
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 7,802 | closed | simple fix for spurious PyTorch->TF BERT weight conversion warning |
# What does this PR do?
Fixes https://github.com/huggingface/transformers/issues/7797
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [ X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [X] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@LysandreJik
| 10-15-2020 05:24:51 | 10-15-2020 05:24:51 | @LysandreJik yeah I think you're right, thanks! made the change<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 7,801 | closed | Can not convert the the custom trained BERT model to pytorch model for further use which should give me .bin file | # 📚 Migration
## Information
I pre trained a bert model from scratch with custom corpus and now want to use that model for further purpose like Qand A, masked word prediction etc. After pre- training I got below files:
bert_config.json bert_model.ckpt.data-00000-of-00001 bert_model.ckpt.index vocab.txt bert_model.ckpt.meta
Now , I need to convert the the model to pytorch model for further use which will give me .bin file . I am running below :+1:
%cd /content/drive/My Drive/Anirban_test_pytorch/
!python convert_bart_original_pytorch_checkpoint_to_pytorch.py "/content/drive/My Drive/Anirban_test_pytorch/model.ckpt.index" "/content/sample_data"\
But getting below error:
File "convert_bart_original_pytorch_checkpoint_to_pytorch.py", line 75, in load_xsum_checkpoint
sd = torch.load(checkpoint_path, map_location="cpu")
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 585, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 755, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
_pickle.UnpicklingError: invalid load key, '\x00'.
Please help me to fix the same.
| 10-15-2020 02:39:12 | 10-15-2020 02:39:12 | Hello! It seems you're running the BART conversion script for a BERT model?<|||||>Yeah, but I got to fix this.
-Anirban
On Thu, 15 Oct, 2020, 2:52 PM Lysandre Debut, <[email protected]>
wrote:
> Hello! It seems you're running the BART conversion script for a BERT model?
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/7801#issuecomment-709032258>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AMTD2W4GWGTXTL5DFR3DHPDSK25O3ANCNFSM4SRMD3AQ>
> .
>
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,800 | closed | Empty Conversation Responses | ## Environment info
Mac OS 10.14
My work is in rust, and I have an issue open in guillaume-be/rust-bert#87 however the authour of the repo asked that I also open it here to get HugginFace's opinion as it pertains to code that matches the intention of that in this repo.
- `transformers` version: rust-bert 0.10.0
- Platform: Mac OS
- PyTorch version (GPU?): No
- Tensorflow version (GPU?): No
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: Yes
### Who can help
TextGeneration: @TevenLeScao (This is in how min_ and max_length are treated during text generation of the conversation model)
## Information
Model I am using: DialgoGPT with the Conversation Moel
The problem arises when using:
* [x] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The problem occurs in the offical example of the rust and the owner of the the rust code assures me that there is exact same behaviour in this code too
The tasks I am working on is:
* [x] my own task or dataset: (give details below)
I am making a small chatbot, I have my own fine tuned model but the same behaviour is obseved with the stock DiagloGPT model
## To reproduce
Steps to reproduce the behavior:
1. Create a conversation model with `min_length` set
2. Talk with the conversation for about 10-12 responses
3. Responses will be zero length despite min_length begin set
## Expected behavior
Min length to be upheld during conversation
## Details
The root cause of this is how cur_len and min/max_len are handled in the code
https://github.com/huggingface/transformers/blob/15a189049e01fbd3bef902848a09f58a5f006c37/src/transformers/generation_utils.py#L86-L88
https://github.com/huggingface/transformers/blob/15a189049e01fbd3bef902848a09f58a5f006c37/src/transformers/generation_utils.py#L533
The cur_len is initalised with the length of current input which contains all previous dialogue with the bot as context
https://github.com/huggingface/transformers/blob/15a189049e01fbd3bef902848a09f58a5f006c37/src/transformers/generation_utils.py#L451
This means that min_length of the new utterence from the bot is already satisfied. It also means that max_length can be exceeded if a long conversation is held.
cur_len should perhaps be initialised differently in the ConverstaionModel | 10-15-2020 02:15:36 | 10-15-2020 02:15:36 | Also pinging @patrickvonplaten for info<|||||>Hey @QuantumEntangledAndy, I updated the config parameters of all DialoGPT models to `max_length=1000`, see here: https://github.com/huggingface/transformers/issues/7764 -> this problem should now be solved for the DialoGPT models.
I think this is the correct way to tackle this problem - we don't want to change the `generation` code logic here just for Conversational models.<|||||>I do not believe this will resolve the issue with min_length. Surly the expected behavior of min_length in a conversation model would be the min length of the new utterence not the length of context + new utterence.
Lets say I set min length to 2, because I want my bot to always say something and I say, "What shall we watch?" This has a length of 4 (five with with eos) this is added into the context and counts towards the length for min_length. The bot therefore has every chance of saying nothing.
What would be the ideal way to deal with this situation?<|||||>Sorry I misread your issue a bit here.
> Surly the expected behavior of min_length in a conversation model would be the min length of the new utterence not the length of context + new utterence
I understand your reasoning here. Are you using the pipelines or the "normal" generate() function?
I think we could tweak the `ConversationPipeline` a bit to better handle the `min_length` parameter.
Note that because the `input_ids` get longer with every conversation you have with the bot, `min_length` only works for the very first conversation in pipelines.
If you directly use `generate()` you could just set `min_length=input_ids.shape[-1] + 2` to solve your problem.
<|||||>I use the ConversationPipeline. I think perhaps the ConversationPipeline should update the min_length on call like this:
```python
min_length=input_ids.shape[-1] + self.min_length_for_response
```
Since we do have such a member in the class although it is set to 32 which seems a little high
https://github.com/huggingface/transformers/blob/0911b6bd86b39d55ddeae42fbecef75a1244ea85/src/transformers/pipelines.py#L2375-L2382
However I think it is high as this is the member that decides how many old responses need to be cleared to make room for new input.<|||||>If you want to test this out for yourself and see the blank responses this should work
```python
#! /usr/bin/env python3
"""Small example of conversational pipeline in python."""
from transformers.pipelines import (
Conversation,
ConversationalPipeline,
)
from transformers import (
AutoConfig,
AutoModelForCausalLM,
AutoTokenizer,
)
cache_dir = "cached"
model_name_or_path = "microsoft/DialoGPT-medium"
config_name = "microsoft/DialoGPT-medium"
tokenizer_name = "microsoft/DialoGPT-medium"
config = AutoConfig.from_pretrained(
config_name, cache_dir=cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name, cache_dir=cache_dir,
)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
from_tf=False,
config=config,
cache_dir=cache_dir,
)
config.min_length = 2
config.max_length = 1000
print(f"min_length: {config.min_length}")
print(f"max_length: {config.max_length}")
conversation = Conversation()
conversation_manager = ConversationalPipeline(model=model,
tokenizer=tokenizer)
conversation.add_user_input("Is it an action movie?")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("Is it a love movie?")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("What is it about?")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("Would you recommend it?")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("If not what would you recommend?")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("I think you need to think about it more.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("After all action is the best.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("But maybe not.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("What really matters is quality.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("Quality over all other things.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("But not at the expense of tradition.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("For advancement for advancments sake must"
" be curtailed.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("Unethical practises must be trimmed.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("In truth nothing is of any good.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("Unless it is traditional.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
conversation.add_user_input("And sometimes not even then.")
conversation_manager([conversation])
print(f"Response: {conversation.generated_responses[-1]}")
```<|||||>> I use the ConversationPipeline. I think perhaps the ConversationPipeline should update the min_length on call like this:
>
> ```python
> min_length=input_ids.shape[-1] + self.min_length_for_response
> ```
>
> Since we do have such a member in the class although it is set to 32 which seems a little high
>
> https://github.com/huggingface/transformers/blob/0911b6bd86b39d55ddeae42fbecef75a1244ea85/src/transformers/pipelines.py#L2375-L2382
>
> However I think it is high as this is the member that decides how many old responses need to be cleared to make room for new input.
I think I would be fine to add this to the Conversation Pipeline. Do you want to open a PR and we see how to integrate it? <|||||>Before I do any PR Id like some input on design choices.
- Should I also set max_length?
- If I do set it too I believe it will no longer be necessary to remove old conversations to have room for new content.
- However for very long chats perhaps a chat bot that saves and reloads it's memory this may become computational expensive
- In light of this would a convenience function that trims memory down to n last inputs be acceptable?
- I am thinking to make min_length an optional parameter to init. It defaults to None, when None is given as input it sets min_length to that of the model at init time. With similar behaviour for max_length<|||||>Thank you @QuantumEntangledAndy for sharing the issue here, as I believe it affects both implementation.
If I may, I'd like to add my view on the issue, which I believe is not tied to the `ConversationPipeline`, but rather on how `min_length` and `max_length` and handled for non-"encoder-decoder" architectures.
I would like to question the validity of setting the `cur_len` to the input sequence for pure decoder architectures:
https://github.com/huggingface/transformers/blob/15a189049e01fbd3bef902848a09f58a5f006c37/src/transformers/generation_utils.py#L451.
I would argue for setting the `cur_len` to 1 (or 0?) for pure-decoder architectures as well for a few reasons:
- I would believe that user looking to generate a sequence would be generally looking to set how many tokens they would like to generate, and not the length of the context + generated inputs. It would be great if you could share some use-cases where that is typically not the case.
- This definition of `cur_len` leads to somewhat "hacky" workarounds when the context needs to be extended by a prefix (for example, XLNet). Setting `min_length` and `max_length` to refer to generated content would make it independent of any context pre-processing
- The current behaviour differs between "encoder-decoder" and "decoders", and I am not entirely sure why. A definition based on the length generated would bring the behaviour of both together.
- Lastly, and in my opinion more importantly, the current solution does not work for batched generation. Let's say the input is made of 2 sentences, with initial length of 3 and 8. For batched generation, the input prompt will be padded as follows (`0` indicates a padded token, `x` an input token):
```
[ x x x x x x x x]
[ 0 0 0 0 0 x x x]
```
the `cur_len` will be set to 8 (`input_ids.shape[-1]`). Let's assume the `min_len` is 12. The model could generate the following sequence (`g` indicates a generated token):
```
[ x x x x x x x x g g g g]
[ 0 0 0 0 0 x x x g g g g]
```
This shows that while the first sequence respects the `min_len` of 12, the effective length of the second sequence is below the minimum value. Using `min_length` and `max_length` to refer to generated content would lead to valid constraints on all of the sequences in the batch, regardless of padding. For example, with the previous example if `min_length` is 6, both sequence would have at a minimum 6 generated token. In summary, I believe the current handling of `min_length` and `max_length` make them misleading as soon as inputs are passed as batches - but working on generated sequences would prevent that.
I would be more in favor of initializing`cur_len` to 1 (0) for decoders as well - I would be interested in your thoughts on that.<|||||>Hmmm I think I see what you mean with batch generation.
I am wondering what the use case of treating non encoder-decoders differently is. If for some reason we cannot reasonably change the definition perhaps we should consider adding different types of new lengths.
- minmax document length
- This is current definition of min/max
- minmax generated length
- This is the effective length the model generates.
- This of course would mean new config variables. But we could default them to none and then ignore that condition in this case.<|||||>Hey @guillaume-be,
I fully understand your point of view and I also tend to agree that the handling of `min_length` and `max_length` as described by you and I tend to agree with you (actually @sshleifer suggested this change a while back as well).
I guess the disadvantages of changing `max_length's` logic (making it "max added tokens" vs. "max total tokens") is the following:
- For models like GPT2, users might want to generate multiple articles < 100 words including the prefix. The output of decoder models is always prefix + generated text so it makes sense to me that `max_length` is the maximum length of the output. It's also safer regarding the `max_embedding_positions` provided by the model - by setting `max_length=512`, there will never be an error independent of the prefix. I guess all arguments are based on the advantages one might have from knowing that `max_length` is independent of the input.
That's the main argument.
- Changing the logic now would break backward compatibility quite heavily. Beam search is highly dependent on max_length *e.g.* - not sure whether we want that.
Let's put @LysandreJik and @yjernite and @sshleifer in cc as well to see their opinions on changing the `max_length` logic.<|||||>We could make it an option like `use_relative` lengths. It defaults to `None` meaning auto (the current behavour) but can be set to `True` of `False` in order to explicitly override the current auto logic. Ultimately I think the auto logic is not perfect and there will always be situations where it choices incorrectly, making it configurable will at least allow the library user to choose the appropiate choice.<|||||>My opinion is that I have never seen "users might want to generate multiple articles < 100 words including the prefix", and I have seen, "Why does prefix count?" a number of times and had the same misunderstanding the first few times I used it. So I think we should change the behavior to not count `decoder_start_token_id` or tokens in `input_ids`.
Another argument that might land: you would expect a function called `generate` to `generate` N tokens. Not generate N tokens where N varies based on your inputs.
The `use_relative` compromise is my second favorite option.
The status quo is my least favorite.<|||||>Was there any progress on making these changes?<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 7,799 | closed | model card for bert-base-NER | @julien-c
Model card with some details on training, eval, dataset for my bert-base-NER model | 10-15-2020 01:38:53 | 10-15-2020 01:38:53 | |
transformers | 7,798 | closed | Herbert polish model | The HerBERT model is a transformer model pretrained using masked language modeling (MLM) and Sentence Structural (SSO) objectives for the Polish language.
It was added to the library in PyTorch with the following checkpoints:
- `allegro/herbert-base-cased`
- `allegro/herbert-large-cased`
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patrickvonplaten
@julien-c
@LysandreJik
| 10-14-2020 22:09:37 | 10-14-2020 22:09:37 | Great point! I've already simplified the code and left only the tokenizer. Ideally, `XLMTokenizer` should have a converter to the appropriate `Fast` class. On second thought, I can see the problem would be to program the Moses pretokenization in the `tokenizers` library.<|||||>Hi @rmroczkowski
As far as I know, you employed fastBPE to train a tokenizer: https://github.com/huggingface/transformers/tree/b23d3a5ad4aa08decd10671f85be5950767dd052/model_cards/allegro/herbert-klej-cased-tokenizer-v1
I also employed fastBPE for the Vietnamese BERT-based tokenizer (i.e. PhoBERTTokenizer https://github.com/huggingface/transformers/pull/6129 ), but I am still struggling to implement a fast tokenizer based on fastBPE, e.g. handling the suffix "@@" of subword tokens. In particular, given https://huggingface.co/vinai/phobert-base/tree/main I can convert "bpe.codes" into a "merge.txt"-style file, but I am not sure about how to convert our "vocab.txt" into your "vocab.json"-style file.
How can you convert your fastBPE's code and vocab outputs into HuggingFace's tokenizers? So that you can call the tokenizer with the use_fast=True option.
cc: @LysandreJik is there any idea for implementing a fast version of a fastBPE-based slow one?
Thank you both.
|
transformers | 7,797 | closed | BertForSequenceClassification -> TFBertForSequenceClassification causes 'bert.embeddings.position_ids' not used error | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.3.1
- Platform: Linux-4.9.0-13-amd64-x86_64-with-debian-9.13
- Python version: 3.7.8
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): 2.3.1 (True)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
-->
## Information
Model I am using (Bert, XLNet ...):
```
from transformers import BertTokenizer, TFBertModel, TFBertForSequenceClassification,BertForSequenceClassification
import tensorflow as tf
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = TFBertForSequenceClassification.from_pretrained('output', from_pt=True)
```
I'm loading TFBertForSequenceClassification from a BertForSequenceClassification pytorch SavedModel and get this error:
`Some weights of the PyTorch model were not used when initializing the TF 2.0 model TFBertForSequenceClassification: ['bert.embeddings.position_ids']`
I've done this before with this exact model and not had these issues.
| 10-14-2020 21:09:35 | 10-14-2020 21:09:35 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hi, I'm still getting this warning on version 4.3.2. |
transformers | 7,796 | closed | T5 finetune outputting gibberish | ## Environment info
- `transformers` version: 3.3.1
- Platform: Linux-4.4.0-116-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: (tried with both 1 and 2 gpus)
### Who can help
Summarization: @sshleifer
T5: @patrickvonplaten
examples/seq2seq: @sshleifer
## Information
I am trying to finetune on a custom dataset. I posted about my specific use case here in the forums: https://discuss.huggingface.co/t/t5-tips-for-finetuning-on-crossword-clues-clue-answer/1514
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X ] my own task or dataset: (give details below)
## To reproduce
* clone transformers from master
* pip install -e . ; pip install -r requirements.txt
* cd exampls/seq2seq
* modify finetune_t5.sh script to run with a local data set (data_set/[val|test|train].[source|target])
(Note that I have changed nothing else)
`python finetune.py \
--model_name_or_path=t5-small \
--tokenizer_name=t5-small \
--data_dir=${HOME}/data_set \
--learning_rate=3e-4 \
--output_dir=$OUTPUT_DIR \
--max_source_length=100 \
--max_target_length=100 \
--num_train_epochs=300 \
--train_batch_size=64 \
--eval_batch_size=64 \
--gpus=1 \
--auto_select_gpus=True \
--save_top_k=3 \
--output_dir=$OUTPUT_DIR \
--do_train \
--do_predict \
"$@"
`
As a baseline "does the T5 work", my input outputs are of the form (one per line)
(this is one line in train.source): This is a sentence
(this is corresponding line in train.target): This
The lines are exactly as above, with a new line after each example, but with no other punctuation. I have not modified tokens or the model.
## Expected behavior
Expect T5 to learn to output the first word.
## Observed
T5 outputs first word followed by gibberish:
After 300 epochs, here is what we see for the first 5 lines of source vs test_generation (test.target is just the first word of each line in test.source)
Test.source:
We raised a bloom, a monster
I let Satan corrupt and torment
Chapter in play is an old piece
Old skin disease liable to drain confidence
Keep a riot going inside a musical academy
test_generations:
We vsahmoastuosastostassymbossa
Issahrastahmoormentostormentastoshomment
Chapter vshygie'ny-futtahraffahtaftast
Old hygienohmahrastassahuasairtia
Keep'astifiahuassaivrasastoshygiesana
I wonder if any of the following could be affecting this:
* choice of loss function
* a corrupted character somewhere in one of the input/output
* choice of task (I think it defaults to summarization)
* need more epochs?
* some other parameter to change?
| 10-14-2020 21:09:04 | 10-14-2020 21:09:04 | `some other parameter to change?`: BINGO
there is a `min_length`/`max_length` parameter you can pass to beam search (in many ways) that is affecting your generations.
If you eval offline with min_length=0, max_length=3 it should work.
<|||||>Cool! Sorry for the n00biness.
1. Is there somewhere I can read about when / why this happens? (or in brief, why does it happen?)
2. min_length and max_length will just limit how long the output sequence can be? Where's the best place to input them? Just directly from finetune.py?
3. Is there a different way to have the model learn when to stop outputting? (i.e to learn by itself that it should only be outputting one "word" since that's what all the train examples show)<|||||>1) you can read the [docstring for `generate`](https://github.com/huggingface/transformers/blob/master/src/transformers/generation_utils.py#L135)
2) I would edit `finetune.py ` around [here](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/finetune.py#L215)
3) It should learn good lengths within the hardcoded range. It's simply not allowed to go out of the hardcoded range.
If you set `min_length=0`, `max_length=10` I would guess it will learn to always generate word followed by `</s>` (This "eos" symbol is automatically added to input sequences by the `T5Tokenizer`.)
<|||||>Thanks! I am rerunning with the max length (I didn't see a spot for min length).
I'm still a little confused as to why this happens though. For example,
* why doesn't it get penalized for the gibberish? (is padding somehow affecting what it gets penalized for?)
* why isn't the gibberish at all linguistic, even? I would expect it at least to add mostly english-like tokens? These strings seem entirely non-lingustic.
Related: is there an easy flag to change so that I could view part of the validation outputs at each epoch to keep track of when it learns to truncate? Right now I'm just waiting until end of training to look at the test generations.
<|||||>+ You need the min_length, just pass min_length=0 to `model.generate`
+ re padding, yes. There is no loss for pad tokens.
+ no flag to see intermediate generations, but https://github.com/huggingface/transformers/blob/master/examples/seq2seq/callbacks.py#L83 should maybe work.<|||||>Okay thanks, I will work on these.
I realize these are unrelated T5 issues, but before I file other feature requests /bugs I just wanted to run them by you:
* auto_lr_find and auto_scale_batch_size (pytorch lightning flags) when used from the finetune.sh script throw errors. Should these be usable? (I can debug and figure out why they're not working; but I want to know if they should be working)
* I am unable to get the finetune.sh script to resume from a checkpoint (I played around with this for ~2 hours last night) and was unable to make it resume. Should this be supported?<|||||>auto*: Would be nice if they worked!
it should work with `--resume_from_checkpoint`, but that part of lightning has been very flaky.
I probably won't fix either of these but would definitely accept a PR that allow clargs that currently don't work. If you can't fix, you could also make separate issues for clargs that don't work, label them "Help Wanted" and see what happens.
If you make issues, make sure to include your PL version.
<|||||>@jsrozner did you `finetune.py` work for fine-tuning T5?
We're also having [some difficulties](https://discuss.huggingface.co/t/issue-with-finetuning-a-seq-to-seq-model/1680/2). Wanted to make sure if it has worked for someone else, at least. <|||||>@danyaljj will be fixed by #8435<|||||>Thanks, @jsrozner for the update!
Does this address the issue [here](https://discuss.huggingface.co/t/issue-with-finetuning-a-seq-to-seq-model/1680/27?u=danyaljj)? Mainly your observation that:
> But even after setting eval_beams=1, eval_max_gen_length=40, it still continues to generate many more tokens than it should <|||||>Did you pass `min_length=0` to generate?<|||||>See issue #5142 for resolution |
transformers | 7,795 | closed | Fix TF savedmodel in Roberta | # What does this PR do?
This PR fixes an issue in the TensorFlow version of Roberta. The issue prevented to save any Roberta model in SavedModel format.
Fixes #7783
| 10-14-2020 20:02:17 | 10-14-2020 20:02:17 | |
transformers | 7,794 | closed | Updated Tokenizer to 0.9.1 from prerelease version | Use latest stable version instead of RC prerelease.
# What does this PR do?
Upgrades Tokenizer to update release version, from pre-release version.
<!-- Remove if not applicable -->
Fixes # (issue)
#7794
## Before submitting
- [ x] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [ x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
| 10-14-2020 19:14:14 | 10-14-2020 19:14:14 | Why not `>= 0.9.1` or `>=0.8.1.rc2`?<|||||>Hi, we have a strict requirement on `tokenizers==0.8.1rc2`. We're updating it in https://github.com/huggingface/transformers/pull/7659 but the current `transformers` `master` branch will stay pinned until that PR is merged.
Both libraries evolve quickly and generally evolve together, so having a strict `==` dependency is necessary until tokenizers version 1.0.0 is released. |
transformers | 7,793 | closed | Add specific notebook ProgressCalback | # What does this PR do?
This PR introduces a new `NotebookProgressCallback` that is more suitable for trainings in notebook. There are two problems with the current use of tqdm:
- tqdm uses widgets, which disappear when you close and reopen your notebook, or download it from github. Instead of seeing
the full progress bar, a message "A Jupyter widget could not be displayed because the widget state could not be found. This
could happen if the kernel storing the widget is no longer available, or if the widget state was not saved in the notebook. You
may be able to create the widget by running the appropriate cells." appears
- tqdm creates a new widget each time you open a new progress bar, which, when closed, leaves a blank line there is absolutely
no way to remove (and I have tried!) This means we have one such blank line for every evaluation.
What's more, notebooks can properly render html code, so we can structure the output displayed during and at the end of training a bit better, using a table for instance.
This PR aims at tackling the issues above by:
- writing its own progress bar in pure HTML and using the `IPython.display` module to display and update it
- adding a table of results also in pure HTML to that progress bar.
It adds no dependency and just add a test (taken from tqdm.auto) to determine if the user is executing code in a notebook environment or not, and picking the best `ProgressCallback` accordingly.
It goes from the previous results:

To those new ones:

With a bit more work, it's also possible to add a graph of the losses/metrics that gets updated as the training progresses.
| 10-14-2020 18:41:57 | 10-14-2020 18:41:57 | |
transformers | 7,792 | closed | [stas/sam] Newsroom dataset wierdness | #### get data
```bash
cd examples/seq2seq/
curl -L -o stas_data.tgz https://www.dropbox.com/sh/ctpx2pflb9nmt0n/AABRTDak-W06RD8KxuCOUdXla\?dl\=0 && unzip stas_data.tgz
tar -xzvf newsroom-test.tgz
```
```python
from utils import Seq2SeqDataset
tok = PegasusTokenizer.from_pretrained('google/pegasus-newsroom')
ds = Seq2SeqDataset(tok, 'newsroom/data', tok.model_max_length, tok.model_max_length, type_path='test')
ds[659]['tgt_texts']
# "Insomniac's Pasquale Rotella has gone from throwing illegal raves in warehouses to throwing the nation's most iconic dance music festival in Las Vegas' Electric Daisy Carnival. "
ds[660]
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-17-7fbeab38f815> in <module>
----> 1 ds[660]
~/transformers_fork/examples/seq2seq/utils.py in __getitem__(self, index)
248 tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
249 assert source_line, f"empty source line for index {index}"
--> 250 assert tgt_line, f"empty tgt line for index {index}"
251 return {"tgt_texts": tgt_line, "src_texts": source_line, "id": index - 1}
252
AssertionError: empty tgt line for index 661
```
Clue:
In vim, the "Pasquale Rotella" line is 654 (off by 7/possible other bug), but it is 659/660 in the ds.
similarly, `linecache` disagrees with `wc -l` about file lengths.
```python
import linecache
src_lns = linecache.getlines(str(ds.src_file))
tgt_lns = linecache.getlines(str(ds.tgt_file))
assert len(src_lns) == len(tgt_lns),f'{ len(src_lns)} != {len(tgt_lns)}'
AssertionError: 108717 != 110412
```
| 10-14-2020 18:19:33 | 10-14-2020 18:19:33 | Here is part of the problem
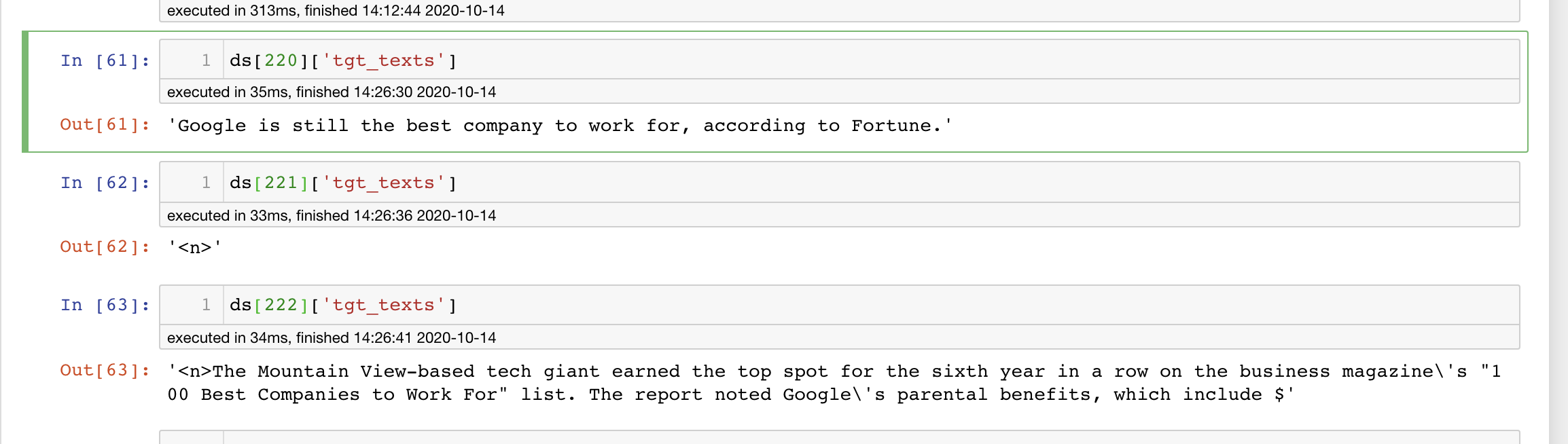
all one line (221 in vim)
<|||||>Oh, I know - it's \cM characters. Let me take care of it.
```
Google is still the best company to work for, according to Fortune
.^M<n>^M<n>The Mountain View-based tech giant earned the top
^^^^^^^^^^^^^
```<|||||>Easiest way to clarify will be to say how I fixed (in vim)
(1) `%s/^M//g` # This is not ctrl-m it must be typed by following these [instructions](https://stackoverflow.com/questions/5843495/what-does-m-character-mean-in-vim#:~:text=Windows%20uses%20a%20combination%20of,letter%20in%20the%20English%20alphabet).&text=Where%20%5EM%20is%20entered%20by,m%20%2C%20and%20then%20releasing%20Ctrl%20.)
(2)`%s/<n><n>/<n>/g` (probably not necesarry, but did it anyway).
