
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 16,347 | closed | `FeaturesManager.get_model_from_feature` should be a staticmethod | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.17.0
- Platform: Linux (Pop!_OS)
- Python version: 3.9.6
- PyTorch version (GPU?): 1.9.0+cu111
- Tensorflow version (GPU?): /
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@michaelbenayoun who committed #14358
## Information
Type error for Pylance in VsCode:
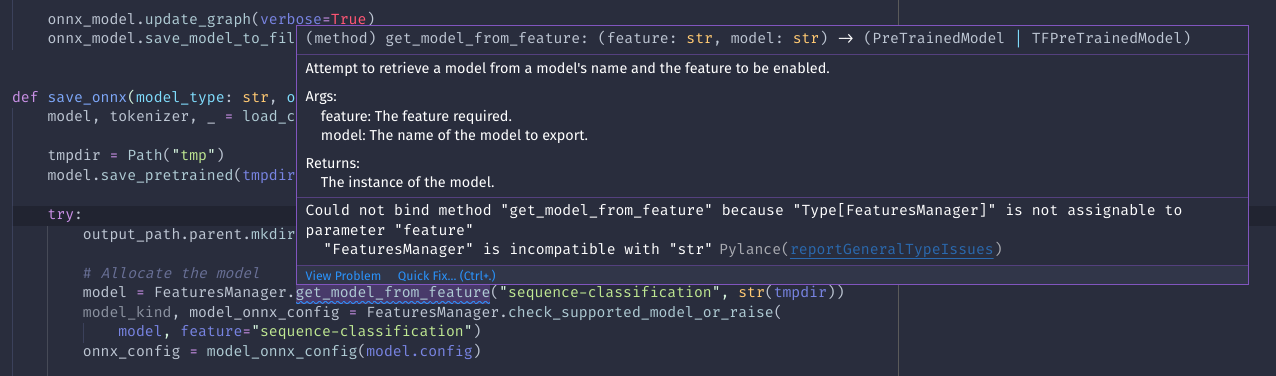
## Fix
https://github.com/huggingface/transformers/blob/77321481247787c97568c3b9f64b19e22351bab8/src/transformers/onnx/features.py#L336-L345
I believe the above function should have the `@staticmethod` decorator.
| 03-23-2022 00:14:27 | 03-23-2022 00:14:27 | |
transformers | 16,346 | closed | Fix code repetition in serialization guide | # What does this PR do?
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger @stevhliu | 03-22-2022 20:34:48 | 03-22-2022 20:34:48 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,345 | closed | [FlaxBart] make sure no grads are computed an bias | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Makes sure that no gradients are computed on FlaxBart bias. Note that in PyTorch we don't compute a gradient because the bias logits are saved as a PyTorch buffer: https://discuss.pytorch.org/t/what-is-the-difference-between-register-buffer-and-register-parameter-of-nn-module/32723
Also see results of: https://discuss.huggingface.co/t/gradients-verification-between-jax-flax-models-and-pytorch/15970
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-22-2022 20:21:39 | 03-22-2022 20:21:39 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16345). All of your documentation changes will be reflected on that endpoint.<|||||>@patil-suraj @sanchit-gandhi - this surely makes a difference when training - I'm not sure how much of a difference though. Will be interesting to try out though.<|||||>The `stop_gradient` fix looks good - the results you cited verify nicely that the gradients are only frozen for the `final_logits_bias` parameters, and not for any other additional parameters upstream in the computation graph.
One small comment in regards to the testing script `check_gradients_pt_flax.py` that you used to generate the gradient comparison results. Currently, we are comparing the PyTorch gradients relative to the Flax ones (https://huggingface.co/patrickvonplaten/codesnippets/blob/main/check_gradients_pt_flax.py#L86):
```python
diff_rel = np.abs(ak_norm - bk_norm) / np.abs(ak_norm)
```
Since we are taking the PyTorch gradients as our ground truth values, we should compare the Flax gradients relative to the PyTorch ones:
```python
diff_rel = np.abs(ak_norm - bk_norm) / np.abs(bk_norm)
``` |
transformers | 16,344 | closed | [Bug template] Shift responsibilities for long-range | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
@ydshieh knows Longformer and BigBird probably better than me now
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-22-2022 19:02:05 | 03-22-2022 19:02:05 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,343 | closed | Checkpoint sharding | # What does this PR do?
This PR introduces the ability to create and load sharded checkpoints. It introduces a new argument in `save_pretrained` that controls the maximum size of a checkpoint before being auto-sharded into smaller parts (which defaults to 10GB after internal discussion, which should be good with the Hub and environment with low RAM like Colab).
When the model total size is less than this maximum size, it's saved exactly like before. When the model size is bigger, while traversing the state dict, each time a new weight tips the size above that threshold, a new shard is created. Therefore each shard is usually of size less than the max size, but if an individual weight has a size bigger than this threshold, it will spawn a shard containing only itself that will be of a bigger size.
On the `from_pretrained` side, a bit of refactoring was necessary to make the API deal with several state dict files. The main part is isolating the code that loads a state dict into a model in a separate function, so I can call it for each shard. I'm leaving comments on the PR to facilitate the review and I will follow up with another PR that refactors `from_pretrained` even more for cleaning but with no change of actual code.
cc @julien-c @thomwolf @stas00 @Narsil who interacted in the RFC.
Linked issue: #13548 | 03-22-2022 19:01:10 | 03-22-2022 19:01:10 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger is it possibile to apply sharding to a current pretrained model that is bigger than 10gb (let's say t0pp like), using
load_pretrained-> save_pretrained
To save a sharded version, and the again
load_pretrained
That should handle therefore load the sharded checkpoint?
Thanks<|||||>Yes, that's exactly what you should do!
We'll also create a new branch of the t0pp checkpoint with a sharded checkpoint (we can't do it on the main branch or it would break compatibility with older versions of Transformers).<|||||>Hahaha amazing! Where is it? <|||||>@sgugger we could possibly upload the sharded checkpoint **in addition to** the current checkpoint in the same repo branch no?
I thought that's what we wanted to do to preserve backward compat while still upgrading those big models
<|||||>If you put them in the same branch, `from_pretrained` will only download the full checkpoint as it's the first in order of priority.<|||||>I see. should we consider changing this behavior? we've seen that git-branches are not super practical for those large models (cc @osanseviero )<|||||>(yep, i know this is going to require to call something like /api/models/xxx at the start of `from_pretrained`... :) )<|||||>or maybe we can say that we'll just push sharded models from now on (for example the bigscience models will be sharded-only) I think that's actually fine<|||||>or we can default to the shared model for the new version of `transformers`?<|||||>yep that was what i was suggesting but implementation wise is a bit more complex (and affects all model repos not just the sharded ones) |
transformers | 16,342 | closed | Adopt framework-specific blocks for content | This PR adopts the framework-specific blocks from [#130](https://github.com/huggingface/doc-builder/pull/130) for PyTorch/TensorFlow code samples and content. | 03-22-2022 17:52:49 | 03-22-2022 17:52:49 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,341 | closed | Modeling Outputs | # What does this PR do?
This PR tries to add new model outputs to cover avoid implementing custom outputs for models that do not have attentions. Three new outputs are added:
- `BaseModelOutputWithNoAttention`
- `BaseModelOutputWithPoolingAndNoAttention`
- `ImageClassifierOutputWithNoAttention`
The docstring of the `hidden_states` and `hidden_states` shape is changed to `(batch_size, num_channels, height, width)`. The thinking behind it is models that do not output attentions are usually conv models. However, this is not quite general.
Another solution is to change the docstring of `BaseModelOutput***` to state that `attentions` will be returned only if the model has an attention mechanism.
A custom `ModelOutput` will still be needed if the returned tensors' shapes are not the ones in the docstring. One solution may be making the outputs "model aware". For example, I can define a `BaseModelOutput2D` that returns 2d tensors (`batch_size, num_channels, height, width`). Doing so will unfortunately result in a lot of new model outputs.
Let me know your feedbacks | 03-22-2022 17:13:57 | 03-22-2022 17:13:57 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Updated the docstring of the outputs and replaced multiple models' outputs with the new ones<|||||>@NielsRogge Not sure what the point of your last comments. We know the modeling outputs won't work for every model and we have a strategy for that (subclass and overwrite the docstring). Did you have a suggestion on how to make the docstring more general?<|||||>Maybe we can add a statement that says that the `hidden_states` optionally include the initial embeddings, if the model has an embedding layer.<|||||>+1 on @NielsRogge idea<|||||>Looks good to me, note that we have some more vision models:
* Swin Transformer
* DeiT
* BEiT
* ViTMAE<|||||>Added correct outputs for
- DeiT
- BEiT
The following models need a custom output
- ViTMAE
- Swin<|||||>Changed the docstring for every `hidden_states` field in every `*ModelOutput*` to specify the embedding hidden state may be optional (depending on the model's architecture)<|||||>Update the docstrings and create a custom model output for SegFormer `SegFormerImageClassifierOutput` |
transformers | 16,340 | closed | VAN: Code sample tests | # What does this PR do?
This PR fixes the wrong name in `_CHECKPOINT_FOR_DOC` for VAN
| 03-22-2022 16:54:22 | 03-22-2022 16:54:22 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,339 | closed | The `convert_tokens_to_string` method fails when the added tokens include a space | ## Environment info
```
- `transformers` version: 4.17.0
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyTorch version (GPU?): 1.10.0+cu111 (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
```
## Information
The bug that was identified [for the decode method regarding added tokens with space ](https://github.com/huggingface/transformers/issues/1133)also occurs with the `convert_tokens_to_string` method.
## To reproduce
```python
from transformers import AutoTokenizer, AddedToken
def print_tokenizer_result(text, tokenizer):
text = tokenizer.convert_tokens_to_string(tokenizer.tokenize(text))
print(f"convert_tokens_to_string method: {text}")
model_name = "patrickvonplaten/norwegian-roberta-base"
tokenizer_init = AutoTokenizer.from_pretrained(model_name)
tokenizer_init.save_pretrained("local_tokenizer")
model_name = "local_tokenizer"
tokenizer_s = AutoTokenizer.from_pretrained(model_name, use_fast=False)
tokenizer_f = AutoTokenizer.from_pretrained(model_name, use_fast=True)
new_token = "token with space"
tokenizer_s.add_tokens(AddedToken(new_token, lstrip=True))
tokenizer_f.add_tokens(AddedToken(new_token, lstrip=True))
text = "Example with token with space"
print("Output for the fast:")
print_tokenizer_result(text, tokenizer_f)
print("\nOutput for the slow:")
print_tokenizer_result(text, tokenizer_s)
```
## Expected behavior
No error or the fact that `convert_tokens_to_string` is a private method.
| 03-22-2022 16:00:10 | 03-22-2022 16:00:10 | One way to solve this problem is to move the logic implemented in the `_decode` method into the `convert_tokens_to_string` method.
https://github.com/huggingface/transformers/blob/9d88be57785dccfb1ce104a1226552cd216b726e/src/transformers/tokenization_utils.py#L933-L946
The only issue will be that we'll need to add new argument (`skip_special_tokens`, `clean_up_tokenization_spaces`, `spaces_between_special_tokens`) to the `convert_tokens_to_string` method of the slow tokenizers.
Another option is to make the method `convert_tokens_to_string` private.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,338 | closed | Add type annotations for Rembert/Splinter and copies | Splinter and Rembert (Torch) type annotations.
Dependencies on Bert (Torch).
Raw files w/o running make fixup or make fix-copies
#16059
@Rocketknight1 | 03-22-2022 15:59:40 | 03-22-2022 15:59:40 | By the way, GitHub is having some issues right now and tests may not be running. Feel free to continue with the PR, but we'll need to wait for them to come back before we can merge!<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Tests are back, going to try fixing copies etc. now, one sec!<|||||>Is this a private file? This was the main error I was receiving after run fix-copies (from the build strack trace)
```
self = <module 'transformers.models.template_bi' from '/home/runner/work/transformers/transformers/src/transformers/models/template_bi/__init__.py'>
module_name = 'modeling_template_bi'
def _get_module(self, module_name: str):
try:
return importlib.import_module("." + module_name, self.__name__)
except Exception as e:
raise RuntimeError(
f"Failed to import {self.__name__}.{module_name} because of the following error (look up to see its traceback):\n{e}"
> ) from e
E RuntimeError: Failed to import transformers.models.template_bi.modeling_template_bi because of the following error (look up to see its traceback):
E name 'Optional' is not defined```<|||||>Ah, I see the problem now! This error is in our template files, and yes, it can be hard to spot, because it only appears when one of our tests tries to generate a new class from the template. Give me a second and I'll see if I can fix it!<|||||>I see. Definitely scratched my head at these for a while - Thanks so much for your help! |
transformers | 16,337 | closed | [TBD] discrepancy regarding the tokenize method behavior - should the token correspond to the token in the vocabulary or to the initial text | ## Environment info
```
- `transformers` version: 4.17.0
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyTorch version (GPU?): 1.10.0+cu111 (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
```
## Information
When adding a token to a tokenizer with a slow backend or to a tokenizer with a fast backend, if you use the `AddedToken` class with the `lstrip=True` argument, the output of the tokenize method is not the same.
This difference should be put into perspective by the fact that the encoding (the sequence of ids) is identical: the model will see the correct input.
## To reproduce
```python
from transformers import AutoTokenizer, AddedToken
def print_tokenizer_result(text, tokenizer):
tokens = tokenizer.tokenize(text)
print(f"tokenize method: {tokens}")
model_name = "patrickvonplaten/norwegian-roberta-base"
tokenizer_init = AutoTokenizer.from_pretrained(model_name)
tokenizer_init.save_pretrained("local_tokenizer")
model_name = "local_tokenizer"
tokenizer_s = AutoTokenizer.from_pretrained(model_name, use_fast=False)
tokenizer_f = AutoTokenizer.from_pretrained(model_name, use_fast=True)
new_token = "added_token_lstrip_false"
tokenizer_s.add_tokens(AddedToken(new_token, lstrip=True))
tokenizer_f.add_tokens(AddedToken(new_token, lstrip=True))
text = "Example with added_token_lstrip_false"
print("Output for the fast:")
print_tokenizer_result(text, tokenizer_f)
print("\nOutput for the slow:")
print_tokenizer_result(text, tokenizer_s)
```
Output:
```
Output for the fast:
tokenize method: ['Ex', 'amp', 'le', 'Ġwith', ' added_token_lstrip_false'] # Note the space at the beginning of ' added_token_lstrip_false'
Output for the slow:
tokenize method: ['Ex', 'amp', 'le', 'Ġwith', 'added_token_lstrip_false']
``` | 03-22-2022 15:46:01 | 03-22-2022 15:46:01 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,336 | closed | A slow tokenizer cannot add a token with the argument `lstrip=False` | ## Environment info
```
- `transformers` version: 4.17.0
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyTorch version (GPU?): 1.10.0+cu111 (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
```
## Information
When adding a token to a tokenizer with a slow backend or to a tokenizer with a fast backend, if you use the `AddedToken` class with the `lstrip=False` argument, the final tokenization will not be the same.
My impression is that the slow tokenizer always strips and that the fast tokenizer takes this argument into account (to be confirmed by the conclusion of [this issue](https://github.com/huggingface/tokenizers/issues/959) in the tokenizers library).
## To reproduce
```python
from transformers import AutoTokenizer, AddedToken
def print_tokenizer_result(text, tokenizer):
ids = tokenizer.encode(text, add_special_tokens=False)
tokens = tokenizer.convert_ids_to_tokens(ids)
print(f"tokens: {tokens}")
model_name = "patrickvonplaten/norwegian-roberta-base"
tokenizer_init = AutoTokenizer.from_pretrained(model_name)
tokenizer_init.save_pretrained("local_tokenizer")
model_name = "local_tokenizer"
tokenizer_s = AutoTokenizer.from_pretrained(model_name, use_fast=False)
tokenizer_f = AutoTokenizer.from_pretrained(model_name, use_fast=True)
new_token = "added_token_lstrip_false"
tokenizer_s.add_tokens(AddedToken(new_token, lstrip=False))
tokenizer_f.add_tokens(AddedToken(new_token, lstrip=False))
text = "Example with added_token_lstrip_false"
print("Output for the fast:")
print_tokenizer_result(text, tokenizer_f)
print("\nOutput for the slow:")
print_tokenizer_result(text, tokenizer_s)
```
Output:
```
Output for the fast:
tokens: ['Ex', 'amp', 'le', 'Ġwith', 'Ġ', 'added_token_lstrip_false']
Output for the slow:
tokens: ['Ex', 'amp', 'le', 'Ġwith', 'added_token_lstrip_false']
```
## Expected behavior
Output:
```
Output for the fast:
tokens: ['Ex', 'amp', 'le', 'Ġwith', 'Ġ', 'added_token_lstrip_false']
Output for the slow:
tokens: ['Ex', 'amp', 'le', 'Ġwith', 'Ġ', 'added_token_lstrip_false']
```
| 03-22-2022 15:26:49 | 03-22-2022 15:26:49 | The logic for `lstrip` **is** implemented for slow tokenizers actually:
https://github.com/huggingface/transformers/blob/main/src/transformers/tokenization_utils.py#L519
The main thing I think is that in that function,the added token is NOT in the `all_special_added_tokens_extended`. If it was, it would work.
Now the function `add_tokens` starts by removing all information about the `AddedToken` which if it didn't maybe we could keep parity here. https://github.com/huggingface/transformers/blob/main/src/transformers/tokenization_utils.py#L411
So my conclusion is that the core issue is that the slow tokenizer discards all the info you are sending it, it probably shouldn't.
That being said, the simplest backward compatible fix, might not be obvious.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,335 | closed | [WIP] test doctest | # What does this PR do?
test doctest | 03-22-2022 14:27:07 | 03-22-2022 14:27:07 | |
transformers | 16,334 | closed | T5Tokenizer Fast and Slow give different results with AddedTokens | When adding a new token to T5TokenizerFast and/or T5Tokenizer, we get different results for the tokenizers which is unexpected.
E.g. running the following code:
```python
from transformers import AutoTokenizer, AddedToken
tok = AutoTokenizer.from_pretrained("t5-small", use_fast=False)
tok_fast = AutoTokenizer.from_pretrained("t5-small", use_fast=True)
tok.add_tokens("$$$")
tok_fast.add_tokens(AddedToken("$$$", lstrip=False))
prompt = "Hello what is going on $$$ no ? We should"
print("Slow")
print(tok.decode(tok(prompt).input_ids))
print("Fast")
print(tok_fast.decode(tok_fast(prompt).input_ids))
```
yields different results for each tokenizer
```
Slow
Hello what is going on $$$ no? We should</s>
Fast
Hello what is going on$$$ no? We should</s>
```
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.18.0.dev0
- Platform: Linux-5.15.15-76051515-generic-x86_64-with-glibc2.34
- Python version: 3.9.7
- Huggingface_hub version: 0.4.0.dev0
- PyTorch version (GPU?): 1.10.2+cu102 (True)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.4.0 (cpu)
- Jax version: 0.3.1
- JaxLib version: 0.3.0
| 03-22-2022 13:49:00 | 03-22-2022 13:49:00 | cc @Narsil @SaulLu <|||||>Hi, The behavior can be explained by the fact that the encode, splits on whitespace and ignores them,
then the decoder uses `Metaspace` (which is for the `spm` behavior) which does not prefix things with spaces even on the added token. The spaces are supposed to already be contained within the tokens themselves.
We could have parity on this at least for sure !
But I am not sure who is right in that case, both decoded values look OK to me. The proposed AddedToken contains no information about the spaces so it's ok to no place one back by default (it would break things when added tokens are specifically intended for stuff not containing spaces).
In that particular instance, because we're coming from a sentence with a space, ofc it makes more sense to put one back to recover the original string. But `decode[999, 998]` with `999="$("` and `998=")$"` It's unclear to me if a user wants `"$( )$"` or `"$()$"` when decoded. (Just trying to take an plausible example where the answer is unclear.)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>should this be reopened if it's not resolved yet?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,333 | closed | Update docs/README.md | # What does this PR do?
Add information about how to perform doc testing **for a specific python module**. Potentially making the process less scaring (a lot of file changes) for the users.
Also make it more clear/transparent that `file_utils.py` should be (almost) always included.
| 03-22-2022 13:37:26 | 03-22-2022 13:37:26 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Do you mean: there are some python module files or doc files, for which if we want to run doctest, it will require changes (preparation) in files other than
- the target files themselves
- `file_utils.py`
<|||||>> Ah sorry, I misread the command! This works indeed but could we maybe wait for the refactor of `file_utils` to merge this (and fix the paths)? I'll probably forget to adapt this otherwise.
Oh, yes for sure!<|||||>Will merge this PR once Sylvain's PR about file_utils is merged. |
transformers | 16,332 | closed | TF - Fix interchangeable past/past_key_values and revert output variable name in GPT2 | # Context
From the discussion in https://github.com/huggingface/transformers/pull/16311 (PR that applies `@unpack_inputs` to TF `gpt2`): In the generate refactor, TF `gpt2` got an updated `prepare_inputs_for_generation()`, where its output `past` got renamed into `past_key_values` (i.e. as in FLAX/PT). Patrick suggested reverting it since this prepared input could be used externally.
# What did I find while working on this PR?
Reverting as suggested above makes TF `gpt2` fail tests related to `encoder_decoder`, which got an updated `prepare_inputs_for_generation()` in the same PR that expects a `past_key_values` (and not a `past`).
Meanwhile, I've also noticed a related bug in the new `@unpack_inputs` decorator, where it was not preserving a previous behavior -- when the model received a `past_key_values` but expected a `past` input (and vice-versa), it automatically swapped the keyword. This feature was the key enabler behind `encoder_decoder`+`gpt2`, as `encoder_decoder` was throwing out `past_key_values` prepared inputs that were caught by `gpt2`'s `past` argument.
# So, what's in this PR?
This PR fixes the two issues above, which are needed for proper behavior in all combinations of inputs to TF `gpt2`, after the introduction of the decorator:
1. corrects the bug in the `@unpack_inputs` decorator and adds tests to ensure we don't regress on some key properties of our TF input handling. After this PR, `gpt2` preserves its ability to receive `past` (and `past_key_values`, if through `encoder_decoder`-like), with and without the decorator.
2. It also reverts `past_key_values` into `past` whenever the change was introduced in https://github.com/huggingface/transformers/pull/15944, and makes the necessary changes in `encoder_decoder`-like models. | 03-22-2022 12:50:17 | 03-22-2022 12:50:17 | ~(Wait, there is an error)~
~Should be good now~
Nope<|||||>@patrickvonplaten hold your review, this change is not conflicting with the `encoder_decoder` models. I believe I know why, digging deeper.<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>@patrickvonplaten now it is properly fixed -- please check the updated description at the top :)
Meanwhile, the scope increased a bit, so I'm tagging a 2nd reviewer (@Rocketknight1 )<|||||>I think Sylvain also tries to avoid `modeling_tf_utils.py` as much as possible too these days, lol. Let me take a look! <|||||>> I'd really like to get rid of these old non-standard arguments next time we can make a breaking change, though!
@Rocketknight1 me too 🙈 that function is a mess |
transformers | 16,331 | closed | [GLPN] Improve docs | # What does this PR do?
This PR adds a link to a notebook. | 03-22-2022 12:21:10 | 03-22-2022 12:21:10 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,330 | closed | Deal with the error when task is regression | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-22-2022 11:45:44 | 03-22-2022 11:45:44 | _The documentation is not available anymore as the PR was closed or merged._<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Sorry for not seeing this earlier! cc @sgugger <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,329 | closed | Spanish translation of the file multilingual.mdx | # What does this PR do?
Adds the Spanish version of [multilingual.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/en/multilingual.mdx) to [transformers/docs/source_es](https://github.com/huggingface/transformers/tree/main/docs/source/es)
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes https://github.com/huggingface/transformers/issues/15947 (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
## Who can review?
@omarespejel @osanseviero
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-22-2022 11:34:02 | 03-22-2022 11:34:02 | _The documentation is not available anymore as the PR was closed or merged._<|||||>any other thing left to do? @omarespejel <|||||>@SimplyJuanjo thank you! 🤗
@sgugger LGTM 👍 |
transformers | 16,328 | closed | [T5] Add t5 download script | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
There have been a lot of issues on converting any of the official T5 checkpoints to HF. All original T5 checkpoints are stored on google cloud bucked and it's not always obvious how to download them. I think it makes sense to provide a bash script to the T5 folder that can help with this.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-22-2022 11:30:10 | 03-22-2022 11:30:10 | cc @peregilk @stefan-it <|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,327 | closed | Arg to begin `Trainer` evaluation on eval data after n steps/epochs | # 🚀 Feature request
It would be great to be able to have the option to delay evaluation on the eval set until after a set number of steps/epochs.
## Motivation
Evaluation metrics can take a while to calculate and are arguably often not as meaningful in the early stages of training (like during warmup). This change would free up time that would be better spent training. Increasing `eval_steps` works until you end up waiting a while at the business end of training so this would not be an ideal compromise.
## Your contribution
First maybe have a training argument such as `evaluation_delay`.
Then:
(Adapted from [here](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/trainer.py#L1578).)
```python
if self.args.evaluation_delay is not None:
if self.args.save_strategy == IntervalStrategy.STEPS:
is_delayed = self.state.global_step <= self.args.evaluation_delay
else:
is_delayed = epoch <= self.args.evaluation_delay
if self.control.should_save and not is_delayed:
self._save_checkpoint(model, trial, metrics=metrics)
self.control = self.callback_handler.on_save(self.args, self.state, self.control)
```
Maybe get some input from @sgugger?
Thanks! | 03-22-2022 10:27:15 | 03-22-2022 10:27:15 | That sounds like a very interesting new feature, and I agree with the proposed implementation. Would you like to work on a PR for this?<|||||>Sure thing! @sgugger <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,326 | closed | Updates the default branch from master to main | Updates the default branch name for the doc-builder. | 03-22-2022 10:11:55 | 03-22-2022 10:11:55 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,325 | open | Implement HybridNets: End-to-End Perception Network | # 🌟 New model addition
## Model description
Quote from the Github repository:
```markdown
HybridNets is an end2end perception network for multi-tasks.
Our work focused on traffic object detection, drivable area segmentation and lane detection.
HybridNets can run real-time on embedded systems, and obtains SOTA Object Detection,
Lane Detection on BDD100K Dataset.
```
## Open source status
* [x] the model implementation is available: yes, they have pushed everything [here](https://github.com/datvuthanh/HybridNets) on Github
* [x] the model weights are available: yes, there are available directly [here](https://github.com/datvuthanh/HybridNets/releases/download/v1.0/hybridnets.pth) on Github.
* [x] who are the authors: Dat Vu and Bao Ngo and Hung Phan (@xoiga123 @datvuthanh)
Btw, I would love to help to implement this kind of models to the Hub if possible :hugs: .
But I don't know if it fits to `Transformers` library or not and if it involves a lot of work to implement it, but I want to try to help! | 03-22-2022 08:52:31 | 03-22-2022 08:52:31 | cc @NielsRogge |
transformers | 16,324 | closed | Add type hints for Pegasus model (PyTorch) | Adding type hints for forward methods in user-facing class for Pegasus model (PyTorch) as mentioned in #16059
@Rocketknight1 | 03-22-2022 08:38:52 | 03-22-2022 08:38:52 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,323 | closed | Funnel type hints | # What does this PR do?
Added type hints for Funnel Transformer and TF Funnel Transformer as described in https://github.com/huggingface/transformers/issues/16059
@Rocketknight1 | 03-22-2022 06:42:45 | 03-22-2022 06:42:45 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,322 | closed | RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB with 8 Ampere GPU's | I am fine tuning masked language model from XLM Roberta large on google machine specs.
I made couple of experiments and was strange to see few results. `I think something is not functioning properly. `
I am using pre-trained Hugging face model.
`I launch it as train.py file which I copy inside docker image and use vertex-ai ( GCP) to launch it using Containerspec`
`machineSpec = MachineSpec(machine_type="a2-highgpu-8g",accelerator_count=8,accelerator_type="NVIDIA_TESLA_A100")`
```
container = ContainerSpec(image_uri="us-docker.pkg.dev/*****",
command=["/bin/bash", "-c", "gsutil cp gs://***/tfr_code2.tar.gz . && tar xvzf tfr_code2.tar.gz && cd pythonPackage/trainer/ && python train.py"])
```
I am using
https://huggingface.co/xlm-roberta-large
I am not using fairseq or anything.
```
tokenizer = tr.XLMRobertaTokenizer.from_pretrained("xlm-roberta-large",local_files_only=True)
model = tr.XLMRobertaForMaskedLM.from_pretrained("xlm-roberta-large", return_dict=True,local_files_only=True)
model.gradient_checkpointing_enable() #included as new line
```
Here is `Nvidia-SMI`
```
b'Tue Mar 22 05:06:40 2022 \n+-----------------------------------------------------------------------------+\n| NVIDIA-SMI 450.119.04 Driver Version: 450.119.04 CUDA Version: 11.0
|\n|-------------------------------+----------------------+----------------------+\n| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |\n| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M.
|\n| | | MIG M. |\n|===============================+======================+======================|\n| 0 A100-SXM4-40GB On | 00000000:00:04.0 Off | 0 |\n| N/A 33C P0 54W / 400W | 0MiB / 40537MiB | 0% Default |\n| | | Disabled
|\n+-------------------------------+----------------------+----------------------+\n| 1 A100-SXM4-40GB On | 00000000:00:05.0 Off | 0 |\n| N/A 31C P0 53W / 400W | 0MiB / 40537MiB | 0% Default |\n| | | Disabled |
\n+-------------------------------+----------------------+----------------------+\n| 2 A100-SXM4-40GB On | 00000000:00:06.0 Off | 0 |\n| N/A 31C P0 54W / 400W | 0MiB / 40537MiB | 0% Default |\n| | | Disabled |
\n+-------------------------------+----------------------+----------------------+\n| 3 A100-SXM4-40GB On | 00000000:00:07.0 Off | 0 |\n| N/A 34C P0 54W / 400W | 0MiB / 40537MiB | 0% Default |\n| | | Disabled |
\n+-------------------------------+----------------------+----------------------+\n| 4 A100-SXM4-40GB On | 00000000:80:00.0 Off | 0 |\n| N/A 32C P0 57W / 400W | 0MiB / 40537MiB | 0% Default |\n| | | Disabled |
\n+-------------------------------+----------------------+----------------------+\n| 5 A100-SXM4-40GB On | 00000000:80:01.0 Off | 0 |\n| N/A 34C P0 54W / 400W | 0MiB / 40537MiB | 0% Default |\n| | | Disabled |
\n+-------------------------------+----------------------+----------------------+\n| 6 A100-SXM4-40GB On | 00000000:80:02.0 Off | 0 |\n| N/A 32C P0 54W / 400W | 0MiB / 40537MiB | 0% Default |\n| | | Disabled |
\n+-------------------------------+----------------------+----------------------+\n| 7 A100-SXM4-40GB On | 00000000:80:03.0 Off | 0 |\n| N/A 34C P0 61W / 400W | 0MiB / 40537MiB | 0% Default |\n| | | Disabled |
\n+-------------------------------+----------------------+----------------------+\n \n+-----------------------------------------------------------------------------+\n| Processes: |\n| GPU GI CI PID Type Process name GPU Memory |\n| ID ID Usage |\n|=============================================================================|\n| No running processes found |\n+-----------------------------------------------------------------------------+\n'
2022-03-22T05:10:07.712355Z
```
**It has lot of free memories but still I get this error.**
`RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 39.59 GiB total capacity; 33.48 GiB already allocated; 3.19 MiB free; 34.03 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF`
```
['Traceback (most recent call last):\n', ' File "train.py", line 144, in <module>\n trainer.train()\n', ' File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1400, in train\n tr_loss_step = self.training_step(model, inputs)\n', ' File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1994, in training_step\n self.scaler.scale(loss).backward()\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/_tensor.py", line 363, in backward\n torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/autograd/__init__.py", line 175, in backward\n allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/autograd/function.py", line 253, in apply\n return user_fn(self, *args)\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/utils/checkpoint.py", line 146, in backward\n torch.autograd.backward(outputs_with_grad, args_with_grad)\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/autograd/__init__.py", line 175, in backward\n allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/autograd/function.py", line 253, in apply\n return user_fn(self, *args)\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/_functions.py", line 34, in backward\n return (None,) + ReduceAddCoalesced.apply(ctx.input_device, ctx.num_inputs, *grad_outputs)\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/_functions.py", line 45, in forward\n return comm.reduce_add_coalesced(grads_, destination)\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/comm.py", line 143, in reduce_add_coalesced\n flat_result = reduce_add(flat_tensors, destination)\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/comm.py", line 95, in reduce_add\n result = torch.empty_like(inputs[root_index])\n', 'RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 39.59 GiB total capacity; 33.48 GiB already allocated; 3.19 MiB free; 34.03 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF\n'] | 2022-03-22T05:11:26.409945Z
-- | --
```
**Training Code**
```
training_args = tr.TrainingArguments(
output_dir='****'
,logging_dir='****' # directory for storing logs
,save_strategy="epoch"
,run_name="****"
,learning_rate=2e-5
,logging_steps=1000
,overwrite_output_dir=True
,num_train_epochs=10
,per_device_train_batch_size=8
,prediction_loss_only=True
,gradient_accumulation_steps=4
# ,gradient_checkpointing=True
,bf16=True #57100
,optim="adafactor"
)
trainer = tr.Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_data
)
```
Also `gradient_checkpointing` never works. Strange.
