
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 15,847 | closed | [UniSpeechSat] Revert previous incorrect change of slow tests | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes `tests/unispeech_sat/test_modeling_unispeech_sat.py::UniSpeechSatModelIntegrationTest::test_inference_encoder_large`
The previous PR: #15818 was incorrect and due to a Datasets library version mismatch. See: https://github.com/huggingface/transformers/pull/15818/files#r815712576
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-28-2022 09:26:20 | 02-28-2022 09:26:20 | |
transformers | 15,846 | closed | [TF-PT-Tests] Fix PyTorch - TF tests for different GPU devices | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes `tests/t5/test_modeling_t5.py::T5EncoderOnlyModelTest::test_pt_tf_model_equivalence`
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-28-2022 09:09:23 | 02-28-2022 09:09:23 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15846). All of your documentation changes will be reflected on that endpoint. |
transformers | 15,845 | closed | Decision transformer gym | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Added the Decision Transformer Model to the transformers library (https://github.com/kzl/decision-transformer)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik | 02-28-2022 09:05:57 | 02-28-2022 09:05:57 | I have:
- Removed the (temporary) changes that were made on the gpt2 model
- Added zeroed position encodings to the call to gpt2 forward, so they are ignored. (as these are implemented in the DT model)
- Fixed issues related to black line length (my IDE was set to the default I think)
- Removed datasets submodule
- Added and fixed many tests for the ModelTesterMixin. I skip:
- test_generate_without_input_ids
- test_pruning
- test_resize_embeddings
- test_head_masking
- test_attention_outputs
- test_hidden_states_output
- test_inputs_embeds
- test_model_common_attributes
- Updated some of the doc strings etc.
Still Todo:
- Example file / notebook. Ideally this would show a model checkpoint being loaded and then demonstrate the performance in an RL environment. Is this what you are thinking? I have checkpoints saved from the author's implementation, but I will need to modify them so the state_dict matches this implementation (it will be missing the gpt2 position encoding weights, for example)
- Integration test. Similar issue as the above.
Please let me know if you have any comments, questions or ideas related to the commits I have just added.
<|||||>Really cool to see the first RL model in Transformers here! Agree with @LysandreJik in that we can just set the position ids to a 0 valued tensor so that the model doesn't need to be adapted.
For me, it would be important to understand how the model would be used in practice so that we can better understand how to best implement the model in Transformers. @edbeeching, do you think it could be possible to add an integration test that verifies that a **minimal** use case of the model works as expected? E.g. maybe we could show how the user would use this implementation to retrieve an action state `a_t` from `s_{t-1}`, `r_{t-1}` and `a_{t-1}` and then how `a_t` would be further treated for the next time step? So a code-snippet showing a two-step inference with some comments/code explaining where the reward and state come from as well.
Very exciting!<|||||>Thanks for the comments, the model is now loaded from a pretrained checkpoint. I have set the seed and have added a comparison between the output and the expected output. Let me know of any other comments or additions.<|||||>Sorry some files got committed unintentially, I have removed them.
Regarding the model checkpoint files, the authors are from Berkley, but I trained the models myself with their codebase (they did not share their checkpoints). So I don't know who the rightful "authors" of the checkpoints are, I am not bothered either way. Let me know what you think.<|||||>> checkpoint
I see! Yeah since you've trained them, then I think it's totally fine to just publish them under your name on the Hub! So I think the PR is good to go for me :-)<|||||>Think we still got some `decision-transformer-gym-halfcheetah-expert` folders though ;-) <|||||>There are five conflicts to resolve, could you take care of this before we do a final review @edbeeching ?<|||||>Ok I went through the conflicts.
One final question, it appears that the test files have been reorganized since I first forked the transformers repo. They now appear to be nested each in their own subdirectory. Should add a directory for my test to reflect this change in organization?<|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,844 | closed | Error:"TypeError: 'NoneType' object is not callable" with model specific Tokenizers | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.17.0.dev0 but also current latest master
- Platform: Colab
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
Models:
- XGLM (although I don't think this is model specific)
## To reproduce
Steps to reproduce the behavior:
1. Try to create a tokenizer from class-specific tokenizers (eg XGLMTokenizer), it fails.
```
from transformers import XGLMTokenizer
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-564M")
```
## Expected behavior
Should work, but it fails with this exception:
```
Error:"TypeError: 'NoneType' object is not callable" with Tokenizers
```
However, creating it with `AutoTokenizer` just works, this is fine, but there're a lot of examples for specific models which do not use AutoTokenizer (I found out this by pasting an example from XGLM) | 02-28-2022 08:09:33 | 02-28-2022 08:09:33 | cc @SaulLu for tokenizers<|||||>Oops #15827 existed already, this seems to be widespread to more than XGLMTokenizer. XLMRobertaTokenizer doesn't seem to work either. AutoTokenizer seems to work but because it's a separate class altogether (`PreTrainedTokenizerFast`)<|||||>Hi @afcruzs ! `XGLMTokenizer` depends on `sentencepiece`, if it's not installed then a None object is imported.
`pip install sentencepiece` should resolve this.
> AutoTokenizer seems to work but because it's a separate class altogether (PreTrainedTokenizerFast)
yes, by default `AutoTokenizer` returns fast tokenizer.<|||||>Oh yes, this works indeed. Thanks! It'd be great to have a meaningful error message though, is not at all evident.<|||||>If I understood correctly, you tried with the version of transformers on master. After running:
```python
from transformers import XGLMTokenizer
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-564M")
```
normally you should see this error message after:
```python
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
[<ipython-input-3-34ff8e92d7d6>](https://localhost:8080/#) in <module>()
----> 1 tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-564M")
1 frames
[/usr/local/lib/python3.7/dist-packages/transformers/file_utils.py](https://localhost:8080/#) in requires_backends(obj, backends)
846 failed = [msg.format(name) for available, msg in checks if not available()]
847 if failed:
--> 848 raise ImportError("".join(failed))
849
850
ImportError:
XGLMTokenizer requires the SentencePiece library but it was not found in your environment. Checkout the instructions on the
installation page of its repo: https://github.com/google/sentencepiece#installation and follow the ones
that match your environment.
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
```
Can you share with us a little more about what you did so we can understand why you didn't receive this error? :slightly_smiling_face: <|||||>@SaulLu I've tried to repro it again and i couldn't, it seems to work just like you said 😐. I'll take a closer look and share a colab if I find something, otherwise will close this. Thanks!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Closing this issue as it seems to be solved :smile: <|||||>> Oh yes, this works indeed. Thanks! It'd be great to have a meaningful error message though, is not at all evident.
Mine does not work still with distilbert tokenizer<|||||>@aiendeveloper , that would be super helpful if you can share with us your environment info (that you can get with the `transformers-cli env` command). Thank you!<|||||>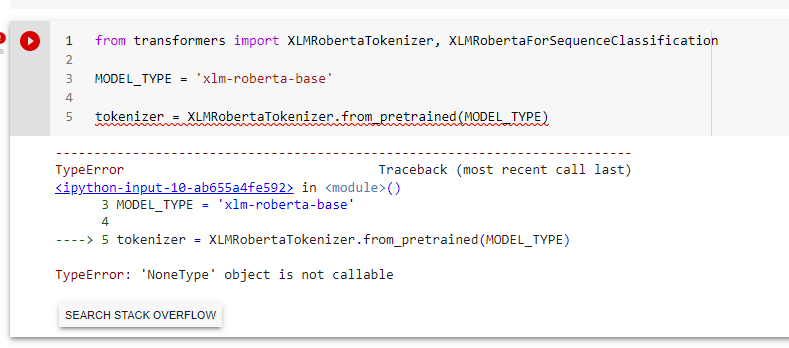
I am getting this error for xlm-roberta-base model. Any help will be very helpful.<|||||>@tanuj2212, My hunch is that you are missing the `sentencepiece` dependency. Could you check if you don't have it in your virtual environment or install it with for example `pip install sentencepiece`?
What version of `transformers` are you using? I would have expected you to get the following message the first time you tried to use `XLMRobertaTokenizer` :
```bash
XLMRobertaTokenizer requires the SentencePiece library but it was not found in your environment. Checkout the instructions on the
installation page of its repo: https://github.com/google/sentencepiece#installation and follow the ones
that match your environment.
```<|||||>I am having the same issue with T5Tokenizer - I have installed sentencepiece and I still get the NoneType error. I am working on a Google Colab file and here is my environment info from the `transformers-cli env` command:
- `transformers` version: 4.24.0
- Platform: Linux-5.10.133+-x86_64-with-glibc2.27
- Python version: 3.8.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.12.1+cu113 (False)
- Tensorflow version (GPU?): 2.9.2 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
Also, `pip install sentencepiece` gave the following output: `Successfully installed sentencepiece-0.1.97`<|||||>What I found it works perfectly with the CPU, this problem arises with GPU. <|||||>I ran my code in colab and on the first try it also gave the same error. But then I restarted the runtime, then it worked.<|||||>@tianshuailu same thing, restarting the kernel worked. Pretty buggy I would say.<|||||>I am also getting the same error message even though I have sentencepiece installed<|||||>Friendly ping to @ArthurZucker <|||||>Hey @91jpark19 could you share the settings in which this is happening or a notebook?
I can't reproduce any of the errors. See this notebook:
https://colab.research.google.com/drive/1RFdXqNwA-kdyx0S_ALRrGzZMR8dk48Ie?usp=sharing
|
transformers | 15,843 | closed | Fixing the timestamps with chunking. | # What does this PR do?
This PR fixes #15840
- Have to change the tokenization word state machine. With chunking we can have 2 chunks
being concatenated, both containing a separate space. Hopefully this code is readable enough.
- Refactored things to keep more alignment on CTC vs CTC_WITH_LM.
- Removed a bunch of code (no more `apply_stride`).
- Added `align_to` mecanism to make sure `stride` is aligned on token space so
that we don't have rounding errors that make an extra stride creep, and mess up the
timestamps.
- I tested 10s chunking on a 36mn long file and the last timings held ot the second at least, so it seems to be good. ~There is still potential room for accumulation of error. Since ctc use convolution to downsample for sample space to logits space, It is regular the `logits_shape * inputs_to_logits_ratio` != `input_shape`. Even when everything is aligned. It seems the real formula is `(logits_shape + 1) * inputs_to_logits_ratio` != `input_shape`. That means the ratio might be slightly off and the resulting timestamps could be shifted.~
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | 02-28-2022 08:09:21 | 02-28-2022 08:09:21 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15843). All of your documentation changes will be reflected on that endpoint.<|||||>```
RUN_SLOW=1 RUN_PIPELINE_TESTS=1 pytest -sv tests/pipelines/test_pipelines_automatic_speech_recognition.py
Results (614.95s):
22 passed
8 skipped
```<|||||>Merging since slow tests are good. |
transformers | 15,842 | closed | Output embedding from each self-attention head from each encoder layer | Hi there!
I wanted the embeddings from each self-attention head of each encoder layer for one of my projects, is this possible with the hugging face library?
If not, can I just slice the original embeddings from each layer (suppose 768/12 = 128 size slice) to get the attention head output?
Thank You | 02-28-2022 07:42:55 | 02-28-2022 07:42:55 | Hi @Sreyan88 ! The best place to ask this question is [the forum](https://discuss.huggingface.co/). We use issues for bug reports and feature requests. Thank you! |
transformers | 15,841 | closed | Make Flax pt-flax equivalence test more aggressive | # What does this PR do?
Make Flax pt-flax equivalence test more aggressive. (Similar to #15839 for PT/TF).
It uses `output_hidden_states=True` and `output_attentions=True` to test all output tensors (in a recursive way).
Also, it lowers the tolerance from `4e-2` to `1e-5`. (From the experience I gained in PT/TF test, if an error > `1e-5`, I always found a bug to fix).
(A bit) surprisingly, but very good news: unlike PT/TF, there is no PT/Flax inconsistency found by this more aggressive test! (@patil-suraj must have done a great job on flax models :-) )
Flax: @patil-suraj @patrickvonplaten
| 02-27-2022 12:05:32 | 02-27-2022 12:05:32 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15841). All of your documentation changes will be reflected on that endpoint.<|||||>Also very surprised that the tests are all passing. @ydshieh - can you double check that the tests are actually passing for most models. Some edge-case models that could be tested locally:
- BigBird
- Pegagus
- GPT2<|||||>@patil-suraj @patrickvonplaten
There are a few things to fix in this PR (same for the PT/TF) - some tests are just ignored by my mistakes.
I will let you know once I fix them.<|||||>**[Updated Info.]**
- The (more aggressive) PT/TF test is merged to `master`
- I fixed some bugs for this new PT/Flax test
- There are 10 failures
- 6 have `very large` difference between PT/Flax ( > `1.8`) --> I will check if I can fix them easily
- 4 have `large` difference (0.01 ~ 0.05) --> Need to verify if these are expected
<|||||>> * 6 have `very large` difference between PT/Flax ( > `1.8`) --> I will check if I can fix them easily
> * 4 have `large` difference (0.01 ~ 0.05) --> Need to verify if these are expected
~~Good news! Once #16167 and #16168 are merged, this more aggressive PT/Flax test will pass with `1e-5` on `CPU`. I will test with `GPU` later.~~
Sorry, but please ignore the above claim. The tests ran flax models on CPU because the GPU version of Jax/Flax were not installed.
----
Running on `GPU` with `1e-5` also passes! (run 3 times per model class)<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Update:
After rebasing on a more recent commit on master (`5a6b3ccd28a320bcde85190b0853ade385bd4158`), this test with `1e-5` work fine!
I ran this new test on GPU (inside docker container that we use for CI GPU testing + with `jax==0.3.0`). The only errors I got is
- Flax/Jax `failed to determine best cudnn convolution algorithm for ...`
- Need to find out the cause eventually.
Think this PR is ready! @patil-suraj @patrickvonplaten
(After installing `jax[cuda11_cudnn805]` instead of `jax[cuda11_cudnn82]`, the errors listed below no longer appear)
----
## Error logs
```
FAILED tests/beit/test_modeling_flax_beit.py::FlaxBeitModelTest::test_equivalence_flax_to_pt - RuntimeError: UNKNOWN: Failed to determine best cudnn convolution algorithm for:
FAILED tests/clip/test_modeling_flax_clip.py::FlaxCLIPVisionModelTest::test_equivalence_flax_to_pt - RuntimeError: UNKNOWN: Failed to determine best cudnn convolution algorithm for:
FAILED tests/clip/test_modeling_flax_clip.py::FlaxCLIPModelTest::test_equivalence_flax_to_pt - RuntimeError: UNKNOWN: Failed to determine best cudnn convolution algorithm for:
FAILED tests/vit/test_modeling_flax_vit.py::FlaxViTModelTest::test_equivalence_flax_to_pt - RuntimeError: UNKNOWN: Failed to determine best cudnn convolution algorithm for:
FAILED tests/wav2vec2/test_modeling_flax_wav2vec2.py::FlaxWav2Vec2ModelTest::test_equivalence_flax_to_pt - RuntimeError: UNKNOWN: Failed to determine best cudnn convolution algorithm for:
```<|||||>It's all green! I will approve my own PR too: LGTM! |
transformers | 15,840 | closed | Timestamps in AutomaticSpeechRecognitionPipeline not aligned in sample space | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.17.0.dev0
- Platform: Linux-5.10.98-1-MANJARO-x86_64-with-glibc2.33
- Python version: 3.9.8
- PyTorch version (GPU?): 1.10.2+cpu (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.4.0 (cpu)
- Jax version: 0.3.1
- JaxLib version: 0.3.0
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@Narsil
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- ALBERT, BERT, XLM, DeBERTa, DeBERTa-v2, ELECTRA, MobileBert, SqueezeBert: @LysandreJik
- T5, BART, Marian, Pegasus, EncoderDecoder: @patrickvonplaten
- Blenderbot, MBART: @patil-suraj
- Longformer, Reformer, TransfoXL, XLNet, FNet, BigBird: @patrickvonplaten
- FSMT: @stas00
- Funnel: @sgugger
- GPT-2, GPT: @patrickvonplaten, @LysandreJik
- RAG, DPR: @patrickvonplaten, @lhoestq
- TensorFlow: @Rocketknight1
- JAX/Flax: @patil-suraj
- TAPAS, LayoutLM, LayoutLMv2, LUKE, ViT, BEiT, DEiT, DETR, CANINE: @NielsRogge
- GPT-Neo, GPT-J, CLIP: @patil-suraj
- Wav2Vec2, HuBERT, SpeechEncoderDecoder, UniSpeech, UniSpeechSAT, SEW, SEW-D, Speech2Text: @patrickvonplaten, @anton-l
If the model isn't in the list, ping @LysandreJik who will redirect you to the correct contributor.
Library:
- Benchmarks: @patrickvonplaten
- Deepspeed: @stas00
- Ray/raytune: @richardliaw, @amogkam
- Text generation: @patrickvonplaten @narsil
- Tokenizers: @SaulLu
- Trainer: @sgugger
- Pipelines: @Narsil
- Speech: @patrickvonplaten, @anton-l
- Vision: @NielsRogge, @sgugger
Documentation: @sgugger
Model hub:
- for issues with a model, report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
For research projetcs, please ping the contributor directly. For example, on the following projects:
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Issue
Generating timestamps in the `AutomaticSpeechRecognitionPipeline` does not match the timestamps generated from `Wav2Vec2CTCTokenizer.decode()`. The timestamps from the pipeline are exceeding the duration of the audio signal because of the strides.
## Expected behavior
Generating timestamps using the pipeline gives the following prediction IDs and offsets:
```python
pred_ids=array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 12, 14, 14, 0, 0,
0, 22, 11, 0, 7, 4, 15, 16, 0, 0, 4, 17, 5, 7, 7, 4, 4,
14, 14, 18, 18, 15, 4, 4, 0, 7, 5, 0, 0, 13, 0, 9, 0, 0,
0, 8, 0, 11, 11, 0, 0, 0, 27, 4, 4, 0, 23, 0, 16, 0, 5,
7, 7, 0, 25, 25, 0, 0, 22, 7, 7, 11, 0, 0, 0, 10, 10, 0,
0, 8, 0, 5, 5, 0, 0, 19, 19, 0, 4, 4, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 6, 4, 4, 0, 25, 0,
14, 14, 16, 0, 0, 0, 0, 10, 9, 9, 0, 0, 0, 0, 25, 0, 0,
0, 0, 0, 26, 26, 16, 12, 12, 0, 0, 0, 19, 0, 5, 0, 8, 8,
4, 4, 27, 0, 16, 0, 0, 4, 4, 0, 3, 3, 0, 0, 0, 0, 0,
0, 0, 0, 4, 4, 17, 11, 11, 13, 0, 13, 11, 14, 16, 16, 0, 6,
5, 6, 6, 4, 0, 5, 5, 16, 16, 0, 0, 7, 14, 0, 0, 4, 4,
12, 5, 0, 0, 0, 26, 0, 13, 14, 0, 0, 0, 0, 23, 0, 0, 21,
11, 11, 11, 0, 5, 5, 5, 7, 7, 0, 8, 0, 4, 4, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 12, 21, 11, 11, 11, 0, 4, 4, 0, 0, 12, 11, 11, 0, 0, 0,
0, 0, 7, 7, 5, 5, 0, 0, 0, 0, 23, 0, 0, 8, 0, 0, 4,
4, 0, 0, 0, 0, 12, 5, 0, 0, 4, 4, 10, 0, 0, 24, 14, 14,
0, 7, 7, 0, 8, 8, 10, 10, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 26, 0, 5, 0, 0, 0, 20, 0, 5, 0,
0, 5, 5, 0, 0, 19, 16, 16, 0, 6, 6, 19, 0, 5, 6, 6, 4,
4, 0, 14, 18, 18, 15, 4, 4, 0, 0, 25, 25, 0, 5, 4, 4, 19,
16, 8, 8, 0, 8, 8, 4, 4, 0, 23, 23, 0, 14, 17, 17, 0, 0,
17, 0, 5, 6, 6, 4, 4])
decoded['word_offsets']=[{'word': 'dofir', 'start_offset': 12, 'end_offset': 22}, {'word': 'hu', 'start_offset': 23, 'end_offset': 25}, {'word': 'mer', 'start_offset': 28, 'end_offset': 32
}, {'word': 'och', 'start_offset': 34, 'end_offset': 39}, {'word': 'relativ', 'start_offset': 42, 'end_offset': 60}, {'word': 'kuerzfristeg', 'start_offset': 63, 'end_offset': 94}, {'word'
: 'en', 'start_offset': 128, 'end_offset': 131}, {'word': 'zousazbudget', 'start_offset': 134, 'end_offset': 170}, {'word': 'vu', 'start_offset': 172, 'end_offset': 175}, {'word': '<unk>',
'start_offset': 180, 'end_offset': 182}, {'word': 'milliounen', 'start_offset': 192, 'end_offset': 207}, {'word': 'euro', 'start_offset': 209, 'end_offset': 217}, {'word': 'deblokéiert',
'start_offset': 221, 'end_offset': 249}, {'word': 'déi', 'start_offset': 273, 'end_offset': 278}, {'word': 'direkt', 'start_offset': 283, 'end_offset': 303}, {'word': 'de', 'start_offset': 311, 'end_offset': 313},
{'word': 'sportsbeweegungen', 'start_offset': 317, 'end_offset': 492}, {'word': 'och', 'start_offset': 495, 'end_offset': 499}, {'word': 'ze', 'start_offset': 503, 'end_offset': 507}, {'word': 'gutt', 'start_offset': 509, 'end_offset': 516},
{'word': 'kommen', 'start_offset': 519, 'end_offset': 532}]
```
However, the following is computed using `Wav2Vec2CTCTokenizer.decode()` and these offsets are expected:
```python
pred_ids=tensor([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 12, 14, 14, 0, 0, 0,
22, 11, 0, 7, 4, 15, 16, 0, 0, 4, 17, 5, 7, 7, 4, 0, 14, 14,
18, 18, 15, 4, 4, 0, 7, 5, 0, 0, 13, 0, 9, 0, 0, 0, 8, 0,
11, 11, 0, 0, 0, 27, 4, 4, 0, 23, 0, 16, 0, 5, 7, 7, 0, 25,
25, 0, 0, 22, 7, 7, 11, 0, 0, 0, 10, 10, 0, 0, 8, 0, 5, 5,
0, 0, 19, 19, 0, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 5, 0, 6, 4, 4, 0, 25, 0, 14, 14, 16, 0, 0, 0, 0, 10,
9, 9, 0, 0, 0, 0, 25, 0, 0, 0, 0, 0, 26, 26, 16, 12, 12, 0,
0, 0, 19, 0, 5, 0, 8, 8, 4, 4, 27, 0, 16, 0, 0, 4, 4, 0,
3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 4, 4, 17, 11, 11, 13, 0, 13,
11, 14, 16, 16, 0, 6, 5, 6, 6, 4, 0, 5, 5, 16, 16, 0, 0, 7,
14, 0, 0, 4, 4, 12, 5, 0, 0, 0, 26, 0, 13, 14, 0, 0, 0, 0,
23, 0, 0, 21, 11, 11, 11, 0, 5, 5, 5, 7, 7, 0, 8, 0, 4, 4,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 12, 21, 11, 11, 11, 0, 4, 4, 0, 0, 12, 11, 11, 0, 0,
0, 0, 0, 7, 7, 5, 5, 0, 0, 0, 0, 23, 0, 0, 8, 0, 0, 4,
4, 0, 0, 0, 0, 12, 5, 0, 0, 4, 4, 10, 0, 0, 24, 14, 14, 0,
7, 7, 0, 8, 8, 10, 10, 0, 0, 0, 26, 5, 5, 0, 0, 0, 20, 5,
0, 0, 0, 5, 0, 0, 19, 0, 16, 16, 6, 6, 19, 19, 5, 5, 6, 6,
4, 0, 14, 0, 18, 15, 15, 4, 4, 0, 0, 25, 0, 16, 0, 4, 4, 19,
16, 8, 0, 0, 8, 0, 4, 0, 0, 23, 0, 14, 0, 17, 0, 0, 0, 17,
5, 5, 6, 6, 4, 4])
word_offsets=[{'word': 'dofir', 'start_offset': 12, 'end_offset': 22}, {'word': 'hu', 'start_offset': 23, 'end_offset': 25}, {'word': 'mer', 'start_offset': 28, 'end_offset': 32}, {'word': 'och', 'start_offset': 34, 'end_offset': 39}, {'word': 'relativ', 'start_offset': 42, 'end_offset': 60}, {'word': 'kuerzfristeg', 'start_offset': 63, 'end_offset': 94}, {'word': 'en', 'start_offset': 128, 'end_offset': 131}, {'word': 'zousazbudget', 'start_offset': 134, 'end_offset': 170}, {'word': 'vu', 'start_offset': 172, 'end_offset': 175}, {'word': '<unk>', 'start_offset': 180, 'end_offset': 182}, {'word': 'milliounen', 'start_offset': 192, 'end_offset': 207}, {'word': 'euro', 'start_offset': 209, 'end_offset': 217}, {'word': 'deblokéiert', 'start_offset': 221, 'end_offset': 249}, {'word': 'déi', 'start_offset': 273, 'end_offset': 278}, {'word': 'direkt', 'start_offset': 283, 'end_offset': 303}, {'word': 'de', 'start_offset': 311, 'end_offset': 313}, {'word': 'sportsbeweegungen', 'start_offset': 317, 'end_offset': 360}, {'word': 'och', 'start_offset': 362, 'end_offset': 367}, {'word': 'zu', 'start_offset': 371, 'end_offset': 374}, {'word': 'gutt', 'start_offset': 377, 'end_offset': 383}, {'word': 'kommen', 'start_offset': 387, 'end_offset': 400}]
```
## Potential Fix
A fix could be removing the strides instead of filling them with `first_letter` and `last_letter` in `apply_stride()`:
```python
def apply_stride(tokens, stride):
input_n, left, right = rescale_stride(tokens, stride)[0]
left_token = left
right_token = input_n - right
return tokens[:, left_token:right_token]
```
<!-- A clear and concise description of what you would expect to happen. -->
| 02-26-2022 21:50:50 | 02-26-2022 21:50:50 | Hi @lemswasabi ,
Thanks for the report. We unfortunately cannot drop the stride as when there's batching involved, the tensors cannot be of different shapes. We can however keep track of the stride and fix the timestamps.
I'll submit a patch tomorrow probably.<|||||>Hi @Narsil,
Thanks for having a look at it.<|||||>@lemswasabi , in the end I aligned most of the code closer to what `ctc_with_lm` did (dropping the stride in the postprocess method as I said, we can't in _forward).
There could still be some slight issue with timings, so the PR is not necessarily finished<|||||>@Narsil, I understand that dropping the stride has to be done in the postprocess method. I tested your patch and it works as expected now.<|||||>Great ! Please let us know if there's any further issue, ctc_with_lm coming right up :D |
transformers | 15,839 | closed | Make TF pt-tf equivalence test more aggressive | # What does this PR do?
Make TF pt-tf equivalence test more aggressive.
After a series of fixes done so far, I think it is a good time to include this more aggressive testing in `master` branch.
(Otherwise, the new models added might have undetected issues. For example, the recent `TFConvNextModel` would have `hidden_states` not transposed to match Pytorch version issue - I tested it on my local branch and informed the author to fix it).
There are still 3 categories of PT/TF inconsistency to address, but they are less urgent in my opinion. See below.
Currently, the test makes a few exception to not test these 3 cases (in order to get green test) - I add `TODO` comments in the code.
TF: @Rocketknight1 @gante
Test: @LysandreJik @sgugger
## TODO in separate PRs
- failing due to the difference of large negative values (used for attn mask) between PT/TF:
- https://circleci.com/api/v1.1/project/github/huggingface/transformers/379126/output/112/0?file=true&allocation-id=621b51ac72134246517cac0c-0-build%2F6E4C1534
- albert, convbert, speech_to_text, t5, tapas
- failing due to cache format difference between PT/TF:
- https://app.circleci.com/pipelines/github/huggingface/transformers/35203/workflows/d0c0fbb4-661b-4a61-96e7-2fd4a3249f44/jobs/379098/parallel-runs/0/steps/0-112
- gpt2, t5, speech_to_text
- failing due to outputting loss or not between PT/TF:
- https://app.circleci.com/pipelines/github/huggingface/transformers/35206/workflows/d2533f38-6877-4db5-9eb6-da92e6421e11/jobs/379144/parallel-runs/0/steps/0-112
- flaubert, funnel, transfo_xl, xlm | 02-26-2022 17:05:21 | 02-26-2022 17:05:21 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15839). All of your documentation changes will be reflected on that endpoint.<|||||>> Thank you for your time spent making this better! Two questions:
>
> * Does it run on GPU?
For now, I haven't tested it with GPU. I can run it on the office's GPU machine this week (a good chance to learn how to connect to those machine!)
> * How long does it take to run? Our test suite is already taking a significant time to run, so aiming for common tests that run as fast as possible is important.
Let me measure the timing of this test with the current master and with this PR. Will report it.
>
>
> There's quite a bit of model-specific logic which I'm not particularly enthusiastic about (pre-training models + convnext), but I understand why it's rigorous to do it like that here.
(Yeah, once we fix all the inconsistency, we can remove all these exceptional conditions.)<|||||>Good news! Testing on single GPU with the small tolerance `1e-5` still works! All models pass `test_pt_tf_model_equivalence`.
(I forgot to install CUDA driver - and I'm glad I double-checked and fixed this silly mistake :-) )
I will address a few style review suggestions. After that, I think it's ready to merge ..?<|||||>It's weird that it took more time when you expected it to take less, no? Can you try running the test suite with `--durations=0` to see all the tests and the time it took for them to run? <|||||>After a thorough verification and a few fixes, this PR is ready (again) from my side.
I would love @sgugger (and @LysandreJik when he is back) to check it again, and @gante & @Rocketknight1 if they want (no particular TF-related change compared to the last commit).
The following summary might save some review (again) time
- **Main fixes** (since the last review):
- In the last commit, the following line forgot to use `to_tuple()`, and the method `check_output` (previous version) only deal with `tuple` or `tensor`. So half test cases passed just because no check was performed at all. (my bad ...).
https://github.com/huggingface/transformers/blob/6f2025054dc49a42dc3de82cbea22f2a5913f122/tests/test_modeling_tf_common.py#L447
This is fixed now, and also `check_output` now raises error if a result is not tested (if its type is not in `[tuple, list, tensor]`).
- In the last commit, I accidentally deleted the following test case (`check the results after save/load checkpoints`, which exists on the current `master`).
https://github.com/huggingface/transformers/blob/6f2025054dc49a42dc3de82cbea22f2a5913f122/tests/test_modeling_tf_common.py#L576
This is added back now.
- Make the test also run on GPU (put models/inputs on the correct device)
- **Style changes**
- Since I have to add back the accidentally deleted test cases , I added `check_pt_tf_models` to avoid duplicated large code block.
- `tfo` -> `tf_outputs` and `pto` -> `pt_outputs`
- no need to use `np.copy` in [here](https://github.com/huggingface/transformers/blob/e9555ea9c75c3fb2741e27a1be7c2240ce8395f2/tests/test_modeling_tf_common.py#L406), which was discussed in [a comment](https://github.com/huggingface/transformers/pull/15256#discussion_r791942224).
I run this new version of test, and with the small tolerance `1e-5`, it pass both on CPU and GPU :tada:!
In order to be super sure, I also ran it on CPU/GPU for 100 times (very aggressive :fire: :fire: )! All models passed for this test, except for:
- `TFSpeech2TextModel`: this is addressed in #15952
- (`TFHubertModel`): There is 1 among 300 runs on CPU where I got a diff > 1e-5. I ran it 10000 times again, and still got only 1 such occurrence. (Guess it's OK to set `1e-5` in this case.)
Regarding the running time, I will measure it and post the results in the next comment.<|||||>In terms of running time:
- Circle CI
- current : [56.11s](https://circleci.com/api/v1.1/project/github/huggingface/transformers/384755/output/112/0?file=true&allocation-id=62238c1d4f148c1110a1efa8-0-build%2F1610CB69)
- this PR : [61.21s](https://circleci.com/api/v1.1/project/github/huggingface/transformers/384731/output/112/0?file=true&allocation-id=622385347ccc3f3894ec7697-0-build%2F351FF724)
- GCP VM (with `-n 1` + CPU)
- current : 178.75s
- this PR : 200.81s
These suggest an increase by roughly 10%.<|||||>I think I made a mistake that ~~TF 2.8 doesn't work with CUDA 11.4 (installed on my GCP VM machine)~~ K80 GPU doesn't work well with Ubuntu 20.04 (regarding the drivers and CUDA), and it fallbacks to CPU instead. I will fix this and re-run the tests.<|||||>After using Tesla T4 GPU (same as for the CI GPU testings), I confirmed that this aggressive PT/TF equivalence test passes with `1e-5` when running on GPU!
I ran this test **1000** times (on GPU) for each TF models.
Think it's ready if @LysandreJik is happy with the [slightly(?) increased running time](https://github.com/huggingface/transformers/pull/15839#issuecomment-1059791405).
(I saved all the differences. I can share the values if you would like to see them!) |
transformers | 15,838 | closed | Issue running run_glue.py at test time | Hi,
I'm using [this script](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) to train a model on my own dataset.
(transformers 4.15.0, datasets 1.17.0, python3.7)
I'm doing single sentence classification, and my CSV files have 2 cols: label, sentence1
I can run the script with no issue when --do_train --do_eval --do_predict are true.