<|||||>```
dos2unix filename
```<|||||>I will fix that in the build script<|||||>```
src = re.sub(r'[\r\n]+', '<n>', src)
tgt = re.sub(r'[\r\n]+', '<n>', tgt)
``` |
transformers | 7,791 | closed | T5 Conversion from Original Tensorflow Produce rubbish Text | ## Environment info
- `transformers` version: 3.0.2
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0+cu101 (False)
- Tensorflow version (GPU?): 2.3.0 (False)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
Text Generation: @TevenLeScao
T5: @patrickvonplaten
## Information
Model I am using (Bert, XLNet ...):
T5
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
https://colab.research.google.com/drive/112Jt7VFwHHT-QmMxFPJ764GNJBn0d5eX?usp=sharing
## Expected behavior
We have started a big project for source code tasks (generation, summarisation, documentation, etc.) using language models. Using T5 text to text library, the model can predict the input correctly, However, after we converted the Tensorflow checkpoint to huggingface the output text is rubbish.
I am not sure if we are doing something wrong during conversion or there is a problem in loading and converting the weights from the original Tensorflow checkpoint to Pytorch.
The above Colab re-produce the issue.
Important Note: We are using a copy of "adapt_t5_for_covid_19_3b" branch which should fix the conversion problem with only one small modification, setting is_tied to false.
Your help is highly appreciated.
| 10-14-2020 18:15:27 | 10-14-2020 18:15:27 | Hey @agemagician - did you train your model using the "newer" T5 model (see here https://github.com/huggingface/transformers/issues/6285) for reference or is it the "original" T5 model?<|||||>No, this is the original T5 model.
I just doubled checked the training script as well as the operative_config :
https://storage.googleapis.com/t5_convert_tranformers/model/operative_config.gin <|||||>Ok! From a first check of your google colab it looks like the model was correctly converted to PT (the `"Weights not copied to PyTorch model:` message is empty meaning that all PT weights are initialiazed).
Do you think you could check if it might be the tokenizer that does not work correctly? Could you maybe run an integration test for some `input_ids` to check if original t5 implementation yields same output as the PT version?<|||||>I have loaded the original T5 tokenizer then encoded the data and performed generation using Pytorch to make sure the input is the same for both original T5 script and Pytorch script, and the results is still rubbish.
I have checked the original T5 tokenizer and Pytorch tokenizer and they produce the same encoding/decoding. The only difference is that Pytorch tokenizer doesn't append Eos.
I have added a new section on the Colab "Part IIII: Check tokenizers" which perform these tests.<|||||>Since the input is the same to both original T5 script and Pytorch script, I think the issue should be in one of the following:
1. The conversion process.
2. The generation process.
3. The loading process.<|||||>Thanks, I hope to be able to take a look at this soon!<|||||>@patrickvonplaten Any update for fixing this issue ?
We started to release our models for the following tasks:
1. api generation
2. code comment generation
3. commit generation
4. function documentation generation
5. program synthesis
6. source code summarization
7. Code generation
for the following languages:
1. go
2. java
3. javascript
4. php
5. python
6. ruby
7. c#
8. SQL
9. LISP
https://github.com/agemagician/CodeTrans
However, we are using T5 original library for now, as huggingface transformers is still producing rubbish text after conversion.
It will be really useful if we can integrate and use huggingface transformers for this project too.
<|||||>Will take a look today!<|||||>@agemagician - I looked into it. It's quite nightmarish to debug in mesh tensorflow ... :-/ I couldn't find the bug sadly and it's getting very time-consuming. I'll gonna spend some time now to integrate mt5 and T5v1.1, so I'll still be working with the mesh tensorflow library. I hope to be able to come back to this problem! A couple of things I found out:
1) The `input_ids` passed to the Encoder for
```
"Code: function isStandardBrowserEnv ( ) { if ( typeof navigator !== 'undefined' && ( navigator . product === 'ReactNative' || navigator . product === 'NativeScript' || navigator . product === 'NS' ) ) { return false ; } return ( typeof window !== 'undefined' && typeof document !== 'undefined' ) ; }
Documentation: Returns true if the browser is a native element ."
```
is actually not the same for Hugging Face T5 and Mesh TF T5. => I suspect the tokenizers to behave differently here or mesh tf to do something under the hood with the input text
2) Sadly even if I pass the exact same `input_ids` to the encoder of both models, the encoder outputs are still different => this means that there is a different in the architecture. I suspect that mesh TensorFlow handles the `relative_attention_bias` different for the `EncoderDecoderSelfAttention`. In the mesh tensorflow's gin it's set no `None`, but in our code its definitely used. Did not manage to check it here in more detail.
=> Overall the problem is that `mesh_tensorflow` is constantly adding new features that are configurable with the gin config, but some of these new features are not implemented in HF and are therefore not used. So what is probably happening is that a mesh tensorflow trained model has the exact same weights as the HF implementation but has a slightly different architecture that cannot be configured with the HF T5 model...it's very hard for us to make sure that mesh tensorflow is kept constantly compatible with HF and we probably won't have the time to make sure it is. The only real solution is to use a HF pre-trained and train it within our environment or make sure that before mesh tensorflow training that the model is compatible with HF (checking the output of the pretrained models).
In case you want to take a deeper look here are my simplified scripts I used for debugging:
for mesh tf model:
```python
import t5
from t5.data.sentencepiece_vocabulary import SentencePieceVocabulary
t5_model = t5.models.MtfModel(
model_dir="./checkpoint",
batch_size=16,
sequence_length={"inputs": 128, "targets": 32},
learning_rate_schedule=0.003,
save_checkpoints_steps=5000,
keep_checkpoint_max=None,
iterations_per_loop=100,
tpu=None
)
vocab_model_path = 'gs://t5_convert_tranformers/spm/code_spm_unigram_40M.model'
vocab = SentencePieceVocabulary(vocab_model_path, extra_ids=100)
t5_model.predict(
input_file="input.txt",
output_file="output.txt",
vocabulary=vocab,
temperature=0
)
```
and HF:
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
input_text = "javascript documentation generation: function isStandardBrowserEnv ( ) { if ( typeof navigator !== 'undefined' && ( navigator . product === 'ReactNative' || navigator . product === 'NativeScript' || navigator . product === 'NS' ) ) { return false ; } return ( typeof window !== 'undefined' && typeof document !== 'undefined' ) ; }"
model = T5ForConditionalGeneration.from_pretrained("./pytorch_model").to("cuda")
tok = T5Tokenizer.from_pretrained("./pytorch_model")
#input_ids = tok(input_text, return_tensors="pt").input_ids.to("cuda")
input_ids = torch.tensor([[69, 8316, 3952, 12059, 171, 69, 34, 11451, 7798,
6614, 5, 6, 12, 29, 5, 644, 16747, 494,
20, 3910, 36, 129, 5, 16747, 4, 1668, 232,
20, 23435, 6462, 36, 194, 16747, 4, 1668, 232,
20, 6462, 2769, 36, 194, 16747, 4, 1668, 232,
20, 4759, 36, 6, 6, 12, 30, 181, 9,
16, 30, 5, 644, 1066, 494, 20, 3910, 36,
129, 644, 722, 494, 20, 3910, 36, 6, 9,
16, 1]], dtype=torch.long, device="cuda")
output = model.generate(input_ids, num_beams=4)
print(tok.batch_decode(output))
```
Then my folders had the following files (same as in your notebook).
```bash
ls checkpoint
checkpoint code_spm_unigram_40M.model graph.pbtxt model.ckpt-16000.data-00000-of-00002 model.ckpt-16000.data-00001-of-00002 model.ckpt-16000.index model.ckpt-16000.meta operative_config.gin
```
and
```bash
ls pytorch_model
config.json pytorch_model.bin special_tokens_map.json spiece.model tokenizer_config.json
```
with all the pytorch models converted from the mesh tf spm and mesh tf checkpoint (as you've done in the colab).
And then one has to put a lot of `mtf.print(x, [x], "output: ", summarize=-1)` statements in the mesh tensorflow code - here e.g.: https://github.com/tensorflow/mesh/blob/165d3dc7b4186ee5b6d31c9b17b3df4f7571cf42/mesh_tensorflow/transformer/transformer_layers.py#L729, but that's very painful ;-)
Also, see here for debugging advice: https://github.com/tensorflow/mesh/issues/235
Maybe by some miracle I find the problem over the next two weeks while further looking into mesh tensorflow.
Sorry, to be not too much of help here.
<|||||>Hi @patrickvonplaten ,
Thanks a lot for looking into this issue.
We highly appreciate your effort and sorry if it wasted your time.
I have also tested our protein model "prot_t5_xl_bfd" for protein sequence generation and it has the same issue. Also our next 11B model for protein sequences "prot_t5_xxl_bfd" will have the same issue.
This means the current results that we have from all our T5 models are not correct.
Do you know if this issue exist in only the decoder or both the encoder and the decoder ?
because currently we are only using the encoder on "prot_t5_xl_bfd" for feature extraction.
I have also checked MT5 and T5v1.1 and they seem to have the same issue as our current models, so if you will work on T5v1.1, you will highly likely find the issue and the solution for path ProtTrans models and ProtCode models.
Thanks again for your time, and I will leave this issue open, until you finish T5v1.1 implementation. <|||||>It's both encoder and decoder. Even the same encoder input yielded a different encoder output<|||||>This is really bad for the ProtTrans project.
Thanks a lot Patrick for your clear reply.
I will try to debug it from my side, and I will update you if I found the issue.<|||||> I got T5v1.1 working now I think: https://github.com/huggingface/transformers/pull/8488. But this code will certainly not work with your example since the Feed-Forward layer has different weights...
Let me take a look again at this issue in a bit. Could you maybe provide me with a code example where I just need to download 1) of your pretrained checkpoints
2) run a code snippet of the following format:
```python
#!/usr/bin/env python3
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3" # or any {'0', '1', '2'}
import t5 # noqa: E402
from t5.data.sentencepiece_vocabulary import SentencePieceVocabulary # noqa: E402
from transformers import T5Tokenizer # noqa: E402
from transformers.convert_t5_v1_1_original_tf_checkpoint_to_pytorch import ( # noqa: E402
convert_tf_checkpoint_to_pytorch,
)
from transformers.modeling_t5v2 import T5Config, T5v2ForConditionalGeneration # noqa: E402
path_to_tf_checkpoint = "/home/patrick/hugging_face/t5v1.1/t5_mesh_checkpoints"
tok = T5Tokenizer.from_pretrained("t5-small")
tok.save_pretrained(path_to_tf_checkpoint)
config = T5Config.from_pretrained("t5-small")
config.d_ff = 1024
config.num_decoder_layers = 8
config.num_layers = 8
config.num_heads = 6
config.save_pretrained(path_to_tf_checkpoint)
convert_tf_checkpoint_to_pytorch(path_to_tf_checkpoint, path_to_tf_checkpoint + "/config.json", path_to_tf_checkpoint)
t5_model = t5.models.MtfModel(
model_dir=path_to_tf_checkpoint,
batch_size=1,
tpu=None,
sequence_length={"inputs": 4, "targets": 4},
)
vocab_model_path = path_to_tf_checkpoint + "/sentencepiece.model"
vocab = SentencePieceVocabulary(vocab_model_path, extra_ids=100)
score = t5_model.score(
inputs=["Hello there"],
targets=["Hi I am"],
vocabulary=vocab,
)
model = T5v2ForConditionalGeneration.from_pretrained(path_to_tf_checkpoint, return_dict=True)
input_ids = tok("Hello there", return_tensors="pt").input_ids
labels = tok("Hi I am", return_tensors="pt").input_ids
# input_ids and labels are ok!
loss = model(input_ids, labels=labels).loss
assert -(labels.shape[-1] * loss.item()) - score[0][0] < 1e-4
```
If all the code would be in one file -> this would really help me save time in debugging. Otherwise, maybe we can have a quick call early next week (Monday maybe?) to discuss how to best tackle the error. I got a bit lost in all the colab notebook. I'm sure it's not that hard to fix actually.<|||||>Great @patrickvonplaten , "du bist der Beste" :
I have created a Colab that runs your code and download one of the CodeTrans models:
https://colab.research.google.com/drive/149F64wSOjm5O-HdLWpdWJE4dAMUA-Waa?usp=sharing
Important notes:
1. This model is using the original T5 model not v1.1. ie (word embedding is tied, uses dropout, uses RELU)
2. It is the base model.
Let me know if anything else is required.<|||||>should be fixed now. Everything is explained in the PR.<|||||>Woohoo, thanks a lot @patrickvonplaten, you are the best 😄 |
transformers | 7,790 | closed | updated bangla-bert-base model card with evaluation results | Hi,
I just updated bangla-bert-base model card with evolution results.
Also fixed some minor typo.
Please check, if possible please merge.
thanks and regards
Sagor | 10-14-2020 16:26:27 | 10-14-2020 16:26:27 | |
transformers | 7,789 | closed | Recommended Adafactor settings for T5 cause error | ## Environment info
- `transformers` version: 3.3.1
- Platform: Darwin-19.6.0-x86_64-i386-64bit
- Python version: 3.7.7
- PyTorch version (GPU?): 1.6.0 (False)
- Tensorflow version (GPU?): 2.2.0 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@sshleifer (from activity on Adafactor PRs)
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
The Adafactor docs recommend the following for T5 : `Adafactor(model.parameters(), lr=1e-3, relative_step=False, warmup_init=True)`
However, the init code then has:
```
if lr is not None and relative_step:
raise ValueError("Cannot combine manual lr and relative_step options")
if warmup_init and not relative_step:
raise ValueError("warmup_init requires relative_step=True")
```
which makes this setting impossible (as well as just changing to `relative_step=True`). So something seems to be missing either in the recommendations or in the implementation.
Thanks!
| 10-14-2020 16:10:34 | 10-14-2020 16:10:34 |
I think the doc should recommend
```python
Adafactor(model.parameters(), relative_step=True, warmup_init=True, lr=None)
```
want to fix it?<|||||>I think what corresponds to the original T5 training code is `Adafactor(model.parameters(), lr=1e-3, relative_step=False, warmup_init=False)`, however that didn't work great for me so far (much slower than Adam, and giving me NaN's even in FP32).<|||||>Hello @OyvindTafjord, have you been able to fine-tune T5 with Adafactor? Thanks, Sonali<|||||>No, I haven't investigated further regarding the slowness and NaN's I was getting.<|||||>This issue persists (i.e. the suggested defaults still produce the error).
I can confirm that `Adafactor(lr=1e-3, relative_step=False, warmup_init=False)` seems to break training (i.e. I observe no learning over 4 epochs, whereas `Adafactor(model.parameters(), relative_step=True, warmup_init=True, lr=None)` works well (much better than adam) |
transformers | 7,788 | closed | error when using the forward() function of the LongformerLayer class from the LongformerForMultipleChoice model | Hello,
Sorry if my question sounds a bit silly, but I just have a question:
I am trying to feed in the hidden output of the embedding layer of the `LongformerForMultipleChoice` model directly into the m-th layer of the same model. Each of my multiple-choice question that has 4 options.
When I do:
```Python
my_Longformer_multiple_choice_model.encoder.layer[layer_index].forward(hidden_output,
attention_mask=my_attention_mask,output_attention=False)
```
, an this error is generated:
```Python
File "/Users/hyunjindominiquecho/opt/anaconda3/lib/python3.7/site-packages/transformers/modeling_longformer.py", line 384, in _sliding_chunks_query_key_matmul
batch_size, seq_len, num_heads, head_dim = query.size()
ValueError: too many values to unpack (expected 4)
```
Here, `my_attention_mask` is the same attention mask that I would specify under the regular `LongformerForMultipleChoice` command. `my_attention_mask` was generated by:
```Python
# I am using the LongformerForMultipleChoice model, where each multiple choice question has 4 options.
encoded_dict = longformer_tokenizer(question_list, option_list,
return_tensors = 'pt',
padding ='max_length')
my_attention_mask = {k: v.unsqueeze(0) for k,v in encoded_dict.items()}['attention_mask']
my_attention_mask
>>> tensor([[[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]]])
# I can use this my_attention_mask in the regular command without an error, as below:
longformer_output= my_Longformer_multiple_choice_model(input_ids=input_ids,....,attention_mask=my_attention_mask)
```
Also, the `hidden_output` in my command was generated by the following:
```Python
encoded_dict = longformer_tokenizer(question_list, option_list,
return_tensors = 'pt',
padding ='max_length')
hidden_output = my_Longformer_multiple_choice_model(**{k: v.unsqueeze(0) for k,v in encoded_dict.items()}, labels = mc_labels)[2][0][:,:,:]
hidden_output.size()
>>> torch.Size([4, 4096, 768])
```
I am suspecting the value error is generated because the form of `my_attention_mask` is wrong. What should I pass for the `attention_mask` parameter in the command `my_Longformer_multiple_choice_model.encoder.layer[layer_index].forward(hidden_output,
attention_mask,output_attention=False)`?
Thank you,
@LysandreJik
@NielsRogge
@sgugger | 10-14-2020 15:53:09 | 10-14-2020 15:53:09 | |
transformers | 7,787 | closed | Fixing beam search output shapes | # What does this PR do?
`generate` in `generation_utils.py` returns a list of size `batch_size * num_beams` where it is much more practical if it returns a list of lists. The first list of size `batch_size` and all internal lists of size `num_beams`. In this way, one can generate using mini-batches of variable size and no do reshapes each time.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patrickvonplaten , @TevenLeScao | 10-14-2020 15:51:45 | 10-14-2020 15:51:45 | |
transformers | 7,786 | closed | Don't use `store_xxx` on optional bools | # What does this PR do?
Optional bool fields in `TrainingArguments` are given the `store_true` attribute by `HFArgumentParser` which can yield to bugs (as highlighted in #7755). This PR fixes this and to avoid breaking existing scripts, removes the optional in the `evaluate_during_training` argument.
It also fixes a few instances with the right argument called (since that argument is deprecated).
Fixes #7755 | 10-14-2020 15:43:10 | 10-14-2020 15:43:10 | |
transformers | 7,785 | closed | [RAG] RagTokenizer failing in decoding RAG Generator output | ## Environment info
- `transformers` version: 3.3.1
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0+cu101 (False)
- Tensorflow version (GPU?): 2.3.0 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
blenderbot: @mariamabarham
Bart: @sshleifer
Marian: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
@patrickvonplaten @LysandreJik
## Information
Model I am using (Bert, XLNet ...): RAG
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: `dummy_dataset`
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Run example code snippet from https://huggingface.co/transformers/master/model_doc/rag.html on `dummy_dataset`
2. Generate string from model output (Tried both `rag-sequence-nq` and `rag-token-nq`
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
!pip install git+https://github.com/huggingface/transformers.git
!pip install datasets
!pip install faiss-cpu
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration, RagSequenceForGeneration
import torch
import faiss
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq", use_dummy_dataset=True)
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
input_dict = tokenizer.prepare_seq2seq_batch("How many people live in Paris?", "In Paris, there are 10 million people.", return_tensors="pt")
input_ids = input_dict["input_ids"]
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
outputs = model(input_ids=input_ids, labels=input_dict["labels"])
generated_string = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(generated_string)
```
Error returned is on executing `tokenizer.batch_decode(outputs, skip_special_tokens=True)` -
```
/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils.py in convert_ids_to_tokens(self, ids, skip_special_tokens)
721 tokens = []
722 for index in ids:
--> 723 index = int(index)
724 if skip_special_tokens and index in self.all_special_ids:
725 continue
ValueError: invalid literal for int() with base 10: 'l'
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Tokenizer should decode to string. Not sure but closely related to https://github.com/huggingface/transformers/pull/4836 | 10-14-2020 15:33:51 | 10-14-2020 15:33:51 | Sorry it was my mistake, I need to get generated ids calling `model.generate` instead of `model`.
Adding fix here if anyone search for the same issue -
```
generated_ids = model.generate(input_ids=input_ids, labels=input_dict["labels"])
generated_string = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_string)
```
|
transformers | 7,784 | closed | Adding prefix constrained beam search | # What does this PR do?
This pull request adds a new decoding strategy that constrains the next token to generate based on a callable function. It mirrors https://github.com/pytorch/fairseq/pull/2646 for fairseq.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [X] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patrickvonplaten , @TevenLeScao
| 10-14-2020 15:29:33 | 10-14-2020 15:29:33 | The failed tests are not from this pull request but from RAG. Can someone review this, please?
@patrickvonplaten , @TevenLeScao<|||||>Hey @nicola-decao - thanks a lot for your PR here! The failing tests are actually due to this pull request. See a part of the error message here:
```
)
E TypeError: _generate_beam_search() missing 1 required positional argument: 'prefix_allowed_tokens_fn'
src/transformers/modeling_rag.py:1400: TypeError
_______________________ RagDPRT5Test.test_model_generate _______________________
[gw6] linux -- Python 3.7.9 /usr/local/bin/python
self = <tests.test_modeling_rag.RagDPRT5Test testMethod=test_model_generate>
def test_model_generate(self):
inputs_dict = self.config_and_inputs
> self.check_model_generate(**inputs_dict)
```
Could you fix the errors by slightly adapting the `generate` method in RAG to make it pass with your example?
In general I'm fine with this PR :-) <|||||>@patrickvonplaten now It should be ready for the merge :)<|||||>Awesome! There is probably going to be a merge conflict with the big `generate()` refactor PR that will be merged today: https://github.com/huggingface/transformers/pull/6949 .
We changed the design for these kinds of "logits processing" methods so that we'll probalby have to change the PR here a bit (and should also add a test). But let's put the PR on hold for a day and then I can help you merge it! <|||||>@nicola-decao, also what would be a typical use case of this function? *E.g.* could you give a quick example of a function that one would use as this function?
Also @sshleifer could you check if this is useful for Fairseq's Blenderbot? And @yjernite this might be interesting to you as well :-) <|||||>@patrickvonplaten we do have a few use cases in mind internally already :)
- prefix-triggered multi task *a la* T5: in many cases having the prefix in the output sequence makes more sense than in the input
- seq2seq model evaluation: some metrics (e.g. ROUGE-20 in the [ELI5 paper](https://arxiv.org/abs/1907.09190)) measure the model's ability to "continue" a generation, which can correlate better with human judgments of quality that full generation ROUGE
- seq2seq diagnostics: being able to measure the the effect of the input vs local context
@nicola-decao did you have something along those lines in mind?<|||||>> @nicola-decao, also what would be a typical use case of this function? _E.g._ could you give a quick example of a function that one would use as this function?
>
> Also @sshleifer could you check if this is useful for Fairseq's Blenderbot? And @yjernite this might be interesting to you as well :-)
@patrickvonplaten an example would be using a seq2seq model to predict a wikipedia title as in **Autoregressive Entity Retrieval** (https://arxiv.org/abs/2010.00904) (I am the fist author and I want to release my models 😊 - that is why I did this PR). In this case the possible outputs are all the 6M wikipedia titles so one can create a prefix tree and constrain the generation only on these 6M strings. Here an example of what I have:
```python
# custom class that creates a prefix tree where only "London" and "Rome" are possible outputs
trie = PrefixTree(["London", "Rome"])
# from a batch of tokens (torch.Tensor) returns a list of lists of allowed tokens (batches/ beams)
# `trie.get` returns the possible next tokens (leaves if any) given a prefix
def prefix_allowed_tokens_fn(batch_tokens):
return [
[
trie.get(tokens.tolist())
for tokens in beam_tokens
]
for beam_tokens in batch_tokens
]
# encoding inputs
input_args = {
k: v.to(model.device) for k, v in tokenizer.batch_encode_plus(
["[START_ENT] London [END_ENT] is the capital of the UK."],
return_tensors="pt"
).items()
}
# generating and decoding
tokenizer.batch_decode(
model.generate(
**input_args,
min_length=0,
num_beams=2,
num_return_sequences=2,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
),
skip_special_tokens=True
)
>> ['London', 'Rome']
```
<|||||>> Awesome! There is probably going to be a merge conflict with the big `generate()` refactor PR that will be merged today: #6949 .
>
> We changed the design for these kinds of "logits processing" methods so that we'll probalby have to change the PR here a bit (and should also add a test). But let's put the PR on hold for a day and then I can help you merge it!
@patrickvonplaten I guess one way to do it is to implement a `logits_processor`. But what I want to touch the log-probabilities directly instead of the logits (I observed that this works better in practice). Maybe we can also add this logic too to the general method? <|||||>@nicola-decao - I think you should be able to directly touch the log-probs with a `LogitsProcessor` since there are applied after the `log_softmax` here: https://github.com/huggingface/transformers/blob/7abc1d96d114873d9c3c2f1bc81343fb1407cec4/src/transformers/generation_utils.py#L967 and from looking at this version of the PR it seems to work with a `LogitsProcessor`
Or do you need to apply it to `log_probs + beam_score` ? so after this line: https://github.com/huggingface/transformers/blob/7abc1d96d114873d9c3c2f1bc81343fb1407cec4/src/transformers/generation_utils.py#L968? his would be more difficult then and we would have to see how to deal with it ... maybe introduce `logits_warper as well for `beam_search`... not sure yet!
It would be great if you could add a `LogitProcessor` - I kinda did the whole refactor to keep the functions clean :sweat_smile: .
I'm sorry that the big generate refactor means that we have to change this PR now. Do you want to give it a shot with the new `generate()` design? Otherwise I'm happy to help :-) <|||||>@patrickvonplaten I can do it :) I'll make another PR today.
<|||||>@patrickvonplaten here the new PR: https://github.com/huggingface/transformers/pull/8529 |
transformers | 7,783 | closed | Unable to serialize/save TF2.3.1 RobertaSequenceClassification model to saved model format | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.3.1
- Platform: Linux-3.13.0-158-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): 2.3.0 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik
@jplu
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
### Steps to reproduce the behavior:
from transformers import RobertaTokenizer, TFRobertaForSequenceClassification
import tensorflow as tf
import wget
import os, sys
local_path = os.path.abspath(os.path.join(__file__, "..", "resources/"))
tokenizer = RobertaTokenizer.from_pretrained("roberta-large-mnli")
model = TFRobertaForSequenceClassification.from_pretrained("roberta-large-mnli")
tf.keras.models.save_model(model, local_path, overwrite=True, include_optimizer=False, save_format='tf')
### Error
`WARNING:tensorflow:From /opt/conda/lib/python3.8/site-packages/tensorflow/python/training/tracking/tracking.py:111: Model.state_updates (from tensorflow.python.keras.engine.training) is deprecated and will be removed in a future version.
Instructions for updating:
This property should not be used in TensorFlow 2.0, as updates are applied automatically.
WARNING:tensorflow:From /opt/conda/lib/python3.8/site-packages/tensorflow/python/training/tracking/tracking.py:111: Layer.updates (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.
Instructions for updating:
This property should not be used in TensorFlow 2.0, as updates are applied automatically.
TypeError Traceback (most recent call last)
<ipython-input-4-1a9d4ccbf378> in <module>
8 model = TFRobertaForSequenceClassification.from_pretrained("roberta-large-mnli")
9
---> 10 tf.keras.models.save_model(model, local_path, overwrite=True, include_optimizer=False, save_format='tf')
/opt/conda/lib/python3.8/site-packages/tensorflow/python/keras/saving/save.py in save_model(model, filepath, overwrite, include_optimizer, save_format, signatures, options)
131 model, filepath, overwrite, include_optimizer)
132 else:
--> 133 saved_model_save.save(model, filepath, overwrite, include_optimizer,
134 signatures, options)
135
/opt/conda/lib/python3.8/site-packages/tensorflow/python/keras/saving/saved_model/save.py in save(model, filepath, overwrite, include_optimizer, signatures, options)
78 # we use the default replica context here.
79 with distribution_strategy_context._get_default_replica_context(): # pylint: disable=protected-access
---> 80 save_lib.save(model, filepath, signatures, options)
81
82 if not include_optimizer:
/opt/conda/lib/python3.8/site-packages/tensorflow/python/saved_model/save.py in save(obj, export_dir, signatures, options)
973 meta_graph_def = saved_model.meta_graphs.add()
974
--> 975 _, exported_graph, object_saver, asset_info = _build_meta_graph(
976 obj, export_dir, signatures, options, meta_graph_def)
977 saved_model.saved_model_schema_version = constants.SAVED_MODEL_SCHEMA_VERSION
/opt/conda/lib/python3.8/site-packages/tensorflow/python/saved_model/save.py in _build_meta_graph(obj, export_dir, signatures, options, meta_graph_def)
1073 function_aliases[fdef.name] = alias
1074
-> 1075 object_graph_proto = _serialize_object_graph(saveable_view,
1076 asset_info.asset_index)
1077 meta_graph_def.object_graph_def.CopyFrom(object_graph_proto)
/opt/conda/lib/python3.8/site-packages/tensorflow/python/saved_model/save.py in _serialize_object_graph(saveable_view, asset_file_def_index)
718
719 for obj, obj_proto in zip(saveable_view.nodes, proto.nodes):
--> 720 _write_object_proto(obj, obj_proto, asset_file_def_index,
721 saveable_view.function_name_map)
722 return proto
/opt/conda/lib/python3.8/site-packages/tensorflow/python/saved_model/save.py in _write_object_proto(obj, proto, asset_file_def_index, function_name_map)
759 version=versions_pb2.VersionDef(
760 producer=1, min_consumer=1, bad_consumers=[]),
--> 761 metadata=obj._tracking_metadata)
762 # pylint:enable=protected-access
763 proto.user_object.CopyFrom(registered_type_proto)
/opt/conda/lib/python3.8/site-packages/tensorflow/python/keras/engine/base_layer.py in _tracking_metadata(self)
3009 @property
3010 def _tracking_metadata(self):
-> 3011 return self._trackable_saved_model_saver.tracking_metadata
3012
3013 def _list_extra_dependencies_for_serialization(self, serialization_cache):
/opt/conda/lib/python3.8/site-packages/tensorflow/python/keras/saving/saved_model/base_serialization.py in tracking_metadata(self)
52 # TODO(kathywu): check that serialized JSON can be loaded (e.g., if an
53 # object is in the python property)
---> 54 return json_utils.Encoder().encode(self.python_properties)
55
56 def list_extra_dependencies_for_serialization(self, serialization_cache):
/opt/conda/lib/python3.8/site-packages/tensorflow/python/keras/saving/saved_model/json_utils.py in encode(self, obj)
42
43 def encode(self, obj):
---> 44 return super(Encoder, self).encode(_encode_tuple(obj))
45
46
/opt/conda/lib/python3.8/json/encoder.py in encode(self, o)
197 # exceptions aren't as detailed. The list call should be roughly
198 # equivalent to the PySequence_Fast that ''.join() would do.
