
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
sequence | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
sequence | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
sequence | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
sequence | cell_types
sequence | cell_type_groups
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
e73b720f831116437f8a79cfbc612e534ac98ddc | 19,633 | ipynb | Jupyter Notebook | Labs/229351-LAB04.ipynb | donlapark/ds351.github.io | b20f4492973c070612bd15ed9c6179b4f86c9b67 | [
"MIT"
] | null | null | null | Labs/229351-LAB04.ipynb | donlapark/ds351.github.io | b20f4492973c070612bd15ed9c6179b4f86c9b67 | [
"MIT"
] | null | null | null | Labs/229351-LAB04.ipynb | donlapark/ds351.github.io | b20f4492973c070612bd15ed9c6179b4f86c9b67 | [
"MIT"
] | null | null | null | 26.968407 | 222 | 0.518158 | [
[
[
"ปฏิบัติการครั้งที่ 4 กระบวนวิชา 229351 Statistical Learning for Data Science\n\nคำชี้แจง\n\n1. ให้เริ่มทำปฏิบัติการจาก colab notebook ที่กำหนดให้ จากนั้นบันทึกเป็นไฟล์ *.ipynb (File -> Download .ipynb)",
"_____no_output_____"
],
[
"#Task 1",
"_____no_output_____"
],
[
"# Empirical risk for virus testing\n\nในปัญหานี้เราจะทำการศึกษาการสร้างวิธีในการจำแนกคนที่เป็นโรคไวรัสจากการทดสอบชนิดหนึ่ง \n\nกำหนดให้ $R$ (reality) เป็นเหตุการณ์ที่คน $N$ คนเป็นหรือไม่เป็นพาหะนำโรคชนิดนี้\n\n`reality = [r1,r2,...,rN]`\n\nโดยที่ผลจากการทดสอบจะบอกถึงโอกาส (probability) ที่คนๆหนึ่งเป็นพาหะของโรคนี้\n\n`p = [p1,p2,...,pN]`\n\nโดยที่เราจะเป็นคนกำหนดค่า threshold $\\alpha$ ที่บอกว่า\n\n* ถ้า `pi` $>\\alpha$ แสดงว่าคนที่ `i` **เป็น**พาหะของโรคนี้\n* ถ้า `pi` $\\leq\\alpha$ แสดงว่าคนที่ `i` **ไม่เป็น**พาหะของโรคนี้\n\nกำหนดให้ $D$ (decision) เป็นการตัดสินใจที่ตามมา\n\n`decisions = [d1,d2,...,dN]`\n\nสมมติว่าเรากำหนดให้ความเสียหายจาก **false negative** (reality = 1 แต่ decision = 0) มีค่าเป็น $k$ เท่าของความเสียหายจาก **false positive** (reality = 0 แต่ decision = 1) loss function ที่ได้คือ (ค่า k กำหนดทีหลัง)\n\n$$\\begin{cases} \\mathcal{l}(di=1,ri=0) = 1\\\\\n\\mathcal{l}(di=0,ri=1) = k\\\\\n\\mathcal{l}(di=0,ri=0)=\\mathcal{l}(di=1,ri=1) = 0\\end{cases}$$\n\nดังนั้น empirical risk function ที่ได้คือ\n\n$$R = \\frac{1}{N}\\sum_{i=1}^N l(di,ri)$$\n\nนั่นคือ เราสามารถคำนวณ $R$ ได้ด้วยการบวก loss ของการทดสอบที่ผิดพลาดทั้งหมด แล้วหารด้วยจำนวณการทดสอบทั้งหมด",
"_____no_output_____"
],
[
"สร้างข้อมูลจำลองด้วยโค้ดข้างล่างนี้",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport seaborn as sns\nfrom scipy.stats import norm\n\n# Note: don't make any changes to this function\ndef generate_ground_truth(N, prevalence):\n \"\"\" สร้างข้อมูลจำลอง\"\"\"\n rs = np.random.RandomState(1)\n reality = rs.binomial(1, prevalence, N)\n p = norm.cdf(rs.randn(N) + reality)\n return(p, reality)\n\n# Generate p: Do not modify\nN = 10000\nprevalence = 0.05\np, reality = generate_ground_truth(N, prevalence)\n",
"_____no_output_____"
],
[
"p",
"_____no_output_____"
],
[
"reality",
"_____no_output_____"
]
],
[
[
"ฟังก์ชัน `alpha_threshold_decisions` ใช้ในการตัดสินใจว่าแต่ละคนเป็นหรือไม่เป็นพาหะ (`decisions`)",
"_____no_output_____"
]
],
[
[
"# Note: don't make any changes to this function, this is exatly the naive thresholding you completed in Lab 1\ndef alpha_threshold_decisions(p, alpha):\n \"\"\"\n Returns decisions on p using naive thresholding.\n \n Inputs:\n p: array p[i] คือความน่าจะเป็นที่ตัวอย่างที่ i มีเชื้อไวรัส\n alpha: threshold: p > alpha ถือว่าเป็น p <= alpha ถือว่าไม่เป็น\n \n Returns:\n decisions: `decisions[i]=1` ถือว่าเป็น \n `decisions[i]=0` ถือว่าไม่เป็น\n \"\"\"\n decisions = p > alpha\n return decisions",
"_____no_output_____"
],
[
"alpha_threshold_decisions(np.array([0.2,0.8]), alpha=0.7)",
"_____no_output_____"
]
],
[
[
"ฟังก์ชัน `report_results` ใช้ในการคำนวณว่าการตัดสินใจถูกหรือผิดอย่างไรบ้าง\n\n* TP (true positive): `ri`=1,`di`=1 \n* TN (true negative): `ri`=0,`di`=0 \n* FP (false positive): `ri`=0,`di`=1 \n* FN (false negative): `ri`=1,`di`=0 ",
"_____no_output_____"
]
],
[
[
"# Note: don't make any changes to this function, this is the report_results function you completed in Lab 1\ndef report_results(decisions, reality):\n \"\"\"\n สร้าง dictionary ที่ประกอบไปด้วยจำนวนตัวอย่างในกลุ่ม true positives, \n true negatives, false negatives, และ false positives \n จากการตัดสินใจด้วย `alpha_threshold_decisions`\n \n Inputs:\n decisions: array ที่มีค่า 0/1, decisions[i] =1 ถ้าการทดสอบบอกว่าคนที่ i มีเชื้อไวรัส\n reality: array ที่มีค่า 0/1, reality[i] =1 ถ้าคนที่ i มีเชื้อไวรัสจริง\n \n Outputs: dictionary ที่ประกอบไปด้วยค่า TN, TP, FN, และ FP \n \"\"\" \n \n TP_count = sum(decisions*reality)\n TN_count = sum((1-decisions)*(1-reality))\n FP_count = sum((decisions)*(1-reality))\n FN_count = sum((1-decisions)*(reality))\n \n results_dictionary = {\"TN_count\": TN_count,\n \"TP_count\": TP_count,\n \"FN_count\": FN_count,\n \"FP_count\": FP_count,\n }\n return results_dictionary",
"_____no_output_____"
]
],
[
[
"`results_dictionary[\"FP_count\"]`",
"_____no_output_____"
],
[
"### Exercise 1a: เติมฟังก์ชันเพื่อคำนวณ empirical risk จากค่าจำนวนความถูกต้องและจำนวนความผิดพลาด (TP, FP, TN, FN) ที่บันทึกใน `results_dictionary` โดยที่ `factor_k` คือค่า $k$ ที่ระบุในนิยามของ loss function ข้างบน",
"_____no_output_____"
],
[
"#### Loss function คือ\n\n$$\\begin{cases} \\mathcal{l}(di=1,ri=0) = 1\\\\\n\\mathcal{l}(di=0,ri=1) = k\\\\\n\\mathcal{l}(di=0,ri=0)=\\mathcal{l}(di=1,ri=1) = 0\\end{cases}$$\n\n#### Empirical risk function คือ\n\n$$R = \\frac{1}{N}\\sum_{i=1}^N l(di,ri)$$\n\nนั่นคือ เราสามารถคำนวณ $R$ ได้ด้วยการบวก loss ของการทดสอบที่ผิดพลาดทั้งหมด แล้วหารด้วยจำนวณการทดสอบทั้งหมด",
"_____no_output_____"
]
],
[
[
"# TODO: fill in\ndef compute_empirical_risk(results_dictionary, factor_k):\n \"\"\" คำนวณ empirical risk ด้วยค่า TP, FP, TN และ FN ใน results_dictionary\n โดยที่ค่าของ false positive คือ 1\n และค่าของ false negative คือ k\n \n Inputs:\n results_dictionary : dictionary ที่มีค่า TP, FP, TN และ FN\n factor_k : ค่า loss ของแต่ละตัวอย่างที่อยู่ในกลุ่ม false negative\n \n Outputs:\n empirical_risk : float\n \"\"\"\n \n TP_count = results_dictionary['TP_count']\n FP_count = results_dictionary['FP_count'] #แต่ละคนได้ค่า loss = 1\n TN_count = results_dictionary['TN_count']\n FN_count = results_dictionary['FN_count'] #แต่ละคนได้ค่า loss = k\n \n N = TP_count + TN_count + FP_count + FN_count\n empirical_risk = 1/N * (factor_k*FN_count + FP_count) # TODO: fill in\n return(empirical_risk)",
"_____no_output_____"
],
[
"res_dict = {'TP_count': 100, 'FP_count': 20, 'TN_count':450, 'FN_count':30}\nk_factors = [0, 10, 100]\nfor i, k in enumerate(k_factors):\n empirical_risk = compute_empirical_risk(res_dict, k)\n print(empirical_risk)\n\n#Answers should be: \n# 0.03333333333333333\n# 0.5333333333333333\n# 5.033333333333333",
"_____no_output_____"
]
],
[
[
"### Exercise 1b: เติมฟังก์ชันเพื่อคำนวณ empirical risk โดยที่มี argument ดังนี้ \n\n* `reality` การเป็นพาหะจริง \n* `p` ความน่าจะเป็นที่ได้จากการทดสอบ \n* `alpha` ค่า threshold ในการตัดสินใจว่าแต่ละคนเป็นพาหะหรือไม่\n* `factor_k` คือค่า $k$ ที่ระบุในนิยามของ loss function ข้างบน",
"_____no_output_____"
]
],
[
[
"# TODO: complete the function\ndef compute_alpha_empirical_risk(p, reality, alpha, factor_k):\n \"\"\" \n คำนวณค่า empirical risk ที่ค่า threshold alpha\n \n Inputs:\n p: array of floats, p[i] คือความน่าจะเป็นที่ตัวอย่างที่ i มีเชื้อไวรัส\n reality: array ที่มีค่า 0/1, reality[i] =1 ถ้าคนที่ i มีเชื้อไวรัสจริง\n alpha: float, threshold สำหรับการตัวสินใจว่าแต่ละคนมีเชื้อไวรัสหรือไม่\n factor_k: float, ค่า loss ของแต่ละตัวอย่างที่อยู่ในกลุ่ม false negative\n \n Outputs:\n empirical_risk: float, empirical risk\n \"\"\"\n\n #From p, alpha return decisions\n decisions = alpha_threshold_decisions(p, alpha)\n #From reality and decisions, return a dictionary of TP, FP, TN ,FN\n results_dictionary = report_results(decisions, reality)\n #From the dictionary and factor_k, compute the empirical risk\n empirical_risk = compute_empirical_risk(results_dictionary, factor_k)\n return empirical_risk",
"_____no_output_____"
],
[
"print('At level alpha=', 0.05 ,' and k=', 0 ,' the average loss is', \\\n compute_alpha_empirical_risk(p, reality,0.05,0))\nprint('At level alpha=', 0.05 ,' and k=', 10 ,' the average loss is', \\\n compute_alpha_empirical_risk(p, reality,0.05,10))\nprint('At level alpha=', 0.05 ,' and k=', 100 ,' the average loss is', \\\n compute_alpha_empirical_risk(p, reality,0.05,100))\n\n#Answers should be 0.0499, 0.3909, 3.4599\n#Answers should be 0.9032, 1.0312, 2.1832",
"_____no_output_____"
],
[
"# Run this as is after completing the `compute_alpha_empirical_risk` function\n# Do not modify\ndef plot_empirical_risk(factor_k):\n N = 10000\n # generate ground truth\n p, reality = generate_ground_truth(N, 0.05)\n # vary alpha from 0 to 1\n alpha_array = np.arange(0,1, 0.05)\n # compute average loss for each alpha\n empirical_risk_array = [compute_alpha_empirical_risk(p, reality, alpha, factor_k) for alpha in alpha_array]\n optimal_alpha = alpha_array[np.argmin(empirical_risk_array)]\n plt.figure(figsize=(10, 6))\n plt.plot(alpha_array, empirical_risk_array, label = 'Average Loss')\n plt.axvline(x=optimal_alpha, ls='--', label = 'Optimal $\\\\alpha$', c='green')\n plt.xlabel('$\\\\alpha$ level')\n plt.ylabel('Average Loss')\n plt.legend()\n plt.show()",
"_____no_output_____"
],
[
"from ipywidgets import interact, interactive\n\n# Visualize interactive plot: Do not modify\ninteractive_plot = interactive(plot_empirical_risk, factor_k=(0, 100, 5))\ninteractive_plot",
"_____no_output_____"
]
],
[
[
"### Exercise 1c: factor_k กับค่า $\\alpha$ ที่ดีทีสุด (Optimal $\\alpha$) มีความสัมพันธ์กันอย่างไร",
"_____no_output_____"
],
[
"คำตอบ:",
"_____no_output_____"
],
[
"#Task 2",
"_____no_output_____"
],
[
"###Sample points",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\n\nN = 8\nx = 10 ** np.linspace(-2, 0, N)\ny = np.random.normal(loc = 10 - 1. / (x + 0.1), scale= 0.5)",
"_____no_output_____"
],
[
"plt.figure()\nplt.scatter(x, y, c='k')\nplt.xlabel('x')\nplt.ylabel('y')\nplt.title('Sample points');",
"_____no_output_____"
]
],
[
[
"### Polynomial regression",
"_____no_output_____"
]
],
[
[
"p = np.polyfit(x, y, 2)\n\n\nxfit = np.linspace(-0.2, 1.2, 1000)\nyfit = np.polyval(p, xfit)\n\np",
"_____no_output_____"
],
[
"plt.figure()\nplt.scatter(x, y, marker='x', c='k', s=50)\nplt.plot(xfit, yfit, '-b')\nplt.xlabel('x')\nplt.ylabel('y')\nplt.title('d = 2')",
"_____no_output_____"
],
[
"xfit = np.linspace(-0.2, 1.2, 1000)\n\ntitles = ['d = 1 (under-fit)', 'd = 2', 'd = 6 (over-fit)']\ndegrees = [1, 2, 6]\n\nplt.figure(figsize = (9, 3.5))\nfor i, d in enumerate(degrees):\n plt.subplot(131 + i, xticks=[], yticks=[])\n plt.scatter(x, y, marker='x', c='k', s=50)\n\n p = np.polyfit(x, y, d)\n yfit = np.polyval(p, xfit)\n plt.plot(xfit, yfit, '-b')\n \n plt.xlim(-0.2, 1.2)\n plt.ylim(0, 12)\n plt.xlabel('x')\n if i == 0:\n plt.ylabel('y')\n\n plt.title(titles[i])",
"_____no_output_____"
],
[
"np.random.seed(42)\n\nNtrain = 20\nNtest = 20\nerror = 1.0\n\nnp.random.seed(0)\nx = np.random.random(Ntrain + Ntest)\ny = np.random.normal(loc = 10 - 1. / (x + 0.1), scale= 0.5)\n\nxtrain = x[:Ntrain]\nytrain = y[:Ntrain]\n\nxtest = x[Ntrain:]\nytest = y[Ntrain:]",
"_____no_output_____"
],
[
"plt.scatter(xtrain, ytrain, c='k')\nplt.xlabel('x')\nplt.ylabel('y')\nplt.title('Training set');",
"_____no_output_____"
],
[
"plt.scatter(xtest, ytest, c='k')\nplt.xlabel('x')\nplt.ylabel('y')\nplt.title('Test set');",
"_____no_output_____"
]
],
[
[
"#### ในกรณีนี้ เราใช้ squared-loss ดังนั้น empirical risk เท่ากับ MSE (mean-squared error) ",
"_____no_output_____"
]
],
[
[
"def empirical_risk(y, yfit):\n return np.mean((y - yfit) ** 2)",
"_____no_output_____"
]
],
[
[
"# Exercise 2: \n1. ทำการสร้าง polynomial regression ที่มีค่า degree ตั้งแต่ 1-10 โดยใช้ training set ข้างบน \n2. หลังจากสร้างโมเดลแต่ละตัวเสร็จแล้ว ให้คำนวณค่า empirical risk ของการทำนายบน test set เก็บค่าที่ได้ไว้ใน list ที่ชื่อว่า `empirical_risks` (เพราะฉะนั้น list นี้จะมีสมาชิก 10 ตัว)\n3. สร้าง plot โดยให้แกนนอนคือค่า degree ของโมเดลแต่ละตัว และแกนตั้งคือค่า empirical risk ของโมเดลตัวนั้น \n4. ระบุค่า degree ที่มี empirical risk ต่ำที่สุด\nค่า degree ไหนบ้างที่ทำให้โมเดล overfit และค่า degree ไหนบ้างที่ทำให้โมเดล underfit",
"_____no_output_____"
]
],
[
[
"max_degree = 10\n\nempirical_risks = [0]*max_degree\n\nfor d in range(1,max_degree+1):\n #TODO: fill code here\n p = np.polyfit(xtrain, ytrain, d)\n ypred = np.polyval(p, xtest)\n r = empirical_risk(ytest, ypred)\n\n\n\n\n\n\n\n\n",
"_____no_output_____"
],
[
"p = np.polyfit(xtrain, ytrain, 6)\n\nplt.figure()\n\nplt.scatter(xtest, ytest)\nxfit2 = np.linspace(0, 1.1, 1000)\nplt.plot(xfit2, np.polyval(p, xfit2))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
e73b7eef1cd82f5c6d169a105d8ef3165ab9189f | 39,009 | ipynb | Jupyter Notebook | notebooks/Payment_Fraud_Detection/Fraud_Detection_Solution.ipynb | LourensWalters/deep-learning-udacity | dfcfe539c10cd7a9dcd2c5f98fdeae117c70b4dd | [
"MIT"
] | 358 | 2019-03-06T07:06:35.000Z | 2022-03-29T18:11:29.000Z | notebooks/Payment_Fraud_Detection/Fraud_Detection_Solution.ipynb | LourensWalters/deep-learning-udacity | dfcfe539c10cd7a9dcd2c5f98fdeae117c70b4dd | [
"MIT"
] | 11 | 2020-04-23T21:32:17.000Z | 2021-09-21T03:17:29.000Z | notebooks/Payment_Fraud_Detection/Fraud_Detection_Solution.ipynb | LourensWalters/deep-learning-udacity | dfcfe539c10cd7a9dcd2c5f98fdeae117c70b4dd | [
"MIT"
] | 476 | 2019-03-15T01:26:54.000Z | 2022-03-30T23:58:43.000Z | 39.126379 | 568 | 0.618985 | [
[
[
"# Detecting Payment Card Fraud\n\nIn this section, we'll look at a credit card fraud detection dataset, and build a binary classification model that can identify transactions as either fraudulent or valid, based on provided, *historical* data. In a [2016 study](https://nilsonreport.com/upload/content_promo/The_Nilson_Report_10-17-2016.pdf), it was estimated that credit card fraud was responsible for over 20 billion dollars in loss, worldwide. Accurately detecting cases of fraud is an ongoing area of research.\n\n<img src=notebook_ims/fraud_detection.png width=50% />\n\n### Labeled Data\n\nThe payment fraud data set (Dal Pozzolo et al. 2015) was downloaded from [Kaggle](https://www.kaggle.com/mlg-ulb/creditcardfraud/data). This has features and labels for thousands of credit card transactions, each of which is labeled as fraudulent or valid. In this notebook, we'd like to train a model based on the features of these transactions so that we can predict risky or fraudulent transactions in the future.\n\n### Binary Classification\n\nSince we have true labels to aim for, we'll take a **supervised learning** approach and train a binary classifier to sort data into one of our two transaction classes: fraudulent or valid. We'll train a model on training data and see how well it generalizes on some test data.\n\nThe notebook will be broken down into a few steps:\n* Loading and exploring the data\n* Splitting the data into train/test sets\n* Defining and training a LinearLearner, binary classifier\n* Making improvements on the model\n* Evaluating and comparing model test performance\n\n### Making Improvements\n\nA lot of this notebook will focus on making improvements, as discussed in [this SageMaker blog post](https://aws.amazon.com/blogs/machine-learning/train-faster-more-flexible-models-with-amazon-sagemaker-linear-learner/). Specifically, we'll address techniques for:\n\n1. **Tuning a model's hyperparameters** and aiming for a specific metric, such as high recall or precision.\n2. **Managing class imbalance**, which is when we have many more training examples in one class than another (in this case, many more valid transactions than fraudulent).\n\n---",
"_____no_output_____"
],
[
"First, import the usual resources.",
"_____no_output_____"
]
],
[
[
"import io\nimport os\nimport matplotlib.pyplot as plt\nimport numpy as np \nimport pandas as pd \nfrom sklearn.model_selection import train_test_split\n\n%matplotlib inline",
"_____no_output_____"
],
[
"import boto3\nimport sagemaker\nfrom sagemaker import get_execution_role",
"_____no_output_____"
]
],
[
[
"I'm storing my **SageMaker variables** in the next cell:\n* sagemaker_session: The SageMaker session we'll use for training models.\n* bucket: The name of the default S3 bucket that we'll use for data storage.\n* role: The IAM role that defines our data and model permissions.",
"_____no_output_____"
]
],
[
[
"# sagemaker session, role\nsagemaker_session = sagemaker.Session()\nrole = sagemaker.get_execution_role()\n\n# S3 bucket name\nbucket = sagemaker_session.default_bucket()\n",
"_____no_output_____"
]
],
[
[
"## Loading and Exploring the Data\n\nNext, I am loading the data and unzipping the data in the file `creditcardfraud.zip`. This directory will hold one csv file of all the transaction data, `creditcard.csv`.\n\nAs in previous notebooks, it's important to look at the distribution of data since this will inform how we develop a fraud detection model. We'll want to know: How many data points we have to work with, the number and type of features, and finally, the distribution of data over the classes (valid or fraudulent).",
"_____no_output_____"
]
],
[
[
"# only have to run once\n!wget https://s3.amazonaws.com/video.udacity-data.com/topher/2019/January/5c534768_creditcardfraud/creditcardfraud.zip\n!unzip creditcardfraud",
"_____no_output_____"
],
[
"# read in the csv file\nlocal_data = 'creditcard.csv'\n\n# print out some data\ntransaction_df = pd.read_csv(local_data)\nprint('Data shape (rows, cols): ', transaction_df.shape)\nprint()\ntransaction_df.head()",
"_____no_output_____"
]
],
[
[
"### EXERCISE: Calculate the percentage of fraudulent data\n\nTake a look at the distribution of this transaction data over the classes, valid and fraudulent. \n\nComplete the function `fraudulent_percentage`, below. Count up the number of data points in each class and calculate the *percentage* of the data points that are fraudulent.",
"_____no_output_____"
]
],
[
[
"# Calculate the fraction of data points that are fraudulent\ndef fraudulent_percentage(transaction_df):\n '''Calculate the fraction of all data points that have a 'Class' label of 1; fraudulent.\n :param transaction_df: Dataframe of all transaction data points; has a column 'Class'\n :return: A fractional percentage of fraudulent data points/all points\n '''\n # counts for all classes\n counts = transaction_df['Class'].value_counts()\n \n # get fraudulent and valid cnts\n fraud_cnts = counts[1]\n valid_cnts = counts[0]\n \n # calculate percentage of fraudulent data\n fraud_percentage = fraud_cnts/(fraud_cnts+valid_cnts)\n \n return fraud_percentage",
"_____no_output_____"
]
],
[
[
"Test out your code by calling your function and printing the result.",
"_____no_output_____"
]
],
[
[
"# call the function to calculate the fraud percentage\nfraud_percentage = fraudulent_percentage(transaction_df)\n\nprint('Fraudulent percentage = ', fraud_percentage)\nprint('Total # of fraudulent pts: ', fraud_percentage*transaction_df.shape[0])\nprint('Out of (total) pts: ', transaction_df.shape[0])\n",
"_____no_output_____"
]
],
[
[
"### EXERCISE: Split into train/test datasets\n\nIn this example, we'll want to evaluate the performance of a fraud classifier; training it on some training data and testing it on *test data* that it did not see during the training process. So, we'll need to split the data into separate training and test sets.\n\nComplete the `train_test_split` function, below. This function should:\n* Shuffle the transaction data, randomly\n* Split it into two sets according to the parameter `train_frac`\n* Get train/test features and labels\n* Return the tuples: (train_features, train_labels), (test_features, test_labels)",
"_____no_output_____"
]
],
[
[
"# split into train/test\ndef split_data(transaction_df, test_size= 0.3, random_state=1):\n '''\n Shuffle the data and randomly split into train and test sets;\n separate the class labels (the column in transaction_df) from the features.\n :param df: Dataframe of all credit card transaction data\n :param train_frac: The decimal fraction of data that should be training data\n :param seed: Random seed for shuffling and reproducibility, default = 1\n :return: Two tuples (in order): (train_features, train_labels), (test_features, test_labels)\n '''\n \n train_df, test_df = train_test_split(transaction_df, test_size=test_size, random_state = random_state)\n train_features = train_df.drop(['Class'], axis=1)\n train_labels = train_df['Class']\n test_features = test_df.drop(['Class'], axis=1)\n test_labels = test_df['Class']\n\n return train_features, test_features, train_labels, test_labels\n",
"_____no_output_____"
]
],
[
[
"### Test Cell\n\nIn the cells below, I'm creating the train/test data and checking to see that result makes sense. The tests below test that the above function splits the data into the expected number of points and that the labels are indeed, class labels (0, 1).",
"_____no_output_____"
]
],
[
[
"# get train/test data\ntrain_features, test_features, train_labels, test_labels = split_data(transaction_df, test_size=0.3, random_state=1)\n",
"_____no_output_____"
],
[
"# manual test\n\n# for a split of 0.7:0.3 there should be ~2.33x as many training as test pts\nprint('Training data pts: ', len(train_features))\nprint('Test data pts: ', len(test_features))\nprint()\n\n# take a look at first item and see that it aligns with first row of data\nprint('First item: \\n', train_features.iloc[0, :])\nprint('Label: ', train_labels[0])\nprint()\n\n# test split\nassert len(train_features) > 2.333*len(test_features), \\\n 'Unexpected number of train/test points for a train_frac=0.7'\n# test labels\nassert np.all(train_labels)== 0 or np.all(train_labels)== 1, \\\n 'Train labels should be 0s or 1s.'\nassert np.all(test_labels)== 0 or np.all(test_labels)== 1, \\\n 'Test labels should be 0s or 1s.'\nprint('Tests passed!')",
"_____no_output_____"
]
],
[
[
"---\n# Modeling\n\nNow that you've uploaded your training data, it's time to define and train a model!\n\nIn this notebook, you'll define and train the SageMaker, built-in algorithm, [LinearLearner](https://sagemaker.readthedocs.io/en/stable/linear_learner.html). \n\nA LinearLearner has two main applications:\n1. For regression tasks in which a linear line is fit to some data points, and you want to produce a predicted output value given some data point (example: predicting house prices given square area).\n2. For binary classification, in which a line is separating two classes of data and effectively outputs labels; either 1 for data that falls above the line or 0 for points that fall on or below the line.\n\n<img src='notebook_ims/linear_separator.png' width=40% />\n\nIn this case, we'll be using it for case 2, and we'll train it to separate data into our two classes: valid or fraudulent. ",
"_____no_output_____"
],
[
"### EXERCISE: Create a LinearLearner Estimator\n\nYou've had some practice instantiating built-in models in SageMaker. All estimators require some constructor arguments to be passed in. See if you can complete this task, instantiating a LinearLearner estimator, using only the [LinearLearner documentation](https://sagemaker.readthedocs.io/en/stable/linear_learner.html) as a resource. This takes in a lot of arguments, but not all are required. My suggestion is to start with a simple model, utilizing default values where applicable. Later, we will discuss some specific hyperparameters and their use cases.\n\n#### Instance Types\n\nIt is suggested that you use instances that are available in the free tier of usage: `'ml.c4.xlarge'` for training and `'ml.t2.medium'` for deployment.",
"_____no_output_____"
]
],
[
[
"# import LinearLearner\nfrom sagemaker import LinearLearner\n\n# specify an output path\nprefix = 'creditcard'\noutput_path = 's3://{}/{}'.format(bucket, prefix)\n\n# instantiate LinearLearner\nlinear = LinearLearner(role=role,\n train_instance_count=1, \n train_instance_type='ml.c4.xlarge',\n predictor_type='binary_classifier',\n output_path=output_path,\n sagemaker_session=sagemaker_session,\n epochs=15)\n",
"_____no_output_____"
]
],
[
[
"### EXERCISE: Convert data into a RecordSet format\n\nNext, prepare the data for a built-in model by converting the train features and labels into numpy array's of float values. Then you can use the [record_set function](https://sagemaker.readthedocs.io/en/stable/linear_learner.html#sagemaker.LinearLearner.record_set) to format the data as a RecordSet and prepare it for training!",
"_____no_output_____"
]
],
[
[
"# convert features/labels to numpy\ntrain_x_np = train_features.astype('float32')\ntrain_y_np = train_labels.astype('float32')\n\n# create RecordSet\nformatted_train_data = linear.record_set(train_x_np, labels=train_y_np)",
"_____no_output_____"
]
],
[
[
"### EXERCISE: Train the Estimator\n\nAfter instantiating your estimator, train it with a call to `.fit()`, passing in the formatted training data.",
"_____no_output_____"
]
],
[
[
"%%time \n# train the estimator on formatted training data\nlinear.fit(formatted_train_data)",
"_____no_output_____"
]
],
[
[
"### EXERCISE: Deploy the trained model\n\nDeploy your model to create a predictor. We'll use this to make predictions on our test data and evaluate the model.",
"_____no_output_____"
]
],
[
[
"%%time \n# deploy and create a predictor\nlinear_predictor = linear.deploy(initial_instance_count=1, instance_type='ml.t2.medium')",
"_____no_output_____"
]
],
[
[
"---\n# Evaluating Your Model\n\nOnce your model is deployed, you can see how it performs when applied to the test data.\n\nAccording to the deployed [predictor documentation](https://sagemaker.readthedocs.io/en/stable/linear_learner.html#sagemaker.LinearLearnerPredictor), this predictor expects an `ndarray` of input features and returns a list of Records.\n> \"The prediction is stored in the \"predicted_label\" key of the `Record.label` field.\"\n\nLet's first test our model on just one test point, to see the resulting list.",
"_____no_output_____"
]
],
[
[
"# test one prediction\ntest_x_np = test_features.astype('float32')\nresult = linear_predictor.predict(test_x_np[0])\n\nprint(result)",
"_____no_output_____"
]
],
[
[
"### Helper function for evaluation\n\n\nThe provided function below, takes in a deployed predictor, some test features and labels, and returns a dictionary of metrics; calculating false negatives and positives as well as recall, precision, and accuracy.",
"_____no_output_____"
]
],
[
[
"# code to evaluate the endpoint on test data\n# returns a variety of model metrics\ndef evaluate(predictor, test_features, test_labels, verbose=True):\n \"\"\"\n Evaluate a model on a test set given the prediction endpoint. \n Return binary classification metrics.\n :param predictor: A prediction endpoint\n :param test_features: Test features\n :param test_labels: Class labels for test data\n :param verbose: If True, prints a table of all performance metrics\n :return: A dictionary of performance metrics.\n \"\"\"\n \n # We have a lot of test data, so we'll split it into batches of 100\n # split the test data set into batches and evaluate using prediction endpoint \n prediction_batches = [predictor.predict(batch) for batch in np.array_split(test_features, 100)]\n \n # LinearLearner produces a `predicted_label` for each data point in a batch\n # get the 'predicted_label' for every point in a batch\n test_preds = np.concatenate([np.array([x.label['predicted_label'].float32_tensor.values[0] for x in batch]) \n for batch in prediction_batches])\n \n # calculate true positives, false positives, true negatives, false negatives\n tp = np.logical_and(test_labels, test_preds).sum()\n fp = np.logical_and(1-test_labels, test_preds).sum()\n tn = np.logical_and(1-test_labels, 1-test_preds).sum()\n fn = np.logical_and(test_labels, 1-test_preds).sum()\n \n # calculate binary classification metrics\n recall = tp / (tp + fn)\n precision = tp / (tp + fp)\n accuracy = (tp + tn) / (tp + fp + tn + fn)\n \n # printing a table of metrics\n if verbose:\n print(pd.crosstab(test_labels, test_preds, rownames=['actual (row)'], colnames=['prediction (col)']))\n print(\"\\n{:<11} {:.3f}\".format('Recall:', recall))\n print(\"{:<11} {:.3f}\".format('Precision:', precision))\n print(\"{:<11} {:.3f}\".format('Accuracy:', accuracy))\n print()\n \n return {'TP': tp, 'FP': fp, 'FN': fn, 'TN': tn, \n 'Precision': precision, 'Recall': recall, 'Accuracy': accuracy}\n",
"_____no_output_____"
]
],
[
[
"### Test Results\n\nThe cell below runs the `evaluate` function. \n\nThe code assumes that you have a defined `predictor` and `test_features` and `test_labels` from previously-run cells.",
"_____no_output_____"
]
],
[
[
"print('Metrics for simple, LinearLearner.\\n')\n\n# get metrics for linear predictor\nmetrics = evaluate(linear_predictor, \n test_features.astype('float32'), \n test_labels, \n verbose=True) # verbose means we'll print out the metrics\n",
"_____no_output_____"
]
],
[
[
"We can see that this model gets a very high accuracy of 99.9% ! But it still misclassifies about 30 (each) of our valid and fraudulent cases, which results in much lower values for recall and precision.\n\nNext, let's delete this endpoint and discuss ways to improve this model.",
"_____no_output_____"
],
[
"## Delete the Endpoint\n\nI've added a convenience function to delete prediction endpoints after we're done with them. And if you're done evaluating the model, you should delete your model endpoint!",
"_____no_output_____"
]
],
[
[
"# Deletes a precictor.endpoint\ndef delete_endpoint(predictor):\n try:\n boto3.client('sagemaker').delete_endpoint(EndpointName=predictor.endpoint)\n print('Deleted {}'.format(predictor.endpoint))\n except:\n print('Already deleted: {}'.format(predictor.endpoint))",
"_____no_output_____"
],
[
"# delete the predictor endpoint \ndelete_endpoint(linear_predictor)",
"_____no_output_____"
]
],
[
[
"---\n\n# Model Improvements\n\nThe default LinearLearner got a high accuracy, but still classified fraudulent and valid data points incorrectly. Specifically classifying more than 30 points as false negatives (incorrectly labeled, fraudulent transactions), and a little over 30 points as false positives (incorrectly labeled, valid transactions). Let's think about what, during training, could cause this behavior and what we could improve.\n\n**1. Model optimization**\n* If we imagine that we are designing this model for use in a bank application, we know that users do *not* want any valid transactions to be categorized as fraudulent. That is, we want to have as few **false positives** (0s classified as 1s) as possible. \n* On the other hand, if our bank manager asks for an application that will catch almost *all* cases of fraud, even if it means a higher number of false positives, then we'd want as few **false negatives** as possible.\n* To train according to specific product demands and goals, we do not want to optimize for accuracy only. Instead, we want to optimize for a metric that can help us decrease the number of false positives or negatives. \n\n<img src='notebook_ims/precision_recall.png' width=40% />\n \nIn this notebook, we'll look at different cases for tuning a model and make an optimization decision, accordingly.\n\n**2. Imbalanced training data**\n* At the start of this notebook, we saw that only about 0.17% of the data was labeled as fraudulent. So, even if a model labels **all** of our data as valid, it will still have a high accuracy. \n* This may result in some overfitting towards valid data, which accounts for some **false negatives**; cases in which fraudulent data (1) is incorrectly characterized as valid (0).\n\nSo, let's address these issues in order; first, tuning our model and optimizing for a specific metric during training, and second, accounting for class imbalance in the training set. \n",
"_____no_output_____"
],
[
"## Improvement: Model Tuning\n\nOptimizing according to a specific metric is called **model tuning**, and SageMaker provides a number of ways to automatically tune a model.\n\n\n### Create a LinearLearner and tune for higher precision \n\n**Scenario:**\n* A bank has asked you to build a model that detects cases of fraud with an accuracy of about 85%. \n\nIn this case, we want to build a model that has as many true positives and as few false negatives, as possible. This corresponds to a model with a high **recall**: true positives / (true positives + false negatives). \n\nTo aim for a specific metric, LinearLearner offers the hyperparameter `binary_classifier_model_selection_criteria`, which is the model evaluation criteria for the training dataset. A reference to this parameter is in [LinearLearner's documentation](https://sagemaker.readthedocs.io/en/stable/linear_learner.html#sagemaker.LinearLearner). We'll also have to further specify the exact value we want to aim for; read more about the details of the parameters, [here](https://docs.aws.amazon.com/sagemaker/latest/dg/ll_hyperparameters.html).\n\nI will assume that performance on a training set will be within about 5% of the performance on a test set. So, for a recall of about 85%, I'll aim for a bit higher, 90%.",
"_____no_output_____"
]
],
[
[
"# instantiate a LinearLearner\n# tune the model for a higher recall\nlinear_recall = LinearLearner(role=role,\n train_instance_count=1, \n train_instance_type='ml.c4.xlarge',\n predictor_type='binary_classifier',\n output_path=output_path,\n sagemaker_session=sagemaker_session,\n epochs=15,\n binary_classifier_model_selection_criteria='precision_at_target_recall', # target recall\n target_recall=0.9) # 90% recall\n",
"_____no_output_____"
]
],
[
[
"### Train the tuned estimator\n\nFit the new, tuned estimator on the formatted training data.",
"_____no_output_____"
]
],
[
[
"%%time \n# train the estimator on formatted training data\nlinear_recall.fit(formatted_train_data)",
"_____no_output_____"
]
],
[
[
"### Deploy and evaluate the tuned estimator\n\nDeploy the tuned predictor and evaluate it.\n\nWe hypothesized that a tuned model, optimized for a higher recall, would have fewer false negatives (fraudulent transactions incorrectly labeled as valid); did the number of false negatives get reduced after tuning the model?",
"_____no_output_____"
]
],
[
[
"%%time \n# deploy and create a predictor\nrecall_predictor = linear_recall.deploy(initial_instance_count=1, instance_type='ml.t2.medium')",
"_____no_output_____"
],
[
"print('Metrics for tuned (recall), LinearLearner.\\n')\n\n# get metrics for tuned predictor\nmetrics = evaluate(recall_predictor, \n test_features.astype('float32'), \n test_labels, \n verbose=True)",
"_____no_output_____"
]
],
[
[
"## Delete the endpoint \n\nAs always, when you're done evaluating a model, you should delete the endpoint. Below, I'm using the `delete_endpoint` helper function I defined earlier.",
"_____no_output_____"
]
],
[
[
"# delete the predictor endpoint \ndelete_endpoint(recall_predictor)",
"_____no_output_____"
]
],
[
[
"---\n## Improvement: Managing Class Imbalance\n\nWe have a model that is tuned to get a higher recall, which aims to reduce the number of false negatives. Earlier, we discussed how class imbalance may actually bias our model towards predicting that all transactions are valid, resulting in higher false negatives and true negatives. It stands to reason that this model could be further improved if we account for this imbalance.\n\nTo account for class imbalance during training of a binary classifier, LinearLearner offers the hyperparameter, `positive_example_weight_mult`, which is the weight assigned to positive (1, fraudulent) examples when training a binary classifier. The weight of negative examples (0, valid) is fixed at 1. \n\n### EXERCISE: Create a LinearLearner with a `positive_example_weight_mult` parameter\n\nIn **addition** to tuning a model for higher recall (you may use `linear_recall` as a starting point), you should *add* a parameter that helps account for class imbalance. From the [hyperparameter documentation](https://docs.aws.amazon.com/sagemaker/latest/dg/ll_hyperparameters.html) on `positive_example_weight_mult`, it reads:\n> \"If you want the algorithm to choose a weight so that errors in classifying negative vs. positive examples have equal impact on training loss, specify `balanced`.\"\n\nYou could also put in a specific float value, in which case you'd want to weight positive examples more heavily than negative examples, since there are fewer of them.",
"_____no_output_____"
]
],
[
[
"# instantiate a LinearLearner\n\n# include params for tuning for higher recall\n# *and* account for class imbalance in training data\nlinear_balanced = LinearLearner(role=role,\n train_instance_count=1, \n train_instance_type='ml.c4.xlarge',\n predictor_type='binary_classifier',\n output_path=output_path,\n sagemaker_session=sagemaker_session,\n epochs=15,\n binary_classifier_model_selection_criteria='precision_at_target_recall', # target recall\n target_recall=0.9,\n positive_example_weight_mult='balanced')\n",
"_____no_output_____"
]
],
[
[
"### EXERCISE: Train the balanced estimator\n\nFit the new, balanced estimator on the formatted training data.",
"_____no_output_____"
]
],
[
[
"%%time \n# train the estimator on formatted training data\nlinear_balanced.fit(formatted_train_data)",
"_____no_output_____"
]
],
[
[
"### EXERCISE: Deploy and evaluate the balanced estimator\n\nDeploy the balanced predictor and evaluate it. Do the results match with your expectations?",
"_____no_output_____"
]
],
[
[
"%%time \n# deploy and create a predictor\nbalanced_predictor = linear_balanced.deploy(initial_instance_count=1, instance_type='ml.t2.medium')",
"_____no_output_____"
],
[
"print('Metrics for balanced, LinearLearner.\\n')\n\n# get metrics for balanced predictor\nmetrics = evaluate(balanced_predictor, \n test_features.astype('float32'), \n test_labels, \n verbose=True)",
"_____no_output_____"
]
],
[
[
"## Delete the endpoint \n\nWhen you're done evaluating a model, you should delete the endpoint.",
"_____no_output_____"
]
],
[
[
"# delete the predictor endpoint \ndelete_endpoint(balanced_predictor)",
"_____no_output_____"
]
],
[
[
"A note on metric variability: \n\nThe above model is tuned for the best possible precision with recall fixed at about 90%. The recall is fixed at 90% during training, but may vary when we apply our trained model to a test set of data.",
"_____no_output_____"
],
[
"---\n## Model Design\n\nNow that you've seen how to tune and balance a LinearLearner. Create, train and deploy your own model. This exercise is meant to be more open-ended, so that you get practice with the steps involved in designing a model and deploying it.\n\n### EXERCISE: Train and deploy a LinearLearner with appropriate hyperparameters, according to the given scenario\n\n**Scenario:**\n* A bank has asked you to build a model that optimizes for a good user experience; users should only ever have up to about 15% of their valid transactions flagged as fraudulent.\n\nThis requires that you make a design decision: Given the above scenario, what metric (and value) should you aim for during training?\n\nYou may assume that performance on a training set will be within about 5-10% of the performance on a test set. For example, if you get 80% on a training set, you can assume that you'll get between about 70-90% accuracy on a test set.\n\nYour final model should account for class imbalance and be appropriately tuned. ",
"_____no_output_____"
],
[
"If we're allowed about 15/100 incorrectly classified valid transactions (false positives), then I can calculate an approximate value for the precision that I want as: 85/(85+15) = 85%. I'll aim for about 5% higher during training to ensure that I get closer to 80-85% precision on the test data.",
"_____no_output_____"
]
],
[
[
"%%time\n# instantiate and train a LinearLearner\n\n# include params for tuning for higher precision\n# *and* account for class imbalance in training data\nlinear_precision = LinearLearner(role=role,\n train_instance_count=1, \n train_instance_type='ml.c4.xlarge',\n predictor_type='binary_classifier',\n output_path=output_path,\n sagemaker_session=sagemaker_session,\n epochs=15,\n binary_classifier_model_selection_criteria='recall_at_target_precision',\n target_precision=0.9,\n positive_example_weight_mult='balanced')\n\n\n# train the estimator on formatted training data\nlinear_precision.fit(formatted_train_data)",
"_____no_output_____"
]
],
[
[
"This model trains for a fixed precision of 90%, and, under that constraint, tries to get as high a recall as possible.",
"_____no_output_____"
]
],
[
[
"%%time \n# deploy and evaluate a predictor\nprecision_predictor = linear_precision.deploy(initial_instance_count=1, instance_type='ml.t2.medium')",
"_____no_output_____"
],
[
"print('Metrics for tuned (precision), LinearLearner.\\n')\n\n# get metrics for balanced predictor\nmetrics = evaluate(precision_predictor, \n test_features.astype('float32'), \n test_labels, \n verbose=True)",
"_____no_output_____"
],
[
"## IMPORTANT\n# delete the predictor endpoint \ndelete_endpoint(precision_predictor)",
"_____no_output_____"
]
],
[
[
"## Final Cleanup!\n\n* Double check that you have deleted all your endpoints.\n* I'd also suggest manually deleting your S3 bucket, models, and endpoint configurations directly from your AWS console.\n\nYou can find thorough cleanup instructions, [in the documentation](https://docs.aws.amazon.com/sagemaker/latest/dg/ex1-cleanup.html).",
"_____no_output_____"
],
[
"---\n# Conclusion\n\nIn this notebook, you saw how to train and deploy a LinearLearner in SageMaker. This model is well-suited for a binary classification task that involves specific design decisions and managing class imbalance in the training set.\n\nFollowing the steps of a machine learning workflow, you loaded in some credit card transaction data, explored that data and prepared it for model training. Then trained, deployed, and evaluated several models, according to different design considerations!",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
e73b9013069318f9cc459124b7b93e2f26aee353 | 854,563 | ipynb | Jupyter Notebook | sklearn/3. Supervised Learning, Digit Classification.ipynb | ltetrel/introML | 7f9f8ba8bebaec85395137f94714a62d5cff1fc4 | [
"MIT"
] | 10 | 2018-11-30T04:38:07.000Z | 2022-01-05T01:51:13.000Z | sklearn/3. Supervised Learning, Digit Classification.ipynb | ltetrel/introML | 7f9f8ba8bebaec85395137f94714a62d5cff1fc4 | [
"MIT"
] | 3 | 2018-12-06T18:41:40.000Z | 2019-01-29T23:14:08.000Z | sklearn/3. Supervised Learning, Digit Classification.ipynb | ltetrel/introML | 7f9f8ba8bebaec85395137f94714a62d5cff1fc4 | [
"MIT"
] | 6 | 2018-12-06T17:53:47.000Z | 2020-05-27T10:56:44.000Z | 323.208396 | 359,863 | 0.903667 | [
[
[
"(Source: http://www.scipy-lectures.org/packages/scikit-learn/index.html#supervised-learning-classification-of-handwritten-digits)",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook",
"_____no_output_____"
],
[
"from sklearn.datasets import load_digits\ndigits = load_digits()",
"_____no_output_____"
]
],
[
[
"## Look at the data",
"_____no_output_____"
]
],
[
[
"from matplotlib import pyplot as plt\nfig = plt.figure(figsize=(6, 6)) # figure size in inches\nfig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)\n\nfor i in range(64):\n ax = fig.add_subplot(8, 8, i + 1, xticks=[], yticks=[])\n ax.imshow(digits.images[i], cmap=plt.cm.binary, interpolation='nearest')\n # label the image with the target value\n ax.text(0, 7, str(digits.target[i]))",
"_____no_output_____"
]
],
[
[
"## Let's look at the first 2 dimensions",
"_____no_output_____"
]
],
[
[
"plt.figure()\n\nfrom sklearn.decomposition import PCA\npca = PCA(n_components=2)\nproj = pca.fit_transform(digits.data)\nplt.scatter(proj[:, 0], proj[:, 1], c=digits.target, cmap=\"Paired\")\nplt.colorbar()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Let's try Naive Bayes Classification...\n\n> Abstractly, naive Bayes is a conditional probability model: given a problem instance to be classified, represented by a vector $ \\mathbf {x} =(x_{1},\\dots ,x_{n}) $ representing some $n$ features (independent variables), it assigns to this instance probabilities, $ p(C_{k}\\mid x_{1},\\dots ,x_{n})\\ $, for each of $K$ possible outcomes or classes $C_{k}$.\n\n(https://en.wikipedia.org/wiki/Naive_Bayes_classifier)",
"_____no_output_____"
]
],
[
[
"from sklearn.naive_bayes import GaussianNB\nfrom sklearn.model_selection import train_test_split\n\n# split the data into training and validation sets\nX_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target)\n\n# train the model\nclf = GaussianNB()\nclf.fit(X_train, y_train)\n\n# use the model to predict the labels of the test data\npredicted = clf.predict(X_test)\nexpected = y_test\n\n# Plot the prediction\nfig = plt.figure(figsize=(6, 6)) # figure size in inches\nfig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)\n\n# plot the digits: each image is 8x8 pixels\nfor i in range(64):\n ax = fig.add_subplot(8, 8, i + 1, xticks=[], yticks=[])\n ax.imshow(X_test.reshape(-1, 8, 8)[i], cmap=plt.cm.binary,\n interpolation='nearest')\n\n # label the image with the target value\n if predicted[i] == expected[i]:\n ax.text(0, 7, str(predicted[i]), color='green')\n else:\n ax.text(0, 7, str(predicted[i]), color='red')\n \nplt.show()",
"_____no_output_____"
],
[
"matches = (predicted == expected)\nprint(matches.sum())",
"365\n"
],
[
"print(len(matches))",
"450\n"
],
[
"matches.sum() / float(len(matches))",
"_____no_output_____"
],
[
"from sklearn import metrics\nprint(metrics.classification_report(expected, predicted))",
" precision recall f1-score support\n\n 0 1.00 0.98 0.99 42\n 1 0.57 0.93 0.70 40\n 2 1.00 0.46 0.63 41\n 3 0.93 0.75 0.83 52\n 4 0.90 0.74 0.81 47\n 5 1.00 0.93 0.96 43\n 6 1.00 0.94 0.97 50\n 7 0.75 0.96 0.84 45\n 8 0.43 0.77 0.55 35\n 9 1.00 0.67 0.80 55\n\n micro avg 0.81 0.81 0.81 450\n macro avg 0.86 0.81 0.81 450\nweighted avg 0.87 0.81 0.82 450\n\n"
],
[
"print(metrics.confusion_matrix(expected, predicted))\nplt.show()",
"[[41 1 0 0 0 0 0 0 0 0]\n [ 0 37 0 0 0 0 0 0 3 0]\n [ 0 7 19 0 0 0 0 0 15 0]\n [ 0 1 0 39 0 0 0 1 11 0]\n [ 0 3 0 0 35 0 0 8 1 0]\n [ 0 2 0 1 0 40 0 0 0 0]\n [ 0 2 0 0 1 0 47 0 0 0]\n [ 0 0 0 0 2 0 0 43 0 0]\n [ 0 7 0 1 0 0 0 0 27 0]\n [ 0 5 0 1 1 0 0 5 6 37]]\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73b902812fd48d8327f2fea7fa0e6a41d9f9d93 | 6,117 | ipynb | Jupyter Notebook | stockML.ipynb | jianwang0212/StockML | da27b1c5c900f2db39b0dc72fff2b6ac6acf8400 | [
"MIT"
] | 5 | 2020-05-05T09:26:31.000Z | 2021-09-02T12:14:34.000Z | stockML.ipynb | jianwang0212/StockML | da27b1c5c900f2db39b0dc72fff2b6ac6acf8400 | [
"MIT"
] | null | null | null | stockML.ipynb | jianwang0212/StockML | da27b1c5c900f2db39b0dc72fff2b6ac6acf8400 | [
"MIT"
] | 6 | 2020-05-08T09:33:53.000Z | 2022-02-17T00:04:57.000Z | 26.947137 | 116 | 0.504659 | [
[
[
"import datetime as dt\nimport matplotlib.pyplot as plt\nfrom matplotlib import style\nimport numpy as np\nimport os\nimport mplfinance as mpf\nimport pandas as pd\nimport pandas_datareader.data as web\nimport bs4 as bs\nimport pickle\nimport requests\nfrom collections import Counter\nfrom sklearn import svm, neighbors\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.ensemble import RandomForestClassifier",
"_____no_output_____"
],
[
"# X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25)",
"_____no_output_____"
],
[
"def process_data_dor_labels(ticker):\n hm_days = 7\n df = pd.read_csv('sp500tickers_joined_closes.csv', index_col=0)\n df.columns = [x.split('.')[0] for x in df.columns]\n tickers=df.columns.values.tolist()\n df.fillna(0,inplace=True)\n \n for i in range(1,hm_days+1):\n df['{}_{}d'.format(ticker,i)]=(df[ticker].shift(-i) - df[ticker])/df[ticker]\n \n df.fillna(0,inplace=True)\n return tickers, df\n\n# process_data_dor_labels('MO')",
"_____no_output_____"
],
[
"def buy_sell_hold(*args):\n cols = [c for c in args]\n# print(cols)\n requirement = 0.028\n for col in cols:\n if col > requirement:\n return 1\n if col < -requirement:\n return -1 \n return 0 \n\n# buy_sell_hold(0.01, -0.03)",
"_____no_output_____"
],
[
"def extract_featuresets(ticker):\n hm_days = 7\n tickers, df = process_data_dor_labels(ticker)\n \n # if any of the price change > 0.02 in last 7 days (latest day), we buy \n df['{}_target'.format(ticker)]=list(map(buy_sell_hold, \n *[df['{}_{}d'.format(ticker, i)]for i in range(1, hm_days+1)]))\n \n vals = df['{}_target'.format(ticker)].values.tolist()\n str_vals = [str(i) for i in vals]\n print('Data spread:', Counter(str_vals))\n \n df.fillna(0,inplace=True)\n df=df.replace([np.inf,-np.inf],np.nan)\n df.dropna(inplace=True)\n \n df_vals = df[[ticker for ticker in tickers]].pct_change() #daiily price change for 500stocks\n df_vals=df_vals.replace([np.inf,-np.inf], 0)\n df_vals.fillna(0,inplace=True)\n \n X = df_vals.values # what the actual price change for all stocks\n y = df['{}_target'.format(ticker)].values # what our strategy tells us to do (buy, sell,hold)\n \n return X, y ,df\n\nX, y ,df = extract_featuresets('MO')\ntickers, dff = process_data_dor_labels('MO')\ndf['{}_target'.format('MO')]",
"Data spread: Counter({'0': 2132, '1': 1256, '-1': 889})\n"
],
[
"def do_ml(ticker):\n X, y, df = extract_featuresets(ticker)\n \n X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25)\n \n \n# clf = neighbors.KNeighborsClassifier()\n# clf = svm.LinearSVC()\n clf = RandomForestClassifier() # set up the classifer \n\n clf.fit(X_train, y_train)\n confidence = clf.score(X_test, y_test)\n prediction = clf.predict(X_test)\n \n print('Predicted spread:', Counter(prediction))\n print('Accuracy:', confidence)\n return confidence\n\ndo_ml('BAC')",
"Data spread: Counter({'1': 1485, '0': 1438, '-1': 1354})\nPredicted spread: Counter({0: 431, 1: 355, -1: 284})\nAccuracy: 0.4934579439252336\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73b91a49cfcc89af449a4879867fc18ac1bd845 | 39,444 | ipynb | Jupyter Notebook | notebooks/Day3_2-Model-selection-and-validation.ipynb | vcalderon2009/cqs_machine_learning | 935fe29bf355931c0fcdca01d965802fd166c4a1 | [
"MIT"
] | 5 | 2018-07-26T20:05:02.000Z | 2019-08-14T05:04:36.000Z | notebooks/Day3_2-Model-selection-and-validation.ipynb | vcalderon2009/cqs_machine_learning | 935fe29bf355931c0fcdca01d965802fd166c4a1 | [
"MIT"
] | null | null | null | notebooks/Day3_2-Model-selection-and-validation.ipynb | vcalderon2009/cqs_machine_learning | 935fe29bf355931c0fcdca01d965802fd166c4a1 | [
"MIT"
] | 17 | 2018-08-03T17:08:36.000Z | 2022-03-16T15:03:42.000Z | 34.328982 | 555 | 0.586477 | [
[
[
"# Model Selection and Validation\n\nModel selection and validation are fundamental steps in statistical learning applications. In particular, we wish to select the model that performs optimally, both with respect to the training data and to external data. A model's performance on external data is known as its generalization performance. \n\nDepending on the type of learning method we use, we may be interested in one or more of the following:\n\n* how many variables should be included in the model?\n* what hyperparameter values should be used in fitting the model?\n* how many groups should we use to cluster our data?\n\nWe will almost almost always use a model's generalization performance to answer these questions.\n\n[Givens and Hoeting (2012)](#references) includes a dataset for salmon spawning success. We can use this data to fix ideas. If we plot the number of recruits against the number of spawners, we see a distinct positive relationship, as we would expect. The question is, *what sort of polynomial relationship best describes the relationship?*",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set_context('notebook')\nimport warnings\nwarnings.simplefilter(\"ignore\")\n\nsalmon = pd.read_table(\"../data/salmon.dat\", sep=r'\\s+', index_col=0)\nsalmon.plot(x='spawners', y='recruits', kind='scatter')",
"_____no_output_____"
]
],
[
[
"On the one extreme, a linear relationship is underfit; on the other, we see that including a very large number of polynomial terms is clearly overfitting the data.",
"_____no_output_____"
]
],
[
[
"fig, axes = plt.subplots(1, 2, figsize=(14,6))\n\nxvals = np.arange(salmon.spawners.min(), salmon.spawners.max())\n\nfit1 = np.polyfit(salmon.spawners, salmon.recruits, 1)\np1 = np.poly1d(fit1)\naxes[0].plot(xvals, p1(xvals))\naxes[0].scatter(x=salmon.spawners, y=salmon.recruits)\n\nfit15 = np.polyfit(salmon.spawners, salmon.recruits, 15)\np15 = np.poly1d(fit15)\naxes[1].plot(xvals, p15(xvals))\naxes[1].scatter(x=salmon.spawners, y=salmon.recruits)",
"_____no_output_____"
]
],
[
[
"We can select an appropriate polynomial order for the model using **cross-validation**, in which we hold out a testing subset from our dataset, fit the model to the remaining data, and evaluate its performance on the held-out subset.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\n\nxtrain, xtest, ytrain, ytest = train_test_split(salmon.spawners, \n salmon.recruits, test_size=0.3, random_state=42)",
"_____no_output_____"
]
],
[
[
"A natural criterion to evaluate model performance is root mean square error.\n\n$$L\\left(Y, \\hat{f}(X) \\right) = \\sqrt{\\frac{1}{N}(Y - \\hat{f}(X))^2}$$",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import mean_squared_error",
"_____no_output_____"
],
[
"def rmse(x, y, coefs):\n yfit = np.polyval(coefs, x)\n return mean_squared_error(y, yfit) ** .5",
"_____no_output_____"
]
],
[
[
"We can now evaluate the model at varying polynomial degrees, and compare their fit.",
"_____no_output_____"
]
],
[
[
"degrees = np.arange(11)\ntrain_err = np.zeros(len(degrees))\nvalidation_err = np.zeros(len(degrees))\n\nfor i, d in enumerate(degrees):\n p = np.polyfit(xtrain, ytrain, d)\n\n train_err[i] = rmse(xtrain, ytrain, p)\n validation_err[i] = rmse(xtest, ytest, p)\n\nfig, ax = plt.subplots()\n\nax.plot(degrees, validation_err, lw=2, label = 'cross-validation error')\nax.plot(degrees, train_err, lw=2, label = 'training error')\n\nax.legend(loc=0)\nax.set_xlabel('degree of fit')\nax.set_ylabel('rms error')",
"_____no_output_____"
]
],
[
[
"In the cross-validation above, notice that the error is high for both very low and very high polynomial values, while training error declines monotonically with degree. The cross-validation error (sometimes referred to as test error or generalization error) is composed of two components: **bias** and **variance**. When a model is underfit, bias is low but variance is high, while when a model is overfit, the reverse is true.\n\nOne can show that the MSE decomposes into a sum of the bias (squared) and variance of the estimator:\n\n$$\\begin{aligned}\n\\text{Var}(\\hat{\\theta}) &= E[\\hat{\\theta} - \\theta]^2 - (E[\\hat{\\theta} - \\theta])^2 \\\\\n\\Rightarrow E[\\hat{\\theta} - \\theta]^2 &= \\text{Var}(\\hat{\\theta}) + \\text{Bias}(\\hat{\\theta})^2\n\\end{aligned}$$\n\nThe training error, on the other hand, does not have this tradeoff; it will always decrease (or at least, never increase) as variables (polynomial terms) are added to the model.",
"_____no_output_____"
],
[
"### Information-theoretic Model Selection\n\nOne approach to model selection relies on the in-sample prediction error. One popular approach uses an information-theoretic criterion to identify the most appropriate model. Akaike (1973) found a formal relationship between Kullback-Leibler information (a dominant paradigm in information and coding theory) and likelihood theory. Akaike's Information Criterion (AIC) is an estimator of expected relative K-L information based on the maximized log-likelihood function, corrected for asymptotic bias. \n\n$$\\text{AIC} = -2 \\log(L(\\theta|data)) + 2K$$\n\nAIC balances the fit of the model (in terms of the likelihood) with the number of parameters required to achieve that fit. We can easily calculate AIC from the residual sums of squares as:\n\n$$\\text{AIC} = n \\log(\\text{RSS}/n) + 2k$$\n\nwhere $k$ is the number of parameters in the model. Notice that as the number of parameters increase, the residual sum of squares goes down, but the second term (a penalty) increases.\n\nTo apply AIC to a model selection problem, we choose the model that has the lowest AIC value.\n\n[AIC can be shown to be equivalent to leave-one-out cross-validation](http://www.jstor.org/stable/2984877).",
"_____no_output_____"
]
],
[
[
"def aic(rss, n, k):\n return n * np.log(float(rss) / n) + 2 * k",
"_____no_output_____"
]
],
[
[
"We can use AIC to select the appropriate polynomial degree.",
"_____no_output_____"
]
],
[
[
"aic_values = np.zeros(len(degrees))\nparams = np.zeros((len(degrees), len(degrees)))\n\nfor i, d in enumerate(degrees):\n p, residuals, rank, singular_values, rcond = np.polyfit(\n salmon.spawners, salmon.recruits, d, full=True)\n aic_values[i] = aic((residuals).sum(), len(salmon.spawners), d+1)\n params[i, :(d+1)] = p\n\nplt.plot(degrees, aic_values, lw=2)\nplt.xlabel('degree of fit')\nplt.ylabel('AIC')",
"_____no_output_____"
]
],
[
[
"For ease of interpretation, AIC values can be transformed into model weights via:\n\n$$p_i = \\frac{\\exp^{-\\frac{1}{2} AIC_i}}{\\sum_j \\exp^{-\\frac{1}{2} AIC_j} }$$",
"_____no_output_____"
]
],
[
[
"aic_trans = np.exp(-0.5 * aic_values)\naic_probs = aic_trans / aic_trans.sum()\naic_probs.round(2)",
"_____no_output_____"
]
],
[
[
"## Metrics for Classification\n\nFor classifiers such as decision trees and random forests, we may judge our model performance a little differently than the above.\n\nFirst, let's describe four concepts to help evaluate a classifier.\n\nA **true positive** (TP) occurs when we correctly predict the positive class.\n\nA **true negative** (TN) occurs when we correctly predict the negative class.\n\nA **false positive** (FP) occurs when we incorrectly predict the positice class.\n\nA **false negative** (FN) occurs when we incorrectly predict the negative class.\n\nThese concepts can be taken together to produce many different aspects of a classifier that we may care about.\n\n**accuracy** - Overall, how often is the classifier right.\n:\t`sklearn.metrics.accuracy_score`\n\n$$\\frac{TP + TN}{TP + TN + FP + FN}$$\n\n**precision**\n:\t`sklearn.metrics.precision_score`\n\n$$\\frac{TP}{TP + FP}$$\n\n**recall** (sensitivity)\n:\t`sklearn.metrics.recall_score`\n\n$$\\frac{TP}{TP + FN}$$\n\n**roc_auc** - The area under the receiver operating characteristic (ROC) curve. Measure of the trade-off between the true positive rate (TPR) and the false positive rate (FPR) as we vary the classification threshold. Equivalently, it's the probability that an observation drawn at random is classified correctly.\n:\t`sklearn.metrics.roc_auc_score`\n\n**f1**\n:\t`sklearn.metrics.f1_score` - the harmonic mean between recall and precision\n\n$$\\frac{2TP}{2TP + FP + FN}$$",
"_____no_output_____"
],
[
"## Exercise\n\nConsider the following generated data. Compute the above measures, using any classifier we have seen so far. Use `sklearn.metrics.confusion_matrix` to calculate the quantities by hand. Confirm that they are correct by using the functions noted above.\n\n\n* What is the accuracy of this classifier?\n* The precision and recall?\n* The ROC AUC score?\n* The f1-measure?",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import make_classification\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.linear_model import LogisticRegression",
"_____no_output_____"
],
[
"X, y = make_classification(\n n_samples=1000, \n n_features=50, \n n_informative=25, \n n_redundant=0, \n random_state=123\n)\n\nX_train = X[:750]\ny_train = y[:750]\n\nX_test = X[750:]\ny_test = y[750:]",
"_____no_output_____"
],
[
"# Write answer here",
"_____no_output_____"
]
],
[
[
"## K-fold Cross-validation\n\nAs introduced above, cross-validation is probably the most widely used method for estimating generalization error. In particularly data rich environments, we may split our sample into a training set, a testing set, and a validation set that is completely set aside until we have performed model selection.\n\n**K-fold cross-validation** is the next best thing. In k-folds cross-validation, the training set is split into *k* smaller sets. Then, for each of the k \"folds\":\n\n1. trained model on *k-1* of the folds as training data\n2. validate this model the remaining fold, using an appropriate metric\n\nThe performance measure reported by k-fold CV is then the average of the *k* computed values. This approach can be computationally expensive, but does not waste too much data, which is an advantage over having a fixed test subset.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score, KFold\n\nnfolds = 3\nkf = KFold(n_splits=nfolds, shuffle=True)\n\nfig, axes = plt.subplots(1, nfolds, figsize=(14,4))\n\nfor i, fold in enumerate(kf.split(salmon.values)):\n training, validation = fold\n y, x = salmon.values[training].T\n axes[i].plot(x, y, 'ro', label='training')\n y, x = salmon.values[validation].T\n axes[i].plot(x, y, 'bo', label='validation')\n axes[i].legend(fontsize='large')\n \nfig.tight_layout()",
"_____no_output_____"
],
[
"k = 5\ndegrees = np.arange(8)\nk_fold_err = np.empty(len(degrees))\n\nfor i, d in enumerate(degrees):\n \n error = np.empty(k)\n \n for j, fold in enumerate(KFold(n_splits=k).split(salmon.values)):\n\n training, validation = fold\n \n y_train, x_train = salmon.values[training].T\n y_test, x_test = salmon.values[validation].T\n \n p = np.polyfit(x_train, y_train, d)\n \n error[j] = rmse(x_test, y_test, p)\n\n k_fold_err[i] = error.mean()\n \n\nfig, ax = plt.subplots()\n\nax.plot(degrees, k_fold_err, lw=2)\nax.set_xlabel('degree of fit')\nax.set_ylabel('average rms error')",
"_____no_output_____"
]
],
[
[
"If the model shows high **bias**, the following actions might help:\n\n- **Add more features**. In our example of predicting home prices,\n it may be helpful to make use of information such as the neighborhood\n the house is in, the year the house was built, the size of the lot, etc.\n Adding these features to the training and test sets can improve\n a high-bias estimator\n- **Use a more sophisticated model**. Adding complexity to the model can\n help improve on bias. For a polynomial fit, this can be accomplished\n by increasing the degree d. Each learning technique has its own\n methods of adding complexity.\n- **Decrease regularization**. Regularization is a technique used to impose\n simplicity in some machine learning models, by adding a penalty term that\n depends on the characteristics of the parameters. If a model has high bias,\n decreasing the effect of regularization can lead to better results.\n \nIf the model shows **high variance**, the following actions might help:\n\n- **Use fewer features**. Using a feature selection technique may be\n useful, and decrease the over-fitting of the estimator.\n- **Use a simpler model**. Model complexity and over-fitting go hand-in-hand.\n- **Use more training samples**. Adding training samples can reduce\n the effect of over-fitting, and lead to improvements in a high\n variance estimator.\n- **Increase regularization**. Regularization is designed to prevent\n over-fitting. In a high-variance model, increasing regularization\n can lead to better results.",
"_____no_output_____"
],
[
"## Bootstrap aggregating regression\n\nSplitting datasets into training, cross-validation and testing subsets is inefficient, particularly when the original dataset is not large. As an alternative, we can use bootstrapping to both develop and validate our model without dividing our dataset. One algorithm to facilitate this is the **bootstrap aggreggation** (or *bagging*) algorithm.\n\nThe **bootstrap** is a tool for assessing statistical accuracy. It involves sampling training, target pairs *with replacement* from the original dataset $B$ times. Each sample is the same size as the original dataset.\n\nA Bagging regressor is an **ensemble meta-estimator** that fits base regressors each on bootstrapped random subsets of the original dataset and then aggregate their individual predictions (either by voting or by averaging) to form a final prediction.",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import BaggingRegressor\nfrom sklearn.preprocessing import PolynomialFeatures\nfrom sklearn.linear_model import LinearRegression\n\nX,y = salmon.values.T\nbr = BaggingRegressor(LinearRegression(), oob_score=True, random_state=20090425)\nX2 = PolynomialFeatures(degree=2).fit_transform(X[:, None])\nbr.fit(X2, y)",
"_____no_output_____"
]
],
[
[
"In order to evaluate a particular model, the samples that were not selected for a particular resampled dataset (the **out-of-bag** sample) can be used to estimate the generalization error.",
"_____no_output_____"
]
],
[
[
"br.oob_score_",
"_____no_output_____"
]
],
[
[
"Scikit-learn includes a convenient facility called a **pipeline**, which can be used to chain two or more estimators into a single function. We will hear more about using pipelines later. \n\nHere, we will use it to join the bagging regressor, polynomial feature selection, and linear regression into a single function.",
"_____no_output_____"
]
],
[
[
"from sklearn.pipeline import make_pipeline\n\ndef polynomial_bagging_regression(degree, **kwargs):\n return make_pipeline(PolynomialFeatures(degree=degree),\n BaggingRegressor(LinearRegression(), **kwargs))",
"_____no_output_____"
],
[
"scores = []\n\nfor d in degrees:\n \n print('fitting', d)\n pbr = polynomial_bagging_regression(d, oob_score=True)\n pbr.fit(X[:, None], y)\n scores.append(pbr.score(X[:, None], y))",
"_____no_output_____"
],
[
"plt.plot(scores)",
"_____no_output_____"
]
],
[
[
"## Regularization\n\nThe `scikit-learn` package includes a built-in dataset of diabetes progression, taken from [Efron *et al.* (2003)](http://arxiv.org/pdf/math/0406456.pdf), which includes a set of 10 normalized predictors.",
"_____no_output_____"
]
],
[
[
"from sklearn import datasets\n\n# Predictors: \"age\" \"sex\" \"bmi\" \"map\" \"tc\" \"ldl\" \"hdl\" \"tch\" \"ltg\" \"glu\"\ndiabetes = datasets.load_diabetes()",
"_____no_output_____"
]
],
[
[
"Let's examine how a linear regression model performs across a range of sample sizes.",
"_____no_output_____"
]
],
[
[
"diabetes['data'].shape",
"_____no_output_____"
],
[
"from sklearn import model_selection\n\ndef plot_learning_curve(estimator, label=None):\n scores = list()\n train_sizes = np.linspace(10, 200, 10).astype(np.int)\n for train_size in train_sizes:\n test_error = model_selection.cross_val_score(estimator, diabetes['data'], diabetes['target'],\n cv=model_selection.ShuffleSplit(train_size=train_size, \n test_size=200, \n random_state=0)\n )\n scores.append(test_error)\n\n plt.plot(train_sizes, np.mean(scores, axis=1), label=label or estimator.__class__.__name__)\n plt.ylim(0, 1)\n plt.ylabel('Explained variance on test set')\n plt.xlabel('Training set size')\n plt.legend(loc='best', fontsize='x-large')",
"_____no_output_____"
],
[
"plot_learning_curve(LinearRegression())",
"_____no_output_____"
]
],
[
[
"Notice the linear regression is not defined for scenarios where the number of features/parameters exceeds the number of observations. It performs poorly as long as the number of sample is not several times the number of features.\n\n",
"_____no_output_____"
],
[
"One approach for dealing with overfitting is to **regularize** the regession model.\n\nThe **ridge estimator** is a simple, computationally efficient regularization for linear regression.\n\n$$\\hat{\\beta}^{ridge} = \\text{argmin}_{\\beta}\\left\\{\\sum_{i=1}^N (y_i - \\beta_0 - \\sum_{j=1}^k x_{ij} \\beta_j)^2 + \\lambda \\sum_{j=1}^k \\beta_j^2 \\right\\}$$\n\nTypically, we are not interested in shrinking the mean, and coefficients are **standardized** to have zero mean and unit L2 norm. Hence,\n\n$$\\hat{\\beta}^{ridge} = \\text{argmin}_{\\beta} \\sum_{i=1}^N (y_i - \\sum_{j=1}^k x_{ij} \\beta_j)^2$$\n\n$$\\text{subject to } \\sum_{j=1}^k \\beta_j^2 < \\lambda$$\n\nNote that this is *equivalent* to a Bayesian model $y \\sim N(X\\beta, I)$ with a Gaussian prior on the $\\beta_j$:\n\n$$\\beta_j \\sim \\text{N}(0, \\lambda)$$\n\nThe estimator for the ridge regression model is:\n\n$$\\hat{\\beta}^{ridge} = (X'X + \\lambda I)^{-1}X'y$$",
"_____no_output_____"
]
],
[
[
"from sklearn import preprocessing\nfrom sklearn.linear_model import Ridge\n\nk = diabetes['data'].shape[1]\nalphas = np.linspace(0, 4)\nparams = np.zeros((len(alphas), k))\n\nfor i,a in enumerate(alphas):\n X = preprocessing.scale(diabetes['data'])\n y = diabetes['target']\n \n fit = Ridge(alpha=a, normalize=True).fit(X, y)\n params[i] = fit.coef_\n\nfix, ax = plt.subplots(figsize=(14,6))\nfor param in params.T:\n ax.plot(alphas, param)\n ax.set_xlabel(\"$\\\\alpha$\")\n ax.set_ylabel(\"$\\\\beta$\", rotation=0)",
"_____no_output_____"
],
[
"plot_learning_curve(LinearRegression())\nplot_learning_curve(Ridge())",
"_____no_output_____"
]
],
[
[
"Notice that at very small sample sizes, the ridge estimator outperforms the unregularized model.\n\nThe regularization of the ridge is a **shrinkage**: the coefficients learned are shrunk towards zero.\n\nThe amount of regularization is set via the `alpha` parameter of the ridge, which is tunable. The `RidgeCV` method in `scikits-learn` automatically tunes this parameter via cross-validation.",
"_____no_output_____"
]
],
[
[
"for a in [0.001, 0.01, 0.1, 1, 10]:\n plot_learning_curve(Ridge(a), a)",
"_____no_output_____"
]
],
[
[
"scikit-learn's `RidgeCV` class automatically tunes the L2 penalty using Generalized Cross-Validation.",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import RidgeCV\n\nplot_learning_curve(LinearRegression())\nplot_learning_curve(Ridge())\nplot_learning_curve(RidgeCV())",
"_____no_output_____"
]
],
[
[
"In contrast to the Ridge estimator, **the Lasso estimator** is useful to impose sparsity on the coefficients. In other words, it is to be prefered if we believe that many of the features are not relevant.\n\n$$\\hat{\\beta}^{lasso} = \\text{argmin}_{\\beta}\\left\\{\\frac{1}{2}\\sum_{i=1}^N (y_i - \\beta_0 - \\sum_{j=1}^k x_{ij} \\beta_j)^2 + \\lambda \\sum_{j=1}^k |\\beta_j| \\right\\}$$\n\nor, similarly:\n\n$$\\hat{\\beta}^{lasso} = \\text{argmin}_{\\beta} \\frac{1}{2}\\sum_{i=1}^N (y_i - \\sum_{j=1}^k x_{ij} \\beta_j)^2$$\n$$\\text{subject to } \\sum_{j=1}^k |\\beta_j| < \\lambda$$\n\nNote that this is *equivalent* to a Bayesian model $y \\sim N(X\\beta, I)$ with a **Laplace** prior on the $\\beta_j$:\n\n$$\\beta_j \\sim \\text{Laplace}(\\lambda) = \\frac{\\lambda}{2}\\exp(-\\lambda|\\beta_j|)$$\n\nNote how the Lasso imposes sparseness on the parameter coefficients:",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import Lasso\n\nk = diabetes['data'].shape[1]\nalphas = np.linspace(0.1, 3)\nparams = np.zeros((len(alphas), k))\nfor i,a in enumerate(alphas):\n X = preprocessing.scale(diabetes['data'])\n y = diabetes['target']\n \n fit = Lasso(alpha=a, normalize=True).fit(X, y)\n params[i] = fit.coef_\n\nplt.figure(figsize=(14,6))\nfor param in params.T:\n plt.plot(alphas, param)",
"_____no_output_____"
],
[
"plot_learning_curve(RidgeCV())\nplot_learning_curve(Lasso(0.05))",
"_____no_output_____"
]
],
[
[
"In this example, the ridge estimator performs better than the lasso, but when there are fewer observations, the lasso matches its performance. Otherwise, the variance-reducing effect of the lasso regularization is unhelpful relative to the increase in bias.\n\nWith the lasso too, me must tune the regularization parameter for good performance. There is a corresponding `LassoCV` function in `scikit-learn`, but it is computationally expensive. To speed it up, we can reduce the number of values explored for the alpha parameter.",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LassoCV\n\nplot_learning_curve(RidgeCV())\nplot_learning_curve(LassoCV(n_alphas=10, max_iter=5000))",
"_____no_output_____"
]
],
[
[
"Can't decide? **ElasticNet** is a compromise between lasso and ridge regression.\n\n$$\\hat{\\beta}^{elastic} = \\text{argmin}_{\\beta}\\left\\{\\frac{1}{2}\\sum_{i=1}^N (y_i - \\beta_0 - \\sum_{j=1}^k x_{ij} \\beta_j)^2 + (1 - \\alpha) \\sum_{j=1}^k \\beta^2_j + \\alpha \\sum_{j=1}^k |\\beta_j| \\right\\}$$\n\nwhere $\\alpha = \\lambda_1/(\\lambda_1 + \\lambda_2)$. Its tuning parameter $\\alpha$ (`l1_ratio` in `scikit-learn`) controls this mixture: when set to 0, ElasticNet is a ridge regression, when set to 1, it is a lasso. The sparser the coefficients, the higher we should set $\\alpha$. \n\nNote that $\\alpha$ can also be set by cross-validation, though it is computationally costly.",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import ElasticNetCV\n\nplot_learning_curve(RidgeCV())\nplot_learning_curve(ElasticNetCV(l1_ratio=.7, n_alphas=10))",
"_____no_output_____"
]
],
[
[
"## Using Cross-validation for Parameter Tuning",
"_____no_output_____"
]
],
[
[
"lasso = Lasso()",
"_____no_output_____"
],
[
"alphas = np.logspace(-4, -1, 20)\n\nscores = np.empty(len(alphas))\nscores_std = np.empty(len(alphas))\n\nfor i,alpha in enumerate(alphas):\n lasso.alpha = alpha\n s = model_selection.cross_val_score(lasso, diabetes.data, diabetes.target, n_jobs=-1)\n scores[i] = s.mean()\n scores_std[i] = s.std()",
"_____no_output_____"
],
[
"plt.semilogx(alphas, scores)\nplt.semilogx(alphas, np.array(scores) + np.array(scores_std)/20, 'b--')\nplt.semilogx(alphas, np.array(scores) - np.array(scores_std)/20, 'b--')\nplt.yticks(())\nplt.ylabel('CV score')\nplt.xlabel('alpha')\nplt.axhline(np.max(scores), linestyle='--', color='.5')\nplt.text(5e-2, np.max(scores)+1e-4, str(np.max(scores).round(3)))",
"_____no_output_____"
]
],
[
[
"## Model Checking using Learning Curves\n\nA useful way of checking model performance (in terms of bias and/or variance) is to plot learning curves, which illustrates the learning process as your model is exposed to more data. When the dataset is small, it is easier for a model of a particular complexity to be made to fit the training data well. As the dataset grows, we expect the training error to increase (model accuracy decreases). Conversely, a relatively small dataset will mean that the model will not generalize well, and hence the cross-validation score will be lower, on average.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import learning_curve\n\ntrain_sizes, train_scores, test_scores = learning_curve(lasso, \n diabetes.data, diabetes.target, \n train_sizes=[50, 70, 90, 110, 130], cv=5)",
"_____no_output_____"
],
[
"train_scores_mean = np.mean(train_scores, axis=1)\ntrain_scores_std = np.std(train_scores, axis=1)\ntest_scores_mean = np.mean(test_scores, axis=1)\ntest_scores_std = np.std(test_scores, axis=1)\nplt.grid()\n\nplt.fill_between(train_sizes, train_scores_mean - train_scores_std,\n train_scores_mean + train_scores_std, alpha=0.1,\n color=\"r\")\nplt.fill_between(train_sizes, test_scores_mean - test_scores_std,\n test_scores_mean + test_scores_std, alpha=0.1, color=\"g\")\nplt.plot(train_sizes, train_scores_mean, 'o-', color=\"r\",\n label=\"Training score\")\nplt.plot(train_sizes, test_scores_mean, 'o-', color=\"g\",\n label=\"Cross-validation score\")\nplt.legend(loc=\"best\")",
"_____no_output_____"
]
],
[
[
"For models with high bias, training and cross-validation scores will tend to converge at a low value (high error), indicating that adding more data will not improve performance. \n\nFor models with high variance, there may be a gap between the training and cross-validation scores, suggesting that model performance could be improved with additional information.",
"_____no_output_____"
]
],
[
[
"X,y = salmon.values.T\nX2 = PolynomialFeatures(degree=2).fit_transform(X[:, None])\n\ntrain_sizes, train_scores, test_scores = learning_curve(LinearRegression(), X2, y, \n train_sizes=[10, 15, 20, 30], cv=5)",
"_____no_output_____"
],
[
"train_scores_mean = np.mean(train_scores, axis=1)\ntrain_scores_std = np.std(train_scores, axis=1)\ntest_scores_mean = np.mean(test_scores, axis=1)\ntest_scores_std = np.std(test_scores, axis=1)\nplt.grid()\n\nplt.fill_between(train_sizes, train_scores_mean - train_scores_std,\n train_scores_mean + train_scores_std, alpha=0.1,\n color=\"r\")\nplt.fill_between(train_sizes, test_scores_mean - test_scores_std,\n test_scores_mean + test_scores_std, alpha=0.1, color=\"g\")\nplt.plot(train_sizes, train_scores_mean, 'o-', color=\"r\",\n label=\"Training score\")\nplt.plot(train_sizes, test_scores_mean, 'o-', color=\"g\",\n label=\"Cross-validation score\")\nplt.legend(loc=\"best\")",
"_____no_output_____"
]
],
[
[
"## Exercise: Very low birthweight infants\n\nCompare logistic regression models (using the `linear_model.LogisticRegression` interface) with varying degrees of regularization for the VLBW infant database. Use a relevant metric such as the Brier's score as a metric.\n\n$$B = \\frac{1}{n} \\sum_{i=1}^n (\\hat{p}_i - y_i)^2$$",
"_____no_output_____"
]
],
[
[
"vlbw = pd.read_csv(\"../data/vlbw.csv\", index_col=0)\n\nvlbw = vlbw.replace(\n {\n 'inout': {\n 'born at Duke': 0,\n 'transported': 1\n },\n 'delivery': {\n 'abdominal':0,\n 'vaginal':1\n },\n 'ivh': {\n 'absent': 0, \n 'present': 1,\n 'possible': 1,\n 'definite': 1\n }, \n 'sex': {\n 'female': 0,\n 'male': 1\n }\n }\n)\n\nvlbw = vlbw[['birth', 'exit', 'hospstay', 'lowph', 'pltct', \n 'bwt', 'gest', 'meth', 'toc', 'delivery', 'apg1', \n 'vent', 'pneumo', 'pda', 'cld', 'ivh']].dropna()",
"_____no_output_____"
],
[
"# Write your answer here",
"_____no_output_____"
]
],
[
[
"---\n## References\n\n- Burnham, K. P., & Anderson, D. R. (2002). [Model Selection and Multi-Model Inference: A Practical, Information-theoretic Approach](http://www.amazon.com/Model-Selection-Multimodel-Inference-Information-Theoretic/dp/0387953647). Springer Verlag.\n- Givens, G. H.; Hoeting, J. A. (2012). [Computational Statistics](http://www.stat.colostate.edu/computationalstatistics/) (Wiley Series in Computational Statistics)\n- Hastie, T., Tibshirani, R., & Friedman, J. H. (2009). [The elements of statistical learning](http://www-stat.stanford.edu/~tibs/ElemStatLearn/). Springer Verlag.\n- Vanderplas, J. [Scikit-learn tutorials for the Scipy 2013 conference](https://github.com/jakevdp/sklearn_scipy2013).",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
e73b992b86f6f5b6c8f26c2dc4ed8cf9e34d8aff | 2,421 | ipynb | Jupyter Notebook | docs/source/examples/Index.ipynb | dharmaquark/ipywidgets | 7626dc807e07a1e6bff66cd8f25418711fffcbf6 | [
"BSD-3-Clause"
] | 1 | 2021-09-22T04:09:07.000Z | 2021-09-22T04:09:07.000Z | docs/source/examples/Index.ipynb | dharmaquark/ipywidgets | 7626dc807e07a1e6bff66cd8f25418711fffcbf6 | [
"BSD-3-Clause"
] | 200 | 2019-02-07T18:19:36.000Z | 2021-07-29T08:37:12.000Z | docs/source/examples/Index.ipynb | y1ngyang/ipywidgets | 4d10dc9abdbfc26b62dcf2d5cd660d4e7a603ae5 | [
"BSD-3-Clause"
] | null | null | null | 23.970297 | 236 | 0.579513 | [
[
[
"Back to the main [Index](../Index.ipynb)",
"_____no_output_____"
],
[
"# Interactive Widgets",
"_____no_output_____"
],
[
"IPython includes an architecture for interactive widgets that tie together Python code running in the kernel and JavaScript/HTML/CSS running in the browser. These widgets enable users to explore their code and data interactively.",
"_____no_output_____"
],
[
"## Tutorials",
"_____no_output_____"
],
[
"- [Using Interact](Using Interact.ipynb)\n- [Widget Basics](Widget Basics.ipynb) \n- [Widget Events](Widget Events.ipynb) \n- [Widget List](Widget List.ipynb) \n- [Widget Styling](Widget Styling.ipynb) \n- [Widget Custom](Widget Custom.ipynb)\n- [Widget Asynchronous](Widget Asynchronous.ipynb): how to pause and listen in the kernel for widget changes in the frontend.",
"_____no_output_____"
],
[
"## Examples of custom widgets",
"_____no_output_____"
],
[
"- [Variable Inspector](Variable Inspector.ipynb) \n- [Export As (nbconvert)](Export As (nbconvert%29.ipynb)",
"_____no_output_____"
],
[
"## Examples using `interact`/`interactive`",
"_____no_output_____"
],
[
"* [Beat Frequencies](Beat Frequencies.ipynb)\n* [Exploring Graphs](Exploring Graphs.ipynb)\n* [Factoring](Factoring.ipynb)\n* [Image Browser](Image Browser.ipynb)\n* [Image Processing](Image Processing.ipynb)\n* [Lorenz Differential Equations](Lorenz Differential Equations.ipynb)",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
e73ba160bc22f36633f20bcf50307bf61a9ca324 | 200,426 | ipynb | Jupyter Notebook | Ariane/DomainPlot.ipynb | UBC-MOAD/analysis-becca | 961b864bc837d1b3154ea5c9804f96de2b379628 | [
"Apache-2.0"
] | null | null | null | Ariane/DomainPlot.ipynb | UBC-MOAD/analysis-becca | 961b864bc837d1b3154ea5c9804f96de2b379628 | [
"Apache-2.0"
] | null | null | null | Ariane/DomainPlot.ipynb | UBC-MOAD/analysis-becca | 961b864bc837d1b3154ea5c9804f96de2b379628 | [
"Apache-2.0"
] | null | null | null | 1,178.976471 | 193,488 | 0.954013 | [
[
[
"# SalishSeaCast Domain + Ariane CS plot\nbased on Ben's code from https://github.com/SalishSeaCast/analysis-ben/blob/master/notebooks/Maps.ipynb",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport xarray as xr\nimport matplotlib.pyplot as plt\nfrom scipy.io import loadmat\nfrom cmocean import cm\nimport warnings\nfrom cartopy import crs, feature\nfrom cartopy.mpl.gridliner import LONGITUDE_FORMATTER, LATITUDE_FORMATTER\nfrom salishsea_tools import viz_tools, geo_tools\n\n# import LambertConformalTicks as lct\n\n%matplotlib inline\nplt.rcParams['font.size'] = 11\nwarnings.simplefilter('ignore')",
"_____no_output_____"
],
[
"# Increase font size\nplt.rcParams['font.size'] = 14\n\n# Load grid and mask files\ngrid = xr.open_dataset('/data/bmoorema/MEOPAR/grid/bathymetry_201702.nc', mask_and_scale=False)\nmask = xr.open_dataset('/ocean/rbeutel/MEOPAR/grid/mesh_mask201702.nc')\n\n# Make plot area\nxlim, ylim = [-126.5, -121.2], [46.8, 51.2]\nfig, ax = plt.subplots(figsize=(8, 10), subplot_kw={'projection': crs.Mercator(np.mean(xlim), *ylim)})\nax.set_extent(xlim + ylim)\n\n# Draw coastline\nax.add_feature(feature.GSHHSFeature('full', edgecolor='k', facecolor='burlywood'))\n\n# Overlay domain landmask and coastline\nax.contourf(grid.nav_lon, grid.nav_lat,mask.tmask[0, 0, ...], levels=[-0.01, 0.01], colors='lightgray',transform=crs.PlateCarree(), zorder =2)\nax.contour(grid.nav_lon, grid.nav_lat,mask.tmask[0, 0, ...], levels=[-0.01, 0.01], colors='k',transform=crs.PlateCarree(), zorder=2)\n\n# Draw box around domain\nlons, lats = [], []\ncorners = (0, 0), (0, -1), (-1, -1), (-1, 0), (0, 0)\nfor i in corners: lons.append(grid.nav_lon[i]), lats.append(grid.nav_lat[i])\nax.plot(lons, lats, 'k-', transform=crs.PlateCarree(), zorder=2)\n\n# Add gridlines\nxlocs, ylocs = [np.arange(np.floor(l[0]), np.ceil(l[1])+1) for l in [xlim, ylim]]\ngl = ax.gridlines(linestyle=\":\", color='k', draw_labels=True, xlocs=xlocs, ylocs=ylocs)\ngl.xformatter, gl.yformatter = LONGITUDE_FORMATTER, LATITUDE_FORMATTER\ngl.xlabels_top, gl.ylabels_right = False, False\n\n# Add cross-sections\na = [grid.nav_lon[204,255],grid.nav_lon[204,267],grid.nav_lat[204,255],grid.nav_lat[204,267]]\nd = [grid.nav_lon[246,309],grid.nav_lon[247,309],grid.nav_lat[246,309],grid.nav_lat[247,309]]\nr = [grid.nav_lon[266,286],grid.nav_lon[266,307],grid.nav_lat[266,286],grid.nav_lat[266,307]]\ns = [grid.nav_lon[280,264],grid.nav_lon[280,266],grid.nav_lat[280,264],grid.nav_lat[280,266]]\nh = [grid.nav_lon[304,218],grid.nav_lon[304,242],grid.nav_lat[304,218],grid.nav_lat[304,242]]\nax.plot([a[0],a[1]],[a[2],a[3]],zorder=11,transform=crs.PlateCarree(),lw=4,c='cyan')\nax.plot([d[0],d[1]],[d[2],d[3]],zorder=11,transform=crs.PlateCarree(),lw=4,c='magenta')\nax.plot([r[0],r[1]],[r[2],r[3]],zorder=11,transform=crs.PlateCarree(),lw=4,c='g')\nax.plot([s[0],s[1]],[s[2],s[3]],zorder=11,transform=crs.PlateCarree(),lw=4,c='b')\nax.plot([h[0],h[1]],[h[2],h[3]],zorder=11,transform=crs.PlateCarree(),lw=4,c='r')\n\n# Add annoying JDF CS\nnums = [[374,18],[374,27],[375,27],[375,36],[376,36],[376,45],[377,45],[377,54],[378,54],[378,63],[379,63],[379,71]]\njr_lat = [grid.nav_lat[i[0],i[1]] for i in nums]\njr_lon = [grid.nav_lon[i[0],i[1]] for i in nums]\nax.plot(jr_lon, jr_lat,zorder=11,transform=crs.PlateCarree(),lw=4,c='brown')\n\n# Add annotations\nax.text(0.15, 0.1, 'Pacific\\nOcean', transform=ax.transAxes)\nax.text(0.79, 0.18, 'Puget\\nSound', transform=ax.transAxes)\nax.text(0.33, 0.30, 'Juan de Fuca Strait', transform=ax.transAxes, rotation=-15,zorder = 11)\nax.text(0.35, 0.52, 'Strait of Georgia', transform=ax.transAxes, rotation=-20)\nax.text(0.03, 0.77, 'Johnstone', transform=ax.transAxes, rotation=-20)\nax.text(0.17, 0.70, 'Strait', transform=ax.transAxes, rotation=-65)\nax.text(0.45, 0.38, 'Haro\\nStrait', transform=ax.transAxes)\nax.text(0.50, 0.22, 'Admiralty\\n Inlet', transform=ax.transAxes)\nax.text(0.79, 0.45, 'Rosario\\n Strait', transform=ax.transAxes)\nax.text(0.83, 0.39, 'Deception\\n Pass', transform=ax.transAxes)\nax.text(0.74, 0.51, 'San Juan\\n Channel', transform=ax.transAxes)\nax.text(0.08,0.33,'(Initialisation\\ncross-section)', transform=ax.transAxes)\nax.arrow(0.54, 0.39, 0.04, -0.01, head_width=0.015, edgecolor='r', facecolor='r', transform=ax.transAxes, zorder=10)\nax.arrow(0.75, 0.53, -0.07, -0.13, head_width=0.015, edgecolor='b', facecolor='b', transform=ax.transAxes, zorder=10)\nax.arrow(0.80, 0.47, -0.07, -0.08, head_width=0.015, edgecolor='g', facecolor='g', transform=ax.transAxes, zorder=10)\nax.arrow(0.84, 0.41, -0.08, -0.04, head_width=0.015, edgecolor='magenta', facecolor='magenta', transform=ax.transAxes, zorder=10)\nax.arrow(0.66, 0.26, 0.02, 0.02, head_width=0.015, edgecolor='cyan', facecolor='cyan', transform=ax.transAxes, zorder=10)\nax.arrow(0.3,0.35,0.05,0, head_width=0.015, edgecolor='brown', facecolor='brown', transform=ax.transAxes, zorder=10)\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
]
] |
e73ba7e4cf2f7204b21facdaa0d0554cb73c551d | 276,398 | ipynb | Jupyter Notebook | notebooks/plots.ipynb | MaximLippeveld/riverreliability | a4f2c1a3f533c503bf330d4e3f3cbe2c3a728cc5 | [
"Apache-2.0"
] | 1 | 2021-03-12T09:58:56.000Z | 2021-03-12T09:58:56.000Z | notebooks/plots.ipynb | MaximLippeveld/riverreliability | a4f2c1a3f533c503bf330d4e3f3cbe2c3a728cc5 | [
"Apache-2.0"
] | null | null | null | notebooks/plots.ipynb | MaximLippeveld/riverreliability | a4f2c1a3f533c503bf330d4e3f3cbe2c3a728cc5 | [
"Apache-2.0"
] | null | null | null | 374.016238 | 65,752 | 0.927883 | [
[
[
"# default_exp plots",
"_____no_output_____"
]
],
[
[
"# Plots\n\nThis notebook defines functions for plotting the river reliability and confidence reliability diagrams. Both types of diagrams can be plotted with one figure per class (class-wise) or one aggregated figure for the classifier.",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"#hide\nfrom nbdev.showdoc import *",
"_____no_output_____"
],
[
"# export\n\nfrom riverreliability import utils, metrics as rmetrics\n\nimport matplotlib.pyplot as plt\nimport matplotlib.axes\nfrom matplotlib import cm\n\nimport numpy as np\nfrom scipy.stats import beta\nfrom scipy import interpolate\nfrom riverreliability.beta import get_beta_parameters, beta_avg_pdf\n\nimport sklearn.datasets\nimport sklearn.model_selection\nimport sklearn.svm\nfrom sklearn.metrics import confusion_matrix, accuracy_score, balanced_accuracy_score\nimport sklearn.utils",
"_____no_output_____"
],
[
"# exporti\n\ndef _decorate_ax(ax:matplotlib.axes.Axes):\n \"\"\"Apply styling changes to a matplotlib axis.\n\n Arguments:\n ax -- matplotlib axis\n \"\"\"\n\n ax.set_xlim(0, 1)\n ax.set_ylim(0, 1)\n ax.spines[\"top\"].set_visible(False)\n ax.spines[\"right\"].set_visible(False)\n plt.setp(ax.spines.values(), color=cm.tab20c(18))\n plt.setp([ax.get_xticklines(), ax.get_yticklines()], color=cm.tab20c(18))\n\ndef _get_beta_pdf(dist):\n \"\"\"Get pdf and beta parameters from `dist`.\n\n `dist` is either:\n - a tuple which contains a and b, in which case the exact pdf is sampled\n - a vector containing samples from a beta pdf (with unknown a and b), in which case MLE is used to estimate a and b\n\n Returns:\n tuple containing a, b, pdf and linspace x over which the pdf was sampled\n \"\"\"\n\n if len(dist) == 2:\n # dist contains the parameters of the beta distribution\n a, b = dist\n\n # sample the beta\n x = np.linspace(0, 1, 500)\n pdf = beta.pdf(x, a, b)\n else:\n # dist contains samples of the beta pdf\n\n ## sample from the beta distribution using the pdf probabilities\n\n # make it impossible to sample 0 or 1\n # in theory this should never happen, but approximations introduce errors\n prob = dist.copy()\n prob[0] = 0.0\n prob[-1] = 0.0\n\n x = np.linspace(0, 1, len(dist))\n samples = np.random.choice(x, size=500, p=prob/prob.sum())\n\n ## fit a beta distribution to the samples\n a, b, loc, scale = beta.fit(samples, floc=0, fscale=1)\n\n pdf = dist\n\n return a, b, pdf, x\n\ndef _pre_plot_checks(y_probs, y_preds, y_true, ax, ci=None, required_axes=None):\n \"\"\"Perform some pre-plotting checks on input data, create required axes if necessary and compute number of classes.\"\"\"\n\n num_classes = len(sklearn.utils.multiclass.unique_labels(y_preds, y_true))\n\n if (required_axes == 1) and (ax is None):\n fig, ax = plt.subplots(subplot_kw={\"aspect\": 0.75}, dpi=100, tight_layout=True)\n else:\n required_axes = num_classes if required_axes is None else required_axes\n if ax is None:\n fig, ax = plt.subplots(1, required_axes, figsize=(3*required_axes, 3), subplot_kw={\"aspect\": 0.75}, constrained_layout=True, sharex=True, sharey=True, dpi=100)\n if (required_axes != 1) and (len(ax) != required_axes):\n raise ValueError(f\"Wrong amount of axes provided: {required_axes} needed, but {len(ax)} provided.\")\n\n sklearn.utils.check_consistent_length(y_probs, y_preds, y_true)\n\n if ci is not None:\n ci = ci if isinstance(ci, list) else [ci]\n for a in ci:\n if (a > 1) or (a < 0):\n raise ValueError(f\"CI must be in [0, 1]\")\n\n return num_classes, ax\n\n\nclass clipped_cm:\n def __init__(self, n, base_cm=cm.Greys, clip_range=(0.5, 1.0)):\n self.n = n\n self.space = np.linspace(*clip_range, n+1)\n self.cm = [base_cm(p) for p in self.space]\n\n def __call__(self, x):\n return self.cm[int(x*self.n)]",
"_____no_output_____"
]
],
[
[
"## Probabilistic classification: toy example",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)",
"_____no_output_____"
],
[
"X, y = sklearn.datasets.make_classification(n_samples=5000, n_features=12, n_informative=3, n_classes=3)\nX_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, test_size=0.2, shuffle=True)",
"_____no_output_____"
],
[
"logreg = sklearn.svm.SVC(probability=True)",
"_____no_output_____"
],
[
"logreg.fit(X_train, y_train)",
"_____no_output_____"
],
[
"y_probs = logreg.predict_proba(X_test)\n\nprint(f\"Accuracy: {accuracy_score(y_test, y_probs.argmax(axis=1))}\")\nprint(f\"Balanced accuracy: {balanced_accuracy_score(y_test, y_probs.argmax(axis=1))}\")",
"Accuracy: 0.808\nBalanced accuracy: 0.8084048918146675\n"
]
],
[
[
"## Ridge reliability diagram",
"_____no_output_____"
]
],
[
[
"# exporti\n\ndef river_diagram(distributions:np.array, confidence_levels:np.array, ax:matplotlib.axes.Axes, ci:list):\n\n ci = sorted(ci)[::-1]\n\n _decorate_ax(ax)\n ax.set_ylim(0, 1)\n\n intervals = np.empty((len(confidence_levels), len(ci), 2), dtype=float)\n means = np.empty((len(confidence_levels),), dtype=float)\n for i, (cl, dist) in enumerate(zip(confidence_levels, distributions)):\n if cl is np.nan:\n continue\n\n a, b, pdf, _ = _get_beta_pdf(dist)\n\n for j, l in enumerate(ci):\n intervals[i, j] = beta.interval(l, a, b)\n means[i] = a/(a+b)\n\n x = np.linspace(min(confidence_levels), max(confidence_levels), 1000)\n for i, l in enumerate(ci):\n f0 = interpolate.PchipInterpolator(confidence_levels, intervals[:, i, 0])\n f1 = interpolate.PchipInterpolator(confidence_levels, intervals[:, i, 1])\n\n ax.fill_between(x, f0(x), f1(x), zorder=i, color=cm.Greys(0.2+i*0.1), label=f\"{int(l*100):2d}% CI\")\n\n fm = interpolate.PchipInterpolator(confidence_levels, means)\n ax.plot(x, fm(x), color=\"black\", zorder=4, label=\"Mean\")\n ax.scatter(confidence_levels, means, s=20, color=\"black\", zorder=4)\n ax.plot([0,1], [0,1], color=cm.Greys(0.8), linestyle=\"--\", zorder=5, label=\"Perfect calibration\")",
"_____no_output_____"
],
[
"# export\n\ndef river_reliability_diagram(y_probs:np.array, y_preds:np.array, y_true:np.array, ax:matplotlib.axes.Axes=None, bins=\"fd\", ci=[0.90, 0.95, 0.99], **bin_args):\n \"\"\"Plot the posterior balanced accuracy-based reliability diagram.\n\n Arguments:\n y_probs -- Array containing prediction confidences\n y_preds -- Array containing predicted labels (shape (N,))\n y_true -- Array containing true labels (shape (N,))\n ax -- Axes on which the diagram will be plotted (will be decorated by `_decorate_ax`)\n bins -- Description of amount of bins in which to divide prediction confidences (see `numpy.histogram_bin_edges` for options)\n ci -- Confidence interval level to plot. When style is river provide a list, otherwise a float.\n\n Returns:\n Axes containing the plot\n \"\"\"\n\n num_classes, ax = _pre_plot_checks(y_probs, y_preds, y_true, ax, ci, required_axes=1)\n\n # bin the probabilities\n bin_indices, edges = utils.get_bin_indices(y_probs, bins, 0.0, 1.0, return_edges=True, **bin_args)\n unique_bin_indices = sorted(np.unique(bin_indices))\n\n confidence_levels = np.empty((len(unique_bin_indices),), dtype=np.float32) # store mean confidence\n\n if len(np.unique(y_preds)) > 1:\n # the beta distribution will be the average of the per-class distribution\n n_samples = 10000\n distributions = np.empty((len(unique_bin_indices), n_samples), dtype=np.float32) # store beta parameters\n x = np.linspace(0, 1, n_samples)\n else:\n # the beta distributions will be exact\n distributions = np.empty((len(unique_bin_indices), 2), dtype=np.int)\n\n # compute beta distribution per bin\n for i, bin_idx in enumerate(unique_bin_indices):\n\n # select instances in this bin\n selector = bin_indices == bin_idx\n\n # set the confidence level to the average confidence reported in the bin\n confidence_levels[i] = y_probs[selector].mean()\n\n if len(np.unique(y_preds)) > 1:\n # compute the average beta distribution\n conf = confusion_matrix(y_true[selector], y_preds[selector])#, labels=np.arange(0, num_classes))\n parameters = get_beta_parameters(conf)\n distributions[i] = np.clip(beta_avg_pdf(x, parameters, fft=True), 0, None)\n else:\n # compute the exact beta distribution\n correct = (y_true[selector] == y_preds[selector]).sum()\n incorrect = len(y_true[selector]) - correct\n distributions[i] = correct + 1, incorrect + 1\n\n # plot the actual diagram\n ax.set_xlabel(\"Confidence level\")\n ax.set_ylabel(\"Posterior balanced accuracy\")\n ci = [0.90, 0.95, 0.99] if ci is None else ci\n river_diagram(distributions, confidence_levels, ax, ci=ci)\n\n return ax",
"_____no_output_____"
],
[
"ax = river_reliability_diagram(y_probs.max(axis=1), y_probs.argmax(axis=1), y_test, bins=\"equal-count\", ci=[0.90, 0.99], n_bins=10)\nax.legend(loc=\"lower right\")\n# plt.savefig(\"example.pdf\")",
"_____no_output_____"
],
[
"ax = river_reliability_diagram(y_probs.max(axis=1), y_probs.argmax(axis=1), y_test, bins=\"fd\", ci=[0.90, 0.99])\nax.legend(loc=\"lower right\")\nplt.savefig(\"example.pdf\")",
"_____no_output_____"
],
[
"# export\n\ndef class_wise_river_reliability_diagram(y_probs:np.array, y_preds:np.array, y_true:np.array, axes:matplotlib.axes.Axes=None, bins=\"fd\", metric=None, show_k_least_calibrated:int=None, ci=[0.90, 0.95, 0.99], **bin_args):\n \"\"\"Plot the class-wise posterior balanced accuracy-based reliability diagram.\n\n Arguments:\n y_probs -- Array containing prediction confidences\n y_preds -- Array containing predicted labels (shape (N,))\n y_true -- Array containing true labels (shape (N,))\n axes -- Axes on which the diagram will be plotted (will be decorated by `_decorate_ax`)\n bins -- Description of amount of bins in which to divide prediction confidences (see `numpy.histogram_bin_edges` for options)\n ci -- Confidence interval level to plot. When style is river provide a list, otherwise a float.\n\n Returns:\n Axes containing the plot\n \"\"\"\n\n\n num_classes, axes = _pre_plot_checks(y_probs, y_preds, y_true, axes, ci, show_k_least_calibrated)\n\n if metric is None:\n a = np.arange(num_classes)\n else:\n metric_values = []\n for c in np.arange(num_classes):\n selector = y_preds == c\n metric_values.append(metric(y_probs[selector, c], y_preds[selector], y_true[selector]))\n\n a = np.argsort(metric_values)[::-1][:show_k_least_calibrated]\n\n for ax, c in zip(axes, a):\n selector = y_preds == c\n\n if metric is None:\n ax.set_title(f\"Class {c}\")\n else:\n ax.set_title(f\"Class {c} ({metric_values[c]:.3f})\")\n\n river_reliability_diagram(y_probs[selector, c], y_preds[selector], y_true[selector], ax, bins, ci=ci)\n\n return axes",
"_____no_output_____"
],
[
"class_wise_river_reliability_diagram(y_probs, y_probs.argmax(axis=1), y_test, bins=10)",
"_____no_output_____"
]
],
[
[
"Provide an error metric to show the plots ordered according decreasing error.",
"_____no_output_____"
]
],
[
[
"class_wise_river_reliability_diagram(y_probs, y_probs.argmax(axis=1), y_test, bins=\"equal-count\", metric=rmetrics.peace)",
"_____no_output_____"
]
],
[
[
"## Confidence reliability diagram",
"_____no_output_____"
]
],
[
[
"# exporti\n\ndef bar_diagram(edges:np.array, bin_accuracies:np.array, bin_confidences:np.array, ax:matplotlib.axes.Axes, bin_sem:np.array=None):\n \"\"\"Plot a bar plot confidence reliability diagram.\n\n Arguments:\n edges -- Edges of the probability bins\n bin_accuracies -- Accuracy per bin\n bin_confidences -- Average confidence of predictions in bin\n ax -- Axes on which the diagram will be plotted (will be decorated by `_decorate_ax`)\n \"\"\"\n\n _decorate_ax(ax)\n cmap = clipped_cm(len(bin_accuracies), clip_range=(0.2, 0.7))\n\n ax.plot([0,1], [0,1], linestyle=\"--\", color=cmap(1), alpha=0.9, linewidth=1)\n\n width = (edges - np.roll(edges, 1))[1:]\n for i, (xi, yi, bi) in enumerate(zip(edges, bin_accuracies, bin_confidences)):\n if np.isnan(bi):\n continue\n if yi < 0:\n continue\n if bin_sem is not None:\n sem = bin_sem[i]\n else:\n sem = 0.\n\n # plot bin value\n ax.bar(xi, yi, width=width[i], align=\"edge\", color=cmap(1-bi), edgecolor=\"grey\", yerr=sem, linewidth=1, zorder=0)\n\n # plot gap to ideal value\n ax.bar(\n xi+width[i]/2, np.abs(bi-yi), bottom=min(bi, yi), width=width[i],\n align=\"center\", color=cmap(0), edgecolor=\"grey\", linewidth=1, zorder=1\n )",
"_____no_output_____"
],
[
"# export\n\ndef confidence_reliability_diagram(y_probs:np.array, y_preds:np.array, y_true:np.array, ax:matplotlib.axes.Axes=None, bins=\"fd\", balanced:bool=True, **bin_args):\n \"\"\"Plot a confidence reliability diagram.\n\n Arguments:\n y_probs -- Array containing prediction confidences\n y_preds -- Array containing predicted labels (shape (N,))\n y_true -- Array containing true labels (shape (N,))\n ax -- Axes on which the diagram will be plotted (will be decorated by `_decorate_ax`)\n bins -- Description of amount of bins in which to divide prediction confidences (see `numpy.histogram_bin_edges` for options)\n balanced -- Flag for using balanced accuracy score\n \"\"\"\n\n num_classes, ax = _pre_plot_checks(y_probs, y_preds, y_true, ax, required_axes=1)\n\n bin_indices, edges = utils.get_bin_indices(y_probs, bins, 0.0, 1.0, return_edges=True, **bin_args)\n unique_bin_indices = sorted(np.unique(bin_indices))\n\n mean_confidences = np.full((len(edges)-1,), dtype=np.float32, fill_value=np.nan)\n bin_metric = np.full((len(edges)-1,), dtype=np.float32, fill_value=np.nan)\n\n metric = balanced_accuracy_score if balanced else accuracy_score\n\n ax.set_xlabel(\"Confidence level\")\n ax.set_ylabel(\"Balanced accuracy\" if balanced else \"Accuracy\")\n\n for bin_idx in unique_bin_indices:\n selector = bin_indices == bin_idx\n\n mean_confidences[bin_idx-1] = np.mean(y_probs[selector])\n bin_metric[bin_idx-1] = metric(y_true[selector], y_preds[selector])\n\n bar_diagram(edges, bin_metric, mean_confidences, ax)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(subplot_kw={\"aspect\": 0.75})\nconfidence_reliability_diagram(y_probs.max(axis=1), y_probs.argmax(axis=1), y_test, ax, bins=\"equal-count\", n_bins=10)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(subplot_kw={\"aspect\": 0.75})\nconfidence_reliability_diagram(y_probs.max(axis=1), y_probs.argmax(axis=1), y_test, ax, bins=10, balanced=True)",
"_____no_output_____"
],
[
"# export\n\ndef class_wise_confidence_reliability_diagram(y_probs:np.array, y_preds:np.array, y_true:np.array, axes:matplotlib.axes.Axes, bins=\"fd\", **bin_args):\n \"\"\"Plot a class-wise confidence reliability diagram.\n\n Arguments:\n y_probs -- Array containing prediction confidences\n y_preds -- Array containing predicted labels (shape (N,))\n y_true -- Array containing true labels (shape (N,))\n ax -- Axes on which the diagram will be plotted (will be decorated by `_decorate_ax`)\n bins -- Description of amount of bins in which to divide prediction confidences (see `numpy.histogram_bin_edges` for options)\n balanced -- Flag for using balanced accuracy score\n \"\"\"\n\n classes = np.unique(y_true)\n\n for ax, c in zip(axes, range(len(classes))):\n ax.set_title(f\"Class {c}\")\n\n selector = y_preds == c\n\n confidence_reliability_diagram(y_probs[selector, c], y_preds[selector], y_true[selector], ax, bins, balanced=False, **bin_args)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 3, subplot_kw={\"aspect\": 1}, constrained_layout=True, sharex=True, sharey=True)\nclass_wise_confidence_reliability_diagram(y_probs, y_probs.argmax(axis=1), y_test, ax, bins=\"equal-count\", n_bins=8)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73bced3c37778d962154952fc2d2df8d5562747 | 400,592 | ipynb | Jupyter Notebook | tutorials/W2D1_BayesianStatistics/student/W2D1_Tutorial3.ipynb | KeerthanaManikandan/NMA-course-content | c741463b360c366b8fe3aa368cd0a277b5ec78bc | [
"CC-BY-4.0"
] | null | null | null | tutorials/W2D1_BayesianStatistics/student/W2D1_Tutorial3.ipynb | KeerthanaManikandan/NMA-course-content | c741463b360c366b8fe3aa368cd0a277b5ec78bc | [
"CC-BY-4.0"
] | null | null | null | tutorials/W2D1_BayesianStatistics/student/W2D1_Tutorial3.ipynb | KeerthanaManikandan/NMA-course-content | c741463b360c366b8fe3aa368cd0a277b5ec78bc | [
"CC-BY-4.0"
] | null | null | null | 251.628141 | 80,996 | 0.911097 | [
[
[
"<a href=\"https://colab.research.google.com/github/NeuromatchAcademy/course-content/blob/master/tutorials/W2D1_BayesianStatistics/student/W2D1_Tutorial3.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Neuromatch Academy: Week 2, Day 1, Tutorial 3:\n# Fitting to data\n\n__Content creators:__ Vincent Valton, Konrad Kording\n\n__Content reviewers:__ Matt Krause, Jesse Livezey, Karolina Stosio, Saeed Salehi, Michael Waskom",
"_____no_output_____"
],
[
"---\n# Tutorial objectives\n \nIn this notebook, we'll have a look at computing all the necessary steps to perform model inversion (estimate the model parameters such as $p_{common}$ that generated data similar to that of a participant). We will describe all the steps of the generative model first, and in the last exercise we will use all these steps to estimate the parameter $p_{common}$ of a single participant using simulated data. \n\nThe generative model will be the same Bayesian model we have been using throughout tutorial 2: a mixture of Gaussian prior (common + independent priors) and a Gaussian likelihood.\n\nSteps:\n\n* First, we'll create the prior, likelihood, posterior, etc in a form that will make it easier for us to visualise what is being computed and estimated at each step of the generative model: \n 1. Creating a mixture of Gaussian prior for multiple possible stimulus inputs\n 2. Generating the likelihood for multiple possible stimulus inputs\n 3. Estimating our posterior as a function of the stimulus input\n 4. Estimating a participant response given the posterior\n \n* Next, we'll perform the model inversion/fitting:\n 5. Create an distribution for the input as a function of possible inputs\n 6. Marginalization\n 7. Generate some data using the generative model provided\n 8. Perform model inversion (model fitting) using the generated data and see if you recover the orignal parameters.\n",
"_____no_output_____"
],
[
"---\n# Setup\n\nPlease execute the cell below to initialize the notebook environment",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib as mpl\nfrom scipy.optimize import minimize",
"_____no_output_____"
],
[
"#@title Figure Settings\nimport ipywidgets as widgets\nplt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/nma.mplstyle\")\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'",
"_____no_output_____"
],
[
"# @title Helper Functions\n\ndef my_gaussian(x_points, mu, sigma):\n \"\"\"\n Returns un-normalized Gaussian estimated at points `x_points`, with parameters: `mu` and `sigma`\n \n Args :\n x_points (numpy arrays of floats)- points at which the gaussian is evaluated\n mu (scalar) - mean of the Gaussian\n sigma (scalar) - std of the gaussian\n\n Returns: \n un-normalized Gaussian evaluated at `x`\n \"\"\"\n return np.exp(-(x_points-mu)**2/(2*sigma**2))\n\ndef moments_myfunc(x_points, function):\n \"\"\"\n DO NOT EDIT THIS FUNCTION !!!\n\n Returns the mean, median and mode of an arbitrary function\n\n Args : \n x_points (numpy array of floats) - x-axis values\n function (numpy array of floats) - y-axis values of the function evaluated at `x_points`\n\n Returns:\n (tuple of 3 scalars): mean, median, mode\n \"\"\"\n \n # Calc mode of arbitrary function\n mode = x_points[np.argmax(function)]\n\n # Calc mean of arbitrary function\n mean = np.sum(x_points * function)\n\n # Calc median of arbitrary function\n cdf_function = np.zeros_like(x_points)\n accumulator = 0\n for i in np.arange(x_points.shape[0]):\n accumulator = accumulator + function[i]\n cdf_function[i] = accumulator\n idx = np.argmin(np.abs(cdf_function - 0.5))\n median = x_points[idx]\n\n return mean, median, mode\n\ndef plot_myarray(array, xlabel, ylabel, title):\n \"\"\" Plot an array with labels.\n\n Args : \n array (numpy array of floats) \n xlabel (string) - label of x-axis\n ylabel (string) - label of y-axis\n title (string) - title of plot\n\n Returns:\n None\n \"\"\"\n fig = plt.figure()\n ax = fig.add_subplot(111)\n colormap = ax.imshow(array, extent=[-10, 10, 8, -8])\n cbar = plt.colorbar(colormap, ax=ax)\n cbar.set_label('probability')\n ax.set_xlabel(xlabel)\n ax.set_title(title)\n ax.set_ylabel(ylabel)\n ax.set_aspect('auto')\n return None\n\ndef plot_my_bayes_model(model) -> None:\n \"\"\"Pretty-print a simple Bayes Model (ex 7), defined as a function:\n\n Args:\n - model: function that takes a single parameter value and returns \n the negative log-likelihood of the model, given that parameter\n Returns: \n None, draws plot\n \"\"\"\n x = np.arange(-10,10,0.07)\n\n # Plot neg-LogLikelihood for different values of alpha\n alpha_tries = np.arange(0.01, 0.3, 0.01)\n nll = np.zeros_like(alpha_tries)\n for i_try in np.arange(alpha_tries.shape[0]):\n nll[i_try] = model(np.array([alpha_tries[i_try]]))\n\n plt.figure()\n plt.plot(alpha_tries, nll)\n plt.xlabel('p_independent value')\n plt.ylabel('negative log-likelihood')\n\n # Mark minima\n ix = np.argmin(nll)\n plt.scatter(alpha_tries[ix], nll[ix], c='r', s=144)\n\n #plt.axvline(alpha_tries[np.argmin(nll)])\n plt.title('Sample Output')\n plt.show()\n\n return None\n\n\ndef plot_simulated_behavior(true_stim, behaviour):\n fig = plt.figure(figsize=(7, 7))\n ax = fig.add_subplot(1,1,1)\n ax.set_facecolor('xkcd:light grey')\n plt.plot(true_stim, true_stim - behaviour, '-k', linewidth=2, label='data')\n plt.axvline(0, ls='dashed', color='grey')\n plt.axhline(0, ls='dashed', color='grey')\n plt.legend()\n plt.xlabel('Position of true visual stimulus (cm)')\n plt.ylabel('Participant deviation from true stimulus (cm)')\n plt.title('Participant behavior')\n plt.show()\n\n return None",
"_____no_output_____"
]
],
[
[
"---\n# Introduction\n",
"_____no_output_____"
]
],
[
[
"#@title Video 1: Intro\nfrom IPython.display import YouTubeVideo\nvideo = YouTubeVideo(id='YSKDhnbjKmA', width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"Video available at https://youtube.com/watch?v=YSKDhnbjKmA\n"
]
],
[
[
"\n\n\nHere is a graphical representation of the generative model:\n\n 1. We present a stimulus $x$ to participants. \n 2. The brain encodes this true stimulus $x$ noisily (this is the brain's representation of the true visual stimulus: $p(\\tilde x|x)$.\n 3. The brain then combine this brain encoded stimulus (likelihood: $p(\\tilde x|x)$) with prior information (the prior: $p(x)$) to make up the brain's estimated position of the true visual stimulus, the posterior: $p(x|\\tilde x)$. \n 3. This brain's estimated stimulus position: $p(x|\\tilde x)$, is then used to make a response: $\\hat x$, which is the participant's noisy estimate of the stimulus position (the participant's percept). \n \nTypically the response $\\hat x$ also includes some motor noise (noise due to the hand/arm move being not 100% accurate), but we'll ignore it in this tutorial and assume there is no motor noise.\n\n\n\nWe will use the same experimental setup as in [tutorial 2](https://colab.research.google.com/drive/15pbgrfGjSKbUQoX51RdcNe3UXb4R5RRx#scrollTo=tF5caxVGYURh) but with slightly different probabilities. This time, participants are told that they need to estimate the sound location of a puppet that is hidden behind a curtain. The participants are told to use auditory information and are also informed that the sound could come from 2 possible causes: a common cause (95% of the time it comes from the puppet hidden behind the curtain at position 0), or an independent cause (5% of the time the sound comes from loud-speakers at more distant locations).",
"_____no_output_____"
],
[
"---\n# Section 1: Likelihood array\n \nFirst, we want to create a likelihood, but for the sake of visualization we will create multiple likelihoods $\\tilde x$ (one for each true stimumulus position: $x$). We will then be able to visualize the likelihood as a function of various true stimulus positions: $x$.\n\nWe now want to create a likelihood $\\tilde x$ for each value of the true stimulus position $x$. To do so we will stack each likelihood vertically for each true stimulus position $x$. We will end up with a 2D array where each row represents a different brain encoding of the stimulus position ($\\tilde x$). \n\n Using the equation for the un-normalized Gaussian `my_gaussian` and the values in `hypothetical_stim`:\n* Create a Gaussian likelihood with mean varying from `hypothetical_stim`, keeping $\\sigma_{likelihood}$ constant at 1.\n* Each likelihood with a different mean will make up a different row-likelihood of your 2D array, such that you end up with a likelihood array made up of 1,000 row-Gaussians with different means. (_Hint_: `np.tile` won't work here. You may need a for-loop).\n* Plot the array using the function `plot_myarray()` already pre-written and commented-out in your script",
"_____no_output_____"
],
[
"###Exercise 1. Implement the auditory likelihood as a function of true stimulus position",
"_____no_output_____"
]
],
[
[
"x = np.arange(-10, 10, 0.1)\nhypothetical_stim = np.linspace(-8, 8, 1000)\n\ndef compute_likelihood_array(x_points, stim_array, sigma=1.):\n\n # initializing likelihood_array\n likelihood_array = np.zeros((len(stim_array), len(x_points)))\n\n # looping over stimulus array \n for i in range(len(stim_array)):\n ########################################################################\n ## Insert your code here to:\n ## - Generate a likelihood array using `my_gaussian` function, \n ## with std=1, and varying the mean using `stim_array` values.\n ## - normalize\n ## remove the raise below to test your function\n raise NotImplementedError(\"You need to complete the function!\")\n ########################################################################\n likelihood_array[i, :] = ...\n likelihood_array[i, :] = ... # normalize\n\n return likelihood_array\n\n# Uncomment following lines to test your code\n# likelihood_array = compute_likelihood_array(x, hypothetical_stim)\n# plot_myarray(likelihood_array,\n# '$\\~x$ : Brain representation of $x$',\n# 'Hypothetical True Stimulus $x$',\n# 'Sample Likelihood Array : $p(\\~x | x)$')",
"_____no_output_____"
]
],
[
[
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W2D1_BayesianStatistics/solutions/W2D1_Tutorial3_Solution_9e34b2b1.py)\n\n*Example output:*\n\n<img alt='Solution hint' align='left' width=422 height=280 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W2D1_BayesianStatistics/static/W2D1_Tutorial3_Solution_9e34b2b1_0.png>\n\n",
"_____no_output_____"
],
[
"---\n# Section 2: Causal mixture of Gaussian prior\n",
"_____no_output_____"
]
],
[
[
"#@title Video 2: Prior array\nvideo = YouTubeVideo(id='F0IYpUicXu4', width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"Video available at https://youtube.com/watch?v=F0IYpUicXu4\n"
]
],
[
[
"\nAs in Tutorial 2, we want to create a prior that will describe the participants' prior knowledge that sounds come 75% of the time from a common position around the puppet, and 25% of the time from another independent position. We will embody this information into a prior using a mixture of Gaussians. For visualization reasons, we will create a prior that has the same shape (form) as the likelihood array we created in the previous exercise. That is, we want to create a mixture of Gaussian prior as a function the the presented hypothetical stimulus $x$. Since the prior does not change as a function of $x$ it will be identical on each row of the prior 2D array. \n\nUsing the equation for the un-normalised Gaussian `my_gaussian`:\n* Generate a Gaussian $Common$ with mean 0 and standard deviation 0.5\n* Generate another Gaussian $Independent$ with mean 0 and standard deviation 10\n* Combine the two Gaussians (Common + Independent) to make a new prior by mixing the two Gaussians with mixing parameter $p_{independent}$ = 0.05. Make it such that the peakier Gaussian has 95% of the weight (don't forget to normalize afterwards)\n* This will be the first row of your prior 2D array\n* Now repeat for varying hypoethtical stimuli $x$. Since the prior does not depend on $x$ you can just repeat the prior for each hypothetical $x$ (hint: use np.tile) that row prior to make an array of 1,000 (i.e. `hypothetical_stim.shape[0]`) row-priors.\n* Plot the matrix using the function `plot_myarray()` already pre-written and commented-out in your script",
"_____no_output_____"
],
[
"### Exercise 2: Implement the prior array",
"_____no_output_____"
]
],
[
[
"x = np.arange(-10, 10, 0.1)\n\ndef calculate_prior_array(x_points, stim_array, p_indep, \n prior_mean_common=.0, prior_sigma_common=.5,\n prior_mean_indep=.0, prior_sigma_indep=10):\n \"\"\"\n 'common' stands for common\n 'indep' stands for independent \n \"\"\"\n\n prior_common = my_gaussian(x_points, prior_mean_common, prior_sigma_common)\n prior_indep = my_gaussian(x_points, prior_mean_indep, prior_sigma_indep)\n\n ############################################################################\n ## Insert your code here to:\n ## - Create a mixture of gaussian priors from 'prior_common'\n ## and 'prior_indep' with mixing parameter 'p_indep'\n ## - normalize\n ## - repeat the prior array and reshape it to make a 2D array\n ## of 1000 rows of priors (Hint: use np.tile() and np.reshape())\n ## remove the raise below to test your function\n raise NotImplementedError(\"You need to complete the function!\")\n ############################################################################\n \n prior_mixed = ...\n prior_mixed = ... # normalize\n \n prior_array = np.tile(...).reshape(...)\n return prior_array\n\np_independent=.05\n# Uncomment following lines, once the task is complete.\n# prior_array = calculate_prior_array(x, hypothetical_stim, p_independent)\n# plot_myarray(prior_array,\n# 'prior: p(x)', 'Hypothetical True Stimulus x',\n# 'Prior as a fcn x : p(x)')",
"_____no_output_____"
]
],
[
[
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W2D1_BayesianStatistics/solutions/W2D1_Tutorial3_Solution_89e387f7.py)\n\n*Example output:*\n\n<img alt='Solution hint' align='left' width=421 height=280 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W2D1_BayesianStatistics/static/W2D1_Tutorial3_Solution_89e387f7_0.png>\n\n",
"_____no_output_____"
],
[
"---\n# Section 3: Bayes rule and Posterior array",
"_____no_output_____"
]
],
[
[
"#@title Video 3: Posterior array\nvideo = YouTubeVideo(id='HpOzXZUKFJc', width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"Video available at https://youtube.com/watch?v=HpOzXZUKFJc\n"
]
],
[
[
"We now want to calcualte the posterior using *Bayes Rule*. Since we have already created a likelihood and a prior for each hypothetical stimulus x, all we need to do is to multiply them row-wise. That is, each row of the posterior array will be the posterior resulting from the multiplication of the prior and likelihood of the same equivalent row.\n\nMathematically:\n\n\\begin{eqnarray}\n Posterior\\left[i, :\\right] \\propto Likelihood\\left[i, :\\right] \\odot Prior\\left[i, :\\right]\n\\end{eqnarray}\n\nwhere $\\odot$ represents the [Hadamard Product](https://en.wikipedia.org/wiki/Hadamard_product_(matrices)) (i.e., elementwise multiplication) of the corresponding prior and likelihood row vectors `i` from each matrix.\n\nFollow these steps to build the posterior as a function of the hypoethtical stimulus $x$:\n* For each row of the prior and likelihood (i.e. each hypothetical $x$), fill in the posterior matrix so that every row of the posterior array represents the posterior density for a different hypothetical $x$.\n* Plot the array using the function `plot_myarray()` already pre-written and commented-out in your script\n\nOptional:\n* Do you need to operate on one element--or even one row--at a time? NumPy operations can often process an entire matrix in a single \"vectorized\" operation. This approach is often much faster and much easier to read than an element-by-element calculation. Try to write a vectorized version that calculates the posterior without using any for-loops. _Hint_: look at `np.sum` and its keyword arguments.",
"_____no_output_____"
],
[
"### Exercise 3: Calculate the posterior as a function of the hypothetical stimulus x",
"_____no_output_____"
]
],
[
[
"def calculate_posterior_array(prior_array, likelihood_array):\n\n ############################################################################\n ## Insert your code here to:\n ## - calculate the 'posterior_array' from the given\n ## 'prior_array', 'likelihood_array'\n ## - normalize\n ## remove the raise below to test your function\n raise NotImplementedError(\"You need to complete the function!\")\n ############################################################################\n posterior_array = ...\n posterior_array = ... # normalize each row separately\n\n return posterior_array\n\n# Uncomment following lines, once the task is complete.\n# posterior_array = calculate_posterior_array(prior_array, likelihood_array)\n# plot_myarray(posterior_array,\n# 'posterior: $p(x | \\~x)$',\n# 'Hypothetical True Stimulus $x$',\n# 'Posterior as a fcn of $x$ : $p(x | \\~x)$')",
"_____no_output_____"
]
],
[
[
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W2D1_BayesianStatistics/solutions/W2D1_Tutorial3_Solution_9cdc9264.py)\n\n*Example output:*\n\n<img alt='Solution hint' align='left' width=421 height=280 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W2D1_BayesianStatistics/static/W2D1_Tutorial3_Solution_9cdc9264_0.png>\n\n",
"_____no_output_____"
],
[
"---\n# Section 4: Estimating the position $\\hat x$",
"_____no_output_____"
]
],
[
[
"#@title Video 4: Binary decision matrix\nvideo = YouTubeVideo(id='gy3GmlssHgQ', width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"Video available at https://youtube.com/watch?v=gy3GmlssHgQ\n"
]
],
[
[
"Now that we have a posterior distribution that represents the brain's estimated stimulus position: $p(x|\\tilde x)$, we want to make an estimate (response) of the sound location $\\hat x$ using the posterior distribution. The participant's noisy estimate of the stimulus position $\\hat x$ is the participant's percept. \n\nThis effectively encodes the *decision* that a participant would make for a given hypothetical stimulus $x$. In this exercise, we make the assumptions that participants take the mean of the posterior (decision rule) as a response estimate for the sound location (use the function `moments_myfunc()` provided to calculate the mean of the posterior).\n\nUsing this knowledge, we will now represent $\\hat x$ as a function of the hypothetical stimulus values $x$. This will result in a 2D binary decision array. To do so, we will scan the posterior matrix (i.e. row-wise), and set the array cell value to 1 at the mean of the row-wise posterior.\n\n**Suggestions**\n* For each hypoethetical stimulus $x$ (row of the posterior array), calculate the mean of the posterior, and set the corresponding cell of the binary decision array to 1. (e.g., if the mean of the posterior is at position 0, then set the cell with x_column == 0 to 1).\n* Plot the matrix using the function `plot_myarray()` already pre-written and commented-out in your script",
"_____no_output_____"
],
[
"### Exercise 4: Calculate the estimated response as a function of the hypothetical stimulus x",
"_____no_output_____"
]
],
[
[
"def calculate_binary_decision_array(x_points, posterior_array):\n\n binary_decision_array = np.zeros_like(posterior_array)\n\n for i in range(len(posterior_array)):\n\n ########################################################################\n ## Insert your code here to:\n ## - For each hypothetical stimulus x (row of posterior),\n ## calculate the mean of the posterior using the povided function \n ## `moments_myfunc()`, and set the corresponding cell of the \n ## Binary Decision array to 1.\n ## Hint: you can run 'help(moments_myfunc)' to see the docstring\n ## remove the raise below to test your function\n raise NotImplementedError(\"You need to complete the function!\")\n ########################################################################\n \n mean, _, _ = ... # calculate mean of posterior using 'moments_myfunc'\n idx = ... # find the postion of mean in x_points (closest position)\n binary_decision_array[i, idx] = 1 \n\n return binary_decision_array\n\n# Uncomment following lines, once the task is complete.\n# binary_decision_array = calculate_binary_decision_array(x, posterior_array)\n# plot_myarray(binary_decision_array,\n# '$\\^x$', 'Hypothetical True Stimulus $x$',\n# 'Sample Binary Decision array\\n $\\^x$ = mean($\\~x$)')",
"_____no_output_____"
]
],
[
[
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W2D1_BayesianStatistics/solutions/W2D1_Tutorial3_Solution_d0399098.py)\n\n*Example output:*\n\n<img alt='Solution hint' align='left' width=419 height=280 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W2D1_BayesianStatistics/static/W2D1_Tutorial3_Solution_d0399098_0.png>\n\n",
"_____no_output_____"
],
[
"---\n# Section 5: Probabilities of encoded stimuli",
"_____no_output_____"
]
],
[
[
"#@title Video 5: Input array\nvideo = YouTubeVideo(id='C1d1n_Si83o', width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"Video available at https://youtube.com/watch?v=C1d1n_Si83o\n"
]
],
[
[
"Because the brain does not have access to the true presented stimulus, we had to compute the binary decision array for hypothetical stimulus values of $x$. We will then use that information when presented with a real stimulus $x$. \n\nFirst however, we need to create the input from the true presented stimulus. That is, we will now create a Gaussian centered around the true presented stimulus, with sigma = 1. , and repeat that gaussian distribution across as a function of hypothetical stimulus values x. That is, we want to make a *column* gaussian centered around the true presented stimulus, and repeat this *column* Gaussian across all hypothetical stimulus values $x$.\n\nThis, effectively encodes the distribution of the true stimulus (one single simulus) for that a participant and enable us to link the true stimulus $x$, to hypoethetical ones we have already pre-computed. \n\n**Suggestions**\n\nFor this exercise, we will assume the true stimulus is presented at direction -2.5\n* Create a Gaussian likelihood with mean = -2.5 and $\\sigma$ of 1.\n* Make this the first column of your array and repeat that *column* to fill in the true presented stimulus input as a function of hypothetical stimulus locations.\n* Plot the array using the function `plot_myarray()` already pre-written and commented-out in your script",
"_____no_output_____"
],
[
"###Exercise 5: Generate an input as a function of hypothetical stimulus x",
"_____no_output_____"
]
],
[
[
"def generate_input_array(x_points, stim_array, posterior_array,\n mean=-2.5, sigma=1.):\n\n input_array = np.zeros_like(posterior_array)\n\n ########################################################################\n ## Insert your code here to:\n ## - Generate a gaussian centered on the true stimulus -2.5\n ## and sigma = 1. for each column\n ## remove the raise below to test your function\n raise NotImplementedError(\"You need to complete the function!\")\n ########################################################################\n for i in range(len(x_points)):\n input_array[:, i] = ...\n input_array[:, i] = ... # normalize\n\n return input_array\n\n# Uncomment following lines, once the task is complete.\n# input_array = generate_input_array(x, hypothetical_stim, posterior_array)\n# plot_myarray(input_array,\n# 'hypothetical stimulus $x$', '$\\~x$',\n# 'Sample Input Matrix: $p(\\~x | x = -2.5)$')",
"_____no_output_____"
]
],
[
[
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W2D1_BayesianStatistics/solutions/W2D1_Tutorial3_Solution_41daa20a.py)\n\n*Example output:*\n\n<img alt='Solution hint' align='left' width=422 height=280 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W2D1_BayesianStatistics/static/W2D1_Tutorial3_Solution_41daa20a_0.png>\n\n",
"_____no_output_____"
],
[
"---\n# Section 6: Normalization and expected estimate distribution",
"_____no_output_____"
]
],
[
[
"#@title Video 6: Marginalization\nvideo = YouTubeVideo(id='5alwtNS4CGw', width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"Video available at https://youtube.com/watch?v=5alwtNS4CGw\n"
]
],
[
[
"Now that we have a true stimulus $x$ and a way to link it to hypothetical stimulus locations, we will be able to estimate what is the brain's representation of the true stimulus $x$ by integrating over all the possible hypothetical stimulus locations that the brain could have been expecting. This is because the brain does not have access to the true stimulus $x$, and as a result we need to integrate over all possible hypothetical values of $x$ it could have expected. \n\nTo integrate over all possible hypothetical values of $x$ we marginalize, that is, we first compute the dot-product from the true presented stimulus and our binary decision array and then sum over x. \n\nMathematically, this means that we want to compute:\n\n\\begin{eqnarray}\n Marginalization Array = Input Array \\odot Binary Decision Array\n\\end{eqnarray}\n\n\\begin{eqnarray}\n Marginal = \\int_{x} Marginalization Array\n\\end{eqnarray}\n\nSince we are performing integration over discreete values using arrays for visualization purposes, the integration reduces to a simple sum over x.\n\n**Suggestions**\n\n* For each row of the input and binary arrays, calculate product of the two and fill in the 2D marginal array.\n* Plot the result using the function `plot_myarray()` already pre-written and commented-out in your script\n* Calculate and plot the marginal over `x` using the code snippet commented out in your script\n - Note how the limitations of numerical integration create artifacts on your marginal ",
"_____no_output_____"
],
[
"###Exercise 6: Implement the marginalization matrix",
"_____no_output_____"
]
],
[
[
"def my_marginalization(input_array, binary_decision_array):\n\n ############################################################################\n ## Insert your code here to:\n ## - Compute 'marginalization_array' by multiplying pointwise the Binary\n ## decision array over hypothetical stimuli and the Input array\n ## - Compute 'marginal' from the 'marginalization_array' by summing over x \n ## (hint: use np.sum() and only marginalize along the columns)\n ## remove the raise below to test your function\n raise NotImplementedError(\"You need to complete the function!\")\n ############################################################################\n\n marginalization_array = ...\n marginal = ... # when using np.sum(), be careful about the applied axis\n marginal = ... # normalize\n\n return marginalization_array, marginal\n\n# Uncomment following lines, once the task is complete.\n# marginalization_array, marginal = my_marginalization(input_array, binary_decision_array)\n# plot_myarray(marginalization_array, '$x$', '$\\^x$', 'Marginalization array: $p(\\^x | x)$')\n# plt.figure()\n# plt.plot(x, marginal)\n# plt.xlabel('$\\^x$')\n# plt.ylabel('probability')\n# plt.show()",
"_____no_output_____"
]
],
[
[
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W2D1_BayesianStatistics/solutions/W2D1_Tutorial3_Solution_910a90df.py)\n\n*Example output:*\n\n<img alt='Solution hint' align='left' width=414 height=272 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W2D1_BayesianStatistics/static/W2D1_Tutorial3_Solution_910a90df_0.png>\n\n<img alt='Solution hint' align='left' width=416 height=272 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W2D1_BayesianStatistics/static/W2D1_Tutorial3_Solution_910a90df_1.png>\n\n",
"_____no_output_____"
],
[
"---\n# Generate some data\n\nNow that we've seen how to calculate the posterior and marginalize to get $p(\\hat{x} \\mid x)$, we will generate some artificial data for a single participant using the `generate_data()` function provided, and mixing parameter $p_{independent}$ = 0.1. \n\nOur goal in the next exercise will be to recover that parameter. These parameter recovery experiments are a powerful method for planning and debugging Bayesian analyses--if you cannot recover the given parameters, something has gone wrong!\n\nPlease run the code below to generate some synthetic data. You do not need to edit anything, but check that the plot below matches what you would expect from the video. ",
"_____no_output_____"
]
],
[
[
"#@title\n#@markdown #### Run the 'generate_data' function (this cell)\ndef generate_data(x_stim, p_independent):\n \"\"\"\n DO NOT EDIT THIS FUNCTION !!!\n\n Returns generated data using the mixture of Gaussian prior with mixture \n parameter `p_independent`\n\n Args : \n x_stim (numpy array of floats) - x values at which stimuli are presented\n p_independent (scalar) - mixture component for the Mixture of Gaussian prior\n\n Returns:\n (numpy array of floats): x_hat response of participant for each stimulus\n \"\"\"\n x = np.arange(-10,10,0.1)\n x_hat = np.zeros_like(x_stim)\n\n prior_mean = 0\n prior_sigma1 = .5\n prior_sigma2 = 3\n prior1 = my_gaussian(x, prior_mean, prior_sigma1)\n prior2 = my_gaussian(x, prior_mean, prior_sigma2)\n\n prior_combined = (1-p_independent) * prior1 + (p_independent * prior2) \n prior_combined = prior_combined / np.sum(prior_combined)\n\n for i_stim in np.arange(x_stim.shape[0]):\n likelihood_mean = x_stim[i_stim]\n likelihood_sigma = 1\n likelihood = my_gaussian(x, likelihood_mean, likelihood_sigma)\n likelihood = likelihood / np.sum(likelihood)\n\n posterior = np.multiply(prior_combined, likelihood)\n posterior = posterior / np.sum(posterior)\n \n # Assumes participant takes posterior mean as 'action'\n x_hat[i_stim] = np.sum(x * posterior)\n return x_hat\n\n# Generate data for a single participant\ntrue_stim = np.array([-8, -4, -3, -2.5, -2, -1.5, -1, -0.5, 0, 0.5, 1, 1.5, 2, \n 2.5, 3, 4, 8])\nbehaviour = generate_data(true_stim, 0.10)\n\nplot_simulated_behavior(true_stim, behaviour)",
"_____no_output_____"
]
],
[
[
"---\n#Section 7: Model fitting",
"_____no_output_____"
]
],
[
[
"#@title Video 7: Log likelihood\nvideo = YouTubeVideo(id='jbYauFpyZhs', width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"Video available at https://youtube.com/watch?v=jbYauFpyZhs\n"
]
],
[
[
"Now that we have generated some data, we will attempt to recover the parameter $p_{independent}$ that was used to generate it.\n\nWe have provided you with an incomplete function called `my_Bayes_model_mse()` that needs to be completed to perform the same computations you have performed in the previous exercises but over all the participant's trial, as opposed to a single trial.\n\nThe likelihood has already been constructed; since it depends only on the hypothetical stimuli, it will not change. However, we will have to implement the prior matrix, since it depends on $p_{independent}$. We will therefore have to recompute the posterior, input and the marginal in order to get $p(\\hat{x} \\mid x)$. \n\nUsing $p(\\hat{x} \\mid x)$, we will then compute the negative log-likelihood for each trial and find the value of $p_{independent}$ that minimizes the negative log-likelihood (i.e. maximises the log-likelihood. See the model fitting tutorial from W1D3 for a refresher).\n\nIn this experiment, we assume that trials are independent from one another. This is a common assumption--and it's often even true! It allows us to define negative log-likelihood as:\n\n\\begin{eqnarray}\n -LL = - \\sum_i \\log p(\\hat{x}_i \\mid x_i)\n\\end{eqnarray}\n\nwhere $\\hat{x}_i$ is the participant's response for trial $i$, with presented stimulus $x_i$ \n\n* Complete the function `my_Bayes_model_mse`, we've already pre-completed the function to give you the prior, posterior, and input arrays on each trial\n* Compute the marginalization array as well as the marginal on each trial\n* Compute the negative log likelihood using the marginal and the participant's response\n* Using the code snippet commented out in your script to loop over possible values of $p_{independent}$\n",
"_____no_output_____"
],
[
"###Exercise 7: Fitting a model to generated data\n\n\n",
"_____no_output_____"
]
],
[
[
"def my_Bayes_model_mse(params):\n \"\"\"\n Function fits the Bayesian model from Tutorial 4 \n \n Args : \n params (list of positive floats): parameters used by the model \n (params[0] = posterior scaling)\n \n Returns :\n (scalar) negative log-likelihood :sum of log probabilities\n \"\"\"\n\n # Create the prior array\n p_independent=params[0]\n prior_array = calculate_prior_array(x,\n hypothetical_stim,\n p_independent, \n prior_sigma_indep= 3.)\n\n # Create posterior array\n posterior_array = calculate_posterior_array(prior_array, likelihood_array)\n\n # Create Binary decision array\n binary_decision_array = calculate_binary_decision_array(x, posterior_array)\n\n # we will use trial_ll (trial log likelihood) to register each trial\n trial_ll = np.zeros_like(true_stim)\n\n # Loop over stimuli\n for i_stim in range(len(true_stim)):\n\n # create the input array with true_stim as mean\n input_array = np.zeros_like(posterior_array)\n for i in range(len(x)):\n input_array[:, i] = my_gaussian(hypothetical_stim, true_stim[i_stim], 1)\n input_array[:, i] = input_array[:, i] / np.sum(input_array[:, i])\n \n # calculate the marginalizations\n marginalization_array, marginal = my_marginalization(input_array, \n binary_decision_array)\n\n action = behaviour[i_stim]\n idx = np.argmin(np.abs(x - action))\n\n ########################################################################\n ## Insert your code here to:\n ## - Compute the log likelihood of the participant\n ## remove the raise below to test your function\n raise NotImplementedError(\"You need to complete the function!\")\n ########################################################################\n\n trial_ll[i_stim] = ... # Hint: use 'np.finfo(float).eps' to avoid overflow\n\n neg_ll = - trial_ll.sum()\n\n return neg_ll\n\n# Uncomment following lines, once the task is complete.\n# plot_my_bayes_model(my_Bayes_model_mse)",
"_____no_output_____"
]
],
[
[
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W2D1_BayesianStatistics/solutions/W2D1_Tutorial3_Solution_4dc32c4b.py)\n\n*Example output:*\n\n<img alt='Solution hint' align='left' width=416 height=272 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W2D1_BayesianStatistics/static/W2D1_Tutorial3_Solution_4dc32c4b_0.png>\n\n",
"_____no_output_____"
],
[
"# Section 8: Summary",
"_____no_output_____"
]
],
[
[
"#@title Video 8: Outro\nvideo = YouTubeVideo(id='F5JfqJonz20', width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"Video available at https://youtube.com/watch?v=F5JfqJonz20\n"
]
],
[
[
"Congratuations! You found $p_{independent}$, the parameter that describes how much weight subjects assign to the same-cause vs. independent-cause origins of a sound. In the preceeding notebooks, we went through the entire Bayesian analysis pipeline:\n\n* developing a model\n* simulating data, and\n* using Bayes' Rule and marginalization to recover a hidden parameter from the data\n\nThis example was simple, but the same princples can be used to analyze datasets with many hidden variables and complex priors and likelihoods. Bayes' Rule will also play a cruical role in many of the other techniques you will see later this week. \n\n---\n\nIf you're still intrigued as to why we decided to use the mean of the posterior as a decision rule for a response $\\hat{x}$, we have an extra [(Bonus) tutorial 4](https://colab.research.google.com/drive/1bRENTJSvP4fHBs65_4PNRSTgTNWbT7Qk#scrollTo=LqkrbIEeyqVl) which goes through the most common decision rules and how these rules correspond to minimizing different cost functions.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73bd0596c6bc1c43a66d9a60d2ab9632f67cfe1 | 71,594 | ipynb | Jupyter Notebook | PyCitySchools/JamesWilliams_PyCitySchools.ipynb | jtwilliams17/pandas-challenge | ebc6bf9c2ef12e3fe8ecaecb54f5c20c6c4f5a61 | [
"ADSL"
] | null | null | null | PyCitySchools/JamesWilliams_PyCitySchools.ipynb | jtwilliams17/pandas-challenge | ebc6bf9c2ef12e3fe8ecaecb54f5c20c6c4f5a61 | [
"ADSL"
] | null | null | null | PyCitySchools/JamesWilliams_PyCitySchools.ipynb | jtwilliams17/pandas-challenge | ebc6bf9c2ef12e3fe8ecaecb54f5c20c6c4f5a61 | [
"ADSL"
] | null | null | null | 37.542737 | 202 | 0.419993 | [
[
[
"### Note\n* Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps.",
"_____no_output_____"
]
],
[
[
"# Dependencies and Setup\nimport pandas as pd\n\n# File to Load (Remember to Change These)\nschool_data_to_load = \"../Resources/JamesWilliams_schools_complete.csv\"\nstudent_data_to_load = \"../Resources/JamesWilliams_students_complete.csv\"\n\n# Read School and Student Data File and store into Pandas DataFrames\nschool_data = pd.read_csv(school_data_to_load)\nstudent_data = pd.read_csv(student_data_to_load)\n\n# Combine the data into a single dataset. \nschool_data_complete = pd.merge(student_data, school_data, how=\"left\", on=[\"school_name\", \"school_name\"])\nschool_data_complete.head()",
"_____no_output_____"
]
],
[
[
"## District Summary\n\n* Calculate the total number of schools\n\n* Calculate the total number of students\n\n* Calculate the total budget\n\n* Calculate the average math score \n\n* Calculate the average reading score\n\n* Calculate the percentage of students with a passing math score (70 or greater)\n\n* Calculate the percentage of students with a passing reading score (70 or greater)\n\n* Calculate the percentage of students who passed math **and** reading (% Overall Passing)\n\n* Create a dataframe to hold the above results\n\n* Optional: give the displayed data cleaner formatting",
"_____no_output_____"
]
],
[
[
"# count number of schools and students using nunique function\ntotal_number_schools = school_data_complete[\"school_name\"].nunique()\ntotal_number_students = school_data_complete[\"student_name\"].count()\n\n# extract and sum all budgets for each high school\nunique_budgets = school_data_complete[\"budget\"].unique()\ntotal_budget = unique_budgets.sum()\n\n# calculate average math and reading score\navg_math_score = school_data_complete[\"math_score\"].mean()\navg_reading_score = school_data_complete[\"reading_score\"].mean()\n\n# calculate percentage of passing math, reading, and both scores\nmath_above_70 = school_data_complete[(school_data_complete[\"math_score\"] >= 70)]\nmath_above_70_count = math_above_70[\"math_score\"].count()\nmath_pass_percent = (math_above_70_count / school_data_complete[\"math_score\"].count())*100\n\nreading_above_70 = school_data_complete[(school_data_complete[\"reading_score\"] >= 70)]\nreading_above_70_count = reading_above_70[\"reading_score\"].count()\nreading_pass_percent = (reading_above_70_count / (school_data_complete[\"reading_score\"].count()))*100\n\nboth_above_70 = math_above_70[(school_data_complete[\"reading_score\"] >= 70)]\nboth_above_70_count = both_above_70[\"reading_score\"].count()\nboth_pass_percent = (both_above_70_count / (school_data_complete[\"reading_score\"].count()))*100\n\n# create data frame of district summary data\ndistrict_summary = pd.DataFrame({\"Total Number of Schools\": [total_number_schools],\n \"Total Number of Students\": [total_number_students],\n \"Total Budget\": [total_budget],\n \"Average Math Score\": [avg_math_score],\n \"Average Reading Score\": [avg_reading_score],\n \"% Passing Math\": [math_pass_percent],\n \"% Passing Reading\": [reading_pass_percent],\n \"% Overall Passing\": [both_pass_percent]})\n# correct formatting in summary\ndistrict_summary[\"Total Number of Students\"] = district_summary[\"Total Number of Students\"].map(\"{:,}\".format)\ndistrict_summary[\"Total Budget\"] = district_summary[\"Total Budget\"].map(\"${:,.2f}\".format)\n\n\ndistrict_summary",
"<ipython-input-3-a007a1ef4fd9>:22: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n both_above_70 = math_above_70[(school_data_complete[\"reading_score\"] >= 70)]\n"
]
],
[
[
"## School Summary",
"_____no_output_____"
],
[
"* Create an overview table that summarizes key metrics about each school, including:\n * School Name\n * School Type\n * Total Students\n * Total School Budget\n * Per Student Budget\n * Average Math Score\n * Average Reading Score\n * % Passing Math\n * % Passing Reading\n * % Overall Passing (The percentage of students that passed math **and** reading.)\n \n* Create a dataframe to hold the above results",
"_____no_output_____"
]
],
[
[
"# Collect school names and group by each school\nhigh_school_names = school_data_complete[\"school_name\"].unique\nhigh_school_group = school_data_complete.groupby([\"school_name\"])\n# calculations for the grouped schools\nschool_type = high_school_group[\"type\"].unique()\ntotal_students_per_school = high_school_group[\"student_name\"].count()\nunique_budget_per_school = high_school_group[\"budget\"].unique()\nper_student_budget = unique_budget_per_school / total_students_per_school\navg_math_score_per_school = high_school_group[\"math_score\"].mean()\navg_reading_score_per_school = high_school_group[\"reading_score\"].mean()\n\n# percent above pass calculations using the above 70 grades from District Summary\nmath_above_70_per_school = math_above_70.groupby([\"school_name\"]).count()\nmath_above_70_per_school = math_above_70_per_school[\"math_score\"]\nmath_pass_percent_per_school = (math_above_70_per_school / high_school_group[\"math_score\"].count())*100\n\nreading_above_70_per_school = reading_above_70.groupby([\"school_name\"]).count()\nreading_above_70_per_school = reading_above_70_per_school[\"reading_score\"]\nreading_pass_percent_per_school = (reading_above_70_per_school / high_school_group[\"reading_score\"].count())*100\n\nboth_above_70_per_school = both_above_70.groupby([\"school_name\"]).count()\nboth_above_70_per_school = both_above_70_per_school[\"math_score\"]\nboth_pass_percent_per_school = (both_above_70_per_school / (high_school_group[\"reading_score\"].count()))*100\n\n# create data frame of school summary data\nper_school_summary = pd.DataFrame({\"School Type\": school_type,\n \"Total Students\": total_students_per_school,\n \"Total School Budget\": unique_budget_per_school,\n \"Per Student Budget\": per_student_budget,\n \"Average Math Score\": avg_math_score_per_school,\n \"Average Reading Score\": avg_reading_score_per_school,\n \"% Passing Math\": math_pass_percent_per_school,\n \"% Passing Reading\": reading_pass_percent_per_school,\n \"% Overall Passing\": both_pass_percent_per_school})\n\n# correction for some values shwoing as lists in table\nper_school_summary[\"School Type\"] = per_school_summary[\"School Type\"].str.get(0)\nper_school_summary[\"Total School Budget\"] = per_school_summary[\"Total School Budget\"].str.get(0)\nper_school_summary[\"Per Student Budget\"] = per_school_summary[\"Per Student Budget\"].str.get(0)\n\n# correct formatting in summary\nper_school_summary[\"Total School Budget\"] = per_school_summary[\"Total School Budget\"].map(\"${:,.2f}\".format)\nper_school_summary[\"Per Student Budget\"] = per_school_summary[\"Per Student Budget\"].map(\"${:.2f}\".format)\n\nper_school_summary",
"_____no_output_____"
]
],
[
[
"## Top Performing Schools (By % Overall Passing)",
"_____no_output_____"
],
[
"* Sort and display the top five performing schools by % overall passing.",
"_____no_output_____"
]
],
[
[
"# sort values base on % overall pass descending\noverall_pass_summary_desc = per_school_summary.sort_values(\"% Overall Passing\", ascending=False)\n# display the top five schools\ntop5_overall_pass_summary = overall_pass_summary_desc.head()\ntop5_overall_pass_summary",
"_____no_output_____"
]
],
[
[
"## Bottom Performing Schools (By % Overall Passing)",
"_____no_output_____"
],
[
"* Sort and display the five worst-performing schools by % overall passing.",
"_____no_output_____"
]
],
[
[
"# sort values base on % overall pass ascending\noverall_pass_summary_asc = per_school_summary.sort_values(\"% Overall Passing\")\n# display the bottom five schools\nbottom5_overall_pass_summary = overall_pass_summary_asc.head()\nbottom5_overall_pass_summary",
"_____no_output_____"
]
],
[
[
"## Math Scores by Grade",
"_____no_output_____"
],
[
"* Create a table that lists the average Reading Score for students of each grade level (9th, 10th, 11th, 12th) at each school.\n\n * Create a pandas series for each grade. Hint: use a conditional statement.\n \n * Group each series by school\n \n * Combine the series into a dataframe\n \n * Optional: give the displayed data cleaner formatting",
"_____no_output_____"
]
],
[
[
"# create series' for each grade\nninth_school_data = school_data_complete[(school_data_complete[\"grade\"] == \"9th\")]\ntenth_school_data = school_data_complete[(school_data_complete[\"grade\"] == \"10th\")]\neleventh_school_data = school_data_complete[(school_data_complete[\"grade\"] == \"11th\")]\ntwelfth_school_data = school_data_complete[(school_data_complete[\"grade\"] == \"12th\")]\n\n# group each grade's series by school name\nninth_school_data_per_school = ninth_school_data.groupby([\"school_name\"])\ntenth_school_data_per_school = tenth_school_data.groupby([\"school_name\"])\neleventh_school_data_per_school = eleventh_school_data.groupby([\"school_name\"])\ntwelfth_school_data_per_school = twelfth_school_data.groupby([\"school_name\"])\n\n# average math score for each grade\nninth_avg_math = ninth_school_data_per_school[\"math_score\"].mean()\ntenth_avg_math = tenth_school_data_per_school[\"math_score\"].mean()\neleventh_avg_math = eleventh_school_data_per_school[\"math_score\"].mean()\ntwelfth_avg_math = twelfth_school_data_per_school[\"math_score\"].mean()\n\n#create math summary data frame\nper_school_math_summary = pd.DataFrame({\"9th\": ninth_avg_math,\n \"10th\": tenth_avg_math,\n \"11th\": eleventh_avg_math,\n \"12th\": twelfth_avg_math})\nper_school_math_summary",
"_____no_output_____"
]
],
[
[
"## Reading Score by Grade ",
"_____no_output_____"
],
[
"* Perform the same operations as above for reading scores",
"_____no_output_____"
]
],
[
[
"# average reading score for each grade\nninth_avg_reading = ninth_school_data_per_school[\"reading_score\"].mean()\ntenth_avg_reading = tenth_school_data_per_school[\"reading_score\"].mean()\neleventh_avg_reading = eleventh_school_data_per_school[\"reading_score\"].mean()\ntwelfth_avg_reading = twelfth_school_data_per_school[\"reading_score\"].mean()\n\n#create reading summary data frame\nper_school_reading_summary = pd.DataFrame({\"9th\": ninth_avg_reading,\n \"10th\": tenth_avg_reading,\n \"11th\": eleventh_avg_reading,\n \"12th\": twelfth_avg_reading})\nper_school_reading_summary",
"_____no_output_____"
]
],
[
[
"## Scores by School Spending",
"_____no_output_____"
],
[
"* Create a table that breaks down school performances based on average Spending Ranges (Per Student). Use 4 reasonable bins to group school spending. Include in the table each of the following:\n * Average Math Score\n * Average Reading Score\n * % Passing Math\n * % Passing Reading\n * Overall Passing Rate (Average of the above two)",
"_____no_output_____"
]
],
[
[
"# create bins\nbins = [0,584,629,644,675]\n\n# create names for the bins\ngroup_names = [\"<$584\",\"$585-629\",\"$630-644\",\"$645-675\"]\n\n# convert data type back to float from $ (found on stack overflow)\nper_school_summary[\"Per Student Budget\"] = per_school_summary[\"Per Student Budget\"]\\\n .replace('[\\$,]', '', regex=True).astype(float)\n\n# slice and put into bins, then place as series into data frame\nper_school_summary[\"Spending Ranges (Per Student)\"] = pd.cut(per_school_summary[\"Per Student Budget\"], \n bins, labels=group_names)\n\n#group summary table by the spending ranges\nper_stu_budget_group = per_school_summary.groupby(\"Spending Ranges (Per Student)\")\n\n# calculations after groups created\nround(per_stu_budget_group[[\"Average Math Score\", \"Average Reading Score\", \"% Passing Math\",\n \"% Passing Reading\" , \"% Overall Passing\"]].mean(),2)\n",
"_____no_output_____"
]
],
[
[
"## Scores by School Size",
"_____no_output_____"
],
[
"* Perform the same operations as above, based on school size.",
"_____no_output_____"
]
],
[
[
"# create bins\nbins = [0,1000,2000,5000]\n\n# create names for the bins\ngroup_names = [\"Small (<1000)\",\"Medium (1000-2000)\",\"Large (2000-5000)\"]\n\n# slice and put into bins, then place as series into data frame\nper_school_summary[\"School Size\"] = pd.cut(per_school_summary[\"Total Students\"], \n bins, labels=group_names)\n\n#group summary table by the spending ranges\nper_school_size_group = per_school_summary.groupby(\"School Size\")\n\n# calculations after groups created\nper_school_size_group[[\"Average Math Score\", \"Average Reading Score\", \"% Passing Math\",\n \"% Passing Reading\" , \"% Overall Passing\"]].mean()",
"_____no_output_____"
]
],
[
[
"## Scores by School Type",
"_____no_output_____"
],
[
"* Perform the same operations as above, based on school type",
"_____no_output_____"
]
],
[
[
"# group summary table by the spending ranges\nper_school_type_group = per_school_summary.groupby(\"School Type\")\n\n# calculations after groups created\nper_school_type_group[[\"Average Math Score\", \"Average Reading Score\", \"% Passing Math\",\n \"% Passing Reading\" , \"% Overall Passing\"]].mean()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
e73bd9613c725d7f11a47123c55c3c91c9da0d83 | 79,314 | ipynb | Jupyter Notebook | feature_engg_text.ipynb | bipinKrishnan/fastai_course | 670dd2615480c72f543fbcff97ba863ac026fc0f | [
"MIT"
] | 5 | 2020-11-04T07:26:25.000Z | 2021-07-29T13:11:28.000Z | feature_engg_text.ipynb | bipinKrishnan/fastai_course | 670dd2615480c72f543fbcff97ba863ac026fc0f | [
"MIT"
] | null | null | null | feature_engg_text.ipynb | bipinKrishnan/fastai_course | 670dd2615480c72f543fbcff97ba863ac026fc0f | [
"MIT"
] | 1 | 2022-03-09T09:22:47.000Z | 2022-03-09T09:22:47.000Z | 35.710941 | 243 | 0.245177 | [
[
[
"<a href=\"https://colab.research.google.com/github/bipinKrishnan/fastai_course/blob/master/feature_engg_text.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import CountVectorizer\nimport nltk\nimport numpy as np\nimport pandas as pd\nimport re\n\nnltk.download('stopwords')",
"_____no_output_____"
],
[
"corpus = ['The sky is blue and beautiful.',\n 'Love this blue and beautiful sky!',\n 'The quick brown fox jumps over the lazy dog.',\n \"A king's breakfast has sausages, ham, bacon, eggs, toast and beans\",\n 'I love green eggs, ham, sausages and bacon!',\n 'The brown fox is quick and the blue dog is lazy!',\n 'The sky is very blue and the sky is very beautiful today',\n 'The dog is lazy but the brown fox is quick!' \n]\n\nlabels = ['weather', 'weather', 'animals', 'food', 'food', 'animals', 'weather', 'animals']",
"_____no_output_____"
],
[
"corpus = np.array(corpus)\ndf = pd.DataFrame({\"text\": corpus, \"label\": labels})",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"wpt = nltk.WordPunctTokenizer()\nstop_words = nltk.corpus.stopwords.words('english')\nwpt.tokenize(corpus[0])",
"_____no_output_____"
],
[
"def preprocess(doc):\n doc = doc.lower().strip()\n tokens = wpt.tokenize(doc)\n tok = [token for token in tokens if token not in stop_words]\n\n doc = ' '.join(tok)\n return doc",
"_____no_output_____"
],
[
"normalize_corpus = np.vectorize(preprocess)",
"_____no_output_____"
],
[
"norm_corp = normalize_corpus(corpus)",
"_____no_output_____"
],
[
"norm_corp",
"_____no_output_____"
]
],
[
[
"## Vectorizing text",
"_____no_output_____"
]
],
[
[
"cv = CountVectorizer(min_df=0., max_df=1.)\ncv_matrix = cv.fit_transform(norm_corp).toarray()\n\ncv_matrix",
"_____no_output_____"
],
[
"vocab = cv.get_feature_names()\nvocab",
"_____no_output_____"
],
[
"pd.DataFrame(cv_matrix, columns=vocab)",
"_____no_output_____"
],
[
"cv.transform(['sky is good and beautiful beautiful today']).toarray()",
"_____no_output_____"
]
],
[
[
"ngram_range --> if set to (1, 2)\n\n --> creates uni-gram and bi-gram\n\n --> if set to (2, 2) --> creates only bi-gram\n\n --> if set to (1, 3) --> creates only uni-gram, bi-gram and tri-gram",
"_____no_output_____"
]
],
[
[
"cv = CountVectorizer(ngram_range=(2, 2))",
"_____no_output_____"
],
[
"cv_matrix = cv.fit_transform(norm_corp).toarray()",
"_____no_output_____"
],
[
"pd.DataFrame(cv_matrix, columns=cv.get_feature_names())",
"_____no_output_____"
],
[
"cv1 = CountVectorizer(ngram_range=(1, 3))\ncv1_matrix = cv1.fit_transform(norm_corp).toarray()\npd.DataFrame(cv1_matrix, columns=cv1.get_feature_names())",
"_____no_output_____"
]
],
[
[
"# Tfidf(Term frequency and Inverse document frequency)",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import TfidfVectorizer",
"_____no_output_____"
]
],
[
[
"Creates vector based on the frequency and inverse document frequency value of ech words and displays the words based on the value or threshold frequency passed to the min_df and max_df value",
"_____no_output_____"
]
],
[
[
"tfidf = TfidfVectorizer()",
"_____no_output_____"
],
[
"tf_matrix = tfidf.fit_transform(norm_corp).toarray()\ntf_matrix",
"_____no_output_____"
],
[
"pd.DataFrame(tf_matrix, columns=tfidf.get_feature_names())",
"_____no_output_____"
],
[
"len(tfidf.get_feature_names()), len(cv.get_feature_names())",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
e73bdfaef60faef41e6314a513997e00eaad7557 | 13,154 | ipynb | Jupyter Notebook | Kaggle/Mercedes-Benz Greener Manufacturing/feed_neural_network.ipynb | datitran/Krimskrams | 24089f960c31934287ee8ad4eba8093991c06d7a | [
"MIT"
] | null | null | null | Kaggle/Mercedes-Benz Greener Manufacturing/feed_neural_network.ipynb | datitran/Krimskrams | 24089f960c31934287ee8ad4eba8093991c06d7a | [
"MIT"
] | null | null | null | Kaggle/Mercedes-Benz Greener Manufacturing/feed_neural_network.ipynb | datitran/Krimskrams | 24089f960c31934287ee8ad4eba8093991c06d7a | [
"MIT"
] | 2 | 2020-02-15T08:10:42.000Z | 2020-02-15T08:36:16.000Z | 26.255489 | 325 | 0.542877 | [
[
[
"import numpy as np\nimport pandas as pd \nimport xgboost as xgb\nimport keras.backend as K\n\nfrom datetime import datetime\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Activation, Dropout\nfrom keras.callbacks import EarlyStopping, ModelCheckpoint\nfrom keras.optimizers import RMSprop\nfrom keras.wrappers.scikit_learn import KerasRegressor\nfrom sklearn.preprocessing import LabelEncoder, MinMaxScaler\nfrom sklearn.decomposition import PCA, FastICA\nfrom sklearn.metrics import r2_score",
"Using TensorFlow backend.\n"
],
[
"train = pd.read_csv(\"data/train.csv\", index_col=\"ID\")\ntest = pd.read_csv(\"data/test.csv\", index_col=\"ID\")",
"_____no_output_____"
],
[
"for c in train.columns:\n if train[c].dtype == \"object\":\n lbl = LabelEncoder() \n lbl.fit(list(train[c].values) + list(test[c].values)) \n train[c] = lbl.transform(list(train[c].values))\n test[c] = lbl.transform(list(test[c].values))",
"_____no_output_____"
],
[
"n_comp = 10\n\n# PCA\npca = PCA(n_components=n_comp, random_state=42)\npca2_results_train = pca.fit_transform(train.drop([\"y\"], axis=1))\npca2_results_test = pca.transform(test)\n\n# ICA\nica = FastICA(n_components=n_comp, random_state=42)\nica2_results_train = ica.fit_transform(train.drop([\"y\"], axis=1))\nica2_results_test = ica.transform(test)",
"/Users/datitran/anaconda/envs/kaggle/lib/python3.5/site-packages/scipy/linalg/basic.py:1018: RuntimeWarning: internal gelsd driver lwork query error, required iwork dimension not returned. This is likely the result of LAPACK bug 0038, fixed in LAPACK 3.2.2 (released July 21, 2010). Falling back to 'gelss' driver.\n warnings.warn(mesg, RuntimeWarning)\n"
],
[
"#train = train.iloc[:, :9].copy()\n#test = test.iloc[:, :8].copy()",
"_____no_output_____"
],
[
"for i in range(1, n_comp+1):\n train[\"pca_\" + str(i)] = pca2_results_train[:,i-1]\n test[\"pca_\" + str(i)] = pca2_results_test[:, i-1]\n \n train[\"ica_\" + str(i)] = ica2_results_train[:,i-1]\n test[\"ica_\" + str(i)] = ica2_results_test[:, i-1]\n \ny_train = train[\"y\"]\ny_mean = np.mean(y_train)",
"_____no_output_____"
],
[
"x_train = train.drop(\"y\", axis=1).values.astype(np.float32)\nx_test = test.values.astype(np.float32)",
"_____no_output_____"
],
[
"x_train.shape, x_test.shape",
"_____no_output_____"
],
[
"scaler = MinMaxScaler()\nx_train_scaled = scaler.fit_transform(x_train)\nx_test_scaled = scaler.fit_transform(x_test)",
"_____no_output_____"
],
[
"def r2_keras(y_true, y_pred):\n SS_res = K.sum(K.square( y_true-y_pred )) \n SS_tot = K.sum(K.square( y_true - K.mean(y_true) ) ) \n return ( 1 - SS_res/(SS_tot + K.epsilon()) )",
"_____no_output_____"
],
[
"rmsprop = RMSprop(lr=0.0001, rho=0.9, epsilon=1e-08, decay=0.0)\n\ndef model():\n model = Sequential()\n model.add(Dense(units=, activation=\"relu\",input_dim=x_train.shape[1]))\n model.add(Dense(units=396, activation=\"relu\"))\n model.add(Dense(units=, activation=\"relu\"))\n model.add(Dense(units=512, activation=\"relu\"))\n model.add(Dense(units=512, activation=\"relu\"))\n model.add(Dense(units=512, activation=\"relu\"))\n model.add(Dense(units=1, activation=\"linear\"))\n model.compile(loss=\"mse\", optimizer=rmsprop, metrics=[r2_keras])\n #model.summary()\n return model",
"_____no_output_____"
],
[
"callbacks = [\n EarlyStopping(monitor=\"val_r2_keras\", patience=20)\n #ModelCheckpoint(\"weights.{epoch:02d}-{val_loss:.2f}.hdf5\")\n]\n\nestimator = KerasRegressor(\n build_fn=model, \n nb_epoch=100, \n batch_size=32,\n verbose=0\n)",
"_____no_output_____"
],
[
"estimator.fit(x_train_scaled, y_train, batch_size=32, epochs=200, verbose=2, callbacks=callbacks, validation_split=0.02)",
"_____no_output_____"
],
[
"y_pred_train = estimator.predict(x_train_scaled)",
"_____no_output_____"
],
[
"prediction = estimator.predict(x_test_scaled)",
"_____no_output_____"
],
[
"prediction",
"_____no_output_____"
],
[
"print(\"the R2 score is : {}\".format(r2_score(y_train, y_pred_train)))",
"_____no_output_____"
]
],
[
[
"### Ensemble the model",
"_____no_output_____"
]
],
[
[
"r2_score_list = []\nprediction_list = []\nfor i in range(1):\n estimator.fit(x_train_scaled, y_train, batch_size=32, \n epochs=50, verbose=2, callbacks=callbacks,\n validation_split=0.1, shuffle=False)\n y_pred_train = estimator.predict(x_train_scaled)\n prediction = estimator.predict(x_test_scaled)\n prediction_list.append(prediction)\n r2_value = r2_score(y_train, y_pred_train)\n print(\"Number: {}, R^2: {}\".format(i, r2_value))\n r2_score_list.append((i, r2_value))",
"Train on 3788 samples, validate on 421 samples\nEpoch 1/50\n0s - loss: 8497.0696 - r2_keras: -5.9802e+01 - val_loss: 5688.8226 - val_r2_keras: -4.7048e+01\nEpoch 2/50\n0s - loss: 3063.7014 - r2_keras: -2.0552e+01 - val_loss: 596.3211 - val_r2_keras: -3.9942e+00\nEpoch 3/50\n0s - loss: 265.6156 - r2_keras: -7.4332e-01 - val_loss: 156.3795 - val_r2_keras: -2.6558e-01\nEpoch 4/50\n0s - loss: 154.8358 - r2_keras: 0.0207 - val_loss: 104.6440 - val_r2_keras: 0.1623\nEpoch 5/50\n0s - loss: 121.1724 - r2_keras: 0.2567 - val_loss: 77.3172 - val_r2_keras: 0.3868\nEpoch 6/50\n0s - loss: 103.4057 - r2_keras: 0.3806 - val_loss: 63.6953 - val_r2_keras: 0.4983\nEpoch 7/50\n0s - loss: 93.7359 - r2_keras: 0.4478 - val_loss: 56.8824 - val_r2_keras: 0.5542\nEpoch 8/50\n0s - loss: 88.1637 - r2_keras: 0.4862 - val_loss: 53.2024 - val_r2_keras: 0.5848\nEpoch 9/50\n0s - loss: 84.7483 - r2_keras: 0.5097 - val_loss: 50.9846 - val_r2_keras: 0.6035\nEpoch 10/50\n0s - loss: 82.5202 - r2_keras: 0.5249 - val_loss: 49.5240 - val_r2_keras: 0.6160\nEpoch 11/50\n0s - loss: 80.9714 - r2_keras: 0.5355 - val_loss: 48.4918 - val_r2_keras: 0.6250\nEpoch 12/50\n0s - loss: 79.8321 - r2_keras: 0.5432 - val_loss: 47.7326 - val_r2_keras: 0.6316\nEpoch 13/50\n0s - loss: 78.9550 - r2_keras: 0.5491 - val_loss: 47.1445 - val_r2_keras: 0.6368\nEpoch 14/50\n0s - loss: 78.2526 - r2_keras: 0.5538 - val_loss: 46.6723 - val_r2_keras: 0.6409\nEpoch 15/50\n0s - loss: 77.6721 - r2_keras: 0.5577 - val_loss: 46.2824 - val_r2_keras: 0.6444\nEpoch 16/50\n0s - loss: 77.1796 - r2_keras: 0.5609 - val_loss: 45.9422 - val_r2_keras: 0.6473\nEpoch 17/50\n0s - loss: 76.7505 - r2_keras: 0.5637 - val_loss: 45.6478 - val_r2_keras: 0.6499\nEpoch 18/50\n0s - loss: 76.3729 - r2_keras: 0.5661 - val_loss: 45.4004 - val_r2_keras: 0.6520\nEpoch 19/50\n0s - loss: 76.0353 - r2_keras: 0.5683 - val_loss: 45.1856 - val_r2_keras: 0.6539\nEpoch 20/50\n0s - loss: 75.7311 - r2_keras: 0.5702 - val_loss: 45.0010 - val_r2_keras: 0.6554\nEpoch 21/50\n0s - loss: 75.4521 - r2_keras: 0.5719 - val_loss: 44.8445 - val_r2_keras: 0.6568\nEpoch 22/50\n0s - loss: 75.1957 - r2_keras: 0.5735 - val_loss: 44.7094 - val_r2_keras: 0.6579\nNumber: 0, R^2: 0.527942307065526\n"
],
[
"value = np.zeros(len(prediction_list[0]))\nfor i in prediction_list:\n value += i",
"_____no_output_____"
],
[
"average_prediction = value / len(prediction_list)",
"_____no_output_____"
],
[
"average_prediction",
"_____no_output_____"
],
[
"output = pd.DataFrame({\"id\": test.index, \"y\": average_prediction})",
"_____no_output_____"
],
[
"output.to_csv(\"submission_neural_network_average.csv\", index=False)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73bef2aae7561b4966ea6563a5fead0c1bef2ac | 12,881 | ipynb | Jupyter Notebook | Practica3/Practica 3. Sistemas Inteligentes .ipynb | gonzalofdv/SI20-21 | 1855430efd3f655bad9c3f940e8ba661141a0d11 | [
"MIT"
] | null | null | null | Practica3/Practica 3. Sistemas Inteligentes .ipynb | gonzalofdv/SI20-21 | 1855430efd3f655bad9c3f940e8ba661141a0d11 | [
"MIT"
] | null | null | null | Practica3/Practica 3. Sistemas Inteligentes .ipynb | gonzalofdv/SI20-21 | 1855430efd3f655bad9c3f940e8ba661141a0d11 | [
"MIT"
] | null | null | null | 32.2025 | 823 | 0.628833 | [
[
[
"- Número de grupo:\n- Nombre de los integrantes del grupo:\n",
"_____no_output_____"
],
[
"# Práctica 3 : representación de conocimiento \n\n\n## Parte 1: consultas SPARQL sobre Wikidata.",
"_____no_output_____"
],
[
"### Ejemplo\n\nRecuperar todas las instancias directas de la clase [Cabra (Q2934)](https://www.wikidata.org/wiki/Q2934) que aparecen en la base de conocimiento.",
"_____no_output_____"
],
[
"En esta práctica vamos a usar el punto de acceso [SPARQL](https://query.wikidata.org/) de Wikidata para contestar las preguntas que se formulan a continuación. Cada pregunta debe ser respondida realizando una única consulta SPARQL. Para cada una de las entidades recuperadas se mostrará __tanto su identificador como su etiqueta__ (nombre de la entidad en lenguaje natural). ",
"_____no_output_____"
]
],
[
[
"#Esta celda es de tipo Raw NBConvert y así jupyter notebook no la interpreta al ejecutarla. \n#Hay que copiar y pegar la consulta en el punto de acceso SPARQL en https://query.wikidata.org/\nSELECT ?item ?itemLabel \nWHERE \n{\n ?item wdt:P31 wd:Q2934. # instancias directas de la clase Cabra (goat (Q2934)) instance of (P31)\n SERVICE wikibase:label { bd:serviceParam wikibase:language \"[AUTO_LANGUAGE],en\". }\n}",
"_____no_output_____"
]
],
[
[
"<html><head><meta charset=\"utf-8\"></head><body><table><thead><tr><th>item</th><th>itemLabel</th></tr></thead><tbody><tr><td>http://www.wikidata.org/entity/Q151345</td><td>Billygoat Hennes</td></tr><tr><td>http://www.wikidata.org/entity/Q3569037</td><td>William Windsor</td></tr><tr><td>http://www.wikidata.org/entity/Q23003932</td><td>His Whiskers</td></tr><tr><td>http://www.wikidata.org/entity/Q24287064</td><td>Taffy</td></tr><tr><td>http://www.wikidata.org/entity/Q41239734</td><td>Lance Corporal Shenkin III</td></tr><tr><td>http://www.wikidata.org/entity/Q41240892</td><td>Lance Corporal Shenkin II</td></tr><tr><td>http://www.wikidata.org/entity/Q41241416</td><td>Lance Corporal Shenkin I</td></tr><tr><td>http://www.wikidata.org/entity/Q65326499</td><td>Konkan kanyal</td></tr></tbody></table></body></html>",
"_____no_output_____"
],
[
"El punto de acceso SPARQL de Wikidata ofrece ciertos extras sobre el estándar. Por ejemplo, la línea SERVICE de la consulta nos permite obtener automáticamente la etiqueta de cualquier item con sólo crear una nueva variable que termine en Label (por ejemplo ?itemLabel en la consulta).",
"_____no_output_____"
],
[
"Podemos utilizar el paquete [qwikidata](https://qwikidata.readthedocs.io/en/stable/) para acceder a Wikidata desde un programa Python.\n#### Descomentar para instalar el paquete",
"_____no_output_____"
]
],
[
[
"#%pip install qwikidata",
"_____no_output_____"
],
[
"from qwikidata.sparql import return_sparql_query_results\n\nsparql_query = \"\"\"\nSELECT ?item ?itemLabel \nWHERE \n{\n ?item wdt:P31 wd:Q2934.\n SERVICE wikibase:label { bd:serviceParam wikibase:language \"en\". }\n}\n\"\"\"\nres = return_sparql_query_results(sparql_query)\nres",
"_____no_output_____"
],
[
"# También hay alguna función de utilidad extra que nos permite, por ejemplo, obtener las subclases de una entidad.\nfrom qwikidata.sparql import get_subclasses_of_item\nQ_RIVER = \"Q4022\"\nsubclasses_of_river = get_subclasses_of_item(Q_RIVER)\nsubclasses_of_river",
"_____no_output_____"
]
],
[
[
"### Interfaz Linked data\n\nPodemos recuperar la información de distintas entidades y propiedades de Wikidata y acceder a ellas mediante objetos de Python. En este ejemplo vamos a trabajar con el item [Douglas Adams (Q42)](https://www.wikidata.org/wiki/Q42).",
"_____no_output_____"
]
],
[
[
"from qwikidata.entity import WikidataItem, WikidataProperty, WikidataLexeme \nfrom qwikidata.linked_data_interface import get_entity_dict_from_api\n\n# obtener un objeto con la información del escritor douglas Adams\nQ_DOUGLAS_ADAMS = 'Q42'\nq42_dict = get_entity_dict_from_api(Q_DOUGLAS_ADAMS)\nq42 = WikidataItem(q42_dict)\nq42",
"_____no_output_____"
],
[
"#Podemos navegar por la información del objeto q42\nq42.entity_type",
"_____no_output_____"
],
[
"q42.get_label()",
"_____no_output_____"
],
[
"q42.get_description()",
"_____no_output_____"
],
[
"q42.get_aliases()",
"_____no_output_____"
],
[
"# prueba a meter la info de cabra wd:Q2934\nQ_CABRA = 'Q2934'\nq_dict = get_entity_dict_from_api(Q_CABRA)\nq = WikidataItem(q_dict)\nq",
"_____no_output_____"
]
],
[
[
"Haz lo mismo para encontrar algo de información sobre [Steven Spielberg](https://www.wikidata.org/wiki/Q8877).",
"_____no_output_____"
],
[
"Se proponen varias consultas. Para cada una de las preguntas debes mostrar tanto la consulta como la respuesta obtenida.\n\n - La __consulta__ debe estar en una celda de tipo _Raw NBConvert_ para que jupyter no trate de interpretarla. Cada tripleta de la consulta debe tener un breve comentario a la derecha que la explique (los comentarios empiezan con #). \n - La __respuesta__ debe estar en una celda de tipo _Markdown_. Puedes descargar las respuestas usando la opción _Descargar >> HTML Table_ y copiar el código HTML en esta celda. Al ejecutar la celda se mostrará en forma de tabla.\n - Si lo consideras necesario, puedes añadir celdas adicionales en formato _Markdown_ para explicar decisiones que hayas tomado al crear la consulta o cualquier otro dato que consideres interesante.\n \n \n__Para resolver estas consultas necesitarás aprender algo más de SPARQL de lo que hemos contado en clase__. Los dos recursos que te recomendamos consultar son:\n\n- [Este tutorial de SPARQL](https://www.wikidata.org/wiki/Wikidata:SPARQL_tutorial).\n- [Esta recopilación de ejemplos](https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service/queries/examples)\n\n\nPuedes probar las consultas en el punto de acceso SPARQL[SPARQL](https://query.wikidata.org/) de Wikidata y copiar la respuesta en otra celda. \nNo es necesario lanzar las consultas desde el paquete [qwikidata](https://qwikidata.readthedocs.io/en/stable/) para acceder a Wikidata desde un programa Python aunque puedes hacerlo si lo prefieres.\n\nLo importante son las consultas SPARQL. Cada pregunta debe ser respondida realizando una única consulta SPARQL. Para cada una de las entidades recuperadas se mostrará __tanto su identificador como su etiqueta__ (nombre de la entidad en lenguaje natural). ",
"_____no_output_____"
],
[
"### Consulta 1\n\n[Steven Allan Spielberg (Q8877)](https://www.wikidata.org/wiki/Q8877) es uno de los directores más reconocidos y populares de la industria cinematográfica mundial. Escribe una consulta que te permita averiguar su fecha y lugar de nacimiento.",
"_____no_output_____"
],
[
"El resultado es: Nacio el 18 de diciembre de 1946\ten wd:Q43196\tCincinnati\nDebes escribir una consulta para obtener estos datos.\nPistas: Lugar de nacimiento (P19) de Spielberg (Q8877)\n Fecha de nacimiento (P569) de Spielberg (Q8877)",
"_____no_output_____"
],
[
"### Consulta 2\n\nAdemás, se sabe que Spielberg es muy polifacetico.. vamos a averiguar todas las distintas profesiones (ocupaciones) (P106) de Spielberg (Q8877)en la base de conocimiento. Queremos obtener los resultados ordenados alfabéticamente por el nombre de la profesión.",
"_____no_output_____"
],
[
"### Consulta 3\nAverigua también el nombre de su padre y de sus hermanos.\n",
"_____no_output_____"
],
[
"### Consulta 4\nAhora queremos conocer el título de todas las películas que Spielberg ha dirigido. Se mostrarán ordenadas alfabéticamente y debes tener cuidado de no mostrar resultados repetidos. Ten en cuenta que puede haber distintos tipos de películas.",
"_____no_output_____"
],
[
"### Consulta 5\n\nAhora queremos conocer el título de todas las películas que Spielberg ha dirigido. Se mostrarán ordenadas alfabéticamente y debes tener cuidado de no mostrar resultados repetidos. Ten en cuenta que puede haber distintos tipos de películas.",
"_____no_output_____"
],
[
"### Consulta 6\n\nSpielberg es sin duda un director prolífico. ¿Exactamente cuántas películas de ciencia ficción ha dirigido?",
"_____no_output_____"
],
[
"### Consulta 7\n\nEs importante que las películas tengan una duración adecuada, ni muy cortas ni demasiado largas. De todas las películas que ha dirigido Spielberg, ¿cuales duran entre 90 y 150 minutos? Para cada película muestra el título y la duración. Los resultados se deben mostrar ordenados alfabéticamente.",
"_____no_output_____"
],
[
"## Parte II: \nElige un tema de tu interés y realiza consultas para obtener información relevante de la base de conocimiento de Wikidata. \nPor ejemplo, puede ser una serie de televisión (como Game of Thrones (Q23572) o los Bridgerton (Q85748936), saga de películas (Star Wars (Q462)) o tu cantante o grupo favorito (Alejandro Sanz (Q276170)). \nO cualquier otro tema: instrumentos musicales, videojuegos (Q659563), geografía, arte,.. \n",
"_____no_output_____"
],
[
"__Fecha de las consultas: RELLENAR__",
"_____no_output_____"
]
]
] | [
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
e73bf0cc603e07e71accac4c0b40591677d1a68b | 3,848 | ipynb | Jupyter Notebook | python-pandas-vs-julia-dataframes/pandas-rolling.ipynb | StatisticalMice/experiments | f1835aa46e1ec30594d562e40490745122dbd444 | [
"CC-BY-3.0",
"MIT"
] | null | null | null | python-pandas-vs-julia-dataframes/pandas-rolling.ipynb | StatisticalMice/experiments | f1835aa46e1ec30594d562e40490745122dbd444 | [
"CC-BY-3.0",
"MIT"
] | null | null | null | python-pandas-vs-julia-dataframes/pandas-rolling.ipynb | StatisticalMice/experiments | f1835aa46e1ec30594d562e40490745122dbd444 | [
"CC-BY-3.0",
"MIT"
] | null | null | null | 20.146597 | 80 | 0.443867 | [
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"data = pd.Series(np.random.randn(1_000_000))",
"_____no_output_____"
],
[
"%timeit pd.Series(np.random.randn(1_000_000))",
"30.1 ms ± 35.7 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)\n"
],
[
"%timeit data.rolling(10).mean()",
"31.3 ms ± 1.04 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)\n"
],
[
"def udf(x):\n return np.mean(x)",
"_____no_output_____"
],
[
"%time data.rolling(10).apply(udf, raw=True)",
"CPU times: user 6.24 s, sys: 12 ms, total: 6.25 s\nWall time: 6.26 s\n"
],
[
"%time data.rolling(10).apply(udf, raw=True, engine=\"numba\")",
"CPU times: user 1.04 s, sys: 93.7 ms, total: 1.14 s\nWall time: 1.28 s\n"
],
[
"%timeit data.rolling(10).apply(udf, raw=True, engine=\"numba\")",
"202 ms ± 2.54 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73c04593273ef8e22041f8b38608fdb12b2972a | 55,477 | ipynb | Jupyter Notebook | tv-script-generation/dlnd_tv_script_generation.ipynb | dxl0632/deeplearning_nd_udacity | 019c55e49782d9e5553eb74f7e38f3054c3d5f5a | [
"MIT"
] | null | null | null | tv-script-generation/dlnd_tv_script_generation.ipynb | dxl0632/deeplearning_nd_udacity | 019c55e49782d9e5553eb74f7e38f3054c3d5f5a | [
"MIT"
] | null | null | null | tv-script-generation/dlnd_tv_script_generation.ipynb | dxl0632/deeplearning_nd_udacity | 019c55e49782d9e5553eb74f7e38f3054c3d5f5a | [
"MIT"
] | null | null | null | 39.06831 | 556 | 0.561566 | [
[
[
"# TV Script Generation\nIn this project, you'll generate your own [Simpsons](https://en.wikipedia.org/wiki/The_Simpsons) TV scripts using RNNs. You'll be using part of the [Simpsons dataset](https://www.kaggle.com/wcukierski/the-simpsons-by-the-data) of scripts from 27 seasons. The Neural Network you'll build will generate a new TV script for a scene at [Moe's Tavern](https://simpsonswiki.com/wiki/Moe's_Tavern).\n## Get the Data\nThe data is already provided for you. You'll be using a subset of the original dataset. It consists of only the scenes in Moe's Tavern. This doesn't include other versions of the tavern, like \"Moe's Cavern\", \"Flaming Moe's\", \"Uncle Moe's Family Feed-Bag\", etc..",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nimport helper\n\ndata_dir = './data/simpsons/moes_tavern_lines.txt'\ntext = helper.load_data(data_dir)\n# Ignore notice, since we don't use it for analysing the data\ntext = text[81:]",
"_____no_output_____"
]
],
[
[
"## Explore the Data\nPlay around with `view_sentence_range` to view different parts of the data.",
"_____no_output_____"
]
],
[
[
"view_sentence_range = (0, 10)\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nimport numpy as np\n\nprint('Dataset Stats')\nprint('Roughly the number of unique words: {}'.format(len({word: None for word in text.split()})))\nscenes = text.split('\\n\\n')\nprint('Number of scenes: {}'.format(len(scenes)))\nsentence_count_scene = [scene.count('\\n') for scene in scenes]\nprint('Average number of sentences in each scene: {}'.format(np.average(sentence_count_scene)))\n\nsentences = [sentence for scene in scenes for sentence in scene.split('\\n')]\nprint('Number of lines: {}'.format(len(sentences)))\nword_count_sentence = [len(sentence.split()) for sentence in sentences]\nprint('Average number of words in each line: {}'.format(np.average(word_count_sentence)))\n\nprint()\nprint('The sentences {} to {}:'.format(*view_sentence_range))\nprint('\\n'.join(text.split('\\n')[view_sentence_range[0]:view_sentence_range[1]]))",
"Dataset Stats\nRoughly the number of unique words: 11492\nNumber of scenes: 262\nAverage number of sentences in each scene: 15.248091603053435\nNumber of lines: 4257\nAverage number of words in each line: 11.50434578341555\n\nThe sentences 0 to 10:\nMoe_Szyslak: (INTO PHONE) Moe's Tavern. Where the elite meet to drink.\nBart_Simpson: Eh, yeah, hello, is Mike there? Last name, Rotch.\nMoe_Szyslak: (INTO PHONE) Hold on, I'll check. (TO BARFLIES) Mike Rotch. Mike Rotch. Hey, has anybody seen Mike Rotch, lately?\nMoe_Szyslak: (INTO PHONE) Listen you little puke. One of these days I'm gonna catch you, and I'm gonna carve my name on your back with an ice pick.\nMoe_Szyslak: What's the matter Homer? You're not your normal effervescent self.\nHomer_Simpson: I got my problems, Moe. Give me another one.\nMoe_Szyslak: Homer, hey, you should not drink to forget your problems.\nBarney_Gumble: Yeah, you should only drink to enhance your social skills.\n\n\n"
]
],
[
[
"## Implement Preprocessing Functions\nThe first thing to do to any dataset is preprocessing. Implement the following preprocessing functions below:\n- Lookup Table\n- Tokenize Punctuation\n\n### Lookup Table\nTo create a word embedding, you first need to transform the words to ids. In this function, create two dictionaries:\n- Dictionary to go from the words to an id, we'll call `vocab_to_int`\n- Dictionary to go from the id to word, we'll call `int_to_vocab`\n\nReturn these dictionaries in the following tuple `(vocab_to_int, int_to_vocab)`",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport problem_unittests as tests\nfrom collections import Counter\n\ndef create_lookup_tables(text):\n \"\"\"\n Create lookup tables for vocabulary\n :param text: The text of tv scripts split into words\n :return: A tuple of dicts (vocab_to_int, int_to_vocab)\n \"\"\"\n # TODO: Implement Function\n vocab = set(text)\n vocab_to_int = {word: index for index, word in enumerate(vocab)}\n int_to_vocab = dict(enumerate(vocab))\n return vocab_to_int, int_to_vocab\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_create_lookup_tables(create_lookup_tables)",
"Tests Passed\n"
]
],
[
[
"### Tokenize Punctuation\nWe'll be splitting the script into a word array using spaces as delimiters. However, punctuations like periods and exclamation marks make it hard for the neural network to distinguish between the word \"bye\" and \"bye!\".\n\nImplement the function `token_lookup` to return a dict that will be used to tokenize symbols like \"!\" into \"||Exclamation_Mark||\". Create a dictionary for the following symbols where the symbol is the key and value is the token:\n- Period ( . )\n- Comma ( , )\n- Quotation Mark ( \" )\n- Semicolon ( ; )\n- Exclamation mark ( ! )\n- Question mark ( ? )\n- Left Parentheses ( ( )\n- Right Parentheses ( ) )\n- Dash ( -- )\n- Return ( \\n )\n\nThis dictionary will be used to token the symbols and add the delimiter (space) around it. This separates the symbols as it's own word, making it easier for the neural network to predict on the next word. Make sure you don't use a token that could be confused as a word. Instead of using the token \"dash\", try using something like \"||dash||\".",
