
## Information
Model I am using (Bert, XLNet ...):FlaxGPT2ForMultipleChoice(custom model)
The problem arises when using:
1.when i try to load the weights of saved weights in hugging face hub there seems to be an error.
The tasks I am working on is:
* Dataset: COSMOS QA
Expected Behaviour :To able to load the weights and the configuration without any error
Colab Notebook:https://colab.research.google.com/drive/1C-M1GLMk7jiomXIpngbLZvCNvEJMfJ1K?usp=sharing
## To reproduce
``` python
new_model=FlaxGPT2ForMultipleChoice.from_pretrained('/content/gpt2-common-sense-reasoning',
input_shape=(1,4,1), config=config)```
| 07-15-2021 11:21:19 | 07-15-2021 11:21:19 | |
transformers | 12,731 | closed | Remove framework mention | Remove mention of framework for `transformers.onnx` | 07-15-2021 09:16:15 | 07-15-2021 09:16:15 | |
transformers | 12,730 | closed | Adding a Wav2Vec2ForSpeechClassification class | # Adding a Wav2Vec2ForSpeechClassification class 🚀
Right now, using any of the Wav2Vec 2.0 models available on the 🤗hub and make a fine-tuning process to resolve a __speech classification task__ implies creating a new class that inherit his behaviour from the Wav2Vec2PreTrainedModel class. Although creating this types of models can be done with a bit of research, I find too complicated to just use a fine-tuned model when shared on the 🤗hub, because you need to have access to the code of the model class in order to instantiate it and retrieve the model with the `from_pretrained()` method (which may or may not be available at that time).
I think that adding a class to the 🤗transformers library like `Wav2Vec2ForSpeechClassification` (i.e. the same way that works for the `BertForSequenceClassification` models and others similar) will be a very nice feature in order to not just be able to fine-tune Wav2Vec 2.0 for classification tasks but also it would simplify and accelerate the way one can use a shared model.
## Motivation
Speech has always been a very awesome field of research both in the way a user interacts with a physical system, and vice versa. Taking this into account, and with the great news of having the new Wav2Vec 2.0 model integrated on the 🤗transformers library 🎉, I started a research project on Speech Emotion Recognition (SER) with the idea of fine-tune a Wav2Vec 2.0 model in this type of emotional datasets. The results that I've obtained are very promising and the model seems to work extremely well, so I decided to put the fine-tuned model on the [🤗hub](https://huggingface.co/ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition) (wip). Additionally, I saw on the 🤗 discussion forums a [topic](https://discuss.huggingface.co/t/using-wav2vec-in-speech-classification-regression-problems/6361) about this same task of SER implementation with its corresponding model on the [🤗hub](https://huggingface.co/m3hrdadfi/wav2vec2-xlsr-greek-speech-emotion-recognition), which have the same issue when importig it.
With all this, I think that the number of use cases of the Wav2Vec2 model for speech classification tasks are huge and having a feature like this one implemented would simplify a lot the way other developers and researchers can work with this type of pretrained models.
## Your contribution
I can start working in a new PR to overcome this situation by implementing the `Wav2Vec2ForSpeechClassification` class that I mentioned before in the library. I already have the code working and in fact it's pretty similar to the other nlp models that include the SequenceClassification feature.
The idea behind this is to have a much more simplified and generalized way to use and train this models, getting as final result this snippet for a straight forward use of them.
```python
from transformers import Wav2Vec2FeatureExtractor, Wav2Vec2ForSpeechClassification
processor = Wav2Vec2FeatureExtractor.from_pretrained("ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition")
model = Wav2Vec2ForSpeechClassification.from_pretrained("ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition")
```
Let me know if this feature fits the needs of the library in terms of simplicity and integration, and I will start a new PR with these changes. Also let me know if it is useful and cover an adecuate number of use cases, making it worth of implementing.
