
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 8,806 | closed | Create README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-26-2020 19:17:24 | 11-26-2020 19:17:24 | |
transformers | 8,805 | closed | Revert "[s2s] finetune.py: specifying generation min_length" | Reverts huggingface/transformers#8478 | 11-26-2020 19:05:51 | 11-26-2020 19:05:51 | |
transformers | 8,804 | closed | MPNet: Masked and Permuted Pre-training for Language Understanding | # Model addition
[MPNet](https://arxiv.org/abs/2004.09297)
## Model description
MPNet introduces a novel self-supervised objective named masked and permuted language modeling for language understanding. It inherits the advantages of both the masked language modeling (MLM) and the permuted language modeling (PLM) to addresses the limitations of MLM/PLM, and further reduce the inconsistency between the pre-training and fine-tuning paradigms.
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-26-2020 17:17:32 | 11-26-2020 17:17:32 | Hey @StillKeepTry - could you maybe link the paper corresponding to your model add a small PR description? :-) That would be very helpful<|||||>Thanks for the new PR @StillKeepTry - could you add a `test_modeling_mpnet.py` file - it would be important to test the model :-)
Also it would be amazing if you could give some context of MPNet - is there a paper, blog post, analysis, results that go along with the model? And are there pretrained weights?
Thanks a lot! <|||||>> Thanks for the new PR @StillKeepTry - could you add a `test_modeling_mpnet.py` file - it would be important to test the model :-)
>
>
>
> Also it would be amazing if you could give some context of MPNet - is there a paper, blog post, analysis, results that go along with the model? And are there pretrained weights?
>
>
>
> Thanks a lot!
https://arxiv.org/abs/2004.09297<|||||>> > Thanks for the new PR @StillKeepTry - could you add a `test_modeling_mpnet.py` file - it would be important to test the model :-)
> > Also it would be amazing if you could give some context of MPNet - is there a paper, blog post, analysis, results that go along with the model? And are there pretrained weights?
> > Thanks a lot!
>
> https://arxiv.org/abs/2004.09297
ok<|||||>Oh and another thing to do after the merge will be to add your new model to the main README and the documentation so that people can use it! The template should give you a file for the `.rst` (or you can use `docs/model_doc/bert.rst` as an example).<|||||>I have updated `test_modeling_mpnet.py` now.<|||||>Hi, every reviewer. Thank you for your valuable reviews. I have fixed previous comments (like doc, format, and so on) and updated the `tokenization_mpnet.py` and `tokenization_mpnet_fast.py` by removing the inheritance. Besides, I also upload test files (`test_modeling_mpnet.py`, `test_modeling_tf_mpnet.py`) for testing, and model weights into the model hub. <|||||>Fantastic, thanks for working on it! Will review today.<|||||>@patrickvonplaten Hi, are there any new comments?<|||||>Hello!
Still some comments:
1. Update the inputs handling in the TF file, we have merged an update for the booleans last Friday. You can see an example in the TF BERT file if you need one.
2. rebase and fix the conflicting files.
3. Fix the check_code_quality test.<|||||>I think something went wrong with the merge here :-/ Could you try to open a new PR that does not include all previous commits or fix this one? <|||||>> I think something went wrong with the merge here :-/ Could you try to open a new PR that does not include all previous commits or fix this one?
OK, it seems something wrong when I update to the latest version. :(<|||||>@patrickvonplaten @JetRunner @sgugger @LysandreJik @jplu The new PR is moved to [https://github.com/huggingface/transformers/pull/8971](https://github.com/huggingface/transformers/pull/8971) |
transformers | 8,803 | closed | Get locally cached models programatically | # 🚀 Feature request
A small utility function to allow users to get a list of model binaries that are cached locally. Each list entry would be a tuple in the form `(model_url, etag, size_in_MB)`.
## Motivation
I have quite a few environments on my local machine containing the package and have downloaded a number of models. Over time these begin to stack up in terms of storage usage so I thought it would be useful at the very least to be able to retrieve a list of the models that are stored locally as well as some info regarding their size. I had also thought about building on this further and providing a function to remove a model from the local cache programmatically. However, for now I think getting a list is a good start.
## Your contribution
I have a PR ready to go if you think this would be a suitable feature to add. I've added it inside `file_utils.py` as this seemed like the most appropriate place. The function only adds files to the list that endwith `.bin` so right now only model binaries are included.
An example usage of the function is below:
```python
from transformers import file_utils
models = file_utils.get_cached_models()
for model in models:
print(model)
>>> ('https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin', '"2d19e321961949b7f761cdffefff32c0-66"', 548.118077)
>>> ('https://cdn.huggingface.co/distilbert-base-uncased-finetuned-sst-2-english-pytorch_model.bin', '"1d085de7c065928ccec2efa407bd9f1e-16"', 267.844284)
>>> ('https://cdn.huggingface.co/twmkn9/bert-base-uncased-squad2/pytorch_model.bin', '"e5f04c87871ae3a98e6eea90f1dec146"', 437.985356)
```
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| 11-26-2020 16:30:27 | 11-26-2020 16:30:27 | I think that would be a cool addition! What do you think @julien-c?<|||||>Yes, I almost wrote something like that a while ago, so go for it 👍
To remove old weights you don't use anymore @cdpierse, we could also document a unix command to `find` files sorted by last access time and `rm` them
(I think @sshleifer or @patrickvonplaten had a bash alias for this at some point?)<|||||>@julien-c I have the PR for handling cached models pushed but I've been trying to think of some way to add a function that allows model deletion, we could use the model names and etags returned by `get_cached_models()` to select specfic model `.bin` files to delete but the problem is that it will still leave behind stray config and tokenizer files which probably isn't great. The filenames for tokenizers, configs, and models don't seem to be related so I'm not sure if they can be deleted that way. The two approaches seem to be to delete from last accessed date or just delete model `.bin` files. <|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,802 | closed | Use GPT to assign sentence probability/perplexity given previous sentence? | Hi!
Is it possible to use GPT to assign a sentence probability given the previous sentences?
I have seen this code here, which can be used to assign a perplexity score to a sentence:
https://github.com/huggingface/transformers/issues/473
But is there a way to compute this score given a certain context (up to 1024 tokens)?
| 11-26-2020 15:29:50 | 11-26-2020 15:29:50 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
Thanks! |
transformers | 8,801 | closed | Multiprocessing behavior change 3.1.0 -> 3.2.0 | ## Environment info
```
- `transformers` version: 3.2.0
- Platform: Linux-4.15.0-88-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0 (True)
- Tensorflow version (GPU?): 2.3.0 (False)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes (Python multiprocessing)
```
## Information
I am writing a custom script that uses Python's multiprocessing. The goal of it is to have multiple child processes that run inference (using `torch.nn.Module`) **on separate GPUs**.
See below a minimal example of the issue. Please note that script contains pure `torch` code, however, it seems like importing `transformers` (**and not even using it afterwards**) changes some internal states.
```python
import multiprocessing as mp
import os
import torch
import transformers # <-- Just imported, never used
def diagnostics(name):
"""Print diagnostics."""
print(name)
print(f"CUDA initialized: {torch.cuda.is_initialized()}")
print(f"Is bad fork: {torch._C._cuda_isInBadFork()}")
print(80 * "*")
def fun(gpu):
current_process = mp.current_process()
diagnostics(current_process.pid)
os.environ["CUDA_VISIBLE_DEVICES"] = str(gpu)
model = torch.nn.Linear(200, 300)
model = model.to("cuda") # Trouble maker
while True:
model(torch.ones(32, 200, device="cuda"))
if __name__ == "__main__":
n_processes = 2
gpus = [0, 1]
start_method = "fork" # fork, forkserver, spawn
diagnostics("Parent")
mp.set_start_method(start_method)
processes = []
for i in range(n_processes):
p = mp.Process(name=str(i), target=fun, kwargs={"gpu": gpus[i]})
p.start()
processes.append(p)
for p in processes:
p.join()
```
The above script works as expected in `3.1.0` or when we do not import transformers at all. Each subprocess does inference on a separate GPU. See below the standard output.
```
Parent
CUDA initialized: False
Is bad fork: False
********************************************************************************
21091
CUDA initialized: False
Is bad fork: False
********************************************************************************
21092
CUDA initialized: False
Is bad fork: False
********************************************************************************
```
However, for `3.2.0` and higher there is the following error.
```
Parent
CUDA initialized: False
Is bad fork: False
********************************************************************************
21236
CUDA initialized: False
Is bad fork: True
********************************************************************************
Process 0:
Traceback (most recent call last):
File "/usr/lib/python3.6/multiprocessing/process.py", line 258, in _bootstrap
self.run()
File "/usr/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "git_example.py", line 21, in fun
model = model.to("cuda") # Trouble maker
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 612, in to
return self._apply(convert)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 381, in _apply
param_applied = fn(param)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 610, in convert
return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 164, in _lazy_init
"Cannot re-initialize CUDA in forked subprocess. " + msg)
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method
21237
CUDA initialized: False
Is bad fork: True
********************************************************************************
Process 1:
Traceback (most recent call last):
File "/usr/lib/python3.6/multiprocessing/process.py", line 258, in _bootstrap
self.run()
File "/usr/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "git_example.py", line 21, in fun
model = model.to("cuda") # Trouble maker
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 612, in to
return self._apply(convert)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 381, in _apply
param_applied = fn(param)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 610, in convert
return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 164, in _lazy_init
"Cannot re-initialize CUDA in forked subprocess. " + msg)
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method
```
Changing the `start_method` to `"forkserver"` or `"spawn"` prevents the exception from being raised. However, only a single GPU for all child processes is used.
| 11-26-2020 15:20:28 | 11-26-2020 15:20:28 | Sorry to insist. Could you at least share your thoughts on this? @LysandreJik @patrickvonplaten <|||||>Is the only dependency you change `transformers`? The PyTorch version remained the same (v.1.7.0) for both `transformers` versions? If so, I'll take a deeper look this week.<|||||>@LysandreJik In both experiments `torch==v1.7.0`. However, downgrading to `torch==v.1.6.0` (in both experiments) leads to exactly the same problem. I did `pip install transformers==v3.1.0` and `pip install transformers==v3.2.0` back and forth so that could be the only way other dependencies got updated.
Thank you!<|||||>Okay, thanks for checking. I'll have a look this week.<|||||>Hello @LysandreJik , is there any update on this issue?
Thank in advance!<|||||>This issue has been stale for 1 month.<|||||>I think I managed to solve the problem.
Instead of using the environment variable `os.environ["CUDA_VISIBLE_DEVICES"] = str(gpu)` to specify the GPUs one needs to provide it via `torch.device(f"cuda:{gpu}")`. |
transformers | 8,800 | closed | Problem with using custom tokenizers with run_mlm.py | Hi! I have an issue with running the `run_mlm.py` script with a tokenizer I myself trained. If I use pretrained tokenizers everything works.
Versions:
```
python: 3.8.3
transformers: 3.5.1
tokenizers: 0.9.4
torch: 1.7.0
```
This is how I train my tokenizer:
```
from tokenizers import BertWordPieceTokenizer
tokenizer = BertWordPieceTokenizer(lowercase=False, strip_accents=False, clean_text=True)
tokenizer.train(files=['/mounts/data/proj/antmarakis/wikipedia/wikipedia_en_1M.txt'], vocab_size=350, special_tokens=[
"[PAD]",
"[UNK]",
"[CLS]",
"[SEP]",
"[MASK]",
])
tokenizer.save_model('wikipedia_en')
```
The above results in a vocab.txt file.
And this is how I try to train my model (using the `run_mlm.py` script):
```
python run_mlm.py \
--model_type bert \
--config_name bert_custom.json \
--train_file wikipedia_en_1M.txt \
--tokenizer_name wikipedia_en \
--output_dir lm_temp \
--do_train \
--num_train_epochs 1 \
--overwrite_output_dir
```
If I use a pretrained model/tokenizer, this script works (that is, I replace `config_name` and `tokenizer_name` with `model_name_or_path roberta-base` or something). But using the above code, I get the following error message:
```
Traceback (most recent call last):
File "run_mlm.py", line 392, in <module>
main()
File "run_mlm.py", line 334, in main
tokenized_datasets = tokenized_datasets.map(
File "/mounts/Users/cisintern/antmarakis/.local/lib/python3.8/site-packages/datasets/dataset_dict.py", line 283, in map
{
File "/mounts/Users/cisintern/antmarakis/.local/lib/python3.8/site-packages/datasets/dataset_dict.py", line 284, in <dictcomp>
k: dataset.map(
File "/mounts/Users/cisintern/antmarakis/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1240, in map
return self._map_single(
File "/mounts/Users/cisintern/antmarakis/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 156, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/mounts/Users/cisintern/antmarakis/.local/lib/python3.8/site-packages/datasets/fingerprint.py", line 163, in wrapper
out = func(self, *args, **kwargs)
File "/mounts/Users/cisintern/antmarakis/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1525, in _map_single
writer.write_batch(batch)
File "/mounts/Users/cisintern/antmarakis/.local/lib/python3.8/site-packages/datasets/arrow_writer.py", line 278, in write_batch
pa_table = pa.Table.from_pydict(typed_sequence_examples)
File "pyarrow/table.pxi", line 1531, in pyarrow.lib.Table.from_pydict
File "pyarrow/array.pxi", line 295, in pyarrow.lib.asarray
File "pyarrow/array.pxi", line 195, in pyarrow.lib.array
File "pyarrow/array.pxi", line 107, in pyarrow.lib._handle_arrow_array_protocol
File "/mounts/Users/cisintern/antmarakis/.local/lib/python3.8/site-packages/datasets/arrow_writer.py", line 100, in __arrow_array__
if trying_type and out[0].as_py() != self.data[0]:
File "pyarrow/array.pxi", line 949, in pyarrow.lib.Array.__getitem__
File "pyarrow/array.pxi", line 362, in pyarrow.lib._normalize_index
IndexError: index out of bounds
```
This approach used to work for previous versions, but after I upgraded to the latest releases this doesn't seem to work anymore and I do not know where it broke. Any help would be appreciated! | 11-26-2020 13:56:00 | 11-26-2020 13:56:00 | I have simplified the code to show that it is definitely the pretrained tokenizer that breaks the execution:
```
python run_mlm.py \
--model_name_or_path bert-base-cased \
--train_file data.txt \
--tokenizer_name custom_tokenizer \
--output_dir output \
--do_train \
--num_train_epochs 1 \
--overwrite_output_dir
```<|||||>This seems like an issue that concerns the new mlm script, `tokenizers` and `datasets` so I'll ping the holy trinity that may have an idea where the error comes from: @sgugger @n1t0 @lhoestq <|||||>Looks like the tokenizer returns an empty batch of elements, which causes an `IndexError` ?<|||||>is this issue resolved? ran into the same error.<|||||>From recent experience, I think this might happen if no `model_max_length` is set for the tokenizer.
In the directory where your tokenizer files live, do you mind adding another file called `tokenizer_config.json`, with the following information: `{"model_max_length": 512}`?
Thank you.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,799 | closed | Warning about too long input for fast tokenizers too | # What does this PR do?
If truncation is not set in tokenizers, but the tokenization is too long
for the model (`model_max_length`), we used to trigger a warning that
The input would probably fail (which it most likely will).
This PR re-enables the warning for fast tokenizers too and uses common code
for the trigger to make sure it's consistent across.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@LysandreJik
@thomwolf
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
--> | 11-26-2020 11:35:12 | 11-26-2020 11:35:12 | Failing tests seem to come from some other code (seq2seq)<|||||>@thomwolf could you review this PR as you're the mastermind behind this code?<|||||>@LysandreJik May I merge (failing tests and quality is linked to unrelated `finetune.py` code, I tried to rebase but it does not seem to be enough) |
transformers | 8,798 | closed | Fix setup.py on Windows | # What does this PR do?
This PR fixes the target `deps_table_update` on Windows by forcing the newline to be LF. | 11-26-2020 10:55:49 | 11-26-2020 10:55:49 | |
transformers | 8,797 | closed | Minor docs typo fixes | # What does this PR do?
Just a few typo fixes in the docs.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
@sgugger | 11-26-2020 10:28:00 | 11-26-2020 10:28:00 | Looks like you have a styling problem, could you run the command `make style` after doing a dev install with
```
pip install -e .[dev]
```
in the repo?<|||||>Oops! Done. |
transformers | 8,796 | closed | QARiB Arabic and dialects models | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-26-2020 08:49:20 | 11-26-2020 08:49:20 | Thanks @ahmed451!
For context, please also read https://discuss.huggingface.co/t/announcement-all-model-cards-will-be-migrated-to-hf-co-model-repos/2755 |
transformers | 8,795 | closed | Use model.from_pretrained for DataParallel also | When training on multiple GPUs, the code wraps a model with torch.nn.DataParallel. However if the model has custom from_pretrained logic, it does not get applied during load_best_model_at_end.
This commit uses the underlying model during load_best_model_at_end, and re-wraps the loaded model with DataParallel.
If you choose to reject this change, then could you please move the this logic to a function, e.g. def load_best_model_checkpoint(best_model_checkpoint) or something, so that it can be overridden?
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-26-2020 08:36:39 | 11-26-2020 08:36:39 | Oh, looks like there is a last code-style issue to fix. Could you run `make style` on your branch? Then we can merge this.<|||||>I don't have `make` installed 😄 , what is the style issue? Wonder what style issue can go wrong in such a simple patch. The only thing we added is `self.` in those 2 lines<|||||>`check_code_quality` complains about `finetune.py`, but it's not modified by this patch<|||||>Weird indeed. Will merge and fix if the issue persists. |
transformers | 8,794 | closed | Can I get logits for each sequence I acqired from model.generate()? | Hi, I’m currently stucked in getting logits from model.generate. I’m wondering if it is possible to get logits of each seqeucne returned by model.generate. (like logits for each token returned by model.logits) | 11-26-2020 07:33:02 | 11-26-2020 07:33:02 | Sadly not at the moment... -> we are currently thinking about how to improve the `generate()` outputs though! <|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,793 | closed | Loss pooling layer parameters after Fine-tune. | According to the [code](https://github.com/huggingface/transformers/blob/master/src/transformers/models/bert/modeling_bert.py#L1005): if I want to fine-tune BERT with LM, we don't init pooling layer.
So we loss the original(pre-trained by Google) parameters if we save the fine-tune model and reload it.
Mostly, we use this model for downstream task( text classification), this (may) lead to a worse result.
This `add_pooling_layer` should be `true` for all time even if we don't update them in fine-tune.
@thomwolf @LysandreJik | 11-26-2020 06:40:20 | 11-26-2020 06:40:20 | The pooling layer is not used during the fine-tuning if doing MLM, so gradients are not retro-propagated through that layer; the parameters are not updated.<|||||>@LysandreJik The pooling parameters are not needed in MLM fine-tune. But usually, we use MLM to fine-tune BERT on our own corpus, then we use the saved model weight(missed pooling parameters) in downstream task.
It's unreasonable for us to random initialize the pool parameters, we should reload google's original pooling parameter(though it was not update in MLM fine-tune).<|||||>I see, thank you for explaining! In that case, would using the `BertForPreTraining` model fit your needs? You would only need to pass the masked LM labels, not the NSP labels, but you would still have all the layers that were used for the pre-training.
This is something we had not taken into account when implementing the `add_pooling_layer` argument cc @patrickvonplaten @sgugger <|||||>Hi @LysandreJik,
I also tried to further pre-train BERT with new, domain specific text data using the recommended run_mlm_wwm.py file, since I read a paper which outlines the benefits of this approach. I also got the warning that the Pooling Layers are not initialized from the model checkpoint. I have a few follow up questions to that:
- Does that mean that the final hidden vector of the [CLS] token is randomly initialized? That would be an issue for me since I need it in my downstream application.
- If the former point is true: Why is not at least the hidden vector of the source model copied?
- I think to get a proper hidden vector for [CLS], NSP would be needed. If I understand your answers in issue #6330 correctly, you don't support the NSP objective due to the results of the RoBERTa paper. Does that mean there is no code for pre-training BERT in the whole huggingface library which yields meaningful final [CLS] hidden vectors?
- Is there an alternative to [CLS] for downstream tasks that use sentence/document embeddings rather than token embeddings?
I would really appreciate any kind of help. Thanks a lot!
<|||||>The [CLS] token was not randomly initialized. It's a token in BERT vocabulary.
We talk about Pooling Layer in [here](https://github.com/huggingface/transformers/blob/master/src/transformers/models/bert/modeling_bert.py#L609).
<|||||>Oh okay, I see. Only the weight matrix and the bias vector of that feed forward operation on the [CLS] vector are randomly initalized, not the [CLS] vector itself. I misunderstood a comment in another forum. Thanks for clarification @wlhgtc!<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,792 | closed | [finetune_trainer] --evaluate_during_training is no more | In `examples/seq2seq/builtin_trainer/` all scripts reference `--evaluate_during_training ` but it doesn't exist in pt trainer, but does exist in tf trainer:
```
grep -Ir evaluate_during
builtin_trainer/finetune.sh: --do_train --do_eval --do_predict --evaluate_during_training \
builtin_trainer/train_distil_marian_enro.sh: --do_train --do_eval --do_predict --evaluate_during_training\
builtin_trainer/finetune_tpu.sh: --do_train --do_eval --evaluate_during_training \
builtin_trainer/train_distilbart_cnn.sh: --do_train --do_eval --do_predict --evaluate_during_training \
builtin_trainer/train_distil_marian_enro_tpu.sh: --do_train --do_eval --evaluate_during_training \
builtin_trainer/train_mbart_cc25_enro.sh: --do_train --do_eval --do_predict --evaluate_during_training \
```
```
Traceback (most recent call last):
File "finetune_trainer.py", line 310, in <module>
main()
File "finetune_trainer.py", line 118, in main
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/transformers/hf_argparser.py", line 144, in parse_args_into_dataclasses
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--evaluate_during_training']
```
Is this meant to be replaced by: `--evaluation_strategy` - this is the closest I found in `training_args.py`
If so which one? `steps` or `epoch`?
Also the help output is borked:
```
$ python finetune_trainer.py -h
...
[--evaluation_strategy {EvaluationStrategy.NO,EvaluationStrategy.STEPS,EvaluationStrategy.EPOCH}]
```
probably this is not what what's intended, but
```
[--evaluation_strategy {no, steps, epochs}
```
But perhaps it's a bigger issue - I see `trainer.args.evaluate_during_training`:
```
src/transformers/integrations.py: ) and (not trainer.args.do_eval or not trainer.args.evaluate_during_training):
```
and also `--evaluate_during_training` in many other files under `examples/`.
Thank you.
@sgugger, @patrickvonplaten
| 11-26-2020 06:37:54 | 11-26-2020 06:37:54 | Found the source of breakage: https://github.com/huggingface/transformers/pull/8604 - I guess that PR needs more work |
transformers | 8,791 | closed | [FlaxBert] Fix non-broadcastable attention mask for batched forward-passes | # What does this PR do?
Fixes #8790
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@mfuntowicz
@avital
@LysandreJik
| 11-26-2020 06:10:31 | 11-26-2020 06:10:31 | @mfuntowicz @avital
I just fixed the bug that I was hitting. There might be other places that need this fix as well.<|||||>Wuuhu - first Flax PR :-). This looks great to me @KristianHolsheimer - think you touched all necessary files as well!
@mfuntowicz - maybe you can take a look as well<|||||>**EDIT** I re-enabled GPU memory preallocation but set the mem fraction < 1/parallelism. That seemed to fix the tests. The problem with this is that future tests might fail if a model doesn't fit in 1/8th of the GPU memory.
---
The flax tests time out. When I ran the tests locally with `pytest -n auto`, I did notice OOM issues due to preallocation of GPU memory by XLA. I addressed this in commit 6bb1f5e600cd35c712f4f980699df7735b4f59eb.
Other than that, it's hard to debug the tests when there's no output.
Would it be an option to run these tests single-threaded instead?<|||||>I had the changes in another branche I'm working on, happy to merge this one and will rebase mine 👍.
Thanks for looking at it @KristianHolsheimer |
transformers | 8,790 | closed | [FlaxBert] Non-broadcastable attention mask in batched forward-pass | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: Linux
- Python version: 3.8
- JAX version:
- jax==0.2.6
- jaxlib==0.1.57+cuda110
- flax==0.2.2
- PyTorch version (GPU?): n/a
- Tensorflow version (GPU?): n/a
- Using GPU in script?: **yes** (cuda 11.0)
- Using distributed or parallel set-up in script?: **no**
### Who can help
@mfuntowicz
@avital
@LysandreJik
## Information
I ran the script from the recent Twitter [post](https://twitter.com/huggingface/status/1331255460033400834):
The only thing I changed was that I fed in multiple sentences:
```python
from transformers import FlaxBertModel, BertTokenizerFast, TensorType
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
model = FlaxBertModel.from_pretrained('bert-base-cased')
# apply_fn = jax.jit(model.model.apply)
sentences = ["this is an example sentence", "this is another", "and a third one"]
encodings = tokenizer(sentences, return_tensors=TensorType.JAX, padding=True, truncation=True)
tokens, pooled = model(**encodings)
```
> ValueError: Incompatible shapes for broadcasting: ((3, 12, 7, 7), (1, 1, 3, 7))
See full stack trace: https://pastebin.com/sPUSjGVi
| 11-26-2020 06:09:09 | 11-26-2020 06:09:09 | |
transformers | 8,789 | closed | KeyError: 'eval_loss' when fine-tuning gpt-2 with run_clm.py | ## Environment info
- `transformers` version: 4.0.0-rc-1
- Platform: Linux-4.19.0-12-amd64-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): 2.2.0 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: default option
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
Trainer: @sgugger
## Information
Model I am using (Bert, XLNet ...): GPT2
The problem arises when using:
* [x] the official example scripts: (give details below)
Bug occurs when running run_clm.py file from transformers/examples/language-modeling/ , the evaluation step (--do_eval) will crash with a python error related to missing KeyError 'eval_loss',
## To reproduce
Steps to reproduce the behavior:
1. Use run_clm.py file from transformers/examples/language-modeling/
2. Try to fine-tune gpt-2 model, with your own train file and your own validation file
3. When you add "--do_eval" option in run_clm.py then an error will occur when the step "evaluation" is reached :
```
File "run_clm.py", line 353, in <module>
main()
File "run_clm.py", line 333, in main
perplexity = math.exp(eval_output["eval_loss"])
KeyError: 'eval_loss'
```
when I try to print the content of eval_output then there is just one key : "epoch"
the way I execute run_clm.py :
```
python run_clm.py \
--model_name_or_path gpt2 \
--train_file train.txt \
--validation_file dev.txt \
--do_train \
--do_eval \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--output_dir results/test-clm
```
## Expected behavior
The evaluation step should run without problems. | 11-26-2020 04:15:56 | 11-26-2020 04:15:56 | This is weird, as the script is tested for evaluation. What does your `dev.txt` file look like?<|||||>Dev.txt contains text in english, one sentence by line.
The PC I use has 2 graphic cards, so run_clm.py uses the 2 cards for the training, perhaps the bug occurs only when 2 or more graphic card are used for the training ?<|||||>The script is tested on 2 GPUs as well as one. Are you sure this file contains enough text to have a least one batch during evaluation? This is the only thing I can think of for not having an eval_loss returned.<|||||>The dev.txt file contains 46 lines, the train file contains 268263 lines.
the specifications of the PC I use :
- Intel Xeon E5-2650 v4 (Broadwell, 2.20GHz)
- 128 Gb ram
- 2 x Nvidia GeForce GTX 1080 Ti
<|||||>Like I said, the dev file is maybe too short to provide at least one batch and return a loss. You should try with a longer dev file.<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,788 | closed | Add QCRI Arabic and Dialectal BERT (QARiB) models | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-25-2020 20:51:34 | 11-25-2020 20:51:34 | Thanks for sharing; your filenames are wrong, they should be nested inside folders named from your model id<|||||>> Thanks for sharing; your filenames are wrong, they should be nested inside folders named from your model id
Thanks Julien, I have updated the branch accordingly.<|||||>closing in favor of #8796 |
transformers | 8,787 | closed | QA pipeline fails during convert_squad_examples_to_features | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.0.0-rc-1
- Platform: Linux-3.10.0-1062.9.1.el7.x86_64-x86_64-with-redhat-7.8-Maipo
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.0 (True)
- Tensorflow version (GPU?): 2.3.1 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help
@LysandreJik @mfuntowicz
IDK who else can help, but in sort, I am looking for someone who can help me in QA tasks.
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
Blenderbot: @patrickvonplaten
Bart: @patrickvonplaten
Marian: @patrickvonplaten
Pegasus: @patrickvonplaten
mBART: @patrickvonplaten
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSMT: @stas00
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: run_squad.py (modifying to run using jupyter notebook, using "HfArgumentParser")
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: SQUaD
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. modified all argparse to HfArgumentParser
2. created "ModelArguments" dataclass function for HfArgumentParser (Ref: https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb)
3. need to small changes in the whole script.
The test fails with error `TypeError: TextInputSequence must be str`
Complete failure result:
```
RemoteTraceback Traceback (most recent call last)
RemoteTraceback:
"""
Traceback (most recent call last):
File "/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/multiprocessing/pool.py", line 121, in worker
result = (True, func(*args, **kwds))
File "/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/multiprocessing/pool.py", line 44, in mapstar
return list(map(*args))
File "/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/site-packages/transformers/data/processors/squad.py", line 175, in squad_convert_example_to_features
return_token_type_ids=True,
File "/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 2439, in encode_plus
**kwargs,
File "/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/site-packages/transformers/tokenization_utils_fast.py", line 463, in _encode_plus
**kwargs,
File "/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/site-packages/transformers/tokenization_utils_fast.py", line 378, in _batch_encode_plus
is_pretokenized=is_split_into_words,
TypeError: TextInputSequence must be str
"""
The above exception was the direct cause of the following exception:
TypeError Traceback (most recent call last)
<ipython-input-19-263240bbee7e> in <module>
----> 1 main()
<ipython-input-18-61d7f0eab618> in main()
111 # Training
112 if train_args.do_train:
--> 113 train_dataset = load_and_cache_examples((model_args, train_args), tokenizer, evaluate=False, output_examples=False)
114 global_step, tr_loss = train(args, train_dataset, model, tokenizer)
115 logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
<ipython-input-8-79eb3ed364c2> in load_and_cache_examples(args, tokenizer, evaluate, output_examples)
54 max_query_length=model_args.max_query_length,
55 is_training=not evaluate,
---> 56 return_dataset="pt",
57 # threads=model_args.threads,
58 )
/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/site-packages/transformers/data/processors/squad.py in squad_convert_examples_to_features(examples, tokenizer, max_seq_length, doc_stride, max_query_length, is_training, padding_strategy, return_dataset, threads, tqdm_enabled)
366 total=len(examples),
367 desc="convert squad examples to features",
--> 368 disable=not tqdm_enabled,
369 )
370 )
/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/site-packages/tqdm/std.py in __iter__(self)
1131
1132 try:
-> 1133 for obj in iterable:
1134 yield obj
1135 # Update and possibly print the progressbar.
/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/multiprocessing/pool.py in <genexpr>(.0)
323 result._set_length
324 ))
--> 325 return (item for chunk in result for item in chunk)
326
327 def imap_unordered(self, func, iterable, chunksize=1):
/data/user/tr27p/.conda/envs/DeepBioComp/lib/python3.7/multiprocessing/pool.py in next(self, timeout)
746 if success:
747 return value
--> 748 raise value
749
750 __next__ = next # XXX
TypeError: TextInputSequence must be str
```
## Expected behavior
#### for more details check here:
link: https://github.com/uabinf/nlp-group-project-fall-2020-deepbiocomp/blob/cancer_ask/scripts/qa_script/qa_squad_v1.ipynb
<!-- A clear and concise description of what you would expect to happen. -->
| 11-25-2020 17:28:10 | 11-25-2020 17:28:10 | After updating the run_squad.py script with a newer version of transformers, it works now!