"_____no_output_____"
]
],
[
[
"def token_lookup():\n \"\"\"\n Generate a dict to turn punctuation into a token.\n :return: Tokenize dictionary where the key is the punctuation and the value is the token\n \"\"\"\n # TODO: Implement Function\n rs = {\".\": \"||period||\",\n \",\": \"||comma||\",\n '\"': \"||quotation||\",\n \";\": \"||semicolon||\",\n \"!\": \"||exclamation||\",\n \"?\": \"||question||\",\n \"(\": \"||left_p||\",\n \")\": \"||right_p||\",\n \"--\": \"||dash||\",\n \"\\n\": \"||return||\"\n }\n return rs\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_tokenize(token_lookup)",
"Tests Passed\n"
]
],
[
[
"## Preprocess all the data and save it\nRunning the code cell below will preprocess all the data and save it to file.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\n# Preprocess Training, Validation, and Testing Data\nhelper.preprocess_and_save_data(data_dir, token_lookup, create_lookup_tables)",
"_____no_output_____"
]
],
[
[
"# Check Point\nThis is your first checkpoint. If you ever decide to come back to this notebook or have to restart the notebook, you can start from here. The preprocessed data has been saved to disk.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nimport helper\nimport numpy as np\nimport problem_unittests as tests\n\nint_text, vocab_to_int, int_to_vocab, token_dict = helper.load_preprocess()",
"_____no_output_____"
]
],
[
[
"## Build the Neural Network\nYou'll build the components necessary to build a RNN by implementing the following functions below:\n- get_inputs\n- get_init_cell\n- get_embed\n- build_rnn\n- build_nn\n- get_batches\n\n### Check the Version of TensorFlow and Access to GPU",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nfrom distutils.version import LooseVersion\nimport warnings\nimport tensorflow as tf\n\n# Check TensorFlow Version\nassert LooseVersion(tf.__version__) >= LooseVersion('1.0'), 'Please use TensorFlow version 1.0 or newer'\nprint('TensorFlow Version: {}'.format(tf.__version__))\n\n# Check for a GPU\nif not tf.test.gpu_device_name():\n warnings.warn('No GPU found. Please use a GPU to train your neural network.')\nelse:\n print('Default GPU Device: {}'.format(tf.test.gpu_device_name()))",
"TensorFlow Version: 1.1.0\nDefault GPU Device: /gpu:0\n"
]
],
[
[
"### Input\nImplement the `get_inputs()` function to create TF Placeholders for the Neural Network. It should create the following placeholders:\n- Input text placeholder named \"input\" using the [TF Placeholder](https://www.tensorflow.org/api_docs/python/tf/placeholder) `name` parameter.\n- Targets placeholder\n- Learning Rate placeholder\n\nReturn the placeholders in the following tuple `(Input, Targets, LearningRate)`",
"_____no_output_____"
]
],
[
[
"def get_inputs():\n \"\"\"\n Create TF Placeholders for input, targets, and learning rate.\n :return: Tuple (input, targets, learning rate)\n \"\"\"\n # TODO: Implement Function\n inputs = tf.placeholder(tf.int32, [None, None], name='input')\n targets = tf.placeholder(tf.int32, [None, None], name='targets')\n learing_rate = tf.placeholder(tf.float32, name='learing_rate')\n return inputs, targets, learing_rate\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_inputs(get_inputs)",
"Tests Passed\n"
]
],
[
[
"### Build RNN Cell and Initialize\nStack one or more [`BasicLSTMCells`](https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/BasicLSTMCell) in a [`MultiRNNCell`](https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/MultiRNNCell).\n- The Rnn size should be set using `rnn_size`\n- Initalize Cell State using the MultiRNNCell's [`zero_state()`](https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/MultiRNNCell#zero_state) function\n - Apply the name \"initial_state\" to the initial state using [`tf.identity()`](https://www.tensorflow.org/api_docs/python/tf/identity)\n\nReturn the cell and initial state in the following tuple `(Cell, InitialState)`",
"_____no_output_____"
]
],
[
[
"def lstm_cell(lstm_size, keep_prob):\n cell = tf.contrib.rnn.BasicLSTMCell(lstm_size, reuse=tf.get_variable_scope().reuse)\n return tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=keep_prob)\n\ndef get_init_cell(batch_size, rnn_size, num_layers=3, keep_prob=0.5):\n \"\"\"\n Create an RNN Cell and initialize it.\n :param batch_size: Size of batches\n :param rnn_size: Size of RNNs\n :return: Tuple (cell, initialize state)\n # no dropoputs?\n \"\"\"\n # TODO: Implement Function\n # Stack up multiple LSTM layers, for deep learning\n cell = tf.contrib.rnn.MultiRNNCell([lstm_cell(rnn_size, keep_prob) for _ in range(num_layers)], state_is_tuple=True)\n initial_state = cell.zero_state(batch_size, tf.float32)\n initial_state = tf.identity(initial_state, 'initial_state')\n \n return cell, initial_state\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_init_cell(get_init_cell)",
"Tests Passed\n"
]
],
[
[
"### Word Embedding\nApply embedding to `input_data` using TensorFlow. Return the embedded sequence.",
"_____no_output_____"
]
],
[
[
"def get_embed(input_data, vocab_size, embed_dim):\n \"\"\"\n Create embedding for <input_data>.\n :param input_data: TF placeholder for text input.\n :param vocab_size: Number of words in vocabulary.\n :param embed_dim: Number of embedding dimensions\n :return: Embedded input.\n \"\"\"\n # TODO: Implement Function\n # init embedding matrix\n # embedding = tf.Variable(tf.random_uniform([vocab_size, embed_dim], minval=-1, maxval=1))\n # embed = tf.nn.embedding_lookup(embedding, input_data)\n return tf.contrib.layers.embed_sequence(input_data, vocab_size, embed_dim)\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_embed(get_embed)",
"Tests Passed\n"
]
],
[
[
"### Build RNN\nYou created a RNN Cell in the `get_init_cell()` function. Time to use the cell to create a RNN.\n- Build the RNN using the [`tf.nn.dynamic_rnn()`](https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn)\n - Apply the name \"final_state\" to the final state using [`tf.identity()`](https://www.tensorflow.org/api_docs/python/tf/identity)\n\nReturn the outputs and final_state state in the following tuple `(Outputs, FinalState)` ",
"_____no_output_____"
]
],
[
[
"def build_rnn(cell, inputs):\n \"\"\"\n Create a RNN using a RNN Cell\n :param cell: RNN Cell\n :param inputs: Input text data\n :return: Tuple (Outputs, Final State)\n \"\"\"\n # TODO: Implement Function\n outputs, state = tf.nn.dynamic_rnn(cell, inputs, dtype=tf.float32)\n state = tf.identity(state, name='final_state')\n return outputs, state\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_build_rnn(build_rnn)",
"Tests Passed\n"
]
],
[
[
"### Build the Neural Network\nApply the functions you implemented above to:\n- Apply embedding to `input_data` using your `get_embed(input_data, vocab_size, embed_dim)` function.\n- Build RNN using `cell` and your `build_rnn(cell, inputs)` function.\n- Apply a fully connected layer with a linear activation and `vocab_size` as the number of outputs.\n\nReturn the logits and final state in the following tuple (Logits, FinalState) ",
"_____no_output_____"
]
],
[
[
"def build_nn(cell, rnn_size, input_data, vocab_size, embed_dim):\n \"\"\"\n Build part of the neural network\n :param cell: RNN cell\n :param rnn_size: Size of rnns\n :param input_data: Input data\n :param vocab_size: Vocabulary size\n :param embed_dim: Number of embedding dimensions\n :return: Tuple (Logits, FinalState)\n \"\"\"\n # TODO: Implement Function\n embeded = get_embed(input_data, vocab_size, embed_dim)\n outputs, state = build_rnn(cell, embeded)\n wt_init = tf.truncated_normal_initializer(mean=0, stddev=0.1)\n bias_init = tf.zeros_initializer()\n\n logits = tf.contrib.layers.fully_connected(outputs,\n vocab_size,\n activation_fn=None,\n weights_initializer=wt_init,\n biases_initializer=bias_init)\n return logits, state\n \n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_build_nn(build_nn)",
"Tests Passed\n"
]
],
[
[
"### Batches\nImplement `get_batches` to create batches of input and targets using `int_text`. The batches should be a Numpy array with the shape `(number of batches, 2, batch size, sequence length)`. Each batch contains two elements:\n- The first element is a single batch of **input** with the shape `[batch size, sequence length]`\n- The second element is a single batch of **targets** with the shape `[batch size, sequence length]`\n\nIf you can't fill the last batch with enough data, drop the last batch.\n\nFor exmple, `get_batches([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20], 3, 2)` would return a Numpy array of the following:\n```\n[\n # First Batch\n [\n # Batch of Input\n [[ 1 2], [ 7 8], [13 14]]\n # Batch of targets\n [[ 2 3], [ 8 9], [14 15]]\n ]\n\n # Second Batch\n [\n # Batch of Input\n [[ 3 4], [ 9 10], [15 16]]\n # Batch of targets\n [[ 4 5], [10 11], [16 17]]\n ]\n\n # Third Batch\n [\n # Batch of Input\n [[ 5 6], [11 12], [17 18]]\n # Batch of targets\n [[ 6 7], [12 13], [18 1]]\n ]\n]\n```\n\nNotice that the last target value in the last batch is the first input value of the first batch. In this case, `1`. This is a common technique used when creating sequence batches, although it is rather unintuitive.",
"_____no_output_____"
]
],
[
[
"def get_batches(int_text, batch_size, seq_length):\n \"\"\"\n Return batches of input and target\n :param int_text: Text with the words replaced by their ids\n :param batch_size: The size of batch\n :param seq_length: The length of sequence\n :return: Batches as a Numpy array\n \"\"\"\n # TODO: Implement Function\n n_batches = len(int_text) // (batch_size * seq_length)\n valid_len = n_batches * batch_size * seq_length\n inputs = int_text[:valid_len]\n targets = int_text[1:valid_len] + [int_text[0]]\n\n x = np.reshape(inputs, (batch_size, n_batches, seq_length))\n y = np.reshape(targets, (batch_size, n_batches, seq_length))\n out = []\n \n for i in range(n_batches):\n out.append([x[:,i], y[:,i]])\n return np.array(out)\n\n## from review\n# num_batches = len(int_text) // (batch_size * seq_length)\n\n# xdata = np.array(int_text[:n_batches * batch_size * seq_length])\n# ydata = np.array(int_text[1:n_batches * batch_size * seq_length + 1])\n\n# x_batches = np.split(xdata.reshape(batch_size, -1), n_batches, 1)\n# y_batches = np.split(ydata.reshape(batch_size, -1), n_batches, 1)\n\n# batches = np.array(list(zip(y_batches, x_batches)))\n\n# return batches\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_batches(get_batches)",
"Tests Passed\n"
]
],
[
[
"## Neural Network Training\n### Hyperparameters\nTune the following parameters:\n\n- Set `num_epochs` to the number of epochs.\n- Set `batch_size` to the batch size.\n- Set `rnn_size` to the size of the RNNs.\n- Set `embed_dim` to the size of the embedding.\n- Set `seq_length` to the length of sequence.\n- Set `learning_rate` to the learning rate.\n- Set `show_every_n_batches` to the number of batches the neural network should print progress.",
"_____no_output_____"
]
],
[
[
"# Number of Epochs\n# Enough epochs to get near a minimum in the training loss, \n# no real upper limit on this. Just need to make sure the \n# training loss is low and not improving much with more training.\nnum_epochs = 200\n\n# Batch Size\n# Batch size is large enough to train efficiently, but small \n# enough to fit the data in memory. No real “best” value here, \n# depends on GPU memory usually.\nbatch_size = 128\n\n# RNN Size\n# Size of the RNN cells (number of units in the hidden layers) \n# is large enough to fit the data well. Again, no real “best” value.\nrnn_size = 256\n\n# Number of layers\nnum_layers = 2\n\n# Dropout\nkeep_prob = 0.7\n\n# Embedding Dimension Size\nembed_dim = 512\n\n# Sequence Length\n# The sequence length (seq_length) here should be about \n# the size of the length of sentences you want to generate. \n# Should match the structure of the data.\n# here about 10-12\nseq_length = 32\n\n# Learning Rate\nlearning_rate = 0.005\n# Show stats for every n number of batches\nshow_every_n_batches = 20\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\nsave_dir = './save'",
"_____no_output_____"
]
],
[
[
"### Build the Graph\nBuild the graph using the neural network you implemented.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nfrom tensorflow.contrib import seq2seq\n\ntrain_graph = tf.Graph()\nwith train_graph.as_default():\n vocab_size = len(int_to_vocab)\n input_text, targets, lr = get_inputs()\n input_data_shape = tf.shape(input_text)\n cell, initial_state = get_init_cell(input_data_shape[0], rnn_size, num_layers, keep_prob)\n logits, final_state = build_nn(cell, rnn_size, input_text, vocab_size, embed_dim)\n\n # Probabilities for generating words\n probs = tf.nn.softmax(logits, name='probs')\n\n # Loss function\n cost = seq2seq.sequence_loss(\n logits,\n targets,\n tf.ones([input_data_shape[0], input_data_shape[1]]))\n\n # Optimizer\n optimizer = tf.train.AdamOptimizer(lr)\n\n # Gradient Clipping\n gradients = optimizer.compute_gradients(cost)\n capped_gradients = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gradients if grad is not None]\n train_op = optimizer.apply_gradients(capped_gradients)",
"_____no_output_____"
]
],
[
[
"## Train\nTrain the neural network on the preprocessed data. If you have a hard time getting a good loss, check the [forms](https://discussions.udacity.com/) to see if anyone is having the same problem.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nbatches = get_batches(int_text, batch_size, seq_length)\n\nwith tf.Session(graph=train_graph) as sess:\n sess.run(tf.global_variables_initializer())\n\n for epoch_i in range(num_epochs):\n state = sess.run(initial_state, {input_text: batches[0][0]})\n\n for batch_i, (x, y) in enumerate(batches):\n feed = {\n input_text: x,\n targets: y,\n initial_state: state,\n lr: learning_rate}\n train_loss, state, _ = sess.run([cost, final_state, train_op], feed)\n\n # Show every <show_every_n_batches> batches\n if (epoch_i * len(batches) + batch_i) % show_every_n_batches == 0:\n print('Epoch {:>3} Batch {:>4}/{} train_loss = {:.3f}'.format(\n epoch_i,\n batch_i,\n len(batches),\n train_loss))\n\n # Save Model\n saver = tf.train.Saver()\n saver.save(sess, save_dir)\n print('Model Trained and Saved')",
"Epoch 0 Batch 0/16 train_loss = 8.832\nEpoch 0 Batch 10/16 train_loss = 6.254\nEpoch 1 Batch 4/16 train_loss = 5.598\nEpoch 1 Batch 14/16 train_loss = 5.381\nEpoch 2 Batch 8/16 train_loss = 5.181\nEpoch 3 Batch 2/16 train_loss = 5.019\nEpoch 3 Batch 12/16 train_loss = 4.798\nEpoch 4 Batch 6/16 train_loss = 4.689\nEpoch 5 Batch 0/16 train_loss = 4.543\nEpoch 5 Batch 10/16 train_loss = 4.507\nEpoch 6 Batch 4/16 train_loss = 4.362\nEpoch 6 Batch 14/16 train_loss = 4.275\nEpoch 7 Batch 8/16 train_loss = 4.204\nEpoch 8 Batch 2/16 train_loss = 4.155\nEpoch 8 Batch 12/16 train_loss = 3.971\nEpoch 9 Batch 6/16 train_loss = 3.965\nEpoch 10 Batch 0/16 train_loss = 3.844\nEpoch 10 Batch 10/16 train_loss = 3.854\nEpoch 11 Batch 4/16 train_loss = 3.737\nEpoch 11 Batch 14/16 train_loss = 3.629\nEpoch 12 Batch 8/16 train_loss = 3.621\nEpoch 13 Batch 2/16 train_loss = 3.550\nEpoch 13 Batch 12/16 train_loss = 3.405\nEpoch 14 Batch 6/16 train_loss = 3.385\nEpoch 15 Batch 0/16 train_loss = 3.318\nEpoch 15 Batch 10/16 train_loss = 3.298\nEpoch 16 Batch 4/16 train_loss = 3.204\nEpoch 16 Batch 14/16 train_loss = 3.129\nEpoch 17 Batch 8/16 train_loss = 3.139\nEpoch 18 Batch 2/16 train_loss = 3.086\nEpoch 18 Batch 12/16 train_loss = 2.967\nEpoch 19 Batch 6/16 train_loss = 2.913\nEpoch 20 Batch 0/16 train_loss = 2.861\nEpoch 20 Batch 10/16 train_loss = 2.862\nEpoch 21 Batch 4/16 train_loss = 2.782\nEpoch 21 Batch 14/16 train_loss = 2.703\nEpoch 22 Batch 8/16 train_loss = 2.718\nEpoch 23 Batch 2/16 train_loss = 2.675\nEpoch 23 Batch 12/16 train_loss = 2.603\nEpoch 24 Batch 6/16 train_loss = 2.517\nEpoch 25 Batch 0/16 train_loss = 2.521\nEpoch 25 Batch 10/16 train_loss = 2.472\nEpoch 26 Batch 4/16 train_loss = 2.434\nEpoch 26 Batch 14/16 train_loss = 2.386\nEpoch 27 Batch 8/16 train_loss = 2.386\nEpoch 28 Batch 2/16 train_loss = 2.393\nEpoch 28 Batch 12/16 train_loss = 2.323\nEpoch 29 Batch 6/16 train_loss = 2.243\nEpoch 30 Batch 0/16 train_loss = 2.222\nEpoch 30 Batch 10/16 train_loss = 2.227\nEpoch 31 Batch 4/16 train_loss = 2.178\nEpoch 31 Batch 14/16 train_loss = 2.074\nEpoch 32 Batch 8/16 train_loss = 2.135\nEpoch 33 Batch 2/16 train_loss = 2.092\nEpoch 33 Batch 12/16 train_loss = 2.051\nEpoch 34 Batch 6/16 train_loss = 1.963\nEpoch 35 Batch 0/16 train_loss = 2.025\nEpoch 35 Batch 10/16 train_loss = 1.960\nEpoch 36 Batch 4/16 train_loss = 1.934\nEpoch 36 Batch 14/16 train_loss = 1.863\nEpoch 37 Batch 8/16 train_loss = 1.856\nEpoch 38 Batch 2/16 train_loss = 1.860\nEpoch 38 Batch 12/16 train_loss = 1.845\nEpoch 39 Batch 6/16 train_loss = 1.752\nEpoch 40 Batch 0/16 train_loss = 1.795\nEpoch 40 Batch 10/16 train_loss = 1.773\nEpoch 41 Batch 4/16 train_loss = 1.749\nEpoch 41 Batch 14/16 train_loss = 1.665\nEpoch 42 Batch 8/16 train_loss = 1.723\nEpoch 43 Batch 2/16 train_loss = 1.687\nEpoch 43 Batch 12/16 train_loss = 1.648\nEpoch 44 Batch 6/16 train_loss = 1.563\nEpoch 45 Batch 0/16 train_loss = 1.614\nEpoch 45 Batch 10/16 train_loss = 1.576\nEpoch 46 Batch 4/16 train_loss = 1.589\nEpoch 46 Batch 14/16 train_loss = 1.528\nEpoch 47 Batch 8/16 train_loss = 1.534\nEpoch 48 Batch 2/16 train_loss = 1.485\nEpoch 48 Batch 12/16 train_loss = 1.523\nEpoch 49 Batch 6/16 train_loss = 1.435\nEpoch 50 Batch 0/16 train_loss = 1.513\nEpoch 50 Batch 10/16 train_loss = 1.513\nEpoch 51 Batch 4/16 train_loss = 1.445\nEpoch 51 Batch 14/16 train_loss = 1.388\nEpoch 52 Batch 8/16 train_loss = 1.406\nEpoch 53 Batch 2/16 train_loss = 1.401\nEpoch 53 Batch 12/16 train_loss = 1.380\nEpoch 54 Batch 6/16 train_loss = 1.299\nEpoch 55 Batch 0/16 train_loss = 1.351\nEpoch 55 Batch 10/16 train_loss = 1.346\nEpoch 56 Batch 4/16 train_loss = 1.316\nEpoch 56 Batch 14/16 train_loss = 1.286\nEpoch 57 Batch 8/16 train_loss = 1.268\nEpoch 58 Batch 2/16 train_loss = 1.306\nEpoch 58 Batch 12/16 train_loss = 1.275\nEpoch 59 Batch 6/16 train_loss = 1.195\nEpoch 60 Batch 0/16 train_loss = 1.238\nEpoch 60 Batch 10/16 train_loss = 1.244\nEpoch 61 Batch 4/16 train_loss = 1.242\nEpoch 61 Batch 14/16 train_loss = 1.161\nEpoch 62 Batch 8/16 train_loss = 1.171\nEpoch 63 Batch 2/16 train_loss = 1.172\nEpoch 63 Batch 12/16 train_loss = 1.178\nEpoch 64 Batch 6/16 train_loss = 1.102\nEpoch 65 Batch 0/16 train_loss = 1.139\nEpoch 65 Batch 10/16 train_loss = 1.096\nEpoch 66 Batch 4/16 train_loss = 1.115\nEpoch 66 Batch 14/16 train_loss = 1.095\nEpoch 67 Batch 8/16 train_loss = 1.081\nEpoch 68 Batch 2/16 train_loss = 1.086\nEpoch 68 Batch 12/16 train_loss = 1.074\nEpoch 69 Batch 6/16 train_loss = 1.008\nEpoch 70 Batch 0/16 train_loss = 1.065\nEpoch 70 Batch 10/16 train_loss = 1.043\nEpoch 71 Batch 4/16 train_loss = 1.030\nEpoch 71 Batch 14/16 train_loss = 0.996\nEpoch 72 Batch 8/16 train_loss = 1.014\nEpoch 73 Batch 2/16 train_loss = 1.016\nEpoch 73 Batch 12/16 train_loss = 1.024\nEpoch 74 Batch 6/16 train_loss = 0.932\nEpoch 75 Batch 0/16 train_loss = 0.984\nEpoch 75 Batch 10/16 train_loss = 0.941\nEpoch 76 Batch 4/16 train_loss = 0.962\nEpoch 76 Batch 14/16 train_loss = 0.950\nEpoch 77 Batch 8/16 train_loss = 0.923\nEpoch 78 Batch 2/16 train_loss = 0.934\nEpoch 78 Batch 12/16 train_loss = 0.956\nEpoch 79 Batch 6/16 train_loss = 0.866\nEpoch 80 Batch 0/16 train_loss = 0.941\nEpoch 80 Batch 10/16 train_loss = 0.932\nEpoch 81 Batch 4/16 train_loss = 0.909\nEpoch 81 Batch 14/16 train_loss = 0.900\nEpoch 82 Batch 8/16 train_loss = 0.895\nEpoch 83 Batch 2/16 train_loss = 0.943\nEpoch 83 Batch 12/16 train_loss = 0.938\nEpoch 84 Batch 6/16 train_loss = 0.853\nEpoch 85 Batch 0/16 train_loss = 0.891\nEpoch 85 Batch 10/16 train_loss = 0.888\nEpoch 86 Batch 4/16 train_loss = 0.889\nEpoch 86 Batch 14/16 train_loss = 0.892\nEpoch 87 Batch 8/16 train_loss = 0.908\nEpoch 88 Batch 2/16 train_loss = 0.869\nEpoch 88 Batch 12/16 train_loss = 0.881\nEpoch 89 Batch 6/16 train_loss = 0.832\nEpoch 90 Batch 0/16 train_loss = 0.864\nEpoch 90 Batch 10/16 train_loss = 0.869\nEpoch 91 Batch 4/16 train_loss = 0.880\nEpoch 91 Batch 14/16 train_loss = 0.817\nEpoch 92 Batch 8/16 train_loss = 0.824\nEpoch 93 Batch 2/16 train_loss = 0.801\nEpoch 93 Batch 12/16 train_loss = 0.803\nEpoch 94 Batch 6/16 train_loss = 0.761\nEpoch 95 Batch 0/16 train_loss = 0.804\nEpoch 95 Batch 10/16 train_loss = 0.811\nEpoch 96 Batch 4/16 train_loss = 0.820\nEpoch 96 Batch 14/16 train_loss = 0.772\nEpoch 97 Batch 8/16 train_loss = 0.772\nEpoch 98 Batch 2/16 train_loss = 0.777\nEpoch 98 Batch 12/16 train_loss = 0.761\nEpoch 99 Batch 6/16 train_loss = 0.708\nEpoch 100 Batch 0/16 train_loss = 0.730\nEpoch 100 Batch 10/16 train_loss = 0.760\nEpoch 101 Batch 4/16 train_loss = 0.780\nEpoch 101 Batch 14/16 train_loss = 0.742\nEpoch 102 Batch 8/16 train_loss = 0.751\nEpoch 103 Batch 2/16 train_loss = 0.737\nEpoch 103 Batch 12/16 train_loss = 0.754\nEpoch 104 Batch 6/16 train_loss = 0.735\nEpoch 105 Batch 0/16 train_loss = 0.834\nEpoch 105 Batch 10/16 train_loss = 0.840\nEpoch 106 Batch 4/16 train_loss = 0.796\nEpoch 106 Batch 14/16 train_loss = 0.786\nEpoch 107 Batch 8/16 train_loss = 0.772\nEpoch 108 Batch 2/16 train_loss = 0.779\nEpoch 108 Batch 12/16 train_loss = 0.788\nEpoch 109 Batch 6/16 train_loss = 0.718\nEpoch 110 Batch 0/16 train_loss = 0.730\nEpoch 110 Batch 10/16 train_loss = 0.722\nEpoch 111 Batch 4/16 train_loss = 0.685\nEpoch 111 Batch 14/16 train_loss = 0.690\nEpoch 112 Batch 8/16 train_loss = 0.658\nEpoch 113 Batch 2/16 train_loss = 0.693\nEpoch 113 Batch 12/16 train_loss = 0.680\nEpoch 114 Batch 6/16 train_loss = 0.616\nEpoch 115 Batch 0/16 train_loss = 0.669\nEpoch 115 Batch 10/16 train_loss = 0.679\nEpoch 116 Batch 4/16 train_loss = 0.658\nEpoch 116 Batch 14/16 train_loss = 0.627\nEpoch 117 Batch 8/16 train_loss = 0.631\nEpoch 118 Batch 2/16 train_loss = 0.639\nEpoch 118 Batch 12/16 train_loss = 0.651\nEpoch 119 Batch 6/16 train_loss = 0.585\nEpoch 120 Batch 0/16 train_loss = 0.614\nEpoch 120 Batch 10/16 train_loss = 0.632\nEpoch 121 Batch 4/16 train_loss = 0.633\nEpoch 121 Batch 14/16 train_loss = 0.604\nEpoch 122 Batch 8/16 train_loss = 0.646\nEpoch 123 Batch 2/16 train_loss = 0.625\nEpoch 123 Batch 12/16 train_loss = 0.619\nEpoch 124 Batch 6/16 train_loss = 0.571\nEpoch 125 Batch 0/16 train_loss = 0.598\nEpoch 125 Batch 10/16 train_loss = 0.625\nEpoch 126 Batch 4/16 train_loss = 0.620\nEpoch 126 Batch 14/16 train_loss = 0.576\nEpoch 127 Batch 8/16 train_loss = 0.585\nEpoch 128 Batch 2/16 train_loss = 0.590\nEpoch 128 Batch 12/16 train_loss = 0.627\nEpoch 129 Batch 6/16 train_loss = 0.575\nEpoch 130 Batch 0/16 train_loss = 0.596\nEpoch 130 Batch 10/16 train_loss = 0.631\nEpoch 131 Batch 4/16 train_loss = 0.621\nEpoch 131 Batch 14/16 train_loss = 0.603\nEpoch 132 Batch 8/16 train_loss = 0.596\nEpoch 133 Batch 2/16 train_loss = 0.589\nEpoch 133 Batch 12/16 train_loss = 0.604\nEpoch 134 Batch 6/16 train_loss = 0.589\nEpoch 135 Batch 0/16 train_loss = 0.632\nEpoch 135 Batch 10/16 train_loss = 0.627\nEpoch 136 Batch 4/16 train_loss = 0.604\nEpoch 136 Batch 14/16 train_loss = 0.570\nEpoch 137 Batch 8/16 train_loss = 0.589\nEpoch 138 Batch 2/16 train_loss = 0.610\nEpoch 138 Batch 12/16 train_loss = 0.663\nEpoch 139 Batch 6/16 train_loss = 0.596\nEpoch 140 Batch 0/16 train_loss = 0.592\nEpoch 140 Batch 10/16 train_loss = 0.589\nEpoch 141 Batch 4/16 train_loss = 0.596\nEpoch 141 Batch 14/16 train_loss = 0.554\nEpoch 142 Batch 8/16 train_loss = 0.588\nEpoch 143 Batch 2/16 train_loss = 0.561\nEpoch 143 Batch 12/16 train_loss = 0.584\nEpoch 144 Batch 6/16 train_loss = 0.511\nEpoch 145 Batch 0/16 train_loss = 0.550\nEpoch 145 Batch 10/16 train_loss = 0.568\nEpoch 146 Batch 4/16 train_loss = 0.540\nEpoch 146 Batch 14/16 train_loss = 0.543\nEpoch 147 Batch 8/16 train_loss = 0.530\nEpoch 148 Batch 2/16 train_loss = 0.548\nEpoch 148 Batch 12/16 train_loss = 0.530\nEpoch 149 Batch 6/16 train_loss = 0.484\nEpoch 150 Batch 0/16 train_loss = 0.540\nEpoch 150 Batch 10/16 train_loss = 0.557\nEpoch 151 Batch 4/16 train_loss = 0.523\nEpoch 151 Batch 14/16 train_loss = 0.502\nEpoch 152 Batch 8/16 train_loss = 0.510\nEpoch 153 Batch 2/16 train_loss = 0.524\nEpoch 153 Batch 12/16 train_loss = 0.507\nEpoch 154 Batch 6/16 train_loss = 0.475\nEpoch 155 Batch 0/16 train_loss = 0.514\nEpoch 155 Batch 10/16 train_loss = 0.494\nEpoch 156 Batch 4/16 train_loss = 0.491\nEpoch 156 Batch 14/16 train_loss = 0.491\nEpoch 157 Batch 8/16 train_loss = 0.500\nEpoch 158 Batch 2/16 train_loss = 0.512\nEpoch 158 Batch 12/16 train_loss = 0.507\nEpoch 159 Batch 6/16 train_loss = 0.464\nEpoch 160 Batch 0/16 train_loss = 0.519\nEpoch 160 Batch 10/16 train_loss = 0.533\nEpoch 161 Batch 4/16 train_loss = 0.486\nEpoch 161 Batch 14/16 train_loss = 0.504\nEpoch 162 Batch 8/16 train_loss = 0.505\nEpoch 163 Batch 2/16 train_loss = 0.538\nEpoch 163 Batch 12/16 train_loss = 0.515\nEpoch 164 Batch 6/16 train_loss = 0.444\nEpoch 165 Batch 0/16 train_loss = 0.500\nEpoch 165 Batch 10/16 train_loss = 0.532\nEpoch 166 Batch 4/16 train_loss = 0.535\nEpoch 166 Batch 14/16 train_loss = 0.498\nEpoch 167 Batch 8/16 train_loss = 0.498\nEpoch 168 Batch 2/16 train_loss = 0.492\nEpoch 168 Batch 12/16 train_loss = 0.519\nEpoch 169 Batch 6/16 train_loss = 0.483\nEpoch 170 Batch 0/16 train_loss = 0.510\nEpoch 170 Batch 10/16 train_loss = 0.511\nEpoch 171 Batch 4/16 train_loss = 0.485\nEpoch 171 Batch 14/16 train_loss = 0.492\nEpoch 172 Batch 8/16 train_loss = 0.502\nEpoch 173 Batch 2/16 train_loss = 0.519\nEpoch 173 Batch 12/16 train_loss = 0.526\nEpoch 174 Batch 6/16 train_loss = 0.476\nEpoch 175 Batch 0/16 train_loss = 0.510\nEpoch 175 Batch 10/16 train_loss = 0.504\nEpoch 176 Batch 4/16 train_loss = 0.476\nEpoch 176 Batch 14/16 train_loss = 0.508\nEpoch 177 Batch 8/16 train_loss = 0.490\nEpoch 178 Batch 2/16 train_loss = 0.499\nEpoch 178 Batch 12/16 train_loss = 0.501\nEpoch 179 Batch 6/16 train_loss = 0.458\nEpoch 180 Batch 0/16 train_loss = 0.444\nEpoch 180 Batch 10/16 train_loss = 0.523\nEpoch 181 Batch 4/16 train_loss = 0.477\nEpoch 181 Batch 14/16 train_loss = 0.464\nEpoch 182 Batch 8/16 train_loss = 0.478\nEpoch 183 Batch 2/16 train_loss = 0.487\nEpoch 183 Batch 12/16 train_loss = 0.485\nEpoch 184 Batch 6/16 train_loss = 0.436\nEpoch 185 Batch 0/16 train_loss = 0.456\nEpoch 185 Batch 10/16 train_loss = 0.485\nEpoch 186 Batch 4/16 train_loss = 0.446\nEpoch 186 Batch 14/16 train_loss = 0.452\nEpoch 187 Batch 8/16 train_loss = 0.472\nEpoch 188 Batch 2/16 train_loss = 0.481\nEpoch 188 Batch 12/16 train_loss = 0.481\nEpoch 189 Batch 6/16 train_loss = 0.407\nEpoch 190 Batch 0/16 train_loss = 0.465\nEpoch 190 Batch 10/16 train_loss = 0.460\nEpoch 191 Batch 4/16 train_loss = 0.476\nEpoch 191 Batch 14/16 train_loss = 0.461\nEpoch 192 Batch 8/16 train_loss = 0.443\nEpoch 193 Batch 2/16 train_loss = 0.443\nEpoch 193 Batch 12/16 train_loss = 0.483\nEpoch 194 Batch 6/16 train_loss = 0.435\nEpoch 195 Batch 0/16 train_loss = 0.435\nEpoch 195 Batch 10/16 train_loss = 0.476\nEpoch 196 Batch 4/16 train_loss = 0.442\nEpoch 196 Batch 14/16 train_loss = 0.464\nEpoch 197 Batch 8/16 train_loss = 0.456\nEpoch 198 Batch 2/16 train_loss = 0.436\nEpoch 198 Batch 12/16 train_loss = 0.478\nEpoch 199 Batch 6/16 train_loss = 0.402\nModel Trained and Saved\n"
]
],
[
[
"## Save Parameters\nSave `seq_length` and `save_dir` for generating a new TV script.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\n# Save parameters for checkpoint\nhelper.save_params((seq_length, save_dir))",
"_____no_output_____"
]
],
[
[
"# Checkpoint",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nimport tensorflow as tf\nimport numpy as np\nimport helper\nimport problem_unittests as tests\n\n_, vocab_to_int, int_to_vocab, token_dict = helper.load_preprocess()\nseq_length, load_dir = helper.load_params()",
"_____no_output_____"
]
],
[
[
"## Implement Generate Functions\n### Get Tensors\nGet tensors from `loaded_graph` using the function [`get_tensor_by_name()`](https://www.tensorflow.org/api_docs/python/tf/Graph#get_tensor_by_name). Get the tensors using the following names:\n- \"input:0\"\n- \"initial_state:0\"\n- \"final_state:0\"\n- \"probs:0\"\n\nReturn the tensors in the following tuple `(InputTensor, InitialStateTensor, FinalStateTensor, ProbsTensor)` ",
"_____no_output_____"
]
],
[
[
"def get_tensors(loaded_graph):\n \"\"\"\n Get input, initial state, final state, and probabilities tensor from <loaded_graph>\n :param loaded_graph: TensorFlow graph loaded from file\n :return: Tuple (InputTensor, InitialStateTensor, FinalStateTensor, ProbsTensor)\n \"\"\"\n # TODO: Implement Function\n inputs = loaded_graph.get_tensor_by_name('input:0')\n ini_state = loaded_graph.get_tensor_by_name('initial_state:0')\n final_state = loaded_graph.get_tensor_by_name('final_state:0')\n probs = loaded_graph.get_tensor_by_name('probs:0')\n return inputs, ini_state, final_state, probs\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_tensors(get_tensors)",
"Tests Passed\n"
]
],
[
[
"### Choose Word\nImplement the `pick_word()` function to select the next word using `probabilities`.",
"_____no_output_____"
]
],
[
[
"# import numpy as np\ndef pick_word(probabilities, int_to_vocab):\n \"\"\"\n Pick the next word in the generated text\n :param probabilities: Probabilites of the next word\n :param int_to_vocab: Dictionary of word ids as the keys and words as the values\n :return: String of the predicted word\n \"\"\"\n # TODO: Implement Function\n chosen_id = np.random.choice(list(int_to_vocab.keys()), p=probabilities)\n return int_to_vocab[chosen_id]\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_pick_word(pick_word)",
"Tests Passed\n"
]
],
[
[
"## Generate TV Script\nThis will generate the TV script for you. Set `gen_length` to the length of TV script you want to generate.",
"_____no_output_____"
]
],
[
[
"gen_length = 200\n# homer_simpson, moe_szyslak, or Barney_Gumble\nprime_word = 'moe_szyslak'\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\nloaded_graph = tf.Graph()\nwith tf.Session(graph=loaded_graph) as sess:\n # Load saved model\n loader = tf.train.import_meta_graph(load_dir + '.meta')\n loader.restore(sess, load_dir)\n\n # Get Tensors from loaded model\n input_text, initial_state, final_state, probs = get_tensors(loaded_graph)\n\n # Sentences generation setup\n gen_sentences = [prime_word + ':']\n prev_state = sess.run(initial_state, {input_text: np.array([[1]])})\n\n # Generate sentences\n for n in range(gen_length):\n # Dynamic Input\n dyn_input = [[vocab_to_int[word] for word in gen_sentences[-seq_length:]]]\n dyn_seq_length = len(dyn_input[0])\n\n # Get Prediction\n probabilities, prev_state = sess.run(\n [probs, final_state],\n {input_text: dyn_input, initial_state: prev_state})\n \n pred_word = pick_word(probabilities[dyn_seq_length-1], int_to_vocab)\n\n gen_sentences.append(pred_word)\n \n # Remove tokens\n tv_script = ' '.join(gen_sentences)\n for key, token in token_dict.items():\n ending = ' ' if key in ['\\n', '(', '\"'] else ''\n tv_script = tv_script.replace(' ' + token.lower(), key)\n tv_script = tv_script.replace('\\n ', '\\n')\n tv_script = tv_script.replace('( ', '(')\n \n print(tv_script)",
"INFO:tensorflow:Restoring parameters from ./save\nmoe_szyslak:(victorious chuckle) no more-- that's them for lenny and i can run ziffcorp, the time you ever heard you could save mckinley.\nhomer_simpson: i can't close a man named much lost with him, on the little woman. you can do about the bathroom who whatever those lenny and that?\nbart_simpson: that's right.(points to coaster) woo hoo...\nlou: chief, jer. how come get i've back to buy ya on the tasimeter, the pipes and wreck there, he's dumb..(looks at) you're new a bears guy floating in front of his nuclear old-time motorcycle lord....\nkent_brockman: and the night are with me, but i was ready for the bank. manjula i've never been in the vacuum fellow of stays watching his stupid and garbage--\" their inspection.\nseymour_skinner: moe, edna was time.\nwanted wow, i was a boy.\nlenny_leonard: off it go! he's an second.\"(etc.\nlenny_leonard: then we got them drinks into a\n"
]
],
[
[
"# The TV Script is Nonsensical\nIt's ok if the TV script doesn't make any sense. We trained on less than a megabyte of text. In order to get good results, you'll have to use a smaller vocabulary or get more data. Luckly there's more data! As we mentioned in the begging of this project, this is a subset of [another dataset](https://www.kaggle.com/wcukierski/the-simpsons-by-the-data). We didn't have you train on all the data, because that would take too long. However, you are free to train your neural network on all the data. After you complete the project, of course.\n# Submitting This Project\nWhen submitting this project, make sure to run all the cells before saving the notebook. Save the notebook file as \"dlnd_tv_script_generation.ipynb\" and save it as a HTML file under \"File\" -> \"Download as\". Include the \"helper.py\" and \"problem_unittests.py\" files in your submission.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73c07e25677f0b6310284509cf6c14d0cac2a1f | 76,608 | ipynb | Jupyter Notebook | Notebooks/Filter_feature_selection_parkinson.ipynb | CS-savvy/Transformer-for-Parkinsons-disease | 42ef54071092f4aab74c8b9ec82c52e944806a5b | [
"MIT"
] | null | null | null | Notebooks/Filter_feature_selection_parkinson.ipynb | CS-savvy/Transformer-for-Parkinsons-disease | 42ef54071092f4aab74c8b9ec82c52e944806a5b | [
"MIT"
] | null | null | null | Notebooks/Filter_feature_selection_parkinson.ipynb | CS-savvy/Transformer-for-Parkinsons-disease | 42ef54071092f4aab74c8b9ec82c52e944806a5b | [
"MIT"
] | null | null | null | 77.69574 | 36,680 | 0.721765 | [
[
[
"import pandas as pd\nfrom pathlib import Path\nimport numpy as np\nfrom sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"from pandas_ods_reader import read_ods\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.metrics import classification_report\nfrom sklearn.metrics import precision_recall_curve\nfrom sklearn.metrics import plot_confusion_matrix\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.metrics import roc_curve,auc\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.feature_selection import f_classif\nfrom sklearn.feature_selection import VarianceThreshold\nfrom sklearn.feature_selection import SelectKBest, SelectPercentile\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.ensemble import RandomForestClassifier\n",
"_____no_output_____"
],
[
"this_dir = Path.cwd()",
"_____no_output_____"
],
[
"dataset_file = this_dir / \"pd_speech_features.ods\"",
"_____no_output_____"
],
[
"df = pd.read_excel(dataset_file, header=[0, 1], engine=\"odf\")",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.drop(columns=['Basic Info'], inplace=True)\ndata = df.to_numpy(dtype=np.float32)",
"/home/sahitya/.local/lib/python3.8/site-packages/pandas/core/generic.py:4153: PerformanceWarning: dropping on a non-lexsorted multi-index without a level parameter may impact performance.\n obj = obj._drop_axis(labels, axis, level=level, errors=errors)\n"
],
[
"\nfeatures, labels = data[:, :-1], data[:, -1]",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.3, random_state=0) # 70% training and 30% test\nX_train.shape, X_test.shape, y_train.shape, y_test.shape",
"_____no_output_____"
],
[
"#remove constant and quasi constant feature\nconstant_filter=VarianceThreshold(threshold=0.01)\nconstant_filter.fit(X_train)\nX_train_filter=constant_filter.transform(X_train)\nX_test_filter=constant_filter.transform(X_test)",
"_____no_output_____"
],
[
"X_train_filter.shape,X_test_filter.shape",
"_____no_output_____"
],
[
"#remove duplicate feature\nX_train_T=X_train_filter.T\nX_test_T=X_test_filter.T\n",
"_____no_output_____"
],
[
"X_train_T=pd.DataFrame(X_train_T)\nX_test_T=pd.DataFrame(X_test_T)\n",
"_____no_output_____"
],
[
"X_train_T.duplicated().sum()",
"_____no_output_____"
],
[
"duplicated_features=X_train_T.duplicated()",
"_____no_output_____"
],
[
"feature_to_keep=[not index for index in duplicated_features ]\n",
"_____no_output_____"
],
[
"X_train_unique=X_train_T[feature_to_keep].T\nX_test_unique=X_test_T[feature_to_keep].T\n",
"_____no_output_____"
],
[
"X_train_unique.shape,X_train.shape,X_test_unique.shape",
"_____no_output_____"
],
[
"#Now do F-test\nsel=f_classif(X_train_unique,y_train)\nsel",
"_____no_output_____"
],
[
"p_values=pd.Series(sel[1])\np_values.index=X_train_unique.columns\np_values.sort_values(ascending=True,inplace=True)",
"_____no_output_____"
],
[
"p_values.plot.bar(figsize=(16,5))",
"_____no_output_____"
],
[
"print(p_values)",
"255 2.845335e-23\n34 1.516572e-22\n319 6.423118e-22\n343 9.948993e-22\n219 4.154244e-21\n ... \n85 9.778228e-01\n367 9.789623e-01\n327 9.908094e-01\n143 9.939024e-01\n53 1.000000e+00\nLength: 424, dtype: float32\n"
],
[
"p_values[p_values<0.5]",
"_____no_output_____"
],
[
"p_values.index",
"_____no_output_____"
],
[
"X_train_p=X_train_unique[p_values.index]",
"_____no_output_____"
],
[
"X_test_p=X_test_unique[p_values.index]",
"_____no_output_____"
],
[
"clf=LogisticRegression(tol=0.1)#tolerence is 0.1\nclf.fit(X_train_p,y_train) \ny_pred=clf.predict(X_test_p)\nprint(\"Accuracy:\",accuracy_score(y_test,y_pred))",
"Accuracy: 0.775330396475771\n"
],
[
"\n",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73c0c3070b829a2e8b506c2db50f2afccb6bf7c | 9,627 | ipynb | Jupyter Notebook | notebooks/.ipynb_checkpoints/Misc-checkpoint.ipynb | PierreBarrat/FluPredictibility | 2325bc3eba688e9d882622704bf4a9713c36fbc4 | [
"MIT"
] | 1 | 2021-07-05T23:10:33.000Z | 2021-07-05T23:10:33.000Z | notebooks/.ipynb_checkpoints/Misc-checkpoint.ipynb | PierreBarrat/FluPredictibility | 2325bc3eba688e9d882622704bf4a9713c36fbc4 | [
"MIT"
] | null | null | null | notebooks/.ipynb_checkpoints/Misc-checkpoint.ipynb | PierreBarrat/FluPredictibility | 2325bc3eba688e9d882622704bf4a9713c36fbc4 | [
"MIT"
] | null | null | null | 23.711823 | 125 | 0.524462 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
e73c279e9c8ddeedf7fe23bbf38e15562b3f32bb | 16,175 | ipynb | Jupyter Notebook | NoteBooks/pecularities_data_source.ipynb | gunnerVivek/Abusive-language-detection-in-Online-content | 8f33a8b0194eb77e3018f16c153291bd451fb072 | [
"MIT"
] | null | null | null | NoteBooks/pecularities_data_source.ipynb | gunnerVivek/Abusive-language-detection-in-Online-content | 8f33a8b0194eb77e3018f16c153291bd451fb072 | [
"MIT"
] | null | null | null | NoteBooks/pecularities_data_source.ipynb | gunnerVivek/Abusive-language-detection-in-Online-content | 8f33a8b0194eb77e3018f16c153291bd451fb072 | [
"MIT"
] | null | null | null | 21.769852 | 353 | 0.503679 | [
[
[
"# <center>Purpose of this Notebook</center>\n\n\n\n\n### Purpose of this Notebook\n\nIn this Notebook we perform an initial eyeball exploration of the datasets to find cleaning steps that might be particular to the individual datsets only (does not include generall cleaning steps like mentions, hashtags, punctuation removal, etc).\n\nThis helps to reduce computing cost instead of brute forcing the same cleaning steps for all of the combined data sources. ",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\nimport re",
"_____no_output_____"
],
[
"pd.set_option('display.max_colwidth', 700)\n#('MAX_COL_WIDTH', 500)",
"_____no_output_____"
]
],
[
[
"# Face Book Hate Speech",
"_____no_output_____"
]
],
[
[
"fb = pd.read_csv(\"transformed_data/facebook_hate_speech_translated.csv\", encoding='utf-8')",
"_____no_output_____"
],
[
"# drop the duplicates\nfb = fb.drop_duplicates(subset=['translated_message'])",
"_____no_output_____"
],
[
"fb.label.value_counts()",
"_____no_output_____"
]
],
[
[
"# Observe\nTo find the nuances of this dataset we will observe the dataset by sampling it multiple times.\n\nRemove:\n- "\n- '(unicode in dataset) with '. In fact remove all decimal encoded puctuation marks with the actual punctuation marks.\n\n\nNote:\n- remove accented characters\n- URL\n- @ 137c9c6970afb7fc\n- repeating !!!\n\n[^a-zA-Z_\\.\\s,] --> Unnecessary characters could be removed. All characters except alphabets, full stop, unsderscore, comma and white space.\nMultiple white spaces by one white space.\n\n\nEach sentence of the document should be predicted and then if any of the sentences are abusive, whole document should be classified as abusive.\nAlso highlight the abusive part.",
"_____no_output_____"
],
[
"## Steps for cleaning\n\n- puctuation marks correction\n- Mentions, Hashtags",
"_____no_output_____"
]
],
[
[
"x = fb.loc[643,'translated_message']\nre.sub(\"[^a-zA-Z_\\.\\s,]\",'', x) # remove all special characters and numbers\nre.sub(r\"\\b(([a-z]+\\d+)|(\\d+[a-z]+))(\\w)+\\b\", '', x) # 02ab63aad79877f5, ab63aad79877f5, 3f3g6hj7j5v and fg54jkk098ui\n\n# re.sub(\"'\", \"'\", x)",
"_____no_output_____"
],
[
"\nre.findall(\"\\d+\", ''.join(re.findall(\"&#\\d+;\", \"Hello !\")))\n\n# re.findall(\"\\d+\", \"!\") ",
"_____no_output_____"
],
[
"x = fb.translated_message.loc[56]\nre.sub(r\"\\b(([a-z]+\\d+)|(\\d+[a-z]+))(\\w)+\\b\", '', x)",
"_____no_output_____"
]
],
[
[
"Also remove sentences that are abusive only in specific context. We want a generalised system.\n\nRemove :\n0, 9, 10, 13, 18, 31, 34, 35, 39, 41, 52, 55, 59, 69, 70, 72, 73, 78, 101, 103, 107, 116, 117",
"_____no_output_____"
]
],
[
[
"delete_rows = [0, 9, 10, 13, 18, 31, 34, 35, 39, 41, 52, 55, 59, 69, 70, 72, 73, 78, 101, 103, 107, 116, 117]",
"_____no_output_____"
],
[
"fb.drop(index=delete_rows).shape",
"_____no_output_____"
]
],
[
[
"# Wikipedia Personal Attacks",
"_____no_output_____"
]
],
[
[
"wiki = pd.read_csv(\"transformed_data/wikipedia_personal_attacks.csv\", encoding='utf-8')",
"_____no_output_____"
],
[
"wiki.shape",
"_____no_output_____"
],
[
"wiki = wiki.drop_duplicates(subset=['comment'])",
"_____no_output_____"
],
[
"wiki.label.value_counts()",
"_____no_output_____"
],
[
"msg = \"NEWLINE_TOKENNEWLINE_TOKEN== Statement ==NEWLINE_TOKENI would like to be unblocked please, my actions four years ago were unwarranted and I apologise, I would like to contribute constructively.\"\nre.sub(\"[^a-zA-Z_\\.\\s,]\", \"\", re.sub(r\"NEWLINE_TOKEN\", \"\", msg))",
"_____no_output_____"
]
],
[
[
"## Observations\nRemove:\n- NEWLINE_TOKEN\n- ``.*`` indicates quotes\n- (UTC)\n\nNotes:\n- remove accented characters\n- u with you",
"_____no_output_____"
],
[
"# White Supremist ",
"_____no_output_____"
]
],
[
[
"w_s = pd.read_csv(\"transformed_data/white_supremist_data.csv\", encoding=\"utf-8\")",
"_____no_output_____"
],
[
"print('Original Shape: {0}'.format(w_s.shape))\nprint('After Duplicate removal:', w_s.drop_duplicates(subset=['text']).shape)",
"Original Shape: (10703, 2)\nAfter Duplicate removal: (10534, 2)\n"
],
[
"w_s.label.value_counts()",
"_____no_output_____"
]
],
[
[
"## Observations\n\n- \"[....]\" | '[....]' : every document is a list element.\n\n\nNotes:\nn't --> not",
"_____no_output_____"
]
],
[
[
"# x = ''.join(w_s.text.loc[[6310, 2334]].values)\nx = ''.join(w_s.text.loc[6310])\n# re.sub('([(\\\"|\\')).*((\\\"|\\')])', \"\", x)\n# ''.join(re.sub('''(\"|')\\]''', \"\", re.sub('''\\[(\"|')''', \"\", x)))\n# x\nx.replace('[\"', '').replace('\"]', '')",
"_____no_output_____"
]
],
[
[
"# Tweeter",
"_____no_output_____"
]
],
[
[
"tweetr = pd.read_csv(\"transformed_data/tweeter_data.csv\")",
"_____no_output_____"
],
[
"tweetr.columns",
"_____no_output_____"
],
[
"print('Original Shape: {0}'.format(tweetr.shape))\nprint('After Duplicate removal:', tweetr.drop_duplicates(subset=['tweet']).shape)",
"Original Shape: (67079, 2)\nAfter Duplicate removal: (20484, 2)\n"
],
[
"tweetr = tweetr.drop_duplicates(subset=['tweet'])",
"_____no_output_____"
],
[
"tweetr.label.unique()",
"_____no_output_____"
],
[
"tweetr = tweetr.drop(index=0)",
"_____no_output_____"
]
],
[
[
"## Observation\n\nRemove:\n\n- RT\n\nNOte:\n- emoji ♡ 💦 😜 --> &#\\d+;\n- “ 😎”\n- Emojis have similar regex compared to apostrophe. Hence they must be removed only after apostrophe substitution.\nColumn name change in combined data. Data in DB already has same column names.",
"_____no_output_____"
]
],
[
[
"x = tweetr.tweet.loc[14721]\n\nre.sub(\"&#\\d+;\", \"\", x)",
"_____no_output_____"
],
[
"del tweetr",
"_____no_output_____"
]
],
[
[
"# Toxic Comments",
"_____no_output_____"
]
],
[
[
"toxic = pd.read_csv(\"transformed_data/toxic_comments.csv\", encoding='utf-8')",
"_____no_output_____"
],
[
"toxic.columns",
"_____no_output_____"
],
[
"print(\"Shape of original data:\", toxic.shape)",
"Shape of original data: (2223063, 2)\n"
],
[
"toxic = toxic.drop_duplicates(subset=['comment_text'])",
"_____no_output_____"
],
[
"print(\"Shape after duplicate removal:\", toxic.shape)",
"Shape after duplicate removal: (2195400, 2)\n"
],
[
"toxic.label.unique()",
"_____no_output_____"
]
],
[
[
"## Observation\n\nRemove:\n\n- \\n \\r\n- dawggg\n\nNote:\n\n- 50% -> fifty percent : Eg: Rihanna is 50% black. Her mother is also mixed race, not black.",
"_____no_output_____"
]
],
[
[
"x = toxic.comment_text.loc[377713]# 1839087\n\n# x.replace(\"\\n\", '')\nx",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
e73c361a84c0925cd212acb5ecd8cd20e3bc2f00 | 19,913 | ipynb | Jupyter Notebook | Tutorials/03_Hartree-Fock/3b_rhf-diis.ipynb | konpat/psi4numpy | dc0b51d9a05286023474e1e5b4828705676bf60d | [
"BSD-3-Clause"
] | null | null | null | Tutorials/03_Hartree-Fock/3b_rhf-diis.ipynb | konpat/psi4numpy | dc0b51d9a05286023474e1e5b4828705676bf60d | [
"BSD-3-Clause"
] | null | null | null | Tutorials/03_Hartree-Fock/3b_rhf-diis.ipynb | konpat/psi4numpy | dc0b51d9a05286023474e1e5b4828705676bf60d | [
"BSD-3-Clause"
] | null | null | null | 44.950339 | 1,405 | 0.580576 | [
[
[
"# Direct Inversion of the Iterative Subspace\n\nWhen solving systems of linear (or nonlinear) equations, iterative methods are often employed. Unfortunately, such methods often suffer from convergence issues such as numerical instability, slow convergence, and significant computational expense when applied to difficult problems. In these cases, convergence accelleration methods may be applied to both speed up, stabilize and/or reduce the cost for the convergence patterns of these methods, so that solving such problems become computationally tractable. One such method is known as the direct inversion of the iterative subspace (DIIS) method, which is commonly applied to address convergence issues within self consistent field computations in Hartree-Fock theory (and other iterative electronic structure methods). In this tutorial, we'll introduce the theory of DIIS for a general iterative procedure, before integrating DIIS into our previous implementation of RHF.\n\n## I. Theory\n\nDIIS is a widely applicable convergence acceleration method, which is applicable to numerous problems in linear algebra and the computational sciences, as well as quantum chemistry in particular. Therefore, we will introduce the theory of this method in the general sense, before seeking to apply it to SCF. \n\nSuppose that for a given problem, there exist a set of trial vectors $\\{\\mid{\\bf p}_i\\,\\rangle\\}$ which have been generated iteratively, converging toward the true solution, $\\mid{\\bf p}^f\\,\\rangle$. Then the true solution can be approximately constructed as a linear combination of the trial vectors,\n$$\\mid{\\bf p}\\,\\rangle = \\sum_ic_i\\mid{\\bf p}_i\\,\\rangle,$$\nwhere we require that the residual vector \n$$\\mid{\\bf r}\\,\\rangle = \\sum_ic_i\\mid{\\bf r}_i\\,\\rangle\\,;\\;\\;\\; \\mid{\\bf r}_i\\,\\rangle \n=\\, \\mid{\\bf p}_{i+1}\\,\\rangle - \\mid{\\bf p}_i\\,\\rangle$$\nis a least-squares approximate to the zero vector, according to the constraint\n$$\\sum_i c_i = 1.$$\nThis constraint on the expansion coefficients can be seen by noting that each trial function ${\\bf p}_i$ may be represented as an error vector applied to the true solution, $\\mid{\\bf p}^f\\,\\rangle + \\mid{\\bf e}_i\\,\\rangle$. Then\n\\begin{align}\n\\mid{\\bf p}\\,\\rangle &= \\sum_ic_i\\mid{\\bf p}_i\\,\\rangle\\\\\n&= \\sum_i c_i(\\mid{\\bf p}^f\\,\\rangle + \\mid{\\bf e}_i\\,\\rangle)\\\\\n&= \\mid{\\bf p}^f\\,\\rangle\\sum_i c_i + \\sum_i c_i\\mid{\\bf e}_i\\,\\rangle\n\\end{align}\nConvergence results in a minimization of the error (causing the second term to vanish); for the DIIS solution vector $\\mid{\\bf p}\\,\\rangle$ and the true solution vector $\\mid{\\bf p}^f\\,\\rangle$ to be equal, it must be that $\\sum_i c_i = 1$. We satisfy our condition for the residual vector by minimizing its norm,\n$$\\langle\\,{\\bf r}\\mid{\\bf r}\\,\\rangle = \\sum_{ij} c_i^* c_j \\langle\\,{\\bf r}_i\\mid{\\bf r}_j\\,\\rangle,$$\nusing Lagrange's method of undetermined coefficients subject to the constraint on $\\{c_i\\}$:\n$${\\cal L} = {\\bf c}^{\\dagger}{\\bf Bc} - \\lambda\\left(1 - \\sum_i c_i\\right)$$\nwhere $B_{ij} = \\langle {\\bf r}_i\\mid {\\bf r}_j\\rangle$ is the matrix of residual vector overlaps. Minimization of the Lagrangian with respect to the coefficient $c_k$ yields (for real values)\n\\begin{align}\n\\frac{\\partial{\\cal L}}{\\partial c_k} = 0 &= \\sum_j c_jB_{jk} + \\sum_i c_iB_{ik} - \\lambda\\\\\n&= 2\\sum_ic_iB_{ik} - \\lambda\n\\end{align}\nwhich has matrix representation\n\\begin{equation}\n\\begin{pmatrix}\n B_{11} & B_{12} & \\cdots & B_{1m} & -1 \\\\\n B_{21} & B_{22} & \\cdots & B_{2m} & -1 \\\\\n \\vdots & \\vdots & \\ddots & \\vdots & \\vdots \\\\\n B_{n1} & B_{n2} & \\cdots & B_{nm} & -1 \\\\\n -1 & -1 & \\cdots & -1 & 0\n\\end{pmatrix}\n\\begin{pmatrix}\nc_1\\\\\nc_2\\\\\n\\vdots \\\\\nc_n\\\\\n\\lambda\n\\end{pmatrix}\n=\n\\begin{pmatrix}\n0\\\\\n0\\\\\n\\vdots\\\\\n0\\\\\n-1\n\\end{pmatrix},\n\\end{equation}\n\nwhich we will refer to as the Pulay equation, named after the inventor of DIIS. It is worth noting at this point that our trial vectors, residual vectors, and solution vector may in fact be tensors of arbitrary rank; it is for this reason that we have used the generic notation of Dirac in the above discussion to denote the inner product between such objects.\n\n## II. Algorithms for DIIS\nThe general DIIS procedure, as described above, has the following structure during each iteration:\n#### Algorithm 1: Generic DIIS procedure\n1. Compute new trial vector, $\\mid{\\bf p}_{i+1}\\,\\rangle$, append to list of trial vectors\n2. Compute new residual vector, $\\mid{\\bf r}_{i+1}\\,\\rangle$, append to list of trial vectors\n3. Check convergence criteria\n - If RMSD of $\\mid{\\bf r}_{i+1}\\,\\rangle$ sufficiently small, and\n - If change in DIIS solution vector $\\mid{\\bf p}\\,\\rangle$ sufficiently small, break\n4. Build **B** matrix from previous residual vectors\n5. Solve Pulay equation for coefficients $\\{c_i\\}$\n6. Compute DIIS solution vector $\\mid{\\bf p}\\,\\rangle$\n\nFor SCF iteration, the most common choice of trial vector is the Fock matrix **F**; this choice has the advantage over other potential choices (e.g., the density matrix **D**) of **F** not being idempotent, so that it may benefit from extrapolation. The residual vector is commonly chosen to be the orbital gradient in the AO basis,\n$$g_{\\mu\\nu} = ({\\bf FDS} - {\\bf SDF})_{\\mu\\nu},$$\nhowever the better choice (which we will make in our implementation!) is to orthogonormalize the basis of the gradient with the inverse overlap metric ${\\bf A} = {\\bf S}^{-1/2}$:\n$$r_{\\mu\\nu} = ({\\bf A}^{\\rm T}({\\bf FDS} - {\\bf SDF}){\\bf A})_{\\mu\\nu}.$$\nTherefore, the SCF-specific DIIS procedure (integrated into the SCF iteration algorithm) will be:\n#### Algorithm 2: DIIS within an SCF Iteration\n1. Compute **F**, append to list of previous trial vectors\n2. Compute AO orbital gradient **r**, append to list of previous residual vectors\n3. Compute RHF energy\n3. Check convergence criteria\n - If RMSD of **r** sufficiently small, and\n - If change in SCF energy sufficiently small, break\n4. Build **B** matrix from previous AO gradient vectors\n5. Solve Pulay equation for coefficients $\\{c_i\\}$\n6. Compute DIIS solution vector **F_DIIS** from $\\{c_i\\}$ and previous trial vectors\n7. Compute new orbital guess with **F_DIIS**",
"_____no_output_____"
],
[
"## III. Implementation\n\nIn order to implement DIIS, we're going to integrate it into an existing RHF program. Since we just-so-happened to write such a program in the last tutorial, let's re-use the part of the code before the SCF integration which won't change when we include DIIS:",
"_____no_output_____"
]
],
[
[
"# ==> Basic Setup <==\n# Import statements\nimport psi4\nimport numpy as np\n\n# Memory specification\npsi4.set_memory(int(5e8))\nnumpy_memory = 2\n\n# Set output file\npsi4.core.set_output_file('output.dat', False)\n\n# Define Physicist's water -- don't forget C1 symmetry!\nmol = psi4.geometry(\"\"\"\nO\nH 1 1.1\nH 1 1.1 2 104\nsymmetry c1\n\"\"\")\n\n# Set computation options\npsi4.set_options({'basis': 'cc-pvdz',\n 'scf_type': 'pk',\n 'e_convergence': 1e-8})\n\n# Maximum SCF iterations\nMAXITER = 40\n# Energy convergence criterion\nE_conv = 1.0e-6\nD_conv = 1.0e-3",
"_____no_output_____"
],
[
"# ==> Static 1e- & 2e- Properties <==\n# Class instantiation\nwfn = psi4.core.Wavefunction.build(mol, psi4.core.get_global_option('basis'))\nmints = psi4.core.MintsHelper(wfn.basisset())\n\n# Overlap matrix\nS = np.asarray(mints.ao_overlap())\n\n# Number of basis Functions & doubly occupied orbitals\nnbf = S.shape[0]\nndocc = wfn.nalpha()\n\nprint('Number of occupied orbitals: %d' % ndocc)\nprint('Number of basis functions: %d' % nbf)\n\n# Memory check for ERI tensor\nI_size = (nbf**4) * 8.e-9\nprint('\\nSize of the ERI tensor will be %4.2f GB.' % I_size)\nmemory_footprint = I_size * 1.5\nif I_size > numpy_memory:\n psi4.core.clean()\n raise Exception(\"Estimated memory utilization (%4.2f GB) exceeds allotted memory \\\n limit of %4.2f GB.\" % (memory_footprint, numpy_memory))\n\n# Build ERI Tensor\nI = np.asarray(mints.ao_eri())\n\n# Build core Hamiltonian\nT = np.asarray(mints.ao_kinetic())\nV = np.asarray(mints.ao_potential())\nH = T + V",
"Number of occupied orbitals: 5\nNumber of basis functions: 24\n\nSize of the ERI tensor will be 0.00 GB.\n"
],
[
"# ==> CORE Guess <==\n# AO Orthogonalization Matrix\nA = mints.ao_overlap()\nA.power(-0.5, 1.e-16)\nA = np.asarray(A)\n\n# Transformed Fock matrix\nF_p = A.dot(H).dot(A)\n\n# Diagonalize F_p for eigenvalues & eigenvectors with NumPy\ne, C_p = np.linalg.eigh(F_p)\n\n# Transform C_p back into AO basis\nC = A.dot(C_p)\n\n# Grab occupied orbitals\nC_occ = C[:, :ndocc]\n\n# Build density matrix from occupied orbitals\nD = np.einsum('pi,qi->pq', C_occ, C_occ)\n\n# Nuclear Repulsion Energy\nE_nuc = mol.nuclear_repulsion_energy()",
"_____no_output_____"
]
],
[
[
"Now let's put DIIS into action. Before our iterations begin, we'll need to create empty lists to hold our previous residual vectors (AO orbital gradients) and trial vectors (previous Fock matrices), along with setting starting values for our SCF energy and previous energy:",
"_____no_output_____"
]
],
[
[
"# ==> Pre-Iteration Setup <==\n# SCF & Previous Energy\nSCF_E = 0.0\nE_old = 0.0",
"_____no_output_____"
]
],
[
[
"Now we're ready to write our SCF iterations according to Algorithm 2. Here are some hints which may help you along the way:\n\n#### Starting DIIS\nSince DIIS builds the approximate solution vector $\\mid{\\bf p}\\,\\rangle$ as a linear combination of the previous trial vectors $\\{\\mid{\\bf p}_i\\,\\rangle\\}$, there's no need to perform DIIS on the first SCF iteration, since there's only one trial vector for DIIS to use!\n\n#### Building **B**\n1. The **B** matrix in the Lagrange equation is really $\\tilde{\\bf B} = \\begin{pmatrix} {\\bf B} & -1\\\\ -1 & 0\\end{pmatrix}$.\n2. Since **B** is the matrix of residual overlaps, it will be a square matrix of dimension equal to the number of residual vectors. If **B** is an $N\\times N$ matrix, how big is $\\tilde{\\bf B}$?\n3. Since our residuals are real, **B** will be a symmetric matrix.\n4. To build $\\tilde{\\bf B}$, make an empty array of the appropriate dimension, then use array indexing to set the values of the elements.\n\n#### Solving the Pulay equation\n1. Use built-in NumPy functionality to make your life easier.\n2. The solution vector for the Pulay equation is $\\tilde{\\bf c} = \\begin{pmatrix} {\\bf c}\\\\ \\lambda\\end{pmatrix}$, where $\\lambda$ is the Lagrange multiplier, and the right hand side is $\\begin{pmatrix} {\\bf 0}\\\\ -1\\end{pmatrix}$. ",
"_____no_output_____"
]
],
[
[
"# Start from fresh orbitals\nF_p = A.dot(H).dot(A)\ne, C_p = np.linalg.eigh(F_p)\nC = A.dot(C_p)\nC_occ = C[:, :ndocc]\nD = np.einsum('pi,qi->pq', C_occ, C_occ)\n\n# Trial & Residual Vector Lists\nF_list = []\nDIIS_RESID = []\n\n# ==> SCF Iterations w/ DIIS <==\nprint('==> Starting SCF Iterations <==\\n')\n\n# Begin Iterations\nfor scf_iter in range(1, MAXITER + 1):\n # Build Fock matrix\n J = np.einsum('pqrs,rs->pq', I, D)\n K = np.einsum('prqs,rs->pq', I, D)\n F = H + 2*J - K\n \n # Build DIIS Residual\n diis_r = A.dot(F.dot(D).dot(S) - S.dot(D).dot(F)).dot(A)\n \n # Append trial & residual vectors to lists\n F_list.append(F)\n DIIS_RESID.append(diis_r)\n \n # Compute RHF energy\n SCF_E = np.einsum('pq,pq->', (H + F), D) + E_nuc\n dE = SCF_E - E_old\n dRMS = np.mean(diis_r**2)**0.5\n print('SCF Iteration %3d: Energy = %4.16f dE = % 1.5E dRMS = %1.5E' % (scf_iter, SCF_E, dE, dRMS))\n \n # SCF Converged?\n if (abs(dE) < E_conv) and (dRMS < D_conv):\n break\n E_old = SCF_E\n \n if scf_iter >= 2:\n # Build B matrix\n B_dim = len(F_list) + 1\n B = np.empty((B_dim, B_dim))\n B[-1, :] = -1\n B[:, -1] = -1\n B[-1, -1] = 0\n for i in range(len(F_list)):\n for j in range(len(F_list)):\n B[i, j] = np.einsum('ij,ij->', DIIS_RESID[i], DIIS_RESID[j])\n\n # Build RHS of Pulay equation \n rhs = np.zeros((B_dim))\n rhs[-1] = -1\n \n # Solve Pulay equation for c_i's with NumPy\n coeff = np.linalg.solve(B, rhs)\n \n # Build DIIS Fock matrix\n F = np.zeros_like(F)\n for x in range(coeff.shape[0] - 1):\n F += coeff[x] * F_list[x]\n \n # Compute new orbital guess with DIIS Fock matrix\n F_p = A.dot(F).dot(A)\n e, C_p = np.linalg.eigh(F_p)\n C = A.dot(C_p)\n C_occ = C[:, :ndocc]\n D = np.einsum('pi,qi->pq', C_occ, C_occ)\n \n # MAXITER exceeded?\n if (scf_iter == MAXITER):\n psi4.core.clean()\n raise Exception(\"Maximum number of SCF iterations exceeded.\")\n\n# Post iterations\nprint('\\nSCF converged.')\nprint('Final RHF Energy: %.8f [Eh]' % SCF_E)",
"_____no_output_____"
]
],
[
[
"Congratulations! You've written your very own Restricted Hartree-Fock program with DIIS convergence accelleration! Finally, let's check your final RHF energy against <span style='font-variant: small-caps'> Psi4</span>:",
"_____no_output_____"
]
],
[
[
"# Compare to Psi4\nSCF_E_psi = psi4.energy('SCF')\npsi4.compare_values(SCF_E_psi, SCF_E, 6, 'SCF Energy')",
"_____no_output_____"
]
],
[
[
"## References\n1. P. Pulay. *Chem. Phys. Lett.* **73**, 393-398 (1980)\n2. C. David Sherrill. *\"Some comments on accellerating convergence of iterative sequences using direct inversion of the iterative subspace (DIIS)\".* Available at: vergil.chemistry.gatech.edu/notes/diis/diis.pdf. (1998)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73c43886f72b44bc940bb95b9ff8dc7e877eec7 | 4,135 | ipynb | Jupyter Notebook | notebooks/Filter_20k.ipynb | krishnamrith12/DCST | 7ba956d7e648aaeb25816ccfc709106db9293270 | [
"MIT"
] | null | null | null | notebooks/Filter_20k.ipynb | krishnamrith12/DCST | 7ba956d7e648aaeb25816ccfc709106db9293270 | [
"MIT"
] | null | null | null | notebooks/Filter_20k.ipynb | krishnamrith12/DCST | 7ba956d7e648aaeb25816ccfc709106db9293270 | [
"MIT"
] | 1 | 2020-06-09T09:03:45.000Z | 2020-06-09T09:03:45.000Z | 21.994681 | 98 | 0.465296 | [
[
[
"### Phase:I\nMove exact matching",
"_____no_output_____"
]
],
[
[
"import os\nimport pandas as pd\npath='../data/sanskrit_treebank/'\nGT = []\nfor folder in os.listdir(path):\n for file in os.listdir(path+folder):\n temp = []\n data = pd.read_csv(path+folder+'/'+file, sep=',')\n for i in range(len(data)):\n temp.append(data.iloc[i,3])\n temp = sorted(temp)\n GT.append(temp)",
"_____no_output_____"
],
[
"import shutil\ncount = 0\nfor file in os.listdir('../data/train_20k/'):\n data = pd.read_csv('../data/train_20k/'+file, sep=',')\n temp = []\n for i in range(len(data)):\n temp.append(data.iloc[i,3])\n temp = sorted(temp)\n for G in GT:\n if temp == G:\n count+=1\n shutil.move('../data/train_20k/'+file,'../data/train_12k/exact_match/'+file)\n break\ncount",
"_____no_output_____"
]
],
[
[
"### Phase II\nCheck sentence length atleast 6",
"_____no_output_____"
]
],
[
[
"count = 0\nfor file in os.listdir('../data/train_20k/'):\n data = pd.read_csv('../data/train_20k/'+file, sep=',')\n temp = []\n for i in range(len(data)):\n temp.append(data.iloc[i,3])\n temp = sorted(temp)\n if len(temp)>=6:\n count+=1\n shutil.move('../data/train_20k/'+file,'../data/train_12k/atleast_6_length/'+file)\ncount",
"_____no_output_____"
],
[
"8456+1568-1095 +2700",
"_____no_output_____"
],
[
"count = 0\nfor file in os.listdir('../data/train_12k/exact_match/'):\n data = pd.read_csv('../data/train_12k/exact_match/'+file, sep=',')\n if len(data)<6:\n count+=1\ncount",
"_____no_output_____"
],
[
"# Rename the files to gold and silver\nimport argparse\nimport os\npath = '../data/train_12k/atleast_6_length/'\ncount = 0\nfor file in os.listdir(path):\n count= count + 1\n dst =\"Silver_filtered_\" + str(count) + \".csv\"\n src =file\n os.rename(path+src,path+dst) ",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
e73c4b6c071a2ed92de60d097d521a20d5cf9c34 | 18,555 | ipynb | Jupyter Notebook | machineLearning/Regression Algorithms/regre.ipynb | WebClub-NITK/Hacktoberfest-2k19 | 69fafb354f0da58220a7ba68696b4d7fde0a3d5c | [
"MIT"
] | 28 | 2019-10-01T09:13:50.000Z | 2021-04-18T18:15:34.000Z | machineLearning/Regression Algorithms/regre.ipynb | arpita221b/Hacktoberfest-2k19-1 | 6f682ea2226a8ce6f5a913da9ecdafff7a9fa5bd | [
"MIT"
] | 236 | 2019-09-30T16:06:09.000Z | 2022-02-26T18:37:03.000Z | machineLearning/Regression Algorithms/regre.ipynb | arpita221b/Hacktoberfest-2k19-1 | 6f682ea2226a8ce6f5a913da9ecdafff7a9fa5bd | [
"MIT"
] | 184 | 2019-09-30T16:08:04.000Z | 2022-03-09T05:00:29.000Z | 52.563739 | 4,936 | 0.673457 | [
[
[
"#1.Logistic regression For Gender Voice Dataset",
"_____no_output_____"
],
[
"import pandas as p\nimport warnings\nwarnings.filterwarnings(\"ignore\")\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.metrics import classification_report\nfrom sklearn.metrics import confusion_matrix\n\nd=p.read_csv('gender_voice_dataset.csv')\n#d.fillna(d['median'].mean(),inplace=True)\nd.dropna(inplace=True)\nd['label']=d['label'].map({'female':0,'male':1})\n\n\nx=d[['meanfreq','sd','median','Q25','Q75','IQR','sfm','mode','centroid','meanfun','minfun','maxfun','meandom','mindom','maxdom','dfrange','modindx']]\n\ny=d[['label']]\n\n\nx_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.20)\nc=LogisticRegression(random_state=0,solver='lbfgs',multi_class='multinomial')\n\nc.fit(x_train,y_train)\nprediction=c.predict(x_test)\naccuracy=accuracy_score(y_test,prediction)\n\nprint(\"confusion matrix:\",confusion_matrix(y_test,prediction))\nprint(\"accuracy :\" ,accuracy)\nprint(\"classification report: \",classification_report(y_test,prediction))\n",
"confusion matrix: [[289 34]\n [ 8 300]]\naccuracy : 0.9334389857369255\nclassification report: precision recall f1-score support\n\n 0 0.97 0.89 0.93 323\n 1 0.90 0.97 0.93 308\n\n accuracy 0.93 631\n macro avg 0.94 0.93 0.93 631\nweighted avg 0.94 0.93 0.93 631\n\n"
],
[
"#2 Naïve bayes ",
"_____no_output_____"
],
[
"import pandas as p\nimport matplotlib.pyplot as plt\nfrom sklearn import metrics\nimport warnings\nwarnings.filterwarnings(\"ignore\")\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.metrics import classification_report\nfrom sklearn.naive_bayes import GaussianNB\n\nd=p.read_csv('gender_voice_dataset.csv')\nd.dropna(inplace=True)\nd['label']=d['label'].map({'female':0,'male':1})\nx=d[['meanfreq','sd','median','Q25','Q75','IQR','sfm','mode','centroid','meanfun','minfun','maxfun','meandom','mindom','maxdom','dfrange','modindx']]\ny=d[['label']]\n\nx_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.20)\n\ng=GaussianNB()\ng.fit(x_train,y_train)\nprediction=g.predict(x_test)\naccuracy=accuracy_score(y_test,prediction)\n\nprint(\"confusion matrix:\",confusion_matrix(y_test,prediction))\nprint(\"accuracy :\" ,accuracy)\nprint(\"classification report: \",classification_report(y_test,prediction))\n\ncm=confusion_matrix(y_test,prediction)\ntn=cm[0][0]\nfn=cm[1][0]\ntp=cm[1][1]\nfp=cm[0][1]\n\nfpr=fp/(fp+tn)\ntpr=tp/(tp+fn)\n\nfig,ax=plt.subplots(figsize=(5,5))\nfpr, tpr, _ = metrics.roc_curve(y_test,prediction)\nauc = metrics.roc_auc_score(y_test,prediction)\n\n",
"confusion matrix: [[265 39]\n [ 25 302]]\naccuracy : 0.8985736925515055\nclassification report: precision recall f1-score support\n\n 0 0.91 0.87 0.89 304\n 1 0.89 0.92 0.90 327\n\n accuracy 0.90 631\n macro avg 0.90 0.90 0.90 631\nweighted avg 0.90 0.90 0.90 631\n\n"
],
[
"# Linear Regression ",
"_____no_output_____"
],
[
"\nimport pandas as p\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import *\nfrom sklearn.metrics import *\nfrom sklearn.ensemble import *\n\ndata=p.read_csv('insurance.csv')\ndata.dropna(inplace=True)\ndata['sex']=data['sex'].map({'female':0,'male':1})\ndata['smoker']=data['smoker'].map({'yes':1,'no':0})\ndata['region']=data['region'].map({'northeast':0,'northwest':1,'southeast':2,'southwest':3})\n\nx=data[['age','sex','bmi','children','smoker','region']]\ny=data[['charges']]\n\nlr=LinearRegression()\nx_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.20)\nlr.fit(x_train,y_train)\n\nprediction=lr.predict([[19,0,27.9,0,1,3]])\nprint(\"charges :\",prediction)\nprint(\"mean square error\",mean_squared_error(y_test,lr.predict(x_test)))\n\nelastic=ElasticNet(alpha=0.00001)\nelastic.fit(x_train,y_train)\nprint(mean_squared_error(y_test,elastic.predict(x_test)))\nprint(mean_absolute_error(y_test,elastic.predict(x_test)))\nprint(median_absolute_error(y_test,elastic.predict(x_test)))\n\n\nlasso=Lasso(alpha=0.00001,normalize=True)\nlasso.fit(x_train,y_train)\nlasso.predict(x_test)\n\n\ngrad=GradientBoostingRegressor()\ngrad.fit(x_train,y_train)\ngrad.predict(x_test)",
"charges : [[24949.27193451]]\nmean square error 38262818.002736315\n38262944.57774873\n4073.0016657325764\n2265.478118767092\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73c57035284cabbbe925b712ad5e8cb5c33e0ca | 38,011 | ipynb | Jupyter Notebook | src/notebooks/171-basic-venn-diagram-with-3-groups.ipynb | nrslt/The-Python-Graph-Gallery | 55898de66070ae716c95442466783ee986576e7d | [
"0BSD"
] | null | null | null | src/notebooks/171-basic-venn-diagram-with-3-groups.ipynb | nrslt/The-Python-Graph-Gallery | 55898de66070ae716c95442466783ee986576e7d | [
"0BSD"
] | null | null | null | src/notebooks/171-basic-venn-diagram-with-3-groups.ipynb | nrslt/The-Python-Graph-Gallery | 55898de66070ae716c95442466783ee986576e7d | [
"0BSD"
] | null | null | null | 348.724771 | 19,270 | 0.750046 | [
[
[
"Welcome in the introductory template of the python graph gallery. Here is how to proceed to add a new `.ipynb` file that will be converted to a blogpost in the gallery!",
"_____no_output_____"
],
[
"## Notebook Metadata",
"_____no_output_____"
],
[
"It is very important to add the following fields to your notebook. It helps building the page later on:\n- **slug**: the URL of the blogPost. It should be exactly the same as the file title. Example: `70-basic-density-plot-with-seaborn`\n- **chartType**: the chart type like density or heatmap. For a complete list see [here](https://github.com/holtzy/The-Python-Graph-Gallery/blob/master/src/util/sectionDescriptions.js), it must be one of the `id` options.\n- **title**: what will be written in big on top of the blogpost! use html syntax there.\n- **description**: what will be written just below the title, centered text.\n- **keyword**: list of keywords related with the blogpost\n- **seoDescription**: a description for the bloppost meta. Should be a bit shorter than the description and must not contain any html syntax.",
"_____no_output_____"
],
[
"## Add a chart description",
"_____no_output_____"
],
[
"A chart example always come with some explanation. It must:\n\ncontain keywords\nlink to related pages like the parent page (graph section)\ngive explanations. In depth for complicated charts. High level for beginner level charts",
"_____no_output_____"
],
[
"## Add a chart",
"_____no_output_____"
]
],
[
[
"import seaborn as sns, numpy as np\nnp.random.seed(0)\nx = np.random.randn(100)\nax = sns.distplot(x)",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
e73c7960a8885d451044264cbfebeb35584928b5 | 216,577 | ipynb | Jupyter Notebook | pytorch_ipynb/cnn/cnn-resnet18-celeba-dataparallel.ipynb | chloe-wang/deeplearning-models | cab9700ff57d3de67b652f2dcd6f440c3036cc4e | [
"MIT"
] | 7 | 2019-06-30T10:50:02.000Z | 2022-01-09T17:20:17.000Z | pytorch_ipynb/cnn/cnn-resnet18-celeba-dataparallel.ipynb | lichao312214129/deeplearning-models | cab9700ff57d3de67b652f2dcd6f440c3036cc4e | [
"MIT"
] | 1 | 2019-06-14T05:24:13.000Z | 2019-06-14T05:24:13.000Z | pytorch_ipynb/cnn/cnn-resnet18-celeba-dataparallel.ipynb | lichao312214129/deeplearning-models | cab9700ff57d3de67b652f2dcd6f440c3036cc4e | [
"MIT"
] | 3 | 2019-06-27T17:13:30.000Z | 2020-10-10T23:26:17.000Z | 172.296738 | 125,324 | 0.883524 | [
[
[
"*Accompanying code examples of the book \"Introduction to Artificial Neural Networks and Deep Learning: A Practical Guide with Applications in Python\" by [Sebastian Raschka](https://sebastianraschka.com). All code examples are released under the [MIT license](https://github.com/rasbt/deep-learning-book/blob/master/LICENSE). If you find this content useful, please consider supporting the work by buying a [copy of the book](https://leanpub.com/ann-and-deeplearning).*\n \nOther code examples and content are available on [GitHub](https://github.com/rasbt/deep-learning-book). The PDF and ebook versions of the book are available through [Leanpub](https://leanpub.com/ann-and-deeplearning).",
"_____no_output_____"
]
],
[
[
"%load_ext watermark\n%watermark -a 'Sebastian Raschka' -v -p torch",
"Sebastian Raschka \n\nCPython 3.6.8\nIPython 7.2.0\n\ntorch 1.0.0\n"
]
],
[
[
"# Model Zoo -- CNN Gender Classifier (ResNet-18 Architecture, CelebA) with Data Parallelism",
"_____no_output_____"
],
[
"### Network Architecture",
"_____no_output_____"
],
[
"The network in this notebook is an implementation of the ResNet-18 [1] architecture on the CelebA face dataset [2] to train a gender classifier. \n\n\nReferences\n \n- [1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778). ([CVPR Link](https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html))\n\n- [2] Zhang, K., Tan, L., Li, Z., & Qiao, Y. (2016). Gender and smile classification using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 34-38).\n",
"_____no_output_____"
],
[
"The following figure illustrates residual blocks with skip connections such that the input passed via the shortcut matches the dimensions of the main path's output, which allows the network to learn identity functions.\n\n\n\n\nThe ResNet-18 architecture actually uses residual blocks with skip connections such that the input passed via the shortcut matches is resized to dimensions of the main path's output. Such a residual block is illustrated below:\n\n",
"_____no_output_____"
],
[
"For a more detailed explanation see the other notebook, [resnet-ex-1.ipynb](resnet-ex-1.ipynb).",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"import os\nimport time\n\nimport numpy as np\nimport pandas as pd\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nfrom torch.utils.data import Dataset\nfrom torch.utils.data import DataLoader\n\nfrom torchvision import datasets\nfrom torchvision import transforms\n\nimport matplotlib.pyplot as plt\nfrom PIL import Image\n\n\nif torch.cuda.is_available():\n torch.backends.cudnn.deterministic = True",
"_____no_output_____"
]
],
[
[
"## Settings",
"_____no_output_____"
]
],
[
[
"##########################\n### SETTINGS\n##########################\n\n# Hyperparameters\nRANDOM_SEED = 1\nLEARNING_RATE = 0.001\nNUM_EPOCHS = 10\n\n# Architecture\nNUM_FEATURES = 128*128\nNUM_CLASSES = 2\nBATCH_SIZE = 256*torch.cuda.device_count()\nDEVICE = 'cuda:0' # default GPU device\nGRAYSCALE = False",
"_____no_output_____"
]
],
[
[
"## Dataset",
"_____no_output_____"
],
[
"### Downloading the Dataset",
"_____no_output_____"
],
[
"Note that the ~200,000 CelebA face image dataset is relatively large (~1.3 Gb). The download link provided below was provided by the author on the official CelebA website at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html. ",
"_____no_output_____"
],
[
"1) Download and unzip the file `img_align_celeba.zip`, which contains the images in jpeg format.\n\n2) Download the `list_attr_celeba.txt` file, which contains the class labels\n\n3) Download the `list_eval_partition.txt` file, which contains training/validation/test partitioning info",
"_____no_output_____"
],
[
"### Preparing the Dataset",
"_____no_output_____"
]
],
[
[
"df1 = pd.read_csv('list_attr_celeba.txt', sep=\"\\s+\", skiprows=1, usecols=['Male'])\n\n# Make 0 (female) & 1 (male) labels instead of -1 & 1\ndf1.loc[df1['Male'] == -1, 'Male'] = 0\n\ndf1.head()",
"_____no_output_____"
],
[
"df2 = pd.read_csv('list_eval_partition.txt', sep=\"\\s+\", skiprows=0, header=None)\ndf2.columns = ['Filename', 'Partition']\ndf2 = df2.set_index('Filename')\n\ndf2.head()",
"_____no_output_____"
],
[
"df3 = df1.merge(df2, left_index=True, right_index=True)\ndf3.head()",
"_____no_output_____"
],
[
"df3.to_csv('celeba-gender-partitions.csv')\ndf4 = pd.read_csv('celeba-gender-partitions.csv', index_col=0)\ndf4.head()",
"_____no_output_____"
],
[
"df4.loc[df4['Partition'] == 0].to_csv('celeba-gender-train.csv')\ndf4.loc[df4['Partition'] == 1].to_csv('celeba-gender-valid.csv')\ndf4.loc[df4['Partition'] == 2].to_csv('celeba-gender-test.csv')",
"_____no_output_____"
],
[
"img = Image.open('img_align_celeba/000001.jpg')\nprint(np.asarray(img, dtype=np.uint8).shape)\nplt.imshow(img);",
"(218, 178, 3)\n"
]
],
[
[
"### Implementing a Custom DataLoader Class",
"_____no_output_____"
]
],
[
[
"class CelebaDataset(Dataset):\n \"\"\"Custom Dataset for loading CelebA face images\"\"\"\n\n def __init__(self, csv_path, img_dir, transform=None):\n \n df = pd.read_csv(csv_path, index_col=0)\n self.img_dir = img_dir\n self.csv_path = csv_path\n self.img_names = df.index.values\n self.y = df['Male'].values\n self.transform = transform\n\n def __getitem__(self, index):\n img = Image.open(os.path.join(self.img_dir,\n self.img_names[index]))\n \n if self.transform is not None:\n img = self.transform(img)\n \n label = self.y[index]\n return img, label\n\n def __len__(self):\n return self.y.shape[0]",
"_____no_output_____"
],
[
"# Note that transforms.ToTensor()\n# already divides pixels by 255. internally\n\ncustom_transform = transforms.Compose([transforms.CenterCrop((178, 178)),\n transforms.Resize((128, 128)),\n #transforms.Grayscale(), \n #transforms.Lambda(lambda x: x/255.),\n transforms.ToTensor()])\n\ntrain_dataset = CelebaDataset(csv_path='celeba-gender-train.csv',\n img_dir='img_align_celeba/',\n transform=custom_transform)\n\nvalid_dataset = CelebaDataset(csv_path='celeba-gender-valid.csv',\n img_dir='img_align_celeba/',\n transform=custom_transform)\n\ntest_dataset = CelebaDataset(csv_path='celeba-gender-test.csv',\n img_dir='img_align_celeba/',\n transform=custom_transform)\n\n\ntrain_loader = DataLoader(dataset=train_dataset,\n batch_size=BATCH_SIZE,\n shuffle=True,\n num_workers=4)\n\nvalid_loader = DataLoader(dataset=valid_dataset,\n batch_size=BATCH_SIZE,\n shuffle=False,\n num_workers=4)\n\ntest_loader = DataLoader(dataset=test_dataset,\n batch_size=BATCH_SIZE,\n shuffle=False,\n num_workers=4)",
"_____no_output_____"
],
[
"torch.manual_seed(0)\n\nfor epoch in range(2):\n\n for batch_idx, (x, y) in enumerate(train_loader):\n \n print('Epoch:', epoch+1, end='')\n print(' | Batch index:', batch_idx, end='')\n print(' | Batch size:', y.size()[0])\n \n x = x.to(DEVICE)\n y = y.to(DEVICE)\n time.sleep(1)\n break",
"Epoch: 1 | Batch index: 0 | Batch size: 1024\nEpoch: 2 | Batch index: 0 | Batch size: 1024\n"
]
],
[
[
"## Model",
"_____no_output_____"
],
[
"The following code cell that implements the ResNet-34 architecture is a derivative of the code provided at https://pytorch.org/docs/0.4.0/_modules/torchvision/models/resnet.html.",
"_____no_output_____"
]
],
[
[
"##########################\n### MODEL\n##########################\n\n\ndef conv3x3(in_planes, out_planes, stride=1):\n \"\"\"3x3 convolution with padding\"\"\"\n return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n\n\nclass BasicBlock(nn.Module):\n expansion = 1\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(BasicBlock, self).__init__()\n self.conv1 = conv3x3(inplanes, planes, stride)\n self.bn1 = nn.BatchNorm2d(planes)\n self.relu = nn.ReLU(inplace=True)\n self.conv2 = conv3x3(planes, planes)\n self.bn2 = nn.BatchNorm2d(planes)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.bn2(out)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n\n out += residual\n out = self.relu(out)\n\n return out\n\n\n\n\nclass ResNet(nn.Module):\n\n def __init__(self, block, layers, num_classes, grayscale):\n self.inplanes = 64\n if grayscale:\n in_dim = 1\n else:\n in_dim = 3\n super(ResNet, self).__init__()\n self.conv1 = nn.Conv2d(in_dim, 64, kernel_size=7, stride=2, padding=3,\n bias=False)\n self.bn1 = nn.BatchNorm2d(64)\n self.relu = nn.ReLU(inplace=True)\n self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)\n self.layer1 = self._make_layer(block, 64, layers[0])\n self.layer2 = self._make_layer(block, 128, layers[1], stride=2)\n self.layer3 = self._make_layer(block, 256, layers[2], stride=2)\n self.layer4 = self._make_layer(block, 512, layers[3], stride=2)\n self.avgpool = nn.AvgPool2d(7, stride=1, padding=2)\n self.fc = nn.Linear(2048 * block.expansion, num_classes)\n\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels\n m.weight.data.normal_(0, (2. / n)**.5)\n elif isinstance(m, nn.BatchNorm2d):\n m.weight.data.fill_(1)\n m.bias.data.zero_()\n\n def _make_layer(self, block, planes, blocks, stride=1):\n downsample = None\n if stride != 1 or self.inplanes != planes * block.expansion:\n downsample = nn.Sequential(\n nn.Conv2d(self.inplanes, planes * block.expansion,\n kernel_size=1, stride=stride, bias=False),\n nn.BatchNorm2d(planes * block.expansion),\n )\n\n layers = []\n layers.append(block(self.inplanes, planes, stride, downsample))\n self.inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.inplanes, planes))\n\n return nn.Sequential(*layers)\n\n def forward(self, x):\n x = self.conv1(x)\n x = self.bn1(x)\n x = self.relu(x)\n x = self.maxpool(x)\n\n x = self.layer1(x)\n x = self.layer2(x)\n x = self.layer3(x)\n x = self.layer4(x)\n\n x = self.avgpool(x)\n x = x.view(x.size(0), -1)\n logits = self.fc(x)\n probas = F.softmax(logits, dim=1)\n return logits, probas\n\n\n\ndef resnet18(num_classes):\n \"\"\"Constructs a ResNet-18 model.\"\"\"\n model = ResNet(block=BasicBlock, \n layers=[2, 2, 2, 2],\n num_classes=NUM_CLASSES,\n grayscale=GRAYSCALE)\n return model",
"_____no_output_____"
],
[
"torch.manual_seed(RANDOM_SEED)\n\n##########################\n### COST AND OPTIMIZER\n##########################\n\n\n\nmodel = resnet18(NUM_CLASSES)\n\n\n#### DATA PARALLEL START ####\nif torch.cuda.device_count() > 1:\n print(\"Using\", torch.cuda.device_count(), \"GPUs\")\n model = nn.DataParallel(model)\n#### DATA PARALLEL END ####\n\n\nmodel.to(DEVICE)\n\n\n\ncost_fn = torch.nn.CrossEntropyLoss() \noptimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE) ",
"Using 4 GPUs\n"
]
],
[
[
"## Training",
"_____no_output_____"
]
],
[
[
"def compute_accuracy(model, data_loader, device):\n correct_pred, num_examples = 0, 0\n for i, (features, targets) in enumerate(data_loader):\n \n features = features.to(device)\n targets = targets.to(device)\n\n logits, probas = model(features)\n _, predicted_labels = torch.max(probas, 1)\n num_examples += targets.size(0)\n correct_pred += (predicted_labels == targets).sum()\n return correct_pred.float()/num_examples * 100\n \n\nstart_time = time.time()\nfor epoch in range(NUM_EPOCHS):\n \n model.train()\n for batch_idx, (features, targets) in enumerate(train_loader):\n \n features = features.to(DEVICE)\n targets = targets.to(DEVICE)\n \n ### FORWARD AND BACK PROP\n logits, probas = model(features)\n cost = cost_fn(logits, targets)\n optimizer.zero_grad()\n \n cost.backward()\n \n ### UPDATE MODEL PARAMETERS\n optimizer.step()\n \n ### LOGGING\n if not batch_idx % 50:\n print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f' \n %(epoch+1, NUM_EPOCHS, batch_idx, \n len(train_loader), cost))\n\n \n\n model.eval()\n with torch.set_grad_enabled(False): # save memory during inference\n print('Epoch: %03d/%03d | Train: %.3f%% | Valid: %.3f%%' % (\n epoch+1, NUM_EPOCHS, \n compute_accuracy(model, train_loader, device=DEVICE),\n compute_accuracy(model, valid_loader, device=DEVICE)))\n \n print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))\n \nprint('Total Training Time: %.2f min' % ((time.time() - start_time)/60))",
"Epoch: 001/010 | Batch 0000/0159 | Cost: 0.6782\nEpoch: 001/010 | Batch 0050/0159 | Cost: 0.1445\nEpoch: 001/010 | Batch 0100/0159 | Cost: 0.1169\nEpoch: 001/010 | Batch 0150/0159 | Cost: 0.0913\nEpoch: 001/010 | Train: 93.687% | Valid: 94.101%\nTime elapsed: 3.83 min\nEpoch: 002/010 | Batch 0000/0159 | Cost: 0.0851\nEpoch: 002/010 | Batch 0050/0159 | Cost: 0.0910\nEpoch: 002/010 | Batch 0100/0159 | Cost: 0.0736\nEpoch: 002/010 | Batch 0150/0159 | Cost: 0.0946\nEpoch: 002/010 | Train: 96.940% | Valid: 97.025%\nTime elapsed: 7.60 min\nEpoch: 003/010 | Batch 0000/0159 | Cost: 0.0587\nEpoch: 003/010 | Batch 0050/0159 | Cost: 0.0506\nEpoch: 003/010 | Batch 0100/0159 | Cost: 0.0613\nEpoch: 003/010 | Batch 0150/0159 | Cost: 0.0495\nEpoch: 003/010 | Train: 98.260% | Valid: 97.896%\nTime elapsed: 11.39 min\nEpoch: 004/010 | Batch 0000/0159 | Cost: 0.0387\nEpoch: 004/010 | Batch 0050/0159 | Cost: 0.0413\nEpoch: 004/010 | Batch 0100/0159 | Cost: 0.0462\nEpoch: 004/010 | Batch 0150/0159 | Cost: 0.0366\nEpoch: 004/010 | Train: 98.561% | Valid: 97.705%\nTime elapsed: 15.21 min\nEpoch: 005/010 | Batch 0000/0159 | Cost: 0.0323\nEpoch: 005/010 | Batch 0050/0159 | Cost: 0.0431\nEpoch: 005/010 | Batch 0100/0159 | Cost: 0.0433\nEpoch: 005/010 | Batch 0150/0159 | Cost: 0.0263\nEpoch: 005/010 | Train: 98.692% | Valid: 97.715%\nTime elapsed: 18.99 min\nEpoch: 006/010 | Batch 0000/0159 | Cost: 0.0285\nEpoch: 006/010 | Batch 0050/0159 | Cost: 0.0280\nEpoch: 006/010 | Batch 0100/0159 | Cost: 0.0302\nEpoch: 006/010 | Batch 0150/0159 | Cost: 0.0451\nEpoch: 006/010 | Train: 98.880% | Valid: 97.730%\nTime elapsed: 22.76 min\nEpoch: 007/010 | Batch 0000/0159 | Cost: 0.0307\nEpoch: 007/010 | Batch 0050/0159 | Cost: 0.0257\nEpoch: 007/010 | Batch 0100/0159 | Cost: 0.0247\nEpoch: 007/010 | Batch 0150/0159 | Cost: 0.0227\nEpoch: 007/010 | Train: 99.276% | Valid: 97.966%\nTime elapsed: 26.55 min\nEpoch: 008/010 | Batch 0000/0159 | Cost: 0.0142\nEpoch: 008/010 | Batch 0050/0159 | Cost: 0.0185\nEpoch: 008/010 | Batch 0100/0159 | Cost: 0.0092\nEpoch: 008/010 | Batch 0150/0159 | Cost: 0.0345\nEpoch: 008/010 | Train: 99.536% | Valid: 97.972%\nTime elapsed: 30.36 min\nEpoch: 009/010 | Batch 0000/0159 | Cost: 0.0130\nEpoch: 009/010 | Batch 0050/0159 | Cost: 0.0160\nEpoch: 009/010 | Batch 0100/0159 | Cost: 0.0112\nEpoch: 009/010 | Batch 0150/0159 | Cost: 0.0235\nEpoch: 009/010 | Train: 99.211% | Valid: 97.926%\nTime elapsed: 34.16 min\nEpoch: 010/010 | Batch 0000/0159 | Cost: 0.0049\nEpoch: 010/010 | Batch 0050/0159 | Cost: 0.0135\nEpoch: 010/010 | Batch 0100/0159 | Cost: 0.0225\nEpoch: 010/010 | Batch 0150/0159 | Cost: 0.0236\nEpoch: 010/010 | Train: 99.520% | Valid: 97.972%\nTime elapsed: 37.94 min\nTotal Training Time: 37.94 min\n"
]
],
[
[
"## Evaluation",
"_____no_output_____"
]
],
[
[
"with torch.set_grad_enabled(False): # save memory during inference\n print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader, device=DEVICE)))",
"Test accuracy: 97.38%\n"
],
[
"for batch_idx, (features, targets) in enumerate(test_loader):\n\n features = features\n targets = targets\n break\n \nplt.imshow(np.transpose(features[0], (1, 2, 0)))",
"_____no_output_____"
],
[
"model.eval()\nlogits, probas = model(features.to(DEVICE)[0, None])\nprint('Probability Female %.2f%%' % (probas[0][0]*100))",
"Probability Female 100.00%\n"
],
[
"%watermark -iv",
"numpy 1.15.4\npandas 0.23.4\ntorch 1.0.0\nPIL.Image 5.3.0\n\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
e73c7e369627d963c46d9e522685cdafffd00543 | 42,806 | ipynb | Jupyter Notebook | user_logs.ipynb | jwarwick/netrunner_stats | 8f565cbc790acd4055a16282ca7347af0df59a10 | [
"MIT"
] | null | null | null | user_logs.ipynb | jwarwick/netrunner_stats | 8f565cbc790acd4055a16282ca7347af0df59a10 | [
"MIT"
] | null | null | null | user_logs.ipynb | jwarwick/netrunner_stats | 8f565cbc790acd4055a16282ca7347af0df59a10 | [
"MIT"
] | null | null | null | 119.236769 | 10,164 | 0.655843 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
e73c97e8aca2d6dad65ee4cbb1bc7cd4582a5d43 | 645,163 | ipynb | Jupyter Notebook | machine_learning/anomaly_detection/tf_pca/pca_anomaly_detection_local.ipynb | ryangillard/artificial_intelligence | f7c21af221f366b075d351deeeb00a1b266ac3e3 | [
"Apache-2.0"
] | 4 | 2019-07-04T05:15:59.000Z | 2020-06-29T19:34:33.000Z | machine_learning/anomaly_detection/tf_pca/pca_anomaly_detection_local.ipynb | ryangillard/artificial_intelligence | f7c21af221f366b075d351deeeb00a1b266ac3e3 | [
"Apache-2.0"
] | null | null | null | machine_learning/anomaly_detection/tf_pca/pca_anomaly_detection_local.ipynb | ryangillard/artificial_intelligence | f7c21af221f366b075d351deeeb00a1b266ac3e3 | [
"Apache-2.0"
] | 1 | 2019-05-23T16:06:51.000Z | 2019-05-23T16:06:51.000Z | 99.824076 | 73,492 | 0.745979 | [
[
[
"# Import libraries and modules\nimport sys\nimport tensorflow as tf\nimport numpy as np\nimport shutil\nprint(tf.__version__)\nprint(np.__version__)\nnp.set_printoptions(threshold = np.inf)",
"1.13.1\n1.16.4\n"
],
[
"# tf.enable_eager_execution()\ntf.executing_eagerly()",
"_____no_output_____"
]
],
[
[
"# Create data",
"_____no_output_____"
],
[
"## Create data generator",
"_____no_output_____"
]
],
[
[
"simple_data_genertator = False\n\npercent_sequence_before_anomaly = 70.0\npercent_sequence_after_anomaly = 0.0\n\ndef create_time_series_normal_parameters():\n normal_freq_noise_scale = 1.0\n normal_frequence_noise_shift = 1.0\n\n normal_ampl_noise_scale = 1.0\n normal_ampl_noise_shift = 1.0\n\n normal_noise_noise_scale = 1.0\n\n if simple_data_genertator == True:\n normal_freq = 1.0\n normal_ampl = 1.0\n else:\n normal_freq = np.random.random() * normal_freq_noise_scale + normal_frequence_noise_shift\n normal_ampl = np.random.random() * normal_ampl_noise_scale + normal_ampl_noise_shift\n \n return {\"normal_freq\": normal_freq, \n \"normal_ampl\": normal_ampl, \n \"normal_noise_noise_scale\": normal_noise_noise_scale}\n \ndef create_time_series_normal(\n number_of_sequences, \n seq_len, \n normal_freq, \n normal_ampl, \n normal_noise_noise_scale):\n # Normal parameters\n if simple_data_genertator == True:\n sequence = np.stack(\n arrays = [np.sin(np.arange(0, seq_len) * normal_freq) * normal_ampl \n for _ in range(number_of_sequences)], axis = 0)\n else:\n sequence = np.stack(\n arrays = [np.sin(np.arange(0, seq_len) * normal_freq) * normal_ampl + \\\n [np.random.random() * normal_noise_noise_scale \n for i in range(seq_len)] for _ in range(number_of_sequences)], axis = 0)\n\n return sequence\n\ndef create_time_series_with_anomaly(\n number_of_sequences, \n seq_len, \n percent_sequence_before_anomaly, \n percent_sequence_after_anomaly, \n normal_freq, \n normal_ampl, \n normal_noise_noise_scale):\n seq_len_before_anomaly = int(seq_len * percent_sequence_before_anomaly / 100.0)\n seq_len_after_anomaly = int(seq_len * percent_sequence_after_anomaly / 100.0)\n seq_len_anomaly = seq_len - seq_len_before_anomaly - seq_len_after_anomaly\n\n # Anomalous parameters\n anomalous_ampl_multipler_min = 8.0\n anomalous_ampl_multipler_max = 20.0\n\n if simple_data_genertator == True:\n sequence_with_anomaly = np.stack(\n arrays = [np.sin(np.arange(0, seq_len) * normal_freq) * normal_ampl \n for _ in range(number_of_sequences)], axis = 0)\n else:\n sequence_with_anomaly = create_time_series_normal(\n number_of_sequences, seq_len, normal_freq, normal_ampl, normal_noise_noise_scale)\n sequence_with_anomaly[:, seq_len_before_anomaly:seq_len_before_anomaly + seq_len_anomaly] *= \\\n ((anomalous_ampl_multipler_max - anomalous_ampl_multipler_min) * \\\n np.random.random_sample([number_of_sequences, seq_len_anomaly]) + anomalous_ampl_multipler_min) * \\\n (np.random.randint(2, size = [number_of_sequences, seq_len_anomaly]) * -2 + 1)\n \n return sequence_with_anomaly",
"_____no_output_____"
],
[
"test_normal_parameters = create_time_series_normal_parameters()",
"_____no_output_____"
],
[
"import seaborn as sns\nflatui = [\"#9b59b6\", \"#3498db\", \"#95a5a6\", \"#e74c3c\", \"#34495e\", \"#2ecc71\"]\nfor i in range(0, 5):\n sns.tsplot(create_time_series_normal(1, 10, test_normal_parameters[\"normal_freq\"], test_normal_parameters[\"normal_ampl\"], test_normal_parameters[\"normal_noise_noise_scale\"]).reshape(-1), color=flatui[i%len(flatui)] )",
"/usr/local/lib/python3.5/dist-packages/seaborn/timeseries.py:183: UserWarning: The `tsplot` function is deprecated and will be removed in a future release. Please update your code to use the new `lineplot` function.\n warnings.warn(msg, UserWarning)\n"
],
[
"import seaborn as sns\nflatui = [\"#9b59b6\", \"#3498db\", \"#95a5a6\", \"#e74c3c\", \"#34495e\", \"#2ecc71\"]\nfor i in range(0, 10):\n sns.tsplot(create_time_series_with_anomaly(1, 10, percent_sequence_before_anomaly, percent_sequence_after_anomaly, test_normal_parameters[\"normal_freq\"], test_normal_parameters[\"normal_ampl\"], test_normal_parameters[\"normal_noise_noise_scale\"]).reshape(-1), color=flatui[i%len(flatui)] )",
"_____no_output_____"
]
],
[
[
"## Create training and evaluation data",
"_____no_output_____"
]
],
[
[
"number_of_training_normal_sequences = 64000\n\nnumber_of_validation_normal_1_sequences = 6400\nnumber_of_validation_normal_2_sequences = 6400\nnumber_of_validation_anomalous_sequences = 6400\n\nnumber_of_test_normal_sequences = 6400\nnumber_of_test_anomalous_sequences = 6400\n\nseq_len = 30\nnumber_of_tags = 5\ntag_columns = [\"tag_{0}\".format(tag) for tag in range(0, number_of_tags)]",
"_____no_output_____"
],
[
"tag_data_list = [create_time_series_normal_parameters() \n for tag in range(0, number_of_tags)]\ntag_data_list",
"_____no_output_____"
],
[
"# Create training set using normal sequences\ntraining_normal_sequences_list = [create_time_series_normal(\n number_of_training_normal_sequences, seq_len, tag[\"normal_freq\"], tag[\"normal_ampl\"], tag[\"normal_noise_noise_scale\"]) \n for tag in tag_data_list]\ntraining_normal_sequences_array = np.stack(\n arrays = list(map(\n lambda i: np.stack(\n arrays = list(map(\n lambda j: np.array2string(\n a = training_normal_sequences_list[i][j], separator = ',').replace('[', '').replace(']', '').replace(' ', '').replace('\\n', ''), \n np.arange(0, number_of_training_normal_sequences))), \n axis = 0), \n np.arange(0, number_of_tags))), \n axis = 1)\nnp.random.shuffle(training_normal_sequences_array)\nprint(\"training_normal_sequences_array.shape = \\n{}\".format(training_normal_sequences_array.shape))",
"training_normal_sequences_array.shape = \n(64000, 5)\n"
],
[
"# Create validation sets\n# Create set vn1 of normal sequences which will be used for early stopping during training as well as using the error vectors to learn mu and sigma for mahalanobis distance\nvalidation_normal_1_sequences_list = [create_time_series_normal(\n number_of_validation_normal_1_sequences, seq_len, tag[\"normal_freq\"], tag[\"normal_ampl\"], tag[\"normal_noise_noise_scale\"]) \n for tag in tag_data_list]\nvalidation_normal_1_sequences_array = np.stack(\n arrays = list(map(\n lambda i: np.stack(\n arrays = list(map(\n lambda j: np.array2string(\n a = validation_normal_1_sequences_list[i][j], separator = ',').replace('[', '').replace(']', '').replace(' ', '').replace('\\n', ''), \n np.arange(0, number_of_validation_normal_1_sequences))), \n axis = 0), \n np.arange(0, number_of_tags))), \n axis = 1)\nprint(\"validation_normal_1_sequences_array.shape = \\n{}\".format(validation_normal_1_sequences_array.shape))\n\n# Create set vn2 of normal sequences which will be used for tuning the anomaly thresholds\nvalidation_normal_2_sequences_list = [create_time_series_normal(\n number_of_validation_normal_2_sequences, seq_len, tag[\"normal_freq\"], tag[\"normal_ampl\"], tag[\"normal_noise_noise_scale\"]) \n for tag in tag_data_list]\nvalidation_normal_2_sequences_array = np.stack(\n arrays = list(map(lambda i: np.stack(arrays = list(map(\n lambda j: np.array2string(\n a = validation_normal_2_sequences_list[i][j], separator = ',').replace('[', '').replace(']', '').replace(' ', '').replace('\\n', ''), \n np.arange(0, number_of_validation_normal_2_sequences))), \n axis = 0), \n np.arange(0, number_of_tags))), \n axis = 1)\nprint(\"validation_normal_2_sequences_array.shape = \\n{}\".format(validation_normal_2_sequences_array.shape))\n\n# Create set va of anomalous sequences which will be used for tuning the anomaly thresholds\nvalidation_anomalous_sequences_list = [create_time_series_with_anomaly(\n number_of_validation_anomalous_sequences, seq_len, percent_sequence_before_anomaly, percent_sequence_after_anomaly, tag[\"normal_freq\"], tag[\"normal_ampl\"], tag[\"normal_noise_noise_scale\"]) \n for tag in tag_data_list]\nvalidation_anomalous_sequences_array = np.stack(\n arrays = list(map(\n lambda i: np.stack(arrays = list(map(\n lambda j: np.array2string(\n a = validation_anomalous_sequences_list[i][j], separator = ',').replace('[', '').replace(']', '').replace(' ', '').replace('\\n', ''), \n np.arange(0, number_of_validation_anomalous_sequences))), \n axis = 0), \n np.arange(0, number_of_tags))), \n axis = 1)\nprint(\"validation_anomalous_sequences_array.shape = \\n{}\".format(validation_anomalous_sequences_array.shape))",
"validation_normal_1_sequences_array.shape = \n(6400, 5)\nvalidation_normal_2_sequences_array.shape = \n(6400, 5)\nvalidation_anomalous_sequences_array.shape = \n(6400, 5)\n"
],
[
"# Create test sets\n# Create set tn of normal sequences which will be used for testing model\ntest_normal_sequences_list = [create_time_series_normal(\n number_of_test_normal_sequences, seq_len, tag[\"normal_freq\"], tag[\"normal_ampl\"], tag[\"normal_noise_noise_scale\"]) \n for tag in tag_data_list]\ntest_normal_sequences_array = np.stack(\n arrays = list(map(\n lambda i: np.stack(\n arrays = list(map(\n lambda j: np.array2string(\n a = test_normal_sequences_list[i][j], separator = ',').replace('[', '').replace(']', '').replace(' ', '').replace('\\n', ''), \n np.arange(0, number_of_test_normal_sequences))), \n axis = 0), \n np.arange(0, number_of_tags))), \n axis = 1)\nprint(\"test_normal_sequences_array.shape = \\n{}\".format(test_normal_sequences_array.shape))\n\n# Create set ta of anomalous sequences which will be used for testing model\ntest_anomalous_sequences_list = [create_time_series_with_anomaly(\n number_of_test_anomalous_sequences, seq_len, percent_sequence_before_anomaly, percent_sequence_after_anomaly, tag[\"normal_freq\"], tag[\"normal_ampl\"], tag[\"normal_noise_noise_scale\"]) \n for tag in tag_data_list]\ntest_anomalous_sequences_array = np.stack(\n arrays = list(map(\n lambda i: np.stack(\n arrays = list(map(\n lambda j: np.array2string(\n a = test_anomalous_sequences_list[i][j], separator = ',').replace('[', '').replace(']', '').replace(' ', '').replace('\\n', ''), \n np.arange(0, number_of_test_anomalous_sequences))), \n axis = 0), \n np.arange(0, number_of_tags))), \n axis = 1)\nprint(\"test_anomalous_sequences_array.shape = \\n{}\".format(test_anomalous_sequences_array.shape))",
"test_normal_sequences_array.shape = \n(6400, 5)\ntest_anomalous_sequences_array.shape = \n(6400, 5)\n"
],
[
"# Combine vn2 and va sets for tuning anomaly thresholds\nlabeled_validation_normal_2_sequences_array = np.concatenate(\n seq = [validation_normal_2_sequences_array, \n np.zeros(shape = [validation_normal_2_sequences_array.shape[0], 1], dtype = np.int64)], \n axis = 1)\nlabeled_validation_anomalous_sequences_array = np.concatenate(\n seq = [validation_anomalous_sequences_array, \n np.ones(shape = [validation_anomalous_sequences_array.shape[0], 1], dtype = np.int64)], \n axis = 1)\nlabeled_validation_mixed_sequences_array = np.concatenate(\n seq = [labeled_validation_normal_2_sequences_array, \n labeled_validation_anomalous_sequences_array], \n axis = 0)\nnp.random.shuffle(labeled_validation_mixed_sequences_array)\nprint(\"labeled_validation_mixed_sequences_array.shape = \\n{}\".format(labeled_validation_mixed_sequences_array.shape))\n\n# Combine tn and ta sets for testing model\nlabeled_test_normal_sequences_array = np.concatenate(\n seq = [test_normal_sequences_array, \n np.zeros(shape = [test_normal_sequences_array.shape[0], 1], dtype = np.int64)], \n axis = 1)\nlabled_test_anomalous_sequences_array = np.concatenate(\n seq = [test_anomalous_sequences_array, \n np.ones(shape = [test_anomalous_sequences_array.shape[0], 1], dtype = np.int64)], \n axis = 1)\nlabeled_test_mixed_sequences_array = np.concatenate(\n seq = [labeled_test_normal_sequences_array, \n labled_test_anomalous_sequences_array], \n axis = 0)\nnp.random.shuffle(labeled_test_mixed_sequences_array)\nprint(\"labeled_test_mixed_sequences_array.shape = \\n{}\".format(labeled_test_mixed_sequences_array.shape))",
"labeled_validation_mixed_sequences_array.shape = \n(12800, 6)\nlabeled_test_mixed_sequences_array.shape = \n(12800, 6)\n"
],
[
"np.savetxt(fname = \"data/training_normal_sequences.csv\", \n X = training_normal_sequences_array, \n fmt = '%s', \n delimiter = \";\")\n\nnp.savetxt(fname = \"data/validation_normal_1_sequences.csv\", \n X = validation_normal_1_sequences_array, \n fmt = '%s', \n delimiter = \";\")\n\nnp.savetxt(fname = \"data/labeled_validation_mixed_sequences.csv\", \n X = labeled_validation_mixed_sequences_array, \n fmt = '%s', \n delimiter = \";\")\n\nnp.savetxt(fname = \"data/labeled_test_mixed_sequences.csv\", \n X = labeled_test_mixed_sequences_array, \n fmt = '%s', \n delimiter = \";\")",
"_____no_output_____"
],
[
"!head -3 data/training_normal_sequences.csv",
"5.35341916e-01,1.62427963e+00,-8.48290170e-01,-7.92330818e-01,1.59996964e+00,5.64005220e-01,-9.07497732e-01,1.88866411e+00,1.65763543e+00,-1.27944017e+00,-6.63829108e-02,1.73915404e+00,1.07570263e-03,-7.39967011e-01,1.84565666e+00,9.28276580e-01,-8.74367697e-01,1.27776350e+00,1.49317525e+00,-1.42381813e+00,2.21023277e-01,2.20340863e+00,-7.08605703e-02,-3.27685956e-01,2.21231328e+00,1.17254985e+00,-1.26874553e+00,7.32650805e-01,1.71587898e+00,-1.23273838e+00;5.71968350e-01,1.82454962e+00,1.23135221e+00,-1.79925892e-01,-3.46167663e-01,8.65595492e-01,1.94980511e+00,6.60658713e-01,-6.17245801e-01,3.54957096e-01,1.75640757e+00,1.91006305e+00,-5.87121839e-01,-8.92522845e-01,1.02031589e-03,1.97031076e+00,1.23410796e+00,-1.09194440e+00,-6.62450576e-01,1.47048656e+00,2.28795090e+00,7.59581061e-01,-1.07127455e+00,3.42989503e-01,1.51512834e+00,1.54757652e+00,1.26256070e-01,-1.25381215e+00,6.20069084e-01,1.42975931e+00;0.04041749,2.17130087,-0.82793375,-0.15106699,2.48897918,0.05826132,-0.83910785,1.96015166,0.31707854,-1.45744715,1.98098997,0.61929429,-1.81473356,1.48689583,1.60007956,-1.28876276,1.03232804,2.09565164,-1.13037095,0.94897382,2.32626869,-1.16164566,0.23964132,2.78192426,-0.36087278,-1.02487422,2.31734009,0.08873291,-0.71140634,1.71783641;0.16872237,1.78881863,1.10485672,-0.36670979,0.20210896,2.15327941,1.57503497,-0.28407101,-0.39956792,1.40002263,1.46060574,0.28821711,-1.17150701,0.8861364,1.41915452,0.73979186,-0.34723808,0.56648762,2.22832049,1.04563291,-0.3105694,0.03662565,1.52395591,1.84836432,-0.13452528,-0.77465493,0.89775907,1.56865048,0.05364581,-0.5701422;0.37961138,1.94378327,1.42450355,-0.18444716,-1.18787607,-0.28370447,1.31919054,2.34745393,1.42887916,-0.40392965,-1.36342688,0.55787225,1.52586536,1.58774969,0.07801215,-1.08019655,-0.51273497,1.11983776,2.25666144,1.06977335,-0.20246668,-0.91860281,-0.53195867,1.51024183,1.59061086,0.90363579,-1.37541786,-1.21292863,0.78575938,2.37864527\n0.2602004,2.48233792,-0.41381181,-0.76114926,1.99494192,0.74378047,-0.79170169,1.13344156,1.12676903,-1.32874245,0.24596586,2.45958821,-0.65972089,-0.24062394,1.63344271,0.26243652,-1.32864232,1.68340341,1.78967474,-1.22476797,0.1106989,2.08695084,-0.35110384,-1.01394517,1.57086853,1.20999375,-0.66572333,0.85800154,1.58415937,-0.62815065;0.23469976,1.75050568,1.31411267,-0.85669968,-0.8362449,1.49024407,2.13763772,0.16381593,-0.95273687,-0.4007523,1.63038912,2.09314758,-0.20690308,-1.34597322,0.67570461,1.77154783,0.65853527,-0.97392787,-0.52775122,0.62485619,1.40468976,0.60909374,-1.31220085,0.03644744,1.1484256,1.48564052,0.41218962,-0.69819502,0.7742268,2.04466751;0.46859689,2.48622875,-0.7853151,0.24026016,2.6299793,-0.51039766,-0.38297005,2.51403234,0.37961149,-0.63169775,1.72900655,1.17553976,-1.66244179,2.07586567,0.95206888,-1.11051538,0.84080415,1.85820131,-1.3701203,0.55284476,2.4891916,-0.64395124,-0.29881928,2.48860857,-0.03052662,-0.82976661,2.0497083,0.05272003,-1.53910444,2.61679798;0.99619504,2.08872921,1.25023039,-1.11856791,0.09196802,1.4669389,0.92888246,-0.57624939,-0.02647685,1.29205692,1.41019329,0.24568315,-0.64592869,0.63935239,1.85422597,-0.02135339,-0.97701303,0.57430981,1.84291182,0.56002813,-0.89572446,-0.12119884,1.73205881,1.37068025,-0.7371197,-0.98386574,1.1502662,1.49638324,0.29966131,-0.50865443;0.56605675,1.97350775,2.0389121,-0.00737451,-1.32432832,-0.722319,1.43448865,2.44604697,1.6323029,-0.91593955,-1.38236188,-0.24036408,1.49494586,2.07162301,0.75749583,-0.69630148,-0.58778329,0.88077192,1.90812517,1.72279132,-0.05576286,-1.40131892,-0.25805979,2.07911163,1.69100386,0.7139946,-0.76560661,-0.66959291,0.60401445,2.40474621\n0.84063513,1.97734602,0.01706111,-0.75056884,2.51073458,0.7781541,-1.35809639,1.01811699,1.36316999,-1.08393951,0.52615926,2.33282048,-0.23658086,-0.60222465,2.30324575,1.12735415,-0.96162237,1.25890958,1.76157889,-0.79266032,-0.14816672,2.2006363,-0.06675485,-0.96192377,1.69827222,0.60821498,-1.03354102,1.40560189,1.36733329,-0.8273873;0.27055167,1.42992938,1.34182188,-0.65795315,-0.39899255,0.86514925,1.99190146,0.28434371,-0.73315032,-0.56063395,1.60552145,1.21619736,0.10080515,-0.46339836,0.17928405,1.42671868,1.00014017,-0.57030957,-1.11595881,0.96096854,1.61778043,0.14836915,-1.15632086,0.2050103,1.86447279,1.9135405,-0.17046792,-0.40166579,0.73673069,1.55172769;0.50594646,1.83949406,-1.12433157,0.34237022,2.31396523,-0.00904462,-1.16343187,2.21277549,0.37908595,-1.39264823,1.9517893,0.40056429,-1.77431878,1.39502377,1.76797423,-1.63698356,0.77731866,1.52779513,-1.11269195,0.57279819,1.90148565,-1.28338019,-0.05386019,2.57151364,-0.08453135,-1.11260829,2.51302673,0.47505024,-1.08224956,2.03610192;0.46864173,2.15562547,0.44369658,-0.34046021,-0.42493875,2.08340081,1.20338812,-0.34173066,-0.41360194,0.89818675,1.53652164,-0.5954464,-0.99298827,0.70516556,1.5420833,0.2733227,-0.43528032,0.19100755,1.78002545,1.16783555,-0.86503463,0.13309003,1.97230526,1.14919548,-0.59162439,-0.76525942,0.86221836,1.99117562,0.17277567,-0.70010443;0.09475408,1.73236004,1.87092371,0.19073487,-0.73053452,-0.22236442,1.53058733,2.63903106,1.1964234,-0.88912797,-0.58458228,0.59689665,1.63872123,1.87928401,0.65065878,-1.2249867,-0.50808142,0.65315224,2.03636414,1.13315132,-0.64852075,-1.46391883,-0.42418218,1.34768821,2.35109917,0.86657091,-1.16344751,-0.41956729,0.93177153,2.37071414\n"
],
[
"!head -3 data/validation_normal_1_sequences.csv",
"2.48715103e-01,1.62175262e+00,-9.12525495e-01,-5.86126844e-01,2.28422271e+00,8.61252550e-01,-1.16519211e+00,1.39795451e+00,1.31418670e+00,-1.08491479e+00,3.22526432e-01,2.41272800e+00,-5.56473650e-01,-4.85464280e-01,1.66794903e+00,4.85484849e-01,-1.60420171e+00,1.30309719e+00,1.84602707e+00,-1.01641569e+00,1.57240345e-03,2.09407586e+00,-7.36438695e-02,-4.10629450e-01,1.79816238e+00,8.97090503e-01,-6.44621956e-01,1.36032753e+00,1.80122457e+00,-7.70890291e-01;0.23489636,2.33118171,0.9126118,-0.73581593,-0.51859759,0.87806913,1.64429126,0.20297636,-0.53504252,-0.06464885,1.82596899,2.06415412,-0.50503614,-1.09498558,0.17603853,1.94053523,1.5803737,-0.49716577,-1.02599978,1.17905052,1.90411504,0.05301807,-0.81102558,0.1631754,1.16003548,1.37027317,-0.48235681,-0.43521739,0.38226107,1.61213118;0.85629382,1.98722511,-0.95176538,0.2330893,2.33878411,-0.01755494,-0.92500531,2.68099096,0.17424442,-1.53224424,2.26040027,0.94759146,-0.96205877,1.23475587,1.02613023,-1.36271358,1.26221017,1.5493181,-1.01127567,0.84380764,2.70322235,-1.17219657,-0.13480626,2.59328872,-0.56304344,-0.23021399,2.49425348,0.10075216,-1.41099412,2.14338616;0.94564434,2.21716354,0.98434472,-1.19772116,0.05741413,1.60044522,1.28050004,-0.5310433,-0.89418324,1.29684894,1.53075252,-0.09450053,-0.35036743,1.15485015,1.76299084,-0.03536621,-0.56847222,0.65994342,1.56540087,1.13754488,-0.63263373,-0.46845018,1.28905579,1.42175684,-0.22308182,-1.03983973,1.2470325,1.21237256,-0.46779175,-0.42844322;0.13415295,1.77336937,1.7299702,-0.31417765,-1.52167256,-0.92274617,1.31271037,1.84630897,0.67792501,-0.83149101,-1.03256738,0.31992214,2.22173245,1.77450926,0.67562096,-1.46003043,-0.75680366,0.7531998,2.42885848,1.35533345,-0.86236617,-0.89861568,-0.07507593,2.0077291,1.97520236,0.62138944,-1.08771896,-0.5271541,0.82769105,2.19918201\n0.19204478,1.85939294,0.00338506,-0.44971487,1.74192131,0.66357635,-1.43726804,0.93210753,1.51276565,-1.21409524,0.39224134,2.38158636,-0.00409569,-0.99390788,1.68556236,1.0258493,-1.06530314,1.53731942,1.32499734,-0.83968793,-0.18386097,2.10994121,-0.70170423,-0.69674673,1.7793711,0.33760471,-1.0205506,0.72474438,1.60504743,-0.64322073;0.75269253,1.67165631,1.32444553,-0.84289169,-0.77489857,0.83668049,1.73731779,0.07811043,-1.19732156,-0.50674829,1.11820356,1.43350108,0.35884078,-1.02300482,0.16640899,1.77869749,1.51373802,-0.6658277,-1.08284843,1.05113482,1.68074902,0.1547451,-0.63330346,-0.63830738,1.29839394,1.40921803,0.35747533,-0.54706211,0.03577627,2.25349734;0.44737277,2.779025,-1.11627316,0.01522823,2.06950608,-0.35632386,-0.63625179,1.98513988,0.0196317,-1.08833926,1.85682826,0.33834233,-1.83836941,1.79102139,1.44295084,-1.93327226,1.39500249,1.98814462,-1.07900841,0.81466403,2.7616398,-0.73686543,0.21783537,2.44246172,-0.53920107,-0.65236015,2.61628095,0.29301016,-1.45298742,2.39831257;0.90805365,1.49974158,0.59534898,-0.38878993,0.1411726,1.49048367,1.55075427,-0.18618573,-0.07782981,1.44976611,1.54535885,0.04850263,-0.33118491,0.6009069,1.32614592,0.2498967,-0.97082726,0.37747798,2.24001724,1.12328596,-1.07658171,-0.43229511,1.96475327,1.74295664,-0.14118032,-0.86503052,1.61198497,2.13077094,0.45149785,-0.52207611;0.28785644,1.89965887,2.1710481,0.05263587,-1.32631114,-0.81730146,1.69914933,1.7192553,0.76447779,-0.64525369,-0.92775571,0.33492638,2.22658416,2.38349442,0.76786914,-1.44357526,-1.18825324,1.39155908,2.60241641,1.29418994,-0.6489557,-0.69689131,-0.45078808,1.77921133,2.4634979,0.18242928,-1.20402436,-0.39679781,1.09518033,2.44771309\n0.75562822,2.36147622,-0.49505024,-0.1712139,2.26351208,0.91351884,-1.18703414,1.85705908,1.75136352,-0.5655695,0.07563872,2.06690441,-0.55146638,-0.28246617,2.3207978,0.92969995,-0.63462606,1.37282322,1.97509329,-1.38732962,0.58292319,2.39620482,0.05101636,-0.2998909,1.95433423,0.34063904,-1.43583983,1.62097346,2.22999739,-0.5461922;0.72148837,1.98057401,1.45312443,-0.81017995,-1.00993214,0.71158553,1.76957779,0.29188121,-1.09354801,-0.42473183,1.35852987,1.29835491,-0.57036288,-1.15461517,0.56726032,1.94688193,0.85097666,-0.7677409,-0.48807909,1.22774128,1.57676626,0.77299272,-0.96964089,0.23618601,1.82587684,1.78887869,0.3565319,-1.31459686,0.03678805,1.78869717;0.41518029,2.36543841,-1.01924185,0.2102281,2.19689453,-0.68525817,-1.06584,2.76341555,0.20300132,-1.50846359,2.2108864,1.2698323,-1.30826446,1.61315047,1.50179365,-1.42928931,1.04763048,1.5647525,-1.57362058,0.61337976,2.76900123,-1.1121613,-0.47629216,2.3646322,-0.47265578,-0.74058561,2.31655735,0.28413936,-0.96826959,2.46092146;0.7931507,1.84943121,0.32059657,-0.53313096,-0.16884413,1.46348279,1.69554763,-0.48590796,-0.78100915,1.01127551,2.05210338,0.02049089,-0.33894181,0.74016293,2.16104633,0.375756,-1.08502856,0.53568091,1.45932894,0.41405331,-0.94804111,0.31534035,2.04865269,0.97822097,-0.34131158,-0.34035768,1.45748498,1.58132236,0.13877847,-1.02755287;0.54430292,1.53096225,2.20155808,0.37600528,-1.6071552,-0.44680971,0.9353374,1.9551478,1.0135857,-0.90537305,-1.39407481,-0.08340271,1.44929331,1.52074432,0.59157562,-1.24532274,-1.05628242,1.46991227,1.81818106,1.47520718,-0.47392634,-0.77534746,0.34007815,2.00691024,1.82947709,0.67532909,-1.01138157,-0.41531867,1.1396664,1.68203361\n"
],
[
"!head -3 data/labeled_validation_mixed_sequences.csv",
"0.40886148,2.39504759,-0.55302762,-0.55478917,2.30622592,0.67449508,-0.94157254,1.60540933,1.70671472,-1.50637399,0.82949467,2.40668831,-0.81730588,-0.43564232,2.0841169,0.82949334,-1.42912269,0.92982979,1.37675986,-0.85020253,0.4046131,-15.024334,1.71799593,-11.06375405,-38.91428899,17.30140724,-24.04905217,-20.01671982,17.6639791,-10.40381479;0.46111383,2.29717119,0.99114519,-0.26482821,-0.37153034,0.99728653,1.52786684,0.88508088,-0.71679897,0.19989925,1.87731372,1.80267086,-0.35547713,-0.75250433,0.18574105,1.65548219,1.23272834,-0.13323377,-0.95855019,1.15783445,1.86053493,-7.54780983,12.97943581,-3.35284686,-30.54466942,-24.27887067,-4.33351329,-8.06494212,-5.31672227,-20.6856232;0.38483964,2.36075772,-0.46435472,0.1616821,1.97677941,-0.45743495,-0.47487812,2.2853423,-0.1728357,-1.43431693,2.5373648,1.14680217,-1.16381733,1.46537679,1.2645245,-0.96817583,0.74742504,1.70301806,-1.40351771,0.50367278,2.20136987,-6.99736346,-4.15886965,-28.15191758,-14.92525769,-4.65161111,-27.33138425,-0.48588009,10.25206868,41.37053723;0.11151948,1.37291247,0.6699767,-1.01628629,-0.10495727,1.74106986,0.77366617,-0.96289214,-0.72705585,1.50935897,1.96546285,0.08992015,-0.92407168,0.69795121,2.29516443,0.04256646,-1.04526618,0.24088783,1.7577832,1.06235391,-0.58638564,-6.36158856,-23.19232766,28.69782275,-13.42344228,4.01997785,29.45398473,-21.64290289,-3.78419635,7.98488032;6.04393215e-01,2.46658638e+00,1.49509047e+00,-2.47326949e-01,-7.27800781e-01,-9.30193453e-01,1.47010612e+00,2.19057490e+00,1.14727376e+00,-5.77855111e-01,-1.01913285e+00,2.91011199e-01,1.40704273e+00,1.60129559e+00,-2.56684511e-03,-1.04899011e+00,-4.60772004e-01,7.17679337e-01,2.27734242e+00,1.67797472e+00,2.78803481e-02,2.20836888e+01,-1.33125536e+00,-1.26830058e+01,1.55841334e+01,-6.78591647e+00,1.00001482e+01,-1.07853035e+01,7.99877433e+00,2.62917216e+01;1\n0.57592027,2.21247896,-0.40563198,-0.48462745,1.71938664,0.27878901,-1.05968898,1.60067688,1.82251988,-1.06450935,0.17809231,2.54309087,-0.21748352,-0.2948246,1.89607307,0.95077202,-1.05573235,0.96152862,1.44421781,-0.57722887,0.44077753,29.7940127,9.17467921,-6.24015743,-26.72650377,-17.78467204,-12.52855792,14.10231292,23.68819667,-10.79775581;0.54874536,2.08749082,1.40686308,-0.92009878,-1.05411449,0.6271087,1.63602861,0.37661651,-0.95168211,0.16546699,1.88493272,1.58694637,-0.05173918,-0.99059813,0.63672138,2.1059496,0.94683317,-0.45270764,-0.91276063,0.83164209,2.16804353,5.40520544,-15.56869248,-7.04302145,15.84475463,-17.32635165,-4.72050874,7.88338202,6.62903831,14.91105017;0.61552671,2.41331328,-0.46289745,-0.19453245,2.16856615,-0.2641711,-1.16210155,2.39384561,0.04504267,-1.47083467,2.40608245,0.55844028,-1.52259068,2.16250955,1.52117579,-1.06868863,1.2691356,1.94874327,-1.0741582,0.76788827,2.35431159,-11.00523457,-7.56164054,27.75513297,-6.85628753,10.95721906,-33.471224,5.19825889,-26.13942721,33.12252999;0.66896912,1.47375819,0.51919394,-0.70337108,-0.10682183,1.29153962,0.76196445,-0.81234179,-0.39488053,1.56433961,1.1484851,-0.02886706,-1.0965562,1.15912962,1.88512747,0.63651102,-1.28478469,0.59637129,2.04507333,0.43662417,-0.93794033,-5.41133544,27.15818664,22.64805507,-5.96750292,-2.03556488,-24.65442064,17.27132195,7.90033561,-10.82503429;0.52855851,1.71001871,1.58638948,0.31385483,-0.73247688,-0.48649756,1.14877897,2.10661857,1.52518828,-0.77992247,-1.22988289,0.60416383,2.10698666,2.05007537,0.06821813,-0.64574246,-0.76227495,1.5057128,2.18854355,1.63144589,-0.08627825,-15.6998536,-3.26750645,33.46871842,19.34701955,12.5470187,7.27850717,-12.62951749,12.82365191,19.35032297;1\n0.54751005,2.56094712,-0.10907187,-0.42744684,2.31994745,0.95745595,-0.80530813,1.46972443,1.11260174,-1.1638333,0.73283175,1.78887312,-0.28565913,-0.67529375,1.8700179,0.61783432,-1.36696737,1.66311185,1.58935779,-0.9802303,0.04901749,2.24942147,-0.44963402,-0.80690064,1.88869691,0.94539279,-0.65402284,1.02981979,2.22996191,-1.28309621;0.90221137,1.49429845,1.58388789,-0.81529227,-0.41398801,1.21712907,1.45226498,0.83736955,-0.38974919,-0.08028781,1.57353433,1.6173948,0.10450874,-1.0080846,0.42137768,2.23317213,0.70318309,-0.50048882,-0.15459107,0.88693107,2.10114703,0.76541606,-0.54094102,-0.29181225,1.97943649,1.42352429,0.35427681,-1.1531866,0.04010965,1.71185269;9.26367913e-01,2.24626845e+00,-8.21404649e-01,2.20786669e-01,2.45871473e+00,3.92634848e-02,-1.06108158e+00,2.82912639e+00,5.43814568e-01,-1.46213984e+00,1.73694896e+00,8.44509566e-01,-9.33574575e-01,1.28132325e+00,1.91361075e+00,-1.29461148e+00,1.61775585e+00,1.48430620e+00,-1.35078166e+00,2.14618668e-03,1.94489394e+00,-9.41538693e-01,-2.12865866e-01,2.60606391e+00,-2.14134589e-01,-8.80624628e-01,2.32917926e+00,4.19795303e-01,-1.15406261e+00,2.33501750e+00;0.98366387,1.55082006,1.06105474,-1.10964851,0.12581015,1.72169748,1.68560459,-0.13166553,-0.63795371,1.74181299,1.82804599,-0.27430002,-0.7777287,1.28748148,2.06386998,0.2298471,-0.95511519,0.04303626,2.2742835,1.09170447,-0.82046117,-0.26953832,1.24983606,1.11989965,-0.85157484,-0.74017968,1.58489528,2.03325618,0.4498802,-1.06455017;0.11384507,2.09599737,2.1524338,0.12449434,-1.51367378,-0.55149376,0.88236057,1.81177196,1.04816661,-1.04628837,-1.5229686,0.01153481,1.49969643,2.15529703,-0.01653507,-1.36165091,-0.57722604,1.31108972,2.54345842,0.94006485,-0.32855081,-0.63742083,-0.31320205,2.15613858,1.95302998,0.80577621,-0.50331665,-0.39102453,0.56494622,2.33251314;0\n"
],
[
"!head -3 data/labeled_test_mixed_sequences.csv",
"0.21651224,2.04016484,-0.47583765,-0.23555634,2.45546603,0.3235766,-1.2904606,1.67762694,1.68130188,-0.78770077,0.47435638,1.63288897,-0.1088109,-0.80535951,1.5247533,0.6913622,-1.02549557,1.50642533,1.64192016,-1.29912246,0.42280094,2.57050962,-0.07996142,-0.77842833,1.84379046,1.13805856,-0.82112047,1.65391633,1.95786461,-0.46802792;0.10486821,2.14364583,0.73950086,-0.84900565,-0.4411125,1.17802588,1.71316834,0.94595023,-0.61553838,-0.29301354,1.65156104,1.88037668,-0.52328465,-0.72529186,0.51490249,2.07481068,1.55328056,-0.30451872,-0.6619568,1.14089066,1.48774799,0.59462235,-0.77851109,-0.59419571,1.97041589,1.31435977,-0.05711114,-0.8745225,0.61078849,1.70311224;0.18871692,2.05629687,-0.61333644,-0.62836699,2.22542975,-0.39199273,-1.08371676,1.93101803,0.59474894,-0.71773314,2.23869201,0.36138261,-1.40254869,1.63957311,1.04135741,-1.30427018,1.30502351,1.5772577,-1.11509646,0.82729339,2.10960403,-0.62838693,0.1367821,1.94202738,-0.36754195,-0.30217653,2.36818257,-0.00936663,-1.47573712,2.43240397;4.55015690e-01,1.93772230e+00,6.95707565e-01,-7.27544420e-01,-2.90995283e-01,2.10692172e+00,1.46464253e+00,-8.08744688e-01,-6.09387061e-01,1.18249562e+00,1.16888889e+00,-4.83253791e-01,-1.11024766e+00,1.02889186e+00,1.92258381e+00,7.16887396e-04,-5.56826099e-01,2.80638938e-01,1.49711693e+00,1.15004805e+00,-1.18805237e+00,2.70744343e-01,1.32022309e+00,1.66670464e+00,-6.28212264e-01,-1.03915344e+00,1.06902123e+00,1.70314214e+00,6.62003474e-02,-3.58854418e-01;0.06302585,1.93695503,1.48362931,-0.23643493,-1.29545269,-0.88110033,1.61372704,2.45272909,0.96818084,-0.96615933,-1.37924951,-0.10624624,1.97069734,2.27744041,-0.01271905,-1.1303886,-0.40370981,0.87258148,1.78765771,0.99673726,-0.63734282,-1.39528098,0.25016578,1.30054457,1.75162414,0.25937745,-0.83495246,-1.08897422,1.14749944,1.82825962;0\n0.90804263,2.33498995,-0.35695428,-0.03835368,2.31204918,0.82800963,-1.01449198,1.21177167,2.04857908,-1.43898456,0.80290771,1.90094552,-0.63571202,-0.71208476,1.51819964,0.99688854,-1.55906862,1.17113118,1.7061942,-1.31650169,0.25312569,2.2393715,0.11990364,-0.59957358,1.75082821,1.26150797,-1.48793821,1.63886154,1.32748088,-0.97128947;0.35120691,1.70689551,1.29333498,-0.19082135,-0.79311399,1.10744705,1.65994899,0.67300239,-1.35600933,-0.11152398,1.29336419,2.06290234,-0.34736543,-0.95767098,0.18266629,2.01787013,1.1325402,-0.2334463,-0.44103416,1.05315236,1.85698203,0.13189133,-0.40654654,-0.34345969,1.64787168,1.15286674,-0.55749928,-0.76976829,0.00241018,1.42025048;0.65377511,2.49812946,-0.81958405,0.17996892,2.44625263,-0.38834411,-0.2564829,2.722651,0.07289123,-0.70533591,2.18422124,0.77414562,-1.46532719,1.61271374,1.47093501,-1.88375945,1.3588185,1.50928544,-1.19718842,0.58611954,2.36083424,-0.69601212,-0.13961105,2.16208349,-0.65818626,-0.89448709,2.032778,0.23744903,-0.74039182,1.80363537;0.74442065,1.70092644,0.754966,-0.7060769,-0.00917029,2.09712337,1.24315502,-0.97428658,-0.0058725,1.23445026,1.30758499,-0.47094065,-0.28720437,0.44924257,1.31301819,0.49085746,-0.80600493,0.01463632,1.56137505,1.21302949,-0.83110822,0.28811578,1.64111338,1.10130591,-0.24182142,-0.73514349,1.1845411,1.83839681,0.36562794,-1.23484726;0.37766755,1.76091686,2.04419644,-0.02000481,-1.06386616,-0.78164838,1.19712271,2.21952393,1.35872378,-0.12865625,-0.63476516,0.12185728,1.63886311,2.35157201,-0.03641768,-1.23106871,-0.23121079,1.23176825,1.76429579,1.1675374,-0.03206593,-1.37202816,-0.34635147,1.27693678,2.01705029,0.24547622,-0.68588496,-1.24305536,0.98168498,2.29688088;0\n9.00532980e-01,2.18609376e+00,-2.25099755e-02,-6.98523986e-01,2.09203593e+00,8.68152056e-01,-8.34314138e-01,1.04267942e+00,1.48473363e+00,-1.27827053e+00,1.39254660e-03,1.70191435e+00,6.71776914e-02,-6.34767133e-01,2.14444313e+00,6.10658053e-01,-8.23287230e-01,1.05889535e+00,1.61032940e+00,-4.97841462e-01,-1.11263133e-01,1.88411707e+00,-1.80990954e-01,-5.51116884e-01,1.66195076e+00,5.58022730e-01,-6.44045055e-01,1.16853280e+00,2.17834915e+00,-7.84678407e-01;0.08590837,1.99785051,0.90702894,-0.47153867,-0.12633253,1.14995883,2.05384665,0.23902149,-0.48671972,-0.27492599,1.7628949,1.64236296,-0.32798395,-0.46659862,0.85956639,1.84840086,0.70047061,-0.97006214,-0.57671904,0.68193782,1.92618816,0.73021472,-1.08004442,-0.45532636,1.14497479,1.39781108,-0.34348533,-0.46946141,0.69303256,1.63692062;0.18055667,2.36108559,-0.90093896,-0.21996393,2.57824167,-0.02497519,-0.61019487,2.04729679,0.06568188,-1.24469331,2.10905843,0.62597383,-0.90048964,2.01903484,1.90112471,-1.15708502,1.46125345,1.74623861,-1.43212348,0.75360791,2.33883331,-1.33695334,0.01310766,1.99261781,-0.33386579,-1.19148421,2.59997675,-0.26911609,-1.50200778,2.41036029;0.24939282,1.77665073,1.15488622,-0.55121784,-0.28747112,1.4382656,1.22329882,-0.73128775,-0.66629836,1.18808276,1.5404464,-0.46545627,-0.37956771,0.71897574,1.85103714,0.86127603,-1.19921543,0.70803453,2.27198586,0.83224113,-0.77969919,0.18148688,1.90126884,1.81668596,-0.67962348,-0.81283254,1.07996006,1.92344756,-0.05957113,-0.61765987;0.73286176,2.4768188,2.16015832,-0.07526624,-0.75610114,-0.16489968,1.43274861,2.09307054,1.49779657,-0.44154821,-0.6069175,-0.13400091,1.35750083,2.22660009,0.31295216,-0.66521376,-0.88817528,0.86550506,2.17497892,1.04922781,-0.00602454,-1.0799633,0.14401806,1.27881065,1.64808457,0.4502882,-0.62899433,-0.71341303,0.91813073,1.88463125;0\n"
]
],
[
[
"# Local Development",
"_____no_output_____"
]
],
[
[
"# Set logging to be level of INFO\ntf.logging.set_verbosity(tf.logging.INFO)",
"_____no_output_____"
],
[
"# Determine CSV and label columns\nUNLABELED_CSV_COLUMNS = tag_columns\n\nLABEL_COLUMN = \"anomalous_sequence_flag\"\nLABELED_CSV_COLUMNS = UNLABELED_CSV_COLUMNS + [LABEL_COLUMN]\n\n# Set default values for each CSV column\nUNLABELED_DEFAULTS = [[\"\"] for _ in UNLABELED_CSV_COLUMNS]\n\nLABELED_DEFAULTS = UNLABELED_DEFAULTS + [[0.0]]",
"_____no_output_____"
],
[
"# Create an input function reading a file using the Dataset API\n# Then provide the results to the Estimator API\ndef read_dataset(filename, mode, batch_size, params):\n def _input_fn():\n def decode_csv(value_column, seq_len):\n def convert_sequences_from_strings_to_floats(features, column_list):\n def split_and_convert_string(string_tensor):\n # Split string tensor into a sparse tensor based on delimiter\n split_string = tf.string_split(source = tf.expand_dims(\n input = string_tensor, axis = 0), delimiter = \",\")\n\n # Converts the values of the sparse tensor to floats\n converted_tensor = tf.string_to_number(\n string_tensor = split_string.values, \n out_type = tf.float64)\n\n # Create a new sparse tensor with the new converted values, \n # because the original sparse tensor values are immutable\n new_sparse_tensor = tf.SparseTensor(\n indices = split_string.indices, \n values = converted_tensor, \n dense_shape = split_string.dense_shape)\n\n # Create a dense tensor of the float values that were converted from text csv\n dense_floats = tf.sparse_tensor_to_dense(\n sp_input = new_sparse_tensor, default_value = 0.0)\n\n dense_floats_vector = tf.squeeze(input = dense_floats, axis = 0)\n\n return dense_floats_vector\n \n for column in column_list:\n features[column] = split_and_convert_string(features[column])\n features[column].set_shape([seq_len])\n\n return features\n \n if mode == tf.estimator.ModeKeys.TRAIN or (mode == tf.estimator.ModeKeys.EVAL and params[\"training_mode\"] != \"tune_anomaly_thresholds\"):\n columns = tf.decode_csv(\n records = value_column, \n record_defaults = UNLABELED_DEFAULTS, \n field_delim = \";\")\n features = dict(zip(UNLABELED_CSV_COLUMNS, columns))\n features = convert_sequences_from_strings_to_floats(\n features, UNLABELED_CSV_COLUMNS)\n return features\n else:\n columns = tf.decode_csv(\n records = value_column, \n record_defaults = LABELED_DEFAULTS, \n field_delim = \";\")\n features = dict(zip(LABELED_CSV_COLUMNS, columns))\n labels = tf.cast(x = features.pop(LABEL_COLUMN), dtype = tf.float64)\n features = convert_sequences_from_strings_to_floats(\n features, LABELED_CSV_COLUMNS[0:-1])\n return features, labels\n \n # Create list of files that match pattern\n file_list = tf.gfile.Glob(filename = filename)\n\n # Create dataset from file list\n dataset = tf.data.TextLineDataset(filenames = file_list) # Read text file\n\n # Decode the CSV file into a features dictionary of tensors\n dataset = dataset.map(map_func = lambda x: decode_csv(x, params[\"seq_len\"]))\n \n # Determine amount of times to repeat file based on if we are training or evaluating\n if mode == tf.estimator.ModeKeys.TRAIN:\n num_epochs = None # indefinitely\n else:\n num_epochs = 1 # end-of-input after this\n\n # Repeat files num_epoch times\n dataset = dataset.repeat(count = num_epochs)\n\n # Group the data into batches\n dataset = dataset.batch(batch_size = batch_size)\n \n # Determine if we should shuffle based on if we are training or evaluating\n if mode == tf.estimator.ModeKeys.TRAIN:\n dataset = dataset.shuffle(buffer_size = 10 * batch_size)\n\n # Create a iterator and then pull the next batch of features from the example queue\n batched_dataset = dataset.make_one_shot_iterator().get_next()\n\n return batched_dataset\n return _input_fn",
"_____no_output_____"
],
[
"def try_out_input_function():\n with tf.Session() as sess:\n fn = read_dataset(\n filename = \"data/labeled_validation_mixed_sequences.csv\",\n mode = tf.estimator.ModeKeys.EVAL,\n batch_size = 8,\n params = {\"seq_len\": seq_len,\n \"training_mode\": \"tune_anomaly_thresholds\"})\n\n features = sess.run(fn())\n print(\"try_out_input_function: features = \\n{}\".format(features))\n\n# print(\"try_out_input_function: features[tag_0].shape = {}\".format(features[\"tag_0\"].shape))",
"_____no_output_____"
],
[
"# try_out_input_function()",
"_____no_output_____"
],
[
"# This function updates the count of records used\ndef update_count(count_a, count_b):\n return count_a + count_b\n\n# This function updates the mahalanobis distance variables when number_of_rows equals 1\ndef singleton_batch_cov_variable_updating(\n inner_size, \n X, \n count_variable, \n mean_variable, \n cov_variable, \n eps):\n # This function updates the mean vector incrementally\n def update_mean_incremental(count_a, mean_a, value_b):\n mean_ab = (mean_a * tf.cast(x = count_a, dtype = tf.float64) + \\\n tf.squeeze(input = value_b, axis = 0)) / tf.cast(x = count_a + 1, dtype = tf.float64)\n return mean_ab\n\n # This function updates the covariance matrix incrementally\n def update_cov_incremental(count_a, mean_a, cov_a, value_b, mean_ab, sample_cov):\n if sample_cov == True:\n cov_ab = (cov_a * tf.cast(x = count_a - 1, dtype = tf.float64) + \\\n tf.matmul(a = value_b - mean_a, b = value_b - mean_ab, transpose_a = True)) \\\n / tf.cast(x = count_a, dtype = tf.float64)\n else:\n cov_ab = (cov_a * tf.cast(x = count_a, dtype = tf.float64) + \\\n tf.matmul(a = value_b - mean_a, b = value_b - mean_ab, transpose_a = True)) \\\n / tf.cast(x = count_a + 1, dtype = tf.float64)\n return cov_ab\n\n # Calculate new combined mean to use for incremental covariance matrix calculation\n mean_ab = update_mean_incremental(\n count_a = count_variable, \n mean_a = mean_variable, \n value_b = X) # time_shape = (num_features,), features_shape = (sequence_length,)\n\n # Update running variables from single example\n count_tensor = update_count(\n count_a = count_variable, \n count_b = 1) # time_shape = (), features_shape = ()\n\n mean_tensor = mean_ab # time_shape = (num_features,), features_shape = (sequence_length,)\n\n if inner_size == 1:\n cov_tensor = tf.zeros_like(\n tensor = cov_variable, dtype = tf.float64)\n else:\n # time_shape = (num_features, num_features)\n # features_shape = (sequence_length, sequence_length)\n cov_tensor = update_cov_incremental(\n count_a = count_variable, \n mean_a = mean_variable, \n cov_a = cov_variable, \n value_b = X, \n mean_ab = mean_ab, \n sample_cov = True)\n\n # Assign values to variables, use control dependencies around return to enforce the mahalanobis \n # variables to be assigned, the control order matters, hence the separate contexts\n with tf.control_dependencies(\n control_inputs = [tf.assign(\n ref = cov_variable, \n value = cov_tensor)]):\n with tf.control_dependencies(\n control_inputs = [tf.assign(\n ref = mean_variable, \n value = mean_tensor)]):\n with tf.control_dependencies(\n control_inputs = [tf.assign(\n ref = count_variable, \n value = count_tensor)]):\n return tf.identity(input = cov_variable), tf.identity(input = mean_variable), tf.identity(input = count_variable)\n\n# This function updates the mahalanobis distance variables when number_of_rows does NOT equal 1\ndef non_singleton_batch_cov_variable_updating(\n cur_batch_size, \n inner_size, \n X, \n count_variable, \n mean_variable, \n cov_variable, \n eps):\n # This function updates the mean vector using a batch of data\n def update_mean_batch(count_a, mean_a, count_b, mean_b):\n mean_ab = (mean_a * tf.cast(x = count_a, dtype = tf.float64) + \\\n mean_b * tf.cast(x = count_b, dtype = tf.float64)) \\\n / tf.cast(x = count_a + count_b, dtype = tf.float64)\n return mean_ab\n\n # This function updates the covariance matrix using a batch of data\n def update_cov_batch(count_a, mean_a, cov_a, count_b, mean_b, cov_b, sample_cov):\n mean_diff = tf.expand_dims(input = mean_a - mean_b, axis = 0)\n\n if sample_cov == True:\n cov_ab = (cov_a * tf.cast(x = count_a - 1, dtype = tf.float64) + \\\n cov_b * tf.cast(x = count_b - 1, dtype = tf.float64) + \\\n tf.matmul(a = mean_diff, b = mean_diff, transpose_a = True) * \\\n tf.cast(x = count_a * count_b, dtype = tf.float64) \\\n / tf.cast(x = count_a + count_b, dtype = tf.float64)) \\\n / tf.cast(x = count_a + count_b - 1, dtype = tf.float64)\n else:\n cov_ab = (cov_a * tf.cast(x = count_a, dtype = tf.float64) + \\\n cov_b * tf.cast(x = count_b, dtype = tf.float64) + \\\n tf.matmul(a = mean_diff, b = mean_diff, transpose_a = True) * \\\n tf.cast(x = count_a * count_b, dtype = tf.float64) \\\n / tf.cast(x = count_a + count_b, dtype = tf.float64)) \\\n / tf.cast(x = count_a + count_b, dtype = tf.float64)\n return cov_ab \n\n # Find statistics of batch\n number_of_rows = cur_batch_size * inner_size\n\n # time_shape = (num_features,), features_shape = (sequence_length,)\n X_mean = tf.reduce_mean(input_tensor = X, axis = 0)\n\n # time_shape = (cur_batch_size * sequence_length, num_features)\n # features_shape = (cur_batch_size * num_features, sequence_length)\n X_centered = X - X_mean\n\n if inner_size > 1:\n # time_shape = (num_features, num_features)\n # features_shape = (sequence_length, sequence_length)\n X_cov = tf.matmul(\n a = X_centered,\n b = X_centered, \n transpose_a = True) / tf.cast(x = number_of_rows - 1, dtype = tf.float64)\n\n # Update running variables from batch statistics\n count_tensor = update_count(\n count_a = count_variable, \n count_b = number_of_rows) # time_shape = (), features_shape = ()\n\n mean_tensor = update_mean_batch(\n count_a = count_variable, \n mean_a = mean_variable, \n count_b = number_of_rows, \n mean_b = X_mean) # time_shape = (num_features,), features_shape = (sequence_length,)\n\n if inner_size == 1:\n cov_tensor = tf.zeros_like(\n tensor = cov_variable, dtype = tf.float64)\n else:\n # time_shape = (num_features, num_features)\n # features_shape = (sequence_length, sequence_length)\n cov_tensor = update_cov_batch(\n count_a = count_variable, \n mean_a = mean_variable, \n cov_a = cov_variable, \n count_b = number_of_rows, \n mean_b = X_mean, \n cov_b = X_cov, \n sample_cov = True)\n\n # Assign values to variables, use control dependencies around return to enforce the mahalanobis \n # variables to be assigned, the control order matters, hence the separate contexts\n with tf.control_dependencies(\n control_inputs = [tf.assign(ref = cov_variable, value = cov_tensor)]):\n with tf.control_dependencies(\n control_inputs = [tf.assign(ref = mean_variable, value = mean_tensor)]):\n with tf.control_dependencies(\n control_inputs = [tf.assign(ref = count_variable, value = count_tensor)]):\n return tf.identity(input = cov_variable), tf.identity(input = mean_variable), tf.identity(input = count_variable)",
"_____no_output_____"
],
[
"def mahalanobis_distance(error_vectors_reshaped, mean_vector, inv_covariance, final_shape):\n # time_shape = (current_batch_size * seq_len, num_features)\n # features_shape = (current_batch_size * num_features, seq_len)\n error_vectors_reshaped_centered = error_vectors_reshaped - mean_vector\n\n # time_shape = (num_features, current_batch_size * seq_len)\n # features_shape = (seq_len, current_batch_size * num_features)\n mahalanobis_right_product = tf.matmul(\n a = inv_covariance,\n b = error_vectors_reshaped_centered,\n transpose_b = True)\n\n # time_shape = (current_batch_size * seq_len, current_batch_size * seq_len)\n # features_shape = (current_batch_size * num_features, current_batch_size * num_features)\n mahalanobis_distance_vectorized = tf.matmul(\n a = error_vectors_reshaped_centered,\n b = mahalanobis_right_product)\n\n # time_shape = (current_batch_size * seq_len,)\n # features_shape = (current_batch_size * num_features,)\n mahalanobis_distance_flat = tf.diag_part(input = mahalanobis_distance_vectorized)\n\n # time_shape = (current_batch_size, seq_len)\n # features_shape = (current_batch_size, num_features)\n mahalanobis_distance_final_shaped = tf.reshape(\n tensor = mahalanobis_distance_flat, \n shape = [-1, final_shape])\n\n # time_shape = (current_batch_size, seq_len)\n # features_shape = (current_batch_size, num_features)\n mahalanobis_distance_final_shaped_abs = tf.abs(x = mahalanobis_distance_final_shaped)\n\n return mahalanobis_distance_final_shaped_abs",
"_____no_output_____"
],
[
"def update_anomaly_threshold_variables(\n labels_normal_mask, \n labels_anomalous_mask, \n num_thresholds, \n anomaly_thresholds, \n mahalanobis_distance, \n tp_at_thresholds_variable, \n fn_at_thresholds_variable, \n fp_at_thresholds_variable, \n tn_at_thresholds_variable,\n mode):\n \n if mode == tf.estimator.ModeKeys.TRAIN:\n # time_shape = (num_time_anomaly_thresholds, current_batch_size, sequence_length)\n # features_shape = (num_features_anomaly_thresholds, current_batch_size, number_of_features)\n mahalanobis_distance_over_thresholds = tf.map_fn(\n fn = lambda anomaly_threshold: mahalanobis_distance > anomaly_threshold, \n elems = anomaly_thresholds, \n dtype = tf.bool)\n else:\n # time_shape = (current_batch_size, sequence_length)\n # features_shape = (current_batch_size, number_of_features)\n mahalanobis_distance_over_thresholds = mahalanobis_distance > anomaly_thresholds\n\n # time_shape = (num_time_anomaly_thresholds, current_batch_size)\n # features_shape = (num_features_anomaly_thresholds, current_batch_size) \n mahalanobis_distance_any_over_thresholds = tf.reduce_any(\n input_tensor = mahalanobis_distance_over_thresholds, \n axis = -1)\n \n if mode == tf.estimator.ModeKeys.EVAL:\n # time_shape = (1, current_batch_size)\n # features_shape = (1, current_batch_size)\n mahalanobis_distance_any_over_thresholds = tf.expand_dims(\n input = mahalanobis_distance_any_over_thresholds, axis = 0)\n\n # time_shape = (num_time_anomaly_thresholds, current_batch_size)\n # features_shape = (num_features_anomaly_thresholds, current_batch_size)\n predicted_normals = tf.equal(\n x = mahalanobis_distance_any_over_thresholds, \n y = False)\n\n # time_shape = (num_time_anomaly_thresholds, current_batch_size)\n # features_shape = (num_features_anomaly_thresholds, current_batch_size)\n predicted_anomalies = tf.equal(\n x = mahalanobis_distance_any_over_thresholds, \n y = True)\n \n # Calculate confusion matrix of current batch\n # time_shape = (num_time_anomaly_thresholds,)\n # features_shape = (num_features_anomaly_thresholds,)\n tp = tf.reduce_sum(\n input_tensor = tf.cast(\n x = tf.map_fn(\n fn = lambda threshold: tf.logical_and(\n x = labels_anomalous_mask, \n y = predicted_anomalies[threshold, :]), \n elems = tf.range(start = 0, limit = num_thresholds, dtype = tf.int64), \n dtype = tf.bool), \n dtype = tf.int64), \n axis = 1)\n\n fn = tf.reduce_sum(\n input_tensor = tf.cast(\n x = tf.map_fn(\n fn = lambda threshold: tf.logical_and(\n x = labels_anomalous_mask, \n y = predicted_normals[threshold, :]), \n elems = tf.range(start = 0, limit = num_thresholds, dtype = tf.int64), \n dtype = tf.bool), \n dtype = tf.int64), \n axis = 1)\n\n fp = tf.reduce_sum(\n input_tensor = tf.cast(\n x = tf.map_fn(\n fn = lambda threshold: tf.logical_and(\n x = labels_normal_mask, \n y = predicted_anomalies[threshold, :]), \n elems = tf.range(start = 0, limit = num_thresholds, dtype = tf.int64), \n dtype = tf.bool), \n dtype = tf.int64), \n axis = 1)\n\n tn = tf.reduce_sum(\n input_tensor = tf.cast(\n x = tf.map_fn(\n fn = lambda threshold: tf.logical_and(\n x = labels_normal_mask, \n y = predicted_normals[threshold, :]), \n elems = tf.range(start = 0, limit = num_thresholds, dtype = tf.int64), \n dtype = tf.bool), \n dtype = tf.int64), \n axis = 1)\n \n if mode == tf.estimator.ModeKeys.EVAL:\n # shape = ()\n tp = tf.squeeze(input = tp)\n fn = tf.squeeze(input = fn)\n fp = tf.squeeze(input = fp)\n tn = tf.squeeze(input = tn)\n\n with tf.control_dependencies(\n control_inputs = [tf.assign_add(ref = tp_at_thresholds_variable, value = tp), \n tf.assign_add(ref = fn_at_thresholds_variable, value = fn), \n tf.assign_add(ref = fp_at_thresholds_variable, value = fp), \n tf.assign_add(ref = tn_at_thresholds_variable, value = tn)]):\n return tf.identity(input = tp_at_thresholds_variable), tf.identity(input = fn_at_thresholds_variable), tf.identity(input = fp_at_thresholds_variable), tf.identity(input = tn_at_thresholds_variable)",
"_____no_output_____"
],
[
"def calculate_composite_classification_metrics(anomaly_thresholds, tp, fn, fp, tn, f_score_beta):\n # time_shape = (num_time_anomaly_thresholds,)\n # features_shape = (num_features_anomaly_thresholds,)\n acc = tf.cast(x = tp + tn, dtype = tf.float64) \\\n / tf.cast(x = tp + fn + fp + tn, dtype = tf.float64)\n pre = tf.cast(x = tp, dtype = tf.float64) / tf.cast(x = tp + fp, dtype = tf.float64)\n rec = tf.cast(x = tp, dtype = tf.float64) / tf.cast(x = tp + fn, dtype = tf.float64)\n f_beta_score = (1.0 + f_score_beta ** 2) * (pre * rec) / (f_score_beta ** 2 * pre + rec)\n\n return acc, pre, rec, f_beta_score",
"_____no_output_____"
],
[
"def find_best_anomaly_threshold(\n anomaly_thresholds, f_beta_score, user_passed_anomaly_threshold, anomaly_threshold_variable):\n if user_passed_anomaly_threshold == None:\n best_anomaly_threshold = tf.gather(\n params = anomaly_thresholds, \n indices = tf.argmax(input = f_beta_score, \n axis = 0)) # shape = ()\n else:\n best_anomaly_threshold = user_passed_anomaly_threshold # shape = ()\n\n with tf.control_dependencies(\n control_inputs = [\n tf.assign(ref = anomaly_threshold_variable, value = best_anomaly_threshold)]):\n return tf.identity(input = anomaly_threshold_variable)",
"_____no_output_____"
],
[
"# Create our model function to be used in our custom estimator\ndef pca_anomaly_detection(features, labels, mode, params):\n print(\"\\npca_anomaly_detection: features = \\n{}\".format(features))\n print(\"pca_anomaly_detection: labels = \\n{}\".format(labels))\n print(\"pca_anomaly_detection: mode = \\n{}\".format(mode))\n print(\"pca_anomaly_detection: params = \\n{}\".format(params))\n\n # 0. Get input sequence tensor into correct shape\n # Get dynamic batch size in case there was a partially filled batch\n cur_batch_size = tf.shape(\n input = features[UNLABELED_CSV_COLUMNS[0]], out_type = tf.int64)[0]\n\n # Get the number of features \n num_features = len(UNLABELED_CSV_COLUMNS)\n\n # Stack all of the features into a 3-D tensor\n X = tf.stack(\n values = [features[key] for key in UNLABELED_CSV_COLUMNS], \n axis = 2) # shape = (cur_batch_size, seq_len, num_features)\n\n # Reshape into a 2-D tensors\n # Time based\n # shape = (cur_batch_size * seq_len, num_features)\n X_time = tf.reshape(\n tensor = X, \n shape = [cur_batch_size * params[\"seq_len\"], num_features])\n \n # Features based\n # shape = (cur_batch_size, num_features, seq_len)\n X_transposed = tf.transpose(a = X, perm = [0, 2, 1])\n # shape = (cur_batch_size * num_features, seq_len)\n X_features = tf.reshape(\n tensor = X_transposed, \n shape = [cur_batch_size * num_features, params[\"seq_len\"]])\n\n ################################################################################\n \n # Variables for calculating error distribution statistics\n with tf.variable_scope(name_or_scope = \"pca_variables\", reuse = tf.AUTO_REUSE):\n # Time based\n pca_time_count_variable = tf.get_variable(\n name = \"pca_time_count_variable\", # shape = ()\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False)\n\n pca_time_mean_variable = tf.get_variable(\n name = \"pca_time_mean_variable\", # shape = (num_features,)\n dtype = tf.float64,\n initializer = tf.zeros(shape = [num_features], dtype = tf.float64),\n trainable = False)\n\n pca_time_cov_variable = tf.get_variable(\n name = \"pca_time_cov_variable\", # shape = (num_features, num_features)\n dtype = tf.float64,\n initializer = tf.zeros(shape = [num_features, num_features], dtype = tf.float64),\n trainable = False)\n\n pca_time_eigenvalues_variable = tf.get_variable(\n name = \"pca_time_eigenvalues_variable\", # shape = (num_features,)\n dtype = tf.float64,\n initializer = tf.zeros(shape = [num_features], dtype = tf.float64),\n trainable = False)\n\n pca_time_eigenvectors_variable = tf.get_variable(\n name = \"pca_time_eigenvectors_variable\", # shape = (num_features, num_features)\n dtype = tf.float64,\n initializer = tf.zeros(shape = [num_features, num_features], dtype = tf.float64),\n trainable = False)\n\n # Features based\n pca_features_count_variable = tf.get_variable(\n name = \"pca_features_count_variable\", # shape = ()\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False)\n\n pca_features_mean_variable = tf.get_variable(\n name = \"pca_features_mean_variable\", # shape = (seq_len,)\n dtype = tf.float64,\n initializer = tf.zeros(shape = [params[\"seq_len\"]], dtype = tf.float64),\n trainable = False)\n\n pca_features_cov_variable = tf.get_variable(\n name = \"pca_features_cov_variable\", # shape = (seq_len, seq_len)\n dtype = tf.float64,\n initializer = tf.zeros(shape = [params[\"seq_len\"], params[\"seq_len\"]], dtype = tf.float64),\n trainable = False)\n\n pca_features_eigenvalues_variable = tf.get_variable(\n name = \"pca_features_eigenvalues_variable\", # shape = (seq_len,)\n dtype = tf.float64,\n initializer = tf.zeros(shape = [params[\"seq_len\"]], dtype = tf.float64),\n trainable = False)\n\n pca_features_eigenvectors_variable = tf.get_variable(\n name = \"pca_features_eigenvectors_variable\", # shape = (seq_len, seq_len)\n dtype = tf.float64,\n initializer = tf.zeros(shape = [params[\"seq_len\"], params[\"seq_len\"]], dtype = tf.float64),\n trainable = False)\n \n # Variables for calculating error distribution statistics\n with tf.variable_scope(\n name_or_scope = \"mahalanobis_distance_variables\", reuse = tf.AUTO_REUSE):\n # Time based\n abs_err_count_time_variable = tf.get_variable(\n name = \"abs_err_count_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n abs_err_mean_time_variable = tf.get_variable(\n name = \"abs_err_mean_time_variable\",\n dtype = tf.float64,\n initializer = tf.zeros(shape = [num_features], dtype = tf.float64),\n trainable = False) # shape = (num_features,)\n\n abs_err_cov_time_variable = tf.get_variable(\n name = \"abs_err_cov_time_variable\",\n dtype = tf.float64,\n initializer = tf.zeros(shape = [num_features, num_features], dtype = tf.float64),\n trainable = False) # shape = (num_features, num_features)\n\n abs_err_inv_cov_time_variable = tf.get_variable(\n name = \"abs_err_inv_cov_time_variable\",\n dtype = tf.float64,\n initializer = tf.zeros(shape = [num_features, num_features], dtype = tf.float64),\n trainable = False) # shape = (num_features, num_features)\n\n # Features based\n abs_err_count_features_variable = tf.get_variable(\n name = \"abs_err_count_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n abs_err_mean_features_variable = tf.get_variable(\n name = \"abs_err_mean_features_variable\",\n dtype = tf.float64,\n initializer = tf.zeros(shape = [params[\"seq_len\"]], dtype = tf.float64),\n trainable = False) # shape = (seq_len,)\n\n abs_err_cov_features_variable = tf.get_variable(\n name = \"abs_err_cov_features_variable\",\n dtype = tf.float64,\n initializer = tf.zeros(shape = [params[\"seq_len\"], params[\"seq_len\"]], dtype = tf.float64),\n trainable = False) # shape = (seq_len, seq_len)\n\n abs_err_inv_cov_features_variable = tf.get_variable(\n name = \"abs_err_inv_cov_features_variable\",\n dtype = tf.float64,\n initializer = tf.zeros(shape = [params[\"seq_len\"], params[\"seq_len\"]], dtype = tf.float64),\n trainable = False) # shape = (seq_len, seq_len)\n \n # Variables for automatically tuning anomaly thresholds\n with tf.variable_scope(\n name_or_scope = \"mahalanobis_distance_threshold_variables\", reuse = tf.AUTO_REUSE):\n # Time based\n tp_at_thresholds_time_variable = tf.get_variable(\n name = \"tp_at_thresholds_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [params[\"num_time_anomaly_thresholds\"]], dtype = tf.int64),\n trainable = False) # shape = (num_time_anomaly_thresholds,)\n\n fn_at_thresholds_time_variable = tf.get_variable(\n name = \"fn_at_thresholds_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [params[\"num_time_anomaly_thresholds\"]], dtype = tf.int64),\n trainable = False) # shape = (num_time_anomaly_thresholds,)\n\n fp_at_thresholds_time_variable = tf.get_variable(\n name = \"fp_at_thresholds_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [params[\"num_time_anomaly_thresholds\"]], dtype = tf.int64),\n trainable = False) # shape = (num_time_anomaly_thresholds,)\n\n tn_at_thresholds_time_variable = tf.get_variable(\n name = \"tn_at_thresholds_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [params[\"num_time_anomaly_thresholds\"]], dtype = tf.int64),\n trainable = False) # shape = (num_time_anomaly_thresholds,)\n\n time_anomaly_threshold_variable = tf.get_variable(\n name = \"time_anomaly_threshold_variable\",\n dtype = tf.float64,\n initializer = tf.zeros(shape = [], dtype = tf.float64),\n trainable = False) # shape = ()\n\n # Features based\n tp_at_thresholds_features_variable = tf.get_variable(\n name = \"tp_at_thresholds_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [params[\"num_features_anomaly_thresholds\"]], dtype = tf.int64),\n trainable = False) # shape = (num_features_anomaly_thresholds,)\n\n fn_at_thresholds_features_variable = tf.get_variable(\n name = \"fn_at_thresholds_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [params[\"num_features_anomaly_thresholds\"]], dtype = tf.int64),\n trainable = False) # shape = (num_features_anomaly_thresholds,)\n\n fp_at_thresholds_features_variable = tf.get_variable(\n name = \"fp_at_thresholds_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [params[\"num_features_anomaly_thresholds\"]], dtype = tf.int64),\n trainable = False) # shape = (num_features_anomaly_thresholds,)\n\n tn_at_thresholds_features_variable = tf.get_variable(\n name = \"tn_at_thresholds_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [params[\"num_features_anomaly_thresholds\"]], dtype = tf.int64),\n trainable = False) # shape = (num_features_anomaly_thresholds,)\n\n features_anomaly_threshold_variable = tf.get_variable(\n name = \"features_anomaly_threshold_variable\", # shape = ()\n dtype = tf.float64,\n initializer = tf.zeros(shape = [], dtype = tf.float64),\n trainable = False)\n\n # Variables for automatically tuning anomaly thresholds\n with tf.variable_scope(\n name_or_scope = \"anomaly_threshold_eval_variables\", reuse = tf.AUTO_REUSE):\n # Time based\n tp_at_threshold_eval_time_variable = tf.get_variable(\n name = \"tp_at_threshold_eval_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n fn_at_threshold_eval_time_variable = tf.get_variable(\n name = \"fn_at_threshold_eval_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n fp_at_threshold_eval_time_variable = tf.get_variable(\n name = \"fp_at_threshold_eval_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n tn_at_threshold_eval_time_variable = tf.get_variable(\n name = \"tn_at_threshold_eval_time_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n # Features based\n tp_at_threshold_eval_features_variable = tf.get_variable(\n name = \"tp_at_threshold_eval_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n fn_at_threshold_eval_features_variable = tf.get_variable(\n name = \"fn_at_threshold_eval_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n fp_at_threshold_eval_features_variable = tf.get_variable(\n name = \"fp_at_threshold_eval_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n tn_at_threshold_eval_features_variable = tf.get_variable(\n name = \"tn_at_threshold_eval_features_variable\",\n dtype = tf.int64,\n initializer = tf.zeros(shape = [], dtype = tf.int64),\n trainable = False) # shape = ()\n\n dummy_variable = tf.get_variable(\n name = \"dummy_variable\",\n dtype = tf.float64,\n initializer = tf.zeros(shape = [], dtype = tf.float64),\n trainable = True) # shape = ()\n \n # Now branch off based on which mode we are in\n predictions_dict = None\n loss = None\n train_op = None\n eval_metric_ops = None\n export_outputs = None\n \n # 3. Loss function, training/eval ops\n if mode == tf.estimator.ModeKeys.TRAIN and params[\"training_mode\"] == \"reconstruction\":\n with tf.variable_scope(name_or_scope = \"pca_variables\", reuse = tf.AUTO_REUSE):\n # Check if batch is a singleton or not, very important for covariance math\n\n # Time based ########################################\n singleton_condition = tf.equal(\n x = cur_batch_size * params[\"seq_len\"], y = 1) # shape = ()\n\n pca_time_cov_variable, pca_time_mean_variable, pca_time_count_variable = tf.cond(\n pred = singleton_condition, \n true_fn = lambda: singleton_batch_cov_variable_updating(\n params[\"seq_len\"], \n X_time, \n pca_time_count_variable, \n pca_time_mean_variable, \n pca_time_cov_variable,\n params[\"eps\"]), \n false_fn = lambda: non_singleton_batch_cov_variable_updating(\n cur_batch_size, \n params[\"seq_len\"], \n X_time, \n pca_time_count_variable, \n pca_time_mean_variable, \n pca_time_cov_variable,\n params[\"eps\"]))\n\n pca_time_eigenvalues_tensor, pca_time_eigenvectors_tensor = tf.linalg.eigh(\n tensor = pca_time_cov_variable) # shape = (num_features,) & (num_features, num_features)\n\n # Features based ########################################\n singleton_features_condition = tf.equal(\n x = cur_batch_size * num_features, y = 1) # shape = ()\n\n pca_features_cov_variable, pca_features_mean_variable, pca_features_count_variable = tf.cond(\n pred = singleton_features_condition, \n true_fn = lambda: singleton_batch_cov_variable_updating(\n num_features, \n X_features, \n pca_features_count_variable, pca_features_mean_variable, \n pca_features_cov_variable,\n params[\"eps\"]), \n false_fn = lambda: non_singleton_batch_cov_variable_updating(\n cur_batch_size, \n num_features, \n X_features, \n pca_features_count_variable, \n pca_features_mean_variable, \n pca_features_cov_variable,\n params[\"eps\"]))\n\n pca_features_eigenvalues_tensor, pca_features_eigenvectors_tensor = tf.linalg.eigh(\n tensor = pca_features_cov_variable) # shape = (seq_len,) & (seq_len, seq_len)\n\n # Lastly use control dependencies around loss to enforce the mahalanobis variables to be assigned, the control order matters, hence the separate contexts\n with tf.control_dependencies(\n control_inputs = [pca_time_cov_variable, pca_features_cov_variable]):\n with tf.control_dependencies(\n control_inputs = [pca_time_mean_variable, pca_features_mean_variable]):\n with tf.control_dependencies(\n control_inputs = [pca_time_count_variable, pca_features_count_variable]):\n with tf.control_dependencies(\n control_inputs = [tf.assign(ref = pca_time_eigenvalues_variable, value = pca_time_eigenvalues_tensor), \n tf.assign(ref = pca_time_eigenvectors_variable, value = pca_time_eigenvectors_tensor),\n tf.assign(ref = pca_features_eigenvalues_variable, value = pca_features_eigenvalues_tensor), \n tf.assign(ref = pca_features_eigenvectors_variable, value = pca_features_eigenvectors_tensor)]):\n loss = tf.reduce_sum(input_tensor = tf.zeros(shape = (), dtype = tf.float64) * dummy_variable)\n\n train_op = tf.contrib.layers.optimize_loss(\n loss = loss,\n global_step = tf.train.get_global_step(),\n learning_rate = params[\"learning_rate\"],\n optimizer = \"SGD\")\n else:\n # Time based\n # shape = (cur_batch_size * seq_len, num_features)\n X_time_centered = X_time - pca_time_mean_variable\n # shape = (cur_batch_size * seq_len, params[\"k_principal_components\"])\n X_time_projected = tf.matmul(\n a = X_time_centered, \n b = pca_time_eigenvectors_variable[:, -params[\"k_principal_components\"]:])\n # shape = (cur_batch_size * seq_len, num_features)\n X_time_reconstructed = tf.matmul(\n a = X_time_projected, \n b = pca_time_eigenvectors_variable[:, -params[\"k_principal_components\"]:], \n transpose_b = True)\n # shape = (cur_batch_size * seq_len, num_features)\n X_time_abs_reconstruction_error = tf.abs(\n x = X_time_centered - X_time_reconstructed)\n\n # Features based\n # shape = (cur_batch_size * num_features, seq_len)\n X_features_centered = X_features - pca_features_mean_variable\n # shape = (cur_batch_size * num_features, params[\"k_principal_components\"])\n X_features_projected = tf.matmul(\n a = X_features_centered, \n b = pca_features_eigenvectors_variable[:, -params[\"k_principal_components\"]:])\n # shape = (cur_batch_size * num_features, seq_len)\n X_features_reconstructed = tf.matmul(\n a = X_features_projected, \n b = pca_features_eigenvectors_variable[:, -params[\"k_principal_components\"]:], \n transpose_b = True)\n # shape = (cur_batch_size * num_features, seq_len)\n X_features_abs_reconstruction_error = tf.abs(\n x = X_features_centered - X_features_reconstructed)\n\n if mode == tf.estimator.ModeKeys.TRAIN and params[\"training_mode\"] == \"calculate_error_distribution_statistics\":\n ################################################################################\n\n with tf.variable_scope(name_or_scope = \"mahalanobis_distance_variables\", reuse = tf.AUTO_REUSE):\n # Time based ########################################\n singleton_time_condition = tf.equal(\n x = cur_batch_size * params[\"seq_len\"], y = 1) # shape = ()\n \n cov_time_variable, mean_time_variable, count_time_variable = tf.cond(\n pred = singleton_time_condition, \n true_fn = lambda: singleton_batch_cov_variable_updating(\n params[\"seq_len\"], \n X_time_abs_reconstruction_error, \n abs_err_count_time_variable, \n abs_err_mean_time_variable, \n abs_err_cov_time_variable,\n params[\"eps\"]), \n false_fn = lambda: non_singleton_batch_cov_variable_updating(\n cur_batch_size, \n params[\"seq_len\"], \n X_time_abs_reconstruction_error, \n abs_err_count_time_variable, \n abs_err_mean_time_variable, \n abs_err_cov_time_variable,\n params[\"eps\"]))\n\n # Features based ########################################\n singleton_features_condition = tf.equal(\n x = cur_batch_size * num_features, y = 1) # shape = ()\n \n cov_features_variable, mean_features_variable, count_features_variable = tf.cond(\n pred = singleton_features_condition, \n true_fn = lambda: singleton_batch_cov_variable_updating(\n num_features, \n X_features_abs_reconstruction_error, \n abs_err_count_features_variable, \n abs_err_mean_features_variable, \n abs_err_cov_features_variable,\n params[\"eps\"]), \n false_fn = lambda: non_singleton_batch_cov_variable_updating(\n cur_batch_size, \n num_features, \n X_features_abs_reconstruction_error, \n abs_err_count_features_variable, \n abs_err_mean_features_variable, \n abs_err_cov_features_variable,\n params[\"eps\"]))\n\n # Lastly use control dependencies around loss to enforce the mahalanobis variables to be assigned, the control order matters, hence the separate contexts\n with tf.control_dependencies(\n control_inputs = [cov_time_variable, cov_features_variable]):\n with tf.control_dependencies(\n control_inputs = [mean_time_variable, mean_features_variable]):\n with tf.control_dependencies(\n control_inputs = [count_time_variable, count_features_variable]):\n # Time based\n # shape = (num_features, num_features)\n abs_err_inv_cov_time_tensor = \\\n tf.matrix_inverse(input = cov_time_variable + \\\n tf.eye(num_rows = tf.shape(input = cov_time_variable)[0], \n dtype = tf.float64) * params[\"eps\"])\n # Features based\n # shape = (seq_len, seq_len)\n abs_err_inv_cov_features_tensor = \\\n tf.matrix_inverse(input = cov_features_variable + \\\n tf.eye(num_rows = tf.shape(input = cov_features_variable)[0], \n dtype = tf.float64) * params[\"eps\"])\n \n with tf.control_dependencies(\n control_inputs = [tf.assign(ref = abs_err_inv_cov_time_variable, value = abs_err_inv_cov_time_tensor), \n tf.assign(ref = abs_err_inv_cov_features_variable, value = abs_err_inv_cov_features_tensor)]):\n loss = tf.reduce_sum(input_tensor = tf.zeros(shape = (), dtype = tf.float64) * dummy_variable)\n\n train_op = tf.contrib.layers.optimize_loss(\n loss = loss,\n global_step = tf.train.get_global_step(),\n learning_rate = params[\"learning_rate\"],\n optimizer = \"SGD\")\n elif mode == tf.estimator.ModeKeys.EVAL and params[\"training_mode\"] != \"tune_anomaly_thresholds\":\n # Reconstruction loss on evaluation set\n loss = tf.losses.mean_squared_error(labels = X_time_centered, predictions = X_time_abs_reconstruction_error)\n\n if params[\"training_mode\"] == \"reconstruction\":\n # Reconstruction eval metrics\n eval_metric_ops = {\n \"rmse\": tf.metrics.root_mean_squared_error(labels = X_time_centered, predictions = X_time_abs_reconstruction_error),\n \"mae\": tf.metrics.mean_absolute_error(labels = X_time_centered, predictions = X_time_abs_reconstruction_error)\n }\n elif mode == tf.estimator.ModeKeys.PREDICT or ((mode == tf.estimator.ModeKeys.TRAIN or mode == tf.estimator.ModeKeys.EVAL) and params[\"training_mode\"] == \"tune_anomaly_thresholds\"):\n with tf.variable_scope(name_or_scope = \"mahalanobis_distance_variables\", reuse = tf.AUTO_REUSE):\n # Time based\n mahalanobis_distance_time = mahalanobis_distance(\n error_vectors_reshaped = X_time_abs_reconstruction_error,\n mean_vector = abs_err_mean_time_variable, \n inv_covariance = abs_err_inv_cov_time_variable, \n final_shape = params[\"seq_len\"]) # shape = (cur_batch_size, seq_len)\n \n # Features based\n mahalanobis_distance_features = mahalanobis_distance(\n error_vectors_reshaped = X_features_abs_reconstruction_error,\n mean_vector = abs_err_mean_features_variable, \n inv_covariance = abs_err_inv_cov_features_variable,\n final_shape = num_features) # shape = (cur_batch_size, num_features)\n\n if mode != tf.estimator.ModeKeys.PREDICT:\n labels_normal_mask = tf.equal(x = labels, y = 0)\n labels_anomalous_mask = tf.equal(x = labels, y = 1)\n\n if mode == tf.estimator.ModeKeys.TRAIN:\n with tf.variable_scope(\n name_or_scope = \"mahalanobis_distance_variables\", reuse = tf.AUTO_REUSE):\n # Time based\n # shape = (num_time_anomaly_thresholds,)\n time_anomaly_thresholds = tf.linspace(\n start = tf.constant(value = params[\"min_time_anomaly_threshold\"], dtype = tf.float64),\n stop = tf.constant(value = params[\"max_time_anomaly_threshold\"], dtype = tf.float64), \n num = params[\"num_time_anomaly_thresholds\"])\n\n tp_time_update_op, fn_time_update_op, fp_time_update_op, tn_time_update_op = \\\n update_anomaly_threshold_variables(\n labels_normal_mask, \n labels_anomalous_mask, \n params[\"num_time_anomaly_thresholds\"], \n time_anomaly_thresholds, \n mahalanobis_distance_time, \n tp_at_thresholds_time_variable, \n fn_at_thresholds_time_variable, \n fp_at_thresholds_time_variable, \n tn_at_thresholds_time_variable,\n mode)\n\n # Features based\n # shape = (num_features_anomaly_thresholds,)\n features_anomaly_thresholds = tf.linspace(\n start = tf.constant(value = params[\"min_features_anomaly_threshold\"], dtype = tf.float64),\n stop = tf.constant(value = params[\"max_features_anomaly_threshold\"], dtype = tf.float64), \n num = params[\"num_features_anomaly_thresholds\"])\n\n tp_features_update_op, fn_features_update_op, fp_features_update_op, tn_features_update_op = \\\n update_anomaly_threshold_variables(\n labels_normal_mask, \n labels_anomalous_mask, \n params[\"num_features_anomaly_thresholds\"], \n features_anomaly_thresholds, \n mahalanobis_distance_features, \n tp_at_thresholds_features_variable, \n fn_at_thresholds_features_variable, \n fp_at_thresholds_features_variable, \n tn_at_thresholds_features_variable, \n mode)\n\n # Reconstruction loss on evaluation set\n with tf.control_dependencies(\n control_inputs = [\n tp_time_update_op, \n fn_time_update_op, \n fp_time_update_op, \n tn_time_update_op, \n tp_features_update_op, \n fn_features_update_op, \n fp_features_update_op, \n tn_features_update_op]):\n # Time based\n acc_time, pre_time, rec_time, f_beta_score_time = \\\n calculate_composite_classification_metrics(\n time_anomaly_thresholds, \n tp_at_thresholds_time_variable, \n fn_at_thresholds_time_variable, \n fp_at_thresholds_time_variable, \n tn_at_thresholds_time_variable,\n params[\"f_score_beta\"])\n\n # Features based\n acc_features, pre_features, rec_features, f_beta_score_features = \\\n calculate_composite_classification_metrics(\n features_anomaly_thresholds, \n tp_at_thresholds_features_variable, \n fn_at_thresholds_features_variable, \n fp_at_thresholds_features_variable, \n tn_at_thresholds_features_variable,\n params[\"f_score_beta\"])\n\n with tf.control_dependencies(\n control_inputs = [pre_time, pre_features]):\n with tf.control_dependencies(\n control_inputs = [rec_time, rec_features]):\n with tf.control_dependencies(\n control_inputs = [f_beta_score_time, f_beta_score_features]):\n # Time based\n best_anomaly_threshold_time = find_best_anomaly_threshold(\n time_anomaly_thresholds, \n f_beta_score_time, \n params[\"time_anomaly_threshold\"], \n time_anomaly_threshold_variable)\n\n # Features based\n best_anomaly_threshold_features = find_best_anomaly_threshold(\n features_anomaly_thresholds, \n f_beta_score_features, \n params[\"features_anomaly_threshold\"], \n features_anomaly_threshold_variable)\n\n with tf.control_dependencies(\n control_inputs = [\n tf.assign(\n ref = time_anomaly_threshold_variable, \n value = best_anomaly_threshold_time), \n tf.assign(ref = \n features_anomaly_threshold_variable, \n value = best_anomaly_threshold_features)]):\n\n loss = tf.reduce_sum(\n input_tensor = tf.zeros(shape = (), dtype = tf.float64) * dummy_variable)\n\n train_op = tf.contrib.layers.optimize_loss(\n loss = loss,\n global_step = tf.train.get_global_step(),\n learning_rate = params[\"learning_rate\"],\n optimizer = \"SGD\")\n elif mode == tf.estimator.ModeKeys.EVAL:\n with tf.variable_scope(\n name_or_scope = \"anomaly_threshold_eval_variables\", reuse = tf.AUTO_REUSE):\n # Time based\n tp_time_update_op, fn_time_update_op, fp_time_update_op, tn_time_update_op = \\\n update_anomaly_threshold_variables(\n labels_normal_mask, \n labels_anomalous_mask, \n 1,\n time_anomaly_threshold_variable, \n mahalanobis_distance_time, \n tp_at_threshold_eval_time_variable, \n fn_at_threshold_eval_time_variable, \n fp_at_threshold_eval_time_variable, \n tn_at_threshold_eval_time_variable,\n mode)\n\n # Features based\n tp_features_update_op, fn_features_update_op, fp_features_update_op, tn_features_update_op = \\\n update_anomaly_threshold_variables(\n labels_normal_mask, \n labels_anomalous_mask, \n 1,\n features_anomaly_threshold_variable, \n mahalanobis_distance_features, \n tp_at_threshold_eval_features_variable, \n fn_at_threshold_eval_features_variable, \n fp_at_threshold_eval_features_variable, \n tn_at_threshold_eval_features_variable,\n mode)\n\n with tf.variable_scope(\n name_or_scope = \"anomaly_threshold_eval_variables\", reuse = tf.AUTO_REUSE):\n # Time based\n acc_time_update_op, pre_time_update_op, rec_time_update_op, f_beta_score_time_update_op = \\\n calculate_composite_classification_metrics(\n time_anomaly_threshold_variable, \n tp_at_threshold_eval_time_variable, \n fn_at_threshold_eval_time_variable, \n fp_at_threshold_eval_time_variable, \n tn_at_threshold_eval_time_variable,\n params[\"f_score_beta\"]) \n\n # Features based\n acc_features_update_op, pre_features_update_op, rec_features_update_op, f_beta_score_features_update_op = \\\n calculate_composite_classification_metrics(\n features_anomaly_threshold_variable, \n tp_at_threshold_eval_features_variable, \n fn_at_threshold_eval_features_variable, \n fp_at_threshold_eval_features_variable, \n tn_at_threshold_eval_features_variable,\n params[\"f_score_beta\"]) \n\n loss = tf.losses.mean_squared_error(labels = X_time_centered, predictions = X_time_reconstructed)\n\n acc_at_threshold_eval_time_variable = tf.cast(x = tp_at_threshold_eval_time_variable + tn_at_threshold_eval_time_variable, dtype = tf.float64) \\\n / tf.cast(x = tp_at_threshold_eval_time_variable + fn_at_threshold_eval_time_variable + fp_at_threshold_eval_time_variable + tn_at_threshold_eval_time_variable, dtype = tf.float64)\n pre_at_threshold_eval_time_variable = tf.cast(x = tp_at_threshold_eval_time_variable, dtype = tf.float64) \\\n / tf.cast(x = tp_at_threshold_eval_time_variable + fp_at_threshold_eval_time_variable, dtype = tf.float64)\n rec_at_threshold_eval_time_variable = tf.cast(x = tp_at_threshold_eval_time_variable, dtype = tf.float64) \\\n / tf.cast(x = tp_at_threshold_eval_time_variable + fn_at_threshold_eval_time_variable, dtype = tf.float64)\n f_beta_score_at_threshold_eval_time_variable = (1.0 + params[\"f_score_beta\"] ** 2) * pre_at_threshold_eval_time_variable * rec_at_threshold_eval_time_variable \\\n / (params[\"f_score_beta\"] ** 2 * pre_at_threshold_eval_time_variable + rec_at_threshold_eval_time_variable)\n\n acc_at_threshold_eval_features_variable = tf.cast(x = tp_at_threshold_eval_features_variable + tn_at_threshold_eval_features_variable, dtype = tf.float64) \\\n / tf.cast(x = tp_at_threshold_eval_features_variable + fn_at_threshold_eval_features_variable + fp_at_threshold_eval_features_variable + tn_at_threshold_eval_features_variable, dtype = tf.float64)\n pre_at_threshold_eval_features_variable = tf.cast(x = tp_at_threshold_eval_features_variable, dtype = tf.float64) \\\n / tf.cast(x = tp_at_threshold_eval_features_variable + fp_at_threshold_eval_features_variable, dtype = tf.float64)\n rec_at_threshold_eval_features_variable = tf.cast(x = tp_at_threshold_eval_features_variable, dtype = tf.float64) \\\n / tf.cast(x = tp_at_threshold_eval_features_variable + fn_at_threshold_eval_features_variable, dtype = tf.float64)\n f_beta_score_at_threshold_eval_features_variable = (1.0 + params[\"f_score_beta\"] ** 2) * pre_at_threshold_eval_features_variable * rec_at_threshold_eval_features_variable \\\n / (params[\"f_score_beta\"] ** 2 * pre_at_threshold_eval_features_variable + rec_at_threshold_eval_features_variable)\n\n # Anomaly detection eval metrics\n eval_metric_ops = {\n # Time based\n \"time_anomaly_tp\": (tp_at_threshold_eval_time_variable, tp_time_update_op),\n \"time_anomaly_fn\": (fn_at_threshold_eval_time_variable, fn_time_update_op),\n \"time_anomaly_fp\": (fp_at_threshold_eval_time_variable, fp_time_update_op),\n \"time_anomaly_tn\": (tn_at_threshold_eval_time_variable, tn_time_update_op),\n\n \"time_anomaly_acc\": (acc_at_threshold_eval_time_variable, acc_time_update_op),\n \"time_anomaly_pre\": (pre_at_threshold_eval_time_variable, pre_time_update_op),\n \"time_anomaly_rec\": (rec_at_threshold_eval_time_variable, rec_time_update_op),\n \"time_anomaly_f_beta_score\": (f_beta_score_at_threshold_eval_time_variable, f_beta_score_time_update_op),\n\n # Features based\n \"features_anomaly_tp\": (tp_at_threshold_eval_features_variable, tp_features_update_op),\n \"features_anomaly_fn\": (fn_at_threshold_eval_features_variable, fn_features_update_op),\n \"features_anomaly_fp\": (fp_at_threshold_eval_features_variable, fp_features_update_op),\n \"features_anomaly_tn\": (tn_at_threshold_eval_features_variable, tn_features_update_op),\n\n \"features_anomaly_acc\": (acc_at_threshold_eval_features_variable, acc_features_update_op),\n \"features_anomaly_pre\": (pre_at_threshold_eval_features_variable, pre_features_update_op),\n \"features_anomaly_rec\": (rec_at_threshold_eval_features_variable, rec_features_update_op),\n \"features_anomaly_f_beta_score\": (f_beta_score_at_threshold_eval_features_variable, f_beta_score_features_update_op)\n }\n else: # mode == tf.estimator.ModeKeys.PREDICT\n # Flag predictions as either normal or anomalous\n time_anomaly_flags = tf.where(\n condition = tf.reduce_any(\n input_tensor = tf.greater(\n x = tf.abs(x = mahalanobis_distance_time),\n y = time_anomaly_threshold_variable), \n axis = 1), \n x = tf.ones(shape = [cur_batch_size], dtype = tf.int64), \n y = tf.zeros(shape = [cur_batch_size], dtype = tf.int64)) # shape = (cur_batch_size,)\n\n features_anomaly_flags = tf.where(\n condition = tf.reduce_any(\n input_tensor = tf.greater(\n x = tf.abs(x = mahalanobis_distance_features),\n y = features_anomaly_threshold_variable), \n axis = 1), \n x = tf.ones(shape = [cur_batch_size], dtype = tf.int64), \n y = tf.zeros(shape = [cur_batch_size], dtype = tf.int64)) # shape = (cur_batch_size,)\n\n # Create predictions dictionary\n predictions_dict = {\n \"X_time_abs_reconstruction_error\": tf.reshape(\n tensor = X_time_abs_reconstruction_error, \n shape = [cur_batch_size, params[\"seq_len\"], num_features]), \n \"X_features_abs_reconstruction_error\": tf.transpose(\n a = tf.reshape(\n tensor = X_features_abs_reconstruction_error, \n shape = [cur_batch_size, num_features, params[\"seq_len\"]]), \n perm = [0, 2, 1]),\n \"mahalanobis_distance_time\": mahalanobis_distance_time, \n \"mahalanobis_distance_features\": mahalanobis_distance_features, \n \"time_anomaly_flags\": time_anomaly_flags, \n \"features_anomaly_flags\": features_anomaly_flags}\n\n # Create export outputs\n export_outputs = {\n \"predict_export_outputs\": tf.estimator.export.PredictOutput(\n outputs = predictions_dict)}\n\n # Return EstimatorSpec\n return tf.estimator.EstimatorSpec(\n mode = mode,\n predictions = predictions_dict,\n loss = loss,\n train_op = train_op,\n eval_metric_ops = eval_metric_ops,\n export_outputs = export_outputs)",
"_____no_output_____"
],
[
"# Create our serving input function to accept the data at serving and send it in the \n# right format to our custom estimator\ndef serving_input_fn(seq_len):\n # This function fixes the shape and type of our input strings\n def fix_shape_and_type_for_serving(placeholder):\n current_batch_size = tf.shape(input = placeholder, out_type = tf.int64)[0]\n \n # String split each string in batch and output values from the resulting SparseTensors\n split_string = tf.stack(values = tf.map_fn( # shape = (batch_size, seq_len)\n fn = lambda x: tf.string_split(source = [placeholder[x]], delimiter = ',').values, \n elems = tf.range(start = 0, limit = current_batch_size, dtype = tf.int64), \n dtype = tf.string), axis = 0)\n \n # Convert each string in the split tensor to float\n # shape = (batch_size, seq_len)\n feature_tensor = tf.string_to_number(string_tensor = split_string, out_type = tf.float64)\n \n return feature_tensor\n \n # This function fixes dynamic shape ambiguity of last dimension so that we will be able to \n # use it in our DNN (since tf.layers.dense require the last dimension to be known)\n def get_shape_and_set_modified_shape_2D(tensor, additional_dimension_sizes):\n # Get static shape for tensor and convert it to list\n shape = tensor.get_shape().as_list()\n # Set outer shape to additional_dimension_sizes[0] since know this is the correct size\n shape[1] = additional_dimension_sizes[0]\n # Set the shape of tensor to our modified shape\n tensor.set_shape(shape = shape) # shape = (batch_size, additional_dimension_sizes[0])\n\n return tensor\n \n # Create placeholders to accept the data sent to the model at serving time\n # All features come in as a batch of strings, shape = (batch_size,), \n # this was so because of passing the arrays to online ml-engine prediction\n feature_placeholders = {\n feature: tf.placeholder(\n dtype = tf.string, shape = [None]) for feature in UNLABELED_CSV_COLUMNS\n }\n \n # Create feature tensors\n features = {key: fix_shape_and_type_for_serving(placeholder = tensor) \n for key, tensor in feature_placeholders.items()}\n \n # Fix dynamic shape ambiguity of feature tensors for our DNN\n features = {key: get_shape_and_set_modified_shape_2D(\n tensor = tensor, additional_dimension_sizes = [seq_len]) for key, tensor in features.items()}\n\n return tf.estimator.export.ServingInputReceiver(\n features = features, receiver_tensors = feature_placeholders)",
"_____no_output_____"
],
[
"# Create estimator to train and evaluate\ndef train_and_evaluate(args):\n # Create our custom estimator using our model function\n estimator = tf.estimator.Estimator(\n model_fn = pca_anomaly_detection,\n model_dir = args[\"output_dir\"],\n params = {\n \"seq_len\": args[\"seq_len\"],\n \"learning_rate\": args[\"learning_rate\"],\n \"training_mode\": args[\"training_mode\"],\n \"k_principal_components\": args[\"k_principal_components\"],\n \"num_time_anomaly_thresholds\": args[\"num_time_anomaly_thresholds\"],\n \"num_features_anomaly_thresholds\": args[\"num_features_anomaly_thresholds\"],\n \"min_time_anomaly_threshold\": args[\"min_time_anomaly_threshold\"],\n \"max_time_anomaly_threshold\": args[\"max_time_anomaly_threshold\"],\n \"min_features_anomaly_threshold\": args[\"min_features_anomaly_threshold\"],\n \"max_features_anomaly_threshold\": args[\"max_features_anomaly_threshold\"],\n \"time_anomaly_threshold\": args[\"time_anomaly_threshold\"], \n \"features_anomaly_threshold\": args[\"features_anomaly_threshold\"],\n \"eps\": args[\"eps\"],\n \"f_score_beta\": args[\"f_score_beta\"]})\n \n if args[\"training_mode\"] == \"reconstruction\":\n estimator.train(\n input_fn = read_dataset(\n filename = args[\"train_file_pattern\"], \n mode = tf.estimator.ModeKeys.EVAL, \n batch_size = args[\"train_batch_size\"],\n params = args),\n steps = None)\n else:\n if args[\"training_mode\"] == \"calculate_error_distribution_statistics\":\n # Get final mahalanobis statistics over the entire validation_1 dataset\n estimator.train(\n input_fn = read_dataset(\n filename = args[\"train_file_pattern\"], \n mode = tf.estimator.ModeKeys.EVAL, \n batch_size = args[\"train_batch_size\"],\n params = args),\n steps = None)\n\n elif args[\"training_mode\"] == \"tune_anomaly_thresholds\":\n # Tune anomaly thresholds using valdiation_2 and validation_anomaly datasets\n estimator.train(\n input_fn = read_dataset(\n filename = args[\"train_file_pattern\"], \n mode = tf.estimator.ModeKeys.EVAL, \n batch_size = args[\"train_batch_size\"],\n params = args),\n steps = None)\n \n estimator.evaluate(\n input_fn = read_dataset(\n filename = args[\"eval_file_pattern\"], \n mode = tf.estimator.ModeKeys.EVAL, \n batch_size = args[\"eval_batch_size\"],\n params = args),\n steps = None)\n\n # Export savedmodel with learned error distribution statistics to be used for inference\n estimator.export_savedmodel(\n export_dir_base = args['output_dir'] + \"/export/exporter\", \n serving_input_receiver_fn = lambda: serving_input_fn(args[\"seq_len\"]))\n \n return estimator",
"_____no_output_____"
],
[
"arguments = {}\n# File arguments\narguments[\"train_file_pattern\"] = \"data/training_normal_sequences.csv\"\narguments[\"eval_file_pattern\"] = \"data/validation_normal_1_sequences.csv\"\narguments[\"output_dir\"] = \"trained_model\"\n\n# Sequence shape hyperparameters\narguments[\"seq_len\"] = seq_len\n\n# Training parameters\narguments[\"train_batch_size\"] = 32\narguments[\"eval_batch_size\"] = 32\narguments[\"train_steps\"] = 2000\narguments[\"learning_rate\"] = 0.01\narguments[\"start_delay_secs\"] = 60\narguments[\"throttle_secs\"] = 120\n\n# Anomaly detection\narguments[\"training_mode\"] = \"reconstruction\"\narguments[\"k_principal_components\"] = min(number_of_tags, 3)\narguments[\"num_time_anomaly_thresholds\"] = 300\narguments[\"num_features_anomaly_thresholds\"] = 300\narguments[\"min_time_anomaly_threshold\"] = 1\narguments[\"max_time_anomaly_threshold\"] = 100\narguments[\"min_features_anomaly_threshold\"] = 1\narguments[\"max_features_anomaly_threshold\"] = 100\narguments[\"time_anomaly_threshold\"] = None\narguments[\"features_anomaly_threshold\"] = None\narguments[\"eps\"] = 10**-12\narguments[\"f_score_beta\"] = 0.05",
"_____no_output_____"
]
],
[
[
"## Train reconstruction variables",
"_____no_output_____"
]
],
[
[
"# Train the model\nshutil.rmtree(path = arguments[\"output_dir\"], ignore_errors = True) # start fresh each time\nestimator = train_and_evaluate(arguments)",
"INFO:tensorflow:Using default config.\nINFO:tensorflow:Using config: {'_save_checkpoints_secs': 600, '_device_fn': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7efb36cceda0>, '_save_checkpoints_steps': None, '_num_worker_replicas': 1, '_global_id_in_cluster': 0, '_model_dir': 'trained_model', '_service': None, '_log_step_count_steps': 100, '_train_distribute': None, '_keep_checkpoint_every_n_hours': 10000, '_evaluation_master': '', '_is_chief': True, '_keep_checkpoint_max': 5, '_experimental_distribute': None, '_protocol': None, '_task_type': 'worker', '_eval_distribute': None, '_num_ps_replicas': 0, '_save_summary_steps': 100, '_task_id': 0, '_session_config': allow_soft_placement: true\ngraph_options {\n rewrite_options {\n meta_optimizer_iterations: ONE\n }\n}\n, '_tf_random_seed': None, '_master': ''}\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nColocations handled automatically by placer.\nINFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'IteratorGetNext:2' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'IteratorGetNext:1' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'IteratorGetNext:0' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'IteratorGetNext:3' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'IteratorGetNext:4' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nNone\npca_anomaly_detection: mode = \ntrain\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'reconstruction', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\n\nWARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.\nFor more information, please see:\n * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md\n * https://github.com/tensorflow/addons\nIf you depend on functionality not listed there, please file an issue.\n\nINFO:tensorflow:Done calling model_fn.\nINFO:tensorflow:Create CheckpointSaverHook.\nINFO:tensorflow:Graph was finalized.\nINFO:tensorflow:Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nINFO:tensorflow:Saving checkpoints for 0 into trained_model/model.ckpt.\nINFO:tensorflow:loss = 0.0, step = 1\nINFO:tensorflow:global_step/sec: 91.8903\nINFO:tensorflow:loss = 0.0, step = 101 (1.091 sec)\nINFO:tensorflow:global_step/sec: 99.7892\nINFO:tensorflow:loss = 0.0, step = 201 (1.006 sec)\nINFO:tensorflow:global_step/sec: 105.418\nINFO:tensorflow:loss = 0.0, step = 301 (0.945 sec)\nINFO:tensorflow:global_step/sec: 103.969\nINFO:tensorflow:loss = 0.0, step = 401 (0.962 sec)\nINFO:tensorflow:global_step/sec: 98.8128\nINFO:tensorflow:loss = 0.0, step = 501 (1.012 sec)\nINFO:tensorflow:global_step/sec: 109.885\nINFO:tensorflow:loss = 0.0, step = 601 (0.910 sec)\nINFO:tensorflow:global_step/sec: 117.526\nINFO:tensorflow:loss = 0.0, step = 701 (0.856 sec)\nINFO:tensorflow:global_step/sec: 116.806\nINFO:tensorflow:loss = 0.0, step = 801 (0.853 sec)\nINFO:tensorflow:global_step/sec: 113.876\nINFO:tensorflow:loss = 0.0, step = 901 (0.880 sec)\nINFO:tensorflow:global_step/sec: 126.525\nINFO:tensorflow:loss = 0.0, step = 1001 (0.791 sec)\nINFO:tensorflow:global_step/sec: 111.411\nINFO:tensorflow:loss = 0.0, step = 1101 (0.898 sec)\nINFO:tensorflow:global_step/sec: 110.287\nINFO:tensorflow:loss = 0.0, step = 1201 (0.902 sec)\nINFO:tensorflow:global_step/sec: 116.223\nINFO:tensorflow:loss = 0.0, step = 1301 (0.860 sec)\nINFO:tensorflow:global_step/sec: 111.819\nINFO:tensorflow:loss = 0.0, step = 1401 (0.899 sec)\nINFO:tensorflow:global_step/sec: 110.72\nINFO:tensorflow:loss = 0.0, step = 1501 (0.903 sec)\nINFO:tensorflow:global_step/sec: 127.042\nINFO:tensorflow:loss = 0.0, step = 1601 (0.782 sec)\nINFO:tensorflow:global_step/sec: 104.452\nINFO:tensorflow:loss = 0.0, step = 1701 (0.957 sec)\nINFO:tensorflow:global_step/sec: 93.3587\nINFO:tensorflow:loss = 0.0, step = 1801 (1.071 sec)\nINFO:tensorflow:global_step/sec: 87.7794\nINFO:tensorflow:loss = 0.0, step = 1901 (1.144 sec)\nINFO:tensorflow:Saving checkpoints for 2000 into trained_model/model.ckpt.\nINFO:tensorflow:Loss for final step: 0.0.\n"
]
],
[
[
"## Look at PCA variable values",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_names()",
"_____no_output_____"
],
[