Thank you all for your amazing work 🥇 | 07-15-2021 07:30:13 | 07-15-2021 07:30:13 | Hey @ehcalabres,
I'm only seeing your issue now sadly :-/ Super sorry to not have answered sooner. @anton-l is working on an official `Wav2Vec2-` and `HubertForSequenceClassification` at the moment, here: https://github.com/huggingface/transformers/pull/13153 which should serve your needs then :-)
It would be great if you could take a look at https://github.com/huggingface/transformers/pull/13153 to see whether this design/architecture fits your needs<|||||>Hey @patrickvonplaten, @anton-l,
Thanks a lot for your answer! As I'm seeing on the issue #13153 , it seems like it's pretty much the same as I was proposing here, so I think it'll do the job for this kind of audio classification tasks. I'll try it when it comes out but it seems to be fine by the moment. Great!
Only one thing, I've work mostly in PyTorch but as I was checking the code I've seen that there's no TensorFlow version of these models (neither for Hubert or Wav2Vec2), do you think it's relevant to implement them? If so maybe I can help with that, but I don't know if it's something critical.
Anyway, is there anything else I can do to help you with this? Just let me know.
Thanks again! |
transformers | 12,729 | closed | Checkpoints are saved multiple times during hyperparameter tuning / How to get the best model? | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.8.2
- Platform: Linux-4.19.0-16-amd64-x86_64-with-glibc2.10
- Python version: 3.8.0
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
Probably @amogkam because issue is related to ray tune.
## Information
Model I am using (Bert, XLNet ...): distilbert-base-uncased
The problem arises when using:
* my own modified scripts:
The tasks I am working on is:
* an official GLUE/SQUaD task: MRPC
My ultimate goal is to tune the hyperparameters of a model and save the best model in a folder.
Therefore I created the script below. It runs a simple hyperparameter search.
After the run, the folder `trainer_output_dir` is empty and the `ray_local_dir` folder has following structure:
````
ray_local_dir/
├── tune_transformer_pbt/
│ ├── _objective_081f1_00000_0_learning_rate=2.4982e-05_2021-07-13_14-44-15
│ │ ├── checkpoint_001377
│ │ │ ├── checkpoint-1377
│ │ ├── trainer_output_dir
│ │ │ ├── run-081f1_00000
│ │ │ │ ├── checkpoint-459
│ │ │ │ ├── checkpoint-918
│ │ │ │ ├── checkpoint-1377
````
When the attribute `save_strategy` (of the `TrainingArguments`) is set to `epoch` the folder structure like above is generated.
When the attribute `save_strategy` is set to `no`, then no checkpoints are written at all.
In folder `checkpoint_001377` the checkpoints are removed by ray tune but the checkpoints from the trainer_output_dir are not removed. The main reason is that the checkpoints are generated in two functions:
1. in function [`_tune_save_checkpoint`](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py#L892) which is called only when `self.control.should_save` is true
2. in function [`_save_checkpoint`](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py#L1436) which is also called only when `self.control.should_save` is true
I care about these checkpoint folders, because this is the only way to load the best model.
[The example from ray tune](https://docs.ray.io/en/master/tune/examples/pbt_transformers.html) sets `load_best_model_at_end=True` but this has no effect and the trainer has no model which could be saved.
Thus I decided to load the model from the checkpoint folder.
The info in the BestRun object returned by `hyperparameter_search` is:
```
BestRun(run_id='081f1_00000', objective=0.5750986933708191, hyperparameters={'learning_rate': 2.49816047538945e-05})
```
It contains only the `run_id` and I search for the folder `_objective_081f1_00000.*` (glob pattern) in `tune_transformer_pbt` to get the right trials folder and then search for one folder which starts with `checkpoint`.
Is this the best way to load the model?
At the end of the notebook [How to fine-tune a model on text classification](https://github.com/huggingface/notebooks/blob/master/examples/text_classification.ipynb), it is stated:
`To reproduce the best training, just set the hyperparameters in your TrainingArgument before creating a Trainer:` but with PBT the hyperparameters might change during one trial. Furthermore, the model is already trained and it should not be necessary to train it once again.
Another question about the same topic:
Ray tune allows to set the scope for the function [`get_best_trial`](https://docs.ray.io/en/master/tune/api_docs/analysis.html#ray.tune.ExperimentAnalysis.get_best_trial) of the `ExperimentAnalysis` object which defines if the last result of a trial should be used to return the best one or if all intermediate evaluations should be also taken into account. At least what I can see in the [trainer class](https://github.com/huggingface/transformers/blob/master/src/transformers/integrations.py#L255), this parameter can not be modified. Due to the fact, that only one checkpoint per trial is saved (`keep_checkpoints_num=1`) and with the parameter `checkpoint_score_attr` we can also define the measure to compare, then it should be possible to only store the best checkpoint( according to the specified measure).