**Also, is it using all 8 GPU's?**
### Versions
Versions
torch==1.11.0+cu113
torchvision==0.12.0+cu113
torchaudio==0.11.0+cu113
transformers==4.17.0
**Train.py**
```
import torch
import numpy as np
import pandas as pd
from transformers import BertTokenizer, BertForSequenceClassification
import transformers as tr
from sentence_transformers import SentenceTransformer
from transformers import XLMRobertaTokenizer, XLMRobertaForMaskedLM
from transformers import AdamW
from transformers import AutoTokenizer
from transformers import BertTokenizerFast as BertTokenizer, BertModel, AdamW, get_linear_schedule_with_warmup,BertForMaskedLM
from transformers import DataCollatorForLanguageModeling
from scipy.special import softmax
import scipy
import random
import pickle
import os
import time
import subprocess as sp
# torch.cuda.empty_cache()
print(sp.check_output('nvidia-smi'))
print("current device",torch.cuda.current_device())
print("device count",torch.cuda.device_count())
# os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
# os.environ["CUDA_VISIBLE_DEVICES"]="0,1,2,3,4,5,6,7"
import sys
from traceback import format_exception
def my_except_hook(exctype, value, traceback):
print(format_exception(exctype, value, traceback))
sys.__excepthook__(exctype, value, traceback)
sys.excepthook = my_except_hook
start=time.time()
print("package imported completed")
os.environ['TRANSFORMERS_OFFLINE']='1'
os.environ['HF_MLFLOW_LOG_ARTIFACTS']='TRUE'
# os.environ['PYTORCH_CUDA_ALLOC_CONF']='max_split_size_mb'
print("env setup completed")
print( "transformer",tr.__version__)
print("torch",torch.__version__)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print("Using", device)
torch.backends.cudnn.deterministic = True
tr.trainer_utils.set_seed(0)
print("here")
tokenizer = tr.XLMRobertaTokenizer.from_pretrained("xlm-roberta-large",local_files_only=True)
model = tr.XLMRobertaForMaskedLM.from_pretrained("xlm-roberta-large", return_dict=True,local_files_only=True)
model.gradient_checkpointing_enable() #included as new line
print("included gradient checkpoint")
model.to(device)
print("Model loaded successfully")
df=pd.read_csv("gs://******/data.csv")
print("read csv")
# ,engine='openpyxl',sheet_name="master_data"
train_df=df.text.tolist()
print(len(train_df))
train_df=list(set(train_df))
train_df = [x for x in train_df if str(x) != 'nan']
print("Length of training data is \n ",len(train_df))
print("DATA LOADED successfully")
train_encodings = tokenizer(train_df, truncation=True, padding=True, max_length=512, return_tensors="pt")
print("encoding done")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
print("data collector done")
class SEDataset(torch.utils.data.Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
return item
def __len__(self):
return len(self.encodings["attention_mask"])
train_data = SEDataset(train_encodings)
print("train data created")
training_args = tr.TrainingArguments(
output_dir='gs://****/results_mlm_exp1'
,logging_dir='gs://****logs_mlm_exp1' # directory for storing logs
,save_strategy="epoch"
# ,run_name="MLM_Exp1"
,learning_rate=2e-5
,logging_steps=500
,overwrite_output_dir=True
,num_train_epochs=20
,per_device_train_batch_size=4
,prediction_loss_only=True
,gradient_accumulation_steps=2
# ,sharded_ddp='zero_dp_3'
# ,gradient_checkpointing=True
,bf16=True #Ampere GPU
# ,fp16=True
# ,optim="adafactor"
# ,dataloader_num_workers=20
# ,logging_strategy='no'
# per_device_train_batch_size
# per_gpu_train_batch_size
# disable_tqdm=True
)
print("training sample is 400001")
print("Included ,gradient_accumulation_steps=4 ,bf16=True and per_device_train_batch_size=4 " )
print(start)
trainer = tr.Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_data
)
print("training to start without bf16")
trainer.train()
print("model training finished")
trainer.save_model("gs://*****/model_mlm_exp1")
print("training finished")
end=time.time()
print("total time taken in hours is", (end-start)/3600)
``` | 03-22-2022 05:35:00 | 03-22-2022 05:35:00 | @sgugger <|||||>Please follow the issue template. You're not showing the script you are running or how you are launching it, so there is nothing anyone can do to help.<|||||>> Please follow the issue template. You're not showing the script you are running or how you are launching it, so there is nothing anyone can do to help.
Edited and Showing you the script. <|||||>You're launching the script with just `python`. As highlighted in the [examples README](https://github.com/huggingface/transformers/tree/master/examples/pytorch#distributed-training-and-mixed-precision) for distributed training, you need to use `python -m torch.distributed.launch` to use the 8 GPUs.<|||||>> You're launching the script with just `python`. As highlighted in the [examples README](https://github.com/huggingface/transformers/tree/master/examples/pytorch#distributed-training-and-mixed-precision) for distributed training, you need to use `python -m torch.distributed.launch` to use the 8 GPUs.
Ok.
You mean to say I should use this:
`command=["/bin/bash", "-c", "gsutil cp gs://***/tfr_code2.tar.gz . && tar xvzf tfr_code2.tar.gz && cd pythonPackage/trainer/ && python -m torch.distributed.launch train.py"])`
<|||||>> > You're launching the script with just `python`. As highlighted in the [examples README](https://github.com/huggingface/transformers/tree/master/examples/pytorch#distributed-training-and-mixed-precision) for distributed training, you need to use `python -m torch.distributed.launch` to use the 8 GPUs.
>
> Ok.
>
> You mean to say I should use this:
>
> `command=["/bin/bash", "-c", "gsutil cp gs://***/tfr_code2.tar.gz . && tar xvzf tfr_code2.tar.gz && cd pythonPackage/trainer/ && python -m torch.distributed.launch train.py"])`
I get this error:
```
RuntimeError: CUDA out of memory. Tried to allocate 7.63 GiB (GPU 0; 39.59 GiB total capacity; 23.22 GiB already allocated; 3.52 GiB free; 33.88 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF | 2022-03-22T16:24:41.763613Z
-- | --
```
Why its showing `GPU 0` only<|||||>I am using this parameters or am I missing anything.
@sgugger
```
training_args = tr.TrainingArguments(
output_dir='**'
,logging_dir='**' # directory for storing logs
,save_strategy="epoch"
,learning_rate=2e-5
,logging_steps=2500
,overwrite_output_dir=True
,num_train_epochs=20
,per_device_train_batch_size=4
,prediction_loss_only=True
,bf16=True #Ampere GPU
)
And Launching using this:
python -m torch.distributed.launch --nproc_per_node 8 train.py --bf16
```
**ERROR**
```
Traceback (most recent call last):\n', ' File "train.py", line 159, in <module>\n trainer.train()\n',
' File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1400, in train\n tr_loss_step = self.training_step(model, inputs)\n',
' File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1984, in training_step\n loss = self.compute_loss(model, inputs)\n',
' File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 2016, in compute_loss\n outputs = model(**inputs)\n',
' File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl\n return forward_call(*input, **kwargs)\n',
' File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/distributed.py", line 963, in forward\n output = self.module(*inputs[0], **kwargs[0])\n',
' File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl\n return forward_call(*input, **kwargs)\n',
' File "/opt/conda/lib/python3.7/site-packages/transformers/models/roberta/modeling_roberta.py", line 1114, in forward\n masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))\n', ' File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl\n return forward_call(*input, **kwargs)\n',
' File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/loss.py", line 1165, in forward\n label_smoothing=self.label_smoothing)\n',
' File "/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py", line 2996, in cross_entropy\n return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)\n',
'RuntimeError: CUDA out of memory. Tried to allocate 978.00 MiB (GPU 0; 39.59 GiB total capacity; 6.40 GiB already allocated; 690.19 MiB free; 6.45 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
If your script expects `--local_rank` argument to be set, please change it to read from `os.environ['LOCAL_RANK']`
```<|||||>Any help?<|||||>@sgugger If I use distributed training, then would `trainer.save_model("gs://*****/model_mlm_exp1")` will work or do I need to pass any extra parameter so that only 1 model is saved from multiple GPU's?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Assalamu alekum, I also came across such a mistake
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.80 GiB total capacity; 6.41 GiB already allocated; 1.69 MiB free; 6.82 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF |
transformers | 16,321 | closed | First token misses the first character in its `offsets_mapping` WHEN `add_prefix_space=True` is used | ## Environment info
- `transformers` version: 3.5.1
- Python version: 3.9.7
- PyTorch version (GPU?): 1.6.0 (GPU)
### Who can help
@SaulLu
## Information
Model I am using (Bert, XLNet ...): roberta-large
## To reproduce
Steps to reproduce the behavior:
```
tokenizer = AutoTokenizer.from_pretrained('roberta-large', use_fast=True)
tokenizer("This is a sentence", return_offsets_mapping=True)['offset_mapping']
[(0, 0), **(0, 4)**, (5, 7), (8, 9), (10, 18), (0, 0)]}
tokenizer = AutoTokenizer.from_pretrained('roberta-large', use_fast=True, add_prefix_space=True)
tokenizer("This is a sentence", return_offsets_mapping=True)['offset_mapping']
[(0, 0), **(1, 4)**, (5, 7), (8, 9), (10, 18), (0, 0)]}
```
## Expected behavior
Should be [(0, 0), **(0, 4)**, (5, 7), (8, 9), (10, 18), (0, 0)]} | 03-22-2022 05:31:02 | 03-22-2022 05:31:02 | Hi @ciaochiaociao ,
I've just tested you're snippet of code with the latest version of transformers (`transformers==4.17.0`) and the result correspond to what you're expecting:
```python
tokenizer = AutoTokenizer.from_pretrained('roberta-large', use_fast=True)
print(tokenizer("This is a sentence", return_offsets_mapping=True)['offset_mapping'])
# [(0, 0), **(0, 4)**, (5, 7), (8, 9), (10, 18), (0, 0)]}
tokenizer = AutoTokenizer.from_pretrained('roberta-large', use_fast=True, add_prefix_space=True)
print(tokenizer("This is a sentence", return_offsets_mapping=True)['offset_mapping'])
# [(0, 0), **(0, 4)**, (5, 7), (8, 9), (10, 18), (0, 0)]}
```
I've also tried to test with the version 3.5.1 of `transformers` but I think got this error when I tried to import AutoTokenizer -that you use in your snippet of code - from transformers:
```
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
[<ipython-input-3-939527a2a513>](https://localhost:8080/#) in <module>()
----> 1 from transformers import AutoTokenizer
2 frames
[/usr/local/lib/python3.7/dist-packages/transformers/trainer_pt_utils.py](https://localhost:8080/#) in <module>()
38 SAVE_STATE_WARNING = ""
39 else:
---> 40 from torch.optim.lr_scheduler import SAVE_STATE_WARNING
41
42 logger = logging.get_logger(__name__)
ImportError: cannot import name 'SAVE_STATE_WARNING' from 'torch.optim.lr_scheduler' (/usr/local/lib/python3.7/dist-packages/torch/optim/lr_scheduler.py)
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
```
Let me know if upgrading to the last version of transformers work for you :smile:
<|||||>Cool. Thank you for your reply. 4.17.0 did work. <|||||>By the way, FYI
`4.16.2` also works, while `4.14.1` does not, which shows the same results of `3.5.1`.<|||||>Yes, I think 2 PRs helped to solve this issue:
1. One in the transformers lib: https://github.com/huggingface/transformers/pull/14752. That was integrated into transformers v4.15.0
2. One in the tokenizers lib: https://github.com/huggingface/tokenizers/pull/844. That was integrated into tokenizers v0.11.0
With previous version, we might indeed have issues with offset mappings. :slightly_smiling_face:
I'm closing this issue since this seems to be solved :smile: |
transformers | 16,320 | closed | Can we support the trace of ViT and Swin-Transformer based on torch.fx? | # 🚀 Feature request
Can we support the trace of ViT and Swin-Transformer based on torch.fx()? If not, what's the difficulty for that?
## Motivation
ViT and Swin-Transformation is widely used in CV scenarios. Hope we could support the trace of torch.fx, so we can do the quantization based on the work.
## Your contribution
I'm not sure right now. Currently I wanda whether we could support the ViT and Swin-Transformer. If not, the reason.
| 03-22-2022 01:52:27 | 03-22-2022 01:52:27 | @michaelbenayoun May I know the current situation or your schedule first? Thanks.<|||||>Hi,
The plan is to work on a nicer solution for tracing the model as soon as possible.
I will take a look to add those models in the mean time as they might not be hard to add in the current setting.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,319 | closed | ibert seems to be quite slow in quant_mode = True | Hi, for iBert -
I found it is MUCH slower in quant_mode = True. here's a notebook with a slightly modified version of the HF code to allow dynamically switching quant_mode. You can see the timing difference.
https://colab.research.google.com/drive/1DkYFGc18oPvAn5nyGEL1aIFHmD_aNlXW
@patrickvonplaten
https://github.com/kssteven418/I-BERT/issues/21
| 03-22-2022 01:19:25 | 03-22-2022 01:19:25 | Hey @ontocord,
I don't have much experience with iBERT. @kssteven418 any ideas here? Is such a slowdown expected? <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,318 | closed | Fix the issue #16317 in judging module names starting with base_model_prefix | This fixed #16317:
```
Keys are still reported as "missing" during model loading even though
specified in `_keys_to_ignore_on_load_missing`
```
as described in detail in #16317.
The cause of the issue is:
* The code that judges if a module name has the `base_model_prefix`
would match it with *any* beginning part of the name. This caused
the first part of the module name being stripped off unexpectedly
sometimes, hence not able to match the prefix in
`_keys_to_ignore_on_load_missing`.
Fix:
* Match `base_model_prefix` as a whole beginning word followed by
`.` in module names.
Also added test into `test_modeling_common`.
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten @sgugger
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-22-2022 00:39:10 | 03-22-2022 00:39:10 | _The documentation is not available anymore as the PR was closed or merged._<|||||>See discussion on #16317 :-) |
transformers | 16,317 | closed | [modeling_utils] Keys are still reported as "missing" during model loading even though specified in `_keys_to_ignore_on_load_missing` | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.18.0.dev0
- Platform: Ubuntu 18.04.6 LTS Linux 4.15.0-167-generic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.11.0 (True)
- Tensorflow version (GPU?): N/A
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten @sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
Models:
- ALBERT, BERT, XLM, DeBERTa, DeBERTa-v2, ELECTRA, MobileBert, SqueezeBert: @LysandreJik
- T5, Pegasus, EncoderDecoder: @patrickvonplaten
- Blenderbot, MBART, BART, Marian, Pegasus: @patil-suraj
- Longformer, Reformer, TransfoXL, XLNet, FNet, BigBird: @patrickvonplaten
- FSMT: @stas00
- Funnel: @sgugger
- GPT-2, GPT: @patil-suraj, @patrickvonplaten, @LysandreJik
- RAG, DPR: @patrickvonplaten, @lhoestq
- TensorFlow: @Rocketknight1
- JAX/Flax: @patil-suraj
- TAPAS, LayoutLM, LayoutLMv2, LUKE, ViT, BEiT, DEiT, DETR, CANINE: @NielsRogge
- GPT-Neo, GPT-J, CLIP: @patil-suraj
- Wav2Vec2, HuBERT, SpeechEncoderDecoder, UniSpeech, UniSpeechSAT, SEW, SEW-D, Speech2Text: @patrickvonplaten, @anton-l
If the model isn't in the list, ping @LysandreJik who will redirect you to the correct contributor.
Library:
- Benchmarks: @patrickvonplaten
- Deepspeed: @stas00
- Ray/raytune: @richardliaw, @amogkam
- Text generation: @patrickvonplaten @narsil
- Tokenizers: @SaulLu
- Trainer: @sgugger
- Pipelines: @Narsil
- Speech: @patrickvonplaten, @anton-l
- Vision: @NielsRogge, @sgugger
Documentation: @sgugger
Model hub:
- for issues with a model, report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
For research projetcs, please ping the contributor directly. For example, on the following projects:
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): BERT, but the issue should apply to any model
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Define a model class extending PreTrainedModel, with `base_model_prefix`, e.g.`aabbcc`, and a module with name starting with `base_model_prefix`, e.g. `aabbcc_encoder`;
2. Specify `_keys_to_ignore_on_load_missing` to include the module name, e.g. `aabbcc_encoder`;
3. When loading from pretrained, if the keys starting with `aabbcc_encoder` are missing, they are still reported as missing in warning although we specified to ignore them in step 2.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
Here is a much simplified code snippet that reproduces the issue.
```py
from transformers import (
AutoModel,
PreTrainedModel,
BertConfig,
)
class TestClass(PreTrainedModel):
base_model_prefix = "aabbcc"
_keys_to_ignore_on_load_missing = [r"position_ids", r"aabbcc_encoder"]
def __init__(self, config):
super(TestClass, self).__init__(config)
self.aabbcc_encoder = AutoModel.from_config(config)
def _init_weights(self, module):
return
model_name = "bert-base-uncased"
config = BertConfig.from_pretrained(model_name)
model, loading_info = TestClass.from_pretrained(
pretrained_model_name_or_path=model_name,
config=config,
output_loading_info=True,
)
print("Missing keys: {}".format(loading_info['missing_keys']))
```
This is the output.
```
Missing keys: ['encoder.layer.10.attention.self.key.bias', 'encoder.layer.1.attention.self.query.weight', 'encoder.layer.8.attention.output.dense.weight', ....
```
And the logging includes:
```
Some weights of TestClass were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['encoder.layer.10.attention.self.key.bias', 'encoder.layer.1.attention.self.query.weight', 'encoder.layer.8.attention.output.dense.weight', ...
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Expected output:
```
Missing keys: []
```
(And the logging should not include the warning for the missing keys.) | 03-22-2022 00:21:52 | 03-22-2022 00:21:52 | Hey @hui-wan,
Thanks a lot for opening this issue. I'm having some problems following the exact error though here:
If `base_model_prefix = "aabbcc"`, then why is the line: `self.aabbcc_encoder = AutoModel.from_config(config)` and not `self.aabbcc = AutoModel.from_config(config)`?
If the `base_model_prefix` is set to `aabbcc` then the name of the encoder should also be exactly this<|||||>Thank you @patrickvonplaten.
If the name of the encoder is set to `aabbcc` in the above code snippet, the same output and warning of missing keys are produced:
```
Missing keys: ['encoder.layer.10.attention.self.key.bias', 'encoder.layer.1.attention.self.query.weight', 'encoder.layer.8.attention.output.dense.weight', ....
```
and
```
Some weights of TestClass were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['encoder.layer.10.attention.self.key.bias', 'encoder.layer.1.attention.self.query.weight', 'encoder.layer.8.attention.output.dense.weight', ...
```
The issue goes away if the encoder name is set to `bert` or sth like `encoder_aabbcc` (also set in `_keys_to_ignore_on_load_missing`).
* In the former case, there would not be missing keys in the first place. However, in my actual code (not the simplified snippet), there is a real need not to set the encoder to just bert.
* In the latter case, `startswith(prefix)` in `modeling_utils.py` would not be triggered, so the missing keys would successfully match `_keys_to_ignore_on_load_missing`.
The latter is my current get-around which works well. Nonetheless, I wanted to report the issue and the easy fix, just in case someone else got into the same situation and got puzzled by the warning. :-)
Thanks!<|||||>Ok I think I see. Yes I think in this case it would be advised to not try to overwrite the `base_model_prefix` (think this doesn't work) and instead one should the official prefix of the `AutoModel` being `bert`.
So I think this code snippet would work:
```py
from transformers import (
AutoModel,
PreTrainedModel,
BertConfig,
)
class TestClass(PreTrainedModel):
_keys_to_ignore_on_load_missing = [r"position_ids", r"aabbcc_encoder"]
def __init__(self, config):
super(TestClass, self).__init__(config)
self.bert = AutoModel.from_config(config)
def _init_weights(self, module):
return
model_name = "bert-base-uncased"
config = BertConfig.from_pretrained(model_name)
model, loading_info = TestClass.from_pretrained(
pretrained_model_name_or_path=model_name,
config=config,
output_loading_info=True,
)
print("Missing keys: {}".format(loading_info['missing_keys']))
```<|||||>I see. Thank you @patrickvonplaten! By removing `base_model_prefix`, indeed the issue is not triggered in the code snippet.
IMHO, the small change in #16318 still would be useful in preventing something similar from happening when `base_model_prefix` happens to be the beginning (but not whole module name) of missing keys or unexpected keys. Would appreciate your opinion on this. Thanks!
<|||||>Glad that I could be a bit helpful here :-)
I'm a bit nervous about the PR because it changes one of the core functions that is literally used by **everybody** using Transformers for a rather specific use case. If I understand correctly the PR aims to solve a problem when official code `BertModel` is wrapped into custom code (a higher level class such as `TestClass`) for which we cannot guarantee that things work correctly. So if possible, I'd really like to avoid having to make core changes to `from_pretrained(...)` for this edge case :sweat_smile: <|||||>The PR changes the judging of prefix matching from part-of-word matching to whole-word matching of the first part of model/key, which I believe is the correct logic here. And it passed all the tests. With that being said, I understand your concern about making changes to the core function. :-) Thanks a lot for your help and prompt replies! Also many thanks for your great work!!!
|
transformers | 16,316 | closed | Fix Respect output device in the Pipeline base impl. | changes hardcoded `"cpu"` device in return in the forward method to `self.device`
# What does this PR do?
The base class in pipeline surprisingly returns a tensor on the right device, and this is then moved to the "cpu" for some reason. This PR makes sure that the input and the output to the `forward(..)` method remain on the same device.
Fixes #16315
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? https://github.com/huggingface/transformers/issues/16315
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@LysandreJik
| 03-21-2022 23:44:18 | 03-21-2022 23:44:18 | _The documentation is not available anymore as the PR was closed or merged._<|||||>1/ Is my fix correct? Was there any other reason to keep this on CPU?
2/ Do I need to write any tests?
3/ Could someone rerun the Model templates runner / run_tests_templates (pull_request) task for me?<|||||>cc @Narsil <|||||>@LysandreJik The discussion happened in the original issue: https://github.com/huggingface/transformers/issues/16315 |
transformers | 16,315 | closed | Pipeline always returns to device="cpu" | ## Environment info
- `transformers` version: 4.16.1
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.29
- Python version: 3.8.5
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@Narsil
## Information
Model I am using : Bert:
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
I'm using a variant of BERT in a complex pipeline. I've noticed that the Pipeline always returns a tensor in CPU no matter what device is specified.
| 03-21-2022 23:35:38 | 03-21-2022 23:35:38 | @prassanna-ravishankar ,
This is actually expected, the `post_process` step needs to happen on CPU (the goal is to return something in JSON so fetching the data back from the GPU is necessary at some point).
Do you mind sharing a little more details on what you attempt to do ? Maybe there's another solution ?<|||||>I was trying to chain the pipeline object with some other ad-hoc pytorch gpu operations. Since it is in a loop, I would ideally like to keep everything on the GPU. Maybe I'm doing it wrong?
Shall I close that PR I created?<|||||>The PR as-is won't fit yes.
If you have a looping operation maybe everything should be within `_forward` function ? This is how it is handled for `text-generation` for instance.
The design of pipelines is as follows:
- `pre_preprocess` : Take in raw python objects , output feedbable data to the models.
- `_forward`: Make everything that requires the model happen here (potentially looping)
- `post_process`: Take back tensors, and output back something JSON friendly without tensors anymore (if possible)
This could evolve for sure, but we would need a bit more background to consider if and how it could fit the current design, or how we could evolve the design to fit the use-case.
Cheers.<|||||>Thanks, will reach out on the forum if I have some more questions.
Orthogonal to this, does it make sense to a `post_process_gpu` or `post_process_device` whenever we want device specific post processing (and if it has been implemented)?
<|||||>As long as the pipelines do NOT output tensors, I don't see how `post_process_gpu` can ever make sense. The objects outputted by the pipeline are CPU data in all pipelines I think. Like a `string` cannot live on GPU, can it ?
The only very specific use case I can think of would be in some sort of game, where the text/image would be then used by some sort of shader directly, then you would need to have a GPU tokenizer for text (which doesn't exist afaik).
I think this is slightly outside the `pipeline`'s scope (which is to enable non ML-practictionners to use models), but not too far off that finding an elegant solution could be interesting.
> Thanks, will reach out on the forum if I have some more questions.
Don't hesitate to ping me for visibility on the forums. Cheers.
|
transformers | 16,314 | closed | Updates in Trainer to support partial checkpointing for SM Model Parallel library | # What does this PR do?
- Adds 2 new training args(`smp_save_partial` and `smp_load_partial`) to support partial checkpointing with SMP
- Uses the right ranks for partial checkpoint saving in should_save.
- Uses `local_state_dict()` with partial checkpoint saving.
- Uses `smp.save` instead of `torch.save` when partial checkpoint saving is enabled.
- Uses `smp.load` instead of `torch.load` when partial checkpoint loading is enabled. Reorders partial checkpoint loading to happen after wrapping of model, since `smp.load` can only load to a smp model.
- Updated checks for the existence of checkpoint files since smp partial checkpoints contain postfixes in addition to filename(example: filename_0_0 or filename_0_0_0).
- `smp_gather` is causing increased memory usage on GPU0 when tensor parallelism is enabled. Switches to `distributed_concat` for ddp.
- adds `load_best_model_at_end` support for SMP.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-21-2022 21:34:57 | 03-21-2022 21:34:57 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16314). All of your documentation changes will be reflected on that endpoint.<|||||>Hey! It seems a bad rebase/merge happened on your PR. Usually, closing this PR and opening a new one from the same branch solves the problem.<|||||>Closing this PR.
Created a new [PR](https://github.com/huggingface/transformers/pull/16734)
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,313 | closed | Support SageMaker distributed data parallel library v1.4.0 | Hi,
SageMaker Distributed Data Parallel Library (SMDDP) just release v1.4.0. https://docs.aws.amazon.com/sagemaker/latest/dg/data-parallel.html
In this version, we release a new API to allow SMDDP to work as a PyTorch distributed backend.
Here are the changes needed to use SMDDP v1.4.0 in HF.
Following imports are deprecated:
```
import smdistributed.dataparallel.torch.distributed as dist
from smdistributed.dataparallel.torch.parallel.distributed import DistributedDataParallel as DDP
```
You can replace with vanilla PyTorch imports
```
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
```
You need to import SMDDP, so PyTorch knows there is an additional backend, then initialize process group with `smddp` backend
```
import smdistributed.dataparallel.torch.torch_smddp
dist.init_process_group(backend='smddp')
```
now you can perform regular distributed collectives same as using PyTorch with NCCL.
Our documentation:
https://docs.aws.amazon.com/sagemaker/latest/dg/data-parallel-modify-sdp-pt.html | 03-21-2022 21:28:27 | 03-21-2022 21:28:27 | Please let us know how we can help upgrading to new SMDDP APIs, thanks!
relevant PRs:
https://github.com/aws/deep-learning-containers/pull/1630
https://github.com/huggingface/transformers/pull/9798/files<|||||>Thank you @roywei .. @philschmid FYI. Looking forward to hearing your input. Also, please let us know who can be point of contact and how we can get this change, hopefully with upcoming HF transformer release.<|||||>Hello @roywei @sandeep-krishnamurthy,
Thanks for opening the issue! if you already know what changes need to be made, could you open a PR, this would be easier to review and test then?
<|||||>Are those the release notes? https://sagemaker.readthedocs.io/en/stable/api/training/smd_data_parallel_release_notes/smd_data_parallel_change_log.html#sagemaker-distributed-data-parallel-1-4-0-release-notes
**Breaking Changes**
* As the library is migrated into the PyTorch distributed package as a backend,
the following smdistributed implementation APIs are deprecated in
the SageMaker data parallal library v1.4.0 and later.
Please use the [PyTorch distributed APIs](https://pytorch.org/docs/stable/distributed.html) instead.
* ``smdistributed.dataparallel.torch.distributed``
* ``smdistributed.dataparallel.torch.parallel.DistributedDataParallel``
* Please note the slight differences between the deprecated
``smdistributed.dataparallel.torch`` APIs and the
[PyTorch distributed APIs](https://pytorch.org/docs/stable/distributed.html).
* [torch.distributed.barrier](https://pytorch.org/docs/master/distributed.html#torch.distributed.barrier)
takes ``device_ids``, which the ``smddp`` backend does not support.
* The ``gradient_accumulation_steps`` option in
``smdistributed.dataparallel.torch.parallel.DistributedDataParallel``
is no longer supported. Please use the PyTorch
[no_sync](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html?highlight=no_sync#torch.nn.parallel.DistributedDataParallel.no_sync) API.
<|||||>Yes, existing API is backward compatible so you will get deprecated warning now |
transformers | 16,312 | closed | Getting a signal: aborted (core dumped) or Segmentation fault (core dumped) error when trying to train on a single GPU | ## Environment info
- `transformers` version: 4.17.0
- Platform: Linux-3.10.0-1160.59.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.7
- PyTorch version (GPU?): 1.11.0+cu102 (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
- Wav2Vec2, HuBERT, SpeechEncoderDecoder, UniSpeech, UniSpeechSAT, SEW, SEW-D, Speech2Text: @patrickvonplaten, @anton-l
## Information
Model I am using Wav2Vec and I'm not able to train the model on GPU. Everytime I try, I get a core dump error and I cannot figure out why. The problem does not occur when I run the code without a GPU. I'm on a virtual machine using bitfusion so when I run the command bitfusion -n 1 python script.py but if I fun python script.py, it runs and trains the model:
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. run the code below using the gpu (bitfusion -n 1 python script.py) and I get either segmentation fault (core dumped) or aborted (core dumped)
2. run the code without python script.py and the code runs.
```
import os
import pickle
import torch
import json
import time
import random
import re
import numpy as np
import pandas as pd
from datasets import Dataset, load_metric, load_dataset
from datasets import ClassLabel
from dataclasses import dataclass, field
from tqdm import tqdm
# from torch.utils.data import Dataset
from transformers import Wav2Vec2CTCTokenizer
from transformers import Wav2Vec2FeatureExtractor
from transformers import Wav2Vec2Processor
from transformers import Wav2Vec2ForCTC
from transformers import TrainingArguments
from transformers import Trainer
from transformers import Wav2Vec2Config
from typing import Dict, List, Optional, Union
def main():
class wordSignalDataset(Dataset):
def __init__(self, signal_file, wordfile,processor, padding):
self.xdata = np.load(signal_file)
self.ydata = np.load(wordfile)
self.processor = processor
self.padding = padding
self.pad_to_multiple_of_label= None
self.pad_to_multiple_of = None
#
def __len__(self):
return len(self.xdata)
#
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
batch = self.processor.pad([{'input_values':self.xdata[idx]}],
padding=self.padding,
return_tensors='pt',
)
print(batch)
# batch['input_values'] = batch['input_values'].cuda()
with self.processor.as_target_processor():
labels_batch = self.processor.pad([{'input_ids':self.ydata[idx]}],
padding=self.padding,
return_tensors='pt',
)
# #
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["input_ids"] = labels
# batch["input_ids"] = labels.cuda()
# batch['attention_mask']=batch['attention_mask'].cuda()
return batch
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
max_length_labels (:obj:`int`, `optional`):
Maximum length of the ``labels`` returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
#
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
max_length: Optional[int] = None
max_length_labels: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
#
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lenghts and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
#
batch = self.processor.pad(
input_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
with self.processor.as_target_processor():
labels_batch = self.processor.pad(
label_features,
padding=self.padding,
max_length=self.max_length_labels,
pad_to_multiple_of=self.pad_to_multiple_of_labels,
return_tensors="pt",
)
#
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
#
batch["labels"] = labels
#
return batch
def prepare_dataset(batch):
inputseq = batch["input_values"]
#
# batched output is "un-batched" to ensure mapping is correct
batch["input_values"] = processor(inputseq, sampling_rate=5000).input_values[0]
#
with processor.as_target_processor():
batch["labels"] = processor("".join(batch["labels"])).input_ids
return batch
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
#
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
#
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
#
wer = wer_metric.compute(predictions=pred_str, references=label_str)
#
return {"wer": wer}
sampling_rate = 5_000
vocab_list = ["[PAD]",'A', 'B', 'C', 'D', 'E', 'F', 'G']
vocab_dict = {v: k for k, v in enumerate(vocab_list)}
rev_vocab_dict = {k:v for k, v in enumerate(vocab_list)}
print(len(vocab_dict))
with open('note_vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=sampling_rate, padding_value=0.0,
do_normalize=True, return_attention_mask=False)
tokenizer = Wav2Vec2CTCTokenizer("note_vocab.json", unk_token="[UNK]", pad_token="[PAD]")
print(tokenizer.pad_token_id)
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
wer_metric = load_metric("wer")
xdata = np.random.rand(20,4800)
ydata = np.random.randint(1,len(vocab_list),(20,400))
df=pd.DataFrame.from_dict({'input_values':[xdata[i] for i,x in enumerate(xdata)],'labels':[[rev_vocab_dict[x] for x in ydata[i]] for i,y in enumerate(ydata)]},orient='columns')
worddataloader = Dataset.from_dict(df)
worddataloader = worddataloader.map(prepare_dataset, num_proc=4)
config = Wav2Vec2Config(vocab_size=tokenizer.vocab_size,
hidden_size=144,
m_hidden_layers = 12, num_attention_heads = 12,
pad_token_id=tokenizer.pad_token_id,
ctc_loss_reduction='sum', mask_time_length=2, mask_feature_length=3,
conv_dim=(10, 6),conv_kernel=(3, 3), conv_stride=(2, 2),
tdnn_dim = (8, 8 , 8, 7, 88))
model = Wav2Vec2ForCTC(config=config)
timestr = time.strftime("%Y%m%d-%H%M%S")
reponame='model_'+timestr
training_args = TrainingArguments(
output_dir=reponame,
group_by_length=True,
per_device_train_batch_size=8,
evaluation_strategy="steps",
num_train_epochs=45,
fp16=False,
gradient_checkpointing=True,
save_steps=500,
eval_steps=500,
logging_steps=1,
learning_rate=1e-4,
weight_decay=0.005,
warmup_steps=1000,
save_total_limit=3,
)
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=worddataloader,
eval_dataset=worddataloader,
tokenizer=processor.feature_extractor,
)
trainer.train()
if __name__ == '__main__':
main()
```
Based on print statements, it doesn't seems to break here:
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=worddataloader,
eval_dataset=worddataloader,
tokenizer=processor.feature_extractor,
)
But what gets very confusing is I can run the demo here without problems. It just on my code and I can't figure out why. https://huggingface.co/blog/fine-tune-xlsr-wav2vec2 | 03-21-2022 21:11:38 | 03-21-2022 21:11:38 | Hey @dberma15,
What is `bitfusion`? do you have to use it? I'm not familiar with this command<|||||>@patrickvonplaten Bitfusion is for using a GPU on a shared resource. Using it is equivalent to saying you want to use GPU resources. If you simply type python script.py, you do not use the GPU resources.
