
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 4,700 | closed | Add community notebook for T5 sentiment span extraction | This is an example notebook that aims to increase the coverage of T5 fine-tuning examples to address #4426 .
This notebook presents a high level overview of T5, its significance for the future of NLP in practice, and a thoroughly commented tutorial on how to fine-tune T5 for sentiment span extraction with an extractive Q&A format.
I recently presented this in a webinar published on [youtube](https://www.youtube.com/watch?v=4LYw_UIdd4A). | 06-01-2020 01:51:25 | 06-01-2020 01:51:25 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4700?src=pr&el=h1) Report
> Merging [#4700](https://codecov.io/gh/huggingface/transformers/pull/4700?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0866669e751bef636fa693b704a28c1fea9a17f3&el=desc) will **decrease** coverage by `1.41%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4700?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4700 +/- ##
==========================================
- Coverage 77.14% 75.72% -1.42%
==========================================
Files 128 128
Lines 21070 21070
==========================================
- Hits 16255 15956 -299
- Misses 4815 5114 +299
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4700?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4700/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `18.70% <0.00%> (-74.83%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4700/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `76.92% <0.00%> (-23.08%)` | :arrow_down: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/4700/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `77.18% <0.00%> (-6.35%)` | :arrow_down: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4700/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4700/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `86.77% <0.00%> (-0.19%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4700/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.17% <0.00%> (+0.23%)` | :arrow_up: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4700/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `81.78% <0.00%> (+1.37%)` | :arrow_up: |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4700/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `86.21% <0.00%> (+14.10%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4700?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4700?src=pr&el=footer). Last update [0866669...34c9a46](https://codecov.io/gh/huggingface/transformers/pull/4700?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Nice webinar, and cool notebook :)
@patrickvonplaten, do you want to take a look?<|||||>Thanks @LysandreJik ! :smile:<|||||>Awesome notebook @enzoampil!
LGTM for merge!
Which dataset do you use exactly to fine-tune T5 here? <|||||>Thanks @patrickvonplaten ! 😄
For the dataset, I got it from an ongoing Kaggle competition called [Tweet Sentiment Extraction](https://www.kaggle.com/c/tweet-sentiment-extraction/data).
**The objective is to extract the span from a tweet that indicates its sentiment**
Example input:
```
sentiment: negative
tweet: How did we just get paid and still be broke as hell?! No shopping spree for me today
```
Example output:
```
broke as hell?!
```
<|||||>I was thinking about contributing this to the `nlp` library, but I'm not sure if Kaggle has policies regarding uploading their datasets to other public sources ...<|||||>I see! Yeah no worries - I don't think we currently handle dataset processing from on-going kaggle competition links. |
transformers | 4,699 | closed | NER example doesn’t work with tensorflow | I’m working through the Pytorch text tokenization example here using the tensorflow version run_tf_ner.py: https://github.com/huggingface/transformers/tree/master/examples/token-classification
The PyTorch version using run_ner.py works. I believe the difference is in https://github.com/huggingface/transformers/blob/master/examples/token-classification/utils_ner.py starting at line 139 where it has different logic for tensorflow. Narrowing down to utils_ner.py line 149:
`pad_token_label_id: int = -1`
The Pytorch version uses -100. This seems to be the only labeling difference that I can tell. I tried to change this line to -100 as well. But tensorflow code doesn’t seem to accept -1 or -100.
Anyone know how to get this example to work using the tensorflow version? Thanks!
I created a Colab for the example here: https://colab.research.google.com/drive/10GrYSYx5sUVMXplgUS79fIV73bFtoiHX?usp=sharing
This is the error I keep getting:
```
05/31/2020 00:07:45 - INFO - utils_ner - tokens: [CLS] dar ##aus en ##t ##wick ##elt ##e sic ##h im ro ##ko ##ko die sit ##te des gem ##ein ##sam ##en wei ##nen ##s im theater , das die stand ##es ##gren ##zen inner ##hal ##b des pub ##lik ##ums uber ##bruck ##en sol ##lt ##e . [SEP]
05/31/2020 00:07:45 - INFO - utils_ner - input_ids: 101 18243 20559 4372 2102 7184 20042 2063 14387 2232 10047 20996 3683 3683 3280 4133 2618 4078 17070 12377 21559 2368 11417 10224 2015 10047 4258 1010 8695 3280 3233 2229 13565 10431 5110 8865 2497 4078 9047 18393 18163 19169 28985 2368 14017 7096 2063 1012 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
05/31/2020 00:07:45 - INFO - utils_ner - input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
05/31/2020 00:07:45 - INFO - utils_ner - segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
05/31/2020 00:07:45 - INFO - utils_ner - label_ids: -1 24 -1 24 -1 -1 -1 -1 24 -1 24 6 -1 -1 24 24 -1 24 24 -1 -1 -1 24 -1 -1 24 24 24 24 24 24 -1 -1 -1 24 -1 -1 24 24 -1 -1 24 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
05/31/2020 00:07:54 - WARNING - transformers.training_args - Using deprecated `--per_gpu_train_batch_size` argument which will be removed in a future version. Using `--per_device_train_batch_size` is preferred.
05/31/2020 00:07:54 - WARNING - transformers.training_args - Using deprecated `--per_gpu_train_batch_size` argument which will be removed in a future version. Using `--per_device_train_batch_size` is preferred.
05/31/2020 00:07:54 - INFO - transformers.trainer_tf - Created an/a adam optimizer
05/31/2020 00:07:54 - INFO - transformers.trainer_tf - ***** Running training *****
05/31/2020 00:07:54 - INFO - transformers.trainer_tf - Num examples = 24000
05/31/2020 00:07:54 - INFO - transformers.trainer_tf - Num Epochs = 3
05/31/2020 00:07:54 - INFO - transformers.trainer_tf - Total optimization steps = 750
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py:360: StrategyBase.experimental_run_v2 (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version.
Instructions for updating:
renamed to `run`
05/31/2020 00:07:54 - WARNING - tensorflow - From /usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py:360: StrategyBase.experimental_run_v2 (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version.
Instructions for updating:
renamed to `run`
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/resource_variable_ops.py:1817: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
05/31/2020 00:08:02 - WARNING - tensorflow - From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/resource_variable_ops.py:1817: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/indexed_slices.py:434: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
2020-05-31 00:08:52.364556: W tensorflow/core/framework/op_kernel.cc:1753] OP_REQUIRES failed at sparse_xent_op.cc:90 : Invalid argument: Received a label value of -1 which is outside the valid range of [0, 25). Label values: -1 24 -1 -1 -1 -1 24 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 24 24 2 -1 -1 -1 24 0 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 -1 -1 -1 24 24 -1 -1 24 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 24 -1 24 -1 24 -1 -1 24 -1 24 24 6 24 -1 24 -1 24 -1 24 -1 -1 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0 24 3 -1 24 24 24 24 -1 -1 1 24 -1 -1 -1 -1 9 21 -1 -1 24 0 -1 -1 -1 24 24 24 24 -1 -1 24 24 -1 -1 24 24 -1 -1 -1 3 15 15 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 24 24 -1 -1 24 -1 24 24 -1 -1 24 -1 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 6 24 24 24 6 18 18 24 24 6 24 -1 -1 24 24 24 -1 -1 -1 24 24 9 21 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 -1 24 -1 24 -1 24 -1 24 -1 24 -1 24 24 24 -1 -1 24 24 24 -1 24 -1 24 -1 24 -1 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 -1 -1 -1 24 -1 -1 -1 24 -1 9 24 9 21 24 24 -1 24 24 0 -1 -1 24 -1 -1 24 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 24 -1 24 -1 24 24 -1 -1 -1 24 -1 24 24 -1 24 -1 24 -1 24 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 -1 -1 24 -1 0 -1 24 2 -1 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 -1 -1 -1 -1 24 24 3 -1 -1 -1 -1 -1 -1 24 -1 24 -1 -1 24 24 -1 -1 24 24 24 -1 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 24 24 -1 24 -1 24 -1 24 -1 24 24 -1 24 -1 -1 24 -1 24 24 24 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 24 -1 -1 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 24 24 -1 24 24 24 -1 -1 24 -1 -1 -1 24 -1 24 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 24 -1 -1 -1 24 -1 -1 24 -1 24 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 24 24 -1 24 -1 24 24 24 24 -1 9 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 24 -1 24 24 -1 24 -1 24 -1 24 -1 24 24 24 24 -1 -1 24 -1 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 24 -1 -1 24 -1 24 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 24 -1 24 24 -1 24 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 6 18 24 -1 -1 24 -1 -1 24 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 8 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 24 24 -1 -1 -1 8 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 -1 24 -1 24 24 -1 -1 -1 24 -1 -1 24 24 24 24 8 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 6 -1 -1 18 18 -1 -1 -1 18 18 18 -1 18 18 -1 -1 -1 24 24 -1 -1 -1 -1 24 24 0 -1 24 -1 -1 -1 24 -1 -1 24 -1 -1 -1 24 24 -1 -1 24 24 -1 24 24 0 -1 24 -1 -1 24 24 -1 24 5 -1 -1 -1 -1 -1 -1 24 0 12 12 24 -1 -1 -1 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 24 24 24 24 -1 -1 -1 -1 -1 24 -1 -1 -1 24 -1 -1 24 24 -1 24 24 24 24 -1 -1 24 24 -1 -1 -1 -1 0 -1 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 24 24 -1 24 -1 24 -1 6 -1 -1 24 24 1 -1 24 -1 -1 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 -1 24 3 -1 -1 24 24 24 24 24 24 -1 24 -1 24 24 24 -1 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 24 24 -1 24 24 24 -1 -1 -1 24 24 -1 24 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 -1 -1 -1 -1 -1 24 24 24 -1 -1 -1 -1 24 -1 24 -1 -1 24 24 3 15 15 -1 -1 -1 -1 -1 24 0 12 12 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 0 -1 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 0 -1 -1 24 -1 24 -1 24 -1 24 -1 -1 24 24 -1 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 -1 9 21 -1 24 9 -1 21 24 9 21 24 24 -1 -1 -1 -1 24 -1 -1 -1 -1 24 -1 -1 24 24 -1 24 -1 24 24 -1 24 24 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 24 -1 24 -1 24 -1 24 24 1 -1 -1 24 24 24 -1 24 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 9 -1 24 -1 -1 -1 -1 24 -1 24 24 -1 24 24 9 24 24 24 24 -1 -1 -1 -1 24 24 -1 -1 -1 24 0 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 9 -1 24 24 -1 24 24 -1 24 -1 -1 -1 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 24 24 24 -1 24 -1 -1 24 24 -1 24 -1 -1 -1 24 24 6 -1 -1 24 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 24 -1 24 24 -1 -1 -1 -1 -1 24 24 -1 -1 -1 -1 24 -1 -1 24 24 -1 24 24 -1 24 24 -1 -1 -1 24 -1 -1 -1 -1 24 -1 24 -1 24 24 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 24 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 24 -1 24 -1 -1 24 24 24 -1 -1 -1 -1 -1 24 24 24 -1 -1 -1 24 -1 -1 24 -1 -1 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
Traceback (most recent call last):
File "run_tf_ner.py", line 281, in <module>
main()
File "run_tf_ner.py", line 213, in main
trainer.train()
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py", line 277, in train
for training_loss in self._training_steps():
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py", line 321, in _training_steps
for i, loss in enumerate(self._accumulate_next_gradients()):
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py", line 354, in _accumulate_next_gradients
yield _accumulate_next()
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py", line 580, in __call__
result = self._call(*args, **kwds)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py", line 708, in _call
return function_lib.defun(fn_with_cond)(*canon_args, **canon_kwds)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 2420, in __call__
return graph_function._filtered_call(args, kwargs) # pylint: disable=protected-access
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 1665, in _filtered_call
self.captured_inputs)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 1746, in _call_flat
ctx, args, cancellation_manager=cancellation_manager))
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 598, in call
ctx=ctx)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Received a label value of -1 which is outside the valid range of [0, 25). Label values: -1 24 -1 -1 -1 -1 24 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 24 24 2 -1 -1 -1 24 0 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 -1 -1 -1 24 24 -1 -1 24 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 24 -1 24 -1 24 -1 -1 24 -1 24 24 6 24 -1 24 -1 24 -1 24 -1 -1 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0 24 3 -1 24 24 24 24 -1 -1 1 24 -1 -1 -1 -1 9 21 -1 -1 24 0 -1 -1 -1 24 24 24 24 -1 -1 24 24 -1 -1 24 24 -1 -1 -1 3 15 15 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 24 24 -1 -1 24 -1 24 24 -1 -1 24 -1 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 6 24 24 24 6 18 18 24 24 6 24 -1 -1 24 24 24 -1 -1 -1 24 24 9 21 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 -1 24 -1 24 -1 24 -1 24 -1 24 -1 24 24 24 -1 -1 24 24 24 -1 24 -1 24 -1 24 -1 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 -1 -1 -1 24 -1 -1 -1 24 -1 9 24 9 21 24 24 -1 24 24 0 -1 -1 24 -1 -1 24 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 24 -1 24 -1 24 24 -1 -1 -1 24 -1 24 24 -1 24 -1 24 -1 24 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 -1 -1 24 -1 0 -1 24 2 -1 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 -1 -1 -1 -1 24 24 3 -1 -1 -1 -1 -1 -1 24 -1 24 -1 -1 24 24 -1 -1 24 24 24 -1 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 24 24 -1 24 -1 24 -1 24 -1 24 24 -1 24 -1 -1 24 -1 24 24 24 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 24 -1 -1 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 24 24 -1 24 24 24 -1 -1 24 -1 -1 -1 24 -1 24 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 24 -1 -1 -1 24 -1 -1 24 -1 24 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 24 24 -1 24 -1 24 24 24 24 -1 9 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 24 -1 24 24 -1 24 -1 24 -1 24 -1 24 24 24 24 -1 -1 24 -1 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 24 -1 -1 24 -1 24 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 24 -1 24 24 -1 24 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 6 18 24 -1 -1 24 -1 -1 24 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 8 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 24 24 -1 -1 -1 8 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 -1 24 -1 24 24 -1 -1 -1 24 -1 -1 24 24 24 24 8 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 6 -1 -1 18 18 -1 -1 -1 18 18 18 -1 18 18 -1 -1 -1 24 24 -1 -1 -1 -1 24 24 0 -1 24 -1 -1 -1 24 -1 -1 24 -1 -1 -1 24 24 -1 -1 24 24 -1 24 24 0 -1 24 -1 -1 24 24 -1 24 5 -1 -1 -1 -1 -1 -1 24 0 12 12 24 -1 -1 -1 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 24 24 24 24 -1 -1 -1 -1 -1 24 -1 -1 -1 24 -1 -1 24 24 -1 24 24 24 24 -1 -1 24 24 -1 -1 -1 -1 0 -1 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 24 24 -1 24 -1 24 -1 6 -1 -1 24 24 1 -1 24 -1 -1 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 -1 24 3 -1 -1 24 24 24 24 24 24 -1 24 -1 24 24 24 -1 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 24 24 -1 24 24 24 -1 -1 -1 24 24 -1 24 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 -1 -1 -1 -1 -1 24 24 24 -1 -1 -1 -1 24 -1 24 -1 -1 24 24 3 15 15 -1 -1 -1 -1 -1 24 0 12 12 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 0 -1 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 24 24 24 -1 0 -1 -1 24 -1 24 -1 24 -1 24 -1 -1 24 24 -1 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 -1 9 21 -1 24 9 -1 21 24 9 21 24 24 -1 -1 -1 -1 24 -1 -1 -1 -1 24 -1 -1 24 24 -1 24 -1 24 24 -1 24 24 -1 -1 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 24 24 -1 24 -1 24 -1 24 24 1 -1 -1 24 24 24 -1 24 -1 -1 24 24 -1 -1 -1 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 9 -1 24 -1 -1 -1 -1 24 -1 24 24 -1 24 24 9 24 24 24 24 -1 -1 -1 -1 24 24 -1 -1 -1 24 0 24 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 9 -1 24 24 -1 24 24 -1 24 -1 -1 -1 -1 24 -1 -1 -1 24 -1 -1 -1 -1 -1 24 24 24 -1 24 -1 -1 24 24 -1 24 -1 -1 -1 24 24 6 -1 -1 24 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 24 -1 24 24 -1 -1 -1 -1 -1 24 24 -1 -1 -1 -1 24 -1 -1 24 24 -1 24 24 -1 24 24 -1 -1 -1 24 -1 -1 -1 -1 24 -1 24 -1 24 24 -1 -1 24 24 -1 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 24 -1 -1 24 24 -1 -1 -1 -1 24 -1 -1 24 -1 -1 -1 -1 -1 -1 24 -1 24 -1 -1 24 24 24 -1 -1 -1 -1 -1 24 24 24 -1 -1 -1 24 -1 -1 24 -1 -1 24 -1 24 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
[[{{node cond/else/_1/StatefulPartitionedCall/sparse_categorical_crossentropy/SparseSoftmaxCrossEntropyWithLogits/SparseSoftmaxCrossEntropyWithLogits}}]] [Op:__inference_fn_with_cond_30948]
Function call stack:
fn_with_cond
``` | 05-31-2020 22:41:04 | 05-31-2020 22:41:04 | Also, the example was missing this parameter in the python3 run_tf_ner.py command to work. Would be good to update the doc:
`--logging_dir ./my-model/`<|||||>@chuckabees I got the same issue, did you solve this problem?<|||||>@YuqiShen Unfortunately no. I even wrote to the code's author but no response :(<|||||>I got the same problem. This issue helped me https://github.com/huggingface/transformers/issues/4631#issuecomment-636063607
I added `--mode token-classification` param in the shell command and now it works fine :)<|||||>@donuzium thanks but when I try, I get this error now:
```
Traceback (most recent call last):
File "run_tf_ner.py", line 281, in <module>
main()
File "run_tf_ner.py", line 135, in main
cache_dir=model_args.cache_dir,
File "/usr/local/lib/python3.6/dist-packages/transformers/configuration_auto.py", line 203, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/configuration_utils.py", line 252, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'token-classification'. Make sure that:
- 'token-classification' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'token-classification' is the correct path to a directory containing a config.json file
```
Going to https://huggingface.co/models, I don't see 'token-classification' there.<|||||>@chuckabees it's under `tags`<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Closing as solved. |
transformers | 4,698 | closed | Transformer-XL: Input and labels for Language Modeling | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
I'm trying to finetune the pretrained Transformer-XL model `transfo-xl-wt103` for a language modeling task. Therfore, I use the model class `TransfoXLLMHeadModel`.
To iterate over my dataset I use the `LMOrderedIterator` from the file [tokenization_transfo_xl.py](https://github.com/huggingface/transformers/blob/5e737018e1fcb22c8b76052058279552a8d6c806/src/transformers/tokenization_transfo_xl.py#L467) which yields a tensor with the `data` and its `target` for each batch (and the sequence length).
**My question**:
Let's assume the following data with `batch_size = 1` and `bptt = 8`:
data = tensor([[1,2,3,4,5,6,7,8]])
target = tensor([[2,3,4,5,6,7,8,9]])
mems # from the previous output
I currently pass this data into the model like this:
output = model(input_ids=data, labels=target, mems=mems)
Is this correct?
I am wondering because the documentation says for the `labels` parameter:
> labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
Labels for language modeling.
Note that the labels **are shifted** inside the model, i.e. you can set ``lm_labels = input_ids``
So what is it about the parameter `lm_labels`? I only see `labels` defined in the `forward` method.
And when the labels "are shifted" inside the model, does this mean I have to pass in `data` twice (for `input_ids` and `labels`) because `labels` shifted inside? But how does the model then know the next token to predict (in the case above: `9`) ?
I also read through [this bug](https://github.com/huggingface/transformers/issues/3711) and the fix in [this pull request](https://github.com/huggingface/transformers/pull/3716) but I don't quite understand how to treat the model now (before vs. after fix). Maybe someone could explain me both versions.
Thanks in advance for some help!
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on Stack Overflow**: https://stackoverflow.com/q/62069350/9478384
| 05-31-2020 18:18:42 | 05-31-2020 18:18:42 | Hi there!
> I currently pass this data into the model like this:
>
> ```
> output = model(input_ids=data, labels=target, mems=mems)
> ```
>
> Is this correct?
No, this is not correct, because the labels are shifted inside the model (as the documentation suggests). This happens [here](https://github.com/huggingface/transformers/blob/ec8717d5d8f6edc2c595ff6954ffaa2078dcc97d/src/transformers/modeling_transfo_xl_utilities.py#L104) so in your example, the target vector will become
```
tensor([[3,4,5,6,7,8,9]])
```
to be matched with the predictions corresponding to
```
tensor([[1,2,3,4,5,6,7]])
```
so you'll try to predict the token that is two steps ahead of the current one.
I am guessing that `lm_labels` is a typo for `labels`, and that you should either:
- pass `labels = input_ids` as suggested by the doc string (in this case you will not compute any loss for the last prediction, but that's probably okay)
- add something at the beginning of your target tensor (anything can work since it will be removed by the shift) : `target = tensor([[42,2,3,4,5,6,7,8,9]])`
I'm still learning the library, so tagging @TevenLeScao (since he worked on the issue/PR you mentioned) to make sure I'm not saying something wrong (also, do we want to update `LMOrderedIterator` from tokenization_transfo_xl.py to return target tensors that can be used as labels?)<|||||>Ah yes that does sound like a typo from another model's convention! You do have to pass `data` twice, once to `input_ids` and once to `labels` (in your case, `[1, ... , 8]` for both). The model will then attempt to predict `[2, ... , 8]` from `[1, ... , 7]`). I am not sure adding something at the beginning of the target tensor would work as that would probably cause size mismatches later down the line.
Passing twice is the default way to do this in `transformers`; before the aforementioned PR, `TransfoXL` did not shift labels internally and you had to shift the labels yourself. The PR changed it to be consistent with the library and the documentation, where you have to pass the same data twice. I believe #4711 fixed the typo, you should be all set ! I'll also answer on StackOverflow in case someone finds that question there.<|||||>Thanks @sgugger and @TevenLeScao for your help!
@TevenLeScao
> before the aforementioned PR, TransfoXL did not shift labels internally and you had to shift the labels yourself
So this means that in the versions before the fix my method with shifting the labels beforehand was correct? Because I'm currently using `transformers 2.6`.<|||||>Yes, it was changed in 2.9.0. You should probably consider updating ;)<|||||>> The model will then attempt to predict `[2, ... , 8]` from `[1, ... , 7]`).
Note that if you are using the state, the memory returned is computed on the whole `[1, ... , 8]`, so you should use `[9,10,... , 16]` as your next batch.<|||||>Thanks guys!
Sorry for asking this here, but maybe one of you can help me with my workaround in issue #3554 ? That would help me a lot!<|||||>Hello again, sorry for bothering again, but I have update my code from version 2.6 to 2.11 as @TevenLeScao has suggested. Now I experience a drop in my model's performance, but I don't know why. I use the same code as before except passing `data` in twice as suggested.
I know that this can have several other reasons but I just want to know if there where other breaking changes to `TransformerXLLMHeadModel` or to the generation process?
I skipped through the changelog in the releases but could not find anything.
Thanks in advance!<|||||>Sorry, by a drop in model performance you mean the loss is worse right? I've noticed discrepancies between CMU code performance (better) and ours in the past, so maybe a bug was introduced between 2.6 and 2.11 (never used 2.6 myself). I'm comparing the two.<|||||>Well mainly I saw differences during text generation with `model.generate()` The sequences tend to be shorter and end more often with an <eos> in 2.11, where before in 2.6 they were just cut of at some point.
But I can't guarantee that there are no mistakes from my side.<|||||>Could it be that this is also related to #4826 ?<|||||>FYI: The issue regarding worse model performance on the newer version of `transformers` is solved. There were some errors on my side.
Nevertheless, I hope that the fix in the PR linked above will improve the generated texts, since I also experience low quality output despite proper finetuning. |
transformers | 4,697 | closed | SpanBert always predicts the same token | I tried to use this implementation - https://huggingface.co/SpanBERT/spanbert-base-cased, but as a prediction I always get the same exect outoput no matter where I put [MASK] in a sentence. Here is the code. Am I doing something wrong?
import torch
from transformers import AutoTokenizer,AutoModel
tokenizer = AutoTokenizer.from_pretrained("SpanBERT/spanbert-base-cased")
model = AutoModel.from_pretrained("SpanBERT/spanbert-base-cased")
model.eval()
model.to('cuda')
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = tokenizer.tokenize(text)
print("tokenized_text",tokenized_text)
themask = 2
tokenized_text[themask] = '[MASK]'
indexes = tokenizer.convert_tokens_to_ids(tokenized_text)
indexes_tensor = torch.tensor([indexes])
indexes_tensor = indexes_tensor.to('cuda')
with torch.no_grad():
outputs = model(indexes_tensor)
predictions0 = outputs[0]
the_index = torch.argmax(predictions0[0, themask]).item()
theresult = tokenizer.convert_ids_to_tokens([the_index])[0]
print("theresult",theresult)
print("the_index",the_index)
| 05-31-2020 18:13:49 | 05-31-2020 18:13:49 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,696 | closed | Loading config file bug | Hi guys.
I have released a new (XLNet based) transformer model for low-resource language Tigrinya
[(TigXLNet)](https://github.com/abryeemessi/Transferring-Monolingual-Model-to-Low-Resource-Language) and found a bug when loading a pre-trained config file:
My config file looks like:
https://s3.amazonaws.com/models.huggingface.co/bert/abryee/TigXLNet/config.json
config = AutoConfig.from_pretrained("abryee/TigXLNet")
print(config.d_head) #prints 48 even though d_head in the given config file is 64.
| 05-31-2020 16:30:32 | 05-31-2020 16:30:32 | Hello! The `d_head` is actually computed in the configuration: `self.d_head = d_model // n_head`.
It would probably be better to handle `d_head` directly, but currently the `d_model` and `d_head` are linked to each other.
This would crash in your case as `d_model // n_head != d_head`<|||||>@LysandreJik Thanks a lot. Yes, I am setting d_head directly before loading my model. But it would be nice to see the model load its configuration from the given config file. Just my opinion though :)<|||||>You're right! Raising an error if the `d_head` is wrong in #4747 |
transformers | 4,695 | closed | Please add the functionality to save tokenizer model for run_language_modeling.py | # 🚀 Feature request
Please add the feature to save the tokenizer model during training to the checkpoint folders.
## Motivation
When I tried out the script for [fine-tuning with language modeling](transformers/examples/language_modeling/run_language_modeling.py), I realized that the generated checkpoints during training cannot allow continue training, because under the checkpoint folders, the corresponding tokenizer model is not saved (including the files: tokenizer_config.json, special_tokens_map.json, vocab.txt). As I checked the [script](https://github.com/huggingface/transformers/blob/0866669e751bef636fa693b704a28c1fea9a17f3/examples/language-modeling/run_language_modeling.py#L250), and noticed that the tokenizer model is only saved after the training process.
## Your contribution
Haven't looked into the code in details so it might be best to have someone familiar with the Trainer class to integrate this. | 05-31-2020 16:28:54 | 05-31-2020 16:28:54 | This would be good indeed (cc @julien-c). In the meantime I think you can specify
```
--tokenizer_name=$TOKENIZER_NAME_OR_PATH
```
so that it always loads the initial tokenizer (which does not change during training).<|||||>> This would be good indeed (cc @julien-c). In the meantime I think you can specify
>
> ```
> --tokenizer_name=$TOKENIZER_NAME_OR_PATH
> ```
>
> so that it always loads the initial tokenizer (which does not change during training).
Thank you!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I'm trying to figure out how to use a custom made or create a tokenizer using this script and having significant difficulty. There does not seem to be any documentation on how to do this. I attempted to follow [this ](https://huggingface.co/blog/how-to-train) example but it makes no mention of how the tokenizer gets loaded / used. I get errors like:
```
OSError: Can't load config for 'EsperBERTo-small'. Make sure that:
- 'EsperBERTo-small' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'EsperBERTo-small' is the correct path to a directory containing a config.json file
```<|||||>Hi @EdwardRaff ,
I'm facing the same issue while trying to train BERT model from scratch on my own dateset. Did you figure out how to solve it?
```
OSError: Can't load config for './models/BuckBERTer-small/'. Make sure that:
- './models/BuckBERTer-small/' is a correct model identifier listed on 'https://huggingface.co/models'
- or './models/BuckBERTer-small/' is the correct path to a directory containing a config.json file
```<|||||>@EdwardRaff @FerchichiNourchene `run_language_modeling.py` doesn't work if a tokenizer is specified, but it does not contain the model configuration files. [This](https://stackoverflow.com/a/64795300/3950710) workaround worked for me.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@vincentwen1995, did you manage to get the tokenizers somehow? One year later and it seems like the `Trainer` is still not saving `tokenizer_config.json` in the checkpoint folders.
Where is it even saved? |
transformers | 4,694 | closed | Adding Neutral Score | # 🚀 Feature request
After performing some experimentation and comparison to VADER, we come to consensus that "pretrained BERT-based Hugging Face transfomer" is performing way beyond the other lexicons, but VADER is also good at social media context + it provides "neutral" label which turns out to be useful in some context.
I was wondering whether it is possible to manipulate the Transformer Sentiment Analysis in a way that it can calculate the **"neutral" score**?
| 05-31-2020 16:20:53 | 05-31-2020 16:20:53 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hey all, any chance anyone else is working around this? I think a neutral label or a standard sentiment score would be great for such an extensive model. Neutral statements are not caught with this adjustment:
classifier('I do not know the answer.')
Out[16]: [{'label': 'NEGATIVE', 'score': 0.9995205402374268}]
classifier('This is meant to be a very neutral statement.')
Out[17]: [{'label': 'NEGATIVE', 'score': 0.987031102180481}]
classifier('The last president of US is Donald Trump.')
Out[18]: [{'label': 'POSITIVE', 'score': 0.9963828325271606}]
classifier('There is going to be an election in two months.')
Out[19]: [{'label': 'NEGATIVE', 'score': 0.9604763984680176}]
Just raising this thread again to see if there is a common interest...
Cheers! |
transformers | 4,693 | closed | TypeError: cannot create 'BPE' instances | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...):
Language I am using the model on (English, Chinese ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
01-training-tokenizers.ipynb
```
# For the user's convenience `tokenizers` provides some very high-level classes encapsulating
# the overall pipeline for various well-known tokenization algorithm.
# Everything described below can be replaced by the ByteLevelBPETokenizer class.
from tokenizers import Tokenizer
from tokenizers.decoders import ByteLevel as ByteLevelDecoder
from tokenizers.models import BPE
from tokenizers.normalizers import Lowercase, NFKC, Sequence
from tokenizers.pre_tokenizers import ByteLevel
# First we create an empty Byte-Pair Encoding model (i.e. not trained model)
tokenizer = Tokenizer(BPE())
# Then we enable lower-casing and unicode-normalization
# The Sequence normalizer allows us to combine multiple Normalizer that will be
# executed in order.
tokenizer.normalizer = Sequence([
NFKC(),
Lowercase()
])
# Our tokenizer also needs a pre-tokenizer responsible for converting the input to a ByteLevel representation.
tokenizer.pre_tokenizer = ByteLevel()
# And finally, let's plug a decoder so we can recover from a tokenized input to the original one
tokenizer.decoder = ByteLevelDecoder()
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Flawless Run
## Environment info
- `transformers` version: 2.10.0
- Platform: Linux-5.4.0-31-generic-x86_64-with-debian-bullseye-sid
- Python version: 3.7.6
- PyTorch version (GPU?): 1.4.0 (False)
- Tensorflow version (GPU?): 2.1.0 (False)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
Specific recurring Error:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-f099004b011b> in <module>
10
11 # First we create an empty Byte-Pair Encoding model (i.e. not trained model)
---> 12 tokenizer = Tokenizer(BPE())
13
14 # Then we enable lower-casing and unicode-normalization
TypeError: cannot create 'BPE' instances
NB. I have gone through this issue:https://github.com/huggingface/transformers/issues/3787,
It dosent solve it either.
| 05-31-2020 04:06:54 | 05-31-2020 04:06:54 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,692 | closed | Gradient overflow issue when i try to train gpt2 with run_language_modeling in fp16 with 02. Any idea why that maybe happen? | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on Stack Overflow**:
| 05-31-2020 01:36:07 | 05-31-2020 01:36:07 | 
I get this message every 2000 steps.
"Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 262144.0"
The train run on rtx 2070 and seems to not have other problem but that message keeps going on every 2000 steps.
pytorch 1.5.0
python 3.7
cuda 10.1
<|||||>Do you have the same issue with opt level O1? Using O2 is discouraged. The issue may also be related to PyTorch 1.5, so if switching to O1 does not help, try a previous PyTorch version. Note that it is highly likely that this is an AMP problem, not a transformers issue. Have a look here https://github.com/NVIDIA/apex/issues/318<|||||>@BramVanroy Yes i guess you 're right. It seems problem of the AMP. I asked and in APEX the same question and their answer was :
"The loss scaler tries to increase the loss scaling factor after a threshold of successful steps was reached. In your case it seems that the scaling factor is being downgraded to the same value, so it should be fine."
So, according to that answer, is not a problem. But still i am not sure.
<|||||>I guess that skipping one step every 2000 steps is not a problem. You can monitor the loss, and as long as it seems to decrease normally, then you should be fine. <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,691 | closed | [EncoderDecoder] Add RoBERTa as a decoder | * Add crossattention input
* Add EncoderDecoder tests for RoBERTa
Since RoBERTa is a subclass of BERT, it inherits all the crossattention mechanics in the model itself. This change allows RobertaForMaskedLM to take in encoder hidden states and language model labels to work with the EncoderDecoder framework. | 05-30-2020 22:52:32 | 05-30-2020 22:52:32 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4691?src=pr&el=h1) Report
> Merging [#4691](https://codecov.io/gh/huggingface/transformers/pull/4691?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0866669e751bef636fa693b704a28c1fea9a17f3&el=desc) will **increase** coverage by `0.19%`.