--> 199 chunks = self.iterencode(o, _one_shot=True)
200 if not isinstance(chunks, (list, tuple)):
201 chunks = list(chunks)
/opt/conda/lib/python3.8/json/encoder.py in iterencode(self, o, _one_shot)
255 self.key_separator, self.item_separator, self.sort_keys,
256 self.skipkeys, _one_shot)
--> 257 return _iterencode(o, 0)
258
259 def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,
/opt/conda/lib/python3.8/site-packages/tensorflow/python/keras/saving/saved_model/json_utils.py in default(self, obj)
39 items = obj.as_list() if obj.rank is not None else None
40 return {'class_name': 'TensorShape', 'items': items}
---> 41 return serialization.get_json_type(obj)
42
43 def encode(self, obj):
/opt/conda/lib/python3.8/site-packages/tensorflow/python/util/serialization.py in get_json_type(obj)
70 return obj.__wrapped__
71
---> 72 raise TypeError('Not JSON Serializable:', obj)
TypeError: ('Not JSON Serializable:', RobertaConfig {
"_num_labels": 3,
"architectures": [
"RobertaForSequenceClassification"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 1024,
"id2label": {
"0": "CONTRADICTION",
"1": "NEUTRAL",
"2": "ENTAILMENT"
},
"initializer_range": 0.02,
"intermediate_size": 4096,
"label2id": {
"CONTRADICTION": 0,
"ENTAILMENT": 2,
"NEUTRAL": 1
},
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 16,
"num_hidden_layers": 24,
"pad_token_id": 1,
"type_vocab_size": 1,
"vocab_size": 50265
}
)
`
## Expected behavior
Save the model correctly as a tf.keras model.
| 10-14-2020 15:22:50 | 10-14-2020 15:22:50 | |
transformers | 7,782 | closed | RAG finetuning - unexpected keyword argument 'early_stop_callback' | ## Environment info
transformers version: 3.3.1
Platform: Ubuntu
Python version:3.6.12
PyTorch version (GPU: yes): 1.6.0
Using GPU in script?: 1 gpu
Using distributed or parallel set-up in script?: no
### Who can help
@patrickvonplaten @sgugger
## Information
model name: facebook/rag-token-base
The problem arises when using:
* [x ] the official example scripts: (give details below)
The tasks I am working on is:
* [x ] my own task or dataset: (give details below)
## To reproduce
Call finetune ona rag model
`python examples/rag/finetune.py --data_dir=$(pwd)/examples/rag/ioannis-data --output_dir $(pwd)/examples/rag/ioannis-output --model_name_or_path=facebook/rag-token-base --model_type rag_sequence --fp16 --gpus 1`
```
Traceback (most recent call last):
File "examples/rag/finetune.py", line 469, in <module>
main(args)
File "examples/rag/finetune.py", line 442, in main
logger=logger,
File "/home/ioannis/Desktop/transformers/examples/lightning_base.py", line 379, in generic_train
**train_params,
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/pytorch_lightning/trainer/properties.py", line 122, in from_argparse_args
return argparse_utils.from_argparse_args(cls, args, **kwargs)
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/pytorch_lightning/utilities/argparse_utils.py", line 50, in from_argparse_args
return cls(**trainer_kwargs)
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/pytorch_lightning/trainer/connectors/env_vars_connector.py", line 41, in overwrite_by_env_vars
return fn(self, **kwargs)
TypeError: __init__() got an unexpected keyword argument 'early_stop_callback'
```
I noticed a variable named early_stopping_callback in finetune.py. A typo perhaps?
| 10-14-2020 15:22:04 | 10-14-2020 15:22:04 | If you don't need early stopping just comment out `early_stop_callback=early_stopping_callback` on line 379 of `/home/ioannis/Desktop/transformers/examples/lightning_base.py`. You should be able to run your script.
I think lightning may have changed their api
You can also just uninstall your pytorch lightning and do `pip install pytorch_lightning==0.9.0` and script should work<|||||>Awesome! Installing 0.9.0 worked.
I manually installed pytorch_lightning and gitpython as they were not included in the transformers installation and the rag requirements file. |
transformers | 7,781 | closed | `decoder_config` variable not defined in EncoderDecoderModel.from_encoder_decoder_pretrained | https://github.com/huggingface/transformers/blob/890e790e16084e58a1ecb9329c98ec3e76c45994/src/transformers/modeling_encoder_decoder.py#L330
Using this function results in an error:
`UnboundLocalError: local variable 'decoder_config' referenced before assignment`
Suggest changing `decoder_config.add_cross_attention` to `kwargs_decoder["config"].add_cross_attention`
| 10-14-2020 14:53:35 | 10-14-2020 14:53:35 | @jsilter - great catch! I agree 100% with your suggestion! Do you want to open a PR to fix it? :-) <|||||>https://github.com/huggingface/transformers/pull/7903 this is already fixed yesterday @jsilter |
transformers | 7,780 | closed | How can I tweak the `Longformer` code to control the input of a `Longformer`'s layer? | Hello,
I have asked a similar question on the HuggingFace forum, but I didn't get a clear answer that I was hoping for.
I tried the following to control the input of a `Longformer` layer:
`best_model_longformer.longformer.encoder.layer[layer_index](my_input_hidden_vector)`
which of course, does not work.
How can I tweak the `Longformer` (or `BERT`) code to control the input of a `Longformer`'s layer?
Would this do the trick?:
```Python
self_attention_outputs = Longformer_model.LongformerLayer.forward(hidden_states,
attention_mask=None,
output_attentions=False)
Longformer_model.LongformerLayer.ff_chunk(self, self_attention_outputs)
```
But in this case, I don't know how to properly access the `LongformerLayer` class. I don't know if `Longformer_model.LongformerLayer` is the proper way.
I am not a programmer and I really do need more help on this. I know this can be a bit cumbersome to answer, but could you please help me on this? Your help is much appreciated.
Thank you, | 10-14-2020 14:03:56 | 10-14-2020 14:03:56 | The answer you got on the forum is pretty much the only one we have: copy paste the model code and customize it to your needs. If you're not a programmer, then you will need to learn a bit of Python/PyTorch to do this, but apart from making sure each model file contains the full code of each model, there is little more we can do to help you. There is an API to use the models in the common cases, users are expected to make the customizations they want if that does not suit their needs.<|||||>Hello, thank you for your reply.
Sorry if my question sounds a bit silly, but I just have a question:
When I do `my_Longformer_model.encoder.layer[layer_index].forward(hidden_output,my_attention_mask,output_attention=False)`, this error is generated:
```python
File "/Users/hyunjindominiquecho/opt/anaconda3/lib/python3.7/site-packages/transformers/modeling_longformer.py", line 384, in _sliding_chunks_query_key_matmul
batch_size, seq_len, num_heads, head_dim = query.size()
ValueError: too many values to unpack (expected 4)
```
Here, `my_attention_mask` is the same attention mask that I would specify under the regular
```python
longformer_output= my_longformer_model(input_ids=input_ids,....,attention_mask=my_attention_mask)
```
why exactly is the above error generated, and how can I remedy it?
Thank you, |
transformers | 7,779 | closed | I'm getting "nan" value for loss, while following a tutorial from the documentation | # ❓ Questions & Help
## Details
Hi,
I’m following the “Fine-tuning with Custom Dataset” tutorial for Question Answering on the SQuaD dataset tutorial: [available here](https://huggingface.co/transformers/custom_datasets.html#question-answering-with-squad-2-0). I’ve copy-pasted all the code shown in the tutorial step by step. However, when my model starts training, I don’t get the expected metric values for loss as I normally would, instead I get “nan”. Here is the code for training
`model.fit(train_dataset.shuffle(1000).batch(16), epochs=3, batch_size=16)`
Here is the output with the "nan" values for the losses.
```
Epoch 1/3
5427/5427 [==============================] - 4604s 848ms/step - loss: nan - output_1_loss: nan - output_2_loss: nan
Epoch 2/3
365/5427 [=>…] - ETA: 1:11:28 - loss: nan - output_1_loss: nan - output_2_loss: nan
```
I don’t know what is wrong, and I don’t think this output is what is supposed to be.
Would appreciate any help with this regard.
Thank you.
**A link to original question on the forum/Stack Overflow**:
https://discuss.huggingface.co/t/im-getting-nan-value-for-loss-while-following-a-tutorial-from-the-documentatin/1530 | 10-14-2020 13:50:52 | 10-14-2020 13:50:52 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>@sunnyville01
hi, facing the same issue, did you manage to solve this? |
transformers | 7,778 | closed | multi task roberta | add a RobertaForMultiTask model.
the model has both RobertaLMHead and RobertaClassificationHead.
when doing the forward pass, we provide an extra 'task' field.
when doing the 'mlm' task, we use RobertaLMHead similarly to RobertaForMaskedLM.
when doing the 'classification' task we use the RobertaClassificationHead, similarly to RobertaForSequenceClassification.
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
| 10-14-2020 11:59:43 | 10-14-2020 11:59:43 | |
transformers | 7,777 | closed | Adding RAG to text-generation pipeline | # 🚀 Feature request
Thank you for the awesome work. I am working on https://github.com/deepset-ai/haystack/issues/443 and just wanted to check whether any plan to add RAG into `text-generation` pipeline.
## Motivation
`text-generation` already have other models, hence it I would be great to have it in there. And this will help keeping our code clean by not adding classes for each type of generators.
```
model = pipeline('text-generation', model="facebook/rag-token-nq", tokenizer=None, device=-1)
# ValueError: Unrecognized configuration class <class 'transformers.configuration_rag.RagConfig'> for this kind of AutoModel: AutoModelForCausalLM.
Model type should be one of CamembertConfig, XLMRobertaConfig, RobertaConfig, BertConfig, OpenAIGPTConfig, GPT2Config, TransfoXLConfig, XLNetConfig, XLMConfig, CTRLConfig, ReformerConfig, BertGenerationConfig.
```
## Your contribution
If you guide me I am happy to help.
| 10-14-2020 09:32:29 | 10-14-2020 09:32:29 | Hey @lalitpagaria - RAG is quite different to other generation models so we don't have it on the short-term roadmap to add it to pipelines. We are still thinking about how to integrate retrieval augmented models to the pipelines.<|||||>Thanks @patrickvonplaten
Yeah I totally agree with you.
Please let me know whether I close this issue or keep it open for future reference.<|||||>Leave it open - I'll put it under projects so that I don't forget it :-)
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>@patrickvonplaten Great work! I noticed that `transformers` included the implementation for `DPR`. But for `RAG`, I only find a [demo](https://huggingface.co/rag/). Is there a source code for `RAG`? Or do you know where is Facebook's source code for `RAG`? <|||||>transformers does include RAG.
You can even find the documentation here: https://huggingface.co/transformers/model_doc/rag.html |
transformers | 7,776 | closed | Fix bert position ids in DPR convert script | https://github.com/huggingface/transformers/commit/614fef1691edb806de976756d4948ecbcd0c0ca3 introduced buffers for position ids for BERT that breaks the DPR convert script since the DPR weights don't have those.
To fix that I followed @LysandreJik 's suggestion to manually add the position ids to the state dict before loading it into the model. | 10-14-2020 09:23:33 | 10-14-2020 09:23:33 | |
transformers | 7,775 | closed | Create README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
| 10-14-2020 08:12:29 | 10-14-2020 08:12:29 | This is great, thanks for uploading and sharing.
Will merge this now, but had two questions:
- should we add a link back to your repo at https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT
- Is this checkpoint version 1 or version 2 from https://github.com/huawei-noah/Pretrained-Language-Model/blame/master/TinyBERT/README.md#L62-L72
Thank you! |
transformers | 7,774 | closed | XLM-RoBERTa model for QA seems not properly work | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.3.1 (and I've also tried installing Transformers from `master`, see details below)
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0+cu101 (False)
- Tensorflow version (GPU?): 2.3.0 (False)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
## Information
Model I am using (Bert, XLNet ...):
[deepset/xlm-roberta-large-squad2](https://huggingface.co/deepset/xlm-roberta-large-squad2)
The problem arises when using:
* [x] the official example scripts: [run_squad.py](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: **SQuAD 2.0 dev set evaluation**
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
! wget https://raw.githubusercontent.com/rajpurkar/SQuAD-explorer/master/dataset/dev-v2.0.json
! python transformers/examples/question-answering/run_squad.py \
--model_type xlm-roberta \
--model_name_or_path 'deepset/xlm-roberta-large-squad2' \
--do_eval \
--do_lower_case \
--predict_file 'dev-v2.0.json' \
--output_dir 'output' \
--overwrite_output_dir \
--version_2_with_negative
```
## Expected behavior
There are some values mismatch between:
1. values reported in the model card [here](https://huggingface.co/deepset/xlm-roberta-large-squad2#performance)
2. values obtained when Transformers is installed using `pip install transformers`
3. values obtained when Transformers is installed from master
In particular:
- Reported metrics in the model card: `"exact": 79.45759285774446, "f1": 83.79259828925511`
- Transformers installed from pip: `'exact': 64.67615598416576, 'f1': 77.27580544355429`
- Transformers installed from master: `'exact': 60.11959090373114, 'f1': 76.13129575803934`
| 10-14-2020 07:12:46 | 10-14-2020 07:12:46 | Thanks for reporting, will investigate.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>hello, this command " --model_type xlm-roberta \" not work for me,
can you help me? please |
transformers | 7,773 | closed | Error in run_ner.py - ModuleNotFoundError: No module named 'tasks' | ## Environment info
- Google colab notebook.
- `transformers` version: 3.3.1
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0+cu101 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@stefan-it
## Information
Model I am using is NER model
Script: run_ner.py:
https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner.py
The problem arises when using:
* [X ] the official example scripts: (give details below)
The tasks I am working on is:
* building the NER model from model "bert-base-multilingual-cased" using GermEval data with instructions here:
https://huggingface.co/transformers/v2.4.0/examples.html#named-entity-recognition
## To reproduce
Steps to reproduce the behavior:
```
# Eliminate --model_type; it creates an error and said it isn't used.
# sys.path.append(os.getcwd())
! python3 run_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_gpu_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
Error output:
/usr/local/lib/python3.6/dist-packages/transformers/training_args.py:332: FutureWarning: The `evaluate_during_training` argument is deprecated in favor of `evaluation_strategy` (which has more options)
FutureWarning,
Traceback (most recent call last):
File "run_ner.py", line 308, in <module>
main()
File "run_ner.py", line 118, in main
module = import_module("tasks")
File "/usr/lib/python3.6/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 953, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'tasks'
```
## Expected behavior
According to the example page, the model should get fine-tuned and tested on the GermEval test dataset.
| 10-14-2020 07:02:23 | 10-14-2020 07:02:23 | Update - this is not a bug in run_ner.py, but sort-of a documentation bug. The page that describes how to do NER does not document that you first need to copy "tasks.py" and other scripts, into your local current directory.
https://github.com/huggingface/transformers/tree/master/examples/token-classification/README.md
For instance, you could provide a list of "wget" commands. This may seem obvious to experienced developers, but it really helps to spell it out for the occasional clueless people like me :-)<|||||>Hello! In order to run the script, you should generally clone the repository and run the scripts from there. Running a single script will very rarely work. You'd be way safer doing the following (showing you the full setup + venv setup):
```py
git clone https://github.com/huggingface/transformers
cd transformers
python -m venv .env
source .env/bin/activate
pip install -e .
cd examples
pip install -r requirements.txt
# You can run your scripts now :)
```<|||||>Thank you; for future users, that would be super helpful to add that to the README.
Also, I think you need to cd to https://github.com/huggingface/transformers/tree/master/examples because the scripts assume that tasks.py etc are in the current directory. But the “activate” may take care of that.
Thanks for everything – great software!
Dana
From: Lysandre Debut <[email protected]>
Sent: Thursday, October 15, 2020 2:00 AM
To: huggingface/transformers <[email protected]>
Cc: Ludwig, Dana <[email protected]>; Author <[email protected]>
Subject: Re: [huggingface/transformers] Error in run_ner.py - ModuleNotFoundError: No module named 'tasks' (#7773)
Hello! In order to run the script, you should generally clone the repository and run the scripts from there. Running a single script will very rarely work. You'd be way safer doing the following (showing you the full setup + venv setup):
git clone https://github.com/huggingface/transformers
cd transformers
python -m venv .env
source .env/bin/activate
pip install -e .
cd examples
pip install -r requirements.txt
# You can run your scripts now :)
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub<https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_huggingface_transformers_issues_7773-23issuecomment-2D709013098&d=DwMCaQ&c=iORugZls2LlYyCAZRB3XLg&r=A2YbHreGE4p0vzAywzM_Uctk-D3fPuXcmLPnjKJ7Gqc&m=QMIf0fCBI0DJve9mdTNWpHYcZNw6G6lbgNMtwt27-LI&s=_PAC-teAXIZpD6bvXaxJJooVSpQXCW-g1E0P6Xx0nzE&e=>, or unsubscribe<https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_notifications_unsubscribe-2Dauth_ABUXNRIKGTLERRFCOBWSGRTSK22XTANCNFSM4SQGNKXQ&d=DwMCaQ&c=iORugZls2LlYyCAZRB3XLg&r=A2YbHreGE4p0vzAywzM_Uctk-D3fPuXcmLPnjKJ7Gqc&m=QMIf0fCBI0DJve9mdTNWpHYcZNw6G6lbgNMtwt27-LI&s=JROY2gIxImDPq_udIaCyPb85pHW64zCpy7-aa4ggSQY&e=>.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,772 | closed | Added gpt2 model parallelism | # Model Parallelism for GPT2LMHead
Addresses [issue 7526](https://github.com/huggingface/transformers/issues/7526)
Adds two new methods to `GPT2LMHead` and the `GPT2Model` classes to enable you to generate and fine-tune models using model parallelism. This feature is most applicable for `gpt2-large` and `gpt2-xl`. Minor modifications are made to the `TrainingArguments` and `Trainer` classes to avoid conflicting data parallelism behavior and related batch_size increases which would negate model parallelism. Note that nearly 64GB of GPU (4 Tesla v100s) are needed to fine-tune `gpt2-xl` @ 1024 tokens.
It is critically important to provide users the ability to specify where to put the blocks of a model because the GPU sizes and numbers are likely to be very diverse. This is done with a dictionary called `device_map`. I am planning on providing some examples and guidelines for the p3, p2 and g3 AWS instances.
Model parallelism has to be baked into the model class itself. Currently working on the T5 model. From my calculations the 11B model cannot fit on the largest p3 instance that I have access to (8 Tesla v100 GPUs). The 3B model can.
The methods are:
- `parallelize`, which will distribute the attention blocks of the model across several devices according to a device map
- `deparallelize`, which will move the model back to cpu
# Example
```
model = GPT2LMHeadModel.from_pretrained('gpt2-xl')
device_map = {0: [0, 1, 2, 3, 4, 5, 6, 7, 8],
1: [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21],
2: [22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34],
3: [35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47]}
model.parallelize(device_map) # Distributes the model's attention blocks across several devices
model.deparallelize() # Puts the model back on cpu and calls torch.cuda.empty_cache() to liberate GPU memory
```
## Reviewers
`TrainingArguments`: @sgugger
- Added a new parameter `model_parallel` and attribute `self.model_parallel` to control model parallelism behavior
- Slightly modified the `train_batch_size` and `eval_batch_size` calculations to avoid automatically increasing the batch size if `self.model_parallel` (automatically increasing the batch size defeats the purpose of model parallelism because you won't be able to train a larger model if the batch_size increases proportionally to the number of devices)
`Trainer`: @sgugger
- Minor changes controlled by new `args.model_parallel `attribute
`GPT2LMHead`: @patrickvonplaten
- Adds parallelize and deparallelize methods
- Adds new `self.model_parallel` and `self.device_map` attributes
- Changes forward behavior when `self.model_parallel == True` to ensure tensors are on the right device
| 10-14-2020 06:39:37 | 10-14-2020 06:39:37 | Very cool implementation that would interest a few of our team, pinging them here :)<|||||>Indeed, adding a test would be nice! Will trigger the multi-gpu slow tests once the test is added.<|||||>@LysandreJik @patrickvonplaten @sgugger Glad you like it! Yes, the basic form of the implementation works on T5. I've been working on that too. Testing solutions to the items you brought up locally and should make the improvements to the PR in the next day or two.<|||||>Hi @alexorona! Before we merge this, having a test would really be necessary. Have you had any luck in implementing such a test?
If you're lacking time, we can also take over from here.<|||||>Hi, I've successfully been able to start training gpt2-xl on multiple gpu's using the model parallelism code from this pull request, but I'm running into an issue when restarting the training process from a checkpoint model. It seems that in this case when reloading the model, only the memory of the first GPU keeps increasing until it reaches an Out Of Memory error, instead of spreading over all GPUs like it did when training from scratch. Is it possible that reloading from checkpoint triggers a different code path that has been overlooked until now?
(edit)
I seem to have found an issue and potential fix. Line 609 in Trainer.train() loads the optimizer saved in the checkpoint. This function has a _map_location_ parameter which seems to force the optimizer to load fully onto _self.args.device_ which I'm guessing would be the first GPU.
`self.optimizer.load_state_dict(torch.load(os.path.join(model_path, "optimizer.pt"), map_location=self.args.device))`
Removing the _map_location_ parameter makes the function properly put back all the loaded parameters onto the correct devices. Maybe there is a better way of handling this but at least it is an indication.<|||||>@LysandreJik Just haven't had the time to do that and it might be awhile before I can get around to writing tests. However, I have been able to implement the same thing on T5 and it's working. Fine-tuned a 3B model this weekend. Maybe I can add that to this branch tonight and the team can handle the tests?
@MichielRuelens Did you try loading to CPU and then calling model.parallelize() ? <|||||>@LysandreJik I worked on t5 last weekend. Added that. Happy to explain things like why `get_device_map `should probably take a list of devices rather than a number. Can you help get this across the finish line?<|||||>Very cool, thanks! Will take a look at it and open a PR on your branch.<|||||>Great, with the tests PR merged this seems close to merge! Could you rebase & run the code quality tools (`make fixup` or `make style && make quality`) so that the test suite passes?
Also @patrickvonplaten and could you check the tests?<|||||>Awesome, LGTM!<|||||>oof that's a tough rebase. I don't think we'll be able to merge that. Could you close the PR and open a new one, so that we can see the diff? I don't think you need to do anything on the branch, just close the PR and open a new one.<|||||>I'm researching doing the same for BART (https://github.com/huggingface/transformers/issues/8344) and stumbled upon the open source library DeepSpeed/ZeRO:
https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
I'm yet to experiment with deepspeed and fairscale, but I thought I'd ask whether you have already done this and decided that implementing from scratch is better.
What are the pros/cons for using an in-house implementation as compared to using an external library, other than the obvious potential bugs and issues of using external libs and not having control over those?
If this has been discussed already please kindly send me to that issue/page? Thank you!
Whatever the outcome, we can also qualititatively compare the results of this PR once it's done with doing the same via deepspeed and/or fairscale.
<|||||>Rebased with transformers 4.0.0 and moved PR to [here](https://github.com/huggingface/transformers/pull/8696).
> I'm researching doing the same for BART (#8344) and stumbled upon the open source library DeepSpeed/ZeRO:
> https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
Great point, @stas00 ! From the description, DeepSpeed is an optimization on top of data parallelism and model parallelism. I think you've identified the next step! My reading of DeepSpeed this that one still has to implement data parallelism or model parallelism, but DeepSpeed will reduce the GPU memory footprint. Practically speaking, this could open the door to even larger models. During the development of the [final model parallel PR](https://github.com/huggingface/transformers/pull/8696), I ran into hard limits on AWS GPU instance with t5-11b and t5-11b in terms of the number of tokens you can train. You'll need the largest AWS instances to train 512 tokens on t5-3b. For t5-11b, you're restricted even more. Note that I haven't tried this with apex, so it might be possible to squeeze out a little more from the current implementation.<|||||>Thanks for the follow up, @alexorona. From what I read deepspeed implements parallelism too, but I'm still in the process of studying - didn't get to play with it yet. I've started with fairscale first.
What about [`fairscale`](https://github.com/facebookresearch/fairscale) then? It implements the model parallelism w/o needing to make any changes to the model. All that code is abstracted into the trainer-level calls.
Now that you added T5+gpt2 model parallelism `transformers` needs to add a separate code for each model architecture. Why not follow `fairscale`-style and do it outside the model?<|||||>Similarly to what we've done with the `tie_weights` methods which ties weights thanks to the `get_input_embeddings()` and `get_output_embeddings()` methods, we could probably have a model-agnostic way of enabling parallelization using a `get_layers()` method, like [this](https://github.com/huggingface/transformers/blob/gradient-checkpointing-v2/src/transformers/modeling_utils.py#L669-L682) for example.
This would allow to have the same code for each model architecture, provided the `get_layers()` utility is correctly implemented.<|||||>Would need to look into how `deepspeed` is implemented. My reading is that it supports parallelism, but still requires you to go through the process of defining how parallelism will work in the model definition (which modules on which devices).
Not sure on `fairscale`. It may or may not be a simplification. There were quirks in implementing model parallelism on gpt2 and t5 that have to do with the pytorch graph:
- The LM head has to be loaded on the same device as the embedding layer
- Tensors (not just layers) have to be shifted to the appropriate device during training
Initially, I went to `eisen` to see if it could handle model parallelism, but it couldn't deal with transformer models. If `fairscale` can abstract that process, that would be great.<|||||>I hear you, @alexorona, that you're saying that each model may have its special needs. So we need to see if perhaps this can be done via some sort of callbacks and add the callbacks points as we discover new needs.
As I was planning to do the same for BART, perhaps I should replicate your implementation for Bart and then based on 3 different models we can then see how we can make this model-agnostic. What do you think?
Perhaps we should continue this discussion in a dedicated issue where we discuss model_parallelism for all of `transformers`, including considering using or forking existing implemenations.<|||||>I think those are both great ideas, @stas00. Should give us a better understanding of how to move forward with this. Created [this issue](https://github.com/huggingface/transformers/issues/8771) to continue conversation. |
transformers | 7,771 | closed | Cannot trace_module on models using model's generate function | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.3.1
- Platform: Linux-5.8.14_1-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
@patrickvonplaten, @sshleifer
-->
@patrickvonplaten, @sshleifer
## Information
Model I am using BART
The problem arises when using:
* [*] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [*] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. load any model that uses the generate function
2. try to trace it using trace_module
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
Can be easily reproduced with the following snippet:
```
import torch
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = 'sshleifer/bart-tiny-random'
tokenizer = AutoTokenizer.from_pretrained(model)
sqgen_model = AutoModelForSeq2SeqLM.from_pretrained(model, torchscript=True)
sqgen_model.eval()
dummy_input = ' '.join('dummy' for dummy in range(512))
batch = tokenizer(
[dummy_input], return_tensors='pt', truncation=True, padding='longest',
)
with torch.no_grad():
traced_model = torch.jit.trace_module( # type: ignore
sqgen_model,
{
'forward': (batch.input_ids, batch.attention_mask),
'generate': (batch.input_ids, batch.attention_mask),
},
)
```
It throws an error:
```
File "/home/void/.miniconda3/envs/lexml/src/transformers/src/transformers/generation_utils.py", line 288, in generate
assert isinstance(max_length, int) and max_length > 0, "`max_length` should be a strictly positive integer."
AssertionError: `max_length` should be a strictly positive integer.
```
obviously because the generate function's second argument is supposed to be max_length and not attention_mask
## Expected behavior
Should be able to trace models that use the generate function.
<!-- A clear and concise description of what you would expect to happen. -->
| 10-14-2020 04:35:09 | 10-14-2020 04:35:09 | `generate` currently does not support `torch.jit.trace`. This is sadly also not on the short-term roadmap.<|||||>@patrickvonplaten, thanks for the response. In that case is there no way to trace the inference process of generative models provided here ? So any kind of inference of the form text -> text (for eg: summarization) cannot be exported to torchscript ? <|||||>Yes, if you want to make it faster, reduce `num_beams`.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hi, are summarization kinds of models still not traceable ??