However, later, when I use the same test set used when training, but this time with only "--do_predict" on one of the checkpoints of the models I previously trained, I get the following error:
> File "/lib/python3.7/site-packages/datasets/arrow_writer.py", line 473, in <listcomp>
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "pyarrow/table.pxi", line 1339, in pyarrow.lib.Table.__getitem__
File "pyarrow/table.pxi", line 1900, in pyarrow.lib.Table.column
File "pyarrow/table.pxi", line 1875, in pyarrow.lib.Table._ensure_integer_index
KeyError: 'Field "sentence2" does not exist in table schema'
I would appreciate any tips on how to fix this, thanks!
| 02-25-2022 18:59:41 | 02-25-2022 18:59:41 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,837 | closed | Problems with convert_blenderbot_original_pytorch_checkpoint_to_pytorch.py | I am trying to use `the convert_blenderbot_original_pytorch_checkpoint_to_pytorch.py` script to convert a finetuned ParlAI Blenderbot-1B-distill model. I call it this way:
```python convert.py --src_path model --hf_config_json config.json```
Where the `config.json` file is downloaded from the HuggingFace repository. Unfortunately, I get the following error:
```
raceback (most recent call last):
File "C:\Users\micha\Documents\Chatbot\AI\persona3\convert.py", line 114, in <module>
convert_parlai_checkpoint(args.src_path, args.save_dir, args.hf_config_json)
File "C:\Users\micha\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Users\micha\Documents\Chatbot\AI\persona3\convert.py", line 99, in convert_parlai_checkpoint
rename_layernorm_keys(sd)
File "C:\Users\micha\Documents\Chatbot\AI\persona3\convert.py", line 68, in rename_layernorm_keys
v = sd.pop(k)
KeyError: 'model.encoder.layernorm_embedding.weight'
```
And after commenting lines 98 and 99 of the script, it gives a further error:
```
raceback (most recent call last):
File "C:\Users\micha\Documents\Chatbot\AI\persona3\convert.py", line 114, in <module>
convert_parlai_checkpoint(args.src_path, args.save_dir, args.hf_config_json)
File "C:\Users\micha\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Users\micha\Documents\Chatbot\AI\persona3\convert.py", line 100, in convert_parlai_checkpoint
m.model.load_state_dict(mapping, strict=True)
File "C:\Users\micha\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\nn\modules\module.py", line 1497, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for BartModel:
size mismatch for encoder.embed_positions.weight: copying a param with shape torch.Size([128, 2560]) from checkpoint, the shape in current model is torch.Size([130, 2560]).
size mismatch for decoder.embed_positions.weight: copying a param with shape torch.Size([128, 2560]) from checkpoint, the shape in current model is torch.Size([130, 2560]).
```
I tried changing `BartConfig` to `BlenderbotConfig` and `BartForConditionalGeneration` to `BlenderbotForConditionalGeneration` but then it gives still another error:
```
Traceback (most recent call last):
File "C:\Users\micha\Documents\Chatbot\AI\persona3\convert.py", line 114, in <module>
convert_parlai_checkpoint(args.src_path, args.save_dir, args.hf_config_json)
File "C:\Users\micha\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Users\micha\Documents\Chatbot\AI\persona3\convert.py", line 100, in convert_parlai_checkpoint
m.model.load_state_dict(mapping, strict=True)
File "C:\Users\micha\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\nn\modules\module.py", line 1497, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for BlenderbotModel:
Missing key(s) in state_dict: "encoder.layer_norm.weight", "encoder.layer_norm.bias", "decoder.layer_norm.weight", "decoder.layer_norm.bias".
```
I changed `strict=True` to `strict=False` and commented out lines 98 & 99 and the script was finally executed, but I am not sure if this is the correct way. I would appreciate help in making the script work as intended.
| 02-25-2022 18:00:47 | 02-25-2022 18:00:47 | Hi @MichalPleban ! The blenderbot conversion script has not been updated in a long time. It should actually blenderbot classes instead of bart. Feel free to open a PR to fix this if you are interested. Happy to help! <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,836 | closed | Inference for multilingual models | This PR updates the multilingual model docs to include M2M100 and MBart whose inference usage is different (basically forcing the `bos` token as the target language id). Let me know if I'm missing any other multilingual models that have a different method for inference! :)
Other notes:
- Moved this doc to the How-to guide section because it seems like it is more of an intermediate-level topic.
- Changed a section heading because the ampersand wasn't being properly displayed in the right navbar:

| 02-25-2022 17:52:34 | 02-25-2022 17:52:34 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15836). All of your documentation changes will be reflected on that endpoint. |
transformers | 15,835 | closed | [FlaxT5 Example] Fix flax t5 example pretraining | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #12755 . 0 can be a pad_token that occurs in the text
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-25-2022 17:46:46 | 02-25-2022 17:46:46 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15835). All of your documentation changes will be reflected on that endpoint.<|||||>Gently pinging @stefan-it and @yhavinga here<|||||>Ok merging now - would love to get some feedback if this fixes the problem :-)<|||||>I just tested the fix and the reshape error is gone! Thanks @patrickvonplaten ! |
transformers | 15,834 | closed | Embedding index getting out of range while running onlplab/alephbert-base model | ## Environment info
- Platform: Google colab
## Information
Model I am using: 'onlplab/alephbert-base'
The problem arises when using:
[* ] the official example scripts:
I tried to implement the code written in your official course (https://huggingface.co/course/chapter7/7?fw=pt)
When the only change I want to make is to replace the model with an 'onlplab/alephbert-base'.
I mean I want to do a finetuning question answering to the 'onlplab/alephbert-base'.
The tasks I am working on is:
[ *] an official task: SQUaD
## To reproduce
Steps to reproduce the behavior:
1.Run the script:
!pip install datasets transformers[sentencepiece]
!pip install accelerate
!apt install git-lfs
from huggingface_hub import notebook_login
from datasets import load_dataset
from transformers import AutoTokenizer,BertTokenizerFast
from transformers import AutoModelForQuestionAnswering, BertForQuestionAnswering
import collections
import numpy as np
from datasets import load_metric
from tqdm.auto import tqdm
from transformers import TrainingArguments
from transformers import Trainer
from transformers import pipeline
import torch
raw_datasets = load_dataset("squad")
raw_datasets["train"].filter(lambda x: len(x["answers"]["text"]) != 1)
# model_checkpoint = "bert-base-cased"
model_checkpoint = "onlplab/alephbert-base"
# tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
tokenizer = BertTokenizerFast.from_pretrained(model_checkpoint)
context = raw_datasets["train"][0]["context"]
question = raw_datasets["train"][0]["question"]
inputs = tokenizer(question, context)
tokenizer.decode(inputs["input_ids"])
max_length = 384
stride = 128
def preprocess_training_examples(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=max_length,
truncation="only_second",
stride=stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
offset_mapping = inputs.pop("offset_mapping")
sample_map = inputs.pop("overflow_to_sample_mapping")
answers = examples["answers"]
start_positions = []
end_positions = []
for i, offset in enumerate(offset_mapping):
sample_idx = sample_map[i]
answer = answers[sample_idx]
start_char = answer["answer_start"][0]
end_char = answer["answer_start"][0] + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
# Find the start and end of the context
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
# If the answer is not fully inside the context, label is (0, 0)
if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
start_positions.append(0)
end_positions.append(0)
else:
# Otherwise it's the start and end token positions
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs
train_dataset = raw_datasets["train"].map(
preprocess_training_examples,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)
len(raw_datasets["train"]), len(train_dataset)
def preprocess_validation_examples(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=max_length,
truncation="only_second",
stride=stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
sample_map = inputs.pop("overflow_to_sample_mapping")
example_ids = []
for i in range(len(inputs["input_ids"])):
sample_idx = sample_map[i]
example_ids.append(examples["id"][sample_idx])
sequence_ids = inputs.sequence_ids(i)
offset = inputs["offset_mapping"][i]
inputs["offset_mapping"][i] = [
o if sequence_ids[k] == 1 else None for k, o in enumerate(offset)
]
inputs["example_id"] = example_ids
return inputs
validation_dataset = raw_datasets["validation"].map(
preprocess_validation_examples,
batched=True,
remove_columns=raw_datasets["validation"].column_names,
)
len(raw_datasets["validation"]), len(validation_dataset)
metric = load_metric("squad")
n_best = 20
max_answer_length = 30
def compute_metrics(start_logits, end_logits, features, examples):
example_to_features = collections.defaultdict(list)
for idx, feature in enumerate(features):
example_to_features[feature["example_id"]].append(idx)
predicted_answers = []
for example in tqdm(examples):
example_id = example["id"]
context = example["context"]
answers = []
# Loop through all features associated with that example
for feature_index in example_to_features[example_id]:
start_logit = start_logits[feature_index]
end_logit = end_logits[feature_index]
offsets = features[feature_index]["offset_mapping"]
start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist()
end_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Skip answers that are not fully in the context
if offsets[start_index] is None or offsets[end_index] is None:
continue
# Skip answers with a length that is either < 0 or > max_answer_length
if (
end_index < start_index
or end_index - start_index + 1 > max_answer_length
):
continue
answer = {
"text": context[offsets[start_index][0] : offsets[end_index][1]],
"logit_score": start_logit[start_index] + end_logit[end_index],
}
answers.append(answer)
# Select the answer with the best score
if len(answers) > 0:
best_answer = max(answers, key=lambda x: x["logit_score"])
predicted_answers.append(
{"id": example_id, "prediction_text": best_answer["text"]}
)
else:
predicted_answers.append({"id": example_id, "prediction_text": ""})
theoretical_answers = [{"id": ex["id"], "answers": ex["answers"]} for ex in examples]
return metric.compute(predictions=predicted_answers, references=theoretical_answers)
# model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
model = BertForQuestionAnswering.from_pretrained(model_checkpoint)
args = TrainingArguments(
"alephbert-finetuned-squad",
evaluation_strategy="no",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
fp16=False,
push_to_hub=False, #TODO enable it if we eant push to hub
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=validation_dataset,
tokenizer=tokenizer,
)
trainer.train() #TODO enable it if we want to train
predictions, _ = trainer.predict(validation_dataset)
start_logits, end_logits = predictions
compute_metrics(start_logits, end_logits, validation_dataset, raw_datasets["validation"])
# Save the model
output_dir = "aleph_bert-finetuned-squad"
trainer.save_model(output_dir)
# Replace this with your own checkpoint
#model_checkpoint = "huggingface-course/bert-finetuned-squad"
model_checkpoint=output_dir
question_answerer = pipeline("question-answering", model=model_checkpoint)
context = """
🤗 Transformers is backed by the three most popular deep learning libraries — Jax, PyTorch and TensorFlow — with a seamless integration
between them. It's straightforward to train your models with one before loading them for inference with the other.
"""
question = "Which deep learning libraries back 🤗 Transformers?"
question_answerer(question=question, context=context)
2. The problem arises on trainer.train()
3. If i change the model back to Bert the code runs well.
4. I dont know what is the problem
Thanks
## Expected behavior
from: torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self
--> 211 trainer.train() #TODO enable it if we want to train
212
213 predictions, _ = trainer.predict(validation_dataset)
11 frames
[/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py](https://localhost:8080/#) in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
2042 # remove once script supports set_grad_enabled
2043 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)
-> 2044 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
2045
2046
IndexError: index out of range in self
[Question_answering_(PyTorch).zip](https://github.com/huggingface/transformers/files/8142807/Question_answering_.PyTorch.zip)
| 02-25-2022 16:40:48 | 02-25-2022 16:40:48 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,833 | closed | [examples/summarization and translation] fix readme | # What does this PR do?
Remove the `TASK_NAME` which is never used in the command.
cc @michaelbenayoun | 02-25-2022 14:51:34 | 02-25-2022 14:51:34 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,832 | closed | Adding Decision Transformer Model (WIP) | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Added the Decision Transformer Model to the transformers library (https://github.com/kzl/decision-transformer)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@LysandreJik
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-25-2022 14:43:27 | 02-25-2022 14:43:27 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,831 | closed | support new marian models | # What does this PR do?
This PR updates the Marian model:
1. To allow not sharing embeddings between encoder and decoder.
2. Allow tying only decoder embeddings with `lm_head`.
3. Separate two `vocabs` in `tokenizer` for `src` and `tgt` language
To support this, the PR introduces the following new methods:
- `get_decoder_input_embeddings` and `set_decoder_input_embeddings`
To get and set the decoder embeddings when the embeddings are not shared. These methods will raise an error if the embeddings are shared.
- `resize_decoder_token_embeddings`
To only resize the decoder embeddings. Will raise an error if the embeddings are shared.
This PR also adds two new config attributes to `MarianConfig`:
- `share_encoder_decoder_embeddings`: to indicate if emb should be shared or not
- `decoder_vocab_size`: to specify the vocab size for decoder when emb are not shared.
And the following methods from `PreTrainedModel` class are overridden to support these changes:
- `tie_weights`
- `_resize_token_embeddings`
Fixes #15109 | 02-25-2022 13:27:44 | 02-25-2022 13:27:44 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15831). All of your documentation changes will be reflected on that endpoint. |
transformers | 15,830 | closed | Re-enable doctests for task_summary | # What does this PR do?
This PR re-enables doctests for the task_summary. It should be merged after #15828 | 02-25-2022 12:28:23 | 02-25-2022 12:28:23 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,829 | closed | BART model parameters should not contain biases for Q, K and V | ## Environment info
- `transformers` version: 4.16.2
- Platform: Linux-5.11.0-1018-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.10.2+cu102 (False)
- Tensorflow version (GPU?): 2.7.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.4.0 (cpu)
- Jax version: 0.3.0
- JaxLib version: 0.3.0
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help
@patrickvonplaten
## Information
Model I am using: BART
## To reproduce
Steps to reproduce the behavior:
```python
>>> from transformers import FlaxBartForConditionalGeneration
>>> import jax.numpy as np
>>> model = FlaxBartForConditionalGeneration.from_pretrained('facebook/bart-base', dtype=np.bfloat16)
>>> model.params['model']['decoder']['layers']['0']['encoder_attn']['q_proj']['bias']
DeviceArray([-6.86645508e-02, 3.71704102e-02, 3.40820312e-01,
-3.87451172e-01, 1.04980469e-01, -9.60693359e-02,
-2.45361328e-01, -1.50985718e-02, 2.50244141e-01,
-2.20581055e-01, 9.33074951e-03, 1.28295898e-01,
...
>>> model.params['model']['decoder']['layers']['0']['encoder_attn']['k_proj']['bias']
DeviceArray([-4.09317017e-03, 3.31687927e-03, 5.46646118e-03,
-9.59777832e-03, 4.63104248e-03, -4.14276123e-03,
-6.32858276e-03, -3.68309021e-03, 2.80380249e-03,
-2.85339355e-03, 1.19304657e-03, 1.88636780e-03,
...
>>> model.params['model']['decoder']['layers']['0']['encoder_attn']['v_proj']['bias']
DeviceArray([-6.41479492e-02, -5.52749634e-03, -4.86145020e-02,
5.64575195e-03, -6.95800781e-02, -2.50053406e-03,
6.31332397e-03, -1.13952637e-01, 8.81195068e-03,
4.99877930e-02, 1.15814209e-02, 8.41617584e-04,
...
```
## Expected behavior
The parameters should not contain biases for Q, K and V. However, it turns out that there exists non-zero biases for Q, K and V.
Reason:
> BART (https://arxiv.org/pdf/1910.13461.pdf): BART uses the standard sequence-to-sequence Transformer architecture from (Vaswani et al., 2017), except, following GPT, that we modify ReLU activation functions to GeLUs (Hendrycks & Gimpel, 2016) and initialise parameters from N (0, 0.02).
>
> Transformer (https://arxiv.org/pdf/1706.03762.pdf): In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V.
This proves that Q, K and V are **matrices** instead of **linear layers**. Therefore, they should not contain biases. | 02-25-2022 11:42:41 | 02-25-2022 11:42:41 | Hey @ayaka14732 !
Note that the original BART checkpoints use `bias` in Q, K, V layers.
> This proves that Q, K and V are matrices instead of linear layers. Therefore, they should not contain biases.
The weights of linear layers are also just matrices or for that matter, every layer weights in transformers are just matrices.<|||||>Hey @patil-suraj !
This should be very clear in the Transformer paper. There is a formula for scaled dot-product attention:

And for multi-head attention:

You can see the difference clearly if you compare them with the formula for feed-forward network:

Besides, if you read any of the Transformer tutorials online, they will say Q, K and V are three **matrices**. And there is a nice illustration for that (https://jalammar.github.io/illustrated-transformer/):

<|||||>Hey @ayaka14732, if you load the original BART checkpoints https://github.com/pytorch/fairseq/blob/main/examples/bart/README.md#pre-trained-models you will see that Q, K, and V have bias weights attached to them.<|||||>Thanks for pointing out!
I can confirm that the original BART checkpoints have bias weights attached to Q, K, and V.
```python
>>> import torch
>>> bart = torch.hub.load('pytorch/fairseq', 'bart.large')
>>> bart.model.encoder.layers[0].self_attn.k_proj.bias
Parameter containing:
tensor([-1.8740e-03, -2.8801e-03, -1.6394e-03, ..., -1.9321e-03,
-5.0664e-06, -3.0565e-04], requires_grad=True)
```
It should be somewhat concerned if any researcher wants to compare BART with their models, since BART would be in an advantageous position due to the extra parameters. |
transformers | 15,828 | closed | Re-enable doctests for the quicktour | # What does this PR do?
This PR re-enables the doctests for the quicktour. It shouldn't be merged without its [companion PR](https://github.com/huggingface/doc-builder/pull/112) on the doc-builder side to properly recognize the new framework split comment and to remove the doctest flags on some lines.
I've adapted the example applying the pipeline on the whole superb dataset because:
1. it was way too long
2. writing a custom generator using an object not documented and not even in the main init of Transformers is too advanced for the quicktour.
I've also update the guide for doctests. | 02-25-2022 10:12:49 | 02-25-2022 10:12:49 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,827 | closed | Absence | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- ALBERT, BERT, XLM, DeBERTa, DeBERTa-v2, ELECTRA, MobileBert, SqueezeBert: @LysandreJik
- T5, BART, Marian, Pegasus, EncoderDecoder: @patrickvonplaten
- Blenderbot, MBART: @patil-suraj
- Longformer, Reformer, TransfoXL, XLNet, FNet, BigBird: @patrickvonplaten
- FSMT: @stas00
- Funnel: @sgugger
- GPT-2, GPT: @patrickvonplaten, @LysandreJik
- RAG, DPR: @patrickvonplaten, @lhoestq
- TensorFlow: @Rocketknight1
- JAX/Flax: @patil-suraj
- TAPAS, LayoutLM, LayoutLMv2, LUKE, ViT, BEiT, DEiT, DETR, CANINE: @NielsRogge
- GPT-Neo, GPT-J, CLIP: @patil-suraj
- Wav2Vec2, HuBERT, SpeechEncoderDecoder, UniSpeech, UniSpeechSAT, SEW, SEW-D, Speech2Text: @patrickvonplaten, @anton-l
If the model isn't in the list, ping @LysandreJik who will redirect you to the correct contributor.
Library:
- Benchmarks: @patrickvonplaten
- Deepspeed: @stas00
- Ray/raytune: @richardliaw, @amogkam
- Text generation: @patrickvonplaten @narsil
- Tokenizers: @SaulLu
- Trainer: @sgugger
- Pipelines: @Narsil
- Speech: @patrickvonplaten, @anton-l
- Vision: @NielsRogge, @sgugger
Documentation: @sgugger
Model hub:
- for issues with a model, report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
For research projetcs, please ping the contributor directly. For example, on the following projects:
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| 02-25-2022 09:41:51 | 02-25-2022 09:41:51 | model_name = "Helsinki-NLP/opus-mt-en-roa"
tokenizer = MarianTokenizer.from_pretrained(model_name)
Error:"TypeError: 'NoneType' object is not callable"
<|||||>`MarianTokenizer` depends on `sentencepiece`. Make sure to install it before importing the tokenizer.
`pip install sentencepiece` should resolve this.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,826 | closed | Fix semantic segmentation pipeline test | # What does this PR do?
This fixes the pipeline test for semantic segmentation, which now fails as a consequence of the revert in #15722 | 02-25-2022 07:51:20 | 02-25-2022 07:51:20 | _The documentation is not available anymore as the PR was closed or merged._<|||||>I don't think we'll make another breaking change like this soon, so we're safe :-) <|||||>@sgugger I am more thinking along the line of the resampling algorithm changes subtly in torch or different hardware has different floating errors.
Shouldn't happen in theory, but we all know theory is a far far away galaxy. |
transformers | 15,825 | closed | Framework split model report | This updates the CI report for *models* to be split by framework.
From the following:

To the following:
 | 02-24-2022 21:52:51 | 02-24-2022 21:52:51 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,824 | closed | HFTracer.trace should use self.graph to be compatible with torch.fx.Tracer |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR makes HFTracer.trace compatible with [torch.fx.Tracer.trace](https://github.com/pytorch/pytorch/blob/f51a497f92b64df2f6c31a6f4f9662bfd9937160/torch/fx/_symbolic_trace.py#L571) by modifying `self.graph`(which can be accessed later by clients)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-24-2022 19:33:00 | 02-24-2022 19:33:00 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,823 | closed | Fine tune TrOCR using bert-base-multilingual-cased | I am trying to use TrOCR for recognizing Urdu text from image. For feature extractor, I am using DeiT and bert-base-multilingual-cased as decoder. I can't figure out what will be the requirements if I want to fine tune pre-trained TrOCR model but with decoder of multilingual cased. I've followed https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR tutorial but, it cant understand urdu text as expected I guess. Please guide me on how should I proceed? Should I create and train new tokenizer build for urdu? If yes, then how can I integrate it with ViT? | 02-24-2022 18:55:12 | 02-24-2022 18:55:12 | Hi,
In case you want train a TrOCR model on another language, you can warm-start (i.e. initialize the weights of) the encoder and decoder with pretrained weights from the hub, as follows:
```
from transformers import VisionEncoderDecoderModel
# initialize the encoder from a pretrained ViT and the decoder from a pretrained BERT model.
# Note that the cross-attention layers will be randomly initialized, and need to be fine-tuned on a downstream dataset
model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(
"google/vit-base-patch16-224-in21k", "urduhack/roberta-urdu-small"
)
```
Here, I'm initializing the weights of the decoder from a RoBERTa language model trained on the Urdu language from the hub.<|||||>Thankyou @NielsRogge . I was not adding last two configurations. Luckily, its working now. Thanks a lot again :)<|||||>Hey there, I want to know is not using processor will affect training accuracy? As I've tried to replace TrOCR processor with ViT feature extractor and roberta as detokenizer as follows:
```
class IAMDataset(Dataset):
def __init__(self, root_dir, df, feature_extractor,tokenizer, max_target_length=128):
self.root_dir = root_dir
self.df = df
self.feature_extractor = feature_extractor
self.tokenizer = tokenizer
self.max_target_length = max_target_length
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
file_name = self.df['file_name'][idx]
text = self.df['text'][idx]
image = Image.open(self.root_dir + file_name).convert("RGB")
pixel_values = self.feature_extractor(image, return_tensors="pt").pixel_values
labels = self.tokenizer(text, padding="max_length", max_length=self.max_target_length).input_ids
labels = [label if label != self.tokenizer.pad_token_id else -100 for label in labels]
encoding = {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)}
return encoding
```
After training on 998 images(IAM Handwritten) with text-image pair, model even cant recognize text from trained image. Is it related to size of training dataset or processor is important for OCR case? <|||||>Hi,
Are you using the following tokenizer:
```
from transformers import RobertaTokenizer
tokenizer = RobertaTokenizer.from_pretrained("urduhack/roberta-urdu-small")
```
?
Cause that is required for the model to work on another language.<|||||>Yes, I'm calling Vit + urduhack/roberta as encoder and decoder. For testing purpose, I've trained this model on 20 image-text pairs. When I'm trying to recognize text from image, output text is composed of repeating words as shown in image.

I know training sample is not under requirement, please highlight what I'm doing wrong while recognizing text from image:
```
model = VisionEncoderDecoderModel.from_pretrained("./wo_processor")
image = Image.open('/content/10.png').convert("RGB")
pixel_values = feature_extractor(image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text= decoder_tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
<|||||>Which version of Transformers are you using? Cause the `eos_token_id` must be properly set in the decoder.
We recently fixed the `generate()` method to take the `eos_token_id` of the decoder into account (see #14905).
Can the model properly overfit the 20 image-text pairs?<|||||>Transformers version: 4.17.0
Currently, `model.config.eos_token_id = decoder_tokenizer.sep_token_id` is set.<|||||>Can the model properly overfit the 20 image-text pairs?
Is the image you're testing on included in the 20 pairs?<|||||>No..model is not generating correct text even for image from training set. <|||||>Ok then I suggest to first debug that, see also [this post](http://karpathy.github.io/2019/04/25/recipe/).<|||||>Hey @NielsRogge , after double-checking image text list and saving model via `trainer.save_model`, code is running and output is as expected ..Thanks for all guidance. 👍<|||||>> Hi,
>
> In case you want train a TrOCR model on another language, you can warm-start (i.e. initialize the weights of) the encoder and decoder with pretrained weights from the hub, as follows:
>
> ```
> from transformers import VisionEncoderDecoderModel
>
> # initialize the encoder from a pretrained ViT and the decoder from a pretrained BERT model.
> # Note that the cross-attention layers will be randomly initialized, and need to be fine-tuned on a downstream dataset
> model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(
> "google/vit-base-patch16-224-in21k", "urduhack/roberta-urdu-small"
> )
> ```
>
> Here, I'm initializing the weights of the decoder from a RoBERTa language model trained on the Urdu language from the hub.
Hi @NielsRogge. Thank you for your wonderful tutorial on fine tuning the TrOCR. I am trying to tune the TrOCR for Arabic Language. I have collected and arranged the data as explained in your tutorial. Which pre-trained model, I need to use. Like the one you have mentioned above for Urudu, any pretrined weights are available for Arabic ?. <|||||>Hi,
You can filter on your language by clicking on the "models" tab, then selecting a language on the left: https://huggingface.co/models?language=ar&sort=downloads
So you can for instance initialize the weights of the decoder with those of https://huggingface.co/aubmindlab/bert-base-arabertv02<|||||>Hi @NielsRogge Thanks a lot for the tutorial. When using VisionEncoderDecoder and training it on a new dataset as in the tutorial, which parts of the model (encoder and decoder) are frozen and which are trainable?<|||||>Hi!
> When using VisionEncoderDecoder and training it on a new dataset as in the tutorial, which parts of the model (encoder and decoder) are frozen and which are trainable?
All weights are updated! You initialize the weights of the encoder with those of a pre-trained vision encoder (like ViT), initialize the weights of the decoder with those of a pre-trained text model (like BERT, GPT-2) and randomly initialize the weights of the cross-attention layers in the decoder. Next, all weights are updated based on a labeled dataset of (image, text) pairs.<|||||>Thanks for your answer @NielsRogge
I have another question and it's about the configuration cell in the [TrOCR tutorial](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Fine_tune_TrOCR_on_IAM_Handwriting_Database_using_Seq2SeqTrainer.ipynb) ; the cell in which we set special tokens etc.
Is it normal that once we set `model.config.decoder_start_token_id` to `processor.tokenizer.cls_token_id` and go back to the model (still in stage1 and no fine-tuning was performed), the pretrained model's output changes (to worse).
> Example:
I have the following image:

I apply the pretrained model (TrOCR-base-stage1) on this image of printed text, it works fine and the generated ids are:
```
tensor([[ 2, 417, 108, 879, 3213, 4400, 10768, 438, 1069, 21454,
579, 293, 4685, 4400, 40441, 20836, 5332, 2]])
```
I notice tha it starts and ends with the id number 2 (does that mean that cls=eos in pretraining phase?)
When these `generated_ids` are decoded I get exactly what's on the image:
```
d’un accident et décrivant ses causes et circonstances
```
But once I run the configuration cell (specificly the line setting `model.config.decoder_start_token_id`), the `generated_ids` from the same image becomes:
```
tensor([[0, 4, 2]])
```
which is just a dot when decoded by tokenizer.
I want to know if this is normal/expected behavior ?<|||||>Yeah that definitely will change behaviour. If you check
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-stage1")
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-stage1")
print(model.config.decoder.decoder_start_token_id)
```
you'll see that it's set to 2.
However, if you set it to `processor.tokenizer.cls_token_id`, then you set it to 0. But the model was trained with ID=2 as decoder start token ID.<|||||>Hi @NielsRogge,
Thank you for your detail responses. I followed your reply to my query and used your tutorial to train the TrOCR model
My objective is to recognize the Arabic characters from the license plate image. I have segmented the words alone using EAST. Few words are displayed below:



I have trained the TrOCR with my custom data (Arabic Alphabets). 29 alphabet characters are there in the dataset (only one alphabet per image). Combination of basic alphabets lead to new letter. I need to include these letters in the dataset.

Dataset contains 2900 images (100 image for each alphabet).
I have used the following models for encoder and decoder:
- "microsoft/trocr-base-printed" for TrOCR Processor
- "google/vit-base-patch16-384" for Encoder
- "aubmindlab/bert-base-arabertv02" for decoder (Arabic letter warm start)
I changed the max_length as 4 and n_gram_size as 1. I have not changed the vocab_size.
I trained the model and for 3 epochs. CER is fluctuating. At 1400 step, got a CER of 0.54, after that it was increased and fluctuated, but not reduced below 0.54.
On the saved model, I tested the image with single character, it is doing reasonably well in predicting that character. But while I am giving multiple character in one single image, it is failing miserably.

-- Predicted correctly by printing the correct text

-- Predicted correctly by printing the correct text

-- Predicted correctly by printing the correct text

-- NOT Predicting anything, retuning null.
I am using following code to predict the above images on the trained model:

Please let me know the mistake I am committing. Is it because that I am training the model with individual character images rather that word images ? Do I need to do some modifications in config settings or Do I need to do something with tokenizer.
I have attached my training code link here:
[https://colab.research.google.com/drive/11ARSwRinMj4l8qwGhux074G6RL9hCdrW?usp=sharing](https://colab.research.google.com/drive/11ARSwRinMj4l8qwGhux074G6RL9hCdrW?usp=sharing)
<|||||>Hi,
If you're only training the model on individual character images, then I'm pretty sure it won't be able to produce a reasonable prediction if you give it a sequence of characters at inference time. You would have to train on a sequence of characters as well during training.
Also, a max length of 4 is rather low, I would increase this during training.<|||||>Thank you. I will collect the images of words and train again. Any suggestion on how many images minimum we need for reasonable training ?<|||||>I would start with at least 100 (image, text) pairs, and as usual, the more data you have, the better.<|||||>> you'll see that it's set to 2.
>
> However, if you set it to `processor.tokenizer.cls_token_id`, then you set it to 0. But the model was trained with ID=2 as decoder start token ID.
Can you explain to me why `model.config.decoder_start_token_id` (null) is set to `processor.tokenizer.cls_token_id` (0) and not to `model.decoder.config.decoder_start_token_id` (2) because it seems to me like the less confusing optiopn (for the model).<|||||>@Samreenhabib hi, can i get your contact ? I want to ask more about fine tuned for multilingual case<|||||>> Can you explain to me why model.config.decoder_start_token_id (null) is set to processor.tokenizer.cls_token_id (0) and not to model.decoder.config.decoder_start_token_id (2) because it seems to me like the less confusing optiopn (for the model).
I think that's because the TrOCR authors initialized the decoder with the weights of RoBERTa, an encoder-only Transformer model. Hence, they used the CLS token as start token.<|||||>Hi @NielsRogge , I'm having a problem with fine-tuning Base-TrOCR. I launched the training two times and it stopped at an intermediate training step raising the error :
```
RuntimeError: stack expects each tensor to be equal size, but got [128] at entry 0 and [152] at entry 3
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<command-2931901844376276> in <module>
11 )
12
---> 13 training_results = trainer.train()
/databricks/python/lib/python3.7/site-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1394
1395 step = -1
-> 1396 for step, inputs in enumerate(epoch_iterator):
1397
1398 # Skip past any already trained steps if resuming training
/databricks/python/lib/python3.7/site-packages/torch/utils/data/dataloader.py in __next__(self)
433 if self._sampler_iter is None:
434 self._reset()
--> 435 data = self._next_data()
436 self._num_yielded += 1
437 if self._dataset_kind == _DatasetKind.Iterable and \
/databricks/python/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _next_data(self)
473 def _next_data(self):
474 index = self._next_index() # may raise StopIteration
--> 475 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
476 if self._pin_memory:
477 data = _utils.pin_memory.pin_memory(data)
/databricks/python/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py in fetch(self, possibly_batched_index)
45 else:
46 data = self.dataset[possibly_batched_index]
---> 47 return self.collate_fn(data)
/databricks/python/lib/python3.7/site-packages/transformers/data/data_collator.py in default_data_collator(features, return_tensors)
64
65 if return_tensors == "pt":
---> 66 return torch_default_data_collator(features)
67 elif return_tensors == "tf":
68 return tf_default_data_collator(features)
/databricks/python/lib/python3.7/site-packages/transformers/data/data_collator.py in torch_default_data_collator(features)
126 if k not in ("label", "label_ids") and v is not None and not isinstance(v, str):
127 if isinstance(v, torch.Tensor):
--> 128 batch[k] = torch.stack([f[k] for f in features])
129 else:
130 batch[k] = torch.tensor([f[k] for f in features])
RuntimeError: stack expects each tensor to be equal size, but got [128] at entry 0 and [152] at entry 3
```
I'm not sure if it's from the tokenizer or the feature extractor (both in th TrOCR processor from the tutorial). or is it because we are calling the dataset's label output `labels` instead of `label`/`label_ids` (see last if statement in the traceback). I don't want to use more compute power to test all my hypotheses. Can you help me with this one? I hope you're more familiar with the internals of the seq2seq trainer. Thank you very much in advance.<|||||>I see we are using the `default_data_collator` but our dataset returns `labels` instead of `labels_ids` could that be the problem?
https://huggingface.co/docs/transformers/main/en/main_classes/data_collator#transformers.default_data_collator
but it doesn't explain why one of the "features" would be of size 152.<|||||>Hi, the `default_data_collator` just stacks the pixel values and labels along the first (batch) dimension.