<|||||>Why not use PyTorch's DDP? E.g.: https://github.com/huggingface/transformers/tree/main/examples/pytorch#distributed-training-and-mixed-precision<|||||>Or is this a different use case here?<|||||>I was simply following the demo in https://huggingface.co/blog/fine-tune-xlsr-wav2vec2<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>This issue is most likely because the last version of bitfusion (currently version 4.5) only supports PyTorch up to version 1.8.
See [here ](https://docs.vmware.com/en/VMware-vSphere-Bitfusion/4.5/rn/vmware-vsphere-bitfusion-45-release-notes/index.html) for more. Although PyTorch 1.8.2 is no longer supported it can still be installed, see [here](https://pytorch.org/get-started/previous-versions/#v182-with-lts-support). The only downside of using such an old version is that you might get into trouble when trying to use more than one GPU (at least that's what I experienced). If you're lucky VMware might support newer PyTorch versions in the future but up to now that's the only thing you can do. Also be careful with the CUDA version you're using. Bitfusion 4.5 only supports CUDA up to 11.4.4.
Good luck. |
transformers | 16,311 | closed | TF GPT2: clearer model variable naming with @unpack_inputs | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Addresses https://github.com/huggingface/transformers/issues/16051
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)?
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@gante @Rocketknight1
| 03-21-2022 20:12:38 | 03-21-2022 20:12:38 | Some tests failed locally: `12 failed, 37 passed, 1 skipped, 1 warning in 205.75s (0:03:25)`
One such test: `ValueError: The following keyword arguments are not supported by this model: ['past_key_values'].` even though GPT2 calls it `past` as opposed to `past_key_values`. Shouldn't the test be rewritten?<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Hey @cakiki 👋 The problem you're seeing is related to another change that is happening at the same time -- we are refactoring the auto-regressive generation function, where the `past` input variable in some old models got updated to `past_key_values`, to be consistent throughout models/frameworks.
(see next comment)<|||||>@sgugger @patrickvonplaten calling for your opinion here.
TL;DR:
- In a `generate()` refactor past PR, I made `prepare_inputs_for_generate()` uniform across famerworks. In the process, one of the output keys in TF GPT2 was updated from `past` to `past_key_values` -- removing the `past` was one of the TODO goals flagged by @patrickvonplaten;
- However, the current version of the model expects `past` as an input, if passed as a keyword argument [which raises the error @cakiki is seeing];
- In [PT](https://github.com/huggingface/transformers/blob/master/src/transformers/models/gpt2/modeling_gpt2.py#L1025)/[FLAX](https://github.com/huggingface/transformers/blob/master/src/transformers/models/gpt2/modeling_flax_gpt2.py#L456), this input is called `past_key_values`.
To fix it we have two options:
1. Revert the output of `prepare_inputs_for_generate()` from `past_key_values` to `past`;
2. We update the GPT2 input from `past` to `past_key_values`. It would be an API change, but this variable is mostly used in `generate()`, right?
I'm pro option 2, but WDYT?<|||||>I'm in favor of 1). I haven't done a good job at reviewing the refactor PR I think - see: https://github.com/huggingface/transformers/pull/15944#discussion_r832052267.
Backwards compatibility for models such as GPT2 is **extremely** important and people do use `past` outside of `generate`. Think the easy fix here is to just revert the line above.
The other possibility is to deprecate `past` in general for all models in TF, but this should be done over a deprecation cycle so that users are aware of the change.<|||||>Were there other models where we renamed `past` to `past_key_values` without changing the keyword argument name in the forward function?<|||||>> Were there other models where we renamed `past` to `past_key_values` without changing the keyword argument name in the forward function?
Perhaps, going to check and open a PR to fix it (including this one)
@cakiki I will fix the issue in a separate PR, and will ping you to rebase with `main` when it is sorted<|||||>@cakiki the fix is merged -- rebasing with `main` should fix the problems you're seeing :)<|||||>(please rerun the tests locally before merging, and confirm here that they pass)<|||||>Rebasing with `main` did indeed solve most of the failing tests. The following 3 are still failing, but they're unrelated to the previous issue.
```
======================================================================================================= short test summary info =======================================================================================================
FAILED tests/gpt2/test_modeling_tf_gpt2.py::TFGPT2ModelTest::test_gpt2_xla_generate - TypeError: function() got an unexpected keyword argument 'jit_compile'
FAILED tests/gpt2/test_modeling_tf_gpt2.py::TFGPT2ModelTest::test_onnx_runtime_optimize - ModuleNotFoundError: No module named 'onnxruntime'
FAILED tests/gpt2/test_modeling_tf_gpt2.py::TFGPT2ModelLanguageGenerationTest::test_lm_generate_gpt2_xla - TypeError: function() got an unexpected keyword argument 'jit_compile'
```<|||||>@cakiki
- `jit_compile` as a flag of `tf.function()` was added in TF2.5, can you confirm that you have TF >= 2.5? If not, can you try reruning after updating TF to a version equal or higher than 2.5? [added a personal TODO to throw an error if TF<2.5]
- for the other error, can you try reruning the tests after reinstalling `transformers` with `pip install -e ".[dev,onnx]"`? It should be because of the onnx special dependencies :)
<|||||>@gante I uninstalled tensorflow and explicitly pinned it >=2.5 and that worked. I noticed that `pip install .[dev]` was installing a bunch of tensorflow versions then finally settling on version 2.3 (fresh virtual env). (setup.py sets it to >=2.3)

---
`test_onnx_runtime_optimize` is the only test still failing:
```
E onnxruntime.capi.onnxruntime_pybind11_state.InvalidGraph: [ONNXRuntimeError] : 10 : INVALID_GRAPH : This is an invalid model. In Node, ("tfgp_t2for_sequence_classification_22/GatherV2", GatherV2, "", -1) : ("tfgp_t2for_sequence_classification_22/score/Tensordot:0": tensor(float),"tfgp_t2for_sequence_classification_22/sub:0": tensor(int32),"tfgp_t2for_sequence_classification_22/sub/y:0": tensor(int32),) -> ("logits": tensor(float),) , Error No Op registered for GatherV2 with domain_version of 10
../venv/lib/python3.6/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py:370: InvalidGraph
```
```
ERROR tf2onnx.tfonnx:tfonnx.py:303 Failed to convert node 'tfgp_t2for_sequence_classification_22/GatherV2' (fct=<bound method GatherV2.version_1 of <class 'tf2onnx.onnx_opset.tensor.GatherV2'>>)
'OP=GatherV2\nName=tfgp_t2for_sequence_classification_22/GatherV2\nInputs:\n\ttfgp_t2for_sequence_classification_22/score/Tensordot:0=Reshape, [-1, -1, 2], 1\n\ttfgp_t2for_sequence_classification_22/sub:0=Sub, [-1], 6\n\ttfgp_t2for_sequence_classification_22/GatherV2/axis:0=Const, [], 6\nOutpus:\n\ttfgp_t2for_sequence_classification_22/GatherV2:0=[-1, 2], 1'
Traceback (most recent call last):
File "/media/ssd/BIGSCIENCE/venv/lib/python3.6/site-packages/tf2onnx/tfonnx.py", line 292, in tensorflow_onnx_mapping
func(g, node, **kwargs, initialized_tables=initialized_tables, dequantize=dequantize)
File "/media/ssd/BIGSCIENCE/venv/lib/python3.6/site-packages/tf2onnx/onnx_opset/tensor.py", line 444, in version_1
utils.make_sure(node.get_attr_value("batch_dims", 0) == 0, err_msg)
File "/media/ssd/BIGSCIENCE/venv/lib/python3.6/site-packages/tf2onnx/utils.py", line 260, in make_sure
raise ValueError("make_sure failure: " + error_msg % args)
ValueError: make_sure failure: Opset 12 required for batch_dims attribute of GatherV2
```<|||||>If it helps:
```
- `transformers` version: 4.18.0.dev0
- Platform: Linux-4.15.0-171-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- Huggingface_hub version: 0.4.0
- PyTorch version (GPU?): 1.10.1+cu102 (True)
- Tensorflow version (GPU?): 2.6.2 (False)
- Flax version (CPU?/GPU?/TPU?): 0.3.5 (cpu)
- Jax version: 0.2.17
- JaxLib version: 0.1.69
```<|||||>@cakiki It is settling on TF 2.3 because of python 3.6-related limitations on several packages :( We are actually having an internal discussion about potentially dropping support to python 3.6, since it is causing issues with both TF and PT (e.g. TF 2.8 requires python >= 3.7).
As for the onnx test, let's not worry about it, since it is failing on master as well.<|||||>I see that there are further errors in the tests, I will take a look (I think I know how to fix it). I will ping here again when the related fix is merged.
Hah, it seems like you got the best model to apply `@unpack_inputs` on :D <|||||>@cakiki I've been working on issues related to TF GPT-2, and it seems like I've also solved the errors here. I've tested locally with these changes on top of `main`, and all tests pass (except the `onnx` one, which is also failing on `main`).
We've recently renamed our branch from `master` to `main`, so CI won't turn green until we rebase -- which I've just pushed :)<|||||>@gante Thank you for the update!<|||||>The failing test is being tracked internally -- merging
@cakiki thank you for the contribution! (and for the patience) |
transformers | 16,310 | closed | Fix BigBirdModelTester | # What does this PR do?
Current `BigBirdModelTester` with `block_size=16` will cause the model to change `attention_type` from `block_sparse` to `original_full`.
https://github.com/huggingface/transformers/blob/9fef668338b15e508bac99598dd139546fece00b/src/transformers/models/big_bird/modeling_big_bird.py#L2059-L2070
In the PT/Flax equivalence test (from `ModelTesterMixin`), the `FlaxBigBird` model will still use `block_sparse`. This causes the test failed with `1e-5`.
I couldn't find any word `not possible` or `impossible` in `modeling_flax_big_bird.py`.
Currently, I change `block_size=16` to `block_size=8` in order to make both models run with `block_sparse` and pass the test.
However, it would be good at some point to check if we should have the same `self.set_attention_type("original_full")` for `FlaxBigBirdModel`.
Question: is `block_size=16` chosen intentionally to test `self.set_attention_type` in PT's BigBird? | 03-21-2022 20:04:53 | 03-21-2022 20:04:53 | _The documentation is not available anymore as the PR was closed or merged._<|||||>The expected value in `test_fast_integration` needs to be updated - if the change in this PR is OK.<|||||>Totally fine to switch to `block_size=8` if both test run the `"block_sparse"` mode this way :-) Thanks a lot for looking into this!<|||||>Update the expected value in `test_fast_integration` - to take into account of the change `block_size=8` and therefore `block_sparse`. |
transformers | 16,309 | closed | Add LayoutLMv2 OnnxConfig | # What does this PR do?
Add LayoutLMv2 OnnxConfig to make this model available for conversion.
I took the same config as `LayoutLM` and added the adapted shebang.
## Who can review?
Models: @LysandreJik @lewtun
| 03-21-2022 19:15:57 | 03-21-2022 19:15:57 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16309). All of your documentation changes will be reflected on that endpoint.<|||||>There's quite some interest for ONNX support of LayoutLMv2, see #14368 and #14555.<|||||>> There's quite some interest for ONNX support of LayoutLMv2, see #14368 and #14555.
Ok thanks for the links, I will look at them when I got some time and start improving the actual PR (it seems that the last PR has been closed due to inactivity, so I will take what I can from this and improve my own PR)
Thanks!<|||||>So, with the previous add the dummy inputs generation is working, but it seems that the `forward` function is facing a problem with the position embedding tensors.
There is a problem when `forward` is trying to calculate text embeddings, the `position_embeddings` tensor has not the same shape and can't be added with others
```bash
embeddings = inputs_embeds + position_embeddings + spatial_position_embeddings + token_type_embeddings
torch.Size([1, 14, 768]) torch.Size([1, 63, 768]) torch.Size([1, 14, 768]) torch.Size([1, 14, 768])
```
Here is the error trace :
```bash
Traceback (most recent call last):
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/transformers/onnx/__main__.py", line 99, in <module>
main()
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/transformers/onnx/__main__.py", line 81, in main
onnx_inputs, onnx_outputs = export(
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/transformers/onnx/convert.py", line 308, in export
return export_pytorch(preprocessor, model, config, opset, output, tokenizer=tokenizer)
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/transformers/onnx/convert.py", line 171, in export_pytorch
raise err
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/transformers/onnx/convert.py", line 148, in export_pytorch
onnx_export(
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/onnx/__init__.py", line 275, in export
return utils.export(model, args, f, export_params, verbose, training,
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/onnx/utils.py", line 88, in export
_export(model, args, f, export_params, verbose, training, input_names, output_names,
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/onnx/utils.py", line 689, in _export
_model_to_graph(model, args, verbose, input_names,
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/onnx/utils.py", line 458, in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args,
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/onnx/utils.py", line 422, in _create_jit_graph
graph, torch_out = _trace_and_get_graph_from_model(model, args)
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/onnx/utils.py", line 373, in _trace_and_get_graph_from_model
torch.jit._get_trace_graph(model, args, strict=False, _force_outplace=False, _return_inputs_states=True)
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/jit/_trace.py", line 1160, in _get_trace_graph
outs = ONNXTracedModule(f, strict, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/jit/_trace.py", line 127, in forward
graph, out = torch._C._create_graph_by_tracing(
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/jit/_trace.py", line 118, in wrapper
outs.append(self.inner(*trace_inputs))
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1039, in _slow_forward
result = self.forward(*input, **kwargs)
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/transformers/models/layoutlmv2/modeling_layoutlmv2.py", line 893, in forward
text_layout_emb = self._calc_text_embeddings(
File "/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/transformers/models/layoutlmv2/modeling_layoutlmv2.py", line 758, in _calc_text_embeddings
embeddings = inputs_embeds + position_embeddings + spatial_position_embeddings + token_type_embeddings
RuntimeError: The size of tensor a (14) must match the size of tensor b (63) at non-singleton dimension 1
```
I'm investigating to fix the tensors problem.
<|||||>@ChainYo have you find a solution for tensors problem ? 🤗<|||||>> @ChainYo have you find a solution for tensors problem ? hugs
It seems that one tensor size is changing for no reason on my previous tests. I will dig more this week, I had no time last week.<|||||>Great,if you want, we can organise a Google meet and looking the issue together. You can send me an email at : [email protected]<|||||>@ChainYo I am getting errors while using your PR during inference time. I am using the below code for token-classification (FUNSD):
processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
image_path = '../funsd/page1.png'
image = Image.open(image_path).convert("RGB")
words, bboxes = get_words_and_boxes_textract(textract_client, image_path)
encoded_inputs = processor(image, words, boxes=bboxes, padding="max_length", truncation=True, return_tensors="pt")
for k,v in encoded_inputs.items():
encoded_inputs[k] = v.to(device)
dt = datasets.Dataset.from_dict(encoded_inputs)
outputs = loaded_ort_model.evaluation_loop(dt)
Error:
InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Invalid Feed Input Name:token_type_ids
Any help is really appreciated. @ChainYo @lewtun @michaelbenayoun <|||||>You can try to add to the processor function token_type_ids like this :
```
input_ids = batch['input_ids'].to(device)
bbox = batch['bbox'].to(device)
image = batch['image'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch['token_type_ids'].to(device)
labels = batch['labels'].to(device)
# forward pass
outputs = model(input_ids=input_ids, bbox=bbox, image=image, attention_mask=attention_mask,
token_type_ids=token_type_ids, labels=labels)
```<|||||>> outputs = model(input_ids=input_ids, bbox=bbox, image=image, attention_mask=attention_mask,
> token_type_ids=token_type_ids, labels=labels)
there is a method called evaluation_loop which does inferencing for loaded onnx models. it expects only huggingface dataset as per https://github.com/huggingface/optimum.
Please look at the snippet which I posted earlier.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi! Thanks for working on this @ChainYo 🙏 I am interested in this work. Are you still working on this? If you no longer have the time or resources to do so, would you be able to provide any next steps as you see it for this ONNX export to work? Thank you for your time and effort 🤗 <|||||>Hey @ChainYo, regarding your error with the tests - my guess is that the dummy data generation is the culprit. My suggestion would be to:
* First pick an input that works with the `torch` model
* Export the model to ONNX and check the forward pass still works with the same input
* Generalise to the dummy input case<|||||>@malcolmgreaves I don't even remember where I was with this issue months ago. But I will try to work on it this week if I can.<|||||>@lewtun You are right! It seems that someone solved the things I was trying to achieve by doing it with LayoutLMv3. So I will check that and see what I can apply to v2.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hey @ChainYo
Were you able to check this?
Any direction on this would be really helpful.
> @lewtun You are right! It seems that someone solved the things I was trying to achieve by doing it with LayoutLMv3. So I will check that and see what I can apply to v2.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,308 | closed | ONNXConfig: Add a configuration for all available models | **ISSUE TRANSFER: Optimum repository -> https://github.com/huggingface/optimum/issues/555**
This issue is about the working group specially created for this task. If you are interested in helping out, take a look at this [organization](https://huggingface.co/OWG), or add me on Discord: `ChainYo#3610`
We want to contribute to HuggingFace's ONNX implementation for all available models on HF's hub. There are already a lot of architectures implemented for converting PyTorch models to ONNX, but we need more! We need them all!
Feel free to join us in this adventure! Join the org by clicking [here](https://huggingface.co/organizations/OWG/share/TskjfGaGjGnMXXssbPPXrQWEIbosGqZshZ)
Here is a non-exhaustive list of models that all models available:
- [x] Albert
- [x] BART
- [x] BeiT
- [x] BERT
- [x] BigBird
- [x] BigBirdPegasus
- [x] Blenderbot
- [x] BlenderbotSmall
- [x] BLOOM
- [x] CamemBERT
- [ ] CANINE
- [x] CLIP
- [x] CodeGen
- [x] ConvNext
- [x] ConvBert
- [ ] CTRL
- [ ] CvT
- [x] Data2VecText
- [x] Data2VecVision
- [x] Deberta
- [x] DebertaV2
- [x] DeiT
- [ ] DecisionTransformer
- [x] DETR
- [x] Distilbert
- [ ] DPR
- [ ] DPT
- [x] ELECTRA
- [ ] FNet
- [ ] FSMT
- [x] Flaubert
- [ ] FLAVA
- [ ] Funnel Transformer
- [ ] GLPN
- [x] GPT2
- [x] GPTJ
- [x] GPT-Neo
- [ ] GPT-NeoX
- [ ] Hubert
- [x] I-Bert
- [ ] ImageGPT
- [ ] LED
- [x] LayoutLM
- [ ] 🛠️ LayoutLMv2
- [x] LayoutLMv3
- [ ] LayoutXLM
- [ ] LED
- [x] LeViT
- [x] Longformer
- [x] LongT5
- [ ] 🛠️ Luke
- [ ] Lxmert
- [x] M2M100
- [ ] MaskFormer
- [x] mBart
- [ ] MCTCT
- [ ] MPNet
- [x] MT5
- [x] MarianMT
- [ ] MegatronBert
- [x] MobileBert
- [x] MobileViT
- [ ] Nyströmformer
- [x] OpenAIGPT-2
- [ ] 🛠️ OPT
- [x] OWLViT
- [x] PLBart
- [ ] Pegasus
- [x] Perceiver
- [ ] PoolFormer
- [ ] ProphetNet
- [ ] QDQBERT
- [ ] RAG
- [ ] REALM
- [ ] 🛠️ Reformer
- [x] RemBert
- [x] ResNet
- [ ] RegNet
- [ ] RetriBert
- [x] RoFormer
- [x] RoBERTa
- [ ] SEW
- [ ] SEW-D
- [ ] SegFormer
- [ ] Speech2Text
- [ ] Speech2Text2
- [ ] Splinter
- [x] SqueezeBERT
- [ ] Swin Transformer
- [x] T5
- [ ] TAPAS
- [ ] TAPEX
- [ ] Transformer XL
- [x] TrOCR
- [ ] UniSpeech
- [ ] UniSpeech-SAT
- [ ] VAN
- [x] ViT
- [ ] Vilt
- [ ] VisualBERT
- [ ] Wav2Vec2
- [ ] WavLM
- [ ] XGLM
- [x] XLM
- [ ] XLMProphetNet
- [x] XLM-RoBERTa
- [x] XLM-RoBERTa-XL
- [ ] 🛠️ XLNet
- [x] YOLOS
- [ ] Yoso
🛠️ next to a model suggests that the PR is in progress. If there is nothing next to a model, it means that ONNX does not yet support the model, and thus we need to add support for it.
If you need help implementing an unsupported model, here is a [guide](https://huggingface.co/docs/transformers/serialization#exporting-a-model-for-an-unsupported-architecture) from HuggingFace's documentation.
If you want an example of implementation, I did one for [CamemBERT ](https://github.com/huggingface/transformers/pull/14059) months ago. | 03-21-2022 18:15:54 | 03-21-2022 18:15:54 | - `GPT-J`: #16274
- `FlauBERT`: #16279<|||||>- `LayoutLMv2`: #16309 <|||||>Let me try with `BigBird`<|||||>- `Bigbird` #16427 <|||||>Love the initiative here, thanks for opening an issue! Added the `Good First Issue` label so that it's more visible :)<|||||>> Love the initiative here, thanks for opening an issue! Added the `Good First Issue` label so that it's more visible :)
Thanks for the label. I don't know if it's easy to begin, but it's cool if more people see this and can contribute!<|||||>I would like to try with Luke. However, Luke doesn't support any features apart from default AutoModel. It's main feature is LukeForEntityPairClassification for relation extraction. Should I convert luke-base to Onnx or LukeForEntityPairClassification which has a classifier head?<|||||>`Data2vecAudio` doesn't have `ONNXConfig` yet. I write its `ONNXConfig` according to `Data2VecTextOnnxConfig ` but it throws error. Can anyone help me?
```
from typing import Mapping, OrderedDict
from transformers.onnx import OnnxConfig
from transformers import AutoConfig
from pathlib import Path
from transformers.onnx import export
from transformers import AutoTokenizer, AutoModel
class Data2VecAudioOnnxConfig(OnnxConfig):
@property
def inputs(self):
return OrderedDict(
[
("input_values", {0: "batch", 1: "sequence"}),
("attention_mask", {0: "batch", 1: "sequence"}),
]
)
config = AutoConfig.from_pretrained("facebook/data2vec-audio-base-960h")
onnx_config = Data2VecAudioOnnxConfig(config)
onnx_path = Path("facebook/data2vec-audio-base-960h")
model_ckpt = "facebook/data2vec-audio-base-960h"
base_model = AutoModel.from_pretrained(model_ckpt)
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
```
errors
```
ValueError Traceback (most recent call last)
/var/folders/2t/0w65vdjs2m32w5mmzzgtqrhw0000gn/T/ipykernel_59977/667985886.py in <module>
27 tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
28
---> 29 onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
~/miniconda3/lib/python3.9/site-packages/transformers/onnx/convert.py in export(tokenizer, model, config, opset, output)
255
256 if is_torch_available() and issubclass(type(model), PreTrainedModel):
--> 257 return export_pytorch(tokenizer, model, config, opset, output)
258 elif is_tf_available() and issubclass(type(model), TFPreTrainedModel):
259 return export_tensorflow(tokenizer, model, config, opset, output)
~/miniconda3/lib/python3.9/site-packages/transformers/onnx/convert.py in export_pytorch(tokenizer, model, config, opset, output)
112
113 if not inputs_match:
--> 114 raise ValueError("Model and config inputs doesn't match")
115
116 config.patch_ops()
ValueError: Model and config inputs doesn't match
```<|||||>> I would like to try with Luke. However, Luke doesn't support any features apart from default AutoModel. It's main feature is LukeForEntityPairClassification for relation extraction. Should I convert luke-base to Onnx or LukeForEntityPairClassification which has a classifier head?
When you implement the ONNX Config for a model it's working for all kind of task, because the base model and the ones pre-packaged for fine-tuning have the same inputs.
So you can base your implementation on the base model and other tasks will work too.<|||||>- `LUKE` #16562 from @aakashb95 :+1: <|||||>Still learning<|||||>## Issue description
Hello, thank you for supporting GPTJ with ONNX. But when I exported an ONNX checkpoint using transformers-4.18.0, I got the issue like below.
```
(venv) root@V100:~# python -m transformers.onnx --model=gpt-j-6B/ onnx/
Traceback (most recent call last):
File "/usr/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/data/lvenv/lib/python3.8/site-packages/transformers/onnx/__main__.py", line 99, in <module>
main()
File "/data/venv/lib/python3.8/site-packages/transformers/onnx/__main__.py", line 62, in main
raise ValueError(f"Unsupported model type: {config.model_type}")
ValueError: Unsupported model type: gptj
```
I found GPTJ with ONNX seems supported when I checked your document transformers-4.18.0 [https://huggingface.co/docs/transformers/serialization#exporting-a-model-for-an-unsupported-architecture] and code [src/transformers/onnx/features.py etc.]. But I still got this issue. And then, I checked the parameter of config.model_type in File "/data/venv/lib/python3.8/site-packages/transformers/onnx/__main__.py", which is related to two parameters [from ..models.auto.feature_extraction_auto import FEATURE_EXTRACTOR_MAPPING_NAMES, from ..models.auto.tokenization_auto import TOKENIZER_MAPPING_NAMES]. I did not find GPTJ's config in these configs. It seems not sensible.
## Environment info
* Platform: Ubuntu 20.04.2
* python: 3.8.10
* PyTorch: 1.10.0+cu113
* transformers: 4.18.0
* GPU: V100<|||||>> Hello, thank you for supporting GPTJ with ONNX. But when I exported an ONNX checkpoint using transformers-4.18.0, I got the issue like below.
Hello @pikaqqqqqq, thanks for reporting the problem. I opened a PR with a quick fix to avoid this problem, check #16780<|||||>* `ConvBERT`: #16859<|||||>Hello 👋🏽, I added RoFormer onnx config here #16861, I'm not 100% sure who to ask for review so I'm posting this here. Thanks 🙏🏽 <|||||>Hi! I would like try building the ONNX config for `Reformer`.<|||||>> Hi! I would like try building the ONNX config for `Reformer`.
Hi @Tanmay06 that would be awesome. Don't hesitate to open a PR with your work when you feel it's quite good. You can ping me anytime if you need help!<|||||>Hello! I would like to work on ONNX config for `ResNet`.<|||||>> Hello! I would like to work on ONNX config for `ResNet`.
Nice, don't hesitate to ping me if help is needed :hugs:
<|||||>Hi! I would like to work on ONNX config for `BigBirdPegasus`.<|||||>> Hi! I would like to work on ONNX config for `BigBirdPegasus`.
Hi, nice! If you need help you can tag me.<|||||>#17027 Here is one for XLNet!<|||||>#17029 PR for MobileBert.<|||||>#17030 Here is the PR for XLM<|||||>#17078 PR for `BigBirdPegasus`<|||||>#17213 for `Perceiver`
#17176 for `Longformer` (work in progress 🚧 help appreciated)<|||||>Hi @ChainYo , I would like to work on getting the ONNX Config for SqueezeBert . Thanks!
<|||||>@ChainYo I would like to get started on the ONNX Config for DeBERTaV2!<|||||>> @ChainYo, I would like to get started on the ONNX Config for DeBERTaV2!
Ok noted! Ping me on the PR you open if you need help. 🤗 <|||||>@ChainYo ResNet and ConvNeXT are now supported, see #17585 and #17627 <|||||>> @ChainYo ResNet and ConvNeXT are now supported, see #17585 and #17627
Super cool! I update the list then.<|||||>Updated the list to leverage Github tasks instead. You can now see that 33 of the 93 models are supported. However, there are some new models to be added to the list which were added in v4.20<|||||>> Updated the list to leverage Github tasks instead. You can now see that 33 of the 93 models are supported. However, there are some new models to be added to the list which were added in v4.20
Thanks!
I will update the list very soon then.
**EDIT:** I Added 13 new models to the list! 🎉<|||||>@ChainYo OPT-30B here https://github.com/huggingface/transformers/pull/17771<|||||>@ChainYo Support for DETR has been added in #17904 <|||||>@ChainYo Support for LayoutLMv3 has been added in #17953 <|||||>> @ChainYo Support for LayoutLMv3 has been added in #17953
So cool, thanks a lot! @regisss <|||||>@ChainYo I have added LeViT support here https://github.com/huggingface/transformers/pull/18154<|||||>Actually I was using Hugging Face for a while and wanted to contribute,
[16308](https://github.com/huggingface/transformers/issues/16308) I was trying Swin Transformer one, following . .. replicating ViT one: [here](https://github.com/huggingface/transformers/compare/main...bibhabasumohapatra:transformers:onnx--SwinTransformer) ,
running tests I got,
```
FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_120_swin_default - ModuleNotFoundError: No module named 'onnxruntime'
FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_121_swin_image_classification - ModuleNotFoundError: No module named 'onnxruntime'
FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_122_swin_masked_im - ModuleNotFoundError: No module named 'onnxruntime'
FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_on_cuda_120_swin_default - ModuleNotFoundError: No module named 'onnxruntime'
FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_on_cuda_121_swin_image_classification - ModuleNotFoundError: No module named 'onnxruntime'
FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_on_cuda_122_swin_masked_im - ModuleNotFoundError: No module named 'onnxruntime'
```
the same was case in ViT implementation, the test gave same errors. also some DETR issue was also present for both ViT and swin Transformer (some related to from _lzma import *)<|||||>> Actually I was using Hugging Face for a while and wanted to contribute, [16308](https://github.com/huggingface/transformers/issues/16308) I was trying Swin Transformer one, following . .. replicating ViT one: [here](https://github.com/huggingface/transformers/compare/main...bibhabasumohapatra:transformers:onnx--SwinTransformer) , running tests I got,
>
> ```
> FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_120_swin_default - ModuleNotFoundError: No module named 'onnxruntime'
> FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_121_swin_image_classification - ModuleNotFoundError: No module named 'onnxruntime'
> FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_122_swin_masked_im - ModuleNotFoundError: No module named 'onnxruntime'
> FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_on_cuda_120_swin_default - ModuleNotFoundError: No module named 'onnxruntime'
> FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_on_cuda_121_swin_image_classification - ModuleNotFoundError: No module named 'onnxruntime'
> FAILED tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_on_cuda_122_swin_masked_im - ModuleNotFoundError: No module named 'onnxruntime'
> ```
>
> the same was case in ViT implementation, the test gave same errors. also some DETR issue was also present for both ViT and swin Transformer (some related to from _lzma import *)
@bibhabasumohapatra you have to install ONNX runtime:
`pip install '.[onnxruntime]'`<|||||>Hello @ChainYo I would like to contribute the Onnx config for the Decision Transformer, I'd love some guidance on how to go about this as this is my first contribution, really appreciate your guidance in getting me off the ground.<|||||>> Hello @ChainYo I would like to contribute the Onnx config for the Decision Transformer, I'd love some guidance on how to go about this as this is my first contribution, really appreciate your guidance in getting me off the ground.
@skanjila You can check how to do it here, it is well described: https://huggingface.co/docs/transformers/v4.20.1/en/serialization#exporting-a-model-for-an-unsupported-architecture
Do not hesitate to open a PR and we will support you if needed :)<|||||>> > Hello @ChainYo I would like to contribute the Onnx config for the Decision Transformer, I'd love some guidance on how to go about this as this is my first contribution, really appreciate your guidance in getting me off the ground.
>
> @skanjila You can check how to do it here, it is well described: https://huggingface.co/docs/transformers/v4.20.1/en/serialization#exporting-a-model-for-an-unsupported-architecture Do not hesitate to open a PR, and we will support you if needed :)
Thanks @regisss, for the appropriate link!
There are also multiple merged PR that adds ONNX Config that can give you an idea of all files you need to update to make it works.
Look at: #16274, #16279, #16427, #17213 or #18154
Sometimes there are some edge cases where you have to implement more things (like LayoutLMv3), but we could help you through the PR when you start implementing it, as @regiss said!<|||||>@ChainYo will get started on this, thank you so much for your help, expect a PR coming soon<|||||>Hi :hugs:
I am facing this error while trying to load up my DeBERTaV3 model into a ONNX format.
```
2022-07-21 10:21:22.414296: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Some weights of the model checkpoint at deberta-v3-large-conll-doccano/ were not used when initializing DebertaV2Model: ['classifier.bias', 'classifier.weight']
- This IS expected if you are initializing DebertaV2Model from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DebertaV2Model from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Traceback (most recent call last):
File "/usr/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.7/dist-packages/transformers/onnx/__main__.py", line 107, in <module>
main()
File "/usr/local/lib/python3.7/dist-packages/transformers/onnx/__main__.py", line 76, in main
model_kind, model_onnx_config = FeaturesManager.check_supported_model_or_raise(model, feature=args.feature)
File "/usr/local/lib/python3.7/dist-packages/transformers/onnx/features.py", line 519, in check_supported_model_or_raise
model_features = FeaturesManager.get_supported_features_for_model_type(model_type, model_name=model_name)
File "/usr/local/lib/python3.7/dist-packages/transformers/onnx/features.py", line 422, in get_supported_features_for_model_type
f"{model_type_and_model_name} is not supported yet. "
KeyError: "deberta-v2 is not supported yet. Only ['albert', 'bart', 'beit', 'bert', 'big-bird', 'bigbird-pegasus', 'blenderbot', 'blenderbot-small', 'camembert', 'convbert', 'convnext', 'data2vec-text', 'deit', 'distilbert', 'electra', 'flaubert', 'gpt2', 'gptj', 'gpt-neo', 'ibert', 'layoutlm', 'longt5', 'marian', 'mbart', 'mobilebert', 'm2m-100', 'perceiver', 'resnet', 'roberta', 'roformer', 'squeezebert', 't5', 'vit', 'xlm', 'xlm-roberta'] are supported. If you want to support deberta-v2 please propose a PR or open up an issue."