I am trying to deploy this onto AWS inferentia, whose prerequisite is that the model should be traceable !!
for example this sshleifer/distilbart-cnn-12-6
@sshleifer, @patrickvonplaten can you guys please help ??<|||||>Hey @DevBey,
Could you maybe open a new issue that states exactly what doesn't work in your case? This issue is quite old now and it would be nice to have a reproducible code snippet with the current `transformers` version. |
transformers | 7,770 | closed | How to create a QA model where the answer can be from the question text as well? | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
SQuAD QA dataset has questions where the answer is a span in the context,
How do I create a QA system where the answer string can be from the context or question text?
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
| 10-14-2020 01:26:40 | 10-14-2020 01:26:40 | Normally there's no difference. You just provide `[CLS] question [SEP] answer [SEP]` examples to the model, and the `start_positions` and `end_positions` can be indexes of the question. <|||||>Yes,
Can you point me to such an implementation?
huggingface Squad Question answering code handles a lot of edge cases like start token should be before the end token, find n best predictions etc.
@NielsRogge , Is there a simpler implementation for the question answering task?
I found one in the documentation but that doesn't handle the predictions, sanity checks, n_best predictions etc.
|
transformers | 7,769 | closed | from transformers import RagSequenceForGeneration gives ImportError | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.3.1
- Platform: Linux
- Python version:3.6.3
- PyTorch version (GPU?):
- Tensorflow version (GPU?):2.3.0
- Using GPU in script?:no
- Using distributed or parallel set-up in script?:no
### Who can help
@patrickvonplaten @sgugger
## Information
Model I am using ():
The problem arises when using:
## To reproduce
1.python
>> from transformers import RagSequenceForGeneration <- RagTokenizer is imported without any errors
## Expected behavior
I shouldn't get
ImportError: cannot import name 'RagSequenceForGeneration'
| 10-13-2020 21:51:05 | 10-13-2020 21:51:05 | You don't have PyTorch installed in your environment. This is a PyTorch model.<|||||>Indeed , that was the problem.
The code in https://huggingface.co/transformers/model_doc/rag.html has import torch after the "from transformers import RagSequenceForGeneration,..." statement, so I incorrectly concluded that torch is not needed for the import. Also, that RagTokenizer got imported without errors.
Thanks!
|
transformers | 7,768 | closed | Is there any way to control the input of a layer of `Longformer`? | Hello,
Is there any way that I can directly control the input to a layer of the `Longformer` model, similar to `GPT2.transformer.h[]`?
I tried `best_model_longformer.longformer.encoder.layer[layer_index](input_hidden_state_for_layer)` but it's giving this error:
```python
Traceback (most recent call last):
File "SEED_125_V20_15_LONGFORMER.py", line 426, in <module>
main_function('/home/ec2-user/G1G2.txt','/home/ec2-user/G1G2_answer_num.txt', num_iter)
File "SEED_125_V20_15_LONGFORMER.py", line 388, in main_function
best_model_longformer)
File "SEED_125_V20_15_LONGFORMER.py", line 205, in fill_MC_loss_accuracy_tensor
best_model_longformer.longformer.encoder.layer[j](input_hidden_state)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/transformers/modeling_longformer.py", line 852, in forward
output_attentions=output_attentions,
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/transformers/modeling_longformer.py", line 796, in forward
output_attentions,
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/transformers/modeling_longformer.py", line 241, in forward
attention_mask = attention_mask.squeeze(dim=2).squeeze(dim=1)
AttributeError: 'NoneType' object has no attribute 'squeeze'
```
:S thank you, | 10-13-2020 21:15:35 | 10-13-2020 21:15:35 | |
transformers | 7,767 | closed | Add predict step accumulation | # What does this PR do?
Currently, the Trainer accumulates all predictions on the host (GPU or TPU) before gathering across all hosts (in case of distributed training) and moving back to the CPU. This can result in OOM errors when users have a big dataset (the model is already taking up a lot of space on the host) as highlighted in #7232. However moving the predictions to the CPU at each prediction step is also inefficient (particularly on TPU).
This PR aims at fixing the OOM problem while retaining efficiency by introducing a new training argument called `eval_accumulation_step`. If left untouched, the behavior is the same as right now (all predictions accumulated on the host and moved at the end of the prediction loop). If set to an int, the predictions are gathered and moved every `eval_accumulation_step`. This required some clever reorganization of the predictions (see the docstring of `DistributedTensorGatherer` for more details).
In passing I cleaned up the code related to gathering tensors across multiple hosts and fixed the issue of the `loss.item()` (big slow down to do that at every step on TPUs) and accumulated the losses the same way predictions and labels are. This still works for any number of outputs/labels of the model.
To check those changes did not break anything, I ran `test_trainer_distributed.py` on my local setup and created an equivalent for TPUs that I also ran (they both pass).
This slightly change Seq2SeqTrainer (since we don't want the `loss.item()`) so cc @patil-suraj I don't think this should break anything in it.
<!-- Remove if not applicable -->
Fixes #7232
| 10-13-2020 20:25:56 | 10-13-2020 20:25:56 | Thanks so much @sgugger - you're a legend! 🙇 <|||||>> # What does this PR do?
> Currently, the Trainer accumulates all predictions on the host (GPU or TPU) before gathering across all hosts (in case of distributed training) and moving back to the CPU. This can result in OOM errors when users have a big dataset (the model is already taking up a lot of space on the host) as highlighted in #7232. However moving the predictions to the CPU at each prediction step is also inefficient (particularly on TPU).
>
> This PR aims at fixing the OOM problem while retaining efficiency by introducing a new training argument called `eval_accumulation_step`. If left untouched, the behavior is the same as right now (all predictions accumulated on the host and moved at the end of the prediction loop). If set to an int, the predictions are gathered and moved every `eval_accumulation_step`. This required some clever reorganization of the predictions (see the docstring of `DistributedTensorGatherer` for more details).
>
> In passing I cleaned up the code related to gathering tensors across multiple hosts and fixed the issue of the `loss.item()` (big slow down to do that at every step on TPUs) and accumulated the losses the same way predictions and labels are. This still works for any number of outputs/labels of the model.
>
> To check those changes did not break anything, I ran `test_trainer_distributed.py` on my local setup and created an equivalent for TPUs that I also ran (they both pass).
>
> This slightly change Seq2SeqTrainer (since we don't want the `loss.item()`) so cc @patil-suraj I don't think this should break anything in it.
>
> Fixes #7232
Thanks so much @sgugger
`eval_accumulation_steps` for the argument name and not `eval_accumulation_step` 😉 |
transformers | 7,766 | closed | Use Marian-MT to evaluate translated outputs by printing out per-word log-probility | # ❓ Questions & Help
I am going to evaluate the Marian's opus-mt to evaluate the translated output y given the input x.
I want to get the model's log-probability of y given x, i.e., P(y|x).
I didn't find any usage example in the document [here](https://huggingface.co/transformers/model_doc/marian.html#multilingual-models).
@sshleifer do you know an example in this case? Thanks!
For example:
Source input (x): I would like to run this experiment.
Translated output (y) in Chinese: 我 希望 跑 这个 实验 。
The word-level log probability: -0.3 -0.4 -0.23 -0.43 -0.23 -0.8
BTW, fairseq supports this function in their [comment-line tools](https://fairseq.readthedocs.io/en/latest/command_line_tools.html).
| 10-13-2020 19:18:41 | 10-13-2020 19:18:41 | Would love a contribution that implemented it.
Can you paste a working fairseq command to try to emulate?
Alternatively you could just send a PR.<|||||>Hi @sshleifer
Marian NMT seems to have such functionality as well. Please check their script [here](https://github.com/marian-nmt/marian-examples/blob/master/wmt2017-transformer/run-me.sh#L189).
I modify the [translation code](https://fairseq.readthedocs.io/en/latest/command_line_tools.html#fairseq-generate) in fairseq named as *validate_lm.py*, and run the bash script to get the per-word log-probability.
```bash
python validate_lm.py \
$binarized_data_dir \
--source-lang en --target-lang fr \
--path $path_to_checkpoint \
--task translation \
--valid-subset train \
--max-sentences 16 \
--nll-file $out_file
```
validate_lm.py
```python
import logging
import sys
import torch
from fairseq import checkpoint_utils, distributed_utils, options, utils, tasks
from fairseq.logging import metrics, progress_bar
from fairseq.options import add_distributed_training_args
from fairseq.criterions.cross_entropy import CrossEntropyCriterion
logging.basicConfig(
format='%(asctime)s | %(levelname)s | %(name)s | %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=logging.INFO,
stream=sys.stdout,
)
logger = logging.getLogger('fairseq_cli.validate')
def main(args, override_args=None):
utils.import_user_module(args)
assert args.max_tokens is not None or args.max_sentences is not None, \
'Must specify batch size either with --max-tokens or --max-sentences'
use_fp16 = args.fp16
use_cuda = torch.cuda.is_available() and not args.cpu
if override_args is not None:
if isinstance(override_args, dict):
overrides = override_args
else:
overrides = vars(override_args)
print('override_args')
overrides.update(eval(getattr(override_args, 'model_overrides', '{}')))
else:
overrides = None
# Load ensemble
logger.info('loading model(s) from {}'.format(args.path))
task = tasks.setup_task(args)
models, _model_args = checkpoint_utils.load_model_ensemble(
[args.path],
arg_overrides=overrides,
task=task,
)
model = models[0]
# Move models to GPU
for model in models:
if use_fp16:
model.half()
if use_cuda:
model.cuda()
# Print args
logger.info('args', args)
logger.info('overrides', overrides)
# Build criterion
# criterion = task.build_criterion(args)
criterion = CrossEntropyCriterion(task, False)
criterion.eval()
for subset in args.valid_subset.split(','):
try:
task.load_dataset(subset, combine=False, epoch=1)
dataset = task.dataset(subset)
except KeyError:
raise Exception('Cannot find dataset: ' + subset)
# Initialize data iterator
itr = task.get_batch_iterator(
dataset=dataset,
max_tokens=args.max_tokens,
max_sentences=args.max_sentences,
max_positions=utils.resolve_max_positions(
task.max_positions(),
*[m.max_positions() for m in models],
),
ignore_invalid_inputs=args.skip_invalid_size_inputs_valid_test,
required_batch_size_multiple=args.required_batch_size_multiple,
seed=args.seed,
num_workers=args.num_workers,
).next_epoch_itr(shuffle=False)
progress = progress_bar.progress_bar(
itr,
log_format=args.log_format,
log_interval=args.log_interval,
prefix=f"valid on '{subset}' subset",
default_log_format=('tqdm' if not args.no_progress_bar else 'simple'),
)
fout = open(args.nll_file, 'w')
nll = []
for i, sample in enumerate(progress):
sample = utils.move_to_cuda(sample) if use_cuda else sample
model.eval()
with torch.no_grad():
loss, sample_size, log_output = criterion(model, sample, reduce=False)
nsentences = log_output['nsentences']
loss = loss.view(nsentences, -1).tolist()
for j, sample_id in enumerate(sample['id'].tolist()):
loss_j = [ll for ll in loss[j] if ll > 0]
avg_nll = sum(loss_j) / len(loss_j)
lstr = '\t'.join([f'{ll:.4f}' for ll in loss_j])
fout.write(f'{sample_id}\t{avg_nll}\t{lstr}\n')
nll.append((sample_id, avg_nll, lstr))
fout.close()
def cli_main():
parser = options.get_validation_parser()
add_distributed_training_args(parser)
args = options.parse_args_and_arch(parser)
# only override args that are explicitly given on the command line
override_parser = options.get_validation_parser()
group = override_parser.add_argument_group("Valid BW")
group.add_argument('--nll-file', type=str, default=None)
add_distributed_training_args(override_parser)
override_args = options.parse_args_and_arch(override_parser, suppress_defaults=True)
distributed_utils.call_main(args, main, override_args=override_args)
if __name__ == '__main__':
cli_main()
```
<|||||>I'd tinker with that - perhaps in a few days.<|||||>I started looking into this but to be able to reproduce any of these examples in order to replicate this in transformers I need to spend hours just to set things up :( It'd have been much easier if such requests came with ready data that we could use right away.
Currently waiting for very sloooooooow downloads of data from statmt.org - will try to setup fairseq for en-fr...
will keep you posted on the progress.
p.s. marianmt I couldn't even build on ubuntu-20.04, so hoping I could sort it out with fairseq<|||||>OK, I found an easy way to set up something that your script would run on:
```
mkdir -p data-bin
curl https://dl.fbaipublicfiles.com/fairseq/models/wmt14.v2.en-fr.fconv-py.tar.bz2 | tar xvjf - -C data-bin
curl https://dl.fbaipublicfiles.com/fairseq/data/wmt14.v2.en-fr.newstest2014.tar.bz2 | tar xvjf - -C data-bin
python validate_lm.py data-bin/wmt14.en-fr.joined-dict.newstest2014 --source-lang en --target-lang fr --path data-bin/wmt14.en-fr.joined-dict.transformer/model.pt --task translation --valid-subset test --max-tokens 128
```
(in the future requests please provide something similar so that the devs could quickly reproduce your example. And of course test that it works. Thank you)
Your script won't run as is, had to do some tweaks to it. But it doesn't matter for now.
What it produces is:
```
1596 0.7027008545895418 1.2075 1.4464 1.1499 0.1134 0.1958 0.1032
1615 3.4015886902809145 5.8378 9.5874 0.6482 0.7548 0.1797
2837 1.7323936596512794 0.8643 0.1775 7.3694 0.1477 0.1032
256 1.5152931759754817 0.8425 7.1255 0.8411 0.0599 0.1208 0.1020
556 2.3045735328147807 6.7926 0.0528 1.0420 2.4513 3.3704 0.1184
2922 1.7860032822936773 0.4388 3.8867 1.9373 0.2531 6.5018 0.1011 1.0688 0.1005
612 1.598365530371666 3.2449 2.8535 0.1290 0.1661
605 1.7411062990625699 4.9944 0.1142 0.1147
1481 0.4938086899263518 0.3987 0.5716 1.2258 0.5801 0.4607 0.1157 0.1041
2013 0.7291228858133157 2.0326 0.1758 0.1322 1.7975 0.1314 0.1051
75 1.2818062901496887 0.6200 0.2217 0.0730 0.1697 7.2470 0.4181 0.2230
279 1.4058668922100748 8.1397 1.1370 0.1082 0.1427 0.0871 0.1210 0.1053
2641 0.1703926378062793 0.3318 0.1146 0.2372 0.1261 0.1727 0.1082 0.1022
1120 2.3883045655157833 2.9336 0.8035 1.6985 4.0525 8.6964 3.0033 0.0963 0.1081 0.1024
1031 0.6803936168551445 4.6826 0.7309 0.0864 0.1111 0.1247 0.0863 0.5777 0.0856 0.2151 0.1035
2484 0.17211276292800903 0.3391 0.2407 0.0678 0.4290 0.1203 0.0990 0.1382 0.1095 0.0758 0.1018
2600 1.3488108797797136 4.0854 0.1176 1.0209 0.1188 0.0373 3.7863 0.2754
2814 1.5876335703900881 1.6473 2.3662 0.2776 0.0731 4.8990 1.7478 0.1024
2822 0.6652300975152424 0.6418 0.1277 0.6620 2.6037 0.4055 0.1121 0.1038
2854 0.396458768418857 0.5300 0.1097 1.1606 0.4882 0.2649 0.1183 0.1035
169 1.5903700785711408 4.9675 0.0435 0.1813 1.8350 0.1336 5.2166 0.2192 0.1262
234 2.0860743997618556 2.8854 0.2894 0.3069 0.1739 0.0880 12.6388 0.1717 0.1345
368 0.9114988259971142 0.7726 0.7938 1.8604 3.4764 0.0779 0.0802 0.1271 0.1035
387 0.24928769376128912 0.4698 0.0763 0.2203 0.1345 0.3810 0.4948 0.1152 0.1024
596 0.7321822415105999 5.0991 0.1796 0.1138 0.1113 0.1246 0.0427 0.0759 0.1104
1200 0.587307695299387 1.3917 1.1277 1.4277 0.0914 0.1485 0.1969 0.2117 0.1029
2015 1.1963263098150492 5.4510 1.0897 0.4743 0.0972 0.2240 1.2175 0.8575 0.1595
2216 1.3388446755707264 4.0211 4.2651 0.4503 0.1335 0.0482 0.3432 1.3127 0.1366
2994 0.3156363896559924 0.1788 0.1143 0.1824 1.7381 0.0294 0.0742 0.1021 0.1059
```
I don't suppose this is what you are after, do you?
<|||||>i think the original poster wants a way to get those log probs for models that are not in fair aew, like MarianMT.<|||||>I think I understood that, I'm referring to:
> I modify the translation code in fairseq named as validate_lm.py, and run the bash script to get the per-word log-probability.
which is what I run and displayed the top of the results above. But in the OP it was requested:
> For example:
> Source input (x): I would like to run this experiment.
> Translated output (y) in Chinese: 我 希望 跑 这个 实验 。
> The word-level log probability: -0.3 -0.4 -0.23 -0.43 -0.23 -0.8
So the example code doesn't match the original request and I'm asking to clarify to what output is desired.
In other words - do you want the word and the average log probability of its tokens printed? If yes, I guess we gather the log probs for each token and then somehow keep track of the de-tokenizer and then average the ones that end up comprising each word. I don't have any experience with Kanji - do tokenizers there split the characters into sub-characters, or is it the case where each token is a word, in which case you're asking to just print the log probabilities of each token in the translation output?
Could you redefine your request in terms of latin 2 latin language to remove this possible ambiguity and then once working adapt it to Chinese? I hope it makes sense where I am not sure what exactly you're after.
<|||||>@JunjieHu Is this roughly what you are looking for?
```python
batch = tokenizer.prepare_seq2seq_batch(": I would like to run this experiment.")
model = AutoModelForSeq2SeqLM.from_pretrained('opus-mt/marian-en-zh')
generated_ids = model.generate(batch)
outputs = model(batch.input_ids, labels=generated_ids)
log_probas == outputs.logits[:, generated_ids]
```
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hi @sshleifer Sorry for the late response! Yes! This is exactly what I want! Thanks! |
transformers | 7,765 | closed | Seq2seq finetune example: "Please save or load state of the optimizer" | When running the example scripts in examples/seq2seq/finetune_bart and finetune_t5, get warning messages:
## Environment info
- `transformers` version: 3.3.1
- Platform: Linux-4.15.0-66-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Ran both with and without gpus; same result
- Using distributed or parallel set-up in script?: no
### Who can help
@sshleifer for examples/seq2seq, Bart
@patrickvonplaten (maybe because this also happens in T5?)
## Information
Model I am using (Bert, XLNet ...):
Occurs when running bart and also when running T5 via the examples/seq2seq/finetune
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [X ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
Steps to reproduce:
1) clone transformers into new directory
2) Set up environment (new): cd transformers && pip install .e; cd examples && pip install -r requirements.txt
3) cd seq2seq && ./finetune_t5_bart_tiny.sh
Observe that warnings are printed:
../python3.8/site-packages/pytorch_lightning/utilities/distributed.py:37: UserWarning: Could not log computational graph since the `model.example_input_array` attribute is not set or `input_array` was not given
warnings.warn(*args, **kwargs)
.../python3.8/site-packages/torch/optim/lr_scheduler.py:200: UserWarning: Please also save or load the state of the optimzer when saving or loading the scheduler.
warnings.warn(SAVE_STATE_WARNING, UserWarning)
(There is both the optimizer warning and the computational graph logging warning)
## Expected behavior
Should not see warnings for the given example.
## Other notes:
There was a related issue where supplementary files / checkpoints were not being saved, but that seems to be fixed now. | 10-13-2020 18:20:47 | 10-13-2020 18:20:47 | I'll leave it to @sshleifer - haven't really used the seq2seq fine-tuning too much.
Maybe @patil-suraj has also an idea here :-) <|||||>You can safely ignore the `lr_scheduler` warning. `optimzer` is saved, but torch `lr_scheduler` warns you anyway just so you don't forget.
Not sure about the first warning, but you can also safely ignore that
<|||||>@patil-suraj Thank you! Would there be an easy way to somehow silence the warning, or print a logging statement from huggingface library that the warning can be safely ignored? <|||||>I believe this warning has been hidden on the `master` branch, and will be hidden in the next release. See [this](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer_pt_utils.py#L114-L119).<|||||>Cool! Looks like originally in #7401. I pulled master and confirmed that this is fixed.
Any notes on the computational graph warning that also pops up?
../python3.8/site-packages/pytorch_lightning/utilities/distributed.py:37: UserWarning: Could not log computational graph since the model.example_input_array attribute is not set or input_array was not given |
transformers | 7,764 | closed | Update of DialoGPT `max_length` | ### Who can help
@patrickvonplaten
## Information
Following https://github.com/huggingface/transformers/pull/5516, the DialoGPT models `max_length` has not been updated, and defaults to the `generate` value of 20. This value is very low for a conversational pipeline and would lead to answers that completely ignore the history (truncation happens to ensure enough space is available for the response).
## Expected behavior
- The configuration files (e.g. https://s3.amazonaws.com/models.huggingface.co/bert/microsoft/DialoGPT-medium/config.json) need to store a `max_length` equal to 1000.
- If the suggested config file structure from the PR is adopted, the code should be updated to read this value instead
```json
"task_specific_params" : {
"dialogue": {
"max_length": 1000
}
}
```
| 10-13-2020 17:10:37 | 10-13-2020 17:10:37 | Very true! Thanks for the notification - will upload all DialoGPT configs.<|||||>Done - note however that the "task" name was `conversational` not `dialogue` |
transformers | 7,763 | closed | Allow Custom Dataset in RAG Retriever | As asked in #7725 , #7462 and #7631 , I added a way to let users build and load their own knowledge dataset for RAG.
I also added an example script that shows how to do that from csv files.
Before merging I'd like to make sure it creates the exact same embeddings that the one that were computed by the RAG team. I might need to do adjustments to the tokenization and maybe change the DPR encoder from the one trained on Natural Questions to the one trained ont the multiset/hybrid dataset.
Any feedbacks on the example and the HFIndex changes are welcome !
More details about the changes:
Previously the HFIndex only allowed to load existing datasets ("canonical" datasets) from the datasets library. So I split it into two classes `CanonicalHFIndex` to load canonical datasets and `CustomHFIndex` for custom user-defined ones.
Moreover the `config.index_name` used to accept any canonical dataset name, or "legacy" for the index the RAG team first provided. Now `config.index_name` can also accept "custom" for custom user-defined indexed datasets. | 10-13-2020 16:33:14 | 10-13-2020 16:33:14 | I took your comments into account, let me know if you have other things to improve.
Also I had to change the DPR encoder from the one trained on Natural Questions to the one trained ont the multiset/hybrid dataset to match the embeddings used by the Rag team.<|||||>can't wait to try this out.
@lhoestq , can this functionality be adapted to address #6399 ?<|||||>Glad this got implemented! Many thanks @lhoestq . I checked out a copy, added a custom 25MB CSV file, and gave it a run:
python examples/rag/use_own_knowledge_dataset.py
Got this.
```
Traceback (most recent call last):
File "examples/rag/use_own_knowledge_dataset.py", line 195, in <module>
main(tmp_dir, rag_example_args, processing_args, index_hnsw_args)
File "examples/rag/use_own_knowledge_dataset.py", line 84, in main
ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1544, in from_pretrained
list(cls.vocab_files_names.values()),
OSError: Model name 'facebook/dpr-ctx_encoder-multiset-base' was not found in tokenizers model name list (facebook/dpr-ctx_encoder-single-nq-base). We assumed 'facebook/dpr-ctx_encoder-multiset-base' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url.
```
I then switched to **dpr-ctx_encoder-single-nq-base**. In this case, indexing was successful. However, after Step 3 - Load RAG, the script started downloading the 74G wiki dataset (which should not be necessary) and then errored out on line 195.
```
$ python examples/rag/use_own_knowledge_dataset.py
INFO:__main__:Step 1 - Create the dataset
Using custom data configuration default
Reusing dataset csv (/home/ioannis/.cache/huggingface/datasets/csv/default-49c04e2dbd1cfa6f/0.0.0/49187751790fa4d820300fd4d0707896e5b941f1a9c644652645b866716a4ac4)
100%|█████████████████████████████████████████| 155/155 [00:01<00:00, 82.27ba/s]
100%|█████████████████████████████████████| 18531/18531 [28:23<00:00, 10.88ba/s]
INFO:__main__:Step 2 - Index the dataset
100%|█████████████████████████████████████████| 297/297 [30:22<00:00, 6.14s/it]
INFO:__main__:Step 3 - Load RAG
Using custom data configuration psgs_w100.nq.no_index
Downloading and preparing dataset wiki_dpr/psgs_w100.nq.no_index (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/ioannis/.cache/huggingface/datasets/wiki_dpr/psgs_w100.nq.no_index/0.0.0/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2...
Downloading: 100%|█████████████████████████| 11.2k/11.2k [00:00<00:00, 2.65MB/s]
Downloading: 100%|███████████████████████| 78.4G/78.4G [1:54:59<00:00, 11.4MB/s]
Dataset wiki_dpr downloaded and prepared to /home/ioannis/.cache/huggingface/datasets/wiki_dpr/psgs_w100.nq.no_index/0.0.0/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2. Subsequent calls will reuse this data.
Using custom data configuration psgs_w100.nq.custom
Downloading and preparing dataset wiki_dpr/psgs_w100.nq.custom (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/ioannis/.cache/huggingface/datasets/wiki_dpr/psgs_w100.nq.custom/0.0.0/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2...
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
...
...
Downloading: 100%|██████████████████████████| 1.33G/1.33G [29:21<00:00, 753kB/s]
Downloading: 100%|██████████████████████████| 1.33G/1.33G [29:30<00:00, 749kB/s]
...
...
Traceback (most recent call last):
File "examples/rag/use_own_knowledge_dataset.py", line 195, in <module>
main(tmp_dir, rag_example_args, processing_args, index_hnsw_args)
File "examples/rag/use_own_knowledge_dataset.py", line 116, in main
rag_example_args.rag_model_name, index_name="custom", indexed_dataset=dataset
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 321, in from_pretrained
config, question_encoder_tokenizer=question_encoder_tokenizer, generator_tokenizer=generator_tokenizer
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 310, in __init__
self.init_retrieval()
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 338, in init_retrieval
self.index.init_index()
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 248, in init_index
dummy=self.use_dummy_dataset,
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/datasets/load.py", line 611, in load_dataset
ignore_verifications=ignore_verifications,
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/datasets/builder.py", line 476, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/datasets/builder.py", line 553, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/datasets/builder.py", line 841, in _prepare_split
generator, unit=" examples", total=split_info.num_examples, leave=False, disable=not_verbose
File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/tqdm/std.py", line 1133, in __iter__
for obj in iterable:
File "/home/ioannis/.cache/huggingface/modules/datasets_modules/datasets/wiki_dpr/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2/wiki_dpr.py", line 124, in _generate_examples
id, text, title = line.strip().split("\t")
ValueError: not enough values to unpack (expected 3, got 2)
```
<|||||>> Glad this got implemented! Many thanks @lhoestq . I checked out a copy, added a custom 25MB CSV file, and gave it a run:
> python examples/rag/use_own_knowledge_dataset.py
>
> Got this.
>
> ```
> Traceback (most recent call last):
> File "examples/rag/use_own_knowledge_dataset.py", line 195, in <module>
> main(tmp_dir, rag_example_args, processing_args, index_hnsw_args)
> File "examples/rag/use_own_knowledge_dataset.py", line 84, in main
> ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1544, in from_pretrained
> list(cls.vocab_files_names.values()),
> OSError: Model name 'facebook/dpr-ctx_encoder-multiset-base' was not found in tokenizers model name list (facebook/dpr-ctx_encoder-single-nq-base). We assumed 'facebook/dpr-ctx_encoder-multiset-base' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url.
> ```
>
> I then switched to **dpr-ctx_encoder-single-nq-base**. In this case, indexing was successful. However, after Step 3 - Load RAG, the script started downloading the 74G wiki dataset (which should not be necessary) and then errored out on line 195.
>
> ```
> $ python examples/rag/use_own_knowledge_dataset.py
> INFO:__main__:Step 1 - Create the dataset
> Using custom data configuration default
> Reusing dataset csv (/home/ioannis/.cache/huggingface/datasets/csv/default-49c04e2dbd1cfa6f/0.0.0/49187751790fa4d820300fd4d0707896e5b941f1a9c644652645b866716a4ac4)
> 100%|█████████████████████████████████████████| 155/155 [00:01<00:00, 82.27ba/s]
> 100%|█████████████████████████████████████| 18531/18531 [28:23<00:00, 10.88ba/s]
> INFO:__main__:Step 2 - Index the dataset
> 100%|█████████████████████████████████████████| 297/297 [30:22<00:00, 6.14s/it]
> INFO:__main__:Step 3 - Load RAG
> Using custom data configuration psgs_w100.nq.no_index
> Downloading and preparing dataset wiki_dpr/psgs_w100.nq.no_index (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/ioannis/.cache/huggingface/datasets/wiki_dpr/psgs_w100.nq.no_index/0.0.0/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2...