However, in order to stack tensors, they all need to have the same shape. It seems like you didn't truncate some labels (which are `input_ids` of the encoded text). Can you verify that you pad + truncate when creating the `labels`? <|||||>Hi @Samreenhabib kindly share with me model configuration on urdu images data.Thanks<|||||>Hey @NielsRogge , I am stuck at one place, need your help.
I trained tokenizer on Urdu text lines using following:
```
tokenizer = ByteLevelBPETokenizer(lowercase=True)
tokenizer.train(files=paths, vocab_size=8192, min_frequency=2,
show_progress=True,
special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>",
])
tokenizer.save_model(tokenizer_folder)
```
Here are encoder decoder configurations:
```
config = RobertaConfig(
vocab_size=8192,
max_position_embeddings=514,
num_attention_heads=12,
num_hidden_layers=6,
type_vocab_size=1,
)
decoder = RobertaModel(config=config)
decoder_tokenizer = RobertaTokenizerFast.from_pretrained(tokenizer_folder, max_len=512)
decoder.resize_token_embeddings(len(decoder_tokenizer))
encoder_config = ViTConfig(image_size=384)
encoder = ViTModel(encoder_config)
model = VisionEncoderDecoderModel(encoder=encoder, decoder=decoder)
model.config.decoder.is_decoder = True
model.config.decoder.add_cross_attention = True
```
Upon `trainer.train()` this is what I'm receiving: BaseModelOutputWithPoolingAndCrossAttentions' object has no attribute 'logits'
<|||||>> Hi @Samreenhabib kindly share with me model configuration on urdu images data.Thanks
Hey, apologies for late reply. I dont know if you still looking for configurations. The code was exact same as in [https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Fine_tune_TrOCR_on_IAM_Handwriting_Database_using_Seq2SeqTrainer.ipynb](url)
However, to call trainer trained on your dataset , ensure you save it :`trainer.save_model('./urdu_trainer')`. Then simply call
```
model = VisionEncoderDecoderModel.from_pretrained("./urdu_trainer")
image = Image.open('/content/40.png').convert("RGB")
image
pixel_values = processor.feature_extractor(image, return_tensors="pt").pixel_values
print(pixel_values.shape)
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text)
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>For more questions, please use the [forum](https://discuss.huggingface.co/), as we'd like to keep Github issues for bugs/feature requests.<|||||>> I am trying to use TrOCR for recognizing Urdu text from image. For feature extractor, I am using DeiT and bert-base-multilingual-cased as decoder. I can't figure out what will be the requirements if I want to fine tune pre-trained TrOCR model but with decoder of multilingual cased. I've followed https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR tutorial but, it cant understand urdu text as expected I guess. Please guide me on how should I proceed? Should I create and train new tokenizer build for urdu? If yes, then how can I integrate it with ViT?
> > Hi @Samreenhabib kindly share with me model configuration on urdu images data.Thanks
>
> Hey, apologies for late reply. I dont know if you still looking for configurations. The code was exact same as in [https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Fine_tune_TrOCR_on_IAM_Handwriting_Database_using_Seq2SeqTrainer.ipynb](url) However, to call trainer trained on your dataset , ensure you save it :`trainer.save_model('./urdu_trainer')`. Then simply call
>
> ```
> model = VisionEncoderDecoderModel.from_pretrained("./urdu_trainer")
> image = Image.open('/content/40.png').convert("RGB")
> image
> pixel_values = processor.feature_extractor(image, return_tensors="pt").pixel_values
> print(pixel_values.shape)
> generated_ids = model.generate(pixel_values)
> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
> print(generated_text)
> ```
Hi @Samreenhabib, Can you please share your code with me? I am trying to fine tune trocr with bangla dataset and being a beginner, I am facing lots of problem. If would be very helpful, if you could share your code. I will be grateful to you. Thanks!<|||||>Hi @SamithaShetty, as @NielsRogge notes [in the comment above](https://github.com/huggingface/transformers/issues/15823#issuecomment-1355033806), questions like these are best placed in our [forums](https://discuss.huggingface.co/). We try to reserve the github issues for feature requests and bug reports.<|||||>> Hey there, I want to know is not using processor will affect training accuracy? As I've tried to replace TrOCR processor with ViT feature extractor and roberta as detokenizer as follows:
>
> ```
> class IAMDataset(Dataset):
> def __init__(self, root_dir, df, feature_extractor,tokenizer, max_target_length=128):
> self.root_dir = root_dir
> self.df = df
> self.feature_extractor = feature_extractor
> self.tokenizer = tokenizer
> self.max_target_length = max_target_length
> def __len__(self):
> return len(self.df)
> def __getitem__(self, idx):
> file_name = self.df['file_name'][idx]
> text = self.df['text'][idx]
> image = Image.open(self.root_dir + file_name).convert("RGB")
> pixel_values = self.feature_extractor(image, return_tensors="pt").pixel_values
> labels = self.tokenizer(text, padding="max_length", max_length=self.max_target_length).input_ids
> labels = [label if label != self.tokenizer.pad_token_id else -100 for label in labels]
> encoding = {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)}
> return encoding
> ```
>
> After training on 998 images(IAM Handwritten) with text-image pair, model even cant recognize text from trained image. Is it related to size of training dataset or processor is important for OCR case?
Hi,
I have been working on TrOCR recently, and I am very new to these things.
I am trying to extend TrOCR to all 22 scheduled Indian Languages.
From my understanding,
I have used AutoImageProcessor and AutoTokenizer class and for ecoder i have used BEiT and IndicBERTv2 respectively as it supports all the 22 languages.
But, i have been facing some issue,
I am using Synthtetic generated dataset, which of almost of the same config of IAMDataset.
I have been training the model out with 2M examples for Bengali.
And 20M examples of Hindi+Bengali(10M each) seperately.
For my training with Bengali only(2M) -
Upon running the inference after 10 epochs, I am facing the same error as mentioned by @Samreenhabib ,Generated text has repetation of first word only.
For my training on Hindi+Bengali(20M)-
Upon running inference after 3 epochs, I am facing the same issue as mentioned by (@IlyasMoutawwakil ) ,where the generated texts are just dots and commas,
I am using the same code as mentioned in @NielsRogge 's tutorial with pytorch, just i have added the implementation of Accelerate to train on multiple GPU's.
Any kind of help or suggestions would really help a lot as my internship is getiing over within a week, so i have to figure the error out as soon as possible.
Thank you so much
I will attatch the initialisation cell below:
from transformers import AutoImageProcessor, AutoTokenizer,TrOCRProcessor
image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
tokenizer = AutoTokenizer.from_pretrained("ai4bharat/IndicBERTv2-MLM-only")
processor = TrOCRProcessor(feature_extractor = image_processor, tokenizer = tokenizer)
#processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-stage1")
train_dataset = IAMDataset(root_dir='/home/ruser1/Anustup/NewNOISE/bn/images/',
df=train_df,
processor=processor)
eval_dataset = IAMDataset(root_dir='/home/ruser1/Anustup/NewNOISE/bn/images/',
df=test_df,
processor=processor)
-----------------------------------------------------------------------------------------------------------------------------------------------------
from transformers import VisionEncoderDecoderModel
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device="cpu"
enc='microsoft/beit-base-patch16-224-pt22k-ft22k'
dec='ai4bharat/IndicBERTv2-MLM-only'
model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(enc,dec)
model.to(device)
-----------------------------------------------------------------------------------------------------------------------------------------------------
Thank you again<|||||>> > Hey there, I want to know is not using processor will affect training accuracy? As I've tried to replace TrOCR processor with ViT feature extractor and roberta as detokenizer as follows:
> > ```
> > class IAMDataset(Dataset):
> > def __init__(self, root_dir, df, feature_extractor,tokenizer, max_target_length=128):
> > self.root_dir = root_dir
> > self.df = df
> > self.feature_extractor = feature_extractor
> > self.tokenizer = tokenizer
> > self.max_target_length = max_target_length
> > def __len__(self):
> > return len(self.df)
> > def __getitem__(self, idx):
> > file_name = self.df['file_name'][idx]
> > text = self.df['text'][idx]
> > image = Image.open(self.root_dir + file_name).convert("RGB")
> > pixel_values = self.feature_extractor(image, return_tensors="pt").pixel_values
> > labels = self.tokenizer(text, padding="max_length", max_length=self.max_target_length).input_ids
> > labels = [label if label != self.tokenizer.pad_token_id else -100 for label in labels]
> > encoding = {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)}
> > return encoding
> > ```
> >
> >
> >
> >
> >
> >
> >
> >
> >
> >
> >
> > After training on 998 images(IAM Handwritten) with text-image pair, model even cant recognize text from trained image. Is it related to size of training dataset or processor is important for OCR case?
>
> Hi, I have been working on TrOCR recently, and I am very new to these things. I am trying to extend TrOCR to all 22 scheduled Indian Languages. From my understanding, I have used AutoImageProcessor and AutoTokenizer class and for ecoder i have used BEiT and IndicBERTv2 respectively as it supports all the 22 languages.
>
> But, i have been facing some issue, I am using Synthtetic generated dataset, which of almost of the same config of IAMDataset. I have been training the model out with 2M examples for Bengali. And 20M examples of Hindi+Bengali(10M each) seperately. For my training with Bengali only(2M) - Upon running the inference after 10 epochs, I am facing the same error as mentioned by @Samreenhabib ,Generated text has repetation of first word only.
>
> For my training on Hindi+Bengali(20M)- Upon running inference after 3 epochs, I am facing the same issue as mentioned by (@IlyasMoutawwakil ) ,where the generated texts are just dots and commas, I am using the same code as mentioned in @NielsRogge 's tutorial with pytorch, just i have added the implementation of Accelerate to train on multiple GPU's. Any kind of help or suggestions would really help a lot as my internship is getiing over within a week, so i have to figure the error out as soon as possible.
>
> Thank you so much
>
> I will attatch the initialisation cell below: from transformers import AutoImageProcessor, AutoTokenizer,TrOCRProcessor
>
> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
>
> tokenizer = AutoTokenizer.from_pretrained("ai4bharat/IndicBERTv2-MLM-only")
>
> processor = TrOCRProcessor(feature_extractor = image_processor, tokenizer = tokenizer) #processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-stage1") train_dataset = IAMDataset(root_dir='/home/ruser1/Anustup/NewNOISE/bn/images/', df=train_df, processor=processor) eval_dataset = IAMDataset(root_dir='/home/ruser1/Anustup/NewNOISE/bn/images/', df=test_df, processor=processor)
>
> from transformers import VisionEncoderDecoderModel import torch
>
> ## device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
> device="cpu"
> enc='microsoft/beit-base-patch16-224-pt22k-ft22k'
> dec='ai4bharat/IndicBERTv2-MLM-only'
> model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(enc,dec)
> model.to(device)
> Thank you again
@AnustupOCR , it seems like you are not saving processor according to your requirement. Please take a look on the code here: https://github.com/Samreenhabib/Urdu-OCR/blob/main/Custom%20Transformer%20OCR/Custom%20TrOCR.ipynb |
transformers | 15,822 | closed | [TFXLNet] Correct tf xlnet generate | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
The TF XLNet integration test (https://github.com/huggingface/transformers/blob/35ecf99cc4e1046e5908f5933a4548e43a0f4f1d/tests/xlnet/test_modeling_tf_xlnet.py#L845) was not in-line with the PT XLNet integration test (https://github.com/huggingface/transformers/blob/35ecf99cc4e1046e5908f5933a4548e43a0f4f1d/tests/xlnet/test_modeling_xlnet.py#L1058) probably because our previous TF generate method incorrectly did **not** forward the `mems` (=XLNet's `past_key_value` states) during generation whereas the PT generate method does.
Since the TF generate refactor: https://github.com/huggingface/transformers/pull/15562 the generation method was correctly implemented however which now allows us to align the tests.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-24-2022 18:08:47 | 02-24-2022 18:08:47 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,821 | closed | addeing tokens to tokenizer for training and inference worsens prediction immensely | I use the huggingface Trainer class to finetune a mT5 model. Since my data (AMR graphs) contains mayn tokens like `:ARG0`, `:op2` or `:name`, which are generally split into wordpieces I added those 219 tokens to the tokenizer with
```
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
tokenizer = MT5Tokenizer.from_pretrained("google/mt5-base")
model = MT5ForConditionalGeneration.from_pretrained("google/mt5-base")
toks = [ ... my ist of tokens ...]
tokenizer.add_tokens(toks, special_tokens=False)
model.resize_token_embeddings(len(tokenizer))
```
and than starting the training.
Once the model is finetuned I run my test, and once again I add the same tokens in the same order to the tokenizer. But the result is catastrophic, it drops from 80% F1 to 50%, so evidently something is going wrong. I compared the tokenisation with and without added tokens and this looks OK. But I have not the slightest idea where to check. Can you give me a hint about the error I'm committing ?
## Environment info
- `transformers` version: 4.11.3
- Platform: Linux-5.13.0-30-generic-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyTorch version (GPU): 1.9.1
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no | 02-24-2022 16:54:01 | 02-24-2022 16:54:01 | To clarify me question: I thought (possibly erroneously) that the new tokens will have random vectors which will be "learned" during the finetuning. If this is not the case, I have my answer ...<|||||>Hey @jheinecke. The best place to ask this question would be the [forum](https://discuss.huggingface.co/). We use issues for bug reports and feature requests. Thanks! <|||||>OK, thanks, I missed that. I'll pose my question there |
transformers | 15,820 | closed | fix megatron bert convert state dict naming | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes some key of state_dict changing error in Megatron-Bert convert script. In checkpoint v3, MegatronLM seems to change `attention` -> `self_attention`, and HF has updated this key at GPT convert script[#12007](https://github.com/huggingface/transformers/pull/12007/files) while the BERT is still not.
```
layers.0.input_layernorm.weight
layers.0.input_layernorm.bias
layers.0.self_attention.query_key_value.weight
layers.0.self_attention.query_key_value.bias
layers.0.self_attention.dense.weight
layers.0.self_attention.dense.bias
layers.0.post_attention_layernorm.weight
layers.0.post_attention_layernorm.bias
layers.0.mlp.dense_h_to_4h.weight
layers.0.mlp.dense_h_to_4h.bias
layers.0.mlp.dense_4h_to_h.weight
layers.0.mlp.dense_4h_to_h.bias
```
## Who can review?
@LysandreJik
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-24-2022 16:09:27 | 02-24-2022 16:09:27 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15820). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Merging |
transformers | 15,819 | closed | How to enable multi-heads outputs in segformer? | Dear all,
Thanks for the awesome work:)
I was wondering how to enable segformer to output two maps? E.g., one map for multi-class labels (default) and the other map for distance map

https://github.com/huggingface/transformers/blob/35ecf99cc4e1046e5908f5933a4548e43a0f4f1d/src/transformers/models/segformer/modeling_segformer.py#L681 | 02-24-2022 15:59:39 | 02-24-2022 15:59:39 | Hi,
Thanks for your interest in SegFormer! Here's how you can easily create a SegFormer with custom loss:
```
import transformers import SegformerPreTrainedModel, SegformerForSemanticSegmentation
from transformers.modeling_outputs import SemanticSegmentationModelOutput
import torch.nn as nn
class CustomSegFormer(SegformerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.segformer = SegformerForSemanticSegmentation.from_pretrained("...")
def forward(self, pixel_values, labels=None):
# forward to get raw logits
outputs = self.segformer(pixel_values)
logits = outputs.logits
# next, do whatever you want with the logits to compute loss
loss = None
if labels is not None:
# upsample logits here
upsampled_logits = nn.functional.interpolate(logits, size=pixel_values.shape[-2:], mode="bilinear", align_corners=False)
# calculate custom loss (or losses) here
loss = ...
return SemanticSegmentationModelOutput(loss=loss, logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions)
```
A few notes here:
* I'm inheriting from `SegformerPreTrainedModel` rather than `nn.Module` since you can then also use nice utility methods such as `from_pretrained`, `save_pretrained` and `push_to_hub`. It will also take care of proper weights initialization as seen [here](https://github.com/huggingface/transformers/blob/7566734d6f6467f1442bf0494cb14108d72c61b3/src/transformers/models/segformer/modeling_segformer.py#L416).
* I'm returning a `SemanticSegmentationModelOutput`. This makes the model compatible with HuggingFace's Trainer class.<|||||>Hi @NielsRogge,
Thanks for your kind help very much.
The above demo is very useful to me but it only has one output branch. I want the `segformer` output to have two branches and then, I can apply different loss functions to the two branches.
I'm a newcomer to hugging face, could you please give a quick check to my modification?
Thanks for your time very much.
```python
import transformers import SegformerPreTrainedModel, SegformerForSemanticSegmentation
from transformers.modeling_outputs import SemanticSegmentationModelOutput
import torch.nn as nn
class CustomSegFormer(SegformerPreTrainedModel):
def __init__(self, config, in_channel, n_classes=3):
super().__init__(config)
self.segformer = SegformerForSemanticSegmentation.from_pretrained("...")
self.logits_outputs = nn.Conv2d(in_channel, output_channel=n_classes, kernel_size=1, stride=1, padding=0)
self.distance_outputs = nn.Conv2d(in_channel, output_channel=1, kernel_size=1, stride=1, padding=0)
def forward(self, pixel_values, calss_labels, distance_labels):
# forward to get raw logits
outputs = self.segformer(pixel_values) # what's the number of output channels?
logits_outputs = self.logits_outputs(outputs)
distancemap_outputs = self.distance_outputs(outputs)
# next, do whatever you want with the logits to compute loss
# upsample logits here; the predicted distance map is also needed to unsampled, right?
upsampled_logits = nn.functional.interpolate(logits_outputs, size=pixel_values.shape[-2:], mode="bilinear", align_corners=False)
upsampled_distancemaps = nn.functional.interpolate(distancemap_outputs , size=pixel_values.shape[-2:], mode="bilinear", align_corners=False)
# calculate losses for logits and distance map respectively and sum the two losses
loss_logits = nn.functional.cross_entropy(unsampled_logits, calss_labels)
loss_dists = torch.norm(distance_labels- upsampled_distancemaps)/torch.numel(distance_labels)
loss = loss_logits + loss_dists
```
<|||||>It depends on how you want to compute the logits and distance maps.
Note that the model (`SegformerForSemanticSegmentation`) returns a `SemanticSegmentationModelOutput`, which already contains `logits` as well as all intermediate `hidden_states` (feature maps). The latter will only be included in the outputs if you pass `output_hidden_states=True`;
```
outputs = self.segformer(pixel_values, output_hidden_states=True)
logits = outputs.logits
hidden_states = outputs.hidden_states
```
As you'll see, the `hidden_states` are a tuple of `torch.FloatTensor`, containing the intermediate feature maps.
How do you want the distance maps to be computed? Based on the features of the last layer of the model?
|
transformers | 15,818 | closed | [Unispeech] Fix slow tests | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes:
```
tests/unispeech/test_modeling_unispeech.py::UniSpeechModelIntegrationTest::test_inference_pretraining
tests/unispeech_sat/test_modeling_unispeech_sat.py::UniSpeechSatModelIntegrationTest::test_inference_encoder_large
tests/unispeech_sat/test_modeling_unispeech_sat.py::UniSpeechSatModelIntegrationTest::test_inference_encoder_base
```
Unispeech still used the "old" datasets' way of loading datasamples and the outdated dummy librispeech `patrickvonplaten/...` instead of `hf-internal-testing/...`
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-24-2022 12:57:16 | 02-24-2022 12:57:16 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,817 | closed | Add ONNX Runtime quantization for text classification notebook | Adds link to the notebook showing how to quantize a model with ONNX Runtime for text classification tasks. | 02-24-2022 12:06:36 | 02-24-2022 12:06:36 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,816 | closed | Return entities extracted from the raw input for TokenClassificationPipeline | # 🚀 Feature request
Allow TokenClassificationPipeline to return entities extracted from the raw input.
## Motivation
Pretokenization (pre_tokenizer) can affect the "word" returned by the TokenClassificationPipeline. In this case `entity["word"] != sentence[entity["start"]:entity["end"]]` (see #15785):
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
MODEL_NAME = "elastic/distilbert-base-uncased-finetuned-conll03-english"
sentence = "My name is Clara and I live in Berkeley, California."
model = AutoModelForTokenClassification.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
pipe = pipeline("token-classification", model=model, tokenizer=tokenizer, aggregation_strategy="simple")
entities = pipe(sentence)
print([(sentence[entity["start"]:entity["end"]], entity["word"]) for entity in entities])
# [('Clara', 'clara'), ('Berkeley', 'berkeley'), ('California', 'california')]
```
The pipeline should optionally return entities extracted from the input `sentence[entity["start"]:entity["end"]]`
## Who can contribute
@Narsil @LysandreJik | 02-24-2022 11:36:44 | 02-24-2022 11:36:44 | I am in favor of adding a new key `text` for this.
- That does not break BC
- `text` is already used in other places (like `ASR Pipeline`)
The reason to add this is for users that might not be easily able to capture from the original sentence:
```python
from i, tokens in enumerate(pipe(dataset)):
...
# logic
sentence = dataset[i]
...
```
Now that code works only if the dataset is deterministic, in the case that is it not (like reading from a queue in various readers), then it's a bit more cumbersome to do. Making it easy is something I think is a good idea.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>bumped into this while looking for a similar issue ("f-16" is returned as "f - 16").
I couldn't find this option, is there any plan to include it? |
transformers | 15,815 | closed | [Barthez Tokenizer] Fix saving | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Adapting Barthez tokenizer save analogous to T5 to fix:
```
tests/barthez/test_tokenization_barthez.py::BarthezTokenizationTest::test_save_slow_from_fast_and_reload_fast
```
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-24-2022 11:33:57 | 02-24-2022 11:33:57 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,814 | closed | Fix from_pretrained with default base_model_prefix | # What does this PR do?
There is a subtle bug in `from_pretrained` that was discovered by @NielsRogge with the Enformer model. Basically, `from_pretrained` will silently not load anything when a subclass does not define `base_model_prefix`. This is because the defaults is left at `""` which then:
- sets `has_prefix_module` to `True`
- changes the `prefix` to `"."` since the model does not have any attribute named `""`
- then ignore all weights
This PR fixes that and removes the `base_model_prefix` attribute from the custom modeling classes used during the test, to make sure we don't have any regression on this. | 02-24-2022 07:54:41 | 02-24-2022 07:54:41 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Ah yeah that makes sense! Thanks a lot! |
transformers | 15,813 | open | Add OFA to transformers | # 🌟 New model addition
We recently proposed OFA, a unified model for multimodal pretraining, which achieves multiple SoTAs on downstream tasks, including image captioning, text-to-image generation, referring expression comprehension, etc. We would like to implement OFA on transformers if it is possible.
## Model description
OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework. For more information, please refer to our paper: [Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework](http://arxiv.org/abs/2202.03052).
<!-- Important information -->
Our code base is Fairseq. We wonder if there is any simpler solution for the transfer from Fairseq to transformers. To email us, please contact [email protected] or [email protected].
## Open source status
* [x] the model implementation is available: ([OFA official repo](https://github.com/OFA-Sys/OFA))
* [x] the model weights are available: ([OFA checkpoints](https://github.com/OFA-Sys/OFA/blob/main/checkpoints.md))
* [x] who are the authors: (Peng Wang @[logicwong](https://github.com/logicwong), An Yang @[yangapku](https://github.com/yangapku), Rui Men @[jxst539246](https://github.com/jxst539246), Junyang Lin @[JustinLin610](https://github.com/JustinLin610), Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, Hongxia Yangf)
| 02-24-2022 07:42:42 | 02-24-2022 07:42:42 | cc @gchhablani you might find this interesting :-) <|||||>@patil-suraj Yes! Definitely would love to take this up :)<|||||>Awesome! Happy to help you with this! Let me know if you have questions :) <|||||>> Not sure if this is was a coordinated collaborative effort, but the OFA-Sys team seems to have made a preliminary release of a transformers implementation on a [separate OFA branch](https://github.com/OFA-Sys/OFA/tree/feature/add_transformers/transformers/src/transformers/models/ofa).
Any news on this ? If the implementation exists a new PR could be opened without too much work.
Also, I have question on the OFA-large huggingface [repo](https://huggingface.co/OFA-Sys/ofa-large/tree/main) the model is 2.45 GB but on the checkpoint in the OFA [repo](https://github.com/OFA-Sys/OFA/blob/feature/add_transformers/checkpoints.md#pretraining) it downloads a 5.8 GB file. Why such a difference between the two ? |
transformers | 15,812 | closed | Evaluate on subset of evaluation dataset during training | # 🚀 Feature request
Allow evaluating the model on a random subset of the evaluation dataset at each evaluation step during training.
## Motivation
While participating in the Robust Speech Recognition Challenge in January / February 2022, I noticed that evaluating the model on the whole evaluation dataset increased the training time considerably (Swedish Common Voice, in that specific case).
Sampling a subset of the evaluation set before training is not the optimal approach as it would lead to a less realistic model evaluation.
The same issue was discussed [here](https://discuss.huggingface.co/t/evaluate-subset-of-data-during-training/10952).
## Your contribution
I will update the Trainer and TrainingArguments classes, HFArgumentParser (if needed), tests, and docs to allow this feature, before submitting a Pull Request.
## Usage example
```
from transformers import TrainingArguments
[...]
training_args = TrainingArguments(
...,
eval_subset_ratio=0.1,
eval_subset_seed=0
)
[...]
| 02-24-2022 06:56:09 | 02-24-2022 06:56:09 | cc @patrickvonplaten @anton-l <|||||>Hey @marinone94,
Thanks for your issue! Do you think the https://github.com/huggingface/transformers/blob/b7e292aebdb638e2238cd9febf8c09253195fb5d/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L181 option is not enough here?<|||||>Hej @patrickvonplaten, by using `max_eval_samples` one always evaluates on the same subset (in the example, the top `max_eval_samples` examples, but it could well be a random selection, it would not change my point).
What I would like to offer (and use myself) is to dynamically sample `max_eval_samples` before each eval step, so that the model is not always evaluated on the same subset during training, and then run a full evaluation at the end of the training. I think it would expand the library's offer while keeping it fully compatible with previous versions.<|||||>It's pretty difficult to compare randomly sampled eval datasets to each other no? E.g. if epoch 1 gives me 40% WER on a subset 1 and epoch 2 gives me 40% on a subset 2 which is completely different from 1 then I can't really use this information this much no? <|||||>Well, if the model generalises well the trend should be similar, but I see your point.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,811 | closed | update world_size and process_index for SMP |
This PR updates world_size and process_index for SMP when prescaled_batch is True/False. | 02-24-2022 03:51:29 | 02-24-2022 03:51:29 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15811). All of your documentation changes will be reflected on that endpoint.<|||||>Prescaled batch is a new construct in SMP. SMP does tensor parallelism within a DP group. What this means is that it shuffles around the samples read by all ranks so that the rank which owns the shard of a layer/parameter can see relevant portion of samples for all samples across the data parallel group. To reduce the communication before layer execution, and to support cases where we can't use a large batch size (i.e. all ranks can't get their own sample), we recommend using prescaled batch, where all ranks in same rdp group read the same batch of data. Hence this usage affects the number of examples seen. From data loading perspective, the number of ranks which read different data changes in prescaled and non-prescaled case. World size and process index in transformers seem to relate to number of times data parallelism happens in the job, hence this change.
More details here
https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html#prescaled-batch<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,810 | closed | repeat tokenization | Hello, when using the example script run_clm.py in examples/pytorch/language-modeling/ with distributed training it seems to repeat the tokenization for each GPU. The messages “Running tokenizer on dataset” and “Grouping texts in chunks of {block_size}” repeat over and over. This does not happen when running on a single GPU. Also the tokenization takes significantly longer. My script call is:
deepspeed run_clm.py
–model_name_or_path EleutherAI/gpt-neo-125M
–train_file $TRAIN_FILE
–validation_file $VAL_FILE
–block_size $BLOCK_SIZE
–overwrite_output_dir
–fp16
–per_device_train_batch_size 3
–per_device_eval_batch_size 3
–do_train
–do_eval
–group_by_length
–gradient_accumulation_steps 4
–deepspeed “deepspeed_zero2_config.json”
–output_dir $OUTPUT_DIR
This is a huge issue when using a large body of text. Any help would be appreciated. | 02-24-2022 03:06:24 | 02-24-2022 03:06:24 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,809 | closed | Update distributed sampler for smp | # What does this PR do?
This PR updates world_size and process_index for SMP when prescaled_batch is True/False.
| 02-24-2022 00:58:20 | 02-24-2022 00:58:20 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15809). All of your documentation changes will be reflected on that endpoint.<|||||> Please close this as it's replaced by PR https://github.com/huggingface/transformers/pull/15811 <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,808 | closed | Audio/vision task guides | This PR adds fine-tuning guides for image classification, audio classification, and ASR since the APIs for these tasks are stable. Some general notes:
- The audio guides don't have TensorFlow sections yet.
- For image classification, there is a difference between the PyTorch and TensorFlow preprocessing methods. The TensorFlow example doesn't really add any transforms because I couldn't figure out how to integrate the Keras preprocessing/augmentation layers. ☹️ If we want to show some more substantial transforms, let me know and I can share my notebook or create an issue.
- Would be cool to add a widget to each guide so users can see the end result and what they can create! | 02-24-2022 00:28:59 | 02-24-2022 00:28:59 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15808). All of your documentation changes will be reflected on that endpoint. |
transformers | 15,807 | closed | Fixes the "push" CI run | Introduce the old notification service to be used by the "push" CI which has not been updated. | 02-23-2022 22:35:54 | 02-23-2022 22:35:54 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,806 | closed | Fix model templates | This fixes the model templates by first creating the testing directory in which the testing files will be moved. | 02-23-2022 20:59:18 | 02-23-2022 20:59:18 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,805 | closed | Fix add-new-model-like when old model checkpoint is not found | # What does this PR do?
This PR fixes the add-new-model-like command when the old model checkpoint can't be read in its modeling file (because there is no `_CHECKPOINT_FOR_DOC` basically). In this case, the user will be asked to provide it to avoid random failures like when trying to build a new model from rag. | 02-23-2022 20:58:00 | 02-23-2022 20:58:00 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,804 | closed | update dp_rank to rdp_rank for opt_state_dict |
This PR fixes hang for SMP when calling state_dict().
| 02-23-2022 20:38:55 | 02-23-2022 20:38:55 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15804). All of your documentation changes will be reflected on that endpoint.<|||||>When only pipeline parallelism is used, dp_rank works. But with newer features of SageMaker model parallel library we support Tensor parallelism too. Tensor parallelism is done within a DP group. In such a case, we need to save the state on all ranks with rdp_rank=0. Essentially two ranks in an RDP group have copies of the same shard of parameter. More details on ranking mechanism here https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-ranking-mechanism.html
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,803 | closed | Fix build_documentation CI | # What does this PR do?
We add more memory to the html build step with `NODE_OPTIONS: --max-old-space-size=6656` in the env.
We also mark the CI as failure if the html generation fails, or the git push fails afterwards.
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| 02-23-2022 20:29:11 | 02-23-2022 20:29:11 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,802 | closed | Test if github action stops running when doc fails | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-23-2022 20:08:01 | 02-23-2022 20:08:01 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,801 | closed | run_glue_no_trainer.py | Line 428 in "text-classification/run_glue_no_trainer.py":
if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
replace it with:
if (step + 1) % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1: | 02-23-2022 19:36:39 | 02-23-2022 19:36:39 | Hi @backurs -- would you like to open a PR with the change? :)<|||||>Hi Joao,
I get this error when trying to push my branch to the origin:
[image: image.png]
How do I fix this problem?
Thanks,
Arturs
On Mon, Feb 28, 2022 at 5:38 AM Joao Gante ***@***.***> wrote:
> Hi @backurs <https://github.com/backurs> -- would you like to open a PR
> with the change? :)
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/15801#issuecomment-1054118985>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AODENVAOBFJST45ZDDNIAXLU5NGDNANCNFSM5PFKGZ7A>
> .
> Triage notifications on the go with GitHub Mobile for iOS
> <https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
> or Android
> <https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
>
> You are receiving this because you were mentioned.Message ID:
> ***@***.***>
>
<|||||>Hi @backurs -- there was a problem with the image attachment (possibly because your comment was an email reply). Can you resubmit it through a GitHub comment, please?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,800 | closed | Fix docs on master | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-23-2022 19:33:44 | 02-23-2022 19:33:44 | |
transformers | 15,799 | closed | How to Use Transformers pipeline with multiple GPUs | I'm using an tweaked version of the `uer/roberta-base-chinese-extractive-qa` model. While I know how to train using multiple GPUs, it is not clear how to use multiple GPUs when coming to this stage. Essentially this is what I have:
```
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
model = AutoModelForQuestionAnswering.from_pretrained('uer/roberta-base-chinese-extractive-qa')
tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-chinese-extractive-qa')
QA = pipeline('question-answering', model=model, tokenizer=tokenizer, device=0)
```
Except the model I'm using is a tweaked version of the base model shown above. I'm trying to process a large number of documents and at the rate it's going at it would take on the order of weeks. Is there anyway to set the pipeline to use multiple gpus? So I could use something like
```
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
device = torch.device("cuda")
```
And then use both devices?