```
Though, @ChainYo in your original post you mention DeBERTaV2 should be available. Based on this error, I feel like there might be a bug in this.
Could someone help me sort this out or tell me how to get past this?
(if this is the wrong place to ask this, I have a post on the HF Community ref [link](https://discuss.huggingface.co/t/debertav3-onnx-conversion-error/20679))
thanks<|||||>> Hi hugs
>
> I am facing this error while trying to load up my DeBERTaV3 model into a ONNX format.
>
> ```
> 2022-07-21 10:21:22.414296: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
> Some weights of the model checkpoint at deberta-v3-large-conll-doccano/ were not used when initializing DebertaV2Model: ['classifier.bias', 'classifier.weight']
> - This IS expected if you are initializing DebertaV2Model from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
> - This IS NOT expected if you are initializing DebertaV2Model from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
> Traceback (most recent call last):
> File "/usr/lib/python3.7/runpy.py", line 193, in _run_module_as_main
> "__main__", mod_spec)
> File "/usr/lib/python3.7/runpy.py", line 85, in _run_code
> exec(code, run_globals)
> File "/usr/local/lib/python3.7/dist-packages/transformers/onnx/__main__.py", line 107, in <module>
> main()
> File "/usr/local/lib/python3.7/dist-packages/transformers/onnx/__main__.py", line 76, in main
> model_kind, model_onnx_config = FeaturesManager.check_supported_model_or_raise(model, feature=args.feature)
> File "/usr/local/lib/python3.7/dist-packages/transformers/onnx/features.py", line 519, in check_supported_model_or_raise
> model_features = FeaturesManager.get_supported_features_for_model_type(model_type, model_name=model_name)
> File "/usr/local/lib/python3.7/dist-packages/transformers/onnx/features.py", line 422, in get_supported_features_for_model_type
> f"{model_type_and_model_name} is not supported yet. "
> KeyError: "deberta-v2 is not supported yet. Only ['albert', 'bart', 'beit', 'bert', 'big-bird', 'bigbird-pegasus', 'blenderbot', 'blenderbot-small', 'camembert', 'convbert', 'convnext', 'data2vec-text', 'deit', 'distilbert', 'electra', 'flaubert', 'gpt2', 'gptj', 'gpt-neo', 'ibert', 'layoutlm', 'longt5', 'marian', 'mbart', 'mobilebert', 'm2m-100', 'perceiver', 'resnet', 'roberta', 'roformer', 'squeezebert', 't5', 'vit', 'xlm', 'xlm-roberta'] are supported. If you want to support deberta-v2 please propose a PR or open up an issue."
> ```
>
> Though, @ChainYo, in your original post, you mention DeBERTaV2 should be available. Based on this error, I feel like there might be a bug in this.
>
> Could someone help me sort this out or tell me how to get past this?
>
> (if this is the wrong place to ask this, I have a post on the HF Community ref [link](https://discuss.huggingface.co/t/debertav3-onnx-conversion-error/20679))
>
> thanks
Hey @Bhavnick-Yali, can you tell me which version of `Transformers` you are using? Because I see Deberta on available models in the source code.
Check it here: https://github.com/huggingface/transformers/blob/main/src/transformers/onnx/features.py#L240<|||||>Hi @ChainYo! :hugs:
I am working on Colab and using the `!pip install transformers[onnx]` command so I believe it's the latest version.
Yes, that's the issue, I see it as well but it gives me the error while trying to run it. So I tried something else as well after this ref: [link](https://discuss.huggingface.co/t/debertav3-onnx-conversion-error/20679/2) where I copied the onnxconfig class of DeBERTaV2 but even that was resulting in a unreadable error. <|||||>> I am working on Colab and using the `!pip install transformers[onnx]` command, so I believe it's the latest version.
Could you verify it precisely, please? To be sure, it's not a Colab problem with an older version.
```python
import transformers
print(transformers.__version__)
```
Could you also try to install transformers from the main GitHub branch?
```bash
$ pip install git+https://github.com/huggingface/transformers.git@main
```
<|||||>@ChainYo I'd like to work on LongT5.
Edit : Taking up Pegasus instead since there already seems to be an implementation for LongT5 :-D<|||||>Hi @ChainYo! :hugs:
Colab version says 4.20.1 which was 22 June Release and should be having the DeBERTaV2 config

It isn't working in this version as I tried earlier.
Using the main GitHub branch it installs 4.21.0.dev0 version, from which the ONNX conversion works.
Not sure what the issue is.
Thanks!<|||||>> Colab version says 4.20.1, which was the 22 June Release and should have the DeBERTaV2 config !
Are you sure about this?
> Using the main GitHub branch, it installs 4.21.0.dev0 version, from which the ONNX conversion works. Not sure what the issue is.
I'm glad it solved your problem! :fireworks:
<|||||>@ChainYo would love to take up CLIP if there's no one working on it yet?<|||||>@ChainYo I'd like to take up VisualBERT if no one is working on it yet?<|||||>Hi @ChainYo, while converting the CLIP model to onnx, I'm getting this error, while it's validating the ONNX model-
```
Validating ONNX model...
Traceback (most recent call last):
File "/Users/dhruv/.pyenv/versions/3.8.12/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/Users/dhruv/.pyenv/versions/3.8.12/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/__main__.py", line 107, in <module>
main()
File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/__main__.py", line 100, in main
validate_model_outputs(onnx_config, preprocessor, model, args.output, onnx_outputs, args.atol)
File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/convert.py", line 375, in validate_model_outputs
session = InferenceSession(onnx_model.as_posix(), options, providers=["CPUExecutionProvider"])
File "/Users/dhruv/Documents/code/transformers/.venv/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 347, in __init__
self._create_inference_session(providers, provider_options, disabled_optimizers)
File "/Users/dhruv/Documents/code/transformers/.venv/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 395, in _create_inference_session
sess.initialize_session(providers, provider_options, disabled_optimizers)
onnxruntime.capi.onnxruntime_pybind11_state.NotImplemented: [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : Could not find an implementation for ArgMax(13) node with name 'ArgMax_3468'
```
This is supposedly solved in the original repo by: https://github.com/openai/CLIP/pull/219
Does that change need to be included inside transformers as well?
<|||||>> Does that change need to be included inside transformers as well?
Yes, modeling files are often updated to work with ONNX or torch.fx for instance (as long as the changes are minimal).<|||||>> Hi @ChainYo, while converting the CLIP model to onnx, I'm getting this error, while it's validating the ONNX model-
>
> ```
> Validating ONNX model...
> Traceback (most recent call last):
> File "/Users/dhruv/.pyenv/versions/3.8.12/lib/python3.8/runpy.py", line 194, in _run_module_as_main
> return _run_code(code, main_globals, None,
> File "/Users/dhruv/.pyenv/versions/3.8.12/lib/python3.8/runpy.py", line 87, in _run_code
> exec(code, run_globals)
> File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/__main__.py", line 107, in <module>
> main()
> File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/__main__.py", line 100, in main
> validate_model_outputs(onnx_config, preprocessor, model, args.output, onnx_outputs, args.atol)
> File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/convert.py", line 375, in validate_model_outputs
> session = InferenceSession(onnx_model.as_posix(), options, providers=["CPUExecutionProvider"])
> File "/Users/dhruv/Documents/code/transformers/.venv/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 347, in __init__
> self._create_inference_session(providers, provider_options, disabled_optimizers)
> File "/Users/dhruv/Documents/code/transformers/.venv/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 395, in _create_inference_session
> sess.initialize_session(providers, provider_options, disabled_optimizers)
> onnxruntime.capi.onnxruntime_pybind11_state.NotImplemented: [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : Could not find an implementation for ArgMax(13) node with name 'ArgMax_3468'
> ```
>
> This is supposedly solved in the original repo by: [openai/CLIP#219](https://github.com/openai/CLIP/pull/219) Does that change need to be included inside transformers as well?
Do you want to work on this PR? If so open it and ping CLIP maintainer from Hugging Face, it should be cool. If not, just tell me I could try to open the PR.<|||||>> > Hi @ChainYo, while converting the CLIP model to onnx, I'm getting this error, while it's validating the ONNX model-
> > ```
> > Validating ONNX model...
> > Traceback (most recent call last):
> > File "/Users/dhruv/.pyenv/versions/3.8.12/lib/python3.8/runpy.py", line 194, in _run_module_as_main
> > return _run_code(code, main_globals, None,
> > File "/Users/dhruv/.pyenv/versions/3.8.12/lib/python3.8/runpy.py", line 87, in _run_code
> > exec(code, run_globals)
> > File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/__main__.py", line 107, in <module>
> > main()
> > File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/__main__.py", line 100, in main
> > validate_model_outputs(onnx_config, preprocessor, model, args.output, onnx_outputs, args.atol)
> > File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/convert.py", line 375, in validate_model_outputs
> > session = InferenceSession(onnx_model.as_posix(), options, providers=["CPUExecutionProvider"])
> > File "/Users/dhruv/Documents/code/transformers/.venv/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 347, in __init__
> > self._create_inference_session(providers, provider_options, disabled_optimizers)
> > File "/Users/dhruv/Documents/code/transformers/.venv/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 395, in _create_inference_session
> > sess.initialize_session(providers, provider_options, disabled_optimizers)
> > onnxruntime.capi.onnxruntime_pybind11_state.NotImplemented: [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : Could not find an implementation for ArgMax(13) node with name 'ArgMax_3468'
> > ```
> >
> >
> >
> >
> >
> >
> >
> >
> >
> >
> >
> > This is supposedly solved in the original repo by: [openai/CLIP#219](https://github.com/openai/CLIP/pull/219) Does that change need to be included inside transformers as well?
>
> Do you want to work on this PR? If so open it and ping CLIP maintainer from Hugging Face, it should be cool. If not, just tell me I could try to open the PR.
Sure, I"ll open the PR, happy to work on it<|||||>> > Hi @ChainYo, while converting the CLIP model to onnx, I'm getting this error, while it's validating the ONNX model-
> > ```
> > Validating ONNX model...
> > Traceback (most recent call last):
> > File "/Users/dhruv/.pyenv/versions/3.8.12/lib/python3.8/runpy.py", line 194, in _run_module_as_main
> > return _run_code(code, main_globals, None,
> > File "/Users/dhruv/.pyenv/versions/3.8.12/lib/python3.8/runpy.py", line 87, in _run_code
> > exec(code, run_globals)
> > File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/__main__.py", line 107, in <module>
> > main()
> > File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/__main__.py", line 100, in main
> > validate_model_outputs(onnx_config, preprocessor, model, args.output, onnx_outputs, args.atol)
> > File "/Users/dhruv/Documents/code/transformers/src/transformers/onnx/convert.py", line 375, in validate_model_outputs
> > session = InferenceSession(onnx_model.as_posix(), options, providers=["CPUExecutionProvider"])
> > File "/Users/dhruv/Documents/code/transformers/.venv/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 347, in __init__
> > self._create_inference_session(providers, provider_options, disabled_optimizers)
> > File "/Users/dhruv/Documents/code/transformers/.venv/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 395, in _create_inference_session
> > sess.initialize_session(providers, provider_options, disabled_optimizers)
> > onnxruntime.capi.onnxruntime_pybind11_state.NotImplemented: [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : Could not find an implementation for ArgMax(13) node with name 'ArgMax_3468'
> > ```
> >
> >
> >
> >
> >
> >
> >
> >
> >
> >
> >
> > This is supposedly solved in the original repo by: [openai/CLIP#219](https://github.com/openai/CLIP/pull/219) Does that change need to be included inside transformers as well?
>
> Do you want to work on this PR? If so open it and ping CLIP maintainer from Hugging Face, it should be cool. If not, just tell me I could try to open the PR.
Added the PR here: https://github.com/huggingface/transformers/pull/18515<|||||>added PR for OWLViT : https://github.com/huggingface/transformers/pull/18588<|||||>Hi!, just wondering when are all this new configs going to be included? Wich release! Great work, will try to add one or two myself<|||||>> Hi!, just wondering when are all this new configs going to be included? Wich release! Great work, will try to add one or two myself
Hey @irg1008, it's integrated continuously with each `transformers` release. If you are looking for a model that is not available in the last version, you can still install the package with the main branch:
`pip install git+https://github.com/huggingface/transformers.git`<|||||>- `DonutSwin`: #19401<|||||>@ChainYo Hi, I would like to work on `TrOCR`.<|||||>TrOCR and Donut are now supported per #19254 <|||||>> @ChainYo Hi, I would like to work on `TrOCR`.
> TrOCR and Donut are now supported per #19254
@RaghavPrabhakar66 Maybe there is another model you could implement?
<|||||>Sure. I can work on `ImageGPT`.<|||||>Can we re-open this? Please @sgugger :hugs: <|||||>@ChainYo After gaining some experience with `ImageGPT`, I would like to work on `CANINE` and `DecisionTransformer` (if working on more than one model is allowed.)<|||||>@ChainYo would love to take up ```PoolFormer``` if there's no one working on it yet?<|||||>> @ChainYo After gaining some experience with `ImageGPT`, I would like to work on `CANINE` and `DecisionTransformer` (if working on more than one model is allowed.)
@RaghavPrabhakar66 Yes of course! :+1:
> @ChainYo would love to take up `PoolFormer` if there's no one working on it yet?
I don't think so, it's open! :hugs: @BakingBrains <|||||>@ChainYo I was working on `Canine` and was facing some errors while running the following command:
```bash
python -m transformers.onnx onnx --model="google/canine-s"
```
CanineOnnxConfig:
```python
class CanineOnnxConfig(OnnxConfig):
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
if self.task == "multiple-choice":
dynamic_axis = {0: "batch", 1: "choice", 2: "sequence"}
else:
dynamic_axis = {0: "batch", 1: "sequence"}
return OrderedDict(
[
("input_ids", dynamic_axis),
("token_type_ids", dynamic_axis),
("attention_mask", dynamic_axis),
]
)
@property
def default_onnx_opset(self) -> int:
return 13
def generate_dummy_inputs(
self,
preprocessor: "PreTrainedTokenizerBase",
batch_size: int = 1,
seq_length: int = 6,
num_choices: int = -1,
is_pair: bool = False,
framework: Optional[TensorType] = None,
tokenizer: "PreTrainedTokenizerBase" = None,
) -> Mapping[str, Any]:
batch_size = compute_effective_axis_dimension(
batch_size, fixed_dimension=OnnxConfig.default_fixed_batch, num_token_to_add=0
)
token_to_add = preprocessor.num_special_tokens_to_add(is_pair)
seq_length = compute_effective_axis_dimension(
seq_length, fixed_dimension=OnnxConfig.default_fixed_sequence, num_token_to_add=token_to_add
)
dummy_inputs = [" ".join(["<unk>"]) * seq_length, " ".join(["<unk>"]) * (seq_length+3)] * batch_size
inputs = dict(preprocessor(dummy_inputs, padding="longest", truncation=True, return_tensors=framework))
return inputs
```
Error:
```bash
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ │
│ /usr/lib/python3.10/runpy.py:196 in _run_module_as_main │
│ │
│ 193 │ main_globals = sys.modules["__main__"].__dict__ │
│ 194 │ if alter_argv: │
│ 195 │ │ sys.argv[0] = mod_spec.origin │
│ ❱ 196 │ return _run_code(code, main_globals, None, │
│ 197 │ │ │ │ │ "__main__", mod_spec) │
│ 198 │
│ 199 def run_module(mod_name, init_globals=None, │
│ /usr/lib/python3.10/runpy.py:86 in _run_code │
│ │
│ 83 │ │ │ │ │ __loader__ = loader, │
│ 84 │ │ │ │ │ __package__ = pkg_name, │
│ 85 │ │ │ │ │ __spec__ = mod_spec) │
│ ❱ 86 │ exec(code, run_globals) │
│ 87 │ return run_globals │
│ 88 │
│ 89 def _run_module_code(code, init_globals=None, │
│ │
│ /home/luke/dev/huggingface/transformers/src/transformers/onnx/__main__.py:180 in <module> │
│ │
│ 177 if __name__ == "__main__": │
│ 178 │ logger = logging.get_logger("transformers.onnx") # pylint: disable=invalid-name │
│ 179 │ logger.setLevel(logging.INFO) │
│ ❱ 180 │ main() │
│ 181 │
│ │
│ /home/luke/dev/huggingface/transformers/src/transformers/onnx/__main__.py:173 in main │
│ │
│ 170 │ │ if args.atol is None: │
│ 171 │ │ │ args.atol = onnx_config.atol_for_validation │
│ 172 │ │ │
│ ❱ 173 │ │ validate_model_outputs(onnx_config, preprocessor, model, args.output, onnx_outpu │
│ 174 │ │ logger.info(f"All good, model saved at: {args.output.as_posix()}") │
│ 175 │
│ 176 │
│ │
│ /home/luke/dev/huggingface/transformers/src/transformers/onnx/convert.py:417 in │
│ validate_model_outputs │
│ │
│ 414 │ │ │ onnx_inputs[name] = value.numpy() │
│ 415 │ │
│ 416 │ # Compute outputs from the ONNX model │
│ ❱ 417 │ onnx_outputs = session.run(onnx_named_outputs, onnx_inputs) │
│ 418 │ │
│ 419 │ # Check we have a subset of the keys into onnx_outputs against ref_outputs │
│ 420 │ ref_outputs_set, onnx_outputs_set = set(ref_outputs_dict.keys()), set(onnx_named_out │
│ │
│ /home/luke/dev/huggingface/transformers/venv/lib/python3.10/site-packages/onnxruntime/capi/onnxr │
│ untime_inference_collection.py:200 in run │
│ │
│ 197 │ │ if not output_names: │
│ 198 │ │ │ output_names = [output.name for output in self._outputs_meta] │
│ 199 │ │ try: │
│ ❱ 200 │ │ │ return self._sess.run(output_names, input_feed, run_options) │
│ 201 │ │ except C.EPFail as err: │
│ 202 │ │ │ if self._enable_fallback: │
│ 203 │ │ │ │ print("EP Error: {} using {}".format(str(err), self._providers)) │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
Fail: [ONNXRuntimeError] : 1 : FAIL : Non-zero status code returned while running Concat node. Name:'Concat_1713' Status Message: concat.cc:159 PrepareForCompute Non concat axis dimensions
must match: Axis 2 has mismatched dimensions of 5 and 4
```<|||||>> @ChainYo I was working on Canine and was facing some errors while running the following command
Hey @RaghavPrabhakar66, it comes from how you preprocess the `dummy_inputs`.
Before returning it print the shape of the dummy_inputs and check if they look like the expected inputs, you defined in the config.
<|||||>Hi @ChainYo, I would like to take `LED` and `CvT` if there aren't folks working on them. 😃<|||||>> Hi @ChainYo, I would like to take `LED` and `CvT` if there aren't folks working on them. smiley
Go for it. Feel free to open a PR (one per architecture) once you are done with your implementation!<|||||>Hi @ChainYo, I added ONNX config for RemBERT in this [PR](https://github.com/huggingface/transformers/pull/20520). Please take a look and appreciate any guidance. <|||||>The ONNX export is now part of the `optimum` library. For backward compatibility, we will keep what is inside Transformers for now but we won't add any new configs. We will just merge the PRs currently opened once all comments have been addressed, but we won't accept new ones in the Transformers code base.
Closing this issue here, if you want to work on ONNX export, I invite you to go on the [optimum repo](https://github.com/huggingface/optimum/issues/555#issue-1481937260) :-) <|||||>hi I'm working on Swin Transformer<|||||>Hi,
Swin is already supported as can be seen [here](https://github.com/huggingface/transformers/blob/7f1cdf18958efef6339040ba91edb32ae7377720/src/transformers/models/swin/configuration_swin.py#L166). Also, all ONNX exports are now being discussed here: https://github.com/huggingface/optimum/issues/555<|||||>Please unsubscibe
On Sat, Feb 18, 2023, 7:41 PM NielsRogge ***@***.***> wrote:
> Hi,
>
> Swin is already supported as can be seen here
> <https://github.com/huggingface/transformers/blob/7f1cdf18958efef6339040ba91edb32ae7377720/src/transformers/models/swin/configuration_swin.py#L166>.
> Also, all ONNX export is now being discussed here: huggingface/optimum#555
> <https://github.com/huggingface/optimum/issues/555>
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/16308#issuecomment-1435649801>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AL5G67G7JJJMJ6NUBGDMSNLWYCYN3ANCNFSM5RIQTGKA>
> .
> You are receiving this because you commented.Message ID:
> ***@***.***>
>
<|||||>Thanks @NielsRogge I'm newcomer and about to start contributing to this repo :) |
transformers | 16,307 | closed | added type hints for blenderbot and blenderbot_small (v2) | # What does this PR do?
Added type hints for Blenderbot and BlenderbotSmall Tensorflow & PyTorch as described in https://github.com/huggingface/transformers/issues/16059
This new PR is a replacement for the [old one](https://github.com/huggingface/transformers/pull/16273) which has BART dependencies merge conflicts.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@Rocketknight1 @gante
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-21-2022 18:05:33 | 03-21-2022 18:05:33 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,306 | closed | Update Makefile Phonies | # What does this PR do?
This PR fixes vestiges of previously existing targets in the Makefile, and potentially adds missing entries as well.
Please let me know if any other recipes are to be added? My understanding is that we want to force the invokation of the recipe even if the file with same name exists, based on [this](https://www.gnu.org/software/make/manual/html_node/Phony-Targets.html#:~:text=A%20phony%20target%20is%20one,name%2C%20and%20to%20improve%20performance). Please correct me if I'm wrong.
## Who can review?
@sgugger | 03-21-2022 18:03:14 | 03-21-2022 18:03:14 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,305 | closed | add xglm conversion script | # What does this PR do?
Add conversion script for the XGLM model. | 03-21-2022 17:20:17 | 03-21-2022 17:20:17 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,304 | closed | Finetune Luke | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `adapter-transformers` version: 2.3.0
- Platform: Linux-5.4.0-91-generic-x86_64-with-glibc2.10
- Python version: 3.8.3
- PyTorch version (GPU?): 1.8.0+cu111 (True)
- Tensorflow version (GPU?): 2.3.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?:
### Who can help
@jplu @NielsRogge
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- ALBERT, BERT, XLM, DeBERTa, DeBERTa-v2, ELECTRA, MobileBert, SqueezeBert: @LysandreJik
- T5, Pegasus, EncoderDecoder: @patrickvonplaten
- Blenderbot, MBART, BART, Marian, Pegasus: @patil-suraj
- Longformer, Reformer, TransfoXL, XLNet, FNet, BigBird: @patrickvonplaten
- FSMT: @stas00
- Funnel: @sgugger
- GPT-2, GPT: @patil-suraj, @patrickvonplaten, @LysandreJik
- RAG, DPR: @patrickvonplaten, @lhoestq
- TensorFlow: @Rocketknight1
- JAX/Flax: @patil-suraj
- TAPAS, LayoutLM, LayoutLMv2, LUKE, ViT, BEiT, DEiT, DETR, CANINE: @NielsRogge
- GPT-Neo, GPT-J, CLIP: @patil-suraj
- Wav2Vec2, HuBERT, SpeechEncoderDecoder, UniSpeech, UniSpeechSAT, SEW, SEW-D, Speech2Text: @patrickvonplaten, @anton-l
If the model isn't in the list, ping @LysandreJik who will redirect you to the correct contributor.
Library:
- Benchmarks: @patrickvonplaten
- Deepspeed: @stas00
- Ray/raytune: @richardliaw, @amogkam
- Text generation: @patrickvonplaten @narsil
- Tokenizers: @SaulLu
- Trainer: @sgugger
- Pipelines: @Narsil
- Speech: @patrickvonplaten, @anton-l
- Vision: @NielsRogge, @sgugger
Documentation: @sgugger
Model hub:
- for issues with a model, report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
For research projetcs, please ping the contributor directly. For example, on the following projects:
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): LUKE
The problem arises when using:
* [x] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Convert the CONLL or custom NER dataset to the json format `{"data": [{"tokens": [], "ner_tags": []}, ...]}`
2. Add `field` params in the 349 line of `examples/research_project/run_luke_ner_no_trainer.py`: `raw_datasets = load_dataset(extension, data_files=data_files, field="data")`
3. Run the script
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
The script runs with no issues
## Problem
It seems like in the `compute_entity_spans_for_luke` function, the `labels_positions` is a dictionary with keys are tuple of `(start, end)` character position of every possible span in the sentence, and values are the `LABEL` in `str` type (because it is from `examples[text_column_name]`). But when adding values to `labels_entity_spans`, it checks if the tuple `(start, end)` of a span is an entity or not, it will add the corresponded label from `labels_positions` else add `0` (this also may need to be more generalize than just add the 0, because if the index of `OTHER` tag not at 0, that would be wrong tho). This would lead to `labels_entity_spans` has `int` and `str` type mixed together, and then fails on `cast_to_python_objects` from `arrow_writer`.
I found other problems as well but it would be too long to address here and some technical problems related to splitting the sample to multiples one due to the `max_entity_length` compared to the original logic code of @ikuyamada. For example generating 20 tokens sentence length would lead to an `entity_ids` with 210 elements length, do we need to split it to multiple samples of `max_entity_length` like the original code?
<!-- A clear and concise description of what you would expect to happen. -->
| 03-21-2022 16:23:14 | 03-21-2022 16:23:14 | Can you just run the given command without to proceed to any update in the script:
```
export TASK_NAME=ner
python run_luke_ner_no_trainer.py \
--model_name_or_path studio-ousia/luke-base \
--dataset_name conll2003 \
--task_name $TASK_NAME \
--max_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
And tell me if you get the cast error, and if not to copy/paste the eval results. And then run the original code with the exact same parameters and tell me if you get similar results.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @jplu
I ran the script on conll2003 dataset with the default hyperparameters. However the performance is not upto the mark. Here are the performance numbers I am getting:
{‘precision’: 0.8983516483516484, ‘recall’: 0.40541976620616366, ‘f1’: 0.5587014888943129, ‘accuracy’: 0.8970917690009956}
I tried with different batch sizes (8, 16, 24, 32) and learning rates (1e-5, 1e-8, 2e-5) but with no luck in reproducing the results mentioned in the paper.
Any suggestions on how to match the performance reported in the paper?
|
transformers | 16,303 | closed | How to do mask prediction with ByT5? | # 🚀 Feature request
It is currently not very clear on how to do mask prediction using ByT5.
For T5, we, *e.g.* know that the first 100 sentinel tokens are used as masks, e.g. the following code snippet somewhat shows how `t5-base` does mask denoising:
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("t5-base")
model = T5ForConditionalGeneration.from_pretrained("t5-base")
input_ids = tokenizer("The dog <extra_id_0> a ball <extra_id_1> park", return_tensors="pt").input_ids
print("Input_ids", input_ids) # <- gives tensor([[ 37, 1782, 32099, 3, 9, 1996, 32098, 2447, 1]])
output_ids = model.generate(input_ids)
print("Output ids", output_ids) # <- gives tensor([[ 0, 32099, 19, 32098, 16, 8, 32097, 19, 32096, 19,
32095, 16, 8, 32094, 19, 32093, 16, 8, 32092, 16]])
print("Output string", tokenizer.batch_decode(output_ids)) # <- gives ['<pad> <extra_id_0> is<extra_id_1> in the<extra_id_2> is<extra_id_3> is<extra_id_4> in the<extra_id_5> is<extra_id_6> in the<extra_id_7> in']
```
Here we can see that the model learns to do the correct masking pattern and also gives somewhat sensible predictions for `<extra_id_1>` and `<extra_id_2>`, being "is" and "in the".
Since the ByT5 paper states:
```bash
Second, we modify the pre-training task. mT5 uses the “span corruption” pre-training objective first proposed by Raffel et al. (2020) where spans of tokens in unlabeled text data are replaced with a single “sentinel” ID and the model must fill in the missing spans. Rather than adding 100 new tokens for the sentinels, we find it sufficient to reuse the final 100 byte IDs. While mT5 uses an average span length of 3 subword tokens, we find that masking longer byte-spans is valuable. Specifically, we set our mean mask span length to 20 bytes, and show ablations of this value in section 6.
```
IMO one should use the masking ids starting from 258 (256 + 3 special tokens - 1). E.g. the following code snippet should work more or less for ByT5:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
input_ids_prompt = "The dog chases a ball in the park."
input_ids = tokenizer(input_ids_prompt).input_ids
# Now Mask
# Note that we can add "{extra_id_...}" to the string directly
# as the Byte tokenizer would incorrectly merge the tokens
# We need to work on the character level directly here
# => mask to "The dog [258]a ball [257]park."
input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
print("In IDs", input_ids) # <- gives tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100,
111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
# ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
output_ids = model.generate(input_ids, max_length=100)[0].tolist()
print("Out IDs", output_ids)
"""^ gives [0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122,
107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107,
104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104,
35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106,
35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107,
114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35,
108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117,
110, 49] <- Note how 258 descends to 257, 256, 255
"""
# Now we need to split on the sentinel tokens, let's write a short loop for this
output_ids_list = []
start_token = 0
sentinel_token = 258
while sentinel_token in output_ids:
split_idx = output_ids.index(sentinel_token)
output_ids_list.append(output_ids[start_token: split_idx])
start_token = split_idx
sentinel_token -= 1
output_ids_list.append(output_ids[start_token:])
output_string = tokenizer.batch_decode(output_ids_list)
print("Out string", output_string) # <- gives ['<pad>', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
```
We can see here that this also makes somewhat sense, e.g. "The dog [is the one who does] a ball [in the disco park]"
I think it would be a good idea to document this somewhere in our Transformers docs. Happy to do so.
@craffel lintingxue - could you take a quick look at whether my description above is correct here?
E.g. for ByT5 the masking starts with the token `258` and then descends down to at most `257` no? | 03-21-2022 15:43:35 | 03-21-2022 15:43:35 | Also we should probably change the ByT5 tokenizer configs: https://huggingface.co/google/byt5-small/blob/main/tokenizer_config.json as its at best very confusing to write that the token ids from 259 to 383 are sentinel tokens. This is just wrong no? There are no sentinel tokens and the last 124 tokens are just there to round the number up to 3 * 2**7 = 384 for TPU no?<|||||>Yes, this is correct to the best of my recollection - I think we just forgot to allocate additional sentinel token IDs. @adarob can probably confirm.<|||||>Putting it in the official ByT5 docs here: https://github.com/huggingface/transformers/pull/16646<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,302 | closed | Feature Extractor: correctly pass **kwargs upon creation | # What does this PR do?
This PR correctly passes over the `**kwargs` parameter to the feature extractor class upon creation in the `.from_dict` method | 03-21-2022 15:01:06 | 03-21-2022 15:01:06 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16302). All of your documentation changes will be reflected on that endpoint.<|||||>Then it will only work on parameters that are not used at `__init__` time, I am not sure if this is what we want. Assume we check a parameter and that parameter is not in the serialized config, the code will fail even if we pass it in `**kwargs`<|||||>The check should thus be done outside of the init, at the first use. But this is a big change in the logic of feature extractor that, as you can see, makes a lot of tests fail.<|||||>So, a user is allowed to instantiate a ***extractor with missing/wrong parameters?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,301 | closed | fix last element in hidden_states for XGLM | # What does this PR do?
Same fix as in #16167 (where the last element in `hidden_states` is different between PT/Flax version.)
This was missed in the previous PR - because XGLM model test overwrites the common (more thorough) PT/Flax equivalence test.
This fix is tested with #16280 and passed ! | 03-21-2022 14:59:35 | 03-21-2022 14:59:35 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,300 | closed | Fix Marian conversion script | # What does this PR do?
Fixes the `Marian` conversion script to use the correct value for `activation_function` and also
set `tied-embeddings=True` when `tied-embeddings-all=True`
cc @tiedemann | 03-21-2022 14:48:10 | 03-21-2022 14:48:10 | Trust you on this :-) <|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,299 | closed | Spanish translation of the file preprocessing.mdx | Hi, I made the translation of the **preprocessing.mdx** file to add it to the Spanish documentation (transformers/docs/source_es/).
I will be waiting for any correction, thanks.
@omarespejel @LysandreJik @sgugger | 03-21-2022 14:23:13 | 03-21-2022 14:23:13 | _The documentation is not available anymore as the PR was closed or merged._<|||||>All good to me from the syntax point of view. Be careful though, as you PR files include the `training.mdx` so we can't know if there are small changes in it.<|||||>You're right, it was a mistake, It's just the preprocessing file<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @yharyarias! Could you please review what Sylvain[ commented above](https://github.com/huggingface/transformers/pull/16299#issuecomment-1074021882)? We are almost done.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Muchas gracias @yharyarias for the PR! 🤗 Please let me know if you wish to translate another one. Fixes issue #15947.
@sgugger LGTM :) |
transformers | 16,298 | closed | [FlaxGPTJ] Fix bug in rotary embeddings | # What does this PR do?
The rotary embeddings in `FlaxGPTJ` are computed in-correctly and they don't match with the PT version. This PR fixes `rotate_every_two` function to match with PT version.
Thanks a lot @ydshieh for finding this issue!
Fixes #16288 | 03-21-2022 13:41:27 | 03-21-2022 13:41:27 | _The documentation is not available anymore as the PR was closed or merged._<|||||>> Shouldn't the slow test have failed here?
The difference(s) - for hidden states - I got are in the range like of `1e-2`. Not sure if this will affect the outputs of slow test.
I can run the slow tests to see what happen internally.<|||||>> > Shouldn't the slow test have failed here?
