
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 7,102 | closed | Longformer inference time | The longformer-base-4096 model should be faster than bert-base-cased ,However I find that the former one takes more time to inference | 09-13-2020 13:28:50 | 09-13-2020 13:28:50 | hi @cmdllx , I don't think longformer will be necessarily faster than bert-base-cased. The goal of longformer is to make memory complexity of attention layer liner w.r.t to seq length instead of quadratic, so it saves memory, not compute. More the seq-length , more will be inference time.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,101 | closed | [docs] add testing documentation | This PR adds the initial version of the testing doc.
* This is partially based on the work I did for [fastai last year](https://fastai1.fast.ai/dev/test.html), but rewritten to match the `transformers` environment. It's full of useful tips and tools for running tests. it's very useful for those who do a lot of testing.
* then adding most of the helpers in `testing_utils.py`
* adding CI information
More work is surely needed, but this is a start.
Thanks to @sshleifer for the detailed info on CIs.
@sgugger
| 09-13-2020 05:41:02 | 09-13-2020 05:41:02 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7101?src=pr&el=h1) Report
> Merging [#7101](https://codecov.io/gh/huggingface/transformers/pull/7101?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/90cde2e938638e64a8696a12b79ee5f52364b162?el=desc) will **increase** coverage by `0.31%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7101?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7101 +/- ##
==========================================
+ Coverage 79.62% 79.94% +0.31%
==========================================
Files 168 168
Lines 32284 32284
==========================================
+ Hits 25706 25809 +103
+ Misses 6578 6475 -103
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7101?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9sb25nZm9ybWVyLnB5) | `16.37% <0.00%> (-82.31%)` | :arrow_down: |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `19.71% <0.00%> (-72.34%)` | :arrow_down: |
| [src/transformers/tokenization\_bert\_generation.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYmVydF9nZW5lcmF0aW9uLnB5) | `39.28% <0.00%> (-55.36%)` | :arrow_down: |
| [src/transformers/tokenization\_mbart.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fbWJhcnQucHk=) | `57.14% <0.00%> (-39.69%)` | :arrow_down: |
| [src/transformers/tokenization\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZnVubmVsLnB5) | `62.79% <0.00%> (-34.89%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `75.00% <0.00%> (-25.00%)` | :arrow_down: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `75.91% <0.00%> (-21.17%)` | :arrow_down: |
| [src/transformers/modeling\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tb2JpbGViZXJ0LnB5) | `79.21% <0.00%> (-10.25%)` | :arrow_down: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `86.46% <0.00%> (-0.26%)` | :arrow_down: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `80.75% <0.00%> (-0.25%)` | :arrow_down: |
| ... and [8 more](https://codecov.io/gh/huggingface/transformers/pull/7101/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7101?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7101?src=pr&el=footer). Last update [90cde2e...52a9e54](https://codecov.io/gh/huggingface/transformers/pull/7101?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>I'm curious - why is it OK to have XXX in the code, but not in the docs? especially developer-oriented (i.e. end users most likely won't read this). Is it XXX that's the problem and not the fact that there is a note suggesting more to come in the future/this section is incomplete? Would TODO be acceptable?<|||||>@sgugger, thank you for much for this very detailed feedback. I think I got it all. I will make another path on back quotes to catch any that you and I have missed that are in markdown style.
github sucked big way on this PR with multiple code suggestions - every time I approved the suggested change, it'd reload the page, hide all the other suggestion and scroll away - I had to unhide suggestions, scroll to find the next item, and so on - about 20 times! :( May I suggest that in such a situation of dozens of proposed doc changes, it'd be faster for both of us, if you were to just commit the changes directly. (please correct me if I'm wrong and this is not faster for you) I will learn from the diffs, the changes are mostly self-explanatory.
<|||||>> Note that you can check a preview of the docs built on top of this PR [here](https://84533-155220641-gh.circle-artifacts.com/0/docs/_build/html/testing.html).
I just run `make docs` and checked the result - but obviously i didn't see many things you did see.
Let me know if anything else needs to be changed. The doc will have extra additions later I just had to stop somewhere for the first pass.
<|||||>Thanks for updating, this looks great so merging! |
transformers | 7,100 | closed | [logging] remove no longer needed verbosity override | As the project's verbosity level is now at `logging.WARN` this PR removes the now redundant code.
p.s. another change probably is needed to switch from `logging.getLogger()` to the new API
```
grep -Ir getLogger tests examples | wc -l
56
```
| 09-13-2020 05:00:56 | 09-13-2020 05:00:56 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7100?src=pr&el=h1) Report
> Merging [#7100](https://codecov.io/gh/huggingface/transformers/pull/7100?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/90cde2e938638e64a8696a12b79ee5f52364b162?el=desc) will **decrease** coverage by `1.23%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7100?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7100 +/- ##
==========================================
- Coverage 79.62% 78.39% -1.24%
==========================================
Files 168 168
Lines 32284 32284
==========================================
- Hits 25706 25308 -398
- Misses 6578 6976 +398
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7100?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3JlZm9ybWVyLnB5) | `21.62% <0.00%> (-78.38%)` | :arrow_down: |
| [src/transformers/modeling\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yZWZvcm1lci5weQ==) | `16.87% <0.00%> (-77.64%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl94bG0ucHk=) | `18.94% <0.00%> (-74.32%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9ncHQyLnB5) | `71.84% <0.00%> (-23.17%)` | :arrow_down: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `86.46% <0.00%> (-0.26%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `93.91% <0.00%> (-0.14%)` | :arrow_down: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `93.18% <0.00%> (ø)` | |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `87.33% <0.00%> (+0.64%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hbGJlcnQucHk=) | `90.90% <0.00%> (+69.43%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/7100/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl94bG5ldC5weQ==) | `92.17% <0.00%> (+71.04%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7100?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7100?src=pr&el=footer). Last update [90cde2e...1935a23](https://codecov.io/gh/huggingface/transformers/pull/7100?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,099 | closed | [examples testing] restore code | For some reason https://github.com/huggingface/transformers/pull/5512 re-added temp dir creation code that was removed by
https://github.com/huggingface/transformers/pull/6494 in the process undoing what the latter PR did those tests, leading to the temp dir created twice in a row.
I see now that it was an older PR that was committed much later, so that explains why the new code was not noticed.
@Joel-hanson | 09-13-2020 00:38:55 | 09-13-2020 00:38:55 | Sorry, @stas00 I didn't notice that.<|||||>All is good, it was easy to miss, @Joel-hanson. |
transformers | 7,098 | closed | broken pypi scipy package that affects tests under `examples` | In case someone runs into this:
```
PYTHONPATH="src" pytest examples/test_examples.py
ImportError while importing test module '/mnt/nvme1/code/huggingface/transformers-examples/examples/test_examples.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
/home/stas/anaconda3/envs/main-38/lib/python3.8/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
examples/test_examples.py:38: in <module>
import run_glue
examples/text-classification/run_glue.py:30: in <module>
from transformers import (
E ImportError: cannot import name 'glue_compute_metrics' from 'transformers' (/mnt/nvme1/code/huggingface/transformers-examples/src/transformers/__init__.py)
```
Looking into the code, the problem was coming from:
```
if is_sklearn_available():
from .data import glue_compute_metrics, xnli_compute_metrics
```
for some reason, it was returning `False`.
Looking deeper, I got here:
```
try:
from sklearn.metrics import f1_score, matthews_corrcoef
from scipy.stats import pearsonr, spearmanr
_has_sklearn = True
except (AttributeError, ImportError):
_has_sklearn = False
def is_sklearn_available():
return _has_sklearn
```
So next trying:
```
python -c "from sklearn.metrics import f1_score, matthews_corrcoef"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/sklearn/__init__.py", line 80, in <module>
from .base import clone
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/sklearn/base.py", line 21, in <module>
from .utils import _IS_32BIT
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/sklearn/utils/__init__.py", line 20, in <module>
from scipy.sparse import issparse
ModuleNotFoundError: No module named 'scipy.sparse'
```
but the requirement was already installed:
```
pip install scipy
```
A search gave this answer: https://stackoverflow.com/a/59692528/9201239 which solved the problem.
```
pip uninstall scipy
conda install scipy
```
So there is something wrong with that `scipy` package on pypi.
| 09-13-2020 00:29:47 | 09-13-2020 00:29:47 | The solution is above, so closing this - as it was a FYI post if someone else runs into this. |
transformers | 7,097 | closed | Create README.md | Model card for PEGASUS model finetuned for paraphrasing task
<!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #{issue number}
| 09-12-2020 23:49:21 | 09-12-2020 23:49:21 | |
transformers | 7,096 | closed | Trying to speed up lost speed of tokenizer.encode | Fixes #6962 (at least tries to fix)
@mfuntowicz | 09-12-2020 23:45:39 | 09-12-2020 23:45:39 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7096?src=pr&el=h1) Report
> Merging [#7096](https://codecov.io/gh/huggingface/transformers/pull/7096?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/26d5475d4b6644528956df3020dbaa436b443706?el=desc) will **increase** coverage by `3.91%`.
> The diff coverage is `94.59%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7096?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7096 +/- ##
==========================================
+ Coverage 75.91% 79.82% +3.91%
==========================================
Files 195 168 -27
Lines 39827 32326 -7501
==========================================
- Hits 30233 25803 -4430
+ Misses 9594 6523 -3071
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7096?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `93.70% <87.50%> (+0.76%)` | :arrow_up: |
| [src/transformers/tokenization\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fY3RybC5weQ==) | `80.00% <100.00%> (-16.12%)` | :arrow_down: |
| [src/transformers/tokenization\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZ3B0Mi5weQ==) | `97.31% <100.00%> (+3.80%)` | :arrow_up: |
| [src/transformers/tokenization\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fbWFyaWFuLnB5) | `99.20% <100.00%> (+0.06%)` | :arrow_up: |
| [src/transformers/tokenization\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fb3BlbmFpLnB5) | `84.89% <100.00%> (+1.18%)` | :arrow_up: |
| [src/transformers/tokenization\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxtLnB5) | `83.39% <100.00%> (+0.32%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9sb25nZm9ybWVyLnB5) | `16.37% <0.00%> (-82.22%)` | :arrow_down: |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `19.71% <0.00%> (-54.44%)` | :arrow_down: |
| [src/transformers/tokenization\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fY2FtZW1iZXJ0LnB5) | `37.03% <0.00%> (-53.13%)` | :arrow_down: |
| [src/transformers/optimization.py](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb24ucHk=) | `34.28% <0.00%> (-48.00%)` | :arrow_down: |
| ... and [163 more](https://codecov.io/gh/huggingface/transformers/pull/7096/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7096?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7096?src=pr&el=footer). Last update [26d5475...6ca458e](https://codecov.io/gh/huggingface/transformers/pull/7096?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 7,095 | closed | Create README.md | Create model card for Pegasus QA
<!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #{issue number}
| 09-12-2020 21:10:18 | 09-12-2020 21:10:18 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7095?src=pr&el=h1) Report
> Merging [#7095](https://codecov.io/gh/huggingface/transformers/pull/7095?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b76cb1c3dfc64d1dcaddc3d6d9313dddeb626d05?el=desc) will **decrease** coverage by `1.28%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7095?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7095 +/- ##
==========================================
- Coverage 81.63% 80.34% -1.29%
==========================================
Files 168 168
Lines 32257 32257
==========================================
- Hits 26333 25918 -415
- Misses 5924 6339 +415
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7095?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mdW5uZWwucHk=) | `18.53% <0.00%> (-75.51%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9lbGVjdHJhLnB5) | `25.13% <0.00%> (-73.83%)` | :arrow_down: |
| [src/transformers/modeling\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tYXJpYW4ucHk=) | `60.00% <0.00%> (-30.00%)` | :arrow_down: |
| [src/transformers/activations.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9hY3RpdmF0aW9ucy5weQ==) | `85.00% <0.00%> (-5.00%)` | :arrow_down: |
| [src/transformers/configuration\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JhcnQucHk=) | `90.00% <0.00%> (-4.00%)` | :arrow_down: |
| [src/transformers/modeling\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iYXJ0LnB5) | `93.77% <0.00%> (-0.68%)` | :arrow_down: |
| [...rc/transformers/data/datasets/language\_modeling.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFzZXRzL2xhbmd1YWdlX21vZGVsaW5nLnB5) | `92.94% <0.00%> (-0.59%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9iZXJ0LnB5) | `98.38% <0.00%> (-0.36%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `93.77% <0.00%> (-0.14%)` | :arrow_down: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `93.18% <0.00%> (ø)` | |
| ... and [9 more](https://codecov.io/gh/huggingface/transformers/pull/7095/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7095?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7095?src=pr&el=footer). Last update [b76cb1c...bfde495](https://codecov.io/gh/huggingface/transformers/pull/7095?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Thanks! |
transformers | 7,094 | closed | fix bug in pegasus converter | <!-- This line specifies which issue to close after the pull request is merged. -->
Reported https://discuss.huggingface.co/t/pegasus-questions/838/14
The bug was that I was passing `**cfg_updates` instead of `**cfg_kwargs`. Then I did some extra cleanup to make the code refer to bart less. | 09-12-2020 20:41:35 | 09-12-2020 20:41:35 | |
transformers | 7,093 | closed | Update convert_pegasus_tf_to_pytorch.py | Instead of full config we were only sending updated config dict.
“sshleifer/pegasus” to “google/pegasus-aeslc” in Tokenizer
<!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #{issue number}
| 09-12-2020 18:45:17 | 09-12-2020 18:45:17 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7093?src=pr&el=h1) Report
> Merging [#7093](https://codecov.io/gh/huggingface/transformers/pull/7093?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b76cb1c3dfc64d1dcaddc3d6d9313dddeb626d05?el=desc) will **decrease** coverage by `0.75%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7093?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7093 +/- ##
==========================================
- Coverage 81.63% 80.87% -0.76%
==========================================
Files 168 168
Lines 32257 32257
==========================================
- Hits 26333 26088 -245
- Misses 5924 6169 +245
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7093?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mdW5uZWwucHk=) | `18.53% <0.00%> (-75.51%)` | :arrow_down: |
| [src/transformers/modeling\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tYXJpYW4ucHk=) | `60.00% <0.00%> (-30.00%)` | :arrow_down: |
| [src/transformers/activations.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9hY3RpdmF0aW9ucy5weQ==) | `85.00% <0.00%> (-5.00%)` | :arrow_down: |
| [src/transformers/configuration\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JhcnQucHk=) | `90.00% <0.00%> (-4.00%)` | :arrow_down: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `84.21% <0.00%> (-2.26%)` | :arrow_down: |
| [src/transformers/modeling\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iYXJ0LnB5) | `93.77% <0.00%> (-0.68%)` | :arrow_down: |
| [...rc/transformers/data/datasets/language\_modeling.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFzZXRzL2xhbmd1YWdlX21vZGVsaW5nLnB5) | `92.94% <0.00%> (-0.59%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9iZXJ0LnB5) | `98.38% <0.00%> (-0.36%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `93.77% <0.00%> (-0.14%)` | :arrow_down: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `93.18% <0.00%> (ø)` | |
| ... and [8 more](https://codecov.io/gh/huggingface/transformers/pull/7093/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7093?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7093?src=pr&el=footer). Last update [b76cb1c...c0db32e](https://codecov.io/gh/huggingface/transformers/pull/7093?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,092 | closed | needing area to put download/convert/eval scripts | # 🚀 Feature request
Would it be useful to allocate a sub-dir in the source code for conversion/eval bash scripts? Some of them are quite complex including a bunch of downloads, moving files around, etc. It'd be good to have those in the repo, so that it'd be easy to re-build data if there was a change/mistake/etc.
note: I'm not proposing to move `src/transformers/convert*py`.
Let the data speak for itself.
I currently have 2 scripts for fairseq transformer models:
```
# Convert fairseq transform wmt19 checkpoint.
# To convert run:
# assuming the fairseq data is under data/wmt19.ru-en.ensemble, data/wmt19.en-ru.ensemble, etc
export ROOT=/code/huggingface/transformers-fair-wmt
cd $ROOT
mkdir data
# get data (run once)
wget https://dl.fbaipublicfiles.com/fairseq/models/wmt19.en-de.joined-dict.ensemble.tar.gz
wget https://dl.fbaipublicfiles.com/fairseq/models/wmt19.de-en.joined-dict.ensemble.tar.gz
wget https://dl.fbaipublicfiles.com/fairseq/models/wmt19.en-ru.ensemble.tar.gz
wget https://dl.fbaipublicfiles.com/fairseq/models/wmt19.ru-en.ensemble.tar.gz
tar -xvzf wmt19.en-de.joined-dict.ensemble.tar.gz
tar -xvzf wmt19.de-en.joined-dict.ensemble.tar.gz
tar -xvzf wmt19.en-ru.ensemble.tar.gz
tar -xvzf wmt19.ru-en.ensemble.tar.gz
# run conversions and uploads
export PAIR=ru-en
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19.$PAIR.ensemble --pytorch_dump_folder_path data/fsmt-wmt19-$PAIR
export PAIR=en-ru
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19.$PAIR.ensemble --pytorch_dump_folder_path data/fsmt-wmt19-$PAIR
export PAIR=de-en
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19.$PAIR.joined-dict.ensemble --pytorch_dump_folder_path data/fsmt-wmt19-$PAIR
export PAIR=en-de
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19.$PAIR.joined-dict.ensemble --pytorch_dump_folder_path data/fsmt-wmt19-$PAIR
# upload
cd data
transformers-cli upload -y fsmt-wmt19-ru-en
transformers-cli upload -y fsmt-wmt19-en-ru
transformers-cli upload -y fsmt-wmt19-de-en
transformers-cli upload -y fsmt-wmt19-en-de
cd -
# if updating just small files and not the large models, here is a script to generate the right commands:
perl -le 'for $f (@ARGV) { print qq[transformers-cli upload -y $_/$f --filename $_/$f] for map { "fsmt-wmt19-$_" } ("en-ru", "ru-en", "de-en", "en-de")}' vocab-src.json vocab-tgt.json tokenizer_config.json config.json
# add/remove files as needed
```
Eval script:
```
# to match fairseq you need to set num_beams=50 in `configuration_fsmt.py` and lower BS
# quick estimate version for quick testing
export PAIR=en-ru
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=8
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src | head -100 > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref | head -100 > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py stas/fsmt-wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# ru-en
export PAIR=ru-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=50
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py stas/fsmt-wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# (expected BLEU: 41.3 http://matrix.statmt.org/matrix/output/1907?run_id=6937)
# en-ru
export PAIR=en-ru
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=50
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py stas/fsmt-wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# (expected BLEU: 36.4 http://matrix.statmt.org/matrix/output/1914?score_id=37605)
# en-de
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py stas/fsmt-wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# (expected BLEU: 43.1 http://matrix.statmt.org/matrix/output/1909?run_id=6862)
# de-en
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=50
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py stas/fsmt-wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# (expected BLEU: 42.3 http://matrix.statmt.org/matrix/output/1902?run_id=6750)
```
Then I have a different script for 2 sets of other models for wmt from allen nlp, with 2 scripts each:
```
# Convert fairseq transform wmt16 en-de checkpoints from https://github.com/jungokasai/deep-shallow
pip install gdown
# get data (run once)
cd data
gdown 'https://drive.google.com/uc?id=1x_G2cjvM1nW5hjAB8-vWxRqtQTlmIaQU'
gdown 'https://drive.google.com/uc?id=1oA2aqZlVNj5FarxBlNXEHpBS4lRetTzU'
gdown 'https://drive.google.com/uc?id=1Wup2D318QYBFPW_NKI1mfP_hXOfmUI9r'
tar -xvzf trans_ende_12-1_0.2.tar.gz
tar -xvzf trans_ende-dist_12-1_0.2.tar.gz
tar -xvzf trans_ende-dist_6-1_0.2.tar.gz
gdown 'https://drive.google.com/uc?id=1mNufoynJ9-Zy1kJh2TA_lHm2squji0i9'
gdown 'https://drive.google.com/uc?id=1iO7um-HWoNoRKDtw27YUSgyeubn9uXqj'
tar -xvzf wmt16.en-de.deep-shallow.dist.tar.gz
tar -xvzf wmt16.en-de.deep-shallow.tar.gz
cp wmt16.en-de.deep-shallow/data-bin/dict.*.txt trans_ende_12-1_0.2
cp wmt16.en-de.deep-shallow.dist/data-bin/dict.*.txt trans_ende-dist_12-1_0.2
cp wmt16.en-de.deep-shallow.dist/data-bin/dict.*.txt trans_ende-dist_6-1_0.2
cp wmt16.en-de.deep-shallow/bpecodes trans_ende_12-1_0.2
cp wmt16.en-de.deep-shallow.dist/bpecodes trans_ende-dist_12-1_0.2
cp wmt16.en-de.deep-shallow.dist/bpecodes trans_ende-dist_6-1_0.2
# another set wmt19-6-6-de-en
gdown 'https://drive.google.com/uc?id=1j6z9fYdlUyOYsh7KJoumRlr1yHczxR5T'
gdown 'https://drive.google.com/uc?id=1yT7ZjqfvUYOBXvMjeY8uGRHQFWoSo8Q5'
gdown 'https://drive.google.com/uc?id=15gAzHeRUCs-QV8vHeTReMPEh1j8excNE'
tar -xvzf wmt19.de-en.tar.gz
tar -xvzf wmt19_deen_base_dr0.1_1.tar.gz
tar -xvzf wmt19_deen_big_dr0.1_2.tar.gz
cp wmt19.de-en/data-bin/dict.en.txt wmt19_deen_base_dr0.1_1
cp wmt19.de-en/data-bin/dict.en.txt wmt19_deen_big_dr0.1_2
cp wmt19.de-en/data-bin/dict.de.txt wmt19_deen_base_dr0.1_1
cp wmt19.de-en/data-bin/dict.de.txt wmt19_deen_big_dr0.1_2
cd -
# run conversions and uploads
# wmt16-en-de set
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/trans_ende-dist_12-1_0.2 --pytorch_dump_folder_path data/fsmt-wmt16-en-de-dist-12-1
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/trans_ende-dist_6-1_0.2 --pytorch_dump_folder_path data/fsmt-wmt16-en-de-dist-6-1
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/trans_ende_12-1_0.2 --pytorch_dump_folder_path data/fsmt-wmt16-en-de-12-1
# wmt19-de-en set
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19_deen_base_dr0.1_1 --pytorch_dump_folder_path data/fsmt-wmt19-de-en-6-6-base
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19_deen_big_dr0.1_2 --pytorch_dump_folder_path data/fsmt-wmt19-de-en-6-6-big
```
Eval:
```
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=64
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
MODEL_PATH=/code/huggingface/transformers-fair-wmt/data/fsmt-wmt16-en-de-dist-12-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
MODEL_PATH=/code/huggingface/transformers-fair-wmt/data/fsmt-wmt16-en-de-dist-6-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
MODEL_PATH=/code/huggingface/transformers-fair-wmt/data/fsmt-wmt16-en-de-12-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# wmt19-de-en set
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=64
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
MODEL_PATH=/code/huggingface/transformers-fair-wmt/data/fsmt-wmt19-de-en-6-6-base
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
MODEL_PATH=/code/huggingface/transformers-fair-wmt/data/fsmt-wmt19-de-en-6-6-big
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
So perhaps:
```
model_scripts/
arch/
model1-build.sh
model1-eval.sh
model2-build.sh
model2-eval.sh
[...]
```
So in the case of the above scripts, they could be:
```
model_scripts/fsmt/fairseq-build.sh
model_scripts/fsmt/fairseq-eval.sh
model_scripts/fsmt/allennlp-build.sh
model_scripts/fsmt/allennlp-eval.sh
```
Thoughts?
Of course, I could just start with this proposal as a PR and we can adjust from there.
Thank you.
([fsmt](https://github.com/huggingface/transformers/pull/6940) is not yet merged, in case you wonder about an unfamiliar name) | 09-12-2020 18:43:36 | 09-12-2020 18:43:36 | Feel free to PR `examples/seq2seq/scripts/fsmt`, `examples/seq2seq/fsmt_scripts`, or another git repo that you link to from model cards.
I have some bulk marian converters I can check in also.
<|||||>Thank you for the suggestions, @sshleifer.
For eval scripts I can see some place under `examples`, but for conversion scripts - these are core models we are talking about.
I think those should be close to the code that generates/converts models - so that anybody in the future could regenerate things - if any issues were found. That's why I propose a dedicated area under `transformers` repo root directory.
Some of those scripts are somewhat complex - it's not just downloading a single tar ball and running convert on it. In the case of allenai models that are about to be added different tarballs are needed and they need to be combined in a certain way. Hence I believe it'll save time to the project in the future.
And the eval scripts now feed into the conversion scripts - so no longer examples either. we can now search the hparams and get the model config include `generate` params that are pre-optimized - so core, not examples.<|||||>OK, you've convinced me. @julien-c, @LysandreJik @sgugger what do you guys think about
`transformers/scripts/{model_name}/` as a place to checkin end to end (possibly bulk) conversion scripts?
Rationale:
Marian + FSMT require a few steps before `transformers-cli convert` + `transformers-cli upload` to
+ (a) fetch correct tarballs
+ (b) name them correctly
+ (c) (just fsmt) decide on correct beam search parameters
and it would aid reproducibility to have all that logic/knowledge checked in.<|||||>I have another set of scripts - automatic model card writers - useful for when we have sets of models, which are mainly the same, but the sample code/scores are unique.
So currently for 9 `fsmt` models that were just put on s3 I have 9 scripts:
- 3 conversion scripts (bash)
- 3 model_card scripts (python)
- 3 hparam search eval scripts (bash)
and I currently have 3 sets of the above (a set for 4 wmt19 fairseq models, a set for 3 wmt16 allenai models, a set for 2 wmt19 allenai models), so 9 scripts in total.
<|||||>Made a PR: https://github.com/huggingface/transformers/pull/7155 |
transformers | 7,091 | closed | is config argument necessary for XXModel.from_pretrained method? And when is needed? | # ❓ Questions & Help
I find the model can be loaded with `XXModel.from_pretrained` function even if no `config` argument is given. But if the `config` is given, the argument `gradient_checkpointing` cannot be enabled. I wonder why the config argument can lead to the unable of `gradient_checkpointing`???
I test the conclusion with longformer model. Thanks!
| 09-12-2020 16:56:54 | 09-12-2020 16:56:54 | Hi @xixiaoyao
The `config` argument is not required for `from_pretrained`, when `config` is not passed it loads the saved config from the model dir. However, it's necessary to pass `config` when you wan't to override some config value, like setting `gradient_checkpointing` to `True`. Here's how you can override the `config` and pass it to `from_pretrained`.
```python
config = XXConfig.from_pretrained(path, gradient_checkpointing=True)
model = XXModel.from_pretrained(path, config=config)
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,090 | closed | TypeError: __init__() got an unexpected keyword argument 'gradient_checkpointing' | ## Environment info
- `transformers` version: 3.1.0
- Platform: Linux-3.10.0_3-0-0-17-x86_64-with-debian-buster-sid
- Python version: 3.7.7
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
Longformer/Reformer: @patrickvonplaten
-->
## Information
Model I am using (Longformer):
The problem arises when using:
[ * ] the official example scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: SQuAD v1.1
## To reproduce
Steps to reproduce the behavior:
1. add gradient_checkpointing argument for AutoModelForQuestionAnswering in examples/question-answering/run_squad.py
2. run with longformer-base-4096
runtime errors as belows
```
File "run_squad.py", line 821, in <module>
main()
File "run_squad.py", line 739, in main
gradient_checkpointing=True,
File "/opt/conda/lib/python3.7/site-packages/transformers/modeling_utils.py", line 852, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
TypeError: __init__() got an unexpected keyword argument 'gradient_checkpointing'
```
even if you explicitly replace AutoModel with LongformerModel like following, error is the same.

When I run with python/ipython interactive mode, the model loaded success.

And I have ensured the python enviroment is the same during these two runs.
## Expected behavior
Longformer can be loaded with gradient checkpointing
| 09-12-2020 16:15:55 | 09-12-2020 16:15:55 | Hey @xixiaoyao,
Sorry I cannot reproduce the error. Both when running `run_squad.py` and this snippet (which is essentially the same as in `run_squad.py`):
```python
from transformers import AutoModelForQuestionAnswering
model = AutoModelForQuestionAnswering.from_pretrained("allenai/longformer-base-4096", gradient_checkpointing=True)
```
I do not get any error. Can you post a code snippet (at short as possible) that I could copy paste to reproduce the error?
Thanks!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,089 | closed | German electra model card v3 update | Model Card Update | 09-12-2020 15:49:58 | 09-12-2020 15:49:58 | |
transformers | 7,088 | closed | train/eval step results log not shown in terminal for tf_trainer.py | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.1.0
- Platform: Linux-5.4.0-42-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0 (False)
- Tensorflow version (GPU?): 2.2.0 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
-->
Trainer: @sgugger
tensorflow: @jplu
@LysandreJik
## Information
In the current code, which is without setting `logger.setLevel(logging.INFO)` in `trainer_tf.py`:
09/12/2020 03:42:41 - INFO - absl - Load dataset info from /home/imo/tensorflow_datasets/glue/sst2/1.0.0
09/12/2020 03:42:41 - INFO - absl - Reusing dataset glue (/home/imo/tensorflow_datasets/glue/sst2/1.0.0)
09/12/2020 03:42:41 - INFO - absl - Constructing tf.data.Dataset for split validation, from /home/imo/tensorflow_datasets/glue/sst2/1.0.0
2020-09-12 03:42:57.010229: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:184] Filling up shuffle buffer (this may take a while): 41707 of 67349
2020-09-12 03:43:03.412045: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:233] Shuffle buffer filled.
2020-09-12 03:43:56.636791: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:184] Filling up shuffle buffer (this may take a while): 36279 of 67349
2020-09-12 03:44:04.474751: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:233] Shuffle buffer filled.
09/12/2020 03:44:51 - INFO - __main__ - *** Evaluate ***
09/12/2020 03:45:02 - INFO - __main__ - ***** Eval results *****
09/12/2020 03:45:02 - INFO - __main__ - eval_loss = 0.712074209790711
09/12/2020 03:45:02 - INFO - __main__ - eval_acc = 0.48977272727272725
You can see that the train/eval step logs are not shown.
If I specify, manually, `logger.setLevel(logging.INFO)` in `trainer_tf.py`:
09/12/2020 06:04:39 - INFO - absl - Load dataset info from /home/imo/tensorflow_datasets/glue/sst2/1.0.0
09/12/2020 06:04:39 - INFO - absl - Reusing dataset glue (/home/imo/tensorflow_datasets/glue/sst2/1.0.0)
09/12/2020 06:04:39 - INFO - absl - Constructing tf.data.Dataset for split validation, from /home/imo/tensorflow_datasets/glue/sst2/1.0.0
You are instantiating a Trainer but W&B is not installed. To use wandb logging, run `pip install wandb; wandb login` see https://docs.wandb.com/huggingface.
To use comet_ml logging, run `pip/conda install comet_ml` see https://www.comet.ml/docs/python-sdk/huggingface/
***** Running training *****
Num examples = 67349
Num Epochs = 1
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 4
Gradient Accumulation steps = 1
Steps per epoch = 4
Total optimization steps = 4
2020-09-12 06:04:49.637373: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:184] Filling up shuffle buffer (this may take a while): 39626 of 67349
2020-09-12 06:04:56.805687: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:233] Shuffle buffer filled.
{'loss': 0.6994307, 'learning_rate': 3.7499998e-05, 'epoch': 0.5, 'step': 1}
{'loss': 0.6897122, 'learning_rate': 2.5e-05, 'epoch': 0.75, 'step': 2}
Saving checkpoint for step 2 at ./sst-2/checkpoint/ckpt-1
{'loss': 0.683386, 'learning_rate': 1.25e-05, 'epoch': 1.0, 'step': 3}
{'loss': 0.68290234, 'learning_rate': 0.0, 'epoch': 1.25, 'step': 4}
Saving checkpoint for step 4 at ./sst-2/checkpoint/ckpt-2
Training took: 0:00:43.099437
Saving model in ./sst-2/
09/12/2020 06:05:26 - INFO - __main__ - *** Evaluate ***
***** Running Evaluation *****
Num examples = 872
Batch size = 8
{'eval_loss': 0.6990196158032899, 'eval_acc': 0.49204545454545456, 'epoch': 1.25, 'step': 4}
09/12/2020 06:05:35 - INFO - __main__ - ***** Eval results *****
09/12/2020 06:05:35 - INFO - __main__ - eval_loss = 0.6990196158032899
09/12/2020 06:05:35 - INFO - __main__ - eval_acc = 0.49204545454545456
We see more information like
{'loss': 0.6994307, 'learning_rate': 3.7499998e-05, 'epoch': 0.5, 'step': 1}
More importantly, we also see this message
You are instantiating a Trainer but W&B is not installed. To use wandb logging, run `pip install wandb; wandb login` see https://docs.wandb.com/huggingface.
To use comet_ml logging, run `pip/conda install comet_ml` see https://www.comet.ml/docs/python-sdk/huggingface/
, which won't be shown if logging level is not set to INFO.
## Related
In the PR #6097, @LysandreJik changed `logger.info(output)` to `print(output)` in `trainer.py` in order to show logs on the screen.
Maybe we should do the same thing for `tf_trainer.py`. If not, could we set logging level to INFO in `tf_trainer.py` - however this would become different from `trainer.py` where the logging level is not set (at least, not in the trainer script).
## To reproduce
python3 run_tf_glue.py \
--task_name sst-2 \
--model_name_or_path distilbert-base-uncased \
--output_dir ./sst-2/ \
--max_seq_length 16 \
--num_train_epochs 2 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 1 \
--max_steps 4 \
--logging_steps 1 \
--save_steps 2 \
--seed 1 \
--do_train \
--do_eval \
--do_predict \
--overwrite_output_dir
## Expected behavior
I expect the train/eval step logs will be shown on the screen.
## Remark
I can make a PR once a decision is made by the team. | 09-12-2020 12:53:59 | 09-12-2020 12:53:59 | You are user the wrong logger I think. Transformers now uses a centralized logger so you should go:
```
import transformers
transformers.logging.set_verbosity_info()
```
to set the verbosity to the INFO level. Not sure it there is an additional issue in tf_trainer or not.<|||||>>
>
> You are user the wrong logger I think. Transformers now uses a centralized logger so you should go:
>
> ```
> import transformers
> transformers.logging.set_verbosity_info()
> ```
>
> to set the verbosity to the INFO level. Not sure it there is an additional issue in tf_trainer or not.
@sgugger , but I am testing `run_tf_glue.py`, not my own script. I assume it should work directly, no? Other scripts like `run_tf_ner.py` also have the same issue. And it seems there is no logging level command-line argument to specify.<|||||>As @sgugger said, all the examples uses the Python logging lib instead of the HF wrapper.
I will do a fix early next week.<|||||>@sgugger
While I worked on #7125, I found that in `trainer.py`, I found that
logger.info(" Continuing training from checkpoint, will skip to saved global_step")
logger.info(" Continuing training from epoch %d", epochs_trained)
logger.info(" Continuing training from global step %d", self.global_step)
logger.info(" Continuing training from %d non-embedding floating-point operations", self.total_flos)
logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
are not shown while I launched example scripts like `run_glue.py`.<|||||>Yes the default log level is `warning`, you have to change it in the script to info if you want, by adding the line:
```
logging.set_verbosity_info()
```
Or if you always want info, there is an env variable you can set called `TRANSFORMERS_VERBOSITY` (set it to 20 for info level).<|||||>There is a small issue with the HF logger. I'm currently working on it and checking with @LysandreJik <|||||>No problem. If this is the default behavior expected (at least for pytorch trainer), I am fine.<|||||>@jplu As you might know, I open this issue, but I don't necessary have the whole context. So I leave you to decide the desired behavior for tf_trainer.<|||||>alternatively you can simply modify the following line in transormers/utils/logging.py to change the default behaviour:
from `_default_log_level = logging.WARNING ` to `_default_log_level = logging.INFO`<|||||>A fix has been pushed, you just have to write `transformers.logging.set_verbosity_info()`<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,087 | closed | Transformer-XL: Remove unused parameters | Fixes #6943
Since `tgt_len` and `ext_len` is removed, the method `reset_length` was renamed to `reset_memory_length` to be more meaningful.