Also looks like someone else had the same question: https://stackoverflow.com/questions/64193049/how-to-use-transformers-pipeline-with-multi-gpu
| 02-23-2022 19:08:36 | 02-23-2022 19:08:36 | cc @Narsil <|||||>Hi @vikramtharakan,
Currently no, it's not possible in the pipeline to do that.
We not ruling out putting it in at a later stage, but it's probably a very involved process, because there are many ways someone could want to use multiple GPUs for inference.
- If the model fits a single GPU, then get parallel processes, 1 on all GPUs and run inference on those
- If the model doesn't fit a single GPU, then there are multiple options too, involving deepspeed or JaX or TF tools to handle model parallelism, or data parallelism or all of the, above.
If your model fits a single GPU, then you could easily have something like:
`myfile.py`
```python
import os
START=int(os.getenv("START"))
STOP=int(os.getenv("STOP"))
DEVICE=os.getenv("DEVICE")
for result in pipe(dataset[START:STOP], device=DEVICE):
print(result)
.. # logic
```
Then start a single process on each GPU with something like
```
START=0 STOP=100 DEVICE=0 python myfile.py &
START=100 STOP=200 DEVICE=1 python myfile.py &
```
This would launch a single process per GPU, with controllable access to the dataset and the device.
Would that sort of approach work for you ?
Note: In order to feed the GPU as fast as possible, the pipeline uses a DataLoader which has the option `num_workers`. A good default would be to set it to `num_workers = num_cpus (logical + physical) / num_gpus` so that you don't overdo parallelism.
Note2: As in all things considering performance, measure and keep measuring there are many things that could go wrong when attempting to maximise performance hardware, sometimes unexpectedly<|||||>@Narsil sorry for the late reply; I understand what you're saying and I think I will have to implement something to this effect in practice but what you suggested won't quite work for me. The model does fit a single GPU but ideally I'd like data to be able to flow through it continuously. So we'd essentially have one pipeline set up per GPU that each runs one process, and the data can flow through with each context being randomly assigned to one of these pipes using something like python's multiprocessing tool, and then aggregate all the data at the end. Do you have any tips on how to implement this? I'm struggling to find the best way to implement this<|||||>> Do you have any tips on how to implement this?
Could you have a queue instead maybe of choosing the offsets in the datasets ?
Both processes could be iteratively fetching from the queue (that can be fed in random order or not).
Hashing the id `if hash(id) % num_processes == my_process_id: process else: skip`can be used if you want to fetch in random order without a queue but making sure you're not duplicating the work
Many programs can be used to implement a queue simply, rabbitmq, mongo, maybe the pure Python `multiprocessing.Queue`.
That's the first idea to come to mind, but I would have many questions to assess the best solution.
Do you want to be able to steal work from others because you are sensitive to latency ?
Do you not care and have a simple round-robin ?
Why is the randomness important ?
Is you data very large and not easy to pass around in queue system X, do you need shared memory ?
Are you passing memory efficiently down on each GPU ?
Is the data on disk or RAM ?
This is again beyond of the scope of `pipelines` since there are many solutions to this problem where there's no obvious better solution and it all depends on what you want to achieve and what you are your constraints.<|||||>@Narsil Gotcha, thank you for the quick reply! I'll look into that
I was also wondering if there's any documentation on all the steps going on under the hood when using these pipelines? Because if it's really just tokenizing the data and then sending it through the model, I feel like I could also just load the model separately using pytorch and then load the model to multiple devices using either pytorch's `DataParallel` or `DistributedDataParallel`. The tokenization could be done outside of that as well, as I imagine it doesn't need the GPU as much as the model will for making predictions<|||||>Hi @vikramtharakan ,
Pipeline are intended for users not knowing machine learning to provide easy to use API.
It should work with the sanest possible defaults, and have a very standard preprocessing/postprocessing.
It is not meant to be the best possible production ready inference tool on all hardware (This is too vast a problem to be solved by a single solution).
It does use DataLoader when available, it makes the batching works even on non-obvious inputs (like question answering with long contexts or speech recognition on long audio files).
Currently there's no recap of all the features they provide, that's a good thing to add this.
But if you want fine grained over your inference loops, using the bare tools FeatureExtractor/Tokenizer/AutoModel is definitely the easiest way to take control over everything. You will just have to write a lot of boilerplate code again.
You can also subclass your pipeline class, but that won't make multi GPU easy. At the core the pipeline assume s1 model only.
Again personally, I would first try 1 pipeline per process as that seems pretty easy way to do things and this is how we use it internally for the API, but your mileage may vary and `DataParallel` is also a good choice.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>For compatible models, [parallelformers](https://github.com/tunib-ai/parallelformers) models work as a drop-in replacement. <|||||>> Hi @vikramtharakan ,
>
> Pipeline are intended for users not knowing machine learning to provide easy to use API. It should work with the sanest possible defaults, and have a very standard preprocessing/postprocessing. It is not meant to be the best possible production ready inference tool on all hardware (This is too vast a problem to be solved by a single solution).
>
> It does use DataLoader when available, it makes the batching works even on non-obvious inputs (like question answering with long contexts or speech recognition on long audio files). Currently there's no recap of all the features they provide, that's a good thing to add this.
>
> But if you want fine grained over your inference loops, using the bare tools FeatureExtractor/Tokenizer/AutoModel is definitely the easiest way to take control over everything. You will just have to write a lot of boilerplate code again. You can also subclass your pipeline class, but that won't make multi GPU easy. At the core the pipeline assume s1 model only.
>
> Again personally, I would first try 1 pipeline per process as that seems pretty easy way to do things and this is how we use it internally for the API, but your mileage may vary and `DataParallel` is also a good choice.
Hi, @Narsil ,
I have the same problem and I agree with your solution. But I had some trouble implementing it. I used spawn of torch, tried to implement shared variables with Manager, nothing worked. Do you have any good ways to implement it?<|||||>@hasakikiki
It depends really as I said.
What model are you trying to load, on what hardware ?
Do you need to split the model itself on various GPUs (like `bloom` for instance) ?
Do you even need multiple nodes for this ?
Do you have 1 node with several GPUs and just want to be able to use them in parallel ? (Then using `pipeline(.., device=n)` should suffice for instance.
I unfortunately don't really know what is torch `Manager` and shared variables.<|||||>@Narsil
I'm sorry my description is too vague.
Yes, I have a machine with 8 GPUs. And I don't need to split the model. I want to use them in parallel during inference. But in the `pipeline` API documentation, it seems that only one GPU can be used, which is the `device=n` you provided.<|||||>> Yes, I have a machine with 8 GPUs. And I don't need to split the model. I want to use them in parallel during inference. But in the pipeline API documentation, it seems that only one GPU can be used, which is the device=n you provided.
Then just start 8 processes each with a pipeline attributed on a single GPU, and distribute the work through a queue of some kind like redis/rabbitmq or any other similar mecanism ?<|||||>@Narsil I am trying to run the feature extraction pipeline on multiple GPU via composing the code using snippets you share:
```python
import os
import numpy as np
import hickle as hkl
import torch
from torch.utils.data import Dataset
from tqdm import tqdm
tqdm.pandas()
from transformers import AutoModel, pipeline
from transformers import AutoTokenizer
from torch.multiprocessing import Pool, Process, set_start_method, get_context
set_start_method("spawn", force=True)
pipe = None
model_name="anferico/bert-for-patents"
class NoDaemonProcess(Process):
@property
def daemon(self):
return False
@daemon.setter
def daemon(self, value):
pass
class NoDaemonContext(type(get_context("fork"))):
Process = NoDaemonProcess
class ListDataset(Dataset):
def __init__(self, original_list):
self.original_list = original_list
def __len__(self):
return len(self.original_list)
def __getitem__(self, i):
return self.original_list[i]
def get_pipe(device_index):
# This will load the pipeline on demand on the current PROCESS/THREAD.
# And load it only once.
global pipe
if pipe is None:
print(f"Creating pipeline for device: {device_index}")
tokenizer = AutoTokenizer.from_pretrained(model_name, do_lower_case=True, model_max_length=512, truncation=True,
padding=True, pad_to_max_length=True)
device = torch.device(f'cuda:{device_index}' if torch.cuda.is_available() else 'cpu')
model = AutoModel.from_pretrained(model_name).to(device)
pipe = pipeline('feature-extraction', model=model, tokenizer=tokenizer, max_length=512, truncation=True,
padding=True, pad_to_max_length=True, device=device, framework="pt", batch_size=16)
return pipe
def extract_chunk_embedding(dataset, device_index):
extractor = get_pipe(device_index)
print(f"Getting embeddings for device: {device_index}, chunked data length: {len(dataset)}")
return [np.squeeze(embedding)[0] for embedding in
tqdm(extractor(dataset, max_length=512, truncation=True, num_workers=8), total=len(dataset))]
def extract_embeddings(df, col, prefix, mode="cls", overwrite=False, num_gpu=2):
embedding_file = f'transformer_embeddings_cls_{prefix}.hkl'
if not overwrite:
if mode == "cls" and os.path.isfile(embedding_file):
try:
embeddings_dict = hkl.load(embedding_file)
print(f"Loading from the disk: {embedding_file}...")
return df['text_hash'].map(embeddings_dict).to_list()
except Exception as err:
print(f"Error reading file: {embedding_file} -> {err}")
pass
dataset = ListDataset(df[col].tolist())
if mode == "cls":
print(f"Creating embeddings: {embedding_file}...")
num_gpu = min(num_gpu, torch.cuda.device_count())
mp_context = NoDaemonContext()
multi_pool = mp_context.Pool(processes=num_gpu)
data_indices = tuple(np.ceil(np.linspace(start=0, stop=len(dataset), num=num_gpu + 1)).astype(np.int32))
arg_list = []
for device_index, (start, stop) in enumerate(zip(data_indices, data_indices[1:])):
chunked_data = dataset[start: stop]
arg_list.append((chunked_data, device_index))
print("Starting multi-processing...")
res = multi_pool.starmap(extract_chunk_embedding, arg_list)
multi_pool.close()
multi_pool.join()
return res
```
So the input is a data frame with a column name in which the column has text data and I am trying to extract features. Unfortunately, it is hanging on the multiprocessing step, and I could not find why it is the case, thank you for your answer.<|||||>Could you try using:
```python
from transformers import pipeline, AutoTokenizer, AutoModel
import torch
from torch.utils.data import Dataset
from multiprocessing import Pool
MODEL_NAME = "anferico/bert-for-patents"
def get_pipeline(device_index):
print(f"Creating pipeline for device: {device_index}")
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME, do_lower_case=True, model_max_length=512, truncation=True, padding=True, pad_to_max_length=True
)
device = torch.device(f"cuda:{device_index}" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained(MODEL_NAME).to(device)
pipe = pipeline(
"feature-extraction",
model=model,
tokenizer=tokenizer,
max_length=512,
truncation=True,
padding=True,
pad_to_max_length=True,
device=device,
framework="pt",
batch_size=16,
)
return pipe
dummy = ["This is a test"] * 100
class MyDataset(Dataset):
def __init__(self, device_index, world_size):
super().__init__()
self.device_index = device_index
self.data = dummy[device_index::world_size]
print(self.data)
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def run(arg):
device_index, world_size = arg
pipe = get_pipeline(device_index)
data = MyDataset(device_index, world_size)
for out in pipe(data):
pass
# Do something here, directly on the process
# Out is what you want on a single item
def main():
num_gpus = 8
with Pool(num_gpus) as p:
p.map(run, [(i, num_gpus) for i in range(num_gpus)])
if __name__ == "__main__":
main()
```
I escaped the issues with pandas and your dataset which I don't know, but the idea is to handle the loading directly in the dataset, and to create the pipelines only once, and directly within the subprocess.
Also I recommend that you treat directly results as you receive them so that you don't have to save n tensors and grow your memory usage indefinitely.<|||||>> You are using
@Narsil I do not get it.<|||||>> @Narsil I do not get it.
I started the comment, and misfired send as obviously it wasn't ready.<|||||>Is there a fix for this ?
I want to run `GPT-NeoX-20b` on multiple gpus as a single one is not possible<|||||>As I said earlier, it's a complex problem and there's no one solution to making things Parallel.
**Please be considerate or your problem space and think about how you going about things. I can't stress that enough, every use has different potential solutions**
There is no 1-click solution for all options.
That being said, since this first comment was published the libs did make progress and you can now use `accelerate` and use
```python
pipe = pipeline(...., device_map="auto")
```
Which will attempt to put the model on multiple GPUs.
This method works by putting the splitting the model across layers, and putting layer 0, 1, 2 on GPU 0 and layer 3, 4, 5 on GPU1 (it's an example).
This is extremely simple, but it's possibly the worst solution if you care about latency. If you care about throughput, then you are not optimal either since you could make things multiprocessed to be able to process different parts of data on each GPU separately.
But if you just want to take the model out for a spin, this is the easiest solution.<|||||>I want to use GPT-NeoX on AWS EC2 g4dn.12xlarge.
GPUs: 4
GPU model: NVIDIA Tesla M60
GPU memory: 32 GiB
Is there any better option than pipe = pipeline(...., device_map="auto")?
What option will work?
pipe = pipeline(model="EleutherAI/gpt-neox-20b", device_map="auto")
or
pipe = pipeline(model="EleutherAI/gpt-neox-20b", device=0, device_map="auto")<|||||>You cannot specify both `device=0` (which means put everything on the first GP) and `device_map="auto"` ( which will try to put everything on each GPU as it sees fit, it will even use CPU and disk if needed).
So unfortunately no there is no better option than
```python
pipe = pipeline(...., device_map="auto")
```
as least as a one line thing.
For more complete solutions, there's probably a lot of blogpost and tutorials out there.
For a webserver trying to optimize latency you can check out : https://github.com/huggingface/text-generation-inference/ which is a repo we're using for bloom. NB: Do not expect the same level of support as in core transformers since this is meant as an internal tool (we're just publishing it so others can see/improve and use it).
It does quite a few things, by batching queries dynamically, using custom kernels (not available for neox) and using Tensor Parallelism instead of Pipeline Parallelism (what `accelerate` does). |
transformers | 15,798 | closed | Fix indent in doc-builder CI | # What does this PR do?
Fix the build documentation github action
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
| 02-23-2022 18:57:57 | 02-23-2022 18:57:57 | |
transformers | 15,797 | closed | Unable to load a pretrained model from disc using transformers api | I am trying to load a pretrained model from a checkpoint saved on my disc using Hugging face transformers library. Model is saved inside a directory `'new_tun_bert'`. Following is the directory tree of new_tun_bert.
```
.
├── config.json
├── pytorch_model.bin
└── vocab.txt
```
The code I used for loading the model is as following:
```
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained('new_tun_bert')
```
which is giving the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/centos/.local/lib/python3.6/site-packages/transformers/models/auto/auto_factory.py", line 419, in from_pretrained
return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, config=config, **kwargs)
File "/home/centos/.local/lib/python3.6/site-packages/transformers/modeling_utils.py", line 1429, in from_pretrained
_fast_init=_fast_init,
File "/home/centos/.local/lib/python3.6/site-packages/transformers/modeling_utils.py", line 1457, in _load_state_dict_into_model
for key in state_dict.keys():
File "/home/centos/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 948, in __getattr__
type(self).__name__, name))
AttributeError: 'BertModel' object has no attribute 'keys'
```
However, model is loading just fine if I load it using native `torch.load` method.
```
>>> import torch
>>> model = torch.load('new_tun_bert/pytorch_model.bin')
>>> model
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
```
The content of the `config.json` is as following:
```
{
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 28274
}
```
What is going wrong? I am able to do a complete forward pass using the model loaded through torch api.
| 02-23-2022 18:34:35 | 02-23-2022 18:34:35 | Hey, could you share the information relative to your environment? Specifically the results of the `transformers-cli env` command.<|||||>Sure, this is what i got exactly while running the `transformers-cli env `
```
WARNING:tensorflow:From /home/centos/.local/lib/python3.6/site-packages/transformers/commands/env.py:50: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
2022-02-24 01:15:02.755810: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-02-24 01:15:02.759070: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-02-24 01:15:02.804907: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: cannot open shared object file: No such file or directory
2022-02-24 01:15:02.804945: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1835] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.11.3
- Platform: Linux-4.18.0-305.3.1.el8.x86_64-x86_64-with-centos-8.4.2105
- Python version: 3.6.8
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): 2.6.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```<|||||>Hi, did you figure out how to do this? |
transformers | 15,796 | closed | Create optimizer after model creation for SMP |
This PR enables optimizer creation after model creation which is a requirement for the newer version of SMP.
| 02-23-2022 18:28:59 | 02-23-2022 18:28:59 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15796). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,795 | closed | Support PEP 563 for HfArgumentParser | # What does this PR do?
Fixes #15739, support for [PEP 563](https://www.python.org/dev/peps/pep-0563/) is added, making it possible to write `from __future__ import annotations` in the file of dataclasses for `HfArgumentParser`. But this will not be available for Python with a version lower than 3.7, thus adding `from __future__ import annotations` in the test is currently infeasible because `__future__` imports should always occur at the beginning of the file. Instead, I write a test case with string literal annotations.
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case.
- [x] Did you make sure to update the documentation with your changes?
- [x] Did you write any new necessary tests?
## Who can review?
@LysandreJik
| 02-23-2022 18:01:27 | 02-23-2022 18:01:27 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15795). All of your documentation changes will be reflected on that endpoint.<|||||>@LysandreJik Hello, would be great if you could help or ask someone to give any feedback on this, thanks!
Seems #15951 updated the parser as well (just resolved the conflict), I've done the same work, and added a comment at the corresponding changing line.<|||||>Looking forward to any feedback.<|||||>Thanks for the ping! @sgugger could you give this a quick look? It's similar to the work merged in https://github.com/huggingface/transformers/pull/15951<|||||>It looks like you did a rebase on your PR that GitHub did not appreciate (the diff shows 292 files). Could you close this PR and open a fresh one?<|||||>@sgugger Github encountered some internal error a little while ago, it seems to be fine now.<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger Thanks so much for the feedback! I've adopted that. In addition, I've replaced `... != type(None)` with `isinstance` to pass the quality check.<|||||>Cool, thanks again for your contribution! |
transformers | 15,794 | closed | Html docs 4.16.2 | Use CI to rebuild 4.16.2 docs with HTML. Do not merge. | 02-23-2022 16:30:32 | 02-23-2022 16:30:32 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15794). All of your documentation changes will be reflected on that endpoint. |
transformers | 15,793 | closed | TF generate refactor - Sample | # What does this PR do?
This PR is step 3 of the `generate()` refactor plan (see https://github.com/huggingface/transformers/pull/15562) -- it refactors the sample case.
A few notes:
- `_generate_no_beam_search()` was no longer reachable, so it was removed;
- I've tested the changes against the example in `_generate()` and all looks well. There are also a bunch of related tests that are passing after the changes (e.g. pipeline tests). However, the output is non-deterministic. Is there any way I can do stricter testing?
- While inspecting other `generate` files, I came across a few incorrect type hints and corrected them. LMK if you want me to move it to a different PR; | 02-23-2022 16:08:48 | 02-23-2022 16:08:48 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15793). All of your documentation changes will be reflected on that endpoint.<|||||>Looks good to me & thanks for cleaning up the type-hints, but we need tests here. Both for the `TFLogitsWarpers` and we should add at least one aggressive GPT2-sample and T5-sample slow test - similar to what was added here: https://github.com/huggingface/transformers/pull/15562/files#r814868995 . Such a test should include **all** logits processors and logits warpers and be a batched test and be added before doing the change so that we can be sure we didn't break anything (there are lots of subtleties for generate).
@gante it would be great if you could do the following:
- On current master add an aggressive test for `do_sample=True` with https://www.tensorflow.org/api_docs/python/tf/random/set_seed and a lot or all the possible logits warpers and processors and set the expected output to what the model gives you - it should be sensible.
- Then, copy-paste the test into this PR and verify that it passes.
We need to be sure everything works as expected here :-)<|||||>@patrickvonplaten absolutely agreed, running != being correct. I will add those in a separate PR and rebase this one as soon as the new stricter tests get merged. Hopefully, no changes will be needed here 🤞 <|||||>@patrickvonplaten @Rocketknight1 rebased with the recently merged TF sample generate integration tests (which are passing), with TF logit wrapper tests added on top. We should be ready to merge, but I'd like to get your eyes for explicit approval :)<|||||>@gante Before merging could you run a final test that all of the following tests pass in TF:
```
RUN_SLOW=1 pytest -sv \
tests/test_modeling_tf_bart.py \
tests/test_modeling_tf_t5.py \
tests/test_modeling_tf_gpt2.py \
tests/test_modeling_tf_vision_encoder_decoder.py \
tests/test_modeling_tf_encoder_decoder.py \
tests/test_modeling_tf_speech_to_text.py
```<|||||>> @gante Before merging could you run a final test that all of the following tests pass in TF:
>
> ```
> RUN_SLOW=1 pytest -sv \
> tests/test_modeling_tf_bart.py \
> tests/test_modeling_tf_t5.py \
> tests/test_modeling_tf_gpt2.py \
> tests/test_modeling_tf_vision_encoder_decoder.py \
> tests/test_modeling_tf_encoder_decoder.py \
> tests/test_modeling_tf_speech_to_text.py
> ```
Running the tests -- will merge if all pass.<|||||>Tests passing after this commit -- merging as soon as CI gets to green |
transformers | 15,792 | closed | Adding the option to return_timestamps on pure CTC ASR models. | # What does this PR do?
Adding the option to return_timestamps on pure CTC ASR models.
This works by using the `output_char_offsets` during the decoding and
simply recovering the actual offset in seconds instead of number of tokens.
Works only on pure CTC right now.
Thanks @patrickvonplaten for the earlier PR, made this one a breeze.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | 02-23-2022 15:29:43 | 02-23-2022 15:29:43 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@patrickvonplaten , it seems `math.prod` is a Python 3.8 function, so the CI failed: https://app.circleci.com/pipelines/github/huggingface/transformers/34931/workflows/cf399730-6207-41bb-8c19-76f4b2036fe7/jobs/375024
I changed it but maybe I missed something to make it work.<|||||>> @patrickvonplaten , it seems `math.prod` is a Python 3.8 function, so the CI failed: https://app.circleci.com/pipelines/github/huggingface/transformers/34931/workflows/cf399730-6207-41bb-8c19-76f4b2036fe7/jobs/375024
>
> I changed it but maybe I missed something to make it work.
Thanks for changing - LGTM!<|||||>@patrickvonplaten Do you think we can merge ?<|||||>Sorry checking now!<|||||>Thank you so much for the NITs ! |
transformers | 15,791 | closed | [ViLT] Add link to notebooks | # What does this PR do?
Add link to my ViLT notebooks in the docs. | 02-23-2022 13:57:49 | 02-23-2022 13:57:49 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15791). All of your documentation changes will be reflected on that endpoint.<|||||>I think we should consolidate all the notebooks linked from the documentation inside the [notebooks repository](https://github.com/huggingface/notebooks) (apart from the community page of course). Would you mind mirroring your notebook there, with a clear line at the top "This notebook is a copy of the notebook developed by @NielsRogge [here](linked to notebook in your repo]"?<|||||>Can I keep those in my repo Transformers-Tutorials and link to that repo instead?
I'm kind of free with the format there, it's not really following the official example notebooks (I'm mostly using native PyTorch for training). |
transformers | 15,790 | closed | [ViLT] Fix checkpoint url in config | # What does this PR do?
Fix the checkpoint name in config and add checkpoint in `VILT_PRETRAINED_CONFIG_ARCHIVE_MAP` `dict` | 02-23-2022 13:11:06 | 02-23-2022 13:11:06 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,789 | closed | [CLIP] fix gradient checkpointing | # What does this PR do?
Fix gradient checkpointing in CLIP.
Fixes #15783 | 02-23-2022 12:59:15 | 02-23-2022 12:59:15 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,788 | closed | How can I create a longformer model without position embedding? | null | 02-23-2022 12:38:52 | 02-23-2022 12:38:52 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discuss.huggingface.co) instead?
Thanks!<|||||>Ok! Thanks! |
transformers | 15,787 | closed | A question about BertForSequenceClassification | In my experiments, I trained a simple sentiment classification model on the SST dataset. But it is interest that it is hardly for the model to converge with BertForSequenceClassification but could converge easily with the simple BertModel's [CLS] +Linear. Did any one else met this problem and could explain the problem to me which part of the pool ,the tanh or the pretrained linear made this problem? | 02-23-2022 12:35:07 | 02-23-2022 12:35:07 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discuss.huggingface.co) instead?
Thanks!<|||||>Ok,thank your |
transformers | 15,786 | closed | TF XLA greedy generation | This is a first attempt at refactoring greedy generation in TF to use XLA. It has a couple of main problems still:
- Very hardcoded for GPT-2 right now
- No stopping based on EOS tokens yet (EDIT: Fixed!)
- Some really ugly array update hackery caused by the lack of tools like `dynamic_update_slice` (EDIT: Fixed!)
- `prepare_inputs_for_generation` assumes greedy generation, this is wrong (EDIT: Fixed)
- Outputs are slightly wrong compared to a manual loop - I'm still investigating (EDIT: Fixed!)
However, the outputs are coherent and the speedup compared to the old method is approximately 25X.
**UPDATE (from Patrick)**
PR should be good to go. See description below. | 02-23-2022 12:30:45 | 02-23-2022 12:30:45 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15786). All of your documentation changes will be reflected on that endpoint.<|||||>Outputs now correctly match a manual loop, up to minor float32 errors. Code has been simplified with the addition of direct calls to XLA, and we're now at >30X speedup versus the original code.<|||||>@Rocketknight1
I've been testing the code by running the following code example - put it in a `run.py` file:
```python
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
import tensorflow as tf
import sys
use_xla = bool(int(sys.argv[1]))
physical_devices = tf.config.list_physical_devices('GPU')
for device in physical_devices:
tf.config.experimental.set_memory_growth(device, True)
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = TFGPT2LMHeadModel.from_pretrained("gpt2")
input_ids = tokenizer("hello there can you continue", return_tensors="tf").input_ids
outputs = model.generate(input_ids, use_xla=use_xla)
print("Output", tokenizer.batch_decode(outputs))
```
XLA-case `python run.py 1`
Non-XLA-case `python run.py 0`
Can you try it out? Note that it's a pretty hacky solution that I've quickly done - we can surely make it cleaner. But overall I really don't see the problem with make xla_generate compatible for the non-xla case.
Could you take a look, try it out and see whether my idea is too limited?<|||||>Pr is ready to go. Ran all of the following slow tests:
```python
RUN_SLOW=1 pytest -sv \
tests/bart/test_modeling_tf_bart.py \
tests/t5/test_modeling_tf_t5.py \
tests/gpt2/test_modeling_tf_gpt2.py \
tests/vision_encoder_decoder/test_modeling_tf_vision_encoder_decoder.py \
tests/encoder_decoder/test_modeling_tf_encoder_decoder.py \
tests/speech_to_text/test_modeling_tf_speech_to_text.py
```
as well as
```bash
RUN_SLOW=1 pytest -sv tests/rag/test_modeling_tf_rag.py
```
(this one is tested on brutasse as it requires a heavy index).
Everything passes now.<|||||>The PR is now ready for merge - we now have a XLA-compileable `greedy_search` method which fully replaced the old `greedy_search` generate method. The XLA-compilable `greedy_search` behaves exactly the same way as the previous one for eager execution, but also allows for XLA compilation.
This was made possible at the expense of some code overhead (see function decorator flags), and a couple of `if use_xla` statements.
Since XLA-compileable `generate` has model-dependent cache tensors, we need to add a **single** new function to every model we want to make XLA-compilable, called `_update_model_kwargs_for_xla_generation`. One is added for GPT2 now so that GPT2 now works with XLA. The method is a bit hacky at the moment and could definitely be cleaned up in a future PR - I've copy-pasted some code from the previous state of the PR. XLA gpt2 generate gives the same result as non-XLA generate though.
IMO, the design is more or less fixed now as we have 0 breaking changes, no duplicated (non-XLA and XLA) generate methods, and relatively clean code.
Some important things that should be discussed here though:
1 - At the moment the way the cache and attention_mask is padded to make it XLA-compatible is a bit hacky (see code in `_update_model_kwargs_for_xla_generation`), but it allows for 0 breaking changes. It might be preferable to change the way `past_key_values` is implemented inside the model to potentially make generate even faster and less "hacky". This would mean however that `past_key_values` would change its tensor shape which is a breaking change though since we do return `past_key_values` when one passes `use_cache=True`. So might not be worth it
2 - XLA can be enabled with a flag `use_xla=True/False` which defaults to `False` at the moment. Once we make all models XLA compileable we could default the flag to `True`. TF has a somewhat weird way of enabling jit-XLA compilation with the function decorator which is why we have so many functions inside functions now in this PR. I do think it's the most intuitive way though is to allow the user to pass a `use_xla=True/False` flag. But I'm no TF expert - what do you think @sgugger @Rocketknight1 @gante ?
3. XLA generate does **not** cut before `max_length` is reached. It'll just output 0's in the end for now (think we should change this in a follow-up PR). The reason is that cutting the final outputs for some reason changes the axes and it's also "cleaner"/more "barebone" IMO to just output the whole `max_length` tensor. We should just make sure that the tensor is always padded with 0's. Would be nice to do this in a follow-up PR though.
In terms of next steps cc @Rocketknight1 @gante:
- a) GPT2 is mostly used with `do_sample=True`. So we should refactor this method analogs to this one. Should not be difficult now that it's done for greedy search.
- b) We should add more models (should be trivial to make GPT-J, GPT-Neo, ...) XLA-compatible. Also shouldn't be too hard for T5 now.
- c) We now should make the logits processors XLA-compileable - I left a TODO in the PR. It won't be easily possible to make **all** logits processors XLA-compileable, but we should aim to do it for the important ones. Again one should just look at how it's done for Flax and more or less copy-paste the design<|||||>Might be a bit difficult to review the git diff here. Would be nice if @Rocketknight1 and @gante, you could go through the new file and carefully check if everything makes sense - happy to answer any question you might have.<|||||>> 2 - XLA can be enabled with a flag use_xla=True/False which defaults to False at the moment. Once we make all models XLA compileable we could default the flag to True. TF has a somewhat weird way of enabling jit-XLA compilation with the function decorator which is why we have so many functions inside functions now in this PR. I do think it's the most intuitive way though is to allow the user to pass a use_xla=True/False flag. But I'm no TF expert - what do you think @sgugger @Rocketknight1 @gante ?
There is an alternative solution -- using the `tf.config` functions to trigger whether we want [XLA](https://www.tensorflow.org/api_docs/python/tf/config/optimizer/set_jit) or [eager execution](https://www.tensorflow.org/api_docs/python/tf/config/run_functions_eagerly) on functions decorated with `tf.function`. This approach has pros and cons, with respect to the current one.
Pros:
1. No need to define inner functions with `@xla_compile`. Everything that might get XLA compilation gets a `@tf.function`, and the exec mode is set by calling the appropriate config at the beginning of `generate()`
2. Repeated `generate()` calls do not redefine the functions, so they should benefit from previous XLA warmup -- not sure if this is a significant advantage or not 🤔 (could be, for instance, on hosted APIs that expect repeated calls on the same function)
Cons:
1. Setting any of these `tf.config` methods requires an empty TF session. This means we can't call a generate without and with XLA without resetting the session. Also, if we were to call it at the beginning of `generate()`, no compiled TF model could exist (again, because it needs an empty session).
Personally, I'm slightly leaning towards this approach (with the `tf.config` calls) if we could make it work, but no strong feelings :) <|||||>> > 2 - XLA can be enabled with a flag use_xla=True/False which defaults to False at the moment. Once we make all models XLA compileable we could default the flag to True. TF has a somewhat weird way of enabling jit-XLA compilation with the function decorator which is why we have so many functions inside functions now in this PR. I do think it's the most intuitive way though is to allow the user to pass a use_xla=True/False flag. But I'm no TF expert - what do you think @sgugger @Rocketknight1 @gante ?
>
> There is an alternative solution -- using the `tf.config` functions to trigger whether we want [XLA](https://www.tensorflow.org/api_docs/python/tf/config/optimizer/set_jit) or [eager execution](https://www.tensorflow.org/api_docs/python/tf/config/run_functions_eagerly) on functions decorated with `tf.function`. This approach has pros and cons, with respect to the current one.
>
> Pros:
>
> 1. No need to define inner functions with `@xla_compile`. Everything that might get XLA compilation gets a `@tf.function`, and the exec mode is set by calling the appropriate config at the beginning of `generate()`
> 2. Repeated `generate()` calls do not redefine the functions, so they should benefit from previous XLA warmup -- not sure if this is a significant advantage or not thinking (could be, for instance, on hosted APIs that expect repeated calls on the same function)
>
> Cons:
>
> 1. Setting any of these `tf.config` methods requires an empty TF session. This means we can't call a generate without and with XLA without resetting the session. Also, if we were to call it at the beginning of `generate()`, no compiled TF model could exist (again, because it needs an empty session).