> Downloading: 100%|█████████████████████████| 11.2k/11.2k [00:00<00:00, 2.65MB/s]
> Downloading: 100%|███████████████████████| 78.4G/78.4G [1:54:59<00:00, 11.4MB/s]
> Dataset wiki_dpr downloaded and prepared to /home/ioannis/.cache/huggingface/datasets/wiki_dpr/psgs_w100.nq.no_index/0.0.0/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2. Subsequent calls will reuse this data.
> Using custom data configuration psgs_w100.nq.custom
> Downloading and preparing dataset wiki_dpr/psgs_w100.nq.custom (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/ioannis/.cache/huggingface/datasets/wiki_dpr/psgs_w100.nq.custom/0.0.0/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2...
> huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
> To disable this warning, you can either:
> - Avoid using `tokenizers` before the fork if possible
> - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
> huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
> ...
> ...
> Downloading: 100%|██████████████████████████| 1.33G/1.33G [29:21<00:00, 753kB/s]
> Downloading: 100%|██████████████████████████| 1.33G/1.33G [29:30<00:00, 749kB/s]
> ...
> ...
> Traceback (most recent call last):
> File "examples/rag/use_own_knowledge_dataset.py", line 195, in <module>
> main(tmp_dir, rag_example_args, processing_args, index_hnsw_args)
> File "examples/rag/use_own_knowledge_dataset.py", line 116, in main
> rag_example_args.rag_model_name, index_name="custom", indexed_dataset=dataset
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 321, in from_pretrained
> config, question_encoder_tokenizer=question_encoder_tokenizer, generator_tokenizer=generator_tokenizer
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 310, in __init__
> self.init_retrieval()
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 338, in init_retrieval
> self.index.init_index()
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 248, in init_index
> dummy=self.use_dummy_dataset,
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/datasets/load.py", line 611, in load_dataset
> ignore_verifications=ignore_verifications,
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/datasets/builder.py", line 476, in download_and_prepare
> dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/datasets/builder.py", line 553, in _download_and_prepare
> self._prepare_split(split_generator, **prepare_split_kwargs)
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/datasets/builder.py", line 841, in _prepare_split
> generator, unit=" examples", total=split_info.num_examples, leave=False, disable=not_verbose
> File "/home/ioannis/anaconda3/envs/transformers/lib/python3.6/site-packages/tqdm/std.py", line 1133, in __iter__
> for obj in iterable:
> File "/home/ioannis/.cache/huggingface/modules/datasets_modules/datasets/wiki_dpr/14b973bf2a456087ff69c0fd34526684eed22e48e0dfce4338f9a22b965ce7c2/wiki_dpr.py", line 124, in _generate_examples
> id, text, title = line.strip().split("\t")
> ValueError: not enough values to unpack (expected 3, got 2)
> ```
I am facing the same issue.<|||||>Thanks for reporting I'm looking into it<|||||>> Glad this got implemented! Many thanks @lhoestq . I checked out a copy, added a custom 25MB CSV file, and gave it a run:
> python examples/rag/use_own_knowledge_dataset.py
>
> Got this.
>
> ```
> OSError: Model name 'facebook/dpr-ctx_encoder-multiset-base' was not found in tokenizers model name list (facebook/dpr-ctx_encoder-single-nq-base). We assumed 'facebook/dpr-ctx_encoder-multiset-base' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url.
> ```
>
> I then switched to **dpr-ctx_encoder-single-nq-base**. In this case, indexing was successful. However, after Step 3 - Load RAG, the script started downloading the 74G wiki dataset (which should not be necessary) and then errored out on line 195.
>
> ```
> $ python examples/rag/use_own_knowledge_dataset.py
> ...
> ValueError: not enough values to unpack (expected 3, got 2)
> ```
You're having this issue because you are running the script with a version of transformers that doesn't include the changes I had to make in this PR to support custom datasets. This PR not only adds an example script, but there are also changes to make it possible in the core code of the RAG retriever.
Everything works fine if you have all the changes of this PR<|||||>> > Glad this got implemented! Many thanks @lhoestq . I checked out a copy, added a custom 25MB CSV file, and gave it a run:
> > python examples/rag/use_own_knowledge_dataset.py
> > Got this.
> > ```
> > OSError: Model name 'facebook/dpr-ctx_encoder-multiset-base' was not found in tokenizers model name list (facebook/dpr-ctx_encoder-single-nq-base). We assumed 'facebook/dpr-ctx_encoder-multiset-base' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url.
> > ```
> >
> >
> > I then switched to **dpr-ctx_encoder-single-nq-base**. In this case, indexing was successful. However, after Step 3 - Load RAG, the script started downloading the 74G wiki dataset (which should not be necessary) and then errored out on line 195.
> > ```
> > $ python examples/rag/use_own_knowledge_dataset.py
> > ...
> > ValueError: not enough values to unpack (expected 3, got 2)
> > ```
>
> You're having this issue because you are running the script with a version of transformers that doesn't include the changes I had to make in this PR to support custom datasets. This PR not only adds an example script, but there are also changes to make it possible in the core code of the RAG retriever.
>
> Everything works fine if you have all the changes of this PR
Having a separate script to fine-tune with custom datasets would be super useful!<|||||>> Having a separate script to fine-tune with custom datasets would be super useful!
I am adding flags to the fine-tuning scripts to make it work with a custom retriever ;)<|||||>Ah, I think my mistake was that I was using the previous conda environment of transformers (with the new branch). Trying this again with a new env now :)<|||||>> > I just checkd out [14420dc](https://github.com/huggingface/transformers/commit/14420dcbfa0f06012152cc66a7af84d7165a2a17) (committed one hour ago) and I am still getting the same error. Also, it was this branch that was giving the previous errors, not the main transformers branch. Perhaps some of your files have not been updated in the repository? Confused :)
> > `OSError: Model name 'facebook/dpr-ctx_encoder-multiset-base' was not found in tokenizers model name list (facebook/dpr-ctx_encoder-single-nq-base). We assumed 'facebook/dpr-ctx_encoder-multiset-base' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url.`
>
> Could you try to run
>
> ```python
> from transformers import DPRContextEncoderTokenizerFast
> tokenizer = DPRContextEncoderTokenizerFast.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
> ```
>
> and let me know if you're having the OSError on [14420dc](https://github.com/huggingface/transformers/commit/14420dcbfa0f06012152cc66a7af84d7165a2a17) ?
>
> Also just to help me fix this issue, could you also tell me the input of this code please:
>
> ```python
> from transformers.tokenization_dpr_fast import CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
> print(CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES)
> # it should print {'facebook/dpr-ctx_encoder-single-nq-base': 512, 'facebook/dpr-ctx_encoder-multiset-base': 512}
> ```
I was using the old transformers conda env. Doing things over again now and will report back asap!<|||||>Ok thanks !
I deleted my comment since I just noticed yours about the wrong env.
It should work for you now in a new env<|||||>I added some tests for the distributed retriever for fine-tuning.
Unless you still have an issue @ioannist this PR should be ready.
Cc @patrickvonplaten if you want to take a look at the new changes<|||||>> Ok thanks !
> I deleted my comment since I just noticed yours about the wrong env.
> It should work for you now in a new env
I created a new conda env from 14420dcb, installed pytorch and tf 2.2 (2.0 did not work). I ran again into the OS error. Here is the output on the tests you asked me to run +1 more.
(HEAD detached at 14420dcb)
```
from transformers import DPRContextEncoderTokenizerFast
tokenizer = DPRContextEncoderTokenizerFast.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
```
No error
```
from transformers.tokenization_dpr_fast import CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
print(CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES)
```
ModuleNotFoundError: No module named 'transformers.tokenization_dpr_fast'
I checked if the tokenization_dpr_fast file is under src/transformers. It's there.
```
from transformers.tokenization_dpr import CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
print(CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES)
```
{'facebook/dpr-ctx_encoder-single-nq-base': 512}
<|||||>Give me an hour to test this more. I may be messing up somewhere and don't wanna waste your time..<|||||>If you can't import `transformers.tokenization_dpr_fast` that must be an environment issue. This file was added recently on the master branch. It looks like your env imports a version of transformers that is not up-to-date. That's why you're having an OSError.
Maybe you can run `pip show transformers` to check the location of your transformers installation ?<|||||>> If you can't import `transformers.tokenization_dpr_fast` that must be an environment issue. This file was added recently on the master branch. It looks like your env imports a version of transformers that is not up-to-date. That's why you're having an OSError.
>
> Maybe you can run `pip show transformers` to check the location of your transformers installation ?
Ok, I just did the env again for the 3rd time and it works! No idea what i messed up before.
Step -3 Load Rag in progress :)
<|||||>Slow tests pass. This one is ready to merge.
<|||||>@lhoestq - feel free to merge whenever!<|||||>When I do "from transformers import DPRContextEncoder", I get an error :
File "convert_slow_tokenizer.py", line 24, in <module>
from tokenizers.models import BPE, Unigram, WordPiece
ImportError: cannot import name 'Unigram'
Unigram is missing in tokenizers 0.8.1.rc2. Needed to update to 0.9.0<|||||>> I took your comments into account, let me know if you have other things to improve.
> Also I had to change the DPR encoder from the one trained on Natural Questions to the one trained ont the multiset/hybrid dataset to match the embeddings used by the Rag team.
@lhoestq
Hi, can you elaborate on the change you made in the DPR bit more? My understanding is, you have pretrained the DPR with a hybrid dataset to improve the performance when encoding a custom knowledge base.
If you have pretrained the DPR, can you please publish the code?
Can you please refer to this issue also.
https://github.com/huggingface/transformers/issues/8037
Thanks a lot.<|||||>There are two versions of DPR in the paper. One trained on NQ and one trained on various datasets. The authors released the code and the weights in this [this repo](https://github.com/facebookresearch/DPR).
The change I did was just to use the weight of the second one, since it was the one used for RAG.<|||||>Thanks. So as mentioned in the RAG paper, we can use the doc encoder to get
embeddings for any custom dataset. Later we can only fine tune the BART
model and the question encoder.
On Tue, Oct 27, 2020, 01:42 Quentin Lhoest <[email protected]> wrote:
> There are two versions of DPR in the paper. One trained on NQ and one
> trained on various datasets. The authors released the code and the weights
> in this this repo <https://github.com/facebookresearch/DPR>.
>
> The change I did was just to use the weight of the second one, since it
> was the one used for RAG.
>
> —
> You are receiving this because you commented.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/pull/7763#issuecomment-716521222>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AEA4FGUJ5EC6J2ROO56RXB3SMVVDPANCNFSM4SPHCGQQ>
> .
>
<|||||>Yes exactly :) <|||||>@lhoestq , I tried use_own_knowledge_dataset.py to try and retrieve passages from a custom dataset in response to queries. It works, though the relevance of the results isn't great.
I wanted to try and use finetune.sh. Is it possible to finetune just the retriever ? Is there a sample format for the training data ? Looks like it will need the question and passages as input. Need positive and negative passages ?
Thanks!<|||||>@mchari He previously said (https://github.com/huggingface/transformers/issues/8037), it is possible to retrain DPR with Facebook code and then convert the checkpoint to the huge face compatible.
What if you fine-tune the RAG system with your own data letting the question encoder to get fine-tuned? It seems like the pre-training of DPR can be a hard task since the results can depend on the selection procedure of the negative samples as mentioned in the paper. |
transformers | 7,762 | closed | Faster pegasus tokenization test with reduced data size | This used to take 10s (and tokenize 100K words) now tokenizes 1k words and takes 1s.
| 10-13-2020 15:59:17 | 10-13-2020 15:59:17 | |
transformers | 7,761 | closed | Deutsch to English Translation Model by Google doesn't work anymore... | Hi, the model in: https://huggingface.co/google/bert2bert_L-24_wmt_de_en doesn't work anymore. It seems that the library has changed a lot since the model was added, therefore the classes themselves seem to have changed in names etc.
Can anyone tell me how could I apply with the current library functionality?
Thanks in advance! :) | 10-13-2020 15:13:24 | 10-13-2020 15:13:24 | Do you want to post the full error message? (and the information asked in the issue template)<|||||>These models have been added last months, so they shouldn't have changed much. The full issue template filled would be very helpful here!<|||||>This is the error:
ValueError: Unrecognized model identifier: bert-generation. Should contain one of retribert, t5, mobilebert, distilbert, albert, camembert, xlm-roberta, pegasus, marian, mbart, bart, reformer, longformer, roberta, flaubert, bert, openai-gpt, gpt2, transfo-xl, xlnet, xlm, ctrl, electra, encoder-decoder
Using exactly the code appearing in the link I passed:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/bert2bert_L-24_wmt_de_en", pad_token="<pad>", eos_token="</s>", bos_token="<s>")
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_de_en")
sentence = "Willst du einen Kaffee trinken gehen mit mir?"
input_ids = tokenizer(sentence, return_tensors="pt", add_special_tokens=False).input_ids
output_ids = model.generate(input_ids)[0]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
```
Transformers version: 3.1.0
<|||||>@patrickvonplaten what should be done here? The `BertGeneration` model cannot be loaded directly through the `AutoModelForSeq2SeqLM` auto-model, can it?<|||||>Then how could I load it?
<|||||>Hey @alexvaca0 - the google/encoder-decoder models were released in transformers 3.2.0 => so you will have to update your transformers version for it :-) It should then work as expected.<|||||>Ohhh so sorry, my bad :( Thanks a lot for the quick response! :) <|||||>I think this may not have been fully resolved? I'm getting a simmilar error:
```
Traceback (most recent call last):
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/transformers/modeling_utils.py", line 926, in from_pretrained
state_dict = torch.load(resolved_archive_file, map_location="cpu")
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/torch/serialization.py", line 527, in load
with _open_zipfile_reader(f) as opened_zipfile:
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/torch/serialization.py", line 224, in __init__
super(_open_zipfile_reader, self).__init__(torch._C.PyTorchFileReader(name_or_buffer))
RuntimeError: version_ <= kMaxSupportedFileFormatVersion INTERNAL ASSERT FAILED at /opt/conda/conda-bld/pytorch_1579022060824/work/caffe2/serialize/inline_container.cc:132, please report a bug to PyTorch. Attempted to read a PyTorch file with version 3, but the maximum supported version for reading is 2. Your PyTorch installation may be too old. (init at /opt/conda/conda-bld/pytorch_1579022060824/work/caffe2/serialize/inline_container.cc:132)
frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x47 (0x7fd86f9d2627 in /home/ubuntu/anaconda3/lib/python3.7/site-packages/torch/lib/libc10.so)
frame #1: caffe2::serialize::PyTorchStreamReader::init() + 0x1f5b (0x7fd82fbbb9ab in /home/ubuntu/anaconda3/lib/python3.7/site-packages/torch/lib/libtorch.so)
frame #2: caffe2::serialize::PyTorchStreamReader::PyTorchStreamReader(std::string const&) + 0x64 (0x7fd82fbbcbc4 in /home/ubuntu/anaconda3/lib/python3.7/site-packages/torch/lib/libtorch.so)
frame #3: <unknown function> + 0x6d2146 (0x7fd87067e146 in /home/ubuntu/anaconda3/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
frame #4: <unknown function> + 0x28ba06 (0x7fd870237a06 in /home/ubuntu/anaconda3/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
<omitting python frames>
frame #37: __libc_start_main + 0xe7 (0x7fd87474cb97 in /lib/x86_64-linux-gnu/libc.so.6)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "wmt_test.py", line 26, in <module>
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_de_en").to(device)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/transformers/modeling_auto.py", line 1073, in from_pretrained
return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, config=config, **kwargs)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/transformers/modeling_utils.py", line 929, in from_pretrained
"Unable to load weights from pytorch checkpoint file. "
OSError: Unable to load weights from pytorch checkpoint file. If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
```
python = 3.76, torch==1.4.0, transformers==3.2.0<|||||>Hi @ezekielbarnett could you open a new issue and fill the issue template? A reproducible code example would be particularly helpful here. |
transformers | 7,760 | closed | AttributeError: 'tuple' object has no attribute 'detach' | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: bert-base-uncased
- Platform: pytorch
- Python version: 3.6
- PyTorch version (GPU?): 1.6.0
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
documentation: @sgugger
-->
## Information
Model I am using (Bert,):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [.] my own modified scripts: (give details below)
I am using bert for keyphrase extraction, based on the allenai-scibert code.
When evaluating the model,
`
for _ in range(params.eval_steps):
# fetch the next evaluation batch
batch_data, batch_tags = next(data_iterator)
batch_masks = batch_data.gt(0)
loss, _ = model(batch_data, token_type_ids=None, attention_mask=batch_masks, labels=batch_tags)
if params.n_gpu > 1 and params.multi_gpu:
loss = loss.mean()
loss_avg.update(loss.item())
batch_output = model(batch_data, token_type_ids=None, attention_mask=batch_masks) # shape: (batch_size, max_len, num_labels)
batch_output = batch_output.detach().cpu().numpy()
batch_tags = batch_tags.to('cpu').numpy()
pred_tags.extend([idx2tag.get(idx) for indices in np.argmax(batch_output, axis=2) for idx in indices])
true_tags.extend([idx2tag.get(idx) for indices in batch_tags for idx in indices])
assert len(pred_tags) == len(true_tags)`
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [.] my own task or dataset: (give details below)
SemEval 2017, task 1
## To reproduce
Steps to reproduce the behavior:
1. run the train.py script from [this repo](https://github.com/pranav-ust/BERT-keyphrase-extraction), but with `transformers` library instead of `pytorch-pretrained-bert`
2. The script gives the error:
`Traceback (most recent call last):
File "train.py", line 219, in <module>
train_and_evaluate(model, train_data, val_data, optimizer, scheduler, params, args.model_dir, args.restore_file)
File "train.py", line 106, in train_and_evaluate
train_metrics = evaluate(model, train_data_iterator, params, mark='Train')
File "/content/BERT-keyphrase-extraction/evaluate.py", line 54, in evaluate
batch_output = batch_output.detach().cpu().numpy()
AttributeError: 'tuple' object has no attribute 'detach'`
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
The model should continue training after the first epoch
| 10-13-2020 15:03:30 | 10-13-2020 15:03:30 | As the error says, you've applied a `.detach()` method to a model output, which are *always* tuples. You can check the [documentation here](https://huggingface.co/transformers/main_classes/output.html).
You probably want the first output of your model so change this line:
```py
batch_output = model(batch_data, token_type_ids=None, attention_mask=batch_masks)
```
to
```py
batch_output = model(batch_data, token_type_ids=None, attention_mask=batch_masks)[0]
``` |
transformers | 7,759 | closed | Adding optional trial argument to model_init | # Model structure optimization
This PR proposes to add the "trial" argument to the model_init function when using `trainer.hyperparameter_search`.
It's backward compatible using six to check the number of arguments of model_init through Python reflection.
```
def model_init(trial):
if trial != None:
layer_count = trial.suggest_int("layer_count", 2, 4)
else:
layer_count = 2
return MyModel(layer_count)
trainer = Trainer(
...
model_init=model_init,
...
)
trainer.hyperparameter_search(direction="maximize")
```
| 10-13-2020 14:29:43 | 10-13-2020 14:29:43 | |
transformers | 7,758 | closed | fixed lots of typos. | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixed lots of typos in the documentation.
For the record, I used a chrome spell check extension to find common typos and used vim + ripgrep + fzf to do bulk corrections.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
| 10-13-2020 13:53:03 | 10-13-2020 13:53:03 | |
transformers | 7,757 | closed | Help with finetuning mBART on an unseen language | I wanted to know how could we finetune mBART on summarization task on a different language than that of English. Also, how can we finetune mBART on translation task where one of the languages is not present in the language code list that mBART has been trained on.
Appreciate any help!! Thank you.
| 10-13-2020 12:54:54 | 10-13-2020 12:54:54 | Hey @laibamehnaz , that's a great question for forum
https://discuss.huggingface.co/.
Could you post it there, someone might have tried it and the forum is better to discuss such questions :) <|||||>Great. I will post it there. Thanks a lot.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,756 | closed | [Rag] Fix loading of pretrained Rag Tokenizer | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #7710, #7690
A bug was introduced in https://github.com/huggingface/transformers/pull/7141#discussion_r503800703 that changes the loading of pre-trained special tokens files. This PR more or less reverts the critical changes so that RAG works again. This can be verified by running this test:
```
RUN_SLOW=1 pytest tests/test_modeling_rag.py::RagModelIntegrationTests::test_rag_sequence_generate_batch
```
A new RAG tokenizer test was added.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
Running all slow tests to check that nothing breaks.
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> @thomwolf @LysandreJik @sgugger | 10-13-2020 09:54:57 | 10-13-2020 09:54:57 | Got 2 offline yes! from @thomwolf and @LysandreJik => merging. |
transformers | 7,755 | closed | HfArgumentParser not support optional bools | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.3.1
- Platform: Linux-3.10.0
- Python version: 3.7.3
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people. -->
@sgugger
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
Part of the code are copied from [examples/text-classification/run_glue.py](https://github.com/huggingface/transformers/blob/v3.3.1/examples/text-classification/run_glue.py)
## To reproduce
Steps to reproduce the behavior:
1.
Save the following code as 'test.py' then `python test.py --output_dir 123`
```python
from transformers import TrainingArguments, HfArgumentParser
parser = HfArgumentParser(TrainingArguments)
training_args, = parser.parse_args_into_dataclasses()
# All of the following fields has a default value of `None`
print(training_args.greater_is_better) # type=Optional[bool]
print(training_args.disable_tqdm) # type=Optional[bool]
print(training_args.metric_for_best_model) # type=Optional[str]
print(training_args.save_total_limit) # type=Optional[int]
```
2.
Got following output:
False
False
None
None
Notice the first two fields' default values are changed. They should be remain `None` as long as I don't pass the args from the cli.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
It should be the following output:
None
None
None
None
Because all of these four fields are **Optional** and their default values are `None` (See [training_args.py](https://github.com/huggingface/transformers/blob/v3.3.1/src/transformers/training_args.py)).
Also, in
https://github.com/huggingface/transformers/blob/1ba08dc221ff101a751c16462c3a256d726e7c85/src/transformers/training_args.py#L324
https://github.com/huggingface/transformers/blob/1ba08dc221ff101a751c16462c3a256d726e7c85/src/transformers/training_args.py#L342
both `greater_is_better` and `disable_tqdm` are detected whether they are None, which means the author intends them to be None when they are unspecific in passing args.
This may caused by
https://github.com/huggingface/transformers/blob/1ba08dc221ff101a751c16462c3a256d726e7c85/src/transformers/hf_argparser.py#L67-L68
Since they have a type of `Optional[bool]`,their `kwargs["action"]` is set to `store_true`. So when I don't pass the args from the cli, they have a default value of `False` instead of `None`.
I'm not sure if this is a intended design or a mistake, sorry for disturbing.
<!-- A clear and concise description of what you would expect to happen. -->
| 10-13-2020 09:43:46 | 10-13-2020 09:43:46 | Yes optional bools are not supported by the `HFArgumentParser` because it wants to either `store_true` or `store_false` them. I have fixed the `TrainingArguments` to work around that (e.g., the defaults that come from the parser are okay) but when I have a bit of time I'll try to fix this better.<|||||>Thanks. I want to report a related issue:
For the same reason above, the argument `evaluate_during_training` would be set to either `store_true` or `store_false`, so its default value of `None` doesn't work.
https://github.com/huggingface/transformers/blob/1ba08dc221ff101a751c16462c3a256d726e7c85/src/transformers/training_args.py#L188-L191
And this may lead to another problem:
https://github.com/huggingface/transformers/blob/1ba08dc221ff101a751c16462c3a256d726e7c85/src/transformers/training_args.py#L326-L335
Line 326 will always be `True`, and the `EvaluationStrategy` can only be chosen from `STEPS` and `NO`, but without `EPOCH`.
The final result is(I remove unimportant args):
`python main.py --evaluation_strategy epoch`
may lead to `evaluation_strategy=EvaluationStrategy.NO`
while
`python main.py --evaluate_during_training --evaluation_strategy epoch`
may lead to `evaluation_strategy=EvaluationStrategy.STEPS` |
transformers | 7,754 | closed | ElectraTokenizerFast | Before the fix, when loading an `ElectraTokenizerFast`:
```py
from transformers import ElectraTokenizerFast
tokenizer = ElectraTokenizerFast.from_pretrained("ahotrod/electra_large_discriminator_squad2_512")
```
```
Traceback (most recent call last):
File "/Users/jik/Library/Application Support/JetBrains/PyCharm2020.2/scratches/7735.py", line 3, in <module>
tokenizer = ElectraTokenizerFast.from_pretrained("ahotrod/electra_large_discriminator_squad2_512")
File "/Users/jik/Workspaces/python/transformers/src/transformers/tokenization_utils_base.py", line 1555, in from_pretrained
resolved_vocab_files, pretrained_model_name_or_path, init_configuration, *init_inputs, **kwargs
File "/Users/jik/Workspaces/python/transformers/src/transformers/tokenization_utils_base.py", line 1623, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/Users/jik/Workspaces/python/transformers/src/transformers/tokenization_bert.py", line 641, in __init__
**kwargs,
File "/Users/jik/Workspaces/python/transformers/src/transformers/tokenization_utils_fast.py", line 89, in __init__
self._tokenizer = convert_slow_tokenizer(slow_tokenizer)
File "/Users/jik/Workspaces/python/transformers/src/transformers/convert_slow_tokenizer.py", line 565, in convert_slow_tokenizer
converter_class = CONVERTERS[transformer_tokenizer.__class__.__name__]
KeyError: 'ElectraTokenizer'
``` | 10-13-2020 08:48:27 | 10-13-2020 08:48:27 | |
transformers | 7,753 | closed | New TF model design | # What does this PR do?
This PR aims to improve the TensorFlow code base of transformers. For sake of simplicity the changes are made only on the BERT model, but the new features can be applied to all the others. The PR brings among some bug fix the following main new features;
1. It is now possible to train an LM model from scratch (see this [notebook ](https://colab.research.google.com/drive/1As9iz2_2eQp1Ct8trxRG3ScNfxeaVAH2?usp=sharing)as example).
2. The default outputs of the models are now dictionaries. One can only return tuples in eager execution otherwise a warning message will be displayed saying that only dictionaries are allowed in graph mode. This update fix two issues, the first one in graph mode where a layer cannot return different size of outputs, and a second one where an output cannot have a `None` value.
3. Better inputs handle. Now the inputs of each model and the main layer are parsed with a single generic function bringing a more robust parsing and a better error handling in case of wrong input. This feature fix an issue when the input was a list of symbolic inputs (i.e. `tf.keras.layers.Input`).
4. TensorFlow models looks now much more similar to what looks PyTorch models making easier for users to switch from a PyTorch model to its TensorFlow implementation and vice versa.
5. Old and new model implementations can coexist in the library making this new implementation 100% backward compatible. Including the tests. | 10-13-2020 07:12:44 | 10-13-2020 07:12:44 | Thanks for your comments! I will try to answer as clearly as possible.
### From embedding building to `tf.keras.layers.Embedding`
> Would we now be relying on the LM head weights being in the checkpoint?
Exactly, also another difference is to have the `word_embeddings` weights initialized at the model instanciation instead of model building (after a first call). The weights are anyway saved in the checkpoints and shared with the layers that needs to have access to it. You can also see that with the `resize_token_embeddings` methods. The only test with a decoder we have for BERT is `create_and_check_bert_lm_head` and is passing. Do you see any other test we can apply to check if the sharing part works as expected?
### Dense -> DenseEinsum
> Does the change from tf.keras.layers.Dense to tf.keras.layers.experimental.EinsumDense imply a breaking change or some magic that we must do to ensure that the weights get correctly loaded?
No breaking change at all. Old model format can be loaded in the new one and vice versa. And the magic is as simple as a single `reshape` call because both must have compliant shapes:
```
if K.int_shape(symbolic_weight) != saved_weight_value.shape:
try:
array = np.reshape(saved_weight_value, K.int_shape(symbolic_weight))
except AssertionError as e:
e.args += (K.int_shape(symbolic_weight), saved_weight_value.shape)
raise e
else:
array = saved_weight_value
```
And this is already integrated in the current release https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_tf_utils.py#L290
> Is that change the main one that unlocks better performance?
Exactly! Only that change to unlock serving performance.
### Tuples -> tf.TensorArray
> Why is that change necessary? Does it give better performance? Is it necessary for graph mode?
As you said it is necessary to be able to use the `output_hidden_states` and `output_attentions` boolean parameters in graph mode. Otherwise we have to disable them 100% of the time in graph mode and it is pitty to remove that feature. I don't think it gives better performance but thanks to this we can have a variable output size. Second good reason to adopt this feature is for serving, if a SavedModel has been created with `output_attentions=True` the model will give you 12 outputs (one for each element of the tuple) instead of just one as it is the case with `tf.TensorArray`. At the end it is not really a breaking change as a tensor can be used as a tuple, you can test this by yourself simply by doing:
```
import tensorflow as tf
t = tf.constant([[1,2],[3,4]])
a, b = t
```
### Joining the `nsp` + `mlm` in one `cls`
> This is cool as it's more similar to what we do in PyTorch! However, you're now handling the names of the weights directly in the `modeling_tf_utils.py` file. I cannot imagine that scales as more models are converted to this implementation?