> The diff coverage is `16.66%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4691?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4691 +/- ##
==========================================
+ Coverage 77.14% 77.34% +0.19%
==========================================
Files 128 128
Lines 21070 21087 +17
==========================================
+ Hits 16255 16309 +54
+ Misses 4815 4778 -37
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4691?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/4691/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `89.42% <16.66%> (-6.29%)` | :arrow_down: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4691/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4691/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.83% <0.00%> (+0.16%)` | :arrow_up: |
| [src/transformers/modeling\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/4691/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190cmFuc2ZvX3hsLnB5) | `77.22% <0.00%> (+0.21%)` | :arrow_up: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4691/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.29% <0.00%> (+0.35%)` | :arrow_up: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4691/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `81.78% <0.00%> (+1.37%)` | :arrow_up: |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4691/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `86.21% <0.00%> (+14.10%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4691?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4691?src=pr&el=footer). Last update [0866669...b0bbd24](https://codecov.io/gh/huggingface/transformers/pull/4691?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,690 | closed | Keyword errors on tokenizer.encode_plus | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): BertTokenizer
Language I am using the model on (English, Chinese ...): English (`bert-base-uncased`)
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
Code:
```
tokenizer = BERTTokenizer.from_pretrained('bert-base-uncased')`
result = tokenizer.encode_plus("This is an example sentence", add_special_tokens=True,
max_length=64, pad_to_max_length=True, return_attention_masks=True, return_tensors='pt'
```
Result:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../python3.8/site-packages/transformers/tokenization_utils.py", line 786, in encode_plus
first_ids = get_input_ids(text)
File ".../python3.8/site-packages/transformers/tokenization_utils.py", line 778, in get_input_ids
return self.convert_tokens_to_ids(self.tokenize(text, **kwargs))
File ".../python3.8/site-packages/transformers/tokenization_utils.py", line 649, in tokenize
tokenized_text = split_on_tokens(added_tokens, text)
File ".../python3.8/site-packages/transformers/tokenization_utils.py", line 644, in split_on_tokens
return sum((self._tokenize(token, **kwargs) if token not \
File ".../python3.8/site-packages/transformers/tokenization_utils.py", line 644, in <genexpr>
return sum((self._tokenize(token, **kwargs) if token not \
TypeError: _tokenize() got an unexpected keyword argument 'pad_to_max_length'
```
A similar issue occurs if I remove the `pad_to_max_length` keyword; then `return_attention_masks` is the unexpected keyword.
## Expected behavior
Expected: the function returns without error a dict with the attention masks, padded sequence, and some other info, as specified by the documentation.
## Environment info
- `transformers` version: 2.1.1
- Platform: WSL 2, Ubuntu 18.04.4 LTS
- Python version: 3.8
- PyTorch version (GPU?): 1.4.0
- Tensorflow version (GPU?): N/A
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
| 05-30-2020 21:36:24 | 05-30-2020 21:36:24 | @tchainzzz Can you tell how you resolved the particular issue?
|
transformers | 4,689 | closed | Same logits value for different input | # ❓ Questions & Help
## Details
I use BartForSequenceClassification pre-trained model from the HuggingFace Transformers library. During training phase logits from classification head gets different values, but during validation phase all logits values are equal even for different input texts.
I use BartTokenizer.batch_encode_plus to encode the text before feeding into the model.
I fine-tuned the model for 1 epoch using the following code:
```
config = BartConfig.from_pretrained(model_name)
config.num_labels = 3
config.output_hidden_states = False
config.output_attentions = False
transformer_model = BartForSequenceClassification.from_pretrained(model_name, config=config)
transformer_model.cuda();
optimizer = AdamW(transformer_model.parameters())
NUM_TRAIN_EPOCHS = 1
print("Training:")
for i in range(1, 1+NUM_TRAIN_EPOCHS):
transformer_model.train()
for batch_index, (batch_input_ids, batch_attention_masks, batch_y) in enumerate(train_dataloader, start=1):
batch_input_ids_cuda = batch_input_ids.to(device)
batch_attention_masks_cuda = batch_attention_masks.to(device)
batch_y_cuda = batch_y.to(device)
loss, logits, _ = transformer_model(batch_input_ids_cuda, attention_mask=batch_attention_masks_cuda, labels=batch_y_cuda)
transformer_model.zero_grad()
loss.backward()
optimizer.step()
```
And for validation I use the following code:
```
transformer_model.eval()
with torch.no_grad():
for batch_index, (batch_input_ids, batch_attention_masks, batch_y) in enumerate(test_dataloader, start=1):
batch_input_ids_cuda = batch_input_ids.to(device)
batch_attention_masks_cuda = batch_attention_masks.to(device)
batch_y_cuda = batch_y.to(device)
loss, logits, _ = transformer_model(batch_input_ids_cuda, attention_mask=batch_attention_masks_cuda, labels=batch_y_cuda)
print("Input ids:", batch_input_ids_cuda)
print("Attention masks:", batch_attention_masks_cuda)
print("Logits:", logits)
```
Output of validation phase is:
```
Input ids: tensor([[ 0, 3655, 9, ..., 1, 1, 1],
[ 0, 31524, 347, ..., 1, 1, 1],
[ 0, 12806, 24220, ..., 1, 1, 1],
...,
[ 0, 8518, 7432, ..., 1, 1, 1],
[ 0, 15006, 23613, ..., 1, 1, 1],
[ 0, 14729, 13178, ..., 1, 1, 1]], device='cuda:0')
Attention masks: tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]], device='cuda:0')
Logits: tensor([[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862],
[-1.3014, -0.7394, 0.7862]], device='cuda:0')
```
Why all the logits have exact same value for every input?
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on Stack Overflow**: https://stackoverflow.com/questions/62097267/same-logits-value-for-different-input-in-huggingfaces-transformer
| 05-30-2020 18:57:17 | 05-30-2020 18:57:17 | Can you post a minimal dataset that we can test this with? So for instance two sentences that give the same result for you.<|||||>```
[
["Nah I don't think he goes to usf, he lives around here though", 2],
["URGENT! You have won a 1 week FREE membership in our $100,000 Prize Jackpot!", 1]
]
```
**The model outputs same results only after fine-tuning phase.**
This is my Dataset subclass:
```
class SequenceClassificationDataset(Dataset):
def __init__(self, df, tokenizer, max_length):
encodings = tokenizer.batch_encode_plus(df.values[:, 0].tolist(), return_tensors="pt", max_length=max_length, pad_to_max_length=True)
self.input_ids = encodings.input_ids
self.attention_masks = encodings.attention_mask
self.y = torch.LongTensor(df.values[:,1].tolist())
def __getitem__(self, index):
return self.input_ids[index], self.attention_masks[index], self.y[index]
def __len__(self):
return self.input_ids.shape[0]
```
Am I passing the "y" value incorrectly? It's not one-hot encoded matrix, but it's vector with size (batch_size, ) where each element represents the category for that text.<|||||>Yes, your labels are correct.
I can't reproduce your problem, though. This seems to work correctly.
```python
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer, BartForSequenceClassification
import pandas as pd
class SequenceClassificationDataset(Dataset):
def __init__(self, df, tokenizer, max_length):
encodings = tokenizer.batch_encode_plus(df.values[:, 0].tolist(), return_tensors="pt",
max_length=max_length, pad_to_max_length=True)
self.input_ids = encodings.input_ids
self.attention_masks = encodings.attention_mask
self.y = torch.LongTensor(df.values[:, 1].tolist())
def __getitem__(self, index):
return self.input_ids[index], self.attention_masks[index], self.y[index]
def __len__(self):
return self.input_ids.shape[0]
def main():
df = pd.DataFrame([
["Nah I don't think he goes to usf, he lives around here though", 2],
["URGENT! You have won a 1 week FREE membership in our $100,000 Prize Jackpot!", 1]
])
tokenizer = AutoTokenizer.from_pretrained("bart-large")
model = BartForSequenceClassification.from_pretrained("bart-large")
ds = SequenceClassificationDataset(df, tokenizer, 32)
dl = DataLoader(ds)
with torch.no_grad():
for batch_index, (batch_input_ids, batch_attention_masks, batch_y) in enumerate(dl, start=1):
batch_input_ids_cuda = batch_input_ids
batch_attention_masks_cuda = batch_attention_masks
batch_y_cuda = batch_y
loss, logits, _ = model(batch_input_ids_cuda, attention_mask=batch_attention_masks_cuda,
labels=batch_y_cuda)
print("Input ids:", batch_input_ids_cuda)
print("Attention masks:", batch_attention_masks_cuda)
print("Loss:", loss)
print("Logits:", logits)
print("y:", batch_y)
if __name__ == '__main__':
main()
```
Are you running this in a notebook? If so, try restarting the notebook. Having unexpected results like this can be a sign of cached cells.<|||||>Everything works fine if I don't fine-tune the model, the problem occurs after fine-tuning. Can you please check my training subroutine?<|||||>The training code seems okay. Even if there was a bug in the loop, you would not expect that any input gives the same output. I can't debug this unfortunately since I can't reproduce your issue. Can you share the dataset that you use for fine-tuning?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>> # ❓ Questions & Help
> ## Details
> I use BartForSequenceClassification pre-trained model from the HuggingFace Transformers library. During training phase logits from classification head gets different values, but during validation phase all logits values are equal even for different input texts.
>
> I use BartTokenizer.batch_encode_plus to encode the text before feeding into the model.
>
> I fine-tuned the model for 1 epoch using the following code:
>
> ```
> config = BartConfig.from_pretrained(model_name)
> config.num_labels = 3
> config.output_hidden_states = False
> config.output_attentions = False
>
> transformer_model = BartForSequenceClassification.from_pretrained(model_name, config=config)
> transformer_model.cuda();
> optimizer = AdamW(transformer_model.parameters())
>
> NUM_TRAIN_EPOCHS = 1
> print("Training:")
> for i in range(1, 1+NUM_TRAIN_EPOCHS):
> transformer_model.train()
> for batch_index, (batch_input_ids, batch_attention_masks, batch_y) in enumerate(train_dataloader, start=1):
> batch_input_ids_cuda = batch_input_ids.to(device)
> batch_attention_masks_cuda = batch_attention_masks.to(device)
> batch_y_cuda = batch_y.to(device)
> loss, logits, _ = transformer_model(batch_input_ids_cuda, attention_mask=batch_attention_masks_cuda, labels=batch_y_cuda)
> transformer_model.zero_grad()
> loss.backward()
> optimizer.step()
> ```
>
> And for validation I use the following code:
>
> ```
> transformer_model.eval()
> with torch.no_grad():
> for batch_index, (batch_input_ids, batch_attention_masks, batch_y) in enumerate(test_dataloader, start=1):
> batch_input_ids_cuda = batch_input_ids.to(device)
> batch_attention_masks_cuda = batch_attention_masks.to(device)
> batch_y_cuda = batch_y.to(device)
> loss, logits, _ = transformer_model(batch_input_ids_cuda, attention_mask=batch_attention_masks_cuda, labels=batch_y_cuda)
> print("Input ids:", batch_input_ids_cuda)
> print("Attention masks:", batch_attention_masks_cuda)
> print("Logits:", logits)
> ```
>
> Output of validation phase is:
>
> ```
> Input ids: tensor([[ 0, 3655, 9, ..., 1, 1, 1],
> [ 0, 31524, 347, ..., 1, 1, 1],
> [ 0, 12806, 24220, ..., 1, 1, 1],
> ...,
> [ 0, 8518, 7432, ..., 1, 1, 1],
> [ 0, 15006, 23613, ..., 1, 1, 1],
> [ 0, 14729, 13178, ..., 1, 1, 1]], device='cuda:0')
> Attention masks: tensor([[1, 1, 1, ..., 0, 0, 0],
> [1, 1, 1, ..., 0, 0, 0],
> [1, 1, 1, ..., 0, 0, 0],
> ...,
> [1, 1, 1, ..., 0, 0, 0],
> [1, 1, 1, ..., 0, 0, 0],
> [1, 1, 1, ..., 0, 0, 0]], device='cuda:0')
> Logits: tensor([[-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862],
> [-1.3014, -0.7394, 0.7862]], device='cuda:0')
> ```
>
> Why all the logits have exact same value for every input?
>
> **A link to original question on Stack Overflow**: https://stackoverflow.com/questions/62097267/same-logits-value-for-different-input-in-huggingfaces-transformer
same problem occurs to me<|||||>> Yes, your labels are correct.
>
> I can't reproduce your problem, though. This seems to work correctly.
>
> ```python
> import torch
> from torch.utils.data import Dataset, DataLoader
> from transformers import AutoTokenizer, BartForSequenceClassification
>
> import pandas as pd
>
>
> class SequenceClassificationDataset(Dataset):
> def __init__(self, df, tokenizer, max_length):
> encodings = tokenizer.batch_encode_plus(df.values[:, 0].tolist(), return_tensors="pt",
> max_length=max_length, pad_to_max_length=True)
> self.input_ids = encodings.input_ids
> self.attention_masks = encodings.attention_mask
> self.y = torch.LongTensor(df.values[:, 1].tolist())
>
> def __getitem__(self, index):
> return self.input_ids[index], self.attention_masks[index], self.y[index]
>
> def __len__(self):
> return self.input_ids.shape[0]
>
>
> def main():
> df = pd.DataFrame([
> ["Nah I don't think he goes to usf, he lives around here though", 2],
> ["URGENT! You have won a 1 week FREE membership in our $100,000 Prize Jackpot!", 1]
> ])
>
> tokenizer = AutoTokenizer.from_pretrained("bart-large")
> model = BartForSequenceClassification.from_pretrained("bart-large")
> ds = SequenceClassificationDataset(df, tokenizer, 32)
> dl = DataLoader(ds)
>
> with torch.no_grad():
> for batch_index, (batch_input_ids, batch_attention_masks, batch_y) in enumerate(dl, start=1):
> batch_input_ids_cuda = batch_input_ids
> batch_attention_masks_cuda = batch_attention_masks
> batch_y_cuda = batch_y
> loss, logits, _ = model(batch_input_ids_cuda, attention_mask=batch_attention_masks_cuda,
> labels=batch_y_cuda)
> print("Input ids:", batch_input_ids_cuda)
> print("Attention masks:", batch_attention_masks_cuda)
> print("Loss:", loss)
> print("Logits:", logits)
> print("y:", batch_y)
>
> if __name__ == '__main__':
> main()
> ```
>
> Are you running this in a notebook? If so, try restarting the notebook. Having unexpected results like this can be a sign of cached cells.
you should set the mode of the model to 'eval'.
https://huggingface.co/transformers/main_classes/model.html#transformers.PreTrainedModel.from_pretrained
`The model is set in evaluation mode by default using model.eval() (Dropout modules are deactivated). To train the model, you should first set it back in training mode with model.train().`<|||||>@xylcbd No. The _default_ is already eval, as the documentation writes. So you do not have to explicitly set it to eval() again. But if you want to train, you need to set it to train(). |
transformers | 4,688 | closed | Compressive Transformer | # 🌟 New model addition
## Model description
<table>
<tr><th>Title</th><td>Compressive Transformers for Long-Range Sequence Modelling (ICLR '20)</td></tr>
<tr><th>arXiv</th><td><a href="https://arxiv.org/pdf/1911.05507.pdf">1911.05507</a></td></tr>
<tr><th>Blog</th><td><a href="https://deepmind.com/blog/article/A_new_model_and_dataset_for_long-range_memory">A new model and dataset for long-range memory</a></td></tr>
</table>
__Compressive Transformer__ is an attentive sequence model which __compresses past memories__ for long-range sequence learning. The idea is similar to [Transformer-XL](https://arxiv.org/pdf/1901.02860.pdf). However, the memories are compressed in __Compressive Transformer__, making it leverage longer past memories compared to __Transformer-XL__.
## Open source status
- [ ] the model implementation is available
- [ ] the model weights are available
- [ ] who are the authors | 05-30-2020 13:12:24 | 05-30-2020 13:12:24 | Interested in model weights too but currently not available. Author does mention releasing tf code here:
https://news.ycombinator.com/item?id=22290227
Requires tf 1.15+ and deepmind/sonnet ver 1.36. Link to python script here:
https://github.com/deepmind/sonnet/blob/cd5b5fa48e15e4d020f744968f5209949ebe750f/sonnet/python/modules/nets/transformer.py#L915
Have tried running as-is but doesn't appear to have options for training on custom data as per the paper and available data sets.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,687 | closed | Update HooshvareLab/bert-base-parsbert-uncased | mBERT results added regarding NER datasets! | 05-30-2020 12:16:21 | 05-30-2020 12:16:21 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4687?src=pr&el=h1) Report
> Merging [#4687](https://codecov.io/gh/huggingface/transformers/pull/4687?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0866669e751bef636fa693b704a28c1fea9a17f3&el=desc) will **decrease** coverage by `1.44%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4687?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4687 +/- ##
==========================================
- Coverage 77.14% 75.70% -1.45%
==========================================
Files 128 128
Lines 21070 21070
==========================================
- Hits 16255 15950 -305
- Misses 4815 5120 +305
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4687?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `18.70% <0.00%> (-74.83%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `76.92% <0.00%> (-23.08%)` | :arrow_down: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `77.18% <0.00%> (-6.35%)` | :arrow_down: |
| [src/transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19jdHJsLnB5) | `95.94% <0.00%> (-2.71%)` | :arrow_down: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `86.77% <0.00%> (-0.19%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.50% <0.00%> (-0.17%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.29% <0.00%> (+0.35%)` | :arrow_up: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `81.78% <0.00%> (+1.37%)` | :arrow_up: |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4687/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `86.21% <0.00%> (+14.10%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4687?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4687?src=pr&el=footer). Last update [0866669...d473be4](https://codecov.io/gh/huggingface/transformers/pull/4687?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,686 | closed | [pipeline] Tokenizer should not add special tokens for text generation | This PR fixes generation in pipelines for all models whose tokenizer adds special tokens to the input, *e.g.* XLNet.
I think this is good for now, but I think the `_parse_and_tokenize()` function needs a larger refactoring to allow more flexibility in the future, also see Issue: #4501 | 05-30-2020 10:49:04 | 05-30-2020 10:49:04 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4686?src=pr&el=h1) Report
> Merging [#4686](https://codecov.io/gh/huggingface/transformers/pull/4686?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/9c17256447b91cf8483c856cb15e95ed30ace538&el=desc) will **increase** coverage by `0.24%`.
> The diff coverage is `75.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4686?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4686 +/- ##
==========================================
+ Coverage 77.23% 77.47% +0.24%
==========================================
Files 128 128
Lines 21050 21051 +1
==========================================
+ Hits 16257 16309 +52
+ Misses 4793 4742 -51
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4686?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/4686/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `76.15% <75.00%> (+0.04%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4686/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (ø)` | |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4686/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.17% <0.00%> (+0.23%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4686/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4686/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `81.78% <0.00%> (+1.37%)` | :arrow_up: |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4686/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `86.21% <0.00%> (+14.10%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4686?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4686?src=pr&el=footer). Last update [9c17256...95cf209](https://codecov.io/gh/huggingface/transformers/pull/4686?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,685 | closed | AutoModel.from_config loads random parameter values. | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): Bert
Language I am using the model on (English, Chinese ...): English
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
Model parameters are (apparently) random initialized when using `AutoModel.from_config`.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. `git clone https://github.com/gkutiel/transformers-bug`
2. `cd transformers-bug`
3. `pipenv shell`
4. `pipenv install`
5. `python main.py`
```python
from transformers import (
AutoModel,
AutoConfig,
)
pretrained = 'bert-base-uncased'
model_from_pretrained = AutoModel.from_pretrained(pretrained)
model_from_config = AutoModel.from_config(AutoConfig.from_pretrained(pretrained))
model_from_pretrained_params = list(model_from_pretrained.parameters())
model_from_config_params = list(model_from_config.parameters())
assert len(model_from_pretrained_params) == len(model_from_config_params)
model_from_pretrained_first_param = model_from_pretrained_params[0][0][0]
model_from_config_first_param = model_from_config_params[0][0][0]
assert model_from_pretrained_first_param == model_from_config_first_param, (
f'{model_from_pretrained_first_param} != {model_from_config_first_param}'
)
```
## Expected behavior
An assertion error should not happen.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 2.10.0
- Platform: MacOS
- Python version:3.6
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
| 05-30-2020 08:54:58 | 05-30-2020 08:54:58 | This is expected behaviour, but I understand your confusion.
```python
model_from_pretrained = AutoModel.from_pretrained(pretrained)
```
This actually loads the pretrained weights. It looks up the mapping and locations of the config file and the weights, and loads both.
```python
model_from_config = AutoModel.from_config(AutoConfig.from_pretrained(pretrained))
```
Here, the pretrained weights are never requested. You request the pretrained _config_ (basically the pretraining settings for the architecture), and (randomly) initialise an AutoModel given that config - but the weights are never requested and, thus, never loaded.
This means that both initialised models will have the same architecture, the same config, but different weights. The former has pretrained weights, the latter is randomly initialised.
I think that what you expected or wanted is actually this, which will load pretrained weights and taking into account a pretrained config (however, this is practically the same as the first option):
```python
model_from_config = AutoModel.from_pretrained(pretrained, config=AutoConfig.from_pretrained(pretrained))
```
Hope that helps.<|||||>Thank you very much for the fast response.
I think that the documentation is not clear enough about this difference, especially when there are pre-trained models such as `bert-base-uncased` and `bert-base-cased`, and there is the `AutoModelForPreTraining` class (that now I'm not sure what is for).
<|||||>If I understand correctly, your confusion lies in "well I called `.from_pretrained` so I would expect the model to have pretrained weights". However, the distinction is that if you run .from_pretrained on Auto**Config** you are not loading weights but you are loading a pre-existing config file. Loading pre-existing weights can only be done in a **Model** by using its `from_pretrained` method. But I agree that this could be improved in the documentation. I'll reopen this, try to improve the documentation, and close the issue when it's done.
Thanks for bringing this to the attention!<|||||>Hi, we tried to make it clear in the documentation by specifying [it in the `PretrainedConfig` class](https://huggingface.co/transformers/main_classes/configuration.html#pretrainedconfig).
I think we could add this note to `AutoConfig` as well, as I doubt users using `AutoConfig` read the documentation of `PretrainedConfig` as well.<|||||>Oh, sorry @BramVanroy I didn't see you assigned it to yourself. Do you want to add the documentation note? Maybe you have additional ideas of where it should be added?<|||||>I think that another place to mention this note is under the [from-config](https://huggingface.co/transformers/model_doc/auto.html#transformers.AutoModel.from_config) method.<|||||>You're right, it would be nice to specify it there as well!<|||||>> Oh, sorry @BramVanroy I didn't see you assigned it to yourself. Do you want to add the documentation note? Maybe you have additional ideas of where it should be added?
Oh, go ahead! You know the library better than I do so your judgement of where to add a note is better. |
transformers | 4,684 | closed | Create README.md | 05-30-2020 08:39:24 | 05-30-2020 08:39:24 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4684?src=pr&el=h1) Report
> Merging [#4684](https://codecov.io/gh/huggingface/transformers/pull/4684?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0866669e751bef636fa693b704a28c1fea9a17f3&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4684?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4684 +/- ##
=======================================
Coverage 77.14% 77.15%
=======================================
Files 128 128
Lines 21070 21070
=======================================
+ Hits 16255 16256 +1
+ Misses 4815 4814 -1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4684?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4684/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.83% <0.00%> (+0.16%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4684?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4684?src=pr&el=footer). Last update [0866669...e12a141](https://codecov.io/gh/huggingface/transformers/pull/4684?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 4,683 | closed | when I encode [unused1], return not one token | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): bert
Language I am using the model on (English, Chinese ...): English
The problem arises when using: tokenizer.encode('[unused1]')
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:relation extraction
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. tokenizer.encode("[unused1]")
2. but return not one token, if using keras-bert, it will return me only one token
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: least version
- Platform:
- Python version: 3.7
- PyTorch version (GPU?): 1.1.0
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
| 05-30-2020 07:44:30 | 05-30-2020 07:44:30 | I can reproduce this. cc @n1t0 @mfuntowicz Special "unused" tokens are not tokenised correctly. This happens in the fast tokenizers as well as the slow ones. See test case below.
```python
from transformers import BertTokenizer
USE_FAST = True
tokenizer = BertTokenizer.from_pretrained("bert-base-cased", use_fast=USE_FAST)
print('"[unused1]" in vocab?', "[unused1]" in tokenizer.vocab)
print('"[unused1]" index in vocab', tokenizer.vocab["[unused1]"] if "[unused1]" in tokenizer.vocab else "NA")
idxs = tokenizer.encode("[unused1]", add_special_tokens=False)
print("indices", idxs)
recoded = tokenizer.decode(idxs)
print("recoded", recoded)
```<|||||>Hi @jxyxiangyu, thanks for reporting this, thanks @BramVanroy to making a code to reproduce.
So far, the behavior you want to achieve needs to be done by deactivating the `do_basic_tokenize` feature on `BertTokenizer`, otherwise the input will be splitted on ponctuation chars before actually going through the wordpiece tokenizer.
_I don't think we have an equivalent on the Rust implementation of Bert, let me check internally and get back to you on this point._
Here a snippet of code which should achieve the desired behavior:
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased", do_basic_tokenize=False)
tokenizer.tokenize("[unused1]")
>>> ['[unused1]']
tokenizer.encode("[unused1]", add_special_tokens=False)
>>> [1]
tokenizer.decode([1])
>>> '[unused1]'
```<|||||>Thanks for responding to my query. After I tried the method you gave, ‘[unused1]’ could indeed be tokenized correctly, but I want to use '[unused1]' to concatenate two words with little relation. In my opinion, may I set other words do_basic_tokenize as True, and '[unused1]' as False?<|||||>Hi @jxyxiangyu! Thank you @BramVanroy & @mfuntowicz for the help on this!
I think in this case the easiest way to handle this, is by adding the tokens you plan to use as special tokens. After all, that's what they are. They are not added by default since only a handful of them are actually used so you need to do it manually with
```python
tokenizer.add_special_tokens({ "additional_special_tokens": [ "[unused1]" ] })
```
Then, it should work for both fast and slow tokenizers:
```python
>>> from transformers import AutoTokenizer
>>> slow = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
>>> fast = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=True)
>>> slow.add_special_tokens({ "additional_special_tokens": [ "[unused1]" ] })
>>> fast.add_special_tokens({ "additional_special_tokens": [ "[unused1]" ] })
>>> slow.encode("[unused1]", add_special_tokens=False)
[1]
>>> fast.encode("[unused1]", add_special_tokens=False)
[1]
```<|||||>Thank you very much for your response, which solved my confusion<|||||>Awesome! Closing the issue, do not hesitate to reopen if needed!<|||||>Hi @n1t0 , I had a related question. I want to re-register a token's id in the vocab so that I don't need to add a new token and expand the size of the vocab. Specifically, for example I want to register "qazwsx" to id 1, which means I want to replace "[unused1]" : 1 by "qazwsx" : 1. Do you know how to achieve this?
Another question is how to synchronize two tokens with the same id, to avoid expanding the size of vocab. For example, instead of replacing [unused1]" : 1 by "qazwsx" : 1, I want to keep both in the new vocab.
Thank you so much for the help! |
transformers | 4,682 | closed | XLNet Generation appears to reference padding text in run_generation script | When generating with XLNet in the `run_generation.py` script, the outputs seem to reference the context from the padding text. For instance, given the prompt "We propose a", XLNet generates "We propose a boy Go Ya Ya, a young Iriel Farg, to be named Rasputin."
This seems to reference the padding text:
https://github.com/huggingface/transformers/blob/0866669e751bef636fa693b704a28c1fea9a17f3/examples/text-generation/run_generation.py#L62-L71
From what I understand, this padding text should not influence the generation, since the padding ends with an end of sentence token. Is this behavior expected?
Full command I used for reference:
```bash
python -m examples.run_generation --model_type xlnet --model_name_or_path xlnet-base-cased --prompt "We propose a"
``` | 05-30-2020 07:29:10 | 05-30-2020 07:29:10 | Hi @thesamuel,
Ideally, the padding text should not influence the outcome, but this is more a hack to make XLNet work with short prompts, than actual science.
Also note that it is recommended now to use the TextGeneration Pipeline instead of the `run_generation` script:
```
from transformers import pipeline
generator = pipeline("text-generation", model="xlnet-base-cased")
print(generator("We propose a "))
```
**Note**: This works well for XLNet only after merging PR: #4686. So for pipelines to work, you either have to wait a bit or work on the branch of the PR: #4686.
As a default the pipeline employs sampling instead of greedy search. You might also want to play around with the generation hyperparameters here a bit for better results. To learn more about how to effectively use the many parameters for text generation, you might want to take a look at: https://huggingface.co/blog/how-to-generate
|
transformers | 4,681 | closed | NER: Add new WNUT’17 example | Hi,
this PR extends the NER example section, and adds an extra section for fine-tuning a NER model on the (difficult) WNUT’17 shared task:
> The WNUT’17 shared task focuses on identifying unusual, previously-unseen entities in the context of emerging discussions.
> Named entities form the basis of many modern approaches to other tasks (like event clustering and summarization), but recall on
> them is a real problem in noisy text - even among annotators. This drop tends to be due to novel entities and surface forms.
I also added my pre-processing script, that splits longer sentences into smaller ones (once the max. subtoken length is reached). | 05-29-2020 23:57:16 | 05-29-2020 23:57:16 | Looks great!<|||||>(I've relaunched the failing CI test that's unrelated)<|||||>@julien-c do you think rebasing onto latest master would fix that problem? |
transformers | 4,680 | closed | [EncoderDecoder] Fix initialization and save/load bug | This PR fixes two bugs:
- Cross attention layers were not initialized when initiating the `EncoderDecoderModel` via `from_encoder_decoder_pretrained()`. Thanks goes to https://github.com/huggingface/transformers/issues/4293 for finding this bug! A slow test is including in this PR to prevent future bugs of this kind.
- Saving / loading of pretrained models didn't work because the weights were initialized from the `model_to_load` weights because of a missing `base_model_prefix` in the `EncoderDecoderModel` class. Another slow test is included in this PR to prevent future bugs. I think this problem was mentioned in this issue: https://github.com/huggingface/transformers/issues/4517. I didn't rerun the code attached here: https://github.com/huggingface/transformers/issues/4517#issuecomment-636189365 but I'm quite positive that this is the bug that will be fixed in this PR.
## IMPORTANT
*To everybody who has been training Bert2Bert using the EncoderDecoder framework: Training with the EncoderDecoderModel before this PR did not work because there were no cross attention layers to be trained if you initialized your `EncoderDecoderModel` using `.from_encoder_decoder_pretrained(...)`. - I'm very sorry for the wasted compute and energy! Training should work now. I will add an encoder decoder notebook in the next 1-2 weeks showing in-detail how Bert2Bert can be used with `EncoderDecoder`*
This regards the Issues: #4445, #4647, #4517, #4443, #4293, #4640 | 05-29-2020 22:51:50 | 05-29-2020 22:51:50 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4680?src=pr&el=h1) Report
> Merging [#4680](https://codecov.io/gh/huggingface/transformers/pull/4680?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a801c7fd74f56a651ba43bfc93eba93c63e84766&el=desc) will **decrease** coverage by `0.01%`.
> The diff coverage is `75.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4680?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4680 +/- ##
==========================================
- Coverage 78.02% 78.01% -0.02%
==========================================
Files 124 124
Lines 20626 20634 +8
==========================================
+ Hits 16094 16098 +4
- Misses 4532 4536 +4
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4680?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_encoder\_decoder.py](https://codecov.io/gh/huggingface/transformers/pull/4680/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19lbmNvZGVyX2RlY29kZXIucHk=) | `92.20% <75.00%> (-3.45%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4680/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.41% <0.00%> (-0.12%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4680?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4680?src=pr&el=footer). Last update [a801c7f...a61742a](https://codecov.io/gh/huggingface/transformers/pull/4680?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>@thomwolf @LysandreJik @sshleifer - merging for now to solve a bunch of issues. On a side-note, we have not really released the `EncoderDecoderModel` feature of `transformers` yet, or? Are we planning on doing something semi-official for this?<|||||>>I will add an encoder decoder notebook in the next 1-2 weeks showing in-detail how Bert2Bert can be used with EncoderDecoder
@patrickvonplaten
I'm already working on a EncoderDecoder notebook for summarization task using kaggle news summery dataset. Hope to finish it in a week :)<|||||>> > I will add an encoder decoder notebook in the next 1-2 weeks showing in-detail how Bert2Bert can be used with EncoderDecoder
>
> @patrickvonplaten
>
> I'm already working on a EncoderDecoder notebook for summarization task using kaggle news summery dataset. Hope to finish it in a week :)
That's great news! Do you use a Bert2Bert implementation? <|||||>Yes, I am using Bert2Bert<|||||>@patrickvonplaten I noticed that since this change was merged this issue happens #5826, is it possible I'm using the config api incorrectly or may be a real issue?
Sorry for tagging you, thanks in advance!<|||||>Hey @afcruzs - will answer on the issue :-) <|||||>Hey, @patrickvonplaten , I wonder if there is any way to get the cross attention weights in the decoder from `EncoderDecoderModel` model. I looked at the document, it only will return the self-attention weights (`decoder_attentions `) in the decoder from `EncoderDecoderModel`? Thanks very much, it bothers me for a while.<|||||>Hey @kimmo1019 - could you please open a new issue about this? :-) |
transformers | 4,679 | closed | GPT-3 | Paper: https://arxiv.org/pdf/2005.14165
GitHub: https://github.com/openai/gpt-3
Author: @8enmann | 05-29-2020 19:36:38 | 05-29-2020 19:36:38 | Thanks, looks like a duplicate of #4658 <|||||>Ups, haven't seen this on mobile.