>
> Personally, I'm slightly leaning towards this approach (with the `tf.config` calls) if we could make it work, but no strong feelings :)
Happy to switch to using `tf.config(...)` if you guys prefer! I'm not familiar with what is intuitive in TF so trusting you guys here. But I'm also not too happy with all those subfunctions and complicated function wrappers, so this approach makes a lot of sense.
Just to understand better, do you think it make more sense to set `tf.config.optimizer.set_jit(enabled=use_xla)` right after `generate(...)` or should we move it out completely of `generate()` and let the user set it before calling generate? In this case we wouldn't need a `use_xla` flag here at all no? Not sure what's better here<|||||>> Just to understand better, do you think it make more sense to set tf.config.optimizer.set_jit(enabled=use_xla) right after generate(...) or should we move it out completely of generate() and let the user set it before calling generate? In this case we wouldn't need a use_xla flag here at all no? Not sure what's better here
There would be no need for the `use_xla` flag in `tf.function`. I'd say to keep it in `generate()`, as it should be the outermost function that may need XLA inside. @Rocketknight1 what do you think (current approach vs `tf.config`?)<|||||>@Rocketknight1 and I were talking on Slack, and @Rocketknight1 came up with a third option, which is better in our opinion :D
The current approach has the disadvantages described above -- it has nested functions to implement the decorator on and, because of that, it may lose the ability to cache XLA compiled functions (= performance loss on repeated calls)
The approach I suggested relies on clearing sessions under some circumstances, which is not user-friendly.
The third option:
1. Let's not use `tf.function()` as a decorator, but as a function. We could do something like `xla_greedy_generate = tf.function(greedy_generate, jit_compile=True)` -- have a function called by `__init__()` that initializes all needed XLA functions;
2. `tf.function()` doesn't accept `**kwargs`, so we couldn't rely on a `use_xla` flag. Instead, we could use `tf.executing_eagerly()` to determine the mode of operation, inside `greedy_generate`.
This third option would be the best of both worlds -- we would avoid nested functions, ensure we can cache XLA compilation, and avoid relying on functions that need clear sessions. @patrickvonplaten what do you think? I'd be happy to give it a go if you're busy with other things :)<|||||>> @Rocketknight1 and I were talking on Slack, and @Rocketknight1 came up with a third option, which is better in our opinion :D
>
> The current approach has the disadvantages described above -- it has nested functions to implement the decorator on and, because of that, it may lose the ability to cache XLA compiled functions (= performance loss on repeated calls)
>
> The approach I suggested relies on clearing sessions under some circumstances, which is not user-friendly.
>
> The third option:
>
> 1. Let's not use `tf.function()` as a decorator, but as a function. We could do something like `xla_greedy_generate = tf.function(greedy_generate, jit_compile=True)` -- have a function called by `__init__()` that initializes all needed XLA functions;
> 2. `tf.function()` doesn't accept `**kwargs`, so we couldn't rely on a `use_xla` flag. Instead, we could use `tf.executing_eagerly()` to determine the mode of operation, inside `greedy_generate`.
>
> This third option would be the best of both worlds -- we would avoid nested functions, ensure we can cache XLA compilation, and avoid relying on functions that need clear sessions. @patrickvonplaten what do you think? I'd be happy to give it a go if you're busy with other things :)
Ah yes, I see! Using `tf.function(greedy_search)` is def better than the function decorator logic. Not 100% sure whether overwriting greedy search at `model.__init__(...)` is the way to go though. Wouldn't it in that case just be better to just mention in the docs that the generate method can be compiled as follows:
```
jitted_generate = tf.function(model.generate, jit_compile=True)
output = jitted_generate(input_ids)
```
? We could make use of `tf.executing_eagerly()` inside the code to figure out if we need XLA or not no?
|
transformers | 15,785 | closed | Handling preprocessing with token-classification pipeline | Hi,
Token classification tasks (e.g NER) usually rely on splitted inputs (a list of words). The tokenizer is then used with is_split_into_words=True argument during training.
However the pipeline for token-classification does not handle this preprocessing and tokenizes the raw input.
This can lead to different predictions if we use some custom preprocessing because tokens are different.
```
from transformers import AutoTokenizer
from tokenizers import pre_tokenizers
from tokenizers.pre_tokenizers import Punctuation, WhitespaceSplit
MODEL_NAME = "camembert-base"
pre_tokenizer = pre_tokenizers.Sequence([WhitespaceSplit(), Punctuation()])
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
text = "Ceci est un exemple n'est-ce pas ?"
splitted_text = [w[0] for w in pre_tokenizer.pre_tokenize_str(text)]
tokenizer.convert_ids_to_tokens(tokenizer(text).input_ids)
> ['<s>', '▁Ceci', '▁est', '▁un', '▁exemple', '▁n', "'", 'est', '-', 'ce', '▁pas', '▁?', '</s>']
tokenizer.convert_ids_to_tokens(tokenizer(splitted_text, is_split_into_words=True).input_ids)
> ['<s>', '▁Ceci', '▁est', '▁un', '▁exemple', '▁n', '▁', "'", '▁est', '▁-', '▁ce', '▁pas', '▁?', '</s>']
```
How can you make reliable predictions if you exactly know how the input is preprocessed ?
Pre-tokenizer and tokenizer mapping_offsets have to be merged somehow. | 02-23-2022 11:49:42 | 02-23-2022 11:49:42 | cc @SaulLu @Narsil <|||||>Hi @tkon3 ,
Normally this should be taken care of directly by the pre_tokenizer.
It seems `camembert-base` uses `WhitespaceSplit()` and `Metaspace` and you merely want to add `Punctuation`.
Doing something like
```python
from transformers import AutoTokenizer
from tokenizers import pre_tokenizers
from tokenizers.pre_tokenizers import Punctuation, WhitespaceSplit, Metaspace
MODEL_NAME = "camembert-base"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer._tokenizer.pre_tokenizer = pre_tokenizers.Sequence([WhitespaceSplit(), Punctuation(), Metaspace()])
text = "Ceci est un exemple n'est-ce pas ?"
print(tokenizer.convert_ids_to_tokens(tokenizer(text).input_ids))
print(tokenizer(text).tokens())
# ['<s>', '▁Ceci', '▁est', '▁un', '▁exemple', '▁n', '▁', "'", '▁est', '▁-', '▁ce', '▁pas', '▁?', '</s>']
# ['<s>', '▁Ceci', '▁est', '▁un', '▁exemple', '▁n', '▁', "'", '▁est', '▁-', '▁ce', '▁pas', '▁?', '</s>']
tokenizer.save_pretrained("camembert-punctuation")
```
Should be enough so that no one forgets how the input was preprocessed at training and make pipelines work along offsets. Does that work ?
There's no real other way to handle custom pretokenization in pipelines, it needs to be included somehow directly in the tokenizer's method. <|||||>hi @Narsil
Thank you for the quick answer, your idea works.
But the pipeline partially returns the expected result (aggregation_strategy="simple"):
- "start" and "end" indexes are fine
- the returned "word" is wrong (the pipeline adds additional spaces)
To get the correct word, I have to manually extract it from the input sentence. Not a big deal in my case but can be a problem for someone else:
```
sentence = "Ceci est un exemple n'est-ce pas ?"
pipe = TokenClassificationPipeline(model, tokenizer, aggregation_strategy="simple")
entities = pipe(sentence)
true_entities = [sentence[e["start"]: e["end"]] for e in entities]
```<|||||>Well, "words" don't really exist for this particular brand of tokenizer (Unigram with WhitespaceSplit). If I am not mistaken.
Extracting from the original string like you did is the only way to do it consistently.
The "word" is the decoded version of the token(s) and it's what the model sees. (so there's an extra space since there's no difference between " this" and "this" for this tokenizer.)
Do you mind creating a new issue for this, since it seems like a new problem ?
I do think what you're implying is correct that we should have `entity["word"] == sentence[entity["start"]: entity["stop"]]`.
Unfortunately that seems like a breaking change, so extra caution would have to be taken should we make such a change (or add a new key for instance)
<|||||>You are right, this is more general than what I expected. It is similar with uncased tokenizers:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
MODEL_NAME = "elastic/distilbert-base-uncased-finetuned-conll03-english"
text = "My name is Clara and I live in Berkeley, California."
model = AutoModelForTokenClassification.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
pipe = pipeline("token-classification", model=model, tokenizer=tokenizer, aggregation_strategy="simple")
entities = pipe(text)
print([(text[entity["start"]:entity["end"]], entity["word"]) for entity in entities])
# [('Clara', 'clara'), ('Berkeley', 'berkeley'), ('California', 'california')]
```
Adding a new key is probably the easiest way.
I guess this can implemented inside the [postprocess](https://github.com/huggingface/transformers/blob/db7d6a80e82d66127b2a44b6e3382969fdc8b207/src/transformers/pipelines/token_classification.py#L226) function with a postprocess param:
```python
grouped_entities = self.aggregate(pre_entities, aggregation_strategy)
if some_postprocess_param:
grouped_entities = [{"raw_word": sentence[e["start"]:e["end"]], **e} for e in grouped_entities]
```
Want me to do a feature request ?<|||||>I think we should move to another issue/feature request for this yes (the discussion has diverged since the first message).
Can you ping me, and Lysandre on it and refer to this original issue for people wanting more context ?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,784 | closed | Trainer is not so compatible with customized optimizer | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.16.2
- Platform: Linux-5.4.56.bsk.6-amd64-x86_64-with-debian-10.11
- Python version: 3.7.3
- PyTorch version (GPU?): 1.10.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help
- Trainer: @sgugger
## Information
Model I am using BART for conditional generation
The problem arises when using:
* [ ] trainer with customized optimizer
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] generation, but I guess this problem applies to other tasks
## To reproduce
Steps to reproduce the behavior:
The reason to create a customized optimizer: I want to set different learning rate for different parameters
__Distributed Training with sharded=simple__
1. create the customized optimizer
```python
model = BART.from_pretrained('facebook/bart-base')
def create_optimizer_and_scheduler(model: nn.Module, sharded_ddp:List[ShardedDDPOption], total_trainin_steps:int,
default_lr:float, resnet_lr: float,
optim_args:TrainingArguments, weight_decay=0.0):
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
decay_parameters = [name for name in decay_parameters if "bias" not in name]
param_no_decay = [p for n, p in model.named_parameters() if n not in decay_parameters]
resnet_param_with_decay = [p for n, p in model.named_parameters() if "patch_embedding" in n and n in decay_parameters]
other_param_with_decay = [p for n, p in model.named_parameters() if "patch_embedding" not in n and n in decay_parameters]
optimizer_grouped_parameters = [
{
"params": other_param_with_decay,
"weight_decay": weight_decay,
"lr": default_lr
},
{
"params": resnet_param_with_decay,
"weight_decay": weight_decay,
"lr": resnet_lr
},
{
"params": param_no_decay,
"weight_decay": 0.0,
"lr": default_lr
},
]
optimizer_cls, optimizer_kwargs = Trainer.get_optimizer_cls_and_kwargs(optim_args)
if ShardedDDPOption.SIMPLE in sharded_ddp:
optimizer = OSS(
params=optimizer_grouped_parameters,
optim=optimizer_cls,
**optimizer_kwargs,
)
else:
optimizer = AdamW(optimizer_grouped_parameters, **optimizer_kwargs)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0,
num_training_steps=total_trainin_steps)
return optimizer, scheduler
```
2. Put the optimizer to model
```python3
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset.remove_columns('metadata'),
eval_dataset=eval_dataset.remove_columns('metadata'),
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=(build_compute_metrics_fn(tokenizer=tokenizer)),
optimizer=create_optimizer_and_scheduler(model = model, ....)
)
```
## Expected behavior
```shell
Traceback (most recent call last):
File "vl_bart_main.py", line 216, in <module>
hf_trainer_main()
File "vl_bart_main.py", line 157, in hf_trainer_main
train_result = trainer.train()
File "/home/tiger/.local/lib/python3.7/site-packages/transformers/trainer.py", line 1365, in train
tr_loss_step = self.training_step(model, inputs)
File "/home/tiger/.local/lib/python3.7/site-packages/transformers/trainer.py", line 1940, in training_step
loss = self.compute_loss(model, inputs)
File "/home/tiger/.local/lib/python3.7/site-packages/transformers/trainer.py", line 1972, in compute_loss
outputs = model(**inputs)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1120, in _call_impl
result = forward_call(*input, **kwargs)
File "/home/tiger/.local/lib/python3.7/site-packages/fairscale/nn/data_parallel/sharded_ddp.py", line 219, in forward
self.refresh_trainable()
File "/home/tiger/.local/lib/python3.7/site-packages/fairscale/nn/data_parallel/sharded_ddp.py", line 300, in refresh_trainable
optim.refresh_trainable()
File "/home/tiger/.local/lib/python3.7/site-packages/fairscale/optim/oss.py", line 478, in refresh_trainable
self._setup_flat_buffers()
File "/home/tiger/.local/lib/python3.7/site-packages/fairscale/optim/oss.py", line 652, in _setup_flat_buffers
bucket.add_param(param)
File "/usr/local/lib/python3.7/dist-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/tiger/.local/lib/python3.7/site-packages/fairscale/nn/misc/param_bucket.py", line 69, in add_param
self._add_param_as_view(param)
File "/usr/local/lib/python3.7/dist-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/tiger/.local/lib/python3.7/site-packages/fairscale/nn/misc/param_bucket.py", line 81, in _add_param_as_view
), f"Different devices for the bucket and the param, cannot proceed: {param.device} - {self.buffer.device}"
AssertionError: Different devices for the bucket and the param, cannot proceed: cuda:2 - cpu
```
## Suspected Reason
The model is wrapped with something else in the initialization of `Trainer`, but that changes do not reflect in the process of optimizer instantiation.
## My Workaround Solution
Get the optimizer after initialize the trainer
```python3
model = BART.from_pretrained('facebook/bart-base')
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset.remove_columns('metadata'),
eval_dataset=eval_dataset.remove_columns('metadata'),
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=(build_compute_metrics_fn(tokenizer=tokenizer)),
)
## get trainer's model
optim_scheduler = create_optimizer_and_scheduler(model=trainer.model, ....)
## override the default optimizer
trainer.optimizer = optim_scheduler[0]
```
But this approach seems not really elegant.
| 02-23-2022 10:45:03 | 02-23-2022 10:45:03 | You can't pass along your own optimizer with the Fairscale or DeepSpeed integration indeed. As far as I can tell, your workaround is the best way to do it.<|||||>I see. Thanks. I guess that it would be good to throw an exception/error if "sharded_ddp or deepspeed is enable" and "customized optimizer is passed in"?<|||||>Sure, would you like making a PR with it?
Another way to use your custom optimizer is to subclass and override the `create_optimizer` method btw.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,783 | closed | [Bug] Gradient Checkpointing In CLIP Model | https://github.com/huggingface/transformers/blob/master/src/transformers/models/clip/modeling_clip.py#L575
Hi, there,
I believe `hidden_states = layer_outputs[0]` should be in the for loop. I try to enable the gradient checkpointing for the clip model but find this bug. | 02-23-2022 10:33:36 | 02-23-2022 10:33:36 | Great catch! Fix is here https://github.com/huggingface/transformers/pull/15789 |
transformers | 15,782 | closed | Supporting Merges.txt files than contain an endline. (`hf-internal-testing/tiny-clip` for instance) | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | 02-23-2022 10:31:32 | 02-23-2022 10:31:32 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,781 | closed | Add Semantic Segmentation for ConvNext | # What does this PR do?
This PR adds Semantic Segmentation to ConvNext model, original code [here](https://github.com/facebookresearch/ConvNeXt/tree/main/semantic_segmentation).
## Who can review?
@NielsRogge
| 02-23-2022 08:32:54 | 02-23-2022 08:32:54 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15781). All of your documentation changes will be reflected on that endpoint.<|||||>The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15781). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Still working on this.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Still working
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,780 | closed | how to save a model with additional layers, so it can be loaded using .from_pretrained()? | ## Environment info
- `transformers` version: 2.3.0
- Platform: Linux-4.15.0-135-generic-x86_64-with-glibc2.27
- Python version: 3.8.12
- PyTorch version (GPU?): 1.8.1+cu111 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: YES (T4 TESLA)
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik
## Information
Model I am using Bert: Text-classification
## To reproduce
Steps to reproduce the behavior:
I have a custom model
`class BERTClass(torch.nn.Module):
def __init__(self, num_labels=4):
super(BERTClass, self).__init__()
self.l1 = BertModel.from_pretrained('bert-base-multilingual-uncased')
self.l2 = torch.mean
self.l3 = torch.nn.Linear(768, num_labels)
def forward(self, ids, masks, token_type_ids):
last_hidden_state, _ = self.l1(ids, attention_mask=masks, token_type_ids=token_type_ids)
avg_pooling = self.l2(last_hidden_state, dim=1)
output = self.l3(avg_pooling)
return output`
How do I go about saving my custom model so that I can run BertModel.from_pretrained('./mycustomodel')
Do you have an example I can follow by chance?
Currently I am saving the model this way
`
model_2_save = model.module if hasattr(model, "module") else model
checkpoint = {
'epoch': args.epochs,
'num_labels': args.num_labels,
'max_text_length': MAX_TEXT_LENGTH,
'state_dict': model_2_save.state_dict()
}
torch.save(checkpoint, args.model_dir + "/pt_model.pt")
`
Thanks for the help!
| 02-23-2022 06:41:50 | 02-23-2022 06:41:50 | Hi! For questions like this, it would be best to ask this on the [forum](https://discuss.huggingface.co/). We use issues for bug reports and feature requests. Thanks!
To answer your question: The [sharing custom model guide](https://huggingface.co/docs/transformers/master/en/custom_models) might help with this .<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>@christianjoun did you solve this problem? |
transformers | 15,779 | closed | LMV2Processor Decoder string not matching with original string | ## Environment info
- `transformers` version: 4.11.0
- Platform: Linux-5.4.0-1063-aws-x86_64-with-debian-buster-sid
- Python version: 3.7.10
- PyTorch version (GPU?): 1.8.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?[/GPU]()?[/TPU]()?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
@NielsRogge @SaulLu
## Information
Model I am using LayoutLMv2:
The problem arises when using the processor to decode:
```
from transformers import LayoutLMv2Processor
from PIL import Image
import cv2
processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
large = cv2.imread('Employee_ID_2.png')
words = ["hello", "world", "10/12/2021","O +ve"]
boxes = [[1, 2, 3, 4], [5, 6, 7, 8], [1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
encoding = processor(large, words, boxes=boxes, return_tensors="pt",add_special_tokens = True)
print(encoding.keys())
```
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
```
encoding['input_ids'].tolist()[0]
```
[101, 7592, 2088, 2184, 1013, 2260, 1013, 25682, 1051, 1009, 2310, 102]
```
processor.tokenizer.decode(encoding['input_ids'].tolist()[0],skip_special_tokens= True)
```
'hello world 10 / 12 / 2021 o + ve'
#### Issue:
Decoder splits the date and blood group which are not the same as the original text. What changes can i make to get the desired results.
## To reproduce
Use the above code to reproduce
## Expected behavior
Decoder output should match the original text.
["hello", "world", "10/12/2021","O +ve"] | 02-23-2022 06:40:54 | 02-23-2022 06:40:54 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi,
I assume this is due to the WordPiece algorithm. cc'ing @SaulLu who knows this better than me.<|||||>Hi @purnasai,
I also agree with Niels, I think that the proposed decoding here is the best we can do. :disappointed:
_As a reminder, the method is developed for the case of generated tokens (in other words, for the case where the initial input is not known)._
For context, the LayoutLMv2 tokenizer is based on the BERT tokenizer. Like all other tokenizers, the BERT tokenizer consists of a succession of several operations: normalization, pre-tokenization, application of the tokenization model and finally post-processing. Decoding is a final operation performed on the output given by the previous pipeline.
During the pre-tokenization phase, the BERT decides, among other things, to split the initial textual input on spaces (by removing them) and also on punctuation (without removing them). It is therefore at the time of this operation that we lose information forever: were the tokens separated by a space or not?
For example, `"this is a test 10/12/2421"` will be pre-tokenized in:
```
[('this', (0, 4)),
('is', (5, 7)),
('a', (8, 9)),
('test', (10, 14)),
('10', (15, 17)),
('/', (17, 18)),
('12', (18, 20)),
('/', (20, 21)),
('2421', (21, 25))]
```
The Worpiece tokenization algorithm will then be applied to this pre-tokenized input, resulting in: `['this', 'is', 'a', 'test', '10', '/', '12', '/', '242', '##1']`. To do the best, at the time of decoding we add a space between each pair of tokens if the 2nd token of the pair does not start with "##".
I hope this explanation was helpful for you!
Could you share with us for which use case you want to use the decode method? :blush: <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,778 | closed | Tfperceiver | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-23-2022 06:12:37 | 02-23-2022 06:12:37 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15778). All of your documentation changes will be reflected on that endpoint.<|||||>cc @NielsRogge <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,777 | closed | infer_framework_load_model function docs typo and grammar fixes | # What does this PR do?
- Fix typo because words should not be mispelled
- Fix grammar to more properly describe the code
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-23-2022 01:55:41 | 02-23-2022 01:55:41 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15777). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,776 | closed | Fix dummy_inputs() to dummy_inputs in symbolic_trace doc string | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-23-2022 00:42:41 | 02-23-2022 00:42:41 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,775 | closed | 🚨 🚨 🚨 Fix Issue 15003: SentencePiece Tokenizers Not Adding Special Tokens in `convert_tokens_to_string` | Hello! 👋
This PR fixes issue #15003 and is also related to issue #11716.
First, I've expanded the `test_sentencepiece_tokenize_and_convert_tokens_to_string` test in `test_tokenization_common.py` which, in addition to checking a round-trip from string to tokens and back, performs a check whether the tokens corresponding to `input_ids` (using `convert_ids_to_tokens`) followed by `convert_tokens_to_string` and then re-tokenized, give the same number of tokens as `input_ids`. This is because not all SentencePIece tokenizers have a `*Fast` flavor, and so I couldn't compare behaviors similar to the `T5Tokenizer` test.
This test failed for the following tokenizers:
- `AlbertTokenizer`
- `BarthezTokenizer`
- `CamembertTokenizer`
- `DebertaV2Tokenizer`
- `FNetTokenizer`
- `LayoutXLMTokenizer`
- `M2M100Tokenizer`
- `MarianTokenizer`
- `MBart50Tokenizer`
- `PegasusTokenizer`
- `Speech2TextTokenizer`
Most of these tokenizers had the same implementation for `convert_tokens_to_string`:
```python
def convert_tokens_to_string(self, tokens):
return self.sp_model.decode(tokens)
```
All tokenizers who had this implementation, or something that can be reduced to it, are now inheriting `SentencePieceStringConversionMixin` (defined in `tokenization_utils.py`), and the implementation uses the same code as PR #8435. The rest have a variation of this code, and perhaps a future refactor can DRY it a bit.
The only tokenizer that doesn't pass the test, and is therefore excluded from it, is `LayoutXLMTokenizer`, whose `convert_tokens_to_string` method doesn't use the SentencePiece model in its implementation, and so I figured the lack of special tokens is intentional, rather than a byproduct of SentencePiece like the rest.
I think this PR is relevant for @NielsRogge who initially opened the issue on `AlbertTokenizer`, and following the PR guidelines, I think this is also relevant to @LysandreJik and @patrickvonplaten.
This has been a very fun project, and hopefully you will allow me to contribute more in the future 🙂
Thanks,
Ben | 02-22-2022 23:10:24 | 02-22-2022 23:10:24 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15775). All of your documentation changes will be reflected on that endpoint.<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>GitHub Actions, stop marking this PR as stale! 😅
Hi @SaulLu, how are you? I started a new job so kind of lost track with this PR, is it still relevant? I'd really like to see this PR merged at some point 😁 <|||||>Hi @beneyal !
Congrats for your new job :confetti_ball:
Yes it's still relevant: I'm also sorry, I can't find the time to propose the last fixes to merge your PR. I think it would be good to 1) [standardize between tokenizers with only a slow version and the one with a slow and a fast](https://github.com/huggingface/transformers/pull/15775#discussion_r864030843) and also 2) to find a solution to [avoid hardcoded values in Deberta-v2](https://github.com/huggingface/transformers/pull/15775#discussion_r864034981).
Sorry, you didn't picked the easier bug to fix :hugs: <|||||>Hi again @SaulLu 🙂
I found something interesting.
Running this code:
```python
from transformers import AutoTokenizer
tokenizers = [
(
"microsoft/deberta-v2-xlarge",
AutoTokenizer.from_pretrained("microsoft/deberta-v2-xlarge", use_fast=True),
AutoTokenizer.from_pretrained("microsoft/deberta-v2-xlarge", use_fast=False),
),
(
"albert-base-v2",
AutoTokenizer.from_pretrained("albert-base-v2", use_fast=True),
AutoTokenizer.from_pretrained("albert-base-v2", use_fast=False),
),
(
"bert-large-uncased",
AutoTokenizer.from_pretrained("bert-large-uncased", use_fast=True),
AutoTokenizer.from_pretrained("bert-large-uncased", use_fast=False),
),
(
"camembert-base",
AutoTokenizer.from_pretrained("camembert-base", use_fast=True),
AutoTokenizer.from_pretrained("camembert-base", use_fast=False),
),
]
text = "This is some {} to the tokenizer."
print("| Checkpoint Name | Fast Tokenizer | Slow Tokenizer |")
for ckpt, fast, slow in tokenizers:
fast_tokens = fast.tokenize(text.format(fast.unk_token))
slow_tokens = slow.tokenize(text.format(slow.unk_token))
assert (
fast_tokens == slow_tokens
), f"tokens should be identical in the same model. {ckpt = }, {slow_tokens =}, {fast_tokens = }"
fast_string = fast.convert_tokens_to_string(fast_tokens)
slow_string = slow.convert_tokens_to_string(fast_tokens)
print(f"| {ckpt} | {fast_string} | {slow_string} |")
```
Gives us the following table:
| Checkpoint Name | Fast Tokenizer | Slow Tokenizer |
|---|---|---|
| microsoft/deberta-v2-xlarge | This is some[UNK] to the tokenizer. | This is some[UNK]to the tokenizer. |
| albert-base-v2 | this is some\<unk\> to the tokenizer. | this is some\<unk\>to the tokenizer. |
| bert-large-uncased | this is some [UNK] to the tokenizer. | this is some [UNK] to the tokenizer . |
| camembert-base | This is some\<unk\> to the tokenizer. | This is some\<unk\>to the tokenizer. |
So we can see that DeBERTa v2, Albert and CamemBERT have the same behavior w.r.t UNK:
* Fast tokenizer has no space between a non-special token and UNK
* Slow tokenizer has no spaces on both sides of the UNK
That's weird, because then we would expect DeBERTa v2's `convert_tokens_to_string` code (which I made identical to Albert's) to pass the tests we wrote.
So I made a slight change to the test (`test_tokenization_deberta_v2.py:40`):
```python
# tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="<unk>")
tokenizer = DebertaV2Tokenizer.from_pretrained(
"https://huggingface.co/microsoft/deberta-v2-xlarge/resolve/main/spm.model"
)
```
Now the `convert_tokens_to_string` tests pass, and the only failing tests are ones that rely on the size of the test vocabulary and some casing (`<pad>` vs `<PAD>`). Add this to the fact the only DeBERTa v2's test needed to specify a different UNK token, I believe the logic is fine, but something is amiss with the test vocab. What do you think?
Have a lovely weekend!<|||||>Hello @SaulLu 🙂 Just a little ping in case you didn't see my written novel of a comment above 😅 Thank you again for your time and have a lovely day!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @SaulLu, GitHub Actions wants to close this issue again 😅 Hope everything is well!
I haven't worked on this since June 11th because I'm waiting for your insights 🙂
Have a great week!<|||||>Hi @beneyal ,
I wanted to leave you a message to let you know that I haven't had time so far to dive into your PR (and I, unfortunately, have no idea what the right answer is by reading your findings) and that unfortunately, I'm going to be off next week.
I appreciate a lot all the efforts you made for this fix, I really hope we will find a satisfactory solution! <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @SaulLu 🙂 Any news? The bot wants to close the issue again 😅 <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @SaulLu, how are you? 🙂
Anything new regarding this PR? 🙏 <|||||>This PR is still in progress 🙂 <|||||>The Albert changes resolved the lack of `[MASK]` for me. Plans to get this merged?<|||||>@sgugger Wonderful to have you on board! 🚀
I can't comment on the Deberta snippet, so I'll try here: we basically want the code for Deberta V2 be the same as the code for the other tokenizers like Albert, i.e., without the special `seen_unk` hack?
I also changed the title as requested 🙂 <|||||>Yes, that would be great! And if you could fix the merge conflicts/rebase on main that would also be awesome!<|||||>@sgugger I have a rather silly question: I see in GitHub there are two conflicts: `tests/deberta_v2/test_tokenization_deberta_v2.py` and `tests/layoutxlm/test_tokenization_layoutxlm.py`. When merging `upstream/main` to my branch, there are no conflicts. Regarding rebasing, I've never done it so I'm not familiar with that functionality and what do I rebase into what. Could you please help me with this? 😅 <|||||>If you have merged your branch with upstream then just a push should be enough to resolve the conflicts.
To rebase just do this on your branch:
```
git rebase origin/main
```
then you'll need to force-push
```
git push -u origin branch_name --force
```<|||||>@sgugger Done 🙂 Whisper's test failed because an HTTP timeout, but the rest seem fine. Deberta V2 is now excluded from the sentencepiece tests, but has the same logic as Albert.<|||||>@sgugger Done, thanks for the suggestions!<|||||>Thanks again and sorry for the long wait on this PR!<|||||>Hi @beneyal First, thank you for working on this. I have a question as we have a CI failure. With the following code snippet,
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
sequence_ids = model.generate(input_ids)
sequences = tokenizer.batch_decode(sequence_ids)
print(sequences)
```
we have different results:
**Before this PR**
```python
['<pad> <extra_id_0> park offers<extra_id_1> the<extra_id_2> park.</s>']
```
**After this PR**
```python
['<pad><extra_id_0> park offers<extra_id_1> the<extra_id_2> park.</s>']
```
We no longer have the space between `<pad>` and `<extra_id_0>`. Is this expected? 🙏 Thank you.<|||||>@ydshieh Glad to do it!
Yes, this is intended behavior, as it mimics the fast tokenizer:
```python
from transformers import T5Tokenizer, T5TokenizerFast, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("t5-small")
tokenizer_fast = T5TokenizerFast.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
inputs_ids_fast = tokenizer_fast("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
assert input_ids.tolist() == inputs_ids_fast.tolist()
sequence_ids = model.generate(input_ids)
sequences = tokenizer.batch_decode(sequence_ids)
sequences_fast = tokenizer_fast.batch_decode(sequence_ids)
print(sequences, sequences == sequences_fast) # outputs True
``` |
transformers | 15,774 | closed | Fix tf.concatenate + test past_key_values for TF models | # What does this PR do?
- Fix `tf.concatenate` (#15477)
- it should be `tf.concat`
- Add testing about `past_key_values` for TF models
Currently, only added to
- `testing_modeling_tf_bert.py`
- TF model testing template
The changes include:
- add tests for: causal lm **base model** / causal lm model / decoder (i.e. with cross attention)
- rename some methods / add docstrings, to make them more clear (without reading their codes)
- Fix `extended_attention_mask` when `past_key_values` is passed:
- it should be the mask for the present inputs (i.e. shouldn't contain the past part)
(detected when the above tests are added)
(this is already done for `TFT5Model`, see [here](https://github.com/huggingface/transformers/blob/7f921bcf47f2d6875feb6c1232dc6cfbeb4668e8/src/transformers/models/t5/modeling_tf_t5.py#L732))
TF: @gante @Rocketknight1
Also cc @sgugger for the changes in the templates | 02-22-2022 20:44:46 | 02-22-2022 20:44:46 | _The documentation is not available anymore as the PR was closed or merged._<|||||>> This all looks good to me, thanks a lot for fixing! Pinging @patrickvonplaten for the `past_key_values` change, to make sure it's all okay.
>
> Re-the test. Is BERT the only test file to adapt?
Hi, I don't understand this question, but let me try to answer
- the test file for TF-BERT is already changed.
- we need to add the same tests to other TF models, like `roberta`, `electra` (the encoder-like models that can also be used as decoder)
(Let me know if I misunderstand your question, @sgugger )<|||||>Yes, that was my question. Will you add those other test files in the same PR?<|||||>> Yes, that was my question. Will you add those other test files in the same PR?
Sure, I intend to do so (after an approval for the change in TF-BERT test).
I will wait a bit - to have reviews from other people - and add to other test files :-)<|||||>@patrickvonplaten
I have a few questions while looking other models like TF-T5: (see the end of the actual question)
https://github.com/huggingface/transformers/blob/d1fcc90abf34cc498c8a65a717ad0d9354ceca97/src/transformers/models/t5/modeling_tf_t5.py#L717-L734
- Line 717-718 implies that if **3D attention mask** is passed, then it means `from_seq_length - cached_seq_length` (because there is no slice)
- Line 732 implies if 2D mask + is_decoder + pass_key_values, attn mask means `from_seq_length`, and we slice it to become `from_seq_length - cached_seq_length`.