I'm not sure whether a deprecation warning should be included in `TransfoXLConfig`. Maybe someone can make suggestions regarding this. | 09-12-2020 09:55:10 | 09-12-2020 09:55:10 | As far I can see only the test `tests/test_trainer.py` is failing...<|||||>Hey! We changed the name of `nlp` to `datasets` from Thursday to Friday and I am pretty sure that's what's causing the CI bug, but it was fixed just afterwards. Could you pull the latest changes from master and rebase on your branch so you get the fix?<|||||>Sure!
Is there a way to avoid that all "new" commits from master will end up in this PR even if they are already in the master branch? So that after the rebase still only my changes are listed in this PR?<|||||>I am not sure, as I haven't had this issue before (I remember your previous PR did). But using `git pull --rebase` on your local branch should do the trick.<|||||>Thanks I will try that!<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7087?src=pr&el=h1) Report
> Merging [#7087](https://codecov.io/gh/huggingface/transformers/pull/7087?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/85ffda96fcadf70d2558ba0a59c84b9f5a2d6f0f?el=desc) will **increase** coverage by `0.20%`.
> The diff coverage is `50.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7087?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7087 +/- ##
==========================================
+ Coverage 78.44% 78.65% +0.20%
==========================================
Files 168 168
Lines 32309 32306 -3
==========================================
+ Hits 25346 25411 +65
+ Misses 6963 6895 -68
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7087?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3RyYW5zZm9feGwucHk=) | `87.03% <0.00%> (-2.06%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90cmFuc2ZvX3hsLnB5) | `88.10% <57.14%> (-0.03%)` | :arrow_down: |
| [src/transformers/modeling\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190cmFuc2ZvX3hsLnB5) | `79.73% <57.14%> (-0.04%)` | :arrow_down: |
| [src/transformers/tokenization\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxtLnB5) | `16.26% <0.00%> (-66.67%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9kaXN0aWxiZXJ0LnB5) | `34.03% <0.00%> (-64.79%)` | :arrow_down: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `25.85% <0.00%> (-55.15%)` | :arrow_down: |
| [src/transformers/optimization.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb24ucHk=) | `34.28% <0.00%> (-48.00%)` | :arrow_down: |
| [src/transformers/tokenization\_mbart.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fbWJhcnQucHk=) | `57.14% <0.00%> (-39.69%)` | :arrow_down: |
| [src/transformers/optimization\_tf.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb25fdGYucHk=) | `33.33% <0.00%> (-24.33%)` | :arrow_down: |
| [src/transformers/modeling\_lxmert.py](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19seG1lcnQucHk=) | `70.01% <0.00%> (-20.75%)` | :arrow_down: |
| ... and [22 more](https://codecov.io/gh/huggingface/transformers/pull/7087/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7087?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7087?src=pr&el=footer). Last update [b00cafb...775bc0a](https://codecov.io/gh/huggingface/transformers/pull/7087?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>I am unsure whether it's better, in terms of user experience, to add default values to `tgt_len` and `ext_len` in `reset_length` and a deprecation warning or to change the name of the function altogether to `reset_memory_length` as you do. @LysandreJik could you take a look at this?<|||||>@TevenLeScao Since we remove `tgt_len` and `ext_len` from the model anyway I thought that the name `reset_memory_length` gives a better description of what the function is actually doing.<|||||>Alright, LGTM! |
transformers | 7,086 | closed | Longformer run error | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
When I train on a classification model by Longformer
def forward(self,input):
embding=input['enc']
att_mask=input['mask']
att_mask[:,[100,300,500,800,1200,]]=2
labels=input['targets']
print('jeff:',embding.device,att_mask.device,self.l1.device,embding.shape,att_mask.shape,self.maxlen)
logit=self.l1(inputs_embeds=embding,attention_mask=att_mask)#[:2]
return [logit,labels]
Meet error:
pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [205,0,0], thread: [95,0,0] Assertion `srcIndex < srcSelectDimSize` failed
max_num_extra_indices_per_batch = num_extra_indices_per_batch.max()
RuntimeError: cuda runtime error (710) : device-side assert triggered at /pytorch/aten/src/THC/THCReduceAll.cuh:327
I checked the length of the attention_mask is same as the config.max_len which is like [bs,max_len]
Do anyone meet the same issue?
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: | 09-12-2020 08:22:44 | 09-12-2020 08:22:44 | i fixed finally<|||||>> i fixed finally
What was the solution?<|||||>@Yangxiaojun1230 How to fix it? I meet this problem too.<|||||>For my case, the problem is due to the miss correct of the length padding |
transformers | 7,085 | closed | Distilbart's summaries start with an empty space? | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 2.11.0
- Platform: linux
- Python version: 3.7
- PyTorch version (GPU?): 1.51, gpu
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
@sshleifer
Steps to reproduce the behavior:
```
from transformers import BartTokenizer, BartForConditionalGeneration, BartConfig
model = BartForConditionalGeneration.from_pretrained('sshleifer/distilbart-xsum-12-3')
tokenizer = BartTokenizer.from_pretrained('sshleifer/distilbart-xsum-12-3')
ARTICLE_TO_SUMMARIZE = "\"The accident meant the motorway was closed, making travel to Mourneview Park impossible for the team and fans travelling from Belfast, \" said the Irish Football Association . A new date for the match has yet to be confirmed by Uefa . Northern Ireland have three points from their first two Group Six qualifiers."
inputs = tokenizer.batch_encode_plus([ARTICLE_TO_SUMMARIZE], max_length=512, return_tensors='pt')
summary_ids = model.generate(inputs['input_ids'], num_beams=5, max_length=62, min_length=10, early_stopping=True)
print([tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in summary_ids])
```
[" The Republic of Ireland's Euro 2016 qualifier against Northern Ireland has been postponed because of a motorway crash."]
facebook/large-bart-xsum will give a correct summary. Why this summary starts with an empty space? What shall we pay attention to these inconsitency
| 09-12-2020 06:07:42 | 09-12-2020 06:07:42 | I think i figure it out now. in BART, " The", " Republic" are individual words.<|||||>I'm having a similar issue as @songwanguw where each line of my output summaries start with a blank space when using Distilbart. This does not happen when I use facebook/bart-large-cnn.<|||||>Unfortunately, I don't know any way to fix this besides postprocessing or retraining.
You're using the model correctly. I probably trained on targets with an extra prefixed space. My bad!
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,084 | closed | How to implement LayoutLM for information extraction | Hi,
I am new to nlp
Can someone please guide me on How to implement the layoutLM using transformers for information extraction (from images like receipt)
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("microsoft/layoutlm-large-uncased")
model = AutoModel.from_pretrained("microsoft/layoutlm-large-uncased")
| 09-12-2020 06:00:07 | 09-12-2020 06:00:07 | I think the model's integration is still a work-in-progress @SandyRSK, but will let model author @liminghao1630 chime in if necessary<|||||>Similar help required. I want to use the layoutLM model finetuned on DocBank data. As per my understanding, this will be a token classification task, but any example code will be extremely helpful.
Thanks <|||||>@SandyRSK the integration is still on-going. You may refer to https://github.com/microsoft/unilm/tree/master/layoutlm if you want to use the model right now.<|||||>Is this still work-in-progress?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hi, is it possible to load the docbank pretrained model in your implementation?<|||||>It should be possible to load the LayoutLM weights from the official repository in ours. Please feel free to try and upload it on the hub!
Let us know if you run into trouble by opening a new issue and we'll take a look.<|||||>Thanks! I'm just worried about the changes you made (all the classes commented with `Copied from transformers.models.bert.modeling_bert.BertEncoder with Bert->LayoutLM`): https://huggingface.co/transformers/_modules/transformers/models/layoutlm/modeling_layoutlm.html<|||||>Right, this is for maintainability purposes. Instead of refactoring models in shared layers, we instead keep the entire forward pass in a single file. Doing it this way makes it easy to edit a single file or to read a paper side by side with the code, whereas refactored code would be harder to navigate in. These comments allow us to ensure that the files do not diverge: we have tests that check that the contents of `LayoutEncoder` is identical to `BertEncoder`, with the only change being utterances of "bert" changed to "layoutlm".
As you can see, the differences between BERT and LayoutLM are especially the embeddings.<|||||>Hi, I loaded the pretained DocBank model, which is a LayoutLM from the original unilm repository, using the LayoutLM from HuggingFace.
I get a warning of the form:
```
Some weights of the model checkpoint at layoutlm_large_500k_epoch_1/ were not used when initializing LayoutLMForTokenClassification: ['bert.embeddings.word_embeddings.weight' [...]
- This IS expected if you are initializing LayoutLMForTokenClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing LayoutLMForTokenClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of LayoutLMForTokenClassification were not initialized from the model checkpoint at layoutlm_large_500k_epoch_1/ and are newly initialized: ['embeddings.word_embeddings.weight' [...]
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
For the full warning see https://paste.ofcode.org/WxFiUf8bYL3TEjc9jLAG4J
However, even after running model.eval(), I get random outputs.
Edit:
Moreover, the outputs don't seem to make any sense.
Finally, >90% tokens always get the predicted label. But this label changes at each inference pass. |
transformers | 7,083 | closed | SqueezeBERT architecture | # Burn-down list:
Here an overview of the general workflow:
- [x] Add model/configuration/tokenization classes.
- [ ] ~~Add conversion scripts.~~ This model was originally developed in PyTorch.
- [x] Add tests and a @slow integration test.
- [x] Document your model.
- [x] Finalize.
Let's detail what should be done at each step.
## Adding model/configuration/tokenization classes
Here is the workflow for adding model/configuration/tokenization classes:
- [x] Copy the python files from the present folder to the main folder and rename them, replacing `xxx` with your model
name.
- [x] Edit the files to replace `XXX` (with various casing) with your model name.
- [x] Copy-paste or create a simple configuration class for your model in the `configuration_...` file.
- [x] Copy-paste or create the code for your model in the `modeling_...` files (PyTorch ~~and TF 2.0~~).
- [x] Copy-paste or create a tokenizer class for your model in the `tokenization_...` file.
### loose ends:
- [ ] support for head_mask, encoder_hidden_states, encoder_attention_mask (Not planning to do for this PR)
- [x] Make sure finetuning works.
## ~~Adding conversion scripts~~
Here is the workflow for the conversion scripts:
- [ ] ~~Copy the conversion script (`convert_...`) from the present folder to the main folder.~~
- [ ] ~~Edit this script to convert your original checkpoint weights to the current pytorch ones.~~
## Adding tests:
Here is the workflow for the adding tests:
- [ ] ~~Copy the python files from the `tests` sub-folder of the present folder to the `tests` subfolder of the main
folder and rename them, replacing `xxx` with your model name.~~
- [ ] ~~Edit the tests files to replace `XXX` (with various casing) with your model name.~~
- [ ] ~~Edit the tests code as needed.~~
- [x] Create tests, using the DistilBERT tests as a starting point
- [x] `test_modeling_squeezebert.py` (based on `test_modeling_distilbert.py`)
- [x] `test_tokeization_squeezebert.py` (based on `test_tokenization_distilbert.py`)
## Documenting your model:
Here is the workflow for documentation:
- [x] Make sure all your arguments are properly documented in your configuration and tokenizer.
- [x] Most of the documentation of the models is automatically generated, you just have to make sure that
`XXX_START_DOCSTRING` contains an introduction to the model you're adding and a link to the original
article and that `XXX_INPUTS_DOCSTRING` contains all the inputs of your model.
- [x] Create a new page `xxx.rst` in the folder `docs/source/model_doc` and add this file in `docs/source/index.rst`.
Make sure to check you have no sphinx warnings when building the documentation locally and follow our
[documentation guide](https://github.com/huggingface/transformers/tree/master/docs#writing-documentation---specification).
## Final steps
You can then finish the addition step by adding imports for your classes in the common files:
- [x] Add import for all the relevant classes in `__init__.py`.
- [x] Add your configuration in `configuration_auto.py`.
- [x] Add your PyTorch and ~~TF 2.0~~ model respectively in `modeling_auto.py` ~~and `modeling_tf_auto.py`~~.
- [x] Add your tokenizer in `tokenization_auto.py`.
- [ ] ~~Add a link to your conversion script in the main conversion utility (in `commands/convert.py`)~~
- [ ] ~~Edit the PyTorch to TF 2.0 conversion script to add your model in the `convert_pytorch_checkpoint_to_tf2.py`
file.~~
- [x] Add a mention of your model in...
- [x] `README.md`
- [x] `docs/source/index.rst`
- [x] `docs/source/pretrained_models.rst`.
- [x] Upload the vocabulary files, configurations, and pretrained weights .
- squeezebert-uncased
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-uncased/vocab.txt
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-uncased/pytorch_model.bin
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-uncased/config.json
- squeezebert-mnli-headless
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-mnli-headless/vocab.txt
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-mnli-headless/pytorch_model.bin
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-mnli-headless/config.json
- squeezebert-mnli
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-mnli/vocab.txt
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-mnli/pytorch_model.bin
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert-mnli/config.json
- [x] Create model card(s) for your models on huggingface.co (These go in the repo, not in the file upload).
For those last two steps, check the [model sharing documentation](https://huggingface.co/transformers/model_sharing.html).
- [ ] Delete these files (I uploaded these to the wrong directories)
- https://s3.amazonaws.com/models.huggingface.co/bert/squeezebert/squeezebert/squeezebert-uncased-vocab.txt
- https://s3.amazonaws.com/models.huggingface.co/squeezebert/squeezebert/squeezebert-uncased-config.json
- https://s3.amazonaws.com/models.huggingface.co/squeezebert/squeezebert/squeezebert-uncased.bin
- https://s3.amazonaws.com/models.huggingface.co/squeezebert/squeezebert/squeezebert-mnli.bin
- https://s3.amazonaws.com/models.huggingface.co/squeezebert/squeezebert/squeezebert-mnli-headless.bin
| 09-12-2020 02:10:28 | 09-12-2020 02:10:28 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7083?src=pr&el=h1) Report
> Merging [#7083](https://codecov.io/gh/huggingface/transformers/pull/7083?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/de4d7b004a24e4bb087eb46d742ea7939bc74644?el=desc) will **increase** coverage by `0.97%`.
> The diff coverage is `97.70%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7083?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7083 +/- ##
==========================================
+ Coverage 77.00% 77.98% +0.97%
==========================================
Files 184 184
Lines 36734 36216 -518
==========================================
- Hits 28288 28244 -44
+ Misses 8446 7972 -474
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7083?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_squeezebert.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19zcXVlZXplYmVydC5weQ==) | `97.38% <97.38%> (ø)` | |
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `99.39% <100.00%> (ø)` | |
| [src/transformers/configuration\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2F1dG8ucHk=) | `96.34% <100.00%> (ø)` | |
| [src/transformers/configuration\_squeezebert.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3NxdWVlemViZXJ0LnB5) | `100.00% <100.00%> (ø)` | |
| [src/transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hdXRvLnB5) | `86.08% <100.00%> (-1.04%)` | :arrow_down: |
| [src/transformers/tokenization\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYXV0by5weQ==) | `92.64% <100.00%> (ø)` | |
| [src/transformers/tokenization\_squeezebert.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fc3F1ZWV6ZWJlcnQucHk=) | `100.00% <100.00%> (ø)` | |
| [src/transformers/modeling\_tf\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9sb25nZm9ybWVyLnB5) | `17.46% <0.00%> (-81.13%)` | :arrow_down: |
| [src/transformers/tokenization\_fsmt.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZnNtdC5weQ==) | `20.34% <0.00%> (-74.90%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9vcGVuYWkucHk=) | `22.03% <0.00%> (-73.03%)` | :arrow_down: |
| ... and [39 more](https://codecov.io/gh/huggingface/transformers/pull/7083/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7083?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7083?src=pr&el=footer). Last update [de4d7b0...c0521ee](https://codecov.io/gh/huggingface/transformers/pull/7083?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>@sgugger @patrickvonplaten - Thanks so much for the feedback! I will make these changes later this week.<|||||>@sgugger @patrickvonplaten - I made all the changes that you suggested. Ready to merge? |
transformers | 7,082 | closed | Longformer output_hidden_states=True outputs sequence length=512 for all inputs of different lengths | Can someone explain why cc[2][0].shape != dd[2][0].shape?
>>> from transformers import LongformerModel, RobertaModel
>>> import torch
>>> from transformers import RobertaTokenizer
>>> tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
>>> aa = RobertaModel.from_pretrained('roberta-base', return_dict=True)
>>> bb = LongformerModel.from_pretrained('allenai/longformer-large-4096', return_dict=True)
Some weights of LongformerModel were not initialized from the model checkpoint at allenai/longformer-large-4096 and are newly initialized: ['longformer.embeddings.position_ids']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> cc = aa(**inputs, output_hidden_states=True)
>>> cc[2][0].shape
torch.Size([1, 8, 768])
>>> dd = bb(**inputs, output_hidden_states=True)
>>> dd[2][0].shape
torch.Size([1, 512, 1024])
>>> dd[0].shape
torch.Size([1, 8, 1024])
| 09-11-2020 23:29:24 | 09-11-2020 23:29:24 | When I use longformer-base-4096, it works well.<|||||>The reason is that `LongformerModel` pads its input to the `window_size` configuration param, which is 512 for `allenai/longformer-large-4096`. Therefore all `hidden_states` are of length 512. We could think about cutting the hidden states to the actual inputt length...<|||||>Gotcha. But I also tested with longformer-base. It works fine with hidden states cut. Thank you. |
transformers | 7,081 | closed | Clean up autoclass doc | Clean up and standardize the documentation of the auto classes. | 09-11-2020 21:36:13 | 09-11-2020 21:36:13 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7081?src=pr&el=h1) Report
> Merging [#7081](https://codecov.io/gh/huggingface/transformers/pull/7081?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ae736163d0d7a3a167ff0df3bf6c824437bbba2a?el=desc) will **increase** coverage by `0.09%`.
> The diff coverage is `89.47%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7081?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7081 +/- ##
==========================================
+ Coverage 79.44% 79.54% +0.09%
==========================================
Files 168 168
Lines 32260 32285 +25
==========================================
+ Hits 25630 25680 +50
+ Misses 6630 6605 -25
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7081?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7081/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2F1dG8ucHk=) | `96.10% <ø> (ø)` | |
| [src/transformers/modeling\_tf\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7081/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | `72.36% <ø> (+1.77%)` | :arrow_up: |
| [src/transformers/tokenization\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7081/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYXV0by5weQ==) | `91.80% <ø> (ø)` | |
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/7081/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `54.90% <71.42%> (+0.22%)` | :arrow_up: |
| [src/transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7081/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hdXRvLnB5) | `82.29% <100.00%> (+1.07%)` | :arrow_up: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7081/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `93.54% <0.00%> (+0.35%)` | :arrow_up: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7081/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `86.46% <0.00%> (+5.76%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7081?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7081?src=pr&el=footer). Last update [4cbd50e...dad4fcd](https://codecov.io/gh/huggingface/transformers/pull/7081?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,080 | closed | Importing unittests using python unittest framework | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.0.2
- Platform: Linux-5.3.0-1034-azure-x86_64-with-debian-buster-sid
- Python version: 3.6.9
- PyTorch version (GPU?): 1.5.0a0+8f84ded (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
blenderbot: @mariamabarham
Bart: @sshleifer
Marian: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
@sgugger
## Information
I am trying to run unit tests after cloning fresh repo. I use python unittest framework and try to load the tests using "unittest.defaultTestLoader". Most of the tests pass, but I get few errors. All the errors are same - "**cannot initialize type "_CudaDeviceProperties": an object with that name is already defined**". This problem goes away if I user python unittest command line .
The problem arises when using:
* [ ] my own modified scripts: (give details below)
I use following script to load tests.
```
import os
import glob
import unittest
test_files_path='./tests/*'
test_files = [os.path.basename(x) for x in glob.glob(test_files_path)]
module_strings = ['tests.'+test_file[0:len(test_file)-3] for test_file in test_files]
print(module_strings)
suites = [unittest.defaultTestLoader.loadTestsFromName(test_file) for test_file in module_strings]
test_suite = unittest.TestSuite(suites)
test_runner = unittest.TextTestRunner().run(test_suite)
```
## To reproduce
Steps to reproduce the behavior:
1. Paste above code in a python file under transformers directory.
2.Run python file.
## Expected behavior
All tests should pass since I just cloned a fresh repo. | 09-11-2020 18:40:02 | 09-11-2020 18:40:02 | Does the problem go away if you install the latest stable pytorch 1.6.0, see https://pytorch.org/get-started/locally/?
Also the test suite uses `pytest` to run the tests - have you tried using it?
```
pytest tests
```
Do you get the same issue running it this way?
Is it possible that your script ends up running tests in a different order from how they are normally tested on CI and uncovers some bug where several tests are dependent on each other and can only be run in a particular order? If so it might be helpful to find out the minimal sequence that leads to this error.
I'm asking since the test suite is not 100% perfect, and I saw just recently that if you change the order of tests things start to fail.
<|||||>I have run your script and didn't get this error - but got 15 other errors, most `RuntimeError: Physical devices cannot be modified after being initialized` in tf tests.
My env is:
```
- `transformers` version: 3.1.0
- Platform: Linux-4.15.0-112-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.0.dev20200910 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,079 | closed | ignore FutureWarning in tests | As discussed in https://github.com/huggingface/transformers/pull/7033 we can't deal with transformers' `FutureWarning` in tests, since we have to keep those tests around until they become normal warnings and then the tests will get fixed/adjusted. So currently they just generate noise that can't be acted upon.
The only side-effect I can see is with other libraries' FutureWarnings, which now will be silenced too, but again we can easily fix those as soon as those aren't futuristic any more.
| 09-11-2020 18:33:25 | 09-11-2020 18:33:25 | Yes, I agree with this. Thanks @stas00! |
transformers | 7,078 | closed | [T5Tokenizer] remove prefix_tokens |
Fixes #7077
@sshleifer
| 09-11-2020 18:00:15 | 09-11-2020 18:00:15 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7078?src=pr&el=h1) Report
> Merging [#7078](https://codecov.io/gh/huggingface/transformers/pull/7078?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ae736163d0d7a3a167ff0df3bf6c824437bbba2a?el=desc) will **decrease** coverage by `1.09%`.
> The diff coverage is `77.77%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7078?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7078 +/- ##
==========================================
- Coverage 79.44% 78.35% -1.10%
==========================================
Files 168 168
Lines 32260 32257 -3
==========================================
- Hits 25630 25274 -356
- Misses 6630 6983 +353
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7078?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `54.90% <71.42%> (+0.22%)` | :arrow_up: |
| [src/transformers/tokenization\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdDUucHk=) | `95.04% <100.00%> (-0.19%)` | :arrow_down: |
| [src/transformers/configuration\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3JlZm9ybWVyLnB5) | `21.62% <0.00%> (-78.38%)` | :arrow_down: |
| [src/transformers/modeling\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yZWZvcm1lci5weQ==) | `16.87% <0.00%> (-77.64%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl94bG0ucHk=) | `18.94% <0.00%> (-74.32%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `24.53% <0.00%> (-63.81%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `87.29% <0.00%> (+0.65%)` | :arrow_up: |
| [src/transformers/modeling\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tb2JpbGViZXJ0LnB5) | `89.45% <0.00%> (+10.24%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90cmFuc2ZvX3hsLnB5) | `88.13% <0.00%> (+68.28%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl94bG5ldC5weQ==) | `92.17% <0.00%> (+71.04%)` | :arrow_up: |
| ... and [1 more](https://codecov.io/gh/huggingface/transformers/pull/7078/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7078?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7078?src=pr&el=footer). Last update [4cbd50e...c0dcfc7](https://codecov.io/gh/huggingface/transformers/pull/7078?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Thanks @suraj, great catch!<|||||>Also very clean implem :) |
transformers | 7,077 | closed | T5Tokenizer shouldn't add pad token as prefix to labels |
## Information
`prepare_seq2seq_batch` method in `T5Tokenizer` now prefixes `pad` token to the `labels`. [here](https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_t5.py#L362)
But in finetune.py [here](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/finetune.py#L149) we are calling `_shift_right` for T5 , which again adds another `pad` token at the beginning, so now `decoder_input_ids` contain two `pad` tokens.
## To reproduce
```python
from transformers import T5Tokenizer, T5Model
model = T5Model.from_pretrained("t5-small")
tok = T5Tokenizer.from_pretrained("t5-small")
enc = tok.prepare_seq2seq_batch("src text", "target text", return_tensors="pt")
print(enc["labels"])
# tensor([[ 0, 2387, 1499, 1]])
decoder_input_ids = model._shift_right(enc["labels"]) # call _shift_right
print(decoder_input_ids)
#tensor([[ 0, 0, 2387, 1499]])
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
There should be no special prefix token for T5 `labels`
@sshleifer
| 09-11-2020 17:57:51 | 09-11-2020 17:57:51 | |
transformers | 7,076 | closed | some sshleifer/xsum hub models have bart-large-cnn task_specific_params['summarization'] | S3 only fix!
| 09-11-2020 16:22:35 | 09-11-2020 16:22:35 | Done. <|||||>- [x] pegasus xsum students
- [x] uploaded distilled pegasus
- [x] re-evaluate updated layerdrop model (te: 23.5291: quickly worsens)
- [x] re-evaluate bart-xsum pseudolabel model(s). |
transformers | 7,075 | closed | [Benchmarks] Change all args to from `no_...` to their positive form | Fixes #7072
As @stas00 pointed out a while back, there were a bunch of negative args formulations in `benchmarks.py` which are hard to understand and make the code unnecessarly complex.
This PR fixes this problem by
a) Formulating all args in their positive form
b) Improving their docstring
c) Making the code more readable
**!!! This has breaking changes for the command line args of `examples/run_benchmark.py `and `examples/run_benchmark_tf.py` !!!**
People that were using `--no_...` on command line previously, now should use `--no-...`. *E.g.* `--no_inference` is changed to `--no-inference` on the command line.
Thanks a lot @fmcurti for leading this PR! | 09-11-2020 16:15:48 | 09-11-2020 16:15:48 | Hey @fmcurti - this looks great, thanks a lot for your contribution here!
In order to pass the `check_code_quality` test it would be great if you can run `make style` as described in https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md .
And it would be important to make the benchmarks.py test pass.
As said in the comment above, it'd be great if you could add a line stating how to disable `default=True` params from the config.
Let me know if you are stuck and need help :-) <|||||>Hi @patrickvonplaten =)
I think I modified the tests so that they pass, but i think the tests running on circleci are the ones on the master branch and not on my commit maybe? because the error messages I see seem to be from things I already changed<|||||>@LysandreJik @sgugger - For some reason the git-diff is messed up in this PR. I checked the changes offline using `vimdiff` and the changes look good to me!
Think the breaking changes are not super relevant here because it's only the benchmarking argument class that is affected and not too many people seem to be using the benchmarking tools.<|||||>Great! My first contribution to an open source library 🤗
Small one but it's a start,<|||||>The first post looks confusing, it looks like someone with admin rights edited it, but didn't indicate so, so it appears that @fmcurti praises himself ;) perhaps a ----- bar and a note that it was edited, so that it's clear to the readers that "this and below" wasn't part of the original post?<|||||>I'm in agreement with @patrickvonplaten - I don't think this API is being used much and it's an important change for the long run, so it's worth the breaking. Good APIs are not easy.
but if it's really needed one could keep the old args and code them to set the new args. and have a deprecation cycle. Definitely doable.
@fmcurti - great work, thank you for your contribution!<|||||>> @LysandreJik @sgugger - For some reason the git-diff is messed up in this PR. I checked the changes offline using `vimdiff` and the changes look good to me!
You need to tell github to ignore whitespaces and then it works:
https://github.com/huggingface/transformers/pull/7075/files?diff=split&w=1
Got it via this:

<|||||>> I'm in agreement with @patrickvonplaten - I don't think this API is being used much and it's an important change for the long run, so it's worth the breaking. Good APIs are not easy.
>
> but if it's really needed one could keep the old args and code them to set the new args. and have a deprecation cycle. Definitely doable.
I agree that this change is welcome, and the proposed API here is indeed much better than the previous one. However, I think this can be done better by having, as you mentioned, some deprecation warnings while still maintaining backwards compatibility for some time.<|||||>@LysandreJik - I'm fine with keeping the old arguments with deprecation warnings - will add this to the PR.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7075?src=pr&el=h1) Report
> Merging [#7075](https://codecov.io/gh/huggingface/transformers/pull/7075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/28cf873036d078b47fb9dd38ac3421a7c874da44?el=desc) will **increase** coverage by `1.81%`.
> The diff coverage is `71.45%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7075?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7075 +/- ##
==========================================
+ Coverage 76.58% 78.39% +1.81%
==========================================
Files 181 181
Lines 34828 34851 +23
==========================================
+ Hits 26674 27323 +649
+ Misses 8154 7528 -626
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7075?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/benchmark/benchmark.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9iZW5jaG1hcmsvYmVuY2htYXJrLnB5) | `82.17% <ø> (ø)` | |
| [src/transformers/benchmark/benchmark\_tf.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9iZW5jaG1hcmsvYmVuY2htYXJrX3RmLnB5) | `65.51% <ø> (ø)` | |
| [src/transformers/benchmark/benchmark\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9iZW5jaG1hcmsvYmVuY2htYXJrX3V0aWxzLnB5) | `69.00% <69.00%> (-0.50%)` | :arrow_down: |
| [src/transformers/benchmark/benchmark\_args.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9iZW5jaG1hcmsvYmVuY2htYXJrX2FyZ3MucHk=) | `83.33% <76.92%> (-2.72%)` | :arrow_down: |
| [src/transformers/benchmark/benchmark\_args\_tf.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9iZW5jaG1hcmsvYmVuY2htYXJrX2FyZ3NfdGYucHk=) | `85.29% <78.57%> (-2.21%)` | :arrow_down: |
| [src/transformers/benchmark/benchmark\_args\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9iZW5jaG1hcmsvYmVuY2htYXJrX2FyZ3NfdXRpbHMucHk=) | `89.13% <89.13%> (ø)` | |
| [src/transformers/modeling\_layoutlm.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sYXlvdXRsbS5weQ==) | `25.06% <0.00%> (-69.40%)` | :arrow_down: |
| [src/transformers/tokenization\_rag.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fcmFnLnB5) | `32.55% <0.00%> (-37.21%)` | :arrow_down: |
| [src/transformers/tokenization\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZnVubmVsLnB5) | `62.79% <0.00%> (-34.89%)` | :arrow_down: |
| [src/transformers/configuration\_layoutlm.py](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xheW91dGxtLnB5) | `80.00% <0.00%> (-20.00%)` | :arrow_down: |
| ... and [16 more](https://codecov.io/gh/huggingface/transformers/pull/7075/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7075?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7075?src=pr&el=footer). Last update [28cf873...9019232](https://codecov.io/gh/huggingface/transformers/pull/7075?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,074 | closed | Compute loss method | Make it easier to write a custom loss by isolating the loss computation in a separate method.
Also document how to write a Trainer using such a custom loss. | 09-11-2020 15:59:11 | 09-11-2020 15:59:11 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7074?src=pr&el=h1) Report
> Merging [#7074](https://codecov.io/gh/huggingface/transformers/pull/7074?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e841b75decf5ec9c8829dc1a3c43426ffa9f6907?el=desc) will **increase** coverage by `1.15%`.
> The diff coverage is `71.42%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7074?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7074 +/- ##
==========================================
+ Coverage 78.27% 79.43% +1.15%
==========================================
Files 168 168
Lines 32251 32252 +1
==========================================
+ Hits 25246 25618 +372
+ Misses 7005 6634 -371
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7074?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `54.90% <71.42%> (+0.22%)` | :arrow_up: |
| [...c/transformers/modeling\_tf\_transfo\_xl\_utilities.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90cmFuc2ZvX3hsX3V0aWxpdGllcy5weQ==) | `10.00% <0.00%> (-76.00%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl94bG5ldC5weQ==) | `21.12% <0.00%> (-71.05%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90cmFuc2ZvX3hsLnB5) | `19.85% <0.00%> (-68.29%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9ncHQyLnB5) | `71.84% <0.00%> (-23.17%)` | :arrow_down: |
| [src/transformers/modeling\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tb2JpbGViZXJ0LnB5) | `79.21% <0.00%> (-10.25%)` | :arrow_down: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `72.25% <0.00%> (-10.00%)` | :arrow_down: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `79.19% <0.00%> (-4.27%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `86.64% <0.00%> (-0.66%)` | :arrow_down: |
| [...rc/transformers/data/datasets/language\_modeling.py](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFzZXRzL2xhbmd1YWdlX21vZGVsaW5nLnB5) | `92.94% <0.00%> (-0.59%)` | :arrow_down: |
| ... and [8 more](https://codecov.io/gh/huggingface/transformers/pull/7074/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7074?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7074?src=pr&el=footer). Last update [e841b75...a3cf42f](https://codecov.io/gh/huggingface/transformers/pull/7074?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>This is very nice. Many thanks for this feature. :-) |
transformers | 7,073 | closed | Add tests and fix various bugs in ModelOutput | Fix a few bugs in `ModelOutput` and adds tests, mainly:
- if there is only one attribute not `None`, it wasn't accessible by key (and recognized inside the dictionary)
- if an attribute was set with `model_output.att_name` = ..., the corresponding key in the dictionary was not updated
- if an attribute was set with `model_output["key"] = ...`, the corresponding attribute was not updated. | 09-11-2020 15:37:55 | 09-11-2020 15:37:55 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7073?src=pr&el=h1) Report
> Merging [#7073](https://codecov.io/gh/huggingface/transformers/pull/7073?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0054a48cdd64e7309184a64b399ab2c58d75d4e5?el=desc) will **decrease** coverage by `1.76%`.
> The diff coverage is `100.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7073?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7073 +/- ##
==========================================
- Coverage 80.53% 78.76% -1.77%
==========================================
Files 168 168
Lines 32179 32188 +9
==========================================
- Hits 25915 25354 -561
- Misses 6264 6834 +570
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7073?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `82.80% <100.00%> (+0.13%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9kaXN0aWxiZXJ0LnB5) | `34.03% <0.00%> (-64.79%)` | :arrow_down: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `25.85% <0.00%> (-55.15%)` | :arrow_down: |
| [src/transformers/optimization.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb24ucHk=) | `34.28% <0.00%> (-48.00%)` | :arrow_down: |
| [src/transformers/tokenization\_xlm\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxtX3JvYmVydGEucHk=) | `48.80% <0.00%> (-46.43%)` | :arrow_down: |
| [src/transformers/tokenization\_mbart.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fbWJhcnQucHk=) | `57.14% <0.00%> (-39.69%)` | :arrow_down: |
| [src/transformers/tokenization\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZnVubmVsLnB5) | `62.79% <0.00%> (-34.89%)` | :arrow_down: |
| [src/transformers/optimization\_tf.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb25fdGYucHk=) | `33.33% <0.00%> (-24.33%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | `49.10% <0.00%> (-17.97%)` | :arrow_down: |
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `13.76% <0.00%> (-14.38%)` | :arrow_down: |
| ... and [15 more](https://codecov.io/gh/huggingface/transformers/pull/7073/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7073?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7073?src=pr&el=footer). Last update [0054a48...18e2891](https://codecov.io/gh/huggingface/transformers/pull/7073?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,072 | closed | Clean up `benchmark_args_utils.py` "no_..." arguments | # 🚀 Feature request
Currently we have a mixture of negative and positive formulated arguments, *e.g.* `no_cuda` and `training` here: https://github.com/huggingface/transformers/blob/0054a48cdd64e7309184a64b399ab2c58d75d4e5/src/transformers/benchmark/benchmark_args_utils.py#L61.
We should change all arguments to be positively formulated, *e.g. from `no_cuda` to `cuda`. These arguments should then change their default value from `False` to `True`.
Also the help text should be updated to something that is better formulated: "Don't ...." as a help text is not very easy to understand.
The motivation is clear: It's better to be consistent in a library and have the code as easy and intuitive to understand.
## Your contribution
This is a "good first issue", so I'm happy to help anybody who wants to take a shot at this :-)
| 09-11-2020 14:35:23 | 09-11-2020 14:35:23 | Hmm I seem to have forgotten to change the references in the tests |
transformers | 7,071 | closed | added bangla-bert-base model card and also modified other model cards | Hi,
I added model card for bangla-bert-base model and also modified some typo in other model cards also.
Please check and if possible please merge.
thanks and regards
Sagor
| 09-11-2020 13:27:12 | 09-11-2020 13:27:12 | This is great, thanks for sharing!
In case you have time and want to contribute default sample inputs for Bengali, you can just open a pull request against https://github.com/huggingface/widgets-server/blob/master/DefaultWidget.ts
Your model page's inference widgets will then display relevant sample inputs.<|||||>PS/ your models are now correctly linked from https://huggingface.co/datasets/lince<|||||>Hi,
Thank you so much.