My apologies |
transformers | 4,677 | closed | Documentation for non-nlp experts | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
I want to use these models as an end-user, without having to read academic papers describing them.
I have been following deep learning in the field of computer vision, had no idea that NLP had advanced SO much (for me, Word2vec is still state of the art).
At work I have large amounts of text: articles, transcripts from voice and chat, chatbot exchanges, etc. I would love to Try out the functionality provided by the contributors here, but the documentation seems to assume one already know which models to use.
Perhaps someone can write a “Modern NLP for technical managers” type post (or link to an existing one).
I’m excited by the immense amount of work done here, but will have to start all the way back with RNNs and work my way up to this stuff. Hoping to be able to use this stuff without that detour!
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| 05-29-2020 17:59:24 | 05-29-2020 17:59:24 | Since no one else answers this:
Check out the simpletransformers library, it's and wrapper of this one and there are some blog posts linked to examples.
https://github.com/ThilinaRajapakse/simpletransformers
The author is very open to every idea and the work with him is pretty good.
Maybe it will help you.
For most common tasks the distilroberta model gives good results and doesn't need as much computing power as longformer or t5 needs<|||||>Thanks for the link, very helpful. I’m also finding that if I know what I need to do and which model to use, the API docs do have well coded examples.<|||||>If you don't know which model to use you can even just checkout the model hub.
For example for question answering tasks just search for "squad" models, then you will find a lot of pretrained models for this task<|||||>> Since no one else answers this:
I marked this question as a "Good First Issue". The idea is that we encourage people who are new to contributing to add their input. Particularly, you can add new examples that are very entry-level to explain the basic principles of the library.
<|||||>@falconair Thanks for raising this issue. We think we can make things better here.
If any one is interested in helping out, let me know. In particular it would be helpful to have examples of (non-nlp) projects that do this well. We could also use some beta testers.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>> @falconair Thanks for raising this issue. We think we can make things better here.
>
> If any one is interested in helping out, let me know. In particular it would be helpful to have examples of (non-nlp) projects that do this well. We could also use some beta testers.
Ping me if you need beta testers. I can test for Windows, Linux, Linux DDP. <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,676 | closed | Include `nlp` notebook for model evaluation | 05-29-2020 17:38:22 | 05-29-2020 17:38:22 | ||
transformers | 4,675 | closed | Gpt2 generation of text larger than 1024 | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
I know the context supported by GPT2 is 1024, but I assume there's some technique they utilized to train and generate text longer than that in their results. Also, I saw many gpt2-based repos training text with length longer than 1024. But when I tried generating text longer than 1024 it throws a runtime error :The size of tensor a (1025) must match the size of tensor b (1024) at non-singleton dimension 3. I have the following questions:
1) Shouldn't it be possible to generate longer text since a sliding window is used?
2) Can you please explain what's necessary to generate longer text? What changes will I have to make to the run_generation.py code?
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
| 05-29-2020 17:22:23 | 05-29-2020 17:22:23 | After looking over `modeling_utils.generate` (the function used for generation by `run_generation.py`), I believe that the sliding window approach is not yet implemented.
This method was implemented for CTRL generation in their repo, so you may be able to adapt some of their code for your use case: https://github.com/salesforce/ctrl/blob/master/generation.py#L186-L189<|||||>The iterative approach to generation (using `past`) may work better because you can control the sliding window manually.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>@patrickvonplaten @rautnikita77 @minimaxir Has anyone attempted to implement this (using cached keys and values)? |
transformers | 4,674 | closed | KeyError in Camembert in QuestionAnsweringPipeline | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...):
`Camembert ("illuin/camembert-large-fquad")`
Language I am using the model on (English, Chinese ...):
`French`
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Load model and create a question answering pipeline
Steps to reproduce the behavior:
1.
```
from transformers import (QuestionAnsweringPipeline, CamembertForQuestionAnswering, CamembertModel, CamembertTokenizer)
```
2.
```
QA_model = "illuin/camembert-large-fquad"
CamTokQA = CamembertTokenizer.from_pretrained(QA_model)
CamQA = CamembertForQuestionAnswering.from_pretrained(QA_model)
```
3.
```
device_pipeline = 0 if torch.cuda.is_available() else -1
q_a_pipeline = QuestionAnsweringPipeline(model=CamQA,
tokenizer=CamTokQA,
device=device_pipeline)
```
4.
```
res = q_a_pipeline({'question': question, 'context': ctx})
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
File "/mnt/Documents/Projets/BotPress/R_D/R_D_q_a/sdk/readers.py", line 15, in get_answers
res = q_a_pipeline({'question': question, 'context': ctx})
File "/home/pedro/.local/lib/python3.8/site-packages/transformers/pipelines.py", line 1213, in __call__
answers += [
File "/home/pedro/.local/lib/python3.8/site-packages/transformers/pipelines.py", line 1216, in <listcomp>
"start": np.where(char_to_word == feature.token_to_orig_map[s])[0][0].item(),
KeyError: 339
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Get answer from the Q_a pipeline
*Is working on transformers version 2.8.0* (but not on next ones)
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 2.10.0
- Platform: Linux-5.6.14-arch1-1-x86_64-with-glibc2.2.5
- Python version: 3.8.3
- PyTorch version (GPU?): 1.5.0 (True)
- Tensorflow version (GPU?): 2.2.0-rc4 (False)
- Using GPU in script?: Yes (but same problem with cpu only)
- Using distributed or parallel set-up in script?: No
| 05-29-2020 17:16:57 | 05-29-2020 17:16:57 | I can't reproduce on master. Do you mind specifying the context/question?<|||||>Because you couldn't reproduce, I tried with the latest version (from git : 2.11.0) and the problem seems gone (tested with random articles from wikipedia).
Maybe my first text had bad format or non utf-8 characters (but I remember to have tested with many differents inputs before openning an issue) or it was due to a bug fixed in 2.11
Sorry to have bothered you, thanks for the support !
<|||||>Alright, no worries! Let me know if you have an issue down the road.<|||||>@LysandreJik
I got the exact same error using Camembert ("illuin/camembert-large-fquad") and the question answering pipeline.
Opening a new issue.
Questions :
Le loyer est-il révisé annuellement ou triennalemment ?
Quel est la nature de l’indice de base ?
Le bail est-il soumis à TVA ou non soumis à TVA ?
Context :
[context_mono.txt](https://github.com/huggingface/transformers/files/4752269/context_mono.txt)
```
Traceback (most recent call last):
File "qa.py", line 164, in <module>
main_file()
File "qa.py", line 161, in main_file
analayse(mode)
File "qa.py", line 85, in analayse
answer_C = nlp_camembert_gpu_f(question=question_text, context=context)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/transformers/pipelines.py", line 1229, in __call__
for s, e, score in zip(starts, ends, scores)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/transformers/pipelines.py", line 1229, in <listcomp>
for s, e, score in zip(starts, ends, scores)
KeyError: 377
``` |
transformers | 4,673 | closed | QUESTION: How do I know what type of positional encoding to input during fine-tuning or pretrained BERT? | Hello HuggingFace team,
I am familiarizing myself with the HuggingFace tutorials and understand the functionality of the various methods. However, I have a general question for example when using models like BERT.
Considering that I am doing sentiment classification and I want to fine-tune the whole BERT based on pre-trained weights, how do I know what should be the positional encoding as input during the `forward ( )` method?
I know it has a default value of None, but doesn't it mean that during fine-tuning I need to input the same value that it was originally trained on in the first place? If so, how do I know what it was trained on during its original training from scratch? Is there a documentation for that somewhere?
Following to this, if I am freezing the weights of BERT for sentiment classification, I again have the same question on what should be my positional encoding input to the `forward ( )` method.
Please clarify this. Thanks for your time!
| 05-29-2020 13:55:23 | 05-29-2020 13:55:23 | Hi! If you're new to the library, I heavily recommend taking a look at the [glossary (position IDs in this case)](https://huggingface.co/transformers/glossary.html#position-ids), which explains how to use such inputs.
If you ignore the `position_ids`, then they're always automatically generated to be the same as the model's pre-training scheme. If you're fine-tuning and wish to keep the same position embeddings, then you don't need to pass them to the model.<|||||>THanks @LysandreJik , your second statement pretty much answered it completely! Thanks<|||||>@LysandreJik Hi, does that mean the position embeddings won't get updated if `position_ids` are not passed to the model (or with the default value of `None`)? Would you point me to the related lines in the code that implements this logic? Thanks!<|||||>This means that the position IDs will be generated on the fly, and the position embeddings will be exactly the same than during the pre-training. You can check the code [here](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L192-L214). |
transformers | 4,672 | closed | [Longformer] Better handling of global attention mask vs local attention mask | This PR extends Longformer's API to also take a `global_attention_mask` besides the usual `attention_mask` as an input as discussed with @thomwolf @ibeltagy.
Docs are updated. | 05-29-2020 13:27:51 | 05-29-2020 13:27:51 | Regarding the Multiple Choice `global_attention_mask`. Discussion taken from PR: https://github.com/huggingface/transformers/pull/4645#issuecomment-635429380
> @patil-suraj, we can leave it to the user, or we can just do as you suggested earlier, put global attention on the question and all choices, which should work.
>
> @patrickvonplaten, what do you think?
Regarding the multiple choice, I think we usually have the following tensor:
```
[
[ context, choice_a],
[ context, choice_b],
[ context, choice_c],
...
]
```
see here: https://github.com/huggingface/transformers/blob/9c17256447b91cf8483c856cb15e95ed30ace538/examples/multiple-choice/utils_multiple_choice.py#L529
So I'd suggest if no `global_attention_mask` is provided by the user, we initialize the `global_attention_mask` so that all choice contexts do global attention. If the user wants a different global attention he has now the possibility to define it himself.
@ibeltagy <|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4672?src=pr&el=h1) Report
> Merging [#4672](https://codecov.io/gh/huggingface/transformers/pull/4672?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/9c17256447b91cf8483c856cb15e95ed30ace538&el=desc) will **decrease** coverage by `0.05%`.
> The diff coverage is `41.37%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4672?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4672 +/- ##
==========================================
- Coverage 77.23% 77.17% -0.06%
==========================================
Files 128 128
Lines 21050 21060 +10
==========================================
- Hits 16257 16253 -4
- Misses 4793 4807 +14
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4672?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4672/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `93.52% <41.37%> (-3.53%)` | :arrow_down: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4672/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4672?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4672?src=pr&el=footer). Last update [9c17256...9ad5319](https://codecov.io/gh/huggingface/transformers/pull/4672?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Ok, checked the notebook: https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing and results are the same as before so no breaking changes.
Good to merge for me!<|||||>> Ok, checked the notebook: https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing and results are the same as before so no breaking changes.
>
> Good to merge for me!
This is great !
Just noticed one typo in the first line
> This notebook shows how `nlp` can be leveraged `nlp` to evaluate Longformer on TriviaQA |
transformers | 4,671 | closed | get_from_cache in file_utils.py gobbles up error in making url requests | # 🐛 Bug
No information from the package on SSL error encountered, making it difficult to troubleshoot or figure out a workaround
## Information
When trying to do:
`TFAutoModelWithLMHead.from_pretrained("t5-small")`
Get an error:
`TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType`
The above is a result of an SSL error encountered when trying to fetch the model, however, since the exception handling isn't proper within file_utils.py I don't come to know of it, unless I debug.
Model I am using (Bert, XLNet ...): T5
Language I am using the model on (English, Chinese ...): English
The problem arises when using:
* [ x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
https://huggingface.co/transformers/usage.html#summarization
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ x] my own task or dataset: (give details below)
Just getting familiar with transformers for summarization
## To reproduce
You need a machine with an expired certificate for proxy etc.
Steps to reproduce the behavior:
1. See information above
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
If there has been an issue in fetching the pre-trained model from s3 bucket etc. I should get an error to that effect.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 2.10.0
- Platform: Windows 10
- Python version: 3.7.4
- PyTorch version (GPU?): NA
- Tensorflow version (GPU?): 2.0.0 (Yes)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
| 05-29-2020 12:50:53 | 05-29-2020 12:50:53 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Ran into this today, this is a major issue behind corporate proxy/CA self signed certs. @SinghB maybe you can reopen this, I'm not sure who to `@mention`?
```python
get_from_cache(
# ...
etag = None
if not local_files_only:
try:
response = requests.head(url, allow_redirects=True, proxies=proxies, timeout=etag_timeout)
if response.status_code == 200:
etag = response.headers.get("ETag")
except (EnvironmentError, requests.exceptions.Timeout):
# etag is already None
# THIS ALSO SWALLOWS ALL OTHER NON "404" ERRORS (e.g. SSL, Proxy, etc.)
pass
# ....
```<|||||>Yes I want to track and solve that issue in the next couple of weeks.<|||||>+1 from me.
Currently I get this error message:
```
OSError: Can't load weights for 'bert-base-uncased'. Make sure that:
- 'bert-base-uncased' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'bert-base-uncased' is the correct path to a directory containing a file named one of pytorch_model.bin, tf_model.h5, model.ckpt.
```
But if I add a `raise` after the `# etag is already None` comment in stadelmanma's snippet, I see:
```
requests.exceptions.SSLError: HTTPSConnectionPool(host='cdn.huggingface.co', port=443): Max retries exceeded with url: /bert-base-uncased-pytorch_model.bin (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1056)')))
```
This leads to confusing debugging... the behavior of this error shouldn't be to indicate to the user that models like `bert-based-uncased` don't exist.<|||||>Hi @julien-c , I'm having the same issue as @stadelmanma (I'm behind a coporate proxy as well)
``` File "/home/USER/anaconda3/envs/codebert/lib/python3.7/site-packages/transformers/configuration_utils.py", line 376, in from_pretrained
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/USER/anaconda3/envs/codebert/lib/python3.7/site-packages/transformers/configuration_utils.py", line 436, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'microsoft/deberta-base'. Make sure that:
- 'microsoft/deberta-base' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'microsoft/deberta-base' is the correct path to a directory containing a config.json file
```
I even tried setting the proxy in `proxies`:
```config = config_class.from_pretrained(args.config_name, proxies={'http://': '<HOST>:<PORT>'})```
But same thing happens.
Maybe there's a workaround for this?
Many thanks! |
transformers | 4,670 | closed | Coversion between tokenizers | I want to convert GPT2 tokens to BERT tokens. Is there any API that can directly convert between the Tokenizers? | 05-29-2020 12:39:35 | 05-29-2020 12:39:35 | GPT-2 and BERT have very different tokenization mechanism. What do you mean by "convert between the tokenizers"? What do you want to do?<|||||>I want to use Bert as encoder and GPT2 as decoder. Then I want to evaluate the generated text with another Bert as discriminator (like the technique [here](https://arxiv.org/pdf/1703.00955.pdf)). I want the decoder to generate text just based on the context vector (refer to the above link). So I don't think I can use EncoderDecoderModel (am I right?) |
transformers | 4,669 | closed | Cannot load labels from old models | # ❓ Questions & Help
If I load a model from 2.8 or older in 2.9 o newer, the labels from my model are changed automatically so all the tests in my code start to fail because instead of predicting `I-PER` it predicts `LABEL_2`.
After reading the source code I think I found what happens but I'm not quite sure. I think it all started here in #3967
https://github.com/huggingface/transformers/blob/e7cfc1a313cc928e962bb8699868f5dcf46f11eb/src/transformers/configuration_utils.py#L123
In the code above you can see that the labels dicts are modified if we set `num_labels`. I couldn't find the place in the code where that is done, but it definetly modifies 2 attributes from the class. I don't really think that a setter for attribute A, should change attributes B and C.
Am I missing something when loading my models?
Thanks you so much for reading and for the library, we all love it <3
| 05-29-2020 12:14:27 | 05-29-2020 12:14:27 | I think I see where that could be a problem, indeed. Do you mind sharing your model configuration file so that I may take a closer look?<|||||>Here it is:
```
{
"architectures": [
"BertForTokenClassification"
],
"attention_probs_dropout_prob": 0.3,
"bos_token_id": 0,
"do_sample": false,
"eos_token_ids": 0,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.3,
"hidden_size": 768,
"id2label": {
"0": "I-MISC",
"1": "B-MISC",
"2": "O",
"3": "I-LOC",
"4": "I-ORG",
"5": "B-LOC",
"6": "B-ORG",
"7": "I-PER",
"8": "B-PER"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"label2id": {
"I-MISC": 0,
"B-MISC": 1,
"O": 2,
"I-LOC": 3,
"I-ORG": 4,
"B-LOC": 5,
"B-ORG": 6,
"I-PER": 7,
"B-PER": 8
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_labels": 9,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pad_token_id": 0,
"pruned_heads": {},
"repetition_penalty": 1.0,
"temperature": 1.0,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 28996
}
```
<|||||>@GuillemGSubies Thanks for reporting, I can reproduce this issue.
To fix it on your side while we push a fix, you can just remove the `num_labels` attribute from your config.json, it's not needed anymore. Let me know if this solves your issue.<|||||>Thanks you very much. I will do that :heart: <|||||>Should also be fixed on master by 751a1e08904fda197366e4b0033bdfb8b10d256c |
transformers | 4,668 | closed | Colab crashes due to tcmalloc large allocation | I am pretraining a RoBERTa model on the Newsroom dataset on colab. I have trained a custom tokenizer on the text data. I am using the Text Dataset LinebyLineTextDataset as I have a single file and each line is the text of a news article. The colab crashes when I run this code
_%%time
from transformers import LineByLineTextDataset
dataset = LineByLineTextDataset(tokenizer=tokenizer,
file_path="/content/drive/My Drive/Newsroom Dataset/newsroom-firsthalf.txt",
block_size=128)_
I tried with the full dataset and reduced it to half and have also tried it by reducing the block size.
The config is
_config = RobertaConfig(
vocab_size=52000,
max_position_embeddings=514,
num_attention_heads=12,
num_hidden_layers=6,
type_vocab_size=1)_
and the error log is
_tcmalloc: large alloc 7267041280 bytes == 0x9d916000 @ 0x7f3ea16311e7 0x5aca9b 0x4bb106 0x5bcf53 0x50a2bf 0x50bfb4 0x507d64 0x509042 0x594931 0x549e5f 0x5513d1 0x5a9cbc 0x50a5c3 0x50cd96 0x507d64 0x516345 0x50a2bf 0x50bfb4 0x507d64 0x588d41 0x59fc4e 0x50d356 0x507d64 0x509a90 0x50a48d 0x50bfb4 0x507d64 0x509a90 0x50a48d 0x50bfb4 0x509758._
Additional Notes: The increase RAM message doesnt come when colab crashes so I am essentially working 12.72 GB RAM.
Please help me
| 05-29-2020 11:29:16 | 05-29-2020 11:29:16 | Hi! This is indeed a memory error. At which point does it crash?<|||||>A similar problem like this has been reported when using the Lazy version of LinebyLineTextDataset. Colab deals badly with situation where you are using 90+% of memory - it'll kick you out or throw OOM errors - which you would not get on local machines. This is unfortunate and hard to get around.
In this case, I think you are simply running out of memory. The newsroom dataset is huge (1M+ news _articles_). So that is likely the issue.<|||||>@LysandreJik It crashes when suddenly the ram usage increases to around 7-8 GB and the increase is also very sudden. Its like it stays at 2-3 GB usage for a minute or so and then suddenly it shoots to 8GB and crashes.
@BramVanroy I tried reducing the dataset by half and running it but I am still getting the same error. So would you suggest running it on local machine?I will have to run this part on local as on my local I have a little better ram (16GB ) but then I will have to train in colab only as I dont have a GPU on my local laptop. Is there a better workaround
Also thanks guys for giving such a quick answer.<|||||>The sudden increase in RAM may be due to a sudden very large sentence/text which results in the whole batch having to be very large, exponentially increasing the memory usage.
How large is the dataset in terms of GB/number of lines?
Unfortunately sometimes you cannot do what you would want due to practical restrictions (mostly money). If you want to train or finetune a model with a huge dataset, it is likely that you need more hardware than is available in free plans.
Perhaps you can try out https://github.com/huggingface/nlp and find out if it has the dataset that you need. If not you can open an issue there and ask whether the dataset can be included. That should solve some issues since it takes into account RAM issues.<|||||>@BramVanroy I have tried with 26GB ram, but it still crashes, is there any minimum requirement of hardware mentioned?<|||||>No. I fear that this might simply not work on Colab. Line cache loads as much of the file as it can in memory and goes from there but Colab is being annoying and locks you out because it thinks you are going to throw an OOM error (but you won't on a regular system). <|||||>@BramVanroy , I am using "notebook" platform from google AI platforms with 26GB ram, (without GPU) but after running 2% for the very 1st epoch, it says :
**can't allocate memory: you tried to allocate 268435456 bytes. Error code 12 (Cannot allocate memory)** .
Am I doing something wrong?<|||||>Just read my previous post. This is a problem about how Google deals with increasing memory usage and thinks an OOM will occur even though it won't. The problem is not with the implementation. It seems that you cannot. Use this functionality in these kinds of VMs. <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Could anybody find a solution for the issue? |
transformers | 4,667 | closed | HooshvareLab readme parsbert-peymaner | Readme for HooshvareLab/bert-base-parsbert-peymaner-uncased | 05-29-2020 09:41:24 | 05-29-2020 09:41:24 | |
transformers | 4,666 | closed | HooshvareLab readme parsbert-armananer | Readme for HooshvareLab/bert-base-parsbert-armananer-uncased | 05-29-2020 09:35:01 | 05-29-2020 09:35:01 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4666?src=pr&el=h1) Report
> Merging [#4666](https://codecov.io/gh/huggingface/transformers/pull/4666?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b5015a2a0f4ea63035a877f5626cb0c3ce97e25d&el=desc) will **increase** coverage by `0.63%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4666?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4666 +/- ##
==========================================
+ Coverage 77.19% 77.83% +0.63%
==========================================
Files 128 128
Lines 21021 21021
==========================================
+ Hits 16228 16362 +134
+ Misses 4793 4659 -134
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4666?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4666/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.17% <0.00%> (+0.23%)` | :arrow_up: |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4666/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `86.21% <0.00%> (+14.10%)` | :arrow_up: |
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/4666/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `56.68% <0.00%> (+28.02%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4666?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4666?src=pr&el=footer). Last update [b5015a2...49068a5](https://codecov.io/gh/huggingface/transformers/pull/4666?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,665 | closed | HooshvareLab readme parsbert-ner | Readme for HooshvareLab/bert-base-parsbert-ner-uncased | 05-29-2020 09:25:58 | 05-29-2020 09:25:58 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4665?src=pr&el=h1) Report
> Merging [#4665](https://codecov.io/gh/huggingface/transformers/pull/4665?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b5015a2a0f4ea63035a877f5626cb0c3ce97e25d&el=desc) will **increase** coverage by `0.21%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4665?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4665 +/- ##
==========================================
+ Coverage 77.19% 77.41% +0.21%
==========================================
Files 128 128
Lines 21021 21021
==========================================
+ Hits 16228 16274 +46
+ Misses 4793 4747 -46
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4665?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4665/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (ø)` | |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4665/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.17% <0.00%> (+0.23%)` | :arrow_up: |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4665/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `86.21% <0.00%> (+14.10%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4665?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4665?src=pr&el=footer). Last update [b5015a2...e727442](https://codecov.io/gh/huggingface/transformers/pull/4665?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,664 | closed | run_tf_ner.py TFTrainer logdir cannot be none | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): bert
Language I am using the model on (English, Chinese ...): bert-base-multilingual-cased
The problem arises when using:
* [x] the official example scripts: (give details below)
run_tf_ner.py
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
germeval2014ner
* [ ] my own task or dataset: (give details below)
## To reproduce
run_tf_ner.py (original)
run.sh (see below)
Steps to reproduce the behavior:
1.
run.sh
```
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
export OUTPUT_DIR=germeval-model
export BATCH_SIZE=32
export NUM_EPOCHS=1
export SAVE_STEPS=750
export SEED=1
export data_dir=data
python run_tf_ner.py --data_dir ./data/ \
--labels ./data/labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_gpu_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
```
2. error message
```
Traceback (most recent call last):
File "run_tf_ner.py", line 295, in <module>
main()
File "run_tf_ner.py", line 220, in main
compute_metrics=compute_metrics,
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py", line 48, in __init__
self._setup_training()
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py", line 65, in _setup_training
self._create_summary_writer()
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py", line 88, in _create_summary_writer
self.writer = tf.summary.create_file_writer(self.args.logging_dir)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py", line 377, in create_file_writer_v2
raise ValueError("logdir cannot be None")
ValueError: logdir cannot be None
```
## Expected behavior
I did not change the code or the data. I was trying to reproduce exactly the German NER tf2.0 example: [https://github.com/huggingface/transformers/tree/master/examples/token-classification](url)
<!-- A clear and concise description of what you would expect to happen. -->
## Environment info
google colab gpu
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?): tensorflow gpu 2.2.0
- Using GPU in script?:yes
- Using distributed or parallel set-up in script?: no
| 05-29-2020 08:22:39 | 05-29-2020 08:22:39 | Hello,
This is because you have to specify `--logging_dir /path/to/logs` as parameter. There will be a default location for the next release of the TF Trainer.<|||||>Right. I later passed a parameter in run_tf_ner.py and it worked. I felt somewhere in the Trainer or run_tf_ner.py, it needs to be indicated.
Thanks for your prompt response! |
transformers | 4,663 | closed | End-to-end object detection with Transformers | # 🚀 Feature request
A modular Transformer Encoder-Decoder block that can be attached to ConvNets for many tasks.
## Motivation
As shown in the recent paper [End-to-end Object Detection with Transformers](https://ai.facebook.com/research/publications/end-to-end-object-detection-with-transformers) which used Transformer for Object Detection. [https://github.com/facebookresearch/detr](https://github.com/facebookresearch/detr)
## Your contribution
| 05-29-2020 04:33:09 | 05-29-2020 04:33:09 | I might be wrong, but I think the focus of this library is on NLP which at most is multimodal. Also including object detection transformers may fall out of the scope of this project. |
transformers | 4,662 | closed | run_tf_ner.py cannot run | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): Bert
Language I am using the model on (English, Chinese ...):bert-base-multilingual-cased
The problem arises when using:
* [ ] the official example scripts: (give details below)
original code in _run_tf_ner.py_
original data from _germaeval2014eval_
original data process from _preprocess.py_
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
_germaeval2014eval_ NER
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. this is the structure
--data
---train.txt
---dev.txt
---test.txt
---label.txt
run.sh (see below)
run_tf_ner.py (orignal)
utils_ner.py (original)
preprocess.py(original)
2. run.sh
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
export OUTPUT_DIR=germeval-model
export BATCH_SIZE=32
export NUM_EPOCHS=1
export SAVE_STEPS=750
export SEED=1
export data_dir=data
python3 run_tf_ner.py \
--data_dir . \
--labels $data_dir/labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_gpu_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
3. sh run.sh will return the invalid configuration error
```
--05/29/2020 11:21:48 - INFO - __main__ - n_gpu: 2, distributed training: True, 16-bits training: False
05/29/2020 11:21:48 - INFO - __main__ - Training/evaluation parameters TFTrainingArguments(output_dir='germeval-model', overwrite_output_dir=False, do_train=True, do_eval=True, do_predict=True, evaluate_during_training=False, per_gpu_train_batch_size=32, per_gpu_eval_batch_size=8, gradient_accumulation_steps=1, learning_rate=5e-05, weight_decay=0.0, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=1.0, max_steps=-1, warmup_steps=0, logging_dir=None, logging_first_step=False, logging_steps=500, save_steps=750, save_total_limit=None, no_cuda=False, seed=1, fp16=False, fp16_opt_level='O1', local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, optimizer_name='adam', mode='text-classification', loss_name='SparseCategoricalCrossentropy', tpu_name=None, end_lr=0, eval_steps=1000, debug=False)
05/29/2020 11:21:50 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-config.json from cache at /home/ll/.cache/torch/transformers/45629519f3117b89d89fd9c740073d8e4c1f0a70f9842476185100a8afe715d1.65df3cef028a0c91a7b059e4c404a975ebe6843c71267b67019c0e9cfa8a88f0
05/29/2020 11:21:50 - INFO - transformers.configuration_utils - Model config BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "B-LOC",
"1": "B-LOCderiv",
"2": "B-LOCpart",
"3": "B-ORG",
"4": "B-ORGderiv",
"5": "B-ORGpart",
"6": "B-OTH",
"7": "B-OTHderiv",
"8": "B-OTHpart",
"9": "B-PER",
"10": "B-PERderiv",
"11": "B-PERpart",
"12": "I-LOC",
"13": "I-LOCderiv",
"14": "I-LOCpart",
"15": "I-ORG",
"16": "I-ORGderiv",
"17": "I-ORGpart",
"18": "I-OTH",
"19": "I-OTHderiv",
"20": "I-OTHpart",
"21": "I-PER",
"22": "I-PERderiv",
"23": "I-PERpart",
"24": "O"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"label2id": {
"B-LOC": 0,
"B-LOCderiv": 1,
"B-LOCpart": 2,
"B-ORG": 3,
"B-ORGderiv": 4,
"B-ORGpart": 5,
"B-OTH": 6,
"B-OTHderiv": 7,
"B-OTHpart": 8,
"B-PER": 9,
"B-PERderiv": 10,
"B-PERpart": 11,
"I-LOC": 12,
"I-LOCderiv": 13,
"I-LOCpart": 14,
"I-ORG": 15,
"I-ORGderiv": 16,
"I-ORGpart": 17,
"I-OTH": 18,
"I-OTHderiv": 19,
"I-OTHpart": 20,
"I-PER": 21,
"I-PERderiv": 22,
"I-PERpart": 23,
"O": 24
},
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 119547
}
05/29/2020 11:21:51 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-config.json from cache at /home/ll/.cache/torch/transformers/45629519f3117b89d89fd9c740073d8e4c1f0a70f9842476185100a8afe715d1.65df3cef028a0c91a7b059e4c404a975ebe6843c71267b67019c0e9cfa8a88f0
05/29/2020 11:21:51 - INFO - transformers.configuration_utils - Model config BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 119547
}
05/29/2020 11:21:52 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt from cache at /home/ll/.cache/torch/transformers/96435fa287fbf7e469185f1062386e05a075cadbf6838b74da22bf64b080bc32.99bcd55fc66f4f3360bc49ba472b940b8dcf223ea6a345deb969d607ca900729
05/29/2020 11:21:54 - INFO - transformers.modeling_tf_utils - loading weights file https://cdn.huggingface.co/bert-base-multilingual-cased-tf_model.h5 from cache at /home/ll/.cache/torch/transformers/273ed844d60ef1d5a4ea8f7857e3c3869d05d7b22296f4ae9bc56026ed40eeb7.1b4841f14bf42137fc7ecee17a46c1b2f22b417f636347e4b810bd06dd9c45ea.h5
2020-05-29 11:21:55.520823: F ./tensorflow/core/kernels/random_op_gpu.h:232] Non-OK-status: GpuLaunchKernel(FillPhiloxRandomKernelLaunch<Distribution>, num_blocks, block_size, 0, d.stream(), gen, data, size, dist) status: Internal: invalid configuration argument
Aborted (core dumped)
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
I was trying to run the training of transformer ner extraction
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: Ubuntu 16.04.4 LTS
- Python version: Python 3.6.10 :: Anaconda, Inc.
- PyTorch version (GPU?):
- Tensorflow version (GPU?): 2.2.0 GPU
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?:
| 05-29-2020 03:47:35 | 05-29-2020 03:47:35 | Delete. It may be a hardware issue. When I changed it to Colab, this problem disappeared |
transformers | 4,661 | closed | Write With Transformer: PPLM page is broken | # 🐛 Bug
Triggering autocomplete results in endless spinning.
iOS safari But also desktop Safari, Firefox and Chrome.
| 05-29-2020 02:44:11 | 05-29-2020 02:44:11 | I cannot reproduce your problem. Can you try again?<|||||>I tried again.
Console on dev tools shows:
```
DevTools failed to load SourceMap: Could not load content for chrome-extension://ibnejdfjmmkpcnlpebklmnkoeoihofec/dist/contentScript.js.map: HTTP error: status code 404, net::ERR_UNKNOWN_URL_SCHEME
DevTools failed to load SourceMap: Could not load content for chrome-extension://nkbihfbeogaeaoehlefnkodbefgpgknn/sourcemaps/contentscript.js.map: HTTP error: status code 404, net::ERR_UNKNOWN_URL_SCHEME
DevTools failed to load SourceMap: Could not load content for chrome-extension://nkbihfbeogaeaoehlefnkodbefgpgknn/sourcemaps/inpage.js.map: HTTP error: status code 404, net::ERR_UNKNOWN_URL_SCHEME
DevTools failed to load SourceMap: Could not load content for chrome-extension://ibnejdfjmmkpcnlpebklmnkoeoihofec/dist/pageHook.js.map: HTTP error: status code 404, net::ERR_UNKNOWN_URL_SCHEME
```<|||||>Those are unrelated warnings related to source maps. I can;t reproduce your problem and I tried on different browsers. Can you clear the cache/try in private mode/incognito?<|||||><img width="2543" alt="Screen Shot 2020-06-01 at 1 50 50 am" src="https://user-images.githubusercontent.com/597346/83359074-6acfea00-a3aa-11ea-97e9-d9fa0ed872ea.png">
Still no luck<|||||>D'oh, I didn't check the PPLM page. The other versions of Write With Transformer seem to work, but you are right that it doesn't seem to work for [PPLM](https://transformer.huggingface.co/doc/pplm). When you trigger "autocomplete", the web page seems to hang.
cc @julien-c <|||||>Yes, we turned off the PPLM machine as it was costly to host. We need to add a notice to try it locally instead, and/or re-spawn a cheaper machine. Both are on our todo-list.<|||||>Added a notice there: https://transformer.huggingface.co/doc/pplm |
transformers | 4,660 | closed | Assert message error in Reformer chunking | # 🐛 Bug
In the function `apply_chunking_to_forward`, an assertion checking the input tensor shape is trying to print the contents of the tensor itself instead of its shape:
https://github.com/huggingface/transformers/blob/b5015a2a0f4ea63035a877f5626cb0c3ce97e25d/src/transformers/modeling_utils.py#L2195
I'm pretty sure that line should be `input_tensors[0].shape[chunk_dim], chunk_size` | 05-29-2020 02:42:48 | 05-29-2020 02:42:48 | |
transformers | 4,659 | closed | Add support for gradient checkpointing in BERT | This PR adds support for gradient checkpointing in `modeling_bert.py` to save memory at training time at the expense of a slower backward pass. This is particularly useful if we want to pretrain a version of BERT for sequences longer than 512. It is also useful for long-document models like Longformer.