Furthermore, from
https://github.com/huggingface/transformers/blob/d1fcc90abf34cc498c8a65a717ad0d9354ceca97/src/transformers/models/t5/modeling_tf_t5.py#L388-L393
- `TFT5Attention` requires `mask` to be `from_seq_length - cached_seq_length`.
**My Question**: depending **3D** or **2D** format, `attention_mask` in `TFT5MainLayer` has different meaning (in terms of the query length). It could make sense - but only if we document it clearly.
Or, is this rather a mistake, and even for 3D case, it should actually mean to have the full sequence length, and we need to slice it to the present sequence only (so a fix is required here) ?
I think it expects the user to provide the correct shape in 3D case, i.e already sliced to only the present sequence length. Just want to have a double check from you.<|||||>One point about the `extended_attention_mask` - when we call `generate()` with the new changes we **do** expect that the `attention_mask` can be used to mask positions in the `past_key_values`. This is something I only realized when I started working on `generate()`! It probably only applies to causal LMs, but the fact that we seem to be truncating the attention mask in some cases is concerning, as it will cause that method to break. Are we sure that that truncation is only happening in models that don't have a `generate()` method?<|||||>> One point about the `extended_attention_mask` - when we call `generate()` with the new changes we **do** expect that the `attention_mask` can be used to mask positions in the `past_key_values`. This is something I only realized when I started working on `generate()`! It probably only applies to causal LMs, but the fact that we seem to be truncating the attention mask in some cases is concerning, as it will cause that method to break. Are we sure that that truncation is only happening in models that don't have a `generate()` method?
Hi, @Rocketknight1
- 1. the truncation `extended_attention_mask[:, :, -seq_length:, :]` - I only see it when a model is used as a decoder, which has `generate` in general. This happens when the provided attention mask is 2D (with full past+present length).
- 2. For 3D attention mask, from the code, no such truncation - so I think it expects the one only contains for the `present` inputs without `past`. (and this is what I want to have a confirmation from @patrickvonplaten)
- 3. For `generate`, do you ever see in the code dealing with a case that uses 3D attention mask? If only 2D case occurrs, I think the code for dealing with attention mask in the models is fine, from point 1.<|||||>Add the tests to other TF models:
- roberta (2 failed - need to investigate) [Fixed](https://github.com/huggingface/transformers/pull/15774/files#r814551298)
- rembert
- electra (no `TFElectraForCausalLM` at this moment)<|||||>> One point about the `extended_attention_mask` - when we call `generate()` with the new changes we **do** expect that the `attention_mask` can be used to mask positions in the `past_key_values`. This is something I only realized when I started working on `generate()`! It probably only applies to causal LMs, but the fact that we seem to be truncating the attention mask in some cases is concerning, as it will cause that method to break. Are we sure that that truncation is only happening in models that don't have a `generate()` method?
That's not true really I think. When `past_key_values` is used there is no need to mask them with `attention_mask`.
The reason is that `past_key_values` are **only** used for causal LM models so that future tokens coming after `past_key_values` can never influence previous tokens (that's the whole reason why we are able to cache past key values states). This means that when `attention_mask` is used in combination with `past_key_values`, the `attention_mask` can only influence the `input_ids` that are forwarded with it - never previous cached `past_key_values`.
Now when talking about XLA-compatible generation note that even there this should hold true because all "padded"/"non-reached" vectors of `past_key_values` should be padded anyways with -10,000.0<|||||>@ydshieh, this PR looks very nice and it's an important one. Let's try to keep the discussion and the code focus on just this issue here which is:
**Correct `past_key_values` concatenation and `attention_mask`-slicing behavior if BERT-like models are used for generation**
Given that literally the syntax is not even correct, there were 0 tests, 0 usage, so it's great that we are adding tests here. That's it - nothing more.
`past_key_values` is one of the most complicated topics, so I'd be very happy if we could move further discussions / changes to issues.
<|||||>> > One point about the `extended_attention_mask` - when we call `generate()` with the new changes we **do** expect that the `attention_mask` can be used to mask positions in the `past_key_values`. This is something I only realized when I started working on `generate()`! It probably only applies to causal LMs, but the fact that we seem to be truncating the attention mask in some cases is concerning, as it will cause that method to break. Are we sure that that truncation is only happening in models that don't have a `generate()` method?
>
> That's not true really I think. When `past_key_values` is used there is no need to mask them with `attention_mask`. The reason is that `past_key_values` are **only** used for causal LM models so that future tokens coming after `past_key_values` can never influence previous tokens (that's the whole reason why we are able to cache past key values states). This means that when `attention_mask` is used in combination with `past_key_values`, the `attention_mask` can only influence the `input_ids` that are forwarded with it - never previous cached `past_key_values`.
>
> Now when talking about XLA-compatible generation note that even there this should hold true because all "padded"/"non-reached" vectors of `past_key_values` should be padded anyways with -10,000.0
After some discussion with @Rocketknight1 offline, there is actually one use case where it's very important to make sure that the `attention_mask` when forwarding `past_key_values` states. So for completeness and correctness I want to outline this here real quick. When doing batched generation where one input is longer than another one we usually make sure to do **left-padding** meaning that the input_ids and attention_mask would look like this:
```python
input_ids = [["hello", "this", "is", "very", "long"], ["<PAD>", "<PAD>", "This", "is", "short"]]
attention_mask = [[1,1,1,1,1], [0, 0, 1, 1, 1]]
```
In this case, the second `attention_mask`'s 0s will mask cached `past_key_values` for all future query vectors to come. But apart from this there should really be no use case where the `attention_mask` should influence `past_key_values`.
<|||||>@patrickvonplaten
Could you check this part, please:
https://github.com/huggingface/transformers/pull/15774/files#r814551298
The computation of `position_ids` in Roberta model (regarding to `padding_idx`) failed some testing for `past` -> I need to ensure `padding_idx` not in the initial input ids.
(Finally, the tests are all green 🚀)<|||||>Although currently there is no `TFElectraForCausalLM`, but we can still add tests like
- create_and_check_causal_lm_model_past
- create_and_check_causal_lm_model_past_with_attn_mask
- create_and_check_causal_lm_model_past_large_inputs
- create_and_check_decoder_model_past_large_inputs
by using `TFElectraModel` (as decoder and/or add cross attention) - although the method names here are a bit misleading in this case.
Let me add them before merge!
==> Done. Think everything is fine from my side, waiting for reviews when you have time :-)<|||||>@ydshieh I have a couple of questions I left as comments, but overall this seems like a good PR and I'm happy to merge after those are addressed!<|||||>> Just finished reviewing and this looks good! In my earlier comment, I hadn't looked at these changes thoroughly and didn't realize that the attention mask crop only applied when cross-attention was being performed for encoder-decoder models - this was my bad, I'm sorry!
No worry, I am a fan of TFBoys :-)
I think it is used when `past_key_values` is provided, and this can happen in 2 cases:
- causal LM (without cross-attention)
- decoder in an encoder-decoder setting (with cross-attention)
Hope I understand your words correctly. |
transformers | 15,773 | open | [Community] Add fairseq FastSpeech2 | # What does this PR do?
This PR adds FastSpeech2, a transformer-based text-to-speech model. Fixes #15166.
## Motivation
While HF transformers has great support for ASR and other audio processing tasks, there is not much support for text-to-speech. There are many transformer-based TTS models that would be great to have in the library. FastSpeech2 is perhaps the most well-known and popular of transformer-based TTS models. With TTS support, we could potentially have really cool demos that go from ASR -> NLU -> NLG -> TTS to build full-fledged voice assistants!
## Who can review?
Anton, Patrick (will tag when PR is ready) | 02-22-2022 20:37:19 | 02-22-2022 20:37:19 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15773). All of your documentation changes will be reflected on that endpoint.<|||||>Here is a (tried-to-keep-short-but-long) update on this PR, summarizing some of the things discussed with @anton-l for public visibility.
1. Checkpoint loading: The model weight loads properly and produces roughly the same output as the fairseq model. On preliminary tests, I've found that `torch.allclose` passes with `atol=1e-6`. On this branch, the model can be loaded via
```python
from transformers import AutoModel
model = AutoModel.from_pretrained("jaketae/fastspeech2-lj")
```
2. Grapheme-to-phoneme: Fairseq uses [`g2p_en`](https://github.com/Kyubyong/g2p). I've added this as a dependency via `requires_backend` in the tokenizer. One thing I'm not too sure about is whether to enforce this from the get-go at `__init__`, or only require it in the `phonemize` function.
3. Tokenizer: The tokenizer can be loaded as shown. For some reason, `AutoTokenizer` doesn't work at the moment, but this can likely be fixed by reviewing import statements. One consideration is that the fairseq code seems to add an EOS token at the end of every sequence, whereas HF's tokenizers do not by default (correct me if I'm wrong). In my code, I manually add the EOS token at the end for consistency.
```python
from transformers.models.fastspeech2 import FastSpeech2Tokenizer
tokenizer = FastSpeech2Tokenizer.from_pretrained("jaketae/fastspeech2-lj")
```
4. Vocoder: (Note: This is not directly related to the source code in this PR.) Using Griffin-Lim for vocoding yields very poor audio quality and is likely a bad idea for demos. An alternative is to use neural vocoders like HiFi-GAN. I've added HiFi-GAN on the model hub, which can be imported via `vocoder = AutoModel.from_pretrained("jaketae/hifigan-lj-v1", trust_remote_code=True)`. At the moment, for some reason the model weights do not load properly, debugging required.
I have some questions for discussion.
1. Model output: What should the output of the model be? At the moment, it returns a tuple of mel-spectrograms, mel-spectrogram after postnet, output lengths (number of spectrogram frames), duration predictor output, predicted pitch, and predicted energy. I assume we need to subclass `BaseModelOutput` for something like `TTSModelOutput`, and also optionally return loss when duration, pitch, and energy ground-truth labels are supplied in `forward`.
2. Mean and standard deviation: Fairseq's FastSpeech2 model technically does not predict a mel-spectrogram, but a normalized mean spectrogram according to mu and sigma values extracted from the training set. In fairseq's TTS pipeline, FS2 output is denormalized by some mu and sigma before being vocoded. I've added the mu and sigma values as `register_buffer` to the model, and created `set_mean` and `set_std` functions so that users can set these values according to their own training set. By default, mean and variance are set to 0 and 1 so that no rescaling is performed. Is this good design?
3. TTS pipeline: At the moment, there is only `FastSpeech2Model`, which outputs mel-spectrograms as indicated above. While people might want to use acoustic feature generators for mel-spectrogram synthesis, more often they will want to obtain raw audio in waveform. As mentioned, this requires a vocoder, and we need to discuss ways to integrate this. Some API ideas I have include:
- Introducing a `FastSpeech2ForAudioSynthesis` class with an integrated vocoder
- Adding a `pipeline` that supports full-fledged TTS via something like `pipeline("text-to-speech", model="fastspeech2", vocoder="hifigan")`. But this is again contingent on how we want to integrate the vocoder.
To-do's on my end (will be updated as I find more).
- [x] Writing tests
- [ ] Documentation
- [x] Cleaning up imports
- [x] Debugging why `AutoTokenizer` fails
- [ ] Debugging why HiFi-GAN weights do not load
cc @anton-l @patrickvonplaten <|||||>Hey @anton-l, here are some long overdue updates:
* Incorporated LJSpeech and Common Voice checkpoints to the model hub
* Wrote unit and fairseq integration tests
At the moment, `test_initialization` is failing, and I'm still investigating how to fix it. I also skipped a number of tests (e.g., ones that test for `output_attentions` or `hidden_states`), because FS2 does not return these keys.
I've added one simple `test_inference_integration` test to check that the expected mel-spectrogram output by the fairseq model is `torch.allclose` to the HF port. However, mel-spectrograms are too big in dimension, e.g., `(batch_size, seq_len, mel_dim)`, where `mel_dim` is typically 80. Therefore, I've sliced the first 100 elements for inspection instead. If you think there is a more robust check (i.e., more elements, different text, etc), please let me know.
An updated to-do's:
- [ ] docstrings/documentation
- [ ] debug `test_initialization`
- [ ] debug any failing tests
Thank you!<|||||>The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15773). All of your documentation changes will be reflected on that endpoint.<|||||>@LysandreJik @sgugger would be awesome if you take a look at this PR too, since it introduces a novel modality :) <|||||>@patrickvonplaten after a brief discussion with @jaketae, I think we should keep the spectrogram2waveform generators as separate models on the Hub for several reasons:
* the models for waveform generation are more or less interchangeable between different models (maybe with some finetuning) and are trained separately from the TTS models
* since the generators can be quite diverse, it would be cumbersome to support training for them, e.g. we probably don't have GANs or diffusion models in `transformers` for that very reason
* if I understand correctly, the generators usually don't support batched inference on inputs of varying lengths, so they're more suitable for `pipelines` rather than an integrated module
Having said that, I suggest that we finish this PR as a first step without adding any waveform generators. After that we can work on a TTS `pipeline` that runs inference on FastSpeech2 and decodes the output using either a Griffin-Lim synthesizer or any of the GAN models from the Hub (e.g. HiFiGAN) that we'll port.
<|||||>Hi, may I ask a couple of questions:
1. Is there some estimated time of merging for this PR?
2. Are there any experiments/examples of training using this implementation Fastspeech2?
And somewhat more general question:
3. Is there work in progress related to `text-to-speech` pipeline?
I'm working training/fine-tuning fastspeech2 models and would like to deploy using HF inference API.
Would be happy to help out with testing and contribute to pipeline and/or porting HiFiGAN or provide any assistance I can to speed things up with TTS<|||||>@anton-l, think it's not high priority but once you have a free day let's maybe add the model :-)<|||||>Wish I could have iterated faster to finish it earlier. Let me know if you need anything from me @anton-l @patrickvonplaten!<|||||>> Wish I could have iterated faster to finish it earlier. Let me know if you need anything from me @anton-l @patrickvonplaten!
@jaketae if you want, would you like to finish this PR maybe ? E.g. fix the failing tests and add **all** the necessary code (including the vocoders) to the modeling file?<|||||>@anton-l I still think we should go ahead with this PR - it's been stale for a while now. Wdyt?<|||||>@patrickvonplaten definitely! I'm trying to find some time alongside other tasks to work on FS2 :sweat_smile: <|||||>Hey @anton-l @patrickvonplaten, hope you're doing well! I was wondering where FS2 fits within the transformers road map, and whether it would make sense for me to update this branch and wrap up the work. I feel responsible for leaving this stale, and I still think it would be cool to have this feature pushed out. Thank you!<|||||>Hey @jaketae,
We definitely still want to add the model - would you like to go ahead and update the branch?<|||||>I don't think anybody will have time to work on it soon. If anybody from the community wants to give it a shot, please feel free to do so! <|||||>> I don't think anybody will have time to work on it soon. If anybody from the community wants to give it a shot, please feel free to do so!
Can I try working on this?<|||||>@JuheonChu I'm also interested in working on this, any interest in collaborating? Planning to get up to speed then open a fresh pr.<|||||>Hi @JuheonChu @connor-henderson, internally at HF we've been discussing what to do with this model. This PR has a lot of good work done already and FastSpeech 2 is a popular model, so it makes a lot of sense to add this to Transformers. If you want to help with this, that's great. 😃
There are a few different implementations of FastSpeech 2 out there and we'd like to add the best one to Transformers. As far as we can tell, there is a Conformer-based FastSpeech 2 model in ESPNet that outperforms regular FastSpeech 2, so that might be an interesting candidate. You can find the [Conformer FastSpeech 2 checkpoints here](https://huggingface.co/models?sort=downloads&search=espnet+fastspeech2+conformer).
In addition, PortaSpeech is very similar to FastSpeech 2 but it replaces the post-net and possibly a few other parts of the model. So that might be an interesting variation of FS2 to add as well.
We're still trying to figure out which of these models we'd prefer to have, but since you've shown an interest in working on this, I wanted to point out the direction we were thinking of taking these models internally. And I'd like to hear your opinions on this as well. 😄
P.S. Make sure to check out the implementation of SpeechT5. It has many features in common with FastSpeech2 (such as the vocoder and the generation loop) and so we'd want to implement FS2 mostly in the same manner.
|
transformers | 15,772 | closed | Cuda error when using T5 with the new Apex FusedRMSNorm | Hi there, thanks for the work integrating the new Apex kernel to accelerate T5! Unfortunately, however, I'm having some trouble getting it to run. I installed the Apex library following the instructions on their repo and am trying to run a small test script on an RTX A6000 with cuda 11.1.
## Environment info
- `transformers` version: 4.17.0.dev0
- Platform: Linux-4.15.0-135-generic-x86_64-with-glibc2.27
- Python version: 3.8.12
- PyTorch version (GPU?): 1.9.0+cu111 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes (RTX A6000)
- Using distributed or parallel set-up in script?: no
### Who can help
@stas00
## Information
Model I am using (Bert, XLNet ...): T5ForConditionalGeneration
## To reproduce
I get the error on my environment by running this script (named `debug.py`):
```python
import transformers
from transformers import T5ForConditionalGeneration, T5Tokenizer
transformers.logging.set_verbosity_info()
device = "cuda"
model_name = "t5-small"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name).to(device)
input_ids = tokenizer(
"translate English to French: All grown-ups were once children—although few of them remember it.",
return_tensors="pt",
).input_ids.to(device)
outputs = model.generate(input_ids, max_length=100)
outputs = tokenizer.decode(outputs[0])
print(f"{outputs = }")
```
and I get this stack trace when I run: `CUDA_LAUNCH_BLOCKING=1 python debug.py`:
```
Traceback (most recent call last):
File "temp.py", line 17, in <module>
outputs = model.generate(input_ids, max_length=100)
File "/home/derrick/env/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/derrick/projects/transformers/src/transformers/generation_utils.py", line 1102, in generate
model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(
File "/home/derrick/projects/transformers/src/transformers/generation_utils.py", line 510, in _prepare_encoder_decoder_kwargs_for_generation
model_kwargs["encoder_outputs"]: ModelOutput = encoder(**encoder_kwargs)
File "/home/derrick/env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/derrick/projects/transformers/src/transformers/models/t5/modeling_t5.py", line 1030, in forward
layer_outputs = layer_module(
File "/home/derrick/env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/derrick/projects/transformers/src/transformers/models/t5/modeling_t5.py", line 665, in forward
self_attention_outputs = self.layer[0](
File "/home/derrick/env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/derrick/projects/transformers/src/transformers/models/t5/modeling_t5.py", line 572, in forward
attention_output = self.SelfAttention(
File "/home/derrick/env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/derrick/projects/transformers/src/transformers/models/t5/modeling_t5.py", line 498, in forward
query_states = shape(self.q(hidden_states)) # (batch_size, n_heads, seq_length, dim_per_head)
File "/home/derrick/env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/derrick/env/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 96, in forward
return F.linear(input, self.weight, self.bias)
File "/home/derrick/env/lib/python3.8/site-packages/torch/nn/functional.py", line 1847, in linear
return torch._C._nn.linear(input, weight, bias)
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)`
```
Any ideas about what the issue might be? | 02-22-2022 17:33:21 | 02-22-2022 17:33:21 | thank you for the report, @dblakely
I tested your code and it works on my rtx-3090 / pt-1.10
I wonder if you need to set device, with the older pytorch? Does this work?
```
import transformers
import os
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
transformers.logging.set_verbosity_info()
local_rank = int(os.environ.get("LOCAL_RANK", 0))
torch.cuda.set_device(local_rank)
device = "cuda"
model_name = "t5-small"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name).to(device)
input_ids = tokenizer(
"translate English to French: All grown-ups were once children—although few of them remember it.",
return_tensors="pt",
).input_ids.to(device)
outputs = model.generate(input_ids, max_length=100)
outputs = tokenizer.decode(outputs[0])
print(f"{outputs = }")
```
Alternatively, could you please test with pt-1.10? Perhaps it only works with the newer version
cc: @eqy<|||||>Thanks! I did upgrade torch to 1.10.2+cu111 and ran your script and it worked. However, now I'm realizing that how I specify the device seems to be determining whether or not I get the error I mentioned above. I'm using a machine with 4 GPUs and if I just say `device = "cuda"`, it works. But if I say `device = "cuda:3"`, it doesn't work.
On the other hand, if I put in my script `device="cuda"` and then run it using `CUDA_VISIBLE_DEVICES=3 python debug.py`, it works (indicating it's not an issue with that GPU per se). So at the end of the day, I am able to get the Apex kernel to run. However, it's being kind of finicky with respect to device ordinals in a way that T5 normally is not. Any ideas about why that would be the case? If not, it's fine because I believe the issue is solved.<|||||>does the following make any difference?
```
local_rank = int(os.environ.get("LOCAL_RANK", 0))
device = torch.device(f'cuda:{local_rank}')
torch.cuda.set_device(device)
```
so did your original script w/o my changes work with pt-1.10? i.e. w/o setting the device explicitly - trying to understand if the initial issue lays with pt-1.9 - there could be multiple issues as well.
and you never shared how you launch this - sorry edit - you did share that info - not distributed. oh, I get it, but `CUDA_VISIBLE_DEVICES=3` still is `cuda:0`
so perhaps tell me what you're trying to do. running on one gpu out of 4, or running in parallel with DDP, or else?<|||||>- `python debug.py` will always run on gpu 0 if the code does `device = "cuda"`
- `CUDA_VISIBLE_DEVICES=3 python debug.py` is still running on gpu 0, software-wise for `device = "cuda"`
`CUDA_VISIBLE_DEVICES` simply narrows down or reorders the gpus visible to the program, so unless you use DDP `device("cuda") == device("cuda:0")` or just `tensor.cuda()`
see: https://huggingface.co/docs/transformers/master/main_classes/trainer#specific-gpus-selection<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,771 | closed | shift_tokens_right function missing for mt5 models | ## Environment info
- `transformers` version: 4.17.0.dev0
- Platform: Linux-5.11.0-1028-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.11.0a0+git06838ce (False)
- Tensorflow version (GPU?): 2.9.0-dev20220221 (False)
- Flax version (CPU?/GPU?/TPU?): 0.4.0 (cpu)
- Jax version: 0.3.1
- JaxLib version: 0.3.0
### Who can help
@patil-suraj
## Information
Hello
I am trying to finetune with Flax on TPU a mt5-small model on a summarization task, using the examples/flax/summarization/run_summarization_flax.py script.
When I run the script, I get an error about the fact that shift_tokens_right is not defined for mt5 models:
``
File "/home/prod/transformers/examples/flax/summarization/run_summarization_flax.py", line 521, in main
# shift_tokens_right_fn = getattr(model_module, "shift_tokens_right")
AttributeError: module 'transformers.models.mt5.modeling_flax_mt5' has no attribute 'shift_tokens_right'
``
Moreover, the current flax summarization script has a typo line 516 :
See https://github.com/huggingface/transformers/blob/master/examples/flax/summarization/run_summarization_flax.py#L516 :
``
model_module = __import__(model.__module__, fromlist=["shift_tokens_tight"])
``
(tight should be right !)
I have been able to fix the issue by copying the function shift_tokens_right defined in `src/transformers/models/t5/modeling_flax_mt5.py` into the file `src/transformers/models/mt5/modeling_flax_mt5.py` .
Now the Flax summarization script works fine.
Hope you can fix the mt5 code accordingly !
| 02-22-2022 16:23:32 | 02-22-2022 16:23:32 | Good catch, thanks for opening the issue!
Would you be interested to open a PR to add this function in flax mT5?<|||||>Hey Suraj,
Sure ! Will do it tomorrow and keep you posted. Thanks !<|||||>Also noticed that `adafactor` parameter is not used to instantiate the optimizer in the `run_summarization_flax.py` script.
Will add it in my PR, to have support for both adamW and adafactor.
<|||||>> Also noticed that `adafactor` parameter is not used to instantiate the optimizer in the `run_summarization_flax.py` script. Will add it in my PR, to have support for both adamW and adafactor.
Ahh, Good catch! It would be better two open a new PR for this since these are two different changes.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Bump - will do PR soon<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Will make a PR for this shortly :) |
transformers | 15,770 | closed | Resnet | # What does this PR do?
This WIP PR adds [ResNet](https://arxiv.org/abs/1512.03385).
Currently, the model can be used as follows
```python
import requests
from io import BytesIO
res = requests.get('https://github.com/huggingface/transformers/blob/master/tests/fixtures/tests_samples/COCO/000000039769.png?raw=true')
image = Image.open(BytesIO(res.content))
feature_extractor = AutoFeatureExtractor.from_pretrained("Francesco/resnet50")
model = ResNetForImageClassification.from_pretrained("Francesco/resnet50").eval()
inputs = feature_extractor(image, return_tensors="pt")
outputs = model(**inputs)
print(model.config.id2label[torch.argmax(outputs.logits).item()])
# tiger cat
``` | 02-22-2022 15:05:08 | 02-22-2022 15:05:08 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15770). All of your documentation changes will be reflected on that endpoint.<|||||>I've removed the `regression` loss from `ForImageClassification` since it is not a loss used for image classification. This open for discussion<|||||>I've removed the `D` variant code, it will be added by a different PR. Three new models outputs have been added: `BaseModelOutputWithNoAttention`, `BaseModelOutputWithNoAttentionAndWithPooling` and `ImageClassificationModelOutput`<|||||>Address most of the comments, the blocking ones are related to outputs docstring |
transformers | 15,769 | closed | Docstring says target_sizes is optional (in DETR post_process) but the code disagrees | https://github.com/huggingface/transformers/blob/db7d6a80e82d66127b2a44b6e3382969fdc8b207/src/transformers/models/detr/feature_extraction_detr.py#L677
The Docstring marks the `target_sizes` parameter as `*optional*` but the parameter has no default value and is used without any conditional checking for whether it is `None`, so it would seem to be required. | 02-22-2022 15:02:33 | 02-22-2022 15:02:33 | Thanks for pointing that out. Could you open a PR to remove the "optional" string?<|||||>Is this resolved?<|||||>This issue should be marked closed. The problem seems to be resolved.<|||||>We're actually updating this at the moment (see #19205), it will become optional. Closing this issue for now. |
transformers | 15,768 | closed | [doc] custom_models: mention security features of the Hub | cc @McPatate @n1t0 and @SBrandeis @osanseviero and everyone reading this, don't hesitate to regularly read the doc and create links between the hub doc and the libraries docs | 02-22-2022 13:06:11 | 02-22-2022 13:06:11 | _The documentation is not available anymore as the PR was closed or merged._<|||||>your last change @stevhliu looks good to me, ready to merge for everyone? |
transformers | 15,767 | closed | Cleanup transformers-cli | Note to maintainers:
- the `ListReposObjsCommand` (using `HfApi.list_repos_objs`) (which has been deprecated for a while) is going to be removed server-side soon (cc @coyotte508 @XciD @Pierrci) so we should also remove them from transformers now IMO
- the other stuff is just removing deprecation errors (no actual functionality is removed) so I'd advocate to also remove it now. (no need to wait for a major version IMHO)
Related PR: https://github.com/huggingface/huggingface_hub/pull/702 | 02-22-2022 12:58:57 | 02-22-2022 12:58:57 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,766 | closed | [Discussion] Loading and initialising large models with Flax | Opening up this issue to discuss how to initialise and load large models with Flax.
# Goals:
1. Be able to initialise and pjit really large models that don’t fit on a single device.
2. Avoid memory fragmentation when loading pre-trained weights in `from_pretrained`.
# Issues:
- With the current API it’s not possible to initialise a model which does not fit on a single device, since the model
weights are always initialised on the available device when we init the model class.
```python
model = FlaxPretrainedModel(conifg) # weights are always initialised in this call. OOMs when the model can't fit on the device.
```
It’s also not easy to use with pjit or init on CPU as described by @borisdayma in this [colab](https://colab.research.google.com/drive/1S06sYeuJ8n7P2EiHunYI6SPPq-Ycfum8?usp=sharing)
- The `from_pretrained` method creates memory fragmentation and also fails to load large models. Because in `from_pretrained` the model is first initialised randomly to get names and shapes of parameters and then the pre-trained weights are loaded. Here both the random weights and pre-trained weights are on the device so we have two copies of weights in device memory.
# Possible solutions:
Posting the two options proposed by @borisdayma
## Option 1: params returned separately
```python
model, params = FlaxPretrainedModel(…)
predictions = model(params, input)
```
Cons:
- Would be a big breaking change and doesn’t really fit well with the rest of the Transformers API.
- Still doesn’t solve the problem of initialising really large models.
## Option 2: params created separately
```python
model = FlaxPretrainedModel(…)
params = model.init_weights(…)
```
- here we can pjit the `init_weights` method or jit it with cpu backend to initialise the weights on CPU.
How would we implement this?
- introduce a new flag `do_init` (need a better name) which will default to `True`, and the API will stay the same as it is now.
- if it’s `False` then don’t init the params. In this case `model.params` will always be `None` and the users will always have to pass
params to the forward call. We use `eval_shape` to get the params tree with shapes and save it on `model.params_shape_tree` (better name ?)
It would look something like this:
```python
# existing API
model = FlaxPretrainedModel(…)
model.params # this will store the model params
# with do_init=False
model = FlaxPretrainedModel(do_init=False)
model.params # this will be None
model(inputs) # this will raise error since params are not initialised
params = model.init_weights()
# always pass params to forward
model(inputs, params=params)
```
### How to handle `from_pretrained` in this case (`do_init=False`)?
This is also related to the second goal. To avoid fragmentation we could use `jax.eval_shape` here to get the params shape info that is required when loading pre-trained weights.
But there are a few issues with this:
**1. How to load a model with a head with pre-trained weights from the base model?**
In this case, we need to randomly initialise only the head weights and load rest from pre-trained. But there seems to be no way of only initialising some parameters and not others.
One possible solution is to add a method called `init_head` to every module with a head and when head weights are missing we call that method. See #15584 for what that would look like.
But this adds a lot of boilerplate code since we’ll need to do this for every head module in every flax model.
It’s also not possible to do this when some other intermediate weights are missing and need to be initialised randomly.
@marcvanzee @jheek @Avital is there any way in Flax where we could just initialise certain parameters without initialising the whole model?
**2. What if the pre-trained weights don’t fit on a single device?**
In this case, we’ll need to load the weights on the CPU and then let the user shard those across devices.
Should we introduce an argument called `device` or `backend` which will specify where to load the weights? (cc @patrickvonplaten )
**3. Should we return the loaded weights or assign them to `model.params` ?**
When `do_init` is `False` we always set `model.params` to `None` and keep the params external as described above. But then the `from_pretrained` API will look something like below.
```python
model, params = FlaxPretrainedModel.from_pretrained(do_init=False)
```
which again is not well aligned with the rest of the API. What do we think about this? Looking forward to your suggestions @patrickvonplaten @borisdayma @LysandreJik
@jheek @marcvanzee @avital It would be awesome if you could take a look at this and share how large model loading is handled in Flax. | 02-22-2022 10:38:19 | 02-22-2022 10:38:19 | Had an offline discussion with @patrickvonplaten and here's what we discussed.
We can go with option 2 with the following behaviour:
- introduce a new argument `FlaxPretrainedModel.__init__` called `do_init`, default to `True`. The API stays as it is right now.
`do_init` will be completely optional behaviour only to be used initialising and/or loading large models.
- If `do_init=False`, don't initialise the params, set `model.params=None`. And let the user call `model.init_weights`. Here the user has control so he can shard the init or init on CPU.
**For `from_pretrained`:**
- if `do_init=True`, which is the default behaviour, nothing changes.
- if `do_init=False`, don't do random initialisation and only load the pre-trained weights. And _**return weights along with the model**_.
- The user here will still have to call the `model.init_weights` method. If `do_init=False` the user will always have to call `model.init_weights` even when loading pre-trained weights. This will ensure to initialise any missing head params (if there are any) otherwise it'll be a no-op.
- if `do_init=False` we always load pre-trained params on CPU. We can then transfer these to the device by pjitting or jitting `init_weights` method. ~~This is a breaking change, but since this is an edge case and only required for large models here we think the user should be aware of these things.~~
This is how it would look like
```python
model, params = FlaxPretrainedModel.from_pretrained(do_init=False) # params on CPU
params = model.init_weights(params) # randomly initialise missing weights.
# We could also `pjit` this method to shard the params which will also take care of moving these to the device from CPU.
```
This should help resolve both issues while still offering compatibility with the API. Curious to hear what you think @borisdayma and others.<|||||>One small addition:
> This is a breaking change, but since this is an edge case and only required for large models here we think the user should be aware of these things.
It's not really a breaking change since we introduce a new behavior with `do_init=False` so this can't by definition break anything existing. Very interested in hearing others opinion on this!<|||||>This is great, I like it!!!
I'm just wondering if `from_pretrained` could even be pjitted directly though not sure if it works with loading weights from an external file.<|||||>Hi, sorry for the late reply on this!
For the single-host case, initializing parameters simply comes down to pjitting the init function with a PartitioningSpec, there is nothing special about it. Since Flax Modules have a functional API, calling `init` just returns the parameters (we don't have a `model.params`), so I think the problems you are running into in this issue do not apply in our examples.
For the multi-host case, we recommend using GlobalDeviceArray (GDA)'s serialization library. (there unfortunately is not much documentation on this yet, but [these tests give some examples](https://github.com/google/jax/blob/main/jax/experimental/gda_serialization/serialization_test.py)). However, I think you are mainly talking about the single-host case here.<|||||>Thanks for the answer @marcvanzee !
> I think you are mainly talking about the single-host case here.
Yes, the example posted above is single-host. But we also want to enable this for multi-host. If I'm not wrong pjiting
`init` should also work on multi-host, no ?<|||||>> `init` should also work on multi-host, no ?
