
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 2,691 | closed | how can i finetune BertTokenizer? | Is it possible to fine tune BertTokenizer so that the new vocab.txt file which it uses gets updated on my custom dataset? or do i need to retrain the bert model from scratch for the same? | 01-31-2020 09:23:11 | 01-31-2020 09:23:11 | You can add new words to the tokenizer with [add_tokens](https://huggingface.co/transformers/main_classes/tokenizer.html?highlight=add_tokens#transformers.PreTrainedTokenizer.add_tokens):
`tokenizer.add_tokens(['newWord', 'newWord2'])`
After that you need to resize the dictionary size of the embedding layer with:
`model.resize_token_embeddings(len(tokenizer))`
<|||||>> You can add new words to the tokenizer with [add_tokens](https://huggingface.co/transformers/main_classes/tokenizer.html?highlight=add_tokens#transformers.PreTrainedTokenizer.add_tokens):
> `tokenizer.add_tokens(['newWord', 'newWord2'])`
> After that you need to resize the dictionary size of the embedding layer with:
> `model.resize_token_embeddings(len(tokenizer))`
Note that this simply adds a new token to the vocabulary but doesn't train its embedding (obviously). This implies that your results will be quite poor if your training data contains a lot of newly added (untrained) tokens.<|||||>@cronoik once the dictionary is resized don't I have to train the tokenizer model again?
@BramVanroy umm.. so what could be the probable solution if I am having a custom data set? How can I can retrain this BertTokenizer Model to get new vocab.txt file?<|||||>What do you mean with tokenizer model? The tokenizer in simple terms is a class which splits your text in tokens from a huge dictionary. What you have to train is the embedding layer of your model because the weights of the new tokens will be random. This will happen during the training of your model (but it could be undertrained for the new tokens).
In case you have a plenty of new words (e.g. technical terms) or even a different language, it might makes sense to start from scratch (definitely for the later). Here is blogpost from huggingface which shows you how to train a tokenizer+model for Esperanto: [link](https://github.com/huggingface/blog/blob/master/how-to-train.md). It really depends on your data (e.g. number of new tokens, importance of new tokens, relation between the tokens...).<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hi @cronoik,
I tried replacing `RobertaTokenizerFast` with `DistilBertTokenizerFast`
```
from transformers import RobertaConfig
config = RobertaConfig(
vocab_size=52_000,
max_position_embeddings=514,
num_attention_heads=12,
num_hidden_layers=6,
type_vocab_size=1,
)
from transformers import RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained("/content/EsperBERTo", max_len=512)
```
worked absolutely fine. But,
```
from transformers import DistilBertConfig
config = DistilBertConfig(
vocab_size=52_000,
max_position_embeddings=514,
#num_attention_heads=12,
#num_hidden_layers=6,
#type_vocab_size=1,
)
from transformers import DistilBertTokenizerFast
tokenizer = DistilBertTokenizerFast.from_pretrained("/content/EsperBERTo", max_len=512)
```
throws error:
```
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-17-7f80e1d47bf5> in <module>()
1 from transformers import DistilBertTokenizerFast
2
----> 3 tokenizer = DistilBertTokenizerFast.from_pretrained("/content/EsperBERTo", max_len=512)
/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py in from_pretrained(cls, pretrained_model_name_or_path, *init_inputs, **kwargs)
1772 f"- or '{pretrained_model_name_or_path}' is the correct path to a directory containing relevant tokenizer files\n\n"
1773 )
-> 1774 raise EnvironmentError(msg)
1775
1776 for file_id, file_path in vocab_files.items():
OSError: Can't load tokenizer for '/content/EsperBERTo'. Make sure that:
- '/content/EsperBERTo' is a correct model identifier listed on 'https://huggingface.co/models'
- or '/content/EsperBERTo' is the correct path to a directory containing relevant tokenizer files
```
Can I know what is the best way to add vocabulary into **DistilBertTokenizer**?<|||||>@rakesh4real What is `/content/EsperBERTo`? Which files are in this directory? Please keep in mind that Roberta uses a BPE tokenizer, while Bert a WordpieceTokenizer. You can't simply use different kinds of tokenization with the same configuration files.<|||||>Thank you @cronoik. I did not know tokenizers needed to be changed. Are there any references where I can learn what tokenizers must be used for a given model / task.
And I had to use different special tokens as well. Kindly let me know where to find what special tokens must be used (when and why)
Using `BertWordpieceTokenizer` the code runs just perfect. Added code [here](https://colab.research.google.com/gist/rakesh4real/9783c37f89bc599fb1bf8faf1287cceb/01_how-to-train-distilbert-lm-scratch.ipynb)<|||||>@rakesh4real This site [1] gives you a general overview of different tokenization approaches and the site for each model tells you which tokenization algorithm was used (e.g. [2] for BERT).
[1] https://huggingface.co/transformers/tokenizer_summary.html
[2] https://huggingface.co/transformers/model_doc/bert.html#berttokenizer<|||||>> What do you mean with tokenizer model? The tokenizer in simple terms is a class which splits your text in tokens from a huge dictionary. What you have to train is the embedding layer of your model because the weights of the new tokens will be random. This will happen during the training of your model (but it could be undertrained for the new tokens).
>
> In case you have a plenty of new words (e.g. technical terms) or even a different language, it might makes sense to start from scratch (definitely for the later). Here is blogpost from huggingface which shows you how to train a tokenizer+model for Esperanto: [link](https://github.com/huggingface/blog/blob/master/how-to-train.md). It really depends on your data (e.g. number of new tokens, importance of new tokens, relation between the tokens...).
As far as I understand there are two options mentioned. The first one is training from scratch using `tokenizer.train(files, trainer)`. But this method requires training the Bert model from scratch too, as mentioned in #747. And the second option is extending the vocabulary as @cronoik said, but this leads to the problem @BramVanroy mentioned.
The options are either train from scratch or, randomly initialize embeddings of the tokenizer and hope for a good performance. Isn't it possible to finetune the model to train the embeddings of these newly added tokens? Why does it have to be either using random embeddings, or training from scratch? Am I missing something?
Thanks in advance. <|||||>> The options are either train from scratch or, randomly initialize embeddings of the tokenizer and hope for a good performance. Isn't it possible to finetune the model to train the embeddings of these newly added tokens? Why does it have to be either using random embeddings, or training from scratch? Am I missing something?
resize_token_embeddings does not reset the embedding layer, it just extends it. The new tokens are randomly initialized and you need to train them:
- In case you have only a few new tokens, you can do it during finetuning
- In case you have a lot of new tokens, you should probably train your model with the pretraining objective that was used to train the model the first time. You might want to add an additional word_embedding layer for the new tokens and freeze all other layers to save some time.
- in case you have a lot a lot new tokens (like a new language that is not related to the original language of your model), you should probably train a model from scratch.
@tolgayan<|||||>Thank you for the nice and clear explanation! @cronoik <|||||>Hello,
I know it is has been a long period since the last comment in this issue but I couldn't hold it and I have ti ask @cronoik.
Could you, please, explain more what do you mean by...
> In case you have only a few new tokens, you can do it during finetuning
by 'during finetuning', you mean the new tokens will be randomly initialised first and then the embedding with update during the model training?
For my cas I have a list of emojis (all the emojis that we have so it is a size of 3,633 emojis) and the vocab_size of my tokenizer is 32005. does this make the 'few new tokens' of not? should I consider training my model from scratch?
thanks in advance!<|||||>I still don't know how one can finetune tokenizer - by finetuning I don't mean just adding words to the dictionary - but also updating the embedding.
I am dealing with a text classification - since the text uses informal language (Arabic) e.g. `salam`, vs `saloom` or `sssaam` - a lot of vowels spell out differently. do I have to train a new language model from scrach ?! or I can use the existing model and finetune ?<|||||>Tokenizers are nothing but _seperators_. They split the sentences into subparts. The most common splitting method is using the whitespaces. When we say "training a tokenizer", it actually creates a vocabulary from a given text data. It assigns an id to each token so that you can feed these tokens as numbers to a BERT model. When you tokenize a sentence with a so-called "pretrained" tokenizer, it splits the sentence with its splitting algorithm, and assigns ids to each token from its vocabulary. Sometimes, it encounters with unknown words. In this case, it further splits that word further to meaningful subparts, that the subparts are in the vocabulary. They generally looks like: "Hou## ##se". The purpose of this "training" operation is to prevent the tokenizer from splitting important or domain-specific tokens so that the meaning will be kept.
Back to your question. When you have some specific words that need to be in the vocabulary, you can directly add them to the vocabulary, and they will be assigned with ids, continuing from the last id in the vocabulary I guess (I would be happy if somebody verify me here.) But the main problem is your model does not know what to do with these new numbers. In this case, the embeddings will be created randomly for these tokens. Here you have three options as @cronoik suggested to train the embedding layer for these new tokens.
- You can leave them, and while finetuning, the model figure out what to do with these new tokens by updating the embedding layer.
- You can add a new embedding layer, and freeze all the previous layers. Then finetune the model with the same task of the base model so that the new layer will cover your new embeddings.
- You can start from scratch, adding your tokens to the training corpus, initializing the tokenizer from ground, and pretrain a language model from scratch.
|
transformers | 2,690 | closed | Hardware requirements for BERT QA inference | Hi,
I am using **bert-large-uncased-whole-word-masking-finetuned-squad** model for QA inference.
I used my laptop's CPU to build the pipeline and try it out.
Now I want to deploy it, and so I would like to know what is the minimum hardware requirement?(If I use the same settings as in your usage example script)?
I am more interested in the **minimum size of the GPU**.
Of course I don't want it to be too slow. Is there any studies on this matter, or measurement?
Thanks! | 01-30-2020 22:01:55 | 01-30-2020 22:01:55 | @LysandreJik wrote an article about benchmarking transformers (focusing on inference) that might be of interest to you.
https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2<|||||>Thanks for the reply!
I checked the benchmarks, there you tested with 16GB GPU and bert-base model. I suppose then I have to try different, smaller size of GPUs, and figure out which can handle my task.
It is really informative though, nice work. |
transformers | 2,689 | closed | Correct PyTorch distributed training command in examples/README.md | Running the command currently detailed in the documentation yields
`58.4/70.3 EM/F1` with Ubuntu 18.04 and torch 1.4.0, not `86.9/93.1` as promised. It also looks wrong because we're using a cased model with `--do_lower_case`.
Switching it to match the PyTorch distributed training example given in the main README gives me the approximately-correct `86.68/93.03` results. | 01-30-2020 21:55:23 | 01-30-2020 21:55:23 | That's cool, thanks @jarednielsen ! |
transformers | 2,688 | closed | Config: reference array of architectures | 01-30-2020 21:48:08 | 01-30-2020 21:48:08 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2688?src=pr&el=h1) Report
> Merging [#2688](https://codecov.io/gh/huggingface/transformers/pull/2688?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b43cb09aaa6d81f4e1f4a2537764e37aa823b30b?src=pr&el=desc) will **decrease** coverage by `1.08%`.
> The diff coverage is `100%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2688?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2688 +/- ##
=========================================
- Coverage 74.09% 73% -1.09%
=========================================
Files 92 92
Lines 15172 15173 +1
=========================================
- Hits 11241 11077 -164
- Misses 3931 4096 +165
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2688?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19mbGF1YmVydC5weQ==) | `28.67% <ø> (-0.53%)` | :arrow_down: |
| [src/transformers/configuration\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3V0aWxzLnB5) | `96.46% <100%> (+0.03%)` | :arrow_up: |
| [src/transformers/tokenization\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYXV0by5weQ==) | `96.87% <100%> (ø)` | :arrow_up: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `61.15% <100%> (+0.06%)` | :arrow_up: |
| [src/transformers/configuration\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2F1dG8ucHk=) | `100% <100%> (ø)` | :arrow_up: |
| [src/transformers/modeling\_tf\_pytorch\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9weXRvcmNoX3V0aWxzLnB5) | `8.72% <0%> (-81.21%)` | :arrow_down: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `55.39% <0%> (-9.86%)` | :arrow_down: |
| [src/transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ194bG5ldC5weQ==) | `70.94% <0%> (-2.28%)` | :arrow_down: |
| [src/transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19jdHJsLnB5) | `92.07% <0%> (-2.21%)` | :arrow_down: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2688/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `80.06% <0%> (-1.33%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2688?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2688?src=pr&el=footer). Last update [b43cb09...1cdc6d3](https://codecov.io/gh/huggingface/transformers/pull/2688?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 2,687 | closed | Issue about pipeline of sentiment-analysis | Hi,
I tried the `pipeline` code on the README:
```
from transformers import pipeline
nlp = pipeline('sentiment-analysis')
print(nlp('We are very happy to include pipeline into the transformers repository.'))
```
However, it shows the following error:
```
I0131 01:02:23.627610 4420611520 file_utils.py:35] PyTorch version 1.1.0.post2 available.
I0131 01:02:28.316742 4420611520 file_utils.py:362] https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt not found in cache or force_download set to True, downloading to /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmp_lgvnb3l
I0131 01:02:30.348834 4420611520 file_utils.py:377] copying /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmp_lgvnb3l to cache at /Users/yantong/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
I0131 01:02:30.349704 4420611520 file_utils.py:381] creating metadata file for /Users/yantong/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
I0131 01:02:30.350285 4420611520 file_utils.py:390] removing temp file /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmp_lgvnb3l
I0131 01:02:30.350615 4420611520 tokenization_utils.py:398] loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /Users/yantong/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
I0131 01:02:31.742653 4420611520 file_utils.py:362] https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-finetuned-sst-2-english-config.json not found in cache or force_download set to True, downloading to /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmp7wk7u8_r
I0131 01:02:32.793608 4420611520 file_utils.py:377] copying /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmp7wk7u8_r to cache at /Users/yantong/.cache/torch/transformers/437d6b3001e14ea1853bcee09a1b2557f230862c5a03d3ebd78a4cdb94a79020.7a412cd94061214ced4285ea8f65100868e4c9757c85781d11a83acd01fa14a4
I0131 01:02:32.794027 4420611520 file_utils.py:381] creating metadata file for /Users/yantong/.cache/torch/transformers/437d6b3001e14ea1853bcee09a1b2557f230862c5a03d3ebd78a4cdb94a79020.7a412cd94061214ced4285ea8f65100868e4c9757c85781d11a83acd01fa14a4
I0131 01:02:32.794360 4420611520 file_utils.py:390] removing temp file /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmp7wk7u8_r
I0131 01:02:32.794815 4420611520 configuration_utils.py:185] loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-finetuned-sst-2-english-config.json from cache at /Users/yantong/.cache/torch/transformers/437d6b3001e14ea1853bcee09a1b2557f230862c5a03d3ebd78a4cdb94a79020.7a412cd94061214ced4285ea8f65100868e4c9757c85781d11a83acd01fa14a4
I0131 01:02:32.795076 4420611520 configuration_utils.py:199] Model config {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"finetuning_task": "sst-2",
"hidden_dim": 3072,
"id2label": {
"0": "NEGATIVE",
"1": "POSITIVE"
},
"initializer_range": 0.02,
"is_decoder": false,
"label2id": {
"NEGATIVE": 0,
"POSITIVE": 1
},
"max_position_embeddings": 512,
"n_heads": 12,
"n_layers": 6,
"num_labels": 2,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pruned_heads": {},
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"tie_weights_": true,
"torchscript": false,
"use_bfloat16": false,
"vocab_size": 30522
}
I0131 01:02:33.892992 4420611520 file_utils.py:362] https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-finetuned-sst-2-english-modelcard.json not found in cache or force_download set to True, downloading to /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmpgd57b64v
I0131 01:02:35.001976 4420611520 file_utils.py:377] copying /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmpgd57b64v to cache at /Users/yantong/.cache/torch/transformers/57ded08a298ef01c397973781194aa0abf6176e6f720f660a2b93e8199dc0bc7.455d944f3d1572ab55ed579849f751cf37f303e3388980a42d94f7cd57a4e331
I0131 01:02:35.002447 4420611520 file_utils.py:381] creating metadata file for /Users/yantong/.cache/torch/transformers/57ded08a298ef01c397973781194aa0abf6176e6f720f660a2b93e8199dc0bc7.455d944f3d1572ab55ed579849f751cf37f303e3388980a42d94f7cd57a4e331
I0131 01:02:35.002778 4420611520 file_utils.py:390] removing temp file /var/folders/bg/126twh7d29bdtfqxjf_s2kr40000gn/T/tmpgd57b64v
I0131 01:02:35.003092 4420611520 modelcard.py:154] loading model card file https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-finetuned-sst-2-english-modelcard.json from cache at /Users/yantong/.cache/torch/transformers/57ded08a298ef01c397973781194aa0abf6176e6f720f660a2b93e8199dc0bc7.455d944f3d1572ab55ed579849f751cf37f303e3388980a42d94f7cd57a4e331
I0131 01:02:35.003378 4420611520 modelcard.py:192] Model card: {
"caveats_and_recommendations": {},
"ethical_considerations": {},
"evaluation_data": {},
"factors": {},
"intended_use": {},
"metrics": {},
"model_details": {},
"quantitative_analyses": {},
"training_data": {}
}
I0131 01:02:36.353755 4420611520 modeling_utils.py:406] loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-finetuned-sst-2-english-pytorch_model.bin from cache at /Users/yantong/.cache/torch/transformers/f62a0baccbff4fbb83b3b6c63168af997d5aea02fc1a8ea2ab0a26dd79ac6517.461f3160566473d3587f9f4776a5131b1ed527b0d5fccb4b5f06003f457154bc
Traceback (most recent call last):
File "/Users/yantong/Library/Python/3.7/lib/python/site-packages/transformers/modeling_utils.py", line 415, in from_pretrained
state_dict = torch.load(resolved_archive_file, map_location='cpu')
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/torch/serialization.py", line 387, in load
return _load(f, map_location, pickle_module, **pickle_load_args)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/torch/serialization.py", line 581, in _load
deserialized_objects[key]._set_from_file(f, offset, f_should_read_directly)
RuntimeError: unexpected EOF, expected 75086145 more bytes. The file might be corrupted.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/yantong/PycharmProjects/Attribute_Inference_Attack_Reviews/transformer_pipelines.py", line 5, in <module>
nlp = pipeline('sentiment-analysis')
File "/Users/yantong/Library/Python/3.7/lib/python/site-packages/transformers/pipelines.py", line 905, in pipeline
model = model_class.from_pretrained(model, config=config, **model_kwargs)
File "/Users/yantong/Library/Python/3.7/lib/python/site-packages/transformers/modeling_auto.py", line 601, in from_pretrained
return DistilBertForSequenceClassification.from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
File "/Users/yantong/Library/Python/3.7/lib/python/site-packages/transformers/modeling_utils.py", line 417, in from_pretrained
raise OSError("Unable to load weights from pytorch checkpoint file. "
OSError: Unable to load weights from pytorch checkpoint file. If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
Process finished with exit code 134 (interrupted by signal 6: SIGABRT)
```
I tried downloading the `distilbert-base-uncased-finetuned-sst-2-english-pytorch_model.bin` and copied to the `.cache/torch/transformers` directory, but it still doesn't work.
OS: MacOS
transformers version: 2.3.0
Could somebody help me fix this issue? Thanks in advance! | 01-30-2020 17:11:41 | 01-30-2020 17:11:41 | I can't reproduce this. It works fine for me. Can you try deleting the cache directory and trying again?<|||||>@BramVanroy
Yes, I tried deleting the cached file under the `.cached` directory, but it still doesn't work for me.<|||||>Works for me too. Are you sure you deleted the right file?
<|||||>@julien-c
Yes, I deleted all the files under the `.cached/torch` directory and run the code again. It has been downloading the file for 12+ hours but still doesn't show any results. Could you please give me some advice?<|||||>Finally, it works. Solved by deleting all the cached files under the `.cached/torch` directory. I guessed the reason for the failure of downloading or lasting for a long time is the network speed.😓
Thank you so much for your guidance and patience!<|||||>@icmpnorequest
Could you please show me where is the **.cached/torch** directory, I got the same problem and I'd like to try your solutions to delete this directory.
Thanks for your guidance in advance.<|||||>@stepbystep88
I use macOS and it is `/USERNAME/.cached/torch` (USERNAME should be replaced by your own). May it would help. |
transformers | 2,686 | closed | Add layerdrop to Flaubert | This PR adds `layerdrop` to Flaubert. | 01-30-2020 16:04:38 | 01-30-2020 16:04:38 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2686?src=pr&el=h1) Report
> Merging [#2686](https://codecov.io/gh/huggingface/transformers/pull/2686?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/df27648bd942d59481a13842904f8cb500136e31?src=pr&el=desc) will **decrease** coverage by `0.01%`.
> The diff coverage is `16.66%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2686?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2686 +/- ##
==========================================
- Coverage 74.1% 74.09% -0.02%
==========================================
Files 92 92
Lines 15168 15172 +4
==========================================
+ Hits 11240 11241 +1
- Misses 3928 3931 +3
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2686?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/configuration\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/2686/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2ZsYXViZXJ0LnB5) | `75% <ø> (ø)` | :arrow_up: |
| [src/transformers/modeling\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/2686/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19mbGF1YmVydC5weQ==) | `29.19% <16.66%> (-0.13%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2686?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2686?src=pr&el=footer). Last update [df27648...15f8b5d](https://codecov.io/gh/huggingface/transformers/pull/2686?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Great, thanks!<|||||>Thanks so much for the quick merge, @LysandreJik! |
transformers | 2,685 | closed | German Bert tokenizer does not recognize (some) special characters (!,?,...) | # 🐛 Bug
## Information
Model I am using (Bert, XLNet ...):
**Bert**
Language I am using the model on (English, Chinese ...):
**German**
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
`tokenizer = BertTokenizer.from_pretrained('bert-base-german-cased')`
`tokenizer.encode("Hallo!", add_special_tokens=False)`
returns:
`[5850, 26910, 2]`
where `2` is the index of '[UNK]' (unknown) token. Same would happen with 'Hallo?'. In the vocab.txt we have tokens '##!' and '##?' but not '?' or '!'. On the other hand some special characters are recognized, like ':' or ';'.
## Expected behavior
At least such common characters as '!' and '?' should be recognized by tokenizer
## Environment
* OS: Ubuntu
* Python version: 3.7
* `transformers` version (or branch): 2.3 | 01-30-2020 14:28:12 | 01-30-2020 14:28:12 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Sounds like this was fixed by @Timoeller in #3618, @andrey999333 <|||||>Thanks for referencing. This bug should be fixed with the changes we applied to the vocabulary.
Find more infos in the separate issue here: deepset-ai/FARM/issues/60 |
transformers | 2,684 | closed | distilbert_multilingual_cased model for multiple language | By when distilbert_multilingual_cased model is going to be released.because I tried to finetune the
distilbert_multilingual_cased model , but it said "OSError: file distilbert-base-multilingual-cased not found", which means the above-mentioned model is not included in the list. Or let me know if I am doing any wrong assumption? | 01-30-2020 14:21:17 | 01-30-2020 14:21:17 | Could you try to install a newer version of the library? The `distilbert-base-multilingual-cased` checkpoint is available in recent transformers versions, as you can see in the [source code](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_distilbert.py#L42).<|||||>thanks a lot<|||||>hi,
I am trying to finetune distilbert multilingual cased model, but i am getting error while training the model:
error is :
```
ValueError: Error when checking model target: the list of Numpy arrays that you are passing to your model is not the size the model expected. Expected to see 8 array(s), for inputs ['output_1', 'output_2', 'output_3', 'output_4', 'output_5', 'output_6', 'output_7', 'output_8'] but instead got the following list of 1 arrays: [<tf.Tensor 'ExpandDims:0' shape=(None, 1) dtype=int64>]...
while with the same code using distilbert uncased , there is no such error.
Can you please check if there is some problem with distilbert multilingual cased model?<|||||>please open the issue<|||||>Hello, please open a new issue with information that can help us help you. Your software versions as well as the situation where this error happens being the minimum for us to help you, and a reproducible code example being the most useful. |
transformers | 2,683 | closed | TFCamembertModel | Hi,
I wanted to use the tensorflow version of Camembert : TFCamembertModel, but the implememtation is not available with the v2.3.0 version : https://huggingface.co/transformers/v2.3.0/model_doc/camembert.html.
But TFCamembertModel seems to be available with another version of transformers : https://huggingface.co/transformers/model_doc/camembert.html.
Is this a new or old version of the library ?
Any way, have you already succeeded importing TFCamembertModel ?
Thanks a lot !
| 01-30-2020 13:33:03 | 01-30-2020 13:33:03 | Hi, the CamemBERT model for tensorflow was merged yesterday, and is therefore available from the master branch right now. You can install it with
```py
pip install git+https://github.com/huggingface/transformers
```
It will be in the next transformers release (2.4.0 or 2.3.1), which should be released later today.<|||||>Awesome, thank you !<|||||>Hi again @LysandreJik ,
I have checked the new version of Transformers and an error occurred when I tried to load TFCamembertModel:
`TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType`
I think I found what was missing. The pretrained models are not available, I mean the list is empty when I try to load a pretrained model.
`OSError: Model name 'test_list' was not found in model name list. We assumed 'https://s3.amazonaws.com/models.huggingface.co/bert/test_list/config.json' was a path, a model identifier, or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.`
So I checked the pretrained model archives avaible in "modeling_tf_camembert.py" and, indeed, the dictionnary is empty :
`TF_CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_MAP = {}`
Is it on purpose ?
Thanks
<|||||>Hi, indeed there are not checkpoints in the archive map. The contributor (@jplu) that contributed the tensorflow architecture has uploaded checkpoints that you can use: https://huggingface.co/jplu/tf-camembert-base.
We're currently working on our website so that it better reflects the following:
- The CamemBERT model has official weights that are usable in PyTorch, but do not currently have any TensorFlow equivalent
- There are community models (cf. jplu/tf-camembert-base) which can be used instead.
We're trying to make sure that contributing models is easy and that weights are easily identifiable for users. This is still a work in progress.
cc @julien-c @joshchagani
TLDR: in transformers v2.4.0, the following should work:
```py
from transformers import TFCamembertModel
model = TFCamembertModel.from_pretrained("jplu/tf-camembert-base")
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,682 | closed | Issue with my profile on the upload/share models webpage | Hello,
The URL of my [profile](https://huggingface.co/jplu) on the upload/share models webpage looks like if there was a model called `jplu`. Any idea why?
Thanks. | 01-30-2020 11:11:18 | 01-30-2020 11:11:18 | Should be fixed.<|||||>Nice! Thanks :)<|||||>By the way, you should also add a README.md to the same `pretrained_model` folders so that it's displayed on the model pages (see [this one](https://huggingface.co/dbmdz/bert-base-german-cased) for instance)
I'll document this feature better today.
<|||||>Should `jplu/camembert-base` be `jplu/tf-camembert-base`?<|||||>The name should be ok now, it was an issue in the naming.
I will work on a README file, this is a super cool feature!!<|||||>(note that the READMEs will be in this repo in the future – that way we can collaborate on them/link them together/etc)
(see https://github.com/huggingface/transformers/issues/2520#issuecomment-579009439 if you haven't already)
Thanks a lot @jplu! |
transformers | 2,681 | closed | How to add a fc classification head to BertForQA to make a MTL-BertForQA model? | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on Stack Overflow**: | 01-30-2020 09:46:53 | 01-30-2020 09:46:53 | I am currently trying to figure out how to add an additional classification head to the BertForQA model. I am not sure which is the best / most efficient way to do that. Should I rewrite the source code for BertForQA and inherit from BertPretrainedModel, or should I rather inherit from BertForQA and change the forward pass? The forward pass needs to be fairly similar though... Any help is appreciated!<|||||>This is a matter of taste. I would write my own class which inherits from BertModel but this is completely up to you.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,680 | closed | Does loss function in the run_tf_ner.py takes logits or probabilities? | The model used for ner model is TFBertForTokenClassification in case of Tensorflow. According to documentation this model produces logits for every token. But the loss function that is used in `run_tf_ner.py` is `tf.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)` which has default argument `from_logits=False`. In this case the loss function expects probabilities but not the logits. So i would think that correct loss function should have additional argument `from_logits=True`. I'm building my own code using the `run_ner_tf.py` as an example, that is why i want to understand it. Am i missing something here? Because it looks like people can train the model and get some reasonable results... | 01-30-2020 09:34:45 | 01-30-2020 09:34:45 | I think you are right, I also find this bug, see [🐛Bugs in run_tf_ner.py](https://github.com/huggingface/transformers/issues/3389)<|||||>Hey @andrey999333! I answered to the question just here https://github.com/huggingface/transformers/issues/3389<|||||>Hey @jplu Thanks a lot, i have not noticed that line for some reason. I was wandering coz my code was working fine with the flag and yours without. Now the mystery is solved :) |
transformers | 2,679 | closed | Add classifier dropout in ALBERT | As mentioned in the original [paper](https://arxiv.org/pdf/1909.11942.pdf), they separated the dropout rates of the transformer cells and the classifier, moreover, in V2 the dropouts are 0 (expect for the classifier, again).
Current implementation does not supports this and models are not training well (can't reproduce results of GLUE benchmark using V2 models). I manually updated these values and got V2 models converging.
This issue was raised in #2337 and also mentioned in https://github.com/google-research/ALBERT/issues/23
I added a separate parameter in the config file and update the sequence classification head.
Please also update the configuration of ALBERT V2 models ([base](https://huggingface.co/albert-base-v2), [large](https://huggingface.co/albert-large-v2), [xlarge](https://huggingface.co/albert-xlarge-v2)) in your repository.
More specifically, the configuration of the **attention and hidden dropout rates** of ALBERT V2 models in your repository as well (see as in https://tfhub.dev/google/albert_base/3, https://tfhub.dev/google/albert_large/3, https://tfhub.dev/google/albert_xlarge/3 and https://tfhub.dev/google/albert_xxlarge/3)
| 01-30-2020 08:22:23 | 01-30-2020 08:22:23 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2679?src=pr&el=h1) Report
> Merging [#2679](https://codecov.io/gh/huggingface/transformers/pull/2679?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/83446a88d902661fab12bf8c37a1aa2845cdca5f?src=pr&el=desc) will **increase** coverage by `<.01%`.
> The diff coverage is `100%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2679?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2679 +/- ##
==========================================
+ Coverage 74.59% 74.59% +<.01%
==========================================
Files 89 89
Lines 14971 14972 +1
==========================================
+ Hits 11168 11169 +1
Misses 3803 3803
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2679?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/2679/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hbGJlcnQucHk=) | `79.14% <100%> (ø)` | :arrow_up: |
| [src/transformers/configuration\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/2679/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2FsYmVydC5weQ==) | `100% <100%> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2679?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2679?src=pr&el=footer). Last update [83446a8...12c7809](https://codecov.io/gh/huggingface/transformers/pull/2679?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>That's fantastic, thank you for taking the time to do this @peteriz !<|||||>The configuration files were updated. The type of GELU activation function used was also changed to "gelu_new", which is the appropriate activation function that is used in the google-research repository.
[Original gelu](https://github.com/google-research/ALBERT/blob/e8f8339b003cf2ddbb5ee9fc34a32651b33dd64e/modeling.py#L296-L309)
[Our gelu new](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L138-L142) |
transformers | 2,678 | closed | Bug in consecutive creation of tokenizers with different parameters | # 🐛 Bug
Creating a tokenizer with do_lower_case set to True overwrites it for the consecutive creation.
## Information
Model I am using: bert-base-cased
Language I am using the model on (English, Chinese ...):
English
## To reproduce
```python
from transformers import AutoTokenizer
text = "Hello there!"
tokenizer_first = AutoTokenizer.from_pretrained("bert-base-cased")
print(tokenizer_first.tokenize(text))
tokenizer_forced_lowercase = AutoTokenizer.from_pretrained("bert-base-cased", do_lower_case=True)
print(tokenizer_forced_lowercase.tokenize(text))
tokenizer_second = AutoTokenizer.from_pretrained("bert-base-cased")
print(tokenizer_second.tokenize(text))
```
The output on my machine ubuntu 18.04, transformers 2.3.0 installed just now from the repo:
```
['Hello', 'there', '!']
['hello', 'there', '!']
['hello', 'there', '!']
```
Steps to reproduce the behavior:
Execute code snippet from above.
## Expected behavior
Expected output:
```
['Hello', 'there', '!']
['hello', 'there', '!']
['Hello', 'there', '!']
```
## Environment
* OS: ubuntu 18.04
* Python version: Python 3.7.3
* PyTorch version: 1.2.0
* `transformers` version (or branch): 2.3.0 just installed from master
| 01-29-2020 20:00:45 | 01-29-2020 20:00:45 | Just to be clear: I understand that specifying `do_lower_case=True` for a cased model is wrong. The point is in overwriting or somewhat caching the parameter for future calls of the class constructor.<|||||>Here is the full output with logger.
```
I0129 23:25:47.064881 140331667420992 file_utils.py:38] PyTorch version 1.2.0 available.
I0129 23:25:48.127733 140331667420992 file_utils.py:54] TensorFlow version 2.0.0-rc1 available.
I0129 23:25:48.948472 140331667420992 configuration_utils.py:253] loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-config.json from cache at /home/hawkeoni/.cache/torch/transformers/b945b69218e98b3e2c95acf911789741307dec43c698d35fad11c1ae28bda352.d7a3af18ce3a2ab7c0f48f04dc8daff45ed9a3ed333b9e9a79d012a0dedf87a6
I0129 23:25:48.949648 140331667420992 configuration_utils.py:289] Model config BertConfig {
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"do_sample": false,
"eos_token_ids": 0,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_labels": 2,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pad_token_id": 0,
"pruned_heads": {},
"repetition_penalty": 1.0,
"temperature": 1.0,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 28996
}
I0129 23:25:49.533885 140331667420992 tokenization_utils.py:418] loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt from cache at /home/hawkeoni/.cache/torch/transformers/5e8a2b4893d13790ed4150ca1906be5f7a03d6c4ddf62296c383f6db42814db2.e13dbb970cb325137104fb2e5f36fe865f27746c6b526f6352861b1980eb80b1
['Hello', 'there', '!']
I0129 23:25:50.130188 140331667420992 configuration_utils.py:253] loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-config.json from cache at /home/hawkeoni/.cache/torch/transformers/b945b69218e98b3e2c95acf911789741307dec43c698d35fad11c1ae28bda352.d7a3af18ce3a2ab7c0f48f04dc8daff45ed9a3ed333b9e9a79d012a0dedf87a6
I0129 23:25:50.130913 140331667420992 configuration_utils.py:289] Model config BertConfig {
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"do_sample": false,
"eos_token_ids": 0,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_labels": 2,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pad_token_id": 0,
"pruned_heads": {},
"repetition_penalty": 1.0,
"temperature": 1.0,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 28996
}
I0129 23:25:50.711892 140331667420992 tokenization_utils.py:418] loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt from cache at /home/hawkeoni/.cache/torch/transformers/5e8a2b4893d13790ed4150ca1906be5f7a03d6c4ddf62296c383f6db42814db2.e13dbb970cb325137104fb2e5f36fe865f27746c6b526f6352861b1980eb80b1
['hello', 'there', '!']
I0129 23:25:51.325906 140331667420992 configuration_utils.py:253] loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-config.json from cache at /home/hawkeoni/.cache/torch/transformers/b945b69218e98b3e2c95acf911789741307dec43c698d35fad11c1ae28bda352.d7a3af18ce3a2ab7c0f48f04dc8daff45ed9a3ed333b9e9a79d012a0dedf87a6
I0129 23:25:51.326717 140331667420992 configuration_utils.py:289] Model config BertConfig {
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"do_sample": false,
"eos_token_ids": 0,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_labels": 2,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pad_token_id": 0,
"pruned_heads": {},
"repetition_penalty": 1.0,
"temperature": 1.0,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 28996
}
I0129 23:25:51.991283 140331667420992 tokenization_utils.py:418] loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt from cache at /home/hawkeoni/.cache/torch/transformers/5e8a2b4893d13790ed4150ca1906be5f7a03d6c4ddf62296c383f6db42814db2.e13dbb970cb325137104fb2e5f36fe865f27746c6b526f6352861b1980eb80b1
['hello', 'there', '!']
```<|||||>Actually even this code has the same trouble, so the problem is probably not in the creation of a new object.
```python
from transformers import AutoTokenizer
text = "Hello there!"
tokenizer_first = AutoTokenizer.from_pretrained("bert-base-cased")
print(tokenizer_first.tokenize(text))
tokenizer_forced_lowercase = AutoTokenizer.from_pretrained("bert-base-cased", do_lower_case=True)
print(tokenizer_forced_lowercase.tokenize(text))
print(tokenizer_first.tokenize(text))
```
outputs:
```
['Hello', 'there', '!']
['hello', 'there', '!']
['hello', 'there', '!']
```
<|||||>Indeed, I could reproduce and patch. I'm adding a unit test and will push the fix in a bit.<|||||>Should have been patched with 2173490!<|||||>Thanks, this seems to resolve the issue. |
transformers | 2,677 | closed | Flaubert | From PR #2632 by [formiel](https://github.com/formiel).
This PR adds [FlauBERT](https://github.com/getalp/Flaubert). Most of the code is derived from XLM (there are some new features in FlauBERT such as pre_norm and layerdrop).
The failing tests were fixed. | 01-29-2020 19:26:00 | 01-29-2020 19:26:00 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2677?src=pr&el=h1) Report
> Merging [#2677](https://codecov.io/gh/huggingface/transformers/pull/2677?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/adb8c93134f02fd0eac2b52189364af21977004c?src=pr&el=desc) will **decrease** coverage by `0.49%`.
> The diff coverage is `36.22%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2677?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2677 +/- ##
========================================
- Coverage 74.59% 74.1% -0.5%
========================================
Files 89 92 +3
Lines 14971 15167 +196
========================================
+ Hits 11168 11239 +71
- Misses 3803 3928 +125
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2677?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/2677/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `98.87% <100%> (+0.03%)` | :arrow_up: |
| [src/transformers/configuration\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2677/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2F1dG8ucHk=) | `100% <100%> (ø)` | :arrow_up: |
| [src/transformers/modeling\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/2677/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19mbGF1YmVydC5weQ==) | `29.32% <29.32%> (ø)` | |
| [src/transformers/tokenization\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/2677/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZmxhdWJlcnQucHk=) | `40.42% <40.42%> (ø)` | |
| [src/transformers/configuration\_flaubert.py](https://codecov.io/gh/huggingface/transformers/pull/2677/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2ZsYXViZXJ0LnB5) | `75% <75%> (ø)` | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2677?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2677?src=pr&el=footer). Last update [adb8c93...924cb7e](https://codecov.io/gh/huggingface/transformers/pull/2677?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Is the `layerdrop` configuration argument used anywhere? I don't see any usage in the modeling file.<|||||>Hi @LysandreJik,
Thanks a lot for working on my PR!
Good catch on layerdrop! It is currently not used for inference (it might be in a future version), so I decided to remove it from the code. As it may be useful for fine-tuning, let me add it and create a new PR. Sorry for the inconvenience!<|||||>Alright, I've completely updated the documentation as well as the tests. I'm merging this PR, feel free to open a new one concerning the `layerdrop`.<|||||>I've just opened a new PR for `layerdrop`. Thank you so much for your kind support to the integration of our model into your library!<|||||>A pleasure! |
transformers | 2,676 | closed | Trouble fine tuning Huggingface GPT-2 on Colab — Assertion error | [Cross posted from SO]
I wish to fine tune Huggingface's GPT-2 transformer model on my own text data. I want to do this on a Google Colab notebook. However, it doesn't seem to work.
I install the various bits and pieces via the Colab:
```
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r ./examples/requirements.txt
```
Following the example, I upload the suggested WikiText sample data to the for training and run the suggested CLI commands in the notebook.