I will create a pull request for DefaultWidget.ts
regards
Sagor |
transformers | 7,070 | closed | MobileBERT inconsistent output (padded / not padded text) | ## Environment info
- `transformers` version: 3.0.2
- Platform: Linux-5.4.0-47-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.3
- PyTorch version (GPU?): 1.5.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik, @mfuntowicz
## Information
When using MobileBERT model `google/mobilebert-uncased`, I get different model outputs for the same text when it contains padding and when it does not contain any padding (is the longest text in the batch). The same code produces correct results for other models, such as `bert-base-uncased`, so the issue is probably only with MobileBERT. The problem happens for both `CLS` output and all features.
Model I am using (Bert, XLNet ...): MobileBERT
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
```python
from transformers import AutoModel, AutoTokenizer
model = 'google/mobilebert-uncased'
tokenizer = AutoTokenizer.from_pretrained(model)
model = AutoModel.from_pretrained(model)
text = 'Hey, how are you?'
i1 = tokenizer.batch_encode_plus([text], padding=True, return_tensors='pt')
emb1 = model(**i1)[1][0] # Only one in batch (not padded): [-2.5088e+07, 7.3279e+04, 1.7544e+05, ...]
i2 = tokenizer.batch_encode_plus([text, text + ' hey'], padding=True, return_tensors='pt')
emb2 = model(**i2)[1][0] # Not longest (padded): [-2.4871e+07, 8.1873e+04, 1.6693e+05, ...]
i3 = tokenizer.batch_encode_plus([text, text[:-10]], padding=True, return_tensors='pt')
emb3 = model(**i3)[1][0] # Longest in batch (not padded): [-2.5088e+07, 7.3281e+04, 1.7544e+05, ...]
i4 = tokenizer.encode(text, return_tensors='pt')
emb4 = model(i4)[1][0] # Without attention masks (not padded): [-2.5088e+07, 7.3279e+04, 1.7544e+05, ...]
i5 = tokenizer.encode_plus(text, return_tensors='pt')
emb5 = model(**i5)[1][0] # With attention masks (not padded): [-2.5088e+07, 7.3279e+04, 1.7544e+05, ...]
```
## Expected behavior
I would expect the model to always return the same embeddings, but I don't really know which of the two variants is correct. | 09-11-2020 10:19:57 | 09-11-2020 10:19:57 | Just confirming that the issue happens also for the latest `transformers`, PyTorch and Python 3.8.
- `transformers` version: 3.1.0
- Platform: Linux-5.4.0-47-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,069 | closed | How to use hugging on onw embedding | i already get a embedding,or i have a matrix for input. Then I want to use transformer to train on. For example use Longformer,i set input_ids to None,and set the input on parameter embed_input. Could it be OK? anything else need to take care? I also input the mask. | 09-11-2020 09:41:32 | 09-11-2020 09:41:32 | Hello @Yangxiaojun1230 ,
From your message I assume you are trying to train a Longformer model using embeddings as the input of the model.
You can either use input_ids or inputs_embeds in the forward function of the models. I think your idea will work, please let us know if it does.
You can look at more information about your model in the documentation: https://huggingface.co/transformers/model_doc/longformer.html
<|||||>@na
> Hello @Yangxiaojun1230 ,
>
> From your message I assume you are trying to train a Longformer model using embeddings as the input of the model.
>
> You can either use input_ids or inputs_embeds in the forward function of the models. I think your idea will work, please let us know if it does.
>
> You can look at more information about your model in the documentation: https://huggingface.co/transformers/model_doc/longformer.html
Thank you for your answer, actually I try to train the model and meet an error.
My code:
att_mask[:,[100,300,500,800,1200,]]=2
logit=LongformerForSequenceClassification(inputs_embeds=embding,attention_mask=att_mask)
but error occurs:
pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [205,0,0], thread: [95,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
THCudaCheck FAIL file=/pytorch/aten/src/THC/THCReduceAll.cuh line=327 error=710 : device-side assert triggered
"/home/yangjeff/anaconda3/lib/python3.6/site-packages/transformers/modeling_longformer.py", line 272, in forward
max_num_extra_indices_per_batch = num_extra_indices_per_batch.max()
RuntimeError: cuda runtime error (710) : device-side assert triggered at /pytorch/aten/src/THC/THCReduceAll.cuh:327
In the modeling_longformer.py:
after:extra_attention_mask = attention_mask > 0
I could not access to extra_attention_mask,
But in the example:
attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to local attention
attention_mask[:, [1, 4, 21,]] = 2 # Set global attention based on the task. For example,
# classification: the <s> token
# QA: question tokens
# LM: potentially on the beginning of sentences and paragraphs
sequence_output, pooled_output = model(input_ids, attention_mask=attention_mask)
The only different in my code is I input inputs_embeds instead input_ids<|||||>I fixed finally |
transformers | 7,068 | closed | [BertGeneration] Clean naming | This PR removes all "old" naming of "bert-for-seq-generation" and "BertForSeqGeneration" repectively.
| 09-11-2020 06:52:15 | 09-11-2020 06:52:15 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7068?src=pr&el=h1) Report
> Merging [#7068](https://codecov.io/gh/huggingface/transformers/pull/7068?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8fcbe486e1592321e868f872545c8fd9d359a515?el=desc) will **decrease** coverage by `2.39%`.
> The diff coverage is `100.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7068?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7068 +/- ##
==========================================
- Coverage 80.93% 78.53% -2.40%
==========================================
Files 168 168
Lines 32179 32179
==========================================
- Hits 26044 25273 -771
- Misses 6135 6906 +771
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7068?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2F1dG8ucHk=) | `93.61% <ø> (ø)` | |
| [src/transformers/modeling\_bert\_generation.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0X2dlbmVyYXRpb24ucHk=) | `69.19% <ø> (ø)` | |
| [src/transformers/configuration\_bert\_generation.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JlcnRfZ2VuZXJhdGlvbi5weQ==) | `100.00% <100.00%> (ø)` | |
| [src/transformers/tokenization\_bert\_generation.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYmVydF9nZW5lcmF0aW9uLnB5) | `94.64% <100.00%> (ø)` | |
| [src/transformers/modeling\_tf\_lxmert.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9seG1lcnQucHk=) | `22.49% <0.00%> (-71.63%)` | :arrow_down: |
| [src/transformers/tokenization\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxtLnB5) | `16.26% <0.00%> (-66.67%)` | :arrow_down: |
| [src/transformers/tokenization\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fbWFyaWFuLnB5) | `67.79% <0.00%> (-31.36%)` | :arrow_down: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `75.91% <0.00%> (-21.17%)` | :arrow_down: |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `71.60% <0.00%> (-20.44%)` | :arrow_down: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `72.25% <0.00%> (-10.00%)` | :arrow_down: |
| ... and [8 more](https://codecov.io/gh/huggingface/transformers/pull/7068/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7068?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7068?src=pr&el=footer). Last update [8fcbe48...351c75d](https://codecov.io/gh/huggingface/transformers/pull/7068?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Thanks for catching that @sgugger ! |
transformers | 7,067 | closed | Create model card | Create model card for microsoft/layoutlm-large-uncased | 09-11-2020 06:45:24 | 09-11-2020 06:45:24 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7067?src=pr&el=h1) Report
> Merging [#7067](https://codecov.io/gh/huggingface/transformers/pull/7067?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8fcbe486e1592321e868f872545c8fd9d359a515?el=desc) will **decrease** coverage by `2.41%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7067?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7067 +/- ##
==========================================
- Coverage 80.93% 78.52% -2.42%
==========================================
Files 168 168
Lines 32179 32179
==========================================
- Hits 26044 25267 -777
- Misses 6135 6912 +777
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7067?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9kaXN0aWxiZXJ0LnB5) | `34.03% <0.00%> (-64.79%)` | :arrow_down: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `25.85% <0.00%> (-55.15%)` | :arrow_down: |
| [src/transformers/optimization.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb24ucHk=) | `34.28% <0.00%> (-48.00%)` | :arrow_down: |
| [src/transformers/tokenization\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZnVubmVsLnB5) | `62.79% <0.00%> (-34.89%)` | :arrow_down: |
| [src/transformers/tokenization\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fbWFyaWFuLnB5) | `67.79% <0.00%> (-31.36%)` | :arrow_down: |
| [src/transformers/optimization\_tf.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb25fdGYucHk=) | `33.33% <0.00%> (-24.33%)` | :arrow_down: |
| [src/transformers/tokenization\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdHJhbnNmb194bC5weQ==) | `20.53% <0.00%> (-21.21%)` | :arrow_down: |
| [src/transformers/modeling\_lxmert.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19seG1lcnQucHk=) | `70.01% <0.00%> (-20.75%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | `49.10% <0.00%> (-17.97%)` | :arrow_down: |
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `13.76% <0.00%> (-14.38%)` | :arrow_down: |
| ... and [19 more](https://codecov.io/gh/huggingface/transformers/pull/7067/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7067?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7067?src=pr&el=footer). Last update [8fcbe48...a4dd71e](https://codecov.io/gh/huggingface/transformers/pull/7067?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,066 | closed | Create model card | Create model card for microsoft/layoutlm-base-uncased | 09-11-2020 06:43:05 | 09-11-2020 06:43:05 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7066?src=pr&el=h1) Report
> Merging [#7066](https://codecov.io/gh/huggingface/transformers/pull/7066?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8fcbe486e1592321e868f872545c8fd9d359a515?el=desc) will **decrease** coverage by `1.46%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7066?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7066 +/- ##
==========================================
- Coverage 80.93% 79.47% -1.47%
==========================================
Files 168 168
Lines 32179 32179
==========================================
- Hits 26044 25573 -471
- Misses 6135 6606 +471
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7066?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [...c/transformers/modeling\_tf\_transfo\_xl\_utilities.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90cmFuc2ZvX3hsX3V0aWxpdGllcy5weQ==) | `10.00% <0.00%> (-76.00%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl94bG5ldC5weQ==) | `21.12% <0.00%> (-71.05%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90cmFuc2ZvX3hsLnB5) | `19.85% <0.00%> (-68.29%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9ncHQyLnB5) | `71.84% <0.00%> (-23.17%)` | :arrow_down: |
| [src/transformers/modeling\_lxmert.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19seG1lcnQucHk=) | `70.01% <0.00%> (-20.75%)` | :arrow_down: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `72.25% <0.00%> (-10.00%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `86.64% <0.00%> (-0.66%)` | :arrow_down: |
| [src/transformers/generation\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3V0aWxzLnB5) | `96.92% <0.00%> (-0.28%)` | :arrow_down: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `86.46% <0.00%> (-0.26%)` | :arrow_down: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `82.66% <0.00%> (+0.25%)` | :arrow_up: |
| ... and [8 more](https://codecov.io/gh/huggingface/transformers/pull/7066/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7066?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7066?src=pr&el=footer). Last update [8fcbe48...71e0391](https://codecov.io/gh/huggingface/transformers/pull/7066?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Thank you! |
transformers | 7,065 | closed | Further Pretraining of Longformer RAM Consumption | Hello everybody,
I'm interested in continued pretraining of the longformer on in-domain text. I'm using the `run_language_modeling.py` script from the examples with the following options.
!python run_language_modeling.py \
--output_dir=$output_dir$ \
--model_type=longformer \
--model_name_or_path=allenai/longformer-base-4096 \
--do_train \
--train_data_file=$train_file$ \
--save_steps=5000 \
--save_total_limit=1 \
--overwrite_output_dir \
--num_train_epochs=1 \
--fp16 \
--fp16_opt_level="O1" \
--gradient_accumulation_steps=8 \
--per_device_train_batch_size=1 \
--logging_steps=100 \
--line_by_line \
--mlm
I tried running the script on Google Colab, spell.run and kaggle-notebooks with different behaviour. While on colab and spell.run the consumption of RAM continuously increases while training, it's constant on kaggle. On colab and spell.run the script terminates whenever the limit is reached (around 26gb on spell.run). Since AllenAI provides some code for pretraining as well I tried their implementation as well with the same behaviour, however it reaches RAM limits faster. The text file I'm using is rather small with a few hundred MB in size.
Can someone explain what's going on here and how solve this issue? I'm linking @patrickvonplaten as it was suggested by the repo. Thanks a lot for any help!
Cheers
| 09-11-2020 06:02:20 | 09-11-2020 06:02:20 | Hi, there's been some issues with memory in our recent script versions. It is possible that on kaggle you have the very latest version of the scripts, or a way older version of the scripts where the memory issue didn't exist.
I recommend you use the latest version of the script, as the memory issue is fixed and it is the most feature-complete version.<|||||>Thanks for info and help! However, the issue persists in the current version of the script.
Is it an issue specific to the longformer or do other models experience the same behaviour?
Do you know when the memory issues began so I can check whether older versions might work? <|||||>So I tested older versions of the script, specifically from the commits that resulted in a new version (3.0.0, 3.0.1, 3.0.2, 3.1.0). The issue persists with all of them *but* only on google colab. RAM consumption begins at around 1.88gb and after around 5 minutes of training increases continuously.
I tried the same script from the commits on kaggle and observed a very different behaviour. RAM consumption at training is constant around 5.5gb.
When running the script on roberta the same behaviour occurs.
I'd be happy about any help or suggestions!<|||||>So the docker image that kaggle uses seemed to be a work-around. If more ressources are necessary than those provided by kaggle then one can use the image easily on GCP. Though kaggle publishes the image as well in their repo.
However by now the issues seems resolved as I switched back to colab and no problems with RAM consumption occured. I'm not sure what caused this effect but no issues for now - thus I'm closing this thread. |
transformers | 7,064 | closed | Add LayoutLM Model | # Introduction
This pull request implements the LayoutLM model, as defined in [the paper](https://arxiv.org/abs/1912.13318):
```
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou, KDD 2020
```
LayoutLM is a simple but effective pre-training method of text and layout for document image understanding and information extraction tasks, such as form understanding and receipt understanding. LayoutLM archives the SOTA results on multiple datasets.
# Typical workflow for including a model
Here an overview of the general workflow:
- [x] Add model/configuration/tokenization classes.
- [ ] Add conversion scripts.
- [x] Add tests and a @slow integration test.
- [ ] Document your model.
- [ ] Finalize.
Let's detail what should be done at each step.
## Adding model/configuration/tokenization classes
Here is the workflow for adding model/configuration/tokenization classes:
- [x] Copy the python files from the present folder to the main folder and rename them, replacing `xxx` with your model
name.
- [x] Edit the files to replace `XXX` (with various casing) with your model name.
- [x] Copy-paste or create a simple configuration class for your model in the `configuration_...` file.
- [x] Copy-paste or create the code for your model in the `modeling_...` files (PyTorch and TF 2.0).
- [x] Copy-paste or create a tokenizer class for your model in the `tokenization_...` file.
## Adding conversion scripts
Here is the workflow for the conversion scripts:
- [ ] Copy the conversion script (`convert_...`) from the present folder to the main folder.
- [ ] Edit this script to convert your original checkpoint weights to the current pytorch ones.
## Adding tests:
Here is the workflow for the adding tests:
- [x] Copy the python files from the `tests` sub-folder of the present folder to the `tests` subfolder of the main
folder and rename them, replacing `xxx` with your model name.
- [x] Edit the tests files to replace `XXX` (with various casing) with your model name.
- [x] Edit the tests code as needed.
## Documenting your model:
Here is the workflow for documentation:
- [ ] Make sure all your arguments are properly documented in your configuration and tokenizer.
- [x] Most of the documentation of the models is automatically generated, you just have to make sure that
`XXX_START_DOCSTRING` contains an introduction to the model you're adding and a link to the original
article and that `XXX_INPUTS_DOCSTRING` contains all the inputs of your model.
- [x] Create a new page `xxx.rst` in the folder `docs/source/model_doc` and add this file in `docs/source/index.rst`.
Make sure to check you have no sphinx warnings when building the documentation locally and follow our
[documentaiton guide](https://github.com/huggingface/transformers/tree/master/docs#writing-documentation---specification).
## Final steps
You can then finish the addition step by adding imports for your classes in the common files:
- [x] Add import for all the relevant classes in `__init__.py`.
- [x] Add your configuration in `configuration_auto.py`.
- [x] Add your PyTorch and TF 2.0 model respectively in `modeling_auto.py` and `modeling_tf_auto.py`.
- [x] Add your tokenizer in `tokenization_auto.py`.
- [ ] Add a link to your conversion script in the main conversion utility (in `commands/convert.py`)
- [ ] Edit the PyTorch to TF 2.0 conversion script to add your model in the `convert_pytorch_checkpoint_to_tf2.py`
file.
- [x] Add a mention of your model in the doc: `README.md` and the documentation itself
in `docs/source/index.rst` and `docs/source/pretrained_models.rst`.
- [x] Upload the pretrained weights, configurations and vocabulary files.
- [ ] Create model card(s) for your models on huggingface.co. For those last two steps, check the
[model sharing documentation](https://huggingface.co/transformers/model_sharing.html). | 09-11-2020 03:34:14 | 09-11-2020 03:34:14 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7064?src=pr&el=h1) Report
> Merging [#7064](https://codecov.io/gh/huggingface/transformers/pull/7064?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7cbf0f722d23440f3342aafc27697b50ead5996b?el=desc) will **decrease** coverage by `0.09%`.
> The diff coverage is `31.25%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7064?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7064 +/- ##
==========================================
- Coverage 80.32% 80.23% -0.10%
==========================================
Files 174 177 +3
Lines 33446 33878 +432
==========================================
+ Hits 26867 27181 +314
- Misses 6579 6697 +118
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7064?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_layoutlm.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sYXlvdXRsbS5weQ==) | `25.56% <25.56%> (ø)` | |
| [src/transformers/activations.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9hY3RpdmF0aW9ucy5weQ==) | `86.36% <50.00%> (-3.64%)` | :arrow_down: |
| [src/transformers/configuration\_layoutlm.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xheW91dGxtLnB5) | `80.00% <80.00%> (ø)` | |
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `99.37% <100.00%> (+0.01%)` | :arrow_up: |
| [src/transformers/configuration\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2F1dG8ucHk=) | `96.20% <100.00%> (+0.04%)` | :arrow_up: |
| [src/transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hdXRvLnB5) | `82.46% <100.00%> (+0.08%)` | :arrow_up: |
| [src/transformers/tokenization\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYXV0by5weQ==) | `92.30% <100.00%> (+0.12%)` | :arrow_up: |
| [src/transformers/tokenization\_layoutlm.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fbGF5b3V0bG0ucHk=) | `100.00% <100.00%> (ø)` | |
| [src/transformers/modeling\_tf\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mdW5uZWwucHk=) | `18.53% <0.00%> (-75.51%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `24.53% <0.00%> (-63.81%)` | :arrow_down: |
| ... and [18 more](https://codecov.io/gh/huggingface/transformers/pull/7064/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7064?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7064?src=pr&el=footer). Last update [7cbf0f7...4e95220](https://codecov.io/gh/huggingface/transformers/pull/7064?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Hi, I have moved and renamed the classes from modeling_bert to modeling_layoutlm and the code is ready for review and merge. @JetRunner @sgugger <|||||>@JetRunner @sgugger @LysandreJik The new suggestions have been adopted. |
transformers | 7,063 | closed | EncoderDecoderModel generate function | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
I follow the EncoderDecoder tutorials(https://huggingface.co/transformers/model_doc/encoderdecoder.html), but it seems that when i use generate function,
generated = model.generate(input_ids, decoder_start_token_id=tokenizer.pad_token_id)
i have to use pad_token_id.If i ommit that parmas, there is a error message, I can't figure out why.
device=next(self.parameters()).device,
TypeError: full() received an invalid combination of arguments - got (tuple, NoneType, device=torch.device, dtype=torch.dtype), but expected one of:
* (tuple of ints size, Number fill_value, *, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool pin_memory, bool requires_grad)
* (tuple of ints size, Number fill_value, *, tuple of names names, torch.dtype dtype, torch.layout layout, torch.device device, bool pin_memory, bool requires_grad)
tutorials code:
>>> from transformers import EncoderDecoderModel, BertTokenizer
>>> import torch
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
>>> model = EncoderDecoderModel.from_encoder_decoder_pretrained('bert-base-uncased', 'bert-base-uncased') # initialize Bert2Bert from pre-trained checkpoints
>>> # forward
>>> input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
>>> outputs = model(input_ids=input_ids, decoder_input_ids=input_ids)
>>> # training
>>> outputs = model(input_ids=input_ids, decoder_input_ids=input_ids, labels=input_ids, return_dict=True)
>>> loss, logits = outputs.loss, outputs.logits
>>> # save and load from pretrained
>>> model.save_pretrained("bert2bert")
>>> model = EncoderDecoderModel.from_pretrained("bert2bert")
>>> # generation
>>> generated = model.generate(input_ids, decoder_start_token_id=model.config.decoder.pad_token_id)
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: | 09-11-2020 02:20:43 | 09-11-2020 02:20:43 | Hey @lonelydancer ,
yeah I think I know why you get this error message. I very recently fixed the error message you get.
1) Could you try to pull from master and run your code again? If I am correct you should now get an error message saying:
```
"decoder_start_token_id or bos_token_id has to be defined for encoder-decoder generation"
```
2) You have to provide either a `bos_token_id` or `decoder_token_id` for generation, otherwise the decoder part for `EncoderDecoderModel` does not know with which token it should start the generation.
Please let me know if this helps. <|||||>@patrickvonplaten It works! Thanks~ |
transformers | 7,062 | closed | circleci testing issue | Sorry, this is not a bug report about `transformers` library. But I don't know what's the best place to ask.
While working on a pull request #6998 , after pushing the code, I got
==================================== ERRORS ====================================
____________________ ERROR collecting tests/test_trainer.py ____________________
ImportError while importing test module '/home/circleci/transformers/tests/test_trainer.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
/usr/local/lib/python3.7/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
tests/test_trainer.py:3: in <module>
import nlp
E ModuleNotFoundError: No module named 'nlp'
The PR #6998 has already been tested several times without problem. And it seems that the error `No module named 'nlp'` is not on my side. Could you help me to resolve this? | 09-10-2020 21:59:11 | 09-10-2020 21:59:11 | This has been fixed in master already, it's due to the change of name of the nlp library to datasets. You will need to install datasets to have the full test suite working.<|||||>Thanks, @sgugger . So in order to make my pull request pass the test online, I have to merge remote master intomy local branch and repush? Is this an acceptable approach of doing PR?<|||||>You can either rebase master on your PR branch, or not worry if this is the only test not passing (merging will make the CI green). |
transformers | 7,061 | closed | Automate the lists in auto-xxx docs | This PR adds a decorate to automate the creation of the lists in the documentation of `AutoConfig`, `AutoTokenizer`, `AutoModel`.
Apart from adding the docstrings of `AutoModelForMultipleChoice` and removing some parts of some class docstrings (because three lists is a bit too much for one class!) this PR does not fix the docstrings in themselves (that's for the next one). | 09-10-2020 21:34:06 | 09-10-2020 21:34:06 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7061?src=pr&el=h1) Report
> Merging [#7061](https://codecov.io/gh/huggingface/transformers/pull/7061?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0054a48cdd64e7309184a64b399ab2c58d75d4e5?el=desc) will **increase** coverage by `1.21%`.
> The diff coverage is `100.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7061?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7061 +/- ##
==========================================
+ Coverage 80.53% 81.74% +1.21%
==========================================
Files 168 168
Lines 32179 32251 +72
==========================================
+ Hits 25915 26365 +450
+ Misses 6264 5886 -378
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7061?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2F1dG8ucHk=) | `96.10% <100.00%> (+2.48%)` | :arrow_up: |
| [src/transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hdXRvLnB5) | `81.21% <100.00%> (+2.12%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | `70.58% <100.00%> (+3.52%)` | :arrow_up: |
| [src/transformers/tokenization\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYXV0by5weQ==) | `91.80% <100.00%> (+0.27%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9lbGVjdHJhLnB5) | `25.13% <0.00%> (-73.83%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `24.53% <0.00%> (-63.81%)` | :arrow_down: |
| [src/transformers/modeling\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tYXJpYW4ucHk=) | `60.00% <0.00%> (-30.00%)` | :arrow_down: |
| [src/transformers/activations.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9hY3RpdmF0aW9ucy5weQ==) | `85.00% <0.00%> (-5.00%)` | :arrow_down: |
| [src/transformers/configuration\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JhcnQucHk=) | `90.00% <0.00%> (-4.00%)` | :arrow_down: |
| [src/transformers/modeling\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iYXJ0LnB5) | `93.77% <0.00%> (-0.68%)` | :arrow_down: |
| ... and [9 more](https://codecov.io/gh/huggingface/transformers/pull/7061/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7061?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7061?src=pr&el=footer). Last update [0054a48...9eceac7](https://codecov.io/gh/huggingface/transformers/pull/7061?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,060 | closed | mBART 50 | # mBART 50
## Additional languages to the mBART 25 model
The model is described in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/pdf/2008.00401.pdf)
## Open source status
* [x] the model implementation is available: [mBART](https://github.com/pytorch/fairseq/tree/master/examples/mbart)
* [ ] the model weights are available: They should be released with the benchmark dataset, but I can't find them.
* [ ] who are the authors: @tangyuq @huihuifan @xianxl ...
| 09-10-2020 19:58:45 | 09-10-2020 19:58:45 | Thank you for your interest. We are doing a few clean-up and will release them shortly. <|||||>Waiting for the model too :)
Thanks<|||||>@tangyuq Is the benchmark included in [Beyond English-Centric Multilingual Machine Translation](https://github.com/pytorch/fairseq/tree/master/examples/m2m_100)?<|||||>We'll be adding a full evaluation on the ML50 benchmark in an updated version. The main reason why I haven't added it yet is that we want to update ML50's evaluation pairs done on WMT20 to the WMT20 test sets. When ML50 was originally released, the WMT20 test sets were not released yet. So we'll update both works together.
A portion of ML50 evaluation, from the original mBART paper, is available in Beyond English Centric MMT work already. <|||||>Hi, thanks for the great work and releasing the models to public.
Do we have any update on mBART50 model release? <|||||>The [mBART50 model](https://github.com/pytorch/fairseq/tree/master/examples/multilingual#mbart50-models) is now available on the fairseq repository.<|||||>@jaspock Has someone been able to load these mBART50 models with huggingface mBART version?
I was able to convert it (and the weight appear to be right). However, when generating translations, it just repeats the same word over and over again.
<|||||>Maybe @patil-suraj has some input?<|||||>Hi @jaspock
I'm also facing the same issue, I've been able to convert the weights, but as you said the generation is not working, I'm investigating this currently.<|||||>mBART-50 is now available on master!
https://huggingface.co/transformers/master/model_doc/mbart.html#overview-of-mbart-50
https://huggingface.co/models?filter=mbart-50<|||||>Hi, I want to finetune the multilingual model for some languages.
I cannot find the exact script , number of updates used to finetune mbart50.
The paper suggested 500k updates for training the model that was trained from scratch. Paper [Link](https://arxiv.org/pdf/2008.00401.pdf)
The multilingual fine-tuning script shows 40k updates in the training [script](https://github.com/pytorch/fairseq/tree/master/examples/multilingual#mbart50-models) (Which was also used for Bilingual model in mBart paper)
But I cannot find specifications for MT-FT (Multilingual Fine Tuning) for 50 languages.
I suspect 40k won't be enough if combined data for all languages is high.
Can anyone guide me if I am missing something
<|||||>> Hi, I want to finetune the multilingual model for some languages.
> I cannot find the exact script , number of updates used to finetune mbart50.
> The paper suggested 500k updates for training the model that was trained from scratch. Paper [Link](https://arxiv.org/pdf/2008.00401.pdf)
> The multilingual fine-tuning script shows 40k updates in the training [script](https://github.com/pytorch/fairseq/tree/master/examples/multilingual#mbart50-models) (Which was also used for Bilingual model in mBart paper)
>
> But I cannot find specifications for MT-FT (Multilingual Fine Tuning) for 50 languages.
> I suspect 40k won't be enough if combined data for all languages is high.
> Can anyone guide me if I am missing something
Hi @kaivu1999 Did you figure out how to fine-tune? I am also exploring for finetuning the multilingual model but haven't found a proper specification yet.<|||||>Hi @kaivu1999, @pdakwal
> I cannot find the exact script
There is a `run_translation.py` script [here](https://github.com/huggingface/transformers/tree/master/examples/pytorch/translation), which can be used for fine-tuning mBART-50 but it does not support multi-lingual fine-tuning. But it should be easy to adapt to do that.
For multi-lingual fine-tuning, what we need to do here is, say we are fine-tuning on two language pairs, in that case, we need to concatenate the two datasets or in case the two language pairs don't have the same number of examples then add some sort of sampler which will sample the example from the datasets depending on the number of examples in each one. And when processing each language pair, set the appropriate `src_lang` and `tgt_lang` tokens. The processing part is explained in the [docs](https://huggingface.co/transformers/model_doc/mbart.html#overview-of-mbart-50).<|||||>Hi @kaivu1999, @pdakwal were u able to finetune mbart50 on custom data? Please help. |
transformers | 7,059 | closed | these tests require non-multigpu env | fix for https://github.com/huggingface/transformers/issues/7055#issuecomment-690648438
Fixes: #7055
@sgugger | 09-10-2020 19:52:53 | 09-10-2020 19:52:53 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7059?src=pr&el=h1) Report
> Merging [#7059](https://codecov.io/gh/huggingface/transformers/pull/7059?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/77950c485a6f6bcb4db6501bffbbd0cd96c0cd1a?el=desc) will **increase** coverage by `0.79%`.
> The diff coverage is `71.42%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7059?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7059 +/- ##
==========================================
+ Coverage 80.25% 81.05% +0.79%
==========================================
Files 168 168
Lines 32172 32179 +7
==========================================
+ Hits 25821 26082 +261
+ Misses 6351 6097 -254
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7059?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/testing\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90ZXN0aW5nX3V0aWxzLnB5) | `69.48% <71.42%> (+0.09%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9tb2JpbGViZXJ0LnB5) | `24.55% <0.00%> (-72.36%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `24.53% <0.00%> (-63.81%)` | :arrow_down: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `77.73% <0.00%> (-19.35%)` | :arrow_down: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `92.83% <0.00%> (-0.36%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9iZXJ0LnB5) | `98.74% <0.00%> (+0.35%)` | :arrow_up: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `93.77% <0.00%> (+3.51%)` | :arrow_up: |
| [src/transformers/modeling\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tb2JpbGViZXJ0LnB5) | `89.45% <0.00%> (+10.24%)` | :arrow_up: |
| [src/transformers/modeling\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190cmFuc2ZvX3hsLnB5) | `79.77% <0.00%> (+12.66%)` | :arrow_up: |
| [src/transformers/modeling\_transfo\_xl\_utilities.py](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190cmFuc2ZvX3hsX3V0aWxpdGllcy5weQ==) | `66.41% <0.00%> (+13.43%)` | :arrow_up: |
| ... and [4 more](https://codecov.io/gh/huggingface/transformers/pull/7059/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7059?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7059?src=pr&el=footer). Last update [77950c4...22a45b8](https://codecov.io/gh/huggingface/transformers/pull/7059?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Let's merge this for now, I'll work on some of those tests to remove the decorator |
transformers | 7,058 | closed | Document the dependcy on datasets | We need the latest version of datasets to run the tests (since Trainer uses it). When datasets is more settled and we don't necessarily need to quickly update it, we can change this to a regular dep in "dev" with a minimal version pinned. | 09-10-2020 19:22:56 | 09-10-2020 19:22:56 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7058?src=pr&el=h1) Report
> Merging [#7058](https://codecov.io/gh/huggingface/transformers/pull/7058?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/514486739cc732ad05549d81bd48c0aa9e03a0f3?el=desc) will **increase** coverage by `0.14%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7058?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7058 +/- ##
==========================================
+ Coverage 79.32% 79.47% +0.14%
==========================================
Files 168 168
Lines 32172 32172
==========================================
+ Hits 25522 25568 +46
+ Misses 6650 6604 -46
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7058?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7058/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `82.41% <0.00%> (-0.26%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7058/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `93.91% <0.00%> (-0.14%)` | :arrow_down: |
| [src/transformers/modeling\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7058/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iYXJ0LnB5) | `94.44% <0.00%> (+0.16%)` | :arrow_up: |
| [src/transformers/configuration\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7058/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JhcnQucHk=) | `94.00% <0.00%> (+4.00%)` | :arrow_up: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7058/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `93.54% <0.00%> (+5.37%)` | :arrow_up: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7058/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `86.71% <0.00%> (+7.51%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7058?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7058?src=pr&el=footer). Last update [5144867...d360cf8](https://codecov.io/gh/huggingface/transformers/pull/7058?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,057 | closed | Add option to pass parameters to the loss function. | This PR is by far not finished. In the current state it is just a demo how I would implement it. See #7024
- loss_function_params is a dict that gets passed to the CrossEntropyLoss constructor
- that way you can set class_weights for the `CrossEntropyLoss ` for example
- this is a very important thing to do when working with unbalanced data and can improve your metric by a large amount
- it should be no breaking change since `loss_function_params` is always initialized with `None` which is just the current behavior
Example:
```python
model_name = 'bert-base-german-dbmdz-uncased'
config = AutoConfig.from_pretrained(
model_name,
num_labels=3,
)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
config=config,
loss_function_params={"weight": [0.8, 1.2, 0.97]}
)
```
## ToDo
- [ ] discuss with @LysandreJik @sgugger @nvs-abhilash
- [ ] implement for other models
- [ ] add docstrings
- [ ] write tests
- [ ] maybe implement for TF also | 09-10-2020 18:36:34 | 09-10-2020 18:36:34 | Closed by this answer: https://github.com/huggingface/transformers/issues/7024#issuecomment-691481436 |
transformers | 7,056 | closed | [wip/s2s] DistributedSortishSampler | This allows sortish sampler logic to work on multiple GPU.
The strategy is
1) find the indices that the current rank's data loader should be using (like `DistributedSampler`)
2) reorder those using the `SortishSampler` logic.
### Results
The results on a small MT task are similar to the 1 GPU setting.
+ 2 GPU, random sampler: 13 mins/epoch BLEU 8.6
+ 2 GPU, `DistributedSortishSampler`: 10 mins/epoch, BLEU 8.6
In the chart below, you can see that the sortish sampler gets to a higher BLEU score in the same number of minutes (x axis) (because it has finished a full epoch rather than 70% of one).