"arr_training_normal_sequences = np.genfromtxt(fname = \"data/training_normal_sequences.csv\", delimiter = ';', dtype = str)\nprint(\"arr_training_normal_sequences.shape = {}\".format(arr_training_normal_sequences.shape))\nif number_of_tags == 1:\n arr_training_normal_sequences = np.expand_dims(a = arr_training_normal_sequences, axis = -1)\n \narr_training_normal_sequences_features = np.stack(\n arrays = [np.stack(\n arrays = [np.array(arr_training_normal_sequences[example_index, tag_index].split(',')).astype(np.float) \n for tag_index in range(number_of_tags)], axis = 1) \n for example_index in range(len(arr_training_normal_sequences))], axis = 0)\n\nprint(\"arr_training_normal_sequences_features.shape = {}\".format(arr_training_normal_sequences_features.shape))",
"arr_training_normal_sequences.shape = (64000, 5)\narr_training_normal_sequences_features.shape = (64000, 30, 5)\n"
]
],
[
[
"### Time based",
"_____no_output_____"
]
],
[
[
"X_time = arr_training_normal_sequences_features.reshape(arr_training_normal_sequences_features.shape[0] * arr_training_normal_sequences_features.shape[1], number_of_tags)\nX_time.shape",
"_____no_output_____"
]
],
[
[
"#### Count",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"pca_variables/pca_time_count_variable\")",
"_____no_output_____"
],
[
"time_count = X_time.shape[0]\ntime_count",
"_____no_output_____"
]
],
[
[
"#### Mean",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"pca_variables/pca_time_mean_variable\")",
"_____no_output_____"
],
[
"time_mean = np.mean(X_time, axis = 0)\ntime_mean",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"pca_variables/pca_time_mean_variable\") / time_mean",
"_____no_output_____"
]
],
[
[
"#### Covariance",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"pca_variables/pca_time_cov_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"pca_variables/pca_time_cov_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"pca_variables/pca_time_cov_variable\").shape)",
"[[ 1.44188229 -0.01370197 -0.02521143 -0.03415416 -0.02290388]\n [-0.01370197 1.09438171 0.01517352 -0.15795746 0.03609734]\n [-0.02521143 0.01517352 1.9724199 0.02706946 0.02331364]\n [-0.03415416 -0.15795746 0.02706946 0.97274093 -0.09024727]\n [-0.02290388 0.03609734 0.02331364 -0.09024727 1.41801289]]\n"
],
[
"if arguments[\"seq_len\"] == 1:\n time_cov = np.zeros(shape = [number_of_tags, number_of_tags])\nelse:\n time_cov = np.cov(np.transpose(X_time))\nif time_cov.shape[0] <= 10:\n print(time_cov)\nelse:\n print(time_cov.shape)",
"[[ 1.44188229 -0.01370197 -0.02521143 -0.03415416 -0.02290388]\n [-0.01370197 1.09438171 0.01517352 -0.15795746 0.03609734]\n [-0.02521143 0.01517352 1.9724199 0.02706946 0.02331364]\n [-0.03415416 -0.15795746 0.02706946 0.97274093 -0.09024727]\n [-0.02290388 0.03609734 0.02331364 -0.09024727 1.41801289]]\n"
],
[
"estimator.get_variable_value(name = \"pca_variables/pca_time_cov_variable\") / time_cov",
"_____no_output_____"
]
],
[
[
"#### Eigenvalues",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"pca_variables/pca_time_eigenvalues_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"pca_variables/pca_time_eigenvalues_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"pca_variables/pca_time_eigenvalues_variable\").shape)",
"[0.85552299 1.17608319 1.43092125 1.46139796 1.97551233]\n"
],
[
"time_eigenvalues, time_eigenvectors = np.linalg.eigh(a = time_cov)\nif time_eigenvalues.shape[0] <= 10:\n print(time_eigenvalues)\nelse:\n print(time_eigenvalues.shape)",
"[0.85552299 1.17608319 1.43092125 1.46139796 1.97551233]\n"
],
[
"estimator.get_variable_value(name = \"pca_variables/pca_time_eigenvalues_variable\") / time_eigenvalues",
"_____no_output_____"
]
],
[
[
"#### Eigenvectors",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"pca_variables/pca_time_eigenvectors_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"pca_variables/pca_time_eigenvectors_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"pca_variables/pca_time_eigenvectors_variable\").shape)",
"[[-0.06389873 -0.04638795 0.76318494 0.63932772 0.05073392]\n [-0.54031815 0.8153906 0.13620877 -0.15619737 -0.01562119]\n [ 0.02821099 0.00860242 0.01719566 0.06207252 -0.99748757]\n [-0.83225322 -0.48744957 -0.21945062 0.14520043 -0.02248908]\n [-0.10262541 -0.30871547 0.59206558 -0.73615643 -0.04116842]]\n"
],
[
"if time_eigenvectors.shape[0] <= 10:\n print(time_eigenvectors)\nelse:\n print(time_eigenvectors.shape)",
"[[ 0.06389873 -0.04638795 -0.76318494 -0.63932772 -0.05073392]\n [ 0.54031815 0.8153906 -0.13620877 0.15619737 0.01562119]\n [-0.02821099 0.00860242 -0.01719566 -0.06207252 0.99748757]\n [ 0.83225322 -0.48744957 0.21945062 -0.14520043 0.02248908]\n [ 0.10262541 -0.30871547 -0.59206558 0.73615643 0.04116842]]\n"
],
[
"estimator.get_variable_value(name = \"pca_variables/pca_time_eigenvectors_variable\") / time_eigenvectors",
"_____no_output_____"
]
],
[
[
"### Features based",
"_____no_output_____"
]
],
[
[
"X_features = np.transpose(arr_training_normal_sequences_features, [0, 2, 1]).reshape(arr_training_normal_sequences_features.shape[0] * number_of_tags, arr_training_normal_sequences_features.shape[1])\nX_features.shape",
"_____no_output_____"
]
],
[
[
"#### Count",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"pca_variables/pca_features_count_variable\")",
"_____no_output_____"
],
[
"feat_count = X_features.shape[0]\nfeat_count",
"_____no_output_____"
]
],
[
[
"#### Mean",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"pca_variables/pca_features_mean_variable\")",
"_____no_output_____"
],
[
"feat_mean = np.mean(X_features, axis = 0)\nfeat_mean",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"pca_variables/pca_features_mean_variable\") / feat_mean",
"_____no_output_____"
]
],
[
[
"#### Covariance",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"pca_variables/pca_features_cov_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"pca_variables/pca_features_cov_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"pca_variables/pca_features_cov_variable\").shape)",
"(30, 30)\n"
],
[
"if number_of_tags == 1:\n feat_cov = np.zeros(shape = [arguments[\"seq_len\"], arguments[\"seq_len\"]])\nelse:\n feat_cov = np.cov(np.transpose(X_features))\nif feat_cov.shape[0] <= 10:\n print(feat_cov)\nelse:\n print(feat_cov.shape)",
"(30, 30)\n"
],
[
"estimator.get_variable_value(name = \"pca_variables/pca_features_cov_variable\") / feat_cov",
"_____no_output_____"
]
],
[
[
"#### Eigenvalues",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"pca_variables/pca_features_eigenvalues_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"pca_variables/pca_features_eigenvalues_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"pca_variables/pca_features_eigenvalues_variable\").shape)",
"(30,)\n"
],
[
"feat_eigenvalues, feat_eigenvectors = np.linalg.eigh(a = feat_cov)\nif feat_eigenvalues.shape[0] <= 10:\n print(feat_eigenvalues)\nelse:\n print(feat_eigenvalues.shape)",
"(30,)\n"
],
[
"estimator.get_variable_value(name = \"pca_variables/pca_features_eigenvalues_variable\") / feat_eigenvalues",
"_____no_output_____"
]
],
[
[
"#### Eigenvectors",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"pca_variables/pca_features_eigenvectors_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"pca_variables/pca_features_eigenvectors_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"pca_variables/pca_features_eigenvectors_variable\").shape)",
"(30, 30)\n"
],
[
"if feat_eigenvectors.shape[0] <= 10:\n print(feat_eigenvectors)\nelse:\n print(feat_eigenvectors.shape)",
"(30, 30)\n"
],
[
"estimator.get_variable_value(name = \"pca_variables/pca_features_eigenvectors_variable\") / feat_eigenvectors",
"_____no_output_____"
]
],
[
[
"## Train error distribution statistics variables",
"_____no_output_____"
]
],
[
[
"arguments[\"training_mode\"] = \"calculate_error_distribution_statistics\"\narguments[\"train_file_pattern\"] = \"data/validation_normal_1_sequences.csv\"\narguments[\"eval_file_pattern\"] = \"data/validation_normal_1_sequences.csv\"\narguments[\"train_batch_size\"] = 32\narguments[\"eval_batch_size\"] = 32\nestimator = train_and_evaluate(arguments)",
"INFO:tensorflow:Using default config.\nINFO:tensorflow:Using config: {'_save_checkpoints_secs': 600, '_device_fn': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7efaac0ae9b0>, '_save_checkpoints_steps': None, '_num_worker_replicas': 1, '_global_id_in_cluster': 0, '_model_dir': 'trained_model', '_service': None, '_log_step_count_steps': 100, '_train_distribute': None, '_keep_checkpoint_every_n_hours': 10000, '_evaluation_master': '', '_is_chief': True, '_keep_checkpoint_max': 5, '_experimental_distribute': None, '_protocol': None, '_task_type': 'worker', '_eval_distribute': None, '_num_ps_replicas': 0, '_save_summary_steps': 100, '_task_id': 0, '_session_config': allow_soft_placement: true\ngraph_options {\n rewrite_options {\n meta_optimizer_iterations: ONE\n }\n}\n, '_tf_random_seed': None, '_master': ''}\nINFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'IteratorGetNext:2' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'IteratorGetNext:1' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'IteratorGetNext:0' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'IteratorGetNext:3' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'IteratorGetNext:4' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nNone\npca_anomaly_detection: mode = \ntrain\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'calculate_error_distribution_statistics', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\nINFO:tensorflow:Done calling model_fn.\nINFO:tensorflow:Create CheckpointSaverHook.\nINFO:tensorflow:Graph was finalized.\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/training/saver.py:1266: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse standard file APIs to check for files with this prefix.\nINFO:tensorflow:Restoring parameters from trained_model/model.ckpt-2000\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/training/saver.py:1070: get_checkpoint_mtimes (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse standard file utilities to get mtimes.\nINFO:tensorflow:Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nINFO:tensorflow:Saving checkpoints for 2000 into trained_model/model.ckpt.\nINFO:tensorflow:loss = 0.0, step = 2001\nINFO:tensorflow:global_step/sec: 53.792\nINFO:tensorflow:loss = 0.0, step = 2101 (1.865 sec)\nINFO:tensorflow:Saving checkpoints for 2200 into trained_model/model.ckpt.\nINFO:tensorflow:Loss for final step: 0.0.\nINFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'StringToNumber:0' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'StringToNumber_1:0' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'StringToNumber_2:0' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'StringToNumber_3:0' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'StringToNumber_4:0' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nNone\npca_anomaly_detection: mode = \ninfer\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'calculate_error_distribution_statistics', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\nINFO:tensorflow:Done calling model_fn.\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/saved_model/signature_def_utils_impl.py:205: build_tensor_info (from tensorflow.python.saved_model.utils_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis function will only be available through the v1 compatibility library as tf.compat.v1.saved_model.utils.build_tensor_info or tf.compat.v1.saved_model.build_tensor_info.\nINFO:tensorflow:Signatures INCLUDED in export for Train: None\nINFO:tensorflow:Signatures INCLUDED in export for Eval: None\nINFO:tensorflow:Signatures INCLUDED in export for Classify: None\nINFO:tensorflow:Signatures INCLUDED in export for Regress: None\nINFO:tensorflow:Signatures INCLUDED in export for Predict: ['serving_default', 'predict_export_outputs']\nINFO:tensorflow:Restoring parameters from trained_model/model.ckpt-2200\nINFO:tensorflow:Assets added to graph.\nINFO:tensorflow:No assets to write.\nINFO:tensorflow:SavedModel written to: trained_model/export/exporter/temp-b'1561008004'/saved_model.pb\n"
]
],
[
[
"## Look at variable values",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_names()",
"_____no_output_____"
],
[
"arr_validation_normal_1_sequences = np.genfromtxt(fname = \"data/validation_normal_1_sequences.csv\", delimiter = ';', dtype = str)\nprint(\"arr_validation_normal_1_sequences.shape = {}\".format(arr_validation_normal_1_sequences.shape))\nif number_of_tags == 1:\n arr_validation_normal_1_sequences = np.expand_dims(a = arr_validation_normal_1_sequences, axis = -1)\n \narr_validation_normal_1_sequences_features = np.stack(\n arrays = [np.stack(\n arrays = [np.array(arr_validation_normal_1_sequences[example_index, tag_index].split(',')).astype(np.float) \n for tag_index in range(number_of_tags)], axis = 1) \n for example_index in range(len(arr_validation_normal_1_sequences))], axis = 0)\n\ndict_validation_normal_1_sequences_features = {tag: arr_validation_normal_1_sequences_features[:, :, index] for index, tag in enumerate(UNLABELED_CSV_COLUMNS)}\n\nvalidation_normal_1_predictions_list = [prediction for prediction in estimator.predict(\n input_fn = tf.estimator.inputs.numpy_input_fn(\n x = dict_validation_normal_1_sequences_features,\n y = None,\n batch_size = 32,\n num_epochs = 1,\n shuffle = False,\n queue_capacity = 1000))]",
"arr_validation_normal_1_sequences.shape = (6400, 5)\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow_estimator/python/estimator/inputs/queues/feeding_queue_runner.py:62: QueueRunner.__init__ (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nTo construct input pipelines, use the `tf.data` module.\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow_estimator/python/estimator/inputs/queues/feeding_functions.py:500: add_queue_runner (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nTo construct input pipelines, use the `tf.data` module.\nINFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'fifo_queue_DequeueUpTo:3' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'fifo_queue_DequeueUpTo:4' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'fifo_queue_DequeueUpTo:1' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'fifo_queue_DequeueUpTo:2' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'fifo_queue_DequeueUpTo:5' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nNone\npca_anomaly_detection: mode = \ninfer\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'calculate_error_distribution_statistics', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\nINFO:tensorflow:Done calling model_fn.\nINFO:tensorflow:Graph was finalized.\nINFO:tensorflow:Restoring parameters from trained_model/model.ckpt-2200\nINFO:tensorflow:Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/training/monitored_session.py:809: start_queue_runners (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nTo construct input pipelines, use the `tf.data` module.\n"
]
],
[
[
"### Time based",
"_____no_output_____"
]
],
[
[
"validation_normal_1_time_absolute_error = np.stack(arrays = [prediction[\"X_time_abs_reconstruction_error\"] for prediction in validation_normal_1_predictions_list], axis = 0)\ntime_abs_err = validation_normal_1_time_absolute_error.reshape(validation_normal_1_time_absolute_error.shape[0] * validation_normal_1_time_absolute_error.shape[1], number_of_tags)\ntime_abs_err.shape",
"_____no_output_____"
]
],
[
[
"#### Count",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_count_time_variable\")",
"_____no_output_____"
],
[
"time_count = time_abs_err.shape[0]\ntime_count",
"_____no_output_____"
]
],
[
[
"#### Mean",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_mean_time_variable\")",
"_____no_output_____"
],
[
"time_mean = np.mean(time_abs_err, axis = 0)\ntime_mean",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_mean_time_variable\") / time_mean",
"_____no_output_____"
]
],
[
[
"#### Covariance",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_cov_time_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_cov_time_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_cov_time_variable\").shape)",
"[[1.71439271e-03 4.05046771e-03 5.17809520e-04 2.02817328e-02\n 5.32124653e-03]\n [4.05046771e-03 2.54474453e-01 1.10764331e-03 4.24197055e-02\n 4.52634374e-02]\n [5.17809520e-04 1.10764331e-03 2.40792497e-04 6.96405572e-03\n 3.76192364e-04]\n [2.02817328e-02 4.24197055e-02 6.96405572e-03 2.49010451e-01\n 4.95000452e-02]\n [5.32124653e-03 4.52634374e-02 3.76192364e-04 4.95000452e-02\n 4.40680257e-02]]\n"
],
[
"if arguments[\"seq_len\"] == 1:\n time_cov = np.zeros(shape = [number_of_tags, number_of_tags])\nelse:\n time_cov = np.cov(np.transpose(time_abs_err))\nif time_cov.shape[0] <= 10:\n print(time_cov)\nelse:\n print(time_cov.shape)",
"[[1.71439271e-03 4.05046771e-03 5.17809520e-04 2.02817328e-02\n 5.32124653e-03]\n [4.05046771e-03 2.54474453e-01 1.10764331e-03 4.24197055e-02\n 4.52634374e-02]\n [5.17809520e-04 1.10764331e-03 2.40792497e-04 6.96405572e-03\n 3.76192364e-04]\n [2.02817328e-02 4.24197055e-02 6.96405572e-03 2.49010451e-01\n 4.95000452e-02]\n [5.32124653e-03 4.52634374e-02 3.76192364e-04 4.95000452e-02\n 4.40680257e-02]]\n"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_cov_time_variable\") / time_cov",
"_____no_output_____"
]
],
[
[
"#### Inverse Covariance",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_inv_cov_time_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_inv_cov_time_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_inv_cov_time_variable\").shape)",
"[[ 1.71468013e+05 1.03974676e+02 1.13545281e+05 -1.65176304e+04\n -3.22731131e+03]\n [ 1.03974676e+02 6.92922894e+00 -3.54085884e+02 4.58770755e+00\n -2.18027223e+01]\n [ 1.13545281e+05 -3.54085884e+02 1.62462584e+05 -1.39080849e+04\n 8.88588939e+02]\n [-1.65176304e+04 4.58770755e+00 -1.39080849e+04 1.69741906e+03\n 2.01881590e+02]\n [-3.22731131e+03 -2.18027223e+01 8.88588939e+02 2.01881590e+02\n 2.00434599e+02]]\n"
],
[
"time_inv = np.linalg.inv(time_cov + np.eye(number_of_tags) * arguments[\"eps\"])\nif time_inv.shape[0] <= 10:\n print(time_inv)\nelse:\n print(time_inv.shape)",
"[[ 1.71468013e+05 1.03974676e+02 1.13545281e+05 -1.65176304e+04\n -3.22731131e+03]\n [ 1.03974676e+02 6.92922894e+00 -3.54085884e+02 4.58770755e+00\n -2.18027223e+01]\n [ 1.13545281e+05 -3.54085884e+02 1.62462584e+05 -1.39080849e+04\n 8.88588939e+02]\n [-1.65176304e+04 4.58770755e+00 -1.39080849e+04 1.69741906e+03\n 2.01881590e+02]\n [-3.22731131e+03 -2.18027223e+01 8.88588939e+02 2.01881590e+02\n 2.00434599e+02]]\n"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_inv_cov_time_variable\") / time_inv",
"_____no_output_____"
]
],
[
[
"### Features based",
"_____no_output_____"
]
],
[
[
"validation_normal_1_features_absolute_error = np.stack(arrays = [prediction[\"X_features_abs_reconstruction_error\"] for prediction in validation_normal_1_predictions_list], axis = 0)\nfeat_abs_err = np.transpose(validation_normal_1_features_absolute_error, [0, 2, 1]).reshape(validation_normal_1_features_absolute_error.shape[0] * number_of_tags, validation_normal_1_features_absolute_error.shape[1])\nfeat_abs_err.shape",
"_____no_output_____"
]
],
[
[
"#### Count",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_count_features_variable\")",
"_____no_output_____"
],
[
"feat_count = feat_abs_err.shape[0]\nfeat_count",
"_____no_output_____"
]
],
[
[
"#### Mean",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_mean_features_variable\")",
"_____no_output_____"
],
[
"feat_mean = np.mean(feat_abs_err, axis = 0)\nfeat_mean",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_mean_features_variable\") / feat_mean",
"_____no_output_____"
]
],
[
[
"#### Covariance",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_cov_features_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_cov_features_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_cov_features_variable\").shape)",
"(30, 30)\n"
],
[
"if number_of_tags == 1:\n feat_cov = np.zeros(shape = [arguments[\"seq_len\"], arguments[\"seq_len\"]])\nelse:\n feat_cov = np.cov(np.transpose(feat_abs_err))\nif feat_cov.shape[0] <= 10:\n print(feat_cov)\nelse:\n print(feat_cov.shape)",
"(30, 30)\n"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_cov_features_variable\") / feat_cov",
"_____no_output_____"
]
],
[
[
"#### Inverse Covariance",
"_____no_output_____"
]
],
[
[
"if estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_inv_cov_features_variable\").shape[0] <= 10:\n print(estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_inv_cov_features_variable\"))\nelse:\n print(estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_inv_cov_features_variable\").shape)",
"(30, 30)\n"
],
[
"feat_inv = np.linalg.inv(feat_cov + np.eye(arguments[\"seq_len\"]) * arguments[\"eps\"])\nif feat_inv.shape[0] <= 10:\n print(feat_inv)\nelse:\n print(feat_inv.shape)",
"(30, 30)\n"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_variables/abs_err_inv_cov_features_variable\") / feat_inv",
"_____no_output_____"
]
],
[
[
"## Tune anomaly thresholds",
"_____no_output_____"
]
],
[
[
"arguments[\"training_mode\"] = \"tune_anomaly_thresholds\"\narguments[\"train_file_pattern\"] = \"data/labeled_validation_mixed_sequences.csv\"\narguments[\"eval_file_pattern\"] = \"data/labeled_validation_mixed_sequences.csv\"\narguments[\"train_batch_size\"] = 64\narguments[\"eval_batch_size\"] = 64\nestimator = train_and_evaluate(arguments)",
"INFO:tensorflow:Using default config.\nINFO:tensorflow:Using config: {'_save_checkpoints_secs': 600, '_device_fn': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7ef771a4f6a0>, '_save_checkpoints_steps': None, '_num_worker_replicas': 1, '_global_id_in_cluster': 0, '_model_dir': 'trained_model', '_service': None, '_log_step_count_steps': 100, '_train_distribute': None, '_keep_checkpoint_every_n_hours': 10000, '_evaluation_master': '', '_is_chief': True, '_keep_checkpoint_max': 5, '_experimental_distribute': None, '_protocol': None, '_task_type': 'worker', '_eval_distribute': None, '_num_ps_replicas': 0, '_save_summary_steps': 100, '_task_id': 0, '_session_config': allow_soft_placement: true\ngraph_options {\n rewrite_options {\n meta_optimizer_iterations: ONE\n }\n}\n, '_tf_random_seed': None, '_master': ''}\nINFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'IteratorGetNext:2' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'IteratorGetNext:1' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'IteratorGetNext:0' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'IteratorGetNext:3' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'IteratorGetNext:4' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nTensor(\"IteratorGetNext:5\", shape=(?,), dtype=float64, device=/device:CPU:0)\npca_anomaly_detection: mode = \ntrain\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'tune_anomaly_thresholds', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\nINFO:tensorflow:Done calling model_fn.\nINFO:tensorflow:Create CheckpointSaverHook.\nINFO:tensorflow:Graph was finalized.\nINFO:tensorflow:Restoring parameters from trained_model/model.ckpt-2200\nINFO:tensorflow:Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nINFO:tensorflow:Saving checkpoints for 2200 into trained_model/model.ckpt.\nINFO:tensorflow:loss = 0.0, step = 2201\nINFO:tensorflow:global_step/sec: 7.95191\nINFO:tensorflow:loss = 0.0, step = 2301 (12.578 sec)\nINFO:tensorflow:Saving checkpoints for 2400 into trained_model/model.ckpt.\nINFO:tensorflow:Loss for final step: 0.0.\nINFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'IteratorGetNext:2' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'IteratorGetNext:1' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'IteratorGetNext:0' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'IteratorGetNext:3' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'IteratorGetNext:4' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nTensor(\"IteratorGetNext:5\", shape=(?,), dtype=float64, device=/device:CPU:0)\npca_anomaly_detection: mode = \neval\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'tune_anomaly_thresholds', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/losses/losses_impl.py:667: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.cast instead.\nINFO:tensorflow:Done calling model_fn.\nINFO:tensorflow:Starting evaluation at 2019-06-20T05:20:42Z\nINFO:tensorflow:Graph was finalized.\nINFO:tensorflow:Restoring parameters from trained_model/model.ckpt-2400\nINFO:tensorflow:Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nINFO:tensorflow:Finished evaluation at 2019-06-20-05:20:49\nINFO:tensorflow:Saving dict for global step 2400: features_anomaly_acc = 1.0, features_anomaly_f_beta_score = 1.0, features_anomaly_fn = 0, features_anomaly_fp = 0, features_anomaly_pre = 1.0, features_anomaly_rec = 1.0, features_anomaly_tn = 6400, features_anomaly_tp = 6400, global_step = 2400, loss = 16.127884, time_anomaly_acc = 0.999609375, time_anomaly_f_beta_score = 0.9992213050926647, time_anomaly_fn = 0, time_anomaly_fp = 5, time_anomaly_pre = 0.9992193598750976, time_anomaly_rec = 1.0, time_anomaly_tn = 6395, time_anomaly_tp = 6400\nINFO:tensorflow:Saving 'checkpoint_path' summary for global step 2400: trained_model/model.ckpt-2400\nINFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'StringToNumber:0' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'StringToNumber_1:0' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'StringToNumber_2:0' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'StringToNumber_3:0' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'StringToNumber_4:0' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nNone\npca_anomaly_detection: mode = \ninfer\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'tune_anomaly_thresholds', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\nINFO:tensorflow:Done calling model_fn.\nINFO:tensorflow:Signatures INCLUDED in export for Train: None\nINFO:tensorflow:Signatures INCLUDED in export for Eval: None\nINFO:tensorflow:Signatures INCLUDED in export for Classify: None\nINFO:tensorflow:Signatures INCLUDED in export for Regress: None\nINFO:tensorflow:Signatures INCLUDED in export for Predict: ['serving_default', 'predict_export_outputs']\nINFO:tensorflow:Restoring parameters from trained_model/model.ckpt-2400\nINFO:tensorflow:Assets added to graph.\nINFO:tensorflow:No assets to write.\nINFO:tensorflow:SavedModel written to: trained_model/export/exporter/temp-b'1561008050'/saved_model.pb\n"
]
],
[
[
"#### Time based",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/tp_at_thresholds_time_variable\")",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/fn_at_thresholds_time_variable\")",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/fp_at_thresholds_time_variable\")",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/tn_at_thresholds_time_variable\")",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/time_anomaly_threshold_variable\")",
"_____no_output_____"
]
],
[
[
"#### Features based",
"_____no_output_____"
]
],
[
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/tp_at_thresholds_features_variable\")",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/fn_at_thresholds_features_variable\")",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/fp_at_thresholds_features_variable\")",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/tn_at_thresholds_features_variable\")",
"_____no_output_____"
],
[
"estimator.get_variable_value(name = \"mahalanobis_distance_threshold_variables/features_anomaly_threshold_variable\")",
"_____no_output_____"
]
],
[
[
"#### Numpy",
"_____no_output_____"
]
],
[
[
"arr_validation_mixed_sequences = np.genfromtxt(\n fname = \"data/labeled_validation_mixed_sequences.csv\", delimiter = ';', dtype = str)\nprint(\"arr_validation_mixed_sequences.shape = {}\".format(arr_validation_mixed_sequences.shape))\n\narr_validation_mixed_sequences_features = np.stack(\n arrays = [np.stack(\n arrays = [np.array(\n object = arr_validation_mixed_sequences[example_index, tag_index].split(',')).astype(np.float) \n for tag_index in range(number_of_tags)], axis = 1) \n for example_index in range(len(arr_validation_mixed_sequences))], axis = 0)\nprint(\"arr_validation_mixed_sequences_features.shape = {}\".format(arr_validation_mixed_sequences_features.shape))\n\ndict_validation_mixed_sequences_features = {tag: arr_validation_mixed_sequences_features[:, :, index] \n for index, tag in enumerate(UNLABELED_CSV_COLUMNS)}\n\nvalidation_mixed_predictions_list = [prediction for prediction in estimator.predict(\n input_fn = tf.estimator.inputs.numpy_input_fn(\n x = dict_validation_mixed_sequences_features,\n y = None,\n batch_size = 128,\n num_epochs = 1,\n shuffle = False,\n queue_capacity = 1000))]\n\narr_validation_mixed_sequences_labels = arr_validation_mixed_sequences[:, -1].astype(np.float64)\nprint(\"arr_validation_mixed_sequences_labels.shape = {}\".format(arr_validation_mixed_sequences_labels.shape))",
"arr_validation_mixed_sequences.shape = (12800, 6)\narr_validation_mixed_sequences_features.shape = (12800, 30, 5)\nINFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'fifo_queue_DequeueUpTo:3' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'fifo_queue_DequeueUpTo:4' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'fifo_queue_DequeueUpTo:1' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'fifo_queue_DequeueUpTo:2' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'fifo_queue_DequeueUpTo:5' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nNone\npca_anomaly_detection: mode = \ninfer\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'tune_anomaly_thresholds', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\nINFO:tensorflow:Done calling model_fn.\nINFO:tensorflow:Graph was finalized.\nINFO:tensorflow:Restoring parameters from trained_model/model.ckpt-2400\nINFO:tensorflow:Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\narr_validation_mixed_sequences_labels.shape = (12800,)\n"
],
[
"labels_normal_mask = arr_validation_mixed_sequences_labels.astype(np.float64) == 0\nlabels_anomalous_mask = arr_validation_mixed_sequences_labels.astype(np.float64) == 1",
"_____no_output_____"
]
],
[
[
"### Time based",
"_____no_output_____"
]
],
[
[
"arr_validation_mixed_predictions_mahalanobis_distance_batch_time = np.stack(\n arrays = [prediction[\"mahalanobis_distance_time\"] \n for prediction in validation_mixed_predictions_list], axis = 0)\nprint(\"arr_validation_mixed_predictions_mahalanobis_distance_batch_time.shape = {}\".format(arr_validation_mixed_predictions_mahalanobis_distance_batch_time.shape))",
"arr_validation_mixed_predictions_mahalanobis_distance_batch_time.shape = (12800, 30)\n"
],
[
"min_normal_mahalanobis_distance_batch_time = np.min(np.max(\n arr_validation_mixed_predictions_mahalanobis_distance_batch_time[labels_normal_mask, :], axis = -1))\nmax_normal_mahalanobis_distance_batch_time = np.max(np.max(\n arr_validation_mixed_predictions_mahalanobis_distance_batch_time[labels_normal_mask, :], axis = -1))\nprint(\"min_normal_mahalanobis_distance_batch_time = {} & max_normal_mahalanobis_distance_batch_time = {}\".format(min_normal_mahalanobis_distance_batch_time, max_normal_mahalanobis_distance_batch_time))\n\nmin_anomalous_mahalanobis_distance_batch_time = np.min(np.max(\n arr_validation_mixed_predictions_mahalanobis_distance_batch_time[labels_anomalous_mask, :], axis = -1))\nmax_anomalous_mahalanobis_distance_batch_time = np.max(np.max(\n arr_validation_mixed_predictions_mahalanobis_distance_batch_time[labels_anomalous_mask, :], axis = -1))\nprint(\"min_anomalous_mahalanobis_distance_batch_time = {} & max_anomalous_mahalanobis_distance_batch_time = {}\".format(min_anomalous_mahalanobis_distance_batch_time, max_anomalous_mahalanobis_distance_batch_time))\n",
"min_normal_mahalanobis_distance_batch_time = 6.3399655807595385 & max_normal_mahalanobis_distance_batch_time = 106.43218889293736\nmin_anomalous_mahalanobis_distance_batch_time = 1524.7993852263544 & max_anomalous_mahalanobis_distance_batch_time = 60131.47094965863\n"
],
[
"num_time_anomaly_thresholds = arguments[\"num_time_anomaly_thresholds\"];\nbatch_time_anomaly_thresholds = np.linspace(start = arguments[\"min_time_anomaly_threshold\"], \n stop = arguments[\"max_time_anomaly_threshold\"], \n num = num_time_anomaly_thresholds)\nprint(\"batch_time_anomaly_thresholds.shape = {}\".format(batch_time_anomaly_thresholds.shape))",
"batch_time_anomaly_thresholds.shape = (300,)\n"
],
[
"arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds = np.stack(\n arrays = [arr_validation_mixed_predictions_mahalanobis_distance_batch_time > batch_time_anomaly_threshold \n for batch_time_anomaly_threshold in batch_time_anomaly_thresholds], axis = -1)\nprint(\"arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds.shape = {}\".format(arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds.shape))\narr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds = np.any(\n a = arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds, axis = 1)\nprint(\"arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds.shape = {}\".format(arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds.shape))\n",
"arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds.shape = (12800, 30, 300)\narr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds.shape = (12800, 300)\n"
],
[
"predicted_normals = arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds == 0\nprint(\"predicted_normals.shape = {}\".format(predicted_normals.shape))\npredicted_anomalies = arr_validation_mixed_predictions_mahalanobis_distance_batch_time_anomalies_multi_thresholds == 1\nprint(\"predicted_anomalies.shape = {}\".format(predicted_anomalies.shape))",
"predicted_normals.shape = (12800, 300)\npredicted_anomalies.shape = (12800, 300)\n"
],
[
"true_positives = np.sum(\n a = np.stack(arrays = [\n np.logical_and(\n labels_anomalous_mask, predicted_anomalies[:, threshold]) \n for threshold in range(num_time_anomaly_thresholds)], \n axis = -1), \n axis = 0)\n\nfalse_negatives = np.sum(\n a = np.stack(arrays = [\n np.logical_and(\n labels_anomalous_mask, predicted_normals[:, threshold]) \n for threshold in range(num_time_anomaly_thresholds)], \n axis = -1), \n axis = 0)\n\nfalse_positives = np.sum(\n a = np.stack(arrays = [\n np.logical_and(\n labels_normal_mask, predicted_anomalies[:, threshold]) \n for threshold in range(num_time_anomaly_thresholds)], \n axis = -1), \n axis = 0)\n\ntrue_negatives = np.sum(\n a = np.stack(arrays = [np.logical_and(\n labels_normal_mask, predicted_normals[:, threshold]) \n for threshold in range(num_time_anomaly_thresholds)], \n axis = -1), \n axis = 0)\nprint(\"true_positives.shape = {}, false_negatives.shape = {}, false_positives.shape = {}, true_negatives.shape = {}\".format(true_positives.shape, false_negatives.shape, false_positives.shape, true_negatives.shape))",
"true_positives.shape = (300,), false_negatives.shape = (300,), false_positives.shape = (300,), true_negatives.shape = (300,)\n"
],
[
"print(\"true_positives = \\n{}\".format(true_positives))\nprint(\"false_negatives = \\n{}\".format(false_negatives))\nprint(\"false_positives = \\n{}\".format(false_positives))\nprint(\"true_negatives = \\n{}\".format(true_negatives))\nprint(\"true_positives + false_negatives + false_positives + true_negatives = \\n{}\".format(true_positives + false_negatives + false_positives + true_negatives))",
"true_positives = \n[6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400]\nfalse_negatives = \n[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0]\nfalse_positives = \n[6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6397 6395 6392 6390 6379 6363 6345 6320 6281 6235 6197\n 6117 6041 5938 5851 5754 5651 5542 5462 5386 5305 5244 5186 5114 5043\n 4986 4908 4854 4784 4711 4642 4566 4487 4431 4379 4300 4238 4183 4126\n 4059 4000 3935 3875 3818 3767 3705 3653 3602 3535 3463 3398 3347 3295\n 3254 3206 3152 3097 3061 3007 2956 2909 2873 2821 2752 2694 2638 2593\n 2547 2507 2468 2413 2366 2324 2274 2236 2190 2157 2117 2072 2040 2002\n 1961 1917 1884 1849 1830 1797 1757 1718 1676 1650 1620 1593 1564 1541\n 1511 1487 1451 1420 1393 1364 1339 1307 1283 1257 1236 1207 1188 1166\n 1138 1119 1102 1077 1059 1047 1023 1000 984 966 946 921 905 884\n 868 855 837 822 812 797 779 769 754 742 728 719 701 691\n 673 659 645 634 623 606 593 584 572 559 549 537 527 515\n 502 491 478 469 462 453 447 440 437 431 424 413 403 399\n 392 382 377 370 368 360 351 343 336 328 323 318 313 310\n 305 300 293 287 277 270 266 261 252 249 243 240 237 230\n 227 223 218 212 207 201 195 191 187 182 178 174 165 161\n 156 152 149 143 140 134 128 124 121 116 116 113 111 107\n 106 104 101 100 100 97 95 93 89 86 79 76 73 71\n 69 66 62 61 57 53 53 51 51 51 50 48 46 46\n 43 41 38 38 37 35 35 34 34 33 32 31 30 28\n 25 23 21 20 17 16 15 14 12 11 10 10 9 9\n 9 7 7 7 5 5]\ntrue_negatives = \n[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 3 5 8 10 21 37 55 80 119 165 203\n 283 359 462 549 646 749 858 938 1014 1095 1156 1214 1286 1357\n 1414 1492 1546 1616 1689 1758 1834 1913 1969 2021 2100 2162 2217 2274\n 2341 2400 2465 2525 2582 2633 2695 2747 2798 2865 2937 3002 3053 3105\n 3146 3194 3248 3303 3339 3393 3444 3491 3527 3579 3648 3706 3762 3807\n 3853 3893 3932 3987 4034 4076 4126 4164 4210 4243 4283 4328 4360 4398\n 4439 4483 4516 4551 4570 4603 4643 4682 4724 4750 4780 4807 4836 4859\n 4889 4913 4949 4980 5007 5036 5061 5093 5117 5143 5164 5193 5212 5234\n 5262 5281 5298 5323 5341 5353 5377 5400 5416 5434 5454 5479 5495 5516\n 5532 5545 5563 5578 5588 5603 5621 5631 5646 5658 5672 5681 5699 5709\n 5727 5741 5755 5766 5777 5794 5807 5816 5828 5841 5851 5863 5873 5885\n 5898 5909 5922 5931 5938 5947 5953 5960 5963 5969 5976 5987 5997 6001\n 6008 6018 6023 6030 6032 6040 6049 6057 6064 6072 6077 6082 6087 6090\n 6095 6100 6107 6113 6123 6130 6134 6139 6148 6151 6157 6160 6163 6170\n 6173 6177 6182 6188 6193 6199 6205 6209 6213 6218 6222 6226 6235 6239\n 6244 6248 6251 6257 6260 6266 6272 6276 6279 6284 6284 6287 6289 6293\n 6294 6296 6299 6300 6300 6303 6305 6307 6311 6314 6321 6324 6327 6329\n 6331 6334 6338 6339 6343 6347 6347 6349 6349 6349 6350 6352 6354 6354\n 6357 6359 6362 6362 6363 6365 6365 6366 6366 6367 6368 6369 6370 6372\n 6375 6377 6379 6380 6383 6384 6385 6386 6388 6389 6390 6390 6391 6391\n 6391 6393 6393 6393 6395 6395]\ntrue_positives + false_negatives + false_positives + true_negatives = \n[12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800]\n"
],
[
"accuracy = (true_positives + true_negatives) / (true_positives + false_negatives + false_positives + true_negatives)\naccuracy",
"_____no_output_____"
],
[
"precision = true_positives / (true_positives + false_positives)\nprecision",
"_____no_output_____"
],
[
"recall = true_positives / (true_positives + false_negatives)\nrecall",
"_____no_output_____"
],
[
"f_beta_score = (1 + arguments[\"f_score_beta\"] ** 2) * (precision * recall) / (arguments[\"f_score_beta\"] ** 2 * precision + recall)\nf_beta_score",
"_____no_output_____"
],
[
"batch_time_anomaly_thresholds[np.argmax(f_beta_score)]",
"_____no_output_____"
]
],
[
[
"### Features based",
"_____no_output_____"
]
],
[
[
"arr_validation_mixed_predictions_mahalanobis_distance_batch_features = np.stack(\n arrays = [prediction[\"mahalanobis_distance_features\"] \n for prediction in validation_mixed_predictions_list], axis = 0)\nprint(\"arr_validation_mixed_predictions_mahalanobis_distance_batch_features.shape = {}\".format(arr_validation_mixed_predictions_mahalanobis_distance_batch_features.shape))",
"arr_validation_mixed_predictions_mahalanobis_distance_batch_features.shape = (12800, 5)\n"
],
[
"min_normal_mahalanobis_distance_batch_features = np.min(np.max(\n arr_validation_mixed_predictions_mahalanobis_distance_batch_features[labels_normal_mask, :], axis = -1))\nmax_normal_mahalanobis_distance_batch_features = np.max(np.max(\n arr_validation_mixed_predictions_mahalanobis_distance_batch_features[labels_normal_mask, :], axis = -1))\nprint(\"min_normal_mahalanobis_distance_batch_features = {} & max_normal_mahalanobis_distance_batch_features = {}\".format(min_normal_mahalanobis_distance_batch_features, max_normal_mahalanobis_distance_batch_features))\n\nmin_anomalous_mahalanobis_distance_batch_features = np.min(np.max(\n arr_validation_mixed_predictions_mahalanobis_distance_batch_features[labels_anomalous_mask, :], axis = -1))\nmax_anomalous_mahalanobis_distance_batch_features = np.max(np.max(\n arr_validation_mixed_predictions_mahalanobis_distance_batch_features[labels_anomalous_mask, :], axis = -1))\nprint(\"min_anomalous_mahalanobis_distance_batch_features = {} & max_anomalous_mahalanobis_distance_batch_features = {}\".format(min_anomalous_mahalanobis_distance_batch_features, max_anomalous_mahalanobis_distance_batch_features))\n",
"min_normal_mahalanobis_distance_batch_features = 24.475095659894738 & max_normal_mahalanobis_distance_batch_features = 62.06891175223389\nmin_anomalous_mahalanobis_distance_batch_features = 62412.33870616385 & max_anomalous_mahalanobis_distance_batch_features = 261987.22271740055\n"
],
[
"num_features_anomaly_thresholds = arguments[\"num_features_anomaly_thresholds\"];\nbatch_features_anomaly_thresholds = np.linspace(start = arguments[\"min_features_anomaly_threshold\"], \n stop = arguments[\"max_features_anomaly_threshold\"], \n num = num_features_anomaly_thresholds)\nprint(\"batch_features_anomaly_thresholds.shape = {}\".format(batch_features_anomaly_thresholds.shape))",
"batch_features_anomaly_thresholds.shape = (300,)\n"
],
[
"arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds = np.stack(\n arrays = [arr_validation_mixed_predictions_mahalanobis_distance_batch_features > batch_features_anomaly_threshold \n for batch_features_anomaly_threshold in batch_features_anomaly_thresholds], axis = -1)\nprint(\"arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds.shape = {}\".format(arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds.shape))\narr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds = np.any(\n a = arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds, axis = 1)\nprint(\"arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds.shape = {}\".format(arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds.shape))\n",
"arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds.shape = (12800, 5, 300)\narr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds.shape = (12800, 300)\n"
],
[
"predicted_normals = arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds == 0\nprint(\"predicted_normals.shape = {}\".format(predicted_normals.shape))\npredicted_anomalies = arr_validation_mixed_predictions_mahalanobis_distance_batch_features_anomalies_multi_thresholds == 1\nprint(\"predicted_anomalies.shape = {}\".format(predicted_anomalies.shape))",
"predicted_normals.shape = (12800, 300)\npredicted_anomalies.shape = (12800, 300)\n"
],
[
"true_positives = np.sum(\n a = np.stack(arrays = [\n np.logical_and(\n labels_anomalous_mask, predicted_anomalies[:, threshold]) \n for threshold in range(num_features_anomaly_thresholds)], \n axis = -1), \n axis = 0)\n\nfalse_negatives = np.sum(\n a = np.stack(arrays = [\n np.logical_and(\n labels_anomalous_mask, predicted_normals[:, threshold]) \n for threshold in range(num_features_anomaly_thresholds)], \n axis = -1), \n axis = 0)\n\nfalse_positives = np.sum(\n a = np.stack(arrays = [\n np.logical_and(\n labels_normal_mask, predicted_anomalies[:, threshold]) \n for threshold in range(num_features_anomaly_thresholds)], \n axis = -1), \n axis = 0)\n\ntrue_negatives = np.sum(\n a = np.stack(arrays = [np.logical_and(\n labels_normal_mask, predicted_normals[:, threshold]) \n for threshold in range(num_features_anomaly_thresholds)], \n axis = -1), \n axis = 0)\nprint(\"true_positives.shape = {}, false_negatives.shape = {}, false_positives.shape = {}, true_negatives.shape = {}\".format(true_positives.shape, false_negatives.shape, false_positives.shape, true_negatives.shape))",
"true_positives.shape = (300,), false_negatives.shape = (300,), false_positives.shape = (300,), true_negatives.shape = (300,)\n"
],
[
"print(\"true_positives = \\n{}\".format(true_positives))\nprint(\"false_negatives = \\n{}\".format(false_negatives))\nprint(\"false_positives = \\n{}\".format(false_positives))\nprint(\"true_negatives = \\n{}\".format(true_negatives))\nprint(\"true_positives + false_negatives + false_positives + true_negatives = \\n{}\".format(true_positives + false_negatives + false_positives + true_negatives))",
"true_positives = \n[6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400]\nfalse_negatives = \n[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0]\nfalse_positives = \n[6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6399 6399 6399 6399 6399 6398 6395 6391 6388 6381 6376 6367 6351\n 6335 6314 6292 6262 6223 6177 6123 6060 5989 5920 5834 5725 5612 5524\n 5399 5256 5115 4996 4838 4668 4503 4352 4195 4015 3850 3667 3492 3318\n 3146 2949 2786 2630 2479 2310 2167 2025 1870 1764 1641 1521 1415 1304\n 1191 1104 1002 924 853 785 725 661 598 540 485 437 406 357\n 326 287 257 232 205 180 162 151 135 119 103 93 85 78\n 70 67 63 57 49 41 35 27 21 20 15 13 10 9\n 7 7 3 3 3 3 2 2 2 2 2 1 1 1\n 1 1 1 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0]\ntrue_negatives = \n[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 1 1 1 1 1 2 5 9 12 19 24 33 49\n 65 86 108 138 177 223 277 340 411 480 566 675 788 876\n 1001 1144 1285 1404 1562 1732 1897 2048 2205 2385 2550 2733 2908 3082\n 3254 3451 3614 3770 3921 4090 4233 4375 4530 4636 4759 4879 4985 5096\n 5209 5296 5398 5476 5547 5615 5675 5739 5802 5860 5915 5963 5994 6043\n 6074 6113 6143 6168 6195 6220 6238 6249 6265 6281 6297 6307 6315 6322\n 6330 6333 6337 6343 6351 6359 6365 6373 6379 6380 6385 6387 6390 6391\n 6393 6393 6397 6397 6397 6397 6398 6398 6398 6398 6398 6399 6399 6399\n 6399 6399 6399 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400 6400\n 6400 6400 6400 6400 6400 6400]\ntrue_positives + false_negatives + false_positives + true_negatives = \n[12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800\n 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800 12800]\n"
],
[
"accuracy = (true_positives + true_negatives) / (true_positives + false_negatives + false_positives + true_negatives)\naccuracy",
"_____no_output_____"
],
[
"precision = true_positives / (true_positives + false_positives)\nprecision",
"_____no_output_____"
],
[
"recall = true_positives / (true_positives + false_negatives)\nrecall",
"_____no_output_____"
],
[
"f_beta_score = (1 + arguments[\"f_score_beta\"] ** 2) * (precision * recall) / (arguments[\"f_score_beta\"] ** 2 * precision + recall)\nf_beta_score",
"_____no_output_____"
],
[
"batch_features_anomaly_thresholds[np.argmax(f_beta_score)]",
"_____no_output_____"
]
],
[
[
"# Local Prediction",
"_____no_output_____"
]
],
[
[
"arr_labeled_test_mixed_sequences = np.genfromtxt(fname = \"data/labeled_test_mixed_sequences.csv\", delimiter = ';', dtype = str)\narr_labeled_test_mixed_sequences_features = np.stack(\n arrays = [np.stack(\n arrays = [np.array(arr_labeled_test_mixed_sequences[example_index, tag_index].split(',')).astype(np.float) \n for tag_index in range(number_of_tags)], axis = 1) \n for example_index in range(len(arr_labeled_test_mixed_sequences))], axis = 0)\ndict_labeled_test_mixed_sequences_features = {tag: arr_labeled_test_mixed_sequences_features[:, :, index] for index, tag in enumerate(UNLABELED_CSV_COLUMNS)}\narr_test_labels = arr_labeled_test_mixed_sequences[:, -1]",
"_____no_output_____"
],
[
"predictions_list = [prediction for prediction in estimator.predict(\n input_fn = tf.estimator.inputs.numpy_input_fn(\n x = dict_labeled_test_mixed_sequences_features,\n y = None,\n batch_size = 128,\n num_epochs = 1,\n shuffle = False,\n queue_capacity = 1000))]",
"INFO:tensorflow:Calling model_fn.\n\npca_anomaly_detection: features = \n{'tag_2': <tf.Tensor 'fifo_queue_DequeueUpTo:3' shape=(?, 30) dtype=float64>, 'tag_3': <tf.Tensor 'fifo_queue_DequeueUpTo:4' shape=(?, 30) dtype=float64>, 'tag_0': <tf.Tensor 'fifo_queue_DequeueUpTo:1' shape=(?, 30) dtype=float64>, 'tag_1': <tf.Tensor 'fifo_queue_DequeueUpTo:2' shape=(?, 30) dtype=float64>, 'tag_4': <tf.Tensor 'fifo_queue_DequeueUpTo:5' shape=(?, 30) dtype=float64>}\npca_anomaly_detection: labels = \nNone\npca_anomaly_detection: mode = \ninfer\npca_anomaly_detection: params = \n{'time_anomaly_threshold': None, 'training_mode': 'tune_anomaly_thresholds', 'max_features_anomaly_threshold': 100, 'num_features_anomaly_thresholds': 300, 'min_features_anomaly_threshold': 1, 'features_anomaly_threshold': None, 'k_principal_components': 3, 'seq_len': 30, 'learning_rate': 0.01, 'max_time_anomaly_threshold': 100, 'num_time_anomaly_thresholds': 300, 'min_time_anomaly_threshold': 1, 'f_score_beta': 0.05, 'eps': 1e-12}\nINFO:tensorflow:Done calling model_fn.\nINFO:tensorflow:Graph was finalized.\nINFO:tensorflow:Restoring parameters from trained_model/model.ckpt-2400\nINFO:tensorflow:Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\n"
],
[
"arr_test_labels[0:10]",
"_____no_output_____"
]
],
[
[
"### Normal example",
"_____no_output_____"
]
],
[
[
"normal_test_example_index = np.argmax(arr_test_labels == '0')",
"_____no_output_____"
],
[
"predictions_list[normal_test_example_index]",
"_____no_output_____"
],
[
"flatui = [\"#9b59b6\", \"#3498db\", \"#95a5a6\", \"#e74c3c\", \"#34495e\", \"#2ecc71\"]\nfor i, arr in enumerate(np.split(ary = predictions_list[normal_test_example_index][\"X_time_abs_reconstruction_error\"].flatten(), indices_or_sections = len(UNLABELED_CSV_COLUMNS), axis = 0)):\n sns.tsplot(arr, color = flatui[i%len(flatui)] )",
"/usr/local/lib/python3.5/dist-packages/seaborn/timeseries.py:183: UserWarning: The `tsplot` function is deprecated and will be removed in a future release. Please update your code to use the new `lineplot` function.\n warnings.warn(msg, UserWarning)\n"
],
[
"flatui = [\"#9b59b6\", \"#3498db\", \"#95a5a6\", \"#e74c3c\", \"#34495e\", \"#2ecc71\"]\nfor i, arr in enumerate(np.split(ary = predictions_list[normal_test_example_index][\"X_features_abs_reconstruction_error\"].flatten(), indices_or_sections = len(UNLABELED_CSV_COLUMNS), axis = 0)):\n sns.tsplot(arr, color = flatui[i%len(flatui)] )",
"_____no_output_____"
]
],
[
[
"### Anomalous Example",
"_____no_output_____"
]
],
[
[
"anomalous_test_example_index = np.argmax(arr_test_labels == '1')",
"_____no_output_____"
],
[
"predictions_list[anomalous_test_example_index]",
"_____no_output_____"
],
[
"flatui = [\"#9b59b6\", \"#3498db\", \"#95a5a6\", \"#e74c3c\", \"#34495e\", \"#2ecc71\"]\nfor i, arr in enumerate(np.split(ary = predictions_list[anomalous_test_example_index][\"X_time_abs_reconstruction_error\"].flatten(), indices_or_sections = len(UNLABELED_CSV_COLUMNS), axis = 0)):\n sns.tsplot(arr, color = flatui[i%len(flatui)] )",
"_____no_output_____"
],
[
"flatui = [\"#9b59b6\", \"#3498db\", \"#95a5a6\", \"#e74c3c\", \"#34495e\", \"#2ecc71\"]\nfor i, arr in enumerate(np.split(ary = predictions_list[anomalous_test_example_index][\"X_features_abs_reconstruction_error\"].flatten(), indices_or_sections = len(UNLABELED_CSV_COLUMNS), axis = 0)):\n sns.tsplot(arr, color = flatui[i%len(flatui)] )",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
e73c9a762815eca052de0f686b6cef88fd8398cc | 411,121 | ipynb | Jupyter Notebook | Realtime_Rt_mcmc_NYC.ipynb | dathere/notebooks | 3a108919d4109ba7b26f8ec501915550266de698 | [
"MIT"
] | null | null | null | Realtime_Rt_mcmc_NYC.ipynb | dathere/notebooks | 3a108919d4109ba7b26f8ec501915550266de698 | [
"MIT"
] | null | null | null | Realtime_Rt_mcmc_NYC.ipynb | dathere/notebooks | 3a108919d4109ba7b26f8ec501915550266de698 | [
"MIT"
] | null | null | null | 169.324959 | 146,494 | 0.844973 | [
[
[
"<a href=\"https://colab.research.google.com/github/dathere/notebooks/blob/master/Realtime_Rt_mcmc_NYC.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Estimating COVID-19's $R_t$ in Real-Time for all US counties\n\nModified version of the work by [Kevin Systrom](https://github.com/k-sys/covid-19) to estimate $R_t$ for all US states based on the [NYT](https://github.com/nytimes/covid-19-data) county level data",
"_____no_output_____"
]
],
[
[
"!pip install pymc3==3.8",
"Collecting pymc3==3.8\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/32/19/6c94cbadb287745ac38ff1197b9fadd66500b6b9c468e79099b110c6a2e9/pymc3-3.8-py3-none-any.whl (908kB)\n\u001b[K |████████████████████████████████| 911kB 2.8MB/s \n\u001b[?25hRequirement already satisfied: theano>=1.0.4 in /usr/local/lib/python3.6/dist-packages (from pymc3==3.8) (1.0.4)\nRequirement already satisfied: patsy>=0.4.0 in /usr/local/lib/python3.6/dist-packages (from pymc3==3.8) (0.5.1)\nRequirement already satisfied: h5py>=2.7.0 in /usr/local/lib/python3.6/dist-packages (from pymc3==3.8) (2.10.0)\nCollecting arviz>=0.4.1\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/6c/23/73ae3b88a6837fa5a162d984acabfd2e75dc847ed67e5690aa44d02f491a/arviz-0.7.0-py3-none-any.whl (1.5MB)\n\u001b[K |████████████████████████████████| 1.5MB 47.3MB/s \n\u001b[?25hRequirement already satisfied: scipy>=0.18.1 in /usr/local/lib/python3.6/dist-packages (from pymc3==3.8) (1.4.1)\nRequirement already satisfied: pandas>=0.18.0 in /usr/local/lib/python3.6/dist-packages (from pymc3==3.8) (1.0.3)\nRequirement already satisfied: tqdm>=4.8.4 in /usr/local/lib/python3.6/dist-packages (from pymc3==3.8) (4.41.1)\nRequirement already satisfied: numpy>=1.13.0 in /usr/local/lib/python3.6/dist-packages (from pymc3==3.8) (1.18.4)\nRequirement already satisfied: six>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from theano>=1.0.4->pymc3==3.8) (1.12.0)\nRequirement already satisfied: packaging in /usr/local/lib/python3.6/dist-packages (from arviz>=0.4.1->pymc3==3.8) (20.3)\nRequirement already satisfied: matplotlib>=3.0 in /usr/local/lib/python3.6/dist-packages (from arviz>=0.4.1->pymc3==3.8) (3.2.1)\nCollecting netcdf4\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/35/4f/d49fe0c65dea4d2ebfdc602d3e3d2a45a172255c151f4497c43f6d94a5f6/netCDF4-1.5.3-cp36-cp36m-manylinux1_x86_64.whl (4.1MB)\n\u001b[K |████████████████████████████████| 4.1MB 34.9MB/s \n\u001b[?25hRequirement already satisfied: xarray>=0.11 in /usr/local/lib/python3.6/dist-packages (from arviz>=0.4.1->pymc3==3.8) (0.15.1)\nRequirement already satisfied: python-dateutil>=2.6.1 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.18.0->pymc3==3.8) (2.8.1)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.18.0->pymc3==3.8) (2018.9)\nRequirement already satisfied: pyparsing>=2.0.2 in /usr/local/lib/python3.6/dist-packages (from packaging->arviz>=0.4.1->pymc3==3.8) (2.4.7)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=3.0->arviz>=0.4.1->pymc3==3.8) (0.10.0)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=3.0->arviz>=0.4.1->pymc3==3.8) (1.2.0)\nCollecting cftime\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/0f/5e/ee154e2aabb0beea0c4c7dc3d93c6f64f96a2a2019bbd05afc905439d042/cftime-1.1.3-cp36-cp36m-manylinux1_x86_64.whl (322kB)\n\u001b[K |████████████████████████████████| 327kB 48.5MB/s \n\u001b[?25hRequirement already satisfied: setuptools>=41.2 in /usr/local/lib/python3.6/dist-packages (from xarray>=0.11->arviz>=0.4.1->pymc3==3.8) (46.3.0)\nInstalling collected packages: cftime, netcdf4, arviz, pymc3\n Found existing installation: pymc3 3.7\n Uninstalling pymc3-3.7:\n Successfully uninstalled pymc3-3.7\nSuccessfully installed arviz-0.7.0 cftime-1.1.3 netcdf4-1.5.3 pymc3-3.8\n"
],
[
"import warnings\nwarnings.simplefilter(action='ignore', category=FutureWarning)\n\nimport os\nimport requests\nimport pymc3 as pm\nimport pandas as pd\nimport numpy as np\nimport theano\nimport theano.tensor as tt\n\nfrom matplotlib import pyplot as plt\nfrom matplotlib import dates as mdates\nfrom matplotlib import ticker\n\nfrom datetime import date\nfrom datetime import datetime\n\nfrom IPython.display import clear_output\n\n%config InlineBackend.figure_format = 'retina'",
"_____no_output_____"
]
],
[
[
"## Load COUNTY Information",
"_____no_output_____"
]
],
[
[
"# Import NYT data\nurl = 'https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv'\ncounties = pd.read_csv(url,parse_dates=['date']).sort_index()\n\ncounties",
"_____no_output_____"
],
[
"#counties[counties.county != 'Unknown']\ncounties=counties[counties.county != 'Unknown']\ncounties.insert(0, 'key', counties['state'] + '_' + counties['county'])\ncounties.set_index(['key', 'date'],inplace=True)\n\n# Example\n#print(counties[counties['state'] == \"Maine\"]['county'].unique())\nprint(counties.head())",
" county state fips cases deaths\nkey date \nWashington_Snohomish 2020-01-21 Snohomish Washington 53061.0 1 0\n 2020-01-22 Snohomish Washington 53061.0 1 0\n 2020-01-23 Snohomish Washington 53061.0 1 0\nIllinois_Cook 2020-01-24 Cook Illinois 17031.0 1 0\nWashington_Snohomish 2020-01-24 Snohomish Washington 53061.0 1 0\n"
],
[
"# Import USA Facts data\nurl = \"https://usafactsstatic.blob.core.windows.net/public/data/covid-19/covid_confirmed_usafacts.csv\"\nconfirmed_df=pd.read_csv(url)#,parse_dates=['date']).sort_index()\n\n#reshape USAFacts feed to expected format\ncounties_df = confirmed_df\n\n#first, create a pseudo state called \"NYC\"\ncounties_df.loc[(confirmed_df['countyFIPS'].isin([36005, 36061, 36081, 36085, 36047])), 'State'] = 'NYC'\ncounties_df.loc[confirmed_df['County Name'] == 'New York City Unallocated/Probable', 'State'] = 'NYC'\n\ncounties_df = counties_df.melt(id_vars=[\"countyFIPS\", \"County Name\", \"State\", \"stateFIPS\"], var_name=\"date\", value_name=\"cases\")\n\ncounties_df=counties_df.drop(columns=['countyFIPS', 'stateFIPS'])\ncounties_df.rename(columns={'State':'state', 'County Name':'county'}, inplace=True)\n\n# create county aggregations so we can compute statewide Rt\ncounty_agg = counties_df.groupby(['state','date']).agg({'cases':['sum']})\ncounty_agg.columns = ['cases']\ncounty_agg = county_agg.reset_index()\ncounty_agg.insert(0, 'county', county_agg['state'])\n\ncounty_agg\n\n# merge state_aggregations with counties \ncounties_df = counties_df.append(county_agg, ignore_index=True)\ncounties_df['date'] = pd.to_datetime(counties_df['date'])\n\n# after aggregating statewide cases, remove the Unallocated entries\ncounties_df.drop(counties_df[counties_df.county.str.contains('Unallocated') ].index, inplace=True)\n#counties_df.set_index(['county','date'], inplace=True)\n\ncounties_df\n",
"_____no_output_____"
],
[
"# Merge New York City data from NYT feed to USA Facts county feed to get best of both worlds\n\nnycnyt = counties[counties['county'] == 'New York City']\ndel nycnyt['fips']\ndel nycnyt['deaths']\nnycnyt['state'] = 'NYC'\nnycnyt.reset_index(inplace=True)\ndel nycnyt['key']\n\nnycnyt\n\ncounties_df = pd.concat([counties_df, nycnyt])",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:6: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \n"
],
[
"\ncounties_df=counties_df[counties_df.county != 'Unknown']\ncounties_df.insert(0, 'key', counties_df['state'] + '_' + counties_df['county'])\ncounties_df.set_index(['key', 'date'],inplace=True)\n\ncounties_df",
"_____no_output_____"
],
[
"counties = counties_df",
"_____no_output_____"
]
],
[
[
"## Load Patient Information\n#### Download\n~100mb download (be ... patient!)",
"_____no_output_____"
]
],
[
[
"def download_file(url, local_filename):\n \"\"\"From https://stackoverflow.com/questions/16694907/\"\"\"\n with requests.get(url, stream=True) as r:\n r.raise_for_status()\n with open(local_filename, 'wb') as f:\n for chunk in r.iter_content(chunk_size=8192): \n if chunk: # filter out keep-alive new chunks\n f.write(chunk)\n return local_filename\n\n\n#URL = \"https://raw.githubusercontent.com/beoutbreakprepared/nCoV2019/master/latest_data/latestdata.csv\"\nURL = \"https://github.com/beoutbreakprepared/nCoV2019/raw/master/latest_data/latestdata.tar.gz\"\n\nLINELIST_PATH = 'data/linelist.csv.gz'\n\nos.makedirs(os.path.dirname(LINELIST_PATH), exist_ok=True)\n\nif not os.path.exists(LINELIST_PATH):\n print('Downloading file, this will take a while ~100mb')\n try:\n download_file(URL, LINELIST_PATH)\n clear_output(wait=True)\n print('Done downloading.')\n except:\n print('Something went wrong. Try again.')\nelse:\n print('Already downloaded CSV')",
"Done downloading.\n"
],
[
"#unzip file\n\nimport gzip\nimport shutil\nwith gzip.open(LINELIST_PATH, 'rb') as f_in:\n with open('data/linelist.csv', 'wb') as f_out:\n shutil.copyfileobj(f_in, f_out)",
"_____no_output_____"
]
],
[
[
"#### Parse & Clean Patient Info",
"_____no_output_____"
]
],
[
[
"# Load the patient CSV\npatients = pd.read_csv(\n 'data/linelist.csv',\n parse_dates=False,\n usecols=[\n 'date_confirmation',\n 'date_onset_symptoms'],\n low_memory=False)\n\npatients.columns = ['Onset', 'Confirmed']\n# colnames renamed ~05-07. rename back for code below to work\n#patients.columns = ['date_confirmation', 'date_onset_symptoms']\n\n# There's an errant reversed date\npatients = patients.replace('01.31.2020', '31.01.2020')\n\n# Only keep if both values are present\npatients = patients.dropna()\n\n# Must have strings that look like individual dates\n# \"2020.03.09\" is 10 chars long\nis_ten_char = lambda x: x.str.len().eq(10)\npatients = patients[is_ten_char(patients.Confirmed) & \n is_ten_char(patients.Onset)]\n\n# Convert both to datetimes\npatients.Confirmed = pd.to_datetime(\n patients.Confirmed, format='%d.%m.%Y')\npatients.Onset = pd.to_datetime(\n patients.Onset, format='%d.%m.%Y')\n\n# Only keep records where confirmed > onset\npatients = patients[patients.Confirmed >= patients.Onset]",
"_____no_output_____"
]
],
[
[
"#### Show Relationship between Onset of Symptoms and Confirmation",
"_____no_output_____"
]
],
[
[
"ax = patients.plot.scatter(\n title='Onset vs. Confirmed Dates - COVID19',\n x='Onset',\n y='Confirmed',\n alpha=.1,\n lw=0,\n s=10,\n figsize=(6,6))\n\nformatter = mdates.DateFormatter('%m/%d')\nlocator = mdates.WeekdayLocator(interval=2)\n\nfor axis in [ax.xaxis, ax.yaxis]:\n axis.set_major_formatter(formatter)\n axis.set_major_locator(locator)",
"_____no_output_____"
]
],
[
[
"#### Calculate the Probability Distribution of Delay",
"_____no_output_____"
]
],
[
[
"# Calculate the delta in days between onset and confirmation\ndelay = (patients.Confirmed - patients.Onset).dt.days\n\n# Convert samples to an empirical distribution\np_delay = delay.value_counts().sort_index()\nnew_range = np.arange(0, p_delay.index.max()+1)\np_delay = p_delay.reindex(new_range, fill_value=0)\np_delay /= p_delay.sum()\n\n# Show our work\nfig, axes = plt.subplots(ncols=2, figsize=(9,3))\np_delay.plot(title='P(Delay)', ax=axes[0])\np_delay.cumsum().plot(title='P(Delay <= x)', ax=axes[1])\nfor ax in axes:\n ax.set_xlabel('days')",
"_____no_output_____"
]
],
[
[
"# A single County",
"_____no_output_____"
]
],
[
[
"#key = 'Nebraska_Douglas'\nkey = 'NYC_NYC'\nkey = 'NYC_New York City'\n#key = 'New York_New York City'\n#key = 'New Jersey_Hudson'\nconfirmed = counties.xs(key).cases.diff().dropna().clip(0) # new cases (not cumulative)\nconfirmed",
"_____no_output_____"
]
],
[
[
"### Translate Confirmation Dates to Onset Dates\n\nOur goal is to translate positive test counts to the dates where they likely occured. Since we have the distribution, we can distribute case counts back in time according to that distribution. To accomplish this, we reverse the case time series, and convolve it using the distribution of delay from onset to confirmation. Then we reverse the series again to obtain the onset curve. Note that this means the data will be 'right censored' which means there are onset cases that have yet to be reported so it looks as if the count has gone down.",
"_____no_output_____"
]
],
[
[
"def confirmed_to_onset(confirmed, p_delay):\n\n assert not confirmed.isna().any()\n \n # Reverse cases so that we convolve into the past\n convolved = np.convolve(confirmed[::-1].values, p_delay)\n\n # Calculate the new date range\n dr = pd.date_range(end=confirmed.index[-1],\n periods=len(convolved))\n\n # Flip the values and assign the date range\n onset = pd.Series(np.flip(convolved), index=dr)\n \n return onset\n\n",
"_____no_output_____"
],
[
"# onset for the selected county\nonset = confirmed_to_onset(confirmed, p_delay)",
"_____no_output_____"
]
],
[
[
"### Adjust for Right-Censoring\n\nSince we distributed observed cases into the past to recreate the onset curve, we now have a right-censored time series. We can correct for that by asking what % of people have a delay less than or equal to the time between the day in question and the current day.\n\nFor example, 5 days ago, there might have been 100 cases onset. Over the course of the next 5 days some portion of those cases will be reported. This portion is equal to the cumulative distribution function of our delay distribution. If we know that portion is say, 60%, then our current count of onset on that day represents 60% of the total. This implies that the total is 166% higher. We apply this correction to get an idea of what actual onset cases are likely, thus removing the right censoring.",
"_____no_output_____"
]
],
[
[
"def adjust_onset_for_right_censorship(onset, p_delay):\n cumulative_p_delay = p_delay.cumsum()\n \n # Calculate the additional ones needed so shapes match\n ones_needed = len(onset) - len(cumulative_p_delay)\n padding_shape = (0, ones_needed)\n \n # Add ones and flip back\n cumulative_p_delay = np.pad(\n cumulative_p_delay,\n padding_shape,\n constant_values=1)\n cumulative_p_delay = np.flip(cumulative_p_delay)\n \n # Adjusts observed onset values to expected terminal onset values\n adjusted = onset / cumulative_p_delay\n \n return adjusted, cumulative_p_delay",
"_____no_output_____"
],
[
"# adjusted for the selected county\nadjusted, cumulative_p_delay = adjust_onset_for_right_censorship(onset, p_delay)",
"_____no_output_____"
]
],
[
[
"Take a look at all three series: confirmed, onset and onset adjusted for right censoring.",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(5,3))\n\nconfirmed.plot(\n ax=ax,\n label='Confirmed',\n title=key,\n c='k',\n alpha=.25,\n lw=1)\n\nonset.plot(\n ax=ax,\n label='Onset',\n c='k',\n lw=1)\n\nadjusted.plot(\n ax=ax,\n label='Adjusted Onset',\n c='k',\n linestyle='--',\n lw=1)\n\nax.legend();",
"_____no_output_____"
]
],
[
[
"Let's have the model run on days where we have enough data ~last 50 or so",
"_____no_output_____"
],
[
"### Sample the Posterior with PyMC3",
"_____no_output_____"
],
[
"We assume a poisson likelihood function and feed it what we believe is the onset curve based on reported data. We model this onset curve based on the same math in the previous notebook:\n\n$$ I^\\prime = Ie^{\\gamma(R_t-1)} $$\n\nWe define $\\theta = \\gamma(R_t-1)$ and model $ I^\\prime = Ie^{\\theta} $ where $\\theta$ observes a random walk. We let $\\gamma$ vary independently based on known parameters for the serial interval. Therefore, we can recover $R_t$ easily by $R_t = \\frac{\\theta}{\\gamma}+1$\n\nThe only tricky part is understanding that we're feeding in _onset_ cases to the likelihood. So $\\mu$ of the poisson is the positive, non-zero, expected onset cases we think we'd see today.\n\nWe calculate this by figuring out how many cases we'd expect there to be yesterday total when adjusted for bias and plugging it into the first equation above. We then have to re-bias this number back down to get the expected amount of onset cases observed that day.",
"_____no_output_____"
]
],
[
[
"class MCMCModel(object):\n \n def __init__(self, region, onset, cumulative_p_delay, window=50):\n \n # Just for identification purposes\n self.region = region\n \n # For the model, we'll only look at the last N\n self.onset = onset.iloc[-window:]\n self.cumulative_p_delay = cumulative_p_delay[-window:]\n \n # Where we store the results\n self.trace = None\n self.trace_index = self.onset.index[1:]\n\n def run(self, chains=1, tune=3000, draws=1000, target_accept=.95):\n\n with pm.Model() as model:\n\n # Random walk magnitude\n step_size = pm.HalfNormal('step_size', sigma=.03)\n\n # Theta random walk\n theta_raw_init = pm.Normal('theta_raw_init', 0.1, 0.1)\n theta_raw_steps = pm.Normal('theta_raw_steps', shape=len(self.onset)-2) * step_size\n theta_raw = tt.concatenate([[theta_raw_init], theta_raw_steps])\n theta = pm.Deterministic('theta', theta_raw.cumsum())\n\n # Let the serial interval be a random variable and calculate r_t\n serial_interval = pm.Gamma('serial_interval', alpha=6, beta=1.5)\n gamma = 1.0 / serial_interval\n r_t = pm.Deterministic('r_t', theta/gamma + 1)\n\n inferred_yesterday = self.onset.values[:-1] / self.cumulative_p_delay[:-1]\n \n expected_today = inferred_yesterday * self.cumulative_p_delay[1:] * pm.math.exp(theta)\n\n # Ensure cases stay above zero for poisson\n mu = pm.math.maximum(.1, expected_today)\n observed = self.onset.round().values[1:]\n cases = pm.Poisson('cases', mu=mu, observed=observed)\n\n self.trace = pm.sample(\n chains=chains,\n tune=tune,\n draws=draws,\n target_accept=target_accept)\n \n return self\n \n def run_gp(self):\n with pm.Model() as model:\n gp_shape = len(self.onset) - 1\n\n length_scale = pm.Gamma(\"length_scale\", alpha=3, beta=.4)\n\n eta = .05\n cov_func = eta**2 * pm.gp.cov.ExpQuad(1, length_scale)\n\n gp = pm.gp.Latent(mean_func=pm.gp.mean.Constant(c=0), \n cov_func=cov_func)\n\n # Place a GP prior over the function f.\n theta = gp.prior(\"theta\", X=np.arange(gp_shape)[:, None])\n\n # Let the serial interval be a random variable and calculate r_t\n serial_interval = pm.Gamma('serial_interval', alpha=6, beta=1.5)\n gamma = 1.0 / serial_interval\n r_t = pm.Deterministic('r_t', theta / gamma + 1)\n\n inferred_yesterday = self.onset.values[:-1] / self.cumulative_p_delay[:-1]\n expected_today = inferred_yesterday * self.cumulative_p_delay[1:] * pm.math.exp(theta)\n\n # Ensure cases stay above zero for poisson\n mu = pm.math.maximum(.1, expected_today)\n observed = self.onset.round().values[1:]\n cases = pm.Poisson('cases', mu=mu, observed=observed)\n\n self.trace = pm.sample(chains=1, tune=1000, draws=1000, target_accept=.8)\n return self",
"_____no_output_____"
]
],
[
[
"### Run Pymc3 Model",
"_____no_output_____"
]
],
[
[
"def df_from_model(model):\n \n r_t = model.trace['r_t']\n mean = np.mean(r_t, axis=0)\n median = np.median(r_t, axis=0)\n hpd_90 = pm.stats.hpd(r_t, credible_interval=.9)\n hpd_50 = pm.stats.hpd(r_t, credible_interval=.5)\n \n idx = pd.MultiIndex.from_product([\n [model.region],\n model.trace_index\n ], names=['region', 'date'])\n \n df = pd.DataFrame(data=np.c_[mean, median, hpd_90, hpd_50], index=idx,\n columns=['mean', 'median', 'lower_90', 'upper_90', 'lower_50','upper_50'])\n return df",
"_____no_output_____"
],
[
"def create_and_run_model_counties(name, county):\n confirmed = county.cases.diff().dropna().clip(0) # new cases (not cumulative)\n onset = confirmed_to_onset(confirmed, p_delay)\n adjusted, cumulative_p_delay = adjust_onset_for_right_censorship(onset, p_delay)\n return MCMCModel(name, onset, cumulative_p_delay).run()",
"_____no_output_____"
],
[
"print(counties[counties.state== 'NYC']['county'].unique())\n#print(counties[counties.state== 'New York']['county'].unique())\n#print(counties[counties.state== 'New Jersey']['county'].unique())",
"['Bronx County' 'Kings County' 'New York County' 'Queens County'\n 'Richmond County' 'NYC' 'New York City']\n"
],
[
"models = {}\nfor state_county, grp in counties[counties['state']=='NYC'].groupby(level='key'): # only the selected state\n#for state_county, grp in counties.groupby(level='key'): # all counties all states\n\n print(state_county)\n #print(grp.droplevel(0))\n if state_county in models:\n print(f'Skipping {state_county}, already in cache')\n continue\n models[state_county] = create_and_run_model_counties(state_county,grp.droplevel(0))",
"NYC_Bronx County\n"
]
],
[
[
"### Handle Divergences",
"_____no_output_____"
]
],
[
[
"# Check to see if there were divergences\nn_diverging = lambda x: x.trace['diverging'].nonzero()[0].size\ndivergences = pd.Series([n_diverging(m) for m in models.values()], index=models.keys())\nhas_divergences = divergences.gt(0)\n\nprint('Diverging states:')\ndisplay(divergences[has_divergences])\n\n# Rerun states with divergences\nfor state, n_divergences in divergences[has_divergences].items():\n models[state].run()",
"Diverging states:\n"
]
],
[
[
"## Compile Results",
"_____no_output_____"
]
],
[
[
"results = None\n\nfor state_county, model in models.items():\n\n df = df_from_model(model)\n\n if results is None:\n results = df\n else:\n results = pd.concat([results, df], axis=0)",
"_____no_output_____"
],
[
"results",
"_____no_output_____"
]
],
[
[
"### Render to CSV",
"_____no_output_____"
]
],
[
[
"!pip install ckanapi",
"Collecting ckanapi\n Downloading https://files.pythonhosted.org/packages/07/c6/50449e18aaf1600dfda955805c58aa7462493511f3ebbb20d0a65874397c/ckanapi-4.3.tar.gz\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from ckanapi) (46.3.0)\nRequirement already satisfied: docopt in /usr/local/lib/python3.6/dist-packages (from ckanapi) (0.6.2)\nRequirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from ckanapi) (2.23.0)\nRequirement already satisfied: python-slugify>=1.0 in /usr/local/lib/python3.6/dist-packages (from ckanapi) (4.0.0)\nRequirement already satisfied: six<2.0,>=1.9 in /usr/local/lib/python3.6/dist-packages (from ckanapi) (1.12.0)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->ckanapi) (1.24.3)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->ckanapi) (2020.4.5.1)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->ckanapi) (2.9)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->ckanapi) (3.0.4)\nRequirement already satisfied: text-unidecode>=1.3 in /usr/local/lib/python3.6/dist-packages (from python-slugify>=1.0->ckanapi) (1.3)\nBuilding wheels for collected packages: ckanapi\n Building wheel for ckanapi (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for ckanapi: filename=ckanapi-4.3-cp36-none-any.whl size=38647 sha256=7386e673e4632f06bee1b28edcf6729a59e61b0111092de5a95282d8d06122a3\n Stored in directory: /root/.cache/pip/wheels/41/f2/fb/c8ce857007de64cc6b36b8f1048272396bc0817c35ee3a3e73\nSuccessfully built ckanapi\nInstalling collected packages: ckanapi\nSuccessfully installed ckanapi-4.3\n"
],
[
"# New York City\nresultscsv=results.reset_index()\nresultscsv.drop(resultscsv[resultscsv['region'] == 'NYC_NYC'].index, inplace=True)\n\nresultscsv['region']= resultscsv['region'].str.replace(\"NYC_\", \"\", case = False) \nresultscsv.rename(columns={\"region\": \"county\"}, inplace=True)\n\nresultscsv",
"_____no_output_____"
],
[
"maxdate = resultscsv['date'].max().strftime('%Y-%m-%d')\nmaxdate",
"_____no_output_____"
],
[
"os.makedirs(os.path.dirname('results/'), exist_ok=True)\nresultscsv.to_csv('results/rt_mcmc_nyc.csv', index=False)\n#resultscsv.to_csv('results/rt_mcmc_nj.csv', index=False)",
"_____no_output_____"
],
[
"from ckanapi import RemoteCKAN\nua = 'ckanapi/4.3 (+https://data.beta.nyc)'\n\nckan = RemoteCKAN('https://data.beta.nyc', user_agent=ua,\n apikey='55369753-0071-41e3-9c90-20432a12af3c')\n#groups = dataportal.action.group_list(id='data-explorer')\n#groups",
"_____no_output_____"
],
[
"#NYC\npayload = {'description': 'COVID-19 Rt for NYC as of ' + maxdate + ' using https://rt.live Apr 26 mcmc model',\n 'format': 'csv',\n 'id': u'e38f973d-afe0-4589-8416-e0ff8b9b8194',\n 'mimetype': 'application/csv',\n 'name': 'rt_mcmc_nyc.csv',\n 'package_id': 'nyc-rt-effective-reproduction-number',\n 'upload': open('results/rt_mcmc_nyc.csv', 'rb')}\n\nckan.action.resource_update(**payload)",
"_____no_output_____"
],
[
"ckan.close()",
"_____no_output_____"
]
],
[
[
"### Render Charts",
"_____no_output_____"
]
],
[
[
"def plot_rt(name, result, ax, c=(.3,.3,.3,1), ci=(0,0,0,.05)):\n ax.set_ylim(-1, 2) # change y-axis limits\n ax.set_title(name)\n ax.plot(result['median'],\n marker='o',\n markersize=4,\n markerfacecolor='w',\n lw=1,\n c=c,\n markevery=2)\n ax.fill_between(\n result.index,\n result['lower_50'].values,\n result['upper_50'].values,\n color=ci,\n lw=0)\n ax.axhline(1.0, linestyle=':', lw=1)\n \n ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))\n ax.xaxis.set_major_locator(mdates.WeekdayLocator(interval=2))",
"_____no_output_____"
],
[
"ncols = 4\nnrows = int(np.ceil(results.index.levels[0].shape[0] / ncols))\n\nfig, axes = plt.subplots(\n nrows=nrows,\n ncols=ncols,\n figsize=(14, nrows*3),\n sharey='row')\n\nfor ax, (state, result) in zip(axes.flat, results.groupby('region')):\n plot_rt(state, result.droplevel(0), ax)\n\nfig.tight_layout()\nfig.set_facecolor('w')",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
e73c9d6e58c1e26d8e270185d3c7f97ba309e52d | 6,611 | ipynb | Jupyter Notebook | components/gcp/dataproc/submit_pyspark_job/sample.ipynb | ryan-williams/pipelines | 2accf4180a10e5513bf3f070051644d0119d78ff | [
"Apache-2.0"
] | 9 | 2019-03-28T02:20:45.000Z | 2021-12-01T22:43:36.000Z | components/gcp/dataproc/submit_pyspark_job/sample.ipynb | ryan-williams/pipelines | 2accf4180a10e5513bf3f070051644d0119d78ff | [
"Apache-2.0"
] | 1 | 2019-04-11T12:13:57.000Z | 2019-04-11T12:13:57.000Z | components/gcp/dataproc/submit_pyspark_job/sample.ipynb | ryan-williams/pipelines | 2accf4180a10e5513bf3f070051644d0119d78ff | [
"Apache-2.0"
] | 4 | 2019-04-11T12:09:59.000Z | 2020-10-11T15:53:53.000Z | 29.779279 | 208 | 0.607321 | [
[
[
"# Dataproc - Submit PySpark Job\n\n## Intended Use\nA Kubeflow Pipeline component to submit a PySpark job to Google Cloud Dataproc service. \n\n## Run-Time Parameters:\nName | Description\n:--- | :----------\nproject_id | Required. The ID of the Google Cloud Platform project that the cluster belongs to.\nregion | Required. The Cloud Dataproc region in which to handle the request.\ncluster_name | Required. The cluster to run the job.\nmain_python_file_uri | Required. The HCFS URI of the main Python file to use as the driver. Must be a .py file.\nargs | Optional. The arguments to pass to the driver. Do not include arguments, such as --conf, that can be set as job properties, since a collision may occur that causes an incorrect job submission.\npyspark_job | Optional. The full payload of a [PySparkJob](https://cloud.google.com/dataproc/docs/reference/rest/v1/PySparkJob).\njob | Optional. The full payload of a [Dataproc job](https://cloud.google.com/dataproc/docs/reference/rest/v1/projects.regions.jobs).\nwait_interval | Optional. The wait seconds between polling the operation. Defaults to 30s.\n\n## Output:\nName | Description\n:--- | :----------\njob_id | The ID of the created job.",
"_____no_output_____"
],
[
"## Sample\n\nNote: the sample code below works in both IPython notebook or python code directly.\n\n### Setup a Dataproc cluster\nFollow the [guide](https://cloud.google.com/dataproc/docs/guides/create-cluster) to create a new Dataproc cluster or reuse an existing one.\n\n### Prepare PySpark job\nUpload your PySpark code file to a Google Cloud Storage (GCS) bucket. For example, here is a public accessible hello-world.py in GCS:",
"_____no_output_____"
]
],
[
[
"!gsutil cat gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py",
"_____no_output_____"
]
],
[
[
"### Set sample parameters",
"_____no_output_____"
]
],
[
[
"PROJECT_ID = '<Please put your project ID here>'\nCLUSTER_NAME = '<Please put your existing cluster name here>'\nREGION = 'us-central1'\nPYSPARK_FILE_URI = 'gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py'\nARGS = ''\nEXPERIMENT_NAME = 'Dataproc - Submit PySpark Job'\nSUBMIT_PYSPARK_JOB_SPEC_URI = 'https://raw.githubusercontent.com/kubeflow/pipelines/e5b0081cdcbef6a056c0da114d2eb81ab8d8152d/components/gcp/dataproc/submit_pyspark_job/component.yaml'",
"_____no_output_____"
]
],
[
[
"### Install KFP SDK\nInstall the SDK (Uncomment the code if the SDK is not installed before)",
"_____no_output_____"
]
],
[
[
"# KFP_PACKAGE = 'https://storage.googleapis.com/ml-pipeline/release/0.1.12/kfp.tar.gz'\n# !pip3 install $KFP_PACKAGE --upgrade",
"_____no_output_____"
]
],
[
[
"### Load component definitions",
"_____no_output_____"
]
],
[
[
"import kfp.components as comp\n\ndataproc_submit_pyspark_job_op = comp.load_component_from_url(SUBMIT_PYSPARK_JOB_SPEC_URI)\ndisplay(dataproc_submit_pyspark_job_op)",
"_____no_output_____"
]
],
[
[
"### Here is an illustrative pipeline that uses the component",
"_____no_output_____"
]
],
[
[
"import kfp.dsl as dsl\nimport kfp.gcp as gcp\nimport json\[email protected](\n name='Dataproc submit PySpark job pipeline',\n description='Dataproc submit PySpark job pipeline'\n)\ndef dataproc_submit_pyspark_job_pipeline(\n project_id = PROJECT_ID, \n region = REGION,\n cluster_name = CLUSTER_NAME,\n main_python_file_uri = PYSPARK_FILE_URI, \n args = ARGS, \n pyspark_job='{}', \n job='{}', \n wait_interval='30'\n):\n dataproc_submit_pyspark_job_op(project_id, region, cluster_name, main_python_file_uri, \n args, pyspark_job, job, wait_interval).apply(gcp.use_gcp_secret('user-gcp-sa'))\n ",
"_____no_output_____"
]
],
[
[
"### Compile the pipeline",
"_____no_output_____"
]
],
[
[
"pipeline_func = dataproc_submit_pyspark_job_pipeline\npipeline_filename = pipeline_func.__name__ + '.pipeline.tar.gz'\nimport kfp.compiler as compiler\ncompiler.Compiler().compile(pipeline_func, pipeline_filename)",
"_____no_output_____"
]
],
[
[
"### Submit the pipeline for execution",
"_____no_output_____"
]
],
[
[
"#Specify pipeline argument values\narguments = {}\n\n#Get or create an experiment and submit a pipeline run\nimport kfp\nclient = kfp.Client()\nexperiment = client.create_experiment(EXPERIMENT_NAME)\n\n#Submit a pipeline run\nrun_name = pipeline_func.__name__ + ' run'\nrun_result = client.run_pipeline(experiment.id, run_name, pipeline_filename, arguments)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
e73ca7210c2ab1370edcee73bbc7dba0b14d8779 | 16,870 | ipynb | Jupyter Notebook | materials/00 Course introduction.ipynb | mschoemann272/python4geosciences | 01b9d33aa4dd3dd6e5ff60cc98f862f0652098ce | [
"MIT"
] | null | null | null | materials/00 Course introduction.ipynb | mschoemann272/python4geosciences | 01b9d33aa4dd3dd6e5ff60cc98f862f0652098ce | [
"MIT"
] | null | null | null | materials/00 Course introduction.ipynb | mschoemann272/python4geosciences | 01b9d33aa4dd3dd6e5ff60cc98f862f0652098ce | [
"MIT"
] | null | null | null | 62.713755 | 635 | 0.686307 | [
[
[
"# 00 Course introduction",
"_____no_output_____"
],
[
"## A. Overview",
"_____no_output_____"
],
[
"### Am I ready to take this course?\n\nYes. Probably. Some programming experience will help, but is not required. There are lots of online resource that you can use to supplement things we learn in class. Some examples are:\n\n * [python.org Tutorial](https://docs.python.org/3/tutorial/index.html)\n * [software carpentry](http://software-carpentry.org)\n * [Google](http://google.com) (Just type in your question and follow the first [stackoverflow](http://stackoverflow.com) link. This is surprisingly effective; do this first.)",
"_____no_output_____"
],
[
"### What computational resources do I need for class?\n\nWe assume you have a laptop that you will bring to class and use to follow along. If you don't have access to some sort of portable device that you can use in class, please let us know as soon as possible.",
"_____no_output_____"
],
[
"### Who is teaching this class?\n\n#### Rob Hetland ([email protected], github: hetland, http://pong.tamu.edu/~rob/, O&M 618)\nRob has been a professor at TAMU since 2000, and has about a decade worth of scientific python experience.\n\n#### Kristen Thyng ([email protected], github: kthyng, http://kristenthyng.com, O&M 608)\nKristen is an assistant research scientist, and has been at TAMU since 2012. She has been active in scientific python and has helped organized the Scientific Python meetings in Austin since 2014.",
"_____no_output_____"
],
[
"### There are two instructors then?\n\nYes. We will take turns teaching and helping out with the class. Please email both of us for all class-related contact, though feel free to address whoever is most relevant, if appropriate.",
"_____no_output_____"
],
[
"### Geosciences?!?\n\nThe goal of this class is to provide information for all fields in geoscience. To that end, we will try to cover topics from geology, geography, atmospheric sciences, and oceanography. Specifically, we will focus on 1D timeseries, and 2D geospatial (i.e., on a map) analysis. If you have any topics you would like to cover, please let us know, and we will do our best to accommodate.",
"_____no_output_____"
],
[
"### Which version of Python should I use.\n\nUnless you have a good reason to do differently, you should use Python 3 (as opposed to Python version 2.x). The syntax between Python 2 and 3 is very similar, but there are some subtle differences. You should learn the newest version, so you don't need to unlearn those things later.\n\nUnless you have a good reason to do differently, you should use [Anaconda scientific python](https://www.continuum.io/downloads). This is the Python distribution we will use in class. Others will also work, but the Anaconda distribution is easy to install and maintain, and has everything we will need for class. It is also free, both as in speech and as in beer.",
"_____no_output_____"
],
[
"### Class setup\n\n#### Class format\n\nWe will go through course materials during class time. You should bring a laptop to class so that you can follow along and participate in exercises.\n\n\n#### Git and GitHub\n\nAll class materials will be shared through a [GitHub](http://github.org) repository. GitHub is a way to share and access code online which has been version-controlled using git. Version control allows changes in code to be tracked over time; this is important for reproducibility, retrieving code in case of accidents, and working on code in groups. Git is one way to version control your code — other methods include subversion (svn), cvs, and mercurial. More information on this is provided below.\n\n\n#### Get the course materials\n\nThe course materials are available in the [class repository](https://github.com/hetland/python4geosciences). To do this, in your terminal window, navigate to the location where you want the class materials, and then type: `git clone https://github.com/hetland/python4geosciences`.\n\n\n#### Access the materials\n\n* The class materials are located in `python4geosciences/materials/` and are in the form of [Jupyter notebooks](http://jupyter.org/). More information on notebooks below.\n* Navigate to the class directory on your computer, then start a local iPython notebook server with `ipython notebook`. This will open a browser window to the local server through which you can select notebooks in the `materials` directory for the class notebooks.\n\n#### Course introduction email items\n\n1. We are using a github repository to share materials for this class: https://github.com/hetland/python4geosciences. Please browse it and bookmark it — we are making changes all the time and will continue to do so throughout the semester. All course materials and homework will be shared through this site. \n\n2. You can look at an overview of the class here: https://github.com/hetland/python4geosciences/blob/master/materials/00%20Course%20introduction.ipynb. \nThere will be some setup required for your laptop and if you have time it'd be great to get a head start on it; it is described here: https://github.com/hetland/python4geosciences/blob/master/homework/hw00.ipynb.\nAt minimum, it would be great if you can download the Anaconda python package before you get to class since it is a large package. https://www.continuum.io/downloads\n\n3. I have set up a class Google Group. We can use it to email each other as needed. Also, it is linked with a Google Calendar for the class that we will update through the semester with our anticipated (and subsequently, actual) material and homework by date. You should be able to go to this site and request to join, then subsequently have access to the calendar: https://groups.google.com/forum/#!forum/python4geosciences2016\n\n#### Course textbook\n\nThere is no textbook for the course. But if you'd like an outside resource, here are two recommendations:\n\n1. From O'Reilly, Learning Python: http://www.amazon.com/Learning-Python-Edition-Mark-Lutz/dp/1449355730 (you can find both print and e versions)\n2. Allen Downey has written a number of books on Python and related scientific subjects. And as a bonus, they are free (digital versions): http://greenteapress.com/wp/. In particular you would want to check out Think Python (2nd edition).",
"_____no_output_____"
],
[
"### How do I submit homework?\n\nYou will need to submit your homework through [github](http://github.org) from your own repository that you will use for the class. Your homeworks will be in the form of Jupyter notebooks.",
"_____no_output_____"
],
[
"## B. Command-line interface\n\nA command-line interface is a way to interact with your computer using text instead of a Graphical User Interface (GUI), a GUI being visually based with icons etc. We will use these in this class. On a Macintosh or Linux machine, this is a terminal window. On a PC this is often called a command prompt.\n\nHere are some commonly-used commands:\n\n* `cd [path]`: change directory from current location to [path]. `cd ..` can be used to move up a single directory, and `cd ../..` moves up two directories, etc.\n* `pwd`: print working directory, as in write out the current location in the terminal window.\n* `ls`: list files in current directory. `ls -l` list files in long format to include more information, `ls -a` to list all files even those that are usually not shown because the have a `.` in front, `ls -h` to show file sizes in human readable format. Flags can always be combined to use multiple options at once, as in `ls -ah` to show all files in human readable format.\n* [tab]: Tab completion. You can always push tab in the terminal window to see available options. As you have some letters entered and push tab, the options will be limited to those that fit the pattern you have started.\n* `mkdir [dirname]`: make directory called dirname.\n* `rm [filename]`: remove a file called filename. To remove a directory called dirname, use `rm -r [dirname]`.",
"_____no_output_____"
],
[
"## C. Jupyter notebooks\n\nThis file format makes it easy to seamlessly combine text and code. The text can be plain or formatted with [Markdown](https://daringfireball.net/projects/markdown/). The code can be written in over 40 languages including Python, R, and Scala. Most importantly, the code can be interacted with when the notebook is opened in a local (that is, on your computer) iPython server. Alternatively, it can simply be viewed through a github repository (like [this very notebook](https://github.com/hetland/python4geosciences/blob/master/materials/00%20Course%20introduction.ipynb)) or through [nbviewer](http://nbviewer.ipython.org/).\n\n### Open a local iPython server\n\nNavigate to the directory on your computer with the Jupyter notebooks you want to open, then start a local iPython notebook server with `ipython notebook`. This will open a browser window to the local server through which you can select available notebooks or create new ones.\n\n### Create a new notebook\n\nStart up your local notebook server in your new repo and create a new Jupyter notebook from the local server page.\n\n### Choose syntax for a cell\n\nNotebooks are built of cells. Cells can have multiple built-in formats including code and Markdown for text. You can select the desired format from a dropdown menu at the top.\n\nIf you want to type words, use \"Markdown\"; if you want to write code, choose \"code\".\n\n### Move between cells\n\nTo run a given cell, type `[shift-enter]` which active in that cell. You can run all of the cells with Cell > Run all; other variations are available in that drop down menu.",
"_____no_output_____"
],
[
"## D. Short git and GitHub tutorial\n\nRemember: you can always google to learn more! Google is an infinite resource that you can ask at any time of the day. Here we summarize a brief overview of how to use git.\n\nTo get changes in a file in a local version of a repository tracked, saved, and then shared with the internet (on github), do the following:\n\n* `git add` to initially tell the system to track your file and subsequently to tell the system that you want to take into account new changes to the file (you can do add more than one file in this process). Then \n* `git commit -m [commit note]` to save the changes. Then\n* `git push` to share the changes with the version of your repository on github. Now you should be able to look at your repo on github and see your updated file there.\n\n**GitHub Desktop**\n\nAfter you have made your repository on GitHub (the website), you should clone it to GitHub Desktop (which is on your local machine). (This should be very easy if you are properly signed into your github account in GitHub Desktop.) Then to get your file tracked and pushed to GitHub (the website):\n\n* While inspecting the relevant repository, any untracked files or changes to tracked files are shown in the middle window (it is white with horizontal lines). To do the equivalent of `git add`, you should check the box of the file.\n* To commit your changes, fill out the form at the bottom of the same window. One short window leaves space for a \"Summary\" of your changes, and if you have more to say you can put it in the \"Description\" box.\n* To push your local changes out to GitHub online, use the Sync button on the upper right hand corner of the window. As a side note, this sync button is also how you should pull down changes to a repository you are following (the equivalent of `git pull`).\n\n\nNote that you do not want to have a directory covered by two git repositories. So for file structure for this class, for example, you might want to have one directory for the class (\"Python_x89\") which contains two version-controlled subdirectories: the course materials (python4geosciences) and your homework repository (\"homework\"). That will keep everything properly separated. \n\n\n\n[Git as explained by XKCD](https://xkcd.com/1597/)\n\n### `git status`\n\nType this in a git-monitored subdirectory on your computer to see the status of files that are under git version control and which files are not being monitored.\n\n### `git add`\n\nUse this to add local files to your git repository. `git add [filename]`.\n\n### `git commit`\n\nUse this to save to your repository local file changes. First you need to add the file with `git add`, then you can `git commit -m [commit message]`, where the commit message is a concise and useful note to explain what changes you have made. You may skip the `git add` step if you would like to commit at once all changes that have been made (you can see what changes would be committed by first consulting `git status`) with `git commit -am [commit message]`. The `-a` flag stands for \"all\" as in commit all changes.\n\n### `git push`\n\nTo move your local changes to github so that they are saved and also for sharing with others, you need to `git push`. After making whatever commits you want to make, you can run this command to finalize your changes on github.\n\n### `git merge`\n\nIf changes have been made in multiple places (say, by another person working on the same code base, or by yourself on two different machines) between `git push`es, git will try to merge if possible — which it will do if the changes don't overlap and therefore don't require your input. If the changes do overlap, you will have to merge the two versions of the code together. You probably won't need to do this in this class.\n\n\n### Get set up with GitHub\n\nYou'll need an account on github if you don't already have one, and to have git installed on your computer. We will interact with github through a terminal window in class and through the website. You may also download the [GitHub Desktop application](https://desktop.github.com/) to use if you prefer, though we won't be able to help you much with the details of it.\n\n### Create a new repo\n\nIn your account on the github webpage, click on the Repositories tab and then the green \"New\" button in the upper right. You'll need to keep this repo public. After creating this new repo, follow the instructions on the next page for quick setup or to create a new repository on the command line. This makes it so that you have the repo both on github and on your local machine. \n\n### Clone a repo\n\nIn a terminal window in the location you want to save the repo materials, type: `git clone [repo address, e.g. https://github.com/hetland/python4geosciences]`.",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
e73cbf13e67cb934bbd03a9f2e9c8498b533a0f9 | 16,392 | ipynb | Jupyter Notebook | fetcher.ipynb | ferdinandwp/dataprep | c5fe22e6011610908c275e8f6591ba92529e8127 | [
"MIT"
] | null | null | null | fetcher.ipynb | ferdinandwp/dataprep | c5fe22e6011610908c275e8f6591ba92529e8127 | [
"MIT"
] | null | null | null | fetcher.ipynb | ferdinandwp/dataprep | c5fe22e6011610908c275e8f6591ba92529e8127 | [
"MIT"
] | null | null | null | 40.275184 | 1,284 | 0.560029 | [
[
[
"# Import library\nimport numpy as np \nimport pandas as pd \nimport os \nimport glob \nimport sys \nfrom sqlalchemy import create_engine \nimport sqlalchemy as db \n\nfrom fetcher.async_fetcher import FetchMSPDataAsync ",
"_____no_output_____"
],
[
"MSP_ROOT_URL = \"https://allegiscloud.sharepoint.com\"\nMSP_USERNAME = \"[email protected]\"\nMSP_PASS = \"Dart23499\"\n\nif __name__ == \"__main__\":\n \n table_df_dict = FetchMSPDataAsync(\n [MSP_ROOT_URL, MSP_USERNAME, MSP_PASS],\n [\n \"Projects\"\n# \"Tasks\",\n# \"Assignments\",\n# \"Resources\"\n# \"ResourceTimephasedDataSet\",\n# \"ResourceDemandTimephasedDataSet\",\n# \"AssignmentTimephasedDataSet\",\n# \"AssignmentBaselineTimephasedDataSet\",\n# \"ProjectBaselines\" \n ],\n ) ",
"------- Getting available fields in MSP Project Online -------\n"
],
[
"# Fetch dataframe\nprj_df = table_df_dict['Projects']\ntsk_df = table_df_dict['Tasks']\nass_df = table_df_dict['Assignments']\nres_df = table_df_dict['Resources']\nrt_df = table_df_dict['ResourceTimephasedDataSet']\nrdt_df = table_df_dict['ResourceDemandTimephasedDataSet'] # May not need this\nast_df = table_df_dict['AssignmentTimephasedDataSet']\nasbt_df = table_df_dict['AssignmentBaselineTimephasedDataSet']\nprjb_df = table_df_dict['ProjectBaselines']",
"_____no_output_____"
],
[
"prj_df.shape, res_df.shape, ass_df.shape, tsk_df.shape, rdt_df.shape, rt_df.shape, ast_df.shape",
"_____no_output_____"
],
[
"# Filter active vs unactive project\nprj_df = prj_df[prj_df.ProjectActualFinishDate.isnull()]\nres_df = res_df[res_df['DataCentralID'].apply(lambda x: len(str(x)) == 8)]",
"_____no_output_____"
],
[
"# MAIN DATAFRAME\ntemp1_df = prj_df.merge(tsk_df, left_on='ProjectId', right_on='ProjectId', how='right') # This is for project and task dataset\ntemp2_df = temp1_df.merge(ass_df, left_on='TaskId', right_on='TaskId', how='inner') # join to assignment df\ntemp3_df = temp2_df.loc[temp2_df['ResourceId'].isin(res_df['ResourceId'])]\n\nnature_filter = ['Actual Work','Potential Work','At risk Work']\ntemp4_df = temp3_df.loc[temp3_df['ProjectNature'].isin(nature_filter)]\ntemp5_df = temp4_df.loc[:,['ResourceId',\n 'ProjectNature']]\n\ntemp5_df.rename({'ProjectNature':'work_nature'}, axis=1, inplace=True)",
"_____no_output_____"
],
[
"# CAPACITY DATASET\nrt_temp_df = rt_df.loc[rt_df['ResourceId'].isin(res_df['ResourceId'])]\nres_capacity_df = rt_temp_df.merge(res_df, left_on=['ResourceId','ResourceName','ResourceModifiedDate'], right_on=['ResourceId','ResourceName','ResourceModifiedDate'], how='inner')\n\n# DEMAND DATASET\nrdt_temp_df = rdt_df.loc[rdt_df['ResourceId'].isin(res_df['ResourceId'])]\nres_demand_df = rdt_temp_df.merge(res_df, left_on=['ResourceId','ResourceName'], right_on=['ResourceId','ResourceName'], how='inner')\n\n# MERGE LOAD & CAPACITY\ncombined_df = res_capacity_df.merge(res_demand_df, on=['ResourceId','TimeByDay'], how='inner')\n\n# DATA LOC for processing\ndem_cap_df = combined_df.loc[:,['ResourceId',\n 'DataCentralID_x',\n 'TimeByDay',\n 'Capacity',\n 'ResourceDemand']]\ndem_cap_df.rename({'DataCentralID_x':'easi_id',\n 'TimeByDay':'time',\n 'Capacity':'capacity',\n 'ResourceDemand':'demand'},axis=1,inplace=True)\ndem_cap_df.dropna()\ndem_cap_df.shape",
"_____no_output_____"
],
[
"# COMBINED MAIN DATAFRAME & LOAD CAP DATAFRAME\nx = dem_cap_df.merge(temp5_df, on='ResourceId', how='inner')\n\n# Change datatypes for optmization\nx['easi_id'] = x['easi_id'].astype('int64')\nx['demand'] = x['demand'].astype('float16')\nx['capacity'] = x['capacity'].astype('float16')\nx['time'] = x['time'].astype('datetime64[ns]')",
"_____no_output_____"
],
[
"# CALL DATASET FROM DB\nengine = db.create_engine('mysql+pymysql://mikeez:[email protected]:3306/dc_dev', echo=False)\nres_db_df = pd.read_sql_query(\"SELECT easi_id, first_name, last_name, team, base FROM resources\", engine)\nteam_db_df = pd.read_sql_query(\"SELECT * FROM teams\", engine)\ndep_db_df = pd.read_sql_query(\"SELECT * FROM departments\", engine)\n\n# Data prep\ndb1_df = res_db_df.merge(team_db_df, left_on='team', right_on='id', how='left')\ndb2_df = db1_df.merge(dep_db_df, left_on='department',right_on='id', how='left')\ndb2_df['full_name'] = db2_df['last_name'] + \",\" + db2_df['first_name']\ndb3_df = db2_df.loc[:,['easi_id',\n 'full_name',\n 'name_x',\n 'name_y'\n ]]\ndb3_df.rename({'name_x':'team',\n 'name_y':'department'}, axis=1, inplace=True)\n\nres_db_fil = ['MEC','SES']\ndb4_df = db3_df.loc[db3_df['department'].isin(res_db_fil)]",
"_____no_output_____"
],
[
"# JOIN WITH DB DATAFRAME\nx1 = x.merge(db4_df, left_on='easi_id', right_on='easi_id', how='inner')\n\nx2 = x1.loc[:,['work_nature',\n 'demand',\n 'capacity',\n 'time',\n 'full_name',\n 'team',\n 'department']]",
"_____no_output_____"
],
[
"# FILTER OUT EXPIRED DATASET\nend_df = x2.loc[x2['time'] > '2019-12-31']",
"_____no_output_____"
],
[
"# Split into 3 dataframes depending on work nature\nend_df['time'] = pd.to_datetime(end_df['time']).apply(lambda x: '{year}-{month}'.format(year=x.year, month=x.month))\n\nact_filter = ['Actual Work']\npot_filter = ['Potential Work']\nris_filter = ['At risk Work']\n\nact_df = end_df.loc[end_df['work_nature'].isin(act_filter)]\npot_df = end_df.loc[end_df['work_nature'].isin(pot_filter)]\nris_df = end_df.loc[end_df['work_nature'].isin(ris_filter)]\n",
"_____no_output_____"
],
[
"# Group by the time and name\nact_agg_df = act_df.groupby(['full_name','time'])['demand','capacity'].sum().reset_index()\npot_agg_df = pot_df.groupby(['full_name','time'])['demand','capacity'].sum().reset_index()\nris_agg_df = ris_df.groupby(['full_name','time'])['demand','capacity'].sum().reset_index()",
"_____no_output_____"
],
[
"act_agg_df.shape",
"_____no_output_____"
],
[
"end_df['time'] = pd.to_datetime(end_df['time']).apply(lambda x: '{year}-{month}'.format(year=x.year, month=x.month))\ntest = end_df.groupby(['full_name','time'])['demand','capacity'].sum().reset_index()\ntest.head()",
"_____no_output_____"
],
[
"# INJECT TO DB\n# end_df.to_sql('timephases',con=engine, if_exists='append', index=False)",
"_____no_output_____"
],
[
"#---------------------- TO BE TESTED----------------------#\n#------------- TEST METHOD SPLIT per dataset -------------#\n#----------------------TO BE TESTED----------------------#\nres_cap_df = res_capacity_df.loc[:,['ResourceId',\n 'Capacity',\n 'TimeByDay',\n 'DataCentralID'\n ]]\n\nres_cap_df.rename({'Capacity':'capacity',\n 'TimeByDay':'time',\n 'DataCentralID':'easi_id'}, axis=1, inplace=True)\n\n\nres_cap_df.shape",
"_____no_output_____"
],
[
"temp5_df.loc[temp5_df['ResourceId']== 'ee4cf8ec-b0de-e811-9640-d4258bdae0ca']\n",
"_____no_output_____"
],
[
"# merge with main df\nz = res_cap_df.merge(temp5_df, on='ResourceId', how='inner')\n\n# convert dataset\nz['easi_id'] = z['easi_id'].astype('int64')\nz['capacity'] = z['capacity'].astype('float16')\nz['time'] = z['time'].astype('datetime64[ns]')\nz['capacity'] = z['capacity'].apply(lambda x: round(x,1))\n\n# JOIN WITH DB DATAFRAME\nz1 = z.merge(db4_df, left_on='easi_id', right_on='easi_id', how='inner')\n\nz2 = z1.loc[:,['work_nature',\n 'capacity',\n 'time',\n 'full_name',\n 'team',\n 'department']]\n\n\nz2['time'] = pd.to_datetime(z['time']).apply(lambda x: '{year}-{month}'.format(year=x.year, month=x.month))\n\nz2_act_filter = ['Actual Work']\nz2_pot_filter = ['Potential Work']\nz2_ris_filter = ['At risk Work']\n\nz2_act_df = z2.loc[z2['work_nature'].isin(z2_act_filter)]\nz2_pot_df = z2.loc[z2['work_nature'].isin(z2_pot_filter)]\nz2_ris_df = z2.loc[z2['work_nature'].isin(z2_ris_filter)]\n\nz2_act_df = z2_act_df.loc[z2_act_df['time'] > '2020-00']\n",
"_____no_output_____"
],
[
"z3 = z2_act_df.loc[z2_act_df['time'] > '2020-00']\n",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73cbff35ca303caaad884b241484ad4a0befc52 | 11,562 | ipynb | Jupyter Notebook | lectures/21_lecture/bnb_integer.ipynb | edmund735/companion | 95ef489b6f79f8c375c4ac060c3c1a1506332f8c | [
"MIT"
] | 6 | 2021-01-12T08:56:54.000Z | 2022-02-09T01:01:34.000Z | lectures/21_lecture/bnb_integer.ipynb | edmund735/companion | 95ef489b6f79f8c375c4ac060c3c1a1506332f8c | [
"MIT"
] | null | null | null | lectures/21_lecture/bnb_integer.ipynb | edmund735/companion | 95ef489b6f79f8c375c4ac060c3c1a1506332f8c | [
"MIT"
] | 25 | 2021-01-31T00:44:40.000Z | 2022-03-25T12:43:56.000Z | 32.661017 | 101 | 0.43617 | [
[
[
"import matplotlib.pyplot as plt\nimport cvxpy as cp\nimport numpy as np\nplt.rcParams.update({\n \"text.usetex\": True,\n \"font.family\": \"sans-serif\",\n \"font.sans-serif\": [\"Helvetica Neue\"],\n \"font.size\": 28,\n})",
"_____no_output_____"
],
[
"# Utility functions\ndef polish(x, tol=1e-03):\n idx = np.isclose(x, np.round(x), rtol=1e-03, atol=1e-04)\n x = np.copy(x)\n x[idx] = np.round(x[idx])\n return x\n\n\ndef is_feasible(x, tol=1e-3):\n \"\"\"Determines if x is in the feasible set Ax <= b (with tolerance).\"\"\"\n if np.any(A @ x - b > tol):\n return False\n return True\n\n \ndef argmin_leaves(nodes, Uglob):\n \"\"\"Returns the node with lowest lower bound, from a list of nodes.\n \"\"\"\n m = min([x.lower for x in nodes])\n for x in nodes:\n if x.lower == m:\n return x\n \ndef incumbent(Uglob, incumbent, left, right):\n if Uglob == left.upper:\n return left.incumbent\n elif Uglob == right.upper:\n return right.incumbent\n else:\n return incumbent",
"_____no_output_____"
],
[
"# Define node object\nclass node:\n \"\"\"Create node of a branch-and-bound tree with size n. Specify the\n optional parent if the node is not at the top of the tree.\n \"\"\"\n\n def __init__(self, n, cuts=[], parent=None):\n self.cuts = cuts\n self.parent = parent\n self.left = None\n self.right = None\n self.n = n\n self.alive = True\n self.incumbent = None\n self.x_relaxed = None\n self.lower = np.inf\n self.upper = np.inf\n \n def depth(self):\n d = 0\n p = self.parent\n while p is not None:\n d += 1\n p = p.parent \n return d\n \n def solve(self):\n \"\"\"Find upper and lower bounds of the sub-problem belonging to\n this node.\"\"\"\n x = cp.Variable(self.n)\n\n constraints = [A @ x <= b]\n for i, d, f in self.cuts:\n constraints += [d * x[i] <= f]\n\n problem = cp.Problem(cp.Minimize(c @ x), constraints)\n problem.solve()\n\n if x.value is None:\n # We couldn't find a solution.\n self.raw = None\n self.lower = np.inf\n self.upper = np.inf\n return np.inf\n\n # Use heuristic to choose which variable we should split on next. Don't\n # choose a variable we have already set.\n x_polish = polish(x.value)\n self.x_relaxed = x_polish\n x_round = np.round(x_polish)\n self.picknext = np.argmax(abs(x_polish - x_round))\n self.lower = problem.objective.value\n\n if is_feasible(x_round):\n self.upper = c @ x_round\n self.incumbent = x_round\n else:\n self.upper = np.inf\n \n return self.upper\n\n def addleft(self):\n \"\"\"Add a node to the left-hand side of the tree and solve.\"\"\"\n if self.left is None:\n # add cut by rounding relaxation solution\n new_cut = [(self.picknext, 1, np.floor(self.x_relaxed[self.picknext]))]\n self.left = node(self.n, self.cuts + new_cut, self)\n\n self.left.solve()\n return self.left\n \n def addright(self):\n \"\"\"Add a node to the right-hand side of the tree and solve.\"\"\"\n if self.right is None:\n # add cut by rounding relaxation solution\n new_cut = [(self.picknext, -1, -np.ceil(self.x_relaxed[self.picknext]))]\n self.right = node(self.n, self.cuts + new_cut, self)\n\n self.right.solve()\n return self.right\n \n def nodes(self, all=False):\n \"\"\"Returns a list of all nodes that live at, or below, this point.\n\n If all is False, return nodes only if they are stil alive.\n \"\"\"\n\n coll = []\n if self.alive or all:\n coll += [self]\n if self.left is not None and (self.left.alive or all):\n coll += self.left.nodes(all)\n if self.right is not None and (self.right.alive or all):\n coll += self.right.nodes(all)\n\n return coll\n\n def __repr__(self, level=0):\n \"\"\"Utility to display bnb tree\"\"\"\n ret = \"\\t\"*level+repr(self.depth())\n ret += ' <node: cuts=%d, L=%.2f, U=%.2f>' % (len(self.cuts), self.lower, self.upper)\n if any(self.cuts):\n ret += \"\\n\"\n for i, d, f in self.cuts:\n ret += \"\\t\"*level+\" %.2f x_%d <= %.2f\\n\" % (d, i, f)\n else:\n ret += \"\\n\"\n \n if self.incumbent is not None:\n ret += \"\\t\"*level+\" incumbent = \" + str(self.incumbent) + \"\\n\"\n \n if self.x_relaxed is not None:\n ret += \"\\t\"*level+\" x_rel = \" + str(self.x_relaxed) + \"\\n\"\n \n if self.left is not None:\n ret += self.left.__repr__(level+1)\n if self.right is not None:\n ret += self.right.__repr__(level+1)\n return ret\n ",
"_____no_output_____"
],
[
"def solve_bb(c, A, b):\n # Initialize history\n uppers = []\n lowers = []\n leavenums = []\n incumbents = []\n\n # Create the top node in the tree.\n top = node(n)\n\n Uglob = top.solve()\n incumbents.append(top.incumbent)\n Lglob = -np.inf\n leaves = [top]\n iter = 0\n max_iter = 20000\n tol = 1e-03\n\n # Expand the tree until the gap has disappeared.\n print(\"Branch and bound iterations\")\n while Uglob - Lglob > tol:\n iter += 1\n # Expand the leaf with lowest lower bound.\n l = argmin_leaves(leaves, Uglob)\n left = l.addleft()\n right = l.addright()\n leaves.remove(l)\n leaves += [left, right]\n\n Lglob = min([x.lower for x in leaves])\n Uglob = min(Uglob, left.upper, right.upper)\n x_bb = incumbent(Uglob, incumbents[-1], left, right)\n\n # Prune anything except the currently optimal solution. Doesn't\n # actually affect the progress of the algorithm.\n for x in top.nodes():\n if x.lower > Uglob and x.upper != Uglob:\n x.alive = False\n\n print(\"iter %3d. L: %.5f, U: %.0f\" %\n (iter, Lglob, Uglob))\n\n # History\n lowers.append(Lglob)\n uppers.append(Uglob)\n leavenums.append(len([1 for x in leaves if x.alive]))\n incumbents.append(x_bb)\n\n if iter >= max_iter:\n break\n\n print(\"done.\")\n \n return x_bb, top, iter, lowers, uppers, leavenums",
"_____no_output_____"
],
[
"# Solve small integer optimization from lecture\nm, n = 4, 2\nA = np.array([[2/9, 1/4],\n [1/7, 1/3],\n [-1, 0],\n [0, -1]])\nb = np.array([1, 1, 0, 0])\nc = np.array([-2, -3])\n\n\n# Solve with BB\nx_bb, tree, iter, lowers, uppers, leavenums = solve_bb(c, A, b)\n\n# Solve with GLPK\nx = cp.Variable(n, integer=True)\nproblem = cp.Problem(cp.Minimize(c @ x), [A @ x <= b])\nproblem.solve(solver=cp.GLPK_MI)\nx_glpk = x.value\n\nprint(\"bnb solution x = \", x_bb)\nprint(\"glpk solution x = \", x_glpk)",
"Branch and bound iterations\niter 1. L: -10.42857, U: -10\niter 2. L: -10.00000, U: -10\ndone.\nbnb solution x = [2. 2.]\nglpk solution x = [2. 2.]\n"
],
[
"# Print branch and bound tree\ntree",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73ccf57a9e7b3a3cae84ec0e8b78a5a32d1032b | 37,648 | ipynb | Jupyter Notebook | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode | 613391c4c263afa34d440b3c120d9a446471b9ad | [
"MIT"
] | 12 | 2019-08-23T18:52:20.000Z | 2022-02-23T18:55:27.000Z | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode | 613391c4c263afa34d440b3c120d9a446471b9ad | [
"MIT"
] | null | null | null | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode | 613391c4c263afa34d440b3c120d9a446471b9ad | [
"MIT"
] | 510 | 2019-05-23T17:45:22.000Z | 2022-03-16T02:13:45.000Z | 30.484211 | 633 | 0.544544 | [
[
[
"# Module 2 - Python Fundamentals\n## Sequence: Lists \n- **List Creation**\n- **List Access**\n- List Append\n- List Insert\n- List Delete\n\n----- \n\n><font size=\"5\" color=\"#00A0B2\" face=\"verdana\"> <B>Student will be able to</B></font> \n- **Create Lists**\n- **Access items in a list**\n- Add Items to the end of a list\n- Insert items into a list\n- Delete items from a list",
"_____no_output_____"
],
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## Creating Lists\n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/933c4e57-93ae-4660-8725-6eff3987dd1c/Unit2_Section2.1a-Creating_Lists.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/933c4e57-93ae-4660-8725-6eff3987dd1c/Unit2_Section2.1a-Creating_Lists.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\nA simple lists contains **comma separated** objects enclosed in **square brackets** \n```python\nempty_list = [ ]\nsample_list = [1, 1, 2, 3, 3, 3, 3, 4, 5, 5, 5, 5, 5]\n```\n\nList object types are not restricted so a mix of object types can be in single list\n```python\nmixed_list = [1, 1, \"one\", \"two\", 2.0, sample_list, \"Hello World\"]\n```",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Examples</B></font>",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\n# define list of strings\nft_bones = [\"calcaneus\", \"talus\", \"cuboid\", \"navicular\", \"lateral cuneiform\", \"intermediate cuneiform\", \"medial cuneiform\"]\n\n# display type information\nprint(\"ft_bones: \", type(ft_bones))\n\n# print the list\nprint(ft_bones)",
"_____no_output_____"
],
[
"# [ ] review and run example\n# define list of integers\nage_survey = [12, 14, 12, 29, 12, 14, 12, 12, 13, 12, 14, 13, 13, 46, 13, 12, 12, 13, 13, 12, 12]\n\n# display type information\nprint(\"age_survey: \", type(age_survey))\n\n# print the list\nprint(age_survey)",
"_____no_output_____"
],
[
"# [ ] review and run example\n# define list of mixed data type\nmixed_list = [1, 34, 0.999, \"dog\", \"cat\", ft_bones, age_survey]\n\n# display type information\nprint(\"mixed_list: \", type(mixed_list))\n\n# print the list\nprint(mixed_list)",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 1</B></font>\n\n## Create Lists",
"_____no_output_____"
]
],
[
[
"# [ ] create team_names list and populate with 3-5 team name strings\n\n# [ ] print the list\n\n",
"_____no_output_____"
],
[
"# [ ] Create a list mix_list with numbers and strings with 4-6 items\n\n# [ ] print the list\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## List Access \n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/efc23682-3b15-4c73-afe0-77067fac2769/Unit2_Section2.1b-Accessing_Lists.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/efc23682-3b15-4c73-afe0-77067fac2769/Unit2_Section2.1b-Accessing_Lists.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\n### Counting like a computer\n#### To access a list we need to count like a computer, and that means starting with zero (0)\nLists give an **index** number to each list item\n\n- first element in a list is index 0\n- second element in a list is index 1\n\nTo access the first item in a list use the list name, followed by square brackets containing the index number\n```python\nage_survey[0]\n```\n",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Examples</B></font>\n\n|run previous examples before running the examples below|\n|-----------------------------------------------------------|\n",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\nprint(ft_bones[0], \"is the 1st bone on the list\")\nprint(ft_bones[2], \"is the 3rd bone on the list\")\nprint(ft_bones[-1], \"is the last bone on the list\")",
"_____no_output_____"
],
[
"# [ ] review and run example\nprint(ft_bones[1], \"is connected to the\",ft_bones[3])",
"_____no_output_____"
],
[
"# [ ] review and run example\nthree_ages_sum = age_survey[0] + age_survey[1] + age_survey[2]\nprint(\"The first three ages total\", three_ages_sum)",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 2</B></font>\n",
"_____no_output_____"
]
],
[
[
"# [ ] Create a list, streets, that lists the name of 5 street name strings\n\n# [ ] print a message that there is \"No Parking\" on index 0 or index 4 streets\n\n",
"_____no_output_____"
],
[
"# [ ] Create a list, num_2_add, made of 5 different numbers between 0 - 25\n\n# [ ] print the sum of the numbers\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 3</B></font> \n## Fix the Errors",
"_____no_output_____"
]
],
[
[
"# [ ] Review & Run, but ***Do Not Edit*** this code cell\n# [ ] Fix the error by only editing and running the block below\n\nprint(\" Total of checks 3 & 4 = $\", pay_checks[2] + pay_checks[3])\n",
"_____no_output_____"
],
[
"# [ ] Fix the error above by creating and running code in this cell\n\n",
"_____no_output_____"
]
],
[
[
"# Module 2 Part 2\n## Lists \n- List Creation\n- List Access\n- **List Append**\n- List Insert\n- List Delete\n\n----- \n\n><font size=\"5\" color=\"#00A0B2\" face=\"verdana\"> <B>Student will be able to</B></font> \n- Create Lists\n- Access items in a list\n- **Add Items to the end of a list**\n- Insert items into a list\n- Delete items from a list",
"_____no_output_____"
],
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## Appending to Lists\n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/121939c6-f81e-4787-a7a9-15ab15c69168/Unit2_Section2.2a-Appending_to_Lists.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/121939c6-f81e-4787-a7a9-15ab15c69168/Unit2_Section2.2a-Appending_to_Lists.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\n**`.append()`** method adds an item to the end of a list \n```python\nparty_list.append(\"Alton\")\n```",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Examples</B></font>",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\n# the list before append\nsample_list = [1, 1, 2]\nprint(\"sample_list before: \", sample_list)\n\nsample_list.append(3)\n# the list after append\nprint(\"sample_list after: \", sample_list)",
"_____no_output_____"
],
[
"# [ ] review and run example\n# append number to sample_list\nprint(\"sample_list start: \", sample_list)\nsample_list.append(3)\nprint(\"sample_list added: \", sample_list)\n\n# append again\nsample_list.append(8)\nprint(\"sample_list added: \", sample_list)\n\n# append again\nsample_list.append(5)\nprint(\"sample_list added: \", sample_list)\n\n# [ ] run this cell several times in a row \n# [ ] run cell above, then run this cell again",
"_____no_output_____"
],
[
"# [ ] review and run example\nmixed_types = [1, \"cat\"]\n# append number\nmixed_types.append(3)\nprint(\"mixed_types list: \", mixed_types)\n\n# append string\nmixed_types.append(\"turtle\")\nprint(\"mixed_types list: \", mixed_types)",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 4</B></font>\n\n## `.append()`",
"_____no_output_____"
]
],
[
[
"# Currency Values\n# [ ] create a list of 3 or more currency denomination values, cur_values\n# cur_values, contains values of coins and paper bills (.01, .05, etc.)\n\n# [ ] print the list\n\n\n# [ ] append an item to the list and print the list\n \n",
"_____no_output_____"
],
[
"# Currency Names\n# [ ] create a list of 3 or more currency denomination NAMES, cur_names\n# cur_names contains the NAMES of coins and paper bills (penny, etc.)\n\n# [ ] print the list\n\n\n# [ ] append an item to the list and print the list\n \n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 5</B></font> \n## Append items to a list with `input()` ",
"_____no_output_____"
]
],
[
[
"# [ ] append additional values to the Currency Names list using input()\n\n# [ ] print the appended list\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 6</B></font>\n## `while` loop `.append()`\n- define an empty list: **`bday_survey`** \n- get user input, **`bday`**, asking for the day of the month they were born (1-31) or \"q\" to finish \n- using a **`while`** loop (while user not entering \"quit\")\n - append the **`bday`** input to the **`bday_survey`** list \n - get user input, **`bday`**, asking for the day of the month they were born (1-31) or \"q\" to finish \n- print bday_survey list \n",
"_____no_output_____"
]
],
[
[
"# [ ] complete the Birthday Survey task above\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 7</B></font>\n## Fix The Error\n",
"_____no_output_____"
]
],
[
[
"# [ ] Fix the Error\nthree_numbers = [1, 1, 2]\nprint(\"an item in the list is: \", three_numbers[3])\n\n",
"_____no_output_____"
]
],
[
[
"# Module 2 Part 3\n## Lists \n- List Creation\n- List Access\n- List Append\n- **List *modify* and Insert**\n- List Delete\n\n----- \n\n><font size=\"5\" color=\"#00A0B2\" face=\"verdana\"> <B>Student will be able to</B></font> \n- Create Lists\n- Access items in a list\n- Add Items to the end of a list\n- **Modify and insert items into a list**\n- Delete items from a list",
"_____no_output_____"
],
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## Insert a new value for an index\n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/219b35cf-03b5-4b57-8fbc-f5864281312d/Unit2_Section2.3a-Overwriting_an_Index.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/219b35cf-03b5-4b57-8fbc-f5864281312d/Unit2_Section2.3a-Overwriting_an_Index.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\n### overwrite a specific index in a list\n```python\nparty_list[2] = \"Tobias\"\n```\n- **Overwrites** existing index\n- **Cannot** use to **Append** a new index to the list\n",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Examples</B></font>",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\n# the list before Insert\nparty_list = [\"Joana\", \"Alton\", \"Tobias\"]\nprint(\"party_list before: \", party_list)\n\n# the list after Insert\nparty_list[1] = \"Colette\"\nprint(\"party_list after: \", party_list)",
"_____no_output_____"
],
[
"# [ ] review and run example\nparty_list = [\"Joana\", \"Alton\", \"Tobias\"]\nprint(\"before:\",party_list)\n\n# modify index value\nparty_list[1] = party_list[1] + \" Derosa\"\nprint(\"\\nafter:\", party_list)",
"_____no_output_____"
]
],
[
[
"<font size=\"3\" color=\"#00A0B2\" face=\"verdana\"> <B>Example</B></font> \n**IndexError** ",
"_____no_output_____"
]
],
[
[
"# IndexError Example\n# [ ] review and run example which results in an IndexError\n# if result is NameError run cell above before running this cell\n\n# IndexError trying to append to end of list\nparty_list[3] = \"Alton\"\nprint(party_list)",
"_____no_output_____"
],
[
"# [ ] review and run example changes the data type of an element\n# replace a string with a number (int)\nsingle_digits = [\"zero\", \"one\", \"two\", \"three\", \"four\", \"five\", \"six\", \"seven\", \"eight\", \"nine\"] \nprint(\"single_digits: \", single_digits)\nprint(\"single_digits[3]: \", single_digits[3], type(single_digits[3]),\"\\n\")\n\n# replace string with an int\nsingle_digits[3] = 3\nprint(\"single_digits: \", single_digits)\nprint(\"single_digits[3]: \", single_digits[3], type(single_digits[3]))",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 8</B></font>\n\n## replace items in a list\n- create a list, **`three_num`**, containing 3 single digit integers\n- print three_num\n- check if index 0 value is < 5\n - if < 5 , replace index 0 with a string: \"small\"\n - else, replace index 0 with a string: \"large\"\n- print three_num",
"_____no_output_____"
]
],
[
[
"# [ ] complete \"replace items in a list\" task\n\n \n",
"_____no_output_____"
]
],
[
[
"## Function Challenge: create replacement function\n- Create a function, **str_replace**, that takes 2 arguments: int_list and index \n - int_list is a list of single digit integers\n - index is the index that will be checked - such as with int_list[index]\n- Function replicates purpose of task \"replace items in a list\" above and replaces an integer with a string \"small\" or \"large\"\n- return int_list\n\nTest the function!",
"_____no_output_____"
]
],
[
[
"# [ ] create challenge function\n\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 9</B></font>\n\n## modify items in a list\n- create a list, **`three_words`**, containing 3 different capitalized word stings\n- print three_words\n- modify the first item in three_words to uppercase\n- modify the third item to swapcase\n- print three_words",
"_____no_output_____"
]
],
[
[
"# [ ] complete coding task described above\n\n \n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## Insert items into a list\n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/659b9cd2-1e84-4ead-8a69-015c737577cd/Unit2_Section2.3b-Inserting_Items_into_Lists.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/659b9cd2-1e84-4ead-8a69-015c737577cd/Unit2_Section2.3b-Inserting_Items_into_Lists.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\n### use `.insert()` to define an index to insert an item\n```python\nparty_list.insert(2,\"Tobias\")\n```\n- Inserts, **doesn't overwrite**\n- **Increases index by 1**, at and above the insertion point\n- **Can** use to **Append** a new index to the end of the list\n",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Examples</B></font>",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\n# the list before Insert\nparty_list = [\"Joana\", \"Alton\", \"Tobias\"]\nprint(\"party_list before: \", party_list)\nprint(\"index 1 is\", party_list[1], \"\\nindex 2 is\", party_list[2], \"\\n\")\n\n# the list after Insert\nparty_list.insert(1,\"Colette\")\nprint(\"party_list after: \", party_list)\nprint(\"index 1 is\", party_list[1], \"\\nindex 2 is\", party_list[2], \"\\nindex 3 is\", party_list[3])",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 10</B></font> \n## `insert()` input into a list ",
"_____no_output_____"
]
],
[
[
"# [ ] insert a name from user input into the party_list in the second position (index 1)\nparty_list = [\"Joana\", \"Alton\", \"Tobias\"]\n\n# [ ] print the updated list\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 11</B></font>\n## Fix The Error\n",
"_____no_output_____"
]
],
[
[
"# [ ] Fix the Error\ntree_list = \"oak\"\nprint(\"tree_list before =\", tree_list)\ntree_list.insert(1,\"pine\")\nprint(\"tree_list after =\", tree_list)\n\n",
"_____no_output_____"
]
],
[
[
"# Module 2 Part 4\n## Lists \n- List Creation\n- List Access\n- List Append\n- List Insert\n- **List Delete (`del`, `.pop()` & `.remove()`)**\n\n----- \n\n><font size=\"5\" color=\"#00A0B2\" face=\"verdana\"> <B>Student will be able to</B></font> \n- Create Lists\n- Access items in a list\n- Add Items to the end of a list\n- Insert items into a list\n- **Delete items from a list with `del`, `.pop()` & `.remove()`**",
"_____no_output_____"
],
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## Delete a specific List index\n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/072d8761-7811-438e-a77f-72c9634c0f8c/Unit2_Section2.4a-Deleting_Specific_Index.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/072d8761-7811-438e-a77f-72c9634c0f8c/Unit2_Section2.4a-Deleting_Specific_Index.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\n### `del ` statement \n```python\ndel party_list[2]\n```",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Examples</B></font>",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\n# the list before delete\nsample_list = [11, 21, 13, 14, 51, 161, 117, 181]\nprint(\"sample_list before: \", sample_list)\n\ndel sample_list[1]\n# the list after delete\nprint(\"sample_list after: \", sample_list)",
"_____no_output_____"
],
[
"# [ ] review and run example Multiple Times\n# [ ] consider how to reset the list values?\nprint(\"sample_list before:\", sample_list)\ndel sample_list[0]\nprint(\"sample_list after:\", sample_list)",
"_____no_output_____"
],
[
"# [ ] review and run example\nmixed_types = [1, \"cat\"]\n# append number\nmixed_types.append(3)\nprint(\"mixed_types list: \", mixed_types)\n\n# append string\nmixed_types.append(\"turtle\")\nprint(\"mixed_types list: \", mixed_types)",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 12</B></font>\n\n## `del` statement",
"_____no_output_____"
]
],
[
[
"# [ ] print ft_bones list\n# [ ] delete \"cuboid\" from ft_bones\n# [ ] reprint list\nft_bones = [\"calcaneus\", \"talus\", \"cuboid\", \"navicular\", \"lateral cuneiform\", \n \"intermediate cuneiform\", \"medial cuneiform\"]\n\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 13</B></font> \n## multiple `del` statements ",
"_____no_output_____"
]
],
[
[
"# [ ] print ft_bones list\n# [ ] delete \"cuboid\" from ft_bones\n# [ ] delete \"navicular\" from list\n# [ ] reprint list\n# [ ] check for deletion of \"cuboid\" and \"navicular\"\nft_bones = [\"calcaneus\", \"talus\", \"cuboid\", \"navicular\", \"lateral cuneiform\", \n \"intermediate cuneiform\", \"medial cuneiform\"]\n\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## .pop() gets and deletes item in list\n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/67b83f30-a92c-4d1f-a7a3-ca257dd4db4e/Unit2_Section2.4b-List_Pop_Method.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/67b83f30-a92c-4d1f-a7a3-ca257dd4db4e/Unit2_Section2.4b-List_Pop_Method.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\n### `.pop()` method default is last item in a list\n```python\nlast_item = party_list.pop()\nfirst_item = party_list.pop(0)\n```",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Examples</B></font>",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\n# pop() gets the last item by default\nparty_list = [\"Joana\", \"Alton\", \"Tobias\"]\nprint(party_list)\nprint(\"Hello,\", party_list.pop())\n\nprint(\"\\n\", party_list)\nprint(\"Hello,\", party_list.pop())\n\nprint(\"\\n\", party_list)\nprint(\"Hello,\", party_list.pop())\n\nprint(\"\\n\", party_list)",
"_____no_output_____"
],
[
"# [ ] review and run example\n# can pop specific index like pop(3)\nnumber_list = [11, 21, 13, 14, 51, 161, 117, 181]\nprint(\"before:\", number_list)\nnumber_list.pop(3)\nprint(\"after :\", number_list)\n",
"_____no_output_____"
],
[
"# [ ] review and run example\n# set a variable to a poped value\nnumber_list = [11, 21, 13, 14, 51, 161, 117, 181]\nprint(\"list before:\", number_list)\nnum_1 = number_list.pop()\nnum_2 = number_list.pop()\nprint(\"list after :\", number_list)\nprint(\"add the popped values:\", num_1, \"+\", num_2, \"=\", num_1 + num_2)",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 14</B></font> \n## `pop()`",
"_____no_output_____"
]
],
[
[
"# [ ] pop() and print the first and last items from the ft_bones list\nft_bones = [\"calcaneus\", \"talus\", \"cuboid\", \"navicular\", \"lateral cuneiform\", \n \"intermediate cuneiform\", \"medial cuneiform\"]\n\n# [ ] print the remaining list\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## an empty list is False\n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/20e00a13-a9d2-4a35-b75d-f6533fa15cbd/Unit2_Section2.4c-Empty_List_is_False.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/20e00a13-a9d2-4a35-b75d-f6533fa15cbd/Unit2_Section2.4c-Empty_List_is_False.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\n### in a conditional an empty list will evaluate `False`\nThis allows creating a while loop that runs until a list is empty\n```python\nwhile dog_types: \n```",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Example</B></font>",
"_____no_output_____"
]
],
[
[
"dog_types = [\"Lab\", \"Pug\", \"Poodle\"]\n\nwhile dog_types: \n print(dog_types.pop())",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 15 pt 1</B></font>\n# Cash Register Input\n- create a empty list `purchase_amounts`\n- populate the list with user input for the price of items\n- continue adding to list with `while` until \"done\" is entered\n - can use `while True:` with `break`\n- print `purchase_amounts`\n- continue to pt 2",
"_____no_output_____"
]
],
[
[
"#[ ] complete the Register Input task above\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 15 pt 2</B></font>\n# Cash Register Total\n- create a **`subtotal`** variable = 0\ncreate a while loop that runs **`while`** purchase_amount (is not empty)\n- inside the loop \n - **`pop()`** the last list value cast as a float type\n - add the float value to a **`subtotal`** variable\n- after exiting the loop print **`subtotal`** \n \n *be sure to populate purchase_amounts by running pt 1 above*",
"_____no_output_____"
]
],
[
[
"# [ ] complete the Register Total task above\n\n",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#00A0B2\" face=\"verdana\"> <B>Concepts</B></font>\n## Delete a specific object from a list with `.remove()`\n[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/31fadf38-670c-4ba9-aa68-1934db459c4d/Unit2_Section2.4d-Removing_Object_from_List.ism/manifest\",\"type\":\"application/vnd.ms-sstr+xml\"}],[{\"src\":\"http://jupyternootbookwams.streaming.mediaservices.windows.net/31fadf38-670c-4ba9-aa68-1934db459c4d/Unit2_Section2.4d-Removing_Object_from_List.vtt\",\"srclang\":\"en\",\"kind\":\"subtitles\",\"label\":\"english\"}])\n### `.remove(object)` removes the 1st item that matches\n\n```python\ndog_types.remove(\"Pug\")\n```\n>**`ValueError`** occurs if the object is not available to be removed ",
"_____no_output_____"
],
[
"\n<font size=\"4\" color=\"#00A0B2\" face=\"verdana\"> <B>Examples</B></font>",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\ndog_types = [\"Lab\", \"Pug\", \"Poodle\"]\n\nif \"Pug\" in dog_types:\n dog_types.remove(\"Pug\")\nelse:\n print(\"no Pug found\")\nprint(dog_types)",
"_____no_output_____"
],
[
"# [ ] review and run example\ndogs = [\"Lab\", \"Pug\", \"Poodle\", \"Poodle\", \"Pug\", \"Poodle\"]\n\nprint(dogs)\nwhile \"Poodle\" in dogs:\n dogs.remove(\"Poodle\")\n print(dogs)",
"_____no_output_____"
]
],
[
[
"### ValueError",
"_____no_output_____"
]
],
[
[
"# [ ] review and run example\n# Change to \"Lab\", etc... to fix error\ndogs.remove(\"Collie\")\nprint(dogs)",
"_____no_output_____"
]
],
[
[
"# \n<font size=\"6\" color=\"#B24C00\" face=\"verdana\"> <B>Task 16</B></font> \n## `.remove()`",
"_____no_output_____"
]
],
[
[
"# [ ] remove one \"Poodle\" from the list: dogs , or print \"no Poodle found\"\n# [ ] print list before and after\ndogs = [\"Lab\", \"Pug\", \"Poodle\", \"Poodle\", \"Pug\", \"Poodle\"]\n\n",
"_____no_output_____"
]
],
[
[
"[Terms of use](http://go.microsoft.com/fwlink/?LinkID=206977) [Privacy & cookies](https://go.microsoft.com/fwlink/?LinkId=521839) © 2017 Microsoft",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73cd6add3fe3012cd028f3427c928738d1f262a | 2,485 | ipynb | Jupyter Notebook | examples/ch13/snippets_ipynb/13_04selfcheck.ipynb | edson-gomes/Intro-to-Python | 00a2f549916616b0f2036401573e35d66317f998 | [
"MIT"
] | null | null | null | examples/ch13/snippets_ipynb/13_04selfcheck.ipynb | edson-gomes/Intro-to-Python | 00a2f549916616b0f2036401573e35d66317f998 | [
"MIT"
] | null | null | null | examples/ch13/snippets_ipynb/13_04selfcheck.ipynb | edson-gomes/Intro-to-Python | 00a2f549916616b0f2036401573e35d66317f998 | [
"MIT"
] | null | null | null | 35 | 202 | 0.523139 | [
[
[
"\n# 13.4 Self Check",
"_____no_output_____"
],
[
"**1. _(Fill-In)_** The consumer key, consumer secret, access token and access token secret are each part of the `________` authentication process that Twitter uses to enable access to its APIs.\n\n**Answer:** OAuth 2.0.\n\n**2. _(True/False)_** Once you have a Twitter developer account, you must obtain credentials to interact with APIs. To do so, you’ll create an app. Each app has separate credentials. \n\n**Answer:** True.\n\n\n",
"_____no_output_____"
]
],
[
[
"##########################################################################\n# (C) Copyright 2019 by Deitel & Associates, Inc. and #\n# Pearson Education, Inc. All Rights Reserved. #\n# #\n# DISCLAIMER: The authors and publisher of this book have used their #\n# best efforts in preparing the book. These efforts include the #\n# development, research, and testing of the theories and programs #\n# to determine their effectiveness. The authors and publisher make #\n# no warranty of any kind, expressed or implied, with regard to these #\n# programs or to the documentation contained in these books. The authors #\n# and publisher shall not be liable in any event for incidental or #\n# consequential damages in connection with, or arising out of, the #\n# furnishing, performance, or use of these programs. #\n##########################################################################\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
]
] |
e73ce85aafb83b357d9f9128c6f837fce711ca0e | 17,293 | ipynb | Jupyter Notebook | Applied Text Mining/Week1 - Working with Text in Python/Regex+with+Pandas+and+Named+Groups.ipynb | rajatgarg149/Data-Science-Python------Coursera-MICHIGAN- | 175d21881be7fcd7e0cb71c88351d31d35253863 | [
"MIT"
] | 2 | 2020-01-20T19:02:04.000Z | 2022-02-24T13:29:13.000Z | Applied Text Mining/Week1 - Working with Text in Python/Regex+with+Pandas+and+Named+Groups.ipynb | rajatgarg149/Data-Science-Python------Coursera-MICHIGAN- | 175d21881be7fcd7e0cb71c88351d31d35253863 | [
"MIT"
] | null | null | null | Applied Text Mining/Week1 - Working with Text in Python/Regex+with+Pandas+and+Named+Groups.ipynb | rajatgarg149/Data-Science-Python------Coursera-MICHIGAN- | 175d21881be7fcd7e0cb71c88351d31d35253863 | [
"MIT"
] | 1 | 2020-01-20T19:02:08.000Z | 2020-01-20T19:02:08.000Z | 26.241275 | 294 | 0.371653 | [
[
[
"---\n\n_You are currently looking at **version 1.0** of this notebook. To download notebooks and datafiles, as well as get help on Jupyter notebooks in the Coursera platform, visit the [Jupyter Notebook FAQ](https://www.coursera.org/learn/python-text-mining/resources/d9pwm) course resource._\n\n---",
"_____no_output_____"
],
[
"# Working with Text Data in pandas",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ntime_sentences = [\"Monday: The doctor's appointment is at 2:45pm.\", \n \"Tuesday: The dentist's appointment is at 11:30 am.\",\n \"Wednesday: At 7:00pm, there is a basketball game!\",\n \"Thursday: Be back home by 11:15 pm at the latest.\",\n \"Friday: Take the train at 08:10 am, arrive at 09:00am.\"]\n\ndf = pd.DataFrame(time_sentences, columns=['text'])\ndf",
"_____no_output_____"
],
[
"# find the number of characters for each string in df['text']\ndf['text'].str.len()",
"_____no_output_____"
],
[
"# find the number of tokens for each string in df['text']\ndf['text'].str.split().str.len()",
"_____no_output_____"
],
[
"# find which entries contain the word 'appointment'\ndf['text'].str.contains('appointment')",
"_____no_output_____"
],
[
"# find how many times a digit occurs in each string\ndf['text'].str.count(r'\\d')",
"_____no_output_____"
],
[
"# find all occurances of the digits\ndf['text'].str.findall(r'\\d')",
"_____no_output_____"
],
[
"# group and find the hours and minutes\ndf['text'].str.findall(r'(\\d?\\d):(\\d\\d)')",
"_____no_output_____"
],
[
"# replace weekdays with '???'\ndf['text'].str.replace(r'\\w+day\\b', '???')",
"_____no_output_____"
],
[
"# replace weekdays with 3 letter abbrevations\ndf['text'].str.replace(r'(\\w+day\\b)', lambda x: x.groups()[0][:3])",
"_____no_output_____"
],
[
"# create new columns from first match of extracted groups\ndf['text'].str.extract(r'(\\d?\\d):(\\d\\d)')",
"/opt/conda/lib/python3.6/site-packages/ipykernel/__main__.py:2: FutureWarning: currently extract(expand=None) means expand=False (return Index/Series/DataFrame) but in a future version of pandas this will be changed to expand=True (return DataFrame)\n from ipykernel import kernelapp as app\n"
],
[
"# extract the entire time, the hours, the minutes, and the period\ndf['text'].str.extractall(r'((\\d?\\d):(\\d\\d) ?([ap]m))')",
"_____no_output_____"
],
[
"# extract the entire time, the hours, the minutes, and the period with group names\ndf['text'].str.extractall(r'(?P<time>(?P<hour>\\d?\\d):(?P<minute>\\d\\d) ?(?P<period>[ap]m))')",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73ceba2025bc47f8151107309b11a7221b2e1f5 | 21,028 | ipynb | Jupyter Notebook | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python | 1aa02a5c0a5d2f194c20a56a68088012fbfa5da3 | [
"MIT"
] | 8 | 2020-09-02T03:59:02.000Z | 2022-01-08T23:36:19.000Z | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python | 1aa02a5c0a5d2f194c20a56a68088012fbfa5da3 | [
"MIT"
] | 1 | 2021-05-10T10:49:44.000Z | 2021-05-10T10:49:44.000Z | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python | 1aa02a5c0a5d2f194c20a56a68088012fbfa5da3 | [
"MIT"
] | 6 | 2019-11-13T13:33:30.000Z | 2021-10-06T09:56:43.000Z | 26.617722 | 396 | 0.551741 | [
[
[
"# Object Oriented Programming\n\nObject Oriented Programming (OOP) tends to be one of the major obstacles for beginners when they are first starting to learn Python.\n\nThere are many, many tutorials and lessons covering OOP so feel free to Google search other lessons, and I have also put some links to other useful tutorials online at the bottom of this Notebook.\n\nFor this lesson we will construct our knowledge of OOP in Python by building on the following topics:\n\n* Objects\n* Using the *class* keyword\n* Creating class attributes\n* Creating methods in a class\n* Learning about Inheritance\n* Learning about Special Methods for classes\n\nLets start the lesson by remembering about the Basic Python Objects. For example:",
"_____no_output_____"
]
],
[
[
"lst = [1,2,3]",
"_____no_output_____"
]
],
[
[
"Remember how we could call methods on a list?",
"_____no_output_____"
]
],
[
[
"lst.count(2)",
"_____no_output_____"
]
],
[
[
"What we will basically be doing in this lecture is exploring how we could create an Object type like a list. We've already learned about how to create functions. So let's explore Objects in general:\n\n## Objects\nIn Python, *everything is an object*. Remember from previous lectures we can use type() to check the type of object something is:",
"_____no_output_____"
]
],
[
[
"print(type(1))\nprint(type([]))\nprint(type(()))\nprint(type({}))",
"<class 'int'>\n<class 'list'>\n<class 'tuple'>\n<class 'dict'>\n"
]
],
[
[
"So we know all these things are objects, so how can we create our own Object types? That is where the <code>class</code> keyword comes in.\n## class\nUser defined objects are created using the <code>class</code> keyword. The class is a blueprint that defines the nature of a future object. From classes we can construct instances. An instance is a specific object created from a particular class. For example, above we created the object <code>lst</code> which was an instance of a list object. \n\nLet see how we can use <code>class</code>:",
"_____no_output_____"
]
],
[
[
"# Create a new object type called Sample\nclass Sample:\n pass\n\n# Instance of Sample\nx = Sample()\n\nprint(type(x))",
"<class '__main__.Sample'>\n"
]
],
[
[
"By convention we give classes a name that starts with a capital letter. Note how <code>x</code> is now the reference to our new instance of a Sample class. In other words, we **instantiate** the Sample class.\n\nInside of the class we currently just have pass. But we can define class attributes and methods.\n\nAn **attribute** is a characteristic of an object.\nA **method** is an operation we can perform with the object.\n\nFor example, we can create a class called Dog. An attribute of a dog may be its breed or its name, while a method of a dog may be defined by a .bark() method which returns a sound.\n\nLet's get a better understanding of attributes through an example.\n\n## Attributes\nThe syntax for creating an attribute is:\n \n self.attribute = something\n \nThere is a special method called:\n\n __init__()\n\nThis method is used to initialize the attributes of an object. For example:",
"_____no_output_____"
]
],
[
[
"class Dog:\n def __init__(self,breed):\n self.breed = breed\n \nsam = Dog(breed='Lab')\nfrank = Dog(breed='Huskie')",
"_____no_output_____"
]
],
[
[
"Lets break down what we have above.The special method \n\n __init__() \nis called automatically right after the object has been created:\n\n def __init__(self, breed):\nEach attribute in a class definition begins with a reference to the instance object. It is by convention named self. The breed is the argument. The value is passed during the class instantiation.\n\n self.breed = breed",
"_____no_output_____"
],
[
"Now we have created two instances of the Dog class. With two breed types, we can then access these attributes like this:",
"_____no_output_____"
]
],
[
[
"sam.breed",
"_____no_output_____"
],
[
"frank.breed",
"_____no_output_____"
]
],
[
[
"Note how we don't have any parentheses after breed; this is because it is an attribute and doesn't take any arguments.\n\nIn Python there are also *class object attributes*. These Class Object Attributes are the same for any instance of the class. For example, we could create the attribute *species* for the Dog class. Dogs, regardless of their breed, name, or other attributes, will always be mammals. We apply this logic in the following manner:",
"_____no_output_____"
]
],
[
[
"class Dog:\n \n # Class Object Attribute\n species = 'mammal'\n \n def __init__(self,breed,name):\n self.breed = breed\n self.name = name",
"_____no_output_____"
],
[
"sam = Dog('Lab','Sam')",
"_____no_output_____"
],
[
"sam.name",
"_____no_output_____"
]
],
[
[
"Note that the Class Object Attribute is defined outside of any methods in the class. Also by convention, we place them first before the init.",
"_____no_output_____"
]
],
[
[
"sam.species",
"_____no_output_____"
]
],
[
[
"## Methods\n\nMethods are functions defined inside the body of a class. They are used to perform operations with the attributes of our objects. Methods are a key concept of the OOP paradigm. They are essential to dividing responsibilities in programming, especially in large applications.\n\nYou can basically think of methods as functions acting on an Object that take the Object itself into account through its *self* argument.\n\nLet's go through an example of creating a Circle class:",
"_____no_output_____"
]
],
[
[
"class Circle:\n pi = 3.14\n\n # Circle gets instantiated with a radius (default is 1)\n def __init__(self, radius=1):\n self.radius = radius \n self.area = radius * radius * Circle.pi\n\n # Method for resetting Radius\n def setRadius(self, new_radius):\n self.radius = new_radius\n self.area = new_radius * new_radius * self.pi\n\n # Method for getting Circumference\n def getCircumference(self):\n return self.radius * self.pi * 2\n\n\nc = Circle()\n\nprint('Radius is: ',c.radius)\nprint('Area is: ',c.area)\nprint('Circumference is: ',c.getCircumference())",
"Radius is: 1\nArea is: 3.14\nCircumference is: 6.28\n"
]
],
[
[
"In the \\__init__ method above, in order to calculate the area attribute, we had to call Circle.pi. This is because the object does not yet have its own .pi attribute, so we call the Class Object Attribute pi instead.<br>\nIn the setRadius method, however, we'll be working with an existing Circle object that does have its own pi attribute. Here we can use either Circle.pi or self.pi.<br><br>\nNow let's change the radius and see how that affects our Circle object:",
"_____no_output_____"
]
],
[
[
"c.setRadius(2)\n\nprint('Radius is: ',c.radius)\nprint('Area is: ',c.area)\nprint('Circumference is: ',c.getCircumference())",
"Radius is: 2\nArea is: 12.56\nCircumference is: 12.56\n"
]
],
[
[
"Great! Notice how we used self. notation to reference attributes of the class within the method calls. Review how the code above works and try creating your own method.\n\n## Inheritance\n\nInheritance is a way to form new classes using classes that have already been defined. The newly formed classes are called derived classes, the classes that we derive from are called base classes. Important benefits of inheritance are code reuse and reduction of complexity of a program. The derived classes (descendants) override or extend the functionality of base classes (ancestors).\n\nLet's see an example by incorporating our previous work on the Dog class:",
"_____no_output_____"
]
],
[
[
"class Animal:\n def __init__(self):\n print(\"Animal created\")\n\n def whoAmI(self):\n print(\"Animal\")\n\n def eat(self):\n print(\"Eating\")\n\n\nclass Dog(Animal):\n def __init__(self):\n Animal.__init__(self)\n print(\"Dog created\")\n\n def whoAmI(self):\n print(\"Dog\")\n\n def bark(self):\n print(\"Woof!\")",
"_____no_output_____"
],
[
"d = Dog()",
"Animal created\nDog created\n"
],
[
"d.whoAmI()",
"Dog\n"
],
[
"d.eat()",
"Eating\n"
],
[
"d.bark()",
"Woof!\n"
]
],
[
[
"In this example, we have two classes: Animal and Dog. The Animal is the base class, the Dog is the derived class. \n\nThe derived class inherits the functionality of the base class. \n\n* It is shown by the eat() method. \n\nThe derived class modifies existing behavior of the base class.\n\n* shown by the whoAmI() method. \n\nFinally, the derived class extends the functionality of the base class, by defining a new bark() method.",
"_____no_output_____"
],
[
"## Polymorphism\n\nWe've learned that while functions can take in different arguments, methods belong to the objects they act on. In Python, *polymorphism* refers to the way in which different object classes can share the same method name, and those methods can be called from the same place even though a variety of different objects might be passed in. The best way to explain this is by example:",
"_____no_output_____"
]
],
[
[
"class Dog:\n def __init__(self, name):\n self.name = name\n\n def speak(self):\n return self.name+' says Woof!'\n \nclass Cat:\n def __init__(self, name):\n self.name = name\n\n def speak(self):\n return self.name+' says Meow!' \n \nniko = Dog('Niko')\nfelix = Cat('Felix')\n\nprint(niko.speak())\nprint(felix.speak())",
"Niko says Woof!\nFelix says Meow!\n"
]
],
[
[
"Here we have a Dog class and a Cat class, and each has a `.speak()` method. When called, each object's `.speak()` method returns a result unique to the object.\n\nThere a few different ways to demonstrate polymorphism. First, with a for loop:",
"_____no_output_____"
]
],
[
[
"for pet in [niko,felix]:\n print(pet.speak())",
"Niko says Woof!\nFelix says Meow!\n"
]
],
[
[
"Another is with functions:",
"_____no_output_____"
]
],
[
[
"def pet_speak(pet):\n print(pet.speak())\n\npet_speak(niko)\npet_speak(felix)",
"Niko says Woof!\nFelix says Meow!\n"
]
],
[
[
"In both cases we were able to pass in different object types, and we obtained object-specific results from the same mechanism.\n\nA more common practice is to use abstract classes and inheritance. An abstract class is one that never expects to be instantiated. For example, we will never have an Animal object, only Dog and Cat objects, although Dogs and Cats are derived from Animals:",
"_____no_output_____"
]
],
[
[
"class Animal:\n def __init__(self, name): # Constructor of the class\n self.name = name\n\n def speak(self): # Abstract method, defined by convention only\n raise NotImplementedError(\"Subclass must implement abstract method\")\n\n\nclass Dog(Animal):\n \n def speak(self):\n return self.name+' says Woof!'\n \nclass Cat(Animal):\n\n def speak(self):\n return self.name+' says Meow!'\n \nfido = Dog('Fido')\nisis = Cat('Isis')\n\nprint(fido.speak())\nprint(isis.speak())",
"Fido says Woof!\nIsis says Meow!\n"
]
],
[
[
"Real life examples of polymorphism include:\n* opening different file types - different tools are needed to display Word, pdf and Excel files\n* adding different objects - the `+` operator performs arithmetic and concatenation",
"_____no_output_____"
],
[
"## Special Methods\nFinally let's go over special methods. Classes in Python can implement certain operations with special method names. These methods are not actually called directly but by Python specific language syntax. For example let's create a Book class:",
"_____no_output_____"
]
],
[
[
"class Book:\n def __init__(self, title, author, pages):\n print(\"A book is created\")\n self.title = title\n self.author = author\n self.pages = pages\n\n def __str__(self):\n return \"Title: %s, author: %s, pages: %s\" %(self.title, self.author, self.pages)\n\n def __len__(self):\n return self.pages\n\n def __del__(self):\n print(\"A book is destroyed\")",
"_____no_output_____"
],
[
"book = Book(\"Python Rocks!\", \"Jose Portilla\", 159)\n\n#Special Methods\nprint(book)\nprint(len(book))\ndel book",
"A book is created\nTitle: Python Rocks!, author: Jose Portilla, pages: 159\n159\nA book is destroyed\n"
]
],
[
[
" The __init__(), __str__(), __len__() and __del__() methods\nThese special methods are defined by their use of underscores. They allow us to use Python specific functions on objects created through our class.\n\n**Great! After this lecture you should have a basic understanding of how to create your own objects with class in Python. You will be utilizing this heavily in your next milestone project!**\n\nFor more great resources on this topic, check out:\n\n[Mozilla's Post](https://developer.mozilla.org/en-US/Learn/Python/Quickly_Learn_Object_Oriented_Programming)\n\n[Tutorial's Point](http://www.tutorialspoint.com/python/python_classes_objects.htm)\n\n[Official Documentation](https://docs.python.org/3/tutorial/classes.html)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
e73cf6efb70b79322d8e7af65fc4fd9ab15f2090 | 24,068 | ipynb | Jupyter Notebook | Automated TL Binary.ipynb | AlexanderStoyanov/Transfer-Learning | b0e94af38d5209a02374c1b267d806300cef66ad | [
"MIT"
] | null | null | null | Automated TL Binary.ipynb | AlexanderStoyanov/Transfer-Learning | b0e94af38d5209a02374c1b267d806300cef66ad | [
"MIT"
] | null | null | null | Automated TL Binary.ipynb | AlexanderStoyanov/Transfer-Learning | b0e94af38d5209a02374c1b267d806300cef66ad | [
"MIT"
] | null | null | null | 50.037422 | 7,240 | 0.67517 | [
[
[
"#Partially adopted from Tensorflow/docs/basic_text_classification\n#https://github.com/tensorflow/docs/blob/master/site/en/tutorials/keras/basic_text_classification.ipynb\n\n#As well as https://developers.google.com/machine-learning/guides/text-classification/",
"_____no_output_____"
],
[
"import tensorflow as tf\nfrom tensorflow import keras\n\nfrom sklearn.utils import shuffle\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.feature_selection import SelectKBest\nfrom sklearn.feature_selection import f_classif\n\nimport numpy as np\nimport pandas as pd\n\nfrom data import Data, TestData, WikiData",
"[nltk_data] Downloading package punkt to /root/nltk_data...\n[nltk_data] Package punkt is already up-to-date!\n[nltk_data] Downloading package stopwords to /root/nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\n"
],
[
"data = []\nnoise = []\nwith open('Data/NFR.csv') as f:\n # Create two instances of data: fake (noise) and real (data)\n for sentence in f:\n cl = sentence[:sentence.find(',')]\n sentence = sentence[sentence.find(',')+1:]\n if cl == 'Security':\n data.append(sentence)\n else:\n noise.append(sentence)\n\n# Create two instances of data from fake and real\ntest_0 = TestData(noise, '0')\ntest_1 = TestData(data, '1')\n\n# Balance the data based on min length of both lists\ndeleteAfter = min(len(test_0.data), len(test_1.data))\ndel test_0.data[deleteAfter:]\ndel test_1.data[deleteAfter:]\ndel test_0.labels[deleteAfter:]\ndel test_1.labels[deleteAfter:]\n\n# Test that the data is balanced\nassert len(test_0.data) == len(test_1.data), 'Lengths of test datas are not equal'\nassert len(test_0.labels) == len(test_1.labels), 'Lengths of test labels are not equal'\nassert len(test_0.data) == len(test_0.labels), 'Lengths of test data and labels do not match'\nassert len(test_1.data) == len(test_1.labels), 'Lengths of test data and labels do not match'",
"Labels made successfully\nLabels made successfully\n"
],
[
"# Get train data from Wiki articles\ntrain_0 = WikiData(articlesFile='Data/enwiki-latest-all-titles-in-ns0', keyword='rand', size=500, labelValue='0')\ntrain_1 = WikiData(articlesFile='Data/enwiki-latest-all-titles-in-ns0', keyword='security', size=500, labelValue='1')",
"Article names in random list: 500\nLabels made successfully\nArticle names in the security list: 500\nLabels made successfully\n"
],
[
"# Balance the data based on min length of both lists\ndeleteAfter = min(len(train_0.data), len(train_1.data))\n\n# If min length is less than 100 sentences, test is invalid\nassert deleteAfter > 100, 'Train set is too small'\n\ndel train_0.data[deleteAfter:]\ndel train_1.data[deleteAfter:]\ndel train_0.labels[deleteAfter:]\ndel train_1.labels[deleteAfter:]\n\n# Test that the data is balanced\nassert len(train_0.data) == len(train_1.data), 'Lengths of train datas are not equal'\nassert len(train_0.labels) == len(train_1.labels), 'Lengths of train labels are not equal'\nassert len(train_0.data) == len(train_0.labels), 'Lengths of train data and labels do not match'\nassert len(train_1.data) == len(train_1.labels), 'Lengths of train data and labels do not match'\n\n#Collapse into single list\ntrainData = train_0.data + train_1.data\ntrainLabels = train_0.labels + train_1.labels\nx_test = test_0.data + test_1.data\ny_test = test_0.labels + test_1.labels\n\n#Shuffle two lists, save the order\ntrainData, trainLabels = shuffle(trainData, trainLabels)\nx_test, y_test = shuffle(x_test, y_test)\n\n#Get validation data\nvalidationToTrainRatio = 0.05\nvalidationSize = int(validationToTrainRatio * len(trainData))\nvalidationData = trainData[:validationSize]\nvalidationLabels = trainLabels[:validationSize]\ntrainData = trainData[validationSize:]\ntrainLabels = trainLabels[validationSize:]\n\n\nprint(\"\\nTest set length: %d\" % len(x_test))\nprint(\"Test labels set length: %d\" % len(y_test))\nprint(\"\\nValidation set length: %d\" % len(validationData))\nprint(\"Validation labels set length: %d\" % len(validationLabels))\nprint(\"\\nTrain set length: %d\" % len(trainData))\nprint(\"Train labels set length: %d\" % len(trainLabels))",
"\nTest set length: 708\nTest labels set length: 708\n\nValidation set length: 2248\nValidation labels set length: 2248\n\nTrain set length: 42722\nTrain labels set length: 42722\n"
],
[
"# Vectorizing train, validation, and test data\ntrainData = train_0.ngram_vectorize(data=trainData, labels=trainLabels)\n\nvalidationData = train_0.ngram_vectorize(\n data=validationData,\n vectorizer=train_0.vectorizer, \n selector=train_0.selector)\n\nx_test = train_0.ngram_vectorize(\n data=x_test,\n vectorizer=train_0.vectorizer, \n selector=train_0.selector)",
"_____no_output_____"
],
[
"# Binary classifier (model) construction method\ndef mlp_model(layers, units, dropout_rate, input_shape, num_classes):\n model = keras.Sequential()\n model.add(keras.layers.Dropout(rate=dropout_rate, input_shape=input_shape))\n for _ in range(layers-1):\n model.add(keras.layers.Dense(units=units, activation=tf.nn.relu))\n model.add(keras.layers.Dropout(rate=dropout_rate))\n\n model.add(keras.layers.Dense(units=32, activation=tf.nn.relu))\n model.add(keras.layers.Dropout(rate=dropout_rate))\n model.add(keras.layers.Dense(units=num_classes, activation=tf.nn.sigmoid))\n return model",
"_____no_output_____"
],
[
"# For parameters refer to the upper cell\nmodel = mlp_model(2, 64, 0.3, trainData.shape[1:], 1)\nmodel.summary()",
"WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/keras/layers/core.py:143: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/control_flow_ops.py:423: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nColocations handled automatically by placer.\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndropout (Dropout) (None, 20000) 0 \n_________________________________________________________________\ndense (Dense) (None, 64) 1280064 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 64) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 32) 2080 \n_________________________________________________________________\ndropout_2 (Dropout) (None, 32) 0 \n_________________________________________________________________\ndense_2 (Dense) (None, 1) 33 \n=================================================================\nTotal params: 1,282,177\nTrainable params: 1,282,177\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"# Learning rate could be further decreased for additional accuracy\nmodel.compile(optimizer=tf.train.AdamOptimizer(learning_rate=0.001),\n loss='binary_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"# Callbacks will prevent model from running if val_loss starts to increase\ncallbacks = [tf.keras.callbacks.EarlyStopping(\n monitor='val_loss', patience=2)]\n\n# Training the classifier (model)\nhistory = model.fit(trainData,\n trainLabels,\n epochs=20,\n callbacks=callbacks,\n batch_size=1024,\n validation_data=(validationData, validationLabels),\n verbose=2)",
"Train on 42722 samples, validate on 2248 samples\nWARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.cast instead.\nEpoch 1/20\n - 32s - loss: 0.6249 - acc: 0.7819 - val_loss: 0.4863 - val_acc: 0.8603\nEpoch 2/20\n - 31s - loss: 0.3863 - acc: 0.8677 - val_loss: 0.2877 - val_acc: 0.8901\nEpoch 3/20\n - 31s - loss: 0.2663 - acc: 0.8944 - val_loss: 0.2320 - val_acc: 0.9070\nEpoch 4/20\n - 33s - loss: 0.2265 - acc: 0.9079 - val_loss: 0.2159 - val_acc: 0.9181\nEpoch 5/20\n - 33s - loss: 0.2111 - acc: 0.9131 - val_loss: 0.2112 - val_acc: 0.9159\nEpoch 6/20\n - 30s - loss: 0.1961 - acc: 0.9189 - val_loss: 0.2119 - val_acc: 0.9124\nEpoch 7/20\n - 29s - loss: 0.1882 - acc: 0.9204 - val_loss: 0.2090 - val_acc: 0.9110\nEpoch 8/20\n - 29s - loss: 0.1819 - acc: 0.9236 - val_loss: 0.2093 - val_acc: 0.9141\nEpoch 9/20\n - 29s - loss: 0.1802 - acc: 0.9231 - val_loss: 0.2053 - val_acc: 0.9173\nEpoch 10/20\n - 29s - loss: 0.1732 - acc: 0.9245 - val_loss: 0.2051 - val_acc: 0.9141\nEpoch 11/20\n - 29s - loss: 0.1696 - acc: 0.9264 - val_loss: 0.2066 - val_acc: 0.9181\nEpoch 12/20\n - 28s - loss: 0.1623 - acc: 0.9301 - val_loss: 0.2055 - val_acc: 0.9150\n"
],
[
"# Calculating results\nresults = model.predict(x_test)\npred_labels = []\noccurences = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]\nfor x in results:\n if x <= 0.05:\n occurences[0] += 1\n pred_labels.append(0)\n elif x <= 0.15 and x > 0.05:\n occurences[1] += 1\n pred_labels.append(0)\n elif x <= 0.25 and x > 0.15:\n occurences[2] += 1\n pred_labels.append(0)\n elif x <= 0.35 and x > 0.25:\n occurences[3] += 1\n pred_labels.append(0)\n elif x <= 0.45 and x > 0.35:\n occurences[4] += 1\n pred_labels.append(0)\n elif x <= 0.55 and x > 0.45:\n occurences[5] += 1\n pred_labels.append(0)\n elif x <= 0.65 and x > 0.55:\n occurences[6] += 1\n pred_labels.append(0)\n elif x <= 0.75 and x > 0.65:\n occurences[7] += 1\n pred_labels.append(0)\n elif x <= 0.85 and x > 0.75:\n occurences[8] += 1\n pred_labels.append(0)\n elif x <= 0.95 and x > 0.85:\n occurences[9] += 1\n pred_labels.append(0)\n elif x <= 0.98 and x > 0.95:\n occurences[10] += 1\n pred_labels.append(1)\n elif x > 0.98:\n occurences[11] += 1\n pred_labels.append(1)\n\nTP = 0\nTN = 0\nFP = 0\nFN = 0\nfor x, y in zip(pred_labels, y_test):\n if x == 1 and y == 1:\n TP += 1\n elif x == 1 and y == 0:\n FP += 1\n elif x == 0 and y == 1:\n FN += 1\n elif x == 0 and y == 0:\n TN += 1",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score\nprint(occurences)\naccuracy = accuracy_score(y_test, pred_labels)\nprecision = precision_score(y_test, pred_labels)\nrecall = recall_score(y_test, pred_labels)\nfscore = f1_score(y_test, pred_labels)\nprint(\"Accuracy: %.4f\" % accuracy)\nprint(\"\\nPrecision: %.4f\\nRecall: %.4f\\nF-score: %.4f\" % (precision, recall, fscore))\nprint(\"\\nTP %d, TN %d, FP %d, FN %d\" % (TP, TN, FP, FN))\n\ndf = pd.DataFrame({'Occurences': occurences}, index=[0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95, 0.98])\nax = df.plot.bar(rot=0)",
"[10, 18, 15, 17, 12, 24, 25, 48, 75, 120, 99, 245]\nAccuracy: 0.7825\n\nPrecision: 0.7907\nRecall: 0.7684\nF-score: 0.7794\n\nTP 272, TN 282, FP 72, FN 82\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73d040ef328971ba42cc6d427b79a51a4e4950c | 4,339 | ipynb | Jupyter Notebook | astr-119-hw-3-corrected.ipynb | carlisavannah/astr-119-hw-3 | f4ecef1887f0539136786b6f249cf556cfa7a230 | [
"MIT"
] | null | null | null | astr-119-hw-3-corrected.ipynb | carlisavannah/astr-119-hw-3 | f4ecef1887f0539136786b6f249cf556cfa7a230 | [
"MIT"
] | 2 | 2018-10-25T19:49:41.000Z | 2018-11-06T07:12:00.000Z | astr-119-hw-3-corrected.ipynb | carlisavannah/astr-119-hw-3 | f4ecef1887f0539136786b6f249cf556cfa7a230 | [
"MIT"
] | null | null | null | 25.674556 | 80 | 0.439041 | [
[
[
"%matplotlib inline\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"def function_for_roots(x):\n a = 1.01\n b = -3.04\n c = 2.07\n return a*x**2 + b*x + c #returns the function 1.01x^2 - 3.04x + 2.07",
"_____no_output_____"
],
[
"def bisect(f,x_left,x_right,tol = 10e-6):\n if abs(f(x_left))<=tol and abs(f(x_right))<=tol:\n print(str(x_left)+ \" and \" + str(x_right) + \" is a zero.\")\n return [x_left, x_right]\n \n if abs(f(x_left))<=tol:\n print(str(x_left)+\" is a zero.\")\n return x_left\n \n if abs(f(x_right))<=tol:\n print(str(x_right)+\" is a zero.\")\n return x_right\n \n if(f(x_left)*f(x_right)>=0.0):\n print(\"same signs\")\n return None\n \n i_max = 10e5\n i = 0\n \n while True:\n if i > i_max:\n print(\"Max iteration\")\n break\n \n x_mid = (x_left + x_right) / 2.\n \n if abs(f(x_mid))<=tol:\n print(str(x_mid)+\" is a zero.\")\n return x_mid\n \n case =0\n \n if(f(x_left)*f(x_mid)>=0.0):\n case = 2\n # x_right = x_mid\n \n if(f(x_right)*f(x_mid)>=0.0):\n case = 1\n #x_left = x_mid\n \n if case == 1:\n x_right = x_mid\n if case == 2:\n x_left = x_mid\n \n i += 1\n print(i,x_left,x_right,x_mid,f(x_mid))",
"_____no_output_____"
],
[
"#Roots\nx1 = bisect(function_for_roots, 1.5, 2, 1e-6) #Root 1\nprint('x1=',x1)\nx2 = bisect(function_for_roots, 0, 1.5, 1e-6) #Root 2 \nprint('x2=',x2)\ny = 0.000001\nmin_fr = np.min(function_for_roots(x1))\nmax_fr = np.max(function_for_roots(x2)) \nprint(min_fr)\nprint(max_fr)\n\nprint(\"Root 1 took 15 iterations.\")\nprint(\"Root 2 took 17 iterations.\")",
"_____no_output_____"
],
[
"f = plt.figure(figsize=(10,10))\nn = 1000\n\nx=np.linspace(0,3,1000)\n\n#plots max and min\nplt.plot(1.5,min_fr,marker='o',color = 'r',label = 'Min')\nplt.plot(0,max_fr,marker='o',color = 'y',label = 'Max')\nplt.plot(3.0,max_fr,marker='o',color = 'y')\n\n\n#plots the roots of function\nplt.plot(x1,y,marker='o',color = 'b',label = 'Root')\nplt.plot(x2,y,marker='o',color = 'b')\n\n\nplt.plot(x,function_for_roots(x),label='Function')\n\n\nplt.xlabel('x')\nplt.ylabel('f(x)')\nplt.axhline(y=0, color='g', linestyle='-')\nplt.xlim(0,3)\nplt.ylim(-0.5,2.1)\nplt.legend(loc=3)\nplt.grid()\nplt.show()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
e73d116f28eb3c7a060b2e57d85be7ada1a2e55c | 10,521 | ipynb | Jupyter Notebook | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst | ce170aa970d2d57866cadca0a73d56eac550eeb5 | [
"MIT"
] | 22 | 2018-09-29T03:39:29.000Z | 2022-03-21T08:52:25.000Z | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst | ce170aa970d2d57866cadca0a73d56eac550eeb5 | [
"MIT"
] | null | null | null | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst | ce170aa970d2d57866cadca0a73d56eac550eeb5 | [
"MIT"
] | 23 | 2018-02-19T16:12:07.000Z | 2022-02-06T09:07:53.000Z | 22.674569 | 202 | 0.422869 | [
[
[
"# Getting some data",
"_____no_output_____"
],
[
"Scikit-learn comes with some datasets that we can use to produce examples.",
"_____no_output_____"
]
],
[
[
"from sklearn import datasets",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"iris = datasets.load_iris()\niris_features = iris.data\niris_target = iris.target",
"_____no_output_____"
],
[
"iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)\niris_df['target'] = iris.target_names[iris.target]\niris_df.head()",
"_____no_output_____"
],
[
"iris.target_names",
"_____no_output_____"
]
],
[
[
"If we would like to predict the species of the flower using the features, then we are doing a **classification** problem.",
"_____no_output_____"
],
[
"# Estimators objects",
"_____no_output_____"
],
[
"The main API implemented by scikit-learn is that of the **estimator**. An estimator is the object that contains the model that we can use to learn from data.",
"_____no_output_____"
],
[
"## 1. Import the estimator (model)",
"_____no_output_____"
],
[
"You should know what is the object you would like to use, here you can find a very nice resource from the scikit-lear [documentation](http://scikit-learn.org/stable/tutorial/machine_learning_map/)",
"_____no_output_____"
]
],
[
[
"from sklearn.neighbors import KNeighborsClassifier",
"_____no_output_____"
]
],
[
[
"## 2. Create an instance of the estimator",
"_____no_output_____"
]
],
[
[
"flower_classifier = KNeighborsClassifier(n_neighbors=3)",
"_____no_output_____"
]
],
[
[
"## 3. Use the data to train the estimator",
"_____no_output_____"
],
[
"Remember: \n1. Scikit-learn only accepts numbers\n2. The object containing the features must be a two dimentional np.array",
"_____no_output_____"
]
],
[
[
"iris_features[:10,:]",
"_____no_output_____"
],
[
"iris_target",
"_____no_output_____"
]
],
[
[
"0 == > setosa\n\n1 == > versicolor\n\n2 == > virginica",
"_____no_output_____"
]
],
[
[
"flower_classifier.fit(X=iris_features, y=iris_target)",
"_____no_output_____"
]
],
[
[
"## 4. Evaluate the model\n\nWe will skip this important step here.",
"_____no_output_____"
],
[
"## 5. Use the data to make \"predictions\"",
"_____no_output_____"
]
],
[
[
"# The features must be two-dimensional array\nnew_flower1 = np.array([[5.1, 3.0, 1.1, 0.5]])\nnew_flower2 = np.array([[6.0, 2.9, 4.5, 1.1]])",
"_____no_output_____"
]
],
[
[
"0 == > setosa\n\n1 == > versicolor\n\n2 == > virginica",
"_____no_output_____"
]
],
[
[
"flower_classifier.predict(new_flower1)",
"_____no_output_____"
],
[
"flower_classifier.predict(new_flower2)",
"_____no_output_____"
],
[
"new_flowers = np.array([[5.1, 3.0, 1.1, 0.5],[6.0, 2.9, 4.5, 1.1]])\npredictions = flower_classifier.predict(new_flowers)\npredictions",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
e73d12d4d0e72191bcd666493d42a2be7664fb23 | 43,780 | ipynb | Jupyter Notebook | Pandas/codebasics-pandas/01-03 pandas basics/1-codebasics-pandas.ipynb | kevinlee05/python-snippets | 359b127f2e55113a628503d1ff69ba1cfac1f77d | [
"MIT"
] | null | null | null | Pandas/codebasics-pandas/01-03 pandas basics/1-codebasics-pandas.ipynb | kevinlee05/python-snippets | 359b127f2e55113a628503d1ff69ba1cfac1f77d | [
"MIT"
] | null | null | null | Pandas/codebasics-pandas/01-03 pandas basics/1-codebasics-pandas.ipynb | kevinlee05/python-snippets | 359b127f2e55113a628503d1ff69ba1cfac1f77d | [
"MIT"
] | null | null | null | 33.859242 | 87 | 0.241731 | [
[
[
"import pandas as pd\nimport os\ndf = pd.read_csv(os.getcwd() + '/nyc_weather.csv')\ndf",
"_____no_output_____"
],
[
"df['Temperature'].max() #get the maximum temparature",
"_____no_output_____"
],
[
"df['EST'][df['Events']=='Rain'] \n#get the dates on which there was a 'Rain' event\n#calls .loc with a boolean array",
"_____no_output_____"
],
[
"#what is the average windspeed\ndf['WindSpeedMPH'].mean()",
"_____no_output_____"
],
[
"df.fillna(0, inplace=True) # fill all NaN values with 0\ndf",
"_____no_output_____"
],
[
"df['WindSpeedMPH'].mean()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73d211c24e803796a696edd46e122af04c1a3b9 | 5,578 | ipynb | Jupyter Notebook | jupyterhub/notebooks/import_analysis_result_to_superset.ipynb | n-syuichi/LAaaS-docker | 0b4ca1e6632c7cea136639c29a658f1dfd7bae37 | [
"MIT"
] | 7 | 2019-06-25T01:06:14.000Z | 2022-01-31T18:57:43.000Z | jupyterhub/notebooks/import_analysis_result_to_superset.ipynb | n-syuichi/LAaaS-docker | 0b4ca1e6632c7cea136639c29a658f1dfd7bae37 | [
"MIT"
] | 11 | 2021-04-29T22:53:44.000Z | 2022-03-29T22:28:13.000Z | jupyterhub/notebooks/import_analysis_result_to_superset.ipynb | n-syuichi/LAaaS-docker | 0b4ca1e6632c7cea136639c29a658f1dfd7bae37 | [
"MIT"
] | 4 | 2020-01-17T03:01:05.000Z | 2021-11-19T05:08:25.000Z | 29.989247 | 276 | 0.489423 | [
[
[
"import json\nimport requests\nimport socket\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport psycopg2\nimport seaborn as sns\nfrom sqlalchemy import create_engine",
"_____no_output_____"
],
[
"# superset_dbコンテナのjupyterデータベースを指定(変更不可)\nengine = create_engine('postgresql://postgres@superset_db:5432/jupyter')",
"_____no_output_____"
],
[
"# ステートメントをAPIサーバから取得(以下はxAPIステートメント取得の例)\n\n## http://docs.learninglocker.net/http-aggregation/\nurl = 'http://{}:8080/statements/aggregate?cache=false&maxTimeMS=5000&maxScan=10000&pipeline=%5B%7B%22%24limit%22%3A%203000%7D%2C%20%7B%22%24project%22%3A%20%7B%20%22statement%22%3A%201%2C%20%22_id%22%3A%200%20%7D%7D%5D'.format(socket.gethostbyname('learninglocker'))\n## Learning Lockerのクライアント情報を設定\nuser = '2b15bab38dcf7f81b6e6db54849d01b6208b4f1d'\npasswd = 'dd9b4af4520a82a6c9cb66f241aafd12f24427a1'\n## Learning LockerのAGGREGATION APIでxAPIステートメントを取得\nr = requests.get(url, auth=(user, passwd))\n## Jsonを辞書型に変換\nresponse_data = json.loads(r.text)\n## 辞書からステートメントのみを抽出\nstats = [d['statement'] for d in response_data]\n",
"_____no_output_____"
],
[
"# ステートメントの分析\n# 分析結果は最終的にpandasのDataframe形式とすること\n\n## ネスト項目をフラットにしてpandasのDataFrameを作成\ndf = pd.io.json.json_normalize(stats)\n## 特定ユーザのステートメントを選択\ndf = df[df['actor.account.name'] == '2']\n## オブジェクトとタイムスタンプの射影\ndf = df[['object.definition.description.en', 'object.id', 'timestamp']]\ndf",
"_____no_output_____"
],
[
"# Supersetのjupyterデータベースに処理結果を保存\n# 次にエラーが表示される場合はテーブル名称を変更すること : ValueError: Table '<tablename>' already exists.\n\ntablename = 'user_2_objects'\ndf.to_sql(tablename, engine)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
e73d2e2a4b1ba16e1e1b20d7d05a3deac675f736 | 14,323 | ipynb | Jupyter Notebook | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama | 5224ab6cacc9f354e49f3234fb32c09fcd99f760 | [
"Apache-2.0"
] | null | null | null | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama | 5224ab6cacc9f354e49f3234fb32c09fcd99f760 | [
"Apache-2.0"
] | null | null | null | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama | 5224ab6cacc9f354e49f3234fb32c09fcd99f760 | [
"Apache-2.0"
] | null | null | null | 44.899687 | 613 | 0.581792 | [
[
[
"# Introduction\n\nIan Guinn, UNC\n\nPresented at [LEGEND Software Tutorial, Nov. 2021](https://indico.legend-exp.org/event/561/)\n\n**\"Have you tried looking at the waveforms from those events?\" - David Radford**\n\nThis is a tutorial demonstrating several ways to use the Waveform browser to examine data from LEGEND. This will consist of multiple examples, increasing in complexity, and will use data from the PGT. The waveform browser (pygama.dsp.WaveformBrowser) is a pygama utility for accessing waveforms from raw files in an interactive way, enabling you to access, draw, or even process waveforms. Some use cases for this utility include investigating a population of waveforms, and debugging waveform processors.\n\nWhy do we need a waveform browser when we can access data via pandas dataframes?\nPandas dataframes work extremely well for reading tables of simple values from multiple HDF5 files. However, they are less optimal for waveforms. The reason for this is that they require holding all waveforms in memory at once. If we want to look at waveforms spread out across multiple files, this can potentially take up GBs of memory, which will cause problems! To get around this, we want to load only bits of the files into memory at a time and pull out only what we need. Since this is an inconvenient process, the WaveformBrowser will do this for you, while hiding the details as much as possible.\n\n## Contents:\n**Example 1:** Minimal usage of the waveform browser \n**Example 2:** Draw waveforms using a data cut to investigate a population; fill a legend \n**Example 3:** Draw waveforms from multiple populations with different cuts for comparison; using more advanced formatting options \n**Example 4:** Draw processed waveforms from a DSP config file to inspect processors \n**Example 5:** Access waveforms without drawing",
"_____no_output_____"
]
],
[
[
"#First, import necessary modules and set some input values for use later\n%matplotlib inline\nimport pygama.io.lh5 as lh5\nfrom pygama.dsp.WaveformBrowser import WaveformBrowser\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport numpy as np\nimport os, json\n\n# Set input values for where to find our data. This will grab all calibration runs from run 30, parsing wildcards\n\n# pgt_dir = '$LEGENDDATADIR/lngs/pgt/'\npgt_dir = '/global/cfs/cdirs/m2676/data/lngs/l200_commissioning/orca_data/Data'\n\n#raw_files = pgt_dir + 'raw/geds/LPGTA_r0030_*_calib_geds_raw.lh5'\nraw_files = '/global/cfs/cdirs/m2676/users/jarunge/Jan2022_HDF5/*.lh5'\n\n#dsp_files = pgt_dir + 'dsp/geds/LPGTA_r0030_*_calib_geds_dsp.lh5'\n#channel = 'g040'\nchannel = '0'\n\n# Set defaults for figures\nplt.rcParams['figure.figsize'] = (12, 8)\nplt.rcParams['font.size'] = 16",
"_____no_output_____"
]
],
[
[
"## Example 1\n\nFirst, a minimal example simply drawing waveforms from the raw file",
"_____no_output_____"
]
],
[
[
"# Create a minimal waveform browser; a file or list of files is required\n#browser = WaveformBrowser(raw_files, channel+'/raw')\nbrowser = WaveformBrowser(raw_files, 'ORFlashCamADCWaveformDecoder/raw/')\n\n\n# Draw the 100th waveform in the file\nbrowser.draw_entry(101)\n\n# To draw multiple figures in a single cell, you must explicitly create a new one:\nbrowser.new_figure()\nbrowser.draw_entry([200, 300, 400])",
"_____no_output_____"
],
[
"# Draw the next waveform in the file. You can run this cell multiple times to scroll through many WFs\nbrowser.draw_next()",
"_____no_output_____"
]
],
[
[
"## Example 2\nOk, that was nice, but how often do we just want to scroll through all of our waveforms?\n\nFor our next example, we will select a population of waveforms from within the files, and draw multiple at once. Selecting a population of events to draw uses the same syntax as numpy and pandas, and can be done either with a list of entries or a boolean numpy array. This selection can be made using data from a dsp or hit hit file.\n\nWe will also learn how to set a few other properties of the figure",
"_____no_output_____"
]
],
[
[
"# First, load a dataframe from a DSP file that we can use to make our selection:\ndf = lh5.load_dfs(dsp_files, ['trapE', 'AoE'], channel+'/dsp')",
"_____no_output_____"
],
[
"# Create a selection mask around the 2614 keV peak\ntrapE = df['trapE']\nenergy_selection = (trapE>22100) & (trapE<22400)\n\ntrapE.hist(bins=1000, range=(0, 30000))\ntrapE[energy_selection].hist(bins=1000, range=(0, 30000))\nplt.yscale('log')",
"_____no_output_____"
],
[
"# Now construct a WaveformBrowser with this cut\nbrowser = WaveformBrowser(raw_files, channel+'/raw',\n verbosity = 0, # Silence output on construction\n legend = (trapE, df['AoE']), # Values to put in the legend\n x_lim = (22000, 30000), # Range for time-axis\n selection = energy_selection , # Apply cut\n n_drawn = 10 # number to draw for draw_next\n )\n\n# Draw the next 5 batches of 10 waveforms, and move the legend outside\nfor entries, i in zip(browser, range(5)):\n print(\"Entries:\", entries)\n browser.new_figure()\n #plt.pause(1) # If you can use interactive plots (i.e. not on nersc), you can comment the above line and uncomment this one to draw a slideshow!\n",
"_____no_output_____"
]
],
[
[