```
!export TRAIN_FILE=wiki.train.raw
!export TEST_FILE=wiki.test.raw
!python run_lm_finetuning.py \
--output_dir=output \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE
```
This chugs along for a bit, but then I get an assertion error:
```
Traceback (most recent call last):
File "run_lm_finetuning.py", line 790, in <module>
main()
File "run_lm_finetuning.py", line 735, in main
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)
File "run_lm_finetuning.py", line 149, in load_and_cache_examples
return TextDataset(tokenizer, args, file_path=file_path, block_size=args.block_size)
File "run_lm_finetuning.py", line 88, in __init__
assert os.path.isfile(file_path)
AssertionError
```
When I run this script via CLI on my own machine it works fine, with the problem that it takes forever to do anything. Why does Colab present this specific problem? Thanks! | 01-29-2020 17:22:25 | 01-29-2020 17:22:25 | The error raised means that it cannot find the files you gave it. Do you manage to load the files using the
`with open` syntax without using the script?<|||||>> Do you manage to load the files using the `with open` syntax without using the script?
Thanks for the reply. I guess the answer is 'no', as I'm not sure what you mean. The files are in the same directory as the script. Should I interpret what you say to mean that I open the files as text and then upload the result? I.e.
```
open("wiki.train.raw", "rb") as file:
data = file.read()
with open("wiki_train.txt") as f:
f.write(data)
```
Then upload wiki_train.txt to the Colab and use the CLI to access that when fine tuning?
<|||||>LysandreJik wants to know if you can open and read the files with 'regular' python on Colab (i.e. just read the file and print some lines in another cell). The error message tells us that the script can't find the train dataset (i.e. wiki.train.raw) and this suggests somekind of a path issue. Maybe you can resolve this with by using the absolute path to the file. <|||||>>LysandreJik wants to know if you can open and read the files with 'regular' python on Colab (i.e. just read the file and print some lines in another cell).
Ah, sorry. But yes, I can do this no problem:
```
with open("/content/wiki.test.raw") as file:
data = file.read()
data[:100]
' \n = Robert Boulter = \n \n Robert Boulter is an English film , television and theatre actor . He had '
```
I then attempted to use absolute filepaths, just to be sure, but no joy:
```
!export TRAIN_FILE=/content/wiki.train.raw
!export TEST_FILE=/content/wiki.test.raw
!python /content/transformers/examples/run_lm_finetuning.py \
--output_dir=output \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE
```
```
Traceback (most recent call last):
File "/content/transformers/examples/run_lm_finetuning.py", line 790, in <module>
main()
File "/content/transformers/examples/run_lm_finetuning.py", line 735, in main
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)
File "/content/transformers/examples/run_lm_finetuning.py", line 149, in load_and_cache_examples
return TextDataset(tokenizer, args, file_path=file_path, block_size=args.block_size)
File "/content/transformers/examples/run_lm_finetuning.py", line 88, in __init__
assert os.path.isfile(file_path)
AssertionError
```
I am entirely stumped by this. Any further ideas what might be happening?<|||||>Is there a way for you to share your colab notebook so that I can take a look?<|||||>> Is there a way for you to share your colab notebook so that I can take a look?
Absolutely; please use the link below. This has all the steps outlined in my previous replies. I'll keep the Colab active for as long as I can.
https://colab.research.google.com/drive/1qx2t0KleLyY_EncLyM1leSRFz7VooP0e<|||||>Environment variables exported with !export are not registered by google colab in them same shell (they are registered in a sub-shell). Just set them with %env like
```
%env TRAIN_FILE=/content/wiki.train.raw
%env TEST_FILE=/content/wiki.test.raw
```
or avoid them by setting them directly:
```
!python /content/transformers/examples/run_lm_finetuning.py \
--output_dir=output \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=/content/wiki.train.raw \
--do_eval \
--eval_data_file=/content/wiki.test.raw
```<|||||>>Environment variables exported with !export are not registered by google colab in them same shell (they are registered in a sub-shell). Just set them with %env
This is fantastic, thanks; it has completely resolved the issue with respect to the initial error. However, I'm now having a different set of issues. When I run the fine tuning script, training doesn't seem to occur; it stops before the first epoch and iteration is complete:
```
01/30/2020 18:25:44 - INFO - __main__ - ***** Running training *****
01/30/2020 18:25:44 - INFO - __main__ - Num examples = 244
01/30/2020 18:25:44 - INFO - __main__ - Num Epochs = 1
01/30/2020 18:25:44 - INFO - __main__ - Instantaneous batch size per GPU = 4
01/30/2020 18:25:44 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 4
01/30/2020 18:25:44 - INFO - __main__ - Gradient Accumulation steps = 1
01/30/2020 18:25:44 - INFO - __main__ - Total optimization steps = 61
Epoch: 0% 0/1 [00:00<?, ?it/s]
Iteration: 0% 0/61 [00:00<?, ?it/s]^C
```
But there is nevertheless a model saved: `content/gpt2_cached_lm_1024_GE_train.txt`
However, when I run the text generation script,
```
!python /content/transformers/examples/run_generation.py \
--model_type=gpt2 \
--model_name_or_path=content/gpt2_cached_lm_1024_GE_train.txt
```
I get the following error:
```
Traceback (most recent call last):
File "/content/transformers/examples/run_generation.py", line 237, in <module>
main()
File "/content/transformers/examples/run_generation.py", line 200, in main
tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path)
File "/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils.py", line 309, in from_pretrained
return cls._from_pretrained(*inputs, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils.py", line 410, in _from_pretrained
list(cls.vocab_files_names.values()),
OSError: Model name 'content/gpt2_cached_lm_1024_GE_train.txt' was not found in tokenizers model name list (gpt2, gpt2-medium, gpt2-large, gpt2-xl, distilgpt2). We assumed 'content/gpt2_cached_lm_1024_GE_train.txt' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.json', 'merges.txt'] but couldn't find such vocabulary files at this path or url.
```
Now, I don't know if this is because the training hasn't occurred successfully, or if I'm loading the model incorrectly. Sorry for being such a pain on this, and thanks for the help so far!<|||||>> content/gpt2_cached_lm_1024_GE_train.txt
That is not the model, but the features generated from your training data. I assume that GE_train.txt is a file which contains your training data (environment variable $TRAIN_FILE)?
Does the script work for you with the WikiText-2 dataset? It works for me on colab with a reduced batch size (i.e. --per_gpu_train_batch_size=2).
<|||||>>Does the script work for you with the WikiText-2 dataset? It works for me on colab with a reduced batch size (i.e. --per_gpu_train_batch_size=2).
Yes, reducing the batch size works nicely, thanks.
Two final questions and I'll close this, if that's OK.
1. So when I fine tune in the colab, I don't need to load the fine tuned model separately? As in, my local GPT-2 model _is_ the fine tuned model, and I can call it in the usual way?
2. Is there any way of increasing the length of both the prompt text and the generated text from `run_generation.py`? As of now, the prompt text just gets reproduced if it's too long and the generated text is usually just one sentence length piece. I assume that this is the line of code responsible for this,
`text = text[: text.find(args.stop_token) if args.stop_token else None]`
but i wonder is there any parameter I can adjust in the CLI without digging into the bowels of the script itself?<|||||>Glad you could get the script to work! Concerning your questions:
1. You can load the fine-tuned model as you would any model, just point the `model_name_or_path` from `run_generation` to the directory containing your finetuned model.
2. You can increase the length by specifying the `--length` argument to `run_generation`. Up until this morning there was an issue with the script where it wouldn't sample from the generation, instead always taking the argmax of all tokens generated. This generally results in some repetition, which might be what you were facing as you say the `prompt text just gets reproduced`.
I would try to pull the repository once again, making sure you have the last version so that it samples correctly according to the `--k` and `--p` arguments, which you can modify to generate different completions.
If you don't specify a stop token, it should not stop at the end of a sentence. For example, with the following arguments for `run_generation`:
```
--model_type=gpt2
--model_name_or_path=gpt2
--k=50
--p=0.9
--length=200
```
With the following sample text: `The horse is`, I get the following completion:
```
The horse is just barely alive as he's been playing with the dog. The dog is trying to get its life back. She's been waiting for him for a long time. It's been long and hard. I have to move her to the backseat of my car.
When we start talking, he looks over at us like it's about to move off the road. He tells me he's been trying to get a good driver since he moved in. I don't know what to think. The only way he can drive me like that is to ride his horse to get his life back.
My sister has been following my life. I am her daughter now. She has always been my mother and always has been.
My dad has been the only one in my family. He never told me. He was a nice guy, but he was very controlling. He didn't tell anyone. He always would take a picture of me with his horse.
!
```<|||||>>Glad you could get the script to work! Concerning your questions:
Thanks so much for all the help! This is a really comprehensive answer and therefore very useful––and not just for me either, I'll wager. Great, I'll get cracking with my project so with all these provisos duly noted!<|||||>Happy to help! |
transformers | 2,675 | closed | Best weights/models after fine-tuning gpt2 | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
I am fine-tuning gpt2 on a new dataset and it checkpoints after every 50 iterations and saves the model. It stretches my local storage to extreme and would want to delete redundant models. So my queries are following:
1) Is it possible to only save the best weights (which gave the lowest perplexity/loss on evaluation data)?
2) When we run_generation.py and passed the directory of our fine-tuned model, which model weights are actually used for generation? ( as there are so many checkpoint folders with model weights).
3) And hence, related to above 2 questions how does the model consider "the best" model/weights from the fine-tuned model directory we pass as arguments? and can we just mention the chekcpoint folder as well in run_generation.py?
Thanks
| 01-29-2020 16:58:10 | 01-29-2020 16:58:10 | Hi! Indeed saving checkpoints after every 50 iterations is quite a lot, therefore we've upped this value to 500 yesterday in 335dd5e. Concerning your questions:
1. You can use the `--evaluate_during_training` flag to evaluate the model every `--logging_step`, or you can use the `--evaluate_all_checkpoints` to evaluate all the checkpoints at the end. There is no feature to save only the best model, but you could easily do it by modifying the script to save only when the evaluation yields better results than the previous one.
2. For the `run_generation.py` script, pass it the folder which contains the weights you want to use for generation. The folder must contain a `pytorch_model.bin`, a `config.json`, as well as a tokenizer object.
3. Yes, just mention the checkpoint folder in `run_generation.py`. <|||||>Thank you. My bad i did not pay full attention to the arguments present in the generation script. That answers my queries. |
transformers | 2,674 | closed | Integrate fast tokenizers library inside transformers | Integrate the BPE-based tokenizers inside transformers.
- [x] Bert (100% match)
- [x] DistilBert (100% match)
- [x] OpenAI GPT (100% match)
- [x] GPT2 (100% match if no trailing \n)
- [x] Roberta (100% match if no trailing \n)
- [x] TransformerXL
- [x] CTRL (No binding will be provided).
Added priority for Tokenizer with fast implementation in `AutoTokenizer` this is done through a new mapping (name: class) -> (name: Tuple[class, class]) which represents both the Python and Rust implementation classes. if no Rust implementation is available, it is simply set to None. AutoTokenizer will try to pick the Rust class if not None, otherwise it defaults to the Python one.
Added some matching tests which basically checks that there is a huge % of element wise matching tokens. This is set arbitrary to 0.05 (5%) _[i.e. at max, 5% of differences between Python and Rust]_.
Added parameter `return_offsets_mapping=False` over encoding methods which will return the offset mapping if using a Rust tokenizer. If using a Python tokenizer, a warning message is displayed through the module logger and the argument is discarded.
| 01-29-2020 16:30:28 | 01-29-2020 16:30:28 | only took a superficial look, but looks very clean 👍
Excited to use fast tokenizers by default!<|||||>Current CI issues are real and "normal" we need to release the next version of tokenizers lib which will bring all the dependencies.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2674?src=pr&el=h1) Report
> Merging [#2674](https://codecov.io/gh/huggingface/transformers/pull/2674?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/20fc18fbda3669c2f4a3510e0705b2acd54bff07?src=pr&el=desc) will **increase** coverage by `0.29%`.
> The diff coverage is `83.01%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2674?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2674 +/- ##
=========================================
+ Coverage 75% 75.3% +0.29%
=========================================
Files 94 94
Lines 15288 15424 +136
=========================================
+ Hits 11467 11615 +148
+ Misses 3821 3809 -12
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2674?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `98.87% <100%> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fcm9iZXJ0YS5weQ==) | `100% <100%> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYmVydC5weQ==) | `96.92% <100%> (+0.3%)` | :arrow_up: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `70.88% <100%> (+0.14%)` | :arrow_up: |
| [src/transformers/tokenization\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZGlzdGlsYmVydC5weQ==) | `100% <100%> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZ3B0Mi5weQ==) | `96.85% <100%> (+0.58%)` | :arrow_up: |
| [src/transformers/tokenization\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYXV0by5weQ==) | `97.22% <100%> (+0.25%)` | :arrow_up: |
| [src/transformers/tokenization\_transfo\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdHJhbnNmb194bC5weQ==) | `37.91% <51.42%> (+5.04%)` | :arrow_up: |
| [src/transformers/tokenization\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fb3BlbmFpLnB5) | `82.27% <81.57%> (+0.46%)` | :arrow_up: |
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `90.08% <87.23%> (+3.98%)` | :arrow_up: |
| ... and [30 more](https://codecov.io/gh/huggingface/transformers/pull/2674/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2674?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2674?src=pr&el=footer). Last update [20fc18f...56748e8](https://codecov.io/gh/huggingface/transformers/pull/2674?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,673 | closed | Fine tuning XLMRoberta for Question Answering | # ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on Stack Overflow**:
I'm trying to fine tune XLM Roberta for Question Answering in tensorflow version, and the question is do i need to convert the pytorch pretrained model to tensorflow because 'xlm-roberta-case' = "https://s3.amazonaws.com/models.huggingface.co/bert/xlm-roberta-base-pytorch_model.bin", if so how can i do it? i tried to use load_pytorch_model_in_tf2_model() but i had errors!!
thank you for help in advance.
| 01-29-2020 15:48:42 | 01-29-2020 15:48:42 | Hi, we don't currently have an implementation of XLM RoBERTa in tensorflow.<|||||>I guess this one can now be closed since TensorFlow XLM-RoBERTa was released with 2.4.0. Thanks @LysandreJik @jplu . Quick question though: I guess you are not retraining the LM but convert the pytorch weighs. Is there any script in huggingface to do this?<|||||>Right now the easiest way to convert the PyTorch weights to TensorFlow when the two implementations are in huggingface/transformers is the following, for e.g. XLM-R:
```py
from transformers import XLMRobertaModel, TFXLMRobertaModel
pytorch_model = XLMRobertaModel.from_pretrained("xlm-roberta-base") # Checkpoint on S3
pytorch_model.save_pretrained("pytorch_checkpoint_directory") # Save it to a directory
tensorflow_model = TFXLMRobertaModel.from_pretrained("pytorch_checkpoint_directory", from_pt=True) # Load from directory in TF
```
You can then save that TensorFlow model using the `save_pretrained` method, and you can do it the other way around too to conver TensorFlow models to PyTorch models.<|||||>@houdaM97, as @nchocho said XLM-R in TensorFlow was released in v2.4.0 last week. There are no official checkpoints on our s3 however, but there are contributed community checkpoints from @jplu you can use instead:
```py
from transformers import TFXLMRobertaModel
model = TFXLMRobertaModel.from_pretrained("jplu/tf-xlm-roberta-base")
``` |
transformers | 2,672 | closed | bert-base-uncased have weird result on Squad 2.0 | I followed the example to fine-tuning BERT on SQuAD2.0:
https://huggingface.co/transformers/examples.html#fine-tuning-bert-on-squad1-0
I run the code as follow:
```
python /content/drive/My\ Drive/squad2/run_squad.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--do_train \
--do_eval \
--do_lower_case \
--train_file /content/drive/My\ Drive/squad2/train-v2.0.json \
--predict_file /content/drive/My\ Drive/squad2/dev-v2.0.json \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/drive/My\ Drive/squad2_model/
```
However, I got weird results as follow:
```
Results: {'exact': 40.722648024930514, 'f1': 44.3783712849203, 'total': 11873, 'HasAns_exact': 81.5620782726046, 'HasAns_f1': 88.88400847939587, 'HasAns_total': 5928, 'NoAns_exact': 0.0, 'NoAns_f1': 0.0, 'NoAns_total': 5945, 'best_exact': 50.11370336056599, 'best_exact_thresh': 0.0, 'best_f1': 50.11370336056599, 'best_f1_thresh': 0.0}
```
'NoAns_exact' and 'NoAns_f1' are zero.
Do I miss anything when running the example code?
| 01-29-2020 15:18:32 | 01-29-2020 15:18:32 | Hi, running the exact same command but specifying you're using the version 2 with `--version_2_with_negative` gives me the following results:
```
01/29/2020 13:20:35 - INFO - __main__ - Results: {'exact': 73.29234397372188, 'f1': 76.50792180947842, 'total': 11873, 'HasAns_exact': 71.94669365721997, 'HasAns_f1': 78.38707079013807, 'HasAns_total': 5928, 'NoAns_exact': 74.63414634146342, 'NoAns_f1': 74.63414634146342, 'NoAns_total': 5945, 'best_exact': 73.29234397372188, 'best_exact_thresh': 0.0, 'best_f1': 76.50792180947839, 'best_f1_thresh': 0.0}
```
Here are the exact arguments I used:
```
--model_type=bert --model_name_or_path=bert-base-uncased --do_train --do_eval --do_lower_case --version_2_with_negative --train_file=../../datasets/squad-v2.0/train-v2.0.json --predict_file=../../datasets/squad-v2.0/dev-v2.0.json --per_gpu_train_batch_size=12 --learning_rate=3e-5 --num_train_epochs=2.0 --max_seq_length=384 --doc_stride=128 --save_steps=10000 --output_dir=output_pt --overwrite_output_dir
```<|||||>@LysandreJik thanks for your reply.
I will try again.<|||||>My result is the same as yours. Maybe we not use the argument `--version_2_with_negative` ? |
transformers | 2,671 | closed | is SOP(sentence order prediction) implemented? | # ❓ Questions & Help
I am reviewing huggingface's version of Albert.
However, I cannot find any code or comment about SOP.
I can find NSP(Next Sentence Prediction) implementation from modeling_from src/transformers/modeling_bert.py.
Is SOP inherited from here with SOP-style labeling? or Is there anything I am missing?
## Details
https://stackoverflow.com/questions/59961023/is-sopsentence-order-prediction-implemented | 01-29-2020 05:39:18 | 01-29-2020 05:39:18 | Hi, the layer that was used for SOP is the pooler layer, which is available in the base `AlbertModel`. When doing a forward pass, the model returns the `pooled_output` as a second value in the returned tuple. You can use this for doing a SOP task.<|||||>Oh I see! Thank you so much :)<|||||>Sorry for reopening this issue.
As you suggested, I have checked the `pooled_output` which is the second value in the returned tuple at `AlbertModel`
```python
import torch
from transformers import AlbertTokenizer, AlbertModel
model_nm = 'albert-large-v1'
# Load pre-trained model tokenizer (vocabulary)
tokenizer = AlbertTokenizer.from_pretrained(model_nm)
# SOP label should be 1
sent_1 = 'I want to eat'
sent_2 = 'because I am hungry'
# Tokenized input
text = ' '.join(['[CLS]', sent_1, '[SEP]', sent_2, '[SEP]'])
tokenized_text = tokenizer.tokenize(text)
# Convert token to vocabulary indices
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = (len(tokenizer.tokenize(sent_1))+2)*[0] + (len(tokenizer.tokenize(sent_2))+1)*[1]
# Convert inputs to PyTorch tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
# Load pre-trained model (weights)
model = AlbertModel.from_pretrained(model_nm)
model.eval()
output = model(tokens_tensor, segments_tensors)
output[0].shape, output[1].shape
```
When I check `output[1].shape` it is just a vector of `torch.Size([1, 1024]))`.
How can I do SOP with this? Unlike `BertModel` in `modeling_bert.py`, there is no code like
```python
self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
```<|||||>From `src/transformers/modeling_albert.py`
```python
# No ALBERT model currently handles the next sentence prediction task
if "seq_relationship" in name:
continue
```
I think current ALBERT model does not handle SOP. Let me know if I am wrong :)<|||||>ALBERT doesn't do NSP but SOP - as you said. I think the following is a copy-paste error (@LysandreJik could you confirm?). It should refer to SOP and not NSP.
https://github.com/huggingface/transformers/blob/ddb6f9476b58ed9bf4433622ca9aa49932929bc0/src/transformers/modeling_albert.py#L496-L500
I am not sure about the seq_relationship line.
https://github.com/huggingface/transformers/blob/ddb6f9476b58ed9bf4433622ca9aa49932929bc0/src/transformers/modeling_albert.py#L113-L115
Perhaps the final relationship classification isn't implemented in transformers. Shouldn't be too hard to implement by yourself, though. You can use `AlbertForSequenceClassification` for that.<|||||>Yeah, implementing SOP by my self is not difficult one. As you suggested, I can just use `AlbertForSequenceClassification`. By the way, what I really want to know is ...
when I load AlbertModel by `model = AlbertModel.from_pretrained(model_nm)`, does pre-trained model has already learnt SOP? or not? I think it has not learnt yet, because `AlbertModel` has never used `AlbertForSequenceClassification`.<|||||>The model names are just abstractions of the weights and layers. They weren't trained with this library. That being said, I would expect AlbertModel to load only the weights and layers except the last classifying layers.
You can see for instance that
```python
from transformers import AlbertForSequenceClassification
import logging
logging.basicConfig(level=logging.INFO)
model = AlbertForSequenceClassification.from_pretrained('albert-base-v1')
```
will log:
```
INFO:transformers.modeling_utils:Weights of AlbertForSequenceClassification not initialized from pretrained model: ['classifier.weight', 'classifier.bias']
INFO:transformers.modeling_utils:Weights from pretrained model not used in AlbertForSequenceClassification: ['predictions.bias', 'predictions.LayerNorm.weight', 'predictions.LayerNorm.bias', 'predictions.dense.weight', 'predictions.dense.bias', 'predictions.decoder.weight', 'predictions.decoder.bias']
```
Indicating that the pretrained weights that you are loading haven't all been loaded (the prediction layer) because that layer doesn't exist in this architecture. On the other hand, the classification layer that is present in the XXXSequenceClassification model has not been pretrained, so its weights are not in the pretrained weights.
I would have expected to see a similar message indicating that not all weights could be loaded in AlbertModel because it doesn't contain the prediction layer, but I don't get any such message - which seems odd to me.
```python
from transformers import AlbertModel
import logging
logging.basicConfig(level=logging.INFO)
model = AlbertModel.from_pretrained('albert-base-v1')
# doesn't log any info messages
```
<|||||>Oh I see thank you so much.
Your answer is clear to me :)
Thanks<|||||>Hi all! What situation with Albert's SOP now?
@jinkilee do you have worked approach for SOP?
Thank you!<|||||>@jinkilee Hi, please
I went through the discussion and tried to use "AlbertForSequenceClassification" instead but I cannot understand what does logits exactly indicates!
```
import torch
from transformers import AlbertTokenizer, AlbertModel
from transformers import AlbertForSequenceClassification
import logging
model_nm = 'albert-large-v1'
# Load pre-trained model tokenizer (vocabulary)
tokenizer = AlbertTokenizer.from_pretrained(model_nm)
# SOP label should be 1
sent_1 = 'I was having cough and headache'
sent_2 = 'so I went to the doctor'
# Tokenized input
text = ' '.join(['[CLS]', sent_2, '[SEP]', sent_1, '[SEP]'])
tokenized_text = tokenizer.tokenize(text)
# Convert token to vocabulary indices
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = (len(tokenizer.tokenize(sent_1))+2)*[0] + (len(tokenizer.tokenize(sent_2))+1)*[1]
# Convert inputs to PyTorch tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
# Load pre-trained model (weights)
logging.basicConfig(level=logging.INFO)
model = AlbertForSequenceClassification.from_pretrained('albert-base-v1')
model.eval()
output = model(tokens_tensor, segments_tensors)
output#[0].shape, output[1].shape
```
The output value is:
SequenceClassifierOutput(loss=None, logits=tensor([[ 1.0192, -0.3174]], grad_fn=<AddmmBackward>), hidden_states=None, attentions=None)
Thanks in advance.
|
transformers | 2,670 | closed | Remove unnecessary `del` in run_tf_glue.py example | Platform: Ubuntu 18.04 (Linux-4.15.0-1054-aws-x86_64-with-Ubuntu-18.04-bionic)
Python: 3.6.9
PyTorch: 1.4.0
TensorFlow: 2.0.0
Running `./examples/run_tf_glue.py` gives `KeyError: 'special_tokens_mask'`.
Diving into the code, it looks like there's an optional keyword argument in [`encode_plus()`](https://github.com/huggingface/transformers/blob/9d87eafd118739a4c121d69d7cff425264f01e1c/src/transformers/tokenization_utils.py#L834) named `return_special_tokens_mask` that defaults to False. I'm guessing that this argument was added recently and the example just needs to be updated? | 01-29-2020 01:30:41 | 01-29-2020 01:30:41 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2670?src=pr&el=h1) Report
> Merging [#2670](https://codecov.io/gh/huggingface/transformers/pull/2670?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/9d87eafd118739a4c121d69d7cff425264f01e1c?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2670?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2670 +/- ##
=======================================
Coverage 74.51% 74.51%
=======================================
Files 87 87
Lines 14920 14920
=======================================
Hits 11117 11117
Misses 3803 3803
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2670?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2670?src=pr&el=footer). Last update [9d87eaf...ff1a4b3](https://codecov.io/gh/huggingface/transformers/pull/2670?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Indeed, thanks for catching that and removing it! |
transformers | 2,669 | closed | models and tokenizers trained with pytorch_pretrained_bert are not compatible with transformers | # 📚 Migration
## Information
The models and tokenizers in transformers 2.3.0 are backward incompatible with pytorch_pretrained_bert 0.6.2.
## Details
```
>>> import transformers
>>> transformers.__version__
'2.3.0'
>>> import pytorch_pretrained_bert
>>> pytorch_pretrained_bert.__version__
'0.6.2'
>>> from pytorch_pretrained_bert import OpenAIGPTTokenizer
>>> tokenizer = OpenAIGPTTokenizer.from_pretrained("runs/mymodel")
ftfy or spacy is not installed using BERT BasicTokenizer instead of SpaCy & ftfy.
>>> len(tokenizer)
40483
>>> from transformers import OpenAIGPTTokenizer
>>> tokenizer = OpenAIGPTTokenizer.from_pretrained("runs/mymodel")
ftfy or spacy is not installed using BERT BasicTokenizer instead of SpaCy & ftfy.
>>> len(tokenizer)
40478
>>>
```
`runs/mymodel` contains a model that was trained using pytorch_pretrained_bert 0.6.2, specifically with the `transfer-learning-conv-ai` repo.
Expected behavior from transformers 2.3.0: `len(tokenizer)` must be 40483, like with pytorch_pretrained_bert 0.6.2.
## Environment
* OS: Amazon Linux
* Python version: 3.6
* PyTorch version:
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch): 0.6.2
* `transformers` version (or branch): 2.3.0
* Using GPU? Yes
* Distributed or parallel setup? N/A
## Checklist
- [Y] I have read the migration guide in the readme.
([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
[pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [Y] I checked if a related official extension example runs on my machine.
-------
UPDATE: this issue is also the case for models, see below:
```
>>> from pytorch_pretrained_bert import OpenAIGPTLMHeadModel
>>> model = OpenAIGPTLMHeadModel.from_pretrained("runs/mymodel")
>>> from transformers import OpenAIGPTLMHeadModel
>>> model = OpenAIGPTLMHeadModel.from_pretrained("runs/mymodel")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ec2-user/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/transformers/modeling_utils.py", line 486, in from_pretrained
model.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for OpenAIGPTLMHeadModel:
size mismatch for transformer.tokens_embed.weight: copying a param with shape torch.Size([40483, 768]) from checkpoint, the shape in current model is torch.Size([40478, 768]).
```
| 01-28-2020 23:30:08 | 01-28-2020 23:30:08 | Can you share your vocabulary so we can have a look at the differences?<|||||>@thomwolf I took the `vocab.json` located inside `runs/mymodel` and the `openai-gpt-vocab.json` hosted in the Hugging Face [S3](https://s3.amazonaws.com/models.huggingface.co/bert/openai-gpt-vocab.json) bucket and compared the two as follows:
```
>>> with open("openai-gpt-vocab.json", "r") as f:
... a = json.load(f)
...
>>> with open("vocab.json", "r") as f:
... b = json.load(f)
...
>>> a == b
True
```
So the `vocab.json` inside `runs/mymodel` is exactly the same as that hosted in the S3 bucket.
------
Some of the other files located in `runs/mymodel` include `config.json`, `merges.txt` and `special_tokens.txt`. If you're interested in the contents of the last file, it is the following:
```
<bos>
<eos>
<speaker1>
<speaker2>
<pad>
```<|||||>From looking at the different releases, I would assume that in the current master branch, more tokens are added (don't have the time to dig through to see where they come from). It happens in `__len__`:
https://github.com/huggingface/transformers/blob/5a6b138b00eef2506e0fc2c6088fb81c064161bf/src/transformers/tokenization_utils.py#L535-L537
That being said, to only get the size of the base vocabulary, there is another method called `vocab_size` which is implemented in the OpenAI tokenizer like so:
https://github.com/huggingface/transformers/blob/5a6b138b00eef2506e0fc2c6088fb81c064161bf/src/transformers/tokenization_openai.py#L115-L117
In the 0.6.2 release, the length is the encoder + the special tokens.
https://github.com/huggingface/transformers/blob/b832d5bb8a6dfc5965015b828e577677eace601e/pytorch_pretrained_bert/tokenization_openai.py#L157-L158
So it seems that the added special tokens are different in the releases, that is `self.added_tokens_encoder` (current master) vs `self.special_tokens` (0.6.2).
Perhaps when I have more time I can look more closely into this.<|||||>@BramVanroy yes indeed, but this is a more serious, systemic issue since it occurs not just for tokenizers but for models as well, as I noted in the original post.
Basically anyone who trained models with pytorch_pretrained_bert 0.6.2 and later upgraded their entire code-base (both training and inference) to transformers 2.3.0 will have to discard those models and train fresh ones.<|||||>Can we get an update on this @thomwolf and @LysandreJik ? Is this expected behavior? Should we have to re-train all models?<|||||>Hi, I'm having a hard time replicating this on my end. Could you try specifying explicitly to the model that you're trying to load a state dict of a certain size, by using the configuration? If I understand correctly, you have a directory `runs/mymodel `, which must contain a `config.json` file and a `pytorch_model.bin` file.
Loading the model as such fails:
```py
from transformers import OpenAIGPTModel
model = OpenAIGPTModel.from_pretrained("runs/mymodel")
```
with the error you mentioned above. Can you try by loading the configuration separately, and then instantiating the model with it, as follows:
```py
from transformers import OpenAIGPTModel, OpenAIGPTConfig
config = OpenAIGPTConfig.from_pretrained("runs/mymodel", vocab_size=40483)
model = OpenAIGPTModel.from_pretrained("runs/mymodel", config=config)
```<|||||>@LysandreJik when I try loading the model like you mentioned above, I don't get any errors. However, `vocab_size=40483` is something that `from_pretrained()` is supposed to figure out from the contents of `runs/mymodel`, right?
And yes, `runs/mymodel` contains all of the following:
```
model_training_args.bin
config.json
vocab.json
special_tokens.txt
merges.txt
checkpoint_mymodel_1.pth
checkpoint_mymodel_2.pth
pytorch_model.bin
```
I trained a separate model with transformers 2.3.0 and its trained model directory within `runs/` didn't have `special_tokens.txt`, but instead I see `special_tokens_map.json` and `added_tokens.json`. These files didn't exist when training models with pytorch_pretrained_bert 0.6.2, understandably because you guys changed the special tokens from a list to a dictionary when you upgraded from 0.6.2.
However, this upgrade should not mean that old models are no longer supported.
Also, while what you are suggesting works for loading the model, can you tell me what would ensure that both tokenizers return the exact same length, i.e., 40483?
Basically what the `OpenAIGPTTokenizer` needs to ensure is that it not only reads the contents of `vocab.json` from `runs/mymodel`, but also the contents of `special_tokens.txt`. This was happening with pytorch_pretrained_bert 0.6.2, and it should continue to happen in transformers 2.3.0. I understand that you guys wanted to change the special tokens from a list to a dictionary for 2.3.0, but that change should be backward compatible.
Look for a `special_tokens.txt` if it exists, and use it if it does.
See how this was being done in 0.6.2 (I'm only pasting the example of the tokenizer, but the same is applicable to the model as well): https://github.com/huggingface/transformers/blob/v0.6.2/pytorch_pretrained_bert/tokenization_openai.py#L128L132
<|||||>@thomwolf @LysandreJik Any updates?
It would be great if y'all could let everyone know if you're working to fix this.
Alternately, please make a recommendation to the community on how to handle this scenario. Should we revert back to pytorch_pretrained_bert 0.6.2 for our old models? Should we just re-train all old models?<|||||>Hi @g-karthik we **don't** plan to assure backward compatibility between `pytorch-pretrained-bert` and `transformers`'s tokenizers.
There were deep changes in the way we handle added tokens from `pytorch-pretrained-bert` (in which it was basic, specific to BERT and broken on some hedge cases) to `transformers` (in which it is more reliable and unified across models).
So in your case, my recommendation is thus to stick with `pytorch_pretrained_bert` indeed.<|||||>@thomwolf Thanks for letting us know!
Just to clarify, it's not just the tokenizers, it's also the models trained with `pytorch_pretrained_bert` 0.6.2 (which includes more than just BERT, btw) that will not be compatible with `transformers` 2.3.0 at run-time/inference-time. |
transformers | 2,668 | closed | How to get .ckpt files for tensorflow DistilBERT model | `model.save_pretrained('dir')` tf_model.h5 how to get .ckpt files for it | 01-28-2020 21:16:56 | 01-28-2020 21:16:56 | Hello JKP0,
What do you need the .ckpt files for?<|||||>@Poaz Dear,
We are working on NLG models for coreference resolution. We started our project with BERT, so our implementations are dependent with the pre-trained [ BERT-model](https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip) available from Google-API. Now we want to do study for the same with DistilBERT. Our implementation is based on TensorFlow 1.14.0
Actually our requirement is something like bellow
```
assignment_map, initialized_variable_names = modeling.get_assignment_map_from_checkpoint(tvars, config['tf_checkpoint']) # essential, unresolved
init_from_checkpoint = tf.train.init_from_checkpoint if config['init_checkpoint'].endswith('ckpt') else load_from_pytorch_checkpoint # essential, unresolved
model.get_all_encoder_layers() # this is our essential, right now completely unresolved for us
model.get_sequence_output() # this is our essential, right now completely unresolved for us
```
but any method (e.g. `get_all_encoder_layers(); get_sequence_output(); get_assignment_map_from_checkpoint(); ...`) implemented in `DistilBertModel` class to get this kind of thing is out-of my knowledge. I have checked a loat. In our earlier implementation, we have defined this method where we have used `tf.train.list_variables(init_checkpoint)` and other tf-1 API to meet the need for which .ckpt files are essential.
And most of the tf-1 API uses checkpoint configuration (or serialized object), but we are unable to resolve it with the non-sequential .h5 model file by TFDistiBertModel. So we are in need to the same file for DistilBert which provided [here ](https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip) for BERT.
If you or anyone can suggest a way to come out from it or possible convenient way to get .ckpt files for DistilBERT, I have lots of thanks in advance. Thanks! <|||||>Okay, thanks for the context. If you in anyway able to use PyTorch for your implementation you can get outputs from all layers using the following code:
```
from transformers import DistilBertTokenizer, DistilBertModel, DistilBertConfig
import torch
config = DistilBertConfig.from_pretrained('distilbert-base-uncased', output_hidden_states=True)
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased', config=config)
model.eval()
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0)
outputs = model(input_ids)
```
The output will then be outputs[0] (batch_size, seq_length, hidden_state) for the final layer
and outputs[1] (batch_size, seq_length, hidden_state) for each layer in the model, with index 0 being the last layer.
If that is not an option, it is possible to convert the .h5 file to .ckpt using Keras and Tensorflow
For tf 1.x
```
saver = tf.train.Saver()
model = keras.models.load_model("model.h5")
sess = keras.backend.get_session()
save_path = saver.save(sess, "model.ckpt")
```
for tf 2.x
```
saver = tf.train.Checkpoint()
model = keras.models.load_model('model.hdf5', compile=False)
sess = tf.compat.v1.keras.backend.get_session()
save_path = saver.save('model.ckpt')
```
Hope it helps!<|||||>@Poaz your first idea is good, but it will cost us for other changes.
And second one giving error we have tried a lot, as DistilBERT model saved by `model.save_pretrained('dir')` is not a sequential or serialized object and `keras.models.load_model("model.h5")` only loads sequential and serialized .h5 model.
> to save model
```
import tensorflow as tf
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertModel.from_pretrained('distilbert-base-uncased')
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"), dtype="int32")[None, :] # Batch size 1
outputs = model(input_ids)
last_hidden_states = outputs[0]
model.save_pretrained("./DSB/")
model.save_weights("./DSB/DistDistilBERT_weights.h5")
```
> tf-1.14.0
```
import tensorflow as tf
from keras.models import load_model
```
```
saver = tf.train.Saver()
model = keras.models.load_model("DSB/tf_model.h5")
sess = keras.backend.get_session()
save_path = saver.save(sess, "/tmp/model.ckpt")
```
>
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-3-01f1268a6c60> in <module>()
----> 1 saver = tf.train.Saver()
2 model = load_model("DSB/tf_model.h5")
3 sess = keras.backend.get_session()
4 save_path = saver.save(sess, "model.ckpt")
2 frames
/usr/local/lib/python3.6/dist-packages/tensorflow/python/training/saver.py in __init__(self, var_list, reshape, sharded, max_to_keep, keep_checkpoint_every_n_hours, name, restore_sequentially, saver_def, builder, defer_build, allow_empty, write_version, pad_step_number, save_relative_paths, filename)
823 time.time() + self._keep_checkpoint_every_n_hours * 3600)
824 elif not defer_build:
--> 825 self.build()
826 if self.saver_def:
827 self._check_saver_def()
/usr/local/lib/python3.6/dist-packages/tensorflow/python/training/saver.py in build(self)
835 if context.executing_eagerly():
836 raise RuntimeError("Use save/restore instead of build in eager mode.")
--> 837 self._build(self._filename, build_save=True, build_restore=True)
838
839 def _build_eager(self, checkpoint_path, build_save, build_restore):
/usr/local/lib/python3.6/dist-packages/tensorflow/python/training/saver.py in _build(self, checkpoint_path, build_save, build_restore)
860 return
861 else:
--> 862 raise ValueError("No variables to save")
863 self._is_empty = False
864
ValueError: No variables to save
> tf-2.0.0
```
import tensorflow as tf
from tensorflow.keras.models import load_model
```
```
saver = tf.train.Checkpoint()
model = load_model('DSB/tf_model.h5', compile=False)
sess = tf.compat.v1.keras.backend.get_session()
save_path = saver.save('model.ckpt')
```
>
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-13-13dd44da36a5> in <module>()
1 saver = tf.train.Checkpoint()
----> 2 model = load_model('DSB/tf_model.h5', compile=False)
3 sess = tf.compat.v1.keras.backend.get_session()
4 save_path = saver.save('model.ckpt')
1 frames
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/saving/save.py in load_model(filepath, custom_objects, compile)
144 if (h5py is not None and (
145 isinstance(filepath, h5py.File) or h5py.is_hdf5(filepath))):
--> 146 return hdf5_format.load_model_from_hdf5(filepath, custom_objects, compile)
147
148 if isinstance(filepath, six.string_types):
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/saving/hdf5_format.py in load_model_from_hdf5(filepath, custom_objects, compile)
163 model_config = f.attrs.get('model_config')
164 if model_config is None:
--> 165 raise ValueError('No model found in config file.')