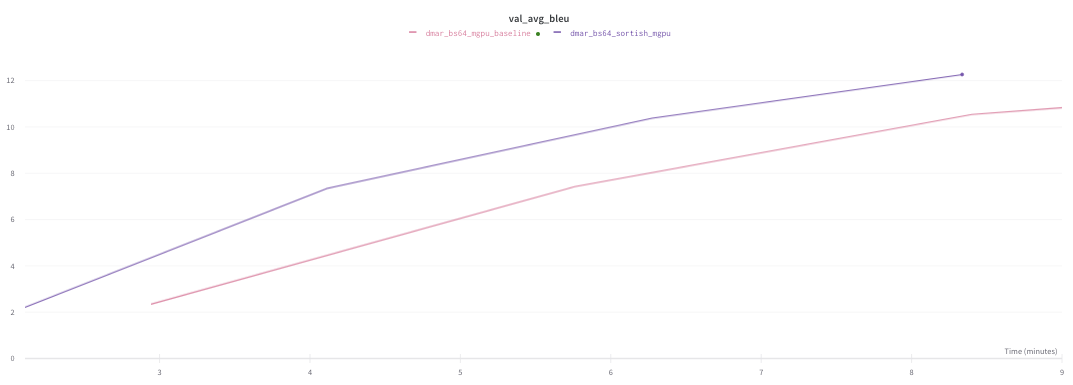
@sgugger let me know if you want this in Trainer! | 09-10-2020 18:34:40 | 09-10-2020 18:34:40 | Not necessarily the base Trainer, but definitely the `Seq2SeqTrainer` in preparation if you use this sampler often.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7056?src=pr&el=h1) Report
> Merging [#7056](https://codecov.io/gh/huggingface/transformers/pull/7056?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/514486739cc732ad05549d81bd48c0aa9e03a0f3?el=desc) will **increase** coverage by `0.25%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7056?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7056 +/- ##
==========================================
+ Coverage 79.32% 79.58% +0.25%
==========================================
Files 168 168
Lines 32172 32172
==========================================
+ Hits 25522 25605 +83
+ Misses 6650 6567 -83
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7056?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9sb25nZm9ybWVyLnB5) | `16.37% <0.00%> (-82.31%)` | :arrow_down: |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `19.71% <0.00%> (-72.34%)` | :arrow_down: |
| [src/transformers/tokenization\_bert\_generation.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYmVydF9nZW5lcmF0aW9uLnB5) | `39.28% <0.00%> (-55.36%)` | :arrow_down: |
| [src/transformers/optimization.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb24ucHk=) | `34.28% <0.00%> (-48.00%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `75.00% <0.00%> (-25.00%)` | :arrow_down: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `75.91% <0.00%> (-21.17%)` | :arrow_down: |
| [src/transformers/tokenization\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fcm9iZXJ0YS5weQ==) | `87.67% <0.00%> (-10.96%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `86.87% <0.00%> (-7.18%)` | :arrow_down: |
| [src/transformers/tokenization\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fb3BlbmFpLnB5) | `82.57% <0.00%> (-1.52%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_fast.py](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfZmFzdC5weQ==) | `92.85% <0.00%> (-1.43%)` | :arrow_down: |
| ... and [16 more](https://codecov.io/gh/huggingface/transformers/pull/7056/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7056?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7056?src=pr&el=footer). Last update [5144867...41dca6e](https://codecov.io/gh/huggingface/transformers/pull/7056?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,055 | closed | [testing] test_trainer.py is failing | ```
pytest tests/test_trainer.py
```
```
platform linux -- Python 3.7.9, pytest-6.0.1, py-1.9.0, pluggy-0.13.1
rootdir: /mnt/nvme1/code/huggingface/transformers-master
plugins: xdist-2.1.0, forked-1.3.0
collected 11 items
tests/test_trainer.py F.FF.FF...F [100%]
====================================================================== FAILURES ======================================================================
____________________________________________________ TrainerIntegrationTest.test_custom_optimizer ____________________________________________________
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_custom_optimizer>
def test_custom_optimizer(self):
train_dataset = RegressionDataset()
args = TrainingArguments("./regression")
model = RegressionModel()
optimizer = torch.optim.SGD(model.parameters(), lr=1.0)
lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda x: 1.0)
trainer = Trainer(model, args, train_dataset=train_dataset, optimizers=(optimizer, lr_scheduler))
trainer.train()
> self.assertTrue(torch.abs(trainer.model.a - 1.8950) < 1e-4)
E AssertionError: tensor(False, device='cuda:0') is not true
tests/test_trainer.py:240: AssertionError
---------------------------------------------------------------- Captured stderr call ----------------------------------------------------------------
Iteration: 100%|██████████| 4/4 [00:00<00:00, 4.15it/s]
Iteration: 100%|██████████| 4/4 [00:00<00:00, 584.41it/s]
Iteration: 100%|██████████| 4/4 [00:00<00:00, 570.73it/s]
Epoch: 100%|██████████| 3/3 [00:00<00:00, 3.06it/s]
_______________________________________________________ TrainerIntegrationTest.test_model_init _______________________________________________________
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_model_init>
def test_model_init(self):
train_dataset = RegressionDataset()
args = TrainingArguments("./regression", learning_rate=0.1)
trainer = Trainer(args=args, train_dataset=train_dataset, model_init=lambda: RegressionModel())
trainer.train()
> self.check_trained_model(trainer.model)
tests/test_trainer.py:249:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/test_trainer.py:105: in check_trained_model
self.assertTrue(torch.abs(model.a - 0.6975) < 1e-4)
E AssertionError: tensor(False, device='cuda:0') is not true
---------------------------------------------------------------- Captured stderr call ----------------------------------------------------------------
Iteration: 100%|██████████| 4/4 [00:00<00:00, 540.05it/s]
Iteration: 100%|██████████| 4/4 [00:00<00:00, 510.99it/s]
Iteration: 100%|██████████| 4/4 [00:00<00:00, 553.37it/s]
Epoch: 100%|██████████| 3/3 [00:00<00:00, 130.01it/s]
______________________________________________ TrainerIntegrationTest.test_number_of_steps_in_training _______________________________________________
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_number_of_steps_in_training>
def test_number_of_steps_in_training(self):
# Regular training has n_epochs * len(train_dl) steps
trainer = get_regression_trainer(learning_rate=0.1)
train_output = trainer.train()
> self.assertEqual(train_output.global_step, self.n_epochs * 64 / self.batch_size)
E AssertionError: 12 != 24.0
tests/test_trainer.py:129: AssertionError
---------------------------------------------------------------- Captured stderr call ----------------------------------------------------------------
Iteration: 100%|██████████| 4/4 [00:00<00:00, 547.43it/s]
Iteration: 100%|██████████| 4/4 [00:00<00:00, 573.03it/s]
Iteration: 100%|██████████| 4/4 [00:00<00:00, 557.12it/s]
Epoch: 100%|██████████| 3/3 [00:00<00:00, 136.18it/s]
_________________________________________________ TrainerIntegrationTest.test_reproducible_training __________________________________________________
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_reproducible_training>
def test_reproducible_training(self):
# Checks that training worked, model trained and seed made a reproducible training.
trainer = get_regression_trainer(learning_rate=0.1)
trainer.train()
> self.check_trained_model(trainer.model)
tests/test_trainer.py:118:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/test_trainer.py:105: in check_trained_model
self.assertTrue(torch.abs(model.a - 0.6975) < 1e-4)
E AssertionError: tensor(False, device='cuda:0') is not true
---------------------------------------------------------------- Captured stderr call ----------------------------------------------------------------
Iteration: 100%|██████████| 4/4 [00:00<00:00, 388.21it/s]
Iteration: 100%|██████████| 4/4 [00:00<00:00, 556.31it/s]
Iteration: 100%|██████████| 4/4 [00:00<00:00, 544.31it/s]
Epoch: 100%|██████████| 3/3 [00:00<00:00, 117.50it/s]
_______________________________________________ TrainerIntegrationTest.test_train_and_eval_dataloaders _______________________________________________
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_train_and_eval_dataloaders>
def test_train_and_eval_dataloaders(self):
trainer = get_regression_trainer(learning_rate=0.1, per_device_train_batch_size=16)
> self.assertEqual(trainer.get_train_dataloader().batch_size, 16)
E AssertionError: 32 != 16
tests/test_trainer.py:143: AssertionError
____________________________________________________ TrainerIntegrationTest.test_trainer_with_nlp ____________________________________________________
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_trainer_with_nlp>
def test_trainer_with_nlp(self):
np.random.seed(42)
x = np.random.normal(size=(64,)).astype(np.float32)
y = 2.0 * x + 3.0 + np.random.normal(scale=0.1, size=(64,))
train_dataset = nlp.Dataset.from_dict({"input_x": x, "label": y})
# Base training. Should have the same results as test_reproducible_training
model = RegressionModel()
args = TrainingArguments("./regression", learning_rate=0.1)
> trainer = Trainer(model, args, train_dataset=train_dataset)
tests/test_trainer.py:212:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
src/transformers/trainer.py:285: in __init__
self._remove_unused_columns(self.train_dataset, description="training")
src/transformers/trainer.py:311: in _remove_unused_columns
dataset.set_format(type=dataset.format["type"], columns=columns)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = Dataset(features: {'input_x': Value(dtype='float32', id=None), 'label': Value(dtype='float64', id=None)}, num_rows: 64), type = 'python'
columns = ['input_x', 'label'], output_all_columns = False, format_kwargs = {}
def set_format(
self,
type: Optional[str] = None,
columns: Optional[List] = None,
output_all_columns: bool = False,
**format_kwargs,
):
""" Set __getitem__ return format (type and columns)
Args:
type (Optional ``str``): output type selected in [None, 'numpy', 'torch', 'tensorflow', 'pandas']
None means __getitem__ returns python objects (default)
columns (Optional ``List[str]``): columns to format in the output
None means __getitem__ returns all columns (default)
output_all_columns (``bool`` default to False): keep un-formated columns as well in the output (as python objects)
format_kwargs: keywords arguments passed to the convert function like `np.array`, `torch.tensor` or `tensorflow.ragged.constant`.
"""
# Check return type
if type == "torch":
try:
import torch # noqa: F401
except ImportError:
logger.error("PyTorch needs to be installed to be able to return PyTorch tensors.")
elif type == "tensorflow":
try:
import tensorflow # noqa: F401
except ImportError:
logger.error("Tensorflow needs to be installed to be able to return Tensorflow tensors.")
else:
assert not (
type == "pandas" and (output_all_columns or format_kwargs)
), "Format type 'pandas' doesn't allow the use of `output_all_columns` or `**format_kwargs`."
assert (
type is None or type == "numpy" or type == "pandas"
> ), "Return type should be None or selected in ['numpy', 'torch', 'tensorflow', 'pandas']."
E AssertionError: Return type should be None or selected in ['numpy', 'torch', 'tensorflow', 'pandas'].
/home/stas/anaconda3/envs/main-37/lib/python3.7/site-packages/nlp/arrow_dataset.py:542: AssertionError
================================================================== warnings summary ==================================================================
/home/stas/anaconda3/envs/main-37/lib/python3.7/site-packages/tensorflow/python/data/ops/iterator_ops.py:546
/home/stas/anaconda3/envs/main-37/lib/python3.7/site-packages/tensorflow/python/data/ops/iterator_ops.py:546: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working
class IteratorBase(collections.Iterator, trackable.Trackable,
/home/stas/anaconda3/envs/main-37/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:106
/home/stas/anaconda3/envs/main-37/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:106: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working
class DatasetV2(collections.Iterable, tracking_base.Trackable,
/home/stas/anaconda3/envs/main-37/lib/python3.7/site-packages/tensorflow/python/autograph/utils/testing.py:21
/home/stas/anaconda3/envs/main-37/lib/python3.7/site-packages/tensorflow/python/autograph/utils/testing.py:21: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
src/transformers/modeling_tf_utils.py:718
/mnt/nvme1/code/huggingface/transformers-master/src/transformers/modeling_tf_utils.py:718: DeprecationWarning: invalid escape sequence \s
"""
src/transformers/modeling_funnel.py:130
/mnt/nvme1/code/huggingface/transformers-master/src/transformers/modeling_funnel.py:130: DeprecationWarning: invalid escape sequence \d
layer_index = int(re.search("layer_(\d+)", m_name).groups()[0])
tests/test_trainer.py::TrainerIntegrationTest::test_custom_optimizer
tests/test_trainer.py::TrainerIntegrationTest::test_evaluate
tests/test_trainer.py::TrainerIntegrationTest::test_model_init
tests/test_trainer.py::TrainerIntegrationTest::test_number_of_steps_in_training
tests/test_trainer.py::TrainerIntegrationTest::test_predict
tests/test_trainer.py::TrainerIntegrationTest::test_reproducible_training
/home/stas/anaconda3/envs/main-37/lib/python3.7/site-packages/torch/nn/parallel/_functions.py:61: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
-- Docs: https://docs.pytest.org/en/stable/warnings.html
============================================================== short test summary info ===============================================================
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_custom_optimizer - AssertionError: tensor(False, device='cuda:0') is not true
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_model_init - AssertionError: tensor(False, device='cuda:0') is not true
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_number_of_steps_in_training - AssertionError: 12 != 24.0
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_reproducible_training - AssertionError: tensor(False, device='cuda:0') is not true
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_train_and_eval_dataloaders - AssertionError: 32 != 16
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_trainer_with_nlp - AssertionError: Return type should be None or selected in ['numpy', '...
===================================================== 6 failed, 5 passed, 11 warnings in 10.28s ==================================================
```
Env:
```
- `transformers` version: 3.1.0
- Platform: Linux-4.15.0-112-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.9
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?: yes
```
Thanks.
@sgugger?
| 09-10-2020 18:30:19 | 09-10-2020 18:30:19 | So with more look, the issue has to do with multiple GPUs. The problem goes away if I do:
`CUDA_VISIBLE_DEVICES="0" pytest tests/test_trainer.py`<|||||>> Looks like those tests need a decorator to run on the CPU only.
They work with 1 gpu too, but we don't have such a setup to force 1 gpu?
Though isn't this exposing a problem and we will just hide it by setting CPU-only?<|||||>Yes, 2 GPUs end up doing half the updates, hence the error when counting the number of steps or the wrong value for a/b. This not a problem per se: it's logical to do half the steps since the batch size is multiplied by 2 and it's also logical that the seeded training end up to a different value with a different batch size.
But I wasn't expecting those to run on 2 GPUs, so we should add something to not use the 2 GPUs, which I don't think is possible since Trainer is there to automatically use all of them...<|||||>The best I can think of is to skip when detecting multiple GPUs. At least the tests that test the seeded training. For the number of steps, we can adapt to use the proper batch size.<|||||>ok, let me try - will post PR when working.<|||||>Odd, now it's failing with 1 or 0 gpus too, but only 4 tests.
```
collecting ...
tests/test_trainer.py ✓ 9% ▉
―――――――――――――――――――――――――――――――――――――――――――――――――――――――――― TrainerIntegrationTest.test_custom_optimizer ――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_custom_optimizer>
@require_non_multigpu
def test_custom_optimizer(self):
train_dataset = RegressionDataset()
args = TrainingArguments("./regression")
model = RegressionModel()
optimizer = torch.optim.SGD(model.parameters(), lr=1.0)
lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda x: 1.0)
trainer = Trainer(model, args, train_dataset=train_dataset, optimizers=(optimizer, lr_scheduler))
trainer.train()
> self.assertTrue(torch.abs(trainer.model.a - 1.8950) < 1e-4)
E AssertionError: tensor(False, device='cuda:0') is not true
tests/test_trainer.py:245: AssertionError
---------------------------------------------------------------------- Captured stderr call ----------------------------------------------------------------------
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1064.58it/s]
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1292.20it/s]
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1446.00it/s]
Epoch: 100%|██████████| 3/3 [00:00<00:00, 152.11it/s]
tests/test_trainer.py ⨯ 18% █▊
――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――― TrainerIntegrationTest.test_model_init ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_model_init>
@require_non_multigpu
def test_model_init(self):
train_dataset = RegressionDataset()
args = TrainingArguments("./regression", learning_rate=0.1)
trainer = Trainer(args=args, train_dataset=train_dataset, model_init=lambda: RegressionModel())
trainer.train()
> self.check_trained_model(trainer.model)
tests/test_trainer.py:255:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/test_trainer.py:105: in check_trained_model
self.assertTrue(torch.abs(model.a - 0.6975) < 1e-4)
E AssertionError: tensor(False, device='cuda:0') is not true
---------------------------------------------------------------------- Captured stderr call ----------------------------------------------------------------------
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1122.63it/s]
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1000.25it/s]
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1124.70it/s]
Epoch: 100%|██████████| 3/3 [00:00<00:00, 131.09it/s]
tests/test_trainer.py ⨯ 27% ██▊
――――――――――――――――――――――――――――――――――――――――――――――――――――――― TrainerIntegrationTest.test_trainer_with_datasets ――――――――――――――――――――――――――――――――――――――――――――――――――――――――
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_trainer_with_datasets>
@require_non_multigpu
def test_trainer_with_datasets(self):
np.random.seed(42)
x = np.random.normal(size=(64,)).astype(np.float32)
y = 2.0 * x + 3.0 + np.random.normal(scale=0.1, size=(64,))
train_dataset = datasets.Dataset.from_dict({"input_x": x, "label": y})
# Base training. Should have the same results as test_reproducible_training
model = RegressionModel()
args = TrainingArguments("./regression", learning_rate=0.1)
trainer = Trainer(model, args, train_dataset=train_dataset)
trainer.train()
> self.check_trained_model(trainer.model)
tests/test_trainer.py:218:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/test_trainer.py:105: in check_trained_model
self.assertTrue(torch.abs(model.a - 0.6975) < 1e-4)
E AssertionError: tensor(False, device='cuda:0') is not true
---------------------------------------------------------------------- Captured stderr call ----------------------------------------------------------------------
Set __getitem__(key) output type to python objects for ['input_x', 'label'] columns (when key is int or slice) and don't output other (un-formatted) columns.
Iteration: 100%|██████████| 8/8 [00:00<00:00, 941.46it/s]
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1036.33it/s]
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1004.92it/s]
Epoch: 100%|██████████| 3/3 [00:00<00:00, 121.20it/s]
tests/test_trainer.py ⨯ 36% ███▋
――――――――――――――――――――――――――――――――――――――――――――――――――――――― TrainerIntegrationTest.test_reproducible_training ――――――――――――――――――――――――――――――――――――――――――――――――――――――――
self = <tests.test_trainer.TrainerIntegrationTest testMethod=test_reproducible_training>
@require_non_multigpu
def test_reproducible_training(self):
# Checks that training worked, model trained and seed made a reproducible training.
trainer = get_regression_trainer(learning_rate=0.1)
trainer.train()
> self.check_trained_model(trainer.model)
tests/test_trainer.py:119:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/test_trainer.py:105: in check_trained_model
self.assertTrue(torch.abs(model.a - 0.6975) < 1e-4)
E AssertionError: tensor(False, device='cuda:0') is not true
---------------------------------------------------------------------- Captured stderr call ----------------------------------------------------------------------
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1168.66it/s]
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1169.27it/s]
Iteration: 100%|██████████| 8/8 [00:00<00:00, 1208.34it/s]
Epoch: 100%|██████████| 3/3 [00:00<00:00, 143.97it/s]
tests/test_trainer.py ⨯✓✓✓✓✓✓ 100% ██████████
======================================================================== warnings summary ========================================================================
/home/stas/anaconda3/envs/main/lib/python3.8/site-packages/tensorflow/python/pywrap_tensorflow_internal.py:15
/home/stas/anaconda3/envs/main/lib/python3.8/site-packages/tensorflow/python/pywrap_tensorflow_internal.py:15: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
-- Docs: https://docs.pytest.org/en/stable/warnings.html
==================================================================== short test summary info =====================================================================
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_custom_optimizer - AssertionError: tensor(False, device='cuda:0') is not true
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_model_init - AssertionError: tensor(False, device='cuda:0') is not true
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_trainer_with_datasets - AssertionError: tensor(False, device='cuda:0') is not true
FAILED tests/test_trainer.py::TrainerIntegrationTest::test_reproducible_training - AssertionError: tensor(False, device='cuda:0') is not true
Results (9.28s):
7 passed
4 failed
- tests/test_trainer.py:235 TrainerIntegrationTest.test_custom_optimizer
- tests/test_trainer.py:249 TrainerIntegrationTest.test_model_init
- tests/test_trainer.py:206 TrainerIntegrationTest.test_trainer_with_datasets
- tests/test_trainer.py:114 TrainerIntegrationTest.test_reproducible_training
```<|||||>OK, so I found at least one difference - fails on py38 env, but works on py37 - I will check if it's python or some libs that are different and report back.
**edit**: I rebuilt a fresh py38 env and the problem is gone, so it must be some other packages. I will post more if I find the culprit.<|||||>Hmm, I was trying to match the environments and accidentally updated the environment the test breaks in and it no longer breaks. So it must have been some package. The main suspect was pytorch as I had a nightly version, but I reverted back to that old version and it still works.
So this issue is resolved once this is merged https://github.com/huggingface/transformers/pull/7059 |
transformers | 7,054 | closed | Fix CI with change of name of nlp | Fixes #7055 (because yes, I can see the future) | 09-10-2020 18:15:32 | 09-10-2020 18:15:32 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7054?src=pr&el=h1) Report
> Merging [#7054](https://codecov.io/gh/huggingface/transformers/pull/7054?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d6c08b07a087e83915b4b3156bbf464cebc7b9b5?el=desc) will **increase** coverage by `2.11%`.
> The diff coverage is `100.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7054?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7054 +/- ##
==========================================
+ Coverage 78.74% 80.85% +2.11%
==========================================
Files 168 168
Lines 32172 32172
==========================================
+ Hits 25335 26014 +679
+ Misses 6837 6158 -679
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7054?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `99.33% <ø> (ø)` | |
| [src/transformers/tokenization\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxtLnB5) | `82.93% <ø> (ø)` | |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `82.66% <100.00%> (+0.25%)` | :arrow_up: |
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `54.68% <100.00%> (ø)` | |
| [src/transformers/modeling\_tf\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mdW5uZWwucHk=) | `18.53% <0.00%> (-75.51%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `24.53% <0.00%> (-63.81%)` | :arrow_down: |
| [src/transformers/modeling\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tYXJpYW4ucHk=) | `60.00% <0.00%> (-30.00%)` | :arrow_down: |
| [src/transformers/activations.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9hY3RpdmF0aW9ucy5weQ==) | `85.00% <0.00%> (-5.00%)` | :arrow_down: |
| [src/transformers/configuration\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JhcnQucHk=) | `90.00% <0.00%> (-4.00%)` | :arrow_down: |
| [src/transformers/modeling\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iYXJ0LnB5) | `93.77% <0.00%> (-0.68%)` | :arrow_down: |
| ... and [26 more](https://codecov.io/gh/huggingface/transformers/pull/7054/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7054?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7054?src=pr&el=footer). Last update [df4594a...f8b9682](https://codecov.io/gh/huggingface/transformers/pull/7054?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Merging to make the CI green but happy to address any comment in a follow-up PR.<|||||>```
_______________________________________________________ ERROR collecting tests/test_trainer.py _______________________________________________________
ImportError while importing test module '/mnt/nvme1/code/huggingface/transformers-master/tests/test_trainer.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
/home/stas/anaconda3/envs/main-37/lib/python3.7/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
tests/test_trainer.py:3: in <module>
import datasets
E ModuleNotFoundError: No module named 'datasets'
```<|||||>and after `pip install datasets` (needed in `setup.py`), the failure is still the same as in https://github.com/huggingface/transformers/issues/7055<|||||>I think you need an install from source.
<|||||>not sure what you mean? install from source `datasets`?
I did:
```
git pull
pip install -e .[dev]
```
in transformers<|||||>It's not in the depencies of transformers and requires a separate install from source for now. It does work on the CI and my machine:
```
git clone https://github.com/huggingface/datasets
cd datasets
pip install -e .
```<|||||>I did what you suggested, same failures.<|||||>Are you sure you are in the same env?
nlp was never in `setup.py`. It is an additional dep required for the full test suite as a source install for now, will become a dep when it's stable enough. I'll add that to the CONTRIBUTING but trying to understand why it fails for you before.<|||||>I have 2 gpus, you probably don't?
Indeed, if I run:
```CUDA_VISIBLE_DEVICES="" pytest tests/test_trainer.py```
it works.<|||||>Yup, it's multi-gpu that is the problem. It works if I do `CUDA_VISIBLE_DEVICES="0" pytest tests/test_trainer.py`<|||||>Mmmm, why would the multi-gpu not see a new module. That's weird.<|||||>I'm not sure you have looked at the errors https://github.com/huggingface/transformers/issues/7055 - they are of numeric mismatch nature. Have a look?
`12 != 24.0` looks like 1 vs 2 gpu issue.
let's move back into #7055 and continue there.<|||||>Oh this is a different error, not a missing model. Looks like those tests need a decorator to run on the CPU only.<|||||>> nlp was never in setup.py. It is an additional dep required for the full test suite as a source install for now, will become a dep when it's stable enough. I'll add that to the CONTRIBUTING but trying to understand why it fails for you before.
`datasets` needs to be in requirements for `dev` - otherwise test suite fails.<|||||>Yes, like I said you need a separate source install of it. You can't have a source install from dev that is properly up to date AFAIK.
Documented this in #7058 |
transformers | 7,053 | closed | [examples] bump pl=0.9.0 | 09-10-2020 17:58:41 | 09-10-2020 17:58:41 | cc @patil-suraj @stas00 |
|
transformers | 7,052 | closed | TFBert activation layer will be casted into float32 under mixed precision policy | ### To reproduce
```
import tensorflow as tf
from transformers import TFBertForQuestionAnswering
tf.keras.mixed_precision.experimental.set_policy('mixed_float16')
model = TFBertForQuestionAnswering.from_pretrained('bert-base-uncased')
```
User will receive warning saying
```
WARNING:tensorflow:Layer activation is casting an input tensor from dtype float16 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because its dtype defaults to floatx.
If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.
To change all layers to have dtype float16 by default, call `tf.keras.backend.set_floatx('float16')`. To change just this layer, pass dtype='float16' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.
```
This log means that under mixed-precision policy, the gelu activation layer in TFBert will be executed with float32 dtype. So the input x([link](https://github.com/huggingface/transformers/blob/d6c08b07a087e83915b4b3156bbf464cebc7b9b5/src/transformers/modeling_tf_bert.py#L91)) will be casted into float32 before sent into activation layer and casted back into float16 after finishing computation.
### Causes
This issue is mainly due to two reasons:
- The dict of [ACT2FN](https://github.com/huggingface/transformers/blob/d6c08b07a087e83915b4b3156bbf464cebc7b9b5/src/transformers/modeling_tf_bert.py#L121) is defined outside of [TFBertIntermediate class](https://github.com/huggingface/transformers/blob/d6c08b07a087e83915b4b3156bbf464cebc7b9b5/src/transformers/modeling_tf_bert.py#L347). The mixed-precision policy will not be broadcasted into the activation layer defined in this way. This can be verified by adding `print(self.intermediate_act_fn._compute_dtype)` below this [line](https://github.com/huggingface/transformers/blob/d6c08b07a087e83915b4b3156bbf464cebc7b9b5/src/transformers/modeling_tf_bert.py#L360). float32 will be given.
- tf.math.sqrt(2.0) used in [gelu](https://github.com/huggingface/transformers/blob/d6c08b07a087e83915b4b3156bbf464cebc7b9b5/src/transformers/modeling_tf_bert.py#L98) will always return a float32 tensor even if it is under mixed-precision policy. So there will be dtype incompatibility error after we move the ACT2FN into TFBertIntermediate class. This can be further solved by specifying dtype of tf.math.sqrt(2.0) to be consistent with `tf.keras.mixed_precision.experimental.global_policy().compute_dtype
`.
### Pros & Cons
Pros: activation layer will have higher precision as it is computed with float32 dtype
Cons: the two additional Cast operation will increase latency.
### PR
The PR that can help getting rid of warning log and make the activation layer be executed in float16 under mixed-precision policy: https://github.com/jlei2/transformers/pull/3 This PR is not a concrete one because there are some other models importing this ACT2FN dict so it can only solve the issue existed in TFBert related model.
### Benchmark Results
As Huggingface official benchmark tests don't support mixed-precision, the comparison was made using Tensorflow Profiling Tool(https://www.tensorflow.org/tfx/serving/tensorboard).
1 GPU-V100
Model: Huggingface FP16 Bert-Base with batch_size=128 and seq_len = 128.
<img width="350" alt="image (5)" src="https://user-images.githubusercontent.com/70337521/92769405-cae10f80-f34d-11ea-87c0-df4ec9ecdae2.png">
<img width="350" alt="image (5)" src="https://user-images.githubusercontent.com/70337521/92769851-39be6880-f34e-11ea-9926-2e8014c17e4e.png">
After applying the PR, the two Cast ops disappear and the time spent on activation layer is reduced from 3.745 ms to 1.75ms.
This issue is not like a bug or error and the pros & cons are listed above. Will you consider make changes corresponding to this? @patrickvonplaten Thanks! | 09-10-2020 17:56:05 | 09-10-2020 17:56:05 | Hello @jlei2!
This issue should be fixed in https://github.com/huggingface/transformers/pull/7022 <|||||>Gotcha! Thanks!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hi @jplu , you mentioned that this issue should be fixed in #7022. But I noticed that that PR has been closed. Are you still planning to look at this? Thanks!<|||||>Did you try with the master version?<|||||>Yes. I got same warning indicating that the gelu activation layer will be executed in fp32.<|||||>Thanks! I will rework this.<|||||>Hey @jlei2 ! Can you let me know if your issue is fixed in this PR please https://github.com/huggingface/transformers/pull/9163<|||||>Hi @jplu,
Thanks for creating the PR! Unfortunately the PR doesn't fix the issue. It resolves the 2nd causes I mentioned in this PR description but not the 1st one. It means after applying your PR, the activation layer will always has a compute dtype of fp32, no matter we are in mixed_fp16 mode or pure fp16 mode. As I said for the 1st cause, I think it is because the activation layer is defined outside of the BertIntermediate layer and the computation policy is not broadcasted into it.
For example, under your branch, with the code below:
```
import tensorflow as tf
from transformers import TFBertForQuestionAnswering
tf.keras.mixed_precision.experimental.set_policy('float16')
model = TFBertForQuestionAnswering.from_pretrained('bert-base-uncased')
```
We still got
```
WARNING:tensorflow:Layer activation is casting an input tensor from dtype float16 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because its dtype defaults to f
loatx.
If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.
To change all layers to have dtype float16 by default, call `tf.keras.backend.set_floatx('float16')`. To change just this layer, pass dtype='float16' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.
```
indicating that the activation layer is casted into float32.
The behavior is different from Google's official Bert codebase where the activation layer will be executed as float16. And the two cast ops converting float16 to float32 and then converting it back can slow down the forward computation but provide higher precision.<|||||>Did you pull the Last version? I don't get the same behavior than you.<|||||>I think so. I am on your branch of fix-activations. Does it require any specific version of TF? I am using tf==2.3.0. Do you mean you don't get the warning info?<|||||>I'm using 2.4 and no, I don't have the warning. Try to git pull once again to check.<|||||>Just tried with 2.3 as well and I still don't get the warning.<|||||>With TF2.4, I don't get the warning because in your PR after tf2.4 we start to use tf.keras.activations.gelu which is introduced in tf2.4. But I still think you should be able to get the warning with tf 2.3, because in that case we are using tf.keras.layers.Activation to create the activation layer. This is weird. Could you double-check you are using tf 2.3 and the execution flow does go through here(https://github.com/huggingface/transformers/blob/4ba0b792767c2dfff61afbf4fd36b8bc521518a1/src/transformers/activations_tf.py#L21)?<|||||>I confirm, including with gelu_new<|||||>Ok, I know why, I was setting the mixed precision before to import the transformers lib, now if I switch the two I get the warning with 2.3. I will remove the usage of the Activation layer and use only the function then.<|||||>I just did the update, now it should works!<|||||>Oh good catch! I didn't know the order would make a difference. It now works well on my side!<|||||>Awesome! Happy to know that the issue is fixed on your side as well!! The PR should be merged this week :)<|||||>Great! I really appreciate your effort on this issue! |
transformers | 7,051 | closed | How to pass tokenized hypotheses to TFRobertaForSequenceClassification model directly for faster inference? | Hi,
I have been running the zero shot classification pipeline for my use case by passing each text and it’s corresponding list of hypotheses labels, however it takes around 3 hours on a 32B GPU to classify ~22000 sentences(each sentence can have a varying number of labels ranging from 70 to 140 labels).
Is there a way to reduce the computation time by passing the embeddings to the sequence classification model directly rather than the raw list of labels? | 09-10-2020 17:47:30 | 09-10-2020 17:47:30 | Hello @akshatapatel!
Pinging @joeddav as he is the person who takes care of the zero-shot classification in the lib.
Can you share with us a piece of code on how you are trying to do your sequence classification?<|||||>Question moved to [the forums](https://discuss.huggingface.co/t/new-pipeline-for-zero-shot-text-classification/681/30?u=joeddav). Other discussions on speeding up zero shot classification [here](https://discuss.huggingface.co/t/speeding-up-zero-shot-classification-solved/692) and [here](https://discuss.huggingface.co/t/way-to-make-inference-zero-shot-pipeline-faster/1384) |
transformers | 7,050 | closed | [BertGeneration, Docs] Fix another old name in docs | 09-10-2020 15:11:41 | 09-10-2020 15:11:41 | ||
transformers | 7,049 | closed | Convert 12-1 and 6-1 en-de models from AllenNLP | https://github.com/jungokasai/deep-shallow#download-trained-deep-shallow-models
+ These should be FSMT models, so can be part of #6940 or done after.
+ They should be uploaded to the AllenNLP namespace. If stas takes this, they can start in stas/ and I will move them.
+ model card(s) should link to the original repo and paper.
+ I hope same en-de tokenizer already ported.
+ Would be interesting to compare BLEU to the initial models in that PR. There is no ensemble so we should be able to reported scores pretty well.
+ **Ideally** this requires 0 lines of checked in python code, besides maybe an integration test.
Desired Signature:
```python
model = FSMT.from_pretrained('allen_nlp/en-de-12-1')
```
Weights can be downloaded with gdown https://pypi.org/project/gdown/
```bash
pip install gdown
gdown https://drive.google.com/uc?id=1x_G2cjvM1nW5hjAB8-vWxRqtQTlmIaQU
```
@stas00 if you are blocked in the late stages of #6940 and have extra cycles, you could give this a whirl. We could also wait for that to be finalized and then either of us can take this. | 09-10-2020 15:09:02 | 09-10-2020 15:09:02 | I can work on these
But first I have a question: who would be a user of these wmt16-based models when there are several wmt19 en-de models (marian+fairseq wmt) which are significantly better with scores at ~41 and 43 respectively, vs 28 in this one.
wmt19 is a vastly bigger dataset, so it makes sense that it'd beat wmt16-based pre-trained models.
<|||||>+ since different dataset, different val set, which implies that 28 and 41 are not comparable BLEU scores.
+ These models should be significantly faster than the Marian models at similar performance levels.
+ We can finetune them on the new data if we think that will help.
+ FYI `Helinki-NLP/opus-mt-en-de` trained on way more data than the fairseq model I think, not totally sure.<|||||>Seems like embeddings will be shared in these.<|||||>Converted and did the initial eval with the same wmt19 val set, with beam=15
```
checkpoint_best.pt:
allen_nlp-wmt16-en-de-dist_12-1
{'bleu': 30.1995, 'n_obs': 1997, 'runtime': 233, 'seconds_per_sample': 0.1167}
allen_nlp-wmt16-en-de-dist_6-1
{'bleu': 29.3692, 'n_obs': 1997, 'runtime': 236, 'seconds_per_sample': 0.1182}
allen_nlp-wmt16-en-de-12-1
{'bleu': 24.3901, 'n_obs': 1997, 'runtime': 280, 'seconds_per_sample': 0.1402}
checkpoint_top5_average.pt:
allen_nlp-wmt16-en-de-dist_12-1
{'bleu': 30.1078, 'n_obs': 1997, 'runtime': 239, 'seconds_per_sample': 0.1197}
```
which is more or less about the same BLEU scores reported on the model's page.
I will re-check tomorrow that I haven't made any mistakes, but this is far from wmt19 model's scores, which is not surprising given the difference in the amount of training data.
Using wmt16 dataset was probably sufficient to support the ideas in the paper, but it doesn't appear to be very practical for the end user, unless it's re-trained with a much bigger dataset (and wmt20 is imminent and probably will be even bigger).
I guess I should also re-eval against wmt16 eval set, so that we also compare their bleu scores to the ported model - to ensure it works as good as the original. Will post results tomorrow.<|||||>That is shockingly low/suggests a bug somewhere. To big of a discrepancy to explain with training data. I can't find your en-de BLEU from the en-de but I remember 40.8 for Marian, which shouldn't be worse.
Can you check your work/ look at translations a bit, then upload the model to `stas/` so that I can take a look from your PR branch?
Bug sources I've seen before:
- special tokens (`eos_token_id`, `decoder_start_token_id`)
- assumption that tokenizer is identical
- Redundant generations: suggests caching issue.
<|||||>So as promised here is the bleu scores with the wmt16 test set (3K items), beam=50:
```
dist_12-1
{'bleu': 26.1883, 'n_obs': 2999, 'runtime': 1151, 'seconds_per_sample': 0.3838}
dist_6-1
{'bleu': 26.685, 'n_obs': 2999, 'runtime': 1054, 'seconds_per_sample': 0.3515}
12-1
{'bleu': 24.7299, 'n_obs': 2999, 'runtime': 1134, 'seconds_per_sample': 0.3781}
```
which are about 2 points behind if we assume they have run their eval on the wmt16 test data set.
**edit**: but I also don't get the advertised scores with their instructions: https://github.com/jungokasai/deep-shallow/issues/3
I will explore the model more today and see if I find anything, then yes, will upload the model.
Thank you for the pointers, @sshleifer
> I can't find your en-de BLEU from the en-de but I remember 40.8 for Marian, which shouldn't be worse.
github hides older comments, here is the one you're after:
https://github.com/huggingface/transformers/pull/6940#issuecomment-687709700
pair | fairseq | transformers
-------|----|----------
"en-ru"|36.4| 33.29
"ru-en"|41.3| 38.93
"de-en"|42.3| 41.18
"en-de"|43.1| 42.79
<|||||>New model's config should be `{'num_beams':5}` according to https://github.com/jungokasai/deep-shallow#evaluation<|||||>> New model's config should be `{'num_beams':5}` according to https://github.com/jungokasai/deep-shallow#evaluation
I'm not 100% sure what to do with this.
fariseq uses `num_beams=50` in their eval, but that would be an overkill as the default for normal use. So may I propose we set a reasonable beam size for FSMT (currently 8) and leave it at it.