>
> The difference(s) - for hidden states - I got are in the range like of `1e-2`. Not sure if this will affect the outputs of slow test. I can run the slow tests to see what happen internally.
Yes, the diff for the output was surprisingly small and didn't affect generation when I last tested. |
transformers | 16,297 | closed | Fix Bart type hints | # What does this PR do?
This PR adds type-hints to PLBart PyTorch.
A few queries:
1. What about the configuration files? Do they not need type-hinting?
2. I understand someone is working on the BART model: https://github.com/huggingface/transformers/pull/16270/files. There are some copies on there, can I wait for that PR to be merged and see if there are any fixes needed after doing `make fixup` from their PR?
@Rocketknight1 | 03-21-2022 13:41:05 | 03-21-2022 13:41:05 | Hi @gchhablani that is correct. We have just merged the BART PR, which has overwritten parts of `modeling_plbart.py`. Please check if any further changes are needed to `modeling_plbart.py` - if they are, you can either submit a new PR for them, or rebase this PR onto the updated main/master branch.<|||||>But also, thanks for doing this - your PR looks very solid otherwise! <|||||>@Rocketknight1 I have tried to make things a bit more consistent with Bart.
For example:
1. One place was using `torch.FloatTensor` for `encoder_attention_mask`, which should be `torch.LongTensor`.
2. Another discrepancy was that `encoder_hidden_states` were `FloatTensor` in one place, while `Tensor` in another.
3. `input_ids` are actually optional because we can also pass `input_embeds` but it was not present.
4. `past_key_values` was `List[torch.Tensor]` in some places, while `Tuple[torch.Tensor]` in some. Not 100% sure which is correct. I used `List` for now.
PLBart has some additional changes, which may be included. Wdyt?<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Hi @gchhablani I think this PR is quite difficult to review right now because of all the changes! If possible, could you close this PR, make sure your local repo is updated to the latest changes, then make a new branch and make the plBART PR there? I think if you do that, and only add annotations to the methods that are missing them, then we shouldn't have the problem of multiple affected files.
Thanks, and I'm sorry for the confusion here!<|||||>Hi @Rocketknight1!
Sure!
What about the issues with BART?
I think the changes in BART and PLBart are the only ones that need reviewing. Wdyt?<|||||>I think it's fine to focus on plBART for this PR. The issues with BART aren't serious, and if we decide to be consistent with `Tuple` or `List` across the whole repo, we can do that with a simple find-replace. So in your plBART PR, don't worry about making changes that will also require changes to BART - just annotate missing types for methods that don't have any yet, and that's perfect!<|||||>@Rocketknight1 Can you please review it now?
Thanks!<|||||>Looks great to me, thanks for the PR! |
transformers | 16,296 | closed | Remove disclaimer from Longformer docs | # What does this PR do?
This PR removes disclaimer from the Longformer docs. Checked with @patil-suraj.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
Documentation: @sgugger
CC: @patil-suraj | 03-21-2022 12:51:02 | 03-21-2022 12:51:02 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,295 | closed | Fix Seq2SeqTrainingArguments docs | # What does this PR do?
This PR fixes the Seq2SeqTrainingArguments docs. The current docs have a problem in rendering as shown in the image below:
.
Specifically, the parameters added in the sub-class are now showing up in the parameter list but as a messy paragraph at the end.
I believe the issue is because of the indentation in the docs for Seq2SeqTrainingArguments. If there is any other way this should be addressed, please let me know.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
Documentation: @sgugger
## EDIT 1:
This is after fixing the indentation:

| 03-21-2022 12:38:30 | 03-21-2022 12:38:30 | _The documentation is not available anymore as the PR was closed or merged._<|||||>The style checks are failing because `style_doc.py` check/fixing will undo the changes I made.
I may be totally off here, but:
1. Does this point to a potential issue in the `style_doc.py`? The `style_docstring` method only takes the current file into consider, and not the fact that some additional docstring is added in the beginning or end?
2. Or, should this be handled in the `add_start_docstrings` decorator? In that case, should we indent things manually always?
I believe the second option sounds better since we almost always add only parameters when we use `add_start_docstrings`?
Would love to get your opinion on this. If needed, I can quickly create a PR which does this?
Wdyt @sgugger?
CC: @patil-suraj <|||||>I'd have to take a closer look, but I think it's actually black undoing your changes, not `style_doc`. This may need some more work on our internal tooling. |
transformers | 16,294 | closed | ResNet & VAN: Fixed code sample tests | # What does this PR do?
This PR fixes the code samples for `ResNet` and `Van` | 03-21-2022 12:12:12 | 03-21-2022 12:12:12 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,293 | closed | Update for bs_msfp integration | Some modification for calling Brainwave encoder library. | 03-21-2022 12:03:13 | 03-21-2022 12:03:13 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hello! Sorry for not seeing this earlier. In the README of the examples folder, there is written the following:
> While we strive to present as many use cases as possible, the example scripts are just that - examples. It is expected that they won't work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data, allowing you to tweak and edit them as required.
To that end, we don't intend to add additional features to existing scripts. However, feel free to upload a gist somewhere with the code that you have and share it on the [forum](https://discuss.huggingface.co), I'm sure some users would love to see it!
Thanks! |
transformers | 16,292 | open | [Community Event] Doc Tests Sprint | ### This issue is part of our **Doc Test Sprint**. If you're interested in helping out come [join us on Discord](https://discord.gg/J8bW9u5abB) and talk with other contributors!
Docstring examples are often the first point of contact when trying out a new library! So far we haven't done a very good job at ensuring that all docstring examples work correctly in 🤗 Transformers - but we're now very dedicated to ensure that all documentation examples work correctly by testing each documentation example via Python's doctest (https://docs.python.org/3/library/doctest.html) on a daily basis.
In short we should do the following for all models for both PyTorch and Tensorflow:
1. - Check the current doc examples will run without failure
2. - Check whether the current doc example of the forward method is a sensible example to better understand the model or whether it can be improved. E.g. is the example of https://huggingface.co/docs/transformers/v4.17.0/en/model_doc/bert#transformers.BertForQuestionAnswering.forward a good example of the model? Could it be improved?
3. - Add an expected output to the doc example and test it via Python's doc test (see **Guide to contributing** below)
Adding a documentation test for a model is a great way to better understand how the model works, a simple (possibly first) contribution to Transformers and most importantly a very important contribution to the Transformers community 🔥
If you're interested in adding a documentation test, please read through the **Guide to contributing** below.
This issue is a call for contributors, to make sure docstring exmaples of existing model architectures work correctly. If you wish to contribute, reply in this thread which architectures you'd like to take :)
### Guide to contributing:
1. Ensure you've read our contributing [guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) 📜
2. Claim your architecture(s) in this thread (confirm no one is working on it) 🎯
3. Implement the changes as in https://github.com/huggingface/transformers/pull/15987 (see the diff on the model architectures for a few examples) 💪
- The file you want to look at is in `src/transformers/models/[model_name]/modeling_[model_name].py`, `src/transformers/models/[model_name]/modeling_tf_[model_name].py` or `src/transformers/doc_utils.py` or `src/transformes/file_utils.py`
- Make sure to run the doc example doc test locally as described in https://github.com/huggingface/transformers/tree/master/docs#for-python-files
- Optionally, change the example docstring to a more sensible example that gives a better suited result
- Make the test pass
- Add the file name to https://github.com/huggingface/transformers/blob/master/utils/documentation_tests.txt (making sure the file stays in alphabetical order)
- Run the doc example test again locally
In addition, there are a few things we can also improve, for example :
- Fix some style issues: for example, change **``decoder_input_ids```** to **\`decoder_input_ids\`**.
- Using a small model checkpoint instead of a large one: for example, change **"facebook/bart-large"** to **"facebook/bart-base"** (and adjust the expected outputs if any)
4. Open the PR and tag me @patrickvonplaten @ydshieh or @patil-suraj (don't forget to run `make fixup` before your final commit) 🎊
- Note that some code is copied across our codebase. If you see a line like `# Copied from transformers.models.bert...`, this means that the code is copied from that source, and our scripts will automatically keep that in sync. If you see that, you should not edit the copied method! Instead, edit the original method it's copied from, and run make fixup to synchronize that across all the copies. Be sure you installed the development dependencies with `pip install -e ".[dev]"`, as described in the contributor guidelines above, to ensure that the code quality tools in `make fixup` can run.
### PyTorch Model Examples added to tests:
- [ ] **ALBERT** (@vumichien)
- [x] **BART** (@abdouaziz)
- [x] BEiT
- [ ] **BERT** (@vumichien)
- [ ] Bert
- [ ] BigBird (@vumichien)
- [x] BigBirdPegasus
- [x] Blenderbot
- [x] BlenderbotSmall
- [ ] CamemBERT (@abdouaziz)
- [ ] Canine (@NielsRogge)
- [ ] **CLIP** (@Aanisha)
- [ ] ConvBERT (@simonzli)
- [x] ConvNext
- [ ] CTRL (@jeremyadamsfisher)
- [x] Data2VecAudio
- [ ] Data2VecText
- [ ] DeBERTa (@Tegzes)
- [ ] **DeBERTa-v2** (@Tegzes)
- [x] DeiT
- [ ] DETR
- [ ] **DistilBERT** (@jmwoloso)
- [ ] DPR
- [ ] **ELECTRA** (@bhadreshpsavani)
- [ ] Encoder
- [ ] FairSeq
- [ ] FlauBERT (@abdouaziz)
- [ ] FNet
- [ ] Funnel
- [ ] **GPT2** (@ArEnSc)
- [ ] GPT-J (@ArEnSc)
- [x] Hubert
- [ ] I-BERT (@abdouaziz)
- [ ] ImageGPT
- [ ] LayoutLM (chiefchiefling @ discord)
- [ ] LayoutLMv2
- [ ] LED
- [x] **Longformer** (@KMFODA)
- [ ] LUKE (@Tegzes)
- [ ] LXMERT
- [ ] M2M100
- [x] **Marian**
- [x] MaskFormer (@reichenbch)
- [x] **mBART**
- [ ] MegatronBert
- [ ] MobileBERT (@vumichien)
- [ ] MPNet
- [ ] mT5
- [ ] Nystromformer
- [ ] OpenAI
- [ ] OpenAI
- [x] Pegasus
- [ ] Perceiver
- [x] PLBart
- [x] PoolFormer
- [ ] ProphetNet
- [ ] QDQBert
- [ ] RAG
- [ ] Realm
- [ ] **Reformer**
- [x] ResNet
- [ ] RemBERT
- [ ] RetriBERT
- [ ] **RoBERTa** (@patrickvonplaten )
- [ ] RoFormer
- [x] SegFormer
- [x] SEW
- [x] SEW-D
- [x] SpeechEncoderDecoder
- [x] Speech2Text
- [x] Speech2Text2
- [ ] Splinter
- [ ] SqueezeBERT
- [x] Swin
- [ ] **T5** (@MarkusSagen)
- [ ] TAPAS (@NielsRogge)
- [ ] Transformer-XL (@simonzli)
- [ ] TrOCR (@arnaudstiegler)
- [x] UniSpeech
- [x] UniSpeechSat
- [x] Van
- [x] ViLT
- [x] VisionEncoderDecoder
- [ ] VisionTextDualEncoder
- [ ] VisualBert
- [x] **ViT**
- [x] ViTMAE
- [x] **Wav2Vec2**
- [x] WavLM
- [ ] XGLM
- [ ] **XLM**
- [ ] **XLM-RoBERTa** (@AbinayaM02)
- [ ] XLM-RoBERTa-XL
- [ ] XLMProphetNet
- [ ] **XLNet**
- [ ] YOSO
### Tensorflow Model Examples added to tests:
- [ ] **ALBERT** (@vumichien)
- [ ] **BART**
- [ ] BEiT
- [ ] **BERT** (@vumichien)
- [ ] Bert
- [ ] BigBird (@vumichien)
- [ ] BigBirdPegasus
- [ ] Blenderbot
- [ ] BlenderbotSmall
- [ ] CamemBERT
- [ ] Canine
- [ ] **CLIP** (@Aanisha)
- [ ] ConvBERT (@simonzli)
- [ ] ConvNext
- [ ] CTRL
- [ ] Data2VecAudio
- [ ] Data2VecText
- [ ] DeBERTa
- [ ] **DeBERTa-v2**
- [ ] DeiT
- [ ] DETR
- [ ] **DistilBERT** (@jmwoloso)
- [ ] DPR
- [ ] **ELECTRA** (@bhadreshpsavani)
- [ ] Encoder
- [ ] FairSeq
- [ ] FlauBERT
- [ ] FNet
- [ ] Funnel
- [ ] **GPT2** (@cakiki)
- [ ] GPT-J (@cakiki)
- [ ] Hubert
- [ ] I-BERT
- [ ] ImageGPT
- [ ] LayoutLM
- [ ] LayoutLMv2
- [ ] LED
- [x] **Longformer** (@KMFODA)
- [ ] LUKE
- [ ] LXMERT
- [ ] M2M100
- [ ] **Marian**
- [x] MaskFormer (@reichenbch)
- [ ] **mBART**
- [ ] MegatronBert
- [ ] MobileBERT (@vumichien)
- [ ] MPNet
- [ ] mT5
- [ ] Nystromformer
- [ ] OpenAI
- [ ] OpenAI
- [ ] Pegasus
- [ ] Perceiver
- [ ] PLBart
- [ ] PoolFormer
- [ ] ProphetNet
- [ ] QDQBert
- [ ] RAG
- [ ] Realm
- [ ] **Reformer**
- [ ] ResNet
- [ ] RemBERT
- [ ] RetriBERT
- [ ] **RoBERTa** (@patrickvonplaten)
- [ ] RoFormer
- [ ] SegFormer
- [ ] SEW
- [ ] SEW-D
- [ ] SpeechEncoderDecoder
- [ ] Speech2Text
- [ ] Speech2Text2
- [ ] Splinter
- [ ] SqueezeBERT
- [ ] Swin (@johko)
- [ ] **T5** (@MarkusSagen)
- [ ] TAPAS
- [ ] Transformer-XL (@simonzli)
- [ ] TrOCR (@arnaudstiegler)
- [ ] UniSpeech
- [ ] UniSpeechSat
- [ ] Van
- [ ] ViLT
- [ ] VisionEncoderDecoder
- [ ] VisionTextDualEncoder
- [ ] VisualBert
- [ ] **ViT** (@johko)
- [ ] ViTMAE
- [ ] **Wav2Vec2**
- [ ] WavLM
- [ ] XGLM
- [ ] **XLM**
- [ ] **XLM-RoBERTa** (@AbinayaM02)
- [ ] XLM-RoBERTa-XL
- [ ] XLMProphetNet
- [ ] **XLNet**
- [ ] YOSO | 03-21-2022 11:53:20 | 03-21-2022 11:53:20 | @patrickvonplaten I would like to start with Maskformer for Tensorflow/Pytorch. Catch up with how the event goes.<|||||>Awesome! Let me know if you have any questions :-)<|||||>Hello! I'd like to take on Longformer for Tensorflow/Pytorch please.<|||||>@patrickvonplaten I would like to start with T5 for pytorch and tensorflow<|||||>Sounds great!<|||||>LayoutLM is also taken as mentioned by a contributor on Discord!<|||||>@patrickvonplaten I would take GPT and GPT-J (TensorFlow editions) if those are still available.
I'm guessing GPT is GPT2?<|||||>I will take Bert, Albert, and Bigbird for both Tensorflow/Pytorch<|||||>I'll take Swin and ViT for Tensorflow<|||||>I'd like DistilBERT for both TF and PT please<|||||>> @patrickvonplaten I would take GPT and GPT-J (TensorFlow editions) if those are still available.
>
> I'm guessing GPT is GPT2?
@cakiki You can go for GPT2 (I updated the name in the test)<|||||>Can I try GPT2 and GPTJ for Pytorch? if @ydshieh you are not doing so?<|||||>I would like to try CLIP for Tensorflow and PyTorch.<|||||>I'll take CANINE and TAPAS.<|||||>> Can I try GPT2 and GPTJ for Pytorch? if @ydshieh you are not doing so?
@ArEnSc
No, you can work on these 2 models :-) Thank you!<|||||>@ydshieh Since the MobileBertForSequenceClassification is the copy of BertForSequenceClassification, so I think I will do check doc-test of MobileBert as well to overcome the error from `make fixup`<|||||>I'll take FlauBERT and CamemBERT.<|||||>@abdouaziz Awesome! Do you plan to work on both PyTorch and TensorFlow versions, or only one of them?
<|||||>I would like to work on LUKE model for both TF and PT<|||||>@Tegzes you're lucky because there's no LUKE in TF ;) the list above actually just duplicates all models, but many models aren't available yet in TF.<|||||>In this case, I will also take DeBERTa and DeBERTa-v2 for PyTorch<|||||>> @ydshieh
I plan to work only with PyTorch<|||||>> @Tegzes you're lucky because there's no LUKE in TF ;) the list above actually just duplicates all models, but many models aren't available yet in TF.
True - sorry I've been lazy at creating this list! <|||||>Happy to work on TrOCR (pytorch and TF)<|||||>I take RoBERTa in PT and TF<|||||>I would like to pick up XLM-RoBERTa in PT and TF.<|||||>I can work on `ELECTRA` for PT and TF<|||||>Hey guys,
We've just merged the first template for Roberta-like model doc tests: https://github.com/huggingface/transformers/pull/16363 :-)
Lots of models like `ELETRA`, `XLM-RoBERTa`, `DeBERTa`, `BERT` are very similar in spirit, it would be great if you could try to rebase your PR to the change done in https://github.com/huggingface/transformers/pull/16363 . Usually all you need to do is to add the correct `{expected_outputs}`, `{expected_loss}` and `{checkpoint}` to the docstring of each model (ideally giving sensible results :-)) until it passes locally and then the file can be added to the tester :-) <|||||>Also if you have open PRs and need help, feel free to ping me or @ydshieh and link the PR here so that we can nicely gather everything :-)<|||||>One of the most difficult tasks here might be to actually find a well-working model. As a tip what you can do:
1. Find all models of your architecture as it's always stated in the modeling files here: https://github.com/huggingface/transformers/blob/77c5a805366af9f6e8b7a9d4006a3d97b6d139a2/src/transformers/models/roberta/modeling_roberta.py#L67 e.g. for ELECTRA: https://huggingface.co/models?filter=electra
2. Now click on the task (in left sidebar) your working on, e.g. say you work on `ForSequenceClassification` of a text model go under this task metric: https://huggingface.co/models?other=electra&pipeline_tag=text-classification&sort=downloads
3. Finally, click on the framework metric (in left sidebar) you're working with: e.g. for TF: https://huggingface.co/models?library=tf&other=electra&pipeline_tag=text-classification&sort=downloads . If you see too few or too many not well performing models in TF you might also want to think about converting a good PT model to TF under your Hub name and to use this one instead :-)<|||||>I'll take a shot with the PyTorch implementation of CTRL<|||||>Here the mirror of RoBERTa for Tensorflow: https://github.com/huggingface/transformers/pull/16370<|||||>Hi, contributors, thank you very much for participating this sprint ❤️.
Here is one tip that might reduce some issues:
Considering the following 2 facts:
- A previous file `file_utils.py` contains some code regarding documentation. It was recently refactorized to different files. It might be a good idea (necessary in some case) to update your working branch in your local clone.
- The file `transformers/utils/documentation_tests.txt` will be updated frequently by different contributors during this event.
Some testing issues could be resolved as:
```bash
git checkout main # or `master`, depends on your local clone
git fetch upstream
git pull upstream main # Hugging Face `transformers` renamed the default branch to `main` recently
git checkout your_working_branch_for_this_sprint
git rebase main # or `master`
```
Don't hesitate if you encounter any problem. Enjoy~<|||||>I take BART and IBERT for PT<|||||>I'd like to take a crack on Transformer-XL and ConvBert<|||||>Hi, contributors!
For the model(s) you work with for this sprint, if you could not find any checkpoint for a downstream task, say `XXXModelForTokenClassification` model, but there is a checkpoint for the base model, what you could do is:
```python
model = XXXModelForTokenClassification.from_pretrained(base_model_checkpoint_name)
model.save_pretrained(local_path)
```
Then you can upload this new saved checkpoint to Hugging Face Hub, and you can use this uploaded model for the docstring example.
The head part of the model will have randomly initialized weights, and the result is likely to be imperfect, but it is fine for this sprint :-)<|||||>> I'd like to take a crack on Transformer-XL and ConvBert
@simonzli, great :-). Do you plan to work with the PyTorch or TensorFlow version, or both?<|||||>> > I'd like to take a crack on Transformer-XL and ConvBert
>
>
>
> @simonzli, great :-). Do you plan to work with the PyTorch or TensorFlow version, or both?
I'll work on both PyTorch and TensorFlow😊<|||||>@patrickvonplaten: I chose XLM-RoBERTa and it's a sub-class of RoBERTa. The comments in the file for both PyTorch and TF suggests that the superclass should be referred for the appropriate documentation alongside usage examples (XLM-RoBERTa documentations shows RoBERTa examples). Should I still be adding examples for XLM-RoBERTa or should I pick some other model?
<|||||>@AbinayaM02 :
Could you show me which line you see `suggests that the superclass should be referred for the appropriate documentation` in the `XLM-RoBERTa` model file, please? Thank you :-)
<|||||>> @AbinayaM02 :
>
> Could you show me which line you see `suggests that the superclass should be referred for the appropriate documentation` in the `XLM-RoBERTa` model file, please? Thank you :-)
Hi @ydshieh: Here are the files https://github.com/huggingface/transformers/blob/main/src/transformers/models/xlm_roberta/modeling_xlm_roberta.py
https://github.com/huggingface/transformers/blob/main/src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py
Snippet for some classes:
```python
@add_start_docstrings(
"The bare XLM-RoBERTa Model transformer outputting raw hidden-states without any specific head on top.",
XLM_ROBERTA_START_DOCSTRING,
)
class XLMRobertaModel(RobertaModel):
"""
This class overrides [`RobertaModel`]. Please check the superclass for the appropriate documentation alongside
usage examples.
"""
config_class = XLMRobertaConfig
@add_start_docstrings(
"XLM-RoBERTa Model with a `language modeling` head on top for CLM fine-tuning.",
XLM_ROBERTA_START_DOCSTRING,
)
class XLMRobertaForCausalLM(RobertaForCausalLM):
"""
This class overrides [`RobertaForCausalLM`]. Please check the superclass for the appropriate documentation
alongside usage examples.
"""
config_class = XLMRobertaConfig
```
<|||||>@AbinayaM02
Thank you. You can leave `XLM-RoBERTa` as it is.
We should prepare the model list for this sprint in a better way, sorry for this inconvenience.
Would you like to look into another architecture? You can try to check the models whose names are in bold font first,
but other models are also welcomed (they **might** have fewer checkpoints available though).
<|||||>Sure @ydshieh. I'll pick up XLM for both PyTorch and TF then!<|||||>Hi again, contributors:
In a previous comment, I mentioned uploading a checkpoint with random head - if no checkpoint for a specific model + downstream task could be found on the Hub. After some internal discussion, we think there should be a better approach.
Actually, it would be a good idea to check some checkpoints in [hf-internal-testing](https://huggingface.co/hf-internal-testing). In this page, you don't need to check the task type, just check the model architecture.
If you could not find any checkpoint for the model you work with at that page, we encourage you to work with other models for which you could find checkpoints**.
I update the model list to use bold font to indicate those models that are likely to have checkpoints.
> Hi, contributors!
>
> For the model(s) you work with for this sprint, if you could not find any checkpoint for a downstream task, say `XXXModelForTokenClassification` model, but there is a checkpoint for the base model, what you could do is:
>
> ```python
> model = XXXModelForTokenClassification.from_pretrained(base_model_checkpoint_name)
> model.save_pretrained(local_path)
> ```
>
> Then you can upload this new saved checkpoint to Hugging Face Hub, and you can use this uploaded model for the docstring example.
>
> The head part of the model will have randomly initialized weights, and the result is likely to be imperfect, but it is fine for this sprint :-)
<|||||>@ydshieh It throws this error when I tried to load one of [hf-internal-testing](https://huggingface.co/hf-internal-testing).
```---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
[<ipython-input-239-5c839d6ee084>](https://localhost:8080/#) in <module>()
3 from transformers import AlbertTokenizer, BertTokenizer, BigBirdTokenizer, MobileBertTokenizer
4 checkpoint = "hf-internal-testing/tiny-random-big_bird"
----> 5 tokenizer = BigBirdTokenizer.from_pretrained(f"{checkpoint}")
6 model = BigBirdForSequenceClassification.from_pretrained(f"{checkpoint}" )
7 inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
4 frames
[/usr/local/lib/python3.7/dist-packages/sentencepiece/__init__.py](https://localhost:8080/#) in LoadFromFile(self, arg)
169
170 def LoadFromFile(self, arg):
--> 171 return _sentencepiece.SentencePieceProcessor_LoadFromFile(self, arg)
172
173 def DecodeIdsWithCheck(self, ids):
TypeError: not a string
```<|||||>Thank you. I think it is because we didn't upload the necessary tokenizer file.
I will talk to the team members. Thank you for spotting this!<|||||>I would like to take XLNet for PT and TF.<|||||>I'd like to work on DistilBERT for PT and TF with my coworker @jmwoloso <|||||>I just wanted to start on the doc tests for TF Swin, turns out it doesn't exist, only the PyTorch version. So I suppose that can be seen as done ;)<|||||>> I just wanted to start on the doc tests for TF Swin, turns out it doesn't exist, only the PyTorch version. So I suppose that can be seen as done ;)
Sure, thank you for the feedback :-). We should have better prepared the model list.
And thank you for the work on TFViT - I will keep you updated after some discussion with our team!<|||||>Hi, I'd like to work on Reformer PyTorch.<|||||>hey @ydshieh / @patrickvonplaten, should we avoid having `expected_outputs` & `expected_loss` for models that are randomly initialised?<|||||>> hey @ydshieh / @patrickvonplaten, should we avoid having `expected_outputs` & `expected_loss` for models that are randomly initialised?
Hi, @KMFODA
It's ok to add them, but as in a previous comment [here](https://github.com/huggingface/transformers/issues/16292#issuecomment-1078999353), we decide that we would like to **use the tiny random models in [hf-internal-testing](https://huggingface.co/hf-internal-testing)**, instead of creating big models with random weights in their heads.
Could you find a checkpoint in `hf-internal-testing` for the model your are working with?<|||||>I couldn't find my model no. I'm working with Longformer.<|||||>I'd like to try working on the Perceiver<|||||>> I couldn't find my model no. I'm working with Longformer.
@KMFODA I have put your GitHub user name after the model name in the model list (in this page).<|||||>> hey @ydshieh / @patrickvonplaten, should we avoid having `expected_outputs` & `expected_loss` for models that are randomly initialised?
No, please try to add them. We know this is not ideal, but as long as the checkpoint name contains `random`, it should be fine for now :)
But it would be really appreciated that if you could first try to check if there are existing checkpoint on the Hub for the model + the task. ❤️<|||||>@ydshieh
I got the same error with [hf-internal-testing](https://huggingface.co/hf-internal-testing/tiny-random-reformer) working on Reformer. And I couldn't find any checkpoints without randomly initialized.
https://github.com/huggingface/transformers/issues/16292#issuecomment-1079036359<|||||>> @ydshieh I got the same error with [hf-internal-testing](https://huggingface.co/hf-internal-testing/tiny-random-reformer) working on Reformer. And I couldn't find any checkpoints without randomly initialized. [#16292 (comment)](https://github.com/huggingface/transformers/issues/16292#issuecomment-1079036359)
Hi, @hiromu166
Looks like we didn't upload a tokenizer for `hf-internal-testing/tiny-random-reformer`. These tiny models are created for some internal testing purpose, and we didn't have the intention to use it for doctest until now.
I will upload a tokenizer today! Thank you very much for pointing out this.<|||||>@hiromu166
I uploaded the tokenizer file **spiece.model** to [hf-internal-testing/tiny-random-reformer](https://huggingface.co/hf-internal-testing/tiny-random-reformer/tree/main).
Let me know if you have any problem using it in the doctest 🙏, thanks!
<|||||>@ydshieh
Thank you for dealing with it quickly!!
I'll check it soon.<|||||>Hi @ydshieh,
For TFElectra i am getting answer index [issue](https://colab.research.google.com/drive/1buzYMKgm3b8kfTcyVvnToJCFLqdnZDxM?usp=sharing)
`doc.py` file `TF_QUESTION_ANSWERING_SAMPLE` has target index at `14` and `15`, while i am getting my prediction at `10`, `12` index<|||||>@ydshieh quick question. @jessecambon and I are working on the DistilBert model but we're seeing many of the examples are actually drawn and built from the examples in `src/transformers/utils/doc.py` which seems to be a global location, meaning it seems multiple models get their doc tests from this single file. So my question is whether someone else has edited those already or if we're free to edit them as part of our work, which will then flow out to other model architectures.<|||||>Hi @bhadreshpsavani , Yes there is an issue regarding the target indices. Please follow this discussion
https://github.com/huggingface/transformers/pull/16523#issuecomment-1088635272
https://github.com/huggingface/transformers/pull/16523#issuecomment-1090346578
I will discuss the team.
> Hi @ydshieh,
>
> For TFElectra i am getting answer index [issue](https://colab.research.google.com/drive/1buzYMKgm3b8kfTcyVvnToJCFLqdnZDxM?usp=sharing)
>
> `doc.py` file `TF_QUESTION_ANSWERING_SAMPLE` has target index at `14` and `15`, while i am getting my prediction at `10`, `12` index
<|||||>Hi, @jmwoloso & @jessecambon
`doc.py` is not meant to be modified by the sprint contributor :-)
In order to customize, you can use `add_code_sample_docstrings`, and provide it with `expected_output=...`, `expected_loss=...`, `checkpoint=...`, etc.
You can looks [this change on Roberta](https://github.com/huggingface/transformers/pull/16363/files#diff-5707805d290617078f996faf1138de197fa813f78c0aa5ea497e73b5228f1103) as a reference.
Let me know if you have any difficulty using this approach.
> @ydshieh quick question. @jessecambon and I are working on the DistilBert model but we're seeing many of the examples are actually drawn and built from the examples in `src/transformers/utils/doc.py` which seems to be a global location, meaning it seems multiple models get their doc tests from this single file. So my question is whether someone else has edited those already or if we're free to edit them as part of our work, which will then flow out to other model architectures.
<|||||>> Hi @bhadreshpsavani , Yes there is an issue regarding the target indices. Please follow this discussion
>
> [#16523 (comment)](https://github.com/huggingface/transformers/pull/16523#issuecomment-1088635272) [#16523 (comment)](https://github.com/huggingface/transformers/pull/16523#issuecomment-1090346578)
>
> I will discuss the team.
>
> > Hi @ydshieh,
> > For TFElectra i am getting answer index [issue](https://colab.research.google.com/drive/1buzYMKgm3b8kfTcyVvnToJCFLqdnZDxM?usp=sharing)
> > `doc.py` file `TF_QUESTION_ANSWERING_SAMPLE` has target index at `14` and `15`, while i am getting my prediction at `10`, `12` index
By the way, you don't have this issue for `Electra` (PyTorch version)? Do you use different checkpoint for PyTorch/TensorFlow Electra?<|||||>> > Hi @bhadreshpsavani , Yes there is an issue regarding the target indices. Please follow this discussion
> > [#16523 (comment)](https://github.com/huggingface/transformers/pull/16523#issuecomment-1088635272) [#16523 (comment)](https://github.com/huggingface/transformers/pull/16523#issuecomment-1090346578)
> > I will discuss the team.
> > > Hi @ydshieh,
> > > For TFElectra i am getting answer index [issue](https://colab.research.google.com/drive/1buzYMKgm3b8kfTcyVvnToJCFLqdnZDxM?usp=sharing)
> > > `doc.py` file `TF_QUESTION_ANSWERING_SAMPLE` has target index at `14` and `15`, while i am getting my prediction at `10`, `12` index
>
> By the way, you don't have this issue for `Electra` (PyTorch version)? Do you use different checkpoint for PyTorch/TensorFlow Electra?
Hi @ydshieh,
Actually, I am using the same checkpoint.<|||||>> Hi @ydshieh, Actually, I am using the same checkpoint. In python, we use `where` to find index but here its hardcoded i guess
What I saw in `PT_QUESTION_ANSWERING_SAMPLE`
```
```python
>>> # target is "nice puppet"
>>> target_start_index, target_end_index = torch.tensor([14]), torch.tensor([15])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = outputs.loss
>>> round(loss.item(), 2)
{expected_loss}
```
So if you use the same checkpoint for PT/TF Electra, the PyTorch should have the same issue I think.
Could you try run the doc test (for PT Electra) and see if it pass?
Also, let's move this discussion to your PR.<|||||>@ydshieh ok, thank you for the clarification. so is the goal then to move away from doc.py and have individual doc tests in the specific model architecture files?<|||||>Hi, @jmwoloso not exactly. We still use `doc.py`, but in the individual model file(s), we tried to use a method `add_code_sample_docstrings` and provide some arguments.
The method `add_code_sample_docstrings` itself will use the example in `doc.py` and customize the doc examples using the arguments you provide.<|||||>ok, awesome. thanks @ydshieh!<|||||>Hi,
Is anyone working on BART TF version? If not I can try and contribute WRT that model.
Else can you suggest some model from above list(with slightly lower complexity as this will be my first attempt at contribution to transformers library :) ) which can be taken up?
Thanks <|||||>Not sure if someone is working on TF Bart. You can search the Pull request list.