Thank you!<|||||>@TrupeshKumarPatel Seems that this is not working still. What was the actual solution to this?<|||||>Hi @aleSuglia,
here is the updated link: https://github.com/uabinf/nlp-group-project-fall-2020-deepbiocomp/blob/main/scripts/qa_script/qa_squad_v1.ipynb , see if this help. If not then please elaborate on the error or problem that you are facing. <|||||>I have exactly the same error that you reported: `TypeError: TextInputSequence must be str`
By debugging, I can see that the variable `truncated_query` has a list of integers (which should be the current question's token ids). However, when you pass that to the [encode_plus](https://github.com/huggingface/transformers/blob/df2af6d8b8765b1ac2cda12d2ece09bf7240fba8/src/transformers/data/processors/squad.py#L181) method, you get the error. I guess it's because `encode_plus` expects strings and not integers. Do you have any suggestion?<|||||>If you googled this error and you are reading this post, please do the following. When you create your tokenizer make sure that you set the flag `use_fast` to `False` like this:
```python
AutoTokenizer.from_pretrained(tokenizer_name, use_fast=False)
```
This fixes the error. However, I wonder why there is no backward compatibility...<|||||>Had the similar issue with the above. What @aleSuglia suggested indeed works, but the issue still persists; fast version of the tokenizer should be compatible with the previous methods. In my case, I narrowed the problem down to `InputExample`, where `text_b` can be `None`, https://github.com/huggingface/transformers/blob/447808c85f0e6d6b0aeeb07214942bf1e578f9d2/src/transformers/data/processors/utils.py#L47-L48
but the tokenizer apparently doesn't accept `None` as an input. So, I found a workaround by changing
```
InputExample(guid=some_id, text_a=some_text, label=some_label)
-> InputExample(guid=some_id, text_a=some_text, text_b='', label=some_label)
```
I'm not sure this completely solves the issue though.<|||||>Potentially related issues: https://github.com/huggingface/transformers/issues/6545 https://github.com/huggingface/transformers/issues/7735 https://github.com/huggingface/transformers/issues/7011 |
transformers | 8,786 | closed | What would be the license of the model files available in Hugging face repository? | Dear Team,
Could you clarify what would be the license for different models pushed to hugging face repo like legal_bert, contracts_bert etc? Would the model file follows the same license i.e. Apache 2.0 like the hugging face library?
Regards
Gaurav | 11-25-2020 16:52:40 | 11-25-2020 16:52:40 | Maybe @julien-c can answer!<|||||>You can check on the model hub:
eg. apache-2.0 models: https://huggingface.co/models?filter=license:apache-2.0
mit models: https://huggingface.co/models?filter=license:mit
etc.<|||||>Thanks @julien-c for the update. |
transformers | 8,785 | closed | Update README.md | Disable Hosted Inference API while output inconsistency is not solved.
"How to use" section.
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-25-2020 16:51:51 | 11-25-2020 16:51:51 | Decided to delete "inference: false" |
transformers | 8,784 | closed | Different ouputs from code and Hosted Inference API | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.5.1
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
## To reproduce
Steps to reproduce the behavior:
1. Run the following code:
```python
from transformers import BertForTokenClassification, DistilBertTokenizerFast, pipeline
model = BertForTokenClassification.from_pretrained('monilouise/ner_pt_br')
tokenizer = DistilBertTokenizerFast.from_pretrained('neuralmind/bert-base-portuguese-cased', model_max_length=512, do_lower_case=False)
nlp = pipeline('ner', model=model, tokenizer=tokenizer)
result = nlp("O Tribunal de Contas da União é localizado em Brasília e foi fundado por Rui Barbosa. Fiscaliza contratos, por exemplo com empresas como a Veigamed e a Buyerbr.")
print(result)
````
It'll ouput:
[{'word': 'Tribunal', 'score': 0.9858521819114685, 'entity': 'B-PUB', 'index': 2}, {'word': 'de', 'score': 0.9954801201820374, 'entity': 'I-PUB', 'index': 3}, {'word': 'Contas', 'score': 0.9929609298706055, 'entity': 'I-PUB', 'index': 4}, {'word': 'da', 'score': 0.9949454665184021, 'entity': 'I-PUB', 'index': 5}, {'word': 'União', 'score': 0.9913719296455383, 'entity': 'L-PUB', 'index': 6}, {'word': 'Brasília', 'score': 0.9405767321586609, 'entity': 'B-LOC', 'index': 10}, {'word': 'Rui', 'score': 0.979736328125, 'entity': 'B-PESSOA', 'index': 15}, {'word': 'Barbosa', 'score': 0.988306999206543, 'entity': 'L-PESSOA', 'index': 16}, {'word': 'Veiga', 'score': 0.9748793244361877, 'entity': 'B-ORG', 'index': 29}, {'word': '##med', 'score': 0.9309309124946594, 'entity': 'L-ORG', 'index': 30}, {'word': 'Bu', 'score': 0.9679405689239502, 'entity': 'B-ORG', 'index': 33}, {'word': '##yer', 'score': 0.6654638051986694, 'entity': 'L-ORG', 'index': 34}, {'word': '##br', 'score': 0.9575732350349426, 'entity': 'L-ORG', 'index': 35}]
including all entity types (PUB, PESSOA, ORG and LOC)
2. In Hosted Inference API, the following result is returned for the same sentence, ignoring PUB entity type and giving incorrect and incomplete results:
```json
[
{
"entity_group": "LOC",
"score": 0.8127626776695251,
"word": "bras"
},
{
"entity_group": "PESSOA",
"score": 0.7101765692234039,
"word": "rui barbosa"
},
{
"entity_group": "ORG",
"score": 0.7679458856582642,
"word": "ve"
},
{
"entity_group": "ORG",
"score": 0.45047426223754883,
"word": "##igamed"
},
{
"entity_group": "ORG",
"score": 0.8467527627944946,
"word": "bu"
},
{
"entity_group": "ORG",
"score": 0.6024420410394669,
"word": "##yerbr"
}
]
```
## Expected behavior
How can it be possible the same model file give different results?(!) May I be missing anything?
| 11-25-2020 16:29:44 | 11-25-2020 16:29:44 | Hi @moniquebm .
The hosted inference is running `nlp = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)` by default.
There is currently no way to overload it.
Does that explain the difference? <|||||>Hi @Narsil
>Does that explain the difference?
I'm afraid it doesn't explain... I've just tested nlp = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True) and the following (correct) result is generated programmatically:
[{'entity_group': 'PUB', 'score': 0.9921221256256103, 'word': 'Tribunal de Contas da União'}, {'entity_group': 'LOC', 'score': 0.9405767321586609, 'word': 'Brasília'}, {'entity_group': 'PESSOA', 'score': 0.9840216636657715, 'word': 'Rui Barbosa'}, {'entity_group': 'ORG', 'score': 0.9529051184654236, 'word': 'Veigamed'}, {'entity_group': 'ORG', 'score': 0.8636592030525208, 'word': 'Buyerbr'}]
But in fact it seems the API does not group entities:
```json
[
{
"entity_group": "LOC",
"score": 0.8127626776695251,
"word": "bras"
},
{
"entity_group": "PESSOA",
"score": 0.7101765692234039,
"word": "rui barbosa"
},
{
"entity_group": "ORG",
"score": 0.7679458856582642,
"word": "ve"
},
{
"entity_group": "ORG",
"score": 0.45047426223754883,
"word": "##igamed"
},
{
"entity_group": "ORG",
"score": 0.8467527627944946,
"word": "bu"
},
{
"entity_group": "ORG",
"score": 0.6024420410394669,
"word": "##yerbr"
}
]
```
The tokens are also different. One possible explaination is that the Hosted Inference API may be using English tokenizer, but my model/code used Portuguese tokenizer from this model: https://huggingface.co/neuralmind/bert-base-portuguese-cased
Does it make sense?<|||||>You need to update your tokenizer on your model in the hub: 'monilouise/ner_pt_br' to reflect this. The hosted inference can't know how to use a different tokenizer than the one you provide.
If you are simply using the one from `neuralmind/bert-base-portuguese-case`, you probably just download theirs, and reupload it as your own following this doc: https://huggingface.co/transformers/model_sharing.html<|||||>May I suggest moving the discussion here:
https://discuss.huggingface.co/c/intermediate/6
As it's not really and transformers problem but a Hub one.
I am closing the issue here. Feel free to comment here to show the new location of the discussion or ping me directly on discuss.
|
transformers | 8,783 | closed | MPNet: Masked and Permuted Pre-training for Natural Language Understanding | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-25-2020 16:28:09 | 11-25-2020 16:28:09 | |
transformers | 8,782 | closed | Unexpected output from bart-large | I am looking this thread about generation, https://stackoverflow.com/questions/64904840/why-we-need-a-decoder-start-token-id-during-generation-in-huggingface-bart
I re-run his code,
Use ```facebook/bart-base``` model,
```
from transformers import *
import torch
model = BartForConditionalGeneration.from_pretrained('facebook/bart-base')
tokenizer = BartTokenizer.from_pretrained('facebook/bart-base')
input_ids = torch.LongTensor([[0, 894, 213, 7, 334, 479, 2]])
res = model.generate(input_ids, num_beams=1, max_length=100)
print(res)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True).strip() for g in res]
print(preds)
```
I get output:
```
tensor([[ 2, 0, 894, 213, 7, 334, 479, 2]])
['He go to school.']
```
Then I just simply change the model to ```facebook/bart-large``` with everything kept the same, i.e.
```
from transformers import *
import torch
model = BartForConditionalGeneration.from_pretrained('facebook/bart-large')
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large')
input_ids = torch.LongTensor([[0, 894, 213, 7, 334, 479, 2]])
res = model.generate(input_ids, num_beams=1, max_length=100)
print(res)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True).strip() for g in res]
print(preds)
```
Then I get output:
```
tensor([[ 2, 894, 894, 213, 7, 334, 479, 2]])
['HeHe go to school.']
```
Is this normal?
Thanks.
| 11-25-2020 16:24:47 | 11-25-2020 16:24:47 | @jc-hou: I just tested the above script and I get the same output as you. Why did you close the issue?<|||||>`res = model.generate(input_ids, num_beams=1, max_length=100, forced_bos_token_id=0)` solves the issue |
transformers | 8,781 | closed | NerPipeline (TokenClassification) now outputs offsets of words | # What does this PR do?
- It happens that the offsets are missing, it forces the user to pattern
match the "word" from his input, which is not always feasible.
For instance if a sentence contains the same word twice, then there
is no way to know which is which.
- This PR proposes to fix that by outputting 2 new keys for this
pipelines outputs, "start" and "end", which correspond to the string
offsets of the word. That means that we should always have the
invariant:
```python
input[entity["start"]: entity["end"]] == entity["entity_group"]
# or entity["entity"] if not grouped
```
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Example of users that encounter problems:
https://huggingface.co/dslim/bert-base-NER?text=Hello+Sarah+Jessica+Parker+who+Jessica+lives+in+New+York
https://discuss.huggingface.co/t/token-positions-when-using-the-inference-api/2188
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
--> | 11-25-2020 15:18:54 | 11-25-2020 15:18:54 | |
transformers | 8,780 | closed | Can't load tokenizer for 'facebook/rag-token-base/question_encoder_tokenizer'. | Hi all! I'm getting this error when trying to run the example code:
Can't load tokenizer for 'facebook/rag-token-base/question_encoder_tokenizer'. Make sure that:
- 'facebook/rag-token-base/question_encoder_tokenizer' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'facebook/rag-token-base/question_encoder_tokenizer' is the correct path to a directory containing relevant tokenizer files | 11-25-2020 14:05:35 | 11-25-2020 14:05:35 | Was fixed on master, could you try from master?
cc @lhoestq @patrickvonplaten <|||||>Thanks @julien-c ! It worked using master. But I had this other issue:
`Using custom data configuration dummy.psgs_w100.nq.no_index
Reusing dataset wiki_dpr (/Users/rcoutin/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.no_index-dummy=True,with_index=False/0.0.0/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2)
Using custom data configuration dummy.psgs_w100.nq.exact
Reusing dataset wiki_dpr (/Users/rcoutin/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.exact-80150455dfcf97d4/0.0.0/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2)
Traceback (most recent call last):
File "/Users/rcoutin/git/examples/backup/rag.py", line 5, in <module>
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
File "/Users/rcoutin/git/transformers/src/transformers/modeling_utils.py", line 947, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
File "/Users/rcoutin/git/transformers/src/transformers/models/rag/modeling_rag.py", line 1009, in __init__
self.rag = RagModel(config=config, question_encoder=question_encoder, generator=generator, retriever=retriever)
File "/Users/rcoutin/git/transformers/src/transformers/models/rag/modeling_rag.py", line 487, in __init__
question_encoder = AutoModel.from_config(config.question_encoder)
File "/Users/rcoutin/git/transformers/src/transformers/models/auto/modeling_auto.py", line 615, in from_config
return MODEL_MAPPING[type(config)](config)
File "/Users/rcoutin/git/transformers/src/transformers/models/dpr/modeling_dpr.py", line 514, in __init__
self.question_encoder = DPREncoder(config)
File "/Users/rcoutin/git/transformers/src/transformers/models/dpr/modeling_dpr.py", line 155, in __init__
self.bert_model = BertModel(config)
File "/Users/rcoutin/git/transformers/src/transformers/models/bert/modeling_bert.py", line 764, in __init__
self.embeddings = BertEmbeddings(config)
File "/Users/rcoutin/git/transformers/src/transformers/models/bert/modeling_bert.py", line 181, in __init__
self.position_embedding_type = config.position_embedding_type
AttributeError: 'DPRConfig' object has no attribute 'position_embedding_type'`<|||||>Not sure about this one, sorry :/ Calling the RAG gurus!<|||||>Thanks man. I’ll try debug little more my env. Thanks!
Em qua, 25 de nov de 2020 às 20:22, Julien Chaumond <
[email protected]> escreveu:
> Not sure about this one, sorry :/ Calling the RAG gurus!
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/8780#issuecomment-733988235>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/ABBZZ6SQTOLH4JHX3MVUUTTSRWGT7ANCNFSM4UCODMUA>
> .
>
<|||||>Looks like the issue comes from the changes of #8276
cc @patrickvonplaten @LysandreJik @zhiheng-huang<|||||>Thanks a lot for spotting the bug @racoutinho and pinpointing it @lhoestq. The PR should fix it<|||||>I love how well maintained this repo is ❤️
Just ran into this issue yesterday, and was very surprised to see it fixed just 1 day later 👍 <|||||>Thank you, guys!!!! You are rock stars!!!! |
transformers | 8,779 | closed | Fix PPLM | # What does this PR do?
API changes break PPLM example, this PR should fix it. However I haven't test it on 'run_pplm_discrim_train.py'.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-25-2020 13:35:56 | 11-25-2020 13:35:56 | PPLM is unfortunately not maintained anymore. The fix would be to pin the `transformers` version in the PPLM README.<|||||>pinging @w4nderlust and @mimosavvy just in case<|||||>This looks good to me, I believe the return of dict (very welcome change by the way) from the model should be the only thing breaking the pplm code, right?<|||||>> This looks good to me, I believe the return of dict (very welcome change by the way) from the model should be the only thing breaking the pplm code, right?
Yeah and the named argument of model `past_key_values`. I have no issue running the provided example command in [here]( https://github.com/huggingface/transformers/tree/master/examples/text-generation/pplm) and `python run_pplm_discrim_train.py --dataset SST --epochs 1 --batch_size 8`.<|||||>Can you run `make style` to fix the code quality check? Then we should be good for merge :-) <|||||>Much appreciated! |
transformers | 8,778 | closed | Using the XLNet or Tranformer-XL as an EncoderDecoder | I want to train a long sequence dataset (MIDI text event representation like the one in [MuseNet](https://openai.com/blog/musenet/#dataset)) from scratch. Since, I can't split the sequence to "sentences" I am using XLNet (or Transformer-XL). I am modelling the task as a sequence2sequence task (with max input seq length of around 40k tokens and output length of 4k tokens) so I want to use an Encoder Decoder Framework.
Is it possible to use XLNet as the encoder and decoder, or just the encoder and use GPT-2 for example to do the decoding (because of the smaller output sequence length).
Thank you 🤗 | 11-25-2020 13:17:06 | 11-25-2020 13:17:06 | @patrickvonplaten any thoughts on this? Since, I found your work on Bert2Bert very informative :)<|||||>Hey @gulnazaki - you can use XLNet as an encoder, but not as a decoder because it'll be very difficult to add cross-attention functionality to XLNet for the decoder...<|||||>Thanks @patrickvonplaten , I thought so.
Also, the concept of XLNet is kinda the opposite of uni-directional.
I will try to increase the sequence length of GPT2 for the output sequence.<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,777 | closed | Better booleans handling in the TF models | # What does this PR do?
This PR provides a better handling for the booleans. More precisely, the execution mode (eager or graph) is detected and the booleans are accordingly set to have a proper execution. Nevertheless, this brings a small breaking change in graph mode, it is not possible anymore to update the booleans with the model parameters but only with through the config and the `return_dict` is forced to be `True`.
Now to activate the `output_attentions` or `output_hidden_states` values in graph mode one has to create the model config like:
```
config = XConfig.from_pretrained("name", output_attentions=True, output_hidden_states=True)
```
| 11-25-2020 12:01:38 | 11-25-2020 12:01:38 | Thanks @patrickvonplaten!
As detailed in the first post, boolean parameters cannot be set during the model call in graph mode. This is the major feature brought by this PR. I wanted to focus of TF T5 and TF Bart on a later PR once this logic is ok at least for all the others.<|||||>There is now a better warning message.<|||||>> You say there is a breaking change in graph mode. Does it mean that currently, both eager & graph mode can handle arguments through the configuration & through the function call? I'm unsure on where we stand on this currently.
Yes, both can be done, but it raises issues when through the function call in graph mode. So this PR fixes this with a better handling of this case.
> It seems like the tests that would be impacted by these changes are the slow tests. Have you run the slow tests? If not, could you run the slow tensorflow tests on this PR? If you don't know how to do that, happy to show you how for next time.
This PR partially fixes these tests. Remembert that they do not pass for T5 and BART for the reasons expressed by Patrick. These models, including the saved model tests, will be fixed in same time in a PR just after this one.
Also, in a future PR I will rethink the way the attributes are handled in all the layers.<|||||>> Yes, both can be done, but it raises issues when through the function call in graph mode. So this PR fixes this with a better handling of this case.
So right now it fails, and with this PR it also fails but with better error handling?
> This PR partially fixes these tests. Remembert that they do not pass for T5 and BART for the reasons expressed by Patrick. These models, including the saved model tests, will be fixed in same time in a PR just after this one.
I meant *all* the slow tests, not only the saved models with saved attentions tests. And this PR doesn't only impact the T5 and BART models, so re-running all the slow tests on this PR seems necessary.<|||||>> So right now it fails, and with this PR it also fails but with better error handling?
No, before nothing was working in graph mode when the boolean was updated through the function call. Now, I disabled this functionality and there is no more fail, and everything works properly and as expected in eager+graph mode except T5 and BART in graph mode, which will be handled in a later PR.
> I meant all the slow tests, not only the saved models with saved attentions tests. And this PR doesn't only impact the T5 and BART models, so re-running all the slow tests on this PR seems necessary.
Ok, I will run all of them.<|||||>@LysandreJik All the slow tests are passing but two:
- `tests/test_modeling_tf_transfo_xl.py::TFTransfoXLModelLanguageGenerationTest::test_lm_generate_transfo_xl_wt103`, I started to see that with @patrickvonplaten
- `tests/test_utils_check_copies.py::CopyCheckTester::test_is_copy_consistent`, @sgugger any idea why this test don't pass anymore? Here the output:
```
def test_is_copy_consistent(self):
# Base copy consistency
> self.check_copy_consistency(
"# Copied from transformers.models.bert.modeling_bert.BertLMPredictionHead",
"BertLMPredictionHead",
REFERENCE_CODE + "\n",
)
tests\test_utils_check_copies.py:71:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests\test_utils_check_copies.py:59: in check_copy_consistency
self.assertTrue(len(check_copies.is_copy_consistent(fname)) == 0)
E AssertionError: False is not true
```<|||||>@LysandreJik Any other needs for this PR to be merged?<|||||>I investigated why the `test_is_copy_consistent` test failed, that is probably because you launched your command from inside the `tests/` directory, and it has a path hardcoded to `src/transformers`, and therefore cannot find the path `tests/src/transformers`.
No issues there it seems! Reviewing a final time and merging if all is good.<|||||>@patrickvonplaten you haven't approved this PR, do you want to give it a final look and merge if ok for you?<|||||>> @LysandreJik All the slow tests are passing but two:
>
> * `tests/test_modeling_tf_transfo_xl.py::TFTransfoXLModelLanguageGenerationTest::test_lm_generate_transfo_xl_wt103`, I started to see that with @patrickvonplaten
> * `tests/test_utils_check_copies.py::CopyCheckTester::test_is_copy_consistent`, @sgugger any idea why this test don't pass anymore? Here the output:
>
> ```
> def test_is_copy_consistent(self):
> # Base copy consistency
> > self.check_copy_consistency(
> "# Copied from transformers.models.bert.modeling_bert.BertLMPredictionHead",
> "BertLMPredictionHead",
> REFERENCE_CODE + "\n",
> )
>
> tests\test_utils_check_copies.py:71:
> _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
> tests\test_utils_check_copies.py:59: in check_copy_consistency
> self.assertTrue(len(check_copies.is_copy_consistent(fname)) == 0)
> E AssertionError: False is not true
> ```
I'll investigate for `tests/test_modeling_tf_transfo_xl.py::TFTransfoXLModelLanguageGenerationTest::test_lm_generate_transfo_xl_wt103` -> thanks for pinging me on that! PR is good for me! |
transformers | 8,776 | closed | Documentation and source for `RobertaClassificationHead` | The docstring for `RobertaForSequenceClassification` says
```
RoBERTa Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled output) e.g. for GLUE tasks
```
Looking at the code, this does not seem correct. Here, the RoBERTa output is fed into an instance of the class `RobertaClassificationHead`, which feeds the pooled output into a multilayer feedforward-network with one hidden layer and tanh activation. So this is more than only a simple linear layer.
I have two questions:
1. Should the documentation reflect this different classification head for RoBERTa?
2. Where does this classification head originally come from? I could not find a citable source where such a "deep" classification head is used. The original RoBERTa paper only seems to state that their task-specific fine-tuning procedure is the same as BERT uses (which is only a linear layer).
I would be glad if someone could shed light on this. | 11-25-2020 06:47:03 | 11-25-2020 06:47:03 | > which feeds the pooled output into a multilayer feedforward-network with one hidden layer and tanh activation. So this is more than only a simple linear layer.
Actually, the final hidden representation of the `[CLS]` token (or `<s>` token in case of RoBERTa) is not the pooled output. Applying the feedforward neural network with tanh activation on this hidden representation actually gives you the pooled output (which is a vector of size 768 in case of the base sized model). Then, after this, a linear layer called [`out_proj`](https://github.com/huggingface/transformers/blob/90d5ab3bfe8c20d9beccfe89fdfd62a8e5ac31e5/src/transformers/models/roberta/modeling_roberta.py#L1248) is used to project the pooled output of size 768 into a vector of size `num_labels`. So the documentation is still correct.
For the second question, actually BERT does the same, it is just implemented differently. In `modeling_bert.py`, they use the `pooled_output` of `BertModel`, and then apply the linear layer on top of this. This pooled output has already applied the feedforward neural network + tanh activation on top of the `[CLS]` token hidden representation, as you can see [here](https://github.com/huggingface/transformers/blob/90d5ab3bfe8c20d9beccfe89fdfd62a8e5ac31e5/examples/movement-pruning/emmental/modeling_bert_masked.py#L371). In `modeling_roberta.py`, they implement it differently: they start from the `sequence_output` (which is a tensor containing the final hidden representations of all tokens in the sequence), then get the hidden repr of the `<s>` token by typing `[:,0,:]`, then apply the feedforward nn + tanh and finally the linear projection layer.
So your confusion probably comes from the different ways in which this is implemented in BERT vs RoBERTa, and the meaning of `pooled_output`. Actually, some people use "pooled output" to denote the final hidden representation of the [CLS] token, but in HuggingFace transformers, this always refers to the output of a linear layer + tanh on top of this vector. <|||||>Thank you very much for the explanation @NielsRogge !
My confusion indeed comes from the different implementations and the meaning of "pooled output".
So this makes it consistent for the HuggingFace transformers library. But do you know the origin of it (now I am interested for both models)? Why is the `[CLS]` token representation transformed by a linear layer with tanh? I couldn't find any reference to tanh in the [original BERT paper](https://www.aclweb.org/anthology/N19-1423/). What they describe in section 4.1, e.g., sounds to me like there is only one linear layer on top of the [CLS] token representation. Is this a HuggingFace invention then? They don't seem to mention it in [their arXiv paper](https://arxiv.org/abs/1910.03771) either.<|||||>Interesting question! Turns out this has [already been asked before here](https://github.com/huggingface/transformers/issues/782) and the answer by the author is [here](https://github.com/google-research/bert/issues/43#issuecomment-435980269).<|||||>Thank you again @NielsRogge !
I had only searched for issues with RoBERTa. Now it makes sense! |
transformers | 8,775 | open | Converting all model Config classes to dataclasses | It seems that we could save a lot of boilerplate code and potentially prevent some bugs if we migrated all of the model config classes over to being dataclasses. Already many of our classes (BaseModelOutput, TrainingArguments, etc.) are dataclasses, so we are already committed to having dataclasses as a dependency.
It's relatively low priority, but I would be willing to help implement the change since I'm kind of a neat freak about code. | 11-25-2020 04:34:33 | 11-25-2020 04:34:33 | I think it would be nice indeed.
It's been on the TO-DO list for a long time (cc @julien-c) but I think nobody's reached it yet so feel free to tackle it :)
Full (and tested) backward compatibility will be paramount though<|||||>@thomwolf Thanks for responding— I can start working on this once I get done with my current project, which is adding support for Performer-style attention ([see issue here](https://github.com/huggingface/transformers/issues/7675)).<|||||>Seems like this issue is a bit stale but I could use it as a first issue to start contributing. Mind if I take this?<|||||>What do you think @sgugger @patrickvonplaten?<|||||>Not sure it's worth the time: what exactly would we gain from it apart avoiding storing all args from the init? Since we would need to convert all configurations together (for inheritance you need to go from dataclasses to dataclasses) this is work that can't be split across several PRs and needs to happen all at once.
I also had trouble several times in `TrainingArguments` where the fact it's a dataclass made things harder than they should be, so we may very well lost some of the features of configs (settings params with harmonized names for instance).<|||||>> Not sure it's worth the time: what exactly would we gain from it apart avoiding storing all args from the init? Since we would need to convert all configurations together (for inheritance you need to go from dataclasses to dataclasses) this is work that can't be split across several PRs and needs to happen all at once.
>
> I also had trouble several times in `TrainingArguments` where the fact it's a dataclass made things harder than they should be, so we may very well lost some of the features of configs (settings params with harmonized names for instance).
I think this is a bit easier than you thought because `class` can inherit from `dataclass` and vice versa. We don't have to have a gigantic PR that changes 150+ files. We can change `PretrainedConfig` into `dataclass` first and do the rest in separate PRs in a backward compatible fashion. See the example blow:
```
@dataclass
class PretrainedConfig:
x: int = 10
y: int = 15
def __post_init__(self):
# for the logic that wouldn't fit in the data class constructor, we can add it here
self.z = self.x+ self.y
@dataclass
class AlbertConfig(PretrainedConfig):
xy: int = 100
# this should be backward compatible
class BertConfig(PretrainedConfig):
def __init__(self, a, b, *args, **kwargs):
super().__init__(*args, **kwargs)
self.a = a
self.b = b
```
But I do agree that this is not the best ROI and quite a bit of trivial work just to shave off some boilerplate code.<|||||>In that case, okay for me if you want to try to convert `PretrainedConfig` first. If the tests don't pass and you struggle to fix them though, don't spend too much time on it and look for another way to contribute :-)<|||||>Hmm this is more complicated than I thought. `PretrainedConfig`, with all that logic in the constructor, properties and class methods, is too heavy of a class to be a textbook `dataclass`. You are right that I should look for something else :) |
transformers | 8,774 | closed | Big model table | # What does this PR do?
This PR adds a big table in the first page of the doc, indicating whether each of our models has support for a slow/fast tokenizer, PyTorch, TensorFlow and Flax. Result can be found [here](https://125258-155220641-gh.circle-artifacts.com/0/docs/_build/html/index.html) (scroll a bit down).
It is updated automatically via `make fix-copies` and checked for updates in `make quality`, being built form the content of the auto models module.
There were a few issues with the imports on the flax side that I fixed in passing, and I renamed a constant to add the `FLAX` prefix. @mfuntowicz this doesn't really change anything but pinging you just so you're aware. | 11-25-2020 01:23:24 | 11-25-2020 01:23:24 | |
transformers | 8,773 | closed | saving checkpoints on gs bucket | Hi
In case of running on cloud, the model does not work to save the checkpoints on gs bucket, could you help please?
thanks | 11-24-2020 21:49:52 | 11-24-2020 21:49:52 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,772 | closed | Possible to add additional features as input to TFBertForSequenceClassification? | Say I have a binary classification problem, but in addition to the sentence I'd like to also input some scalar value as well. Is it possible to just tack on this scalar as input to the last linear layer of BERT?
For example, I'd like to detect if a particular sentence is from my source data or generated. And I know that many instances of a repeated word increases the likelihood that it is a generated sentence. So I'd like to pass the sentence itself into BERT as well as a scalar feature such as the number of unique words in the sentence. | 11-24-2020 21:06:45 | 11-24-2020 21:06:45 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
Thanks! |
transformers | 8,771 | open | Model Parallelism and Big Models | # 🚀 Feature request
This is a discussion issue for training/fine-tuning very large transformer models. Recently, model parallelism was added for gpt2 and t5. The current implementation is for PyTorch only and requires manually modifying the model classes for each model. Possible routes (thanks to @stas00 for identifying these):
- `fairscale` to avoid individual model implementation
- `deepspeed` to possibly enable even larger models to be trained | 11-24-2020 20:29:42 | 11-24-2020 20:29:42 | Thank you, @alexorona!
I'm still in the process of gathering info/reading up and doing some small experimentation, so will post my thoughts once I have something concrete to share.
Here are some resources if someone wants to join in:
Abbreviations:
- MP = Model Parallelism
- DP = Data Parallelism
- PP = Pipeline Parallelism
Resources:
- Parallel and Distributed Training tutorials at pytorch - a handful, starting with https://pytorch.org/tutorials/beginner/dist_overview.html
- fairscale
* github https://github.com/facebookresearch/fairscale
* the MP part of fairscale is a fork of https://github.com/NVIDIA/Megatron-LM
- ZeRO and deepspeed:
* paper ZeRO: Memory Optimizations Toward Training Trillion Parameter Models https://arxiv.org/abs/1910.02054
* paper ZeRO-Offload: Democratizing Billion-Scale Model Training https://arxiv.org/abs/1910.02054
* detailed blog posts with diagrams:
- https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/
- https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
- https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
* github https://github.com/microsoft/DeepSpeed
* deepspeed examples git https://github.com/microsoft/DeepSpeedExamples
* deepspeed in PL https://github.com/PyTorchLightning/pytorch-lightning/issues/817
* deepspeed in PT https://github.com/pytorch/pytorch/issues/42849
* discussion of the paper with visuals https://www.youtube.com/watch?v=tC01FRB0M7w
- Pipeline Parallelism
* DeepSpeed https://www.deepspeed.ai/tutorials/pipeline/
* Fairscale https://fairscale.readthedocs.io/en/latest/api/nn/pipe.html
* GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism https://arxiv.org/abs/1811.06965
* PipeDream: Fast and Efficient Pipeline Parallel DNN Training https://arxiv.org/abs/1806.03377
<|||||>Update: so we have
* fairscale's sharded_ddp pretty much ready to go https://github.com/huggingface/transformers/pull/9208
* and deepspeed is nicely coming along https://github.com/huggingface/transformers/pull/9211
I don't have proper benchmarks yet, but I can definitely see 3-5 times less gpu ram usage! So these would be the first go-to solution when a model doesn't fit onto a single GPU.<|||||>OK, so studying @alexorona's t5 MP implementation I think we have a few issues related to how we spread out the models across different devices.