But when comparing bleu scores we match what the researchers advertised.
Is this a reasonable approach?
<|||||>+ `FSMT` defaulting to 8 is fine. 5 would also be fine.
+ Each model's config should either have `num_beams` used by the author or a lower value that is close to as good (up to you).
<|||||>So do you suggest we use `num_beams=50` for fairseq? that'd be imposing a significant slowdown on a user, when 5-10 scores about the same.
The competitors try to win and thus try to squeeze all they can, at a compute/time cost, so I'm not sure the number reported in the paper is always a good one to use for that model.
But if you think the model's default should match the paper as a rule, then a rule is a rule.<|||||>+ lets do 5 for fairseq
+ Possible source of discrepancy for the allen-nlp models is the tokenizer.
They are using whatever tokenizer `transformer.wmt16.en-de` uses
[here](https://github.com/pytorch/fairseq/blob/master/examples/translation/README.md#pre-trained-models)
my convo with the 1st author:
https://github.com/jungokasai/deep-shallow/issues/1#issuecomment-678549967<|||||>> * Possible source of discrepancy for the allen-nlp models is the tokenizer.
> They are using whatever tokenizer `transformer.wmt16.en-de` uses
> [here](https://github.com/pytorch/fairseq/blob/master/examples/translation/README.md#pre-trained-models)
You're very likely correct:
```
# fairseq/models/transformer.py
'transformer.wmt14.en-fr': moses_subword('https://dl.fbaipublicfiles.com/fairseq/models/wmt14.en-fr.joined-dict.transformer.tar.bz2'),
'transformer.wmt16.en-de': 'https://dl.fbaipublicfiles.com/fairseq/models/wmt16.en-de.joined-dict.transformer.tar.bz2',
'transformer.wmt18.en-de': moses_subword('https://dl.fbaipublicfiles.com/fairseq/models/wmt18.en-de.ensemble.tar.gz'),
'transformer.wmt19.en-de': moses_fastbpe('https://dl.fbaipublicfiles.com/fairseq/models/wmt19.en-de.joined-dict.ensemble.tar.gz'),
'transformer.wmt19.en-ru': moses_fastbpe('https://dl.fbaipublicfiles.com/fairseq/models/wmt19.en-ru.ensemble.tar.gz'),
```
on it.<|||||>I verified your suggestion and they didn't do it like `transformer.wmt16.en-de` does, as they have in model args:
```
'bpe': 'fastbpe',
'tokenizer': 'moses',
```
but it's a good point that I need to ensure inside the convert script that this is so, otherwise there will be bugs in porting future models that may use a different tokenizer/bpe.
`transformer.wmt16.en-de` uses a basic split to words tokenizer and no sub-words:
```
def tokenize_line(line):
line = SPACE_NORMALIZER.sub(" ", line)
line = line.strip()
return line.split()
```
<|||||>It was [suggested](https://github.com/jungokasai/deep-shallow/issues/3#issuecomment-691392148) `checkpoint_top5_average.pt` should have a better score than `checkpoint_best.pt`, but I get a slightly better result with the latter on `dist-12-1`. Here is the full table at the moment using the ported to FSMT weights.
`num_beams=5` on `wmt19` test set:
chkpt file| top5_average | best
----------|--------------|-----
dist-12-1 | 29.9134 | 30.2591
dist-6-1 | 29.9837 | 29.3349
12-1 | 26.4008 | 24.1803<|||||>I rerun eval after adding `length_penalty = 0.6` and getting better scores:
chkpt file| top5_average
----------|--------------
dist-12-1 | 30.1637
dist-6-1 | 30.2214
12-1 | 26.9763
<|||||>For en-de datasets, I think they used moses+joint fastbpe. The model just assumes input data are already preprocessed with these tools, so that's why they just split with space. <|||||>for wmt16 en/de, as you said fairseq transformer does only whitespace-splitting, and no moses/fastbpe.
But your model appears to do moses/fastbpe according to the args stored in the checkpoint, so our code copies your settings.
<|||||>OK, I did search the hparam space and came up with:
```
# based on the results of a search on a range of `num_beams`, `length_penalty` and `early_stopping`
# values against wmt19 test data to obtain the best BLEU scores, we will use the following defaults:
#
# * `num_beams`: 5 (higher scores better, but requires more memory/is slower, can be adjusted by users)
# * `early_stopping`: `False` consistently scored better
# * `length_penalty` varied, so will assign the best one depending on the model
best_score_hparams = {
# fairseq:
"wmt19-ru-en": {"length_penalty": 1.1},
"wmt19-en-ru": {"length_penalty": 1.15},
"wmt19-en-de": {"length_penalty": 1.0},
"wmt19-de-en": {"length_penalty": 1.1},
# allen-nlp :
"wmt16-en-de-dist-12-1": {"length_penalty": 0.6},
"wmt16-en-de-dist-6-1": {"length_penalty": 0.6},
"wmt16-en-de-12-1": {"length_penalty": 0.8},
"wmt19-de-en-6-6-base": {"length_penalty": 0.6 },
"wmt19-de-en-6-6-big": {"length_penalty": 0.6 },
}
}
```
Here are the full results for allen-nlp:
* wmt16-en-de-dist-12-1
bleu | num_beams | length_penalty
----- | --------- | --------------
30.36 | 15 | 0.6
30.35 | 15 | 0.7
30.29 | 10 | 0.6
30.27 | 15 | 0.8
30.23 | 10 | 0.7
30.21 | 15 | 0.9
30.16 | 5 | 0.6
30.16 | 10 | 0.8
30.11 | 10 | 0.9
30.11 | 15 | 1.0
30.10 | 5 | 0.7
30.03 | 5 | 0.8
30.03 | 5 | 0.9
30.02 | 10 | 1.0
29.99 | 15 | 1.1
29.94 | 10 | 1.1
29.91 | 5 | 1.0
29.88 | 5 | 1.1
* wmt16-en-de-dist-6-1
bleu | num_beams | length_penalty
----- | --------- | --------------
30.22 | 5 | 0.6
30.17 | 10 | 0.7
30.17 | 15 | 0.7
30.16 | 5 | 0.7
30.11 | 15 | 0.8
30.10 | 10 | 0.6
30.07 | 10 | 0.8
30.05 | 5 | 0.8
30.05 | 15 | 0.9
30.04 | 5 | 0.9
30.03 | 15 | 0.6
30.00 | 10 | 0.9
29.98 | 5 | 1.0
29.95 | 15 | 1.0
29.92 | 5 | 1.1
29.91 | 10 | 1.0
29.82 | 15 | 1.1
29.80 | 10 | 1.1
* wmt16-en-de-12-1
bleu | num_beams | length_penalty
----- | --------- | --------------
27.71 | 15 | 0.8
27.60 | 15 | 0.9
27.35 | 15 | 0.7
27.33 | 10 | 0.7
27.19 | 10 | 0.8
27.17 | 10 | 0.6
27.13 | 5 | 0.8
27.07 | 5 | 0.7
27.07 | 15 | 0.6
27.02 | 15 | 1.0
26.98 | 5 | 0.6
26.97 | 10 | 0.9
26.69 | 5 | 0.9
26.48 | 10 | 1.0
26.40 | 5 | 1.0
26.18 | 15 | 1.1
26.04 | 10 | 1.1
25.65 | 5 | 1.1
* wmt19-de-en-6-6-base
bleu | num_beams | length_penalty
----- | --------- | --------------
38.37 | 5 | 0.6
38.31 | 5 | 0.7
38.29 | 15 | 0.7
38.25 | 10 | 0.7
38.25 | 15 | 0.6
38.24 | 10 | 0.6
38.23 | 15 | 0.8
38.17 | 5 | 0.8
38.11 | 10 | 0.8
38.11 | 15 | 0.9
38.03 | 5 | 0.9
38.02 | 5 | 1.0
38.02 | 10 | 0.9
38.02 | 15 | 1.0
38.00 | 10 | 1.0
37.86 | 5 | 1.1
37.77 | 10 | 1.1
37.74 | 15 | 1.1
* wmt19-de-en-6-6-big
bleu | num_beams | length_penalty
----- | --------- | --------------
40.12 | 15 | 0.6
40.01 | 10 | 0.6
39.96 | 15 | 0.7
39.90 | 5 | 0.6
39.90 | 10 | 0.7
39.76 | 5 | 0.7
39.74 | 10 | 0.8
39.74 | 15 | 0.8
39.65 | 5 | 0.8
39.56 | 10 | 0.9
39.48 | 5 | 0.9
39.46 | 15 | 0.9
39.42 | 10 | 1.0
39.32 | 5 | 1.0
39.29 | 15 | 1.0
39.21 | 10 | 1.1
39.16 | 5 | 1.1
38.83 | 15 | 1.1<|||||>https://github.com/huggingface/transformers/pull/7153 once merged should close this issue. |
transformers | 7,048 | closed | [BertGeneration] Correct Doc Title | All is in the title. | 09-10-2020 15:08:20 | 09-10-2020 15:08:20 | |
transformers | 7,047 | closed | T5-11b model parallelism | # 🚀 Feature request
I would like to finetune t5-11b model on my dataset, but found that it doesn't fit in TPU or GPU memory - colab notebook just crash when I run it.
I tried to find a ready model parallelism solution. First I found this PR:
https://github.com/huggingface/transformers/pull/3578
but it seems it haven't released. I tried to merge it to master branch locally, and use it, but it's crashed.
Also I have found Eisen library that propose "model parallelism with one code line", but works only for models with only one input ( t5 have 2 inputs - tokens and mask).
I need to distribute model on several GPU, and I see somebody tried to perform it. If this development (pull request 3578) is still in process, can you tell is there are any plans to release it? | 09-10-2020 15:00:39 | 09-10-2020 15:00:39 | Hey @exelents,
yes we are still looking into a good way of doing model parallelism. Could you post the error message you received when using #3578? <|||||>Here is it
> -input-22-5591bd8e45c0> in main()
> 143 cache_dir=model_args.cache_dir,
> 144 )
> --> 145 model = model.spread_on_devices(['cpu', 'cpu'])
> 146
> 147 # Get datasets
>
> /usr/local/lib/python3.6/dist-packages/transformers/modeling_t5.py in spread_on_devices(self, devices)
> 936 return
> 937
> --> 938 modules_to_move = set(self.modules)
> 939
> 940 # Evenly spread the blocks on devices
>
> TypeError: 'method' object is not iterable
As I don't have several GPU at the moment, I tried to run it on CPU (see line 145 in error stack)<|||||>patrickvonplaten,
The following should be interesting.
https://www.microsoft.com/en-us/research/publication/training-large-neural-networks-with-constant-memory-using-a-new-execution-algorithm/
I have engaged them and they are planning to release the open source several months back but faces some issues with Microsoft internals. Heard the author is planning to release open source themselves.
Can anyone work with them?
Cheers,
Dr. Patrick
<|||||>That does look interesting. Thanks for sharing! I'm not sure if we are planning on working with the author - but feel free to reach out to him and maybe this can help resolve the T5 model parallelism.<|||||>Hello, guys.
As I still need to train t5-11b, and Google doesn't want to give me access to his TPU's despite I can pay for it... So I have made some changes to T5 model to make it live on several GPU simultaneously.
my fork: https://github.com/huggingface/transformers/compare/master...exelents:model_parallelism_t5
The point is: transformer blocks (T5Block) is most large parts of network. First step is to evenly spread them aross all GPUs. In the second step we spread across GPUs all other blocks of our transformer, that are incomparably smaller than main blocks. Also there are some modification of original model code to make tensors move to nesessary GPU when incoming tensor and a layer are on the different devices.
Unfortunately testing this code on 8-gpu server I found that first GPU is going to spend memory resource faster than others:
> +-----------------------------------------------------------------------------+
> | NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
> |-------------------------------+----------------------+----------------------+
> | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
> | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
> | | | MIG M. |
> |===============================+======================+======================|
> | 0 Tesla V100-SXM2... On | 00000000:00:17.0 Off | 0 |
> | N/A 53C P0 65W / 300W | 16108MiB / 16160MiB | 0% Default |
> | | | N/A |
> +-------------------------------+----------------------+----------------------+
> | 1 Tesla V100-SXM2... On | 00000000:00:18.0 Off | 0 |
> | N/A 53C P0 64W / 300W | 10224MiB / 16160MiB | 0% Default |
> | | | N/A |
> +-------------------------------+----------------------+----------------------+
> | 2 Tesla V100-SXM2... On | 00000000:00:19.0 Off | 0 |
> | N/A 57C P0 63W / 300W | 10224MiB / 16160MiB | 0% Default |
> | | | N/A |
> +-------------------------------+----------------------+----------------------+
> | 3 Tesla V100-SXM2... On | 00000000:00:1A.0 Off | 0 |
> | N/A 51C P0 64W / 300W | 10224MiB / 16160MiB | 0% Default |
> | | | N/A |
> +-------------------------------+----------------------+----------------------+
> | 4 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 |
> | N/A 51C P0 63W / 300W | 13296MiB / 16160MiB | 0% Default |
> | | | N/A |
> +-------------------------------+----------------------+----------------------+
> | 5 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 |
> | N/A 56C P0 65W / 300W | 13296MiB / 16160MiB | 0% Default |
> | | | N/A |
> +-------------------------------+----------------------+----------------------+
> | 6 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | 0 |
> | N/A 52C P0 62W / 300W | 13296MiB / 16160MiB | 0% Default |
> | | | N/A |
> +-------------------------------+----------------------+----------------------+
> | 7 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 |
> | N/A 51C P0 64W / 300W | 13548MiB / 16160MiB | 0% Default |
> | | | N/A |
> +-------------------------------+----------------------+----------------------+
It seems in the beginning of our graph we have a large block which have a size comparable to T5Block size. The smarter way would be to split layers according to these memory usage, but I don't know a simple way to know how much memory every module use.
Maybe a simple workaround would be to find which layer can use so much memory and provide it's memory in first step, with T5Block's.
What do you think about this?<|||||>I tested this script on a machine with 8x32GB GPUs and have seen the same symptoms - first gpu's memoru gets fully loaded while other GPUs consume around 5 gigabytes:
https://pastebin.com/cV3CAQMk
Looking on output of device assignation array I see that all layers get spreaded evenly, so I can't imagine why it consumes memory of only one GPU....
If somebody could help with this code - please tell me, I can prepare running script for you. Also, you can use my code with only one line of code:
rc = model.split_across_gpus(devices=['cuda:0', 'cuda:1','cuda:2','cuda:3', 'cuda:4', 'cuda:5', 'cuda:6', 'cuda:7',])
print(rc)<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hi @exelents,
I also need model parallelism for T5 and your code should be very helpful. However, the link to your code seems invalid. Could you please share the code with me?
Best,
Jingxuan<|||||>Hello, @LostBenjamin.
Unfortunately, this my code didn't worked when I tested 11B model on 8 V100 GPU, so I didn't fixed it.
@alexorona did some work for model parallelism, here https://github.com/huggingface/transformers/pull/9384 you can find a discussion about already existing MP in transformers library. It's about Bart, but the same functions exists in T5 model class too. There is a code to spread model on several GPUs:
`model.parallelize() # autogenerated`
`inputs = inputs.to("cuda:0")`
Also, you can try DeepSpeed:
https://github.com/exelents/try_t5_qa
I haven't used this code for model parallelism, but in DeepSpeed community people say MP is exists in this library. So maybe this repo would be helpful.<|||||>Hi @exelents,
Thanks for your help! I will try the MP in transformers library. |
transformers | 7,046 | closed | Usage of targets argument in fill-mask pipeline (Pipeline cannot handle mixed args and kwargs) | I'm trying to use the `targets` keyword in the fill mask pipeline as described in #6239 but I'm getting a `ValueError: Pipeline cannot handle mixed args and kwargs`
Full example
nlp = pipeline('fill-mask', topk=2)
nlp("The acting was believable and the action was outstanding. The sentiment of this review is <mask>.", targets=[' positive', ' negative'])
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-44-2f6d875aee9b> in <module>
----> 1 nlp("The acting was believable and the action was outstanding. The sentiment of this review is <mask>.",
2 targets=[' positive', ' negative'])
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/pipelines.py in __call__(self, *args, **kwargs)
1054
1055 def __call__(self, *args, **kwargs):
-> 1056 inputs = self._parse_and_tokenize(*args, **kwargs)
1057 outputs = self._forward(inputs, return_tensors=True)
1058
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/pipelines.py in _parse_and_tokenize(self, padding, add_special_tokens, *args, **kwargs)
503 """
504 # Parse arguments
--> 505 inputs = self._args_parser(*args, **kwargs)
506 inputs = self.tokenizer(
507 inputs, add_special_tokens=add_special_tokens, return_tensors=self.framework, padding=padding,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/pipelines.py in __call__(self, *args, **kwargs)
167 def __call__(self, *args, **kwargs):
168 if len(kwargs) > 0 and len(args) > 0:
--> 169 raise ValueError("Pipeline cannot handle mixed args and kwargs")
170
171 if len(kwargs) > 0:
ValueError: Pipeline cannot handle mixed args and kwargs
| 09-10-2020 14:56:49 | 09-10-2020 14:56:49 | Looks like I was using v3.0.2 and this was introduced in v3.1.0 |
transformers | 7,045 | closed | max_length does not seem to work | So I may have understood the definition wrong, but in my understanding max_length defines the amount of characters you want your summary to be. i.e. max_length=50, the summary is not over 50 characters.
I have installed the transformers, work with the summarizer pipeline, which I assume is the bartsummarizer.
I try to summarize the standard text from the tutorial about the woman who married a lotta guys.
I fill in the following string:
`summarizer = pipeline('summarization')
summarizer(TEXT_TO_SUMMARIZE, min_length=50, max_length=100)`
The summary is this
` Liana Barrientos pleaded not guilty to two counts of "offering a false instrument for filing in the first degree" She has been married to 10 men, nine of them between 1999 and 2002 . At one time, she was married to eight men at once, prosecutors say .`
Which is 249 characters and has weird errors with the . being placed after a space.
It is probably a rookie question, but I can't seem to figure it out.
ps. I run it on Google Colab, if that makes a difference | 09-10-2020 14:50:14 | 09-10-2020 14:50:14 | Hey @MarijnQ,
`max_length` defines the number of maximum output *tokens* (which is usually a bit less than number of words). You can get the number of tokens of a text by doing:
```python
from transformers import T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("t5-base")
input_ids = tokenizer('Liana Barrientos pleaded not guilty to two counts of "offering a false instrument for filing in the first degree" She has been married to 10 men, nine of them between 1999 and 2002 . At one time, she was married to eight men at once, prosecutors say .')
print(f"Num tokens {len(input_ids.input_ids)}")
``` |
transformers | 7,044 | closed | Small fixes in tf template | 09-10-2020 14:35:02 | 09-10-2020 14:35:02 | ||
transformers | 7,043 | closed | Batch_encode_plus with is_pretokenized=True outputs incomplete input_ids | ## Environment info
- `transformers` version: 2.11.0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.5.1+cu101 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
tokenizers: @mfuntowicz
## Information
Model I am using (Bert, XLNet ...): Distilbert, Roberta
I am trying to use batch_encode_plus with pretokenized inputs but the input_encodings are different than if the same text is run individually through encode_plus or if the same text is batch encoded without pretokenization.
## To reproduce
Code and outputs:
```python
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-cased', use_fast=True)
input_text = ['Roman Atwood is a content creator.', 'The Boston Celtics play their home games at TD Garden.']
sample_batch = [x.split(' ') for x in input_text]
sample_batch
```
Output: [['Roman', 'Atwood', 'is', 'a', 'content', 'creator.'],
['The', 'Boston', 'Celtics', 'play', 'their', 'home', 'games', 'at', 'TD', 'Garden.']]
```python
encoded_dict_batch = tokenizer.batch_encode_plus(sample_batch, is_pretokenized=True, padding=True, return_tensors='pt', truncation=True, max_length=125)
print(encoded_dict_batch)
```
The output is this which was far fewer non-zero tokens than I expected:
{'input_ids': tensor([[ 101, 2264, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 102],
[ 101, 1109, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 102]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1]])}
The attention mask is also a problem with all the padded indices being 1s.
Run only the first sentence through encoding (not in batch). All other parameters remain the same.
```python
encoded_dict_single = tokenizer.encode_plus(sample_batch[0], is_pretokenized=True, padding=True, return_tensors='pt', truncation=True, max_length=125)
print(encoded_dict_single)
```
This produces a much more sane output:
{'input_ids': tensor([[ 101, 2264, 1335, 2615, 1110, 170, 3438, 9264, 119, 102]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
The input ids here from index 2 onwards are replaced by 0 in the previous output even though it's well below max_length.
The words are truncated as well:
```python
print(encoded_dict_single.words())
print(encoded_dict_batch.words())
```
[None, 0, 1, 1, 2, 3, 4, 5, 6, None]
[None, 0, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None]
Strangely enough, when calling batch_encode_plus with a pretokenized batch that consists of only 1 item in the list, it works fine.
```python
batch_of_one = [sample_batch[0]]
encoded_dict_batch_of_one = tokenizer.batch_encode_plus(batch_of_one, is_pretokenized=True, padding=True, return_tensors='pt', truncation=True, max_length=125)
print(encoded_dict_batch_of_one)
```
Output:
{'input_ids': tensor([[ 101, 2264, 1335, 2615, 1110, 170, 3438, 9264, 119, 102]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
I've tried with roberta as well and had the same results. Also, the same sentences in a batch but without pretokenization produces the correct outputs. It seems to be only the combination of pretokenized and batched sentences that are a problem.
## Expected behavior
The input_ids should not be replaced by 0s when tokenizing batched and pre-tokenized inputs.
| 09-10-2020 13:36:10 | 09-10-2020 13:36:10 | I ran this example using the v3.1.0 and it seems the issue was resolved in the latest versions:
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-cased', use_fast=True)
input_text = ['Roman Atwood is a content creator.', 'The Boston Celtics play their home games at TD Garden.']
sample_batch = [x.split(' ') for x in input_text]
print(sample_batch)
encoded_dict_batch = tokenizer.batch_encode_plus(sample_batch, is_pretokenized=True, padding=True, return_tensors='pt', truncation=True, max_length=125)
print(encoded_dict_batch)
```
outputs
```
[['Roman', 'Atwood', 'is', 'a', 'content', 'creator.'], ['The', 'Boston', 'Celtics', 'play', 'their', 'home', 'games', 'at', 'TD', 'Garden.']]
{'input_ids': tensor([[ 101, 2264, 1335, 2615, 1110, 170, 3438, 9264, 119, 102,
0, 0, 0],
[ 101, 1109, 2859, 25931, 1505, 1147, 1313, 1638, 1120, 15439,
5217, 119, 102]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
```
Would it be possible for you to upgrade to version v3.1.0?<|||||>I was able to upgrade to 3.0.2 and it was working with that. Thanks! |
transformers | 7,042 | closed | the time of loading different models to GPU is nearly the same? | I once used the old script for text-classification,the time of loading different models(mode.to_device) to GPU is different,
However, when I run the lastest version of script, I find that loading different models to GPU nearly takes the same time(which is in the process of initing the Trainer)
I want to know the reason. | 09-10-2020 13:26:27 | 09-10-2020 13:26:27 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,041 | closed | [wip/token clasification] Introduce datasets and metrics in token classification examples | This PR further simplifies token classification examples by introducing the use of HF nlp datasets and metrics.
In summary, we introduce:
- use of GermEval canonical dataset
- two additional local datasets: [Conll2003](https://github.com/vblagoje/transformers/blob/b58c6186fd589ea6f4c86e10df5a54aa63516d10/examples/token-classification/conll2003.py) and [UDEnglishEWT](https://github.com/vblagoje/transformers/blob/b58c6186fd589ea6f4c86e10df5a54aa63516d10/examples/token-classification/ud_english_ewt.py) (demonstrate custom nlp dataset use in training)
- nlp metrics, splits, removal of seqeval
- removal of all the clutter related to direct download and preprocessing of raw datasets
- further minor simplifications
I have verified the training of all the PyTorch and PL examples works but I was not able to verify the TensorFlow portion due to a faulty GPU setup on my cloud machine. Perhaps @jplu could help me there? Also @stefan-it could you please have a look as well. Therefore, I leave wip tag on, although the PR should be 99% ready.
| 09-10-2020 13:15:54 | 09-10-2020 13:15:54 | > Thanks a lot for this PR!
>
> The files `conll2003.py` and `ud_english_ewt.py` should be in the `nlp` package and not here. Can you open a PR there to propose these new datasets please.
Ok no problem. That makes more sense.
>
> In overrall I really like it! Nevertheless, it brings an important breaking change, because it is not possible anymore to use its own files without making an `nlp` script. Instead of modifying the existing script can you add a new one? For example `run_ner_with_nlp.py` or something like that?
Can you please clarify what do you mean by 'it is not possible anymore to use its own files without making an nlp script.' Do you mean that it would be preferred to use raw datasets just like before (as it is now)?
<|||||>> Can you please clarify what do you mean by 'it is not possible anymore to use its own files without making an nlp script.' Do you mean that it would be preferred to use raw datasets just like before (as it is now)?
This is exaclty what I mean, and what you have done would be better suited as a new script.<|||||>Well, the idea of `datasets` is that you can also use your own data files or python/pandas objects @jplu.
See here: https://huggingface.co/docs/datasets/loading_datasets.html#from-local-files
and here: https://huggingface.co/docs/datasets/loading_datasets.html#from-in-memory-data
So I'm not sure we need several scripts actually.<|||||>True, I know, but CoNLL2003 is the most used NER dataset, it is the must have evaluation when developing a new NER approach. Same thing with UDEnglishEWT for POS. They are so popular that I think it would be a nice to have in `datasets`.<|||||>@jplu I looked at the changes needed to accommodate both: dataset use and raw dataset download + use (without dataset API). It makes things a bit more complicated, clutters the token classification example, and defeats the purpose of simplifying things for new HF users.
Experienced users know how to download raw datasets and load them into the models. The proposed use of the new datasets package lowers the barrier to entry, makes everything simple and easy to understand for the new users.
In summary, we can add new datasets to the datasets project, use them in examples, that's given. However, having both the old approach (raw datasets download, script preprocessing, and use) and the new approach (just datasets) defeats the purpose of having clean, easy to understand and simple examples for the new users. On top of it, maintaining and testing these examples will be additional headache for us. But you guys let me know wdyt @sshleifer @thomwolf @stefan-it and we'll proceed forward. <|||||>@vblagoje Sorry, I'm not saying that you have to modify the existing script, but to create a new one. Basically you don't touch the current `run_tf_ner.py` and you create a new `run_tf_ner_with_datasets.py` where you do what you want here.
The advantage here is that you are not introducing breaking changes in the scripts people already uses. Think of those who are already using this script with their own data and don't want to move their dataset to datasets (for some reason). How do they do?<|||||>Or a better compromise IMO, as @thomwolf proposed, to add the possiblity to use a raw dataset, something that you can do with `datasets` pretty easily. Because here the problem is that you force people to use a specific dataset, which is quite odd for me, we should be able to let people use the dataset they want (from `datasets` or their own) in a smart way.<|||||>@jplu Yes, I am all for compromise solution, people can use any token level dataset they want (canonical, community or local dataset)- easily. Have a look at https://github.com/vblagoje/transformers/blob/refactor_token_examples/examples/token-classification/tasks.py All the users have to do is to supply the reference to dataset, source/target columns, labels and off they go with token level classification. That's all. <|||||>That's the point, they should not be forced to build their own `datasets` script or modify the existing one. We should provide a simple way to use the built-in local dataset (https://huggingface.co/docs/datasets/loading_datasets.html#from-local-files) + having the possibility to select a dataset from the `datasets` list. These two things can be done by adding some arguments to the script.<|||||>@jplu ok understood, good idea! Let's do that!
<|||||>@jplu I looked into how users could use the local dataset without providing a dataset script. Although local datasets give us the convenience of loading datasets easily they can't parse input out-of-the-box without, at least some, parsing customization. For example, GermEval has a specific [format](https://github.com/huggingface/transformers/blob/master/examples/token-classification/tasks.py#L18) and so do other token level datasets. They are almost never in json or csv format so that we can parse them with some generic [load_dataset](https://huggingface.co/docs/datasets/loading_datasets.html#from-local-files) approach.
What we can do is keep the level of abstraction of InputExample so that a new classification task returns a list of InputExamples just like [here](https://github.com/huggingface/transformers/blob/master/examples/token-classification/tasks.py#L18) That way users don't have to create a dataset script but can read examples from a local file, parse and return them as InputExample list. For existing datasets, we convert them to the InputExample list. If you have other ideas on how this could be done lmk but I don't see how we can achieve this just by adding some arguments to the script. <|||||>> I looked into how users could use the local dataset without providing a dataset script. Although local datasets give us the convenience of loading datasets easily they can't parse input out-of-the-box without, at least some, parsing customization. For example, GermEval has a specific format and so do other token level datasets. They are almost never in json or csv format so that we can parse them with some generic load_dataset approach.
Indeed, CoNLL files have a specific format with the `-docstart-` header for separating each document. The `csv` script cannot handle this.
> What we can do is keep the level of abstraction of InputExample so that a new classification task returns a list of InputExamples just like here That way users don't have to create a dataset script but can read examples from a local file, parse and return them as InputExample list. For existing datasets, we convert them to the InputExample list. If you have other ideas on how this could be done lmk but I don't see how we can achieve this just by adding some arguments to the script.
Might be another solution yes. Let's try this one and see how it goes.
<|||||>@jplu The commit change is [here](https://github.com/huggingface/transformers/pull/7041/commits/f381a0b17ed3046a96e5adc96c6a71d592c58cdf) So instead of relying on `get_dataset` API contract users can simply implement `get_input_examples`. We implement both approaches: using datasets and if needed loading from raw datasets. I am now checking that all PyTorch examples indeed work. <|||||>There are still several changes to do but it looks much better. Among what I could see:
- the `--labels` much be kept otherwise we always get the same list of labels.
- `conll2003.py` and `ud_english_ewt.py` should be moved. And a `--dataset_name` parameter should be added to the `run_*` scripts.
- `CoNLL2003` is not for chunking, then it should not belong to the chunking task, it is counter intuitive. Use CoNLL2000 here https://github.com/teropa/nlp/tree/master/resources/corpora/conll2000
- the method `read_examples_from_file` should not be removed.
You should also update the README by giving an example for at least these cases:
1. I want to train a NER model over CoNLL2003
2. I have a `train.txt`, `test.txt` and `dev.txt` with my own labels and want to train a NER model over it
3. I want to train a NER model over GERMEVAL2004<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,040 | closed | Fix template | 09-10-2020 12:39:53 | 09-10-2020 12:39:53 | ||
transformers | 7,039 | closed | fix to ensure that returned tensors after the tokenization is Long | <!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #7026
| 09-10-2020 12:16:18 | 09-10-2020 12:16:18 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7039?src=pr&el=h1) Report
> Merging [#7039](https://codecov.io/gh/huggingface/transformers/pull/7039?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/762cba3bdaf70104dc17cc7ff0f8ce13ba23d558?el=desc) will **not change** coverage.
> The diff coverage is `0.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7039?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7039 +/- ##
=======================================
Coverage 79.13% 79.13%
=======================================
Files 164 164
Lines 31143 31143
=======================================
Hits 24646 24646
Misses 6497 6497
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7039?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7039/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `93.18% <0.00%> (+0.35%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7039/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `82.41% <0.00%> (-0.26%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7039?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7039?src=pr&el=footer). Last update [762cba3...db8ea89](https://codecov.io/gh/huggingface/transformers/pull/7039?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Wouldn't it be better to do `torch.tensor(e, dtype=torch.long)` when creating the tensor, instead of casting the batch once the tensors are created?<|||||>@LysandreJik, made the suggested changes. :+1: <|||||>Thanks for the fix! |
transformers | 7,038 | closed | Question about the test results of my own testsets with a fine-tuned BERT | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
Hi, I have a fine-tuned BERT model and I want to use it to predict on my own testset which have 40k sentence pairs. I use the script like:
`export GLUE_DIR=./glue_data
export TASK_NAME=QQP
CUDA_VISIBLE_DEVICES=3 python ./examples/text-classification/run_glue.py \
--model_name_or_path ./pretrained_weights/bert_base_uncased \
--task_name $TASK_NAME \
--do_predict \
--data_dir $GLUE_DIR/$TASK_NAME \
--max_seq_length 128 \
--per_device_eval_batch_size=32 \
--per_device_train_batch_size=32 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--overwrite_output_dir \
--output_dir ./tmp/filter_nouns_pairs \`
It stands to reason that I should get a prediction file containing 40k rows, but in fact the output result is still only 10,000 rows. Is the result truncated during prediction? Thanks!
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: | 09-10-2020 11:46:20 | 09-10-2020 11:46:20 | I found the cause of the problem. If you want to predict on your own test set, you need to delete the previous "cached_test_BertTokenizer_128_qqp.lock" file and "cached_test_BertTokenizer_128_qqp" file. |
transformers | 7,037 | closed | Update eval dataset to pick start_position at first index | <!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #7032
| 09-10-2020 09:14:58 | 09-10-2020 09:14:58 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7037?src=pr&el=h1) Report
> Merging [#7037](https://codecov.io/gh/huggingface/transformers/pull/7037?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/76818cc4c6a1275a23ba261ca337b9f9070c397e?el=desc) will **increase** coverage by `0.20%`.
> The diff coverage is `0.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7037?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7037 +/- ##
==========================================
+ Coverage 79.43% 79.63% +0.20%
==========================================
Files 164 164
Lines 31026 31029 +3
==========================================
+ Hits 24645 24710 +65
+ Misses 6381 6319 -62
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7037?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `27.87% <0.00%> (-0.26%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9sb25nZm9ybWVyLnB5) | `16.37% <0.00%> (-82.31%)` | :arrow_down: |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `19.71% <0.00%> (-72.34%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `24.53% <0.00%> (-63.81%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `75.00% <0.00%> (-25.00%)` | :arrow_down: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `76.70% <0.00%> (-6.07%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `86.66% <0.00%> (-0.55%)` | :arrow_down: |
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `88.28% <0.00%> (-0.17%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `94.04% <0.00%> (+0.13%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `87.29% <0.00%> (+1.95%)` | :arrow_up: |
| ... and [5 more](https://codecov.io/gh/huggingface/transformers/pull/7037/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7037?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7037?src=pr&el=footer). Last update [76818cc...657fab8](https://codecov.io/gh/huggingface/transformers/pull/7037?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,036 | closed | "You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference" when I am finetuning on distilert pretrained model, After printing this it is taking a lot of time and using only one CPU, how can we parallelized to all the cores in the system ( even I hve 8 GPU's but it is not using tht) | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: | 09-10-2020 05:32:28 | 09-10-2020 05:32:28 | Hi, could you fill in the issue template rather than the issue title?<|||||>python ./examples/text-classification/run_glue.py \
--model_name_or_path ./examples/language-modeling/output/SIA_Ontopof_RISK/DistilBERT/Trained_on_iRisk/ \
--do_train \
--do_predict \
--task_name=mrpc \
--data_dir=/mnt/share/app/proj/ph/com/gbl/irisk/project_ph_com_irisk/Udita/Code_evaluation/Data//Train_Test_Data_BERTformat_Biz13Aug/BusinessRules_more_0s/ \
--output_dir=./proc_data/mrpc/BusinessRules_more_0s \
--max_seq_length=512 \
--per_device_train_batch_size=24 \
--per_device_eval_batch_size=32 \
--gradient_accumulation_steps=1 \
--max_steps=16323 \
--save_steps=10000 \
This is the command i am executing (finetuning a distilbert on a customer pre trained on a specific dataset)
Train.tsv file is of 1GB.
Feature creation is taking longer time(more than 24 hours and it is still running)
<|||||>
<|||||>This warning means that the weights of `pre_classifier` and `classifier` have not been initialized by your checkpoint. This is normal since you seem to be loading a checkpoint right after a language modeling training. These layers will now be trained for sequence classification using the command you've shown.<|||||>Hi, Can we use multi core CPU's here, if yes, where to change and in which function?