"## Example 3\nLets take it a step further: this time, lets draw waveforms from multiple populations for the sake of comparison. This will require creating two separate waveform browsers and drawing them onto the same axes. We'll also normalization of the waveforms. Finally, we'll add some formatting options to the lines and legend.",
"_____no_output_____"
]
],
[
[
"AoE = df['AoE']\nenergy_cut = (trapE>10000)\naoe_cut = (AoE<0.056) & energy_cut\naoe_accept = (AoE>0.056) & energy_cut\n\nAoE[energy_cut].hist(bins=200, range=(-0, 0.2))\nAoE[aoe_cut].hist(bins=200, range=(-0, 0.2))",
"_____no_output_____"
],
[
"browser1 = WaveformBrowser(raw_files, channel+'/raw',\n verbosity = 0, # Silence output on construction\n wf_styles = {'color':['red', 'orange', 'salmon', 'darkorange', 'maroon']}, # set a color cycle for this\n legend = (\"E={:.0f} ADC, A/E={:.3f}\", trapE, AoE), # Formatted values to put in the legend\n norm = trapE, # Normalize waveforms by energy\n selection = aoe_cut, # Apply cut\n n_drawn = 5 # number to draw for draw_next\n )\n\nbrowser2 = WaveformBrowser(raw_files, channel+'/raw',\n verbosity = 0, # Silence output on construction\n wf_styles = {'color':['blue', 'purple', 'cyan', 'violet', 'indigo']}, # set a color cycle for this\n legend = (\"E={:.0f} ADC, A/E={:.3f}\", trapE, AoE), # Formatted values to put in the legend\n legend_opts = {'loc':\"center\",'bbox_to_anchor':(1,0.35)}, # set options for drawing the legend\n norm = trapE, # Normalize waveforms by energy\n x_lim = (25000, 30000), # Range for time-axis\n selection = aoe_accept, # Apply cut\n n_drawn = 5 # number to draw for draw_next\n )",
"_____no_output_____"
],
[
"browser1.draw_next()\nbrowser2.set_figure(browser1) # use the same figure/axis as the other browser\nbrowser2.draw_next(clear=False) # Set clear to false to draw on the same axis!",
"_____no_output_____"
]
],
[
[
"## Example 4\nNow, we'll shift from drawing populations of waveforms to drawing waveform transforms. We can draw any waveforms that are defined in a DSP JSON configuration file. This is useful for debugging purposes and for developing processors. We will draw the baseline subtracted WF, pole-zero corrected WF, and trapezoidal filter WF. We will also draw horizontal and vertical lines for trapE (the max of the trapezoid) and tp_0 (our estimate of the start of the waveform's rise). The browser will determine whether these lines should be horizontal or vertical based on the unit.",
"_____no_output_____"
]
],
[
[
"# Use the lpgta dsp json file. TODO: get this from DataGroup\n# dsp_config_file = os.path.expandvars(\"$HOME/pygama/experiments/lpgta/LPGTA_dsp.json\")\ndsp_config_file = os.path.expandvars(\"./metadata/LPGTA_dsp.json\")\n",
"_____no_output_____"
],
[
"browser = WaveformBrowser(raw_files, channel+'/raw', dsp_config_file, # Need to include a dsp config file!\n database={\"pz_const\":'396.9*us'}, # TODO: use metadata instead of manually defining...\n waveforms=['wf_blsub', 'wf_pz', 'wf_trap'], # names of waveforms from dsp config file\n wf_styles=[{'linestyle':['-']},{'linestyle':[':']},{'ls':['--']}],\n legend=['Waveform', 'PZ Corrected', \"Trap (max={trapE:.0f})\"],\n legend_opts={'loc':\"upper left\"},\n lines=['trapE', 'tp_0'], # add hlines and vlines\n x_lim=(15000, 55000) # x axis range\n )",
"_____no_output_____"
],
[
"browser.draw_next()",
"_____no_output_____"
]
],
[
[
"## Example 5\nSometimes you just want to access the waveforms without drawing them. There can be many reasons for this: maybe you want to try processing them with a function that isn't part of the pygama dsp framework yet. Maybe the drawing options provided aren't right for you. Either way, if you need more control over what happens with waveforms, it is possible to directly and quickly access them through the waveform browser.\n\nThe waveforms are stored in the class as a list of lists of pairs of numpy arrays. The outer list is across the waveforms we have requested. The inner list contains the number of waveforms we have requested. Each waveform is stored as a tuple pair of (time, waveform)\n\nWhen accessing waveforms in this way, you can also do the same things previously shown, such as applying a data cut and grabbing processed waveforms. For this example, we are going to get waveforms and trap-waveforms that pass the A/E cut. We will simply print them, but the possibility exists to do whatever we want!",
"_____no_output_____"
]
],
[
[
"browser = WaveformBrowser(raw_files, channel+'/raw', dsp_config_file, # Need to include a dsp config file!\n database = {\"pz_const\":'396.9*us'}, # TODO: use metadata instead of manually defining...\n waveforms = ['waveform', 'wf_trap'], # names of waveforms from dsp config file\n selection = aoe_accept, # apply A/E cut\n n_drawn = 5 # get two at a time\n )",
"_____no_output_____"
],
[
"browser.find_next()\nwaveforms = browser.wf_data[0]\ntraps = browser.wf_data[1]\nfor wf, trap in zip(waveforms, traps):\n print(\"Raw waveform:\", wf[1])\n print(\"Trap-filtered waveform\", trap[1], '\\n')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
e73d35e24534d155a6212c234bf18a0b5d51ed42 | 103,543 | ipynb | Jupyter Notebook | ch12/ch12_per_pbr.ipynb | systemquant/book-pandas-for-finance | 90b7eb9be1de20a12ae72b9bb5d51424a979b174 | [
"MIT"
] | 10 | 2021-02-04T12:49:56.000Z | 2022-03-26T11:28:11.000Z | ch12/ch12_per_pbr.ipynb | systemquant/book-pandas-for-finance | 90b7eb9be1de20a12ae72b9bb5d51424a979b174 | [
"MIT"
] | 1 | 2022-03-24T03:47:14.000Z | 2022-03-24T03:54:52.000Z | ch12/ch12_per_pbr.ipynb | systemquant/book-pandas-for-finance | 90b7eb9be1de20a12ae72b9bb5d51424a979b174 | [
"MIT"
] | 4 | 2021-07-17T16:50:15.000Z | 2022-03-22T05:55:34.000Z | 37.556402 | 17,272 | 0.505626 | [
[
[
"# 12.1 저 PER 전략",
"_____no_output_____"
],
[
"2021년 04월 01일 데이터가 저장된 엑셀 파일을 불러옵니다. ",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ndf_factor = pd.read_excel(\n \"data/data_kosdaq_20210401_per.xlsx\", \n index_col=0, \n usecols=[0, 1, 6, 8] # 종목코드, 종목명, PER, PBR\n)\ndf_factor.head()",
"C:\\Users\\jongh\\anaconda3\\lib\\site-packages\\openpyxl\\styles\\stylesheet.py:221: UserWarning: Workbook contains no default style, apply openpyxl's default\n warn(\"Workbook contains no default style, apply openpyxl's default\")\n"
],
[
"df_factor.info()",
"<class 'pandas.core.frame.DataFrame'>\nIndex: 1475 entries, 060310 to 238490\nData columns (total 3 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 종목명 1475 non-null object\n 1 PER 1475 non-null object\n 2 PBR 1475 non-null object\ndtypes: object(3)\nmemory usage: 46.1+ KB\n"
],
[
"import numpy as np\n\ndf_factor.replace('-', np.nan, inplace=True)\ndf_factor.head()",
"_____no_output_____"
],
[
"df_factor.info()",
"<class 'pandas.core.frame.DataFrame'>\nIndex: 1475 entries, 060310 to 238490\nData columns (total 3 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 종목명 1475 non-null object \n 1 PER 857 non-null float64\n 2 PBR 1389 non-null float64\ndtypes: float64(2), object(1)\nmemory usage: 46.1+ KB\n"
],
[
"import pandas as pd\n\ndf = pd.read_excel(\"data/data_kosdaq_20210401_sise.xlsx\", index_col=0)\ndf_volume = df[['거래량']]\n#df_volume.shape\ndf_volume.head()",
"C:\\Users\\jongh\\anaconda3\\lib\\site-packages\\openpyxl\\styles\\stylesheet.py:221: UserWarning: Workbook contains no default style, apply openpyxl's default\n warn(\"Workbook contains no default style, apply openpyxl's default\")\n"
],
[
"df2 = df_factor.join(df_volume)\ndf2.head()",
"_____no_output_____"
],
[
"df2.shape",
"_____no_output_____"
],
[
"import pandas as pd\n\ndf_change = pd.read_excel(\"data/data_kosdaq_change_2021.xlsx\", index_col=0, usecols=[0, 5])\ndf_change.head()",
"C:\\Users\\jongh\\anaconda3\\lib\\site-packages\\openpyxl\\styles\\stylesheet.py:221: UserWarning: Workbook contains no default style, apply openpyxl's default\n warn(\"Workbook contains no default style, apply openpyxl's default\")\n"
],
[
"df_change.info()",
"<class 'pandas.core.frame.DataFrame'>\nIndex: 1478 entries, 060310 to 238490\nData columns (total 1 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 등락률 1478 non-null float64\ndtypes: float64(1)\nmemory usage: 23.1+ KB\n"
],
[
"df3 = df2.join(df_change)\ndf3.head()",
"_____no_output_____"
],
[
"df3.shape",
"_____no_output_____"
]
],
[
[
"2021년 4월 1일에 거래량이 0인 종목은 거래정지된 종목입니다. 따라서 먼저 거래량을 기준으로 필터링합니다. ",
"_____no_output_____"
]
],
[
[
"cond = df3['거래량'] !=0\ndf4 = df3[cond].copy()\ndf4.shape",
"_____no_output_____"
]
],
[
[
"PER 값을 기준으로 오른차순 정렬합니다. ",
"_____no_output_____"
]
],
[
[
"df5 = df4.sort_values(by=\"PER\", ascending=True)\ndf5.reset_index(inplace=True)\ndf5",
"_____no_output_____"
],
[
"low_per30 = df5.iloc[:30]\nlow_per30['등락률'].mean()",
"_____no_output_____"
],
[
"import pandas as pd\n\ndf5['group'] = pd.cut(df5.index, bins=20, labels=False)\ndf5.head()",
"_____no_output_____"
],
[
"df6 = df5.groupby(by='group')[['등락률']].mean()",
"_____no_output_____"
],
[
"df6",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt \nimport platform\n\nif platform.system() == 'Darwin':\n plt.rc('font', family='AppleGothic') \nelse:\n plt.rc('font', family='Malgun Gothic')\n\nfig = plt.figure(figsize=(12, 8))\nax = fig.add_subplot(1, 1, 1)\n\nax.bar(df6.index, df6[\"등락률\"], width=0.5)\nplt.title(\"PER 그룹별 수익률\")\nplt.xlabel(\"PER 그룹\")\nplt.ylabel(\"수익률\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"# 12.2 PBR + PER 콤보전략",
"_____no_output_____"
]
],
[
[
"df4",
"_____no_output_____"
],
[
"cond = (df4['PER'] >= 2.5) & (df4['PER'] <= 10)\ndf5 = df4[cond].copy()\ndf5",
"_____no_output_____"
],
[
"df6 = df5.sort_values(by='PBR')[:30]\ndf6.describe()",
"_____no_output_____"
],
[
"df6[df6['등락률'] == df6['등락률'].min()]",
"_____no_output_____"
]
],
[
[
"# 12.3\t시가총액별 콤보 전략",
"_____no_output_____"
]
],
[
[
"from pykrx import stock\nimport pandas as pd \n\ndf1 = stock.get_market_cap_by_ticker(\"20100104\")\ndf1 = df1[[\"종가\", \"시가총액\"]]\ndf1.columns = [\"시가\", \"시가총액\"]\ndf1 = df1.sort_values('시가총액')\ndf1['group'] = pd.cut(df1.reset_index().index, bins=3, labels=['소형주', '중형주', '대형주'])\ndf1.tail()",
"_____no_output_____"
],
[
"df2 = stock.get_market_fundamental_by_ticker(\"20100104\")\ndf2 = df2[['PER', 'PBR']]\ndf2.head()",
"_____no_output_____"
],
[
"df3 = stock.get_market_ohlcv_by_ticker(\"20101231\", prev=True)\ndf3 = df3[['종가']]\ndf3.head()",
"_____no_output_____"
],
[
"t0 = pd.merge(left=df1, right=df2, left_index=True, right_index=True)\ndf = pd.merge(left=t0, right=df3, left_index=True, right_index=True)\ndf.head()",
"_____no_output_____"
],
[
"df = df.query('PBR != 0')\ndf['수익률'] = df['종가'] / df['시가']\ncond = (df['PER'] >= 2.5) & (df['PER'] <= 10)\ntop30 = df[cond].sort_values('PBR').groupby('group').head(30)\ntop30.head()",
"_____no_output_____"
],
[
"import numpy as np\n\nhow = {\n '수익률' : np.mean\n}\nyoy = top30.groupby('group').agg(how)\nyoy.columns = ['2010']\nyoy",
"_____no_output_____"
],
[
"def low_per_pbr(year):\n df1 = stock.get_market_cap_by_ticker(f\"{year}0101\")\n df1 = df1[[\"종가\", \"시가총액\"]]\n df1.columns = [\"시가\", \"시가총액\"]\n df1 = df1.sort_values('시가총액')\n df1['group'] = pd.cut(df1.reset_index().index, bins=3, labels=['소형주', '중형주', '대형주'])\n \n df2 = stock.get_market_fundamental_by_ticker(f\"{year}0101\")\n df2 = df2[['PER', 'PBR']]\n \n df3 = stock.get_market_ohlcv_by_ticker(f\"{year}1231\", prev=True)\n df3 = df3[['종가']]\n \n t0 = pd.merge(left=df1, right=df2, left_index=True, right_index=True)\n df = pd.merge(left=t0, right=df3, left_index=True, right_index=True)\n \n df = df.query('PBR != 0').copy()\n df['수익률'] = df['종가'] / df['시가']\n cond = (df['PER'] >= 2.5) & (df['PER'] <= 10)\n top30 = df[cond].sort_values('PBR').groupby('group').head(30)\n \n how = {\n '수익률' : np.mean\n }\n yoy = top30.groupby('group').agg(how)\n yoy.columns = [year]\n return yoy",
"_____no_output_____"
],
[
"import time \n\ndfs = [ ]\nfor date in range(2010, 2021):\n df = low_per_pbr(f\"{date}\")\n dfs.append(df)\n time.sleep(1)\n \ndf = pd.concat(dfs, axis=1)\ndf",
"_____no_output_____"
],
[
"df.cumprod(axis=1)",
"_____no_output_____"
],
[
"df.cumprod(axis=1).transpose().plot.line()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73d3ce67dcb56ebc540a60fb82f46838028bbb9 | 68,043 | ipynb | Jupyter Notebook | trainUnet.ipynb | wp-cdas/UNet-Humphries | a44be7374b203dbfeb1368389cf9a93ff8ad08a7 | [
"MIT"
] | null | null | null | trainUnet.ipynb | wp-cdas/UNet-Humphries | a44be7374b203dbfeb1368389cf9a93ff8ad08a7 | [
"MIT"
] | null | null | null | trainUnet.ipynb | wp-cdas/UNet-Humphries | a44be7374b203dbfeb1368389cf9a93ff8ad08a7 | [
"MIT"
] | 1 | 2020-06-04T22:16:34.000Z | 2020-06-04T22:16:34.000Z | 106.483568 | 44,176 | 0.826742 | [
[
[
"from model import *\nfrom dilateModel import *\n#from model_edge import *\nfrom data import *\nfrom PIL import Image\nimport cv2",
"Using TensorFlow backend.\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:517: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:518: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:519: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:520: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\n/srv/conda/envs/notebook/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\n"
]
],
[
[
"## Train your Unet with membrane data\nmembrane data is in folder membrane/, it is a binary classification task.\n\nThe input shape of image and mask are the same :(batch_size,rows,cols,channel = 1)",
"_____no_output_____"
],
[
"### Train with data generator",
"_____no_output_____"
]
],
[
[
"data_gen_args = dict(rotation_range=0.2,\n width_shift_range=0.05,\n height_shift_range=0.05,\n shear_range=0.05,\n zoom_range=0.05,\n horizontal_flip=True,\n fill_mode='nearest')\nmyGene = trainGenerator(16,'/data/spacenet/bldg/AllTrain','PAN-PNG','GT-PNG',data_gen_args,save_to_dir = None)\nmodel = unet()\nmodel_checkpoint = ModelCheckpoint('30_Epoch.hdf5', monitor='loss',verbose=1, save_best_only=True)\nmodel.fit_generator(myGene,steps_per_epoch=2000,epochs=15,callbacks=[model_checkpoint])",
"WARNING:tensorflow:From /srv/conda/envs/notebook/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:4070: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.\n\nWARNING:tensorflow:From /srv/conda/envs/notebook/lib/python3.7/site-packages/tensorflow/python/ops/nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\n"
],
[
"1451 + 1475 + 1473 + 1476 + 1478 + 1480 + 1526 + 1533 + 1538 + 1532 + 1487 + 1537 + 1542 + 1538 + 1053",
"_____no_output_____"
],
[
"(22119/60)/60",
"_____no_output_____"
]
],
[
[
"### Train with npy file",
"_____no_output_____"
]
],
[
[
"#imgs_train,imgs_mask_train = geneTrainNpy(\"data/membrane/train/aug/\",\"data/membrane/train/aug/\")\n#model.fit(imgs_train, imgs_mask_train, batch_size=2, nb_epoch=10, verbose=1,validation_split=0.2, shuffle=True, callbacks=[model_checkpoint])",
"_____no_output_____"
],
[
"##Use AllTest\n",
"_____no_output_____"
],
[
"model = unet()\nmodel.load_weights(\"unet_membrane_AllTrain_8.hdf5\")",
"_____no_output_____"
],
[
"#results = model.predict_generator(testGene,30,verbose=1)\n#saveResult(\"data/membrane/test2\",results)",
"_____no_output_____"
]
],
[
[
"### test your model and save predicted results",
"_____no_output_____"
]
],
[
[
"from PIL import Image\nimport numpy as np\nfrom skimage import transform",
"_____no_output_____"
],
[
"#testGene = testGenerator(\"/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG\")\nmodel = unet()\nmodel.load_weights(\"unet_membrane.hdf5\")\nnp_image = Image.open('/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG/PAN_AOI_2_Vegas_img1005.png')\nnp_image = np.array(np_image).astype('float32')/255\nnp_image = transform.resize(np_image, (256, 256, 1))\nnp_image = np.expand_dims(np_image, axis=0)\n\n\n#model.predict(\"/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG/PAN_AOI_2_Vegas_img1005.png\")\n#results = model.predict_generator(testGene,30,verbose=1)\n#saveResult(\"data/membrane/test2\",results)",
"_____no_output_____"
],
[
"im = model.predict(np_image)\n#saveResult(\"data/membrane/test2\",im)",
"_____no_output_____"
],
[
"np_image1 = Image.open('/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG/PAN_AOI_2_Vegas_img1008.png')\nnp_image1 = np.array(np_image1).astype('float32')/255\nnp_image1 = transform.resize(np_image1, (256, 256, 1))\nnp_image1 = np.expand_dims(np_image1, axis=0)\n\nim1 = model.predict(np_image1)\n\nnp_image2 = Image.open('/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG/PAN_AOI_2_Vegas_img100.png')\nnp_image2 = np.array(np_image2).astype('float32')/255\nnp_image2 = transform.resize(np_image2, (256, 256, 1))\nnp_image2 = np.expand_dims(np_image2, axis=0)\n\nim2 = model.predict(np_image2)\nsaveResult(\"data/membrane/test2\",im2)\n\nnp_image3 = Image.open('/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG/PAN_AOI_2_Vegas_img1012.png')\nnp_image3 = np.array(np_image3).astype('float32')/255\nnp_image3 = transform.resize(np_image3, (256, 256, 1))\nnp_image3 = np.expand_dims(np_image3, axis=0)\n\nim3 = model.predict(np_image3)\n\n\nnp_image4 = Image.open('/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG/PAN_AOI_2_Vegas_img1013.png')\nnp_image4 = np.array(np_image4).astype('float32')/255\nnp_image4 = transform.resize(np_image4, (256, 256, 1))\nnp_image4 = np.expand_dims(np_image4, axis=0)\n\nim4 = model.predict(np_image4)\n\nim_list = [im, im1, im2, im3, im4]\nsaveResult(\"data/membrane/test2\",im1)",
"Lossy conversion from float32 to uint8. Range [0, 1]. Convert image to uint8 prior to saving to suppress this warning.\nLossy conversion from float32 to uint8. Range [0, 1]. Convert image to uint8 prior to saving to suppress this warning.\n"
],
[
"saveResult(\"data/membrane/test2\",im4)",
"Lossy conversion from float32 to uint8. Range [0, 1]. Convert image to uint8 prior to saving to suppress this warning.\n"
]
],
[
[
"## Thresholding Results",
"_____no_output_____"
]
],
[
[
"model = unet()\nmodel.load_weights(\"Humphries_Bragg_Weights.hdf5\")\n#model.load_weights('unet_membrane_AllTrain_8.hdf5')",
"WARNING:tensorflow:From /srv/conda/envs/notebook/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:4070: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.\n\nWARNING:tensorflow:From /srv/conda/envs/notebook/lib/python3.7/site-packages/tensorflow/python/ops/nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\n"
],
[
"def predImgGen(imgPath, target_size=(256,256)):\n img = io.imread(imgPath,as_gray = True)\n img = img / 255\n img = trans.resize(img,target_size)\n img = np.reshape(img,img.shape+(1,))\n img = np.reshape(img,(1,)+img.shape)\n return img",
"_____no_output_____"
],
[
"def predImgGen2(imgPath, target_size=(256,256)):\n img = io.imread(imgPath,as_gray = True)\n #img = img / 255\n img = trans.resize(img,target_size)\n img = np.reshape(img,img.shape+(1,))\n img = np.reshape(img,(1,)+img.shape)\n return img",
"_____no_output_____"
],
[
"maskImg_List = []\ntest_dir = '/data/spacenet/bldg/AllTest/PAN-PNG'\nfor i,j,k in os.walk(test_dir):\n for file in k:\n if (os.path.splitext(file)[1] == '.png'):\n PANImgPath = os.path.join(test_dir, file)\n testImg = predImgGen(PANImgPath)\n pred = model.predict(testImg)\n \n predRe = pred.reshape(256,256)\n maskArrThresh = np.zeros((predRe.shape[0], predRe.shape[1], 4)) \n maskArrThresh[:,:, 0] = 50\n maskArrThresh[:,:, 1] = 255\n maskArrThresh[:,:, 2] = 0\n for row in range(0, predRe.shape[0]):\n for col in range(0, predRe.shape[1]):\n maskArrThresh[row, col, 3] = 255 - int(predRe[row, col] * 255)\n maskArrThresh = maskArrThresh.astype(\"uint8\")\n maskImg = Image.fromarray(maskArrThresh, 'RGBA')\n #maskImg_List += [maskImg]\n maskImg.save(file)\n \n PANImg = Image.open(PANImgPath)\n PANImgT = PANImg.convert('RGBA')\n \n PANDim = (PANImgT.width, PANImgT.height)\n maskImgRe = maskImg.resize(PANDim) \n \n comp = Image.alpha_composite(PANImgT, maskImgRe)\n #comp.save(file)",
"WARNING:tensorflow:From /srv/conda/envs/notebook/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.\n\n"
],
[
"np_image1 = np.array(maskImgRe).astype('float32')/255\nnp_image1 = transform.resize(np_image1, (256, 256, 1))\nnp_image1 = np.expand_dims(np_image1, axis=0)\n\ninvert1 = cv2.bitwise_not(np_image1)\n\n",
"_____no_output_____"
],
[
"saveResult(\"data\",invert1)",
"Lossy conversion from float32 to uint8. Range [-21.848297119140625, -7.974299430847168]. Convert image to uint8 prior to saving to suppress this warning.\n"
],
[
"maskImg_List[1]",
"_____no_output_____"
],
[
"np_image1 = np.array(maskImg_List[3]).astype('float32')/255\nnp_image1 = transform.resize(np_image1, (256, 256, 1))\nnp_image1 = np.expand_dims(np_image1, axis=0)\n\n#saveResult(\"data\",np_image1)",
"_____no_output_____"
],
[
"np_image2 = np.array(maskImg_List[1]).astype('float32')/255\nnp_image2 = transform.resize(np_image2, (256, 256, 1))\nnp_image2 = np.expand_dims(np_image2, axis=0)",
"_____no_output_____"
],
[
"#maskImg\n#image = cv2.imread('/data/spacenet/bldg/AllTrain/PAN-PNG/PAN_AOI_2_Vegas_img1002.png')\n\n#image = cv2.imread(im1)\ninvert1 = cv2.bitwise_not(np_image1)\ninvert2 = cv2.bitwise_not(np_image2)\n\ninvert_list = [invert1, invert2]\nsaveResult(\"data\",invert_list)\n",
"Lossy conversion from float32 to uint8. Range [-12.235958099365234, -11.882962226867676]. Convert image to uint8 prior to saving to suppress this warning.\nLossy conversion from float32 to uint8. Range [-12.235958099365234, -10.097213745117188]. Convert image to uint8 prior to saving to suppress this warning.\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73d43e8cb48b93f8fc94e7c99cc3979a1d4f954 | 15,315 | ipynb | Jupyter Notebook | notebooks/archive/custom_image_dataset_dir_function_test.ipynb | paultanger/CampsitePredict | 1985d3a207a724e278ab8a00c56560af45c14e92 | [
"MIT"
] | null | null | null | notebooks/archive/custom_image_dataset_dir_function_test.ipynb | paultanger/CampsitePredict | 1985d3a207a724e278ab8a00c56560af45c14e92 | [
"MIT"
] | 2 | 2020-08-29T01:02:04.000Z | 2020-08-29T18:03:22.000Z | notebooks/archive/custom_image_dataset_dir_function_test.ipynb | paultanger/CampsitePredict | 1985d3a207a724e278ab8a00c56560af45c14e92 | [
"MIT"
] | null | null | null | 34.649321 | 150 | 0.575645 | [
[
[
"# generic imports\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom scipy import stats\n# notebook settings\n%config IPCompleter.greedy=True\n%load_ext autoreload\n%autoreload 2 \n# precision and plot settings\nnum_precision = 3\nnp.set_printoptions(precision=num_precision, suppress=True)\npd.set_option('display.float_format', lambda x: f'{x:,.{num_precision}f}')\npd.set_option(\"display.precision\", num_precision)\npd.set_option('display.max_columns', None)\nplt.rcParams['font.size'] = 16\nplt.rcParams['legend.fontsize'] = 'large'\nplt.rcParams['figure.titlesize'] = 'medium'\nplt.rcParams['lines.linewidth'] = 2",
"_____no_output_____"
],
[
"# setup dir and import helper functions\nimport sys, os\nsys.path.append(os.path.join(os.path.dirname(sys.path[0]),'src'))\nimport helper_funcs as my_funcs\nfrom image_dataset_from_dir_return_paths import image_dataset_from_directory_paths",
"_____no_output_____"
],
[
"# from tensorflow.keras.preprocessing import image_dataset_from_directory\nfrom tensorflow import keras\nfrom tensorflow.keras import layers\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow import data\nfrom tensorflow.keras import callbacks",
"_____no_output_____"
],
[
"directory = '../data/symlink_data/wild_est_test'",
"_____no_output_____"
],
[
"batch_size = 32\nimg_size = 256",
"_____no_output_____"
],
[
"# make a dataset of 2\nX_train, X_train_img_paths = image_dataset_from_directory_paths(\n directory, labels='inferred', class_names=None, \n color_mode='rgb', batch_size=8, image_size=(img_size, img_size), shuffle=True, seed=42,\n validation_split=0.25, subset='training', interpolation='bilinear', follow_links=True\n)",
"Found 7834 files belonging to 2 classes.\nUsing 5876 files for training.\n"
],
[
"X_train_img_paths",
"_____no_output_____"
],
[
"X_test, X_test_img_paths = image_dataset_from_directory_paths(\n directory, labels='inferred', class_names=None, \n color_mode='rgb', batch_size=batch_size, image_size=(img_size, img_size), shuffle=True, seed=42, \n validation_split=0.25, subset='validation', interpolation='bilinear', follow_links=True\n)",
"Found 7834 files belonging to 2 classes.\nUsing 1958 files for validation.\n"
],
[
"X_test_img_paths",
"_____no_output_____"
],
[
"X_train_img_paths[:2]",
"_____no_output_____"
],
[
"def get_class_weights(X_train):\n class_names = X_train.class_names\n labels = np.concatenate([y for x, y in X_train], axis=0)\n if np.ndim(labels) == 1:\n # for binary\n weights = [len(labels) - labels.sum(), labels.sum()]\n else:\n weights = list(np.sum(labels, axis=0))\n class_weights = {}\n # for class_, weight in zip(class_names, weights):\n # class_weights[class_] = weight\n for i, weight in enumerate(weights):\n class_weights[i] = weight\n return class_names, class_weights",
"_____no_output_____"
],
[
"directory = '/Users/pault/Desktop/github/CampsitePredict/data/symlink_data/unique_wild_est_for_aligned_model' ",
"_____no_output_____"
],
[
"class_names, class_weights = get_class_weights(X_train)",
"_____no_output_____"
],
[
"class_weights",
"_____no_output_____"
],
[
"num_classes = 2\nepochs = 1 \nAUTOTUNE = data.experimental.AUTOTUNE\nimg_height = 256\nimg_width = 256\nnb_filters = 32 # number of convolutional filters to use - want 1 for each \"feature\" you think exists in images if more, more parameters\npool_size = (2, 2) # pooling decreases image size, reduces computation, adds translational invariance\nkernel_size = (2, 2) # convolutional kernel size, slides over image to learn features\nX_train = X_train.cache().shuffle(32).prefetch(buffer_size=AUTOTUNE) \nX_test = X_test.cache().prefetch(buffer_size=AUTOTUNE)",
"_____no_output_____"
],
[
"model = Sequential([\n layers.experimental.preprocessing.Rescaling(1./255, input_shape=(256, 256, 3)),\n layers.experimental.preprocessing.RandomFlip(\"horizontal\", \n input_shape=(img_height, \n img_width,\n 3)),\n layers.experimental.preprocessing.RandomRotation(0.1),\n layers.experimental.preprocessing.RandomZoom(0.1),\n layers.Conv2D(nb_filters, (kernel_size[0], kernel_size[1]), padding='same', activation='relu'), # was 16, 32, 64\n layers.MaxPooling2D(pool_size=pool_size),\n layers.Conv2D(nb_filters*2, (kernel_size[0], kernel_size[1]), padding='same', activation='relu'), # drop layers.. for initial testing\n layers.MaxPooling2D(pool_size=pool_size),\n layers.Conv2D(nb_filters*3, (kernel_size[0], kernel_size[1]), padding='same', activation='relu'),\n layers.MaxPooling2D(pool_size=pool_size),\n layers.Conv2D(nb_filters*4, (kernel_size[0], kernel_size[1]), padding='same', activation='relu'),\n layers.MaxPooling2D(pool_size=pool_size),\n layers.Flatten(),\n layers.Dense(256, activation='relu'), # increase this? add another dense layer?\n layers.Dropout(0.5),\n #layers.Dense(num_classes, activation='relu') # or sigmoid for binary? relu?\n layers.Dense(1, activation='sigmoid') # or sigmoid for binary? relu?\n])",
"_____no_output_____"
],
[
"model.compile(optimizer='adam',\n loss=keras.losses.BinaryCrossentropy(from_logits=False),\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nrescaling (Rescaling) (None, 256, 256, 3) 0 \n_________________________________________________________________\nrandom_flip (RandomFlip) (None, 256, 256, 3) 0 \n_________________________________________________________________\nrandom_rotation (RandomRotat (None, 256, 256, 3) 0 \n_________________________________________________________________\nrandom_zoom (RandomZoom) (None, 256, 256, 3) 0 \n_________________________________________________________________\nconv2d (Conv2D) (None, 256, 256, 32) 416 \n_________________________________________________________________\nmax_pooling2d (MaxPooling2D) (None, 128, 128, 32) 0 \n_________________________________________________________________\nconv2d_1 (Conv2D) (None, 128, 128, 64) 8256 \n_________________________________________________________________\nmax_pooling2d_1 (MaxPooling2 (None, 64, 64, 64) 0 \n_________________________________________________________________\nconv2d_2 (Conv2D) (None, 64, 64, 96) 24672 \n_________________________________________________________________\nmax_pooling2d_2 (MaxPooling2 (None, 32, 32, 96) 0 \n_________________________________________________________________\nconv2d_3 (Conv2D) (None, 32, 32, 128) 49280 \n_________________________________________________________________\nmax_pooling2d_3 (MaxPooling2 (None, 16, 16, 128) 0 \n_________________________________________________________________\nflatten (Flatten) (None, 32768) 0 \n_________________________________________________________________\ndense (Dense) (None, 256) 8388864 \n_________________________________________________________________\ndropout (Dropout) (None, 256) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 1) 257 \n=================================================================\nTotal params: 8,471,745\nTrainable params: 8,471,745\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"# run it\nhistory = model.fit(\n X_train,\n validation_data = X_test,\n epochs = 5,\n #batch_size=batch_size,\n verbose = 1,\n# callbacks=my_callbacks\n) # weighted_metrics",
"Epoch 1/5\n1/1 [==============================] - 0s 233ms/step - loss: 0.7025 - accuracy: 0.3333 - val_loss: 0.7181 - val_accuracy: 0.5000\nEpoch 2/5\n1/1 [==============================] - 0s 59ms/step - loss: 0.7819 - accuracy: 0.5000 - val_loss: 0.6475 - val_accuracy: 0.5000\nEpoch 3/5\n1/1 [==============================] - 0s 56ms/step - loss: 0.6793 - accuracy: 0.5000 - val_loss: 0.6652 - val_accuracy: 0.5000\nEpoch 4/5\n1/1 [==============================] - 0s 59ms/step - loss: 0.6546 - accuracy: 0.6667 - val_loss: 0.6750 - val_accuracy: 0.5000\nEpoch 5/5\n1/1 [==============================] - 0s 62ms/step - loss: 0.5894 - accuracy: 0.6667 - val_loss: 0.6842 - val_accuracy: 0.5000\n"
],
[
"# testing this plot function\nmodel_name = 'test'\nfig, axs = plt.subplots(1, 2, figsize=(10, 8))\nmy_funcs.plot_train_val_acc(history, 5, model_name, axs)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73d4dfde878278360449a1c5cfee711d068fe92 | 931,170 | ipynb | Jupyter Notebook | Neural_Network_Keras_Multiclass.ipynb | gsdataenthusiast/Keras-Neural-Network-Trial | 19ce699cd5214d8bf3b8cecbe23426afacc12948 | [
"MIT"
] | null | null | null | Neural_Network_Keras_Multiclass.ipynb | gsdataenthusiast/Keras-Neural-Network-Trial | 19ce699cd5214d8bf3b8cecbe23426afacc12948 | [
"MIT"
] | null | null | null | Neural_Network_Keras_Multiclass.ipynb | gsdataenthusiast/Keras-Neural-Network-Trial | 19ce699cd5214d8bf3b8cecbe23426afacc12948 | [
"MIT"
] | null | null | null | 1,246.546185 | 326,078 | 0.952435 | [
[
[
"# Importing libraries <a name=\"Import-Libraries\"></a>",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\nimport numpy as np\nimport seaborn as sns\nimport warnings\n\nwarnings.filterwarnings('ignore')\npd.options.display.float_format = '{:,.2f}'.format\npd.set_option('display.max_rows', 100)\npd.set_option('display.max_columns', 200)\n\n\nfrom datetime import datetime\nfrom matplotlib.colors import ListedColormap\nfrom sklearn.datasets import make_classification, make_moons, make_circles\nfrom sklearn.metrics import confusion_matrix, classification_report, mean_squared_error, mean_absolute_error, r2_score\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.utils import shuffle\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Dropout, BatchNormalization, Activation\nfrom keras.optimizers import Adam, SGD\nfrom keras.callbacks import EarlyStopping\nfrom keras.utils.np_utils import to_categorical\nfrom sklearn.preprocessing import StandardScaler, LabelEncoder, OneHotEncoder, MinMaxScaler\nfrom sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold, KFold\nimport keras.backend as K\nfrom keras.wrappers.scikit_learn import KerasClassifier",
"_____no_output_____"
],
[
"from __future__ import print_function",
"_____no_output_____"
]
],
[
[
"# Utility Functions <a name=\"Utility-Functions\"></a>",
"_____no_output_____"
]
],
[
[
"def plot_multiclass_decision_boundary(model, X, y):\n x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1\n y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1\n xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101))\n cmap = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])\n\n Z = model.predict_classes(np.c_[xx.ravel(), yy.ravel()], verbose=0)\n Z = Z.reshape(xx.shape)\n fig = plt.figure(figsize=(8, 8))\n plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)\n plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)\n plt.xlim(xx.min(), xx.max())\n plt.ylim(yy.min(), yy.max())\n\ndef plot_loss_accuracy(history):\n historydf = pd.DataFrame(history.history, index=history.epoch)\n plt.figure(figsize=(8, 6))\n historydf.plot(ylim=(0, max(1, historydf.values.max())))\n loss = history.history['loss'][-1]\n acc = history.history['accuracy'][-1]\n plt.title('Loss: %.3f, Accuracy: %.3f' % (loss, acc))\n \ndef plot_confusion_matrix(model, X, y):\n y_pred = model.predict_classes(X, verbose=0)\n plt.figure(figsize=(8, 6))\n sns.heatmap(pd.DataFrame(confusion_matrix(y, y_pred)), annot=True, fmt='d', cmap='YlGnBu', alpha=0.8, vmin=0)\n\ndef make_multiclass(N=500, D=2, K=3):\n \"\"\"\n N: number of points per class\n D: dimensionality\n K: number of classes\n \"\"\"\n np.random.seed(0)\n X = np.zeros((N*K, D))\n y = np.zeros(N*K)\n for j in range(K):\n ix = range(N*j, N*(j+1))\n # radius\n r = np.linspace(0.0,1,N)\n # theta\n t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2\n X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]\n y[ix] = j\n fig = plt.figure(figsize=(6, 6))\n plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu, alpha=0.8)\n plt.xlim([-1,1])\n plt.ylim([-1,1])\n return X, y",
"_____no_output_____"
]
],
[
[
"# Multiclass Classification <a name=\"MultiClass\"></a>",
"_____no_output_____"
]
],
[
[
"X, y = make_multiclass(K=4) # number of class = 4",
"_____no_output_____"
]
],
[
[
"## Deep Neural Network <a name=\"Deep-Net2\"></a>",
"_____no_output_____"
]
],
[
[
" ##first trial model with dense layers and tanh activation\nmodel = Sequential()\nmodel.add(Dense(64, input_shape=(2,), activation='tanh'))\nmodel.add(Dense(32, activation='tanh'))\nmodel.add(Dense(units=4, activation='softmax'))\n\n\nmodel.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])\n\ny_cat = to_categorical(y)\nhistory = model.fit(X, y_cat, verbose=0, epochs=50)\nplot_loss_accuracy(history)",
"_____no_output_____"
],
[
"plot_multiclass_decision_boundary(model, X, y)",
"WARNING:tensorflow:From <ipython-input-5-5150429cfdf2>:7: Sequential.predict_classes (from tensorflow.python.keras.engine.sequential) is deprecated and will be removed after 2021-01-01.\nInstructions for updating:\nPlease use instead:* `np.argmax(model.predict(x), axis=-1)`, if your model does multi-class classification (e.g. if it uses a `softmax` last-layer activation).* `(model.predict(x) > 0.5).astype(\"int32\")`, if your model does binary classification (e.g. if it uses a `sigmoid` last-layer activation).\n"
],
[
"y_pred = model.predict_classes(X, verbose=0)\nprint(classification_report(y, y_pred))\nplot_confusion_matrix(model, X, y)",
" precision recall f1-score support\n\n 0.0 0.83 0.93 0.87 500\n 1.0 0.99 0.97 0.98 500\n 2.0 0.96 0.99 0.98 500\n 3.0 0.92 0.80 0.85 500\n\n accuracy 0.92 2000\n macro avg 0.92 0.92 0.92 2000\nweighted avg 0.92 0.92 0.92 2000\n\n"
],
[
"##MODEL TRIAL 2\n\nmodel = Sequential()\nmodel.add(Dense(64, input_shape=(2,), activation='tanh'))\nmodel.add(Dense(32, activation='tanh'))\nmodel.add(Dense(16, activation='tanh'))\nmodel.add(Dense(units=4, activation='softmax'))\n\n\nmodel.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])\n\ny_cat = to_categorical(y)\nhistory = model.fit(X, y_cat, verbose=0, epochs=50)\nplot_loss_accuracy(history)",
"_____no_output_____"
],
[
"##MODEL TRIAL 2\n\nmodel = Sequential()\nmodel.add(Dense(128, input_shape=(2,), activation='tanh'))\nmodel.add(Dense(64, activation='tanh'))\nmodel.add(Dense(32, activation='tanh'))\nmodel.add(Dense(units=4, activation='softmax'))\n\n\nmodel.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])\n\ny_cat = to_categorical(y)\nhistory = model.fit(X, y_cat, verbose=0, epochs=50)\nplot_loss_accuracy(history)",
"_____no_output_____"
],
[
"##MODEL TRIAL 2\n\nmodel = Sequential()\nmodel.add(Dense(128, input_shape=(2,), activation='tanh'))\nmodel.add(Dense(64, activation='tanh'))\nmodel.add(Dense(32, activation='tanh'))\nmodel.add(Dense(units=4, activation='softmax'))\n\n\nmodel.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])\n\ny_cat = to_categorical(y)\nhistory = model.fit(X, y_cat, verbose=0, epochs=50)\nplot_loss_accuracy(history)",
"_____no_output_____"
],
[
"model = Sequential()\nmodel.add(Dense(128, input_shape=(2,),activation='tanh'))\nmodel.add(Dense(64, activation='tanh'))\nmodel.add(Dense(32, activation='tanh'))\nmodel.add(Dense(16, activation='tanh'))\nmodel.add(Dense(4, activation='softmax'))\n\n\nmodel.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])\n\ny_cat = to_categorical(y)\nhistory = model.fit(X, y_cat, verbose=0, epochs=50)\nplot_loss_accuracy(history)",
"_____no_output_____"
],
[
"model = Sequential()\nmodel.add(Dense(128, input_shape=(2,),activation='tanh'))\nmodel.add(Dense(64, activation='tanh'))\nmodel.add(Dense(32, activation='tanh'))\nmodel.add(Dense(16, activation='tanh'))\nmodel.add(Dense(4, activation='softmax'))\n\n\nmodel.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])\n\ny_cat = to_categorical(y)\nhistory = model.fit(X, y_cat, verbose=0, epochs=50)\nplot_loss_accuracy(history)",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_3 (Dense) (None, 128) 384 \n_________________________________________________________________\ndense_4 (Dense) (None, 64) 8256 \n_________________________________________________________________\ndense_5 (Dense) (None, 32) 2080 \n_________________________________________________________________\ndense_6 (Dense) (None, 16) 528 \n_________________________________________________________________\ndense_7 (Dense) (None, 4) 68 \n=================================================================\nTotal params: 11,316\nTrainable params: 11,316\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"model = Sequential()\nmodel.add(Dense(64, input_shape=(2,),activation='tanh'))\nmodel.add(Dense(64, activation='tanh'))\nmodel.add(Dense(32, activation='tanh'))\nmodel.add(Dense(4, activation='softmax'))\n\n\nmodel.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])\n\ny_cat = to_categorical(y)\nhistory = model.fit(X, y_cat, verbose=0, epochs=50)\nplot_loss_accuracy(history)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73d60f630b2b780f2379a711005186eda853151 | 2,356 | ipynb | Jupyter Notebook | E42.ipynb | DanielM63/python-exercises | b6fd0297fc9400ab26ed15f00db18de0a0113c20 | [
"MIT"
] | null | null | null | E42.ipynb | DanielM63/python-exercises | b6fd0297fc9400ab26ed15f00db18de0a0113c20 | [
"MIT"
] | null | null | null | E42.ipynb | DanielM63/python-exercises | b6fd0297fc9400ab26ed15f00db18de0a0113c20 | [
"MIT"
] | null | null | null | 23.098039 | 53 | 0.463073 | [
[
[
"## Animal is-a object\nclass Animal(object):\n pass\n\n## Dog is-a Animal \nclass Dog(Animal):\n def __init__(self, name):\n ## Dog has-a name\n self.name = name\n\n## Cat is-a Animal\nclass Cat(Animal):\n def __init__(self, name):\n ## Cat has-a name\n self.name = name\n\n## Person is-a object\nclass Person(object):\n def __init__(self, name):\n ## Person has-a name\n self.name =name\n ## Person has-a pet\n self.pet = None\n\n## Emmployee is-a Perosn\nclass Employee(Person):\n def __init__(self, name, salary):\n super(Employee, self).__init__(name)\n self.salary = salary\n\n## Fish is-a object\nclass Fish(object):\n pass\n\n## Salmon is-a Fish\nclass Salmon(Fish):\n pass\n\n## Halibut is-a Fish\nclass Halibut(Fish):\n pass\n\n## rover is-a Dog\nrover = Dog(\"Rover\")\n\n## satan is-a Cat\nsatan = Cat(\"Satan\")\n\n## mary is-a Person\nmary = Person(\"Mary\")\n\n## mary has-a cat\nmary.pet = satan\n\n## frank is-a Employee which has-a salary\nfrank = Employee(\"Frank\", 120000)\n\n## frank has-a dog\nfrank.pet = rover\n\n## flipper is-a Fish\nflipper = Fish()\n\n## crouse is-a salmon\ncrouse = Salmon()\n\n## harry is-a halibut\nharry = Halibut()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code"
]
] |
e73d68ab98e407d81862bc1a3b60d78c4bfc74ea | 22,462 | ipynb | Jupyter Notebook | logregModel.ipynb | joanitolopo/sentimen-analisis | 60724d5e9d866389be55e968ab371ae285313412 | [
"MIT"
] | null | null | null | logregModel.ipynb | joanitolopo/sentimen-analisis | 60724d5e9d866389be55e968ab371ae285313412 | [
"MIT"
] | null | null | null | logregModel.ipynb | joanitolopo/sentimen-analisis | 60724d5e9d866389be55e968ab371ae285313412 | [
"MIT"
] | null | null | null | 29.400524 | 486 | 0.480055 | [
[
[
"Dataset yang digunakan dapat didownload di: https://github.com/rizalespe/Dataset-Sentimen-Analisis-Bahasa-Indonesia atau menggunakan ***git clone*** seperti contoh dibawah ini. Folder yang di _clone_ tersimpan ke dalam folder tempat file project ini disimpan.",
"_____no_output_____"
]
],
[
[
"#!git clone https://github.com/rizalespe/Dataset-Sentimen-Analisis-Bahasa-Indonesia",
"_____no_output_____"
]
],
[
[
"## Install Package",
"_____no_output_____"
],
[
"**Requirement Package**:\n\n```\n1. nltk : https://www.nltk.org/\n2. Sastrawi: https://github.com/sastrawi/sastrawi\n3. numpy: https://numpy.org/\n4. pandas: https://pandas.pydata.org/\n5. sklearn: https://scikit-learn.org/stable/\n\n```",
"_____no_output_____"
],
[
"# Import Package",
"_____no_output_____"
]
],
[
[
"#!pip install Sastrawi\n#nltk.download('stopwords')\n#nltk.download('punkt')",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\nimport re\nimport pickle\nfrom string import punctuation\nimport os\nimport json\n\nfrom nltk.corpus import stopwords\nfrom nltk.tokenize import word_tokenize\n\nfrom Sastrawi.Stemmer.StemmerFactory import StemmerFactory\nfrom Sastrawi.StopWordRemover.StopWordRemoverFactory import StopWordRemoverFactory\n\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.compose import ColumnTransformer\n\nfrom jcopml.pipeline import num_pipe, cat_pipe\nfrom jcopml.utils import save_model, load_model\nfrom jcopml.plot import plot_missing_value\nfrom jcopml.feature_importance import mean_score_decrease\n\nfactory_stopwords = StopWordRemoverFactory()\nsw_indo = factory_stopwords.get_stop_words() + stopwords.words('indonesian')",
"_____no_output_____"
]
],
[
[
"# Process Data",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(\"data/dataset_komentar_instagram_cyberbullying.csv\")\ndf.head()",
"_____no_output_____"
],
[
"df.loc[(df.Sentiment == 'negative'),'Sentiment']=0\ndf.loc[(df.Sentiment == 'positive'),'Sentiment']=1",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"def process_tweet(tweet):\n \n tweet = tweet.values.squeeze().tolist()\n \n # kumpulan stemming\n factory_stem = StemmerFactory()\n stemmer = factory_stem.create_stemmer()\n\n # kumpulan stopwords\n factory_stopwords = StopWordRemoverFactory()\n stopword = factory_stopwords.get_stop_words() + stopwords.words('indonesian')\n \n result = []\n \n for tweet in tweet:\n \n # menghapus kata-kata yang tidak penting seperti @, #\n tweet = re.sub(r'\\$\\w*', '', tweet)\n tweet = re.sub(r'^RT[\\s]+', '', tweet)\n tweet = re.sub(r'https?:\\/\\/.*[\\r\\n]*', '', tweet)\n tweet = re.sub(r'#', '', tweet)\n tweet = re.sub(r'<USERNAME>', '', tweet)\n \n # tokenizer word\n tweet_tokens = word_tokenize(tweet)\n \n # membersihkan word\n tweets_clean = [stemmer.stem(word) for word in tweet_tokens if (word not in stopword and word not in punctuation)]\n \n result.append(' '.join(tweets_clean))\n \n return result",
"_____no_output_____"
],
[
"df['Instagram Comment Text'] = process_tweet(df['Instagram Comment Text'])",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"# df.to_csv('data/komentarDataset')",
"_____no_output_____"
]
],
[
[
"# Import Data",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(\"data/komentarDataset\", usecols=['Sentiment', 'Instagram Comment Text'])\ndf.head()",
"_____no_output_____"
]
],
[
[
"# Dataset Splitting",
"_____no_output_____"
]
],
[
[
"X = df[\"Instagram Comment Text\"]\ny = df.Sentiment\n\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)\nX_train.shape, X_test.shape, y_train.shape, y_test.shape",
"_____no_output_____"
]
],
[
[
"# Training",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import SVC\nfrom sklearn.model_selection import RandomizedSearchCV\nfrom jcopml.tuning import random_search_params as rsp",
"_____no_output_____"
],
[
"pipeline = Pipeline([\n ('prep', TfidfVectorizer(tokenizer=word_tokenize, stop_words=sw_indo, ngram_range=(1,3))),\n ('algo', SVC(max_iter=500))\n])\n\nmodel = RandomizedSearchCV(pipeline, rsp.svm_params, cv=3, n_iter=50, n_jobs=-1, verbose=1, random_state=42)\nmodel.fit(X_train, y_train)\n\nprint(model.best_params_)\nprint(model.score(X_train, y_train), model.best_score_, model.score(X_test, y_test))",
"Fitting 3 folds for each of 50 candidates, totalling 150 fits\n"
]
],
[
[
"# Sanity Check",
"_____no_output_____"
]
],
[
[
"text = [X_train[9].lower()]\ntext",
"_____no_output_____"
],
[
"model.predict(text)",
"_____no_output_____"
],
[
"# save_model(model, \"model_best_svm.pkl\")",
"Model is pickled as model/model_best_svm.pkl\n"
]
],
[
[
"# Error Analysis",
"_____no_output_____"
]
],
[
[
"X_test, y_test = X_test.tolist(), np.array([y_test.tolist()])",
"_____no_output_____"
],
[
"print('Truth Predicted Tweet')\nfor x, y in zip(X_pred_, y_pred_[-1]):\n x = x.lower()\n x = [x]\n y_hat = model.predict(x)\n if y != (np.sign(y_hat) > 0):\n print('%d\\t%0.2f\\t%s' % (y, np.sign(y_hat) > 0, ' '.join(x).encode('ascii', 'ignore')))",
"Truth Predicted Tweet\n0\t1.00\tb'jelek,lecek,bantet ??????'\n0\t1.00\tb'semoga pelakor2 kena karma dan semoga dapat karma yg meninggalkan istrinya yg bwrjuang dg dia dr nol tp setelah sukses selingkuh dan sok jd penguasa ke istri ya..'\n1\t0.00\tb'kasian anaknya,, jgn sampek anaknya rusak jugak kek emaknya yaa'\n1\t0.00\tb'beruntungnya bella.. orang2 jadi fokus ama komen lakinya. coba kalo ngga, pasti model bajunya yang diceramahin ama netizen ??'\n0\t1.00\tb'yg gk becus tuh loh jedun...hidup nya cuma bisanya ngerusak kbhgiaan org lain .mau hidup serba mewah tp g mau krja mlh morotin laki org..karma psti akn mnghampirimu????????'\n0\t1.00\tb'geblek lo tata...cowo bgt dibela2in balikan...hadeww...ntar ditinggal lg nyalahin tuh cowo...padahal kitenya yg oon.'\n1\t0.00\tb'yg komen kenapa si mbak ini ga sedih malah ketawa2.. ya iyalah klo kita dah disakiti sm pasangan smpe berlarut2 ngapain juga sih kita sedih ampe depresi segala.. serahin sm allah aja..bawa happy aja mski sakit.. lagian si mba senyum2 di wajahnya tp hatinya mana tau kan... senyumannya bs jd buat menetralisir kondisi hatinya yg lg terpuruk... ada pepatah bilang ,, klo bahagia jgn trllu bahagia, klo sedih juga jgn trllu sedih... diimbangi aja biar ga gila ??????'\n0\t1.00\tb' <username> yutub apaan ya mba? aplikasi baru ya? sy taunya youtube. mba gak tau apa ya seseorg bs dpt penghasilan besar salah satunya dr youtube loh. mreka jg di bayar apalagi klo bnyk yg ntn video mreka. sekolah yg bener deh mba biar pinter. generasi muda'\n1\t0.00\tb'weewww bangga kali ak liatnya bang <username> pake baju adat karo.... syip'\n1\t0.00\tb' <username> suami saya seumuran sama saya mba, malah tuaan saya beberapa bulan tapi alhamdulillah suami saya gak kekanak kanakan hehe'\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
e73d775607dfca0d1a77fa8a52ea663af4d22005 | 48,162 | ipynb | Jupyter Notebook | armageddon/Accuracy Comparison.ipynb | Ping-ChenTsai417/Astroid-impact-armageddon-itokawa-acse4 | 91a03881087369bbc7fd84be96e816515da9ff65 | [
"MIT"
] | null | null | null | armageddon/Accuracy Comparison.ipynb | Ping-ChenTsai417/Astroid-impact-armageddon-itokawa-acse4 | 91a03881087369bbc7fd84be96e816515da9ff65 | [
"MIT"
] | null | null | null | armageddon/Accuracy Comparison.ipynb | Ping-ChenTsai417/Astroid-impact-armageddon-itokawa-acse4 | 91a03881087369bbc7fd84be96e816515da9ff65 | [
"MIT"
] | null | null | null | 172.623656 | 22,612 | 0.871122 | [
[
[
"import solver\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.integrate import solve_ivp",
"_____no_output_____"
],
[
"def compare_num_to_analytic(\n radius=10, velocity=20e3, density=3000, strength=1e5, angle=45,\n init_altitude=1e5, radians=False):\n \n input_data = {'radius': radius,\n 'velocity': velocity,\n 'density': density,\n 'strength': strength,\n 'angle': angle,\n 'init_altitude': init_altitude,\n 'radians': radians}\n\n z0 = input_data['init_altitude'] # entry altitude\n th0 = input_data['angle'] * np.pi/180 # entry angle\n v0 = input_data['velocity'] # entry velocity\n r = input_data['radius'] # object radius\n rhom = input_data['density'] # object density\n m = (4/3) * np.pi * r**3 * rhom # object mass\n A = np.pi * r**2 # object cross-sectional area\n\n planet = solver.Planet(Cd=1., Ch=0, Q=1, Cl=0, alpha=0,\n Rp=np.inf, g=0, H=8000., rho0=1.2)\n result = planet.solve_atmospheric_entry(**input_data)\n\n ts_list = [0.001, 0.002, 0.005, 0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1]\n\n numerical_error = []\n for time_step in ts_list:\n results = planet.solve_atmospheric_entry(**input_data, ts=time_step, dt=time_step)\n height_n = results.altitude.values\n velocity_n = results.velocity.values\n\n # define a constant in the solution\n x = planet.H * (-planet.Cd * A / (2*m) * planet.rho0 / np.sin(th0))\n\n # analytical solution gives v as a function of z\n z = height_n\n velocity_a = v0 * \\\n (np.exp(x * (np.exp(-z/planet.H) - np.exp(-z0/planet.H))))\n\n e = np.abs(velocity_a[-1] - velocity_n[-1])\n numerical_error.append(e)\n\n fig, ax = plt.subplots(1, 1, figsize=(8, 8))\n ax.loglog(ts_list, numerical_error, 'b.', markersize=12, label='RK4')\n ax.set_xlabel('Time Step (s)')\n ax.set_ylabel('Error')\n\n start_fit = 2\n end_fit = -3\n line_fit = np.polyfit(np.log(ts_list[start_fit:end_fit]), np.log(\n numerical_error[start_fit:end_fit]), 1)\n ax.loglog(ts_list, np.exp(line_fit[1]) * ts_list**(line_fit[0]),\n 'k-', label='slope: {:.2f}'.format(line_fit[0]))\n ax.legend(loc='best')\n plt.show()",
"_____no_output_____"
],
[
"# New planet comparison with solve_ivp\n\ndef compare_with_scipy(\n radius=10, velocity=20e3, density=3000, strength=1e5, angle=45, init_altitude=1e5, \n radians=False, ts_list=[0.001, 0.002, 0.005, 0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1],\n alpha=0, tol=1e-6):\n\n input_data = {'radius': radius,\n 'velocity': velocity,\n 'density': density,\n 'strength': strength,\n 'angle': angle,\n 'init_altitude': init_altitude,\n 'radians': radians}\n\n z0 = input_data['init_altitude'] # entry altitude\n th0 = input_data['angle'] * np.pi/180 # entry angle\n v0 = input_data['velocity'] # entry velocity\n r = input_data['radius'] # object radius\n rhom = input_data['density'] # object density\n m = (4/3) * np.pi * r**3 * rhom # object mass\n A = np.pi * r**2 # object cross-sectional area\n\n planet_nofrag = solver.Planet(alpha=0)\n planet_frag = solver.Planet(alpha=alpha)\n\n radius = input_data['radius']\n velocity = input_data['velocity']\n density = input_data['density']\n strength = input_data['strength']\n angle = input_data['angle']\n init_altitude = input_data['init_altitude']\n radians = input_data['radians']\n\n # initial condition\n v0 = velocity\n m0 = (4/3) * np.pi * radius**3 * density\n if radians:\n theta0 = angle\n else:\n theta0 = angle * np.pi / 180\n\n z0 = init_altitude\n x0 = 0\n r0 = radius\n state0 = np.array([v0, m0, theta0, z0, x0, r0])\n\n error_frag = []\n error_nofrag = []\n\n ts_list = ts_list\n\n frag_error = []\n nofrag_error = []\n\n t0 = 0\n tol = tol\n\n for time_step in ts_list:\n print(time_step)\n # no frag\n result_nofrag = planet_nofrag.solve_atmospheric_entry(**input_data, ts=time_step, dt=time_step)\n tf_nofrag = result_nofrag.time.values[-1]\n t = np.arange(0,tf_nofrag+time_step, time_step) # set different time intervals\n tf_nofrag = result_nofrag.time.values[-1]\n sci = solve_ivp(lambda t, y: planet_nofrag.system(t, y, strength, density), [\n t0, t[-1]], state0, method='Radau',t_eval=t, atol=tol, rtol=tol)\n scipy_last = sci.y[:,-1]\n ours_last = result_nofrag.drop(['time'], axis=1).to_numpy()[-1,:]\n e = np.linalg.norm(np.abs(scipy_last - ours_last)) / np.linalg.norm(scipy_last)\n nofrag_error.append(e)\n\n # frag\n result_frag = planet_frag.solve_atmospheric_entry(**input_data, ts=time_step, dt=time_step)\n tf_frag = result_frag.time.values[-1]\n t = np.arange(0,tf_frag+time_step, time_step) # set different time intervals\n tf_frag = result_frag.time.values[-1]\n sci = solve_ivp(lambda t, y: planet_frag.system(t, y, strength, density), [\n t0, t[-1]], state0, method='Radau', t_eval=t, atol=tol, rtol=tol)\n scipy_last = sci.y[:,-1]\n ours_last = result_frag.drop(['time'], axis=1).to_numpy()[-1,:]\n e = np.linalg.norm(np.abs(scipy_last - ours_last)) / np.linalg.norm(scipy_last)\n frag_error.append(e)\n\n fig, ax = plt.subplots(1, 1, figsize=(8, 8))\n ax.loglog(ts_list, nofrag_error, 'b.', markersize=12, label='No Fragmentation')\n ax.loglog(ts_list, frag_error, 'r.', markersize=12, label='Fragmentation')\n ax.set_xlabel('Time Step (s)')\n ax.set_ylabel('Error')\n\n start_fit = 2\n end_fit = -3\n line_fit_nofrag = np.polyfit(np.log(ts_list[start_fit:end_fit]), np.log(\n nofrag_error[start_fit:end_fit]), 1)\n ax.loglog(ts_list, np.exp(line_fit_nofrag[1]) * ts_list**(line_fit_nofrag[0]),\n 'k-', label='slope: {:.2f}'.format(line_fit_nofrag[0]))\n line_fit_frag = np.polyfit(np.log(ts_list[start_fit:end_fit]), np.log(\n frag_error[start_fit:end_fit]), 1)\n ax.loglog(ts_list, np.exp(line_fit_frag[1]) * ts_list**(line_fit_frag[0]),\n 'k-', label='slope: {:.2f}'.format(line_fit_frag[0]))\n ax.legend(loc='best')\n plt.show()",
"_____no_output_____"
],
[
"compare_num_to_analytic()",
"_____no_output_____"
],
[
"compare_with_scipy(alpha=0.3)",
"0.001\n0.002\n0.005\n0.01\n0.02\n0.05\n0.1\n0.2\n0.5\n1\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
e73d860ef3818d15ffef5e8aa1275f1531e58466 | 27,212 | ipynb | Jupyter Notebook | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance | 6b8510b96d864f009e212a23e3c0762f9f4acf50 | [
"MIT"
] | null | null | null | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance | 6b8510b96d864f009e212a23e3c0762f9f4acf50 | [
"MIT"
] | null | null | null | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance | 6b8510b96d864f009e212a23e3c0762f9f4acf50 | [
"MIT"
] | 2 | 2019-05-26T14:03:35.000Z | 2019-10-31T08:53:53.000Z | 30.852608 | 310 | 0.481442 | [
[
[
"# A broad study on `Chi^2` algorithm\n<hr>\n#### Before going to broad discussion, first lets understand what is `Chi^2` algorithm ? What it does? Why we need to learn it?",
"_____no_output_____"
],
[
"* __`Chi^2` (pronounced as kai-square) is an algorithm that helps us to understand the relationship between two [categorical](https://youtu.be/o8gs-zgPfp4) variables.__ \n* __It helps us to compare what we actually observed with what we expected.__\n* __We use it to accept or reject our [hypothesis](https://youtu.be/AYSbHbM7Wp0).__\n* __It also used for feature selection__\n\n",
"_____no_output_____"
],
[
"### There are tow types of Hypotheses test are present in `Chi^2` algorithm \n * test for fitting/ goodness of fit\n * test for independence\n \n \n#### `Chi^2` test for fitting or goodness of fit\nChi-squared __goodness-of-fit__ test is an analog of the one way to test for categorical variables: it tests whether the distribution of sample categorical data matches an expected distribution.\n#### `Chi^2` test of independence\nThe Chi-Square test of independence is a statistical test to determine if there is a __significant relationship__ between 2 categorical variables.",
"_____no_output_____"
],
[
"<hr>",
"_____no_output_____"
],
[
"## `Chi^2` test for goodness of fit\n\nLets understand the scenerio first:\n\nMr. Rahim thinking about buying a restaurant. So, he go and ask the owner what is the distribution of the `number of customer` you get in each day. The owner gives him distribution data of 6 days. BUT Mr. Rahim get little bit suspicious and he dicide to see how good the owners provided distribution! \n\nSo he started observing the number of customer came to the restaurant in a week. And he finally collect the observed distribution data. Both Owner's distribution and observed distribution data showing below:\n\n> __The above example taken from [Khan Academy](https://youtu.be/2QeDRsxSF9M)__\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ndata = pd.read_csv(r\"C:\\Users\\DIU\\Desktop\\goodness_of_fit.csv\")\n\ndata",
"_____no_output_____"
]
],
[
[
"`Chi^2` has a standard distribution [table](https://en.wikipedia.org/wiki/Chi-squared_distribution#Table_of_%CF%872_values_vs_p-values). We need this table on both test",
"_____no_output_____"
],
[
"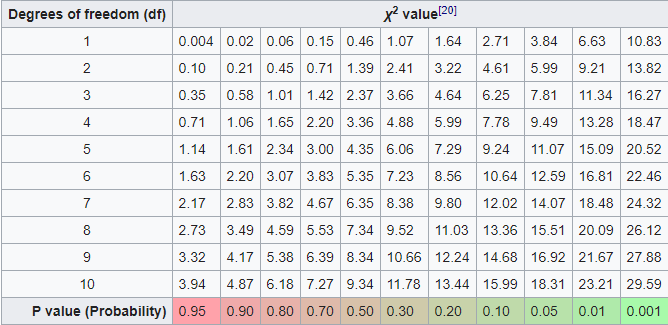",
"_____no_output_____"
],
[
"The Equation of `Chi^2`:",
"_____no_output_____"
],
[
"\\begin{equation}\n\\chi=\\sum\\frac{\\ (observed - expected)^2}{expected}\n\\end{equation}",
"_____no_output_____"
],
[
"In `data` dataframe we have __Owner's distribution__ and __observed distribution__, but we do not have expected values! The formula of finding __expected__ values:",
"_____no_output_____"
],
[
"> expected = total no. of observed customer * (% of owners observation each day)",
"_____no_output_____"
],
[
"lets find out the expected values first.",
"_____no_output_____"
]
],
[
[
"data[\"expected\"] = (sum(data[\"observed_distribution\"]) * (data[\"owners_distribution\"]/100)).astype(int)\ndata",
"_____no_output_____"
]
],
[
[
"__There are maily two hypothesis in `Chi^2`__\n\n\\begin{equation}\nH_o = Null Hypothesis\\\\\nH_a = Alternative Hypothesis\n\\end{equation}\n\n\n* __Null Hypothesis => There's no significent relationship between specified features__\n* __Alternative Hypothesis => reverse of Null Hypothesis__\n",
"_____no_output_____"
],
[
"__Now lets calculate the `chi-square` and find out the Null hypothesis of `Owners_distribution` is correct or not__\n\n> `Correct means => Accepted => when Chi-square value less than Critical Value`\n\n> `Incorrect means => Rejected => when Chi-square value greater than Critical Value`",
"_____no_output_____"
],
[
"|Calculating Chi-square value by Hand||#|#|#|#|#|#|\n| --- | ---- | ---- | ---- | --- | -- | --- |\n| \\begin{equation}Observed\\end{equation} || 30 | 14 | 34 | 45 | 57 | 20|\n| \\begin{equation}Expected\\end{equation}|| 20 | 20 | 30 | 40 | 60 | 30 |\n| \\begin{equation}(O-E)\\end{equation}|| 10 | -6 | 4 | 5 | -3 | -10 |\n|\\begin{equation}(O-E)^2\\end{equation} || 100 | 36 | 16 | 25 | 9 | 100 |\n|\\begin{equation}\\frac{(O-E)^2}{E}\\end{equation} || 5 | 1.8 | 0.54 | 0.625 | 0.15 | 3.34 |\n|\\begin{equation}\\sum\\end{equation}||||||| __11.45__|",
"_____no_output_____"
]
],
[
[
"# Same calculation using python manually\n\nsubtract = data[\"observed_distribution\"] - data[\"expected\"]\nsubtract_sqr = subtract**2\ndivision = subtract_sqr / data[\"expected\"]\nchi_square = division.sum()\n\nprint(round(chi_square, 3))",
"11.442\n"
]
],
[
[
"Now we need to check whether `owner's disribution` is accepted or not, to do this we need some extra information:\n\n* What is the `Degree of freedom`?\n* What is the significant level ?\n* What is the Critical Value?\n\n__Answer:__\n\nDegree of freedom = number of observation - 1 = __5__\n\nSignificant Level : 0.05 (_most used significant level by statistians_)\n\nCritical Value: we need to find the critical value from the chi^2 distribution [table](https://en.wikipedia.org/wiki/Chi-squared_distribution#Table_of_%CF%872_values_vs_p-values).\n\nWe need to look at where the degree of freedom intersect the significant level(P value):\nso we can see that, degree of freedom => 5 and significant level 0.05 will intersect at: 11.07\n\nHence, Critical Value = 11.07",
"_____no_output_____"
]
],
[
[
"critical_value = 11.07\n\nif(chi_square<critical_value):\n print(\"Owner's distribution is correct, Accepted\")\nelse:\n print(\"Owner's distribution is not correct, Rejected\")",
"Owner's distribution is not correct, Rejected\n"
]
],
[
[
"### We can achive exact same thing by using `scipy`:",
"_____no_output_____"
]
],
[
[
"import scipy.stats as stats\n\n(chi_square, p) = stats.chisquare(data[\"observed_distribution\"], data[\"expected\"], ddof=1)\nprint ('Chi-square Value = %f, P-value = %f' % (chi_square, p))\n\nalpha = 0.05 # significance level",
"Chi-square Value = 11.441667, P-value = 0.022024\n"
],
[
"# another way to check the observation\n# Correct means => Accepted => p (resulted level) > alpha (significant level)\n# Incorrect means => Rejected => p < alpha\n\nif p <= alpha:\n # we reject null hypothesis and accept alternative hypothesis\n print (\"Owner's distribution is not correct, Rejected\")\nelse:\n # we accept null hypothesis and reject alternative hypothesis\n print(\"Owner's distribution is correct, Accepted\")",
"Owner's distribution is not correct, Rejected\n"
]
],
[
[
"## `Chi^2` test of independence",
"_____no_output_____"
],
[
"__Independence__ is a key concept in probability that describes a situation where knowing the value of one variable tells you nothing about the value of another.\n\nFor instance, the __month__ you were born probably doesn't tell you anything about which __web browser__ you use :p\n\nSo we'd expect birth month and browser preference to be __independent__.\n\nOn the other hand, your month of birth might be related to whether you __excelled__ at sports in school, so month of birth and sports performance might __not__ be __independent__.\n\n* The chi-squared `test of independence` tests whether two categorical variables are independent.\n* The test of independence is commonly used to determine whether variables like education, political views and other preferences vary based on demographic factors like gender, race and religion. \n\n> __The above content collected from this [blog](http://hamelg.blogspot.com)__\n\n\nLet's say there are couple of herbs that people beleives help to prevent __flu__. So to test this, we randomly assign people into three different groups. And first two groups are taking herbs1 and herbs2 and third group doesnot take anything:\n\n> __The above example collected from [KhanAcademy](https://youtu.be/hpWdDmgsIRE)__",
"_____no_output_____"
]
],
[
[
"flu_dataset = pd.read_csv(r\"C:\\Users\\DIU\\Desktop\\flu_dataset.csv\")\n\ncopy_df = flu_dataset.copy()\nflu_dataset",
"_____no_output_____"
]
],
[
[
"__Now we need to find out the total both column and row wise:__",
"_____no_output_____"
]
],
[
[
"# row wise sum added into a new column called 'total'\nflu_dataset[\"total\"] = flu_dataset.iloc[:, 1:].sum(axis=1) \n\n# column wise added into a new row with a index called 'Grand Total'\nflu_dataset = pd.concat([flu_dataset, pd.DataFrame(flu_dataset.sum(axis=0), columns=['Grand Total']).T])\n\nflu_dataset",
"_____no_output_____"
]
],
[
[
"> The main difference between `goodness of fit` and `test of independence` is that in `test of independent` we have to find expected value for every cell in a two dimentional space. \n\nNow firstly we need to find out the expected frequency of getting sick or not sick:\n\n> expected frequency for getting `sick = 80/380 = 0.2105 ~= 21%`\n\n> expected frequency for getting `not sick = 300/380 = 0.7894 ~= 79%`\n\nFor each cell we need to find the expected value:\n\nfor, `sick patient = total frequency of getting sick * Total number of people taking herb or not`\n\nfor, `not sick patient = total frequency of getting not sick * Total number of people taking herb or not`\n\nExpected `frequency for sick patient who takes Herb1 = total frequency of getting sick * Total number of people whom are taking herb1`\n\n> expected_sick_herb1 = 21% * 120 = 25.2\n\n> expected_sick_herb2 = 21% * 140 = 29.4\n\n> expected_sick_noherb = 21% * 120 = 25.2\n\n> expected_notsick_herb1 = 79% * 120 = 94.8\n\n> expected_notsick_herb2 = 79% * 140 = 110.6\n\n> expected_notsick_noherb = 79% * 120 = 94.8\n\n|status| herb1| herb2|noherb|total|\n|------|------|------|------|-----|\n|sick|20|30|30|80|\n|__Exp. Freq.__|__25.2__|__29.4__|__25.2__|__21%__|\n|not_sick|100|110|90|300|\n|__Exp. Freq.__|__94.8__|__110.6__|__94.8__|__79%__|\n|GrandTotal|120|140|120|380|\n\nNo we need to calculate the chi-square:\n\\begin{equation}\n\\chi^2 = \\sum\\frac{(Observed - Expected)^2}{Expected}\\\\\n=\\frac{(20-25.2)^2}{25.2} + \\frac{(30-29.4)^2}{29.4} + \\frac{(30-25.2)^2}{25.2} + \\frac{(100-94.7)^2}{94.7} + \\frac{(110-110.6)^2}{110.6} + \\frac{(90-94.7)^2}{94.7}\\\\\n= 2.52825\\\\\n\\end{equation}\n\n### We can achive exact same thing in python using `stats` Library:",
"_____no_output_____"
]
],
[
[
"del copy_df[\"status\"]\ncopy_df",
"_____no_output_____"
],
[
"chiStats = stats.chi2_contingency(observed = copy_df)\nprint ('Chi-square Value = %f, p-value=%f' % (chiStats[0], chiStats[1]))",
"Chi-square Value = 2.525794, p-value=0.282834\n"
]
],
[
[
"__Now to Accept or Reject the hypothesis we need to look at chi-square distribution [table](https://en.wikipedia.org/wiki/Chi-squared_distribution#Table_of_%CF%872_values_vs_p-values).__\n\nFirst thing first, we have a significant level/alpha for this problem = 10% = 0.10\n\nand the degree of freedom for Contingency = (number of row - 1)* (number of column - 1) = (2-1) * (3-1) = 2\n\n__Now, we need to find out the critical value where the `degree of freedom => 2` interset the `significant level 0.10`__\n\naccording to the chi-square distribution table the `intersect/ critical value is = 4.61`\n\nIf the `chi-square` value less than the `critical value` then the hypothesis is acceted (and that means variables are independent)\n",
"_____no_output_____"
]
],
[
[
"significant_level = 0.10\ndegree_of_freedom = 2\n\ncritical_value = crit = stats.chi2.ppf(q = 1 - significant_level, df = degree_of_freedom)\n\nprint(\"Critical Value: \", critical_value)\n\nobserve_chi_square = chiStats[0]\n\nprint(\"Observed Chi Value: \", observe_chi_square)\n\nif observe_chi_square <= critical_value:\n # observed chi square value is not in critical area therefore we accept null hypothesis\n print ('Null hypothesis Accetped (variables are Independent)')\nelse:\n # observed value is in critical area therefore we reject null hypothesis\n print ('Null hypothesis Rejected (variables are related/dependent)')",
"Critical Value: 4.605170185988092\nObserved Chi Value: 2.5257936507936507\nNull hypothesis Accetped (variables are Independent)\n"
]
],
[
[
"<script src=\"https://gist.github.com/78526Nasir/111e6405b7ac0d34823839df42e2fc67.js\"></script>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73d926a23198e917c77322540df5eb901063766 | 17,969 | ipynb | Jupyter Notebook | json_file_process/json_processing.ipynb | INFO6105-Spring19/hyperparameter-db-project-db17 | 0d604096db5ccae6dbed0a24396a6b7381cc7d27 | [
"MIT"
] | null | null | null | json_file_process/json_processing.ipynb | INFO6105-Spring19/hyperparameter-db-project-db17 | 0d604096db5ccae6dbed0a24396a6b7381cc7d27 | [
"MIT"
] | null | null | null | json_file_process/json_processing.ipynb | INFO6105-Spring19/hyperparameter-db-project-db17 | 0d604096db5ccae6dbed0a24396a6b7381cc7d27 | [
"MIT"
] | 1 | 2019-04-12T01:37:52.000Z | 2019-04-12T01:37:52.000Z | 37.357588 | 132 | 0.434637 | [
[
[
"import os\nimport json\nimport pandas as pd\nfrom collections import defaultdict\ndirectory = '/Users/qijin/Desktop/Northeastern/DataBase/final/Hyperparameter/Iteration1_200secs/JjUS31JGhX/'\nfor filename in os.listdir(directory):\n #print(filename)\n if filename.endswith(\".json\") and 'metadata' not in filename and \"Stacked\" not in filename:\n with open(directory+filename) as file:\n \n data = json.load(file)\n mf = pd.DataFrame(data) \n mf.loc['actual','model_id'] = mf.loc['actual','model_id']['name']\n mf.loc['actual','training_frame'] = mf.loc['actual','training_frame']['name']\n mf.loc['actual','response_column'] = mf.loc['actual','response_column']['column_name']\n #mf.loc['actual','base_models'] = mf.loc['actual','base_models']['name']\n \n mf.to_csv(directory+'CSV/'+filename[:-5]+'.csv')\n continue\n if filename.endswith(\".json\") and 'metadata' not in filename and \"Stacked\" in filename:\n with open(directory+filename) as file:\n data = json.load(file)\n mf = pd.DataFrame(data) \n mf.loc['actual','model_id'] = mf.loc['actual','model_id']['name']\n mf.loc['actual','training_frame'] = mf.loc['actual','training_frame']['name']\n mf.loc['actual','response_column'] = mf.loc['actual','response_column']['column_name']\n #print(mf.loc['actual','base_models'])\n lst = []\n\n for item in mf.loc['actual','base_models']:\n #print(item)\n item = item.get('name')\n #item = pd.DataFrame(item)\n lst.append(item)\n \n #print(mf.at['actual','base_models'])\n #print(lst)\n\n mf.at['actual','base_models'] = lst\n #mf.loc['actual','base_models'] = mf.loc['actual','base_models'][]['name']\n mf.to_csv(directory+'CSV/'+filename[:-5]+'.csv')\n continue",
"_____no_output_____"
],
[
"with open(directory+\"metadata.json\") as file:\n data = json.load(file)\n #meta = pd.DataFrame(data)\n meta = pd.DataFrame(data,index=[0])\n meta.to_csv(directory+'CSV/'+'meta.csv')",
"_____no_output_____"
],
[
"import csv\nimport re\ndf = pd.read_csv(directory+ \"200leaderboard.csv\")\n\ndf[\"model_category\"] = 0\ncate = ['GBM','GLM','StackedEnsemble_AllModels','DeepLearning','StackedEnsemble_BestOfFamily','DRF','XRT']\ni=0\nfor item in df[\"model_id\"]:\n #print(item)\n for case in cate:\n #print(case)\n if case in item:\n #print(case)\n df[\"model_category\"][i] = case\n i+=1\n break\n \ndf = df.drop(['Unnamed: 0'],1)\ndf.to_csv(directory+'CSV/'+\"200leaderboard.csv\")",
"/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:14: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py:190: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n self._setitem_with_indexer(indexer, value)\n"
],
[
"df",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
e73d99ff1b33f5b1c0f6012fefddc623a9a67609 | 814,464 | ipynb | Jupyter Notebook | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN | 0e1f64a9d57863f398444e2ba4a2bb547c7c83f6 | [
"MIT"
] | null | null | null | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN | 0e1f64a9d57863f398444e2ba4a2bb547c7c83f6 | [
"MIT"
] | null | null | null | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN | 0e1f64a9d57863f398444e2ba4a2bb547c7c83f6 | [
"MIT"
] | null | null | null | 860.955603 | 782,598 | 0.951723 | [
[
[
"# Mask R-CNN - Inspect Ballon Trained Model\n\nCode and visualizations to test, debug, and evaluate the Mask R-CNN model.",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nimport random\nimport math\nimport re\nimport time\nimport numpy as np\nimport tensorflow as tf\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport matplotlib.patches as patches\n\n# Root directory of the project\nROOT_DIR = os.path.abspath(\"../../\")\n\n# Import Mask RCNN\nsys.path.append(ROOT_DIR) # To find local version of the library\nfrom mrcnn import utils\nfrom mrcnn import visualize\nfrom mrcnn.visualize import display_images\nimport mrcnn.model as modellib\nfrom mrcnn.model import log\n\nfrom samples.balloon import balloon\n\n%matplotlib inline \n\n# Directory to save logs and trained model\nMODEL_DIR = os.path.join(ROOT_DIR, \"logs\")\n\n# Path to Ballon trained weights\n# You can download this file from the Releases page\n# https://github.com/matterport/Mask_RCNN/releases\nBALLON_WEIGHTS_PATH = os.path.join(ROOT_DIR, \"mask_rcnn_balloon.h5\")",
"_____no_output_____"
]
],
[
[
"## Configurations",
"_____no_output_____"
]
],
[
[
"config = balloon.BalloonConfig()\nBALLOON_DIR = os.path.join(ROOT_DIR, \"datasets/balloon\")",
"_____no_output_____"
],
[
"# Override the training configurations with a few\n# changes for inferencing.\nclass InferenceConfig(config.__class__):\n # Run detection on one image at a time\n GPU_COUNT = 1\n IMAGES_PER_GPU = 1\n\nconfig = InferenceConfig()\nconfig.display()",
"\nConfigurations:\nBACKBONE resnet101\nBACKBONE_STRIDES [4, 8, 16, 32, 64]\nBATCH_SIZE 1\nBBOX_STD_DEV [0.1 0.1 0.2 0.2]\nCOMPUTE_BACKBONE_SHAPE None\nDETECTION_MAX_INSTANCES 100\nDETECTION_MIN_CONFIDENCE 0.9\nDETECTION_NMS_THRESHOLD 0.3\nFPN_CLASSIF_FC_LAYERS_SIZE 1024\nGPU_COUNT 1\nGRADIENT_CLIP_NORM 5.0\nIMAGES_PER_GPU 1\nIMAGE_CHANNEL_COUNT 3\nIMAGE_MAX_DIM 1024\nIMAGE_META_SIZE 14\nIMAGE_MIN_DIM 800\nIMAGE_MIN_SCALE 0\nIMAGE_RESIZE_MODE square\nIMAGE_SHAPE [1024 1024 3]\nLEARNING_MOMENTUM 0.9\nLEARNING_RATE 0.001\nLOSS_WEIGHTS {'rpn_class_loss': 1.0, 'rpn_bbox_loss': 1.0, 'mrcnn_class_loss': 1.0, 'mrcnn_bbox_loss': 1.0, 'mrcnn_mask_loss': 1.0}\nMASK_POOL_SIZE 14\nMASK_SHAPE [28, 28]\nMAX_GT_INSTANCES 100\nMEAN_PIXEL [123.7 116.8 103.9]\nMINI_MASK_SHAPE (56, 56)\nNAME balloon\nNUM_CLASSES 2\nPOOL_SIZE 7\nPOST_NMS_ROIS_INFERENCE 1000\nPOST_NMS_ROIS_TRAINING 2000\nPRE_NMS_LIMIT 6000\nROI_POSITIVE_RATIO 0.33\nRPN_ANCHOR_RATIOS [0.5, 1, 2]\nRPN_ANCHOR_SCALES (32, 64, 128, 256, 512)\nRPN_ANCHOR_STRIDE 1\nRPN_BBOX_STD_DEV [0.1 0.1 0.2 0.2]\nRPN_NMS_THRESHOLD 0.7\nRPN_TRAIN_ANCHORS_PER_IMAGE 256\nSTEPS_PER_EPOCH 100\nTOP_DOWN_PYRAMID_SIZE 256\nTRAIN_BN False\nTRAIN_ROIS_PER_IMAGE 200\nUSE_MINI_MASK True\nUSE_RPN_ROIS True\nVALIDATION_STEPS 50\nWEIGHT_DECAY 0.0001\n\n\n"
]
],
[
[
"## Notebook Preferences",
"_____no_output_____"
]
],
[
[
"# Device to load the neural network on.\n# Useful if you're training a model on the same \n# machine, in which case use CPU and leave the\n# GPU for training.\nDEVICE = \"/cpu:0\" # /cpu:0 or /gpu:0\n\n# Inspect the model in training or inference modes\n# values: 'inference' or 'training'\n# TODO: code for 'training' test mode not ready yet\nTEST_MODE = \"inference\"",
"_____no_output_____"
],
[
"def get_ax(rows=1, cols=1, size=16):\n \"\"\"Return a Matplotlib Axes array to be used in\n all visualizations in the notebook. Provide a\n central point to control graph sizes.\n \n Adjust the size attribute to control how big to render images\n \"\"\"\n _, ax = plt.subplots(rows, cols, figsize=(size*cols, size*rows))\n return ax",
"_____no_output_____"
]
],
[
[
"## Load Validation Dataset",
"_____no_output_____"
]
],
[
[
"# Load validation dataset\ndataset = balloon.BalloonDataset()\ndataset.load_balloon(BALLOON_DIR, \"val\")\n\n# Must call before using the dataset\ndataset.prepare()\n\nprint(\"Images: {}\\nClasses: {}\".format(len(dataset.image_ids), dataset.class_names))",
"Images: 13\nClasses: ['BG', 'balloon']\n"
]
],
[
[
"## Load Model",
"_____no_output_____"
]
],
[
[
"# Create model in inference mode\nwith tf.device(DEVICE):\n model = modellib.MaskRCNN(mode=\"inference\", model_dir=MODEL_DIR,\n config=config)",
"WARNING:tensorflow:From e:\\Protohaus\\GitHub\\Mask_RCNN\\venv\\lib\\site-packages\\tensorflow\\python\\util\\deprecation.py:620: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nUse fn_output_signature instead\n"
],
[
"# Set path to balloon weights file\n\n# Download file from the Releases page and set its path\n# https://github.com/matterport/Mask_RCNN/releases\nweights_path = BALLON_WEIGHTS_PATH\n\n# Or, load the last model you trained\n#weights_path = model.find_last()\n\n# Load weights\nprint(\"Loading weights \", weights_path)\nmodel.load_weights(weights_path, by_name=True)",
"Loading weights e:\\Protohaus\\GitHub\\Mask_RCNN\\mask_rcnn_balloon.h5\nWARNING:tensorflow:OMP_NUM_THREADS is no longer used by the default Keras config. To configure the number of threads, use tf.config.threading APIs.\n"
]
],
[
[
"## Run Detection",
"_____no_output_____"
]
],
[
[
"image_id = random.choice(dataset.image_ids)\nimage, image_meta, gt_class_id, gt_bbox, gt_mask =\\\n modellib.load_image_gt(dataset, config, image_id)\ninfo = dataset.image_info[image_id]\nprint(\"image ID: {}.{} ({}) {}\".format(info[\"source\"], info[\"id\"], image_id, \n dataset.image_reference(image_id)))\n\n# Run object detection\nresults = model.detect([image], verbose=1)\n\n# Display results\nax = get_ax(1)\nr = results[0]\n\nvisualize.display_instances(image, r['rois'], r['masks'], r['class_ids'], \n dataset.class_names, r['scores'], ax=ax,\n title=\"Predictions\")\nlog(\"gt_class_id\", gt_class_id)\nlog(\"gt_bbox\", gt_bbox)\nlog(\"gt_mask\", gt_mask)",
"image ID: balloon.410488422_5f8991f26e_b.jpg (12) e:\\Protohaus\\GitHub\\Mask_RCNN\\datasets/balloon\\val\\410488422_5f8991f26e_b.jpg\nProcessing 1 images\nimage shape: (1024, 1024, 3) min: 0.00000 max: 255.00000 uint8\nmolded_images shape: (1, 1024, 1024, 3) min: -123.70000 max: 151.10000 float64\nimage_metas shape: (1, 14) min: 0.00000 max: 1024.00000 int32\nanchors shape: (1, 261888, 4) min: -0.35390 max: 1.29134 float32\nWARNING:tensorflow:OMP_NUM_THREADS is no longer used by the default Keras config. To configure the number of threads, use tf.config.threading APIs.\n"
]
],
[
[
"## Color Splash\n\nThis is for illustration. You can call `balloon.py` with the `splash` option to get better images without the black padding.",
"_____no_output_____"
]
],
[
[
"splash = balloon.color_splash(image, r['masks'])\ndisplay_images([splash], cols=1)",
"_____no_output_____"
]
],
[
[
"## Step by Step Prediction",
"_____no_output_____"
],
[
"## Stage 1: Region Proposal Network\n\nThe Region Proposal Network (RPN) runs a lightweight binary classifier on a lot of boxes (anchors) over the image and returns object/no-object scores. Anchors with high *objectness* score (positive anchors) are passed to the stage two to be classified.\n\nOften, even positive anchors don't cover objects fully. So the RPN also regresses a refinement (a delta in location and size) to be applied to the anchors to shift it and resize it a bit to the correct boundaries of the object.",
"_____no_output_____"
],
[
"### 1.a RPN Targets\n\nThe RPN targets are the training values for the RPN. To generate the targets, we start with a grid of anchors that cover the full image at different scales, and then we compute the IoU of the anchors with ground truth object. Positive anchors are those that have an IoU >= 0.7 with any ground truth object, and negative anchors are those that don't cover any object by more than 0.3 IoU. Anchors in between (i.e. cover an object by IoU >= 0.3 but < 0.7) are considered neutral and excluded from training.\n\nTo train the RPN regressor, we also compute the shift and resizing needed to make the anchor cover the ground truth object completely.",
"_____no_output_____"
]
],
[
[
"# Generate RPN trainig targets\n# target_rpn_match is 1 for positive anchors, -1 for negative anchors\n# and 0 for neutral anchors.\ntarget_rpn_match, target_rpn_bbox = modellib.build_rpn_targets(\n image.shape, model.anchors, gt_class_id, gt_bbox, model.config)\nlog(\"target_rpn_match\", target_rpn_match)\nlog(\"target_rpn_bbox\", target_rpn_bbox)\n\npositive_anchor_ix = np.where(target_rpn_match[:] == 1)[0]\nnegative_anchor_ix = np.where(target_rpn_match[:] == -1)[0]\nneutral_anchor_ix = np.where(target_rpn_match[:] == 0)[0]\npositive_anchors = model.anchors[positive_anchor_ix]\nnegative_anchors = model.anchors[negative_anchor_ix]\nneutral_anchors = model.anchors[neutral_anchor_ix]\nlog(\"positive_anchors\", positive_anchors)\nlog(\"negative_anchors\", negative_anchors)\nlog(\"neutral anchors\", neutral_anchors)\n\n# Apply refinement deltas to positive anchors\nrefined_anchors = utils.apply_box_deltas(\n positive_anchors,\n target_rpn_bbox[:positive_anchors.shape[0]] * model.config.RPN_BBOX_STD_DEV)\nlog(\"refined_anchors\", refined_anchors, )\n",
"_____no_output_____"
],
[
"# Display positive anchors before refinement (dotted) and\n# after refinement (solid).\nvisualize.draw_boxes(image, boxes=positive_anchors, refined_boxes=refined_anchors, ax=get_ax())",
"_____no_output_____"
]
],
[
[
"### 1.b RPN Predictions\n\nHere we run the RPN graph and display its predictions.",
"_____no_output_____"
]
],
[
[
"# Run RPN sub-graph\npillar = model.keras_model.get_layer(\"ROI\").output # node to start searching from\n\n# TF 1.4 and 1.9 introduce new versions of NMS. Search for all names to support TF 1.3~1.10\nnms_node = model.ancestor(pillar, \"ROI/rpn_non_max_suppression:0\")\nif nms_node is None:\n nms_node = model.ancestor(pillar, \"ROI/rpn_non_max_suppression/NonMaxSuppressionV2:0\")\nif nms_node is None: #TF 1.9-1.10\n nms_node = model.ancestor(pillar, \"ROI/rpn_non_max_suppression/NonMaxSuppressionV3:0\")\n\nrpn = model.run_graph([image], [\n (\"rpn_class\", model.keras_model.get_layer(\"rpn_class\").output),\n (\"pre_nms_anchors\", model.ancestor(pillar, \"ROI/pre_nms_anchors:0\")),\n (\"refined_anchors\", model.ancestor(pillar, \"ROI/refined_anchors:0\")),\n (\"refined_anchors_clipped\", model.ancestor(pillar, \"ROI/refined_anchors_clipped:0\")),\n (\"post_nms_anchor_ix\", nms_node),\n (\"proposals\", model.keras_model.get_layer(\"ROI\").output),\n])",
"_____no_output_____"
],
[
"# Show top anchors by score (before refinement)\nlimit = 100\nsorted_anchor_ids = np.argsort(rpn['rpn_class'][:,:,1].flatten())[::-1]\nvisualize.draw_boxes(image, boxes=model.anchors[sorted_anchor_ids[:limit]], ax=get_ax())",
"_____no_output_____"
],
[
"# Show top anchors with refinement. Then with clipping to image boundaries\nlimit = 50\nax = get_ax(1, 2)\npre_nms_anchors = utils.denorm_boxes(rpn[\"pre_nms_anchors\"][0], image.shape[:2])\nrefined_anchors = utils.denorm_boxes(rpn[\"refined_anchors\"][0], image.shape[:2])\nrefined_anchors_clipped = utils.denorm_boxes(rpn[\"refined_anchors_clipped\"][0], image.shape[:2])\nvisualize.draw_boxes(image, boxes=pre_nms_anchors[:limit],\n refined_boxes=refined_anchors[:limit], ax=ax[0])\nvisualize.draw_boxes(image, refined_boxes=refined_anchors_clipped[:limit], ax=ax[1])",
"_____no_output_____"
],
[
"# Show refined anchors after non-max suppression\nlimit = 50\nixs = rpn[\"post_nms_anchor_ix\"][:limit]\nvisualize.draw_boxes(image, refined_boxes=refined_anchors_clipped[ixs], ax=get_ax())",
"_____no_output_____"
],
[
"# Show final proposals\n# These are the same as the previous step (refined anchors \n# after NMS) but with coordinates normalized to [0, 1] range.\nlimit = 50\n# Convert back to image coordinates for display\nh, w = config.IMAGE_SHAPE[:2]\nproposals = rpn['proposals'][0, :limit] * np.array([h, w, h, w])\nvisualize.draw_boxes(image, refined_boxes=proposals, ax=get_ax())",
"_____no_output_____"
]
],
[
[
"## Stage 2: Proposal Classification\n\nThis stage takes the region proposals from the RPN and classifies them.",
"_____no_output_____"
],
[
"### 2.a Proposal Classification\n\nRun the classifier heads on proposals to generate class propbabilities and bounding box regressions.",
"_____no_output_____"
]
],
[
[
"# Get input and output to classifier and mask heads.\nmrcnn = model.run_graph([image], [\n (\"proposals\", model.keras_model.get_layer(\"ROI\").output),\n (\"probs\", model.keras_model.get_layer(\"mrcnn_class\").output),\n (\"deltas\", model.keras_model.get_layer(\"mrcnn_bbox\").output),\n (\"masks\", model.keras_model.get_layer(\"mrcnn_mask\").output),\n (\"detections\", model.keras_model.get_layer(\"mrcnn_detection\").output),\n])",
"_____no_output_____"
],
[
"# Get detection class IDs. Trim zero padding.\ndet_class_ids = mrcnn['detections'][0, :, 4].astype(np.int32)\ndet_count = np.where(det_class_ids == 0)[0][0]\ndet_class_ids = det_class_ids[:det_count]\ndetections = mrcnn['detections'][0, :det_count]\n\nprint(\"{} detections: {}\".format(\n det_count, np.array(dataset.class_names)[det_class_ids]))\n\ncaptions = [\"{} {:.3f}\".format(dataset.class_names[int(c)], s) if c > 0 else \"\"\n for c, s in zip(detections[:, 4], detections[:, 5])]\nvisualize.draw_boxes(\n image, \n refined_boxes=utils.denorm_boxes(detections[:, :4], image.shape[:2]),\n visibilities=[2] * len(detections),\n captions=captions, title=\"Detections\",\n ax=get_ax())",
"_____no_output_____"
]
],
[
[
"### 2.c Step by Step Detection\n\nHere we dive deeper into the process of processing the detections.",
"_____no_output_____"
]
],
[
[
"# Proposals are in normalized coordinates. Scale them\n# to image coordinates.\nh, w = config.IMAGE_SHAPE[:2]\nproposals = np.around(mrcnn[\"proposals\"][0] * np.array([h, w, h, w])).astype(np.int32)\n\n# Class ID, score, and mask per proposal\nroi_class_ids = np.argmax(mrcnn[\"probs\"][0], axis=1)\nroi_scores = mrcnn[\"probs\"][0, np.arange(roi_class_ids.shape[0]), roi_class_ids]\nroi_class_names = np.array(dataset.class_names)[roi_class_ids]\nroi_positive_ixs = np.where(roi_class_ids > 0)[0]\n\n# How many ROIs vs empty rows?\nprint(\"{} Valid proposals out of {}\".format(np.sum(np.any(proposals, axis=1)), proposals.shape[0]))\nprint(\"{} Positive ROIs\".format(len(roi_positive_ixs)))\n\n# Class counts\nprint(list(zip(*np.unique(roi_class_names, return_counts=True))))",
"_____no_output_____"
],
[
"# Display a random sample of proposals.\n# Proposals classified as background are dotted, and\n# the rest show their class and confidence score.\nlimit = 200\nixs = np.random.randint(0, proposals.shape[0], limit)\ncaptions = [\"{} {:.3f}\".format(dataset.class_names[c], s) if c > 0 else \"\"\n for c, s in zip(roi_class_ids[ixs], roi_scores[ixs])]\nvisualize.draw_boxes(image, boxes=proposals[ixs],\n visibilities=np.where(roi_class_ids[ixs] > 0, 2, 1),\n captions=captions, title=\"ROIs Before Refinement\",\n ax=get_ax())",
"_____no_output_____"
]
],
[
[
"#### Apply Bounding Box Refinement",
"_____no_output_____"
]
],
[
[
"# Class-specific bounding box shifts.\nroi_bbox_specific = mrcnn[\"deltas\"][0, np.arange(proposals.shape[0]), roi_class_ids]\nlog(\"roi_bbox_specific\", roi_bbox_specific)\n\n# Apply bounding box transformations\n# Shape: [N, (y1, x1, y2, x2)]\nrefined_proposals = utils.apply_box_deltas(\n proposals, roi_bbox_specific * config.BBOX_STD_DEV).astype(np.int32)\nlog(\"refined_proposals\", refined_proposals)\n\n# Show positive proposals\n# ids = np.arange(roi_boxes.shape[0]) # Display all\nlimit = 5\nids = np.random.randint(0, len(roi_positive_ixs), limit) # Display random sample\ncaptions = [\"{} {:.3f}\".format(dataset.class_names[c], s) if c > 0 else \"\"\n for c, s in zip(roi_class_ids[roi_positive_ixs][ids], roi_scores[roi_positive_ixs][ids])]\nvisualize.draw_boxes(image, boxes=proposals[roi_positive_ixs][ids],\n refined_boxes=refined_proposals[roi_positive_ixs][ids],\n visibilities=np.where(roi_class_ids[roi_positive_ixs][ids] > 0, 1, 0),\n captions=captions, title=\"ROIs After Refinement\",\n ax=get_ax())",
"_____no_output_____"
]
],
[
[
"#### Filter Low Confidence Detections",
"_____no_output_____"
]
],
[
[
"# Remove boxes classified as background\nkeep = np.where(roi_class_ids > 0)[0]\nprint(\"Keep {} detections:\\n{}\".format(keep.shape[0], keep))",
"_____no_output_____"
],
[
"# Remove low confidence detections\nkeep = np.intersect1d(keep, np.where(roi_scores >= config.DETECTION_MIN_CONFIDENCE)[0])\nprint(\"Remove boxes below {} confidence. Keep {}:\\n{}\".format(\n config.DETECTION_MIN_CONFIDENCE, keep.shape[0], keep))",
"_____no_output_____"
]
],
[
[
"#### Per-Class Non-Max Suppression",
"_____no_output_____"
]
],
[
[
"# Apply per-class non-max suppression\npre_nms_boxes = refined_proposals[keep]\npre_nms_scores = roi_scores[keep]\npre_nms_class_ids = roi_class_ids[keep]\n\nnms_keep = []\nfor class_id in np.unique(pre_nms_class_ids):\n # Pick detections of this class\n ixs = np.where(pre_nms_class_ids == class_id)[0]\n # Apply NMS\n class_keep = utils.non_max_suppression(pre_nms_boxes[ixs], \n pre_nms_scores[ixs],\n config.DETECTION_NMS_THRESHOLD)\n # Map indicies\n class_keep = keep[ixs[class_keep]]\n nms_keep = np.union1d(nms_keep, class_keep)\n print(\"{:22}: {} -> {}\".format(dataset.class_names[class_id][:20], \n keep[ixs], class_keep))\n\nkeep = np.intersect1d(keep, nms_keep).astype(np.int32)\nprint(\"\\nKept after per-class NMS: {}\\n{}\".format(keep.shape[0], keep))",
"_____no_output_____"
],
[
"# Show final detections\nixs = np.arange(len(keep)) # Display all\n# ixs = np.random.randint(0, len(keep), 10) # Display random sample\ncaptions = [\"{} {:.3f}\".format(dataset.class_names[c], s) if c > 0 else \"\"\n for c, s in zip(roi_class_ids[keep][ixs], roi_scores[keep][ixs])]\nvisualize.draw_boxes(\n image, boxes=proposals[keep][ixs],\n refined_boxes=refined_proposals[keep][ixs],\n visibilities=np.where(roi_class_ids[keep][ixs] > 0, 1, 0),\n captions=captions, title=\"Detections after NMS\",\n ax=get_ax())",
"_____no_output_____"
]
],
[
[
"## Stage 3: Generating Masks\n\nThis stage takes the detections (refined bounding boxes and class IDs) from the previous layer and runs the mask head to generate segmentation masks for every instance.",
"_____no_output_____"
],
[
"### 3.a Mask Targets\n\nThese are the training targets for the mask branch",
"_____no_output_____"
]
],
[
[
"display_images(np.transpose(gt_mask, [2, 0, 1]), cmap=\"Blues\")",
"_____no_output_____"
]
],
[
[
"### 3.b Predicted Masks",
"_____no_output_____"
]
],
[
[
"# Get predictions of mask head\nmrcnn = model.run_graph([image], [\n (\"detections\", model.keras_model.get_layer(\"mrcnn_detection\").output),\n (\"masks\", model.keras_model.get_layer(\"mrcnn_mask\").output),\n])\n\n# Get detection class IDs. Trim zero padding.\ndet_class_ids = mrcnn['detections'][0, :, 4].astype(np.int32)\ndet_count = np.where(det_class_ids == 0)[0][0]\ndet_class_ids = det_class_ids[:det_count]\n\nprint(\"{} detections: {}\".format(\n det_count, np.array(dataset.class_names)[det_class_ids]))",
"_____no_output_____"
],
[
"# Masks\ndet_boxes = utils.denorm_boxes(mrcnn[\"detections\"][0, :, :4], image.shape[:2])\ndet_mask_specific = np.array([mrcnn[\"masks\"][0, i, :, :, c] \n for i, c in enumerate(det_class_ids)])\ndet_masks = np.array([utils.unmold_mask(m, det_boxes[i], image.shape)\n for i, m in enumerate(det_mask_specific)])\nlog(\"det_mask_specific\", det_mask_specific)\nlog(\"det_masks\", det_masks)",
"_____no_output_____"
],
[
"display_images(det_mask_specific[:4] * 255, cmap=\"Blues\", interpolation=\"none\")",
"_____no_output_____"
],
[
"display_images(det_masks[:4] * 255, cmap=\"Blues\", interpolation=\"none\")",
"_____no_output_____"
]
],
[
[
"## Visualize Activations\n\nIn some cases it helps to look at the output from different layers and visualize them to catch issues and odd patterns.",
"_____no_output_____"
]
],
[
[
"# Get activations of a few sample layers\nactivations = model.run_graph([image], [\n (\"input_image\", tf.identity(model.keras_model.get_layer(\"input_image\").output)),\n (\"res2c_out\", model.keras_model.get_layer(\"res2c_out\").output),\n (\"res3c_out\", model.keras_model.get_layer(\"res3c_out\").output),\n (\"res4w_out\", model.keras_model.get_layer(\"res4w_out\").output), # for resnet100\n (\"rpn_bbox\", model.keras_model.get_layer(\"rpn_bbox\").output),\n (\"roi\", model.keras_model.get_layer(\"ROI\").output),\n])",
"_____no_output_____"
],
[
"# Input image (normalized)\n_ = plt.imshow(modellib.unmold_image(activations[\"input_image\"][0],config))",
"_____no_output_____"
],
[
"# Backbone feature map\ndisplay_images(np.transpose(activations[\"res2c_out\"][0,:,:,:4], [2, 0, 1]), cols=4)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
e73d9f576bc2cac5292abe15724a7159095a73b0 | 3,413 | ipynb | Jupyter Notebook | bayesian-notes-santa-cruz/02_MLE.ipynb | AlxndrMlk/bayesian-stuff | 86a45f4a2835d512093813faa27775c2dddc25e2 | [
"MIT"
] | null | null | null | bayesian-notes-santa-cruz/02_MLE.ipynb | AlxndrMlk/bayesian-stuff | 86a45f4a2835d512093813faa27775c2dddc25e2 | [
"MIT"
] | null | null | null | bayesian-notes-santa-cruz/02_MLE.ipynb | AlxndrMlk/bayesian-stuff | 86a45f4a2835d512093813faa27775c2dddc25e2 | [
"MIT"
] | null | null | null | 18.961111 | 174 | 0.47993 | [
[
[
"import numpy as np\nimport pandas as pd\n\nimport math\n\nimport matplotlib.pyplot as plt\nplt.style.use('fivethirtyeight')",
"_____no_output_____"
]
],
[
[
"# MLE",
"_____no_output_____"
],
[
"## Approximate $95$% CI for Bernoulli distribution",
"_____no_output_____"
],
[
"$$ \\large \\hat{\\theta} \\pm 1.96 \\sqrt{\\frac{\\hat{\\theta}(1-{\\hat{\\theta}})}{n}}$$",
"_____no_output_____"
]
],
[
[
"def approx_ci(x, n):\n return x - 1.96 * np.sqrt((x * (1 - x)) / n), x + 1.96 * np.sqrt((x * (1 - x)) / n)",
"_____no_output_____"
],
[
"approx_ci(.47, 100)",
"_____no_output_____"
]
],
[
[
"## Examples",
"_____no_output_____"
],
[
"If $X1,…,Xn∼iidExponential(λ)$ (iid means independent and identically distributed), then the MLE for $\\lambda$ is $1/\\hat{x}$ where $\\hat{x}$ is the sample mean. \n\nSuppose we observe the following data: X1=2.0, X2=2.5, X3=4.1, X4=1.8, X5=4.0",
"_____no_output_____"
]
],
[
[
"x = [2, 2.5, 4.1, 1.8, 4]",
"_____no_output_____"
],
[
"1 / np.mean(x)",
"_____no_output_____"
]
],
[
[
"Suppose we observe n=4 data points from a normal distribution with unknown mean $\\mu$. The data are x={−1.2, 0.5, 0.8, −0.3}.",
"_____no_output_____"
]
],
[
[
"x2 = [-1.2, .5, .8, -.3]",
"_____no_output_____"
],
[
"np.mean(x2)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
e73da532934bd62cef66ab630c30f38970f00bb7 | 17,038 | ipynb | Jupyter Notebook | ooi-botpt.ipynb | tjcrone/ooi-pangeo-virtual-booth-2021 | 49565a166b7e57b22d1b8b0b91ec6c1363533088 | [
"MIT"
] | 2 | 2021-12-15T19:08:20.000Z | 2021-12-15T20:16:38.000Z | ooi-botpt.ipynb | tjcrone/ooi-pangeo-virtual-booth-2021 | 49565a166b7e57b22d1b8b0b91ec6c1363533088 | [
"MIT"
] | null | null | null | ooi-botpt.ipynb | tjcrone/ooi-pangeo-virtual-booth-2021 | 49565a166b7e57b22d1b8b0b91ec6c1363533088 | [
"MIT"
] | 1 | 2021-12-13T20:49:04.000Z | 2021-12-13T20:49:04.000Z | 22.330275 | 461 | 0.538502 | [
[
[
"# Using OOI data in the cloud with Pangeo\nIn this workshop we will use [Pangeo's](http://pangeo.io/) [Binderhub](https://binderhub.readthedocs.io/en/latest/) to do some science with OOI data in the cloud together. Since we are working today on the Binderhub our work will be ephemeral but if you would like to continue working with Pangeo and OOI in the cloud, please join the [OOICloud](https://www.ooicloud.org/) GitHub organization and continue working at [ooi.pangeo.io](ooi.pangeo.io).\n\nSome key packages we will use are [Erddapy](https://ioos.github.io/erddapy/), [Pandas](https://pandas.pydata.org/docs/) and [Xarray](http://xarray.pydata.org/en/stable/) to explore some data from a bottom pressure recorder at Axial Seamount along with an earthquake catalog generated by William Wilcock.\n\nWe will then look at how to use Erddapy to search multiple ERDDAP servers at once, and if we have time we will explore [Dask](https://docs.dask.org/en/latest/) and [Dask Delayed](https://docs.dask.org/en/latest/delayed.html) functions to parallelize a data analysis workflow in the cloud.\n\nFurther information on using Python to analyze Earth science datasets can be found in the book [Earth and Environmental Data Science](https://earth-env-data-science.github.io/intro) which I use to teach Research Computing in the Earth Sciences.",
"_____no_output_____"
],
[
"## Bottom pressure data at Axial Seamount\nLet's find some OOI data using the new [OOI Data Explorer](https://dataexplorer.oceanobservatories.org/) and use Erdappy to load these data into Xarray and plot a smoothed representation of the bottom pressure at Axial Seamount using [hvplot](https://hvplot.holoviz.org/).",
"_____no_output_____"
],
[
"### First import some required packages",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport xarray as xr\nimport hvplot.xarray\nimport hvplot.pandas",
"_____no_output_____"
],
[
"from matplotlib import pyplot as plt\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (14, 8)",
"_____no_output_____"
]
],
[
[
"### Next find some data on the OOI Data Explorer",
"_____no_output_____"
],
[
"Link to new OOI Data Explorer: https://dataexplorer.oceanobservatories.org/",
"_____no_output_____"
]
],
[
[
"from erddapy import ERDDAP",
"_____no_output_____"
],
[
"server = 'http://erddap.dataexplorer.oceanobservatories.org/erddap'\nprotocol = 'tabledap'\n\ne = ERDDAP(\n server=server,\n protocol=protocol\n)",
"_____no_output_____"
],
[
"e.dataset_id = 'ooi-rs03ccal-mj03f-05-botpta301'",
"_____no_output_____"
],
[
"e.get_info_url()",
"_____no_output_____"
],
[
"info_df = pd.read_csv(e.get_info_url(response='csv'))",
"_____no_output_____"
],
[
"info_df.head()",
"_____no_output_____"
],
[
"info_df[info_df['Row Type']=='variable']",
"_____no_output_____"
],
[
"e.variables = ['time', 'botpres']",
"_____no_output_____"
],
[
"e.constraints = {\n 'time>=': '2014-01-01T00:00:00Z',\n 'time<=': '2015-12-31T00:00:00Z',\n}",
"_____no_output_____"
],
[
"botpt_df = e.to_pandas()",
"_____no_output_____"
],
[
"botpt_df.head()",
"_____no_output_____"
],
[
"botpt_df.plot();",
"_____no_output_____"
],
[
"botpt_ds = e.to_xarray()\nbotpt_ds",
"_____no_output_____"
],
[
"botpt_ds = e.to_xarray(drop_variables=['station', 'rowSize'])\nbotpt_ds",
"_____no_output_____"
],
[
"botpt_ds = botpt_ds.swap_dims({'obs': 'time'})\nbotpt_ds",
"_____no_output_____"
],
[
"botpt_ds= botpt_ds.drop_dims('timeseries')\nbotpt_ds",
"_____no_output_____"
],
[
"import hvplot.xarray",
"_____no_output_____"
],
[
"botpt_ds.botpres.hvplot()",
"_____no_output_____"
],
[
"botpt_ds.botpres.sel(time=slice('2015-05-01', '2015-07-01')).hvplot()",
"_____no_output_____"
],
[
"botpt_rolling = botpt_ds.rolling(time=60*24*7, min_periods=60*24*7, center=True).mean()",
"_____no_output_____"
],
[
"botpt_rolling.botpres.hvplot()",
"_____no_output_____"
]
],
[
[
"## Earthquake catalog from the OOI seismic array at Axial Seamount\nHere we parse and plot Axial Seamount earthquake catalog data from [William Wilcock's near-real-time automated earthquake location system](http://axial.ocean.washington.edu/). The data we will use is a text file in they HYPO71 output format located here: http://axial.ocean.washington.edu/hypo71.dat.",
"_____no_output_____"
]
],
[
[
"eqs_url = 'hypo71.dat'",
"_____no_output_____"
],
[
"col_names = ['ymd', 'hm', 's', 'lat_deg', 'lat_min', 'lon_deg', 'lon_min',\n 'depth', 'MW', 'NWR', 'GAP', 'DMIN', 'RMS', 'ERH', 'ERZ', 'ID', 'PMom', 'SMom']",
"_____no_output_____"
],
[
"eqs = pd.read_csv(eqs_url, sep = '\\s+', header=0, names=col_names)",
"_____no_output_____"
],
[
"eqs.head()",
"_____no_output_____"
],
[
"from datetime import datetime\ndef parse_hypo_date(ymd, hm, s):\n hour = int(hm.zfill(4)[0:2])\n minute = int(hm.zfill(4)[2:])\n second = float(s)\n if second == 60:\n second = 0\n minute += 1\n if minute == 60:\n minute=0\n hour +=1\n eq_date_str = ('%s%02.0f%02.0f%05.2f' % (ymd, hour, minute, second))\n return datetime.strptime(eq_date_str, '%Y%m%d%H%M%S.%f')",
"_____no_output_____"
],
[
"eqs = pd.read_csv(eqs_url, sep = '\\s+', header=0, names=col_names, parse_dates=[[0,1,2]],\n date_parser=parse_hypo_date)",
"_____no_output_____"
],
[
"eqs.head()",
"_____no_output_____"
],
[
"eqs['lat'] = eqs.lat_deg+eqs.lat_min/60\neqs['lon'] = -(eqs.lon_deg+eqs.lon_min/60)",
"_____no_output_____"
],
[
"eqs.head()",
"_____no_output_____"
],
[
"eqs.rename(columns={'ymd_hm_s':'time', 'MW':'mw'}, inplace=True)",
"_____no_output_____"
],
[
"eqs.set_index('time', inplace=True)",
"_____no_output_____"
],
[
"eqs = eqs[['lat','lon','depth','mw']]",
"_____no_output_____"
],
[
"eqs.head()",
"_____no_output_____"
],
[
"eqs.to_pickle('hypo71.pkl')",
"_____no_output_____"
]
],
[
[
"### Load earthquake catalog pickle file",
"_____no_output_____"
]
],
[
[
"eqs_df = pd.read_pickle('hypo71.pkl')",
"_____no_output_____"
],
[
"eqs_df.head()",
"_____no_output_____"
],
[
"eqs_ds = eqs_df.to_xarray()",
"_____no_output_____"
],
[
"eqs_ds",
"_____no_output_____"
],
[
"eqs_ds = eqs_ds.set_coords(['lat', 'lon'])",
"_____no_output_____"
],
[
"eqs_ds",
"_____no_output_____"
],
[
"eqs_ds.mw.hvplot.scatter(x='time', datashade=True)",
"_____no_output_____"
]
],
[
[
"https://xarray.pydata.org/en/stable/user-guide/combining.html",
"_____no_output_____"
]
],
[
[
"all_ds = xr.merge([eqs_ds, botpt_ds])",
"_____no_output_____"
],
[
"all_ds",
"_____no_output_____"
],
[
"all_ds.mw.plot(marker='.', linestyle='', markersize=1);",
"_____no_output_____"
],
[
"all_ds.mw.hvplot.scatter(datashade=True)",
"_____no_output_____"
],
[
"all_ds.mw.hvplot.scatter(datashade=True, x='time')",
"_____no_output_____"
]
],
[
[
"### Daily Counts",
"_____no_output_____"
]
],
[
[
"daily_count = all_ds.mw.resample(time='1D').count()",
"_____no_output_____"
],
[
"daily_count",
"_____no_output_____"
],
[
"daily_count.plot();",
"_____no_output_____"
],
[
"fig, ax1 = plt.subplots()\nax1.bar(daily_count.to_series()['2015'].index, daily_count.to_series()['2015'].values, width=3)\nax2 = ax1.twinx()\nax2.plot(botpt_rolling.botpres.to_series()['2015'], color='cyan');",
"_____no_output_____"
]
],
[
[
"### Mapping eq data\nLet's make some maps just because we can.",
"_____no_output_____"
]
],
[
[
"import cartopy.crs as ccrs\nimport cartopy\nimport numpy as np",
"_____no_output_____"
],
[
"caldera = pd.read_csv('caldera.csv')",
"_____no_output_____"
],
[
"caldera.head()",
"_____no_output_____"
],
[
"now = pd.Timestamp('now')\neqs_sub = eqs[now-pd.Timedelta(weeks=2):]",
"_____no_output_____"
],
[
"ax = plt.axes(projection = ccrs.Robinson(central_longitude=-130))\nax.plot(caldera.lon, caldera.lat, transform=ccrs.Geodetic())\nax.gridlines()\n\nsc = ax.scatter(eqs_sub.lon, eqs_sub.lat, c=eqs_sub.mw, transform=ccrs.PlateCarree(),\n cmap='magma', edgecolor='k', s=40)\nplt.colorbar(sc, label='magnitude')",
"_____no_output_____"
]
],
[
[
"## OOI Seafloor Camera Data\nNow let's look at some video data from the [OOI Seafloor Camera](https://oceanobservatories.org/instrument-class/camhd/) system deployed at Axial Volcano on the Juan de Fuca Ridge. We will make use of the [Pycamhd](https://github.com/tjcrone/pycamhd) library, which can be used to extract frames from the ProRes encoded Quicktime files. These data are hosted on Microsoft's [Azure Open Datasets](https://azure.microsoft.com/en-us/services/open-datasets/).",
"_____no_output_____"
]
],
[
[
"dbcamhd_url = 'https://ooiopendata.blob.core.windows.net/camhd/dbcamhd.json'",
"_____no_output_____"
],
[
"def show_image(frame_number):\n plt.rc('figure', figsize=(12, 6))\n plt.rcParams.update({'font.size': 8})\n frame = camhd.get_frame(mov.url, frame_number)\n fig, ax = plt.subplots();\n im1 = ax.imshow(frame);\n plt.yticks(np.arange(0,1081,270))\n plt.xticks(np.arange(0,1921,480))\n plt.title('Deployment: %s File: %s Frame: %s' % (mov.deployment, mov['name'], frame_number));",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
e73db00789d0fa52d7b2c9a9ef307ecf79bff772 | 16,484 | ipynb | Jupyter Notebook | gen_roster.ipynb | nicidob/bbgm | 415a58d24518f3d25c4ddeaaec015ac7ffb8d0fa | [
"MIT"
] | 11 | 2019-06-25T17:20:48.000Z | 2020-07-04T03:09:17.000Z | gen_roster.ipynb | nicidob/bbgm | 415a58d24518f3d25c4ddeaaec015ac7ffb8d0fa | [
"MIT"
] | null | null | null | gen_roster.ipynb | nicidob/bbgm | 415a58d24518f3d25c4ddeaaec015ac7ffb8d0fa | [
"MIT"
] | 10 | 2019-06-28T06:26:28.000Z | 2022-01-17T18:12:36.000Z | 31.458015 | 126 | 0.455108 | [
[
[
"import os\nimport sys\nimport json",
"_____no_output_____"
],
[
"with open('eu4.json','rt') as fp:\n data = json.load(fp)\nflags = data['f']\npos = data['pos']\nprov = data['prov']\nstate = data['c']",
"_____no_output_____"
],
[
"tmp = sorted(sum([[k for k,v in _.items() if k.count('.')==2] for k,_ in prov.items()],[]))\nfy,ly = tmp[0],tmp[-1]\nfy,ly\nny = '1444.11.11'",
"_____no_output_____"
],
[
"owners = {}\nfor p in prov:\n if 'controller' in prov[p]:\n owners[p] = prov[p]['controller']",
"_____no_output_____"
],
[
"e_owner = set()\nf_owner = set(owners.values())\nfor c in f_owner:\n for item in state[c]:\n if item.count('.') == 2:\n e_owner.add(c)\n break",
"_____no_output_____"
],
[
"len(e_owner),len(f_owner)",
"_____no_output_____"
],
[
"events = set()\nfor sidx,s in state.items():\n for et,e in s.items():\n if et.count('.') == 2:\n if type(e) == list:\n for tmp in e:\n if type(e) == dict:\n events.add(list(tmp.keys())[0])\n elif type(e) == dict:\n events.add(list(e.keys())[0])",
"_____no_output_____"
],
[
"# maybe only capital matters in state events\n\n# otherwise go by provinces\n# keep track of owners properties\n# go by provices ",
"_____no_output_____"
],
[
"event_list = []\nfor idx,p in prov.items():\n for k,res in p.items():\n if k.count('.') == 2:\n if type(res) == list:\n for tmp in res:\n if type(tmp) == dict:\n for typ,evt in tmp.items():\n if typ in ['owner']:\n event_list.append((k,idx,typ,evt))\n elif typ == 'capital':\n event_list.append((k,idx,'cap2',evt))\n #raise\n elif type(res) == dict:\n for typ,evt in res.items():\n if typ in ['owner']:\n event_list.append((k,idx,typ,evt))\n elif typ == 'capital':\n event_list.append((k,idx,'cap2',evt))\n",
"_____no_output_____"
],
[
"for idx,p in state.items():\n for k,res in p.items():\n if k.count('.') == 2:\n #print(res)\n if type(res) == list:\n for tmp in res:\n if type(tmp) == dict:\n for typ,evt in tmp.items():\n if typ in ['capital']:\n event_list.append((k,idx,typ,evt))\n #raise\n elif type(res) == dict:\n for typ,evt in res.items():\n if typ in ['capital']:\n event_list.append((k,idx,typ,evt))",
"_____no_output_____"
],
[
"from sklearn.cluster import KMeans\nfrom scipy.spatial import distance\nimport numpy as np\nfrom collections import defaultdict\n\nyear_events = defaultdict(list)\nfor event in event_list:\n yr,m,d = event[0].split('.')\n year_events[yr].append(event)\n \ndef gen_divs(locations):\n keys = sorted(locations.keys())\n values = [locations[k] for k in keys]\n clf = KMeans(6,n_init=1000)\n div_clust = clf.fit_predict(values)\n\n\n conf_divs = (clf.cluster_centers_[:,0].argsort().argsort() < 3).astype(int)\n print(conf_divs)\n print(clf.cluster_centers_)\n divs_divs = np.zeros_like(conf_divs)\n for c in range(2):\n cf = np.where(conf_divs == c)\n divs_divs[cf] = (clf.cluster_centers_[cf,1].argsort().argsort()[::-1] + 3*c)[0]\n #divs_divs = sum(divs_divs,[])\n\n div_lookup = {}\n print(len(keys),len(div_clust))\n for k,di in zip(keys,div_clust):\n div_lookup[k] = (int(conf_divs[di]),int(divs_divs[di]))\n return div_lookup,clf.cluster_centers_,conf_divs,divs_divs\n#tmp = gen_divs({k:pos[v]['position'][:2] for k,v in current_loc.items() if k in valid_teams})\n",
"_____no_output_____"
],
[
"tmp[-1],tmp[-2]",
"_____no_output_____"
],
[
"teams = defaultdict(set)\ncurrent_loc = {}\nprov_owners = {}\nfor idx, p in prov.items():\n if 'owner' in p:\n owner = p['owner']\n teams[owner].add(idx)\n prov_owners[idx] = owner\n current_loc[owner] = pos[str(state[owner]['capital'])]['position'][:2]\n \nfrom copy import deepcopy\n\nVALID_TEAMS = set()\n\nfor year in sorted(year_events.keys()):\n old_teams = [t for t,i in teams.items() if len(i) >= 10]\n for team in old_teams:\n VALID_TEAMS.add(team)\n for event in sorted(year_events[year]):\n tm, i, t, j = event\n if t =='owner':\n if i in prov_owners:\n teams[prov_owners[i]].remove(i)\n prov_owners[i] = j\n teams[j].add(i)\n if j not in current_loc:\n current_loc[j] = pos[str(i)]['position'][:2]\n\n elif t == 'capital':\n current_loc[i] = pos[str(j)]['position'][:2]\n\n new_teams = [t for t,i in teams.items() if len(i) >= 10]\n\n for team in new_teams:\n VALID_TEAMS.add(team)",
"_____no_output_____"
],
[
"teams = defaultdict(set)\ncurrent_loc = {}\ncurrent_city = {}\nprov_owners = {}\nTIDS = {}\nfor idx, p in prov.items():\n if 'owner' in p:\n owner = p['owner']\n teams[owner].add(idx)\n prov_owners[idx] = owner\n current_loc[owner] = pos[str(state[owner]['capital'])]['position'][:2]\n if 'capital' in p:\n current_city[idx] = p['capital']",
"_____no_output_____"
],
[
"team_hax = {}\n\nvalid_teams = {k:v for k,v in teams.items() if k in VALID_TEAMS}\ntest_label,test_pos,conf_div,div_div = gen_divs({k:v for k,v in current_loc.items() if k in valid_teams})\nfor team, ps in valid_teams.items():\n if team == '---':\n continue\n d = {}\n d['abbrev'] = team\n if team in flags:\n d['imgURL'] = 'http://eu4.paradoxwikis.com' + flags[team]\n d['name'] = state[team]['name']\n total = 0\n for p in ps:\n total += prov[p]['base_tax'] + prov[p]['base_manpower'] + prov[p]['base_production']\n d['pop'] = round(total/10,2) + 0.1\n d['region'] = current_city[str(state[team]['capital'])]#['name']\n d['stadiumCapacity'] = 20000\n d['cid'] = test_label[team][0]\n d['did'] = test_label[team][1]\n TIDS[team] = len(TIDS)\n d['tid'] = TIDS[team]\n #d['colors'] = color_u2[name]\n team_hax[team] = d\n",
"_____no_output_____"
],
[
"data = {}\ndata['teams'] = list(team_hax.values())\nimport json\ndata['version'] = 36\ndata['gameAttributes'] = [ { \"key\": \"startingSeason\",\"value\": 1364},{ \"key\": \"season\",\"value\": 1364} ]\nwith open('history_initial.json','wt') as fp:\n json.dump(data,fp, sort_keys=True)",
"_____no_output_____"
],
[
"A = np.array([_['position'][:2] for _ in pos.values()])\nimport matplotlib.pyplot as plt\nplt.scatter(A[:,0],A[:,1],s=1)\nplt.scatter(test_pos[:,0],test_pos[:,1],s=400,c=np.array(div_div)%3,cmap='RdYlBu')\nconf_div\nplt.figure()\nplt.hist(A[:,0])",
"_____no_output_____"
],
[
"from copy import deepcopy\n\nroster_events = defaultdict(list)\nteamedit = []\n\nfor year in sorted(year_events.keys()):\n edraft = []\n\n old_teams = {t:len(i) for t,i in teams.items() if len(i) >= 0}\n for event in sorted(year_events[year]):\n tm, i, t, j = event\n if t =='owner':\n if i in prov_owners:\n teams[prov_owners[i]].remove(i)\n prov_owners[i] = j\n teams[j].add(i)\n if j not in current_loc:\n current_loc[j] = pos[str(i)]['position'][:2]\n elif t == 'capital' and i in VALID_TEAMS:\n current_loc[i] = pos[str(j)]['position'][:2]\n roster_events[year].append(('cap',i,j))\n d2 = {'type':'teamInfo','season':int(year),'phase':0,'id':len(teamedit)}\n if i not in TIDS:\n TIDS[i] = len(TIDS)\n if j not in current_city:\n current_city[j] = prov[str(j)]['capital'] \n d2i = {'tid':TIDS[i],'region':current_city[j]}\n d2['info'] = d2i\n teamedit.append(d2)\n\n elif t == 'cap2':\n current_city[i] = j\n roster_events[year].append(('cap2',i,j))\n else:\n #print(event)\n pass\n new_teams = {t:len(i) for t,i in teams.items() if len(i) >= 0}\n # who disappeared\n for team in old_teams:\n if team not in new_teams and team in VALID_TEAMS:\n roster_events[year].append(('remove',team))\n d2 = {'type':'contraction','season':int(year),'phase':4,'id':len(teamedit), 'info':{'tid':TIDS[team]}}\n teamedit.append(d2)\n print(\"CONTRACTION\")\n\n # who appeared\n for team in new_teams:\n if team not in old_teams and team in VALID_TEAMS:\n roster_events[year].append(('add',team))\n TIDS[team] = len(TIDS)\n for team in new_teams:\n if team in old_teams and team in VALID_TEAMS:\n if new_teams[team] != old_teams[team]:\n total = 0\n for p in teams[team]:\n total += prov[p]['base_tax'] + prov[p]['base_manpower'] + prov[p]['base_production']\n roster_events[year].append(('size',team,total))\n d2 = {'type':'teamInfo','season':int(year),'phase':0,'id':len(teamedit)}\n d2i = {'tid':TIDS[team],'pop': round(total/10+ 0.1,2) }\n d2['info'] = d2i\n teamedit.append(d2)\n # add events\n for event in roster_events[year]:\n if event[0] == 'add' and event[1] != '---':\n edraft.append(event[1])\n if len(edraft) > 0:\n d2 = {'type':'expansionDraft','season':int(year),'phase':4,'id':len(teamedit), 'info':{'teams':[]}}\n for team in edraft:\n d = {}\n d['abbrev'] = team\n TIDS[team] = len(TIDS)\n if team in flags:\n d['imgURL'] = 'http://eu4.paradoxwikis.com' + flags[team]\n d['name'] = state[team]['name']\n total = 0\n for p in ps:\n total += prov[p]['base_tax'] + prov[p]['base_manpower'] + prov[p]['base_production']\n d['pop'] = round(total/30+ 0.1,2) \n d['region'] = current_city[str(state[team]['capital'])]#['name']\n #d['stadiumCapacity'] = 20000\n div = np.linalg.norm(test_pos - current_loc[team],axis=1).argmin()\n d['cid'] = int(conf_div[div])\n d['did'] = int(div_div[div])\n\n d['tid'] = TIDS[team]\n #d['colors'] = color_u2[name]\n d2['info']['teams'].append(d)\n teamedit.append(d2)",
"_____no_output_____"
],
[
"year_events[year],current_loc['USA']",
"_____no_output_____"
],
[
"[(k,v) for k,v in current_city.items() if v == event[1]]",
"_____no_output_____"
],
[
"year_events['1823']",
"_____no_output_____"
],
[
"teamedit",
"_____no_output_____"
],
[
"data = {}\ndata['teams'] = list(team_hax.values())\nimport json\ndata['version'] = 37\ndata['gameAttributes'] = [ { \"key\": \"startingSeason\",\"value\": 1364},{ \"key\": \"season\",\"value\": 1364} ]\ndata['scheduledEvents'] = teamedit\nwith open('history_final.json','wt') as fp:\n json.dump(data,fp, sort_keys=True)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73dd62dfa7b6bfc66aff249dd79c20277a84c8a | 50,708 | ipynb | Jupyter Notebook | doc/Class4.ipynb | juniorworld/python-workshop-2018 | 3359f7311991f0fce4a5561223fdfacab59907e8 | [
"MIT"
] | 2 | 2020-06-09T06:25:09.000Z | 2020-06-09T08:00:49.000Z | doc/Class4.ipynb | juniorworld/python-workshop-2018 | 3359f7311991f0fce4a5561223fdfacab59907e8 | [
"MIT"
] | 1 | 2020-04-30T00:53:10.000Z | 2020-04-30T00:53:10.000Z | doc/Class4.ipynb | juniorworld/python-workshop-2018 | 3359f7311991f0fce4a5561223fdfacab59907e8 | [
"MIT"
] | 1 | 2019-05-29T21:32:55.000Z | 2019-05-29T21:32:55.000Z | 29.142529 | 340 | 0.567524 | [
[
[
"## Data Visualization",
"_____no_output_____"
],
[
"- Pie Chart: Compare Percentages\n- Bar Chart: Compare Scores across groups\n- Histogram: Show frequency of values/value range\n- Line Chart: Show trend of Scores\n- Scatter Plot: Show Relationship between a pair of Scores\n- Map: Show Geo Distribution of data",
"_____no_output_____"
],
[
"|Type|Variable Y|Variable X|\n|:--:|:--:|:--:|\n|Pie Chart|Fractions|None|\n|Bar Chart|Numbers|Categories|\n|Histogram|Integer|Categories/Value Range|\n|Line Chart|Numbers|Time/Date/Period|\n|Scatter Plot|Numbers|Numbers|\n|Map|Latitude|Longtitude|",
"_____no_output_____"
],
[
"### Sign up for Plot.ly",
"_____no_output_____"
],
[
"1. Sign up for Plot.ly: https://plot.ly/Auth/login/?action=signup#\n2. Get your API token: Settings -> API Keys -> Regenerate Key -> Copy your newly created key\n3. Save your API key somewhere",
"_____no_output_____"
],
[
"<div class=\"alert alert-block alert-warning\">\n**<b>Reminder</b>** Free account can only call Plot.ly API 100 times per day and generate up to 25 graphs.</div>",
"_____no_output_____"
]
],
[
[
"import plotly.plotly as py #Import library and give it an abbreviated name\nimport plotly.graph_objs as go #go: graph object\nfrom plotly import tools\n\npy.sign_in('USER NAME', 'API TOKEN') #fill in your user name and API token",
"_____no_output_____"
]
],
[
[
"***",
"_____no_output_____"
],
[
"## Pie Chart",
"_____no_output_____"
]
],
[
[
"labels = ['Female','Male']\nvalues = [40,20]\n\ntrace = go.Pie(labels=labels, values=values)\n\npy.iplot([trace], filename='pie_chart')",
"_____no_output_____"
],
[
"#change data labels by re-defining parameter \"textinfo\"\nlabels = ['Female','Male']\nvalues = [40,20]\n\ntrace = go.Pie(labels=labels, values=values, textinfo='label+value')\n\npy.iplot([trace], filename='pie_chart')",
"_____no_output_____"
],
[
"#change color setting by re-defining \"marker\" parameter\nlabels = ['Female','Male']\nvalues = [40,20]\n\ntrace = go.Pie(labels=labels, values=values, marker={'colors':['red','blue']})\n\npy.iplot([trace], filename='pie_chart')",
"_____no_output_____"
],
[
"#turn the pie chart into a donut by re-defining \"hole\" parameter\nlabels = ['Female','Male']\nvalues = [40,20]\n\ntrace = go.Pie(labels=labels, values=values, hole=0.2)\n\npy.iplot([trace], filename='pie_chart')",
"_____no_output_____"
],
[
"#change the graph size to 400*300 and add a title by re-defining \"width\" and \"height\" in \"layout\"\nlabels = ['Female','Male']\nvalues = [40,20]\n\ntrace = go.Pie(labels=labels, values=values)\nlayout=go.Layout(width=400,height=300,title='Gender Distribution')\nfig=go.Figure([trace],layout)\n\npy.iplot(fig, filename='pie_chart')",
"_____no_output_____"
]
],
[
[
"#### <font style=\"color: blue\">Practice:</font>\n---\n<font style=\"color: blue\"> Please download the Hong Kong census data about educational attainment from <a href='https://juniorworld.github.io/python-workshop-2018/doc/Hong Kong Census Educational Attainment.csv'>this link</a>.\n <p>Create a pie chart to visualize the percentages of different education levels in 2016. The pie chart should meet following requirements:</p>\n 1. Donut style\n 2. Change slice colors\n</font>",
"_____no_output_____"
]
],
[
[
"#Write down your code here\n#---------------------------------------------------------\n\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"***",
"_____no_output_____"
],
[
"## Bar Chart\n<br>For more details: https://plot.ly/python/reference/#bar",
"_____no_output_____"
]
],
[
[
"x = ['Female','Male']\ny = [1.6,1.8]\n\ntrace = go.Bar(x=x,y=y)\n\npy.iplot([trace], filename='bar_chart')",
"_____no_output_____"
],
[
"#Widen the gap between bars by increasing \"bargap\" parameters in layout\nx = ['Female','Male']\ny = [40,20]\n\ntrace = go.Bar(x=x,y=y)\nlayout = go.Layout(bargap=0.5)\nfig = go.Figure([trace],layout)\n\npy.iplot(fig, filename='bar_chart')",
"_____no_output_____"
],
[
"#Grouped bar chart\nx = ['Female','Male']\ny1 = [40,20]\ny2 = [30,50]\n\ntrace1 = go.Bar(x=x,y=y1,name='class1')\ntrace2 = go.Bar(x=x,y=y2,name='class2')\n\npy.iplot([trace1,trace2], filename='bar_chart')",
"_____no_output_____"
],
[
"#Stacked/Relative bar chart by re-defining \"barmode\" in layout\nx = ['Female','Male']\ny1 = [40,20]\ny2 = [30,50]\n\ntrace1 = go.Bar(x=x,y=y1)\ntrace2 = go.Bar(x=x,y=y2)\n\nlayout = go.Layout(barmode='stack')\nfig = go.Figure([trace1,trace2],layout)\n\npy.iplot(fig, filename='bar_chart')",
"_____no_output_____"
],
[
"#100% Stacked bar chart by re-defining \"barnorm\" as \"percent\" in layout\nx = ['Female','Male']\ny1 = [40,20]\ny2 = [30,50]\n\ntrace1 = go.Bar(x=x,y=y1)\ntrace2 = go.Bar(x=x,y=y2)\n\nlayout = go.Layout(barmode='stack',barnorm='percent')\nfig = go.Figure([trace1,trace2],layout)\n\npy.iplot(fig, filename='bar_chart')",
"_____no_output_____"
],
[
"x = ['Female','Male']\ny1 = [40,20]\ny2 = [30,50]\n\ntrace1 = go.Bar(x=x,y=y1)\ntrace2 = go.Bar(x=x,y=y2)\n\nlayout = go.Layout(barmode='stack',barnorm='fraction',yaxis={'tickformat':'%'})\nfig = go.Figure([trace1,trace2],layout)\n\npy.iplot(fig, filename='bar_chart')",
"_____no_output_____"
]
],
[
[
"#### <font style=\"color: blue\">Practice:</font>\n---\n<font style=\"color: blue\"> Please refer to \"Hong Kong Census Educational Attainment.csv\".\n <p>Create a bar chart to visualize the percentages of different education levels in different years, i.e. 2006, 2011 and 2016. The bar chart should meet following requirements:</p>\n 1. A bar represents a year\n 2. 100% Stacked bar chart: higher education levels stacked on top of lower ones and the bar's full length is 100%\n 2. The gap between bar groups = 0.2\n</font>",
"_____no_output_____"
]
],
[
[
"#Write down your code here\n#---------------------------------------------------------\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"***",
"_____no_output_____"
],
[
"## Break",
"_____no_output_____"
],
[
"***",
"_____no_output_____"
],
[
"## Histogram\nHistogram is a special type of bar chart where one's y value is its count. It is used to show data distribution: viusalize the skewness and central tendency.\n<br>For more details: https://plot.ly/python/reference/#histogram",
"_____no_output_____"
]
],
[
[
"a=[1,2,3,3,4,4,4,5,5,6,7,3,3,2]\ntrace=go.Histogram(x=a)\npy.iplot([trace],filename='Histogram')",
"_____no_output_____"
],
[
"#Change the bins by re-defining \"size\" parameter in xbins\na=[1,2,3,3,4,4,4,5,5,6,7,3,3,2]\ntrace=go.Histogram(x=a,xbins={'size':1})\npy.iplot([trace],filename='Histogram')",
"_____no_output_____"
],
[
"#Convert into a 100% Histogram whose y value is percentage of getting a value\n#Re-define the \"histnorm\" to a \"percent\" mode\na=[1,2,3,3,4,4,4,5,5,6,7,3,3,2]\ntrace=go.Histogram(x=a,xbins={'size':1},histnorm='probability')\nlayout=go.Layout(yaxis={'tickformat':'%'})\nfig=go.Figure([trace],layout)\npy.iplot(fig,filename='Histogram')",
"_____no_output_____"
],
[
"#Decrease every element in \"a\" by one unit to create a new list \"b\"\n#Grouped Histogram\na=[1,2,3,3,4,4,4,5,5,6,7,3,3,2]\nb= #Write your code here\n\ntrace1=go.Histogram(x=a,xbins={'size':1})\ntrace2=go.Histogram(x=b,xbins={'size':1})\n\npy.iplot([trace1,trace2],filename='Histogram')",
"_____no_output_____"
],
[
"#Overlay Histogram of a and b\n#Increase the transparency by re-defining \"opacity\" parameter\n#Change color by re-defining \"color\" parameter in \"marker\"\n#Change the value of \"barmode\" parameter in layout to \"overlay\"\n\ntrace1=go.Histogram(x=a,xbins={'size':1},opacity=0.5,marker={'color':'blue'})\ntrace2=go.Histogram(x=b,xbins={'size':1},opacity=0.5,marker={'color':'red'})\n\nlayout=go.Layout(barmode='overlay')\n\nfig=go.Figure([trace1,trace2],layout)\npy.iplot(fig,filename='Histogram')",
"_____no_output_____"
]
],
[
[
"#### <font style=\"color: blue\">Practice:</font>\n---\n<font style=\"color: blue\"> <font style=\"color: blue\"> Please download YouTube Popularity data from <a href='https://juniorworld.github.io/python-workshop-2018/doc/Youtube.csv'>this link</a>.\n <p>Create three Histograms to visualize the distribution of views, likes, dislikes and comments. The histograms should meet following requirements:</p>\n 1. One basic histogram to show distribution of \"views\"\n 2. One basic histogram to show distribution of \"log(views)\"\n 3. One 100% overlay histogram to show distributions of log(likes), log(dislikes) and log(comments)\nHint: to apply logarithmic transformation, you can use numpy's log10 function. For example: to calcualte the logrithm of a variable \"a\".\n</font>\n\n>```python\nimport numpy as np\na=np.log10(a)```",
"_____no_output_____"
]
],
[
[
"#Write your code here\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"## Line Chart\nIn Plot.ly, line chart is defined as a special scatter plot whose scatters are connected by lines.\n<br>For more details: https://plot.ly/python/reference/#scatter",
"_____no_output_____"
]
],
[
[
"#create your first line chart\nx=[1,2,3]\ny=[10,22,34]\ntrace1=go.Scatter(x=x,y=y,mode='lines') #mode='lines','markers','lines+markers'\n\npy.iplot([trace1],filename='line chart')",
"_____no_output_____"
],
[
"#add markers to it by changing mode to \"lines+markers\"\nx=[1,2,3]\ny=[10,22,34]\ntrace1=go.Scatter(x=x,y=y,mode='lines+markers')\n\npy.iplot([trace1],filename='line chart')",
"_____no_output_____"
],
[
"#make it a dashed line by re-defining the \"dash\" parameters in \"line\"\n#try other alternative shapes: \"solid\", \"dot\", \"dash\", \"longdash\", \"dashdot\", or \"longdashdot\"\nx=[1,2,3]\ny=[10,22,34]\ntrace1=go.Scatter(x=x,y=y,mode='lines+markers',line={'dash':'dash'})\n\npy.iplot([trace1],filename='line chart')",
"_____no_output_____"
],
[
"#fill the area below\nx=[1,2,3]\ny=[-10,22,34]\ntrace1=go.Scatter(x=x,y=y,mode='lines',fill='tozeroy') #mode='lines'\n\npy.iplot([trace1],filename='line chart')",
"_____no_output_____"
],
[
"#add another trace to it\nx=[1,2,3]\ny1=[10,22,34]\ny2=[34,22,10]\ntrace1=go.Scatter(x=x,y=y1,mode='lines')\ntrace2=go.Scatter(x=x,y=y2,mode='lines')\npy.iplot([trace1,trace2],filename='line chart')",
"_____no_output_____"
],
[
"#change the range of axis\nx=[1,2,3]\ny1=[10,22,34]\ny2=[34,22,10]\ntrace1=go.Scatter(x=x,y=y1,mode='lines')\ntrace2=go.Scatter(x=x,y=y2,mode='lines')\nlayout=go.Layout(yaxis={'range':[0,35]},xaxis={'range':[0,3]})\nfig=go.Figure([trace1,trace2],layout)\npy.iplot(fig,filename='line chart')",
"_____no_output_____"
],
[
"#stacked line chart by re-defining \"stackgroup\" parameter\nx=[1,2,3]\ny1=[10,22,34]\ny2=[34,22,10]\ntrace1=go.Scatter(x=x,y=y1,mode='lines',stackgroup='1')\ntrace2=go.Scatter(x=x,y=y2,mode='lines',stackgroup='1')\n\npy.iplot([trace1,trace2],filename='line chart')",
"_____no_output_____"
]
],
[
[
"#### <font style=\"color: blue\">Practice:</font>\n---\n<font style=\"color: blue\"> <font style=\"color: blue\"> Please download stock price data from <a href='https://juniorworld.github.io/python-workshop-2018/doc/stock.csv'>this link</a>.\n <p>Create a line chart to visualize the trend of these five listed companies. The line chart should meet following requirements:</p>\n 1. Name lines after companies\n</font>",
"_____no_output_____"
]
],
[
[
"#Write your code here\n\n\n",
"_____no_output_____"
]
],
[
[
"## Scatter Plot\n<br>For more details: https://plot.ly/python/reference/#scatter",
"_____no_output_____"
]
],
[
[
"#create your first scatter plot\nx=[1,2,3,4,5]\ny=[10,22,34,40,50]\ntrace1=go.Scatter(x=x,y=y,mode='markers')\n\npy.iplot([trace1],filename='scatter')",
"_____no_output_____"
],
[
"#style the markers\nx=[1,2,3,4,5]\ny=[10,22,34,40,50]\ntrace1=go.Scatter(x=x,y=y,mode='markers',marker={'size':10,'color':'red'})\n\npy.iplot([trace1],filename='scatter')",
"_____no_output_____"
],
[
"#assign different sizes and colors to markers\nx=[1,2,3,4,5]\ny=[10,22,34,40,50]\ntrace1=go.Scatter(x=x,y=y,mode='markers',marker={'size':y,'color':x})\n\npy.iplot([trace1],filename='scatter')",
"_____no_output_____"
],
[
"#assign color according to values in colorscale\n#\"Colorscale\" options: Greys,YlGnBu,Greens,YlOrRd,Bluered,RdBu,Reds,Blues,Picnic,Rainbow,Portland,Jet,Hot,Blackbody,Earth,Electric,Viridis,Cividis\nx=[1,2,3,4,5]\ny=[10,22,34,40,50]\ntrace1=go.Scatter(x=x,y=y,mode='markers',marker={'size':y,'color':x,'colorscale':'Rainbow'})\n\npy.iplot([trace1],filename='scatter')",
"_____no_output_____"
],
[
"#give names to them\nx=[1,2,3,4,5]\ny=[10,22,34,40,50]\ntrace1=go.Scatter(x=x,y=y,mode='markers',marker={'size':y,'color':x,'colorscale':'Rainbow'},text=['a','b','c','d','e'])\n\npy.iplot([trace1],filename='scatter')",
"_____no_output_____"
],
[
"#try plotting scatters in a 3D space\nx=[1,2,3,4,5]\ny=[10,22,34,40,50]\nz=[2,3,4,5,6]\ntrace1=go.Scatter3d(x=x,y=y,z=z,mode='markers')\n\npy.iplot([trace1],filename='scatter')",
"_____no_output_____"
],
[
"#Change axis titles\nx=[1,2,3,4,5]\ny=[10,22,34,40,50]\nz=[2,3,4,5,6]\ntrace1=go.Scatter3d(x=x,y=y,z=z,mode='markers')\nlayout=go.Layout(scene={'xaxis':{'title':'length'},'yaxis':{'title':'width'},'zaxis':{'title':'height'}})\nfig=go.Figure([trace1],layout)\npy.iplot(fig,filename='scatter')",
"_____no_output_____"
]
],
[
[
"#### <font style=\"color: blue\">Practice:</font>\n---\n<font style=\"color: blue\"> <font style=\"color: blue\"> Please download box office data from <a href='https://juniorworld.github.io/python-workshop-2018/doc/movies.csv'>this link</a>.\n <p>Create a 3D scatter plot to visualize these movies. The scatter plot should meet following requirements:</p>\n 1. X axis represents \"Production Budget\"\n 2. Y axis represents \"Box Office\"\n 3. Z axis represents \"ROI\" (Return on Investment)\n 4. Size scatters according to their \"IMDB Ratings\"\n 5. Color scatters according to their \"Genre\"\n 6. Name scatters after movies\n</font>",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nmovies=pd.read_csv('movies.csv')\ncolors=[]\nfor genre in movies['Genre']:\n if genre =='Comedy':\n colors.extend([1])\n else:\n colors.extend([len(genre)])",
"_____no_output_____"
],
[
"#Write your code here\n\n\n\n",
"_____no_output_____"
]
],
[
[
"***",
"_____no_output_____"
],
[
"## Break",
"_____no_output_____"
],
[
"***",
"_____no_output_____"
],
[
"## Map\nWe will learn two types of maps: scatter map and filled map. Scatter map is to show scattering points on the geo map while filled map is to show the value of a region by changing its color on the map.\n<br>For more details: https://plot.ly/python/reference/#scattermapbox and https://plot.ly/python/reference/#choropleth",
"_____no_output_____"
],
[
"### 1. Scatter Map",
"_____no_output_____"
],
[
"We will rely on a built-in tool in plot.ly, named \"mapbox\". Mapbox is an independent IT company focusing on developing GIS-related service. It has connections with plot.ly, IBM, and Google to provide far-reaching and accessible tools in their platforms. In order to use it, you need to apply for its account: https://www.mapbox.com/",
"_____no_output_____"
]
],
[
[
"mapbox_token='YOUR TOKEN'",
"_____no_output_____"
]
],
[
[
"Besides, we need to use google map api to search for place's coordinates. So please go to google cloud platform: https://console.cloud.google.com/google/maps-apis and activate Place API.",
"_____no_output_____"
]
],
[
[
"#install googlemaps library\n! pip3 install googlemaps",
"_____no_output_____"
],
[
"import googlemaps\n\nplace_api='YOUR TOKEN'",
"_____no_output_____"
],
[
"client=googlemaps.Client(key=place_api) #create a client variable with your api",
"_____no_output_____"
],
[
"univs=client.places('universities in hong kong') #search for some places",
"_____no_output_____"
],
[
"type(univs) #look into the search result. It's a dictionary.",
"_____no_output_____"
],
[
"univs.keys() #search results are stored with the key of \"results\"",
"_____no_output_____"
],
[
"names=[]\ngeos=[]\nratings=[]\nfor i in univs['results']: #go over every university and store its name, geolocation and rating into three blank lists respectively\n names.append(i['name'])\n geos.append(list(i['geometry']['location'].values()))\n ratings.append(i['rating'])",
"_____no_output_____"
],
[
"#create a list of Scttermapbox objects. Each object stands for one scatter point on the map.\ndata=[]\nfor i in range(len(names)):\n trace=go.Scattermapbox(lat=[geos[i][0]],lon=[geos[i][1]],text=names[i],\n marker={'size':ratings[i]*2})\n data.append(trace)",
"_____no_output_____"
],
[
"#update the layout\nlayout = go.Layout(\n mapbox={\n 'accesstoken':mapbox_token,\n 'style':'dark',\n 'center':{'lat':geos[0][0],'lon':geos[0][1]},\n 'zoom':10\n },\n showlegend=False\n)",
"_____no_output_____"
],
[
"fig=go.Figure(data,layout)\npy.iplot(fig,filename='map')",
"_____no_output_____"
]
],
[
[
"### 2. Filled Map\nFill regions on the map with certain colors to represent the statistics. This type of map has an academic name of \"choropleth map\".",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfreedom_table=pd.read_csv('https://juniorworld.github.io/python-workshop-2018/doc/human-freedom-index.csv')",
"_____no_output_____"
],
[
"freedom_table.head() #first column, i.e. iso contry code, can be used to create a map.",
"_____no_output_____"
],
[
"trace=go.Choropleth(\n locations=freedom_table['ISO_code'],\n z=freedom_table['human freedom'],\n text=freedom_table['countries']\n \n)\npy.iplot([trace],filename='map')",
"_____no_output_____"
],
[
"#change color scale\ntrace=go.Choropleth(\n locations=freedom_table['ISO_code'],\n z=freedom_table['human freedom'],\n text=freedom_table['countries'],\n colorscale='RdBu'\n \n)\npy.iplot([trace],filename='map')",
"_____no_output_____"
],
[
"#change the map design by redefining line setting in marker parameter\ntrace=go.Choropleth(\n locations=freedom_table['ISO_code'],\n z=freedom_table['human freedom'],\n text=freedom_table['countries'],\n colorscale='RdBu',\n marker={'line':{'color':'white','width':0.2}}\n \n)\n\npy.iplot([trace],filename='map')",
"_____no_output_____"
],
[
"#remove coastlines\ntrace=go.Choropleth(\n locations=freedom_table['ISO_code'],\n z=freedom_table['human freedom'],\n text=freedom_table['countries'],\n colorscale='RdBu',\n marker={'line':{'color':'white','width':0.2}}\n \n)\nlayout=go.Layout(geo={'showcoastlines':False})\nfig=go.Figure([trace],layout)\npy.iplot(fig,filename='map')",
"_____no_output_____"
],
[
"#try other alternative types of projection in the map layout\n#Alternative types: 'equirectangular', 'mercator', 'orthographic', 'natural earth', 'kavrayskiy7', 'miller', 'robinson',\n#'eckert4', 'azimuthal equal area', 'azimuthal equidistant', 'conic equal area', 'conic conformal', 'conic equidistant', \n#'gnomonic', 'stereographic', 'mollweide', 'hammer', 'transverse mercator', 'albers usa', 'winkel tripel', 'aitoff', 'sinusoidal'\ntrace=go.Choropleth(\n locations=freedom_table['ISO_code'],\n z=freedom_table['human freedom'],\n text=freedom_table['countries'],\n colorscale='RdBu',\n marker={'line':{'color':'white','width':0.2}}\n \n)\nlayout=go.Layout(geo={'projection':{'type':'orthographic'}})\nfig=go.Figure([trace],layout)\npy.iplot(fig,filename='map')",
"_____no_output_____"
]
],
[
[
"#### <font style=\"color: blue\">Practice:</font>\n---\n<font style=\"color: blue\">Please create a world map representing the GDP values of the countries recorded in freedom_table. The map should meet following requirements:<br>\n 1. colorscale = Reds\n 2. projection type: natural earth\n</font>",
"_____no_output_____"
]
],
[
[
"#Write your code here\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-block alert-info\">\n**<b>Tips</b>** Two tools to better work with colors in Python:\n <br>1. W3S color palette: https://www.w3schools.com/colors/colors_palettes.asp\n<br>2. colorlover: https://github.com/jackparmer/colorlover</div>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73ddf46e7f1d2951ae472b4b0cf235b425ea5b0 | 58,835 | ipynb | Jupyter Notebook | part_5.ipynb | Da3dalu2/numerical-methods | 57b4c73945edfc14c9127ff25d28a78753d1d4c0 | [
"MIT"
] | 1 | 2022-03-07T23:51:58.000Z | 2022-03-07T23:51:58.000Z | part_5.ipynb | Da3dalu2/numerical-methods | 57b4c73945edfc14c9127ff25d28a78753d1d4c0 | [
"MIT"
] | null | null | null | part_5.ipynb | Da3dalu2/numerical-methods | 57b4c73945edfc14c9127ff25d28a78753d1d4c0 | [
"MIT"
] | null | null | null | 77.721268 | 22,076 | 0.782001 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
e73e019372bbcf1a0984936a8fe151eb9f6ec519 | 109,186 | ipynb | Jupyter Notebook | 1-dl-project/dl-9-baseline-model-analysis.ipynb | luiul/statistics-meets-logistics | 44a13558a8fcb4fab5add3616c818470aae2922e | [
"MIT"
] | 4 | 2020-12-31T12:03:03.000Z | 2021-11-09T19:24:33.000Z | 1-dl-project/dl-9-baseline-model-analysis.ipynb | luiul/stats-meets-log | 44a13558a8fcb4fab5add3616c818470aae2922e | [
"MIT"
] | null | null | null | 1-dl-project/dl-9-baseline-model-analysis.ipynb | luiul/stats-meets-log | 44a13558a8fcb4fab5add3616c818470aae2922e | [
"MIT"
] | 1 | 2021-01-08T11:59:49.000Z | 2021-01-08T11:59:49.000Z | 167.46319 | 30,680 | 0.855403 | [
[
[
"# MODIFY!\nnotebook_name = 'baseline'",
"_____no_output_____"
]
],
[
[
"# Import Libaries & Define Functions",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport glob",
"_____no_output_____"
],
[
"sns.set(style='whitegrid')",
"_____no_output_____"
],
[
"def frame_it(path):\n csv_files = glob.glob(path + '/*.csv')\n df_list = []\n \n for filename in csv_files:\n df = pd.read_csv(filename, index_col='Unnamed: 0', header=0)\n df_list.append(df)\n\n return pd.concat(df_list, axis=1)",
"_____no_output_____"
],
[
"def show_values_on_bars(axs, h_v=\"v\", space=0.4,pct=False,neg=False):\n def _show_on_single_plot(ax):\n if h_v == \"v\":\n for p in ax.patches:\n _x = p.get_x() + p.get_width() / 2\n _y = p.get_y() + p.get_height()\n if pct == True: \n value = '{:.2%}'.format(p.get_height())\n else: \n value = '{:.2f}'.format(p.get_height())\n ax.text(_x, _y, value, ha=\"center\") \n \n elif h_v == \"h\":\n for p in ax.patches:\n _x = p.get_x() + p.get_width() + float(space)\n _y = p.get_y() + p.get_height()\n if pct == True: \n value = '{:.2%}'.format(p.get_width())\n else: \n value = '{:.2f}'.format(p.get_width())\n if neg == True: \n ax.text(_x, _y, value, ha=\"right\")\n else:\n ax.text(_x, _y, value, ha=\"left\")\n\n if isinstance(axs, np.ndarray):\n for idx, ax in np.ndenumerate(axs):\n _show_on_single_plot(ax)\n else:\n _show_on_single_plot(axs)",
"_____no_output_____"
]
],
[
[
"# Analysis",
"_____no_output_____"
]
],
[
[
"# MODIFY!\ndf = frame_it('./baseline-err')\n# we tranpose the data frame for the analysis",
"_____no_output_____"
],
[
"df = df.T\n# we transpose the data frame due to way we exported the data",
"_____no_output_____"
],
[
"df_rmse = df.sort_values('RMSE')\ndf_rmse",
"_____no_output_____"
],
[
"df_rmse.to_csv(f'./analysis/{notebook_name}.csv')",
"_____no_output_____"
]
],
[
[
"## ERR Values [MBit/s] and [(MBit/s)^2]",
"_____no_output_____"
]
],
[
[
"df_rmse.style.highlight_min(color = 'lightgrey', axis = 0).set_table_styles([{'selector': 'tr:hover','props': [('background-color', '')]}])",
"_____no_output_____"
]
],
[
[
"## RMSE Performance Decline based on Best Performance [%]",
"_____no_output_____"
]
],
[
[
"df_rmse_min = df_rmse.apply(lambda value : -((value/df.min())-1),axis=1)",
"_____no_output_____"
],
[
"df_rmse_min = df_rmse_min.sort_values('RMSE',ascending=False)",
"_____no_output_____"
],
[
"df_rmse_min.to_csv(f'./analysis/{notebook_name}-min.csv')",
"_____no_output_____"
],
[
"df_rmse_min.style.highlight_max(color = 'lightgrey', axis = 0).set_table_styles([{'selector': 'tr:hover','props': [('background-color', '')]}]).format('{:.2%}')",
"_____no_output_____"
]
],
[
[
"## RMSE Performance Increment based on Worst Performance [%]",
"_____no_output_____"
]
],
[
[
"df_rmse_max = df.apply(lambda value : abs((value/df.max())-1),axis=1)",
"_____no_output_____"
],
[
"df_rmse_max = df_rmse_max.sort_values('RMSE',ascending=False)",
"_____no_output_____"
],
[
"df_rmse_max.to_csv(f'./analysis/{notebook_name}-max.csv')",
"_____no_output_____"
],
[
"df_rmse_max.style.highlight_max(color = 'lightgrey', axis = 0).set_table_styles([{'selector': 'tr:hover','props': [('background-color', '')]}]).format('{:.2%}')\n# the information in this table is not that meaningful / useful",
"_____no_output_____"
]
],
[
[
"# Visualization",
"_____no_output_____"
]
],
[
[
"ax = sns.barplot(data=df_rmse, x='RMSE',y=df_rmse.index, palette='mako')\nshow_values_on_bars(ax, \"h\", 0.1)\nax.set(ylabel='Model',xlabel='RMSE [MBit/s]')\nax.tick_params(axis=u'both', which=u'both',length=0)\n\nax.set_title('Baseline Model RMSE');",
"_____no_output_____"
],
[
"ax = sns.barplot(data=df_rmse_min,x='RMSE',y=df_rmse_min.index,palette='mako')\n\nax.set(ylabel='Model',xlabel='RMSE Performance Decline [%]')\n\nax.yaxis.set_label_position(\"right\")\nax.yaxis.set_ticks_position(\"right\")\nax.tick_params(axis=u'both', which=u'both',length=0)\n\nshow_values_on_bars(ax,\"h\",0.001,True,True)\n\nax.set_title('Baseline Model RMSE Perfomance Decline based on Best Performance');",
"_____no_output_____"
],
[
"ax = sns.barplot(data=df_rmse_max,x='RMSE',y=df_rmse_max.index,palette='mako')\nshow_values_on_bars(ax,\"h\",0.001,True)\n\nax.tick_params(axis=u'both', which=u'both',length=0)\n\nax.set(ylabel='Model',xlabel='RMSE Performance Increment [%]')\n\nax.set_title('Baseline Model RMSE Perfomance Increment based on Worst Performance');",
"_____no_output_____"
]
],
[
[
"DONE!",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
e73e02e42870d6f27384f2863f26e2cbfff2a9df | 669,985 | ipynb | Jupyter Notebook | OLS.ipynb | Animeshrockn/github-slideshow | a91aacf92d18082401324c58709dac9d69a24aa5 | [
"MIT"
] | null | null | null | OLS.ipynb | Animeshrockn/github-slideshow | a91aacf92d18082401324c58709dac9d69a24aa5 | [
"MIT"
] | 3 | 2021-01-07T11:14:53.000Z | 2021-01-07T11:35:42.000Z | OLS.ipynb | Animeshrockn/github-slideshow | a91aacf92d18082401324c58709dac9d69a24aa5 | [
"MIT"
] | null | null | null | 427.014022 | 33,758 | 0.929648 | [
[
[
"<a href=\"https://colab.research.google.com/github/Animeshrockn/github-slideshow/blob/main/OLS.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"# Based on Jupyter Notebook created by Josh Tobin for CS 189 at UC Berkeley\n\n%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom timeit import default_timer as timer",
"_____no_output_____"
]
],
[
[
"# Part 1: Create a synthetic dataset\n",
"_____no_output_____"
],
[
"## Let's generate some data from a polynomial",
"_____no_output_____"
],
[
"$$y_i = -0.1 x_i^4 - 0.4 x_i^3 - 0.5 x_i^2 + 0.5 x_i + 1 + \\epsilon_i\\mbox{, where }\\epsilon_i \\sim \\mathcal{N}(0,0.1), x_i \\sim \\mathrm{Uniform}(-1,1)$$",
"_____no_output_____"
]
],
[
[
"def polynomial(values, coeffs):\n assert len(values.shape) == 2\n # Coeffs are assumed to be in order 0, 1, ..., n-1\n expanded = np.hstack([coeffs[i] * (values ** i) for i in range(0, len(coeffs))])\n return np.sum(expanded, axis=-1)",
"_____no_output_____"
],
[
"def polynomial_data(coeffs, n_data=100, x_range=[-1, 1], eps=0.1):\n x = np.random.uniform(x_range[0], x_range[1], n_data).reshape([-1, 1])\n poly = polynomial(x, coeffs).reshape([-1, 1])\n noisy_poly = poly + eps * np.random.standard_normal(size=poly.shape)\n return x, noisy_poly",
"_____no_output_____"
],
[
"np.random.seed(100)\n# 1 + 0.5 * x - 0.5 x^2 - 0.4 x^3 - 0.1 x^4\ncoeffs = [1., 0.5, -0.5, -0.4, -0.1]\nx, y = polynomial_data(coeffs, 50)",
"_____no_output_____"
]
],
[
[
"## Let's inspect it",
"_____no_output_____"
]
],
[
[
"# Good to look at shapes, some values\nprint(x.shape)\nprint(y.shape)\nprint(x[:5])\nprint(y[:5])",
"_____no_output_____"
],
[
"def plot_polynomial(coeffs, x_range=[-1, 1], color='red', label='polynomial', alpha=1.0):\n values = np.linspace(x_range[0], x_range[1], 1000).reshape([-1, 1])\n poly = polynomial(values, coeffs)\n plt.plot(values, poly, color=color, linewidth=2, label=label, alpha=alpha)",
"_____no_output_____"
],
[
"plt.figure(figsize=(10, 5))\nplt.scatter(x, y, color='green')\nplot_polynomial(coeffs)",
"_____no_output_____"
]
],
[
[
"# Part 2: Ordinary least squares (OLS)",
"_____no_output_____"
],
[
"## Let's code up a naive implementation of the OLS solution",
"_____no_output_____"
],
[
"$$L(\\vec{w}) = \\sum_{i=1}^{N} (y_i - \\vec{w}^\\top\\vec{x}_i)^2 = \\Vert \\vec{y} - X\\vec{w} \\Vert_2^2$$",
"_____no_output_____"
],
[
"$$\\tilde{L}(\\vec{w}) := {1 \\over N}L(\\vec{w}) = {1 \\over N}\\sum_{i=1}^{N} (y_i - \\vec{w}^\\top\\vec{x}_i)^2 \\mbox{ (\"Mean Squared Error\")}$$",
"_____no_output_____"
],
[
"$$\\vec{w}^{*} := \\arg \\min_{\\vec{w}} \\tilde{L}(\\vec{w}) = \\arg \\min_{\\vec{w}} L(\\vec{w}) = \\left( X^\\top X \\right)^{-1} X^\\top \\vec{y} = X^\\dagger \\vec{y}, \\mbox{where } X = \\left(\\begin{matrix}\n\\vec{x}_1^\\top \\\\\n\\vdots \\\\\n\\vec{x}_N^\\top \\\\\n\\end{matrix}\\right) \\mbox{ and } \\vec{y}= \\left(\\begin{matrix}\ny_{1} \\\\\n\\vdots \\\\\ny_{N} \\\\\n\\end{matrix}\\right) $$",
"_____no_output_____"
]
],
[
[
"def least_squares(x, y):\n xTx = x.T.dot(x)\n xTx_inv = np.linalg.inv(xTx)\n w = xTx_inv.dot(x.T.dot(y))\n return w",
"_____no_output_____"
],
[
"def avg_loss(x, y, w):\n y_hat = x.dot(w)\n loss = np.mean((y - y_hat) ** 2)\n return loss",
"_____no_output_____"
]
],
[
[
"## How well does it work?",
"_____no_output_____"
],
[
"$$\\hat{y} := wx + b$$",
"_____no_output_____"
],
[
"This is equivalent to:",
"_____no_output_____"
],
[
"$$\\hat{y} = \\vec{w}^\\top\\vec{x}\\mbox{ where }\\vec{w} = \\left(\\begin{matrix}\nw \\\\\nb \\\\\n\\end{matrix}\\right)\\mbox{ and }\\vec{x} = \\left(\\begin{matrix}\nx \\\\\n1 \\\\\n\\end{matrix}\\right)$$",
"_____no_output_____"
]
],
[
[
"augmented_x = np.hstack([x, np.ones_like(x)])\n\nlinear_coeff = least_squares(augmented_x, y)\n\nloss = avg_loss(augmented_x, y, linear_coeff)",
"_____no_output_____"
],
[
"plt.figure(figsize=(10, 5))\nplt.scatter(x, y, color='green')\nplot_polynomial([linear_coeff[1,0], linear_coeff[0,0]])\nprint(loss)",
"0.03848975511265433\n"
]
],
[
[
"# Part 3: Polynomial features",
"_____no_output_____"
],
[
"$$\\vec{x} = \\left(\\begin{matrix}\n1 \\\\\nx \\\\\nx^2 \\\\\n\\vdots \\\\\nx^d \\\\\n\\end{matrix}\\right)$$",
"_____no_output_____"
],
[
"$$\\hat{y} = \\vec{w}^\\top\\vec{x}\\mbox{ where }\\vec{w} = \\sum_{i=1}^{d}w_i x^i$$",
"_____no_output_____"
],
[
"Can fit a model that is *non-linear* in the input with *linear* regression!",
"_____no_output_____"
]
],
[
[
"def polynomial_features(x, order):\n features = np.hstack([x**i for i in range(0, order+1)])\n return features",
"_____no_output_____"
],
[
"def plot_regression(x, y, degree):\n start = timer()\n features = polynomial_features(x, degree)\n w = least_squares(features, y)\n loss = avg_loss(features, y, w)\n end = timer()\n \n plt.figure(figsize=(10, 5))\n plt.scatter(x, y, color='green')\n plot_polynomial(w)\n plt.title(f\"Polynomial degree: {degree}, loss: {loss}, time: {end-start}\")",
"_____no_output_____"
],
[
"plot_regression(x, y, 4)\nplot_polynomial(coeffs, color='blue')",
"_____no_output_____"
]
],
[
[
"# Part 4: Hyperparameters",
"_____no_output_____"
],
[
"What degree of polynomial features should we choose? (Previously we picked 4 because we know how the data was generated, but in practice we don't.)",
"_____no_output_____"
],
[
"This is known as \"model selection\", since different hyperparameter choices result in different models, so we are effectively choosing the model. ",
"_____no_output_____"
]
],
[
[
"times = []\nerrs = []\nfor degree in range(0, 6):\n plot_regression(x, y, degree)",
"_____no_output_____"
],
[
"def plot_losses(losses, label='loss', color='b'):\n plt.plot(losses, color=color, label=label)\n plt.semilogy()\n plt.legend()\n plt.title(f\"Minimum loss achieved at hyperparam value {np.argmin(losses)}\")\n plt.xticks(np.arange(len(losses)))",
"_____no_output_____"
],
[
"losses = []\nfor degree in range(21):\n features = polynomial_features(x, degree)\n w = least_squares(features, y)\n loss = avg_loss(features, y, w)\n losses.append(loss)\n\nplt.figure(figsize=(10, 5))\nplot_losses(losses)",
"_____no_output_____"
]
],
[
[
"Loss never goes up as we increase the degree!",
"_____no_output_____"
],
[
"## Should we choose degree 20?",
"_____no_output_____"
]
],
[
[
"plot_regression(x, y, 20)",
"_____no_output_____"
],
[
"plot_regression(x, y, 10)",
"_____no_output_____"
],
[
"plot_regression(x, y, 5)",
"_____no_output_____"
]
],
[
[
"## Why does this happen?",
"_____no_output_____"
],
[
"$$\\mbox{Recall }\\vec{w}^{*} = X^\\dagger \\vec{y} \\mbox{ and } X^\\dagger = V \\Sigma^{-1} U^\\top $$",
"_____no_output_____"
],
[
"$$\\mbox{Let's take a look at the singular values of }X \\mbox{, i.e.: diagonal entries of }\\Sigma$$",
"_____no_output_____"
]
],
[
[
"features_20 = polynomial_features(x, 20)\nfeatures_20.shape",
"_____no_output_____"
],
[
"_, singular_values_20, _ = np.linalg.svd(features_20)\nsingular_values_20.min()",
"_____no_output_____"
],
[
"features_5 = polynomial_features(x, 5)\nfeatures_5.shape",
"_____no_output_____"
],
[
"_, singular_values_5, _ = np.linalg.svd(features_5)\nsingular_values_5.min()",
"_____no_output_____"
]
],
[
[
"$$\\mbox{Very small singular value - } X^\\top X \\mbox{ is close to being non-invertible. As a result, computing }X^\\top X \\mbox{ and }X^\\dagger\\mbox{ is numerically unstable.}$$",
"_____no_output_____"
]
],
[
[
"w_20 = least_squares(features_20, y)\nnp.abs(w_20).max()",
"_____no_output_____"
],
[
"w_5 = least_squares(features_5, y)\nnp.abs(w_5).max()",
"_____no_output_____"
]
],
[
[
"$$\\mbox{Since }\\vec{w}^{*} := \\left( X^\\top X \\right)^{-1} X^\\top \\vec{y} = X^\\dagger \\vec{y}\\mbox{, small singular values of }X\\mbox{ causes }\\vec{w}^{*}\\mbox{ to have elements that are large in magnitude.}$$",
"_____no_output_____"
],
[
"$$\\mbox{This is bad - large coordinate values of }\\vec{w}^{*}\\mbox{ make the prediction sensitive to tiny changes in the input. As a result, the model is not robust to noise in the input.}$$",
"_____no_output_____"
],
[
"## What happens if we generate new data?",
"_____no_output_____"
]
],
[
[
"np.random.seed(200)\nx_new, y_new = polynomial_data(coeffs, 50)",
"_____no_output_____"
],
[
"plt.figure(figsize=(10, 5))\nplt.scatter(x, y, color='green')\nplt.scatter(x_new, y_new, color='blue')",
"_____no_output_____"
],
[
"def plot_regression_new(x, y, x_new, y_new, degree, y_axis_limits = None):\n start = timer()\n features = polynomial_features(x, degree)\n w = least_squares(features, y)\n loss = avg_loss(features, y, w)\n end = timer()\n\n features_new = polynomial_features(x_new, degree)\n loss_new = avg_loss(features_new, y_new, w)\n\n plt.figure(figsize=(10, 5))\n plt.scatter(x, y, color='green')\n plt.scatter(x_new, y_new, color='blue')\n plot_polynomial(w)\n if y_axis_limits is not None:\n plt.ylim(y_axis_limits)\n plt.title(f\"Polynomial degree: {degree}, loss: {loss}, loss (new): {loss_new}\")",
"_____no_output_____"
],
[
"plot_regression_new(x, y, x_new, y_new, 5)",
"_____no_output_____"
],
[
"plot_regression_new(x, y, x_new, y_new, 20, y_axis_limits=(0.0, 1.4))",
"_____no_output_____"
]
],
[
[
"High-degree polynomial doesn't generalize as well to new data.",
"_____no_output_____"
],
[
"Old data which we have access to is known as \"training data\" or \"train data\".",
"_____no_output_____"
],
[
"New data which we don't have access to is known as \"testing data\" or \"test data\".",
"_____no_output_____"
],
[
"Loss on the old data is known as \"training loss\" or \"train loss\", loss on the new data is known as \"testing loss\" or \"test loss\".",
"_____no_output_____"
],
[
"Testing loss should approximate the loss we expect the model to incur when it is fed real unseen data. ",
"_____no_output_____"
],
[
"When both training loss and testing loss are low, the model is said to \"generalize\" to the testing data.",
"_____no_output_____"
],
[
"When testing loss is much higher than the training loss, the model is fitted *too* well to the training data. It fails to generalize to testing data and is said to be \"overfitting\".",
"_____no_output_____"
],
[
"When testing loss is similar to the training loss and is high, the model is not fitted well enough to the training data. In this case, it is said to be \"underfitting\".",
"_____no_output_____"
],
[
"## Another Problem: Instability",
"_____no_output_____"
]
],
[
[
"plot_regression(x, y, 4)\nplot_regression(x_new, y_new, 4)",
"_____no_output_____"
],
[
"plot_regression(x, y, 20)\nplot_regression(x_new, y_new, 20)",
"_____no_output_____"
]
],
[
[
"This instability is another sign of overfitting.",
"_____no_output_____"
],
[
"## What happens if we had more data?",
"_____no_output_____"
]
],
[
[
"x_big, y_big = polynomial_data(coeffs, 200)\nplot_regression(x_big, y_big, 5)\nplot_regression(x_big, y_big, 10)\nplot_regression(x_big, y_big, 20)",
"_____no_output_____"
]
],
[
[
"## Back to picking the optimal hyperparameters",
"_____no_output_____"
]
],
[
[
"train_losses = []\ntest_losses = []\nfor degree in range(21):\n features = polynomial_features(x, degree)\n w = least_squares(features, y)\n train_loss = avg_loss(features, y, w)\n train_losses.append(train_loss)\n\n features_new = polynomial_features(x_new, degree)\n test_loss = avg_loss(features_new, y_new, w)\n test_losses.append(test_loss)\n\nplt.figure(figsize=(10, 5))\nplot_losses(train_losses, label='training loss', color='b')\nplot_losses(test_losses, label='testing loss', color='r')",
"_____no_output_____"
]
],
[
[
"The difference between the training loss and the testing loss is known as the \"generalization gap\".",
"_____no_output_____"
],
[
"Would like to pick the hyperparameter that results in the lowest testing loss - but can't use testing loss for training or model selection! (Otherwise will overfit to the testing set and make the testing set pointless)",
"_____no_output_____"
],
[
"## A Realistic Approach: Validation Sets",
"_____no_output_____"
],
[
"Idea: Divide our data into two subsets. Then train model on one subset and pick the hyperparameters based on the other subset.",
"_____no_output_____"
]
],
[
[
"N_TRAIN = x.shape[0] // 2\nx_train, y_train = x[:N_TRAIN], y[:N_TRAIN]\nx_val, y_val = x[N_TRAIN:], y[N_TRAIN:]",
"_____no_output_____"
],
[
"train_losses = []\nval_losses = []\ntest_losses = []\nfor degree in range(21):\n features_train = polynomial_features(x_train, degree)\n w = least_squares(features_train, y_train)\n train_loss = avg_loss(features_train, y_train, w)\n train_losses.append(train_loss)\n\n features_val = polynomial_features(x_val, degree)\n val_loss = avg_loss(features_val, y_val, w)\n val_losses.append(val_loss)\n\n features_new = polynomial_features(x_new, degree)\n test_loss = avg_loss(features_new, y_new, w)\n test_losses.append(test_loss)\n\nplt.figure(figsize=(10, 5))\nplot_losses(train_losses, label='training loss', color='b')\nplot_losses(test_losses, label='testing loss', color='r')\nplot_losses(val_losses, label='validation loss', color='g')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
e73e0359a7a4581be0e28ff38dc5ef6945da6ca3 | 60,316 | ipynb | Jupyter Notebook | Crowd_Counter_(InceptionResnetV2).ipynb | imdeepmind/CrowdCounter | 597c36d5076541bde0462fd38ca2230659acad05 | [
"MIT"
] | null | null | null | Crowd_Counter_(InceptionResnetV2).ipynb | imdeepmind/CrowdCounter | 597c36d5076541bde0462fd38ca2230659acad05 | [
"MIT"
] | null | null | null | Crowd_Counter_(InceptionResnetV2).ipynb | imdeepmind/CrowdCounter | 597c36d5076541bde0462fd38ca2230659acad05 | [
"MIT"
] | 1 | 2020-10-15T16:27:08.000Z | 2020-10-15T16:27:08.000Z | 106.003515 | 21,642 | 0.784071 | [
[
[
"<a href=\"https://colab.research.google.com/github/imdeepmind/CrowdCounter/blob/master/Crowd_Counter_(InceptionResnetV2).ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"# Getting the dataset into proper place\n!mkdir data\n!cp '/content/drive/My Drive/datasets/dataset.zip' ./\n!unzip -qq dataset.zip -d ./data/\n!rm dataset.zip",
"_____no_output_____"
],
[
"# Script to generate the processed.csv file\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.image as mpimg\nimport os\n\nlabels = pd.read_csv('data/labels.csv')\n\npreprocessed_labels = []\npreprocessed_images = []\n\nimages = os.listdir(\"/content/data/frames/frames\")\n\nfor (id, count) in labels.values:\n preprocessed_labels.append(count)\n preprocessed_images.append(images[id-1])\n\ndf = pd.DataFrame(columns=['image', 'count'])\ndf['image'] = preprocessed_images\ndf['count'] = preprocessed_labels\n\ndf.head()\n\ndf.to_csv('./data/processed.csv', index=False)",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Conv2D, Dense, MaxPooling2D, Dropout, Flatten\nfrom tensorflow.keras.preprocessing.image import ImageDataGenerator\nfrom tensorflow.keras.losses import MeanSquaredError, Huber\nfrom tensorflow.keras.optimizers import Adam\nfrom tensorflow.keras.callbacks import EarlyStopping\nfrom tensorflow.keras.applications import InceptionResNetV2",
"_____no_output_____"
],
[
"# Reading data\ndata = pd.read_csv(\"./data/processed.csv\")\n\ndata.head()",
"_____no_output_____"
],
[
"train, test = train_test_split(data, test_size=0.1, random_state=1969)\n\ntrain.head()",
"_____no_output_____"
],
[
"train_generator = ImageDataGenerator(rotation_range=180, horizontal_flip=True, vertical_flip=True, rescale=1/255.)\ntest_generator = ImageDataGenerator(rescale=1/255.)",
"_____no_output_____"
],
[
"train_data = train_generator.flow_from_dataframe(train, \n directory='./data/frames/frames/', \n x_col='image', \n y_col='count', \n target_size=(640, 480),\n color_mode='rgb',\n class_mode='raw',\n batch_size=16,\n shuffle=True)\n\ntest_data = test_generator.flow_from_dataframe(test, \n directory='./data/frames/frames/', \n x_col='image', \n y_col='count', \n target_size=(640, 480),\n color_mode='rgb',\n class_mode='raw',\n batch_size=16,\n shuffle=True)\n",
"Found 1800 validated image filenames.\nFound 200 validated image filenames.\n"
],
[
"model = Sequential()\n\npretrainedModels = InceptionResNetV2(include_top=False,\n weights=\"imagenet\", \n input_shape=(640,480,3),\n pooling=\"avg\")\nmodel = Sequential()\n\nmodel.add(pretrainedModels)\nmodel.add(Dense(1))",
"_____no_output_____"
],
[
"model.compile(loss='mean_squared_error', optimizer='adam', metrics=['mae'])",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"sequential_2\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninception_resnet_v2 (Functio (None, 1536) 54336736 \n_________________________________________________________________\ndense_1 (Dense) (None, 1) 1537 \n=================================================================\nTotal params: 54,338,273\nTrainable params: 54,277,729\nNon-trainable params: 60,544\n_________________________________________________________________\n"
],
[
"earlyStopper = EarlyStopping(patience=3, restore_best_weights=True)",
"_____no_output_____"
],
[
"history = model.fit(train_data, \n steps_per_epoch=1800//16,\n validation_data=test_data,\n validation_steps=200//16,\n epochs=100,\n callbacks=[earlyStopper])",
"Epoch 1/100\n112/112 [==============================] - 177s 2s/step - loss: 136.3566 - mae: 8.7602 - val_loss: 80.4020 - val_mae: 7.1151\nEpoch 2/100\n112/112 [==============================] - 172s 2s/step - loss: 49.9170 - mae: 5.6307 - val_loss: 200.1891 - val_mae: 8.0073\nEpoch 3/100\n112/112 [==============================] - 172s 2s/step - loss: 49.4899 - mae: 5.6102 - val_loss: 67.2501 - val_mae: 6.4062\nEpoch 4/100\n112/112 [==============================] - 171s 2s/step - loss: 53.5209 - mae: 5.7480 - val_loss: 103.4653 - val_mae: 8.0692\nEpoch 5/100\n112/112 [==============================] - 171s 2s/step - loss: 50.1675 - mae: 5.6509 - val_loss: 86.9294 - val_mae: 8.0185\nEpoch 6/100\n112/112 [==============================] - 171s 2s/step - loss: 49.6040 - mae: 5.6256 - val_loss: 47.3859 - val_mae: 5.2739\nEpoch 7/100\n112/112 [==============================] - 170s 2s/step - loss: 49.1995 - mae: 5.5989 - val_loss: 48.4284 - val_mae: 5.6566\nEpoch 8/100\n112/112 [==============================] - 167s 1s/step - loss: 48.7072 - mae: 5.5635 - val_loss: 46.4351 - val_mae: 5.3770\nEpoch 9/100\n112/112 [==============================] - 166s 1s/step - loss: 49.3613 - mae: 5.6077 - val_loss: 46.1705 - val_mae: 5.4379\nEpoch 10/100\n112/112 [==============================] - 164s 1s/step - loss: 48.8343 - mae: 5.5700 - val_loss: 45.9821 - val_mae: 5.4154\nEpoch 11/100\n112/112 [==============================] - 164s 1s/step - loss: 48.9694 - mae: 5.5923 - val_loss: 46.5334 - val_mae: 5.4070\nEpoch 12/100\n112/112 [==============================] - 166s 1s/step - loss: 49.1108 - mae: 5.5853 - val_loss: 83.0793 - val_mae: 7.8132\nEpoch 13/100\n112/112 [==============================] - 167s 1s/step - loss: 49.4128 - mae: 5.6048 - val_loss: 47.2378 - val_mae: 5.2866\n"
],
[
"plt.plot(history.history['mae'])\nplt.plot(history.history['val_mae'])\nplt.title('Model MAE')\nplt.ylabel('MAE')\nplt.xlabel('Epoch')\nplt.legend(['train', 'test'], loc='upper left')\nplt.show()\n\nplt.plot(history.history['loss'])\nplt.plot(history.history['val_loss'])\nplt.title('Model Loss')\nplt.ylabel('Loss')\nplt.xlabel('Epoch')\nplt.legend(['train', 'test'], loc='upper left')\nplt.show()",
"_____no_output_____"
],
[
"model.save(\"best.h5\")",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73e0b1140dfabba04d0039c1d447fe6b38a5b98 | 4,981 | ipynb | Jupyter Notebook | Chapman/Ch3-Problem_3-11.ipynb | dietmarw/EK5312 | 33b31d953f782043db0264116881060c9f059731 | [
"Unlicense"
] | 12 | 2017-07-16T22:28:25.000Z | 2021-11-08T05:45:58.000Z | Chapman/Ch3-Problem_3-11.ipynb | dietmarw/EK5312 | 33b31d953f782043db0264116881060c9f059731 | [
"Unlicense"
] | null | null | null | Chapman/Ch3-Problem_3-11.ipynb | dietmarw/EK5312 | 33b31d953f782043db0264116881060c9f059731 | [
"Unlicense"
] | 7 | 2018-01-17T15:01:33.000Z | 2021-07-02T19:57:22.000Z | 22.236607 | 698 | 0.533829 | [
[
[
"# Excercises Electric Machinery Fundamentals\n## Chapter 3",
"_____no_output_____"
],
[
"## Problem 3-11",
"_____no_output_____"
]
],
[
[
"%pylab notebook",
"Populating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"### Description",
"_____no_output_____"
],
[
"In later years, motors improved and could be run directly from a 60 Hz power supply. As a result, 25 Hz power systems shrank and disappeared. However, there were many perfectly-good working 25 Hz motors in factories around the country that owners were not ready to discard. To keep them running, some users created their own 25 Hz power in the plant using motor-generator sets. A motor generator set consists of two machines connected on a common shaft, one acting as a motor and the other acting as a generator. If the two machines have different numbers of poles but exactly the same shaft speed, then the electrical frequency of the two machines will be different due to Equation below.\n\n$$f_{se} = \\frac{p\\cdot n_{sm}}{120}$$",
"_____no_output_____"
]
],
[
[
"fse1 = 60. # [Hz]\nfse2 = 25. # [Hz]",
"_____no_output_____"
]
],
[
[
" * What combination of poles on the two machines could convert 60 Hz power to 25 Hz power?",
"_____no_output_____"
],
[
"### SOLUTION",
"_____no_output_____"
],
[
"From Equation, the speed of rotation of the 60 Hz machines would be:\n\n$$n_{sm1} = \\frac{120f_{se1}}{p_1} = \\frac{7200}{p_1}$$\n\nand the speed of rotation of the 25 Hz machines would be:\n\n$$n_{sm2} = \\frac{120f_{se2}}{p_2} = \\frac{3000}{p_2}$$\n\nIf the machines are tied together in a motor-generator set, the shaft speed must be the same for both machines, so\n\n$$n_{sm1} = n_{sm2}$$\n\nWhich means that\n\n$$\\frac{7200}{p_1}=\\frac{3000}{p_2}$$\n\nand in turn this means the relation ship of the poles must be\n\n$$\\frac{p_1}{p_2}=\\frac{7200}{3000}=\\frac{72}{30}=\\frac{24}{10}$$\n\nSo the fraction between $p_1$ and $p_2$ needs to be:",
"_____no_output_____"
]
],
[
[
"P1_P2 =(120*fse1) / (120*fse2)\nP1_P2",
"_____no_output_____"
]
],
[
[
"Let's take an example where $p_1 = 72$. The mechanical speed for machine 1 is therefore:",
"_____no_output_____"
]
],
[
[
"p1 = 72\nn_m1 = (120*fse1)/p1\nn_m1",
"_____no_output_____"
]
],
[
[
"Calculating the speed for machine 2 gives:",
"_____no_output_____"
]
],
[
[
"p2 = p1 / P1_P2\nn_m2 = (120*fse2)/p2\nn_m2",
"_____no_output_____"
]
],
[
[
"This shows that the mechanical speed for this combination of poles is the same. Mind that the number of poles always needs to be **even**.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73e0eaa08147675637f139c50599532ac0d67c9 | 86,999 | ipynb | Jupyter Notebook | Deep Learning Specialisation/Convolutional Neural Networks/Convolution model - Application.ipynb | rakeshbal99/Machine-Learning-Coursera | 2abf947df42f6b5f766c4a462a2d58e7def8921d | [
"MIT"
] | null | null | null | Deep Learning Specialisation/Convolutional Neural Networks/Convolution model - Application.ipynb | rakeshbal99/Machine-Learning-Coursera | 2abf947df42f6b5f766c4a462a2d58e7def8921d | [
"MIT"
] | null | null | null | Deep Learning Specialisation/Convolutional Neural Networks/Convolution model - Application.ipynb | rakeshbal99/Machine-Learning-Coursera | 2abf947df42f6b5f766c4a462a2d58e7def8921d | [
"MIT"
] | null | null | null | 96.237832 | 18,850 | 0.802435 | [
[
[
"# Convolutional Neural Networks: Application\n\nWelcome to Course 4's second assignment! In this notebook, you will:\n\n- Implement helper functions that you will use when implementing a TensorFlow model\n- Implement a fully functioning ConvNet using TensorFlow \n\n**After this assignment you will be able to:**\n\n- Build and train a ConvNet in TensorFlow for a classification problem \n\nWe assume here that you are already familiar with TensorFlow. If you are not, please refer the *TensorFlow Tutorial* of the third week of Course 2 (\"*Improving deep neural networks*\").",
"_____no_output_____"
],
[
"## 1.0 - TensorFlow model\n\nIn the previous assignment, you built helper functions using numpy to understand the mechanics behind convolutional neural networks. Most practical applications of deep learning today are built using programming frameworks, which have many built-in functions you can simply call. \n\nAs usual, we will start by loading in the packages. ",
"_____no_output_____"
]
],
[
[
"import math\nimport numpy as np\nimport h5py\nimport matplotlib.pyplot as plt\nimport scipy\nfrom PIL import Image\nfrom scipy import ndimage\nimport tensorflow as tf\nfrom tensorflow.python.framework import ops\nfrom cnn_utils import *\n\n%matplotlib inline\nnp.random.seed(1)",
"_____no_output_____"
]
],
[
[
"Run the next cell to load the \"SIGNS\" dataset you are going to use.",
"_____no_output_____"
]
],
[
[
"# Loading the data (signs)\nX_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()",
"_____no_output_____"
]
],
[
[
"As a reminder, the SIGNS dataset is a collection of 6 signs representing numbers from 0 to 5.\n\n<img src=\"images/SIGNS.png\" style=\"width:800px;height:300px;\">\n\nThe next cell will show you an example of a labelled image in the dataset. Feel free to change the value of `index` below and re-run to see different examples. ",
"_____no_output_____"
]
],
[
[
"# Example of a picture\nindex = 265\nplt.imshow(X_train_orig[index])\nprint (\"y = \" + str(np.squeeze(Y_train_orig[:, index])))",
"y = 2\n"
]
],
[
[
"In Course 2, you had built a fully-connected network for this dataset. But since this is an image dataset, it is more natural to apply a ConvNet to it.\n\nTo get started, let's examine the shapes of your data. ",
"_____no_output_____"
]
],
[
[
"X_train = X_train_orig/255.\nX_test = X_test_orig/255.\nY_train = convert_to_one_hot(Y_train_orig, 6).T\nY_test = convert_to_one_hot(Y_test_orig, 6).T\nprint (\"number of training examples = \" + str(X_train.shape[0]))\nprint (\"number of test examples = \" + str(X_test.shape[0]))\nprint (\"X_train shape: \" + str(X_train.shape))\nprint (\"Y_train shape: \" + str(Y_train.shape))\nprint (\"X_test shape: \" + str(X_test.shape))\nprint (\"Y_test shape: \" + str(Y_test.shape))\nconv_layers = {}",
"number of training examples = 1080\nnumber of test examples = 120\nX_train shape: (1080, 64, 64, 3)\nY_train shape: (1080, 6)\nX_test shape: (120, 64, 64, 3)\nY_test shape: (120, 6)\n"
]
],
[
[
"### 1.1 - Create placeholders\n\nTensorFlow requires that you create placeholders for the input data that will be fed into the model when running the session.\n\n**Exercise**: Implement the function below to create placeholders for the input image X and the output Y. You should not define the number of training examples for the moment. To do so, you could use \"None\" as the batch size, it will give you the flexibility to choose it later. Hence X should be of dimension **[None, n_H0, n_W0, n_C0]** and Y should be of dimension **[None, n_y]**. [Hint](https://www.tensorflow.org/api_docs/python/tf/placeholder).",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: create_placeholders\n\ndef create_placeholders(n_H0, n_W0, n_C0, n_y):\n \"\"\"\n Creates the placeholders for the tensorflow session.\n \n Arguments:\n n_H0 -- scalar, height of an input image\n n_W0 -- scalar, width of an input image\n n_C0 -- scalar, number of channels of the input\n n_y -- scalar, number of classes\n \n Returns:\n X -- placeholder for the data input, of shape [None, n_H0, n_W0, n_C0] and dtype \"float\"\n Y -- placeholder for the input labels, of shape [None, n_y] and dtype \"float\"\n \"\"\"\n\n ### START CODE HERE ### (≈2 lines)\n X = tf.placeholder(tf.float32,[None,n_H0,n_W0,n_C0], name = 'X')\n Y = tf.placeholder(tf.float32,[None,n_y], name = 'Y')\n ### END CODE HERE ###\n \n return X, Y",
"_____no_output_____"
],
[
"X, Y = create_placeholders(64, 64, 3, 6)\nprint (\"X = \" + str(X))\nprint (\"Y = \" + str(Y))",
"X = Tensor(\"X:0\", shape=(?, 64, 64, 3), dtype=float32)\nY = Tensor(\"Y:0\", shape=(?, 6), dtype=float32)\n"
]
],
[
[
"**Expected Output**\n\n<table> \n<tr>\n<td>\n X = Tensor(\"Placeholder:0\", shape=(?, 64, 64, 3), dtype=float32)\n\n</td>\n</tr>\n<tr>\n<td>\n Y = Tensor(\"Placeholder_1:0\", shape=(?, 6), dtype=float32)\n\n</td>\n</tr>\n</table>",
"_____no_output_____"
],
[
"### 1.2 - Initialize parameters\n\nYou will initialize weights/filters $W1$ and $W2$ using `tf.contrib.layers.xavier_initializer(seed = 0)`. You don't need to worry about bias variables as you will soon see that TensorFlow functions take care of the bias. Note also that you will only initialize the weights/filters for the conv2d functions. TensorFlow initializes the layers for the fully connected part automatically. We will talk more about that later in this assignment.\n\n**Exercise:** Implement initialize_parameters(). The dimensions for each group of filters are provided below. Reminder - to initialize a parameter $W$ of shape [1,2,3,4] in Tensorflow, use:\n```python\nW = tf.get_variable(\"W\", [1,2,3,4], initializer = ...)\n```\n[More Info](https://www.tensorflow.org/api_docs/python/tf/get_variable).",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_parameters\n\ndef initialize_parameters():\n \"\"\"\n Initializes weight parameters to build a neural network with tensorflow. The shapes are:\n W1 : [4, 4, 3, 8]\n W2 : [2, 2, 8, 16]\n Returns:\n parameters -- a dictionary of tensors containing W1, W2\n \"\"\"\n \n tf.set_random_seed(1) # so that your \"random\" numbers match ours\n \n ### START CODE HERE ### (approx. 2 lines of code)\n W1 = tf.get_variable(\"W1\",[4,4,3,8],initializer = tf.contrib.layers.xavier_initializer(seed = 0))\n W2 = tf.get_variable(\"W2\",[2,2,8,16],initializer = tf.contrib.layers.xavier_initializer(seed = 0))\n ### END CODE HERE ###\n\n parameters = {\"W1\": W1,\n \"W2\": W2}\n \n return parameters",
"_____no_output_____"
],
[
"tf.reset_default_graph()\nwith tf.Session() as sess_test:\n parameters = initialize_parameters()\n init = tf.global_variables_initializer()\n sess_test.run(init)\n print(\"W1 = \" + str(parameters[\"W1\"].eval()[1,1,1]))\n print(\"W2 = \" + str(parameters[\"W2\"].eval()[1,1,1]))",
"W1 = [ 0.00131723 0.14176141 -0.04434952 0.09197326 0.14984085 -0.03514394\n -0.06847463 0.05245192]\nW2 = [-0.08566415 0.17750949 0.11974221 0.16773748 -0.0830943 -0.08058\n -0.00577033 -0.14643836 0.24162132 -0.05857408 -0.19055021 0.1345228\n -0.22779644 -0.1601823 -0.16117483 -0.10286498]\n"
]
],
[
[
"** Expected Output:**\n\n<table> \n\n <tr>\n <td>\n W1 = \n </td>\n <td>\n[ 0.00131723 0.14176141 -0.04434952 0.09197326 0.14984085 -0.03514394 <br>\n -0.06847463 0.05245192]\n </td>\n </tr>\n\n <tr>\n <td>\n W2 = \n </td>\n <td>\n[-0.08566415 0.17750949 0.11974221 0.16773748 -0.0830943 -0.08058 <br>\n -0.00577033 -0.14643836 0.24162132 -0.05857408 -0.19055021 0.1345228 <br>\n -0.22779644 -0.1601823 -0.16117483 -0.10286498]\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 1.2 - Forward propagation\n\nIn TensorFlow, there are built-in functions that carry out the convolution steps for you.\n\n- **tf.nn.conv2d(X,W1, strides = [1,s,s,1], padding = 'SAME'):** given an input $X$ and a group of filters $W1$, this function convolves $W1$'s filters on X. The third input ([1,f,f,1]) represents the strides for each dimension of the input (m, n_H_prev, n_W_prev, n_C_prev). You can read the full documentation [here](https://www.tensorflow.org/api_docs/python/tf/nn/conv2d)\n\n- **tf.nn.max_pool(A, ksize = [1,f,f,1], strides = [1,s,s,1], padding = 'SAME'):** given an input A, this function uses a window of size (f, f) and strides of size (s, s) to carry out max pooling over each window. You can read the full documentation [here](https://www.tensorflow.org/api_docs/python/tf/nn/max_pool)\n\n- **tf.nn.relu(Z1):** computes the elementwise ReLU of Z1 (which can be any shape). You can read the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/nn/relu)\n\n- **tf.contrib.layers.flatten(P)**: given an input P, this function flattens each example into a 1D vector it while maintaining the batch-size. It returns a flattened tensor with shape [batch_size, k]. You can read the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/contrib/layers/flatten)\n\n- **tf.contrib.layers.fully_connected(F, num_outputs):** given a the flattened input F, it returns the output computed using a fully connected layer. You can read the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/contrib/layers/fully_connected)\n\nIn the last function above (`tf.contrib.layers.fully_connected`), the fully connected layer automatically initializes weights in the graph and keeps on training them as you train the model. Hence, you did not need to initialize those weights when initializing the parameters. \n\n\n**Exercise**: \n\nImplement the `forward_propagation` function below to build the following model: `CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED`. You should use the functions above. \n\nIn detail, we will use the following parameters for all the steps:\n - Conv2D: stride 1, padding is \"SAME\"\n - ReLU\n - Max pool: Use an 8 by 8 filter size and an 8 by 8 stride, padding is \"SAME\"\n - Conv2D: stride 1, padding is \"SAME\"\n - ReLU\n - Max pool: Use a 4 by 4 filter size and a 4 by 4 stride, padding is \"SAME\"\n - Flatten the previous output.\n - FULLYCONNECTED (FC) layer: Apply a fully connected layer without an non-linear activation function. Do not call the softmax here. This will result in 6 neurons in the output layer, which then get passed later to a softmax. In TensorFlow, the softmax and cost function are lumped together into a single function, which you'll call in a different function when computing the cost. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: forward_propagation\n\ndef forward_propagation(X, parameters):\n \"\"\"\n Implements the forward propagation for the model:\n CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED\n \n Arguments:\n X -- input dataset placeholder, of shape (input size, number of examples)\n parameters -- python dictionary containing your parameters \"W1\", \"W2\"\n the shapes are given in initialize_parameters\n\n Returns:\n Z3 -- the output of the last LINEAR unit\n \"\"\"\n \n # Retrieve the parameters from the dictionary \"parameters\" \n W1 = parameters['W1']\n W2 = parameters['W2']\n \n ### START CODE HERE ###\n # CONV2D: stride of 1, padding 'SAME'\n Z1 = tf.nn.conv2d(X,W1, strides = [1,1,1,1], padding = 'SAME')\n # RELU\n A1 = tf.nn.relu(Z1)\n # MAXPOOL: window 8x8, sride 8, padding 'SAME'\n P1 = tf.nn.max_pool(A1, ksize = [1,8,8,1], strides = [1,8,8,1], padding = 'SAME')\n # CONV2D: filters W2, stride 1, padding 'SAME'\n Z2 = tf.nn.conv2d(P1,W2, strides = [1,1,1,1], padding = 'SAME')\n # RELU\n A2 = tf.nn.relu(Z2)\n # MAXPOOL: window 4x4, stride 4, padding 'SAME'\n P2 = tf.nn.max_pool(A2, ksize = [1,4,4,1], strides = [1,4,4,1], padding = 'SAME')\n # FLATTEN\n P2 = tf.contrib.layers.flatten(P2)\n # FULLY-CONNECTED without non-linear activation function (not not call softmax).\n # 6 neurons in output layer. Hint: one of the arguments should be \"activation_fn=None\" \n Z3 = tf.contrib.layers.fully_connected(P2, num_outputs=6, activation_fn=None)\n ### END CODE HERE ###\n\n return Z3",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as sess:\n np.random.seed(1)\n X, Y = create_placeholders(64, 64, 3, 6)\n parameters = initialize_parameters()\n Z3 = forward_propagation(X, parameters)\n init = tf.global_variables_initializer()\n sess.run(init)\n a = sess.run(Z3, {X: np.random.randn(2,64,64,3), Y: np.random.randn(2,6)})\n print(\"Z3 = \" + str(a))",
"Z3 = [[-0.44670227 -1.57208765 -1.53049231 -2.31013036 -1.29104376 0.46852064]\n [-0.17601591 -1.57972014 -1.4737016 -2.61672091 -1.00810647 0.5747785 ]]\n"
]
],
[
[
"**Expected Output**:\n\n<table> \n <td> \n Z3 =\n </td>\n <td>\n [[-0.44670227 -1.57208765 -1.53049231 -2.31013036 -1.29104376 0.46852064] <br>\n [-0.17601591 -1.57972014 -1.4737016 -2.61672091 -1.00810647 0.5747785 ]]\n </td>\n</table>",
"_____no_output_____"
],
[
"### 1.3 - Compute cost\n\nImplement the compute cost function below. You might find these two functions helpful: \n\n- **tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels = Y):** computes the softmax entropy loss. This function both computes the softmax activation function as well as the resulting loss. You can check the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/nn/softmax_cross_entropy_with_logits)\n- **tf.reduce_mean:** computes the mean of elements across dimensions of a tensor. Use this to sum the losses over all the examples to get the overall cost. You can check the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/reduce_mean)\n\n** Exercise**: Compute the cost below using the function above.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_cost \n\ndef compute_cost(Z3, Y):\n \"\"\"\n Computes the cost\n \n Arguments:\n Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples)\n Y -- \"true\" labels vector placeholder, same shape as Z3\n \n Returns:\n cost - Tensor of the cost function\n \"\"\"\n \n ### START CODE HERE ### (1 line of code)\n cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels = Y))\n ### END CODE HERE ###\n \n return cost",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as sess:\n np.random.seed(1)\n X, Y = create_placeholders(64, 64, 3, 6)\n parameters = initialize_parameters()\n Z3 = forward_propagation(X, parameters)\n cost = compute_cost(Z3, Y)\n init = tf.global_variables_initializer()\n sess.run(init)\n a = sess.run(cost, {X: np.random.randn(4,64,64,3), Y: np.random.randn(4,6)})\n print(\"cost = \" + str(a))",
"cost = 2.91034\n"
]
],
[
[
"**Expected Output**: \n\n<table>\n <td> \n cost =\n </td> \n \n <td> \n 2.91034\n </td> \n</table>",
"_____no_output_____"
],
[
"## 1.4 Model \n\nFinally you will merge the helper functions you implemented above to build a model. You will train it on the SIGNS dataset. \n\nYou have implemented `random_mini_batches()` in the Optimization programming assignment of course 2. Remember that this function returns a list of mini-batches. \n\n**Exercise**: Complete the function below. \n\nThe model below should:\n\n- create placeholders\n- initialize parameters\n- forward propagate\n- compute the cost\n- create an optimizer\n\nFinally you will create a session and run a for loop for num_epochs, get the mini-batches, and then for each mini-batch you will optimize the function. [Hint for initializing the variables](https://www.tensorflow.org/api_docs/python/tf/global_variables_initializer)",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: model\n\ndef model(X_train, Y_train, X_test, Y_test, learning_rate = 0.009,\n num_epochs = 100, minibatch_size = 64, print_cost = True):\n \"\"\"\n Implements a three-layer ConvNet in Tensorflow:\n CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED\n \n Arguments:\n X_train -- training set, of shape (None, 64, 64, 3)\n Y_train -- test set, of shape (None, n_y = 6)\n X_test -- training set, of shape (None, 64, 64, 3)\n Y_test -- test set, of shape (None, n_y = 6)\n learning_rate -- learning rate of the optimization\n num_epochs -- number of epochs of the optimization loop\n minibatch_size -- size of a minibatch\n print_cost -- True to print the cost every 100 epochs\n \n Returns:\n train_accuracy -- real number, accuracy on the train set (X_train)\n test_accuracy -- real number, testing accuracy on the test set (X_test)\n parameters -- parameters learnt by the model. They can then be used to predict.\n \"\"\"\n \n ops.reset_default_graph() # to be able to rerun the model without overwriting tf variables\n tf.set_random_seed(1) # to keep results consistent (tensorflow seed)\n seed = 3 # to keep results consistent (numpy seed)\n (m, n_H0, n_W0, n_C0) = X_train.shape \n n_y = Y_train.shape[1] \n costs = [] # To keep track of the cost\n \n # Create Placeholders of the correct shape\n ### START CODE HERE ### (1 line)\n X, Y = create_placeholders(n_H0, n_W0, n_C0, n_y)\n ### END CODE HERE ###\n\n # Initialize parameters\n ### START CODE HERE ### (1 line)\n parameters = initialize_parameters()\n ### END CODE HERE ###\n \n # Forward propagation: Build the forward propagation in the tensorflow graph\n ### START CODE HERE ### (1 line)\n Z3 = forward_propagation(X,parameters)\n ### END CODE HERE ###\n \n # Cost function: Add cost function to tensorflow graph\n ### START CODE HERE ### (1 line)\n cost = compute_cost(Z3,Y)\n ### END CODE HERE ###\n \n # Backpropagation: Define the tensorflow optimizer. Use an AdamOptimizer that minimizes the cost.\n ### START CODE HERE ### (1 line)\n optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)\n ### END CODE HERE ###\n \n # Initialize all the variables globally\n init = tf.global_variables_initializer()\n \n # Start the session to compute the tensorflow graph\n with tf.Session() as sess:\n \n # Run the initialization\n sess.run(init)\n \n # Do the training loop\n for epoch in range(num_epochs):\n\n minibatch_cost = 0.\n num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set\n seed = seed + 1\n minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)\n\n for minibatch in minibatches:\n\n # Select a minibatch\n (minibatch_X, minibatch_Y) = minibatch\n # IMPORTANT: The line that runs the graph on a minibatch.\n # Run the session to execute the optimizer and the cost, the feedict should contain a minibatch for (X,Y).\n ### START CODE HERE ### (1 line)\n _ , temp_cost = sess.run([optimizer,cost],feed_dict={X:minibatch_X, Y:minibatch_Y})\n ### END CODE HERE ###\n \n minibatch_cost += temp_cost / num_minibatches\n \n\n # Print the cost every epoch\n if print_cost == True and epoch % 5 == 0:\n print (\"Cost after epoch %i: %f\" % (epoch, minibatch_cost))\n if print_cost == True and epoch % 1 == 0:\n costs.append(minibatch_cost)\n \n \n # plot the cost\n plt.plot(np.squeeze(costs))\n plt.ylabel('cost')\n plt.xlabel('iterations (per tens)')\n plt.title(\"Learning rate =\" + str(learning_rate))\n plt.show()\n\n # Calculate the correct predictions\n predict_op = tf.argmax(Z3, 1)\n correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))\n \n # Calculate accuracy on the test set\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n print(accuracy)\n train_accuracy = accuracy.eval({X: X_train, Y: Y_train})\n test_accuracy = accuracy.eval({X: X_test, Y: Y_test})\n print(\"Train Accuracy:\", train_accuracy)\n print(\"Test Accuracy:\", test_accuracy)\n \n return train_accuracy, test_accuracy, parameters",