For the purpose of this discussion let's use a simplistic approach of having just 2 GPUs (g1 and g2)
@alexorona's current approach is to assume that encoder and decoder are of the same size and then split 1/2 encoder layers onto g1 and the other half onto g2. Repeat the same for decoder.
This approach has 3 issues:
1. it doesn't work if encoder and decoder aren't of the same size, which is the case with many models.
2. it introduces unnecessary copying of data from g1 to g2 in the middle of encoder and then again in the middle of decoder, rather than doing just one copy between end of encoder and beginning of decoder. 3 times vs 1 (in our simplistic 2-gpu example).
3. it leaves out all other layers from the device map and assigns them to the first or the last device in a hardcoded way depending to where they fit better, so the user has no control over where these go.
It does make the implementation relatively simple, since we just need to move half the layers of the encoder to g1 and the other half to g2 and bring the inputs/outputs to the right devices.
* Issue 1 can be fixed by providing 2 device maps - one for encoder and a different one for decoder. They would be the same if `len(encoder) == len(decoder)`. i.e. we are still using @alexorona, split-encoder and split-decoder approach.
* Issue 2 can be solved again by 2 separate device maps, but the first one will map encoder - the second decoder. So there will be no splitting of the layers of encoder or decoder between separate devices. I think I may try to use this solution for Bart.
```
encoder_device_map > {0 => [1...6]}
decoder_device_map=> {1 => [1..6]}
```
(note: I'm using a non-python notation of a range here)
It will be trickier to allow overlap if the number of layers is different between encoder and decoder - say 6:9 or 6:12 - In which case it might be:
```
encoder_device_map > {0 => [1...6]} # 6 layer encoder
decoder_device_map=> {0 => [1..2], 1=> [3..9]} # 9 layer decoder
```
So the model will need to be able to transparently handle switching layers and inputs/outputs not only through its encode/decoder layers but also from encoder to decoder - but it's quite doable.
This uneven situation would also be the case on some weird setups like mine where the gpus are of different sizes. On my setup I have one card of 8GB and another 24GB. This won't be an issue with @alexorona's current implementation.
* To solve Issue 3 would be much more complicated as then almost any main layer/param can be on any device. Not sure about this one. It'd be trivial if pytorch could automatically bring inputs to the device of the params. I sent out a feeler for such possibility here https://github.com/pytorch/pytorch/issues/49961
If any of you have had a chance to think about possible solutions and some totally different ways of approaching that please share your insights.<|||||>I was so full of hope that a simple dictionary could serve as a `device_map` for everything, but now you have shattered my blissful ignorance @stas00. But thanks so much for pointing this out! Super important! The characterization is not quite right and I think it's because you're using 2 GPUs, but the problem you identified is real. Basically both the decoder and encoder use the same map, so the first attention block of the decoder is located on the same device as the first attention block of the encoder. The performance degradation is trivial because the hand-off between GPUs when you have 8 or less is pretty efficient (when you have more, there's problems you have to work around by changing the NCCL environment variables). I thought about trying to do what you've suggested, but it meant that the `device_map` would have to get more complicated, which I was trying to avoid. However, if some of the decoder architectures have a different number of layers in the decoder than the encoder, the generalizability of the implementation will just collapse. Oh well. It was nice while it lasted.
It looks like you've really busy the last week. Responding to your comments and PRs...<|||||>Thank you for your follow up, @alexorona.
As you're saying that from your experience the copying overhead is negligible then your current solution would work perfectly fine in some situations, like the balanced t5, but will need to be altered in others. So very likely it's this and that, rather than not this but that. i.e. no shuttered hopes.
And if this doesn't fit in other situations it can be extended with a separate device_map for encoder and decoder. Perhaps for some models it'd be most efficient to keep the encoder on one set of devices and decoder on the other, and others shared. So that means we need to come with a way of accepting a variety of different device maps.
Perhaps, we make the device_map to have two parts, but the second part (decoder) to be optional and if not passed then the first one is used for both? Then the simple solution remains mainly unchanged.
May I ask if you have used some existing implementation to model your current implementation after, and perhaps you have a list of various MP implementations so that we could study and find the most suitable way that would fit. So far I have only studied the way you approached it.
Thank you.
p.s. here are some examples of models with different encoder/decoder sizes:
* https://huggingface.co/models?search=mbart_
* https://huggingface.co/models?search=allenai%2Fwmt<|||||>I have a few follow up questions, @alexorona
1. on use of `torch.cuda.empty_cache()` - I guess as long as it remains in `deparallelize` it is not really going to interfere with whatever normal caching is going on. I don't think it will do what you intended it to do with an explicit `gc.collect()` as I explained in https://github.com/huggingface/transformers/pull/9354
2. when do you think it's better to use this split as you implemented it (again simplifying to 2 gpus 6 layers in encoder and same in decoder):
```
encoder decoder
gpu0 1 2 3 1 2 3
gpu1 4 5 6 4 5 6
```
vs giving the whole gpu to one of them:
```
encoder decoder
gpu0 1 2 3 4 5 6
gpu1 1 2 3 4 5 6
```
Thank you!<|||||>@alexorona I had a chance to briefly look at your approach to model-parallelism via explicit device map construction. What are your thoughts on extending this approach via the construction of a generic Megatron-style `mpu` object that implements basic methods such as `get_{model,data}_parallel_{rank,group,world_size}()`? My understanding is that DeepSpeed works with any model-parallelism approach that implements these methods (the `mpu` object needs to be passed to `deepspeed.initialize()`), it doesn't have to necessarily be a tensor-splicing approach like Megatron.
Would it make sense to extend/tweak the device map approach to model-parallelism to fit within the `mpu` setup, as opposed to trying to get deepspeed's memory optimization primitives to work with the MP implementation without leveraging `mpu`?<|||||>@alexorona, I think I found at least one culprit for needing `torch.cuda.set_device(id)` all over the place. There could be more than one culprit, but at least with pytorch-nightly I have to add it in a bunch of places if `apex.normalization.FusedLayerNorm` is used. https://github.com/NVIDIA/apex/issues/1022 If I remove its use, I don't need any `torch.cuda.set_device(id)`.
On the other hand I don't see `apex.normalization.FusedLayerNorm` is being used in either t5 or gpt2. So perhaps it's something else. I see many bug reports wrt to switching devices and some ops failing without `torch.cuda.set_device(id)` or some solid pytorch op running just before it. It sounds like a bug in some pytorch operations.
<|||||>Meanwhile I've finished porting `BartForConditionalGeneration` to MP and pretty much adopted a variation of your device_map, so it won't change much from your original design if accepted.
It supports either type of map - your split approach or the one I proposed (flat). Here are some examples:
```
device_maps_flat = {
"sshleifer/tinier_bart": {
"encoder": {0: [0, 1] },
"decoder": {1: [0] },
},
"sshleifer/distilbart-xsum-6-6": {
"encoder": {0: [0, 1, 2, 3, 4, 5] },
"decoder": {1: [0, 1, 2, 3, 4, 5] },
},
}
device_maps_split = {
"sshleifer/tinier_bart": {
"encoder": {0: [0],
1: [1],
},
"decoder": {1: [0] },
},
"sshleifer/distilbart-xsum-6-6": {
"encoder": {0: [0, 1, 2],
1: [3, 4, 5],
},
"decoder": {0: [0, 1, 2],
1: [3, 4, 5],
},
},
}
```
I think down the road we could support other types by simply using different keys for whatever other configuration is desired.
I think eventually we will need to benchmark the different splits and see which one is more efficient. e.g. the flat approach currently suffers from the shared embeddings since they need to be constantly switched back and forth between devices!
I also have much improved magical device switching functions so it should be much faster to port to MP in the future.
One other design change I will propose is to drop first/last devices and instead have `self.main_device`, so that everything happens on just one device and we only send to other devices whatever needs to be offloaded - layer/block work that is. So probably it'd mean that the main device should have less than equal number of layers/blocks assigned to it as it'll use more memory for all the inputs and outputs. I still need to polish this idea.<|||||>We also may need to take into consideration @osalpekar's suggestion at https://github.com/pytorch/pytorch/issues/49961#issuecomment-754306157 - I haven't studied that side of things yet so can't comment at the moment. On one side it appear much more complex to setup, on the other side it might make things much easier model-side-wise. If you already familiar with that side of things please share your insights.
<|||||>And another suggestion is to potentially use Pipe Parallelism here: https://github.com/pytorch/pytorch/issues/49961#issuecomment-754326342 by @pritamdamania87
The main issue would be that it'll be enabled in pt-1.8
But @pritamdamania87 raises a super-important point - and that the current implementation doesn't take advantage of the multiple gpus, other than for their memory. So all the other gpus idle while one works, which is probably not what we want.
Unless I'm missing something then this means that the current approach that we have been discussing (and released) is really a no-go. Please correct me if I'm wrong.<|||||>Pipeline parallelism is already supported in DeepSpeed, although I haven't played around with it.
https://www.deepspeed.ai/tutorials/pipeline/<|||||>yes, and `fairscale` too!
<|||||>@alexorona, please have a look at this super-important comment https://github.com/pytorch/pytorch/issues/49961#issuecomment-754319348
which I understand that `torch.cuda.set_device()` is not just for fixing bugs in some pytorch ops, but it's actually an essential tool to avoid back-n-forth copying of data which happens when `torch.cuda.set_device()` is not set to the device the ops are happening on. Ouch. I couldn't find any docs covering that culprit.
We were trying to get rid of it. Now it looks like we need to make sure we have it in every place we switch to a new device. So when switching to a new device we need:
1. `torch.cuda.set_device(device)`
2. `inputs.to(device)`
3. `layer.to(device)`
<|||||>I was asked to share a sort of design/explanation of what we have implemented so far, so here you go (@alexorona please correct me if I have missed anything - thank you!)
-------------------
Here is an example of a `sshleifer/distilbart-xsum-6-6` `BartForConditionalGeneration` model:
```
(model): BartModel(
(shared): Embedding(50264, 1024, padding_idx=1)
(encoder): BartEncoder(
(embed_tokens): Embedding(50264, 1024, padding_idx=1)
(embed_positions): BartLearnedPositionalEmbedding(1026, 1024, padding_idx=1)
(layers): ModuleList( 6 x BartEncoderLayer)
(layernorm_embedding): FusedLayerNorm(torch.Size([1024]), eps=1e-05, elementwise_affine=True)
)
(decoder): BartDecoder(
(embed_tokens): Embedding(50264, 1024, padding_idx=1)
(embed_positions): BartLearnedPositionalEmbedding(1026, 1024, padding_idx=1)
(layers): ModuleList( 6 x BartDecoderLayer)
(layernorm_embedding): FusedLayerNorm(torch.Size([1024]), eps=1e-05, elementwise_affine=True)
)
)
(lm_head): Linear(in_features=1024, out_features=50264, bias=False)
)
```
Note that I collapsed the huge bulk of it and it's represented by just 2 lines that I wrote myself - it was not the output of the model dump.
```
(layers): ModuleList( 6 x BartEncoderLayer)
(layers): ModuleList( 6 x BartDecoderLayer)
```
this is some 90% of the model and that's what we want to spread out through multiple gpus.
So we have the bulk of memory used by 6 x `BartEncoderLayer` and 6 x `BartDecoderLayer`, plus some other components.
For the simplicity of the example let's say we have 2 gpus we want to split the model into.
Currently the idea is to put the 6 encoder layers on gpu 0 and the same for decoder layers but on gpu 1:
```
device_map = {
"encoder": {0: [0, 1, 2, 3, 4, 5] },
"decoder": {1: [0, 1, 2, 3, 4, 5] },
}
```
or alternatively, splice each group as following:
```
device_map = {
"encoder": {0: [0, 1, 2],
1: [3, 4, 5],
},
"decoder": {0: [0, 1, 2],
1: [3, 4, 5],
},
}
```
and the remaining non-encoder/decoder layer modules can be all on gpu 0 or grouped closer to where they are needed. We still haven't quite finalized that map.
Of course, other models may have more or less layers and they don't have to have the same number of layers in encoder and decoder.
Now that we have the map, we can place different layers/blocks on different devices
A simplified explanation would be with the usual drawing of the deep nn (random blocks in this example)
```
blocks | [blk] ... [blk 2] | [blk 3] ... [blk 5] | [blk 6] ... [blk 7] | [head]
devices | 0 | 1 | 2 | 0
```
Implementation details:
1. create model
2. `model.parallelize()`: run through the model's layers and remap them to specific devices as defined by the device map by simply runnin `to(device)`
3. inside `forward` we switch inputs to the same device as the layer's params using a handy wrapper I shared here: https://github.com/pytorch/pytorch/issues/49961#issuecomment-753441248
4. some outputs need to be brought back to the device where the logic of the main program happens (e.g. beam search)
Complications:
* shared embeds are a performance issue - we have to switch them back and forth between different devices.
* because some layers have params on different devices the developer has to explicitly choose which device to switch input to
* looks like we may need to sort out that `torch.cuda.set_device()` which apparently is needed too - sometimes to cover for bugs in pytorch, other times for performance - I haven't figured it out yet, I opened an issue:
https://github.com/pytorch/pytorch/issues/50112
* beam search works extremely slow with this approach - 10x slowdown.
To port a model one needs to apply the device map (stage 2 above) and then gradually deal with wrong device errors, by remapping the inputs to the devices of the params of the layer. Alex was doing each variable manually, which is a huge pain. I automated this process (it's in 2 PRs that haven't been merged yet, the Bart PR has a smarter function)
Transitions:
- Alex defined first/last devices to work with. In Bart MP I shifted to a different mapping where everything happens on main_device (say 0), and we only ever switch devices for those stacks of encoder/decoder layers that repeat, but all the helping params remain on device 0, which greatly simplifies things.
- So when we pass data to the parallelized model we `.to(main_device)` and most of the layers are already on the main_device, so now we only need to switch devices when the stacks end. So if you take the following map:
```
device_map = {
"encoder": {0: [0, 1, 2, 3, 4, 5] },
"decoder": {1: [0, 1, 2, 3, 4, 5] },
}
```
Here one only need to change devices twice
1. once when switching between encoder.5 and encoder.0 and
2. once more when returning from forward of decoder.5,
but of course, since the user may choose to split them vertically as so:
```
device_map = {
"encoder": {0: [0, 1, 2],
1: [3, 4, 5],
},
"decoder": {0: [0, 1, 2],
1: [3, 4, 5],
},
}
```
there will be more switches here.
So with the automation of switching `forward` input to the desired device it's only a few surprises that one has to resolve, since each model has some unexpected needs.
Overall, with the great foundation @alexorona laid out and with a bit of the automation I added the implementation is solid and would work just fine for those who can afford idling gpus.
What we need to figure out next is how these idling gpus will co-operate with all the other great components we have been working on (fairscale/deepspeed/pytorch pipelines/etc.)
<|||||>Great recap @stas00 <|||||>update: I made t5 work with HF trainer and --model_parallel in eval mode https://github.com/huggingface/transformers/pull/9323 - needed to copy the outputs back to the first device - it's more or less fine in the training stage (it worked in the first place), **but w/ beam search size 4 it's 10x slower on eval w/ MP than w/o MP** - it gets hit badly by the back-n-forth data copying.<|||||>The more I'm reading on various Parallelization strategies the more I see how confusing the terminology is.
What's most call Model Parallel (MP) should probably be called "Model Distributed" - since all we are doing here is splitting the model across several GPUs, as such "Model Distributed" is a much closer to reality term.
Next comes Pipeline Parallelism (PP) - where we split the mini-batch into micro-batches and feed into Model Parallel / Model Distributed, so that while a GPU that completed its `forward` idles waiting for other GPUs to compute their chunks of layers of the model and backprop, it can start on a new input. It is a Pipeline for sure, is this parallel though - I have a hard time calling it Parallel, since all the ops are sequential still.
It's much easier to understand this by studying this diagram from the [GPipe paper](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)

This diagram makes it very clear why what we have implemented is what it calls a a naive MP, and you can see the huge idling with 4 GPUs.
It then shows how it tries to resolve this idling problem with Pipeline. There is still idling but less so.
It also misrepresents the length of time forward and backward paths take. From asking the experts in general backward is ~2x slower than forward. But as I was corrected on slack, the length of the bubble is about the same regardless of their execution speed. (Thanks @deepakn94)
And Deepak also stressed out that since with PP there is a splitting into micro-batches, the effective batch size has to be big enough, otherwise PP will be idling too - so it requires experimentation to find a good batch size.
Bottom line, PP is an improved version of MP, according to my current understanding. I'm still still researching.
I think the real Parallelization is the [ZeRO paper](https://arxiv.org/abs/1910.02054) where Sharding/Partitioning is done and then it's truly parallel processing, but I'm still trying to understand what exactly is going on there. (Need to find a good diagram visually showing what it does) Grr, I see others use sharding/partitioning as a replacement for parallelism... so confusing.
I updated https://github.com/huggingface/transformers/issues/8771#issuecomment-733224520 with resources on PP and next need to try to convert perhaps t5 to PP and see how it works in practice. There will be issues to overcome due to BN and tied weights.<|||||>@deepakn94 helped me to finally grasp ZeRO-powered data parallelism, as it's described on this diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)
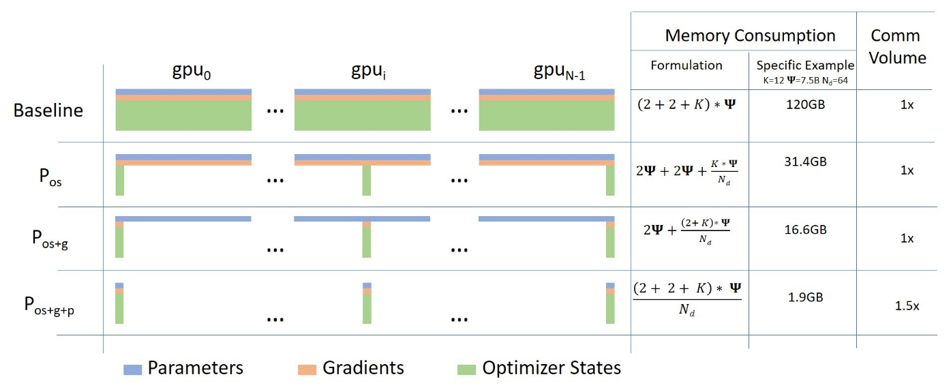
So it's quite simple conceptually, this is just your usual DataParallel (DP), except, instead of replicating the full model params, gradients and optimizer states, each gpu stores only a slice of it. And then at run-time when the full layer params are needed just for the given layer, all gpus sync to give each other parts that they miss - this is it.
Consider this simple model with 3 layers and each layer has 3 params:
```
La | Lb | Lc
---|----|---
a0 | b0 | c0
a1 | b1 | c1
a2 | b2 | c2
```
Lx being the layer and we have 3 layers, and ax being the weights - 3 weights
If we have 3 GPUs, the Sharded DDP (= Zero DP) splits the model onto 3 GPUs like so:
```
GPU0:
La | Lb | Lc
---|----|---
a0 | b0 | c0
GPU1:
La | Lb | Lc
---|----|---
a1 | b1 | c1
GPU2:
La | Lb | Lc
---|----|---
a2 | b2 | c2
```
In a way this is horizontal slicing, if you imagine the typical DNN diagram. Vertical slicing is where one puts whole layer-groups on different GPUs. But it's just the starting point.
Now each of these GPUs will get the usual mini-batch as it works in DP:
```
x0 => GPU0
x1 => GPU1
x2 => GPU2
```
The inputs are unmodified - they think they are going to be processed by the normal model.
So the inputs first hit the first layer La.
Let's focus just on GPU0: x0 needs a0, a1, a2 params to do its forward path, but GPU0 has only a0 - so what it does is it gets sent a1 from GPU1 and a2 from GPU2. Now the forward step can happen.
In parallel GPU1 gets mini-batch x1 and it only has a1, but needs a0 and a2 params, so it gets those from GPU0 and GPU2.
Same happens to GPU2 that gets input x2. It gets a0 and a1 from GPU0 and GPU1.
As soon as the calculation is done, the data that is no longer needed gets dropped - it's only used during the calculation.
The same is repeated at every other stage.
And the whole larger thing is repeated for layer Lb, then Lc forward-wise, and then backward Lc -> Lb -> La.
To me this sounds like an efficient group backpacking weight distribution strategy:
1. person A carries the tent
2. person B carries the stove
3. person C carries the entertainment system
Now each night they all share what they have with others and get from others what the don't have, and in the morning they pack up their allocated type of gear and continue on their way. This is Sharded DDP / Zero DP.
Compare this strategy to the simple one where each person has to carry their own tent, stove and entertainment system, which would be far more inefficient. This is DataParallel in pytorch.
And I think pretty much everywhere I read Sharded == Partitioned, so I think those are synonyms in the context of distributed models.
<|||||>**edit: 2021-02-15: Note that `finetune_trainer.py` was moved to `examples/legacy/seq2seq/`, and there is a new script `run_seq2seq.py` that took over `finetune_trainer.py`, you will find transition notes [here](https://github.com/huggingface/transformers/issues/10036)**
The simplest way to quickly reproduce the following is to switch to the transformers sha of the time this was posted, that is:
```
git clone https://github.com/huggingface/transformers
cd transformers
git checkout 7e662e6a3be0ece4
```
--------------
The amazing discovery of the day is DeepSpeed's [Zero-Offload](https://www.deepspeed.ai/tutorials/zero-offload/). ZeRO-Offload is a ZeRO optimization that offloads the optimizer memory and computation from the GPU to the host CPU.
You can use DeepSpeed with a single GPU and train with huge models that won't normally fit onto a single GPU.
First let's try to finetune the huge `t5-3b` with a 24GB rtx-3090:
```
export BS=1; rm -r output_dir; CUDA_VISIBLE_DEVICES=0 PYTHONPATH=../../src USE_TF=0 ./finetune_trainer.py \
--model_name_or_path t5-3b --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval \
--do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 \
--logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 \
--overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate \
--eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 \
--val_max_target_length 128 --warmup_steps 5 --n_train 60 --n_val 10 --n_test 10 --fp16
```
No cookie, even with BS=1
```
RuntimeError: CUDA out of memory. Tried to allocate 64.00 MiB (GPU 0; 23.70 GiB total capacity; 21.37 GiB already allocated; 45.69 MiB free; 22.05 GiB reserved in total by PyTorch)
```
Now update your `transformers` to master, then install deepspeed:
```
pip install deepspeed
```
and let's try again:
```
export BS=20; rm -r output_dir; CUDA_VISIBLE_DEVICES=0 PYTHONPATH=../../src USE_TF=0 deepspeed --num_gpus=1 \
./finetune_trainer.py --model_name_or_path t5-3b --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro \
--do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 \
--logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 \
--overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate \
--eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 \
--val_max_target_length 128 --warmup_steps 5 --n_train 60 --n_val 10 --n_test 10 --deepspeed ds_config_1gpu.json --fp16
```
et voila! we get a BS=20 trained just fine. I can probably push BS even further. It OOMed at BS=30.
```
2021-01-12 19:06:31 | INFO | __main__ | train_n_objs = 60
2021-01-12 19:06:31 | INFO | __main__ | train_runtime = 8.8511
2021-01-12 19:06:35 | INFO | __main__ | val_n_objs = 10
2021-01-12 19:06:35 | INFO | __main__ | val_runtime = 3.5329
2021-01-12 19:06:39 | INFO | __main__ | test_n_objs = 10
2021-01-12 19:06:39 | INFO | __main__ | test_runtime = 4.1123
```
Amazing!
Important note - I used `CUDA_VISIBLE_DEVICES=0` to single out one gpu, but deepspeed has a bug now where it ignores that env var, so it'll be using the first GPU instead. microsoft/DeepSpeed#662 But hoping it will get fixed eventually.
The config file `ds_config_1gpu.json` is:
```
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true,
"cpu_offload": true
},
"optimizer": {
"type": "Adam",
"params": {
"adam_w_mode": true,
"lr": 3e-5,
"betas": [ 0.9, 0.999 ],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
}
}
```
I had to lower the ZeRO buffers from the default 5e8 to 2e8, otherwise it was OOM'ing even on BS=1.
**important**: DeepSpeed made some changes in the non-released version as of this writing and so the above config won't work anymore. It dropped `adam_w_mode` and added a proper `AdamW` optimizer (it was always there, but just not exposed normally), so replace that section with:
```
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [ 0.9, 0.999 ],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
```
And it's not optimized yet, I just found at least one config that worked for this simple proof-of-concept test.
Go and check it out!
**edit:** I was asked about RAM usage for this task, it was 71GB peak, I re-run the same command as above with:
`/usr/bin/time -v ` before `deepspeed` and got:
```
User time (seconds): 117.12
System time (seconds): 53.46
Percent of CPU this job got: 122%
Elapsed (wall clock) time (h:mm:ss or m:ss): 2:19.38
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 70907544
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 3245
Minor (reclaiming a frame) page faults: 31346864
Voluntary context switches: 16348
Involuntary context switches: 52489
Swaps: 0
File system inputs: 1402864
File system outputs: 11143504
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
```
So the peak RSS entry is 71GB:
```
Maximum resident set size (kbytes): 70907544
```
The doc is here: https://huggingface.co/transformers/master/main_classes/trainer.html#deepspeed
And it's already slightly outdated - I need to modify it to cover that it works with single GPUs too!
@alexorona, I think you'd be super-happy about this one.
p.s. if you need to setup the dir and the data, first do:
```
git clone https://github.com/huggingface/transformers/
cd transformers/
cd examples/seq2seq
wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
tar -xzvf wmt_en_ro.tar.gz
```
before running any of the above scripts.
Oh, and I'm on pytorch-nightly since that's the only version that works at the moment with rtx-3090.<|||||>**edit: 2021-02-15: Note that `finetune_trainer.py` was moved to `examples/legacy/seq2seq/`, and there is a new script `run_seq2seq.py` that took over `finetune_trainer.py`, you will find the transition notes [here](https://github.com/huggingface/transformers/issues/10036)**
The simplest way to quickly reproduce the following is to switch to the transformers sha of the time this was posted, that is:
```
git clone https://github.com/huggingface/transformers
cd transformers
git checkout 7e662e6a3be0ece4
```
--------------
OK and to finish the day here are some benchmarks - thank you @sgugger for letting me run those on your machine with dual titan rtx.
Let's start with the results table:
| Method | max BS | train time | eval time |
|---------------------------|--------|------------|-----------|
| baseline | 16 | 30.9458 | 56.3310 |
| fp16 | 20 | 21.4943 | 53.4675 |
| sharded_ddp | 30 | 25.9085 | 47.5589 |
| sharded_ddp+fp16 | 30 | 17.3838 | 45.6593 |
| deepspeed w/o cpu offload | 40 | **10.4007** | 34.9289 |
| deepspeed w/ cpu offload | **50** | 20.9706 | **32.1409** |
Baseline + data setup was:
```
git clone https://github.com/huggingface/transformers/
cd transformers/
cd examples/seq2seq
wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
tar -xzvf wmt_en_ro.tar.gz
export BS=16; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python -m torch.distributed.launch \
--nproc_per_node=2 ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir \
--adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_train --evaluation_strategy=steps --freeze_embeds \
--label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 \
--max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS \
--per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler \
--task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 500 \
--n_train 2000 --n_val 500
```
Notes:
- We are doing a small train=2000, eval=500 items to do the comparisons. Eval does by default beam search size=4, so it's slower than training with the same number of samples, that's why I used 4x less eval items
- task: translation
- model: t5-large
- We have 2x 24GB GPUs
- DeepSpeed wasn't really designed for evaluation according to its developers but you can see it rocks there too.
Results: Well, Deepspeed beats all solutions that were compared - it's much faster and can fit much bigger batches into the given hardware. as you can see from the previous post https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685 - the cpu offloading while is slower on training it can fit more into your hardware. and it's the winner for eval!
Note: these benchmarks aren't perfect as they take a lot of time to handle you can see that BS numbers are pretty rounded - surely they can be somewhat bigger and speed somewhat better as a result, so I'm sure both sharded ddp and deepspeed can be optimized further.
But that's a good start. As both sharded ddp and deepspeed are now in master https://huggingface.co/transformers/master/main_classes/trainer.html#trainer-integrations please go ahead and do your own benchmarks.
And now the raw results - sorry it's not markdown'ed:
```
# setup
conda install -y pytorch==1.7.1 torchvision cudatoolkit=10.2 -c pytorch
pip install deepspeed fairscale
# versions
PyTorch version: 1.7.1
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.1 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.16.3
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: 10.0.130
GPU models and configuration:
GPU 0: TITAN RTX
GPU 1: TITAN RTX
Nvidia driver version: 450.102.04
cuDNN version: Probably one of the following:
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.7.6.5
transformers_version": "4.2.0dev0", (master)
# baseline
max that I could fit was BS=16
export BS=16; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 500 --n_train 2000 --n_val 500
01/13/2021 05:31:19 - INFO - __main__ - train_runtime = 30.9458
01/13/2021 05:32:15 - INFO - __main__ - val_bleu = 25.8269
01/13/2021 05:32:15 - INFO - __main__ - val_runtime = 56.331
# w/ --fp16
could fit BS=20
export BS=20; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 500 --n_train 2000 --n_val 500 --fp16
01/13/2021 05:33:49 - INFO - __main__ - train_runtime = 21.4943
01/13/2021 05:34:42 - INFO - __main__ - val_bleu = 25.7895
01/13/2021 05:34:42 - INFO - __main__ - val_runtime = 53.4675
------------------------------------------------
# w/ --sharded_ddp
to compare with BS=20
export BS=20; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 500 --n_train 2000 --n_val 500 --sharded_ddp
01/13/2021 06:26:11 - INFO - __main__ - train_runtime = 28.9404
01/13/2021 05:36:16 - INFO - __main__ - val_bleu = 25.7201
01/13/2021 05:36:16 - INFO - __main__ - val_runtime = 55.0909
but can fit more now, so same with BS=30
export BS=30; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 500 --n_train 2000 --n_val 500 --sharded_ddp
01/13/2021 06:28:02 - INFO - __main__ - train_runtime = 25.9085
01/13/2021 05:39:08 - INFO - __main__ - val_bleu = 25.7178
01/13/2021 05:39:08 - INFO - __main__ - val_runtime = 47.5589
# w/ --sharded_ddp --fp16
export BS=20; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 500 --n_train 2000 --n_val 500 --sharded_ddp --fp16
01/13/2021 06:29:08 - INFO - __main__ - train_runtime = 21.4775
01/13/2021 05:41:39 - INFO - __main__ - val_bleu = 25.7162
01/13/2021 05:41:39 - INFO - __main__ - val_runtime = 53.2397
but can fit more now, so same with BS=30
01/13/2021 06:30:03 - INFO - __main__ - train_runtime = 17.3838
01/13/2021 05:43:56 - INFO - __main__ - val_bleu = 25.7314
01/13/2021 05:43:56 - INFO - __main__ - val_runtime = 45.6593
# w/ --deepspeed ds_config.json (stage 2 w/o cpu offloading)
I changed the config file to:
"cpu_offload": false
export BS=40; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 deepspeed ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 500 --n_train 2000 --n_val 500 --deepspeed ds_config.json
01/13/2021 06:32:35 - INFO - __main__ - train_runtime = 10.4007
01/13/2021 06:33:10 - INFO - __main__ - val_bleu = 25.9687
01/13/2021 06:33:10 - INFO - __main__ - val_runtime = 34.9289
# w/ --deepspeed ds_config.json (stage 2 w/ cpu offloading)
if we lower the buffers to `1.5e8` and enable cpu offloading:
"allgather_bucket_size": 1.5e8,
"reduce_bucket_size": 1.5e8,
"cpu_offload": true
we can get to BS=50!