166 model_config = json.loads(model_config.decode('utf-8'))
167 model = model_config_lib.model_from_config(model_config,
ValueError: No model found in config file.
> tf-2.0.0
```
import tensorflow as tf
from keras.models import load_model
```
```
saver = tf.train.Checkpoint()
model = load_model('DSB/tf_model.h5', compile=False)
sess = tf.compat.v1.keras.backend.get_session()
save_path = saver.save('model.ckpt')
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-15-13dd44da36a5> in <module>()
1 saver = tf.train.Checkpoint()
----> 2 model = load_model('DSB/tf_model.h5', compile=False)
3 sess = tf.compat.v1.keras.backend.get_session()
4 save_path = saver.save('model.ckpt')
3 frames
/usr/local/lib/python3.6/dist-packages/keras/engine/saving.py in load_wrapper(*args, **kwargs)
456 os.remove(tmp_filepath)
457 return res
--> 458 return load_function(*args, **kwargs)
459
460 return load_wrapper
/usr/local/lib/python3.6/dist-packages/keras/engine/saving.py in load_model(filepath, custom_objects, compile)
548 if H5Dict.is_supported_type(filepath):
549 with H5Dict(filepath, mode='r') as h5dict:
--> 550 model = _deserialize_model(h5dict, custom_objects, compile)
551 elif hasattr(filepath, 'write') and callable(filepath.write):
552 def load_function(h5file):
/usr/local/lib/python3.6/dist-packages/keras/engine/saving.py in _deserialize_model(h5dict, custom_objects, compile)
237 return obj
238
--> 239 model_config = h5dict['model_config']
240 if model_config is None:
241 raise ValueError('No model found in config.')
/usr/local/lib/python3.6/dist-packages/keras/utils/io_utils.py in __getitem__(self, attr)
316 else:
317 if self.read_only:
--> 318 raise ValueError('Cannot create group in read-only mode.')
319 val = H5Dict(self.data.create_group(attr))
320 return val
ValueError: Cannot create group in read-only mode.<|||||>I see.. The h5 does not contain the model structure, therefore it can not be recreated. That means that it is necessary to rebuild the model in Keras for that method to work. That is simply not feasible for you I think. <|||||>hey,you can load the model as :
loaded_model = TFDistilBertForSequenceClassification.from_pretrained("directory")<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>@JKP0 were u able to solve the issue?<|||||> How did you solve this problem, can any one help in this. How to get .ckpt files for muril-base-cased/tf_model.h5 |
transformers | 2,667 | closed | Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated | <!-- A clear and concise description of the question. -->
I recently downloaded the [ALBERT_base_v2](https://storage.googleapis.com/albert_models/albert_base_v2.tar.gz) TF pretrained model and converted it to a pytorch with the following code:
`(base) enoch@enoch-pc:~/dl_repos/transformers/src/transformers$ python convert_albert_original_tf_checkpoint_to_pytorch.py --tf_checkpoint_path '/home/enoch/Documents/experiment/ALBERT_pretrained_models/albert_base_v2/albert_base/model.ckpt-best.index' --albert_config_file '/home/enoch/Documents/experiment/ALBERT_pretrained_models/albert_base_v2/albert_base/albert_config.json' --pytorch_dump_path '/home/enoch/Documents/experiment/albert_base_v2.ckpt'`
However, when I run
`tokenizer = AlbertTokenizer.from_pretrained('albert_base_v2.ckpt')`
I get
```
Calling AlbertTokenizer.from_pretrained() with the path to a single file or url is deprecated
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<timed exec> in <module>
~/anaconda3/lib/python3.7/site-packages/transformers/tokenization_utils.py in from_pretrained(cls, *inputs, **kwargs)
307
308 """
--> 309 return cls._from_pretrained(*inputs, **kwargs)
310
311 @classmethod
~/anaconda3/lib/python3.7/site-packages/transformers/tokenization_utils.py in _from_pretrained(cls, pretrained_model_name_or_path, *init_inputs, **kwargs)
456 # Instantiate tokenizer.
457 try:
--> 458 tokenizer = cls(*init_inputs, **init_kwargs)
459 except OSError:
460 raise OSError(
~/anaconda3/lib/python3.7/site-packages/transformers/tokenization_albert.py in __init__(self, vocab_file, do_lower_case, remove_space, keep_accents, bos_token, eos_token, unk_token, sep_token, pad_token, cls_token, mask_token, **kwargs)
109
110 self.sp_model = spm.SentencePieceProcessor()
--> 111 self.sp_model.Load(vocab_file)
112
113 @property
~/anaconda3/lib/python3.7/site-packages/sentencepiece.py in Load(self, filename)
116
117 def Load(self, filename):
--> 118 return _sentencepiece.SentencePieceProcessor_Load(self, filename)
119
120 def LoadOrDie(self, filename):
RuntimeError: Internal: /sentencepiece/src/sentencepiece_processor.cc(73) [model_proto->ParseFromArray(serialized.data(), serialized.size())]
```
Please, how do I use or load the downloaded pretrained models? Thank you. | 01-28-2020 15:31:00 | 01-28-2020 15:31:00 | You're trying to load a checkpoint in a tokenizer. Use `AlbertModel` to load the model, not `AlbertTokenizer`.<|||||>Okay. Thanks.
These two work okay
model = TFAlbertModel.from_pretrained('albert-base-v2')
model = TFAlbertForSequenceClassification.from_pretrained('albert-base-v2')
because they are being downloaded from the internet. The issue is how to load the one I have downloaded, which is loacted here, experiment/ALBERT_pretrained_models/albert_base_v2.tar.gz, on my system. Please kindly help or provide sample code <|||||>what is in your tar.gz file ?<|||||>you should probably untar into a folder and it _should_ just work.<|||||>These are the content of the tar.gz:
30k-clean.model albert_config.json, model.ckpt-best.index, 30k-clean.vocab, model.ckpt-best.data-00000-of-00001, model.ckpt-best.meta
<|||||>You would need to convert it using the `convert_albert_original_tf_checkpoint_to_pytorch`, as you did in your first question. You can then load the exported dump using `AlbertModel`.<|||||>I converted it using model.ckpt-best.index, albert_config.json and saved it as albert_base_v2.ckpt.
When I run
`model = TFAlbertModel.from_pretrained('albert_base_v2.ckpt')`
I get
```
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-2-3fd924302d83> in <module>
----> 1 model = TFAlbertModel.from_pretrained('albert_base_v2.ckpt')
~/anaconda3/lib/python3.7/site-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
277 force_download=force_download,
278 resume_download=resume_download,
--> 279 **kwargs,
280 )
281 else:
~/anaconda3/lib/python3.7/site-packages/transformers/configuration_utils.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
173
174 """
--> 175 config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
176 return cls.from_dict(config_dict, **kwargs)
177
~/anaconda3/lib/python3.7/site-packages/transformers/configuration_utils.py in get_config_dict(cls, pretrained_model_name_or_path, pretrained_config_archive_map, **kwargs)
223 if resolved_config_file is None:
224 raise EnvironmentError
--> 225 config_dict = cls._dict_from_json_file(resolved_config_file)
226
227 except EnvironmentError:
~/anaconda3/lib/python3.7/site-packages/transformers/configuration_utils.py in _dict_from_json_file(cls, json_file)
312 def _dict_from_json_file(cls, json_file: str):
313 with open(json_file, "r", encoding="utf-8") as reader:
--> 314 text = reader.read()
315 return json.loads(text)
316
~/anaconda3/lib/python3.7/codecs.py in decode(self, input, final)
320 # decode input (taking the buffer into account)
321 data = self.buffer + input
--> 322 (result, consumed) = self._buffer_decode(data, self.errors, final)
323 # keep undecoded input until the next call
324 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte
```
Please, what am I doing wrong?<|||||>Does the error still happen if you use `AlbertModel` instead of `TFAlbertModel` ?<|||||>> Does the error still happen if you use `AlbertModel` instead of `TFAlbertModel` ?
Yes the error still happens. Same error report.<|||||>Please is there a fix for this
On Tue, Jan 28, 2020, 16:49 Lysandre Debut <[email protected]> wrote:
> Does the error still happen if you use AlbertModel instead of
> TFAlbertModel ?
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/2667?email_source=notifications&email_token=AGZQ72EECOAB4HT3X7CLBTTRABO2RA5CNFSM4KMUNI72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEKEB5WA#issuecomment-579346136>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AGZQ72DOAMFVHKA6WBG5XNTRABO2RANCNFSM4KMUNI7Q>
> .
>
<|||||>This might be far-fetched but did you do any of the conversion process on Windows and now you're trying to load the model on Linux (or the other way around)? That _might_ explain encoding issues. <|||||>> This might be far-fetched but did you do any of the conversion process on Windows and now you're trying to load the model on Linux (or the other way around)? That _might_ explain encoding issues.
No please. I did everything on a Linux machine. In fact, I only use Linux. Will try to find a fix. <|||||>Other far-fetched idea: did you train the model on Python 2 and now try to load it in Python 3 or vice-versa?<|||||>> Other far-fetched idea: did you train the model on Python 2 and now try to load it in Python 3 or vice-versa?
I downloaded the ALBERT official pre-trained model. I didn't train anything.<|||||>I had no issues loading your checkpoint in both `AlbertModel` and `TFAlbertModel`. Here is what I did:
- Download your file
- Untar `albert_base_v2.tar.gz` into a folder, I called mine `albert_base`
- run the convert command:
```
python convert_albert_original_tf_checkpoint_to_pytorch.py --tf_checkpoint_path=albert_base/model.ckpt-best --albert_config_file=albert_base=albert_config.json --pytorch_dump_path=albert_base/pytorch_model.bin
```
- When loading a model from a directory, it requires `config.json` and `pytorch_model.bin`, so rename the config:
```
cp albert_base/albert_config.json albert_base/config.json
```
- Now if you `ls` the folder, here are the contents:
```
30k-clean.model 30k-clean.vocab albert_config.json config.json model.ckpt-best.data-00000-of-00001 model.ckpt-best.index model.ckpt-best.meta pytorch_model.bin
```
Then, in Python (pytorch):
```py
from transformers import AlbertModel
model = AlbertModel.from_pretrained("albert_base")
```
or in tf:
```py
from transformers import TFAlbertModel
model = TFAlbertModel.from_pretrained("albert_base", from_pt=True)
```
If you didn't train anything, you could have loaded the albert model using the simple command:
```py
from transformers import AlbertModel
model = AlbertModel.from_pretrained("albert-base-v2")
```<|||||>Thanks a lot for your help. I tried your fix and it worked.
What I missed from my previous approaches were the .bin file, renaming the
config file and the main thing was I wasn't passing model.ckpt-best but
instead one of the model.ckpt-best (.index).
Another question is, can I pass embeddings from a different pretrained
model?
I'm using a clinical dataset, and I'm wondering if it's possible to learn
embeddings and pass it to the existing AlbertModel.
On Mon, Feb 3, 2020, 21:27 Lysandre Debut <[email protected]> wrote:
> I had no issues loading your checkpoint in both AlbertModel and
> TFAlbertModel. Here is what I did:
>
> - Download your file
> - Untar albert_base_v2.tar.gz into a folder, I called mine albert_base
> - run the convert command:
>
> python convert_albert_original_tf_checkpoint_to_pytorch.py --tf_checkpoint_path=albert_Base/model.ckpt-best --albert_config_file=albert_base=albert_config.json --pytorch_dump_path=albert_base/pytorch_model.bin
>
>
> - When loading a model from a directory, it requires config.json and
> pytorch_model.bin, so rename the config:
>
> cp albert_base/albert_config.json albert_base/config.json
>
>
> - Now if you ls the folder, here are the contents:
>
> 30k-clean.model 30k-clean.vocab albert_config.json config.json model.ckpt-best.data-00000-of-00001 model.ckpt-best.index model.ckpt-best.meta pytorch_model.bin
>
> Then, in Python (pytorch):
>
> from transformers import AlbertModel
>
> model = AlbertModel.from_pretrained("albert_base")
>
> or in tf:
>
> from transformers import TFAlbertModel
>
> model = TFAlbertModel.from_pretrained("albert_base", from_pt=True)
>
> If you didn't train anything, you could have loaded the albert model using
> the simple command:
>
> from transformers import AlbertModel
>
> model = AlbertModel.from_pretrained("albert-base-v2")
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/2667?email_source=notifications&email_token=AGZQ72AOUYFUP4SJ3IBF6DDRBCD45A5CNFSM4KMUNI72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEKVOV4Y#issuecomment-581626611>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AGZQ72CSMUWJGYURTSK3IE3RBCD45ANCNFSM4KMUNI7Q>
> .
>
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,666 | closed | Multiple token IDs for same token | ## ❓ Questions & Help
I am using GPT2Tokenizer. I observed that some tokens are duplicated in the vocabulary with a space appended to them in the beginning. For example, there exist two separate tokens - `can` and `<space>can`. Both of them are mapped to different token IDs - `5171` and `460` respectively.
Although, both -
```
can_token_id = tokenizer.encode(' can', add_special_tokens=False)
```
and
```
can_token_id = tokenizer.encode('can', add_special_tokens=False)
```
return can_token_id as `[5171]`
Is this an intended property of the tokenizer? Is there a mapping available between what token IDs are just a space appended version of other tokenIDs? | 01-28-2020 14:21:25 | 01-28-2020 14:21:25 | Okay, I found that the symbol is not `<space>` but this `Ġ`
So there exist two words in the vocab - `can` and `Ġcan`
Why is this so?<|||||>Hi! This is indeed an intended property of the tokenizer. The GPT-2 tokenizer is a byte-level BPE that has a sufficient vocabulary size to make the distinction between tokens that are at the beginning of a sentence (not prepended by a space), and those that are in the middle of a sentence (prepended by a space).
The tokens `the` and ` the` are therefore encoded differently, however the tokenizer strips the spaces from the sequences it receives as input. You can suppress that behavior by setting the `add_prefix_space` flag to `True`:
```py
tokenizer.encode("the")
# [1169]
tokenizer.encode("the", add_prefix_space=True)
# [262]
```
Concerning your question regarding why the vocabulary displays `can` and `Ġcan`, you can actually see the `Ġcan` as being ` can` (notice the space). The GPT-2 tokenizer converts all spaces/control characters to other tokens. These spaces and control characters could have some unwanted behavior when using a BPE tokenizer (for example if it splits on whitespace).
The space token is switched to `Ġ`. You can see it being done using the `bytes_to_unicode` method in the [tokenization_gpt2.py](https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_gpt2.py#L63-L85) file.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,665 | closed | standardize CTRL BPE files - upload models to S3 | This PR:
- update CTRL BPE files (`vocab.json` and `merges.txt`) to use a single format for sub-word splitting (selected to use `</w>` at the end of words)
- upload CTRL updated vocabulary files and pytorch model (not updated) to AWS.
cc @mfuntowicz | 01-28-2020 12:51:59 | 01-28-2020 12:51:59 | Also cc @keskarnitish! |
transformers | 2,664 | closed | Updates to the templates | This PR updates the existing GitHub templates. Main changes are:
- motivate users to post general question on Stack Overflow, tagged [huggingface-transformers](https://stackoverflow.com/questions/tagged/huggingface-transformers)
- removing the 'additional context' section as it might not add much and just bloats the template
- changed references to pytorch-transformers to transformers
closes https://github.com/huggingface/transformers/issues/2529 | 01-28-2020 12:21:07 | 01-28-2020 12:21:07 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2664?src=pr&el=h1) Report
> Merging [#2664](https://codecov.io/gh/huggingface/transformers/pull/2664?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ea2600bd5f1d36f2fb61958be21db5b901e33884?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2664?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2664 +/- ##
=======================================
Coverage 74.51% 74.51%
=======================================
Files 87 87
Lines 14920 14920
=======================================
Hits 11117 11117
Misses 3803 3803
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2664?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2664?src=pr&el=footer). Last update [ea2600b...1cfc4af](https://codecov.io/gh/huggingface/transformers/pull/2664?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,663 | closed | Add check to verify existence of pad_token_id | In batch_encode_plus we have to ensure that the tokenizer has a pad_token_id so that, when padding, no None values are added as padding. That would happen with gpt2, openai, transfoxl.
closes https://github.com/huggingface/transformers/issues/2640 | 01-28-2020 10:45:25 | 01-28-2020 10:45:25 | Tests failed on loading the Bert Whole Word Masking model:
> OSError: Couldn't reach server at 'https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-whole-word-masking-config.json' to download pretrained model configuration file.
Fetching that file from the browser does work, though.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2663?src=pr&el=h1) Report
> Merging [#2663](https://codecov.io/gh/huggingface/transformers/pull/2663?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ea2600bd5f1d36f2fb61958be21db5b901e33884?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `100%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2663?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2663 +/- ##
=======================================
Coverage 74.51% 74.51%
=======================================
Files 87 87
Lines 14920 14920
=======================================
Hits 11117 11117
Misses 3803 3803
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2663?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2663/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `85.69% <100%> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2663?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2663?src=pr&el=footer). Last update [ea2600b...8d04f9b](https://codecov.io/gh/huggingface/transformers/pull/2663?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Hi Bram, thanks for opening a pull request. The problem with this approach is that checking if the `pad_token_id` is `None` will print a warning: `Using pad_token, but it is not set yet.`
It would probably be annoying for the user to be facing that warning each time they call `batch_encode_plus`. I would argue using the private attribute `_pad_token` instead would be better, as it can be used for the same purpose without raising a warning.<|||||>> Hi Bram, thanks for opening a pull request. The problem with this approach is that checking if the `pad_token_id` is `None` will print a warning: `Using pad_token, but it is not set yet.`
>
> It would probably be annoying for the user to be facing that warning each time they call `batch_encode_plus`. I would argue using the private attribute `_pad_token` instead would be better, as it can be used for the same purpose without raising a warning.
Ah, didn't know that. Thanks! I can make the changes tomorrow, but feel free to edit now if you want the changes faster. <|||||>Great, thanks Bram !
|
transformers | 2,662 | closed | 'Embedding' object has no attribute 'shape' | ## ❓ Questions & Help
**version**
tensorflow : 2.0.0
tensorflow-gpu : 2.0.0
torch : 1.3.1
transformers : 2.3.0
Also I'm using **google Colab**
I want to convert tf pretrained-model(for Korean) to pytorch model.
I just tried below code
**config = BertConfig.from_json_file(BERT_PATH+'/config.json')
model = BertForPreTraining.from_pretrained(BERT_PATH, from_tf=True, config=config)**
However,

this error comes out.. ;(
in the BERT_PATH,
-config.json
-model.ckpt.data-00000-of-00001
-model.ckpt.meta
-model.ckpt.index
-vocab.txt
Can anyone help me?
I found some similar issues, but it didn't help...
| 01-28-2020 08:59:30 | 01-28-2020 08:59:30 | You can't import a .ckpt file directly in a PyTorch model. You first need to convert your obtained BERT model to our format, using the script [convert_bert_original_tf_checkpoint_to_pytorch](https://github.com/huggingface/transformers/blob/master/src/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py). It will then be usable in our TensorFlow/PyTorch architectures.<|||||>@LysandreJik
Thanks for the comment! I've used 'convert_bert_original_tf_checkpoint_to_pytorch' but, same issue occurred.. ;(


<|||||>If I understand correctly, you used this `convert_bert_original_tf_checkpoint_to_pytorch` script to convert it to a PyTorch model, which was dumpes in a `HanBert-54kN` folder?
Did you try using:
```py
model = BertForPreTraining.from_pretrained("HanBert-54kN")
```
? Does it raise the same error ?<|||||>yes, I've tried that before.
Is it because of the version conflict?
I recently recognized that the HanBert is pre-trained under tensorflow-gpu 1.11.0.<|||||>For me, the same problem occurred and I solved it by changing the corresponding block of load_tf_weights_in_bert function as follows:
Original:
```
try:
assert pointer.shape == array.shape
except AssertionError as e:
e.args += (pointer.shape, array.shape)
raise
```
Changed
```
try:
if type(pointer).__name__ != 'Parameter':
assert pointer.shape == array.shape
else:
if pointer.shape != array.shape:
if pointer.shape == array.transpose().shape:
array = array.transpose()
assert pointer.shape == array.shape
except AssertionError as e:
e.args += (pointer.shape, array.shape)
raise
```
I found that this code works without previous error, but I don't check the working of the converted parameter with this code yet... So please warn about that.<|||||>@whitedelay
I've also confront the same issue. It's because the convert function can't skip the `optimizer parameter`. I've raised the [PR](https://github.com/huggingface/transformers/pull/2652) regarding with this issue.<|||||>@monologg
Oh, I see. Thank you so much! 😊<|||||>I have the same problem (perhaps the PR didn't solve this issue). what can I do about it?<|||||>Hello, i am facing this same issue. If anyone found a solution already, please share it.<|||||>hi how to solve it? @monologg @henrique-voni |
transformers | 2,661 | closed | [Umberto] model shortcuts | cc @loretoparisi @simonefrancia
see #2485 | 01-27-2020 23:04:37 | 01-27-2020 23:04:37 | Failing test is Heisenbug<|||||>@julien-c thank you we are looking at it right now.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2661?src=pr&el=h1) Report
> Merging [#2661](https://codecov.io/gh/huggingface/transformers/pull/2661?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/9ca21c838bce6a4311124eafac58ef7dbabf6a0e?src=pr&el=desc) will **increase** coverage by `<.01%`.
> The diff coverage is `100%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2661?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2661 +/- ##
==========================================
+ Coverage 74.51% 74.51% +<.01%
==========================================
Files 87 87
Lines 14920 14921 +1
==========================================
+ Hits 11117 11118 +1
Misses 3803 3803
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2661?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/2661/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19jYW1lbWJlcnQucHk=) | `100% <ø> (ø)` | :arrow_up: |
| [src/transformers/configuration\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/2661/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2NhbWVtYmVydC5weQ==) | `100% <ø> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/2661/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fY2FtZW1iZXJ0LnB5) | `34.56% <100%> (+0.81%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2661?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2661?src=pr&el=footer). Last update [9ca21c8...27a9dd3](https://codecov.io/gh/huggingface/transformers/pull/2661?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Model pages are at:
- https://huggingface.co/Musixmatch/umberto-commoncrawl-cased-v1
- https://huggingface.co/Musixmatch/umberto-wikipedia-uncased-v1
<|||||>@julien-c Thanks, very happy to contribute! Is it possibile to update the profile image [here](https://huggingface.co/Musixmatch) to the right one in the model's readme [here](https://huggingface.co/Musixmatch/umberto-commoncrawl-cased-v1)?
Thanks a lot again.<|||||>Do you mean using this image: https://user-images.githubusercontent.com/163333/72244273-396aa380-35ee-11ea-894b-4ea48230c02b.png
?
We don't have a feature for this for now, but I will change it manually.<|||||>@julien-c yep! |
transformers | 2,660 | closed | PPLM with Tensorflow | ## ❓ Questions & Help
Hello,
I am still quite new to the library, so I do apologize if the answer is straightforward.
The latest release (https://github.com/huggingface/transformers/releases/tag/v2.3.0) mentions the inclusion of PPLM as a new architecture, both as Pytorch and TF.
I can't however seem to figure out how to import **PPLM** as a **Tensorflow** model. Any help would be greatly appreciated.
Thank you | 01-27-2020 22:18:19 | 01-27-2020 22:18:19 | I think this is a mistake on our part. cc @LysandreJik @w4nderlust <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Yes, the code I / we contributed is only for PyTorch. I think porting it to TensorFlow is feasible, but it's not in there at the moment.<|||||>The release notes were fixed then. Thanks! |
transformers | 2,659 | closed | [FIX] #2658 Inconsistent values returned by batch_encode_plus and enc… | As ticket describe, when using batch_encode_plus, instead of encode_plus, tokens type and mask are different. They should be the same using batch processing or not. Proposed fix here solve the issue | 01-27-2020 20:57:45 | 01-27-2020 20:57:45 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2659?src=pr&el=h1) Report
> Merging [#2659](https://codecov.io/gh/huggingface/transformers/pull/2659?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e0849a66accda8aa435a3db164c373175115a5b0?src=pr&el=desc) will **increase** coverage by `<.01%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2659?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2659 +/- ##
==========================================
+ Coverage 74.51% 74.51% +<.01%
==========================================
Files 87 87
Lines 14920 14920
==========================================
+ Hits 11117 11118 +1
+ Misses 3803 3802 -1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2659?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `85.85% <ø> (+0.16%)` | :arrow_up: |
| [src/transformers/commands/serving.py](https://codecov.io/gh/huggingface/transformers/pull/2659/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb21tYW5kcy9zZXJ2aW5nLnB5) | `0% <ø> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2659?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2659?src=pr&el=footer). Last update [e0849a6...6efcbec](https://codecov.io/gh/huggingface/transformers/pull/2659?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,658 | closed | Inconsistent values returned by batch_encode_plus and encode_plus | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): bert-base-uncased
The problem arise when using:
* batch_encode_plus and encode_plus with pad_to_max_length & max_length
## To Reproduce
Minimal exemple :
I compare tokens created via batch or not, and they are different for **masks** and **types**
```
pretrained = 'bert-base-uncased'
tokenizer = FixedAutoTokenizer.from_pretrained(pretrained)
model = AutoModel.from_pretrained(pretrained)
text = "My"
text1 = "features are ok"
mylist = list()
mylist.append(text)
mylist.append(text1)
#####################################################################################################
batch_encoding = tokenizer.batch_encode_plus(mylist,
return_tensors='pt',
add_special_tokens=False)
######################################################################################################
text_encoding = tokenizer.encode_plus(text,
return_tensors='pt',
add_special_tokens=False,
max_length=3,
pad_to_max_length=True)
print("\n--Batch Encoding \n")
print(batch_encoding['input_ids'])
print(batch_encoding['token_type_ids'])
print(batch_encoding['attention_mask'])
print("\n--One-by-one encoding\n")
print(text_encoding['input_ids'])
print(text_encoding['token_type_ids'])
print(text_encoding['attention_mask'])
```
It gives
```
--Batch Encoding
tensor([[2026, 0, 0],
[2838, 2024, 7929]])
tensor([[0, 1, 1],
[0, 0, 0]])
tensor([[1, 1, 1],
[1, 1, 1]])
--One-by-one encoding
tensor([[2026, 0, 0]])
tensor([[0, 0, 0]])
tensor([[1, 0, 0]])
```
## Expected behavior
It should return the same value, like following
```
--Batch Encoding
tensor([[2026, 0, 0],
[2838, 2024, 7929]])
tensor([[0, 0, 0],
[0, 0, 0]])
tensor([[1, 0, 0],
[1, 1, 1]])
--One-by-one encoding
tensor([[2026, 0, 0]])
tensor([[0, 0, 0]])
tensor([[1, 0, 0]])
```
## Environment
* OS: MacOs Mojave (reproduced also on Ubuntu)
* Python version: 3.7
* PyTorch version: torch==1.3.1
* PyTorch Transformers version (or branch): transformers==2.3.0
* Using GPU ? no | 01-27-2020 19:47:02 | 01-27-2020 19:47:02 | I've been experimenting with `batch_encode_plus` with my current project and I have found few more inconsistencies and code affected:
* `batch_encode_plus` is not introduced in any tests, so it is hard to tell what was desired behavior of this method
* `batch_encode_plus` is not extending `encode_plus` in context of input parameters:
* `encode_plus` is using input parameters like: `text, text_pair=None, add_special_tokens=True ...`
* `batch_encode_plus` is using input parameters like: `batch_text_or_text_pairs=None, add_special_tokens=False ...`
* `batch_encode_plus` is not extending `encode_plus` in context of implementation logic, ie. is not reusing `prepare_for_model` as `encode_plus` (and `encode` via `encode_plus`), instead encoding is implemented in alternative way
* `batch_encode_plus` was used in pipleines https://github.com/huggingface/transformers/blob/eb59e9f70513b538d2174d4ea1efea7ba8554b58/src/transformers/pipelines.py#L426 in MR https://github.com/huggingface/transformers/pull/1548 which is currently in 2.3.0 release
* `batch_encode_plus` is used in https://github.com/huggingface/transformers/blob/335dd5e68a1b6ab6f51952c36a9ff6d8822c963f/examples/run_lm_finetuning.py#L135 on current master branch
Taking the inconsistency with `encode` and `encode_plus` it seems that above usage of `batch_encode_plus` can produce undesired output.
Also because of inconsistency I think that `batch_encode_plus` name is highly misleading and this method should be at least renamed to something like `batch_alternative_encode`.
Letting know @thomwolf, as he was reviewing #1548<|||||>@knuser agreed, whole implementation of batch_encode_plus is very different from encode_plus. I found it weird also but I am not aware of all different uses cases / features that it support. Anyway, I would like to you if you agree on the fact that encode_plus and batch_encode_plus should give the same results for same input as described in the ticket ?<|||||>I agree<|||||>I also experienced this inconsistency and it would be great if the problem can be fixed soon. |
transformers | 2,657 | closed | Add `return_special_tokens_mask` to `batch_encode_plus()` | Proposal to add the keyword argument `return_special_tokens_mask` to the method `batch_encode_plus()` to match the functionality of `encode_plus()`. The implementation simply adds the argument in the `encode_plus()` call, so it inherits its implementation and should be compatible with other changes to the `batch_encode_plus()` arguments. | 01-27-2020 17:11:40 | 01-27-2020 17:11:40 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2657?src=pr&el=h1) Report
> Merging [#2657](https://codecov.io/gh/huggingface/transformers/pull/2657?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/875c4ae48f97af9792ab0b87b49a426ca7e7586b?src=pr&el=desc) will **decrease** coverage by `1.1%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2657?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2657 +/- ##
==========================================
- Coverage 74.58% 73.47% -1.11%
==========================================
Files 87 87
Lines 14892 14892
==========================================
- Hits 11107 10942 -165
- Misses 3785 3950 +165
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2657?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2657/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `85.69% <ø> (ø)` | :arrow_up: |
| [src/transformers/modeling\_tf\_pytorch\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2657/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9weXRvcmNoX3V0aWxzLnB5) | `8.72% <0%> (-81.21%)` | :arrow_down: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2657/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `55.39% <0%> (-9.86%)` | :arrow_down: |
| [src/transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2657/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ194bG5ldC5weQ==) | `70.94% <0%> (-2.28%)` | :arrow_down: |
| [src/transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2657/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19jdHJsLnB5) | `92.07% <0%> (-2.21%)` | :arrow_down: |
| [src/transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2657/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19vcGVuYWkucHk=) | `80.06% <0%> (-1.33%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2657?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2657?src=pr&el=footer). Last update [875c4ae...1f3e2b6](https://codecov.io/gh/huggingface/transformers/pull/2657?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,656 | closed | Using Transformers for a Sequence with Multiple Variables at Each Step | ## ❓ Questions & Help
I have sequence data which I want to classify and predict future sequence. However, I know that there are a few additional features which aso affect the subsequent values, each to a different extent. So I have multiple features for each step of input sequence. However, the output sequence can be just one feature for each step.
Input - [(x1, y1, z1), (x2,y2,z2), (x3,y3,z3)]
Output - [x4, x5, x6] or classification (a,b or c)
I do not want to concatenate x,y, and z as they have varying effects on the label and I think concatenating would give an erroneous result.
Need advise on whether Transformers, and specifically Huggingface Transformers can be used for this use case?
Thanks.
<!-- -->
| 01-27-2020 16:20:13 | 01-27-2020 16:20:13 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,655 | closed | Fix AutoModelForQuestionAnswering for Roberta | When using `AutoModelForQuestionAnswering()` to load a Roberta model, we are currently instantiating a `BertForQuestionAnswering` class. This is happening because `RobertaConfig` is an instance of `BertConfig` (due to inheritance) and there's no other mapping for Roberta in here:
https://github.com/huggingface/transformers/blob/bac51fba3a6b96f02f482e9a352601242b200e47/src/transformers/modeling_auto.py#L176-L184
| 01-27-2020 16:19:49 | 01-27-2020 16:19:49 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2655?src=pr&el=h1) Report
> Merging [#2655](https://codecov.io/gh/huggingface/transformers/pull/2655?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/babd41e7fa07bdd764f8fe91c33469046ab7dbd1?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2655?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2655 +/- ##
=======================================
Coverage 74.58% 74.58%
=======================================
Files 87 87
Lines 14892 14892
=======================================
Hits 11107 11107
Misses 3785 3785
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2655?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2655/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hdXRvLnB5) | `75.55% <ø> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2655?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2655?src=pr&el=footer). Last update [babd41e...213877a](https://codecov.io/gh/huggingface/transformers/pull/2655?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>can you run `make style` @tholor? Seems like I can't push to your fork or I'd have done it myself.
Thank you!<|||||>Actually I'll do it myself. Thanks! |
transformers | 2,654 | closed | Add keyword arguments to batch_encode_plus() to match encode_plus() | ## 🚀Consistent Keyword arguments for batch_encode_plus() to match encode_plus()
Currently, features such as `return_special_tokens_mask` that are available for the `encode_plus()` method are not available for `batch_encode_plus()`. It would be nice if all keyword arguments worked in a similar fashion.
## Motivation
`batch_encode_plus()` is extremely useful to seamlessly tokenize batches, however, the lack of features forces to fall back to encode_plus() and an _uglier_ implementation. | 01-27-2020 16:15:47 | 01-27-2020 16:15:47 | This should require adding a simple `**kwargs` at the end of
https://github.com/huggingface/transformers/blob/f1e8a51f08eeecacf0cde33d40702d70c737003b/src/transformers/tokenization_utils.py#L977 |
transformers | 2,653 | closed | Fix token_type_ids for XLM-R | 01-27-2020 15:04:46 | 01-27-2020 15:04:46 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2653?src=pr&el=h1) Report
> Merging [#2653](https://codecov.io/gh/huggingface/transformers/pull/2653?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/babd41e7fa07bdd764f8fe91c33469046ab7dbd1?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `0%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2653?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2653 +/- ##
=======================================
Coverage 74.58% 74.58%
=======================================
Files 87 87
Lines 14892 14892
=======================================
Hits 11107 11107
Misses 3785 3785
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2653?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_xlm\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2653/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxtX3JvYmVydGEucHk=) | `32.91% <0%> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2653?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2653?src=pr&el=footer). Last update [babd41e...56133cd](https://codecov.io/gh/huggingface/transformers/pull/2653?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 2,652 | closed | Fix importing unofficial TF models with extra optimizer weights | Hi:)
I was trying to convert the BERT `tf model` to `torch model`, and tf model has *extra optimizer weights* ([This file](https://drive.google.com/file/d/1mNDA-SNCsnu60wzKVe_Y3k-dq3LoDHB2/view) is the one I've tried to convert).
But it encounters the error, and I've printed the parameters' name in tf model.
<img width="686" alt="Screen Shot 2020-01-27 at 10 21 50 PM" src="https://user-images.githubusercontent.com/28896432/73183937-f87e9d00-415e-11ea-9317-2611aecdefe7.png">
I've found out the instead of "adam_v" for "adam_m, names are saved as "AdamWeightDecayOptimizer" or "AdamWeightDecayOptimizer_1".
There was a similar issue that also encountered the issue that I had. ([Issue Link from DeepPavlov repo](https://github.com/deepmipt/DeepPavlov/issues/863))
I can't find out the exact reason why the parameters are named as "AdamWeightDecayOptimizer" or "AdamWeightDecayOptimizer_1" instead of "adam_v" or "adam_m", but it might be safe to cover all the exceptional cases:) | 01-27-2020 14:50:31 | 01-27-2020 14:50:31 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2652?src=pr&el=h1) Report
> Merging [#2652](https://codecov.io/gh/huggingface/transformers/pull/2652?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/babd41e7fa07bdd764f8fe91c33469046ab7dbd1?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `0%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2652?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2652 +/- ##
=======================================
Coverage 74.58% 74.58%
=======================================
Files 87 87
Lines 14892 14892
=======================================
Hits 11107 11107
Misses 3785 3785
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2652?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2652/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `87.9% <0%> (ø)` | :arrow_up: |
| [src/transformers/modeling\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/2652/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hbGJlcnQucHk=) | `79.14% <0%> (ø)` | :arrow_up: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/2652/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `81.09% <0%> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2652?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2652?src=pr&el=footer). Last update [babd41e...d338eb0](https://codecov.io/gh/huggingface/transformers/pull/2652?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,651 | closed | XLNET SQuAD2.0 Fine-Tuning - What May Have Changed? | ## ❓ Questions & Help
I fine-tuned XLNet_large_cased on SQuAD 2.0 last November 2019 with Transformers V2.1.1 yielding satisfactory results:
```
xlnet_large_squad2_512_bs48
{
"exact": 82.07698138633876,
"f1": 85.898874470488,
"total": 11873,
"HasAns_exact": 79.60526315789474,
"HasAns_f1": 87.26000954590184,
"HasAns_total": 5928,
"NoAns_exact": 84.54163162321278,
"NoAns_f1": 84.54163162321278,
"NoAns_total": 5945,
"best_exact": 83.22243746315169,
"best_exact_thresh": -11.112004280090332,
"best_f1": 86.88541353813282,
"best_f1_thresh": -11.112004280090332
}
```
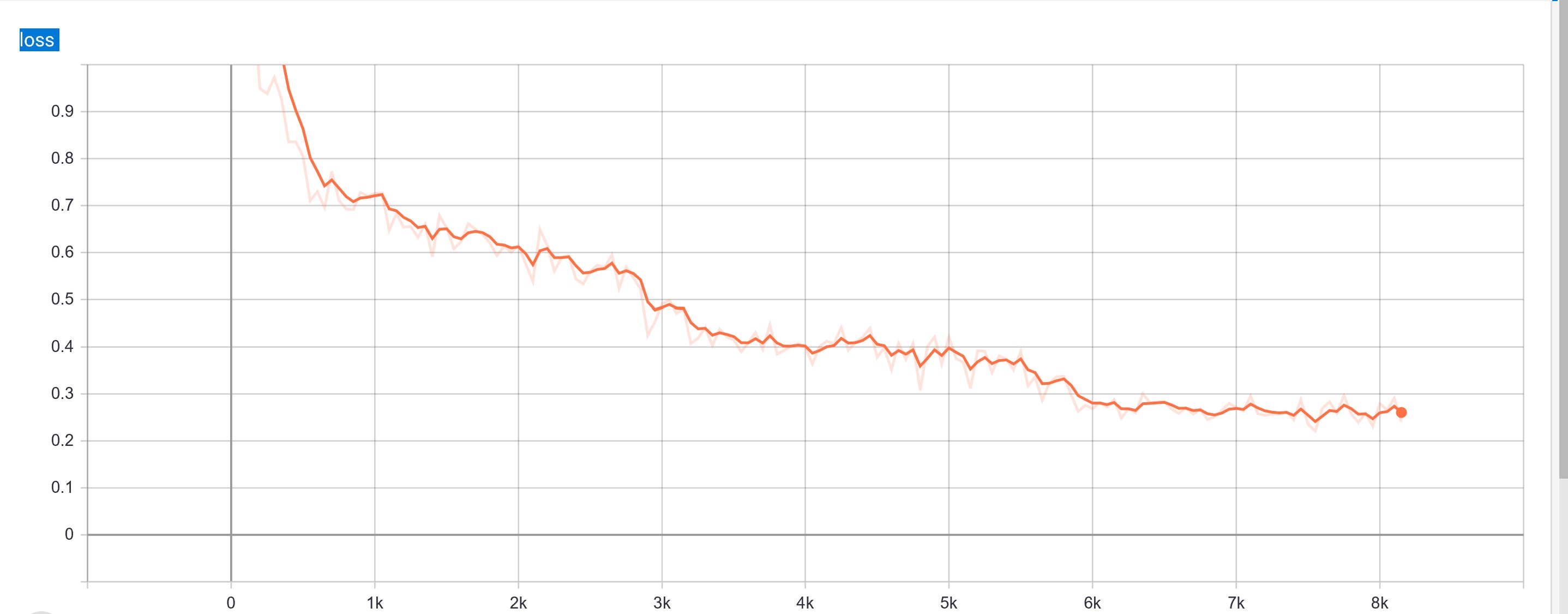
with script:
```
#!/bin/bash
export OMP_NUM_THREADS=6
RUN_SQUAD_DIR=/media/dn/dssd/nlp/transformers/examples
SQUAD_DIR=${RUN_SQUAD_DIR}/scripts/squad2.0
MODEL_PATH=${RUN_SQUAD_DIR}/runs/xlnet_large_squad2_512_bs48
python -m torch.distributed.launch --nproc_per_node=2 ${RUN_SQUAD_DIR}/run_squad.py \
--model_type xlnet \
--model_name_or_path xlnet-large-cased \
--do_train \
--train_file ${SQUAD_DIR}/train-v2.0.json \
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
--version_2_with_negative \
--num_train_epochs 3 \
--learning_rate 3e-5 \
--adam_epsilon 1e-6 \
--max_seq_length 512 \
--doc_stride 128 \
--save_steps 2000 \
--per_gpu_train_batch_size 1 \
--gradient_accumulation_steps 24 \
--output_dir ${MODEL_PATH}
CUDA_VISIBLE_DEVICES=0 python ${RUN_SQUAD_DIR}/run_squad.py \
--model_type xlnet \
--model_name_or_path ${MODEL_PATH} \
--do_eval \
--train_file ${SQUAD_DIR}/train-v2.0.json \
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
--version_2_with_negative \
--max_seq_length 512 \
--per_gpu_eval_batch_size 48 \
--output_dir ${MODEL_PATH}
$@
```
After upgrading Transformers to Version 2.3.0 I decided to see if there would be any improvements in the fine-tuning results using the same script above. I got the following results:
```
xlnet_large_squad2_512_bs48
Results: {
'exact': 45.32131727448834,
'f1': 45.52929325627209,
'total': 11873,
'HasAns_exact': 0.0,
'HasAns_f1': 0.4165483859174251,
'HasAns_total': 5928,
'NoAns_exact': 90.51303616484441,
'NoAns_f1': 90.51303616484441,
'NoAns_total': 5945,
'best_exact': 50.07159100480081,
'best_exact_thresh': 0.0,
'best_f1': 50.07229287739689,
'best_f1_thresh': 0.0}
```
No learning takes place:
Looking for potential explanation(s)/source(s) for the loss of performance. I have searched Transformer releases and issues for anything pertaining to XLNet with no clues. Are there new fine-tuning hyperparameters I've missed that now need to be assigned, or maybe didn't exist in earlier Transformer versions? Any PyTorch/Tensorflow later version issues? I may have to recreate the Nov 2019 environment for a re-run to verify the earlier results, and then incrementally update Transformers, PyTorch, Tensorflow, etc.?