Exactly, everything will rely on the `load_tf_weights()` function in `modeling_tf_utils.py`. I didn't have major issues to handle that case, it was quite simple, at least in BERT. Let's see how it goes for the others.<|||||>Ok @sgugger I should have addressed all your comments.<|||||>Ok @patrickvonplaten @sgugger @LysandreJik I should have done the changes you proposed. May I proceed the same way for the other models? Or you want me to do other updates?<|||||>I gave up to filter out the empty tensors from the output, it was too complex to implement. So now we will always have 3 outputs corresponding to `attentions`, `hidden_states` and `logits`. But if `output_attentions` or `output_hidden_states` equals `False` they will be empty tensors (first dim equals to 0).<|||||>Ok, now BERT looks exactly like I expected. Properly optimized + cleaner code base + full compliance with AutoGraph. Next step is to apply the same changes to the other models.<|||||>> flip the return_dict=True switch (I don't think this should be done here - as it affects all PT models as well)
This flip is part of the improvements, if this flip is not here I can remove basically almost half of the improvements because the model will not be able to run properly in graph mode.
> discuss whether we want to do the parameter renaming
Ok. But for now as far as I have seen, it concerns only BERT, but I still need to update other models I did not updated all of them, just few for now (wait the big next push).
I agree that this PR concerns already huge changes with only updating BERT, and indeed to do one PR per model would be easier to handle. Nevertheless, I already started to update the other models, so I will revert locally and create one branch for each on my fork.<|||||>@patrickvonplaten I removed the naming updates in order to better discuss this in a later PR.
I still have work to do on the model part, mainly still two things:
- Being able to properly read the model summary
- Being able to properly build a graph visualization
Saying this because usual subclass models cannot be parsed by Keras internals ([see this issue](https://github.com/tensorflow/tensorflow/issues/31647) to have a better explanation of the problem)<|||||>Thanks @sgugger for your comments.
> On the comments related to this PR specifically now, the big problem is that we cannot change the global switch of return_dict now. This will break changes in TF, PyTorch and Flax fopr all users of the library. Depending on the time needed to finish the TF push, there might be intermediate releases before v4 where we can't afford to have that breaking change. There is a crude way to have that switch set to True for the TFBert models just now I suggested in the comments and there is probably some clever way with a private flag that could allow us to add the TF models one by one with a new default without breaking anything. I can look more into it if you want.
I don't expect this PR to be released before the v4.0 (to appear in an intermediate release). All would like that all the TF improvements comes directly in once in the next major release. Then I'm acting like if it was the next major release, thus the `return_dict=True` by default in the config. But for sure I can open a PR for each model, I agree that it will be easier to handle. Also nothing prevent to make this change in a specific PR and I will rebase this one on it, this will be the same.
> Another comment is that we should add some more tests of forward/backward compatibility with the new loading function, just to be absolutely sure we don't break anything.
Any idea of what are the other tests I can add, for this? For me being able to load "old" and "new" model in same time is enough. I will be happy to have your opinion on how to improve this :)<|||||>@sgugger @patrickvonplaten @LysandreJik I have revert the conflicting changes in order to move the discussion into another PR (the general `return_dict` update and the layers naming).
@sgugger I have put a warning as you suggested. But please let me know if you have a better one, I'm not really happy of the one I put.
In general, do you have any other comments on this? So I can move to the other models in order to apply the same updates if we all agree of these new changes.<|||||>Once you're happy with the state of that PR, could you close this PR and open a new one explaining the exact changes? This is a very big thread that takes a while to load, and it's hard to understand the state this current PR is in. Thanks!<|||||>You are totally right and this was my plan. Since last week I'm shrinking this PR to get only the optimization part and put the other improvements into separate PRs. Once done, I will reopen a clean one 👍 <|||||>Fantastic! Thanks @jplu! |
transformers | 7,752 | closed | Model Card | # What does this PR do?
New model card for model uploaded to https://huggingface.co/sentence-transformers
## Who can review?
Model Cards: @julien-c
| 10-13-2020 06:48:56 | 10-13-2020 06:48:56 | Looks great! |
transformers | 7,751 | closed | Unicode issue with tokenizer.decode() | ## Environment info
- `transformers` version: 3.3.1
- Platform: Ubuntu 18.04.1 LTS
- Python version: 3.6.9
- PyTorch version (GPU?): 1.5.0 (No)
- Tensorflow version (GPU?): 1.14.0 (No)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
Since the issue regards tokenizers, tagging @mfuntowicz.
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Run this (I'm running in a Python shell, but it's reproducible in a script)
```python
>>> from transformers import T5Tokenizer
>>> tokenizer = T5Tokenizer.from_pretrained('t5-3b')
>>> sent = 'Luis Fonsi. Luis Alfonso Rodríguez López-Cepero, more commonly known by his stage name Luis Fonsi, (born April 15, 1978) is a Puerto Rican singer, songwriter and actor.'
>>> tokenizer.decode(tokenizer.encode(sent))
'Luis Fonsi. Luis Alfonso Rodr ⁇ guez López-Cepero, more commonly known by his stage name Luis Fonsi, (born April 15, 1978) is a Puerto Rican singer, songwriter and actor.'
```
The "í" character turns into "⁇", while other unicode characters like "ó" come out fine.
## Expected behavior
If I use a different set of functions that should end up with the same result, I get the expected:
```python
>>> tokenizer.convert_tokens_to_string(tokenizer.tokenize(sent))
'Luis Fonsi. Luis Alfonso Rodríguez López-Cepero, more commonly known by his stage name Luis Fonsi, (born April 15, 1978) is a Puerto Rican singer, songwriter and actor.'
``` | 10-13-2020 04:46:34 | 10-13-2020 04:46:34 | This is not a bug, but a lack of vocabulary diversity in T5's tokenizer. T5's tokenizer was not trained on a corpus containing that character, and therefore cannot encode it: it encodes it to an unknown token which is represented by `⁇`.
You can try using other characters that the tokenizer doesn't know how to process, for example emojis:
```py
from transformers import T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained('t5-3b')
sent = 'Luis 😃 Fonsi. Luis Alfonso Rodríguez López-Cepero, more commonly known by his stage name Luis Fonsi, (born April 15, 1978) is a Puerto Rican singer, songwriter and actor.'
print(tokenizer.decode(tokenizer.encode(sent)))
# Luis ⁇ Fonsi. Luis Alfonso Rodr ⁇ guez López-Cepero, more commonly known by his stage name Luis Fonsi, (born April 15, 1978) is a Puerto Rican singer, songwriter and actor.
```
You can use the `tokenize` + `convert_tokens_to_string` because the sequence has never been converted to IDs, only to tokens:
```py
print(tokenizer.tokenize(sent))
# ['▁Lu', 'is', '▁', '😃', '▁F', 'on', 's', 'i', '.', '▁Lu', 'is', '▁Al', 'f', 'on', 's', 'o', '▁Rod', 'r', 'í', 'gu', 'ez', '▁L', 'ó', 'p', 'ez', '-', 'C', 'e', 'per', 'o', ',', '▁more', '▁commonly', '▁known', '▁by', '▁his', '▁stage', '▁name', '▁Lu', 'is', '▁F', 'on', 's', 'i', ',', '▁(', 'born', '▁April', '▁15,', '▁1978', ')', '▁is', '▁', 'a', '▁Puerto', '▁Rica', 'n', '▁singer', ',', '▁', 'songwriter', '▁and', '▁actor', '.']
```
If your dataset contains a lot of such characters, you should think about [adding these to the tokenizer's vocabulary.](https://huggingface.co/transformers/internal/tokenization_utils.html#transformers.tokenization_utils_base.SpecialTokensMixin.add_tokens) |
transformers | 7,750 | closed | Update pyarrow to meet datasets 1.1.2 | # What does this PR do?
Update pyarrow to meet the requirement of y'alls awesome datasets 1.1.2 library for running the examples (tested on the finetune_tiny_bart.sh seq2seq example). You can see the colab I tested on here: https://colab.research.google.com/drive/12XSQoFRlpXLEd_tfvwC5wUVYJZUPKFwE?usp=sharing
Fixes #7691
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Issue #7691
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@sshleifer | 10-13-2020 03:48:22 | 10-13-2020 03:48:22 | The `datasets` library already has a requirement on `pyarrow>=0.17.1`: https://github.com/huggingface/datasets/blob/master/setup.py#L68, so this line should not be necessary!<|||||>OH whoops, this must be a colab thing since it already has a `pyarrow` version installed, so what I needed to do was run the pip install with the [`--ignore-installed` flag](https://stackoverflow.com/questions/24764549/upgrade-python-packages-from-requirements-txt-using-pip-command). |
transformers | 7,749 | closed | Does bart need to cache prev_key_padding_mask? | This is only be used for self attention, presumably to remember to ignore if the last token generated was a pad. But if the last token generated was a pad, we are done with the hypothesis anyways so may not need this.
If this is unnec it will save 5-10 lines of annoying stuff. | 10-13-2020 02:46:20 | 10-13-2020 02:46:20 | |
transformers | 7,748 | closed | Create README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> | 10-13-2020 02:16:52 | 10-13-2020 02:16:52 | Thank you! You can add more metadata and/or links to eval results if necessary. |
transformers | 7,747 | closed | BertTokenizer meet multilingual corpus, it fails to work.@mfuntowicz | 10-13-2020 02:08:43 | 10-13-2020 02:08:43 | ||
transformers | 7,746 | closed | Keep getting the same `Target 1 is out of bounds` error with `LongformerForMultipleChoice` | Hello,
I am a Transformer user who posted the similar question yesterday.
I am trying to use `LongformerForMultipleChoice` model, I've updated my code according to the answer that was provided. However, I am still getting the same error `Target out of bounds`. The correct answers are coded correctly, like my multiple-choice answers works very well with the `GPT2DoubleHeadsModel`. I am not sure why I am keep getting this error:
```python
# import the pre-trained HuggingFace Longformer tokenizer.
longformer_tokenizer = LongformerTokenizer.from_pretrained('allenai/longformer-base-4096')
# get the pre-trained HuggingFace Longformer
best_model_longformer = LongformerForMultipleChoice.from_pretrained('allenai/longformer-base-4096',
output_hidden_states = True)
# my multiple choice question has 4 options.
question_list = [main_question, main_question, main_question, main_question]
options_list = [option1, option2, option3, option4]
# unsqueeze the answer
mc_labels = torch.tensor(my_answer).unsqueeze(0)
encoded_dict = longformer_tokenizer(question_list, options_list,
return_tensors = 'pt',
add_prefix_space = True,
padding = True)
input_hidden_state = best_model_longformer(
**{k: v.unsqueeze(0) for k,v in encoded_dict.items()},
labels = mc_labels, return_dict=True)[2][0][:,:,:].detach()
```
and I am getting the error below:
```
Traceback (most recent call last):
File "SEED_125_V20_15_LONGFORMER.py", line 427, in <module>
main_function('/home/ec2-user/G1G2.txt','/home/ec2-user/G1G2_answer_num.txt', num_iter)
File "SEED_125_V20_15_LONGFORMER.py", line 389, in main_function
best_model_longformer)
File "SEED_125_V20_15_LONGFORMER.py", line 198, in fill_MC_loss_accuracy_tensor
input_hidden_state = best_model_longformer(**{k: v.unsqueeze(0) for k,v in encoded_dict.items()}, labels = mc_labels, return_dict = True)[2][0][:,:,:].detach()
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/transformers/modeling_longformer.py", line 1808, in forward
loss = loss_fct(reshaped_logits, labels)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/torch/nn/modules/loss.py", line 948, in forward
ignore_index=self.ignore_index, reduction=self.reduction)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py", line 2422, in cross_entropy
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
File "/home/ec2-user/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py", line 2218, in nll_loss
ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
IndexError: Target 1 is out of bounds.
```
When I do instead `mc_labels = torch.tensor([my_answer]).unsqueeze(0)` (note the square brackets around `my_answer`), another error occurs, the error is something like `cannot process multiple answers`.
How can I solve this issue?
Thank you, | 10-13-2020 00:29:09 | 10-13-2020 00:29:09 | Hey there. Please just reply on the previous issue you posted, rather than opening a new issue.
I made a mistake in my previous answer, you shouldn't `unsqueeze` the answer, because it's just a tensor of shape (batch_size,).
I've created a notebook that illustrates how to use BertForMultipleChoice (LongformerForMultipleChoice would be the same): https://colab.research.google.com/drive/1mWx3R7-1lPldJqH26d3fnoyZX6Qa4IpV?usp=sharing |
transformers | 7,745 | closed | Attention masks are ignored when using model.generate() in batch setting for GPT-2 | ## Environment info
- `transformers` version: '3.3.1' and '2.1.0' (Tested on both)
- Platform: Linux Azure VM
- Python version: 3.6.8
- PyTorch version (GPU?): 1.3.0 (Yes)
- Tensorflow version (GPU?): N/A
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik @TevenLeScao
## Information
Model I am using (Bert, XLNet ...): GPT-2
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```python
import argparse
import logging
import os
import sys
import time
sys.path.append('transformers/src')
import numpy as np
import torch
import csv
import copy
from transformers import (
GPT2LMHeadModel,
GPT2Tokenizer
)
from multiprocessing import Pool, cpu_count
from tqdm import tqdm
MODEL_CLASSES = {
"gpt2": (GPT2LMHeadModel, GPT2Tokenizer),
}
def set_seed():
np.random.seed(42)
torch.manual_seed(42)
torch.cuda.manual_seed_all(42)
def generate_sequences_parallel(model, tokenizer, orig_prompt_list):
set_seed()
proc_cnt = cpu_count() - 2
prompt_list = copy.deepcopy(orig_prompt_list)
max_seq_len = 128
requires_preprocessing = False
if not requires_preprocessing:
# GPT-2 doesn't require prepocess so we don't need to parallelize that
inputs = tokenizer(orig_prompt_list, add_special_tokens=False, return_tensors="pt", padding=True)
input_ids = inputs["input_ids"]
attn_masks = inputs["attention_mask"]
max_len_input_ids = max([len(input_id) for input_id in input_ids])
input_ids = input_ids.to('cuda')
attn_masks = attn_masks.to('cuda')
output_sequences = model.generate(
input_ids=input_ids,
max_length=10 + max_len_input_ids,
temperature=1.0,
top_k=0,
top_p=0.9,
repetition_penalty=1.0,
do_sample=True,
num_return_sequences=1,
attention_mask=attn_masks
)
return output_sequences
prompt_list_single = [['Good Morning Who is up with the sun Starting my morning routine with some Yoga and my mood was'], ['What do you all do to make it a great day and my mood was']]
prompt_list_batch = ['Good Morning Who is up with the sun Starting my morning routine with some Yoga and my mood was', 'What do you all do to make it a great day and my mood was']
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
model.to('cuda')
tokenizer.padding_side = "left"
# Define PAD Token = EOS Token = 50256
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
single = []
for elem in prompt_list_single:
single.append(generate_sequences_parallel(model, tokenizer, elem))
print('BATCH')
print()
batch = generate_sequences_parallel(model, tokenizer, prompt_list_batch)
assert(torch.eq(single[0],batch[0]))
assert(torch.eq(single[1],batch[1]))
```
## Expected behavior
I expect the results of this script with batch size 1 to be the size as batch size 2 but it just ignores all the generated attention_ masks and position_ids. I've looked at #3021 and #3167 but those don't seem to offer a concrete solution. Is there some way to use GPT-2's batch generation?
Thanks!
| 10-12-2020 21:50:29 | 10-12-2020 21:50:29 | @patrickvonplaten can you help with this?<|||||>Hey @rohit497,
Could you please take a look at this entry in the forum:
https://discuss.huggingface.co/t/batch-generation-with-gpt2/1517
?
It also links to a test verifying that batch generation works correctly<|||||>@patrickvonplaten I tried modifying my code to reflect the test (updated in the original issue as well) and updated to the latest version of transformers but it seems like the batch generation still doesn't work. Here are the values of `batch` and `single` that I get.
```
SINGLE:
tensor([[10248, 14410, 5338, 318, 510, 351, 262, 4252, 17962, 616,
3329, 8027, 351, 617, 32856, 290, 616, 10038, 373, 2712,
16576, 416, 3589, 13, 314, 635, 1392, 616, 1492]],
device='cuda:0')
tensor([[ 2061, 466, 345, 477, 466, 284, 787, 340, 257, 1049,
1110, 290, 616, 10038, 373, 1972, 38427, 1701, 383, 2368,
1048, 508, 1965, 502, 326]], device='cuda:0')
BATCH:
tensor([[10248, 14410, 5338, 318, 510, 351, 262, 4252, 17962, 616,
3329, 8027, 351, 617, 32856, 290, 616, 10038, 373, 2712,
16576, 416, 3589, 13, 314, 635, 1392, 616, 1492],
[50256, 50256, 50256, 50256, 2061, 466, 345, 477, 466, 284,
787, 340, 257, 1049, 1110, 290, 616, 10038, 373, 257,
1310, 1180, 30, 50256, 50256, 50256, 50256, 50256, 50256]],
device='cuda:0')
```
As you can see, the first sentence (i.e. the longer one) is matched because it needs no padding. However, the second sentence has padding on the left and it seems like it generates the eos token (the pad token) a lot. Am I missing something here?
<|||||>On further investigation, I found that if `do_sample ` is set to `False`, the batch generation works as expected but it fails with sampling. For my project, I'm trying to get diverse sentences from gpt2 using the same prompt, so sampling is very important. Is there a fix on the way for when `do_sample = True`?<|||||>Hey @rohit497,
I checked your sample and the code seems to work fine! Here to reproduce my results:
```python
#!/usr/bin/env python3
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
MODEL_CLASSES = {
"gpt2": (GPT2LMHeadModel, GPT2Tokenizer),
}
def set_seed():
torch.manual_seed(42)
def generate_sequences_parallel(model, tokenizer, orig_prompt_list):
set_seed()
inputs = tokenizer(
orig_prompt_list, add_special_tokens=False, return_tensors="pt", padding=True
)
input_ids = inputs["input_ids"]
attn_masks = inputs["attention_mask"]
max_len_input_ids = max([len(input_id) for input_id in input_ids])
output_sequences = model.generate(
input_ids=input_ids,
max_length=10 + max_len_input_ids,
temperature=1.0,
top_k=0,
top_p=0.9,
repetition_penalty=1.0,
do_sample=True,
num_return_sequences=1,
attention_mask=attn_masks,
)
return output_sequences
prompt_list_single = [
[
"Good Morning Who is up with the sun Starting my morning routine with some Yoga and my mood was"
],
["What do you all do to make it a great day and my mood was"],
]
prompt_list_batch = [
"Good Morning Who is up with the sun Starting my morning routine with some Yoga and my mood was",
"What do you all do to make it a great day and my mood was",
]
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer.padding_side = "left"
# Define PAD Token = EOS Token = 50256
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
single = []
for elem in prompt_list_single:
single.append(generate_sequences_parallel(model, tokenizer, elem))
print("BATCH")
print()
batch = generate_sequences_parallel(model, tokenizer, prompt_list_batch)
print(tokenizer.batch_decode(batch, skip_special_tokens=True))
```
The outputs look good so I think the attention_mask is correctly applied and batch generation works.
The reason that you the results are not identical is becasue you sample from two different distributions. When you pass a single example the softmax output has `batch_size=1` while when you use a batch the softmax output has `batch_size=2` dimension. That means that the first time you sample from a `(1, vocab_size)` distribution whereas the second time you sample from a `(2, vocab_size)` distribution. Now while each part of `(2, vocab_size)` is the same as for the single batch passes, the sampled output can differ because `torch.multinomial` does not yield the same results IMO (maybe you can check that actually). I adapted the test slightly for which there was a `torch.manual_seed()` for some reason which might be misleading. The test only checks for argmax as this is deterministic.
Hope this helps. |
transformers | 7,744 | closed | cannot load "layoutlm-base-uncased" | hi,
im trying to do "LayoutLMTokenizer.from_pretrained('layoutlm-base-uncased')", and got an error saying "OSError: Model name 'layoutlm-base-uncased' was not found in tokenizers model name list (microsoft/layoutlm-base-uncased, microsoft/layoutlm-large-uncased). We assumed 'layoutlm-base-uncased' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url."
thank you!
- `transformers` version: 3.3.1
- Python version: 3.7.7
- PyTorch version (GPU?): 1.6.0, GPU
@mfuntowicz
| 10-12-2020 19:26:51 | 10-12-2020 19:26:51 | Hi,
Yes the error message is right, you have to add "microsoft/" before the name:
```
LayoutLMTokenizer.from_pretrained('microsoft/layoutlm-base-uncased')
```<|||||>ah i see, i directly used the line in the example here https://huggingface.co/transformers/model_doc/layoutlm.html#layoutlmmodel
thank you for helping! |
transformers | 7,743 | closed | should PegasusTokenizer replace `/n` with `<n>`? | On the `encode`/text -> ids side I'm certain.
On the `decode`/ids -> text side, I'm worried about breaking `run_eval.py`, which reads the generations from disk before calculating rouge [here](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_eval.py#L141)
cc @stas00
| 10-12-2020 17:07:47 | 10-12-2020 17:07:47 | Yes, will have to ensure we add a test then. you can assign this to me, @sshleifer <|||||>Mildly off topic:
I wonder if there is a way to read in a file one "line" at a time, where the system for deciding line numbers is the one text-editors use rather than splitting by '\n'.
Here `vim` allows me to write a line with many newline symbols!

<|||||>Which means they are probable escaped `\n` chars - check the saved file in `less` and see if it's really a new line or just `\\n`? between line 1 and line 2 in your snapshot there lies a real `\n`.
I think what you are after is some sort of binary format ala python's `b"line\nline2"` <|||||>Your first line is composed of the characters `\` and `n` and not the actual character customarily represented by `\n` which is `hex(0a)` (ascii code = 10), no?<|||||>a few clarification questions, @sshleifer:
> On the encode/text -> ids side I'm certain.
Do we want this for the Reformer (As it's pegasus' super-class) or just pegasus?
> On the decode/ids -> text side, I'm worried about breaking run_eval.py, which reads the generations from disk before calculating rouge here
Surely, returning `<n>` in the final results is half-baked. And surely, replacing those will break run_eval
How does run_eval currently handle this situation for other multiline generators? If it doesn't, then we should switch it to a different from plain text format to handle this, since sooner or later we will run into this limitation anyway. Switching to a csv format would probably be the simplest "upgrade", that will take care of new lines automatically.<|||||>(1) just pegasus
(2) It doesn't handle the situation -- it leaves `<n>` in the output and trusts `calculate_rouge_score` (which calls `add_newline_to_end_of_each_sentence`) to temporarily remove `<n>` and then add `\n` between sentences, thereby computing `rougeLsum` correctly. This happens after results are saved, and therefore generations still have `<n>`.
https://github.com/huggingface/transformers/blob/dc552b9b7025ea9c38717f30ad3d69c2a972049d/examples/seq2seq/sentence_splitter.py#L18
<|||||>What I'm asking is shouldn't pegasus's `decode` deliver final results devoid of internally used tokens like `<n>`? If the input may contain `\n`, the output should match and also contain `\n` if the generator intended so.
If this is correct then our tools need to work with this requirement and not bend the requirements to their needs.<|||||>OK, I did the override and don't know enough about pegasus to tell whether it does the right thing.
Currently: `"a\nb"` gets tokenized as `"_a", "_b"`.
If I add a `_tokenize` override (pegasus inherits it) and add `text = re.sub(r"\r?\n", "<n>", text)`, now the above produces: `"_a", "<n>", "b" ` - notice that b is no longer tokenized in the same way - it's missing the leading "_".
Here is a much longer test:
```
from transformers.tokenization_pegasus import PegasusTokenizer, PegasusTokenizerFast
tokenizer = PegasusTokenizer.from_pretrained("google/pegasus-large")
s1 = "This is test."
s2 = "Testing!"
inputs = [f"{s1} {s2}", f"{s1}\n{s2}", f"{s1}\r\n{s2}", f"{s1}\n\n{s2}"]
e1 = ['▁This', '▁is', '▁test', '.']
e2 = ['▁Testing', '!']
expected = [ e1 + e2, e1 + ['<n>'] + e2, e1 + ['<n>'] + e2, e1 + ['<n>', '<n>'] + e2]
for i, t in enumerate(inputs):
i
f"inp: {t}"
o = tokenizer._tokenize(t)
f"got: {o}"
f"exp: {expected[i]}"
#assert o == expected[i], "not matched"
```
So with the new line we get:
```
"got: ['▁This', '▁is', '▁test', '.', '<n>', 'Testing', '!']"
"exp: ['▁This', '▁is', '▁test', '.', '<n>', '▁Testing', '!']"
```
This doesn't look right, correct?<|||||>You can play with the new test and check that it does the right thing, PR https://github.com/huggingface/transformers/pull/7877<|||||>@sshleifer, you probably need to close this one too<|||||>Hi all, I'm back on this thread to possibly re-open the discussion: it's important for my model to learn where the newlines should be placed in the output, and from my understanding, this information is being removed by the Pegasus tokenizer:
For example, if my target output is
```
SECTION HEADING \n\nHere is the output for this section, cool!
```
If I encode and decode through the tokenizer, it becomes
```
SECTION HEADING Here is the output for this section, cool!
```
So I guess my question would be
1. Am I missing something, and is there some toggle I can enable that would allow for the tokenizer to preserve new lines?
2. If there is not a toggle, is there a reason that one shouldn't be added?
Of course I have the option of pre-processing my text to convert new lines to `<n>` and then post-processing to turn the `<n>` back to `\n`, but seems a little hacky for my liking 😅
<|||||>It might help to open a new issue, @njbrake
As you can see from https://github.com/huggingface/transformers/pull/7877 why this one was closed.
I'm not sure who maintains Pegasus these days as Sam has moved on, but surely you will discover in the new Issue.
|
transformers | 7,742 | closed | Avoid unnecessary DDP synchronization when gradient_accumulation_steps > 1 | # What does this PR do?
This PR avoid unnecessary ```DistributedDataParallel``` synchronization when gradient_accumulation_steps > 1 by using ```DistributedDataParallel.no_sync```.
This lead to speedup when training with multiple gpu's for example the ```run_language_modeling.py``` complete wiki-2 epoch in 85 seconds instead of 111
```bash
python run_language_modeling.py --output_dir=runs --model_type=gpt2 --model_name_or_path=gpt2 --per_device_train_batch_size 6 --do_train --train_data_file=$TRAIN_FILE --gradient_accumulation_steps=32 --fp16 --block_size 513 --overwrite_output_dir
```
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> | 10-12-2020 16:42:15 | 10-12-2020 16:42:15 | |
transformers | 7,741 | closed | Avoid unnecessary DDP synchronization when gradient_accumulation_steps > 1 | # What does this PR do?
This PR avoid unnecessary ```DistributedDataParallel``` synchronization when gradient_accumulation_steps > 1 by using ```DistributedDataParallel.no_sync```.
This lead to speedup when training with multiple gpu's for example the ```run_language_modeling.py``` complete wiki-2 epoch in 85 seconds instead of 111
```bash
python run_language_modeling.py --output_dir=runs --model_type=gpt2 --model_name_or_path=gpt2 --per_device_train_batch_size 6 --do_train --train_data_file=$TRAIN_FILE --gradient_accumulation_steps=32 --fp16 --block_size 513 --overwrite_output_dir
```
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> | 10-12-2020 16:31:22 | 10-12-2020 16:31:22 | |
transformers | 7,740 | closed | examples/seq2seq/finetune_trainer.py: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. | ## Environment info
- `transformers` version: 3.3.1
- I did `pip install -e .` in the repository cloned from
https://github.com/huggingface/transformers/tree/ba4bbd92bcb55febbfa06aaa1551738388ec7eb0
- Platform: Linux
- Python version: 3.8.3 (anaconda3-2020.07)
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
examples/seq2seq: @sshleifer
## Information
Model I am using (Bert, XLNet ...): Bart (facebook/bart-base)
The problem arises when using:
* [x] the official example scripts: (give details below)
The tasks I am working on is:
* [x] an official XSUM summarization task
## To reproduce
Running examples/seq2seq/finetune_trainer.py as below.
```sh
$ CUDA_VISIBLE_DEVICES=3 python finetune_trainer.py \
--learning_rate=3e-5 \
--fp16 \
--do_train --do_eval --do_predict --evaluate_during_training \
--predict_with_generate \
--n_val 1000 \
--model_name_or_path facebook/bart-base \
--data_dir ********/xsum/ \
--output_dir ******** \
2>&1 | tee test.log
```
Then, I get an UserWarning message:
```sh
0%| | 0/76506 [00:00<?, ?it/s]/********/.pyenv/versions/anaconda3-2020.07/lib/python3.8/site-packages/torch/optim/lr_scheduler.py:118: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Detected call of `lr_scheduler.step()` before `optimizer.step()`. "
```
## Expected behavior
It's an UserWarning, not an Error. It may be not critical, but I want to know why this is caused.