Stats:
```
Forward/backward - no grad checkpointing: 40.1GB memory, 25.3 seconds.
Forward/backward - with grad checkpointing: 8.2GB memory (~5x less), 33.5 seconds (~1.3x more)
Forward pass only - with/without gradient checkpointing: 4GB memory, 6.1 seconds.
``` | 05-29-2020 01:59:21 | 05-29-2020 01:59:21 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4659?src=pr&el=h1) Report
> Merging [#4659](https://codecov.io/gh/huggingface/transformers/pull/4659?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f4e1f022100834bd00d4f877a883b5946c4cac37&el=desc) will **decrease** coverage by `0.34%`.
> The diff coverage is `50.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4659?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4659 +/- ##
==========================================
- Coverage 78.40% 78.06% -0.35%
==========================================
Files 138 138
Lines 23757 23766 +9
==========================================
- Hits 18627 18552 -75
- Misses 5130 5214 +84
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4659?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `87.50% <44.44%> (-0.72%)` | :arrow_down: |
| [src/transformers/configuration\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JlcnQucHk=) | `100.00% <100.00%> (ø)` | |
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/4659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `34.07% <0.00%> (-22.62%)` | :arrow_down: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `79.51% <0.00%> (-1.39%)` | :arrow_down: |
| [src/transformers/tokenization\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYmVydC5weQ==) | `90.45% <0.00%> (-0.83%)` | :arrow_down: |
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `94.81% <0.00%> (-0.38%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `85.81% <0.00%> (-0.30%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `91.28% <0.00%> (+0.12%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4659?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4659?src=pr&el=footer). Last update [f4e1f02...400070b](https://codecov.io/gh/huggingface/transformers/pull/4659?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>> we'll look at upstreaming it in the `transformers.PretrainedModel` if everyone's on board.
Thanks, @LysandreJik. It would be great to make `gradient_checkpointing` available to more models. While the configuration can be upstreamed in `transformers.PretrainedConfig`, the implementation is model specific, where you need to call `torch.utils.checkpoint.checkpoint` inside the layers loop as in [here](https://github.com/huggingface/transformers/blob/bf4342743ad2f5a5e1090818ecb72f2ebc6e4f73/src/transformers/modeling_bert.py#L404).<|||||>I was thinking of having the implementation be model agnostic as well. I haven't really thought out the best way, but a possible way to achieve it would be with a decorator; for example, in `PretrainedModel` we could have something like:
```py
@staticmethod
def gradient_checkpointing(layer):
@functools.wraps(layer)
def wrapper(*args):
layer_instance = args[0]
# Remove the wrapper to prevent infinite recursion on the wrapper
layer_instance.forward = functools.partial(layer_instance.forward.__wrapped__, layer_instance)
if args[0].config.gradient_checkpointing:
return torch.utils.checkpoint.checkpoint(layer_instance, *args[1:])
else:
return layer(*args)
return wrapper
```
Then we can very simply add that decorator on the layers where we want the checkpoint:
```py
class BertLayer(nn.Module):
...
@PreTrainedModel.gradient_checkpointing
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
):
...
```
This would require that these layers have access to the configuration so that they're aware of gradient check-pointing or not.
Pretty convenient, but pretty different from our coding style as well cc @thomwolf <|||||>neat <|||||>A model agnostic approach might be best. In my research for isolating https://github.com/minimaxir/aitextgen/issues/6 for finetuning larger GPT-2 models, it appeared that checkpointing would have to be implemented at the model level, as this PR does for BERT.<|||||>torch.utils.checkpoint.checkpoint works well in single GPU. But it causes OOM in multi-gpu with torch.nn.DataParallel.<|||||>> I was thinking of having the implementation be model agnostic as well. I haven't really thought out the best way, but a possible way to achieve it would be with a decorator; for example, in `PretrainedModel` we could have something like:
>
> ```python
> @staticmethod
> def gradient_checkpointing(layer):
> @functools.wraps(layer)
> def wrapper(*args):
> layer_instance = args[0]
> # Remove the wrapper to prevent infinite recursion on the wrapper
> layer_instance.forward = functools.partial(layer_instance.forward.__wrapped__, layer_instance)
>
> if args[0].config.gradient_checkpointing:
> return torch.utils.checkpoint.checkpoint(layer_instance, *args[1:])
> else:
> return layer(*args)
> return wrapper
> ```
>
> Then we can very simply add that decorator on the layers where we want the checkpoint:
>
> ```python
> class BertLayer(nn.Module):
>
> ...
>
> @PreTrainedModel.gradient_checkpointing
> def forward(
> self,
> hidden_states,
> attention_mask=None,
> head_mask=None,
> encoder_hidden_states=None,
> encoder_attention_mask=None,
> ):
>
> ...
> ```
>
> This would require that these layers have access to the configuration so that they're aware of gradient check-pointing or not.
>
> Pretty convenient, but pretty different from our coding style as well cc @thomwolf
I like idea of having a decorator function! Would it be enough to have this wrapper only at all "Model" forward functions, like `BertModel.forward()`? <|||||>> torch.utils.checkpoint.checkpoint works well in single GPU. But it causes OOM in multi-gpu with torch.nn.DataParallel.
I haven't tried `torch.nn.DataParallel` but it works well with `torch.nn.DistributedDataParallel` on a single or multiple machines. <|||||>> I like idea of having a decorator function! Would it be enough to have this wrapper only at all "Model" forward functions, like `BertModel.forward()`?
I don't think so. Even with the decorator, it is still model-specific; the decorator just makes the syntax easier. You still need to decide where to call it because too few calls (e.g. only on `BertModel.forward`), and you won't save enough memory, too many calls (e.g. on every `.forward` function) and the backward pass will be very slow.<|||||>Pinging @julien-c so he can take a look.<|||||>> > torch.utils.checkpoint.checkpoint works well in single GPU. But it causes OOM in multi-gpu with torch.nn.DataParallel.
>
> I haven't tried `torch.nn.DataParallel` but it works well with `torch.nn.DistributedDataParallel` on a single or multiple machines.
Thanks for the advice. But I try `torch.nn.DistributedDataParallel` and meet the same problem in https://github.com/pytorch/pytorch/issues/24005. The pytorch version is 1.2.0.
The code is:
```
if n_gpu > 1:
# model = torch.nn.DataParallel(model)
torch.distributed.init_process_group(backend="nccl")
model = torch.nn.parallel.DistributedDataParallel(model, find_unused_parameters=True)
```
Both `find_unused_parameters=True` and `find_unused_parameters=False` get errors.


<|||||>@ibeltagy, after some back and forth offline with @julien-c and @thomwolf, the way you implemented it is preferred as it's simpler to understand and adheres better to the library's philosophy.
I think we can merge this and then in a following PR add it to all the other models. Would you like to take care of that? No worries if not, I can definitely take care of it.<|||||>@LysandreJik, glad this will be merged.
> Would you like to take care of that? No worries if not, I can definitely take care of it.
I will pass :D
<|||||>> > > torch.utils.checkpoint.checkpoint works well in single GPU. But it causes OOM in multi-gpu with torch.nn.DataParallel.
> >
> >
> > I haven't tried `torch.nn.DataParallel` but it works well with `torch.nn.DistributedDataParallel` on a single or multiple machines.
>
> Thanks for the advice. But I try `torch.nn.DistributedDataParallel` and meet the same problem in [pytorch/pytorch#24005](https://github.com/pytorch/pytorch/issues/24005). The pytorch version is 1.2.0.
>
> The code is:
>
> ```
> if n_gpu > 1:
> # model = torch.nn.DataParallel(model)
> torch.distributed.init_process_group(backend="nccl")
> model = torch.nn.parallel.DistributedDataParallel(model, find_unused_parameters=True)
> ```
>
> Both `find_unused_parameters=True` and `find_unused_parameters=False` get errors.
> 
> 
I encounter the same issue with torch 1.5.0 and latest transformers<|||||>@ewrfcas, @schinger, do you have a small example that reproduces the error?
I don't think we can fix this issue (needs a PyTorch fix https://github.com/pytorch/pytorch/issues/24005), but I think we can work around it by removing the unused parameters mentioned in the error message. <|||||>> @ewrfcas, @schinger, do you have a small example that reproduces the error?
>
> I don't think we can fix this issue (needs a PyTorch fix [pytorch/pytorch#24005](https://github.com/pytorch/pytorch/issues/24005)), but I think we can work around it by removing the unused parameters mentioned in the error message.
squad example training can reproduce this error: https://github.com/huggingface/transformers/tree/master/examples/question-answering
python -m torch.distributed.launch --nproc_per_node=8 ./examples/question-answering/run_squad.py \
--model_type bert \
--model_name_or_path bert-large-uncased-whole-word-masking \
--do_train \
--do_eval \
--do_lower_case \
--train_file SQUAD_DIR/dev-v1.1.json \
--predict_file SQUAD_DIR/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./examples/models/wwm_uncased_finetuned_squad/ \
--per_gpu_eval_batch_size=1 \
--per_gpu_train_batch_size=1 \
no matter find_unused_parameters is ture or false<|||||>Thanks. It would be more helpful if you provide a simpler and smaller example that I can easily run.<|||||>> Thanks. It would be more helpful if you provide a simpler and smaller example that I can easily run.
you can change --train_file to SQUAD_DIR/dev-v1.1.json, dev set is small for quickly run<|||||>> > torch.utils.checkpoint.checkpoint works well in single GPU. But it causes OOM in multi-gpu with torch.nn.DataParallel.
>
> I haven't tried `torch.nn.DataParallel` but it works well with `torch.nn.DistributedDataParallel` on a single or multiple machines.
could you show me a example about gradient checkpoint works successfully with `torch.nn.DistributedDataParallel` on multi-gpu?<|||||>> @ewrfcas, @schinger, do you have a small example that reproduces the error?
>
> I don't think we can fix this issue (needs a PyTorch fix [pytorch/pytorch#24005](https://github.com/pytorch/pytorch/issues/24005)), but I think we can work around it by removing the unused parameters mentioned in the error message.
I have trained a base model instead of large to delay this problem.
The only differences in the code are
```
class BertEncoder(nn.Module):
def forward(...):
...
for i, layer_module in enumerate(self.layer):
...
if self.use_grad_ckpt:
layer_outputs = torch.utils.checkpoint.checkpoint(layer_module, hidden_states, attention_mask, head_mask[i],
encoder_hidden_states, encoder_attention_mask)
else:
layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i],
encoder_hidden_states, encoder_attention_mask)
...
...
```
and
```
torch.distributed.init_process_group(backend="nccl")
model = torch.nn.parallel.DistributedDataParallel(model, find_unused_parameters=True)
```
Other codes are the same as normal finetuning codes.<|||||>Here's a small example to replicate the error
```
import os
import torch
from transformers import BertForPreTraining
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
torch.distributed.init_process_group(backend="nccl", rank=0, world_size=1)
model = BertForPreTraining.from_pretrained('bert-base-uncased', gradient_checkpointing=True).cuda()
model = torch.nn.parallel.DistributedDataParallel(model, find_unused_parameters=True)
outputs = model(torch.tensor([[1, 2, 3]]).cuda())
outputs[0].sum().backward()
```
Use `find_unused_parameters=True` and you will get
```
RuntimeError: Expected to mark a variable ready only once. This error is caused by use of a module parameter outside the `forward` function.
```
Use `find_unused_parameters=False`, and things will work just fine.
I couldn't replicate the other error,
```
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one.
```
@ewrfcas, do you know how to modify the example above to reproduce it?
@schinger, can you try `find_unused_parameters=False` see if it fixes your problem.<|||||>> Here's a small example to replicate the error
>
> ```
> import os
> import torch
> from transformers import BertForPreTraining
> os.environ['MASTER_ADDR'] = 'localhost'
> os.environ['MASTER_PORT'] = '12355'
> torch.distributed.init_process_group(backend="nccl", rank=0, world_size=1)
>
> model = BertForPreTraining.from_pretrained('bert-base-uncased').cuda()
> model = torch.nn.parallel.DistributedDataParallel(model, find_unused_parameters=True)
> outputs = model(torch.tensor([[1, 2, 3]]).cuda())
> outputs[0].sum().backward()
> ```
>
> Use `find_unused_parameters=True` and you will get
>
> ```
> RuntimeError: Expected to mark a variable ready only once. This error is caused by use of a module parameter outside the `forward` function.
> ```
>
> Use `find_unused_parameters=False`, and things will work just fine.
>
> I couldn't replicate the other error,
>
> ```
> RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one.
> ```
>
> @ewrfcas, do you know how to modify the example above to reproduce it?
>
> @schinger, can you try `find_unused_parameters=False` see if it fixes your problem.
I have tried this code. Although it works in the first, the second forword will be failed. You can try to repeat the loss.backward for few times.<|||||>@ewrfcas, I get this error with `gradient_checkpointing=True` and `gradient_checkpointing=False` (btw, `gradient_checkpointing` was set to `False` in the example above and I just updated it), so it is a problem with the example, not gradient checkpointing. Can you try to fix the example? or can you try it in a training loop that uses DDP correctly, either with pytorch-lightning or hugginface trainer?<|||||>> @ewrfcas, I get this error with `gradient_checkpointing=True` and `gradient_checkpointing=False` (btw, `gradient_checkpointing` was set to `False` in the example above and I just updated it), so it is a problem with the example, not gradient checkpointing. Can you try to fix the example? or can you try it in a training loop that uses DDP correctly, either with pytorch-lightning or hugginface trainer?
I have solved this problem by removing the self.pooler layer in BertModel because it did not forward any thing during the training. As the error saied, all parameters should be used in loss for DistributedDataParallel with find_unused_parameters=False, and find_unused_parameters=True is incompatible with gradient_checkpointing.
Maybe we need this code after the first backward
```
# check parameters with no grad
for n, p in model.named_parameters():
if p.grad is None and p.requires_grad is True:
print('No forward parameters:', n, p.shape)
```<|||||>Nice finding, @ewrfcas.
@LysandreJik, what is the best way to address this problem? do we need to fix it or can we leave it to the user to make sure all the model params are used? maybe in a separate PR we can find a way to automatically remove unused model params?
Also, aside from this issue, anything else we need to merge the PR? <|||||>Right, I think this should be looked at in a separate PR. Will take a final look and merge this PR tomorrow, and then look at implementing gradient checkpointing to the rest of the models. |
transformers | 4,658 | closed | Add upcoming GPT-3 model | # 🌟 New model addition
## Model description
The GPT-3 paper just landed on ArXiv: https://arxiv.org/abs/2005.14165.
Would be great to integrate it into Transformers, whenever models are available.
> Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.
## Open source status
* [x] GitHub repository is available: [here](https://github.com/openai/gpt-3)
* [ ] the model implementation is available: (give details)
* [ ] the model weights are available: (give details)
* [ ] who are the authors: (mention them, if possible by @gh-username)
| 05-29-2020 01:00:46 | 05-29-2020 01:00:46 | My god, the paper hasn't even been up for a day...
Said being, +1<|||||>So who can run 175B parameters and what do I have to do for a favor?<|||||>The full model will be at least 350 GB (16-bit parameters). You'd need to partition it across more than (350 GB) / (16 GB) ~ **22 GPUs** just to run it! Not to mention the egress costs of making a model that size available.
Of course, the paper shows **8** different-sized models, **4 of which are smaller than GPT-2**, so some of those could be practical. 🙂
<|||||>Is there any Colab to test at least GPT-3 XL ?<|||||>> Is there any Colab to test at least GPT-3 XL ?
They haven't released any code or pretrained models yet. See the issue on the official repo: https://github.com/openai/gpt-3/issues/1<|||||>Note that the released models may be FP16, which may require forcing FP16 for use/finetuning (and therefore hardware-limited), or casting up to FP32.<|||||>> Of course, the paper shows **8** different-sized models, **4 of which are smaller than GPT-2**, so some of those could be practical. slightly_smiling_face
One of the main benefits of the smaller gpt-3 models compared to their gpt-2 counterparts could be the increased context length of 2048 tokens.<|||||>Yeah, personally, I wouldn't be able to use the models that won't fit in a Tesla P100<|||||>The [GPT-3 repo](https://github.com/openai/gpt-3) is now archived (read-only) so perhaps OpenAI isn't planning on releasing anything this time around.<|||||>> The [GPT-3 repo](https://github.com/openai/gpt-3) is now archived (read-only) so perhaps OpenAI isn't planning on releasing anything this time around.
That is a crying shame, because my system could do-er... :(<|||||>Hopefully they have a better excuse than last time.<|||||>> Hopefully they have a better excuse than last time.
@flarn2006 You mean the....ooohhhh we created something scary and have soggy diapers excuse with GPT-3?<|||||>@flarn2006 If they don't make excuses or drag their feet, and I finish my system build in a relatively congruent time frame, hopefully I can help...<|||||>A little update: OpenAI's now running their own API with GPT-3 on it. https://beta.openai.com
You can apply for access, but seems like they're aiming mostly for big companies, not researchers. Sad, way too sad.<|||||>But who put the "Open" in OpenAI then 🤔<|||||>I guess we will need to "fundraise" enough GPU-compute to run the GPT3 model. :smile: <|||||>It should be possible to run lower-models on regular GPUs, like 1b model. But we don't have the model itself, and seems that OpenAI is against releasing it and would rather commercialize it :(<|||||>I wonder if you could hardcode the 175B model into an electronic chip(like an ASIC but more specific)<|||||>> I wonder if you could hardcode the 175B model into an electronic chip(like an ASIC but more specific)
Very interesting as an idea. @StealthySemicolon do you have reference to other similar work done in the past?<|||||>> > I wonder if you could hardcode the 175B model into an electronic chip(like an ASIC but more specific)
>
> Very interesting as an idea. @StealthySemicolon do you have reference to other similar work done in the past?
No, just a hunch. Even if I did know how to do this, it's not like OpenAI would publicly release the model weights...<|||||>Guys when is this gonna be integrated!?<|||||>When OpenAI decides to release GPT-3 open-sourcely, but this won't happen it seems, they just want to sell access to big corporations.<|||||>https://bdtechtalks.com/2020/08/17/openai-gpt-3-commercial-ai/amp/
Here it goes...<|||||>https://arxiv.org/abs/2009.07118
https://github.com/timoschick/pet<|||||>> Hopefully they have a better excuse than last time.
Because Microsoft [gave us money.](https://openai.com/blog/openai-licenses-gpt-3-technology-to-microsoft/) <|||||>GPT-3 is not coming out anytime soon :(<|||||>this thread signifies capitalism's pros and cons at the same time...😅<|||||>> The full model will be at least 350 GB (16-bit parameters). You'd need to partition it across more than (350 GB) / (16 GB) ~ **22 GPUs** just to run it! Not to mention the egress costs of making a model that size available.
>
> Of course, the paper shows **8** different-sized models, **4 of which are smaller than GPT-2**, so some of those could be practical. 🙂
>
> 
@AdamDanielKing is there a way to estimate the size of the GPT-3 XL model?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>we're still waiting.. :(<|||||>it seems that a replication of GPT3 might be open source soon!! :
https://www.eleuther.ai/
https://github.com/EleutherAI<|||||>Nice! Hope that works out!
On Mon, Jan 4, 2021, 5:00 PM srulikbd <[email protected]> wrote:
> it seems that a replication of GPT3 might be open source soon!! :
> https://www.eleuther.ai/
> https://github.com/EleutherAI
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/4658#issuecomment-754247106>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AAFHZUO5O7O247EHFDWH7Q3SYI27BANCNFSM4NNTN5GQ>
> .
>
<|||||>Closing this as GPT-3 won't be open-sourced unfortunately.
Have a look at an open-source effort (a 176-billion parameter multilingual language model called BLOOM) to replicate it here:
* blog post: https://bigscience.huggingface.co/blog/bloom
* model: https://huggingface.co/bigscience/bloom.
Besides that, [EleutherAI](https://huggingface.co/EleutherAI) and other groups (such as [this one](https://github.com/THUDM/GLM-130B)) have been working on several open-source variants of GPT-3. <|||||>Don't worry, if they made it, some other people going to make it, inshaAllah.
There are already replications, so wait for that.<|||||>anyone told me is there GPT-3 available? the official one <|||||>@sarahwang93 No. It's not open sourced and they won't probably. Because they are able to make money using that.
Replying to myself: Yes you are right. Other people made millions of it, Alhamdulillah.<|||||>@Yusuf-YENICERI Hope that they could opensource after they made enough money, my phd dissertation is waiting for it. <|||||>@sarahwang93 Why do you need it? You can't run it simply. It's a real huge model. Maybe 700GB VRAM required to run it. If you want to know about how its made you can check the paper of it.
There are other open source models. You may want to check them.<|||||>There's also the Open LLM leaderboard which benchmarks all openly available LLMs on 4 benchmarks: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
Of course this is not perfect as it only includes 4 benchmarks, but is still gives a nice overview of the best open-source LLMs out there.<|||||>@NielsRogge
https://chat.lmsys.org/?arena
This is better for simplicity, InshaAllah. |
transformers | 4,657 | closed | --fp causes an issue when running example scripts in distributed mode | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...):
`roberta-large`
Language I am using the model on (English, Chinese ...):
`English`
The problem arises when using:
* the official example scripts
The tasks I am working on is:
* Finetuning a LM with `run_language_modeling.py` and the SST-2 task with `run_glue.py`
* my own dataset
## To reproduce
If I run either of the following commands, I get the error included below. However, if I remove `--fp`, everything works normally. Also, if I add `--fp`, but run it non-distributed, everything works normally. So, it appears there is an issue with my running `-fp` in a distributed fashion. I haven't had an issue with this before; so, I'm not sure what the problem is. Any ideas? Thanks in advance.
I installed apex in two different way, but still get the same results.
```
#Install package required for fp16 computations
RUN git clone https://github.com/NVIDIA/apex.git \
&& cd apex \
&& python3 setup.py install --cuda_ext --cpp_ext
```
```
Install package required for fp16 computations
RUN git clone https://github.com/NVIDIA/apex.git \
&& cd apex \
&& pip3 install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
```
```
python3 -m torch.distributed.launch --nproc_per_node 2 run_language_modeling.py --output_dir=/ptcc/shared/lm_roberta_20200528_164228 --model_type=roberta --do_train --train_data_file=/ptcc/data/train.txt --do_eval --eval_data_file=/ptcc/data/test.txt --evaluate_during_training --per_gpu_train_batch_size=2 --per_gpu_eval_batch_size=2 --learning_rate=5e-06 --model_name_or_path=roberta-large --mlm --max_steps=120000 --warmup_steps=10000 --save_steps=12000 --seed=42 --fp16 --logging_dir=/ptcc/shared/roberta_20200528_164228_tf_logs'
```
```
python3 -m torch.distributed.launch --nproc_per_node 2 run_glue.py --model_type roberta --task_name SST-2 --do_train --do_eval --evaluate_during_training --data_dir /ptcc/data/ --per_gpu_train_batch_size 2 --per_gpu_eval_batch_size 2 --learning_rate 1e-06 --output_dir clf_roberta_20200528_162937 --model_name_or_path /ptcc/shared/lm_roberta_20200528_113420 --num_train_epochs 2.0 --save_steps 1000 --seed 42 --fp16 --logging_dir=/ptcc/shared/roberta_20200528_162937_tf_logs
```
```
ptcc_1 | 05/28/2020 20:30:38 - INFO - transformers.trainer - Starting fine-tuning.
Epoch: 0%| | 0/2 [00:00<?, ?it/s] Traceback (most recent call last):
ptcc_1 | File "/ptcc/run_glue.py", line 228, in <module>
ptcc_1 | main()
ptcc_1 | File "/ptcc/run_glue.py", line 160, in main
ptcc_1 | model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
ptcc_1 | File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 470, in train
ptcc_1 | tr_loss += self._training_step(model, inputs, optimizer)
ptcc_1 | File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 577, in _training_step
ptcc_1 | scaled_loss.backward()
ptcc_1 | File "/usr/lib/python3.6/contextlib.py", line 88, in __exit__
ptcc_1 | next(self.gen)
ptcc_1 | File "/usr/local/lib/python3.6/dist-packages/apex-0.1-py3.6-linux-x86_64.egg/apex/amp/handle.py", line 127, in scale_loss
ptcc_1 | should_skip = False if delay_overflow_check else loss_scaler.update_scale()
ptcc_1 | File "/usr/local/lib/python3.6/dist-packages/apex-0.1-py3.6-linux-x86_64.egg/apex/amp/scaler.py", line 200, in update_scale
ptcc_1 | self._has_overflow = self._overflow_buf.item()
ptcc_1 | RuntimeError: CUDA error: an illegal memory access was encountered
ptcc_1 | /usr/local/lib/python3.6/dist-packages/torch/optim/lr_scheduler.py:114: UserWarning: Seems like `optimizer.step()` has been overridden after learning rate scheduler initialization. Please, make sure to call `optimizer.step()` before `lr_scheduler.step()`. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
ptcc_1 | "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
ptcc_1 | terminate called after throwing an instance of 'c10::Error'
ptcc_1 | what(): CUDA error: an illegal memory access was encountered (insert_events at /pytorch/c10/cuda/CUDACachingAllocator.cpp:771)
ptcc_1 | frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x46 (0x7f69777f6536 in /usr/local/lib/python3.6/dist-packages/torch/lib/libc10.so)
ptcc_1 | frame #1: c10::cuda::CUDACachingAllocator::raw_delete(void*) + 0x7ae (0x7f6977a39fbe in /usr/local/lib/python3.6/dist-packages/torch/lib/libc10_cuda.so)
ptcc_1 | frame #2: c10::TensorImpl::release_resources() + 0x4d (0x7f69777e6abd in /usr/local/lib/python3.6/dist-packages/torch/lib/libc10.so)
ptcc_1 | frame #3: std::vector<c10d::Reducer::Bucket, std::allocator<c10d::Reducer::Bucket> >::~vector() + 0x1d9 (0x7f69c3926ef9 in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #4: c10d::Reducer::~Reducer() + 0x23a (0x7f69c391c84a in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #5: std::_Sp_counted_ptr<c10d::Reducer*, (__gnu_cxx::_Lock_policy)2>::_M_dispose() + 0x12 (0x7f69c38fb7c2 in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #6: std::_Sp_counted_base<(__gnu_cxx::_Lock_policy)2>::_M_release() + 0x46 (0x7f69c32be466 in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #7: <unknown function> + 0x87146b (0x7f69c38fc46b in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #8: <unknown function> + 0x240500 (0x7f69c32cb500 in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #9: <unknown function> + 0x24174e (0x7f69c32cc74e in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #10: /usr/bin/python3() [0x572a27]
ptcc_1 | frame #11: /usr/bin/python3() [0x54eef2]
ptcc_1 | frame #12: /usr/bin/python3() [0x588948]
ptcc_1 | frame #13: /usr/bin/python3() [0x5ad438]
ptcc_1 | frame #14: /usr/bin/python3() [0x5ad44e]
ptcc_1 | frame #15: /usr/bin/python3() [0x5ad44e]
ptcc_1 | frame #16: /usr/bin/python3() [0x56b276]
ptcc_1 | frame #17: PyDict_SetItemString + 0x153 (0x5709f3 in /usr/bin/python3)
ptcc_1 | frame #18: PyImport_Cleanup + 0x76 (0x4f2fc6 in /usr/bin/python3)
ptcc_1 | frame #19: Py_FinalizeEx + 0x5e (0x637e2e in /usr/bin/python3)
ptcc_1 | frame #20: Py_Main + 0x395 (0x638e95 in /usr/bin/python3)
ptcc_1 | frame #21: main + 0xe0 (0x4b0d00 in /usr/bin/python3)
ptcc_1 | frame #22: __libc_start_main + 0xe7 (0x7f69e4727b97 in /lib/x86_64-linux-gnu/libc.so.6)
ptcc_1 | frame #23: _start + 0x2a (0x5b250a in /usr/bin/python3)
```
## Environment info
- `transformers` version: 2.10.0
- Platform: Linux-5.3.0-26-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.5.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Y, 2 Tesla V100-SXM2
- Using distributed or parallel set-up in script?: Y, 2 Tesla V100-SXM2
| 05-28-2020 21:07:43 | 05-28-2020 21:07:43 | I've tried `transformers 2.10.0` under `CUDA 10.2` with `PyTorch 1.5.0` and apex compiled for that environment, as well as under `CUDA 10.1` with both PyTorch 1.5.0 and 1.4.1, as well as apex compiled for both of those. However, I get pretty much the same issue. Should I down convert to a different version of transformers?
```
Epoch: 0%| | 0/2 [00:00<?, ?it/s] Traceback (most recent call last):
ptcc_1 | File "/ptcc/run_language_modeling.py", line 281, in <module>
ptcc_1 | main()
ptcc_1 | File "/ptcc/run_language_modeling.py", line 245, in main
ptcc_1 | trainer.train(model_path=model_path)
ptcc_1 | File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 470, in train
ptcc_1 | tr_loss += self._training_step(model, inputs, optimizer)
ptcc_1 | File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 577, in _training_step
ptcc_1 | scaled_loss.backward()
ptcc_1 | File "/usr/lib/python3.6/contextlib.py", line 88, in __exit__
ptcc_1 | next(self.gen)
ptcc_1 | File "/usr/local/lib/python3.6/dist-packages/apex-0.1-py3.6-linux-x86_64.egg/apex/amp/handle.py", line 127, in scale_loss
ptcc_1 | should_skip = False if delay_overflow_check else loss_scaler.update_scale()
ptcc_1 | File "/usr/local/lib/python3.6/dist-packages/apex-0.1-py3.6-linux-x86_64.egg/apex/amp/scaler.py", line 200, in update_scale
ptcc_1 | self._has_overflow = self._overflow_buf.item()
ptcc_1 | RuntimeError: CUDA error: an illegal memory access was encountered
ptcc_1 | Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
ptcc_1 | /usr/local/lib/python3.6/dist-packages/torch/optim/lr_scheduler.py:114: UserWarning: Seems like `optimizer.step()` has been overridden after learning rate scheduler initialization. Please, make sure to call `optimizer.step()` before `lr_scheduler.step()`. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
ptcc_1 | "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
ptcc_1 | terminate called after throwing an instance of 'c10::Error'
ptcc_1 | what(): CUDA error: an illegal memory access was encountered (insert_events at /pytorch/c10/cuda/CUDACachingAllocator.cpp:771)
ptcc_1 | frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x46 (0x7f2ededfd536 in /usr/local/lib/python3.6/dist-packages/torch/lib/libc10.so)
ptcc_1 | frame #1: c10::cuda::CUDACachingAllocator::raw_delete(void*) + 0x7ae (0x7f2edf040fbe in /usr/local/lib/python3.6/dist-packages/torch/lib/libc10_cuda.so)
ptcc_1 | frame #2: c10::TensorImpl::release_resources() + 0x4d (0x7f2edededabd in /usr/local/lib/python3.6/dist-packages/torch/lib/libc10.so)
ptcc_1 | frame #3: std::vector<c10d::Reducer::Bucket, std::allocator<c10d::Reducer::Bucket> >::~vector() + 0x1d9 (0x7f2f26356d99 in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #4: c10d::Reducer::~Reducer() + 0x23a (0x7f2f2634c6ea in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #5: std::_Sp_counted_ptr<c10d::Reducer*, (__gnu_cxx::_Lock_policy)2>::_M_dispose() + 0x12 (0x7f2f2632b662 in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #6: std::_Sp_counted_base<(__gnu_cxx::_Lock_policy)2>::_M_release() + 0x46 (0x7f2f25cee306 in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #7: <unknown function> + 0x87130b (0x7f2f2632c30b in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #8: <unknown function> + 0x2403a0 (0x7f2f25cfb3a0 in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #9: <unknown function> + 0x2415ee (0x7f2f25cfc5ee in /usr/local/lib/python3.6/dist-packages/torch/lib/libtorch_python.so)
ptcc_1 | frame #10: /usr/bin/python3() [0x572a27]
ptcc_1 | frame #11: /usr/bin/python3() [0x54eef2]
ptcc_1 | frame #12: /usr/bin/python3() [0x588948]
ptcc_1 | frame #13: /usr/bin/python3() [0x5ad438]
ptcc_1 | frame #14: /usr/bin/python3() [0x5ad44e]
ptcc_1 | frame #15: /usr/bin/python3() [0x5ad44e]
ptcc_1 | frame #16: /usr/bin/python3() [0x56b276]
ptcc_1 | frame #17: PyDict_SetItemString + 0x153 (0x5709f3 in /usr/bin/python3)
ptcc_1 | frame #18: PyImport_Cleanup + 0x76 (0x4f2fc6 in /usr/bin/python3)
ptcc_1 | frame #19: Py_FinalizeEx + 0x5e (0x637e2e in /usr/bin/python3)
ptcc_1 | frame #20: Py_Main + 0x395 (0x638e95 in /usr/bin/python3)
ptcc_1 | frame #21: main + 0xe0 (0x4b0d00 in /usr/bin/python3)
ptcc_1 | frame #22: __libc_start_main + 0xe7 (0x7f2f2b53cb97 in /lib/x86_64-linux-gnu/libc.so.6)
ptcc_1 | frame #23: _start + 0x2a (0x5b250a in /usr/bin/python3)``` <|||||>I've also tried 3 different machines. All ubuntu 18.04, but with different GPUs sets. 2 Tesla V100-SXM2, 2 P100-SXM2, and 2 Tesla M40, but still get the same error.<|||||>Can you install the repo from source and try again? There have been some issues with PyTorch upstream that Julien addressed here: https://github.com/huggingface/transformers/pull/4300. So you can try with the latest master branch.<|||||>@BramVanroy, that merge request appears to have been merged prior to v2.10.0 release. I've installed both `v2.10.0` and `master` from source and unfortunately get the same error above when I tried to train a model distributed using mixed precision. <|||||>The one thing I can think of that you can try is specifically setting the current device for each process.