Current system configuration:
OS: Linux Mint 19.3 based on Ubuntu 18.04. 3 LTS and Linux Kernel 5.0
GPU/CPU: 2 x NVIDIA 1080Ti / Intel i7-8700
Seasonic 1300W Prime Gold Power Supply
CyberPower 1500VA/1000W battery backup
Transformers: 2.3.0
PyTorch: 1.3.0
TensorFlow: 2.0.0
Python: 3.7.5
| 01-26-2020 20:48:28 | 01-26-2020 20:48:28 | I have been facing the same problem with RoBERTa finetuning for multiple choice QA datasets. I have even tried going back to the older version of transformers (version 2.1.0 from Oct 2019) and re-running my experiments but I am not able to replicate results from before anymore. The loss just varies within a range of +/- 0.1. <|||||>Are you using one of the recent versions of run_squad.py? It was quite heavily refactored in december. Maybe there is a mistake now. Can you try it with the run_squad.py of the 2.1.1 release again?<|||||>Could it be related to 96e8350? Before november 29 there was a mistake where the script would only evaluate on 1/N_GPU of the entire evaluation set.<|||||>@cronoik good suggestion
> Are you using one of the recent versions of run_squad.py? It was quite heavily refactored in december. Maybe there is a mistake now. Can you try it with the run_squad.py of the 2.1.1 release again?
I'm attempting to recreate the environment that existed for the successful fine-turning above that was dated 26Nov2019. I have the .yml file for that environment but after re-creating & re-running the script I get errors of missing "Albert files" and others. Not making much sense since this is using XLNET. I'm keeping after it.
@LysandreJik helpful information
> Could it be related to [96e8350](https://github.com/huggingface/transformers/commit/96e83506d1ddee8e19b07118668be73d175decb6)? Before november 29 there was a mistake where the script would only evaluate on 1/N_GPU of the entire evaluation set.
Perhaps, but given that the successful run was before 29Nov2019, plus my eval script uses single GPU ( CUDA_VISIBLE_DEVICES=0 ), could [96e8350] be a culprit?
How best to debug my latest, up-to-date environment?
Transformers: 2.3.0
PyTorch: 1.4.0
TensorFlow: 2.1.0
Python: 3.7.6
<|||||>How about the cached files at .cache/torch/transformers?
I have over 6GB of models cached dating back to November 2019.
Any chance the wrong config.json, spiece.model, model.bin, etc. are getting loaded from the cache which don't match-up with new Transformer code/libraries?
I think it's time to clear out the cache.
Ran single GPU0 on script above with gradient accumulation set to 48, everything else the same. Results and loss were the same. Apparently it is not a distributed processing issue.
**Update 30Jan20:** Cleared the caches, ran the distributed processing script in the first post above adding `--overwrite_cache`, same results and losses.<|||||>Hi guys! I just run into the same issue. I fine-tuned XLNet on the squad 2 trainingset over the weekend, exactly as instructed on the examples page, and got the same inferior results:
`
python examples/run_squad.py
--model_type xlnet
--model_name_or_path xlnet-large-cased
--do_train
--do_eval
--version_2_with_negative
--train_file ./squad/train-v2.0.json
--predict_file ./squad/dev-v2.0.json
--learning_rate 3e-5
--num_train_epochs 4
--max_seq_length 384
--doc_stride 128
--output_dir ./xlnet_large_squad2_out/
--per_gpu_eval_batch_size=2
--per_gpu_train_batch_size=2
--save_steps 50000
`
`02/01/2020 00:50:47 - WARNING - __main__ - Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: False`
...
`02/03/2020 01:50:51 - INFO - __main__ - Results: {'exact': 45.35500715910048, 'f1': 45.42776379790963, 'total': 11873, 'HasAns_exact': 0.08434547908232119, 'HasAns_f1': 0.23006740428154376, 'HasAns_total': 5928, 'NoAns_exact': 90.49621530698066, 'NoAns_f1': 90.49621530698066, 'NoAns_total': 5945, 'best_exact': 50.07159100480081, 'best_exact_thresh': 0.0, 'best_f1': 50.07159100480081, 'best_f1_thresh': 0.0}`
My versions:
transformers: `0aa40e9` (same as v2.4.0)
python `3.6.8`
pytorch `1.2.0+cu92`
I will proceed to run it again on transformers v2.1.1 and report back whether the old code still works for XLNet.<|||||>Hi @WilliamNurmi, thank you for taking the time to do this. Do you mind making sure that you're using `SequentialSampler` in your evaluation, even when running against transformers v2.1.1? This affects the evaluation, which should be the same as the one you did in v2.4.0.
This should only affect setups with more than 1 gpu and this does not seem to be your case, but if it is, it would be great to update the sampler.<|||||>Hi @LysandreJik, I'm indeed using only 1 gpu, so we should be good there!<|||||>No dice with XLNet on v2.1.1. I used the same parameters as @ahotrod except for slight changes for gradient_accumulation_steps (not used), max_seq_length (368) and per_gpu_train_batch_size (1).
`python examples/run_squad.py --model_type xlnet --model_name_or_path xlnet-large-cased --do_train --do_eval --version_2_with_negative --train_file ./squad/train-v2.0.json --predict_file ./squad/dev-v2.0.json --learning_rate 3e-5 --num_train_epochs 3 --max_seq_length 368 --doc_stride 128 --output_dir ./xlnet_cased_finetuned_squad/ --per_gpu_eval_batch_size=2 --per_gpu_train_batch_size=2 --save_steps 63333 --logging_steps 63333 --evaluate_during_training --adam_epsilon 1e-6`
Inferior results:
`{
"exact": 37.45472921755243,
"f1": 41.95943914787417,
"total": 11873,
"HasAns_exact": 70.05735492577598,
"HasAns_f1": 79.07969315160429,
"HasAns_total": 5928,
"NoAns_exact": 4.945332211942809,
"NoAns_f1": 4.945332211942809,
"NoAns_total": 5945,
"best_exact": 50.07159100480081,
"best_exact_thresh": 0.0,
"best_f1": 50.07159100480081,
"best_f1_thresh": 0.0
}`
I tried to mimic the setup at the time with the following versions:
Transformers `v2.1.1`
Python `3.6.9
Pytorch `1.3.1`
Interestingly the first run with `v2.4.0` gave an answer to only 5% of the test questions, while this v2.1.1 version dared to an answer 90% of the questions.
Does anyone have any idea what could have changed since last November that completely broke the SQuAD2 training? Could it be the files (pretrained network, tokenization, hyperparameters etc) that transformers lib is downloading at the beginning of the training ?<|||||>Is the run_squad.py the 2.1.1 version?<|||||>@cronoik, yeah. I'm installing from source and I re-cloned the whole repo.
I didn't realize to clean `~/.cache/torch/transformers/` though, but @ahotrod seems to have tried that with no luck.
EDIT: and looking at the cache file timestamps, it seems it has downloaded new files anyways.<|||||>As noted on other issues, plain old Bert is working better, so the issue seems to be specific to XLNet, RoBERTa ~and ALBERT(?)~.
On transformers `2.4.0`
`python examples/run_squad.py --model_type=bert --model_name_or_path=bert-base-uncased --do_train --do_eval --do_lower_case --version_2_with_negative --train_file=./squad/train-v2.0.json --predict_file=./squad/dev-v2.0.json --per_gpu_train_batch_size=12 --learning_rate=3e-5 --num_train_epochs=2.0 --max_seq_length=384 --doc_stride=128 --save_steps=20000 --output_dir=bert_out --overwrite_output_dir`
`Results: {'exact': 73.04809231028383, 'f1': 76.29336127902307, 'total': 11873, 'HasAns_exact': 71.99730094466936, 'HasAns_f1': 78.49714549018896, 'HasAns_total': 5928, 'NoAns_exact': 74.09587888982338, 'NoAns_f1': 74.09587888982338, 'NoAns_total': 5945, 'best_exact': 73.04809231028383, 'best_exact_thresh': 0.0, 'best_f1': 76.29336127902297, 'best_f1_thresh': 0.0}`<|||||>After nearly two weeks of unsuccessful varied XLNet fine-tunes, I gave-up and switched to fine-tuning ALBERT for an alternative model:
```
albert_xxlargev1_sqd2_512_bs48 results:
{'exact': 85.65653162637918,
'f1': 89.260458954177,
'total': 11873,
'HasAns_exact': 82.6417004048583,
'HasAns_f1': 89.85989020967376,
'HasAns_total': 5928,
'NoAns_exact': 88.66274179983179,
'NoAns_f1': 88.66274179983179,
'NoAns_total': 5945,
'best_exact': 85.65653162637918,
'best_exact_thresh': 0.0,
'best_f1': 89.2604589541768,
'best_f1_thresh': 0.0}
```
Ahhh, the beauty and flexibility of Transformers, out with one model and in with another.
My QA app is performing well with ALBERT.
Current system configuration:
OS: Linux Mint 19.3 based on Ubuntu 18.04. 3 LTS and Linux Kernel 5.0
GPU/CPU: 2 x NVIDIA 1080Ti / Intel i7-8700
Transformers: 2.3.0
PyTorch: 1.4.0
TensorFlow: 2.1.0
Python: 3.7.6<|||||>I was originally going for ALBERT, but tried XLNet instead because many people seemed to be reporting that ALBERT doesn't work ([#202](https://github.com/deepset-ai/FARM/issues/202), [#2609](https://github.com/huggingface/transformers/issues/2609)). But looking into it more, it looks like it is only the v2 model that doesn't work!<|||||>> After nearly two weeks of unsuccessful varied XLNet fine-tunes, I gave-up and switched to fine-tuning ALBERT for an alternative model:
>
> ```
> albert_xxlargev1_sqd2_512_bs48 results:
> {'exact': 85.65653162637918,
> 'f1': 89.260458954177,
Nice results @ahotrod! Better than [what you got in Dec](https://github.com/huggingface/transformers/issues/1974#issuecomment-562814997):
`albert_xxlargev1_squad2_512_bs48:
"exact": 83.65198349195654,
"f1": 87.4736247587816,`
Could you share the hyper-parameters you used?
And ellaborate a bit whether you train it with `run_squad.py` or some custom code? `run_squad.py` doesn't seem allow us to apply 0.1 dropout for the classification layer as suggested in the [paper](https://openreview.net/pdf?id=H1eA7AEtvS).
<|||||>@WilliamNurmi thanks for your feedback
When Google Research released their v2 of ALBERT LMs they stated that xxlarge-v1 outperforms xxlarge-v2 and have a discussion as to why: https://github.com/google-research/ALBERT. So I've stuck with v1 for that reason plus the "teething" issues that have been associated with v2 LMs.
Yes, seems there have been transfomers revisions positively impacting ALBERT SQuAD 2.0 fine-tuning since my results Dec19 as you noted. I think including `--max_steps 8144` & `--warmup_steps 814` in my script produced the improvement listed above.
Additional ALBERT & transformers refinements, hopefully significant, are in transformers v2.4.1: `classifier dropout` and `gelu_new`, thanks to @peteriz & @LysandreJik #2679. I am 18 hours in to a 67 hour fine-tune & eval of `albert_xxlargev1_sqd2_512_bs48` with script below using transformers v2.4.1. I will post results when processing is complete.
BTW the heat produced from my hardware-challenged computer, **hotrod**, is a welcome tuning by-product for my winter office, summer not so much. Hoping for a NVIDIA Ampere upgrade before this summer's heat.
My fine-tuning has been with transformer's `run_squad.py` not custom code. Here's my latest script:
```
albert_xxlargev1_sqd2_512_bs48.sh:
#!/bin/bash
export OMP_NUM_THREADS=8
RUN_SQUAD_DIR=/media/dn/dssd/nlp/transformers/examples
SQUAD_DIR=${RUN_SQUAD_DIR}/scripts/squad2.0
MODEL_PATH=${RUN_SQUAD_DIR}/runs/albert_xxlargev1_squad2_512_bs48
python -m torch.distributed.launch --nproc_per_node=2 ${RUN_SQUAD_DIR}/run_squad.py \
--model_type albert \
--model_name_or_path albert-xxlarge-v1 \
--do_train \
--train_file ${SQUAD_DIR}/train-v2.0.json \
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
--version_2_with_negative \
--num_train_epochs 3 \
--max_steps 8144 \
--warmup_steps 814 \
--do_lower_case \
--learning_rate 3e-5 \
--max_seq_length 512 \
--doc_stride 128 \
--save_steps 1000 \
--per_gpu_train_batch_size 1 \
--gradient_accumulation_steps 24 \
--overwrite_cache \
--logging_steps 100 \
--threads 8 \
--output_dir ${MODEL_PATH}
CUDA_VISIBLE_DEVICES=0 python ${RUN_SQUAD_DIR}/run_squad.py \
--model_type albert \
--model_name_or_path ${MODEL_PATH} \
--do_eval \
--train_file ${SQUAD_DIR}/train-v2.0.json \
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
--version_2_with_negative \
--do_lower_case \
--max_seq_length 512 \
--per_gpu_eval_batch_size 24 \
--eval_all_checkpoints \
--overwrite_output_dir \
--output_dir ${MODEL_PATH}
$@
```<|||||>Thanks for all the details @ahotrod, I had missed the fact that classifier dropout had just been added! I restarted my run with v2.4.1. Loss seems to be going down nicely, so far so good.
It's gonna be 6 days for me since I'm on a single Ti 1080. I'm gonna have to look for some new hardware / instances soon as well. Any bigger model or sequence length and I couldn't fit a single batch on this GPU anymore :D
Looking forward to the sneak peak of the results when your run finishes!<|||||>@ahotrod could you consider sharing trained ALBERT SQUAD trained model on https://huggingface.co/models?<|||||>> @ahotrod could you consider sharing trained ALBERT SQUAD trained model on https://huggingface.co/models?
@knuser Absolutely, I signed-up some time ago with that intent but have yet to contribute.
I'm 26 hours from this v2.4.1 `albert_xxlargev1_sqd2_512_bs48` run completion and afterwards will share the best run to date.
FYI, 11 question inferencing/prediction with this 512 max_seq_length xxlarge ALBERT model takes 37 seconds CPU and 5 secs single GPU w/large batches on my computer, **hotrod**, described above.
BTW, sharing can definitely save some energy & lower the carbon footprint. As an example my office electric bill doubled last month from just under $100 to over $200 with nearly constant **hotrod** fine-tuning. Perhaps the gas heater didn't need to fire-up as often though. ;-]<|||||>@WilliamNurmi @knuser :
Fine-tuning the `albert_xxlargev1_sqd2_512_bs48` script with Transformers 2.4.1 yielded the following results:
```
{'exact': 85.47123726101238,
'f1': 89.0856118938743,
'total': 11873,
'HasAns_exact': 82.11875843454791,
'HasAns_f1': 89.35787280971171,
'HasAns_total': 5928,
'NoAns_exact': 88.81412952060555,
'NoAns_f1': 88.81412952060555,
'NoAns_total': 5945,
'best_exact': 85.46281478985935,
'best_exact_thresh': 0.0,
'best_f1': 89.07718942272103,
'best_f1_thresh': 0.0}
```
which is no improvement over fine-tuning the same script with Transformers 2.3.0
My best model to date is now posted at: https://huggingface.co/ahotrod/albert_xxlargev1_squad2_512
You can access this albert_xxlargev1_sqd2_512 fine-tuned model with:
```
config_class, model_class, tokenizer_class = \
AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer
model_name_or_path = "ahotrod/albert_xxlargev1_squad2_512"
config = config_class.from_pretrained(model_name_or_path)
tokenizer = tokenizer_class.from_pretrained(model_name_or_path, do_lower_case=True)
model = model_class.from_pretrained(model_name_or_path, config=config)
```
The AutoModels: (AutoConfig, AutoTokenizer & AutoModel) should also work, however I
have yet to use them.
Hope this furthers your efforts!<|||||>Hi guys, thanks for the great discussion. I've been trying to reproduce the XLNet fine-tuning myself, but have failed to do so so far. I stumbled upon a few issues along the way, mostly related to the padding side.
There was an issue that I fixed this morning related to the `tokens` that were used for evaluation, which were not correctly computed. I updated that in 125a75a, however it does not improve the accuracy.
I'm still actively working on it and will let you know as I progress (it is quite a lengthy process as a finetuning requires a full-day of computing on my machine).<|||||>Hi @LysandreJik, thanks for hunting the bugs! It's going to be a great help for many people.
I don't know the details of the remaining bugs, but at least the bugs I encountered were so bad that I think you should see whether or not it works very quickly after starting fine-tuning by checking if the loss is decreasing on tensorboard.<|||||>I can also confirm the issue after fine-tuning xlnet-large-cased on Squad 2.0 for 1 epoch. The F1 score is 46.53 although the NoAns_F1 was 89.05, probably because the model is predicting so many blanks (most with "start_log_prob": -1000000.0, "end_log_prob": -1000000.0) while HasAns_exact is close to 0.
Not sure if it is related to the CLS token position mentioned in #947 and #1088. But it might be specific to the unanswerable questions in Squad 2.0. Hopefully the bug will be found and fixed soon :-)
Transformers: 2.5.1
PyTorch: 1.4.0
Python: 3.8.1<|||||>@ahotrod I saw you're using a different eval script (`run_squad_II.py`) for your model at https://huggingface.co/ahotrod/xlnet_large_squad2_512 — have you figured out what was wrong with `run_squad.py`? Thanks!<|||||>@elgeish - good eye on my eval script using `run_squad_II.py`, as posted in my model card. Unfortunately I have not figured-out what is wrong with training using the latest `run_squad.py` versions as outlined in this issue.
My https://huggingface.co/ahotrod/xlnet_large_squad2_512 model is from Nov 2019, same as the successful fine-tuned model described in my first post above. `run_squad_II.py` contained experimental code I was working on at the time trying to overcome the multi-GPU distributed processing eval limitation. Fortunately, when `run_squad_II.py` evals were run single GPU `(CUDA_VISIBLE_DEVICES=0)`, evals were the same as the Transformers v2.1.1 original `run_squad.py`, as I did not modify that portion of the code. I failed to change that eval script back to `run_squad.py`, but again since the `run_squad_II.py` eval in that script was run single GPU, it performed the same eval as the original. Sorry for the confusion.<|||||>@ahotrod thanks for the explanation!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Any update on this issue? I am facing same issue when fine tuning custom RoBERTa.
Cheers<|||||>I'm on `4.4.0dev` |
transformers | 2,650 | closed | loss function error when running run_lm_finetuning.py file | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): BERT
Language I am using the model on (English, Chinese....): Multilingual model (trying to finetune with Bengali)
The problem arise when using:
* [run_lm_finetuning.py] the official example scripts: I wanted to fine tune the multilingual bert model on Bengali text.
## To Reproduce
Steps to reproduce the behavior:
1. Running the script mentioned using the command I used below and Bengali txt. For now I simply put Bengali wikidump in a text file.
student_1@gpuserver:~/aysha_anis_thesis/thesis$ python3 run_lm_finetuning.py --output_dir=lm_out --model_type=bert --model_name_or_path=bert-base-multilingual-cased --do_train --train_data_file=wikiText.txt --mlm --save_total_limit=2
2020-01-26 22:28:55.372480: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0
2020-01-26 22:28:55.377886: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0
/usr/lib/python3/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
01/26/2020 22:28:56 - WARNING - __main__ - Process rank: -1, device: cuda, n_gpu: 2, distributed training: False, 16-bits training: False
01/26/2020 22:28:57 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-config.json from cache at /home/student_1/.cache/torch/transformers/45629519f3117b89d89fd9c740073d8e4c1f0a70f9842476185100a8afe715d1.83b0fa3d7f1ac0e113ad300189a938c6f14d0588a4200f30eef109d0a047c484
01/26/2020 22:28:57 - INFO - transformers.configuration_utils - Model config {
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"num_labels": 2,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"pruned_heads": {},
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 119547
}
01/26/2020 22:28:59 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt from cache at /home/student_1/.cache/torch/transformers/96435fa287fbf7e469185f1062386e05a075cadbf6838b74da22bf64b080bc32.99bcd55fc66f4f3360bc49ba472b940b8dcf223ea6a345deb969d607ca900729
01/26/2020 22:29:00 - INFO - transformers.modeling_utils - loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-pytorch_model.bin from cache at /home/student_1/.cache/torch/transformers/5b5b80054cd2c95a946a8e0ce0b93f56326dff9fbda6a6c3e02de3c91c918342.7131dcb754361639a7d5526985f880879c9bfd144b65a0bf50590bddb7de9059
01/26/2020 22:29:04 - INFO - transformers.modeling_utils - Weights from pretrained model not used in BertForMaskedLM: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias']
01/26/2020 22:29:06 - INFO - __main__ - Training/evaluation parameters Namespace(adam_epsilon=1e-08, block_size=510, cache_dir=None, config_name=None, device=device(type='cuda'), do_eval=False, do_train=True, eval_all_checkpoints=False, eval_data_file=None, evaluate_during_training=False, fp16=False, fp16_opt_level='O1', gradient_accumulation_steps=1, learning_rate=5e-05, line_by_line=False, local_rank=-1, logging_steps=50, max_grad_norm=1.0, max_steps=-1, mlm=True, mlm_probability=0.15, model_name_or_path='bert-base-multilingual-cased', model_type='bert', n_gpu=2, no_cuda=False, num_train_epochs=1.0, output_dir='lm_out', overwrite_cache=False, overwrite_output_dir=False, per_gpu_eval_batch_size=4, per_gpu_train_batch_size=4, save_steps=50, save_total_limit=2, seed=42, server_ip='', server_port='', should_continue=False, tokenizer_name=None, train_data_file='wikiText.txt', warmup_steps=0, weight_decay=0.0)
01/26/2020 22:29:06 - INFO - __main__ - Loading features from cached file bert_cached_lm_510_wikiText.txt
01/26/2020 22:29:08 - INFO - __main__ - ***** Running training *****
01/26/2020 22:29:08 - INFO - __main__ - Num examples = 103717
01/26/2020 22:29:08 - INFO - __main__ - Num Epochs = 1
01/26/2020 22:29:08 - INFO - __main__ - Instantaneous batch size per GPU = 4
01/26/2020 22:29:08 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 8
01/26/2020 22:29:08 - INFO - __main__ - Gradient Accumulation steps = 1
01/26/2020 22:29:08 - INFO - __main__ - Total optimization steps = 12965
Epoch: 0%| | 0/1 [00:00<?, ?it/s/home/student_1/.local/lib/python3.6/site-packages/torch/nn/parallel/_functions.py:61: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [0,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [2,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [3,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [4,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [5,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [6,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [7,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [8,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [9,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [10,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [11,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [12,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [13,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [14,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [15,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [16,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [17,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [19,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [20,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [21,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [22,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [23,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [25,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [27,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [28,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [29,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [31,0,0] Assertion `t >= 0 && t < n_classes` failed.
Traceback (most recent call last):
File "run_lm_finetuning.py", line 785, in <module>
main()
File "run_lm_finetuning.py", line 735, in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
File "run_lm_finetuning.py", line 353, in train
loss.backward()
File "/home/student_1/.local/lib/python3.6/site-packages/torch/tensor.py", line 166, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/home/student_1/.local/lib/python3.6/site-packages/torch/autograd/__init__.py", line 99, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: CUDA error: device-side assert triggered
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [0,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [2,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [3,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [5,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [6,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [7,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [8,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [10,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [11,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [12,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [13,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [14,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [16,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [17,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [18,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [19,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [21,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [22,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [23,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [24,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [25,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [26,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [27,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [28,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [29,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:106: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype *, Dtype *, Dtype *, long *, Dtype *, int, int, int, int, long) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [31,0,0] Assertion `t >= 0 && t < n_classes` failed.
Epoch: 0%| | 0/1 [00:02<?, ?it/s]
Iteration: 0%| | 0/12965 [00:02<?, ?it/s]
| 01-26-2020 17:48:35 | 01-26-2020 17:48:35 | I got the exact same error while trying to finetune BERT with mlm on ENRON emails dataset. This problem doesn't occur in older versions of this repo (before Jan 5th). So perhaps you can try that while they fix this issue?<|||||>I had your same error. Trying with different block size and batch size, with a certain configuration (I don't remember which one) the program gave me your error, with a different one it blocked on the tokenization of the training set. I followed this advice and it worked : https://github.com/huggingface/transformers/issues/2611#issuecomment-577696982
Don't know if it can be solution, hope so 😁<|||||>@cgnarendiran Thanks a lot. Previous version is working fine. Is there any major update since then? In terms of bert and finetuning it, that you know of?
@paulthemagno I tried --line_by_line too. It had the same issue. Also, I am testing with a small dataset, so for now dataset size isn't an issue.<|||||>Hi, the scripts are kept up to date with the `master` branch and not with the latest release. Do you think you could try and install from source (`pip install git+https://github.com/huggingface/transformers`) and let me know if you still have the same errors?
Thank you.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,649 | closed | Using a Model without any pretrained data | ## ❓ Questions & Help
<!-- Sorry for a very basic question. Can I use your library without any pertained data? For example, I want to use a BERT transformer model, but using only my corpus of data. In the docs, I only see examples using pretrained models. Thanks. -->
| 01-26-2020 17:07:32 | 01-26-2020 17:07:32 | Just don't use the [from_pretrained](https://huggingface.co/transformers/main_classes/model.html#transformers.PreTrainedModel.from_pretrained) method and initialize the class with a config.
```
from transformers import BertModel, BertConfig
#model with pretrained weights
model_with_Pretrained = BertModel.from_pretrained('bert-base-uncased')
#model without pretrained weights
config = BertConfig()
model_without_Pretrained = BertModel(config)
```<|||||>@cronoik Thanks<|||||>Hi, I also encounter the same question, is the solution still valid in the latest v4.28?
thanks! |
transformers | 2,648 | closed | run_lm_finetuning.py for GPT2 throw error "Using pad_token, but it is not set yet." | I used the official setting.
```bash
python transformers/examples/run_lm_finetuning.py \
--output_dir=gpt2_q_model \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=txt/{q_files[0]} \
```
But it says the padding id was not set.
```python
ERROR - transformers.tokenization_utils - Using pad_token, but it is not set yet.
Traceback (most recent call last):
File "transformers/examples/run_lm_finetuning.py", line 785, in <module>
main()
File "transformers/examples/run_lm_finetuning.py", line 735, in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
File "transformers/examples/run_lm_finetuning.py", line 330, in train
for step, batch in enumerate(epoch_iterator):
File "/usr/local/lib/python3.6/dist-packages/tqdm/_tqdm.py", line 979, in __iter__
for obj in iterable:
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py", line 346, in __next__
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py", line 47, in fetch
return self.collate_fn(data)
File "transformers/examples/run_lm_finetuning.py", line 231, in collate
return pad_sequence(examples, batch_first=True, padding_value=tokenizer.pad_token_id)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/utils/rnn.py", line 384, in pad_sequence
out_tensor = sequences[0].data.new(*out_dims).fill_(padding_value)
TypeError: fill_() received an invalid combination of arguments - got (NoneType), but expected one of:
* (Tensor value)
didn't match because some of the arguments have invalid types: (NoneType)
* (Number value)
didn't match because some of the arguments have invalid types: (NoneType)
``` | 01-26-2020 15:21:28 | 01-26-2020 15:21:28 | I am having same error as well. Did you manage to fix it or any other updates?<|||||>Can you let me know if 6b4c3ee234db010ae2fb0554c0099fbf1f7f1f51 fixes your issue?<|||||>I encountered this issue and sure enough it is fixed with `6b4c3ee`.
Thanks @julien-c. It's mind blowing that I found the error 15 mins ago, searched here, found that you'd just patched it, and am now able to continue.<|||||>Thanks @julien-c , that fixes it.<|||||>Thanks guys! (and hat/tip @LysandreJik)<|||||>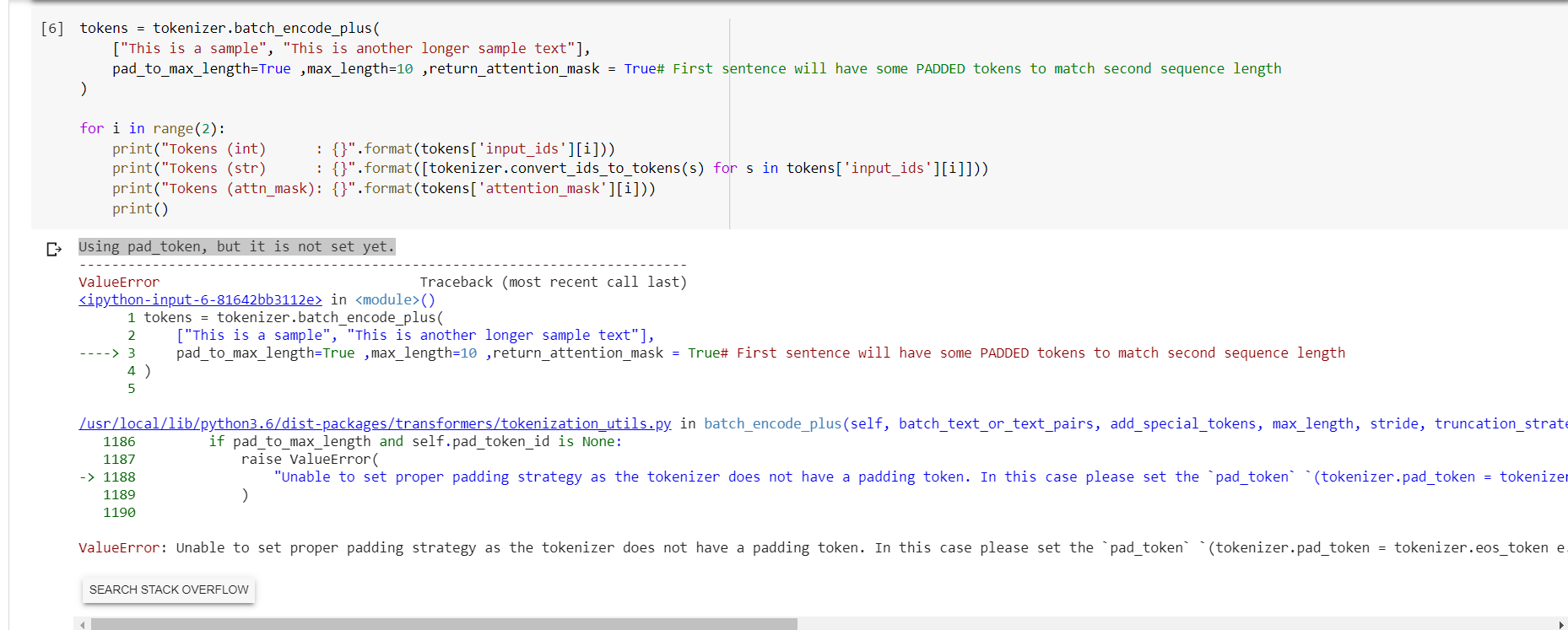
<|||||>ValueError: Unable to set proper padding strategy as the tokenizer does not have a padding token. In this case please set the `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via the function add_special_tokens if you want to use a padding strategy
|
transformers | 2,647 | closed | Question Answering with Japanese | ## ❓ Questions & Help
Hi @singletongue,
I am trying to use Question-Answering for Japanese, however I could not find any model trained for that.
I tried with the available models but the results were way off (as expected...).
Any suggestions on available models, or other library that already handle QnA with Japanese?
If it is supposed to work as-is, could you share a simple example?
Thank you in advance! | 01-26-2020 12:33:15 | 01-26-2020 12:33:15 | Hi @Mukei,
As far as I know, there is no Transformer-based model fine-tuned for Japanese question answering tasks.
It is partly due to the scarcity of Japanese QA datasets (like SQuAD) to train the models on.
(Of course, we do wish to release models for QA, and it is left for our future work.)<|||||>As a workaround you could load the [bert-base-japanese](https://huggingface.co/bert-base-japanese) weights for the BertForQuestionAnswering model and just finetune the qa_outputs layer (in case of a single span prediction task). It will be quickly trained and maybe produces already sufficient results. <|||||>@singletongue Thank you for your reply!
You might already know about it, but I found this [project](https://github.com/AkariAsai/extractive_rc_by_runtime_mt) with SQuAD V1.1 partially translated to Japanese: [Context](https://github.com/AkariAsai/extractive_rc_by_runtime_mt/blob/master/data/ja_question_v5_context.csv), [QA](https://github.com/AkariAsai/extractive_rc_by_runtime_mt/blob/master/data/ja_question_v5.csv)<|||||>@cronoik Thank you for the advice.
I tried but unfortunately the results were pretty bad even for some simple phrase.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,646 | closed | glue.py: AttributeError: 'numpy.str_' object has no attribute 'text_a' | when I am executing the glue data conversion i.e.
`sequences = glue_convert_examples_to_features(X_train, tokenizer, max_length=MAX_SEQUENCE_LENGTH, task='mrpc')
`
I'm getting this error:
> I0126 11:57:07.862119 16252 glue.py:70] Using label list ['0', '1'] for task mrpc
> I0126 11:57:07.863118 16252 glue.py:73] Using output mode classification for task mrpc
> I0126 11:57:07.864120 16252 glue.py:80] Writing example 0
> ---------------------------------------------------------------------------
>
> AttributeError Traceback (most recent call last)
>
> <ipython-input-11-621d8071aa9a> in <module>
> 2 #test_sequences = [tokenizer.encode(xxt,add_special_tokens=True) for xxt in X_test]
> 3 #val_sequences = [tokenizer.encode(xxt,add_special_tokens=True) for xxt in X_val]
> ----> 4 sequences = glue_convert_examples_to_features(df['cleantext'], tokenizer, max_length=MAX_SEQUENCE_LENGTH, task='mrpc')
> 5 val_sequences = glue_convert_examples_to_features(X_val, tokenizer, max_length=MAX_SEQUENCE_LENGTH, task='mrpc')
> 6 test_sequences = glue_convert_examples_to_features(X_val, tokenizer, max_length=MAX_SEQUENCE_LENGTH, task='mrpc')
>
> d:\anaconda3\envs\t2\lib\site-packages\transformers\data\processors\glue.py in glue_convert_examples_to_features(examples, tokenizer, max_length, task, label_list, output_mode, pad_on_left, pad_token, pad_token_segment_id, mask_padding_with_zero)
> 84
> 85 inputs = tokenizer.encode_plus(
> ---> 86 example.text_a,
> 87 example.text_b,
> 88 add_special_tokens=True,
>
> AttributeError: 'str' object has no attribute 'text_a'
As tokenizer I'm using
`tokenizer = BertTokenizer.from_pretrained('bert-base-cased')`
and my numpy version is 1.18.1, tensorflow version 2.1.0 (base 2.1.0), transformers version 2.3.0
| 01-26-2020 11:02:12 | 01-26-2020 11:02:12 | I think the problem was due to the dataset not being set to (index,example) structure<|||||>@pacebrian0 Could you post what changes did you make?<|||||>I decided to use simpletransformers python package, which allows you to train custom datasets.