I'm sorry if the "Bug Report" isn't the right choice for this issue.
I'm new to Transformers Trainer. I apologize that I can't distinguish whether this UserWarning belongs to examples/seq2seq/ or Trainer itself.
Thank you in advance. | 10-12-2020 16:14:53 | 10-12-2020 16:14:53 | This happens in every trainer I've ever used and you should just ignore it. It's happening in pytorch so we cant control the type of error.<|||||>cc @sgugger who may have a different opinion.<|||||>This is a warning that appears all the time from PyTofh if you save your learning rate scheduler. You should file an issue on their side if you find it annoying.
Normally, the latest version of transformers should catch that warning from you though.<|||||>@sshleifer @sgugger
Thank you for quickly answering my question!
I apologize that I misunderstood this UserWarning as to be caused by your codes.
Thanks to your kind explanations, I now understand that this is caused not by examples/seq2seq and transformers Trainer, but by PyTorch.
I also understand that I will come across the same UserWarning all the time if I save the learning rate scheduler.
I'm relieved to hear that I can ignore it if I don't find it annoying.
Thanks again! |
transformers | 7,739 | closed | Cannot load pretrained microsoft's layoutlm | ## Environment info
- `transformers` version: 3.3.1
- Platform: Linux-4.15.0-112-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.4.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@julien-c @sshleifer
## Information
Model I am using: LayoutLM
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
from transformers import LayoutLMTokenizer, LayoutLMForTokenClassification
import torch
tokenizer = LayoutLMTokenizer.from_pretrained('microsoft/layoutlm-base-uncased')
model = LayoutLMForTokenClassification.from_pretrained('microsoft/layoutlm-base-uncased')
```
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
~/anaconda3/envs/nlp/lib/python3.8/site-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
926 try:
--> 927 state_dict = torch.load(resolved_archive_file, map_location="cpu")
928 except Exception:
~/anaconda3/envs/nlp/lib/python3.8/site-packages/torch/serialization.py in load(f, map_location, pickle_module, **pickle_load_args)
526 if _is_zipfile(opened_file):
--> 527 with _open_zipfile_reader(f) as opened_zipfile:
528 return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
~/anaconda3/envs/nlp/lib/python3.8/site-packages/torch/serialization.py in __init__(self, name_or_buffer)
223 def __init__(self, name_or_buffer):
--> 224 super(_open_zipfile_reader, self).__init__(torch._C.PyTorchFileReader(name_or_buffer))
225
RuntimeError: version_ <= kMaxSupportedFileFormatVersion INTERNAL ASSERT FAILED at /pytorch/caffe2/serialize/inline_container.cc:132, please report a bug to PyTorch. Attempted to read a PyTorch file with version 3, but the maximum supported version for reading is 2. Your PyTorch installation may be too old. (init at /pytorch/caffe2/serialize/inline_container.cc:132)
frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x33 (0x7faec0a9f193 in /home/user/anaconda3/envs/nlp/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #1: caffe2::serialize::PyTorchStreamReader::init() + 0x1f5b (0x7faec3c279eb in /home/user/anaconda3/envs/nlp/lib/python3.8/site-packages/torch/lib/libtorch.so)
frame #2: caffe2::serialize::PyTorchStreamReader::PyTorchStreamReader(std::string const&) + 0x64 (0x7faec3c28c04 in /home/user/anaconda3/envs/nlp/lib/python3.8/site-packages/torch/lib/libtorch.so)
frame #3: <unknown function> + 0x6c1ef6 (0x7faf0bb54ef6 in /home/user/anaconda3/envs/nlp/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #4: <unknown function> + 0x295928 (0x7faf0b728928 in /home/user/anaconda3/envs/nlp/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #5: PyCFunction_Call + 0x56 (0x5640b0549f76 in /home/user/anaconda3/envs/nlp/bin/python)
frame #6: _PyObject_MakeTpCall + 0x22f (0x5640b050785f in /home/user/anaconda3/envs/nlp/bin/python)
frame #7: <unknown function> + 0x18bfdc (0x5640b0555fdc in /home/user/anaconda3/envs/nlp/bin/python)
frame #8: PyVectorcall_Call + 0x71 (0x5640b0507041 in /home/user/anaconda3/envs/nlp/bin/python)
frame #9: <unknown function> + 0x18c92a (0x5640b055692a in /home/user/anaconda3/envs/nlp/bin/python)
frame #10: _PyObject_MakeTpCall + 0x1a4 (0x5640b05077d4 in /home/user/anaconda3/envs/nlp/bin/python)
frame #11: _PyEval_EvalFrameDefault + 0x4596 (0x5640b058ef56 in /home/user/anaconda3/envs/nlp/bin/python)
frame #12: _PyEval_EvalCodeWithName + 0x659 (0x5640b0554e19 in /home/user/anaconda3/envs/nlp/bin/python)
frame #13: _PyObject_FastCallDict + 0x20c (0x5640b055648c in /home/user/anaconda3/envs/nlp/bin/python)
frame #14: _PyObject_Call_Prepend + 0x63 (0x5640b0556733 in /home/user/anaconda3/envs/nlp/bin/python)
frame #15: <unknown function> + 0x18c8ca (0x5640b05568ca in /home/user/anaconda3/envs/nlp/bin/python)
frame #16: _PyObject_MakeTpCall + 0x1a4 (0x5640b05077d4 in /home/user/anaconda3/envs/nlp/bin/python)
frame #17: _PyEval_EvalFrameDefault + 0x475 (0x5640b058ae35 in /home/user/anaconda3/envs/nlp/bin/python)
frame #18: _PyEval_EvalCodeWithName + 0x2d2 (0x5640b0554a92 in /home/user/anaconda3/envs/nlp/bin/python)
frame #19: _PyFunction_Vectorcall + 0x1e3 (0x5640b0555943 in /home/user/anaconda3/envs/nlp/bin/python)
frame #20: <unknown function> + 0x10011a (0x5640b04ca11a in /home/user/anaconda3/envs/nlp/bin/python)
frame #21: _PyEval_EvalCodeWithName + 0x7df (0x5640b0554f9f in /home/user/anaconda3/envs/nlp/bin/python)
frame #22: <unknown function> + 0x18bd20 (0x5640b0555d20 in /home/user/anaconda3/envs/nlp/bin/python)
frame #23: <unknown function> + 0x10077f (0x5640b04ca77f in /home/user/anaconda3/envs/nlp/bin/python)
frame #24: _PyEval_EvalCodeWithName + 0x2d2 (0x5640b0554a92 in /home/user/anaconda3/envs/nlp/bin/python)
frame #25: PyEval_EvalCodeEx + 0x44 (0x5640b0555754 in /home/user/anaconda3/envs/nlp/bin/python)
frame #26: PyEval_EvalCode + 0x1c (0x5640b05e3edc in /home/user/anaconda3/envs/nlp/bin/python)
frame #27: <unknown function> + 0x24f083 (0x5640b0619083 in /home/user/anaconda3/envs/nlp/bin/python)
frame #28: <unknown function> + 0x140699 (0x5640b050a699 in /home/user/anaconda3/envs/nlp/bin/python)
frame #29: <unknown function> + 0xfeb84 (0x5640b04c8b84 in /home/user/anaconda3/envs/nlp/bin/python)
frame #30: _PyGen_Send + 0x149 (0x5640b054edc9 in /home/user/anaconda3/envs/nlp/bin/python)
frame #31: _PyEval_EvalFrameDefault + 0x49a3 (0x5640b058f363 in /home/user/anaconda3/envs/nlp/bin/python)
frame #32: _PyGen_Send + 0x149 (0x5640b054edc9 in /home/user/anaconda3/envs/nlp/bin/python)
frame #33: _PyEval_EvalFrameDefault + 0x49a3 (0x5640b058f363 in /home/user/anaconda3/envs/nlp/bin/python)
frame #34: _PyGen_Send + 0x149 (0x5640b054edc9 in /home/user/anaconda3/envs/nlp/bin/python)
frame #35: <unknown function> + 0x1701cd (0x5640b053a1cd in /home/user/anaconda3/envs/nlp/bin/python)
frame #36: <unknown function> + 0x10075e (0x5640b04ca75e in /home/user/anaconda3/envs/nlp/bin/python)
frame #37: _PyFunction_Vectorcall + 0x10b (0x5640b055586b in /home/user/anaconda3/envs/nlp/bin/python)
frame #38: <unknown function> + 0xfeb84 (0x5640b04c8b84 in /home/user/anaconda3/envs/nlp/bin/python)
frame #39: _PyFunction_Vectorcall + 0x10b (0x5640b055586b in /home/user/anaconda3/envs/nlp/bin/python)
frame #40: <unknown function> + 0x10075e (0x5640b04ca75e in /home/user/anaconda3/envs/nlp/bin/python)
frame #41: _PyEval_EvalCodeWithName + 0x2d2 (0x5640b0554a92 in /home/user/anaconda3/envs/nlp/bin/python)
frame #42: _PyFunction_Vectorcall + 0x1e3 (0x5640b0555943 in /home/user/anaconda3/envs/nlp/bin/python)
frame #43: <unknown function> + 0x18be79 (0x5640b0555e79 in /home/user/anaconda3/envs/nlp/bin/python)
frame #44: PyVectorcall_Call + 0x71 (0x5640b0507041 in /home/user/anaconda3/envs/nlp/bin/python)
frame #45: _PyEval_EvalFrameDefault + 0x1fdb (0x5640b058c99b in /home/user/anaconda3/envs/nlp/bin/python)
frame #46: _PyEval_EvalCodeWithName + 0x659 (0x5640b0554e19 in /home/user/anaconda3/envs/nlp/bin/python)
frame #47: <unknown function> + 0x18bd20 (0x5640b0555d20 in /home/user/anaconda3/envs/nlp/bin/python)
frame #48: <unknown function> + 0x10011a (0x5640b04ca11a in /home/user/anaconda3/envs/nlp/bin/python)
frame #49: <unknown function> + 0x215056 (0x5640b05df056 in /home/user/anaconda3/envs/nlp/bin/python)
frame #50: <unknown function> + 0x1847f3 (0x5640b054e7f3 in /home/user/anaconda3/envs/nlp/bin/python)
frame #51: <unknown function> + 0x140699 (0x5640b050a699 in /home/user/anaconda3/envs/nlp/bin/python)
frame #52: <unknown function> + 0xfeb84 (0x5640b04c8b84 in /home/user/anaconda3/envs/nlp/bin/python)
frame #53: _PyEval_EvalCodeWithName + 0x659 (0x5640b0554e19 in /home/user/anaconda3/envs/nlp/bin/python)
frame #54: _PyFunction_Vectorcall + 0x1e3 (0x5640b0555943 in /home/user/anaconda3/envs/nlp/bin/python)
frame #55: <unknown function> + 0x10075e (0x5640b04ca75e in /home/user/anaconda3/envs/nlp/bin/python)
frame #56: <unknown function> + 0x215056 (0x5640b05df056 in /home/user/anaconda3/envs/nlp/bin/python)
frame #57: <unknown function> + 0x1847f3 (0x5640b054e7f3 in /home/user/anaconda3/envs/nlp/bin/python)
frame #58: <unknown function> + 0x140699 (0x5640b050a699 in /home/user/anaconda3/envs/nlp/bin/python)
frame #59: <unknown function> + 0xfeb84 (0x5640b04c8b84 in /home/user/anaconda3/envs/nlp/bin/python)
frame #60: _PyEval_EvalCodeWithName + 0x659 (0x5640b0554e19 in /home/user/anaconda3/envs/nlp/bin/python)
frame #61: <unknown function> + 0x18bd20 (0x5640b0555d20 in /home/user/anaconda3/envs/nlp/bin/python)
frame #62: <unknown function> + 0xfeb84 (0x5640b04c8b84 in /home/user/anaconda3/envs/nlp/bin/python)
frame #63: <unknown function> + 0x215056 (0x5640b05df056 in /home/user/anaconda3/envs/nlp/bin/python)
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
<ipython-input-6-29a9c0941587> in <module>
3
4 tokenizer = LayoutLMTokenizer.from_pretrained('microsoft/layoutlm-base-uncased')
----> 5 model = LayoutLMForTokenClassification.from_pretrained('microsoft/layoutlm-base-uncased')
6
~/anaconda3/envs/nlp/lib/python3.8/site-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
927 state_dict = torch.load(resolved_archive_file, map_location="cpu")
928 except Exception:
--> 929 raise OSError(
930 "Unable to load weights from pytorch checkpoint file. "
931 "If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True. "
OSError: Unable to load weights from pytorch checkpoint file. If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
```
## Expected behavior
Load pretrained layoutlm
| 10-12-2020 16:09:28 | 10-12-2020 16:09:28 | Not a bug, when updating to torch 1.6 it works |
transformers | 7,738 | closed | Add license info to nlptown/bert-base-multilingual-uncased-sentiment | PR to close this thread: https://discuss.huggingface.co/t/what-is-the-license-of-nlptown-bert-base-multilingual-uncased-sentiment/1445/4 | 10-12-2020 15:16:57 | 10-12-2020 15:16:57 | Thanks Alex! |
transformers | 7,737 | closed | blenderbot-3B has wrong model card | bb90 too | 10-12-2020 15:10:25 | 10-12-2020 15:10:25 | fixed lazily. |
transformers | 7,736 | closed | Make T5 Supports Gradient Checkpointing | # What does this PR do?
Since T5 3B and 11B models are really huge models to be fine-tuned on a single GPU, Gradient Checkpointing will allow this model to be fine-tuned on a single GPU but at the cost of more training time.
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
T5: @patrickvonplaten
| 10-12-2020 14:26:10 | 10-12-2020 14:26:10 | I've tested your code, it raise an error
`TypeError('CheckpointFunctionBackward.forward: expected Variable (got NoneType) for return value 1')
> /share/home/dwaydwaydway/miniconda3/envs/t5/lib/python3.7/site-packages/torch/utils/checkpoint.py(163)checkpoint()
162
--> 163 return CheckpointFunction.apply(function, preserve, *args)
164`<|||||>@dwaydwaydway yes, it is really annoying issue. I will try to fix it and open a new pull when it is done. |
transformers | 7,735 | closed | Tokenizer Fast bug: ValueError: TextInputSequence must be str | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: In a Colab enviroment aswell as on my local windows version
- Python version: 3.7.4
- PyTorch version (GPU?): Yes and No
- Tensorflow version (GPU?): I didn't try with tensorflow, but I suspect that it has nothing to do with it
- Using GPU in script?: I used the automodeling on a GPU session in Colab
- Using distributed or parallel set-up in script?: Nope
### Who can help
@mfuntowicz
## Information
Model I am using: Initially Electra but I tested it out with BERT, DistilBERT and RoBERTa
It's using your scripts, but again, it believe it wouldn't work if I did it myself. The model is trained on SQuAD.
#### Error traceback
```
"""
Traceback (most recent call last):
File "/usr/lib/python3.6/multiprocessing/pool.py", line 119, in worker
result = (True, func(*args, **kwds))
File "/usr/lib/python3.6/multiprocessing/pool.py", line 44, in mapstar
return list(map(*args))
File "/usr/local/lib/python3.6/dist-packages/transformers/data/processors/squad.py", line 165, in squad_convert_example_to_features
return_token_type_ids=True,
File "/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py", line 2050, in encode_plus
**kwargs,
File "/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_fast.py", line 473, in _encode_plus
**kwargs,
File "/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_fast.py", line 376, in _batch_encode_plus
is_pretokenized=is_split_into_words,
File "/usr/local/lib/python3.6/dist-packages/tokenizers/implementations/base_tokenizer.py", line 212, in encode
return self._tokenizer.encode(sequence, pair, is_pretokenized, add_special_tokens)
ValueError: TextInputSequence must be str
"""
```
## To reproduce
Steps to reproduce the behavior:
1. Download model and tokenizer (fast)
2. Test it out with the transformers pipeline for a question answering task
I've also made a small notebook to test it out for yourself. [here](https://colab.research.google.com/drive/11_qK3w7OWBTYC_GdspAjFna2XJkBgODU?usp=sharing)
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Instead of giving an error, I would expect the tokenizer to work...
<!-- A clear and concise description of what you would expect to happen. --> | 10-12-2020 14:25:46 | 10-12-2020 14:25:46 | Hi, thanks for opening such a detailed issue with a notebook!
Unfortunately, fast tokenizers don’t currently work with the QA pipeline. They will in the second pipeline version which is expected in a few weeks to a few months, but right now please use the slow tokenizers for the QA pipeline.
Thanks!<|||||>I think the issue is still there.<|||||>Please open a new issue with your environment, an example of what the issue is and how you expect it to work. Thank you.<|||||>> Hi, thanks for opening such a detailed issue with a notebook!
>
> Unfortunately, fast tokenizers don’t currently work with the QA pipeline. They will in the second pipeline version which is expected in a few weeks to a few months, but right now please use the slow tokenizers for the QA pipeline.
>
> Thanks!
~and how do I do that? I don't understand the difference from slow and fast tokenizers. Do I need to train my tokenizer again, or can I just somehow "cast" the fast into the slow version?~
I could fix this simply by changing:
from transformers import RobertaTokenizerFast
tokenizer = RobertaTokenizerFast
to:
from transformers import RobertaTokenizer
tokenizer = RobertaTokenizer<|||||>I also find this problem when using transformers. I check my data and find that if csv file contains much Null data or the length of str is 0, this error will be returned. I filter these data and I can successfully run my code.<|||||>double check the data and make sure there is no nan in your data, this is the problem i encountered |
transformers | 7,734 | closed | GLUE STS-B on longer sequence lengths doesn't work? | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
I have an issue where I tried to use the [standard GLUE finetuning script](https://github.com/huggingface/transformers/blob/master/examples/text-classification/run_glue.py) for task STS-B with longer sequence lengths and the results are **bad** (see below). Correlation decreases massively when using longer sequence lengths, and when I instead use binary classification with two classes instead of regression, it is the same situation. For 128 and with some data (e. g. Yelp) 256 works well but longer sequence lengths then simply fail.
My _assumption_ was that longer sequence lengths should results in similar or sometimes better results and that for shorter input sequences padding is added but not incorporated into the embedding because of masking (where the input sequence is and where it is not)?
Initially, I was using the Yelp Business Review dataset for sentiment prediction (which worked well for sequence lengths of 128, 256 and 512) but pairing same reviews sentiments for the same business should be similar to sequence pair classification (I know the task/data works) but it only gave good results for a sequence length of 128 and 256, but 400 or 512 just predicted zeros (as far as I observed). I then tried to just use this with the GLUE STS-B data with the same issue happening.
Background:
Before that, I was using GluonNLP (MXNet) and the [BERT demo finetuning script](https://gluon-nlp.mxnet.io/examples/sentence_embedding/bert.html) (also GLUE STS-B like) with the same data and basically same framework/workflow (even hyperparameters) as here in PyTorch but there all sequence lengths worked, and longer sequence length even improved results (even with smaller batch sizes because of GPU RAM and longer training durations). As the input texts were were smaller and longer (about a third of the data, I guess) this was not that surprising. I'm currently trying to switch to `transformers` because of the larger choice and support of models...
So, what am **I** doing wrong?
I tried using a constant learning rate schedule (using the default learning rate in the code) but it gave no improvements.
I tried different datasets also with almost similar end results. (even if input texts were longer than the maximum sequence length)
Can others reproduce this? (Just switch to seqlen 512 and batchsize 8 / seqlen 256 and batchsize 16)
Do I have to choose another padding strategy?
---
Results on GeForce RTX 2080 with `transformers` version `3.3.1` and CUDA 10.2:
```bash
# my script args (basically just changing the output dir and the sequence length (batch size for GPU memory reasons))
# transformers_copy being the cloned repo root folder
export GLUE_DIR=data/glue
export TASK_NAME=STS-B
python transformers_copy/examples/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --data_dir data/sentiment/yelp-pair-b/ --max_seq_length 128 --per_device_train_batch_size 32 --learning_rate 2e-5 --num_train_epochs 3.0 --output_dir output/glue_yelp_128_32
CUDA_VISIBLE_DEVICES=1 python transformers_copy/examples/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --data_dir data/glue/STS-B/ --max_seq_length 256 --per_device_train_batch_size 16 --per_device_eval_batch_size 16 --learning_rate 2e-5 --num_train_epochs 3.0 --output_dir output/glue_STS-B_256_16 --save_steps 1000
CUDA_VISIBLE_DEVICES=1 python transformers_copy/examples/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --data_dir data/glue/STS-B/ --max_seq_length 512 --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --learning_rate 2e-5 --num_train_epochs 3.0 --output_dir output/glue_STS-B_512_8 --save_steps 2000
```
```python
# cat glue_STS-B_128_32/eval_results_sts-b.txt
# seqlen 128
eval_loss = 0.5857866220474243
eval_pearson = 0.8675888610991327
eval_spearmanr = 0.8641174656753431
eval_corr = 0.865853163387238
epoch = 3.0
total_flos = 1434655122529536
```
```python
# cat glue_STS-B_256_16/eval_results_sts-b.txt
# seqlen 256
# this result should be bad, as far as I would think
eval_loss = 2.2562920122146606
eval_pearson = 0.22274851498729242
eval_spearmanr = 0.09065396938535858
eval_corr = 0.1567012421863255
epoch = 3.0
total_flos = 2869310245059072
```
```python
# cat glue_STS-B_512_8/eval_results_sts-b.txt
# seqlen 512
eval_loss = 2.224635926246643
eval_pearson = 0.24041184048438544
eval_spearmanr = 0.08133980923357159
eval_corr = 0.1608758248589785
epoch = 3.0
total_flos = 5738620490118144
```
Yelp (sentiment, single sequence) with sequence length of 512
```python
# cat yelp-sentiment-b_512_16_1/eval_results_sent-b.txt
eval_loss = 0.2301591751359403
eval_acc = 0.92832
eval_f1 = 0.945765994794504
eval_acc_and_f1 = 0.937042997397252
eval_pearson = 0.8404006160382227
eval_spearmanr = 0.8404006160382247
eval_corr = 0.8404006160382237
eval_class_report = {'not same': {'precision': 0.9099418011639767, 'recall': 0.8792393761957215, 'f1-score': 0.8943271612218422, 'support': 17249}, 'same': {'precision': 0.937509375093751, 'recall': 0.954169338340814, 'f1-score': 0.945765994794504, 'support': 32751}, 'accuracy': 0.92832, 'macro avg': {'precision': 0.9237255881288639, 'recall': 0.9167043572682677, 'f1-score': 0.920046578008173, 'support': 50000}, 'weighted avg': {'precision': 0.9279991134394574, 'recall': 0.92832, 'f1-score': 0.928020625988607, 'support': 50000}}
epoch = 0.08
total_flos = 26906733281280000
```
Yelp (sequence pairs) with 128, 256 and 512 (were 512 fails)
```python
# cat yelp-pair-b_128_32_3/eval_results_same-b.txt
# seqlen 128
eval_loss = 0.4788903475597093
eval_acc = 0.8130612708878027
eval_f1 = 0.8137388152678672
eval_acc_and_f1 = 0.813400043077835
eval_pearson = 0.6262220422479998
eval_spearmanr = 0.6262220422479998
eval_corr = 0.6262220422479998
eval_class_report = {'not same': {'precision': 0.8189660129967221, 'recall': 0.8058966668552996, 'f1-score': 0.8123787792355962, 'support': 35342}, 'same': {'precision': 0.8072925445249733, 'recall': 0.8202888622481018, 'f1-score': 0.8137388152678672, 'support': 35034}, 'accuracy': 0.8130612708878027, 'macro avg': {'precision': 0.8131292787608477, 'recall': 0.8130927645517008, 'f1-score': 0.8130587972517317, 'support': 70376}, 'weighted avg': {'precision': 0.8131548231814548, 'recall': 0.8130612708878027, 'f1-score': 0.8130558211583339, 'support': 70376}}
epoch = 3.0
total_flos = 71009559802626048
```
```python
# cat yelp-pair-b_256_16_1/eval_results_same-b.txt
# seqlen 256
eval_loss = 0.3369856428101318
eval_acc = 0.8494088893941116
eval_f1 = 0.8505977218901545
eval_acc_and_f1 = 0.850003305642133
eval_pearson = 0.6990572001217541
eval_spearmanr = 0.6990572001217481
eval_corr = 0.6990572001217511
eval_class_report = {'not same': {'precision': 0.8588791553054476, 'recall': 0.8377850715862147, 'f1-score': 0.8482009854474619, 'support': 35342}, 'same': {'precision': 0.840315302768648, 'recall': 0.8611348975281156, 'f1-score': 0.8505977218901545, 'support': 35034}, 'accuracy': 0.8494088893941116, 'macro avg': {'precision': 0.8495972290370477, 'recall': 0.8494599845571651, 'f1-score': 0.8493993536688083, 'support': 70376}, 'weighted avg': {'precision': 0.8496378513129752, 'recall': 0.8494088893941116, 'f1-score': 0.8493941090198912, 'support': 70376}}
epoch = 1.0
total_flos = 47339706535084032
```
```python
# cat yelp-pair-b_512_8_3/eval_results_same-b.txt
# seqlen 512
# here it basically just predicts zeros all the time (as fas as I saw)
eval_loss = 0.6931421184073636
eval_acc = 0.5021882459929522
eval_f1 = 0.0
eval_acc_and_f1 = 0.2510941229964761
eval_pearson = nan
eval_spearmanr = nan
eval_corr = nan
eval_class_report = {'not same': {'precision': 0.5021882459929522, 'recall': 1.0, 'f1-score': 0.6686089407669461, 'support': 35342}, 'same': {'precision': 0.0, 'recall': 0.0, 'f1-score': 0.0, 'support': 35034}, 'accuracy': 0.5021882459929522, 'macro avg': {'precision': 0.2510941229964761, 'recall': 0.5, 'f1-score': 0.33430447038347305, 'support': 70376}, 'weighted avg': {'precision': 0.25219303441347785, 'recall': 0.5021882459929522, 'f1-score': 0.3357675512189583, 'support': 70376}}
epoch = 3.0
total_flos = 284038239210504192
```
Side note:
I also ran Yelp with regression and it worked for 128 but for 512 the correlation was below 0.3 so it also failed again.
And I worked on another (private) dataset with similar results...
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: n/a | 10-12-2020 14:16:08 | 10-12-2020 14:16:08 | Hello! Thanks for opening such a detailed issue! You would have more luck asking such an open ended/research question on the [forums](https://discuss.huggingface.co), however!<|||||>Thank you, I have asked the same question in the forums. I currently only want feedback whether others have the same issue with the standard GLUE script. And then what solutions can be considered...
Link: https://discuss.huggingface.co/t/finetuning-sequence-pairs-glue-with-higher-sequence-lengths-seems-to-fail/1656
_I created the issue because GitHub is my first starting point when I have such an question, and it does not seem to fit StackOverflow? Maybe another stackexchange?_<|||||>So, I will rework this answer with more details later on. But the TL;DR for now.
_Gradient Accumulation for the win._
I'm still not exactly sure why it will not train with a batch size of 16 and sequence length of 256 (as the results will just skew to either 0 or 1), but using gradient accumulation (e. g. 64 samples, 4 * 16) to virtually augment the batch size before backpropagation seems to work fine and results are as expected (same or better compared to default sequence length of 128).
Reasons seem to vary and are not exactly clear, like different data (not shuffled but completely different topic/structure) or learning rate + optimizer. I will continue to look into this.<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 7,733 | closed | [Prophetnet] Develop in parallel | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> | 10-12-2020 13:00:06 | 10-12-2020 13:00:06 | |
transformers | 7,732 | closed | Fix #7731 | Fixes #7731 | 10-12-2020 12:47:52 | 10-12-2020 12:47:52 | |
transformers | 7,731 | closed | Pytorch 1.6 DataParallel | I get an error similar to that of [#4189](https://github.com/huggingface/transformers/issues/4189) and [#3936](https://github.com/huggingface/transformers/issues/3936), when using DataParallel with GPT2.
The issue should be resolved in newer versions of transformers, but I still get an error.
## Environment info
- `transformers` version: 3.3.1
- Platform: Linux-3.10.0-1062.18.1.el7.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
CUDA compilation tools, release 10.2, V10.2.89
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
TextGeneration: @TevenLeScao
## Information
Model I am using: GPT2
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behaviour:
1. Run forward on GPT2 with 2 GPUs
### Small example
```python
import torch
from torch.nn import DataParallel
from transformers import GPT2Tokenizer, GPT2LMHeadModel
device = "cuda:0"
# Get model
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
model = DataParallel(model, device_ids=list(range(torch.cuda.device_count())))
model.to(device=device)
# Run forward
inputs = tokenizer(["This is an example"], return_tensors="pt")
outputs = model(
input_ids=inputs["input_ids"].to(device),
attention_mask=inputs["attention_mask"].to(device),
labels=inputs["input_ids"].to(device),
)
print(f"outputs: {outputs}")
print("Success.")
```
### Output
```
Traceback (most recent call last):
File "minimum_example.py", line 15, in <module>
outputs = model(
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 155, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 165, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 85, in parallel_apply
output.reraise()
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
StopIteration: Caught StopIteration in replica 0 on device 0.