But the default value of `scope` is set to compare only the measure of the last result and it could happen that a trial's last measure is better even tough another trial had a much better result somewhen during the training (and exactly this checkpoint is kept on disk by `checkpoint_score_attr`) .
How do I need to configure hyperparameter search and training arguments such that I get the best model from all (intermediate) evaluations?
## To reproduce
Steps to reproduce the behavior:
Execute the following script:
```
from datasets import load_dataset, load_metric
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from ray import tune
model_name = 'distilbert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_name)
dataset = load_dataset('glue', 'mrpc')
def encode(examples):
outputs = tokenizer(examples['sentence1'], examples['sentence2'], truncation=True)
return outputs
encoded_dataset = dataset.map(encode, batched=True)
def model_init():
return AutoModelForSequenceClassification.from_pretrained(model_name, return_dict=True)
def compute_metrics(eval_pred):
metric = load_metric('glue', 'mrpc')
predictions, labels = eval_pred
predictions = predictions.argmax(axis=-1)
return metric.compute(predictions=predictions, references=labels)
training_args = TrainingArguments(
output_dir='./trainer_output_dir',
skip_memory_metrics=True, # see https://github.com/huggingface/transformers/issues/11249
disable_tqdm=True,
do_eval=True,
evaluation_strategy='epoch',
save_strategy='epoch', # 'no', # TODO: change here to see the different behaviour
logging_dir='./logs'
)
trainer = Trainer(
args=training_args,
tokenizer=tokenizer,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
model_init=model_init,
compute_metrics=compute_metrics,
)
trainer.hyperparameter_search(
direction="minimize",
compute_objective=lambda x: x['eval_loss'],
backend="ray",
n_trials=1,
hp_space = lambda _: {
#toy example
"learning_rate": tune.uniform(1e-5, 5e-5),
},
scheduler=tune.schedulers.PopulationBasedTraining(
time_attr="training_iteration",
perturbation_interval=1,
metric="objective",
mode='min',
hyperparam_mutations={
"learning_rate": tune.uniform(1e-5, 5e-5),
}
),
keep_checkpoints_num=1,
checkpoint_score_attr="training_iteration",
resources_per_trial={"cpu": 1, "gpu": 1},
local_dir="./ray_local_dir/",
name="tune_transformer_pbt",
)
```
## Expected behavior
The checkpoints in the `trainer_output_dir` should not be written to disk.
| 07-15-2021 07:14:07 | 07-15-2021 07:14:07 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 12,728 | closed | How can I generate sentencepiece file or vocabulary from tokenizers? | After I make custom tokenizer using Tokenizers library, I could load it into XLNetTokenizerFast using
```
tokenizer = Tokenizer.from_file("unigram.json")
tok = XLNetTokenizerFast(tokenizer_object=tokenizer)
```
After I called
```
tok .save_vocabulary("ss")
```
it throws an error since I didnt load XLNetTokenizerFast using spm file. I believe save_vocabulary is looking for vocab_file parameter.
Is there any way to save_vocab after loading it from XLNetTokenizer?