The above problem can only be solved by using tensorflow-datasets data as far as I know<|||||>Ah! The same as me. I am using that same package, but had no idea that those problems could be solved only with tensorflow-datasets. |
transformers | 2,645 | closed | How to load locally saved tensorflow DistillBERT model | I have got tf model for DistillBERT by the following python line
> `import tensorflow as tf
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertModel.from_pretrained('distilbert-base-uncased')
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"), dtype="int32")[None, :] # Batch size 1
outputs = model(input_ids)
last_hidden_states = outputs[0]`
> These lines have been executed successfully. But I am facing error with model.save()
> `model.save("DSB/DistilBERT.h5")`
> `model.save("DSB")`
> `model.save("DSB/")`
> all the above 3 line gives errors
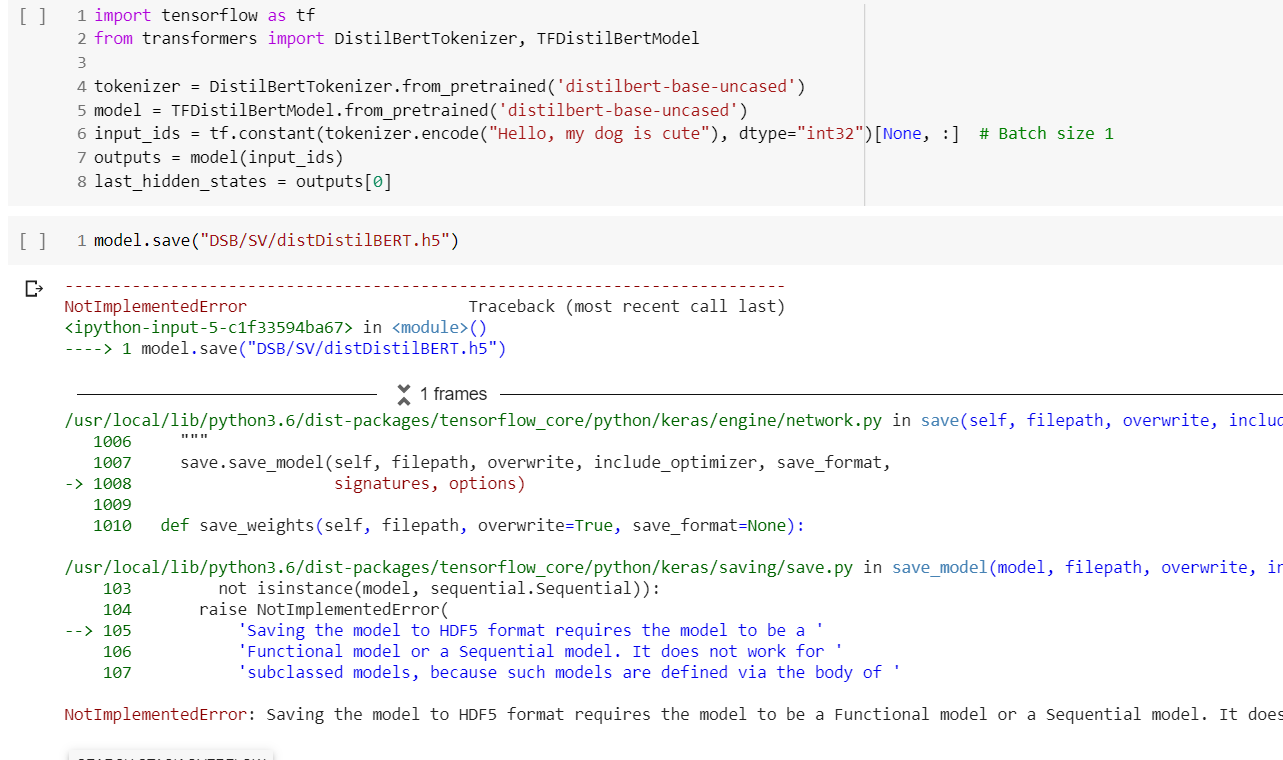

> but downlines works
>`model.save_pretrained("DSB")`
this saves 2 file tf_model.h5 and config.json
>`model.save_weights("DSB/DistDistilBERT_weights.h5")`
this also have saved the file

> but I am not able to re-load this locally saved model any how, I have tried with all down-lines it gives error
> `from tensorflow.keras.models import load_model
from transformers import DistilBertConfig, PretrainedConfig
from transformers import TFPreTrainedModel
config = DistilBertConfig.from_json_file('DSB/config.json') conf2=PretrainedConfig.from_pretrained("DSB")
config=TFPreTrainedModel.from_config("DSB/config.json")`
> all these load configuration , but I am unable to load model , tried with all down-line
> `model=TFPreTrainedModel.from_pretrained("DSB")`
> `model=PreTrainedModel.from_pretrained("DSB/tf_model.h5", from_tf=True, config=config)`
> `model=TFPreTrainedModel.from_pretrained("DSB/")`
> ` model=TFPreTrainedModel.from_pretrained("DSB/tf_model.h5", config=config)`
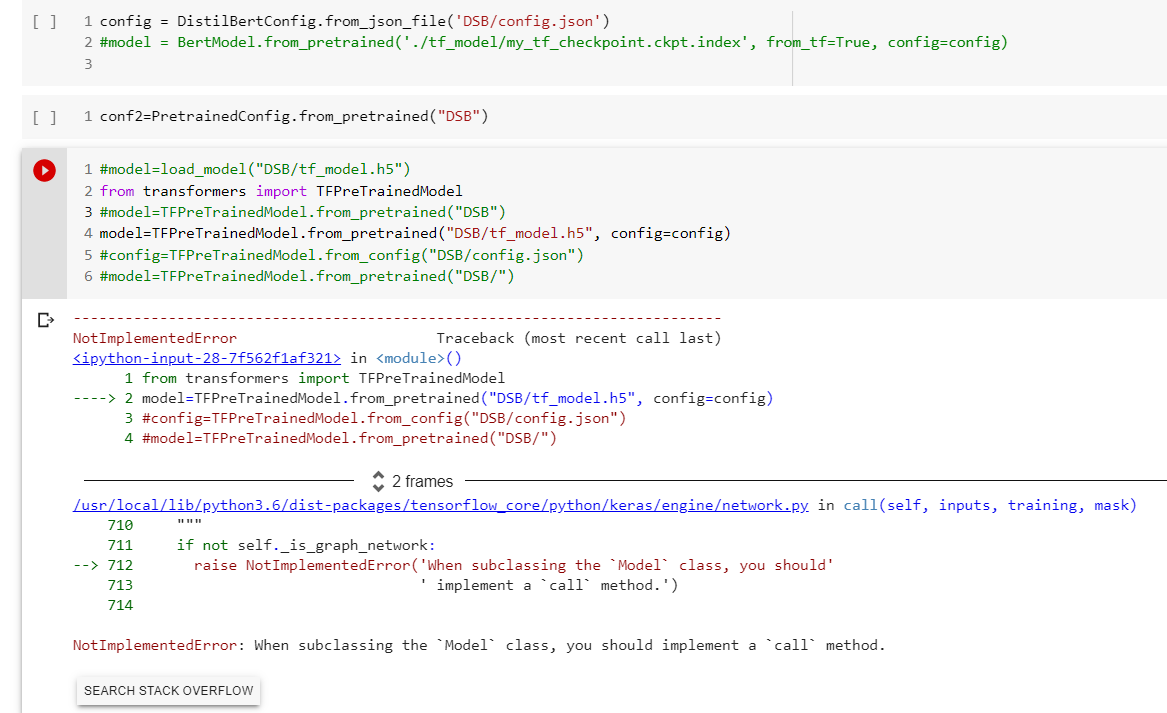
> NotImplementedError Traceback (most recent call last)
<ipython-input-28-7f562f1af321> in <module>()
1 from transformers import TFPreTrainedModel
----> 2 model=TFPreTrainedModel.from_pretrained("DSB/tf_model.h5", config=config)
3 #config=TFPreTrainedModel.from_config("DSB/config.json")
4 #model=TFPreTrainedModel.from_pretrained("DSB/")
2 frames
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
309 return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file, allow_missing_keys=True)
310
--> 311 ret = model(model.dummy_inputs, training=False) # build the network with dummy inputs
312
313 assert os.path.isfile(resolved_archive_file), "Error retrieving file {}".format(resolved_archive_file)
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/base_layer.py in __call__(self, inputs, *args, **kwargs)
820 with base_layer_utils.autocast_context_manager(
821 self._compute_dtype):
--> 822 outputs = self.call(cast_inputs, *args, **kwargs)
823 self._handle_activity_regularization(inputs, outputs)
824 self._set_mask_metadata(inputs, outputs, input_masks)
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/network.py in call(self, inputs, training, mask)
710 """
711 if not self._is_graph_network:
--> 712 raise NotImplementedError('When subclassing the `Model` class, you should'
713 ' implement a `call` method.')
714
NotImplementedError: When subclassing the `Model` class, you should implement a `call` method.
| 01-26-2020 07:10:25 | 01-26-2020 07:10:25 | Please format your code correctly using code tags and not quote tags, and don't use screenshots but post your actual code so that we can copy-paste it and reproduce your errors. https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks<|||||>Thanks to your response, now it will be convenient to copy-paste.
```
import tensorflow as tf
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertModel.from_pretrained('distilbert-base-uncased')
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"), dtype="int32")[None, :] # Batch size 1
outputs = model(input_ids)
last_hidden_states = outputs[0]
```
>############################################ success
```
model.save("DSB/SV/distDistilBERT.h5")
```
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
<ipython-input-5-c1f33594ba67> in <module>()
----> 1 model.save("DSB/SV/distDistilBERT.h5")
1 frames
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/network.py in save(self, filepath, overwrite, include_optimizer, save_format, signatures, options)
1006 """
1007 save.save_model(self, filepath, overwrite, include_optimizer, save_format,
-> 1008 signatures, options)
1009
1010 def save_weights(self, filepath, overwrite=True, save_format=None):
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/saving/save.py in save_model(model, filepath, overwrite, include_optimizer, save_format, signatures, options)
103 not isinstance(model, sequential.Sequential)):
104 raise NotImplementedError(
--> 105 'Saving the model to HDF5 format requires the model to be a '
106 'Functional model or a Sequential model. It does not work for '
107 'subclassed models, because such models are defined via the body of '
NotImplementedError: Saving the model to HDF5 format requires the model to be a Functional model or a Sequential model. It does not work for subclassed models, because such models are defined via the body of a Python method, which isn't safely serializable. Consider saving to the Tensorflow SavedModel format (by setting save_format="tf") or using `save_weights`.
> #############################################
```
model.save("DSB/")
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-8-75503fb9f2ea> in <module>()
----> 1 model.save("DSB/")
3 frames
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/network.py in save(self, filepath, overwrite, include_optimizer, save_format, signatures, options)
1006 """
1007 save.save_model(self, filepath, overwrite, include_optimizer, save_format,
-> 1008 signatures, options)
1009
1010 def save_weights(self, filepath, overwrite=True, save_format=None):
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/saving/save.py in save_model(model, filepath, overwrite, include_optimizer, save_format, signatures, options)
113 else:
114 saved_model_save.save(model, filepath, overwrite, include_optimizer,
--> 115 signatures, options)
116
117
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/saving/saved_model/save.py in save(model, filepath, overwrite, include_optimizer, signatures, options)
63
64 if save_impl.should_skip_serialization(model):
---> 65 saving_utils.raise_model_input_error(model)
66
67 if not include_optimizer:
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/saving/saving_utils.py in raise_model_input_error(model)
111 'set. Usually, input shapes are automatically determined from calling'
112 ' .fit() or .predict(). To manually set the shapes, call '
--> 113 'model._set_inputs(inputs).'.format(model))
114
115
ValueError: Model <transformers.modeling_tf_distilbert.TFDistilBertModel object at 0x7f6905c1fbe0> cannot be saved because the input shapes have not been set. Usually, input shapes are automatically determined from calling .fit() or .predict(). To manually set the shapes, call model._set_inputs(inputs).
>#######################################################
```
model.save_pretrained("DSB")
model.save_weights("DSB/DistDistilBERT_weights.h5")
```
>######################################################### success
```
from transformers import DistilBertConfig, PretrainedConfig
config = DistilBertConfig.from_json_file('DSB/config.json')
conf2=PretrainedConfig.from_pretrained("DSB")
```
> ############################################################# success
```
#from tensorflow.keras.models import load_model
#model=load_model("DSB/tf_model.h5") # error
```
> ################ error, It looks because-of saved model is not by `model.save("path")`
```
from transformers import TFPreTrainedModel
#model=TFPreTrainedModel.from_pretrained("DSB") # error
model=TFPreTrainedModel.from_pretrained("DSB/tf_model.h5", config=config) # error
#config=TFPreTrainedModel.from_config("DSB/config.json") # error
#model=TFPreTrainedModel.from_pretrained("DSB/") # error
```
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
<ipython-input-28-7f562f1af321> in <module>()
1 from transformers import TFPreTrainedModel
2 #model=TFPreTrainedModel.from_pretrained("DSB") # error
----> 3 model=TFPreTrainedModel.from_pretrained("DSB/tf_model.h5", config=config)
4 #config=TFPreTrainedModel.from_config("DSB/config.json")
5 #model=TFPreTrainedModel.from_pretrained("DSB/")
2 frames
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
309 return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file, allow_missing_keys=True)
310
--> 311 ret = model(model.dummy_inputs, training=False) # build the network with dummy inputs
312
313 assert os.path.isfile(resolved_archive_file), "Error retrieving file {}".format(resolved_archive_file)
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/base_layer.py in __call__(self, inputs, *args, **kwargs)
820 with base_layer_utils.autocast_context_manager(
821 self._compute_dtype):
--> 822 outputs = self.call(cast_inputs, *args, **kwargs)
823 self._handle_activity_regularization(inputs, outputs)
824 self._set_mask_metadata(inputs, outputs, input_masks)
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/network.py in call(self, inputs, training, mask)
710 """
711 if not self._is_graph_network:
--> 712 raise NotImplementedError('When subclassing the `Model` class, you should'
713 ' implement a `call` method.')
714
NotImplementedError: When subclassing the `Model` class, you should implement a `call` method.
<|||||>To save/load a model:
```py
model = TFDistilBertModel(config)
# Saving the model
model.save_pretrained("directory")
# Loading the model
loaded_model = TFDistilBertModel.from_pretrained("directory") # automatically loads the configuration.
```<|||||>Thanks @LysandreJik
It works.
greedy guidelines poped by `model.svae_pretrained` have confused me. It pops up like this
```
model.save_pretrained("directory")
save a model and its configuration file to the directory, so that it can be re-loaded using the
:func: ~transformers.PreTrainedModel.from_pretrained`
class method
```

|
transformers | 2,644 | closed | XLNet run_squad.py IndexError: tuple index out of range | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): XLNet
Language I am using the model on (English, Chinese....): English (xlnet-base-cased)
The problem arise when using:
* [x] the official example scripts: run_squad.py
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: run_squad.py
* [ ] my own task or dataset: (give details)
## To Reproduce
CUDA_VISIBLE_DEVICES=0,1,2,3 python run_squad.py \
--model_type xlnet \
--model_name_or_path xlnet-base-cased \
--do_train \
--do_eval \
--do_lower_case \
--version_2_with_negative \
--train_file /data/medg/misc/phuongpm/squadv2/train-v2.0.json \
--predict_file /data/medg/misc/phuongpm/squadv2/dev-v2.0.json \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps 10000 \
--output_dir /scratch/phuongpm/tuned/squad_xlnet/
## Expected behavior
Epoch: 0%| | 0/2 [00:00<?, ?it/sTraceback (most recent call last): | 0/2791 [00:00<?, ?it/s]
File "run_squad.py", line 837, in <module>
main()
File "run_squad.py", line 776, in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
File "run_squad.py", line 221, in train
inputs.update({"is_impossible": batch[7]})
IndexError: tuple index out of range
Epoch: 0%| | 0/2 [00:00<?, ?it/s]
Iteration: 0%| | 0/2791 [00:00<?, ?it/s]
## Environment
* OS: Linux
* Python version: 3.6
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch):
commit babd41e7fa07bdd764f8fe91c33469046ab7dbd1
Author: Lysandre <[email protected]>
Date: Fri Jan 24 17:06:55 2020 -0500
* Using GPU ? Yes
* Distributed or parallel setup ?
* Any other relevant information:
| 01-26-2020 01:47:24 | 01-26-2020 01:47:24 | Hi, are you sure you're running on commit babd41e, and that you didn't take the script from this version without updating the library itself? I believe this was patched in 073219b.
Could you try to install from source `pip install git+https://github.com/huggingface/transformers` and let me know if it fixes this issue?<|||||>It works after updating reinstalling the library. I think I might forget to install after git pull.
Thank you! |
transformers | 2,643 | closed | BERT LOSS FUNCTION | My question is that can I use KLDivLoss instead of CrossEntropyLoss when I fine-tune BERT for classification? the reason for that is that I want to pass the weight of each class(e.g for binary classification, instead of 1 or 0 I will pass the probability distribution )
Thank you in advance | 01-25-2020 22:44:39 | 01-25-2020 22:44:39 | Sure you can do that. Create a class which inherits from [BertForSequenceClassification](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L1122) and overwrite the [forward](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L1134) method.<|||||>Instead of overwriting the forward method you can retrieve the hidden states and compute the loss as you would do with any PyTorch model.
The loss is only computed by the model when you hand the `labels` to the model, which is not a required argument.<|||||>> Instead of overwriting the forward method you can retrieve the hidden states and compute the loss as you would do with any PyTorch model.
>
> The loss is only computed by the model when you hand the `labels` to the model, which is not a required argument.
Could you please elaborate on the same please? @LysandreJik
<|||||>What do you want me to elaborate on?<|||||>> Instead of overwriting the forward method you can retrieve the hidden states and compute the loss as you would do with any PyTorch model.
This @LysandreJik <|||||>I got this error when I called
loss.backward()
loss is "torch.float64" type
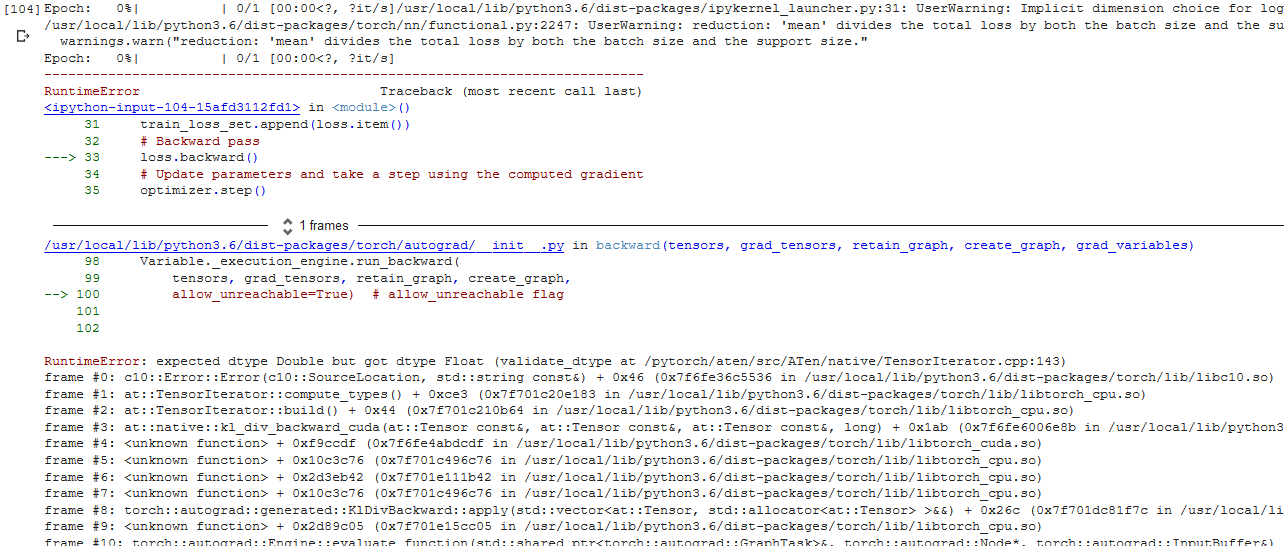
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>> My question is that can I use KLDivLoss instead of CrossEntropyLoss when I fine-tune BERT for classification? the reason for that is that I want to pass the weight of each class(e.g for binary classification, instead of 1 or 0 I will pass the probability distribution )
>
> Thank you in advance
Hi did you manage to do this? I also need to pass class probability distribution instead of the labels and am not sure how to do this.<|||||>BertForSequenceClassification.forward() returns the logits also. You can use these in any pytorch loss function (eg: KLDivLoss, not sure if you'll need to softmax them first) and then run backward on the resulting loss. It's a bit redundant (since BertForSequenceClassification's loss is still calculated), but works.<|||||>> Sure you can do that. Create a class which inherits from [BertForSequenceClassification](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L1122) and overwrite the [forward](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L1134) method.
That link to the forward function is stale, as of Feb 24 it's [here](https://github.com/huggingface/transformers/blob/7e662e6a3be0ece455b4c4ae2c3348beab11bad5/src/transformers/models/bert/modeling_bert.py#L1475). |
transformers | 2,642 | closed | Scrambled dimensions on output of forward pass | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): XLNet
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X] my own modified scripts: see attached minimum working example.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: see attached minimum working example.
## To Reproduce
Steps to reproduce the behavior:
1. Run the minimal working example (see below) with the command: `python xl_mwe.py`
2. Observe the following output:
```
Embedded batch: torch.Size([3, 13, 300])
XLNet output : torch.Size([13, 3, 300])
```
3. Per the documentation, the correct dimensions for the output should have been [3, 13, 300]. From the documentation of `last_hidden_state` in `XLNetModel.forward`: last_hidden_state (torch.FloatTensor of shape (batch_size, sequence_length, hidden_size)):
4. While constructing the minimal working example, I also observed another bug. If I change d_model to 25 (d_model = 300 in the code below) and n_heads to 5 (default is 10 in the code below), I get an error from einsum:
```
Traceback (most recent call last):
File "xl_mwe.py", line 43, in <module>
main()
File "xl_mwe.py", line 37, in main
xlnet_output = xlnet(inputs_embeds=embedded_batch)[0]
File "C:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\transformers\modeling_xlnet.py", line 858, in forward
head_mask=head_mask[i])
File "C:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\transformers\modeling_xlnet.py", line 436, in forward
head_mask=head_mask)
File "C:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "C:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\transformers\modeling_xlnet.py", line 383, in forward
k_head_r = torch.einsum('ibh,hnd->ibnd', r, self.r)
File "C:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\torch\functional.py", line 202, in einsum
return torch._C._VariableFunctions.einsum(equation, operands)
RuntimeError: size of dimension does not match previous size, operand 1, dim 0
```
## Minimal working example
```
import numpy as np
import torch
from transformers import XLNetConfig, XLNetModel, XLNetTokenizer
def embed(input_str, dims=25, fix_len=-1):
result = []
for word in input_str.split():
result.append(np.random.rand(dims))
if fix_len > -1:
result = result[0: fix_len]
if len(result) < fix_len:
result = result + [np.zeros(dims)] * (fix_len - len(result))
return result
def embed_batch(batch, dims=25, fix_len=-1):
return np.stack([embed(x, dims, fix_len) for x in batch], axis=0)
def main():
batch = [
"Hello, how are you doing?",
"Please go to the store and buy some bread.",
"Trump was not exonerated by the Mueller report."
]
d_model = 300
config = XLNetConfig(d_model=d_model, n_head=10)
xlnet = XLNetModel(config)
embedded_batch = embed_batch(batch, dims=d_model, fix_len=13)
embedded_batch = torch.from_numpy(embedded_batch).float()
print(f"Embedded batch: {embedded_batch.shape}")
xlnet_output = xlnet(inputs_embeds=embedded_batch)[0]
print(f"XLNet output : {xlnet_output.shape}")
if __name__ == "__main__":
main()
```
## Environment
* OS: Windows 10
* Python version: 3.7.4
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 2.3.0
* Using GPU ? Yes
* Distributed or parallel setup ? No
## Additional context
<!-- Add any other context about the problem here. -->
| 01-25-2020 20:05:07 | 01-25-2020 20:05:07 | Hi! There was a mistake with the re-arrangement of the input embeddings inside the forward method of XLNet. I've fixed it with f09f42d.
Concerning the issue with `d_model=25` and `n_heads=5`, this is due to the model dimension being an odd number which doesn't fare well with [`torch.arange` leveraging the model dimension to build relative positional embeddings](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_xlnet.py#L665). We should probably update this to allow for odd dimension XLNet architectures cc @thomwolf @julien-c.<|||||>Thanks for the quick fix on the the re-arrangement issue. I don't know how difficult the odd model dimension fix is. At the least, the model could throw a `ValueError` in the constructor if the dimension is odd. That would, at least, give users clear guidance.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Any updates, or do you want to close this one?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Any updates here? It's an easy fix to add a more informative error message.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,641 | closed | ImportError: cannot import name 'TFDistilBertModel' | ```
import tensorflow as tf
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertModel.from_pretrained('distilbert-base-uncased')
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
outputs = model(input_ids)
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
```
###################
these line of codes gives the error
ImportError: cannot import name 'TFDistilBertModel'
############
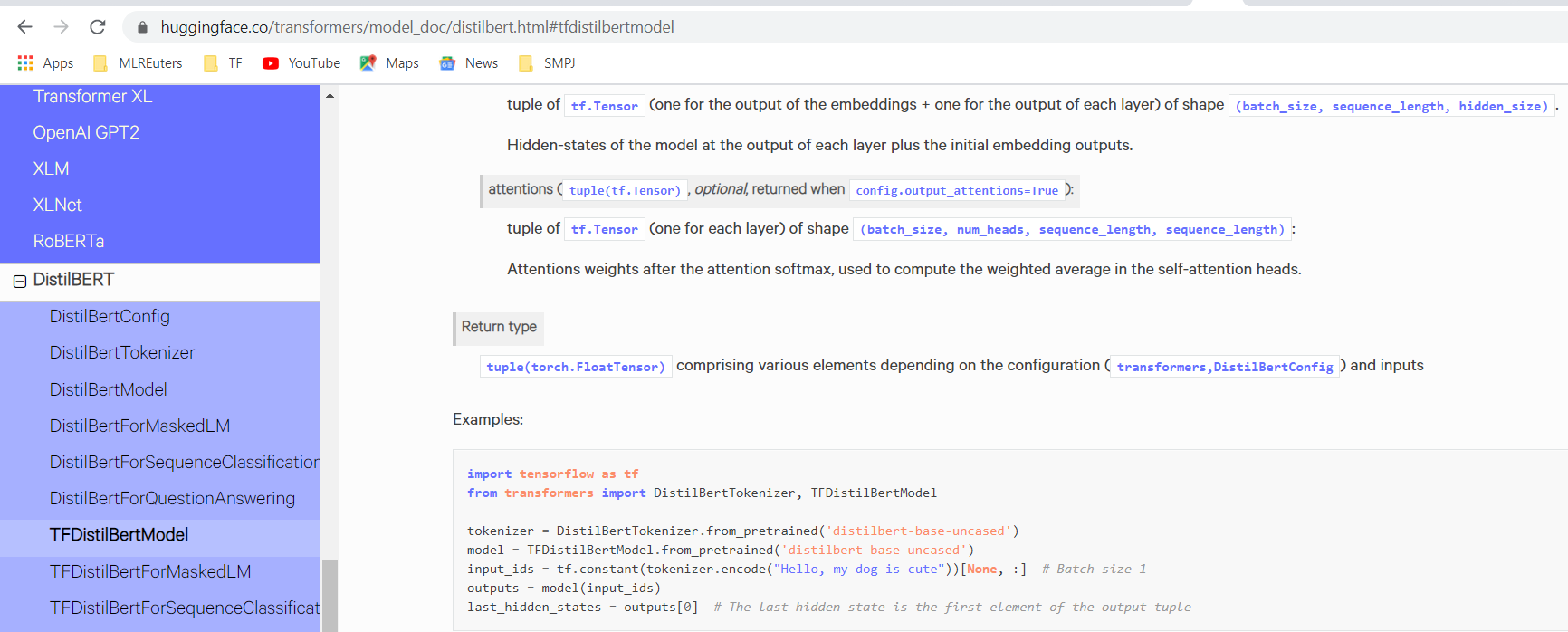
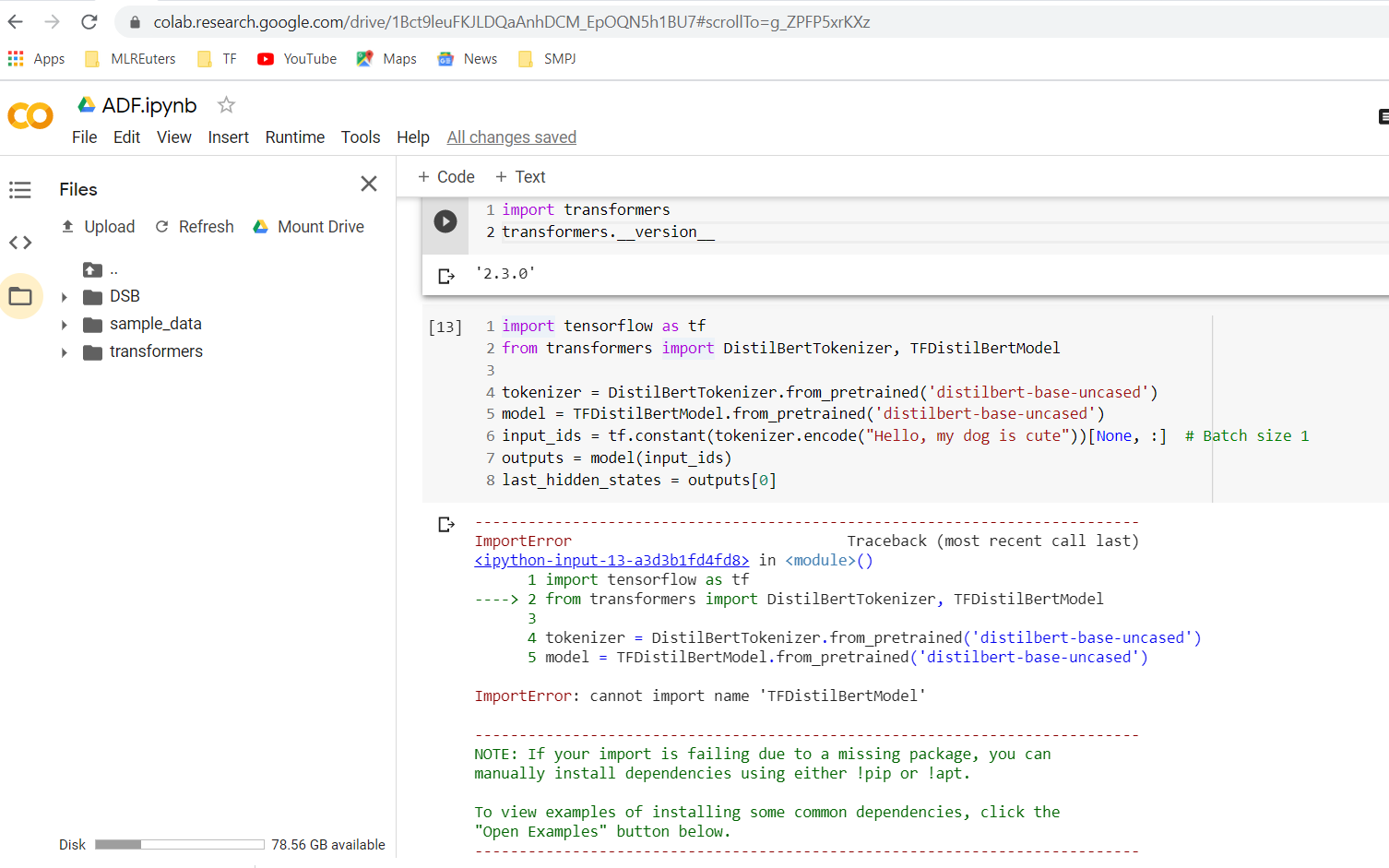
| 01-25-2020 12:44:24 | 01-25-2020 12:44:24 | Does the following import work?
`from transformers.modeling_tf_distilbert import TFDistilBertModel`
and what is the output of:
```
from transformers.file_utils import is_tf_available
is_tf_available()
```<|||||>Thank you for response. Thanks!
> Does the following import work?
> `from transformers.modeling_tf_distilbert import TFDistilBertModel`
> This import works but gives the error.
TypeError: Expected int32, got 0.0 of type 'float' instead.
> TypeError Traceback (most recent call last)
<ipython-input-6-e6dacece142c> in <module>()
3
4 tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
----> 5 model = TFDistilBertModel.from_pretrained('distilbert-base-uncased')
6 input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
7 outputs = model(input_ids)
2 frames
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
309 return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file, allow_missing_keys=True)
310
--> 311 ret = model(model.dummy_inputs, training=False) # build the network with dummy inputs
312
313 assert os.path.isfile(resolved_archive_file), "Error retrieving file {}".format(resolved_archive_file)
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/base_layer.py in __call__(self, inputs, *args, **kwargs)
852 outputs = base_layer_utils.mark_as_return(outputs, acd)
853 else:
--> 854 outputs = call_fn(cast_inputs, *args, **kwargs)
855
856 except errors.OperatorNotAllowedInGraphError as e:
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/autograph/impl/api.py in wrapper(*args, **kwargs)
235 except Exception as e: # pylint:disable=broad-except
236 if hasattr(e, 'ag_error_metadata'):
--> 237 raise e.ag_error_metadata.to_exception(e)
238 else:
239 raise
TypeError: in converted code:
relative to /usr/local/lib/python3.6/dist-packages:
transformers/modeling_tf_distilbert.py:569 call *
outputs = self.distilbert(inputs, **kwargs)
tensorflow_core/python/keras/engine/base_layer.py:854 __call__
outputs = call_fn(cast_inputs, *args, **kwargs)
transformers/modeling_tf_distilbert.py:455 call *
embedding_output = self.embeddings(input_ids, inputs_embeds=inputs_embeds) # (bs, seq_length, dim)
tensorflow_core/python/keras/engine/base_layer.py:824 __call__
self._maybe_build(inputs)
tensorflow_core/python/keras/engine/base_layer.py:2146 _maybe_build
self.build(input_shapes)
transformers/modeling_tf_distilbert.py:97 build
initializer=get_initializer(self.initializer_range))
tensorflow_core/python/keras/engine/base_layer.py:529 add_weight
aggregation=aggregation)
tensorflow_core/python/training/tracking/base.py:712 _add_variable_with_custom_getter
**kwargs_for_getter)
tensorflow_core/python/keras/engine/base_layer_utils.py:139 make_variable
shape=variable_shape if variable_shape else None)
tensorflow_core/python/ops/variables.py:258 __call__
return cls._variable_v1_call(*args, **kwargs)
tensorflow_core/python/ops/variables.py:219 _variable_v1_call
shape=shape)
tensorflow_core/python/ops/variables.py:197 <lambda>
previous_getter = lambda **kwargs: default_variable_creator(None, **kwargs)
tensorflow_core/python/ops/variable_scope.py:2503 default_variable_creator
shape=shape)
tensorflow_core/python/ops/variables.py:262 __call__
return super(VariableMetaclass, cls).__call__(*args, **kwargs)
tensorflow_core/python/ops/resource_variable_ops.py:1406 __init__
distribute_strategy=distribute_strategy)
tensorflow_core/python/ops/resource_variable_ops.py:1537 _init_from_args
initial_value() if init_from_fn else initial_value,
tensorflow_core/python/keras/engine/base_layer_utils.py:119 <lambda>
init_val = lambda: initializer(shape, dtype=dtype)
tensorflow_core/python/ops/init_ops.py:369 __call__
shape, self.mean, self.stddev, dtype, seed=self.seed)
tensorflow_core/python/ops/random_ops.py:171 truncated_normal
mean_tensor = ops.convert_to_tensor(mean, dtype=dtype, name="mean")
tensorflow_core/python/framework/ops.py:1184 convert_to_tensor
return convert_to_tensor_v2(value, dtype, preferred_dtype, name)
tensorflow_core/python/framework/ops.py:1242 convert_to_tensor_v2
as_ref=False)
tensorflow_core/python/framework/ops.py:1297 internal_convert_to_tensor
ret = conversion_func(value, dtype=dtype, name=name, as_ref=as_ref)
tensorflow_core/python/framework/tensor_conversion_registry.py:52 _default_conversion_function
return constant_op.constant(value, dtype, name=name)
tensorflow_core/python/framework/constant_op.py:227 constant
allow_broadcast=True)
tensorflow_core/python/framework/constant_op.py:265 _constant_impl
allow_broadcast=allow_broadcast))
tensorflow_core/python/framework/tensor_util.py:449 make_tensor_proto
_AssertCompatible(values, dtype)
tensorflow_core/python/framework/tensor_util.py:331 _AssertCompatible
(dtype.name, repr(mismatch), type(mismatch).__name__))
TypeError: Expected int32, got 0.0 of type 'float' instead.
> and what is the output of:
>
> ```
> from transformers.file_utils import is_tf_available
> is_tf_available()
> ```
> Output of this line is
`False`
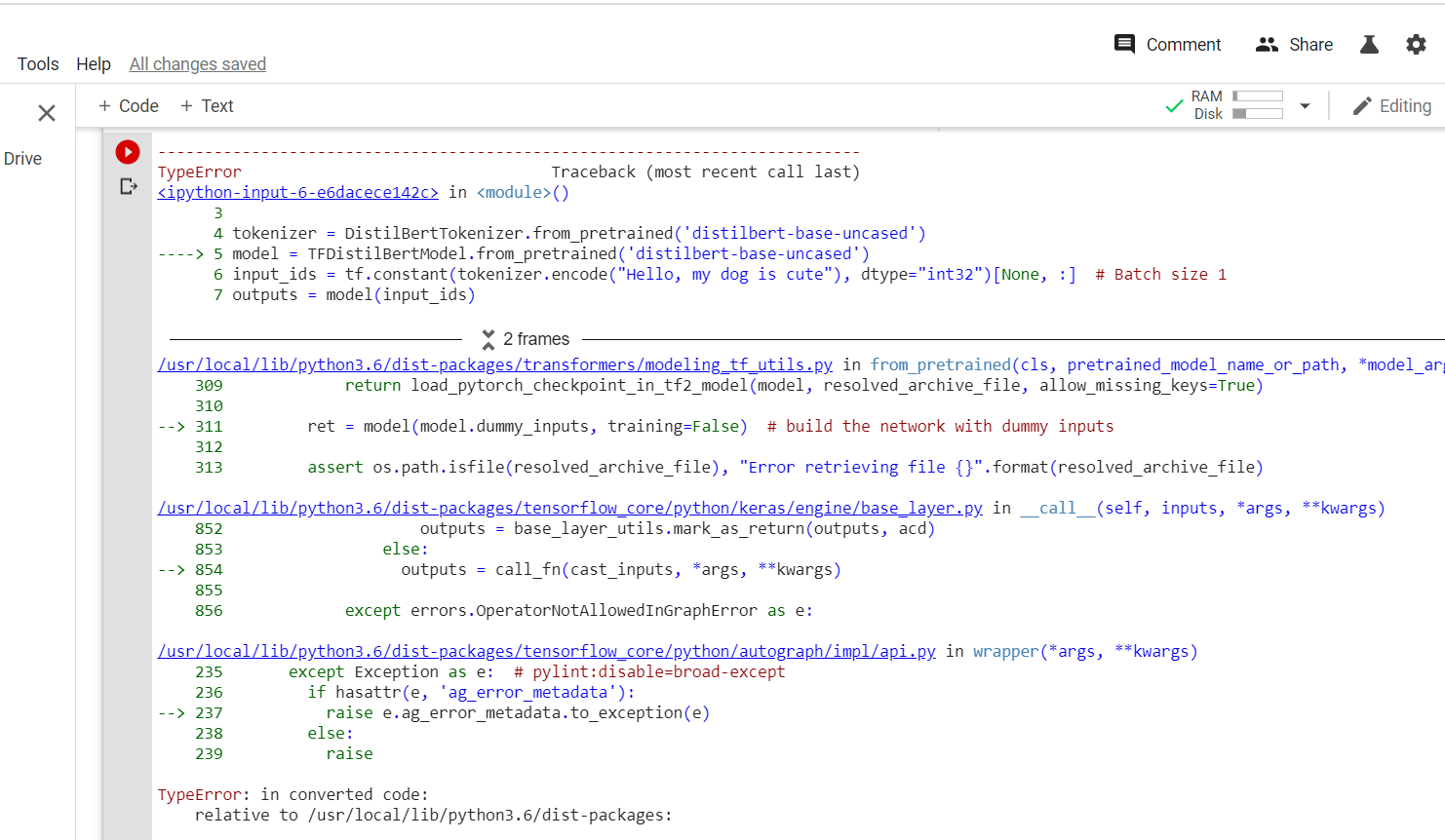
<|||||>In my case it got resolved by (but have reached to another issue)
> conda create -n bcm python==3.6.8 anaconda
> conda activate bcm
> conda install tensorflow-gpu
> pip install transformers <|||||>> Does the following import work?
> `from transformers.modeling_tf_distilbert import TFDistilBertModel`
> and what is the output of:
>
> ```
> from transformers.file_utils import is_tf_available
> is_tf_available()
> ```
I have the same error with TFBertModel, and when I run this, I get "False"
Any suggestions? @cronoik <|||||>@sbecon
That means that you haven't installed tensorflow 2.0 (or you have installed it in a different virtual environment). Please follow the [instructions](https://www.tensorflow.org/install/pip#tensorflow-2.0-rc-is-available) and install it. It should work afterwards. |
transformers | 2,640 | closed | batch_encode_plus not working for GPT2, OpenAI, TransfoXL when returning PyTorch tensors | ## 🐛 Bug
`batch_encode_plus` does not work on GPT2, OpenAI, and TransfoXL when returning PyTorch tensors. Note that the code does work when leaving out the `return_tensors` argument. In that case, the output of `encoded` looks normal.