Original Traceback (most recent call last):
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 60, in _worker
output = module(*input, **kwargs)
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/transformers/modeling_gpt2.py", line 752, in forward
transformer_outputs = self.transformer(
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/user/.conda/envs/main/lib/python3.8/site-packages/transformers/modeling_gpt2.py", line 587, in forward
attention_mask = attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
StopIteration
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
I simply expect to get an output and no error :)
<!-- A clear and concise description of what you would expect to happen. -->
| 10-12-2020 11:58:33 | 10-12-2020 11:58:33 | Fixed by #7732! |
transformers | 7,730 | closed | Upgrading in pipelines TFAutoModelWithLMHead to new Causal/Masked/Seq2Seq LM classes | # What does this PR do?
Updates code to remove deprecation warning.
No tests as it simply removes current warnings from tests.
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@mfuntowicz
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> | 10-12-2020 09:35:19 | 10-12-2020 09:35:19 | |
transformers | 7,729 | closed | Fix DeBERTa integration tests | Fix the two DeBERTa integration tests.
- The classification test doesn't actually make sense, since there is no classification head saved in `microsoft/deberta-base`
- Fix to the way the attention was initialized according to the pos type.
closes https://github.com/huggingface/transformers/issues/7565
closes https://github.com/huggingface/transformers/pull/7645 | 10-12-2020 09:34:40 | 10-12-2020 09:34:40 | |
transformers | 7,728 | closed | Improving Pipelines by defaulting to framework='tf' when pytorch seems unavailable. | # What does this PR do?
When loading a model that was `tf` only and by passing only model by string without framework argument, it would fail with an odd error message:
```python
>>> transformers.AutoModel.from_pretrained('Narsil/small')
OSError: Can't load weights for 'Narsil/small'. Make sure that:
- 'Narsil/small' is a correct model identifier listed on 'https://huggingface.co/models' (It exists and contains tf_model.h5)
- or 'Narsil/small' is the correct path to a directory containing a file named one of pytorch_model.bin, tf_model.h5, model.ckpt.
```
This PR corrects the `get_framework` that happens very early in the pipeline to detect the type of model
automatically. It does trigger an early download, but that will happen anyway later.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@mfuntowicz
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> | 10-12-2020 09:13:37 | 10-12-2020 09:13:37 | Actually, This introduced a pretty big bug where
```python
nlp = pipeline(task)
```
Would not work anymore. I tried a different solution around that. |
transformers | 7,727 | closed | what is the perplexity of distilbert-base-uncased ? | # ❓ Questions & Help
## Details
In the [readme](https://github.com/huggingface/transformers/tree/master/examples/distillation) , it is said that distilbert-base-uncased is pretraind on the same data used to pretrain Bert, so I wonder what is the final perplexity or cross entropy of the pretrain?
| 10-12-2020 09:11:49 | 10-12-2020 09:11:49 | Hey @OleNet ,
You probably have a better chance of getting an anwser by posting your question on the discussion forum here: `http://discuss.huggingface.co/`.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,726 | closed | Do not softmax when num_labels==1 | When `config.num_labels=1`, the text classification pipeline shouldn't softmax over the results as it will always return 1. Instead, when the number of labels is 1, this will run a sigmoid over the result.
cf https://github.com/huggingface/transformers/issues/7493#issuecomment-706413792 | 10-12-2020 09:09:10 | 10-12-2020 09:09:10 | |
transformers | 7,725 | closed | how we can replace/swap the Wikipedia data with our custom data for knowledge retrieval in the RAG model and the format of the retrieval data. | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: | 10-12-2020 09:02:56 | 10-12-2020 09:02:56 | I am also playing with RAG model and I am trying to understand how to replace the Wikipedia data with my custom data. From transformes/model-cards/facebook/rag-sequence-nq I see that the train dataset is wiki_dpr. So I loaded it with the following
`
from datasets import load_dataset
dataset = load_dataset("wiki_dpr")
`
The dataset is loaded with arrow into RAM(it's prety big, 75 GB). I was wandering, the custom dataset must have the same format as `wiki_dpr` ? If you can help with a tutorial on how to replace wiki dataset with a custom one, it will be very helpful. Thank you :D<|||||>I think @lhoestq is working on this right now? <|||||>Yes indeed. I'll create the PR later today to allow users to use their own data. I'll also add code examples<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hi, Sorry to bump a closed issue but it's the first one in a google search for Rag (or DPR) and huggingface.
Could we please have links here for the code exemples or informations about custom datas ?
Thanks a lot :smiley: <|||||>Hi !
Sure. You can find more information in [the RAG examples readme](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag#use-your-own-knowledge-source). Also feel free to take a look at [the code that shows how to do it step by step](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag/use_own_knowledge_dataset.py).<|||||>from this link using snippet of code to download the Wikipedia data.(https://huggingface.co/datasets/wiki_dpr/blob/main/wiki_dpr.py)
this is the command to download all 50 batches of data : !wget https://dl.fbaipublicfiles.com/dpr/data/wiki_encoded/single/nq/wiki_passages_{1..50}.
Then based on your system config merge the batches and go further.
|
transformers | 7,724 | closed | Fix tf text class | # What does this PR do?
This PR fixes an issue in the `run_tf_text_classification.py` where the tokenizer was raising an error when the CSV file had 3 columns.
Fixes #7706 | 10-12-2020 08:47:03 | 10-12-2020 08:47:03 | |
transformers | 7,723 | closed | T5: Finetuning the language modelling objective on a new dataset | # ❓ Questions & Help
I was wondering if there is a way I could fine tune T5 model on my own dataset. There are scripts for fine tuning help for GPT2, BERT and XLNET in language modelling examples, so was thinking if that could be extended to T5 as well?
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: | 10-12-2020 08:34:21 | 10-12-2020 08:34:21 | have a look on: https://github.com/huggingface/transformers/tree/master/examples
for conditional generation in the folder seq2seq is an example for finetuning<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,722 | closed | Create Model-card for LIMIT-BERT | # What does this PR do?
Adds a model card Readme for the LIMIT-BERT language model | 10-12-2020 07:46:38 | 10-12-2020 07:46:38 | |
transformers | 7,721 | closed | can u help me out with how to input custom data files in RAG retriever and the data format | sign me up, Sam
_Originally posted by @stas00 in https://github.com/huggingface/transformers/issues/7715#issuecomment-706769068_ | 10-12-2020 07:14:45 | 10-12-2020 07:14:45 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,720 | closed | Fix trainer callback | Fix a bug that happends when subclassing Trainer and
overwriting evaluate() without calling prediciton_loop()
# What does this PR do?
Fixes #7702
@sgugger
| 10-12-2020 03:22:30 | 10-12-2020 03:22:30 | |
transformers | 7,719 | closed | wrong decoder_input_ids[:,0] for MarianMT models ? | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.3.1
- Platform: Linux
- Python version: 3.7.0
- PyTorch version (GPU?): 1.6.0
- Using GPU in script?: Yes
### Who can help: @sshleifer
## Information
Model I am using (Bert, XLNet ...): MarianMTModel
The problem arises when using:
* [x] the official example scripts: (give details below)
```from transformers import MarianTokenizer
tok = MarianTokenizer.from_pretrained('Helsinki-NLP/opus-mt-en-de')
src_texts = [ "I am a small frog.", "Tom asked his teacher for advice."]
tgt_texts = ["Ich bin ein kleiner Frosch.", "Tom bat seinen Lehrer um Rat."] # optional
batch_enc: BatchEncoding = tok.prepare_seq2seq_batch(src_texts, tgt_texts=tgt_texts)
# model(**batch) should work
```
model(**batch) doesn't work as intended because [shift_tokens_right](https://github.com/huggingface/transformers/blob/03ec02a667d5ed3075ea65b9f89ef7135e97f6b4/src/transformers/modeling_bart.py#L226) adds eos token to generate the target sequence.
```
shift_tokens_right(batch["labels"], model.config.pad_token_id)
```
returns
```
[[0, 105, 495, 53, 5324, 17279, 649, 3],
[0, 2136, 8818, 715, 5832, 91, 688, 3]]
```
instead of
```
[[58100, 105, 495, 53, 5324, 17279, 649, 3],
[58100, 2136, 8818, 715, 5832, 91, 688, 3]]
```
Here, "58100" is the decoder_start_token_id. | 10-12-2020 00:49:02 | 10-12-2020 00:49:02 | This is the intended behavior.
It is very counterintuitive to me as well, but changing `prepare_seq2seq_batch` or `shift_tokens_right` to end up with `decoder_start_token_id` at the 0th position of `decoder_input_ids` seems to lead to worse fine-tuning performance.
If you have evidence to the contrary, I would be happy to change it.<|||||>I'm running the experiment now on wmt-en-ro, we'll see how it goes!<|||||>Thanks! I was using the pre-trained model for scoring (src, tgt) pairs and didn't actually get a chance to check the impact on finetuning yet. <|||||>I ran this last night, and finetuning loss was identical with and without the change.
Bleu was within 0.1 (`master` was slightly higher).
Here is the branch if you want to play with it: https://github.com/sshleifer/transformers_fork/tree/hack-batches-v2 |
transformers | 7,718 | closed | fixed typo in warning line 207. | replace 'men_len' with 'mem_len' to match parameter name
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dimiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> | 10-12-2020 00:15:36 | 10-12-2020 00:15:36 | |
transformers | 7,717 | closed | The input training data files (multiple files in glob format). | Very often Corpus comes in [split files (book-large-p1.txt, book-large-p2.txt)](https://huggingface.co/datasets/bookcorpus); Also splitting large files to smaller files can prevent [language_modeling's tokenizer going out of memory](https://github.com/huggingface/transformers/blob/6303b5a7185fba43830db0cbb06c61861f57ddff/src/transformers/data/datasets/language_modeling.py#L67) in environment like Colab that does not have swap memory and limited to Standard (12Gb) or High RAM (25Gb) instances.
To avoid making any assumption and prematurely truncate the file to avoid such error, we add support to concatenate training data on Dataset level. User can split files to multiple 512Mb, in that case language_modeling's tokenizer would be less to go out of memory.
In addition, it would even further enhance the memory limitation if we keep [pytorch tensor in memory](https://github.com/huggingface/transformers/blob/6303b5a7185fba43830db0cbb06c61861f57ddff/src/transformers/data/datasets/language_modeling.py#L88) instead of python list. We leave this in future work.
@LysandreJik @sgugger | 10-11-2020 23:12:16 | 10-11-2020 23:12:16 | |
transformers | 7,716 | closed | Hosted Inference API for Token Classification doesn't Highlight Tokens correctly | ## Environment info
- `transformers` version: 3.3.1
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0+cu101 (False)
- Tensorflow version (GPU?): 2.3.0 (False)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
Model Cards: @julien-c
examples/token-classification: @stefan-it
## Information
Model I am using (Bert, XLNet ...):
Bert
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
https://huggingface.co/Rostlab/prot_bert_bfd_ss3?text=N+L+Y+I+Q+W+L+K+D+G+G+P+S+S+G+R+P+P+P+S
https://huggingface.co/Rostlab/prot_bert_bfd_ss3?text=T+G+N+L+Y+I+Q+W+L+K+D+G+G+P+S+S+G+R+P+P+P+S+A+T+G
## Expected behavior
When the Hosted inference API finds a token tag for special tokens like "[CLS] and [SEP]" also occurs with next or previous tokens, it doesn't highlight it and tag it properly.
Example:
<img width="617" alt="Screenshot 2020-10-11 at 23 31 35" src="https://user-images.githubusercontent.com/6087313/95690715-f17aba80-0c19-11eb-803d-c439cd9b137d.png">
Because token "N" had the same token group as the previous special token "[CLS]", it was not highlighted. However, it was detected correctly. | 10-11-2020 21:34:22 | 10-11-2020 21:34:22 | @julien-c @mfuntowicz any insights or updates for this issue ?<|||||>I see the issue, but not sure how to best fix it to be honest – as it seems a very specific problem (token classification models that classify the special tokens as non-`O`)
When we run fast tokenizers by default we'll get token alignment offsets into the original inputs, so that might solve this issue elegantly.
May I ask what's your use case here and do you need this use case supported by the inference widget (and at which horizon)?<|||||>Our main project called [ProtTrans](https://github.com/agemagician/ProtTrans), which trains various language modelling models for protein sequences at large scale.
This specific use case predicts the secondary structure for protein sequences. It is one step behind predicting the 3D structure of protein sequences (like Google AlphaFold) that allows companies to find a drug or a cure for a virus like Covid-19.
For us we want to use the inference widget to show a live example for the prediction power of our fine-tuned models on different tasks. Later, companies or researchers might need to use it at large scale to make this prediction using your APIs.
Hopefully, this anwer your question 😄
References:
https://blogs.nvidia.com/blog/2020/07/16/ai-reads-proteins-covid/
https://www.youtube.com/watch?v=04E3EjsQLYo&t=89s<|||||>👍 Oh yes I know (and love) your project and general goal/use case. I was referring to the specific use of the inference widget.
I'll see what we can do. Out of curiosity, any specific reason you trained with special tokens (vs. just the raw sequence)? To be able to also do document-level classification from the same pretrained model?<|||||>The original pretrained model [ProtBert-BFD](prot_bert_bfd) was trained using [Google Bert script](https://github.com/google-research/bert) on TPU, which automatically add these special tokens.
This allows us to perform also document-level classification as you mentioned. Like [ProtBert-BFD-MS](https://huggingface.co/Rostlab/prot_bert_bfd_membrane?text=M+G+L+P+V+S+W+A+P+P+A+L+W+V+L+G+C+C+A+L+L+L+S+L+W+A+L+C+T+A+C+R+R+P+E+D+A+V+A+P+R+K+R+A+R+R+Q+R+A+R+L+Q+G+S+A+T+A+A+E+A+S+L+L+R+R+T+H+L+C+S+L+S+K+S+D+T+R+L+H+E+L+H+R+G+P+R+S+S+R+A+L+R+P+A+S+M+D+L+L+R+P+H+W+L+E+V+S+R+D+I+T+G+P+Q+A+A+P+S+A+F+P+H+Q+E+L+P+R+A+L+P+A+A+A+A+T+A+G+C+A+G+L+E+A+T+Y+S+N+V+G+L+A+A+L+P+G+V+S+L+A+A+S+P+V+V+A+E+Y+A+R+V+Q+K+R+K+G+T+H+R+S+P+Q+E+P+Q+Q+G+K+T+E+V+T+P+A+A+Q+V+D+V+L+Y+S+R+V+C+K+P+K+R+R+D+P+G+P+T+T+D+P+L+D+P+K+G+Q+G+A+I+L+A+L+A+G+D+L+A+Y+Q+T+L+P+L+R+A+L+D+V+D+S+G+P+L+E+N+V+Y+E+S+I+R+E+L+G+D+P+A+G+R+S+S+T+C+G+A+G+T+P+P+A+S+S+C+P+S+L+G+R+G+W+R+P+L+P+A+S+L+P) fine-tuned model.
We found out that using also the special tokens during fine-tuning [ProtBert-BFD-SS3](https://huggingface.co/Rostlab/prot_bert_bfd_ss3) model perform better than not using it. I would assume because: 1)The positional encoding. 2) It matches the original Bert training method. 3) you recommended to use it in your token classification example :)
Thanks in advance for looking into this issue.<|||||>not to keep pushing my own PR https://github.com/huggingface/transformers/pull/5970 but this solves some existing problems related to NER pipelines. The current hold-up is whether or not this provides a general enough solution for various models/langs [*](https://github.com/huggingface/transformers/pull/5970#discussion_r504519659).
If fast tokenizers are supported by all I can switch to a better implementation on the pipeline too, but at the current state I don't have an alternative. (suggestions are welcome)<|||||>@julien-c Any progress for this issue ?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,715 | open | examples/rag: test coverage, tiny model | Disclaimer: I don't know this code very well, this may be much harder than it seems.
Blocking PR: #7713
[`examples/rag/finetune.py`, `examples/rag/finetune.sh`, `eval_rag.py`] do not seem to be tested at all.
It would be good to have a `test_finetune.py` like `examples/seq2seq` that tested these.
cc @stas00 if interested, rag is a cool new retrieval model https://arxiv.org/pdf/2005.11401.pdf | 10-11-2020 21:09:58 | 10-11-2020 21:09:58 | sign me up, Sam<|||||>@sshleifer
examples/rag/finetune.py is not that stable. Seems like it depends on the pytorch_lightning version also. It would be nice if we can test it properly. <|||||>I think this is still waiting for: https://github.com/huggingface/transformers/issues/8284 to complete the missing info and perhaps some tests were added since then?
<|||||>This issue has been stale for 1 month.<|||||>As the required to implement this info was never provided and I since then moved to work on other things I removed self-assignment to this ticket... |
transformers | 7,714 | closed | Fix typo in all model docs | # What does this PR do?
Like #7703 but for all other models (maked-> masked) | 10-11-2020 20:51:31 | 10-11-2020 20:51:31 | |
transformers | 7,713 | closed | rag examples tests fail | ```
================================================================ ERRORS =================================================================
______________________________________ ERROR collecting examples/rag/test_distributed_retriever.py ______________________________________
ImportError while importing test module '/Users/shleifer/transformers_fork/examples/rag/test_distributed_retriever.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
examples/rag/test_distributed_retriever.py:26: in <module>
from examples.rag.distributed_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
E ModuleNotFoundError: No module named 'examples.rag'
``` | 10-11-2020 20:50:32 | 10-11-2020 20:50:32 | |
transformers | 7,712 | closed | fix examples/rag imports, tests | Before
```bash
pytest examples/rag
```
fails with
```
================================================================ ERRORS =================================================================
______________________________________ ERROR collecting examples/rag/test_distributed_retriever.py ______________________________________
ImportError while importing test module '/Users/shleifer/transformers_fork/examples/rag/test_distributed_retriever.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
examples/rag/test_distributed_retriever.py:26: in <module>
from examples.rag.distributed_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
E ModuleNotFoundError: No module named 'examples.rag'
```
After, the same command passes.
The fix was to change
`from examples.rag.file_name -> from filename`
and add the same `sys.path` magic that `examples/seq2seq/` uses.
### TODO
- test the scripts in `examples/rag/README.md` after this change
| 10-11-2020 20:49:41 | 10-11-2020 20:49:41 | @stas00 does this look reasonable? Am I missing anything you did for `examples/seq2seq`?<|||||>yes, except you shouldn't need
```
sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # noqa: E402 # isort:skip
```
that's what `__init__.py` already did for you.
and once removed, all those subsequent import `# noqa:` comments can be removed too. (except PL import)
besides using `cwd` is a bad idea - who knows where the script is invoked from and not just from the same dir as the script itself. Use `__file__` instead, which is deterministic. but it's not needed here.
<|||||>Scripts work, will merge on CI success.<|||||>btw, you can also remove most of the `# noqa: E402 # isort:skipq` as they are no longer needed. |
transformers | 7,711 | closed | 2 Deberta test failures | I suspect these are related to recent tokenizer changes:
https://github.com/huggingface/transformers/runs/1236753957?check_suite_focus=true
```
FAILED tests/test_tokenization_deberta.py::DebertaTokenizationTest::test_torch_encode_plus_sent_to_model
FAILED tests/test_modeling_deberta.py::DebertaModelIntegrationTest::test_inference_classification_head
``` | 10-11-2020 20:47:05 | 10-11-2020 20:47:05 | Duplicate of https://github.com/huggingface/transformers/issues/7565
Working on it in https://github.com/huggingface/transformers/pull/7645 |
transformers | 7,710 | closed | 2 RAG test failures | The two failures here look related to recent tokenizer changes:
https://github.com/huggingface/transformers/runs/1236753957?check_suite_focus=true
```
=========================== short test summary info ============================
FAILED tests/test_modeling_rag.py::RagModelIntegrationTests::test_rag_sequence_generate_batch
FAILED tests/test_modeling_rag.py::RagModelIntegrationTests::test_rag_token_generate_batch
``` | 10-11-2020 20:46:14 | 10-11-2020 20:46:14 | @sshleifer - thanks a lot for the issue!
This error seems related to https://github.com/huggingface/transformers/issues/7690#issuecomment-707382445. |
transformers | 7,709 | closed | [marian] Automate Tatoeba-Challenge conversion | This allows conversion of marian models from the Tatoeba-Challenge repo through the command line,
with instructions at `scripts/tatoeba/README.md`. This was previously impossible.
Tests are in `examples/` because the conversion requires examples dependencies (wget and pandas).
In my opinion, it would be a lot of work for very little benefit to remove these dependencies.
The goal of this PR is to allow @jorgtied to upload his own models. | 10-11-2020 16:13:14 | 10-11-2020 16:13:14 | |
transformers | 7,708 | closed | Fine Tuning SciBERT NLI model | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Hi,
I am a novice in the domain of fine-tuning any Transformer models using my own dataset. I want to fine-tune the SciBERT NLI model(https://huggingface.co/gsarti/scibert-nli) using my dataset. The dataset formation is
S1 [SEP] S2 [SEP] Inference
I am not sure how to fine-tune my dataset on the SciBERT NLI model(https://huggingface.co/gsarti/scibert-nli).
I am sorry for asking a very simple question. But any suggestion or link helps me. Thanks in advance. -->
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**:
Hi,
I am a novice in the domain of fine-tuning any Transformer models using my own dataset. I want to fine-tune the SciBERT NLI model(https://huggingface.co/gsarti/scibert-nli) using my dataset. The dataset formation is
S1 [SEP] S2 [SEP] Inference
I am not sure how to fine-tune my dataset on the SciBERT NLI model(https://huggingface.co/gsarti/scibert-nli).
I am sorry for asking a very simple question. But any suggestion or link helps me. Thanks in advance. | 10-11-2020 13:55:33 | 10-11-2020 13:55:33 | Take a look at the official tutorial on fine-tuning a model on your own dataset here: https://huggingface.co/transformers/custom_datasets.html
What's your dataset about? Is it text classification, question answering?
BTW, please post any questions which are not bugs/new features you would like to see added on the [forum](https://discuss.huggingface.co/) rather than here. <|||||>Thanks @NielsRogge for the reply.
My dataset contains two clinical sentences (S1, S2) and its corresponding relation ('Entailment'/'Contradiction'/'Neutral'). So it basically contains three columns. <|||||>Ok so that's sentence pair classification. There's an example notebook on that [here](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb).<|||||>Oh that's really helpful. Thank you again @NielsRogge . |
transformers | 7,707 | closed | [NEW MODEL] Multilingual document embeddings: cT-LASER | # 🌟 New model addition
## Model description
Multilingual document embeddings by adapting the LASER architecture (which is based on BiLSTM) to transformer architectures.
## Open source status
* [x] the model implementation is available: open source implementation is here: https://github.com/ever4244/tfm_laser_0520
* [ ] the model weights are available: i haven't found them
* [x] who are the authors: @ever4244
| 10-11-2020 12:03:44 | 10-11-2020 12:03:44 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,706 | closed | run_tf_text_classification.py for custom dataset | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: master
- Platform: ubuntu 18.04
- Python version: 3.6
- PyTorch version (GPU?): 2080ti
- Tensorflow version (GPU?): 2080ti
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: No
### Who can help
@stefan-it
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
blenderbot: @mariamabarham
Bart: @sshleifer
Marian: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...): Longformer
The problem arises when using: run_tf_text_classification.py
The tasks I am working on is: customize dataset for text classification
## To reproduce
create a csv file like below
```
exp.csv
id,sentence1,sentence2
0,you,he
0,you,he
0,you,he
0,you,he
0,you,he
0,you,he
0,you,he
0,you,he
0,you,he
```
run official script (though actually I split them in jupyter notebook cell, but the code is the same)
python run_tf_text_classification.py \
--train_file exp.csv \ ### training dataset file location (mandatory if running with --do_train option)
--dev_file exp.csv \ ### development dataset file location (mandatory if running with --do_eval option)
--test_file exp.csv \ ### test dataset file location (mandatory if running with --do_predict option)
--label_column_id 0 \ ### which column corresponds to the labels
--model_name_or_path allenai/longformer-base-4096\
--output_dir model \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 32 \
--do_train \
--do_eval \
--do_predict \
--logging_steps 10 \
--evaluate_during_training \
--save_steps 10 \
--overwrite_output_dir \
--max_seq_length 128
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-43-1bd059d64d85> in <module>
5 tokenizer=tokenizer,
6 label_column_id=0,
----> 7 max_seq_length=200,
8 )
<ipython-input-42-7c289105c656> in get_tfds(train_file, eval_file, test_file, tokenizer, label_column_id, max_seq_length)
43 padding="max_length",
44 ),
---> 45 batched=True,
46 )
47 def gen_train():
~/anaconda3/envs/longtext-longformer/lib/python3.6/site-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)
1254 fn_kwargs=fn_kwargs,
1255 new_fingerprint=new_fingerprint,
-> 1256 update_data=update_data,
1257 )
1258 else:
~/anaconda3/envs/longtext-longformer/lib/python3.6/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
154 "output_all_columns": self._output_all_columns,
155 }
--> 156 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
157 if new_format["columns"] is not None:
158 new_format["columns"] = list(set(out.column_names) - unformatted_columns)
~/anaconda3/envs/longtext-longformer/lib/python3.6/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
161 # Call actual function
162
--> 163 out = func(self, *args, **kwargs)
164
165 # Update fingerprint of in-place transforms + update in-place history of transforms
~/anaconda3/envs/longtext-longformer/lib/python3.6/site-packages/datasets/arrow_dataset.py in _map_single(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, update_data)
1515 try:
1516 batch = apply_function_on_filtered_inputs(
-> 1517 batch, indices, check_same_num_examples=len(self.list_indexes()) > 0, offset=offset
1518 )
1519 except NumExamplesMismatch:
~/anaconda3/envs/longtext-longformer/lib/python3.6/site-packages/datasets/arrow_dataset.py in apply_function_on_filtered_inputs(inputs, indices, check_same_num_examples, offset)
1433 effective_indices = [i + offset for i in indices] if isinstance(indices, list) else indices + offset
1434 processed_inputs = (
-> 1435 function(*fn_args, effective_indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
1436 )
1437 if not update_data:
<ipython-input-42-7c289105c656> in <lambda>(example)
41 truncation=True,
42 max_length=max_seq_length,
---> 43 padding="max_length",
44 ),
45 batched=True,
~/anaconda3/envs/longtext-longformer/lib/python3.6/site-packages/transformers/tokenization_utils_base.py in batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
2211 return_length=return_length,
2212 verbose=verbose,
-> 2213 **kwargs,
2214 )
2215
~/anaconda3/envs/longtext-longformer/lib/python3.6/site-packages/transformers/tokenization_utils.py in _batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding_strategy, truncation_strategy, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
558 ids, pair_ids = ids_or_pair_ids, None
559 else:
--> 560 ids, pair_ids = ids_or_pair_ids
561
562 first_ids = get_input_ids(ids)
ValueError: too many values to unpack (expected 2)
```
### suggestion for fix:
in line 60 - 69, my suggestion is as comment.
```
for k in files.keys():
transformed_ds[k] = ds[k].map(
lambda example: tokenizer.batch_encode_plus(
(example[features_name[0]], features_name[1]), # it should be (example[features_name[0]], example[features_name[1]])
truncation=True,
max_length=max_seq_length,
padding="max_length",
),
batched=True, # batched need to be set as True, I don't why batched=True doesn't work
)
```
<!-- A clear and concise description of what you would expect to happen. -->
| 10-11-2020 12:01:03 | 10-11-2020 12:01:03 | @jplu might be interested in that issue. |
transformers | 7,705 | closed | Recording training loss and perplexity during training | I'm fine-tuning GPT-2 text generation with the following command on Colab:
python run_language_modeling.py \
--output_dir=$OUTPUT_DIR \
--model_type=gpt2 \
--model_name_or_path=$MODEL_NAME \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--per_gpu_train_batch_size=1 \
--save_steps=-1 \
--num_train_epochs=5
I was wondering if I can record the training loss, perplexity ... etc per epoch into a csv file or saved as a variable on Colab?
Thank you so much! | 10-11-2020 09:17:04 | 10-11-2020 09:17:04 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,704 | closed | SQuAD example docs inaccurately suggest settings for bert-large-uncased on a single V100 | Hi!
In the SQuAD example docs, it's noted that ( https://github.com/huggingface/transformers/blob/3f42eb979f7bd20448ff6b15ab316d63f5489a6f/docs/source/examples.md#fine-tuning-bert-on-squad10 ) `This example code fine-tunes BERT on the SQuAD1.0 dataset. It runs in 24 min (with BERT-base) or 68 min (with BERT-large) on a single tesla V100 16GB.`
Could just be me, but I don't think the example as provided works with `s/bert-base-uncased/bert-large-uncased/`---even with FP16, you run into a GPU OOM.
It might be useful to revisit this recommendation and/or remove it. | 10-11-2020 07:51:27 | 10-11-2020 07:51:27 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,703 | closed | Corrected typo: maked → masked | # What does this PR do?
Fixed small typo in the BERT documentation.
## Before submitting
✅ This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
@LysandreJik @sgugger | 10-11-2020 06:31:07 | 10-11-2020 06:31:07 | Ugh and I copied that docstrings to all other models... Thanks for fixing! |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.