Otherwise, TF Wav2Vec2 should be a good one to try. Should be quite easy with the recent change in
https://github.com/huggingface/transformers/pull/16494#issue-1186617056<|||||>Since no one seems to have taken layoutlmv2 and the last activity on this thread was 25 days ago, I’m going to start working on layoutlmv2 :)
Edit: The PR is ready for review now<|||||>@patrickvonplaten I would like to start with `RoFormer` for TF and PT.<|||||>@nandwalritik - that's great! Do you want to open a PR for this?<|||||>Hi @patrickvonplaten , I am interested in working on data2VecText. Thanks!<|||||>Hi @patrickvonplaten, I would like to work on DETR for TF and PT.<|||||>That's awesome! Noted! Also cc @ydshieh <|||||>Great, @ti-ginkgo, looking forward to review your PR!<|||||>@patrickvonplaten I would love to work on SqueezeBert for TF and PT<|||||>I would like to try to work on DETR (I did a PR already...sorry about that !)<|||||>@ydshieh please reassign DETR task to @qherreros
I will take another one<|||||>I'll work on `perceiver`.<|||||>hello, I would love to contribute to encoder for PT and TF
Thankyou @sgugger <|||||>I'd like to try Reformer for PyTorch and Tensorflow ☕ <|||||>I would to try for Data2VecText @patrickvonplaten <|||||>@SauravMaheshkar It looks PyTorch Reformer is already done, see [here](https://github.com/huggingface/transformers/blob/10100979ed0594d4cfe1982cdfac9642a68e473e/utils/documentation_tests.txt#L68)
Or do you mean `docs/source/en/model_doc/reformer.mdx`?<|||||>@patrickvonplaten I would like to work on Marian for TensorFlow please. Thank You<|||||>I would like to work on OpenAI for Pytorch and Tensorflow @ydshieh <|||||>@ydshieh I am working on clip model
|
transformers | 16,291 | closed | Fix a typo (add a coma) | As mentioned: https://github.com/huggingface/transformers/issues/16277
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #16277
Fixed a typo that missed a coma.
@gante As you said, I opened a pull request, and I hope I've made it in a correct way.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-21-2022 11:47:16 | 03-21-2022 11:47:16 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Awesome, thanks @PolarisRisingWar! 🚀 |
transformers | 16,290 | closed | Fix XGLM cross attention | # What does this PR do?
Fix a typo in `XGLMDecoderLayer`
Fixes: #16286 | 03-21-2022 11:41:38 | 03-21-2022 11:41:38 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,289 | closed | Changing the default branch from `master` to `main`. | Over the next 24 hours, we'll change the default branch from `master` to `main`.
We'll leverage GitHub's renaming utility which should take care of the entire migration and handle redirection when the previous branch name was erroneously entered.
This will not update local environments, where running the following commands the first time will be necessary (will be mentioned on GitHub directly):
```bash
git branch -m master main
git fetch origin
git branch -u origin/main main
git remote set-head origin -a
```
Thanks for your understanding! | 03-21-2022 11:40:02 | 03-21-2022 11:40:02 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>closing as completed |
transformers | 16,288 | closed | apply_rotary_pos_emb gives different results between PT & Flax | ## Environment info
- `transformers` version: 4.18.0.dev0
- Platform: Linux-5.13.0-1019-gcp-x86_64-with-glibc2.31
- Python version: 3.9.7
- Huggingface_hub version: 0.4.0
- PyTorch version (GPU?): 1.10.2+cu102 (False)
- Tensorflow version (GPU?): 2.7.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.4.0 (cpu)
- Jax version: 0.3.1
- JaxLib version: 0.3.0
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
- Flax + GPT-J,: @patil-suraj
(I could try to help after finalizing some other PRs if you are busy)
## Description
The method `apply_rotary_pos_emb` in `modeling_gptj.py` and `modeling_flax_gptj.py` give different results while having the same inputs. See the next section.
While working on the #16280, this difference cause the more aggressive PT/Flax equivalence test failing with `1e-5`.
(This was not detected in #15841 because `FlaxGPTJModelTest` overwrite the equivalence test, which wasn't updated at that time.)
## To reproduce
```python
from transformers.models.gptj.modeling_gptj import apply_rotary_pos_emb as apply_rotary_pos_emb_pt
from transformers.models.gptj.modeling_flax_gptj import apply_rotary_pos_emb as apply_rotary_pos_emb_flax
import numpy as np
import torch
batch_size = 1
seq_len = 3
num_heads = 2
rotary_dim = 4
k_rot = np.ones(shape=(batch_size, seq_len, num_heads, rotary_dim), dtype=np.float32)
sin = np.array([[ 0. , 0. ],
[ 0.84147096, 0.00999983],
[ 0.9092974 , 0.01999867],
[ 0.14112 , 0.0299955 ],
[-0.7568025 , 0.03998933],
[-0.9589243 , 0.04997917],
[-0.2794155 , 0.059964 ]], dtype=np.float32)
cos = np.array([[ 1. , 1. ],
[ 0.54030234, 0.99995 ],
[-0.41614684, 0.9998 ],
[-0.9899925 , 0.99955004],
[-0.6536436 , 0.9992001 ],
[ 0.2836622 , 0.99875027],
[ 0.96017027, 0.99820054]], dtype=np.float32)
sin = sin[:seq_len]
cos = cos[:seq_len]
pt_output = apply_rotary_pos_emb_pt(torch.FloatTensor(k_rot), sincos=(torch.FloatTensor(sin), torch.FloatTensor(cos)))
flax_output = apply_rotary_pos_emb_flax(k_rot, sincos=(sin.reshape((batch_size, seq_len, 2)), cos.reshape((batch_size, seq_len, 2))))
pt_output = pt_output.numpy()
flax_output = np.array(flax_output)
max_diff = np.amax(np.abs(pt_output - flax_output))
print(max_diff)
```
gives
```
1.8185948
```
The expected outputs (`max_diff`) should be small, like < `1e-5`.
| 03-21-2022 11:29:16 | 03-21-2022 11:29:16 | Thanks for reporting this, looking into it. |
transformers | 16,287 | closed | creating transformer for tamil language | hi im trying to create a new transformer for tamil language
dataset is downloaded from oscar-corpus
from tokenizers import ByteLevelBPETokenizer
tokenizer = ByteLevelBPETokenizer()
tokenizer.train(files = path, vocab_size = 200000, min_frequency = 2, special_tokens=['<s>', '<pad>', '</s>', '<unk>', '<mask>'])
import os
os.mkdir('./tamberto')
tokenizer.save_model('tamberto')
after executing this code tokenizer creates the two files
`megres.txt` `vocab.json`
but the contents of the file are showing like junks
{"<s>":0,"<pad>":1,"</s>":2,"<unk>":3,"<mask>":4,"!":5,"\"":6,"#":7,"$":8,"%":9,"&":10,"'":11,"(":12,")":13,"*":14,"+":15,",":16,"-":17,".":18,"/":19,"0":20,"1":21,"2":22,"3":23,"4":24,"5":25,"6":26,"7":27,"8":28,"9":29,":":30,";":31,"<":32,"=":33,">":34,"?":35,"@":36,"A":37,"B":38,"C":39,"D":40,"E":41,"F":42,"G":43,"H":44,"I":45,"J":46,"K":47,"L":48,"M":49,"N":50,"O":51,"P":52,"Q":53,"R":54,"S":55,"T":56,"U":57,"V":58,"W":59,"X":60,"Y":61,"Z":62,"[":63,"\\":64,"]":65,"^":66,"_":67,"`":68,"a":69,"b":70,"c":71,"d":72,"e":73,"f":74,"g":75,"h":76,"i":77,"j":78,"k":79,"l":80,"m":81,"n":82,"o":83,"p":84,"q":85,"r":86,"s":87,"t":88,"u":89,"v":90,"w":91,"x":92,"y":93,"z":94,"{":95,"|":96,"}":97,"~":98,"¡":99,"¢":100,"£":101,"¤":102,"¥":103,"¦":104,"§":105,"¨":106,"©":107,"ª":108,"«":109,"¬":110,"®":111,"¯":112,"°":113,"±":114,"²":115,"³":116,"´":117,"µ":118,"¶":119,"·":120,"¸":121,"¹":122,"º":123,"»":124,"¼":125,"½":126,"¾":127,"¿":128,"À":129,"Á":130,"Â":131,"Ã":132,"Ä":133,"Å":134,"Æ":135,"Ç":136,"È":137,"É":138,"Ê":139,"Ë":140,"Ì":141,"Í":142,"Î":143,"Ï":144,"Ð":145,"Ñ":146,"Ò":147,"Ó":148,"Ô":149,"Õ":150,"Ö":151,"×":152,"Ø":153,"Ù":154,"Ú":155,"Û":156,"Ü":157,"Ý":158,"Þ":159,"ß":160,"à":161,"á":162,"â":163,"ã":164,"ä":165,"å":166,"æ":167,"ç":168,"è":169,"é":170,"ê":171,"ë":172,"ì":173,"í":174,"î":175,"ï":176,"ð":177,"ñ":178,"ò":179,"ó":180,"ô":181,"õ":182,"ö":183,"÷":184,"ø":185,"ù":186,"ú":187,"û":188,"ü":189,"ý":190,"þ":191,"ÿ":192,"Ā":193,"ā":194,"Ă":195,"ă":196,"Ą":197,"ą":198,"Ć":199,"ć":200,"Ĉ":201,"ĉ":202,"Ċ":203,"ċ":204,"Č":205,"č":206,"Ď":207,"ď":208,"Đ":209,"đ":210,"Ē":211,"ē":212,"Ĕ":213,"ĕ":214,"Ė":215,"ė":216,"Ę":217,"ę":218,"Ě":219,"ě":220,"Ĝ":221,"ĝ":222,"Ğ":223,"ğ":224,"Ġ":225,"ġ":226,"Ģ":227,"ģ":228,"Ĥ":229,"ĥ":230,"Ħ":231,"ħ":232,"Ĩ":233,"ĩ":234,"Ī":235,"ī":236,"Ĭ":237,"ĭ":238,"Į":239,"į":240,"İ":241,"ı":242,"IJ":243,"ij":244,"Ĵ":245,"ĵ":246,"Ķ":247,"ķ":248,"ĸ":249,"Ĺ":250,"ĺ":251,"Ļ":252,"ļ":253,"Ľ":254,"ľ":255,"Ŀ":256,"ŀ":257,"Ł":258,"ł":259,"Ń":260,"à®":261,"à¯":262,"à¯į":263,"Ġà®":264,"à¯ģ":265,"ி":266,"à®ķ":267,"த":268,"à®°":269,"ா":270,"à®Ł":271,"ன":272,"à®®":273,"ல":274,"ப":275,"à¯Ī":276,"ய":277,"ள":278,"à®±":279,"வ":280,"Ġப":281,"Ġà®ķ":282,"Ġவ":283,"à®ķள":284,"Ġà®®":285,"à®ļ":286,"Ġà®ħ":287,"à¯ĩ":288,"ந":289,"ண":290,"Ġத":291,"Ġà®ļ":292,"Ġà®ĩ":293,"à¯Ĩ":294,"Ġந":295,"à¯ĭ":296,"Ġà®İ":297,"à¯į.":298,"à¯Ĭ":299,"à®Ļ":300,"à®"
µà®°":307,"à¯į,":308,"Ġà®Ĩ":309,"à¯ģ.":310,"Ġà®ĩà®°":311,"Ġà®Ĵ":312,"Ġà®ħத":313,"ஸ":314,"பத":315,"âĢ":316,"வத":317,"à®Łà®¤":318,"Ġவர":319,"Ġà®Ĵà®°":320,"à®Łà®®":321,"றத":322,"Ġà®ĩந":323,"னர":324,"à®ķப":325,"à®ķà®®":326,"Ġà®ħவர":327,"Ġà®ĩத":328,"Ġà®°":329,"தத":330,"Ġà®ķà®Ł":331,"தல":332,"ÂŃ":333,"à®°à®®":334,"à®ķத":335,"à®ķவ":336,"..":337,"Ġà®ı":338,"à®Łà®©":339,"à¯ģ,":340,"வன":341,"Ġà®¨à®Ł":342,"Ġà®ħà®°":343,"யத":344,"à®ľ":345,"à®ķà®°":346,"யல":347,"ளத":348,"யம":349,"Ġà®ħà®®":350,"தம":351,"à®·":352,"Ġà®ªà®Ł":353,"Ġமற":354,"à®Łà®°":355,"Ġà®īள":356,"யர":357,"Ġà®ĩல":358,"னத":359,"Ġ1":360,"ĠâĢ":361,"Ġà®ħன":362,"Ġà®ħà®Ł":363,"Ġதம":364,"Ġà®Ł":365,"தன":366,"à®ŀ":367,"Ġபல":368,"ளர":369,"Ġà®ĩன":370,"ரத":371,"Ġà®ľ":372,"Ġ2":373,"à¯Ī.":374,"Ġà®ħà®±":375,"Ġà®ķண":376,"Ġவà®
How to change this encoding property??
| 03-21-2022 11:19:50 | 03-21-2022 11:19:50 | cc @SaulLu <|||||>Hi @AswiN-7,
Could you tell me more about what you mean when you say "How to change this encoding property??". :blush:
I would like to comment on your impression that the tokens produced by BPE are showing like junks. This type of output is indeed surprising but well expected by a byte-level BPE tokenizer!
I'll link you to an [old comment](https://github.com/huggingface/tokenizers/issues/203#issuecomment-605105611) that details why the vocabulary tokens look like this. Don't hesitate if you need more info!<|||||>what i think about this problem is
maybe the model saves the text as ascii ensure =true this will make clash with utf-8 encoding where Tamil language format is utf-8 encoded
is there anyway to change this tokenizer.save_model function? <|||||>> maybe the model saves the text as ascii ensure =true this will make clash with utf-8 encoding where Tamil language format is utf-8 encoded
Why do you think there would be this problem? :slightly_smiling_face: <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,286 | closed | `self.encoder_attn` not defined for PyTorch XGLM | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.17.0
- Platform: Ubuntu
- Python version: 3.7
- PyTorch version (GPU?): 1.10.0+cu111
- Tensorflow version (GPU?): NA
- Using GPU in script?: Y
- Using distributed or parallel set-up in script?: N
### Who can help
@patil-suraj
## Information
Model I am using (Bert, XLNet ...): XGLM
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```python
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-564M")
model = EncoderDecoderModel.from_encoder_decoder_pretrained("facebook/xglm-564M", "facebook/xglm-564M")
model.config.decoder_start_token_id = tokenizer.cls_token_id
model.config.pad_token_id = tokenizer.pad_token_id
inputs = tokenizer("Test input", return_tensors="pt").input_ids
labels = tokenizer("Test label", return_tensors="pt").input_ids
with torch.no_grad():
outputs = model(input_ids=inputs, labels=labels)
print(outputs.loss)
```
You should get:
```python
AttributeError: 'XGLMDecoderLayer' object has no attribute 'encoder_attn'
```
This is because `self.encoder_attn` [here](https://github.com/huggingface/transformers/blob/master/src/transformers/models/xglm/modeling_xglm.py#L472) hasn't been defined. It looks like it should be an instance of `XGLMAttention` looking at the Flax version [here](https://github.com/huggingface/transformers/blob/master/src/transformers/models/xglm/modeling_flax_xglm.py#L330).
## Expected behavior
The example above should print out a loss number.
Thanks!
| 03-21-2022 10:23:22 | 03-21-2022 10:23:22 | Good catch! Should be fixed in https://github.com/huggingface/transformers/pull/16290 |
transformers | 16,285 | closed | [SegFormer] Remove unused attributes | # What does this PR do?
This PR removes the unused attributes `image_size` and `downsampling_rates` from the configuration. As they simply aren't used by the model, this is not a breaking change.
It also adds a link to the blog post in SegFormer's docs, and clarifies that the model works on any input size as it pads the input.
It also improves the overall readability of `modeling_segformer.py`. | 03-21-2022 08:49:17 | 03-21-2022 08:49:17 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,284 | closed | Add argument "cache_dir" for transformers.onnx | # What does this PR do?
Add argument "cache_dir" for transformer.onnx ,to enables the user to select the cache path when exporting large ONNX model. Because the default cache directory may run out of space.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-21-2022 08:33:22 | 03-21-2022 08:33:22 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Looking at the CI, it seems you need to format your files @happyXia - can you please run:
```
make style && make quality
```
and commit / push the formatted files?<|||||>> Looking at the CI, it seems you need to format your files @happyXia - can you please run:
>
> ```
> make style && make quality
> ```
>
> and commit / push the formatted files?
Sure, I have reformated and pushed the flawed files.
<|||||>I checked that the slow tests pass with
```
RUN_SLOW=1 python -m pytest -x tests/onnx/test_onnx_v2.py
```
so this all looks good to me - merging now. Thank you @happyXia 🚀 ! |
transformers | 16,283 | closed | Weights of lm_head and input embedding are not tied in google/mt5-base | ## Environment info
- `transformers` version: 4.16.2
- Python version: 3.7.11
- PyTorch version (GPU?): 1.10.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
### Who can help
@patrickvonplaten
## Information
I am tring to prune the embedding matrix of [google/mt5-base](https://huggingface.co/google/mt5-base), which can be tracked in [this thread](https://discuss.huggingface.co/t/pruning-a-model-embedding-matrix-for-memory-efficiency/5502/7?u=bookworm).
During the process, I find that the weights of lm_head and the input embedding are not tied.
So I wonder:
1. Is this the expected behaviour for mT5?
2. How can I prune the embedding matrix correctly if its weights are shared with lm_head?
## To reproduce
```python
import torch
from transformers import MT5ForConditionalGeneration
model = MT5ForConditionalGeneration.from_pretrained("google/mt5-base")
lm_weight = model.lm_head.weight # shape: torch.Size([250112, 768])
em_weight = model.get_input_embeddings().state_dict()["weight"] # shape: torch.Size([250112, 768])
# Expect: less than 1e-3
# Actual: 113.6006
print(torch.max(lm_weight - em_weight))
```
| 03-21-2022 03:41:16 | 03-21-2022 03:41:16 | Hey @z-bookworm,
Yes this should be correct. As MT5 is built upon T5v1.1: https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511 the input and output embeddings should not be tied as you can read upon in the link<|||||>@patrickvonplaten Thanks for the reference |
transformers | 16,282 | closed | ONNX export results for hidden states/attentions are incorrect if enabled | ONNX export results for hidden states/attentions are incorrect if enabled (e.g. via `config.output_attentions = True` and `config.output_hidden_states = True` before loading the model). This is likely due to the returning-tuples nature of the corresponding `forward` functions which ONNX may not be able to trace correctly; wrapping said functions and using `torch.stack` to handle said tuples is a workaround to the issue.
## Environment info
- `transformers` version: 4.18.0.dev0
- Platform: macOS-12.3-x86_64-i386-64bit
- Python version: 3.9.7
- Huggingface_hub version: 0.1.1
- PyTorch version (GPU?): 1.11.0 (False)
### Who can help
@lewtun
## Information
Taking from the [new export tutorial](https://huggingface.co/docs/transformers/serialization):
```python3
from transformers import AutoConfig
from typing import Mapping, OrderedDict
from transformers.onnx import OnnxConfig
import torch
from pathlib import Path
from transformers.onnx import export
from transformers import AutoTokenizer, AutoModel
model_ckpt = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(model_ckpt)
config.output_attentions = True
config.output_hidden_states = True
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
base_model = AutoModel.from_pretrained(model_ckpt, config=config)
pt_inputs = tokenizer(["Using DistilBERT with ONNX Runtime is so very cool!"]*2, return_tensors="pt")
pt_outputs = base_model(**pt_inputs)
# Expected results:
# torch.Size([2, 16, 768])
# torch.Size([2, 7, 16, 768])
# torch.Size([2, 6, 12, 16, 16])
print(pt_outputs['last_hidden_state'].shape)
for key in ["hidden_states", "attentions"]:
print(torch.transpose(torch.stack(list(pt_outputs[key])), 0, 1).shape) # transposing to set the batch dimension first
class DistilBertOnnxConfig(OnnxConfig):
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("input_ids", {0: "batch", 1: "sequence"}),
("attention_mask", {0: "batch", 1: "sequence"}),
]
)
@property
def outputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("last_hidden_state", {0: "batch", 1: "sequence_length"}),
("hidden_states", {0: "batch", 1: "sequence_length"}),
("attentions", {0: "batch", 1: "sequence_length"},),
]
)
onnx_path = Path("onnx/model.onnx")
onnx_config = DistilBertOnnxConfig(config)
onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
session = InferenceSession(str(onnx_path))
onnx_inputs = tokenizer(["Using DistilBERT with ONNX Runtime is so very cool!"]*2, return_tensors="np")
onnx_outputs = session.run(output_names=["last_hidden_state", "hidden_states", "attentions"], input_feed=dict(onnx_inputs))
# Incorrect results; using the same shape as the first `last_hidden_state`:
# (2, 16, 768)
# (2, 16, 768)
# (2, 16, 768)
for i in range(len(outputs)):
print(outputs[i].shape)
```
The ugly workaround:
```python3
from transformers import AutoConfig
from typing import Mapping, OrderedDict
from transformers.onnx import OnnxConfig
import torch
from pathlib import Path
from transformers.onnx import export
from transformers import AutoTokenizer, AutoModel
model_ckpt = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(model_ckpt)
config.output_attentions = True
config.output_hidden_states = True
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
base_model = AutoModel.from_pretrained(model_ckpt, config=config)
from transformers.modeling_utils import PreTrainedModel
class ExportModel(PreTrainedModel):
def __init__(self):
super().__init__(config)
self.model = base_model
def forward(self, input_ids=None,
attention_mask=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,):
out = self.model(input_ids, attention_mask)
return {
"last_hidden_state": out["last_hidden_state"],
"hidden_states": torch.transpose(torch.stack(list(out["hidden_states"])), 1, 0),
"attentions": torch.transpose(torch.stack(list(out["attentions"])), 1, 0)
}
def call(self, input_ids=None,
attention_mask=None,):
self.forward(input_ids,
attention_mask,)
class DistilBertOnnxConfig(OnnxConfig):
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("input_ids", {0: "batch", 1: "sequence"}),
("attention_mask", {0: "batch", 1: "sequence"}),
]
)
@property
def outputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("last_hidden_state", {0: "batch", 1: "sequence_length"}),
("hidden_states", {0: "batch", 2: "sequence_length"}),
("attentions",{0: "batch", 3: "sequence_length", 4: "sequence_length"},),
]
)
new_model = ExportModel()
onnx_path = Path("onnx/model.onnx")
onnx_config = DistilBertOnnxConfig(config)
onnx_inputs, onnx_outputs = export(tokenizer, new_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
session = InferenceSession(str(onnx_path))
onnx_inputs = tokenizer(["Using DistilBERT with ONNX Runtime is so very cool!"]*2, return_tensors="np")
onnx_outputs = session.run(output_names=["last_hidden_state", "hidden_states", "attentions"], input_feed=dict(onnx_inputs))
# correct results
# (2, 16, 768)
# (2, 7, 16, 768)
# (2, 6, 12, 16, 16)
for i in range(len(outputs)):
print(outputs[i].shape)
``` | 03-20-2022 20:13:00 | 03-20-2022 20:13:00 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Thanks for reporting this bug @minimaxir ! I'll need to have a closer look at what's going wrong in the tracing, but I think your hunch about tuples in the forward pass is the source of the problem.
cc @michaelbenayoun <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,281 | closed | Adding missing type hints for mBART model (TF) | Tensorflow Implementation model added with missing type hints
# What does this PR do?
Added type hints for mBART Tensorflow as described in https://github.com/huggingface/transformers/issues/16059
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@Rocketknight1 @gante
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
| 03-20-2022 17:03:27 | 03-20-2022 17:03:27 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16281). All of your documentation changes will be reflected on that endpoint. |
transformers | 16,280 | closed | Update pt flax equivalence tests in pt | # What does this PR do?
Update the PT/Flax equivalence in PT common test script.
This PR should be merged after #16298 and #16301 (then the test should be all green).
| 03-20-2022 13:49:26 | 03-20-2022 13:49:26 | _The documentation is not available anymore as the PR was closed or merged._<|||||>For `BigBird` model test failure, please see #16310.
<|||||>Good for me to merge then here as everybody else seems to agree with the PR.
I do like the argument that centralized tests enforce the same API which is very important to the library!
However, I don't think we do this currently in many tests, e.g. `test_attention_outputs` is far from enforcing the same API by statements like those: https://github.com/huggingface/transformers/blob/9badcecf694f174da929bcfe668ca57851960ad8/tests/test_modeling_common.py#L566 or https://github.com/huggingface/transformers/blob/9badcecf694f174da929bcfe668ca57851960ad8/tests/test_modeling_common.py#L459
The same tests can pass many different output attention shapes.
The same holds true for: `test_headmasking`, `test_hidden_states_output`, `test_retain_grad_hidden_states_attentions` and pretty much every test that has an `if is_encoder_decoder` statement (to a big part I'm responsible for this hacks actually, but don't think it's the right approach).
So, if we go down the road of centralized testing than we we should probably be to clean up those tests and create larger `Mixin` Testers for `EncoderDecoder`, `Encoder-only`, `Vision`, `Speech`, ...
Still worried about readability & making it more difficult to add a new model in this case and also want to note here that IMO we rarely change the core functionality of modeling code once it's been added - our philosophy goes against it. E.g. as discussed new features like rotational position embeddings should **not** be added to existing models. Therefore I think it's not that much of a problem that tests might diverge<|||||>Here some of my thoughts:
1. in this particular place, I was able to use `super` because the (logic) difference (check the class and to keep or skip testing) doesn't depend on the code in the actual testing code (the one in `super` here).
2. for other places, like [here](https://github.com/huggingface/transformers/blob/f5e8c9bdeab96c3426583cf1aa572ce7ede8a070/tests/gpt2/test_modeling_flax_gpt2.py#L233), without changing the design, I think we won't be able to call super (or not in an easy way)
3. I think most of the cases will be case 2., so this PR using `super` is just a special case. **We would very likely to continue the `# overwrite from common since ..` for most cases.**
4. The `copy from` won't be very helpful I think when a common test is changed. For example, in PR #16301, a more thorough Flax common test didn't detect issues in `FlaxXGLM` (and I had the wrong impression all PT/Flax equivalence tests passed).
Of course, this is probably the responsibility to keep this in mind that some tests are overwritten.
5. (for model, because there is no `common model`, so we are able to use `copy from ...`)
6. Regarding readability, (personally) I sometimes found it is not easy to understand what are the difference in the testing code between the common one and the model specific one. (Although I didn't find cases where this causes real problems in the library)
<|||||>Thank you for all the discussion, I will merge this PR as it is (after rebase and make sure tests green).
It is nice we have this chance to discuss the design 🔥.
Think a further discussion is needed if we want to make some (big) change(s) mentioned in @patrickvonplaten comment.
<|||||>> So, if we go down the road of centralized testing than we we should probably be to clean up those tests and create larger Mixin Testers for EncoderDecoder, Encoder-only, Vision, Speech, ...
This is the way to make tests more readable while making sure the reviewers have it easy when looking at new model additions, so definitely the right solution IMO! Note that the large mixin tests should be able to inherit most tests from the core mixin, but they would just overwrite the ones where we currently have an `if is_encoder_decoder` (or things like that). |
transformers | 16,279 | closed | Add Flaubert OnnxConfig to Transformers | # What does this PR do?
Add Flaubert OnnxConfig to make this model available for conversion.
## Who can review?
Models:
- albert, bert, xlm: @LysandreJik | 03-20-2022 10:13:25 | 03-20-2022 10:13:25 | > Thanks a lot for adding support for this model @ChainYo!
>
> It looks like the CI tests are failing because `FlaubertOnnxConfig` cannot be imported. This is a bit weird because the implementation looks OK, but can you check that the slow tests pass locally with:
>
> ```
> RUN_SLOW=1 python -m pytest -x tests/onnx/test_onnx_v2.py -k "flaubert"
> ```
It seems that it's exactly the same problem locally
```bash
(transformers) chainyo@workstation:~/code/transformers$ pytest -x tests/onnx/test_onnx_v2.py -k "flaubert"
======================================= test session starts =======================================
platform linux -- Python 3.8.12, pytest-7.1.1, pluggy-1.0.0
rootdir: /home/chainyo/code/transformers, configfile: setup.cfg
plugins: timeout-2.1.0, xdist-2.5.0, dash-2.3.0, hypothesis-6.39.4, forked-1.4.0
collected 0 items / 1 error
============================================= ERRORS ==============================================
___________________________ ERROR collecting tests/onnx/test_onnx_v2.py ___________________________
ImportError while importing test module '/home/chainyo/code/transformers/tests/onnx/test_onnx_v2.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
../../miniconda3/envs/transformers/lib/python3.8/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
tests/onnx/test_onnx_v2.py:21: in <module>
from transformers.onnx.features import FeaturesManager
src/transformers/onnx/features.py:11: in <module>
from ..models.flaubert import FlaubertOnnxConfig
E ImportError: cannot import name 'FlaubertOnnxConfig' from 'transformers.models.flaubert' (/home/chainyo/code/transformers/src/transformers/models/flaubert/__init__.py)
----------------------------------------- Captured stderr -----------------------------------------
2022-03-21 19:30:32.268001: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2022-03-21 19:30:32.268048: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
======================================== warnings summary =========================================
../../miniconda3/envs/transformers/lib/python3.8/site-packages/flatbuffers/compat.py:19
/home/chainyo/miniconda3/envs/transformers/lib/python3.8/site-packages/flatbuffers/compat.py:19: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
===================================== short test summary info =====================================
ERROR tests/onnx/test_onnx_v2.py
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! stopping after 1 failures !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Interrupted: 1 error during collection !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
=================================== 1 warning, 1 error in 0.29s ===================================
```
<|||||>Ok I got it, it was a problem of indentation... :+1: <|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,278 | closed | Connection error, when I run a service in a docker image, which is offline | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- ALBERT, BERT, XLM, DeBERTa, DeBERTa-v2, ELECTRA, MobileBert, SqueezeBert: @LysandreJik
- T5, Pegasus, EncoderDecoder: @patrickvonplaten
- Blenderbot, MBART, BART, Marian, Pegasus: @patil-suraj
- Longformer, Reformer, TransfoXL, XLNet, FNet, BigBird: @patrickvonplaten
- FSMT: @stas00
- Funnel: @sgugger
- GPT-2, GPT: @patil-suraj, @patrickvonplaten, @LysandreJik
- RAG, DPR: @patrickvonplaten, @lhoestq
- TensorFlow: @Rocketknight1
- JAX/Flax: @patil-suraj
- TAPAS, LayoutLM, LayoutLMv2, LUKE, ViT, BEiT, DEiT, DETR, CANINE: @NielsRogge
- GPT-Neo, GPT-J, CLIP: @patil-suraj
- Wav2Vec2, HuBERT, SpeechEncoderDecoder, UniSpeech, UniSpeechSAT, SEW, SEW-D, Speech2Text: @patrickvonplaten, @anton-l
If the model isn't in the list, ping @LysandreJik who will redirect you to the correct contributor.
Library:
- Benchmarks: @patrickvonplaten
- Deepspeed: @stas00
- Ray/raytune: @richardliaw, @amogkam
- Text generation: @patrickvonplaten @narsil
- Tokenizers: @SaulLu
- Trainer: @sgugger
- Pipelines: @Narsil
- Speech: @patrickvonplaten, @anton-l
- Vision: @NielsRogge, @sgugger
Documentation: @sgugger
Model hub:
- for issues with a model, report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
For research projetcs, please ping the contributor directly. For example, on the following projects:
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| 03-20-2022 09:18:31 | 03-20-2022 09:18:31 | |
transformers | 16,277 | closed | Typo: Missing a coma in document | In `https://huggingface.co/docs/transformers/master/en/task_summary#extractive-question-answering`, this sentence:

Should it be `model-specific separators, token type ids and attention masks`? | 03-20-2022 08:10:34 | 03-20-2022 08:10:34 | Thank you for flagging this typo 👍 Would you like to open a PR with the fix, @PolarisRisingWar? (source file [here](https://github.com/huggingface/transformers/blob/master/docs/source/task_summary.mdx))
If not, I can take care of it :) |
transformers | 16,276 | closed | Freezing layers does not work with torch.utils.checkpoint | Hi,
I am using BERT with `pytorch_transformers V1.1.0`. In this version, gradients checkpointing was not implemented, so I do it by myself simply by replacing `layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])` with `layer_outputs = checkpoint(layer_module, hidden_states, attention_mask, head_mask[i])`. This works fine when I try to fine-tune the entire BERT model. However, when I tried to freeze several layers of BERT with the code below:
```python
if layers_to_freeze is not None:
modules = [self.transformer_model.embeddings,
*self.transformer_model.encoder.layer[:layers_to_freeze]]
for module in modules:
for param in module.parameters():
param.requires_grad = False
```
The training procedures behave the same no matter what `layers_to_freeze` I set (i.e., the trace of loss is exactly the same for different `layers_to_freeze`), while after I disable gradient checkpointing, it works as expected. I think this suggest that using `torch.utils.checkpoint` might interfere with `param.requires_grad = False` for freezing layers.
I notice that in your official implementation for gradient checkpointing, you [define ` create_custom_forward` first](https://github.com/huggingface/transformers/blob/f466936476ed10410b07999fa7dd65b1dd0a961a/src/transformers/models/bert/modeling_bert.py#L570-L574) instead of directly call `layer_module`. I haven't tested whether doing this would avoid the issue I mentioned so far. Before I test it, I am curious about out of what concern you are implementing it in this way? Will directly calling `layer_module` lead to any serious issue? | 03-20-2022 04:54:22 | 03-20-2022 04:54:22 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,275 | closed | Adding type hints & decorator for TFT5 | @Rocketknight1 | 03-20-2022 00:47:47 | 03-20-2022 00:47:47 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16275). All of your documentation changes will be reflected on that endpoint.<|||||>Hi @Dahlbomii, thanks for this PR! It looks good, and thanks for doing both the type hinting and decorator change in the same PR. There's one failing TF test that's worrying us, but I've reviewed the whole PR and I can't see what would cause that, so I suspect it might be a problem with the test. We're investigating!<|||||>@Rocketknight1 the failing test is in a function associated to the decorator -- I can take a look 🔍 <|||||>HF was down when the tests were executed (HTTP errors all around) - rerunning tests :)<|||||>@Dahlbomii we have renamed our key branch from `master` to `main`. Fetching new commits in your fork, running these instructions (https://github.com/huggingface/transformers/issues/16289), then rebasing this branch should fix the tests.