| 07-15-2021 04:09:43 | 07-15-2021 04:09:43 | Could you try `save_pretrained` instead?<|||||>It throws
```
Traceback (most recent call last):
File "~/pretrain.py", line 26, in <module>
tokenizer.save_pretrained('./test_Spm')
File ~/anaconda3/envs/deltalake/lib/python3.9/site-packages/transformers/tokenization_utils_base.py", line 1958, in save_pretrained
save_files = self._save_pretrained(
File "~/anaconda3/envs/deltalake/lib/python3.9/site-packages/transformers/tokenization_utils_fast.py", line 555, in _save_pretrained
vocab_files = self.save_vocabulary(save_directory, filename_prefix=filename_prefix)
File "~/anaconda3/envs/deltalake/lib/python3.9/site-packages/transformers/models/xlnet/tokenization_xlnet_fast.py", line 232, in save_vocabulary
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
File "~/anaconda3/envs/deltalake/lib/python3.9/posixpath.py", line 374, in abspath
path = os.fspath(path)
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
It looked for vocab file (spm), but since I initiated it with tokenizer_object, there is no vocab_file<|||||>Could you share your `unigram.json` file or mention how you obtained it so that I can reproduce the issue? Thank you!<|||||>Here it is
[unigram.json.zip](https://github.com/huggingface/transformers/files/6839324/unigram.json.zip)
Edit:
```
from transformers import AutoTokenizer, XLNetTokenizerFast
tokenizer = AutoTokenizer.from_pretrained('xlnet-base-cased')
print(tokenizer.save_pretrained("./dump"))
tokenizer = XLNetTokenizerFast(tokenizer_file='./dump/tokenizer.json')
print(tokenizer.save_pretrained("./dump"))
```
Above Throws an error
```
from transformers import AutoTokenizer, XLNetTokenizerFast, BertTokenizerFast
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
print(tokenizer.save_pretrained("./dump"))
tokenizer = BertTokenizerFast(tokenizer_file='./dump/tokenizer.json')
print(tokenizer.save_pretrained("./dump"))
```
Above does not throw an error<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Sorry, is there any progress on this?<|||||>@SaulLu can you give this one a look?<|||||>Thank you very much for reporting this problem @darwinharianto .
I have the impression that it linked to the problem reported in [this issue](https://github.com/huggingface/transformers/issues/12762) and that I had started to work on in this [PR](https://github.com/huggingface/transformers/pull/12806). As the cleanest looking fix requires quite a bit of work, I had put it on hold. I'll try to work on it again at the beginning of the week.<|||||>@darwinharianto, to answer the question in the issue title, at the moment it is not possible to transform a fast tokenizer initialized only with a `tokenizer_object` into an spm file compatible with the `SentencePiece` library. The conversion is only supported in the opposite direction.
Why did you want the vocabulary? Because the vocabulary can be found in the `tokenizer.json` file or by doing:
```
tok.get_vocab()
```
<|||||>Since I tried to make my own XLNet tokenizer, i wanted to check if the saved format for vocabulary is the same as the published models.
I thought the fastest way would be comparing saved vocab file from huggingface model hub with mine.
Just for sanity check.<|||||>Duly noted! If it's to do a sanity check, would it be ok to compare the files of the fast version of the tokenizers (in particular the `tokenizer.json` file)?
To retrieve these files for the new tokenizer `tok` you made, the following command should work:
```
tok.save_pretrained("./dump", legacy_format=False)
```
For information, the vocabulary will be visible in the `tokenizer.json` file.<|||||>Thanks! it works.
One more question, I can see this
```
"type": "Precompiled",
"precompiled_charsmap":
```
under normalizers, when I tried to save a pretrained tokenizer.
My custom tokenizer doesn't have this attribute. Is this normal?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>I'm sorry, I realize that I never answered your last question.
This type of `Precompiled` normalizer is only used to recover the normalization operation which would be contained in a file generated by the sentencepiece library. If you have ever created your tokenizer with the tokenizers library it is perfectly normal that you do not have this type of normalization. Nevertheless, if you want to have an equivalent normalization for your tokenizer, it is generally possible to build it with the tokenizers library but it requires to know exactly which normalizations you want to apply. :slightly_smiling_face: <|||||>> @darwinharianto, to answer the question in the issue title, at the moment it is not possible to transform a fast tokenizer initialized only with a `tokenizer_object` into an spm file compatible with the `SentencePiece` library. The conversion is only supported in the opposite direction.
>
> Why did you want the vocabulary? Because the vocabulary can be found in the `tokenizer.json` file or by doing:
>
> ```
> tok.get_vocab()
> ```
Hi @SaulLu,
Sorry to open this old thread, I noticed that you mentioned transferring from spm tokenizer to a huggingface one is easy, but I could not find any function which does that for me. I would be grateful if you could share any piece of code to help me with that.
(Just to give you a quick background, I trained a SPM tokenizer and would like to use it in huggingface, but I have .vocab and .model for it, and huggingface expect a .json file)
Thank you,
Soheila |
transformers | 12,727 | closed | Getting incompatible shapes when using global_attention_mask in TFLongformerModel | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.8.2
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@patrickvonplaten
## Information
I am using TFLongformerModel.