Can you try cloning the library and installing in dev mode, and adding a line here:
https://github.com/huggingface/transformers/blob/0866669e751bef636fa693b704a28c1fea9a17f3/examples/language-modeling/run_language_modeling.py#L134-L136
So that it looks like this:
```python
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
torch.cuda.set_device(training_args.device)
if data_args.eval_data_file is None and training_args.do_eval:
```
<|||||>Thanks @BramVanroy , you suggestion worked. I really appreciate it.<|||||>Re-opening so that we can close this in a PR.<|||||>@BramVanroy, while your suggestion works for multiple GPUs. I get the following error when trying to use a single GPU.
```
Traceback (most recent call last):
File "/ptcc/run_language_modeling.py", line 283, in <module>
main()
File "/ptcc/run_language_modeling.py", line 136, in main
torch.cuda.set_device(training_args.device)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 243, in set_device
device = _get_device_index(device)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/_utils.py", line 34, in _get_device_index
'or an integer, but got: '.format(device))
ValueError: Expected a cuda device with a specified index or an integer, but got:
```
and
```
Traceback (most recent call last):
File "/ptcc/run_glue.py", line 230, in <module>
main()
File "/ptcc/run_glue.py", line 78, in main
torch.cuda.set_device(training_args.device)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 243, in set_device
device = _get_device_index(device)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/_utils.py", line 34, in _get_device_index
'or an integer, but got: '.format(device))
ValueError: Expected a cuda device with a specified index or an integer, but got:
```<|||||>@CMobley7 Thanks for the update! I pushed another update to my PR, can you try that one out? When we are not using DDP (and local_rank is -1), we do not specify the GPU id to use. It's best to strictly select that main device, so now we select it by using index 0. (This will still work if you set different devices with CUDA_VISIBLE_DEVICES, it'll just select the first device available _in that environment_).<|||||>@BramVanroy , I can confirm that the changes made in https://github.com/huggingface/transformers/pull/4728 successfully fix the apex issues with both a single and multiple GPUs. I've tested on 3 different machines. All ubuntu 18.04, but with different GPUs sets. 2 Tesla V100-SXM2, 2 P100-SXM2, and 2 Tesla M40. Thanks for your help.<|||||>Thank you @CMobley7 for the extensive testing, this is very valuable.
And thanks @BramVanroy for fixing! |
transformers | 4,656 | closed | Electra training from scratch | # Electra Trainer
_**Still in testing process. Feedback welcome!**_
This PR introduces:
## New features
- A new language modeling script based on the [ELECTRA pre-training method](https://github.com/google-research/electra).
### Combined model
- Combines `ElectraForMaskedLM` and `ElectraForPreTraining` with embedding sharing + custom masking/replaced token detection
### Lazy Dataset for OpenWebText
- Tokenizes text into multiple files
- Lazy loads files into memory
## Trainer
- Introduces `IterableDataset` handling to the trainer
- New evaluation [_to be discussed_]:
Up to now the evaluation was only possible when the trainer was provided `preds` and `label_ids`. The `compute_metrics` function allowed the user to compute specific metrics, but not to customize which inputs to use for this function.
This re-vamped evaluation works with DataParallel and with TPU.
- Better logging when a limiting a training to a specific amount of steps (both training and evaluation)
- `max_eval_steps` flag
## Bugfix
- Fixes a bug in the ELECTRA model for batch sizes of 1
Left to do:
- [ ] Post wandb graphs here as they complete
- [ ] Allow all models to be used as discriminator/generator (same tokenizer, same embedding matrix)
- [ ] Better way to handle dataset building when using TPUs | 05-28-2020 20:48:50 | 05-28-2020 20:48:50 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4656?src=pr&el=h1) Report
> Merging [#4656](https://codecov.io/gh/huggingface/transformers/pull/4656?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/76779363160a598f130433209a77f8a747351b61&el=desc) will **decrease** coverage by `0.03%`.
> The diff coverage is `52.38%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4656?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4656 +/- ##
==========================================
- Coverage 77.38% 77.34% -0.04%
==========================================
Files 128 128
Lines 21071 21096 +25
==========================================
+ Hits 16305 16316 +11
- Misses 4766 4780 +14
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4656?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/4656/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `39.37% <48.27%> (-0.11%)` | :arrow_down: |
| [src/transformers/modeling\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/4656/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19lbGVjdHJhLnB5) | `76.42% <100.00%> (ø)` | |
| [src/transformers/trainer\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4656/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyX3V0aWxzLnB5) | `100.00% <100.00%> (ø)` | |
| [src/transformers/training\_args.py](https://codecov.io/gh/huggingface/transformers/pull/4656/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmluZ19hcmdzLnB5) | `76.66% <100.00%> (+0.26%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4656/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4656?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4656?src=pr&el=footer). Last update [7677936...e50654c](https://codecov.io/gh/huggingface/transformers/pull/4656?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Hi @Frozenwords, thanks for your comments! These were introduced in the latest commit, reverting part of that commit now.<|||||>It runs correctly now. If you run it, please let me know of the results!<|||||>Hey @LysandreJik !
I'm in the process of training an electra-small model and I'm having some issues.
I'm running the `run_electra_pretraining` script with the following command:
<img width="694" alt="Screenshot 2020-06-08 at 19 11 24" src="https://user-images.githubusercontent.com/32191917/84064906-bf372300-a9c3-11ea-9d61-68d1c9644e2a.png">
Here are my generator and discriminator configurations:
<img width="291" alt="Screenshot 2020-06-08 at 18 35 30" src="https://user-images.githubusercontent.com/32191917/84064927-c78f5e00-a9c3-11ea-9feb-fe3ead8f5afc.png">
<img width="290" alt="Screenshot 2020-06-08 at 18 35 07" src="https://user-images.githubusercontent.com/32191917/84064946-ce1dd580-a9c3-11ea-9707-8ce65712291d.png">
After making the fixes I suggested the script is running just fine but I suspect either an error with my configurations/tokenizer setup or a case of silent failure. Indeed, the training loss quickly goes down but then slightly increases and plateaus after only 2000 training steps (which is quite different from the training curves shown in the original electra repository).
<img width="992" alt="Screenshot 2020-06-04 at 09 58 47" src="https://user-images.githubusercontent.com/32191917/84065306-79c72580-a9c4-11ea-9e65-cf6c3a5ec470.png">
The only changes I've made to the script are the following:
- Replace the `OpenWebTextDataset` by a `LineByLineTextDataset`
- Set the CLS token ID to 5 in line 424 since I'm using Camembert's tokenizer
I've been through the script a few times and I can't seem to find the potential issue. Maybe you've observed that behaviour in your end-to-end tests ?
<|||||>Do you have any graph of your generator/discriminator accuracies?<|||||>I don't have any validation metrics at the moment since I'm using a `LineByLineTextDataset`. Indeed, `_prediction_loop` in the `Trainer` concatenates predictions per batches of sequences (line 804). However in my case sequences have variable lengths (dynamic padding is done at the batch level by the `DataCollatorForLanguageModeling`) thus a variable number of tokens are being masked resulting in a mismatch of shapes. I believe a fix would be to flatten predictions before concatenation.<|||||>Hey @LysandreJik, any news on the testing process ? If the model performs as expected on your end then there must be something wrong with my setup 🤔 <|||||>I can't reproduce yet either unfortunately, still trying to find out what's wrong.<|||||>I am not sure if this is the right place to ask this question, so apologies in advance.
why are position_ids fed twice here?
1) [generator](https://github.com/huggingface/transformers/blob/e50654c03cd28e79bded1276774abe7572793a2c/examples/language-modeling/run_electra_pretraining.py#L434)
2) [discriminator](https://github.com/huggingface/transformers/blob/e50654c03cd28e79bded1276774abe7572793a2c/examples/language-modeling/run_electra_pretraining.py#L457)
```python
generator_loss, generator_output = self.generator(
masked_lm_inputs,
attention_mask,
token_type_ids,
position_ids, # <--
head_mask,
position_ids, # <--
masked_lm_labels=masked_lm_labels,
)[:2]
```
<|||||>Is this planned for the next release of transformers lib?<|||||>@LysandreJik
Hello, I have a little confusion. In ELECTRA paper, word embedding, type embedding, position embedding are all shared. However in this pretraining code, it seems only word embedding shared. I'm not very sure, so is it a correct way to set the embedding?
Thank you.<|||||>> It runs correctly now. If you run it, please let me know of the results!
Hi. I’m not sure if we should use the call masked_lm_inputs.scatter_(-1, replace_with_mask_positions, masked_tokens) or use the mask_fill method in line 425. It seems that the current version is using the scatter call, is it ok or we should switch to the mask_fill call as suggested by @Frozenwords ? Thanks!<|||||>> Hey @LysandreJik !
>
> I'm in the process of training an electra-small model and I'm having some issues.
@Frozenwords - any chance you could share the exact script/text you're running? I'd be happy to test this on my own dataset (sentences without spaces, requiring tokenization from scratch, followed by finetuning), but i'd like to make sure i'm using the right "script". (I haven't used HF much before, i'm a keras person :))<|||||># Training a small Electra on custom data
I have changed my data to have a fixed length (128), and now everything seems to work. However, I do not have anything to compare with. I am training on a small ARM device (Xavier AGX), and it will take a few days before training is done and I can benchmark the model :)
## Traning with variable length tensors
I think that the current version can not support dynamically padded/variable length tensors. I suspect this is what was giving me issues with earlier runs.
At least the ```mask_inputs``` function would probably have to change a bit. As I mentioned above, the fake tokens will get scattered to the padding tokens. Moreover, when choosing how many tokens will be masked in ```mask_inputs```, a single number, ```number_of_tokens_to_be_masked``` is calculated, based on the longest tensor. I think this would need to vary along the batch dimension, and the sample probabilities would also need to vary.
## Data
I use my own data. It is around 18.5gb raw and 34gb in precomputed tensors. I precompute and save tensors using the ```tokenizers``` library, much like the OpenWebText data loader. The data has been transliterated to ASCII characters, with the exception of special danish letters. The tensors all have length 128. The tokenizer is the word piece tokenizer. Evaluation is run on the same 1024 tensors each time.
## Changes to the code
Aside from the custom data loader, I have only changed line 424, to use the token_id for my [CLS] token, instead of 101.
## Script parameters and model configs
```
python3 ~/nvme/elektra/transformers/examples/language-modeling/run_electra_pretraining.py \
--output_dir ./model_electra/models_dense_128 \
--logging_dir ./model_electra/logging \
--generator_config_name generator_config.json \
--discriminator_config_name discriminator_config.json \
--tokenizer_name ./tokenizer/ \
--do_train \
--do_eval \
--evaluate_during_training \
--max_eval_steps 10 \
--danish_corpus_directory ./features_dense_128 \
--overwrite_output_dir \
--block_size 128 \
--num_tensors_per_file 65536 \
--fp16 \
--seed 31 \
--max_steps -1 \
--logging_steps 100 \
--save_steps 32768 \
--save_total_limit 20 \
--learning_rate 5e-4 \
--adam_epsilon 1e-6 \
--per_device_train_batch_size=64 \
--per_device_eval_batch_size=64 \
--num_train_epochs=1 \
--warmup_steps 10000
```
## Discriminator config
```
{
"architectures": [
"ElectraForPreTraining"
],
"attention_probs_dropout_prob": 0.1,
"embedding_size": 128,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 256,
"initializer_range": 0.02,
"intermediate_size": 1024,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "electra",
"num_attention_heads": 4,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 46997
}
```
## Generator config
```
{
"architectures": [
"ElectraForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"embedding_size": 128,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 64,
"initializer_range": 0.02,
"intermediate_size": 256,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "electra",
"num_attention_heads": 1,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 46997
}
```
## Graphs




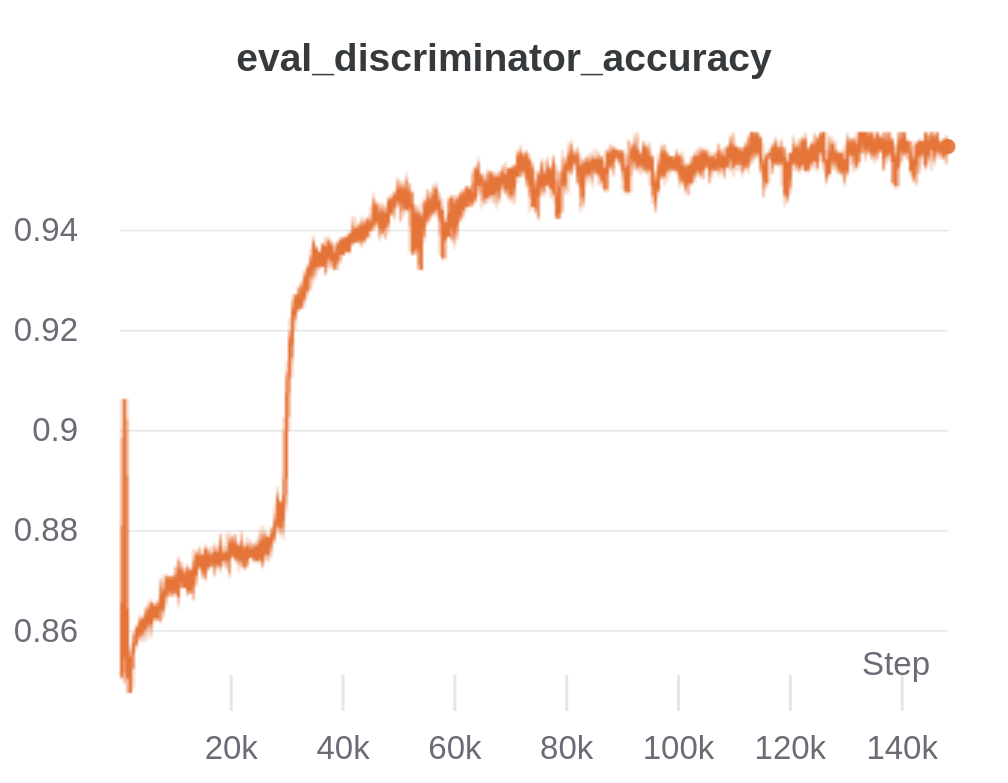
<|||||>@EmilLaursen I had same requirement, i.e. to have different number of masked tokens per sample in batch, because of huge variation in my (non-padded) sentence lengths. This is how I modified the electra pretraining model:
(I am training on a non-NLP application, so I won't share any metrics or losses as they won't mean much)
```python
class CombinedModel(nn.Module):
...
def mask_inputs_by_row(
self, input_ids: torch.Tensor, tokens_to_ignore, proposal_distribution=1.0,
):
input_ids = input_ids.clone()
inputs_which_can_be_masked = torch.ones_like(input_ids)
for token in tokens_to_ignore:
inputs_which_can_be_masked -= torch.eq(input_ids, token).long()
total_number_of_tokens = input_ids.shape[-1]
# Identify the number of tokens to be masked, which should be: 1 < num < max_predictions per seq.
# It is set to be: n_tokens * mask_probability, but is truncated if it goes beyond bounds.
num_mask_per_row = (inputs_which_can_be_masked.sum(dim=1) *
self.mask_probability).type(torch.long)
device = inputs_which_can_be_masked.device
number_of_tokens_to_be_masked = torch.max(
torch.tensor(1).to(device),
torch.min(
torch.min(
torch.tensor(self.max_predictions_per_sequence,
dtype=torch.long),
torch.tensor(int(total_number_of_tokens *
self.mask_probability), dtype=torch.long),
).to(device),
num_mask_per_row
)
)
# The probability of each token being masked
sample_prob = proposal_distribution * inputs_which_can_be_masked
sample_prob /= torch.sum(sample_prob, dim=1).view(-1, 1)
# At this point each row should sum to 1.
# i.e. all maskable tokens treated equally (equal opportunity)
masked_lm_positions = torch.full_like(sample_prob, False).type(torch.bool)
# Not sure if there is a way around using a for loop
for i in range(sample_prob.size(0)):
masked = sample_prob[i].multinomial(
number_of_tokens_to_be_masked[i])
masked_lm_positions[i, masked] = True
return masked_lm_positions
def forward(
self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, labels=None,
):
# get the masked positions as well as their original values
masked_lm_positions = self.mask_inputs_by_row(
input_ids, [self.tokenizer.cls_token_id,
self.tokenizer.sep_token_id,
self.tokenizer.mask_token_id,
self.tokenizer.pad_token_id],
)
# masked_lm_ids = masked_lm_positions * input_ids
# # Of the evaluated tokens, 15% of those will keep their original tokens
# replace_with_mask_positions = masked_lm_positions * (
# torch.rand(masked_lm_positions.shape, device=masked_lm_positions.device) < (
# 1 - self.mask_probability)
# )
masked_lm_inputs = input_ids.clone()
# use a bool mask of positions we want to MASKed to insert MASK token ids
# bool_masked_positions = (masked_lm_positions > 0)
masked_lm_inputs[masked_lm_positions] = self.tokenizer.mask_token_id
# create MASKED labels with real token ids in positions where the MASKed tokens
# were inserted, -100 otherwise
masked_lm_labels = torch.full_like(input_ids, -100)
masked_lm_labels[masked_lm_positions] = input_ids[masked_lm_positions]
generator_loss, generator_output = self.generator(
masked_lm_inputs,
attention_mask,
token_type_ids,
position_ids,
head_mask,
None, # position_ids,
masked_lm_labels=masked_lm_labels,
)[:2]
# softmax the predictions
fake_softmaxed = torch.softmax(generator_output, dim=-1)
# At this point if we sum 3rd dim, we should get a tensor of ones, the same size as input
# i.e. fake_softmaxed.sum(dim=2) == torch.ones_like(input_ids)
# for each position in sentence, sample ONE token from the generator probability distribution
# this is why the 3rd dim is ONE.
fake_sampled = torch.zeros_like(input_ids).view(
input_ids.shape[0], input_ids.shape[1], 1)
# multinomial cannot be applid to 3d array. so loop over examples
# what we are doing here is for each position in a sentence,
# we will sample a token using Generator's learned probability
# distribution.
for i in range(fake_softmaxed.shape[0]):
fake_sampled[i] = fake_softmaxed[i,:,:].multinomial(1)
# At this point we have generator samples for ALL the positions in the sentence.
# But we only need the predictions for the positions corresponding to MASKED tokens
# First, align shape with the input. Get rid of 3rd dim which was created to make
# sampling easier
fake_sampled = fake_sampled.view(input_ids.shape[0], input_ids.shape[1])
# Discriminator input is same as generator, except instead of masked tokens
# we insert tokens sampled from the generator distribution.
fake_tokens = input_ids.clone()
fake_tokens[masked_lm_positions] = fake_sampled[masked_lm_positions]
# D labels are binary labels indicating whether the
discriminator_labels = (labels != fake_tokens).int()
discriminator_loss, discriminator_output = self.discriminator(
fake_tokens,
attention_mask,
token_type_ids,
position_ids,
head_mask,
None, # position_ids,
labels=discriminator_labels,
)[:2]
discriminator_predictions = torch.round(
(torch.sign(discriminator_output) + 1.0) * 0.5)
total_loss = (self.discriminator_weight * discriminator_loss) + \
(self.generator_weight * generator_loss)
# For evaluation, pass tensors of masked tokens and sampled tokens
masked_input_ids = input_ids[masked_lm_positions]
fake_sampled_ids = fake_sampled[masked_lm_positions]
return (
total_loss,
(generator_output, discriminator_output),
(masked_input_ids, fake_sampled_ids),
(discriminator_labels, discriminator_predictions),
)
```<|||||>@EmilLaursen
Can you train your model on glue to see the dev accuracy ? (especially matthew correlation for CoLA task)
I used another training script and found even train loss 1x may still result in very bad glue accuracy, so I am wondering if your model score good acc on GLUE. <|||||>@richarddwang
My model is trained on danish text, so I suspect the glue score would be terrible. I have assembled my own danish benchmark suite, with 3 objectives: pos-tag, NER, and text classification.
For what it is worth, my model scores about 4-5% F1 lower than BERT multilingual and the Danish BERT model (uncased and same size as bert-base) on the NER task (0.845 vs 0.795). On the pos tagging task, it is about 0.5 F1 lower, (0.977 vs 0.972). I have not tried the text classification task yet.
To me, this seems comparable with what is stated in the Electra paper, i.e. glue score about 4-5 points lower on the small model compared to the base-sized models.<|||||>Thanks! It is very kind of you to share such detailed results.<|||||>@LysandreJik This would be very helpful! Is there any plan to get this merged soon?<|||||>@LysandreJik I and Phil have implemented and verified Electra on the Glue downstream task.
https://github.com/lucidrains/electra-pytorch
The forward pass is based on your replica of the TF forward pass (HF 3.0.2).
The remaining code is written to closely replicate the TF reference code.
That is, data-preprocessing (including ExampleBuilder), learning rate schedule, gradient clipping, etc. might differ.
I believe the two main difference between this PR and our code might be:
(1) For the "small" setting, for the generator, there is a discrepancy of the configuration reported in the paper and used in the TF reference code.
(2) Data preprocessing with example builder.
For the TF reference, after 1M updates, the Glue MRPC accuracy is ~87%. Note, there is high variance in these measurements.
For our code, after 200k updates, the Glue MRPC accuracy is ~82%, which might approach ~87% accuracy after 1M updates.<|||||>Hi @enijkamp , nick work !
Could you share both dev and test score for every task in GLUE ?
It will help a lot, thanks !<|||||>Hi, can I use `electra-trainer` branch to run pre-trianing, then save the model `checkpoint`.
Is there problem to use the saved `checkpoint ` in the latest master branch?
Thanks~<|||||>Hi @LysandreJik @enijkamp and all !
After develop and debug for a long time. My implementaion of ELECTRA training and finetuning finally successfully pretrains a model from scratch and replicates the results in the paper.
|Model|CoLA|SST|MRPC|STS|QQP|MNLI|QNLI|RTE|Avg.|
|---|---|---|---|---|---|---|---|---|---|
|ELECTRA-Small|54.6|89.1|83.7|80.3|88.0|79.7|87.7|60.8|78.0|
|ELECTRA-Small (electra_pytorch)|57.2|87.1|82.1|80.4|88|78.9|87.9|63.1|78.08
💻Code: https://github.com/richarddwang/electra_pytorch
📰Post: https://discuss.huggingface.co/t/electra-training-reimplementation-and-discussion/1004
🐦Tweet: https://twitter.com/_RichardWang_/status/1302545459374772224?s=20
I've listed details that are easy to be overlooked when reimplementing ELECTRA, includes a bug in the original official implementation. I would be glad if this helps 😊<|||||>Hey @LysandreJik and all
I was wondering if you have tried to run this with pytorch 1.6 ? I am currently on a device, where i'd have to reinstall from scratch to downgrade to a lower version of pytorch. I am getting some strange result, and I am considering if it is a compatibility issue, after trying with different learning rates, tokenizers and batch sizes. It seems that my generator does not learn anything, and does not converge. I used fixed-length tensors as @EmilLaursen of size 256. My discriminator does seem to converge, however performs poorly on downstream tasks (Danish NER and POSTAG tasks), which is suspect is caused by the generator not converging.
### Update (18 October)
I can confirm that this behavior is **not** observed when using PyTorch 1.5.0. Perhaps it has something to do with PyTorch "Automatic Mixed Precision" feature released in version 1.6. If anyone else is experiencing the same issue, then i recommend you use PyTorch < 1.6.
### Changes to code
Custom data loader (danish corpus), and changed the [CLS] token in line 426 to the one of my vocab.
### Configs
#### Discriminator
```json
{
"architectures": [
"ElectraForPreTraining"
],
"attention_probs_dropout_prob": 0.1,
"embedding_size": 128,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 256,
"initializer_range": 0.02,
"intermediate_size": 1024,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "electra",
"num_attention_heads": 4,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 45000
}
```
#### Generator
```json
{
"architectures": [
"ElectraForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"embedding_size": 128,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 64,
"initializer_range": 0.02,
"intermediate_size": 256,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "electra",
"num_attention_heads": 1,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 45000
}
```
#### Run config
```shell
python3 pretraining/run_electra_pretraining.py \
--output_dir ./models/electra/small_256 \
--discriminator_config_name ./pretraining/config/discriminator_config.json \
--generator_config_name ./pretraining/config/generator_config.json \
--tokenizer_name ./models/tokenizers/ \
--do_train \
--do_eval \
--evaluate_during_training \
--max_eval_steps 16 \
--danish_feature_directory ./data/features_dense_256 \
--overwrite_output_dir \
--block_size 256 \
--num_tensors_per_file 65536 \
--fp16 \
--seed 1337 \
--max_steps -1 \
--logging_steps 200 \
--save_steps 20000 \
--save_total_limit 20 \
--learning_rate 2.5e-4 \
--adam_epsilon 1e-6 \
--per_device_train_batch_size=64 \
--per_device_eval_batch_size=64 \
--num_train_epochs=1 \
--warmup_steps 10000
```
### Logged metrics



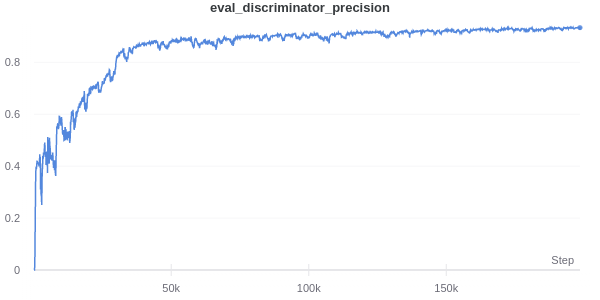
<|||||>I am wondering when will "electra training from scratch" feature be released? <|||||>This PR is unfortunately in a stale state, with no projects to work on it further in the near future. You can take a look at this discussion: https://discuss.huggingface.co/t/electra-training-reimplementation-and-discussion/1004 or at the above comment by @richarddwang for a PyTorch implementation of the ELECTRA training from scratch.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 4,655 | closed | Tokenization_utils doesn't work with Pytorch-Lightning on 2.10.0 version | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): Bert with pytorch-lightning
Language I am using the model on (English, Chinese ...): English
The problem arises when using
* my own modified scripts: Pytorch Dataset with tokenizer inside
The tasks I am working on is:
* my own task or dataset
## To reproduce
Take a look at [this colab link](https://colab.research.google.com/drive/1SH1xRzhNwgnSn382OLCoMFi_-8CCqk5y?usp=sharing).
I've copied the method from pytorch-lightning which shows an error on 2.10.0 transformers when process a batch. Doing the same with transformers 2.8.0 cause no error.
```
/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils.py in __getattr__(self, item)
201
202 def __getattr__(self, item: str):
--> 203 return self.data[item]
204
205 def keys(self):
KeyError: 'cuda'
```
## Expected behavior
No error
- `transformers` version: 2.10.0
- Platform: Linux
- Python version: 3.6.9
- PyTorch version (GPU?): 1.5.0+cu101
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No | 05-28-2020 18:04:14 | 05-28-2020 18:04:14 | If you are using `pytorch-lightning` then you won't need to transfer data on GPU or TPU manually. `lightning` takes care of that for you<|||||>I have copied the method, which transfer data from pytorch-lightning, so you can reproduce the error.<|||||>Okay, sorry I misunderstood the question.<|||||>It is my bad English, I guess. Do you need more explanation, or the question is clear now?<|||||>The reason is in latest version `batch_encode_plus` returns an instance of `BatchEncoding` and in 2.8.0 it return a `dict`. So you can just do it like this
in your collate function
```
return dict(tokens), torch.tensor(labels, dtype=torch.long)
```
I think tokenizer should handle it itself, so tagging @mfuntowicz <|||||>BatchEncoding is indeed a UserDict, if you want to access the actual dict, you can use the data attribute:
```python
be = tokenizer.batch_encode_plus(...)
be.data
```<|||||>Thank you! So it's not a bug, but an expected behaviour |
transformers | 4,654 | closed | TfElectraForSequenceClassification | This pull request add functionality for sequence classification with Electra. The only missing bit is that I have put the activation function as "tanh" instead of "gelu" (in the orig. implementation) | 05-28-2020 17:12:45 | 05-28-2020 17:12:45 | @LysandreJik this should work (assuming tf >=2.2.0) let me know if I can do anything to help.<|||||>Hello !
Thanks a lot for this PR!! Can you rebase on master plz? It will be easier to review :)<|||||>@jplu (I think/hope) I just did it. Let me know if everything is ok. Great work by the way, congrats to all of Huggingface team!<|||||>Well no, you did a merge not a rebase :smile: can you revert your merge with the following command line:
```
git reset --hard e4741ef
git fetch upstream
git pull --rebase upstream master
git push --force
```
Also be careful because the tests are broken.
<|||||>:blush: yes sorry, I had done all the above but with a commit before the final push. Now it should (hopefully) be ok. I saw the tests are failing, but I was able to successfully use electra for some text classification tasks of interest.<|||||>Awesome!! Thanks for having re-pushed ^^
Now there are several things to change, the output of the `call` method should be like the PyTorch one, it means `(loss), logits, (hidden_states), (attentions)`. Can you add the following updates:
1) just before the return add:
```python
if labels is not None:
loss = self.compute_loss(labels, logits)
outputs = (loss,) + outputs
```
2) add the `labels` parameter to the method.
3) The `TFElectraForSequenceClassification` should inherit from the `TFSequenceClassificationLoss` class.<|||||>Sorry my bad, the signature of the `call` method should look like this:
```python
def call(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
training=False,
):
```<|||||>I also changed the call to self.electra<|||||>Here are the errors raised by the tests:
```
=================================== FAILURES ===================================
__________________ TFElectraModelTest.test_attention_outputs ___________________
[gw0] linux -- Python 3.7.7 /usr/local/bin/python
self = <tests.test_modeling_tf_electra.TFElectraModelTest testMethod=test_attention_outputs>
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
decoder_seq_length = (
self.model_tester.decoder_seq_length
if hasattr(self.model_tester, "decoder_seq_length")
else self.model_tester.seq_length
)
encoder_seq_length = (
self.model_tester.encoder_seq_length
if hasattr(self.model_tester, "encoder_seq_length")
else self.model_tester.seq_length
)
decoder_key_length = (
self.model_tester.key_length if hasattr(self.model_tester, "key_length") else decoder_seq_length
)
encoder_key_length = (
self.model_tester.key_length if hasattr(self.model_tester, "key_length") else encoder_seq_length
)
for model_class in self.all_model_classes:
config.output_attentions = True
config.output_hidden_states = False
model = model_class(config)
outputs = model(inputs_dict)
attentions = [t.numpy() for t in outputs[-1]]
self.assertEqual(model.config.output_attentions, True)
self.assertEqual(model.config.output_hidden_states, False)
> self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
E AssertionError: 13 != 5
tests/test_modeling_tf_common.py:324: AssertionError
_________________ TFElectraModelTest.test_hidden_states_output _________________
[gw0] linux -- Python 3.7.7 /usr/local/bin/python
self = <tests.test_modeling_tf_electra.TFElectraModelTest testMethod=test_hidden_states_output>
def test_hidden_states_output(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
config.output_hidden_states = True
config.output_attentions = False
model = model_class(config)
outputs = model(inputs_dict)
hidden_states = [t.numpy() for t in outputs[-1]]
self.assertEqual(model.config.output_attentions, False)
self.assertEqual(model.config.output_hidden_states, True)
> self.assertEqual(len(hidden_states), self.model_tester.num_hidden_layers + 1)
E AssertionError: 13 != 6
tests/test_modeling_tf_common.py:369: AssertionError
______________________ TFElectraModelTest.test_save_load _______________________
[gw0] linux -- Python 3.7.7 /usr/local/bin/python
self = <tests.test_modeling_tf_electra.TFElectraModelTest testMethod=test_save_load>
def test_save_load(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
outputs = model(inputs_dict)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model = model_class.from_pretrained(tmpdirname)
after_outputs = model(inputs_dict)
> self.assert_outputs_same(after_outputs, outputs)
tests/test_modeling_tf_common.py:93:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/test_modeling_tf_common.py:154: in assert_outputs_same
self.assertLessEqual(max_diff, 1e-5)
E AssertionError: 0.24899402 not less than or equal to 1e-05
```<|||||>Hello! Any news on this PR? :)<|||||>> Hello! Any news on this PR? :)
Hi, sorry I am a bit pressed at the moment, I'd be glad if you would want to take over, otherwise it might take some time for me to re-grab this.<|||||>Ok, no problem I will try to retake what you have done. Thanks a lot for the update.<|||||>Any news on this PR @ypapanik @jplu ? Can I help in some way ?<|||||>Sorry, no time on my side to work on this for now.<|||||>@maxibor The code should be working I have used it successfully to get a better acc than BERT, but some tests had failed. Meanwhile the main codebase has evolved and there should be some conflicts, easy to resolve probably.