Apologies for the extra work 🙏 <|||||>It's probably easier if I just make a new PR in a new fork, one sec! |
transformers | 16,274 | closed | add GPT-J ONNX config to Transformers | # What does this PR do?
I'm looking for contributing to `Transformers` repository by adding more OnnxConfig to available models on the hub.
I have created a little organization [ONNXConfig for all](https://huggingface.co/OWG) to track the models that needs support for ONNX.
This is the first contribution since CamemBERT OnnxConfig some months ago.
I took example on `GPT2` and `GPT-Neo` OnnxConfig but I'm not sure if everything is good or if `GPT-J` needs special things to be added.
So this PR is a work in progress. If anyone can send me ressources to read to understand if it lacks anything, it would be awesome! :hugs:
## Who can review?
Models GPT2 / GPT-Neo
@LysandreJik @michaelbenayoun
| 03-19-2022 20:12:13 | 03-19-2022 20:12:13 | _The documentation is not available anymore as the PR was closed or merged._<|||||>So what is the next step to make it merged ?<|||||>Hey @ChainYo the last thing to check is that the slow tests pass with:
```
RUN_SLOW=1 python -m pytest tests/onnx/test_onnx_v2.py -k "gpt-j"
```
We only run these on the `main` branch, so it would be good to know that they pass before we merge.
Apart from that, the PR looks really good - gently pinging @sgugger or @LysandreJik for final approval |
transformers | 16,273 | closed | added type hints for Blenderbot and BlenderbotSmall (TF & PyTorch) | # What does this PR do?
Added type hints for Blenderbot and BlenderbotSmall Tensorflow & PyTorch as described in https://github.com/huggingface/transformers/issues/16059
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@Rocketknight1 @gante
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-19-2022 19:24:28 | 03-19-2022 19:24:28 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16273). All of your documentation changes will be reflected on that endpoint.<|||||>Hi @IvanLauLinTiong, we actually just merged a BART PR that covers the same changes! It's probably easiest if you take a look at the most recent changes and see if a separate BlenderBot PR is needed - if so, you can make a new PR on a new branch that just changes BlenderBot and copy your changes over.
It's unfortunate, though - this looks like a really solid PR, but I just got two PRs covering BART at the same time!<|||||>Hi @Rocketknight1 , haha ok noted. I will try take a look at the recent changes and see what I can do here at BlenderBot model. |
transformers | 16,272 | closed | Add type hints for ProphetNet PyTorch | Adding type hints for forward methods in user-facing class for ProphetNet model (PyTorch) as mentioned in #16059
@Rocketknight1 | 03-19-2022 16:46:39 | 03-19-2022 16:46:39 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@Rocketknight1 |
transformers | 16,271 | closed | Fix missing output_attentions in PT/Flax equivalence test | # What does this PR do?
In a previous PR #15841, `output_attentions` was not set (I accidentally removed the whole block containing it).
This PR sets `output_attentions` to make the test more thorough.
The test still runs successfully with `1e-5` on both CPU/GPU. However, see the 2nd points in the remarks below.
It also adds `has_attentions` attribute to `FlaxModelTesterMixin` (as done in PyTorch's `ModelTesterMixin`).
# Remarks:
- In a follow up PR, we might use `has_attentions` in some existing methods (to make sure the attentions are only tested if `has_attentions` is `True`), see #15909
- There are 4 Flax model testers overwrite the Flax common `test_equivalence_pt_to_flax` and `test_equivalence_flax_to_pt`.
- I will update them in a next PR.
- These include `FlaxGPTJ` and `FlaxXGLM`, which will fail with `1e-5`. I need to debug them. | 03-19-2022 14:50:14 | 03-19-2022 14:50:14 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16271). All of your documentation changes will be reflected on that endpoint.<|||||>Think this (quite small) PR is ready. Nothing particular but adding the missing `config.output_attentions = self.has_attentions`.
The `super()` thing was discussed in #16280.
Will merge it today. |
transformers | 16,270 | closed | added type hints for BART model | # What does this PR do?
I have added type hints for BART model (both in PyTorch and Tensorflow) as described in #16059
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
@Rocketknight1
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-19-2022 12:59:22 | 03-19-2022 12:59:22 | @Rocketknight1 here is the PR which i've created since i am on Windows so i didnt run ``make fixup`` command<|||||>Hi @robotjellyzone, thanks for the PR! I see a lot of tests failing but I think that's our fault, not yours. Let me try running `make fixup` and then rerun them, and hopefully it all passes<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>@robotjellyzone Tests pass now! Will merge and then update the other PRs depending on these copied models. |
transformers | 16,269 | closed | TypeError loading tokenizer for gpssohi/distilbart-qgen-6-6 | Attempting to create a summary pipeline using "gpssohi/distilbart-qgen-6-6" as I get the message:
```
OSError: Can't load config for 'gpssohi/distilbart-qgen-6-6'. Make sure that:
- 'gpssohi/distilbart-qgen-6-6' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'gpssohi/distilbart-qgen-6-6' is the correct path to a directory containing a config.json file
```
This despite the instructions on the model card:
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("gpssohi/distilbart-qgen-6-6")
model = AutoModelForSeq2SeqLM.from_pretrained("gpssohi/distilbart-qgen-6-6")
```
So I downloaded the model files locally and ran:
```
from transformers import BartTokenizer
tokenizer = BartTokenizer.from_pretrained("/pub/models/gpssohi/distilbart-qgen-6-6")
```
which produces the error:
```
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3343, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-4-9811fff8faaa>", line 2, in <module>
tokenizer = BartTokenizer.from_pretrained("/pub/models/gpssohi/distilbart-qgen-6-6")
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1428, in from_pretrained
return cls._from_pretrained(*inputs, **kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1575, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_roberta.py", line 174, in __init__
**kwargs,
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_gpt2.py", line 169, in __init__
super().__init__(bos_token=bos_token, eos_token=eos_token, unk_token=unk_token, **kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils.py", line 116, in __init__
super().__init__(**kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1314, in __init__
super().__init__(**kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 658, in __init__
"special token {} has to be either str or AddedToken but got: {}".format(key, type(value))
TypeError: special token bos_token has to be either str or AddedToken but got: <class 'dict'>
```
I did some spelunking through the code and found that bos_token (and its siblings) are loaded via file tokenizer_config.json, which contains:
`{"unk_token": {"content": "<unk>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "bos_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "eos_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "add_prefix_space": false, "errors": "replace", "sep_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "cls_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "pad_token": {"content": "<pad>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "mask_token": {"content": "<mask>", "single_word": false, "lstrip": true, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "model_max_length": 1024, "special_tokens_map_file": null, "name_or_path": "sshleifer/distilbart-cnn-6-6", "tokenizer_class": "BartTokenizer"}`
This is loaded via json.load, resulting in the value of each token being (yup!), a dictionary! Now the value of the __type key for each token makes it seem like these are serialized AddedToken values, which, if properly reconstituted, would let this run without error.
FYI, from site-packages/torch/version.py:
```
version = ‘1.8.1+cu102’
debug = False
cuda = ‘10.2’
git_version = ‘56b43f4fec1f76953f15a627694d4bba34588969’
hip = None
``` | 03-19-2022 11:03:16 | 03-19-2022 11:03:16 | Hello! Was this a temporary error? Running your code sample seems to work for me:
```
In [1]: from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
...:
...: tokenizer = AutoTokenizer.from_pretrained("gpssohi/distilbart-qgen-6-6")
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████| 1.10k/1.10k [00:00<00:00, 471kB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████| 780k/780k [00:00<00:00, 1.53MB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████| 446k/446k [00:00<00:00, 1.03MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████| 1.29M/1.29M [00:00<00:00, 2.28MB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████| 772/772 [00:00<00:00, 209kB/s]
In [2]: model = AutoModelForSeq2SeqLM.from_pretrained("gpssohi/distilbart-qgen-6-6")
...:
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████| 1.83k/1.83k [00:00<00:00, 1.41MB/s]
Downloading: 35%|█████████████████████████████▊ | 311M/877M [00:25<04:32, 2.18MB/s]
```<|||||>Thank you for responding! I greatly appreciate it.
I'm afraid to say this is a permanent error (for me anyway). :(
Perhaps this is a version issue?
From pip list:
```
torch 1.8.1
transformers 3.3.1
```
Also:
```
transformers-cli env
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 3.3.1
- Platform: Linux-3.10.0-1160.59.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
- Python version: 3.6.8
- PyTorch version (GPU?): 1.8.1+cu102 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
```
When I run in this environment (in the Python Console in PyCharm):
```
/usr/bin/python3.6 /pub/apps/pycharm-community-2020.3.4/plugins/python-ce/helpers/pydev/pydevconsole.py --mode=client --port=36152
import sys; print('Python %s on %s' % (sys.version, sys.platform))
sys.path.extend(['/pub/dev/ner-extract'])
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help.
PyDev console: using IPython 7.16.1
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("gpssohi/distilbart-qgen-6-6")
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/transformers/configuration_utils.py", line 359, in get_config_dict
raise EnvironmentError
OSError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3343, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-2-511f5761aa2d>", line 2, in <module>
tokenizer = AutoTokenizer.from_pretrained("gpssohi/distilbart-qgen-6-6")
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_auto.py", line 216, in from_pretrained
config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/configuration_auto.py", line 310, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/configuration_utils.py", line 368, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'gpssohi/distilbart-qgen-6-6'. Make sure that:
- 'gpssohi/distilbart-qgen-6-6' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'gpssohi/distilbart-qgen-6-6' is the correct path to a directory containing a config.json file
model = AutoModelForSeq2SeqLM.from_pretrained("gpssohi/distilbart-qgen-6-6")
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/transformers/configuration_utils.py", line 359, in get_config_dict
raise EnvironmentError
OSError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3343, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-3-3fbaa62107f0>", line 1, in <module>
model = AutoModelForSeq2SeqLM.from_pretrained("gpssohi/distilbart-qgen-6-6")
File "/usr/local/lib/python3.6/site-packages/transformers/modeling_auto.py", line 1074, in from_pretrained
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/usr/local/lib/python3.6/site-packages/transformers/configuration_auto.py", line 310, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/configuration_utils.py", line 368, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for 'gpssohi/distilbart-qgen-6-6'. Make sure that:
- 'gpssohi/distilbart-qgen-6-6' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'gpssohi/distilbart-qgen-6-6' is the correct path to a directory containing a config.json file
```
So, I downloaded all torch related files from https://huggingface.co/gpssohi/distilbart-qgen-6-6/tree/main to local directory /pub/models/gpssohi/distilbart-qgen-6-6 and ran:
```
/usr/bin/python3.6 /pub/apps/pycharm-community-2020.3.4/plugins/python-ce/helpers/pydev/pydevconsole.py --mode=client --port=38897
import sys; print('Python %s on %s' % (sys.version, sys.platform))
sys.path.extend(['/pub/dev/ner-extract'])
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help.
PyDev console: using IPython 7.16.1
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
from transformers import AutoConfig, BartTokenizer
config = AutoConfig.from_pretrained("/pub/models/gpssohi/distilbart-qgen-6-6")
tokenizer = BartTokenizer.from_pretrained("/pub/models/gpssohi/distilbart-qgen-6-6")
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3343, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-2-55dbdfaca761>", line 5, in <module>
tokenizer = BartTokenizer.from_pretrained("/pub/models/gpssohi/distilbart-qgen-6-6")
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1428, in from_pretrained
return cls._from_pretrained(*inputs, **kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1575, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_roberta.py", line 174, in __init__
**kwargs,
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_gpt2.py", line 169, in __init__
super().__init__(bos_token=bos_token, eos_token=eos_token, unk_token=unk_token, **kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils.py", line 116, in __init__
super().__init__(**kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1314, in __init__
super().__init__(**kwargs)
File "/usr/local/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 658, in __init__
"special token {} has to be either str or AddedToken but got: {}".format(key, type(value))
TypeError: special token bos_token has to be either str or AddedToken but got: <class 'dict'>
```
As I said earlier, it seems unable to load the list of AddedToken from the content of the tokenizer_config.json.<|||||>So this *does* appear to be a version issue. I had to upgrade transformers to 4.1.0 (4.0.0 did not work), which also required upgrading sentence-transformers and it upgraded tokenizers to 0.9.4. |
transformers | 16,268 | closed | RuntimeError opening google/pegasus-xsum | I get the error:
```
Traceback (most recent call last):
File “/usr/local/lib/python3.6/site-packages/IPython/core/interactiveshell.py”, line 3343, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File “”, line 3, in
model=“google/pegasus-large”)
File “/usr/local/lib/python3.6/site-packages/transformers/pipelines.py”, line 2742, in pipeline
model = model_class.from_pretrained(model, config=config, **model_kwargs)
File “/usr/local/lib/python3.6/site-packages/transformers/modeling_auto.py”, line 1079, in from_pretrained
pretrained_model_name_or_path, *model_args, config=config, **kwargs
File “/usr/local/lib/python3.6/site-packages/transformers/modeling_utils.py”, line 923, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
File “/usr/local/lib/python3.6/site-packages/transformers/modeling_bart.py”, line 978, in init
base_model = BartModel(config)
File “/usr/local/lib/python3.6/site-packages/transformers/modeling_bart.py”, line 857, in init
self.encoder = BartEncoder(config, self.shared)
File “/usr/local/lib/python3.6/site-packages/transformers/modeling_bart.py”, line 298, in init
config.max_position_embeddings, embed_dim, self.padding_idx
File “/usr/local/lib/python3.6/site-packages/transformers/modeling_bart.py”, line 1344, in init
self.weight = self._init_weight(self.weight)
File “/usr/local/lib/python3.6/site-packages/transformers/modeling_bart.py”, line 1355, in _init_weight
out[:, 0 : dim // 2] = torch.FloatTensor(np.sin(position_enc[:, 0::2])) # This line breaks for odd n_pos
RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.
```
when I run:
```
from transformers import pipeline
summarizer = pipeline(“summarization”,
model=“google/pegasus-large”)
```
I get the same error trying to load google/pegasus-large.
I also tried loading the models locally. The config and tokenizer load fine. The error occurs when trying to load the model:
```
model = BartForConditionalGeneration.from_pretrained(model_dir,
config=model_config)
```
FYI, from site-packages/torch/version.py:
```
version = ‘1.8.1+cu102’
debug = False
cuda = ‘10.2’
git_version =
``` | 03-19-2022 10:46:25 | 03-19-2022 10:46:25 | This appears to be a version issue. I upgraded transformers to 4.1.0 to address another model issue and this now loads.l |
transformers | 16,267 | closed | Add type hints transfoxl | # What does this PR do?
Adds type annotations for transfo_xl models as per https://github.com/huggingface/transformers/issues/16059
@Rocketknight1 | 03-19-2022 09:18:52 | 03-19-2022 09:18:52 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,266 | closed | Removed the 'optional' string (in DETR post_process) | Removed the 'optional' string (in DETR post_process) #15769 @sgugger @NielsRogge | 03-19-2022 02:40:11 | 03-19-2022 02:40:11 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,265 | closed | Add OFA | # What does this PR do?
This PR adds OFA to transformers.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
<!-- Remove if not applicable -->
Fixes #15813
<!--
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-18-2022 21:29:57 | 03-18-2022 21:29:57 | Hello, glad to find you start to add `OFA` to `transformers` :tada:. I'm a member of [OFA-sys](https://github.com/OFA-Sys/OFA). If you encounter any difficulties or need any materials, please feel free to contact me. We are willing to do anything that helps.<|||||>will OFA be added to transformers models soon?<|||||>@chenxwh I will try to get the basics ready in a week where you may be able to start with the experimentation. Sorry for the delay.<|||||>Not sure if this is was a coordinated collaborative effort, but the OFA-Sys team seems to have made a preliminary release of a transformers implementation on a [separate OFA branch](https://github.com/OFA-Sys/OFA/tree/feature/add_transformers/transformers/src/transformers/models/ofa). <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,264 | closed | Reorganize file utils | # What does this PR do?
This PR reorganizes the gigantic `file_utils` in several submodules, namely:
- `doc_utils` contain all the decorators we use for our docstrings as well as the generic examples
- `file_utils` keep all Hub-related functionality (it might warrant a rename to `hub_utils` see below)
- `generic_utils` contain the "real" utils like custom Enums, to_py_obj etc.
- `import_utils` contains all the `is_xxx_available` as well as the modules that power our lazy inits
To avoid any breaking change, this is all done while reimporting the objects moved into `file_utils`. The only thing that will break is if a user imported a private object from there that has moved, but I think that's okay. The fact all tests pass while no import (except the private objects) was changed (yet) proves it.
The easiest way to review this PR is to just look at the `file_utils` module and look after my comment, where you will find a summary of the functions/classes/constants that were moved in the form of imports. The rest of the diff (apart from the main util files) come from private objects imports, and one import that was incorrect.
I have kept the PR simple for now but will change all the relative imports in every file to take each object from its real source, but before that I wanted to have your opinion on the splits done, as well as the two following points:
- as said above, we could also rename `file_utils` to a more appropriate `hub_utils` (while keeping a `file_utils` for backward compatibility but with just the imports).
- also, the modules I have created could also go in the utils subfolder instead of the root subfolder (and be named `.utils.doc`, `.utils.hub`, `.utils.generic` and `.utils.import` for instance), still with keeping BC.
As soon as we all agree on the move and the names of the new submodules, I will make the changes of import paths in all the files of the lib :-) | 03-18-2022 20:55:48 | 03-18-2022 20:55:48 | _The documentation is not available anymore as the PR was closed or merged._<|||||>> also, the modules I have created could also go in the utils subfolder instead of the root subfolder (and be named .utils.doc, .utils.hub, .utils.generic and .utils.import for instance), still with keeping BC.
Related question: we have many files named `xxx_utils.py` outside the `utils` folder. Is it due to legacy files, or is it intentional? <|||||>Thanks a lot for working on this! Very much needed change :-)
Regarding the two points above:
- I'd be in favor of keep calling the file `file_utils.py` actually as I think it's not **only** related to the Hub. E.g. the name of the model weights is also how they will be called locally "pytorch_model.bin". So don't think it's worth renaming the file here
- I would be in favor of moving everything into a utils folder actually<|||||>As per your comments, I've put everything in a `utils` submodule and reimported everything:
- in `file_utils` for backward compatibility (again see all tests passing with no change yet)
- in the `utils` init: this way if we deprecate `file_utils` at some point, the code migration is super easy: replace `from transfomers.file_utils import xxx` by `from transformers.utils import xxx`.
If you agree, I'll clean up all internal imports then merge @patil-suraj @patrickvonplaten @LysandreJik <|||||>> Related question: we have many files named xxx_utils.py outside the utils folder. Is it due to legacy files, or is it intentional?
@gante This is more or less legacy from where the repo was flat and had no subfolders. Some could probably go in the utils subfolder as well, though I'm keeping this PR focused on `file_utils` (it will be big enou already ;-) ) |
transformers | 16,263 | closed | Add type annotations of config for vision models | I added type annotations for config parameters for Beit, ViT and Deit models at PyTorc. Original issue https://github.com/huggingface/transformers/issues/16059
@Rocketknight1
Just completing the #16151 as describe in #16251 | 03-18-2022 19:59:52 | 03-18-2022 19:59:52 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_16263). All of your documentation changes will be reflected on that endpoint. |
transformers | 16,262 | closed | Do you fine-tunde both encoder and decoder | Hi @patil-suraj
https://github.com/huggingface/transformers/blob/277fc2cc782d8c5c28ec399b1ee2fc1c6aed7b6e/examples/pytorch/summarization/run_summarization.py#L500
I am not sure why the `input_models` does not take `decoder_attention_mask` into account ?
**debugging:**
just print the `train_dataset` after this line
https://github.com/huggingface/transformers/blob/277fc2cc782d8c5c28ec399b1ee2fc1c6aed7b6e/examples/pytorch/summarization/run_summarization.py#L518
`print(train_dataset)` gives:
```
Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 2069
})
```
the `attention_mask` is the attention mask of the encoder | 03-18-2022 19:23:00 | 03-18-2022 19:23:00 | @rafikg Could you elaborate the question in a bit more detail? Maybe with a minimal code example that demonstrates the issue/question. In particular, could you check what are the keys in `model_inputs` at this line (when you run your example code)
https://github.com/huggingface/transformers/blob/277fc2cc782d8c5c28ec399b1ee2fc1c6aed7b6e/examples/pytorch/summarization/run_summarization.py#L501
Thank you!<|||||>@ydshieh I update the question<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 16,261 | closed | GPT2 TensorFlow Type Hints | # What does this PR do?
Add type hints to the TF GPT2 model
Also remove two unused imports that were breaking `make fixup`
<!-- Remove if not applicable -->
Addresses https://github.com/huggingface/transformers/issues/16059
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes?
- [ ] Did you write any new necessary tests?
## Who can review?
@Rocketknight1 @gante
| 03-18-2022 18:22:35 | 03-18-2022 18:22:35 | Potential issues (not very sure about those):
- Pytorch GPT2 has a `GPT2ForTokenClassification` class with no equivalent in the TF version.
- TF GPT2 uses `past` for the parameter that other models (e.g. pytorch gpt2 and tf roberta) call `past_key_values`<|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,260 | closed | TF - update (vision_)encoder_decoder past variable | # What does this PR do?
I missed these 2 in the `past` refactor PR (https://github.com/huggingface/transformers/pull/15944). It reverts the error from as mentioned here (https://github.com/huggingface/transformers/pull/16230) to its previous form, as tracked here (https://github.com/huggingface/transformers/issues/15983). | 03-18-2022 17:58:27 | 03-18-2022 17:58:27 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,259 | closed | [WIP] add `has_attentions` as done in PyTorch side | # What does this PR do?
My original intention is to clean up `TFModelTesterMixin.test_pt_tf_model_equivalence`. This is done in this first commit.
Would like to hear from @sgugger to see if it is better to apply the same change found in #15909 here.
| 03-18-2022 17:04:19 | 03-18-2022 17:04:19 | _The documentation is not available anymore as the PR was closed or merged._<|||||>So I will merge as it is, and work in a follow up PR to use `has_attentions` to other (TF) test methods like `test_model_outputs_equivalence` etc. |
transformers | 16,258 | closed | Update flaubert with TF decorator | Unpacks TF model inputs through a decorator, improving code clarity for the FlauBERT model. Linked to issue #16051
@gante | 03-18-2022 16:56:10 | 03-18-2022 16:56:10 | Report for the pytest run:
```
RUN_SLOW=1 pytest -vv tests/flaubert/test_modeling_tf_flaubert.py
========================================================================================= test session starts =========================================================================================
platform linux -- Python 3.7.11, pytest-7.1.1, pluggy-1.0.0 -- /home/tegzes/anaconda3/envs/transf/bin/python
cachedir: .pytest_cache
hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/home/tegzes/Desktop/transformers/.hypothesis/examples')
rootdir: /home/tegzes/Desktop/transformers, configfile: setup.cfg
plugins: dash-2.3.0, xdist-2.5.0, timeout-2.1.0, hypothesis-6.39.4, forked-1.4.0
collected 36 items
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_attention_outputs <- tests/test_modeling_tf_common.py PASSED [ 2%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_compile_tf_model <- tests/test_modeling_tf_common.py PASSED [ 5%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_config PASSED [ 8%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_determinism <- tests/test_modeling_tf_common.py PASSED [ 11%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_flaubert_lm_head PASSED [ 13%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_flaubert_model PASSED [ 16%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_flaubert_qa PASSED [ 19%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_flaubert_sequence_classif PASSED [ 22%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_for_multiple_choice PASSED [ 25%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_for_token_classification PASSED [ 27%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_forward_signature <- tests/test_modeling_tf_common.py PASSED [ 30%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_generate_with_headmasking <- tests/test_modeling_tf_common.py PASSED [ 33%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_headmasking <- tests/test_modeling_tf_common.py PASSED [ 36%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_hidden_states_output <- tests/test_modeling_tf_common.py PASSED [ 38%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_initialization <- tests/test_modeling_tf_common.py PASSED [ 41%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_inputs_embeds <- tests/test_modeling_tf_common.py PASSED [ 44%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_keras_save_load <- tests/test_modeling_tf_common.py PASSED [ 47%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_keyword_and_dict_args <- tests/test_modeling_tf_common.py PASSED [ 50%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_lm_head_model_beam_search_generate_dict_outputs <- tests/test_modeling_tf_common.py PASSED [ 52%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_lm_head_model_no_beam_search_generate_dict_outputs <- tests/test_modeling_tf_common.py PASSED [ 55%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_lm_head_model_random_beam_search_generate <- tests/test_modeling_tf_common.py PASSED [ 58%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_lm_head_model_random_no_beam_search_generate <- tests/test_modeling_tf_common.py PASSED [ 61%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_load_with_mismatched_shapes <- tests/test_modeling_tf_common.py PASSED [ 63%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_loss_computation <- tests/test_modeling_tf_common.py PASSED [ 66%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_model_common_attributes <- tests/test_modeling_tf_common.py PASSED [ 69%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_model_from_pretrained PASSED [ 72%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_model_main_input_name <- tests/test_modeling_tf_common.py PASSED [ 75%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_model_outputs_equivalence <- tests/test_modeling_tf_common.py PASSED [ 77%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_numpy_arrays_inputs <- tests/test_modeling_tf_common.py PASSED [ 80%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_onnx_compliancy <- tests/test_modeling_tf_common.py PASSED [ 83%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_onnx_runtime_optimize <- tests/test_modeling_tf_common.py PASSED [ 86%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_pt_tf_model_equivalence <- tests/test_modeling_tf_common.py SKIPPED (test is PT+TF test) [ 88%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_resize_token_embeddings <- tests/test_modeling_tf_common.py PASSED [ 91%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_save_load <- tests/test_modeling_tf_common.py PASSED [ 94%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelTest::test_save_load_config <- tests/test_modeling_tf_common.py PASSED [ 97%]
tests/flaubert/test_modeling_tf_flaubert.py::TFFlaubertModelIntegrationTest::test_output_embeds_base_model PASSED [100%]
```<|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,257 | closed | Added type hints for PyTorch T5 model | # What does this PR do?
Adds type hints for PyTorch T5 model. See #16059.
@Rocketknight1 | 03-18-2022 16:25:44 | 03-18-2022 16:25:44 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,256 | closed | Cannot replicate the scores from the pipeline | I am trying to build a custom function that replicates the transfomers' pipeline in order to optimize runtimes for the roberta model, like in [this section of the documentation](https://huggingface.co/joeddav/xlm-roberta-large-xnli#with-manual-pytorch).
The blueprint to write my custom function is the [ZeroShotClassificationPipeline](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/pipelines/zero_shot_classification.py).
Even though I managed to run the model and get similar results, I cannot fully replicate the scores coming from the pipeline.
Below the example:
## 1. ZeroShotClassificationPipeline
```
classifier_cuda = pipeline("zero-shot-classification",
model=os.path.abspath('../models/xlm-roberta-large-xnli'),
device=torch.cuda.current_device()
)
classifier_cuda("Mi sono divertito a teatro ieri", ["money", "entertainment", "food", "rent"],hypothesis="This example is related to {}")
```
The ouput scores related to this example are the following:
```
{'sequence': 'Mi sono divertito a teatro ieri',
'labels': ['entertainment', 'rent', 'money', 'food'],
'scores': [0.9842655062675476,
0.010558217763900757,
0.003464417764917016,
0.0017118172254413366]
}
```
## 2. Custom function
```
device = torch.device('cuda:0')
tokenizer = AutoTokenizer.from_pretrained(os.path.abspath('../models/xlm-roberta-large-xnli'))
nli_model = AutoModelForSequenceClassification.from_pretrained(os.path.abspath('../models/xlm-roberta-large-xnli')).to(device)
sequence = "Mi sono divertito a teatro ieri"
hypothesis_template = "This example is related to {}"
labels = ["money", "entertainment", "food", "rent"]
sequence_pairs = []
sequence_pairs.extend([[sequence, hypothesis_template.format(label)] for label in labels])
inputs=tokenizer(
sequence_pairs,
add_special_tokens=True,
padding=True,
return_tensors='pt',
truncation='only_first'
)
for key,value in inputs.items():
inputs[key]=value.to(device)
model_out = nli_model(**inputs)
entailments = model_out['logits'].cpu().detach().numpy()[:,nli_model.config.label2id['entailment']]
entailments = entailments.reshape((-1,len(labels)))
entailments_logits=np.exp(entailments)
result=(entailments_logits/entailments_logits.sum(-1, keepdims=True))
print(labels)
print(list(result[0]))
```
Results:
```
['money', 'entertainment', 'food', 'rent']
[0.0014175308, 0.99700063, 0.00071506965, 0.00086674973]
```
| 03-18-2022 16:15:17 | 03-18-2022 16:15:17 | cc @Narsil <|||||>Hi @DanieleBarreca ,
Can you try with `hypothesis_template` as a variable, I think that's the issue.
@LysandreJik , We're very tolerant on arguments, what do you think about raising errors on pipelines that do not accept `*kwargs` when the passed argument is not understood (would prevent silent errors like this one)<|||||>@Narsil
Thank you very much for your support. Your suggestion is not super-clear to me unfortunately, can you help me to understand in which function call should I pass the hypothesis_template as a varibale (i.e. to the tokenizer, to the model, ...) or how should I modify my code? <|||||>Sorry about that, here is the modified example to get the same scores.
```python
classifier_cuda = pipeline("zero-shot-classification",
model=os.path.abspath('../models/xlm-roberta-large-xnli'),
device=torch.cuda.current_device()
)
classifier_cuda(
"Mi sono divertito a teatro ieri",
["money", "entertainment", "food", "rent"],
# THIS LINE IS DIFFERENT
hypothesis_template="This example is related to {}"
)
```
Basically you `hypothesis` argument was ignored and it used the default instead
<|||||>@Narsil Thank you very much! It worked correctly and I can replicate the pipeline scores. |
transformers | 16,255 | closed | Add TF ViT MAE | This PR adds the MAE [1] model in TensorFlow. It was developed by @arig23498 and myself.
Fun facts about this PR:
* Probably the third pure vision model in TensorFlow in `transformers`.
**References**:
[1] [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377)
**Update**
The PR is now ready for review. @gante @Rocketknight1 @sgugger | 03-18-2022 15:51:08 | 03-18-2022 15:51:08 | I just have a quick look and left a comment.
I feel strange that there are style changes like `omega = 1.0 / 10000 ** omega # (D/2,)`. Do you have a previous version of `black`?
I thought you already updated the version (during your work on `TFConvNext`), via
```
pip install -e .[quality]
```
Maybe you were in a different virtual Python environment while working on this PR?<|||||>> I just have a quick look and left a comment.
>
> I feel strange that there are style changes like `omega = 1.0 / 10000 ** omega # (D/2,)`. Do you have a previous version of `black`?
>
> I thought you already updated the version (during your work on `TFConvNext`), via
>
> ```
> pip install -e .[quality]
> ```
>
> Maybe you were in a different virtual Python environment while working on this PR?
So, first I deactivate the current Python virtual environment and then run the installation and run `make style`?
I think I should fetch upstream before that and rebase. <|||||>
> So, first I deactivate the current Python virtual environment and then run the installation and run `make style`?
Yeah, if your current venv is specific to your other work/projects, and you don't want to change its installed packages.
Maybe it would better if you create a new virtual environment, say, `venv-transformers-pr`, and switch to it.
>
> I think I should fetch upstream before that and rebase.
You can try it. I always try to have (very) recent commit from master to work on a new PR. Hope the rebase is smooth in your case here.
<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Thank you for working on this model, @sayakpaul (and the patience for the randomness issue!).
I went through the parts (in the test files) involving the randomness and left a few comments.<|||||>@sgugger @ydshieh thank you for your positive comments. In the world of open-source, we couldn't have asked for me. So, thank you once again.
We've addressed the PR comments. Let us know your thoughts. <|||||>On top of the code quality issue flagged above, the two following tests are failing:
```
FAILED tests/vit_mae/test_modeling_vit_mae.py::ViTMAEModelTest::test_pt_tf_model_equivalence
FAILED tests/vit_mae/test_modeling_tf_vit_mae.py::TFViTMAEModelTest::test_pt_tf_model_equivalence
```
Could you fix them so we can merge the PR? Thanks a lot!<|||||>> On top of the code quality issue flagged above, the two following tests are failing:
>
> ```
> FAILED tests/vit_mae/test_modeling_vit_mae.py::ViTMAEModelTest::test_pt_tf_model_equivalence
> FAILED tests/vit_mae/test_modeling_tf_vit_mae.py::TFViTMAEModelTest::test_pt_tf_model_equivalence
> ```
>
> Could you fix them so we can merge the PR? Thanks a lot!