I guess the main issue would be when loading a checkpoint if it doesn't fit on CPU (which we have not yet reached so maybe can keep it for later?)<|||||>`pjit` is meant to work for both single- and multi-host settings, with the latter using the newer GDA abstraction should help automate some tedious multihost details when later dealing w. checkpointing, etc.<|||||>Thanks a lot for the feedback guys! Think we're going in the right direction then by fully seperating the `params` from the model architecture by doing `_do_init=False`. By setting this flag to False, we'll not allow to set `model.params` at all, so one can be sure that `params` are fully separated from the model architecture.
I think this is very natural when initializing a model from scratch, e.g.:
```py
model = FlaxBertModel(config, _do_init=False) # calling or setting model.params will error out now
params = model.init_weighs()
```
but not very natural when using `from_pretrained(...)`:
```py
model, params = FlaxBertForQuestionAnswering.from_pretrained("bert-base-cased", _do_init=False) # calling or setting model.params will also error out, returned params are *only* the pretrained weights
params = model.init_weighs(params=params) # in case of missing uninitialized layers - *e.g.* the QA head, we'll pass params to the model init function
```
Flax will then probably be the only framework the returns both model parameters and the model architecture when `from_pretrained(...)` is called with `_do_init=False`. This is not very "transformers-like", but it's the only way in our opinion we can ensure a more JAX-like approach to dealing with pretrained models and weights.<|||||>I think the proposed API fits the JAX philosophy nicely, we've experienced that maintaining a state will eventually bite you, so it seems like a good decision to choose this functional API.
It is somewhat unfortunate though you had to make an exception in your API, hopefully it will not be too confusing for your users.
@cgarciae |
transformers | 15,765 | closed | do not support deepcopy when using deepspeed? | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.16.2
- Platform: Ubuntu
- Python version: 3.8
- PyTorch version (GPU?): 1.8
- Tensorflow version (GPU?): none
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- ALBERT, BERT, XLM, DeBERTa, DeBERTa-v2, ELECTRA, MobileBert, SqueezeBert: @LysandreJik
- T5, BART, Marian, Pegasus, EncoderDecoder: @patrickvonplaten
- Blenderbot, MBART: @patil-suraj
- Longformer, Reformer, TransfoXL, XLNet, FNet, BigBird: @patrickvonplaten
- FSMT: @stas00
- Funnel: @sgugger
- GPT-2, GPT: @patrickvonplaten, @LysandreJik
- RAG, DPR: @patrickvonplaten, @lhoestq
- TensorFlow: @Rocketknight1
- JAX/Flax: @patil-suraj
- TAPAS, LayoutLM, LayoutLMv2, LUKE, ViT, BEiT, DEiT, DETR, CANINE: @NielsRogge
- GPT-Neo, GPT-J, CLIP: @patil-suraj
- Wav2Vec2, HuBERT, SpeechEncoderDecoder, UniSpeech, UniSpeechSAT, SEW, SEW-D, Speech2Text: @patrickvonplaten, @anton-l
If the model isn't in the list, ping @LysandreJik who will redirect you to the correct contributor.
Library:
- Benchmarks: @patrickvonplaten
- Deepspeed: @stas00
- Ray/raytune: @richardliaw, @amogkam
- Text generation: @patrickvonplaten @narsil
- Tokenizers: @SaulLu
- Trainer: @sgugger
- Pipelines: @Narsil
- Speech: @patrickvonplaten, @anton-l
- Vision: @NielsRogge, @sgugger
Documentation: @sgugger
Model hub:
- for issues with a model, report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
For research projetcs, please ping the contributor directly. For example, on the following projects:
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@stas00
## Information
Model I am using (Bert, XLNet ...): m2m100
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. copy the follwing code as ```copy_test.py```
```
import copy
from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
from transformers.deepspeed import HfDeepSpeedConfig
import deepspeed
config = M2M100Config.from_pretrained('facebook/m2m100_418M')
model_hidden_size = config.d_model
ds_config = {
"fp16": {
"enabled": False,
},
"bf16": {
"enabled": False,
},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": True
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_bucket_size": model_hidden_size * model_hidden_size,
"stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
"stage3_param_persistence_threshold": 10 * model_hidden_size
},
"steps_per_print": 2000,
"train_batch_size": 1,
"gradient_accumulation_steps": 1,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": False
}
dschf = HfDeepSpeedConfig(ds_config)
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="fr")
src_text = "Life is like a box of chocolates."
tgt_text = "La vie est comme une boîte de chocolat."
model_inputs = tokenizer(src_text, return_tensors="pt")
with tokenizer.as_target_tokenizer():
labels = tokenizer(tgt_text, return_tensors="pt").input_ids
engine = deepspeed.initialize(model=model, config_params=ds_config)
copy_model = copy.deepcopy(model)
loss = copy_model(**model_inputs, labels=labels) # forward pass
```
2. Run ```deepspeed --num_gpus=1 copy_test.py```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
we can using ```copy.deepcopy(model)``` successful when do not using ```deepspeed```, but failed when using ```deepspeed```.
+ The error message can be seen as follwing:
```
Using /mounts/Users/student/lavine/.cache/torch_extensions as PyTorch extensions root...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Time to load utils op: 0.0015609264373779297 seconds
Traceback (most recent call last):
File "test_copy.py", line 66, in <module>
copy_model = copy.deepcopy(model)
File "/mounts/work/lavine/envs/anaconda/envs/lavine-notebook/lib/python3.8/copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/mounts/work/lavine/envs/anaconda/envs/lavine-notebook/lib/python3.8/copy.py", line 270, in _reconstruct
state = deepcopy(state, memo)
File "/mounts/work/lavine/envs/anaconda/envs/lavine-notebook/lib/python3.8/copy.py", line 146, in deepcopy
y = copier(x, memo)
File "/mounts/work/lavine/envs/anaconda/envs/lavine-notebook/lib/python3.8/copy.py", line 230, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/mounts/work/lavine/envs/anaconda/envs/lavine-notebook/lib/python3.8/copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/mounts/work/lavine/envs/anaconda/envs/lavine-notebook/lib/python3.8/copy.py", line 264, in _reconstruct
y = func(*args)
TypeError: __init__() missing 1 required positional argument: 'parent_module'
[2022-02-22 11:11:14,919] [INFO] [launch.py:160:sigkill_handler] Killing subprocess 28425
[2022-02-22 11:11:14,920] [ERROR] [launch.py:166:sigkill_handler] ['/mounts/work/lavine/envs/anaconda/envs/lavine-notebook/bin/python', '-u', 'test_copy.py', '--local_rank=0'] exits with return code = 1
```
| 02-22-2022 10:23:18 | 02-22-2022 10:23:18 | @lavine-lmu,
deepspeed installs all kinds of hooks into the model, which perhaps makes it impossible to `deepcopy`
Have you tried copying the model before deepspeed init? and then initing on the copy?
Overall this question belongs to https://github.com/microsoft/DeepSpeed as it's not related to the transformers integration.
But if you look at:
https://github.com/microsoft/DeepSpeed/blob/2151c787a27166f795eb4516f1e191e6730e823d/deepspeed/runtime/zero/stage3.py#L131-L132
you can see that deepspeed uses a custom dict class which it appears that `deepcopy` can't handle, as it's probably not designed to handle objects with custom dict classes. I don't know if it can be instrumented to support custom dict classes.
<|||||>Hi @stas00, I am doing meta-learning now, so I need to do the ```copy``` process after deepspeed init. Thanks for your reply, I will try other methods to solve this problem. |
transformers | 15,764 | closed | Resnet weights should not be downloaded when building DETR by from_pretrained | ## Describe the bug
Hello, the building process of DETR in transformers uses timm to construct a resnet backbone.
```
backbone = create_model(name, pretrained=True, features_only=True, out_indices=(1, 2, 3, 4), **kwargs)
```
However, `pretrained=True` should only be enabled when building an initial DETR. When building DETR with `from_pretrained`, the pretrained weights of Resnet are redundant. If there is a lack of internet connection or a poor network environment, this can cause the code to get stuck even if the model is building from local files.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.15.0
- Platform: Linux-5.11.0-46-generic-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyTorch version (GPU?): 1.8.2 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
Models:
DETR
| 02-22-2022 08:55:47 | 02-22-2022 08:55:47 | Hi,
That totally makes sense.
To solve this, we can add an attribute to `DetrConfig` called `use_pretrained_backbone` which is set to `True` by default, but can be set to `False`. In that way, when initializing a DetrModel as follows:
```
from transformers import DetrConfig, DetrModel
config = DetrConfig(use_pretrained_backbone=False)
model = DetrModel(config)
```
You will have both a convolutional backbone + encoder-decoder Transformer with randomly initialized weights.
In case you want to build a `DetrForObjectDetection` from a local pytorch_model.bin file:
```
from transformers import DetrForObjectDetection
model = DetrForObjectDetection.from_pretrained("path_to_local_folder", use_pretrained_backbone=False)
```
However, we're also planning to have a ResNet implementation in the library soon which is independent from timm, cc @FrancescoSaverioZuppichini. This might also solve the issue.<|||||>Hi, Thanks for pointing this out. I agree with @NielsRogge about adding a flag to control the backbones' weight download. Definitely, having our standalone implementation of ResNet embedded in Detr solves the issue.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I'd like to work on this. Please clarify if the standalone resnet implementation is preferred over the config flag or not.<|||||>Hi @divinit7 , thanks for your interest :) Yes, we want to add a flag to avoid downloading the weights. In the future, we would like to use our new ResNet implementation by default while keeping the option to use timm. <|||||>Hello. Was this issue fixed ? I would like to work on this. <|||||>> Hello. Was this issue fixed ? I would like to work on this.
Hey, please go ahead. I got busy with studies and work. |
transformers | 15,763 | open | Add TUNet | # 🌟 New model addition
The TUNet model for audio superresolution
## Model description
[TUNet: A Block-online Bandwidth Extension Model based on Transformers and Self-supervised Pretraining](https://arxiv.org/abs/2110.13492v3) is a paper by Viet-Anh Nguyen, Anh H. T. Nguyen, and Andy W. H. Khong, introducing a model for audio superresolution based on transformers.
Audio superresolution allows for the upsampling of audio with minimal loss of quality. This is very useful for ASR tasks that require audio to be resampled during preprocessing, which has a big impact on transcriptions depending on the native sample rate.
## Open source status
* [x] the model implementation is available: [The official repo](https://github.com/NXTProduct/TUNet)
* [x] the model weights are available: [ONNX weights](https://github.com/NXTProduct/TUNet/tree/master/lightning_logs)
* [x] who are the authors: Viet-Anh Nguyen, Anh H. T. Nguyen, and Andy W. H. Khong
| 02-22-2022 06:51:17 | 02-22-2022 06:51:17 | cc @patrickvonplaten @anton-l |
transformers | 15,762 | closed | Simplify selection of indices in FlaxCLIPTextTransformer to support JAX model conversion tooling | # What does this PR do?
It makes a simple change so that `FlaxCLIPModel` compatible with the `jax2tf` conversion tool, which currently doesn't support certain types of gather operations. It's explained by a JAX engineer here: https://github.com/google/jax/issues/9572#issuecomment-1047162054
## Who can review?
@patil-suraj
Note that I haven't ran any tests. Please feel free to close this if testing is required on my part, or if there simply isn't interest in making this change at this point (`jax2tf` will eventually support a larger subset of gather operations, so it's not super high-priority in that sense).
| 02-22-2022 05:55:20 | 02-22-2022 05:55:20 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15762). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,761 | closed | Constrained Beam Search [*With* Disjunctive Decoding] | # ***Disjunctive*** Positive Constraint Decoding
@patrickvonplaten @Narsil
A follow up to #15416, as a complete fix to #14081, as requested [here](https://github.com/huggingface/transformers/pull/15416#issuecomment-1031803308). On top of the current implementation of constrained beam search, it now allows for the "disjunctive" generation mentioned in the original issue and integrates a keyword argument for `model.generate()`.
It actually also fixes a logical error that was in the previous PR. It was a simple one-line fix found [here](https://github.com/huggingface/transformers/pull/15761/files#r811574539). I was treating the `beam_idx` within a batch as if it can be used as a `batch_beam_idx` across all the batches.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Example Uses
These examples are tested in `tests/test_generation_utils.py`.
### Example 1: Simple Strong Constraint
Objective: Use `force_words_ids` keyword argument to force the word `"sind"` in the output.
Here `force_words_ids` is a `List[List[int]]`. This is in direct analogy to `bad_words_ids`. It's a much simpler use-case and I think that documentation & publicization of this feature would show this use to introduce users about it.
```python
@slow
def test_constrained_beam_search_example_translation_mixin(self):
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
force_words = ["sind"]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
force_words_ids = tokenizer(force_words, add_special_tokens=False, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
outputs = tokenizer.batch_decode(outputs, skip_special_tokens=True)
self.assertListEqual(outputs, ["Wie alter sind Sie?"])
```
### Example 2: A Mix of Strong Constraint and a Disjunctive Constraint.
Objective: complete the input sentence such that it must include the word `"scared"` and includes any of the word forms of `"scream"` (i.e. `["scream", "screams", "screaming", "screamed"]`)
Here `force_words_ids` is a `List[List[List[int]]]`. It's a list of disjunctive constraints, each of which is a list of words, and words are obviously a list of ids.
```python
def test_constrained_beam_search_mixed_mixin(self):
model = GPT2LMHeadModel.from_pretrained("gpt2").to(torch_device)
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
force_word = "scared"
force_flexible = ["scream", "screams", "screaming", "screamed"]
force_words_ids = [
tokenizer([force_word], add_prefix_space=True, add_special_tokens=False).input_ids,
tokenizer(force_flexible, add_prefix_space=True, add_special_tokens=False).input_ids,
]
starting_text = ["The soldiers", "The child"]
input_ids = tokenizer(starting_text, return_tensors="pt").input_ids.to(torch_device)
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
self.assertListEqual(
generated_text,
[
"The soldiers, who were all scared and screaming at each other as they tried to get out of the",
"The child was taken to a local hospital where she screamed and scared for her life, police said.",
],
)
```
## Future Improvements
I'm thinking of adding `OrderedConstraints`, `TemplateConstraints` further down the line. Currently, the generation is fulfilled by including the sequences, wherever in the output. For example, the above example has one sequence with scared -> screaming and the other has screamed -> scared. `OrderedConstraints` will allow the user to specify the order in which these constraints are fulfilled.
`TemplateConstraints` will allow for a more niche use of the feature, where the objective can be something like:
```python
starting_text = "The woman"
template = ["the", "", "School of", "", "in"]
possible_outputs == [
"The woman attended the Ross School of Business in Michigan.",
"The woman was the administrator for the Harvard school of Business in MA."
]
```
or:
```python
starting_text = "The woman"
template = ["the", "", "", "University", "", "in"]
possible_outputs == [
"The woman attended the Carnegie Mellon University in Pittsburgh.",
]
impossible_outputs == [
"The woman attended the Harvard University in MA."
]
```
or if the user does not care about the number of tokens that can go in between two words, then one can just use `OrderedConstraint`.
But these are just minor things I might try adding, among the plethora of possible `Constraint` classes that anyone could add. The current implementation of `constrained_beam_search` is ***flexible*** enough to allow for any crazy way to constrain the beam search, as long as the `Constraint` object adheres to the ***strict*** definitions of `Constraint` as defined in the abstract base class.
Thanks for reviewing!
| 02-22-2022 04:44:34 | 02-22-2022 04:44:34 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15761). All of your documentation changes will be reflected on that endpoint.<|||||>@patrickvonplaten Yes, I was worried about that part as well. It does seem kind of dangerous to allow two different behaviors given the input types to the same keyword argument.
But here were the reasons why I went with the current direction:
1. In general I feel like the approach that clutters the keyword args less to the already cluttered `generate()` function is better.
2. In disagreement with what you said above, I felt that it's not that perverse to call disjunctive constraints as something like a "word to be forced", since something like `["scream", "screamed", ...]` is supposed to be representing just one word after all, while trying to remain flexible to word forms.
3. I don't think it reduces much complexity (at least enough to justify hard-to-understand nascent keyword names & cluttering keyword args) to separate it into two keyword arguments. A user that understands the feature would use either systems equally effectively, and a user that hasn't bothered to learn about the disjunctive case could treat `force_words_ids` as a direct analogy to `bad_words_ids` and live without problems.
Though if the team agrees there should be separate keyword args then I'm always open to switch it up! I think more opinion might be needed.<|||||>> @patrickvonplaten Yes, I was worried about that part as well. It does seem kind of dangerous to allow two different behaviors given the input types to the same keyword argument.
>
> But here were the reasons why I went with the current direction:
>
> 1. In general I feel like the approach that clutters the keyword args less to the already cluttered `generate()` function is better.
> 2. In disagreement with what you said above, I felt that it's not that perverse to call disjunctive constraints as something like a "word to be forced", since something like `["scream", "screamed", ...]` is supposed to be representing just one word after all, while trying to remain flexible to word forms.
> 3. I don't think it reduces much complexity (at least enough to justify hard-to-understand nascent keyword names & cluttering keyword args) to separate it into two keyword arguments. A user that understands the feature would use either systems equally effectively, and a user that hasn't bothered to learn about the disjunctive case could treat `force_words_ids` as a direct analogy to `bad_words_ids` and live without problems.
>
> Though if the team agrees there should be separate keyword args then I'm always open to switch it up! I think more opinion might be needed.
Good arguments! Ok to leave as it is then :-)
From my side everything looks good. I agree with most of @Narsil's comments, but I also do think we can correct this in a follow-up PR.
Happy to leave it up to you and @Narsil to decide on what to change before merging :-)<|||||>Hi @Narsil
Don't worry about it! Actually I appreciate the clear-cutting comments. I'm really doing these PRs for personal learning purposes as a first-year college student and the feedback has been immensely helpful. Writing maintainable code is definitely something I'm trying to practice, so I really appreciate your thorough comments.
As for the type checking, from the very start of this PR, I've felt uncomfortable about how buggy it looks and the problems this could lead to. The reason why it hasn't been easy is because, in the generation process, the `token_ids` stored inside each `Constraint` object ends up interacting with `input_ids`, which is always a tensor.
But I also couldn't make `token_ids` completely into tensors, because for the disjunctive case, it needs a list of list of words, whose varying sizes make it impossible to treat it as a 2D tensor. Also, in the user-side, it might be equally intuitive to put in a list of ints but also a tensor with a list of ids, and I wanted to cover that case too.
After giving it more thought with the feedback, I agree with you that the complexity is just not worth covering all the cases. I've overhauled all the code so that `Constraint` and everything related to is is ***completely torch free***. The constraints file does not even `import torch` anymore. All future implementations will need to follow this paradigm and, despite potential ineffiencies, it gives us maintanable consistency.
<|||||>@Narsil thanks for the final check and thanks again for your thorough feedback!
@patrickvonplaten as soon as this merges, I’ll get started on a blog post! I just got it started by copying what you did for your [post on text generation](https://huggingface.co/blog/how-to-generate). Is writing everything with a similar format in a colab notebook the pushing it to huggingface/blogs repo the right way to proceed?<|||||>Softly pinging @patrickvonplaten for merge to really get going with the blog & future additions to this feature. Also wondering if rebasing with master again is necessary since its been a week since.<|||||>Thanks for the ping - thought this was already merged. Looked over it again and everything looks good to me :-) @Narsil also approved the PR so merging now. Great job!<|||||>Does this PR support the application of different constraints for different elements in a batch? For example, `starting_text = ["The soldiers", "The child"]` where I want to force the word `scared` only for the first item and `played` only for the second item.
I am trying to apply the constrained beam search method on a large dataset, with different constraints for each instance. Using a batch size of 1 seems to be the only solution as of now. |
transformers | 15,760 | closed | Save Finetuned XLM-RoBERTa on Tf-Keras | I am finetuning XLM-RoBERTa for text classification. I am finetuning model on Tensorflow-keras. I have trained model on google colab GPU. I used below save method from keras as shown below to save my model.
```
model.save("/content/drive/MyDrive/TrainedModel")
loaded_model = tf.keras.models.load_model("/content/drive/MyDrive/TrainedModel")
```
It saves saved model but gives below error when loading the model on CPU. How can I load model to run it?
[/usr/local/lib/python3.7/dist-packages/tensorflow/python/training/py_checkpoint_reader.py](https://localhost:8080/#) in get_tensor(self, tensor_str)
65 try:
66 return CheckpointReader.CheckpointReader_GetTensor(
---> 67 self, compat.as_bytes(tensor_str))
68 # TODO(b/143319754): Remove the RuntimeError casting logic once we resolve the
69 # issue with throwing python exceptions from C++.
** IndexError: Read less bytes than requested**
I got below warning when saving the model using above function. The saved model size is 7.43 MB.
WARNING:absl:Found untraced functions such as encoder_layer_call_fn, encoder_layer_call_and_return_conditional_losses, embeddings_layer_call_fn, embeddings_layer_call_and_return_conditional_losses, dense_layer_call_fn while saving (showing 5 of 422). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: /content/drive/MyDrive/TrainedModel/assets
INFO:tensorflow:Assets written to: /content/drive/MyDrive/TrainedModel/assets | 02-22-2022 04:22:13 | 02-22-2022 04:22:13 | cc @gante @Rocketknight1 <|||||>Hi @Komalrathod55 👋 The `.save` method saves a myriad of TensorFlow-related objects, which may be tricky to serialize and/or load due to our complex architectures. We recommend using TF's `model.save_weights("some_folder/your_model_name.h5")` (with the `.h5` file extension) to store the weights, and then our `.from_pretrained("some_folder")` model class method to restore them.
Let me know if this solves your issue :)<|||||>Hi @gante , Thank you for your response. I tried the solution provided by you. But I was getting error regarding config file and model name.
1. OSError: Error no file named tf_model.h5 found in directory
2. file some_folder/config.json not found
So I renamed model as tf_model.h5 and put config.json in "some_folder".
This works well but this model runs very slow. The time to process a single file is 3.6 seconds. Can you let me know your insights about this issue? Thank you.<|||||>My apologies, I should have mentioned that the model must be named `tf_model.h5` -- I'm glad that it runs now. As for speed, I'm afraid we'll need more details -- for instance, if you are trying to run `model.generate()`, speed is a known issue that we are addressing at the moment.
Since the goal of these issues is to report and solve potential bugs, which we've discarded, I'd like to ask you to move the conversation to [our forum](https://discuss.huggingface.co/), where our members and the community can pitch in with solutions. |
transformers | 15,759 | open | Add EfficientNet Model - PyTorch | # 🌟 New model addition
I would like to add the EfficientNet model to the Transformers library
## Model description
EfficientNet was proposed in the paper, **[EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)**.
EfficientNet is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a compound coefficient. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients.
EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters.
<!-- Important information -->
## Open source status
* [x] the model implementation is available: [EfficientNet-PyTorch](https://github.com/lukemelas/EfficientNet-PyTorch)
* [x] the model weights are available: [PyTorch weights](https://github.com/lukemelas/EfficientNet-PyTorch/releases/tag/1.0)
* [x] who are the authors: Mingxing Tan, Quoc V. Le
| 02-22-2022 04:04:14 | 02-22-2022 04:04:14 | cc @NielsRogge <|||||>@LysandreJik is anyone working on this?? if not can i work on this<|||||>Hi @IMvision12, because of existing commitments, I am no longer working on this.
If you want, you can take it up :)<|||||>@NielsRogge Will it be worthwhile to include this model? |
transformers | 15,758 | closed | Fix `HfArgumentParser` when passing a generator | # What does this PR do?
It fixes `HfArgumentParser.__init__` when `dataclass_types` is a generator. Without this, when a generator is passed, after the init it's exhausted so then a call to `parse_args_into_dataclasses` will return a wrong result.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
I think pretty much anyone. | 02-22-2022 01:45:38 | 02-22-2022 01:45:38 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,757 | closed | Add support to export Blenderbot models to onnx | # 🚀 Feature request
Add support to export Blenderbot models to onnx. Please! Or help guide towards a correct direction!
## Motivation
There is someone working to implement Blenderbot 2.0 into transformers [12807](https://github.com/huggingface/transformers/issues/12807#issuecomment-1039315898), yet we still do not have a proper 1.0 export to onnx.
## Your contribution
### Error with torch.onnx.export
Tried to export Blenderbot 1.0 model via ```torch.onnx.export(model, input_values, output_path)``` and it failed with an error:
```ValueError: You have to specify either decoder_input_ids or decoder_inputs_embeds```
I've seen issues like this around with seq2seq models being encoder and decoder at the same time, thus needing to somehow export to models. Seems that onnx export of Bart model being of similar type has been properly implemeneted, as there's an onnx [config object](https://github.com/huggingface/transformers/blob/master/src/transformers/models/bart/configuration_bart.py).
### Weird outcome with transformers.onnx.export
Next thing I tried was to follow T5 model export implementation using Bart config as an example. I am not experienced enough in this, so obviously I stumbled onto a weird outcome which I cannot grasp / google out what's happening and why. I created a ```BlenderbotOnnxConfig(OnnxSeq2SeqConfigWithPast)``` class using simply same properties as in ```BartOnnxConfig(OnnxSeq2SeqConfigWithPast)```.
It then succesfully save files to a designated directory, but there's hundreds of them!!! Seems as if each layer is exported with its bias files separate...
When trying to do ```onnx.load``` console cries out the error about ```final_logits_bias``` file being missing. After digging into it, seems this file is in mentioned in a variable ```_keys_to_ignore_on_load_missing```, but still seems getting included. Not sure what I missed and where to go on from, therefore writing this issue for help / support.
### Notebook
You can [see the notebook](https://www.kaggle.com/danieliusv/blenderbot1-0-test-and-export) with my unsuccessful tries.
| 02-21-2022 15:06:02 | 02-21-2022 15:06:02 | >**Motivation**
There is someone working to implement Blenderbot 2.0 into transformers https://github.com/huggingface/transformers/issues/12807#issuecomment-1039315898, yet we still do not have a proper 1.0 export to onnx.
Nice motivation! More seriously though, note that onnx support is optional and is not a core feature. There will always be some models that don't have onnx support and we usually tend to add it only when some users request it.
Also pinging our onnx expert @lewtun :) <|||||>Sorry, didn't really know what to write in the *Motivation* section... uh.. "we need it for a project"? ¯\_(ツ)_/¯
Just to be clear, we'd much rather use Blenderbot 2.0, but since it's not yet implemented, not reasonable to ask.<|||||>Hey @Darth-Carrotpie thanks for raising this issue and sharing a solid first stab at the export! I'll take a look at this later in the week and see what the problem is :)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Re-open this issue |
transformers | 15,756 | closed | added link to our writing-doc document | # What does this PR do?
This PR adds a link to our writing-documentation guide in the add new model guide.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
| 02-21-2022 12:58:48 | 02-21-2022 12:58:48 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,755 | closed | TF train_step docstring | # What does this PR do?
Small PR that elaborates on the beautiful black magic behind our TF `train_step`. | 02-21-2022 12:53:35 | 02-21-2022 12:53:35 | _The documentation is not available anymore as the PR was closed or merged._<|||||>LGTM! Maybe wait until tomorrow to merge because people are off, though, and I want to confirm a verbose docstring like this is okay.<|||||>Tagging @sgugger to check @Rocketknight1's question above ☝️ <|||||>Also, don't forget `make style`!<|||||>> Can we break the docstring in several paragraphs? For instance at the "However" and then "This is" (but whatever you think is best works too).
Done 👍 |
transformers | 15,754 | closed | Diverging PT-Flax Wav2Vec2 Hidden-States | I noticed an absence of PT-Flax cross-tests in the [test file](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_flax_wav2vec2.py) for the FlaxWav2Vec2 model. I was wondering if at any point a layer-by-layer comparison of the PT-Flax hidden-states was performed? I was having a look through for myself and found that whilst the final hidden-states agreed to within the prescribed 4e-2 threshold (see final line of output), many of the intermediate states did not. Running the script reveals this:
```python
from transformers import FlaxWav2Vec2Model, Wav2Vec2Model
import torch
import numpy as np
model_fx = FlaxWav2Vec2Model.from_pretrained("facebook/wav2vec2-large-lv60", from_pt=True)
model_pt = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-large-lv60")
input_torch = torch.ones((2, 5000), dtype=torch.float32)
input_fx = input_torch.cpu().numpy()
with torch.no_grad():
output_hidden_states_pt = model_pt(input_torch, output_hidden_states=True)
output_hidden_states_fx = model_fx(input_fx, output_hidden_states=True)
features_pt = output_hidden_states_pt.extract_features
features_fx = output_hidden_states_fx.extract_features
for feature_fx, feature_pt in zip(features_fx, features_pt):
print(f"Feature diff {np.max(np.abs(feature_pt.numpy()) - np.asarray(np.abs(feature_fx)))}")
hidden_states_pt = output_hidden_states_pt.hidden_states
hidden_states_fx = output_hidden_states_fx.hidden_states
for layer, (hidden_state_fx, hidden_state_pt) in enumerate(zip(hidden_states_fx, hidden_states_pt)):
print(f"Layer {layer} diff: {np.max(np.abs(hidden_state_pt.numpy()) - np.asarray(np.abs(hidden_state_fx)))}")
output_logits_pt = output_hidden_states_pt.last_hidden_state
output_logits_fx = output_hidden_states_fx.last_hidden_state
print("Check if shapes are equal")
print(f"Shape PyTorch {output_logits_pt.shape} | Shape Flax {output_logits_fx.shape}")
print("Check if output values are equal")
print(f"Diff {np.max(np.abs(output_logits_pt.numpy()) - np.asarray(np.abs(output_logits_fx)))})")
```
Output:
```
Feature diff 0.18386149406433105
Feature diff 0.18386149406433105
Layer 0 diff: 0.3600578308105469
Layer 1 diff: 0.8296781778335571
Layer 2 diff: 0.7679004669189453
Layer 3 diff: 0.8805904388427734
Layer 4 diff: 0.8832664489746094
Layer 5 diff: 1.0264105796813965
Layer 6 diff: 0.9948457479476929
Layer 7 diff: 3.742971420288086
Layer 8 diff: 4.417335510253906
Layer 9 diff: 3.787109375
Layer 10 diff: 4.51409912109375
Layer 11 diff: 5.208351135253906
Layer 12 diff: 4.7732086181640625
Layer 13 diff: 6.4005889892578125
Layer 14 diff: 5.65545654296875
Layer 15 diff: 5.3276214599609375
Layer 16 diff: 5.1604156494140625
Layer 17 diff: 6.2522430419921875
Layer 18 diff: 6.3909912109375
Layer 19 diff: 7.9093780517578125
Layer 20 diff: 7.6656036376953125
Layer 21 diff: 5.81195068359375
Layer 22 diff: 206.0625
Layer 23 diff: 150.2744140625
Layer 24 diff: -0.012473279610276222
Check if shapes are equal
Shape PyTorch torch.Size([2, 15, 1024]) | Shape Flax (2, 15, 1024)
Check if output values are equal
Diff 0.0317840576171875)
```
Environment:
```
- `transformers` version: 4.17.0.dev0
- Platform: Darwin-20.2.0-x86_64-i386-64bit
- Python version: 3.7.9
- PyTorch version (GPU?): 1.10.2 (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.4.0 (cpu)
- Jax version: 0.3.0
- JaxLib version: 0.3.0
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
```
| 02-21-2022 12:51:46 | 02-21-2022 12:51:46 | Just looked into this and I'm pretty sure the reason is because matrix multiplication is approximated on TPU whereas it is not really on CPU. I'm getting identical results to the ones @sanchit-gandhi has reported above, when the code is run on TPU.