BS=50 rm -r output_dir; PYTHONPATH=../../src USE_TF=0 deepspeed ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 500 --n_train 2000 --n_val 500 --deepspeed ds_config.json
01/13/2021 06:40:51 - INFO - __main__ - train_runtime = 20.9706
01/13/2021 06:41:23 - INFO - __main__ - val_bleu = 25.9244
01/13/2021 06:41:23 - INFO - __main__ - val_runtime = 32.1409
I'm pretty sure if the buffers are even smaller it could do even higher BS. But it's late and I'm going to sleep.
```
Here is the config file that was used for deepspeed: https://github.com/huggingface/transformers/blob/69ed36063a732c37fdf72c605c65ebb5b2e85f44/examples/seq2seq/ds_config.json
<|||||>Whoah! ZeRO stage 1: sharded optimizer has been just merged into pytorch! https://github.com/pytorch/pytorch/pull/46750
With complements of @blefaudeux and the FairScale and DeepSpeed teams!
Pipeline too: https://github.com/pytorch/pytorch/tree/master/torch/distributed/pipeline
And more coming later: https://github.com/pytorch/pytorch/issues/42849
<|||||>> Whoah! ZeRO stage 1: sharded optimizer has been just merged into pytorch! [pytorch/pytorch#46750](https://github.com/pytorch/pytorch/pull/46750)
> With complements of @blefaudeux and the FairScale and DeepSpeed teams!
>
> Pipeline too: https://github.com/pytorch/pytorch/tree/master/torch/distributed/pipeline
>
> And more coming later: [pytorch/pytorch#42849](https://github.com/pytorch/pytorch/issues/42849)
thanks ! the whole fairscale suite will take a little more time, so it's good that HF is integrated already, the work will not be lost. Great [blog post](https://github.com/huggingface/blog/pull/71) also, and thanks for the numbers ! Some improvements planned over time speed wise within fairscale/shardedddp which should trickle down automatically, thinking for instance about the experimental optimizers in pytorch which flatten the params or better bucketing for the reduce part<|||||>These are great news, @blefaudeux! Thank you for sharing.
I hope you create a page on github with such news, so it'd be easy to keep abreast of the speed improvements and to appraise users of the need to update to this or that version if they want certain improvements/speed ups.
If it's not too much trouble that is.
p.s. my fantasy is that there will be a ZeRO Central, where updates from the all collaborating ZeRO implementations get posted.
e.g. DeepSpeed just released a new paper: https://arxiv.org/abs/1910.02054 - this would have been a great candidate for such sharing.<|||||>This is very impressive work!
From the perspective of an end-user doing seq2seq (e.g. T5), running the above examples for T5-11B (both sharded_ddp and deepspeed) doesn't appear to be performing complete model parallelism (or, at least, I am getting OOM errors on a machine with four A100-SXM4-40GBs, Python 3.7, pull of HF ~4.3.0 master from yesterday, CUDA 11.0, Pytorch 1.7.1, DeepSpeed compiled from source with the A100 8.0 arch enabled for the A100, BS=1). I understand from the blog post this is likely because sharding is only currently implemented for the optimizer and gradients, but not the model parameters? Is there an interim suggestion for easily running these large models in 4.3? It looks like there's currently confusion since --model_parallel was removed in 4.2 (and some confusion about how to run large models using the /examples/ now, e.g. #9243 ) <|||||>> This is very impressive work!
Totally agree. Those both teams and the inventors of ZeRO are awesome!
> From the perspective of an end-user doing seq2seq (e.g. T5), running the above examples for T5-11B (both sharded_ddp and deepspeed)
one of them - not both. Will send a PR to block such attempts. https://github.com/huggingface/transformers/pull/9712/
DeepSpeed already does sharded ddp. Slowly, slowly we will get a better understanding and better documentation.
> doesn't appear to be performing complete model parallelism (or, at least, I am getting OOM errors on a machine with four A100-SXM4-40GBs, Python 3.7, pull of HF ~4.3.0 master from yesterday, CUDA 11.0, Pytorch 1.7.1, DeepSpeed compiled from source with the A100 8.0 arch enabled for the A100, BS=1). I understand from the blog post this is likely because sharding is only currently implemented for the optimizer and gradients, but not the model parameters?
That's correct. Not yet.
* With fairscale you get sharding or optim/grads.
* With deepspeed you get all that, plus cpu-offload, plus better memory management.
We would need to have Pipeline parallelism working to support 2D parallelism, which probably should fit t5-11b onto 4 gpus. I'm working on this at the moment, but run into multiple limitations of the PP implementations https://github.com/pytorch/pytorch/pull/50693 and https://github.com/microsoft/DeepSpeed/pull/659.
In any case please update your master as I merged a bug fix some 6 hours ago, but I don't think it'd make any difference to your situation.
> Is there an interim suggestion for easily running these large models in 4.3? It looks like there's currently confusion since --model_parallel was removed in 4.2 (and some confusion about how to run large models using the /examples/ now, e.g. #9243 )
The `--model_parallel` flag was half-baked so it was removed until the day we actually have something solid in place. but you can still use model parallelism.
What you can do now is to activate our naive model parallelism, which I think may just fit the 45GB model over 4x 40GB GPUs. See: https://huggingface.co/transformers/model_doc/t5.html?highlight=parallel#transformers.T5EncoderModel.parallelize
We currently have t5, gpt2 and (unmerged bart pr) with this version of naive MP.
But it's going to be slow, see: https://github.com/huggingface/transformers/issues/8771#issuecomment-758250421 because 3 out of 4 gpus will be idling at any given moment. Basically, you will have a speed of a single gpu, with extra slowdown due to data being copied between gpus back and forth. We need to get PP working to overcome this.<|||||>@PeterAJansen As Stas points out, you should use the model parallelism implementation from 4.1.0. You'll likely need somewhere around 256 GB total GPU memory to train t5-11b with max 512 input tokens and 320 GB for 1024 tokens (so p4 instance in AWS).
In 4.1.0, there's only a few changes to the code you'd need to do to accomplish this: 1) set `train_args = TrainingArguments(model_parallel = True) `and, 2) after loading the model, call `model.parallelize()` (no arguments needed -- custom device map won't help you with t5-11b). @stas00, can you confirm what the procedure is for >= 4.2.0? I haven't been able to keep up with the changes with the move. <|||||>@alexorona, as the doc [goes](https://huggingface.co/transformers/model_doc/t5.html?highlight=parallel#transformers.T5EncoderModel.parallelize), in the current master incarnation all you need to do is to call:
```
model.parallelize()
```
before you do the training. This then sets:
`self.is_model_parallel` to `True` and the trainer does the same thing it was doing when `--model_parallel` was used. It just does it smarter now and no longer requires an extra flag.
The new logic is:
```
if hasattr(model, "is_parallelizable") and model.is_parallelizable and model.model_parallel:
self.is_model_parallel = True
else:
self.is_model_parallel = False
```
The reason `--model_parallel` was removed is because it exposed that flag to all example scripts, but the scripts like `finetune_trainer.py` weren't synced, so as a user would run `finetune_trainer.py --model_parallel` nothing would happen, that's why just that flag was removed.
But nothing else changed from your original implementation API-wise, @alexorona. The PRs I proposed which would change the device map have been parked for now.
We may re-add this flag in the future once the scripts will be able to activate MP internally.<|||||>@stas00 The flag was exposed because `TrainingArguments` would automatically increase the batch size if more than one GPU was detected (it would default to model parallelism behavior), thus defeating the purpose of model parallelism. Did you change that behavior?<|||||>As I was trying to convey we found a way to do the exact same thing without needing an extra flag. That's it's enough to run
`model.parallelize()` right after creating the model, for the trainer to do the right thing.
> TrainingArguments would automatically increase the batch size if more than one GPU was detected
As you can see it forces it to appear as having just 1 gpu, so no DP will be activated.
https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/trainer.py#L285-L290
Please let me know if we have missed anything in the re-shuffle.
<|||||>(Thanks both @stas00 and @alexorona for the very clear descriptions -- it does sound like it will be even more impressive when 4.3+ includes the full model parallelism, and thank you for your efforts! It does look like rolling back to 4.1.1 and using --model_parallel / model.parallelize() is able to just squeak in T5-11B with a 128 token length @ 160GB (~155GB) on 4 A100s (see below). I'll tinker more with 4.3.0 parameters and see if the fit is also possible with longer sequences/more speed as currently afforded by DeepSpeed)

<|||||>@PeterAJansen glad to hear it!
@stas00 Got it. Yeah, the problem was with `TrainingArguments`, specifically `train_batch_size()` and `eval_batch_size()` using `self.n_gpu` to automatically increase the batch size. Looks like you rearranged `TrainingArguments` and the `Trainer` to fix that.<|||||>> it does sound like it will be even more impressive when 4.3+ includes the full model parallelism
I'm encouraged by your ability to read the future! That means I will successfully make it work ;)
> It does look like rolling back to 4.1.1 and using --model_parallel / model.parallelize() is able to just squeak in T5-11B with a 128 token length @ 160GB (~155GB) on 4 A100s (see below).
I'm pretty sure you can do it with master just the same, you just don't need ` --model_parallel ` at all.
That's awesome that you validated that as I'm sure others would want to know as well. Thank you.
If you come up with an optimized ds config file for this specific setup and task, please share back. I encourage you to open a DeepSpeed Issue to show your current ds config, your hardware and the model size and my fantasy is that they will tell you how you could squeeze even more out of it.
There are some features of DS we haven't tapped in as of yet.
BTW, fairscale is also working on implementing ZeRO stage 3 (sharded params) - so surely we should have one of them help solve this problem even sooner.
<|||||>> @stas00 Got it. Yeah, the problem was with `TrainingArguments`, specifically `train_batch_size()` and `eval_batch_size()` using `self.n_gpu` to automatically increase the batch size. Looks like you rearranged `TrainingArguments` and the `Trainer` to fix that.
That's correct. Someone detected this bug a few days ago and @sgugger did his magic to fix it.<|||||>@stas00 Oh, was the flag removed in 4.2.0 but `TrainingArguments` wasn't fixed? In that case, 4.2.0 without the bug fix effectively doesn't support model parallelism for most use cases. The model GPU memory requirements will scale with the number of GPUs, so a user will not be able to train a larger model than they would with just one GPU in most cloud instances. If that's the case, we should tell people that only transformers 4.1.0 currently supports model parallelism. <|||||>>was the flag removed in 4.2.0 but TrainingArguments wasn't fixed?
Ah, my bad, it must have been [a different bug then that I remembered as it was about a similar thing](https://github.com/huggingface/transformers/pull/9578)
No, 4.2.1 has it just right:
https://github.com/huggingface/transformers/blob/236cc365aff2512ef773c6b1786555dab6fb182f/src/transformers/trainer.py#L284-L289
We have tests, so this problem would have been detected.
<|||||>When the flag was removed, the change in `TrainingArguments` and `Trainer` was introduced simultaneously, right? Otherwise there would be versions of transformers where model parallelism won't really work.<|||||>I'm pretty sure it's so, at least as far as I see in the code: https://github.com/huggingface/transformers/pull/9451/files<|||||>There were initial problems with the removal of the flag in 4.2.0, which was one of the reason for the patch release 4.2.1. It's working (and tested) on v4.2.1.<|||||>Amazing!Thanks for your efforts!
I am very interested in training T5-3B on a single 3090, but I want to know how much CPU memory is needed to complete it? I tried to reproduce it on 1x24G TiTan RTX, but it was unsuccessful and no out of memory error was given. My server has 64G of cpu memory.<|||||>> I am very interested in training T5-3B on a single 3090, but I want to know how much CPU memory is needed to complete it?
Yes, of course. `/usr/bin/time -v` reported 71GB for the exact command line I had run.
I updated https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685 with full details.
You can, of course, try to add swap memory on perhaps an nvme drive.
> but it was unsuccessful and no out of memory error was given
Perhaps file an Issue with https://github.com/microsoft/DeepSpeed/issues and tag me on it too? Surely, you should have received a backtrace or something. I remember filing one Issue with them where a similar situation of deepspeed just silently dying - but I think the reason was different.<|||||>@stas00 Thanks for your help!
I changed my server and now I have more RAM and GPU. According to the script, I can reproduce the training of T5-3b on single 3090, the peak memory consumption is about 89G, which is completely acceptable to me. Thank you again for your help.
But I still got some problems:
1. When I try to train MT5-xl, `--freeze_embeds` seems to bring bugs. Here is my report:
```
[INFO|modeling_utils.py:1152] 2021-01-27 15:05:03,683 >> All the weights of MT5ForConditionalGeneration were initialized from the model checkpoint at /<my_model_dir>/models/mt5/xl/v0.
If your task is similar to the task the model of the checkpoint was trained on, you can already use MT5ForConditionalGeneration for predictions without further training.
Traceback (most recent call last):
File "./finetune_trainer.py", line 367, in <module>
main()
File "./finetune_trainer.py", line 230, in main
freeze_embeds(model)
File "/<my_dir>/transformers/examples/seq2seq/utils.py", line 567, in freeze_embeds
freeze_params(model.model.shared)
File "/<my_dir>/miniconda3/envs/nlp/lib/python3.7/site-packages/torch/nn/modules/module.py", line 779, in __getattr__
freeze_params(model.model.shared)
File "/<my_dir>/miniconda3/envs/nlp/lib/python3.7/site-packages/torch/nn/modules/module.py", line 779, in __getattr__
type(self).__name__, name))
torch.nn.modules.module.ModuleAttributeError: 'MT5ForConditionalGeneration' object has no attribute 'model'
type(self).__name__, name))
torch.nn.modules.module.ModuleAttributeError: 'MT5ForConditionalGeneration' object has no attribute 'model'
```
2. So I removed `--freeze_embeds` and tried to train MT5-xl again, but I got CUDA out of memory. My device is 4*24G 3090, with BS=1, ZeRO stage=2, and CPU_offload=true. I assume that T5-3b and MT5-xl should be in the same order of magnitude, so I think this should not happen.
3. I also tried training MT5-large. Under the same conditions in question 2. And I got the overflow problem. This is not surprising me because MT5-large seems not fixed FP16 yet. In short, I want to know if there is any problem with my operation or if this is the case. If it is because the MT5-large has not been repaired, does huggingface have any plans to repair it?
By the way,
> but it was unsuccessful and no out of memory error was given
I reproduced this problem by limiting the memory used by the program. I found that this happens when the memory required by the program exceeds the memory that can actually be used. The program will get stuck without any prompts and will not be killed. This may be due to my script on slurm. I repeated the experiment several times. If I run on slurm and limit its memory usage, the program will get stuck and will not be killed. When I cancel the task, I will receive an oom prompt; if I run it directly on the server When the memory limit is exceeded, it will be killed directly, but there is still no error prompt, which is more reasonable to me.
This problem reminded me of the problem I encountered before. When training mt5-xl under 8gpu, there is always one gpu that cannot load data, and it will also be stuck in the middle step. I thought they had the same reason before, but now I think they may be different. I will collect more information and submit an issue to DeepSpeed.
<|||||>@mxa4646, glad to hear it worked!
but we are now diverging from the topic of this thread. Would you please open a new issue describing the errors above and the full command line that lead to these and we will take it from there. (please tag me). Thank you!
And for the last part - yes absolutely an issue to DeepSpeed with full details to help their team to reproduce it.<|||||>@stas00 Yes, you are right. I raised an issue [#9865](https://github.com/huggingface/transformers/issues/9865#issue-795747456) and we can discuss it there.<|||||>FYI, started tracking 2D Parallelism feasibility in this issue: https://github.com/huggingface/transformers/issues/9931
<|||||>See a new post: [DeepSpeed] [success] trained t5-11b on 1x 40GB gpu https://github.com/huggingface/transformers/issues/9996
Not sure if it's better to pile them up in one thread, or make separate posts and index them in one thread. Experimenting.<|||||>Dear @stas00
thanks for the info, do you mind sharing the version of pytorch, python, deepspeed you used to test?
I am getting this error, although the version seems to be correct, thanks for your help.
```
File "/julia/libs/anaconda3/envs/updated/lib/python3.7/site-packages/deepspeed/ops/op_builder/builder.py", line 57, in assert_no_cuda_mismatch
f"Installed CUDA version {sys_cuda_version} does not match the "
Exception: Installed CUDA version 11.1 does not match the version torch was compiled with 10.2, unable to compile cuda/cpp extensions without a matching cuda version.
```<|||||>@juliahane, to use deepspeed and fairscale you need to make sure that pytorch was built with the same cuda version as the cuda installed system-wide. That's what this error says.
Please see: https://huggingface.co/transformers/master/main_classes/trainer.html#installation-notes
And if after reading this doc you still can't figure it out and want to continue this discussion please kindly start a new Issue and tag me on it and I will help you to sort it out. But let's not continue it in this thread. Thank you.<|||||>sure Stephan, thank you so much for the helpful pointer.
On Mon, Feb 8, 2021 at 6:35 PM Stas Bekman <[email protected]> wrote:
> @juliahane <https://github.com/juliahane>, to use deepspeed and fairscale
> you need to make sure that pytorch was built with the same cuda and as cuda
> installed on your system. Please see:
> https://huggingface.co/transformers/master/main_classes/trainer.html#installation-notes
> And if after reading this doc you still can't figure it out and want to
> continue this discussion please kindly start a new Issue and tag me on it
> and I will help you to sort it out. But let's not continue it in this
> thread. Thank you.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/8771#issuecomment-775316196>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AM3GZM6RT3RIKEYGC2LGMSLS6AOE3ANCNFSM4UBL5QTA>
> .
>
<|||||>Heads up: things are getting re-shuffling in the tests, so the default `ds_config.json` file has moved in master to a new, hopefully permanent home. It's now at `examples/tests/deepspeed/ds_config.json` so you will need to either adjust the command line to reflect this new location or simply copy it over to where the old one used to be. Thank you and apologies for the hassle.<|||||>Hi, a bit of time has passed, and it seems some information here is outdated. If possible, could someone please describe what is necessary in order to train a T5-3b or T5-11b model on 1 or more 32GB or 40GB GPUs and with a sequence length in the input of up to 512 and up to 256 for the target? Has this been achieved?
Are additional pieces of configuration necessary for model parallelism or is the deepspeed wrapper somehow triggering model parallelism in the hf trainer?
My observations so far have been that T5 training is very unstable with --fp16 and torch.distributed.launch, and I am not sure that deepspeed can overcome this problem. Could anyone comment on the training stability? So far this conversation has mostly touched on avoiding OOM while the aspect of training results has not been given much attention.
Thank you!
EDIT: I would also be thankful for an explanation for why *smaller* buffer sizes enable larger batch sizes.<|||||>> Hi, a bit of time has passed, and it seems some information here is outdated. If possible, could someone please describe what is necessary in order to train a T5-3b or T5-11b model on 1 or more 32GB or 40GB GPUs and with a sequence length in the input of up to 512 and up to 256 for the target? Has this been achieved?
I'm pretty sure it should be possible, certainly with t5-3b, with t5-11b I will have to try.
Please let me know what is not working for you (exact command) and I can try to help tune it up.
And if you have access to NVMe you can train even larger models with [DeepSpeed ZeRO-Infinity](https://www.microsoft.com/en-us/research/blog/zero-infinity-and-deepspeed-unlocking-unprecedented-model-scale-for-deep-learning-training/). Just give me a few more days to finalize the ZeRO-Infinity integration into transformers. This is all very new and their docs are very lacking still, but it will be fixed, so I'm trying to gather the information needed to take advantage of it, as it's not trivial to configure - need to run a benchmark first.
In the good news you can extend your CPU memory with any storage, it just might be very slow if the storage is slow :)
> Are additional pieces of configuration necessary for model parallelism or is the deepspeed wrapper somehow triggering model parallelism in the hf trainer?
We don't use the parallelism from Deepspeed, but mainly its ZeRO features, which more or less allow one not to worry about parallelism and be able to train huge models. Parallelism requires huge changes to the models.
> My observations so far have been that T5 training is very unstable with --fp16 and torch.distributed.launch, and I am not sure that deepspeed can overcome this problem. Could anyone comment on the training stability? So far this conversation has mostly touched on avoiding OOM while the aspect of training results has not been given much attention.
Yes, all `bf16`-pretrained models are, please see: https://discuss.huggingface.co/t/compiling-data-on-how-models-were-pre-trained-fp16-fp32-bf16/5671
They weren't meant to be used under fp16 mixed precision.
You will find a handful of issues wrt Nan/Inf in t5 and mt5.
You can try this workaround I experimented with: https://github.com/huggingface/transformers/pull/10956
It seems to overcome a big part of instability in mt5, but one person reported a problem after an extensive run.
If you have access to Ampere-based cards (rtx-3090/A100), please see: https://github.com/huggingface/transformers/issues/11076#issuecomment-823767514
This is not yet in deepspeed master, but soon they will have fp32 mode, which will be equivalent to v100 fp16 since it'd use TF32 on those Ampere cards.
<|||||>Hi @stas00, thanks for the prompt response.
Am I understanding correctly that deepspeed with T5 is inadvisable at the moment because until deepspeed supports FP32 it will use FP16 which will destroy the T5 model?<|||||>Most complaints were mainly about mt5 and not t5 as of recent,
@PeterAJansen, could you please comment here since I know at some point you were extensively working with t5-11b w/ deepspeed - did you run into nan/inf problems there?
I asked @samyam to make a PR from his full-fp32 branch https://github.com/microsoft/DeepSpeed/tree/samyamr/full-precision-for-stage3, but you can already use it. gpt-neo folks appear to have successfully started using it to overcome the over/underflow issue.
- for ZeRO-2 just set `fp16.enabled` to `false` in ds config file .
- for ZeRO-3 I gave instructions here https://github.com/microsoft/DeepSpeed/tree/samyamr/full-precision-for-stage3 - hoping to automate this in the next few days.<|||||>@stas00 it's a good question. I only became aware of the potential T5 fp16 issue recently, and I haven't noticed anything wonky in the models that I've been training -- but that's not to say that everything I've trained might be underperforming and able to perform vastly better, since I've been training models on new tasks rather than existing ones.
To verify things are running as expected, I should probably run an fp16 version of a common dataset task that (ideally) could be trained and evaluated in less than a day. Any suggestions from the examples section?<|||||>Thank you for sharing your experience, @PeterAJansen. I mostly encountered reports with mt5 as of recent.
Since you own A100s (and those with RTX-3090) it shouldn't be too long before pytorch and deepspeed support native `bf16` mixed precision, as both are actively working on adding this support. Once there, the NaN issue is expected to disappear in all `bf16`-pretrained models when they are finetuned/eval'ed in the same mode. So if you aren't in a rush and don't have a deadline to meet, I'd say just wait a bit longer and nothing needs to be done.<|||||>Have you managed to use activation checkpointing?<|||||>> Have you managed to use activation checkpointing?
Would be happy to follow up, but such kind of questions are impossible to answer. Who is "you"? In what context? What is the problem?
May I suggest opening a new Issue and providing full context and the exact problem you're dealing with or a need you have? Thank you!<|||||>Hi @stas00,
Thanks for all your contributions with deepzero integration. I find it fascinating and awesome!
According to your comments, it doesnt seem like deepspeed is able to use model parallelism (not data parallelism). Does this make it impossible to use t5-3b on an nvidia v100 16G 8 gpu card? I have tried a couple of different configurations of deepzero stage 3, including the provided configuration in master; however, I am only able to use a batchsize of 1 or 2. I am using a max sequence length of 512 for both input and output. I can achieve these same results if I use model.parallelism and split t5 across the 8 gpus.
Thanks!<|||||>In general:
1. Deepspeed can do 3D: PP+TP+DP no problem please see https://huggingface.co/transformers/master/parallelism.html
The problem is that HF transformers currently supports only the naive PP for gpt2/t5, i.e. the limitation is on our side.
The plan is to implement TP first and then eventually PP. **(update: DS doesn't currently do TP, only supports it via MPU**, but they are working on it)
2. ZeRO is a completely different approach to scaling which when used with the fast interconnects performs on par with 3D parallelism. The key is that it doesn't require changes to the model (well, sometimes very minor changes). That's why we eagerly adopted Deepspeed as the easy scalability solution.
Now to your specific setup. Offloading some of the memory should do the trick.
Here is some helpful API to estimate the memory needs for params, optim states and gradients: https://deepspeed.readthedocs.io/en/latest/memory.html#api-to-estimate-memory-usage It still is missing the activations and temps memory needs but it already gives you a pretty good picture of which configuration to pick:
Zero2
```
python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage2 import estimate_zero2_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("t5-3b"); \
estimate_zero2_model_states_mem_needs_all_live(model, num_gpus_per_node=8, num_nodes=1)'
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 8 GPUs per node.
SW: Model with 2851M total params.
per CPU | per GPU | Options
127.48GB | 5.31GB | cpu_offload=1
127.48GB | 15.93GB | cpu_offload=0
```
Zero3
```
python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("t5-3b"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=8, num_nodes=1)'
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 8 GPUs per node.
SW: Model with 2851M total params, 32M largest layer params.
per CPU | per GPU | Options
71.71GB | 0.12GB | cpu_offload=1, cpu_offload_params=1, zero_init=1
127.48GB | 0.12GB | cpu_offload=1, cpu_offload_params=1, zero_init=0
63.74GB | 0.79GB | cpu_offload=1, cpu_offload_params=0, zero_init=1
127.48GB | 0.79GB | cpu_offload=1, cpu_offload_params=0, zero_init=0
1.47GB | 6.10GB | cpu_offload=0, cpu_offload_params=0, zero_init=1
127.48GB | 6.10GB | cpu_offload=0, cpu_offload_params=0, zero_init=0
```
So you can see that if you have a nice chunk of CPU memory available, it should be trivial for you to load a large bs with large seqlen.
and this was written pre-NVMe offload addition, so you have that option too if you don't have much CPU memory, but consider it as an extension of CPU memory so the above numbers will still be the same gpu memory-wise.
p.s. Megatron-LM has just added t5 to their arsenal, but it lacks PP as of this writing.<|||||>Yes, specific problem solving is best done in a dedicated thread. So let's continue there. Please tag me so that I see it.<|||||>@stas00 @sacombs Maybe there's two or three typical use cases we could articulate? After having studied the documentation and your threads on this Stas, I'm still only able to get models in the range of 1.5B parameters training on a single 16GB GPU. The advantage is that it uses _far less GPU memory_ than it would normally take (about 30%), but it is 5 times slower. That's a very acceptable trade-off in terms of VM cost.
I haven't been able to effectively train large models like GPTNeo-2.7B and T5 using multiple GPUs. It seems like the deepspeed integration automatically creates a number of nodes/workers equal to the number of GPUs, so if you can't train it on one GPU, adding multiple GPUs makes no difference. I've tried with both zero3 and zero3-nvme configurations.
@stas00
Most of the big model use cases are around T5, GPTNeo and less frequently CTRL, DeBERTa and M2M100. T5 has a lot of use cases and GPTNeo is the most in-demand for generative tasks. Let's assume someone has a training script that cleans data, trains and evaluates. Training uses `Trainer`. Would it be possible to provide something like this:
**Example 1: Fine-tuning t5-3B Using zero3 and zero3-nvme with Multiple GPUs**
**Requirements**
- Install deepspeed with `pip install deepspeed`, `pip install transformers[deepspeed]`, or from source (see Installation)
- Use [zero3_config.json](url) for zero3 and [zero3_nvme_config.json](url) for zero3_nvme
- You'll need to run on Linux, as the preferred nccl backend that deepspeed uses is not supported on Windows. You **cannot** use WSL to get around this requirement.
- You **cannot** use a Notebook like Google Colab or Jupyter because of how deepspeed initiates processes when multiple GPUs are used.
- Create a training script that prepares your data and trains your model. To make this example work, the deepspeed configuration file must be passed to `Trainer`, e.g. `trainer = Trainer(deepspeed = "zero3_config.json", ...)`
- It is best to keep most of the values in `zero3_config.json` or `zero3_nvme.json` on `"auto"` and use `TrainingArguments` to adjust the deepspeed configuration
- For zero3: You'll need at least x GPU memory and x CPU memory for this example -- you might be able to get away with less GPU memory (see GPU OOM Messages below)
- For zero3 with nvme: You'll need at least x GPU memory, x CPU memory and NVMe with about x spare GB for this example -- you might be able to get away with less GPU memory (see GPU OOM Messages below)
**Running**
Here's how to run it:
`deepspeed -your_training_script.py <normal cl args> --deepspeed zero3_config.json`
**GPU OOM Messages**
If you are running out of memory, here's what you can try tweaking:
- Reduce `batch_size` passed to `TrainingArguments`
- Reduce `gradient_accumulation_steps` passed to `TrainingArguments`
- In the `zero3_config.json` or `zero3_nvme_config.json` file, reduce the size of the `"stage3_max_live_parameters"` and `"stage3_max_reuse_distance"`
**Example 2: Fine-tuning EleutherAI/gpt-neo-1.3B Using zero3 on a Single GPU**
**Requirements**
- Install deepspeed with `pip install deepspeed`, `pip install transformers[deepspeed]`, or from source (see Installation)
- Use [zero3_config.json](url)
- You'll need to run on Linux, as the preferred nccl backend that deepspeed uses is not supported on Windows. You **cannot** use WSL to get around this requirement.
- It is possible to do this in a Notebook when using just one GPU. See Deployment in Notebooks below.
- Create a training script that prepares your data and trains your model. To make this example work, the deepspeed configuration file must be passed to `Trainer`, e.g. `trainer = Trainer(deepspeed = "zero3_config.json", ...)`
- It is best to keep most of the values in `zero3_config.json` or `zero3_nvme.json` on `"auto"` and use `TrainingArguments` to adjust the deepspeed configuration
- For zero3: You'll need at least 16GB GPU memory and x CPU memory for this example -- you might be able to get away with less GPU memory (see GPU OOM Messages below)
**Running**
Here's how to run it:
`deepspeed -your_training_script.py <normal cl args> --deepspeed zero3_config.json`
**GPU OOM Messages**
If you are running out of memory, here's what you can try tweaking:
- Reduce `batch_size` passed to `TrainingArguments`
- Reduce `gradient_accumulation_steps` passed to `TrainingArguments`
- In the `zero3_config.json` file, reduce the size of the `"stage3_max_live_parameters"` and `"stage3_max_reuse_distance"`<|||||>That's a great idea, @alexorona! These would be super-useful.
Let's do it!
Do you want to also define the actual GPU sizes? It'd be very different if one uses 80GB A100 comparatively to 16GB V100.
Perhaps repasting each of these into a separate issue so that we could work on tuning these up independently?
Let's start with 2-3 and then we can expand it to more.
I'm a bit busy in the next few days with the bigscience first launch, but otherwise can work on it when I get some free time and we can of course ask the Deepspeed to help.
Once polished these would make a great article/blog_post.<|||||>Just to update: I think we will get the best outcome if one or a few people with an actual need and hardware to match will post an issue and then we will work on solving it and while at it come up with the settings/guidelines for models in question.
Also I'm at the moment mostly busy with the bigscience project, which takes the lion's share of my time. So I'd be delighted to support someone with a need, but probably won't have enough incentive to carve out the time to act on both sides.
I hope this makes sense.<|||||>Hi, I followed what you said [here](https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685), but it said that "TypeError: issubclass() arg 1 must be a class".
And even I replace the finetuner.py with run_seq2seq.py, it still doesn't work.