"_____no_output_____"
]
],
[
[
"Run the following cell to train your model for 100 epochs. Check if your cost after epoch 0 and 5 matches our output. If not, stop the cell and go back to your code!",
"_____no_output_____"
]
],
[
[
"_, _, parameters = model(X_train, Y_train, X_test, Y_test)",
"Cost after epoch 0: 1.917929\nCost after epoch 5: 1.506757\nCost after epoch 10: 0.955359\nCost after epoch 15: 0.845802\nCost after epoch 20: 0.701174\nCost after epoch 25: 0.571977\nCost after epoch 30: 0.518435\nCost after epoch 35: 0.495806\nCost after epoch 40: 0.429827\nCost after epoch 45: 0.407291\nCost after epoch 50: 0.366394\nCost after epoch 55: 0.376922\nCost after epoch 60: 0.299491\nCost after epoch 65: 0.338870\nCost after epoch 70: 0.316400\nCost after epoch 75: 0.310413\nCost after epoch 80: 0.249549\nCost after epoch 85: 0.243457\nCost after epoch 90: 0.200031\nCost after epoch 95: 0.175452\n"
]
],
[
[
"**Expected output**: although it may not match perfectly, your expected output should be close to ours and your cost value should decrease.\n\n<table> \n<tr>\n <td> \n **Cost after epoch 0 =**\n </td>\n\n <td> \n 1.917929\n </td> \n</tr>\n<tr>\n <td> \n **Cost after epoch 5 =**\n </td>\n\n <td> \n 1.506757\n </td> \n</tr>\n<tr>\n <td> \n **Train Accuracy =**\n </td>\n\n <td> \n 0.940741\n </td> \n</tr> \n\n<tr>\n <td> \n **Test Accuracy =**\n </td>\n\n <td> \n 0.783333\n </td> \n</tr> \n</table>",
"_____no_output_____"
],
[
"Congratulations! You have finised the assignment and built a model that recognizes SIGN language with almost 80% accuracy on the test set. If you wish, feel free to play around with this dataset further. You can actually improve its accuracy by spending more time tuning the hyperparameters, or using regularization (as this model clearly has a high variance). \n\nOnce again, here's a thumbs up for your work! ",
"_____no_output_____"
]
],
[
[
"fname = \"images/thumbs_up.jpg\"\nimage = np.array(ndimage.imread(fname, flatten=False))\nmy_image = scipy.misc.imresize(image, size=(64,64))\nplt.imshow(my_image)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
e73e12ca316cb281e52265f2366b1fbe372992a1 | 74,482 | ipynb | Jupyter Notebook | attention_new/model6_transformer.ipynb | wangyuyunmu/2020tencent | 9f59d52b0fce8e687a32e86bcecc00d509828ec9 | [
"MIT"
] | 5 | 2020-06-30T07:57:47.000Z | 2021-06-11T02:17:53.000Z | attention_new/model6_transformer.ipynb | wangyuyunmu/2020tencent | 9f59d52b0fce8e687a32e86bcecc00d509828ec9 | [
"MIT"
] | null | null | null | attention_new/model6_transformer.ipynb | wangyuyunmu/2020tencent | 9f59d52b0fce8e687a32e86bcecc00d509828ec9 | [
"MIT"
] | null | null | null | 58.280125 | 1,387 | 0.61298 | [
[
[
"!pip install keras==2.2.4",
"Looking in indexes: http://mirrors.tencentyun.com/pypi/simple\nRequirement already satisfied: keras==2.2.4 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (2.2.4)\nRequirement already satisfied: keras-applications>=1.0.6 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras==2.2.4) (1.0.8)\nRequirement already satisfied: keras-preprocessing>=1.0.5 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras==2.2.4) (1.1.0)\nRequirement already satisfied: six>=1.9.0 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras==2.2.4) (1.14.0)\nRequirement already satisfied: scipy>=0.14 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras==2.2.4) (1.4.1)\nRequirement already satisfied: numpy>=1.9.1 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras==2.2.4) (1.16.4)\nRequirement already satisfied: h5py in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras==2.2.4) (2.10.0)\nRequirement already satisfied: pyyaml in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras==2.2.4) (5.3)\n"
],
[
"pip install --upgrade keras_applications",
"Looking in indexes: http://mirrors.tencentyun.com/pypi/simple\nRequirement already up-to-date: keras_applications in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (1.0.8)\nRequirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras_applications) (2.10.0)\nRequirement already satisfied, skipping upgrade: numpy>=1.9.1 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras_applications) (1.16.4)\nRequirement already satisfied, skipping upgrade: six in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from h5py->keras_applications) (1.14.0)\nNote: you may need to restart the kernel to use updated packages.\n"
],
[
"from keras.models import Model\nfrom keras.optimizers import SGD,Adam,RMSprop\nfrom keras.layers import *\nimport os\nfrom keras import backend as K\nfrom keras.engine.topology import Layer\nimport h5py\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import confusion_matrix, classification_report, accuracy_score\nimport pandas as pd\nimport numpy as np\nimport keras\nimport tensorflow as tf\n\n# from gensim.models import Word2Vec",
"Using TensorFlow backend.\n"
],
[
"class Embedding(Layer):\n\n def __init__(self, vocab_size, model_dim, **kwargs):\n self._vocab_size = vocab_size\n self._model_dim = model_dim\n super(Embedding, self).__init__(**kwargs)\n\n def build(self, input_shape):\n self.embeddings = self.add_weight(\n shape=(self._vocab_size, self._model_dim),\n initializer='glorot_uniform',\n name=\"embeddings\")\n super(Embedding, self).build(input_shape)\n\n def call(self, inputs):\n if K.dtype(inputs) != 'int32':\n inputs = K.cast(inputs, 'int32')\n embeddings = K.gather(self.embeddings, inputs)\n embeddings *= self._model_dim ** 0.5 # Scale\n return embeddings\n\n def compute_output_shape(self, input_shape):\n\n return input_shape + (self._model_dim,)\n \nclass Add(Layer):\n\n def __init__(self, **kwargs):\n super(Add, self).__init__(**kwargs)\n\n def call(self, inputs):\n input_a, input_b = inputs\n return input_a + input_b\n\n def compute_output_shape(self, input_shape):\n return input_shape[0]\n \nclass ScaledDotProductAttention(Layer):\n\n def __init__(self, masking=True, future=False, dropout_rate=0., **kwargs):\n self._masking = masking\n self._future = future\n self._dropout_rate = dropout_rate\n self._masking_num = -2**32+1\n super(ScaledDotProductAttention, self).__init__(**kwargs)\n\n def mask(self, inputs, masks):\n masks = K.cast(masks, 'float32')\n masks = K.tile(masks, [K.shape(inputs)[0] // K.shape(masks)[0], 1])\n masks = K.expand_dims(masks, 1)\n outputs = inputs + masks * self._masking_num\n return outputs\n \n def future_mask(self, inputs):\n diag_vals = tf.ones_like(inputs[0, :, :])\n tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() \n future_masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(inputs)[0], 1, 1])\n paddings = tf.ones_like(future_masks) * self._masking_num\n outputs = tf.where(tf.equal(future_masks, 0), paddings, inputs)\n return outputs\n\n def call(self, inputs):\n if self._masking:\n assert len(inputs) == 4, \"inputs should be set [queries, keys, values, masks].\"\n queries, keys, values, masks = inputs\n else:\n assert len(inputs) == 3, \"inputs should be set [queries, keys, values].\"\n queries, keys, values = inputs\n\n if K.dtype(queries) != 'float32': queries = K.cast(queries, 'float32')\n if K.dtype(keys) != 'float32': keys = K.cast(keys, 'float32')\n if K.dtype(values) != 'float32': values = K.cast(values, 'float32')\n\n matmul = K.batch_dot(queries, tf.transpose(keys, [0, 2, 1])) # MatMul\n scaled_matmul = matmul / int(queries.shape[-1]) ** 0.5 # Scale\n if self._masking:\n scaled_matmul = self.mask(scaled_matmul, masks) # Mask(opt.)\n\n if self._future:\n scaled_matmul = self.future_mask(scaled_matmul)\n\n softmax_out = K.softmax(scaled_matmul) # SoftMax\n # Dropout\n out = K.dropout(softmax_out, self._dropout_rate)\n \n outputs = K.batch_dot(out, values)\n\n return outputs\n\n def compute_output_shape(self, input_shape):\n return input_shape\n\n \nclass PositionEncoding(Layer):\n\n def __init__(self, model_dim, **kwargs):\n self._model_dim = model_dim\n super(PositionEncoding, self).__init__(**kwargs)\n\n def call(self, inputs):\n seq_length = inputs.shape[1]\n position_encodings = np.zeros((seq_length, self._model_dim))\n for pos in range(seq_length):\n for i in range(self._model_dim):\n position_encodings[pos, i] = pos / np.power(10000, (i-i%2) / self._model_dim)\n position_encodings[:, 0::2] = np.sin(position_encodings[:, 0::2]) # 2i\n position_encodings[:, 1::2] = np.cos(position_encodings[:, 1::2]) # 2i+1\n position_encodings = K.cast(position_encodings, 'float32')\n return position_encodings\n\n def compute_output_shape(self, input_shape):\n return input_shape\n\nclass MultiHeadAttention(Layer):\n\n def __init__(self, n_heads, head_dim, dropout_rate=.1, masking=True, future=False, trainable=True, **kwargs):\n self._n_heads = n_heads\n self._head_dim = head_dim\n self._dropout_rate = dropout_rate\n self._masking = masking\n self._future = future\n self._trainable = trainable\n super(MultiHeadAttention, self).__init__(**kwargs)\n\n def build(self, input_shape):\n self._weights_queries = self.add_weight(\n shape=(input_shape[0][-1], self._n_heads * self._head_dim),\n initializer='glorot_uniform',\n trainable=self._trainable,\n name='weights_queries')\n self._weights_keys = self.add_weight(\n shape=(input_shape[1][-1], self._n_heads * self._head_dim),\n initializer='glorot_uniform',\n trainable=self._trainable,\n name='weights_keys')\n self._weights_values = self.add_weight(\n shape=(input_shape[2][-1], self._n_heads * self._head_dim),\n initializer='glorot_uniform',\n trainable=self._trainable,\n name='weights_values')\n super(MultiHeadAttention, self).build(input_shape)\n\n\n def call(self, inputs):\n if self._masking:\n assert len(inputs) == 4, \"inputs should be set [queries, keys, values, masks].\"\n queries, keys, values, masks = inputs\n else:\n assert len(inputs) == 3, \"inputs should be set [queries, keys, values].\"\n queries, keys, values = inputs\n \n queries_linear = K.dot(queries, self._weights_queries) \n keys_linear = K.dot(keys, self._weights_keys)\n values_linear = K.dot(values, self._weights_values)\n\n queries_multi_heads = tf.concat(tf.split(queries_linear, self._n_heads, axis=2), axis=0)\n keys_multi_heads = tf.concat(tf.split(keys_linear, self._n_heads, axis=2), axis=0)\n values_multi_heads = tf.concat(tf.split(values_linear, self._n_heads, axis=2), axis=0)\n \n if self._masking:\n att_inputs = [queries_multi_heads, keys_multi_heads, values_multi_heads, masks]\n else:\n att_inputs = [queries_multi_heads, keys_multi_heads, values_multi_heads]\n \n attention = ScaledDotProductAttention(\n masking=self._masking, future=self._future, dropout_rate=self._dropout_rate)\n att_out = attention(att_inputs)\n\n outputs = tf.concat(tf.split(att_out, self._n_heads, axis=0), axis=2)\n \n return outputs\n\n def compute_output_shape(self, input_shape):\n return input_shape ",
"_____no_output_____"
],
[
"class PositionWiseFeedForward(Layer):\n \n def __init__(self, model_dim, inner_dim, trainable=True, **kwargs):\n self._model_dim = model_dim\n self._inner_dim = inner_dim\n self._trainable = trainable\n super(PositionWiseFeedForward, self).__init__(**kwargs)\n\n def build(self, input_shape):\n self.weights_inner = self.add_weight(\n shape=(input_shape[-1], self._inner_dim),\n initializer='glorot_uniform',\n trainable=self._trainable,\n name=\"weights_inner\")\n self.weights_out = self.add_weight(\n shape=(self._inner_dim, self._model_dim),\n initializer='glorot_uniform',\n trainable=self._trainable,\n name=\"weights_out\")\n self.bais_inner = self.add_weight(\n shape=(self._inner_dim,),\n initializer='uniform',\n trainable=self._trainable,\n name=\"bais_inner\")\n self.bais_out = self.add_weight(\n shape=(self._model_dim,),\n initializer='uniform',\n trainable=self._trainable,\n name=\"bais_out\")\n super(PositionWiseFeedForward, self).build(input_shape)\n\n def call(self, inputs):\n if K.dtype(inputs) != 'float32':\n inputs = K.cast(inputs, 'float32')\n inner_out = K.relu(K.dot(inputs, self.weights_inner) + self.bais_inner)\n outputs = K.dot(inner_out, self.weights_out) + self.bais_out\n return outputs\n\n def compute_output_shape(self, input_shape):\n return self._model_dim\n\n \nclass LayerNormalization(Layer):\n\n def __init__(self, epsilon=1e-8, **kwargs):\n self._epsilon = epsilon\n super(LayerNormalization, self).__init__(**kwargs)\n\n def build(self, input_shape):\n self.beta = self.add_weight(\n shape=(input_shape[-1],),\n initializer='zero',\n name='beta')\n self.gamma = self.add_weight(\n shape=(input_shape[-1],),\n initializer='one',\n name='gamma')\n super(LayerNormalization, self).build(input_shape)\n\n def call(self, inputs):\n mean, variance = tf.nn.moments(inputs, [-1], keepdims=True)\n normalized = (inputs - mean) / ((variance + self._epsilon) ** 0.5)\n outputs = self.gamma * normalized + self.beta\n return outputs\n\n def compute_output_shape(self, input_shape):\n return input_shape\n \nclass Transformer(Layer):\n\n def __init__(self, vocab_size, model_dim, \n n_heads=8, encoder_stack=6, decoder_stack=6, feed_forward_size=2048, dropout_rate=0.1, **kwargs):\n self._vocab_size = vocab_size\n self._model_dim = model_dim\n self._n_heads = n_heads\n self._encoder_stack = encoder_stack\n self._decoder_stack = decoder_stack\n self._feed_forward_size = feed_forward_size\n self._dropout_rate = dropout_rate\n super(Transformer, self).__init__(**kwargs)\n\n def build(self, input_shape):\n self.embeddings = self.add_weight(\n shape=(self._vocab_size, self._model_dim),\n initializer='glorot_uniform',\n trainable=True,\n name=\"embeddings\")\n super(Transformer, self).build(input_shape)\n\n\n def encoder(self, inputs):\n if K.dtype(inputs) != 'int32':\n inputs = K.cast(inputs, 'int32')\n\n masks = K.equal(inputs, 0)\n # Embeddings\n embeddings = K.gather(self.embeddings, inputs)\n embeddings *= self._model_dim ** 0.5 # Scale\n # Position Encodings\n position_encodings = PositionEncoding(self._model_dim)(embeddings)\n # Embedings + Postion-encodings\n encodings = embeddings + position_encodings\n # Dropout\n encodings = K.dropout(encodings, self._dropout_rate)\n\n for i in range(self._encoder_stack):\n # Multi-head-Attention\n attention = MultiHeadAttention(self._n_heads, self._model_dim // self._n_heads)\n attention_input = [encodings, encodings, encodings, masks]\n attention_out = attention(attention_input)\n # Add & Norm\n attention_out += encodings\n attention_out = LayerNormalization()(attention_out)\n # Feed-Forward\n ff = PositionWiseFeedForward(self._model_dim, self._feed_forward_size)\n ff_out = ff(attention_out)\n # Add & Norm\n ff_out += attention_out\n encodings = LayerNormalization()(ff_out)\n\n return encodings, masks\n\n\n def decoder(self, inputs):\n decoder_inputs, encoder_encodings, encoder_masks = inputs\n if K.dtype(decoder_inputs) != 'int32':\n decoder_inputs = K.cast(decoder_inputs, 'int32')\n\n decoder_masks = K.equal(decoder_inputs, 0)\n # Embeddings\n embeddings = K.gather(self.embeddings, decoder_inputs)\n embeddings *= self._model_dim ** 0.5 # Scale\n # Position Encodings\n position_encodings = PositionEncoding(self._model_dim)(embeddings)\n # Embedings + Postion-encodings\n encodings = embeddings + position_encodings\n # Dropout\n encodings = K.dropout(encodings, self._dropout_rate)\n \n for i in range(self._decoder_stack):\n # Masked-Multi-head-Attention\n masked_attention = MultiHeadAttention(self._n_heads, self._model_dim // self._n_heads, future=True)\n masked_attention_input = [encodings, encodings, encodings, decoder_masks]\n masked_attention_out = masked_attention(masked_attention_input)\n # Add & Norm\n masked_attention_out += encodings\n masked_attention_out = LayerNormalization()(masked_attention_out)\n\n # Multi-head-Attention\n attention = MultiHeadAttention(self._n_heads, self._model_dim // self._n_heads)\n attention_input = [masked_attention_out, encoder_encodings, encoder_encodings, encoder_masks]\n attention_out = attention(attention_input)\n # Add & Norm\n attention_out += masked_attention_out\n attention_out = LayerNormalization()(attention_out)\n\n # Feed-Forward\n ff = PositionWiseFeedForward(self._model_dim, self._feed_forward_size)\n ff_out = ff(attention_out)\n # Add & Norm\n ff_out += attention_out\n encodings = LayerNormalization()(ff_out)\n\n # Pre-Softmax 与 Embeddings 共享参数\n linear_projection = K.dot(encodings, K.transpose(self.embeddings))\n outputs = K.softmax(linear_projection)\n return outputs\n\n def call(self, inputs):\n encoder_inputs, decoder_inputs = inputs\n encoder_encodings, encoder_masks = self.encoder(encoder_inputs)\n encoder_outputs = self.decoder([decoder_inputs, encoder_encodings, encoder_masks])\n return encoder_outputs\n\n def compute_output_shape(self, input_shape):\n return (input_shape[0][0], input_shape[0][1], self._vocab_size)\n \n",
"_____no_output_____"
],
[
"# from tensorflow.keras.models import Model\n# from tensorflow.keras.layers import Input\n# from tensorflow.keras.utils import plot_model\n\nvocab_size = 5000\nmax_seq_len = 256 \nmodel_dim = 512\n\nvocab_size = 32\nmax_seq_len = 256 \nmodel_dim = 5000\n\nencoder_inputs = Input(shape=(max_seq_len,), name='encoder_inputs')\ndecoder_inputs = Input(shape=(max_seq_len,), name='decoder_inputs')\ntran_outputs = Transformer(vocab_size, model_dim)([encoder_inputs, decoder_inputs])\n\noutputs = Bidirectional(LSTM(16,activation='softsign',return_sequences=False))(tran_outputs)\n\nmodel = Model(inputs=[encoder_inputs, decoder_inputs], outputs=outputs)\n\nmodel.summary()",
"WARNING:tensorflow:From /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:517: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n\nWARNING:tensorflow:From /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:74: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.\n\nWARNING:tensorflow:From /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:4138: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.\n\nWARNING:tensorflow:From /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.\nWARNING:tensorflow:From <ipython-input-2-78e7be21646f>:59: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\nencoder_inputs (InputLayer) (None, 256) 0 \n__________________________________________________________________________________________________\ndecoder_inputs (InputLayer) (None, 256) 0 \n__________________________________________________________________________________________________\ntransformer_1 (Transformer) (None, 256, 5000) 2560000 encoder_inputs[0][0] \n decoder_inputs[0][0] \n__________________________________________________________________________________________________\nbidirectional_1 (Bidirectional) (None, 32) 642176 transformer_1[0][0] \n==================================================================================================\nTotal params: 3,202,176\nTrainable params: 3,202,176\nNon-trainable params: 0\n__________________________________________________________________________________________________\n"
],
[
"def buid_model():\n \n vocab_size = 5000\n max_seq_len = 200 \n model_dim = 512\n \n S_inputs = Input(shape=(200,),name='main_input',dtype='int32')\n# with h5py.File('../../get_w2v_feat/w2v1_pre_ad/embeddings_matrix_ad_size_32_w100_count_0.h5','r') as f:\n# embeddings_matrix = np.array(f.get('embeddings_matrix'))\n \n\n# EMBEDDING_DIM = 32 #词向量维度\n# MAX_SEQUENCE_LENGTH = 200\n# embeddings = Embedding(input_dim = len(embeddings_matrix), # 字典长度\n# output_dim = EMBEDDING_DIM, # 词向量 长度(100)\n# weights=[embeddings_matrix], # 重点:预训练的词向量系数\n# input_length=MAX_SEQUENCE_LENGTH, # 每句话的 最大长度(必须padding) \n# trainable=False, # 是否在 训练的过程中 更新词向量\n# mask_zero = True)(S_inputs)\n \n# embeddings = np.random.randint(0,model_dim,(2000,200))\n outputs = Transformer(vocab_size, model_dim)([S_inputs, S_inputs])\n# outputs = Bidirectional(LSTM(32,activation='softsign',return_sequences=False))(outputs)\n outputs = GlobalMaxPool1D()(outputs)\n outputs = Dense(10, activation='softmax', name='main_output')(outputs)\n model = keras.models.Model(inputs=[S_inputs], outputs=outputs)\n \n# O_seq = Bidirectional(LSTM(32,activation='softsign',return_sequences=False))(embeddings)\n# O_seq = Attention()(O_seq)\n# O_seq = Bidirectional(LSTM(16,activation='softsign',return_sequences=False))(O_seq)\n# O_seq = GlobalAveragePooling1D()(O_seq)\n# O_seq = GlobalMaxPool1D()(O_seq)\n# outputs = Dense(10, activation='softmax', name='main_output')(O_seq)\n\n # 定义一个具有两个输入输出的模型\n# model = keras.models.Model(inputs=[S_inputs],#,auxiliary_input],\n# outputs=[outputs]) # 这里的输入输出顺序与fit时一致就好\n \n# model.layers[1].trainable = False\n \n# opt = RMSprop(lr=0.01, clipnorm=1.0)\n opt = Adam(lr=0.01)\n model.compile(optimizer=opt,\n sample_weight_mode='None',#\"temporal\",\n loss={'main_output': 'categorical_crossentropy'},\n metrics=['accuracy'])\n print(model.summary())\n return model\n\n# print(model.summary())\n",
"_____no_output_____"
],
[
"def data_load():\n print('loading data ... \\n')\n\n with h5py.File('../../get_w2v_feat/w2v1_pre_ad/word_train_ad_w2v.h5', 'r') as f:\n data = np.array(f.get('word_data'))\n\n label = pd.read_csv('../../train_preliminary/user.csv').sort_values(by=['user_id'])\n\n train_x, test_x, train_y, test_y = train_test_split(data, label, test_size=0.2, random_state=2020)\n\n train_y_age = train_y['age'].values - 1\n train_y_age = keras.utils.np_utils.to_categorical(train_y_age, num_classes=10)\n train_y_gender = train_y['gender'].values - 1\n\n test_y_age = test_y['age'].values - 1\n test_y_age = keras.utils.np_utils.to_categorical(test_y_age, num_classes=10)\n test_y_gender = test_y['gender'].values - 1\n\n print('get data ... \\n')\n\n return train_x, test_x, train_y_age, train_y_gender,test_y_age,test_y_gender",
"_____no_output_____"
],
[
"model = buid_model()\nprint('lstm model geted...\\n')",
"__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\nmain_input (InputLayer) (None, 200) 0 \n__________________________________________________________________________________________________\ntransformer_3 (Transformer) (None, 200, 5000) 2560000 main_input[0][0] \n main_input[0][0] \n__________________________________________________________________________________________________\nglobal_max_pooling1d_1 (GlobalM (None, 5000) 0 transformer_3[0][0] \n__________________________________________________________________________________________________\nmain_output (Dense) (None, 10) 50010 global_max_pooling1d_1[0][0] \n==================================================================================================\nTotal params: 2,610,010\nTrainable params: 2,610,010\nNon-trainable params: 0\n__________________________________________________________________________________________________\nNone\nlstm model geted...\n\n"
],
[
"train_x, test_x, train_y_age, train_y_gender,test_y_age,test_y_gender = data_load()",
"loading data ... \n\nget data ... \n\n"
],
[
"def get_filename_for_saving(save_dir):\n return os.path.join(save_dir,\n \"self_lstm_attention_max_dense_ad_age_adm_{val_loss:.3f}-{val_acc:.3f}-{epoch:03d}-{loss:.3f}-{acc:.3f}.hdf5\")\n\nprint('lstm model fit...\\n')\ncheckpointer = keras.callbacks.ModelCheckpoint(\n filepath=get_filename_for_saving(''),\n save_best_only=False)\nstopping = keras.callbacks.EarlyStopping(patience=8)\nreduce_lr = keras.callbacks.ReduceLROnPlateau(factor=0.1, patience=2, min_lr=0.0001)\n\n# with h5py.File('../train_data_weight.h5', 'r') as f:\n# weight = np.array(f.get('weight'))\n# train_w, test_w= train_test_split(weight, test_size=0.2, random_state=2020)\n\n# train_w = np.squeeze(train_w)\n# t_w = 10/np.log(train_w)\n\ntest_x = train_x = np.random.randint(0,16,(2000,200))\ntrain_y_age = np.random.randint(0,10,(2000,1))\ntrain_y_age = test_y_age = keras.utils.np_utils.to_categorical(train_y_age, num_classes=10)\n",
"lstm model fit...\n\nWARNING:tensorflow:From /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:986: The name tf.assign_add is deprecated. Please use tf.compat.v1.assign_add instead.\n\nTrain on 2000 samples, validate on 2000 samples\nEpoch 1/100\n"
],
[
"model.fit({'main_input': train_x },#,'aux_input': train_x_sta},\n {'main_output': train_y_age},\n epochs=100,\n batch_size=256,\n validation_data=({'main_input': test_x},#,'aux_input': test_x_sta},\n {'main_output': test_y_age}),\n callbacks=[checkpointer, reduce_lr, stopping])",
"_____no_output_____"
],
[
"!pip install keras-transformer",
"Looking in indexes: http://mirrors.tencentyun.com/pypi/simple\nCollecting keras-transformer\n Downloading http://mirrors.tencentyun.com/pypi/packages/8a/2b/c465241bd3f37a3699246827ff4ad7974c6edeaa69cf9cdcff2fd1d3ba46/keras-transformer-0.37.0.tar.gz (11 kB)\nRequirement already satisfied: numpy in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras-transformer) (1.16.4)\nRequirement already satisfied: Keras in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from keras-transformer) (2.2.4)\nCollecting keras-pos-embd>=0.11.0\n Downloading http://mirrors.tencentyun.com/pypi/packages/09/70/b63ed8fc660da2bb6ae29b9895401c628da5740c048c190b5d7107cadd02/keras-pos-embd-0.11.0.tar.gz (5.9 kB)\nCollecting keras-multi-head>=0.27.0\n Downloading http://mirrors.tencentyun.com/pypi/packages/e6/32/45adf2549450aca7867deccfa04af80a0ab1ca139af44b16bc669e0e09cd/keras-multi-head-0.27.0.tar.gz (14 kB)\nCollecting keras-layer-normalization>=0.14.0\n Downloading http://mirrors.tencentyun.com/pypi/packages/a4/0e/d1078df0494bac9ce1a67954e5380b6e7569668f0f3b50a9531c62c1fc4a/keras-layer-normalization-0.14.0.tar.gz (4.3 kB)\nCollecting keras-position-wise-feed-forward>=0.6.0\n Downloading http://mirrors.tencentyun.com/pypi/packages/e3/59/f0faa1037c033059e7e9e7758e6c23b4d1c0772cd48de14c4b6fd4033ad5/keras-position-wise-feed-forward-0.6.0.tar.gz (4.4 kB)\nCollecting keras-embed-sim>=0.7.0\n Downloading http://mirrors.tencentyun.com/pypi/packages/bc/20/735fd53f6896e2af63af47e212601c1b8a7a80d00b6126c388c9d1233892/keras-embed-sim-0.7.0.tar.gz (4.1 kB)\nRequirement already satisfied: pyyaml in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from Keras->keras-transformer) (5.3)\nRequirement already satisfied: six>=1.9.0 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from Keras->keras-transformer) (1.14.0)\nRequirement already satisfied: keras-preprocessing>=1.0.5 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from Keras->keras-transformer) (1.1.0)\nRequirement already satisfied: scipy>=0.14 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from Keras->keras-transformer) (1.4.1)\nRequirement already satisfied: h5py in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from Keras->keras-transformer) (2.10.0)\nRequirement already satisfied: keras-applications>=1.0.6 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from Keras->keras-transformer) (1.0.8)\nCollecting keras-self-attention==0.46.0\n Downloading http://mirrors.tencentyun.com/pypi/packages/15/6b/c804924a056955fa1f3ff767945187103cfc851ba9bd0fc5a6c6bc18e2eb/keras-self-attention-0.46.0.tar.gz (10 kB)\nBuilding wheels for collected packages: keras-transformer, keras-pos-embd, keras-multi-head, keras-layer-normalization, keras-position-wise-feed-forward, keras-embed-sim, keras-self-attention\n Building wheel for keras-transformer (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for keras-transformer: filename=keras_transformer-0.37.0-py3-none-any.whl size=12941 sha256=3d8488fa9cd4b78419cc5e7ed2d615c8d732db7c87aefd09564562cef86f5168\n Stored in directory: /home/tione/.cache/pip/wheels/84/58/b8/d3d3955c4d41daee7d2d793b0de37973a059db7bac53746c07\n Building wheel for keras-pos-embd (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for keras-pos-embd: filename=keras_pos_embd-0.11.0-py3-none-any.whl size=7553 sha256=5291c2742845d3b2c71ca1d8d41fec915255a91bffee56bbb8c5f914262c6709\n Stored in directory: /home/tione/.cache/pip/wheels/24/3d/17/e81ba1a5486ee02757711dd9f84b62cf6396b6f30a8ae51a19\n Building wheel for keras-multi-head (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for keras-multi-head: filename=keras_multi_head-0.27.0-py3-none-any.whl size=15613 sha256=082e02a933ac1fb487c9329fab95cd0eab43533cf8a834ad4543f5031102959a\n Stored in directory: /home/tione/.cache/pip/wheels/82/a3/cb/cc136aa60959275918dd9059a2cb42e1cd29c96552212ee9db\n Building wheel for keras-layer-normalization (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for keras-layer-normalization: filename=keras_layer_normalization-0.14.0-py3-none-any.whl size=5267 sha256=e40a81510a5fc871c7a841749f1373482b5a5693c64cc8a69bc042f639525fb0\n Stored in directory: /home/tione/.cache/pip/wheels/d1/f7/08/a499940b0159c4694065705422356b7b0dbc7ac2eb80de4a68\n Building wheel for keras-position-wise-feed-forward (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for keras-position-wise-feed-forward: filename=keras_position_wise_feed_forward-0.6.0-py3-none-any.whl size=5623 sha256=62da1bf7261dfc8e23a83e62d879bf9c3130a02e02c0ab84d947d37f62a2ab03\n Stored in directory: /home/tione/.cache/pip/wheels/a9/54/e5/3c88bc4135aef9935fd1a02f2990f37ed477f4056f45ea2bbf\n Building wheel for keras-embed-sim (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for keras-embed-sim: filename=keras_embed_sim-0.7.0-py3-none-any.whl size=4674 sha256=284b6ec9fa0bc6ddf9349873789b0d8d738c4b0af142e4be250c5786e165fdd0\n Stored in directory: /home/tione/.cache/pip/wheels/e6/9d/3d/d28360b51b00d663ed85f927b4000028a16cf27550e32edf98\n Building wheel for keras-self-attention (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for keras-self-attention: filename=keras_self_attention-0.46.0-py3-none-any.whl size=17278 sha256=e80d2f7b32d1013807dcab1ca0203816b54efea6cc0aba2061da99ac70694ff3\n Stored in directory: /home/tione/.cache/pip/wheels/e7/a6/9f/8c92b96b867dbaabe73279acb41670c824ee78fe43cea743de\nSuccessfully built keras-transformer keras-pos-embd keras-multi-head keras-layer-normalization keras-position-wise-feed-forward keras-embed-sim keras-self-attention\nInstalling collected packages: keras-pos-embd, keras-self-attention, keras-multi-head, keras-layer-normalization, keras-position-wise-feed-forward, keras-embed-sim, keras-transformer\nSuccessfully installed keras-embed-sim-0.7.0 keras-layer-normalization-0.14.0 keras-multi-head-0.27.0 keras-pos-embd-0.11.0 keras-position-wise-feed-forward-0.6.0 keras-self-attention-0.46.0 keras-transformer-0.37.0\n"
],
[
"import numpy as np\nfrom keras_transformer import get_model\n\n# Build a small toy token dictionary\ntokens = 'all work and no play makes jack a dull boy'.split(' ')\ntoken_dict = {\n '<PAD>': 0,\n '<START>': 1,\n '<END>': 2,\n}\nfor token in tokens:\n if token not in token_dict:\n token_dict[token] = len(token_dict)",
"_____no_output_____"
],
[
"token_dict",
"_____no_output_____"
],
[
"# Generate toy data\nencoder_inputs_no_padding = []\nencoder_inputs, decoder_inputs, decoder_outputs = [], [], []\nfor i in range(1, len(tokens) - 1):\n encode_tokens, decode_tokens = tokens[:i], tokens[i:]\n encode_tokens = ['<START>'] + encode_tokens + ['<END>'] + ['<PAD>'] * (len(tokens) - len(encode_tokens))\n output_tokens = decode_tokens + ['<END>', '<PAD>'] + ['<PAD>'] * (len(tokens) - len(decode_tokens))\n decode_tokens = ['<START>'] + decode_tokens + ['<END>'] + ['<PAD>'] * (len(tokens) - len(decode_tokens))\n encode_tokens = list(map(lambda x: token_dict[x], encode_tokens))\n decode_tokens = list(map(lambda x: token_dict[x], decode_tokens))\n output_tokens = list(map(lambda x: [token_dict[x]], output_tokens))\n encoder_inputs_no_padding.append(encode_tokens[:i + 2])\n encoder_inputs.append(encode_tokens)\n decoder_inputs.append(decode_tokens)\n decoder_outputs.append(output_tokens)",
"_____no_output_____"
],
[
"encoder_inputs",
"_____no_output_____"
],
[
"decoder_inputs",
"_____no_output_____"
],
[
"S_inputs = Input(shape=(200,),name='main_input',dtype='int32')\n\n# Build the model\nmodel = get_model(\n token_num=len(token_dict),\n embed_dim=30,\n encoder_num=3,\n decoder_num=2,\n head_num=3,\n hidden_dim=120,\n attention_activation='relu',\n feed_forward_activation='relu',\n dropout_rate=0.05,\n embed_weights=np.random.random((13, 30)),\n)\ntran_out = model(x=[np.asarray(encoder_inputs * 1000), np.asarray(decoder_inputs * 1000)],\n y=np.asarray(decoder_outputs * 1000))\nmodel.compile(\n optimizer='adam',\n loss='sparse_categorical_crossentropy',\n)\nmodel.summary()\n\n# Train the model\nmodel.fit(\n x=[np.asarray(encoder_inputs * 1000), np.asarray(decoder_inputs * 1000)],\n y=np.asarray(decoder_outputs * 1000),\n epochs=5,\n)",
"__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\nDecoder-Input (InputLayer) (None, None) 0 \n__________________________________________________________________________________________________\nEncoder-Input (InputLayer) (None, None) 0 \n__________________________________________________________________________________________________\nToken-Embedding (EmbeddingRet) [(None, None, 30), ( 390 Encoder-Input[0][0] \n Decoder-Input[0][0] \n__________________________________________________________________________________________________\nEncoder-Embedding (TrigPosEmbed (None, None, 30) 0 Token-Embedding[0][0] \n__________________________________________________________________________________________________\nEncoder-1-MultiHeadSelfAttentio (None, None, 30) 3720 Encoder-Embedding[0][0] \n__________________________________________________________________________________________________\nEncoder-1-MultiHeadSelfAttentio (None, None, 30) 0 Encoder-1-MultiHeadSelfAttention[\n__________________________________________________________________________________________________\nEncoder-1-MultiHeadSelfAttentio (None, None, 30) 0 Encoder-Embedding[0][0] \n Encoder-1-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nEncoder-1-MultiHeadSelfAttentio (None, None, 30) 60 Encoder-1-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nEncoder-1-FeedForward (FeedForw (None, None, 30) 7350 Encoder-1-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nEncoder-1-FeedForward-Dropout ( (None, None, 30) 0 Encoder-1-FeedForward[0][0] \n__________________________________________________________________________________________________\nEncoder-1-FeedForward-Add (Add) (None, None, 30) 0 Encoder-1-MultiHeadSelfAttention-\n Encoder-1-FeedForward-Dropout[0][\n__________________________________________________________________________________________________\nEncoder-1-FeedForward-Norm (Lay (None, None, 30) 60 Encoder-1-FeedForward-Add[0][0] \n__________________________________________________________________________________________________\nEncoder-2-MultiHeadSelfAttentio (None, None, 30) 3720 Encoder-1-FeedForward-Norm[0][0] \n__________________________________________________________________________________________________\nEncoder-2-MultiHeadSelfAttentio (None, None, 30) 0 Encoder-2-MultiHeadSelfAttention[\n__________________________________________________________________________________________________\nEncoder-2-MultiHeadSelfAttentio (None, None, 30) 0 Encoder-1-FeedForward-Norm[0][0] \n Encoder-2-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nEncoder-2-MultiHeadSelfAttentio (None, None, 30) 60 Encoder-2-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nEncoder-2-FeedForward (FeedForw (None, None, 30) 7350 Encoder-2-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nEncoder-2-FeedForward-Dropout ( (None, None, 30) 0 Encoder-2-FeedForward[0][0] \n__________________________________________________________________________________________________\nEncoder-2-FeedForward-Add (Add) (None, None, 30) 0 Encoder-2-MultiHeadSelfAttention-\n Encoder-2-FeedForward-Dropout[0][\n__________________________________________________________________________________________________\nEncoder-2-FeedForward-Norm (Lay (None, None, 30) 60 Encoder-2-FeedForward-Add[0][0] \n__________________________________________________________________________________________________\nEncoder-3-MultiHeadSelfAttentio (None, None, 30) 3720 Encoder-2-FeedForward-Norm[0][0] \n__________________________________________________________________________________________________\nEncoder-3-MultiHeadSelfAttentio (None, None, 30) 0 Encoder-3-MultiHeadSelfAttention[\n__________________________________________________________________________________________________\nEncoder-3-MultiHeadSelfAttentio (None, None, 30) 0 Encoder-2-FeedForward-Norm[0][0] \n Encoder-3-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nDecoder-Embedding (TrigPosEmbed (None, None, 30) 0 Token-Embedding[1][0] \n__________________________________________________________________________________________________\nEncoder-3-MultiHeadSelfAttentio (None, None, 30) 60 Encoder-3-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nDecoder-1-MultiHeadSelfAttentio (None, None, 30) 3720 Decoder-Embedding[0][0] \n__________________________________________________________________________________________________\nEncoder-3-FeedForward (FeedForw (None, None, 30) 7350 Encoder-3-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nDecoder-1-MultiHeadSelfAttentio (None, None, 30) 0 Decoder-1-MultiHeadSelfAttention[\n__________________________________________________________________________________________________\nEncoder-3-FeedForward-Dropout ( (None, None, 30) 0 Encoder-3-FeedForward[0][0] \n__________________________________________________________________________________________________\nDecoder-1-MultiHeadSelfAttentio (None, None, 30) 0 Decoder-Embedding[0][0] \n Decoder-1-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nEncoder-3-FeedForward-Add (Add) (None, None, 30) 0 Encoder-3-MultiHeadSelfAttention-\n Encoder-3-FeedForward-Dropout[0][\n__________________________________________________________________________________________________\nDecoder-1-MultiHeadSelfAttentio (None, None, 30) 60 Decoder-1-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nEncoder-3-FeedForward-Norm (Lay (None, None, 30) 60 Encoder-3-FeedForward-Add[0][0] \n__________________________________________________________________________________________________\nDecoder-1-MultiHeadQueryAttenti (None, None, 30) 3720 Decoder-1-MultiHeadSelfAttention-\n Encoder-3-FeedForward-Norm[0][0] \n Encoder-3-FeedForward-Norm[0][0] \n__________________________________________________________________________________________________\nDecoder-1-MultiHeadQueryAttenti (None, None, 30) 0 Decoder-1-MultiHeadQueryAttention\n__________________________________________________________________________________________________\nDecoder-1-MultiHeadQueryAttenti (None, None, 30) 0 Decoder-1-MultiHeadSelfAttention-\n Decoder-1-MultiHeadQueryAttention\n__________________________________________________________________________________________________\nDecoder-1-MultiHeadQueryAttenti (None, None, 30) 60 Decoder-1-MultiHeadQueryAttention\n__________________________________________________________________________________________________\nDecoder-1-FeedForward (FeedForw (None, None, 30) 7350 Decoder-1-MultiHeadQueryAttention\n__________________________________________________________________________________________________\nDecoder-1-FeedForward-Dropout ( (None, None, 30) 0 Decoder-1-FeedForward[0][0] \n__________________________________________________________________________________________________\nDecoder-1-FeedForward-Add (Add) (None, None, 30) 0 Decoder-1-MultiHeadQueryAttention\n Decoder-1-FeedForward-Dropout[0][\n__________________________________________________________________________________________________\nDecoder-1-FeedForward-Norm (Lay (None, None, 30) 60 Decoder-1-FeedForward-Add[0][0] \n__________________________________________________________________________________________________\nDecoder-2-MultiHeadSelfAttentio (None, None, 30) 3720 Decoder-1-FeedForward-Norm[0][0] \n__________________________________________________________________________________________________\nDecoder-2-MultiHeadSelfAttentio (None, None, 30) 0 Decoder-2-MultiHeadSelfAttention[\n__________________________________________________________________________________________________\nDecoder-2-MultiHeadSelfAttentio (None, None, 30) 0 Decoder-1-FeedForward-Norm[0][0] \n Decoder-2-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nDecoder-2-MultiHeadSelfAttentio (None, None, 30) 60 Decoder-2-MultiHeadSelfAttention-\n__________________________________________________________________________________________________\nDecoder-2-MultiHeadQueryAttenti (None, None, 30) 3720 Decoder-2-MultiHeadSelfAttention-\n Encoder-3-FeedForward-Norm[0][0] \n Encoder-3-FeedForward-Norm[0][0] \n__________________________________________________________________________________________________\nDecoder-2-MultiHeadQueryAttenti (None, None, 30) 0 Decoder-2-MultiHeadQueryAttention\n__________________________________________________________________________________________________\nDecoder-2-MultiHeadQueryAttenti (None, None, 30) 0 Decoder-2-MultiHeadSelfAttention-\n Decoder-2-MultiHeadQueryAttention\n__________________________________________________________________________________________________\nDecoder-2-MultiHeadQueryAttenti (None, None, 30) 60 Decoder-2-MultiHeadQueryAttention\n__________________________________________________________________________________________________\nDecoder-2-FeedForward (FeedForw (None, None, 30) 7350 Decoder-2-MultiHeadQueryAttention\n__________________________________________________________________________________________________\nDecoder-2-FeedForward-Dropout ( (None, None, 30) 0 Decoder-2-FeedForward[0][0] \n__________________________________________________________________________________________________\nDecoder-2-FeedForward-Add (Add) (None, None, 30) 0 Decoder-2-MultiHeadQueryAttention\n Decoder-2-FeedForward-Dropout[0][\n__________________________________________________________________________________________________\nDecoder-2-FeedForward-Norm (Lay (None, None, 30) 60 Decoder-2-FeedForward-Add[0][0] \n__________________________________________________________________________________________________\nDecoder-Output (EmbeddingSim) (None, None, 13) 13 Decoder-2-FeedForward-Norm[0][0] \n Token-Embedding[1][1] \n==================================================================================================\nTotal params: 63,913\nTrainable params: 63,523\nNon-trainable params: 390\n__________________________________________________________________________________________________\n"
],
[
"!pip install transformers",
"Looking in indexes: http://mirrors.tencentyun.com/pypi/simple\nCollecting transformers\n Downloading http://mirrors.tencentyun.com/pypi/packages/48/35/ad2c5b1b8f99feaaf9d7cdadaeef261f098c6e1a6a2935d4d07662a6b780/transformers-2.11.0-py3-none-any.whl (674 kB)\n\u001b[K |████████████████████████████████| 674 kB 799 kB/s eta 0:00:01\n\u001b[?25hCollecting tokenizers==0.7.0\n Downloading http://mirrors.tencentyun.com/pypi/packages/14/e5/a26eb4716523808bb0a799fcfdceb6ebf77a18169d9591b2f46a9adb87d9/tokenizers-0.7.0-cp36-cp36m-manylinux1_x86_64.whl (3.8 MB)\n\u001b[K |████████████████████████████████| 3.8 MB 1.6 MB/s eta 0:00:01 |██████████████▉ | 1.7 MB 1.6 MB/s eta 0:00:02 |█████████████████████████▉ | 3.0 MB 1.6 MB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: numpy in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from transformers) (1.16.4)\nRequirement already satisfied: requests in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from transformers) (2.20.1)\nCollecting regex!=2019.12.17\n Downloading http://mirrors.tencentyun.com/pypi/packages/1a/a1/6d8fdf4a20ffbbf2bd6003dff47a0628b9e6a4b840c421b0dec27da9376e/regex-2020.6.8-cp36-cp36m-manylinux2010_x86_64.whl (660 kB)\n\u001b[K |███████████████████████████████▊| 655 kB 1.1 MB/s eta 0:00:01 |████████████████████████████████| 660 kB 1.1 MB/s \n\u001b[?25hCollecting filelock\n Downloading http://mirrors.tencentyun.com/pypi/packages/93/83/71a2ee6158bb9f39a90c0dea1637f81d5eef866e188e1971a1b1ab01a35a/filelock-3.0.12-py3-none-any.whl (7.6 kB)\nCollecting sacremoses\n Downloading http://mirrors.tencentyun.com/pypi/packages/7d/34/09d19aff26edcc8eb2a01bed8e98f13a1537005d31e95233fd48216eed10/sacremoses-0.0.43.tar.gz (883 kB)\n\u001b[K |████████████████████████████████| 883 kB 1.6 MB/s eta 0:00:01\n\u001b[?25hCollecting dataclasses; python_version < \"3.7\"\n Downloading http://mirrors.tencentyun.com/pypi/packages/e1/d2/6f02df2616fd4016075f60157c7a0452b38d8f7938ae94343911e0fb0b09/dataclasses-0.7-py3-none-any.whl (18 kB)\nCollecting sentencepiece\n Downloading http://mirrors.tencentyun.com/pypi/packages/68/e5/0366f50a00db181f4b7f3bdc408fc7c4177657f5bf45cb799b79fb4ce15c/sentencepiece-0.1.92-cp36-cp36m-manylinux1_x86_64.whl (1.2 MB)\n\u001b[K |████████████████████████████████| 1.2 MB 1.1 MB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: tqdm>=4.27 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from transformers) (4.42.1)\nCollecting packaging\n Downloading http://mirrors.tencentyun.com/pypi/packages/46/19/c5ab91b1b05cfe63cccd5cfc971db9214c6dd6ced54e33c30d5af1d2bc43/packaging-20.4-py2.py3-none-any.whl (37 kB)\nRequirement already satisfied: urllib3<1.25,>=1.21.1 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from requests->transformers) (1.24.3)\nRequirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from requests->transformers) (2019.11.28)\nRequirement already satisfied: idna<2.8,>=2.5 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from requests->transformers) (2.7)\nRequirement already satisfied: chardet<3.1.0,>=3.0.2 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from requests->transformers) (3.0.4)\nRequirement already satisfied: six in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from sacremoses->transformers) (1.14.0)\nCollecting click\n Downloading http://mirrors.tencentyun.com/pypi/packages/d2/3d/fa76db83bf75c4f8d338c2fd15c8d33fdd7ad23a9b5e57eb6c5de26b430e/click-7.1.2-py2.py3-none-any.whl (82 kB)\n\u001b[K |████████████████████████████████| 82 kB 2.7 MB/s eta 0:00:011\n\u001b[?25hRequirement already satisfied: joblib in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from sacremoses->transformers) (0.14.1)\nRequirement already satisfied: pyparsing>=2.0.2 in /opt/conda/envs/tensorflow_py3/lib/python3.6/site-packages (from packaging->transformers) (2.4.6)\nBuilding wheels for collected packages: sacremoses\n Building wheel for sacremoses (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for sacremoses: filename=sacremoses-0.0.43-py3-none-any.whl size=893259 sha256=2da07ef9dd576c170f5ca18d0e8e3aa3ea965268a01923ac092c76152d2f4b04\n Stored in directory: /home/tione/.cache/pip/wheels/84/1c/87/2507bc9fb552580e00a36152bae7ffb98e9280248c698b0959\nSuccessfully built sacremoses\nInstalling collected packages: tokenizers, regex, filelock, click, sacremoses, dataclasses, sentencepiece, packaging, transformers\nSuccessfully installed click-7.1.2 dataclasses-0.7 filelock-3.0.12 packaging-20.4 regex-2020.6.8 sacremoses-0.0.43 sentencepiece-0.1.92 tokenizers-0.7.0 transformers-2.11.0\n"
],
[
"import tensorflow as tf\nimport tensorflow_datasets\nfrom transformers import *\n\n# Load dataset, tokenizer, model from pretrained model/vocabulary\ntokenizer = BertTokenizer.from_pretrained('bert-base-cased')\nmodel = TFBertForSequenceClassification.from_pretrained('bert-base-cased')\ndata = tensorflow_datasets.load('glue/mrpc')\n\n# Prepare dataset for GLUE as a tf.data.Dataset instance\ntrain_dataset = glue_convert_examples_to_features(data['train'], tokenizer, max_length=128, task='mrpc')\nvalid_dataset = glue_convert_examples_to_features(data['validation'], tokenizer, max_length=128, task='mrpc')\ntrain_dataset = train_dataset.shuffle(100).batch(32).repeat(2)\nvalid_dataset = valid_dataset.batch(64)\n\n# Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule\noptimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)\nloss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\nmetric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')\nmodel.compile(optimizer=optimizer, loss=loss, metrics=[metric])",
"_____no_output_____"
],
[
"\n\n# Train and evaluate using tf.keras.Model.fit()\nhistory = model.fit(train_dataset, epochs=2, steps_per_epoch=115,\n validation_data=valid_dataset, validation_steps=7)\n\n# Load the TensorFlow model in PyTorch for inspection\nmodel.save_pretrained('./save/')\npytorch_model = BertForSequenceClassification.from_pretrained('./save/', from_tf=True)\n\n# Quickly test a few predictions - MRPC is a paraphrasing task, let's see if our model learned the task\nsentence_0 = \"This research was consistent with his findings.\"\nsentence_1 = \"His findings were compatible with this research.\"\nsentence_2 = \"His findings were not compatible with this research.\"\ninputs_1 = tokenizer.encode_plus(sentence_0, sentence_1, add_special_tokens=True, return_tensors='pt')\ninputs_2 = tokenizer.encode_plus(sentence_0, sentence_2, add_special_tokens=True, return_tensors='pt')\n\npred_1 = pytorch_model(inputs_1['input_ids'], token_type_ids=inputs_1['token_type_ids'])[0].argmax().item()\npred_2 = pytorch_model(inputs_2['input_ids'], token_type_ids=inputs_2['token_type_ids'])[0].argmax().item()\n\nprint(\"sentence_1 is\", \"a paraphrase\" if pred_1 else \"not a paraphrase\", \"of sentence_0\")\nprint(\"sentence_2 is\", \"a paraphrase\" if pred_2 else \"not a paraphrase\", \"of sentence_0\")",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73e132f12b29c51c60e3c85a64dbcc623aff28d | 27,182 | ipynb | Jupyter Notebook | Image/06_convolutions.ipynb | giswqs/earthengine-py-documentation | 9637ab56b535f4479160bdb36b32e8bb410ebca3 | [
"MIT"
] | 6 | 2020-02-24T18:58:34.000Z | 2022-02-27T14:39:20.000Z | Image/06_convolutions.ipynb | giswqs/earthengine-py-documentation | 9637ab56b535f4479160bdb36b32e8bb410ebca3 | [
"MIT"
] | null | null | null | Image/06_convolutions.ipynb | giswqs/earthengine-py-documentation | 9637ab56b535f4479160bdb36b32e8bb410ebca3 | [
"MIT"
] | 6 | 2020-03-09T17:48:36.000Z | 2021-11-11T13:05:59.000Z | 115.668085 | 9,056 | 0.852623 | [
[
[
"<table class=\"ee-notebook-buttons\" align=\"left\">\n <td><a target=\"_blank\" href=\"https://github.com/giswqs/earthengine-py-documentation/tree/master/Image/06_convolutions.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /> View source on GitHub</a></td>\n <td><a target=\"_blank\" href=\"https://nbviewer.jupyter.org/github/giswqs/earthengine-py-documentation/blob/master/Image/06_convolutions.ipynb\"><img width=26px src=\"https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png\" />Notebook Viewer</a></td>\n <td><a target=\"_blank\" href=\"https://mybinder.org/v2/gh/giswqs/earthengine-py-documentation/master?filepath=Image/06_convolutions.ipynb\"><img width=58px src=\"https://mybinder.org/static/images/logo_social.png\" />Run in binder</a></td>\n <td><a target=\"_blank\" href=\"https://colab.research.google.com/github/giswqs/earthengine-py-documentation/blob/master/Image/06_convolutions.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /> Run in Google Colab</a></td>\n</table>",
"_____no_output_____"
],
[
"# Convolutions\nTo perform linear convolutions on images, use `image.convolve()`. The only argument to convolve is an `ee.Kernel` which is specified by a shape and the weights in the kernel. Each pixel of the image output by `convolve()` is the linear combination of the kernel values and the input image pixels covered by the kernel. The kernels are applied to each band individually. For example, you might want to use a low-pass (smoothing) kernel to remove high-frequency information. The following illustrates a 15x15 low-pass kernel applied to a Landsat 8 image:",
"_____no_output_____"
],
[
"## Install Earth Engine API\nInstall the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geehydro](https://github.com/giswqs/geehydro). The **geehydro** Python package builds on the [folium](https://github.com/python-visualization/folium) package and implements several methods for displaying Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, `Map.centerObject()`, and `Map.setOptions()`.\nThe following script checks if the geehydro package has been installed. If not, it will install geehydro, which automatically install its dependencies, including earthengine-api and folium.",
"_____no_output_____"
]
],
[
[
"import subprocess\n\ntry:\n import geehydro\nexcept ImportError:\n print('geehydro package not installed. Installing ...')\n subprocess.check_call([\"python\", '-m', 'pip', 'install', 'geehydro'])\n\n# Import libraries \nimport ee\nimport folium\nimport geehydro\n\n# Authenticate and initialize Earth Engine API\ntry:\n ee.Initialize()\nexcept Exception as e:\n ee.Authenticate()\n ee.Initialize()",
"_____no_output_____"
]
],
[
[
"## Create an interactive map \nThis step creates an interactive map using [folium](https://github.com/python-visualization/folium). The default basemap is the OpenStreetMap. Additional basemaps can be added using the `Map.setOptions()` function. \nThe optional basemaps can be `ROADMAP`, `SATELLITE`, `HYBRID`, `TERRAIN`, or `ESRI`.",
"_____no_output_____"
]
],
[
[
"Map = folium.Map(location=[40, -100], zoom_start=4)\nMap.setOptions('HYBRID')",
"_____no_output_____"
]
],
[
[
"## Add Earth Engine Python script ",
"_____no_output_____"
]
],
[
[
"# Load and display an image.\nimage = ee.Image('LANDSAT/LC08/C01/T1_TOA/LC08_044034_20140318')\nMap.setCenter(-121.9785, 37.8694, 11)\nMap.addLayer(image, {'bands': ['B5', 'B4', 'B3'], 'max': 0.5}, 'input image')\n\n# Define a boxcar or low-pass kernel.\n# boxcar = ee.Kernel.square({\n# 'radius': 7, 'units': 'pixels', 'normalize': True\n# })\n\nboxcar = ee.Kernel.square(7, 'pixels', True)\n\n# Smooth the image by convolving with the boxcar kernel.\nsmooth = image.convolve(boxcar)\nMap.addLayer(smooth, {'bands': ['B5', 'B4', 'B3'], 'max': 0.5}, 'smoothed')\n\nMap.setControlVisibility(layerControl=True, fullscreenControl=True, latLngPopup=True)\nMap",
"_____no_output_____"
]
],
[
[
"The output of convolution with the low-pass filter should look something like Figure 1. Observe that the arguments to the kernel determine its size and coefficients. Specifically, with the `units` parameter set to pixels, the `radius` parameter specifies the number of pixels from the center that the kernel will cover. If `normalize` is set to true, the kernel coefficients will sum to one. If the `magnitude` parameter is set, the kernel coefficients will be multiplied by the magnitude (if `normalize` is also true, the coefficients will sum to `magnitude`). If there is a negative value in any of the kernel coefficients, setting `normalize` to true will make the coefficients sum to zero.\n\nUse other kernels to achieve the desired image processing effect. This example uses a Laplacian kernel for isotropic edge detection:",
"_____no_output_____"
]
],
[
[
"Map = folium.Map(location=[40, -100], zoom_start=4)\nMap.setOptions('HYBRID')\n\n# Define a Laplacian, or edge-detection kernel.\nlaplacian = ee.Kernel.laplacian8(1, False)\n\n# Apply the edge-detection kernel.\nedgy = image.convolve(laplacian)\nMap.addLayer(edgy,\n {'bands': ['B5', 'B4', 'B3'], 'max': 0.5},\n 'edges')\nMap.setCenter(-121.9785, 37.8694, 11)\nMap.setControlVisibility(layerControl=True, fullscreenControl=True, latLngPopup=True)\nMap",
"_____no_output_____"
]
],
[
[
"Note the format specifier in the visualization parameters. Earth Engine sends display tiles to the Code Editor in JPEG format for efficiency, however edge tiles are sent in PNG format to handle transparency of pixels outside the image boundary. When a visual discontinuity results, setting the format to PNG results in a consistent display. The result of convolving with the Laplacian edge detection kernel should look something like Figure 2.\n\nThere are also anisotropic edge detection kernels (e.g. Sobel, Prewitt, Roberts), the direction of which can be changed with `kernel.rotate()`. Other low pass kernels include a Gaussian kernel and kernels of various shape with uniform weights. To create kernels with arbitrarily defined weights and shape, use `ee.Kernel.fixed()`. For example, this code creates a 9x9 kernel of 1’s with a zero in the middle:",
"_____no_output_____"
]
],
[
[
"# Create a list of weights for a 9x9 kernel.\nlist = [1, 1, 1, 1, 1, 1, 1, 1, 1]\n# The center of the kernel is zero.\ncenterList = [1, 1, 1, 1, 0, 1, 1, 1, 1]\n# Assemble a list of lists: the 9x9 kernel weights as a 2-D matrix.\nlists = [list, list, list, list, centerList, list, list, list, list]\n# Create the kernel from the weights.\nkernel = ee.Kernel.fixed(9, 9, lists, -4, -4, False)\nprint(kernel.getInfo()) ",
"{'type': 'Kernel.fixed', 'width': 9, 'height': 9, 'weights': '\\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\\n [1.0, 1.0, 1.0, 1.0, 0.0, 1.0, 1.0, 1.0, 1.0]\\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]', 'x': 4, 'y': 4, 'center': [4, 4]}\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
e73e1c9ed813d317a296a26762650760913f10ab | 40,289 | ipynb | Jupyter Notebook | notebooks/reactivex.io/A Decision Tree of Observable Operators. Part I - Creation.ipynb | christiansandberg/RxPY | 036027d2858ea6c9d45839c863bd791e5bb50c36 | [
"MIT"
] | null | null | null | notebooks/reactivex.io/A Decision Tree of Observable Operators. Part I - Creation.ipynb | christiansandberg/RxPY | 036027d2858ea6c9d45839c863bd791e5bb50c36 | [
"MIT"
] | null | null | null | notebooks/reactivex.io/A Decision Tree of Observable Operators. Part I - Creation.ipynb | christiansandberg/RxPY | 036027d2858ea6c9d45839c863bd791e5bb50c36 | [
"MIT"
] | null | null | null | 34.523565 | 337 | 0.510785 | [
[
[
"%run startup.py",
"_____no_output_____"
],
[
"%%javascript\n$.getScript('./assets/js/ipython_notebook_toc.js')",
"_____no_output_____"
]
],
[
[
"# A Decision Tree of Observable Operators\n\n## Part 1: NEW Observables.\n\n> source: http://reactivex.io/documentation/operators.html#tree. \n> (transcribed to RxPY 1.5.7, Py2.7 / 2016-12, Gunther Klessinger, [axiros](http://www.axiros.com)) \n\n**This tree can help you find the ReactiveX Observable operator you’re looking for.** \n\n<h2 id=\"tocheading\">Table of Contents</h2>\n<div id=\"toc\"></div>\n\n## Usage\n\nThere are no configured behind the scenes imports or code except [`startup.py`](./edit/startup.py), which defines output helper functions, mainly:\n\n- `rst, reset_start_time`: resets a global timer, in order to have use cases starting from 0.\n- `subs(observable)`: subscribes to an observable, printing notifications with time, thread, value\n\n\nAll other code is explicitly given in the notebook. \nSince all initialisiation of tools is in the first cell, you always have to run the first cell after ipython kernel restarts. \n**All other cells are autonmous.**\n\nIn the use case functions, in contrast to the official examples we simply use **`rand`** quite often (mapped to `randint(0, 100)`), to demonstrate when/how often observable sequences are generated and when their result is buffered for various subscribers. \n*When in doubt then run the cell again, you might have been \"lucky\" and got the same random.*\n\n### RxJS\nThe (bold printed) operator functions are linked to the [official documentation](http://reactivex.io/documentation/operators.html#tree) and created roughly analogous to the **RxJS** examples. The rest of the TOC lines links to anchors within the notebooks. \n\n### Output\nWhen the output is not in marble format we display it like so:\n\n```\nnew subscription on stream 276507289 \n\n 3.4 M [next] 1.4: {'answer': 42}\n 3.5 T1 [cmpl] 1.6: fin\n \n```\nwhere the lines are syncronously `print`ed as they happen. \"M\" and \"T1\" would be thread names (\"M\" is main thread). \nFor each use case in `reset_start_time()` (alias `rst`), a global timer is set to 0 and we show the offset to it, in *milliseconds* & with one decimal value and also the offset to the start of stream subscription. In the example 3.4, 3.5 are millis since global counter reset, while 1.4, 1.6 are offsets to start of subscription.\n",
"_____no_output_____"
],
[
"# I want to create a **NEW** Observable...",
"_____no_output_____"
],
[
"## ... that emits a particular item: **[just](http://reactivex.io/documentation/operators/just.html) **",
"_____no_output_____"
]
],
[
[
"reset_start_time(O.just)\nstream = O.just({'answer': rand()})\ndisposable = subs(stream)\nsleep(0.5)\ndisposable = subs(stream) # same answer\n# all stream ops work, its a real stream:\ndisposable = subs(stream.map(lambda x: x.get('answer', 0) * 2))",
"\n\n========== return_value ==========\n\nmodule rx.linq.observable.returnvalue\n@extensionclassmethod(Observable, alias=\"just\")\ndef return_value(cls, value, scheduler=None):\n Returns an observable sequence that contains a single element,\n using the specified scheduler to send out observer messages.\n There is an alias called 'just'.\n\n example\n res = reactivex.Observable.return(42)\n res = reactivex.Observable.return(42, rx.Scheduler.timeout)\n\n Keyword arguments:\n value -- Single element in the resulting observable sequence.\n scheduler -- [Optional] Scheduler to send the single element on. If\n not specified, defaults to Scheduler.immediate.\n\n Returns an observable sequence containing the single specified\n element.\n--------------------------------------------------------------------------------\n\n 1.8 M New subscription on stream 273460685\n 2.8 M [next] 0.9: {'answer': 66}\n 3.3 M [cmpl] 1.5: fin\n\n 504.5 M New subscription on stream 273460685\n 505.0 M [next] 0.3: {'answer': 66}\n 505.1 M [cmpl] 0.4: fin\n\n 505.5 M New subscription on stream 272024237\n 506.3 M [next] 0.7: 132\n 506.8 M [cmpl] 1.1: fin\n"
]
],
[
[
"## ..that was returned from a function *called at subscribe-time*: **[start](http://reactivex.io/documentation/operators/start.html)**",
"_____no_output_____"
]
],
[
[
"print('There is a little API difference to RxJS, see Remarks:\\n')\nrst(O.start)\n\ndef f():\n log('function called')\n return rand()\n\nstream = O.start(func=f)\nd = subs(stream)\nd = subs(stream)\n\nheader(\"Exceptions are handled correctly (an observable should never except):\")\n\ndef breaking_f(): \n return 1 / 0\n\nstream = O.start(func=breaking_f)\nd = subs(stream)\nd = subs(stream)\n\n\n\n# startasync: only in python3 and possibly here(?) http://www.tornadoweb.org/en/stable/concurrent.html#tornado.concurrent.Future\n#stream = O.start_async(f)\n#d = subs(stream)\n",
"There is a little API difference to RxJS, see Remarks:\n\n\n\n========== start ==========\n\nmodule rx.linq.observable.start\n@extensionclassmethod(Observable)\ndef start(cls, func, scheduler=None):\n Invokes the specified function asynchronously on the specified\n scheduler, surfacing the result through an observable sequence.\n\n Example:\n res = reactivex.Observable.start(lambda: pprint('hello'))\n res = reactivex.Observable.start(lambda: pprint('hello'), rx.Scheduler.timeout)\n\n Keyword arguments:\n func -- {Function} Function to run asynchronously.\n scheduler -- {Scheduler} [Optional] Scheduler to run the function on. If\n not specified, defaults to Scheduler.timeout.\n\n Returns {Observable} An observable sequence exposing the function's\n result value, or an exception.\n\n Remarks:\n The function is called immediately, not during the subscription of the\n resulting sequence. Multiple subscriptions to the resulting sequence can\n observe the function's result.\n--------------------------------------------------------------------------------\n\n 2.7 T4 function called 3.2 M New subscription on stream 274466149\n\n 3.7 M [next] 0.4: 43\n 3.8 M [cmpl] 0.5: fin\n\n 4.7 M New subscription on stream 274466149\n 5.1 M [next] 0.2: 43\n 5.3 M [cmpl] 0.4: fin\n\n\n========== Exceptions are handled correctly (an observable should never except): ==========\n\n\n 6.9 M New subscription on stream 274466197\n 7.5 M [err ] 0.5: integer division or modulo by zero\n\n 8.4 M New subscription on stream 274466197\n 8.9 M [err ] 0.3: integer division or modulo by zero\n"
]
],
[
[
"## ..that was returned from an Action, Callable, Runnable, or something of that sort, called at subscribe-time: **[from](http://reactivex.io/documentation/operators/from.html)**",
"_____no_output_____"
]
],
[
[
"rst(O.from_iterable)\ndef f():\n log('function called')\n return rand()\n# aliases: O.from_, O.from_list\n# 1.: From a tuple:\nstream = O.from_iterable((1,2,rand()))\nd = subs(stream)\n# d = subs(stream) # same result\n\n# 2. from a generator\ngen = (rand() for j in range(3))\nstream = O.from_iterable(gen)\nd = subs(stream)\n\n",
"\n\n========== from_iterable ==========\n\nmodule rx.linq.observable.fromiterable\n@extensionclassmethod(Observable, alias=[\"from_\", \"from_list\"])\ndef from_iterable(cls, iterable, scheduler=None):\n Converts an array to an observable sequence, using an optional\n scheduler to enumerate the array.\n\n 1 - res = reactivex.Observable.from_iterable([1,2,3])\n 2 - res = reactivex.Observable.from_iterable([1,2,3], rx.Scheduler.timeout)\n\n Keyword arguments:\n :param Observable cls: Observable class\n :param Scheduler scheduler: [Optional] Scheduler to run the\n enumeration of the input sequence on.\n\n :returns: The observable sequence whose elements are pulled from the\n given iterable sequence.\n :rtype: Observable\n--------------------------------------------------------------------------------\n\n 3.3 M New subscription on stream 274466081\n 3.8 M [next] 0.4: 1\n 4.1 M [next] 0.7: 2\n 4.6 M [next] 1.1: 95\n 4.8 M [cmpl] 1.4: fin\n\n 5.4 M New subscription on stream 274466125\n 5.6 M [next] 0.2: 29\n 6.0 M [next] 0.6: 29\n 6.2 M [next] 0.8: 15\n 6.3 M [cmpl] 0.9: fin\n"
],
[
"rst(O.from_callback)\n# in my words: In the on_next of the subscriber you'll have the original arguments,\n# potentially objects, e.g. user original http requests.\n# i.e. you could merge those with the result stream of a backend call to\n# a webservice or db and send the request.response back to the user then.\n\ndef g(f, a, b):\n f(a, b)\n log('called f')\nstream = O.from_callback(lambda a, b, f: g(f, a, b))('fu', 'bar')\nd = subs(stream.delay(200))\n# d = subs(stream.delay(200)) # does NOT work\n",
"\n\n========== from_callback ==========\n\nmodule rx.linq.observable.fromcallback\n@extensionclassmethod(Observable)\ndef from_callback(cls, func, mapper=None):\n Converts a callback function to an observable sequence.\n\n Keyword arguments:\n func -- {Function} Function with a callback as the last parameter to\n convert to an Observable sequence.\n mapper -- {Function} [Optional] A mapper which takes the arguments\n from the callback to produce a single item to yield on next.\n\n Returns {Function} A function, when executed with the required\n parameters minus the callback, produces an Observable sequence with a\n single value of the arguments to the callback as a list.\n--------------------------------------------------------------------------------\n\n 4.6 M New subscription on stream 272024249\n 5.9 M called f\n"
]
],
[
[
"## ...after a specified delay: **[timer](http://reactivex.io/documentation/operators/timer.html)**",
"_____no_output_____"
]
],
[
[
"rst()\n# start a stream of 0, 1, 2, .. after 200 ms, with a delay of 100 ms:\nstream = O.timer(200, 100).time_interval()\\\n .map(lambda x: 'val:%s dt:%s' % (x.value, x.interval))\\\n .take(3)\nd = subs(stream, name='observer1')\n# intermix directly with another one\nd = subs(stream, name='observer2')",
"\n 0.8 M New subscription on stream 274470005\n\n 3.4 M New subscription on stream 274470005\n"
]
],
[
[
"## ...that emits a sequence of items repeatedly: **[repeat](http://reactivex.io/documentation/operators/repeat.html) **",
"_____no_output_____"
]
],
[
[
"rst(O.repeat)\n# repeat is over *values*, not function calls. Use generate or create for function calls!\nsubs(O.repeat({'rand': time.time()}, 3))\n\nheader('do while:')\nl = []\ndef condition(x):\n l.append(1)\n return True if len(l) < 2 else False\nstream = O.just(42).do_while(condition)\nd = subs(stream)\n\n",
"\n\n========== repeat ==========\n\nmodule rx.linq.observable.repeat\n@extensionclassmethod(Observable)\ndef repeat(cls, value=None, repeat_count=None, scheduler=None):\n Generates an observable sequence that repeats the given element the\n specified number of times, using the specified scheduler to send out\n observer messages.\n\n 1 - res = reactivex.Observable.repeat(42)\n 2 - res = reactivex.Observable.repeat(42, 4)\n 3 - res = reactivex.Observable.repeat(42, 4, Rx.Scheduler.timeout)\n 4 - res = reactivex.Observable.repeat(42, None, Rx.Scheduler.timeout)\n\n Keyword arguments:\n value -- Element to repeat.\n repeat_count -- [Optional] Number of times to repeat the element. If not\n specified, repeats indefinitely.\n scheduler -- Scheduler to run the producer loop on. If not specified,\n defaults to ImmediateScheduler.\n\n Returns an observable sequence that repeats the given element the\n specified number of times.\n--------------------------------------------------------------------------------\n\n 2.0 M New subscription on stream 274473961\n 2.9 M [next] 0.9: {'rand': 1482335562.344726}\n 4.5 M [next] 2.4: {'rand': 1482335562.344726}\n 5.1 M [next] 3.0: {'rand': 1482335562.344726}\n 5.2 M [cmpl] 3.1: fin\n\n\n========== do while: ==========\n\n\n 6.8 M New subscription on stream 273460681\n 7.5 M [next] 0.5: 42\n 8.7 M [next] 1.7: 42\n 9.2 M [cmpl] 2.2: fin\n"
]
],
[
[
"## ...from scratch, with custom logic and cleanup (calling a function again and again): **[create](http://reactivex.io/documentation/operators/create.html) **",
"_____no_output_____"
]
],
[
[
"rx = O.create\nrst(rx)\n\ndef f(obs):\n # this function is called for every observer\n obs.on_next(rand())\n obs.on_next(rand())\n obs.on_completed()\n def cleanup():\n log('cleaning up...')\n return cleanup\nstream = O.create(f).delay(200) # the delay causes the cleanup called before the subs gets the vals\nd = subs(stream)\nd = subs(stream)\n\n\n\n\nsleep(0.5)\nrst(title='Exceptions are handled nicely')\nl = []\ndef excepting_f(obs):\n for i in range(3):\n l.append(1)\n obs.on_next('%s %s (observer hash: %s)' % (i, 1. / (3 - len(l)), hash(obs) ))\n obs.on_completed()\n\nstream = O.create(excepting_f)\nd = subs(stream)\nd = subs(stream)\n\n\n\n\nrst(title='Feature or Bug?')\nprint('(where are the first two values?)')\nl = []\ndef excepting_f(obs):\n for i in range(3):\n l.append(1)\n obs.on_next('%s %s (observer hash: %s)' % (i, 1. / (3 - len(l)), hash(obs) ))\n obs.on_completed()\n\nstream = O.create(excepting_f).delay(100)\nd = subs(stream)\nd = subs(stream)\n# I think its an (amazing) feature, preventing to process functions results of later(!) failing functions\n",
"\n\n========== create ==========\n\nmodule rx.linq.observable.create\n@extensionclassmethod(Observable, alias=\"create\")\ndef create(cls, subscribe):\n n.a.\n--------------------------------------------------------------------------------\n\n 2.4 M New subscription on stream 273454757\n 3.9 M cleaning up...\n\n 4.5 M New subscription on stream 273454757\n 5.8 M cleaning up...\n 131.3 T6 [next] 202.3: ['fu', 'bar']\n 131.7 T6 [cmpl] 202.7: fin\n 142.0 T7 [next] 202.4: val:0 dt:0:00:00.202066 (observer1)\n 144.0 T8 [next] 201.8: val:0 dt:0:00:00.201505 (observer2)\n 208.2 T9 [next] 205.7: 59\n 208.8 T9 [next] 206.3: 68\n 209.2 T9 [cmpl] 206.7: fin\n 209.6 T10 [next] 204.9: 84\n 210.0 T10 [next] 205.3: 79\n 210.2 T10 [cmpl] 205.4: fin\n 246.3 T12 [next] 304.1: val:1 dt:0:00:00.102253 (observer2)\n 247.0 T11 [next] 307.4: val:1 dt:0:00:00.104979 (observer1)\n 345.7 T14 [next] 406.1: val:2 dt:0:00:00.098724 (observer1)\n 346.0 T14 [cmpl] 406.4: fin (observer1)\n 348.3 T13 [next] 406.2: val:2 dt:0:00:00.102073 (observer2)\n 348.5 T13 [cmpl] 406.3: fin (observer2)\n"
],
[
"rx = O.generate\nrst(rx)\n\"\"\"The basic form of generate takes four parameters:\n\nthe first item to emit\na function to test an item to determine whether to emit it (true) or terminate the Observable (false)\na function to generate the next item to test and emit based on the value of the previous item\na function to transform items before emitting them\n\"\"\"\ndef generator_based_on_previous(x): return x + 1.1\ndef doubler(x): return 2 * x\nd = subs(rx(0, lambda x: x < 4, generator_based_on_previous, doubler))",
"\n\n========== generate ==========\n\nmodule rx.linq.observable.generate\n@extensionclassmethod(Observable)\ndef generate(cls, initial_state, condition, iterate, result_mapper, scheduler=None):\n Generates an observable sequence by running a state-driven loop\n producing the sequence's elements, using the specified scheduler to\n send out observer messages.\n\n 1 - res = reactivex.Observable.generate(0,\n lambda x: x < 10,\n lambda x: x + 1,\n lambda x: x)\n 2 - res = reactivex.Observable.generate(0,\n lambda x: x < 10,\n lambda x: x + 1,\n lambda x: x,\n Rx.Scheduler.timeout)\n\n Keyword arguments:\n initial_state -- Initial state.\n condition -- Condition to terminate generation (upon returning False).\n iterate -- Iteration step function.\n result_mapper -- Selector function for results produced in the\n sequence.\n scheduler -- [Optional] Scheduler on which to run the generator loop.\n If not provided, defaults to CurrentThreadScheduler.\n\n Returns the generated sequence.\n--------------------------------------------------------------------------------\n\n 4.8 M New subscription on stream 274475993\n 5.7 M [next] 0.7: 0\n 6.4 M [next] 1.4: 2.2\n 6.6 M [next] 1.6: 4.4\n 7.1 M [next] 2.1: 6.6\n 7.3 M [cmpl] 2.3: fin\n"
],
[
"rx = O.generate_with_relative_time\nrst(rx)\nstream = rx(1, lambda x: x < 4, lambda x: x + 1, lambda x: x, lambda t: 100)\nd = subs(stream)\n",
"\n\n========== generate_with_relative_time ==========\n\nmodule rx.linq.observable.generatewithrelativetime\n@extensionclassmethod(Observable)\ndef generate_with_relative_time(cls, initial_state, condition, iterate,\n Generates an observable sequence by iterating a state from an\n initial state until the condition fails.\n\n res = source.generate_with_relative_time(0,\n lambda x: True,\n lambda x: x + 1,\n lambda x: x,\n lambda x: 500)\n\n initial_state -- Initial state.\n condition -- Condition to terminate generation (upon returning false).\n iterate -- Iteration step function.\n result_mapper -- Selector function for results produced in the\n sequence.\n time_mapper -- Time mapper function to control the speed of values\n being produced each iteration, returning integer values denoting\n milliseconds.\n scheduler -- [Optional] Scheduler on which to run the generator loop.\n If not specified, the timeout scheduler is used.\n\n Returns the generated sequence.\n--------------------------------------------------------------------------------\n\n 4.7 M New subscription on stream 274475933\n"
]
],
[
[
"## ...for each observer that subscribes OR according to a condition at subscription time: **[defer / if_then](http://reactivex.io/documentation/operators/defer.html) **",
"_____no_output_____"
]
],
[
[
"rst(O.defer)\n# plural! (unique per subscription)\nstreams = O.defer(lambda: O.just(rand()))\nd = subs(streams)\nd = subs(streams) # gets other values - created by subscription!",
"\n\n========== defer ==========\n\nmodule rx.linq.observable.defer\n@extensionclassmethod(Observable)\ndef defer(cls, observable_factory):\n Returns an observable sequence that invokes the specified factory\n function whenever a new observer subscribes.\n\n Example:\n 1 - res = reactivex.Observable.defer(lambda: reactivex.Observable.from_([1,2,3]))\n\n Keyword arguments:\n :param types.FunctionType observable_factory: Observable factory function\n to invoke for each observer that subscribes to the resulting sequence.\n\n :returns: An observable sequence whose observers trigger an invocation\n of the given observable factory function.\n :rtype: Observable\n--------------------------------------------------------------------------------\n\n 2.7 M New subscription on stream 274475969\n 3.4 M [next] 0.6: 38\n 3.5 M [cmpl] 0.7: fin\n\n 4.4 M New subscription on stream 274475969\n 4.9 M [next] 0.4: 77\n 5.2 M [cmpl] 0.7: fin\n"
],
[
"# evaluating a condition at subscription time in order to decide which of two streams to take.\nrst(O.if_then)\ncond = True\ndef should_run():\n return cond\nstreams = O.if_then(should_run, O.return_value(43), O.return_value(56))\nd = subs(streams)\n\nlog('condition will now evaluate falsy:')\ncond = False\nstreams = O.if_then(should_run, O.return_value(43), O.return_value(rand()))\nd = subs(streams)\nd = subs(streams)",
"\n\n========== if_then ==========\n\nmodule rx.linq.observable.ifthen\n@extensionclassmethod(Observable)\ndef if_then(cls, condition, then_source, else_source=None, scheduler=None):\n Determines whether an observable collection contains values.\n\n Example:\n 1 - res = reactivex.Observable.if(condition, obs1)\n 2 - res = reactivex.Observable.if(condition, obs1, obs2)\n 3 - res = reactivex.Observable.if(condition, obs1, scheduler=scheduler)\n\n Keyword parameters:\n condition -- {Function} The condition which determines if the\n then_source or else_source will be run.\n then_source -- {Observable} The observable sequence or Promise that\n will be run if the condition function returns true.\n else_source -- {Observable} [Optional] The observable sequence or\n Promise that will be run if the condition function returns False.\n If this is not provided, it defaults to reactivex.empty\n scheduler -- [Optional] Scheduler to use.\n\n Returns an observable {Observable} sequence which is either the\n then_source or else_source.\n--------------------------------------------------------------------------------\n\n 3.3 M New subscription on stream 274480673\n 3.6 M [next] 0.2: 43\n 3.8 M [cmpl] 0.5: fin\n 4.0 M condition will now evaluate falsy:\n\n 4.4 M New subscription on stream 274480817\n 4.6 M [next] 0.2: 52\n 4.7 M [cmpl] 0.3: fin\n\n 5.2 M New subscription on stream 274480817\n 5.6 M [next] 0.2: 52\n 5.8 M [cmpl] 0.4: fin\n"
]
],
[
[
"## ...that emits a sequence of integers: **[range](http://reactivex.io/documentation/operators/range.html) **",
"_____no_output_____"
]
],
[
[
"rst(O.range)\nd = subs(O.range(0, 3))",
"\n\n========== range ==========\n\nmodule rx.linq.observable.range\n@extensionclassmethod(Observable)\ndef range(cls, start, count, scheduler=None):\n Generates an observable sequence of integral numbers within a\n specified range, using the specified scheduler to send out observer\n messages.\n\n 1 - res = reactivex.Observable.range(0, 10)\n 2 - res = reactivex.Observable.range(0, 10, rx.Scheduler.timeout)\n\n Keyword arguments:\n start -- The value of the first integer in the sequence.\n count -- The number of sequential integers to generate.\n scheduler -- [Optional] Scheduler to run the generator loop on. If not\n specified, defaults to Scheduler.current_thread.\n\n Returns an observable sequence that contains a range of sequential\n integral numbers.\n--------------------------------------------------------------------------------\n\n 2.9 M New subscription on stream 274475905\n 3.7 M [next] 0.4: 0\n 4.3 M [next] 1.0: 1\n 4.6 M [next] 1.3: 2\n 4.9 M [cmpl] 1.6: fin\n"
]
],
[
[
"### ...at particular intervals of time: **[interval](http://reactivex.io/documentation/operators/interval.html) **\n\n(you can `.publish()` it to get an easy \"hot\" observable)",
"_____no_output_____"
]
],
[
[
"rst(O.interval)\nd = subs(O.interval(100).time_interval()\\\n .map(lambda x, v: '%(interval)s %(value)s' \\\n % ItemGetter(x)).take(3))",
"\n\n========== interval ==========\n\nmodule rx.linq.observable.interval\n@extensionclassmethod(Observable)\ndef interval(cls, period, scheduler=None):\n Returns an observable sequence that produces a value after each\n period.\n\n Example:\n 1 - res = reactivex.Observable.interval(1000)\n 2 - res = reactivex.Observable.interval(1000, rx.Scheduler.timeout)\n\n Keyword arguments:\n period -- Period for producing the values in the resulting sequence\n (specified as an integer denoting milliseconds).\n scheduler -- [Optional] Scheduler to run the timer on. If not specified,\n rx.Scheduler.timeout is used.\n\n Returns an observable sequence that produces a value after each period.\n--------------------------------------------------------------------------------\n\n 1.2 M New subscription (14365) on stream 276610125\n 102.3 T8 [next] 100.9: 0:00:00.100623 0 -> 14365\n 208.2 T9 [next] 206.9: 0:00:00.105960 1 -> 14365\n 310.8 T10 [next] 309.5: 0:00:00.102625 2 -> 14365\n 311.1 T10 [cmpl] 309.8: fin -> 14365\n"
]
],
[
[
"### ...after a specified delay (see timer)",
"_____no_output_____"
],
[
"## ...that completes without emitting items: **[empty](http://reactivex.io/documentation/operators/empty-never-throw.html) **",
"_____no_output_____"
]
],
[
[
"rst(O.empty)\nd = subs(O.empty())",
"\n\n========== empty ==========\n\nmodule rx.linq.observable.empty\n@extensionclassmethod(Observable)\ndef empty(cls, scheduler=None):\n Returns an empty observable sequence, using the specified scheduler\n to send out the single OnCompleted message.\n\n 1 - res = reactivex.empty()\n 2 - res = reactivex.empty(rx.Scheduler.timeout)\n\n scheduler -- Scheduler to send the termination call on.\n\n Returns an observable sequence with no elements.\n--------------------------------------------------------------------------------\n\n 2.9 M New subscription on stream 273460593\n 3.2 M [cmpl] 0.2: fin\n"
]
],
[
[
"## ...that does nothing at all: **[never](http://reactivex.io/documentation/operators/empty-never-throw.html) **",
"_____no_output_____"
]
],
[
[
"rst(O.never)\nd = subs(O.never())",
"\n\n========== never ==========\n\n 0.7 T18 [next] 104.4: 0 -1.0 (observer hash: 274473797)\n 1.1 T18 [next] 104.8: 1 -0.5 (observer hash: 274473797)module rx.linq.observable.never\n@extensionclassmethod(Observable)\ndef never(cls):\n Returns a non-terminating observable sequence, which can be used to\n denote an infinite duration (e.g. when using reactive joins).\n\n Returns an observable sequence whose observers will never get called.\n--------------------------------------------------------------------------------\n\n 2.0 T18 [next] 105.7: 2 -0.333333333333 (observer hash: 274473797)\n\n 2.1 T18 [cmpl] 105.9: fin 2.7 M New subscription on stream 274473849\n\n"
]
],
[
[
"## ...that excepts: **[throw](http://reactivex.io/documentation/operators/empty-never-throw.html) **",
"_____no_output_____"
]
],
[
[
"rst(O.on_error)\nd = subs(O.on_error(ZeroDivisionError))",
"\n\n========== throw ==========\n\nmodule rx.linq.observable.throw\n@extensionclassmethod(Observable, alias=\"throw_exception\")\ndef on_error(cls, exception, scheduler=None):\n Returns an observable sequence that terminates with an exception,\n using the specified scheduler to send out the single OnError message.\n\n 1 - res = reactivex.throw(Exception('Error'))\n 2 - res = reactivex.throw(Exception('Error'),\n rx.Scheduler.timeout)\n\n Keyword arguments:\n exception -- An object used for the sequence's termination.\n scheduler -- Scheduler to send the exceptional termination call on. If\n not specified, defaults to ImmediateScheduler.\n\n Returns the observable sequence that terminates exceptionally with the\n specified exception object.\n--------------------------------------------------------------------------------\n\n 1.8 M New subscription (23467) on stream 276521733\n 2.0 M [err ] 0.2: <type 'exceptions.ZeroDivisionError'> -> 23467\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
e73e1f49ed01569ba9919c20ab93085265922af6 | 754,120 | ipynb | Jupyter Notebook | networkx.ipynb | sierraone/GettingStarted | 44b5a7b2ab6de4571cfd3aaccc58abcc96e48d09 | [
"Apache-2.0"
] | null | null | null | networkx.ipynb | sierraone/GettingStarted | 44b5a7b2ab6de4571cfd3aaccc58abcc96e48d09 | [
"Apache-2.0"
] | 1 | 2020-09-11T15:12:38.000Z | 2020-09-11T22:11:13.000Z | networkx.ipynb | sierraone/GettingStarted | 44b5a7b2ab6de4571cfd3aaccc58abcc96e48d09 | [
"Apache-2.0"
] | 5 | 2020-09-02T19:54:24.000Z | 2021-08-14T23:18:44.000Z | 1,113.914328 | 209,552 | 0.745961 | [
[
[
"import networkx as nx\nimport osmnx as ox\nimport random\nimport itertools",
"_____no_output_____"
]
],
[
[
"`networkx` supports a lot of graph types: simple graph, simple digraph (parallel edges are not acceptable), multidigraph, multigraphs. Read more [here](https://networkx.github.io/documentation/stable/reference/classes/index.html).",
"_____no_output_____"
],
[
"For sure, we want to use multidigraph to handle our maps",
"_____no_output_____"
]
],
[
[
"G = nx.MultiDiGraph()",
"_____no_output_____"
],
[
"# add arbitrary nodes\nnodes = [i for i in range(1,20)]",
"_____no_output_____"
],
[
"G.add_nodes_from(nodes)",
"_____no_output_____"
],
[
"num_edges = 70\nfor _ in range(num_edges):\n u = random.randint(1, 101)\n v = random.randint(1,101)\n G.add_edge(u, v, weight = 5)",
"_____no_output_____"
],
[
"nx.draw(G)",
"_____no_output_____"
]
],
[
[
"One thing that you have probably noticed that the graph that was returned by `osmnx` in the first tutorial could be dealt with as if it was a pure vanilla `networkx` graph.",
"_____no_output_____"
],
[
"That is a very good news for us, because we can use [`networkx` utilities and algorithms](https://networkx.github.io/documentation/stable/reference/algorithms/index.html) to do calculation. ",
"_____no_output_____"
],
[
"We will show a couple of algorithms on `G` graph and then download an actual map and play with it a little bit.",
"_____no_output_____"
]
],
[
[
"nx.number_strongly_connected_components(G)",
"_____no_output_____"
],
[
"# we will take the first 10 simple cycles\nfor cycle in itertools.islice(nx.simple_cycles(G), 10):\n print(cycle)",
"[5]\n[57]\n[30]\n[26]\n[67]\n[1, 53, 2, 76, 23, 89, 55, 16, 6]\n[1, 53, 2, 76, 23, 89, 55, 16, 6, 54, 70, 52, 101, 99, 97, 7, 51, 73]\n[1, 53, 2, 76, 23, 89, 55, 16, 6, 54, 70, 52, 101, 99, 97, 7, 51, 73, 83, 44, 10, 31, 85, 36, 39, 74, 82, 87, 93, 43, 11, 98, 13, 60, 40, 49, 58, 22, 91, 100, 92, 47, 24, 14, 20, 4, 78, 33, 75, 96, 32, 37, 57, 79, 8, 88, 65, 45, 35, 59, 86, 80, 46, 9]\n[1, 53, 2, 76, 23, 89, 55, 16, 6, 54, 70, 52, 101, 99, 97, 7, 51, 73, 83, 44, 10, 31, 85, 36, 39, 74, 82, 87, 93, 43, 11, 98, 13, 60, 40, 49, 58, 22, 91, 100, 92, 47, 24, 14, 20, 4, 78, 33, 75, 96, 32, 37, 57, 79, 8, 88, 65, 45, 35, 59, 86, 80, 46, 9, 29, 50, 42, 63, 66, 95, 81, 41, 56, 90]\n[1, 53, 2, 76, 23, 89, 55, 16, 6, 54, 70, 52, 101, 99, 97, 7, 51, 73, 83, 44, 10, 31, 85, 36, 39, 74, 82, 87, 93, 43, 11, 98, 13, 60, 40, 49, 58, 22, 91, 100, 92, 47, 24, 14, 20, 4, 78, 33, 75, 96, 32, 37, 57, 79, 8, 88, 65, 45, 35, 59, 86, 80, 46, 9, 29, 50, 42, 63, 66, 95, 81, 41, 56, 77, 21]\n"
],
[
"# it returns an iterators so we unpack it\nprint(*nx.all_pairs_shortest_path(G))",
"(1, {1: [1], 16: [1, 16], 70: [1, 70], 79: [1, 79], 69: [1, 69], 53: [1, 53], 48: [1, 16, 48], 56: [1, 16, 56], 9: [1, 16, 9], 81: [1, 16, 81], 4: [1, 16, 4], 6: [1, 16, 6], 37: [1, 70, 37], 84: [1, 70, 84], 64: [1, 70, 64], 52: [1, 70, 52], 3: [1, 79, 3], 8: [1, 79, 8], 22: [1, 79, 22], 93: [1, 69, 93], 46: [1, 69, 46], 25: [1, 69, 25], 26: [1, 69, 26], 86: [1, 53, 86], 45: [1, 53, 45], 55: [1, 53, 55], 2: [1, 53, 2], 7: [1, 16, 48, 7], 36: [1, 16, 48, 36], 5: [1, 16, 48, 5], 101: [1, 16, 48, 101], 99: [1, 16, 48, 99], 77: [1, 16, 56, 77], 10: [1, 16, 56, 10], 90: [1, 16, 56, 90], 58: [1, 16, 56, 58], 85: [1, 16, 9, 85], 50: [1, 16, 9, 50], 94: [1, 16, 9, 94], 31: [1, 16, 9, 31], 98: [1, 16, 9, 98], 75: [1, 16, 9, 75], 29: [1, 16, 9, 29], 74: [1, 16, 9, 74], 61: [1, 16, 81, 61], 30: [1, 16, 81, 30], 42: [1, 16, 81, 42], 68: [1, 16, 81, 68], 41: [1, 16, 81, 41], 28: [1, 16, 81, 28], 40: [1, 16, 81, 40], 78: [1, 16, 4, 78], 23: [1, 16, 4, 23], 83: [1, 16, 4, 83], 57: [1, 16, 6, 57], 54: [1, 16, 6, 54], 32: [1, 70, 84, 32], 13: [1, 70, 84, 13], 14: [1, 70, 84, 14], 73: [1, 70, 64, 73], 89: [1, 70, 64, 89], 82: [1, 70, 64, 82], 65: [1, 70, 64, 65], 15: [1, 70, 64, 15], 39: [1, 70, 64, 39], 96: [1, 70, 64, 96], 35: [1, 70, 64, 35], 72: [1, 79, 3, 72], 62: [1, 79, 3, 62], 44: [1, 79, 3, 44], 88: [1, 79, 8, 88], 43: [1, 79, 22, 43], 59: [1, 79, 22, 59], 91: [1, 79, 22, 91], 97: [1, 79, 22, 97], 34: [1, 69, 93, 34], 71: [1, 69, 93, 71], 18: [1, 69, 46, 18], 12: [1, 69, 46, 12], 51: [1, 69, 46, 51], 87: [1, 69, 25, 87], 67: [1, 69, 25, 67], 66: [1, 69, 25, 66], 17: [1, 53, 86, 17], 80: [1, 53, 86, 80], 60: [1, 53, 2, 60], 76: [1, 53, 2, 76], 49: [1, 16, 48, 36, 49], 19: [1, 16, 48, 36, 19], 21: [1, 16, 48, 101, 21], 100: [1, 16, 56, 90, 100], 24: [1, 16, 9, 94, 24], 33: [1, 16, 9, 31, 33], 47: [1, 16, 9, 98, 47], 38: [1, 16, 9, 98, 38], 92: [1, 16, 81, 61, 92], 63: [1, 16, 81, 42, 63], 20: [1, 16, 81, 41, 20], 11: [1, 16, 6, 54, 11], 95: [1, 79, 8, 88, 95], 27: [1, 79, 22, 43, 27]}) (2, {2: [2], 51: [2, 51], 60: [2, 60], 56: [2, 56], 40: [2, 40], 76: [2, 76], 49: [2, 51, 49], 100: [2, 51, 100], 73: [2, 51, 73], 41: [2, 60, 41], 89: [2, 60, 89], 79: [2, 60, 79], 18: [2, 60, 18], 62: [2, 60, 62], 99: [2, 60, 99], 93: [2, 60, 93], 77: [2, 56, 77], 10: [2, 56, 10], 90: [2, 56, 90], 58: [2, 56, 58], 9: [2, 40, 9], 91: [2, 40, 91], 38: [2, 40, 38], 96: [2, 40, 96], 30: [2, 40, 30], 45: [2, 76, 45], 32: [2, 76, 32], 47: [2, 76, 47], 7: [2, 76, 7], 33: [2, 76, 33], 23: [2, 76, 23], 28: [2, 51, 49, 28], 31: [2, 51, 49, 31], 83: [2, 51, 49, 83], 95: [2, 51, 49, 95], 5: [2, 51, 49, 5], 36: [2, 51, 100, 36], 21: [2, 51, 100, 21], 69: [2, 51, 100, 69], 92: [2, 51, 100, 92], 71: [2, 51, 73, 71], 6: [2, 51, 73, 6], 1: [2, 51, 73, 1], 19: [2, 60, 41, 19], 94: [2, 60, 41, 94], 20: [2, 60, 41, 20], 82: [2, 60, 41, 82], 57: [2, 60, 89, 57], 55: [2, 60, 89, 55], 3: [2, 60, 79, 3], 8: [2, 60, 79, 8], 22: [2, 60, 79, 22], 37: [2, 60, 79, 37], 98: [2, 60, 18, 98], 86: [2, 60, 18, 86], 42: [2, 60, 62, 42], 74: [2, 60, 62, 74], 4: [2, 60, 62, 4], 80: [2, 60, 62, 80], 44: [2, 60, 62, 44], 50: [2, 60, 99, 50], 97: [2, 60, 99, 97], 34: [2, 60, 93, 34], 39: [2, 60, 93, 39], 43: [2, 60, 93, 43], 29: [2, 56, 77, 29], 70: [2, 56, 77, 70], 15: [2, 56, 77, 15], 101: [2, 56, 77, 101], 48: [2, 56, 10, 48], 46: [2, 56, 10, 46], 59: [2, 56, 90, 59], 26: [2, 56, 58, 26], 87: [2, 56, 58, 87], 17: [2, 56, 58, 17], 85: [2, 40, 9, 85], 75: [2, 40, 9, 75], 12: [2, 40, 91, 12], 64: [2, 40, 91, 64], 78: [2, 40, 38, 78], 66: [2, 40, 38, 66], 35: [2, 76, 45, 35], 13: [2, 76, 47, 13], 24: [2, 76, 47, 24], 61: [2, 76, 33, 61], 67: [2, 51, 49, 28, 67], 88: [2, 51, 49, 31, 88], 52: [2, 51, 49, 83, 52], 81: [2, 51, 49, 95, 81], 11: [2, 51, 100, 21, 11], 25: [2, 51, 100, 69, 25], 54: [2, 51, 73, 6, 54], 16: [2, 51, 73, 1, 16], 53: [2, 51, 73, 1, 53], 63: [2, 60, 41, 19, 63], 68: [2, 60, 41, 19, 68], 84: [2, 60, 41, 20, 84], 14: [2, 60, 41, 82, 14], 72: [2, 60, 79, 3, 72], 27: [2, 60, 93, 43, 27], 65: [2, 56, 90, 59, 65]}) (3, {3: [3], 72: [3, 72], 62: [3, 62], 44: [3, 44], 85: [3, 85], 54: [3, 54], 17: [3, 72, 17], 36: [3, 72, 36], 29: [3, 72, 29], 98: [3, 72, 98], 6: [3, 72, 6], 76: [3, 72, 76], 18: [3, 72, 18], 42: [3, 62, 42], 86: [3, 62, 86], 74: [3, 62, 74], 4: [3, 62, 4], 96: [3, 62, 96], 80: [3, 62, 80], 92: [3, 44, 92], 51: [3, 44, 51], 56: [3, 44, 56], 11: [3, 44, 11], 94: [3, 44, 94], 10: [3, 44, 10], 73: [3, 85, 73], 1: [3, 85, 1], 25: [3, 85, 25], 5: [3, 85, 5], 71: [3, 54, 71], 43: [3, 54, 43], 16: [3, 54, 16], 9: [3, 54, 9], 70: [3, 54, 70], 84: [3, 72, 17, 84], 8: [3, 72, 36, 8], 26: [3, 72, 36, 26], 46: [3, 72, 36, 46], 52: [3, 72, 36, 52], 49: [3, 72, 36, 49], 23: [3, 72, 36, 23], 19: [3, 72, 36, 19], 39: [3, 72, 36, 39], 21: [3, 72, 29, 21], 50: [3, 72, 29, 50], 59: [3, 72, 29, 59], 47: [3, 72, 98, 47], 97: [3, 72, 98, 97], 88: [3, 72, 98, 88], 32: [3, 72, 98, 32], 38: [3, 72, 98, 38], 90: [3, 72, 98, 90], 13: [3, 72, 98, 13], 57: [3, 72, 6, 57], 40: [3, 72, 76, 40], 45: [3, 72, 76, 45], 7: [3, 72, 76, 7], 33: [3, 72, 76, 33], 60: [3, 72, 76, 60], 95: [3, 72, 18, 95], 91: [3, 62, 42, 91], 24: [3, 62, 42, 24], 63: [3, 62, 42, 63], 22: [3, 62, 74, 22], 87: [3, 62, 74, 87], 82: [3, 62, 74, 82], 53: [3, 62, 74, 53], 78: [3, 62, 4, 78], 83: [3, 62, 4, 83], 89: [3, 62, 96, 89], 20: [3, 62, 96, 20], 34: [3, 44, 92, 34], 100: [3, 44, 51, 100], 77: [3, 44, 56, 77], 58: [3, 44, 56, 58], 101: [3, 44, 94, 101], 48: [3, 44, 10, 48], 31: [3, 44, 10, 31], 79: [3, 85, 1, 79], 69: [3, 85, 1, 69], 67: [3, 85, 25, 67], 66: [3, 85, 25, 66], 55: [3, 85, 5, 55], 41: [3, 85, 5, 41], 37: [3, 54, 71, 37], 27: [3, 54, 43, 27], 81: [3, 54, 16, 81], 75: [3, 54, 9, 75], 64: [3, 54, 70, 64], 14: [3, 72, 17, 84, 14], 12: [3, 72, 36, 46, 12], 28: [3, 72, 36, 52, 28], 30: [3, 72, 36, 49, 30], 68: [3, 72, 36, 19, 68], 2: [3, 72, 29, 50, 2], 65: [3, 72, 29, 59, 65], 15: [3, 72, 98, 47, 15], 93: [3, 72, 98, 32, 93], 35: [3, 72, 76, 45, 35], 61: [3, 72, 76, 33, 61], 99: [3, 72, 76, 60, 99]}) (4, {4: [4], 53: [4, 53], 78: [4, 78], 23: [4, 23], 83: [4, 83], 69: [4, 53, 69], 86: [4, 53, 86], 45: [4, 53, 45], 55: [4, 53, 55], 2: [4, 53, 2], 31: [4, 78, 31], 59: [4, 78, 59], 13: [4, 78, 13], 12: [4, 78, 12], 81: [4, 78, 81], 33: [4, 78, 33], 101: [4, 23, 101], 89: [4, 23, 89], 52: [4, 83, 52], 43: [4, 83, 43], 93: [4, 83, 93], 44: [4, 83, 44], 22: [4, 53, 69, 22], 8: [4, 53, 69, 8], 46: [4, 53, 69, 46], 25: [4, 53, 69, 25], 26: [4, 53, 69, 26], 18: [4, 53, 86, 18], 17: [4, 53, 86, 17], 6: [4, 53, 86, 6], 80: [4, 53, 86, 80], 16: [4, 53, 86, 16], 70: [4, 53, 45, 70], 34: [4, 53, 45, 34], 35: [4, 53, 45, 35], 85: [4, 53, 45, 85], 29: [4, 53, 55, 29], 42: [4, 53, 55, 42], 51: [4, 53, 2, 51], 60: [4, 53, 2, 60], 56: [4, 53, 2, 56], 40: [4, 53, 2, 40], 76: [4, 53, 2, 76], 48: [4, 78, 31, 48], 88: [4, 78, 31, 88], 91: [4, 78, 31, 91], 96: [4, 78, 59, 96], 62: [4, 78, 59, 62], 11: [4, 78, 59, 11], 97: [4, 78, 59, 97], 36: [4, 78, 59, 36], 65: [4, 78, 59, 65], 14: [4, 78, 13, 14], 30: [4, 78, 13, 30], 27: [4, 78, 12, 27], 68: [4, 78, 12, 68], 3: [4, 78, 81, 3], 61: [4, 78, 81, 61], 41: [4, 78, 81, 41], 58: [4, 78, 81, 58], 28: [4, 78, 81, 28], 73: [4, 78, 33, 73], 71: [4, 78, 33, 71], 75: [4, 78, 33, 75], 94: [4, 23, 101, 94], 21: [4, 23, 101, 21], 99: [4, 23, 101, 99], 57: [4, 23, 89, 57], 1: [4, 83, 52, 1], 39: [4, 83, 52, 39], 74: [4, 83, 43, 74], 47: [4, 83, 43, 47], 63: [4, 83, 43, 63], 72: [4, 83, 44, 72], 92: [4, 83, 44, 92], 10: [4, 83, 44, 10], 9: [4, 53, 69, 46, 9], 84: [4, 53, 69, 25, 84], 87: [4, 53, 69, 25, 87], 67: [4, 53, 69, 25, 67], 32: [4, 53, 69, 25, 32], 66: [4, 53, 69, 25, 66], 98: [4, 53, 69, 26, 98], 95: [4, 53, 86, 18, 95], 49: [4, 53, 86, 18, 49], 54: [4, 53, 86, 6, 54], 79: [4, 53, 86, 16, 79], 37: [4, 53, 45, 70, 37], 64: [4, 53, 45, 70, 64], 20: [4, 53, 45, 34, 20], 38: [4, 53, 45, 34, 38], 5: [4, 53, 45, 85, 5], 19: [4, 53, 55, 29, 19], 50: [4, 53, 55, 29, 50], 24: [4, 53, 55, 42, 24], 90: [4, 53, 55, 42, 90], 100: [4, 53, 2, 51, 100], 77: [4, 53, 2, 56, 77], 7: [4, 53, 2, 76, 7], 15: [4, 78, 59, 65, 15], 82: [4, 78, 13, 14, 82]}) (5, {5: [5], 9: [5, 9], 55: [5, 55], 41: [5, 41], 85: [5, 9, 85], 50: [5, 9, 50], 94: [5, 9, 94], 31: [5, 9, 31], 98: [5, 9, 98], 75: [5, 9, 75], 29: [5, 9, 29], 1: [5, 9, 1], 74: [5, 9, 74], 35: [5, 55, 35], 42: [5, 55, 42], 16: [5, 55, 16], 19: [5, 41, 19], 96: [5, 41, 96], 20: [5, 41, 20], 21: [5, 41, 21], 56: [5, 41, 56], 83: [5, 41, 83], 82: [5, 41, 82], 73: [5, 9, 85, 73], 25: [5, 9, 85, 25], 36: [5, 9, 85, 36], 2: [5, 9, 50, 2], 88: [5, 9, 50, 88], 22: [5, 9, 50, 22], 54: [5, 9, 50, 54], 52: [5, 9, 50, 52], 62: [5, 9, 94, 62], 57: [5, 9, 94, 57], 101: [5, 9, 94, 101], 46: [5, 9, 94, 46], 24: [5, 9, 94, 24], 12: [5, 9, 31, 12], 48: [5, 9, 31, 48], 91: [5, 9, 31, 91], 33: [5, 9, 31, 33], 47: [5, 9, 98, 47], 97: [5, 9, 98, 97], 32: [5, 9, 98, 32], 38: [5, 9, 98, 38], 90: [5, 9, 98, 90], 13: [5, 9, 98, 13], 81: [5, 9, 75, 81], 67: [5, 9, 75, 67], 40: [5, 9, 75, 40], 4: [5, 9, 29, 4], 43: [5, 9, 29, 43], 59: [5, 9, 29, 59], 70: [5, 9, 1, 70], 79: [5, 9, 1, 79], 69: [5, 9, 1, 69], 53: [5, 9, 1, 53], 51: [5, 9, 74, 51], 87: [5, 9, 74, 87], 49: [5, 55, 35, 49], 37: [5, 55, 35, 37], 3: [5, 55, 42, 3], 44: [5, 55, 42, 44], 63: [5, 55, 42, 63], 6: [5, 55, 16, 6], 68: [5, 41, 19, 68], 92: [5, 41, 19, 92], 89: [5, 41, 96, 89], 84: [5, 41, 20, 84], 99: [5, 41, 20, 99], 58: [5, 41, 20, 58], 30: [5, 41, 20, 30], 86: [5, 41, 20, 86], 11: [5, 41, 21, 11], 77: [5, 41, 56, 77], 10: [5, 41, 56, 10], 45: [5, 41, 83, 45], 93: [5, 41, 83, 93], 14: [5, 41, 82, 14], 71: [5, 9, 85, 73, 71], 26: [5, 9, 85, 25, 26], 66: [5, 9, 85, 25, 66], 8: [5, 9, 85, 36, 8], 23: [5, 9, 85, 36, 23], 39: [5, 9, 85, 36, 39], 60: [5, 9, 50, 2, 60], 76: [5, 9, 50, 2, 76], 64: [5, 9, 50, 88, 64], 95: [5, 9, 50, 88, 95], 65: [5, 9, 50, 88, 65], 72: [5, 9, 50, 22, 72], 28: [5, 9, 50, 52, 28], 80: [5, 9, 94, 62, 80], 18: [5, 9, 94, 46, 18], 34: [5, 9, 94, 24, 34], 78: [5, 9, 94, 24, 78], 27: [5, 9, 31, 12, 27], 7: [5, 9, 31, 48, 7], 100: [5, 9, 31, 91, 100], 61: [5, 9, 31, 33, 61], 15: [5, 9, 98, 47, 15], 17: [5, 41, 20, 58, 17]}) (6, {6: [6], 57: [6, 57], 54: [6, 54], 1: [6, 1], 24: [6, 57, 24], 52: [6, 57, 52], 39: [6, 57, 39], 101: [6, 57, 101], 16: [6, 57, 16], 69: [6, 57, 69], 40: [6, 57, 40], 12: [6, 57, 12], 79: [6, 57, 79], 70: [6, 57, 70], 71: [6, 54, 71], 43: [6, 54, 43], 11: [6, 54, 11], 9: [6, 54, 9], 53: [6, 1, 53], 90: [6, 57, 24, 90], 25: [6, 57, 24, 25], 34: [6, 57, 24, 34], 66: [6, 57, 24, 66], 74: [6, 57, 24, 74], 41: [6, 57, 24, 41], 68: [6, 57, 24, 68], 96: [6, 57, 24, 96], 78: [6, 57, 24, 78], 26: [6, 57, 24, 26], 14: [6, 57, 24, 14], 23: [6, 57, 52, 23], 28: [6, 57, 52, 28], 59: [6, 57, 39, 59], 42: [6, 57, 39, 42], 33: [6, 57, 39, 33], 13: [6, 57, 39, 13], 94: [6, 57, 101, 94], 73: [6, 57, 101, 73], 21: [6, 57, 101, 21], 8: [6, 57, 101, 8], 99: [6, 57, 101, 99], 48: [6, 57, 16, 48], 56: [6, 57, 16, 56], 81: [6, 57, 16, 81], 4: [6, 57, 16, 4], 22: [6, 57, 69, 22], 93: [6, 57, 69, 93], 46: [6, 57, 69, 46], 91: [6, 57, 40, 91], 38: [6, 57, 40, 38], 30: [6, 57, 40, 30], 49: [6, 57, 40, 49], 27: [6, 57, 12, 27], 44: [6, 57, 12, 44], 3: [6, 57, 79, 3], 37: [6, 57, 79, 37], 84: [6, 57, 70, 84], 64: [6, 57, 70, 64], 10: [6, 54, 71, 10], 50: [6, 54, 71, 50], 20: [6, 54, 71, 20], 7: [6, 54, 71, 7], 95: [6, 54, 71, 95], 47: [6, 54, 43, 47], 63: [6, 54, 43, 63], 31: [6, 54, 43, 31], 80: [6, 54, 11, 80], 98: [6, 54, 11, 98], 85: [6, 54, 9, 85], 75: [6, 54, 9, 75], 29: [6, 54, 9, 29], 86: [6, 1, 53, 86], 45: [6, 1, 53, 45], 55: [6, 1, 53, 55], 2: [6, 1, 53, 2], 100: [6, 57, 24, 90, 100], 87: [6, 57, 24, 25, 87], 67: [6, 57, 24, 25, 67], 32: [6, 57, 24, 25, 32], 18: [6, 57, 24, 34, 18], 61: [6, 57, 24, 66, 61], 60: [6, 57, 24, 66, 60], 62: [6, 57, 24, 74, 62], 51: [6, 57, 24, 74, 51], 82: [6, 57, 24, 74, 82], 19: [6, 57, 24, 41, 19], 83: [6, 57, 24, 41, 83], 89: [6, 57, 24, 96, 89], 97: [6, 57, 39, 59, 97], 36: [6, 57, 39, 59, 36], 65: [6, 57, 39, 59, 65], 77: [6, 57, 101, 73, 77], 5: [6, 57, 101, 21, 5], 88: [6, 57, 101, 8, 88], 58: [6, 57, 16, 56, 58], 72: [6, 57, 69, 22, 72], 92: [6, 57, 12, 44, 92], 15: [6, 57, 70, 64, 15], 35: [6, 57, 70, 64, 35], 17: [6, 1, 53, 86, 17], 76: [6, 1, 53, 2, 76]}) (7, {7: [7], 51: [7, 51], 49: [7, 51, 49], 100: [7, 51, 100], 73: [7, 51, 73], 28: [7, 51, 49, 28], 40: [7, 51, 49, 40], 30: [7, 51, 49, 30], 31: [7, 51, 49, 31], 83: [7, 51, 49, 83], 95: [7, 51, 49, 95], 10: [7, 51, 49, 10], 5: [7, 51, 49, 5], 58: [7, 51, 49, 58], 47: [7, 51, 100, 47], 36: [7, 51, 100, 36], 21: [7, 51, 100, 21], 69: [7, 51, 100, 69], 92: [7, 51, 100, 92], 71: [7, 51, 73, 71], 6: [7, 51, 73, 6], 77: [7, 51, 73, 77], 1: [7, 51, 73, 1], 62: [7, 51, 49, 28, 62], 37: [7, 51, 49, 28, 37], 80: [7, 51, 49, 28, 80], 67: [7, 51, 49, 28, 67], 32: [7, 51, 49, 28, 32], 74: [7, 51, 49, 28, 74], 9: [7, 51, 49, 40, 9], 91: [7, 51, 49, 40, 91], 38: [7, 51, 49, 40, 38], 96: [7, 51, 49, 40, 96], 12: [7, 51, 49, 31, 12], 48: [7, 51, 49, 31, 48], 88: [7, 51, 49, 31, 88], 33: [7, 51, 49, 31, 33], 85: [7, 51, 49, 31, 85], 89: [7, 51, 49, 83, 89], 45: [7, 51, 49, 83, 45], 52: [7, 51, 49, 83, 52], 43: [7, 51, 49, 83, 43], 93: [7, 51, 49, 83, 93], 44: [7, 51, 49, 83, 44], 34: [7, 51, 49, 95, 34], 20: [7, 51, 49, 95, 20], 46: [7, 51, 49, 95, 46], 81: [7, 51, 49, 95, 81], 3: [7, 51, 49, 10, 3], 55: [7, 51, 49, 5, 55], 41: [7, 51, 49, 5, 41], 26: [7, 51, 49, 58, 26], 87: [7, 51, 49, 58, 87], 17: [7, 51, 49, 58, 17], 22: [7, 51, 49, 58, 22], 15: [7, 51, 100, 47, 15], 13: [7, 51, 100, 47, 13], 29: [7, 51, 100, 47, 29], 98: [7, 51, 100, 47, 98], 19: [7, 51, 100, 47, 19], 24: [7, 51, 100, 47, 24], 2: [7, 51, 100, 47, 2], 8: [7, 51, 100, 36, 8], 23: [7, 51, 100, 36, 23], 39: [7, 51, 100, 36, 39], 11: [7, 51, 100, 21, 11], 82: [7, 51, 100, 21, 82], 25: [7, 51, 100, 69, 25], 50: [7, 51, 73, 71, 50], 57: [7, 51, 73, 6, 57], 54: [7, 51, 73, 6, 54], 4: [7, 51, 73, 77, 4], 56: [7, 51, 73, 77, 56], 70: [7, 51, 73, 77, 70], 101: [7, 51, 73, 77, 101], 16: [7, 51, 73, 1, 16], 79: [7, 51, 73, 1, 79], 53: [7, 51, 73, 1, 53], 42: [7, 51, 49, 28, 62, 42], 86: [7, 51, 49, 28, 62, 86], 59: [7, 51, 49, 28, 74, 59], 94: [7, 51, 49, 40, 9, 94], 75: [7, 51, 49, 40, 9, 75], 99: [7, 51, 49, 40, 91, 99], 64: [7, 51, 49, 40, 91, 64], 78: [7, 51, 49, 40, 38, 78], 66: [7, 51, 49, 40, 38, 66], 27: [7, 51, 49, 31, 12, 27], 68: [7, 51, 49, 31, 12, 68], 65: [7, 51, 49, 31, 88, 65], 61: [7, 51, 49, 31, 33, 61], 35: [7, 51, 49, 83, 45, 35], 63: [7, 51, 49, 83, 43, 63], 72: [7, 51, 49, 83, 44, 72], 18: [7, 51, 49, 95, 34, 18], 84: [7, 51, 49, 95, 20, 84], 60: [7, 51, 49, 58, 87, 60], 97: [7, 51, 49, 58, 22, 97], 14: [7, 51, 100, 47, 13, 14], 90: [7, 51, 100, 47, 98, 90], 76: [7, 51, 100, 47, 2, 76]}) (8, {8: [8], 88: [8, 88], 101: [8, 101], 81: [8, 88, 81], 64: [8, 88, 64], 95: [8, 88, 95], 65: [8, 88, 65], 40: [8, 88, 40], 39: [8, 88, 39], 94: [8, 101, 94], 25: [8, 101, 25], 73: [8, 101, 73], 21: [8, 101, 21], 96: [8, 101, 96], 99: [8, 101, 99], 3: [8, 88, 81, 3], 61: [8, 88, 81, 61], 55: [8, 88, 81, 55], 30: [8, 88, 81, 30], 42: [8, 88, 81, 42], 68: [8, 88, 81, 68], 41: [8, 88, 81, 41], 58: [8, 88, 81, 58], 28: [8, 88, 81, 28], 89: [8, 88, 64, 89], 82: [8, 88, 64, 82], 4: [8, 88, 64, 4], 15: [8, 88, 64, 15], 35: [8, 88, 64, 35], 22: [8, 88, 64, 22], 34: [8, 88, 95, 34], 31: [8, 88, 95, 31], 49: [8, 88, 95, 49], 20: [8, 88, 95, 20], 46: [8, 88, 95, 46], 86: [8, 88, 65, 86], 45: [8, 88, 65, 45], 9: [8, 88, 40, 9], 91: [8, 88, 40, 91], 38: [8, 88, 40, 38], 59: [8, 88, 39, 59], 33: [8, 88, 39, 33], 13: [8, 88, 39, 13], 74: [8, 88, 39, 74], 62: [8, 101, 94, 62], 57: [8, 101, 94, 57], 24: [8, 101, 94, 24], 84: [8, 101, 25, 84], 26: [8, 101, 25, 26], 87: [8, 101, 25, 87], 67: [8, 101, 25, 67], 32: [8, 101, 25, 32], 56: [8, 101, 25, 56], 66: [8, 101, 25, 66], 71: [8, 101, 73, 71], 6: [8, 101, 73, 6], 77: [8, 101, 73, 77], 83: [8, 101, 73, 83], 1: [8, 101, 73, 1], 11: [8, 101, 21, 11], 5: [8, 101, 21, 5], 85: [8, 101, 21, 85], 19: [8, 101, 99, 19], 18: [8, 101, 99, 18], 50: [8, 101, 99, 50], 97: [8, 101, 99, 97], 72: [8, 88, 81, 3, 72], 44: [8, 88, 81, 3, 44], 54: [8, 88, 81, 3, 54], 92: [8, 88, 81, 61, 92], 100: [8, 88, 81, 61, 100], 29: [8, 88, 81, 55, 29], 16: [8, 88, 81, 55, 16], 80: [8, 88, 81, 30, 80], 90: [8, 88, 81, 42, 90], 63: [8, 88, 81, 42, 63], 93: [8, 88, 81, 58, 93], 17: [8, 88, 81, 58, 17], 37: [8, 88, 81, 28, 37], 51: [8, 88, 64, 82, 51], 14: [8, 88, 64, 82, 14], 53: [8, 88, 64, 4, 53], 78: [8, 88, 64, 4, 78], 23: [8, 88, 64, 4, 23], 47: [8, 88, 64, 15, 47], 36: [8, 88, 64, 35, 36], 43: [8, 88, 64, 22, 43], 75: [8, 88, 95, 34, 75], 12: [8, 88, 95, 31, 12], 48: [8, 88, 95, 31, 48], 10: [8, 88, 95, 49, 10], 70: [8, 88, 65, 45, 70], 98: [8, 88, 40, 9, 98], 7: [8, 88, 40, 91, 7], 60: [8, 88, 39, 13, 60], 52: [8, 101, 94, 57, 52], 69: [8, 101, 94, 57, 69], 79: [8, 101, 94, 57, 79], 2: [8, 101, 99, 50, 2], 76: [8, 88, 81, 3, 72, 76], 27: [8, 88, 64, 22, 43, 27]}) (9, {9: [9], 85: [9, 85], 50: [9, 50], 94: [9, 94], 31: [9, 31], 98: [9, 98], 75: [9, 75], 29: [9, 29], 1: [9, 1], 74: [9, 74], 73: [9, 85, 73], 25: [9, 85, 25], 5: [9, 85, 5], 36: [9, 85, 36], 2: [9, 50, 2], 19: [9, 50, 19], 88: [9, 50, 88], 22: [9, 50, 22], 54: [9, 50, 54], 52: [9, 50, 52], 42: [9, 50, 42], 62: [9, 94, 62], 57: [9, 94, 57], 101: [9, 94, 101], 46: [9, 94, 46], 24: [9, 94, 24], 12: [9, 31, 12], 48: [9, 31, 48], 83: [9, 31, 83], 91: [9, 31, 91], 33: [9, 31, 33], 47: [9, 98, 47], 97: [9, 98, 97], 32: [9, 98, 32], 38: [9, 98, 38], 90: [9, 98, 90], 13: [9, 98, 13], 81: [9, 75, 81], 67: [9, 75, 67], 40: [9, 75, 40], 96: [9, 75, 96], 4: [9, 29, 4], 21: [9, 29, 21], 43: [9, 29, 43], 59: [9, 29, 59], 16: [9, 1, 16], 70: [9, 1, 70], 79: [9, 1, 79], 69: [9, 1, 69], 53: [9, 1, 53], 51: [9, 74, 51], 87: [9, 74, 87], 82: [9, 74, 82], 71: [9, 85, 73, 71], 6: [9, 85, 73, 6], 77: [9, 85, 73, 77], 84: [9, 85, 25, 84], 26: [9, 85, 25, 26], 56: [9, 85, 25, 56], 66: [9, 85, 25, 66], 55: [9, 85, 5, 55], 41: [9, 85, 5, 41], 8: [9, 85, 36, 8], 49: [9, 85, 36, 49], 23: [9, 85, 36, 23], 39: [9, 85, 36, 39], 60: [9, 50, 2, 60], 76: [9, 50, 2, 76], 63: [9, 50, 19, 63], 68: [9, 50, 19, 68], 92: [9, 50, 19, 92], 64: [9, 50, 88, 64], 95: [9, 50, 88, 95], 65: [9, 50, 88, 65], 72: [9, 50, 22, 72], 93: [9, 50, 22, 93], 11: [9, 50, 54, 11], 28: [9, 50, 52, 28], 3: [9, 50, 42, 3], 44: [9, 50, 42, 44], 86: [9, 94, 62, 86], 80: [9, 94, 62, 80], 99: [9, 94, 101, 99], 18: [9, 94, 46, 18], 58: [9, 94, 46, 58], 34: [9, 94, 24, 34], 78: [9, 94, 24, 78], 14: [9, 94, 24, 14], 27: [9, 31, 12, 27], 7: [9, 31, 48, 7], 89: [9, 31, 83, 89], 45: [9, 31, 83, 45], 100: [9, 31, 91, 100], 61: [9, 31, 33, 61], 15: [9, 98, 47, 15], 37: [9, 98, 32, 37], 10: [9, 98, 90, 10], 30: [9, 98, 13, 30], 20: [9, 75, 96, 20], 35: [9, 85, 5, 55, 35], 17: [9, 50, 22, 72, 17]}) (10, {10: [10], 48: [10, 48], 46: [10, 46], 3: [10, 3], 31: [10, 31], 7: [10, 48, 7], 36: [10, 48, 36], 5: [10, 48, 5], 101: [10, 48, 101], 99: [10, 48, 99], 18: [10, 46, 18], 12: [10, 46, 12], 58: [10, 46, 58], 51: [10, 46, 51], 22: [10, 46, 22], 9: [10, 46, 9], 23: [10, 46, 23], 72: [10, 3, 72], 62: [10, 3, 62], 44: [10, 3, 44], 85: [10, 3, 85], 54: [10, 3, 54], 83: [10, 31, 83], 88: [10, 31, 88], 91: [10, 31, 91], 33: [10, 31, 33], 8: [10, 48, 36, 8], 26: [10, 48, 36, 26], 52: [10, 48, 36, 52], 49: [10, 48, 36, 49], 19: [10, 48, 36, 19], 29: [10, 48, 36, 29], 39: [10, 48, 36, 39], 55: [10, 48, 5, 55], 41: [10, 48, 5, 41], 94: [10, 48, 101, 94], 25: [10, 48, 101, 25], 73: [10, 48, 101, 73], 21: [10, 48, 101, 21], 96: [10, 48, 101, 96], 4: [10, 48, 99, 4], 28: [10, 48, 99, 28], 77: [10, 48, 99, 77], 50: [10, 48, 99, 50], 97: [10, 48, 99, 97], 98: [10, 46, 18, 98], 95: [10, 46, 18, 95], 6: [10, 46, 18, 6], 86: [10, 46, 18, 86], 32: [10, 46, 18, 32], 27: [10, 46, 12, 27], 81: [10, 46, 12, 81], 68: [10, 46, 12, 68], 93: [10, 46, 58, 93], 100: [10, 46, 58, 100], 87: [10, 46, 58, 87], 17: [10, 46, 58, 17], 43: [10, 46, 22, 43], 59: [10, 46, 22, 59], 75: [10, 46, 9, 75], 1: [10, 46, 9, 1], 74: [10, 46, 9, 74], 69: [10, 46, 23, 69], 89: [10, 46, 23, 89], 76: [10, 3, 72, 76], 42: [10, 3, 62, 42], 80: [10, 3, 62, 80], 92: [10, 3, 44, 92], 56: [10, 3, 44, 56], 11: [10, 3, 44, 11], 71: [10, 3, 54, 71], 16: [10, 3, 54, 16], 70: [10, 3, 54, 70], 45: [10, 31, 83, 45], 64: [10, 31, 88, 64], 65: [10, 31, 88, 65], 40: [10, 31, 88, 40], 38: [10, 31, 91, 38], 61: [10, 31, 33, 61], 30: [10, 48, 36, 49, 30], 63: [10, 48, 36, 19, 63], 13: [10, 48, 36, 39, 13], 35: [10, 48, 5, 55, 35], 20: [10, 48, 5, 41, 20], 82: [10, 48, 5, 41, 82], 57: [10, 48, 101, 94, 57], 24: [10, 48, 101, 94, 24], 84: [10, 48, 101, 25, 84], 67: [10, 48, 101, 25, 67], 66: [10, 48, 101, 25, 66], 53: [10, 48, 99, 4, 53], 78: [10, 48, 99, 4, 78], 37: [10, 48, 99, 28, 37], 15: [10, 48, 99, 77, 15], 2: [10, 48, 99, 50, 2], 47: [10, 46, 18, 98, 47], 90: [10, 46, 18, 98, 90], 34: [10, 46, 18, 95, 34], 14: [10, 46, 12, 27, 14], 60: [10, 46, 58, 87, 60], 79: [10, 46, 9, 1, 79]}) (11, {11: [11], 80: [11, 80], 95: [11, 95], 24: [11, 24], 98: [11, 98], 85: [11, 80, 85], 86: [11, 80, 86], 13: [11, 80, 13], 10: [11, 80, 10], 1: [11, 80, 1], 23: [11, 80, 23], 46: [11, 80, 46], 34: [11, 95, 34], 31: [11, 95, 31], 49: [11, 95, 49], 20: [11, 95, 20], 81: [11, 95, 81], 90: [11, 24, 90], 25: [11, 24, 25], 71: [11, 24, 71], 6: [11, 24, 6], 66: [11, 24, 66], 54: [11, 24, 54], 74: [11, 24, 74], 41: [11, 24, 41], 68: [11, 24, 68], 96: [11, 24, 96], 78: [11, 24, 78], 26: [11, 24, 26], 14: [11, 24, 14], 47: [11, 98, 47], 97: [11, 98, 97], 88: [11, 98, 88], 32: [11, 98, 32], 36: [11, 98, 36], 62: [11, 98, 62], 5: [11, 98, 5], 38: [11, 98, 38], 73: [11, 80, 85, 73], 18: [11, 80, 86, 18], 17: [11, 80, 86, 17], 59: [11, 80, 86, 59], 16: [11, 80, 86, 16], 30: [11, 80, 13, 30], 83: [11, 80, 13, 83], 4: [11, 80, 13, 4], 60: [11, 80, 13, 60], 48: [11, 80, 10, 48], 3: [11, 80, 10, 3], 70: [11, 80, 1, 70], 79: [11, 80, 1, 79], 69: [11, 80, 1, 69], 53: [11, 80, 1, 53], 55: [11, 80, 23, 55], 101: [11, 80, 23, 101], 89: [11, 80, 23, 89], 12: [11, 80, 46, 12], 58: [11, 80, 46, 58], 51: [11, 80, 46, 51], 22: [11, 80, 46, 22], 9: [11, 80, 46, 9], 75: [11, 95, 34, 75], 29: [11, 95, 34, 29], 91: [11, 95, 31, 91], 33: [11, 95, 31, 33], 28: [11, 95, 49, 28], 40: [11, 95, 49, 40], 84: [11, 95, 20, 84], 56: [11, 95, 20, 56], 99: [11, 95, 20, 99], 19: [11, 95, 20, 19], 61: [11, 95, 81, 61], 42: [11, 95, 81, 42], 100: [11, 24, 90, 100], 93: [11, 24, 90, 93], 87: [11, 24, 25, 87], 67: [11, 24, 25, 67], 37: [11, 24, 71, 37], 50: [11, 24, 71, 50], 7: [11, 24, 71, 7], 57: [11, 24, 6, 57], 43: [11, 24, 54, 43], 82: [11, 24, 74, 82], 94: [11, 24, 41, 94], 21: [11, 24, 41, 21], 39: [11, 24, 14, 39], 15: [11, 98, 47, 15], 2: [11, 98, 47, 2], 64: [11, 98, 97, 64], 77: [11, 98, 97, 77], 65: [11, 98, 88, 65], 8: [11, 98, 36, 8], 52: [11, 98, 36, 52], 44: [11, 98, 62, 44], 45: [11, 80, 13, 83, 45], 72: [11, 80, 10, 3, 72], 35: [11, 80, 23, 55, 35], 27: [11, 80, 46, 12, 27], 63: [11, 95, 20, 19, 63], 92: [11, 95, 20, 19, 92], 76: [11, 98, 47, 2, 76]}) (12, {12: [12], 27: [12, 27], 44: [12, 44], 101: [12, 101], 22: [12, 22], 81: [12, 81], 68: [12, 68], 4: [12, 4], 14: [12, 27, 14], 84: [12, 27, 84], 67: [12, 27, 67], 89: [12, 27, 89], 72: [12, 44, 72], 92: [12, 44, 92], 51: [12, 44, 51], 56: [12, 44, 56], 11: [12, 44, 11], 94: [12, 44, 94], 10: [12, 44, 10], 25: [12, 101, 25], 73: [12, 101, 73], 21: [12, 101, 21], 96: [12, 101, 96], 8: [12, 101, 8], 99: [12, 101, 99], 43: [12, 22, 43], 59: [12, 22, 59], 91: [12, 22, 91], 93: [12, 22, 93], 6: [12, 22, 6], 97: [12, 22, 97], 3: [12, 81, 3], 61: [12, 81, 61], 55: [12, 81, 55], 30: [12, 81, 30], 42: [12, 81, 42], 41: [12, 81, 41], 58: [12, 81, 58], 28: [12, 81, 28], 40: [12, 81, 40], 13: [12, 68, 13], 53: [12, 4, 53], 78: [12, 4, 78], 23: [12, 4, 23], 83: [12, 4, 83], 20: [12, 27, 14, 20], 39: [12, 27, 14, 39], 74: [12, 27, 14, 74], 82: [12, 27, 14, 82], 32: [12, 27, 84, 32], 98: [12, 27, 84, 98], 16: [12, 27, 67, 16], 54: [12, 27, 67, 54], 57: [12, 27, 89, 57], 17: [12, 44, 72, 17], 36: [12, 44, 72, 36], 29: [12, 44, 72, 29], 76: [12, 44, 72, 76], 18: [12, 44, 72, 18], 34: [12, 44, 92, 34], 47: [12, 44, 92, 47], 52: [12, 44, 92, 52], 49: [12, 44, 51, 49], 100: [12, 44, 51, 100], 77: [12, 44, 56, 77], 90: [12, 44, 56, 90], 80: [12, 44, 11, 80], 95: [12, 44, 11, 95], 24: [12, 44, 11, 24], 62: [12, 44, 94, 62], 46: [12, 44, 94, 46], 48: [12, 44, 10, 48], 31: [12, 44, 10, 31], 26: [12, 101, 25, 26], 87: [12, 101, 25, 87], 66: [12, 101, 25, 66], 71: [12, 101, 73, 71], 1: [12, 101, 73, 1], 5: [12, 101, 21, 5], 85: [12, 101, 21, 85], 33: [12, 101, 96, 33], 88: [12, 101, 8, 88], 19: [12, 101, 99, 19], 50: [12, 101, 99, 50], 63: [12, 22, 43, 63], 86: [12, 22, 59, 86], 65: [12, 22, 59, 65], 64: [12, 22, 91, 64], 38: [12, 22, 91, 38], 7: [12, 22, 91, 7], 35: [12, 81, 55, 35], 37: [12, 81, 28, 37], 9: [12, 81, 40, 9], 60: [12, 68, 13, 60], 69: [12, 4, 53, 69], 45: [12, 4, 53, 45], 2: [12, 4, 53, 2], 79: [12, 27, 67, 16, 79], 70: [12, 27, 67, 54, 70], 75: [12, 44, 92, 34, 75], 15: [12, 44, 92, 47, 15]}) (13, {13: [13], 14: [13, 14], 30: [13, 30], 83: [13, 83], 4: [13, 4], 60: [13, 60], 59: [13, 14, 59], 20: [13, 14, 20], 39: [13, 14, 39], 74: [13, 14, 74], 82: [13, 14, 82], 80: [13, 30, 80], 28: [13, 30, 28], 89: [13, 83, 89], 45: [13, 83, 45], 52: [13, 83, 52], 43: [13, 83, 43], 93: [13, 83, 93], 44: [13, 83, 44], 53: [13, 4, 53], 78: [13, 4, 78], 23: [13, 4, 23], 41: [13, 60, 41], 79: [13, 60, 79], 18: [13, 60, 18], 62: [13, 60, 62], 40: [13, 60, 40], 99: [13, 60, 99], 96: [13, 14, 59, 96], 26: [13, 14, 59, 26], 8: [13, 14, 59, 8], 11: [13, 14, 59, 11], 97: [13, 14, 59, 97], 36: [13, 14, 59, 36], 86: [13, 14, 59, 86], 65: [13, 14, 59, 65], 84: [13, 14, 20, 84], 22: [13, 14, 20, 22], 56: [13, 14, 20, 56], 19: [13, 14, 20, 19], 58: [13, 14, 20, 58], 68: [13, 14, 20, 68], 81: [13, 14, 20, 81], 32: [13, 14, 20, 32], 46: [13, 14, 20, 46], 101: [13, 14, 39, 101], 42: [13, 14, 39, 42], 33: [13, 14, 39, 33], 51: [13, 14, 74, 51], 87: [13, 14, 74, 87], 95: [13, 30, 80, 95], 85: [13, 30, 80, 85], 10: [13, 30, 80, 10], 1: [13, 30, 80, 1], 73: [13, 30, 28, 73], 31: [13, 30, 28, 31], 37: [13, 30, 28, 37], 67: [13, 30, 28, 67], 57: [13, 83, 89, 57], 55: [13, 83, 89, 55], 70: [13, 83, 45, 70], 34: [13, 83, 45, 34], 35: [13, 83, 45, 35], 47: [13, 83, 43, 47], 63: [13, 83, 43, 63], 27: [13, 83, 43, 27], 25: [13, 83, 43, 25], 48: [13, 83, 43, 48], 71: [13, 83, 93, 71], 72: [13, 83, 44, 72], 92: [13, 83, 44, 92], 94: [13, 83, 44, 94], 69: [13, 4, 53, 69], 2: [13, 4, 53, 2], 12: [13, 4, 78, 12], 21: [13, 60, 41, 21], 3: [13, 60, 79, 3], 98: [13, 60, 18, 98], 6: [13, 60, 18, 6], 49: [13, 60, 18, 49], 9: [13, 60, 40, 9], 91: [13, 60, 40, 91], 38: [13, 60, 40, 38], 77: [13, 60, 99, 77], 50: [13, 60, 99, 50], 88: [13, 14, 59, 8, 88], 24: [13, 14, 59, 11, 24], 64: [13, 14, 59, 97, 64], 7: [13, 14, 59, 97, 7], 29: [13, 14, 59, 36, 29], 17: [13, 14, 59, 86, 17], 16: [13, 14, 59, 86, 16], 15: [13, 14, 59, 65, 15], 90: [13, 14, 20, 56, 90], 100: [13, 14, 20, 58, 100], 61: [13, 14, 20, 81, 61], 75: [13, 14, 39, 33, 75], 5: [13, 30, 80, 85, 5], 54: [13, 30, 28, 67, 54], 66: [13, 83, 43, 63, 66], 76: [13, 83, 44, 72, 76]}) (14, {14: [14], 59: [14, 59], 20: [14, 20], 39: [14, 39], 74: [14, 74], 82: [14, 82], 96: [14, 59, 96], 13: [14, 59, 13], 26: [14, 59, 26], 62: [14, 59, 62], 8: [14, 59, 8], 44: [14, 59, 44], 11: [14, 59, 11], 18: [14, 59, 18], 97: [14, 59, 97], 36: [14, 59, 36], 78: [14, 59, 78], 86: [14, 59, 86], 65: [14, 59, 65], 84: [14, 20, 84], 22: [14, 20, 22], 56: [14, 20, 56], 99: [14, 20, 99], 19: [14, 20, 19], 58: [14, 20, 58], 83: [14, 20, 83], 30: [14, 20, 30], 68: [14, 20, 68], 81: [14, 20, 81], 32: [14, 20, 32], 46: [14, 20, 46], 4: [14, 20, 4], 101: [14, 39, 101], 28: [14, 39, 28], 42: [14, 39, 42], 33: [14, 39, 33], 51: [14, 74, 51], 87: [14, 74, 87], 53: [14, 74, 53], 89: [14, 59, 96, 89], 60: [14, 59, 13, 60], 25: [14, 59, 26, 25], 98: [14, 59, 26, 98], 80: [14, 59, 62, 80], 88: [14, 59, 8, 88], 72: [14, 59, 44, 72], 92: [14, 59, 44, 92], 94: [14, 59, 44, 94], 10: [14, 59, 44, 10], 95: [14, 59, 11, 95], 24: [14, 59, 11, 24], 6: [14, 59, 18, 6], 49: [14, 59, 18, 49], 64: [14, 59, 97, 64], 77: [14, 59, 97, 77], 7: [14, 59, 97, 7], 52: [14, 59, 36, 52], 23: [14, 59, 36, 23], 29: [14, 59, 36, 29], 31: [14, 59, 78, 31], 69: [14, 59, 78, 69], 12: [14, 59, 78, 12], 17: [14, 59, 86, 17], 16: [14, 59, 86, 16], 15: [14, 59, 65, 15], 45: [14, 59, 65, 45], 43: [14, 20, 22, 43], 91: [14, 20, 22, 91], 93: [14, 20, 22, 93], 90: [14, 20, 56, 90], 50: [14, 20, 99, 50], 63: [14, 20, 19, 63], 100: [14, 20, 58, 100], 55: [14, 20, 68, 55], 40: [14, 20, 68, 40], 3: [14, 20, 81, 3], 61: [14, 20, 81, 61], 41: [14, 20, 81, 41], 37: [14, 20, 32, 37], 9: [14, 20, 46, 9], 73: [14, 39, 101, 73], 21: [14, 39, 101, 21], 67: [14, 39, 28, 67], 71: [14, 39, 33, 71], 70: [14, 39, 33, 70], 75: [14, 39, 33, 75], 2: [14, 74, 53, 2], 57: [14, 59, 96, 89, 57], 79: [14, 59, 13, 60, 79], 66: [14, 59, 26, 25, 66], 47: [14, 59, 26, 98, 47], 5: [14, 59, 26, 98, 5], 38: [14, 59, 26, 98, 38], 54: [14, 59, 26, 98, 54], 85: [14, 59, 62, 80, 85], 1: [14, 59, 62, 80, 1], 76: [14, 59, 44, 72, 76], 34: [14, 59, 44, 92, 34], 48: [14, 59, 44, 10, 48], 35: [14, 59, 97, 64, 35], 27: [14, 59, 78, 12, 27]}) (15, {15: [15], 47: [15, 47], 39: [15, 39], 83: [15, 83], 9: [15, 9], 50: [15, 50], 86: [15, 86], 13: [15, 47, 13], 29: [15, 47, 29], 98: [15, 47, 98], 19: [15, 47, 19], 36: [15, 47, 36], 24: [15, 47, 24], 2: [15, 47, 2], 59: [15, 39, 59], 101: [15, 39, 101], 28: [15, 39, 28], 42: [15, 39, 42], 96: [15, 39, 96], 33: [15, 39, 33], 74: [15, 39, 74], 89: [15, 83, 89], 45: [15, 83, 45], 52: [15, 83, 52], 43: [15, 83, 43], 93: [15, 83, 93], 44: [15, 83, 44], 85: [15, 9, 85], 94: [15, 9, 94], 31: [15, 9, 31], 75: [15, 9, 75], 1: [15, 9, 1], 88: [15, 50, 88], 22: [15, 50, 22], 54: [15, 50, 54], 18: [15, 86, 18], 17: [15, 86, 17], 26: [15, 86, 26], 6: [15, 86, 6], 80: [15, 86, 80], 16: [15, 86, 16], 14: [15, 47, 13, 14], 30: [15, 47, 13, 30], 4: [15, 47, 13, 4], 60: [15, 47, 13, 60], 21: [15, 47, 29, 21], 46: [15, 47, 98, 46], 97: [15, 47, 98, 97], 32: [15, 47, 98, 32], 62: [15, 47, 98, 62], 5: [15, 47, 98, 5], 38: [15, 47, 98, 38], 90: [15, 47, 98, 90], 63: [15, 47, 19, 63], 68: [15, 47, 19, 68], 92: [15, 47, 19, 92], 8: [15, 47, 36, 8], 49: [15, 47, 36, 49], 23: [15, 47, 36, 23], 25: [15, 47, 24, 25], 71: [15, 47, 24, 71], 34: [15, 47, 24, 34], 66: [15, 47, 24, 66], 41: [15, 47, 24, 41], 78: [15, 47, 24, 78], 51: [15, 47, 2, 51], 56: [15, 47, 2, 56], 40: [15, 47, 2, 40], 76: [15, 47, 2, 76], 11: [15, 39, 59, 11], 65: [15, 39, 59, 65], 73: [15, 39, 101, 73], 99: [15, 39, 101, 99], 37: [15, 39, 28, 37], 67: [15, 39, 28, 67], 3: [15, 39, 42, 3], 91: [15, 39, 42, 91], 20: [15, 39, 96, 20], 61: [15, 39, 33, 61], 70: [15, 39, 33, 70], 87: [15, 39, 74, 87], 82: [15, 39, 74, 82], 53: [15, 39, 74, 53], 57: [15, 83, 89, 57], 55: [15, 83, 89, 55], 35: [15, 83, 45, 35], 27: [15, 83, 43, 27], 48: [15, 83, 43, 48], 58: [15, 83, 93, 58], 72: [15, 83, 44, 72], 10: [15, 83, 44, 10], 12: [15, 9, 31, 12], 81: [15, 9, 75, 81], 79: [15, 9, 1, 79], 69: [15, 9, 1, 69], 64: [15, 50, 88, 64], 95: [15, 50, 88, 95], 84: [15, 86, 17, 84], 77: [15, 47, 98, 97, 77], 7: [15, 47, 98, 97, 7], 100: [15, 47, 98, 90, 100]}) (16, {16: [16], 48: [16, 48], 56: [16, 56], 9: [16, 9], 81: [16, 81], 4: [16, 4], 79: [16, 79], 6: [16, 6], 7: [16, 48, 7], 36: [16, 48, 36], 5: [16, 48, 5], 101: [16, 48, 101], 99: [16, 48, 99], 77: [16, 56, 77], 10: [16, 56, 10], 90: [16, 56, 90], 58: [16, 56, 58], 85: [16, 9, 85], 50: [16, 9, 50], 94: [16, 9, 94], 31: [16, 9, 31], 98: [16, 9, 98], 75: [16, 9, 75], 29: [16, 9, 29], 1: [16, 9, 1], 74: [16, 9, 74], 3: [16, 81, 3], 61: [16, 81, 61], 55: [16, 81, 55], 30: [16, 81, 30], 42: [16, 81, 42], 68: [16, 81, 68], 41: [16, 81, 41], 28: [16, 81, 28], 40: [16, 81, 40], 53: [16, 4, 53], 78: [16, 4, 78], 23: [16, 4, 23], 83: [16, 4, 83], 8: [16, 79, 8], 22: [16, 79, 22], 37: [16, 79, 37], 57: [16, 6, 57], 54: [16, 6, 54], 51: [16, 48, 7, 51], 26: [16, 48, 36, 26], 46: [16, 48, 36, 46], 52: [16, 48, 36, 52], 49: [16, 48, 36, 49], 19: [16, 48, 36, 19], 39: [16, 48, 36, 39], 25: [16, 48, 101, 25], 73: [16, 48, 101, 73], 21: [16, 48, 101, 21], 96: [16, 48, 101, 96], 18: [16, 48, 99, 18], 97: [16, 48, 99, 97], 45: [16, 56, 77, 45], 70: [16, 56, 77, 70], 15: [16, 56, 77, 15], 43: [16, 56, 77, 43], 100: [16, 56, 90, 100], 93: [16, 56, 90, 93], 59: [16, 56, 90, 59], 34: [16, 56, 90, 34], 87: [16, 56, 58, 87], 17: [16, 56, 58, 17], 2: [16, 9, 50, 2], 88: [16, 9, 50, 88], 62: [16, 9, 94, 62], 24: [16, 9, 94, 24], 12: [16, 9, 31, 12], 91: [16, 9, 31, 91], 33: [16, 9, 31, 33], 47: [16, 9, 98, 47], 32: [16, 9, 98, 32], 38: [16, 9, 98, 38], 13: [16, 9, 98, 13], 67: [16, 9, 75, 67], 69: [16, 9, 1, 69], 82: [16, 9, 74, 82], 72: [16, 81, 3, 72], 44: [16, 81, 3, 44], 92: [16, 81, 61, 92], 35: [16, 81, 55, 35], 80: [16, 81, 30, 80], 63: [16, 81, 42, 63], 20: [16, 81, 41, 20], 86: [16, 4, 53, 86], 89: [16, 4, 23, 89], 71: [16, 6, 54, 71], 11: [16, 6, 54, 11], 95: [16, 48, 36, 49, 95], 84: [16, 48, 101, 25, 84], 66: [16, 48, 101, 25, 66], 64: [16, 48, 99, 97, 64], 27: [16, 56, 77, 43, 27], 65: [16, 56, 90, 59, 65], 60: [16, 56, 58, 87, 60], 76: [16, 9, 50, 2, 76], 14: [16, 9, 94, 24, 14]}) (17, {17: [17], 84: [17, 84], 32: [17, 84, 32], 98: [17, 84, 98], 13: [17, 84, 13], 14: [17, 84, 14], 25: [17, 84, 25], 93: [17, 84, 32, 93], 37: [17, 84, 32, 37], 47: [17, 84, 98, 47], 46: [17, 84, 98, 46], 97: [17, 84, 98, 97], 88: [17, 84, 98, 88], 36: [17, 84, 98, 36], 62: [17, 84, 98, 62], 5: [17, 84, 98, 5], 38: [17, 84, 98, 38], 54: [17, 84, 98, 54], 90: [17, 84, 98, 90], 30: [17, 84, 13, 30], 83: [17, 84, 13, 83], 4: [17, 84, 13, 4], 60: [17, 84, 13, 60], 59: [17, 84, 14, 59], 20: [17, 84, 14, 20], 39: [17, 84, 14, 39], 74: [17, 84, 14, 74], 82: [17, 84, 14, 82], 26: [17, 84, 25, 26], 87: [17, 84, 25, 87], 67: [17, 84, 25, 67], 56: [17, 84, 25, 56], 66: [17, 84, 25, 66], 58: [17, 84, 32, 93, 58], 40: [17, 84, 32, 93, 40], 34: [17, 84, 32, 93, 34], 71: [17, 84, 32, 93, 71], 43: [17, 84, 32, 93, 43], 57: [17, 84, 32, 37, 57], 15: [17, 84, 98, 47, 15], 29: [17, 84, 98, 47, 29], 19: [17, 84, 98, 47, 19], 24: [17, 84, 98, 47, 24], 2: [17, 84, 98, 47, 2], 18: [17, 84, 98, 46, 18], 12: [17, 84, 98, 46, 12], 51: [17, 84, 98, 46, 51], 22: [17, 84, 98, 46, 22], 9: [17, 84, 98, 46, 9], 23: [17, 84, 98, 46, 23], 64: [17, 84, 98, 97, 64], 77: [17, 84, 98, 97, 77], 7: [17, 84, 98, 97, 7], 81: [17, 84, 98, 88, 81], 101: [17, 84, 98, 88, 101], 95: [17, 84, 98, 88, 95], 65: [17, 84, 98, 88, 65], 8: [17, 84, 98, 36, 8], 52: [17, 84, 98, 36, 52], 49: [17, 84, 98, 36, 49], 42: [17, 84, 98, 62, 42], 86: [17, 84, 98, 62, 86], 96: [17, 84, 98, 62, 96], 80: [17, 84, 98, 62, 80], 44: [17, 84, 98, 62, 44], 55: [17, 84, 98, 5, 55], 41: [17, 84, 98, 5, 41], 78: [17, 84, 98, 38, 78], 16: [17, 84, 98, 54, 16], 11: [17, 84, 98, 54, 11], 70: [17, 84, 98, 54, 70], 100: [17, 84, 98, 90, 100], 1: [17, 84, 98, 90, 1], 10: [17, 84, 98, 90, 10], 28: [17, 84, 13, 30, 28], 89: [17, 84, 13, 83, 89], 45: [17, 84, 13, 83, 45], 53: [17, 84, 13, 4, 53], 79: [17, 84, 13, 60, 79], 99: [17, 84, 13, 60, 99], 68: [17, 84, 14, 20, 68], 33: [17, 84, 14, 39, 33], 61: [17, 84, 25, 66, 61], 91: [17, 84, 32, 93, 40, 91], 75: [17, 84, 32, 93, 34, 75], 50: [17, 84, 32, 93, 71, 50], 63: [17, 84, 32, 93, 43, 63], 27: [17, 84, 32, 93, 43, 27], 73: [17, 84, 32, 93, 43, 73], 48: [17, 84, 32, 93, 43, 48], 31: [17, 84, 32, 93, 43, 31], 69: [17, 84, 32, 37, 57, 69], 21: [17, 84, 98, 47, 29, 21], 92: [17, 84, 98, 47, 19, 92], 6: [17, 84, 98, 47, 24, 6], 76: [17, 84, 98, 47, 2, 76], 94: [17, 84, 98, 46, 18, 94], 72: [17, 84, 98, 46, 22, 72], 85: [17, 84, 98, 46, 9, 85], 35: [17, 84, 98, 97, 64, 35], 3: [17, 84, 98, 88, 81, 3]}) (18, {18: [18], 98: [18, 98], 94: [18, 94], 95: [18, 95], 6: [18, 6], 86: [18, 86], 32: [18, 32], 49: [18, 49], 47: [18, 98, 47], 46: [18, 98, 46], 97: [18, 98, 97], 88: [18, 98, 88], 36: [18, 98, 36], 62: [18, 98, 62], 5: [18, 98, 5], 38: [18, 98, 38], 54: [18, 98, 54], 90: [18, 98, 90], 13: [18, 98, 13], 57: [18, 94, 57], 101: [18, 94, 101], 24: [18, 94, 24], 34: [18, 95, 34], 31: [18, 95, 31], 20: [18, 95, 20], 81: [18, 95, 81], 1: [18, 6, 1], 17: [18, 86, 17], 59: [18, 86, 59], 26: [18, 86, 26], 80: [18, 86, 80], 16: [18, 86, 16], 93: [18, 32, 93], 37: [18, 32, 37], 28: [18, 49, 28], 40: [18, 49, 40], 30: [18, 49, 30], 83: [18, 49, 83], 10: [18, 49, 10], 58: [18, 49, 58], 15: [18, 98, 47, 15], 29: [18, 98, 47, 29], 19: [18, 98, 47, 19], 2: [18, 98, 47, 2], 12: [18, 98, 46, 12], 51: [18, 98, 46, 51], 22: [18, 98, 46, 22], 9: [18, 98, 46, 9], 23: [18, 98, 46, 23], 87: [18, 98, 97, 87], 64: [18, 98, 97, 64], 84: [18, 98, 97, 84], 74: [18, 98, 97, 74], 77: [18, 98, 97, 77], 25: [18, 98, 97, 25], 7: [18, 98, 97, 7], 65: [18, 98, 88, 65], 39: [18, 98, 88, 39], 8: [18, 98, 36, 8], 52: [18, 98, 36, 52], 42: [18, 98, 62, 42], 4: [18, 98, 62, 4], 96: [18, 98, 62, 96], 44: [18, 98, 62, 44], 55: [18, 98, 5, 55], 41: [18, 98, 5, 41], 78: [18, 98, 38, 78], 66: [18, 98, 38, 66], 71: [18, 98, 54, 71], 43: [18, 98, 54, 43], 11: [18, 98, 54, 11], 70: [18, 98, 54, 70], 100: [18, 98, 90, 100], 14: [18, 98, 13, 14], 60: [18, 98, 13, 60], 69: [18, 94, 57, 69], 79: [18, 94, 57, 79], 73: [18, 94, 101, 73], 21: [18, 94, 101, 21], 99: [18, 94, 101, 99], 68: [18, 94, 24, 68], 75: [18, 95, 34, 75], 48: [18, 95, 31, 48], 91: [18, 95, 31, 91], 33: [18, 95, 31, 33], 85: [18, 95, 31, 85], 56: [18, 95, 20, 56], 3: [18, 95, 81, 3], 61: [18, 95, 81, 61], 53: [18, 6, 1, 53], 67: [18, 49, 28, 67], 89: [18, 49, 83, 89], 45: [18, 49, 83, 45], 50: [18, 98, 47, 15, 50], 63: [18, 98, 47, 19, 63], 92: [18, 98, 47, 19, 92], 76: [18, 98, 47, 2, 76], 27: [18, 98, 46, 12, 27], 72: [18, 98, 46, 22, 72], 82: [18, 98, 97, 64, 82], 35: [18, 98, 97, 64, 35]}) (19, {19: [19], 63: [19, 63], 68: [19, 68], 62: [19, 62], 98: [19, 98], 97: [19, 97], 92: [19, 92], 10: [19, 63, 10], 100: [19, 63, 100], 20: [19, 63, 20], 88: [19, 63, 88], 4: [19, 63, 4], 81: [19, 63, 81], 55: [19, 63, 55], 66: [19, 63, 66], 15: [19, 63, 15], 13: [19, 68, 13], 40: [19, 68, 40], 42: [19, 62, 42], 86: [19, 62, 86], 74: [19, 62, 74], 96: [19, 62, 96], 80: [19, 62, 80], 44: [19, 62, 44], 47: [19, 98, 47], 46: [19, 98, 46], 32: [19, 98, 32], 36: [19, 98, 36], 5: [19, 98, 5], 38: [19, 98, 38], 54: [19, 98, 54], 90: [19, 98, 90], 87: [19, 97, 87], 64: [19, 97, 64], 84: [19, 97, 84], 77: [19, 97, 77], 25: [19, 97, 25], 7: [19, 97, 7], 34: [19, 92, 34], 52: [19, 92, 52], 48: [19, 63, 10, 48], 3: [19, 63, 10, 3], 31: [19, 63, 10, 31], 58: [19, 63, 100, 58], 21: [19, 63, 100, 21], 69: [19, 63, 100, 69], 22: [19, 63, 20, 22], 56: [19, 63, 20, 56], 99: [19, 63, 20, 99], 83: [19, 63, 20, 83], 30: [19, 63, 20, 30], 101: [19, 63, 88, 101], 95: [19, 63, 88, 95], 65: [19, 63, 88, 65], 39: [19, 63, 88, 39], 53: [19, 63, 4, 53], 78: [19, 63, 4, 78], 23: [19, 63, 4, 23], 61: [19, 63, 81, 61], 41: [19, 63, 81, 41], 28: [19, 63, 81, 28], 29: [19, 63, 55, 29], 35: [19, 63, 55, 35], 16: [19, 63, 55, 16], 60: [19, 63, 66, 60], 9: [19, 63, 15, 9], 50: [19, 63, 15, 50], 14: [19, 68, 13, 14], 91: [19, 68, 40, 91], 49: [19, 68, 40, 49], 33: [19, 62, 42, 33], 24: [19, 62, 42, 24], 18: [19, 62, 86, 18], 17: [19, 62, 86, 17], 59: [19, 62, 86, 59], 26: [19, 62, 86, 26], 6: [19, 62, 86, 6], 51: [19, 62, 74, 51], 82: [19, 62, 74, 82], 89: [19, 62, 96, 89], 85: [19, 62, 80, 85], 1: [19, 62, 80, 1], 72: [19, 62, 44, 72], 11: [19, 62, 44, 11], 94: [19, 62, 44, 94], 2: [19, 98, 47, 2], 12: [19, 98, 46, 12], 93: [19, 98, 32, 93], 37: [19, 98, 32, 37], 8: [19, 98, 36, 8], 71: [19, 98, 54, 71], 43: [19, 98, 54, 43], 70: [19, 98, 54, 70], 73: [19, 97, 64, 73], 45: [19, 97, 77, 45], 67: [19, 97, 25, 67], 75: [19, 92, 34, 75], 79: [19, 63, 55, 16, 79], 57: [19, 62, 86, 6, 57], 76: [19, 62, 44, 72, 76], 27: [19, 98, 46, 12, 27]}) (20, {20: [20], 84: [20, 84], 22: [20, 22], 56: [20, 56], 99: [20, 99], 19: [20, 19], 58: [20, 58], 83: [20, 83], 30: [20, 30], 68: [20, 68], 86: [20, 86], 81: [20, 81], 32: [20, 32], 46: [20, 46], 4: [20, 4], 98: [20, 84, 98], 13: [20, 84, 13], 14: [20, 84, 14], 25: [20, 84, 25], 43: [20, 22, 43], 72: [20, 22, 72], 59: [20, 22, 59], 91: [20, 22, 91], 93: [20, 22, 93], 6: [20, 22, 6], 97: [20, 22, 97], 77: [20, 56, 77], 10: [20, 56, 10], 90: [20, 56, 90], 18: [20, 99, 18], 28: [20, 99, 28], 50: [20, 99, 50], 63: [20, 19, 63], 62: [20, 19, 62], 92: [20, 19, 92], 100: [20, 58, 100], 26: [20, 58, 26], 87: [20, 58, 87], 17: [20, 58, 17], 89: [20, 83, 89], 45: [20, 83, 45], 52: [20, 83, 52], 44: [20, 83, 44], 80: [20, 30, 80], 55: [20, 68, 55], 40: [20, 68, 40], 16: [20, 86, 16], 3: [20, 81, 3], 61: [20, 81, 61], 42: [20, 81, 42], 41: [20, 81, 41], 37: [20, 32, 37], 12: [20, 46, 12], 51: [20, 46, 51], 9: [20, 46, 9], 23: [20, 46, 23], 53: [20, 4, 53], 78: [20, 4, 78], 47: [20, 84, 98, 47], 88: [20, 84, 98, 88], 36: [20, 84, 98, 36], 5: [20, 84, 98, 5], 38: [20, 84, 98, 38], 54: [20, 84, 98, 54], 60: [20, 84, 13, 60], 39: [20, 84, 14, 39], 74: [20, 84, 14, 74], 82: [20, 84, 14, 82], 67: [20, 84, 25, 67], 66: [20, 84, 25, 66], 27: [20, 22, 43, 27], 73: [20, 22, 43, 73], 48: [20, 22, 43, 48], 11: [20, 22, 43, 11], 31: [20, 22, 43, 31], 29: [20, 22, 72, 29], 76: [20, 22, 72, 76], 96: [20, 22, 59, 96], 8: [20, 22, 59, 8], 65: [20, 22, 59, 65], 64: [20, 22, 91, 64], 7: [20, 22, 91, 7], 34: [20, 22, 93, 34], 71: [20, 22, 93, 71], 57: [20, 22, 6, 57], 1: [20, 22, 6, 1], 70: [20, 56, 77, 70], 15: [20, 56, 77, 15], 101: [20, 56, 77, 101], 21: [20, 56, 77, 21], 94: [20, 99, 18, 94], 95: [20, 99, 18, 95], 49: [20, 99, 18, 49], 2: [20, 99, 50, 2], 69: [20, 58, 100, 69], 35: [20, 83, 45, 35], 85: [20, 83, 45, 85], 79: [20, 86, 16, 79], 33: [20, 81, 42, 33], 24: [20, 81, 42, 24], 75: [20, 46, 9, 75]}) (21, {21: [21], 11: [21, 11], 30: [21, 30], 87: [21, 87], 82: [21, 82], 5: [21, 5], 3: [21, 3], 85: [21, 85], 1: [21, 1], 80: [21, 11, 80], 95: [21, 11, 95], 24: [21, 11, 24], 98: [21, 11, 98], 28: [21, 30, 28], 60: [21, 87, 60], 93: [21, 87, 93], 83: [21, 87, 83], 51: [21, 82, 51], 14: [21, 82, 14], 74: [21, 82, 74], 9: [21, 5, 9], 55: [21, 5, 55], 41: [21, 5, 41], 72: [21, 3, 72], 62: [21, 3, 62], 44: [21, 3, 44], 54: [21, 3, 54], 73: [21, 85, 73], 25: [21, 85, 25], 36: [21, 85, 36], 16: [21, 1, 16], 70: [21, 1, 70], 79: [21, 1, 79], 69: [21, 1, 69], 53: [21, 1, 53], 86: [21, 11, 80, 86], 13: [21, 11, 80, 13], 10: [21, 11, 80, 10], 23: [21, 11, 80, 23], 46: [21, 11, 80, 46], 34: [21, 11, 95, 34], 31: [21, 11, 95, 31], 49: [21, 11, 95, 49], 20: [21, 11, 95, 20], 81: [21, 11, 95, 81], 90: [21, 11, 24, 90], 71: [21, 11, 24, 71], 6: [21, 11, 24, 6], 66: [21, 11, 24, 66], 68: [21, 11, 24, 68], 96: [21, 11, 24, 96], 78: [21, 11, 24, 78], 26: [21, 11, 24, 26], 47: [21, 11, 98, 47], 97: [21, 11, 98, 97], 88: [21, 11, 98, 88], 32: [21, 11, 98, 32], 38: [21, 11, 98, 38], 37: [21, 30, 28, 37], 67: [21, 30, 28, 67], 89: [21, 87, 60, 89], 18: [21, 87, 60, 18], 40: [21, 87, 60, 40], 99: [21, 87, 60, 99], 58: [21, 87, 93, 58], 39: [21, 87, 93, 39], 43: [21, 87, 93, 43], 45: [21, 87, 83, 45], 52: [21, 87, 83, 52], 100: [21, 82, 51, 100], 59: [21, 82, 14, 59], 22: [21, 82, 74, 22], 50: [21, 5, 9, 50], 94: [21, 5, 9, 94], 75: [21, 5, 9, 75], 29: [21, 5, 9, 29], 35: [21, 5, 55, 35], 42: [21, 5, 55, 42], 19: [21, 5, 41, 19], 56: [21, 5, 41, 56], 17: [21, 3, 72, 17], 76: [21, 3, 72, 76], 4: [21, 3, 62, 4], 92: [21, 3, 44, 92], 77: [21, 85, 73, 77], 84: [21, 85, 25, 84], 8: [21, 85, 36, 8], 48: [21, 1, 16, 48], 64: [21, 1, 70, 64], 2: [21, 1, 53, 2], 101: [21, 11, 80, 23, 101], 12: [21, 11, 80, 46, 12], 91: [21, 11, 95, 31, 91], 33: [21, 11, 95, 31, 33], 61: [21, 11, 95, 81, 61], 7: [21, 11, 24, 71, 7], 57: [21, 11, 24, 6, 57], 15: [21, 11, 98, 47, 15], 65: [21, 11, 98, 88, 65], 63: [21, 87, 93, 43, 63], 27: [21, 87, 93, 43, 27]}) (22, {22: [22], 43: [22, 43], 72: [22, 72], 59: [22, 59], 91: [22, 91], 93: [22, 93], 6: [22, 6], 97: [22, 97], 74: [22, 43, 74], 47: [22, 43, 47], 63: [22, 43, 63], 27: [22, 43, 27], 25: [22, 43, 25], 73: [22, 43, 73], 48: [22, 43, 48], 11: [22, 43, 11], 31: [22, 43, 31], 17: [22, 72, 17], 36: [22, 72, 36], 29: [22, 72, 29], 98: [22, 72, 98], 76: [22, 72, 76], 18: [22, 72, 18], 96: [22, 59, 96], 13: [22, 59, 13], 26: [22, 59, 26], 62: [22, 59, 62], 8: [22, 59, 8], 44: [22, 59, 44], 78: [22, 59, 78], 86: [22, 59, 86], 65: [22, 59, 65], 12: [22, 91, 12], 99: [22, 91, 99], 50: [22, 91, 50], 32: [22, 91, 32], 64: [22, 91, 64], 38: [22, 91, 38], 7: [22, 91, 7], 100: [22, 91, 100], 58: [22, 93, 58], 40: [22, 93, 40], 34: [22, 93, 34], 71: [22, 93, 71], 39: [22, 93, 39], 83: [22, 93, 83], 57: [22, 6, 57], 54: [22, 6, 54], 1: [22, 6, 1], 87: [22, 97, 87], 84: [22, 97, 84], 77: [22, 97, 77], 51: [22, 43, 74, 51], 82: [22, 43, 74, 82], 53: [22, 43, 74, 53], 15: [22, 43, 47, 15], 19: [22, 43, 47, 19], 24: [22, 43, 47, 24], 2: [22, 43, 47, 2], 10: [22, 43, 63, 10], 20: [22, 43, 63, 20], 88: [22, 43, 63, 88], 4: [22, 43, 63, 4], 81: [22, 43, 63, 81], 55: [22, 43, 63, 55], 66: [22, 43, 63, 66], 14: [22, 43, 27, 14], 67: [22, 43, 27, 67], 89: [22, 43, 27, 89], 56: [22, 43, 25, 56], 5: [22, 43, 48, 5], 101: [22, 43, 48, 101], 80: [22, 43, 11, 80], 95: [22, 43, 11, 95], 33: [22, 43, 31, 33], 85: [22, 43, 31, 85], 46: [22, 72, 36, 46], 52: [22, 72, 36, 52], 49: [22, 72, 36, 49], 23: [22, 72, 36, 23], 21: [22, 72, 29, 21], 90: [22, 72, 98, 90], 45: [22, 72, 76, 45], 60: [22, 72, 76, 60], 94: [22, 72, 18, 94], 30: [22, 59, 13, 30], 42: [22, 59, 62, 42], 92: [22, 59, 44, 92], 69: [22, 59, 78, 69], 16: [22, 59, 86, 16], 68: [22, 91, 12, 68], 28: [22, 91, 99, 28], 37: [22, 91, 32, 37], 35: [22, 91, 64, 35], 9: [22, 93, 40, 9], 75: [22, 93, 34, 75], 79: [22, 6, 57, 79], 70: [22, 6, 57, 70], 41: [22, 43, 47, 24, 41], 3: [22, 43, 63, 10, 3], 61: [22, 43, 63, 81, 61]}) (23, {23: [23], 55: [23, 55], 69: [23, 69], 101: [23, 101], 89: [23, 89], 29: [23, 55, 29], 35: [23, 55, 35], 42: [23, 55, 42], 16: [23, 55, 16], 22: [23, 69, 22], 93: [23, 69, 93], 8: [23, 69, 8], 46: [23, 69, 46], 25: [23, 69, 25], 26: [23, 69, 26], 94: [23, 101, 94], 73: [23, 101, 73], 21: [23, 101, 21], 96: [23, 101, 96], 99: [23, 101, 99], 57: [23, 89, 57], 4: [23, 55, 29, 4], 43: [23, 55, 29, 43], 19: [23, 55, 29, 19], 50: [23, 55, 29, 50], 59: [23, 55, 29, 59], 36: [23, 55, 35, 36], 49: [23, 55, 35, 49], 74: [23, 55, 35, 74], 37: [23, 55, 35, 37], 3: [23, 55, 42, 3], 33: [23, 55, 42, 33], 40: [23, 55, 42, 40], 91: [23, 55, 42, 91], 44: [23, 55, 42, 44], 24: [23, 55, 42, 24], 90: [23, 55, 42, 90], 63: [23, 55, 42, 63], 48: [23, 55, 16, 48], 56: [23, 55, 16, 56], 9: [23, 55, 16, 9], 81: [23, 55, 16, 81], 79: [23, 55, 16, 79], 6: [23, 55, 16, 6], 72: [23, 69, 22, 72], 97: [23, 69, 22, 97], 58: [23, 69, 93, 58], 34: [23, 69, 93, 34], 71: [23, 69, 93, 71], 39: [23, 69, 93, 39], 83: [23, 69, 93, 83], 88: [23, 69, 8, 88], 18: [23, 69, 46, 18], 12: [23, 69, 46, 12], 51: [23, 69, 46, 51], 84: [23, 69, 25, 84], 87: [23, 69, 25, 87], 67: [23, 69, 25, 67], 32: [23, 69, 25, 32], 66: [23, 69, 25, 66], 98: [23, 69, 26, 98], 62: [23, 101, 94, 62], 77: [23, 101, 73, 77], 1: [23, 101, 73, 1], 11: [23, 101, 21, 11], 30: [23, 101, 21, 30], 82: [23, 101, 21, 82], 5: [23, 101, 21, 5], 85: [23, 101, 21, 85], 20: [23, 101, 96, 20], 28: [23, 101, 99, 28], 52: [23, 89, 57, 52], 70: [23, 89, 57, 70], 53: [23, 55, 29, 4, 53], 78: [23, 55, 29, 4, 78], 47: [23, 55, 29, 43, 47], 27: [23, 55, 29, 43, 27], 31: [23, 55, 29, 43, 31], 68: [23, 55, 29, 19, 68], 92: [23, 55, 29, 19, 92], 2: [23, 55, 29, 50, 2], 54: [23, 55, 29, 50, 54], 13: [23, 55, 29, 59, 13], 86: [23, 55, 29, 59, 86], 65: [23, 55, 29, 59, 65], 95: [23, 55, 35, 49, 95], 10: [23, 55, 35, 49, 10], 61: [23, 55, 42, 33, 61], 75: [23, 55, 42, 33, 75], 38: [23, 55, 42, 40, 38], 64: [23, 55, 42, 91, 64], 7: [23, 55, 42, 91, 7], 100: [23, 55, 42, 91, 100], 41: [23, 55, 42, 24, 41], 14: [23, 55, 42, 24, 14], 15: [23, 55, 42, 63, 15], 17: [23, 69, 22, 72, 17], 76: [23, 69, 22, 72, 76], 45: [23, 69, 93, 83, 45], 60: [23, 69, 25, 87, 60], 80: [23, 101, 94, 62, 80]}) (24, {24: [24], 90: [24, 90], 25: [24, 25], 71: [24, 71], 6: [24, 6], 34: [24, 34], 66: [24, 66], 54: [24, 54], 74: [24, 74], 41: [24, 41], 68: [24, 68], 96: [24, 96], 78: [24, 78], 26: [24, 26], 14: [24, 14], 100: [24, 90, 100], 93: [24, 90, 93], 59: [24, 90, 59], 1: [24, 90, 1], 10: [24, 90, 10], 84: [24, 25, 84], 87: [24, 25, 87], 67: [24, 25, 67], 32: [24, 25, 32], 56: [24, 25, 56], 37: [24, 71, 37], 50: [24, 71, 50], 20: [24, 71, 20], 7: [24, 71, 7], 95: [24, 71, 95], 57: [24, 6, 57], 75: [24, 34, 75], 18: [24, 34, 18], 55: [24, 34, 55], 38: [24, 34, 38], 46: [24, 34, 46], 29: [24, 34, 29], 61: [24, 66, 61], 60: [24, 66, 60], 43: [24, 54, 43], 16: [24, 54, 16], 11: [24, 54, 11], 9: [24, 54, 9], 70: [24, 54, 70], 22: [24, 74, 22], 62: [24, 74, 62], 51: [24, 74, 51], 82: [24, 74, 82], 53: [24, 74, 53], 19: [24, 41, 19], 94: [24, 41, 94], 21: [24, 41, 21], 83: [24, 41, 83], 13: [24, 68, 13], 40: [24, 68, 40], 33: [24, 96, 33], 89: [24, 96, 89], 31: [24, 78, 31], 69: [24, 78, 69], 12: [24, 78, 12], 23: [24, 78, 23], 81: [24, 78, 81], 101: [24, 26, 101], 98: [24, 26, 98], 39: [24, 14, 39], 47: [24, 90, 100, 47], 36: [24, 90, 100, 36], 58: [24, 90, 100, 58], 92: [24, 90, 100, 92], 8: [24, 90, 59, 8], 44: [24, 90, 59, 44], 97: [24, 90, 59, 97], 86: [24, 90, 59, 86], 65: [24, 90, 59, 65], 79: [24, 90, 1, 79], 48: [24, 90, 10, 48], 3: [24, 90, 10, 3], 77: [24, 25, 56, 77], 2: [24, 71, 50, 2], 88: [24, 71, 50, 88], 52: [24, 71, 50, 52], 42: [24, 71, 50, 42], 99: [24, 71, 20, 99], 30: [24, 71, 20, 30], 4: [24, 71, 20, 4], 49: [24, 71, 95, 49], 35: [24, 34, 55, 35], 72: [24, 66, 61, 72], 73: [24, 66, 61, 73], 63: [24, 54, 43, 63], 27: [24, 54, 43, 27], 80: [24, 54, 11, 80], 85: [24, 54, 9, 85], 64: [24, 54, 70, 64], 91: [24, 74, 22, 91], 45: [24, 74, 53, 45], 5: [24, 41, 21, 5], 28: [24, 78, 81, 28], 15: [24, 90, 100, 47, 15], 17: [24, 90, 100, 58, 17], 76: [24, 71, 50, 2, 76]}) (25, {25: [25], 84: [25, 84], 26: [25, 26], 87: [25, 87], 67: [25, 67], 32: [25, 32], 56: [25, 56], 66: [25, 66], 98: [25, 84, 98], 13: [25, 84, 13], 14: [25, 84, 14], 101: [25, 26, 101], 83: [25, 26, 83], 60: [25, 87, 60], 93: [25, 87, 93], 23: [25, 67, 23], 16: [25, 67, 16], 54: [25, 67, 54], 37: [25, 32, 37], 77: [25, 56, 77], 10: [25, 56, 10], 90: [25, 56, 90], 58: [25, 56, 58], 61: [25, 66, 61], 95: [25, 66, 95], 68: [25, 66, 68], 47: [25, 84, 98, 47], 46: [25, 84, 98, 46], 97: [25, 84, 98, 97], 88: [25, 84, 98, 88], 36: [25, 84, 98, 36], 62: [25, 84, 98, 62], 5: [25, 84, 98, 5], 38: [25, 84, 98, 38], 30: [25, 84, 13, 30], 4: [25, 84, 13, 4], 59: [25, 84, 14, 59], 20: [25, 84, 14, 20], 39: [25, 84, 14, 39], 74: [25, 84, 14, 74], 82: [25, 84, 14, 82], 94: [25, 26, 101, 94], 73: [25, 26, 101, 73], 21: [25, 26, 101, 21], 96: [25, 26, 101, 96], 8: [25, 26, 101, 8], 99: [25, 26, 101, 99], 89: [25, 26, 83, 89], 45: [25, 26, 83, 45], 52: [25, 26, 83, 52], 43: [25, 26, 83, 43], 44: [25, 26, 83, 44], 41: [25, 87, 60, 41], 79: [25, 87, 60, 79], 18: [25, 87, 60, 18], 40: [25, 87, 60, 40], 34: [25, 87, 93, 34], 71: [25, 87, 93, 71], 55: [25, 67, 23, 55], 69: [25, 67, 23, 69], 48: [25, 67, 16, 48], 9: [25, 67, 16, 9], 81: [25, 67, 16, 81], 6: [25, 67, 16, 6], 11: [25, 67, 54, 11], 70: [25, 67, 54, 70], 57: [25, 32, 37, 57], 29: [25, 56, 77, 29], 15: [25, 56, 77, 15], 3: [25, 56, 10, 3], 31: [25, 56, 10, 31], 100: [25, 56, 90, 100], 1: [25, 56, 90, 1], 17: [25, 56, 58, 17], 22: [25, 56, 58, 22], 92: [25, 66, 61, 92], 72: [25, 66, 61, 72], 49: [25, 66, 95, 49], 19: [25, 84, 98, 47, 19], 24: [25, 84, 98, 47, 24], 2: [25, 84, 98, 47, 2], 12: [25, 84, 98, 46, 12], 51: [25, 84, 98, 46, 51], 64: [25, 84, 98, 97, 64], 7: [25, 84, 98, 97, 7], 65: [25, 84, 98, 88, 65], 42: [25, 84, 98, 62, 42], 86: [25, 84, 98, 62, 86], 80: [25, 84, 98, 62, 80], 78: [25, 84, 98, 38, 78], 28: [25, 84, 13, 30, 28], 53: [25, 84, 13, 4, 53], 33: [25, 84, 14, 39, 33], 85: [25, 26, 101, 21, 85], 50: [25, 26, 101, 99, 50], 35: [25, 26, 83, 45, 35], 63: [25, 26, 83, 43, 63], 27: [25, 26, 83, 43, 27], 91: [25, 87, 60, 40, 91], 75: [25, 87, 93, 34, 75], 76: [25, 66, 61, 72, 76]}) (26, {26: [26], 101: [26, 101], 83: [26, 83], 25: [26, 25], 98: [26, 98], 94: [26, 101, 94], 73: [26, 101, 73], 21: [26, 101, 21], 96: [26, 101, 96], 8: [26, 101, 8], 99: [26, 101, 99], 89: [26, 83, 89], 45: [26, 83, 45], 52: [26, 83, 52], 43: [26, 83, 43], 93: [26, 83, 93], 44: [26, 83, 44], 84: [26, 25, 84], 87: [26, 25, 87], 67: [26, 25, 67], 32: [26, 25, 32], 56: [26, 25, 56], 66: [26, 25, 66], 47: [26, 98, 47], 46: [26, 98, 46], 97: [26, 98, 97], 88: [26, 98, 88], 36: [26, 98, 36], 62: [26, 98, 62], 5: [26, 98, 5], 38: [26, 98, 38], 54: [26, 98, 54], 90: [26, 98, 90], 13: [26, 98, 13], 57: [26, 101, 94, 57], 24: [26, 101, 94, 24], 71: [26, 101, 73, 71], 6: [26, 101, 73, 6], 77: [26, 101, 73, 77], 1: [26, 101, 73, 1], 11: [26, 101, 21, 11], 30: [26, 101, 21, 30], 82: [26, 101, 21, 82], 3: [26, 101, 21, 3], 85: [26, 101, 21, 85], 59: [26, 101, 96, 59], 33: [26, 101, 96, 33], 20: [26, 101, 96, 20], 4: [26, 101, 99, 4], 19: [26, 101, 99, 19], 18: [26, 101, 99, 18], 22: [26, 101, 99, 22], 28: [26, 101, 99, 28], 50: [26, 101, 99, 50], 55: [26, 83, 89, 55], 70: [26, 83, 45, 70], 34: [26, 83, 45, 34], 35: [26, 83, 45, 35], 39: [26, 83, 52, 39], 23: [26, 83, 52, 23], 74: [26, 83, 43, 74], 63: [26, 83, 43, 63], 27: [26, 83, 43, 27], 48: [26, 83, 43, 48], 31: [26, 83, 43, 31], 58: [26, 83, 93, 58], 40: [26, 83, 93, 40], 72: [26, 83, 44, 72], 92: [26, 83, 44, 92], 51: [26, 83, 44, 51], 10: [26, 83, 44, 10], 14: [26, 25, 84, 14], 60: [26, 25, 87, 60], 16: [26, 25, 67, 16], 37: [26, 25, 32, 37], 61: [26, 25, 66, 61], 95: [26, 25, 66, 95], 68: [26, 25, 66, 68], 15: [26, 98, 47, 15], 29: [26, 98, 47, 29], 2: [26, 98, 47, 2], 12: [26, 98, 46, 12], 9: [26, 98, 46, 9], 64: [26, 98, 97, 64], 7: [26, 98, 97, 7], 81: [26, 98, 88, 81], 65: [26, 98, 88, 65], 49: [26, 98, 36, 49], 42: [26, 98, 62, 42], 86: [26, 98, 62, 86], 80: [26, 98, 62, 80], 41: [26, 98, 5, 41], 78: [26, 98, 38, 78], 100: [26, 98, 90, 100], 69: [26, 101, 94, 57, 69], 79: [26, 101, 94, 57, 79], 53: [26, 101, 73, 1, 53], 75: [26, 101, 96, 33, 75], 91: [26, 101, 99, 22, 91], 17: [26, 83, 93, 58, 17], 76: [26, 83, 44, 72, 76]}) (27, {27: [27], 14: [27, 14], 84: [27, 84], 67: [27, 67], 89: [27, 89], 59: [27, 14, 59], 20: [27, 14, 20], 39: [27, 14, 39], 74: [27, 14, 74], 82: [27, 14, 82], 32: [27, 84, 32], 98: [27, 84, 98], 13: [27, 84, 13], 25: [27, 84, 25], 23: [27, 67, 23], 16: [27, 67, 16], 54: [27, 67, 54], 57: [27, 89, 57], 55: [27, 89, 55], 96: [27, 14, 59, 96], 26: [27, 14, 59, 26], 62: [27, 14, 59, 62], 8: [27, 14, 59, 8], 44: [27, 14, 59, 44], 11: [27, 14, 59, 11], 18: [27, 14, 59, 18], 97: [27, 14, 59, 97], 36: [27, 14, 59, 36], 78: [27, 14, 59, 78], 86: [27, 14, 59, 86], 65: [27, 14, 59, 65], 22: [27, 14, 20, 22], 56: [27, 14, 20, 56], 99: [27, 14, 20, 99], 19: [27, 14, 20, 19], 58: [27, 14, 20, 58], 83: [27, 14, 20, 83], 30: [27, 14, 20, 30], 68: [27, 14, 20, 68], 81: [27, 14, 20, 81], 46: [27, 14, 20, 46], 4: [27, 14, 20, 4], 101: [27, 14, 39, 101], 28: [27, 14, 39, 28], 42: [27, 14, 39, 42], 33: [27, 14, 39, 33], 51: [27, 14, 74, 51], 87: [27, 14, 74, 87], 53: [27, 14, 74, 53], 93: [27, 84, 32, 93], 37: [27, 84, 32, 37], 47: [27, 84, 98, 47], 88: [27, 84, 98, 88], 5: [27, 84, 98, 5], 38: [27, 84, 98, 38], 90: [27, 84, 98, 90], 60: [27, 84, 13, 60], 66: [27, 84, 25, 66], 69: [27, 67, 23, 69], 48: [27, 67, 16, 48], 9: [27, 67, 16, 9], 79: [27, 67, 16, 79], 6: [27, 67, 16, 6], 71: [27, 67, 54, 71], 43: [27, 67, 54, 43], 70: [27, 67, 54, 70], 24: [27, 89, 57, 24], 52: [27, 89, 57, 52], 40: [27, 89, 57, 40], 12: [27, 89, 57, 12], 29: [27, 89, 55, 29], 35: [27, 89, 55, 35], 80: [27, 14, 59, 62, 80], 72: [27, 14, 59, 44, 72], 92: [27, 14, 59, 44, 92], 94: [27, 14, 59, 44, 94], 10: [27, 14, 59, 44, 10], 95: [27, 14, 59, 11, 95], 49: [27, 14, 59, 18, 49], 64: [27, 14, 59, 97, 64], 77: [27, 14, 59, 97, 77], 7: [27, 14, 59, 97, 7], 31: [27, 14, 59, 78, 31], 17: [27, 14, 59, 86, 17], 15: [27, 14, 59, 65, 15], 45: [27, 14, 59, 65, 45], 91: [27, 14, 20, 22, 91], 50: [27, 14, 20, 99, 50], 63: [27, 14, 20, 19, 63], 100: [27, 14, 20, 58, 100], 3: [27, 14, 20, 81, 3], 61: [27, 14, 20, 81, 61], 41: [27, 14, 20, 81, 41], 73: [27, 14, 39, 101, 73], 21: [27, 14, 39, 101, 21], 75: [27, 14, 39, 33, 75], 2: [27, 14, 74, 53, 2], 34: [27, 84, 32, 93, 34], 1: [27, 84, 98, 90, 1], 85: [27, 67, 16, 9, 85], 76: [27, 14, 59, 44, 72, 76]}) (28, {28: [28], 73: [28, 73], 62: [28, 62], 31: [28, 31], 37: [28, 37], 80: [28, 80], 67: [28, 67], 32: [28, 32], 74: [28, 74], 71: [28, 73, 71], 6: [28, 73, 6], 77: [28, 73, 77], 83: [28, 73, 83], 1: [28, 73, 1], 42: [28, 62, 42], 86: [28, 62, 86], 4: [28, 62, 4], 96: [28, 62, 96], 44: [28, 62, 44], 12: [28, 31, 12], 48: [28, 31, 48], 88: [28, 31, 88], 91: [28, 31, 91], 33: [28, 31, 33], 85: [28, 31, 85], 57: [28, 37, 57], 95: [28, 80, 95], 13: [28, 80, 13], 10: [28, 80, 10], 23: [28, 80, 23], 46: [28, 80, 46], 16: [28, 67, 16], 54: [28, 67, 54], 93: [28, 32, 93], 22: [28, 74, 22], 59: [28, 74, 59], 51: [28, 74, 51], 87: [28, 74, 87], 82: [28, 74, 82], 53: [28, 74, 53], 50: [28, 73, 71, 50], 20: [28, 73, 71, 20], 7: [28, 73, 71, 7], 9: [28, 73, 77, 9], 29: [28, 73, 77, 29], 45: [28, 73, 77, 45], 56: [28, 73, 77, 56], 70: [28, 73, 77, 70], 15: [28, 73, 77, 15], 43: [28, 73, 77, 43], 101: [28, 73, 77, 101], 21: [28, 73, 77, 21], 89: [28, 73, 83, 89], 52: [28, 73, 83, 52], 79: [28, 73, 1, 79], 69: [28, 73, 1, 69], 3: [28, 62, 42, 3], 40: [28, 62, 42, 40], 24: [28, 62, 42, 24], 90: [28, 62, 42, 90], 63: [28, 62, 42, 63], 18: [28, 62, 86, 18], 17: [28, 62, 86, 17], 26: [28, 62, 86, 26], 78: [28, 62, 4, 78], 72: [28, 62, 44, 72], 92: [28, 62, 44, 92], 11: [28, 62, 44, 11], 94: [28, 62, 44, 94], 27: [28, 31, 12, 27], 81: [28, 31, 12, 81], 68: [28, 31, 12, 68], 36: [28, 31, 48, 36], 5: [28, 31, 48, 5], 99: [28, 31, 48, 99], 64: [28, 31, 88, 64], 65: [28, 31, 88, 65], 39: [28, 31, 88, 39], 38: [28, 31, 91, 38], 100: [28, 31, 91, 100], 61: [28, 31, 33, 61], 75: [28, 31, 33, 75], 25: [28, 31, 85, 25], 34: [28, 80, 95, 34], 49: [28, 80, 95, 49], 14: [28, 80, 13, 14], 30: [28, 80, 13, 30], 60: [28, 80, 13, 60], 55: [28, 80, 23, 55], 58: [28, 80, 46, 58], 97: [28, 74, 22, 97], 8: [28, 74, 59, 8], 2: [28, 74, 53, 2], 19: [28, 73, 71, 50, 19], 84: [28, 73, 71, 20, 84], 98: [28, 73, 77, 9, 98], 35: [28, 73, 77, 45, 35], 47: [28, 73, 77, 15, 47], 66: [28, 62, 42, 24, 66], 41: [28, 62, 42, 24, 41], 76: [28, 62, 44, 72, 76]}) (29, {29: [29], 4: [29, 4], 21: [29, 21], 43: [29, 43], 19: [29, 19], 50: [29, 50], 59: [29, 59], 53: [29, 4, 53], 78: [29, 4, 78], 23: [29, 4, 23], 83: [29, 4, 83], 11: [29, 21, 11], 30: [29, 21, 30], 87: [29, 21, 87], 82: [29, 21, 82], 5: [29, 21, 5], 3: [29, 21, 3], 85: [29, 21, 85], 1: [29, 21, 1], 74: [29, 43, 74], 47: [29, 43, 47], 63: [29, 43, 63], 27: [29, 43, 27], 25: [29, 43, 25], 73: [29, 43, 73], 48: [29, 43, 48], 31: [29, 43, 31], 68: [29, 19, 68], 62: [29, 19, 62], 98: [29, 19, 98], 97: [29, 19, 97], 92: [29, 19, 92], 2: [29, 50, 2], 88: [29, 50, 88], 22: [29, 50, 22], 54: [29, 50, 54], 52: [29, 50, 52], 42: [29, 50, 42], 96: [29, 59, 96], 13: [29, 59, 13], 26: [29, 59, 26], 8: [29, 59, 8], 44: [29, 59, 44], 18: [29, 59, 18], 36: [29, 59, 36], 86: [29, 59, 86], 65: [29, 59, 65], 69: [29, 4, 53, 69], 45: [29, 4, 53, 45], 55: [29, 4, 53, 55], 12: [29, 4, 78, 12], 81: [29, 4, 78, 81], 33: [29, 4, 78, 33], 101: [29, 4, 23, 101], 89: [29, 4, 23, 89], 93: [29, 4, 83, 93], 80: [29, 21, 11, 80], 95: [29, 21, 11, 95], 24: [29, 21, 11, 24], 28: [29, 21, 30, 28], 60: [29, 21, 87, 60], 51: [29, 21, 82, 51], 14: [29, 21, 82, 14], 9: [29, 21, 5, 9], 41: [29, 21, 5, 41], 72: [29, 21, 3, 72], 16: [29, 21, 1, 16], 70: [29, 21, 1, 70], 79: [29, 21, 1, 79], 15: [29, 43, 47, 15], 10: [29, 43, 63, 10], 100: [29, 43, 63, 100], 20: [29, 43, 63, 20], 66: [29, 43, 63, 66], 84: [29, 43, 27, 84], 67: [29, 43, 27, 67], 32: [29, 43, 25, 32], 56: [29, 43, 25, 56], 71: [29, 43, 73, 71], 6: [29, 43, 73, 6], 77: [29, 43, 73, 77], 7: [29, 43, 48, 7], 99: [29, 43, 48, 99], 91: [29, 43, 31, 91], 40: [29, 19, 68, 40], 46: [29, 19, 98, 46], 38: [29, 19, 98, 38], 90: [29, 19, 98, 90], 64: [29, 19, 97, 64], 34: [29, 19, 92, 34], 76: [29, 50, 2, 76], 39: [29, 50, 88, 39], 94: [29, 59, 44, 94], 49: [29, 59, 18, 49], 17: [29, 59, 86, 17], 35: [29, 4, 53, 45, 35], 61: [29, 4, 78, 81, 61], 58: [29, 4, 78, 81, 58], 75: [29, 4, 78, 33, 75], 57: [29, 4, 23, 89, 57], 37: [29, 21, 30, 28, 37]}) (30, {30: [30], 80: [30, 80], 28: [30, 28], 95: [30, 80, 95], 85: [30, 80, 85], 86: [30, 80, 86], 13: [30, 80, 13], 10: [30, 80, 10], 1: [30, 80, 1], 23: [30, 80, 23], 46: [30, 80, 46], 73: [30, 28, 73], 62: [30, 28, 62], 31: [30, 28, 31], 37: [30, 28, 37], 67: [30, 28, 67], 32: [30, 28, 32], 74: [30, 28, 74], 34: [30, 80, 95, 34], 49: [30, 80, 95, 49], 20: [30, 80, 95, 20], 81: [30, 80, 95, 81], 25: [30, 80, 85, 25], 5: [30, 80, 85, 5], 36: [30, 80, 85, 36], 18: [30, 80, 86, 18], 17: [30, 80, 86, 17], 59: [30, 80, 86, 59], 26: [30, 80, 86, 26], 6: [30, 80, 86, 6], 16: [30, 80, 86, 16], 14: [30, 80, 13, 14], 83: [30, 80, 13, 83], 4: [30, 80, 13, 4], 60: [30, 80, 13, 60], 48: [30, 80, 10, 48], 3: [30, 80, 10, 3], 70: [30, 80, 1, 70], 79: [30, 80, 1, 79], 69: [30, 80, 1, 69], 53: [30, 80, 1, 53], 55: [30, 80, 23, 55], 101: [30, 80, 23, 101], 89: [30, 80, 23, 89], 12: [30, 80, 46, 12], 58: [30, 80, 46, 58], 51: [30, 80, 46, 51], 22: [30, 80, 46, 22], 9: [30, 80, 46, 9], 71: [30, 28, 73, 71], 77: [30, 28, 73, 77], 42: [30, 28, 62, 42], 96: [30, 28, 62, 96], 44: [30, 28, 62, 44], 88: [30, 28, 31, 88], 91: [30, 28, 31, 91], 33: [30, 28, 31, 33], 57: [30, 28, 37, 57], 54: [30, 28, 67, 54], 93: [30, 28, 32, 93], 87: [30, 28, 74, 87], 82: [30, 28, 74, 82], 75: [30, 80, 95, 34, 75], 38: [30, 80, 95, 34, 38], 29: [30, 80, 95, 34, 29], 40: [30, 80, 95, 49, 40], 84: [30, 80, 95, 20, 84], 56: [30, 80, 95, 20, 56], 99: [30, 80, 95, 20, 99], 19: [30, 80, 95, 20, 19], 68: [30, 80, 95, 20, 68], 61: [30, 80, 95, 81, 61], 41: [30, 80, 95, 81, 41], 66: [30, 80, 85, 25, 66], 8: [30, 80, 85, 36, 8], 52: [30, 80, 85, 36, 52], 39: [30, 80, 85, 36, 39], 98: [30, 80, 86, 18, 98], 94: [30, 80, 86, 18, 94], 11: [30, 80, 86, 59, 11], 97: [30, 80, 86, 59, 97], 78: [30, 80, 86, 59, 78], 65: [30, 80, 86, 59, 65], 45: [30, 80, 13, 83, 45], 43: [30, 80, 13, 83, 43], 7: [30, 80, 10, 48, 7], 72: [30, 80, 10, 3, 72], 64: [30, 80, 1, 70, 64], 2: [30, 80, 1, 53, 2], 35: [30, 80, 23, 55, 35], 21: [30, 80, 23, 101, 21], 27: [30, 80, 46, 12, 27], 100: [30, 80, 46, 58, 100], 50: [30, 80, 46, 9, 50], 15: [30, 28, 73, 77, 15], 24: [30, 28, 62, 42, 24], 90: [30, 28, 62, 42, 90], 63: [30, 28, 62, 42, 63], 92: [30, 28, 62, 44, 92], 47: [30, 80, 95, 34, 38, 47], 76: [30, 80, 10, 3, 72, 76]}) (31, {31: [31], 12: [31, 12], 48: [31, 48], 83: [31, 83], 88: [31, 88], 91: [31, 91], 33: [31, 33], 85: [31, 85], 27: [31, 12, 27], 44: [31, 12, 44], 101: [31, 12, 101], 22: [31, 12, 22], 81: [31, 12, 81], 68: [31, 12, 68], 4: [31, 12, 4], 7: [31, 48, 7], 36: [31, 48, 36], 5: [31, 48, 5], 99: [31, 48, 99], 89: [31, 83, 89], 45: [31, 83, 45], 52: [31, 83, 52], 43: [31, 83, 43], 93: [31, 83, 93], 64: [31, 88, 64], 95: [31, 88, 95], 65: [31, 88, 65], 40: [31, 88, 40], 39: [31, 88, 39], 74: [31, 91, 74], 50: [31, 91, 50], 32: [31, 91, 32], 38: [31, 91, 38], 100: [31, 91, 100], 73: [31, 33, 73], 71: [31, 33, 71], 61: [31, 33, 61], 70: [31, 33, 70], 75: [31, 33, 75], 1: [31, 85, 1], 25: [31, 85, 25], 14: [31, 12, 27, 14], 84: [31, 12, 27, 84], 67: [31, 12, 27, 67], 72: [31, 12, 44, 72], 92: [31, 12, 44, 92], 51: [31, 12, 44, 51], 56: [31, 12, 44, 56], 11: [31, 12, 44, 11], 94: [31, 12, 44, 94], 10: [31, 12, 44, 10], 21: [31, 12, 101, 21], 96: [31, 12, 101, 96], 8: [31, 12, 101, 8], 59: [31, 12, 22, 59], 6: [31, 12, 22, 6], 97: [31, 12, 22, 97], 3: [31, 12, 81, 3], 55: [31, 12, 81, 55], 30: [31, 12, 81, 30], 42: [31, 12, 81, 42], 41: [31, 12, 81, 41], 58: [31, 12, 81, 58], 28: [31, 12, 81, 28], 13: [31, 12, 68, 13], 53: [31, 12, 4, 53], 78: [31, 12, 4, 78], 23: [31, 12, 4, 23], 26: [31, 48, 36, 26], 46: [31, 48, 36, 46], 49: [31, 48, 36, 49], 19: [31, 48, 36, 19], 29: [31, 48, 36, 29], 9: [31, 48, 5, 9], 18: [31, 48, 99, 18], 77: [31, 48, 99, 77], 57: [31, 83, 89, 57], 34: [31, 83, 45, 34], 35: [31, 83, 45, 35], 47: [31, 83, 43, 47], 63: [31, 83, 43, 63], 82: [31, 88, 64, 82], 15: [31, 88, 64, 15], 20: [31, 88, 95, 20], 86: [31, 88, 65, 86], 62: [31, 91, 74, 62], 87: [31, 91, 74, 87], 2: [31, 91, 50, 2], 54: [31, 91, 50, 54], 37: [31, 91, 32, 37], 66: [31, 91, 38, 66], 69: [31, 91, 100, 69], 79: [31, 33, 70, 79], 16: [31, 85, 1, 16], 98: [31, 12, 27, 84, 98], 17: [31, 12, 44, 72, 17], 76: [31, 12, 44, 72, 76], 90: [31, 12, 44, 56, 90], 80: [31, 12, 44, 11, 80], 24: [31, 12, 44, 11, 24], 60: [31, 12, 68, 13, 60]}) (32, {32: [32], 93: [32, 93], 37: [32, 37], 58: [32, 93, 58], 40: [32, 93, 40], 34: [32, 93, 34], 71: [32, 93, 71], 39: [32, 93, 39], 83: [32, 93, 83], 43: [32, 93, 43], 74: [32, 37, 74], 57: [32, 37, 57], 100: [32, 93, 58, 100], 26: [32, 93, 58, 26], 87: [32, 93, 58, 87], 17: [32, 93, 58, 17], 22: [32, 93, 58, 22], 9: [32, 93, 40, 9], 91: [32, 93, 40, 91], 38: [32, 93, 40, 38], 96: [32, 93, 40, 96], 30: [32, 93, 40, 30], 49: [32, 93, 40, 49], 20: [32, 93, 34, 20], 75: [32, 93, 34, 75], 18: [32, 93, 34, 18], 55: [32, 93, 34, 55], 46: [32, 93, 34, 46], 29: [32, 93, 34, 29], 10: [32, 93, 71, 10], 50: [32, 93, 71, 50], 7: [32, 93, 71, 7], 95: [32, 93, 71, 95], 59: [32, 93, 39, 59], 101: [32, 93, 39, 101], 28: [32, 93, 39, 28], 42: [32, 93, 39, 42], 33: [32, 93, 39, 33], 13: [32, 93, 39, 13], 89: [32, 93, 83, 89], 45: [32, 93, 83, 45], 52: [32, 93, 83, 52], 44: [32, 93, 83, 44], 47: [32, 93, 43, 47], 63: [32, 93, 43, 63], 27: [32, 93, 43, 27], 25: [32, 93, 43, 25], 73: [32, 93, 43, 73], 48: [32, 93, 43, 48], 11: [32, 93, 43, 11], 31: [32, 93, 43, 31], 62: [32, 37, 74, 62], 51: [32, 37, 74, 51], 82: [32, 37, 74, 82], 53: [32, 37, 74, 53], 24: [32, 37, 57, 24], 16: [32, 37, 57, 16], 69: [32, 37, 57, 69], 12: [32, 37, 57, 12], 79: [32, 37, 57, 79], 70: [32, 37, 57, 70], 36: [32, 93, 58, 100, 36], 21: [32, 93, 58, 100, 21], 92: [32, 93, 58, 100, 92], 98: [32, 93, 58, 26, 98], 60: [32, 93, 58, 87, 60], 84: [32, 93, 58, 17, 84], 72: [32, 93, 58, 22, 72], 6: [32, 93, 58, 22, 6], 97: [32, 93, 58, 22, 97], 85: [32, 93, 40, 9, 85], 94: [32, 93, 40, 9, 94], 1: [32, 93, 40, 9, 1], 99: [32, 93, 40, 91, 99], 64: [32, 93, 40, 91, 64], 78: [32, 93, 40, 38, 78], 66: [32, 93, 40, 38, 66], 80: [32, 93, 40, 30, 80], 5: [32, 93, 40, 49, 5], 56: [32, 93, 34, 20, 56], 19: [32, 93, 34, 20, 19], 68: [32, 93, 34, 20, 68], 86: [32, 93, 34, 20, 86], 81: [32, 93, 34, 20, 81], 4: [32, 93, 34, 20, 4], 67: [32, 93, 34, 75, 67], 35: [32, 93, 34, 55, 35], 23: [32, 93, 34, 46, 23], 3: [32, 93, 71, 10, 3], 2: [32, 93, 71, 50, 2], 88: [32, 93, 71, 50, 88], 54: [32, 93, 71, 50, 54], 8: [32, 93, 39, 59, 8], 65: [32, 93, 39, 59, 65], 90: [32, 93, 39, 42, 90], 61: [32, 93, 39, 33, 61], 14: [32, 93, 39, 13, 14], 15: [32, 93, 43, 47, 15], 77: [32, 93, 43, 73, 77], 41: [32, 37, 57, 24, 41], 76: [32, 93, 58, 22, 72, 76]}) (33, {33: [33], 73: [33, 73], 71: [33, 71], 4: [33, 4], 61: [33, 61], 70: [33, 70], 75: [33, 75], 6: [33, 73, 6], 77: [33, 73, 77], 83: [33, 73, 83], 1: [33, 73, 1], 37: [33, 71, 37], 10: [33, 71, 10], 50: [33, 71, 50], 20: [33, 71, 20], 7: [33, 71, 7], 95: [33, 71, 95], 53: [33, 4, 53], 78: [33, 4, 78], 23: [33, 4, 23], 59: [33, 61, 59], 92: [33, 61, 92], 72: [33, 61, 72], 22: [33, 61, 22], 100: [33, 61, 100], 84: [33, 70, 84], 64: [33, 70, 64], 9: [33, 70, 9], 79: [33, 70, 79], 52: [33, 70, 52], 81: [33, 75, 81], 67: [33, 75, 67], 40: [33, 75, 40], 96: [33, 75, 96], 57: [33, 73, 6, 57], 54: [33, 73, 6, 54], 29: [33, 73, 77, 29], 45: [33, 73, 77, 45], 56: [33, 73, 77, 56], 15: [33, 73, 77, 15], 43: [33, 73, 77, 43], 101: [33, 73, 77, 101], 21: [33, 73, 77, 21], 89: [33, 73, 83, 89], 93: [33, 73, 83, 93], 44: [33, 73, 83, 44], 16: [33, 73, 1, 16], 69: [33, 73, 1, 69], 74: [33, 71, 37, 74], 48: [33, 71, 10, 48], 46: [33, 71, 10, 46], 3: [33, 71, 10, 3], 31: [33, 71, 10, 31], 2: [33, 71, 50, 2], 19: [33, 71, 50, 19], 88: [33, 71, 50, 88], 42: [33, 71, 50, 42], 99: [33, 71, 20, 99], 58: [33, 71, 20, 58], 30: [33, 71, 20, 30], 68: [33, 71, 20, 68], 86: [33, 71, 20, 86], 32: [33, 71, 20, 32], 51: [33, 71, 7, 51], 34: [33, 71, 95, 34], 49: [33, 71, 95, 49], 55: [33, 4, 53, 55], 13: [33, 4, 78, 13], 12: [33, 4, 78, 12], 26: [33, 61, 59, 26], 62: [33, 61, 59, 62], 8: [33, 61, 59, 8], 11: [33, 61, 59, 11], 18: [33, 61, 59, 18], 97: [33, 61, 59, 97], 36: [33, 61, 59, 36], 65: [33, 61, 59, 65], 47: [33, 61, 92, 47], 17: [33, 61, 72, 17], 98: [33, 61, 72, 98], 76: [33, 61, 72, 76], 91: [33, 61, 22, 91], 14: [33, 70, 84, 14], 25: [33, 70, 84, 25], 82: [33, 70, 64, 82], 39: [33, 70, 64, 39], 35: [33, 70, 64, 35], 85: [33, 70, 9, 85], 94: [33, 70, 9, 94], 28: [33, 70, 52, 28], 41: [33, 75, 81, 41], 38: [33, 75, 40, 38], 24: [33, 73, 6, 57, 24], 90: [33, 73, 77, 56, 90], 63: [33, 73, 77, 43, 63], 27: [33, 73, 77, 43, 27], 87: [33, 73, 77, 21, 87], 5: [33, 73, 77, 21, 5], 60: [33, 71, 50, 2, 60], 80: [33, 71, 20, 30, 80], 66: [33, 70, 84, 25, 66]}) (34, {34: [34], 20: [34, 20], 75: [34, 75], 18: [34, 18], 55: [34, 55], 38: [34, 38], 46: [34, 46], 29: [34, 29], 84: [34, 20, 84], 22: [34, 20, 22], 56: [34, 20, 56], 99: [34, 20, 99], 19: [34, 20, 19], 58: [34, 20, 58], 83: [34, 20, 83], 30: [34, 20, 30], 68: [34, 20, 68], 86: [34, 20, 86], 81: [34, 20, 81], 32: [34, 20, 32], 4: [34, 20, 4], 67: [34, 75, 67], 40: [34, 75, 40], 96: [34, 75, 96], 98: [34, 18, 98], 94: [34, 18, 94], 95: [34, 18, 95], 6: [34, 18, 6], 49: [34, 18, 49], 35: [34, 55, 35], 42: [34, 55, 42], 16: [34, 55, 16], 78: [34, 38, 78], 47: [34, 38, 47], 66: [34, 38, 66], 12: [34, 46, 12], 51: [34, 46, 51], 9: [34, 46, 9], 23: [34, 46, 23], 21: [34, 29, 21], 43: [34, 29, 43], 50: [34, 29, 50], 59: [34, 29, 59], 13: [34, 20, 84, 13], 14: [34, 20, 84, 14], 25: [34, 20, 84, 25], 72: [34, 20, 22, 72], 91: [34, 20, 22, 91], 93: [34, 20, 22, 93], 97: [34, 20, 22, 97], 77: [34, 20, 56, 77], 10: [34, 20, 56, 10], 90: [34, 20, 56, 90], 28: [34, 20, 99, 28], 63: [34, 20, 19, 63], 62: [34, 20, 19, 62], 92: [34, 20, 19, 92], 100: [34, 20, 58, 100], 26: [34, 20, 58, 26], 87: [34, 20, 58, 87], 17: [34, 20, 58, 17], 89: [34, 20, 83, 89], 45: [34, 20, 83, 45], 52: [34, 20, 83, 52], 44: [34, 20, 83, 44], 80: [34, 20, 30, 80], 3: [34, 20, 81, 3], 61: [34, 20, 81, 61], 41: [34, 20, 81, 41], 37: [34, 20, 32, 37], 53: [34, 20, 4, 53], 54: [34, 75, 67, 54], 33: [34, 75, 96, 33], 88: [34, 18, 98, 88], 36: [34, 18, 98, 36], 5: [34, 18, 98, 5], 57: [34, 18, 94, 57], 101: [34, 18, 94, 101], 24: [34, 18, 94, 24], 31: [34, 18, 95, 31], 1: [34, 18, 6, 1], 74: [34, 55, 35, 74], 48: [34, 55, 16, 48], 79: [34, 55, 16, 79], 69: [34, 38, 78, 69], 15: [34, 38, 47, 15], 2: [34, 38, 47, 2], 60: [34, 38, 66, 60], 27: [34, 46, 12, 27], 73: [34, 46, 51, 73], 85: [34, 46, 9, 85], 11: [34, 29, 21, 11], 82: [34, 29, 21, 82], 8: [34, 29, 59, 8], 65: [34, 29, 59, 65], 39: [34, 20, 84, 14, 39], 76: [34, 20, 22, 72, 76], 64: [34, 20, 22, 91, 64], 7: [34, 20, 22, 91, 7], 71: [34, 20, 22, 93, 71], 70: [34, 20, 56, 77, 70]}) (35, {35: [35], 4: [35, 4], 36: [35, 36], 49: [35, 49], 59: [35, 59], 74: [35, 74], 37: [35, 37], 53: [35, 4, 53], 78: [35, 4, 78], 23: [35, 4, 23], 83: [35, 4, 83], 8: [35, 36, 8], 26: [35, 36, 26], 46: [35, 36, 46], 52: [35, 36, 52], 19: [35, 36, 19], 29: [35, 36, 29], 39: [35, 36, 39], 28: [35, 49, 28], 40: [35, 49, 40], 30: [35, 49, 30], 31: [35, 49, 31], 95: [35, 49, 95], 10: [35, 49, 10], 5: [35, 49, 5], 58: [35, 49, 58], 96: [35, 59, 96], 13: [35, 59, 13], 62: [35, 59, 62], 44: [35, 59, 44], 11: [35, 59, 11], 18: [35, 59, 18], 97: [35, 59, 97], 86: [35, 59, 86], 65: [35, 59, 65], 22: [35, 74, 22], 51: [35, 74, 51], 87: [35, 74, 87], 82: [35, 74, 82], 57: [35, 37, 57], 69: [35, 4, 53, 69], 45: [35, 4, 53, 45], 55: [35, 4, 53, 55], 2: [35, 4, 53, 2], 12: [35, 4, 78, 12], 81: [35, 4, 78, 81], 33: [35, 4, 78, 33], 101: [35, 4, 23, 101], 89: [35, 4, 23, 89], 43: [35, 4, 83, 43], 93: [35, 4, 83, 93], 88: [35, 36, 8, 88], 25: [35, 36, 26, 25], 98: [35, 36, 26, 98], 9: [35, 36, 46, 9], 1: [35, 36, 52, 1], 63: [35, 36, 19, 63], 68: [35, 36, 19, 68], 92: [35, 36, 19, 92], 21: [35, 36, 29, 21], 50: [35, 36, 29, 50], 42: [35, 36, 39, 42], 73: [35, 49, 28, 73], 80: [35, 49, 28, 80], 67: [35, 49, 28, 67], 32: [35, 49, 28, 32], 91: [35, 49, 40, 91], 38: [35, 49, 40, 38], 48: [35, 49, 31, 48], 85: [35, 49, 31, 85], 34: [35, 49, 95, 34], 20: [35, 49, 95, 20], 3: [35, 49, 10, 3], 41: [35, 49, 5, 41], 100: [35, 49, 58, 100], 17: [35, 49, 58, 17], 14: [35, 59, 13, 14], 60: [35, 59, 13, 60], 72: [35, 59, 44, 72], 56: [35, 59, 44, 56], 94: [35, 59, 44, 94], 24: [35, 59, 11, 24], 6: [35, 59, 18, 6], 64: [35, 59, 97, 64], 84: [35, 59, 97, 84], 77: [35, 59, 97, 77], 7: [35, 59, 97, 7], 16: [35, 59, 86, 16], 15: [35, 59, 65, 15], 79: [35, 37, 57, 79], 70: [35, 37, 57, 70], 76: [35, 4, 53, 2, 76], 27: [35, 4, 78, 12, 27], 61: [35, 4, 78, 81, 61], 71: [35, 4, 78, 33, 71], 75: [35, 4, 78, 33, 75], 99: [35, 4, 23, 101, 99], 47: [35, 4, 83, 43, 47], 66: [35, 36, 26, 25, 66], 54: [35, 36, 26, 98, 54], 90: [35, 36, 26, 98, 90]}) (36, {36: [36], 8: [36, 8], 26: [36, 26], 46: [36, 46], 52: [36, 52], 49: [36, 49], 23: [36, 23], 19: [36, 19], 29: [36, 29], 39: [36, 39], 88: [36, 8, 88], 101: [36, 8, 101], 83: [36, 26, 83], 25: [36, 26, 25], 98: [36, 26, 98], 18: [36, 46, 18], 12: [36, 46, 12], 58: [36, 46, 58], 51: [36, 46, 51], 22: [36, 46, 22], 9: [36, 46, 9], 1: [36, 52, 1], 28: [36, 52, 28], 40: [36, 49, 40], 30: [36, 49, 30], 31: [36, 49, 31], 95: [36, 49, 95], 10: [36, 49, 10], 5: [36, 49, 5], 55: [36, 23, 55], 69: [36, 23, 69], 89: [36, 23, 89], 63: [36, 19, 63], 68: [36, 19, 68], 62: [36, 19, 62], 97: [36, 19, 97], 92: [36, 19, 92], 4: [36, 29, 4], 21: [36, 29, 21], 43: [36, 29, 43], 50: [36, 29, 50], 59: [36, 29, 59], 42: [36, 39, 42], 96: [36, 39, 96], 33: [36, 39, 33], 13: [36, 39, 13], 74: [36, 39, 74], 81: [36, 8, 88, 81], 64: [36, 8, 88, 64], 65: [36, 8, 88, 65], 94: [36, 8, 101, 94], 73: [36, 8, 101, 73], 99: [36, 8, 101, 99], 45: [36, 26, 83, 45], 93: [36, 26, 83, 93], 44: [36, 26, 83, 44], 84: [36, 26, 25, 84], 87: [36, 26, 25, 87], 67: [36, 26, 25, 67], 32: [36, 26, 25, 32], 56: [36, 26, 25, 56], 66: [36, 26, 25, 66], 47: [36, 26, 98, 47], 38: [36, 26, 98, 38], 54: [36, 26, 98, 54], 90: [36, 26, 98, 90], 6: [36, 46, 18, 6], 86: [36, 46, 18, 86], 27: [36, 46, 12, 27], 100: [36, 46, 58, 100], 17: [36, 46, 58, 17], 72: [36, 46, 22, 72], 91: [36, 46, 22, 91], 85: [36, 46, 9, 85], 75: [36, 46, 9, 75], 16: [36, 52, 1, 16], 70: [36, 52, 1, 70], 79: [36, 52, 1, 79], 53: [36, 52, 1, 53], 37: [36, 52, 28, 37], 80: [36, 52, 28, 80], 48: [36, 49, 31, 48], 34: [36, 49, 95, 34], 20: [36, 49, 95, 20], 3: [36, 49, 10, 3], 41: [36, 49, 5, 41], 35: [36, 23, 55, 35], 57: [36, 23, 89, 57], 15: [36, 19, 63, 15], 77: [36, 19, 97, 77], 7: [36, 19, 97, 7], 78: [36, 29, 4, 78], 11: [36, 29, 21, 11], 82: [36, 29, 21, 82], 2: [36, 29, 50, 2], 24: [36, 39, 42, 24], 71: [36, 39, 33, 71], 61: [36, 39, 33, 61], 14: [36, 39, 13, 14], 60: [36, 39, 13, 60], 76: [36, 46, 22, 72, 76]}) (37, {37: [37], 74: [37, 74], 57: [37, 57], 22: [37, 74, 22], 62: [37, 74, 62], 59: [37, 74, 59], 51: [37, 74, 51], 87: [37, 74, 87], 82: [37, 74, 82], 53: [37, 74, 53], 24: [37, 57, 24], 52: [37, 57, 52], 39: [37, 57, 39], 101: [37, 57, 101], 16: [37, 57, 16], 69: [37, 57, 69], 40: [37, 57, 40], 12: [37, 57, 12], 79: [37, 57, 79], 70: [37, 57, 70], 43: [37, 74, 22, 43], 72: [37, 74, 22, 72], 91: [37, 74, 22, 91], 93: [37, 74, 22, 93], 6: [37, 74, 22, 6], 97: [37, 74, 22, 97], 42: [37, 74, 62, 42], 86: [37, 74, 62, 86], 4: [37, 74, 62, 4], 96: [37, 74, 62, 96], 80: [37, 74, 62, 80], 44: [37, 74, 62, 44], 13: [37, 74, 59, 13], 26: [37, 74, 59, 26], 8: [37, 74, 59, 8], 11: [37, 74, 59, 11], 18: [37, 74, 59, 18], 36: [37, 74, 59, 36], 78: [37, 74, 59, 78], 65: [37, 74, 59, 65], 49: [37, 74, 51, 49], 100: [37, 74, 51, 100], 73: [37, 74, 51, 73], 60: [37, 74, 87, 60], 83: [37, 74, 87, 83], 14: [37, 74, 82, 14], 45: [37, 74, 53, 45], 55: [37, 74, 53, 55], 2: [37, 74, 53, 2], 90: [37, 57, 24, 90], 25: [37, 57, 24, 25], 71: [37, 57, 24, 71], 34: [37, 57, 24, 34], 66: [37, 57, 24, 66], 54: [37, 57, 24, 54], 41: [37, 57, 24, 41], 68: [37, 57, 24, 68], 1: [37, 57, 52, 1], 23: [37, 57, 52, 23], 28: [37, 57, 52, 28], 33: [37, 57, 39, 33], 94: [37, 57, 101, 94], 21: [37, 57, 101, 21], 99: [37, 57, 101, 99], 48: [37, 57, 16, 48], 56: [37, 57, 16, 56], 9: [37, 57, 16, 9], 81: [37, 57, 16, 81], 46: [37, 57, 69, 46], 38: [37, 57, 40, 38], 30: [37, 57, 40, 30], 27: [37, 57, 12, 27], 3: [37, 57, 79, 3], 84: [37, 57, 70, 84], 64: [37, 57, 70, 64], 47: [37, 74, 22, 43, 47], 63: [37, 74, 22, 43, 63], 31: [37, 74, 22, 43, 31], 17: [37, 74, 22, 72, 17], 29: [37, 74, 22, 72, 29], 98: [37, 74, 22, 72, 98], 76: [37, 74, 22, 72, 76], 50: [37, 74, 22, 91, 50], 32: [37, 74, 22, 91, 32], 7: [37, 74, 22, 91, 7], 58: [37, 74, 22, 93, 58], 77: [37, 74, 22, 97, 77], 89: [37, 74, 62, 96, 89], 20: [37, 74, 62, 96, 20], 95: [37, 74, 62, 80, 95], 85: [37, 74, 62, 80, 85], 10: [37, 74, 62, 80, 10], 92: [37, 74, 62, 44, 92], 88: [37, 74, 59, 8, 88], 19: [37, 74, 59, 36, 19], 15: [37, 74, 59, 65, 15], 5: [37, 74, 51, 49, 5], 35: [37, 74, 53, 45, 35], 67: [37, 57, 24, 25, 67], 75: [37, 57, 24, 34, 75], 61: [37, 57, 24, 66, 61]}) (38, {38: [38], 78: [38, 78], 47: [38, 47], 66: [38, 66], 31: [38, 78, 31], 59: [38, 78, 59], 69: [38, 78, 69], 13: [38, 78, 13], 12: [38, 78, 12], 23: [38, 78, 23], 81: [38, 78, 81], 33: [38, 78, 33], 15: [38, 47, 15], 29: [38, 47, 29], 98: [38, 47, 98], 19: [38, 47, 19], 36: [38, 47, 36], 24: [38, 47, 24], 2: [38, 47, 2], 61: [38, 66, 61], 95: [38, 66, 95], 68: [38, 66, 68], 60: [38, 66, 60], 48: [38, 78, 31, 48], 83: [38, 78, 31, 83], 88: [38, 78, 31, 88], 91: [38, 78, 31, 91], 85: [38, 78, 31, 85], 96: [38, 78, 59, 96], 26: [38, 78, 59, 26], 62: [38, 78, 59, 62], 8: [38, 78, 59, 8], 44: [38, 78, 59, 44], 11: [38, 78, 59, 11], 18: [38, 78, 59, 18], 97: [38, 78, 59, 97], 86: [38, 78, 59, 86], 65: [38, 78, 59, 65], 22: [38, 78, 69, 22], 93: [38, 78, 69, 93], 46: [38, 78, 69, 46], 25: [38, 78, 69, 25], 14: [38, 78, 13, 14], 30: [38, 78, 13, 30], 4: [38, 78, 13, 4], 27: [38, 78, 12, 27], 101: [38, 78, 12, 101], 55: [38, 78, 23, 55], 89: [38, 78, 23, 89], 3: [38, 78, 81, 3], 42: [38, 78, 81, 42], 41: [38, 78, 81, 41], 58: [38, 78, 81, 58], 28: [38, 78, 81, 28], 40: [38, 78, 81, 40], 73: [38, 78, 33, 73], 71: [38, 78, 33, 71], 70: [38, 78, 33, 70], 75: [38, 78, 33, 75], 39: [38, 47, 15, 39], 9: [38, 47, 15, 9], 50: [38, 47, 15, 50], 21: [38, 47, 29, 21], 43: [38, 47, 29, 43], 32: [38, 47, 98, 32], 5: [38, 47, 98, 5], 54: [38, 47, 98, 54], 90: [38, 47, 98, 90], 63: [38, 47, 19, 63], 92: [38, 47, 19, 92], 52: [38, 47, 36, 52], 49: [38, 47, 36, 49], 6: [38, 47, 24, 6], 34: [38, 47, 24, 34], 74: [38, 47, 24, 74], 51: [38, 47, 2, 51], 56: [38, 47, 2, 56], 76: [38, 47, 2, 76], 72: [38, 66, 61, 72], 100: [38, 66, 61, 100], 20: [38, 66, 95, 20], 79: [38, 66, 60, 79], 99: [38, 66, 60, 99], 7: [38, 78, 31, 48, 7], 45: [38, 78, 31, 83, 45], 64: [38, 78, 31, 88, 64], 1: [38, 78, 31, 85, 1], 80: [38, 78, 59, 62, 80], 94: [38, 78, 59, 44, 94], 10: [38, 78, 59, 44, 10], 87: [38, 78, 59, 97, 87], 84: [38, 78, 59, 97, 84], 77: [38, 78, 59, 97, 77], 17: [38, 78, 59, 86, 17], 16: [38, 78, 59, 86, 16], 67: [38, 78, 69, 25, 67], 82: [38, 78, 13, 14, 82], 53: [38, 78, 13, 4, 53], 35: [38, 78, 23, 55, 35], 57: [38, 78, 23, 89, 57], 37: [38, 78, 81, 28, 37]}) (39, {39: [39], 59: [39, 59], 101: [39, 101], 28: [39, 28], 42: [39, 42], 96: [39, 96], 33: [39, 33], 13: [39, 13], 74: [39, 74], 26: [39, 59, 26], 62: [39, 59, 62], 8: [39, 59, 8], 44: [39, 59, 44], 11: [39, 59, 11], 18: [39, 59, 18], 97: [39, 59, 97], 36: [39, 59, 36], 78: [39, 59, 78], 86: [39, 59, 86], 65: [39, 59, 65], 94: [39, 101, 94], 25: [39, 101, 25], 73: [39, 101, 73], 21: [39, 101, 21], 99: [39, 101, 99], 31: [39, 28, 31], 37: [39, 28, 37], 80: [39, 28, 80], 67: [39, 28, 67], 32: [39, 28, 32], 3: [39, 42, 3], 40: [39, 42, 40], 91: [39, 42, 91], 24: [39, 42, 24], 90: [39, 42, 90], 63: [39, 42, 63], 89: [39, 96, 89], 20: [39, 96, 20], 71: [39, 33, 71], 4: [39, 33, 4], 61: [39, 33, 61], 70: [39, 33, 70], 75: [39, 33, 75], 14: [39, 13, 14], 30: [39, 13, 30], 83: [39, 13, 83], 60: [39, 13, 60], 22: [39, 74, 22], 51: [39, 74, 51], 87: [39, 74, 87], 82: [39, 74, 82], 53: [39, 74, 53], 98: [39, 59, 26, 98], 88: [39, 59, 8, 88], 72: [39, 59, 44, 72], 92: [39, 59, 44, 92], 56: [39, 59, 44, 56], 10: [39, 59, 44, 10], 95: [39, 59, 11, 95], 6: [39, 59, 18, 6], 49: [39, 59, 18, 49], 64: [39, 59, 97, 64], 84: [39, 59, 97, 84], 77: [39, 59, 97, 77], 7: [39, 59, 97, 7], 46: [39, 59, 36, 46], 52: [39, 59, 36, 52], 23: [39, 59, 36, 23], 19: [39, 59, 36, 19], 29: [39, 59, 36, 29], 69: [39, 59, 78, 69], 12: [39, 59, 78, 12], 81: [39, 59, 78, 81], 17: [39, 59, 86, 17], 16: [39, 59, 86, 16], 15: [39, 59, 65, 15], 45: [39, 59, 65, 45], 57: [39, 101, 94, 57], 66: [39, 101, 25, 66], 1: [39, 101, 73, 1], 5: [39, 101, 21, 5], 85: [39, 101, 21, 85], 50: [39, 101, 99, 50], 48: [39, 28, 31, 48], 54: [39, 28, 67, 54], 93: [39, 28, 32, 93], 9: [39, 42, 40, 9], 38: [39, 42, 40, 38], 100: [39, 42, 91, 100], 34: [39, 42, 24, 34], 41: [39, 42, 24, 41], 68: [39, 42, 24, 68], 55: [39, 42, 63, 55], 58: [39, 96, 20, 58], 79: [39, 33, 70, 79], 43: [39, 13, 83, 43], 2: [39, 74, 53, 2], 47: [39, 59, 26, 98, 47], 76: [39, 59, 44, 72, 76], 35: [39, 59, 97, 64, 35], 27: [39, 59, 78, 12, 27]}) (78, {78: [78], 31: [78, 31], 59: [78, 59], 69: [78, 69], 13: [78, 13], 12: [78, 12], 23: [78, 23], 81: [78, 81], 33: [78, 33], 48: [78, 31, 48], 83: [78, 31, 83], 88: [78, 31, 88], 91: [78, 31, 91], 85: [78, 31, 85], 96: [78, 59, 96], 26: [78, 59, 26], 62: [78, 59, 62], 8: [78, 59, 8], 44: [78, 59, 44], 11: [78, 59, 11], 18: [78, 59, 18], 97: [78, 59, 97], 36: [78, 59, 36], 86: [78, 59, 86], 65: [78, 59, 65], 22: [78, 69, 22], 93: [78, 69, 93], 46: [78, 69, 46], 25: [78, 69, 25], 14: [78, 13, 14], 30: [78, 13, 30], 4: [78, 13, 4], 60: [78, 13, 60], 27: [78, 12, 27], 101: [78, 12, 101], 68: [78, 12, 68], 55: [78, 23, 55], 89: [78, 23, 89], 3: [78, 81, 3], 61: [78, 81, 61], 42: [78, 81, 42], 41: [78, 81, 41], 58: [78, 81, 58], 28: [78, 81, 28], 40: [78, 81, 40], 73: [78, 33, 73], 71: [78, 33, 71], 70: [78, 33, 70], 75: [78, 33, 75], 7: [78, 31, 48, 7], 5: [78, 31, 48, 5], 99: [78, 31, 48, 99], 45: [78, 31, 83, 45], 52: [78, 31, 83, 52], 43: [78, 31, 83, 43], 64: [78, 31, 88, 64], 95: [78, 31, 88, 95], 39: [78, 31, 88, 39], 74: [78, 31, 91, 74], 50: [78, 31, 91, 50], 32: [78, 31, 91, 32], 38: [78, 31, 91, 38], 100: [78, 31, 91, 100], 1: [78, 31, 85, 1], 20: [78, 59, 96, 20], 98: [78, 59, 26, 98], 80: [78, 59, 62, 80], 72: [78, 59, 44, 72], 92: [78, 59, 44, 92], 51: [78, 59, 44, 51], 56: [78, 59, 44, 56], 94: [78, 59, 44, 94], 10: [78, 59, 44, 10], 24: [78, 59, 11, 24], 6: [78, 59, 18, 6], 49: [78, 59, 18, 49], 87: [78, 59, 97, 87], 84: [78, 59, 97, 84], 77: [78, 59, 97, 77], 19: [78, 59, 36, 19], 29: [78, 59, 36, 29], 17: [78, 59, 86, 17], 16: [78, 59, 86, 16], 15: [78, 59, 65, 15], 34: [78, 69, 93, 34], 9: [78, 69, 46, 9], 67: [78, 69, 25, 67], 66: [78, 69, 25, 66], 82: [78, 13, 14, 82], 53: [78, 13, 4, 53], 79: [78, 13, 60, 79], 21: [78, 12, 101, 21], 35: [78, 23, 55, 35], 57: [78, 23, 89, 57], 54: [78, 81, 3, 54], 90: [78, 81, 42, 90], 63: [78, 81, 42, 63], 37: [78, 81, 28, 37], 47: [78, 31, 83, 43, 47], 2: [78, 31, 91, 50, 2], 76: [78, 59, 44, 72, 76]}) (82, {82: [82], 11: [82, 11], 51: [82, 51], 14: [82, 14], 87: [82, 87], 74: [82, 74], 80: [82, 11, 80], 95: [82, 11, 95], 24: [82, 11, 24], 98: [82, 11, 98], 49: [82, 51, 49], 100: [82, 51, 100], 73: [82, 51, 73], 59: [82, 14, 59], 20: [82, 14, 20], 39: [82, 14, 39], 60: [82, 87, 60], 93: [82, 87, 93], 83: [82, 87, 83], 22: [82, 74, 22], 62: [82, 74, 62], 53: [82, 74, 53], 85: [82, 11, 80, 85], 86: [82, 11, 80, 86], 13: [82, 11, 80, 13], 10: [82, 11, 80, 10], 1: [82, 11, 80, 1], 23: [82, 11, 80, 23], 46: [82, 11, 80, 46], 34: [82, 11, 95, 34], 31: [82, 11, 95, 31], 81: [82, 11, 95, 81], 90: [82, 11, 24, 90], 25: [82, 11, 24, 25], 71: [82, 11, 24, 71], 6: [82, 11, 24, 6], 66: [82, 11, 24, 66], 54: [82, 11, 24, 54], 41: [82, 11, 24, 41], 68: [82, 11, 24, 68], 96: [82, 11, 24, 96], 78: [82, 11, 24, 78], 26: [82, 11, 24, 26], 47: [82, 11, 98, 47], 97: [82, 11, 98, 97], 88: [82, 11, 98, 88], 32: [82, 11, 98, 32], 36: [82, 11, 98, 36], 5: [82, 11, 98, 5], 38: [82, 11, 98, 38], 28: [82, 51, 49, 28], 40: [82, 51, 49, 40], 30: [82, 51, 49, 30], 58: [82, 51, 49, 58], 21: [82, 51, 100, 21], 69: [82, 51, 100, 69], 92: [82, 51, 100, 92], 77: [82, 51, 73, 77], 8: [82, 14, 59, 8], 44: [82, 14, 59, 44], 18: [82, 14, 59, 18], 65: [82, 14, 59, 65], 84: [82, 14, 20, 84], 56: [82, 14, 20, 56], 99: [82, 14, 20, 99], 19: [82, 14, 20, 19], 4: [82, 14, 20, 4], 101: [82, 14, 39, 101], 42: [82, 14, 39, 42], 33: [82, 14, 39, 33], 89: [82, 87, 60, 89], 79: [82, 87, 60, 79], 43: [82, 87, 93, 43], 45: [82, 87, 83, 45], 52: [82, 87, 83, 52], 72: [82, 74, 22, 72], 91: [82, 74, 22, 91], 55: [82, 74, 53, 55], 2: [82, 74, 53, 2], 17: [82, 11, 80, 86, 17], 16: [82, 11, 80, 86, 16], 48: [82, 11, 80, 10, 48], 3: [82, 11, 80, 10, 3], 70: [82, 11, 80, 1, 70], 12: [82, 11, 80, 46, 12], 9: [82, 11, 80, 46, 9], 75: [82, 11, 95, 34, 75], 29: [82, 11, 95, 34, 29], 61: [82, 11, 95, 81, 61], 67: [82, 11, 24, 25, 67], 37: [82, 11, 24, 71, 37], 50: [82, 11, 24, 71, 50], 7: [82, 11, 24, 71, 7], 57: [82, 11, 24, 6, 57], 94: [82, 11, 24, 41, 94], 15: [82, 11, 98, 47, 15], 64: [82, 11, 98, 97, 64], 63: [82, 14, 20, 19, 63], 27: [82, 87, 93, 43, 27], 35: [82, 87, 83, 45, 35], 76: [82, 74, 22, 72, 76]}) (54, {54: [54], 71: [54, 71], 43: [54, 43], 16: [54, 16], 11: [54, 11], 9: [54, 9], 70: [54, 70], 37: [54, 71, 37], 10: [54, 71, 10], 50: [54, 71, 50], 20: [54, 71, 20], 7: [54, 71, 7], 95: [54, 71, 95], 74: [54, 43, 74], 47: [54, 43, 47], 63: [54, 43, 63], 27: [54, 43, 27], 25: [54, 43, 25], 73: [54, 43, 73], 48: [54, 43, 48], 31: [54, 43, 31], 56: [54, 16, 56], 81: [54, 16, 81], 4: [54, 16, 4], 79: [54, 16, 79], 6: [54, 16, 6], 80: [54, 11, 80], 24: [54, 11, 24], 98: [54, 11, 98], 85: [54, 9, 85], 94: [54, 9, 94], 75: [54, 9, 75], 29: [54, 9, 29], 1: [54, 9, 1], 84: [54, 70, 84], 64: [54, 70, 64], 52: [54, 70, 52], 57: [54, 71, 37, 57], 46: [54, 71, 10, 46], 3: [54, 71, 10, 3], 2: [54, 71, 50, 2], 19: [54, 71, 50, 19], 88: [54, 71, 50, 88], 22: [54, 71, 50, 22], 42: [54, 71, 50, 42], 99: [54, 71, 20, 99], 58: [54, 71, 20, 58], 83: [54, 71, 20, 83], 30: [54, 71, 20, 30], 68: [54, 71, 20, 68], 86: [54, 71, 20, 86], 32: [54, 71, 20, 32], 51: [54, 71, 7, 51], 34: [54, 71, 95, 34], 49: [54, 71, 95, 49], 62: [54, 43, 74, 62], 59: [54, 43, 74, 59], 87: [54, 43, 74, 87], 82: [54, 43, 74, 82], 53: [54, 43, 74, 53], 15: [54, 43, 47, 15], 13: [54, 43, 47, 13], 36: [54, 43, 47, 36], 100: [54, 43, 63, 100], 55: [54, 43, 63, 55], 66: [54, 43, 63, 66], 14: [54, 43, 27, 14], 67: [54, 43, 27, 67], 89: [54, 43, 27, 89], 26: [54, 43, 25, 26], 77: [54, 43, 73, 77], 5: [54, 43, 48, 5], 101: [54, 43, 48, 101], 12: [54, 43, 31, 12], 91: [54, 43, 31, 91], 33: [54, 43, 31, 33], 90: [54, 16, 56, 90], 61: [54, 16, 81, 61], 41: [54, 16, 81, 41], 28: [54, 16, 81, 28], 40: [54, 16, 81, 40], 78: [54, 16, 4, 78], 23: [54, 16, 4, 23], 8: [54, 16, 79, 8], 96: [54, 11, 24, 96], 97: [54, 11, 98, 97], 38: [54, 11, 98, 38], 21: [54, 9, 29, 21], 69: [54, 9, 1, 69], 65: [54, 70, 64, 65], 39: [54, 70, 64, 39], 35: [54, 70, 64, 35], 18: [54, 71, 10, 46, 18], 72: [54, 71, 10, 3, 72], 44: [54, 71, 10, 3, 44], 60: [54, 71, 50, 2, 60], 76: [54, 71, 50, 2, 76], 92: [54, 71, 50, 19, 92], 93: [54, 71, 50, 22, 93], 17: [54, 71, 20, 58, 17], 45: [54, 71, 20, 83, 45]}) (71, {71: [71], 37: [71, 37], 10: [71, 10], 50: [71, 50], 20: [71, 20], 7: [71, 7], 95: [71, 95], 74: [71, 37, 74], 57: [71, 37, 57], 48: [71, 10, 48], 46: [71, 10, 46], 3: [71, 10, 3], 31: [71, 10, 31], 2: [71, 50, 2], 19: [71, 50, 19], 88: [71, 50, 88], 22: [71, 50, 22], 54: [71, 50, 54], 52: [71, 50, 52], 42: [71, 50, 42], 84: [71, 20, 84], 56: [71, 20, 56], 99: [71, 20, 99], 58: [71, 20, 58], 83: [71, 20, 83], 30: [71, 20, 30], 68: [71, 20, 68], 86: [71, 20, 86], 81: [71, 20, 81], 32: [71, 20, 32], 4: [71, 20, 4], 51: [71, 7, 51], 34: [71, 95, 34], 49: [71, 95, 49], 62: [71, 37, 74, 62], 59: [71, 37, 74, 59], 87: [71, 37, 74, 87], 82: [71, 37, 74, 82], 53: [71, 37, 74, 53], 24: [71, 37, 57, 24], 39: [71, 37, 57, 39], 101: [71, 37, 57, 101], 16: [71, 37, 57, 16], 69: [71, 37, 57, 69], 40: [71, 37, 57, 40], 12: [71, 37, 57, 12], 79: [71, 37, 57, 79], 70: [71, 37, 57, 70], 36: [71, 10, 48, 36], 5: [71, 10, 48, 5], 18: [71, 10, 46, 18], 9: [71, 10, 46, 9], 23: [71, 10, 46, 23], 72: [71, 10, 3, 72], 44: [71, 10, 3, 44], 85: [71, 10, 3, 85], 91: [71, 10, 31, 91], 33: [71, 10, 31, 33], 60: [71, 50, 2, 60], 76: [71, 50, 2, 76], 63: [71, 50, 19, 63], 98: [71, 50, 19, 98], 97: [71, 50, 19, 97], 92: [71, 50, 19, 92], 64: [71, 50, 88, 64], 65: [71, 50, 88, 65], 43: [71, 50, 22, 43], 93: [71, 50, 22, 93], 6: [71, 50, 22, 6], 11: [71, 50, 54, 11], 1: [71, 50, 52, 1], 28: [71, 50, 52, 28], 90: [71, 50, 42, 90], 13: [71, 20, 84, 13], 14: [71, 20, 84, 14], 25: [71, 20, 84, 25], 77: [71, 20, 56, 77], 100: [71, 20, 58, 100], 26: [71, 20, 58, 26], 17: [71, 20, 58, 17], 89: [71, 20, 83, 89], 45: [71, 20, 83, 45], 80: [71, 20, 30, 80], 55: [71, 20, 68, 55], 61: [71, 20, 81, 61], 41: [71, 20, 81, 41], 78: [71, 20, 4, 78], 73: [71, 7, 51, 73], 75: [71, 95, 34, 75], 38: [71, 95, 34, 38], 29: [71, 95, 34, 29], 96: [71, 37, 74, 62, 96], 8: [71, 37, 74, 59, 8], 66: [71, 37, 57, 24, 66], 94: [71, 37, 57, 101, 94], 21: [71, 37, 57, 101, 21], 27: [71, 37, 57, 12, 27], 47: [71, 50, 2, 76, 47], 15: [71, 50, 19, 63, 15], 35: [71, 50, 88, 64, 35], 67: [71, 50, 52, 28, 67]}) (67, {67: [67], 23: [67, 23], 16: [67, 16], 54: [67, 54], 55: [67, 23, 55], 69: [67, 23, 69], 101: [67, 23, 101], 89: [67, 23, 89], 48: [67, 16, 48], 56: [67, 16, 56], 9: [67, 16, 9], 81: [67, 16, 81], 4: [67, 16, 4], 79: [67, 16, 79], 6: [67, 16, 6], 71: [67, 54, 71], 43: [67, 54, 43], 11: [67, 54, 11], 70: [67, 54, 70], 29: [67, 23, 55, 29], 35: [67, 23, 55, 35], 42: [67, 23, 55, 42], 22: [67, 23, 69, 22], 93: [67, 23, 69, 93], 8: [67, 23, 69, 8], 46: [67, 23, 69, 46], 25: [67, 23, 69, 25], 26: [67, 23, 69, 26], 94: [67, 23, 101, 94], 73: [67, 23, 101, 73], 21: [67, 23, 101, 21], 96: [67, 23, 101, 96], 99: [67, 23, 101, 99], 57: [67, 23, 89, 57], 7: [67, 16, 48, 7], 36: [67, 16, 48, 36], 5: [67, 16, 48, 5], 77: [67, 16, 56, 77], 10: [67, 16, 56, 10], 90: [67, 16, 56, 90], 58: [67, 16, 56, 58], 85: [67, 16, 9, 85], 50: [67, 16, 9, 50], 31: [67, 16, 9, 31], 98: [67, 16, 9, 98], 75: [67, 16, 9, 75], 1: [67, 16, 9, 1], 74: [67, 16, 9, 74], 3: [67, 16, 81, 3], 61: [67, 16, 81, 61], 30: [67, 16, 81, 30], 68: [67, 16, 81, 68], 41: [67, 16, 81, 41], 28: [67, 16, 81, 28], 40: [67, 16, 81, 40], 53: [67, 16, 4, 53], 78: [67, 16, 4, 78], 83: [67, 16, 4, 83], 37: [67, 16, 79, 37], 20: [67, 54, 71, 20], 95: [67, 54, 71, 95], 47: [67, 54, 43, 47], 63: [67, 54, 43, 63], 27: [67, 54, 43, 27], 80: [67, 54, 11, 80], 24: [67, 54, 11, 24], 84: [67, 54, 70, 84], 64: [67, 54, 70, 64], 52: [67, 54, 70, 52], 19: [67, 23, 55, 29, 19], 59: [67, 23, 55, 29, 59], 49: [67, 23, 55, 35, 49], 33: [67, 23, 55, 42, 33], 91: [67, 23, 55, 42, 91], 44: [67, 23, 55, 42, 44], 72: [67, 23, 69, 22, 72], 97: [67, 23, 69, 22, 97], 34: [67, 23, 69, 93, 34], 39: [67, 23, 69, 93, 39], 88: [67, 23, 69, 8, 88], 18: [67, 23, 69, 46, 18], 12: [67, 23, 69, 46, 12], 51: [67, 23, 69, 46, 51], 87: [67, 23, 69, 25, 87], 32: [67, 23, 69, 25, 32], 66: [67, 23, 69, 25, 66], 62: [67, 23, 101, 94, 62], 82: [67, 23, 101, 21, 82], 45: [67, 16, 56, 77, 45], 15: [67, 16, 56, 77, 15], 100: [67, 16, 56, 90, 100], 17: [67, 16, 56, 58, 17], 2: [67, 16, 9, 50, 2], 38: [67, 16, 9, 98, 38], 13: [67, 16, 9, 98, 13], 92: [67, 16, 81, 61, 92], 86: [67, 16, 4, 53, 86], 14: [67, 54, 43, 27, 14], 65: [67, 54, 70, 64, 65], 76: [67, 23, 69, 22, 72, 76], 60: [67, 23, 69, 25, 87, 60]}) (58, {58: [58], 93: [58, 93], 100: [58, 100], 26: [58, 26], 87: [58, 87], 17: [58, 17], 22: [58, 22], 40: [58, 93, 40], 34: [58, 93, 34], 71: [58, 93, 71], 39: [58, 93, 39], 83: [58, 93, 83], 43: [58, 93, 43], 10: [58, 100, 10], 47: [58, 100, 47], 36: [58, 100, 36], 21: [58, 100, 21], 69: [58, 100, 69], 92: [58, 100, 92], 101: [58, 26, 101], 25: [58, 26, 25], 98: [58, 26, 98], 60: [58, 87, 60], 84: [58, 17, 84], 72: [58, 22, 72], 59: [58, 22, 59], 91: [58, 22, 91], 6: [58, 22, 6], 97: [58, 22, 97], 9: [58, 93, 40, 9], 38: [58, 93, 40, 38], 96: [58, 93, 40, 96], 30: [58, 93, 40, 30], 49: [58, 93, 40, 49], 20: [58, 93, 34, 20], 75: [58, 93, 34, 75], 18: [58, 93, 34, 18], 55: [58, 93, 34, 55], 46: [58, 93, 34, 46], 29: [58, 93, 34, 29], 37: [58, 93, 71, 37], 50: [58, 93, 71, 50], 7: [58, 93, 71, 7], 95: [58, 93, 71, 95], 28: [58, 93, 39, 28], 42: [58, 93, 39, 42], 33: [58, 93, 39, 33], 13: [58, 93, 39, 13], 74: [58, 93, 39, 74], 89: [58, 93, 83, 89], 45: [58, 93, 83, 45], 52: [58, 93, 83, 52], 44: [58, 93, 83, 44], 63: [58, 93, 43, 63], 27: [58, 93, 43, 27], 73: [58, 93, 43, 73], 48: [58, 93, 43, 48], 11: [58, 93, 43, 11], 31: [58, 93, 43, 31], 3: [58, 100, 10, 3], 15: [58, 100, 47, 15], 19: [58, 100, 47, 19], 24: [58, 100, 47, 24], 2: [58, 100, 47, 2], 8: [58, 100, 36, 8], 23: [58, 100, 36, 23], 82: [58, 100, 21, 82], 5: [58, 100, 21, 5], 85: [58, 100, 21, 85], 1: [58, 100, 21, 1], 32: [58, 100, 92, 32], 94: [58, 26, 101, 94], 99: [58, 26, 101, 99], 67: [58, 26, 25, 67], 56: [58, 26, 25, 56], 66: [58, 26, 25, 66], 88: [58, 26, 98, 88], 62: [58, 26, 98, 62], 54: [58, 26, 98, 54], 90: [58, 26, 98, 90], 41: [58, 87, 60, 41], 79: [58, 87, 60, 79], 14: [58, 17, 84, 14], 76: [58, 22, 72, 76], 78: [58, 22, 59, 78], 86: [58, 22, 59, 86], 65: [58, 22, 59, 65], 12: [58, 22, 91, 12], 64: [58, 22, 91, 64], 57: [58, 22, 6, 57], 77: [58, 22, 97, 77], 80: [58, 93, 40, 30, 80], 68: [58, 93, 34, 20, 68], 81: [58, 93, 34, 20, 81], 4: [58, 93, 34, 20, 4], 35: [58, 93, 34, 55, 35], 16: [58, 93, 34, 55, 16], 51: [58, 93, 34, 46, 51], 61: [58, 93, 39, 33, 61], 70: [58, 93, 39, 33, 70], 53: [58, 93, 39, 74, 53]}) (93, {93: [93], 58: [93, 58], 40: [93, 40], 34: [93, 34], 71: [93, 71], 39: [93, 39], 83: [93, 83], 43: [93, 43], 100: [93, 58, 100], 26: [93, 58, 26], 87: [93, 58, 87], 17: [93, 58, 17], 22: [93, 58, 22], 9: [93, 40, 9], 91: [93, 40, 91], 38: [93, 40, 38], 96: [93, 40, 96], 30: [93, 40, 30], 49: [93, 40, 49], 20: [93, 34, 20], 75: [93, 34, 75], 18: [93, 34, 18], 55: [93, 34, 55], 46: [93, 34, 46], 29: [93, 34, 29], 37: [93, 71, 37], 10: [93, 71, 10], 50: [93, 71, 50], 7: [93, 71, 7], 95: [93, 71, 95], 59: [93, 39, 59], 101: [93, 39, 101], 28: [93, 39, 28], 42: [93, 39, 42], 33: [93, 39, 33], 13: [93, 39, 13], 74: [93, 39, 74], 89: [93, 83, 89], 45: [93, 83, 45], 52: [93, 83, 52], 44: [93, 83, 44], 47: [93, 43, 47], 63: [93, 43, 63], 27: [93, 43, 27], 25: [93, 43, 25], 73: [93, 43, 73], 48: [93, 43, 48], 11: [93, 43, 11], 31: [93, 43, 31], 36: [93, 58, 100, 36], 21: [93, 58, 100, 21], 69: [93, 58, 100, 69], 92: [93, 58, 100, 92], 98: [93, 58, 26, 98], 60: [93, 58, 87, 60], 84: [93, 58, 17, 84], 72: [93, 58, 22, 72], 6: [93, 58, 22, 6], 97: [93, 58, 22, 97], 85: [93, 40, 9, 85], 94: [93, 40, 9, 94], 1: [93, 40, 9, 1], 12: [93, 40, 91, 12], 99: [93, 40, 91, 99], 32: [93, 40, 91, 32], 64: [93, 40, 91, 64], 78: [93, 40, 38, 78], 66: [93, 40, 38, 66], 80: [93, 40, 30, 80], 5: [93, 40, 49, 5], 56: [93, 34, 20, 56], 19: [93, 34, 20, 19], 68: [93, 34, 20, 68], 86: [93, 34, 20, 86], 81: [93, 34, 20, 81], 4: [93, 34, 20, 4], 67: [93, 34, 75, 67], 35: [93, 34, 55, 35], 16: [93, 34, 55, 16], 51: [93, 34, 46, 51], 23: [93, 34, 46, 23], 57: [93, 71, 37, 57], 3: [93, 71, 10, 3], 2: [93, 71, 50, 2], 88: [93, 71, 50, 88], 54: [93, 71, 50, 54], 62: [93, 39, 59, 62], 8: [93, 39, 59, 8], 65: [93, 39, 59, 65], 24: [93, 39, 42, 24], 90: [93, 39, 42, 90], 61: [93, 39, 33, 61], 70: [93, 39, 33, 70], 14: [93, 39, 13, 14], 82: [93, 39, 74, 82], 53: [93, 39, 74, 53], 15: [93, 43, 47, 15], 77: [93, 43, 73, 77], 41: [93, 58, 87, 60, 41], 79: [93, 58, 87, 60, 79], 76: [93, 58, 22, 72, 76]}) (72, {72: [72], 17: [72, 17], 36: [72, 36], 29: [72, 29], 98: [72, 98], 6: [72, 6], 76: [72, 76], 18: [72, 18], 84: [72, 17, 84], 8: [72, 36, 8], 26: [72, 36, 26], 46: [72, 36, 46], 52: [72, 36, 52], 49: [72, 36, 49], 23: [72, 36, 23], 19: [72, 36, 19], 39: [72, 36, 39], 4: [72, 29, 4], 21: [72, 29, 21], 43: [72, 29, 43], 50: [72, 29, 50], 59: [72, 29, 59], 47: [72, 98, 47], 97: [72, 98, 97], 88: [72, 98, 88], 32: [72, 98, 32], 62: [72, 98, 62], 5: [72, 98, 5], 38: [72, 98, 38], 54: [72, 98, 54], 90: [72, 98, 90], 13: [72, 98, 13], 57: [72, 6, 57], 1: [72, 6, 1], 40: [72, 76, 40], 45: [72, 76, 45], 51: [72, 76, 51], 7: [72, 76, 7], 33: [72, 76, 33], 60: [72, 76, 60], 94: [72, 18, 94], 95: [72, 18, 95], 86: [72, 18, 86], 14: [72, 17, 84, 14], 25: [72, 17, 84, 25], 101: [72, 36, 8, 101], 83: [72, 36, 26, 83], 12: [72, 36, 46, 12], 58: [72, 36, 46, 58], 22: [72, 36, 46, 22], 9: [72, 36, 46, 9], 28: [72, 36, 52, 28], 30: [72, 36, 49, 30], 31: [72, 36, 49, 31], 10: [72, 36, 49, 10], 55: [72, 36, 23, 55], 69: [72, 36, 23, 69], 89: [72, 36, 23, 89], 63: [72, 36, 19, 63], 68: [72, 36, 19, 68], 92: [72, 36, 19, 92], 42: [72, 36, 39, 42], 96: [72, 36, 39, 96], 74: [72, 36, 39, 74], 53: [72, 29, 4, 53], 78: [72, 29, 4, 78], 11: [72, 29, 21, 11], 87: [72, 29, 21, 87], 82: [72, 29, 21, 82], 3: [72, 29, 21, 3], 85: [72, 29, 21, 85], 27: [72, 29, 43, 27], 73: [72, 29, 43, 73], 48: [72, 29, 43, 48], 2: [72, 29, 50, 2], 44: [72, 29, 59, 44], 65: [72, 29, 59, 65], 15: [72, 98, 47, 15], 24: [72, 98, 47, 24], 64: [72, 98, 97, 64], 77: [72, 98, 97, 77], 81: [72, 98, 88, 81], 93: [72, 98, 32, 93], 37: [72, 98, 32, 37], 80: [72, 98, 62, 80], 41: [72, 98, 5, 41], 66: [72, 98, 38, 66], 71: [72, 98, 54, 71], 16: [72, 98, 54, 16], 70: [72, 98, 54, 70], 100: [72, 98, 90, 100], 34: [72, 98, 90, 34], 79: [72, 6, 57, 79], 91: [72, 76, 40, 91], 35: [72, 76, 45, 35], 61: [72, 76, 33, 61], 75: [72, 76, 33, 75], 99: [72, 76, 60, 99], 20: [72, 18, 95, 20], 67: [72, 17, 84, 25, 67], 56: [72, 17, 84, 25, 56]}) (92, {92: [92], 13: [92, 13], 32: [92, 32], 34: [92, 34], 47: [92, 47], 52: [92, 52], 14: [92, 13, 14], 30: [92, 13, 30], 83: [92, 13, 83], 4: [92, 13, 4], 60: [92, 13, 60], 93: [92, 32, 93], 37: [92, 32, 37], 20: [92, 34, 20], 75: [92, 34, 75], 18: [92, 34, 18], 55: [92, 34, 55], 38: [92, 34, 38], 46: [92, 34, 46], 29: [92, 34, 29], 15: [92, 47, 15], 98: [92, 47, 98], 19: [92, 47, 19], 36: [92, 47, 36], 24: [92, 47, 24], 2: [92, 47, 2], 1: [92, 52, 1], 39: [92, 52, 39], 23: [92, 52, 23], 28: [92, 52, 28], 101: [92, 52, 101], 59: [92, 13, 14, 59], 74: [92, 13, 14, 74], 82: [92, 13, 14, 82], 80: [92, 13, 30, 80], 89: [92, 13, 83, 89], 45: [92, 13, 83, 45], 43: [92, 13, 83, 43], 44: [92, 13, 83, 44], 53: [92, 13, 4, 53], 78: [92, 13, 4, 78], 41: [92, 13, 60, 41], 79: [92, 13, 60, 79], 62: [92, 13, 60, 62], 40: [92, 13, 60, 40], 99: [92, 13, 60, 99], 58: [92, 32, 93, 58], 71: [92, 32, 93, 71], 57: [92, 32, 37, 57], 84: [92, 34, 20, 84], 22: [92, 34, 20, 22], 56: [92, 34, 20, 56], 68: [92, 34, 20, 68], 86: [92, 34, 20, 86], 81: [92, 34, 20, 81], 67: [92, 34, 75, 67], 96: [92, 34, 75, 96], 94: [92, 34, 18, 94], 95: [92, 34, 18, 95], 6: [92, 34, 18, 6], 49: [92, 34, 18, 49], 35: [92, 34, 55, 35], 42: [92, 34, 55, 42], 16: [92, 34, 55, 16], 66: [92, 34, 38, 66], 12: [92, 34, 46, 12], 51: [92, 34, 46, 51], 9: [92, 34, 46, 9], 21: [92, 34, 29, 21], 50: [92, 34, 29, 50], 97: [92, 47, 98, 97], 88: [92, 47, 98, 88], 5: [92, 47, 98, 5], 54: [92, 47, 98, 54], 90: [92, 47, 98, 90], 63: [92, 47, 19, 63], 8: [92, 47, 36, 8], 26: [92, 47, 36, 26], 25: [92, 47, 24, 25], 76: [92, 47, 2, 76], 70: [92, 52, 1, 70], 69: [92, 52, 1, 69], 33: [92, 52, 39, 33], 73: [92, 52, 28, 73], 31: [92, 52, 28, 31], 11: [92, 13, 14, 59, 11], 65: [92, 13, 14, 59, 65], 87: [92, 13, 14, 74, 87], 85: [92, 13, 30, 80, 85], 10: [92, 13, 30, 80, 10], 27: [92, 13, 83, 43, 27], 48: [92, 13, 83, 43, 48], 72: [92, 13, 83, 44, 72], 3: [92, 13, 60, 79, 3], 91: [92, 13, 60, 40, 91], 77: [92, 13, 60, 99, 77], 100: [92, 32, 93, 58, 100], 17: [92, 32, 93, 58, 17], 7: [92, 32, 93, 71, 7], 61: [92, 34, 20, 81, 61], 64: [92, 47, 98, 97, 64]}) (98, {98: [98], 47: [98, 47], 46: [98, 46], 97: [98, 97], 88: [98, 88], 32: [98, 32], 36: [98, 36], 62: [98, 62], 5: [98, 5], 38: [98, 38], 54: [98, 54], 90: [98, 90], 13: [98, 13], 15: [98, 47, 15], 29: [98, 47, 29], 19: [98, 47, 19], 24: [98, 47, 24], 2: [98, 47, 2], 18: [98, 46, 18], 12: [98, 46, 12], 58: [98, 46, 58], 51: [98, 46, 51], 22: [98, 46, 22], 9: [98, 46, 9], 23: [98, 46, 23], 87: [98, 97, 87], 64: [98, 97, 64], 84: [98, 97, 84], 74: [98, 97, 74], 77: [98, 97, 77], 25: [98, 97, 25], 7: [98, 97, 7], 81: [98, 88, 81], 101: [98, 88, 101], 95: [98, 88, 95], 65: [98, 88, 65], 40: [98, 88, 40], 39: [98, 88, 39], 93: [98, 32, 93], 37: [98, 32, 37], 8: [98, 36, 8], 26: [98, 36, 26], 52: [98, 36, 52], 49: [98, 36, 49], 42: [98, 62, 42], 86: [98, 62, 86], 4: [98, 62, 4], 96: [98, 62, 96], 80: [98, 62, 80], 44: [98, 62, 44], 55: [98, 5, 55], 41: [98, 5, 41], 78: [98, 38, 78], 66: [98, 38, 66], 71: [98, 54, 71], 43: [98, 54, 43], 16: [98, 54, 16], 11: [98, 54, 11], 70: [98, 54, 70], 100: [98, 90, 100], 59: [98, 90, 59], 1: [98, 90, 1], 10: [98, 90, 10], 34: [98, 90, 34], 14: [98, 13, 14], 30: [98, 13, 30], 83: [98, 13, 83], 60: [98, 13, 60], 50: [98, 47, 15, 50], 21: [98, 47, 29, 21], 63: [98, 47, 19, 63], 68: [98, 47, 19, 68], 92: [98, 47, 19, 92], 6: [98, 47, 24, 6], 56: [98, 47, 2, 56], 76: [98, 47, 2, 76], 94: [98, 46, 18, 94], 27: [98, 46, 12, 27], 17: [98, 46, 58, 17], 73: [98, 46, 51, 73], 72: [98, 46, 22, 72], 91: [98, 46, 22, 91], 85: [98, 46, 9, 85], 31: [98, 46, 9, 31], 75: [98, 46, 9, 75], 69: [98, 46, 23, 69], 89: [98, 46, 23, 89], 82: [98, 97, 64, 82], 35: [98, 97, 64, 35], 53: [98, 97, 74, 53], 45: [98, 97, 77, 45], 67: [98, 97, 25, 67], 3: [98, 88, 81, 3], 61: [98, 88, 81, 61], 28: [98, 88, 81, 28], 99: [98, 88, 101, 99], 20: [98, 88, 95, 20], 33: [98, 88, 39, 33], 57: [98, 32, 37, 57], 48: [98, 54, 43, 48], 79: [98, 54, 16, 79]}) (73, {73: [73], 71: [73, 71], 6: [73, 6], 77: [73, 77], 83: [73, 83], 1: [73, 1], 37: [73, 71, 37], 10: [73, 71, 10], 50: [73, 71, 50], 20: [73, 71, 20], 7: [73, 71, 7], 95: [73, 71, 95], 57: [73, 6, 57], 54: [73, 6, 54], 9: [73, 77, 9], 4: [73, 77, 4], 29: [73, 77, 29], 45: [73, 77, 45], 56: [73, 77, 56], 70: [73, 77, 70], 15: [73, 77, 15], 43: [73, 77, 43], 101: [73, 77, 101], 21: [73, 77, 21], 89: [73, 83, 89], 52: [73, 83, 52], 93: [73, 83, 93], 44: [73, 83, 44], 16: [73, 1, 16], 79: [73, 1, 79], 69: [73, 1, 69], 53: [73, 1, 53], 74: [73, 71, 37, 74], 48: [73, 71, 10, 48], 46: [73, 71, 10, 46], 3: [73, 71, 10, 3], 31: [73, 71, 10, 31], 2: [73, 71, 50, 2], 19: [73, 71, 50, 19], 88: [73, 71, 50, 88], 22: [73, 71, 50, 22], 42: [73, 71, 50, 42], 84: [73, 71, 20, 84], 99: [73, 71, 20, 99], 58: [73, 71, 20, 58], 30: [73, 71, 20, 30], 68: [73, 71, 20, 68], 86: [73, 71, 20, 86], 81: [73, 71, 20, 81], 32: [73, 71, 20, 32], 51: [73, 71, 7, 51], 34: [73, 71, 95, 34], 49: [73, 71, 95, 49], 24: [73, 6, 57, 24], 39: [73, 6, 57, 39], 40: [73, 6, 57, 40], 12: [73, 6, 57, 12], 11: [73, 6, 54, 11], 85: [73, 77, 9, 85], 94: [73, 77, 9, 94], 98: [73, 77, 9, 98], 75: [73, 77, 9, 75], 78: [73, 77, 4, 78], 23: [73, 77, 4, 23], 59: [73, 77, 29, 59], 35: [73, 77, 45, 35], 90: [73, 77, 56, 90], 64: [73, 77, 70, 64], 47: [73, 77, 15, 47], 63: [73, 77, 43, 63], 27: [73, 77, 43, 27], 25: [73, 77, 43, 25], 96: [73, 77, 101, 96], 8: [73, 77, 101, 8], 87: [73, 77, 21, 87], 82: [73, 77, 21, 82], 5: [73, 77, 21, 5], 55: [73, 83, 89, 55], 28: [73, 83, 52, 28], 72: [73, 83, 44, 72], 92: [73, 83, 44, 92], 26: [73, 1, 69, 26], 62: [73, 71, 37, 74, 62], 36: [73, 71, 10, 48, 36], 18: [73, 71, 10, 46, 18], 91: [73, 71, 10, 31, 91], 33: [73, 71, 10, 31, 33], 60: [73, 71, 50, 2, 60], 76: [73, 71, 50, 2, 76], 97: [73, 71, 50, 19, 97], 65: [73, 71, 50, 88, 65], 13: [73, 71, 20, 84, 13], 14: [73, 71, 20, 84, 14], 100: [73, 71, 20, 58, 100], 17: [73, 71, 20, 58, 17], 80: [73, 71, 20, 30, 80], 61: [73, 71, 20, 81, 61], 41: [73, 71, 20, 81, 41], 38: [73, 71, 95, 34, 38], 66: [73, 6, 57, 24, 66], 67: [73, 77, 9, 75, 67]}) (84, {84: [84], 32: [84, 32], 98: [84, 98], 13: [84, 13], 14: [84, 14], 25: [84, 25], 93: [84, 32, 93], 37: [84, 32, 37], 47: [84, 98, 47], 46: [84, 98, 46], 97: [84, 98, 97], 88: [84, 98, 88], 36: [84, 98, 36], 62: [84, 98, 62], 5: [84, 98, 5], 38: [84, 98, 38], 54: [84, 98, 54], 90: [84, 98, 90], 30: [84, 13, 30], 83: [84, 13, 83], 4: [84, 13, 4], 60: [84, 13, 60], 59: [84, 14, 59], 20: [84, 14, 20], 39: [84, 14, 39], 74: [84, 14, 74], 82: [84, 14, 82], 26: [84, 25, 26], 87: [84, 25, 87], 67: [84, 25, 67], 56: [84, 25, 56], 66: [84, 25, 66], 58: [84, 32, 93, 58], 40: [84, 32, 93, 40], 34: [84, 32, 93, 34], 71: [84, 32, 93, 71], 43: [84, 32, 93, 43], 57: [84, 32, 37, 57], 15: [84, 98, 47, 15], 29: [84, 98, 47, 29], 19: [84, 98, 47, 19], 24: [84, 98, 47, 24], 2: [84, 98, 47, 2], 18: [84, 98, 46, 18], 12: [84, 98, 46, 12], 51: [84, 98, 46, 51], 22: [84, 98, 46, 22], 9: [84, 98, 46, 9], 23: [84, 98, 46, 23], 64: [84, 98, 97, 64], 77: [84, 98, 97, 77], 7: [84, 98, 97, 7], 81: [84, 98, 88, 81], 101: [84, 98, 88, 101], 95: [84, 98, 88, 95], 65: [84, 98, 88, 65], 8: [84, 98, 36, 8], 52: [84, 98, 36, 52], 49: [84, 98, 36, 49], 42: [84, 98, 62, 42], 86: [84, 98, 62, 86], 96: [84, 98, 62, 96], 80: [84, 98, 62, 80], 44: [84, 98, 62, 44], 55: [84, 98, 5, 55], 41: [84, 98, 5, 41], 78: [84, 98, 38, 78], 16: [84, 98, 54, 16], 11: [84, 98, 54, 11], 70: [84, 98, 54, 70], 100: [84, 98, 90, 100], 1: [84, 98, 90, 1], 10: [84, 98, 90, 10], 28: [84, 13, 30, 28], 89: [84, 13, 83, 89], 45: [84, 13, 83, 45], 53: [84, 13, 4, 53], 79: [84, 13, 60, 79], 99: [84, 13, 60, 99], 68: [84, 14, 20, 68], 33: [84, 14, 39, 33], 61: [84, 25, 66, 61], 17: [84, 32, 93, 58, 17], 91: [84, 32, 93, 40, 91], 75: [84, 32, 93, 34, 75], 50: [84, 32, 93, 71, 50], 63: [84, 32, 93, 43, 63], 27: [84, 32, 93, 43, 27], 73: [84, 32, 93, 43, 73], 48: [84, 32, 93, 43, 48], 31: [84, 32, 93, 43, 31], 69: [84, 32, 37, 57, 69], 21: [84, 98, 47, 29, 21], 92: [84, 98, 47, 19, 92], 6: [84, 98, 47, 24, 6], 76: [84, 98, 47, 2, 76], 94: [84, 98, 46, 18, 94], 72: [84, 98, 46, 22, 72], 85: [84, 98, 46, 9, 85], 35: [84, 98, 97, 64, 35], 3: [84, 98, 88, 81, 3]}) (74, {74: [74], 22: [74, 22], 62: [74, 62], 59: [74, 59], 51: [74, 51], 87: [74, 87], 82: [74, 82], 53: [74, 53], 43: [74, 22, 43], 72: [74, 22, 72], 91: [74, 22, 91], 93: [74, 22, 93], 6: [74, 22, 6], 97: [74, 22, 97], 42: [74, 62, 42], 86: [74, 62, 86], 4: [74, 62, 4], 96: [74, 62, 96], 80: [74, 62, 80], 44: [74, 62, 44], 13: [74, 59, 13], 26: [74, 59, 26], 8: [74, 59, 8], 11: [74, 59, 11], 18: [74, 59, 18], 36: [74, 59, 36], 78: [74, 59, 78], 65: [74, 59, 65], 49: [74, 51, 49], 100: [74, 51, 100], 73: [74, 51, 73], 60: [74, 87, 60], 83: [74, 87, 83], 14: [74, 82, 14], 69: [74, 53, 69], 45: [74, 53, 45], 55: [74, 53, 55], 2: [74, 53, 2], 47: [74, 22, 43, 47], 63: [74, 22, 43, 63], 27: [74, 22, 43, 27], 25: [74, 22, 43, 25], 48: [74, 22, 43, 48], 31: [74, 22, 43, 31], 17: [74, 22, 72, 17], 29: [74, 22, 72, 29], 98: [74, 22, 72, 98], 76: [74, 22, 72, 76], 12: [74, 22, 91, 12], 99: [74, 22, 91, 99], 50: [74, 22, 91, 50], 32: [74, 22, 91, 32], 64: [74, 22, 91, 64], 38: [74, 22, 91, 38], 7: [74, 22, 91, 7], 58: [74, 22, 93, 58], 40: [74, 22, 93, 40], 34: [74, 22, 93, 34], 71: [74, 22, 93, 71], 39: [74, 22, 93, 39], 57: [74, 22, 6, 57], 54: [74, 22, 6, 54], 1: [74, 22, 6, 1], 84: [74, 22, 97, 84], 77: [74, 22, 97, 77], 3: [74, 62, 42, 3], 33: [74, 62, 42, 33], 24: [74, 62, 42, 24], 90: [74, 62, 42, 90], 16: [74, 62, 86, 16], 23: [74, 62, 4, 23], 89: [74, 62, 96, 89], 20: [74, 62, 96, 20], 95: [74, 62, 80, 95], 85: [74, 62, 80, 85], 10: [74, 62, 80, 10], 46: [74, 62, 80, 46], 92: [74, 62, 44, 92], 56: [74, 62, 44, 56], 94: [74, 62, 44, 94], 30: [74, 59, 13, 30], 101: [74, 59, 26, 101], 88: [74, 59, 8, 88], 52: [74, 59, 36, 52], 19: [74, 59, 36, 19], 81: [74, 59, 78, 81], 15: [74, 59, 65, 15], 28: [74, 51, 49, 28], 5: [74, 51, 49, 5], 21: [74, 51, 100, 21], 41: [74, 87, 60, 41], 79: [74, 87, 60, 79], 70: [74, 53, 45, 70], 35: [74, 53, 45, 35], 66: [74, 22, 43, 63, 66], 67: [74, 22, 43, 27, 67], 68: [74, 22, 91, 12, 68], 37: [74, 22, 91, 32, 37], 9: [74, 22, 93, 40, 9], 75: [74, 22, 93, 34, 75], 61: [74, 62, 42, 33, 61]}) (94, {94: [94], 62: [94, 62], 57: [94, 57], 101: [94, 101], 46: [94, 46], 24: [94, 24], 42: [94, 62, 42], 86: [94, 62, 86], 74: [94, 62, 74], 4: [94, 62, 4], 96: [94, 62, 96], 80: [94, 62, 80], 44: [94, 62, 44], 52: [94, 57, 52], 39: [94, 57, 39], 16: [94, 57, 16], 69: [94, 57, 69], 40: [94, 57, 40], 12: [94, 57, 12], 79: [94, 57, 79], 70: [94, 57, 70], 25: [94, 101, 25], 73: [94, 101, 73], 21: [94, 101, 21], 8: [94, 101, 8], 99: [94, 101, 99], 18: [94, 46, 18], 58: [94, 46, 58], 51: [94, 46, 51], 22: [94, 46, 22], 9: [94, 46, 9], 23: [94, 46, 23], 90: [94, 24, 90], 71: [94, 24, 71], 6: [94, 24, 6], 34: [94, 24, 34], 66: [94, 24, 66], 54: [94, 24, 54], 41: [94, 24, 41], 68: [94, 24, 68], 78: [94, 24, 78], 26: [94, 24, 26], 14: [94, 24, 14], 3: [94, 62, 42, 3], 33: [94, 62, 42, 33], 91: [94, 62, 42, 91], 63: [94, 62, 42, 63], 17: [94, 62, 86, 17], 59: [94, 62, 86, 59], 87: [94, 62, 74, 87], 82: [94, 62, 74, 82], 53: [94, 62, 74, 53], 83: [94, 62, 4, 83], 89: [94, 62, 96, 89], 20: [94, 62, 96, 20], 32: [94, 62, 96, 32], 95: [94, 62, 80, 95], 85: [94, 62, 80, 85], 13: [94, 62, 80, 13], 10: [94, 62, 80, 10], 1: [94, 62, 80, 1], 72: [94, 62, 44, 72], 92: [94, 62, 44, 92], 56: [94, 62, 44, 56], 11: [94, 62, 44, 11], 28: [94, 57, 52, 28], 48: [94, 57, 16, 48], 81: [94, 57, 16, 81], 93: [94, 57, 69, 93], 38: [94, 57, 40, 38], 30: [94, 57, 40, 30], 49: [94, 57, 40, 49], 27: [94, 57, 12, 27], 37: [94, 57, 79, 37], 84: [94, 57, 70, 84], 64: [94, 57, 70, 64], 67: [94, 101, 25, 67], 77: [94, 101, 73, 77], 5: [94, 101, 21, 5], 88: [94, 101, 8, 88], 19: [94, 101, 99, 19], 50: [94, 101, 99, 50], 97: [94, 101, 99, 97], 98: [94, 46, 18, 98], 100: [94, 46, 58, 100], 43: [94, 46, 22, 43], 31: [94, 46, 9, 31], 75: [94, 46, 9, 75], 29: [94, 46, 9, 29], 55: [94, 46, 23, 55], 7: [94, 24, 71, 7], 61: [94, 24, 66, 61], 60: [94, 24, 66, 60], 15: [94, 62, 42, 63, 15], 36: [94, 62, 86, 59, 36], 65: [94, 62, 86, 59, 65], 45: [94, 62, 74, 53, 45], 2: [94, 62, 74, 53, 2], 76: [94, 62, 44, 72, 76], 47: [94, 62, 44, 92, 47], 35: [94, 57, 70, 64, 35]}) (83, {83: [83], 89: [83, 89], 45: [83, 45], 52: [83, 52], 43: [83, 43], 93: [83, 93], 44: [83, 44], 57: [83, 89, 57], 55: [83, 89, 55], 70: [83, 45, 70], 34: [83, 45, 34], 35: [83, 45, 35], 85: [83, 45, 85], 1: [83, 52, 1], 39: [83, 52, 39], 23: [83, 52, 23], 28: [83, 52, 28], 101: [83, 52, 101], 74: [83, 43, 74], 47: [83, 43, 47], 63: [83, 43, 63], 27: [83, 43, 27], 25: [83, 43, 25], 73: [83, 43, 73], 48: [83, 43, 48], 11: [83, 43, 11], 31: [83, 43, 31], 58: [83, 93, 58], 40: [83, 93, 40], 71: [83, 93, 71], 72: [83, 44, 72], 92: [83, 44, 92], 51: [83, 44, 51], 56: [83, 44, 56], 94: [83, 44, 94], 10: [83, 44, 10], 24: [83, 89, 57, 24], 16: [83, 89, 57, 16], 69: [83, 89, 57, 69], 12: [83, 89, 57, 12], 79: [83, 89, 57, 79], 29: [83, 89, 55, 29], 42: [83, 89, 55, 42], 37: [83, 45, 70, 37], 84: [83, 45, 70, 84], 64: [83, 45, 70, 64], 9: [83, 45, 70, 9], 20: [83, 45, 34, 20], 75: [83, 45, 34, 75], 18: [83, 45, 34, 18], 38: [83, 45, 34, 38], 46: [83, 45, 34, 46], 4: [83, 45, 35, 4], 36: [83, 45, 35, 36], 49: [83, 45, 35, 49], 59: [83, 45, 35, 59], 5: [83, 45, 85, 5], 53: [83, 52, 1, 53], 96: [83, 52, 39, 96], 33: [83, 52, 39, 33], 13: [83, 52, 39, 13], 62: [83, 52, 28, 62], 80: [83, 52, 28, 80], 67: [83, 52, 28, 67], 32: [83, 52, 28, 32], 21: [83, 52, 101, 21], 8: [83, 52, 101, 8], 99: [83, 52, 101, 99], 22: [83, 43, 74, 22], 87: [83, 43, 74, 87], 82: [83, 43, 74, 82], 15: [83, 43, 47, 15], 98: [83, 43, 47, 98], 19: [83, 43, 47, 19], 2: [83, 43, 47, 2], 100: [83, 43, 63, 100], 88: [83, 43, 63, 88], 81: [83, 43, 63, 81], 66: [83, 43, 63, 66], 14: [83, 43, 27, 14], 26: [83, 43, 25, 26], 6: [83, 43, 73, 6], 77: [83, 43, 73, 77], 7: [83, 43, 48, 7], 95: [83, 43, 11, 95], 91: [83, 43, 31, 91], 17: [83, 93, 58, 17], 30: [83, 93, 40, 30], 50: [83, 93, 71, 50], 76: [83, 44, 72, 76], 90: [83, 44, 56, 90], 3: [83, 44, 10, 3], 54: [83, 89, 57, 24, 54], 41: [83, 89, 57, 24, 41], 68: [83, 89, 57, 24, 68], 78: [83, 89, 57, 24, 78], 65: [83, 45, 70, 64, 65], 86: [83, 45, 34, 20, 86], 97: [83, 45, 35, 59, 97], 61: [83, 52, 39, 33, 61], 60: [83, 52, 39, 13, 60]}) (89, {89: [89], 57: [89, 57], 55: [89, 55], 24: [89, 57, 24], 52: [89, 57, 52], 39: [89, 57, 39], 101: [89, 57, 101], 16: [89, 57, 16], 69: [89, 57, 69], 40: [89, 57, 40], 12: [89, 57, 12], 79: [89, 57, 79], 70: [89, 57, 70], 29: [89, 55, 29], 35: [89, 55, 35], 42: [89, 55, 42], 90: [89, 57, 24, 90], 25: [89, 57, 24, 25], 71: [89, 57, 24, 71], 6: [89, 57, 24, 6], 34: [89, 57, 24, 34], 66: [89, 57, 24, 66], 54: [89, 57, 24, 54], 74: [89, 57, 24, 74], 41: [89, 57, 24, 41], 68: [89, 57, 24, 68], 96: [89, 57, 24, 96], 78: [89, 57, 24, 78], 26: [89, 57, 24, 26], 14: [89, 57, 24, 14], 1: [89, 57, 52, 1], 23: [89, 57, 52, 23], 28: [89, 57, 52, 28], 59: [89, 57, 39, 59], 33: [89, 57, 39, 33], 13: [89, 57, 39, 13], 94: [89, 57, 101, 94], 73: [89, 57, 101, 73], 21: [89, 57, 101, 21], 8: [89, 57, 101, 8], 99: [89, 57, 101, 99], 48: [89, 57, 16, 48], 56: [89, 57, 16, 56], 9: [89, 57, 16, 9], 81: [89, 57, 16, 81], 4: [89, 57, 16, 4], 22: [89, 57, 69, 22], 93: [89, 57, 69, 93], 46: [89, 57, 69, 46], 91: [89, 57, 40, 91], 38: [89, 57, 40, 38], 30: [89, 57, 40, 30], 49: [89, 57, 40, 49], 27: [89, 57, 12, 27], 44: [89, 57, 12, 44], 3: [89, 57, 79, 3], 37: [89, 57, 79, 37], 84: [89, 57, 70, 84], 64: [89, 57, 70, 64], 43: [89, 55, 29, 43], 19: [89, 55, 29, 19], 50: [89, 55, 29, 50], 36: [89, 55, 35, 36], 63: [89, 55, 42, 63], 100: [89, 57, 24, 90, 100], 10: [89, 57, 24, 90, 10], 87: [89, 57, 24, 25, 87], 67: [89, 57, 24, 25, 67], 32: [89, 57, 24, 25, 32], 20: [89, 57, 24, 71, 20], 7: [89, 57, 24, 71, 7], 95: [89, 57, 24, 71, 95], 75: [89, 57, 24, 34, 75], 18: [89, 57, 24, 34, 18], 61: [89, 57, 24, 66, 61], 60: [89, 57, 24, 66, 60], 11: [89, 57, 24, 54, 11], 62: [89, 57, 24, 74, 62], 51: [89, 57, 24, 74, 51], 82: [89, 57, 24, 74, 82], 53: [89, 57, 24, 74, 53], 83: [89, 57, 24, 41, 83], 31: [89, 57, 24, 78, 31], 98: [89, 57, 24, 26, 98], 80: [89, 57, 52, 28, 80], 97: [89, 57, 39, 59, 97], 86: [89, 57, 39, 59, 86], 65: [89, 57, 39, 59, 65], 77: [89, 57, 101, 73, 77], 5: [89, 57, 101, 21, 5], 85: [89, 57, 101, 21, 85], 88: [89, 57, 101, 8, 88], 58: [89, 57, 16, 56, 58], 72: [89, 57, 69, 22, 72], 47: [89, 57, 40, 38, 47], 92: [89, 57, 12, 44, 92], 15: [89, 57, 70, 64, 15], 2: [89, 55, 29, 50, 2], 45: [89, 57, 24, 74, 53, 45], 17: [89, 57, 39, 59, 86, 17], 76: [89, 57, 69, 22, 72, 76]}) (99, {99: [99], 4: [99, 4], 19: [99, 19], 18: [99, 18], 22: [99, 22], 28: [99, 28], 77: [99, 77], 50: [99, 50], 97: [99, 97], 53: [99, 4, 53], 78: [99, 4, 78], 23: [99, 4, 23], 83: [99, 4, 83], 63: [99, 19, 63], 68: [99, 19, 68], 62: [99, 19, 62], 98: [99, 19, 98], 92: [99, 19, 92], 94: [99, 18, 94], 95: [99, 18, 95], 6: [99, 18, 6], 86: [99, 18, 86], 32: [99, 18, 32], 49: [99, 18, 49], 43: [99, 22, 43], 72: [99, 22, 72], 59: [99, 22, 59], 91: [99, 22, 91], 93: [99, 22, 93], 73: [99, 28, 73], 31: [99, 28, 31], 37: [99, 28, 37], 80: [99, 28, 80], 67: [99, 28, 67], 74: [99, 28, 74], 9: [99, 77, 9], 29: [99, 77, 29], 45: [99, 77, 45], 56: [99, 77, 56], 70: [99, 77, 70], 15: [99, 77, 15], 101: [99, 77, 101], 21: [99, 77, 21], 2: [99, 50, 2], 88: [99, 50, 88], 54: [99, 50, 54], 52: [99, 50, 52], 42: [99, 50, 42], 87: [99, 97, 87], 64: [99, 97, 64], 84: [99, 97, 84], 25: [99, 97, 25], 7: [99, 97, 7], 69: [99, 4, 53, 69], 55: [99, 4, 53, 55], 13: [99, 4, 78, 13], 12: [99, 4, 78, 12], 81: [99, 4, 78, 81], 33: [99, 4, 78, 33], 89: [99, 4, 23, 89], 44: [99, 4, 83, 44], 10: [99, 19, 63, 10], 100: [99, 19, 63, 100], 20: [99, 19, 63, 20], 66: [99, 19, 63, 66], 40: [99, 19, 68, 40], 96: [99, 19, 62, 96], 47: [99, 19, 98, 47], 46: [99, 19, 98, 46], 36: [99, 19, 98, 36], 5: [99, 19, 98, 5], 38: [99, 19, 98, 38], 90: [99, 19, 98, 90], 34: [99, 19, 92, 34], 57: [99, 18, 94, 57], 24: [99, 18, 94, 24], 1: [99, 18, 6, 1], 17: [99, 18, 86, 17], 26: [99, 18, 86, 26], 16: [99, 18, 86, 16], 30: [99, 18, 49, 30], 58: [99, 18, 49, 58], 27: [99, 22, 43, 27], 48: [99, 22, 43, 48], 11: [99, 22, 43, 11], 76: [99, 22, 72, 76], 8: [99, 22, 59, 8], 65: [99, 22, 59, 65], 71: [99, 22, 93, 71], 39: [99, 22, 93, 39], 85: [99, 28, 31, 85], 51: [99, 28, 74, 51], 82: [99, 28, 74, 82], 75: [99, 77, 9, 75], 35: [99, 77, 45, 35], 79: [99, 77, 70, 79], 3: [99, 77, 21, 3], 60: [99, 50, 2, 60], 14: [99, 97, 84, 14], 61: [99, 4, 78, 81, 61], 41: [99, 4, 78, 81, 41]}) (90, {90: [90], 100: [90, 100], 93: [90, 93], 59: [90, 59], 1: [90, 1], 10: [90, 10], 34: [90, 34], 47: [90, 100, 47], 36: [90, 100, 36], 58: [90, 100, 58], 21: [90, 100, 21], 69: [90, 100, 69], 92: [90, 100, 92], 40: [90, 93, 40], 71: [90, 93, 71], 39: [90, 93, 39], 83: [90, 93, 83], 43: [90, 93, 43], 96: [90, 59, 96], 13: [90, 59, 13], 26: [90, 59, 26], 62: [90, 59, 62], 8: [90, 59, 8], 44: [90, 59, 44], 11: [90, 59, 11], 18: [90, 59, 18], 97: [90, 59, 97], 78: [90, 59, 78], 86: [90, 59, 86], 65: [90, 59, 65], 16: [90, 1, 16], 70: [90, 1, 70], 79: [90, 1, 79], 53: [90, 1, 53], 48: [90, 10, 48], 46: [90, 10, 46], 3: [90, 10, 3], 31: [90, 10, 31], 20: [90, 34, 20], 75: [90, 34, 75], 55: [90, 34, 55], 38: [90, 34, 38], 29: [90, 34, 29], 15: [90, 100, 47, 15], 98: [90, 100, 47, 98], 19: [90, 100, 47, 19], 24: [90, 100, 47, 24], 2: [90, 100, 47, 2], 52: [90, 100, 36, 52], 49: [90, 100, 36, 49], 23: [90, 100, 36, 23], 87: [90, 100, 58, 87], 17: [90, 100, 58, 17], 22: [90, 100, 58, 22], 30: [90, 100, 21, 30], 82: [90, 100, 21, 82], 5: [90, 100, 21, 5], 85: [90, 100, 21, 85], 25: [90, 100, 69, 25], 32: [90, 100, 92, 32], 9: [90, 93, 40, 9], 91: [90, 93, 40, 91], 37: [90, 93, 71, 37], 50: [90, 93, 71, 50], 7: [90, 93, 71, 7], 95: [90, 93, 71, 95], 101: [90, 93, 39, 101], 28: [90, 93, 39, 28], 42: [90, 93, 39, 42], 33: [90, 93, 39, 33], 74: [90, 93, 39, 74], 89: [90, 93, 83, 89], 45: [90, 93, 83, 45], 63: [90, 93, 43, 63], 27: [90, 93, 43, 27], 73: [90, 93, 43, 73], 14: [90, 59, 13, 14], 4: [90, 59, 13, 4], 60: [90, 59, 13, 60], 80: [90, 59, 62, 80], 88: [90, 59, 8, 88], 72: [90, 59, 44, 72], 51: [90, 59, 44, 51], 56: [90, 59, 44, 56], 94: [90, 59, 44, 94], 6: [90, 59, 18, 6], 64: [90, 59, 97, 64], 84: [90, 59, 97, 84], 77: [90, 59, 97, 77], 12: [90, 59, 78, 12], 81: [90, 59, 78, 81], 99: [90, 10, 48, 99], 54: [90, 10, 3, 54], 68: [90, 34, 20, 68], 67: [90, 34, 75, 67], 35: [90, 34, 55, 35], 66: [90, 34, 38, 66], 41: [90, 100, 47, 24, 41], 76: [90, 100, 47, 2, 76], 57: [90, 93, 71, 37, 57], 61: [90, 93, 39, 33, 61]}) (66, {66: [66], 61: [66, 61], 95: [66, 95], 68: [66, 68], 60: [66, 60], 59: [66, 61, 59], 92: [66, 61, 92], 72: [66, 61, 72], 22: [66, 61, 22], 100: [66, 61, 100], 73: [66, 61, 73], 34: [66, 95, 34], 31: [66, 95, 31], 49: [66, 95, 49], 20: [66, 95, 20], 46: [66, 95, 46], 81: [66, 95, 81], 55: [66, 68, 55], 13: [66, 68, 13], 40: [66, 68, 40], 41: [66, 60, 41], 89: [66, 60, 89], 79: [66, 60, 79], 18: [66, 60, 18], 62: [66, 60, 62], 99: [66, 60, 99], 93: [66, 60, 93], 96: [66, 61, 59, 96], 26: [66, 61, 59, 26], 8: [66, 61, 59, 8], 44: [66, 61, 59, 44], 11: [66, 61, 59, 11], 97: [66, 61, 59, 97], 36: [66, 61, 59, 36], 78: [66, 61, 59, 78], 86: [66, 61, 59, 86], 65: [66, 61, 59, 65], 32: [66, 61, 92, 32], 47: [66, 61, 92, 47], 52: [66, 61, 92, 52], 17: [66, 61, 72, 17], 29: [66, 61, 72, 29], 98: [66, 61, 72, 98], 6: [66, 61, 72, 6], 76: [66, 61, 72, 76], 43: [66, 61, 22, 43], 91: [66, 61, 22, 91], 10: [66, 61, 100, 10], 58: [66, 61, 100, 58], 21: [66, 61, 100, 21], 69: [66, 61, 100, 69], 71: [66, 61, 73, 71], 77: [66, 61, 73, 77], 83: [66, 61, 73, 83], 1: [66, 61, 73, 1], 75: [66, 95, 34, 75], 38: [66, 95, 34, 38], 12: [66, 95, 31, 12], 48: [66, 95, 31, 48], 88: [66, 95, 31, 88], 33: [66, 95, 31, 33], 85: [66, 95, 31, 85], 28: [66, 95, 49, 28], 30: [66, 95, 49, 30], 5: [66, 95, 49, 5], 84: [66, 95, 20, 84], 56: [66, 95, 20, 56], 19: [66, 95, 20, 19], 4: [66, 95, 20, 4], 51: [66, 95, 46, 51], 9: [66, 95, 46, 9], 23: [66, 95, 46, 23], 3: [66, 95, 81, 3], 42: [66, 95, 81, 42], 35: [66, 68, 55, 35], 16: [66, 68, 55, 16], 14: [66, 68, 13, 14], 94: [66, 60, 41, 94], 82: [66, 60, 41, 82], 57: [66, 60, 89, 57], 37: [66, 60, 79, 37], 74: [66, 60, 62, 74], 80: [66, 60, 62, 80], 50: [66, 60, 99, 50], 39: [66, 60, 93, 39], 101: [66, 61, 59, 26, 101], 25: [66, 61, 59, 26, 25], 24: [66, 61, 59, 11, 24], 87: [66, 61, 59, 97, 87], 64: [66, 61, 59, 97, 64], 7: [66, 61, 59, 97, 7], 15: [66, 61, 59, 65, 15], 45: [66, 61, 59, 65, 45], 2: [66, 61, 92, 47, 2], 54: [66, 61, 72, 98, 54], 90: [66, 61, 72, 98, 90], 63: [66, 61, 22, 43, 63], 27: [66, 61, 22, 43, 27], 70: [66, 61, 73, 77, 70], 53: [66, 61, 73, 1, 53], 67: [66, 95, 34, 75, 67]}) (61, {61: [61], 59: [61, 59], 92: [61, 92], 72: [61, 72], 22: [61, 22], 100: [61, 100], 73: [61, 73], 96: [61, 59, 96], 13: [61, 59, 13], 26: [61, 59, 26], 62: [61, 59, 62], 8: [61, 59, 8], 44: [61, 59, 44], 11: [61, 59, 11], 18: [61, 59, 18], 97: [61, 59, 97], 36: [61, 59, 36], 78: [61, 59, 78], 86: [61, 59, 86], 65: [61, 59, 65], 32: [61, 92, 32], 34: [61, 92, 34], 47: [61, 92, 47], 52: [61, 92, 52], 17: [61, 72, 17], 29: [61, 72, 29], 98: [61, 72, 98], 6: [61, 72, 6], 76: [61, 72, 76], 43: [61, 22, 43], 91: [61, 22, 91], 93: [61, 22, 93], 10: [61, 100, 10], 58: [61, 100, 58], 21: [61, 100, 21], 69: [61, 100, 69], 71: [61, 73, 71], 77: [61, 73, 77], 83: [61, 73, 83], 1: [61, 73, 1], 33: [61, 59, 96, 33], 89: [61, 59, 96, 89], 20: [61, 59, 96, 20], 14: [61, 59, 13, 14], 30: [61, 59, 13, 30], 4: [61, 59, 13, 4], 60: [61, 59, 13, 60], 101: [61, 59, 26, 101], 25: [61, 59, 26, 25], 42: [61, 59, 62, 42], 74: [61, 59, 62, 74], 80: [61, 59, 62, 80], 88: [61, 59, 8, 88], 51: [61, 59, 44, 51], 56: [61, 59, 44, 56], 94: [61, 59, 44, 94], 95: [61, 59, 11, 95], 24: [61, 59, 11, 24], 49: [61, 59, 18, 49], 87: [61, 59, 97, 87], 64: [61, 59, 97, 64], 84: [61, 59, 97, 84], 7: [61, 59, 97, 7], 46: [61, 59, 36, 46], 23: [61, 59, 36, 23], 19: [61, 59, 36, 19], 39: [61, 59, 36, 39], 31: [61, 59, 78, 31], 12: [61, 59, 78, 12], 81: [61, 59, 78, 81], 16: [61, 59, 86, 16], 15: [61, 59, 65, 15], 45: [61, 59, 65, 45], 37: [61, 92, 32, 37], 75: [61, 92, 34, 75], 55: [61, 92, 34, 55], 38: [61, 92, 34, 38], 2: [61, 92, 47, 2], 28: [61, 92, 52, 28], 50: [61, 72, 29, 50], 5: [61, 72, 98, 5], 54: [61, 72, 98, 54], 90: [61, 72, 98, 90], 57: [61, 72, 6, 57], 40: [61, 72, 76, 40], 63: [61, 22, 43, 63], 27: [61, 22, 43, 27], 48: [61, 22, 43, 48], 99: [61, 22, 91, 99], 3: [61, 100, 10, 3], 82: [61, 100, 21, 82], 85: [61, 100, 21, 85], 9: [61, 73, 77, 9], 70: [61, 73, 77, 70], 79: [61, 73, 1, 79], 53: [61, 73, 1, 53], 68: [61, 59, 96, 20, 68], 41: [61, 59, 13, 60, 41], 67: [61, 59, 26, 25, 67], 66: [61, 59, 26, 25, 66], 35: [61, 59, 97, 64, 35]}) (45, {45: [45], 70: [45, 70], 34: [45, 34], 35: [45, 35], 85: [45, 85], 37: [45, 70, 37], 84: [45, 70, 84], 64: [45, 70, 64], 9: [45, 70, 9], 79: [45, 70, 79], 52: [45, 70, 52], 20: [45, 34, 20], 75: [45, 34, 75], 18: [45, 34, 18], 55: [45, 34, 55], 38: [45, 34, 38], 46: [45, 34, 46], 29: [45, 34, 29], 4: [45, 35, 4], 36: [45, 35, 36], 49: [45, 35, 49], 59: [45, 35, 59], 74: [45, 35, 74], 73: [45, 85, 73], 1: [45, 85, 1], 25: [45, 85, 25], 5: [45, 85, 5], 57: [45, 70, 37, 57], 32: [45, 70, 84, 32], 98: [45, 70, 84, 98], 13: [45, 70, 84, 13], 14: [45, 70, 84, 14], 101: [45, 70, 64, 101], 89: [45, 70, 64, 89], 82: [45, 70, 64, 82], 65: [45, 70, 64, 65], 15: [45, 70, 64, 15], 39: [45, 70, 64, 39], 96: [45, 70, 64, 96], 22: [45, 70, 64, 22], 50: [45, 70, 9, 50], 94: [45, 70, 9, 94], 31: [45, 70, 9, 31], 3: [45, 70, 79, 3], 8: [45, 70, 79, 8], 23: [45, 70, 52, 23], 28: [45, 70, 52, 28], 56: [45, 34, 20, 56], 99: [45, 34, 20, 99], 19: [45, 34, 20, 19], 58: [45, 34, 20, 58], 83: [45, 34, 20, 83], 30: [45, 34, 20, 30], 68: [45, 34, 20, 68], 86: [45, 34, 20, 86], 81: [45, 34, 20, 81], 67: [45, 34, 75, 67], 40: [45, 34, 75, 40], 95: [45, 34, 18, 95], 6: [45, 34, 18, 6], 42: [45, 34, 55, 42], 16: [45, 34, 55, 16], 78: [45, 34, 38, 78], 47: [45, 34, 38, 47], 66: [45, 34, 38, 66], 12: [45, 34, 46, 12], 51: [45, 34, 46, 51], 21: [45, 34, 29, 21], 43: [45, 34, 29, 43], 53: [45, 35, 4, 53], 26: [45, 35, 36, 26], 10: [45, 35, 49, 10], 62: [45, 35, 59, 62], 44: [45, 35, 59, 44], 11: [45, 35, 59, 11], 97: [45, 35, 59, 97], 87: [45, 35, 74, 87], 71: [45, 85, 73, 71], 77: [45, 85, 73, 77], 69: [45, 85, 1, 69], 41: [45, 85, 5, 41], 24: [45, 70, 37, 57, 24], 93: [45, 70, 84, 32, 93], 88: [45, 70, 84, 98, 88], 54: [45, 70, 84, 98, 54], 90: [45, 70, 84, 98, 90], 60: [45, 70, 84, 13, 60], 33: [45, 70, 64, 39, 33], 72: [45, 70, 64, 22, 72], 91: [45, 70, 64, 22, 91], 2: [45, 70, 9, 50, 2], 48: [45, 70, 9, 31, 48], 80: [45, 70, 52, 28, 80], 63: [45, 34, 20, 19, 63], 92: [45, 34, 20, 19, 92], 100: [45, 34, 20, 58, 100], 17: [45, 34, 20, 58, 17], 61: [45, 34, 20, 81, 61], 27: [45, 34, 46, 12, 27], 7: [45, 35, 59, 97, 7], 76: [45, 70, 64, 22, 72, 76]}) (53, {53: [53], 69: [53, 69], 86: [53, 86], 45: [53, 45], 55: [53, 55], 2: [53, 2], 22: [53, 69, 22], 93: [53, 69, 93], 8: [53, 69, 8], 46: [53, 69, 46], 25: [53, 69, 25], 26: [53, 69, 26], 18: [53, 86, 18], 17: [53, 86, 17], 59: [53, 86, 59], 6: [53, 86, 6], 80: [53, 86, 80], 16: [53, 86, 16], 70: [53, 45, 70], 34: [53, 45, 34], 35: [53, 45, 35], 85: [53, 45, 85], 29: [53, 55, 29], 42: [53, 55, 42], 51: [53, 2, 51], 60: [53, 2, 60], 56: [53, 2, 56], 40: [53, 2, 40], 76: [53, 2, 76], 43: [53, 69, 22, 43], 72: [53, 69, 22, 72], 91: [53, 69, 22, 91], 97: [53, 69, 22, 97], 58: [53, 69, 93, 58], 71: [53, 69, 93, 71], 39: [53, 69, 93, 39], 83: [53, 69, 93, 83], 88: [53, 69, 8, 88], 101: [53, 69, 8, 101], 12: [53, 69, 46, 12], 9: [53, 69, 46, 9], 23: [53, 69, 46, 23], 84: [53, 69, 25, 84], 87: [53, 69, 25, 87], 67: [53, 69, 25, 67], 32: [53, 69, 25, 32], 66: [53, 69, 25, 66], 98: [53, 69, 26, 98], 94: [53, 86, 18, 94], 95: [53, 86, 18, 95], 49: [53, 86, 18, 49], 96: [53, 86, 59, 96], 13: [53, 86, 59, 13], 62: [53, 86, 59, 62], 44: [53, 86, 59, 44], 11: [53, 86, 59, 11], 36: [53, 86, 59, 36], 78: [53, 86, 59, 78], 65: [53, 86, 59, 65], 57: [53, 86, 6, 57], 54: [53, 86, 6, 54], 1: [53, 86, 6, 1], 10: [53, 86, 80, 10], 48: [53, 86, 16, 48], 81: [53, 86, 16, 81], 4: [53, 86, 16, 4], 79: [53, 86, 16, 79], 37: [53, 45, 70, 37], 64: [53, 45, 70, 64], 52: [53, 45, 70, 52], 20: [53, 45, 34, 20], 75: [53, 45, 34, 75], 38: [53, 45, 34, 38], 74: [53, 45, 35, 74], 73: [53, 45, 85, 73], 5: [53, 45, 85, 5], 21: [53, 55, 29, 21], 19: [53, 55, 29, 19], 50: [53, 55, 29, 50], 3: [53, 55, 42, 3], 33: [53, 55, 42, 33], 24: [53, 55, 42, 24], 90: [53, 55, 42, 90], 63: [53, 55, 42, 63], 100: [53, 2, 51, 100], 41: [53, 2, 60, 41], 89: [53, 2, 60, 89], 99: [53, 2, 60, 99], 77: [53, 2, 56, 77], 30: [53, 2, 40, 30], 47: [53, 2, 76, 47], 7: [53, 2, 76, 7], 27: [53, 69, 22, 43, 27], 31: [53, 69, 22, 43, 31], 28: [53, 69, 93, 39, 28], 68: [53, 69, 46, 12, 68], 14: [53, 69, 25, 84, 14], 61: [53, 69, 25, 66, 61], 92: [53, 86, 59, 44, 92], 15: [53, 86, 59, 65, 15], 82: [53, 45, 70, 64, 82]}) (69, {69: [69], 22: [69, 22], 93: [69, 93], 8: [69, 8], 46: [69, 46], 25: [69, 25], 26: [69, 26], 43: [69, 22, 43], 72: [69, 22, 72], 59: [69, 22, 59], 91: [69, 22, 91], 6: [69, 22, 6], 97: [69, 22, 97], 58: [69, 93, 58], 40: [69, 93, 40], 34: [69, 93, 34], 71: [69, 93, 71], 39: [69, 93, 39], 83: [69, 93, 83], 88: [69, 8, 88], 101: [69, 8, 101], 18: [69, 46, 18], 12: [69, 46, 12], 51: [69, 46, 51], 9: [69, 46, 9], 23: [69, 46, 23], 84: [69, 25, 84], 87: [69, 25, 87], 67: [69, 25, 67], 32: [69, 25, 32], 56: [69, 25, 56], 66: [69, 25, 66], 98: [69, 26, 98], 74: [69, 22, 43, 74], 47: [69, 22, 43, 47], 63: [69, 22, 43, 63], 27: [69, 22, 43, 27], 73: [69, 22, 43, 73], 48: [69, 22, 43, 48], 11: [69, 22, 43, 11], 31: [69, 22, 43, 31], 17: [69, 22, 72, 17], 36: [69, 22, 72, 36], 29: [69, 22, 72, 29], 76: [69, 22, 72, 76], 96: [69, 22, 59, 96], 13: [69, 22, 59, 13], 62: [69, 22, 59, 62], 44: [69, 22, 59, 44], 78: [69, 22, 59, 78], 86: [69, 22, 59, 86], 65: [69, 22, 59, 65], 99: [69, 22, 91, 99], 50: [69, 22, 91, 50], 64: [69, 22, 91, 64], 38: [69, 22, 91, 38], 7: [69, 22, 91, 7], 100: [69, 22, 91, 100], 57: [69, 22, 6, 57], 54: [69, 22, 6, 54], 1: [69, 22, 6, 1], 77: [69, 22, 97, 77], 30: [69, 93, 40, 30], 49: [69, 93, 40, 49], 20: [69, 93, 34, 20], 75: [69, 93, 34, 75], 55: [69, 93, 34, 55], 37: [69, 93, 71, 37], 10: [69, 93, 71, 10], 95: [69, 93, 71, 95], 28: [69, 93, 39, 28], 42: [69, 93, 39, 42], 33: [69, 93, 39, 33], 89: [69, 93, 83, 89], 45: [69, 93, 83, 45], 52: [69, 93, 83, 52], 81: [69, 8, 88, 81], 94: [69, 8, 101, 94], 21: [69, 8, 101, 21], 68: [69, 46, 12, 68], 4: [69, 46, 12, 4], 85: [69, 46, 9, 85], 14: [69, 25, 84, 14], 60: [69, 25, 87, 60], 16: [69, 25, 67, 16], 90: [69, 25, 56, 90], 61: [69, 25, 66, 61], 5: [69, 26, 98, 5], 82: [69, 22, 43, 74, 82], 53: [69, 22, 43, 74, 53], 15: [69, 22, 43, 47, 15], 19: [69, 22, 43, 47, 19], 24: [69, 22, 43, 47, 24], 2: [69, 22, 43, 47, 2], 80: [69, 22, 43, 11, 80], 92: [69, 22, 59, 44, 92], 35: [69, 22, 91, 64, 35], 79: [69, 22, 6, 57, 79], 70: [69, 22, 6, 57, 70], 3: [69, 93, 71, 10, 3], 41: [69, 8, 88, 81, 41]}) (43, {43: [43], 74: [43, 74], 47: [43, 47], 63: [43, 63], 27: [43, 27], 25: [43, 25], 73: [43, 73], 48: [43, 48], 11: [43, 11], 31: [43, 31], 22: [43, 74, 22], 62: [43, 74, 62], 59: [43, 74, 59], 51: [43, 74, 51], 87: [43, 74, 87], 82: [43, 74, 82], 53: [43, 74, 53], 15: [43, 47, 15], 13: [43, 47, 13], 29: [43, 47, 29], 98: [43, 47, 98], 19: [43, 47, 19], 36: [43, 47, 36], 24: [43, 47, 24], 2: [43, 47, 2], 10: [43, 63, 10], 100: [43, 63, 100], 20: [43, 63, 20], 88: [43, 63, 88], 4: [43, 63, 4], 81: [43, 63, 81], 55: [43, 63, 55], 66: [43, 63, 66], 14: [43, 27, 14], 84: [43, 27, 84], 67: [43, 27, 67], 89: [43, 27, 89], 26: [43, 25, 26], 32: [43, 25, 32], 56: [43, 25, 56], 71: [43, 73, 71], 6: [43, 73, 6], 77: [43, 73, 77], 83: [43, 73, 83], 1: [43, 73, 1], 7: [43, 48, 7], 5: [43, 48, 5], 101: [43, 48, 101], 99: [43, 48, 99], 80: [43, 11, 80], 95: [43, 11, 95], 12: [43, 31, 12], 91: [43, 31, 91], 33: [43, 31, 33], 85: [43, 31, 85], 72: [43, 74, 22, 72], 93: [43, 74, 22, 93], 97: [43, 74, 22, 97], 42: [43, 74, 62, 42], 86: [43, 74, 62, 86], 96: [43, 74, 62, 96], 44: [43, 74, 62, 44], 8: [43, 74, 59, 8], 18: [43, 74, 59, 18], 78: [43, 74, 59, 78], 65: [43, 74, 59, 65], 49: [43, 74, 51, 49], 60: [43, 74, 87, 60], 69: [43, 74, 53, 69], 45: [43, 74, 53, 45], 39: [43, 47, 15, 39], 9: [43, 47, 15, 9], 50: [43, 47, 15, 50], 30: [43, 47, 13, 30], 21: [43, 47, 29, 21], 46: [43, 47, 98, 46], 38: [43, 47, 98, 38], 54: [43, 47, 98, 54], 90: [43, 47, 98, 90], 68: [43, 47, 19, 68], 92: [43, 47, 19, 92], 52: [43, 47, 36, 52], 23: [43, 47, 36, 23], 34: [43, 47, 24, 34], 41: [43, 47, 24, 41], 40: [43, 47, 2, 40], 76: [43, 47, 2, 76], 3: [43, 63, 10, 3], 58: [43, 63, 100, 58], 64: [43, 63, 88, 64], 61: [43, 63, 81, 61], 28: [43, 63, 81, 28], 35: [43, 63, 55, 35], 16: [43, 63, 55, 16], 57: [43, 27, 89, 57], 37: [43, 25, 32, 37], 70: [43, 73, 77, 70], 79: [43, 73, 1, 79], 94: [43, 48, 101, 94], 75: [43, 31, 33, 75], 17: [43, 74, 22, 72, 17]}) (86, {86: [86], 18: [86, 18], 17: [86, 17], 59: [86, 59], 26: [86, 26], 6: [86, 6], 80: [86, 80], 16: [86, 16], 98: [86, 18, 98], 94: [86, 18, 94], 95: [86, 18, 95], 32: [86, 18, 32], 49: [86, 18, 49], 84: [86, 17, 84], 96: [86, 59, 96], 13: [86, 59, 13], 62: [86, 59, 62], 8: [86, 59, 8], 44: [86, 59, 44], 11: [86, 59, 11], 97: [86, 59, 97], 36: [86, 59, 36], 78: [86, 59, 78], 65: [86, 59, 65], 101: [86, 26, 101], 83: [86, 26, 83], 25: [86, 26, 25], 57: [86, 6, 57], 54: [86, 6, 54], 1: [86, 6, 1], 85: [86, 80, 85], 10: [86, 80, 10], 23: [86, 80, 23], 46: [86, 80, 46], 48: [86, 16, 48], 56: [86, 16, 56], 9: [86, 16, 9], 81: [86, 16, 81], 4: [86, 16, 4], 79: [86, 16, 79], 47: [86, 18, 98, 47], 88: [86, 18, 98, 88], 5: [86, 18, 98, 5], 38: [86, 18, 98, 38], 90: [86, 18, 98, 90], 24: [86, 18, 94, 24], 34: [86, 18, 95, 34], 31: [86, 18, 95, 31], 20: [86, 18, 95, 20], 93: [86, 18, 32, 93], 37: [86, 18, 32, 37], 28: [86, 18, 49, 28], 40: [86, 18, 49, 40], 30: [86, 18, 49, 30], 58: [86, 18, 49, 58], 14: [86, 17, 84, 14], 33: [86, 59, 96, 33], 89: [86, 59, 96, 89], 60: [86, 59, 13, 60], 42: [86, 59, 62, 42], 74: [86, 59, 62, 74], 72: [86, 59, 44, 72], 92: [86, 59, 44, 92], 51: [86, 59, 44, 51], 87: [86, 59, 97, 87], 64: [86, 59, 97, 64], 77: [86, 59, 97, 77], 7: [86, 59, 97, 7], 52: [86, 59, 36, 52], 19: [86, 59, 36, 19], 29: [86, 59, 36, 29], 39: [86, 59, 36, 39], 69: [86, 59, 78, 69], 12: [86, 59, 78, 12], 15: [86, 59, 65, 15], 45: [86, 59, 65, 45], 73: [86, 26, 101, 73], 21: [86, 26, 101, 21], 99: [86, 26, 101, 99], 43: [86, 26, 83, 43], 67: [86, 26, 25, 67], 66: [86, 26, 25, 66], 70: [86, 6, 57, 70], 71: [86, 6, 54, 71], 53: [86, 6, 1, 53], 3: [86, 80, 10, 3], 55: [86, 80, 23, 55], 22: [86, 80, 46, 22], 50: [86, 16, 9, 50], 75: [86, 16, 9, 75], 61: [86, 16, 81, 61], 68: [86, 16, 81, 68], 41: [86, 16, 81, 41], 2: [86, 18, 98, 47, 2], 100: [86, 18, 98, 90, 100], 91: [86, 18, 95, 31, 91], 82: [86, 17, 84, 14, 82], 63: [86, 59, 62, 42, 63], 76: [86, 59, 44, 72, 76], 35: [86, 59, 97, 64, 35], 27: [86, 59, 78, 12, 27]}) (48, {48: [48], 7: [48, 7], 36: [48, 36], 5: [48, 5], 101: [48, 101], 99: [48, 99], 51: [48, 7, 51], 8: [48, 36, 8], 26: [48, 36, 26], 46: [48, 36, 46], 52: [48, 36, 52], 49: [48, 36, 49], 23: [48, 36, 23], 19: [48, 36, 19], 29: [48, 36, 29], 39: [48, 36, 39], 9: [48, 5, 9], 55: [48, 5, 55], 41: [48, 5, 41], 94: [48, 101, 94], 25: [48, 101, 25], 73: [48, 101, 73], 21: [48, 101, 21], 96: [48, 101, 96], 4: [48, 99, 4], 18: [48, 99, 18], 22: [48, 99, 22], 28: [48, 99, 28], 77: [48, 99, 77], 50: [48, 99, 50], 97: [48, 99, 97], 100: [48, 7, 51, 100], 88: [48, 36, 8, 88], 83: [48, 36, 26, 83], 98: [48, 36, 26, 98], 12: [48, 36, 46, 12], 58: [48, 36, 46, 58], 1: [48, 36, 52, 1], 40: [48, 36, 49, 40], 30: [48, 36, 49, 30], 31: [48, 36, 49, 31], 95: [48, 36, 49, 95], 10: [48, 36, 49, 10], 69: [48, 36, 23, 69], 89: [48, 36, 23, 89], 63: [48, 36, 19, 63], 68: [48, 36, 19, 68], 62: [48, 36, 19, 62], 92: [48, 36, 19, 92], 43: [48, 36, 29, 43], 59: [48, 36, 29, 59], 42: [48, 36, 39, 42], 33: [48, 36, 39, 33], 13: [48, 36, 39, 13], 74: [48, 36, 39, 74], 85: [48, 5, 9, 85], 75: [48, 5, 9, 75], 35: [48, 5, 55, 35], 16: [48, 5, 55, 16], 20: [48, 5, 41, 20], 56: [48, 5, 41, 56], 82: [48, 5, 41, 82], 57: [48, 101, 94, 57], 24: [48, 101, 94, 24], 84: [48, 101, 25, 84], 87: [48, 101, 25, 87], 67: [48, 101, 25, 67], 32: [48, 101, 25, 32], 66: [48, 101, 25, 66], 71: [48, 101, 73, 71], 6: [48, 101, 73, 6], 11: [48, 101, 21, 11], 3: [48, 101, 21, 3], 53: [48, 99, 4, 53], 78: [48, 99, 4, 78], 86: [48, 99, 18, 86], 72: [48, 99, 22, 72], 91: [48, 99, 22, 91], 93: [48, 99, 22, 93], 37: [48, 99, 28, 37], 80: [48, 99, 28, 80], 45: [48, 99, 77, 45], 70: [48, 99, 77, 70], 15: [48, 99, 77, 15], 2: [48, 99, 50, 2], 54: [48, 99, 50, 54], 64: [48, 99, 97, 64], 47: [48, 7, 51, 100, 47], 81: [48, 36, 8, 88, 81], 65: [48, 36, 8, 88, 65], 44: [48, 36, 26, 83, 44], 38: [48, 36, 26, 98, 38], 90: [48, 36, 26, 98, 90], 27: [48, 36, 46, 12, 27], 17: [48, 36, 46, 58, 17], 79: [48, 36, 52, 1, 79], 34: [48, 36, 49, 95, 34], 61: [48, 36, 39, 33, 61], 14: [48, 36, 39, 13, 14], 60: [48, 36, 39, 13, 60], 76: [48, 99, 22, 72, 76]}) (79, {79: [79], 3: [79, 3], 8: [79, 8], 22: [79, 22], 37: [79, 37], 72: [79, 3, 72], 62: [79, 3, 62], 44: [79, 3, 44], 85: [79, 3, 85], 54: [79, 3, 54], 88: [79, 8, 88], 101: [79, 8, 101], 43: [79, 22, 43], 59: [79, 22, 59], 91: [79, 22, 91], 93: [79, 22, 93], 6: [79, 22, 6], 97: [79, 22, 97], 74: [79, 37, 74], 57: [79, 37, 57], 17: [79, 3, 72, 17], 36: [79, 3, 72, 36], 29: [79, 3, 72, 29], 98: [79, 3, 72, 98], 76: [79, 3, 72, 76], 18: [79, 3, 72, 18], 42: [79, 3, 62, 42], 86: [79, 3, 62, 86], 4: [79, 3, 62, 4], 96: [79, 3, 62, 96], 80: [79, 3, 62, 80], 92: [79, 3, 44, 92], 51: [79, 3, 44, 51], 56: [79, 3, 44, 56], 11: [79, 3, 44, 11], 94: [79, 3, 44, 94], 10: [79, 3, 44, 10], 73: [79, 3, 85, 73], 1: [79, 3, 85, 1], 25: [79, 3, 85, 25], 5: [79, 3, 85, 5], 71: [79, 3, 54, 71], 16: [79, 3, 54, 16], 9: [79, 3, 54, 9], 70: [79, 3, 54, 70], 81: [79, 8, 88, 81], 64: [79, 8, 88, 64], 95: [79, 8, 88, 95], 65: [79, 8, 88, 65], 40: [79, 8, 88, 40], 39: [79, 8, 88, 39], 21: [79, 8, 101, 21], 99: [79, 8, 101, 99], 47: [79, 22, 43, 47], 63: [79, 22, 43, 63], 27: [79, 22, 43, 27], 48: [79, 22, 43, 48], 31: [79, 22, 43, 31], 13: [79, 22, 59, 13], 26: [79, 22, 59, 26], 78: [79, 22, 59, 78], 12: [79, 22, 91, 12], 50: [79, 22, 91, 50], 32: [79, 22, 91, 32], 38: [79, 22, 91, 38], 7: [79, 22, 91, 7], 100: [79, 22, 91, 100], 58: [79, 22, 93, 58], 34: [79, 22, 93, 34], 83: [79, 22, 93, 83], 87: [79, 22, 97, 87], 84: [79, 22, 97, 84], 77: [79, 22, 97, 77], 82: [79, 37, 74, 82], 53: [79, 37, 74, 53], 24: [79, 37, 57, 24], 52: [79, 37, 57, 52], 69: [79, 37, 57, 69], 46: [79, 3, 72, 36, 46], 49: [79, 3, 72, 36, 49], 23: [79, 3, 72, 36, 23], 19: [79, 3, 72, 36, 19], 90: [79, 3, 72, 98, 90], 45: [79, 3, 72, 76, 45], 33: [79, 3, 72, 76, 33], 60: [79, 3, 72, 76, 60], 89: [79, 3, 62, 96, 89], 20: [79, 3, 62, 96, 20], 67: [79, 3, 85, 25, 67], 66: [79, 3, 85, 25, 66], 55: [79, 3, 85, 5, 55], 41: [79, 3, 85, 5, 41], 75: [79, 3, 54, 9, 75], 61: [79, 8, 88, 81, 61], 30: [79, 8, 88, 81, 30], 68: [79, 8, 88, 81, 68], 28: [79, 8, 88, 81, 28], 15: [79, 8, 88, 64, 15], 35: [79, 8, 88, 64, 35], 2: [79, 22, 43, 47, 2], 14: [79, 22, 43, 27, 14]}) (97, {97: [97], 87: [97, 87], 64: [97, 64], 84: [97, 84], 74: [97, 74], 77: [97, 77], 25: [97, 25], 7: [97, 7], 60: [97, 87, 60], 93: [97, 87, 93], 83: [97, 87, 83], 73: [97, 64, 73], 101: [97, 64, 101], 89: [97, 64, 89], 82: [97, 64, 82], 65: [97, 64, 65], 4: [97, 64, 4], 15: [97, 64, 15], 39: [97, 64, 39], 96: [97, 64, 96], 35: [97, 64, 35], 22: [97, 64, 22], 32: [97, 84, 32], 98: [97, 84, 98], 13: [97, 84, 13], 14: [97, 84, 14], 62: [97, 74, 62], 59: [97, 74, 59], 51: [97, 74, 51], 53: [97, 74, 53], 9: [97, 77, 9], 29: [97, 77, 29], 45: [97, 77, 45], 56: [97, 77, 56], 70: [97, 77, 70], 43: [97, 77, 43], 21: [97, 77, 21], 26: [97, 25, 26], 67: [97, 25, 67], 66: [97, 25, 66], 41: [97, 87, 60, 41], 79: [97, 87, 60, 79], 18: [97, 87, 60, 18], 40: [97, 87, 60, 40], 99: [97, 87, 60, 99], 58: [97, 87, 93, 58], 34: [97, 87, 93, 34], 71: [97, 87, 93, 71], 52: [97, 87, 83, 52], 44: [97, 87, 83, 44], 6: [97, 64, 73, 6], 1: [97, 64, 73, 1], 94: [97, 64, 101, 94], 8: [97, 64, 101, 8], 57: [97, 64, 89, 57], 55: [97, 64, 89, 55], 11: [97, 64, 82, 11], 20: [97, 64, 65, 20], 86: [97, 64, 65, 86], 78: [97, 64, 4, 78], 23: [97, 64, 4, 23], 47: [97, 64, 15, 47], 50: [97, 64, 15, 50], 28: [97, 64, 39, 28], 42: [97, 64, 39, 42], 33: [97, 64, 39, 33], 36: [97, 64, 35, 36], 49: [97, 64, 35, 49], 37: [97, 64, 35, 37], 72: [97, 64, 22, 72], 91: [97, 64, 22, 91], 46: [97, 84, 98, 46], 88: [97, 84, 98, 88], 5: [97, 84, 98, 5], 38: [97, 84, 98, 38], 54: [97, 84, 98, 54], 90: [97, 84, 98, 90], 30: [97, 84, 13, 30], 80: [97, 74, 62, 80], 100: [97, 74, 51, 100], 69: [97, 74, 53, 69], 2: [97, 74, 53, 2], 85: [97, 77, 9, 85], 31: [97, 77, 9, 31], 75: [97, 77, 9, 75], 19: [97, 77, 29, 19], 10: [97, 77, 56, 10], 63: [97, 77, 43, 63], 27: [97, 77, 43, 27], 48: [97, 77, 43, 48], 3: [97, 77, 21, 3], 16: [97, 25, 67, 16], 61: [97, 25, 66, 61], 95: [97, 25, 66, 95], 68: [97, 25, 66, 68], 17: [97, 87, 93, 58, 17], 92: [97, 87, 83, 44, 92], 24: [97, 64, 101, 94, 24], 12: [97, 64, 89, 57, 12], 81: [97, 64, 65, 20, 81], 76: [97, 64, 22, 72, 76]}) (87, {87: [87], 60: [87, 60], 93: [87, 93], 83: [87, 83], 41: [87, 60, 41], 89: [87, 60, 89], 79: [87, 60, 79], 18: [87, 60, 18], 62: [87, 60, 62], 40: [87, 60, 40], 99: [87, 60, 99], 58: [87, 93, 58], 34: [87, 93, 34], 71: [87, 93, 71], 39: [87, 93, 39], 43: [87, 93, 43], 45: [87, 83, 45], 52: [87, 83, 52], 44: [87, 83, 44], 19: [87, 60, 41, 19], 94: [87, 60, 41, 94], 96: [87, 60, 41, 96], 20: [87, 60, 41, 20], 21: [87, 60, 41, 21], 56: [87, 60, 41, 56], 82: [87, 60, 41, 82], 57: [87, 60, 89, 57], 55: [87, 60, 89, 55], 3: [87, 60, 79, 3], 8: [87, 60, 79, 8], 22: [87, 60, 79, 22], 37: [87, 60, 79, 37], 98: [87, 60, 18, 98], 95: [87, 60, 18, 95], 6: [87, 60, 18, 6], 86: [87, 60, 18, 86], 32: [87, 60, 18, 32], 49: [87, 60, 18, 49], 42: [87, 60, 62, 42], 74: [87, 60, 62, 74], 4: [87, 60, 62, 4], 80: [87, 60, 62, 80], 9: [87, 60, 40, 9], 91: [87, 60, 40, 91], 38: [87, 60, 40, 38], 30: [87, 60, 40, 30], 28: [87, 60, 99, 28], 77: [87, 60, 99, 77], 50: [87, 60, 99, 50], 97: [87, 60, 99, 97], 100: [87, 93, 58, 100], 26: [87, 93, 58, 26], 17: [87, 93, 58, 17], 75: [87, 93, 34, 75], 46: [87, 93, 34, 46], 29: [87, 93, 34, 29], 10: [87, 93, 71, 10], 7: [87, 93, 71, 7], 59: [87, 93, 39, 59], 101: [87, 93, 39, 101], 33: [87, 93, 39, 33], 13: [87, 93, 39, 13], 47: [87, 93, 43, 47], 63: [87, 93, 43, 63], 27: [87, 93, 43, 27], 25: [87, 93, 43, 25], 73: [87, 93, 43, 73], 48: [87, 93, 43, 48], 11: [87, 93, 43, 11], 31: [87, 93, 43, 31], 70: [87, 83, 45, 70], 35: [87, 83, 45, 35], 85: [87, 83, 45, 85], 1: [87, 83, 52, 1], 23: [87, 83, 52, 23], 72: [87, 83, 44, 72], 92: [87, 83, 44, 92], 51: [87, 83, 44, 51], 68: [87, 60, 41, 19, 68], 24: [87, 60, 41, 94, 24], 84: [87, 60, 41, 20, 84], 81: [87, 60, 41, 20, 81], 5: [87, 60, 41, 21, 5], 90: [87, 60, 41, 56, 90], 14: [87, 60, 41, 82, 14], 16: [87, 60, 89, 57, 16], 69: [87, 60, 89, 57, 69], 12: [87, 60, 89, 57, 12], 54: [87, 60, 79, 3, 54], 88: [87, 60, 79, 8, 88], 36: [87, 60, 18, 98, 36], 53: [87, 60, 62, 74, 53], 78: [87, 60, 62, 4, 78], 64: [87, 60, 40, 91, 64], 66: [87, 60, 40, 38, 66], 67: [87, 60, 99, 28, 67], 15: [87, 60, 99, 77, 15], 2: [87, 60, 99, 50, 2], 65: [87, 93, 39, 59, 65], 61: [87, 93, 39, 33, 61], 76: [87, 83, 44, 72, 76]}) (70, {70: [70], 37: [70, 37], 84: [70, 84], 64: [70, 64], 9: [70, 9], 79: [70, 79], 52: [70, 52], 74: [70, 37, 74], 57: [70, 37, 57], 32: [70, 84, 32], 98: [70, 84, 98], 13: [70, 84, 13], 14: [70, 84, 14], 25: [70, 84, 25], 73: [70, 64, 73], 101: [70, 64, 101], 89: [70, 64, 89], 82: [70, 64, 82], 65: [70, 64, 65], 4: [70, 64, 4], 15: [70, 64, 15], 39: [70, 64, 39], 96: [70, 64, 96], 35: [70, 64, 35], 22: [70, 64, 22], 85: [70, 9, 85], 50: [70, 9, 50], 94: [70, 9, 94], 31: [70, 9, 31], 75: [70, 9, 75], 29: [70, 9, 29], 1: [70, 9, 1], 3: [70, 79, 3], 8: [70, 79, 8], 23: [70, 52, 23], 28: [70, 52, 28], 62: [70, 37, 74, 62], 59: [70, 37, 74, 59], 51: [70, 37, 74, 51], 87: [70, 37, 74, 87], 53: [70, 37, 74, 53], 24: [70, 37, 57, 24], 16: [70, 37, 57, 16], 69: [70, 37, 57, 69], 40: [70, 37, 57, 40], 12: [70, 37, 57, 12], 93: [70, 84, 32, 93], 47: [70, 84, 98, 47], 46: [70, 84, 98, 46], 97: [70, 84, 98, 97], 88: [70, 84, 98, 88], 36: [70, 84, 98, 36], 5: [70, 84, 98, 5], 38: [70, 84, 98, 38], 54: [70, 84, 98, 54], 90: [70, 84, 98, 90], 30: [70, 84, 13, 30], 83: [70, 84, 13, 83], 60: [70, 84, 13, 60], 20: [70, 84, 14, 20], 26: [70, 84, 25, 26], 67: [70, 84, 25, 67], 56: [70, 84, 25, 56], 66: [70, 84, 25, 66], 71: [70, 64, 73, 71], 6: [70, 64, 73, 6], 77: [70, 64, 73, 77], 21: [70, 64, 101, 21], 99: [70, 64, 101, 99], 55: [70, 64, 89, 55], 11: [70, 64, 82, 11], 86: [70, 64, 65, 86], 45: [70, 64, 65, 45], 78: [70, 64, 4, 78], 42: [70, 64, 39, 42], 33: [70, 64, 39, 33], 49: [70, 64, 35, 49], 43: [70, 64, 22, 43], 72: [70, 64, 22, 72], 91: [70, 64, 22, 91], 2: [70, 9, 50, 2], 19: [70, 9, 50, 19], 48: [70, 9, 31, 48], 81: [70, 9, 75, 81], 44: [70, 79, 3, 44], 80: [70, 52, 28, 80], 18: [70, 37, 74, 59, 18], 100: [70, 37, 74, 51, 100], 34: [70, 37, 57, 24, 34], 41: [70, 37, 57, 24, 41], 68: [70, 37, 57, 24, 68], 27: [70, 37, 57, 12, 27], 58: [70, 84, 32, 93, 58], 7: [70, 84, 98, 97, 7], 95: [70, 84, 98, 88, 95], 10: [70, 84, 98, 90, 10], 61: [70, 84, 25, 66, 61], 17: [70, 64, 65, 86, 17], 63: [70, 64, 39, 42, 63], 76: [70, 64, 22, 72, 76], 92: [70, 9, 50, 19, 92]}) (42, {42: [42], 3: [42, 3], 33: [42, 33], 40: [42, 40], 91: [42, 91], 44: [42, 44], 24: [42, 24], 90: [42, 90], 63: [42, 63], 72: [42, 3, 72], 62: [42, 3, 62], 85: [42, 3, 85], 54: [42, 3, 54], 73: [42, 33, 73], 71: [42, 33, 71], 4: [42, 33, 4], 61: [42, 33, 61], 70: [42, 33, 70], 75: [42, 33, 75], 9: [42, 40, 9], 38: [42, 40, 38], 96: [42, 40, 96], 30: [42, 40, 30], 49: [42, 40, 49], 74: [42, 91, 74], 12: [42, 91, 12], 99: [42, 91, 99], 50: [42, 91, 50], 32: [42, 91, 32], 64: [42, 91, 64], 7: [42, 91, 7], 100: [42, 91, 100], 92: [42, 44, 92], 51: [42, 44, 51], 56: [42, 44, 56], 11: [42, 44, 11], 94: [42, 44, 94], 10: [42, 44, 10], 25: [42, 24, 25], 6: [42, 24, 6], 34: [42, 24, 34], 66: [42, 24, 66], 41: [42, 24, 41], 68: [42, 24, 68], 78: [42, 24, 78], 26: [42, 24, 26], 14: [42, 24, 14], 93: [42, 90, 93], 59: [42, 90, 59], 1: [42, 90, 1], 20: [42, 63, 20], 88: [42, 63, 88], 81: [42, 63, 81], 55: [42, 63, 55], 15: [42, 63, 15], 17: [42, 3, 72, 17], 36: [42, 3, 72, 36], 29: [42, 3, 72, 29], 98: [42, 3, 72, 98], 76: [42, 3, 72, 76], 18: [42, 3, 72, 18], 86: [42, 3, 62, 86], 80: [42, 3, 62, 80], 5: [42, 3, 85, 5], 43: [42, 3, 54, 43], 16: [42, 3, 54, 16], 77: [42, 33, 73, 77], 83: [42, 33, 73, 83], 37: [42, 33, 71, 37], 95: [42, 33, 71, 95], 53: [42, 33, 4, 53], 23: [42, 33, 4, 23], 22: [42, 33, 61, 22], 84: [42, 33, 70, 84], 79: [42, 33, 70, 79], 52: [42, 33, 70, 52], 67: [42, 33, 75, 67], 31: [42, 40, 9, 31], 47: [42, 40, 38, 47], 89: [42, 40, 96, 89], 28: [42, 40, 30, 28], 58: [42, 40, 49, 58], 87: [42, 91, 74, 87], 82: [42, 91, 74, 82], 27: [42, 91, 12, 27], 101: [42, 91, 12, 101], 19: [42, 91, 99, 19], 97: [42, 91, 99, 97], 2: [42, 91, 50, 2], 65: [42, 91, 64, 65], 39: [42, 91, 64, 39], 35: [42, 91, 64, 35], 21: [42, 91, 100, 21], 69: [42, 91, 100, 69], 13: [42, 44, 92, 13], 57: [42, 44, 94, 57], 46: [42, 44, 94, 46], 48: [42, 44, 10, 48], 60: [42, 24, 66, 60], 8: [42, 90, 59, 8], 45: [42, 3, 72, 76, 45]}) (77, {77: [77], 9: [77, 9], 4: [77, 4], 29: [77, 29], 45: [77, 45], 56: [77, 56], 70: [77, 70], 15: [77, 15], 43: [77, 43], 101: [77, 101], 21: [77, 21], 85: [77, 9, 85], 50: [77, 9, 50], 94: [77, 9, 94], 31: [77, 9, 31], 98: [77, 9, 98], 75: [77, 9, 75], 1: [77, 9, 1], 74: [77, 9, 74], 53: [77, 4, 53], 78: [77, 4, 78], 23: [77, 4, 23], 83: [77, 4, 83], 19: [77, 29, 19], 59: [77, 29, 59], 34: [77, 45, 34], 35: [77, 45, 35], 10: [77, 56, 10], 90: [77, 56, 90], 58: [77, 56, 58], 37: [77, 70, 37], 84: [77, 70, 84], 64: [77, 70, 64], 79: [77, 70, 79], 52: [77, 70, 52], 47: [77, 15, 47], 39: [77, 15, 39], 86: [77, 15, 86], 63: [77, 43, 63], 27: [77, 43, 27], 25: [77, 43, 25], 73: [77, 43, 73], 48: [77, 43, 48], 11: [77, 43, 11], 96: [77, 101, 96], 8: [77, 101, 8], 99: [77, 101, 99], 30: [77, 21, 30], 87: [77, 21, 87], 82: [77, 21, 82], 5: [77, 21, 5], 3: [77, 21, 3], 36: [77, 9, 85, 36], 2: [77, 9, 50, 2], 88: [77, 9, 50, 88], 22: [77, 9, 50, 22], 54: [77, 9, 50, 54], 42: [77, 9, 50, 42], 62: [77, 9, 94, 62], 57: [77, 9, 94, 57], 46: [77, 9, 94, 46], 24: [77, 9, 94, 24], 12: [77, 9, 31, 12], 91: [77, 9, 31, 91], 33: [77, 9, 31, 33], 97: [77, 9, 98, 97], 32: [77, 9, 98, 32], 38: [77, 9, 98, 38], 13: [77, 9, 98, 13], 81: [77, 9, 75, 81], 67: [77, 9, 75, 67], 40: [77, 9, 75, 40], 16: [77, 9, 1, 16], 69: [77, 9, 1, 69], 51: [77, 9, 74, 51], 55: [77, 4, 53, 55], 89: [77, 4, 23, 89], 93: [77, 4, 83, 93], 44: [77, 4, 83, 44], 68: [77, 29, 19, 68], 92: [77, 29, 19, 92], 26: [77, 29, 59, 26], 18: [77, 29, 59, 18], 65: [77, 29, 59, 65], 20: [77, 45, 34, 20], 49: [77, 45, 35, 49], 100: [77, 56, 90, 100], 17: [77, 56, 58, 17], 14: [77, 70, 84, 14], 28: [77, 70, 52, 28], 6: [77, 15, 86, 6], 80: [77, 15, 86, 80], 66: [77, 43, 63, 66], 71: [77, 43, 73, 71], 7: [77, 43, 48, 7], 95: [77, 43, 11, 95], 60: [77, 21, 87, 60], 41: [77, 21, 5, 41], 72: [77, 21, 3, 72], 76: [77, 9, 50, 2, 76], 61: [77, 9, 31, 33, 61]}) (76, {76: [76], 40: [76, 40], 45: [76, 45], 51: [76, 51], 32: [76, 32], 47: [76, 47], 7: [76, 7], 33: [76, 33], 60: [76, 60], 23: [76, 23], 9: [76, 40, 9], 91: [76, 40, 91], 38: [76, 40, 38], 96: [76, 40, 96], 30: [76, 40, 30], 49: [76, 40, 49], 70: [76, 45, 70], 34: [76, 45, 34], 35: [76, 45, 35], 85: [76, 45, 85], 100: [76, 51, 100], 73: [76, 51, 73], 93: [76, 32, 93], 37: [76, 32, 37], 15: [76, 47, 15], 13: [76, 47, 13], 29: [76, 47, 29], 98: [76, 47, 98], 19: [76, 47, 19], 36: [76, 47, 36], 24: [76, 47, 24], 2: [76, 47, 2], 71: [76, 33, 71], 4: [76, 33, 4], 61: [76, 33, 61], 75: [76, 33, 75], 41: [76, 60, 41], 89: [76, 60, 89], 79: [76, 60, 79], 18: [76, 60, 18], 62: [76, 60, 62], 99: [76, 60, 99], 55: [76, 23, 55], 69: [76, 23, 69], 101: [76, 23, 101], 50: [76, 40, 9, 50], 94: [76, 40, 9, 94], 31: [76, 40, 9, 31], 1: [76, 40, 9, 1], 74: [76, 40, 9, 74], 12: [76, 40, 91, 12], 64: [76, 40, 91, 64], 78: [76, 40, 38, 78], 66: [76, 40, 38, 66], 59: [76, 40, 96, 59], 20: [76, 40, 96, 20], 80: [76, 40, 30, 80], 28: [76, 40, 30, 28], 83: [76, 40, 49, 83], 95: [76, 40, 49, 95], 10: [76, 40, 49, 10], 5: [76, 40, 49, 5], 58: [76, 40, 49, 58], 84: [76, 45, 70, 84], 52: [76, 45, 70, 52], 46: [76, 45, 34, 46], 25: [76, 45, 85, 25], 21: [76, 51, 100, 21], 92: [76, 51, 100, 92], 6: [76, 51, 73, 6], 77: [76, 51, 73, 77], 39: [76, 32, 93, 39], 43: [76, 32, 93, 43], 57: [76, 32, 37, 57], 86: [76, 47, 15, 86], 14: [76, 47, 13, 14], 97: [76, 47, 98, 97], 88: [76, 47, 98, 88], 54: [76, 47, 98, 54], 90: [76, 47, 98, 90], 63: [76, 47, 19, 63], 68: [76, 47, 19, 68], 8: [76, 47, 36, 8], 26: [76, 47, 36, 26], 56: [76, 47, 2, 56], 53: [76, 33, 4, 53], 72: [76, 33, 61, 72], 22: [76, 33, 61, 22], 81: [76, 33, 75, 81], 67: [76, 33, 75, 67], 82: [76, 60, 41, 82], 3: [76, 60, 79, 3], 42: [76, 60, 62, 42], 44: [76, 60, 62, 44], 16: [76, 23, 55, 16], 48: [76, 40, 9, 31, 48], 87: [76, 40, 9, 74, 87], 27: [76, 40, 91, 12, 27], 65: [76, 40, 91, 64, 65], 11: [76, 40, 96, 59, 11], 17: [76, 40, 49, 58, 17]}) (40, {40: [40], 9: [40, 9], 91: [40, 91], 38: [40, 38], 96: [40, 96], 30: [40, 30], 49: [40, 49], 85: [40, 9, 85], 50: [40, 9, 50], 94: [40, 9, 94], 31: [40, 9, 31], 98: [40, 9, 98], 75: [40, 9, 75], 29: [40, 9, 29], 1: [40, 9, 1], 74: [40, 9, 74], 12: [40, 91, 12], 99: [40, 91, 99], 32: [40, 91, 32], 64: [40, 91, 64], 7: [40, 91, 7], 100: [40, 91, 100], 78: [40, 38, 78], 47: [40, 38, 47], 66: [40, 38, 66], 59: [40, 96, 59], 33: [40, 96, 33], 89: [40, 96, 89], 20: [40, 96, 20], 80: [40, 30, 80], 28: [40, 30, 28], 83: [40, 49, 83], 95: [40, 49, 95], 10: [40, 49, 10], 5: [40, 49, 5], 58: [40, 49, 58], 73: [40, 9, 85, 73], 25: [40, 9, 85, 25], 36: [40, 9, 85, 36], 2: [40, 9, 50, 2], 19: [40, 9, 50, 19], 88: [40, 9, 50, 88], 22: [40, 9, 50, 22], 54: [40, 9, 50, 54], 52: [40, 9, 50, 52], 42: [40, 9, 50, 42], 62: [40, 9, 94, 62], 57: [40, 9, 94, 57], 101: [40, 9, 94, 101], 46: [40, 9, 94, 46], 24: [40, 9, 94, 24], 48: [40, 9, 31, 48], 97: [40, 9, 98, 97], 90: [40, 9, 98, 90], 13: [40, 9, 98, 13], 81: [40, 9, 75, 81], 67: [40, 9, 75, 67], 4: [40, 9, 29, 4], 21: [40, 9, 29, 21], 43: [40, 9, 29, 43], 16: [40, 9, 1, 16], 70: [40, 9, 1, 70], 79: [40, 9, 1, 79], 69: [40, 9, 1, 69], 53: [40, 9, 1, 53], 51: [40, 9, 74, 51], 87: [40, 9, 74, 87], 82: [40, 9, 74, 82], 27: [40, 91, 12, 27], 44: [40, 91, 12, 44], 68: [40, 91, 12, 68], 18: [40, 91, 99, 18], 77: [40, 91, 99, 77], 93: [40, 91, 32, 93], 37: [40, 91, 32, 37], 65: [40, 91, 64, 65], 15: [40, 91, 64, 15], 39: [40, 91, 64, 39], 35: [40, 91, 64, 35], 92: [40, 91, 100, 92], 23: [40, 38, 78, 23], 61: [40, 38, 66, 61], 60: [40, 38, 66, 60], 26: [40, 96, 59, 26], 8: [40, 96, 59, 8], 11: [40, 96, 59, 11], 86: [40, 96, 59, 86], 71: [40, 96, 33, 71], 55: [40, 96, 89, 55], 84: [40, 96, 20, 84], 56: [40, 96, 20, 56], 45: [40, 49, 83, 45], 34: [40, 49, 95, 34], 3: [40, 49, 10, 3], 41: [40, 49, 5, 41], 17: [40, 49, 58, 17], 6: [40, 9, 85, 73, 6], 76: [40, 9, 50, 2, 76], 63: [40, 9, 50, 19, 63], 72: [40, 9, 50, 22, 72], 14: [40, 9, 94, 24, 14]}) (47, {47: [47], 15: [47, 15], 13: [47, 13], 29: [47, 29], 98: [47, 98], 19: [47, 19], 36: [47, 36], 24: [47, 24], 2: [47, 2], 39: [47, 15, 39], 83: [47, 15, 83], 9: [47, 15, 9], 50: [47, 15, 50], 86: [47, 15, 86], 14: [47, 13, 14], 30: [47, 13, 30], 4: [47, 13, 4], 60: [47, 13, 60], 21: [47, 29, 21], 43: [47, 29, 43], 59: [47, 29, 59], 46: [47, 98, 46], 97: [47, 98, 97], 88: [47, 98, 88], 32: [47, 98, 32], 62: [47, 98, 62], 5: [47, 98, 5], 38: [47, 98, 38], 54: [47, 98, 54], 90: [47, 98, 90], 63: [47, 19, 63], 68: [47, 19, 68], 92: [47, 19, 92], 8: [47, 36, 8], 26: [47, 36, 26], 52: [47, 36, 52], 49: [47, 36, 49], 23: [47, 36, 23], 25: [47, 24, 25], 71: [47, 24, 71], 6: [47, 24, 6], 34: [47, 24, 34], 66: [47, 24, 66], 74: [47, 24, 74], 41: [47, 24, 41], 96: [47, 24, 96], 78: [47, 24, 78], 51: [47, 2, 51], 56: [47, 2, 56], 40: [47, 2, 40], 76: [47, 2, 76], 101: [47, 15, 39, 101], 28: [47, 15, 39, 28], 42: [47, 15, 39, 42], 33: [47, 15, 39, 33], 89: [47, 15, 83, 89], 45: [47, 15, 83, 45], 93: [47, 15, 83, 93], 44: [47, 15, 83, 44], 85: [47, 15, 9, 85], 94: [47, 15, 9, 94], 31: [47, 15, 9, 31], 75: [47, 15, 9, 75], 1: [47, 15, 9, 1], 22: [47, 15, 50, 22], 18: [47, 15, 86, 18], 17: [47, 15, 86, 17], 80: [47, 15, 86, 80], 16: [47, 15, 86, 16], 20: [47, 13, 14, 20], 82: [47, 13, 14, 82], 53: [47, 13, 4, 53], 79: [47, 13, 60, 79], 99: [47, 13, 60, 99], 11: [47, 29, 21, 11], 87: [47, 29, 21, 87], 3: [47, 29, 21, 3], 27: [47, 29, 43, 27], 73: [47, 29, 43, 73], 48: [47, 29, 43, 48], 65: [47, 29, 59, 65], 12: [47, 98, 46, 12], 58: [47, 98, 46, 58], 64: [47, 98, 97, 64], 84: [47, 98, 97, 84], 77: [47, 98, 97, 77], 7: [47, 98, 97, 7], 81: [47, 98, 88, 81], 95: [47, 98, 88, 95], 37: [47, 98, 32, 37], 55: [47, 98, 5, 55], 70: [47, 98, 54, 70], 100: [47, 98, 90, 100], 10: [47, 98, 90, 10], 69: [47, 36, 23, 69], 67: [47, 24, 25, 67], 57: [47, 24, 6, 57], 61: [47, 24, 66, 61], 91: [47, 2, 40, 91], 35: [47, 15, 83, 45, 35], 72: [47, 15, 83, 44, 72]}) (96, {96: [96], 59: [96, 59], 33: [96, 33], 89: [96, 89], 20: [96, 20], 32: [96, 32], 13: [96, 59, 13], 26: [96, 59, 26], 62: [96, 59, 62], 8: [96, 59, 8], 44: [96, 59, 44], 11: [96, 59, 11], 18: [96, 59, 18], 97: [96, 59, 97], 36: [96, 59, 36], 78: [96, 59, 78], 86: [96, 59, 86], 65: [96, 59, 65], 73: [96, 33, 73], 71: [96, 33, 71], 4: [96, 33, 4], 61: [96, 33, 61], 70: [96, 33, 70], 75: [96, 33, 75], 57: [96, 89, 57], 55: [96, 89, 55], 84: [96, 20, 84], 22: [96, 20, 22], 56: [96, 20, 56], 99: [96, 20, 99], 19: [96, 20, 19], 58: [96, 20, 58], 83: [96, 20, 83], 30: [96, 20, 30], 68: [96, 20, 68], 81: [96, 20, 81], 46: [96, 20, 46], 93: [96, 32, 93], 37: [96, 32, 37], 14: [96, 59, 13, 14], 60: [96, 59, 13, 60], 101: [96, 59, 26, 101], 25: [96, 59, 26, 25], 98: [96, 59, 26, 98], 42: [96, 59, 62, 42], 74: [96, 59, 62, 74], 80: [96, 59, 62, 80], 88: [96, 59, 8, 88], 72: [96, 59, 44, 72], 92: [96, 59, 44, 92], 51: [96, 59, 44, 51], 94: [96, 59, 44, 94], 10: [96, 59, 44, 10], 95: [96, 59, 11, 95], 24: [96, 59, 11, 24], 6: [96, 59, 18, 6], 49: [96, 59, 18, 49], 87: [96, 59, 97, 87], 64: [96, 59, 97, 64], 77: [96, 59, 97, 77], 7: [96, 59, 97, 7], 52: [96, 59, 36, 52], 23: [96, 59, 36, 23], 29: [96, 59, 36, 29], 39: [96, 59, 36, 39], 31: [96, 59, 78, 31], 69: [96, 59, 78, 69], 12: [96, 59, 78, 12], 17: [96, 59, 86, 17], 16: [96, 59, 86, 16], 15: [96, 59, 65, 15], 45: [96, 59, 65, 45], 1: [96, 33, 73, 1], 50: [96, 33, 71, 50], 53: [96, 33, 4, 53], 100: [96, 33, 61, 100], 9: [96, 33, 70, 9], 79: [96, 33, 70, 79], 67: [96, 33, 75, 67], 40: [96, 33, 75, 40], 35: [96, 89, 55, 35], 43: [96, 20, 22, 43], 91: [96, 20, 22, 91], 90: [96, 20, 56, 90], 28: [96, 20, 99, 28], 63: [96, 20, 19, 63], 3: [96, 20, 81, 3], 41: [96, 20, 81, 41], 34: [96, 32, 93, 34], 82: [96, 59, 13, 14, 82], 21: [96, 59, 26, 101, 21], 66: [96, 59, 26, 25, 66], 47: [96, 59, 26, 98, 47], 5: [96, 59, 26, 98, 5], 38: [96, 59, 26, 98, 38], 54: [96, 59, 26, 98, 54], 85: [96, 59, 62, 80, 85], 76: [96, 59, 44, 72, 76], 48: [96, 59, 44, 10, 48], 27: [96, 59, 78, 12, 27], 2: [96, 33, 71, 50, 2]}) (59, {59: [59], 96: [59, 96], 13: [59, 13], 26: [59, 26], 62: [59, 62], 8: [59, 8], 44: [59, 44], 11: [59, 11], 18: [59, 18], 97: [59, 97], 36: [59, 36], 78: [59, 78], 86: [59, 86], 65: [59, 65], 33: [59, 96, 33], 89: [59, 96, 89], 20: [59, 96, 20], 32: [59, 96, 32], 14: [59, 13, 14], 30: [59, 13, 30], 83: [59, 13, 83], 4: [59, 13, 4], 60: [59, 13, 60], 101: [59, 26, 101], 25: [59, 26, 25], 98: [59, 26, 98], 42: [59, 62, 42], 74: [59, 62, 74], 80: [59, 62, 80], 88: [59, 8, 88], 72: [59, 44, 72], 92: [59, 44, 92], 51: [59, 44, 51], 56: [59, 44, 56], 94: [59, 44, 94], 10: [59, 44, 10], 95: [59, 11, 95], 24: [59, 11, 24], 6: [59, 18, 6], 49: [59, 18, 49], 87: [59, 97, 87], 64: [59, 97, 64], 84: [59, 97, 84], 77: [59, 97, 77], 7: [59, 97, 7], 46: [59, 36, 46], 52: [59, 36, 52], 23: [59, 36, 23], 19: [59, 36, 19], 29: [59, 36, 29], 39: [59, 36, 39], 31: [59, 78, 31], 69: [59, 78, 69], 12: [59, 78, 12], 81: [59, 78, 81], 17: [59, 86, 17], 16: [59, 86, 16], 15: [59, 65, 15], 45: [59, 65, 45], 73: [59, 96, 33, 73], 71: [59, 96, 33, 71], 61: [59, 96, 33, 61], 70: [59, 96, 33, 70], 75: [59, 96, 33, 75], 57: [59, 96, 89, 57], 55: [59, 96, 89, 55], 22: [59, 96, 20, 22], 99: [59, 96, 20, 99], 58: [59, 96, 20, 58], 68: [59, 96, 20, 68], 93: [59, 96, 32, 93], 37: [59, 96, 32, 37], 82: [59, 13, 14, 82], 28: [59, 13, 30, 28], 43: [59, 13, 83, 43], 53: [59, 13, 4, 53], 41: [59, 13, 60, 41], 79: [59, 13, 60, 79], 40: [59, 13, 60, 40], 21: [59, 26, 101, 21], 67: [59, 26, 25, 67], 66: [59, 26, 25, 66], 47: [59, 26, 98, 47], 5: [59, 26, 98, 5], 38: [59, 26, 98, 38], 54: [59, 26, 98, 54], 90: [59, 26, 98, 90], 3: [59, 62, 42, 3], 91: [59, 62, 42, 91], 63: [59, 62, 42, 63], 85: [59, 62, 80, 85], 1: [59, 62, 80, 1], 76: [59, 44, 72, 76], 34: [59, 44, 92, 34], 100: [59, 44, 51, 100], 48: [59, 44, 10, 48], 35: [59, 97, 64, 35], 9: [59, 97, 77, 9], 50: [59, 36, 29, 50], 27: [59, 78, 12, 27], 2: [59, 13, 4, 53, 2]}) (64, {64: [64], 73: [64, 73], 101: [64, 101], 89: [64, 89], 82: [64, 82], 65: [64, 65], 4: [64, 4], 15: [64, 15], 39: [64, 39], 96: [64, 96], 35: [64, 35], 22: [64, 22], 71: [64, 73, 71], 6: [64, 73, 6], 77: [64, 73, 77], 83: [64, 73, 83], 1: [64, 73, 1], 94: [64, 101, 94], 25: [64, 101, 25], 21: [64, 101, 21], 8: [64, 101, 8], 99: [64, 101, 99], 57: [64, 89, 57], 55: [64, 89, 55], 11: [64, 82, 11], 51: [64, 82, 51], 14: [64, 82, 14], 87: [64, 82, 87], 74: [64, 82, 74], 20: [64, 65, 20], 86: [64, 65, 86], 45: [64, 65, 45], 53: [64, 4, 53], 78: [64, 4, 78], 23: [64, 4, 23], 47: [64, 15, 47], 9: [64, 15, 9], 50: [64, 15, 50], 59: [64, 39, 59], 28: [64, 39, 28], 42: [64, 39, 42], 33: [64, 39, 33], 13: [64, 39, 13], 32: [64, 96, 32], 36: [64, 35, 36], 49: [64, 35, 49], 37: [64, 35, 37], 43: [64, 22, 43], 72: [64, 22, 72], 91: [64, 22, 91], 93: [64, 22, 93], 97: [64, 22, 97], 10: [64, 73, 71, 10], 7: [64, 73, 71, 7], 95: [64, 73, 71, 95], 54: [64, 73, 6, 54], 29: [64, 73, 77, 29], 56: [64, 73, 77, 56], 70: [64, 73, 77, 70], 52: [64, 73, 83, 52], 44: [64, 73, 83, 44], 16: [64, 73, 1, 16], 79: [64, 73, 1, 79], 69: [64, 73, 1, 69], 62: [64, 101, 94, 62], 46: [64, 101, 94, 46], 24: [64, 101, 94, 24], 84: [64, 101, 25, 84], 26: [64, 101, 25, 26], 67: [64, 101, 25, 67], 66: [64, 101, 25, 66], 30: [64, 101, 21, 30], 5: [64, 101, 21, 5], 3: [64, 101, 21, 3], 85: [64, 101, 21, 85], 88: [64, 101, 8, 88], 19: [64, 101, 99, 19], 18: [64, 101, 99, 18], 40: [64, 89, 57, 40], 12: [64, 89, 57, 12], 80: [64, 82, 11, 80], 98: [64, 82, 11, 98], 100: [64, 82, 51, 100], 60: [64, 82, 87, 60], 58: [64, 65, 20, 58], 68: [64, 65, 20, 68], 81: [64, 65, 20, 81], 17: [64, 65, 86, 17], 34: [64, 65, 45, 34], 2: [64, 4, 53, 2], 31: [64, 4, 78, 31], 75: [64, 15, 9, 75], 90: [64, 39, 42, 90], 63: [64, 39, 42, 63], 61: [64, 39, 33, 61], 27: [64, 22, 43, 27], 48: [64, 22, 43, 48], 76: [64, 22, 72, 76], 38: [64, 22, 91, 38], 92: [64, 73, 83, 44, 92], 41: [64, 101, 94, 24, 41]}) (50, {50: [50], 2: [50, 2], 19: [50, 19], 88: [50, 88], 22: [50, 22], 54: [50, 54], 52: [50, 52], 42: [50, 42], 51: [50, 2, 51], 60: [50, 2, 60], 56: [50, 2, 56], 40: [50, 2, 40], 76: [50, 2, 76], 63: [50, 19, 63], 68: [50, 19, 68], 62: [50, 19, 62], 98: [50, 19, 98], 97: [50, 19, 97], 92: [50, 19, 92], 81: [50, 88, 81], 64: [50, 88, 64], 101: [50, 88, 101], 95: [50, 88, 95], 65: [50, 88, 65], 39: [50, 88, 39], 43: [50, 22, 43], 72: [50, 22, 72], 59: [50, 22, 59], 91: [50, 22, 91], 93: [50, 22, 93], 6: [50, 22, 6], 71: [50, 54, 71], 16: [50, 54, 16], 11: [50, 54, 11], 9: [50, 54, 9], 70: [50, 54, 70], 1: [50, 52, 1], 23: [50, 52, 23], 28: [50, 52, 28], 3: [50, 42, 3], 33: [50, 42, 33], 44: [50, 42, 44], 24: [50, 42, 24], 90: [50, 42, 90], 49: [50, 2, 51, 49], 100: [50, 2, 51, 100], 73: [50, 2, 51, 73], 41: [50, 2, 60, 41], 89: [50, 2, 60, 89], 79: [50, 2, 60, 79], 18: [50, 2, 60, 18], 99: [50, 2, 60, 99], 77: [50, 2, 56, 77], 10: [50, 2, 56, 10], 58: [50, 2, 56, 58], 38: [50, 2, 40, 38], 96: [50, 2, 40, 96], 30: [50, 2, 40, 30], 45: [50, 2, 76, 45], 32: [50, 2, 76, 32], 47: [50, 2, 76, 47], 7: [50, 2, 76, 7], 20: [50, 19, 63, 20], 4: [50, 19, 63, 4], 55: [50, 19, 63, 55], 66: [50, 19, 63, 66], 15: [50, 19, 63, 15], 13: [50, 19, 68, 13], 86: [50, 19, 62, 86], 74: [50, 19, 62, 74], 80: [50, 19, 62, 80], 46: [50, 19, 98, 46], 36: [50, 19, 98, 36], 5: [50, 19, 98, 5], 87: [50, 19, 97, 87], 84: [50, 19, 97, 84], 25: [50, 19, 97, 25], 34: [50, 19, 92, 34], 61: [50, 88, 81, 61], 82: [50, 88, 64, 82], 35: [50, 88, 64, 35], 94: [50, 88, 101, 94], 21: [50, 88, 101, 21], 8: [50, 88, 101, 8], 31: [50, 88, 95, 31], 27: [50, 22, 43, 27], 48: [50, 22, 43, 48], 17: [50, 22, 72, 17], 29: [50, 22, 72, 29], 26: [50, 22, 59, 26], 78: [50, 22, 59, 78], 12: [50, 22, 91, 12], 83: [50, 22, 93, 83], 57: [50, 22, 6, 57], 37: [50, 54, 71, 37], 85: [50, 54, 9, 85], 75: [50, 54, 9, 75], 69: [50, 52, 1, 69], 53: [50, 52, 1, 53], 67: [50, 52, 28, 67], 14: [50, 42, 24, 14]}) (85, {85: [85], 73: [85, 73], 1: [85, 1], 25: [85, 25], 5: [85, 5], 36: [85, 36], 71: [85, 73, 71], 6: [85, 73, 6], 77: [85, 73, 77], 83: [85, 73, 83], 16: [85, 1, 16], 70: [85, 1, 70], 79: [85, 1, 79], 69: [85, 1, 69], 53: [85, 1, 53], 84: [85, 25, 84], 26: [85, 25, 26], 87: [85, 25, 87], 67: [85, 25, 67], 32: [85, 25, 32], 56: [85, 25, 56], 66: [85, 25, 66], 9: [85, 5, 9], 55: [85, 5, 55], 41: [85, 5, 41], 8: [85, 36, 8], 46: [85, 36, 46], 52: [85, 36, 52], 49: [85, 36, 49], 23: [85, 36, 23], 19: [85, 36, 19], 29: [85, 36, 29], 39: [85, 36, 39], 37: [85, 73, 71, 37], 10: [85, 73, 71, 10], 50: [85, 73, 71, 50], 20: [85, 73, 71, 20], 7: [85, 73, 71, 7], 95: [85, 73, 71, 95], 57: [85, 73, 6, 57], 54: [85, 73, 6, 54], 4: [85, 73, 77, 4], 45: [85, 73, 77, 45], 15: [85, 73, 77, 15], 43: [85, 73, 77, 43], 101: [85, 73, 77, 101], 21: [85, 73, 77, 21], 89: [85, 73, 83, 89], 93: [85, 73, 83, 93], 44: [85, 73, 83, 44], 48: [85, 1, 16, 48], 81: [85, 1, 16, 81], 64: [85, 1, 70, 64], 3: [85, 1, 79, 3], 22: [85, 1, 79, 22], 86: [85, 1, 53, 86], 2: [85, 1, 53, 2], 98: [85, 25, 84, 98], 13: [85, 25, 84, 13], 14: [85, 25, 84, 14], 60: [85, 25, 87, 60], 90: [85, 25, 56, 90], 58: [85, 25, 56, 58], 61: [85, 25, 66, 61], 68: [85, 25, 66, 68], 94: [85, 5, 9, 94], 31: [85, 5, 9, 31], 75: [85, 5, 9, 75], 74: [85, 5, 9, 74], 35: [85, 5, 55, 35], 42: [85, 5, 55, 42], 96: [85, 5, 41, 96], 82: [85, 5, 41, 82], 88: [85, 36, 8, 88], 18: [85, 36, 46, 18], 12: [85, 36, 46, 12], 51: [85, 36, 46, 51], 28: [85, 36, 52, 28], 40: [85, 36, 49, 40], 30: [85, 36, 49, 30], 63: [85, 36, 19, 63], 62: [85, 36, 19, 62], 97: [85, 36, 19, 97], 92: [85, 36, 19, 92], 59: [85, 36, 29, 59], 33: [85, 36, 39, 33], 99: [85, 73, 71, 20, 99], 34: [85, 73, 71, 95, 34], 24: [85, 73, 6, 57, 24], 11: [85, 73, 6, 54, 11], 78: [85, 73, 77, 4, 78], 47: [85, 73, 77, 15, 47], 27: [85, 73, 77, 43, 27], 72: [85, 73, 83, 44, 72], 65: [85, 1, 70, 64, 65], 91: [85, 1, 79, 22, 91], 17: [85, 1, 53, 86, 17], 80: [85, 1, 53, 86, 80], 76: [85, 1, 53, 2, 76], 38: [85, 25, 84, 98, 38], 100: [85, 25, 56, 90, 100]}) (46, {46: [46], 18: [46, 18], 12: [46, 12], 58: [46, 58], 51: [46, 51], 22: [46, 22], 9: [46, 9], 23: [46, 23], 98: [46, 18, 98], 94: [46, 18, 94], 95: [46, 18, 95], 6: [46, 18, 6], 86: [46, 18, 86], 32: [46, 18, 32], 49: [46, 18, 49], 27: [46, 12, 27], 44: [46, 12, 44], 101: [46, 12, 101], 81: [46, 12, 81], 68: [46, 12, 68], 4: [46, 12, 4], 93: [46, 58, 93], 100: [46, 58, 100], 26: [46, 58, 26], 87: [46, 58, 87], 17: [46, 58, 17], 73: [46, 51, 73], 43: [46, 22, 43], 72: [46, 22, 72], 59: [46, 22, 59], 91: [46, 22, 91], 97: [46, 22, 97], 85: [46, 9, 85], 50: [46, 9, 50], 31: [46, 9, 31], 75: [46, 9, 75], 29: [46, 9, 29], 1: [46, 9, 1], 74: [46, 9, 74], 55: [46, 23, 55], 69: [46, 23, 69], 89: [46, 23, 89], 47: [46, 18, 98, 47], 88: [46, 18, 98, 88], 36: [46, 18, 98, 36], 62: [46, 18, 98, 62], 5: [46, 18, 98, 5], 38: [46, 18, 98, 38], 54: [46, 18, 98, 54], 90: [46, 18, 98, 90], 13: [46, 18, 98, 13], 57: [46, 18, 94, 57], 24: [46, 18, 94, 24], 34: [46, 18, 95, 34], 20: [46, 18, 95, 20], 80: [46, 18, 86, 80], 16: [46, 18, 86, 16], 37: [46, 18, 32, 37], 28: [46, 18, 49, 28], 40: [46, 18, 49, 40], 30: [46, 18, 49, 30], 83: [46, 18, 49, 83], 10: [46, 18, 49, 10], 14: [46, 12, 27, 14], 84: [46, 12, 27, 84], 67: [46, 12, 27, 67], 92: [46, 12, 44, 92], 56: [46, 12, 44, 56], 11: [46, 12, 44, 11], 25: [46, 12, 101, 25], 21: [46, 12, 101, 21], 96: [46, 12, 101, 96], 8: [46, 12, 101, 8], 99: [46, 12, 101, 99], 3: [46, 12, 81, 3], 61: [46, 12, 81, 61], 42: [46, 12, 81, 42], 41: [46, 12, 81, 41], 53: [46, 12, 4, 53], 78: [46, 12, 4, 78], 71: [46, 58, 93, 71], 39: [46, 58, 93, 39], 60: [46, 58, 87, 60], 77: [46, 51, 73, 77], 63: [46, 22, 43, 63], 48: [46, 22, 43, 48], 76: [46, 22, 72, 76], 65: [46, 22, 59, 65], 64: [46, 22, 91, 64], 7: [46, 22, 91, 7], 2: [46, 9, 50, 2], 19: [46, 9, 50, 19], 52: [46, 9, 50, 52], 33: [46, 9, 31, 33], 70: [46, 9, 1, 70], 79: [46, 9, 1, 79], 82: [46, 9, 74, 82], 35: [46, 23, 55, 35], 15: [46, 18, 98, 47, 15], 66: [46, 18, 98, 38, 66], 45: [46, 18, 49, 83, 45]}) (41, {41: [41], 19: [41, 19], 94: [41, 94], 96: [41, 96], 20: [41, 20], 21: [41, 21], 56: [41, 56], 83: [41, 83], 82: [41, 82], 63: [41, 19, 63], 68: [41, 19, 68], 62: [41, 19, 62], 98: [41, 19, 98], 97: [41, 19, 97], 92: [41, 19, 92], 57: [41, 94, 57], 101: [41, 94, 101], 46: [41, 94, 46], 24: [41, 94, 24], 59: [41, 96, 59], 33: [41, 96, 33], 89: [41, 96, 89], 32: [41, 96, 32], 84: [41, 20, 84], 22: [41, 20, 22], 99: [41, 20, 99], 58: [41, 20, 58], 30: [41, 20, 30], 86: [41, 20, 86], 81: [41, 20, 81], 4: [41, 20, 4], 11: [41, 21, 11], 87: [41, 21, 87], 5: [41, 21, 5], 3: [41, 21, 3], 85: [41, 21, 85], 1: [41, 21, 1], 77: [41, 56, 77], 10: [41, 56, 10], 90: [41, 56, 90], 45: [41, 83, 45], 52: [41, 83, 52], 43: [41, 83, 43], 93: [41, 83, 93], 44: [41, 83, 44], 51: [41, 82, 51], 14: [41, 82, 14], 74: [41, 82, 74], 100: [41, 19, 63, 100], 88: [41, 19, 63, 88], 55: [41, 19, 63, 55], 66: [41, 19, 63, 66], 15: [41, 19, 63, 15], 13: [41, 19, 68, 13], 40: [41, 19, 68, 40], 42: [41, 19, 62, 42], 80: [41, 19, 62, 80], 47: [41, 19, 98, 47], 36: [41, 19, 98, 36], 38: [41, 19, 98, 38], 54: [41, 19, 98, 54], 64: [41, 19, 97, 64], 25: [41, 19, 97, 25], 7: [41, 19, 97, 7], 34: [41, 19, 92, 34], 39: [41, 94, 57, 39], 16: [41, 94, 57, 16], 69: [41, 94, 57, 69], 12: [41, 94, 57, 12], 79: [41, 94, 57, 79], 70: [41, 94, 57, 70], 73: [41, 94, 101, 73], 8: [41, 94, 101, 8], 18: [41, 94, 46, 18], 9: [41, 94, 46, 9], 23: [41, 94, 46, 23], 71: [41, 94, 24, 71], 6: [41, 94, 24, 6], 78: [41, 94, 24, 78], 26: [41, 94, 24, 26], 65: [41, 96, 59, 65], 61: [41, 96, 33, 61], 75: [41, 96, 33, 75], 37: [41, 96, 32, 37], 72: [41, 20, 22, 72], 91: [41, 20, 22, 91], 28: [41, 20, 99, 28], 50: [41, 20, 99, 50], 17: [41, 20, 58, 17], 53: [41, 20, 4, 53], 95: [41, 21, 11, 95], 60: [41, 21, 87, 60], 29: [41, 56, 77, 29], 48: [41, 56, 10, 48], 31: [41, 56, 10, 31], 35: [41, 83, 45, 35], 27: [41, 83, 43, 27], 49: [41, 82, 51, 49], 2: [41, 19, 98, 47, 2], 67: [41, 19, 97, 25, 67], 76: [41, 20, 22, 72, 76]}) (62, {62: [62], 42: [62, 42], 86: [62, 86], 74: [62, 74], 4: [62, 4], 96: [62, 96], 80: [62, 80], 44: [62, 44], 3: [62, 42, 3], 33: [62, 42, 33], 40: [62, 42, 40], 91: [62, 42, 91], 24: [62, 42, 24], 90: [62, 42, 90], 63: [62, 42, 63], 18: [62, 86, 18], 17: [62, 86, 17], 59: [62, 86, 59], 26: [62, 86, 26], 6: [62, 86, 6], 16: [62, 86, 16], 22: [62, 74, 22], 51: [62, 74, 51], 87: [62, 74, 87], 82: [62, 74, 82], 53: [62, 74, 53], 78: [62, 4, 78], 23: [62, 4, 23], 83: [62, 4, 83], 89: [62, 96, 89], 20: [62, 96, 20], 32: [62, 96, 32], 95: [62, 80, 95], 85: [62, 80, 85], 13: [62, 80, 13], 10: [62, 80, 10], 1: [62, 80, 1], 46: [62, 80, 46], 72: [62, 44, 72], 92: [62, 44, 92], 56: [62, 44, 56], 11: [62, 44, 11], 94: [62, 44, 94], 54: [62, 42, 3, 54], 73: [62, 42, 33, 73], 71: [62, 42, 33, 71], 61: [62, 42, 33, 61], 70: [62, 42, 33, 70], 75: [62, 42, 33, 75], 9: [62, 42, 40, 9], 38: [62, 42, 40, 38], 30: [62, 42, 40, 30], 49: [62, 42, 40, 49], 12: [62, 42, 91, 12], 99: [62, 42, 91, 99], 50: [62, 42, 91, 50], 64: [62, 42, 91, 64], 7: [62, 42, 91, 7], 100: [62, 42, 91, 100], 25: [62, 42, 24, 25], 34: [62, 42, 24, 34], 66: [62, 42, 24, 66], 41: [62, 42, 24, 41], 68: [62, 42, 24, 68], 14: [62, 42, 24, 14], 93: [62, 42, 90, 93], 88: [62, 42, 63, 88], 81: [62, 42, 63, 81], 55: [62, 42, 63, 55], 15: [62, 42, 63, 15], 98: [62, 86, 18, 98], 84: [62, 86, 17, 84], 8: [62, 86, 59, 8], 97: [62, 86, 59, 97], 36: [62, 86, 59, 36], 65: [62, 86, 59, 65], 101: [62, 86, 26, 101], 57: [62, 86, 6, 57], 48: [62, 86, 16, 48], 79: [62, 86, 16, 79], 43: [62, 74, 22, 43], 60: [62, 74, 87, 60], 69: [62, 74, 53, 69], 45: [62, 74, 53, 45], 2: [62, 74, 53, 2], 31: [62, 4, 78, 31], 52: [62, 4, 83, 52], 19: [62, 96, 20, 19], 58: [62, 96, 20, 58], 37: [62, 96, 32, 37], 5: [62, 80, 85, 5], 29: [62, 44, 72, 29], 76: [62, 44, 72, 76], 47: [62, 44, 92, 47], 77: [62, 44, 56, 77], 67: [62, 42, 33, 75, 67], 28: [62, 42, 40, 30, 28], 27: [62, 42, 91, 12, 27], 39: [62, 42, 91, 64, 39], 35: [62, 42, 91, 64, 35], 21: [62, 42, 91, 100, 21]}) (63, {63: [63], 10: [63, 10], 100: [63, 100], 20: [63, 20], 88: [63, 88], 4: [63, 4], 81: [63, 81], 55: [63, 55], 66: [63, 66], 15: [63, 15], 48: [63, 10, 48], 46: [63, 10, 46], 3: [63, 10, 3], 31: [63, 10, 31], 47: [63, 100, 47], 36: [63, 100, 36], 58: [63, 100, 58], 21: [63, 100, 21], 69: [63, 100, 69], 92: [63, 100, 92], 84: [63, 20, 84], 22: [63, 20, 22], 56: [63, 20, 56], 99: [63, 20, 99], 19: [63, 20, 19], 83: [63, 20, 83], 30: [63, 20, 30], 68: [63, 20, 68], 86: [63, 20, 86], 32: [63, 20, 32], 64: [63, 88, 64], 101: [63, 88, 101], 95: [63, 88, 95], 65: [63, 88, 65], 40: [63, 88, 40], 39: [63, 88, 39], 53: [63, 4, 53], 78: [63, 4, 78], 23: [63, 4, 23], 61: [63, 81, 61], 42: [63, 81, 42], 41: [63, 81, 41], 28: [63, 81, 28], 29: [63, 55, 29], 35: [63, 55, 35], 16: [63, 55, 16], 60: [63, 66, 60], 9: [63, 15, 9], 50: [63, 15, 50], 7: [63, 10, 48, 7], 5: [63, 10, 48, 5], 18: [63, 10, 46, 18], 12: [63, 10, 46, 12], 51: [63, 10, 46, 51], 72: [63, 10, 3, 72], 62: [63, 10, 3, 62], 44: [63, 10, 3, 44], 85: [63, 10, 3, 85], 54: [63, 10, 3, 54], 91: [63, 10, 31, 91], 33: [63, 10, 31, 33], 13: [63, 100, 47, 13], 98: [63, 100, 47, 98], 24: [63, 100, 47, 24], 2: [63, 100, 47, 2], 8: [63, 100, 36, 8], 26: [63, 100, 36, 26], 52: [63, 100, 36, 52], 49: [63, 100, 36, 49], 93: [63, 100, 58, 93], 87: [63, 100, 58, 87], 17: [63, 100, 58, 17], 11: [63, 100, 21, 11], 82: [63, 100, 21, 82], 1: [63, 100, 21, 1], 25: [63, 100, 69, 25], 34: [63, 100, 92, 34], 14: [63, 20, 84, 14], 43: [63, 20, 22, 43], 59: [63, 20, 22, 59], 6: [63, 20, 22, 6], 97: [63, 20, 22, 97], 77: [63, 20, 56, 77], 90: [63, 20, 56, 90], 89: [63, 20, 83, 89], 45: [63, 20, 83, 45], 80: [63, 20, 30, 80], 37: [63, 20, 32, 37], 73: [63, 88, 64, 73], 96: [63, 88, 64, 96], 94: [63, 88, 101, 94], 38: [63, 88, 40, 38], 74: [63, 88, 39, 74], 67: [63, 81, 28, 67], 79: [63, 55, 16, 79], 75: [63, 15, 9, 75], 27: [63, 10, 46, 12, 27], 76: [63, 10, 3, 72, 76], 71: [63, 10, 3, 54, 71], 70: [63, 10, 3, 54, 70], 57: [63, 20, 22, 6, 57]}) (56, {56: [56], 77: [56, 77], 10: [56, 10], 90: [56, 90], 58: [56, 58], 9: [56, 77, 9], 4: [56, 77, 4], 29: [56, 77, 29], 45: [56, 77, 45], 70: [56, 77, 70], 15: [56, 77, 15], 43: [56, 77, 43], 101: [56, 77, 101], 21: [56, 77, 21], 48: [56, 10, 48], 46: [56, 10, 46], 3: [56, 10, 3], 31: [56, 10, 31], 100: [56, 90, 100], 93: [56, 90, 93], 59: [56, 90, 59], 1: [56, 90, 1], 34: [56, 90, 34], 26: [56, 58, 26], 87: [56, 58, 87], 17: [56, 58, 17], 22: [56, 58, 22], 85: [56, 77, 9, 85], 50: [56, 77, 9, 50], 94: [56, 77, 9, 94], 98: [56, 77, 9, 98], 75: [56, 77, 9, 75], 74: [56, 77, 9, 74], 53: [56, 77, 4, 53], 78: [56, 77, 4, 78], 23: [56, 77, 4, 23], 83: [56, 77, 4, 83], 19: [56, 77, 29, 19], 35: [56, 77, 45, 35], 37: [56, 77, 70, 37], 84: [56, 77, 70, 84], 64: [56, 77, 70, 64], 79: [56, 77, 70, 79], 52: [56, 77, 70, 52], 47: [56, 77, 15, 47], 39: [56, 77, 15, 39], 86: [56, 77, 15, 86], 63: [56, 77, 43, 63], 27: [56, 77, 43, 27], 25: [56, 77, 43, 25], 73: [56, 77, 43, 73], 11: [56, 77, 43, 11], 96: [56, 77, 101, 96], 8: [56, 77, 101, 8], 99: [56, 77, 101, 99], 30: [56, 77, 21, 30], 82: [56, 77, 21, 82], 5: [56, 77, 21, 5], 7: [56, 10, 48, 7], 36: [56, 10, 48, 36], 18: [56, 10, 46, 18], 12: [56, 10, 46, 12], 51: [56, 10, 46, 51], 72: [56, 10, 3, 72], 62: [56, 10, 3, 62], 44: [56, 10, 3, 44], 54: [56, 10, 3, 54], 88: [56, 10, 31, 88], 91: [56, 10, 31, 91], 33: [56, 10, 31, 33], 69: [56, 90, 100, 69], 92: [56, 90, 100, 92], 40: [56, 90, 93, 40], 71: [56, 90, 93, 71], 13: [56, 90, 59, 13], 97: [56, 90, 59, 97], 65: [56, 90, 59, 65], 16: [56, 90, 1, 16], 20: [56, 90, 34, 20], 55: [56, 90, 34, 55], 38: [56, 90, 34, 38], 60: [56, 58, 87, 60], 6: [56, 58, 22, 6], 2: [56, 77, 9, 50, 2], 42: [56, 77, 9, 50, 42], 57: [56, 77, 9, 94, 57], 24: [56, 77, 9, 94, 24], 32: [56, 77, 9, 98, 32], 81: [56, 77, 9, 75, 81], 67: [56, 77, 9, 75, 67], 89: [56, 77, 4, 23, 89], 68: [56, 77, 29, 19, 68], 49: [56, 77, 45, 35, 49], 14: [56, 77, 70, 84, 14], 28: [56, 77, 70, 52, 28], 80: [56, 77, 15, 86, 80], 66: [56, 77, 43, 63, 66], 95: [56, 77, 43, 11, 95], 41: [56, 77, 21, 5, 41], 76: [56, 10, 3, 72, 76], 61: [56, 10, 31, 33, 61]}) (75, {75: [75], 81: [75, 81], 67: [75, 67], 40: [75, 40], 96: [75, 96], 3: [75, 81, 3], 61: [75, 81, 61], 55: [75, 81, 55], 30: [75, 81, 30], 42: [75, 81, 42], 68: [75, 81, 68], 41: [75, 81, 41], 58: [75, 81, 58], 28: [75, 81, 28], 23: [75, 67, 23], 16: [75, 67, 16], 54: [75, 67, 54], 9: [75, 40, 9], 91: [75, 40, 91], 38: [75, 40, 38], 49: [75, 40, 49], 59: [75, 96, 59], 33: [75, 96, 33], 89: [75, 96, 89], 20: [75, 96, 20], 32: [75, 96, 32], 72: [75, 81, 3, 72], 62: [75, 81, 3, 62], 44: [75, 81, 3, 44], 85: [75, 81, 3, 85], 92: [75, 81, 61, 92], 22: [75, 81, 61, 22], 100: [75, 81, 61, 100], 73: [75, 81, 61, 73], 29: [75, 81, 55, 29], 35: [75, 81, 55, 35], 80: [75, 81, 30, 80], 24: [75, 81, 42, 24], 90: [75, 81, 42, 90], 63: [75, 81, 42, 63], 13: [75, 81, 68, 13], 19: [75, 81, 41, 19], 94: [75, 81, 41, 94], 21: [75, 81, 41, 21], 56: [75, 81, 41, 56], 83: [75, 81, 41, 83], 82: [75, 81, 41, 82], 93: [75, 81, 58, 93], 26: [75, 81, 58, 26], 87: [75, 81, 58, 87], 17: [75, 81, 58, 17], 31: [75, 81, 28, 31], 37: [75, 81, 28, 37], 74: [75, 81, 28, 74], 69: [75, 67, 23, 69], 101: [75, 67, 23, 101], 48: [75, 67, 16, 48], 4: [75, 67, 16, 4], 79: [75, 67, 16, 79], 6: [75, 67, 16, 6], 71: [75, 67, 54, 71], 43: [75, 67, 54, 43], 11: [75, 67, 54, 11], 70: [75, 67, 54, 70], 50: [75, 40, 9, 50], 98: [75, 40, 9, 98], 1: [75, 40, 9, 1], 12: [75, 40, 91, 12], 99: [75, 40, 91, 99], 64: [75, 40, 91, 64], 7: [75, 40, 91, 7], 78: [75, 40, 38, 78], 47: [75, 40, 38, 47], 66: [75, 40, 38, 66], 95: [75, 40, 49, 95], 10: [75, 40, 49, 10], 5: [75, 40, 49, 5], 8: [75, 96, 59, 8], 18: [75, 96, 59, 18], 97: [75, 96, 59, 97], 36: [75, 96, 59, 36], 86: [75, 96, 59, 86], 65: [75, 96, 59, 65], 57: [75, 96, 89, 57], 84: [75, 96, 20, 84], 46: [75, 96, 20, 46], 76: [75, 81, 3, 72, 76], 51: [75, 81, 3, 44, 51], 25: [75, 81, 3, 85, 25], 34: [75, 81, 61, 92, 34], 52: [75, 81, 61, 92, 52], 77: [75, 81, 61, 73, 77], 14: [75, 81, 42, 24, 14], 88: [75, 81, 42, 63, 88], 15: [75, 81, 42, 63, 15], 60: [75, 81, 68, 13, 60], 45: [75, 81, 41, 83, 45], 39: [75, 81, 58, 93, 39], 53: [75, 81, 28, 74, 53], 27: [75, 67, 54, 43, 27], 2: [75, 40, 9, 50, 2]}) (68, {68: [68], 55: [68, 55], 13: [68, 13], 40: [68, 40], 29: [68, 55, 29], 35: [68, 55, 35], 42: [68, 55, 42], 16: [68, 55, 16], 14: [68, 13, 14], 30: [68, 13, 30], 83: [68, 13, 83], 4: [68, 13, 4], 60: [68, 13, 60], 9: [68, 40, 9], 91: [68, 40, 91], 38: [68, 40, 38], 96: [68, 40, 96], 49: [68, 40, 49], 21: [68, 55, 29, 21], 43: [68, 55, 29, 43], 19: [68, 55, 29, 19], 50: [68, 55, 29, 50], 59: [68, 55, 29, 59], 36: [68, 55, 35, 36], 74: [68, 55, 35, 74], 37: [68, 55, 35, 37], 3: [68, 55, 42, 3], 33: [68, 55, 42, 33], 44: [68, 55, 42, 44], 24: [68, 55, 42, 24], 90: [68, 55, 42, 90], 63: [68, 55, 42, 63], 48: [68, 55, 16, 48], 56: [68, 55, 16, 56], 81: [68, 55, 16, 81], 79: [68, 55, 16, 79], 6: [68, 55, 16, 6], 20: [68, 13, 14, 20], 39: [68, 13, 14, 39], 82: [68, 13, 14, 82], 80: [68, 13, 30, 80], 28: [68, 13, 30, 28], 89: [68, 13, 83, 89], 45: [68, 13, 83, 45], 52: [68, 13, 83, 52], 93: [68, 13, 83, 93], 53: [68, 13, 4, 53], 78: [68, 13, 4, 78], 23: [68, 13, 4, 23], 41: [68, 13, 60, 41], 18: [68, 13, 60, 18], 62: [68, 13, 60, 62], 99: [68, 13, 60, 99], 85: [68, 40, 9, 85], 94: [68, 40, 9, 94], 31: [68, 40, 9, 31], 98: [68, 40, 9, 98], 75: [68, 40, 9, 75], 1: [68, 40, 9, 1], 12: [68, 40, 91, 12], 32: [68, 40, 91, 32], 64: [68, 40, 91, 64], 7: [68, 40, 91, 7], 100: [68, 40, 91, 100], 47: [68, 40, 38, 47], 66: [68, 40, 38, 66], 95: [68, 40, 49, 95], 10: [68, 40, 49, 10], 5: [68, 40, 49, 5], 58: [68, 40, 49, 58], 11: [68, 55, 29, 21, 11], 87: [68, 55, 29, 21, 87], 27: [68, 55, 29, 43, 27], 25: [68, 55, 29, 43, 25], 73: [68, 55, 29, 43, 73], 97: [68, 55, 29, 19, 97], 92: [68, 55, 29, 19, 92], 2: [68, 55, 29, 50, 2], 88: [68, 55, 29, 50, 88], 22: [68, 55, 29, 50, 22], 54: [68, 55, 29, 50, 54], 26: [68, 55, 29, 59, 26], 8: [68, 55, 29, 59, 8], 86: [68, 55, 29, 59, 86], 65: [68, 55, 29, 59, 65], 46: [68, 55, 35, 36, 46], 51: [68, 55, 35, 74, 51], 57: [68, 55, 35, 37, 57], 72: [68, 55, 42, 3, 72], 71: [68, 55, 42, 33, 71], 61: [68, 55, 42, 33, 61], 70: [68, 55, 42, 33, 70], 34: [68, 55, 42, 24, 34], 15: [68, 55, 42, 63, 15], 101: [68, 55, 16, 48, 101], 77: [68, 55, 16, 56, 77], 84: [68, 13, 14, 20, 84], 67: [68, 13, 30, 28, 67], 69: [68, 13, 4, 53, 69], 17: [68, 40, 49, 58, 17], 76: [68, 55, 29, 50, 2, 76]}) (55, {55: [55], 29: [55, 29], 35: [55, 35], 42: [55, 42], 16: [55, 16], 4: [55, 29, 4], 21: [55, 29, 21], 43: [55, 29, 43], 19: [55, 29, 19], 50: [55, 29, 50], 59: [55, 29, 59], 36: [55, 35, 36], 49: [55, 35, 49], 74: [55, 35, 74], 37: [55, 35, 37], 3: [55, 42, 3], 33: [55, 42, 33], 40: [55, 42, 40], 91: [55, 42, 91], 44: [55, 42, 44], 24: [55, 42, 24], 90: [55, 42, 90], 63: [55, 42, 63], 48: [55, 16, 48], 56: [55, 16, 56], 9: [55, 16, 9], 81: [55, 16, 81], 79: [55, 16, 79], 6: [55, 16, 6], 53: [55, 29, 4, 53], 78: [55, 29, 4, 78], 23: [55, 29, 4, 23], 83: [55, 29, 4, 83], 11: [55, 29, 21, 11], 30: [55, 29, 21, 30], 87: [55, 29, 21, 87], 82: [55, 29, 21, 82], 5: [55, 29, 21, 5], 85: [55, 29, 21, 85], 1: [55, 29, 21, 1], 47: [55, 29, 43, 47], 27: [55, 29, 43, 27], 25: [55, 29, 43, 25], 73: [55, 29, 43, 73], 31: [55, 29, 43, 31], 68: [55, 29, 19, 68], 62: [55, 29, 19, 62], 98: [55, 29, 19, 98], 97: [55, 29, 19, 97], 92: [55, 29, 19, 92], 2: [55, 29, 50, 2], 88: [55, 29, 50, 88], 22: [55, 29, 50, 22], 54: [55, 29, 50, 54], 52: [55, 29, 50, 52], 96: [55, 29, 59, 96], 13: [55, 29, 59, 13], 26: [55, 29, 59, 26], 8: [55, 29, 59, 8], 18: [55, 29, 59, 18], 86: [55, 29, 59, 86], 65: [55, 29, 59, 65], 46: [55, 35, 36, 46], 39: [55, 35, 36, 39], 28: [55, 35, 49, 28], 95: [55, 35, 49, 95], 10: [55, 35, 49, 10], 58: [55, 35, 49, 58], 51: [55, 35, 74, 51], 57: [55, 35, 37, 57], 72: [55, 42, 3, 72], 71: [55, 42, 33, 71], 61: [55, 42, 33, 61], 70: [55, 42, 33, 70], 75: [55, 42, 33, 75], 38: [55, 42, 40, 38], 12: [55, 42, 91, 12], 99: [55, 42, 91, 99], 32: [55, 42, 91, 32], 64: [55, 42, 91, 64], 7: [55, 42, 91, 7], 100: [55, 42, 91, 100], 94: [55, 42, 44, 94], 34: [55, 42, 24, 34], 66: [55, 42, 24, 66], 41: [55, 42, 24, 41], 14: [55, 42, 24, 14], 93: [55, 42, 90, 93], 20: [55, 42, 63, 20], 15: [55, 42, 63, 15], 101: [55, 16, 48, 101], 77: [55, 16, 56, 77], 69: [55, 29, 4, 53, 69], 45: [55, 29, 4, 53, 45], 89: [55, 29, 4, 23, 89], 80: [55, 29, 21, 11, 80], 60: [55, 29, 21, 87, 60], 84: [55, 29, 43, 27, 84], 67: [55, 29, 43, 27, 67], 76: [55, 29, 50, 2, 76], 17: [55, 29, 59, 86, 17]}) (95, {95: [95], 34: [95, 34], 31: [95, 31], 49: [95, 49], 20: [95, 20], 46: [95, 46], 81: [95, 81], 75: [95, 34, 75], 18: [95, 34, 18], 55: [95, 34, 55], 38: [95, 34, 38], 29: [95, 34, 29], 12: [95, 31, 12], 48: [95, 31, 48], 83: [95, 31, 83], 88: [95, 31, 88], 91: [95, 31, 91], 33: [95, 31, 33], 85: [95, 31, 85], 28: [95, 49, 28], 40: [95, 49, 40], 30: [95, 49, 30], 10: [95, 49, 10], 5: [95, 49, 5], 58: [95, 49, 58], 84: [95, 20, 84], 22: [95, 20, 22], 56: [95, 20, 56], 99: [95, 20, 99], 19: [95, 20, 19], 68: [95, 20, 68], 86: [95, 20, 86], 32: [95, 20, 32], 4: [95, 20, 4], 51: [95, 46, 51], 9: [95, 46, 9], 23: [95, 46, 23], 3: [95, 81, 3], 61: [95, 81, 61], 42: [95, 81, 42], 41: [95, 81, 41], 67: [95, 34, 75, 67], 96: [95, 34, 75, 96], 98: [95, 34, 18, 98], 94: [95, 34, 18, 94], 6: [95, 34, 18, 6], 35: [95, 34, 55, 35], 16: [95, 34, 55, 16], 78: [95, 34, 38, 78], 47: [95, 34, 38, 47], 66: [95, 34, 38, 66], 21: [95, 34, 29, 21], 43: [95, 34, 29, 43], 50: [95, 34, 29, 50], 59: [95, 34, 29, 59], 27: [95, 31, 12, 27], 44: [95, 31, 12, 44], 101: [95, 31, 12, 101], 7: [95, 31, 48, 7], 36: [95, 31, 48, 36], 89: [95, 31, 83, 89], 45: [95, 31, 83, 45], 52: [95, 31, 83, 52], 93: [95, 31, 83, 93], 64: [95, 31, 88, 64], 65: [95, 31, 88, 65], 39: [95, 31, 88, 39], 74: [95, 31, 91, 74], 100: [95, 31, 91, 100], 73: [95, 31, 33, 73], 71: [95, 31, 33, 71], 70: [95, 31, 33, 70], 1: [95, 31, 85, 1], 25: [95, 31, 85, 25], 62: [95, 49, 28, 62], 37: [95, 49, 28, 37], 80: [95, 49, 28, 80], 26: [95, 49, 58, 26], 87: [95, 49, 58, 87], 17: [95, 49, 58, 17], 13: [95, 20, 84, 13], 14: [95, 20, 84, 14], 72: [95, 20, 22, 72], 97: [95, 20, 22, 97], 77: [95, 20, 56, 77], 90: [95, 20, 56, 90], 63: [95, 20, 19, 63], 92: [95, 20, 19, 92], 53: [95, 20, 4, 53], 69: [95, 46, 23, 69], 54: [95, 81, 3, 54], 24: [95, 81, 42, 24], 82: [95, 81, 41, 82], 57: [95, 34, 18, 94, 57], 79: [95, 34, 55, 16, 79], 15: [95, 34, 38, 47, 15], 2: [95, 34, 38, 47, 2], 60: [95, 34, 38, 66, 60], 11: [95, 34, 29, 21, 11], 8: [95, 34, 29, 59, 8], 76: [95, 20, 22, 72, 76]}) (49, {49: [49], 28: [49, 28], 40: [49, 40], 30: [49, 30], 31: [49, 31], 83: [49, 83], 95: [49, 95], 10: [49, 10], 5: [49, 5], 58: [49, 58], 73: [49, 28, 73], 62: [49, 28, 62], 37: [49, 28, 37], 80: [49, 28, 80], 67: [49, 28, 67], 32: [49, 28, 32], 74: [49, 28, 74], 9: [49, 40, 9], 91: [49, 40, 91], 38: [49, 40, 38], 96: [49, 40, 96], 12: [49, 31, 12], 48: [49, 31, 48], 88: [49, 31, 88], 33: [49, 31, 33], 85: [49, 31, 85], 89: [49, 83, 89], 45: [49, 83, 45], 52: [49, 83, 52], 43: [49, 83, 43], 93: [49, 83, 93], 44: [49, 83, 44], 34: [49, 95, 34], 20: [49, 95, 20], 46: [49, 95, 46], 81: [49, 95, 81], 3: [49, 10, 3], 55: [49, 5, 55], 41: [49, 5, 41], 100: [49, 58, 100], 26: [49, 58, 26], 87: [49, 58, 87], 17: [49, 58, 17], 22: [49, 58, 22], 71: [49, 28, 73, 71], 6: [49, 28, 73, 6], 77: [49, 28, 73, 77], 1: [49, 28, 73, 1], 42: [49, 28, 62, 42], 86: [49, 28, 62, 86], 4: [49, 28, 62, 4], 57: [49, 28, 37, 57], 13: [49, 28, 80, 13], 23: [49, 28, 80, 23], 16: [49, 28, 67, 16], 54: [49, 28, 67, 54], 59: [49, 28, 74, 59], 51: [49, 28, 74, 51], 82: [49, 28, 74, 82], 53: [49, 28, 74, 53], 50: [49, 40, 9, 50], 94: [49, 40, 9, 94], 98: [49, 40, 9, 98], 75: [49, 40, 9, 75], 29: [49, 40, 9, 29], 99: [49, 40, 91, 99], 64: [49, 40, 91, 64], 7: [49, 40, 91, 7], 78: [49, 40, 38, 78], 47: [49, 40, 38, 47], 66: [49, 40, 38, 66], 27: [49, 31, 12, 27], 101: [49, 31, 12, 101], 68: [49, 31, 12, 68], 36: [49, 31, 48, 36], 65: [49, 31, 88, 65], 39: [49, 31, 88, 39], 61: [49, 31, 33, 61], 70: [49, 31, 33, 70], 25: [49, 31, 85, 25], 35: [49, 83, 45, 35], 63: [49, 83, 43, 63], 11: [49, 83, 43, 11], 72: [49, 83, 44, 72], 92: [49, 83, 44, 92], 56: [49, 83, 44, 56], 18: [49, 95, 34, 18], 84: [49, 95, 20, 84], 19: [49, 95, 20, 19], 21: [49, 5, 41, 21], 69: [49, 58, 100, 69], 60: [49, 58, 87, 60], 97: [49, 58, 22, 97], 15: [49, 28, 73, 77, 15], 79: [49, 28, 73, 1, 79], 24: [49, 28, 62, 42, 24], 90: [49, 28, 62, 42, 90], 14: [49, 28, 80, 13, 14], 8: [49, 28, 74, 59, 8], 2: [49, 28, 74, 53, 2], 76: [49, 83, 44, 72, 76]}) (100, {100: [100], 10: [100, 10], 47: [100, 47], 36: [100, 36], 58: [100, 58], 21: [100, 21], 69: [100, 69], 92: [100, 92], 48: [100, 10, 48], 46: [100, 10, 46], 3: [100, 10, 3], 31: [100, 10, 31], 15: [100, 47, 15], 13: [100, 47, 13], 29: [100, 47, 29], 98: [100, 47, 98], 19: [100, 47, 19], 24: [100, 47, 24], 2: [100, 47, 2], 8: [100, 36, 8], 26: [100, 36, 26], 52: [100, 36, 52], 49: [100, 36, 49], 23: [100, 36, 23], 39: [100, 36, 39], 93: [100, 58, 93], 87: [100, 58, 87], 17: [100, 58, 17], 22: [100, 58, 22], 11: [100, 21, 11], 30: [100, 21, 30], 82: [100, 21, 82], 5: [100, 21, 5], 85: [100, 21, 85], 1: [100, 21, 1], 25: [100, 69, 25], 32: [100, 92, 32], 34: [100, 92, 34], 7: [100, 10, 48, 7], 101: [100, 10, 48, 101], 99: [100, 10, 48, 99], 18: [100, 10, 46, 18], 12: [100, 10, 46, 12], 51: [100, 10, 46, 51], 9: [100, 10, 46, 9], 72: [100, 10, 3, 72], 62: [100, 10, 3, 62], 44: [100, 10, 3, 44], 54: [100, 10, 3, 54], 83: [100, 10, 31, 83], 88: [100, 10, 31, 88], 91: [100, 10, 31, 91], 33: [100, 10, 31, 33], 50: [100, 47, 15, 50], 86: [100, 47, 15, 86], 14: [100, 47, 13, 14], 4: [100, 47, 13, 4], 60: [100, 47, 13, 60], 43: [100, 47, 29, 43], 59: [100, 47, 29, 59], 97: [100, 47, 98, 97], 38: [100, 47, 98, 38], 90: [100, 47, 98, 90], 63: [100, 47, 19, 63], 68: [100, 47, 19, 68], 71: [100, 47, 24, 71], 6: [100, 47, 24, 6], 66: [100, 47, 24, 66], 74: [100, 47, 24, 74], 41: [100, 47, 24, 41], 96: [100, 47, 24, 96], 78: [100, 47, 24, 78], 56: [100, 47, 2, 56], 40: [100, 47, 2, 40], 76: [100, 47, 2, 76], 28: [100, 36, 52, 28], 95: [100, 36, 49, 95], 55: [100, 36, 23, 55], 89: [100, 36, 23, 89], 42: [100, 36, 39, 42], 84: [100, 58, 17, 84], 80: [100, 21, 11, 80], 73: [100, 21, 85, 73], 16: [100, 21, 1, 16], 70: [100, 21, 1, 70], 79: [100, 21, 1, 79], 53: [100, 21, 1, 53], 67: [100, 69, 25, 67], 37: [100, 92, 32, 37], 20: [100, 92, 34, 20], 75: [100, 92, 34, 75], 94: [100, 10, 48, 101, 94], 77: [100, 10, 48, 99, 77], 27: [100, 10, 46, 12, 27], 81: [100, 10, 46, 12, 81], 45: [100, 10, 31, 83, 45], 64: [100, 10, 31, 88, 64], 65: [100, 10, 31, 88, 65], 61: [100, 10, 31, 33, 61], 57: [100, 47, 24, 6, 57], 35: [100, 36, 23, 55, 35]}) (57, {57: [57], 24: [57, 24], 52: [57, 52], 39: [57, 39], 101: [57, 101], 16: [57, 16], 69: [57, 69], 40: [57, 40], 12: [57, 12], 79: [57, 79], 70: [57, 70], 90: [57, 24, 90], 25: [57, 24, 25], 71: [57, 24, 71], 6: [57, 24, 6], 34: [57, 24, 34], 66: [57, 24, 66], 54: [57, 24, 54], 74: [57, 24, 74], 41: [57, 24, 41], 68: [57, 24, 68], 96: [57, 24, 96], 78: [57, 24, 78], 26: [57, 24, 26], 14: [57, 24, 14], 1: [57, 52, 1], 23: [57, 52, 23], 28: [57, 52, 28], 59: [57, 39, 59], 42: [57, 39, 42], 33: [57, 39, 33], 13: [57, 39, 13], 94: [57, 101, 94], 73: [57, 101, 73], 21: [57, 101, 21], 8: [57, 101, 8], 99: [57, 101, 99], 48: [57, 16, 48], 56: [57, 16, 56], 9: [57, 16, 9], 81: [57, 16, 81], 4: [57, 16, 4], 22: [57, 69, 22], 93: [57, 69, 93], 46: [57, 69, 46], 91: [57, 40, 91], 38: [57, 40, 38], 30: [57, 40, 30], 49: [57, 40, 49], 27: [57, 12, 27], 44: [57, 12, 44], 3: [57, 79, 3], 37: [57, 79, 37], 84: [57, 70, 84], 64: [57, 70, 64], 100: [57, 24, 90, 100], 10: [57, 24, 90, 10], 87: [57, 24, 25, 87], 67: [57, 24, 25, 67], 32: [57, 24, 25, 32], 50: [57, 24, 71, 50], 20: [57, 24, 71, 20], 7: [57, 24, 71, 7], 95: [57, 24, 71, 95], 75: [57, 24, 34, 75], 18: [57, 24, 34, 18], 55: [57, 24, 34, 55], 29: [57, 24, 34, 29], 61: [57, 24, 66, 61], 60: [57, 24, 66, 60], 43: [57, 24, 54, 43], 11: [57, 24, 54, 11], 62: [57, 24, 74, 62], 51: [57, 24, 74, 51], 82: [57, 24, 74, 82], 53: [57, 24, 74, 53], 19: [57, 24, 41, 19], 83: [57, 24, 41, 83], 89: [57, 24, 96, 89], 31: [57, 24, 78, 31], 98: [57, 24, 26, 98], 80: [57, 52, 28, 80], 97: [57, 39, 59, 97], 36: [57, 39, 59, 36], 86: [57, 39, 59, 86], 65: [57, 39, 59, 65], 63: [57, 39, 42, 63], 77: [57, 101, 73, 77], 5: [57, 101, 21, 5], 85: [57, 101, 21, 85], 88: [57, 101, 8, 88], 58: [57, 16, 56, 58], 72: [57, 69, 22, 72], 47: [57, 40, 38, 47], 92: [57, 12, 44, 92], 15: [57, 70, 64, 15], 35: [57, 70, 64, 35], 2: [57, 24, 71, 50, 2], 45: [57, 24, 74, 53, 45], 17: [57, 39, 59, 86, 17], 76: [57, 69, 22, 72, 76]}) (80, {80: [80], 95: [80, 95], 85: [80, 85], 86: [80, 86], 13: [80, 13], 10: [80, 10], 1: [80, 1], 23: [80, 23], 46: [80, 46], 34: [80, 95, 34], 31: [80, 95, 31], 49: [80, 95, 49], 20: [80, 95, 20], 81: [80, 95, 81], 73: [80, 85, 73], 25: [80, 85, 25], 5: [80, 85, 5], 36: [80, 85, 36], 18: [80, 86, 18], 17: [80, 86, 17], 59: [80, 86, 59], 26: [80, 86, 26], 6: [80, 86, 6], 16: [80, 86, 16], 14: [80, 13, 14], 30: [80, 13, 30], 83: [80, 13, 83], 4: [80, 13, 4], 60: [80, 13, 60], 48: [80, 10, 48], 3: [80, 10, 3], 70: [80, 1, 70], 79: [80, 1, 79], 69: [80, 1, 69], 53: [80, 1, 53], 55: [80, 23, 55], 101: [80, 23, 101], 89: [80, 23, 89], 12: [80, 46, 12], 58: [80, 46, 58], 51: [80, 46, 51], 22: [80, 46, 22], 9: [80, 46, 9], 75: [80, 95, 34, 75], 38: [80, 95, 34, 38], 29: [80, 95, 34, 29], 88: [80, 95, 31, 88], 91: [80, 95, 31, 91], 33: [80, 95, 31, 33], 28: [80, 95, 49, 28], 40: [80, 95, 49, 40], 84: [80, 95, 20, 84], 56: [80, 95, 20, 56], 99: [80, 95, 20, 99], 19: [80, 95, 20, 19], 68: [80, 95, 20, 68], 32: [80, 95, 20, 32], 61: [80, 95, 81, 61], 42: [80, 95, 81, 42], 41: [80, 95, 81, 41], 71: [80, 85, 73, 71], 77: [80, 85, 73, 77], 87: [80, 85, 25, 87], 67: [80, 85, 25, 67], 66: [80, 85, 25, 66], 8: [80, 85, 36, 8], 52: [80, 85, 36, 52], 39: [80, 85, 36, 39], 98: [80, 86, 18, 98], 94: [80, 86, 18, 94], 96: [80, 86, 59, 96], 62: [80, 86, 59, 62], 44: [80, 86, 59, 44], 11: [80, 86, 59, 11], 97: [80, 86, 59, 97], 78: [80, 86, 59, 78], 65: [80, 86, 59, 65], 57: [80, 86, 6, 57], 54: [80, 86, 6, 54], 74: [80, 13, 14, 74], 82: [80, 13, 14, 82], 45: [80, 13, 83, 45], 43: [80, 13, 83, 43], 93: [80, 13, 83, 93], 7: [80, 10, 48, 7], 72: [80, 10, 3, 72], 37: [80, 1, 70, 37], 64: [80, 1, 70, 64], 2: [80, 1, 53, 2], 35: [80, 23, 55, 35], 21: [80, 23, 101, 21], 27: [80, 46, 12, 27], 100: [80, 46, 58, 100], 50: [80, 46, 9, 50], 47: [80, 95, 34, 38, 47], 90: [80, 95, 20, 56, 90], 63: [80, 95, 20, 19, 63], 92: [80, 95, 20, 19, 92], 24: [80, 95, 81, 42, 24], 15: [80, 85, 73, 77, 15], 76: [80, 10, 3, 72, 76]}) (91, {91: [91], 74: [91, 74], 12: [91, 12], 99: [91, 99], 50: [91, 50], 32: [91, 32], 64: [91, 64], 38: [91, 38], 7: [91, 7], 100: [91, 100], 22: [91, 74, 22], 62: [91, 74, 62], 59: [91, 74, 59], 51: [91, 74, 51], 87: [91, 74, 87], 82: [91, 74, 82], 53: [91, 74, 53], 27: [91, 12, 27], 44: [91, 12, 44], 101: [91, 12, 101], 81: [91, 12, 81], 68: [91, 12, 68], 4: [91, 12, 4], 19: [91, 99, 19], 18: [91, 99, 18], 28: [91, 99, 28], 77: [91, 99, 77], 97: [91, 99, 97], 2: [91, 50, 2], 88: [91, 50, 88], 54: [91, 50, 54], 52: [91, 50, 52], 42: [91, 50, 42], 93: [91, 32, 93], 37: [91, 32, 37], 73: [91, 64, 73], 89: [91, 64, 89], 65: [91, 64, 65], 15: [91, 64, 15], 39: [91, 64, 39], 96: [91, 64, 96], 35: [91, 64, 35], 78: [91, 38, 78], 47: [91, 38, 47], 66: [91, 38, 66], 10: [91, 100, 10], 36: [91, 100, 36], 58: [91, 100, 58], 21: [91, 100, 21], 69: [91, 100, 69], 92: [91, 100, 92], 43: [91, 74, 22, 43], 72: [91, 74, 22, 72], 6: [91, 74, 22, 6], 86: [91, 74, 62, 86], 80: [91, 74, 62, 80], 13: [91, 74, 59, 13], 26: [91, 74, 59, 26], 8: [91, 74, 59, 8], 11: [91, 74, 59, 11], 49: [91, 74, 51, 49], 60: [91, 74, 87, 60], 83: [91, 74, 87, 83], 14: [91, 74, 82, 14], 45: [91, 74, 53, 45], 55: [91, 74, 53, 55], 84: [91, 12, 27, 84], 67: [91, 12, 27, 67], 56: [91, 12, 44, 56], 94: [91, 12, 44, 94], 25: [91, 12, 101, 25], 3: [91, 12, 81, 3], 61: [91, 12, 81, 61], 30: [91, 12, 81, 30], 41: [91, 12, 81, 41], 40: [91, 12, 81, 40], 23: [91, 12, 4, 23], 63: [91, 99, 19, 63], 98: [91, 99, 19, 98], 95: [91, 99, 18, 95], 31: [91, 99, 28, 31], 9: [91, 99, 77, 9], 29: [91, 99, 77, 29], 70: [91, 99, 77, 70], 76: [91, 50, 2, 76], 71: [91, 50, 54, 71], 16: [91, 50, 54, 16], 1: [91, 50, 52, 1], 33: [91, 50, 42, 33], 24: [91, 50, 42, 24], 90: [91, 50, 42, 90], 34: [91, 32, 93, 34], 57: [91, 32, 37, 57], 20: [91, 64, 65, 20], 48: [91, 100, 10, 48], 46: [91, 100, 10, 46], 17: [91, 100, 58, 17], 5: [91, 100, 21, 5], 85: [91, 100, 21, 85], 79: [91, 74, 87, 60, 79], 75: [91, 99, 77, 9, 75]}) (52, {52: [52], 1: [52, 1], 39: [52, 39], 23: [52, 23], 28: [52, 28], 101: [52, 101], 16: [52, 1, 16], 70: [52, 1, 70], 79: [52, 1, 79], 69: [52, 1, 69], 53: [52, 1, 53], 59: [52, 39, 59], 42: [52, 39, 42], 96: [52, 39, 96], 33: [52, 39, 33], 13: [52, 39, 13], 74: [52, 39, 74], 55: [52, 23, 55], 89: [52, 23, 89], 73: [52, 28, 73], 62: [52, 28, 62], 31: [52, 28, 31], 37: [52, 28, 37], 80: [52, 28, 80], 67: [52, 28, 67], 32: [52, 28, 32], 94: [52, 101, 94], 25: [52, 101, 25], 21: [52, 101, 21], 8: [52, 101, 8], 99: [52, 101, 99], 48: [52, 1, 16, 48], 56: [52, 1, 16, 56], 9: [52, 1, 16, 9], 81: [52, 1, 16, 81], 4: [52, 1, 16, 4], 6: [52, 1, 16, 6], 84: [52, 1, 70, 84], 64: [52, 1, 70, 64], 3: [52, 1, 79, 3], 22: [52, 1, 79, 22], 93: [52, 1, 69, 93], 46: [52, 1, 69, 46], 26: [52, 1, 69, 26], 86: [52, 1, 53, 86], 45: [52, 1, 53, 45], 2: [52, 1, 53, 2], 44: [52, 39, 59, 44], 11: [52, 39, 59, 11], 18: [52, 39, 59, 18], 97: [52, 39, 59, 97], 36: [52, 39, 59, 36], 78: [52, 39, 59, 78], 65: [52, 39, 59, 65], 40: [52, 39, 42, 40], 91: [52, 39, 42, 91], 24: [52, 39, 42, 24], 90: [52, 39, 42, 90], 63: [52, 39, 42, 63], 20: [52, 39, 96, 20], 71: [52, 39, 33, 71], 61: [52, 39, 33, 61], 75: [52, 39, 33, 75], 14: [52, 39, 13, 14], 30: [52, 39, 13, 30], 83: [52, 39, 13, 83], 60: [52, 39, 13, 60], 51: [52, 39, 74, 51], 87: [52, 39, 74, 87], 82: [52, 39, 74, 82], 29: [52, 23, 55, 29], 35: [52, 23, 55, 35], 57: [52, 23, 89, 57], 77: [52, 28, 73, 77], 12: [52, 28, 31, 12], 88: [52, 28, 31, 88], 85: [52, 28, 31, 85], 95: [52, 28, 80, 95], 10: [52, 28, 80, 10], 54: [52, 28, 67, 54], 66: [52, 101, 25, 66], 5: [52, 101, 21, 5], 19: [52, 101, 99, 19], 50: [52, 101, 99, 50], 7: [52, 1, 16, 48, 7], 58: [52, 1, 16, 56, 58], 98: [52, 1, 16, 9, 98], 68: [52, 1, 16, 81, 68], 41: [52, 1, 16, 81, 41], 15: [52, 1, 70, 64, 15], 72: [52, 1, 79, 3, 72], 43: [52, 1, 79, 22, 43], 34: [52, 1, 69, 93, 34], 17: [52, 1, 53, 86, 17], 76: [52, 1, 53, 2, 76], 92: [52, 39, 59, 44, 92], 49: [52, 39, 59, 18, 49], 38: [52, 39, 42, 40, 38], 100: [52, 39, 42, 91, 100], 27: [52, 28, 31, 12, 27], 47: [52, 1, 16, 9, 98, 47]}) (81, {81: [81], 3: [81, 3], 61: [81, 61], 55: [81, 55], 30: [81, 30], 42: [81, 42], 68: [81, 68], 41: [81, 41], 58: [81, 58], 28: [81, 28], 40: [81, 40], 72: [81, 3, 72], 62: [81, 3, 62], 44: [81, 3, 44], 85: [81, 3, 85], 54: [81, 3, 54], 59: [81, 61, 59], 92: [81, 61, 92], 22: [81, 61, 22], 100: [81, 61, 100], 73: [81, 61, 73], 29: [81, 55, 29], 35: [81, 55, 35], 16: [81, 55, 16], 80: [81, 30, 80], 33: [81, 42, 33], 91: [81, 42, 91], 24: [81, 42, 24], 90: [81, 42, 90], 63: [81, 42, 63], 13: [81, 68, 13], 19: [81, 41, 19], 94: [81, 41, 94], 96: [81, 41, 96], 20: [81, 41, 20], 21: [81, 41, 21], 56: [81, 41, 56], 83: [81, 41, 83], 82: [81, 41, 82], 93: [81, 58, 93], 26: [81, 58, 26], 87: [81, 58, 87], 17: [81, 58, 17], 31: [81, 28, 31], 37: [81, 28, 37], 67: [81, 28, 67], 32: [81, 28, 32], 74: [81, 28, 74], 9: [81, 40, 9], 38: [81, 40, 38], 49: [81, 40, 49], 36: [81, 3, 72, 36], 98: [81, 3, 72, 98], 6: [81, 3, 72, 6], 76: [81, 3, 72, 76], 18: [81, 3, 72, 18], 86: [81, 3, 62, 86], 4: [81, 3, 62, 4], 51: [81, 3, 44, 51], 11: [81, 3, 44, 11], 10: [81, 3, 44, 10], 1: [81, 3, 85, 1], 25: [81, 3, 85, 25], 5: [81, 3, 85, 5], 71: [81, 3, 54, 71], 43: [81, 3, 54, 43], 70: [81, 3, 54, 70], 8: [81, 61, 59, 8], 97: [81, 61, 59, 97], 78: [81, 61, 59, 78], 65: [81, 61, 59, 65], 34: [81, 61, 92, 34], 47: [81, 61, 92, 47], 52: [81, 61, 92, 52], 69: [81, 61, 100, 69], 77: [81, 61, 73, 77], 50: [81, 55, 29, 50], 48: [81, 55, 16, 48], 79: [81, 55, 16, 79], 95: [81, 30, 80, 95], 23: [81, 30, 80, 23], 46: [81, 30, 80, 46], 75: [81, 42, 33, 75], 12: [81, 42, 91, 12], 99: [81, 42, 91, 99], 64: [81, 42, 91, 64], 7: [81, 42, 91, 7], 66: [81, 42, 24, 66], 14: [81, 42, 24, 14], 88: [81, 42, 63, 88], 15: [81, 42, 63, 15], 60: [81, 68, 13, 60], 57: [81, 41, 94, 57], 101: [81, 41, 94, 101], 89: [81, 41, 96, 89], 84: [81, 41, 20, 84], 45: [81, 41, 83, 45], 39: [81, 58, 93, 39], 53: [81, 28, 74, 53], 27: [81, 3, 54, 43, 27], 2: [81, 61, 92, 47, 2]}) (101, {101: [101], 94: [101, 94], 25: [101, 25], 73: [101, 73], 21: [101, 21], 96: [101, 96], 8: [101, 8], 99: [101, 99], 62: [101, 94, 62], 57: [101, 94, 57], 46: [101, 94, 46], 24: [101, 94, 24], 84: [101, 25, 84], 26: [101, 25, 26], 87: [101, 25, 87], 67: [101, 25, 67], 32: [101, 25, 32], 56: [101, 25, 56], 66: [101, 25, 66], 71: [101, 73, 71], 6: [101, 73, 6], 77: [101, 73, 77], 83: [101, 73, 83], 1: [101, 73, 1], 11: [101, 21, 11], 30: [101, 21, 30], 82: [101, 21, 82], 5: [101, 21, 5], 3: [101, 21, 3], 85: [101, 21, 85], 59: [101, 96, 59], 33: [101, 96, 33], 89: [101, 96, 89], 20: [101, 96, 20], 88: [101, 8, 88], 4: [101, 99, 4], 19: [101, 99, 19], 18: [101, 99, 18], 22: [101, 99, 22], 28: [101, 99, 28], 50: [101, 99, 50], 97: [101, 99, 97], 42: [101, 94, 62, 42], 86: [101, 94, 62, 86], 74: [101, 94, 62, 74], 80: [101, 94, 62, 80], 44: [101, 94, 62, 44], 52: [101, 94, 57, 52], 39: [101, 94, 57, 39], 16: [101, 94, 57, 16], 69: [101, 94, 57, 69], 40: [101, 94, 57, 40], 12: [101, 94, 57, 12], 79: [101, 94, 57, 79], 70: [101, 94, 57, 70], 58: [101, 94, 46, 58], 51: [101, 94, 46, 51], 9: [101, 94, 46, 9], 23: [101, 94, 46, 23], 90: [101, 94, 24, 90], 34: [101, 94, 24, 34], 54: [101, 94, 24, 54], 41: [101, 94, 24, 41], 68: [101, 94, 24, 68], 78: [101, 94, 24, 78], 14: [101, 94, 24, 14], 98: [101, 25, 84, 98], 13: [101, 25, 84, 13], 60: [101, 25, 87, 60], 93: [101, 25, 87, 93], 37: [101, 25, 32, 37], 10: [101, 25, 56, 10], 61: [101, 25, 66, 61], 95: [101, 25, 66, 95], 7: [101, 73, 71, 7], 29: [101, 73, 77, 29], 45: [101, 73, 77, 45], 15: [101, 73, 77, 15], 43: [101, 73, 77, 43], 53: [101, 73, 1, 53], 55: [101, 21, 5, 55], 72: [101, 21, 3, 72], 36: [101, 21, 85, 36], 65: [101, 96, 59, 65], 75: [101, 96, 33, 75], 81: [101, 96, 20, 81], 64: [101, 8, 88, 64], 63: [101, 99, 19, 63], 92: [101, 99, 19, 92], 49: [101, 99, 18, 49], 91: [101, 99, 22, 91], 31: [101, 99, 28, 31], 2: [101, 99, 50, 2], 17: [101, 94, 62, 86, 17], 48: [101, 94, 57, 16, 48], 38: [101, 94, 57, 40, 38], 27: [101, 94, 57, 12, 27], 100: [101, 94, 46, 58, 100], 47: [101, 25, 84, 98, 47], 35: [101, 73, 77, 45, 35], 76: [101, 21, 3, 72, 76]}) (51, {51: [51], 49: [51, 49], 100: [51, 100], 73: [51, 73], 28: [51, 49, 28], 40: [51, 49, 40], 30: [51, 49, 30], 31: [51, 49, 31], 83: [51, 49, 83], 95: [51, 49, 95], 10: [51, 49, 10], 5: [51, 49, 5], 58: [51, 49, 58], 47: [51, 100, 47], 36: [51, 100, 36], 21: [51, 100, 21], 69: [51, 100, 69], 92: [51, 100, 92], 71: [51, 73, 71], 6: [51, 73, 6], 77: [51, 73, 77], 1: [51, 73, 1], 62: [51, 49, 28, 62], 37: [51, 49, 28, 37], 80: [51, 49, 28, 80], 67: [51, 49, 28, 67], 32: [51, 49, 28, 32], 74: [51, 49, 28, 74], 9: [51, 49, 40, 9], 91: [51, 49, 40, 91], 38: [51, 49, 40, 38], 96: [51, 49, 40, 96], 12: [51, 49, 31, 12], 48: [51, 49, 31, 48], 88: [51, 49, 31, 88], 33: [51, 49, 31, 33], 85: [51, 49, 31, 85], 89: [51, 49, 83, 89], 45: [51, 49, 83, 45], 52: [51, 49, 83, 52], 43: [51, 49, 83, 43], 93: [51, 49, 83, 93], 44: [51, 49, 83, 44], 34: [51, 49, 95, 34], 20: [51, 49, 95, 20], 46: [51, 49, 95, 46], 81: [51, 49, 95, 81], 3: [51, 49, 10, 3], 55: [51, 49, 5, 55], 41: [51, 49, 5, 41], 26: [51, 49, 58, 26], 87: [51, 49, 58, 87], 17: [51, 49, 58, 17], 22: [51, 49, 58, 22], 15: [51, 100, 47, 15], 13: [51, 100, 47, 13], 29: [51, 100, 47, 29], 98: [51, 100, 47, 98], 19: [51, 100, 47, 19], 24: [51, 100, 47, 24], 2: [51, 100, 47, 2], 8: [51, 100, 36, 8], 23: [51, 100, 36, 23], 39: [51, 100, 36, 39], 11: [51, 100, 21, 11], 82: [51, 100, 21, 82], 25: [51, 100, 69, 25], 50: [51, 73, 71, 50], 7: [51, 73, 71, 7], 57: [51, 73, 6, 57], 54: [51, 73, 6, 54], 4: [51, 73, 77, 4], 56: [51, 73, 77, 56], 70: [51, 73, 77, 70], 101: [51, 73, 77, 101], 16: [51, 73, 1, 16], 79: [51, 73, 1, 79], 53: [51, 73, 1, 53], 42: [51, 49, 28, 62, 42], 86: [51, 49, 28, 62, 86], 59: [51, 49, 28, 74, 59], 94: [51, 49, 40, 9, 94], 75: [51, 49, 40, 9, 75], 99: [51, 49, 40, 91, 99], 64: [51, 49, 40, 91, 64], 78: [51, 49, 40, 38, 78], 66: [51, 49, 40, 38, 66], 27: [51, 49, 31, 12, 27], 68: [51, 49, 31, 12, 68], 65: [51, 49, 31, 88, 65], 61: [51, 49, 31, 33, 61], 35: [51, 49, 83, 45, 35], 63: [51, 49, 83, 43, 63], 72: [51, 49, 83, 44, 72], 18: [51, 49, 95, 34, 18], 84: [51, 49, 95, 20, 84], 60: [51, 49, 58, 87, 60], 97: [51, 49, 58, 22, 97], 14: [51, 100, 47, 13, 14], 90: [51, 100, 47, 98, 90], 76: [51, 100, 47, 2, 76]}) (44, {44: [44], 72: [44, 72], 92: [44, 92], 51: [44, 51], 56: [44, 56], 11: [44, 11], 94: [44, 94], 10: [44, 10], 17: [44, 72, 17], 36: [44, 72, 36], 29: [44, 72, 29], 98: [44, 72, 98], 6: [44, 72, 6], 76: [44, 72, 76], 18: [44, 72, 18], 13: [44, 92, 13], 32: [44, 92, 32], 34: [44, 92, 34], 47: [44, 92, 47], 52: [44, 92, 52], 49: [44, 51, 49], 100: [44, 51, 100], 73: [44, 51, 73], 77: [44, 56, 77], 90: [44, 56, 90], 58: [44, 56, 58], 80: [44, 11, 80], 95: [44, 11, 95], 24: [44, 11, 24], 62: [44, 94, 62], 57: [44, 94, 57], 101: [44, 94, 101], 46: [44, 94, 46], 48: [44, 10, 48], 3: [44, 10, 3], 31: [44, 10, 31], 84: [44, 72, 17, 84], 8: [44, 72, 36, 8], 26: [44, 72, 36, 26], 23: [44, 72, 36, 23], 19: [44, 72, 36, 19], 39: [44, 72, 36, 39], 4: [44, 72, 29, 4], 21: [44, 72, 29, 21], 43: [44, 72, 29, 43], 50: [44, 72, 29, 50], 59: [44, 72, 29, 59], 97: [44, 72, 98, 97], 88: [44, 72, 98, 88], 5: [44, 72, 98, 5], 38: [44, 72, 98, 38], 54: [44, 72, 98, 54], 1: [44, 72, 6, 1], 40: [44, 72, 76, 40], 45: [44, 72, 76, 45], 7: [44, 72, 76, 7], 33: [44, 72, 76, 33], 60: [44, 72, 76, 60], 86: [44, 72, 18, 86], 14: [44, 92, 13, 14], 30: [44, 92, 13, 30], 83: [44, 92, 13, 83], 93: [44, 92, 32, 93], 37: [44, 92, 32, 37], 20: [44, 92, 34, 20], 75: [44, 92, 34, 75], 55: [44, 92, 34, 55], 15: [44, 92, 47, 15], 2: [44, 92, 47, 2], 28: [44, 92, 52, 28], 69: [44, 51, 100, 69], 71: [44, 51, 73, 71], 9: [44, 56, 77, 9], 70: [44, 56, 77, 70], 87: [44, 56, 58, 87], 22: [44, 56, 58, 22], 85: [44, 11, 80, 85], 81: [44, 11, 95, 81], 25: [44, 11, 24, 25], 66: [44, 11, 24, 66], 74: [44, 11, 24, 74], 41: [44, 11, 24, 41], 68: [44, 11, 24, 68], 96: [44, 11, 24, 96], 78: [44, 11, 24, 78], 42: [44, 94, 62, 42], 16: [44, 94, 57, 16], 12: [44, 94, 57, 12], 79: [44, 94, 57, 79], 99: [44, 94, 101, 99], 91: [44, 10, 31, 91], 89: [44, 72, 36, 23, 89], 63: [44, 72, 36, 19, 63], 53: [44, 72, 29, 4, 53], 82: [44, 72, 29, 21, 82], 27: [44, 72, 29, 43, 27], 65: [44, 72, 29, 59, 65], 64: [44, 72, 98, 97, 64], 35: [44, 72, 76, 45, 35], 61: [44, 72, 76, 33, 61], 67: [44, 92, 34, 75, 67]}) (60, {60: [60], 41: [60, 41], 89: [60, 89], 79: [60, 79], 18: [60, 18], 62: [60, 62], 40: [60, 40], 99: [60, 99], 93: [60, 93], 19: [60, 41, 19], 94: [60, 41, 94], 96: [60, 41, 96], 20: [60, 41, 20], 21: [60, 41, 21], 56: [60, 41, 56], 83: [60, 41, 83], 82: [60, 41, 82], 57: [60, 89, 57], 55: [60, 89, 55], 3: [60, 79, 3], 8: [60, 79, 8], 22: [60, 79, 22], 37: [60, 79, 37], 98: [60, 18, 98], 95: [60, 18, 95], 6: [60, 18, 6], 86: [60, 18, 86], 32: [60, 18, 32], 49: [60, 18, 49], 42: [60, 62, 42], 74: [60, 62, 74], 4: [60, 62, 4], 80: [60, 62, 80], 44: [60, 62, 44], 9: [60, 40, 9], 91: [60, 40, 91], 38: [60, 40, 38], 30: [60, 40, 30], 28: [60, 99, 28], 77: [60, 99, 77], 50: [60, 99, 50], 97: [60, 99, 97], 58: [60, 93, 58], 34: [60, 93, 34], 71: [60, 93, 71], 39: [60, 93, 39], 43: [60, 93, 43], 63: [60, 41, 19, 63], 68: [60, 41, 19, 68], 92: [60, 41, 19, 92], 101: [60, 41, 94, 101], 46: [60, 41, 94, 46], 24: [60, 41, 94, 24], 59: [60, 41, 96, 59], 33: [60, 41, 96, 33], 84: [60, 41, 20, 84], 81: [60, 41, 20, 81], 11: [60, 41, 21, 11], 87: [60, 41, 21, 87], 5: [60, 41, 21, 5], 85: [60, 41, 21, 85], 1: [60, 41, 21, 1], 10: [60, 41, 56, 10], 90: [60, 41, 56, 90], 45: [60, 41, 83, 45], 52: [60, 41, 83, 52], 51: [60, 41, 82, 51], 14: [60, 41, 82, 14], 16: [60, 89, 57, 16], 69: [60, 89, 57, 69], 12: [60, 89, 57, 12], 70: [60, 89, 57, 70], 29: [60, 89, 55, 29], 35: [60, 89, 55, 35], 72: [60, 79, 3, 72], 54: [60, 79, 3, 54], 88: [60, 79, 8, 88], 47: [60, 18, 98, 47], 36: [60, 18, 98, 36], 13: [60, 18, 98, 13], 31: [60, 18, 95, 31], 17: [60, 18, 86, 17], 26: [60, 18, 86, 26], 53: [60, 62, 74, 53], 78: [60, 62, 4, 78], 23: [60, 62, 4, 23], 75: [60, 40, 9, 75], 64: [60, 40, 91, 64], 7: [60, 40, 91, 7], 100: [60, 40, 91, 100], 66: [60, 40, 38, 66], 73: [60, 99, 28, 73], 67: [60, 99, 28, 67], 15: [60, 99, 77, 15], 2: [60, 99, 50, 2], 25: [60, 99, 97, 25], 27: [60, 93, 43, 27], 48: [60, 93, 43, 48], 65: [60, 41, 96, 59, 65], 61: [60, 41, 96, 33, 61], 76: [60, 79, 3, 72, 76]}) (88, {88: [88], 81: [88, 81], 64: [88, 64], 101: [88, 101], 95: [88, 95], 65: [88, 65], 40: [88, 40], 39: [88, 39], 3: [88, 81, 3], 61: [88, 81, 61], 55: [88, 81, 55], 30: [88, 81, 30], 42: [88, 81, 42], 68: [88, 81, 68], 41: [88, 81, 41], 58: [88, 81, 58], 28: [88, 81, 28], 73: [88, 64, 73], 89: [88, 64, 89], 82: [88, 64, 82], 4: [88, 64, 4], 15: [88, 64, 15], 96: [88, 64, 96], 35: [88, 64, 35], 22: [88, 64, 22], 94: [88, 101, 94], 25: [88, 101, 25], 21: [88, 101, 21], 8: [88, 101, 8], 99: [88, 101, 99], 34: [88, 95, 34], 31: [88, 95, 31], 49: [88, 95, 49], 20: [88, 95, 20], 46: [88, 95, 46], 86: [88, 65, 86], 45: [88, 65, 45], 9: [88, 40, 9], 91: [88, 40, 91], 38: [88, 40, 38], 59: [88, 39, 59], 33: [88, 39, 33], 13: [88, 39, 13], 74: [88, 39, 74], 72: [88, 81, 3, 72], 62: [88, 81, 3, 62], 44: [88, 81, 3, 44], 85: [88, 81, 3, 85], 54: [88, 81, 3, 54], 92: [88, 81, 61, 92], 100: [88, 81, 61, 100], 29: [88, 81, 55, 29], 16: [88, 81, 55, 16], 80: [88, 81, 30, 80], 24: [88, 81, 42, 24], 90: [88, 81, 42, 90], 63: [88, 81, 42, 63], 19: [88, 81, 41, 19], 56: [88, 81, 41, 56], 83: [88, 81, 41, 83], 93: [88, 81, 58, 93], 26: [88, 81, 58, 26], 87: [88, 81, 58, 87], 17: [88, 81, 58, 17], 37: [88, 81, 28, 37], 67: [88, 81, 28, 67], 32: [88, 81, 28, 32], 71: [88, 64, 73, 71], 6: [88, 64, 73, 6], 77: [88, 64, 73, 77], 1: [88, 64, 73, 1], 57: [88, 64, 89, 57], 11: [88, 64, 82, 11], 51: [88, 64, 82, 51], 14: [88, 64, 82, 14], 53: [88, 64, 4, 53], 78: [88, 64, 4, 78], 23: [88, 64, 4, 23], 47: [88, 64, 15, 47], 50: [88, 64, 15, 50], 36: [88, 64, 35, 36], 43: [88, 64, 22, 43], 97: [88, 64, 22, 97], 84: [88, 101, 25, 84], 66: [88, 101, 25, 66], 5: [88, 101, 21, 5], 18: [88, 101, 99, 18], 75: [88, 95, 34, 75], 12: [88, 95, 31, 12], 48: [88, 95, 31, 48], 10: [88, 95, 49, 10], 70: [88, 65, 45, 70], 98: [88, 40, 9, 98], 7: [88, 40, 91, 7], 60: [88, 39, 13, 60], 76: [88, 81, 3, 72, 76], 52: [88, 81, 61, 92, 52], 69: [88, 81, 61, 100, 69], 79: [88, 81, 55, 16, 79], 2: [88, 64, 4, 53, 2], 27: [88, 64, 22, 43, 27]}) (65, {65: [65], 15: [65, 15], 20: [65, 20], 86: [65, 86], 45: [65, 45], 47: [65, 15, 47], 39: [65, 15, 39], 83: [65, 15, 83], 9: [65, 15, 9], 50: [65, 15, 50], 84: [65, 20, 84], 22: [65, 20, 22], 56: [65, 20, 56], 99: [65, 20, 99], 19: [65, 20, 19], 58: [65, 20, 58], 30: [65, 20, 30], 68: [65, 20, 68], 81: [65, 20, 81], 32: [65, 20, 32], 46: [65, 20, 46], 4: [65, 20, 4], 18: [65, 86, 18], 17: [65, 86, 17], 59: [65, 86, 59], 26: [65, 86, 26], 6: [65, 86, 6], 80: [65, 86, 80], 16: [65, 86, 16], 70: [65, 45, 70], 34: [65, 45, 34], 35: [65, 45, 35], 85: [65, 45, 85], 13: [65, 15, 47, 13], 29: [65, 15, 47, 29], 98: [65, 15, 47, 98], 36: [65, 15, 47, 36], 24: [65, 15, 47, 24], 2: [65, 15, 47, 2], 101: [65, 15, 39, 101], 28: [65, 15, 39, 28], 42: [65, 15, 39, 42], 96: [65, 15, 39, 96], 33: [65, 15, 39, 33], 74: [65, 15, 39, 74], 89: [65, 15, 83, 89], 52: [65, 15, 83, 52], 43: [65, 15, 83, 43], 93: [65, 15, 83, 93], 44: [65, 15, 83, 44], 94: [65, 15, 9, 94], 31: [65, 15, 9, 31], 75: [65, 15, 9, 75], 1: [65, 15, 9, 1], 88: [65, 15, 50, 88], 54: [65, 15, 50, 54], 14: [65, 20, 84, 14], 25: [65, 20, 84, 25], 72: [65, 20, 22, 72], 91: [65, 20, 22, 91], 97: [65, 20, 22, 97], 77: [65, 20, 56, 77], 10: [65, 20, 56, 10], 90: [65, 20, 56, 90], 63: [65, 20, 19, 63], 62: [65, 20, 19, 62], 92: [65, 20, 19, 92], 100: [65, 20, 58, 100], 87: [65, 20, 58, 87], 55: [65, 20, 68, 55], 40: [65, 20, 68, 40], 3: [65, 20, 81, 3], 61: [65, 20, 81, 61], 41: [65, 20, 81, 41], 37: [65, 20, 32, 37], 12: [65, 20, 46, 12], 51: [65, 20, 46, 51], 23: [65, 20, 46, 23], 53: [65, 20, 4, 53], 78: [65, 20, 4, 78], 95: [65, 86, 18, 95], 49: [65, 86, 18, 49], 8: [65, 86, 59, 8], 11: [65, 86, 59, 11], 57: [65, 86, 6, 57], 48: [65, 86, 16, 48], 79: [65, 86, 16, 79], 64: [65, 45, 70, 64], 38: [65, 45, 34, 38], 73: [65, 45, 85, 73], 5: [65, 45, 85, 5], 60: [65, 15, 47, 13, 60], 21: [65, 15, 47, 29, 21], 71: [65, 15, 47, 24, 71], 66: [65, 15, 47, 24, 66], 76: [65, 15, 47, 2, 76], 67: [65, 15, 39, 28, 67], 82: [65, 15, 39, 74, 82], 27: [65, 15, 83, 43, 27], 69: [65, 15, 9, 1, 69], 7: [65, 20, 22, 91, 7]})\n"
]
],
[
[
"Okay let's load UofT map again and see what can we do",
"_____no_output_____"
]
],
[
[
"G = ox.graph_from_address(\"university of toronto\", dist = 300)",
"_____no_output_____"
],
[
"fig, ax = ox.plot_graph(G)",
"_____no_output_____"
],
[
"# here are the nodes\n[*G.nodes()]",
"_____no_output_____"
],
[
"# this will take a while\n# this can come in handy in a lot of case studies\nfor distance_to_others in itertools.islice(nx.all_pairs_shortest_path(G), 5): # we will take only five\n print(distance_to_others)",
"(130170945, {130170945: [130170945], 55808527: [130170945, 55808527], 389677905: [130170945, 389677905], 127284680: [130170945, 127284680], 127284677: [130170945, 127284677], 55808564: [130170945, 55808527, 55808564], 55808512: [130170945, 55808527, 55808512], 2143434279: [130170945, 55808527, 2143434279], 3996671926: [130170945, 389677905, 3996671926], 389678182: [130170945, 389677905, 389678182], 2143468182: [130170945, 55808527, 55808564, 2143468182], 55808518: [130170945, 55808527, 55808564, 55808518], 55808451: [130170945, 55808527, 55808512, 55808451], 3996671921: [130170945, 389677905, 3996671926, 3996671921], 389677904: [130170945, 389677905, 3996671926, 389677904], 3996671930: [130170945, 389677905, 3996671926, 3996671930], 389678181: [130170945, 389677905, 389678182, 389678181], 389677906: [130170945, 389677905, 389678182, 389677906], 2143468197: [130170945, 55808527, 55808564, 2143468182, 2143468197], 2143468186: [130170945, 55808527, 55808564, 2143468182, 2143468186], 306729816: [130170945, 55808527, 55808564, 55808518, 306729816], 389678121: [130170945, 55808527, 55808512, 55808451, 389678121], 50885147: [130170945, 55808527, 55808512, 55808451, 50885147], 313239199: [130170945, 389677905, 3996671926, 3996671921, 313239199], 127283024: [130170945, 389677905, 3996671926, 389677904, 127283024], 389678034: [130170945, 389677905, 3996671926, 389677904, 389678034], 389678157: [130170945, 389677905, 389678182, 389678181, 389678157], 24959549: [130170945, 389677905, 389678182, 389678181, 24959549], 6028561926: [130170945, 389677905, 389678182, 389677906, 6028561926], 50885141: [130170945, 389677905, 389678182, 389677906, 50885141], 389678122: [130170945, 389677905, 389678182, 389677906, 389678122], 2143468192: [130170945, 55808527, 55808564, 2143468182, 2143468197, 2143468192], 80927426: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426], 306729822: [130170945, 55808527, 55808564, 55808518, 306729816, 306729822], 4917890706: [130170945, 55808527, 55808564, 55808518, 306729816, 4917890706], 50885160: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160], 1258707987: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987], 389677892: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892], 389678033: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033], 3996671928: [130170945, 389677905, 3996671926, 389677904, 127283024, 3996671928], 2143404200: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200], 389677903: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903], 3342358889: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889], 389677891: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891], 6028561928: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928], 6028561931: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561931], 3057643410: [130170945, 389677905, 389678182, 389677906, 6028561926, 3057643410], 6028561927: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561927], 6028561925: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561925], 389678180: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180], 1258707990: [130170945, 389677905, 389678182, 389677906, 389678122, 1258707990], 127275360: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360], 306729825: [130170945, 55808527, 55808564, 55808518, 306729816, 306729822, 306729825], 7311083157: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157], 7311083158: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158], 2143485199: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 2143485199], 6028561929: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929], 389678032: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 389678032], 21631731: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731], 3996671922: [130170945, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922], 2473807793: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793], 4920594800: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 4920594800], 389678007: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007], 2143487624: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624], 3342358888: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 3342358888], 389678036: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036], 389678187: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187], 6028561930: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 6028561930], 779168848: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 779168848], 3057643411: [130170945, 389677905, 389678182, 389677906, 6028561926, 3057643410, 3057643411], 2143488529: [130170945, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529], 239055729: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561925, 239055729], 2143436415: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415], 1258706668: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 1258706668], 7153999189: [130170945, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189], 80927418: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418], 24960076: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076], 7311083154: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 7311083154], 2143434860: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860], 856114449: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 856114449], 3057097224: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 3057097224], 779168879: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 389678032, 779168879], 389678008: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008], 389677893: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893], 4920594801: [130170945, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801], 2473807791: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791], 5277943137: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 5277943137], 2143487625: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625], 24959527: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527], 390550471: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471], 24959550: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550], 389678188: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678188], 389678186: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678186], 6391301132: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 6028561930, 6391301132], 779168874: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 779168848, 779168874], 774054378: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 779168848, 774054378], 389677907: [130170945, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529, 389677907], 2143493381: [130170945, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529, 2143493381], 389677890: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561925, 239055729, 389677890], 2143494216: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143494216], 2143436407: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407], 389678124: [130170945, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124], 3311164627: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627], 24960080: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080], 703096142: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 703096142], 2143434862: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862], 856114454: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 856114449, 856114454], 6391312709: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 3057097224, 6391312709], 389678190: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 3057097224, 389678190], 3342358879: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 389678032, 779168879, 3342358879], 3342358877: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 389678032, 779168879, 3342358877], 389678009: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009], 2078205535: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535], 4295105603: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603], 389678194: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194], 4920594802: [130170945, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802], 3342358885: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885], 2498969982: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982], 2143487626: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 2143487626], 389678005: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005], 389678004: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004], 303255446: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446], 127289393: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393], 389678037: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037], 389678210: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210], 389678177: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177], 389678159: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678159], 774054381: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381], 389678158: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678188, 389678158], 2143494214: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214], 2428750571: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 6028561930, 6391301132, 2428750571], 779168865: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 779168848, 779168874, 779168865], 856205360: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 779168848, 774054378, 856205360], 2557542523: [130170945, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529, 389677907, 2557542523], 2143436406: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561925, 239055729, 389677890, 2143436406], 1258706673: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407, 1258706673], 6028561921: [130170945, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921], 6028562355: [130170945, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028562355], 24960058: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058], 316884976: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 316884976], 3707407641: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641], 6028561924: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 6028561924], 2143434863: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 2143434863], 389678146: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146], 3342358873: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 856114449, 856114454, 3342358873], 6391312713: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 3057097224, 6391312709, 6391312713], 389678191: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 3057097224, 389678190, 389678191], 389678029: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 389678032, 779168879, 3342358877, 389678029], 389677894: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894], 389677902: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902], 390545070: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070], 779168853: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853], 24959535: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535], 389678195: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195], 389678026: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678026], 2143485662: [130170945, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662], 2473807790: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790], 3342358878: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 3342358878], 2498969984: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 2498969984], 390548864: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 390548864], 306721042: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042], 390548860: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860], 771950946: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946], 389678003: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003], 390550470: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470], 24959528: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 24959528], 2143435226: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037, 2143435226], 5278007117: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117], 389678209: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209], 389678054: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054], 389678211: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211], 24959555: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 24959555], 24959551: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678159, 24959551], 389678189: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381, 389678189], 774054390: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381, 774054390], 389678185: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185], 779168881: [130170945, 389677905, 389678182, 389678181, 389678157, 6028561928, 779168848, 779168874, 779168865, 779168881], 2557542526: [130170945, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529, 389677907, 2557542523, 2557542526], 1258706666: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561925, 239055729, 389677890, 2143436406, 1258706666], 2143402269: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407, 1258706673, 2143402269], 2143434335: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 2143434335], 305862114: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114], 389678150: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 316884976, 389678150], 3707407638: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 3707407638], 249991437: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437], 5098988924: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 6028561924, 5098988924], 389678113: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 389678113], 2143501174: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174], 3342358872: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 856114449, 856114454, 3342358873, 3342358872], 389678192: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 3057097224, 389678190, 389678191, 389678192], 262732432: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 3057097224, 389678190, 389678191, 262732432], 389678028: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 389678032, 779168879, 3342358877, 389678029, 389678028], 779168877: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877], 390545071: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071], 1038790590: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 1038790590], 390545068: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068], 24959546: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546], 751988323: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 751988323], 389678012: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 389678012], 389678206: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206], 389678025: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678025], 389678013: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013], 389678197: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195, 389678197], 262732431: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678026, 262732431], 389678027: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678026, 389678027], 2143485660: [130170945, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485660], 2143485664: [130170945, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485664], 2143404199: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790, 2143404199], 2473807798: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790, 2473807798], 3342358875: [130170945, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 3342358878, 3342358875], 728157228: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 390548864, 728157228], 306725184: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042, 306725184], 1633441971: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971], 984911356: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 984911356], 771950938: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938], 2143434372: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372], 2143434369: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369], 2143435225: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037, 2143435226, 2143435225], 389678176: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176], 389678160: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160], 3996667045: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045], 24959553: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553], 389678161: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678161], 389678175: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175], 3983181527: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527], 3983181528: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181528], 389678212: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 24959555, 389678212], 2143460109: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381, 774054390, 2143460109], 1633421968: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968], 2143402267: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561925, 239055729, 389677890, 2143436406, 1258706666, 2143402267], 2143402268: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268], 5622365694: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 2143434335, 5622365694], 2143434334: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334], 390547788: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788], 2143501176: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 316884976, 389678150, 2143501176], 24960070: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070], 389678112: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 389678113, 389678112], 703096144: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174, 703096144], 262732448: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389677892, 6028561929, 3057097224, 389678190, 389678191, 262732432, 262732448], 779168845: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845], 307371161: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161], 389677896: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896], 779168880: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 779168880], 390545043: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043], 306725181: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181], 3983186028: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 751988323, 3983186028], 3983186029: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 389678012, 3983186029], 59817394: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394], 389678207: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207], 389678205: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205], 24959544: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544], 389678200: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195, 389678197, 389678200], 2143485661: [130170945, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485660, 2143485661], 1633441985: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985], 1633441972: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972], 984911358: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 984911356, 984911358], 24959547: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938, 24959547], 2143434377: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377], 2143434370: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434370], 389678002: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002], 2143434379: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379], 1480794735: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176, 1480794735], 262817259: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259], 3996667046: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046], 389678162: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162], 389678174: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174], 215726254: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527, 215726254], 2143494205: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205], 2143402266: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561925, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266], 1258706670: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670], 2143402270: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 2143402270], 2143434338: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 2143434338], 733206247: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 733206247], 24960060: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060], 4923076695: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695], 2143501175: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501175], 389678145: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070, 389678145], 24960073: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070, 24960073], 389678111: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 389678113, 389678112, 389678111], 55808582: [130170945, 55808527, 55808512, 55808451, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 389678113, 389678112, 55808582], 390545073: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073], 307371160: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 307371160], 751988322: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 751988322], 24959545: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545], 390545044: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044], 389677901: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043, 389677901], 771950969: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969], 389678015: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015], 59817393: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 59817393], 5934585973: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973], 390549048: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048], 390545077: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077], 390545076: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195, 389678197, 389678200, 390545076], 390548861: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 390548861], 1633441987: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987], 1633441974: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441974], 1633441975: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441975], 390548862: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938, 24959547, 390548862], 2143434375: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 2143434375], 1122032154: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 1122032154], 1633441265: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265], 389678001: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001], 1633441264: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379, 1633441264], 262817257: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257], 340165033: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 340165033], 5934586688: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046, 5934586688], 6662926502: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502], 6662926503: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503], 2143494207: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205, 2143494207], 239055725: [130170945, 389677905, 389678182, 389677906, 6028561926, 6028561925, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725], 1258706665: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670, 1258706665], 304892018: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670, 304892018], 1258706664: [130170945, 389677905, 389678182, 389677906, 50885141, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 2143402270, 1258706664], 244213560: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560], 55808571: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571], 389678151: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151], 390545074: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073, 390545074], 390545075: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 307371160, 390545075], 389678201: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201], 390545045: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045], 771950960: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960], 771931704: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704], 306721038: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043, 389677901, 306721038], 775377001: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001], 969632820: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 969632820], 389678016: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 389678016], 6374142747: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973, 6374142747], 389678204: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204], 390549047: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 390549047], 24959543: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543], 390545078: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078], 1633441983: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441983], 1633441986: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441986], 1633441977: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441974, 1633441977], 1633441979: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441975, 1633441979], 1122032146: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 1122032154, 1122032146], 333554744: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 333554744], 1633441266: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 1633441266], 60654119: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119], 50897859: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859], 1403960963: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 1403960963], 55808839: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 55808839], 5571466141: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046, 5934586688, 5571466141], 6374148725: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502, 6374148725], 6374148719: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 6374148719], 389678172: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 389678172], 2143441662: [130170945, 389677905, 389678182, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205, 2143494207, 2143441662], 1258703092: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092], 244213561: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571, 244213561], 389678142: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142], 390545047: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047], 3554867351: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351], 775377002: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002], 416737815: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704, 416737815], 771950967: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001, 771950967], 969632817: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 969632820, 969632817], 5934585972: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973, 6374142747, 5934585972], 390549041: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041], 59817398: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 390549047, 59817398], 390545049: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049], 389678203: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203], 390545079: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079], 1633441980: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441983, 1633441980], 1633441982: [130170945, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441986, 1633441982], 60654129: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129], 60654120: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654120], 87475456: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 87475456], 50897854: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 50897854], 333554741: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 333554741], 1258703099: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099], 2143488609: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609], 2143489694: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143489694], 390548878: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878], 416737817: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817], 775377006: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002, 775377006], 390549042: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041, 390549042], 390548879: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879], 390545050: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050], 59817397: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203, 59817397], 253807261: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079, 253807261], 390545921: [130170945, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129, 390545921], 703096400: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099, 703096400], 1258703122: [130170945, 55808527, 55808564, 2143468182, 2143468197, 80927426, 127275360, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099, 1258703122], 344202170: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609, 344202170], 938003293: [130170945, 55808527, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609, 938003293], 390548877: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877], 771931720: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720], 24959542: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542], 390548880: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548880], 390545052: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052], 390548876: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877, 390548876], 771931730: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730], 389678202: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 389678202], 253807273: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052, 253807273], 390548875: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877, 390548876, 390548875], 771931732: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931732], 771931749: [130170945, 389677905, 3996671926, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931749]})\n(2557542523, {2557542523: [2557542523], 389677907: [2557542523, 389677907], 2557542526: [2557542523, 2557542526], 6028562355: [2557542523, 6028562355], 2143488529: [2557542523, 389677907, 2143488529], 239055729: [2557542523, 389677907, 239055729], 389678124: [2557542523, 6028562355, 389678124], 3057643410: [2557542523, 389677907, 2143488529, 3057643410], 2143493381: [2557542523, 389677907, 2143488529, 2143493381], 6028561925: [2557542523, 389677907, 239055729, 6028561925], 389677890: [2557542523, 389677907, 239055729, 389677890], 7153999189: [2557542523, 6028562355, 389678124, 7153999189], 6028561921: [2557542523, 6028562355, 389678124, 6028561921], 3057643411: [2557542523, 389677907, 2143488529, 3057643410, 3057643411], 6028561926: [2557542523, 389677907, 2143488529, 3057643410, 6028561926], 50885141: [2557542523, 389677907, 239055729, 6028561925, 50885141], 2143436406: [2557542523, 389677907, 239055729, 389677890, 2143436406], 1258706668: [2557542523, 389677907, 239055729, 389677890, 1258706668], 1258707990: [2557542523, 6028562355, 389678124, 7153999189, 1258707990], 6028561924: [2557542523, 6028562355, 389678124, 6028561921, 6028561924], 389677906: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906], 6028561927: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 6028561927], 24959549: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549], 389678180: [2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180], 1258706666: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666], 2143436407: [2557542523, 389677907, 239055729, 389677890, 2143436406, 2143436407], 389678122: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122], 5098988924: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 5098988924], 24960080: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080], 3707407638: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 3707407638], 389678182: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182], 389677891: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891], 389678181: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181], 2143436415: [2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415], 2143402267: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267], 1258706673: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 1258706673], 50885147: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147], 3707407641: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641], 389677905: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905], 389678157: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157], 389678187: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187], 3996671921: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921], 2143494216: [2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216], 2143402266: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266], 2143402269: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402269], 55808451: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451], 389678121: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121], 249991437: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437], 3996671926: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926], 130170945: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 130170945], 6028561928: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928], 6028561931: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931], 24959550: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550], 389678188: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188], 389678186: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678186], 313239199: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199], 2143494214: [2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214], 239055725: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725], 2143402268: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 2143402268], 2143434279: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 2143434279], 55808512: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512], 55808518: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518], 50885160: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 50885160], 1258707987: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987], 24960070: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070], 389677904: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904], 3996671930: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 3996671930], 55808527: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 130170945, 55808527], 127284680: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 130170945, 127284680], 127284677: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 130170945, 127284677], 6028561930: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930], 779168848: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848], 389677892: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892], 389678210: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210], 389678177: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177], 389678159: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159], 774054381: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 774054381], 389678158: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 389678158], 389678033: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033], 389678185: [2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214, 389678185], 1258706670: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725, 1258706670], 2143402270: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 2143402268, 2143402270], 55808564: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564], 306729816: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816], 7311083157: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 50885160, 7311083157], 7311083158: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158], 2143485199: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 2143485199], 389678145: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145], 24960073: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 24960073], 127283024: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024], 389678034: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034], 6028561929: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929], 6391301132: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6391301132], 779168874: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 779168874], 774054378: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 774054378], 389678032: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032], 5278007117: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 5278007117], 389678209: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209], 389678054: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054], 389678211: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 389678211], 24959555: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 24959555], 24959551: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551], 389678189: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 774054381, 389678189], 774054390: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 774054381, 774054390], 21631731: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731], 1633421968: [2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214, 389678185, 1633421968], 1258706665: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725, 1258706670, 1258706665], 304892018: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725, 1258706670, 304892018], 1258706664: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 2143402268, 2143402270, 1258706664], 2143468182: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564, 2143468182], 306729822: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822], 4917890706: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 4917890706], 24960076: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 50885160, 7311083157, 24960076], 7311083154: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 50885160, 7311083157, 7311083154], 2143434860: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860], 389678151: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151], 389678112: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112], 3996671928: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928], 2143404200: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200], 389677903: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903], 3342358889: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889], 856114449: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 856114449], 3057097224: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224], 2428750571: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6391301132, 2428750571], 6391312709: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6391301132, 6391312709], 779168865: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 779168874, 779168865], 856205360: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 774054378, 856205360], 779168879: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879], 389678176: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176], 389678160: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160], 3996667045: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045], 24959553: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553], 389678161: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678161], 389678175: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175], 3983181527: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527], 3983181528: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181528], 389678212: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 24959555, 389678212], 389678025: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025], 2143460109: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 774054381, 774054390, 2143460109], 389678008: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008], 389677893: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893], 2143494205: [2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214, 389678185, 1633421968, 2143494205], 2143441662: [2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725, 1258706670, 1258706665, 2143441662], 2143468197: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564, 2143468182, 2143468197], 2143468186: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564, 2143468182, 2143468186], 127275360: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360], 306729825: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 306729825], 703096142: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 703096142], 2143434862: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862], 389678142: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142], 389678111: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 389678111], 389678113: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 389678113], 55808582: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582], 80927426: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 80927426], 3996671922: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922], 2473807793: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793], 4920594800: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 4920594800], 389678007: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007], 2143487624: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624], 3342358888: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 3342358888], 389678036: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036], 856114454: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 856114449, 856114454], 389678190: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224, 389678190], 6391312713: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6391301132, 6391312709, 6391312713], 779168881: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 779168874, 779168865, 779168881], 3342358879: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879, 3342358879], 3342358877: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879, 3342358877], 1480794735: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176, 1480794735], 262817259: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259], 3996667046: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046], 389678162: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162], 389678174: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174], 215726254: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527, 215726254], 24959535: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535], 389678026: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678026], 389678207: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678207], 5277943137: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 5277943137], 389678009: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009], 2078205535: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535], 4295105603: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603], 389678194: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194], 2143494207: [2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214, 389678185, 1633421968, 2143494205, 2143494207], 2143468192: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564, 2143468182, 2143468197, 2143468192], 80927418: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418], 2143434863: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 2143434863], 389678146: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146], 2143488609: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609], 2143489694: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143489694], 55808571: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571], 4920594801: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801], 2473807791: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791], 2143487625: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625], 24959527: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527], 390550471: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471], 3342358873: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 856114449, 856114454, 3342358873], 389678191: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224, 389678190, 389678191], 389678029: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879, 3342358877, 389678029], 262817257: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257], 340165033: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 340165033], 5934586688: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046, 5934586688], 6662926502: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502], 6662926503: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503], 389678206: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206], 389678013: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013], 262732431: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678026, 262732431], 389678027: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678026, 389678027], 389678192: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678026, 389678192], 5934585973: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678207, 5934585973], 2498969982: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 5277943137, 2498969982], 389677894: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894], 389677902: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902], 390545070: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070], 779168853: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853], 389678195: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195], 3311164627: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627], 2143501174: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174], 344202170: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609, 344202170], 938003293: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609, 938003293], 244213561: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561], 4923076695: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 4923076695], 4920594802: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802], 3342358885: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885], 2143487626: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 2143487626], 389678005: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005], 389678004: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004], 303255446: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446], 127289393: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393], 389678037: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037], 3342358872: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 856114449, 856114454, 3342358873, 3342358872], 262732432: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224, 389678190, 389678191, 262732432], 389678028: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879, 3342358877, 389678029, 389678028], 1403960963: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 1403960963], 55808839: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 55808839], 5571466141: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046, 5934586688, 5571466141], 6374148725: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502, 6374148725], 6374148719: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 6374148719], 389678172: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 389678172], 59817394: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394], 389678205: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205], 24959544: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544], 6374142747: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678207, 5934585973, 6374142747], 2498969984: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 5277943137, 2498969982, 2498969984], 779168877: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877], 390545071: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071], 1038790590: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 1038790590], 390545068: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068], 24959546: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546], 751988323: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 751988323], 389678012: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 389678012], 389678197: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195, 389678197], 24960058: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058], 316884976: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 316884976], 2143501176: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174, 2143501176], 703096144: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174, 703096144], 24960060: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 24960060], 1258703092: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 1258703092], 390547788: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 4923076695, 390547788], 2143485662: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662], 2473807790: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790], 3342358878: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 3342358878], 390548864: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 390548864], 306721042: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042], 390548860: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860], 771950946: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946], 389678003: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003], 390550470: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470], 24959528: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 24959528], 2143435226: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037, 2143435226], 262732448: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224, 389678190, 389678191, 262732432, 262732448], 389678015: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 389678015], 59817393: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 59817393], 390549048: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048], 390545077: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077], 5934585972: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678207, 5934585973, 6374142747, 5934585972], 779168845: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845], 307371161: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161], 389677896: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896], 779168880: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 779168880], 390545043: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043], 306725181: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181], 3983186028: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 751988323, 3983186028], 3983186029: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 389678012, 3983186029], 389678200: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195, 389678197, 389678200], 2143434335: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335], 305862114: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 305862114], 389678150: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 316884976, 389678150], 2143501175: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174, 2143501176, 2143501175], 244213560: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 24960060, 244213560], 1258703099: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 1258703092, 1258703099], 2143485660: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485660], 2143485664: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485664], 2143404199: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790, 2143404199], 2473807798: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790, 2473807798], 3342358875: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 3342358878, 3342358875], 728157228: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 390548864, 728157228], 306725184: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042, 306725184], 1633441971: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971], 984911356: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 984911356], 771950938: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938], 2143434372: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372], 2143434369: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369], 2143435225: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037, 2143435226, 2143435225], 969632820: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 389678015, 969632820], 389678016: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 389678015, 389678016], 389678204: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 389678204], 390549047: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 390549047], 24959543: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543], 390545078: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545078], 390545076: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545076], 390545073: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073], 307371160: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 307371160], 751988322: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 751988322], 24959545: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545], 390545044: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044], 389677901: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043, 389677901], 771950969: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969], 5622365694: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335, 5622365694], 2143434334: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334], 703096400: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 1258703092, 1258703099, 703096400], 1258703122: [2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 1258703092, 1258703099, 1258703122], 2143485661: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485660, 2143485661], 1633441985: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985], 1633441972: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972], 984911358: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 984911356, 984911358], 24959547: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938, 24959547], 2143434377: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377], 2143434370: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434370], 389678002: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002], 2143434379: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379], 969632817: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 389678015, 969632820, 969632817], 390549041: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041], 59817398: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 390549047, 59817398], 390545049: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049], 389678201: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 389678201], 389678203: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203], 390545079: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079], 390545075: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545076, 390545075], 390545074: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073, 390545074], 390545045: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045], 771950960: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960], 771931704: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704], 306721038: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043, 389677901, 306721038], 775377001: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001], 2143434338: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 2143434338], 733206247: [2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 733206247], 390548861: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 390548861], 1633441987: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987], 1633441974: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441974], 1633441975: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441975], 390548862: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938, 24959547, 390548862], 2143434375: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 2143434375], 1122032154: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 1122032154], 1633441265: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265], 389678001: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001], 1633441264: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379, 1633441264], 390549042: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041, 390549042], 390548879: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879], 390545047: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545047], 390545050: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050], 59817397: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203, 59817397], 253807261: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079, 253807261], 3554867351: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351], 775377002: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002], 416737815: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704, 416737815], 771950967: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001, 771950967], 1633441983: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441983], 1633441986: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441986], 1633441977: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441974, 1633441977], 1633441979: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441975, 1633441979], 1122032146: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 1122032154, 1122032146], 333554744: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 333554744], 1633441266: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 1633441266], 60654119: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119], 50897859: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859], 24959542: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542], 390548880: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548880], 390548878: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548878], 390545052: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052], 416737817: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817], 775377006: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002, 775377006], 1633441980: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441983, 1633441980], 1633441982: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441986, 1633441982], 60654129: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129], 60654120: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654120], 87475456: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 87475456], 50897854: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 50897854], 333554741: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 333554741], 390548876: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 390548876], 389678202: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 389678202], 390548877: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548878, 390548877], 253807273: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052, 253807273], 771931720: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720], 390545921: [2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129, 390545921], 390548875: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 390548876, 390548875], 771931730: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730], 771931732: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931732], 771931749: [2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931749]})\n(2557542526, {2557542526: [2557542526], 2557542523: [2557542526, 2557542523], 389677907: [2557542526, 2557542523, 389677907], 6028562355: [2557542526, 2557542523, 6028562355], 2143488529: [2557542526, 2557542523, 389677907, 2143488529], 239055729: [2557542526, 2557542523, 389677907, 239055729], 389678124: [2557542526, 2557542523, 6028562355, 389678124], 3057643410: [2557542526, 2557542523, 389677907, 2143488529, 3057643410], 2143493381: [2557542526, 2557542523, 389677907, 2143488529, 2143493381], 6028561925: [2557542526, 2557542523, 389677907, 239055729, 6028561925], 389677890: [2557542526, 2557542523, 389677907, 239055729, 389677890], 7153999189: [2557542526, 2557542523, 6028562355, 389678124, 7153999189], 6028561921: [2557542526, 2557542523, 6028562355, 389678124, 6028561921], 3057643411: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 3057643411], 6028561926: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926], 50885141: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141], 2143436406: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406], 1258706668: [2557542526, 2557542523, 389677907, 239055729, 389677890, 1258706668], 1258707990: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990], 6028561924: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924], 389677906: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906], 6028561927: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 6028561927], 24959549: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549], 389678180: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180], 1258706666: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666], 2143436407: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 2143436407], 389678122: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122], 5098988924: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 5098988924], 24960080: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080], 3707407638: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 3707407638], 389678182: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182], 389677891: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891], 389678181: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181], 2143436415: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415], 2143402267: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267], 1258706673: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 1258706673], 50885147: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147], 