The problem arises when using:
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] my own task or dataset: (give details below)
## To reproduce
The task is to classify the relationship between two phrases given the document the phrase is in. There are a total of 8 classes. Separators are added between the phrases and document. I would like to add global attention to phrase 1 and phrase 2.
For example:
```
<s> phrase 1 </s> phrase 2 </s> entire document </s>
```
Checked shape of inputs to ensure they were the same.
```
input ids
tf.Tensor([ 0 35151 19026 ... 1 1 1], shape=(1024,), dtype=int32)
attention mask
tf.Tensor([1 1 1 ... 0 0 0], shape=(1024,), dtype=int32)
global attention mask
tf.Tensor([1 1 1 ... 0 0 0], shape=(1024,), dtype=int32)
```
Example code for creating the model:
```
def create_model(train_layers=False, lr=5e-5):
# Input Layers
input_ids = Input(shape=(max_length,), name='input_ids', dtype='int32')
attention_mask = Input(shape=(max_length,), name='attention_mask', dtype='int32')
global_attention_mask = Input(shape=(max_length,), name='global_attention_mask', dtype='int32')
# Transformer Layer
X = transformer_model(input_ids=input_ids,
attention_mask=attention_mask,
global_attention_mask=global_attention_mask)[0] # Gets the embeddings before the [CLS] pooling
# Deep Neural Net
X = GlobalAveragePooling1D()(X)
X = Dense(512, activation='relu')(X)
X = Dense(512, activation='relu')(X)
X = Dense(512, activation='relu')(X)
X = Dense(256, activation='relu')(X)
X = Dense(128, activation='relu')(X)
X = Dense(64, activation='relu')(X)
X = Dense(8, activation='softmax')(X)
model = Model(inputs=[input_ids, attention_mask, global_attention_mask], outputs = X)
if train_layers == False:
for layer in model.layers[:3]:
layer.trainable = False
elif train_layers == True:
for layer in model.layers[:3]:
layer.trainable = True
opt = tf.keras.optimizers.Adam(learning_rate=lr)
# Compile the model
model.compile(optimizer=opt,
loss='sparse_categorical_crossentropy',
metrics = ['sparse_categorical_accuracy'])
# Print model summary
model.summary()
return model
```
Example code for training:
```
model = create_model(train_layers=False, lr=5e-05)
output = model.fit(x=[X.input_ids, X.attention_mask, X.global_attention_mask,
y=y_resample,
batch_size = 1,
epochs = 5)
```
Error:
```I
InvalidArgumentError: Incompatible shapes: [2,1024,12,513] vs. [2,1024,12,522]
[[node model_8/tf_longformer_model/longformer/encoder/layer_._0/attention/self/dropout_1/dropout/Mul_1 (defined at /usr/local/lib/python3.7/dist-packages/transformers/models/longformer/modeling_tf_longformer.py:823) ]] [Op:__inference_train_function_618763]
Function call stack:
train_function
```
It seems the last dimension in the error message is related to the number of non-zero values in the global_attention_mask. In the example above, there are 9 tokens that have a value of 1 in the global_attention_mask and the rest is zero. (522-513=9)
## Expected behavior
The model should start training.
| 07-15-2021 04:04:55 | 07-15-2021 04:04:55 | It appears that when the number of examples is a multiple of the batch_size, the training starts (i.e. batch_size=2 and num_examples=6). This doesn't work for a batch_size=1.
Unfortunately for my full dataset, I won't be able to run a batch_size=2 without OOM.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hey @sli0111,
I'm very sorry, but I won't find time in the near future to debug this :-/ Gently pinging @Rocketknight1 in case you have some bandwidth to check out longformer training in TF<|||||>Hi @sli0111, sorry for the delay but I'm taking a look at this now! Are you still encountering the issue, and have you discovered anything else about it?<|||||>Hi @Rocketknight1 I was able to workaround the issue by reducing the number of examples to an even number and running a batch_size=2. I was not able to avoid the error when I had a batch_size=1.<|||||>That's interesting - I'll mark this one down for testing and let you know what I find.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.