<|||||>this is a very old thread, could you please open a proper new Issue with full details of what you did, versions, the **full** traceback and how we could reproduce the problem and please tag me. Thank you. |
transformers | 8,770 | closed | Extend typing to path-like objects in `PretrainedConfig` and `PreTrainedModel` | # What does this PR do?
In my experience, I often call the `from_pretrained` and `save_pretrained` methods of models and configurations with a path-like variable rather than a string. Since the paths are then used by various `os` functions, this works just fine: however, the relevant variables are typed as strings only, raising warnings when using an IDE :anguished: .
This PR extends the typing to `Union[str, os.PathLike]` when relevant inside `PretrainedConfig` and `PreTrainedModel` methods.
Since passing a path-like object is already tacitly supported in most cases, no significant changes to the code are necessary. In a few places, the relevant variable needs to be turned to a string in order to support functions such as `is_remote_url`.
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
Maybe (documentation): @sgugger
| 11-24-2020 18:46:11 | 11-24-2020 18:46:11 | Good idea!
This could be done for tokenizers as well, no? (the `from_pretrained` for tokenizers is in `tokenization_utils_base.py`)<|||||>I have extended the same modifications to the tokenizers, as suggested by @thomwolf , and to auto classes too. |
transformers | 8,769 | closed | LXMERT - Visual features don't match original implementation | ## Environment info
- `transformers` version: 4.0.0-rc-1
- Platform: Linux-4.15.0-122-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@eltoto1219
## Information
Model I am using: **unc-nlp/lxmert-gqa-uncased**
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [X] **GQA**
## Details
I've tried to reproduce LXMERT results on GQA -
Using the [visual features from the original repo](https://github.com/airsplay/lxmert#gqa), I got an accuracy of 59.29% on the testdev split (which is a bit less than expected, but close enough).
However, when generating the visual features using the [extraction script](https://github.com/huggingface/transformers/blob/master/examples/lxmert/extracting_data.py) in the examples (which uses "unc-nlp/frcnn-vg-finetuned"), the accuracy is only ~33%.
I checked further, and the bounding boxes are also different.
Any idea to what could be the problem?
| 11-24-2020 17:31:02 | 11-24-2020 17:31:02 | Hi @eladsegal !
This is indeed interesting. The FRCNN config should match the exact setting used in the original demo. I will say, however, everything is finicky, but has been tested + should work.
Could you let me know if you:
- modified any of the settings in the config
- provide a link to the script script you are using so I can see the exact changes you have made
- If also possible, plot the bounding boxes on the original prediction so that I can see how the bounding boxes are different (I think that may be pretty telling)
I think I should be able to figure out what may be happening if you could let me know the above!<|||||>Thanks for the response, @eltoto1219!
The 33% I got previously was a mistake, not sure what change I made that caused it.
I started from scratch now, and the results are a lot closer to the original.
I've made the following changes:
- https://github.com/huggingface/transformers/blob/master/examples/lxmert/utils.py#L552 - do this only if the image is from a URL (https://github.com/huggingface/transformers/issues/8333) (improves accuracy on GQA by ~4 points)
And changes so extracting_data.py will work for batch size larger than 1:
- https://github.com/huggingface/transformers/blob/master/examples/lxmert/extracting_data.py#L95 - changed to if len(batch) > 0
- https://github.com/huggingface/transformers/blob/master/examples/lxmert/modeling_frcnn.py#L42 - added .view(-1, 1, 1) to allow broadcasting
For `extracting_data.py` I made a few more changes to be able to extract only for GQA's testdev images (so it will be a lot faster to run).
You can reproduce everything with the code in:
https://github.com/eladsegal/gqa_lxmert
There's also a notebook there showing the different bounding boxes.
For some reason, inference with different batch sizes in the FRCNN model results in different features for the same image.
I got the following accuracies for GQA for the following different batch sizes:
6: 57.15%
2: 57.64%
1: 58.54%
Using features from the original LXMERT repo results in 59.29%.<|||||>Of course! I am am real glad you were able to catch the color format error for images downloaded via a url (It would have taken me forever to find something like that)! I will have to fix that as soon as possible + do some more testing.
I find the different downstream lxmert accuracies on GQA when different batch sizes are used for feature extraction really interesting aswell. In the original repo, the extraction was set up so that one image went through the faster frcnn at a time. I am thinking something may be getting unordered when using multiple images at once, so I will take a look. I think it would also be worth pointing out that there are multiple releases of visual genome images (from 2014 and 2016). If downloading directly from https://visualgenome.org/ there appears to be quite a few corrupt images.
On the other hand, all visual genome images can be downloaded from https://cs.stanford.edu/people/dorarad/gqa/about.html (which I am assuming is the latest version). That may in part be why the accuracy is lower. (GQA train + val split come from visual genome. GQA testdev split comes from the COCO test split) There may also be some very small changes to some extraction hyper-parameters (most likely the NMS threshold for the post processing of bounding boxes) which may have also resulted in slightly different inaccuracies.
I'll go ahead and extract features across the different versions of visual genome + gqa, and compare element-wise with the features from the original lxmert repo and see if anything is any different, and if so, how different. It should take me a couple of days, but I will get back to you by then!<|||||>Thank you, I really appreciate this!
>I think it would also be worth pointing out that there are multiple releases of visual genome images (from 2014 and 2016). If downloading directly from https://visualgenome.org/ there appears to be quite a few corrupt images.
>
> On the other hand, all visual genome images can be downloaded from https://cs.stanford.edu/people/dorarad/gqa/about.html (which I am assuming is the latest version). That may in part be why the accuracy is lower. (GQA train + val split come from visual genome. GQA testdev split comes from the COCO test split)
Not sure about this as a possible reason for the lower accuracy, as the images I used were downloaded from GQA's website, and I only did comparison on the testdev split, and no additional training at all.
> There may also be some very small changes to some extraction hyper-parameters (most likely the NMS threshold for the post processing of bounding boxes) which may have also resulted in slightly different inaccuracies.
Sounds like a very reasonable explanation for the different and features and the small accuracy difference!
<|||||>@eltoto1219 The issue with batch-wise extraction is known:
https://github.com/airsplay/py-bottom-up-attention/issues/3#issuecomment-624240642<|||||>Hey @eladsegal !
I stumbled upon that actually on Friday myself too. I rewrote the extraction script to only allow frcnn extraction for one image at a time.
I think that the discrepancy in accuracy comes from the fact that Hao actually used a caffe-based frcnn pretrained model trained specifically to predict 36 images, while the pytorch one here was pretrained to predict 10-100 images. That and the potential of slightly different NMS thresholds.
Aslong as the batch-size is 1, the feature quality is most likely the same, however, if we are finetuning with the features from the model used in the aforementioned script, those technically wont be the exact same features used to pretrain lxmert, they should still get the job done if your okay with being ~1% lower than the reported accuracy.
Here is the link to the fixed script:
https://drive.google.com/file/d/1er2axVyGj8eW84QBGrV0dqTmKbxyS8F7/view?usp=sharing
<|||||>Thank you very much @eltoto1219, this has been extremely helpful!<|||||>Why [`examples/lxmert/`](https://github.com/huggingface/transformers/blob/master/examples/lxmert/) no longer exists?<|||||>This was an error, it has been put back a few days ago. Sorry for the inconvenience. |
transformers | 8,768 | closed | Attempt to get a better fix for QA | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-24-2020 17:09:31 | 11-24-2020 17:09:31 | |
transformers | 8,767 | closed | Allow to set truncation strategy for pipeline | # 🚀 Feature request
The highlevel pipeline function should allow to set the truncation strategy of the tokenizer in the pipeline.
## Motivation
Some models will crash if the input sequence has too many tokens and require truncation. Additionally available memory is limited and it is often useful to shorten the amount of tokens. Sadly this is currently not possible using the pipeline-API. One has to call the tokenizer manually to set the truncation strategy or hope that the task specific pipeline has truncation turned on by default (the summarization pipeline for example has not).
## Your contribution
I could potentially create a PR for this, but want to confirm first that the change is welcome. | 11-24-2020 16:50:37 | 11-24-2020 16:50:37 | Indeed, not being able to pass tokenizer arguments is a limiting factor of the pipelines. We're working on pipelines v2 (cc @mfuntowicz) which will allow such arguments to be passed.
In the meantime, we would definitely welcome a PR offering this functionality - but it would have to be agnostic to the argument, not specific to the truncation strategy.<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,766 | closed | [Error: PyTorch to tf]convert_pytorch_checkpoint_to_tf2: AttributeError: bert.pooler.dense.weight not found in PyTorch model | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.5.1
- Platform: Linux-5.4.0-1029-gcp-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.0 (False)
- Tensorflow version (GPU?): 2.3.1 (False)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
I think:
@patrickvonplaten @LysandreJik @VictorSanh
Anyone is welcome!
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
Blenderbot: @patrickvonplaten
Bart: @patrickvonplaten
Marian: @patrickvonplaten
Pegasus: @patrickvonplaten
mBART: @patrickvonplaten
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSMT: @stas00
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Trying to convert my pytorch checkpoint to tf using the below code:
```python
from transformers import convert_pytorch_checkpoint_to_tf2
convert_pytorch_checkpoint_to_tf2.convert_pt_checkpoint_to_tf(
model_type = "bert",
pytorch_checkpoint_path="model/pytorch_model.bin",
config_file="model/config.json",
tf_dump_path="TFmodel",
compare_with_pt_model=False,
use_cached_models=False
)
```
my model folder has a tiny bert trained using HuggingFace: contents of `model` folder are:
`checkpoint-500 special_tokens_map.json
config.json tokenizer_config.json
eval_results_mlm_wwm.txt training_args.bin
pytorch_model.bin vocab.txt`
## To reproduce
Error:
```
Loading PyTorch weights from /home/3551351/bert-mlm/model/pytorch_model.bin
PyTorch checkpoint contains 8,354,548 parameters
Traceback (most recent call last):
File "pt2tf.py", line 7, in <module>
convert_pytorch_checkpoint_to_tf2.convert_pt_checkpoint_to_tf(
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/convert_pytorch_checkpoint_to_tf2.py", line 283, in convert_pt_checkpoint_to_tf
tf_model = load_pytorch_checkpoint_in_tf2_model(tf_model, pytorch_checkpoint_path)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/modeling_tf_pytorch_utils.py", line 96, in load_pytorch_checkpoint_in_tf2_model
return load_pytorch_weights_in_tf2_model(
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/modeling_tf_pytorch_utils.py", line 172, in load_pytorch_weights_in_tf2_model
raise AttributeError("{} not found in PyTorch model".format(name))
AttributeError: bert.pooler.dense.weight not found in PyTorch model
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| 11-24-2020 16:34:18 | 11-24-2020 16:34:18 | Hey @singhsidhukuldeep,
Could you maybe upload your weights to a colab so that I can reproduce the error or upload your weights to the model hub and give me a path to it?
This way, I can reproduce the error and solve it :-)
Thanks a lot!<|||||>Hi @patrickvonplaten ,
I tried this
```Python
pt_model = TFBertForPreTraining.from_pretrained(model_output_location, from_pt=True)
print("\n\n>>> Saving HuggingFace to tensorflow(pb)")
tf.saved_model.save(pt_model,TF_model_output_location)
```
and it worked, but I am not able to understand the limitations here!<|||||>If you want to convert from <del>TF to PT</del> PT to TF this is exactly how you should to it...<|||||>@patrickvonplaten I am looking to convert PyTorch to TF!<|||||>Sorry I meant PT to TF -> your approach is correct here.<|||||>Got it! Thanks for the help.
One last thing, this gives a `*.h5` file (weights only)
Is there a way to get `*.pb` file with structure and weights?<|||||>Hi @singhsidhukuldeep, I tried this, it did save the model in assets, variables, and saved_model.pb format, but couldn't get any .h5 file that I need, am I missing something?
P.S. I am trying to convert a standard config BERT MaskedLM model
> Hi @patrickvonplaten ,
>
> I tried this
>
> ```python
> pt_model = TFBertForPreTraining.from_pretrained(model_output_location, from_pt=True)
>
> print("\n\n>>> Saving HuggingFace to tensorflow(pb)")
> tf.saved_model.save(pt_model,TF_model_output_location)
> ```
>
> and it worked, but I am not able to understand the limitations here!
<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,765 | closed | Fix QA argument handler | The QA argument handler does not handle multiple sequences at a time anymore. This was not tested, so I added it to the tests.
Fix https://github.com/huggingface/transformers/issues/8759
To test it out run the following on `master`:
```py
from transformers import pipeline
nlp = pipeline("question-answering")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text given a question. An example of a
question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune
a model on a SQuAD task, you may leverage the `run_squad.py`.
"""
print(
nlp(
question=["What is extractive question answering?", "What is a good example of a question answering dataset?"],
context=[context, context],
)
)
``` | 11-24-2020 15:46:26 | 11-24-2020 15:46:26 | The errors are due to connection errors. |
transformers | 8,764 | closed | Tokenizers - move from hardcoded configs and models to fully hosted | # What does this PR do?
Fixes #8125 #8117
Tokenizer checkpoint files are now handled the same way than model files.
Also:
- add a `tokenizer_class_name` field in the tokenization config file `tokenizer_config.json`. This field is used when possible by `AutoTokenizer` to disambiguate the tokenizer to instantiate
- concurrently configuration and vocabulary files are updated on the relevant model repo in the hub to wake them independant from the code-base.
- the max length of the models was always the same for all the variante in an architecture. Consequently we simply the `max_model_input_sizes` attribute to make it a single integer instead of a mapping from string (model names) to integers.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-24-2020 15:12:23 | 11-24-2020 15:12:23 | This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,763 | closed | Migration guide from v3.x to v4.x | Additionally to the release notes, this completes the migration guide to showcase the expected breaking changes from v3.x to v4.x, and how to retrieve the original behavior. | 11-24-2020 15:04:32 | 11-24-2020 15:04:32 | Will update the switch to fast tokenizers when a decision has been made @thomwolf @n1t0 <|||||>@sgugger please let me know if this is what you had in mind. |
transformers | 8,762 | closed | AttributeError: type object 'T5ForConditionalGeneration' has no attribute 'from_config' | ## Environment info
- `transformers` version: 3.5.1
- Platform: Linux
- Python version: 3.7
- PyTorch version (GPU?): 1.6
- Tensorflow version (GPU?): -
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
Model Cards: @julien-c
Text Generation: @patrickvonplaten @TevenLeScao
T5: @patrickvonplaten
examples/seq2seq: @patil-suraj
## Information
Hi
I would like to use T5 untrained here is the command I try:
` model = T5ForConditionalGeneration.from_config(config=config)
`
I am getting this error, could you assist me please? thank you Looks weird error to me, since from_config should work based on documentations. thanks
```
File "finetune_t5_trainer.py", line 88, in main
model = T5ForConditionalGeneration.from_config(config=config)
AttributeError: type object 'T5ForConditionalGeneration' has no attribute 'from_config'
```
## To reproduce
Please run the command given
## Expected behavior
load unpretrained model
| 11-24-2020 14:19:18 | 11-24-2020 14:19:18 | I also tried to use automodel for this, I needed to modify the T5Config, I called it like this with automodel. thank you for your help. I need to make this work with not pretrained model.
` model = AutoModel.from_config(config)
`
I am getting this error:
```
Traceback (most recent call last):
File "finetune_t5_trainer.py", line 236, in <module>
main()
File "finetune_t5_trainer.py", line 89, in main
model = AutoModel.from_config(config)
File "/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/transformers/modeling_auto.py", line 604, in from_config
config.__class__, cls.__name__, ", ".join(c.__name__ for c in MODEL_MAPPING.keys())
ValueError: Unrecognized configuration class <class 'seq2seq.models.t5.configuration_t5.T5Config'> for this kind of AutoModel: AutoModel.
Model type should be one of RetriBertConfig, T5Config, DistilBertConfig, AlbertConfig, CamembertConfig, XLMRobertaConfig, BartConfig, LongformerConfig, RobertaConfig, LayoutLMConfig, SqueezeBertConfig, BertConfig, OpenAIGPTConfig, GPT2Config, MobileBertConfig, TransfoXLConfig, XLNetConfig, FlaubertConfig, FSMTConfig, XLMConfig, CTRLConfig, ElectraConfig, ReformerConfig, FunnelConfig, LxmertConfig, BertGenerationConfig, DebertaConfig, DPRConfig, XLMProphetNetConfig, ProphetNetConfig.
```<|||||>solved with model = T5ForConditionalGeneration(config=config) syntax has been changed from 3.5.0 to 3.5.1 thanks |
transformers | 8,761 | closed | Create README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-24-2020 13:24:52 | 11-24-2020 13:24:52 | |
transformers | 8,760 | closed | Create README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-24-2020 13:20:35 | 11-24-2020 13:20:35 | |
transformers | 8,759 | closed | Version 3.5 broke the multi context/questions feature for the QuestionAnsweringPipeline | ## Environment info
- `transformers` version: 3.5.1 (also in 3.5.0)
- Platform: Darwin-20.1.0-x86_64-i386-64bit
- Python version: 3.7.5
- PyTorch version (GPU?): 1.7.0 (False)
- Tensorflow version (GPU?): 2.3.1 (False)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
tokenizers: @mfuntowicz
## Information
Model I am using (Bert, XLNet ...): Default QuestionAnsweringPipeline
The problem arises when using:
* [x] my own modified scripts: (see below, modified from the example given here https://huggingface.co/transformers/usage.html#extractive-question-answering)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: Extractive Question Answering
## To reproduce
Steps to reproduce the behavior:
1. Install transformers 3.5.1 (also in 3.5.0)
2. Run the following:
```python
from transformers import pipeline
nlp = pipeline("question-answering")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text given a question. An example of a
question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune
a model on a SQuAD task, you may leverage the `run_squad.py`.
"""
print(
nlp(
question=["What is extractive question answering?", "What is a good example of a question answering dataset?"],
context=[context, context],
)
)
```
In versions 3.5.0 and 3.5.1, I have this error:
```
multiprocessing.pool.RemoteTraceback:
"""
Traceback (most recent call last):
File "/Users/cytadel/.pyenv/versions/3.7.5/Python.framework/Versions/3.7/lib/python3.7/multiprocessing/pool.py", line 121, in worker
result = (True, func(*args, **kwds))
File "/Users/cytadel/.pyenv/versions/3.7.5/Python.framework/Versions/3.7/lib/python3.7/multiprocessing/pool.py", line 44, in mapstar
return list(map(*args))
File "/Users/cytadel/Library/Caches/pypoetry/virtualenvs/feedly.ml-cyber-attacks-4LjjtgqO-py3.7/lib/python3.7/site-packages/transformers/data/processors/squad.py", line 110, in squad_convert_example_to_features
for (i, token) in enumerate(example.doc_tokens):
AttributeError: 'list' object has no attribute 'doc_tokens'
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/cytadel/feedly/ml/do_not_commit.py", line 14, in <module>
context=[context, context],
File "/Users/cytadel/Library/Caches/pypoetry/virtualenvs/feedly.ml-cyber-attacks-4LjjtgqO-py3.7/lib/python3.7/site-packages/transformers/pipelines.py", line 1787, in __call__
for example in examples
File "/Users/cytadel/Library/Caches/pypoetry/virtualenvs/feedly.ml-cyber-attacks-4LjjtgqO-py3.7/lib/python3.7/site-packages/transformers/pipelines.py", line 1787, in <listcomp>
for example in examples
File "/Users/cytadel/Library/Caches/pypoetry/virtualenvs/feedly.ml-cyber-attacks-4LjjtgqO-py3.7/lib/python3.7/site-packages/transformers/data/processors/squad.py", line 368, in squad_convert_examples_to_features
disable=not tqdm_enabled,
File "/Users/cytadel/Library/Caches/pypoetry/virtualenvs/feedly.ml-cyber-attacks-4LjjtgqO-py3.7/lib/python3.7/site-packages/tqdm/std.py", line 1171, in __iter__
for obj in iterable:
File "/Users/cytadel/.pyenv/versions/3.7.5/Python.framework/Versions/3.7/lib/python3.7/multiprocessing/pool.py", line 325, in <genexpr>
return (item for chunk in result for item in chunk)
File "/Users/cytadel/.pyenv/versions/3.7.5/Python.framework/Versions/3.7/lib/python3.7/multiprocessing/pool.py", line 748, in next
raise value
AttributeError: 'list' object has no attribute 'doc_tokens'
```
## Expected behavior
Same result as in transformers version 3.4.0:
`[{'score': 0.6222442984580994, 'start': 34, 'end': 96, 'answer': 'the task of extracting an answer from a text given a question.'}, {'score': 0.5115318894386292, 'start': 147, 'end': 161, 'answer': 'SQuAD dataset,'}]`
| 11-24-2020 12:59:28 | 11-24-2020 12:59:28 | Thank you for reporting this. Fixing it in #8765 |
transformers | 8,758 | closed | [Help] GPU with query answering | I want to figure out some way to get faster results from a QA model. I did some tests on google cloud with different GPUs and got some results, those tests was made with different GPUs and same CPU using this code:
```
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
from transformers.pipelines import pipeline
tokenizer = AutoTokenizer.from_pretrained("deepset/bert-large-uncased-whole-word-masking-squad2")
model = AutoModelForQuestionAnswering.from_pretrained("deepset/bert-large-uncased-whole-word-masking-squad2")
nlp_qa = pipeline('question-answering', model=model, tokenizer=tokenizer)
X = nlp_qa(context = text, question=queryy, topk = 3, device = 0, max_answer_len = 50)
```
Where context is just a long string and the question a simple query, and I got those results:
```
TESTE 1: **********
4 vCPUs 15Gb RAM
NVIDIA TESLA P100X1
Tempo1: 1:45 min
Tempo2: 1:40 min
Tempo3: 1:45 min
***************
***************
TESTE 2: **********
4 vCPUs 15Gb RAM
NVIDIA TESLA V100X1
Tempo1: 1:58 min
Tempo2: 1:58 min
Tempo3: 1:55 min
***************
***************
TESTE 3: **********
4 vCPUs 15Gb RAM
NVIDIA TESLA K80X1
Tempo1: 2:06 min
Tempo2: 2:18 min
Tempo3: 2:20 min
***************
***************
TESTE 4: **********
4 vCPUs 15Gb RAM
NVIDIA TESLA T4X1
Tempo1: 1:45 min
Tempo2: 1:50 min
Tempo3: 1:50 min
***************
***************
TESTE 5: **********
4 vCPUs 15Gb RAM
NVIDIA NONE
Tempo1: 2:22 min
Tempo2: 1:57 min
Tempo3: 1:57 min
```
I want to know if I am using GPU wrong, or is it normal to get almost same results with and without GPU on this set?.
Is there anyway to get faster results? | 11-24-2020 12:16:30 | 11-24-2020 12:16:30 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
Thanks! |
transformers | 8,757 | closed | UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 49: invalid start byte | ## Environment info
- `transformers` version: 3.5.1
- Platform: Linux-5.4.0-1029-gcp-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.0 (False)
- Tensorflow version (GPU?): 2.3.1 (False)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
I think:
@patrickvonplaten @LysandreJik @VictorSanh
Anyone is welcome!
## Information
I am using `examples/language-modeling/run_mlm_wwm.py` to train my own Tiny BERT model.
## To reproduce
Using Tiny BERT from Google [https://github.com/google-research/bert/blob/master/README.md](https://github.com/google-research/bert/blob/master/README.md)
Using `examples/language-modeling/run_mlm_wwm.py` from HuggingFace to train a language model on raw text.
files in my `google-bert-tiny` are `bert_config.json bert_model.ckpt.data-00000-of-00001 bert_model.ckpt.index vocab.txt`
Steps to reproduce the behavior:
1. install transformers torch and Tensorflow using pip
2. Get `examples/language-modeling/run_mlm_wwm.py` from HuggingFace>Transformers [Link](https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm_wwm.py)
3. Running the following command:
```shell
python run_mlm_wwm.py \
--model_name_or_path google-bert-tiny/bert_model.ckpt.index \
--config_name google-bert-tiny/bert_config.json \
--train_file train.txt \
--validation_file val.txt \
--do_train \
--do_eval \
--output_dir test-mlm-wwm \
--cache_dir cache
```
Error:
```
Traceback (most recent call last):
File "run_mlm_wwm.py", line 340, in <module>
main()
File "run_mlm_wwm.py", line 236, in main
tokenizer = AutoTokenizer.from_pretrained(
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/tokenization_auto.py", line 306, in from_pretrained
config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/configuration_auto.py", line 333, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/configuration_utils.py", line 391, in get_config_dict
config_dict = cls._dict_from_json_file(resolved_config_file)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/configuration_utils.py", line 474, in _dict_from_json_file
text = reader.read()
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 49: invalid start byte
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Want it to train
<!-- A clear and concise description of what you would expect to happen. -->
| 11-24-2020 11:59:34 | 11-24-2020 11:59:34 | You should first convert your checkpoint to a huggingface checkpoint, using the conversion script. You can check the [docs here](https://huggingface.co/transformers/converting_tensorflow_models.html#bert).<|||||>Hi @LysandreJik
Thank you so much for the response,
after training I will get a PyTorch checkpoint, right?
What is the procedure to get a `tf` checkpoint?<|||||>> You should first convert your checkpoint to a huggingface checkpoint, using the conversion script. You can check the [docs here](https://huggingface.co/transformers/converting_tensorflow_models.html#bert).
Hi @LysandreJik ,
I tried the above approach, and I converted it to a huggingface checkpoint.
Now when I run below command:
```
python run_mlm_wwm.py \
--model_name_or_path google-bert-tiny/pytorch_model.bin \
--config_name google-bert-tiny/bert_config.json \
--train_file train.txt \
--validation_file val.txt \
--do_train \
--do_eval \
--output_dir test-mlm-wwm \
--cache_dir cache
```
I am getting this error:
```
Traceback (most recent call last):
File "run_mlm_wwm.py", line 340, in <module>
main()
File "run_mlm_wwm.py", line 236, in main
tokenizer = AutoTokenizer.from_pretrained(
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/tokenization_auto.py", line 306, in from_pretrained
config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/configuration_auto.py", line 333, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/configuration_utils.py", line 391, in get_config_dict
config_dict = cls._dict_from_json_file(resolved_config_file)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/configuration_utils.py", line 474, in _dict_from_json_file
text = reader.read()
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 64: invalid start byte
```
@thomwolf <|||||>I believe the `model_name_or_path` should point to a directory containing both the configuration and model files, with their appropriate name (`config.json`, `pytorch_model.bin`).
```
directory
- config.json
- pytorch_model.bin
```
Regarding your question to convert a model to a TensorFlow implementation, you can first convert your model to PyTorch and then load it in TensorFlow:
Let's say you saved the model in the directory `directory`:
```py
from transformers import TFBertForPreTraining
pt_model = BertForPreTraining.from_pretrained(directory, from_pt=True)
```
You can then save it as any other TensorFlow model.<|||||>Hi @LysandreJik
After giving the folder to config and model,
```Python
from transformers import convert_pytorch_checkpoint_to_tf2
convert_pytorch_checkpoint_to_tf2.convert_pt_checkpoint_to_tf(
model_type = "bert",
pytorch_checkpoint_path="model/",
config_file="model/config.json",
tf_dump_path="TFmodel",
compare_with_pt_model=False,
use_cached_models=False
)
```
I am getting this error:
```shell
Loading PyTorch weights from /home/3551351/bert-mlm/model
Traceback (most recent call last):
File "pt2tf.py", line 7, in <module>
convert_pytorch_checkpoint_to_tf2.convert_pt_checkpoint_to_tf(
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/convert_pytorch_checkpoint_to_tf2.py", line 283, in convert_pt_checkpoint_to_tf
tf_model = load_pytorch_checkpoint_in_tf2_model(tf_model, pytorch_checkpoint_path)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/transformers/modeling_tf_pytorch_utils.py", line 93, in load_pytorch_checkpoint_in_tf2_model
pt_state_dict = torch.load(pt_path, map_location="cpu")
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/torch/serialization.py", line 581, in load
with _open_file_like(f, 'rb') as opened_file:
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/torch/serialization.py", line 230, in _open_file_like
return _open_file(name_or_buffer, mode)
File "/home/3551351/.conda/envs/kuldeepVenv/lib/python3.8/site-packages/torch/serialization.py", line 211, in __init__
super(_open_file, self).__init__(open(name, mode))
IsADirectoryError: [Errno 21] Is a directory: '/home/3551351/bert-mlm/model'
```
<|||||>I'm sorry, I think you misunderstood me. I was saying that about the way you launch your script, not the way you do the conversion:
```
python run_mlm_wwm.py \
--model_name_or_path google-bert-tiny \
--config_name google-bert-tiny \
--train_file train.txt \
--validation_file val.txt \
--do_train \
--do_eval \
--output_dir test-mlm-wwm \
--cache_dir cache
```<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,756 | closed | Continued training of the original BERT models (not to PyTorch) | # 🚀 Feature request
I am looking for continued training of original tiny-bert with my own raw data using masked language modelling.
But I want the final model in TF.
## Motivation
I tried this [LM](https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm_wwm.py), but this only works from pytorch to pytorch.
I tried with using original ckpt and from_tf, it always results in a .h5 error
Please let me know I can explain more OR help in any way.
Basically, we should be able to use tf weights >> masked language modelling >> and have a domain specific pre-trained Tensorflow language model.
| 11-24-2020 11:00:23 | 11-24-2020 11:00:23 | You should first convert your checkpoint to a huggingface checkpoint. You can check the docs on how to do that [here](https://huggingface.co/transformers/converting_tensorflow_models.html#bert).<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,755 | closed | Why there are no such 'cls/' layers in roberta pytorch checkpoints | In pytorch checkpoints of roberta in huggingface transformers, the last two layers are the "pooler layers":
pooler.dense.weight
pooler.dense.bias
However, In original roberta tensorflow checkpoints, the last few layers are not the pooler layers, instead, they are:
cls/predictions/output_bias (DT_FLOAT) [21128]
cls/predictions/transform/LayerNorm/beta (DT_FLOAT) [768]
cls/predictions/transform/LayerNorm/gamma (DT_FLOAT) [768]
cls/predictions/transform/dense/bias (DT_FLOAT) [768]
cls/predictions/transform/dense/kernel (DT_FLOAT) [768,768]
cls/seq_relationship/output_bias (DT_FLOAT) [2]
cls/seq_relationship/output_weights (DT_FLOAT) [2,768]
these 'cls/' layers came after the pooler layers.
I converted the pytorch checkpoints into tensorflow checkpoints. Then when I try to load the weights, all I was told was:
tensorflow.python.framework.errors_impl.NotFoundError: Key cls/predictions/transform/dense/kernel not found in checkpoint
which means the 'cls/' layers do not exist at all! so why these layers are gone in pytorch checkpoints provided by huggingface transformers? What should I do to get the weights of these 'cls/' layers? I am trying to use a roberta checkpoint that is trained by someone else using huggingface transformers, however, I have to convert it to a tensorflow version for my code is in tensorflow version , but this problem occurs. how can I correctly convert the checkpoints? | 11-24-2020 10:11:40 | 11-24-2020 10:11:40 | The authors of RoBERTa removed the next sentence prediction task during pre-training, as it didn't help much. See section 1 of the [paper](https://arxiv.org/pdf/1907.11692.pdf).<|||||>> The authors of RoBERTa removed the next sentence prediction task during pre-training, as it didn't help much. See section 1 of the [paper](https://arxiv.org/pdf/1907.11692.pdf).