## To Reproduce
```python
from transformers import *
TOKENIZERS = {
'albert': (AlbertTokenizer, 'albert-base-v1'),
'bert': (BertTokenizer, 'bert-base-uncased'),
'distilbert': (DistilBertTokenizer, 'distilbert-base-uncased'),
'gpt2': (GPT2Tokenizer, 'gpt2'),
'openai': (OpenAIGPTTokenizer, 'openai-gpt'),
'roberta': (RobertaTokenizer, 'roberta-base'),
'transfoxl': (TransfoXLTokenizer, 'transfo-xl-wt103'),
'xlm': (XLMTokenizer, 'xlm-mlm-enfr-1024'),
'xlnet': (XLNetTokenizer, 'xlnet-base-cased')
}
text = ['I like bananas and cookies .',
'You are not what I thought you were , though .',
'Cookies are awesome .']
for tok_name, (tok_cls, tok_default) in TOKENIZERS.items():
tokenizer = tok_cls.from_pretrained(tok_default)
try:
encoded = tokenizer.batch_encode_plus(text, return_tensors='pt')
except Exception as e:
print(f"{tok_name} failed: {e}")
```
Output on latest master:
```
gpt2 failed: Could not infer dtype of NoneType
openai failed: Could not infer dtype of NoneType
transfoxl failed: Could not infer dtype of NoneType
```
## Environment
* OS: Windows 10
* Python version: 3.7.3
* PyTorch version: 1.3
* PyTorch Transformers version (or branch): latest master
* Using GPU ? yes
* Distributed or parallel setup ? no
| 01-25-2020 10:51:55 | 01-25-2020 10:51:55 | The problem lies here
https://github.com/huggingface/transformers/blob/babd41e7fa07bdd764f8fe91c33469046ab7dbd1/src/transformers/tokenization_utils.py#L1003-L1006
since for these tokenizers `self.pad_token_id` is None.<|||||>Still having this issue running the above script :-(
Any ideas?
Env:
* OS: Windows 10
* Python version: 3.6.12
* PyTorch version: 1.5.0
* PyTorch Transformers version (or branch): transformers-4.5.1
* Using GPU ? yes
* Distributed or parallel setup ? no
|
transformers | 2,639 | closed | AttributeError: 'Tensor' object has no attribute 'transpose' | ## ❓ Questions & Help
<!-- error comes from modeling_xlnet.py file -->
i get this error :
---------------------------------------------------------------------------
```
AttributeError Traceback (most recent call last)
<ipython-input-80-01c16e13fe9a> in <module>()
----> 1 get_ipython().run_cell_magic('time', '', "gkf = GroupKFold(n_splits=5).split(X=df_train.question_body, groups=df_train.question_body)\n\nvalid_preds = []\ntest_preds = []\nfor fold, (train_idx, valid_idx) in enumerate(gkf):\n \n # will actually only do 2 folds (out of 5) to manage < 2h\n if fold in [0, 2]:\n\n train_inputs = [inputs[i][train_idx] for i in range(len(inputs))]\n train_outputs = outputs[train_idx]\n\n valid_inputs = [inputs[i][valid_idx] for i in range(len(inputs))]\n valid_outputs = outputs[valid_idx]\n \n K.clear_session()\n model = create_model()\n optimizer = tf.keras.optimizers.Adam(learning_rate=1e-5)\n #optimizer = AdamW(lr=1e-4)\n model.compile(loss=bce_dice_loss, optimizer=optimizer)\n model.fit(train_inputs, train_outputs, epochs=6, batch_size=6)\n # model.save_weights(f'bert-{fold}.h5')\n valid_preds.append(model.predict(valid_inputs))\n test_preds.append(model.predict(test_inputs))\n \n rho_val = compute_spearmanr_ignore_nan(valid_outputs, valid_preds[-1])\n print('validation score = ', rho_val)\n model.save_weights(f'/content/drive/My Drive/quest/validation-{rho_val}-fold-{fold}.hdf5')")
5 frames
</usr/local/lib/python3.6/dist-packages/decorator.py:decorator-gen-60> in time(self, line, cell, local_ns)
<timed exec> in <module>()
/usr/local/lib/python3.6/dist-packages/transformers/modeling_xlnet.py in forward(self, input_ids, attention_mask, mems, perm_mask, target_mapping, token_type_ids, input_mask, head_mask, inputs_embeds)
726 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
727 elif input_ids is not None:
--> 728 input_ids = input_ids.transpose(0, 1).contiguous()
729 qlen, bsz = input_ids.shape[0], input_ids.shape[1]
730 elif inputs_embeds is not None:
AttributeError: 'Tensor' object has no attribute 'transpose'
```
when i try xlnet but i don't get error when i try bert
code i am using :
```py
from transformers import XLNetConfig, XLNetModel,XLNetTokenizer
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
def compute_spearmanr_ignore_nan(trues, preds):
rhos = []
for tcol, pcol in zip(np.transpose(trues), np.transpose(preds)):
rhos.append(spearmanr(tcol, pcol).correlation)
return np.nanmean(rhos)
def create_model():
q_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
q_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
q_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
#config = BertConfig() # print(config) to see settings
config = XLNetConfig()
config.output_hidden_states = False # Set to True to obtain hidden states
# caution: when using e.g. XLNet, XLNetConfig() will automatically use xlnet-large config
# normally ".from_pretrained('bert-base-uncased')", but because of no internet, the
# pretrained model has been downloaded manually and uploaded to kaggle.
#bert_model = TFBertModel.from_pretrained(BERT_PATH+'bert-base-uncased-tf_model.h5', config=config)
#bert_model = TFBertModel.from_pretrained('xlnet-base-cased')
#bert_model = XLNetModel(config)
bert_model = XLNetModel.from_pretrained('xlnet-large-cased')
# if config.output_hidden_states = True, obtain hidden states via bert_model(...)[-1]
q_embedding = bert_model(q_id, attention_mask=q_mask, token_type_ids=q_atn)[0]
a_embedding = bert_model(a_id, attention_mask=a_mask, token_type_ids=a_atn)[0]
q = tf.keras.layers.GlobalAveragePooling1D()(q_embedding)
a = tf.keras.layers.GlobalAveragePooling1D()(a_embedding)
x = tf.keras.layers.Concatenate()([q, a])
x = tf.keras.layers.Dropout(0.2)(x)
x = tf.keras.layers.Dense(30, activation='sigmoid')(x)
model = tf.keras.models.Model(inputs=[q_id, q_mask, q_atn, a_id, a_mask, a_atn,], outputs=x)
return model
``` | 01-25-2020 10:35:07 | 01-25-2020 10:35:07 | It seems you're passing TensorFlow variables to a PyTorch model. The TensorFlow equivalent of `XLNetModel` is `TFXLNetModel`.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,638 | closed | Get Warning Message: Unable to convert output to tensors format pt | I am running the following code:
```
from transformers.modeling_tf_bert import TFBertForSequenceClassification
pytorch_model = TFBertForSequenceClassification.from_pretrained('./save/')
# Quickly test a few predictions - MRPC is a paraphrasing task, let's see if our model learned the task
sentence_0 = "This research was consistent with his findings."
sentence_1 = "His findings were compatible with this research."
sentence_2 = "His findings were not compatible with this research."
inputs_1 = tokenizer.encode_plus(sentence_0, sentence_1, add_special_tokens=True, return_tensors='pt')
inputs_2 = tokenizer.encode_plus(sentence_0, sentence_2, add_special_tokens=True, return_tensors='pt')
```
Get Warning Message:
```
WARNING:transformers.tokenization_utils:Unable to convert output to tensors format pt, PyTorch or TensorFlow is not available.
WARNING:transformers.tokenization_utils:Unable to convert output to tensors format pt, PyTorch or TensorFlow is not available.
```
Then, when I run:
```
pred_1 = pytorch_model(inputs_1['input_ids'], token_type_ids=inputs_1['token_type_ids'])[0].argmax().item()
pred_2 = pytorch_model(inputs_2['input_ids'], token_type_ids=inputs_2['token_type_ids'])[0].argmax().item()
print("sentence_1 is", "a paraphrase" if pred_1 else "not a paraphrase", "of sentence_0")
print("sentence_2 is", "a paraphrase" if pred_2 else "not a paraphrase", "of sentence_0")
```
I get the error: `AssertionError: Too many inputs.` | 01-25-2020 02:18:46 | 01-25-2020 02:18:46 | It seems that you are loading a tensorflow model, which you incorrectly call pytorch_model. The reason that the function doesn't work, though, is probably because you don't have pytorch installed and only tensorflow. Convert to tensorflow tenors instead <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,637 | closed | Add AutoModelForPreTraining | Add `AutoModelForPretraining` and `TFAutoModelForPretraining` classes which will load the full model used for pretraining (guarantee we should have all the pre-trained weights).
This class can be used for instance to convert between an original PyTorch and a TF2.0 models while being sure that all the pretrained weights are converted:
```python
# PyTorch => TF 2.0 (save TF 2.0 weights from PT weights)
tf_model = TFAutoModelForPretraining.from_pretrained('my-model', from_pt=True)
tf_model.save_pretrained()
# TF 2.0 => PyTorch (save PT weights from TF 2.0 weights)
pt_model = AutoModelForPretraining.from_pretrained('my-model', from_tf=True)
pt_model.save_pretrained()
``` | 01-24-2020 22:53:06 | 01-24-2020 22:53:06 | |
transformers | 2,636 | closed | Gradient checkpointing with GPT2DoubleHeadsModel | ## ❓ Questions & Help
I've been trying to fine-tune `GPT2DoubleHeadsModel` using `gpt2-large` and `gpt2-xl` on the [Topical-Chat](https://github.com/alexa/alexa-prize-topical-chat-dataset) dataset.
I'm finding that loading even a single example into memory is difficult with the larger versions of GPT-2. I found [this](https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255) Medium post by @thomwolf which suggests that gradient checkpointing would be effective at handling this situation.
Is there a gradient-checkpointed version of the code in `GPT2DoubleHeadsModel` or the underlying `GPT2Model` that could be used as-is? I'm trying to do this myself by editing `modeling_gpt2.py`, but I'm facing issues.
https://github.com/huggingface/transformers/blob/babd41e7fa07bdd764f8fe91c33469046ab7dbd1/src/transformers/modeling_gpt2.py#L478-L480
Specifically, I added a checkpoint in the above line like this:
`outputs = checkpoint(block, hidden_states, layer_past, attention_mask, head_mask[i])`
NOTE: I had to remove the key names since it looks like checkpoint does not support key-value arguments, only positional. This might lead to compatibility issues, I'd love to know thoughts on this as well.
This is using the official PyTorch [checkpoint](https://pytorch.org/docs/stable/checkpoint.html). I'm also considering trying [this](https://github.com/csrhddlam/pytorch-checkpoint/blob/master/checkpoint.py) other implementation for checkpoint since I read somewhere that it is supposed to be faster than the official implementation.
With the official PyTorch implementation, I'm getting the following error:
`CheckpointFunctionBackward.forward: expected Variable (got list) for return value 0.`
[This](https://discuss.pytorch.org/t/checkpoint-didnt-support-list-output/16957/3) thread on the PyTorch forums seems to suggest that this error arises when attempting to use `torch.utils.checkpoint` with modules that return a variable number of tensors, which is the case with `Block` within `GPT2Model`.
Could @thomwolf, @LysandreJik or anyone else in the Hugging Face team please help with this? Thanks! | 01-24-2020 22:43:46 | 01-24-2020 22:43:46 | I think I figured this out, it looks like I'll have to change the outputs returned by `Block` to be tuples instead of lists:
https://github.com/huggingface/transformers/blob/babd41e7fa07bdd764f8fe91c33469046ab7dbd1/src/transformers/modeling_gpt2.py#L238
i.e., change the above to `return tuple(outputs)` for checkpointing of the blocks inside `GPT2Model` to work.
@thomwolf @LysandreJik Would this explicit type-casting of the outputs to tuple lead to any unexpected, downstream effects? If not, I think this update should be reflected in the repo as well, given that the README says that every model's forward() method always outputs a `tuple`.
I am also finding that checkpointing the blocks doesn't seem to help fit a single example into memory with `gpt2-xl`. A check-pointed version of these classes would be really helpful!<|||||>Bumping this, I'm training a TensorFlow ALBERT model and with long sequence lengths (512) it's tough to get a large enough batch size - currently I'm constrained to 8 or 16 per GPU. Adding automatic gradient checkpointing support for `tf.recompute_grad()` would be a godsend :)<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I am using `GPT2Model` and would also find this very useful. |
transformers | 2,635 | closed | Improving generation | Fix #2554
TODO:
- add tests on generation
TODO potential:
- this PR could be used to fix #2415 and fix #2482 as well
- add TF 2.0 support for generation | 01-24-2020 22:28:52 | 01-24-2020 22:28:52 | It would be great if this PR could handle the padding index for the models that do not have one. For example, GPT-2 doesn't have a padding index and therefore can't use the `generate` method, nor can it use the `batch_encode_plus` method.<|||||>PR #2885 added the proposed changes. |
transformers | 2,634 | closed | AutoModels Documentation | 01-24-2020 21:37:07 | 01-24-2020 21:37:07 | ||
transformers | 2,633 | closed | Details on T5's current integration status | Hi all,
Regarding Google's T5 model, here is a quick summary of the status:
* the core model is in the library and some people have started to use it, but:
- while the operations are identical or very similar (einsum vs. matmul), there is quite a significantly higher relative error between this model's PT hidden-state and the mesh-tensorflow hidden-state (in particular compared to our previous TF => PT model conversions).
- our guess is that this comes for a combination of bfloat16 vs. fp32, einsum+model parallelism vs. matmul, plus the fact that we are not masking the hidden-states at each layer as the original implementation do (this should not matter much though).
- as a consequence, we are waiting to be able to confirm it's performances on a GLUE fine-tuning before having a wider communication on its addition to the library.
* the full integration with GLUE tests requires a few features that we still need to add:
- a decoding mechanism,
- a pre/post-processing for GLUE to use it in text-to-text setting, and
- a model parallelism feature
^^ we plan to work on these in February (from the more general view of having better encoder-decoder support in the library).
cc @julien-c @LysandreJik @sshleifer @patrickvonplaten | 01-24-2020 18:55:32 | 01-24-2020 18:55:32 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,632 | closed | Add FlauBERT: Unsupervised Language Model Pre-training for French | This PR adds [FlauBERT](https://github.com/getalp/Flaubert). Most of the code is derived from XLM (there are some new features in FlauBERT such as `pre_norm` and `layerdrop`).
`make test` had 1 failure related to BERT and not to FlauBERT:
> [gw0] FAILED tests/test_configuration_auto.py::AutoConfigTest::test_pattern_matching_fallback
`make style` passed.
`make quality` passed. | 01-24-2020 14:58:03 | 01-24-2020 14:58:03 | Hi, I don't really know how it happened but I was denied push access on your repository while patching the failing FlauBERT bug. Instead I pushed to a new branch `flaubert` on this remote (huggingface/transformers), and I'm opening a pull request with your changes.
You're still the author of the commit.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2632?src=pr&el=h1) Report
> Merging [#2632](https://codecov.io/gh/huggingface/transformers/pull/2632?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/adb8c93134f02fd0eac2b52189364af21977004c?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2632?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2632 +/- ##
=======================================
Coverage 74.59% 74.59%
=======================================
Files 89 89
Lines 14971 14971
=======================================
Hits 11168 11168
Misses 3803 3803
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2632?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2632?src=pr&el=footer). Last update [adb8c93...adb8c93](https://codecov.io/gh/huggingface/transformers/pull/2632?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>The PR is #2677. I'm updating the documentation directly on this PR. |
transformers | 2,631 | closed | CamembertTokenizer cannot be pickled | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Camembert
Language I am using the model on (English, Chinese....): French
The problem arise when using my own modified scripts:
I have a nn.Module and, within this module, I store the tokenizers
I can normally save these tokenizers easily, but CamemberTokenizer
gives me a **TypeError: can't pickle SwigPyObject objects**
The tasks I am working on consists in creating a model and saving it using torch.save()
## To Reproduce
```
import torch
from transformers import CamembertTokenizer, BertTokenizer
class MyModelCamembert(torch.nn.Module):
def __init__(self):
super().__init__()
self.cheese = CamembertTokenizer.from_pretrained('camembert-base')
def forward(self, x):
return 1
class MyModelBert(torch.nn.Module):
def __init__(self):
super().__init__()
self.cheese = BertTokenizer.from_pretrained('bert-base')
def forward(self, x):
return 1
# with bert it works
no_cheese = MyModelBert()
torch.save(no_cheese, "~/bert.pkl")
# with camembert it doesn't
cheese = MyModelCamembert()
torch.save(cheese, "~/camembert.pkl")
```
Steps to reproduce the behavior:
1. Try to save a module containing a tokenizer using the torch.save()
2. Find out it works for Bert but not for Camembert
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
Stack Trace when saving CamembertTokenizer
Traceback (most recent call last):
File "/home/swqh0332/Desktop/blablapy.py", line 28, in <module>
torch.save(cheese, "/home/swqh0332/camembert.pkl")
File "/home/swqh0332/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/serialization.py", line 260, in save
return _with_file_like(f, "wb", lambda f: _save(obj, f, pickle_module, pickle_protocol))
File "/home/swqh0332/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/serialization.py", line 185, in _with_file_like
return body(f)
File "/home/swqh0332/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/serialization.py", line 260, in <lambda>
return _with_file_like(f, "wb", lambda f: _save(obj, f, pickle_module, pickle_protocol))
File "/home/swqh0332/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/serialization.py", line 332, in _save
pickler.dump(obj)
TypeError: can't pickle SwigPyObject objects
## Expected behavior
I would like to be able to pickle the CamembertTokenizer as I it is possible with the other models
## Environment
* OS: Ubuntu 18
* Python version: 3.6.9
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): 2.2.2
* Using GPU ? No
* Distributed or parallel setup ? No
| 01-24-2020 14:03:43 | 01-24-2020 14:03:43 | Did you look into just calling `save_pretrained()` on your CamembertTokenizer (and not include it inside your `MyModelCamembert`)?<|||||>No I did not try that because my model class is quite a big class that extends `nn.Module` and not `PreTrainedModel`.
I'm just surprised that saving the model it works for Bert but fails for Camembert<|||||>Indeed, there was the state management lacking in the CamemBERT tokenizer, so it couldn't be pickled. It should have been fixed with 908230d.<|||||>Great ! So I'll just wait for the next release, Thanks ! :))<|||||>You can also install from source using `pip install git+https://github.com/huggingface/transformers` if you want to work with it now |
transformers | 2,630 | closed | Pad token for GPT2 and OpenAIGPT models | ## ❓ Questions & Help
I noticed that out of all the models `pad_token` is not set for only `OpenAIGPTModel` and `GPT-2Model`.
I get a warning: `Using pad_token, but it is not set yet.` and `pad_token_id` is `None`
Is there any specific reason why is that so?
If not, what is the appropriate padding token to be used for these models?
Thanks
| 01-24-2020 13:27:29 | 01-24-2020 13:27:29 | Padding tokens were not used during the pre-training of GPT and GPT-2, therefore they have none. It shouldn't matter as when doing padding, you should specify an [attention mask](https://huggingface.co/transformers/glossary.html#attention-mask) to your model so that it doesn't attend to padded indices, therefore ignoring the value of the token.<|||||>i got the same issues any advice?<|||||>Also look at issue #3021
What do you need the padding for? What is the use case?
For both models using an attention mask over all tokens that you be padded should help (as explained above). <|||||>Yes, using the attention mask over all tokens should help. Thanks<|||||>> Padding tokens were not used during the pre-training of GPT and GPT-2, therefore they have none. It shouldn't matter as when doing padding, you should specify an [attention mask](https://huggingface.co/transformers/glossary.html#attention-mask) to your model so that it doesn't attend to padded indices, therefore ignoring the value of the token.
I thought the same as your reply but my experiments shows this Attention mask does not work.
See my recent [issue](https://github.com/huggingface/transformers/issues/3167), where i provided reproducible code to see my point.
<|||||>should the attention mask cover the labels as well?
for example i want to train "some passage <break> some content <pad> <pad>".
so my input would be "some passage <break>", and my label would be "some passage <break> some content <pad> <pad>", in which the padding is necessary for batch processing.
In such a case how do I mask out the paddings in the labels?
<|||||>Because GPT2 and GPT are causal LM you don't need to pad shorter sentences in batches. It is important though that the loss on these "unnecessary" tokens is not calculated. You should set all lables corresponding to "PADDED" tokens to `-100`. In the code snippet you can see in the `map_to_encoder_decoder_inputs` function how the `labels` are set to -100 for `attention_mask = 0`:
https://huggingface.co/patrickvonplaten/bert2gpt2-cnn_dailymail-fp16#training-script<|||||>> Because GPT2 and GPT are causal LM you don't need to pad shorter sentences in batches.
Why? The pad is to make up the length of the batch. Does this have anything to do with GPT2's causal model? <|||||>> ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`.
Just do `tokenizer.pad_token = tokenizer.eos_token`, and also set `tokenizer.padding_side = 'left'`.
It should work fine with batches. No need of `add_special_tokens`, otherwise the model embedding layer should be resized accordingly.<|||||>
@ecolss Why do we set
```bash
tokenizer.padding_size = 'left'
```
. What is the problem if it stays as 'right' which is by default.
Thank you.<|||||>Specially when looking at these remarks: https://huggingface.co/docs/transformers/v4.30.0/en/model_doc/gpt2#transformers.GPT2Config
```
Tips:
- GPT-2 is a model with absolute position embeddings so it’s usually advised to pad the inputs on the right rather than the left.
``` |
transformers | 2,629 | closed | Question about Architecture of BERT for QA | ## ❓ Questions & Help
I have a question about the architecture of Bert for QA.
In Bert forward function
``` python
class BertForQuestionAnswering(BertPreTrainedModel):
def __init__(self, config):
super(BertForQuestionAnswering, self).__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_callable(BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
start_positions=None,
end_positions=None,
):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output) # The line I don't understand
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
outputs = (start_logits, end_logits,) + outputs[2:]
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions.clamp_(0, ignored_index)
end_positions.clamp_(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
outputs = (total_loss,) + outputs
return outputs # (loss), start_logits, end_logits, (hidden_states), (attentions)
```
I think logits are from linear layer (this is from bert output)
And start_loss and end_loss is calculated by the logits ( just splited by 2)
But, I read BERT article, But It describes
It looks like the model have to use only spans of the paragraph in last layer.
But, I can't get it how the model can know where's start/end span is?
So can you explain it?
It will be really helpful to me if you answer it. | 01-24-2020 11:41:00 | 01-24-2020 11:41:00 | Please don't post screenshots. Use code tags instead and preferably post reproducible code.
https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,628 | closed | Albert on QQP inference | While using Albert model trained on QQP data, i am using following code for inference.
How to manage two sentences and two labels (0,1) like QQP?
ffrom transformers import AlbertTokenizer, AlbertForSequenceClassification
import torch
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = AlbertForSequenceClassification.from_pretrained('albert-base-v2')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, labels=labels)
loss, logits = outputs[:2] | 01-24-2020 11:11:10 | 01-24-2020 11:11:10 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,627 | closed | Why does the hidden state of the same input token change every time I call the same GPT2 model? | Hello,
Say I fixed my input to the GPT2 model:
```python
input_ids = test_i[:,0]
input_ids = torch.tensor(input_ids.tolist()).unsqueeze(0)
```
Then I try to retrieve the hidden state vector of the last token:
```python
tst_hidden_states = best_model(input_ids)[3][1][0, (test_i.size()[0] - 1), :].detach()
tst_hidden_states[0:5]
>>>tensor([-0.0146, 0.0718, -0.0297, -0.0000, -0.0315])
```
but when I repeat the above process with the exactly same input, the hidden state of the last token keeps changing:
```python
tst_hidden_states = best_model(input_ids)[3][1][0, (test_i.size()[0] - 1), :].detach()
tst_hidden_states[0:5]
>>> tensor([-0.0146, 0.0000, -0.0297, -0.0212, -0.0315])
```
Given that I didn't change the model, I don't understand why the hidden state of the same input and the same token keeps changing at each turn. How can I prevent the hidden state from changing?
Thank you,
| 01-23-2020 23:41:04 | 01-23-2020 23:41:04 | Hello,
The hidden state vectors doesn't seem to change with fixed input and token when I use the Hugging Face pre-trained GPT2 model, but in my case, I made and trained my own GPT2 model by doing the following:
```python
bptt = 1024
batch_size = 1
log_int = 50
nlayer = 6
# Define device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
gc.set_threshold(700, 10, 10)
# define the English text field
TEXT_ch2 = Field(init_token = '<sos>',
eos_token = '<eos>',
unk_token = '<unk>',
pad_token = '<pad>',
fix_length = bptt,
lower = True)
# split the PennTreeBank corpus into a train, val, and test set.
train_penn, val_penn, test_penn = torchtext.datasets.PennTreebank.splits(TEXT_ch2)
# initialize new_train_penn
new_train_penn = train_penn
# build vocabulary based on the field that we just defined.
# (building vocabulary over all language datasets)
TEXT_ch2.build_vocab(new_train_penn, val_penn, test_penn,
specials=['<sos>','<eos>','<unk>','<pad>','<mask>','<mcoption>','<question>'])
# define special token indices
mask_index_ch2 = TEXT_ch2.vocab.stoi['<mask>']
pad_index_ch2 = TEXT_ch2.vocab.stoi['<pad>']
mcoption_index_ch2 = TEXT_ch2.vocab.stoi['<mcoption>']
question_index_ch2 = TEXT_ch2.vocab.stoi['<question>']
eos_index_ch2 = TEXT_ch2.vocab.stoi['<eos>']
sos_index_ch2 = TEXT_ch2.vocab.stoi['<sos>']
unk_index_ch2 = TEXT_ch2.vocab.stoi['<unk>']
# set hyperparameter ntokens
ntokens = len(TEXT_ch2.vocab.stoi)
## define GPT-2 configuration.
GPT2config_ch2 = GPT2Config(vocab_size_or_config_json_file = ntokens,
cutoffs = [20000, 40000, 200000],
n_positions = 1024,
n_embd = 768,
n_head = 12,
n_layer = nlayer,
resid_pdrop = 0.1,
embd_pdrop = 0.1,
attn_pdrop = 0.1,
output_hidden_states = True,
output_attentions = True)
# define the GPT-2 model based on the specifiTVD configuration.
model_ch2 = GPT2DoubleHeadsModel(GPT2config_ch2)
# add new tokens to the embeddings of our model
model_ch2.resize_token_embeddings(ntokens)
def train_lm_head(model, train_iter, optimizer, scheduler, log_interval, pad_index):
# turn on a training mode
model.train()
# initialize total_loss to 0
total_loss = 0
# list(enumerate(train_penn_iter))[0][1] would extract the 1st batch
for batch_index, batch in enumerate(train_iter):
gc.collect()
input_ids = [instance for instance in batch.text]
## NOTE: Positions embeddings can be automatically created by the GPT2DoubleHeadsModel as (0, 1, ..., N)
# set the gradient back to 0 (necessary step)
optimizer.zero_grad()
input_ids = torch.tensor([input_ids], dtype=torch.long)
loss = model(input_ids, lm_labels = input_ids)[0]
# 'loss' here is the cross entropy.
# recall: 'input_ids' is defined above.
# calculate gradient by backwarding the loss
# calculate gradient of the loss w.r.t weights
loss.backward()
# clips norm of the gradient of an iterable of parameters.
# The norm is computed over all gradients together, as if they were
# concatenated into a single vector. Gradients are modified in-place.
# so basically just normalizes the gradients and returns them.
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step() # update the weights by following the constLinearSchedule for the lr.
# update the with the calculated loss
total_loss = total_loss + loss
# python format: 's' for string, 'd' to display decimal integers (10-base), and 'f' for floats.
# ex: print("Sammy ate {0:.3f} percent of a pizza!".format(75.765367))
# >> Sammy ate 75.765 percent of a pizza!
# print("Sammy ate {0:f} percent of a {1}!".format(75, "pizza"))
# >> Sammy ate 75.000000 percent of a pizza!
#
# Below is good enough since we are doing the Stochastic Gradient Descent.
# (i.e. 1 batch = 1 sample)
if batch_index % log_interval == 0 and batch_index > 0:
cur_loss = total_loss / log_interval
print('| epoch {:3d} | {:5d}/{:5d} batches | lr {:02.9f} | loss {:5.4f} | ppl {:8.4f}'.format(
epoch, batch_index, len(train_iter), scheduler.get_lr()[0], cur_loss, math.exp(cur_loss)))
total_loss = 0
del input_ids
del loss
gc.collect()
# evaluate (Apply the best model) to check the result with the validation dataset.
def evaluate_lm_head(model, val_iter, pad_index):
model.eval() # Turn on the evaluation mode
total_loss = 0.
with torch.no_grad():
for batch_index, batch in enumerate(val_iter):
gc.collect()
val_input_ids = [instance for instance in batch.text]
val_input_ids = torch.tensor([val_input_ids], dtype=torch.long)
## NOTE: Positions embeddings can be automatically created by the GPT2DoubleHeadsModel as (0, 1, ..., N)
loss = model(val_input_ids, lm_labels = val_input_ids)[0]
total_loss = total_loss + loss
del val_input_ids
del loss
gc.collect()
return total_loss / (len(val_iter) - 1)
# loop over epoch to find the best model (the best GPT2 language model based on pennTreeBank)
optimizer_ch2 = AdamW(model_ch2.parameters(), lr = 0.00000485, correct_bias = True)
scheduler_ch2 = get_constant_schedule(optimizer = optimizer_ch2, last_epoch = -1)
best_val_loss = float("inf")
epochs = 5 # The total number of epochs ... since the treebank is reasonably large-scale, 5 epoch (>1) is likely to be enough
# see: https://stackoverflow.com/questions/38000189/is-it-ok-to-only-use-one-epoch
# initialize best_model_ch2_penn to None
best_model_ch2_penn = None
for epoch in range(1, epochs + 1):
gc.collect()
epoch_start_time = time.time()
# again, log_interval = 1 for Stochastic Gradient Descent
train_lm_head(model_ch2, train_penn_iter,
optimizer_ch2, scheduler_ch2,
log_int, pad_index_ch2)
val_loss = evaluate_lm_head(model_ch2, val_penn_iter,
pad_index_ch2)
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.4f} | '
'valid ppl {:8.4f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model_ch2
gc.collect()
scheduler_ch2.step() # update the learning rate
```
When I use the ```best_model``` that I obtain from this train function, and pass in the same input, the hidden state of the last token keeps changing each time I compute it. How can I prevent this?
Would saving the ```best_model``` as pre-trained model and re-loading it prevent the hidden state from changing? If so, what is the code to save and re-load the ```best_model``` as a pre-trained model? I am having a hard time following the documentation, as I am just a beginner.
Thank you,<|||||>This is too much code for me to debug now. But generally, inconsistent inference is caused by not setting your model to evaluation mode. Do `model.eval()` before retrieving your vector. This will disable dropout/norm (and dropout is pseudorandom, so that may cause inconsistent results).<|||||>Thank you! This solved my problem. Is it necessary to include ```model.eval()``` before retrieving loss to update the weights in my ```train()``` function? or should I NOT use ```model.eval()``` in my ```train()``` function, because the dropout and the norm needs to be applied during the training (which I am not so sure on)?
Thank you,<|||||>This is more a "deep learning with PyTorch" question than a transformers question, so I'll be brief. If you have more question, please ask the question on Stack Overflow.
`.eval()` is used when you are **not** training, i.e. when you wish to get deterministic values from your model. This is typically done during _evaluation_ and _testing_. When you are training, though, you want those things such as dropout because it has been shown that they are beneficial for the training process (e.g. combat overfitting). To ensure that the model is using dropout etc. you should put in back into training mode (in contrast to evaluating mode) by setting `model.train()`.
In addition to `eval()` vs `.train()`, there is also the grad vs no_grad difference. During training, weights `require_grad`, which tells PyTorch that gradients need to be calculated for those parameters. As you can imagine, that is a computationally expensive step, which we don't need during testing/evaluating. So we can disable gradient calculation with a context manager `torch.no_grad()`.
So, in practice your code could look something like this (but it might look different, or you might use steps instead of epochs, etc.). (Note, this is pseudo code.)
```python
for epoch in range(n_epochs):
# train
model.train()
for batch in train_loader:
out = model(batch)
...
# evaluate
model.eval()
with torch.no_grad():
for batch in eval_loader:
out = model(batch)
...
...
# test
model.eval()
with torch.no_grad():
for batch in test_loader:
test = model(batch)
...
```
Again, if you have more detailed questions concerning, please ask them on Stack Overflow. <|||||>Thank you for all your help, I appreciate it! |
transformers | 2,626 | closed | BertModel output the same embedding during Evaluation | ## ❓ Questions & Help
During evaluation, my text model outputs the same embedding regardless of the token id. The following is my model.
```
class BertTextEncoderFactory(nn.Module):
def __init__(self, embedding_dim = 256, model_name_or_path = None, backbone ='bert'):
super(BertTextEncoderFactory, self).__init__()
if (backbone == 'bert'):
self.encoder = BertForRetrival(embedding_dim, 'bert-base-uncased')
```
```
class BertForRetrival(nn.Module):
def __init__(self, single_embedding_dim = 256, model_name_or_path = 'bert-base-uncased'):
super(BertForRetrival, self).__init__()
self.config = BertConfig.from_pretrained(model_name_or_path)
self.bert = BertModel.from_pretrained(model_name_or_path, config=self.config)
self.single_embedding_dim = single_embedding_dim
self.dropout = nn.Dropout(self.config.hidden_dropout_prob)
self.embedding_layer = nn.Sequential(nn.Linear(self.config.hidden_size, self.config.hidden_size),
nn.LeakyReLU(),
self.dropout,
nn.Linear(self.config.hidden_size, int(self.config.hidden_size / 2)),
nn.LeakyReLU(),
self.dropout,
nn.Linear(int(self.config.hidden_size / 2), self.single_embedding_dim),
nn.ReLU())
self.init_weights(self.embedding_layer)
def init_weights(self, module):
for m in module.modules():
if type(m) == nn.Linear:
torch.nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.001)
def forward(self, input_ids, attention_mask=None, token_type_ids=None):
outputs = self.bert(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
print(len(outputs))
print(outputs[0].size())
print(outputs)
first_token_tensor = outputs[0][:,0]
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
single_embedding = self.embedding_layer(pooled_output)
return single_embedding
```
Model initialization
`text_model = BertTextEncoderFactory(embedding_dim = 256, model_name_or_path = None, backbone = 'bert') `
After I finetuned the model, I save it to a checkpoint.
`torch.save(text_model, './pretrainedcheckpoint/checkpoint.pth.tar')`
During evaluation, I first initialize the model in the following way
`text_model = BertTextEncoderFactory(embedding_dim = 256, model_name_or_path = None, backbone = 'bert') `
The output of sample ids is the following. So far so good.
```
text_model.eval()
ids = torch.tensor([[101, 14378, 102]], dtype=torch.long)
text_model(ids, None, None)
```
Ouput is the following
```
2
torch.Size([1, 3, 768])
tensor([[[-0.6077, 0.1454, -0.1540, ..., 0.0763, 0.5157, 0.4968],
[ 0.7466, -0.3633, -0.0637, ..., 0.0403, 0.5987, 0.2889],
[ 0.9683, 0.0883, -0.3452, ..., 0.2865, -0.6153, -0.1851]]],
grad_fn=<NativeLayerNormBackward>)
```
Then, I load the model with trained weights.
```
import os
resume = './pretrainedcheckpoint/checkpoint.pth.tar'
if os.path.isfile(resume):
checkpoint = torch.load(resume)
text_model.load_state_dict(checkpoint)
```
`<All keys matched successfully>`
Now, given the same token id sequences, the model output three exactly same embedding.
```
text_model.eval()
ids = torch.tensor([[101, 14378, 102]], dtype=torch.long)
text_model(ids, None, None)
```
```
2
torch.Size([1, 3, 768])
tensor([[[-0.3972, 0.2239, -0.3335, ..., -0.4338, 0.4992, -0.0618],
[-0.3972, 0.2239, -0.3335, ..., -0.4338, 0.4992, -0.0618],
[-0.3972, 0.2239, -0.3335, ..., -0.4338, 0.4992, -0.0618]]],
grad_fn=<NativeLayerNormBackward>)
```
As you can see, the embedding for the three tokens are all the same !!!!
```
tensor([[[-0.3972, 0.2239, -0.3335, ..., -0.4338, 0.4992, -0.0618],
[-0.3972, 0.2239, -0.3335, ..., -0.4338, 0.4992, -0.0618],
[-0.3972, 0.2239, -0.3335, ..., -0.4338, 0.4992, -0.0618]]],
```
| 01-23-2020 22:12:07 | 01-23-2020 22:12:07 | Wherees the `forward()` function of your `BertTextEncoderFactory(nn.Module)`?<|||||>It problem is caused by the data.<|||||>@nimning hi, i got stuck on the same issue exactly the same as you mentioned, cloud you please tell me how did you solve this problem |
transformers | 2,625 | closed | Pipeline error when creating a model without a model card json file (on Windows) | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Bert
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
```python
import sys
from transformers import pipeline
if __name__ == '__main__':
print("start")
nlp_ft = pipeline('question-answering', model=r'C:\Users\a652726\PycharmProjects\src\data\raw\qa\wwm-bert-uncased-finetuned-squad',
tokenizer='bert-large-uncased')
```
Results in the ValueError: no modelcard.json file (which i do not have)
My fix (hack):
In modelcard.py replace (line 164):
```python
except EnvironmentError:
if pretrained_model_name_or_path in ALL_PRETRAINED_CONFIG_ARCHIVE_MAP:
```
with
```python
except (EnvironmentError, ValueError):
if pretrained_model_name_or_path in ALL_PRETRAINED_CONFIG_ARCHIVE_MAP:
```
This results in:
```python
logger.warning("Creating an empty model card.")
```
And everything works fine after this.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x ] my own task or dataset: (give details)
Changing QA pipeline to work on a fixed set of spans (like multiple choice QA task, or classification)
## To Reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Windows
* Python version: 3.7
* PyTorch version: 1.3
* PyTorch Transformers version (or branch): master (post 2.3)
* Using GPU ? no
* Distributed or parallel setup ? no
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 01-23-2020 21:33:23 | 01-23-2020 21:33:23 | Please format your post correctly by using code blocks. https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,624 | closed | How to merge TFDistilBertForSequenceClassification with another tf.Keras model | ## ❓ Questions & Help
In TensorFlow 2, what is the recommended way to merge `TFDistilBertForSequenceClassification` (or any other Transformer model) with another `tf.keras` model?
In other words, I'd like to do something like this:
```
merged_out = keras.layers.concatenate([other_model.output, distilbert_model.output])
merged_out = layers.Dense(1)(merged_out)
combined_model = keras.Model([other_model.input] + distilbert_model.input, merged_out)
```
The above produces an error because `distilbert_model.output` is not accessible in the same way as vanilla tf.Keras models:
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-48-b15ccf9c0221> in <module>()
----> 1 merged_out = keras.layers.concatenate([other_model.output, distilbert_model.output])
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/base_layer.py in output(self)
1574 """
1575 if not self._inbound_nodes:
-> 1576 raise AttributeError('Layer ' + self.name + ' has no inbound nodes.')
1577 return self._get_node_attribute_at_index(0, 'output_tensors', 'output')
1578
AttributeError: Layer tf_distil_bert_for_sequence_classification has no inbound nodes.