3707407641: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641], 389677905: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905], 389678157: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157], 389678187: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187], 3996671921: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921], 2143494216: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216], 2143402266: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266], 2143402269: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402269], 55808451: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451], 389678121: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121], 249991437: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437], 3996671926: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926], 130170945: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 130170945], 6028561928: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928], 6028561931: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931], 24959550: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550], 389678188: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188], 389678186: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678186], 313239199: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199], 2143494214: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214], 239055725: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725], 2143402268: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 2143402268], 2143434279: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 2143434279], 55808512: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512], 55808518: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518], 50885160: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 50885160], 1258707987: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987], 24960070: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070], 389677904: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904], 3996671930: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 3996671930], 55808527: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 130170945, 55808527], 127284680: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 130170945, 127284680], 127284677: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 130170945, 127284677], 6028561930: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930], 779168848: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848], 389677892: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892], 389678210: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210], 389678177: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177], 389678159: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159], 774054381: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 774054381], 389678158: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 389678158], 389678033: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033], 389678185: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214, 389678185], 1258706670: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725, 1258706670], 2143402270: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 2143402268, 2143402270], 55808564: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564], 306729816: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816], 7311083157: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 50885160, 7311083157], 7311083158: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158], 2143485199: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 2143485199], 389678145: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145], 24960073: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 24960073], 127283024: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024], 389678034: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034], 6028561929: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929], 6391301132: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6391301132], 779168874: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 779168874], 774054378: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 774054378], 389678032: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032], 5278007117: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 5278007117], 389678209: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209], 389678054: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054], 389678211: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 389678211], 24959555: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 24959555], 24959551: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551], 389678189: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 774054381, 389678189], 774054390: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 774054381, 774054390], 21631731: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731], 1633421968: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214, 389678185, 1633421968], 1258706665: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725, 1258706670, 1258706665], 304892018: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725, 1258706670, 304892018], 1258706664: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 2143402268, 2143402270, 1258706664], 2143468182: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564, 2143468182], 306729822: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822], 4917890706: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 4917890706], 24960076: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 50885160, 7311083157, 24960076], 7311083154: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 50885160, 7311083157, 7311083154], 2143434860: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860], 389678151: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151], 389678112: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112], 3996671928: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928], 2143404200: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200], 389677903: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903], 3342358889: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889], 856114449: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 856114449], 3057097224: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224], 2428750571: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6391301132, 2428750571], 6391312709: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6391301132, 6391312709], 779168865: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 779168874, 779168865], 856205360: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 774054378, 856205360], 779168879: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879], 389678176: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176], 389678160: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160], 3996667045: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045], 24959553: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553], 389678161: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678161], 389678175: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175], 3983181527: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527], 3983181528: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181528], 389678212: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 24959555, 389678212], 389678025: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025], 2143460109: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 389678188, 774054381, 774054390, 2143460109], 389678008: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008], 389677893: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893], 2143494205: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214, 389678185, 1633421968, 2143494205], 2143441662: [2557542526, 2557542523, 389677907, 239055729, 389677890, 2143436406, 1258706666, 2143402267, 2143402266, 239055725, 1258706670, 1258706665, 2143441662], 2143468197: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564, 2143468182, 2143468197], 2143468186: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564, 2143468182, 2143468186], 127275360: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360], 306729825: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 306729825], 703096142: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 703096142], 2143434862: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862], 389678142: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142], 389678111: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 389678111], 389678113: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 389678113], 55808582: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582], 80927426: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 80927426], 3996671922: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922], 2473807793: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793], 4920594800: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 4920594800], 389678007: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007], 2143487624: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624], 3342358888: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 3342358888], 389678036: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036], 856114454: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 856114449, 856114454], 389678190: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224, 389678190], 6391312713: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6391301132, 6391312709, 6391312713], 779168881: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 779168848, 779168874, 779168865, 779168881], 3342358879: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879, 3342358879], 3342358877: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879, 3342358877], 1480794735: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176, 1480794735], 262817259: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259], 3996667046: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046], 389678162: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162], 389678174: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174], 215726254: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527, 215726254], 24959535: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535], 389678026: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678026], 389678207: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678207], 5277943137: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 5277943137], 389678009: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009], 2078205535: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535], 4295105603: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603], 389678194: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194], 2143494207: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 389678180, 2143436415, 2143494216, 2143494214, 389678185, 1633421968, 2143494205, 2143494207], 2143468192: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808512, 55808564, 2143468182, 2143468197, 2143468192], 80927418: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418], 2143434863: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 2143434863], 389678146: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146], 2143488609: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609], 2143489694: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143489694], 55808571: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571], 4920594801: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801], 2473807791: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791], 2143487625: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625], 24959527: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527], 390550471: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471], 3342358873: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 856114449, 856114454, 3342358873], 389678191: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224, 389678190, 389678191], 389678029: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879, 3342358877, 389678029], 262817257: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257], 340165033: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 340165033], 5934586688: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046, 5934586688], 6662926502: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502], 6662926503: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503], 389678206: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206], 389678013: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013], 262732431: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678026, 262732431], 389678027: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678026, 389678027], 389678192: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678026, 389678192], 5934585973: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678207, 5934585973], 2498969982: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 5277943137, 2498969982], 389677894: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894], 389677902: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902], 390545070: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070], 779168853: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853], 389678195: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195], 3311164627: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627], 2143501174: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174], 344202170: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609, 344202170], 938003293: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678151, 389678142, 2143488609, 938003293], 244213561: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561], 4923076695: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 4923076695], 4920594802: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802], 3342358885: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885], 2143487626: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 2143487626], 389678005: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005], 389678004: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004], 303255446: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446], 127289393: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393], 389678037: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037], 3342358872: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 856114449, 856114454, 3342358873, 3342358872], 262732432: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224, 389678190, 389678191, 262732432], 389678028: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561931, 389677892, 389678032, 779168879, 3342358877, 389678029, 389678028], 1403960963: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 1403960963], 55808839: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 55808839], 5571466141: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678209, 3996667045, 3996667046, 5934586688, 5571466141], 6374148725: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502, 6374148725], 6374148719: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 6374148719], 389678172: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 389678172], 59817394: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394], 389678205: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205], 24959544: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544], 6374142747: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678207, 5934585973, 6374142747], 2498969984: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 5277943137, 2498969982, 2498969984], 779168877: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877], 390545071: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071], 1038790590: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 1038790590], 390545068: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068], 24959546: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546], 751988323: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 751988323], 389678012: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 389678012], 389678197: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195, 389678197], 24960058: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058], 316884976: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 316884976], 2143501176: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174, 2143501176], 703096144: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174, 703096144], 24960060: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 24960060], 1258703092: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 1258703092], 390547788: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 4923076695, 390547788], 2143485662: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662], 2473807790: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790], 3342358878: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 3342358878], 390548864: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 390548864], 306721042: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042], 390548860: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860], 771950946: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946], 389678003: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003], 390550470: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470], 24959528: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 24959528], 2143435226: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037, 2143435226], 262732448: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678157, 6028561928, 6028561930, 6028561929, 3057097224, 389678190, 389678191, 262732432, 262732448], 389678015: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 389678015], 59817393: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 59817393], 390549048: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048], 390545077: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077], 5934585972: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 389678207, 5934585973, 6374142747, 5934585972], 779168845: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845], 307371161: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161], 389677896: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896], 779168880: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 779168880], 390545043: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043], 306725181: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181], 3983186028: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 751988323, 3983186028], 3983186029: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 4295105603, 779168853, 389678012, 3983186029], 389678200: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389677893, 389678194, 389678195, 389678197, 389678200], 2143434335: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335], 305862114: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 305862114], 389678150: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 316884976, 389678150], 2143501175: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 389678121, 1258707987, 7311083158, 2143434860, 2143434862, 389678146, 2143501174, 2143501176, 2143501175], 244213560: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 24960060, 244213560], 1258703099: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 1258703092, 1258703099], 2143485660: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485660], 2143485664: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485664], 2143404199: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790, 2143404199], 2473807798: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 2473807790, 2473807798], 3342358875: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 2143404200, 2473807793, 2473807791, 3342358885, 3342358878, 3342358875], 728157228: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 390548864, 728157228], 306725184: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042, 306725184], 1633441971: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971], 984911356: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 984911356], 771950938: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938], 2143434372: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372], 2143434369: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369], 2143435225: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 389678037, 2143435226, 2143435225], 969632820: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 389678015, 969632820], 389678016: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 389678015, 389678016], 389678204: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 389678204], 390549047: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 390549047], 24959543: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543], 390545078: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545078], 390545076: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545076], 390545073: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073], 307371160: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 307371160], 751988322: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 751988322], 24959545: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545], 390545044: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044], 389677901: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043, 389677901], 771950969: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969], 5622365694: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335, 5622365694], 2143434334: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334], 703096400: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 1258703092, 1258703099, 703096400], 1258703122: [2557542526, 2557542523, 6028562355, 389678124, 6028561921, 6028561924, 24960080, 3707407641, 249991437, 24960070, 389678145, 389678112, 55808582, 55808571, 244213561, 1258703092, 1258703099, 1258703122], 2143485661: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 127283024, 3996671928, 3996671922, 4920594801, 4920594802, 2143485662, 2143485660, 2143485661], 1633441985: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985], 1633441972: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972], 984911358: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 984911356, 984911358], 24959547: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938, 24959547], 2143434377: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377], 2143434370: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434370], 389678002: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002], 2143434379: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379], 969632817: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 59817394, 389678015, 969632820, 969632817], 390549041: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041], 59817398: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 390549047, 59817398], 390545049: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049], 389678201: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 389678201], 389678203: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203], 390545079: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079], 390545075: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545076, 390545075], 390545074: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073, 390545074], 390545045: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045], 771950960: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960], 771931704: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704], 306721038: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 389677902, 390545068, 390545043, 389677901, 306721038], 775377001: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001], 2143434338: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 2143434338], 733206247: [2557542526, 2557542523, 6028562355, 389678124, 7153999189, 1258707990, 389678122, 50885147, 55808451, 55808518, 306729816, 306729822, 127275360, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 733206247], 390548861: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 390548861], 1633441987: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987], 1633441974: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441974], 1633441975: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441975], 390548862: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 771950946, 771950938, 24959547, 390548862], 2143434375: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 2143434375], 1122032154: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 1122032154], 1633441265: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265], 389678001: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001], 1633441264: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379, 1633441264], 390549042: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041, 390549042], 390548879: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879], 390545047: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545047], 390545050: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050], 59817397: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203, 59817397], 253807261: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079, 253807261], 3554867351: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351], 775377002: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002], 416737815: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704, 416737815], 771950967: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001, 771950967], 1633441983: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441983], 1633441986: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441986], 1633441977: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441974, 1633441977], 1633441979: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441972, 1633441975, 1633441979], 1122032146: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 303255446, 389678003, 2143434372, 2143434377, 1122032154, 1122032146], 333554744: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 333554744], 1633441266: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 1633441266], 60654119: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119], 50897859: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859], 24959542: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542], 390548880: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548880], 390548878: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548878], 390545052: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052], 416737817: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817], 775377006: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002, 775377006], 1633441980: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441983, 1633441980], 1633441982: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 389677903, 2143487624, 24959527, 389678004, 390548860, 1633441971, 1633441985, 1633441987, 1633441986, 1633441982], 60654129: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129], 60654120: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654120], 87475456: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 87475456], 50897854: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 50897854], 333554741: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 333554741], 390548876: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 390548876], 389678202: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 389678202], 390548877: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548878, 390548877], 253807273: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052, 253807273], 771931720: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720], 390545921: [2557542526, 2557542523, 389677907, 2143488529, 3057643410, 6028561926, 389677906, 389678182, 389677905, 3996671926, 389677904, 389678034, 3342358889, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129, 390545921], 390548875: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389677891, 389678187, 24959550, 389678159, 24959551, 389678025, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 390548876, 390548875], 771931730: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730], 771931732: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931732], 771931749: [2557542526, 2557542523, 389677907, 239055729, 6028561925, 50885141, 24959549, 389678181, 3996671921, 313239199, 389678033, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931749]})\n(2143404200, {2143404200: [2143404200], 2473807793: [2143404200, 2473807793], 4920594800: [2143404200, 4920594800], 127283024: [2143404200, 127283024], 2473807791: [2143404200, 2473807793, 2473807791], 389678036: [2143404200, 4920594800, 389678036], 4920594801: [2143404200, 4920594800, 4920594801], 3996671928: [2143404200, 127283024, 3996671928], 389677904: [2143404200, 127283024, 389677904], 3342358885: [2143404200, 2473807793, 2473807791, 3342358885], 390550471: [2143404200, 4920594800, 389678036, 390550471], 3342358889: [2143404200, 4920594800, 389678036, 3342358889], 3996671922: [2143404200, 4920594800, 4920594801, 3996671922], 4920594802: [2143404200, 4920594800, 4920594801, 4920594802], 80927426: [2143404200, 127283024, 3996671928, 80927426], 389678034: [2143404200, 127283024, 389677904, 389678034], 3996671926: [2143404200, 127283024, 389677904, 3996671926], 2473807790: [2143404200, 2473807793, 2473807791, 3342358885, 2473807790], 3342358878: [2143404200, 2473807793, 2473807791, 3342358885, 3342358878], 127289393: [2143404200, 4920594800, 389678036, 390550471, 127289393], 389678037: [2143404200, 4920594800, 389678036, 390550471, 389678037], 3342358888: [2143404200, 4920594800, 389678036, 3342358889, 3342358888], 80927418: [2143404200, 4920594800, 4920594801, 3996671922, 80927418], 2143485662: [2143404200, 4920594800, 4920594801, 4920594802, 2143485662], 2143468197: [2143404200, 127283024, 3996671928, 80927426, 2143468197], 127275360: [2143404200, 127283024, 3996671928, 80927426, 127275360], 389677903: [2143404200, 127283024, 389677904, 389678034, 389677903], 389678033: [2143404200, 127283024, 389677904, 389678034, 389678033], 3996671921: [2143404200, 127283024, 389677904, 3996671926, 3996671921], 389677905: [2143404200, 127283024, 389677904, 3996671926, 389677905], 3996671930: [2143404200, 127283024, 389677904, 3996671926, 3996671930], 2143404199: [2143404200, 2473807793, 2473807791, 3342358885, 2473807790, 2143404199], 2473807798: [2143404200, 2473807793, 2473807791, 3342358885, 2473807790, 2473807798], 3342358875: [2143404200, 2473807793, 2473807791, 3342358885, 3342358878, 3342358875], 390550470: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470], 24959528: [2143404200, 4920594800, 389678036, 390550471, 127289393, 24959528], 303255446: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446], 2143435226: [2143404200, 4920594800, 389678036, 390550471, 389678037, 2143435226], 3311164627: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627], 2143485660: [2143404200, 4920594800, 4920594801, 4920594802, 2143485662, 2143485660], 2143485664: [2143404200, 4920594800, 4920594801, 4920594802, 2143485662, 2143485664], 2143468182: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182], 2143468192: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468192], 306729822: [2143404200, 127283024, 3996671928, 80927426, 127275360, 306729822], 389678007: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007], 21631731: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731], 2143487624: [2143404200, 127283024, 389677904, 389678034, 389677903, 2143487624], 389678032: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032], 313239199: [2143404200, 127283024, 389677904, 389678034, 389678033, 313239199], 389678181: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181], 389678182: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182], 130170945: [2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945], 2143434369: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369], 389678003: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003], 24959527: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527], 2143435225: [2143404200, 4920594800, 389678036, 390550471, 389678037, 2143435226, 2143435225], 24960058: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058], 316884976: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976], 5622365694: [2143404200, 4920594800, 4920594801, 4920594802, 2143485662, 2143485660, 5622365694], 2143485661: [2143404200, 4920594800, 4920594801, 4920594802, 2143485662, 2143485660, 2143485661], 55808564: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564], 2143468186: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 2143468186], 306729816: [2143404200, 127283024, 3996671928, 80927426, 127275360, 306729822, 306729816], 306729825: [2143404200, 127283024, 3996671928, 80927426, 127275360, 306729822, 306729825], 5277943137: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137], 2143487625: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625], 389678008: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008], 389677893: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893], 389677892: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892], 779168879: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879], 389678157: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157], 24959549: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549], 389677906: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906], 55808527: [2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945, 55808527], 127284680: [2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945, 127284680], 127284677: [2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945, 127284677], 389678002: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002], 2143434379: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379], 2143434372: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372], 390548860: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860], 389678004: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004], 2143434335: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 2143434335], 305862114: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114], 389678150: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150], 55808512: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512], 55808518: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808518], 4917890706: [2143404200, 127283024, 3996671928, 80927426, 127275360, 306729822, 306729816, 4917890706], 2498969982: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982], 2143487626: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625, 2143487626], 389678005: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005], 389678009: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009], 2078205535: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535], 4295105603: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603], 389678194: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194], 6028561929: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929], 6028561931: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561931], 3342358879: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358879], 3342358877: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877], 389677891: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891], 6028561928: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928], 50885141: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141], 6028561926: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926], 389678122: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122], 2143434279: [2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945, 55808527, 2143434279], 1633441265: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265], 389678001: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001], 1633441264: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379, 1633441264], 2143434377: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377], 2143434370: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434370], 1633441971: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971], 390548864: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 390548864], 771950946: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946], 2143434334: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 2143434335, 2143434334], 390547788: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788], 2143501176: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176], 55808451: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451], 389677902: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902], 2498969984: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 2498969984], 306721042: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042], 389677894: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894], 390545070: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070], 779168853: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853], 24959535: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535], 389678195: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678195], 389678026: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026], 856114449: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 856114449], 6028561930: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 6028561930], 3057097224: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 3057097224], 3342358873: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358879, 3342358873], 389678029: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877, 389678029], 389678180: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180], 389678187: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187], 779168848: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848], 6028561925: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925], 3057643410: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 3057643410], 6028561927: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 6028561927], 50885147: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 50885147], 1258707990: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990], 333554744: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 333554744], 1633441266: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 1633441266], 60654119: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119], 50897859: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859], 2143434375: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 2143434375], 1122032154: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 1122032154], 1633441985: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985], 1633441972: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972], 728157228: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 390548864, 728157228], 984911356: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946, 984911356], 771950938: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946, 771950938], 2143434338: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 2143434338], 733206247: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 733206247], 24960060: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060], 4923076695: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695], 2143501175: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501175], 2143501174: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174], 389678121: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121], 1038790590: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 1038790590], 390545068: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 390545068], 306725184: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042, 306725184], 779168877: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877], 390545071: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071], 24959546: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546], 751988323: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853, 751988323], 389678012: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853, 389678012], 389678206: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206], 389678025: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678025], 389678013: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013], 389678197: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678195, 389678197], 262732431: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026, 262732431], 389678027: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026, 389678027], 389678192: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026, 389678192], 856114454: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 856114449, 856114454], 6391301132: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 6028561930, 6391301132], 6391312709: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 3057097224, 6391312709], 389678190: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 3057097224, 389678190], 3342358872: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358879, 3342358873, 3342358872], 262732432: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877, 389678029, 262732432], 389678028: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877, 389678029, 389678028], 2143436415: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415], 1258706668: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 1258706668], 24959550: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550], 389678188: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188], 389678186: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186], 779168874: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 779168874], 774054378: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 774054378], 239055729: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925, 239055729], 3057643411: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 3057643410, 3057643411], 2143488529: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529], 7153999189: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189], 60654129: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129], 60654120: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654120], 87475456: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 87475456], 50897854: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 50897854], 333554741: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 333554741], 390548861: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 1122032154, 390548861], 1122032146: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 1122032154, 1122032146], 1633441987: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987], 1633441974: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972, 1633441974], 1633441975: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972, 1633441975], 984911358: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946, 984911356, 984911358], 24959547: [2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946, 771950938, 24959547], 244213560: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560], 55808571: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571], 389678146: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146], 703096144: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 703096144], 50885160: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160], 1258707987: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 1258707987], 390545043: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 390545068, 390545043], 779168845: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845], 307371161: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161], 389677896: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896], 779168880: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 779168880], 306725181: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181], 3983186028: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853, 751988323, 3983186028], 3983186029: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853, 389678012, 3983186029], 59817394: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394], 389678207: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207], 389678205: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205], 24959551: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678025, 24959551], 24959544: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544], 389678200: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678195, 389678197, 389678200], 389678191: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026, 389678192, 389678191], 2428750571: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 6028561930, 6391301132, 2428750571], 6391312713: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 3057097224, 6391312709, 6391312713], 262732448: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877, 389678029, 262732432, 262732448], 2143494216: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143494216], 2143436407: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407], 389677890: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 1258706668, 389677890], 389678210: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210], 389678177: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177], 389678159: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678159], 774054381: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381], 389678158: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188, 389678158], 2143494214: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214], 779168865: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 779168874, 779168865], 856205360: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 774054378, 856205360], 389677907: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925, 239055729, 389677907], 2143493381: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529, 2143493381], 389678124: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124], 390545921: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129, 390545921], 390548862: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 1122032154, 390548861, 390548862], 1633441983: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987, 1633441983], 1633441986: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987, 1633441986], 1633441977: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972, 1633441974, 1633441977], 1633441979: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972, 1633441975, 1633441979], 1258703092: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092], 389678113: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113], 244213561: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571, 244213561], 55808582: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571, 55808582], 2143434862: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146, 2143434862], 7311083157: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157], 7311083158: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 1258707987, 7311083158], 2143485199: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 1258707987, 2143485199], 389677901: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 390545068, 390545043, 389677901], 390545073: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073], 307371160: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 307371160], 751988322: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 751988322], 24959545: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545], 390545044: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044], 771950969: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969], 389678015: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015], 59817393: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 59817393], 5934585973: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973], 3996667046: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 3996667046], 390549048: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048], 390545077: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077], 390545076: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678195, 389678197, 389678200, 390545076], 389678189: [2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 6028561930, 6391301132, 2428750571, 389678189], 2143436406: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406], 1258706673: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673], 5278007117: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117], 389678209: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209], 389678054: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054], 389678211: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211], 24959555: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 24959555], 774054390: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381, 774054390], 389678185: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185], 779168881: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 779168874, 779168865, 779168881], 2557542523: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925, 239055729, 389677907, 2557542523], 6028561921: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921], 6028562355: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028562355], 1633441980: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987, 1633441983, 1633441980], 1633441982: [2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987, 1633441986, 1633441982], 1258703099: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099], 24960070: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070], 389678112: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 389678112], 389678111: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571, 55808582, 389678111], 2143434863: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146, 2143434862, 2143434863], 2143434860: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146, 2143434862, 2143434860], 24960076: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076], 7311083154: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 7311083154], 306721038: [2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 390545068, 390545043, 389677901, 306721038], 390545074: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073, 390545074], 390545075: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 307371160, 390545075], 389678201: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201], 390545045: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045], 771950960: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960], 771931704: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704], 775377001: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001], 969632820: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 969632820], 389678016: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 389678016], 6374142747: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973, 6374142747], 3996667045: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 3996667046, 3996667045], 5934586688: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 3996667046, 5934586688], 389678204: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204], 390549047: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 390549047], 24959543: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543], 390545078: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078], 1258706666: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406, 1258706666], 2143402269: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269], 389678176: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176], 389678160: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160], 24959553: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553], 389678161: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678161], 389678175: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175], 3983181527: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527], 3983181528: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181528], 389678212: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 24959555, 389678212], 2143460109: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381, 774054390, 2143460109], 1633421968: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968], 2557542526: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925, 239055729, 389677907, 2557542523, 2557542526], 6028561924: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921, 6028561924], 703096400: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099, 703096400], 1258703122: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099, 1258703122], 389678145: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145], 24960073: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 24960073], 703096142: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146, 2143434862, 2143434860, 703096142], 24960080: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080], 390545047: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047], 3554867351: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351], 775377002: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002], 416737815: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704, 416737815], 771950967: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001, 771950967], 969632817: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 969632820, 969632817], 5934585972: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973, 6374142747, 5934585972], 5571466141: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 3996667046, 5934586688, 5571466141], 390549041: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041], 59817398: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 390549047, 59817398], 390545049: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049], 389678203: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203], 390545079: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079], 2143402267: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406, 1258706666, 2143402267], 2143402268: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268], 1480794735: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176, 1480794735], 262817259: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259], 389678162: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162], 389678174: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174], 215726254: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527, 215726254], 2143494205: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205], 5098988924: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921, 6028561924, 5098988924], 3707407638: [2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921, 6028561924, 3707407638], 389678151: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151], 3707407641: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641], 390548878: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878], 416737817: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817], 775377006: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002, 775377006], 390549042: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041, 390549042], 390548879: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879], 390545050: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050], 59817397: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203, 59817397], 253807261: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079, 253807261], 2143402266: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406, 1258706666, 2143402267, 2143402266], 1258706670: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670], 2143402270: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 2143402270], 262817257: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257], 340165033: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 340165033], 6662926502: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502], 6662926503: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503], 2143494207: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205, 2143494207], 389678142: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142], 249991437: [2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437], 390548877: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877], 771931720: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720], 24959542: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542], 390548880: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548880], 390545052: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052], 239055725: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406, 1258706666, 2143402267, 2143402266, 239055725], 1258706665: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670, 1258706665], 304892018: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670, 304892018], 1258706664: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 2143402270, 1258706664], 1403960963: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 1403960963], 55808839: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 55808839], 6374148725: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502, 6374148725], 6374148719: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 6374148719], 389678172: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 389678172], 2143441662: [2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205, 2143494207, 2143441662], 2143488609: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142, 2143488609], 2143489694: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142, 2143489694], 390548876: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877, 390548876], 771931730: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730], 389678202: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 389678202], 253807273: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052, 253807273], 344202170: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142, 2143488609, 344202170], 938003293: [2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142, 2143488609, 938003293], 390548875: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877, 390548876, 390548875], 771931732: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931732], 771931749: [2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931749]})\n(2143404199, {2143404199: [2143404199], 2473807790: [2143404199, 2473807790], 3342358885: [2143404199, 2473807790, 3342358885], 3342358878: [2143404199, 2473807790, 3342358878], 2473807798: [2143404199, 2473807790, 2473807798], 2473807791: [2143404199, 2473807790, 3342358885, 2473807791], 3342358875: [2143404199, 2473807790, 3342358878, 3342358875], 2473807793: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793], 2143404200: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200], 4920594800: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800], 127283024: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024], 389678036: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036], 4920594801: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801], 3996671928: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928], 389677904: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904], 390550471: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471], 3342358889: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 3342358889], 3996671922: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922], 4920594802: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 4920594802], 80927426: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426], 389678034: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034], 3996671926: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926], 127289393: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393], 389678037: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 389678037], 3342358888: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 3342358889, 3342358888], 80927418: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418], 2143485662: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 4920594802, 2143485662], 2143468197: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197], 127275360: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 127275360], 389677903: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903], 389678033: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033], 3996671921: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921], 389677905: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905], 3996671930: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671930], 390550470: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470], 24959528: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 24959528], 303255446: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446], 2143435226: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 389678037, 2143435226], 3311164627: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627], 2143485660: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 4920594802, 2143485662, 2143485660], 2143485664: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 4920594802, 2143485662, 2143485664], 2143468182: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182], 2143468192: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468192], 306729822: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 127275360, 306729822], 389678007: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007], 21631731: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731], 2143487624: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 2143487624], 389678032: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032], 313239199: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 313239199], 389678181: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181], 389678182: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182], 130170945: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945], 2143434369: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369], 389678003: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003], 24959527: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527], 2143435225: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 389678037, 2143435226, 2143435225], 24960058: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058], 316884976: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976], 5622365694: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 4920594802, 2143485662, 2143485660, 5622365694], 2143485661: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 4920594802, 2143485662, 2143485660, 2143485661], 55808564: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564], 2143468186: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 2143468186], 306729816: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 127275360, 306729822, 306729816], 306729825: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 127275360, 306729822, 306729825], 5277943137: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137], 2143487625: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625], 389678008: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008], 389677893: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893], 389677892: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892], 779168879: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879], 389678157: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157], 24959549: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549], 389677906: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906], 55808527: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945, 55808527], 127284680: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945, 127284680], 127284677: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945, 127284677], 389678002: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002], 2143434379: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379], 2143434372: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372], 390548860: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860], 389678004: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004], 2143434335: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 2143434335], 305862114: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114], 389678150: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150], 55808512: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512], 55808518: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808518], 4917890706: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 127275360, 306729822, 306729816, 4917890706], 2498969982: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982], 2143487626: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625, 2143487626], 389678005: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005], 389678009: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009], 2078205535: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535], 4295105603: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603], 389678194: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194], 6028561929: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929], 6028561931: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561931], 3342358879: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358879], 3342358877: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877], 389677891: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891], 6028561928: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928], 50885141: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141], 6028561926: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926], 389678122: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122], 2143434279: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 130170945, 55808527, 2143434279], 1633441265: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265], 389678001: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001], 1633441264: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 2143434379, 1633441264], 2143434377: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377], 2143434370: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434370], 1633441971: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971], 390548864: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 390548864], 771950946: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946], 2143434334: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 2143434335, 2143434334], 390547788: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788], 2143501176: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176], 55808451: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451], 389677902: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902], 2498969984: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 2498969984], 306721042: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042], 389677894: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894], 390545070: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070], 779168853: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853], 24959535: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535], 389678195: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678195], 389678026: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026], 856114449: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 856114449], 6028561930: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 6028561930], 3057097224: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 3057097224], 3342358873: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358879, 3342358873], 389678029: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877, 389678029], 389678180: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180], 389678187: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187], 779168848: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848], 6028561925: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925], 3057643410: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 3057643410], 6028561927: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 6028561927], 50885147: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 50885147], 1258707990: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990], 333554744: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 333554744], 1633441266: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 1633441265, 1633441266], 60654119: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119], 50897859: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859], 2143434375: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 2143434375], 1122032154: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 1122032154], 1633441985: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985], 1633441972: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972], 728157228: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 390548864, 728157228], 984911356: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946, 984911356], 771950938: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946, 771950938], 2143434338: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 2143434338], 733206247: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 2143434335, 2143434334, 733206247], 24960060: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060], 4923076695: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695], 2143501175: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501175], 2143501174: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174], 389678121: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121], 1038790590: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 1038790590], 390545068: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 390545068], 306725184: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 2143487625, 389678005, 306721042, 306725184], 779168877: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877], 390545071: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071], 24959546: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546], 751988323: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853, 751988323], 389678012: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853, 389678012], 389678206: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206], 389678025: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678025], 389678013: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013], 389678197: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678195, 389678197], 262732431: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026, 262732431], 389678027: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026, 389678027], 389678192: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026, 389678192], 856114454: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 856114449, 856114454], 6391301132: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 6028561930, 6391301132], 6391312709: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 3057097224, 6391312709], 389678190: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 3057097224, 389678190], 3342358872: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358879, 3342358873, 3342358872], 262732432: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877, 389678029, 262732432], 389678028: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877, 389678029, 389678028], 2143436415: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415], 1258706668: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 1258706668], 24959550: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550], 389678188: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188], 389678186: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186], 779168874: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 779168874], 774054378: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 774054378], 239055729: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925, 239055729], 3057643411: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 3057643410, 3057643411], 2143488529: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529], 7153999189: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189], 60654129: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129], 60654120: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654120], 87475456: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 87475456], 50897854: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 50897854], 333554741: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 50897859, 333554741], 390548861: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 1122032154, 390548861], 1122032146: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 1122032154, 1122032146], 1633441987: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987], 1633441974: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972, 1633441974], 1633441975: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972, 1633441975], 984911358: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946, 984911356, 984911358], 24959547: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 303255446, 24959527, 389678004, 771950946, 771950938, 24959547], 244213560: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560], 55808571: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571], 389678146: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146], 703096144: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 703096144], 50885160: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160], 1258707987: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 1258707987], 390545043: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 390545068, 390545043], 779168845: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845], 307371161: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161], 389677896: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896], 779168880: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 779168880], 306725181: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181], 3983186028: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853, 751988323, 3983186028], 3983186029: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 4295105603, 779168853, 389678012, 3983186029], 59817394: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394], 389678207: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207], 389678205: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205], 24959551: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678025, 24959551], 24959544: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544], 389678200: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678195, 389678197, 389678200], 389678191: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678026, 389678192, 389678191], 2428750571: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 6028561930, 6391301132, 2428750571], 6391312713: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 3057097224, 6391312709, 6391312713], 262732448: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 779168879, 3342358877, 389678029, 262732432, 262732448], 2143494216: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143494216], 2143436407: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407], 389677890: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 1258706668, 389677890], 389678210: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210], 389678177: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177], 389678159: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678159], 774054381: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381], 389678158: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188, 389678158], 2143494214: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214], 779168865: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 779168874, 779168865], 856205360: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 774054378, 856205360], 389677907: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925, 239055729, 389677907], 2143493381: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 6028561926, 3057643410, 2143488529, 2143493381], 389678124: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124], 390545921: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 2143434369, 389678002, 389678001, 60654119, 60654129, 390545921], 390548862: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 2143434372, 2143434377, 1122032154, 390548861, 390548862], 1633441983: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987, 1633441983], 1633441986: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987, 1633441986], 1633441977: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972, 1633441974, 1633441977], 1633441979: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441972, 1633441975, 1633441979], 1258703092: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092], 389678113: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113], 244213561: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571, 244213561], 55808582: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571, 55808582], 2143434862: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146, 2143434862], 7311083157: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157], 7311083158: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 1258707987, 7311083158], 2143485199: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 1258707987, 2143485199], 389677901: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 390545068, 390545043, 389677901], 390545073: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073], 307371160: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 307371160], 751988322: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 751988322], 24959545: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545], 390545044: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044], 771950969: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969], 389678015: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015], 59817393: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 59817393], 5934585973: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973], 3996667046: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 3996667046], 390549048: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048], 390545077: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077], 390545076: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 389678195, 389678197, 389678200, 390545076], 389678189: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389678033, 389678032, 389677892, 6028561929, 6028561930, 6391301132, 2428750571, 389678189], 2143436406: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406], 1258706673: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673], 5278007117: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117], 389678209: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209], 389678054: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054], 389678211: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211], 24959555: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 24959555], 774054390: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381, 774054390], 389678185: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185], 779168881: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 6028561928, 779168848, 779168874, 779168865, 779168881], 2557542523: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925, 239055729, 389677907, 2557542523], 6028561921: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921], 6028562355: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028562355], 1633441980: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987, 1633441983, 1633441980], 1633441982: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 389678036, 390550471, 127289393, 390550470, 389678003, 390548860, 1633441971, 1633441985, 1633441987, 1633441986, 1633441982], 1258703099: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099], 24960070: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070], 389678112: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 389678112], 389678111: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 4923076695, 55808571, 55808582, 389678111], 2143434863: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146, 2143434862, 2143434863], 2143434860: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146, 2143434862, 2143434860], 24960076: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076], 7311083154: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 7311083154], 306721038: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 389678007, 5277943137, 2498969982, 389677902, 390545068, 390545043, 389677901, 306721038], 390545074: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 779168845, 390545073, 390545074], 390545075: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 779168877, 307371161, 307371160, 390545075], 389678201: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201], 390545045: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045], 771950960: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960], 771931704: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704], 775377001: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001], 969632820: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 969632820], 389678016: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 389678016], 6374142747: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973, 6374142747], 3996667045: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 3996667046, 3996667045], 5934586688: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 3996667046, 5934586688], 389678204: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204], 390549047: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 390549047], 24959543: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543], 390545078: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078], 1258706666: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406, 1258706666], 2143402269: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269], 389678176: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176], 389678160: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160], 24959553: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553], 389678161: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678161], 389678175: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175], 3983181527: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527], 3983181528: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181528], 389678212: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 24959555, 389678212], 2143460109: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678188, 774054381, 774054390, 2143460109], 1633421968: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968], 2557542526: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 24959549, 50885141, 6028561925, 239055729, 389677907, 2557542523, 2557542526], 6028561924: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921, 6028561924], 703096400: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099, 703096400], 1258703122: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 1258703092, 1258703099, 1258703122], 389678145: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145], 24960073: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 24960073], 703096142: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 316884976, 389678150, 2143501176, 2143501174, 389678146, 2143434862, 2143434860, 703096142], 24960080: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080], 390545047: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047], 3554867351: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351], 775377002: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002], 416737815: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771931704, 416737815], 771950967: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 2078205535, 390545070, 24959546, 306725181, 771950969, 775377001, 771950967], 969632817: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 59817394, 389678015, 969632820, 969632817], 5934585972: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 5934585973, 6374142747, 5934585972], 5571466141: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678207, 3996667046, 5934586688, 5571466141], 390549041: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041], 59817398: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 390549047, 59817398], 390545049: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049], 389678203: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203], 390545079: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079], 2143402267: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406, 1258706666, 2143402267], 2143402268: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268], 1480794735: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 5278007117, 389678176, 1480794735], 262817259: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259], 389678162: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162], 389678174: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174], 215726254: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678177, 389678211, 3983181527, 215726254], 2143494205: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205], 5098988924: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921, 6028561924, 5098988924], 3707407638: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 389677905, 389678182, 389677906, 389678122, 1258707990, 7153999189, 389678124, 6028561921, 6028561924, 3707407638], 389678151: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151], 3707407641: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641], 390548878: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878], 416737817: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817], 775377006: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 390545044, 771950960, 775377002, 775377006], 390549042: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678206, 389678205, 390549048, 389678204, 390549041, 390549042], 390548879: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879], 390545050: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050], 59817397: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 389678203, 59817397], 253807261: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 390545078, 390545079, 253807261], 2143402266: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406, 1258706666, 2143402267, 2143402266], 1258706670: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670], 2143402270: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 2143402270], 262817257: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257], 340165033: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 340165033], 6662926502: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502], 6662926503: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503], 2143494207: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205, 2143494207], 389678142: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142], 249991437: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 3996671928, 80927426, 2143468197, 2143468182, 55808564, 55808512, 55808451, 389678121, 50885160, 7311083157, 24960076, 24960080, 3707407641, 249991437], 390548877: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877], 771931720: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720], 24959542: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542], 390548880: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 390548880], 390545052: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052], 239055725: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 2143436406, 1258706666, 2143402267, 2143402266, 239055725], 1258706665: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670, 1258706665], 304892018: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 1258706670, 304892018], 1258706664: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678180, 2143436415, 2143436407, 1258706673, 2143402269, 2143402268, 2143402270, 1258706664], 1403960963: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 1403960963], 55808839: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678209, 389678160, 262817259, 262817257, 55808839], 6374148725: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 24959553, 389678162, 6662926502, 6374148725], 6374148719: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 6374148719], 389678172: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 24959550, 389678210, 389678054, 389678175, 389678174, 6662926503, 389678172], 2143441662: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 3996671926, 3996671921, 389678181, 389678157, 389677891, 389678187, 389678186, 2143494214, 389678185, 1633421968, 2143494205, 2143494207, 2143441662], 2143488609: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142, 2143488609], 2143489694: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142, 2143489694], 390548876: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877, 390548876], 771931730: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730], 389678202: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390548879, 24959542, 389678202], 253807273: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389677893, 389678194, 24959535, 389678013, 24959544, 390545077, 24959543, 390545049, 390545050, 390545052, 253807273], 344202170: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142, 2143488609, 344202170], 938003293: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 4920594800, 4920594801, 3996671922, 80927418, 3311164627, 24960058, 305862114, 390547788, 24960060, 244213560, 389678113, 24960070, 389678145, 389678151, 389678142, 2143488609, 938003293], 390548875: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 389678201, 390545047, 390548878, 390548877, 390548876, 390548875], 771931732: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931732], 771931749: [2143404199, 2473807790, 3342358885, 2473807791, 2473807793, 2143404200, 127283024, 389677904, 389678034, 389677903, 21631731, 389678008, 389678009, 389677894, 390545071, 389677896, 24959545, 390545045, 3554867351, 416737817, 771931720, 771931730, 771931749]})\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
e73e3194fea678f41cf0360c7dfc3564573582b4 | 2,092 | ipynb | Jupyter Notebook | Fast.ipynb | Vnicius/text-augmentation | bc4830c60785248da7728314f41e4f6bd7389a83 | [
"MIT"
] | null | null | null | Fast.ipynb | Vnicius/text-augmentation | bc4830c60785248da7728314f41e4f6bd7389a83 | [
"MIT"
] | null | null | null | Fast.ipynb | Vnicius/text-augmentation | bc4830c60785248da7728314f41e4f6bd7389a83 | [
"MIT"
] | null | null | null | 28.27027 | 503 | 0.566922 | [
[
[
"from fastai.text import *",
"_____no_output_____"
],
[
"data_lm = TextLMDataBunch.from_folder('data', train='train')",
"_____no_output_____"
],
[
"data_lm.save('data_lm_export.pkl')",
"_____no_output_____"
],
[
"learn = language_model_learner(data_lm, awd_lstm, drop_mult=0.5)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
e73e4521379843b72058ae612a4db99b0a2bee3e | 2,613 | ipynb | Jupyter Notebook | Quantum_Encoding_Image_data.ipynb | Rukhsan/Quantum_Encoding | ad3fecc4d9124583e5ffd546be9250e3d9fac99c | [
"Apache-2.0"
] | 1 | 2022-02-22T02:40:51.000Z | 2022-02-22T02:40:51.000Z | Quantum_Encoding_Image_data.ipynb | Rukhsan/Quantum_Encoding | ad3fecc4d9124583e5ffd546be9250e3d9fac99c | [
"Apache-2.0"
] | null | null | null | Quantum_Encoding_Image_data.ipynb | Rukhsan/Quantum_Encoding | ad3fecc4d9124583e5ffd546be9250e3d9fac99c | [
"Apache-2.0"
] | null | null | null | 22.144068 | 70 | 0.544967 | [
[
[
"import tensorflow as tf\n#import tensorflow_quantum as tfq\n\nimport cirq\nimport sympy\nimport numpy as np\nimport seaborn as sns\nimport collections\n\n# visualization tools\n%matplotlib inline\nimport matplotlib.pyplot as plt\nfrom cirq.contrib.svg import SVGCircuit\nfrom PIL import Image",
"_____no_output_____"
],
[
"def convert_to_circuit(image):\n values = np.ndarray.flatten(image)\n qubits = cirq.GridQubit.rect(4, 4)\n circuit = cirq.Circuit()\n for i, value in enumerate(values):\n if value:\n circuit.append(cirq.X(qubits[i]))\n return circuit",
"_____no_output_____"
],
[
"image=np.random.randint(255,size=(2,2))\n#image=np.ones(255,size=(2,2))\nplt.imshow(image,cmap='gray',vmin=0,vmax=255)\nplt.show()\nplt.imsave('grayimg.jpeg',image,cmap='gray')",
"_____no_output_____"
],
[
"FILENAME='grayimg.jpeg'\nimage2 = Image.open(FILENAME)\npixels=np.asarray(image2)\npixels=pixels.astype('float32')\npixels2=pixels/255.0\nprint(pixels2)\nTHRESHOLD = 0.5\nimage_new_bin=np.array(pixels2 > THRESHOLD, dtype=np.float32)\nimage_new_bin\nimage_circuit=convert_to_circuit(image_new_bin)",
"_____no_output_____"
],
[
"SVGCircuit(image_circuit)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
e73e4af4d11cfc88679437590fb1d644ed977b7a | 5,011 | ipynb | Jupyter Notebook | notebooks/3. Web Scraping Starter.ipynb | NathanMaton/forked_sushi_chef | da5b83adbcc95ac147d8393b81a1b17ebe2669a7 | [
"MIT"
] | null | null | null | notebooks/3. Web Scraping Starter.ipynb | NathanMaton/forked_sushi_chef | da5b83adbcc95ac147d8393b81a1b17ebe2669a7 | [
"MIT"
] | 2 | 2019-10-01T06:16:18.000Z | 2020-04-08T08:18:57.000Z | notebooks/3. Web Scraping Starter.ipynb | NathanMaton/forked_sushi_chef | da5b83adbcc95ac147d8393b81a1b17ebe2669a7 | [
"MIT"
] | 3 | 2019-01-29T20:30:54.000Z | 2020-08-01T18:24:38.000Z | 23.525822 | 80 | 0.54999 | [
[
[
"from bs4 import BeautifulSoup\nimport requests",
"_____no_output_____"
],
[
"videos_url_en = 'http://www.pointb.is/21cs-videos'\nvideos_url_my = 'http://www.pointb.is/21cs-videos-mm'\n ",
"_____no_output_____"
]
],
[
[
"### English",
"_____no_output_____"
]
],
[
[
"response = requests.get(videos_url_en)\npage = BeautifulSoup(response.text, 'html5lib')\n",
"_____no_output_____"
],
[
"content_divs = page.find_all('div', class_='content-inner')\nlen(content_divs)",
"_____no_output_____"
],
[
"for content_div in content_divs:\n video_block = content_div.find('div', class_='video-block')\n video_wrapper = video_block.find('div', class_='sqs-video-wrapper')\n data_html_raw = video_wrapper['data-html']\n import html\n data_html = html.unescape(data_html_raw)\n chunk = BeautifulSoup(data_html, 'html5lib')\n iframe = chunk.find('iframe')\n print(iframe['src'])",
"https://player.vimeo.com/video/262852998?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/263076119?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/267658709?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/263076752?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/267660772?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/263076533?app_id=122963&wmode=opaque\n"
],
[
"\n ",
"_____no_output_____"
]
],
[
[
"### Burmese",
"_____no_output_____"
]
],
[
[
"response = requests.get(videos_url_my)\npage2 = BeautifulSoup(response.text, 'html5lib')\ncontent_divs2 = page2.find_all('div', class_='content-inner')\nlen(content_divs2)\n",
"_____no_output_____"
],
[
"for content_div in content_divs2:\n video_block = content_div.find('div', class_='video-block')\n video_wrapper = video_block.find('div', class_='sqs-video-wrapper')\n data_html_raw = video_wrapper['data-html']\n import html\n data_html = html.unescape(data_html_raw)\n chunk = BeautifulSoup(data_html, 'html5lib')\n iframe = chunk.find('iframe')\n print(iframe['src'])",
"https://player.vimeo.com/video/262570817?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/262755072?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/262755467?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/262755673?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/267661918?app_id=122963&wmode=opaque\nhttps://player.vimeo.com/video/262572490?app_id=122963&wmode=opaque\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
e73e572af4fd37b6a89b7bb6ef6ba5361b0b5ecf | 288,330 | ipynb | Jupyter Notebook | Higgs_Classification/higgs_classification.ipynb | MonitSharma/MS_Thesis | 9af18f8b25da90ead96a680486caa6dc56e1347a | [
"Apache-2.0"
] | null | null | null | Higgs_Classification/higgs_classification.ipynb | MonitSharma/MS_Thesis | 9af18f8b25da90ead96a680486caa6dc56e1347a | [
"Apache-2.0"
] | null | null | null | Higgs_Classification/higgs_classification.ipynb | MonitSharma/MS_Thesis | 9af18f8b25da90ead96a680486caa6dc56e1347a | [
"Apache-2.0"
] | null | null | null | 218.101362 | 164,538 | 0.872688 | [
[
[
"**This is an example Notebook for running training on Higgs vs background signal classification. **",
"_____no_output_____"
],
[
"**Background:** High-energy collisions at the Large Hadron Collider (LHC) produce particles that interact with particle detectors. One important task is to classify different types of collisions based on their physics content, allowing physicists to find patterns in the data and to potentially unravel new discoveries. ",
"_____no_output_____"
],
[
"**Problem statement:** The discovery of the Higgs boson by CMS and ATLAS Collaborations was announced at CERN in 2012. In this work, we focus on the potential of Machine Learning and Deep Learning in detecting potential Higgs signal from one of the background processes that mimics it. ",
"_____no_output_____"
],
[
"**Dataset:** The dataset is made available by the Center for Machine Learning and Intelligent Systems at University of California, Irvine. \nThe dataset can be found on the [UCI Machine learning Repository](https://archive.ics.uci.edu/ml/datasets/HIGGS)",
"_____no_output_____"
],
[
"**Description:** The dataset consists of a total of 11 million labeled samples of Higgs vs background events produced by Monte Carlo simulations. Each sample consists of 28 features. The first 21 features are kinematic properties measured at the level of the detectors. The last seven are functions of the first 21.\n\n\n",
"_____no_output_____"
],
[
"**Steps to load the training dataset**\n1. Download the dataset from the UCI website. ",
"_____no_output_____"
]
],
[
[
"!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00280/HIGGS.csv.gz",
"--2022-02-25 23:13:36-- https://archive.ics.uci.edu/ml/machine-learning-databases/00280/HIGGS.csv.gz\nResolving archive.ics.uci.edu (archive.ics.uci.edu)... 128.195.10.252\nConnecting to archive.ics.uci.edu (archive.ics.uci.edu)|128.195.10.252|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 2816407858 (2.6G) [application/x-httpd-php]\nSaving to: ‘HIGGS.csv.gz’\n\nHIGGS.csv.gz 100%[===================>] 2.62G 19.5MB/s in 2m 19s \n\n2022-02-25 23:15:55 (19.4 MB/s) - ‘HIGGS.csv.gz’ saved [2816407858/2816407858]\n\n"
]
],
[
[
"2. Unzip the dataset folder",
"_____no_output_____"
]
],
[
[
"!gzip -d HIGGS.csv.gz",
"_____no_output_____"
],
[
"from sklearn.datasets import make_gaussian_quantiles\nfrom sklearn.ensemble import AdaBoostClassifier\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nimport pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"import numpy as np\nnp.random.seed(1337) # for reproducibility\nimport h5py\nfrom keras.models import Sequential\nfrom tensorflow.keras.optimizers import Adam\nfrom keras.initializers import TruncatedNormal\nfrom keras.layers import Input, Dense, Dropout, Flatten, Conv2D, MaxPooling2D\nfrom keras.callbacks import ReduceLROnPlateau\n\nfrom sklearn.metrics import roc_curve, auc\n\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"**Load the file using pandas library**",
"_____no_output_____"
]
],
[
[
"data=pd.read_csv('./HIGGS.csv')",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
]
],
[
[
"Assign first column 0 to class labels (labeled 1 for signal, 0 for background) and all others to feature matrix X.\n\nIn this example, for the sake of fast checking, we use 1000 samples. To train on the entire dataset, proceed with uncommenting the lines below. ",
"_____no_output_____"
]
],
[
[
"X=data.iloc[:1000,1:]#data.iloc[:,1:]\ny=data.iloc[:1000,0]#data.iloc[:,0]",
"_____no_output_____"
]
],
[
[
"Split your data into training and validation samples where the fraction of the data used for validation is 33%. ",
"_____no_output_____"
]
],
[
[
"X_train1, X_val, y_train1, y_val = train_test_split(X, y, test_size=0.2, random_state=42)\nX_train, X_test, y_train, y_test = train_test_split(X_train1, y_train1, test_size=0.2, random_state=42)",
"_____no_output_____"
]
],
[
[
"**Visualize your data - One histogram per feature column**",
"_____no_output_____"
],
[
"Detailed information on what each feature column is can be found in *Attribute Information* section on the [UCI Machine learning Repositery](https://archive.ics.uci.edu/ml/datasets/HIGGS). For further information, refer to the [paper](https://www.nature.com/articles/ncomms5308) by Baldi et. al ",
"_____no_output_____"
]
],
[
[
"from itertools import combinations\nimport matplotlib.pyplot as plt\n\nfig, axes = plt.subplots(len(X_train.columns)//3, 3, figsize=(12, 48))\n\ni = 0\nfor triaxis in axes:\n for axis in triaxis:\n X_train.hist(column = X_train.columns[i], bins = 100, ax=axis)\n i = i+1",
"_____no_output_____"
]
],
[
[
"**Setup the Boosted Decision Tree model** (BDT explanation [here](https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-module-reference/boosted-decision-tree-regression#:~:text=Boosting%20means%20that%20each%20tree,small%20risk%20of%20less%20coverage.))",
"_____no_output_____"
]
],
[
[
"classifier = AdaBoostClassifier(\n DecisionTreeClassifier(max_depth=1),\n n_estimators=200\n)",
"_____no_output_____"
]
],
[
[
"**Train the Boosted Decision Tree model**",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import AdaBoostClassifier\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.datasets import load_breast_cancer\nimport pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.preprocessing import LabelEncoder",
"_____no_output_____"
],
[
"classifier.fit(X_train, y_train)",
"_____no_output_____"
]
],
[
[
"**Predict on new testing data**",
"_____no_output_____"
]
],
[
[
"predictions = classifier.predict(X_test)",
"_____no_output_____"
]
],
[
[
"**Print confusion matrix which describes the performance of the model classification by displaying the number of True Positives, True Negatives, False Positives and False Negatives. More info on [Wikipedia](https://en.wikipedia.org/wiki/Confusion_matrix)**",
"_____no_output_____"
]
],
[
[
"confusion_matrix(y_test, predictions)",
"_____no_output_____"
]
],
[
[
"**Setup the Neural Network** (some useful info [here](https://towardsdatascience.com/a-gentle-introduction-to-neural-networks-series-part-1-2b90b87795bc))",
"_____no_output_____"
]
],
[
[
"from numpy import loadtxt\nfrom keras.models import Sequential\nfrom keras.layers import Dense",
"_____no_output_____"
],
[
"model_nn = Sequential()\nmodel_nn.add(Dense(28, input_dim=28, activation='relu'))\nmodel_nn.add(Dense(8, activation='relu'))\nmodel_nn.add(Dense(1, activation='sigmoid'))",
"_____no_output_____"
]
],
[
[
"**Train the Neural Network and save your model weights in a h5 file**",
"_____no_output_____"
]
],
[
[
"# compile the keras model\nmodel_nn.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n# fit the keras model on the dataset\nhistory=model_nn.fit(X, y,validation_data=(X_val,y_val),epochs=5, batch_size=10)\n# evaluate the keras model\n_, accuracy = model_nn.evaluate(X, y)\nmodel_nn.save('my_model.h5') ##Saving model weights\nprint('Accuracy: %.2f' % (accuracy*100))",
"Epoch 1/5\n100/100 [==============================] - 4s 6ms/step - loss: 0.7080 - accuracy: 0.5000 - val_loss: 0.6864 - val_accuracy: 0.5650\nEpoch 2/5\n100/100 [==============================] - 0s 4ms/step - loss: 0.6879 - accuracy: 0.5370 - val_loss: 0.6800 - val_accuracy: 0.5600\nEpoch 3/5\n100/100 [==============================] - 0s 4ms/step - loss: 0.6783 - accuracy: 0.5810 - val_loss: 0.6719 - val_accuracy: 0.6000\nEpoch 4/5\n100/100 [==============================] - 0s 4ms/step - loss: 0.6677 - accuracy: 0.6100 - val_loss: 0.6685 - val_accuracy: 0.6250\nEpoch 5/5\n100/100 [==============================] - 0s 4ms/step - loss: 0.6581 - accuracy: 0.6280 - val_loss: 0.6623 - val_accuracy: 0.6100\n32/32 [==============================] - 0s 3ms/step - loss: 0.6471 - accuracy: 0.6470\nAccuracy: 64.70\n"
],
[
"# list all data in history\nprint(history.history.keys())",
"dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])\n"
]
],
[
[
"**Plot accuracy wrt number of epochs**",
"_____no_output_____"
]
],
[
[
"\n# summarize history for accuracy\nplt.plot(history.history['accuracy'])\nplt.plot(history.history['val_accuracy'])\nplt.title('model accuracy')\nplt.ylabel('accuracy')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper left')\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"**Plot training loss wrt number of epochs**",
"_____no_output_____"
]
],
[
[
"# summarize history for loss\nplt.plot(history.history['loss'])\nplt.plot(history.history['val_loss'])\nplt.title('model loss')\nplt.ylabel('loss')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper left')\nplt.show()",
"_____no_output_____"
],
[
"y_pred=model_nn.predict(X_test)",
"_____no_output_____"
],
[
"confusion_matrix(y_test, y_pred.round())",
"_____no_output_____"
]
],
[
[
"**Plot the ROC (Receiver Operating Characteristic) Curve** (more info on ROC could be found [here](https://en.wikipedia.org/wiki/Receiver_operating_characteristic)",
"_____no_output_____"
]
],
[
[
"!pip install plot-metric",
"Collecting plot-metric\n Downloading plot_metric-0.0.6-py3-none-any.whl (13 kB)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.7/dist-packages (from plot-metric) (1.21.5)\nRequirement already satisfied: seaborn>=0.9.0 in /usr/local/lib/python3.7/dist-packages (from plot-metric) (0.11.2)\nRequirement already satisfied: colorlover>=0.3.0 in /usr/local/lib/python3.7/dist-packages (from plot-metric) (0.3.0)\nRequirement already satisfied: matplotlib>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from plot-metric) (3.2.2)\nRequirement already satisfied: pandas>=0.23.4 in /usr/local/lib/python3.7/dist-packages (from plot-metric) (1.3.5)\nRequirement already satisfied: scikit-learn>=0.21.2 in /usr/local/lib/python3.7/dist-packages (from plot-metric) (1.0.2)\nRequirement already satisfied: scipy>=1.1.0 in /usr/local/lib/python3.7/dist-packages (from plot-metric) (1.4.1)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0.2->plot-metric) (0.11.0)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0.2->plot-metric) (2.8.2)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0.2->plot-metric) (3.0.7)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0.2->plot-metric) (1.3.2)\nRequirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas>=0.23.4->plot-metric) (2018.9)\nRequirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.1->matplotlib>=3.0.2->plot-metric) (1.15.0)\nRequirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.21.2->plot-metric) (3.1.0)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.21.2->plot-metric) (1.1.0)\nInstalling collected packages: plot-metric\nSuccessfully installed plot-metric-0.0.6\n"
],
[
"from plot_metric.functions import BinaryClassification\n# Visualisation with plot_metric\nbc = BinaryClassification(y_pred.round(), y_test, labels=[\"Class 1\", \"Class 2\"])\n\n# Figures\nplt.figure(figsize=(5,5))\nbc.plot_roc_curve()\nplt.show()",
"_____no_output_____"
]
],
[
[
"**Deliverables**\n\nPlease submit the following: \n\n* Your full notebook used for training including the ROC Curves, model weights and loss and accuracy plots wrt number of epochs. \n\n\n",
"_____no_output_____"
],
[
"**References**\n\nBaldi, P., Sadowski, P. and Whiteson, D. “Searching for Exotic Particles in High-energy Physics with Deep Learning.” Nature Communications 5 (July 2, 2014).\n\n",
"_____no_output_____"
],
[
"**Contributors**\n\nAli Hariri *(American University of Beirut)*\n\nSergei V. Gleyzer *(University of Alabama)*",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
e73e579d9ac9144d29498a79fa93e8f2993fc32f | 24,918 | ipynb | Jupyter Notebook | lessons/ETLPipelines/5_combinedata_exercise/.ipynb_checkpoints/5_combining_data-checkpoint.ipynb | GooseHuang/Udacity-Data-Scientist-Nanodegree | 96980d6f7ce82a961c7f41d26c25fbe5f11ca773 | [
"MIT"
] | null | null | null | lessons/ETLPipelines/5_combinedata_exercise/.ipynb_checkpoints/5_combining_data-checkpoint.ipynb | GooseHuang/Udacity-Data-Scientist-Nanodegree | 96980d6f7ce82a961c7f41d26c25fbe5f11ca773 | [
"MIT"
] | 1 | 2021-06-02T02:39:02.000Z | 2021-06-02T02:39:02.000Z | lessons/ETLPipelines/5_combinedata_exercise/.ipynb_checkpoints/5_combining_data-checkpoint.ipynb | GooseHuang/Udacity-Data-Scientist-Nanodegree | 96980d6f7ce82a961c7f41d26c25fbe5f11ca773 | [
"MIT"
] | null | null | null | 137.668508 | 2,144 | 0.701581 | [
[
[
"# Combining Data\n\nPractice combining data from two different data sets. In the same folder as this Jupyter notebook, there are two csv files:\n* rural_population_percent.csv\n* electricity_access_percent.csv\n\nThey both come from the World Bank Indicators data. \n* https://data.worldbank.org/indicator/SP.RUR.TOTL.ZS\n* https://data.worldbank.org/indicator/EG.ELC.ACCS.ZS\n\nThe rural populaton data represents the percent of a country's population that is rural over time. The electricity access data shows the percentage of people with access to electricity.\n\nIn this exercise, you will combine these two data sets together into one pandas data frame.",
"_____no_output_____"
],
[
"# Exercise 1\n\nCombine the two data sets using the [pandas concat method](https://pandas.pydata.org/pandas-docs/stable/merging.html). In other words, find the union of the two data sets.",
"_____no_output_____"
]
],
[
[
"pd.read_json('http://api.worldbank.org/v2/indicator/SP.RUR.TOTL.ZS/?format=json')",
"_____no_output_____"
],
[
"# TODO: import the pandas library\nimport pandas as pd\n\n# TODO: read in each csv file into a separate variable\n# HINT: remember from the Extract material that these csv file have some formatting issues\n# HINT: The file paths are 'rural_population_percent.csv' and 'electricity_access_percent.csv'\ndf_rural = pd.read_csv('https://data.worldbank.org/indicator/SP.RUR.TOTL.ZS')\ndf_electricity = pd.read_csv('https://data.worldbank.org/indicator/EG.ELC.ACCS.ZS')\n\n# TODO: remove the 'Unnamed:62' column from each data set\n\n\n# TODO: combine the two data sets together using the concat method",
"_____no_output_____"
]
],
[
[
"# Exercise 2 (Challenge)\n\nThis exercise is more challenging.\n\nThe resulting data frame should look like this:\n\n|Country Name|Country Code|Year|Rural_Value|Electricity_Value|\n|--|--|--|--|--|--|\n|Aruba|ABW|1960|49.224|49.239|\n... etc.\n\nOrder the results in the dataframe by country and then by year\n\nHere are a few pandas methods that should be helpful:\n* [melt](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.melt.html)\n* [drop](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.drop.html)\n* [merge](https://pandas.pydata.org/pandas-docs/version/0.23/generated/pandas.DataFrame.merge.html)\n* [sort_values](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sort_values.html)\n\nHINT: You can use country name, country code, and the year as common keys between the data sets",
"_____no_output_____"
]
],
[
[
"# TODO: merge the data sets together according to the instructions. First, use the \n# melt method to change the formatting of each data frame so that it looks like this:\n# Country Name, Country Code, Year, Rural Value\n# Country Name, Country Code, Year, Electricity Value\n\n# TODO: drop any columns from the data frames that aren't needed\n\n# TODO: merge the data frames together based on their common columns\n# in this case, the common columns are Country Name, Country Code, and Year\n\n# TODO: sort the results by country and then by year\n\ndf_combined = None",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
e73e68e9e1af302ac8b28b0b47c8b914b5ccc61d | 136,476 | ipynb | Jupyter Notebook | submissions/2020-07-27-OpenFF-Benchmark-Ligands/Ligand_fragments.ipynb | openforcefield/qca-dataset-submission | df222b8e3e288f45b16749d3061873b1eee263f6 | [
"BSD-3-Clause"
] | 15 | 2019-06-28T19:33:37.000Z | 2022-03-23T18:38:14.000Z | submissions/2020-07-27-OpenFF-Benchmark-Ligands/Ligand_fragments.ipynb | openforcefield/qca-dataset-submission | df222b8e3e288f45b16749d3061873b1eee263f6 | [
"BSD-3-Clause"
] | 251 | 2019-06-26T01:14:52.000Z | 2022-03-31T12:48:40.000Z | submissions/2020-07-27-OpenFF-Benchmark-Ligands/Ligand_fragments.ipynb | openforcefield/qca-dataset-submission | df222b8e3e288f45b16749d3061873b1eee263f6 | [
"BSD-3-Clause"
] | 5 | 2019-06-25T22:26:55.000Z | 2021-02-17T22:16:39.000Z | 71.044248 | 1,495 | 0.675738 | [
[
[
"import os \nfrom qcsubmit.factories import TorsiondriveDatasetFactory\nfrom qcsubmit.datasets import TorsiondriveDataset\nfrom qcsubmit import workflow_components",
"_____no_output_____"
],
[
"# for each of the targets we will create a fragmented dataset to look at the size and number of fragments made\n# set up the factory\nfactory = TorsiondriveDatasetFactory()\nfactory",
"_____no_output_____"
],
[
"fragmenter = workflow_components.WBOFragmenter()\n# apply settings\nfragmenter.keep_non_rotor_ring_substituents = True\n\n# add fragmenter to the pipeline\nfactory.add_workflow_component(fragmenter)\n\n# set up the conformer generator\nconformers = workflow_components.StandardConformerGenerator(max_conformers=10)\nfactory.add_workflow_component(conformers)\nfactory",
"_____no_output_____"
],
[
"# export the factory settings\nfactory.export_settings(\"fragment_settings.yaml\")",
"_____no_output_____"
],
[
"# test making a dataset\ndataset = factory.create_dataset(dataset_name=f\"OpenFF-benchmark-ligand-fragments-v1.0\", molecules=\"sdfs\", description=f\"Torsiondrives of fragments of the JACS benchmark inhibitors.\", tagline=\"Fragmented torsiondrives of JACS benchmark inhibitors.\")\n",
"Warning (not error because allow_undefined_stereo=True): OEMol has unspecified stereochemistry. oemol.GetTitle(): 31\nProblematic atoms are:\nAtom atomic num: 16, name: , idx: 44, aromatic: False, chiral: True with bonds:\nbond order: 1, chiral: False to atom atomic num: 6, name: , idx: 10, aromatic: True, chiral: False\nbond order: 2, chiral: False to atom atomic num: 8, name: , idx: 45, aromatic: False, chiral: False\nbond order: 1, chiral: False to atom atomic num: 6, name: , idx: 46, aromatic: False, chiral: False\n\n"
],
[
"dataset.metadata.elements",
"_____no_output_____"
],
[
"dataset.n_molecules",
"_____no_output_____"
],
[
"dataset.n_records",
"_____no_output_____"
],
[
"# add in the other two specs\ndataset.add_qc_spec(method=\"openff-1.0.0\", basis=\"smirnoff\", program=\"openmm\", spec_name=\"openff-1.0.0\", spec_description=\"default openff-1.0.0 spec\")",
"_____no_output_____"
],
[
"dataset.add_qc_spec(method=\"gaff-2.11\", basis=\"antechamber\", program=\"openmm\", spec_name=\"gaff-2.11\", spec_description=\"default gaff-2.11 spec\")",
"_____no_output_____"
],
[
"dataset.visualize(\"fragments.pdf\")",
"_____no_output_____"
],
[
"dataset.export_dataset(\"dataset.json\")",
"_____no_output_____"
],
[
"dataset.filtered_molecules",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73e6dd460a55b5f4c584aca33b085aab8cee501 | 6,095 | ipynb | Jupyter Notebook | Modulo2/Ejercicios/.ipynb_checkpoints/Problema1-checkpoint.ipynb | Flor246/PythonFlor | 6481e258286bdb939e42190363cdd6d3bb70c00d | [
"Apache-2.0"
] | null | null | null | Modulo2/Ejercicios/.ipynb_checkpoints/Problema1-checkpoint.ipynb | Flor246/PythonFlor | 6481e258286bdb939e42190363cdd6d3bb70c00d | [
"Apache-2.0"
] | null | null | null | Modulo2/Ejercicios/.ipynb_checkpoints/Problema1-checkpoint.ipynb | Flor246/PythonFlor | 6481e258286bdb939e42190363cdd6d3bb70c00d | [
"Apache-2.0"
] | null | null | null | 31.417526 | 513 | 0.611485 | [
[
[
"# MARIO GAME",
"_____no_output_____"
],
[
"<img src='./img/ejercicio1.png'>",
"_____no_output_____"
],
[
"Implemente un programa que imprima una media pirámide de una altura específica, como se indica a continuación.",
"_____no_output_____"
],
[
"<code>$ ./mario\nHeight: 4\n #\n ##\n ###\n####</code>",
"_____no_output_____"
],
[
"## Especificaciones",
"_____no_output_____"
],
[
"- Cree un archivo llamado <code>mario.py</code>,el cual es un programa que recrea una media pirámide usando los hash (#) para los bloques.\n- Para hacer las cosas más interesantes, primero solicite al usuario <code>input</code> la altura de la media pirámide, el cual debe ser un número entero positivo entre <code>1</code> y <code>8</code>, inclusive.\n- Si el usuario no proporciona un número entero positivo no mayor que <code>8</code>, debe volver a solicitar el mismo.\n- Luego, genere (con la ayuda de <code>print</code> uno o más bucles) la media pirámide deseada.\n- Tenga cuidado de alinear la esquina inferior izquierda de su media pirámide con el borde izquierdo de la ventana de su terminal.",
"_____no_output_____"
],
[
"## Uso",
"_____no_output_____"
],
[
"Su programa debería comportarse según el ejemplo siguiente.",
"_____no_output_____"
],
[
"<code>$ ./mario\nHeight: 4\n #\n ##\n ###\n####</code>",
"_____no_output_____"
],
[
"## Pruebas",
"_____no_output_____"
],
[
"- Ejecute su programa como <code>python mario.py</code> y espere una solicitud de entrada. Escribe <code>-1</code> y presiona enter. Su programa debe rechazar esta entrada como inválida, por ejemplo, volviendo a solicitar al usuario que escriba otro número.\n- Ejecute su programa como <code>python mario.py</code> y espere una solicitud de entrada. Escribe <code>0</code> y presiona enter. Su programa debe rechazar esta entrada como inválida, por ejemplo, volviendo a solicitar al usuario que escriba otro número.\n- Ejecute su programa como <code>python mario.py</code> y espere una solicitud de entrada. Escribe <code>1</code> y presiona enter. Su programa debería generar la siguiente salida. Asegúrese de que la pirámide esté alineada con la esquina inferior izquierda de su terminal y de que no haya espacios adicionales al final de cada línea.",
"_____no_output_____"
],
[
"<code>#</code>",
"_____no_output_____"
],
[
"Ejecute su programa como <code>python mario.py</code> y espere una solicitud de entrada. Escribe <code>2</code> y presiona enter. Su programa debería generar la siguiente salida. Asegúrese de que la pirámide esté alineada con la esquina inferior izquierda de su terminal y de que no haya espacios adicionales al final de cada línea.\n",
"_____no_output_____"
],
[
"<code> #\n##</code>",
"_____no_output_____"
],
[
"Ejecute su programa como <code>python mario.py</code> y espere una solicitud de entrada. Escribe <code>8</code> y presiona enter. Su programa debería generar la siguiente salida. Asegúrese de que la pirámide esté alineada con la esquina inferior izquierda de su terminal y de que no haya espacios adicionales al final de cada línea.\n",
"_____no_output_____"
],
[
"<code> #\n ##\n ###\n ####\n #####\n ######\n #######\n########</code>",
"_____no_output_____"
],
[
"Ejecute su programa como <code>python mario.py</code> y espere una solicitud de entrada. Escribe <code>9</code> y presiona enter. Su programa debe rechazar esta entrada como inválida, por ejemplo, volviendo a solicitar al usuario que escriba otro número. Luego, escribe <code>2</code> y presiona enter. Su programa debería generar la siguiente salida. Asegúrese de que la pirámide esté alineada con la esquina inferior izquierda de su terminal y de que no haya espacios adicionales al final de cada línea.\n",
"_____no_output_____"
],
[
"<code> #\n##</code>\n \n ",
"_____no_output_____"
],
[
"- Ejecute su programa como <code>python mario.py</code> y espere una solicitud de entrada. Escribe fooy presiona enter. Su programa debe rechazar esta entrada como inválida, por ejemplo, volviendo a solicitar al usuario que escriba otro número.\n- Ejecute su programa como <code>python mario.py</code> y espere una solicitud de entrada. No escriba nada y presione enter. Su programa debe rechazar esta entrada como inválida, por ejemplo, volviendo a solicitar al usuario que escriba otro número.",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
e73e81c5f9f86620cae68e4aad827f4af0bcca26 | 50,641 | ipynb | Jupyter Notebook | note/dev-1905/190502 - morpheus baby steps.ipynb | eliavw/morpheus | 01c6d15416188254cfdcc7fe9461069cbf8dbe63 | [
"MIT"
] | null | null | null | note/dev-1905/190502 - morpheus baby steps.ipynb | eliavw/morpheus | 01c6d15416188254cfdcc7fe9461069cbf8dbe63 | [
"MIT"
] | null | null | null | note/dev-1905/190502 - morpheus baby steps.ipynb | eliavw/morpheus | 01c6d15416188254cfdcc7fe9461069cbf8dbe63 | [
"MIT"
] | null | null | null | 102.928862 | 33,716 | 0.777058 | [
[
[
"# Morpheus Sandbox\n\nFirst test of actual morpheus being a thing.",
"_____no_output_____"
],
[
"## Preliminaries",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nimport numpy as np\n\nfrom os.path import dirname\nfrom networkx.drawing.nx_pydot import to_pydot\n\n# Import morpheus\nnote_dir = os.getcwd()\nroot_dir = dirname(note_dir)\nsrc_dir = os.path.join(root_dir, \"src\")\n\nsys.path.append(src_dir)\n\nimport morpheus\n\nfrom morpheus import Morpheus\nfrom morpheus.tests import (default_dataset,\n default_m_list_for_mercs,\n random_m_list_for_mercs)\n\n# Visuals\nfrom morpheus.graph import to_dot\nfrom IPython.display import Image, display\nfrom IPython.core.display import HTML ",
"_____no_output_____"
],
[
"data, _ = default_dataset(random_state=10)\ndata.head()",
"_____no_output_____"
],
[
"data = data.values",
"_____no_output_____"
]
],
[
[
"## Fit\n\nHere, I test whether or not it can fit something.",
"_____no_output_____"
]
],
[
[
"m = Morpheus()",
"_____no_output_____"
],
[
"m.fit(data)",
"_____no_output_____"
],
[
"m.m_list[:2]",
"_____no_output_____"
],
[
"m.m_codes",
"_____no_output_____"
],
[
"m.g_list",
"_____no_output_____"
],
[
"m.g_list[3].nodes(data=True)",
"_____no_output_____"
]
],
[
[
"## Predict\n\nNow testing our prediction functionalities.",
"_____no_output_____"
]
],
[
[
"q_code = np.array([0,0,0,0,0,0,0,1])",
"_____no_output_____"
],
[
"f_list = m.predict(data, q_code)",
"['d-06', 'd-05', 'd-04', 'd-03', 'd-02', 'd-01', 'd-00', 'f-04', 'd-07']\nd-06\nd-05\nd-04\nd-03\nd-02\nd-01\nd-00\nf-04\ndict_keys(['d-06', 'd-05', 'd-04', 'd-03', 'd-02', 'd-01', 'd-00'])\nd-07\n"
],
[
"# show your work\nq_grph = m.q_grph\nfname = to_dot(q_grph, fname='q')\n!dot -T png ./tmp/q.dot > ./tmp/q.png # Bash command (This can be done nicer, but is tricky)\n\ndisplay(Image('tmp/q.png'))",
"_____no_output_____"
],
[
"f_list['d-07'](data)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
e73e91a4286b96654a2d3b5fa7db082b5a445b93 | 20,719 | ipynb | Jupyter Notebook | lessons/7.ipynb | BobNobrain/matstat-labs | bf7c95b29a6dc8b65675a780871400fd729f9e35 | [
"MIT"
] | null | null | null | lessons/7.ipynb | BobNobrain/matstat-labs | bf7c95b29a6dc8b65675a780871400fd729f9e35 | [
"MIT"
] | null | null | null | lessons/7.ipynb | BobNobrain/matstat-labs | bf7c95b29a6dc8b65675a780871400fd729f9e35 | [
"MIT"
] | 7 | 2018-11-18T06:31:49.000Z | 2020-11-09T18:36:40.000Z | 66.194888 | 12,456 | 0.752063 | [
[
[
"# 7. Регрессионный анализ\n\n```\nАуд.: 345(330), 350(335), 405(383)\nД/З: 346(331), 351(336), 406(384)\n```",
"_____no_output_____"
],
[
"## Линейная регрессия\n\n$$ M[Y|x] = f(x) = \\beta_{0} + \\beta_{1} x $$\n\n$$ Y = \\beta_{0} + \\beta_{1} x + \\varepsilon, $$\n\n$$ \\varepsilon \\sim N(0, \\sigma^2 (неизв)) $$\n\nМНК-оценки:\n\n$$ \\tilde{\\beta_1} = \\frac{Q_{xy}}{Q_{x}}, $$\n\n$$ Q_{xy} = \\sum (x_i - \\overline{x})(y_i - \\overline{y}), Q_{x} = \\sum (x_i - \\overline{x})^2 $$\n\n$$ \\tilde{\\beta_0} = \\overline{y} - \\tilde{\\beta_1} \\overline{x} $$\n\n$$ e_i = y_i - \\tilde{y_i} $$\n\nОстаточная сумма квадратов:\n\n$$ Q_e = \\sum e_i^2 = \\sum (y_i - \\tilde{y_i})^2 $$\n\n$$ Q_y = Q_R + Q_e, Q_y = \\sum y_i^2 - n \\overline{y}^2, Q_R = \\frac{Q^2_{xy}}{Q_x} $$\n\n$Q_R$ — сумма квадратов, обусловленная регрессией; $Q_e$ — остаточная сумма квадратов\n\n$$ s^2 = \\frac{Q_e}{n-2} $$\n\n### Значимость линейной регрессии\n\nДоверительный интервал для $\\beta_1$:\n\n$$ \\tilde{\\beta_1} \\pm t_{1 - \\alpha/2}(n - 2) s \\sqrt{\\frac{1}{Q_x}} $$\n\nДоверительный интервал для $\\beta_0$:\n\n$$ \\tilde{\\beta_0} \\pm t_{1 - \\alpha/2}(n - 2) s \\sqrt{\\frac{ \\sum x_i^2 }{ n Q_x }} $$\n\nРегрессия значима, если доверительный интервал для $\\beta_1$ не накрывает 0.\n\nДоверительный интервал для $\\overline{Y_0}(x = x_0)$:\n\n$$ \\tilde{y_0} \\pm t_{1 - \\alpha/2}(n - 2) s \\sqrt{\\frac{1}{n} + \\frac{ (x_0 - \\overline{x})^2 }{ Q_x }} $$",
"_____no_output_____"
]
],
[
[
"from scipy import stats\nimport numpy as np\n\nalpha = 0.1\n\nQe = 6.199\nQx = 131.22\nn = 9\nbeta1 = -1.057\nbeta0 = 20.34\n\nq = stats.t(n-2).ppf(1 - alpha/2)\n\nprint(q)\n\ns = np.sqrt(Qe / (n - 2))\n\ndelta_beta1 = q*s*np.sqrt(1 / Qx)\n\ndelta_beta0 = q*s*np.sqrt(865.63/n/Qx)\n\nprint('b1 +- {}'.format(delta_beta1))\nprint('b0 +- {}'.format(delta_beta0))",
"1.89457860506\nb1 +- 0.15564114248683683\nb0 +- 1.526403330710377\n"
]
],
[
[
"## Криволинейная регрессия\n\n$$ M[Y|x] = \\beta_0 + \\beta_1 a_1(x) + ... + \\beta_{k-1} a_{k-1}(x), $$\n\nгде $a_i$ - известные функции.\n\nМНК-оценки параметров регрессии:\n\n$$\nY = \\begin{pmatrix}\ny_1 \\\\\ny_2 \\\\\n\\dots \\\\\ny_n\n\\end{pmatrix}\n$$\n\n$$\nA = \\begin{pmatrix}\n1 & a_1(x_1) & \\dots & a_{k-1}(x_1) \\\\\n1 & a_1(x_2) & \\dots & a_{k-1}(x_2) \\\\\n\\dots & \\dots & \\dots & \\dots \\\\\n1 & a_1(x_n) & \\dots & a_{k-1}(x_n)\n\\end{pmatrix}\n$$\n\n$$\n\\beta = \\begin{pmatrix}\n\\beta_0 \\\\ \\beta_1 \\\\ \\dots \\\\ \\beta_{k-1}\n\\end{pmatrix}\n$$\n\nТогда $ \\tilde{\\beta} = (A^T A)^{-1} A^T Y $",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nx = np.array([0, 2, 4, 6, 8, 10])\ny = np.array([5, -1, -0.5, 1.5, 4.5, 8.5])\n\nplt.scatter(x, y)\n\nA = np.array([\n [1, x_i, x_i ** 2] for x_i in x\n])\n\nbeta = np.dot(np.dot(np.linalg.inv(np.dot(A.T, A)), A.T), y)\n\nprint(\n np.around(\n np.dot(np.linalg.inv(np.dot(A.T, A)), A.T)\n , 3)\n)\nprint(beta)\n\ndomain = np.linspace(min(x), max(x), 100)\nvalues = beta[0] + beta[1] * domain + beta[2] * domain ** 2\n\nplt.plot(domain, values);",
"[[ 0.821 0.321 0. -0.143 -0.107 0.107]\n [-0.295 0.002 0.164 0.193 0.087 -0.152]\n [ 0.022 -0.004 -0.018 -0.018 -0.004 0.022]]\n[ 4. -2.16428571 0.26785714]\n"
]
],
[
[
"## Множественная линейная регрессия\n\n$$ y_i = \\beta_0 + \\beta_1 x_{1i} + \\beta_2 x_{2i} + \\varepsilon_i $$\n\n$Q_y = \\sum y_i^2 - \\frac{\\left( \\sum y_i \\right)^2}{n} $\n\n$Q_{x_j} = \\sum_i x_{ji}^2 - \\frac{\\left( \\sum x_{ji}^2 \\right)^2}{n} $\n\n$Q_{x_jy} = \\sum_i x_{ji} y_i - \\frac{\\left( \\sum_i x_{ji} \\right) \\left( \\sum y_{i} \\right)}{n} $\n\n$Q_{x_1 x_2} = \\sum_i x_{1i} x_{2i} - \\frac{\\left( \\sum_i x_{1i} \\right) \\left( \\sum x_{2i} \\right)}{n} $\n\n$$\nA^T A = \\begin{pmatrix}\nQ_{x_1} & Q_{x_1 x_2} \\\\\nQ_{x_1 x_2} & Q_{x_2}\n\\end{pmatrix}\n$$\n\n$$\n\\tilde{\\beta} = \\begin{pmatrix}\nQ_{x_2} & -Q_{x_1 x_2} \\\\\n-Q_{x_1 x_2} & Q_{x_1}\n\\end{pmatrix}\n\\begin{pmatrix}\nQ_{x_1 y} \\\\\nQ_{x_2 y}\n\\end{pmatrix}\n\\frac{1}{|A^T A|}\n$$\n\n$$ \\tilde{\\beta}_0 = \\overline{y} - \\tilde{\\beta}_1 \\overline{x_1} - \\tilde{\\beta}_2 \\overline{x_2} $$\n",
"_____no_output_____"
],
[
"### Значимость множественной регрессии\n\n$H0: \\beta_1 = \\beta_2 = 0$,\n\n$$ F = \\frac{\\tilde{\\beta}^T A^T Y/2}{Q_e / (n - 3)} < F_{1-\\alpha}(2, n-3) $$\n\n$H0: \\beta_j = 0$,\n\n$$ \\tilde{\\beta_j} \\pm t_{1 - \\alpha/2}(n - 3) s \\sqrt{a_{jj}}, $$\n\nгде $a_{jj} = (A^T A)[j, j]$, $s = \\sqrt{\\frac{Q_e}{n - 3}}$\n",
"_____no_output_____"
],
[
"Кф множественной корреляции $R = \\sqrt{\\frac{ \\tilde{\\beta}^T A^T Y }{ Q_y }}$, где\n\n$$\nA^T Y = \\begin{pmatrix}\nQ_{x_1 y} \\\\\nQ_{x_2 y} \\\\\n\\end{pmatrix}\n$$",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nx1 = np.array([1, 4, 0, 5, -3, 3, -5, -1, 2, -2])\nx2 = np.array([4, -6, 2, -4, 12, -2, 14, 6, 0, 8])\ny = np.array([-4, -5, 4, -1, 4, 0, 5, 1, 2, 7])\n\nn = len(y)\n\nQy = np.sum(y ** 2) - np.sum(y) ** 2 / n\nQx1 = np.sum(x1 ** 2) - np.sum(x1 ** 2) ** 2 / n\nQx2 = np.sum(x2 ** 2) - np.sum(x2 ** 2) ** 2 / n\nQx1y = np.sum(x1 * y) - np.sum(x1) * np.sum(y) / n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
e73e93ceaa0d741b985f48ec3308d6d5018424e8 | 17,413 | ipynb | Jupyter Notebook | sentence_embeddings_examples.ipynb | alinaalborova/sentence-transformers | ec2411377fbc2bddf180ad69b83c8946ab702735 | [
"Apache-2.0"
] | null | null | null | sentence_embeddings_examples.ipynb | alinaalborova/sentence-transformers | ec2411377fbc2bddf180ad69b83c8946ab702735 | [
"Apache-2.0"
] | null | null | null | sentence_embeddings_examples.ipynb | alinaalborova/sentence-transformers | ec2411377fbc2bddf180ad69b83c8946ab702735 | [
"Apache-2.0"
] | null | null | null | 47.969697 | 262 | 0.56722 | [
[
[
"<a href=\"https://colab.research.google.com/github/alinaalborova/sentence-transformers/blob/master/sentence_embeddings_examples.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"!pip install -U sentence-transformers\n",
"Collecting sentence-transformers\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/c9/91/c85ddef872d5bb39949386930c1f834ac382e145fcd30155b09d6fb65c5a/sentence-transformers-0.2.5.tar.gz (49kB)\n\u001b[K |████████████████████████████████| 51kB 1.6MB/s \n\u001b[?25hCollecting transformers==2.3.0\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/50/10/aeefced99c8a59d828a92cc11d213e2743212d3641c87c82d61b035a7d5c/transformers-2.3.0-py3-none-any.whl (447kB)\n\u001b[K |████████████████████████████████| 450kB 8.2MB/s \n\u001b[?25hRequirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from sentence-transformers) (4.28.1)\nRequirement already satisfied, skipping upgrade: torch>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from sentence-transformers) (1.3.1)\nRequirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from sentence-transformers) (1.17.5)\nRequirement already satisfied, skipping upgrade: scikit-learn in /usr/local/lib/python3.6/dist-packages (from sentence-transformers) (0.22.1)\nRequirement already satisfied, skipping upgrade: scipy in /usr/local/lib/python3.6/dist-packages (from sentence-transformers) (1.4.1)\nRequirement already satisfied, skipping upgrade: nltk in /usr/local/lib/python3.6/dist-packages (from sentence-transformers) (3.2.5)\nRequirement already satisfied, skipping upgrade: boto3 in /usr/local/lib/python3.6/dist-packages (from transformers==2.3.0->sentence-transformers) (1.10.47)\nCollecting sacremoses\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/a6/b4/7a41d630547a4afd58143597d5a49e07bfd4c42914d8335b2a5657efc14b/sacremoses-0.0.38.tar.gz (860kB)\n\u001b[K |████████████████████████████████| 870kB 54.3MB/s \n\u001b[?25hRequirement already satisfied, skipping upgrade: regex!=2019.12.17 in /usr/local/lib/python3.6/dist-packages (from transformers==2.3.0->sentence-transformers) (2019.12.20)\nRequirement already satisfied, skipping upgrade: requests in /usr/local/lib/python3.6/dist-packages (from transformers==2.3.0->sentence-transformers) (2.21.0)\nCollecting sentencepiece\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/74/f4/2d5214cbf13d06e7cb2c20d84115ca25b53ea76fa1f0ade0e3c9749de214/sentencepiece-0.1.85-cp36-cp36m-manylinux1_x86_64.whl (1.0MB)\n\u001b[K |████████████████████████████████| 1.0MB 51.1MB/s \n\u001b[?25hRequirement already satisfied, skipping upgrade: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn->sentence-transformers) (0.14.1)\nRequirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.6/dist-packages (from nltk->sentence-transformers) (1.12.0)\nRequirement already satisfied, skipping upgrade: jmespath<1.0.0,>=0.7.1 in /usr/local/lib/python3.6/dist-packages (from boto3->transformers==2.3.0->sentence-transformers) (0.9.4)\nRequirement already satisfied, skipping upgrade: botocore<1.14.0,>=1.13.47 in /usr/local/lib/python3.6/dist-packages (from boto3->transformers==2.3.0->sentence-transformers) (1.13.47)\nRequirement already satisfied, skipping upgrade: s3transfer<0.3.0,>=0.2.0 in /usr/local/lib/python3.6/dist-packages (from boto3->transformers==2.3.0->sentence-transformers) (0.2.1)\nRequirement already satisfied, skipping upgrade: click in /usr/local/lib/python3.6/dist-packages (from sacremoses->transformers==2.3.0->sentence-transformers) (7.0)\nRequirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->transformers==2.3.0->sentence-transformers) (1.24.3)\nRequirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->transformers==2.3.0->sentence-transformers) (3.0.4)\nRequirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->transformers==2.3.0->sentence-transformers) (2.8)\nRequirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->transformers==2.3.0->sentence-transformers) (2019.11.28)\nRequirement already satisfied, skipping upgrade: python-dateutil<3.0.0,>=2.1; python_version >= \"2.7\" in /usr/local/lib/python3.6/dist-packages (from botocore<1.14.0,>=1.13.47->boto3->transformers==2.3.0->sentence-transformers) (2.6.1)\nRequirement already satisfied, skipping upgrade: docutils<0.16,>=0.10 in /usr/local/lib/python3.6/dist-packages (from botocore<1.14.0,>=1.13.47->boto3->transformers==2.3.0->sentence-transformers) (0.15.2)\nBuilding wheels for collected packages: sentence-transformers, sacremoses\n Building wheel for sentence-transformers (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for sentence-transformers: filename=sentence_transformers-0.2.5-cp36-none-any.whl size=64943 sha256=27a2c33167d680e771c8a85a65a2a3c98bcf451fc9914705b3ea98dec23d55a7\n Stored in directory: /root/.cache/pip/wheels/b4/ce/39/5bbda8ac34eb52df8c6531382ca077773fbfcbfb6386e5d66c\n Building wheel for sacremoses (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for sacremoses: filename=sacremoses-0.0.38-cp36-none-any.whl size=884629 sha256=6311f943be9ae9e6796c563bb8ad89baea022b3499d959f695cde86458cedf1f\n Stored in directory: /root/.cache/pip/wheels/6d/ec/1a/21b8912e35e02741306f35f66c785f3afe94de754a0eaf1422\nSuccessfully built sentence-transformers sacremoses\nInstalling collected packages: sacremoses, sentencepiece, transformers, sentence-transformers\nSuccessfully installed sacremoses-0.0.38 sentence-transformers-0.2.5 sentencepiece-0.1.85 transformers-2.3.0\n"
],
[
"from sentence_transformers import SentenceTransformer\nmodel = SentenceTransformer('bert-base-nli-mean-tokens')",
"_____no_output_____"
],
[
"sentences = ['This framework generates embeddings for each input sentence',\n 'Sentences are passed as a list of string.', \n 'The quick brown fox jumps over the lazy dog.']\nsentence_embeddings = model.encode(sentences)",
"_____no_output_____"
],
[
"for sentence, embedding in zip(sentences, sentence_embeddings):\n print(\"Sentence:\", sentence)\n print(\"Embedding:\", len(embedding), embedding[:10])\n print(\"\")",
"Sentence: This framework generates embeddings for each input sentence\nEmbedding: 768 [-0.10409494 0.5274763 1.1797734 0.19436592 0.1591138 0.5455506\n 0.28180864 0.12159112 0.29196844 -0.33685815]\n\nSentence: Sentences are passed as a list of string.\nEmbedding: 768 [-0.13118398 -0.17390281 1.1052189 0.24854158 0.04100083 0.40314466\n -0.3816723 0.17468335 -0.5365215 0.3570093 ]\n\nSentence: The quick brown fox jumps over the lazy dog.\nEmbedding: 768 [-0.74899244 0.7189174 -1.039457 0.06408766 0.05070439 -0.7290621\n -0.37650624 -0.355325 -0.3260921 -0.8520542 ]\n\n"
],
[
"sentence_embeddings = model.encode([\n 'Мама мыла раму'\n])",
"_____no_output_____"
],
[
"rus_sentences = ['мама мыла раму', 'рама мыла маму']\nrus_sentences_embeddings = model.encode(rus_sentences)\nfor sentence, embedding in zip(rus_sentences, rus_sentences_embeddings):\n print(\"Sentence:\", sentence)\n print(\"Embedding:\", len(embedding), embedding[:10])\n print(\"\")",
"Sentence: мама мыла раму\nEmbedding: 768 [ 0.02418214 0.18126705 1.2029917 0.04019723 0.8840116 0.5068431\n 0.28139934 0.49990654 -0.3826871 0.395053 ]\n\nSentence: рама мыла маму\nEmbedding: 768 [ 0.01930119 0.15019166 1.1643051 0.05611518 0.8318267 0.541871\n 0.29248446 0.5805241 -0.36399835 0.3372139 ]\n\n"
],
[
"tatar_sentences = ['Вахит Имамовның бу китабын экстремистик китап дип бәяләргә тырышып, тыю өчен суд-мәхкәмә эшләре бара.', \n 'Суд киләсе елда эшен дәвам итәчәк.', \n 'Ә әлегә документаль әсәр экспертиза уза.', \n 'Әлеге китапны ни сәбәпледер, мин дә үз вакытында укымый калганмын']\ntat_sentences_embeddings = model.encode(tatar_sentences)\nfor sentence, embedding in zip(tatar_sentences, tat_sentences_embeddings):\n print(\"Sentence:\", sentence)\n print(\"Embedding:\", len(embedding), embedding[:10])\n print(\"\") ",
"Sentence: Вахит Имамовның бу китабын экстремистик китап дип бәяләргә тырышып, тыю өчен суд-мәхкәмә эшләре бара.\nEmbedding: 768 [-0.19086 0.5377365 1.1533414 0.36398056 0.94677097 -0.22634238\n 0.671989 0.23747906 -0.02229634 0.29271248]\n\nSentence: Суд киләсе елда эшен дәвам итәчәк.\nEmbedding: 768 [-0.17635995 0.20949318 1.1887797 -0.07288634 0.39875278 -0.01915755\n 0.7602076 0.4387592 -0.05098998 0.07172798]\n\nSentence: Ә әлегә документаль әсәр экспертиза уза.\nEmbedding: 768 [-0.33823296 0.2649719 1.0133282 0.4988816 1.0454834 -0.17264365\n 0.4652237 0.5179101 0.02218292 0.23018488]\n\nSentence: Әлеге китапны ни сәбәпледер, мин дә үз вакытында укымый калганмын\nEmbedding: 768 [-0.3584811 0.48103166 0.9773039 0.37314287 0.78438133 -0.0925061\n 0.6486071 0.55623776 -0.32417202 0.4064436 ]\n\n"
],
[
"my_sentences = ['Mein Hund ist gross', 'Meine Katze ist gross', 'Mein Hund ist klein', 'Meine Katze ist klein']\nmy_sentence_embeddings = model.encode(my_sentences)",
"_____no_output_____"
],
[
"for sentence, embedding in zip(my_sentences, my_sentence_embeddings):\n print(\"Sentence:\", sentence)\n print(\"Embedding:\", len(embedding), embedding[:10])\n print(\"\") ",
"Sentence: Mein Hund ist gross\nEmbedding: 768 [-0.68678665 0.5958039 1.9084399 0.9460534 0.41467735 -0.42681494\n 1.332266 0.5314371 0.5306031 -0.2707733 ]\n\nSentence: Meine Katze ist gross\nEmbedding: 768 [-0.6022346 0.5453127 1.9917436 0.9135115 0.46526656 -0.26661032\n 1.3437456 0.6296472 0.43946677 -0.56163037]\n\nSentence: Mein Hund ist klein\nEmbedding: 768 [-0.64887327 0.505408 1.0070063 0.5067089 0.5015642 -0.14005356\n 0.68576115 0.60723275 0.12251262 -0.04573573]\n\nSentence: Meine Katze ist klein\nEmbedding: 768 [-0.47021928 0.46054146 1.1939256 0.46024287 0.44442078 -0.05121206\n 0.7456379 0.69472706 0.05512092 -0.30690145]\n\n"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73e9ebae0a0148faaffa0bc0e01c2a9013854ed | 10,595 | ipynb | Jupyter Notebook | code/20180913_calcium_imaging_analysis.ipynb | LienDNguyen/calcium_imaging | ea0c09a86b1bf8c5e0605d523624a237dbe9db0f | [
"MIT"
] | 2 | 2018-09-13T16:03:33.000Z | 2018-09-13T20:41:06.000Z | code/Old stuff/20180913_calcium_imaging_analysis.ipynb | LienDNguyen/calcium_imaging | ea0c09a86b1bf8c5e0605d523624a237dbe9db0f | [
"MIT"
] | 7 | 2018-09-13T16:30:17.000Z | 2018-10-29T20:36:12.000Z | code/Old stuff/20180913_calcium_imaging_analysis.ipynb | LienDNguyen/calcium_imaging | ea0c09a86b1bf8c5e0605d523624a237dbe9db0f | [
"MIT"
] | null | null | null | 33.634921 | 162 | 0.536951 | [
[
[
"# Overview",
"_____no_output_____"
],
[
"Functionality implemented so far:\n1. Read excel files and plot raw traces of graphs\n2. Find & calculate responding cells `calc_response_rate`\n3. Graph max utp response for each slide\n3. Plot average values for control groups vs. L89A overexpressed groups\n\nTODO's:\n** Please open an issue for anything that should be implemented! **",
"_____no_output_____"
],
[
"# Code",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"# Import modules for working with excel sheets and for plotting\n\n# matplotlib: module for plotting\n# pandas: module for working with dataframe (can be imported from excel, csv, txt)\n# %: ipython magic, to plot graphs in line\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport numpy as np\nimport seaborn as sns\n%matplotlib inline",
"_____no_output_____"
],
[
"# `PLOT' is a global variable that needs to be set to `True' to actually plot things in this notebook\nPLOT = False",
"_____no_output_____"
]
],
[
[
"## Load Data\n\nThe following dataset is NOT on GitHub. Make sure your local directory structure is as follows:\n\n repository_directory\n / \\ \\\n / \\ \\\n code assets other files (.gitignore, README.md, LICENSE.txt, ...)\n / \\\n / \\\n <jupyter_notebook_file> <data_file>\n \nAlso, if you want to use the functions in this script with another dataset, make sure to change `number_of_rows` \nand the file name in the following import statements.",
"_____no_output_____"
]
],
[
[
"# Import excel file as a `pandas.ExcelFile' object (which basically has all sub-sheets in a big container!)\n# also, only import 1302 rows\nnumber_of_rows = 1302\nca_data = pd.ExcelFile('../assets/2018September11_23h49min14s_sorted_transformed_data.xlsx', nrows=number_of_rows)",
"_____no_output_____"
]
],
[
[
"## Functions\n\nThe following functions are used throughout this notebook to analyze and visualize data.\nThe doc-string should provide enough information on how they work. \nThey basically encapsulate commonly used commands to make re-use easier!",
"_____no_output_____"
]
],
[
[
"# plot every single trace after reading subsheets and alphabetically sorting them\ndef plot_traces(df, plot=False):\n \"\"\"\n this function takes a pandas.io.excel.ExcelFile object and iterates over all sheets\n every column of every such sheet is interpreted as a 'trace' and plotted in a line plot\n a new line plot is created for every sheet in the pandas.io.excel.ExcelFile object\n \n ------------------------------\n arguments:\n df - input data (pandas.io.excel.ExcelFile)\n plot - defaults to False, if True, plot line plots for every sheet in `df'\n \"\"\"\n sheetnames = df.sheet_names.copy()\n sheetnames.sort()\n for sheetname in sheetnames: \n temp = pd.read_excel(df, sheetname)\n if plot:\n temp.plot(title=sheetname, legend=False)",
"_____no_output_____"
],
[
"# Find percentage of responding cells per slide\n# Find average according to grouping\ndef calc_response_rate(df, threshold=1.2, utp_range=(40,480), verbose=False, plot=False):\n \"\"\"\n this function calculates the response rate for calcium imaging data sets\n it takes a pandas.io.excel.ExcelFile and iterates over all data sheets and \n columns in the input data frames\n \n ------------------------------\n arguments:\n df - input data (pandas.io.excel.ExcelFile)\n threshold - defaults to 1.2, the response threshold for your dataset\n utp_range - defaults to (40,480), a tuple indicating the range in which to look \n verbose - defaults to False, if True, verbose output is printed (use it to suppress output)\n plot - defaults to False, if True, plot boxplots to visualize computations\n \"\"\"\n sheetnames = df.sheet_names.copy()\n sheetnames.sort()\n counter = 0\n col_counter = 0\n appended_data = []\n for sheetname in sheetnames: \n #print(\"this is a new sheet: {}\".format(sheetname))\n selected_df = pd.read_excel(df, sheetname)[utp_range[0]:utp_range[1]]\n selected_df_max = selected_df.max()\n \n # counter in 1st but not 2nd loop so it's reset to 0 after every sheet but not after every column\n counter = 0\n col_counter = 0\n for idx in selected_df_max.index:\n col_counter += 1\n if selected_df_max[idx] >= threshold:\n pass\n # TODO: implement actual functionality\n # print(\"current idx: {}\".format(idx))\n # print(utp_max[idx])\n else:\n counter = counter + 1 # shorthand for this is: counter += 1, in cool languages (computer languages): counter++\n \n d = {'Sheet name':[sheetname], 'Total cells':[col_counter], 'Non-responding': [counter],'Percentage responding': [100-(counter*100/col_counter)]}\n data=pd.DataFrame(d)\n appended_data.append(data)\n appended_data = pd.concat(appended_data,ignore_index=True) \n if verbose:\n print(appended_data)\n if plot:\n appended_data.loc[0:5].boxplot()\n appended_data.loc[6:12].boxplot()\n if verbose:\n print('Statistics for control cells')\n print(appended_data.loc[0:5].mean())\n print('Statistics for L89A cells')\n print(appended_data.loc[6:12].mean())",
"_____no_output_____"
]
],
[
[
"## Exploratory Data Analysis (*EDA*)",
"_____no_output_____"
]
],
[
[
"# call the newly created `plot_traces' function (output is suppressed)\nplot_traces(df=ca_data, plot=False)\n\n# call the newly created `calc_response_rate' function (output is suppressed) \ncalc_response_rate(df=ca_data, threshold=1.2, utp_range=(40, 480), verbose=False, plot=False)",
"_____no_output_____"
],
[
"# Find max UTP response for each slide & plot (no threshold so far)\nd = {}\nsheetnames = ca_data.sheet_names.copy()\nsheetnames.sort()\nfor sheetname in sheetnames: \n # print(\"Sheet: {}\".format(name))\n temp = pd.read_excel(ca_data, sheetname).max()\n d[sheetname] = temp\n if PLOT:\n pd.DataFrame(d).boxplot(figsize=(10,10))",
"_____no_output_____"
],
[
"# Find max UTP response for each group & plot (no threshold so far)\nsheetnames = ca_data.sheet_names.copy()\nsheetnames.sort()\nappended_data = []\nfor sheetname in sheetnames: \n temp = pd.read_excel(ca_data, sheetname).max()\n d = {'Sheet name':[sheetname], 'Max UTP response':[temp.mean()]}\n d_utp_max = pd.DataFrame(d)\n # print(d_utp_max)\n appended_data.append(d_utp_max)\nappended_data = pd.concat(appended_data,ignore_index=True) \nprint(appended_data)\n\nif PLOT:\n appended_data.loc[1:5].boxplot()\n print('Statistics for control cells')\n print(appended_data.loc[1:5].mean())",
" Sheet name Max UTP response\n0 CTRL1 3.590547\n1 CTRL2 4.629974\n2 CTRL3 4.076675\n3 CTRL4 5.815918\n4 CTRL5 6.898256\n5 CTRL6 7.632217\n6 L89A1 4.220858\n7 L89A2 4.427743\n8 L89A2.2 7.094816\n9 L89A3 6.349200\n10 L89A4 3.950152\n11 L89A5 4.209603\n12 L89A6 5.316882\n"
],
[
"if PLOT:\n print('Statistics for L89A cells')\n print(appended_data.loc[9:12].mean())\n appended_data.loc[9:12].boxplot()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
e73ea4a69f8a84829f72da8ed1b65374d20d9ba9 | 3,064 | ipynb | Jupyter Notebook | YOLOV4.ipynb | AlexBzrc/bustag | 75953e2cb0468bef706bc7b6c95424759c571a92 | [
"MIT"
] | null | null | null | YOLOV4.ipynb | AlexBzrc/bustag | 75953e2cb0468bef706bc7b6c95424759c571a92 | [
"MIT"
] | null | null | null | YOLOV4.ipynb | AlexBzrc/bustag | 75953e2cb0468bef706bc7b6c95424759c571a92 | [
"MIT"
] | null | null | null | 42.555556 | 336 | 0.583225 | [
[
[
"<a href=\"https://colab.research.google.com/github/AlexBzrc/bustag/blob/master/YOLOV4.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"! python3 \"/content/drive/MyDrive/yolov4-pytorch-master/predict.py\"",
"/content/drive/MyDrive/yolov4-pytorch-master/model_data/yolo4_weights.pth model, anchors, and classes loaded.\nInput image filename:/content/sample_data/img/cap1.jpg\n/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)\n return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)\nTraceback (most recent call last):\n File \"/content/drive/MyDrive/yolov4-pytorch-master/predict.py\", line 63, in <module>\n r_image = yolo.detect_image(image)\n File \"/content/drive/MyDrive/yolov4-pytorch-master/yolo.py\", line 151, in detect_image\n font = ImageFont.truetype(font='model_data/simhei.ttf', size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))\n File \"/usr/local/lib/python3.7/dist-packages/PIL/ImageFont.py\", line 648, in truetype\n return freetype(font)\n File \"/usr/local/lib/python3.7/dist-packages/PIL/ImageFont.py\", line 645, in freetype\n return FreeTypeFont(font, size, index, encoding, layout_engine)\n File \"/usr/local/lib/python3.7/dist-packages/PIL/ImageFont.py\", line 194, in __init__\n font, size, index, encoding, layout_engine=layout_engine\nOSError: cannot open resource\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
]
] |
e73ea56eca84a5b7306fc2111b184a67b627554c | 175,351 | ipynb | Jupyter Notebook | Fall/OldLSTMtemp.ipynb | spewmaker/senior-capstone | d8c58dfa54fdb6d42b76699b541fcca5660a2846 | [
"MIT"
] | null | null | null | Fall/OldLSTMtemp.ipynb | spewmaker/senior-capstone | d8c58dfa54fdb6d42b76699b541fcca5660a2846 | [
"MIT"
] | null | null | null | Fall/OldLSTMtemp.ipynb | spewmaker/senior-capstone | d8c58dfa54fdb6d42b76699b541fcca5660a2846 | [
"MIT"
] | null | null | null | 115.210907 | 65,534 | 0.804438 | [
[
[
"import pandas as pd\nimport numpy as np\nfrom datetime import datetime\nfrom keras.models import Sequential\nfrom keras.layers import Dense, LSTM\nfrom math import sqrt, floor\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.metrics import mean_squared_error\nfrom matplotlib import pyplot",
"_____no_output_____"
]
],
[
[
"## Load Data",
"_____no_output_____"
]
],
[
[
"df_tweets = pd.read_csv(\"trump_tweets.csv\", parse_dates = ['date'], index_col=7)\ndf_tweets.head()",
"_____no_output_____"
],
[
"df_tweets.tail()",
"_____no_output_____"
],
[
"df_doge = pd.read_csv(\"Daily-DOGE-USD.csv\", parse_dates=['Date'], index_col=0)\ndf_doge.head()",
"_____no_output_____"
],
[
"df_doge.tail()",
"_____no_output_____"
]
],
[
[
"# LSTM Application",
"_____no_output_____"
],
[
"## Function For Converting Time Series Data For Supervised Learning",
"_____no_output_____"
]
],
[
[
"# convert series to supervised learning\n# developed in this blog post https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/\ndef series_to_supervised(data, n_in=1, n_out=1, dropnan=True):\n n_vars = 1 if type(data) is list else data.shape[1]\n df = pd.DataFrame(data)\n cols, names = list(), list()\n # input sequence (t-n, ... t-1)\n for i in range(n_in, 0, -1):\n cols.append(df.shift(i))\n names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]\n # forecast sequence (t, t+1, ..., t+n)\n for i in range(0, n_out):\n cols.append(df.shift(-i))\n if i == 0:\n names += [('var%d(t)' % (j+1)) for j in range(n_vars)]\n else:\n names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]\n\t# put it all together\n agg = pd.concat(cols, axis=1)\n agg.columns = names\n\t# drop rows with NaN values\n if dropnan:\n agg.dropna(inplace=True)\n return agg",
"_____no_output_____"
]
],
[
[
"## Preparing Data",
"_____no_output_____"
]
],
[
[
"# Aligning Tweet Data with Doge Data\ndf_tweets = df_tweets.loc[(df_tweets.index > '2017-08-24')]\n# Dropping ID column since it's unexpected to be useful\ndf_tweets = df_tweets.drop(columns=['id'], axis=1)\n\n# Changing by the second data to by the day data\nchanged1 = df_tweets.groupby([df_tweets.index.date]).size().reset_index(name='Tweet Count')\nchanged2 = df_tweets.groupby([df_tweets.index.date]).agg('sum')\nchanged1 = changed1.set_index('index')\n\ndf_tweets = changed1.merge(changed2, how='outer', left_index=True, right_index=True)\ndf_tweets = df_tweets.rename_axis('Date')\ndf_tweets.head()",
"_____no_output_____"
],
[
"# Aligning Doge Data with Tweet Data\ndf_doge = df_doge.loc[(df_doge.index < '2021-01-08')]\n#df_doge = df_doge.drop(columns=['Open', 'High', 'Low', 'Adj Close'], axis=1)\ndf_doge.head()",
"_____no_output_____"
],
[
"df_doge.plot(y='Close', figsize=(15,5)).set_title('DogeCoin Close')",
"_____no_output_____"
],
[
"# Merging Two Data Sets Together\ndf = df_doge.merge(df_tweets, how='outer', left_index=True, right_index=True)\ndf.head()",
"_____no_output_____"
],
[
"values = df.values\n\n# integer encoding of labels (not using yet here)\n#encoder = LabelEncoder()\n\n# ensure all data is float\nvalues = values.astype('float32')\nprint(values.shape)\n# normalize features\nscaler = MinMaxScaler(feature_range=(0,1))\nscaled = scaler.fit_transform(values)\nprint(scaled.shape)\n# frame as supervised learning\nreframed = series_to_supervised(scaled, 1, 1)\n\n# Drop Columns of Variables We Aren't Predicting\nreframed.drop(reframed.columns[[9, 10, 11, 13, 14, 15, 16, 17]], axis=1, inplace=True)\nprint(reframed.shape)\nreframed.head()\n",
"(1234, 9)\n(1234, 9)\n(1212, 10)\n"
],
[
"# split into train and test sets\nvalues = reframed.values\nn_train = floor(len(values) * 0.25)\ntrain = values[:n_train, :]\ntest = values[n_train:, :]\n# split into input and outputs\ntrain_X, train_y = train[:, :-1], train[:, -1]\ntest_X, test_y = test[:, :-1], test[:, -1]\n# reshape input to be 3D [samples, timesteps, features]\ntrain_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))\ntest_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))\nprint(train_X.shape, train_y.shape, test_X.shape, test_y.shape)",
"(303, 1, 9) (303,) (909, 1, 9) (909,)\n"
],
[
"# design network\nmodel = Sequential()\nmodel.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2])))\nmodel.add(Dense(1))\nmodel.compile(loss='mae', optimizer='adam')\n# fit network\nhistory = model.fit(train_X, train_y, epochs=100, batch_size=50, validation_data=(test_X, test_y), verbose=2, shuffle=False)\n# plot history\npyplot.plot(history.history['loss'], label='train')\npyplot.plot(history.history['val_loss'], label='test')\npyplot.legend()\npyplot.show()",
"Epoch 1/100\n7/7 - 2s - loss: 0.1780 - val_loss: 0.0851\nEpoch 2/100\n7/7 - 1s - loss: 0.1416 - val_loss: 0.0486\nEpoch 3/100\n7/7 - 1s - loss: 0.1150 - val_loss: 0.0311\nEpoch 4/100\n7/7 - 0s - loss: 0.0937 - val_loss: 0.0380\nEpoch 5/100\n7/7 - 0s - loss: 0.0806 - val_loss: 0.0484\nEpoch 6/100\n7/7 - 0s - loss: 0.0722 - val_loss: 0.0544\nEpoch 7/100\n7/7 - 0s - loss: 0.0659 - val_loss: 0.0553\nEpoch 8/100\n7/7 - 0s - loss: 0.0602 - val_loss: 0.0519\nEpoch 9/100\n7/7 - 0s - loss: 0.0546 - val_loss: 0.0460\nEpoch 10/100\n7/7 - 0s - loss: 0.0490 - val_loss: 0.0388\nEpoch 11/100\n7/7 - 0s - loss: 0.0434 - val_loss: 0.0315\nEpoch 12/100\n7/7 - 0s - loss: 0.0378 - val_loss: 0.0248\nEpoch 13/100\n7/7 - 0s - loss: 0.0325 - val_loss: 0.0184\nEpoch 14/100\n7/7 - 0s - loss: 0.0284 - val_loss: 0.0129\nEpoch 15/100\n7/7 - 0s - loss: 0.0253 - val_loss: 0.0096\nEpoch 16/100\n7/7 - 0s - loss: 0.0225 - val_loss: 0.0091\nEpoch 17/100\n7/7 - 0s - loss: 0.0207 - val_loss: 0.0094\nEpoch 18/100\n7/7 - 0s - loss: 0.0203 - val_loss: 0.0096\nEpoch 19/100\n7/7 - 0s - loss: 0.0195 - val_loss: 0.0097\nEpoch 20/100\n7/7 - 0s - loss: 0.0194 - val_loss: 0.0092\nEpoch 21/100\n7/7 - 0s - loss: 0.0195 - val_loss: 0.0090\nEpoch 22/100\n7/7 - 0s - loss: 0.0193 - val_loss: 0.0088\nEpoch 23/100\n7/7 - 0s - loss: 0.0192 - val_loss: 0.0086\nEpoch 24/100\n7/7 - 0s - loss: 0.0192 - val_loss: 0.0086\nEpoch 25/100\n7/7 - 0s - loss: 0.0192 - val_loss: 0.0088\nEpoch 26/100\n7/7 - 0s - loss: 0.0192 - val_loss: 0.0087\nEpoch 27/100\n7/7 - 0s - loss: 0.0191 - val_loss: 0.0087\nEpoch 28/100\n7/7 - 0s - loss: 0.0190 - val_loss: 0.0087\nEpoch 29/100\n7/7 - 0s - loss: 0.0189 - val_loss: 0.0089\nEpoch 30/100\n7/7 - 0s - loss: 0.0188 - val_loss: 0.0089\nEpoch 31/100\n7/7 - 0s - loss: 0.0188 - val_loss: 0.0089\nEpoch 32/100\n7/7 - 0s - loss: 0.0187 - val_loss: 0.0090\nEpoch 33/100\n7/7 - 0s - loss: 0.0186 - val_loss: 0.0091\nEpoch 34/100\n7/7 - 0s - loss: 0.0186 - val_loss: 0.0092\nEpoch 35/100\n7/7 - 0s - loss: 0.0185 - val_loss: 0.0093\nEpoch 36/100\n7/7 - 0s - loss: 0.0185 - val_loss: 0.0093\nEpoch 37/100\n7/7 - 0s - loss: 0.0184 - val_loss: 0.0094\nEpoch 38/100\n7/7 - 0s - loss: 0.0184 - val_loss: 0.0095\nEpoch 39/100\n7/7 - 0s - loss: 0.0184 - val_loss: 0.0096\nEpoch 40/100\n7/7 - 0s - loss: 0.0183 - val_loss: 0.0095\nEpoch 41/100\n7/7 - 0s - loss: 0.0183 - val_loss: 0.0097\nEpoch 42/100\n7/7 - 0s - loss: 0.0183 - val_loss: 0.0098\nEpoch 43/100\n7/7 - 0s - loss: 0.0183 - val_loss: 0.0094\nEpoch 44/100\n7/7 - 0s - loss: 0.0182 - val_loss: 0.0093\nEpoch 45/100\n7/7 - 0s - loss: 0.0183 - val_loss: 0.0103\nEpoch 46/100\n7/7 - 0s - loss: 0.0182 - val_loss: 0.0090\nEpoch 47/100\n7/7 - 0s - loss: 0.0182 - val_loss: 0.0101\nEpoch 48/100\n7/7 - 0s - loss: 0.0181 - val_loss: 0.0091\nEpoch 49/100\n7/7 - 0s - loss: 0.0181 - val_loss: 0.0099\nEpoch 50/100\n7/7 - 0s - loss: 0.0180 - val_loss: 0.0091\nEpoch 51/100\n7/7 - 0s - loss: 0.0181 - val_loss: 0.0099\nEpoch 52/100\n7/7 - 0s - loss: 0.0180 - val_loss: 0.0091\nEpoch 53/100\n7/7 - 0s - loss: 0.0180 - val_loss: 0.0098\nEpoch 54/100\n7/7 - 0s - loss: 0.0180 - val_loss: 0.0091\nEpoch 55/100\n7/7 - 0s - loss: 0.0180 - val_loss: 0.0099\nEpoch 56/100\n7/7 - 0s - loss: 0.0179 - val_loss: 0.0091\nEpoch 57/100\n7/7 - 0s - loss: 0.0180 - val_loss: 0.0102\nEpoch 58/100\n7/7 - 0s - loss: 0.0179 - val_loss: 0.0093\nEpoch 59/100\n7/7 - 0s - loss: 0.0179 - val_loss: 0.0099\nEpoch 60/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0092\nEpoch 61/100\n7/7 - 0s - loss: 0.0179 - val_loss: 0.0102\nEpoch 62/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0093\nEpoch 63/100\n7/7 - 0s - loss: 0.0179 - val_loss: 0.0102\nEpoch 64/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0093\nEpoch 65/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0105\nEpoch 66/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0095\nEpoch 67/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0100\nEpoch 68/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0094\nEpoch 69/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0106\nEpoch 70/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0095\nEpoch 71/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0103\nEpoch 72/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0096\nEpoch 73/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0108\nEpoch 74/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0096\nEpoch 75/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0108\nEpoch 76/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0094\nEpoch 77/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0099\nEpoch 78/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0106\nEpoch 79/100\n7/7 - 0s - loss: 0.0175 - val_loss: 0.0088\nEpoch 80/100\n7/7 - 0s - loss: 0.0179 - val_loss: 0.0115\nEpoch 81/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0090\nEpoch 82/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0108\nEpoch 83/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0095\nEpoch 84/100\n7/7 - 0s - loss: 0.0175 - val_loss: 0.0095\nEpoch 85/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0103\nEpoch 86/100\n7/7 - 0s - loss: 0.0175 - val_loss: 0.0088\nEpoch 87/100\n7/7 - 0s - loss: 0.0179 - val_loss: 0.0113\nEpoch 88/100\n7/7 - 0s - loss: 0.0175 - val_loss: 0.0090\nEpoch 89/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0105\nEpoch 90/100\n7/7 - 0s - loss: 0.0175 - val_loss: 0.0090\nEpoch 91/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0106\nEpoch 92/100\n7/7 - 0s - loss: 0.0174 - val_loss: 0.0089\nEpoch 93/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0109\nEpoch 94/100\n7/7 - 0s - loss: 0.0175 - val_loss: 0.0090\nEpoch 95/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0105\nEpoch 96/100\n7/7 - 0s - loss: 0.0175 - val_loss: 0.0090\nEpoch 97/100\n7/7 - 0s - loss: 0.0178 - val_loss: 0.0109\nEpoch 98/100\n7/7 - 0s - loss: 0.0174 - val_loss: 0.0090\nEpoch 99/100\n7/7 - 0s - loss: 0.0177 - val_loss: 0.0112\nEpoch 100/100\n7/7 - 0s - loss: 0.0176 - val_loss: 0.0096\n"
],
[
"# make a prediction\nyhat = model.predict(test_X)\ntest_X = test_X.reshape((test_X.shape[0], test_X.shape[2]))\ninv_yhat = np.concatenate((yhat, test_X[:, 1:]), axis=1)\ninv_yhat = scaler.inverse_transform(inv_yhat)\ninv_yhat = inv_yhat[:,0]\ntest_y = test_y.reshape((len(test_y), 1))\ninv_y = np.concatenate((test_y, test_X[:, 1:]), axis=1)\ninv_y = scaler.inverse_transform(inv_y)\ninv_y = inv_y[:,0]",
"_____no_output_____"
],
[
"# rmse\nrmse = sqrt(mean_squared_error(inv_y, inv_yhat))\nprint('Test RMSE: %.3f' % rmse)\nnormalized_rmse = rmse/(max(max(inv_yhat),max(inv_y))-min(min(inv_yhat),min(inv_y)))\nprint('Normalized RMSE: %.3f' % normalized_rmse)",
"Test RMSE: 0.000\nNormalized RMSE: 0.027\n"
],
[
"pyplot.figure(figsize=(10,10))\npyplot.subplot(2, 1, 1)\npyplot.plot(inv_y, label=\"Actual\")\npyplot.title(\"Actual\")\npyplot.subplot(2, 1, 2)\npyplot.plot(inv_yhat, label=\"Prediction\")\npyplot.title(\"Prediction\")\npyplot.tight_layout()\npyplot.show()",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73eaafee9990db507ed66081786b5ad15fe5f91 | 45,541 | ipynb | Jupyter Notebook | Vince_assignment_kaggle_challenge_2.ipynb | Vincent-Emma/DS-Unit-2-Kaggle-Challenge | 5d6ba38ed52aa21f664b143ca37539aa901ad142 | [
"MIT"
] | null | null | null | Vince_assignment_kaggle_challenge_2.ipynb | Vincent-Emma/DS-Unit-2-Kaggle-Challenge | 5d6ba38ed52aa21f664b143ca37539aa901ad142 | [
"MIT"
] | null | null | null | Vince_assignment_kaggle_challenge_2.ipynb | Vincent-Emma/DS-Unit-2-Kaggle-Challenge | 5d6ba38ed52aa21f664b143ca37539aa901ad142 | [
"MIT"
] | null | null | null | 57.501263 | 303 | 0.587119 | [
[
[
"<a href=\"https://colab.research.google.com/github/Vincent-Emma/DS-Unit-2-Kaggle-Challenge/blob/master/Vince_assignment_kaggle_challenge_2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"Lambda School Data Science, Unit 2: Predictive Modeling\n\n# Kaggle Challenge, Module 2\n\n## Assignment\n- [ ] Read [“Adopting a Hypothesis-Driven Workflow”](https://outline.com/5S5tsB), a blog post by a Lambda DS student about the Tanzania Waterpumps challenge.\n- [ ] Continue to participate in our Kaggle challenge.\n- [ ] Try Ordinal Encoding.\n- [ ] Try a Random Forest Classifier.\n- [ ] Submit your predictions to our Kaggle competition. (Go to our Kaggle InClass competition webpage. Use the blue **Submit Predictions** button to upload your CSV file. Or you can use the Kaggle API to submit your predictions.)\n- [ ] Commit your notebook to your fork of the GitHub repo.\n\n## Stretch Goals\n\n### Doing\n- [ ] Add your own stretch goal(s) !\n- [ ] Do more exploratory data analysis, data cleaning, feature engineering, and feature selection.\n- [ ] Try other [categorical encodings](https://contrib.scikit-learn.org/categorical-encoding/).\n- [ ] Get and plot your feature importances.\n- [ ] Make visualizations and share on Slack.\n\n### Reading\n\nTop recommendations in _**bold italic:**_\n\n#### Decision Trees\n- A Visual Introduction to Machine Learning, [Part 1: A Decision Tree](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/), and _**[Part 2: Bias and Variance](http://www.r2d3.us/visual-intro-to-machine-learning-part-2/)**_\n- [Decision Trees: Advantages & Disadvantages](https://christophm.github.io/interpretable-ml-book/tree.html#advantages-2)\n- [How a Russian mathematician constructed a decision tree — by hand — to solve a medical problem](http://fastml.com/how-a-russian-mathematician-constructed-a-decision-tree-by-hand-to-solve-a-medical-problem/)\n- [How decision trees work](https://brohrer.github.io/how_decision_trees_work.html)\n- [Let’s Write a Decision Tree Classifier from Scratch](https://www.youtube.com/watch?v=LDRbO9a6XPU)\n\n#### Random Forests\n- [_An Introduction to Statistical Learning_](http://www-bcf.usc.edu/~gareth/ISL/), Chapter 8: Tree-Based Methods\n- [Coloring with Random Forests](http://structuringtheunstructured.blogspot.com/2017/11/coloring-with-random-forests.html)\n- _**[Random Forests for Complete Beginners: The definitive guide to Random Forests and Decision Trees](https://victorzhou.com/blog/intro-to-random-forests/)**_\n\n#### Categorical encoding for trees\n- [Are categorical variables getting lost in your random forests?](https://roamanalytics.com/2016/10/28/are-categorical-variables-getting-lost-in-your-random-forests/)\n- [Beyond One-Hot: An Exploration of Categorical Variables](http://www.willmcginnis.com/2015/11/29/beyond-one-hot-an-exploration-of-categorical-variables/)\n- _**[Categorical Features and Encoding in Decision Trees](https://medium.com/data-design/visiting-categorical-features-and-encoding-in-decision-trees-53400fa65931)**_\n- _**[Coursera — How to Win a Data Science Competition: Learn from Top Kagglers — Concept of mean encoding](https://www.coursera.org/lecture/competitive-data-science/concept-of-mean-encoding-b5Gxv)**_\n- [Mean (likelihood) encodings: a comprehensive study](https://www.kaggle.com/vprokopev/mean-likelihood-encodings-a-comprehensive-study)\n- [The Mechanics of Machine Learning, Chapter 6: Categorically Speaking](https://mlbook.explained.ai/catvars.html)\n\n#### Imposter Syndrome\n- [Effort Shock and Reward Shock (How The Karate Kid Ruined The Modern World)](http://www.tempobook.com/2014/07/09/effort-shock-and-reward-shock/)\n- [How to manage impostor syndrome in data science](https://towardsdatascience.com/how-to-manage-impostor-syndrome-in-data-science-ad814809f068)\n- [\"I am not a real data scientist\"](https://brohrer.github.io/imposter_syndrome.html)\n- _**[Imposter Syndrome in Data Science](https://caitlinhudon.com/2018/01/19/imposter-syndrome-in-data-science/)**_\n\n\n\n\n",
"_____no_output_____"
],
[
"### Setup\n\nYou can work locally (follow the [local setup instructions](https://lambdaschool.github.io/ds/unit2/local/)) or on Colab (run the code cell below).",
"_____no_output_____"
]
],
[
[
"import os, sys\nin_colab = 'google.colab' in sys.modules\n\n# If you're in Colab...\nif in_colab:\n # Pull files from Github repo\n os.chdir('/content')\n !git init .\n !git remote add origin https://github.com/LambdaSchool/DS-Unit-2-Kaggle-Challenge.git\n !git pull origin master\n \n # Install required python packages\n !pip install -r requirements.txt\n \n # Change into directory for module\n os.chdir('module2')",
"Initialized empty Git repository in /content/.git/\nremote: Enumerating objects: 85, done.\u001b[K\nremote: Total 85 (delta 0), reused 0 (delta 0), pack-reused 85\nUnpacking objects: 100% (85/85), done.\nFrom https://github.com/LambdaSchool/DS-Unit-2-Kaggle-Challenge\n * branch master -> FETCH_HEAD\n * [new branch] master -> origin/master\nCollecting category_encoders==2.0.0 (from -r requirements.txt (line 1))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/6e/a1/f7a22f144f33be78afeb06bfa78478e8284a64263a3c09b1ef54e673841e/category_encoders-2.0.0-py2.py3-none-any.whl (87kB)\n\u001b[K |████████████████████████████████| 92kB 4.9MB/s \n\u001b[?25hCollecting eli5==0.10.1 (from -r requirements.txt (line 2))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/97/2f/c85c7d8f8548e460829971785347e14e45fa5c6617da374711dec8cb38cc/eli5-0.10.1-py2.py3-none-any.whl (105kB)\n\u001b[K |████████████████████████████████| 112kB 15.0MB/s \n\u001b[?25hRequirement already satisfied: matplotlib!=3.1.1 in /usr/local/lib/python3.6/dist-packages (from -r requirements.txt (line 3)) (3.0.3)\nCollecting pandas-profiling==2.3.0 (from -r requirements.txt (line 4))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/2c/2f/aae19e2173c10a9bb7fee5f5cad35dbe53a393960fc91abc477dcc4661e8/pandas-profiling-2.3.0.tar.gz (127kB)\n\u001b[K |████████████████████████████████| 133kB 43.1MB/s \n\u001b[?25hCollecting pdpbox==0.2.0 (from -r requirements.txt (line 5))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/87/23/ac7da5ba1c6c03a87c412e7e7b6e91a10d6ecf4474906c3e736f93940d49/PDPbox-0.2.0.tar.gz (57.7MB)\n\u001b[K |████████████████████████████████| 57.7MB 1.4MB/s \n\u001b[?25hRequirement already satisfied: plotly==4.1.1 in /usr/local/lib/python3.6/dist-packages (from -r requirements.txt (line 6)) (4.1.1)\nRequirement already satisfied: seaborn==0.9.0 in /usr/local/lib/python3.6/dist-packages (from -r requirements.txt (line 7)) (0.9.0)\nRequirement already satisfied: scikit-learn==0.21.3 in /usr/local/lib/python3.6/dist-packages (from -r requirements.txt (line 8)) (0.21.3)\nCollecting shap==0.30.0 (from -r requirements.txt (line 9))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/3b/98/16829410426bdd08b836c30e164c56646d6a102afb9eadd81a6bd3a8bb65/shap-0.30.0.tar.gz (240kB)\n\u001b[K |████████████████████████████████| 245kB 40.1MB/s \n\u001b[?25hRequirement already satisfied: xgboost==0.90 in /usr/local/lib/python3.6/dist-packages (from -r requirements.txt (line 10)) (0.90)\nRequirement already satisfied: patsy>=0.4.1 in /usr/local/lib/python3.6/dist-packages (from category_encoders==2.0.0->-r requirements.txt (line 1)) (0.5.1)\nRequirement already satisfied: numpy>=1.11.3 in /usr/local/lib/python3.6/dist-packages (from category_encoders==2.0.0->-r requirements.txt (line 1)) (1.16.5)\nRequirement already satisfied: statsmodels>=0.6.1 in /usr/local/lib/python3.6/dist-packages (from category_encoders==2.0.0->-r requirements.txt (line 1)) (0.10.1)\nRequirement already satisfied: pandas>=0.21.1 in /usr/local/lib/python3.6/dist-packages (from category_encoders==2.0.0->-r requirements.txt (line 1)) (0.24.2)\nRequirement already satisfied: scipy>=0.19.0 in /usr/local/lib/python3.6/dist-packages (from category_encoders==2.0.0->-r requirements.txt (line 1)) (1.3.1)\nRequirement already satisfied: tabulate>=0.7.7 in /usr/local/lib/python3.6/dist-packages (from eli5==0.10.1->-r requirements.txt (line 2)) (0.8.3)\nRequirement already satisfied: jinja2 in /usr/local/lib/python3.6/dist-packages (from eli5==0.10.1->-r requirements.txt (line 2)) (2.10.1)\nRequirement already satisfied: attrs>16.0.0 in /usr/local/lib/python3.6/dist-packages (from eli5==0.10.1->-r requirements.txt (line 2)) (19.1.0)\nRequirement already satisfied: graphviz in /usr/local/lib/python3.6/dist-packages (from eli5==0.10.1->-r requirements.txt (line 2)) (0.10.1)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from eli5==0.10.1->-r requirements.txt (line 2)) (1.12.0)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib!=3.1.1->-r requirements.txt (line 3)) (1.1.0)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib!=3.1.1->-r requirements.txt (line 3)) (2.5.3)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib!=3.1.1->-r requirements.txt (line 3)) (0.10.0)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib!=3.1.1->-r requirements.txt (line 3)) (2.4.2)\nRequirement already satisfied: missingno>=0.4.2 in /usr/local/lib/python3.6/dist-packages (from pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.4.2)\nCollecting htmlmin>=0.1.12 (from pandas-profiling==2.3.0->-r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/b3/e7/fcd59e12169de19f0131ff2812077f964c6b960e7c09804d30a7bf2ab461/htmlmin-0.1.12.tar.gz\nCollecting phik>=0.9.8 (from pandas-profiling==2.3.0->-r requirements.txt (line 4))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/45/ad/24a16fa4ba612fb96a3c4bb115a5b9741483f53b66d3d3afd987f20fa227/phik-0.9.8-py3-none-any.whl (606kB)\n\u001b[K |████████████████████████████████| 614kB 37.2MB/s \n\u001b[?25hCollecting confuse>=1.0.0 (from pandas-profiling==2.3.0->-r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/4c/6f/90e860cba937c174d8b3775729ccc6377eb91f52ad4eeb008e7252a3646d/confuse-1.0.0.tar.gz\nRequirement already satisfied: astropy in /usr/local/lib/python3.6/dist-packages (from pandas-profiling==2.3.0->-r requirements.txt (line 4)) (3.0.5)\nRequirement already satisfied: joblib in /usr/local/lib/python3.6/dist-packages (from pdpbox==0.2.0->-r requirements.txt (line 5)) (0.13.2)\nRequirement already satisfied: psutil in /usr/local/lib/python3.6/dist-packages (from pdpbox==0.2.0->-r requirements.txt (line 5)) (5.4.8)\nRequirement already satisfied: retrying>=1.3.3 in /usr/local/lib/python3.6/dist-packages (from plotly==4.1.1->-r requirements.txt (line 6)) (1.3.3)\nRequirement already satisfied: tqdm>4.25.0 in /usr/local/lib/python3.6/dist-packages (from shap==0.30.0->-r requirements.txt (line 9)) (4.28.1)\nRequirement already satisfied: ipython in /usr/local/lib/python3.6/dist-packages (from shap==0.30.0->-r requirements.txt (line 9)) (5.5.0)\nRequirement already satisfied: scikit-image in /usr/local/lib/python3.6/dist-packages (from shap==0.30.0->-r requirements.txt (line 9)) (0.15.0)\nRequirement already satisfied: pytz>=2011k in /usr/local/lib/python3.6/dist-packages (from pandas>=0.21.1->category_encoders==2.0.0->-r requirements.txt (line 1)) (2018.9)\nRequirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.6/dist-packages (from jinja2->eli5==0.10.1->-r requirements.txt (line 2)) (1.1.1)\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from kiwisolver>=1.0.1->matplotlib!=3.1.1->-r requirements.txt (line 3)) (41.2.0)\nCollecting pytest-pylint>=0.13.0 (from phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/64/dc/6f35f114844fb12e38d60c4f3d2441a55baff7043ad4e013777dff55746c/pytest_pylint-0.14.1-py3-none-any.whl\nRequirement already satisfied: jupyter-client>=5.2.3 in /usr/local/lib/python3.6/dist-packages (from phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (5.3.1)\nCollecting pytest>=4.0.2 (from phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/2f/19/d5f71752f71451ccc5ed5f6739e9da4a235f38783fdaf3629cae41b2ca7b/pytest-5.1.2-py3-none-any.whl (224kB)\n\u001b[K |████████████████████████████████| 225kB 42.0MB/s \n\u001b[?25hRequirement already satisfied: numba>=0.38.1 in /usr/local/lib/python3.6/dist-packages (from phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.40.1)\nRequirement already satisfied: nbconvert>=5.3.1 in /usr/local/lib/python3.6/dist-packages (from phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (5.6.0)\nRequirement already satisfied: pyyaml in /usr/local/lib/python3.6/dist-packages (from confuse>=1.0.0->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (3.13)\nRequirement already satisfied: pexpect; sys_platform != \"win32\" in /usr/local/lib/python3.6/dist-packages (from ipython->shap==0.30.0->-r requirements.txt (line 9)) (4.7.0)\nRequirement already satisfied: traitlets>=4.2 in /usr/local/lib/python3.6/dist-packages (from ipython->shap==0.30.0->-r requirements.txt (line 9)) (4.3.2)\nRequirement already satisfied: decorator in /usr/local/lib/python3.6/dist-packages (from ipython->shap==0.30.0->-r requirements.txt (line 9)) (4.4.0)\nRequirement already satisfied: pickleshare in /usr/local/lib/python3.6/dist-packages (from ipython->shap==0.30.0->-r requirements.txt (line 9)) (0.7.5)\nRequirement already satisfied: simplegeneric>0.8 in /usr/local/lib/python3.6/dist-packages (from ipython->shap==0.30.0->-r requirements.txt (line 9)) (0.8.1)\nRequirement already satisfied: pygments in /usr/local/lib/python3.6/dist-packages (from ipython->shap==0.30.0->-r requirements.txt (line 9)) (2.1.3)\nRequirement already satisfied: prompt-toolkit<2.0.0,>=1.0.4 in /usr/local/lib/python3.6/dist-packages (from ipython->shap==0.30.0->-r requirements.txt (line 9)) (1.0.16)\nRequirement already satisfied: imageio>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from scikit-image->shap==0.30.0->-r requirements.txt (line 9)) (2.4.1)\nRequirement already satisfied: pillow>=4.3.0 in /usr/local/lib/python3.6/dist-packages (from scikit-image->shap==0.30.0->-r requirements.txt (line 9)) (4.3.0)\nRequirement already satisfied: PyWavelets>=0.4.0 in /usr/local/lib/python3.6/dist-packages (from scikit-image->shap==0.30.0->-r requirements.txt (line 9)) (1.0.3)\nRequirement already satisfied: networkx>=2.0 in /usr/local/lib/python3.6/dist-packages (from scikit-image->shap==0.30.0->-r requirements.txt (line 9)) (2.3)\nCollecting pylint>=1.4.5 (from pytest-pylint>=0.13.0->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/60/c2/b3f73f4ac008bef6e75bca4992f3963b3f85942e0277237721ef1c151f0d/pylint-2.3.1-py3-none-any.whl (765kB)\n\u001b[K |████████████████████████████████| 768kB 37.5MB/s \n\u001b[?25hRequirement already satisfied: tornado>=4.1 in /usr/local/lib/python3.6/dist-packages (from jupyter-client>=5.2.3->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (4.5.3)\nRequirement already satisfied: pyzmq>=13 in /usr/local/lib/python3.6/dist-packages (from jupyter-client>=5.2.3->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (17.0.0)\nRequirement already satisfied: jupyter-core in /usr/local/lib/python3.6/dist-packages (from jupyter-client>=5.2.3->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (4.5.0)\nRequirement already satisfied: packaging in /usr/local/lib/python3.6/dist-packages (from pytest>=4.0.2->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (19.1)\nRequirement already satisfied: atomicwrites>=1.0 in /usr/local/lib/python3.6/dist-packages (from pytest>=4.0.2->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (1.3.0)\nRequirement already satisfied: wcwidth in /usr/local/lib/python3.6/dist-packages (from pytest>=4.0.2->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.1.7)\nRequirement already satisfied: more-itertools>=4.0.0 in /usr/local/lib/python3.6/dist-packages (from pytest>=4.0.2->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (7.2.0)\nRequirement already satisfied: importlib-metadata>=0.12; python_version < \"3.8\" in /usr/local/lib/python3.6/dist-packages (from pytest>=4.0.2->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.23)\nRequirement already satisfied: py>=1.5.0 in /usr/local/lib/python3.6/dist-packages (from pytest>=4.0.2->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (1.8.0)\nCollecting pluggy<1.0,>=0.12 (from pytest>=4.0.2->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/92/c7/48439f7d5fd6bddb4c04b850bb862b42e3e2b98570040dfaf68aedd8114b/pluggy-0.13.0-py2.py3-none-any.whl\nRequirement already satisfied: llvmlite>=0.25.0dev0 in /usr/local/lib/python3.6/dist-packages (from numba>=0.38.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.29.0)\nRequirement already satisfied: pandocfilters>=1.4.1 in /usr/local/lib/python3.6/dist-packages (from nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (1.4.2)\nRequirement already satisfied: defusedxml in /usr/local/lib/python3.6/dist-packages (from nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.6.0)\nRequirement already satisfied: bleach in /usr/local/lib/python3.6/dist-packages (from nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (3.1.0)\nRequirement already satisfied: mistune<2,>=0.8.1 in /usr/local/lib/python3.6/dist-packages (from nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.8.4)\nRequirement already satisfied: nbformat>=4.4 in /usr/local/lib/python3.6/dist-packages (from nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (4.4.0)\nRequirement already satisfied: entrypoints>=0.2.2 in /usr/local/lib/python3.6/dist-packages (from nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.3)\nRequirement already satisfied: testpath in /usr/local/lib/python3.6/dist-packages (from nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.4.2)\nRequirement already satisfied: ptyprocess>=0.5 in /usr/local/lib/python3.6/dist-packages (from pexpect; sys_platform != \"win32\"->ipython->shap==0.30.0->-r requirements.txt (line 9)) (0.6.0)\nRequirement already satisfied: ipython-genutils in /usr/local/lib/python3.6/dist-packages (from traitlets>=4.2->ipython->shap==0.30.0->-r requirements.txt (line 9)) (0.2.0)\nRequirement already satisfied: olefile in /usr/local/lib/python3.6/dist-packages (from pillow>=4.3.0->scikit-image->shap==0.30.0->-r requirements.txt (line 9)) (0.46)\nCollecting astroid<3,>=2.2.0 (from pylint>=1.4.5->pytest-pylint>=0.13.0->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/d5/ad/7221a62a2dbce5c3b8c57fd18e1052c7331adc19b3f27f1561aa6e620db2/astroid-2.2.5-py3-none-any.whl (193kB)\n\u001b[K |████████████████████████████████| 194kB 36.1MB/s \n\u001b[?25hCollecting mccabe<0.7,>=0.6 (from pylint>=1.4.5->pytest-pylint>=0.13.0->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/87/89/479dc97e18549e21354893e4ee4ef36db1d237534982482c3681ee6e7b57/mccabe-0.6.1-py2.py3-none-any.whl\nCollecting isort<5,>=4.2.5 (from pylint>=1.4.5->pytest-pylint>=0.13.0->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/e5/b0/c121fd1fa3419ea9bfd55c7f9c4fedfec5143208d8c7ad3ce3db6c623c21/isort-4.3.21-py2.py3-none-any.whl (42kB)\n\u001b[K |████████████████████████████████| 51kB 17.1MB/s \n\u001b[?25hRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.6/dist-packages (from importlib-metadata>=0.12; python_version < \"3.8\"->pytest>=4.0.2->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.6.0)\nRequirement already satisfied: webencodings in /usr/local/lib/python3.6/dist-packages (from bleach->nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (0.5.1)\nRequirement already satisfied: jsonschema!=2.5.0,>=2.4 in /usr/local/lib/python3.6/dist-packages (from nbformat>=4.4->nbconvert>=5.3.1->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (2.6.0)\nRequirement already satisfied: wrapt in /usr/local/lib/python3.6/dist-packages (from astroid<3,>=2.2.0->pylint>=1.4.5->pytest-pylint>=0.13.0->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4)) (1.11.2)\nCollecting typed-ast>=1.3.0; implementation_name == \"cpython\" (from astroid<3,>=2.2.0->pylint>=1.4.5->pytest-pylint>=0.13.0->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/31/d3/9d1802c161626d0278bafb1ffb32f76b9d01e123881bbf9d91e8ccf28e18/typed_ast-1.4.0-cp36-cp36m-manylinux1_x86_64.whl (736kB)\n\u001b[K |████████████████████████████████| 737kB 38.0MB/s \n\u001b[?25hCollecting lazy-object-proxy (from astroid<3,>=2.2.0->pylint>=1.4.5->pytest-pylint>=0.13.0->phik>=0.9.8->pandas-profiling==2.3.0->-r requirements.txt (line 4))\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/0e/26/534a6d32572a9dbca11619321535c0a7ab34688545d9d67c2c204b9e3a3d/lazy_object_proxy-1.4.2-cp36-cp36m-manylinux1_x86_64.whl (49kB)\n\u001b[K |████████████████████████████████| 51kB 19.3MB/s \n\u001b[?25hBuilding wheels for collected packages: pandas-profiling, pdpbox, shap, htmlmin, confuse\n Building wheel for pandas-profiling (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for pandas-profiling: filename=pandas_profiling-2.3.0-py2.py3-none-any.whl size=145035 sha256=e2515faeab8aff95e9695b93dfa7f7fc6dc16648b56e8190f336ec6efcdb99ac\n Stored in directory: /root/.cache/pip/wheels/ce/c7/f1/dbfef4848ebb048cb1d4a22d1ed0c62d8ff2523747235e19fe\n Building wheel for pdpbox (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for pdpbox: filename=PDPbox-0.2.0-cp36-none-any.whl size=57690723 sha256=fb880ef75ad9f32b17eef8c7388f65543d3cbc2d09ceb7d9ad7acb9b593130e4\n Stored in directory: /root/.cache/pip/wheels/7d/08/51/63fd122b04a2c87d780464eeffb94867c75bd96a64d500a3fe\n Building wheel for shap (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for shap: filename=shap-0.30.0-cp36-cp36m-linux_x86_64.whl size=356740 sha256=db3d0ce091151889939bf65aa4c70195596e16741e07b9e97d512e8e7590a102\n Stored in directory: /root/.cache/pip/wheels/67/7a/5b/34feab81170fb8bf642a7536b5127e54e00bce373564435808\n Building wheel for htmlmin (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for htmlmin: filename=htmlmin-0.1.12-cp36-none-any.whl size=27084 sha256=730570a11e1c709c1ebd0a51ac40bd6b62b8fc98c9425db27c7c76698d93b9ca\n Stored in directory: /root/.cache/pip/wheels/43/07/ac/7c5a9d708d65247ac1f94066cf1db075540b85716c30255459\n Building wheel for confuse (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for confuse: filename=confuse-1.0.0-cp36-none-any.whl size=17486 sha256=9bafdd06d7b3314e6e8779c352245515b363d5d352b73c921f41f47befda63bf\n Stored in directory: /root/.cache/pip/wheels/b0/b2/96/2074eee7dbf7b7df69d004c9b6ac4e32dad04fb7666cf943bd\nSuccessfully built pandas-profiling pdpbox shap htmlmin confuse\n\u001b[31mERROR: datascience 0.10.6 has requirement folium==0.2.1, but you'll have folium 0.8.3 which is incompatible.\u001b[0m\nInstalling collected packages: category-encoders, eli5, htmlmin, pluggy, pytest, typed-ast, lazy-object-proxy, astroid, mccabe, isort, pylint, pytest-pylint, phik, confuse, pandas-profiling, pdpbox, shap\n Found existing installation: pluggy 0.7.1\n Uninstalling pluggy-0.7.1:\n Successfully uninstalled pluggy-0.7.1\n Found existing installation: pytest 3.6.4\n Uninstalling pytest-3.6.4:\n Successfully uninstalled pytest-3.6.4\n Found existing installation: pandas-profiling 1.4.1\n Uninstalling pandas-profiling-1.4.1:\n Successfully uninstalled pandas-profiling-1.4.1\nSuccessfully installed astroid-2.2.5 category-encoders-2.0.0 confuse-1.0.0 eli5-0.10.1 htmlmin-0.1.12 isort-4.3.21 lazy-object-proxy-1.4.2 mccabe-0.6.1 pandas-profiling-2.3.0 pdpbox-0.2.0 phik-0.9.8 pluggy-0.13.0 pylint-2.3.1 pytest-5.1.2 pytest-pylint-0.14.1 shap-0.30.0 typed-ast-1.4.0\n"