I don't have time to complete those two things now (tests failing, resolve conflicts), perhaps someone from HF should spare a few minutes? @LysandreJik <|||||>Updated version right here https://github.com/huggingface/transformers/pull/6227<|||||>Thanks @jplu for opening the new PR, closing this. |
transformers | 4,653 | closed | [Longformer] fix model name in examples | This PR fixes the model identifier of Longformer to the new standard fomat <organisation/model_name> | 05-28-2020 16:11:50 | 05-28-2020 16:11:50 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4653?src=pr&el=h1) Report
> Merging [#4653](https://codecov.io/gh/huggingface/transformers/pull/4653?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b5015a2a0f4ea63035a877f5626cb0c3ce97e25d&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4653?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4653 +/- ##
=======================================
Coverage 77.19% 77.20%
=======================================
Files 128 128
Lines 21021 21021
=======================================
+ Hits 16228 16230 +2
+ Misses 4793 4791 -2
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4653?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4653/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `96.82% <ø> (ø)` | |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4653/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.83% <0.00%> (+0.16%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4653/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4653?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4653?src=pr&el=footer). Last update [b5015a2...dfce20a](https://codecov.io/gh/huggingface/transformers/pull/4653?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,652 | closed | [Community notebooks] add longformer-for-qa notebook | This PR adds a community notebook to showcase how to fine-tune Longformer for QA task.
@ibeltagy @patrickvonplaten Please provide feedback if you think this notebook can be further improved.
| 05-28-2020 16:03:49 | 05-28-2020 16:03:49 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4652?src=pr&el=h1) Report
> Merging [#4652](https://codecov.io/gh/huggingface/transformers/pull/4652?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5e737018e1fcb22c8b76052058279552a8d6c806&el=desc) will **decrease** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4652?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4652 +/- ##
==========================================
- Coverage 77.19% 77.19% -0.01%
==========================================
Files 128 128
Lines 21021 21021
==========================================
- Hits 16228 16227 -1
- Misses 4793 4794 +1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4652?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4652/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4652/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.50% <0.00%> (-0.17%)` | :arrow_down: |
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/4652/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `39.47% <0.00%> (+0.23%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4652?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4652?src=pr&el=footer). Last update [5e73701...88eab9f](https://codecov.io/gh/huggingface/transformers/pull/4652?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>One small comment, the model name was changed in a recent commit to `allenai/longformer-base-4096'`.
<|||||>The notebook looks great - thanks @patil-suraj ! Apart from @ibeltagy's suggestion, I think it's great!<|||||>Great, thank you! I've updated the model paths. |
transformers | 4,651 | closed | Update modeling_electra for adding ability to using electra as decoder | Adapt electra for using as decoder(code for it borrowed from modeling_bert) | 05-28-2020 14:47:32 | 05-28-2020 14:47:32 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4651?src=pr&el=h1) Report
> Merging [#4651](https://codecov.io/gh/huggingface/transformers/pull/4651?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e444648a302dc8520beec96356a4bf500944355c&el=desc) will **decrease** coverage by `0.29%`.
> The diff coverage is `20.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4651?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4651 +/- ##
==========================================
- Coverage 77.42% 77.13% -0.30%
==========================================
Files 128 128
Lines 21017 21041 +24
==========================================
- Hits 16273 16229 -44
- Misses 4744 4812 +68
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4651?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/4651/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19lbGVjdHJhLnB5) | `71.11% <20.00%> (-5.32%)` | :arrow_down: |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4651/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `72.11% <0.00%> (-14.11%)` | :arrow_down: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4651/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `80.41% <0.00%> (-1.38%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4651/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `89.94% <0.00%> (-0.24%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4651/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4651/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4651?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4651?src=pr&el=footer). Last update [e444648...9660de8](https://codecov.io/gh/huggingface/transformers/pull/4651?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,650 | closed | Allow pathlib.Path to be used on save_pretrained and save_vocabulary | Related to #4541
Signed-off-by: Morgan Funtowicz <[email protected]> | 05-28-2020 14:38:17 | 05-28-2020 14:38:17 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4650?src=pr&el=h1) Report
> Merging [#4650](https://codecov.io/gh/huggingface/transformers/pull/4650?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e444648a302dc8520beec96356a4bf500944355c&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `71.42%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4650?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4650 +/- ##
=======================================
Coverage 77.42% 77.43%
=======================================
Files 128 128
Lines 21017 21019 +2
=======================================
+ Hits 16273 16276 +3
+ Misses 4744 4743 -1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4650?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4650/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `89.54% <71.42%> (+0.02%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4650/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4650?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4650?src=pr&el=footer). Last update [e444648...d453872](https://codecov.io/gh/huggingface/transformers/pull/4650?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,649 | closed | Update modeling_electra for adding ability to using electra as decoder | I added some small change(borrow it from modeling_bert). Now, electra able to work as decoder. | 05-28-2020 14:13:18 | 05-28-2020 14:13:18 | |
transformers | 4,648 | closed | Update modeling_electra for using it as decoder | I add some adding(borrow it from modeling_bert). Now, electra able to work as decoder. | 05-28-2020 13:59:14 | 05-28-2020 13:59:14 | |
transformers | 4,647 | closed | Encode-Decode after training, generation gives the same results regardless of the input | # ❓ Questions & Help
Hi, everyone. I need help with the encoding-decoding model. I'm trying to train the model to create a title for a small text.
I'm creating a basic Encode-Decode model with Bert
```
from transformers import EncoderDecoderModel, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = EncoderDecoderModel.from_encoder_decoder_pretrained('bert-base-uncased', 'bert-base-uncased')
```
After training on my data, when generate I get the same results independent of the input data in model.eval () mode. If you convert model to train, then different results will be generated.
The code I use for training.
```
tokenized_texts = [tokenizer.tokenize(sent) for sent in train_sentences]
tokenized_gt = [tokenizer.tokenize(sent) for sent in train_gt]
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
input_ids = pad_sequences(
input_ids,
maxlen=max_len_abstract,
dtype="long",
truncating="post",
padding="post"
)
attention_masks = [[float(i>0) for i in seq] for seq in input_ids]
input_ids_decode = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_gt]
input_ids_decode = pad_sequences(
input_ids_decode,
maxlen=max_len_title,
dtype="long",
truncating="post",
padding="post"
)
attention_masks_encode = [[float(i>0) for i in seq] for seq in input_ids]
attention_masks_decode = [[float(i>0) for i in seq] for seq in input_ids_decode]
input_ids = torch.tensor(input_ids)
input_ids_decode = torch.tensor(input_ids_decode)
attention_masks_encode = torch.tensor(attention_masks_encode)
attention_masks_decode = torch.tensor(attention_masks_decode)
train_data = TensorDataset(input_ids, input_ids_decode, attention_masks_encode, attention_masks_decode)
train_dataloader = DataLoader(train_data, sampler=RandomSampler(train_data), batch_size=4)
model.cuda()
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'gamma', 'beta']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=2e-5)
model.train()
train_loss_set = []
train_loss = 0
for i in range(4):
for step, batch in enumerate(train_dataloader):
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_ids_de, b_attention_masks_encode, b_attention_masks_decode = batch
optimizer.zero_grad()
model.zero_grad()
loss, outputs = model(input_ids=b_input_ids, decoder_input_ids=b_input_ids_de, lm_labels=b_input_ids_de)[:2]
train_loss_set.append(loss.item())
loss.backward()
optimizer.step()
train_loss += loss.item()
clear_output(True)
plt.plot(train_loss_set)
plt.title("Training loss")
plt.xlabel("Batch")
plt.ylabel("Loss")
plt.show()
if step != 0 and step % 20 == 0:
torch.save(model.state_dict(), model_weigth)
print(f'Epoch {i}')
```
Maybe I'm doing something wrong? I would be grateful for any advice. | 05-28-2020 13:49:32 | 05-28-2020 13:49:32 | I trained a bert model from pretrained models. and the output embedding are all the same regardless of the input and attention mask during prediction. But when set model.train(), the model will give different embeddings for different input. I'm quite confused to be honest. I suppose that's the same problem?<|||||>Hi @Mantisus,
Multiple bugs were fixed in #4680 . Can you please take a look whether this error persists?<|||||>Hi, @patrickvonplaten
Yes, the latest update fixed the generation issue.
But I have suspicions that I am not training the model correctly.
As the parameters decoder_input_is and lm_labels, I supplied the same values, the text to be generated. But logic suggests that in lm_labels we should submit text shifted 1 token to the right and starting with Pad.
I tried to train the model in this way, but in this case the loss drops almost immediately to almost 0 and the model does not learn.
I am somewhat confused about what format the training data should be organized in. I will be glad of any advice from you
However, when training the model decoder_input_is == lm_labels, I get pretty good results even on a small dataset (12500), but I think they can be better.<|||||>Hi @Mantisus,
Doing `decoder_input_is = lm_labels` is correct. Let's say you want to fine-tune a Bert2Bert for summarization. Then you should do the following (untested example):
```python
from transformers import EncoderDecoder, BertTokenizerFast
bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-uncased", "bert-base-uncased")
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
context = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York.
A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband.
Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other.
In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage.
Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the
2010 marriage license application, according to court documents.
Prosecutors said the marriages were part of an immigration scam.
On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further.
After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective
Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.
All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say.
Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages.
Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted.
The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s
Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali.
Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force.
If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18.
"""
summary = "'Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She is believed to still be married to four men, and at one time, she was married to eight men at once. Her eighth husband was deported in 2006 to his native Pakistan."
input_ids = tokenizer.encode(context, return_tensors="pt")
decoder_input_ids = tokenizer.encode(summary, return_tensors="pt")
loss, *args = bert2bert(input_ids=input_ids, decoder_input_ids=decoder_input_ids, lm_labels=decoder_input_ids)
```
The reason that you don't have to shift the `lm_labels` is that Bert does that automatically for you here: https://github.com/huggingface/transformers/blob/0866669e751bef636fa693b704a28c1fea9a17f3/src/transformers/modeling_bert.py#L951
BTW, the summary example was just taken from: https://github.com/huggingface/transformers/blob/master/notebooks/03-pipelines.ipynb<|||||>The best way for us to check your code if it's a longer training setup is to provide a google colab which we can copy and tweak ourselves :-) <|||||>Great, thanks for the example @patrickvonplaten
It is convenient that BERT takes care of everything.
The code that I use for training is not much different from the example that I threw above. The only thing is that since I use Google Ecolab for training, I wrapped the creation of input Tensors in generators, in order to reduce RAM consumption on large datasets.
https://colab.research.google.com/drive/1uVP09ynQ1QUmSE2sjEysHjMfKgo4ssb7?usp=sharing<|||||>> Great, thanks for the example @patrickvonplaten
>
> It is convenient that BERT takes care of everything.
>
> The code that I use for training is not much different from the example that I threw above. The only thing is that since I use Google Ecolab for training, I wrapped the creation of input Tensors in generators, in order to reduce RAM consumption on large datasets.
>
> https://colab.research.google.com/drive/1uVP09ynQ1QUmSE2sjEysHjMfKgo4ssb7?usp=sharing
I am doing something similar to Mantisus, but fine tuning on a large dataset and trying to do it in parallel. My code is actually quite similar to his google colab-- but I am trying to wrap the model in torch.nn.DataParallel so that I can up the batch size to 32 and use two GPU'S. I can get the training to work, as far as i can tell, but since the generate function is only exposed to the underlying model, when I try to run generate, I get blank tokens as output. I must be doing something wrong.
```python
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
if(multi_gpu):
bert2bert_o = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-cased", "bert-base-cased")
bert2bert = torch.nn.DataParallel(bert2bert_o)
else:
bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-cased", "bert-base-cased")
# convert to GPU model
#bert2bert.to(device)
torch.cuda.set_device(0)
bert2bert.cuda(0)
# put in training mode
bert2bert.train()
```
then the rest of the code essentially looks like the @Mantisus code from google colab. How do I access the generate properly, and does anybody know if the same parameters pass all the way through to the underlying model (I would assume .train() and .eval() work?
Here's the training block, I've adapted it to look like the @Mantisus code-- but the other goofy thing I don't understand is how to access the right loss, since the wrapped parallel model returns a squeezed tensor, so I've been doing this and I don't know if it's right:
```python
loss, outputs = bert2bert(input_ids = input_ids_encode,
decoder_input_ids = input_ids_decode,
attention_mask = attention_mask_encode,
decoder_attention_mask = attention_mask_decode,
labels = labels)[:2]
if(multi_gpu):
loss = loss[0]
```
And finally here's the code that's been augmented to attempt to use generate by accessing the module subclass of the wrapped model, that I am not sure is working properly:
```python
bert2bert.eval()
test_input = tokenizer.encode(["This is a test!"], return_tensors='pt')
with torch.no_grad():
generated = bert2bert.module.generate(test_input,
decoder_start_token_id=bert2bert.module.config.decoder.pad_token_id,
do_sample=True,
max_length=100,
top_k=200,
top_p=0.75,
num_return_sequences=10)
```
Thank you. This is all really great stuff by the way.
<|||||>Hey @HodorTheCoder,
Sorry for the late reply. I have been working on the encoder-decoder framework and verified
that it works, but only on single GPU training.
This model + model card shows how to train a Bert2Bert model and how it should be used:
https://huggingface.co/patrickvonplaten/bert2bert-cnn_dailymail-fp16
Regarding your code, why do you do
```python
bert2bert.module.generate(...)
```
instead of just doing
```python
bert2bert.generate(...)
```
?
The encoder decoder inherits from `PretrainedModel` and thus has direct access to `generate(...)`, see here:
https://github.com/huggingface/transformers/blob/0b6c255a95368163d2b1d37635e5ce5bdd1b9423/src/transformers/modeling_encoder_decoder.py#L29
.
Also no need to wrap everything into the `torch.no_grad()` context -> `generate()` is always in `no_grad` mode.
Hope this helps! I will be off for the next two weeks - if it's urgent feel free to ping @sshleifer (hope it's fine to ping you here Sam ;-) )<|||||>Thank you so much for your work @patrickvonplaten <|||||>Yes, all pings are welcome. We also have the https://discuss.huggingface.co/ if you want some hyperparameter advice!<|||||>@patrickvonplaten
Thanks for your response! I successfully trained a bert2bert EncoderDecoderModel wrapped in torch.nn.DataParallel. I could only fit a batchsize of 16 on a single Titan XP, but was able to train a batchsize of 32 using two of them.
You may well be right about the generate propagating properly, and I think when I tried that initially I wasn't training properly (I wasn't updating the loss and optimizer in between batches and there was zero conversion.)
What I ended up doing was training, saving the modeule state dict, and then reloading on a single GPU for inference. Worked great.
Coming from mainly Tensorflow it took me a while to understand how to get torch to do what I wanted but the huggingface documentation has been great, and hopefully, anybody searching will come across these posts.
ALSO:
To anybody else who it was not immediately obvious to when converting to use a parallel model, you have to mean() the loss or it won't take the loss of both GPU's into account when calculating grads/opt. So, in my previous example, I erroneously had loss[0] which isn't right-- I changed it to the following training block that properly uses the loss. It is setup on a flag that I set as input if I want to train on one or two gpu's (multigpu). Below is an abstracted code block.
FYI: I definitely get better results training on batchsize=32 as opposed to 16. Couldn't fit batchsize=64 on the GPU's, might be time to upgrade to some Titan RTX. Anybody got $5k?
```python
tokenizer = BertTokenizer.from_pretrained(case_selection)
if(multi_gpu):
bert2bert_o = EncoderDecoderModel.from_encoder_decoder_pretrained(case_selection, case_selection)
bert2bert = torch.nn.DataParallel(bert2bert_o)
else:
bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained(case_selection, case_selection)
# set up adam optimizer
param_optimizer = list(bert2bert.named_parameters())
no_decay = ['bias', 'gamma', 'beta']
# seperate decay
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.0}
]
# create optimizer object
optimizer = AdamW(optimizer_grouped_parameters, lr=3e-5)
num_epochs=4
for epoch in range(num_epochs):
start = datetime.datetime.now()
batches = batch_generator(tokenizer, input_text, target_text, batch_size=batch_size)
# enumerate over the batch yield function
for step, batch in enumerate(batches):
batch = tuple(t.to(device) for t in batch)
input_ids_encode, attention_mask_encode, input_ids_decode, attention_mask_decode, labels = batch
optimizer.zero_grad()
bert2bert.zero_grad()
loss, outputs = bert2bert(input_ids = input_ids_encode,
decoder_input_ids = input_ids_decode,
attention_mask = attention_mask_encode,
decoder_attention_mask = attention_mask_decode,
labels = labels)[:2]
if(multi_gpu):
train_loss_set.append(loss.mean().item())
loss.mean().backward()
display_loss = loss.mean().item()
else:
train_loss_set.append(loss.item())
loss.backward()
display_loss = loss.item()
optimizer.step()
```
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,646 | closed | add longformer docs | 05-28-2020 12:51:28 | 05-28-2020 12:51:28 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4646?src=pr&el=h1) Report
> Merging [#4646](https://codecov.io/gh/huggingface/transformers/pull/4646?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e444648a302dc8520beec96356a4bf500944355c&el=desc) will **decrease** coverage by `1.57%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4646?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4646 +/- ##
==========================================
- Coverage 77.42% 75.85% -1.58%
==========================================
Files 128 128
Lines 21017 21017
==========================================
- Hits 16273 15942 -331
- Misses 4744 5075 +331
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4646?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4646/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `18.51% <0.00%> (-78.31%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4646/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `76.92% <0.00%> (-23.08%)` | :arrow_down: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/4646/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `77.18% <0.00%> (-6.35%)` | :arrow_down: |
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4646/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `86.77% <0.00%> (-0.19%)` | :arrow_down: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4646/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4646?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4646?src=pr&el=footer). Last update [e444648...200b97a](https://codecov.io/gh/huggingface/transformers/pull/4646?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Docs were provided in another PR - closing. |
|
transformers | 4,645 | closed | [Longformer] Multiple choice for longformer | ## Description:
- This PR adds Multiple Choice for Longformer as in: #4644 (Sorry for not telling you earlier @patil-suraj). @ibeltagy
- The documentation is updated for all models using MultipleChoice since their `input_ids` have 3 dimensions. It is done by use of `{}.format()` for `INPUTS_DOCSTRING`. @LysandreJik
- Adds a couple of models that were missing to the respective `models_page` @LysandreJik
@ibeltagy Regarding global attention - I think we probably should automatically add global attention here since the multiple inputs are flattened across the dimension `num_choices` and then should attend each other. Maybe add global attention always on the first token of each input of the dim `num_choices`?
- Global attention should probably still be implemented. Waiting for @ibeltagy answer.
| 05-28-2020 12:11:14 | 05-28-2020 12:11:14 | As mentioned in the paper, they used global attention on all answer candidates for WikiHop, so maybe we can use global attention on all choice tokens ?<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4645?src=pr&el=h1) Report
> Merging [#4645](https://codecov.io/gh/huggingface/transformers/pull/4645?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e444648a302dc8520beec96356a4bf500944355c&el=desc) will **increase** coverage by `0.01%`.
> The diff coverage is `100.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4645?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4645 +/- ##
==========================================
+ Coverage 77.42% 77.44% +0.01%
==========================================
Files 128 128
Lines 21017 21046 +29
==========================================
+ Hits 16273 16299 +26
- Misses 4744 4747 +3
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4645?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `99.13% <ø> (ø)` | |
| [src/transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hdXRvLnB5) | `73.80% <ø> (ø)` | |
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `86.96% <100.00%> (ø)` | |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `97.05% <100.00%> (+0.22%)` | :arrow_up: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `95.71% <100.00%> (ø)` | |
| [src/transformers/modeling\_tf\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hbGJlcnQucHk=) | `78.74% <100.00%> (ø)` | |
| [src/transformers/modeling\_tf\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9iZXJ0LnB5) | `96.54% <100.00%> (ø)` | |
| [src/transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ194bG5ldC5weQ==) | `75.73% <100.00%> (ø)` | |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `80.41% <0.00%> (-1.38%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4645/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4645?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4645?src=pr&el=footer). Last update [e444648...826c1b0](https://codecov.io/gh/huggingface/transformers/pull/4645?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Looks like multiple choice models are used for datasets with short input like swag (question + multiple choices), and datasets with long context like Wikihop (question + multiple choices + a long context). For the second use case, as @patil-suraj mentioned, we need global attention on all tokens of the question and the choices.
For the first use case, I am not sure how to handle it. Maybe global attention everywhere, but in this case, it is equivalent to n^2 attention. Do you know of a dataset of the first use case with inputs longer than swag?<|||||>@ibeltagy If we have such multiple use-cases then I think it would be better if we leave this to the user. Not entirely sure though.<|||||>@patil-suraj, we can leave it to the user, or we can just do as you suggested earlier, put global attention on the question and all choices, which should work.
@patrickvonplaten, what do you think?
<|||||>Yeah I think ideally we would leave it to the user with a `global_attention_mask` input argument that is automatically set when `None`. We could actually have this for all forward functions...I'll think a bit about it tomorrow!<|||||>We had some internal discussion and decided to change / extend the API of `Longformer` slightly.
We will have two "mask" arguments for every `forward()` function in Longformer: `attention_mask` (as usual composed of 0's and 1's only) and a `global_attention_mask` also composed of zeros and ones (0 => local attention; 1=> global attention). If `global_attention` is not defined by the user we create if necessary `LongformerForQuestionAnswering` and maybe `LongformerForMultipleChoice`.
We will keep the inner workings the same (merge `attention_mask` with `global_attention_mask`) but make sure the user has a more intuitive API, since people always think of masks as boolean tensors in this library.
Is that ok for you @ibeltagy ?
I will merge this PR and open a new one with the proposed changes. |
transformers | 4,644 | closed | LongformerForMultipleChoice | This PR adds `LongformerForMultipleChoice` following `RobertaForMultipleChoice`
@patrickvonplaten , @ibeltagy
Same question as before, do we need any automatic global attention here ? | 05-28-2020 12:10:38 | 05-28-2020 12:10:38 | Haha, I shouldn't have touched this - I kinda already assumed you are working on it :D See PR here: #4645<|||||>Yes 😀 , I was just waiting for `LongformerForTokenClassifiction` to be merged<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4644?src=pr&el=h1) Report
> Merging [#4644](https://codecov.io/gh/huggingface/transformers/pull/4644?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e444648a302dc8520beec96356a4bf500944355c&el=desc) will **decrease** coverage by `2.80%`.
> The diff coverage is `27.58%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4644?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4644 +/- ##
==========================================
- Coverage 77.42% 74.62% -2.81%
==========================================
Files 128 128
Lines 21017 21046 +29
==========================================
- Hits 16273 15705 -568
- Misses 4744 5341 +597
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4644?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `99.13% <ø> (ø)` | |
| [src/transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hdXRvLnB5) | `73.80% <ø> (ø)` | |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `19.16% <27.58%> (-77.67%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_pytorch\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9weXRvcmNoX3V0aWxzLnB5) | `8.72% <0.00%> (-81.21%)` | :arrow_down: |
| [src/transformers/optimization.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9vcHRpbWl6YXRpb24ucHk=) | `28.00% <0.00%> (-68.00%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `76.92% <0.00%> (-23.08%)` | :arrow_down: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `72.81% <0.00%> (-10.72%)` | :arrow_down: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `85.71% <0.00%> (-10.00%)` | :arrow_down: |
| [src/transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19jdHJsLnB5) | `95.94% <0.00%> (-2.71%)` | :arrow_down: |
| ... and [5 more](https://codecov.io/gh/huggingface/transformers/pull/4644/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4644?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4644?src=pr&el=footer). Last update [e444648...5237ac2](https://codecov.io/gh/huggingface/transformers/pull/4644?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Closing in favor of #4645 - sorry should have communicated here better! |
transformers | 4,643 | closed | question-answering examples bug in pipelines document | Regarding
https://github.com/huggingface/transformers/blob/96f57c9ccb6363623005fb3f05166dfd7acb3f53/src/transformers/pipelines.py#L1739
it will cause a reproducible bug:
```python
from transformers import pipeline
nlp_qa = pipeline('question-answering', model='distilbert-base-cased-distilled-squad', tokenizer='bert-base-cased')
nlp_qa(context='Hugging Face is a French company based in New-York.', question='Where is based Hugging Face ?')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/my_name/Library/Python/3.7/lib/python/site-packages/transformers/pipelines.py", line 1188, in __call__
start, end = self.model(**fw_args)
File "/usr/local/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
TypeError: forward() got an unexpected keyword argument 'token_type_ids'
```
but it should use `tokenizer='distilbert-base-cased'`
```python
from transformers import pipeline
nlp_qa = pipeline('question-answering', model='distilbert-base-cased-distilled-squad', tokenizer='distilbert-base-cased')
nlp_qa(context='Hugging Face is a French company based in New-York.', question='Where is based Hugging Face ?')
{'score': 0.9632966867654424, 'start': 42, 'end': 50, 'answer': 'New-York.'}
``` | 05-28-2020 08:56:11 | 05-28-2020 08:56:11 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,642 | closed | [Longformer] Notebook to train Longformer | This PR adds a community notebook that demonstrates how we pretrained Longformer starting from the RoBERTa checkpoint. The same procedure can be followed to convert other existing pretrained models into their Long version.
@patrickvonplaten, @patil-suraj, it would be great if you also check the notebook. Any comments are welcomed. | 05-28-2020 07:31:04 | 05-28-2020 07:31:04 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4642?src=pr&el=h1) Report
> Merging [#4642](https://codecov.io/gh/huggingface/transformers/pull/4642?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5e737018e1fcb22c8b76052058279552a8d6c806&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4642?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4642 +/- ##
=======================================
Coverage 77.19% 77.19%
=======================================
Files 128 128
Lines 21021 21021
=======================================
Hits 16228 16228
Misses 4793 4793
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4642?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4642/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/4642/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `39.47% <0.00%> (+0.23%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4642?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4642?src=pr&el=footer). Last update [5e73701...b86c516](https://codecov.io/gh/huggingface/transformers/pull/4642?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>BTW @patil-suraj - you can also add your longformer squad notebook to the community notebooks if you want<|||||>Made a copy and added some comments here: https://colab.research.google.com/drive/1kS2yerrLwLnc-hM6PlisFVaJT98kUKRV#scrollTo=4TTSvW8MlKJJ
I think the use case is really nice! For better engagement with the notebook, I think it can be polished a bit in terms of small code refactoring / better descriptions. I left some TODO: there as suggestions :-) <|||||>@patrickvonplaten, thanks for the review, the notebook is much better now after incorporating your suggestions. <|||||>Looks great merging! |
transformers | 4,641 | closed | Fix onnx export input names order | This PR makes it possible to export custom bert models to onnx.
It resolves the issue addressed [here](https://github.com/huggingface/transformers/issues/4523#issuecomment-634920569).
TODO:
- [x] update ensure_valid_input function
- [x] update test ensure_valid_input_function
- [x] update convert_pytorch
- [x] add a test of exporting a custom pytorch models
@mfuntowicz | 05-28-2020 07:16:12 | 05-28-2020 07:16:12 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4641?src=pr&el=h1) Report
> Merging [#4641](https://codecov.io/gh/huggingface/transformers/pull/4641?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/14cb5b35faeda7881341656aacf89d12a8a7e07b&el=desc) will **decrease** coverage by `0.02%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4641?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4641 +/- ##
==========================================
- Coverage 78.04% 78.01% -0.03%
==========================================
Files 123 123
Lines 20477 20477
==========================================
- Hits 15981 15975 -6
- Misses 4496 4502 +6
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4641?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/hf\_api.py](https://codecov.io/gh/huggingface/transformers/pull/4641/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9oZl9hcGkucHk=) | `93.06% <0.00%> (-4.96%)` | :arrow_down: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4641/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4641?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4641?src=pr&el=footer). Last update [14cb5b3...a4d4611](https://codecov.io/gh/huggingface/transformers/pull/4641?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>@mfuntowicz what do you think of my proposed changes?
I'm not sure why the CI fails on `TFAutoModelTest.test_from_identifier_from_model_type` as I haven't touched it.<|||||>LGTM! Thanks @RensDimmendaal for looking at this :)<|||||>@LysandreJik should we merge with the failing test? It seems totally unrelated |
transformers | 4,640 | closed | Error when loading a trained Encoder-Decoder model. | # 🐛 Bug Report
When loading the config the in configuration_auto.py the model_type is expected on the form encoder-decoder
but in configuration_encoder_decoder.py
model_type is on the form encoder_decoder which raises a KeyError. | 05-28-2020 06:51:09 | 05-28-2020 06:51:09 | Hi @Xunzhuo,
Multiple bugs were fixed in #4680 . Can you please take a look whether this error persists?<|||||>okay tks! |
transformers | 4,639 | closed | How to generate prediction/answer from a custom model fined-tuned/trained for self-defined questions? | I used run_squad.py to fine-tuned a pre-trained DistilledBERT, and I wonder how exactly to implement my model to answer a list of self-defined questions. It seems to me that the pipeline only works with one of the "regular" models (BERT DistBert, XLM, XLNET, etc.), or a model that has already been uploaded to the community. I spent a lot of time researching this but couldn't find a solution that suits the best for my case. Would anyone please explain, and if possibly, provide a demo? Here are all the files generated after my fine-tuning and evaluation:
config.json
pytorch_model.bin
training_args.bin
nbest_predictions_.json
special_tokens_map.json
vocab.txt
predictions_.json
tokenizer_config.json
Thank you!
SO Link (no answer yet): https://stackoverflow.com/questions/62057333/how-exactly-to-generate-prediction-answer-from-a-custom-model-fined-tuned-traine | 05-28-2020 06:33:25 | 05-28-2020 06:33:25 | Considering you saved the model(the files you mentioned above) in 'model_dir' here's how you can do it.
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
import torch
tokenizer = AutoTokenizer.from_pretrained("model_dir")
model = AutoModelForQuestionAnswering.from_pretrained("model_dir")
question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
encoding = tokenizer.encode_plus(question, text, return_tensors="pt")
input_ids = encoding["input_ids"]
attention_mask = encoding["attention_mask"]
start_scores, end_scores = model(input_ids, attention_mask=attention_mask)
all_tokens = tokenizer.convert_ids_to_tokens(input_ids[0].tolist())
answer_tokens = all_tokens[torch.argmax(start_scores) :torch.argmax(end_scores)+1]
answer = tokenizer.decode(tokenizer.convert_tokens_to_ids(answer_tokens))
```
Or better yet, use the `pipline`
```python
from transformers import pipeline
nlp = pipeline('question-answering', model='model_dir', tokenizer='model_dir')
nlp({
'question': "Who was Jim Henson?"
'context': "Jim Henson was a nice puppet"
})
```<|||||>> Considering you saved the model(the files you mentioned above) in 'model_dir' here's how you can do it.
>
> ```python
> from transformers import AutoTokenizer, AutoModelForQuestionAnswering
> import torch
>
> tokenizer = AutoTokenizer.from_pretrained("model_dir")
> model = AutoModelForQuestionAnswering.from_pretrained("model_dir")
>
> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
> encoding = tokenizer.encode_plus(question, text, return_tensors="pt")
>
> input_ids = encoding["input_ids"]
> attention_mask = encoding["attention_mask"]
>
> start_scores, end_scores = model(input_ids, attention_mask=attention_mask)
> all_tokens = tokenizer.convert_ids_to_tokens(input_ids[0].tolist())
>
> answer_tokens = all_tokens[torch.argmax(start_scores) :torch.argmax(end_scores)+1]
> answer = tokenizer.decode(tokenizer.convert_tokens_to_ids(answer_tokens))
> ```
>
> Or better yet, use the `pipline`
>
> ```python
> from transformers import pipeline
>
> nlp = pipeline('question-answering', model='model_dir', tokenizer='model_dir')
>
> nlp({
> 'question': "Who was Jim Henson?"
> 'context': "Jim Henson was a nice puppet"
> })
> ```
Hey Suraj thank you so much! My mistake was coding the pipeline incorrectly, but now it's doing fine. Thank you!
However, I have another question if you don't mind:
When I used your method above by coding the system from scratch without using "pipeline", I would get this "index out of range" error, unless i limit my input context within about 2,103 characters (my full input text contains 57,373 characters). Nevertheless, this issue never occurred in pipeline. Do you have any idea why this happened? I think I fine-tuned a large-distilled-BERT-uncase so sequence length should not be an issue here. Is there a significant difference between the pipeline and coding the components from scratch?<|||||>Hi @ZhiliWang, the pipeline is a high level abstraction that takes care of several things so that you don't have to. Overflowing sequences is a good example, where the pipeline will automatically truncate it. You can specify `max_seq_length=n` to the pipeline if you want to manage that parameter yourself.
You can do the same with `encode_plus` by specifying the `max_length` argument.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,638 | closed | LongformerForTokenClassification | This PR adds `LongformerForTokenClassification`
@patrickvonplaten @ibeltagy
do we need any automatic global attention here ? | 05-28-2020 05:30:06 | 05-28-2020 05:30:06 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4638?src=pr&el=h1) Report
> Merging [#4638](https://codecov.io/gh/huggingface/transformers/pull/4638?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/96f57c9ccb6363623005fb3f05166dfd7acb3f53&el=desc) will **increase** coverage by `0.04%`.