If i look at all the cores are not utilized. <|||||>
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,035 | closed | add -y to bypass prompt for transformers-cli upload | As discussed here: https://github.com/huggingface/transformers/issues/6934#issuecomment-687365960
adding `-y`/`--yes` to bypass prompt for scripting.
<!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #6934
| 09-10-2020 05:22:57 | 09-10-2020 05:22:57 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7035?src=pr&el=h1) Report
> Merging [#7035](https://codecov.io/gh/huggingface/transformers/pull/7035?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/76818cc4c6a1275a23ba261ca337b9f9070c397e?el=desc) will **decrease** coverage by `0.36%`.
> The diff coverage is `16.66%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7035?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7035 +/- ##
==========================================
- Coverage 79.43% 79.06% -0.37%
==========================================
Files 164 164
Lines 31026 31028 +2
==========================================
- Hits 24645 24532 -113
- Misses 6381 6496 +115
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7035?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/commands/user.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb21tYW5kcy91c2VyLnB5) | `36.73% <16.66%> (+0.18%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9sb25nZm9ybWVyLnB5) | `16.37% <0.00%> (-82.31%)` | :arrow_down: |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `19.71% <0.00%> (-72.34%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `75.00% <0.00%> (-25.00%)` | :arrow_down: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `76.70% <0.00%> (-6.07%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `86.66% <0.00%> (-0.55%)` | :arrow_down: |
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `88.28% <0.00%> (-0.17%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `94.04% <0.00%> (+0.13%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `86.97% <0.00%> (+1.62%)` | :arrow_up: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `86.71% <0.00%> (+7.51%)` | :arrow_up: |
| ... and [3 more](https://codecov.io/gh/huggingface/transformers/pull/7035/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7035?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7035?src=pr&el=footer). Last update [76818cc...8feb8ec](https://codecov.io/gh/huggingface/transformers/pull/7035?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>LGTM (this could lead to more invalidly-named checkpoints being uploaded, but we'll soon have more server-side validation) |
transformers | 7,034 | closed | [xlm tok] config dict: fix str into int to match definition | match arg doc definition:
```
id2lang (:obj:`Dict[int, str`, `optional`):
```
so replacing str with int.
the inverse is correct.
<!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #6734
| 09-10-2020 03:34:03 | 09-10-2020 03:34:03 | |
transformers | 7,033 | closed | fix deprecation warnings | Fixing:
```
pytest tests/test_tokenization_xlm.py
src/transformers/modeling_tf_utils.py:702
/mnt/nvme1/code/huggingface/transformers-xlm/src/transformers/modeling_tf_utils.py:702: DeprecationWarning:
invalid escape sequence \s
"""
src/transformers/modeling_funnel.py:130
/mnt/nvme1/code/huggingface/transformers-xlm/src/transformers/modeling_funnel.py:130: DeprecationWarning:
invalid escape sequence \d
layer_index = int(re.search("layer_(\d+)", m_name).groups()[0])
tests/test_tokenization_xlm.py::XLMTokenizationTest::test_padding_to_max_length
/mnt/nvme1/code/huggingface/transformers-xlm/src/transformers/tokenization_utils_base.py:1764: FutureWarning:
The `pad_to_max_length` argument is deprecated and will be removed in a future version, use `padding=True` or `padding='longest'` to pad to the longest sequence in the batch, or use `padding='max_length'` to pad to a max length. In this case, you can give a specific length with `max_length` (e.g. `max_length=45`) or leave max_length to None to pad to the maximal input size of the model (e.g. 512 for Bert).
warnings.warn(
tests/test_tokenization_xlm.py::XLMTokenizationTest::test_save_and_load_tokenizer
/mnt/nvme1/code/huggingface/transformers-xlm/src/transformers/tokenization_utils_base.py:1319: FutureWarning:
The `max_len` attribute has been deprecated and will be removed in a future version, use `model_max_length` instead.
warnings.warn(
```
ok, removing `tests/test_tokenization_common.py`'s `test_padding_to_max_length` as suggested there:
```
def test_padding_to_max_length(self):
"""We keep this test for backward compatibility but it should be remove when `pad_to_max_length` will e deprecated"""
```
these 2 fail with that test:
```
FAILED tests/test_tokenization_marian.py::MarianTokenizationTest::test_padding_to_max_length
FAILED tests/test_tokenization_pegasus.py::PegasusTokenizationTest::test_padding_to_max_length
```
if I try to fix it:
```
- padded_sequence_right = tokenizer.encode(sequence, pad_to_max_length=True)
+ padded_sequence_right = tokenizer.encode(sequence, padding="max_length")
```
So there is no salvaging it, right?
Oh and I realized that this one was a `FutureWarning` for end users, but the test suite is under our control, so this is the right action, correct? If I'm wrong, please let me know and I will revert this part. | 09-10-2020 03:28:15 | 09-10-2020 03:28:15 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7033?src=pr&el=h1) Report
> Merging [#7033](https://codecov.io/gh/huggingface/transformers/pull/7033?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/76818cc4c6a1275a23ba261ca337b9f9070c397e?el=desc) will **increase** coverage by `1.13%`.
> The diff coverage is `0.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7033?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7033 +/- ##
==========================================
+ Coverage 79.43% 80.57% +1.13%
==========================================
Files 164 164
Lines 31026 31026
==========================================
+ Hits 24645 24998 +353
+ Misses 6381 6028 -353
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7033?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19mdW5uZWwucHk=) | `86.76% <0.00%> (ø)` | |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `87.29% <ø> (+1.95%)` | :arrow_up: |
| [src/transformers/tokenization\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxtLnB5) | `16.26% <0.00%> (-66.67%)` | :arrow_down: |
| [src/transformers/tokenization\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYWxiZXJ0LnB5) | `28.84% <0.00%> (-58.66%)` | :arrow_down: |
| [src/transformers/modeling\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tYXJpYW4ucHk=) | `60.00% <0.00%> (-30.00%)` | :arrow_down: |
| [src/transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ194bG5ldC5weQ==) | `60.81% <0.00%> (-22.62%)` | :arrow_down: |
| [src/transformers/modeling\_transfo\_xl\_utilities.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190cmFuc2ZvX3hsX3V0aWxpdGllcy5weQ==) | `52.98% <0.00%> (-13.44%)` | :arrow_down: |
| [src/transformers/modeling\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190cmFuc2ZvX3hsLnB5) | `67.10% <0.00%> (-12.67%)` | :arrow_down: |
| [src/transformers/modeling\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tb2JpbGViZXJ0LnB5) | `79.21% <0.00%> (-10.25%)` | :arrow_down: |
| [src/transformers/activations.py](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9hY3RpdmF0aW9ucy5weQ==) | `85.00% <0.00%> (-5.00%)` | :arrow_down: |
| ... and [10 more](https://codecov.io/gh/huggingface/transformers/pull/7033/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7033?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7033?src=pr&el=footer). Last update [76818cc...1e3136b](https://codecov.io/gh/huggingface/transformers/pull/7033?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>I hear you, @LysandreJik - it makes sense and I reverted that removal.
It's just that warnings serve a special purpose - they tell users that something could be not right and they are suggested to act on it. So when I was debugging a specific test this showed up - and I had to look at it to see whether this warning is telling me that something is wrong and may affect what I'm debugging.
Yet, the logic you shared is absolutely valid.
So perhaps in the case of the test suite `FutureWarning`s shouldn't be warnings. Does it make sense? If you agree, then perhaps it can be changed to be so.
Here is a potential fix: https://github.com/huggingface/transformers/pull/7079
p.s. CI failure is unrelated. |
transformers | 7,032 | closed | SQuAD: Implement eval in Trainer-backed run_squad_trainer | A very good first issue IMO!
See https://github.com/huggingface/transformers/pull/4829#issuecomment-645994130
> we should update the eval dataset to pick one start_position (or the most frequent one)
Optionally, use the `huggingface/nlp` library to get the eval dataset, and hook it into the Trainer.
Also referenced in https://github.com/huggingface/transformers/issues/6997#issuecomment-688747680 | 09-09-2020 22:08:25 | 09-09-2020 22:08:25 | Hi Julien, I would like to contribute. Could you assign me to the issue?<|||||>Yes, go for it! @sgugger and I (and others) can help if needed<|||||>Hi there! I missed that there was an already an assignee, but I took a crack at it too.
I initially tried to pick the most frequent `start_position` —however the same `start_position` may have `answer_text`s of different length (i.e one answer could be a substring of another answer). I wasn’t sure how this should be best handled in `transformers/data/processors/squad.py(737)` where the length of the `answer_text` is used to calculate the start and end positions (Maybe I could try picking the start_pos of the most frequent *unique* answer_texts?). Given that, I went with picking the answer in the first index as a first attempt. <|||||>How were we doing it in `run_squad.py` again, @LysandreJik?<|||||>In `run_squad.py` we were leveraging the [`squad_metrics.py` evaluation script](https://github.com/huggingface/transformers/blob/master/src/transformers/data/metrics/squad_metrics.py).
If I recall correctly, it gets the sequence predicted by the model from the start and end positions. It then compares that sequence to all the possible answers.
For the evaluation I think it is imperative to compare the model prediction against all possible answers, so I don't think the evaluation can simply be solved by adding a single start/end position.<|||||>Thanks for the pointer, that makes sense. I'm interested in looking into it further, but I'll jump out and return the reigns to @ovbondarenko <|||||>see also the `squad` metrics in the huggingface/nlp library: https://github.com/huggingface/nlp/blob/master/metrics/squad/evaluate.py<|||||>Thanks for the pointers, everyone! .. and I am sorry for hijacking the issue, @kay-wong. @LysandreJik, I agree that we might want to check if predicted answer matches any one for the possible answers. I am going to give this approach a go.<|||||>@julien-c, @LysandreJik I've spent some time trying to decide on the best way to implement the evaluation, and I've realized that I need some help. I think the fastest way would be to basically reuse `load_and_cache_examples()` and `evaluate()` functions from [run_squad.py](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py) with adapted args. But it may not be the best way.
`evaluate()` function from run_squad.py is also handling predictions using `compute_predictions_logits` from [squad.py](https://github.com/huggingface/transformers/blob/master/src/transformers/data/metrics/squad_metrics.py). I would prefer to use the output from `trainer.predict` for a squad evaluator downstream. By design [trainer](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py) allows to substitute `compute_metrics` method by a custom evaluation method, so I am assuming this would ultimately be the preferred implementation of a custom squad evaluator for [run_squad_trainer.py](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad_trainer.py). Problem is, I am struggling to figure out what exactly trainer.predict is returning.
When I call trainer.predict on dev-v2.0 it returns predictions in a form of ndarray, which is clear enough:
```
# from trainer_utils.py:
class PredictionOutput(NamedTuple):
predictions: np.ndarray
label_ids: Optional[np.ndarray]
metrics: Optional[Dict[str, float]]
```
I thought that the predictions ndarray would contain computed probabilities for each question in the dev-v2.0.json dataset, but the length of this array (21454) does not match the number of examples in dev-v2.0 (11873), or the number of examples of train-v2.0.json (130319), or it is a multiple of any of the two. Could you help me understand what the trainer.predict method is returning?
Thanks a lot for any feedback!<|||||>Just realized while reading this that there is a big limitation inside Trainer prediction_loop: it expects just one output (maybe two if there is the loss) when here we have two (or even five in some cases). Will try to fix that on Monday to unlock you on this stage. Will add tests about the number of predictions outputed as well, but it should be the length of the dataset passed.<|||||>@sgugger Awesome, thank you!<|||||>Hi. Are there any updates on this?<|||||>Any progress on this issue?
Trying to define and pass in my own metric for QuestionAnswering tasks, but not quite sure how to calculate the exact loss and F1 when the `compute_metric' only seem to take in the predictions and label_ids.
Or is it possible to override say `EvalPrediction` and `PredictionOutput` to pass in the full input_ids and calculate the SQuAD metrics that way?
<|||||>I would like to take up this issue?<|||||>This has been fixed in #8992 already. I forgot to close this issue as a result, but this is implemented now. |
transformers | 7,031 | closed | Unable to recreate onnx speedups demonstrated in 04-onnx-export.ipynb on mac or linux | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.1.0
- Platform: Mac OS Mojave + Ubuntu 18.04.4
- Python version: 3.7.7
- PyTorch version (GPU?): 1.6.0
- Tensorflow version (GPU?): na
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
blenderbot: @mariamabarham
Bart: @sshleifer
Marian: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...): bert-base-uncased
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
I am running the /notebooks/04-onnx-export.ipynb example
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
I am using the example data in the notebook
## To reproduce
Steps to reproduce the behavior:
1. Within the notebook add `torch.set_num_threads(1)`
2. Replace `environ["OMP_NUM_THREADS"] = str(cpu_count(logical=True))` with `environ["OMP_NUM_THREADS"] = "1"`
3. Run the 04-onnx-export.ipynb example notebook
I am trying to recreate the speedups shown in this example notebook.
Note that without step 1 above I found pytorch to be considerably faster than onnx as presumably it was using more threads than onnx, step 2 doesn't seem to impact the results but I set it for completeness (ensuring every thing is on the same number of threads)
Actual results on a Macbook Pro:

with hardware:
```
machdep.cpu.max_basic: 22
machdep.cpu.max_ext: 2147483656
machdep.cpu.vendor: GenuineIntel
machdep.cpu.brand_string: Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
machdep.cpu.family: 6
machdep.cpu.model: 94
machdep.cpu.extmodel: 5
machdep.cpu.extfamily: 0
machdep.cpu.stepping: 3
machdep.cpu.feature_bits: 9221959987971750911
machdep.cpu.leaf7_feature_bits: 43806655 0
machdep.cpu.leaf7_feature_bits_edx: 2617255424
machdep.cpu.extfeature_bits: 1241984796928
machdep.cpu.signature: 329443
machdep.cpu.brand: 0
machdep.cpu.features: FPU VME DE PSE TSC MSR PAE MCE CX8 APIC SEP MTRR PGE MCA CMOV PAT PSE36 CLFSH DS ACPI MMX FXSR SSE SSE2 SS HTT TM PBE SSE3 PCLMULQDQ DTES64 MON DSCPL VMX EST TM2 SSSE3 FMA CX16 TPR PDCM SSE4.1 SSE4.2 x2APIC MOVBE POPCNT AES PCID XSAVE OSXSAVE SEGLIM64 TSCTMR AVX1.0 RDRAND F16C
machdep.cpu.leaf7_features: RDWRFSGS TSC_THREAD_OFFSET SGX BMI1 HLE AVX2 SMEP BMI2 ERMS INVPCID RTM FPU_CSDS MPX RDSEED ADX SMAP CLFSOPT IPT MDCLEAR TSXFA IBRS STIBP L1DF SSBD
machdep.cpu.extfeatures: SYSCALL XD 1GBPAGE EM64T LAHF LZCNT PREFETCHW RDTSCP TSCI
machdep.cpu.logical_per_package: 16
machdep.cpu.cores_per_package: 8
machdep.cpu.microcode_version: 220
machdep.cpu.processor_flag: 5
machdep.cpu.mwait.linesize_min: 64
machdep.cpu.mwait.linesize_max: 64
machdep.cpu.mwait.extensions: 3
machdep.cpu.mwait.sub_Cstates: 286531872
machdep.cpu.thermal.sensor: 1
machdep.cpu.thermal.dynamic_acceleration: 1
machdep.cpu.thermal.invariant_APIC_timer: 1
machdep.cpu.thermal.thresholds: 2
machdep.cpu.thermal.ACNT_MCNT: 1
machdep.cpu.thermal.core_power_limits: 1
machdep.cpu.thermal.fine_grain_clock_mod: 1
machdep.cpu.thermal.package_thermal_intr: 1
machdep.cpu.thermal.hardware_feedback: 0
machdep.cpu.thermal.energy_policy: 1
machdep.cpu.xsave.extended_state: 31 832 1088 0
machdep.cpu.xsave.extended_state1: 15 832 256 0
machdep.cpu.arch_perf.version: 4
machdep.cpu.arch_perf.number: 4
machdep.cpu.arch_perf.width: 48
machdep.cpu.arch_perf.events_number: 7
machdep.cpu.arch_perf.events: 0
machdep.cpu.arch_perf.fixed_number: 3
machdep.cpu.arch_perf.fixed_width: 48
machdep.cpu.cache.linesize: 64
machdep.cpu.cache.L2_associativity: 4
machdep.cpu.cache.size: 256
machdep.cpu.tlb.inst.large: 8
machdep.cpu.tlb.data.small: 64
machdep.cpu.tlb.data.small_level1: 64
machdep.cpu.address_bits.physical: 39
machdep.cpu.address_bits.virtual: 48
machdep.cpu.core_count: 4
machdep.cpu.thread_count: 8
machdep.cpu.tsc_ccc.numerator: 216
machdep.cpu.tsc_ccc.denominator: 2
```
I obtained even worse results on a linux machine:

with hardware:
```
processor : 11
vendor_id : GenuineIntel
cpu family : 6
model : 63
model name : Intel(R) Core(TM) i7-5820K CPU @ 3.30GHz
stepping : 2
microcode : 0x43
cpu MHz : 1199.433
cache size : 15360 KB
physical id : 0
siblings : 12
core id : 5
cpu cores : 6
apicid : 11
initial apicid : 11
fpu : yes
fpu_exception : yes
cpuid level : 15
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti intel_ppin ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts md_clear flush_l1d
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs itlb_multihit
bogomips : 6596.76
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Expected to speed speedup from using onnx as in the example:

I know this is hardware specific but having tested it on two machines I wonder if there is some config not included in the example that I am missing or some other issue? | 09-09-2020 21:33:28 | 09-09-2020 21:33:28 | @erees1,
torch.set_num_threads(1) will set OpenMP thread number to 1. That will disable all multiple threading optimizations in ONNX Runtime.
It is recommended to set number of threads to align with CPU cores for best performance. If you use ONNX Runtime version >= 1.3, you can try the following in the notebook:
```
torch.set_num_threads(psutil.cpu_count(logical=False))
```
After torch.set_num_threads is called, environ["OMP_NUM_THREADS"] will not have effect. You may set environ["OMP_NUM_THREADS"] if ONNX Runtime does not run with pytorch in the same process.<|||||>Thanks for the reply, just for clarity running the notebook exactly as it is we are unable to reproduce the results.
```python
# These are the settings in the notebook (I have made no changes)
environ["OMP_NUM_THREADS"] = str(cpu_count(logical=True))
options.intra_op_num_threads = 1
```

I have since discovered that changing _only_ the `options.intra_op_num_threads` us to get closer to the results shown in the notebook - but it's odd that we are unable to reproduce the results without changing this setting.
```python
# Have changed intra_op_num_threads from what was in the notebook
environ["OMP_NUM_THREADS"] = str(cpu_count(logical=True))
options.intra_op_num_threads = cpu_count(logical=True)
```

<|||||>Tagging @mfuntowicz :)<|||||>@erees1, your observation is correct.
It is recommended to use default setting (do not set the option intra_op_num_threads) for general usage.
onnxruntime-gpu package is not built with OpenMP, so OMP_NUM_THREADS does not have effect. If cpu cores >= 16, user might try intra_op_num_threads =16 explicitly.
For onnxruntime package, `options.intra_op_num_threads = 1` was advised for version = 1.2.0 at the time that notebook created. User could set OMP_NUM_THREADS etc environment variable before importing onnxruntime to control the intra op thread number. For version >= 1.3.0, it is recommended to use default intra_op_num_threads.
@mfuntowicz, could you help update the setting in the notebook like the following?
Before:
```
# Few properties that might have an impact on performances (provided by MS)
options = SessionOptions()
options.intra_op_num_threads = 1
options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
```
After:
```
options = SessionOptions()
# It is recommended to use default settings.
# onnxruntime package uses environment variable OMP_NUM_THREADS to control the intra op threads.
# For onnxruntime 1.2.0 package, you need set intra_op_num_threads = 1 to enable OpenMP. It is not needed for newer versions.
# For onnxruntime-gpu package, try the following when your cpu has many cores:
# options.intra_op_num_threads = min(16, cpu_count(logical=True))
```<|||||>Thanks for the help, I think that clears things up! - closing the issue. |
transformers | 7,030 | closed | [s2s] dynamic batch size with --max_tokens_per_batch | + adds test coverage for `SortishSampler`+`DistributedSortishSampler`.
+ use fancy samplers for validation if specified.
+ dynamic batch sampler is still experimental. Distributed doesn't work, only slightly faster at the moment, and requires a preprocessing step. | 09-09-2020 20:48:44 | 09-09-2020 20:48:44 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7030?src=pr&el=h1) Report
> Merging [#7030](https://codecov.io/gh/huggingface/transformers/pull/7030?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/efeab6a3f1eeaffc2cec350ffce797f209ba38f8?el=desc) will **decrease** coverage by `2.69%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7030?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7030 +/- ##
==========================================
- Coverage 81.50% 78.81% -2.70%
==========================================
Files 172 172
Lines 33077 33077
==========================================
- Hits 26959 26068 -891
- Misses 6118 7009 +891
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7030?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3JlZm9ybWVyLnB5) | `21.62% <0.00%> (-78.38%)` | :arrow_down: |
| [src/transformers/modeling\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yZWZvcm1lci5weQ==) | `16.87% <0.00%> (-77.64%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl94bG0ucHk=) | `19.02% <0.00%> (-69.35%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `24.53% <0.00%> (-63.81%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `94.04% <0.00%> (+0.13%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `87.33% <0.00%> (+0.32%)` | :arrow_up: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `93.54% <0.00%> (+0.35%)` | :arrow_up: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `87.23% <0.00%> (+0.53%)` | :arrow_up: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `82.76% <0.00%> (+6.06%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/7030/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9lbGVjdHJhLnB5) | `98.95% <0.00%> (+73.62%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7030?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7030?src=pr&el=footer). Last update [efeab6a...f23dd11](https://codecov.io/gh/huggingface/transformers/pull/7030?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,029 | closed | Add TF Funnel Transformer | This adds the TF implementation of the model. Will upload the TF checkpoints as the PR goes under review.
| 09-09-2020 20:17:55 | 09-09-2020 20:17:55 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7029?src=pr&el=h1) Report
> Merging [#7029](https://codecov.io/gh/huggingface/transformers/pull/7029?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/15478c1287a4e7b52c01730ffb0718243d153600?el=desc) will **increase** coverage by `2.52%`.
> The diff coverage is `19.30%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7029?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7029 +/- ##
==========================================
+ Coverage 78.37% 80.90% +2.52%
==========================================
Files 164 165 +1
Lines 31026 31767 +741
==========================================
+ Hits 24318 25702 +1384
+ Misses 6708 6065 -643
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7029?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mdW5uZWwucHk=) | `18.53% <18.53%> (ø)` | |
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `99.32% <100.00%> (+<0.01%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `82.41% <100.00%> (-0.26%)` | :arrow_down: |
| [src/transformers/modeling\_funnel.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19mdW5uZWwucHk=) | `86.76% <100.00%> (ø)` | |
| [src/transformers/modeling\_tf\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | `67.06% <100.00%> (+0.19%)` | :arrow_up: |
| [src/transformers/modeling\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tb2JpbGViZXJ0LnB5) | `79.21% <0.00%> (-10.25%)` | :arrow_down: |
| [src/transformers/modeling\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ194bG0ucHk=) | `88.77% <0.00%> (-2.55%)` | :arrow_down: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `91.90% <0.00%> (-0.41%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `93.64% <0.00%> (-0.14%)` | :arrow_down: |
| ... and [5 more](https://codecov.io/gh/huggingface/transformers/pull/7029/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7029?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7029?src=pr&el=footer). Last update [15478c1...2da2d1e](https://codecov.io/gh/huggingface/transformers/pull/7029?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,028 | closed | No way around "Truncation was not explicitely activated..." error when using SingleSentenceClassificationProcessor. | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.1.0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0+cu101 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
blenderbot: @mariamabarham
Bart: @sshleifer
Marian: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
@LysandreJik, @thomwolf
## Information
Model I am using: BERT.
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
```
from transformers import *
processor = SingleSentenceClassificationProcessor()
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
processor.add_examples(["Thanks for cool stuff!"])
processor.get_features(tokenizer, max_length=3)
```
```
Truncation was not explicitely activated but `max_length` is provided a specific value, please use `truncation=True` to explicitely truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
[InputFeatures(input_ids=[101, 4283, 102], attention_mask=[1, 1, 1], token_type_ids=None, label=0)]
```
## Expected behavior
This is expected, but the problem is that there is no way to suppress that warning, because there is no way to pass `truncation=True` when `tokenizer.encode` is called within `processor.get_features`. Probably one should make `truncation` an argument to `processor.get_features`.
| 09-09-2020 17:02:06 | 09-09-2020 17:02:06 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,027 | closed | Getting underling S3 URL | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
The high performance cluster environment at my work has been great for working with transformers. The downside however is that most access to the internet has been locked down. This means that I have been manually bringing in the models. This is somewhat problematic since it is a laborious process and I have been behind on being able to update to the newest models.
The IT team has however said that they would be able to white list a specific S3 bucket. When I see the link to the models, I see that it is of the form: https://s3.amazonaws.com/models.huggingface.co rather than the usual https://bucket-name.s3.Region.amazonaws.com.
Is there any chance I could obtain that second format for the bucket?
| 09-09-2020 16:13:47 | 09-09-2020 16:13:47 | probably @julien-c can help here<|||||>By default the library actually downloads model weights from `cdn.huggingface.co` so you might want to whitelist that domain.
For config files, we do download from S3. You can check the urls in the model pages' file lists e.g. https://huggingface.co/bert-base-multilingual-cased#list-files
and then replace the prefix:
`https://s3.amazonaws.com/models.huggingface.co/`
by
`http://models.huggingface.co.s3.amazonaws.com/`
<|||||>I experienced this problem and have found at least one cause to it. I added a print to the library to print what URL it was actually fetching. curl-ing that URL was no problem, but from within the package, I got a different response. I then discovered that I was able to run as root with sudo. I then straced with both my regular user and my root user and diffed the results. Then i figured out that my regular user had a .netrc-file in the home directory. Renaming that fixed the issue for me. Only took 7 hours :-\<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,026 | closed | RuntimeError: Expected tensor for argument #1 'indices' to have scalar type Long; but got torch.FloatTensor instead (while checking arguments for embedding) | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.1.0
- Platform: Linux-4.19.0-10-amd64-x86_64-with-debian-10.5
- Python version: 3.6.10
- PyTorch version (GPU?): 1.3.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
-->
## Information
Model I am using (GPT2-large) for fine-tuning on custom data:
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
Trace:
> File "gpt_language_generation.py", line 209, in <module>
> main()
> File "gpt_language_generation.py", line 136, in main
> trainer.train(model_path=None)
> File "<conda_env>/lib/python3.6/site-packages/transformers/trainer.py", line 708, in train
> tr_loss += self.training_step(model, inputs)
> File "<conda_env>/lib/python3.6/site-packages/transformers/trainer.py", line 995, in training_step
> outputs = model(**inputs)
> File "<conda_env>/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
> result = self.forward(*input, **kwargs)
> File "<conda_env>/lib/python3.6/site-packages/transformers/modeling_gpt2.py", line 731, in forward
> return_dict=return_dict,
> File "<conda_env>/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
> result = self.forward(*input, **kwargs)
> File "<conda_env>/lib/python3.6/site-packages/transformers/modeling_gpt2.py", line 593, in forward
> inputs_embeds = self.wte(input_ids)
> File "<conda_env>/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
> result = self.forward(*input, **kwargs)
> File "<conda_env>/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 114, in forward
> self.norm_type, self.scale_grad_by_freq, self.sparse)
> File "<conda_env>/lib/python3.6/site-packages/torch/nn/functional.py", line 1484, in embedding
> return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
model_class, tokenizer_class = GPT2LMHeadModel, GPT2Tokenizer
model = model_class.from_pretrained("gpt2-large")
tokenizer = tokenizer_class.from_pretrained("gpt2-large")
special_tokens_dict = {'bos_token': '<BOS>', 'eos_token': '<EOS>', 'pad_token': '<PAD>'}
num_added_toks = tokenizer.add_special_tokens(special_tokens_dict)
model.resize_token_embeddings(len(tokenizer))
input_text = ["a cat is sitting on the mat"]*100
train_dataset = tokenizer(input_text,add_special_tokens=True, truncation=True, max_length=64)
train_dataset = train_dataset["input_ids"]
eval_dataset = tokenizer(input_text,add_special_tokens=True, truncation=True, max_length=64)
eval_dataset = eval_dataset["input_ids"]
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,mlm=False)
training_args = TrainingArguments(output_dir='./gpt_model/')
training_args.do_train = True
training_args.do_eval = True
training_args.per_device_train_batch_size = 32
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
prediction_loss_only=True)
trainer.train(model_path=None) // The error occurs here
trainer.save_model()
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Expect the training to continue without an error.
| 09-09-2020 16:03:10 | 09-09-2020 16:03:10 | @patrickvonplaten , I did find out that the problem arises from `data collator` (`DataCollatorForLanguageModeling`). The returned tensors (tensor of indices to vocab) are not Long, which is creating the problem. |
transformers | 7,025 | closed | Python | 09-09-2020 15:15:58 | 09-09-2020 15:15:58 | Hey @smithjadhav,
Thanks for your issue. Given that the whole library is built on Python, I think it would require too much work for us to change to a different programming language and it would probably be better to just start a new github repo. |
|
transformers | 7,024 | closed | Adding `class_weights` argument for the loss function of transformers model | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
To provide a parameter called `class_weights` while initializing a sequence classification model. The attribute will be used to calculate the weighted loss which is useful for classification with imbalanced datasets.
```python
from transformers import DistilBertForSequenceClassification
# Note the additional class_weights attribute
model = DistilBertForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=5,
class_weights=[5, 3, 2, 1, 1])
```
class_weights will provide the same functionality as the `weight` parameter of Pytorch losses like [torch.nn.CrossEntropyLoss](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html).
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
There have been similar issues raised before on "How to provide class weights for imbalanced classification dataset". See [#297](https://github.com/huggingface/transformers/issues/297#issuecomment-534185049), [#1755](https://github.com/huggingface/transformers/issues/1755),
And I ended up modifying the transformers code to get the class weights (shown below), and it looks like an easy addition which can benefit many.
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
This should be possible because currently the loss for Sequence classification in the forward method is initialized like below:
```python
loss_fct = nn.CrossEntropyLoss() # <- Defined without the weight parameter
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
```
And we can add the weight attribute of Pytorch and pass the class_weights recorded during model initialization.
```python
loss_fct = nn.CrossEntropyLoss(weight=self.class_weights)
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
```
I am happy to implement this and provide a PR. Although I am new to the transformers package and may require some iterative code reviews from the senior contributors/members. | 09-09-2020 10:13:44 | 09-09-2020 10:13:44 | This would be a cool addition! This would need to be an attribute added to the configuration, similarly to what is done for `num_labels` or other configuration attributes. You can see the implementation in `PretrainedConfig`, [here](https://github.com/huggingface/transformers/blob/master/src/transformers/configuration_utils.py#L31). Feel free to open a PR and ping me on it!<|||||>Thanks @LysandreJik . I'll work on the initial draft and create a PR.<|||||>After having thought about it with @sgugger, it's probably not such a great idea to allow changing this parameter directly in the model configuration. If we enable this change, then we'll eventually have to support more arguments to pass to the loss functions, while the goal of the config and model loss computation isn't to be a feature-complete loss computation system, but to provide the very basic and simple traditional loss for the use-case (classification in this case).
In specific cases like this one where you would like to tweak the loss parameters, it would be better to get the logits back and compute the loss yourself with the logits and labels (no need to modify the `transformers` code when doing so).<|||||>Ok. Understood. Thanks, @LysandreJik and @sgugger for your points. 👍
I'll work on a custom solution for the same.<|||||>@LysandreJik @sgugger
> After having thought about it with @sgugger, it's probably not such a great idea to allow changing this parameter directly in the model configuration. If we enable this change, then we'll eventually have to support more arguments to pass to the loss functions, while the goal of the config and model loss computation isn't to be a feature-complete loss computation system, but to provide the very basic and simple traditional loss for the use-case (classification in this case).
Well, what about allowing a dict to be passed to the prediction heads and then passed to the `CrossEntropyLoss` function.
Like this:
```python
cross_entropy_loss_params = {"weight": [0.8, 1.2, 0.97]}
loss_fct = CrossEntropyLoss(**cross_entropy_loss_params )
```
Here for example: https://github.com/huggingface/transformers/blob/76818cc4c6a1275a23ba261ca337b9f9070c397e/src/transformers/modeling_bert.py#L943
This way you would:
- implement no breaking change
- open up everything for all parameters the API user wants to set
@LysandreJik @sgugger @nvs-abhilash what do you think?<|||||>I'm not sure where you would pass that dict. Could you precise that part?<|||||>> I'm not sure where you would pass that dict. Could you precise that part?
@sgugger I just did start a RP (which is just a demo in the current state) that explains how I would implement it.
See here: #7057
The code would look like this:
```python
model_name = 'bert-base-german-dbmdz-uncased'
config = AutoConfig.from_pretrained(
model_name,
num_labels=3,
)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
config=config,
loss_function_params={"weight": [0.8, 1.2, 0.97]}
)
```
I would be happy about feedback and to finish this PR.
@LysandreJik @nvs-abhilash what do you think?<|||||>Reopening the issue, since the discussion is going on.<|||||>>@LysandreJik @nvs-abhilash what do you think?
It looks good to me and I am happy to contribute but I guess it's up to @sgugger and @LysandreJik to provide more explanation on the feasibility and potential implications on the project.
<|||||>Supporting the last comment made, we don't intend for `PreTrainedModel`s to provide a feature-complete loss computation system. We expect them to provide the simplest loss that's traditionally used in most cases.
We would rather encourage users to retrieve the logits from the models and compute the loss themselves when having different use-cases than the very basic approach, like it is usually done with `nn.Module`s, like so:
```py
logits = model(**input_dict)
loss = CrossEntropyLoss(weight=[0.8, 1.2, 0.97])
output = loss(logits, labels)
```<|||||>Hi @LysandreJik ok...
Could you please briefly explain how those 3 lines of code are used from users (API) perspective?
As a Hugging Face Transformers user: when I want to train a new Text classifier with unbalanced classes and do `model = AutoModelForSequenceClassification.from_pretrained(model_name, config=config)` how do I get `CrossEntropyLoss(weight=[0.8, 1.2, 0.97])` into that?
I could just subclass `BertForSequenceClassification` for example and write the complete `forward` function from scratch again. But this would be 99% cut and paste and IMO not the way a good and open API like _HF Transformers_ should be designed. IMO this is not good from usability point of view.
If I understand you right @LysandreJik you do not want to force new model type developers to support the API that I suggested in my PR #7057 because you think that would be too much work to do. But IMO you do not consider the needs of the API user.<|||||>It's a bit hard to know how to guide you when you don't explain to use how you train your model. Are you using `Trainer`? Then you should subclass it and override the brand new `compute_loss` method that I just added to make this use case super easy. There is an example in the [docs](https://huggingface.co/transformers/master/main_classes/trainer.html) (note that you will need an install from source for this).<|||||>Ok. Super easy. Thanks @sgugger ! Thats it! :-))<|||||>@nvs-abhilash I think the answer closes this issue - right?<|||||>>Then you should subclass it and override the brand new compute_loss method that I just added to make this use case super easy
Thanks, @sgugger , this will definitely solve my problem as well!<|||||>@nvs-abhilash @PhilipMay could you please share your answer here?<|||||>@sgugger Just stumbled upon this - If we are not using Trainer but [HF's Accelerate lib](https://github.com/huggingface/accelerate), is there an easy way to achieve for this? Rather than replicating the entire model which HF already has as-is, all of this just for a custom loss function? Is there an easier alternative?<|||||>@ashutoshsaboo, the model output the logits, so if you don't want to leverage the loss output by the transformer model when passing it the labels, simply compute the loss outside of the model with the retrieved logits and your labels. |
transformers | 7,023 | closed | PreTrained (custom) model not correctly initializing when using AutoModel methods | ## Environment info
- `transformers` version: 3.1.0
- Platform: Windows-10-10.0.18362-SP0
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: ???