```
| 01-23-2020 21:24:44 | 01-23-2020 21:24:44 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Wait, is this just the end? Am also interested in doing this<|||||>This [comment](https://github.com/huggingface/transformers/issues/4733#issuecomment-647414520) may help you? |
transformers | 2,623 | closed | QA pipeline run-time error when there is no answer | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Bert large uncased SQUAD /finetuned on SQUAD2.0 and my dataset
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [x ] the official example scripts: (give details)
```python
from transformers import pipeline
nlp_ft = pipeline('question-answering', model='/data/bert/divorce_qa/wwm-bert-uncased-finetuned-squad', tokenizer='bert-large-uncased')
nlp_ft({
'question': "is it raining?",
'context': ''
})
```
Converting examples to features: 100%|██████████| 1/1 [00:00<00:00, 2486.25it/s]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-13-c7eb59b211f0> in <module>
1 nlp_ft({
2 'question': "is it raining?",
----> 3 'context': ''
4 })
~/miniconda3/envs/nlp2/lib/python3.7/site-packages/transformers/pipelines.py in __call__(self, *texts, **kwargs)
657 # Retrieve the score for the context tokens only (removing question tokens)
658 fw_args = {k: torch.tensor(v) for (k, v) in fw_args.items()}
--> 659 start, end = self.model(**fw_args)
660 start, end = start.cpu().numpy(), end.cpu().numpy()
661
~/miniconda3/envs/nlp2/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
~/miniconda3/envs/nlp2/lib/python3.7/site-packages/transformers/modeling_bert.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, start_positions, end_positions)
1265 position_ids=position_ids,
1266 head_mask=head_mask,
-> 1267 inputs_embeds=inputs_embeds)
1268
1269 sequence_output = outputs[0]
~/miniconda3/envs/nlp2/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
~/miniconda3/envs/nlp2/lib/python3.7/site-packages/transformers/modeling_bert.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask)
687 extended_attention_mask = attention_mask[:, None, None, :]
688 else:
--> 689 raise ValueError("Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(input_shape, attention_mask.shape))
690
691 # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
ValueError: Wrong shape for input_ids (shape torch.Size([0])) or attention_mask (shape torch.Size([0]))
Another case (with topk):
```python
nlp_ft({
'question': "met with client to discuss her house.",
'context': 'snow'
}, topk=5)
```
Converting examples to features: 100%|██████████| 1/1 [00:00<00:00, 998.17it/s]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-21-bdcc590f57c7> in <module>
2 'question': "met with client to discuss her house.",
3 'context': 'snow'
----> 4 }, topk=5)
~/miniconda3/envs/nlp2/lib/python3.7/site-packages/transformers/pipelines.py in __call__(self, *texts, **kwargs)
684 'answer': ' '.join(example.doc_tokens[feature.token_to_orig_map[s]:feature.token_to_orig_map[e] + 1])
685 }
--> 686 for s, e, score in zip(starts, ends, scores)
687 ]
688 if len(answers) == 1:
~/miniconda3/envs/nlp2/lib/python3.7/site-packages/transformers/pipelines.py in <listcomp>(.0)
684 'answer': ' '.join(example.doc_tokens[feature.token_to_orig_map[s]:feature.token_to_orig_map[e] + 1])
685 }
--> 686 for s, e, score in zip(starts, ends, scores)
687 ]
688 if len(answers) == 1:
KeyError: 255
Is SQUAD2.0 no answer (the span is the CLS token) implemented?
A more difficult problem:
The same span 0:42 appears in the answers twice with different probabilities:
```python
nlp_ft({
'question': 'not divorcing?',
'context': 'My son loves ice cream. I hired a lawyer. The weather is beautiful'
}, topk=20)
```
Converting examples to features: 100%|██████████| 1/1 [00:00<00:00, 608.13it/s]
[{'score': 6.8867944232487335e-15,
'start': 24,
'end': 42,
'answer': 'I hired a lawyer.'},
{'score': 5.837555144012473e-15,
'start': 0,
'end': 42,
'answer': 'My son loves ice cream. I hired a lawyer.'},
{'score': 5.104124911876544e-15,
'start': 26,
'end': 42,
'answer': 'hired a lawyer.'},
{'score': 4.480651773242456e-15,
'start': 0,
'end': 23,
'answer': 'My son loves ice cream.'},
{'score': 3.9003458779199145e-15,
'start': 34,
'end': 42,
'answer': 'lawyer.'},
{'score': 3.683094227838328e-15,
'start': 24,
'end': 66,
'answer': 'I hired a lawyer. The weather is beautiful'},
{'score': 3.637585671341453e-15, 'start': 0, 'end': 6, 'answer': 'My son'},
{'score': 3.4290555803043746e-15,
'start': 3,
'end': 42,
'answer': 'son loves ice cream. I hired a lawyer.'},
{'score': 3.1219554896279132e-15,
'start': 0,
'end': 66,
'answer': 'My son loves ice cream. I hired a lawyer. The weather is beautiful'},
{'score': 2.963547353528702e-15,
'start': 32,
'end': 42,
'answer': 'a lawyer.'},
{'score': 2.8398875189274633e-15,
'start': 43,
'end': 66,
'answer': 'The weather is beautiful'},
{'score': 2.7297131068172943e-15,
'start': 26,
'end': 66,
'answer': 'hired a lawyer. The weather is beautiful'},
{'score': 2.631992946944041e-15,
'start': 3,
'end': 23,
'answer': 'son loves ice cream.'},
{'score': 2.4540475046027306e-15,
'start': 17,
'end': 42,
'answer': 'cream. I hired a lawyer.'},
{'score': 2.3835331682965698e-15,
'start': 24,
'end': 42,
'answer': 'I hired a lawyer.'},
{'score': 2.351548698805639e-15,
'start': 7,
'end': 42,
'answer': 'loves ice cream. I hired a lawyer.'},
{'score': 2.136764987640859e-15, 'start': 3, 'end': 6, 'answer': 'son'},
{'score': 2.0859256871447656e-15,
'start': 34,
'end': 66,
'answer': 'lawyer. The weather is beautiful'},
{'score': 2.0203893789166256e-15,
'start': 0,
'end': 42,
'answer': 'My son loves ice cream. I hired a lawyer.'},
{'score': 1.9864633437892544e-15, 'start': 24, 'end': 25, 'answer': 'I'}]
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Ubuntu 18.04.3 LTS
* Python version: 3.7.4
* PyTorch version: 1.3
* PyTorch Transformers version (or branch): master 2.3 (or later)
* Using GPU ? no
* Distributed or parallel setup ? no
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 01-23-2020 19:52:29 | 01-23-2020 19:52:29 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,622 | closed | tokenizer.add_tokens not working | ## 🐛 Bug
<!-- Important information -->
I tried to add new tokens in vocabulary using tokenizer.add_tokens() and then called model() according to the code given in `BertForMaskedLM` class definition. The code is given below:
```
from transformers import BertForMaskedLM, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
tokenizer.add_tokens(['[SPECIAL_TOKEN_1]', '[SPECIAL_TOKEN_2]'])
model.resize_token_embeddings(len(tokenizer))
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
outputs = model(input_ids, masked_lm_labels=input_ids)
```
I get the following error:
`RuntimeError: The size of tensor a (30524) must match the size of tensor b (30522) at non-singleton dimension 2`
| 01-23-2020 17:45:35 | 01-23-2020 17:45:35 | I believe this was fixed recently. Could you please try installing from source `pip install git+https://github.com/huggingface/transformers` and let me know if it fixes the bug?<|||||>I executed the above command and it worked.
Thanks<|||||>Glad it worked.<|||||>I found a similar bug even with the latest version built from source.
After adding new tokens, if I use `len(tokenizer)`, I can see that the total number of tokens has increased. However, if I use `tokenizer.vocab_size`, the size was still the number before adding new tokens. If I save the vocab using `tokenizer.save_vocabulary("./")`, the generated vocab.json file does not contain the new added tokens.
<|||||>Hello! This is not an error. Your added tokens are in `added_tokens.json`.<|||||>> Hello! This is not an error. Your added tokens are in `added_tokens.json`.
Thanks for your reply! However, when I save the RobtertaTokenizer, there are only vocab.json and merge.txt. I can't find the file added_tokens.json.<|||||>Which version of transformers are you using? In the latest version:
```py
>>> from transformers import RobertaTokenizer
>>> tok = RobertaTokenizer.from_pretrained("roberta-base")
>>> tok.add_tokens(["lingjzhu", "LysandreJik"])
2
>>> tok.save_pretrained("here")
('here/vocab.json', 'here/merges.txt', 'here/special_tokens_map.json', 'here/added_tokens.json')
```
When inspecting `here/added_tokens.json`:
```
{"lingjzhu": 50265, "LysandreJik": 50266}
```<|||||>Thanks for your comments! I recompiled the package from the source and it is working now. I am sorry for the negligence!<|||||>I just want to add a comment about the tokenizer. The function `tokenizer.save_vocabulary()` will not save the added tokens even in the latest version. This was my original error. But `tokenizer.save_pretrained()` will solve the problem. <|||||>@lingjzhu, that makes sense, `save_vocabulary` saves the vocabulary. The entire tokenizer (with the special tokens, with the added tokens, with the special added tokens) needs to be saved using `save_pretrained`, as you've said.
The difference is explicitely mentioned in the [documentation](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.save_pretrained).<|||||>> Which version of transformers are you using? In the latest version:
>
> ```python
> >>> from transformers import RobertaTokenizer
> >>> tok = RobertaTokenizer.from_pretrained("roberta-base")
> >>> tok.add_tokens(["lingjzhu", "LysandreJik"])
> 2
> >>> tok.save_pretrained("here")
> ('here/vocab.json', 'here/merges.txt', 'here/special_tokens_map.json', 'here/added_tokens.json')
> ```
>
> When inspecting `here/added_tokens.json`:
>
> ```
> {"lingjzhu": 50265, "LysandreJik": 50266}
> ```
Hi, since I append the origin vocab.json according to the added_tokens.json file, and the vocab size and tokenizer length both added from 21128 to 21300. However, convert_tokens_to_ids() function seems that referenced the origin vocab.json with 21128 length, is there any solutions to use both origin and added tokens to apply the convert_tokens_to_ids() function?
|
transformers | 2,621 | closed | Documentation markup for model descriptions | ## 🐛 Bug
Looking at [the documentation](https://huggingface.co/transformers/model_doc/bert.html#bertforsequenceclassification), it seems something went wrong in markup land. In some models (but not all, e.g. BertModel, BertForMaskedLM, BertForNextSentencePrediction), the model description (i.e. the first paragraph) is split up in one highlighted line (grey background) and the rest of the text is regular. Seems like a formatting issue in the source code. | 01-23-2020 14:21:02 | 01-23-2020 14:21:02 | Hi! Indeed there were quite a few issues with the documentation. #2532 was merged this morning, and hopefully fixes all these issues!
Would love your feedback on the new documentation (be sure to refresh your cache to see the new doc on https://huggingface.co/transformers). <|||||>Ah, sorry, didn't check the recent commits. Just checked a couple of items. Everything seems in order except for a small inconsistency in the tokenizers:
Some (e.g. [openai](https://huggingface.co/transformers/model_doc/gpt.html#openaigpttokenizer)) put the first line (the one with 'peculiarities') in a highlighted block, while others (e.g. [XLNet](https://huggingface.co/transformers/model_doc/xlnet.html#xlnettokenizer)) don't.<|||||>Good catch! Up to now I've reworked the configuration + models + glossary. I've yet to do the tokenizers as well as the abstract classes, will work on them in the coming days.<|||||>If you've finalized that, feel free to close this issue through a commit. I'll have another look, then!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,620 | closed | Document which heads are pretrained and which aren't | ## 🚀 Feature
I was going through the documentation and I realised I never thought about the different heads in much detail (I always start from the base model and built on top of that). Now that I did, I wonder whether users (mistakenly?) assume that models such as `BertForQuestionAnswering` have a pretrained head. I am assuming that these heads are _not_ pretrained but that it is a convenience to have an architecture that can be finetuned on downstream tasks. If I am correct, it might be useful to highlight for these kind of models that the heads are not pretrained.
That being said, when I run
```python
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
model.eval()
torch.set_grad_enabled(False)
for name, parameters in model.named_parameters():
if 'classifier' in name:
print(name)
print(parameters)
```
I get the notice that "Weights of BertForSequenceClassification not initialized from pretrained model: ['classifier.weight', 'classifier.bias']", but still:
```
classifier.weight
Parameter containing:
tensor([[-0.0098, 0.0137, 0.0275, ..., -0.0221, -0.0190, 0.0156],
[ 0.0144, 0.0016, 0.0084, ..., 0.0055, 0.0221, -0.0145]],
requires_grad=True)
````
I've been peaking into the rabbit hole, but I can't seem to find where this random initialisation occurs.
If you agree, I can put some time in putting that in the documentation but I might need help or at least a review. Perhaps this can even be automated? That would be awesome. | 01-23-2020 14:15:42 | 01-23-2020 14:15:42 | I'm certain the random initialisation occurs when we instantiate the class (See `BertPreTrainedModel.init_weights()`)<|||||>> I'm certain the random initialisation occurs when we instantiate the class (See `BertPreTrainedModel.init_weights()`)
You're right. It gets a bit complicated to track down though.
PretrainedModel implements `init_weights` which applies `self._init_weights` to all modules **but** there is no reference in that class to that method. You'll have to find it in the subclasses (e.g. BertPreTrainedModel). But for e.g. RoBERTa, it's of course not needed because RoBERTa extends BERT. It's a bit confusing to follow along - or at least it takes some time to get your head around.
It might be useful to implement the methods that are needed in subclasses in PreTrainedModel. Typically you'd see abstract methods for this, but something as simple as the following would also be nice.
```python
def _init_weights(self):
raise NotImplementedError('Please implement me')
```
(If and only if all subclasses have to implement it.)
This, of course, is not my main question here.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,619 | closed | Adding scibert in the list of pre-trained models? | # 🌟New model addition
## Model description
Would it be possible/is it in the pipeline to add SCIBERT as one of the pre-trained models for Bert? Could be as simple as adding it to the `BERT_PRETRAINED_MODEL_ARCHIVE_MAP`.
## Open Source status
Scibert is available on its own repository (https://github.com/allenai/scibert). The advantage of adding it to the map is that we don't need to download it ad-hoc every time we want to use it, it would be cached in the same repository, etc.
* [x] the model implementation is available:
* [x] the model weights are available:
* [x] who are the authors: Iz Beltagy and Kyle Lo and Arman Cohan authored the ALlenAI
## Additional context
<!-- Add any other context about the problem here. -->
| 01-23-2020 12:57:24 | 01-23-2020 12:57:24 | It would be nice if AllenAI uploaded their models to [the user hub](https://huggingface.co/models). That would allow you to simply load the models like `.from_pretrained('allenai/scibert-scivocab-uncased')`. Perhaps you can open an issue on their repository and ask whether that is possible. It might be too much work/maintenance for them, though.<|||||>Right, I missed that 2.2.2 update for model sharing (https://huggingface.co/transformers/model_sharing.html). So you're right, probably the best thing is for them to upload their model.<|||||>Might be best to close this issue here and keep everything in the issue that you created over at AllenAI.<|||||>Yeah, makes sense. Thanks. |
transformers | 2,618 | closed | summarization codes | Hi
I greatly appreciate to add also possibilities to train the summarization codes from scratch. I see only evaluation part in the codes. Does this also work for training?
thanks a lot for your response.
Kind regards
Rabeeh | 01-23-2020 11:12:05 | 01-23-2020 11:12:05 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,617 | closed | TF Models have no attribute .train() or .eval() | ## 🐛 Bug
Using any of the TF models I am unable to set the **.eval()** or **.train()** properties. In addition, when loading from a pre-trained path (which the documentation seems to imply would mean that the models will be set to eval mode) I see non deterministic outputs given the same input indicating the models do not have dropout turned off.
Basic example:
```
model = TFBert.from_pretrained('path_to_model_directory', from_pt=True)
model.eval() #### This errors with "TFBertModel object has no attribute 'eval'"
tokenizer = BertTokenizer.from_pretrained('path_to_model_directory')
inputs = tokenizer.encode_plus('Dummy text here.', return_tensors='tf')['input_ids']
print(model(inputs)) ## these outputs
print(model(inputs)) ## **will not** be the same
print(model(inputs, training=False)) ## these outputs
print(model(inputs, training=False)) ## **will** be the same
```
Any help would be greatly appreciated!
## Environment
* OS: Windows
* Python version: 3.6
* PyTorch version: 1.4
* PyTorch Transformers version (or branch): 2.3
* Using GPU ? Yes
| 01-23-2020 09:02:08 | 01-23-2020 09:02:08 | `model.eval()` is a PyTorch directive. It will disable dropout/norm, as you point out. On top of that, though, you'd also set the `no_grad` parameter so that weights are not updated.
Typically, your code'd look like this for inference/evaluation/testing.
```python
model.eval()
with torch.no_grad():
# do stuff
```
I am not sure how this should be done in Tensorflow.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Is there a fix available for this because I am currently running a TFBertForSequenceClassification for classification and it gives non determinististic outcomes. I have written my code in tensorflow framework. Looks like the fix is placing model.eval() during evaluation operation as per https://github.com/google-research/bert/issues/583. |
transformers | 2,616 | closed | Adaptive Attention Span for Transformers | # 🌟New model addition
## Model description
<!-- Important information -->
## Open Source status
* [x] the model implementation is available: https://github.com/facebookresearch/adaptive-span
* [x] the model weights are available: get_pretrained.sh
* [x] who are the authors: Facebook Research
## Additional context
No additional dependencies required.
| 01-22-2020 23:01:30 | 01-22-2020 23:01:30 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Any clue about how to integrate that into a BERT model? |
transformers | 2,615 | closed | Question answering pipeline fails with long context | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Question Answering Pipeline / Distilbert
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [x] the official example scripts: (give details): Based on the sample pipeline code form here: https://github.com/huggingface/transformers#quick-tour-of-pipelines
* [] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
## To Reproduce
I think I found a bug in the pipeline code. It fails when there's a long context in a list. See below:
```
from transformers import pipeline
nlp = pipeline('question-answering')
long_str = 'These are some irrelevant words. ' * 100
long_str = 'Pipeline have been included in the huggingface/transformers repository. ' + long_str
#Works
nlp(
{
'question': 'What is the name of the repository ?',
'context': 'Pipeline have been included in the huggingface/transformers repository. '
},
{
'question': 'What is the name of the repository ?',
'context': 'Pipeline have been included in the huggingface/transformers repository. '
}
)
#Long context by itself - works
nlp(
{
'question': 'What is the name of the repository ?',
'context': long_str
})
#Long context in a list - fails
nlp(
{
'question': 'What is the name of the repository ?',
'context': long_str
},
{
'question': 'What is the name of the repository ?',
'context': 'Pipeline have been included in the huggingface/transformers repository. '
}
)
```
Here's the error message:
```
Converting examples to features: 100%|██████████| 2/2 [00:00<00:00, 87.19it/s]
Traceback (most recent call last):
File "<ipython-input-3-e795fc7f26bf>", line 8, in <module>
'context': 'Pipeline have been included in the huggingface/transformers repository. '
File "c:\users\admin\appdata\local\programs\python\python37\lib\site-packages\transformers\pipelines.py", line 686, in __call__
for s, e, score in zip(starts, ends, scores)
File "c:\users\admin\appdata\local\programs\python\python37\lib\site-packages\transformers\pipelines.py", line 686, in <listcomp>
for s, e, score in zip(starts, ends, scores)
IndexError: index 0 is out of bounds for axis 0 with size 0
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
Would like to get the answer for the second example.
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Windows
* Python version: Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)]
* PyTorch version: N/A
* PyTorch Transformers version (or branch): master
* Using GPU ?
* Distributed or parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 01-22-2020 22:10:10 | 01-22-2020 22:10:10 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I also have this issue<|||||>This seems to be fixed when limiting the batch size. |
transformers | 2,614 | closed | Missing module "startlette" when calling transformers-cli | Calling `transformers-cli` in terminal returns error ``ModuleNotFoundError: No module named 'starlette'``.
I assume starlette should be added into dependencies in setup.py and it will be a quick fix. | 01-22-2020 17:09:17 | 01-22-2020 17:09:17 | Hi @tailaiw, thanks for reporting the issue.
Can you try to update to the latest version of transformers ? it should have been fixed in 5004d5af42c61c91d5df07aa139d37599ceb6215.
Feel free to reopen if its not the case ! |
transformers | 2,613 | closed | XLnet memory usage for long sequences | ## ❓ Questions & Help
Hello,
I have some questions regarding how the XLnet memory and output work in this implementation.
1. As it's been mentioned before, by default, XLnet doesn't use memory. So, how is this possible that it accepts long sequences as input (in other words, why there isn't any limit on the number of input tokens), unlike BERT, for example, that will only accept 512 tokens.
2. If I set the memory length to 512, and feed the XLnet with 512 tokens at a time (for a 1024 sequence length), also pass the memory in each step. (like the example code below) Will the final output of the network, includes all the information from the whole sequence?
```
tokenizer = XLNetTokenizer.from_pretrained('xlnet-large-cased')
model = XLNetModel.from_pretrained('xlnet-large-cased')
mems = None
for i in range(2):
input_ids = torch.tensor(tokenizer.encode(text[i])).unsqueeze(0)
outputs = model(input_ids, mems=mems)
mems = outputs[1]
```
To be clear, I want to use XLnet for long text summarization. So I need to feed the XLnet output to a decoder part and need a fixed-length representation. | 01-22-2020 17:08:22 | 01-22-2020 17:08:22 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,612 | closed | Error in fine tuning Roberta for QA | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
I tried to fine tune RobertaModel for question answering task, i implemented TFRobertaForQuestionAnswering but when i run the training script i got this error:
tensorflow.python.framework.errors_impl.InvalidArgumentError: indices[0,11] = 1 is not in [0, 1) [Op:ResourceGather] name: tf_roberta_for_question_answering/tf_roberta_model/roberta/embeddings/token_type_embeddings/embedding_lookup/
Here is my class TFRobertaForQuestionAnswering
```python
from transformers import TFRobertaPreTrainedModel, RobertaConfig, TFRobertaModel
import tensorflow as tf
class TFRobertaForQuestionAnswering(TFRobertaPreTrainedModel):
config_class = RobertaConfig
#pretrained_model_archive_map = ROBERTA_PRETRAINED_MODEL_ARCHIVE_MAP
base_model_prefix = "roberta"
def __init__(self, config, *inputs, **kwargs):
config.vocab_size = config.vocab_size + 2
super().__init__(config, *inputs, **kwargs)
def get_initializer(initializer_range=0.02):
"""Creates a `tf.initializers.truncated_normal` with the given range.
Args:
initializer_range: float, initializer range for stddev.
Returns:
TruncatedNormal initializer with stddev = `initializer_range`.
"""
return tf.keras.initializers.TruncatedNormal(stddev=initializer_range)
self.num_labels = config.num_labels
self.roberta = TFRobertaModel(config)
self.qa_outputs = tf.keras.layers.Dense(
config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="qa_outputs")
def call(
self,
input_ids,
start_positions=None,
end_positions=None,
** kwargs
):
outputs = self.roberta(
input_ids,
** kwargs
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = tf.split(logits, 2, axis=-1)
start_logits = tf.squeeze(start_logits, -1)
end_logits = tf.squeeze(end_logits, -1)
outputs = (start_logits, end_logits,) + outputs[2:]
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(tf.size(start_positions)) > 1:
start_positions = tf.squeeze(start_positions, -1)
if len(tf.size(end_positions)) > 1:
end_positions = tf.squeeze(end_positions, -1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
#ignored_index = tf.size(start_logits, 1)
#with tf.Session() as sess:
# scalar = ignored_index.eval()
#tf.clip_by_value(start_positions, 0, ignored_index)
#tf.clip_by_value(end_positions, 0, ignored_index)
loss_fct = tf.keras.losses.SparseCategoricalCrossentropy(from_logits = True)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
outputs = (total_loss,) + outputs
return outputs # (loss), start_logits, end_logits, (hidden_states), (attentions)
```
and here is my training script:
```python
import tensorflow as tf
from transformers import squad_convert_examples_to_features, SquadV2Processor, RobertaTokenizer
from modelRoberta import TFRobertaForQuestionAnswering
from pathlib import Path
import six
import numpy as np
MAX_QUERY_LENGTH = 64
MAX_SEQ_LENGTH = 384
MAX_DOC_STRIDE = 128
MAX_ANSWER_LENGTH = 64
N_TOK_FOR_CONTEXT = 20
def get_shape_list(tensor):
shape = tensor.shape.as_list()
non_static_indexes = []
for (index, dim) in enumerate(shape):
if dim is None:
non_static_indexes.append(index)
if not non_static_indexes:
return shape
dyn_shape = tf.shape(tensor)
for index in non_static_indexes:
shape[index] = dyn_shape[index]
return shape
tokenizer = RobertaTokenizer.from_pretrained("roberta-base")
model = TFRobertaForQuestionAnswering.from_pretrained("roberta-base")
squad = SquadV2Processor()
train_examples = squad.get_train_examples(data_dir=Path(__file__).parent, filename="train.json")
test_examples = squad.get_dev_examples(data_dir=Path(__file__).parent, filename="test.json")
train_dataset = squad_convert_examples_to_features(train_examples[:1], tokenizer=tokenizer, max_seq_length=MAX_SEQ_LENGTH,
doc_stride=MAX_DOC_STRIDE, max_query_length=MAX_QUERY_LENGTH,
is_training=True, return_dataset='tf')
test_dataset = squad_convert_examples_to_features(test_examples[:1], tokenizer=tokenizer, max_seq_length=MAX_SEQ_LENGTH,
doc_stride=MAX_DOC_STRIDE, max_query_length=MAX_QUERY_LENGTH,
is_training=False, return_dataset='tf')
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
batch_size = 1
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size)
epochs = 3
for epoch in range(epochs):
print('Start of epoch %d' % (epoch,))
for step, batch in enumerate(train_dataset):
with tf.GradientTape() as tape:
inputs_batch = {
"inputs_ids": batch[0]['input_ids'],
"token_type_ids": batch[0]['token_type_ids'],
}
start_position = batch[1]['start_position']
end_position = batch[1]['end_position']
seq_length = get_shape_list(inputs_batch['inputs_ids'])[1]
start_positions = tf.one_hot(start_position, on_value=1.0, off_value=0.0, depth=seq_length, dtype=tf.float32)
end_positions = tf.one_hot(end_position,on_value=1.0, off_value=0.0, depth=seq_length, dtype=tf.float32)
outputs = model(inputs_batch['inputs_ids'], token_type_ids= inputs_batch['token_type_ids'], training=True) # Logits for this minibatch
start_logits, end_logits = outputs[:2]
start_logits = tf.nn.log_softmax(start_logits, axis=-1)
end_logits = tf.nn.log_softmax(end_logits, axis=-1)
seq_height = get_shape_list(inputs_batch['inputs_ids'])[0]
start_logits = tf.keras.backend.reshape(start_logits, shape=(seq_height*seq_length, 1))
end_logits = tf.keras.backend.reshape(end_logits, shape=(seq_height * seq_length, 1))
start_positions = tf.keras.backend.reshape(start_positions, shape=(seq_height * seq_length, 1))
end_positions = tf.keras.backend.reshape(end_positions, shape=(seq_height * seq_length, 1))
start_loss = -tf.reduce_mean(tf.reduce_sum(start_positions * start_logits, axis=-1))
end_loss = -tf.reduce_mean(tf.reduce_sum(end_positions * end_logits, axis=-1))
loss_value = (start_loss + end_loss) / 2
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
if step % 200 == 0:
print('Training loss (for one batch) at step %s: %s' % (step, float(loss_value)))
print('Seen so far: %s samples' % ((step + 1) * batch_size))
context = "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse ('Norman' comes from 'Norseman') raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries."
question = "In what country is Normandy located?"
en_plus = tokenizer.encode_plus(context, question, add_special_tokens=True)
en = en_plus['input_ids']
token_type_ids = en_plus['token_type_ids']
input_ids = tf.constant([en])
segments_tensors = tf.constant([token_type_ids])
outputs = model(input_ids)
start_scores, end_scores = outputs[:2]
ss = tf.argmax(start_scores.numpy()[0]).numpy()
es = tf.argmax(end_scores.numpy()[0]).numpy()
answer = tokenizer.decode(en[ss: es+1], clean_up_tokenization_spaces=True)
print(ss)
print(es)
print(answer)
model.save_pretrained('./save/')
```
Thanks in advance for helping me. | 01-22-2020 17:05:33 | 01-22-2020 17:05:33 | Please [format your code correctly](https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks). Now it is very unreadable.<|||||>Thank you for mentioning this, it's done!<|||||>Something seems to have gone wrong. Can you check? There is a line "and here is my training script:" that is in the code block but shouldn't be. Also the last line.<|||||>yeah i corrected it<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,611 | closed | Finetuning my language model | ## ❓ Questions & Help
I have a problem about a finetuning of my own language model ([model](https://mxmdownloads.s3.amazonaws.com/umberto/umberto-commoncrawl-cased-v1.tar.gz) and [sentencepiece](https://mxmdownloads.s3.amazonaws.com/umberto/umberto-commoncrawl-cased-v1-sentencepiece.bpe.model)). I'm trying to use [run_lm_finetuning.py](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py).
When it tokenizes the text of the training set, the program enters a loop without giving feedback.
It blocks at [Line 105](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py#L105) in the _tokenize_ function.
```python
...
logger.info("Creating features from dataset file at %s", directory)
self.examples = []
with open(file_path, encoding="utf-8") as f:
text = f.read()
tokenized_text = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))
for i in range(0, len(tokenized_text) - block_size + 1, block_size): # Truncate in block of block_size
self.examples.append(tokenizer.build_inputs_with_special_tokens(tokenized_text[i : i + block_size]))
# Note that we are loosing the last truncated example here for the sake of simplicity (no padding)
# If your dataset is small, first you should loook for a bigger one :-) and second you
# can change this behavior by adding (model specific) padding.
...
```
I have tried to wait for more than 1 hour, but nothing. Using BERT instead of my model, the finetuning starts (even if after several minutes with no log meanwhile).
I launched this:
```bash
python3 run_lm_finetuning.py \
--train_data_file /path/to/train.txt \
--eval_data_file /path/to/eval.txt \
--output_dir /path/to/output \
--mlm \
--do_train \
--do_eval \
--model_type roberta \
--model_name_or_path /path/to/my/model \
--per_gpu_train_batch_size 8 \
--per_gpu_eval_batch_size 8 \
--overwrite_output_dir \
--overwrite_cache \
--max_steps 500000 \
--block_size 128\
--save_steps 50000 \
--eval_all_checkpoints
```
My impression is that something is wrong with the tokenization on the model, any ideas? | 01-22-2020 15:35:44 | 01-22-2020 15:35:44 | I am having the same problem when finetuning my own language model with run_lm_finetuning.py on camembert Model. I guess this might be related to the fact that it is reading a big file at once (103M, ~500k lines).
Since the code reads whole data at once, it requires so much memory to handle huge corpus.
This pull request [2339](https://github.com/huggingface/transformers/pull/2339) is suggesting:
- read corpus by each lines
- flatten 2-dimension array by itertools.chain, it requies less memory and fast
You can find the code [here](https://github.com/huggingface/transformers/pull/2339/commits/537a1de53d824b5851bce32cb5eafaef3f9ce5ef#diff-713f433a085810c3d63a417486e56a88)
<|||||>> I am having the same problem when finetuning my own language model with run_lm_finetuning.py on camembert Model. I guess this might be related to the fact that it is reading a big file at once (103M, ~500k lines).
> Since the code reads whole data at once, it requires so much memory to handle huge corpus.
>
> This pull request [2339](https://github.com/huggingface/transformers/pull/2339) is suggesting:
>
> * read corpus by each lines
> * flatten 2-dimension array by itertools.chain, it requies less memory and fast
> You can find the code [here](https://github.com/huggingface/transformers/pull/2339/commits/537a1de53d824b5851bce32cb5eafaef3f9ce5ef#diff-713f433a085810c3d63a417486e56a88)
@HendZouari this is interesting.
I thought the same thing, but I'm not sure the reason is the size of data, since I verified that with multlingual BERT, it works.
<|||||>Can you guys try out the recently-merged-to-master `LineByLineTextDataset`, defined at
https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py#L124 ?
You can use it by adding the `--line_by_line` flag to your command. (btw: tokenization will soon be _way_ faster everywhere in the library as we are rolling out `tokenizers` integration everywhere)<|||||>For large datasets that don't fit in memory, I use a lazy dataset, modified from [this Github post](https://github.com/pytorch/text/issues/130#issuecomment-333306652).
```python
class LazyTextDataset(Dataset):
def __init__(self, fin):
# get absolute path
# convert to str, linecache doesn't accept Path objects
self.fin = str(Path(fin).resolve())
self.num_entries = self._get_n_lines(self.fin)
@staticmethod
def _get_n_lines(fin):
with open(fin, encoding='utf-8') as fhin:
for line_idx, _ in enumerate(fhin, 1):
pass
return line_idx
def __getitem__(self, idx):
# linecache starts counting from one, not zero, +1 the given index
return linecache.getline(self.fin, idx+1)
def __len__(self):
return self.num_entries
```
With a bit of work you can modify this to return the tokenized strings. I would advise you to write a custom collate_fn for the dataloader, which can be parallellized by using the `n_workers` argument.
Something like this (untested)
```python
from torch.utils.data.dataloader import default_collate
def collate(data):
data = default_collate(data)
return tokenizer.encode(data)
```
That being said, it might be easier to just use wait a bit until `tokenizers` is implemented everywhere, as @julien-c mentions.<|||||>@julien-c it's woking now! The flag `--line_by_line` was fundamental for me 🤩.
Thanks also to @HendZouari and @BramVanroy: I guess If I had followed your advices, the program would have worked well in the same way :)<|||||>I am having this issue while using --line_by_line flag
```
Traceback (most recent call last):
File "run_lm_finetuning.py", line 785, in <module>
main()
File "run_lm_finetuning.py", line 730, in main
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)
File "run_lm_finetuning.py", line 147, in load_and_cache_examples
return LineByLineTextDataset(tokenizer, args, file_path=file_path, block_size=args.block_size)
File "run_lm_finetuning.py", line 135, in __init__
self.examples = tokenizer.batch_encode_plus(lines, max_length=block_size)["input_ids"]
AttributeError: 'BertTokenizer' object has no attribute 'batch_encode_plus'
```
Without this flag I run into another loss function related error for which I just opened an issue.<|||||>`AttributeError: 'BertTokenizer' object has no attribute 'batch_encode_plus'`
You need to update `transformers`. `batch_encode_plus` was only introduced recently.<|||||>Yes. Upgraded and now working. Thank you.<|||||>@paulthemagno Can you close this? Thanks <|||||>I have reopened the issue for a stange RuntimeError.
In the middle of the training (after several hours in which it was working with no problem), it crashes with this log:
```
File "finetuning.py", line 801, in <module>51:22, 4.94it/s]
main()
File "finetuning.py", line 750, in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
File "finetuning.py", line 342, in train
inputs, labels = mask_tokens(batch, tokenizer, args) if args.mlm else (batch, batch)
File "finetuning.py", line 222, in mask_tokens
inputs[indices_random] = random_words[indices_random]
RuntimeError: expected dtype Float but got dtype Long
Epoch: 55%|█████▍ | 6/11 [20:26:33<17:02:07, 12265.60s/it]
Iteration: 69%|██████▊ | 33378/48603 [1:47:45<49:09, 5.16it/s]
```
It fails in the _mask_tokens()_ function:
```python
# 10% of the time, we replace masked input tokens with random word
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(tokenizer), labels.shape, dtype=torch.long)
inputs[indices_random] = random_words[indices_random]
```
Should I set `dtype=torch.float`? Why does It work fine for so much time and it suddenly gives this error at the 6th epoch on 11? <|||||>I have the same issue, but to me it fails immediately.
```
File "run_lm_finetuning.py", line 340, in train
inputs, labels = mask_tokens(batch, tokenizer, args) if args.mlm else (batch, batch)
File "run_lm_finetuning.py", line 218, in mask_tokens
inputs[indices_random] = random_words[indices_random]
RuntimeError: expected dtype Float but got dtype Long
```
It is triggered by using `--line_by_line`.<|||||>I have the same issue as @paulthemagno 's. Mine fails while fine-tuning a basic uncased bert model using the new --line_by_line flag about a quarter way through the epoch.
```Traceback (most recent call last):███████████████████▋ | 2184/8205 [06:29<18:54, 5.31it/s]
File "run_lm_finetuning.py", line 692, in <module>
main()
File "run_lm_finetuning.py", line 641, in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
File "run_lm_finetuning.py", line 320, in train
inputs, labels = mask_tokens(batch, tokenizer, args) if args.mlm else (batch, batch)
File "run_lm_finetuning.py", line 193, in mask_tokens
inputs[indices_random] = random_words[indices_random]
RuntimeError: expected dtype Float but got dtype Long
Epoch: 0%| | 0/1 [06:29<?, ?it/s]
Iteration: 27%|████████████████████████████████████▋
2184/8205 [06:29<17:54, 5.61it/s]```<|||||>I tried to set `dtype=torch.float` but it fails immediately after the launch.
The only way I found is to restart from the last saved checkpoint rather than from the original language model. If someone knew how to fix it, I'd appreciate it.<|||||>Can you guys open a new issue for this? (w/ PyTorch version + ideally a small reproduction case)<|||||>> Can you guys open a new issue for this? (w/ PyTorch version + ideally a small reproduction case)
Yes, done now #2728 |
transformers | 2,610 | closed | run_ner.py huge discrepancy between eval and predict (or "dev" and "test" evaluation modes) | ## ❓ Questions & Help
I'm comparing two different pretrained Bert models on the NER task. One is a bert-base-multilingual-cased model, which works fine, consistently, as one would expect. The other is our own pretrained multilingual Bert, which is trained on fewer languages and has so far shown better results on those few languages. However, when running run_ner.py from here, it doesn't evaluate consistently. The `dev.txt` dataset is completely identical to the `test.txt`dataset, so I'd expect identical results, but I get
```
--do_eval
f1 = 0.7603833865814698
loss = 0.06039658671007991
precision = 0.7531645569620253
recall = 0.7677419354838709
```
and
```
--do_predict
f1 = 0.025925925925925925
loss = 0.41404916612165316
precision = 0.030434782608695653
recall = 0.02258064516129032
```
I also tried `--evaluate_during_training` flag and I get "solid" results already from very few steps and identical to `--do_eval` at the end of training, but `--do_predict` are always much worse. Surprisingly, though, this doesn't occur with bert-base-multilingual-cased model even if I save it to disk and point to that folder. Additionally if under the clause if args.predict I change the mode from "test" to "dev" in function evaluate() I get good results. I repeat, dev and test are identical files that differ only in name.
The problem occurs on any max sequence length, after deleting cache, etc. No errors are displayed during training or evaluation/prediction.
Please help if you have any ideas what might be going wrong. | 01-22-2020 14:21:45 | 01-22-2020 14:21:45 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,609 | closed | Bad Results with Albert | ## ❓ Questions & Help
Trying to understand why is the cosine similarity between tokens with Albert way bad in comparison to DistilBert.
Any inferences on the same would be helpful.
Thanks in advance.
Embeddings constructed for a token by summing the last 4 encoded layers.
Distance metric: cosine
Results with DistilBert
<img width="754" alt="Screenshot 2020-01-22 at 4 05 06 PM" src="https://user-images.githubusercontent.com/25073753/72887172-2e6feb80-3d31-11ea-876b-0ba8eac22234.png">
<img width="613" alt="Screenshot 2020-01-22 at 4 12 27 PM" src="https://user-images.githubusercontent.com/25073753/72887650-25334e80-3d32-11ea-8255-26109f604c84.png">
Results with Albert
<img width="735" alt="Screenshot 2020-01-22 at 4 04 56 PM" src="https://user-images.githubusercontent.com/25073753/72887227-447dac00-3d31-11ea-8797-9873c8439879.png">
<img width="499" alt="Screenshot 2020-01-22 at 4 10 16 PM" src="https://user-images.githubusercontent.com/25073753/72887665-2bc1c600-3d32-11ea-95aa-83b3192e9d49.png">
| 01-22-2020 10:33:08 | 01-22-2020 10:33:08 | Hi. Many people are reporting unstable results or just unexpected results. You can search for issues in this library, and even in other ones (e.g. https://github.com/deepset-ai/FARM/issues/202#issuecomment-577077201). It seems that ALBERT is very sensitive to hyperparameters and even then... For now there seems to be no solution. It is probably best to stick to another model. I'd recommend RoBERTa but it depends on your use-case.<|||||>@BramVanroy I tried with roberta-base as well, the token level similarity is coming out very bad.