> The diff coverage is `96.55%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4638?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4638 +/- ##
==========================================
+ Coverage 77.39% 77.43% +0.04%
==========================================
Files 128 128
Lines 20989 21018 +29
==========================================
+ Hits 16244 16275 +31
+ Misses 4745 4743 -2
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4638?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/4638/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `99.13% <ø> (ø)` | |
| [src/transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/4638/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hdXRvLnB5) | `73.80% <ø> (ø)` | |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4638/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `96.83% <96.55%> (-0.03%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4638/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (-0.17%)` | :arrow_down: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4638/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `81.78% <0.00%> (+1.37%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4638?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4638?src=pr&el=footer). Last update [96f57c9...c8bcd05](https://codecov.io/gh/huggingface/transformers/pull/4638?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>No. We didn't use any global attention for token classification tasks. It is possible that certain choices of global attention will improve results, but it is task-specific and better be left to the user. <|||||>Great! Then I think it can be merged.<|||||>Awesome! LGTM |
transformers | 4,637 | closed | Movement pruning | This PR adds the code to reproduce the results of our recent work on Movement pruning.
Some supplemental treats:
- A notebook showcasing how to efficiently store an extremely sparse model
- Sharing a couple of fine-pruned checkpoints (PruneBERT)
- Details of all hyper-parameters and results
| 05-28-2020 04:59:33 | 05-28-2020 04:59:33 | Thanks for the valuable inputs on quantization @mfuntowicz! --> `Saving_PruneBERT.ipynb`<|||||>> This is great. Didn't you want to include the `MaskedBertXXX` directly in the library, as was done with `DistilBERT`?
>
> We can also do it at a later date, as we'll need to write the tests (kudos on the docs, looks nice!)
Good question. I think it's fair for the moment to leave it outside of the library itself: once a pre-trained model has been fine-pruned, it can be pruned once for all and you end up with a standard `BertForSequenceClassification` for instance. So I see it more as an "intermediate tool".<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4637?src=pr&el=h1) Report
> Merging [#4637](https://codecov.io/gh/huggingface/transformers/pull/4637?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ec4cdfdd05d89b243d6d842fce019959291dd92a&el=desc) will **decrease** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4637?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4637 +/- ##
==========================================
- Coverage 78.04% 78.04% -0.01%
==========================================
Files 124 124
Lines 20676 20676
==========================================
- Hits 16137 16136 -1
- Misses 4539 4540 +1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4637?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4637/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (-0.17%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4637?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4637?src=pr&el=footer). Last update [ec4cdfd...bee5496](https://codecov.io/gh/huggingface/transformers/pull/4637?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>> Looks great. Well organized & clearly communicated.
>
> Would it be worthwhile to add the released prunebert encoders to exBERT? I don't think we have any fine-tuned models there right now but it'd be cool to let people see how the movement pruning process affects the attention distributions.
Good point! I'll have a look. |
transformers | 4,636 | closed | Kill model archive maps | Links to model weights inside the code are not useful anymore, on the contrary, defining those shortcuts to URLs in code tend to lead to discrepancies with the canonical naming scheme of models at huggingface.co
As an example, we cannot cleanly load [`facebook/bart-large-cnn`](https://huggingface.co/facebook/bart-large-cnn) from either huggingface.co or the inference API because it's aliased to bart-large-cnn in the code.
If this PR is approved, before merging I will:
- do the same thing for configs (easy)
- just rename the renamed model identifiers for tokenizers. (completely getting rid of "archive maps" for tokenizers is way harder because of the hardcoded maps like `PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES` and `PRETRAINED_INIT_CONFIGURATION`)
---
⚠️ **Note that the change in this PR is breaking for the names of the following models:**
```
"cl-tohoku/bert-base-japanese"
"cl-tohoku/bert-base-japanese-whole-word-masking"
"cl-tohoku/bert-base-japanese-char"
"cl-tohoku/bert-base-japanese-char-whole-word-masking"
"TurkuNLP/bert-base-finnish-cased-v1"
"TurkuNLP/bert-base-finnish-uncased-v1"
"wietsedv/bert-base-dutch-cased"
"flaubert/flaubert_small_cased"
"flaubert/flaubert_base_uncased"
"flaubert/flaubert_base_cased"
"flaubert/flaubert_large_cased"
all variants of "facebook/bart"
```
^^ You'll need to specify the organization prefix for those models from now on. However, no files were moved on S3 so this doesn't change anything for all current versions of the library.
However it's a breaking change so we'll be sure to pinpoint to it in the next release. | 05-28-2020 03:51:37 | 05-28-2020 03:51:37 | Love this! is there a plan to allow aliases moving forward?
typing `'Helsinki-NLP/opus-mt-romance-en'` is not awful so I don't feel very strongly that we should, but interested in your thoughts.<|||||>Hmm no I don't see an obvious need for aliases personally.<|||||>Awesome!<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4636?src=pr&el=h1) Report
> Merging [#4636](https://codecov.io/gh/huggingface/transformers/pull/4636?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/88762a2f8cc409fe15a9e6a049fe69ae3197fc49&el=desc) will **decrease** coverage by `0.08%`.
> The diff coverage is `100.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4636?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4636 +/- ##
==========================================
- Coverage 77.12% 77.04% -0.09%
==========================================
Files 128 128
Lines 21071 20977 -94
==========================================
- Hits 16252 16162 -90
+ Misses 4819 4815 -4
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4636?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2FsYmVydC5weQ==) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JhcnQucHk=) | `93.33% <ø> (-0.15%)` | :arrow_down: |
| [src/transformers/configuration\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JlcnQucHk=) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2NhbWVtYmVydC5weQ==) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2N0cmwucHk=) | `97.05% <ø> (-0.09%)` | :arrow_down: |
| [src/transformers/configuration\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2Rpc3RpbGJlcnQucHk=) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2VsZWN0cmEucHk=) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2ZsYXViZXJ0LnB5) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2dwdDIucHk=) | `97.22% <ø> (-0.08%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `100.00% <ø> (ø)` | |
| ... and [56 more](https://codecov.io/gh/huggingface/transformers/pull/4636/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4636?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4636?src=pr&el=footer). Last update [88762a2...a5f6993](https://codecov.io/gh/huggingface/transformers/pull/4636?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>For configs, I decided to leave the URLs (even if they're not used) to have quick reference and be able to open them from the code. We can always delete them later though.
Ok, merging this! |
transformers | 4,635 | closed | 03-pipelines.ipynb on Colab: error on "Summarization" | ` ` | 05-28-2020 03:49:49 | 05-28-2020 03:49:49 | |
transformers | 4,634 | closed | tensorflow2_gpt2 Slow speed | # ❓ The speed of pytorch_gpt2 based on transformers is 4-5 times faster than that of tensorflow_gpt2, which is unreasonable. Where is my problem
**pytorch_gpt2**
```
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
model.to(dev)
raw_text_2 = "And if so be ye can descrive what ye bear,"
inputs = tokenizer.encode(raw_text_2, add_special_tokens=False, return_tensors="pt")
inputs = inputs.to(dev)
generated = model.generate(inputs, top_k=0, max_length=512)
```
**tensorflow2_gpt2**
```
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = TFGPT2LMHeadModel.from_pretrained('gpt2')
raw_text = "And if so be ye can descrive what ye bear,"
tokens = tokenizer.encode(raw_text, return_tensors="tf")
output_ids = model.generate(tokens, top_k = 0, max_length=512)
```
| 05-28-2020 03:11:50 | 05-28-2020 03:11:50 | With tf. Varibable model for packaging
```
@tf.function(experimental_relax_shapes=True)
def model_static(self, model_inputs):
outputs = self(**model_inputs)
return outputs
```<|||||>Same problem here
@only-yao Did you find a solution yet?<|||||>> @ only-yao这是同样的问题,您找到解决方案了吗?
Wrap the model with @tf.function,the model as a static diagram<|||||>Very interesting! Thanks for your code snippet @only-yao - I will take a closer look in a week or so :-) <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,633 | closed | Merge pull request #1 from huggingface/master | - | 05-28-2020 00:43:16 | 05-28-2020 00:43:16 | |
transformers | 4,632 | closed | Pipelines: miscellanea of QoL improvements and small features... | ...needed for inference API.
see individual commits for description | 05-27-2020 23:08:13 | 05-27-2020 23:08:13 | |
transformers | 4,631 | closed | Numpy format string issue in TFTrainer | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): bert
Language I am using the model on (English, Chinese ...): English
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: tf_ner
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
Running the `run_tf_ner` example raises the following exception:
`Traceback (most recent call last):
File "run_tf_ner.py", line 282, in <module>
main()
File "run_tf_ner.py", line 213, in main
trainer.train()
File "venv/lib/python3.7/site-packages/transformers/trainer_tf.py", line 308, in train
logger.info("Epoch {} Step {} Train Loss {:.4f}".format(epoch, step, training_loss.numpy()))
TypeError: unsupported format string passed to numpy.ndarray.__format__`
This issue was reported by multiple people:
https://github.com/numpy/numpy/issues/12491
https://github.com/numpy/numpy/issues/5543
I think the easiest solution is to avoid using the numpy format string this way in `TFTrainer`.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 2.1.0
- Platform: Ubuntu-18.04
- Python version: 3.7.7
- PyTorch version (GPU?): N/A
- Tensorflow version (GPU?): 2.1.0
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
| 05-27-2020 22:50:48 | 05-27-2020 22:50:48 | same here <|||||>How did you resolve it? Do we have to wait till TFTrainer developer change the code in trainer_tf.py?
Is there a way around it?<|||||>Hello,
Can you give a sample of data and a command line with which I can reproduce the issue? Thanks!<|||||>> Hello,
>
> Can you give a sample of data and a command line with which I can reproduce the issue? Thanks!
I run into the same problem with the exact setting as I posted here. #4664 (comment)
After I fixed the TFTrainer parameter issue, the training started but it returned this error after the normal BERT log.
<|||||>Sorry I don't succeed to reproduce the issue with the command line in #4664 for me it works. Which dataset are you using? Germeval?<|||||>yes, I followed all the process here: https://github.com/huggingface/transformers/tree/master/examples/token-classification<|||||>Sorry, impossible to reproduce the issue :(
I tried with different NER datasets including germeval and everything goes well.<|||||>I would suggest to wait the next version of the TF Trainer to see if it solves your problem or not. It should arrives soon. Sorry :(<|||||>I am trying to reproduce it to see where the glitch is. Unfortunately colab gpu is too busy for me to get connected at the moment. I will post here once I locate the problem.
No worries. Thanks for bring out the TFTrainer!<|||||>I experienced the same issue while trying the latest **run_tf_ner.py**. I have almost no problem with the old version (months ago) of run_tf_ner.py and **utils_ner.py**, Trained several models and got very good predictions. But after update to the latest **run_tf_ner.py,** I got several problems: (1) logging_dir none (this already solved by passing the parameter) (2) the value of pad_token_label_id. In the old version I used this value was set to 0, but in the latest run_tf_ner.py it set to -1, but I got wrong prediction results if this set to -1. (3) The third issue is this.
To force the training process moving, I created a new class inherit from TFTrainer, modified the train method --> added except TypeError logger.info("Epoch {} Step {} Train Loss {}".format(epoch, step, 'TypeError'))
Here is the training_loss and trining_loss.numpy() printed
<class 'tensorflow.python.framework.ops.EagerTensor'>
<class 'numpy.ndarray'>
[3.86757078e-04 6.49182359e-04 1.50194198e-01 1.72556902e-03
7.37545686e-03 7.55832903e-03 2.59326249e-01 1.65126711e-01
1.45479038e-01 2.91670375e-02 1.02433632e-03 1.09142391e-03
7.45586725e-03 1.56116625e-03 6.97672069e-02 6.09296076e-02
1.59586817e-02 2.96084117e-02 3.36027122e-04 2.67877331e-04
2.72625312e-02 3.24607291e-03 2.79245054e-04 8.95933714e-04
1.38876194e-05 4.55974305e-06 7.18232468e-06 6.49688218e-06
4.67895006e-06 4.67895188e-06 4.08290907e-06 5.72202407e-06
5.99023815e-06 5.48360913e-06 1.09671510e-05 1.32022615e-05
7.30153261e-06 4.67895097e-06 4.88756723e-06 4.73855425e-06
4.70875511e-06 5.33459615e-06 4.35112906e-06 8.13599218e-06
4.14251372e-06 3.48686262e-06 7.68894461e-06 4.14251281e-06
4.55974168e-06 4.29152169e-06 9.68567110e-06 2.68220538e-06
3.63587583e-06 4.14251235e-06 3.18884304e-06 4.38093048e-06
4.52994209e-06 4.70875284e-06 3.30805187e-06 5.63261574e-06
3.15904026e-06 6.55648546e-06 5.87103386e-06 4.14251190e-06
3.81468908e-06 3.39745884e-06 4.47033653e-06 6.49688172e-06
6.25846224e-06 4.08290816e-06 4.08290680e-06 3.69548002e-06
4.35112725e-06 3.60607328e-06 4.97697329e-06 6.88430828e-06
5.72202634e-06 4.79816072e-06 5.75182776e-06 6.43727981e-06
3.78488676e-06 1.53479104e-05 6.70549389e-06 7.03331716e-06
3.18884258e-06 7.18232604e-06 5.27499060e-06 6.07965376e-06
3.72528302e-06 9.03003547e-06 5.03657793e-06 6.43727435e-06
5.33459661e-06 4.85776036e-06 9.38766698e-06 4.11270958e-06
3.36765652e-06 5.42400539e-06 5.18558409e-06 6.73529667e-06
9.03001182e-06 4.47033699e-06 3.51666586e-06 5.15578267e-06
3.87429282e-06 3.39745884e-06 4.08290725e-06 7.48034654e-06
7.71875875e-06 3.75508489e-06 3.60607396e-06 3.72528302e-06
5.84123518e-06 2.89082072e-06 4.32132674e-06 6.37766652e-06
4.64915001e-06 7.03332262e-06 3.99350029e-06 9.14925931e-06
4.32132583e-06 5.66242352e-06 3.75508489e-06 6.10945517e-06
4.85776673e-06 5.60281842e-06 4.70875375e-06 3.75508534e-06]
tf.Tensor(
[3.86757078e-04 6.49182359e-04 1.50194198e-01 1.72556902e-03
7.37545686e-03 7.55832903e-03 2.59326249e-01 1.65126711e-01
1.45479038e-01 2.91670375e-02 1.02433632e-03 1.09142391e-03
7.45586725e-03 1.56116625e-03 6.97672069e-02 6.09296076e-02
1.59586817e-02 2.96084117e-02 3.36027122e-04 2.67877331e-04
2.72625312e-02 3.24607291e-03 2.79245054e-04 8.95933714e-04
1.38876194e-05 4.55974305e-06 7.18232468e-06 6.49688218e-06
4.67895006e-06 4.67895188e-06 4.08290907e-06 5.72202407e-06
5.99023815e-06 5.48360913e-06 1.09671510e-05 1.32022615e-05
7.30153261e-06 4.67895097e-06 4.88756723e-06 4.73855425e-06
4.70875511e-06 5.33459615e-06 4.35112906e-06 8.13599218e-06
4.14251372e-06 3.48686262e-06 7.68894461e-06 4.14251281e-06
4.55974168e-06 4.29152169e-06 9.68567110e-06 2.68220538e-06
3.63587583e-06 4.14251235e-06 3.18884304e-06 4.38093048e-06
4.52994209e-06 4.70875284e-06 3.30805187e-06 5.63261574e-06
3.15904026e-06 6.55648546e-06 5.87103386e-06 4.14251190e-06
3.81468908e-06 3.39745884e-06 4.47033653e-06 6.49688172e-06
6.25846224e-06 4.08290816e-06 4.08290680e-06 3.69548002e-06
4.35112725e-06 3.60607328e-06 4.97697329e-06 6.88430828e-06
5.72202634e-06 4.79816072e-06 5.75182776e-06 6.43727981e-06
3.78488676e-06 1.53479104e-05 6.70549389e-06 7.03331716e-06
3.18884258e-06 7.18232604e-06 5.27499060e-06 6.07965376e-06
3.72528302e-06 9.03003547e-06 5.03657793e-06 6.43727435e-06
5.33459661e-06 4.85776036e-06 9.38766698e-06 4.11270958e-06
3.36765652e-06 5.42400539e-06 5.18558409e-06 6.73529667e-06
9.03001182e-06 4.47033699e-06 3.51666586e-06 5.15578267e-06
3.87429282e-06 3.39745884e-06 4.08290725e-06 7.48034654e-06
7.71875875e-06 3.75508489e-06 3.60607396e-06 3.72528302e-06
5.84123518e-06 2.89082072e-06 4.32132674e-06 6.37766652e-06
4.64915001e-06 7.03332262e-06 3.99350029e-06 9.14925931e-06
4.32132583e-06 5.66242352e-06 3.75508489e-06 6.10945517e-06
4.85776673e-06 5.60281842e-06 4.70875375e-06 3.75508534e-06], shape=(128,), dtype=float32)
<|||||>@xl2602 Thanks for your feedback, `-1` was also the default value of `pad_token_label_id` in the previous version of the script.
@jx669 and @xl2602 Can you try to add the `--mode token-classification` parameter?<|||||>@jplu I think this has nothing to do with the context of the training script. To reproduce, just run `logging.info("Here is an error example {:.4f}".format(np.array([1,2,3])))` in python console. Maybe this is related to the `numpy` version. I've tried 1.16.4 and 1.18 and they both failed.<|||||>Tested with 1.18.4 only, I'm gonna try with other versions to see if I succeed to get the same issue.<|||||>numpy 1.18.4 is the same as what I installed.
I just reproduced the same error message with colab gpu:
These are what I installed:
!pip install transformers
!pip install seqeval
!pip install wandb; wandb login
I did not install numpy or TF separately. think they come with the transformers package.
I checked the numpy version:
'1.18.4'
TF version:
'2.2.0'
<|||||>Ok, still don't get any error, including with different versions of Numpy.
@jx669 @xl2602 @VDCN12593 Can you please tell me if you do the exact same thing than in this colab please https://colab.research.google.com/drive/19zAfUN8EEmiT4imwzLeFv6q1PJ5CgcRb?usp=sharing<|||||>It might have something to do with the mode command: `--mode token-classification `
If you remove that line in your colab notebook, the same error message will reoccur. <|||||>Cool! Happy we found the problem.
When you run the TF Trainer you have to specify over which task it will be trained on, here for example it is `token-classification` when it on text content it will be `text-classification` (the default) and the same for the two other tasks QA and MC.
This behavior will be removed in the next version of the TF trainer.<|||||>I see. Good to learn. Thanks!
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,630 | closed | Model evaluated at each checkpoint, but results not in checkpoint file | # ❓ Questions & Help
I start `run_language_modeling.py` and `run_glue.py` with `--do_eval` and `--evaluate_during_training` arguments. While it checkpoints and evaluates the model at each saving step, the evaluation results are not output to the checkpoint folder but merely the terminal at each saving step, as well as logging step. However, the final model is evaluated and its results placed in the appropriate location. I'd like the performance of each checkpoint. Am I doing something wrong? Is there an additional argument I must specify? | 05-27-2020 22:33:20 | 05-27-2020 22:33:20 | What is the proper way to get an `eval.txt` file for each checkpoint?<|||||>No, this is not a built-in feature. I'd suggest you install from source and modify the code directly.
The code in this repo is meant to be optimized for "hackability", feel free to open a new issue if needed. |
transformers | 4,629 | closed | gpt2 typo | From #4572 | 05-27-2020 20:41:09 | 05-27-2020 20:41:09 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4629?src=pr&el=h1) Report
> Merging [#4629](https://codecov.io/gh/huggingface/transformers/pull/4629?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ec4cdfdd05d89b243d6d842fce019959291dd92a&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4629?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4629 +/- ##
=======================================
Coverage 78.04% 78.04%
=======================================
Files 124 124
Lines 20676 20676
=======================================
Hits 16137 16137
Misses 4539 4539
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4629?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hbGJlcnQucHk=) | `77.20% <ø> (ø)` | |
| [src/transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19jdHJsLnB5) | `98.64% <ø> (ø)` | |
| [src/transformers/modeling\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19mbGF1YmVydC5weQ==) | `84.49% <ø> (ø)` | |
| [src/transformers/modeling\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19ncHQyLnB5) | `86.21% <ø> (ø)` | |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `81.78% <ø> (ø)` | |
| [src/transformers/modeling\_reformer.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yZWZvcm1lci5weQ==) | `87.94% <ø> (ø)` | |
| [src/transformers/modeling\_tf\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hbGJlcnQucHk=) | `78.74% <ø> (ø)` | |
| [src/transformers/modeling\_tf\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9jdHJsLnB5) | `98.40% <ø> (ø)` | |
| [src/transformers/modeling\_tf\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9mbGF1YmVydC5weQ==) | `21.89% <ø> (ø)` | |
| [src/transformers/modeling\_tf\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9ncHQyLnB5) | `95.66% <ø> (ø)` | |
| ... and [9 more](https://codecov.io/gh/huggingface/transformers/pull/4629/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4629?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4629?src=pr&el=footer). Last update [ec4cdfd...95e5c41](https://codecov.io/gh/huggingface/transformers/pull/4629?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>I think it's a bogus search and replace by @LysandreJik in #2532 but it applies for all models not just GPT2.<|||||>can you fix in all files?<|||||>Ups, I didn't saw this.
I will do this in a few minutes<|||||>LGTM, thanks! |
transformers | 4,628 | closed | [Longformer] more models + model cards | This PR adds the following:
- Longformer models trained with frozen-roberta weights
- Model cards
- Model names start with `allenai/`
- Remove unnecessary type casting
| 05-27-2020 20:02:38 | 05-27-2020 20:02:38 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4628?src=pr&el=h1) Report
> Merging [#4628](https://codecov.io/gh/huggingface/transformers/pull/4628?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a801c7fd74f56a651ba43bfc93eba93c63e84766&el=desc) will **decrease** coverage by `0.00%`.
> The diff coverage is `100.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4628?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4628 +/- ##
==========================================
- Coverage 78.02% 78.02% -0.01%
==========================================
Files 124 124
Lines 20626 20625 -1
==========================================
- Hits 16094 16093 -1
Misses 4532 4532
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4628?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4628/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `100.00% <ø> (ø)` | |
| [src/transformers/modeling\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4628/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19sb25nZm9ybWVyLnB5) | `97.40% <100.00%> (-0.01%)` | :arrow_down: |
| [src/transformers/tokenization\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4628/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fbG9uZ2Zvcm1lci5weQ==) | `100.00% <100.00%> (ø)` | |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4628/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.41% <0.00%> (-0.12%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4628/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4628?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4628?src=pr&el=footer). Last update [a801c7f...06e80ad](https://codecov.io/gh/huggingface/transformers/pull/4628?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,627 | closed | [WIP] lightning glue example uses nlp package | Main goal here was to use `nlp` library to load datasets instead of custom scripts. I've made some changes to the GLUE example, and will reflect those changes elsewhere if the patterns used seem reasonable. Feedback would be greatly appreciated.
**So far, this PR:**
- Uses `nlp` library instead of manual processing scripts to download/process the benchmark datasets (Ref #4494)
- Uses lightning `Trainer` default arguments instead of previous custom logic. See[ list of available args](https://pytorch-lightning.readthedocs.io/en/latest/trainer.html#trainer-class) in their documentation. Resolves #3925
- Generates submission files on test sets (partially resolves #3692)
- Fixes bug mentioned in #4214
- Pins lightning version to latest stable release, as master branch is a little to volatile for my taste.
- upgrades to pl=.76
**TODOs**
- Validate multi-gpu logic is up to date with lightning base practices
- Validate TPU logic is up to date with lightning best practices
- See if there's a better way to save dataset with `nlp` lib directly instead of current `torch.save` logic
- Run exhaustive test over model types over each dataset
- Optionally generate larger output table reporting benchmarks across models
**Note on Trainer args**
The argument parser will now accept any kwargs from the `Trainer` class's init function. For example, to load a checkpoint and run predictions to get submission files, you could run something like this to get a submission file at `./submissions/mrpc_submission.csv`:
```bash
export TASK=mrpc
export DATA_DIR=./cached_glue_data
export MAX_LENGTH=128
export LEARNING_RATE=2e-5
export BERT_MODEL=bert-base-cased
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SEED=2
export GPUS=1
export NUM_WORKERS=4
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
python3 -i run_pl_glue.py \
--model_name_or_path $BERT_MODEL \
--task $TASK \
--data_dir $DATA_DIR \
--max_seq_length $MAX_LENGTH \
--max_epochs $NUM_EPOCHS \
--learning_rate $LEARNING_RATE \
--seed $SEED \
--gpus $GPUS \
--num_workers $NUM_WORKERS \
--train_batch_size $BATCH_SIZE \
--resume_from_checkpoint ./lightning_logs/version_0/checkpoints/epoch=1.ckpt \
--output_dir ./submissions/
--do_predict
```
CC: @srush @williamFalcon | 05-27-2020 19:56:56 | 05-27-2020 19:56:56 | @julien-c I'm not sure why my checks for isort aren't passing on run_pl_glue.py. Could it be because I imported `pyarrow` which is not listed in third party within `setup.cfg`?<|||||>lmk when you’re ready for me to give this a look over :)
one major feature we added is the option to not rely on hparams, they are of course backward compatible but now you have the option to instead pass all the args to init directly and we’ll still save the correct stuff in the checkpoint<|||||>@sshleifer can you advise on the style check issue when you get the chance, please?<|||||>Adding note for myself...seems `pandas` has been removed from lightning's requirements.txt so we may need to add that to `examples/requirements.txt`.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4627?src=pr&el=h1) Report
> Merging [#4627](https://codecov.io/gh/huggingface/transformers/pull/4627?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/4402879ee48dcff0f657738d8af5e35b266bd0ed&el=desc) will **decrease** coverage by `1.02%`.
> The diff coverage is `79.52%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4627?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4627 +/- ##
==========================================
- Coverage 78.02% 76.99% -1.03%
==========================================
Files 124 128 +4
Lines 20635 21602 +967
==========================================
+ Hits 16100 16633 +533
- Misses 4535 4969 +434
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4627?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2FsYmVydC5weQ==) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_bart.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JhcnQucHk=) | `93.33% <ø> (-0.15%)` | :arrow_down: |
| [src/transformers/configuration\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JlcnQucHk=) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2NhbWVtYmVydC5weQ==) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2Rpc3RpbGJlcnQucHk=) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_electra.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2VsZWN0cmEucHk=) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2ZsYXViZXJ0LnB5) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2dwdDIucHk=) | `97.22% <ø> (-0.08%)` | :arrow_down: |
| [src/transformers/configuration\_longformer.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2xvbmdmb3JtZXIucHk=) | `100.00% <ø> (ø)` | |
| [src/transformers/configuration\_marian.py](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX21hcmlhbi5weQ==) | `100.00% <ø> (ø)` | |
| ... and [119 more](https://codecov.io/gh/huggingface/transformers/pull/4627/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4627?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4627?src=pr&el=footer). Last update [4402879...c394f68](https://codecov.io/gh/huggingface/transformers/pull/4627?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Closing and will reopen cleaner one later. |
transformers | 4,626 | closed | How to use run_glue.py with tensorboard? | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
I'm running `run_glue.py` script, where I added a new task_name in `data/metrics` and `data/processors`. The training happens OK, the checkpoints are being saved, but no tfevent file is being written. Shouldn't it be written in checkpoints folder during training? | 05-27-2020 19:01:53 | 05-27-2020 19:01:53 | What `--logging_dir` have you specified to the `run_glue.py` script?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I'm having this problem how do you fixed this?
I put the direction to the folder to --logging_dir but nothing is written there<|||||>> What `--logging_dir` have you specified to the `run_glue.py` script?
I'm having this problem how do you fixed this?
I put the direction to the folder to --logging_dir but nothing is written there |
transformers | 4,625 | closed | [Model Card] model card for longformer-base-4096-finetuned-squadv1 | @patrickvonplaten | 05-27-2020 16:43:08 | 05-27-2020 16:43:08 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4625?src=pr&el=h1) Report
> Merging [#4625](https://codecov.io/gh/huggingface/transformers/pull/4625?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/6a17688021268fe429e78c66ea0932cb55cd03b1&el=desc) will **decrease** coverage by `0.01%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4625?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4625 +/- ##
==========================================
- Coverage 78.02% 78.00% -0.02%
==========================================
Files 124 124
Lines 20635 20635
==========================================
- Hits 16100 16097 -3
- Misses 4535 4538 +3
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4625?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4625/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4625/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.50% <0.00%> (-0.17%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4625/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.41% <0.00%> (-0.12%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4625?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4625?src=pr&el=footer). Last update [6a17688...8c230e9](https://codecov.io/gh/huggingface/transformers/pull/4625?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>That's great thanks @patil-suraj |
transformers | 4,624 | closed | Can't see logger output | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): RoBERTa
Language I am using the model on (English, Chinese ...): Sanskrit
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
Can't see logger output showing model config and other parameters in Trainer that were printed in training_scripts.
1.
```
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./model_path",
overwrite_output_dir=True,
num_train_epochs=1,
per_gpu_train_batch_size=128,
per_gpu_eval_batch_size =256,
save_steps=1_000,
save_total_limit=2,
logging_first_step = True,
do_train=True,
do_eval = True,
evaluate_during_training=True,
logging_steps = 1000
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset = valid_dataset,
prediction_loss_only=True,
)
```
2.
```
%%time
trainer.train(model_path="./model_path")
```
Is it It is overriden by tqdm?
but I can still see `Using deprecated `--per_gpu_train_batch_size` argument which will be removed in a future version. Using `--per_device_train_batch_size` is preferred.`
## Environment info
- `transformers` version: 2.10.0
- Platform: Linux-4.19.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0a0+916084d (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: TPU
- Using distributed or parallel set-up in script?: No
| 05-27-2020 16:37:44 | 05-27-2020 16:37:44 | Hi, have you tried setting the logging level to `INFO`? You can do so with the following lines:
```py
import logging
logging.basicConfig(level=logging.INFO)
```<|||||>It worked! Thanks<|||||>Hey, this doesn't log the training progress by trainer.train() into a log file. I want to keep appending the training progress to my log file but all I get are the prints and the parameters info at the end of trainer.train(). What would be a way around to achieve this? @parmarsuraj99 @LysandreJik <|||||>+1
same request. @parmarsuraj99 @LysandreJik <|||||>Share a solution, not so elegant but works.
I define a new `Callback` function, which logging the logs using the outside logger. And then pass it to the trainer.
```python
class LoggerLogCallback(transformers.TrainerCallback):
def on_log(self, args, state, control, logs=None, **kwargs):
control.should_log = False
_ = logs.pop("total_flos", None)
if state.is_local_process_zero:
logger.info(logs) # using your custom logger
``` |
transformers | 4,623 | closed | `train.jsonl` file missing in MM-IMDb task | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): Bert
Language I am using the model on (English, Chinese ...): English
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: MM-IMDb
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Download the **raw** MM-IMDb dataset from http://lisi1.unal.edu.co/mmimdb/
2. Download `run_mmimdb.py` and `utils_mmimdb.py` from `/examples/contrib/mm-imdb`
3. Run the command given in [README.md](https://github.com/huggingface/transformers/blob/master/examples/contrib/mm-imdb/README.md#training-on-mm-imdb)
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
Traceback (most recent call last):
File "run_mmimdb.py", line 614, in <module>
main()
File "run_mmimdb.py", line 555, in main
train_dataset = load_examples(args, tokenizer, evaluate=False)
File "run_mmimdb.py", line 339, in load_examples
dataset = JsonlDataset(path, tokenizer, transforms, labels, args.max_seq_length - args.num_image_embeds - 2)
File ".../mmimdb/utils_mmimdb.py", line 50, in __init__
self.data = [json.loads(l) for l in open(data_path)]
FileNotFoundError: [Errno 2] No such file or directory: '.../mmimdb/dataset/train.jsonl'
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
+ `train.jsonl` should be present in the script directory
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: Linux
- Python version: Python 3.6.5
- PyTorch version (GPU?): `1.4.0` (yes)
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
| 05-27-2020 16:00:06 | 05-27-2020 16:00:06 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>It seems like this is the method to get the jsonl files: https://github.com/facebookresearch/mmbt/blob/master/scripts/mmimdb.py |
transformers | 4,622 | closed | GPU memory usage | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
I am training albert from scratch. I am using 8 V100. Issue is gpu 0 is almost completely used but others have around 50% ram unused. I am getting only 85 batch size on this system and above this OOM.
Using transformers from source 2.10.0
```
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:16.0 Off | 0 |
| N/A 77C P0 291W / 300W | 30931MiB / 32510MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... On | 00000000:00:17.0 Off | 0 |
| N/A 71C P0 255W / 300W | 18963MiB / 32510MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-SXM2... On | 00000000:00:18.0 Off | 0 |
| N/A 71C P0 95W / 300W | 18963MiB / 32510MiB | 98% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-SXM2... On | 00000000:00:19.0 Off | 0 |
| N/A 68C P0 89W / 300W | 18963MiB / 32510MiB | 72% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla V100-SXM2... On | 00000000:00:1A.0 Off | 0 |
| N/A 68C P0 78W / 300W | 18963MiB / 32510MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 |
| N/A 69C P0 96W / 300W | 18963MiB / 32510MiB | 65% Default |
+-------------------------------+----------------------+----------------------+
| 6 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 |
| N/A 69C P0 79W / 300W | 18963MiB / 32510MiB | 95% Default |
+-------------------------------+----------------------+----------------------+
| 7 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | 0 |
| N/A 74C P0 80W / 300W | 18963MiB / 32510MiB | 12% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 28066 C python 30917MiB |
| 1 28066 C python 18949MiB |
| 2 28066 C python 18949MiB |
| 3 28066 C python 18949MiB |
| 4 28066 C python 18949MiB |
| 5 28066 C python 18949MiB |
| 6 28066 C python 18949MiB |
| 7 28066 C python 18949MiB |
+-----------------------------------------------------------------------------+
``` | 05-27-2020 15:41:35 | 05-27-2020 15:41:35 | How do you launch your training? Can you paste your command?<|||||>I am using the trainer.