### Who can help
@LysandreJik
## Information
Model I am using (Bert, XLNet ...): bert-base-uncased, roberta-base, albert-large-v2
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
(Conceptual) steps to reproduce the behavior:
1) Derive a custom model from a "PreTrainedModel" like:
class TransformerLSTMDocClassifier(PreTrainedModel):
def __init__(self, model_config: AutoConfig):
super(TransformerLSTMDocClassifier, self).__init__(model_config)
self.transformer = AutoModel.from_config(model_config)
self.dropout = nn.Dropout(p=model_config.hidden_dropout_prob)
self.lstm = LSTM(model_config.hidden_size, model_config.hidden_size)
self.classifier = nn.Sequential(
nn.Dropout(p=model_config.hidden_dropout_prob),
nn.Linear(model_config.hidden_size, model_config.num_labels),
nn.Tanh()
)
2) Train (fine-tune) the custom model starting from a pre-trained (standard) model such as bert-base-uncased, roberta-base, albert-large-v2 (using AutoModel features). My objective is to easily exchange the 'transformer' part in the above model
3) Initializing the model class 'TransformerLSTMDocClassifier' via the 'from_pretrained' method with the fine-tuned model (output of step 2) results in the message:
Some weights of TransformerLSTMDocClassifier were not initialized from the model checkpoint at <MODEL_CHECKPOINT> and are newly initialized: [...]
The list of weights apparently includes ALL weights of the TransformerLSTMDocClassifier (200+in case of using bert-base_uncased)
## Expected behavior
Properly initialized weights
## Addendum
Disclaimer: I am a novice in the "transformers" framework. The above described (unexpected) behavior might result from an incorrect use of 'transformers' features/methods at my end.
However, I was digging a bit in the code and made the following observations:
(1) in case of deriving the custom model from a specific class (e.g. BertPreTrainedModel in case of using bert-base-uncased) instead from the generic class 'PreTrainedModel', the custom model is correctly initialized.
(2) the 'cls.base_model_prefix' (module: modeling_utils; method: from_pretrained) is "" (empty string) in case the custom model is derived from "PreTrainedModel", resulting in 'has_prefix_module' being set to 'True' in line 925, finally resulting in an inappropriate 'start_prefix' (apparently preventing that weights are matched/loaded).
| 09-09-2020 08:30:20 | 09-09-2020 08:30:20 | Could you set your logging level to `INFO` and show us the results?
You can put the following lines above your script:
```py
from transformers import logging
logging.set_verbosity_info()
```
It would really help us debug if you could also put a small script that reproduces the issue, so that we can easily reproduce and help you.<|||||>While trying putting together a minimal sample as you requested, I finally realized that the issue is on my side: as a novice in pytorch, I didn't expect that model (object) names in the code have to match (sub)models (e.g. base_model_prefix).
With a BERT configuration in the above AutoModel example, I replaced
self.transformer = AutoModel.from_config(model_config)
by
self.bert = AutoModel.from_config(model_config)
and it basically worked as expected.
However, this constraint somehow limits my flexibility in "just" replacing the transformer part in my custom model.<|||||>Glad you got it to work! |
transformers | 7,022 | closed | New TF output proposal | Hello!
Currently the TensorFlow have several issues to properly working in graph mode when `output_attentions`, `outout_hidden_states` and `return_dict` takes a boolean tensor (`tf.constant(True/False)`). This is because the graph mode doesn't allows to have an output of different sizes in its conditional branches.
To fix this and lower as much as possible a breaking change with the current behavior of these models, I propose to keep the current behavior but only in eager mode, and disabling these three features (force to have them to False) in graph mode. This is for me the best compromise between having something that works in graph mode and not having a big breaking change.
The graph mode is most of the time used to get fast training/inference and not for doing experiments, and I don't see the point to deploy a model in production that gives you all the attentions/hidden states values, or possibly getting an OOM during the training/inference mostly for the new TFLongformer model.
Here some examples.
Example 1: run in eager mode with default parameters value
```python
from transformers import TFBertForMaskedLM
model = TFBertForMaskedLM.from_pretrained("bert-base-cased")
model(tf.constant([[10,11,12]]))
# Result
(<tf.Tensor: shape=(1, 3, 28996), dtype=float32, numpy=
array([[[ -9.900146 , -10.345711 , -9.721893 , ..., -7.7057724,
-8.035212 , -8.271875 ],
[ -7.866758 , -8.147887 , -7.864182 , ..., -6.7170696,
-6.2896423, -6.79779 ],
[ -9.790001 , -10.2271185, -9.584716 , ..., -7.539982 ,
-7.807548 , -8.135937 ]]], dtype=float32)>,)
```
Example 2: run in eager mode by updating a boolean parameter value
```python
from transformers import TFBertForMaskedLM
model = TFBertForMaskedLM.from_pretrained("bert-base-cased")
model(tf.constant([[10,11,12]]), return_dict=True)
# Result
TFMaskedLMOutput(loss=None, logits=<tf.Tensor: shape=(1, 3, 28996), dtype=float32, numpy=
array([[[ -9.900146 , -10.345711 , -9.721893 , ..., -7.7057724,
-8.035212 , -8.271875 ],
[ -7.866758 , -8.147887 , -7.864182 , ..., -6.7170696,
-6.2896423, -6.79779 ],
[ -9.790001 , -10.2271185, -9.584716 , ..., -7.539982 ,
-7.807548 , -8.135937 ]]], dtype=float32)>, hidden_states=None, attentions=None)
```
Example 3: run in graph mode with default parameters value
```python
from transformers import TFBertForMaskedLM
import tensorflow as tf
model = tf.function(TFBertForMaskedLM.from_pretrained("bert-base-cased"))
model(tf.constant([[10,11,12]]))
# Result
(<tf.Tensor: shape=(1, 3, 28996), dtype=float32, numpy=
array([[[ -9.900146 , -10.345711 , -9.721893 , ..., -7.7057724,
-8.035212 , -8.271875 ],
[ -7.866758 , -8.147887 , -7.864182 , ..., -6.7170696,
-6.2896423, -6.79779 ],
[ -9.790001 , -10.2271185, -9.584716 , ..., -7.539982 ,
-7.807548 , -8.135937 ]]], dtype=float32)>,)
```
Example 4: run in graph mode by updating a boolean parameter value
```python
from transformers import TFBertForMaskedLM
import tensorflow as tf
model = tf.function(TFBertForMaskedLM.from_pretrained("bert-base-cased"))
model(tf.constant([[10,11,12]]), return_dict=tf.constant(True))
# Result
(<tf.Tensor: shape=(1, 3, 28996), dtype=float32, numpy=
array([[[ -9.900146 , -10.345711 , -9.721893 , ..., -7.7057724,
-8.035212 , -8.271875 ],
[ -7.866758 , -8.147887 , -7.864182 , ..., -6.7170696,
-6.2896423, -6.79779 ],
[ -9.790001 , -10.2271185, -9.584716 , ..., -7.539982 ,
-7.807548 , -8.135937 ]]], dtype=float32)>,)
```
As you can see for the last example, no more graph compilation error due to the `tf.constant(True)` value.
For my examples I used only `return_dict` but of course the same behavior is applied to `output_attentions` and `output_hidden_states`. Moreover, this new behavior will be detailed in the documentation of the impacted parameters.
@LysandreJik @sgugger @patrickvonplaten @sshleifer @thomwolf @julien-c What do you think of this solution? | 09-09-2020 08:26:44 | 09-09-2020 08:26:44 | This proposal works for me. It's better to allow graph mode for the "standard" way to do things while keeping backwards compatibility imo. Users that want to leverage hidden states/attentions with graph mode should have no problems in doing a custom architecture that does exactly that.
However, as a user I would feel like the last example is slightly misleading; in eager mode providing the input `return_dict` changes things, while in graph mode it doesn't, with no information whatsoever. I would expect the model to at least throw a warning telling me that this isn't supported in graph mode rather than silently doing nothing.<|||||>Having a warning message for these cases is a great idea! I take care of that to have this added in the next commit!!<|||||>Now everytime `return_dict`, `output_attentions` or `output_hidden_states` will be different of None, the following message will be displayed:
```
Warning: The parameters return_dict, output_attentions and output_hidden_states are disabled in graph mode.
```
@LysandreJik Does it looks ok for you now?
Just to let you know, usual logging is disabled in graph mode, so only way you have to display a message is to use the internal `tf.print()` function.<|||||>@sgugger Just pushed a new commit, let me know if I forgot to address one of your comments.<|||||>I only commented on the first two models, but the same is applicable for all the other ones. Other than that, it looks good yes, thanks for addressing!<|||||>Thanks for taking care of this! I like the approach<|||||>@sshleifer @thomwolf @julien-c Do you have any comments?
@sgugger @patrickvonplaten and @LysandreJik looks to be agree on that.<|||||>I will continue to work on this by applying it to the other models waiting @sshleifer @thomwolf and @julien-c comments.<|||||>Fine with me! In general, no need to wait for my input on tf decisions :)<|||||>I prefer to have the opinion of everyone as it is also a bit a design update :)<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,021 | closed | where can I download the pre-trained pytorch_model.bin files ? | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: | 09-09-2020 05:35:55 | 09-09-2020 05:35:55 | You can go to the model hub, click on a model and select "List all files in model". These are links to the files.

|
transformers | 7,020 | closed | Use `run_language_modeling.py` to finetune gpt2, but it core unexpectedly. | # ❓ Questions & Help
Use `run_language_modeling.py` to finetune gpt2, but it core unexpectedly. How can i find the cause of the core please?
## Details
I'm using transformers's `run_language_modeling.py` to finetune gpt2 as follows.
### (1)with gpu
```shell
python3 run_language_modeling.py --output_dir=/home/xxx/transformers/examples/language-modeling/output_dir --model_type=gpt2 --model_name_or_path=gpt2 --per_gpu_train_batch_size=1 --do_train --train_data_file=/home/xxx/data_info/transformer.data --block_size=512 --save_steps=500 --overwrite_output_dir
```
But it core unexpectedly.
```shell
terminate called after throwing an instance of 'std::runtime_error' | 0/1348 [00:00<?, ?it/s]
what(): NCCL Error 1: unhandled cuda error
Aborted
```
And the returncode is `134`。

### (2) with cpu
```shell
python3 run_language_modeling.py --output_dir=/home/xxx/transformers/examples/language-modeling/output_dir --model_type=gpt2 --model_name_or_path=gpt2 --do_train --train_data_file=/home/xxx/data_info/transformer.data --block_size=512 --save_steps=500 --overwrite_output_dir --no_cuda
```
At first the training is normal , but will quit after a while with return code `137`.

### (3) question
The dataset i use is just a `data.txt` which is a file combined with multiple articles , and a `<|endoftext|>` is added at the end of each article. How can i find the cause of the core please? Hope for your help. Thanks a lot.
| 09-09-2020 02:50:13 | 09-09-2020 02:50:13 | Hi, do you mind copy-pasting the text in your terminal instead of putting images? It'll be easier for us to understand, to debug, and for other users to search for similar issues. Thanks!<|||||>> Hi, do you mind copy-pasting the text in your terminal instead of putting images? It'll be easier for us to understand, to debug, and for other users to search for similar issues. Thanks!
I've figure out the problem of gpu core. According to https://github.com/pytorch/pytorch/issues/31285, my gpu card is not supported by pytorch. I'm trying to build pytorch from source.
But it's weird when i using `run_language_modeling.py ` with `--no_cuda `. There is no error message.
The command i used is
```shell
python3 run_language_modeling.py --output_dir=/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir --model_type=gpt2 --model_name_or_path=gpt2 --per_device_train_batch_size=1 --do_train --train_data_file=/home/xxx/gpt_model/data_info/transformer.data --block_size=512 --save_steps=500 --overwrite_output_dir --no_cuda
```
The output message is
```shell
09/09/2020 16:23:23 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0, distributed training: False, 16-bits training: False
09/09/2020 16:23:23 - INFO - __main__ - Training/evaluation parameters TrainingArguments(output_dir='/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir', overwrite_output_dir=True, do_train=True, do_eval=False, do_predict=False, evaluate_during_training=False, prediction_loss_only=False, per_device_train_batch_size=1, per_device_eval_batch_size=8, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, warmup_steps=0, logging_dir='runs/Sep09_16-23-23_TENCENT64.site', logging_first_step=False, logging_steps=500, save_steps=500, save_total_limit=None, no_cuda=True, seed=42, fp16=False, fp16_opt_level='O1', local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=1000, past_index=-1, run_name=None, disable_tqdm=False, remove_unused_columns=True)
/home/xxx/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/modeling_auto.py:821: FutureWarning: The class `AutoModelWithLMHead` is deprecated and will be removed in a future version. Please use `AutoModelForCausalLM` for causal language models, `AutoModelForMaskedLM` for masked language models and `AutoModelForSeq2SeqLM` for encoder-decoder models.
FutureWarning,
/home/xxx/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/tokenization_utils_base.py:1321: FutureWarning: The `max_len` attribute has been deprecated and will be removed in a future version, use `model_max_length` instead.
FutureWarning,
09/09/2020 16:23:31 - INFO - filelock - Lock 140250526322472 acquired on /home/xxx/gpt_model/data_info/cached_lm_GPT2Tokenizer_512_transformer.data.lock
09/09/2020 16:23:32 - INFO - filelock - Lock 140250526322472 released on /home/xxx/gpt_model/data_info/cached_lm_GPT2Tokenizer_512_transformer.data.lock
/home/xxx/anaconda3/envs/transformers/lib/python3.6/site-packages/transformers/trainer.py:247: FutureWarning: Passing `prediction_loss_only` as a keyword argument is deprecated and won't be possible in a future version. Use `args.prediction_loss_only` instead.
FutureWarning,
<library>In get_train_dataloader ,tarin_batch_size = 1
Epoch: 0%| | 0/3
Killedion: 4%|████▎ | 194/5390 [04:30<2:58:02, 2.06s/it]
```
And `echo $?`, the return code is `137`. Thanks a lot.<|||||>The return code 137 means that you have an out of memory error. Do you get the same error if you use `distilgpt2` with a `--block_size=64`? (Just for testing purposes).
We've also recently patched a memory error on the `Trainer`, could you install from source to benefit from the fix? You can do so as such:
`pip install git+https://github.com/huggingface/transformers`<|||||>> pip install git+https://github.com/huggingface/transformers
Yes, I found `Out of memory` log in `/var/log/messages` and it turns out the process use a lot of memory.
```shell
Sep 9 17:10:44 centos kernel: Out of memory: Kill process 126138 (python3) score 939 or sacrifice child
Sep 9 17:10:44 centos kernel: Killed process 126170 (python3) total-vm:325690732kB, anon-rss:125105968kB, file-rss:0kB
```
And this is my machine info (caused in shell with `top` command)
```shell
top - 17:47:55 up 303 days, 2:35, 4 users, load average: 1.14, 2.98, 3.44
Tasks: 468 total, 1 running, 467 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 13132300+total, 12383201+free, 3294300 used, 4196688 buff/cache
KiB Swap: 2088956 total, 12 free, 2088944 used. 12565272+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2868 root 20 0 3006004 19072 0 S 0.3 0.0 225:15.55 dockerd
```
Then i use `pip uninstall transformers; pip install git+https://github.com/huggingface/transformers` to reinstall the `transformers` library, and run the `run_language_modeling.py` again.
```shell
python3 run_language_modeling.py --output_dir=/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir --model_type=gpt2 --model_name_or_path=distilgpt2 --per_device_train_batch_size=1 --do_train --train_data_file=/home/xxx/gpt_model/data_info/data.txt --block_size=64 --save_steps=500 --overwrite_output_dir --no_cuda
```
This is the memory info showed by `top` after i run `run_language_modeling.py` with cpu.
```shell
top - 17:51:40 up 303 days, 2:38, 4 users, load average: 23.42, 9.30, 5.50
Tasks: 463 total, 2 running, 461 sleeping, 0 stopped, 0 zombie
%Cpu(s): 34.4 us, 49.5 sy, 0.0 ni, 16.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 13132300+total, 12142824+free, 5283664 used, 4611096 buff/cache
KiB Swap: 2088956 total, 12 free, 2088944 used. 12365893+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
25414 xxx 20 0 0.188t 1.945g 83876 R 3356 1.6 47:31.03 python3
```
It already runs about two hours and works well. Thanks a lot.<|||||>By the way, how can i use the fine-tuned model please? There are 6 files generated under `output_dir/checkpoint`, which are
`config.json log_history.json optimizer.pt pytorch_model.bin scheduler.pt training_args.bin`. Then how can i use them? Should i just use them as follows? Does the fine-tuned model need to be renamed? Which level of the checkpoint directory should I specify? Thanks a lot.
```shell
tokenizer = GPT2Tokenizer.from_pretrained('/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir/checkpoint-15000')
```
<|||||>Cool! Yes, the way you load the model is correct. I'm guessing you want to use the resulting model, so given that you passed the following as `--output_dir`: `--output_dir=/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir`, you should be able to load it like
```py
tokenizer = GPT2Tokenizer.from_pretrained('/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir')
model = GPT2LMHeadModel.from_pretrained('/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir')
```<|||||>> Cool! Yes, the way you load the model is correct. I'm guessing you want to use the resulting model, so given that you passed the following as `--output_dir`: `--output_dir=/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir`, you should be able to load it like
>
> ```python
> tokenizer = GPT2Tokenizer.from_pretrained('/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir')
> model = GPT2LMHeadModel.from_pretrained('/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir')
> ```
Got it!
I use `--output_dir`: `--output_dir=/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir` and there are many checkpoint generate under it. Just choose one of them, for example, `checkpoint-14000` and copy `'vocab.json', 'merges.txt'` into `/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir/checkpoint-14000`.
```shell
/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir/checkpoint-14000 >>> wget https://cdn.huggingface.co/distilgpt2-vocab.json -O vocab.json
/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir/checkpoint-14000 >>> wget https://cdn.huggingface.co/distilgpt2-merges.txt -O merges.txt
```
Then i use the [run_generation.py](https://github.com/huggingface/transformers/blob/master/examples/text-generation/run_generation.py) like follows and it generate text as expect.
```shell
python run_generation.py --model_type=gpt2 --model_name_or_path=/home/xxx/gpt_model/transformers/examples/language-modeling/output_dir/checkpoint-14000 --no_cuda
```
Thank you for your help! <|||||>Very cool, glad you got it to work! Let us know if you face any other issues.<|||||>It seems like I still have the same issue. I try to use run_language_modeling.py to train a small-bert model (6 layer) from scratch. The process is killed after about 3 hours of training. The error message is simply "Killed" and I observes there's a constant increasing usage of memory. So I think the issue is also OOM
```
top - 16:36:33 up 5:29, 1 user, load average: 1.07, 1.19, 1.16
Tasks: 353 total, 3 running, 349 sleeping, 0 stopped, 1 zombie
%Cpu(s): 10.4 us, 1.2 sy, 0.0 ni, 88.1 id, 0.1 wa, 0.0 hi, 0.2 si, 0.0 st
MiB Mem : 16010.9 total, 151.5 free, 3386.3 used, 12473.2 buff/cache
MiB Swap: 2048.0 total, 1550.2 free, 497.8 used. 12181.5 avail Mem
```
Is this normal? I can't think of a reason why it would use this much memory. |
transformers | 7,019 | closed | Proposal: Offset based Token Classification utilities | # 🚀 Feature request
Hi. So we work a lot with span annotations on text that isn't tokenized and want a "canonical" way to work with that. I have some ideas and rough implementations, so I'm looking for feedback on if this belongs in the library, and if the proposed implementation is more or less good.
I also think there is a good chance that everything I want exists, and the only solution needed is slightly clearer documentation. I should hope that's the case and happy to document if someone can point me in the right direction.
## The Desired Capabilities
What I'd like is a canonical way to:
* Tokenize the examples in the dataset
* Align my annotations with the output tokens (see notes below)
* Have the tokens and labels correctly padded to the max length of an example in the batch or max_sequence_length
* Have a convenient function that returns predicted offsets
### Some Nice To Haves
* It would be nice if such a utility internally handled tagging schemes like IOB BIOES internally and optionally exposed them in the output or "folded" them to the core entities.
* It would be nice if there was a recommended/default strategy implemented for handling examples that are longer then the max_sequence_length
* It would be amazing if we could pass labels to the tokenizer and have the alignment happen in Rust (in parallel). But I don't know Rust and I have a sense this is complicated so I won't be taking that on myself, and assuming that this is happening in Python.
## Current State and what I'm missing
* The docs and examples for Token Classification assume that the [text is pre-tokenized](https://github.com/huggingface/transformers/blob/1b76936d1a9d01cf99a086a3718060a64329afaa/examples/token-classification/utils_ner.py#L110).
* For a word that has a label and is tokenized to multiple tokens, [it is recommended](https://github.com/huggingface/transformers/blob/1b76936d1a9d01cf99a086a3718060a64329afaa/examples/token-classification/utils_ner.py#L116) to place the label on the first token and "ignore" the following tokens
* However it is not clear where that recommendation came from, and it has [edge cases that seem quite nasty](https://github.com/huggingface/transformers/issues/5077#issuecomment-668384357)
* The [example pads all examples to max_sequence_length](https://github.com/huggingface/transformers/blob/1b76936d1a9d01cf99a086a3718060a64329afaa/examples/token-classification/utils_ner.py#L167) which is a big performance hit (as opposed to bucketing by length and padding dynamically)
* The example loads the entire dataset at once in memory. I'm not sure if this is a real problem or I'm being nitpicky, but I think "the right way" to do this would be to lazy load a batch or a few batches.
### Alignment
The path to align tokens to span annotations is by using the return_offsets_mapping flag on the tokenizer (which is awesome!).
There are probably a few strategies, I've been using this
I use logic like this:
```python
def align_tokens_to_annos(offsets,annos):
anno_ix =0
results =[]
done =len(annos)==0
for offset in offsets:
if done == True:
results.append(dict(offset=offset,tag='O',))
else:
anno = annos[anno_ix]
start, end = offset
if end < anno['start']:
# the offset is before the next annotation
results.append(dict(offset=offset, tag='O', ))
elif start <=anno['start'] and end <=anno['end']:
results.append(dict(offset=offset, tag=f'B-{anno["tag"]}',))
elif start>=anno['start'] and end<=anno['end']:
results.append(dict(offset=offset, tag=f'I-{anno["tag"]}', ))
elif start>=anno['start'] and end>anno['end']:
anno_ix += 1
results.append(dict(offset=offset, tag=f'E-{anno["tag"]}', ))
else:
raise Exception(f"Funny Overlap {offset},{anno}",)
if anno_ix>=len(annos):
done=True
return results
```
And then call that function inside add_labels here
```python
res_batch = tokenizer([s['text'] for s in pre_batch],return_offsets_mapping=True,padding=True)
offsets_batch = res_batch.pop('offset_mapping')
res_batch['labels'] =[]
for i in range(len(offsets_batch)):
labels = add_labels(res_batch['input_ids'][i],offsets_batch[i],pre_batch[i]['annotations'])
res_batch['labels'].append(labels)
````
This works, and it's nice because the padding is consistent with the longest sentence so bucketing gives a big boost. But, the add_labels stuff is in python and thus sequential over the examples and not super fast. I haven't measured this to confirm it's a problem, just bring it up.
## Desired Solution
I need most of this stuff so I'm going to make it. I could do it
The current "NER" examples and issues assume that text is pre-tokenized. Our use case is such that the full text is not tokenized and the labels for "NER" come as offsets. I propose a utility /example to handle that scenario because I haven't been able to find one.
In practice, most values of X don't need any modification, and doing what I propose (below) in Rust is beyond me, so this might boil down to a utility class and documentation.
## Motivation
I make [text annotation tools](https://lighttag.io) and our output is span annotations on untokenized text. I want our users to be able to easily use transformers. I suspect from my (limited) experience that in many non-academic use cases, span annotations on untokenized text is the norm and that others would benefit from this as well.
## Possible ways to address this
I can imagine a few scenarios here
* **This is out of scope** Maybe this isn't something that should be handled by transformers at all, and delegated to a library and blog post
* **This is in scope and just needs documentation** e.g. all the things I mentioned are things transformers should and can already do. In that case the solution would be pointing someone (me) to the right functions and adding some documentation
* **This is in scope and should be a set of utilities ** Solving this could be as simple as making a file similar to [utils_ner.py](https://github.com/huggingface/transformers/blob/1b76936d1a9d01cf99a086a3718060a64329afaa/examples/token-classification/utils_ner.py). I think that would be the simplest way to get something usable and gather feedback see if anyone else cares
* **This is in scope but should be done in Rust soon** If we want to be performance purists, it would make sense to handle the alignment of span based labels in Rust. I don't know Rust so I can't help much and I don't know if there is any appetite or capacity from someone that does, or if it's worth the (presumably) additional effort.
## Your contribution
I'd be happy to implement and submit a PR, or make an external library or add to a relevant existing one.
## Related issues
* #5297
* [This PR](https://github.com/huggingface/transformers/pull/3957)
| 09-08-2020 19:43:43 | 09-08-2020 19:43:43 | Hi, this is a very nice issue and I plan to work soon (in the coming 2 weeks) on related things (improving the examples to make full use of the Rust tokenization features). I'll re-read this issue (and all the links) to extract all the details and likely come back to you at that time.
In the meantime, here are two elements for your project:
- the first is that for the fast tokenizers, the output of the tokenizer (a `BatchEncoding` instance) is actually a special kind of python dict with some super fast alignement methods powered by Rust, including a `char_to_token` alignement method that could maybe make your `align_tokens_to_annos` method a lot simpler and faster. You can read about it here: https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.BatchEncoding.char_to_token
- the second element is that support for sentence piece is almost there in `tokenizers` so we will soon be able to use fast tokenizers for almost all the models.<|||||>Thanks! That's super helpful.
I also found out I can iterate over the batch which is really nice.
I did find a bug and [opened an issue](https://github.com/huggingface/tokenizers/issues/404)
```python
from transformers import BertTokenizerFast,GPT2TokenizerFast
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased',)
for i in range(1,5):
txt = "💩"*i
enc = tokenizer(txt,return_offsets_mapping=True)
token_at_i = enc.char_to_token(i-1)
dec = tokenizer.decode(enc['input_ids'])
print (f" I wrote {txt} but got back '{dec}' and char_to_tokens({i-1}) returned {token_at_i}")
```
```
I wrote 💩 but got back '[CLS] [UNK] [SEP]' and char_to_tokens(0) returned 1
I wrote 💩💩 but got back '[CLS] [UNK] [SEP]' and char_to_tokens(1) returned 1
I wrote 💩💩💩 but got back '[CLS] [UNK] [SEP]' and char_to_tokens(2) returned 1
I wrote 💩💩💩💩 but got back '[CLS] [UNK] [SEP]' and char_to_tokens(3) returned 1
```<|||||>## Progress - But Am I doing this right ?
Hi,
I made some progress and got some logic that aligns the tokens to offset annotations. A function call looks like this
```python
batch,labels = tokenize_with_labels(texts,annotations,tokenizer,label_set=label_set)
```
And then a visualization of the alignment looks like this (which is trying to show annotations across multiple tokens)

## Question
So I'm trying to get the padding /batching working. I think I've got something good but would love some input on how this might subtly fail.
```python
batch,labels = tokenize_with_labels(texts,annotations,tokenizer,label_set=label_set)
batch.data['labels'] =labels # Put the labels in the BatchEncoding dict
padded = tokenizer.pad(batch,padding='longest') # Call pad, which ignores the labels and offset_mappings
batch_size = len(padded['input_ids'][0]) # Get the padded sequence size
for i in range(len(padded['labels'])): #for each label
ls = padded['labels'][i]
difference = batch_size - len(ls) # How much do we need to pad ?
padded['labels'][i] = padded['labels'][i] +[0] *difference # Pad
padded['offset_mapping'][i]+=[(0,0)]*difference #pad the offset mapping so we can call convert_to_tensors
tensors = padded.convert_to_tensors(tensor_type='pt') #convert to a tensor
```
<|||||>Hmm I think we should have an option to pad the labels in `tokenizer.pad`.
Either based on the shape of the labels or with an additional flag.
I'll work on the tokenizers this week. Will add this to the stack.<|||||>I think that presupposes that the user has labels aligned to tokens, or that their is one and only one right way to align labels and tokens, which isn't consistent with the original issue.
When that's not the case, then we need to tokenize, then align labels and finally pad. (Also need to deal with overflow, but I haven't gotten that far yet) . Notably, the user may want to use a BIO,BILSO or other schema and needs access to the tokens to modify the labels accordingly.
Something that confused me as I've been working on this is that the _pad function [operates explicitly on named attributes of the batch encoding dict](https://github.com/huggingface/transformers/blob/15478c1287a4e7b52c01730ffb0718243d153600/src/transformers/tokenization_utils_base.py#L2642-L2663) whereas as a user I'd expect it to operate on everything in the underlying ```encoding.data``` dict. That however doesn't work because the dict includes offset_mappings which don't tensorize nicely.
Because of the logic involved in alignment, I think that padding of the tokens and labels might be better done outside of the tokenizer, probably with a specialized function / module.
The upside of padding in one go is the efficiency of doing so in Rust, but I'd speculate that for token classification, the running time would be dominated by training anyway, and the efficiency gains wouldn't justify the API complexity or documentation burdon of doing it all in one place.
Also, I think that's a theoretical point because it seems that the padding is [done in python anyway](https://github.com/huggingface/transformers/blob/15478c1287a4e7b52c01730ffb0718243d153600/src/transformers/tokenization_utils_base.py#L2646) ?
I ended up doing
``` python
def tokenize_with_labels(
texts: List[str],
raw_labels: List[List[SpanAnnotation]],
tokenizer: PreTrainedTokenizerFast,
label_set: LabelSet, #Basically the alignment strategy
):
batch_encodings = tokenizer(
texts,
return_offsets_mapping=True,
padding="longest",
max_length=256,
truncation=True,
)
batch_labels: IntListList = []
for encoding, annotations in zip(batch_encodings.encodings, raw_labels):
batch_labels.append(label_set.align_labels_to_tokens(encoding, annotations))
return batch_encodings, batch_labels
```
where align_labels_to_tokens operates on already padded tokens.
I found this the most convenient way to get dynamic batches with a collator
```python
@dataclass
class LTCollator:
tokenizer: PreTrainedTokenizerFast
label_set: LabelSet
padding: PaddingStrategy = True
max_length: Optional[int] = None
def __call__(self, texts_and_labels: Example) -> BatchEncoding:
texts: List[str] = []
annotations: List[List[SpanAnnotation]] = []
for (text, annos) in texts_and_labels:
texts.append(text)
annotations.append(annos)
batch, labels = tokenize_with_labels(
texts, annotations, self.tokenizer, label_set=self.label_set
)
del batch["offset_mapping"]
batch.data["labels"] = labels # Put the labels in the BatchEncoding dict
tensors = batch.convert_to_tensors(tensor_type="pt") # convert to a tensor
return tensors
```
<|||||>As an example of the end to end flow, (and please No one use this it's a probably buggy work in progress)
```python
from typing import Any, Optional, List, Tuple
from transformers import (
BertTokenizerFast,
BertModel,
BertForMaskedLM,
BertForTokenClassification,
TrainingArguments,
)
import torch
from transformers import AdamW, Trainer
from dataclasses import dataclass
from torch.utils.data import Dataset
import json
from torch.utils.data.dataloader import DataLoader
from transformers import PreTrainedTokenizerFast, DataCollatorWithPadding, BatchEncoding
from transformers.tokenization_utils_base import PaddingStrategy
from labelset import LabelSet
from token_types import IntListList, SpanAnnotation
from tokenize_with_labels import tokenize_with_labels
Example = Tuple[str, List[List[SpanAnnotation]]]
@dataclass
class LTCollator:
tokenizer: PreTrainedTokenizerFast
label_set: LabelSet
padding: PaddingStrategy = True
max_length: Optional[int] = None
def __call__(self, texts_and_labels: Example) -> BatchEncoding:
texts: List[str] = []
annotations: List[List[SpanAnnotation]] = []
for (text, annos) in texts_and_labels:
texts.append(text)
annotations.append(annos)
batch, labels = tokenize_with_labels(
texts, annotations, self.tokenizer, label_set=self.label_set
)
del batch["offset_mapping"]
batch.data["labels"] = labels # Put the labels in the BatchEncoding dict
tensors = batch.convert_to_tensors(tensor_type="pt") # convert to a tensor
return tensors
class LTDataset(Dataset):
def __init__(
self, data: Any, tokenizer: PreTrainedTokenizerFast,
):
self.tokenizer = tokenizer
for example in data["examples"]:
for a in example["annotations"]:
a["label"] = a["tag"]
self.texts = []
self.annotations = []
for example in data["examples"]:
self.texts.append(example["content"])
self.annotations.append(example["annotations"])
def __len__(self):
return len(self.texts)
def __getitem__(self, idx) -> Example:
return self.texts[idx], self.annotations[idx]
@dataclass
class LTDataControls:
dataset: LTDataset
collator: LTCollator
label_set: LabelSet
def lt_data_factory(
json_path: str, tokenizer: PreTrainedTokenizerFast, max_length=None
):
data = json.load(open(json_path))
dataset = LTDataset(data=data, tokenizer=tokenizer)
tags = list(map(lambda x: x["name"], data["schema"]["tags"]))
label_set = LabelSet(tags)
collator = LTCollator(
max_length=max_length, label_set=label_set, tokenizer=tokenizer
)
return LTDataControls(dataset=dataset, label_set=label_set, collator=collator)
if __name__ == "__main__":
from transformers import BertTokenizerFast, GPT2TokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("bert-base-cased",)
data_controls = lt_data_factory(
"/home/tal/Downloads/small_gold_no_paragr_location_types_false_5_annotations.json",
tokenizer=tokenizer,
max_length=256,
)
dl = DataLoader(
data_controls.dataset, collate_fn=data_controls.collator, batch_size=10
)
model = BertForTokenClassification.from_pretrained(
"bert-base-cased", num_labels=len(data_controls.label_set.ids_to_label.values())
)
train = Trainer(
model=model,
data_collator=data_controls.collator,
train_dataset=data_controls.dataset,
args=TrainingArguments("/tmp/trainer", per_device_train_batch_size=2),
)
train.train()
```<|||||>Also, I found [this comment](https://github.com/huggingface/transformers/issues/6860#issuecomment-684118716) by @sgugger about the trainer
>Note that there are multiple frameworks that provide generic training loops. The goal of Trainer (I'm assuming you're talking about it since there is no train.py file) is **not to replace them or compete with them but to provide an easy way to train and finetune Transformers models**. Those models don't take nested inputs, so Trainer does not support this. Those models are expected to return the loss as the first item of their output, so Trainer expects it too.
I think that sentiment might make sense here, that what I'm looking for is outside the scope of the library. If that's the case I would have preferred it be written in big bold letters, rather than the library trying to cater to this use case
<|||||>So,
After much rabbit hole, I've written a blog post about the [considerations when doing alignment/padding/batching](https://www.lighttag.io/blog/sequence-labeling-with-transformers/) and another [walking through an implementation](https://www.lighttag.io/blog/sequence-labeling-with-transformers/example).