E.g. if I put your code snippet:
```py
from transformers import FlaxWav2Vec2Model, Wav2Vec2Model
import torch
import numpy as np
model_fx = FlaxWav2Vec2Model.from_pretrained("facebook/wav2vec2-large-lv60", from_pt=True)
model_pt = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-large-lv60")
input_torch = torch.ones((2, 5000), dtype=torch.float32)
input_fx = input_torch.cpu().numpy()
with torch.no_grad():
output_hidden_states_pt = model_pt(input_torch, output_hidden_states=True)
output_hidden_states_fx = model_fx(input_fx, output_hidden_states=True)
features_pt = output_hidden_states_pt.extract_features
features_fx = output_hidden_states_fx.extract_features
for feature_fx, feature_pt in zip(features_fx, features_pt):
print(f"Feature diff {np.max(np.abs(feature_pt.numpy()) - np.asarray(np.abs(feature_fx)))}")
hidden_states_pt = output_hidden_states_pt.hidden_states
hidden_states_fx = output_hidden_states_fx.hidden_states
for layer, (hidden_state_fx, hidden_state_pt) in enumerate(zip(hidden_states_fx, hidden_states_pt)):
print(f"Layer {layer} diff: {np.max(np.abs(hidden_state_pt.numpy()) - np.asarray(np.abs(hidden_state_fx)))}")
output_logits_pt = output_hidden_states_pt.last_hidden_state
output_logits_fx = output_hidden_states_fx.last_hidden_state
print("Check if shapes are equal")
print(f"Shape PyTorch {output_logits_pt.shape} | Shape Flax {output_logits_fx.shape}")
print("Check if output values are equal")
print(f"Diff {np.max(np.abs(output_logits_pt.numpy()) - np.asarray(np.abs(output_logits_fx)))})")
```
in a file called `run.py` and then do the following:
```bash
JAX_PLATFORM_NAME=tpu python run.py
```
on a TPUVM v3-8 I'm getting identical results to the ones you reported above. **However**, when force the computation to take place on CPU by doing the following:
```bash
JAX_PLATFORM_NAME=cpu python run.py
```
I'm getting "much better" results which look as follows:
```bash
Feature diff 1.2874603271484375e-05
Feature diff 1.2874603271484375e-05
Layer 0 diff: 0.0005588531494140625
Layer 1 diff: 0.000522613525390625
Layer 2 diff: 0.000514984130859375
Layer 3 diff: 0.0005235671997070312
Layer 4 diff: 0.0005626678466796875
Layer 5 diff: 0.0007305145263671875
Layer 6 diff: 0.0007200241088867188
Layer 7 diff: 0.0028638839721679688
Layer 8 diff: 0.003765106201171875
Layer 9 diff: 0.00331878662109375
Layer 10 diff: 0.0035552978515625
Layer 11 diff: 0.003631591796875
Layer 12 diff: 0.0038299560546875
Layer 13 diff: 0.00469207763671875
Layer 14 diff: 0.004852294921875
Layer 15 diff: 0.0047607421875
Layer 16 diff: 0.0048065185546875
Layer 17 diff: 0.0046844482421875
Layer 18 diff: 0.0043487548828125
Layer 19 diff: 0.0041351318359375
Layer 20 diff: 0.00341796875
Layer 21 diff: 0.00220489501953125
Layer 22 diff: 0.01416015625
Layer 23 diff: 0.091796875
Layer 24 diff: -0.13190405070781708
```<|||||>@sanchit-gandhi , you can also get the same high precision when adding the following flag:
```
JAX_DEFAULT_MATMUL_PRECISION=float32 python run.py
```
This way the code is still run on TPU but now we get a much higher precision which is as good as the one for CPU:
```bash
Feature diff 1.9788742065429688e-05
Feature diff 2.3126602172851562e-05
Layer 0 diff: 0.000499725341796875
Layer 1 diff: 0.00046062469482421875
Layer 2 diff: 0.0004367828369140625
Layer 3 diff: 0.00043582916259765625
Layer 4 diff: 0.0004558563232421875
Layer 5 diff: 0.00041866302490234375
Layer 6 diff: 0.000457763671875
Layer 7 diff: 0.00038313865661621094
Layer 8 diff: 0.0006923675537109375
Layer 9 diff: 0.00075531005859375
Layer 10 diff: 0.00160980224609375
Layer 11 diff: 0.0029754638671875
Layer 12 diff: 0.003421783447265625
Layer 13 diff: 0.0038909912109375
Layer 14 diff: 0.003070831298828125
Layer 15 diff: 0.003139495849609375
Layer 16 diff: 0.0022563934326171875
Layer 17 diff: 0.002674102783203125
Layer 18 diff: 0.0031871795654296875
Layer 19 diff: 0.00322723388671875
Layer 20 diff: 0.003253936767578125
Layer 21 diff: 0.004852294921875
Layer 22 diff: 0.05615234375
Layer 23 diff: 0.228515625
Layer 24 diff: -0.1278175562620163
Check if shapes are equal
Shape PyTorch torch.Size([2, 15, 1024]) | Shape Flax (2, 15, 1024)
Check if output values are equal
Diff 5.14984130859375e-05)
```<|||||>Think we can close this for now - maybe jax will soon change it's default TPU precision behavior<|||||>Info is taken from this PR btw: https://github.com/google/jax/pull/6143 |
transformers | 15,753 | closed | TF Train step docstring | # What does this PR do?
Small PR that elaborates on the beautiful black magic behind our TF `train_step`. | 02-21-2022 12:50:09 | 02-21-2022 12:50:09 | _The documentation is not available anymore as the PR was closed or merged._<|||||>branched from the wrong place 🤦 |
transformers | 15,751 | closed | [M2M100, XGLM] fix create_position_ids_from_inputs_embeds | # What does this PR do?
The `create_position_ids_from_inputs_embeds` method does not use the `past_key_values_length` when creating `input_ids` , which creates issues in generation when `use_cache=True`. This PR fixes the `create_position_ids_from_inputs_embeds` method.
Fixes #15736 | 02-21-2022 10:58:11 | 02-21-2022 10:58:11 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 15,750 | closed | Add TFConvNextModel | This PR adds the ConvNeXt [1] model in TensorFlow. It was developed by @arig23498, @gante, and myself.
Fun facts about this PR:
* Probably the first pure conv model in `transformers`.
* Probably the second pure vision model in TensorFlow in `transformers`.
**References**:
[1] A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545.
@gante @LysandreJik @Rocketknight1 | 02-21-2022 10:44:01 | 02-21-2022 10:44:01 | _The documentation is not available anymore as the PR was closed or merged._<|||||>TODO for me before merging:
1. add image size to the model config files (so we can use models that expect 384x384 inputs)
2. convert checkpoints from PT to TF and add them to the FB org
3. check if the docs are in a good state<|||||>> 2. convert checkpoints from TF to PT and add them to the FB org
(I guess you mean PT -> TF ?)
<|||||>> > ```
> > 2. convert checkpoints from TF to PT and add them to the FB org
> > ```
>
> ```
> (I guess you mean PT -> TF ?)
> ```
haha yes! (edited)<|||||>> I have a few minor comments for clarification, but I don't think any of them are blocking, and the tests look comprehensive.
I think I have addressed them. <|||||>Hi, @sayakpaul
In a (currently not on master) extended test, I found that the returned `hidden_states` (all layers, not just the last layer one) have different format.
See
https://github.com/huggingface/transformers/blob/15c916f416dfc5c820528f25c0257544847ceb50/src/transformers/models/convnext/modeling_tf_convnext.py#L494-L496
(where only the first element, i.e. `last_hidden_states` is changed to mathc PT output).
Would you mind to work on this? (I can work on it too if necessary)
cc @gante (I really need to push this test ASAP, but there are still a few pt/tf issues to fix)<|||||>> Hi, @sayakpaul
>
> In a (currently not on master) extended test, I found that the returned `hidden_states` (all layers, not just the last layer one) have different format.
>
> See
>
> https://github.com/huggingface/transformers/blob/15c916f416dfc5c820528f25c0257544847ceb50/src/transformers/models/convnext/modeling_tf_convnext.py#L494-L495
>
>
> (where only the first element, i.e. `last_hidden_states` is changed to mathc PT output).
> Would you mind to work on this?
This change was from @gante. Let's take their inputs and sure, I can work on it.
> but there are still a few pt/tf issues to fix
Is this something I can do in this PR? Or is it more on the general side? <|||||>> > Hi, @sayakpaul
> > In a (currently not on master) extended test, I found that the returned `hidden_states` (all layers, not just the last layer one) have different format.
> > See
> > https://github.com/huggingface/transformers/blob/15c916f416dfc5c820528f25c0257544847ceb50/src/transformers/models/convnext/modeling_tf_convnext.py#L494-L495
> >
> > (where only the first element, i.e. `last_hidden_states` is changed to mathc PT output).
> > Would you mind to work on this?
>
> This change was from @gante. Let's take their inputs and sure, I can work on it.
OK. Let's see what @gante says.
>
> > but there are still a few pt/tf issues to fix
>
> Is this something I can do in this PR? Or is it more on the general side?
No, it's just a comment for @gante only about a general test (not particular for this PR). Sorry for the confusion.
<|||||>@sayakpaul You can run `make style` to fix the test (check_code_quality)<|||||>>In a (currently not on master) extended test, I found that the returned hidden_states (all layers, not just the last layer one) have different format.
@ydshieh @sayakpaul -- Those are great points and deserve to be thoroughly discussed. This is one of the first vision models for the TF side of `transformers`, so the decision we will make here will likely set a precedence for other models.
The root issue is that PT operates NCHW by default, while TF expects NHWC. In `TFConvNextEmbeddings` we convert from NCHW (the input shape) to NHWC to enable the model's use on CPU, so all dense layers and their outputs will have their dimensions swapped (compared to PT).
We have three main options:
1. Add transpose operations before and after each Conv2D layer, so that the TF model perfectly matches the PT model;
2. [current approach] Ensure that the same input generates the same output, without caring too much about the inner hidden layers;
3. Assume NHWC all the way from the input to the output, as a TF model would.
Keep in mind that options 2. and 3. imply that we will only be able to test TF<>PT equivalence if we transpose layers in the tests, but option 1. adds extra code (and probably a slower model) in addition to a PT-code vibe. Option 3. is more disruptive, as PT and TF would have different interfaces, which seems to be a big no-no.
All in all, option 2. seemed to be the most sensible, so I went with that. I'd like to hear the input from @Rocketknight1 and @LysandreJik, which are more experienced with this sort of trade-offs :)<|||||>Too many transpositions will definitely impact the speed of the model. <|||||>> > In a (currently not on master) extended test, I found that the returned hidden_states (all layers, not just the last layer one) have different format.
>
> @ydshieh @sayakpaul -- Those are great points and deserve to be thoroughly discussed. This is one of the first vision models for the TF side of `transformers`, so the decision we will make here will likely set a precedence for other models.
>
> The root issue is that PT operates NCHW by default, while TF expects NHWC. In `TFConvNextEmbeddings` we convert from NCHW (the input shape) to NHWC to enable the model's use on CPU, so all dense layers and their outputs will have their dimensions swapped (compared to PT).
>
> We have three main options:
>
> 1. Add transpose operations before and after each Conv2D layer, so that the TF model perfectly matches the PT model;
>
> 2. [current approach] Ensure that the same input generates the same output, without caring too much about the inner hidden layers;
>
> 3. Assume NHWC all the way from the input to the output, as a TF model would.
>
>
> Keep in mind that options 2. and 3. imply that we will only be able to test TF<>PT equivalence if we transpose layers in the tests, but option 1. adds extra code (and probably a slower model) in addition to a PT-code vibe. Option 3. is more disruptive, as PT and TF would have different interfaces, which seems to be a big no-no.
>
> All in all, option 2. seemed to be the most sensible, so I went with that. I'd like to hear the input from @Rocketknight1 and @LysandreJik, which are more experienced with this sort of trade-offs :)
Very good point @gante! I completely forgot the option 1.
Option 2 seems good, but in text models, there are a few tests where we test some internal modules.
For example, [BartStandaloneDecoderModelTester](https://github.com/ydshieh/transformers/blob/2b5603f6ac58f0cd3b2116c01d6b9f62575248b2/tests/test_modeling_bart.py#L851)
Not sure if such cases will happen for vision models. However, this is rare, and probably can be treated for individual models.
<|||||>@sayakpaul @ariG23498 -- TF checkpoints uploaded to the hub (e.g. [here](https://huggingface.co/facebook/convnext-tiny-224/tree/main)). The config files were also updated to include `image_size` -- I've confirmed that models for `image_size=384` work as expected and match their PT counterpart.
Feel free to update the tests relying on the `from_pt` flag 👍 <|||||>> @sayakpaul @ariG23498 -- TF checkpoints uploaded to the hub (e.g. [here](https://huggingface.co/facebook/convnext-tiny-224/tree/main)). The config files were also updated to include `image_size` -- I've confirmed that models for `image_size=384` work as expected and match their PT counterpart.
>
> Feel free to update the tests relying on the `from_pt` flag 👍
Done!<|||||>It looks like #15730 (merged) is the likely cause of the failing test in `run_tests_tf` here.
(but that PR has green checks, strange)<|||||>> It looks like #15730 (merged) is the likely cause of the failing test in `run_tests_tf` here. (but that PR has green checks, strange)
I have run this failing test `tests/test_modeling_tf_gpt2.py::TFGPT2ModelTest::test_gpt2_model_past_large_inputs` locally, and the difference of `output_from_past_slice` and `output_from_no_past_slice` in
```
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
```
are in the range `1e-8 ~ 1e-6` for 1000 runs. It's unclear why this test failed.
However, I think the failing test is irrelevant to this PR.<|||||>@sgugger , regarding [the output shapes](https://github.com/huggingface/transformers/pull/15750#issuecomment-1047088954), do you have some opinion?
(it's about the Conv2D - NCHW vs NHWC format in the intermediate values & final outputs)
<|||||>I'm fine with the proposed option for the shapes. Option 1 is a no-go because of performance, and option 3 would be too disruptive for PT/TF compatibility.<|||||>@sgugger I have noted your comments and will address them as soon as I can. I am currently traveling. <|||||>> Keep in mind that options 2. and 3. imply that we will only be able to test TF<>PT equivalence if we transpose layers in the tests, but option 1. adds extra code (and probably a slower model) in addition to a PT-code vibe. Option 3. is more disruptive, as PT and TF would have different interfaces, which seems to be a big no-no.
>
@gante, I didn't realized that, by option 2., you mean we don't change back to `NCHW` for `hidden_states` etc. in the outputs of, say `TFConvNextMainLayer`.
It would be better to have a uniform format between frameworks, at the levels of modules a user will use the library.
(and it will simplify the testing a lot)
What I think is:
- Ensure that the same input generates the same output
- without caring too much about the inner hidden layers **during the computation**
- but change all output values to have the same format as PT (i.e. `NCHW` format) at the `MainLayer` level
- (so the `BaseModel` and `For...Task` models will also have the same format as their PT equivalences)
WDYT?
<|||||>> > Keep in mind that options 2. and 3. imply that we will only be able to test TF<>PT equivalence if we transpose layers in the tests, but option 1. adds extra code (and probably a slower model) in addition to a PT-code vibe. Option 3. is more disruptive, as PT and TF would have different interfaces, which seems to be a big no-no.
>
> @gante, I didn't realized that, by option 2., you mean we don't change back to `NCHW` for `hidden_states` etc. in the outputs of, say `TFConvNextMainLayer`.
>
> It would be better to have a uniform format between frameworks, at the levels of modules a user will use the library. (and it will simplify the testing a lot)
>
> What I think is:
>
> * Ensure that the same input generates the same output
>
> * without caring too much about the inner hidden layers **during the computation**
> * but change all output values to have the same format as PT (i.e. `NCHW` format) at the `MainLayer` level
>
> * (so the `BaseModel` and `For...Task` models will also have the same format as their PT equivalences)
>
> WDYT?
Yeah, that makes sense @ydshieh :) @sayakpaul can you move the final transpose from `TFConvNextModel` to `TFConvNextMainLayer`?<|||||>> > > Keep in mind that options 2. and 3. imply that we will only be able to test TF<>PT equivalence if we transpose layers in the tests, but option 1. adds extra code (and probably a slower model) in addition to a PT-code vibe. Option 3. is more disruptive, as PT and TF would have different interfaces, which seems to be a big no-no.
> >
> >
> > @gante, I didn't realized that, by option 2., you mean we don't change back to `NCHW` for `hidden_states` etc. in the outputs of, say `TFConvNextMainLayer`.
> > It would be better to have a uniform format between frameworks, at the levels of modules a user will use the library. (and it will simplify the testing a lot)
> > What I think is:
> >
> > * Ensure that the same input generates the same output
> >
> > * without caring too much about the inner hidden layers **during the computation**
> > * but change all output values to have the same format as PT (i.e. `NCHW` format) at the `MainLayer` level
> >
> > * (so the `BaseModel` and `For...Task` models will also have the same format as their PT equivalences)
> >
> > WDYT?
>
> Yeah, that makes sense @ydshieh :) @sayakpaul can you move the final transpose from `TFConvNextModel` to `TFConvNextMainLayer`?
Also make `pooler_output` and `hidden_states` have the same shape as PT's `ConvNextModel`, please. Thanks.
A bit subtle here: `hidden_states` not always exists -> requires to check `output_hidden_states`
https://github.com/huggingface/transformers/blob/0f98fb5d55a69729f4efb9315857fdab31ce1034/src/transformers/models/convnext/modeling_tf_convnext.py#L338-L339
<|||||>Sorry that all the tests are failing. I must have messed something up during rebasing. But the good news is I was able to isolate the equivalence test from the TF ConvNeXt modeling subclass. It is passing locally. Now, I will investigate the rebasing issue and update. <|||||>@ydshieh could you clarify this a bit?
https://github.com/huggingface/transformers/pull/15750#issuecomment-1048939309<|||||>> @ydshieh could you clarify this a bit?
>
> [#15750 (comment)](https://github.com/huggingface/transformers/pull/15750#issuecomment-1048939309)
Sure. The objective is to make `TFConvNextModel` return the same values as its PyTorch version `ConvNextModel`.
This includes `last_hidden_state`, `pooler_output`, and `hidden_states` (if `output_hidden_states=True`).
The same requirement is also for `TFConvNextForImageClassification`. (In general, the top level models that users will interact).
Since TF (top level) models in `transformers` use `... MainLayer`, it is easier and clean to make sure `TFConvNextMainLayer` and `ConvNextModel` have the same return value format. This means, we transpose `NHWC` format in `TFConvNextMainLayer` back to `NCHW` for the outputs just once, and there is no need to transpose in `TFConvNextModel`/`TFConvNextForImageClassification`.
Hope this is more clear now :-)
<|||||>> > @ydshieh could you clarify this a bit?
> > [#15750 (comment)](https://github.com/huggingface/transformers/pull/15750#issuecomment-1048939309)
>
> Sure. The objective is to make `TFConvNextModel` return the same values as its PyTorch version `ConvNextModel`. This includes `last_hidden_state`, `pooler_output`, and `hidden_states` (if `output_hidden_states=True`).
>
> The same requirement is also for `TFConvNextForImageClassification`. (In general, the top level models that users will interact).
>
> Since TF (top level) models in `transformers` use `... MainLayer`, it is easier and clean to make sure `TFConvNextMainLayer` and `ConvNextModel` have the same return value format. This means, we transpose `NHWC` format in `TFConvNextMainLayer` back to `NCHW` for the outputs just once, and there is no need to transpose in `TFConvNextModel`/`TFConvNextForImageClassification`.
>
> Hope this is more clear now :-)
Yes, it is! Thank you so much.
I got confused with:
> A bit subtle here: hidden_states not always exists -> requires to check output_hidden_states<|||||>With respect to [`check_code_quality`](https://app.circleci.com/pipelines/github/huggingface/transformers/35050/workflows/bc1915df-9ea9-4876-9b52-3ab7e01095d0/jobs/376812) step being failed:
@ydshieh I did run `make style` before committing. As per the error trace from CircleCI, I also ran black separately. It returned the file unchanged. I am on Black `21.4b0`. Do you have any suggestions?<|||||>> With respect to [`check_code_quality`](https://app.circleci.com/pipelines/github/huggingface/transformers/35050/workflows/bc1915df-9ea9-4876-9b52-3ab7e01095d0/jobs/376812) step being failed:
>
> @ydshieh I did run `make style` before committing. As per the error trace from CircleCI, I also ran black separately. It returned the file unchanged. I am on Black `21.4b0`. Do you have any suggestions?
Let me check (in a few hours though)<|||||>> > With respect to [`check_code_quality`](https://app.circleci.com/pipelines/github/huggingface/transformers/35050/workflows/bc1915df-9ea9-4876-9b52-3ab7e01095d0/jobs/376812) step being failed:
> > @ydshieh I did run `make style` before committing. As per the error trace from CircleCI, I also ran black separately. It returned the file unchanged. I am on Black `21.4b0`. Do you have any suggestions?
>
> Let me check (in a few hours though)
No rush. I appreciate your help :) <|||||>> With respect to [`check_code_quality`](https://app.circleci.com/pipelines/github/huggingface/transformers/35050/workflows/bc1915df-9ea9-4876-9b52-3ab7e01095d0/jobs/376812) step being failed:
>
> @ydshieh I did run `make style` before committing. As per the error trace from CircleCI, I also ran black separately. It returned the file unchanged. I am on Black `21.4b0`. Do you have any suggestions?
@sayakpaul , I am on a newer version
```
(py39) λ black --version
black, 22.1.0 (compiled: yes)
```
When I run `make_style` on this PR branch, there is indeed some changes.
Could you follow the instructions [here](https://github.com/huggingface/transformers/issues/15628#issuecomment-1036418742), and see if it helps?<|||||>@ydshieh I created a new virtual environment and installed `pip install "[.quality]"`. And then ran `make style`. I only committed the files associated with this PR. The tests that do not suppose to fail are not failing. <|||||>> @ydshieh I created a new virtual environment and installed `pip install "[.quality]"`. And then ran `make style`. I only committed the files associated with this PR. The tests that do not suppose to fail are not failing.
Not yet check the detail. But why your last commit changed `tests/test_modeling_common.py` a lot? Do you know the reason?
https://github.com/huggingface/transformers/pull/15750/commits/229a817ad8d9eb004fa11f548c483ad26a3a4283<|||||>> > @ydshieh I created a new virtual environment and installed `pip install "[.quality]"`. And then ran `make style`. I only committed the files associated with this PR. The tests that do not suppose to fail are not failing.
>
> Not yet check the detail. But why your last commit changed `tests/test_modeling_common.py` a lot? Do you know the reason?
>
> [229a817](https://github.com/huggingface/transformers/commit/229a817ad8d9eb004fa11f548c483ad26a3a4283)
I am myself not sure. I just reverted to the original file. <|||||>Just two now probably because of the `output_attentions` thing. I will get to that once the test file that I modified today looks good.<|||||>> After the issue above gets fixed, the transpose gets moved to TFConvNextMainLayer, and self.output_attentions = None gets removed from the config, I'm happy to approve 💪
@gante we're almost there. I was able to move the transposition to `TFConvNextMainLayer` (not committed yet) but I am still having problems with the transposition of `hidden_states`.<|||||>> > After the issue above gets fixed, the transpose gets moved to TFConvNextMainLayer, and self.output_attentions = None gets removed from the config, I'm happy to approve 💪
>
> @gante we're almost there. I was able to move the transposition to `TFConvNextMainLayer` (not committed yet) but I am still having problems with the transposition of `hidden_states`.
not sure if you know it already or not, but `hidden_states` is a tuple of tensors, not a single tensor. You will need to transpose each element, and pack them again into a tuple. Don't hesitate if you have further question about this part.<|||||>> > > After the issue above gets fixed, the transpose gets moved to TFConvNextMainLayer, and self.output_attentions = None gets removed from the config, I'm happy to approve 💪
> >
> >
> > @gante we're almost there. I was able to move the transposition to `TFConvNextMainLayer` (not committed yet) but I am still having problems with the transposition of `hidden_states`.
>
> not sure if you know it already or not, but `hidden_states` is a tuple of tensors, not a single tensor. You will need to transpose each element, and pack them again into a tuple. Don't hesitate if you have further question about this part.
I'm aware :)
I am through and through till the packing but tuple assignment is the blocker now. <|||||>> > > > After the issue above gets fixed, the transpose gets moved to TFConvNextMainLayer, and self.output_attentions = None gets removed from the config, I'm happy to approve 💪
> > >
> > >
> > > @gante we're almost there. I was able to move the transposition to `TFConvNextMainLayer` (not committed yet) but I am still having problems with the transposition of `hidden_states`.
> >
> >
> > not sure if you know it already or not, but `hidden_states` is a tuple of tensors, not a single tensor. You will need to transpose each element, and pack them again into a tuple. Don't hesitate if you have further question about this part.
>
> I'm aware :)
>
> I am through and through till the packing but tuple assignment is the blocker now.
Does this help:
```
hidden_states = tuple([**transpose_method**(h) for h in hidden_states])
```
?
Or you are blocked in another place involving tuple?<|||||>Thanks, @ydshieh. I should have thought about it a bit more. Looks like all the things suggested [here](https://github.com/huggingface/transformers/pull/15750#pullrequestreview-892824548) have been taken care of.
Cc: @gante <|||||>> tests/test_modeling_tf_common.py is still with the unwanted style changes. For me, we can merge the PR after we revert it and the tests pass -- approving
@gante should I run `make fixup` and just commit `tests/test_modeling_tf_common.py` after that? <|||||>> > tests/test_modeling_tf_common.py is still with the unwanted style changes. For me, we can merge the PR after we revert it and the tests pass -- approving
>
> @gante should I run `make fixup` and just commit `tests/test_modeling_tf_common.py` after that?
I'd say `make fixup` should be the last thing it is done before the final commit (assuming it is working well on your env -- if it is not, let us know).<|||||>@sgugger this last commit should have all requested changes factored in (thank you @sayakpaul 🤜 🤛 ), let us know if you approve them <|||||>@sayakpaul Are you sure you are applying the suggestions exactly as I left them? If you leave the trailing comma, black will reformat again on several lines. I've checked out your PR locally and applied all my suggestions/changes requested; `make style` doesn't change it again.
I'm happy to push the result directly to your branch if that helps (and you left permissions for the maintainers) or to make a PR against your branch, whichever is easier to have those fixes inside the PR and we can merge. <|||||>Thank you.
> I'm happy to push the result directly to your branch if that helps
This seems like the fastest route and I am okay with it. <|||||>Ah, I actually checked out the branch by its pull request ID instead of your origin/branch name so then git didn't let me push. There is a PR [here](https://github.com/sayakpaul/transformers/pull/3) if you can merge it, we should be fine here. Sorry about that.<|||||>Thank you!<|||||>Thanks again for all your wok on this model!<|||||>Ccing @ariG23498 @gante and @ydshieh. Thank you so much all. |
transformers | 15,749 | closed | [tests] Improve forward_signature test | # What does this PR do?
The `test_forward_signature` test is currently being overridden in 25 model test files, because these models don't expect `input_ids`, but rather `pixel_values` (for vision models) or `input_values` (for speech models).
This PR instead leverages the `main_input_name` to update the test in `test_modeling_common.py`, `test_modeling_tf_common.py` and `test_modeling_flax_common.py`. | 02-21-2022 10:25:25 | 02-21-2022 10:25:25 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15749). All of your documentation changes will be reflected on that endpoint.<|||||>With this approach we're losing coverage of some checks regarding `attention_mask`<|||||>@LysandreJik can you take a second look? I've improved it by including an additional attribute called `other_arg_names`.<|||||>LGTM! Thanks, can't wait to use it ;) <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 15,748 | open | Fix segformer reshape last stage | # What does this PR do?
This PR improves SegFormer by removing the `reshape_last_stage` attribute of the configuration. In fact, this attribute was not needed at all.
Previously, the `reshape_last_stage` argument was set to `False` for `SegformerForImageClassification` models, however it's perfectly fine to reshape afterwards within this head model.
@sgugger I know you'll warn me about this being a breaking change. Here's why I think this change will not have an impact:
- `reshape_last_stage` was set to `True` by default in the configuration. As this PR only removes the ability to set this to `False`, the only use case in which this might be a breaking change is in case one defined a `SegformerModel` with `config.reshape_last_stage = False`. I am not sure if anyone has done this because there are no use cases for this. | 02-21-2022 10:02:38 | 02-21-2022 10:02:38 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15748). All of your documentation changes will be reflected on that endpoint. |
transformers | 15,747 | closed | Add PreLN to fsmt module | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Add pre-layer normalization module to FSMT module to match fairseq transformers.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@stas00
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-21-2022 04:59:03 | 02-21-2022 04:59:03 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_15747). All of your documentation changes will be reflected on that endpoint.<|||||>cc: @patil-suraj - if you'd like to have another pair of eyes on this PR and also fyi as this will now create a bit of a diversion from your unmerged fsmt PR from long time ago. Not sure what you would want to do about it. It has kind of fallen between cracks due to the performance regression.<|||||>This is typically the type of changes we usually don't accept inside one model architecture as it doesn't pass the test for new models: can an existing checkpoint for FSMT be used with this new config argument and give sensible results? -> No
I think this should warrant a new model.<|||||>This is how BART was initially designed and was refactored to align with the general philosophy of the library to have self-contained model files. cf #9343. So this should be a new model.
Also there are other fairseq models in the library that use `PreLN` for ex mBART and M2M100. Could you maybe check if you can load your checkpoints with these models ?
<|||||>> This is typically the type of changes we usually don't accept inside one model architecture as it doesn't pass the test for new models: can an existing checkpoint for FSMT be used with this new config argument and give sensible results? -> No
Not arguing whether it should be a new model or not, but unless I'm missing something, why the answer to :
> can an existing checkpoint for FSMT be used with this new config argument and give sensible results?
is `No`? I don't see any reason why it shouldn't work and not give identical results with this PR? It won't have any of the new model config entries and will work as intended.<|||||>First of all, thank you for leaving a comment about my PR!
I wanted to port pororo's translation and wsd model to transformers. When I tested it myself, I got the same result as fairseq's reasoning result when I modified it with the corresponding PR.
- https://github.com/kakaobrain/pororo
I will check the following items mentioned above and mention them.
- mBART
- Test results<|||||>> Not arguing whether it should be a new model or not, but unless I'm missing something, why the answer to *can an existing checkpoint for FSMT be used with this new config argument and give sensible results?* is No? I don't see any reason why it shouldn't work and not give identical results with this PR? It won't have any of the new model config entries and will work as intended.
When using an existing pretrained checkpoint with the config option `encoder_normalize_before=True` or `decoder_normalize_before=True`, the pretrained model will load properly (as all weights match) but a user won't get decent results with the model.
We can write a perfect modular toolbox that work with a current model implementation without breaking backward compatibility and have identical results, with just adding many new options in the configuration. That does not mean it conforms to the philosophy or pass the test of "this new option can be used with existing checkpoints".<|||||>> When using an existing pretrained checkpoint with the config option `encoder_normalize_before=True` or `decoder_normalize_before=True`, the pretrained model will load properly (as all weights match) but a user won't get decent results with the model.
If you're talking about the existing checkpoints - they won't have these config flags set in their config and as long as the default value for the new config options is `False` they will get identical results, as essentially they will be running the same modeling code as before this PR.
If the defaults for the new config options are set to True, then indeed it'd break.
<|||||>So talked some more with Sylvain and we aren't using the same test, hence the different pictures. He was using defaults `True` for new configs, I was using defaults `False` - hence the difference in the outcome.
And for me the idea of when using a new arch or not comes down to:
1. the config is for minor settings, like beam width, activation checkpointing, etc. which sometimes may lead to slightly less than optimal outcome but as close as possible to the best result.
2. any new config that changes the control flow (enables/disables code/changes order) which would lead to a different numerical outcome on the modeling level requires a new arch.
In other words no new architectural features can be added once a given modeling code is unleashed into the world and at least one checkpoint started using it, and a new architecture needs to be created.
<|||||>I did a force-pushed on my local branch 30 minutes ago because of my commit mistake. If this behavior is a problem, please let me know! I will close the PR and commit a new one.<|||||>> This is how BART was initially designed and was refactored to align with the general philosophy of the library to have self-contained model files. cf https://github.com/huggingface/transformers/pull/9343. So this should be a new model.
> Also there are other fairseq models in the library that use PreLN for ex mBART and M2M100. Could you maybe check if you can load your checkpoints with these models ?
@patil-suraj Because there is no `SinusoidalPositionalEmbedding` class in mBART script, missing key occurs separately from the convert script. Therefore, porting with the script seems impossible.<|||||>> Overall looks good. I left a few suggestions.
@stas00 I checked all your suggestions and fixed them all in 2982403 commit!
> The next step is to add a functional test, by building upon one of the existing fsmt tests.
Does the functional test need to modify `test_modeling_fsmt.py`? Or can I provide the test result to the PR to see if the `pre_layernorm` option works normally?
> Also if there are pre-trained models we could port that use preLN - it'd be great for then doing a quality test, which would be tricky to do with a dummy random data.
Among the models of the [PORORO library](https://github.com/kakaobrain/pororo) developed by OSLO developer hyunwoong ko, some models such as translation and word sense disambiguation use the `normalize_before` option. Is it okay to test the result and reflect it in the convert script?<|||||>> > This is how BART was initially designed and was refactored to align with the general philosophy of the library to have self-contained model files. cf #9343. So this should be a new model.
>
> > Also there are other fairseq models in the library that use PreLN for ex mBART and M2M100. Could you maybe check if you can load your checkpoints with these models ?
>
> @patil-suraj Because there is no `SinusoidalPositionalEmbedding` class in mBART script, missing key occurs separately from the convert script. Therefore, porting with the script seems impossible.
I see. Could you try with `M2M100` then ? M2M100 also uses `PreLN` and `SinusoidalPositionalEmbedding`.<|||||>> > Overall looks good. I left a few suggestions.
>
> @stas00 I checked all your suggestions and fixed them all in [2982403](https://github.com/huggingface/transformers/commit/298240385f570cae0616cf502b36b8bd909336d7) commit!
Thank you.
> > The next step is to add a functional test, by building upon one of the existing fsmt tests.
>
> Does the functional test need to modify `test_modeling_fsmt.py`? Or can I provide the test result to the PR to see if the `pre_layernorm` option works normally?
I'm not sure I understand your question. What I meant is this new code can't be merged w/o tests exercising it.
And, of course, I'm not trying to contradict the maintainers who requested a new architecture. But it'd need a new test and it'd be something new and not `test_modeling_fsmt.py`, but you can of course model it after. Probably `test_modeling_fsmt_preln.py` or something of the sorts - based on the new arch name that you will choose.
> > Also if there are pre-trained models we could port that use preLN - it'd be great for then doing a quality test, which would be tricky to do with a dummy random data.
>
> Among the models of the [PORORO library](https://github.com/kakaobrain/pororo) developed by OSLO developer hyunwoong ko, some models such as translation and word sense disambiguation use the `normalize_before` option. Is it okay to test the result and reflect it in the convert script?
if these models fit the architecture by all means that would be perfect. Except we would want the model to be on the https://huggingface.co/models hub first, so that the test suite could run reliably. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.