Really appreciate your apply! However, the 2 'cls/seq_relationship/' layers are responsible for the NSP task. The rest should be responsible for the MLM task. What is more, these layers are the exact layers that I extract from the original roberta TensorFlow checkpoint published by the author of the paper... This is confusing. I am just wondering why the huggingface pytorch checkpoints just don't stay the weights of the MLM task, in UNILM, these weights are precious. Of course NSP is not that important.<|||||>Yes you're right, sorry. I think that the masked language modeling head has a different name in Huggingface Transformers. It is simply called `lm_head`. See [here](https://github.com/huggingface/transformers/blob/a7d73cfdd497d7bf6c9336452decacf540c46e20/src/transformers/models/roberta/modeling_roberta.py#L869) for the PyTorch implementation of RoBERTa. Note that you should use `RobertaForMaskedLM` rather than `RobertaModel`, since the latter does not have a masked language modeling head on top.<|||||>> I think that the masked language modeling head has a different name in Huggingface Transformers. It is simply called `lm_head`. See here: https://huggingface.co/transformers/_modules/transformers/modeling_tf_roberta.html#TFRobertaForMaskedLM
Appreciate again! I will have a look tomorrow, and in fact it is 2 a.m. in my city right now and I am
totally in bed hahahh<|||||>> Yes you're right, sorry. I think that the masked language modeling head has a different name in Huggingface Transformers. It is simply called `lm_head`. See [here](https://github.com/huggingface/transformers/blob/a7d73cfdd497d7bf6c9336452decacf540c46e20/src/transformers/models/roberta/modeling_roberta.py#L869) for the PyTorch implementation of RoBERTa. Note that you should use `RobertaForMaskedLM` rather than `RobertaModel`, since the latter does not have a masked language modeling head on top.
That really makes sense to me, even I am in bed. thanks a lot!<|||||>You're welcome! Good night<|||||>> You're welcome! Good night
Your approach sovled my problem perfectly, now I have successfully converted the pytorch weights into tensorflow weights. Time to close the issue now. ^_^ |
transformers | 8,754 | closed | Allow to provide specific params in WandbCallback | # 🚀 Feature request
It would be nice to be able to track additional params in wandb when using the Trainer interface. For example, I need to track down how many layers were frozen in each experiment. I'm currently using a custom WandCallback class to do this.
## Your contribution
I can work on a PR.
| 11-24-2020 10:08:12 | 11-24-2020 10:08:12 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Sorry I just noticed this issue.
You can actually already do it. After your run has been created, you can do `wandb.config['frozen_layers'] = 3`
We need to add a way to let you also create a run first (instead of `Trainer`) and then let `Trainer` adds automatically the extra configuration parameters.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,753 | closed | update README.txt | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-24-2020 10:06:37 | 11-24-2020 10:06:37 | Closing this one as duplicate was already merged!
For context please also read https://discuss.huggingface.co/t/announcement-all-model-cards-will-be-migrated-to-hf-co-model-repos/2755 |
transformers | 8,752 | closed | Create README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-24-2020 05:46:47 | 11-24-2020 05:46:47 | |
transformers | 8,751 | closed | Create README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-24-2020 05:31:48 | 11-24-2020 05:31:48 | Update model card |
transformers | 8,750 | open | Fix minor bug to handle dynamic sequence length | This PR is to fix a minor bug for handling dynamic sequence length, e.g., during building the serving model(s). | 11-24-2020 03:10:14 | 11-24-2020 03:10:14 | Hi! Could you run `make quality` at the root of your clone so that it passes the code quality test?<|||||>@LysandreJik : I did run `make quality` but got the following error:
`(pyvenv3-transformers-forked) ➜ transformers git:(master-minor-fix-t5) make quality
black --check examples tests src utils
All done! ✨ 🍰 ✨
621 files would be left unchanged.
isort --check-only examples tests src utils
flake8 examples tests src utils
python utils/style_doc.py src/transformers docs/source --max_len 119 --check_only
/Library/Developer/CommandLineTools/usr/bin/make extra_quality_checks
/Users/PZ9DU5/vuh/tools/pyvenv3-transformers-forked/lib/python3.7/site-packages/setuptools/dist.py:454: UserWarning: Normalizing '4.0.0-rc-1' to '4.0.0rc1'
warnings.warn(tmpl.format(**locals()))
running deps_table_update
updating src/transformers/dependency_versions_table.py
python utils/check_copies.py
python utils/check_dummies.py
python utils/check_repo.py
Checking all models are properly tested.
Checking all models are properly documented.
Checking all models are in at least one auto class.
Traceback (most recent call last):
File "utils/check_repo.py", line 400, in <module>
check_repo_quality()
File "utils/check_repo.py", line 396, in check_repo_quality
check_all_models_are_auto_configured()
File "utils/check_repo.py", line 342, in check_all_models_are_auto_configured
all_auto_models = get_all_auto_configured_models()
File "utils/check_repo.py", line 316, in get_all_auto_configured_models
for attr_name in dir(transformers.models.auto.modeling_auto):
AttributeError: module 'transformers.models.auto' has no attribute 'modeling_auto'
make[1]: *** [extra_quality_checks] Error 1
make: *** [quality] Error 2` |
transformers | 8,749 | closed | [core] transformers version number normalization | It looks that we need to either normalize the `transformers` version number to one of the accepted formats:
```
x.y.z
x.y.z.dev0
x.y.z.rc1
```
or silence the warning.
Currently, `setuptools` doesn't like `-rc-1` and `-dev`, as you can see from:
```
python setup.py --name
.../python3.8/site-packages/setuptools/dist.py:452: UserWarning: Normalizing '4.0.0-rc-1' to '4.0.0rc1'
```
with `4.0.0-dev`
```
python3.8/site-packages/setuptools/dist.py:452: UserWarning: Normalizing '4.0.0-dev' to '4.0.0.dev0'
```
Otherwise, this warning will be showing up all the time during `make style` and friends once https://github.com/huggingface/transformers/pull/8645 is merged.
@sgugger, @LysandreJik
| 11-24-2020 03:05:23 | 11-24-2020 03:05:23 | We're making a release today, so will change the version number to the proper format just after :-)<|||||>Following what @sgugger said! |
transformers | 8,748 | closed | "AutoTokenizer.from_pretrained" does not work when loading a pretrained Albert model | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: 5.4.0-53-generic #59~18.04.1-Ubuntu SMP Wed Oct 21 12:14:56 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.0
- Tensorflow version (GPU?): N/A
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
Blenderbot: @patrickvonplaten
Bart: @patrickvonplaten
Marian: @patrickvonplaten
Pegasus: @patrickvonplaten
mBART: @patrickvonplaten
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSMT: @stas00
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Install PyTorch from the official website as well as the transformers via pip.
2. Using the following pre-trained model:
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("ckiplab/albert-tiny-chinese")
model = AutoModelForMaskedLM.from_pretrained("ckiplab/albert-tiny-chinese")
```
3. Error:
```
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 683/683 [00:00<00:00, 1.32MB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 112/112 [00:00<00:00, 215kB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 174/174 [00:00<00:00, 334kB/s]
Traceback (most recent call last):
File "/home/faith/torch_tutorials/torch_chatbot.py", line 30, in <module>
tokenizer = AutoTokenizer.from_pretrained("ckiplab/albert-tiny-chinese")
File "/home/faith/miniconda3/envs/torch/lib/python3.7/site-packages/transformers/tokenization_auto.py", line 341, in from_pretrained
return tokenizer_class_py.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "/home/faith/miniconda3/envs/torch/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1653, in from_pretrained
resolved_vocab_files, pretrained_model_name_or_path, init_configuration, *init_inputs, **kwargs
File "/home/faith/miniconda3/envs/torch/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1725, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/home/faith/miniconda3/envs/torch/lib/python3.7/site-packages/transformers/tokenization_albert.py", line 149, in __init__
self.sp_model.Load(vocab_file)
File "/home/faith/miniconda3/envs/torch/lib/python3.7/site-packages/sentencepiece.py", line 367, in Load
return self.LoadFromFile(model_file)
File "/home/faith/miniconda3/envs/torch/lib/python3.7/site-packages/sentencepiece.py", line 177, in LoadFromFile
return _sentencepiece.SentencePieceProcessor_LoadFromFile(self, arg)
TypeError: not a string
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Expect to download this model correctly with error prompting.
| 11-24-2020 01:27:57 | 11-24-2020 01:27:57 | Can you share your version of `transformers`, `tokenizers`?<|||||>I can reproduce this in a Colab notebook when doing `pip install transformers`.
- Transformers version 3.5.1
- Tokenizers version 0.9.3
Might be solved with v4? <|||||>I am having the same issue with AlbertTokenizer.from_pretrained<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread.<|||||>i have the same question! |
transformers | 8,747 | closed | Return correct Bart hidden state tensors | # What does this PR do?
Fixes #8601. When `output_hidden_states=True`, hidden states transposing is done _before_ being fed through the next layer. This ensures that the returned hidden state tensors lie upstream in the graph from the model outputs (allowing their gradients to be computed). | 11-24-2020 00:01:55 | 11-24-2020 00:01:55 | ## UPDATE:
This PR is ready for review.
@sgugger, @LysandreJik - this very-well documented issue: https://github.com/huggingface/transformers/issues/8601 shows that for some models the gradient of the outputted `hidden_states` and the `attentions` cannot be computed because the tensors are excluded from the computation graph via some `transpose`, `permute`, or `slice` operations.
@joeddav found a great fix for Bart and I applied the same fix now for all other models and added a test.
The only models that are not capable of keeping the gradient in `attentions` and `hidden_states` are
- Longformer -> chunked attention slice operations don't allow keeping grad
- Reformer -> customized backward doesn't help here
- ProphetNet -> Decoder part can't keep grad because of slice operations
- TransfoXL, XLNet -> two stream attention doesn't allow to keep the grad either
All other models can keep the grad which is ensured by the test. |
transformers | 8,746 | closed | Fix slow tests v2 | Fix a few tests that were broken in recent PRs. | 11-23-2020 23:32:18 | 11-23-2020 23:32:18 | |
transformers | 8,745 | closed | added instructions for syncing upstream master with forked master via PR | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #8742
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [commit](https://github.com/lucidworks/transformers/commit/46b17d206529206848116fd6219643446bac938c#commitcomment-44356945)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
@stas00 | 11-23-2020 23:25:45 | 11-23-2020 23:25:45 | @LysandreJik, @sgugger
We are trying to give instructions to avoid:
1. this:

This is just one of the many examples - a snapshot is from the bottom of https://github.com/huggingface/transformers/pull/8400
You can browse recent PRs for many more of these.
These are not "legit" references - but automatic replays of PRs.
2. unnecessary notifications for the developers mentioned in PR commit messages when these are replied in user forks.
`CONTRIBUTING.md` is not the most intuitive place for this, but at the moment there is no other place I could think of. At the very least if a new fork user starts doing this, we can refer them to this section.
Of course, the perfect solution would be for github to give repo admins an option to not allow ping-backs from repo forks. But I don't think it's available now.
|
transformers | 8,744 | closed | Added instructions for syncing forked masters to avoid references | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #8742
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [commit](https://github.com/lucidworks/transformers/commit/46b17d206529206848116fd6219643446bac938c#commitcomment-44356945)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
@stas00 | 11-23-2020 23:15:58 | 11-23-2020 23:15:58 | @stas00 I performed the merge using the steps I've written and no references or pings are made, so it works. Let me know if some improvements can be made.
Thanks.<|||||>Sorry, this one should've been for merging into my fork. Created the PR in the wrong place.
I'll do a rebase for merge here. |
transformers | 8,743 | closed | MT5 should have an autotokenizer | MT5 should have an auto-tokenizer.
Currently fails a lot of slow tests. | 11-23-2020 23:11:50 | 11-23-2020 23:11:50 | |
transformers | 8,742 | closed | Add instructions for syncing forked masters to avoid references | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
Ticket created based on discussion https://github.com/lucidworks/transformers/commit/46b17d206529206848116fd6219643446bac938c#commitcomment-44356945
The problem is when someone on a forked repository decides to sync up their masters with upstream (HF master) using a branch and a PR, all the PR and issue references on the upstream will make their way into the forked PR's commit history, if that user creates a merge commit.
Since GitHub autolinks issues and PRs on public forks, this will end up pinging the devs responsible for the referenced PRs creating unnecessary noise. The solution is to use a squashed merge.
One way to educate users with forked repos about this potential issue is to add instructions on how to do so to the `CONTRIBUTING.md` file.
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
A PR with instructions to avoid this situation will be up shortly.
cc @stas00 | 11-23-2020 22:59:16 | 11-23-2020 22:59:16 | |
transformers | 8,741 | closed | Model parallel documentation | Fixes the parallelization docs | 11-23-2020 22:36:47 | 11-23-2020 22:36:47 | |
transformers | 8,740 | closed | Blank line indicates the end of a document for NER training ? | Hi everyone!
In the <https://huggingface.co/transformers/custom_datasets.html#token-classification-with-w-nut-emerging-entities> , it says that each line of the dataset file contains either (1) a word and tag separated by a tab, or (2) a blank line indicating the end of a document.
The blank line should not represent the end of a sentence?
| 11-23-2020 20:42:27 | 11-23-2020 20:42:27 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,739 | closed | AttributeError: 'BertTokenizerFast' object has no attribute 'max_len' | ## Environment info
- `transformers` version: 4.0.0-rc-1
- Platform: Linux-4.9.0-14-amd64-x86_64-with-debian-9.13
- Python version: 3.6.10
- PyTorch version (GPU?): 1.8.0a0+4ed7f36 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: 8-core TPU training
- **Using TPU**
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
## Information
Model I am using (Bert, XLNet ...): bert and roberta
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: mlm
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
2 examples of failing commands:
```
E 2020-11-18T17:38:08.657584093Z python examples/xla_spawn.py \
E 2020-11-18T17:38:08.657588780Z --num_cores 8 \
E 2020-11-18T17:38:08.657593609Z examples/contrib/legacy/run_language_modeling.py \
E 2020-11-18T17:38:08.657598646Z --logging_dir ./tensorboard-metrics \
E 2020-11-18T17:38:08.657604088Z --cache_dir ./cache_dir \
E 2020-11-18T17:38:08.657609492Z --train_data_file /datasets/wikitext-103-raw/wiki.train.raw \
E 2020-11-18T17:38:08.657614614Z --do_train \
E 2020-11-18T17:38:08.657619772Z --do_eval \
E 2020-11-18T17:38:08.657624531Z --eval_data_file /datasets/wikitext-103-raw/wiki.valid.raw \
E 2020-11-18T17:38:08.657629731Z --overwrite_output_dir \
E 2020-11-18T17:38:08.657641827Z --output_dir language-modeling \
E 2020-11-18T17:38:08.657647203Z --logging_steps 100 \
E 2020-11-18T17:38:08.657651823Z --save_steps 3000 \
E 2020-11-18T17:38:08.657656739Z --overwrite_cache \
E 2020-11-18T17:38:08.657661282Z --tpu_metrics_debug \
E 2020-11-18T17:38:08.657667598Z --mlm --model_type=bert \
E 2020-11-18T17:38:08.657672545Z --model_name_or_path bert-base-cased \
E 2020-11-18T17:38:08.657677441Z --num_train_epochs 3 \
E 2020-11-18T17:38:08.657682320Z --per_device_train_batch_size 16 \
E 2020-11-18T17:38:08.657687053Z --per_device_eval_batch_size 16
```
```
2020-11-18T17:51:49.357234955Z Traceback (most recent call last):
E
2020-11-18T17:51:49.357239554Z File "/root/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 329, in _mp_start_fn
E
2020-11-18T17:51:49.357245350Z _start_fn(index, pf_cfg, fn, args)
E
2020-11-18T17:51:49.357249851Z File "/root/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 323, in _start_fn
E
2020-11-18T17:51:49.357254654Z fn(gindex, *args)
E
2020-11-18T17:51:49.357272443Z File "/transformers/examples/contrib/legacy/run_language_modeling.py", line 359, in _mp_fn
E
2020-11-18T17:51:49.357277658Z main()
E
2020-11-18T17:51:49.357281928Z File "/transformers/examples/contrib/legacy/run_language_modeling.py", line 279, in main
E
2020-11-18T17:51:49.357287863Z data_args.block_size = tokenizer.max_len
E
2020-11-18T17:51:49.357292355Z AttributeError: 'BertTokenizerFast' object has no attribute 'max_len'
E
```
```
E 2020-11-18T06:47:53.910306819Z python examples/xla_spawn.py \
E 2020-11-18T06:47:53.910310176Z --num_cores 8 \
E 2020-11-18T06:47:53.910314263Z examples/contrib/legacy/run_language_modeling.py \
E 2020-11-18T06:47:53.910319173Z --logging_dir ./tensorboard-metrics \
E 2020-11-18T06:47:53.910322683Z --cache_dir ./cache_dir \
E 2020-11-18T06:47:53.910325895Z --train_data_file /datasets/wikitext-103-raw/wiki.train.raw \
E 2020-11-18T06:47:53.910329170Z --do_train \
E 2020-11-18T06:47:53.910332491Z --do_eval \
E 2020-11-18T06:47:53.910335626Z --eval_data_file /datasets/wikitext-103-raw/wiki.valid.raw \
E 2020-11-18T06:47:53.910340314Z --overwrite_output_dir \
E 2020-11-18T06:47:53.910343710Z --output_dir language-modeling \
E 2020-11-18T06:47:53.910347004Z --logging_steps 100 \
E 2020-11-18T06:47:53.910350089Z --save_steps 3000 \
E 2020-11-18T06:47:53.910353259Z --overwrite_cache \
E 2020-11-18T06:47:53.910356297Z --tpu_metrics_debug \
E 2020-11-18T06:47:53.910359351Z --mlm --model_type=roberta \
E 2020-11-18T06:47:53.910362484Z --tokenizer=roberta-base \
E 2020-11-18T06:47:53.910365650Z --num_train_epochs 5 \
E 2020-11-18T06:47:53.910368797Z --per_device_train_batch_size 8 \
E 2020-11-18T06:47:53.910371843Z --per_device_eval_batch_size 8
```
```
2020-11-18T06:48:27.357394365Z Traceback (most recent call last):
E
2020-11-18T06:48:27.357399685Z File "/root/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 329, in _mp_start_fn
E
2020-11-18T06:48:27.357405353Z _start_fn(index, pf_cfg, fn, args)
E
2020-11-18T06:48:27.357426600Z File "/root/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 323, in _start_fn
E
2020-11-18T06:48:27.357448514Z fn(gindex, *args)
E
2020-11-18T06:48:27.357454250Z File "/transformers/examples/contrib/legacy/run_language_modeling.py", line 359, in _mp_fn
E
2020-11-18T06:48:27.357460262Z main()
E
2020-11-18T06:48:27.357465843Z File "/transformers/examples/contrib/legacy/run_language_modeling.py", line 279, in main
E
2020-11-18T06:48:27.357471227Z data_args.block_size = tokenizer.max_len
E
2020-11-18T06:48:27.357477576Z AttributeError: 'RobertaTokenizerFast' object has no attribute 'max_len'
E
```
The timing of this issue lines up with https://github.com/huggingface/transformers/pull/8586
Tests started failing on the evening of Nov 17, a few hours after that PR was submitted | 11-23-2020 20:09:00 | 11-23-2020 20:09:00 | It is actually due to https://github.com/huggingface/transformers/pull/8604, where we removed several deprecated arguments. The `run_language_modeling.py` script is deprecated in favor of `language-modeling/run_{clm, plm, mlm}.py`.
Is it possible for you to switch to one of these newer scripts? If not, the fix is to change `max_len` to `model_max_length`. We welcome PRs to fix it, but we won't be maintaining that script ourselves as there exists better alternatives now (which run on TPU too :slightly_smiling_face:)<|||||>Thanks for taking a look! I will try out the new script<|||||>The new runner is working for us on TPUs. Thanks again for the tip!<|||||>Hello, Everything was a few days. I am getting the same error " data_args.block_size = min(data_args.block_size, tokenizer.max_len)
**AttributeError: 'RobertaTokenizerFast' object has no attribute 'max_len"**.
I can't switch to a new script as you mentioned. Kindly help me with this error. I do not know how to fix it. Here is my chunk of codes.
```
`!python "/content/transformers/examples/contrib/legacy/run_language_modeling.py" \
--output_dir "/content/drive/MyDrive/Vancouver" \
--model_name_or_path roberta-base \
--do_train \
--per_gpu_train_batch_size 8 \
--seed 42 \
--train_data_file "/content/input_textOC.txt" \
--block_size 256 \
--line_by_line \
--learning_rate 6e-4 \
--num_train_epochs 3 \
--save_total_limit 2 \
--save_steps 200 \
--weight_decay 0.01 \
--mlm`
```<|||||>> It is actually due to #8604, where we removed several deprecated arguments. The `run_language_modeling.py` script is deprecated in favor of `language-modeling/run_{clm, plm, mlm}.py`.
>
> Is it possible for you to switch to one of these newer scripts? If not, the fix is to change `max_len` to `model_max_length`. We welcome PRs to fix it, but we won't be maintaining that script ourselves as there exists better alternatives now (which run on TPU too )
The fix is mentioned above:
> fix is to change `max_len` to `model_max_length`<|||||>If you cannot switch scripts, I recommend pinning the library. You're having this error because you're using a legacy script with a `master` version that is not compatible.
You could pin it to v3.5.1.<|||||>Thanks, I appreciate your response. However, I am still a basic learner. Can you please explain it a bit? how to pin it to v3.5.1.. Is it mean to use the old version of huggingface.?<|||||>If you wish to stick to that deprecated example, yes! You can do so by checking out the tag v3.5.1:
```
git checkout v3.5.1
```
If you have installed transformers from pypi (and not from source), you should also update your transformers version:
```
pip install -U transformers==3.5.1
```
Please note that the script won't be in "/content/transformers/examples/contrib/legacy/run_language_modeling.py" anymore, but in "/content/transformers/examples/language-modeling/run_language_modeling.py"<|||||>> It is actually due to #8604, where we removed several deprecated arguments. The `run_language_modeling.py` script is deprecated in favor of `language-modeling/run_{clm, plm, mlm}.py`.
Hello, I am facing the same issue with `run_language_modeling.py` (and more). Where can I find this new file `language-modeling/run_{clm, plm, mlm}.py`? Thanks!<|||||>You can find them here https://github.com/huggingface/transformers/tree/master/examples/pytorch/language-modeling<|||||>Thank you! <|||||>> It is actually due to #8604, where we removed several deprecated arguments. The `run_language_modeling.py` script is deprecated in favor of `language-modeling/run_{clm, plm, mlm}.py`.
>
> Is it possible for you to switch to one of these newer scripts? If not, the fix is to change `max_len` to `model_max_length`. We welcome PRs to fix it, but we won't be maintaining that script ourselves as there exists better alternatives now (which run on TPU too 🙂)
Change `max_len` to `model_max_length` where? |
transformers | 8,738 | closed | Fix max length in run_plm script | # What does this PR do?
The XLNet tokenizer has a ridiculously high maximum sequence length, so the `run_plm` was failing without setting the `max_seq_length` argument. This PR fixes that by setting default of 512 to it.
Fixes #8674
| 11-23-2020 19:44:47 | 11-23-2020 19:44:47 | |
transformers | 8,737 | closed | consistent ignore keys + make private | This PR addresses https://github.com/huggingface/transformers/issues/7258
(the proposal has evolved a bit since the initial PR, this comments reflects the current state)
* [x] renames optional model attributes:
```
- authorized_missing_keys => _keys_to_ignore_on_load_missing
- authorized_unexpected_keys => _keys_to_ignore_on_load_unexpected
- keys_to_never_save => _keys_to_ignore_on_save
```
to (1) make them consistent (2) make them private
* [x] removes these from public API docstring (documents them privately as comments in place)
This is a breaking change.
Fixes https://github.com/huggingface/transformers/issues/7258
@LysandreJik, @sgugger
p.s. if we want to postpone it for v5, this PR was a quick one liner:
```
find . -type d -name ".git" -prune -o -type f -exec perl -pi -e 's|authorized_missing_keys|_keys_to_ignore_on_load_missing|g; s|authorized_unexpected_keys|_keys_to_ignore_on_load_unexpected|g'; s|keys_to_never_save|_keys_to_ignore_on_save|g' {} \;
```
and then manually adjusting the docs. | 11-23-2020 19:35:42 | 11-23-2020 19:35:42 | oh, boy, there is also `authorized_unexpected_keys`
https://github.com/huggingface/transformers/blob/49759c0cda29ab614b81e0869972c99f2edba7aa/src/transformers/modeling_tf_utils.py#L346-L354
<|||||>Indeed, very nice catch! How should we rename that one? <|||||>Current `authorized_missing_keys` and `authorized_unexpected_keys` do the same thing overall, just 2 different categories.
perhaps?
```
- authorized_missing_keys => _keys_to_ignore_on_load_missing
- authorized_unexpected_keys => _keys_to_ignore_on_load_unexpected
- keys_to_never_save => _keys_to_ignore_on_save
```<|||||>For me `authorized_unexpected_keys` should be the `_keys_to_ignore_on_load`: they are in the state dict but we ignore them.
The `authorized_missing_keys` should have another name such as `_keys_missing_to_ignore_on_load` or just `_keys_missing_to_ignore`.
Re- documentation. We usually document private stuff in comments in the code, so I think we should remove the public documentation and change it in comments.<|||||>We were writing at the same time @stas00 , your names are better than mine. Go ahead!<|||||>You can safely ignore the failed connections. It's been happening since the change to git-based repos. We're looking into fixing it with @julien-c, it happens very often.<|||||>@LysandreJik, I trust you will document this breaking change - I just don't know where I'd do that...<|||||>Yes, I'm currently documenting all breaking changes in the release notes. |
transformers | 8,736 | closed | [trainer] `model` argument is not the same depending on n_gpus | Extracting the discussion from https://github.com/huggingface/transformers/pull/8716
Summary of the issue: `prediction_step()` has a `model` argument which is a normal model with n_gpu < 2, and a wrapped DataParallel model with n_gpu > 1. So the API suffers from ambiguity here.
The user has to really use `self.model` to be able to call methods like `model.config()` or `model.generate()`, which can't be called on the wrapped model. But it's very likely they will use `model` instead since it'll act like `self.model` unless under multi_gpu. And why do we even have that `model` argument then?
Possible solutions discussed:
1. monkeypatch `torch.nn.DataParallel` to expand its API to support all the methods of the original model transparently by installing a catch all `__getattr__` and remap all the failed method look ups to delegate to `self.module`.
2. not to call the function argument `model` anymore, since it isn't under multi gpu, but is something else.
3. remove the `model` argument completely + document to always use `self.model` - currently in `seq2seq_trainer.py `once we switch to `self.model`, `prediction_step()` no longer needs `model` as an argument (but is it always the case?)
4. pass `self.model `as the `model` arg, and making the wrapped model available via `self.wrapped_model` if the user needs it.
Summary of discussion around proposed solutions:
1. too magical
2. proposed calling it `wrapped_model`, but it's just as confusing since most of the time it's not.
3. need to check whether wrapped model is every needed inside user functions.
4. was not discussed yet
@sgugger, @LysandreJik | 11-23-2020 19:09:13 | 11-23-2020 19:09:13 | Note that this all internal and a user only interacts/get used with that if they subclass `Trainer` and override the `prediction_step` method. I would keep it simple since it's touching a small part of our users that should be experienced enough to be able to read the docstrings, and just detail in the docstrings with a proper warning what this `model` argument represents.
I can also live with 4 if it's the solution selected.<|||||>As I didn't participate in the design of Trainer, and I don't know whether it's meant to be easily sub-classable or not - I currently can only think of some ideas and I trust you guys to choose the most suitable solution. I hope it makes sense.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Well, we have implemented number 4, so closing this. |
transformers | 8,735 | closed | Model can't be downloaded | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.1.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
### Who can help
@julien-c
## To reproduce
I've recently shared a finetunned model - monilouise/ner_pt_br - and despite its model card is already available at https://github.com/huggingface/transformers/tree/master/model_cards, the following error occurs when I try to download it:
OSError: Can't load config for 'monilouise/ner_pt_br'. Make sure that:
- 'monilouise/ner_pt_br' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'monilouise/ner_pt_br' is the correct path to a directory containing a config.json file
BUT the model has config.json available at https://huggingface.co/monilouise/ner_pt_br/tree/main.
I used the following code to download the model:
```python
from transformers import BertForTokenClassification
model = BertForTokenClassification.from_pretrained('monilouise/ner_pt_br')
```
Is there anything else missing from the recommended sharing procedures?
Thanks in advance.
| 11-23-2020 18:46:26 | 11-23-2020 18:46:26 | Hey @moniquebm,
I cannot reproduce this error on master.
it looks like you are working with an old version of transformers. Could you try updating `transformers` to `3.5.0` to see if the error persists?
Another reason why this doesn't work might be that you have a directory locally that is also called `monilouise/ner_pt_br`, so that instead of downloading from the model hub `from.pretrained()` tries to load a local model. You can check whether this might be the problem by running the command from a different directory or checking whether you have a local dir called `monilouise`.<|||||>@patrickvonplaten is 100% right on his first guess that it's due to using transformers < `v3.5.x`
We backport new git-based models back to the previous S3 bucket (for models to be usable on previous versions of the library) automatically, however there was a hiccup yesterday that crashed the process (it's currently sync'ing again).<|||||>Hi @patrickvonplaten and @julien-c ,
I've just updated transformers version and it worked.
Thanks! |
transformers | 8,734 | closed | Change default cache path | # What does this PR do?
In Datasets, the default cache path ends up in `~/.cache/huggingface/datasets`, controlled by the environment variable `HF_HOME`. This PR uses the same env variable for the default cache path.
To avoid breaking changes:
- it still honors old environment variable names, if set
- if none is set, it moves the cache folder from the old location to the new one with a warning.
| 11-23-2020 18:36:57 | 11-23-2020 18:36:57 | |
transformers | 8,733 | closed | [proposal] do not load all 3rd party packaged unless needed | This is a proposal to not load everything with `import transformers`, but instead load things as they are needed.
## Background of the need
* For example what is realistic usage pattern for `tensorflow` in transformers - I know we have `USE_TF=False,` but perhaps it can be made by default `False` and only load it if it's actually needed based on usage patterns and not with `import transformers`? Also there was a particular segfault with [tf/cuda-11 vs pt/cuda-10](https://github.com/pytorch/pytorch/issues/46807) - the 2 couldn't be loaded together - the issue didn't get resolved.
* Same goes for integration packages (`wandb`, `comet_ml`) and probably a bunch of other packages some of which are quite big. The problem is that each of these packages tends to have various issues, e.g. [fetching old libraries](https://github.com/wandb/client/issues/1498), [impacting init](https://github.com/huggingface/transformers/pull/8410), messing with `sys.path` and [overriding global warning settings](https://github.com/mlflow/mlflow/issues/3704) (`mlflow` was imported by PL - a seq2seq issue). Last week I was hunting all these down - and most have been fixed by now I think.
The problem with integrations specifically is that currently we don't assert if say `comet_ml` is misconfigured, we issue a warning which gets lost in the ocean of warnings and nobody sees it. If, for example, the user were to say "use comet_ml" and it were misconfigured their program would have died loud and clear. Much cleaner and faster for the user.
* Relying on "well, it's installed, let's load it" is not always working, since often modules get installed as dependencies of dependencies and aren't necessarily the right versions or configured or else, especially if `transformers` did not specify these modules as explicit dependencies and doesn't know the requirements (versions) were enforced.
* And a lot of these packages emit a lot of noise, especially if one uses more recent python and packages - deprecation warnings are many. `tf` as always takes the first place, but other packages are there too.
* Loading time is important too, especially when one doesn't run a 1-10h program, but is debugging a program that fails to start. e.g. loading `tf` may take several seconds, depending on the hardware.
## Implementation
Clearly `transformers` wants to be easy to use. So perhaps by default `import transformers` should remain load-it-all-I-want-things-simple.
And we need `import transformers_lean_and_mean_and_clean` which wouldn't load anything by default and ask the user to specify what components she really wants. I haven't yet thought specifically of how this could be implemented but wanted to see whether others feel that a more efficient way is needed.
on slack @thomwolf proposed looking at how [Optuna](https://github.com/optuna/optuna) implements lazy loading of packages.