I looked into it but couldn't figure out why they failed. Could you provide us with a starting point to get them fixed? <|||||>Here is the full stack trace:
```
============================= FAILURES SHORT STACK =============================
________________ TFViTMAEModelTest.test_pt_tf_model_equivalence ________________
tf_model = <transformers.models.vit_mae.modeling_tf_vit_mae.TFViTMAEModel object at 0x7f8bef271450>
pt_state_dict = OrderedDict([('embeddings.cls_token', tensor([[[ 0.0355, 0.0288, 0.0095, 0.0219, -0.0116, 0.0049, 0.0247,
...0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0.]))])
tf_inputs = {'pixel_values': <tf.Tensor: shape=(13, 3, 30, 30), dtype=float32, numpy=
array([[[[9.84787583e-01, 7.89411783e-01, 8....20547986e-01, 9.40254509e-01, ...,
1.77839562e-01, 9.66387928e-01, 8.72015655e-01]]]],
dtype=float32)>}
allow_missing_keys = False
def load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=None, allow_missing_keys=False):
"""Load pytorch state_dict in a TF 2.0 model."""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
from tensorflow.python.keras import backend as K
except ImportError:
logger.error(
"Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
if tf_inputs is None:
tf_inputs = tf_model.dummy_inputs
if tf_inputs is not None:
tf_model(tf_inputs, training=False) # Make sure model is built
# Adapt state dict - TODO remove this and update the AWS weights files instead
# Convert old format to new format if needed from a PyTorch state_dict
old_keys = []
new_keys = []
for key in pt_state_dict.keys():
new_key = None
if "gamma" in key:
new_key = key.replace("gamma", "weight")
if "beta" in key:
new_key = key.replace("beta", "bias")
if new_key:
old_keys.append(key)
new_keys.append(new_key)
for old_key, new_key in zip(old_keys, new_keys):
pt_state_dict[new_key] = pt_state_dict.pop(old_key)
# Make sure we are able to load PyTorch base models as well as derived models (with heads)
# TF models always have a prefix, some of PyTorch models (base ones) don't
start_prefix_to_remove = ""
if not any(s.startswith(tf_model.base_model_prefix) for s in pt_state_dict.keys()):
start_prefix_to_remove = tf_model.base_model_prefix + "."
symbolic_weights = tf_model.trainable_weights + tf_model.non_trainable_weights
tf_loaded_numel = 0
weight_value_tuples = []
all_pytorch_weights = set(list(pt_state_dict.keys()))
missing_keys = []
for symbolic_weight in symbolic_weights:
sw_name = symbolic_weight.name
name, transpose = convert_tf_weight_name_to_pt_weight_name(
sw_name, start_prefix_to_remove=start_prefix_to_remove, tf_weight_shape=symbolic_weight.shape
)
# Find associated numpy array in pytorch model state dict
if name not in pt_state_dict:
if allow_missing_keys:
missing_keys.append(name)
continue
elif tf_model._keys_to_ignore_on_load_missing is not None:
# authorized missing keys don't have to be loaded
if any(re.search(pat, name) is not None for pat in tf_model._keys_to_ignore_on_load_missing):
continue
> raise AttributeError(f"{name} not found in PyTorch model")
E AttributeError: vit.embeddings.cls_token not found in PyTorch model
src/transformers/modeling_tf_pytorch_utils.py:198: AttributeError
_________________ ViTMAEModelTest.test_pt_tf_model_equivalence _________________
tf_model = <transformers.models.vit_mae.modeling_tf_vit_mae.TFViTMAEModel object at 0x7f8c0e80add0>
pt_state_dict = OrderedDict([('embeddings.cls_token', tensor([[[-0.0341, -0.0326, 0.0065, -0.0189, 0.0114, 0.0198, 0.0247,
...0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0.]))])
tf_inputs = {'pixel_values': <tf.Tensor: shape=(13, 3, 30, 30), dtype=float32, numpy=
array([[[[0.00428793, 0.00807637, 0.5928316 ...,
[0.0279441 , 0.08120351, 0.30608034, ..., 0.777531 ,
0.6238623 , 0.38510746]]]], dtype=float32)>}
allow_missing_keys = False
def load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=None, allow_missing_keys=False):
"""Load pytorch state_dict in a TF 2.0 model."""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
from tensorflow.python.keras import backend as K
except ImportError:
logger.error(
"Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
if tf_inputs is None:
tf_inputs = tf_model.dummy_inputs
if tf_inputs is not None:
tf_model(tf_inputs, training=False) # Make sure model is built
# Adapt state dict - TODO remove this and update the AWS weights files instead
# Convert old format to new format if needed from a PyTorch state_dict
old_keys = []
new_keys = []
for key in pt_state_dict.keys():
new_key = None
if "gamma" in key:
new_key = key.replace("gamma", "weight")
if "beta" in key:
new_key = key.replace("beta", "bias")
if new_key:
old_keys.append(key)
new_keys.append(new_key)
for old_key, new_key in zip(old_keys, new_keys):
pt_state_dict[new_key] = pt_state_dict.pop(old_key)
# Make sure we are able to load PyTorch base models as well as derived models (with heads)
# TF models always have a prefix, some of PyTorch models (base ones) don't
start_prefix_to_remove = ""
if not any(s.startswith(tf_model.base_model_prefix) for s in pt_state_dict.keys()):
start_prefix_to_remove = tf_model.base_model_prefix + "."
symbolic_weights = tf_model.trainable_weights + tf_model.non_trainable_weights
tf_loaded_numel = 0
weight_value_tuples = []
all_pytorch_weights = set(list(pt_state_dict.keys()))
missing_keys = []
for symbolic_weight in symbolic_weights:
sw_name = symbolic_weight.name
name, transpose = convert_tf_weight_name_to_pt_weight_name(
sw_name, start_prefix_to_remove=start_prefix_to_remove, tf_weight_shape=symbolic_weight.shape
)
# Find associated numpy array in pytorch model state dict
if name not in pt_state_dict:
if allow_missing_keys:
missing_keys.append(name)
continue
elif tf_model._keys_to_ignore_on_load_missing is not None:
# authorized missing keys don't have to be loaded
if any(re.search(pat, name) is not None for pat in tf_model._keys_to_ignore_on_load_missing):
continue
> raise AttributeError(f"{name} not found in PyTorch model")
E AttributeError: vit.embeddings.cls_token not found in PyTorch model
src/transformers/modeling_tf_pytorch_utils.py:198: AttributeError
```
Looks like there is a weight present in the TF model but not the PyTorch one.<|||||>This does seem weird. I think if the TF model didn't have the right variable names as same as the PT one, it would not have loaded the PT weights back into the TF model, no?<|||||>@sgugger there seems to be something weird here. I ran the PT model like so:
```py
from transformers import ViTMAEForPreTraining
model = ViTMAEForPreTraining.from_pretrained("facebook/vit-mae-base")
param_states = model.state_dict()
for k in param_states:
if "cls" in k:
print(k)
```
It prints:
```
vit.embeddings.cls_token
```
But as per the error trace it says:
```
AttributeError: vit.embeddings.cls_token not found in PyTorch model
```
<|||||>Considering it was me working on this PT/TF equivalence test recently, I will try to take a look!
(despite the failure is more in `load_pytorch_weights_in_tf2_model` method)<|||||>@sayakpaul Could you try if the following work 🙏?
```
TFViTMAEModel.from_pretrained("facebook/vit-mae-base", from_pt=True)
```
OK, I saw it is tested indeed in your previous comment.<|||||>@sayakpaul
change [here] from
```
base_model_prefix = "vit_mae"
```
to
```
base_model_prefix = "vit"
```
will fix the loading issue, because that is the value used in the `ViTMAEModel`, see [here](https://github.com/huggingface/transformers/blob/2da1f03f93af37480fdfc23cbc870f5bf038c478/src/transformers/models/vit_mae/modeling_vit_mae.py#L585).
However I still get the large difference value between PT/TF
```
E AssertionError: 3.805268 not less than or equal to 1e-05
```
So something still need to be fixed.
~~@sgugger @NielsRogge Do you think ~~
~~- `vit_mae` is a better value for `base_model_prefix`?~~
~~- if so, should we & are we able to fix this in PyTorch `ViTMAEModel`, considering there might be some (or many) downloads already?~~
~~- (I am completely fine if we don't change it because we can't)~~
Turns out `vit` is the final decision, see
https://github.com/huggingface/transformers/pull/16119/files (#16119)
So @sayakpaul , You need to change the base_model_prefix = "vit_mae" to "vit" in the TF model file. And we will try to see why we get large difference value.<|||||>@ydshieh thanks much for pointing us in the right direction. As for the assertion, it likely can be solved by fixing the `noise` argument like the way we did for the rest of the tests.
If you could suggest where the `noise` argument needs to be added, I can look into it.
**Update**:
Inside `check_pt_tf_models()` we need to pass `noise` to `pt_model` and `tf_model` to ensure the equivalence assertion passes. We can parameterize the `check_pt_tf_models()` method to allow `noise`. But since it's a core library component, let's discuss the best possible way to incorporate this change.
<|||||>@sayakpaul Wow, super! `noise` is something we should keep in mind from now :-)
You can copy/paste the `test_pt_tf_model_equivalence` from `test_modeling_tf_common.py`, then add the `noise` part.
There are a few places we can remove (they only make sense in the common test), but if you are not sure which parts to remove, you can keep it as it is - I will make the change.<|||||>Thank you @ydshieh. Making the changes right away. <|||||>Seems like GitHub Actions is acting weird. But that's not what GitHub's status page says: https://www.githubstatus.com/.
Let's see if the current change can fix the equivalence test. <|||||>> Seems like GitHub Actions is acting weird. But that's not what GitHub's status page says: https://www.githubstatus.com/.
>
> Let's see if the current change can fix the equivalence test.
I had exactly the same situation yesterday - 0 check after force push <|||||>I see. If possible it'd be great if you could review the changes I made so far. <|||||>@sgugger is it possible to trigger the workflows manually from your end? <|||||>Not from side, no. Can you do an empty commit (`git commit -m "Trigger tests" --allow-empty`)?<|||||>@sgugger seems like things are looking good. Let me know if the recent changes to fix equivalence look good to you.
This is one last bit that I think you folks need to take care of: https://github.com/huggingface/transformers/pull/16255#discussion_r833968556. <|||||>> @sgugger seems like things are looking good. Let me know if the recent changes to fix equivalence look good to you.
>
> This is one last bit that I think you folks need to take care of: [#16255 (comment)](https://github.com/huggingface/transformers/pull/16255#discussion_r833968556).
Glad to see the tests being all green!
@gante Before merge, please wait for me to remove some irrelevant parts in the overwritten PT/TF equivalence test, thanks! <|||||>I have pushed a commit to remove irrelevant blocks (that only make sense in the common test) + put pytorch inputs on the correct device (for GPU testing to run)<|||||>Thanks for your help, @ydshieh. The failing tests seem to be unrelated to the PR?<|||||>> Thanks for your help, @ydshieh. The failing tests seem to be unrelated to the PR?
Yeah, I think it is another model `facebook/xglm-564M` causing issue.
You can have a bit of rest for now 💯 💖
I re-run the failed test. ~~Let's see.~~ All green now<|||||>@gante according to https://github.com/huggingface/transformers/pull/16255/commits/debad62d47f5789f9890d3176713345e3a2506c0 there were no key additions or deletions from the code base. Do you know the possible reason for the tests to fail?<|||||>@gante @ydshieh
Updates:
Repo consistency tells us that copied components have inconsistencies. Sorry, if this sounds foolish but we could not actually figure out those inconsistencies. Class name changes and other relevant changes in the comment do not count here I hope. To ensure the copying was indeed right we went ahead used a comparator tool to verify if that's the case. Here are the individual links to the comparison results for the components that are said to have copy inconsistencies:
* SelfAttention: https://www.diffchecker.com/m5VY19Xl
* SelfOutput: https://www.diffchecker.com/j6Pri9fN
* MAEAttention: https://www.diffchecker.com/5qtn9IRh
* Intermediate: https://www.diffchecker.com/hNy0Sg7c
* ViTOutput: https://www.diffchecker.com/CyK4zZUl
* Layer: https://www.diffchecker.com/BESXzSTD
* Encoder: https://www.diffchecker.com/BXHYohx1
Note that we did run `make fix-copies` within the environment as described in https://github.com/huggingface/transformers/pull/16255#discussion_r830432539 (refer to https://github.com/huggingface/transformers/pull/16255/commits/565ec4c1227d9577e0e4e7489880dad2d4c33d01) and it replaced `ViTMAEConfig` with `ViTConfig` which is wrong, I guess.
We have also followed the copy comment format from the PT script ensuring they are well aligned.
What else are we missing out here? <|||||>@ariG23498 @sayakpaul
Probably my [previous comment](https://github.com/huggingface/transformers/pull/16255#discussion_r835623030) didn't explain things clear enough.
Let's take an example with:
```
# Copied from transformers.models.vit.modeling_tf_vit.TFViTSelfAttention with TFViT->TFViTMAE
class TFViTMAESelfAttention(tf.keras.layers.Layer):
def __init__(self, config: ViTMAEConfig, **kwargs):
```
This `# copied from` will check if the block is a copy from `TFViTSelfAttention` after replaceing `TFViT` by `TFViTMAE` (in the RAM).
However, there is `ViTConfig` in the ViT file, and `ViTMAEConfig` in this block **(note: there is no TF prefix here)**, and the instruction `with TFViT->TFViTMAE` in the comment `# Copied from` won't apply to `ViTConfig` (from the ViT file), and during the check, it is `ViTConfig` vs `ViTMAEConfig`, and therefore there is a difference.
In order to fix the issue, they are 2 potential options:
1. In `# Copied from`, change ` with TFViT->TFViTMAE` to ` with ViT->ViTMAE`
- This will only work if the 2 blocks in ViT and ViTMAE are indeed the same after this replace!
2. In `# Copied from`, change ` with TFViT->TFViTMAE` to ` with TFViT->TFViTMAE, ViTConfig->ViTMAEConfig`
- This is more verbose, but sometimes not really necessary
So I would suggest try option 1 first. If there are remaining places, we can use option 2 for that remaining places.
<|||||>For the remaining # copied from issue,
```
# in ViT, layernorm is applied before self-attention
```
to
```
# in ViTMAE, layernorm is applied before self-attention
```
should work.
(This is also what has done in PyTorch ViTMAE)<|||||>It turns out that there is still
```
# in ViT, layernorm is also applied after self-attention
```
to be changed ...I didn't check the whole block previously, sorry.
I don't always pull the latest commit from this PR. In general, it would be easier to detect if you run `make fix-copies` locally and see what have been changed, and you will get the idea where should be fixed.<|||||>Thanks for the prompt feedback @ydshieh
It was my bad to not check the entire code block.<|||||>Don't worry.
And just a **potential** correction (not really important): my previous comment "it would be easier to detect ..." **might** be not True in this particular line: I don't think there will be a diff visible to this particular line, after running `make fix-copies`.
<|||||>All green ✅
Thanks @ydshieh for your prompt and valuable feedback!<|||||>About `shape_list() is a mess for graph mode. We have a plan to get rid of it, and just use .shape everywhere `
https://github.com/huggingface/transformers/pull/16255#discussion_r835525428
I was a bit worried it will break some testing at this moment, so I tested with `shape`. Indeed, the test `test_save_load` will give error at the line `model.save_pretrained(tmpdirname, saved_model=True)` - when calling `autograph_handler` inside. See the full log below.
## Full error log
```python
with tempfile.TemporaryDirectory() as tmpdirname:
> model.save_pretrained(tmpdirname, saved_model=True)
tests\vit_mae\test_modeling_tf_vit_mae.py:616:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
src\transformers\modeling_tf_utils.py:1418: in save_pretrained
self.save(saved_model_dir, include_optimizer=False, signatures=self.serving)
..\..\..\..\miniconda3\envs\py39\lib\site-packages\keras\utils\traceback_utils.py:67: in error_handler
raise e.with_traceback(filtered_tb) from None
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
args = ({'pixel_values': <tf.Tensor 'pixel_values:0' shape=(None, None, None, None) dtype=float32>},)
kwargs = {}
def autograph_handler(*args, **kwargs):
"""Calls a converted version of original_func."""
# TODO(mdan): Push this block higher in tf.function's call stack.
try:
return autograph.converted_call(
original_func,
args,
kwargs,
options=autograph.ConversionOptions(
recursive=True,
optional_features=autograph_options,
user_requested=True,
))
except Exception as e: # pylint:disable=broad-except
if hasattr(e, "ag_error_metadata"):
> raise e.ag_error_metadata.to_exception(e)
E ValueError: in user code:
E
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\models\vit_mae\modeling_tf_vit_mae.py", line 728, in serving *
E return self.call(inputs)
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\modeling_tf_utils.py", line 816, in run_call_with_unpacked_inputs *
E return func(self, **unpacked_inputs)
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\models\vit_mae\modeling_tf_vit_mae.py", line 1074, in call *
E loss = self.forward_loss(pixel_values, logits, mask)
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\models\vit_mae\modeling_tf_vit_mae.py", line 1007, in forward_loss *
E target = self.patchify(imgs)
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\models\vit_mae\modeling_tf_vit_mae.py", line 975, in patchify *
E imgs = tf.cond(
E
E ValueError: Tried to convert 'x' to a tensor and failed. Error: None values not supported.
..\..\..\..\miniconda3\envs\py39\lib\site-packages\tensorflow\python\framework\func_graph.py:1129: ValueError
```<|||||>Changing `shape_list` to `shape` will also cause a test failing
https://github.com/huggingface/transformers/blob/b320d87eceb369ea22d5cd73866499851cb2cca3/tests/utils/test_modeling_tf_core.py#L124-L135
with similar error
```python
E in user code:
E
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\modeling_tf_utils.py", line 816, in run_call_with_unpacked_inputs *
E return func(self, **unpacked_inputs)
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\models\vit_mae\modeling_tf_vit_mae.py", line 1074, in call *
E loss = self.forward_loss(pixel_values, logits, mask)
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\models\vit_mae\modeling_tf_vit_mae.py", line 1007, in forward_loss *
E target = self.patchify(imgs)
E File "C:\Users\33611\Desktop\Projects\transformers-huggingface\transformers\src\transformers\models\vit_mae\modeling_tf_vit_mae.py", line 980, in patchify *
E tf.debugging.assert_equal(imgs.shape[1], imgs.shape[2])
E
E ValueError: None values not supported.
```
**(This test is currently only used for just a few core NLP models)**
**(This test will still fail with `shape_list` here, but the error seems coming from other lines rather than from shape_list itself)**<|||||>Thanks for investigating it, @ydshieh. Is there anything we can do in this PR to mitigate the problem? <|||||>> Thanks for investigating it, @ydshieh. Is there anything we can do in this PR to mitigate the problem?
Let's see what gante think.<|||||>> I was a bit worried it will break some testing at this moment, so I tested with shape. Indeed, the test test_save_load will give error at the line model.save_pretrained(tmpdirname, saved_model=True) - when calling autograph_handler inside. See the full log below.
This is why I used `shape_list()` there. The root cause here is that inside `patchify()` with `.shape` there will be a `None` in the batch size and `tf.random.uniform()` will error out for that. I could not think of any other workaround to mitigate the problem.
For the second one (https://github.com/huggingface/transformers/pull/16255#issuecomment-1079785554) I am not too sure since you mentioned that the test is only applied for some core NLP models.
<|||||>> For the second one ([#16255 (comment)](https://github.com/huggingface/transformers/pull/16255#issuecomment-1079785554)) I am not too sure since you mentioned that the test is only applied for some core NLP models.
My comments above are not about `we should change to shape and fix all the failing tests`.
It is more about a question (to gante) `if we should make this decision and change in this PR, considering some tests will fail.`
(And the second comment is included mainly for us (HF) not to forget there are some tests we want to run for all models ideally, but currently run only for a few models. It might be better for us (HF) not to make a big decision so quickly and see all tests being green for a particular model, but will fail some important tests that are not currently run due to some limitation).
<|||||>Now I understand. Appreciate the class clarification. <|||||>@sayakpaul `vit-mae-base` [TF weights are on the hub](https://huggingface.co/facebook/vit-mae-base/tree/main), the others will soon follow :) I think you can make the final changes now (remove the `from_pt`), to then merge the PR 💪 <|||||>@gante thank you! Changes made. <|||||>> @gante thank you! Changes made.
Can you confirm that the tests run with `RUN_SLOW=1`? Will merge after CI gets to green and I get your confirmation 🚀 <|||||>btw ignore the failure in `Add model like runner / Add new model like template tests (pull_request)`, it's being looked after<|||||>> > @gante thank you! Changes made.
>
> Can you confirm that the tests run with `RUN_SLOW=1`? Will merge after CI gets to green and I get your confirmation 🚀
Yes, I did run the tests before pushing the changes. <|||||>@gante over to you to take the reigns.<|||||>CI green, slow tests were run, all TF weights on the hub 👉 merging.
Great work @sayakpaul @ariG23498 💪 |
transformers | 16,254 | closed | update jax version and re-enable some tests | # What does this PR do?
Update the `JAX` version in `setup.py` to not install `jax==0.3.2`. And also re-enable some skipped tests. | 03-18-2022 14:20:37 | 03-18-2022 14:20:37 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,253 | closed | Add Slack notification support for doc tests | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR enables Slack reports for the daily doc tests. | 03-18-2022 13:28:14 | 03-18-2022 13:28:14 | _The documentation is not available anymore as the PR was closed or merged._<|||||>I will look this later today. Still learn this kind of things. If it is urgent, don't hesitate to go ahead though.<|||||>LGTM (without looking the notification script in detail).
Just 2 questions (due to my lack of expertise):
- why `working-directory: transformers` are removed (they appear in `self_scheduled.yml`)?
- I saw the following block is removed (it doesn't show up in `self_scheduled.yml` though)
```python
with:
repository: 'huggingface/transformers'
path: transformers
```
(just wondering why we don't need this)
<|||||>>
Very good question! And I don't really know the answer :D I just noticed that it didn't work with
```py
with:
repository: 'huggingface/transformers'
path: transformers
```
very well and I also think it's not necessary here so I removed it. Maybe @LysandreJik can give you a better answer. |
transformers | 16,252 | closed | Weird PanicException when trying to save tokenizer using `tokenizer.save_pretrained` | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.17.0
- Platform: Linux-4.14.252-131.483.amzn1.x86_64-x86_64-with-glibc2.9
- Python version: 3.6.13
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Using accelerate but there's only 1 GPU currently
### Who can help
@LysandreJik, @SaulLu, @sgugger
-->
## Information
Model I am using (Bert, XLNet ...): YituTech/conv-bert-base
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below) . Modified scripts but save_model method which is causing issues is exact same as this: https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue_no_trainer.py#L460
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below) - Similar GLUE like paired sentence classification task
## To reproduce
Steps to reproduce the behavior:
For some models such as the one mentioned above, I've seen some times the script abruptly fails with a weird PanicException while trying to save the tokenizer. I don't think this is model specific issue, because other 3p models have saved successfully for me always, so looks like something to do with Transformers/tokenizers lib. See code that I'm using to save the model below, along with detailed logs as well.
I've no idea about this issue, and how to fix it. For other standard models like bert, roberta etc the saving has worked fine always, along with some other 3p models that I've tried as well. Please let me know if you any need more information from me on this?
I'm saving both the model and tokenizer only in main_process, I hope that's right? I find this slightly weird because clearly if you see from the logs below model is getting saved to dir successfully, but tokenizer specifically is failing. Not sure what could be the peculiarity here causing this? Any suggestions that you might have to fix this would be really helpful!
Relevant code to save model, which is causing the issue - same as this: https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue_no_trainer.py#L460 . I've also included a couple of lines at the top in the code blurb below to show how I'm initializing the config/tokenizer/model if that might be of any relevance:
```
config = AutoConfig.from_pretrained(args.model_name_or_path, num_labels=num_labels, finetuning_task=None)
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, use_fast=not args.use_slow_tokenizer)
model = AutoModelForSequenceClassification.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.output_dir
)
def save_model(model, tokenizer, args):
if args.output_dir is not None and accelerator.is_main_process:
# Handle the repository creation
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
tokenizer.save_pretrained(args.output_dir)
```
Logs:
```
03/18/2022 11:51:47 - INFO - __main__ - ***** Running training *****
03/18/2022 11:51:47 - INFO - __main__ - Num examples = 25227
03/18/2022 11:51:47 - INFO - __main__ - Num Epochs = 10
03/18/2022 11:51:47 - INFO - __main__ - Instantaneous batch size per device = 32
03/18/2022 11:51:47 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 32
03/18/2022 11:51:47 - INFO - __main__ - Gradient Accumulation steps = 1
03/18/2022 11:51:47 - INFO - __main__ - Total optimization steps = 7890
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7890/7890 [28:11<00:00, 6.46it/s]03/18/2022 12:20:32 - INFO - __main__ - *** Predict ***
Configuration saved in conv-bert-base/config.json
Model weights saved in conv-bert-base/pytorch_model.bin
tokenizer config file saved in conv-bert-base/tokenizer_config.json
Special tokens file saved in conv-bert-base/special_tokens_map.json
thread '<unnamed>' panicked at 'no entry found for key', /__w/tokenizers/tokenizers/tokenizers/src/models/mod.rs:36:66
Traceback (most recent call last):
File "run.py", line 566, in <module>
main()
File "run.py", line 563, in main
tokenizer.save_pretrained(args.output_dir)
File "/home/ec2-user/anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 2108, in save_pretrained
filename_prefix=filename_prefix,
File "/home/ec2-user/anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/transformers/tokenization_utils_fast.py", line 599, in _save_pretrained
self.backend_tokenizer.save(tokenizer_file)
pyo3_runtime.PanicException: no entry found for key
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7890/7890 [29:26<00:00, 4.47it/s]
Traceback (most recent call last):
File "/home/ec2-user/anaconda3/envs/pytorch_latest_p36/bin/accelerate", line 8, in <module>
sys.exit(main())
File "/home/ec2-user/anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/accelerate/commands/accelerate_cli.py", line 41, in main
args.func(args)
File "/home/ec2-user/anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/accelerate/commands/launch.py", line 384, in launch_command
simple_launcher(args)
File "/home/ec2-user/anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/accelerate/commands/launch.py", line 142, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['/home/ec2-user/anaconda3/envs/pytorch_latest_p36/bin/python', 'run.py', '--model_name_or_path', 'YituTech/conv-bert-base', '--train_file', '../data/train.csv', '--validation_file', '../data/val.csv', '--test_file', '../data/test.csv', '--max_length', '128', '--per_device_train_batch_size', '32', '--learning_rate', '2e-5', '--num_train_epochs', '10', '--output_dir', 'conv-bert-base/']' returned non-zero exit status 1.
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Tokenizer save should be successful.
| 03-18-2022 13:01:24 | 03-18-2022 13:01:24 | It looks like your issues comes from a problem with the fast tokenizer. A simple reproducer is:
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("YituTech/conv-bert-base")
tokenizer.save_pretrained("test-tok")
```<|||||>Ohh, what should I do in that case - should i use the slow one? More specifically, why is the fast tokenizer failing only with this model and not others - not sure if it could be something model specific? @sgugger <|||||>It's probably linked to this specific architecture. Using the slow tokenizer is a workaround, I've pinged @Narsil in private to look at the fast tokenizer :-)<|||||>Thanks look forward to the findings, this issue has been causing me some trouble off late :(. I can't recollect the exact model name now, but I remember briefly seeing this same error for some other models too earlier. I initially thought it might have been some transient error, but looks like clearly it is not as it's been reproduced multiple times off late for me. @sgugger <|||||>Some ablation experiments were going in the background for me, so just noticed: This failed for YituTech/conv-bert-small too btw with the exact same exception. And assuming YituTech/conv-bert-medium-small this would also fail similarly (haven't tested it explicitly). Very weird. Hopefully there's something that can be fixed here for the fast_tokenizer. <|||||>Hi @ashutoshsaboo ,
The fix for the fast tokenizers is here: https://github.com/huggingface/tokenizers/pull/954
The main issue, is that those tokenizers actually contain duplicate tokens. Saving the using the `slow` tokenizer will trigger a bunch of warnings. `tokenizers` will follow the same path.
Please keep in mind that this means that this models underuse its capacity (I counted 1008 tokens are purely ignored, taking up space in the embedding matrix while never being used).
We'll r<|||||>Woah that was quick to get the fix out, thanks so much first of all! What do you mean by "tokens are purely ignored"? Aren't tokens dependent on vocabulary end of the day with some special extra specific tokens like SEP, PAD, CLS etc, or did I infer it wrong? @Narsil <|||||>Hi @ashutoshsaboo ,
> Aren't tokens dependent on vocabulary end of the day
Yes, but for these files, the `vocab.txt` contains duplicate (look at the last few lines for instance).
The problem about those duplicates is that the vocabulary expects one token per line, and here we have duplicates. The way `transformers` and `tokenizers` work in that instance, is the overwrite the previous token when they are duplicates.
The net-effect means that the ids of the tokens that get overwritten, will never show up in you tokenization, meaning they will never get used by your model, and you are using the weight space in your model (in the `embeddings` table) even though you are never going to use it. It's not critical as the model will probably work, but it's a waste of parameter space. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Closing since this has been fixed. |
transformers | 16,251 | closed | ViT-mae missing parameter at comments of `copied from` | ### Who can help
@NielsRogge
## Information
As describe in #16151
When i was type annotating the ViT model, i get some problem when running `make fix-copies` for vit-mae. When i annotated the cofig parameter at ViT, and run `make fix-copies` the script fix at deit model (update the type annotation to Deit config), but at vit-mae he just copied the type annotation of ViT config.
This seems to be because don't have with ViT->VitMAE at the end of the “Copied from …” comment in vit_mae model;
But I don't know if this annotation is really missing, or it was supposed to be this way
## To reproduce
1. Add type annotation at ViTSelfAttention src/transformers/models/vit/modeling_vit.py
2. run `git diff`
```diff
--- a/src/transformers/models/vit/modeling_vit.py
+++ b/src/transformers/models/vit/modeling_vit.py
@@ -192,7 +192,7 @@ class PatchEmbeddings(nn.Module):
class ViTSelfAttention(nn.Module):
- def __init__(self, config) -> None:
+ def __init__(self, config: ViTConfig) -> None:
super().__init__()
```
3. Run `make fix-copies`
4. Run `git diff src/transformers/models/vit_mae/`
```diff
@@ -318,7 +318,7 @@ class PatchEmbeddings(nn.Module):
# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention
class ViTMAESelfAttention(nn.Module):
- def __init__(self, config) -> None:
+ def __init__(self, config: ViTConfig) -> None:
```
## Expected behavior
I was expecting
```diff
@@ -318,7 +318,7 @@ class PatchEmbeddings(nn.Module):
# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention
class ViTMAESelfAttention(nn.Module):
- def __init__(self, config) -> None:
+ def __init__(self, config: ViTMAEConfig) -> None:
```
This can be fixed with
```diff
@@ -316,9 +316,9 @@ class PatchEmbeddings(nn.Module):
return x
-# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention
+# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention ViT->VitMAE
```
But I don't know if this annotation is really missing, or it was supposed to be this way
| 03-18-2022 12:26:05 | 03-18-2022 12:26:05 | Hey,
Yeah you can add the `with ViT->ViTMAE` if you need to. |
transformers | 16,250 | closed | Aggressive PT/TF equivalence test on PT side | # What does this PR do?
Update `test_pt_tf_model_equivalence` in `test_modeling_common.py` to have the same logic in #15839. | 03-18-2022 11:37:07 | 03-18-2022 11:37:07 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 16,249 | closed | is this a bug in TFTrainer.get_train_tfdataset? | my environment below:
transformers==4.0.0
tensorflow-gpu==2.3.0
python==3.7
when I use TFTrainer(model, train_dataset, val_dataset), wether my dataset is tf.data.Dataset.from_generator or tf.data.TFRecordDataset, their dataset.cardinality() always -2, so in TFTrainer.get_train_tfdataset() func,
self.num_train_examples = self.train_dataset.cardinality().numpy()
if self.num_train_examples < 0:
raise ValueError("The training dataset must have an asserted cardinality")
I coludn't use TFTrainer, I think tf.data.Dataset.from_generator or tf.data.TFRecordDataset, should be supported. | 03-18-2022 10:49:12 | 03-18-2022 10:49:12 | Hi @TheHonestBob! The `TFTrainer` class was deprecated a while ago, so it is likely that it fails under a few circumstances (and we don't have plans to maintain it).
Have you tried using the native Keras API? Here are our docs for fine-tuning with Keras: https://huggingface.co/docs/transformers/master/en/training#finetune-with-keras
Let me know if the Keras API solves your issues :)<|||||>thanks for your reply, I also use tf.keras, so I solve it with your docs.<|||||>I'm closing this issue, but feel free to reopen it if the problem persists. |
transformers | 16,248 | closed | NER at the Inference Time | Apology in advance if this question might have already been asked. However, I have not been able to find a convincing answer or the optimum way to deal with this issue.
To my understanding, NER makes a prediction at a token level. Since BERT is using a sub-word tokenizer, it is entirely possible that some part of the word won't get labeled or we have a different label within the same word. Both of these are undesirables because in the end we want the final result to be NER on a word, not token, level.
For example, see [link](https://huggingface.co/dslim/bert-base-NER?text=Seven+of+the+men+are+from+so-called+%22red-flagged%22+countries%2C+including+Egypt%2C+Turkey%2C+Georgia%2C+Pakistan+and+Mali.Her+eighth+husband%2C+Rashid+Rajput%2C+was+deported+in+2006+to+his+native+Pakistan+after+an+investigation+by+the+Joint+Terrorism+Task+Force.If+convicted%2C+Barrientos+faces+up+to+four+years+in+prison.++Her+next+court+appearance+is+scheduled+for+May+18.).
Barr(PER) ien(O) tos(PER)
This should have been Barr(PER) ien(PER) tos(PER).
Another more confusing prediction [here](https://huggingface.co/dslim/bert-base-NER?text=27+Colors+for+Main+Fabric+available+in+singles+%26+together+in+Fatpack+Sweater)
F(MISC) abric (O) .... Fat (LOC) pack Sweater (ORG)
We have inconsistent token production within the same words.
So my questions are the following
1) How can I best convert token-level NER labels to word-level labels? What is the best policy to deal with inconsistent token-level prediction within the same word? Is there a standard way to do this? Has this already been implemented in the huggingface library.
2) Should not there be a way to force the model to recognize that those three tokens came from the same word so they need to have the same token-level label in the first place?
Any suggestions are greatly appreciated. Thank you!
| 03-18-2022 08:14:22 | 03-18-2022 08:14:22 | Hey @ndenStanford !
Thanks for the issue but I think the [forum](https://discuss.huggingface.co/) would be the best place to ask such general questions. We use issues to report bugs and for feature request. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.