It even [comes with a repo](https://github.com/LightTag/sequence-labeling-with-transformers)
so
If we have annotated data like this
```python
[{'annotations': [],
'content': 'No formal drug interaction studies of Aranesp? have been '
'performed.',
'metadata': {'original_id': 'DrugDDI.d390.s0'}},
{'annotations': [{'end': 13, 'label': 'drug', 'start': 6, 'tag': 'drug'},
{'end': 60, 'label': 'drug', 'start': 43, 'tag': 'drug'},
{'end': 112, 'label': 'drug', 'start': 105, 'tag': 'drug'},
{'end': 177, 'label': 'drug', 'start': 164, 'tag': 'drug'},
{'end': 194, 'label': 'drug', 'start': 181, 'tag': 'drug'},
{'end': 219, 'label': 'drug', 'start': 211, 'tag': 'drug'},
{'end': 238, 'label': 'drug', 'start': 227, 'tag': 'drug'}],
'content': 'Since PLETAL is extensively metabolized by cytochrome P-450 '
'isoenzymes, caution should be exercised when PLETAL is '
'coadministered with inhibitors of C.P.A. such as ketoconazole '
'and erythromycin or inhibitors of CYP2C19 such as omeprazole.',
'metadata': {'original_id': 'DrugDDI.d452.s0'}},
{'annotations': [{'end': 58, 'label': 'drug', 'start': 47, 'tag': 'drug'},
{'end': 75, 'label': 'drug', 'start': 62, 'tag': 'drug'},
{'end': 135, 'label': 'drug', 'start': 124, 'tag': 'drug'},
{'end': 164, 'label': 'drug', 'start': 152, 'tag': 'drug'}],
'content': 'Pharmacokinetic studies have demonstrated that omeprazole and '
'erythromycin significantly increased the systemic exposure of '
'cilostazol and/or its major metabolites.',
'metadata': {'original_id': 'DrugDDI.d452.s1'}}]
```
We can do this
```python
from sequence_aligner.labelset import LabelSet
from sequence_aligner.dataset import TrainingDataset
from sequence_aligner.containers import TraingingBatch
import json
raw = json.load(open('./data/ddi_train.json'))
for example in raw:
for annotation in example['annotations']:
#We expect the key of label to be label but the data has tag
annotation['label'] = annotation['tag']
from torch.utils.data import DataLoader
from transformers import BertForTokenClassification,AdamW
model = BertForTokenClassification.from_pretrained(
"bert-base-cased", num_labels=len(dataset.label_set.ids_to_label.values())
)
optimizer = AdamW(model.parameters(), lr=5e-6)
dataloader = DataLoader(
dataset,
collate_fn=TraingingBatch,
batch_size=4,
shuffle=True,
)
for num, batch in enumerate(dataloader):
loss, logits = model(
input_ids=batch.input_ids,
attention_mask=batch.attention_masks,
labels=batch.labels,
)
loss.backward()
optimizer.step()
-------------------------------
I think most of this is out of scope for the transformers library itself, so am all for closing this issue if no one objects<|||||>(I attempted to fix the links above, let me know if this is correct @talolard)<|||||>> (I attempted to fix the links above, let me know if this is correct @talolard)
Links seem kosher, thanks<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,018 | closed | [s2s] --eval_max_generate_length | 09-08-2020 19:25:32 | 09-08-2020 19:25:32 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7018?src=pr&el=h1) Report
> Merging [#7018](https://codecov.io/gh/huggingface/transformers/pull/7018?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d6c08b07a087e83915b4b3156bbf464cebc7b9b5?el=desc) will **increase** coverage by `0.26%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7018?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7018 +/- ##
==========================================
+ Coverage 78.74% 79.01% +0.26%
==========================================
Files 168 164 -4
Lines 32172 30987 -1185
==========================================
- Hits 25335 24483 -852
+ Misses 6837 6504 -333
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7018?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9sb25nZm9ybWVyLnB5) | `16.37% <0.00%> (-82.31%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9lbGVjdHJhLnB5) | `25.13% <0.00%> (-73.83%)` | :arrow_down: |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `19.71% <0.00%> (-72.34%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `75.00% <0.00%> (-25.00%)` | :arrow_down: |
| [src/transformers/utils/logging.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy91dGlscy9sb2dnaW5nLnB5) | `75.00% <0.00%> (-10.90%)` | :arrow_down: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `76.70% <0.00%> (-6.07%)` | :arrow_down: |
| [src/transformers/tokenization\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYWxiZXJ0LnB5) | `87.50% <0.00%> (-5.77%)` | :arrow_down: |
| [src/transformers/testing\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90ZXN0aW5nX3V0aWxzLnB5) | `65.89% <0.00%> (-3.50%)` | :arrow_down: |
| [...rc/transformers/data/datasets/language\_modeling.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFzZXRzL2xhbmd1YWdlX21vZGVsaW5nLnB5) | `90.80% <0.00%> (-2.14%)` | :arrow_down: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `91.90% <0.00%> (-0.93%)` | :arrow_down: |
| ... and [40 more](https://codecov.io/gh/huggingface/transformers/pull/7018/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7018?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7018?src=pr&el=footer). Last update [d6c08b0...6d5adc4](https://codecov.io/gh/huggingface/transformers/pull/7018?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 7,017 | closed | pegasus.rst: fix expected output | <!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #{issue number}
| 09-08-2020 17:09:50 | 09-08-2020 17:09:50 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7017?src=pr&el=h1) Report
> Merging [#7017](https://codecov.io/gh/huggingface/transformers/pull/7017?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5c4eb4b1ac45291e89c1be0fb1fdacd841b19a47?el=desc) will **decrease** coverage by `0.15%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7017?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7017 +/- ##
==========================================
- Coverage 80.39% 80.23% -0.16%
==========================================
Files 164 164
Lines 30986 30986
==========================================
- Hits 24910 24863 -47
- Misses 6076 6123 +47
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7017?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9sb25nZm9ybWVyLnB5) | `16.37% <0.00%> (-82.31%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9lbGVjdHJhLnB5) | `25.13% <0.00%> (-73.83%)` | :arrow_down: |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `79.03% <0.00%> (-7.80%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `84.14% <0.00%> (-3.07%)` | :arrow_down: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `83.45% <0.00%> (-1.76%)` | :arrow_down: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `91.90% <0.00%> (-0.81%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `86.97% <0.00%> (-0.33%)` | :arrow_down: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `81.00% <0.00%> (+0.24%)` | :arrow_up: |
| [src/transformers/configuration\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3V0aWxzLnB5) | `96.64% <0.00%> (+0.67%)` | :arrow_up: |
| [src/transformers/tokenization\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYXV0by5weQ==) | `97.87% <0.00%> (+2.12%)` | :arrow_up: |
| ... and [7 more](https://codecov.io/gh/huggingface/transformers/pull/7017/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7017?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7017?src=pr&el=footer). Last update [5c4eb4b...4de36a2](https://codecov.io/gh/huggingface/transformers/pull/7017?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,016 | closed | [Longformer] Fix longformer documentation | <!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #7015
| 09-08-2020 16:19:10 | 09-08-2020 16:19:10 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7016?src=pr&el=h1) Report
> Merging [#7016](https://codecov.io/gh/huggingface/transformers/pull/7016?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d31031f603043281d4fbac6cbdcfb6497fd500ab?el=desc) will **decrease** coverage by `3.56%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7016?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7016 +/- ##
==========================================
- Coverage 80.03% 76.47% -3.57%
==========================================
Files 161 161
Lines 30120 30120
==========================================
- Hits 24108 23033 -1075
- Misses 6012 7087 +1075
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7016?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `92.02% <ø> (ø)` | |
| [src/transformers/configuration\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3JlZm9ybWVyLnB5) | `21.62% <0.00%> (-78.38%)` | :arrow_down: |
| [src/transformers/modeling\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yZWZvcm1lci5weQ==) | `16.87% <0.00%> (-77.64%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9tb2JpbGViZXJ0LnB5) | `24.55% <0.00%> (-72.36%)` | :arrow_down: |
| [src/transformers/configuration\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX21vYmlsZWJlcnQucHk=) | `26.47% <0.00%> (-70.59%)` | :arrow_down: |
| [src/transformers/modeling\_mobilebert.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tb2JpbGViZXJ0LnB5) | `23.49% <0.00%> (-65.97%)` | :arrow_down: |
| [src/transformers/modeling\_transfo\_xl\_utilities.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190cmFuc2ZvX3hsX3V0aWxpdGllcy5weQ==) | `52.98% <0.00%> (-13.44%)` | :arrow_down: |
| [src/transformers/modeling\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190cmFuc2ZvX3hsLnB5) | `67.10% <0.00%> (-12.67%)` | :arrow_down: |
| [src/transformers/tokenization\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fcm9iZXJ0YS5weQ==) | `87.67% <0.00%> (-10.96%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `86.72% <0.00%> (-7.32%)` | :arrow_down: |
| ... and [14 more](https://codecov.io/gh/huggingface/transformers/pull/7016/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7016?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7016?src=pr&el=footer). Last update [d31031f...2f15fa5](https://codecov.io/gh/huggingface/transformers/pull/7016?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,015 | closed | Longformer global attention mask, 2 or 1? | This example in the LongFormer documentation (https://huggingface.co/transformers/model_doc/longformer.html )
```
attention_mask[:, [1, 4, 21,]] = 2 # Set global attention based on the task. For example,
... # classification: the <s> token
... # QA: question tokens
... # LM: potentially on the beginning of sentences and paragraphs
```
seems to mislead the user to put a 2 as the global attention mask instead of a 1 this is described in the actual documentation. I'm guessing this is a mistake because (a) the example is directly copied from the AllenAI (https://github.com/allenai/longformer#how-to-use), and (b) the source code actually adds a +1 to the attention mask in the function `_merge_to_attention_mask` (https://huggingface.co/transformers/_modules/transformers/modeling_longformer.html#LongformerModel.forward).
Could the documentation please be fixed or clarified? Thanks!
Also what is the 1, 4, 21 in that example?
### Who can help
Longformer/Reformer: @patrickvonplaten
## Information
Model I am using (Bert, XLNet ...): LongFormer
| 09-08-2020 15:55:28 | 09-08-2020 15:55:28 | That is 100% correct - thanks for notifying us :-) PR is linked.<|||||>Also what is the 1, 4, 21 in that example? Can someone answer this?<|||||>Just random indices that will be attended and will attend globally<|||||>So if we are passing a sentence during inferencing `I love Hugging face` and I give value `attention_mask[:, [0,-1]] = 2` then ` <s> and </s>` will be attended globally?? And then I can fetch `<s>` embedding to get embedding of the sentence? |
transformers | 7,014 | closed | [wip] Pegasus: Hack to never generate unk | <!-- This line specifies which issue to close after the pull request is merged. -->
Fixes #{issue number}
| 09-08-2020 15:06:01 | 09-08-2020 15:06:01 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7014?src=pr&el=h1) Report
> Merging [#7014](https://codecov.io/gh/huggingface/transformers/pull/7014?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ce37be9d94da57897cce9c49b3421e6a8a927d4a?el=desc) will **increase** coverage by `2.40%`.
> The diff coverage is `20.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/7014?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7014 +/- ##
==========================================
+ Coverage 77.60% 80.01% +2.40%
==========================================
Files 161 161
Lines 30120 30124 +4
==========================================
+ Hits 23374 24103 +729
+ Misses 6746 6021 -725
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7014?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_pegasus.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19wZWdhc3VzLnB5) | `69.23% <20.00%> (-30.77%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9lbGVjdHJhLnB5) | `25.13% <0.00%> (-73.83%)` | :arrow_down: |
| [src/transformers/modeling\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19tYXJpYW4ucHk=) | `60.00% <0.00%> (-30.00%)` | :arrow_down: |
| [src/transformers/activations.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9hY3RpdmF0aW9ucy5weQ==) | `85.00% <0.00%> (-5.00%)` | :arrow_down: |
| [src/transformers/modeling\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iYXJ0LnB5) | `93.90% <0.00%> (-0.51%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `86.97% <0.00%> (-0.33%)` | :arrow_down: |
| [src/transformers/tokenization\_utils\_base.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHNfYmFzZS5weQ==) | `93.76% <0.00%> (-0.28%)` | :arrow_down: |
| [src/transformers/generation\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9nZW5lcmF0aW9uX3RmX3V0aWxzLnB5) | `86.71% <0.00%> (+2.50%)` | :arrow_up: |
| [src/transformers/modeling\_lxmert.py](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19seG1lcnQucHk=) | `90.76% <0.00%> (+20.74%)` | :arrow_up: |
| ... and [3 more](https://codecov.io/gh/huggingface/transformers/pull/7014/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7014?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7014?src=pr&el=footer). Last update [ce37be9...f841173](https://codecov.io/gh/huggingface/transformers/pull/7014?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,013 | closed | Fixing FLOPS merge by checking if torch is available | 09-08-2020 14:22:53 | 09-08-2020 14:22:53 | ||
transformers | 7,012 | closed | Error in run_language_modeling on TPU: Transferring data with element type U8 has not been implemented on TPUs | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.1.0
- Platform: Linux-4.19.0-10-cloud-amd64-x86_64-with-debian-9.13
- Python version: 3.7.7
- PyTorch version (GPU?): 1.7.0a0+626e410 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No (TPU)
- Using distributed or parallel set-up in script?: No
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @TevenLeScao
blenderbot: @mariamabarham
Bart: @sshleifer
Marian: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...): GPT2 - (Not pretrained)
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
I am trying to train a GPT model from scratch with TPU v2-8 in GCP. I have tried several setups but consistently getting the error below. I have simplified the arguments as much as I can do to increase the reproducibility.
Steps to reproduce the behavior:
1. Pytorch/XLA installed through docker: gcr.io/tpu-pytorch/xla:nightly_3.7
2. Transformers 3.1.0 installed through pip.
3. I used the latest xla_spawn.py with previous version of [run_language_modeling.py](https://github.com/huggingface/transformers/blob/a75c64d80c76c3dc71f735d9197a4a601847e0cd/examples/language-modeling/run_language_modeling.py) because the latest version of run_language_modeling gives error about cache_dir.
4. Simple txt file with 10k lines given as input.
```bash
python xla_spawn.py --num_cores=1 run_language_modeling.py --output_dir=/home/GPT/output --model_type=gpt2 --tokenizer_name=gpt2 --do_train --train_data_file=/home/GPT/corpus/oscar_wiki_opus_eval.txt --per_device_train_batch_size=128
```
Output:
```bash
09/08/2020 11:28:50 - WARNING - run_language_modeling - Process rank: -1, device: xla:1, n_gpu: 0, distributed training: False, 16-bits training: False
09/08/2020 11:28:50 - INFO - run_language_modeling - Training/evaluation parameters TrainingArguments(output_dir='/home/GPT/output', overwrite_output_dir=False, do_train=True, do_eval=False, do_predict=False, evaluate_during_training=False, prediction_loss_only=False, per_device_train_batch_size=128, per_device_eval_batch_size=8, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, warmup_steps=0, logging_dir='runs/Sep08_11-28-39_b0b61c9b1d63', logging_first_step=False, logging_steps=500, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', local_rank=-1, tpu_num_cores=1, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=1000, past_index=-1, run_name=None, disable_tqdm=False, remove_unused_columns=True)
09/08/2020 11:28:50 - WARNING - run_language_modeling - You are instantiating a new config instance from scratch.
09/08/2020 11:28:50 - INFO - run_language_modeling - Training new model from scratch
/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/transformers/modeling_auto.py:732: FutureWarning: The class `AutoModelWithLMHead` is deprecated and will be removed in a future version. Please use `AutoModelForCausalLM` for causal language models, `AutoModelForMaskedLM` for masked language models and `AutoModelForSeq2SeqLM` for encoder-decoder models.
FutureWarning,
/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/transformers/tokenization_utils_base.py:1321: FutureWarning: The `max_len` attribute has been deprecated and will be removed in a future version, use `model_max_length` instead.
FutureWarning,
09/08/2020 11:28:54 - INFO - filelock - Lock 140191457088144 acquired on /home/GPT/corpus/cached_lm_GPT2Tokenizer_1024_oscar_wiki_opus_eval.txt.lock
09/08/2020 11:29:09 - INFO - filelock - Lock 140191457088144 released on /home/GPT/corpus/cached_lm_GPT2Tokenizer_1024_oscar_wiki_opus_eval.txt.lock
Traceback (most recent call last):
File "xla_spawn.py", line 72, in <module>
main()
File "xla_spawn.py", line 68, in main
xmp.spawn(mod._mp_fn, args=(), nprocs=args.num_cores)
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 387, in spawn
_start_fn(0, pf_cfg, fn, args)
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 324, in _start_fn
fn(gindex, *args)
File "/home/GPT/run_language_modeling.py", line 294, in _mp_fn
main()
File "/home/GPT/run_language_modeling.py", line 252, in main
prediction_loss_only=True,
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/transformers/trainer.py", line 229, in __init__
self.model = model.to(args.device) if model is not None else None
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py", line 612, in to
return self._apply(convert)
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py", line 359, in _apply
module._apply(fn)
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py", line 359, in _apply
module._apply(fn)
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py", line 359, in _apply
module._apply(fn)
[Previous line repeated 1 more time]
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py", line 402, in _apply
self._buffers[key] = fn(buf)
File "/root/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py", line 610, in convert
return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
RuntimeError: tensorflow/compiler/xla/xla_client/xrt_computation_client.cc:383 : Check failed: session->session()->Run( session_work->feed_inputs, session_work->outputs_handles, &outputs) == ::tensorflow::Status::OK() (Unimplemented: From /job:tpu_worker/replica:0/task:0:
Attempted to transfer array of shape u8[1,1,1024,1024] to a TPU device. Transferring data with element type U8 has not been implemented on TPUs.
[[{{node XRTAllocateFromTensor_6}}]] vs. OK)
*** Begin stack trace ***
tensorflow::CurrentStackTrace()
xla::util::MultiWait::Complete(std::function<void ()> const&)
clone
*** End stack trace ***
terminate called after throwing an instance of 'std::runtime_error'
what(): tensorflow/compiler/xla/xla_client/xrt_computation_client.cc:1110 : Check failed: session->session()->Run( feed_inputs, {}, {cached_node.operations[0]}, &outputs) == ::tensorflow::Status::OK() (Not found: Op type not registered 'XRTMemoryInfo' in binary running on n-cec96fe8-w-0. Make sure the Op and Kernel are registered in the binary running in this process. Note that if you are loading a saved graph which used ops from tf.contrib, accessing (e.g.) `tf.contrib.resampler` should be done before importing the graph, as contrib ops are lazily registered when the module is first accessed. vs. OK)
*** Begin stack trace ***
tensorflow::CurrentStackTrace()
xla::XrtComputationClient::ReleaseHandles(std::vector<xla::XrtComputationClient::DeviceHandle, std::allocator<xla::XrtComputationClient::DeviceHandle> >*, std::function<xla::XrtSession::CachedNode const& (xla::XrtSession*, tensorflow::Scope const&, std::string const&)> const&, xla::metrics::Metric*, xla::metrics::Counter*)
xla::XrtComputationClient::HandleReleaser()
xla::util::TriggeredTask::Runner()
clone
*** End stack trace ***
Aborted (core dumped)
```
## Expected behavior
I would expect it to train GPT model on TPU with given txt file from scratch.
P.S.:
I have also tried with the stable version of XLA (gcr.io/tpu-pytorch/xla:r1.6) and different model_type and tokenizer_name (bert). I am getting the same error in both cases.
I have tried several things to change the input type to float in the source code of transformers, but I was not successful. Any tips for that direction would be good for me, too. | 09-08-2020 11:35:14 | 09-08-2020 11:35:14 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,011 | closed | getting 'ValueError-TextInputSequence must be str' in 'train_dataset = train_dataset.map(convert_to_features)' | Hello friends,
I want to fine tune longformer QnA for different data. I found this code very relevant to my requirement, so was trying to understand the same thoroughly. but getting an error.
i am trying to run the same code that Suraj has on github.
**
> 'ValueError-TextInputSequence must be str' in 'train_dataset = train_dataset.map(convert_to_features)'.
**
`train_dataset = nlp.load_dataset('squad', split=nlp.Split.TRAIN)
valid_dataset = nlp.load_dataset('squad', split=nlp.Split.VALIDATION)
train_dataset = train_dataset.map(convert_to_features)
valid_dataset = valid_dataset.map(convert_to_features, load_from_cache_file=False)
#patil_suraj | 09-08-2020 10:30:34 | 09-08-2020 10:30:34 | @patil-suraj
Can you help me with this? |
transformers | 7,010 | closed | Huggingface "sentiment-analysis" pipeline always output "POSITIVE" label even for negative sentences | ## Environment info
- `transformers` version: 3.1
- Platform: AWS , Colab etc.
- Python version: 3.6
- PyTorch version (GPU?): NA
- Tensorflow version (GPU?): NA
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
examples/token-classification: @stefan-it
## Information
Model I am using (Bert: https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english):
The problem arises when using:
* [T ] the official example scripts: (give details below)
from transformers import pipeline
classifier = pipeline('sentiment-analysis')
classifier("I hate this thing") -->Returns Postive label
In fact when tested with a large bacth it never returned Negative label at all
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Get transformer 3.1
2. Use pipeline("sentiment-analysis")
3. Get label and score
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
from transformers import pipeline
classifier = pipeline('sentiment-analysis')
classifier("I hate this thing") -->Returns Negative label
Updates post some more experiments:
- I am using distilbert-base-uncased-finetuned-sst-2-english following instruction from :https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english
- When I download the model and save it in local before using it through AutoModel and AutoTokenizer the score for sentence nlp("i dislike it") is 0.5453
- when I directly use it without manually downloading the model to local the same score jumps to 0.99 [same score in hosted modelhub inference api as well]
- another observation is that the tokenizer_config.json has both special_tokens_map_file and full_tokneizer_file as Null. Not sure if it supposed to be like this
- for my purpose I have to use the downloaded and manually loaded style of inferencing
<!-- A clear and concise description of what you would expect to happen. -->
| 09-08-2020 10:11:27 | 09-08-2020 10:11:27 | Upon further updates, I think the issue was with using wrong AutoModel function. I replaced it with AutoModelforSequenceClassification at the time of download and it worked. |
transformers | 7,009 | closed | Index out of range in Bart-large-xsum | Questions & Help
Hello to everyone!!
I am facing a problem summarizing long articles. I mean very long text with larger vocab size than it is pre-trained already i guess.
I see that many of the models have a limitation of maximum input and trying to execute results in error of index out of range.
I am particularly using "BART-large-xsum". Please suggest what is the correct way of using these models with long documents shall I finetuning to increase the vocabsize or do anything else.
A code snippet with an example of how to handle long documents with the "BART-large-xsum" would be perfect to start with!
Thanks in advance,
Teja
| 09-08-2020 09:35:31 | 09-08-2020 09:35:31 | Pinging @sshleifer, the summarization master<|||||>See https://discuss.huggingface.co/t/summarization-on-long-documents/920/2, and feel free to reply there!
I don't have a code snippet but feel free to contribute one to that discussion! |
transformers | 7,008 | closed | Diverse Beam Search decoding | # 🚀 Feature request
Currently, with all the decoding strategies available in this library, there isn't any decoding strategy which helps in producing diverse outputs across the beam of the decoder. Such diversity is useful for tasks such as noisy data augmentation where you want to generate multiple possible outputs. [Diverse Beam Search](https://arxiv.org/abs/1610.02424) paper introduces an extremely simple trick to accomplish this and it works really well.
It is already implemented in the fairseq library and would be cool to have it in transformers too.
## Motivation
Having a decoding strategy which promotes more diversity across the beam.
## Your contribution
I would like to submit a PR for it, but before that I would like to know if there has already been some work internally on exploring this. I would appreciate if someone from the team could guide me on what parts of the code are relevant for this to work.
cc @patrickvonplaten would love some feedback from you since your wrote this [blog](https://huggingface.co/blog/how-to-generate) and you may have seen some work around this.
| 09-08-2020 08:47:47 | 09-08-2020 08:47:47 | Hey @dakshvar22,
Thanks for posting this Diverse Beam Search paper. Looks cool :-)
At the moment, I won't find the time to take a deeper look, but feel free to open a PR to add it to our generate() method and I'm happy to discuss possible design choices :-) <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>My understanding is that this should have been closed by https://github.com/huggingface/transformers/pull/9006? |
transformers | 7,007 | closed | MLM performance difference between bert-base-cased and Conversational BERT | ## Environment info
- `transformers` version: 3.1.0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0+cu101 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
Authors of Conversational BERT: @dilyararimovna @yoptar from DeepPavlov
## Information
I am using `bert-base-cased` and [Conversational BERT](https://huggingface.co/DeepPavlov/bert-base-cased-conversational) for MLM using the pipeline tool. The only difference between the two is that Conversational BERT was initialized with `bert-base-cased` and further pre-trained on social media text data (Twitter and the like) with a custom vocabulary (more info on the model card).
As I'm using models that were not yet finetuned, I understand why I'm getting an output telling me that some weights were not used and that some weights are newly initialized (cf [this issue](https://github.com/huggingface/transformers/issues/5421)). What I don't understand is that even though the two models seem to have the same architecture and were trained on similar tasks (MLM and next sentence prediction), the performance on MLM is really poor for Conversational BERT and pretty good for `bert-base-cased`. This is all the more weird that I used Conversational BERT for tweet classification and found that it performed better than `bert-base-cased` on this downstream task.
For example, when giving '[MASK] lost his job yesterday' as input, the output for `bert-base-cased` (`pipeline_bert('[MASK] lost his job yesterday')`) is
[{'score': 0.8036763072013855,
'sequence': '[CLS] he lost his job yesterday [SEP]',
'token': 2002,
'token_str': 'he'},
{'score': 0.005656923167407513,
'sequence': '[CLS] i lost his job yesterday [SEP]',
'token': 1045,
'token_str': 'i'},
{'score': 0.005227738991379738,
'sequence': '[CLS] dad lost his job yesterday [SEP]',
'token': 3611,
'token_str': 'dad'},
{'score': 0.0032391520217061043,
'sequence': '[CLS] david lost his job yesterday [SEP]',
'token': 2585,
'token_str': 'david'},
{'score': 0.0028738391119986773,
'sequence': '[CLS] and lost his job yesterday [SEP]',
'token': 1998,
'token_str': 'and'}]
and the output for Conversational BERT (`pipeline_convbert('[MASK] lost his job yesterday')`) is:
[{'score': 0.0005837088683620095,
'sequence': '[CLS]As lost his job yesterday [SEP]',
'token': 23390,
'token_str': '##As'},
{'score': 0.0004703140293713659,
'sequence': '[CLS] rock lost his job yesterday [SEP]',
'token': 2067,
'token_str': 'rock'},
{'score': 0.0004569509474094957,
'sequence': '[CLS] ACT lost his job yesterday [SEP]',
'token': 21111,
'token_str': 'ACT'},
{'score': 0.0004535183834377676,
'sequence': '[CLS] colour lost his job yesterday [SEP]',
'token': 5922,
'token_str': 'colour'},
{'score': 0.0004286181356292218,
'sequence': '[CLS]inas lost his job yesterday [SEP]',
'token': 16924,
'token_str': '##inas'}]
I think this has to do with weight initializations but I'm not grasping everything in the output. Some points that are unclear:
- `['cls.seq_relationship.weight', 'cls.seq_relationship.bias']` are not used in the case of `bert-base-cased` (see output) but are used (or missing?) in the case of Conversational BERT
- Only `['cls.predictions.decoder.bias']` is newly initialized in the case of `bert-base-cased` but all of the following weights are initialized in the case of Conversational BERT: `['cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.bias']`
## To reproduce
Steps to reproduce the behavior:
### bert-base-cased:
#### Input:
`pipeline_bert = pipeline('fill-mask', model='bert-base-uncased', tokenizer='bert-base-uncased', config='bert-base-uncased')`
#### Output:
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertForMaskedLM: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias']
- This IS expected if you are initializing BertForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing BertForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForMaskedLM were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['cls.predictions.decoder.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
### Conversational BERT
#### Input:
`pipeline_convbert = pipeline('fill-mask', model='DeepPavlov/bert-base-cased-conversational', tokenizer='DeepPavlov/bert-base-cased-conversational', config='DeepPavlov/bert-base-cased-conversational')`
#### Output:
Some weights of BertForMaskedLM were not initialized from the model checkpoint at DeepPavlov/bert-base-cased-conversational and are newly initialized: ['cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
| 09-08-2020 08:12:42 | 09-08-2020 08:12:42 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 7,006 | closed | __init__() got an unexpected keyword argument 'cache_dir' | I used command
!python /content/transformers/examples/language-modeling/run_language_modeling.py \
--output_dir=/content/output \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=/content/input.txt \
--do_eval \
--eval_data_file=/content/dev.txt
and the error occurs
2020-09-08 06:02:43.113931: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
09/08/2020 06:02:45 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 1, distributed training: False, 16-bits training: False
09/08/2020 06:02:45 - INFO - __main__ - Training/evaluation parameters TrainingArguments(output_dir='/content/output', overwrite_output_dir=False, do_train=True, do_eval=True, do_predict=False, evaluate_during_training=False, prediction_loss_only=False, per_device_train_batch_size=8, per_device_eval_batch_size=8, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, warmup_steps=0, logging_dir='runs/Sep08_06-02-45_58d9f15c989e', logging_first_step=False, logging_steps=500, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=1000, past_index=-1, run_name=None, disable_tqdm=False, remove_unused_columns=True)
09/08/2020 06:02:45 - INFO - filelock - Lock 140608954702032 acquired on /root/.cache/torch/transformers/4be02c5697d91738003fb1685c9872f284166aa32e061576bbe6aaeb95649fcf.db13c9bc9c7bdd738ec89e069621d88e05dc670366092d809a9cbcac6798e24e.lock
Downloading: 100% 665/665 [00:00<00:00, 556kB/s]
09/08/2020 06:02:46 - INFO - filelock - Lock 140608954702032 released on /root/.cache/torch/transformers/4be02c5697d91738003fb1685c9872f284166aa32e061576bbe6aaeb95649fcf.db13c9bc9c7bdd738ec89e069621d88e05dc670366092d809a9cbcac6798e24e.lock
09/08/2020 06:02:46 - INFO - filelock - Lock 140608954701528 acquired on /root/.cache/torch/transformers/f2808208f9bec2320371a9f5f891c184ae0b674ef866b79c58177067d15732dd.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71.lock
Downloading: 100% 1.04M/1.04M [00:00<00:00, 2.47MB/s]
09/08/2020 06:02:47 - INFO - filelock - Lock 140608954701528 released on /root/.cache/torch/transformers/f2808208f9bec2320371a9f5f891c184ae0b674ef866b79c58177067d15732dd.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71.lock
09/08/2020 06:02:48 - INFO - filelock - Lock 140608954701640 acquired on /root/.cache/torch/transformers/d629f792e430b3c76a1291bb2766b0a047e36fae0588f9dbc1ae51decdff691b.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda.lock
Downloading: 100% 456k/456k [00:00<00:00, 1.37MB/s]
09/08/2020 06:02:48 - INFO - filelock - Lock 140608954701640 released on /root/.cache/torch/transformers/d629f792e430b3c76a1291bb2766b0a047e36fae0588f9dbc1ae51decdff691b.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda.lock
/usr/local/lib/python3.6/dist-packages/transformers/modeling_auto.py:821: FutureWarning: The class `AutoModelWithLMHead` is deprecated and will be removed in a future version. Please use `AutoModelForCausalLM` for causal language models, `AutoModelForMaskedLM` for masked language models and `AutoModelForSeq2SeqLM` for encoder-decoder models.
FutureWarning,
09/08/2020 06:02:48 - INFO - filelock - Lock 140608954702312 acquired on /root/.cache/torch/transformers/d71fd633e58263bd5e91dd3bde9f658bafd81e11ece622be6a3c2e4d42d8fd89.778cf36f5c4e5d94c8cd9cefcf2a580c8643570eb327f0d4a1f007fab2acbdf1.lock
Downloading: 100% 548M/548M [00:16<00:00, 33.1MB/s]
09/08/2020 06:03:06 - INFO - filelock - Lock 140608954702312 released on /root/.cache/torch/transformers/d71fd633e58263bd5e91dd3bde9f658bafd81e11ece622be6a3c2e4d42d8fd89.778cf36f5c4e5d94c8cd9cefcf2a580c8643570eb327f0d4a1f007fab2acbdf1.lock
/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py:1321: FutureWarning: The `max_len` attribute has been deprecated and will be removed in a future version, use `model_max_length` instead.
FutureWarning,
Traceback (most recent call last):
File "/content/transformers/examples/language-modeling/run_language_modeling.py", line 313, in <module>
main()
File "/content/transformers/examples/language-modeling/run_language_modeling.py", line 242, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None
File "/content/transformers/examples/language-modeling/run_language_modeling.py", line 143, in get_dataset
cache_dir=cache_dir,
TypeError: __init__() got an unexpected keyword argument 'cache_dir'
I'm working on the Google Colab environment | 09-08-2020 06:55:52 | 09-08-2020 06:55:52 | Hello! On what version of `transformers` are you running?<|||||>> Hello! On what version of `transformers` are you running?
Hi @LysandreJik, It's 3.1.0<|||||>@TikaToka Faced the same problem. Just installed everything again from master and it worked.
<|||||>> @TikaToka Faced the same problem. Just installed everything again from master and it worked.
I'm still having a same issue :(<|||||>You need an install from source to use the current examples (as stated in their [README](https://github.com/huggingface/transformers/tree/master/examples)). In colab you can do so by executing a cell with
```
! pip install git+git://github.com/huggingface/transformers/
```
Alternatively, you can find the version of the example that work with 3.1.0 [here](https://github.com/huggingface/transformers/tree/v3.1.0/examples/language-modeling).<|||||>
> @TikaToka Faced the same problem. Just installed everything again from master and it worked.
This Worked Thanks! I made a mistake while installing <|||||>> You need an install from source to use the current examples (as stated in their [README](https://github.com/huggingface/transformers/tree/master/examples)). In colab you can do so by executing a cell with
>
> ```
> ! pip install git+git://github.com/huggingface/transformers/
> ```
>
> Alternatively, you can find the version of the example that work with 3.1.0 [here](https://github.com/huggingface/transformers/tree/v3.1.0/examples/language-modeling).
Thank you for specific explanation! this worked!<|||||>I still get the error:
TypeError: __init__() got an unexpected keyword argument 'cache_dir'
when running the latest version for transformers (3.1.0).
I'm also running on Colab environment:
Command:
!pip3 install transformers
(also tried #! pip3 install git+git://github.com/huggingface/transformers/)
!wget https://raw.githubusercontent.com/huggingface/transformers/master/examples/language-modeling/run_language_modeling.py
%%bash
export TRAIN_FILE=train_path
export TEST_FILE=valid_path
export MODEL_NAME=gpt2
export OUTPUT_DIR=output
python run_language_modeling.py \
--output_dir=output \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--cache_dir=None
Output:
Traceback (most recent call last):
File "run_language_modeling.py", line 313, in <module>
main()
File "run_language_modeling.py", line 242, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None
File "run_language_modeling.py", line 143, in get_dataset
cache_dir=cache_dir,
TypeError: __init__() got an unexpected keyword argument 'cache_dir' |
transformers | 7,005 | closed | [Community notebooks] Add notebook on fine-tuning GPT-2 Model with Trainer Class | Adding a link to a community notebook containing an example of fine-tuning a German GPT-2 Model with the Trainer Class | 09-08-2020 06:44:52 | 09-08-2020 06:44:52 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7005?src=pr&el=h1) Report
> Merging [#7005](https://codecov.io/gh/huggingface/transformers/pull/7005?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/c18f5916a03d0a161d003e95ffff8120d8addc0c?el=desc) will **decrease** coverage by `0.59%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/7005?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #7005 +/- ##
==========================================
- Coverage 80.63% 80.03% -0.60%
==========================================
Files 161 161
Lines 30123 30123
==========================================
- Hits 24289 24109 -180
- Misses 5834 6014 +180
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/7005?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/7005/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9lbGVjdHJhLnB5) | `25.13% <0.00%> (-73.83%)` | :arrow_down: |
| [src/transformers/data/data\_collator.py](https://codecov.io/gh/huggingface/transformers/pull/7005/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFfY29sbGF0b3IucHk=) | `91.90% <0.00%> (-0.81%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7005/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `86.97% <0.00%> (-0.33%)` | :arrow_down: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/7005/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `82.66% <0.00%> (+0.25%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/7005/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `88.34% <0.00%> (+63.80%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/7005?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/7005?src=pr&el=footer). Last update [c18f591...0d1e538](https://codecov.io/gh/huggingface/transformers/pull/7005?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 7,004 | closed | [seq2seq Examples] Use _step instead of generate for val, test | Addresses a workaround I proposed in #6589 for limiting the memory consumption in `.generate` steps.
@sshleifer | 09-08-2020 05:53:54 | 09-08-2020 05:53:54 | @sshleifer : Does it make sense to still add this? If yes, I can rebase and update based on Suraj's comments earlier. If not, will close.<|||||>Let's hold off for now. I think passing --eval_num_beams=1 is close enough to equivalent.
Thanks for trying! |
transformers | 7,003 | closed | On Gpu sharing mechanism, specify model.to(' CPU '), but still use the Gpu | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
You know that The GPU device(K8s) only supports one container exclusive GPU, In the inferencing stage, it is extremely wasteful. For Tiny-Albert model,It's only using about 500MiB。We try to use GPU share device, support more containers use one GPU device。We expect using torch.cuda.is_available() to control Using CUDA or Not.
Here is My Code:
`
use_cuda = bool(os.environ.get("USE_CUDA"))
if use_cuda and torch.cuda.is_available():
self._device = torch.device("cuda")
else:
self._device = torch.device("cpu")
`
1. USE_CUDA== False and torch.cuda.is_available() is True:
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|============================================================|
| 0 11538 C /usr/bin/python3 **342MiB** |
+-----------------------------------------------------------------------------+
2. USE_CUDA== True and torch.cuda.is_available() is True:
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|============================================================|
| 0 11538 C /usr/bin/python3 **342MiB** |
+-----------------------------------------------------------------------------+
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**: | 09-08-2020 02:59:33 | 09-08-2020 02:59:33 | It's my issue |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.