@LysandreJik, @sgugger, @patrickvonplaten, @thomwolf
| 11-23-2020 18:18:32 | 11-23-2020 18:18:32 | It's hard to debate without seeing actual code on this. Am I 100% happy with the current implementation? Not really. But it's simple enough that the code stays easy to read. I'm afraid something more dynamic (like importing tf only when instantiating a TFModel for instance) would mean harder code. So I reserve my judgement on seeing an actual PoC to evaluate the benefits of a different approach vs the code complexity it introduces.<|||||>Ok, gave it a go and worked on a PoC here: https://github.com/sgugger/lazy_init
It lazily loads objects when they are actually imported, so won't load TF/PyTorch until you try to import your first model (which should speed up the `import transformers` a lot and avoid unnecessary verbosity). Let me know if you have any comments on it @stas00 !<|||||>Looks awesome, @sgugger! Thank you for doing it!
So how do you feel about it now that you have coded it? Will this make things unnecessarily complex and possibly introduce unexpected issues?
Perhaps start with just tf/pt, see how it feels - and then expand to other modules if the first experiment flows well?
<|||||>Since it's limited to the inits, I'm fine with it. The idea is to collect feedback this week and start implementing it in Transformers next week.<|||||>next week ping ;)<|||||>Since we need to perform some special checks for the datasets library, we first need datasets to implement some version of this. Then we can roll it out to transformers. Will ping the datasets team :-) |
transformers | 8,732 | closed | [Benchmark] V100/A100 benchmarks, dashboard concept | # 🖥 Benchmarking `transformers`
I benchmarked a couple of models (training) on V100 and A100 and wrapped everything into a Streamlit dashboard [link here](https://share.streamlit.io/tlkh/transformers-benchmarking/main/app.py).
This dashboard shows the measured performance of GPUs when training various configurations of Transformer networks, showing throughput (seq/s) and GPU memory (VRAM) usage. The idea is to allow users have an easy reference for choosing model configuration (model size/batch size/sequence length) and GPU model.
This is kind of a weekend project done out of curiosity. If there is potential, perhaps a more serious effort can be undertaken here.
## Benchmark
Which part of `transformers` did you benchmark?
Model training: `distilroberta-base`, `roberta-base`, `roberta-large` via `AutoModelForSequenceClassification`
## Set-up
What did you run your benchmarks on? Please include details, such as: CPU, GPU? If using multiple GPUs, which parallelization did you use?
GPUs: V100 16GB, A100 40GB
Single GPU only.
More information and code: https://github.com/tlkh/transformers-benchmarking
## Results
https://share.streamlit.io/tlkh/transformers-benchmarking/main/app.py
| 11-23-2020 17:41:59 | 11-23-2020 17:41:59 | That's incredible @tlkh!<|||||>By the way, did you try to use the [benchmarking tool](https://huggingface.co/transformers/benchmarks.html) that we have in the library to run this evaluation?<|||||>> By the way, did you try to use the benchmarking tool that we have in the library to run this evaluation?
I did take a look at the tools, but I rolled my own in the end:
- I also wanted to write my own training script and benchmark using that, also doing a test drive of the end-to-end PyTorch Lightning + HuggingFace Datasets & Transformers library
- I wanted to do profiling and capture more metrics than just the time and memory (mostly out of curiosity)
In hindsight, I think the time and memory are the most important metrics and those are captured by the benchmarking tool in the library.
I do think putting the benchmarks into the dashboard format would be valuable to let people visualize and see which configurations would work best for them. Can treat the one I made as a proof of concept, and we can see where to go from here if interested. <|||||>Very cool. I was planning on running benchmarks on exactly these cards as well but now I don't need to anymore! Is it possible to update the app in such a way that you can also see a side-by-side comparison of the V100 and the A100? I imagine that some people would like to see the benefit of the A100 easily without having to change the view for each graph. A side-by-side bar chart would be cool!<|||||>> Very cool. I was planning on running benchmarks on exactly these cards as well but now I don't need to anymore! Is it possible to update the app in such a way that you can also see a side-by-side comparison of the V100 and the A100? I imagine that some people would like to see the benefit of the A100 easily without having to change the view for each graph. A side-by-side bar chart would be cool!
That's possible. In any case, the raw results are all in a CSV file [here](https://github.com/tlkh/transformers-benchmarking/blob/main/results.csv) so you can easily do comparisons for any scenarios you're interested in. <|||||>Very cool. For a minute I thought Streamlit had shipped GPU instances in their cloud and the benchmarks were computed directly there 😉 <|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,731 | closed | [Pegasus] Refactor Tokenizer | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #8689, #8594, #8536
This PR refactors the Pegasus Tokenizer.
1st: It decouples the tokenizer from the Reformer Tokenizer because they don't really have much in common.
2nd: Pegasus' masked tokens are added. As stated in the [paper](https://arxiv.org/abs/1912.08777), PEGASUS has two masked tokens which are required for pre-training. Those two tokens `<mask_1>` and `<mask_2>` are added according to https://github.com/google-research/pegasus/blob/master/pegasus/ops/pretrain_parsing_ops.cc#L66 . This should solve or at least enable a solution for all three issues above.
3rd: IMO, all special tokens - which are in the case of Pegasus the tokens 2 to 104 - should be added to the `additional_special_tokens`. This is done here as well.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-23-2020 16:58:16 | 11-23-2020 16:58:16 | Checked all slow and fast tests on GPU.<|||||>> You removed the links to google/sentencepiece but you kept the `Based on SentencePiece.`.
>
> It seems to me that if we reference SentencePiece then it's good to keep a link to the library, no? Based on SentencePiece means that it's based on the library IMO, maybe you wanted to say it's based on Unigram instead?
>
> Great changes, thanks for taking care of it!
Good point! I also think it would be nicer to have a link to it...For now, the text is always:
```
Construct a "fast" ALBERT tokenizer (backed by HuggingFace's `tokenizers` library). Based on SentencePiece.
```
=> So similar to what other FastTokenizers have written in their comments. But I agree that it could be confusing as "SentencePiece" doesn't really exist as an entity in `tokenizers` ... I think the "fast" sentencepiece tokenizers are either `BPE` or `Unigram` in tokenizers, no ? @thomwolf @n1t0 . Should I change the comments and link to their respective `tokenizers` model instead? So to
```
Construct a "fast" ALBERT tokenizer (backed by HuggingFace's `tokenizers` library). Based on `Unigram <link to unigram in tokenizers>`__ .
```<|||||>I think your proposal makes a lot of sense! |
transformers | 8,730 | closed | fix rag index names in eval_rag.py example | There was a mistake in the eval_rag.py parameters choices.
As specified in the rag configuration (see [documentation](https://huggingface.co/transformers/model_doc/rag.html?highlight=rag#transformers.RagConfig)), one can choose between 'legacy', 'exact' and 'compressed'. The legacy index is the original index used for RAG/DPR while the other two use the `datasets` library indexing implementation.
This issue was reported on the forum https://discuss.huggingface.co/t/rag-retriever-hf-vs-legacy-vs-exact-vs-compressed/2135/5 | 11-23-2020 16:32:47 | 11-23-2020 16:32:47 | |
transformers | 8,729 | closed | Create README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-23-2020 16:05:54 | 11-23-2020 16:05:54 | |
transformers | 8,728 | closed | Flax Masked Language Modeling training example | Include a training example running with Flax/JAX framework. (cc @avital @marcvanzee)
TODOs:
- [x] Make the collator working with Numpy/JAX array
- [x] Make sure the training actually works on larger scale
- [x] Make it possible to train from scratch
- [x] Support TPU (`bfloat16`)
- [ ] Support GPU amp (`float16`)
- [x] Improve overall UX | 11-23-2020 14:00:17 | 11-23-2020 14:00:17 | |
transformers | 8,727 | closed | [model_cards]: control input examples of Geotrend models | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-23-2020 11:29:48 | 11-23-2020 11:29:48 | |
transformers | 8,726 | closed | It seem do not support convert multilabel classification model to onnx ? | I have fine tune my multilabel classification model(pytorch),and try to use the `from transformers.convert_graph_to_onnx import convert` to convert the pytorch model to onnx model. As the `pipeline_name` is pre-defined, and it seems not be suited to multilabel classification, therefor I try use `pipeline_name="sentiment-analysis"`, however when reload the onnx model, its prediction result seems wrong. Could you tell how should i do to get the right result? Thanks a lot!
| 11-23-2020 10:37:34 | 11-23-2020 10:37:34 | Hi @MrRace,
thanks for reporting the issue.
What model are you using as multilabels classification support?<|||||>> Hi @MrRace,
>
> thanks for reporting the issue.
>
> What model are you using as multilabels classification support?
Thanks for your reply. I use BERT to do multilabels classification. And want to export the fine tuned model to onnx. <|||||>Looking at it!<|||||>> Looking at it!
Looking forward to your reply!<|||||>Hi @mfuntowicz Is there any suggestion for it?
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,725 | closed | Longformer inference speed is slower than bert of the same length | I used bert-base as the basic model and retrained my long-bert with a length of 1536. Then I compared the difference in inference speed of the original bert-base-1536. After a lot of testing, I found that long-bert-1536 and bert-base-1536 are basically the same in inference speed. I see a similar problem [https://github.com/allenai/longformer/issues/106] , but the length of my test data is all greater than 1000. I think window attention should be faster than self-attention because the amount of calculation is smaller, but why does this problem occur? Here are some settings:
attention windows (each layer is the same): 512
Global attention: only used for cls token
Inference device: cpu
task: text classification
By the way, does the size of the attention window affect the speed of inference? I tested different window sizes, but the speed is basically the same. | 11-23-2020 10:02:06 | 11-23-2020 10:02:06 | Hey @chenlin038,
Can you copy paste the configs of `bert-base-1536` and `long-bert-1536` below? This way I can see exactly which configs you are using. Otherwise, I also can only refer to the answers in https://github.com/allenai/longformer/issues/106 .<|||||>> Hey @chenlin038,
>
> Can you copy paste the configs of `bert-base-1536` and `long-bert-1536` below? This way I can see exactly which configs you are using. Otherwise, I also can only refer to the answers in [allenai/longformer#106](https://github.com/allenai/longformer/issues/106) .
Sorry for the late reply!This is the config of ### bert-base-1536:
{
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 1536,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
}
The following is the config of ### long-bert-1536:
{
"architectures": [
"BertLongForSequenceClassification"
],
"attention_probs_dropout_prob": 0.1,
"attention_window": [
512,
512,
512,
512,
512,
512,
512,
512,
512,
512,
512,
512
],
"directionality": "bidi",
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 1536,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
}
<|||||>Ok, yeah I'm not very surprised that `bert-base-1536` is faster in your case. Longformer should mainly be used to prevent out-of-memory problems for long sequences. To do so it uses a complex attention mechanism than BERT which makes it a bit slower (especially for shorter sequences). So, in your case I would expect the Longformer model to use less memory than the BERT model, but not necessarily to be faster. If `bert-base-1536` fits in memory, then I think it's a good idea to use the model<|||||>> Ok, yeah I'm not very surprised that `bert-base-1536` is faster in your case. Longformer should mainly be used to prevent out-of-memory problems for long sequences. To do so it uses a complex attention mechanism than BERT which makes it a bit slower (especially for shorter sequences). So, in your case I would expect the Longformer model to use less memory than the BERT model, but not necessarily to be faster. If `bert-base-1536` fits in memory, then I think it's a good idea to use the model
Does the longformer use less memory only have an effect on the GPU, or even specific GPU types, such as Nvidia Ampere? If I use CPU as a inference device, can I save more memory? Is there currently any optimization for the storage or calculation of sparse matrices by the CPU?<|||||>You should definitely see an improvement in CPU memory usage when using longformer! <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi, It seems I have a similar issue. However, the time difference between Longformer and Roberta is nearly a factor 10. Does it seem normal? After checking it is in the longformer.encoder step that this is quite slow. Here is the config I use (I have similar factor whatever the config):
LongFormer_TOY_MODEL_HPARAMS = {
"vocab_size": len(LongFormer_VOCAB),
"hidden_size": 64,
"num_hidden_layers": 3,
"num_attention_heads": 8,
"intermediate_size": 32,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512
+ 2, # tokenizer's model_max_length + 2 (<s> / </s> tokens of sequence)
"initializer_range": 0.02,
"layer_norm_eps": 1e-12,
"attention_window": 512
}
Thanks! |
transformers | 8,724 | closed | @ehsan-soe I fixed the problem by truncating incomplete batches. So if there are 2001 examples and my batch size = 2, then I truncate the last example and train on the first 2000. This has fixed it for me both with and without distributed. My load_and_cache function now looks like this | @ehsan-soe I fixed the problem by truncating incomplete batches. So if there are 2001 examples and my batch size = 2, then I truncate the last example and train on the first 2000. This has fixed it for me both with and without distributed. My load_and_cache function now looks like this
```
def load_and_cache_examples(args, tokenizer, evaluate=False, fpath=None):
if fpath:
dataset = TextDataset(tokenizer, args, fpath)
else:
dataset = TextDataset(tokenizer, args, args.eval_data_path if evaluate else args.train_data_path)
# Ignore incomplete batches
# If you don't do this, you'll get an error at the end of training
n = len(dataset) % args.per_gpu_train_batch_size
if n != 0:
dataset.examples = dataset.examples[:-n]
return dataset
```
_Originally posted by @isabelcachola in https://github.com/huggingface/transformers/issues/1220#issuecomment-557237248_ | 11-23-2020 09:18:04 | 11-23-2020 09:18:04 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,723 | closed | Model conversion from PyTorch to TF2 doesn't work properly for XLM-Roberta | ## Environment info
- `transformers` version: 3.4.0
- Platform: MacOS
- Python version: 3.7
- PyTorch version (GPU?): 1.6.0
- Tensorflow version (GPU?): 2.3.1
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
@LysandreJik
## Errors
```
Loading PyTorch weights from pytorch_model.bin
PyTorch checkpoint contains 470,547,238 parameters
Loaded 278,295,186 parameters in the TF 2.0 model.
Some weights of the PyTorch model were not used when initializing the TF 2.0 model TFXLMRobertaForMaskedLM: ['lm_head.decoder.bias', 'roberta.embeddings.position_ids', 'lm_head.decoder.weight']
- This IS expected if you are initializing TFXLMRobertaForMaskedLM from a PyTorch model trained on another task or with another architecture (e.g. initializing a TFBertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing TFXLMRobertaForMaskedLM from a PyTorch model that you expect to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFXLMRobertaForMaskedLM were initialized from the PyTorch model.
If your task is similar to the task the model of the ckeckpoint was trained on, you can already use TFXLMRobertaForMaskedLM for predictions without further training.
All model checkpoint weights were used when initializing XLMRobertaForMaskedLM.
All the weights of XLMRobertaForMaskedLM were initialized from the model checkpoint at None.
If your task is similar to the task the model of the checkpoint was trained on, you can already use XLMRobertaForMaskedLM for predictions without further training.
Traceback (most recent call last):
File "convert_pytorch_checkpoint_to_tf2.py", line 432, in <module>
use_cached_models=args.use_cached_models)
File "convert_pytorch_checkpoint_to_tf2.py", line 297, in convert_pt_checkpoint_to_tf
assert diff <= 2e-2, "Error, model absolute difference is >2e-2: {}".format(diff)
AssertionError: Error, model absolute difference is >2e-2: 1.0000114440917969
Max absolute difference between models outputs 1.0000114440917969
```
There's some weights didn't initialize correctly from pytorch model. | 11-23-2020 07:38:24 | 11-23-2020 07:38:24 | Hello! Could you provide the commands you used to launch the script, and where you obtained the file from? Thanks.<|||||>> Hello! Could you provide the commands you used to launch the script, and where you obtained the file from? Thanks.
I found that I made a mistake when saving the pretrained model, after fix this bug, the script converts the pytorch model correctly.
Thanks for your time!<|||||>@QixinLi , how did you converti this one? I am having similar type of problem while converting xlmroberta to tf.
my code: https://colab.research.google.com/drive/17mOz39gXNHjeGN9tT4oJMBLvSWkgKlDN?usp=sharing
```
AttributeError Traceback (most recent call last)
<ipython-input-6-37732b1a66b9> in <module>()
2 '/content/drive/MyDrive/Colab_Notebooks/models/pytorch_xlmr/pytorch_model.bin',
3 '/content/drive/MyDrive/Colab_Notebooks/models/pytorch_xlmr/config.json',
----> 4 '/content/drive/MyDrive/Colab_Notebooks/models/pytorch_xlmr')
2 frames
/usr/local/lib/python3.7/dist-packages/transformers/modeling_tf_pytorch_utils.py in load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs, allow_missing_keys)
179 continue
180
--> 181 raise AttributeError(f"{name} not found in PyTorch model")
182
183 array = pt_state_dict[name].numpy()
AttributeError: lm_head.bias not found in PyTorch model
```
|
transformers | 8,722 | closed | a bug in generation_beam_search.py | I wanted to implement my own beam_search function and read
> src/transformers/generation_beam_search.py
source code for help.In the process of reading the source code, I found an unreasonable place, maybe it could be seen as a bug.
Here is the problem:
In the process() function of generation_beam_search.py, line 223:
```python
if (eos_token_id is not None) and (next_token.item() == eos_token_id):
# if beam_token does not belong to top num_beams tokens, it should not be added
is_beam_token_worse_than_top_num_beams = beam_token_rank >= self.num_beams
if is_beam_token_worse_than_top_num_beams:
continue
beam_hyp.add(
input_ids[batch_beam_idx].clone(),
next_score.item(),
)
```
when we generate a complete sentence(get a eos_token in top beam_size),we send the `input_ids[batch_beam_id]`(which is the sequence of tokens),and the score to the beam_hyp.add(). eos_token is not included in `input_ids[batch_beam_id]`, but it's ok, beacuse bos_token is included in `input_ids[batch_beam_id]`, when we calculate the score of whole sentence at line 334:
```python
def add(self, hyp: torch.LongTensor, sum_logprobs: float):
"""
Add a new hypothesis to the list.
"""
score = sum_logprobs / (hyp.shape[-1] ** self.length_penalty)
...
```
wo got correct hyp.shape[-1],which can be seen as how many elements are added to get the sum_logprobs.
for example, `input_ids[batch_beam_id] = ['<bos>', ' she', 'is', 'a', 'cute', 'girl']`,and assume the score of this beam is -1.2 .we know that -1.2 is the probability sum of `she`, `is`, `a`, `cute`, `girl`. In next step we generate a eos_token, the score of eos_token is -0.3 and we update socre to -1.5, -1.5 is probability sum of `she`, `is`, `a`, `cute`, `girl`,`<eos>`. we send `input_ids[batch_beam_id] = ['<bos>', ' she', 'is', 'a', 'cute', 'girl']` and -1.5 as parameters to beam_hyp.add(...), and we calculate the whole sentence score by `score = sum_logprobs / (hyp.shape[-1] ** self.length_penalty)`,
because **`len(['<bos>', ' she', 'is', 'a', 'cute', 'girl'])` == `len([' she', 'is', 'a', 'cute', 'girl','<eos>'])`**, so hyp.shape[-1] is correct.
**the real problem is in finalize() function:**
line 227:
```python
# need to add best num_beams hypotheses to generated hyps
for beam_id in range(self.num_beams):
batch_beam_idx = batch_idx * self.num_beams + beam_id
final_score = final_beam_scores[batch_beam_idx].item()
final_tokens = input_ids[batch_beam_idx]
beam_hyp.add(final_tokens, final_score)
```
we use finalize() function to manually add those hypothese which dont generate eos_toekn untill max_length to beam_hyp.
in instance, `final_tokens= input_ids[batch_beam_idx] = ['<bos>', ' she', 'is', 'a', 'cute', 'and', 'smart']` and we need to manually add it to beam_hyp because it reaches the max_length.
look at this line above:
```python
beam_hyp.add(final_tokens, final_score)
```
now len(final_tokens) == len(['\<bos\>', ' she', 'is', 'a', 'cute', 'and', 'smart']) == 7, so hyp.shape[-1] equals 7.But the sum_logprobs is calculated by log probability sum of `she`, `is`, `a`, `cute`, `and`, `smart`, only 6 element! **It's a different case from process(),because we have not add eos_token probablity, so the hyp.shape[-1] should minus 1 in this case!**
My English is poor, hope you can understand my meaning. Looking forward for some feedback.
| 11-23-2020 06:37:45 | 11-23-2020 06:37:45 | Hey @ZhaoQianfeng I think I know what you mean! So in short you are saying that `beam_hyp.add(...)` should be behaving differently depending on whether it finished with or without EOS token right?
Still not sure whether this is a real problem though... -> Could you maybe open a PR that quickly shows the changes you would want beam search to have and we can take a look at some code? This would be super helpful! Thanks a lot for diving into the code :-) <|||||>Hello @patrickvonplaten. Glad you know what i mean. Those hypotheses which finished without EOS are calculated with longer length than they should be, so they have higher scores than they should be, this may cause them to compete unfairly with those with EOS and make us incorrectly throw away those "with EOS" hypotheses .
Maybe it is not a severe problem, above situation maybe not common. Anyway, I modify the code here #8890 but haven't test it.I will be happy if it helps.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,721 | closed | run_clm.py training script failing with CUDA out of memory error, using gpt2 and arguments from docs. | ## Environment info
- `transformers` version: 3.5.1
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?: Yes, via official run_clm.py script
- Using distributed or parallel set-up in script?: No
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
Trainer: @sgugger
## Information
Model I am using: GPT2
The problem arises when using:
* [x] the official example scripts: language-modeling/run_clm.py
* [ ] my own modified scripts: (give details below)
I'm running [the provided example](https://github.com/huggingface/transformers/tree/master/examples/language-modeling):
```
python run_clm.py \
--model_name_or_path gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm
```
and getting this error:
```
RuntimeError: CUDA out of memory.
```
on the first pass through Trainer.training_step()
Full traceback:
```
2020-11-22 22:02:22.921355: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
11/22/2020 22:02:24 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 1distributed training: False, 16-bits training: False
11/22/2020 22:02:24 - INFO - __main__ - Training/evaluation parameters TrainingArguments(output_dir='/tmp/test-clm', overwrite_output_dir=False, do_train=True, do_eval=True, do_predict=False, evaluate_during_training=False, evaluation_strategy=<EvaluationStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=8, per_device_eval_batch_size=8, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, warmup_steps=0, logging_dir='runs/Nov22_22-02-24_f7d2e15228b7', logging_first_step=False, logging_steps=500, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=500, dataloader_num_workers=0, past_index=-1, run_name='/tmp/test-clm', disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None)
Reusing dataset wikitext (/root/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1/1.0.0/47c57a6745aa5ce8e16a5355aaa4039e3aa90d1adad87cef1ad4e0f29e74ac91)
[INFO|configuration_utils.py:413] 2020-11-22 22:02:24,711 >> loading configuration file https://huggingface.co/gpt2/resolve/main/config.json from cache at /root/.cache/torch/transformers/fc674cd6907b4c9e933cb42d67662436b89fa9540a1f40d7c919d0109289ad01.7d2e0efa5ca20cef4fb199382111e9d3ad96fd77b849e1d4bed13a66e1336f51
[INFO|configuration_utils.py:449] 2020-11-22 22:02:24,711 >> Model config GPT2Config {
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"vocab_size": 50257
}
[INFO|configuration_utils.py:413] 2020-11-22 22:02:24,791 >> loading configuration file https://huggingface.co/gpt2/resolve/main/config.json from cache at /root/.cache/torch/transformers/fc674cd6907b4c9e933cb42d67662436b89fa9540a1f40d7c919d0109289ad01.7d2e0efa5ca20cef4fb199382111e9d3ad96fd77b849e1d4bed13a66e1336f51
[INFO|configuration_utils.py:449] 2020-11-22 22:02:24,791 >> Model config GPT2Config {
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"vocab_size": 50257
}
[INFO|tokenization_utils_base.py:1650] 2020-11-22 22:02:25,081 >> loading file https://huggingface.co/gpt2/resolve/main/vocab.json from cache at /root/.cache/torch/transformers/684fe667923972fb57f6b4dcb61a3c92763ad89882f3da5da9866baf14f2d60f.c7ed1f96aac49e745788faa77ba0a26a392643a50bb388b9c04ff469e555241f
[INFO|tokenization_utils_base.py:1650] 2020-11-22 22:02:25,081 >> loading file https://huggingface.co/gpt2/resolve/main/merges.txt from cache at /root/.cache/torch/transformers/c0c761a63004025aeadd530c4c27b860ec4ecbe8a00531233de21d865a402598.5d12962c5ee615a4c803841266e9c3be9a691a924f72d395d3a6c6c81157788b
[INFO|tokenization_utils_base.py:1650] 2020-11-22 22:02:25,082 >> loading file https://huggingface.co/gpt2/resolve/main/tokenizer.json from cache at /root/.cache/torch/transformers/16a2f78023c8dc511294f0c97b5e10fde3ef9889ad6d11ffaa2a00714e73926e.cf2d0ecb83b6df91b3dbb53f1d1e4c311578bfd3aa0e04934215a49bf9898df0
[INFO|modeling_utils.py:940] 2020-11-22 22:02:25,230 >> loading weights file https://huggingface.co/gpt2/resolve/main/pytorch_model.bin from cache at /root/.cache/torch/transformers/752929ace039baa8ef70fe21cdf9ab9445773d20e733cf693d667982e210837e.323c769945a351daa25546176f8208b3004b6f563438a7603e7932bae9025925
[INFO|modeling_utils.py:1056] 2020-11-22 22:02:30,168 >> All model checkpoint weights were used when initializing GPT2LMHeadModel.
[INFO|modeling_utils.py:1065] 2020-11-22 22:02:30,168 >> All the weights of GPT2LMHeadModel were initialized from the model checkpoint at gpt2.
If your task is similar to the task the model of the checkpoint was trained on, you can already use GPT2LMHeadModel for predictions without further training.
Loading cached processed dataset at /root/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1/1.0.0/47c57a6745aa5ce8e16a5355aaa4039e3aa90d1adad87cef1ad4e0f29e74ac91/cache-e3061a317d13eb90.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1/1.0.0/47c57a6745aa5ce8e16a5355aaa4039e3aa90d1adad87cef1ad4e0f29e74ac91/cache-a948c1d62c014b03.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1/1.0.0/47c57a6745aa5ce8e16a5355aaa4039e3aa90d1adad87cef1ad4e0f29e74ac91/cache-ea170b0cdcba7aa4.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1/1.0.0/47c57a6745aa5ce8e16a5355aaa4039e3aa90d1adad87cef1ad4e0f29e74ac91/cache-38ad73a52a8ec98e.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1/1.0.0/47c57a6745aa5ce8e16a5355aaa4039e3aa90d1adad87cef1ad4e0f29e74ac91/cache-dd6364e0f6a6c9eb.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1/1.0.0/47c57a6745aa5ce8e16a5355aaa4039e3aa90d1adad87cef1ad4e0f29e74ac91/cache-c40818aaf33935e0.arrow
[INFO|trainer.py:388] 2020-11-22 22:02:35,382 >> The following columns in the training set don't have a corresponding argument in `GPT2LMHeadModel.forward` and have been ignored: .
[INFO|trainer.py:388] 2020-11-22 22:02:35,382 >> The following columns in the evaluation set don't have a corresponding argument in `GPT2LMHeadModel.forward` and have been ignored: .
[INFO|trainer.py:693] 2020-11-22 22:02:35,385 >> ***** Running training *****
[INFO|trainer.py:694] 2020-11-22 22:02:35,385 >> Num examples = 2318
[INFO|trainer.py:695] 2020-11-22 22:02:35,385 >> Num Epochs = 3
[INFO|trainer.py:696] 2020-11-22 22:02:35,385 >> Instantaneous batch size per device = 8
[INFO|trainer.py:697] 2020-11-22 22:02:35,386 >> Total train batch size (w. parallel, distributed & accumulation) = 8
[INFO|trainer.py:698] 2020-11-22 22:02:35,386 >> Gradient Accumulation steps = 1
[INFO|trainer.py:699] 2020-11-22 22:02:35,386 >> Total optimization steps = 870
0% 0/870 [00:00<?, ?it/s]Traceback (most recent call last):
File "run_clm.py", line 351, in <module>
main()
File "run_clm.py", line 321, in main
trainer.train(model_path=model_path)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 775, in train
tr_loss += self.training_step(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1112, in training_step
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1136, in compute_loss
outputs = model(**inputs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py", line 787, in forward
return_dict=return_dict,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py", line 659, in forward
output_attentions=output_attentions,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py", line 295, in forward
output_attentions=output_attentions,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py", line 239, in forward
attn_outputs = self._attn(query, key, value, attention_mask, head_mask, output_attentions)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py", line 181, in _attn
w = self.attn_dropout(w)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/dropout.py", line 58, in forward
return F.dropout(input, self.p, self.training, self.inplace)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py", line 983, in dropout
else _VF.dropout(input, p, training))
RuntimeError: CUDA out of memory. Tried to allocate 384.00 MiB (GPU 0; 14.73 GiB total capacity; 13.50 GiB already allocated; 137.81 MiB free; 13.55 GiB reserved in total by PyTorch)
0% 0/870 [00:00<?, ?it/s]
```
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
On the transformers wikitext dataset. I also attempted on my own corpus.txt file. Same issue with both.
## To reproduce
Steps to reproduce the behavior:
I have a minimal reproduction on [this Colab notebook](https://colab.research.google.com/drive/1-jYjb-eqUJsJRjkeHeL9UryV8TZJa9XQ?usp=sharing)
## What I've checked out so far:
I traced the problem to the Trainer.training_step() method. It seems [PR 6999](https://github.com/huggingface/transformers/pull/6999) was an attempt to fix a similar problem. However, with my issue, the CUDA OOM error happens before the loss.detach() on the first pass of training_step()
This is similar to [issue 7169](https://github.com/huggingface/transformers/issues/7169), except I'm not doing distributed training.
I've tested this issue both in Google Colab (1xGPU) and then on an AWS EC2 g4dn.12xlarge instance (4xGPU). I was pursuing the obvious possibility of Colab GPU simply being too small. Both max out with a "CUDA out of memory" error.
I also tried using the TPU launcher script, which hit an error, but that's a separate issue.
I also tried using the legacy [run_language_modeling.py](https://github.com/huggingface/transformers/blob/master/examples/contrib/legacy/run_language_modeling.py) script with the same arguments on Colab (a friend had done so a few months ago and had success on Colab). I got this error there:
```AttributeError: 'GPT2TokenizerFast' object has no attribute 'max_len'```
but that's a separate issue.
## Expected behavior
The docs say that expected behavior for running will be the output of a trained model at the --output_dir flag
```This takes about half an hour to train on a single K80 GPU and about one minute for the evaluation to run. It reaches a score of ~20 perplexity once fine-tuned on the dataset.```
How do we fix this to make run_clm.py work? | 11-22-2020 22:44:08 | 11-22-2020 22:44:08 | The comment you are mentioning was about the old `run_language_modeling` script, and probably with some more options for a K80 that what you are running the script with (we should probably remove it or update with a proper command that gives those results). This doesn't look like a memory leak problem, you just don't have enough GPU memory to run the this large model with its full sequence length (of 1,024). You could try:
- a smaller batch size with `--per_device_batch_size 4` or even 2 (or use gradient accumulation)
- a smaller sequence length with `--block_size 512` or even 256
- a smaller model with `--model_name_or_path gpt2-medium` or even distilgpt2.
<|||||>The smaller `--per_device_train_batch_size 2` batch size seems to be working for me. Just started the training process. Thank you very much for the extremely quick response, and for being an OSS maintainer @sgugger!
I'll likely drop one more update in this thread to confirm that it worked all the way through.<|||||>Can confirm - your advice works for me.