```
training_args = TrainingArguments(
output_dir="albert_model",
overwrite_output_dir=True,
num_train_epochs=1,
per_gpu_train_batch_size=85,
learning_rate=5e-5,
save_steps=50,
save_total_limit=20,
do_train=True,
logging_steps=100
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
prediction_loss_only=True,
)
trainer.train()
```<|||||>But how do you launch the actual script?
To efficiently harness your 8 V100s you should probably use torch.distributed, not nn.DataParallel.
So you would need to launch your script with e.g.
```
python -m torch.distributed.launch \
--nproc_per_node 8 your_script.py
```
<|||||>Just tried this. this is loading pretraining data in each GPU independently. Shouldn't data be read once?<|||||>It should, yes.<|||||> Previously this was not the case and all transformer models utilize all GPUs automatically.
.
getting this : reading for each gpu using ` python -m torch.distributed.launch --nproc_per_node 8 test_lm.py
`
```*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
/language_model/lm/lib/python3.6/site-packages/transformers/tokenization_utils.py:830: FutureWarning: Parameter max_len is deprecated and will be removed in a future release. Use model_max_length instead.
category=FutureWarning,
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I face a similar problem. I wonder if this problem is ever resolved?
I try to fine-tune a bert model and found the gpu memory usage behaves exactly like what the original post described "gpu 0 is almost completely used but others have around 50% ram unused"
```
python run_mlm.py \
--model_name_or_path bert-base-uncased \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 10 \
--max_seq_length=256 \
--do_train \
--output_dir /tmp/test \
```
If I run the example training script above, Here's my gpu usage:

After some research, I found people has the same issue when training different model using pytorch. like [this](https://forums.fast.ai/t/training-language-model-with-nn-dataparallel-has-unbalanced-gpu-memory-usage/42494)
Then I found this [post ](https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255) written by Thomas Wolf suggesting using the [PyTorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding) library. However, this post is 2 years old. So I was wondering if there's a more recent solution for it.
@thomwolf @sgugger
Thanks! |
transformers | 4,621 | closed | Cleanup glue | * Make sure that MNLI acc metrics are named differently for match vs mismatch
* Allow writing to `cache_dir` from Glue dataset in case where datasets live in readOnly filesystem
* Flush TB writer at end to not miss any metrics | 05-27-2020 15:40:22 | 05-27-2020 15:40:22 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4621?src=pr&el=h1) Report
> Merging [#4621](https://codecov.io/gh/huggingface/transformers/pull/4621?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/003c4771290b00e6d14b871210c3a369edccaeed&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `33.33%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4621?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4621 +/- ##
=======================================
Coverage 78.03% 78.04%
=======================================
Files 124 124
Lines 20626 20627 +1
=======================================
+ Hits 16096 16098 +2
+ Misses 4530 4529 -1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4621?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/data/datasets/glue.py](https://codecov.io/gh/huggingface/transformers/pull/4621/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL2RhdGFzZXRzL2dsdWUucHk=) | `86.15% <ø> (ø)` | |
| [src/transformers/data/metrics/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/4621/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL21ldHJpY3MvX19pbml0X18ucHk=) | `26.66% <0.00%> (ø)` | |
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/4621/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `39.62% <100.00%> (+0.14%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4621/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4621/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.53% <0.00%> (+0.11%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4621/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.99% <0.00%> (+0.16%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4621?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4621?src=pr&el=footer). Last update [003c477...01a48df](https://codecov.io/gh/huggingface/transformers/pull/4621?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>@julien-c bump..! |
transformers | 4,620 | closed | The new abstractions in /master are counterproductive | I understand the desire to use abstraction to make the library easier to use out-of-the-box, especially for newer users who just want to call run_model.py with some hyparameters.
However, as someone who considers himself a novice-intermediate and frequently needs to look at or modify the source code to achieve what I want, it's been a huge pain adapting to the new changes.
I'll try to be as concrete as possible but here are some big painpoints:
(I will say, these painpoints may come from inexpeience with the library rather than something is just hard/impossible to achieve but either way, as a novice-intermediate, the end result is the same: I have a hard time navigating the library)
- arguments are hidden, so far example in run_language_modeling.py I'm not able to see what all the available parameters are. I feel using abstraction over argument types like training_args, model_args, etc. is overkill and just programming fluff
- model source code is hidden under many layers of abstraction
- support for basic functionality is not implemented when code is refactored. One example is the new run_language_modeling.py doesn't have support for training continuation from a checkpoint
Like for example, it's very hard to tell what any of the XXX.from_pretrained classes are actually doing.
These are just the painpoints I can think of from the top of my head. It's overall been just unsmooth using the new example files like run_language_modeling.py and the rest of the API.
My main suggestion is to rethink the trade-off beween simplicity, abstraction versus flexibility and ability to hack/modify the code. Generally I think abstraction is good, but it seems overly excessive in certain places and I wonder if you can achieve the same goal while doing a bit less.
A tangential observation is the example scripts get way too cumbersome when you try to support all these things within the same file (e.g. run_language_modeling.py): apex, tpu, tensorflow, distributed. There are flags everywhere. | 05-27-2020 15:28:41 | 05-27-2020 15:28:41 | Thanks for your feedback, it's interesting.
We've also heard good feedback on the refactoring you mention (because for instance opening an example script that was 700 lines of code long could be daunting) so it's good to hear a diversity of feedback.
I think the crux of it is that it's not realistic to maintain dozens of combinations – e.g. `{apex, TPU, TF, distributed} x {all possible tasks}` – of self-contained example scripts.
Unless you use code generation (which comes with its own set of problems), things will get out-of-sync and break really fast. CI would be really hard too.
To give a concrete example, adding TPU support to each individual script without refactoring would have been an overwhelming task. With the Trainer, we've been able to do it in a decently easy way and we'll have robust CI in place in the coming weeks.
I do agree that "hackability" of this library is very important and we're trying to find a good trade-off for this. I feel like we don't have many layers of abstraction. (models are mostly self-contained, etc.)
We're very open to any suggestion to improving things so let us know of any ideas you'd have to make this hackability easier.<|||||>I have a different perspective here. Transformer is pretty hackable as it is now. It's very easy to take any model, add any task specific heads on it in all sorts of exotic ways. Also the recently introduced `Trainer` is pretty impressive, it removes lot of the boilerplate from previous examples and I didn't find that it limits hackability. The way Trainer code is structured, its very easy to modify it.
The models are also pretty hackable, here are two really great examples of this
1. [This](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) notebook shows how you can replace the existing attention mechanism in BERT like models and replace them with `LongformerSelfAttention` to convert them to long versions, also trains using new `Trainer`
2. This second [notebook](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) shows how you can train HF models with fastai.
Also I've recently started contributing, and navigating though the codebase and making changes was a breeze.
Also HF models can be trained with all sorts trainers. I've personally trained HF models with my own training loop, HF Trainer, pytorch-lightning, ignite, fastai and it plays nicely with all of these.
And I think the goal of the examples is to give standard templates for doing certain tasks but it doesn't limit or discourage from modifying them in any way.
So considering all this I would say that Transformers is pretty hackable and also provides nice light-weight abstractions wherever needed. I really appreciate this!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,619 | closed | removed deprecated use of Variable API from pplm example | This is same as previous [PR](https://github.com/huggingface/transformers/pull/4156) which I closed due to code styling issue. Didn't know that specific isort version was supposed to be used. | 05-27-2020 15:11:08 | 05-27-2020 15:11:08 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4619?src=pr&el=h1) Report
> Merging [#4619](https://codecov.io/gh/huggingface/transformers/pull/4619?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/842588c12ffbbe3502c5ab4a18646ad31d9c1e34&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4619?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4619 +/- ##
=======================================
Coverage 78.02% 78.03%
=======================================
Files 124 124
Lines 20626 20626
=======================================
+ Hits 16093 16095 +2
+ Misses 4533 4531 -2
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4619?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4619/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.53% <0.00%> (+0.11%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4619/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4619?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4619?src=pr&el=footer). Last update [842588c...8588578](https://codecov.io/gh/huggingface/transformers/pull/4619?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>@julien-c Can you please see this ?<|||||>@sgugger Can you please see it ? |
transformers | 4,618 | closed | per_device instead of per_gpu/error thrown when argument unknown | Modified the trainer argument so that `per_device_train_batch_size` and `per_device_eval_batch_size` are preferred over `per_gpu_*`.
`per_gpu_*` still works when `per_device_*` isn't used, but is deprecated.
The trainer argument parser now throws an error if an argument is unknown, only if the `return_remaining_strings` flag is kept to `False`. | 05-27-2020 14:22:21 | 05-27-2020 14:22:21 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4618?src=pr&el=h1) Report
> Merging [#4618](https://codecov.io/gh/huggingface/transformers/pull/4618?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/842588c12ffbbe3502c5ab4a18646ad31d9c1e34&el=desc) will **decrease** coverage by `0.00%`.
> The diff coverage is `50.00%`.
[](https://codecov.io/gh/huggingface/transformers/pull/4618?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4618 +/- ##
==========================================
- Coverage 78.02% 78.01% -0.01%
==========================================
Files 124 124
Lines 20626 20635 +9
==========================================
+ Hits 16093 16099 +6
- Misses 4533 4536 +3
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4618?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/hf\_argparser.py](https://codecov.io/gh/huggingface/transformers/pull/4618/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9oZl9hcmdwYXJzZXIucHk=) | `61.11% <0.00%> (-0.87%)` | :arrow_down: |
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/4618/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `39.47% <0.00%> (ø)` | |
| [src/transformers/training\_args.py](https://codecov.io/gh/huggingface/transformers/pull/4618/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmluZ19hcmdzLnB5) | `76.40% <58.33%> (-2.61%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4618/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4618/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4618?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4618?src=pr&el=footer). Last update [842588c...eae844b](https://codecov.io/gh/huggingface/transformers/pull/4618?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,617 | closed | run evalation after every epoch in Trainer | # 🚀 Feature request
With the current Trainer implementation:
`trainer.train(..)` is called first followed by `trainer.evaluate(..)`. It would be nice if the user can pass the flag `--run_eval` (something similar) to run evaluation after every epoch. It would be nice for users who want to see how model performs on validation set as training progresses. In some cases, this is the general norm (run evaluation after every epoch). | 05-27-2020 14:09:56 | 05-27-2020 14:09:56 | You should use `--evaluate_during_training` which should do mostly what you're looking for<|||||>@prajjwal1 , you should be able to achieve this with `--evaluate_during_training` provided you set `--save_steps` to `number_of_samples/batch_size`. However, I'm currently having trouble achieving this with that option when using both `run_language_modeling.py` and `run_glue.py` as I specify in https://github.com/huggingface/transformers/issues/4630. Any ideas @julien-c ? Thanks in advance.<|||||>There's a problem with MNLI though. In the example, arguments are changed from `mnli` to `mnli-mm`, so running evaluation after each epoch will happen on MNLI and not the mismatched one with the current implementation. |
transformers | 4,616 | closed | [testing] LanguageModelGenerationTests require_tf or require_torch | 05-27-2020 13:03:05 | 05-27-2020 13:03:05 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4616?src=pr&el=h1) Report
> Merging [#4616](https://codecov.io/gh/huggingface/transformers/pull/4616?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a9aa7456ac824c9027385b149f405e4f5649273f&el=desc) will **increase** coverage by `0.01%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4616?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4616 +/- ##
==========================================
+ Coverage 78.02% 78.04% +0.01%
==========================================
Files 124 124
Lines 20626 20626
==========================================
+ Hits 16093 16097 +4
+ Misses 4533 4529 -4
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4616?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4616/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.53% <0.00%> (+0.11%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4616/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.83% <0.00%> (+0.32%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4616/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4616?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4616?src=pr&el=footer). Last update [a9aa745...4d147b2](https://codecov.io/gh/huggingface/transformers/pull/4616?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 4,615 | closed | [Longformer] longformer in question-answering pipeline | This PR adds `LongformerForQuestionAnswering` in `QuestionAnsweringPipeline`
@patrickvonplaten @ibeltagy | 05-27-2020 12:52:31 | 05-27-2020 12:52:31 | This works well however I noticed some discrepancy in answers generated with pipeline and without pipeline
for this example
```
question = 'Who was Jim Henson?'
text = 'Jim Henson was a nice puppet.'
```
pipeline produces `nice puppet.`
without pipeline `a nice puppet`
@patrickvonplaten is this expected or there's something wrong ? <|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4615?src=pr&el=h1) Report
> Merging [#4615](https://codecov.io/gh/huggingface/transformers/pull/4615?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8cc6807e8997b8b7404c07037bd02c578da98baf&el=desc) will **decrease** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4615?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4615 +/- ##
==========================================
- Coverage 78.03% 78.02% -0.01%
==========================================
Files 124 124
Lines 20647 20647
==========================================
- Hits 16111 16110 -1
- Misses 4536 4537 +1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4615?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/4615/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `28.66% <ø> (ø)` | |
| [src/transformers/trainer.py](https://codecov.io/gh/huggingface/transformers/pull/4615/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90cmFpbmVyLnB5) | `39.24% <0.00%> (-0.24%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4615?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4615?src=pr&el=footer). Last update [8cc6807...8d7469b](https://codecov.io/gh/huggingface/transformers/pull/4615?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>@patrickvonplaten
I seem to have figured out why this is happening.
This line https://github.com/huggingface/transformers/blob/master/src/transformers/data/processors/squad.py#L103
tokenizes the doc text into individual tokens and then this line
https://github.com/huggingface/transformers/blob/master/src/transformers/data/processors/squad.py#L134
uses the list of those tokens for encoding
While this works for other BERT models , for roberta and and longformer tokenizer, the final
encoding results in this
`'<s> Who was Jim Henson?</s></s>JimHensonwasanicepuppet</s>'`
Changing `span_doc_tokens` with `example.context_text` at L134 seems to solve the problem. But I'm not sure if doing this will cause other things to break. <|||||>Thanks for the PR @patil-suraj.
I will put this on hold for a week though since we will most likely do some major changes very soon here.
1) I think the squad preprocessing functions will probably be refactoring building on the new `nlp` library @thomwolf
2) IMO, the function `squad_convert_examples_to_features` should in general not be used in the `QuestionAnsweringPipeline` since we only need `input_ids` and `attention_mask` for inference and some other values for the `score`. Also, we should also be able to use the pipeline for `TriviaQA` (with Longformer, we now have a pretrained model that works very well on TriviaQA). The pipeline should not be dataset specific. I think it might be a good idea to do a bigger refactoring of `QuestionAnsweringPipeline` and make it independent from the `squad_convert_examples_to_features` function. What do you think @julien-c @thomwolf @LysandreJik <|||||>Hi @patrickvonplaten , I think we should fix this now, as the newly launched model inference api uses qa pipeline its failing or giving weird answers for longformer qa models on model hub. This might discourage the users from using them. <|||||>@patrickvonplaten I agree with you, especially because that method is made for heavy processing of large data, which is not the case with pipelines. It's slow to start, and uses multiprocessing by default, something we don't necessarily want with the pipelines.<|||||>Also putting @mfuntowicz in cc here<|||||>Ok we'll have conflicts here (#5496), we need to handle with care.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I believe this issue with roberta models for QA never got fixed. Any plans to continue working here?
> While this works for other BERT models, for roberta and and longformer tokenizer, the final
encoding results in this
< s> Who was Jim Henson?</s></s>JimHensonwasanicepuppet</s>
As mentioned by @patil-suraj, we don't respect whitespace before words in the passage. Therefore, we currently use the input id for "ĠHenson" in the question, but the one for "Henson" in the passage.
The current implementation also leads to quite poor results of our QA models. For example, F1 of `deepset/roberta-base-squad2` on SQuAD 2 dev is down to 0.69 whereas it gets 0.81 with "whitespace preserving" tokenization.
A simple fix could be to add `add_prefix_space=True` here in the tokenizer call for Roberta tokenizers (or similar), but might not be the most elegant solution.
https://github.com/huggingface/transformers/blob/28cf873036d078b47fb9dd38ac3421a7c874da44/src/transformers/data/processors/squad.py#L112
I can to do a PR for this, if that's how you want to fix it.
<|||||>A PR would be very welcome :-) <|||||>@patrickvonplaten Added a PR https://github.com/huggingface/transformers/pull/7387 |
transformers | 4,614 | closed | [Contributing Doc] Update version command when contributing | According to PR: #4131, the `CONTRIBUTING.md` should be updated a bit. @BramVanroy | 05-27-2020 10:28:39 | 05-27-2020 10:28:39 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4614?src=pr&el=h1) Report
> Merging [#4614](https://codecov.io/gh/huggingface/transformers/pull/4614?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a9aa7456ac824c9027385b149f405e4f5649273f&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4614?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4614 +/- ##
=======================================
Coverage 78.02% 78.03%
=======================================
Files 124 124
Lines 20626 20626
=======================================
+ Hits 16093 16095 +2
+ Misses 4533 4531 -2
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4614?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4614/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `90.53% <0.00%> (+0.11%)` | :arrow_up: |
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4614/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4614?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4614?src=pr&el=footer). Last update [a9aa745...cbab365](https://codecov.io/gh/huggingface/transformers/pull/4614?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Good catch, thanks! |
transformers | 4,613 | closed | What does the output of feature-extraction pipeline represent? | I am using the feature-extraction pipeline:
```
nlp_fe = pipeline('feature-extraction')
nlp_fe('there is a book on the desk')
```
As an output I get a list with one element - that is a list with 9 elements - that is a list of 768 features (floats).
What is the output represent? What is every element of the lists, and what is the meaning of the 768 float values?
Thanks | 05-27-2020 09:31:46 | 05-27-2020 09:31:46 | They are embeddings generated from the model. (Bert -Base Model I guess. cause it has a hidden representation of 768 dim). You get 9 elements:- one contextual embedding for each word in your sequence. These values of embeddings represent some hidden features that are not easy to interpret.<|||||>So the pipeline will just return the last layer encoding of Bert?
So what is the differance with a code like
```
input_ids = torch.tensor(bert_tokenizer.encode("Hello, my dog is cute")).unsqueeze(0)
outputs = bert_model(input_ids)
hidden_states = outputs[-1][1:] # The last hidden-state is the first element of the output tuple
layer_hidden_state = hidden_states[n_layer]
return layer_hidden_state
```
Also, does BERT encoding have similar traits as word2vec? e.g. similar word will be closer, France - Paris = England - London , etc?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>> So the pipeline will just return the last layer encoding of Bert?
> So what is the differance with a code like
>
> ```
> input_ids = torch.tensor(bert_tokenizer.encode("Hello, my dog is cute")).unsqueeze(0)
> outputs = bert_model(input_ids)
> hidden_states = outputs[-1][1:] # The last hidden-state is the first element of the output tuple
> layer_hidden_state = hidden_states[n_layer]
> return layer_hidden_state
> ```
>
> Also, does BERT encoding have similar traits as word2vec? e.g. similar word will be closer, France - Paris = England - London , etc?
Hi @orko19,
Did you understand the difference from 'hidden_states' vs. 'feature-extraction pipeline'? I'd like to understand it as well
Thanks!<|||||>@merleyc I do not! Please share if you do :)<|||||>The outputs between "last_hidden_state" and "feature-extraction pipeline" are same, you can try by yourself
"feature-extraction pipeline" just helps us do some jobs from tokenize words to embedding |
transformers | 4,612 | closed | Use fill-mask pipeline to get probability of specific token | Hi,
I am trying to use the fill-mask pipeline:
```
nlp_fm = pipeline('fill-mask')
nlp_fm('Hugging Face is a French company based in <mask>')
```
And get the output:
```
[{'sequence': '<s> Hugging Face is a French company based in Paris</s>',
'score': 0.23106734454631805,
'token': 2201},
{'sequence': '<s> Hugging Face is a French company based in Lyon</s>',
'score': 0.08198195695877075,
'token': 12790},
{'sequence': '<s> Hugging Face is a French company based in Geneva</s>',
'score': 0.04769458621740341,
'token': 11559},
{'sequence': '<s> Hugging Face is a French company based in Brussels</s>',
'score': 0.04762236401438713,
'token': 6497},
{'sequence': '<s> Hugging Face is a French company based in France</s>',
'score': 0.041305914521217346,
'token': 1470}]
```
But let's say I want to get the score & rank on other word - such as London - is this possible?
| 05-27-2020 09:27:34 | 05-27-2020 09:27:34 | Hi, the pipeline doesn't offer such a functionality yet. You're better off using the model directly. Here's an example of how you would replicate the pipeline's behavior, and get a token score at the end:
```py
from transformers import AutoModelWithLMHead, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
model = AutoModelWithLMHead.from_pretrained("distilroberta-base")
sequence = f"Hugging Face is a French company based in {tokenizer.mask_token}"
input_ids = tokenizer.encode(sequence, return_tensors="pt")
mask_token_index = torch.where(input_ids == tokenizer.mask_token_id)[1]
token_logits = model(input_ids)[0]
mask_token_logits = token_logits[0, mask_token_index, :]
mask_token_logits = torch.softmax(mask_token_logits, dim=1)
top_5 = torch.topk(mask_token_logits, 5, dim=1)
top_5_tokens = zip(top_5.indices[0].tolist(), top_5.values[0].tolist())
for token, score in top_5_tokens:
print(sequence.replace(tokenizer.mask_token, tokenizer.decode([token])), f"(score: {score})")
# Get the score of token_id
sought_after_token = "London"
sought_after_token_id = tokenizer.encode(sought_after_token, add_special_tokens=False, add_prefix_space=True)[0] # 928
token_score = mask_token_logits[:, sought_after_token_id]
print(f"Score of {sought_after_token}: {mask_token_logits[:, sought_after_token_id]}")
```
Outputs:
```
Hugging Face is a French company based in Paris (score: 0.2310674488544464)
Hugging Face is a French company based in Lyon (score: 0.08198253810405731)
Hugging Face is a French company based in Geneva (score: 0.04769456014037132)
Hugging Face is a French company based in Brussels (score: 0.047622524201869965)
Hugging Face is a French company based in France (score: 0.04130581393837929)
Score of London: tensor([0.0343], grad_fn=<SelectBackward>)
```
Let me know if it helps.<|||||>@lavanyashukla Great thanks!
And if I want a predicability of a whole sentence, the best way will be just to average all words scores?
<|||||>Yes, that's one way to do it.<|||||>@LysandreJik I get an error:
```
"NLP_engine.py", line 120, in _word_in_sentence_prob
mask_token_index = torch.where(input_ids == bert_tokenizer.mask_token_id)[1]
TypeError: where(): argument 'condition' (position 1) must be Tensor, not bool
```
For the code:
```
def _word_in_sentence_prob(self, sentence, word):
sequence = f"{sentence} {bert_tokenizer.mask_token}"
input_ids = bert_tokenizer.encode(sequence, bert_tokenizer="pt")
mask_token_index = torch.where(input_ids == bert_tokenizer.mask_token_id)[1]
token_logits = bert_model(input_ids)[0]
mask_token_logits = token_logits[0, mask_token_index, :]
mask_token_logits = torch.softmax(mask_token_logits, dim=1)
top_5 = torch.topk(mask_token_logits, 5, dim=1)
top_5_tokens = zip(top_5.indices[0].tolist(), top_5.values[0].tolist())
for token, score in top_5_tokens:
print(sequence.replace(bert_tokenizer.mask_token, bert_tokenizer.decode([token])), f"(score: {score})")
# Get the score of token_id
sought_after_token = word
sought_after_token_id = bert_tokenizer.encode(sought_after_token, add_special_tokens=False, add_prefix_space=True)[
0] # 928
token_score = mask_token_logits[:, sought_after_token_id]
print(f"Score of {sought_after_token}: {mask_token_logits[:, sought_after_token_id]}")
return token_score
```
Any idea why?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>@LysandreJik I also get the error:
```
mask_token_index = torch.where(input_ids == bert_tokenizer.mask_token_id)[1]
TypeError: where(): argument 'condition' (position 1) must be Tensor, not bool
```
for this code.
I have torch version 1.7.1
Any idea what is the problem? Might it be version-related?
If so, what changes should be made in the code? Or what version should I downgrade to? |
transformers | 4,611 | closed | Key error while evaluating the Language Model finetuning | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...): DistilBert
Language I am using the model on (English, Chinese ...): English
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. python run_language_modeling.py \
--output_dir=output \
--model_type=distilbert\
--model_name_or_path=distilbert-base-uncased \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```code
05/27/2020 08:44:42 - INFO - __main__ - *** Evaluate ***
05/27/2020 08:44:42 - INFO - transformers.trainer - ***** Running Evaluation *****
05/27/2020 08:44:42 - INFO - transformers.trainer - Num examples = 329
05/27/2020 08:44:42 - INFO - transformers.trainer - Batch size = 8
Evaluation: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 42/42 [00:04<00:00, 9.09it/s]
Traceback (most recent call last):
File "run_language_modeling.py", line 281, in <module>
main()
File "run_language_modeling.py", line 259, in main
perplexity = math.exp(eval_output["eval_loss"])
KeyError: 'eval_loss'
```
## Expected behavior
Evaluation of the validation data and output the perplexity.
Upon debugging the code, the eval_output doesn't have the key `eval_loss`
```code
-> perplexity = math.exp(eval_output["eval_loss"])
(Pdb) eval_output
{'loss': 1.8573534346762157}
```
Please change the key value accordingly.
<!-- A clear and concise description of what you would expect to happen. -->
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 2.9.0
- Platform: RHEL
- Python version: 3.6.9
- PyTorch version (GPU?): 1.4.0
- Tensorflow version (GPU?):
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
| 05-27-2020 09:12:01 | 05-27-2020 09:12:01 | Looks like your training script is out of sync with the library. Can you install the library from source, as documented in https://github.com/huggingface/transformers/tree/master/examples#important-note ?<|||||>Thanks, @julien-c building from source, solves the issue. <|||||>I also find a problem about this......
If we set the lables_name ="labels" in the TrainerAugments, it would be wrong.
Because lables_name must be a list in TrainerAugments. If we set the labels_name = "labels", the function prediction_steps() in Trainer will set has_lables equal to None. For this line:
has_labels = all(inputs.get(k) is not None for k in self.label_names) in Trainer.py 1462. |
transformers | 4,610 | closed | README for HooshvareLab | HooshvareLab/bert-base-parsbert-uncased | 05-27-2020 07:55:44 | 05-27-2020 07:55:44 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4610?src=pr&el=h1) Report
> Merging [#4610](https://codecov.io/gh/huggingface/transformers/pull/4610?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a9aa7456ac824c9027385b149f405e4f5649273f&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4610?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4610 +/- ##
=======================================
Coverage 78.02% 78.02%
=======================================
Files 124 124
Lines 20626 20626
=======================================
+ Hits 16093 16094 +1
+ Misses 4533 4532 -1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4610?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4610/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4610?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4610?src=pr&el=footer). Last update [a9aa745...3db079d](https://codecov.io/gh/huggingface/transformers/pull/4610?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,609 | closed | How to deal with summarization task to long sequences input? | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
I am going to carry out the sumarization task using the 'transformers' module you provided. But there's a problem. The sequence which i have is too long, so an error occurs when inserting it. Is there any way to summarize the entire document by sliding it?
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on Stack Overflow**:
| 05-27-2020 06:13:24 | 05-27-2020 06:13:24 | Usually, the input is simply cut in this case. Bart cuts the input to 1024 tokens when training on CNN Daily Mail. T5 cuts the input to 512 tokens when training on CNN Daily Mail.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 4,608 | closed | uncased readme | updates to the model card for uncased model with more evaluation results and recommendation to switch to cased model | 05-27-2020 06:00:02 | 05-27-2020 06:00:02 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4608?src=pr&el=h1) Report
> Merging [#4608](https://codecov.io/gh/huggingface/transformers/pull/4608?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a9aa7456ac824c9027385b149f405e4f5649273f&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4608?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4608 +/- ##
=======================================
Coverage 78.02% 78.02%
=======================================
Files 124 124
Lines 20626 20626
=======================================
+ Hits 16093 16094 +1
+ Misses 4533 4532 -1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4608?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4608/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.85% <0.00%> (+0.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4608?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4608?src=pr&el=footer). Last update [a9aa745...470e98f](https://codecov.io/gh/huggingface/transformers/pull/4608?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 4,607 | closed | Create README.md | Model card for cased model | 05-27-2020 05:41:04 | 05-27-2020 05:41:04 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4607?src=pr&el=h1) Report
> Merging [#4607](https://codecov.io/gh/huggingface/transformers/pull/4607?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a9aa7456ac824c9027385b149f405e4f5649273f&el=desc) will **increase** coverage by `0.00%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4607?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4607 +/- ##
=======================================
Coverage 78.02% 78.02%
=======================================
Files 124 124
Lines 20626 20626
=======================================
+ Hits 16093 16094 +1
+ Misses 4533 4532 -1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4607?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4607/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4607?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4607?src=pr&el=footer). Last update [a9aa745...efcdd13](https://codecov.io/gh/huggingface/transformers/pull/4607?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Great – [model page](https://huggingface.co/dkleczek/bert-base-polish-cased-v1) |
transformers | 4,606 | closed | Inconsistency in how Electra doing sentence level prediction | In `ElectraForSequenceClassification`:
We have docstring says, `ELECTRA Model transformer with a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks.`
This is also what I observed in the official repository.
https://github.com/google-research/electra/blob/81f7e5fc98b0ad8bfd20b641aa8bc9e6ac00c8eb/finetune/classification/classification_tasks.py#L270
https://github.com/google-research/electra/blob/79111328070e491b287c307906701ebc61091eb2/model/modeling.py#L254
which is
```
nn.Sequential( nn.Dropout(config.hidden_dropout_prob),
nn.Linear(config.hidden_size, config.num_labels)
```
**But** the implementation of `ElectraClassificationHead` (used by `ElectraForSequenceClassification`) is
```
def forward(self, features, **kwargs):
x = features[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x)
x = self.dense(x)
x = get_activation("gelu")(x) # although BERT uses tanh here, it seems Electra authors used gelu here
x = self.dropout(x)
x = self.out_proj(x)
return x
```
Is there something I overlooked in the official repository ? Hot to explain the inconsistency in doc and implementaion of `ElectraForSequenceClassification`. | 05-27-2020 02:58:23 | 05-27-2020 02:58:23 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Are there any updates on this issue? |
transformers | 4,605 | closed | Glue task cleanup | * Enable writing cache to cache_dir in case dataset lives in readOnly
filesystem
* Differentiate match vs mismatch for MNLI metrics
* Manually flush tensorboard writer to avoid missing metrics. | 05-26-2020 23:35:57 | 05-26-2020 23:35:57 | |
transformers | 4,604 | closed | updated model cards for both models at aubmindlab | - added AraBERT image.
- updated usage examples
- updated results | 05-26-2020 19:36:45 | 05-26-2020 19:36:45 | Great logo!<|||||>link seems broken on huggingface.co but I'll fix directly<|||||>Thank you Julien! |
transformers | 4,603 | closed | Creating a readme for ALBERT in Mongolian | Here I am uploading Mongolian masked language model (ALBERT) on your platform.
https://en.wikipedia.org/wiki/Mongolia | 05-26-2020 15:25:53 | 05-26-2020 15:25:53 | That is awesome, thank you |
transformers | 4,602 | closed | Remove MD emojis | 05-26-2020 15:09:02 | 05-26-2020 15:09:02 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4602?src=pr&el=h1) Report
> Merging [#4602](https://codecov.io/gh/huggingface/transformers/pull/4602?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5ddd8d6531c8c49fdd281b55b93f6c81c9826f4b&el=desc) will **increase** coverage by `0.08%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/4602?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #4602 +/- ##
==========================================
+ Coverage 78.03% 78.11% +0.08%
==========================================
Files 124 124
Lines 20647 20647
==========================================
+ Hits 16111 16128 +17
+ Misses 4536 4519 -17
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/4602?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4602/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9maWxlX3V0aWxzLnB5) | `73.44% <0.00%> (-0.42%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/4602/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `88.66% <0.00%> (+0.16%)` | :arrow_up: |
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/4602/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `34.07% <0.00%> (+5.41%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/4602?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/4602?src=pr&el=footer). Last update [5ddd8d6...a5049de](https://codecov.io/gh/huggingface/transformers/pull/4602?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 4,601 | closed | Which models can be using for encoder-decoder? | Hi, I trying to use EncoderDecoderModel. I tried google/electra-base-discriminator, google/electra-small-discriminator, albert-base-v2 as encoder and decoder:
```python
from transformers import EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained('google/electra-small-discriminator', 'google/electra-small-discriminator')
```
but, I always gate the same error
```python
TypeError: forward() got an unexpected keyword argument 'encoder_hidden_states'
```
Only Bert can be using as encoder and decoder? If so, can you add list of available models for encoder-decoder in documentation? | 05-26-2020 15:02:28 | 05-26-2020 15:02:28 | @blizda did you find an answer to your query - "Only Bert can be using as encoder and decoder? If so, can you add list of available models for encoder-decoder in documentation?"? <|||||>There's an error-message saying which models can be used now;
"... Model type should be one of CamembertConfig, XLMRobertaConfig, RobertaConfig, BertConfig, OpenAIGPTConfig, GPT2Config, TransfoXLConfig, XLNetConfig, XLMConfig, CTRLConfig, ReformerConfig, BertGenerationConfig, XLMProphetNetConfig, ProphetNetConfig." |
transformers | 4,600 | closed | Functionality for addressing imbalance data points? | Is there yet any functionality from transformers library to address or tackle imbalance classes in data points? | 05-26-2020 13:03:47 | 05-26-2020 13:03:47 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.