Smoking is getting matched with software.<|||||>Can you share a repo to your full code?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,608 | closed | Bug in the command line tool: os.DirEntry not supported in Python 3.5 | Hi,
[This line](https://github.com/huggingface/transformers/blob/1a8e87be4e2a1b551175bd6f0f749f3d2289010f/src/transformers/commands/user.py#L162) will cause a syntax error in Python 3.5 as `os.DirEntry` does not exist.
You should either update the code for backward compatibility or update the README replacing 3.5+ by 3.6 (I believe the former would be preferred).
Best regards.
| 01-22-2020 10:25:48 | 01-22-2020 10:25:48 | Though the core of the library is Python 3.5+, the CLI is actually Python3.6+ as for instance the serving subcommand uses FastAPI which is Py36+ only (cc @mfuntowicz)
Do we have a way to make that clear in the doc @LysandreJik?<|||||>Personal opinion: supporting 3.6+ only seems realistic and may make maintenance easier. [AllenNLP](https://github.com/allenai/allennlp) also requires 3.6.1+. Of course I don't know how large the 3.5 user-base is for `transformers` so it might be worth maintaining. That being said, if there are plans to stop support for 3.5, it might be a good idea to announce this in a release ("last supported release for 3.5"). <|||||>@BramVanroy According to the PyPI stats at https://pypistats.org/packages/transformers (look for the `Daily Download Proportions of transformers package - Python Minor` graph) around 1% of _pip installs_ are on Python 3.5.<|||||>> @BramVanroy According to the PyPI stats at https://pypistats.org/packages/transformers (look for the `Daily Download Proportions of transformers package - Python Minor` graph) around 1% of _pip installs_ are on Python 3.5.
Ah, I didn't know this website - thanks! I'm not sure if 1% is worth the effort, then again I don't know how much additional effort (and resources for CI) are needed to maintain for 3.5 anyway. (But 3.6 has f-strings and ordered dicts (officially in 3.7), PathLike, better `typing`, sooo... :D)
PS: I wonder what happened on December 24 or thereabouts, with the spike in 3.5 installations. <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Closing this as the lib is now officially Python 3.6+ |
transformers | 2,607 | closed | Fix inconsistency between T5WithLMHeadModel's doc and it's behavior | The doc string for `T5WithLMHeadModel` is currently inconsistent with it's behavior.
The doc string says that the forward method ignores indices of -1 when computing the loss; however, the method instead ignores indices of -100. This pull request changes the method to ignore indices of -1, making the two consistent.
It's worth noting, there is a [commit](https://github.com/huggingface/transformers/commit/1b59b57b57010e6119282f3dbf37f8c7c6d6313e#diff-7370db3a19209bf984cc40925aaf2b71) by @thomwolf that changed this value from -1 to -100, though I couldn't find why the change was made. Thomas, perhaps you remember if the change is still important? If it is, I can instead update this PR to change the doc string. | 01-22-2020 06:37:05 | 01-22-2020 06:37:05 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2607?src=pr&el=h1) Report
> Merging [#2607](https://codecov.io/gh/huggingface/transformers/pull/2607?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1a8e87be4e2a1b551175bd6f0f749f3d2289010f?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2607?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2607 +/- ##
=======================================
Coverage 74.53% 74.53%
=======================================
Files 87 87
Lines 14819 14819
=======================================
Hits 11046 11046
Misses 3773 3773
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2607?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/2607/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `81.09% <ø> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2607?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2607?src=pr&el=footer). Last update [1a8e87b...980d1f8](https://codecov.io/gh/huggingface/transformers/pull/2607?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Hi! Indeed, we changed all the Cross Entropy ignored indices to be -100 to respect the PyTorch default. The docstrings would need to be changed, instead of the index. We could even remove the argument:
```py
loss_fct = CrossEntropyLoss()
```
to keep in sync with pytorch.<|||||>@LysandreJik, that makes perfect sense. Thanks for the background!
I've updated this PR to change the doc string instead.
Removing the `ignore_index` argument would mean that the behavior of the method depends on which PyTorch version a user has installed, which could be counter-intuitive. Similarly, to ensure the doc string is accurate we'd have to add a unit test for it and run against all versions of PyTorch that a user might reasonably install.
For simplicity / consistency, I'd suggest continuing to explicitly pass the argument.
I'm happy to add a commit removing it though, if you feel otherwise.<|||||>Thanks for updating, we can keep the `ignore_index` argument.
Thanks @nalourie-ai2 ! |
transformers | 2,606 | closed | Upload CLI: on Windows, uniformize paths/urls separators | 01-21-2020 22:11:07 | 01-21-2020 22:11:07 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This was completed but forgot to close the issue. |
|
transformers | 2,605 | closed | glue.py when using mrpc and similar data does not work | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): BERT
Language I am using the model on (English, Chinese....): ENGLISH
The problem arise when using:
* [ ] the official example scripts: (give details):
I am using my dataset with format [idx, sentence1, sentence2, label] in form of dict of tf.data.Dataset and using glue_convert_examples_to_features() to convert my dataset to features
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
I am using MRPC task
## To Reproduce
Steps to reproduce the behavior:
0- Using BertTokenizer.from_pretrained('bert-base-cased') to create tokenizer
1-read csv file as dataframe
2-convert dataframe to dict of tensors using tf.data.Dataset.from_tensor_slices(dict(train))
the element_spec of my data is :
{'idx': TensorSpec(shape=(), dtype=tf.string, name=None),
'sentence1': TensorSpec(shape=(), dtype=tf.string, name=None),
'sentence2': TensorSpec(shape=(), dtype=tf.string, name=None),
'label': TensorSpec(shape=(), dtype=tf.int32, name=None)}
3- when using glue_convert_examples_to_features(train_data, tokenizer, label_list=[1,0], max_length=128 , task='mrpc'), I will have an error in glue.py in glue_convert_examples_to_features : label = label_map[example.label]
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS:
* Python version: 3.7
* PyTorch version: TF 2.1.0
* PyTorch Transformers version (or branch):
* Using GPU ?
* Distributed or parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
I think you can't access the dictionary by example.label. When I copy paste it to my code, it will actually work with example["label"].
| 01-21-2020 21:50:30 | 01-21-2020 21:50:30 | Hello! Indeed, you can't access the dictionary by using `example.label`. Are you passing your `tf.data.Dataset` as the `examples` argument to the `glue_convert_examples_to_features`?<|||||>yes, train_data is the examples. and the spec is:
{'idx': TensorSpec(shape=(), dtype=tf.string, name=None),
'sentence1': TensorSpec(shape=(), dtype=tf.string, name=None),
'sentence2': TensorSpec(shape=(), dtype=tf.string, name=None),
'label': TensorSpec(shape=(), dtype=tf.int32, name=None)}
shouldn't it look like this?
<|||||>I think the code needs to change to example["label"]. <|||||>Here's the format of my data that is passed to glue_convert_examples_to_features():
{'idx': <tf.Tensor: shape=(), dtype=string, numpy=b'TEXT'>, 'sentence1': <tf.Tensor: shape=(), dtype=string, numpy=b"TEXT TEXT TEXT">, 'sentence2': <tf.Tensor: shape=(), dtype=string, numpy=b'text'>, 'label': <tf.Tensor: shape=(), dtype=int32, numpy=1>}
<|||||>Do you mind letting me know on which version of transformers you're running your code?
For a couple of versions now we handle `tf.data.Dataset` using our `get_example_from_tensor_dict` method, as can be seen [here](https://github.com/huggingface/transformers/blob/master/src/transformers/data/processors/glue.py#L85). This transforms your dictionary into an `InputExample`.
It should have been able to convert your dataset as well.<|||||>yes, I use the get_example_from_tensor_dict(). the problem is, even though I pass my label_list=[numpy.int64(1), numpy.int64(0)], and my data type is int32: 'label': <tf.Tensor: shape=(), dtype=int32, numpy=1>,
when glue.py tries to run label = label_map[example.label], the type of example.label is <class: str>! which should not be, and should be int!
What I did, was to clone your repo on my local device, changed that line to label = label_map[int(example.label)], and it works fine now!
I am guessing when you create the label_map dictionary, the keys are str, but needs to be int.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,604 | closed | Can not upload BertTokenizer.from_pretrained() from an AWS S3 bucket | ## 📚 Migration
the model I am using is BertForSequenceClassification
The problem arises when I serialize my Bert model, and then upload to an AWS S3 bucket. Once my model is inside of S3, I can not import the model via BertTokenizer.from_pretrained()
For example, in order to save my model to S3, my code reads,
```
byte_obj = pickle.dumps(model)
s3_resource = boto3.resource('s3')
s3_resource.Object("s3 name", "bertClassifier").put(Body=byte_obj)
```
This saves the BertForSequenceClassification model. I can not use the `model.save_pretrained("s3 name")`, as I get an error from AWS. I beleive in order to transfer files in AWS, one needs to first pickle the file.
When I want to re upload the model, I can not use
`BertTokenizer.from_pretrained("s3 name")`
or
`BertForSequenceClassification.from_pretrained("s3 name")`
because the object I am trying to load is serialized via pickle module. Instead I upload the file this way.
```
session = boto3.session.Session()
s3client = session.client('s3')
response = s3client.get_object(Bucket='s3 name', Key='bertClassifier')
body_string = response['Body'].read()
bert_nn = pickle.loads(body_string)
```
This succesfully loads the BertForSequenceClassification model, but I have no way of loading BertTokenizer from this same pre trained model. Again, becuase I am not able to upload via the BertTokenizer.from_pretrained("s3 name") function.
Is there a work around for this?
| 01-21-2020 19:13:57 | 01-21-2020 19:13:57 | Hi Ben,
Unless I misunderstand what you're trying to do, this is not really what `save_pretrained()` and `from_pretrained()` are made for.
`save_pretrained()` lets you save a tokenizer or a model _locally_, inside a local folder. (you can then upload those files to your own s3 bucket, or use the `transformers-cli` to upload to our bucket).
`from_pretrained()` lets you re-spawn a model or tokenizer from either a local folder, a model shortcut (hardcoded in the library's code), or a community model identifier (which resolves to files on our S3 bucket)
Let me know if things are clearer
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,603 | closed | XLNet: Incorrect segment id for CLS token | Thanks for the great work!
It seems that the XLNetTokenizer assigns an incorrect segment id to the CLS token when a single sequence of token ids is provided. If token_ids_1 is None, all segment ids are '0', including the segment id of the CLS token. In my understanding, the segment ids should always differ.
```python
if token_ids_1 is None:
return len(token_ids_0 + sep + cls) * [0]
return len(token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1] + cls_segment_id
```
https://github.com/huggingface/transformers/blob/983c484fa2fcad307d37cb81f3e1125aa7b9dc37/src/transformers/tokenization_xlnet.py#L243
The original implementation assigns a different segment id to the CLS token in both cases (single sequence of tokens and pair of sequences): https://github.com/zihangdai/xlnet/blob/bbaa3a6fa0b3a2ee694e8cf66167434f9eca9660/classifier_utils.py#L109 | 01-21-2020 16:31:15 | 01-21-2020 16:31:15 | Indeed, this is an error ! Thanks for letting us know, it was patched with 088fa7b!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,602 | closed | Edit a way to get `projected_context_layer` | I edited a way to get `projected_context_layer`.
Instead of doing
'''
w = (
self.dense.weight.t()
.view(self.num_attention_heads, self.attention_head_size, self.hidden_size)
.to(context_layer.dtype)
)
b = self.dense.bias.to(context_layer.dtype)
projected_context_layer = torch.einsum("bfnd,ndh->bfh", context_layer, w) + b
'''
I added `self.merge_last_ndims` at `AlbertAttention`.
'''
def merge_last_ndims(self, x, n_dims):
s = x.size()
assert n_dims > 1 and n_dims < len(s)
return x.view(*s[:-n_dims], -1)
'''
I commited this one yesterday, but that one didn't pass the tests, so I re-wrote my code and re-committing now. | 01-21-2020 15:40:46 | 01-21-2020 15:40:46 | Hi, please check the [contribution guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests) for the code quality tests to pass.
Why did you edit this, does this solve a bug or add new functionality?<|||||>Hi i edited this because i read a comment like..
“ # Should find a better way to do this “
Not because of bug or new features<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2602?src=pr&el=h1) Report
> Merging [#2602](https://codecov.io/gh/huggingface/transformers/pull/2602?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/23c6998bf46e43092fc59543ea7795074a720f08?src=pr&el=desc) will **increase** coverage by `<.01%`.
> The diff coverage is `100%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2602?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2602 +/- ##
==========================================
+ Coverage 74.61% 74.61% +<.01%
==========================================
Files 87 87
Lines 14802 14804 +2
==========================================
+ Hits 11044 11046 +2
Misses 3758 3758
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2602?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/2602/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hbGJlcnQucHk=) | `79.03% <100%> (+0.11%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2602?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2602?src=pr&el=footer). Last update [23c6998...a96e39e](https://codecov.io/gh/huggingface/transformers/pull/2602?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,601 | closed | unexpected keyword argument 'encoder_hidden_states' when using PreTrainedEncoderDecoder | ## ❓ Questions & Help
After I have defined my seq2seq class using Encoder Decoder Architecture in the following way:
```
from transformers import PreTrainedEncoderDecoder
model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased','gpt2')
```
I try to forward tensor through the model in this following way:
```
model(question_batch, answer_batch)
```
but I got this error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-16-bb34e9576e8b> in <module>()
----> 1 model(test_history, test_knowledge)
2 frames
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
TypeError: forward() got an unexpected keyword argument 'encoder_hidden_states'
```
can anyone help me?
| 01-21-2020 15:23:36 | 01-21-2020 15:23:36 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I am facing the same issue. Probably `PreTrainedEncoderDecoder` supports only `Bert` to `Bert` models.<|||||>I'm getting this error too
```
Converting vae...
Converting text encoder...
Downloading100% 1.71G/1.71G [00:24<00:00, 69.1MB/s]
Downloading100% 4.55k/4.55k [00:00<00:00, 746kB/s]
Downloading100% 1.22G/1.22G [00:18<00:00, 66.3MB/s]
Downloading100% 342/342 [00:00<00:00, 57.0kB/s]
Saving diffusion model...
Restored system models.
Checkpoint successfully extracted to /content/gdrive/MyDrive/sd/stable-diffusion-webui/models/dreambooth/TTFM/working
Returning ['default', True, True, 1, '', '', 0, 0, 1, True, True, 50, False, False, 5e-06, 1e-06, 0.0001, '', 5e-05, 1.0, 1.0, 1, 0.5, 1.0, 0.5, 'constant_with_warmup', 0, 75, 'fp16', 100, True, '', 1.0, 512, 1, '', 420420, True, False, True, 25, True, False, True, 5, False, False, False, False, 1, False, 1.0, True, False, True, False, False, '', 7.5, 60, '', '', '', '', '', '', 1, 0, 0, -1, 7.5, 60, '', '', '', '', 7.5, 60, '', '', '', '', '', '', 1, 0, 0, -1, 7.5, 60, '', '', '', '', 7.5, 60, '', '', '', '', '', '', 1, 0, 0, -1, 7.5, 60, '', '', '', 'Loaded config.']
Saved settings.
Custom model name is TTFM
Starting Dreambooth training...
Initializing dreambooth training...
Replace CrossAttention.forward to use default
Instance Bucket 0: Resolution (512, 512), Count: 723
Target Bucket 0: Resolution (512, 512), Count: 0
We need a total of 0 images.
Nothing to generate.
Exception importing 8bit adam: No module named 'bitsandbytes'
WARNING:extensions.sd_dreambooth_extension.dreambooth.train_dreambooth:Exception importing 8bit adam: No module named 'bitsandbytes'
Traceback (most recent call last):
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd_dreambooth_extension/dreambooth/train_dreambooth.py", line 304, in inner_loop
import bitsandbytes as bnb
ModuleNotFoundError: No module named 'bitsandbytes'
Preparing dataset
Preparing dataset
Preparing Dataset (With Caching)
100% 723/723 [00:46<00:00, 15.47it/s]
Train Bucket 1: Resolution (512, 512), Count: 723
Total images: 241
Total dataset length (steps): 241
Sched breakpoint is 108450
***** Running training *****
Instance Images: 723
Class Images: 0
Total Examples: 723
Num batches each epoch = 241
Num Epochs = 300
Batch Size Per Device = 3
Gradient Accumulation steps = 3
Total train batch size (w. parallel, distributed & accumulation) = 9
Text Encoder Epochs: 210
Total optimization steps = 216900
Total training steps = 216900
Resuming from checkpoint: False
First resume epoch: 0
First resume step: 0
Lora: False, Adam: False, Prec: bf16
Gradient Checkpointing: True
EMA: True
LR: 4.5e-05)
Steps: 0% 0/216900 [00:00<?, ?it/s]Traceback (most recent call last):
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd_dreambooth_extension/scripts/dreambooth.py", line 561, in start_training
result = main(config, use_txt2img=use_txt2img)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd_dreambooth_extension/dreambooth/train_dreambooth.py", line 973, in main
return inner_loop()
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd_dreambooth_extension/dreambooth/memory.py", line 116, in decorator
return function(batch_size, grad_size, prof, *args, **kwargs)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd_dreambooth_extension/dreambooth/train_dreambooth.py", line 829, in inner_loop
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/accelerate/utils/operations.py", line 490, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/usr/local/lib/python3.8/dist-packages/torch/amp/autocast_mode.py", line 14, in decorate_autocast
return func(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/diffusers/models/unet_2d_condition.py", line 481, in forward
sample, res_samples = downsample_block(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/diffusers/models/unet_2d_blocks.py", line 781, in forward
hidden_states = torch.utils.checkpoint.checkpoint(
File "/usr/local/lib/python3.8/dist-packages/torch/utils/checkpoint.py", line 249, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "/usr/local/lib/python3.8/dist-packages/torch/utils/checkpoint.py", line 107, in forward
outputs = run_function(*args)
File "/usr/local/lib/python3.8/dist-packages/diffusers/models/unet_2d_blocks.py", line 774, in custom_forward
return module(*inputs, return_dict=return_dict)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/diffusers/models/transformer_2d.py", line 265, in forward
hidden_states = block(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/diffusers/models/attention.py", line 285, in forward
attn_output = self.attn1(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
TypeError: forward_default() got an unexpected keyword argument 'encoder_hidden_states'
Steps: 0% 0/216900 [00:01<?, ?it/s]
Training completed, reloading SD Model.
Restored system models.
Returning result: Exception training model: 'forward_default() got an unexpected keyword argument 'encoder_hidden_states''.
``` |
transformers | 2,600 | closed | Trouble fine tuning multiple choice | ## ❓ Questions & Help
Hi! I have issues with fine-tuning the multi-choice BERT and I am stuck on an error and I can use some help. When I tried to fine-tune it with my own dataset, it threw the Error ```RuntimeError: Assertion `cur_target >= 0 && cur_target < n_classes' failed. at /opt/conda/conda-bld/pytorch_1570711300255/work/aten/src/THNN/generic/ClassNLLCriterion.c:97````
According to what I have found, this normally happened due to the dimension mismatch between the label and the output layer. When I printed the model, it seems that the model does not have a suitable output layer.
```
` (dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=1, bias=True)
)`
```
I have made sure that the Bert Config has received the correct number of the label (`num_labels`)
```
{
"attention_probs_dropout_prob": 0.1,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"num_labels": 3,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pruned_heads": {},
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 30522
}
```
I am using the code from examples/run_multiple_choice.py and examples/utils_multiple_choice.py without touching its logic but I have modified it the data processor.
```
class CSProcessor(object):
def get_train_examples(self):
return self._create_examples(df_all[:8000] ,
df_answer[:8000], "train")
def get_test_examples(self):
"""See base class."""
return self._create_examples(df_sentence[8000:] ,
df_answer[8000:], "test")
def get_labels(self):
"""See base class."""
return ["0", "1", "2"]
def _create_examples(self, df_sentence, df_answer, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for I in range(len(df_sentence)):
race_id = "%s-%s" % (set_type, I)
truth = str(ord(df_answer[1][I]) - ord("A"))
illogicalAnswer = df_sentence["FalseSent"][I]
examples.append(
InputExample(
example_id=race_id,
question="Why it doesn't make senses?",
contexts=[illogicalAnswer],
endings=[df_sentence['OptionA'][I],
df_sentence['OptionB'][I],
df_sentence['OptionC'][I]],
label=truth,
)
)
return examples
```
I appreciate any help :) | 01-21-2020 10:14:47 | 01-21-2020 10:14:47 | Hi! I believe this issue could stem from your label being negative as well. Could you check that it doesn't fail when computing the loss with a negative label?<|||||>I'm not sure what is a negative label in the context of multiple-choice, but here's what I did: it successfully computed loss when the label is 0 (which should be representing the first option?) but it fails for 1, 2, and -1.<|||||>@KerenzaDoxolodeo Hello,I am also trying to finetune RACE on bert model. I am wondering if you had fixed this problem.
Also can you post your fine tuning command with exact hyperparameters? Thanks.<|||||>@KerenzaDoxolodeo I ran into a similar problem. You are right in that the error is due to a shape mismatch. However you don't need to change the config file. Instead adapt your processor class by changing the context parameter of your InputExample from
`contexts=[illogicalAnswer]`
to
`contexts=[illogicalAnswer, illogicalAnswer, illogicalAnswer]`
If you look at the original SwagProcessor, they copied the context several times such that both the context as well as the endings are lists of size num_labels.
Unfortunately, the code does not raise an error if you ignore this requirement. If you look closely at what happens within the convert_examples_to_features() method in examples/utils_multiple_choice.py, you'll notice the line
`enumerate(zip(example.contexts, example.endings))`
This is where everything breaks. Since you only provided a single context per example, this line will lead to also only taking into account a single ending from example.endings.
You don't need to adapt the config file as it will adapt to the number of labels automatically. If, for some reason, you still like to change the config, I think you should not manually overwrite the num_labels parameter as this is likely to introduce further errors (like in the config you showed above). Instead load the config from pretrained and provide the number of labels, e.g. like this
`config = BertConfig.from_pretrained(
'bert-base-uncased',
num_labels=5,
)`
This will also change the mappings "id2label" as well as "label2id" appropriately (both are not set properly in your posted example).<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,599 | closed | Xlnet, Alberta, Roberta are not finetuned for CoLA task | ## 🐛 Bug
I am currently trying to finetune pretrained models on CoLA task by using run_glue.py. Some of the models such as Bert and DistilBert are finetuned correctly as it is expected (the training loss goes down and the evaluation result is as what has been reported). Even though, for other models such as Roberta, Albert and Xlnet the training loss remains the same. I finetune the models for CoLA accordingly:
python run_glue.py --data_dir=./glue_data/CoLA/ --model_type=roberta
--model_name_or_path=roberta-base --task_name=CoLA
--output_dir=./model_roberta/ --max_seq_len=128 --do_train --do_eval --num_train_epochs=3.0 --save_steps=50 --learning_rate=5e-5
## Observed behavior
(for Roberta-base)
"loss": 0.5889998215436936, "step": 50
"loss": 0.649243945479393, "step": 100
"loss": 0.6612952649593353, "step": 150
"loss": 0.6241107112169266, "step": 200
...
"loss": 0.6236384356021881, "step": 50
...
"loss": 0.6253059101104737, "step": 800
...
(I trained for more epochs (different lr )and still, the loss is near 0.5-0.6)
By debugging the code it seems that the model's output (softmax of logits) during training no matter what is the input is always label 1.
Another hint: I tried to finetune Roberta for other tasks such as STS-B and it finetuned well (loss was going down and the output of the model was not identical for all different inputs).
I was wondering if someone also has faced the same issue. How should I solve this?
OS type and version: Linux-3.10.0
Python: 3.7
Pytorch: 1.3.1
| 01-21-2020 08:00:12 | 01-21-2020 08:00:12 | NM, I was able to solve it by changing some of the hyperparameter values.<|||||>Hi, glad you could make it work! Do you mind sharing what hyperparameter values you tuned in order to make it work?<|||||>> Hi, glad you could make it work! Do you mind sharing what hyperparameter values you tuned in order to make it work?
Hi, have you solved the problem? I used bert-base-cased, roberta-base, and xlnet-base-cased to predict CoLA test.tsv, and I got 51.8, 55.6 and 24.7 respectively, I don't know why xlnet got such low Matthew's Corr. Can you help me? thx |
transformers | 2,598 | closed | load tf2 roberta model meet error | ## ❓ Questions & Help
`
config = RobertaConfig() # print(config) to see settings
config.output_hidden_states = False # Set to True to obtain hidden states
model = TFRobertaModel.from_pretrained('/home/wk/Bert_Pretrained/robert_base/roberta-base-tf_model.h5', config=config) `
errors
`ValueError Traceback (most recent call last)
<ipython-input-19-eac9e3228d6c> in <module>
1 config = RobertaConfig() # print(config) to see settings
2 config.output_hidden_states = False # Set to True to obtain hidden states
----> 3 model = TFRobertaModel.from_pretrained('/home/wk/Bert_Pretrained/robert_base/roberta-base-tf_model.h5', config=config)
~/anaconda3/lib/python3.7/site-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
315 # see https://github.com/tensorflow/tensorflow/blob/00fad90125b18b80fe054de1055770cfb8fe4ba3/tensorflow/python/keras/engine/network.py#L1339-L1357
316 try:
--> 317 model.load_weights(resolved_archive_file, by_name=True)
318 except OSError:
319 raise OSError("Unable to load weights from h5 file. "
~/anaconda3/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training.py in load_weights(self, filepath, by_name)
179 raise ValueError('Load weights is not yet supported with TPUStrategy '
180 'with steps_per_run greater than 1.')
--> 181 return super(Model, self).load_weights(filepath, by_name)
182
183 @trackable.no_automatic_dependency_tracking
~/anaconda3/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/network.py in load_weights(self, filepath, by_name)
1173 f = f['model_weights']
1174 if by_name:
-> 1175 saving.load_weights_from_hdf5_group_by_name(f, self.layers)
1176 else:
1177 saving.load_weights_from_hdf5_group(f, self.layers)
~/anaconda3/lib/python3.7/site-packages/tensorflow_core/python/keras/saving/hdf5_format.py in load_weights_from_hdf5_group_by_name(f, layers)
758 symbolic_weights[i])) +
759 ', but the saved weight has shape ' +
--> 760 str(weight_values[i].shape) + '.')
761
762 else:
ValueError: Layer #0 (named "roberta"), weight <tf.Variable 'tf_roberta_model_5/roberta/embeddings/word_embeddings/weight:0' shape=(30522, 768) dtype=float32, numpy=
array([[-0.02175204, 0.01785859, -0.01712652, ..., 0.0088525 ,
-0.00240036, 0.01757819],
[ 0.01320856, 0.01548896, 0.0290868 , ..., -0.01266216,
0.00756532, -0.01283411],
[ 0.02433892, 0.00970818, -0.01082115, ..., 0.01121136,
0.01314066, 0.0088822 ],
...,
[-0.00798688, -0.03137787, -0.00074065, ..., 0.03188593,
0.02637535, 0.02540809],[ 0.01545427, -0.02784344, 0.01380141, ..., -0.02135191,
-0.01506698, -0.00579444],
[-0.01216899, 0.00676558, 0.01336646, ..., -0.00323554,
0.02038151, 0.02287306]], dtype=float32)> has shape (30522, 768), but the saved weight has shape (50265, 7)`
<!-- A clear and concise description of the question. -->
| 01-21-2020 02:11:32 | 01-21-2020 02:11:32 | I am facing the same issue, how did you resolve this? @bestpredicts <|||||>Same issue with portuguese bert version
<|||||>I had the same issue and found that this problem occurs because the default "RobertaConfig" is based on "bert-base-uncased" config, which is different from "roberta-base" config. The right way to initialize the model and configuration is (LysandreJik's solution):
```python
config = RobertaConfig.from_pretrained("roberta-base", output_hidden_states=True)
model = RobertaForSequenceClassification.from_pretrained("roberta-base", config=config)
```
Please refer to the similar issue:
[#1627](https://github.com/huggingface/transformers/issues/1627)<|||||>This is annoying, one doesnt have to do this while setting config for TFDistilBert
https://towardsdatascience.com/working-with-hugging-face-transformers-and-tf-2-0-89bf35e3555a |
transformers | 2,597 | closed | Transfer Learning on Text Summarization Model | Hi all,
Is there any way to do transfer learning on the Text Summarization model (bertabs-finetuned-cnndm)? I would like to continue training it on my dataset.
The code run_summarization.py only does prediction. Thanks! | 01-21-2020 02:09:58 | 01-21-2020 02:09:58 | @imayachita If your succeeded to use transfer learning on your own data, please update here.<|||||>`examples/summarization/bart/run_bart_sum.py` now exists :) |
transformers | 2,596 | closed | changing the attention head size in MultiBert | ## 🐛 Bug
<!-- Important information -->
I'm trying to use a MultiBERT model with not all 12 attention heads but just 8 attention heads. so, in config file, I changed the following keys
config.num_attention_heads = 8
config.hidden_size = 512
config.pooler_fc_size = 512
I assumed similar to layer size that we have flexibility in changing it, we may have a similar freedom in changing the head size. however, the run_xnli.py code throws the following error.
> size mismatch for bert.encoder.layer.11.output.LayerNorm.bias: copying a param with shape torch.Size([768]) from checkpoint, the shape in curr
> ent model is torch.Size([512]).
> size mismatch for bert.pooler.dense.weight: copying a param with shape torch.Size([768, 768]) from checkpoint, the shape in current model is t
> orch.Size([512, 512]).
> size mismatch for bert.pooler.dense.bias: copying a param with shape torch.Size([768]) from checkpoint, the shape in current model is torch.Si
> ze([512]).
Model I am using MultiBERT.
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [X ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [X ] an official GLUE/SQUaD task: run_xnli.py
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. get the run_xnli.py script and added the following config change codes
config.num_attention_heads = 8
config.hidden_size = 512
config.pooler_fc_size = 512
config.pooler_num_attention_heads = 8
## Environment
* OS: windows
* Python version: 3.6
* PyTorch version: 1.1
* PyTorch Transformers version (or branch): 2.2.1
* Using GPU ? yes
* Distributed or parallel setup ? parallel
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 01-20-2020 21:15:59 | 01-20-2020 21:15:59 | I got it working |
transformers | 2,595 | closed | RAM leakage when trying to retrieve the hidden states from the GPT-2 model. | Hello,
I am trying to retrieve hidden state vectors from my trained GPT-2 model from a loop, and there is a huge RAM leakage associated with the operation. Below are my code:
```python
# for loop to calculate TVD
def TVD_loop(test_i, test_dummy_i, nlayer, best_model):
TVD_tensor = torch.zeros(test_i.size()[1], (nlayer+1), test_i.size()[0]).float()
# replace every 0's in TVD_tensor to -2
TVD_tensor = torch.where(TVD_tensor == 0.0, torch.tensor(-2.0), TVD_tensor)
for m in range(test_i.size()[1]):
input_ids = test_i[:,m]
input_ids = torch.tensor(input_ids.tolist()).unsqueeze(0)
# NOTE: Hidden states are in torch.FloatTensor,
# (one for the output of each layer + the output of the embeddings)
# jth layer
for j in range(nlayer+1):
tst_hidden_states = best_model(input_ids)[3][j][0, (test_i.size()[0] - 1), :]
for l in range(m * test_i.size()[0], (m+1) * test_i.size()[0]):
input_ids_dummy = test_dummy_i[:,l]
input_ids_dummy = torch.tensor(input_ids_dummy.tolist()).unsqueeze(0)
tst_hidden_states_dummy = best_model(input_ids_dummy)[3][j][0, (test_i.size()[0] - 1), :]
# TVD_tensor[i,j,k] denotes for TVDC calculated at
# batch i, layer j, and dummy output k
TVD_tensor[m,j,(l % (test_i.size()[0]))] = TVD(tst_hidden_states, tst_hidden_states_dummy)
return TVD_tensor
```
I have about ~400GB of RAM, but each time the hidden state vector is retrieved (e.g. ```tst_hidden_states = best_model(input_ids)[3][j][0, (test_i.size()[0] - 1), :]```), it uses up about ~2GB of RAM. How can I prevent this? Thank you,
| 01-20-2020 18:19:42 | 01-20-2020 18:19:42 | To add more, I fixed my code like below:
```python
# for loop to calculate TVD
def TVD_loop(test_i, test_dummy_i, nlayer, best_model):
TVD_tensor = torch.zeros(test_i.size()[1], (nlayer+1), test_i.size()[0]).float()
# replace every 0's in TVD_tensor to -2
TVD_tensor = torch.where(TVD_tensor == 0.0, torch.tensor(-2.0), TVD_tensor)
for m in range(test_i.size()[1]):
gc.collect()
input_ids = test_i[:,m]
input_ids = torch.tensor(input_ids.tolist()).unsqueeze(0)
# NOTE: Hidden states are in torch.FloatTensor,
# (one for the output of each layer + the output of the embeddings)
# jth layer
for j in range(nlayer+1):
del gc.garbage[:]
gc.collect()
for l in range(m * test_i.size()[0], (m+1) * test_i.size()[0]):
del gc.garbage[:]
gc.collect()
tst_hidden_states = best_model(input_ids)[3][j][0, (test_i.size()[0] - 1), :]
input_ids_dummy = test_dummy_i[:,l]
input_ids_dummy = torch.tensor(input_ids_dummy.tolist()).unsqueeze(0)
tst_hidden_states_dummy = best_model(input_ids_dummy)[3][j][0, (test_i.size()[0] - 1), :]
del input_ids_dummy
del gc.garbage[:]
gc.collect()
# TVD_tensor[i,j,k] denotes for TVD calculated at
# batch i, layer j, and dummy output k
TVD_tensor[m,j,(l % (test_i.size()[0]))] = TVD(tst_hidden_states, tst_hidden_states_dummy)
del tst_hidden_states
del tst_hidden_states_dummy
del gc.garbage[:]
gc.collect()
print('l={}, gc_get_count={}'.format(l,gc.get_count()))
del gc.garbage[:]
gc.collect()
print('j={}, gc_get_count={}'.format(j,gc.get_count()))
del gc.garbage[:]
del input_ids
gc.collect()
print('m={}, gc_get_count={}'.format(m,gc.get_count()))
return TVD_tensor
```
from the code above, when ```m=0, j=0, l=0```, everything is fine, but once ```m=0, j=1, l=0``` is reached, the memory usage starts to accumulate rapidly. How should I fix my code?<|||||>Did you try detaching the gradient from the hidden states by replacing
`
tst_hidden_states = best_model(input_ids)[3][j][0, (test_i.size()[0] - 1), :]
`
with
`
tst_hidden_states = best_model(input_ids)[3][j][0, (test_i.size()[0] - 1), :].detach()
`
?
The gradient needed for backpropagation usually consumes a lot of RAM and is probably not needed in your case.
> <|||||>> Did you try detaching the gradient from the hidden states by replacing
> `tst_hidden_states = best_model(input_ids)[3][j][0, (test_i.size()[0] - 1), :]`
> with
> `tst_hidden_states = best_model(input_ids)[3][j][0, (test_i.size()[0] - 1), :].detach()`
> ?
> The gradient needed for backpropagation usually consumes a lot of RAM and is probably not needed in your case.
>
> >
Detaching _before_ the slice might be even better? Not sure.<|||||>Thank you! .detach() solved this RAM leakage issue :) |
transformers | 2,594 | closed | edited a way to get at AlbertAttention.forward | '''
# Should find a better way to do this
w = (
self.dense.weight.t()
.view(self.num_attention_heads, self.attention_head_size, self.hidden_size)
.to(context_layer.dtype)
)
b = self.dense.bias.to(context_layer.dtype)
'''
I thought the above code is not necessary.
it can be simply fixed by "merging" `context_layer` at forward().
I committed my "merging" function at AlbertAttention
'''
def merge_tensor(self, x):
s = x.size()[-2]
return torch.cat([x[:,:,i,:] for i in range(s)], dim=-1)
'''
I wanted to make a test by "make test' as described in CONTRIBUTING.md
but I couldn't because i faced some make error.
This is my first open source contribution. If i forgot something, please let me know, so I can fix and follow up. | 01-20-2020 16:00:24 | 01-20-2020 16:00:24 | will commit with another pull request |
transformers | 2,593 | closed | Added custom model dir to PPLM train | Just an option to save the model to other than the working directory.
Default functionality hasn't changed. | 01-20-2020 15:47:24 | 01-20-2020 15:47:24 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,592 | closed | RuntimeError: The expanded size of the tensor (449) must match the existing size (2) at non-singleton dimension 2. Target sizes: [4, 2, 449]. Tensor sizes: [1, 2] while using ALBERT | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I wanted to use ALBERT with a double head
as we have one for openaigpt with the name OpenAIGPTDoubleHeadsModel
I am doing it with taking inspiration from OpenAIGPTDoubleHeadsModel
but I am getting this error
` File "train.py", line 266, in <module>
train()
File "train.py", line 258, in train
trainer.run(train_loader, max_epochs=args.n_epochs)
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/ignite/engine/engine.py", line 446, in run
self._handle_exception(e)
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/ignite/engine/engine.py", line 410, in _handle_exception
raise e
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/ignite/engine/engine.py", line 433, in run
hours, mins, secs = self._run_once_on_dataset()
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/ignite/engine/engine.py", line 399, in _run_once_on_dataset
self._handle_exception(e)
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/ignite/engine/engine.py", line 410, in _handle_exception
raise e
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/ignite/engine/engine.py", line 391, in _run_once_on_dataset
self.state.output = self._process_function(self, batch)
File "train.py", line 180, in update
mc_labels=mc_labels, lm_labels=lm_labels
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/transformers/modeling_albert.py", line 956, in forward
inputs_embeds=inputs_embeds)
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/transformers/modeling_albert.py", line 499, in forward
inputs_embeds=inputs_embeds)
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/moha/venv/huggtrans/lib/python3.6/site-packages/transformers/modeling_bert.py", line 171, in forward
position_ids = position_ids.unsqueeze(0).expand(input_shape)
RuntimeError: The expanded size of the tensor (449) must match the existing size (2) at non-singleton dimension 2. Target sizes: [4, 2, 449]. Tensor sizes: [1, 2]`
the code block for AlbertDoubleHeadsModel
`class AlbertDoubleHeadsModel(AlbertPreTrainedModel):`
` def __init__(self, config):`
` super(AlbertDoubleHeadsModel, self).__init__(config)`
self.albert = AlbertModel(config)
self.lm_head = nn.Linear(config.embedding_size, config.vocab_size, bias=False)
self.multiple_choice_head = SequenceSummary(config)
self.init_weights()
def get_output_embeddings(self):
return self.lm_head
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None,
mc_token_ids=None, lm_labels=None, mc_labels=None):
transformer_outputs = self.albert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds)
hidden_states = transformer_outputs[0]
lm_logits = self.lm_head(hidden_states)
mc_logits = self.multiple_choice_head(hidden_states, mc_token_ids).squeeze(-1)
outputs = (lm_logits, mc_logits) + transformer_outputs[1:]
if mc_labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(mc_logits.view(-1, mc_logits.size(-1)),
mc_labels.view(-1))
outputs = (loss,) + outputs
if lm_labels is not None:
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = lm_labels[..., 1:].contiguous()
loss_fct = CrossEntropyLoss(ignore_index=-1)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1))
outputs = (loss,) + outputs
return outputs # (lm loss), (mc loss), lm logits, mc logits, (all hidden_states), (attentions)`
Is there anything that I am missing?
Please do tell me.
| 01-20-2020 11:33:05 | 01-20-2020 11:33:05 | What is the code that you are executing that leads to this error? <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>How did you fix the problem? |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.