In fact, I managed to retrain even the XL on T100 GPUs on the new p4d.24xl instances. Definitely high mem requirements, but doable with `--model_name_or_path gpt2-xl --per_device_train_batch_size 1 --block_size 512`
Thanks, team! Y'all have a https://buymeacoffee.com account I can send some brews to? I appreciate your work.<|||||>Hi,
@sgugger I'm getting the same out of memory error on G Colab, as @erik-dunteman mentioned and I am using the smallest model of distilgpt2, I followed the advice here and added the additional argument to my command:
```python
!python /content/transformers/examples/language-modeling/run_clm.py \
--model_name_or_path distilgpt2 \
--train_file /content/train.txt \
--per_device_batch_size 2 \
--do_train \
--output_dir model_output
```
but am now getting the error:
`ValueError: Some specified arguments are not used by the HfArgumentParser: ['--per_device_batch_size', '2']`
Also, I could not find many parameters that were previously supported by ``run_language_modeling.py`` such as ``--line_by_line``. Were these removed in ``run_clm``? Is there a place where all possible arguments are listed?
Thanks<|||||>The correct argument name is `--per_device_train_batch_size` or `--per_device_eval_batch_size`.
Thee is no `--line_by_line` argument to the `run_clm` script as this option does not make sense for causal language models such as GPT-2, which are pretrained by concatenating all available texts separated by a special token, not by using individual sentences with padding (like masked language models).
To list all available arguments, just use -h or --help as an option for the script. <|||||>> The correct argument name is `--per_device_train_batch_size` or `--per_device_eval_batch_size`.
>
> Thee is no `--line_by_line` argument to the `run_clm` script as this option does not make sense for causal language models such as GPT-2, which are pretrained by concatenating all available texts separated by a special token, not by using individual sentences with padding (like masked language models).
>
> To list all available arguments, just use -h or --help as an option for the script.
Thanks, I figured out the ``--per_device_train_batch_size `` parameter and got ``run_clm`` to work.
I really need ``--line-by-line`` for my dataset as the training dataset is just individual sentences, where the next sentence has no connection with the previous.
Is there any way to get ``line by line `` to work with ``run_clm``?
Thanks<|||||>As I said, this makes no sense for those types of models so this won't be in our official examples. You can adapt the part that does this in `run_mlm` for your own need.<|||||>I get the same out of memory error because it tries to run this on my 1050 ti instead of my k80. I exported CUDA_VISIBLE_DEVICES=1,2 which is my k80, but this script always runs on my tiny 1050ti. Is there a switch to set which gpu to use?<|||||>@LysandreJik @sgugger can we load data in RAM in batches i.e lazy loading of data in RAM from disks and delete it after training on specific data?
|
transformers | 8,720 | closed | Broken links in example for torch.load() after. converting tensorflow checkpoint to pytorch save model | The links for run_bert_extract_features.py, run_bert_classifier.py, and run_bert_squad.py are all broken [here](https://huggingface.co/transformers/v2.4.0/converting_tensorflow_models.html). Could someone point me to a notebook where I can find examples for loading from a PyTorch save file pytorch_model.bin?
| 11-22-2020 22:41:01 | 11-22-2020 22:41:01 | If I understand correctly, you're trying to load a pytorch model from a `pytorch_model.bin`? If so, have you taken a look at the [quickstart](https://huggingface.co/transformers/v2.4.0/quickstart.html#main-concepts)? The `from_pretrained` method is probably what you're looking for.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,719 | closed | Unable to Tie Encoder Decoder Parameters When Using EncoderDecoderModel Constructor | ## Environment info
- `transformers` version: 3.5.0
- Platform: Linux-5.4.0-53-generic-x86_64-with-glibc2.10
- Python version: 3.8.3
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): 2.3.0 (False)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@patrickvonplaten
## Information
Model I am using (Bert, XLNet ...): Encoder (RoBERTa) Decoder (GPT2) model
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
```
from transformers import (
AutoConfig,
AutoModel,
AutoModelForCausalLM,
EncoderDecoderModel,
EncoderDecoderConfig,
GPT2Config,
)
encoder_config = AutoConfig.from_pretrained('microsoft/codebert-base')
encoder = AutoModel.from_pretrained('microsoft/codebert-base')
decoder_config = GPT2Config(
n_layer = 6,
n_head = encoder_config.num_attention_heads,
add_cross_attention= True,
)
decoder = AutoModelForCausalLM.from_config(decoder_config)
encoder_decoder_config = EncoderDecoderConfig.from_encoder_decoder_configs(encoder_config, decoder_config)
encoder_decoder_config.tie_encoder_decoder = True
shared_codebert2gpt = EncoderDecoderModel(encoder = encoder, decoder = decoder, config = encoder_decoder_config)
```
The tasks I am working on is: N/A
## To reproduce
Steps to reproduce the behavior:
Running the above code produces the following message:
```
The following encoder weights were not tied to the decoder ['transformer/pooler', 'transformer/embeddings', 'transformer/encoder']
```
When checking the number of parameters of the model produces a model with `shared_codebert2gpt: 220,741,632` parameters, which is the same number of parameters if I were to not attempt to tie the encoder and decoder parameters :(.
## Expected behavior
The above snippet should produce a model with roughly `172,503,552` parameters.
My big question is, am I doing this correctly? I can correctly tie the model parameters if I use the `EncoderDecoderModel.from_encoder_decoder_pretrained` constructor and pass `tie_encoder_decoder=True`. However, for my task, I don't want to use a pretrained decoder and so am unable to use this constructor.
Any help with this would be greatly appreciated!
| 11-22-2020 22:39:07 | 11-22-2020 22:39:07 | Oops realized it was because this weight tying doesn't work across different architectures. |
transformers | 8,718 | closed | Issues with finetune_trainer.py on multiple gpus | ## Environment info
- `transformers` version:3.5.1
- Platform: google cloud
- Python version: 3.7
- PyTorch version (GPU?): yes 1.6
- Tensorflow version (GPU?): -
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: -
### Who can help
Trainer: @sgugger
Text Generation: @patrickvonplaten @TevenLeScao
T5: @patrickvonplaten
examples/seq2seq: @patil-suraj
## Information
Hi
I am trying to train finetune_trainer.py on multiple gpus, one issue I got is
1) Runtime error: Input,ouptut,and indices must be on the current device,
Looking into the codes, in training_args.py when you set device for the n_gpu > 0 on line 401, this should be changed from cuda:0 to cuda to me.
2) The accuracy on multiple gpus does not match on single gpu and this is much lower, any idea on this.
Thank you.
| 11-22-2020 21:53:16 | 11-22-2020 21:53:16 | Hi there. There is little anyone can do to help without knowing the actual command you are running.
<|||||>Hi
I am running
https://github.com/huggingface/transformers/blob/master/examples/seq2seq/finetune_trainer.py
once
with multiple gpu machines once with 1 machine,
I have adapted it for my usecase, this is hard for me to provide the exact
command, as I need to share the whole codebase.
My question is though more general I observe performance differences if you
run this code on 1 dataset with multiple gpu/gpu, any thoughts on this?
thanks
Rabeeh
On Mon, Nov 23, 2020 at 1:16 AM Sylvain Gugger <[email protected]>
wrote:
> Hi there. There is little anyone can do to help without knowing the actual
> command you are running.
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/8718#issuecomment-731871920>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/ABP4ZCHAF5CQRJP2LDI2XQDSRGSUPANCNFSM4T6X5WFQ>
> .
>
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,717 | closed | Add T5 Encoder for Feature Extraction | # What does this PR do?
While using T5 for feature extraction, I found out that T5 encoder provides better features than T5 decoder. Hence, it makes sense to have T5 encoder only, which should reduce the memory and inference time by half, if feature extraction is needed rather than conditional generation.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
T5: @patrickvonplaten
tensorflow: @jplu
| 11-22-2020 21:52:53 | 11-22-2020 21:52:53 | I like it! <|||||>Great, I am glad that you did like it.
Thanks @patrickvonplaten and @jplu for your feedback.
@patrickvonplaten :
I have adjusted all your code review, and also add it to the T5 documentation.
The only missing part is the tests, it will be great if you could add it.
@jplu :
I have removed the unnecessary parameters from the TF model.
Is there anything else needed from my side to merge the pull request ?<|||||>> Great, I am glad that you did like it.
>
> Thanks @patrickvonplaten and @jplu for your feedback.
>
> @patrickvonplaten :
> I have adjusted all your code review, and also add it to the T5 documentation.
> The only missing part is the tests, it will be great if you could add it.
>
> @jplu :
> I have removed the unnecessary parameters from the TF model.
>
> Is there anything else needed from my side to merge the pull request ?
I think that's great! I'll fix the tests and merge :-) <|||||>## Update:
PR is ready for review IMO. Would be great if @LysandreJik @jplu and @sgugger you can take a look :-) <|||||>> ## Update:
> PR is ready for review IMO. Would be great if @LysandreJik @jplu and @sgugger you can take a look :-)
Thanks a lot @patrickvonplaten ^_^<|||||>> Very clean implementation, thanks a lot @agemagician!
You are welcome.
I am glad that I could help making the library better, even with a small contribution.
I have to say without @patrickvonplaten help, I could not make it ^_^ |
transformers | 8,716 | closed | [trainer] make generate work with multigpu | This PR:
* fixes **torch.nn.modules.module.ModuleAttributeError: 'DataParallel' object has no attribute 'generate'** under DataParallel
* enables test_finetune_bert2bert under multigpu - the test now works with any number of GPUs.
Chances are that this would be the same problem with any other `model.foo` calls as this is [not the first time this is happening](https://github.com/huggingface/transformers/issues/7146). i.e. the base model class most likely needs to made aware of `DataParallel` and transparently get the `model` at the calling point.
@sgugger, @LysandreJik, @patrickvonplaten
Fixes: https://github.com/huggingface/transformers/issues/8713 | 11-22-2020 20:41:24 | 11-22-2020 20:41:24 | > Normally the model attribute of the Trainer is always a reference to the real model (without the module from DataParallel and the likes), so using self.model here should prevent this error.
It did - thank you!
This is a very ambiguous situation for a user who wants to use HF trainer in their code. When to use `model` the argument and when `self.model`.
What happens here is `model = torch.nn.DataParallel(self.model)` in the previous frame (`src/transformers/trainer.py:prediction_loop`), so `model` no longer has its normal methods accessible.
Here are some possible solutions to resolve this ambiguity:
1. monkeypatch `torch.nn.DataParallel` to expand its API to support all the methods of the original model transparently by installing a catch all `__getattr__` and remap all the failed method look ups to delegate to `self.module`.
2. not to call the function argument `model` anymore, since it isn't under multi gpu, but is something else.
3. remove the `model` argument completely + document to always use `self.model` - currently in `seq2seq_trainer.py `once we switch to `self.model`, `prediction_step()` no longer needs `model` as an argument (but is it always the case?)
<|||||>We can certainly improve the documentation and the debugging experience. I think I prefer the solution 2 since 1. is too magic (so will probably make things harder to debug) and 3 is not compatible with the regular `Trainer` (that needs the unwrapped model though I'd need to check to be sure).
Doing `model` -> `wrapped_model` should be enough to clarify things? Wdyt
<|||||>> [...] 3 is not compatible with the regular `Trainer` (that needs the unwrapped model though I'd need to check to be sure).
Did you mean to say "needs the wrapped model"?
Unless I'm misreading what you wrote 3rd solution is the right one, since the Trainer doesn't do anything with the wrapped model. I don't know though whether this is so everywhere.
The 4th solution is passing `self.model `as the `model` arg, and making the wrapped model available via `self.wrapped_model` if the user needs it.
> Doing `model` -> `wrapped_model` should be enough to clarify things? Wdyt
Except it won't be wrapped per se most of the time - very confusing to the user. Currently it should be called `may_be_wrapped_model_use_self_model_instead` variable ;)<|||||>I meant the wrapped model, sorry.<|||||> I'm getting this issue too using a T5 Model on multiple gpus
`AttributeError: 'DataParallel' object has no attribute 'generate'`
Is this supposed to be resolved? I've never seen this before. I've tried with 4.10.0 as well as current master branch<|||||>@JamesDeAntonis
Is it possible you somehow have a really old `transformers` in your `sys.path`?
If not, as always we need a way to reproduce the problem as the first step. And ideally in a new issue so that it can be tracked.
But you can also see the fix in this PR and try to trace it to where the `generate` call is made. Clearly it's not calling it on the correct object.
Thank you. |
transformers | 8,715 | closed | placing the run dir only in the output_dir | Hi
In training_args.py, there is a code which creates a run dir, then anyplace user runs the code there it would create a run dir, could you create it only in the output_dir? thanks
```
def default_logdir() -> str:
"""
Same default as PyTorch
"""
import socket
from datetime import datetime
current_time = datetime.now().strftime("%b%d_%H-%M-%S")
return os.path.join("runs", current_time + "_" + socket.gethostname())
```
| 11-22-2020 19:16:22 | 11-22-2020 19:16:22 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,714 | closed | Add TFGPT2ForSequenceClassification based on DialogRPT | # What does this PR do?
This PR implements TFGPT2ForSequenceClassification in order to support DialogRPT.
Strongly based on modifications made in #7501
Fixes #7622
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@LysandreJik Please review this PR, let me know if there is anything that should be changed =) | 11-22-2020 17:22:09 | 11-22-2020 17:22:09 | Thanks for review @jplu . I'll update my code with review comments and new input processing.
<|||||>> Thank you very much for this very nice addition!!
>
> I left few comments on it. Also can you run the following piece of code and tell me if it works properly:
>
> ```
> import tensorflow as tf
> from transformers import GPT2Tokenizer, TFGPT2ForSequenceClassification
>
> model = tf.function(TFGPT2ForSequenceClassification.from_pretrained("microsoft/dialogrpt"))
> tokenizer = GPT2Tokenizer.from_pretrained("microsoft/dialogrpt")
> inputs = tokenizer("Hello", return_tensors="tf")
> model(inputs)
> ```
>
> @LysandreJik I would recommend as well to wait a bit that the new input processing to be merged.
<img width="1176" alt="output" src="https://user-images.githubusercontent.com/6419011/100481765-2c2da900-311b-11eb-8fdd-15762f7d43df.png">
<|||||>Hello @jplu and @LysandreJik ,
I have refactored code as per review comments and added new input processing as well.
Kindly review.<|||||>> Much better!! Thanks for the updates.
>
> There is still one comment to be addressed and the tests to fix.
@jplu tests are also fixed now.<|||||>@spatil6 we have merged today a PR that updates the way the booleans are processed. You can see an example in the TF BERT file for example, can you rebase and proceed to the same changes please. It would be awesome if you could do it!<|||||>> @spatil6 we have merged today a PR that updates the way the booleans are processed. You can see an example in the TF BERT file for example, can you rebase and proceed to the same changes please. It would be awesome if you could do it!
Sure, will do that. |
transformers | 8,713 | closed | eval of seq2seq/finetune_trainer does not work on multiple gpus | Hi
I am using
transformers = 3.5.1
python = 3.7
8 gpu machine
I am getting this error when trying to run "finetune_trainer.py" with do_eval option on multiple gpus. thanks for your help
@patil-suraj @patrickvonplaten
```
11/22/2020 17:14:20 - INFO - __main__ - *** Evaluate ***
11/22/2020 17:14:20 - INFO - seq2seq.utils.utils - using task specific params for boolq: {'max_length': 4}
Traceback (most recent call last):
File "finetune_t5_trainer.py", line 233, in <module>
main()
File "finetune_t5_trainer.py", line 188, in main
result = trainer.evaluate(eval_datasets, compute_metrics_fn)
File "/home/rabeeh/internship/seq2seq/t5_trainer.py", line 175, in evaluate
prediction_loss_only=True if self.compute_metrics is None else None, # self.compute_metrics[eval_task]
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/trainer.py", line 1417, in prediction_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only)
File "/home/rabeeh/internship/seq2seq/t5_trainer.py", line 249, in prediction_step
generated_tokens = model.generate(
File "/opt/conda/envs/internship/lib/python3.7/site-packages/torch/nn/modules/module.py", line 779, in __getattr__
type(self).__name__, name))
torch.nn.modules.module.ModuleAttributeError: 'DataParallel' object has no attribute 'generate'
```
| 11-22-2020 17:16:38 | 11-22-2020 17:16:38 | seems to be related to #8613 <|||||>Fix https://github.com/huggingface/transformers/pull/8716
|
transformers | 8,712 | closed | distributed_eval does not run | Hi
I am trying to run distributed_eval with latest version of huggingface codes installed from the webpage, (internship)
please find the command below and the errors, thank you for your help.
Info on versions/machine:
python = 3.7
8 gpus
transformers 4.0.0rc1 pypi_0 pypi
```
rabeeh@gpu8:~/transformers/examples/seq2seq$ python -m torch.distributed.launch --nproc_per_node=8 run_distributed_eval.py --model_name sshleifer/distilbart-large-xsum-12-3 --save_dir xsum_generations --data_dir xsum --fp16
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
2020-11-22 16:51:27.894686: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2020-11-22 16:51:27.894685: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2020-11-22 16:51:27.894686: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2020-11-22 16:51:27.894688: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2020-11-22 16:51:27.894688: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2020-11-22 16:51:27.894685: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2020-11-22 16:51:27.894688: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2020-11-22 16:51:27.896156: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 389, in get_config_dict
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 987, in cached_path
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 1108, in get_from_cache
r.raise_for_status()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/requests/models.py", line 943, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_distributed_eval.py", line 248, in <module>
run_generate()
File "run_distributed_eval.py", line 180, in run_generate
**generate_kwargs,
File "run_distributed_eval.py", line 57, in eval_data_dir
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 1141, in from_pretrained
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 341, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 401, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'sshleifer/distilbart-large-xsum-12-3'. Make sure that:
- 'sshleifer/distilbart-large-xsum-12-3' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'sshleifer/distilbart-large-xsum-12-3' is the correct path to a directory containing a config.json file
404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 389, in get_config_dict
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 987, in cached_path
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 1108, in get_from_cache
r.raise_for_status()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/requests/models.py", line 943, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_distributed_eval.py", line 248, in <module>
run_generate()
File "run_distributed_eval.py", line 180, in run_generate
**generate_kwargs,
File "run_distributed_eval.py", line 57, in eval_data_dir
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 1141, in from_pretrained
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 341, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 401, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'sshleifer/distilbart-large-xsum-12-3'. Make sure that:
- 'sshleifer/distilbart-large-xsum-12-3' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'sshleifer/distilbart-large-xsum-12-3' is the correct path to a directory containing a config.json file
404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 389, in get_config_dict
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 987, in cached_path
404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 389, in get_config_dict
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 1108, in get_from_cache
r.raise_for_status()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/requests/models.py", line 943, in raise_for_status
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 987, in cached_path
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_distributed_eval.py", line 248, in <module>
run_generate()
File "run_distributed_eval.py", line 180, in run_generate
**generate_kwargs,
File "run_distributed_eval.py", line 57, in eval_data_dir
local_files_only=local_files_only,
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 1108, in get_from_cache
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 1141, in from_pretrained
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 341, in from_pretrained
r.raise_for_status()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/requests/models.py", line 943, in raise_for_status
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 401, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'sshleifer/distilbart-large-xsum-12-3'. Make sure that:
- 'sshleifer/distilbart-large-xsum-12-3' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'sshleifer/distilbart-large-xsum-12-3' is the correct path to a directory containing a config.json file
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_distributed_eval.py", line 248, in <module>
run_generate()
File "run_distributed_eval.py", line 180, in run_generate
**generate_kwargs,
File "run_distributed_eval.py", line 57, in eval_data_dir
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 1141, in from_pretrained
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 341, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 401, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'sshleifer/distilbart-large-xsum-12-3'. Make sure that:
- 'sshleifer/distilbart-large-xsum-12-3' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'sshleifer/distilbart-large-xsum-12-3' is the correct path to a directory containing a config.json file
404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 389, in get_config_dict
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 987, in cached_path
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 1108, in get_from_cache
r.raise_for_status()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/requests/models.py", line 943, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_distributed_eval.py", line 248, in <module>
run_generate()
File "run_distributed_eval.py", line 180, in run_generate
**generate_kwargs,
File "run_distributed_eval.py", line 57, in eval_data_dir
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 1141, in from_pretrained
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 341, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 401, in get_config_dict
404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
raise EnvironmentError(msg)
OSError: Can't load config for 'sshleifer/distilbart-large-xsum-12-3'. Make sure that:
- 'sshleifer/distilbart-large-xsum-12-3' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'sshleifer/distilbart-large-xsum-12-3' is the correct path to a directory containing a config.json file
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 389, in get_config_dict
404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 389, in get_config_dict
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 987, in cached_path
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 1108, in get_from_cache
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 987, in cached_path
r.raise_for_status()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/requests/models.py", line 943, in raise_for_status
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 1108, in get_from_cache
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_distributed_eval.py", line 248, in <module>
run_generate()
File "run_distributed_eval.py", line 180, in run_generate
r.raise_for_status()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/requests/models.py", line 943, in raise_for_status
**generate_kwargs,
File "run_distributed_eval.py", line 57, in eval_data_dir
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 1141, in from_pretrained
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_distributed_eval.py", line 248, in <module>
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 341, in from_pretrained
run_generate()
File "run_distributed_eval.py", line 180, in run_generate
**generate_kwargs,
File "run_distributed_eval.py", line 57, in eval_data_dir
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 401, in get_config_dict
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 1141, in from_pretrained
raise EnvironmentError(msg)
OSError: Can't load config for 'sshleifer/distilbart-large-xsum-12-3'. Make sure that:
- 'sshleifer/distilbart-large-xsum-12-3' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'sshleifer/distilbart-large-xsum-12-3' is the correct path to a directory containing a config.json file
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 341, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 401, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'sshleifer/distilbart-large-xsum-12-3'. Make sure that:
- 'sshleifer/distilbart-large-xsum-12-3' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'sshleifer/distilbart-large-xsum-12-3' is the correct path to a directory containing a config.json file
404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 389, in get_config_dict
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 987, in cached_path
local_files_only=local_files_only,
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/file_utils.py", line 1108, in get_from_cache
r.raise_for_status()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/requests/models.py", line 943, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/sshleifer/distilbart-large-xsum-12-3/resolve/main/config.json
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_distributed_eval.py", line 248, in <module>
run_generate()
File "run_distributed_eval.py", line 180, in run_generate
**generate_kwargs,
File "run_distributed_eval.py", line 57, in eval_data_dir
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 1141, in from_pretrained
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 341, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/transformers/configuration_utils.py", line 401, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'sshleifer/distilbart-large-xsum-12-3'. Make sure that:
- 'sshleifer/distilbart-large-xsum-12-3' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'sshleifer/distilbart-large-xsum-12-3' is the correct path to a directory containing a config.json file
Traceback (most recent call last):
File "/opt/conda/envs/internship/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/opt/conda/envs/internship/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/opt/conda/envs/internship/lib/python3.7/site-packages/torch/distributed/launch.py", line 260, in <module>
main()
File "/opt/conda/envs/internship/lib/python3.7/site-packages/torch/distributed/launch.py", line 256, in main
cmd=cmd)
subprocess.CalledProcessError: Command '['/opt/conda/envs/internship/bin/python', '-u', 'run_distributed_eval.py', '--local_rank=7', '--model_name', 'sshleifer/distilbart-large-xsum-12-3', '--save_dir', 'xsum_generations', '--data_dir', 'xsum', '--fp16']' returned non-zero exit status 1.
```
| 11-22-2020 16:53:07 | 11-22-2020 16:53:07 | with t5-base seems to run fine, so perhaps the specific model in the README is not available. Thank you. <|||||>Hello! Indeed, it seems this model does not exist. Do you want to open a PR with a model that works? Thanks!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,711 | closed | Model predictions wrong | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.5.0
- Platform: Linux
- Python version: 3.7
- PyTorch version (GPU?):
- Tensorflow version (GPU?): 2.3.1
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
Blenderbot: @patrickvonplaten
Bart: @patrickvonplaten
Marian: @patrickvonplaten
Pegasus: @patrickvonplaten
mBART: @patrickvonplaten
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSMT: @stas00
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...): Bert -> bert-base-uncased
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
Hi @LysandreJik , @sgugger , @jplu , I wan running my own script on a custom dataset by using "bert-base-uncased". It's a simple classification task with two classes. Below some examples:
```
"is_offensive", "text"
"1", "Your service is a shit."
"0", "Really great examples. Thank you for your help @exemple01"
```
This is the definition of the model:
```
from transformers import AutoConfig, BertTokenizer, TFAutoModel
config = AutoConfig.from_pretrained("bert-base-uncased")
config.output_hidden_states = output_hidden_states
model_bert = TFAutoModel.from_pretrained("bert-base-uncased", config=self.config)
model_bert = self.model.bert
input_ids_in = tf.keras.layers.Input(shape=(333,), name='input_token', dtype='int32')
input_masks_in = tf.keras.layers.Input(shape=(333,), name='masked_token', dtype='int32')
embeddings, main_layer = model_bert(input_ids_in, attention_mask=input_masks_in)
X = tf.keras.layers.Dropout(0.2)(main_layer)
X = tf.keras.layers.Dense(2, activation='softmax')(X)
loss_function = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model = tf.keras.Model(
inputs=[input_ids_in, input_masks_in],
outputs=[X]
)
for layer in model.layers[:3]:
layer.trainable = False
model.compile(optimizer=tf.optimizers.Adam(lr=0.00001), loss=loss_function, metrics=['sparse_categorical_accuracy'])
history = model.fit(
X_train,
y_train,
validation_split=0.2,
epochs=10,
batch_size=100
)
```
I've trained the model for 5 epochs, these are results after the last epoch:
```
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_token (InputLayer) [(None, 333)] 0
__________________________________________________________________________________________________
masked_token (InputLayer) [(None, 333)] 0
__________________________________________________________________________________________________
bert (TFBertMainLayer) ((None, 333, 768), ( 109482240 input_token[0][0]
masked_token[0][0]
__________________________________________________________________________________________________
dropout_75 (Dropout) (None, 768) 0 bert[0][1]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 2) 1538 dropout_75[0][0]
==================================================================================================
Total params: 109,483,778
Trainable params: 1,538
Non-trainable params: 109,482,240
__________________________________________________________________________________________________
1475/1475 [==============================] - ETA: 0s - loss: 0.5041 - accuracy: 0.8028
Accuracy: 0.8027665019035339
Loss: 0.5041469931602478
Val Accuracy: 0.8009492754936218
```
Then I save the model in this way:
```
try:
modelName = os.path.join(model_path, model_name)
model_json = model.to_json()
with open(modelName + ".json" "w") as json_file:
json_file.write(model_json)
json_file.close()
model.save_weights(modelName + ".h5")
logger.info("Saved {} to disk".format(modelName))
except Exception as e:
stacktrace = traceback.format_exc()
logger.error("{}".format(stacktrace))
raise e
```
When I try to perform a prediction also on trained sentences, the model completely fails the goal. I think that is something wrong in the training results, I cannot have an ~81% of accuracy during the training and on validation, but when I validate the model on a completely new dataset I obtain an accuracy near to the 10%.
I decided to build my own model and I compared your framework with another one, that gives optimal results(near to the 85%).
Can you help me to understand the mistakes?
Thank you. | 11-22-2020 15:41:18 | 11-22-2020 15:41:18 | If you have an accuracy near 10% on a two-label sequence classification task - does that mean it gets 90% of the results wrong? If so, you might just have switched the labels.<|||||>Hi, no the problem is not related to what you said. I tried also to perform one hot encoding on the labels and change the loss function to "categorical_crossentropy" but the results are the same.
I tried to use the official pre trained english model (**https://github.com/google-research/bert**) with another module and I don't have this problem (the keras model is the same).<|||||>Hello!
Can you try with `TFBertForSequenceClassification`?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,710 | closed | [BUG] Wrong Scores for many SQUAD models | @julien-c
@VictorSanh
## Information
All models trained with run_squad.py have abstaining threshold of 0.0 and possibly wrong evaluation scores.
Those model have their wrong score in their model cards many people rely on.
For example: ahotrod/electra_large_discriminator_squad2_512
The results with current evaluation script:
```
"exact": 87.09677419354838,
"f1": 89.98343832723452,
"total": 11873,
"HasAns_exact": 84.66599190283401,
"HasAns_f1": 90.44759839056285,
"HasAns_total": 5928,
"NoAns_exact": 89.52060555088309,
"NoAns_f1": 89.52060555088309,
"NoAns_total": 5945,
"best_exact": 87.09677419354838,
"best_exact_thresh": 0.0,
"best_f1": 89.98343832723432,
"best_f1_thresh": 0.0
```
The problem and its fix can be found in: [[Bug Fix] Fix run_squad.py evaluation code doesn't use probabilities](https://github.com/huggingface/transformers/pull/7319) #7319
The problem arises when using:
* [ ] run_squad.py
The tasks I am working on is:
* [ ] SQuAD
## To reproduce
Steps to reproduce the behaviour:
1. run `run_squad.py`
## Expected behaviour:
Resulting 'best_f1_thresh' wont be 0.0 .
| 11-22-2020 10:14:16 | 11-22-2020 10:14:16 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,709 | closed | Can't load weights for | # 🌟 New model addition
**Getting the following error after training a question answering problem using ALBERT.**
404 Client Error: Not Found for url: https://huggingface.co/saburbutt/albert_xxlarge_tweetqa_v2/resolve/main/tf_model.h5
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
950 try:
--> 951 state_dict = torch.load(resolved_archive_file, map_location="cpu")
952 except Exception:
13 frames
RuntimeError: [enforce fail at inline_container.cc:145] . PytorchStreamReader failed reading zip archive: failed finding central directory
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
OSError: Unable to load weights from pytorch checkpoint file for 'saburbutt/albert_xxlarge_tweetqa_v2' at '/root/.cache/torch/transformers/280e3f03092e3b52d227bc27519ff98aff017abcc160fc5138df7ce1bddcff1e.b5346cd8c01b1d2591b342ede0146ce26b68ad0a84ff87e5dc8f9d5a03a79910'If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
During handling of the above exception, another exception occurred:
HTTPError Traceback (most recent call last)
HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/saburbutt/albert_xxlarge_tweetqa_v2/resolve/main/tf_model.h5
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
683 f"- or '{pretrained_model_name_or_path}' is the correct path to a directory containing a file named one of {TF2_WEIGHTS_NAME}, {WEIGHTS_NAME}.\n\n"
684 )
--> 685 raise EnvironmentError(msg)
686 if resolved_archive_file == archive_file:
687 logger.info("loading weights file {}".format(archive_file))
OSError: Can't load weights for 'saburbutt/albert_xxlarge_tweetqa_v2'. Make sure that:
- 'saburbutt/albert_xxlarge_tweetqa_v2' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'saburbutt/albert_xxlarge_tweetqa_v2' is the correct path to a directory containing a file named one of tf_model.h5, pytorch_model.bin.
It was working for all the previous models I have tried.
| 11-22-2020 06:23:10 | 11-22-2020 06:23:10 | |
transformers | 8,708 | closed | Fix many typos | 11-22-2020 00:49:48 | 11-22-2020 00:49:48 | ||
transformers | 8,707 | closed | Accuracy changes dramatically | ## Environment info
- `transformers` version: 3.5.1
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
I tried to fine tune a bert model for text classification task using same parameters(learning rate, warmup step, batch size, number of epoch) in pytorch and tensorflow. If I use tensorflow, the validation accuracy changes dramatically. In pytorch accuracy is around %96, in tensorflow %76. One thing I noticed is the gpu memory usage difference (pytorch: ~12gb, tf ~8gb). Shouldn't we expect it to be the similar accuracy?
```python
from transformers import TFBertForSequenceClassification
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels = num_labels)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer, loss=model.compute_loss, metrics=['accuracy'])
history = model.fit(train_dataset.shuffle(1000).batch(32), epochs=epochs, batch_size=32)
```
| 11-21-2020 22:48:08 | 11-21-2020 22:48:08 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
It would be great if you could also include both training scripts, so that we may compare. There should be no difference between the PyTorch training or the TensorFlow training.
Thanks! |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.