],
[
"import pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\n\n# Merge train_features.csv & train_labels.csv\ntrain = pd.merge(pd.read_csv('../data/tanzania/train_features.csv'), \n pd.read_csv('../data/tanzania/train_labels.csv'))\n\n# Read test_features.csv & sample_submission.csv\ntest = pd.read_csv('../data/tanzania/test_features.csv')\nsample_submission = pd.read_csv('../data/tanzania/sample_submission.csv')",
"_____no_output_____"
],
[
"#split\ntrain, val = train_test_split(train, train_size=0.80, test_size=0.20,\n stratify=train['status_group'], random_state=42)\n",
"_____no_output_____"
],
[
"def clean(X):\n X = X.copy()\n \n X = X.drop(columns=['payment', 'quantity_group', 'source_type', 'waterpoint_type', \n 'extraction_type', 'extraction_type_class', 'management_group',\n 'water_quality', 'num_private'])\n\n X['latitude'] = X['latitude'].replace(-2e-08, 0)\n \n cols_with_zeros = ['longitude', 'latitude', 'population', 'construction_year',\n 'gps_height']\n for col in cols_with_zeros:\n X[col] = X[col].replace(0, np.nan)\n \n\n X['date_recorded'] = pd.to_datetime(X['date_recorded'], infer_datetime_format=True)\n X['year_recorded'] = X['date_recorded'].dt.year\n X['month_recorded'] = X['date_recorded'].dt.month\n X['day_recorded'] = X['date_recorded'].dt.day\n\n X = X.drop(columns='date_recorded')\n\n X['pump_age'] = X['year_recorded'] - X['construction_year']\n X['pump_age'] = X['pump_age'].replace([-5, -4, -3, -2, -1, -7], np.nan)\n X['years_missing'] = X['pump_age'].isnull()\n \n X = X.drop(columns=['recorded_by', 'id'])\n \n return X\n\ntrain = clean(train)\nval = clean(val)\ntest = clean(test)",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\n\n# Merge train_features.csv & train_labels.csv\ntrain = pd.merge(pd.read_csv('../data/tanzania/train_features.csv'), \n pd.read_csv('../data/tanzania/train_labels.csv'))\n\n# Read test_features.csv & sample_submission.csv\ntest = pd.read_csv('../data/tanzania/test_features.csv')\nsample_submission = pd.read_csv('../data/tanzania/sample_submission.csv')\n\n\n# Split train into train & val\ntrain, val = train_test_split(train, train_size=0.80, test_size=0.20, \n stratify=train['status_group'], random_state=42)\n\ndef clean(X):\n \n # make a copy before modifying\n X = X.copy()\n \n # duplicates, near duplicates, missing values\n X = X.drop(columns=['payment', 'quantity_group'])\n \n # About 3% of the time, latitude has small values near zero,\n # outside Tanzania, so we'll treat these values like zero.\n X['latitude'] = X['latitude'].replace(-2e-08, 0)\n \n # some columns have zeros and shouldn't, they are like null values\n # replace those zeros with nulls, impute missing values later\n cols_with_zeros = ['longitude', 'latitude', 'population', 'construction_year',\n 'gps_height']\n for col in cols_with_zeros:\n X[col] = X[col].replace(0, np.nan)\n # create a missing vaules column\n X[col+'_missing'] = X[col].isnull()\n \n # extract year, month, day from date_recorded\n X['date_recorded'] = pd.to_datetime(X['date_recorded'], infer_datetime_format=True)\n X['year_recorded'] = X['date_recorded'].dt.year\n X['month_recorded'] = X['date_recorded'].dt.month\n X['day_recorded'] = X['date_recorded'].dt.day\n # delete date_recorded\n X = X.drop(columns='date_recorded')\n\n # age of pump at time of inspection\n X['pump_age'] = X['year_recorded'] - X['construction_year']\n # there are five values with negatives, so we will return those as a np.nan\n X['pump_age'] = X['pump_age'].replace([-5, -4, -3, -2, -1, -7], np.nan)\n # remember to deal with missing years\n X['years_missing'] = X['pump_age'].isnull()\n \n # drop recorded_by (never varies) and id (always varies, random)\n X = X.drop(columns=['recorded_by', 'id'])\n \n # return the clean df\n return X\n\ntrain = clean(train)\nval = clean(val)\ntest = clean(test)",
"_____no_output_____"
],
[
"target = 'status_group'\ntrain_features = train.drop(columns=[target])\nnumeric_features = train_features.select_dtypes(include='number').columns.tolist()\ncardinality = train_features.select_dtypes(exclude='number').nunique()\ncategorical_features = cardinality[cardinality <= 50].index.tolist()\nfeatures = numeric_features + categorical_features",
"_____no_output_____"
],
[
"X_train = train[features]\ny_train = train[target]\nX_val = val[features]\ny_val = val[target]\nX_test = test[features]",
"_____no_output_____"
],
[
"import category_encoders as ce\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.pipeline import make_pipeline\n\n\npipeline = make_pipeline(\n ce.OrdinalEncoder(),\n SimpleImputer(strategy='mean'),\n RandomForestClassifier(n_estimators=500, random_state=42, n_jobs=-1,\n oob_score=True, min_samples_leaf = 1)\n)\n\npipeline.fit(X_train, y_train)\nprint('Validation Accuracy', pipeline.score(X_val, y_val))",
"Validation Accuracy 0.8118686868686869\n"
],
[
"encoder = pipeline.named_steps['ordinalencoder']\nencoded = encoder.transform(X_train)\n\nprint(X_train.shape)\nprint(encoded.shape)",
"(47520, 38)\n(47520, 38)\n"
],
[
"sample_leaf_options = [1,5,10]\n\nfor leaf_size in sample_leaf_options:\n # pipeline\n\n pipeline = make_pipeline(\n ce.OrdinalEncoder(),\n SimpleImputer(strategy='mean'),\n RandomForestClassifier(n_estimators=200, random_state=42, n_jobs=-1,\n min_samples_leaf = leaf_size)\n )\n\n # Fit on train, score on val\n pipeline.fit(X_train, y_train)\n \n print(f\"AUC-ROC, {leaf_size}: \", pipeline.score(X_val, y_val))",
"AUC-ROC, 1: 0.8097643097643098\nAUC-ROC, 5: 0.8087542087542088\nAUC-ROC, 10: 0.7984006734006734\n"
],
[
"import numpy as np\nmax_features_options = [0.1, 0.2, 0.3]\n\nfor num_features in max_features_options:\n # pipeline\n pipeline = make_pipeline(\n ce.OrdinalEncoder(),\n SimpleImputer(strategy='mean'),\n RandomForestClassifier(n_estimators=200, random_state=42, n_jobs=-1,\n max_features = num_features, min_samples_leaf = 1)\n )\n\n # Fit on train, score on val\n pipeline.fit(X_train, y_train)\n \n print(f\"AUC-ROC, {num_features}: \", pipeline.score(X_val, y_val))",
"AUC-ROC, 0.1: 0.80993265993266\nAUC-ROC, 0.2: 0.8111111111111111\nAUC-ROC, 0.3: 0.8101010101010101\n"
],
[
"pipeline = make_pipeline(\n ce.OneHotEncoder(use_cat_names='True'),\n SimpleImputer(strategy='mean'),\n RandomForestClassifier(n_estimators=500, random_state=42, n_jobs=-1,\n oob_score=True, min_samples_leaf = 1)\n)\n\n\npipeline.fit(X_train, y_train)\nprint('Validation Accuracy: ', pipeline.score(X_val, y_val))",
"Validation Accuracy: 0.8115319865319865\n"
],
[
"encoder = pipeline.named_steps['onehotencoder']\nencoder = encoder.transform(X_train)\n\nprint(X_train.shape)\nprint(encoded.shape)",
"(47520, 38)\n(47520, 38)\n"
],
[
"y_pred = pipeline.predict(X_test)",
"_____no_output_____"
],
[
"submission = sample_submission.copy()\nsubmission['status_group'] = y_pred\nsubmission.to_csv('vince_kaggle03.csv', index=False)",
"_____no_output_____"
],
[
"!head vince_kaggle03.csv",
"id,status_group\n50785,functional\n51630,functional\n17168,functional\n45559,non functional\n49871,functional\n52449,functional\n24806,functional\n28965,non functional\n36301,non functional\n"
],
[
"if in_colab:\n from google.colab import files\n files.download('vince_kaggle03.csv')",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73eaf689a39f68539282d2d8c2e292c0d5437d2 | 2,416 | ipynb | Jupyter Notebook | app/modules/talkingHeads/.ipynb_checkpoints/util_example-checkpoint.ipynb | andy6804tw/talking-hands-API | 4895c980565082b0fdcabbc704ee871855e6d5f5 | [
"MIT"
] | null | null | null | app/modules/talkingHeads/.ipynb_checkpoints/util_example-checkpoint.ipynb | andy6804tw/talking-hands-API | 4895c980565082b0fdcabbc704ee871855e6d5f5 | [
"MIT"
] | 4 | 2021-06-08T20:44:12.000Z | 2022-03-12T00:09:38.000Z | app/modules/talkingHeads/.ipynb_checkpoints/util_example-checkpoint.ipynb | andy6804tw/talking-heads-API | 4895c980565082b0fdcabbc704ee871855e6d5f5 | [
"MIT"
] | null | null | null | 23.009524 | 121 | 0.536838 | [
[
[
"import cv2\nimport pickle as pkl\nimport imageio\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport torchvision.transforms.functional as TF\nfrom face_alignment import FaceAlignment, LandmarksType\n\nfrom utils import load_model, generate_image, plot_landmarks, generate_lm, image_to_video, generate_moving_video\nimport network\n\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"G = network.Generator()\nG = load_model(G, \"./resource/han\", \"han\")\nG = G.to(\"cpu\")",
"_____no_output_____"
],
[
"# image_path = \"./resource/image.png\"\n# fa = FaceAlignment(LandmarksType._2D, device='cuda:0')\n\n# finetune_img = cv2.imread(image_path)[:,:,::-1]\n# finetune_img = cv2.resize(finetune_img,(256,256))\n\n# finetune_lm = generate_lm(finetune_img , fa)\n# plt.imshow(finetune_lm)",
"_____no_output_____"
],
[
"# l = TF.to_tensor(finetune_lm)\n# l = l.reshape(1, *l.shape)\n# l = l.to(\"cuda:0\")\n \n# sw = generate_image(G, l, \"./resource/sw.npy\", \"cuda:0\")\n# plt.imshow(sw[0])",
"_____no_output_____"
],
[
"generate_moving_video(G, \"./resource/RecordedVideo.webm\", \"./resource/han/han.npy\", \"test.mp4\", \"cpu\")",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
e73ec7bb65a46b505c1b382ede0a7fd6a10d1005 | 39,514 | ipynb | Jupyter Notebook | MusicRecommendation/TestXgboost.ipynb | HiKapok/KaggleCompetitions | 3d8c0e8d8f98334980c97f761262316edcd6d5e9 | [
"MIT"
] | 1 | 2018-06-27T14:14:01.000Z | 2018-06-27T14:14:01.000Z | MusicRecommendation/TestXgboost.ipynb | HiKapok/KaggleCompetitions | 3d8c0e8d8f98334980c97f761262316edcd6d5e9 | [
"MIT"
] | 1 | 2017-12-30T01:01:52.000Z | 2018-01-05T04:09:32.000Z | MusicRecommendation/TestXgboost.ipynb | HiKapok/KaggleCompetitions | 3d8c0e8d8f98334980c97f761262316edcd6d5e9 | [
"MIT"
] | 1 | 2018-06-27T14:14:16.000Z | 2018-06-27T14:14:16.000Z | 67.545299 | 1,736 | 0.653034 | [
[
[
"# The line below sets the environment\n# variable CUDA_VISIBLE_DEVICES\nget_ipython().magic('env CUDA_VISIBLE_DEVICES = 1')\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport multiprocessing as mp # will come in handy due to the size of the data\nimport os.path\nimport random\nimport io\nfrom datetime import datetime\nimport gc # garbage collector\nimport sklearn\nimport xgboost as xgb\nfrom sklearn.preprocessing import LabelEncoder\nimport math\nfrom collections import defaultdict\nimport re\nimport logging\n\n# This is a bit of magic to make matplotlib figures appear inline in the notebook\n# rather than in a new window.\nget_ipython().magic('matplotlib inline')\nplt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots\nplt.rcParams['image.interpolation'] = 'nearest'\nplt.rcParams['image.cmap'] = 'gray'\n\n# Some more magic so that the notebook will reload external python modules;\n# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython\nget_ipython().magic('load_ext autoreload')\nget_ipython().magic('autoreload 2')",
"env: CUDA_VISIBLE_DEVICES=1\n"
]
],
[
[
"## Write a pandas dataframe to disk as gunzip compressed csv\n- df.to_csv('dfsavename.csv.gz', compression='gzip')\n\n## Read from disk\n- df = pd.read_csv('dfsavename.csv.gz', compression='gzip')\n\n## Magic useful\n- %%timeit for the whole cell\n- %timeit for the specific line\n- %%latex to render the cell as a block of latex\n- %prun and %%prun",
"_____no_output_____"
]
],
[
[
"DATASET_PATH = '/media/rs/0E06CD1706CD0127/Kapok/WSDM/'\nTRAIN_FILE = DATASET_PATH + 'all_train_withextra.csv'\nTEST_FILE = DATASET_PATH + 'all_test_withextra.csv'\nMEMBER_FILE = DATASET_PATH + 'members.csv'\nSONG_FILE = DATASET_PATH + 'fix_songs.csv'\nALL_ARTIST = DATASET_PATH + 'all_artist_name.csv'\nALL_COMPOSER = DATASET_PATH + 'all_composer.csv'\nALL_LYRICIST = DATASET_PATH + 'all_lyricist.csv'",
"_____no_output_____"
],
[
"def set_logging(logger_name, logger_file_name):\n log = logging.getLogger(logger_name)\n log.setLevel(logging.DEBUG)\n\n # create formatter and add it to the handlers\n print_formatter = logging.Formatter('%(message)s')\n file_formatter = logging.Formatter('%(asctime)s - %(name)s_%(levelname)s: %(message)s')\n\n # create file handler which logs even debug messages\n fh = logging.FileHandler(logger_file_name, mode='w')\n fh.setLevel(logging.DEBUG)\n fh.setFormatter(file_formatter)\n log.addHandler(fh)\n # both output to console and file\n consoleHandler = logging.StreamHandler()\n consoleHandler.setFormatter(print_formatter)\n log.addHandler(consoleHandler)\n \n return log",
"_____no_output_____"
],
[
"log = set_logging('MUSIC', DATASET_PATH + 'music_test_xgboost.log')\nlog.info('here is an info message.')",
"here is an info message.\n"
],
[
"train_data = pd.read_csv(TRAIN_FILE)\ntest_data = pd.read_csv(TEST_FILE)",
"_____no_output_____"
],
[
"member_data = pd.read_csv(MEMBER_FILE)\nsong_data = pd.read_csv(SONG_FILE)",
"_____no_output_____"
],
[
"composer_df = pd.read_csv(ALL_COMPOSER)\nartist_name_df = pd.read_csv(ALL_ARTIST)\nlyricist_df = pd.read_csv(ALL_LYRICIST)",
"_____no_output_____"
],
[
"log.info(train_data.head())",
" msno \\\n0 FGtllVqz18RPiwJj/edr2gV78zirAiY/9SmYvia+kCg= \n1 Xumu+NIjS6QYVxDS4/t3SawvJ7viT9hPKXmf0RtLNx8= \n2 Xumu+NIjS6QYVxDS4/t3SawvJ7viT9hPKXmf0RtLNx8= \n3 Xumu+NIjS6QYVxDS4/t3SawvJ7viT9hPKXmf0RtLNx8= \n4 FGtllVqz18RPiwJj/edr2gV78zirAiY/9SmYvia+kCg= \n\n song_id source_system_tab \\\n0 BBzumQNXUHKdEBOB7mAJuzok+IJA1c2Ryg/yzTF6tik= explore \n1 bhp/MpSNoqoxOIB+/l8WPqu6jldth4DIpCm3ayXnJqM= my library \n2 JNWfrrC7zNN7BdMpsISKa4Mw+xVJYNnxXh3/Epw7QgY= my library \n3 2A87tzfnJTSWqD7gIZHisolhe4DMdzkbd6LzO1KHjNs= my library \n4 3qm6XTZ6MOCU11x8FIVbAGH5l5uMkT3/ZalWG1oo2Gc= explore \n\n source_screen_name source_type target city bd gender \\\n0 Explore online-playlist 1 1 0 NaN \n1 Local playlist more local-playlist 1 13 24 female \n2 Local playlist more local-playlist 1 13 24 female \n3 Local playlist more local-playlist 1 13 24 female \n4 Explore online-playlist 1 1 0 NaN \n\n registered_via registration_init_time expiration_date song_length \\\n0 7 20120102 20171005 206471.0 \n1 9 20110525 20170911 284584.0 \n2 9 20110525 20170911 225396.0 \n3 9 20110525 20170911 255512.0 \n4 7 20120102 20171005 187802.0 \n\n genre_ids artist_name composer \\\n0 359 Bastille Dan Smith| Mark Crew \n1 1259 Various Artists NaN \n2 1259 Nas N. Jones、W. Adams、J. Lordan、D. Ingle \n3 1019 Soundway Kwadwo Donkoh \n4 1011 Brett Young Brett Young| Kelly Archer| Justin Ebach \n\n lyricist language name isrc \n0 NaN 52.0 Good Grief GBUM71602854 \n1 NaN 52.0 Lords of Cardboard US3C69910183 \n2 NaN 52.0 Hip Hop Is Dead(Album Version (Edited)) USUM70618761 \n3 NaN -1.0 Disco Africa GBUQH1000063 \n4 NaN 52.0 Sleep Without You QM3E21606003 \n"
],
[
"def clip_by_percent(hist, num_percent):\n return hist[(hist >= hist[int( len(hist.index) * num_percent )]) == True]\ndef clip_by_value(hist, value):\n return hist[(hist >= value) == True]",
"_____no_output_____"
],
[
"def create_bag_of_words(input_df, percent, column_name):\n input_hist = input_df[column_name].value_counts(sort=True, ascending=False)\n input_select = clip_by_percent(input_hist, percent).index\n print('{} item are selected.'.format(len(input_select)))\n # the total number of the other items\n total_others = np.sum(input_hist) - np.sum(input_hist[input_select])\n # all hist values are log transformed accouting the popularity\n clip_hist_with_log = defaultdict(lambda: np.log(total_others))\n for k,v in dict(np.log(input_hist[input_select])).items():\n clip_hist_with_log[k] = v\n# print(input_hist[input_select]) \n# print(dict(np.log(input_hist[input_select])))\n input_map = defaultdict(lambda: column_name + ' ' + 'others')\n for input_item in input_select:\n input_map[input_item] = column_name + ' ' + input_item\n # item name in input_map are \"column_name + ' ' + input_item\"\n # item name in clip_hist_with_log are \"input_item\"\n return input_map, clip_hist_with_log",
"_____no_output_____"
],
[
"# 181 ms ± 420 µs\ndef word_bag_encode(input_data, column, word_map, word_hist):\n col_index = input_data.columns.get_loc(column) + 1\n count_list = [0 for _ in range(len(word_map))]\n count_dict = dict(zip(list(word_map.keys()), count_list))\n count_dict['others'] = 0\n new_columns = [column + ' ' + s for s in count_dict.keys()]\n all_df = pd.DataFrame(data = None, columns = new_columns)\n delay_rate = 0.8 # must be less than 1\n for cur_row in input_data.itertuples():\n if isinstance(cur_row[col_index], str): \n df = pd.DataFrame([list(count_dict.values())], columns=new_columns)\n splited_list = re.split(r'[|/]+',cur_row[col_index])\n list_len = len(splited_list)\n # the weight of each position of the array, are decayed by the ratio delay_rate, and their sum are 1\n # so according to the geometric series summation formula, the iniatial weight are caculate as follow\n initial_weight = (1-delay_rate)/(1 - np.power(delay_rate, list_len))\n for index, s in enumerate(splited_list): \n word_stripped = s.strip(' \\\"\\t\\s\\n')\n df[word_map.get(word_stripped, column + ' others')] += initial_weight / (word_hist.get(word_stripped, word_hist['others'])) #word_hist[word_stripped]\n # defaultdict will auto insert missing key\n #df[word_map[word_stripped]] += initial_weight / (word_hist.get(word_stripped, word_hist['others'])) #word_hist[word_stripped]\n initial_weight *= delay_rate\n all_df = all_df.append(df, ignore_index=True)\n # NAN fix\n else:\n all_df = all_df.append(pd.DataFrame([[0] * len(new_columns)], columns=new_columns), ignore_index=True)\n return all_df",
"_____no_output_____"
],
[
"# 7.09 ms ± 43.2 µs\ndef word_bag_encode_apply(input_data, column, word_map, word_hist):\n new_columns = [column + ' ' + s for s in word_map.keys()]\n new_columns.append(column + ' ' + 'others')\n delay_rate = 0.8 # must be less than 1\n \n def encode_routine(str_value):\n series_dict = dict(zip(new_columns, [0.] * len(new_columns)))\n if isinstance(str_value, str): \n splited_list = re.split(r'[|/]+',str_value)\n list_len = len(splited_list)\n # the weight of each position of the array, are decayed by the ratio delay_rate, and their sum are 1\n # so according to the geometric series summation formula, the iniatial weight are caculate as follow\n initial_weight = (1-delay_rate)/(1 - np.power(delay_rate, list_len))\n for index, s in enumerate(splited_list): \n word_stripped = s.strip(' \\\"\\t\\s\\n')\n series_dict[word_map.get(word_stripped, column + ' others')] += initial_weight / (word_hist.get(word_stripped, word_hist['others'])) #word_hist[word_stripped]\n initial_weight *= delay_rate\n return pd.Series(series_dict)\n return input_data[column].apply(lambda s: encode_routine(s))",
"_____no_output_____"
],
[
"# 171 µs ± 693 ns\ndef word_bag_encode_numpy(input_data, column, word_map, word_hist):\n new_columns = [s for s in word_map.keys()]\n new_columns.append('others')\n delay_rate = 0.8 # must be less than 1\n num_columns = len(new_columns)\n str_indice_dict = dict(zip(new_columns, list(range(num_columns))))\n def encode_routine(str_value):\n temp_hist = np.zeros(num_columns, dtype=float)\n if isinstance(str_value, str): \n splited_list = re.split(r'[|/]+',str_value)\n list_len = len(splited_list)\n # the weight of each position of the array, are decayed by the ratio delay_rate, and their sum are 1\n # so according to the geometric series summation formula, the iniatial weight are caculate as follow\n initial_weight = (1-delay_rate)/(1 - np.power(delay_rate, list_len))\n for index, s in enumerate(splited_list): \n word_stripped = s.strip(' \\\"\\t\\s\\n')\n temp_hist[str_indice_dict.get(word_stripped, num_columns-1)] += initial_weight / (word_hist.get(word_stripped, word_hist['others'])) #word_hist[word_stripped]\n initial_weight *= delay_rate\n return temp_hist\n # actually we cannot use vectorize #vf = np.vectorize(encode_routine)\n\n #def fromiter(x):\n #return np.fromiter((f(xi) for xi in x), x.dtype)\n\n numpy_str = np.array(input_data[column].values, dtype=object)\n #return np.array(map(encode_routine, numpy_str))\n #return np.fromiter((encode_routine(xi) for xi in numpy_str), numpy_str.dtype, count=len(numpy_str))\n return np.array([encode_routine(xi) for xi in numpy_str]), [column + ' ' + s for s in new_columns]",
"_____no_output_____"
],
[
"# example test\n#composer_map, composer_hist = create_bag_of_words(composer_df, 0.001, 'composer')\n#composer_array, head_name = word_bag_encode_numpy(train_data, 'composer', composer_map, composer_hist)\n#composer_encoder = pd.DataFrame(data = composer_array, columns = head_name)",
"_____no_output_____"
],
[
"#composer_map, composer_hist = create_bag_of_words(composer_df, 0.001, 'composer')\n#%timeit composer_encoder = word_bag_encode(train_data, 'composer', composer_map, composer_hist)",
"_____no_output_____"
],
[
"composer_map, composer_hist = create_bag_of_words(composer_df, 0.001, 'composer')\n#composer_encoder = word_bag_encode_apply(train_data, 'composer', composer_map, composer_hist)\ncomposer_array, composer_head_name = word_bag_encode_numpy(train_data, 'composer', composer_map, composer_hist)\ncomposer_encoder = pd.DataFrame(data = composer_array, columns = composer_head_name)\ndel composer_array\nprint('composer_encoder finished')\nartist_name_map, artist_name_hist = create_bag_of_words(artist_name_df, 0.001, 'artist_name')\n#artist_name_encoder = word_bag_encode_apply(train_data, 'artist_name', artist_name_map, artist_name_hist)\nartist_name_array, artist_name_head_name = word_bag_encode_numpy(train_data, 'artist_name', artist_name_map, artist_name_hist)\nartist_name_encoder = pd.DataFrame(data = artist_name_array, columns = artist_name_head_name)\ndel artist_name_array\nprint('artist_name_encoder finished')\nlyricist_map, lyricist_hist = create_bag_of_words(lyricist_df, 0.002, 'lyricist')\n#lyricist_encoder = word_bag_encode_apply(train_data, 'lyricist', lyricist_map, lyricist_hist)\nlyricist_array, lyricist_head_name = word_bag_encode_numpy(train_data, 'lyricist', lyricist_map, lyricist_hist)\nlyricist_encoder = pd.DataFrame(data = lyricist_array, columns = lyricist_head_name)\ndel lyricist_array\nprint('lyricist_encoder finished')",
"309 item are selected.\ncomposer_encoder finished\n232 item are selected.\n"
],
[
"composer_encoder.to_csv(DATASET_PATH + 'composer_encoder.csv', compression='gzip')",
"_____no_output_____"
],
[
"print(pd.read_csv(DATASET_PATH + 'composer_encoder.csv', compression='gzip').head())",
"_____no_output_____"
],
[
"train_data.drop('composer', axis=1, inplace=True)\ntrain_data.drop('artist_name', axis=1, inplace=True)\ntrain_data.drop('lyricist', axis=1, inplace=True)\nfinal_train_data = pd.concat([train_data, composer_encoder, artist_name_encoder, lyricist_encoder], join='inner', axis=1, copy=True)\ndel train_data\ndel composer_encoder\ndel artist_name_encoder\ndel lyricist_encoder",
"_____no_output_____"
],
[
"#composer_encoder_test = word_bag_encode_apply(test_data, 'composer', composer_map, composer_hist)\ncomposer_array_test, composer_head_name_test = word_bag_encode_numpy(test_data, 'composer', composer_map, composer_hist)\ncomposer_encoder_test = pd.DataFrame(data = composer_array_test, columns = composer_head_name_test)\ndel composer_array_test\nprint('composer_encoder_test finished')\n#artist_name_encoder_test = word_bag_encode_apply(test_data, 'artist_name', artist_name_map, artist_name_hist)\nartist_name_array_test, artist_name_head_name_test = word_bag_encode_numpy(test_data, 'artist_name', artist_name_map, artist_name_hist)\nartist_name_encoder_test = pd.DataFrame(data = artist_name_array_test, columns = artist_name_head_name_test)\ndel artist_name_array_test\nprint('artist_name_encoder_test finished')\n#lyricist_encoder_test = word_bag_encode_apply(test_data, 'lyricist', lyricist_map, lyricist_hist)\nlyricist_array_test, lyricist_head_name_test = word_bag_encode_numpy(test_data, 'lyricist', lyricist_map, lyricist_hist)\nlyricist_encoder_test = pd.DataFrame(data = lyricist_array_test, columns = lyricist_head_name_test)\ndel lyricist_array_test\nprint('lyricist_encoder_test finished')\ntest_data.drop('composer', axis=1, inplace=True)\ntest_data.drop('artist_name', axis=1, inplace=True)\ntest_data.drop('lyricist', axis=1, inplace=True)\nfinal_test_data = pd.concat([test_data, composer_encoder_test, artist_name_encoder_test, lyricist_encoder_test], join='inner', axis=1, copy=True)\ndel test_data\ndel composer_encoder_test\ndel artist_name_encoder_test\ndel lyricist_encoder_test",
"_____no_output_____"
],
[
"print(final_train_data.head())\nprint(final_test_data.head())",
"_____no_output_____"
],
[
"final_train_data.to_csv(DATASET_PATH + 'all_train_featured.csv', compression='gzip')\nfinal_test_data.to_csv(DATASET_PATH + 'all_test_featured.csv', compression='gzip')",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73ec869f1f7471f0b840e7652c0e9c238957fd9 | 49,873 | ipynb | Jupyter Notebook | tutorials/First_and_Second_order_random_walks.ipynb | pnrobinson/grape | 8ab9f2307200ac2578893854b6d4377229f24a57 | [
"MIT"
] | 6 | 2021-09-22T17:40:01.000Z | 2022-03-24T04:28:00.000Z | tutorials/First_and_Second_order_random_walks.ipynb | pnrobinson/grape | 8ab9f2307200ac2578893854b6d4377229f24a57 | [
"MIT"
] | 5 | 2021-10-14T10:48:27.000Z | 2022-03-23T11:03:05.000Z | tutorials/First_and_Second_order_random_walks.ipynb | pnrobinson/grape | 8ab9f2307200ac2578893854b6d4377229f24a57 | [
"MIT"
] | 2 | 2021-09-13T16:24:08.000Z | 2021-09-24T16:23:35.000Z | 44.890189 | 4,488 | 0.537585 | [
[
[
"<a href=\"https://colab.research.google.com/github/AnacletoLAB/grape/blob/main/tutorials/First_and_Second_order_random_walks.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# First and Second order random walks\nFirst and second order random walks are a node-sampling mechanism that can be employed in a large number of algorithms. In this notebook we will shortly show how to use Ensmallen to sample a large number of random walks from big graphs.\n\nTo install the GraPE library run:\n\n```bash\npip install grape\n```\n\nTo install the Ensmallen module exclusively, which may be useful when the TensorFlow dependency causes problems, do run:\n\n```bash\npip install ensmallen\n```",
"_____no_output_____"
]
],
[
[
"! pip install -q ensmallen",
"_____no_output_____"
]
],
[
[
"## Retrieving a graph to run the sampling on\nIn this tutorial we will run samples on one of the graph from the ones available from the automatic graph retrieval of Ensmallen, namely the [Homo Sapiens graph from STRING](https://string-db.org/cgi/organisms). If you want to load a graph from an edge list, just follow the examples provided from the Loading a Graph in Ensmallen tutorial.",
"_____no_output_____"
]
],
[
[
"from ensmallen.datasets.string import HomoSapiens",
"_____no_output_____"
]
],
[
[
"Retrieving and loading the graph",
"_____no_output_____"
]
],
[
[
"graph = HomoSapiens()\n# We also create a version of the graph without edge weights\nunweighted_graph = graph.remove_edge_weights()",
"_____no_output_____"
]
],
[
[
"We compute the graph report:",
"_____no_output_____"
]
],
[
[
"graph",
"_____no_output_____"
]
],
[
[
"and the unweighted graph report:",
"_____no_output_____"
]
],
[
[
"unweighted_graph",
"_____no_output_____"
]
],
[
[
"## Random walks are heavily parallelized\nAll the algorithms to sample random walks provided by Ensmallen are heavily parallelized and therefore executing them on instances with a large amount amount of threads will lead to (obviously) better time performance. This notebook is being executed on a COLAB instance with only 2 cores, so the performance will not be as good as what they could be (likely even on your notebook or absurdly on your cellphone).\n\nYes, Ensmallen can run on Android phones.",
"_____no_output_____"
]
],
[
[
"from multiprocessing import cpu_count\n\ncpu_count()",
"_____no_output_____"
]
],
[
[
"## Unweighted first-order random walks\nComputation of first-order random walks ignoring the edge weights.",
"_____no_output_____"
]
],
[
[
"%%time\nunweighted_graph.random_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want to get random walks starting from 1000 random nodes\n quantity=1000,\n # We want 2 iterations from each node\n iterations=2\n)",
"CPU times: user 50.3 ms, sys: 934 µs, total: 51.2 ms\nWall time: 26 ms\n"
],
[
"%%time\nunweighted_graph.complete_walks(\n # We want random walks with length 100\n walk_length=100,\n # We want 2 iterations from each node\n iterations=2\n)",
"CPU times: user 2.85 s, sys: 13.2 ms, total: 2.86 s\nWall time: 1.54 s\n"
]
],
[
[
"## Weighted first-order random walks\nComputation of first-order random walks, biased using the edge weights.",
"_____no_output_____"
]
],
[
[
"%%time\ngraph.random_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want to get random walks starting from 1000 random nodes\n quantity=1000,\n # We want 2 iterations from each node\n iterations=2\n)",
"CPU times: user 1.49 s, sys: 14.9 ms, total: 1.51 s\nWall time: 794 ms\n"
]
],
[
[
"Similarly, to get random walks from all of the nodes in the graph (that are not singletons) it is possible to use:",
"_____no_output_____"
]
],
[
[
"%%time\ngraph.complete_walks(\n # We want random walks with length 100\n walk_length=100,\n # We want 2 iterations from each node\n iterations=2\n)",
"CPU times: user 1min 33s, sys: 401 ms, total: 1min 34s\nWall time: 48 s\n"
]
],
[
[
"## Second-order random walks\nSecondly, we proceed to show the computation of second-order random walks, that is random walks that use [Node2Vec parameters](https://arxiv.org/abs/1607.00653) to bias the random walk towards a BFS or a DFS.",
"_____no_output_____"
]
],
[
[
"%%time\ngraph.random_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want to get random walks starting from 1000 random nodes\n quantity=1000,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n)",
"CPU times: user 2.48 s, sys: 14.9 ms, total: 2.5 s\nWall time: 1.33 s\n"
],
[
"%%time\nunweighted_graph.random_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want to get random walks starting from 1000 random nodes\n quantity=1000,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n)",
"CPU times: user 2.38 s, sys: 18.7 ms, total: 2.4 s\nWall time: 1.28 s\n"
],
[
"%%time\ngraph.complete_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n)",
"CPU times: user 47.6 s, sys: 163 ms, total: 47.8 s\nWall time: 24.3 s\n"
],
[
"%%time\nunweighted_graph.complete_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n)",
"CPU times: user 46.2 s, sys: 149 ms, total: 46.4 s\nWall time: 23.6 s\n"
]
],
[
[
"## Approximated second-order random walks\nOn graphs that include nodes with extremely high node degrees, for instance above 50000, the computation of their transition weights can be a bottleneck. In those use-cases approximated random walks can help make the computation considerably faster, by randomly subsampling each node's neighbours to a maximum number provided. In the considered graph, the most central nodes have a centrality of at most around 7000, so the impact won't be particularly significant. \n\nWe have shown in the GraPE paper that significant subsampling of the nodes (maximum node degree clipped at 10) does not cause the performance of an edge prediction model trained on the SkipGram node embedding to change between exact random walks and approximated random walks. This is likely because of the massive amount of random walks that are made possible.",
"_____no_output_____"
]
],
[
[
"%%time\ngraph.random_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want to get random walks starting from 1000 random nodes\n quantity=1000,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n # We will subsample the neighbours of the nodes\n # dynamically to 100.\n max_neighbours=100\n)",
"CPU times: user 946 ms, sys: 5.94 ms, total: 952 ms\nWall time: 502 ms\n"
],
[
"%%time\ngraph.complete_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n # We will subsample the neighbours of the nodes\n # dynamically to 100.\n max_neighbours=100\n)",
"CPU times: user 18.5 s, sys: 57.7 ms, total: 18.6 s\nWall time: 9.45 s\n"
]
],
[
[
"## Enabling the speedups\nAs explained more in details in the tutorial [add reference to tutorial], there are numerous speed-ups time-memory tradeoffs available in Ensmallen. These speedups allow you to exchange to use more RAM and get faster computation. Generally speaking, these speedups on graphs that have less than a few hundred millions edges have a minimal impact on the memory footprint while enabling seemingly free acceleration of most graph algorithms.",
"_____no_output_____"
]
],
[
[
"graph.enable()",
"_____no_output_____"
]
],
[
[
"### Weighted first order random walks with speedups\nThe first order random walks have about an order of magnitude speed increase.",
"_____no_output_____"
]
],
[
[
"%%time\ngraph.random_walks(\n # We want random walks with length 100\n walk_length=100,\n # We want to get random walks starting from 1000 random nodes\n quantity=1000,\n # We want 10 iterations from each node\n iterations=2\n)",
"CPU times: user 396 ms, sys: 3.99 ms, total: 400 ms\nWall time: 222 ms\n"
],
[
"%%time\ngraph.complete_walks(\n # We want random walks with length 100\n walk_length=100,\n # We want 10 iterations from each node\n iterations=2\n)",
"CPU times: user 7.66 s, sys: 41.8 ms, total: 7.7 s\nWall time: 3.99 s\n"
]
],
[
[
"### Second order random walks with speedups\n",
"_____no_output_____"
]
],
[
[
"%%time\ngraph.random_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want to get random walks starting from 1000 random nodes\n quantity=1000,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n)",
"CPU times: user 1.13 s, sys: 2.93 ms, total: 1.13 s\nWall time: 617 ms\n"
],
[
"%%time\ngraph.complete_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n)",
"CPU times: user 21.9 s, sys: 105 ms, total: 22 s\nWall time: 11.2 s\n"
]
],
[
[
"## Approximated second-order random walks with speedups",
"_____no_output_____"
]
],
[
[
"%%time\ngraph.random_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want to get random walks starting from 1000 random nodes\n quantity=1000,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n # We will subsample the neighbours of the nodes\n # dynamically to 100.\n max_neighbours=100\n)",
"CPU times: user 320 ms, sys: 1.98 ms, total: 322 ms\nWall time: 173 ms\n"
],
[
"%%time\ngraph.complete_walks(\n # We want random walks with length 100\n walk_length=32,\n # We want 2 iterations from each node\n iterations=2,\n return_weight=2.0,\n explore_weight=2.0,\n # We will subsample the neighbours of the nodes\n # dynamically to 100.\n max_neighbours=100\n)",
"CPU times: user 6.3 s, sys: 22.7 ms, total: 6.33 s\nWall time: 3.23 s\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
e73ed46df8dcf439c9d3a87755e2c192ed3c8746 | 74,583 | ipynb | Jupyter Notebook | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | lucasshenv/deep-learning-v2-pytorch | db07c5eaee5e64709b8e122800780fa3ec429785 | [
"MIT"
] | null | null | null | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | lucasshenv/deep-learning-v2-pytorch | db07c5eaee5e64709b8e122800780fa3ec429785 | [
"MIT"
] | null | null | null | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | lucasshenv/deep-learning-v2-pytorch | db07c5eaee5e64709b8e122800780fa3ec429785 | [
"MIT"
] | null | null | null | 88.578385 | 16,772 | 0.793143 | [
[
[
"# Neural networks with PyTorch\n\nDeep learning networks tend to be massive with dozens or hundreds of layers, that's where the term \"deep\" comes from. You can build one of these deep networks using only weight matrices as we did in the previous notebook, but in general it's very cumbersome and difficult to implement. PyTorch has a nice module `nn` that provides a nice way to efficiently build large neural networks.",
"_____no_output_____"
]
],
[
[
"# Import necessary packages\n\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport numpy as np\nimport torch\n\nimport helper\n\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"\nNow we're going to build a larger network that can solve a (formerly) difficult problem, identifying text in an image. Here we'll use the MNIST dataset which consists of greyscale handwritten digits. Each image is 28x28 pixels, you can see a sample below\n\n<img src='assets/mnist.png'>\n\nOur goal is to build a neural network that can take one of these images and predict the digit in the image.\n\nFirst up, we need to get our dataset. This is provided through the `torchvision` package. The code below will download the MNIST dataset, then create training and test datasets for us. Don't worry too much about the details here, you'll learn more about this later.",
"_____no_output_____"
]
],
[
[
"### Run this cell\n\nfrom torchvision import datasets, transforms\n\n# Define a transform to normalize the data\ntransform = transforms.Compose([transforms.ToTensor(),\n transforms.Normalize((0.5,), (0.5,)),\n ])\n\n# Download and load the training data\ntrainset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)",
"_____no_output_____"
]
],
[
[
"We have the training data loaded into `trainloader` and we make that an iterator with `iter(trainloader)`. Later, we'll use this to loop through the dataset for training, like\n\n```python\nfor image, label in trainloader:\n ## do things with images and labels\n```\n\nYou'll notice I created the `trainloader` with a batch size of 64, and `shuffle=True`. The batch size is the number of images we get in one iteration from the data loader and pass through our network, often called a *batch*. And `shuffle=True` tells it to shuffle the dataset every time we start going through the data loader again. But here I'm just grabbing the first batch so we can check out the data. We can see below that `images` is just a tensor with size `(64, 1, 28, 28)`. So, 64 images per batch, 1 color channel, and 28x28 images.",
"_____no_output_____"
]
],
[
[
"dataiter = iter(trainloader)\nimages, labels = dataiter.next()\nprint(type(images))\nprint(images.shape)\nprint(labels.shape)",
"<class 'torch.Tensor'>\ntorch.Size([64, 1, 28, 28])\ntorch.Size([64])\n"
]
],
[
[
"This is what one of the images looks like. ",
"_____no_output_____"
]
],
[
[
"plt.imshow(images[1].numpy().squeeze(), cmap='Greys_r');",
"_____no_output_____"
]
],
[
[
"First, let's try to build a simple network for this dataset using weight matrices and matrix multiplications. Then, we'll see how to do it using PyTorch's `nn` module which provides a much more convenient and powerful method for defining network architectures.\n\nThe networks you've seen so far are called *fully-connected* or *dense* networks. Each unit in one layer is connected to each unit in the next layer. In fully-connected networks, the input to each layer must be a one-dimensional vector (which can be stacked into a 2D tensor as a batch of multiple examples). However, our images are 28x28 2D tensors, so we need to convert them into 1D vectors. Thinking about sizes, we need to convert the batch of images with shape `(64, 1, 28, 28)` to a have a shape of `(64, 784)`, 784 is 28 times 28. This is typically called *flattening*, we flattened the 2D images into 1D vectors.\n\nPreviously you built a network with one output unit. Here we need 10 output units, one for each digit. We want our network to predict the digit shown in an image, so what we'll do is calculate probabilities that the image is of any one digit or class. This ends up being a discrete probability distribution over the classes (digits) that tells us the most likely class for the image. That means we need 10 output units for the 10 classes (digits). We'll see how to convert the network output into a probability distribution next.\n\n> **Exercise:** Flatten the batch of images `images`. Then build a multi-layer network with 784 input units, 256 hidden units, and 10 output units using random tensors for the weights and biases. For now, use a sigmoid activation for the hidden layer. Leave the output layer without an activation, we'll add one that gives us a probability distribution next.",
"_____no_output_____"
]
],
[
[
"## Your solution\nimages = images.view(images.shape[0], -1)\n\nW1 = torch.randn(784, 256)\nB1 = torch.randn(1, 256)\n\nW2 = torch.randn(256, 10)\nB2 = torch.randn(1, 10)\n\ndef fn(x):\n return 1 / (1 + torch.exp(-x))\n\n# output of your network, should have shape (64,10)\nh = fn(torch.mm(images, W1) + B1)\nout = torch.mm(h, W2) + B2\n\nout.shape",
"_____no_output_____"
]
],
[
[
"Now we have 10 outputs for our network. We want to pass in an image to our network and get out a probability distribution over the classes that tells us the likely class(es) the image belongs to. Something that looks like this:\n<img src='assets/image_distribution.png' width=500px>\n\nHere we see that the probability for each class is roughly the same. This is representing an untrained network, it hasn't seen any data yet so it just returns a uniform distribution with equal probabilities for each class.\n\nTo calculate this probability distribution, we often use the [**softmax** function](https://en.wikipedia.org/wiki/Softmax_function). Mathematically this looks like\n\n$$\n\\Large \\sigma(x_i) = \\cfrac{e^{x_i}}{\\sum_k^K{e^{x_k}}}\n$$\n\nWhat this does is squish each input $x_i$ between 0 and 1 and normalizes the values to give you a proper probability distribution where the probabilites sum up to one.\n\n> **Exercise:** Implement a function `softmax` that performs the softmax calculation and returns probability distributions for each example in the batch. Note that you'll need to pay attention to the shapes when doing this. If you have a tensor `a` with shape `(64, 10)` and a tensor `b` with shape `(64,)`, doing `a/b` will give you an error because PyTorch will try to do the division across the columns (called broadcasting) but you'll get a size mismatch. The way to think about this is for each of the 64 examples, you only want to divide by one value, the sum in the denominator. So you need `b` to have a shape of `(64, 1)`. This way PyTorch will divide the 10 values in each row of `a` by the one value in each row of `b`. Pay attention to how you take the sum as well. You'll need to define the `dim` keyword in `torch.sum`. Setting `dim=0` takes the sum across the rows while `dim=1` takes the sum across the columns.",
"_____no_output_____"
]
],
[
[
"def softmax(x):\n ## TODO: Implement the softmax function here\n denum = torch.sum(torch.exp(out), dim=1)\n denum = denum.view(denum.shape[0], 1)\n \n nomin = torch.exp(x)\n \n return nomin / denum\n\n# Here, out should be the output of the network in the previous excercise with shape (64,10)\nprobabilities = softmax(out)\n\n# Does it have the right shape? Should be (64, 10)\nprint(probabilities.shape)\n# Does it sum to 1?\nprint(probabilities.sum(dim=1))",
"torch.Size([64, 10])\ntensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000])\n"
]
],
[
[
"## Building networks with PyTorch\n\nPyTorch provides a module `nn` that makes building networks much simpler. Here I'll show you how to build the same one as above with 784 inputs, 256 hidden units, 10 output units and a softmax output.",
"_____no_output_____"
]
],
[
[
"from torch import nn",
"_____no_output_____"
],
[
"class Network(nn.Module):\n def __init__(self):\n super().__init__()\n \n # Inputs to hidden layer linear transformation\n self.hidden = nn.Linear(784, 256)\n # Output layer, 10 units - one for each digit\n self.output = nn.Linear(256, 10)\n \n # Define sigmoid activation and softmax output \n self.sigmoid = nn.Sigmoid()\n self.softmax = nn.Softmax(dim=1)\n \n def forward(self, x):\n # Pass the input tensor through each of our operations\n x = self.hidden(x)\n x = self.sigmoid(x)\n x = self.output(x)\n x = self.softmax(x)\n \n return x",
"_____no_output_____"
]
],
[
[
"Let's go through this bit by bit.\n\n```python\nclass Network(nn.Module):\n```\n\nHere we're inheriting from `nn.Module`. Combined with `super().__init__()` this creates a class that tracks the architecture and provides a lot of useful methods and attributes. It is mandatory to inherit from `nn.Module` when you're creating a class for your network. The name of the class itself can be anything.\n\n```python\nself.hidden = nn.Linear(784, 256)\n```\n\nThis line creates a module for a linear transformation, $x\\mathbf{W} + b$, with 784 inputs and 256 outputs and assigns it to `self.hidden`. The module automatically creates the weight and bias tensors which we'll use in the `forward` method. You can access the weight and bias tensors once the network (`net`) is created with `net.hidden.weight` and `net.hidden.bias`.\n\n```python\nself.output = nn.Linear(256, 10)\n```\n\nSimilarly, this creates another linear transformation with 256 inputs and 10 outputs.\n\n```python\nself.sigmoid = nn.Sigmoid()\nself.softmax = nn.Softmax(dim=1)\n```\n\nHere I defined operations for the sigmoid activation and softmax output. Setting `dim=1` in `nn.Softmax(dim=1)` calculates softmax across the columns.\n\n```python\ndef forward(self, x):\n```\n\nPyTorch networks created with `nn.Module` must have a `forward` method defined. It takes in a tensor `x` and passes it through the operations you defined in the `__init__` method.\n\n```python\nx = self.hidden(x)\nx = self.sigmoid(x)\nx = self.output(x)\nx = self.softmax(x)\n```\n\nHere the input tensor `x` is passed through each operation and reassigned to `x`. We can see that the input tensor goes through the hidden layer, then a sigmoid function, then the output layer, and finally the softmax function. It doesn't matter what you name the variables here, as long as the inputs and outputs of the operations match the network architecture you want to build. The order in which you define things in the `__init__` method doesn't matter, but you'll need to sequence the operations correctly in the `forward` method.\n\nNow we can create a `Network` object.",
"_____no_output_____"
]
],
[
[
"# Create the network and look at it's text representation\nmodel = Network()\nmodel",
"_____no_output_____"
]
],
[
[
"You can define the network somewhat more concisely and clearly using the `torch.nn.functional` module. This is the most common way you'll see networks defined as many operations are simple element-wise functions. We normally import this module as `F`, `import torch.nn.functional as F`.",
"_____no_output_____"
]
],
[
[
"import torch.nn.functional as F\n\nclass Network(nn.Module):\n def __init__(self):\n super().__init__()\n # Inputs to hidden layer linear transformation\n self.hidden = nn.Linear(784, 256)\n # Output layer, 10 units - one for each digit\n self.output = nn.Linear(256, 10)\n \n def forward(self, x):\n # Hidden layer with sigmoid activation\n x = F.sigmoid(self.hidden(x))\n # Output layer with softmax activation\n x = F.softmax(self.output(x), dim=1)\n \n return x",
"_____no_output_____"
]
],
[
[
"### Activation functions\n\nSo far we've only been looking at the sigmoid activation function, but in general any function can be used as an activation function. The only requirement is that for a network to approximate a non-linear function, the activation functions must be non-linear. Here are a few more examples of common activation functions: Tanh (hyperbolic tangent), and ReLU (rectified linear unit).\n\n<img src=\"assets/activation.png\" width=700px>\n\nIn practice, the ReLU function is used almost exclusively as the activation function for hidden layers.",
"_____no_output_____"
],
[
"### Your Turn to Build a Network\n\n<img src=\"assets/mlp_mnist.png\" width=600px>\n\n> **Exercise:** Create a network with 784 input units, a hidden layer with 128 units and a ReLU activation, then a hidden layer with 64 units and a ReLU activation, and finally an output layer with a softmax activation as shown above. You can use a ReLU activation with the `nn.ReLU` module or `F.relu` function.\n\nIt's good practice to name your layers by their type of network, for instance 'fc' to represent a fully-connected layer. As you code your solution, use `fc1`, `fc2`, and `fc3` as your layer names.",
"_____no_output_____"
]
],
[
[
"## Your solution here\nclass Netowrk(nn.Module):\n def __init__(self):\n super().__init__()\n \n self.fc1 = nn.Linear(784, 128)\n self.fc2 = nn.Linear(128, 64)\n self.output = nn.Linear(64, 10)\n \n def forward(self, x):\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n \n x = F.softmax(self.output(x), dim=1)\n \n return x\n\nmodel = Netowrk()\nmodel",
"_____no_output_____"
]
],
[
[
"### Initializing weights and biases\n\nThe weights and such are automatically initialized for you, but it's possible to customize how they are initialized. The weights and biases are tensors attached to the layer you defined, you can get them with `model.fc1.weight` for instance.",
"_____no_output_____"
]
],
[
[
"print(model.fc1.weight)\nprint(model.fc1.bias)",
"Parameter containing:\ntensor([[-0.0212, -0.0195, 0.0222, ..., -0.0317, -0.0309, -0.0017],\n [-0.0099, 0.0313, -0.0179, ..., -0.0240, -0.0309, -0.0157],\n [-0.0067, 0.0024, 0.0155, ..., -0.0145, -0.0326, 0.0130],\n ...,\n [ 0.0105, -0.0156, 0.0041, ..., -0.0071, 0.0277, -0.0330],\n [ 0.0123, 0.0263, -0.0313, ..., 0.0205, -0.0294, 0.0134],\n [ 0.0333, 0.0193, -0.0259, ..., -0.0356, 0.0248, 0.0100]],\n requires_grad=True)\nParameter containing:\ntensor([ 0.0070, -0.0012, 0.0311, -0.0356, -0.0339, -0.0336, -0.0089, 0.0133,\n 0.0078, 0.0325, 0.0245, 0.0325, 0.0291, -0.0164, 0.0060, 0.0288,\n 0.0237, 0.0028, 0.0275, 0.0111, -0.0214, 0.0091, -0.0357, -0.0054,\n 0.0007, 0.0327, 0.0292, -0.0071, 0.0008, -0.0108, -0.0132, -0.0093,\n 0.0120, -0.0079, 0.0131, -0.0106, 0.0059, 0.0101, -0.0339, -0.0242,\n 0.0033, 0.0237, 0.0301, -0.0150, 0.0131, 0.0002, 0.0028, 0.0133,\n -0.0322, -0.0116, -0.0026, -0.0184, -0.0327, 0.0227, -0.0156, -0.0098,\n -0.0019, -0.0250, -0.0022, -0.0125, 0.0257, 0.0147, -0.0333, -0.0333,\n 0.0146, -0.0243, -0.0298, -0.0094, -0.0127, 0.0203, 0.0280, -0.0134,\n -0.0244, -0.0354, 0.0342, -0.0126, 0.0210, 0.0302, 0.0205, 0.0264,\n 0.0274, 0.0238, 0.0305, 0.0174, -0.0114, 0.0055, 0.0109, 0.0144,\n -0.0178, -0.0160, -0.0122, 0.0271, -0.0347, -0.0141, -0.0106, 0.0144,\n 0.0283, -0.0253, -0.0026, 0.0036, -0.0235, -0.0041, 0.0085, 0.0154,\n 0.0207, -0.0067, 0.0338, 0.0316, 0.0011, -0.0120, -0.0053, -0.0096,\n 0.0117, -0.0268, 0.0060, -0.0167, -0.0314, 0.0113, 0.0229, 0.0221,\n -0.0081, -0.0350, -0.0089, 0.0184, 0.0337, -0.0243, -0.0269, -0.0255],\n requires_grad=True)\n"
]
],
[
[
"For custom initialization, we want to modify these tensors in place. These are actually autograd *Variables*, so we need to get back the actual tensors with `model.fc1.weight.data`. Once we have the tensors, we can fill them with zeros (for biases) or random normal values.",
"_____no_output_____"
]
],
[
[
"# Set biases to all zeros\nmodel.fc1.bias.data.fill_(0)",
"_____no_output_____"
],
[
"# sample from random normal with standard dev = 0.01\nmodel.fc1.weight.data.normal_(std=0.01)",
"_____no_output_____"
]
],
[
[
"### Forward pass\n\nNow that we have a network, let's see what happens when we pass in an image.",
"_____no_output_____"
]
],
[
[
"# Grab some data \ndataiter = iter(trainloader)\nimages, labels = dataiter.next()\n\n# Resize images into a 1D vector, new shape is (batch size, color channels, image pixels) \nimages.resize_(64, 1, 784)\n# or images.resize_(images.shape[0], 1, 784) to automatically get batch size\n\n# Forward pass through the network\nimg_idx = 0\nps = model.forward(images[img_idx,:])\n\nimg = images[img_idx]\nhelper.view_classify(img.view(1, 28, 28), ps)",
"_____no_output_____"
]
],
[
[
"As you can see above, our network has basically no idea what this digit is. It's because we haven't trained it yet, all the weights are random!\n\n### Using `nn.Sequential`\n\nPyTorch provides a convenient way to build networks like this where a tensor is passed sequentially through operations, `nn.Sequential` ([documentation](https://pytorch.org/docs/master/nn.html#torch.nn.Sequential)). Using this to build the equivalent network:",
"_____no_output_____"
]
],
[
[
"# Hyperparameters for our network\ninput_size = 784\nhidden_sizes = [128, 64]\noutput_size = 10\n\n# Build a feed-forward network\nmodel = nn.Sequential(nn.Linear(input_size, hidden_sizes[0]),\n nn.ReLU(),\n nn.Linear(hidden_sizes[0], hidden_sizes[1]),\n nn.ReLU(),\n nn.Linear(hidden_sizes[1], output_size),\n nn.Softmax(dim=1))\nprint(model)\n\n# Forward pass through the network and display output\nimages, labels = next(iter(trainloader))\nimages.resize_(images.shape[0], 1, 784)\nps = model.forward(images[0,:])\nhelper.view_classify(images[0].view(1, 28, 28), ps)",
"Sequential(\n (0): Linear(in_features=784, out_features=128, bias=True)\n (1): ReLU()\n (2): Linear(in_features=128, out_features=64, bias=True)\n (3): ReLU()\n (4): Linear(in_features=64, out_features=10, bias=True)\n (5): Softmax(dim=1)\n)\n"
]
],
[
[
"Here our model is the same as before: 784 input units, a hidden layer with 128 units, ReLU activation, 64 unit hidden layer, another ReLU, then the output layer with 10 units, and the softmax output.\n\nThe operations are available by passing in the appropriate index. For example, if you want to get first Linear operation and look at the weights, you'd use `model[0]`.",
"_____no_output_____"
]
],
[
[
"print(model[0])\nmodel[0].weight",
"Linear(in_features=784, out_features=128, bias=True)\n"
]
],
[
[
"You can also pass in an `OrderedDict` to name the individual layers and operations, instead of using incremental integers. Note that dictionary keys must be unique, so _each operation must have a different name_.",
"_____no_output_____"
]
],
[
[
"from collections import OrderedDict\nmodel = nn.Sequential(OrderedDict([\n ('fc1', nn.Linear(input_size, hidden_sizes[0])),\n ('relu1', nn.ReLU()),\n ('fc2', nn.Linear(hidden_sizes[0], hidden_sizes[1])),\n ('relu2', nn.ReLU()),\n ('output', nn.Linear(hidden_sizes[1], output_size)),\n ('softmax', nn.Softmax(dim=1))]))\nmodel",
"_____no_output_____"
]
],
[
[
"Now you can access layers either by integer or the name",
"_____no_output_____"
]
],
[
[
"print(model[0])\nprint(model.fc1)",
"Linear(in_features=784, out_features=128, bias=True)\nLinear(in_features=784, out_features=128, bias=True)\n"
]
],
[
[
"In the next notebook, we'll see how we can train a neural network to accuractly predict the numbers appearing in the MNIST images.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73ee71b75b712df57c0001f91f7d894f6eb0191 | 2,304 | ipynb | Jupyter Notebook | scripts/Regular Expressions (Toy Data).ipynb | masiyua1/Python_tutorial | e06f0775bfdb5f24953a1ed6b655f3bfa0bed92c | [
"Apache-2.0"
] | null | null | null | scripts/Regular Expressions (Toy Data).ipynb | masiyua1/Python_tutorial | e06f0775bfdb5f24953a1ed6b655f3bfa0bed92c | [
"Apache-2.0"
] | null | null | null | scripts/Regular Expressions (Toy Data).ipynb | masiyua1/Python_tutorial | e06f0775bfdb5f24953a1ed6b655f3bfa0bed92c | [
"Apache-2.0"
] | null | null | null | 23.04 | 584 | 0.518229 | [
[
[
"### Regular Expressions",
"_____no_output_____"
]
],
[
[
"import re",
"_____no_output_____"
]
],
[
[
"#### example data ",
"_____no_output_____"
]
],
[
[
"line = '{\"usernameTweet\": \"Tom\", \"ID\": \"1176953905143590912\", \"text\": \"Cant agree more! RT:Masks + vaccines + boosters = best protection against #Omicron.When you wear a mask, you help protect yourself & others from #COVID19. Choose a mask with the best fit, protection, and comfort for you.\", \"url\": \"/CDCGOV/status/1176953905143590912\", \"nbr_retweet\": 26740, \"nbr_favorite\": 105089, \"nbr_reply\": 17181, \"datetime\": \"2022-01-14 16:17:32\", \"is_reply\": false, \"is_retweet\": true, \"retweet_user_id\": \"16460678\", \"retweet_username\": \"CDCGOV\"}'",
"_____no_output_____"
],
[
"try:\n result = re.search(r'\"usernameTweet\": \"(.*?)\", ', line)\nexcept:\n result = None\n \ntry:\n result2 = re.search(r'retweet_username\": \"(.*?)\"}', line)\nexcept:\n result2 = None\n",
"_____no_output_____"
],
[
"result_list = list([result.group(1),result2.group(1)])\nprint(result_list)\n",
"['Tom', 'CDCGOV']\n"
]
],
[
[
"this is the info we need!",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
e73eef5b6c683d76e24ac41cc8e099b5ffe4c3d3 | 627 | ipynb | Jupyter Notebook | docs/src/tour.ipynb | cstjean/MLJ.jl | db67ed4b73649bc8cd62a15aae55b59c85a897fd | [
"MIT"
] | 1 | 2021-04-12T23:30:00.000Z | 2021-04-12T23:30:00.000Z | docs/src/tour.ipynb | cstjean/MLJ.jl | db67ed4b73649bc8cd62a15aae55b59c85a897fd | [
"MIT"
] | null | null | null | docs/src/tour.ipynb | cstjean/MLJ.jl | db67ed4b73649bc8cd62a15aae55b59c85a897fd | [
"MIT"
] | null | null | null | 18.441176 | 126 | 0.54386 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
e73ef2c4180c7d0365b3f234bfc1d9bb92c2de88 | 52,288 | ipynb | Jupyter Notebook | assignmentnotebook.ipynb | alexandrosstergiou/Bootstrap-for-polling | 0225a3ecdbce6599b6806aaa595fd84ae5be43ce | [
"MIT"
] | null | null | null | assignmentnotebook.ipynb | alexandrosstergiou/Bootstrap-for-polling | 0225a3ecdbce6599b6806aaa595fd84ae5be43ce | [
"MIT"
] | null | null | null | assignmentnotebook.ipynb | alexandrosstergiou/Bootstrap-for-polling | 0225a3ecdbce6599b6806aaa595fd84ae5be43ce | [
"MIT"
] | null | null | null | 41.498413 | 335 | 0.498279 | [
[
[
"%matplotlib inline\nimport matplotlib\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport seaborn as sns\nimport random\n\nfrom sklearn.metrics import confusion_matrix\nimport itertools\n\nfrom sklearn.tree import DecisionTreeRegressor\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.ensemble import GradientBoostingRegressor\nfrom sklearn.ensemble import ExtraTreesClassifier\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import mean_squared_error as mse\nfrom sklearn.metrics import mean_absolute_error as mae\nfrom sklearn.metrics import accuracy_score as acc\nfrom sklearn.metrics import make_scorer\nfrom sklearn.dummy import DummyRegressor\nfrom sklearn.dummy import DummyClassifier\nfrom sklearn.preprocessing import LabelEncoder",
"_____no_output_____"
],
[
"df_online = pd.read_csv(\"./NatRep_Online_Upload.csv\", delimiter = \",\")\ndf_phone = pd.read_csv(\"./NatRep_Phone_upload.csv\", delimiter = \",\")",
"_____no_output_____"
],
[
"df_elections = pd.read_csv(\"./2015_general_elections/2015_voting_gen_election.csv\", delimiter=\",\")",
"_____no_output_____"
],
[
"df_qualifications = pd.read_csv(\"./Education_qualifications/UK_Qualifications.csv\", delimiter=\",\")",
"_____no_output_____"
],
[
"df_sex_to_age = pd.read_csv(\"./Gender_demographics_by_age/UK_M_to_F_ratio_by_age.csv\", delimiter=\",\")",
"_____no_output_____"
],
[
"df_newspaper = pd.read_csv(\"./Newspaper_readability/Newspaper_readerships_uk.csv\", delimiter=\",\")",
"_____no_output_____"
],
[
"df_social_grade = pd.read_csv(\"./Social_grade/Aproximated_social_grade.csv\", delimiter=\",\")",
"_____no_output_____"
],
[
"df_station_ratings = pd.read_csv(\"./Station_ratings/Station_Ratings_UK.csv\", delimiter=\",\")",
"_____no_output_____"
],
[
"#start by deleting the ages that cannot legaly vote\nfor i in range(18):\n df_sex_to_age = df_sex_to_age.drop(df_sex_to_age.index[[0]])",
"_____no_output_____"
],
[
"#to avoid overfitting, create age groups every 4 years\ndf_sex_to_agegroup = df_sex_to_age.groupby(np.arange(len(df_sex_to_age))//4).sum()\ndf_sex_to_agegroup.index = df_sex_to_age.loc[1::4,'Age']",
"_____no_output_____"
],
[
"#Find the total number of men and women\ntotals = df_sex_to_age.sum(axis=0)",
"_____no_output_____"
],
[
"#reconstruct the dataframe to only include the precentages\ndf_sex_to_agegroup[\"Number of males\"] = df_sex_to_agegroup[\"Number of males\"].astype(float)\ndf_sex_to_agegroup[\"Number of females\"] = df_sex_to_agegroup[\"Number of females\"].astype(float)\nfor index, row in df_sex_to_agegroup.iterrows():\n row[0]=(row[0]/totals[\"Number of males\"])\n row[1]=(row[1]/totals[\"Number of females\"])",
"_____no_output_____"
],
[
"#create a dataframe to hold the means for every qualification level\ndf_mean_qualifications = pd.DataFrame({ 'Qualification' : np.array([\"No Qualification\",\"Level 1\",\"Level 2\",\"Level 3\",\"Level 4\",\"Other\"],dtype='string'),\n '%' : np.array([df_qualifications[\"% No Qualifications\"].mean()*0.01,\n df_qualifications[\"% Level 1\"].mean()*0.01,\n df_qualifications[\"% Level 2\"].mean()*0.01,\n df_qualifications[\"% Level 3\"].mean()*0.01,\n df_qualifications[\"% Level 4\"].mean()*0.01,\n df_qualifications[\"% Other\"].mean()*0.01],dtype='float')})",
"_____no_output_____"
],
[
"#find the total number of readers and then use it to compute the precentages\nnews_total = df_newspaper[\"Combined\"].values.sum() \npn = []\nfor readers in df_newspaper[\"Combined\"].values:\n pn.append(\"{0:.5g}\".format((float(readers)/float(news_total))))\ncn = list(df_newspaper[\"Title\"].values)\ndf_percent_newspapers = pd.DataFrame([pn,cn])\ndf_percent_newspapers = df_percent_newspapers.T",
"_____no_output_____"
],
[
"#find the respective precentages in df_online and df_phone in order to perform the bootstrap\ndef find_precentages_in_data(data):\n ######### AGES ##########\n p_ages_male= np.zeros((19,),dtype=np.float)\n p_ages_female = np.zeros((19,), dtype=np.float)\n step = 0\n for i in range(18,90,4):\n p_ages_male[step]=len((data.query( str(i)+'<= Age <='+str(i+3)).query('1 == gender')).index)\n p_ages_female[step]=len((data.query( str(i)+'<= Age <='+str(i+3)).query('2 == gender')).index)\n step = step + 1\n #90+\n p_ages_male[step]=len((data.query( str(90)+'< Age').query('1 == gender')).index)\n p_ages_female[step]=len((data.query( str(90)+'< Age').query('2 == gender')).index)\n \n #precentages per age group\n total_m = p_ages_male.sum()\n total_f = p_ages_female.sum()\n for i in range(0,len(p_ages_male)):\n p_ages_male[i] = \"{0:.3f}\".format(p_ages_male[i]/total_m)\n for i in range(0,len(p_ages_female)):\n p_ages_female[i] = \"{0:.3f}\".format(p_ages_female[i]/total_f)\n \n ########## SOCIAL GRADE ##########\n p_sgrade = np.zeros((4,),dtype=np.float)\n for i in range(0,4):\n p_sgrade[i]=len((data.query(str(i+1)+'== Socgrade_matrix_w8').index))\n \n total_s = p_sgrade.sum()\n for i in range(0,4):\n p_sgrade[i] = \"{0:.3f}\".format(p_sgrade[i]/total_s)\n \n \n ########## 2015 ELECTIONS VOTING ##########\n p_party = np.zeros((9,),dtype=np.float)\n \n voted_data = data.query(str(1)+'== voted2015')['pastvote_2015']\n for i in voted_data:\n temp = int(i)\n if(temp<=9):p_party[temp-1] = p_party[temp-1] + 1\n \n total_p = p_party.sum()\n for i in range(0,9):\n p_party[i] = \"{0:.3f}\".format(p_party[i]/total_p)\n \n \n ########## EDUCATION QUALIFICATIONS ##########\n p_levels = np.zeros((6,),dtype=np.float)\n #No qualifications\n p_levels[0] = len((data.query(str(1)+'== profile_education_level').index))\n #Level 1 qualifications\n p_levels[1] = len((data.query(str(2)+'== profile_education_level').index))+len((data.query(str(5)+'== profile_education_level').index))+len((data.query(str(8)+'== profile_education_level').index))\n #Level 2 qualifications\n p_levels[2] = len((data.query(str(6)+'== profile_education_level').index))+len((data.query(str(9)+'== profile_education_level').index))+len((data.query(str(10)+'== profile_education_level').index))\n \n #Level 3 qualifications\n p_levels[3] = len((data.query(str(11)+'== profile_education_level').index))+len((data.query(str(7)+'== profile_education_level').index))+len((data.query(str(12)+'== profile_education_level').index))+len((data.query(str(13)+'== profile_education_level').index))+len((data.query(str(14)+'== profile_education_level').index))\n #Level 4 qualifications\n p_levels[4] = len((data.query(str(15)+'== profile_education_level').index))+len((data.query(str(16)+'== profile_education_level').index))+len((data.query(str(17)+'== profile_education_level').index))\n #Other qualifications\n p_levels[5] = len((data.query(str(18)+'== profile_education_level').index))\n \n total_l = p_levels.sum()\n for i in range(0,6):\n p_levels[i] = \"{0:.3f}\".format(p_levels[i]/total_l)\n \n ########## NEWSPAPERS PREFERRED ##########\n p_newspapers = np.zeros((15,),dtype=np.float)\n for i in range(0,14):\n p_newspapers[i] = len((data.query(str(i+1)+'== Newspaper_Read').index))\n \n p_newspapers[14] =len((data.query(str(15)+'== Newspaper_Read').index))+len((data.query(str(16)+'== Newspaper_Read').index))+len((data.query(str(17)+'== Newspaper_Read').index))\n \n total_np = p_newspapers.sum()\n p_newsp = np.zeros((15,),dtype=np.float)\n for i in range(0,15):\n p_newsp[i] = \"{0:.3f}\".format(p_newspapers[i]/total_np)\n \n ########## NEWS STATION PREFERRED ##########\n p_newschannel = np.zeros((6,),dtype=np.float)\n for i in range(0,6):\n p_newschannel[i] = len((data.query(str(i+1)+'== TV_News').index))\n \n total_nc = p_newschannel.sum()\n for i in range(0,6):\n p_newschannel[i] = \"{0:.3f}\".format(p_newschannel[i]/total_nc)\n \n \n ########## FINAL ARRAY ##########\n t1 = np.array([[p_ages_male], [p_ages_female], [p_sgrade], [p_party], [p_levels], [p_newsp], [p_newschannel]], dtype=object)\n ########## ########### ##########\n return t1\n \n ",
"_____no_output_____"
],
[
"online_precentages = find_precentages_in_data(df_online)",
"_____no_output_____"
],
[
"#Nearest Neighbour\ndef nn(data, example):\n best = 0\n index = 0\n for row in data.itertuples():\n el = 0\n for i in range (0, len(row)-1):\n if (row[i] == example[i]):\n el = el + 1\n if (el > best):\n best = el\n index = i\n \n return (data.iloc[index][1])\n \n ",
"_____no_output_____"
],
[
"#use bootstrapping to create new examples in order for the data precentages to match the population precentages\ndef bootstrap(data, sample_of_interest, condition):\n column_names = list(data.columns.values)\n #create a new id for the new sample\n new_id = (data[column_names[0]].iloc[-1])+1\n #create a list to add to the dataframe as new example\n temp = []\n temp.append(new_id)\n for column_name in itertools.islice(column_names,1,len(column_names)):\n #create a sample for a data value that was under-represented in the polling\n if (sample_of_interest == column_name):\n pool = data.query(sample_of_interest+condition)\n sample = (np.random.choice(pool[column_name],1)).item(0)\n else:\n sample = (np.random.choice(data[column_name],1)).item(0)\n temp.append(sample)\n return temp\n \n ",
"_____no_output_____"
],
[
"#use multiple conditions to avoid confusion in the code\ndef conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings):\n ##### PRECENTAGE DIFFERENCE IN AGES OF MEN #####\n condition_ages_male = []\n for i in range(0,online_precentages[0][0].size):\n if(\"{0:.3f}\".format(float(online_precentages[0][0][i])) < \"{0:.3f}\".format(float(df_sex_to_agegroup.iat[i,0]))):\n condition_ages_male.append('<')\n elif(\"{0:.3f}\".format(float(online_precentages[0][0][i])) == \"{0:.3f}\".format(float(df_sex_to_agegroup.iat[i,0]))):\n condition_ages_male.append('=')\n else:\n condition_ages_male.append('>')\n \n ##### PRECENTAGE DIFFERENCE IN AGES OF WOMEN #####\n condition_ages_female = []\n for i in range(0,online_precentages[1][0].size):\n if(\"{0:.3f}\".format(float(online_precentages[1][0][i])) < \"{0:.3f}\".format(float(df_sex_to_agegroup.iat[i,1]))):\n condition_ages_female.append('<')\n elif(\"{0:.3f}\".format(float(online_precentages[1][0][i])) == \"{0:.3f}\".format(float(df_sex_to_agegroup.iat[i,1]))):\n condition_ages_female.append('=')\n else:\n condition_ages_female.append('>')\n \n ##### PRECENTAGE DIFFERENCE IN SOCIAL GRADES #####\n condition_social_grades = []\n for i in range(0,online_precentages[2][0].size):\n if(\"{0:.3f}\".format(float(online_precentages[2][0][i])) < \"{0:.3f}\".format(float(df_social_grade.iat[0,(i+5)]))):\n condition_social_grades.append('<')\n elif(\"{0:.3f}\".format(float(online_precentages[2][0][i])) == \"{0:.3f}\".format(float(df_social_grade.iat[0,(i+5)]))):\n condition_social_grades.append('=')\n else:\n condition_social_grades.append('>')\n \n \n ##### PRECENTAGE DIFFERENCE IN 2015 ELECTIONS VOTING #####\n condition_voting_2015 = []\n for i in range(0,online_precentages[3][0].size):\n if(\"{0:.3f}\".format(float(online_precentages[3][0][i])) < \"{0:.3f}\".format(float(df_elections.iat[i,2]))):\n condition_voting_2015.append('<')\n elif(\"{0:.3f}\".format(float(online_precentages[3][0][i])) == \"{0:.3f}\".format(float(df_elections.iat[i,2]))):\n condition_voting_2015.append('=')\n else:\n condition_voting_2015.append('>')\n \n \n ##### PRECENTAGE DIFFERENCE IN POPULATION QUALIFICATIONS #####\n condition_qualifications = []\n for i in range(0,online_precentages[4][0].size):\n if(\"{0:.3f}\".format(float(online_precentages[4][0][i])) < \"{0:.3f}\".format(float(df_mean_qualifications.iat[i,0]))):\n condition_qualifications.append('<')\n elif(\"{0:.3f}\".format(float(online_precentages[4][0][i])) == \"{0:.3f}\".format(float(df_mean_qualifications.iat[i,0]))):\n condition_qualifications.append('=')\n else:\n condition_qualifications.append('>')\n \n \n ##### PRECENTAGE DIFFERENCE IN NEWSPAPERS PREFERENCE #####\n condition_newspapers = []\n for i in range(0,online_precentages[5][0].size):\n if(\"{0:.3f}\".format(float(online_precentages[5][0][i])) < \"{0:.3f}\".format(float(df_percent_newspapers.iat[i,0]))):\n condition_newspapers.append('<')\n elif(\"{0:.3f}\".format(float(online_precentages[5][0][i])) == \"{0:.3f}\".format(float(df_percent_newspapers.iat[i,0]))):\n condition_newspapers.append('=')\n else:\n condition_newspapers.append('>')\n \n \n ##### PRECENTAGE DIFFERENCE IN NEWS STATIONS #####\n condition_tvnews = []\n for i in range(0,online_precentages[6][0].size):\n if(\"{0:.3f}\".format(online_precentages[6][0][i]) < \"{0:.3f}\".format(df_station_ratings.iat[i,1])):\n condition_tvnews.append('<')\n elif(\"{0:.3f}\".format(online_precentages[6][0][i]) == \"{0:.3f}\".format(df_station_ratings.iat[i,1])):\n condition_tvnews.append('=')\n else:\n condition_tvnews.append('>')\n \n \n ########## FINAL CONDITION CONSTRUCTION ##########\n condition = [condition_ages_male ,condition_ages_female ,condition_social_grades ,condition_voting_2015 ,condition_qualifications ,condition_newspapers ,condition_tvnews]\n \n return condition",
"_____no_output_____"
],
[
"loop_condition = conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)",
"_____no_output_____"
],
[
"def check(condition_elements):\n flag = True\n for ar in condition_elements:\n for element in condition_elements:\n if (element!='='):\n flag = False\n break\n if (flag == False): \n break",
"_____no_output_____"
],
[
"def bootstrap_men(data0, loop_con, online_perc, data1, data2, data3, data4, data5, data6):\n #combine all conditions and iterate until they resemble the population\n flag = 0\n for el in loop_con[0]:\n if (el!='='):\n flag = flag + 1\n\n\n j=0 \n ########## MEN BY AGE ##########\n while (flag > 1):\n i = 18\n for c in range (0,len(loop_con[0])):\n while (loop_con[0][c] == '<'):\n age_chosen = random.randint(i,i+3)\n string = str(age_chosen)\n string = \" == \"+string\n if (i>=86):\n string = \" > 90\"\n temp = bootstrap(data0, \"Age\", string)\n while (int(temp[23])!=1):\n temp = bootstrap(data0, \"Age\", string)\n #TO AVOID NOT BOOTSTRAPPING THE AGE CHOSEN\n temp[19] = age_chosen\n #Make sure if the people voted, they voted for someone!\n #(Data with values that show that the person did not vote,\n #but have a voted party will be discarded by the precentages function)\n while ((temp[17] == 1) & (temp[18] == ' ')):\n temp = bootstrap(data0, \"Age\", string)\n temp[1] = nn(data0, temp)\n df_additional = pd.DataFrame([temp], columns=list(data0.columns.values))\n data0 = data0.append(df_additional, ignore_index=True)\n online_prec = find_precentages_in_data(data0)\n loop_con = conditions(online_prec, data1, data2, data3, data4, data5, data6)\n\n i = i+4\n \n flag = 0\n for el in loop_con[0]:\n if (el!='='):\n flag = flag + 1\n\n\n return data0",
"_____no_output_____"
],
[
"def bootstrap_women(data0, loop_con, online_perc, data1, data2, data3, data4, data5, data6):\n #combine all conditions and iterate until they resemble the population\n flag = 0\n for el in loop_con[1]:\n if (el!='='):\n flag = flag + 1\n\n \n ########## WOMEN BY AGE ##########\n while (flag > 1):\n i = 18\n for c in range (0,len(loop_con[1])):\n while (loop_con[1][c] == '<'):\n age_chosen = random.randint(i,i+3)\n string = str(age_chosen)\n string = \" == \"+string\n if (i>=86):\n string = \" > 90\"\n temp = bootstrap(data0, \"Age\", string)\n while (int(temp[23])!=2):\n temp = bootstrap(data0, \"Age\", string)\n #TO AVOID NOT BOOTSTRAPPING THE AGE CHOSEN\n temp[19] = age_chosen\n #Make sure if the people voted, they voted for someone!\n #(Data with values that show that the person did not vote,\n #but have a voted party will be discarded by the precentages function)\n while ((temp[17] == 1) & (temp[18] == ' ')):\n temp = bootstrap(data0, \"Age\", string)\n temp[1] = nn(data0, temp)\n df_additional = pd.DataFrame([temp], columns=list(data0.columns.values))\n data0 = data0.append(df_additional, ignore_index=True)\n online_prec = find_precentages_in_data(data0)\n loop_con = conditions(online_prec, data1, data2, data3, data4, data5, data6)\n\n i = i+4\n \n flag = 0\n for el in loop_con[1]:\n if (el!='='):\n flag = flag + 1\n\n\n return data0",
"_____no_output_____"
],
[
"def bootstrap_social_grades(data0, loop_con, online_perc, data1, data2, data3, data4, data5, data6):\n #combine all conditions and iterate until they resemble the population\n flag = 0\n for el in loop_con[2]:\n if (el!='='):\n flag = flag + 1\n \n ########## SOCIAL GRADES DISTRIBUTION ##########\n while (flag > 1):\n for c in range (0,len(loop_con[2])):\n while (loop_con[2][c] == '<'):\n string = \"== \"+str(c+1)\n temp = bootstrap(data0, \"Socgrade_matrix_w8\", string)\n #Make sure if the people voted, they voted for someone!\n #(Data with values that show that the person did not vote,\n #but have a voted party will be discarded by the precentages function)\n while ((temp[17] == 1) & (temp[18] == ' ')):\n temp = bootstrap(data0, \"Social_matrix_w8\", string)\n temp[1] = nn(data0, temp)\n df_additional = pd.DataFrame([temp], columns=list(data0.columns.values))\n data0 = data0.append(df_additional, ignore_index=True)\n online_prec = find_precentages_in_data(data0)\n loop_con = conditions(online_prec, data1, data2, data3, data4, data5, data6)\n \n \n flag = 0\n for el in loop_con[2]:\n if (el!='='):\n flag = flag + 1\n \n \n return data0",
"_____no_output_____"
],
[
"def bootstrap_past_votings(data0, loop_con, online_perc, data1, data2, data3, data4, data5, data6):\n #combine all conditions and iterate until they resemble the population\n flag = 0\n for el in loop_con[3]:\n if (el!='='):\n flag = flag + 1\n \n ########## PAST VOTINGS BY PARTIES DISTRIBUTION ##########\n while (flag > 3):\n for c in range (0,len(loop_con[3])):\n while (loop_con[3][c] == '<'):\n temp = bootstrap(data0, \"voted_2015\", \"== 1\")\n temp[18] = str(c+1)\n temp[1] = nn(data0, temp)\n df_additional = pd.DataFrame([temp], columns=list(data0.columns.values))\n data0 = data0.append(df_additional, ignore_index=True)\n online_prec = find_precentages_in_data(data0)\n loop_con = conditions(online_prec, data1, data2, data3, data4, data5, data6)\n \n \n flag = 0\n for el in loop_con[3]:\n if (el!='='):\n flag = flag + 1\n \n return data0 ",
"_____no_output_____"
],
[
"def bootstrap_education(data0, loop_con, online_perc, data1, data2, data3, data4, data5, data6):\n #combine all conditions and iterate until they resemble the population\n flag = 0\n for el in loop_con[4]:\n if (el!='='):\n flag = flag + 1\n \n ########## EDUCATION QUALIFICATIONS DISTRIBUTION ##########\n while (flag > 2):\n for c in range (0,len(loop_con[4])):\n while (loop_con[4][c] == '<'):\n i = c\n #No qualification\n if (c==0):\n i = c+1\n #Level 1 qualifications\n elif (c==1):\n i = random.choice([2,5,8])\n #Level 2 qualifications\n elif (c==2):\n i = random.choice([6,9,10])\n #Level 3 qualifications\n elif (c==3):\n i= random.choice([11,7,12,13,14])\n #Level 4+ qualifications\n elif (c==4):\n i= random.choice([15,16,17])\n else:\n i =18\n\n string = \"== \"+str(i)\n temp = bootstrap(data0, \"profile_education_level\", string)\n #Make sure if the people voted, they voted for someone!\n #(Data with values that show that the person did not vote,\n #but have a voted party will be discarded by the precentages function)\n while ((temp[17] == 1) & (temp[18] == ' ')):\n temp = bootstrap(data0, \"profile_education_level\", string)\n temp[1] = nn(data0, temp)\n df_additional = pd.DataFrame([temp], columns=list(data0.columns.values))\n data0 = data0.append(df_additional, ignore_index=True)\n online_prec = find_precentages_in_data(data0)\n loop_con = conditions(online_prec, data1, data2, data3, data4, data5, data6)\n \n \n flag = 0\n for el in loop_con[4]:\n if (el!='='):\n flag = flag + 1\n \n return data0",
"_____no_output_____"
],
[
"def bootstrap_newspapers(data0, loop_con, online_perc, data1, data2, data3, data4, data5, data6):\n #combine all conditions and iterate until they resemble the population\n flag = 0\n for el in loop_con[5]:\n if (el!='='):\n flag = flag + 1\n \n ########## NEWSPAPER PREFERENCE DISTRIBUTION ##########\n while (flag > 1):\n for c in range (0,len(loop_con[5])):\n while (loop_con[5][c] == '<'):\n string = \"== \" + str(c+1)\n temp = bootstrap(data0, \"Newspaper_Read\", string)\n #Make sure if the people voted, they voted for someone!\n #(Data with values that show that the person did not vote,\n #but have a voted party will be discarded by the precentages function)\n while ((temp[17] == 1) & (temp[18] == ' ')):\n temp = bootstrap(data0, \"Newspaper_Read\", string)\n temp[1] = nn(data0, temp)\n df_additional = pd.DataFrame([temp], columns=list(data0.columns.values))\n data0 = data0.append(df_additional, ignore_index=True)\n online_prec = find_precentages_in_data(data0)\n loop_con = conditions(online_prec, data1, data2, data3, data4, data5, data6)\n \n \n \n flag = 0\n for el in loop_con[5]:\n if (el!='='):\n flag = flag + 1\n \n return data0 ",
"_____no_output_____"
],
[
"def bootstrap_tvnews(data0, loop_con, online_perc, data1, data2, data3, data4, data5, data6):\n #combine all conditions and iterate until they resemble the population\n flag = 0\n for el in loop_con[6]:\n if (el!='='):\n flag = flag + 1\n \n ########## NEWS STATION PREFERENCE DISTRIBUTION ##########\n while (flag > 1):\n for c in range (0,len(loop_con[6])):\n while (loop_con[6][c] == '<'):\n i = c+1\n if (i==2): string = \"== \"+str(i-1)\n else: string = \"== \" + str(i)\n temp = bootstrap(data0, \"TV_News\", string)\n if (i==2):temp[10] = 2\n #Make sure if the people voted, they voted for someone!\n #(Data with values that show that the person did not vote,\n #but have a voted party will be discarded by the precentages function)\n while ((temp[17] == 1) & (temp[18] == ' ')):\n temp = bootstrap(data0, \"TV_News\", string)\n if (i==2):temp[10] = 2\n temp[1] = nn(data0, temp)\n df_additional = pd.DataFrame([temp], columns=list(data0.columns.values))\n data0 = data0.append(df_additional, ignore_index=True)\n online_prec = find_precentages_in_data(data0)\n loop_con = conditions(online_prec, data1, data2, data3, data4, data5, data6)\n \n \n flag = 0\n for el in loop_con[6]:\n if (el!='='):\n flag = flag + 1\n \n return data0",
"_____no_output_____"
],
[
"print \"########### MEN POPULATION % ##########\"\nprint df_sex_to_agegroup[\"Number of males\"]\nprint \"\"\nprint \"########### WOMEN POPULATION % ##########\"\nprint df_sex_to_agegroup[\"Number of females\"]\nprint \"\"\nprint \"########### SOCIAL GRADE POPULATION % ##########\"\nprint df_social_grade.iloc[[0]]\nprint \"\"\nprint \"########### VOTING PARTY POPULATION % ##########\"\nprint df_elections\nprint \"\"\nprint \"########### QUALIFICATIONS POPULATION % ##########\"\nprint df_mean_qualifications\nprint \"\"\nprint \"########### NEWSPAPERS POPULATION % ##########\"\nprint df_percent_newspapers\nprint \"\"\nprint \"########### TX NEWS POPULATION % ##########\"\nprint df_station_ratings\nprint \"\"",
"########### MEN POPULATION % ##########\nAge\n18 0.066878\n22 0.072109\n26 0.070812\n30 0.069682\n34 0.065900\n38 0.065440\n42 0.072479\n46 0.074537\n50 0.072203\n54 0.064226\n58 0.057229\n62 0.055368\n66 0.055595\n70 0.041469\n74 0.034191\n78 0.026345\n82 0.018620\n86 0.010553\n90+ 0.006366\nName: Number of males, dtype: float64\n\n########### WOMEN POPULATION % ##########\nAge\n18 0.060318\n22 0.066678\n26 0.067333\n30 0.067036\n34 0.062987\n38 0.062975\n42 0.070616\n46 0.072751\n50 0.070203\n54 0.062309\n58 0.056035\n62 0.055059\n66 0.055897\n70 0.043284\n74 0.037489\n78 0.031315\n82 0.025433\n86 0.017238\n90+ 0.015044\nName: Number of females, dtype: float64\n\n########### SOCIAL GRADE POPULATION % ##########\n Area code Area name Unnamed: 2 Unnamed: 3 \\\n0 K04000001 ENGLAND AND WALES NaN NaN \n\n All categories: Approximated social grade Approximated social grade AB \\\n0 17,266,580 0.227 \n\n Approximated social grade C1 Approximated social grade C2 \\\n0 0.308 0.208 \n\n Approximated social grade DE \n0 0.257 \n\n########### VOTING PARTY POPULATION % ##########\n Party Votes Vote Share\n0 Conservative 11334576 0.369\n1 Labour 9347304 0.304\n2 Liberal Democrat 2415862 0.079\n3 Scotish National Party 1254436 0.047\n4 Paid Cymru 181704 0.006\n5 UKIP 3881099 0.126\n6 Green Party 1157613 0.037\n7 BNP 1667 0.000\n8 Other 708332 0.024\n\n########### QUALIFICATIONS POPULATION % ##########\n % Qualification\n0 0.145020 No Qualification\n1 0.156011 Level 1\n2 0.178316 Level 2\n3 0.144681 Level 3\n4 0.292925 Level 4\n5 0.049727 Other\n\n########### NEWSPAPERS POPULATION % ##########\n 0 1\n0 0.040376 Daily Express\n1 0.016644 Financial Times\n2 0.0058649 The Herald\n3 0.07137 The Guardian\n4 0.049716 The Independent\n5 0.050816 London Evening Standard\n6 0.16251 Daily Mail\n7 0.10653 Metro\n8 0.13001 Daily Mirror/Record\n9 0.0072633 The Scotsman\n10 0.039697 Daily Star\n11 0.18295 The Sun\n12 0.06651 The Daily Telegraph\n13 0.061433 The Times\n14 0.0083087 Other\n\n########### TX NEWS POPULATION % ##########\n Station Ratings\n0 BBC 0.318\n1 ITV 0.226\n2 Chanel 4 0.113\n3 Sky 0.068\n4 other 0.170\n5 do not watch 0.105\n\n"
],
[
"con = 0\nwhile (con<7):\n con = 0\n print \"########## BOOTSTRAPPING MEN ##########\"\n print online_precentages[0][0]\n boot = bootstrap_men(df_online, loop_condition, online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n if (df_online.equals(boot)):con = con +1\n else:\n df_online = boot\n online_precentages = find_precentages_in_data(df_online)\n loop_condition = conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n print online_precentages[0][0]\n print \"New number of examples: \"+str(df_online.tail(1).iat[0,0])\n print df_online[\"EUREF_Int\"].value_counts()\n s = df_online[\"EUREF_Int\"].value_counts().sum()\n for val in df_online[\"EUREF_Int\"].value_counts():\n print (float(val)/float(s))\n \n print \" \"\n print \"########## BOOTSTRAPPING WOMEN ##########\"\n print online_precentages[1][0]\n boot = bootstrap_women(df_online, loop_condition, online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n if (df_online.equals(boot)):con = con +1\n else:\n df_online = boot\n online_precentages = find_precentages_in_data(df_online)\n loop_condition = conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n print online_precentages[1][0]\n print \"New number of examples: \"+str(df_online.tail(1).iat[0,0])\n print df_online[\"EUREF_Int\"].value_counts()\n s = df_online[\"EUREF_Int\"].value_counts().sum()\n for val in df_online[\"EUREF_Int\"].value_counts():\n print (float(val)/float(s))\n \n print \" \"\n print \"########## BOOTSTRAPPING SOCIAL GRADE #########\"\n print online_precentages[2][0]\n boot = bootstrap_social_grades(df_online, loop_condition, online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n if (df_online.equals(boot)):con = con +1\n else:\n df_online = boot\n online_precentages = find_precentages_in_data(df_online)\n loop_condition = conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n print online_precentages[2][0]\n print \"New number of examples: \"+str(df_online.tail(1).iat[0,0])\n print df_online[\"EUREF_Int\"].value_counts()\n s = df_online[\"EUREF_Int\"].value_counts().sum()\n for val in df_online[\"EUREF_Int\"].value_counts():\n print (float(val)/float(s))\n \n print \" \"\n print \"########## BOOTSTRAPPING PAST VOTES ##########\"\n print online_precentages[3][0]\n boot = bootstrap_past_votings(df_online, loop_condition, online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n if (df_online.equals(boot)):con = con +1\n else:\n df_online = boot\n online_precentages = find_precentages_in_data(df_online)\n loop_condition = conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n print online_precentages[3][0]\n print \"New number of examples: \"+str(df_online.tail(1).iat[0,0])\n print df_online[\"EUREF_Int\"].value_counts()\n s = df_online[\"EUREF_Int\"].value_counts().sum()\n for val in df_online[\"EUREF_Int\"].value_counts():\n print (float(val)/float(s))\n \n print \" \"\n print \"########## BOOTSTRAPPING EDUCATION QUALIFICATIONS ##########\"\n print online_precentages[4][0]\n boot = bootstrap_education(df_online, loop_condition, online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n if (df_online.equals(boot)):con = con +1\n else:\n df_online = boot\n online_precentages = find_precentages_in_data(df_online)\n loop_condition = conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n print online_precentages[4][0]\n print \"New number of examples: \"+str(df_online.tail(1).iat[0,0])\n print df_online[\"EUREF_Int\"].value_counts()\n s = df_online[\"EUREF_Int\"].value_counts().sum()\n for val in df_online[\"EUREF_Int\"].value_counts():\n print (float(val)/float(s))\n \n print \" \"\n print \"########## BOOTSTRAPPING NEWSPAPERS ##########\"\n print online_precentages[5][0]\n boot = bootstrap_newspapers(df_online, loop_condition, online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n if (df_online.equals(boot)):con = con +1\n else:\n df_online = boot\n online_precentages = find_precentages_in_data(df_online)\n loop_condition = conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n print online_precentages[5][0]\n print \"New number of examples: \"+str(df_online.tail(1).iat[0,0])\n print df_online[\"EUREF_Int\"].value_counts()\n s = df_online[\"EUREF_Int\"].value_counts().sum()\n for val in df_online[\"EUREF_Int\"].value_counts():\n print (float(val)/float(s))\n \n print \" \"\n print \"########## BOOTSTRAPPING TV NEWS ##########\"\n print online_precentages[6][0]\n boot = bootstrap_tvnews(df_online, loop_condition, online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n if (df_online.equals(boot)):con = con +1\n else:\n df_online = boot\n online_precentages = find_precentages_in_data(df_online)\n loop_condition = conditions(online_precentages, df_sex_to_agegroup, df_social_grade, df_elections, df_mean_qualifications, df_percent_newspapers, df_station_ratings)\n print online_precentages[6][0]\n print \"New number of examples: \"+str(df_online.tail(1).iat[0,0])\n print df_online[\"EUREF_Int\"].value_counts()\n s = df_online[\"EUREF_Int\"].value_counts().sum()\n for val in df_online[\"EUREF_Int\"].value_counts():\n print (float(val)/float(s))\n \n print \" \"\n print \" \"\n print \"##########\"\n print \"New number of examples: \"+str(df_online.tail(1).iat[0,0])\n print \"##########\"\n print \" \"\n print \" \"\n ",
"########## BOOTSTRAPPING MEN ##########\n[ 0.074 0.048 0.058 0.061 0.069 0.073 0.081 0.073 0.058 0.06\n 0.072 0.073 0.084 0.068 0.031 0.013 0.004 0. 0.001]\n[ 0.067 0.072 0.071 0.07 0.066 0.065 0.072 0.075 0.072 0.064\n 0.057 0.055 0.056 0.046 0.034 0.026 0.019 0.011 0.006]\nNew number of examples: 2507\n2 1005\n1 954\n3 408\n4 116\nName: EUREF_Int, dtype: int64\n0.404752315747\n0.384212645993\n0.164317358035\n0.0467176802255\n \n########## BOOTSTRAPPING WOMEN ##########\n[ 0.057 0.065 0.074 0.079 0.075 0.06 0.061 0.057 0.072 0.05\n 0.063 0.064 0.119 0.066 0.02 0.012 0.005 0. 0.002]\n[ 0.06 0.067 0.067 0.067 0.063 0.063 0.071 0.073 0.07 0.062\n 0.056 0.055 0.064 0.043 0.037 0.031 0.025 0.017 0.015]\nNew number of examples: 3498\n2 1433\n1 1322\n3 556\n4 163\nName: EUREF_Int, dtype: int64\n0.412492803685\n0.380541162925\n0.160046056419\n0.0469199769718\n \n########## BOOTSTRAPPING SOCIAL GRADE #########\n[ 0.305 0.295 0.191 0.209]\n[ 0.228 0.308 0.208 0.257]\nNew number of examples: 4833\n2 2012\n1 1815\n3 767\n4 215\nName: EUREF_Int, dtype: int64\n0.418382200042\n0.377417342483\n0.159492618008\n0.0447078394677\n \n########## BOOTSTRAPPING PAST VOTES ##########\n[ 0.363 0.316 0.079 0.033 0.006 0.128 0.045 0.001 0.028]\n[ 0.369 0.304 0.079 0.047 0.006 0.126 0.044 0.001 0.027]\nNew number of examples: 5027\n2 2091\n1 1894\n3 792\n4 226\nName: EUREF_Int, dtype: int64\n0.417949230462\n0.378572856286\n0.15830501699\n0.0451728962622\n \n########## BOOTSTRAPPING EDUCATION QUALIFICATIONS ##########\n[ 0.088 0.066 0.17 0.247 0.313 0.116]\n[ 0.145 0.156 0.178 0.157 0.293 0.073]\nNew number of examples: 7695\n2 3231\n1 2912\n3 1195\n4 333\nName: EUREF_Int, dtype: int64\n0.4211967149\n0.379611523921\n0.155781514796\n0.0434102463825\n \n########## BOOTSTRAPPING NEWSPAPERS ##########\n[ 0.021 0.003 0.006 0.251 0.073 0.024 0.198 0.048 0.034 0.009\n 0.002 0.08 0.083 0.109 0.059]\n[ 0.04 0.017 0.006 0.071 0.05 0.051 0.163 0.107 0.13 0.007\n 0.04 0.183 0.067 0.061 0.014]\nNew number of examples: 17461\n2 7285\n1 6588\n3 2775\n4 789\nName: EUREF_Int, dtype: int64\n0.417789757412\n0.377817285083\n0.159144348225\n0.0452486092791\n \n########## BOOTSTRAPPING TV NEWS ##########\n[ 0.679 0. 0.175 0.047 0.078 0.022]\n[ 0.32 0.226 0.113 0.068 0.17 0.105]\nNew number of examples: 33769\n2 13874\n1 12848\n3 5476\n4 1547\nName: EUREF_Int, dtype: int64\n0.411142391465\n0.380737887094\n0.162275892725\n0.0458438287154\n \n \n##########\nNew number of examples: 33769\n##########\n \n \n########## BOOTSTRAPPING MEN ##########\n[ 0.066 0.068 0.073 0.072 0.062 0.061 0.073 0.079 0.068 0.067\n 0.053 0.056 0.049 0.042 0.036 0.028 0.024 0.012 0.01 ]\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73efdeaa6c0cb10a54416a3102bb82b53eed929 | 3,366 | ipynb | Jupyter Notebook | cd.ipynb | JinYang88/UnsupervisedScalableRepresentationLearningTimeSeries | e02dfff26571e7fdfde0367170b233b7d8b868cc | [
"Apache-2.0"
] | 294 | 2019-02-04T15:12:32.000Z | 2022-03-29T06:23:22.000Z | cd.ipynb | JinYang88/UnsupervisedScalableRepresentationLearningTimeSeries | e02dfff26571e7fdfde0367170b233b7d8b868cc | [
"Apache-2.0"
] | 25 | 2019-07-03T12:17:45.000Z | 2022-02-10T11:36:43.000Z | cd.ipynb | JinYang88/UnsupervisedScalableRepresentationLearningTimeSeries | e02dfff26571e7fdfde0367170b233b7d8b868cc | [
"Apache-2.0"
] | 80 | 2019-02-05T21:01:12.000Z | 2022-03-29T06:23:27.000Z | 23.538462 | 83 | 0.545455 | [
[
[
"Licensed to the Apache Software Foundation (ASF) under one\nor more contributor license agreements. See the NOTICE file\ndistributed with this work for additional information\nregarding copyright ownership. The ASF licenses this file\nto you under the Apache License, Version 2.0 (the\n\"License\"); you may not use this file except in compliance\nwith the License. You may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing,\nsoftware distributed under the License is distributed on an\n\"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\nKIND, either express or implied. See the License for the\nspecific language governing permissions and limitations\nunder the License.",
"_____no_output_____"
],
[
"# Critical Difference Diagram",
"_____no_output_____"
]
],
[
[
"import Orange\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"df = pd.read_csv('results_ucr.csv', usecols=[6, 9, 10, 11, 12, 13])[:85]",
"_____no_output_____"
],
[
"ranks = np.array(df.rank(axis=1, method='min', ascending=False).mean())",
"_____no_output_____"
],
[
"names = df.columns",
"_____no_output_____"
],
[
"cd = Orange.evaluation.compute_CD(ranks, 85)",
"_____no_output_____"
],
[
"t = Orange.evaluation.graph_ranks(ranks, names, cd=cd, filename='cd_ucr.svg')",
"_____no_output_____"
],
[
"df.rank(axis=1, method='min', ascending=False).mean()",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73f082acb8dc59c9720413612e415bc73e80432 | 18,521 | ipynb | Jupyter Notebook | notebooks/.ipynb_checkpoints/transforms-checkpoint.ipynb | david-maine/astnn | 28922cf558662b3b0d18a4186f2c6c604ffbf57e | [
"MIT"
] | null | null | null | notebooks/.ipynb_checkpoints/transforms-checkpoint.ipynb | david-maine/astnn | 28922cf558662b3b0d18a4186f2c6c604ffbf57e | [
"MIT"
] | null | null | null | notebooks/.ipynb_checkpoints/transforms-checkpoint.ipynb | david-maine/astnn | 28922cf558662b3b0d18a4186f2c6c604ffbf57e | [
"MIT"
] | null | null | null | 30.512356 | 133 | 0.342044 | [
[
[
"from pycparser import c_ast, c_parser, c_generator\n\nparser = c_parser.CParser()\ngenerator = c_generator.CGenerator()\n",
"_____no_output_____"
]
],
[
[
"## Dead Code",
"_____no_output_____"
]
],
[
[
"import random",
"_____no_output_____"
],
[
"dead_codes = [\n '''\n int main() {\n int alpha;\n }\n ''',\n '''\n int main() {\n int alpha = 0;\n int beta = 5;\n int gamma = alpha + beta;\n }\n ''',\n '''\n int main() {\n const int ALPHA = 10;\n const int BETA = 5;\n }\n ''',\n '''\n int main() {\n int alpha = 0;\n if(false) {\n alpha = 1;\n }\n }\n '''\n ,\n '''\n int main() {\n int alpha = 0;\n if(false) {\n alpha = 1;\n } else {\n alpha = 2;\n }\n }\n '''\n]",
"_____no_output_____"
],
[
"compounds = []\nfor code in dead_codes:\n ast = parser.parse(code)\n compounds.append(ast.ext[0].body)",
"_____no_output_____"
],
[
"\nclass deadCodeAdder(c_ast.NodeVisitor):\n def visit_FuncDef(self, node):\n if node.decl.name == 'main':\n for compound in compounds:\n index = random.randrange(len(node.body.block_items))\n node.body.block_items = node.body.block_items[:index] + compound.block_items + node.body.block_items[index:]\n\ndef add_dead_code(ast):\n v = deadCodeAdder()\n v.visit(ast)\n ",
"_____no_output_____"
],
[
"src = \"\"\"\nint main()\n{\n int n,i,shuzu[111],count1=0,count3=0,count2=0,count4=0;\n scanf(\"%d\",&n);\n while(n>=100){\n n=n-100;\n count1++;\n }\n while(n>=50){\n n=n-50;\n count2++;\n }\n while(n>=20){\n n=n-20;\n count3++;\n }\n while(n>=10){\n n=n-10;\n count4++;\n return 0;\n }\n}\n\"\"\"\nast = parser.parse(src)\n\nadd_dead_code(ast)\nprint(generator.visit(ast))",
"int main()\n{\n int n;\n int i;\n int shuzu[111];\n int count1 = 0;\n int count3 = 0;\n int count2 = 0;\n int alpha;\n int count4 = 0;\n scanf(\"%d\", &n);\n while (n >= 100)\n {\n n = n - 100;\n count1++;\n }\n\n int alpha = 0;\n int beta = 5;\n int gamma = alpha + beta;\n while (n >= 50)\n {\n n = n - 50;\n count2++;\n }\n\n while (n >= 20)\n {\n n = n - 20;\n count3++;\n }\n\n while (n >= 10)\n {\n n = n - 10;\n count4++;\n return 0;\n }\n\n}\n\n\n"
]
],
[
[
"## Variable Renaimg",
"_____no_output_____"
]
],
[
[
"import pickle\nused_vars = pickle.load( open( \"/home/david/projects/university/astnn/var_names.pkl\", \"rb\" ) )",
"_____no_output_____"
],
[
"src = \"\"\"\nint main() {\n int alpha;\n alpha = 0;\n scanf(\"%d\",&n);\n}\n\"\"\"\n\nast = parser.parse(src)\nprint(ast)\nprint(generator.visit(ast))",
"FileAST(ext=[FuncDef(decl=Decl(name='main',\n quals=[\n ],\n storage=[\n ],\n funcspec=[\n ],\n type=FuncDecl(args=None,\n type=TypeDecl(declname='main',\n quals=[\n ],\n type=IdentifierType(names=['int'\n ]\n )\n )\n ),\n init=None,\n bitsize=None\n ),\n param_decls=None,\n body=Compound(block_items=[Decl(name='alpha',\n quals=[\n ],\n storage=[\n ],\n funcspec=[\n ],\n type=TypeDecl(declname='alpha',\n quals=[\n ],\n type=IdentifierType(names=['int'\n ]\n )\n ),\n init=None,\n bitsize=None\n ),\n Assignment(op='=',\n lvalue=ID(name='alpha'\n ),\n rvalue=Constant(type='int',\n value='0'\n )\n ),\n FuncCall(name=ID(name='scanf'\n ),\n args=ExprList(exprs=[Constant(type='string',\n value='\"%d\"'\n ),\n UnaryOp(op='&',\n expr=ID(name='n'\n )\n )\n ]\n )\n )\n ]\n )\n )\n ]\n )\nint main()\n{\n int alpha;\n alpha = 0;\n scanf(\"%d\", &n);\n}\n\n\n"
],
[
"import os\nimport sys\nmodule_path = os.path.abspath(os.path.join('..'))\nif module_path not in sys.path:\n sys.path.append(module_path)",
"_____no_output_____"
],
[
"from gensim.models.word2vec import Word2Vec\n\nword2vec = Word2Vec.load(\"/home/david/projects/university/astnn/data/train/embedding/node_w2v_128\").wv",
"_____no_output_____"
],
[
"word2vec.most_similar(positive=[], negative=['alpha'], topn=10, restrict_vocab=None)",
"_____no_output_____"
]
],
[
[
"## Restrict to sensible variable names",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ndef restrict_w2v(w2v, restricted_word_set):\n new_vectors = []\n new_vocab = {}\n new_index2entity = []\n new_vectors_norm = []\n\n for i in range(len(w2v.vocab)):\n word = w2v.index2entity[i]\n vec = w2v.vectors[i]\n vocab = w2v.vocab[word]\n vec_norm = w2v.vectors_norm[i]\n if word in restricted_word_set:\n vocab.index = len(new_index2entity)\n new_index2entity.append(word)\n new_vocab[word] = vocab\n new_vectors.append(vec)\n new_vectors_norm.append(vec_norm)\n\n w2v.vocab = new_vocab\n w2v.vectors = np.array(new_vectors)\n w2v.index2entity = np.array(new_index2entity)\n w2v.index2word = np.array(new_index2entity)\n w2v.vectors_norm = np.array(new_vectors_norm)",
"_____no_output_____"
],
[
"restrict_w2v(word2vec, used_vars)\nword2vec.most_similar(positive=[], negative=['alpha'], topn=10, restrict_vocab=None)",
"_____no_output_____"
],
[
"from pycparser.c_ast import TypeDecl, ID\n\ndef get_antonym(word):\n return word2vec.most_similar(positive=[], negative=[word], topn=1, restrict_vocab=None)[0][0]\n\nclass declarationRenamer(c_ast.NodeVisitor):\n def visit_Decl(self, node):\n var_name = node.name\n antonymn = get_antonym(var_name)\n node.name = antonymn\n if type(node.type) is TypeDecl:\n node.type.declname = antonymn\n \nclass assignmentRenamer(c_ast.NodeVisitor):\n def visit_Assignment(self, node):\n if type(node.lvalue) is ID:\n var_name = node.lvalue.name\n antonymn = get_antonym(var_name)\n node.lvalue.name = antonymn\n if type(node.rvalue) is ID:\n var_name = node.rvalue.name\n antonymn = get_antonym(var_name)\n node.rvalue.name = antonymn\n \nclass unaryOpRenamer(c_ast.NodeVisitor):\n def visit_UnaryOp(self, node):\n if type(node.expr) is ID:\n var_name = node.expr.name\n antonymn = get_antonym(var_name)\n node.expr.name = antonymn\n \nclass binaryOpRenamer(c_ast.NodeVisitor):\n def visit_BinaryOp(self, node):\n if type(node.left) is ID:\n var_name = node.left.name\n antonymn = get_antonym(var_name)\n node.left.name = antonymn\n if type(node.right) is ID:\n var_name = node.right.name\n antonymn = get_antonym(var_name)\n node.right.name = antonymn",
"_____no_output_____"
],
[
"def rename_vars(ast):\n declaration_renamer = declarationRenamer()\n assignment_renamer = assignmentRenamer()\n unary_op_renamer = unaryOpRenamer()\n binary_op_renamer = binaryOpRenamer()\n \n declaration_renamer.visit(ast)\n assignment_renamer.visit(ast)\n unary_op_renamer.visit(ast)\n binary_op_renamer.visit(ast)",
"_____no_output_____"
],
[
"src = \"\"\"\nint main()\n{\n int n,i,count1=0,count3=0,count2=0,count4=0;\n scanf(\"%d\",&n);\n while(n>=100){\n n=n-100;\n count1++;\n }\n while(n>=50){\n n=n-50;\n count2++;\n }\n while(n>=20){\n n=n-20;\n count3++;\n }\n while(n>=10){\n n=n-10;\n count4++;\n return 0;\n }\n}\n\"\"\"\nast = parser.parse(src)\n\nrename_vars(ast)\nprint(generator.visit(ast))",
"int main()\n{\n int tempi;\n int win;\n int ws = 0;\n int ml = 0;\n int cos = 0;\n int sen = 0;\n scanf(\"%d\", &tempi);\n while (tempi >= 100)\n {\n tempi = tempi - 100;\n ws++;\n }\n\n while (tempi >= 50)\n {\n tempi = tempi - 50;\n cos++;\n }\n\n while (tempi >= 20)\n {\n tempi = tempi - 20;\n ml++;\n }\n\n while (tempi >= 10)\n {\n tempi = tempi - 10;\n sen++;\n return 0;\n }\n\n}\n\n\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
e73f0aa3e8d6e6eaeb59db53da4129d06e7eee10 | 27,405 | ipynb | Jupyter Notebook | intro-to-pytorch/Part 3 - Training Neural Networks (Exercises).ipynb | aliwajahat12/deep-learning-v2-pytorch-forked | 2aed87a787fc790ad978e163226a10b1d889e28a | [
"MIT"
] | null | null | null | intro-to-pytorch/Part 3 - Training Neural Networks (Exercises).ipynb | aliwajahat12/deep-learning-v2-pytorch-forked | 2aed87a787fc790ad978e163226a10b1d889e28a | [
"MIT"
] | null | null | null | intro-to-pytorch/Part 3 - Training Neural Networks (Exercises).ipynb | aliwajahat12/deep-learning-v2-pytorch-forked | 2aed87a787fc790ad978e163226a10b1d889e28a | [
"MIT"
] | null | null | null | 40.124451 | 871 | 0.586973 | [
[
[
"# Training Neural Networks\n\nThe network we built in the previous part isn't so smart, it doesn't know anything about our handwritten digits. Neural networks with non-linear activations work like universal function approximators. There is some function that maps your input to the output. For example, images of handwritten digits to class probabilities. The power of neural networks is that we can train them to approximate this function, and basically any function given enough data and compute time.\n\n<img src=\"assets/function_approx.png\" width=500px>\n\nAt first the network is naive, it doesn't know the function mapping the inputs to the outputs. We train the network by showing it examples of real data, then adjusting the network parameters such that it approximates this function.\n\nTo find these parameters, we need to know how poorly the network is predicting the real outputs. For this we calculate a **loss function** (also called the cost), a measure of our prediction error. For example, the mean squared loss is often used in regression and binary classification problems\n\n$$\n\\large \\ell = \\frac{1}{2n}\\sum_i^n{\\left(y_i - \\hat{y}_i\\right)^2}\n$$\n\nwhere $n$ is the number of training examples, $y_i$ are the true labels, and $\\hat{y}_i$ are the predicted labels.\n\nBy minimizing this loss with respect to the network parameters, we can find configurations where the loss is at a minimum and the network is able to predict the correct labels with high accuracy. We find this minimum using a process called **gradient descent**. The gradient is the slope of the loss function and points in the direction of fastest change. To get to the minimum in the least amount of time, we then want to follow the gradient (downwards). You can think of this like descending a mountain by following the steepest slope to the base.\n\n<img src='assets/gradient_descent.png' width=350px>",
"_____no_output_____"
],
[
"## Backpropagation\n\nFor single layer networks, gradient descent is straightforward to implement. However, it's more complicated for deeper, multilayer neural networks like the one we've built. Complicated enough that it took about 30 years before researchers figured out how to train multilayer networks.\n\nTraining multilayer networks is done through **backpropagation** which is really just an application of the chain rule from calculus. It's easiest to understand if we convert a two layer network into a graph representation.\n\n<img src='assets/backprop_diagram.png' width=550px>\n\nIn the forward pass through the network, our data and operations go from bottom to top here. We pass the input $x$ through a linear transformation $L_1$ with weights $W_1$ and biases $b_1$. The output then goes through the sigmoid operation $S$ and another linear transformation $L_2$. Finally we calculate the loss $\\ell$. We use the loss as a measure of how bad the network's predictions are. The goal then is to adjust the weights and biases to minimize the loss.\n\nTo train the weights with gradient descent, we propagate the gradient of the loss backwards through the network. Each operation has some gradient between the inputs and outputs. As we send the gradients backwards, we multiply the incoming gradient with the gradient for the operation. Mathematically, this is really just calculating the gradient of the loss with respect to the weights using the chain rule.\n\n$$\n\\large \\frac{\\partial \\ell}{\\partial W_1} = \\frac{\\partial L_1}{\\partial W_1} \\frac{\\partial S}{\\partial L_1} \\frac{\\partial L_2}{\\partial S} \\frac{\\partial \\ell}{\\partial L_2}\n$$\n\n**Note:** I'm glossing over a few details here that require some knowledge of vector calculus, but they aren't necessary to understand what's going on.\n\nWe update our weights using this gradient with some learning rate $\\alpha$. \n\n$$\n\\large W^\\prime_1 = W_1 - \\alpha \\frac{\\partial \\ell}{\\partial W_1}\n$$\n\nThe learning rate $\\alpha$ is set such that the weight update steps are small enough that the iterative method settles in a minimum.",
"_____no_output_____"
],
[
"## Losses in PyTorch\n\nLet's start by seeing how we calculate the loss with PyTorch. Through the `nn` module, PyTorch provides losses such as the cross-entropy loss (`nn.CrossEntropyLoss`). You'll usually see the loss assigned to `criterion`. As noted in the last part, with a classification problem such as MNIST, we're using the softmax function to predict class probabilities. With a softmax output, you want to use cross-entropy as the loss. To actually calculate the loss, you first define the criterion then pass in the output of your network and the correct labels.\n\nSomething really important to note here. Looking at [the documentation for `nn.CrossEntropyLoss`](https://pytorch.org/docs/stable/nn.html#torch.nn.CrossEntropyLoss),\n\n> This criterion combines `nn.LogSoftmax()` and `nn.NLLLoss()` in one single class.\n>\n> The input is expected to contain scores for each class.\n\nThis means we need to pass in the raw output of our network into the loss, not the output of the softmax function. This raw output is usually called the *logits* or *scores*. We use the logits because softmax gives you probabilities which will often be very close to zero or one but floating-point numbers can't accurately represent values near zero or one ([read more here](https://docs.python.org/3/tutorial/floatingpoint.html)). It's usually best to avoid doing calculations with probabilities, typically we use log-probabilities.",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torch import nn\nimport torch.nn.functional as F\nfrom torchvision import datasets, transforms\n\n# Define a transform to normalize the data\ntransform = transforms.Compose([transforms.ToTensor(),\n transforms.Normalize((0.5,), (0.5,)),\n ])\n# Download and load the training data\ntrainset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)",
"_____no_output_____"
]
],
[
[
"### Note\nIf you haven't seen `nn.Sequential` yet, please finish the end of the Part 2 notebook.",
"_____no_output_____"
]
],
[
[
"# Build a feed-forward network\nmodel = nn.Sequential(nn.Linear(784, 128),\n nn.ReLU(),\n nn.Linear(128, 64),\n nn.ReLU(),\n nn.Linear(64, 10))\n\n# Define the loss\ncriterion = nn.CrossEntropyLoss()\n\n# Get our data\ndataiter = iter(trainloader)\n\nimages, labels = next(dataiter)\n\n# Flatten images\nimages = images.view(images.shape[0], -1)\n\n# Forward pass, get our logits\nlogits = model(images)\n# Calculate the loss with the logits and the labels\nloss = criterion(logits, labels)\n\nprint(loss)",
"tensor(2.3003, grad_fn=<NllLossBackward>)\n"
]
],
[
[
"In my experience it's more convenient to build the model with a log-softmax output using `nn.LogSoftmax` or `F.log_softmax` ([documentation](https://pytorch.org/docs/stable/nn.html#torch.nn.LogSoftmax)). Then you can get the actual probabilities by taking the exponential `torch.exp(output)`. With a log-softmax output, you want to use the negative log likelihood loss, `nn.NLLLoss` ([documentation](https://pytorch.org/docs/stable/nn.html#torch.nn.NLLLoss)).\n\n>**Exercise:** Build a model that returns the log-softmax as the output and calculate the loss using the negative log likelihood loss. Note that for `nn.LogSoftmax` and `F.log_softmax` you'll need to set the `dim` keyword argument appropriately. `dim=0` calculates softmax across the rows, so each column sums to 1, while `dim=1` calculates across the columns so each row sums to 1. Think about what you want the output to be and choose `dim` appropriately.",
"_____no_output_____"
]
],
[
[
"# TODO: Build a feed-forward network\nmodel = nn.Sequential(nn.Linear(784,128),\n nn.ReLU(),\n nn.Linear(128,64),\n nn.ReLU(),\n nn.Linear(64,10),\n nn.LogSoftmax(dim=1)\n )\n\n# TODO: Define the loss\ncriterion = nn.NLLLoss()\n\n### Run this to check your work\n# Get our data\ndataiter = iter(trainloader)\n\nimages, labels = next(dataiter)\n\n# Flatten images\nimages = images.view(images.shape[0], -1)\n\n# Forward pass, get our logits\nlogits = model(images)\n# Calculate the loss with the logits and the labels\nloss = criterion(logits, labels)\n\nprint(loss)",
"tensor(2.3045, grad_fn=<NllLossBackward>)\n"
]
],
[
[
"## Autograd\n\nNow that we know how to calculate a loss, how do we use it to perform backpropagation? Torch provides a module, `autograd`, for automatically calculating the gradients of tensors. We can use it to calculate the gradients of all our parameters with respect to the loss. Autograd works by keeping track of operations performed on tensors, then going backwards through those operations, calculating gradients along the way. To make sure PyTorch keeps track of operations on a tensor and calculates the gradients, you need to set `requires_grad = True` on a tensor. You can do this at creation with the `requires_grad` keyword, or at any time with `x.requires_grad_(True)`.\n\nYou can turn off gradients for a block of code with the `torch.no_grad()` content:\n```python\nx = torch.zeros(1, requires_grad=True)\n>>> with torch.no_grad():\n... y = x * 2\n>>> y.requires_grad\nFalse\n```\n\nAlso, you can turn on or off gradients altogether with `torch.set_grad_enabled(True|False)`.\n\nThe gradients are computed with respect to some variable `z` with `z.backward()`. This does a backward pass through the operations that created `z`.",
"_____no_output_____"
]
],
[
[
"x = torch.randn(2,2, requires_grad=True)\nprint(x)",
"tensor([[-0.0848, 0.5251],\n [-0.0086, 1.1436]], requires_grad=True)\n"
],
[
"y = x**2\nprint(y)",
"tensor([[7.1960e-03, 2.7573e-01],\n [7.3863e-05, 1.3079e+00]], grad_fn=<PowBackward0>)\n"
]
],
[
[
"Below we can see the operation that created `y`, a power operation `PowBackward0`.",
"_____no_output_____"
]
],
[
[
"## grad_fn shows the function that generated this variable\nprint(y.grad_fn)",
"<PowBackward0 object at 0x000001E5C27A9CD0>\n"
]
],
[
[
"The autograd module keeps track of these operations and knows how to calculate the gradient for each one. In this way, it's able to calculate the gradients for a chain of operations, with respect to any one tensor. Let's reduce the tensor `y` to a scalar value, the mean.",
"_____no_output_____"
]
],
[
[
"z = y.mean()\nprint(z)",
"tensor(0.3977, grad_fn=<MeanBackward0>)\n"
]
],
[
[
"You can check the gradients for `x` and `y` but they are empty currently.",
"_____no_output_____"
]
],
[
[
"print(x.grad)",
"None\n"
]
],
[
[
"To calculate the gradients, you need to run the `.backward` method on a Variable, `z` for example. This will calculate the gradient for `z` with respect to `x`\n\n$$\n\\frac{\\partial z}{\\partial x} = \\frac{\\partial}{\\partial x}\\left[\\frac{1}{n}\\sum_i^n x_i^2\\right] = \\frac{x}{2}\n$$",
"_____no_output_____"
]
],
[
[
"z.backward()\nprint(x.grad)\nprint(x/2)",
"tensor([[-0.0424, 0.2625],\n [-0.0043, 0.5718]])\ntensor([[-0.0424, 0.2625],\n [-0.0043, 0.5718]], grad_fn=<DivBackward0>)\n"
]
],
[
[
"These gradients calculations are particularly useful for neural networks. For training we need the gradients of the cost with respect to the weights. With PyTorch, we run data forward through the network to calculate the loss, then, go backwards to calculate the gradients with respect to the loss. Once we have the gradients we can make a gradient descent step. ",
"_____no_output_____"
],
[
"## Loss and Autograd together\n\nWhen we create a network with PyTorch, all of the parameters are initialized with `requires_grad = True`. This means that when we calculate the loss and call `loss.backward()`, the gradients for the parameters are calculated. These gradients are used to update the weights with gradient descent. Below you can see an example of calculating the gradients using a backwards pass.",
"_____no_output_____"
]
],
[
[
"# Build a feed-forward network\nmodel = nn.Sequential(nn.Linear(784, 128),\n nn.ReLU(),\n nn.Linear(128, 64),\n nn.ReLU(),\n nn.Linear(64, 10),\n nn.LogSoftmax(dim=1))\n\ncriterion = nn.NLLLoss()\ndataiter = iter(trainloader)\nimages, labels = next(dataiter)\nimages = images.view(images.shape[0], -1)\n\nlogits = model(images)\nloss = criterion(logits, labels)",
"_____no_output_____"
],
[
"print('Before backward pass: \\n', model[0].weight.grad)\n\nloss.backward()\n\nprint('After backward pass: \\n', model[0].weight.grad)",
"Before backward pass: \n None\nAfter backward pass: \n tensor([[-0.0012, -0.0012, -0.0012, ..., -0.0012, -0.0012, -0.0012],\n [-0.0002, -0.0002, -0.0002, ..., -0.0002, -0.0002, -0.0002],\n [-0.0021, -0.0021, -0.0021, ..., -0.0021, -0.0021, -0.0021],\n ...,\n [-0.0005, -0.0005, -0.0005, ..., -0.0005, -0.0005, -0.0005],\n [-0.0036, -0.0036, -0.0036, ..., -0.0036, -0.0036, -0.0036],\n [-0.0009, -0.0009, -0.0009, ..., -0.0009, -0.0009, -0.0009]])\n"
]
],
[
[
"## Training the network!\n\nThere's one last piece we need to start training, an optimizer that we'll use to update the weights with the gradients. We get these from PyTorch's [`optim` package](https://pytorch.org/docs/stable/optim.html). For example we can use stochastic gradient descent with `optim.SGD`. You can see how to define an optimizer below.",
"_____no_output_____"
]
],
[
[
"from torch import optim\n\n# Optimizers require the parameters to optimize and a learning rate\noptimizer = optim.SGD(model.parameters(), lr=0.01)",
"_____no_output_____"
]
],
[
[
"Now we know how to use all the individual parts so it's time to see how they work together. Let's consider just one learning step before looping through all the data. The general process with PyTorch:\n\n* Make a forward pass through the network \n* Use the network output to calculate the loss\n* Perform a backward pass through the network with `loss.backward()` to calculate the gradients\n* Take a step with the optimizer to update the weights\n\nBelow I'll go through one training step and print out the weights and gradients so you can see how it changes. Note that I have a line of code `optimizer.zero_grad()`. When you do multiple backwards passes with the same parameters, the gradients are accumulated. This means that you need to zero the gradients on each training pass or you'll retain gradients from previous training batches.",
"_____no_output_____"
]
],
[
[
"print('Initial weights - ', model[0].weight)\n\ndataiter = iter(trainloader)\nimages, labels = next(dataiter)\nimages.resize_(64, 784)\n\n# Clear the gradients, do this because gradients are accumulated\noptimizer.zero_grad()\n\n# Forward pass, then backward pass, then update weights\noutput = model(images)\nloss = criterion(output, labels)\nloss.backward()\nprint('Gradient -', model[0].weight.grad)",
"Initial weights - Parameter containing:\ntensor([[ 0.0337, -0.0036, -0.0355, ..., 0.0301, -0.0247, 0.0166],\n [-0.0321, 0.0066, 0.0354, ..., 0.0268, 0.0344, -0.0230],\n [ 0.0110, -0.0167, -0.0310, ..., 0.0339, -0.0177, -0.0171],\n ...,\n [ 0.0275, -0.0146, 0.0074, ..., -0.0061, 0.0017, 0.0346],\n [-0.0230, 0.0100, -0.0049, ..., 0.0095, -0.0291, 0.0146],\n [ 0.0068, 0.0282, 0.0076, ..., 0.0350, -0.0289, 0.0233]],\n requires_grad=True)\nGradient - tensor([[-0.0008, -0.0008, -0.0008, ..., -0.0008, -0.0008, -0.0008],\n [ 0.0020, 0.0020, 0.0020, ..., 0.0020, 0.0020, 0.0020],\n [-0.0006, -0.0006, -0.0006, ..., -0.0006, -0.0006, -0.0006],\n ...,\n [-0.0002, -0.0002, -0.0002, ..., -0.0002, -0.0002, -0.0002],\n [ 0.0002, 0.0002, 0.0002, ..., 0.0002, 0.0002, 0.0002],\n [-0.0016, -0.0016, -0.0016, ..., -0.0016, -0.0016, -0.0016]])\n"
],
[
"# Take an update step and view the new weights\noptimizer.step()\nprint('Updated weights - ', model[0].weight)",
"Updated weights - Parameter containing:\ntensor([[ 0.0338, -0.0036, -0.0355, ..., 0.0301, -0.0247, 0.0167],\n [-0.0321, 0.0066, 0.0354, ..., 0.0267, 0.0344, -0.0230],\n [ 0.0110, -0.0167, -0.0310, ..., 0.0339, -0.0177, -0.0171],\n ...,\n [ 0.0275, -0.0146, 0.0074, ..., -0.0061, 0.0017, 0.0346],\n [-0.0230, 0.0100, -0.0049, ..., 0.0095, -0.0291, 0.0145],\n [ 0.0068, 0.0282, 0.0076, ..., 0.0350, -0.0289, 0.0233]],\n requires_grad=True)\n"
]
],
[
[
"### Training for real\n\nNow we'll put this algorithm into a loop so we can go through all the images. Some nomenclature, one pass through the entire dataset is called an *epoch*. So here we're going to loop through `trainloader` to get our training batches. For each batch, we'll doing a training pass where we calculate the loss, do a backwards pass, and update the weights.\n\n>**Exercise:** Implement the training pass for our network. If you implemented it correctly, you should see the training loss drop with each epoch.",
"_____no_output_____"
]
],
[
[
"## Your solution here\n\nmodel = nn.Sequential(nn.Linear(784, 128),\n nn.ReLU(),\n nn.Linear(128, 64),\n nn.ReLU(),\n nn.Linear(64, 10),\n nn.LogSoftmax(dim=1))\n\ncriterion = nn.NLLLoss()\noptimizer = optim.SGD(model.parameters(), lr=0.003)\n\n\n\nepochs = 5\nfor e in range(epochs):\n running_loss = 0\n for images, labels in trainloader:\n # Flatten MNIST images into a 784 long vector\n images = images.view(images.shape[0], -1)\n \n optimizer.zero_grad()\n\n\n # TODO: Training pass\n output = model(images) \n loss = criterion(output, labels)\n loss.backward()\n \n optimizer.step()\n \n running_loss += loss.item()\n else:\n print(f\"Training loss: {running_loss/len(trainloader)}\")",
"Training loss: 1.946036617766057\nTraining loss: 0.8951423045541687\nTraining loss: 0.5485408180303919\nTraining loss: 0.4467467614519062\nTraining loss: 0.39703025616435356\n"
]
],
[
[
"With the network trained, we can check out it's predictions.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport helper\n\ndataiter = iter(trainloader)\nimages, labels = next(dataiter)\n\nimg = images[0].view(1, 784)\n# Turn off gradients to speed up this part\nwith torch.no_grad():\n logps = model(img)\n\n# Output of the network are log-probabilities, need to take exponential for probabilities\nps = torch.exp(logps)\nhelper.view_classify(img.view(1, 28, 28), ps)",
"_____no_output_____"
]
],
[
[
"Now our network is brilliant. It can accurately predict the digits in our images. Next up you'll write the code for training a neural network on a more complex dataset.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
e73f0dcc64a5abaf163e07195e7dadf1bc5c0d1a | 48,439 | ipynb | Jupyter Notebook | Lectures notebooks/(Lectures notebooks) netology Machine learning/15. Convolutional Neural Network (CNN)/005_cnn_mnist.ipynb | Alex110117/data_analysis | 3cac3aac63d617b9fbd862788c778c2858445622 | [
"MIT"
] | 2 | 2020-07-22T07:33:13.000Z | 2020-07-26T16:46:18.000Z | Lectures notebooks/(Lectures notebooks) netology Machine learning/15. Convolutional Neural Network (CNN)/005_cnn_mnist.ipynb | sibalex/data_analysis | 3cac3aac63d617b9fbd862788c778c2858445622 | [
"MIT"
] | null | null | null | Lectures notebooks/(Lectures notebooks) netology Machine learning/15. Convolutional Neural Network (CNN)/005_cnn_mnist.ipynb | sibalex/data_analysis | 3cac3aac63d617b9fbd862788c778c2858445622 | [
"MIT"
] | null | null | null | 65.369771 | 12,904 | 0.702678 | [
[
[
"# Классификация MNIST сверточной сетью",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport cv2\nimport numpy as np\nfrom tensorflow import keras",
"_____no_output_____"
],
[
"train = np.loadtxt('train.csv', delimiter=',', skiprows=1)\ntest = np.loadtxt('test.csv', delimiter=',', skiprows=1)",
"_____no_output_____"
],
[
"# сохраняем разметку в отдельную переменную\ntrain_label = train[:, 0]\n\n# приводим размерность к удобному для обаботки виду\n# добавляем размерность канала\ntrain_img = np.resize(train[:, 1:], (train.shape[0], 28, 28, 1))\ntest_img = np.resize(test, (test.shape[0], 28, 28, 1))",
"_____no_output_____"
]
],
[
[
"## Визуализируем исходные данные",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(20, 10))\nfor i, img in enumerate(train_img[0:5, :], 1):\n subplot = fig.add_subplot(1, 5, i)\n plt.imshow(img[:,:,0], cmap='gray');\n subplot.set_title('%s' % train_label[i - 1]);",
"_____no_output_____"
]
],
[
[
"## Разбиваем выборку на обучение и валидацию",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\ny_train, y_val, x_train, x_val = train_test_split(\n train_label, train_img, test_size=0.2, random_state=42)",
"_____no_output_____"
]
],
[
[
"## Собираем сверточную сеть для обучения",
"_____no_output_____"
]
],
[
[
"seed = 123457\nkernek_initializer = keras.initializers.glorot_normal(seed=seed)\nbias_initializer = keras.initializers.normal(stddev=1., seed=seed)\n\nmodel = keras.models.Sequential()\n\nmodel.add(keras.layers.Conv2D(6, \n kernel_size=(5, 5), \n padding='same', \n activation='relu', \n input_shape=x_train.shape[1:],\n bias_initializer=bias_initializer,\n kernel_initializer=kernek_initializer))\n\nmodel.add(keras.layers.MaxPool2D(pool_size=(2, 2), padding='valid'))\n\nmodel.add(keras.layers.Conv2D(16, \n kernel_size=(5, 5),\n padding='valid',\n activation='relu', \n bias_initializer=bias_initializer,\n kernel_initializer=kernek_initializer))\n\nmodel.add(keras.layers.MaxPool2D(pool_size=(2, 2), padding='valid'))\n\nmodel.add(keras.layers.Flatten())\n\nmodel.add(keras.layers.Dense(32, activation='relu',\n bias_initializer=bias_initializer,\n kernel_initializer=kernek_initializer))\n\nmodel.add(keras.layers.Dense(10, activation='softmax',\n bias_initializer=bias_initializer,\n kernel_initializer=kernek_initializer))\n\nmodel.compile(optimizer='adam',\n loss='categorical_crossentropy',\n metrics=['accuracy'])",
"WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/initializers.py:143: calling RandomNormal.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/resource_variable_ops.py:1630: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.\nInstructions for updating:\nIf using Keras pass *_constraint arguments to layers.\n"
]
],
[
[
"## Выводим информацию о модели",
"_____no_output_____"
]
],
[
[
"model.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d (Conv2D) (None, 28, 28, 6) 156 \n_________________________________________________________________\nmax_pooling2d (MaxPooling2D) (None, 14, 14, 6) 0 \n_________________________________________________________________\nconv2d_1 (Conv2D) (None, 10, 10, 16) 2416 \n_________________________________________________________________\nmax_pooling2d_1 (MaxPooling2 (None, 5, 5, 16) 0 \n_________________________________________________________________\nflatten (Flatten) (None, 400) 0 \n_________________________________________________________________\ndense (Dense) (None, 32) 12832 \n_________________________________________________________________\ndense_1 (Dense) (None, 10) 330 \n=================================================================\nTotal params: 15,734\nTrainable params: 15,734\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## One hot encoding разметки",
"_____no_output_____"
]
],
[
[
"y_train_labels = keras.utils.to_categorical(y_train)",
"_____no_output_____"
],
[
"y_train[:10]",
"_____no_output_____"
],
[
"y_train_labels[:10]",
"_____no_output_____"
]
],
[
[
"## Запускаем обучение",
"_____no_output_____"
]
],
[
[
"model.fit(x_train, \n y_train_labels,\n batch_size=32, \n epochs=5,\n validation_split=0.2)",
"Train on 26880 samples, validate on 6720 samples\nEpoch 1/5\n26880/26880 [==============================] - 19s 708us/sample - loss: 0.9753 - acc: 0.7766 - val_loss: 0.2560 - val_acc: 0.9298\nEpoch 2/5\n26880/26880 [==============================] - 21s 776us/sample - loss: 0.1949 - acc: 0.9466 - val_loss: 0.1530 - val_acc: 0.9589\nEpoch 3/5\n26880/26880 [==============================] - 19s 697us/sample - loss: 0.1254 - acc: 0.9631 - val_loss: 0.1349 - val_acc: 0.9637\nEpoch 4/5\n26880/26880 [==============================] - 18s 687us/sample - loss: 0.0924 - acc: 0.9727 - val_loss: 0.1286 - val_acc: 0.9664\nEpoch 5/5\n26880/26880 [==============================] - 19s 691us/sample - loss: 0.0727 - acc: 0.9779 - val_loss: 0.1151 - val_acc: 0.9677\n"
]
],
[
[
"## Предсказываем класс объекта",
"_____no_output_____"
]
],
[
[
"pred_val = model.predict_classes(x_val)",
"_____no_output_____"
],
[
"pred_val[:10]",
"_____no_output_____"
]
],
[
[
"## Оцениваем качество решение на валидационной выборке",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import accuracy_score\nprint('Accuracy: %s' % accuracy_score(y_val, pred_val))",
"Accuracy: 0.9730952380952381\n"
],
[
"from sklearn.metrics import classification_report\nprint(classification_report(y_val, pred_val))",
" precision recall f1-score support\n\n 0.0 0.99 0.98 0.98 816\n 1.0 0.99 0.99 0.99 909\n 2.0 0.96 0.98 0.97 846\n 3.0 0.97 0.98 0.97 937\n 4.0 0.99 0.96 0.97 839\n 5.0 0.99 0.95 0.97 702\n 6.0 0.99 0.98 0.98 785\n 7.0 0.98 0.96 0.97 893\n 8.0 0.98 0.96 0.97 835\n 9.0 0.91 1.00 0.95 838\n\n accuracy 0.97 8400\n macro avg 0.97 0.97 0.97 8400\nweighted avg 0.97 0.97 0.97 8400\n\n"
],
[
"from sklearn.metrics import confusion_matrix\nprint(confusion_matrix(y_val, pred_val))",
"[[801 0 2 1 0 1 2 0 0 9]\n [ 0 897 5 1 1 0 0 2 0 3]\n [ 0 4 831 3 3 0 1 1 1 2]\n [ 1 0 3 915 0 1 1 5 4 7]\n [ 1 1 2 0 805 0 4 1 3 22]\n [ 1 1 0 11 2 668 3 3 3 10]\n [ 4 2 1 0 0 3 769 0 4 2]\n [ 1 0 11 6 1 0 0 855 1 18]\n [ 3 0 9 9 3 4 0 1 799 7]\n [ 0 0 0 0 0 1 0 1 2 834]]\n"
]
],
[
[
"## Предсказания на тестовыйх данных",
"_____no_output_____"
]
],
[
[
"pred_test = model.predict_classes(test_img)",
"_____no_output_____"
]
],
[
[
"## Визуализируем предсказания",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(20, 10))\nindices = np.random.choice(range(len(test_img)), 5)\nimg_prediction = zip(test_img[indices], pred_test[indices])\nfor i, (img, pred) in enumerate(img_prediction, 1):\n subplot = fig.add_subplot(1, 5, i)\n plt.imshow(img[...,0], cmap='gray');\n subplot.set_title('%d' % pred);",
"_____no_output_____"
]
],
[
[
"## Готовим файл для отправки",
"_____no_output_____"
]
],
[
[
"with open('submit.txt', 'w') as dst:\n dst.write('ImageId,Label\\n')\n for i, p in enumerate(pred_test, 1):\n dst.write('%s,%d\\n' % (i, p))",
"_____no_output_____"
],
[
"# Your submission scored 0.9730952380952381",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
e73f127f27517e6f782f60575dc2db4092464308 | 11,963 | ipynb | Jupyter Notebook | bronze/B50_Superdense_Coding.ipynb | KuantumTurkiye/bronze | b3e7dd06eab8e90c3584fc5b94a53ebb2f2555e4 | [
"Apache-2.0",
"CC-BY-4.0"
] | 1 | 2021-01-31T12:53:57.000Z | 2021-01-31T12:53:57.000Z | bronze/B50_Superdense_Coding.ipynb | KuantumTurkiye/bronze | b3e7dd06eab8e90c3584fc5b94a53ebb2f2555e4 | [
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null | bronze/B50_Superdense_Coding.ipynb | KuantumTurkiye/bronze | b3e7dd06eab8e90c3584fc5b94a53ebb2f2555e4 | [
"Apache-2.0",
"CC-BY-4.0"
] | 1 | 2021-01-24T20:29:18.000Z | 2021-01-24T20:29:18.000Z | 37.501567 | 309 | 0.536237 | [
[
[
"<table width=\"100%\"> <tr>\n <td style=\"background-color:#ffffff;\">\n <a href=\"http://qworld.lu.lv\" target=\"_blank\"><img src=\"..\\images\\qworld.jpg\" width=\"35%\" align=\"left\"> </a></td>\n <td style=\"background-color:#ffffff;vertical-align:bottom;text-align:right;\">\n prepared by Abuzer Yakaryilmaz (<a href=\"http://qworld.lu.lv/index.php/qlatvia/\" target=\"_blank\">QLatvia</a>)\n <br>\n updated by Özlem Salehi | September 17, 2020\n </td> \n</tr></table>",
"_____no_output_____"
],
[
"<table width=\"100%\"><tr><td style=\"color:#bbbbbb;background-color:#ffffff;font-size:11px;font-style:italic;text-align:right;\">This cell contains some macros. If there is a problem with displaying mathematical formulas, please run this cell to load these macros. </td></tr></table>\n$ \\newcommand{\\bra}[1]{\\langle #1|} $\n$ \\newcommand{\\ket}[1]{|#1\\rangle} $\n$ \\newcommand{\\braket}[2]{\\langle #1|#2\\rangle} $\n$ \\newcommand{\\dot}[2]{ #1 \\cdot #2} $\n$ \\newcommand{\\biginner}[2]{\\left\\langle #1,#2\\right\\rangle} $\n$ \\newcommand{\\mymatrix}[2]{\\left( \\begin{array}{#1} #2\\end{array} \\right)} $\n$ \\newcommand{\\myvector}[1]{\\mymatrix{c}{#1}} $\n$ \\newcommand{\\myrvector}[1]{\\mymatrix{r}{#1}} $\n$ \\newcommand{\\mypar}[1]{\\left( #1 \\right)} $\n$ \\newcommand{\\mybigpar}[1]{ \\Big( #1 \\Big)} $\n$ \\newcommand{\\sqrttwo}{\\frac{1}{\\sqrt{2}}} $\n$ \\newcommand{\\dsqrttwo}{\\dfrac{1}{\\sqrt{2}}} $\n$ \\newcommand{\\onehalf}{\\frac{1}{2}} $\n$ \\newcommand{\\donehalf}{\\dfrac{1}{2}} $\n$ \\newcommand{\\hadamard}{ \\mymatrix{rr}{ \\sqrttwo & \\sqrttwo \\\\ \\sqrttwo & -\\sqrttwo }} $\n$ \\newcommand{\\vzero}{\\myvector{1\\\\0}} $\n$ \\newcommand{\\vone}{\\myvector{0\\\\1}} $\n$ \\newcommand{\\vhadamardzero}{\\myvector{ \\sqrttwo \\\\ \\sqrttwo } } $\n$ \\newcommand{\\vhadamardone}{ \\myrvector{ \\sqrttwo \\\\ -\\sqrttwo } } $\n$ \\newcommand{\\myarray}[2]{ \\begin{array}{#1}#2\\end{array}} $\n$ \\newcommand{\\X}{ \\mymatrix{cc}{0 & 1 \\\\ 1 & 0} } $\n$ \\newcommand{\\Z}{ \\mymatrix{rr}{1 & 0 \\\\ 0 & -1} } $\n$ \\newcommand{\\Htwo}{ \\mymatrix{rrrr}{ \\frac{1}{2} & \\frac{1}{2} & \\frac{1}{2} & \\frac{1}{2} \\\\ \\frac{1}{2} & -\\frac{1}{2} & \\frac{1}{2} & -\\frac{1}{2} \\\\ \\frac{1}{2} & \\frac{1}{2} & -\\frac{1}{2} & -\\frac{1}{2} \\\\ \\frac{1}{2} & -\\frac{1}{2} & -\\frac{1}{2} & \\frac{1}{2} } } $\n$ \\newcommand{\\CNOT}{ \\mymatrix{cccc}{1 & 0 & 0 & 0 \\\\ 0 & 1 & 0 & 0 \\\\ 0 & 0 & 0 & 1 \\\\ 0 & 0 & 1 & 0} } $\n$ \\newcommand{\\norm}[1]{ \\left\\lVert #1 \\right\\rVert } $",
"_____no_output_____"
],
[
"<h2>Entanglement and Superdense Coding</h2>\n\nAsja has a qubit, initially set to $ \\ket{0} $.\n\nBalvis has a qubit, initially set to $ \\ket{0} $.",
"_____no_output_____"
],
[
"<h3> Entanglement </h3>\n \nAsja applies Hadamard operator to her qubit. \n\nThe quantum state of Asja's qubit is $ \\vhadamardzero $.\n\nThen, Asja and Balvis combine their qubits. Their quantum state is\n\n$ \\vhadamardzero \\otimes \\vzero = \\myvector{ \\frac{1}{\\sqrt{2}} \\\\ 0 \\\\ \\frac{1}{\\sqrt{2}} \\\\ 0 } $.\n",
"_____no_output_____"
],
[
"Asja and Balvis apply CNOT operator on two qubits.\n\nThe new quantum state is\n\n$ \\CNOT \\myvector{ \\frac{1}{\\sqrt{2}} \\\\ 0 \\\\ \\frac{1}{\\sqrt{2}} \\\\ 0 } = \\myvector{ \\frac{1}{\\sqrt{2}} \\\\ 0 \\\\0 \\\\ \\frac{1}{\\sqrt{2}} } = \\frac{1}{\\sqrt{2}}\\ket{00} + \\frac{1}{\\sqrt{2}}\\ket{11} $.\n\nAt this moment, Asja's and Balvis' qubits are correlated to each other.\n\nIf we measure both qubits, we can observe either state $ \\ket{00} $ or state $ \\ket{11} $. \n\nSuppose that Asja observes her qubit secretly. \n<ul>\n <li> When Asja sees the result $ \\ket{0} $, then Balvis' qubit also collapses to state $ \\ket{0} $. Balvis cannot observe state $ \\ket{1} $. </li>\n <li> When Asja sees the result $ \\ket{1} $, then Balvis' qubit also collapses to state $ \\ket{1} $. Balvis cannot observe state $ \\ket{0} $. </li>\n</ul>\n \nExperimental results have confirmed that this happens even if there is a physical distance between Asja's and Balvis' qubits. \n\nIt seems correlated quantum particles can \"affect each other\" instantly, even if they are in the different part of the universe. \n\nIf two qubits are correlated in this way, then we say that they are <b>entangled</b>.\n\n<a href=\"http://thelifeofpsi.com/2013/10/28/bertlmanns-socks/\">Read more</a>\n\n<i> <u>Technical note</u>: \n \nIf the quantum state of two qubits can be written as $ \\ket{u} \\otimes \\ket{v} $, then two qubits are not correlated, where $ \\ket{u} $ and $ \\ket{v} $ are the quantum states of the first and second qubits.\n\nOn the other hand, if the quantum state of two qubits cannot be written as $ \\ket{u} \\otimes \\ket{v} $, then there is an entanglement between the qubits.\n</i>\n\n<b> Entangled qubits can be useful </b>",
"_____no_output_____"
],
[
"<h3> What is superdense coding ? </h3>\n\nIt is the process of transmitting classical information using quantum communication and previously entangled qubits.\n\n<h3> Protocol </h3>\n\nAfter having the entanglement, Balvis takes his qubit and goes away.\n\nAsja will send two classical bits of information by only sending her qubit.\n\n\n<img src=\"../images/superdense_coding.png\">\n\n<font size=\"-2\">source: https://fi.m.wikipedia.org/wiki/Tiedosto:Superdense_coding.png </font>\n",
"_____no_output_____"
],
[
"\nNow, we describe this protocol.\n\nAsja has two bits of classical information: $ x,y \\in \\{0,1\\} $. \n\nThere are four possible values for the pair $ (x,y) $: $ (0,0), (0,1), (1,0),\\mbox{ or } (1,1) $. \n\nIf $x$ is 1, then Asja applies z-gate, i.e., $ Z = \\Z $, to her qubit.\n\nIf $y$ is 1, then Asja applies x-gate (NOT operator) to her qubit.\n\nThen, Asja sends her qubit to Balvis.",
"_____no_output_____"
],
[
"<h3> After the communication </h3>\n\nBalvis has both qubits.\n\nBalvis applies cx-gate (CNOT operator), where Asja's qubit is the controller.\n\nThen, Balvis applies h-gate (Hadamard operator) to Asja's qubit.\n\nBalvis measures both qubits. \n\nThe measurement result will be exactly $ (x,y) $.",
"_____no_output_____"
],
[
"<h3> Task 1</h3>\n\nVerify the correctness of the above protocol.\n\nFor each pair of $ (x,y) \\in \\left\\{ (0,0), (0,1), (1,0),(1,1) \\right\\} $:\n<ul>\n <li> Create a quantum curcuit with two qubits: Asja's and Balvis' qubits.</li>\n <li> Both are initially set to $ \\ket{0} $.</li>\n <li> Apply h-gate (Hadamard) to the first qubit. </li>\n <li> Apply cx-gate (CNOT) with parameters first-qubit and second-qubit. </li>\n</ul>\n\nAssume that they are separated now.\n\n<ul>\n <li> If $ x $ is 1, then apply z-gate to the first qubit. </li>\n <li> If $ y $ is 1, then apply x-gate (NOT) to the first qubit. </li>\n</ul>\n\nAssume that Asja sends her qubit to Balvis.\n\n<ul>\n <li> Apply cx-gate (CNOT) with parameters first-qubit and second-qubit.</li>\n <li> Apply h-gate (Hadamard) to the first qubit. </li>\n <li> Measure both qubits, and compare the results with pair $ (x,y) $. </li>\n</ul>",
"_____no_output_____"
]
],
[
[
"# import all necessary objects and methods for quantum circuits\nfrom qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\n\nall_pairs = ['00','01','10','11']\n\n#\n# your code is here\n#\n",
"_____no_output_____"
]
],
[
[
"<a href=\"B50_Superdense_Coding_Solutions.ipynb#task1\">click for our solution</a>",
"_____no_output_____"
],
[
"<h3> Task 2 </h3>\n\nVerify each case by tracing the state vector (on paper). ",
"_____no_output_____"
],
[
"<h3> Task 3 [Extra]</h3>\n\nCan the above set-up be used by Balvis?\n\nVerify that the following modified protocol allows Balvis to send two classical bits by sending only his qubit.\n\nFor each pair of $ (a,b) \\in \\left\\{ (0,0), (0,1), (1,0),(1,1) \\right\\} $:\n- Create a quantum curcuit with two qubits: Asja's and Balvis' qubits\n- Both are initially set to $ \\ket{0} $\n- Apply h-gate (Hadamard) to the Asja's qubit\n- Apply cx-gate as CNOT(Asja's-qubit,Balvis'-qubit)\n\nAssume that both qubits are separated from each other.\n\n<ul>\n <li> If $ a $ is 1, then apply z-gate to Balvis' qubit. </li>\n <li> If $ b $ is 1, then apply x-gate (NOT) to Balvis' qubit. </li>\n</ul>\n\nAssume that Balvis sends his qubit to Asja.\n- Apply cx-gate as CNOT(Asja's-qubit,Balvis'-qubit)\n- Apply h-gate (Hadamard) to the Asja's qubit\n- Measure both qubits and compare the results with pair $ (a,b) $",
"_____no_output_____"
]
],
[
[
"# import all necessary objects and methods for quantum circuits\nfrom qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\n\nall_pairs = ['00','01','10','11']\n\n#\n# your code is here\n#\n",
"_____no_output_____"
]
],
[
[
"<a href=\"B54_Superdense_Coding_Solutions.ipynb#task3\">click for our solution</a>",
"_____no_output_____"
],
[
"<h3> Task 4 [Extra]</h3>\n\nVerify each case by tracing the state vector (on paper). \n\n_Hint: Representing quantum states as the linear combinations of basis states makes calculation easier._",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
e73f1299add6e5072fc3819ab458771cc035ac01 | 141,291 | ipynb | Jupyter Notebook | HMM Tagger.ipynb | luiscberrocal/hmm-tagger | c691565fe7bddef25425927362dfa600cda0b0be | [
"MIT"
] | null | null | null | HMM Tagger.ipynb | luiscberrocal/hmm-tagger | c691565fe7bddef25425927362dfa600cda0b0be | [
"MIT"
] | null | null | null | HMM Tagger.ipynb | luiscberrocal/hmm-tagger | c691565fe7bddef25425927362dfa600cda0b0be | [
"MIT"
] | null | null | null | 86.575368 | 27,384 | 0.777374 | [
[
[
"# Project: Part of Speech Tagging with Hidden Markov Models \n---\n### Introduction\n\nPart of speech tagging is the process of determining the syntactic category of a word from the words in its surrounding context. It is often used to help disambiguate natural language phrases because it can be done quickly with high accuracy. Tagging can be used for many NLP tasks like determining correct pronunciation during speech synthesis (for example, _dis_-count as a noun vs dis-_count_ as a verb), for information retrieval, and for word sense disambiguation.\n\nIn this notebook, you'll use the [Pomegranate](http://pomegranate.readthedocs.io/) library to build a hidden Markov model for part of speech tagging using a \"universal\" tagset. Hidden Markov models have been able to achieve [>96% tag accuracy with larger tagsets on realistic text corpora](http://www.coli.uni-saarland.de/~thorsten/publications/Brants-ANLP00.pdf). Hidden Markov models have also been used for speech recognition and speech generation, machine translation, gene recognition for bioinformatics, and human gesture recognition for computer vision, and more. \n\n\n\nThe notebook already contains some code to get you started. You only need to add some new functionality in the areas indicated to complete the project; you will not need to modify the included code beyond what is requested. Sections that begin with **'IMPLEMENTATION'** in the header indicate that you must provide code in the block that follows. Instructions will be provided for each section, and the specifics of the implementation are marked in the code block with a 'TODO' statement. Please be sure to read the instructions carefully!",
"_____no_output_____"
],
[
"<div class=\"alert alert-block alert-info\">\n**Note:** Once you have completed all of the code implementations, you need to finalize your work by exporting the iPython Notebook as an HTML document. Before exporting the notebook to html, all of the code cells need to have been run so that reviewers can see the final implementation and output. You must then **export the notebook** by running the last cell in the notebook, or by using the menu above and navigating to **File -> Download as -> HTML (.html)** Your submissions should include both the `html` and `ipynb` files.\n</div>",
"_____no_output_____"
],
[
"<div class=\"alert alert-block alert-info\">\n**Note:** Code and Markdown cells can be executed using the `Shift + Enter` keyboard shortcut. Markdown cells can be edited by double-clicking the cell to enter edit mode.\n</div>",
"_____no_output_____"
],
[
"### The Road Ahead\nYou must complete Steps 1-3 below to pass the project. The section on Step 4 includes references & resources you can use to further explore HMM taggers.\n\n- [Step 1](#Step-1:-Read-and-preprocess-the-dataset): Review the provided interface to load and access the text corpus\n- [Step 2](#Step-2:-Build-a-Most-Frequent-Class-tagger): Build a Most Frequent Class tagger to use as a baseline\n- [Step 3](#Step-3:-Build-an-HMM-tagger): Build an HMM Part of Speech tagger and compare to the MFC baseline\n- [Step 4](#Step-4:-[Optional]-Improving-model-performance): (Optional) Improve the HMM tagger",
"_____no_output_____"
],
[
"<div class=\"alert alert-block alert-warning\">\n**Note:** Make sure you have selected a **Python 3** kernel in Workspaces or the hmm-tagger conda environment if you are running the Jupyter server on your own machine.\n</div>",
"_____no_output_____"
]
],
[
[
"# Jupyter \"magic methods\" -- only need to be run once per kernel restart\n%load_ext autoreload\n%aimport helpers, tests\n%autoreload 1",
"_____no_output_____"
],
[
"# import python modules -- this cell needs to be run again if you make changes to any of the files\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom IPython.core.display import HTML\nfrom itertools import chain\nfrom collections import Counter, defaultdict\nfrom helpers import show_model, Dataset\nfrom pomegranate import State, HiddenMarkovModel, DiscreteDistribution",
"_____no_output_____"
]
],
[
[
"## Step 1: Read and preprocess the dataset\n---\nWe'll start by reading in a text corpus and splitting it into a training and testing dataset. The data set is a copy of the [Brown corpus](https://en.wikipedia.org/wiki/Brown_Corpus) (originally from the [NLTK](https://www.nltk.org/) library) that has already been pre-processed to only include the [universal tagset](https://arxiv.org/pdf/1104.2086.pdf). You should expect to get slightly higher accuracy using this simplified tagset than the same model would achieve on a larger tagset like the full [Penn treebank tagset](https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html), but the process you'll follow would be the same.\n\nThe `Dataset` class provided in helpers.py will read and parse the corpus. You can generate your own datasets compatible with the reader by writing them to the following format. The dataset is stored in plaintext as a collection of words and corresponding tags. Each sentence starts with a unique identifier on the first line, followed by one tab-separated word/tag pair on each following line. Sentences are separated by a single blank line.\n\nExample from the Brown corpus. \n```\nb100-38532\nPerhaps\tADV\nit\tPRON\nwas\tVERB\nright\tADJ\n;\t.\n;\t.\n\nb100-35577\n...\n```",
"_____no_output_____"
]
],
[
[
"data = Dataset(\"tags-universal.txt\", \"brown-universal.txt\", train_test_split=0.8)\n\nprint(\"There are {} sentences in the corpus.\".format(len(data)))\nprint(\"There are {} sentences in the training set.\".format(len(data.training_set)))\nprint(\"There are {} sentences in the testing set.\".format(len(data.testing_set)))\n\nassert len(data) == len(data.training_set) + len(data.testing_set), \\\n \"The number of sentences in the training set + testing set should sum to the number of sentences in the corpus\"",
"There are 57340 sentences in the corpus.\nThere are 45872 sentences in the training set.\nThere are 11468 sentences in the testing set.\n"
]
],
[
[
"### The Dataset Interface\n\nYou can access (mostly) immutable references to the dataset through a simple interface provided through the `Dataset` class, which represents an iterable collection of sentences along with easy access to partitions of the data for training & testing. Review the reference below, then run and review the next few cells to make sure you understand the interface before moving on to the next step.\n\n```\nDataset-only Attributes:\n training_set - reference to a Subset object containing the samples for training\n testing_set - reference to a Subset object containing the samples for testing\n\nDataset & Subset Attributes:\n sentences - a dictionary with an entry {sentence_key: Sentence()} for each sentence in the corpus\n keys - an immutable ordered (not sorted) collection of the sentence_keys for the corpus\n vocab - an immutable collection of the unique words in the corpus\n tagset - an immutable collection of the unique tags in the corpus\n X - returns an array of words grouped by sentences ((w11, w12, w13, ...), (w21, w22, w23, ...), ...)\n Y - returns an array of tags grouped by sentences ((t11, t12, t13, ...), (t21, t22, t23, ...), ...)\n N - returns the number of distinct samples (individual words or tags) in the dataset\n\nMethods:\n stream() - returns an flat iterable over all (word, tag) pairs across all sentences in the corpus\n __iter__() - returns an iterable over the data as (sentence_key, Sentence()) pairs\n __len__() - returns the nubmer of sentences in the dataset\n```\n\nFor example, consider a Subset, `subset`, of the sentences `{\"s0\": Sentence((\"See\", \"Spot\", \"run\"), (\"VERB\", \"NOUN\", \"VERB\")), \"s1\": Sentence((\"Spot\", \"ran\"), (\"NOUN\", \"VERB\"))}`. The subset will have these attributes:\n\n```\nsubset.keys == {\"s1\", \"s0\"} # unordered\nsubset.vocab == {\"See\", \"run\", \"ran\", \"Spot\"} # unordered\nsubset.tagset == {\"VERB\", \"NOUN\"} # unordered\nsubset.X == ((\"Spot\", \"ran\"), (\"See\", \"Spot\", \"run\")) # order matches .keys\nsubset.Y == ((\"NOUN\", \"VERB\"), (\"VERB\", \"NOUN\", \"VERB\")) # order matches .keys\nsubset.N == 7 # there are a total of seven observations over all sentences\nlen(subset) == 2 # because there are two sentences\n```\n\n<div class=\"alert alert-block alert-info\">\n**Note:** The `Dataset` class is _convenient_, but it is **not** efficient. It is not suitable for huge datasets because it stores multiple redundant copies of the same data.\n</div>",
"_____no_output_____"
],
[
"#### Sentences\n\n`Dataset.sentences` is a dictionary of all sentences in the training corpus, each keyed to a unique sentence identifier. Each `Sentence` is itself an object with two attributes: a tuple of the words in the sentence named `words` and a tuple of the tag corresponding to each word named `tags`.",
"_____no_output_____"
]
],
[
[
"key = 'b100-38532'\nprint(\"Sentence: {}\".format(key))\nprint(\"words:\\n\\t{!s}\".format(data.sentences[key].words))\nprint(\"tags:\\n\\t{!s}\".format(data.sentences[key].tags))",
"Sentence: b100-38532\nwords:\n\t('Perhaps', 'it', 'was', 'right', ';', ';')\ntags:\n\t('ADV', 'PRON', 'VERB', 'ADJ', '.', '.')\n"
]
],
[
[
"<div class=\"alert alert-block alert-info\">\n**Note:** The underlying iterable sequence is **unordered** over the sentences in the corpus; it is not guaranteed to return the sentences in a consistent order between calls. Use `Dataset.stream()`, `Dataset.keys`, `Dataset.X`, or `Dataset.Y` attributes if you need ordered access to the data.\n</div>\n\n#### Counting Unique Elements\n\nYou can access the list of unique words (the dataset vocabulary) via `Dataset.vocab` and the unique list of tags via `Dataset.tagset`.",
"_____no_output_____"
]
],
[
[
"print(\"There are a total of {:,} samples of {:,} unique words in the corpus.\"\n .format(data.N, len(data.vocab)))\nprint(\"There are {:,} samples of {:,} unique words in the training set.\"\n .format(data.training_set.N, len(data.training_set.vocab)))\nprint(\"There are {:,} samples of {:,} unique words in the testing set.\"\n .format(data.testing_set.N, len(data.testing_set.vocab)))\nprint(\"There are {:,} words in the test set that are missing in the training set.\"\n .format(len(data.testing_set.vocab - data.training_set.vocab)))\n\nassert data.N == data.training_set.N + data.testing_set.N, \\\n \"The number of training + test samples should sum to the total number of samples\"",
"There are a total of 1,161,192 samples of 56,057 unique words in the corpus.\nThere are 928,458 samples of 50,536 unique words in the training set.\nThere are 232,734 samples of 25,112 unique words in the testing set.\nThere are 5,521 words in the test set that are missing in the training set.\n"
]
],
[
[
"#### Accessing word and tag Sequences\nThe `Dataset.X` and `Dataset.Y` attributes provide access to ordered collections of matching word and tag sequences for each sentence in the dataset.",
"_____no_output_____"
]
],
[
[
"# accessing words with Dataset.X and tags with Dataset.Y \nfor i in range(2): \n print(\"Sentence {}:\".format(i + 1), data.X[i])\n print()\n print(\"Labels {}:\".format(i + 1), data.Y[i])\n print()",
"Sentence 1: ('Mr.', 'Podger', 'had', 'thanked', 'him', 'gravely', ',', 'and', 'now', 'he', 'made', 'use', 'of', 'the', 'advice', '.')\n\nLabels 1: ('NOUN', 'NOUN', 'VERB', 'VERB', 'PRON', 'ADV', '.', 'CONJ', 'ADV', 'PRON', 'VERB', 'NOUN', 'ADP', 'DET', 'NOUN', '.')\n\nSentence 2: ('But', 'there', 'seemed', 'to', 'be', 'some', 'difference', 'of', 'opinion', 'as', 'to', 'how', 'far', 'the', 'board', 'should', 'go', ',', 'and', 'whose', 'advice', 'it', 'should', 'follow', '.')\n\nLabels 2: ('CONJ', 'PRT', 'VERB', 'PRT', 'VERB', 'DET', 'NOUN', 'ADP', 'NOUN', 'ADP', 'ADP', 'ADV', 'ADV', 'DET', 'NOUN', 'VERB', 'VERB', '.', 'CONJ', 'DET', 'NOUN', 'PRON', 'VERB', 'VERB', '.')\n\n"
]
],
[
[
"#### Accessing (word, tag) Samples\nThe `Dataset.stream()` method returns an iterator that chains together every pair of (word, tag) entries across all sentences in the entire corpus.",
"_____no_output_____"
]
],
[
[
"# use Dataset.stream() (word, tag) samples for the entire corpus\nprint(\"\\nStream (word, tag) pairs:\\n\")\nfor i, pair in enumerate(data.stream()):\n print(\"\\t\", pair)\n if i > 10: break",
"\nStream (word, tag) pairs:\n\n\t ('Mr.', 'NOUN')\n\t ('Podger', 'NOUN')\n\t ('had', 'VERB')\n\t ('thanked', 'VERB')\n\t ('him', 'PRON')\n\t ('gravely', 'ADV')\n\t (',', '.')\n\t ('and', 'CONJ')\n\t ('now', 'ADV')\n\t ('he', 'PRON')\n\t ('made', 'VERB')\n\t ('use', 'NOUN')\n"
]
],
[
[
"\nFor both our baseline tagger and the HMM model we'll build, we need to estimate the frequency of tags & words from the frequency counts of observations in the training corpus. In the next several cells you will complete functions to compute the counts of several sets of counts. ",
"_____no_output_____"
],
[
"## Step 2: Build a Most Frequent Class tagger\n---\n\nPerhaps the simplest tagger (and a good baseline for tagger performance) is to simply choose the tag most frequently assigned to each word. This \"most frequent class\" tagger inspects each observed word in the sequence and assigns it the label that was most often assigned to that word in the corpus.",
"_____no_output_____"
],
[
"### IMPLEMENTATION: Pair Counts\n\nComplete the function below that computes the joint frequency counts for two input sequences.",
"_____no_output_____"
]
],
[
[
"def pair_counts(tags, words):\n \"\"\"Return a dictionary keyed to each unique value in the first sequence list\n that counts the number of occurrences of the corresponding value from the\n second sequences list.\n \n For example, if sequences_A is tags and sequences_B is the corresponding\n words, then if 1244 sequences contain the word \"time\" tagged as a NOUN, then\n you should return a dictionary such that pair_counts[NOUN][time] == 1244\n \"\"\"\n # TODO: Finish this function!\n pair_count = dict()\n i = 0\n j = 0\n for tag_set in tags:\n word_set = words[i]\n for tag in tag_set:\n tag_pair = pair_count.get(tag)\n if tag_pair is None:\n pair_count[tag] = dict()\n try:\n word_pair = pair_count[tag].get(word_set[j])\n if word_pair is None:\n pair_count[tag][word_set[j]] = 1\n else:\n pair_count[tag][word_set[j]] += 1\n except IndexError as e:\n print(f'Index Error {i}, {j} tag {tag}')\n raise e\n \n j += 1\n i += 1\n j = 0\n #print('*'*30)\n \n return pair_count\n\n\n# Calculate C(t_i, w_i)\nemission_counts = pair_counts(data.training_set.Y, data.training_set.X)# TODO: YOUR CODE HERE)\n\nassert len(emission_counts) == 12, \\\n \"Uh oh. There should be 12 tags in your dictionary.\"\nassert max(emission_counts[\"NOUN\"], key=emission_counts[\"NOUN\"].get) == 'time', \\\n \"Hmmm...'time' is expected to be the most common NOUN.\"\nHTML('<div class=\"alert alert-block alert-success\">Your emission counts look good!</div>')",
"_____no_output_____"
],
[
"print(emission_counts[\"NOUN\"]['time'])",
"1275\n"
]
],
[
[
"### IMPLEMENTATION: Most Frequent Class Tagger\n\nUse the `pair_counts()` function and the training dataset to find the most frequent class label for each word in the training data, and populate the `mfc_table` below. The table keys should be words, and the values should be the appropriate tag string.\n\nThe `MFCTagger` class is provided to mock the interface of Pomegranite HMM models so that they can be used interchangeably.",
"_____no_output_____"
]
],
[
[
"# Create a lookup table mfc_table where mfc_table[word] contains the tag label most frequently assigned to that word\nfrom collections import namedtuple\n\nFakeState = namedtuple(\"FakeState\", \"name\")\n\nclass MFCTagger:\n # NOTE: You should not need to modify this class or any of its methods\n missing = FakeState(name=\"<MISSING>\")\n \n def __init__(self, table):\n self.table = defaultdict(lambda: MFCTagger.missing)\n self.table.update({word: FakeState(name=tag) for word, tag in table.items()})\n \n def viterbi(self, seq):\n \"\"\"This method simplifies predictions by matching the Pomegranate viterbi() interface\"\"\"\n return 0., list(enumerate([\"<start>\"] + [self.table[w] for w in seq] + [\"<end>\"]))\n\n\n# TODO: calculate the frequency of each tag being assigned to each word (hint: similar, but not\n# the same as the emission probabilities) and use it to fill the mfc_table\n\nword_counts = pair_counts(data.training_set.Y, data.training_set.X)# TODO: YOUR CODE HERE)\n\nmfc_table = dict() # TODO: YOUR CODE HERE\nfor word in data.training_set.vocab:\n current_count = 0\n current_tag = None\n for tag in word_counts.keys():\n c = word_counts[tag].get(word, 0)\n if c > current_count:\n current_count = c\n current_tag = tag\n mfc_table[word] = current_tag\n\n\n #print(f'{word}')\n# DO NOT MODIFY BELOW THIS LINE\nmfc_model = MFCTagger(mfc_table) # Create a Most Frequent Class tagger instance\n\nassert len(mfc_table) == len(data.training_set.vocab), \"\"\nassert all(k in data.training_set.vocab for k in mfc_table.keys()), \"\"\nassert sum(int(k not in mfc_table) for k in data.testing_set.vocab) == 5521, \"\"\nHTML('<div class=\"alert alert-block alert-success\">Your MFC tagger has all the correct words!</div>')",
"_____no_output_____"
],
[
"#######################\n## MY DATA EXPLORATION\n#######################\nprint(word_counts.keys())\ndef plot_word_count(word_counts, tag, max_count, ax):\n words = dict(sorted(word_counts[tag].items(), key=lambda item: item[1]))\n #print(words)\n top_words = {r[0]:r[1] for r in list(words.items())[-max_count:]}\n \n ax.barh(*zip(*top_words.items()))\n ax.set_title(f'Top {max_count} of tag {tag}')\n #ax.show()\nfig, axs = plt.subplots(2, 2, figsize=(12,8))\nplot_word_count(word_counts, 'VERB', 10, axs[0,0])\nplot_word_count(word_counts, 'NOUN', 10, axs[0, 1])\nplot_word_count(word_counts, 'ADV', 10, axs[1, 0])\nplot_word_count(word_counts, 'CONJ', 10, axs[1, 1])",
"dict_keys(['ADV', 'NOUN', '.', 'VERB', 'ADP', 'ADJ', 'CONJ', 'DET', 'PRT', 'NUM', 'PRON', 'X'])\n"
]
],
[
[
"### Making Predictions with a Model\nThe helper functions provided below interface with Pomegranate network models & the mocked MFCTagger to take advantage of the [missing value](http://pomegranate.readthedocs.io/en/latest/nan.html) functionality in Pomegranate through a simple sequence decoding function. Run these functions, then run the next cell to see some of the predictions made by the MFC tagger.",
"_____no_output_____"
]
],
[
[
"def replace_unknown(sequence):\n \"\"\"Return a copy of the input sequence where each unknown word is replaced\n by the literal string value 'nan'. Pomegranate will ignore these values\n during computation.\n \"\"\"\n return [w if w in data.training_set.vocab else 'nan' for w in sequence]\n\ndef simplify_decoding(X, model):\n \"\"\"X should be a 1-D sequence of observations for the model to predict\"\"\"\n _, state_path = model.viterbi(replace_unknown(X))\n return [state[1].name for state in state_path[1:-1]] # do not show the start/end state predictions",
"_____no_output_____"
]
],
[
[
"### Example Decoding Sequences with MFC Tagger",
"_____no_output_____"
]
],
[
[
"for key in data.testing_set.keys[:3]:\n print(\"Sentence Key: {}\\n\".format(key))\n print(\"Predicted labels:\\n-----------------\")\n print(simplify_decoding(data.sentences[key].words, mfc_model))\n print()\n print(\"Actual labels:\\n--------------\")\n print(data.sentences[key].tags)\n print(\"\\n\")",
"Sentence Key: b100-28144\n\nPredicted labels:\n-----------------\n['CONJ', 'NOUN', 'NUM', '.', 'NOUN', 'NUM', '.', 'NOUN', 'NUM', '.', 'CONJ', 'NOUN', 'NUM', '.', '.', 'NOUN', '.', '.']\n\nActual labels:\n--------------\n('CONJ', 'NOUN', 'NUM', '.', 'NOUN', 'NUM', '.', 'NOUN', 'NUM', '.', 'CONJ', 'NOUN', 'NUM', '.', '.', 'NOUN', '.', '.')\n\n\nSentence Key: b100-23146\n\nPredicted labels:\n-----------------\n['PRON', 'VERB', 'DET', 'NOUN', 'ADP', 'ADJ', 'ADJ', 'NOUN', 'VERB', 'VERB', '.', 'ADP', 'VERB', 'DET', 'NOUN', 'ADP', 'NOUN', 'ADP', 'DET', 'NOUN', '.']\n\nActual labels:\n--------------\n('PRON', 'VERB', 'DET', 'NOUN', 'ADP', 'ADJ', 'ADJ', 'NOUN', 'VERB', 'VERB', '.', 'ADP', 'VERB', 'DET', 'NOUN', 'ADP', 'NOUN', 'ADP', 'DET', 'NOUN', '.')\n\n\nSentence Key: b100-35462\n\nPredicted labels:\n-----------------\n['DET', 'ADJ', 'NOUN', 'VERB', 'VERB', 'VERB', 'ADP', 'DET', 'ADJ', 'ADJ', 'NOUN', 'ADP', 'DET', 'ADJ', 'NOUN', '.', 'ADP', 'ADJ', 'NOUN', '.', 'CONJ', 'ADP', 'DET', '<MISSING>', 'ADP', 'ADJ', 'ADJ', '.', 'ADJ', '.', 'CONJ', 'ADJ', 'NOUN', 'ADP', 'ADV', 'NOUN', '.']\n\nActual labels:\n--------------\n('DET', 'ADJ', 'NOUN', 'VERB', 'VERB', 'VERB', 'ADP', 'DET', 'ADJ', 'ADJ', 'NOUN', 'ADP', 'DET', 'ADJ', 'NOUN', '.', 'ADP', 'ADJ', 'NOUN', '.', 'CONJ', 'ADP', 'DET', 'NOUN', 'ADP', 'ADJ', 'ADJ', '.', 'ADJ', '.', 'CONJ', 'ADJ', 'NOUN', 'ADP', 'ADJ', 'NOUN', '.')\n\n\n"
]
],
[
[
"### Evaluating Model Accuracy\n\nThe function below will evaluate the accuracy of the MFC tagger on the collection of all sentences from a text corpus. ",
"_____no_output_____"
]
],
[
[
"def accuracy(X, Y, model):\n \"\"\"Calculate the prediction accuracy by using the model to decode each sequence\n in the input X and comparing the prediction with the true labels in Y.\n \n The X should be an array whose first dimension is the number of sentences to test,\n and each element of the array should be an iterable of the words in the sequence.\n The arrays X and Y should have the exact same shape.\n \n X = [(\"See\", \"Spot\", \"run\"), (\"Run\", \"Spot\", \"run\", \"fast\"), ...]\n Y = [(), (), ...]\n \"\"\"\n correct = total_predictions = 0\n for observations, actual_tags in zip(X, Y):\n \n # The model.viterbi call in simplify_decoding will return None if the HMM\n # raises an error (for example, if a test sentence contains a word that\n # is out of vocabulary for the training set). Any exception counts the\n # full sentence as an error (which makes this a conservative estimate).\n try:\n most_likely_tags = simplify_decoding(observations, model)\n correct += sum(p == t for p, t in zip(most_likely_tags, actual_tags))\n except:\n pass\n total_predictions += len(observations)\n return correct / total_predictions",
"_____no_output_____"
]
],
[
[
"#### Evaluate the accuracy of the MFC tagger\nRun the next cell to evaluate the accuracy of the tagger on the training and test corpus.",
"_____no_output_____"
]
],
[
[
"mfc_training_acc = accuracy(data.training_set.X, data.training_set.Y, mfc_model)\nprint(\"training accuracy mfc_model: {:.2f}%\".format(100 * mfc_training_acc))\n\nmfc_testing_acc = accuracy(data.testing_set.X, data.testing_set.Y, mfc_model)\nprint(\"testing accuracy mfc_model: {:.2f}%\".format(100 * mfc_testing_acc))\n\nassert mfc_training_acc >= 0.955, \"Uh oh. Your MFC accuracy on the training set doesn't look right.\"\nassert mfc_testing_acc >= 0.925, \"Uh oh. Your MFC accuracy on the testing set doesn't look right.\"\nHTML('<div class=\"alert alert-block alert-success\">Your MFC tagger accuracy looks correct!</div>')",
"training accuracy mfc_model: 95.72%\ntesting accuracy mfc_model: 93.02%\n"
]
],
[
[
"## Step 3: Build an HMM tagger\n---\nThe HMM tagger has one hidden state for each possible tag, and parameterized by two distributions: the emission probabilties giving the conditional probability of observing a given **word** from each hidden state, and the transition probabilities giving the conditional probability of moving between **tags** during the sequence.\n\nWe will also estimate the starting probability distribution (the probability of each **tag** being the first tag in a sequence), and the terminal probability distribution (the probability of each **tag** being the last tag in a sequence).\n\nThe maximum likelihood estimate of these distributions can be calculated from the frequency counts as described in the following sections where you'll implement functions to count the frequencies, and finally build the model. The HMM model will make predictions according to the formula:\n\n$$t_i^n = \\underset{t_i^n}{\\mathrm{argmax}} \\prod_{i=1}^n P(w_i|t_i) P(t_i|t_{i-1})$$\n\nRefer to Speech & Language Processing [Chapter 10](https://web.stanford.edu/~jurafsky/slp3/10.pdf) for more information.",
"_____no_output_____"
],
[
"### IMPLEMENTATION: Unigram Counts\n\nComplete the function below to estimate the co-occurrence frequency of each symbol over all of the input sequences. The unigram probabilities in our HMM model are estimated from the formula below, where N is the total number of samples in the input. (You only need to compute the counts for now.)\n\n$$P(tag_1) = \\frac{C(tag_1)}{N}$$",
"_____no_output_____"
]
],
[
[
"line_len = 60\nprint('data.training_set.X (WORDS)')\nprint('='*line_len)\nmax_display = 3\ni = 1\nfor x in data.training_set.X:\n print(x)\n print('-'*line_len)\n i += 1\n if i >= max_display:\n break\n \nprint('data.training_set.Y (TAGS)')\nprint('='*line_len) \ni = 1\nfor x in data.training_set.Y:\n print(x)\n print('-'*line_len)\n i += 1\n if i >= max_display:\n break",
"data.training_set.X (WORDS)\n============================================================\n('Whenever', 'artists', ',', 'indeed', ',', 'turned', 'to', 'actual', 'representations', 'or', 'molded', 'three-dimensional', 'figures', ',', 'which', 'were', 'rare', 'down', 'to', '800', 'B.C.', ',', 'they', 'tended', 'to', 'reflect', 'reality', '(', 'see', 'Plate', '6a', ',', '9b', ')', ';', ';')\n------------------------------------------------------------\n('For', 'almost', 'two', 'months', ',', 'the', 'defendant', 'and', 'the', 'world', 'heard', 'from', 'individuals', 'escaped', 'from', 'the', 'grave', 'about', 'fathers', 'and', 'mothers', ',', 'graybeards', ',', 'adolescents', ',', 'babies', ',', 'starved', ',', 'beaten', 'to', 'death', ',', 'strangled', ',', 'machine-gunned', ',', 'gassed', ',', 'burned', '.')\n------------------------------------------------------------\ndata.training_set.Y (TAGS)\n============================================================\n('ADV', 'NOUN', '.', 'ADV', '.', 'VERB', 'ADP', 'ADJ', 'NOUN', 'CONJ', 'VERB', 'ADJ', 'NOUN', '.', 'DET', 'VERB', 'ADJ', 'PRT', 'ADP', 'NUM', 'NOUN', '.', 'PRON', 'VERB', 'PRT', 'VERB', 'NOUN', '.', 'VERB', 'NOUN', 'NUM', '.', 'NUM', '.', '.', '.')\n------------------------------------------------------------\n('ADP', 'ADV', 'NUM', 'NOUN', '.', 'DET', 'NOUN', 'CONJ', 'DET', 'NOUN', 'VERB', 'ADP', 'NOUN', 'VERB', 'ADP', 'DET', 'NOUN', 'ADP', 'NOUN', 'CONJ', 'NOUN', '.', 'NOUN', '.', 'NOUN', '.', 'NOUN', '.', 'VERB', '.', 'VERB', 'ADP', 'NOUN', '.', 'VERB', '.', 'VERB', '.', 'VERB', '.', 'VERB', '.')\n------------------------------------------------------------\n"
],
[
"def unigram_counts(tag_sequences):\n \"\"\"Return a dictionary keyed to each unique value in the input sequence list that\n counts the number of occurrences of the value in the sequences list. The sequences\n collection should be a 2-dimensional array.\n \n For example, if the tag NOUN appears 275558 times over all the input sequences,\n then you should return a dictionary such that your_unigram_counts[NOUN] == 275558.\n \"\"\"\n # TODO: Finish this function!\n tag_unigram = dict()\n for tags in tag_sequences:\n for tag in tags:\n tag_count = tag_unigram.get(tag)\n if tag_count is None:\n tag_unigram[tag] = 1\n else:\n tag_unigram[tag] += 1\n return tag_unigram\n \n\n# TODO: call unigram_counts with a list of tag sequences from the training set\ntag_unigrams = unigram_counts(data.training_set.Y)# TODO: YOUR CODE HERE)\n\nassert set(tag_unigrams.keys()) == data.training_set.tagset, \\\n \"Uh oh. It looks like your tag counts doesn't include all the tags!\"\nassert min(tag_unigrams, key=tag_unigrams.get) == 'X', \\\n \"Hmmm...'X' is expected to be the least common class\"\nassert max(tag_unigrams, key=tag_unigrams.get) == 'NOUN', \\\n \"Hmmm...'NOUN' is expected to be the most common class\"\nHTML('<div class=\"alert alert-block alert-success\">Your tag unigrams look good!</div>')",
"_____no_output_____"
],
[
"#######################\n## MY DATA EXPLORATION\n#######################\ndef plot_dictionary(unigrams, ax, title):\n ax.barh(*zip(*unigrams.items()))\n ax.set_title(title)\n #ax.show()\n\nfig, axs = plt.subplots(1, 1, figsize=(12,8))\nplot_dictionary(tag_unigrams, axs, 'Unigrams')\n\nprint(tag_unigrams)\ntotal = sum(tag_unigrams.values())\nprint(total)\nassert total == 928458, 'Houston we have a problem'",
"{'ADV': 44877, 'NOUN': 220632, '.': 117757, 'VERB': 146161, 'ADP': 115808, 'ADJ': 66754, 'CONJ': 30537, 'DET': 109671, 'PRT': 23906, 'NUM': 11878, 'PRON': 39383, 'X': 1094}\n928458\n"
]
],
[
[
"### IMPLEMENTATION: Bigram Counts\n\nComplete the function below to estimate the co-occurrence frequency of each pair of symbols in each of the input sequences. These counts are used in the HMM model to estimate the bigram probability of two tags from the frequency counts according to the formula: $$P(tag_2|tag_1) = \\frac{C(tag_2|tag_1)}{C(tag_2)}$$\n",
"_____no_output_____"
]
],
[
[
"def bigram_counts(tag_sequences):\n \"\"\"Return a dictionary keyed to each unique PAIR of values in the input sequences\n list that counts the number of occurrences of pair in the sequences list. The input\n should be a 2-dimensional array.\n \n For example, if the pair of tags (NOUN, VERB) appear 61582 times, then you should\n return a dictionary such that your_bigram_counts[(NOUN, VERB)] == 61582\n \"\"\"\n\n # TODO: Finish this function!\n tag_bigrams = dict()\n for tags in tag_sequences:\n tag_count = len(tags)\n #print(f'tag count: {tag_count}')\n for i in range(tag_count-1):\n if tag_count > 1:\n key = (tags[i], tags[i+1])\n #print(f'{i} {key}')\n else:\n key = (tags[i])\n tag_pair_count = tag_bigrams.get(key)\n if tag_pair_count is None:\n tag_bigrams[key] = 1\n else:\n tag_bigrams[key] += 1\n return tag_bigrams\n\n# TODO: call bigram_counts with a list of tag sequences from the training set\ntag_bigrams = bigram_counts(data.training_set.Y) # TODO: YOUR CODE HERE)\n\nassert len(tag_bigrams) == 144, \\\n \"Uh oh. There should be 144 pairs of bigrams (12 tags x 12 tags)\"\nassert min(tag_bigrams, key=tag_bigrams.get) in [('X', 'NUM'), ('PRON', 'X')], \\\n \"Hmmm...The least common bigram should be one of ('X', 'NUM') or ('PRON', 'X').\"\nassert max(tag_bigrams, key=tag_bigrams.get) in [('DET', 'NOUN')], \\\n \"Hmmm...('DET', 'NOUN') is expected to be the most common bigram.\"\nHTML('<div class=\"alert alert-block alert-success\">Your tag bigrams look good!</div>')",
"_____no_output_____"
],
[
"#print(tag_bigrams)\n\n#######################\n## MY DATA EXPLORATION\n#######################\n\ndef plot_bigrams(bigrams, max_count, ax):\n bigs = dict(sorted(bigrams.items(), key=lambda item: item[1]))\n #print(words)\n top_bigs = {f'{r[0][0]} {r[0][1]}':r[1] for r in list(bigs.items())[-max_count:]}\n print(top_bigs)\n ax.barh(*zip(*top_bigs.items()))\n ax.set_title(f'Top {max_count} Bigrams')\n #ax.show()\nfig, axs = plt.subplots(1, 1, figsize=(12,8))\nplot_bigrams(tag_bigrams, 10, axs)",
"{'VERB VERB': 26957, 'PRON VERB': 27860, 'ADP NOUN': 29965, 'NOUN NOUN': 32990, 'NOUN VERB': 34972, 'ADJ NOUN': 43664, 'ADP DET': 52841, 'NOUN ADP': 53884, 'NOUN .': 62639, 'DET NOUN': 68785}\n"
]
],
[
[
"### IMPLEMENTATION: Sequence Starting Counts\nComplete the code below to estimate the bigram probabilities of a sequence starting with each tag.",
"_____no_output_____"
]
],
[
[
"def starting_counts(tag_sequences):\n \"\"\"Return a dictionary keyed to each unique value in the input sequences list\n that counts the number of occurrences where that value is at the beginning of\n a sequence.\n \n For example, if 8093 sequences start with NOUN, then you should return a\n dictionary such that your_starting_counts[NOUN] == 8093\n \"\"\"\n # TODO: Finish this function!\n starting_counts = dict()\n for tags in tag_sequences:\n key = tags[0]\n s_count = starting_counts.get(key)\n if s_count is None:\n starting_counts[key] = 1\n else:\n starting_counts[key] += 1\n return starting_counts\n\n# TODO: Calculate the count of each tag starting a sequence\ntag_starts = starting_counts(data.training_set.Y)# TODO: YOUR CODE HERE)\n\nassert len(tag_starts) == 12, \"Uh oh. There should be 12 tags in your dictionary.\"\nassert min(tag_starts, key=tag_starts.get) == 'X', \"Hmmm...'X' is expected to be the least common starting bigram.\"\nassert max(tag_starts, key=tag_starts.get) == 'DET', \"Hmmm...'DET' is expected to be the most common starting bigram.\"\nHTML('<div class=\"alert alert-block alert-success\">Your starting tag counts look good!</div>')",
"_____no_output_____"
],
[
"fig, axs = plt.subplots(1, 1, figsize=(12,8))\nplot_dictionary(tag_starts, axs, 'Start')\n ",
"_____no_output_____"
]
],
[
[
"### IMPLEMENTATION: Sequence Ending Counts\nComplete the function below to estimate the bigram probabilities of a sequence ending with each tag.",
"_____no_output_____"
]
],
[
[
"def ending_counts(tag_sequences):\n \"\"\"Return a dictionary keyed to each unique value in the input sequences list\n that counts the number of occurrences where that value is at the end of\n a sequence.\n \n For example, if 18 sequences end with DET, then you should return a\n dictionary such that your_starting_counts[DET] == 18\n \"\"\"\n # TODO: Finish this function!\n ending_counts = dict()\n for tags in tag_sequences:\n \n if len(tags) > 1:\n last_pos = len(tags) - 1\n key = tags[last_pos]\n else:\n key = tags[0]\n s_count = ending_counts.get(key)\n if s_count is None:\n ending_counts[key] = 1\n else:\n ending_counts[key] += 1\n return ending_counts\n\n# TODO: Calculate the count of each tag ending a sequence\ntag_ends = ending_counts(data.training_set.Y)# TODO: YOUR CODE HERE)\n\nassert len(tag_ends) == 12, \"Uh oh. There should be 12 tags in your dictionary.\"\nassert min(tag_ends, key=tag_ends.get) in ['X', 'CONJ'], \"Hmmm...'X' or 'CONJ' should be the least common ending bigram.\"\nassert max(tag_ends, key=tag_ends.get) == '.', \"Hmmm...'.' is expected to be the most common ending bigram.\"\nHTML('<div class=\"alert alert-block alert-success\">Your ending tag counts look good!</div>')",
"_____no_output_____"
],
[
"print(tag_ends)\n\nfig, axs = plt.subplots(1, 1, figsize=(12,8))\nplot_dictionary(tag_ends, axs, 'Ends')",
"{'.': 44936, 'NOUN': 722, 'NUM': 63, 'VERB': 75, 'ADJ': 25, 'ADV': 16, 'ADP': 7, 'DET': 14, 'CONJ': 2, 'PRON': 4, 'PRT': 7, 'X': 1}\n"
]
],
[
[
"### IMPLEMENTATION: Basic HMM Tagger\nUse the tag unigrams and bigrams calculated above to construct a hidden Markov tagger.\n\n- Add one state per tag\n - The emission distribution at each state should be estimated with the formula: $P(w|t) = \\frac{C(t, w)}{C(t)}$\n- Add an edge from the starting state `basic_model.start` to each tag\n - The transition probability should be estimated with the formula: $P(t|start) = \\frac{C(start, t)}{C(start)}$\n- Add an edge from each tag to the end state `basic_model.end`\n - The transition probability should be estimated with the formula: $P(end|t) = \\frac{C(t, end)}{C(t)}$\n- Add an edge between _every_ pair of tags\n - The transition probability should be estimated with the formula: $P(t_2|t_1) = \\frac{C(t_1, t_2)}{C(t_1)}$",
"_____no_output_____"
]
],
[
[
"#>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>\n#>>> Emission Probabilities\n#>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>\n#states = list()\nstate_data = dict()\nfor tag in word_counts.keys():\n emission_probabilities = dict()\n #P(word|tag) = C(tag, word) / C(tag)\n total_count = tag_unigrams[tag] #sum(word_counts[tag].values())\n for word, count in word_counts[tag].items():\n prob = count/total_count\n emission_probabilities[word] = prob\n #print(f'tag {tag}: word: {word} count: {count} prob: {prob*100:.3}%')\n #CHECK if sum == 1\n tag_probability = round(sum(emission_probabilities.values()), 15)\n assert tag_probability, f'Expected 1.0 for {tag} got {tag_probability}'\n max_tag = max(emission_probabilities, key=emission_probabilities.get)\n print(f'Max for tag {tag:5}: {max_tag:8} {emission_probabilities[max_tag]*100:.4}%')\n \n emissions = DiscreteDistribution(emission_probabilities)\n max_prob_from_emissions = emissions.probability(max_tag)\n print(f'{max_prob_from_emissions*100:.4}')\n state = State(emissions, name=tag)\n state_data[tag] = state\nstates = [s for _, s in state_data.items()]\nassert len(states) == len(word_counts.keys())\n #print('='*60)\n#print(words)",
"Max for tag ADV : not 7.937%\n7.937\nMax for tag NOUN : time 0.5779%\n0.5779\nMax for tag . : , 39.49%\n39.49\nMax for tag VERB : is 5.478%\n5.478\nMax for tag ADP : of 24.84%\n24.84\nMax for tag ADJ : other 1.906%\n1.906\nMax for tag CONJ : and 73.25%\n73.25\nMax for tag DET : the 45.85%\n45.85\nMax for tag PRT : to 49.29%\n49.29\nMax for tag NUM : one 16.19%\n16.19\nMax for tag PRON : it 13.61%\n13.61\nMax for tag X : de 3.473%\n3.473\n"
],
[
"basic_model = HiddenMarkovModel(name=\"base-hmm-tagger\")\n\n# TODO: create states with emission probability distributions P(word | tag) and add to the model\n# (Hint: you may need to loop & create/add new states)\nbasic_model.add_states(*states)\n\n# TODO: add edges between states for the observed transition frequencies P(tag_i | tag_i-1)\n# (Hint: you may need to loop & add transitions\n#basic_model.add_transition()\nfor tag, count in tag_starts.items():\n state = state_data[tag]\n total = len(data.training_set.Y) #sum(tag_starts.values())\n prob = count/total\n print(f'Tag start {tag:6} {prob*100:.4}%')\n basic_model.add_transition(basic_model.start, state, prob)\n \nfor tag, count in tag_ends.items():\n state = state_data[tag]\n #total = sum(tag_ends.values())\n prob = count/tag_unigrams[tag]\n print(f'Tag end {tag:6} {prob*100:.4}%')\n basic_model.add_transition(state, basic_model.end, prob)\n\n \nfor tag_pair, count in tag_bigrams.items():\n total = sum(tag_bigrams.values())\n first_state = state_data[tag_pair[0]]\n second_state = state_data[tag_pair[1]]\n prob = count/total\n basic_model.add_transition(first_state, second_state, prob)\n \n# NOTE: YOU SHOULD NOT NEED TO MODIFY ANYTHING BELOW THIS LINE\n# finalize the model\nbasic_model.bake()\n\nassert all(tag in set(s.name for s in basic_model.states) for tag in data.training_set.tagset), \\\n \"Every state in your network should use the name of the associated tag, which must be one of the training set tags.\"\nassert basic_model.edge_count() == 168, \\\n (\"Your network should have an edge from the start node to each state, one edge between every \" +\n \"pair of tags (states), and an edge from each state to the end node.\")\nHTML('<div class=\"alert alert-block alert-success\">Your HMM network topology looks good!</div>')",
"Tag start ADV 9.123%\nTag start ADP 12.17%\nTag start ADJ 3.449%\nTag start PRT 3.745%\nTag start DET 21.28%\nTag start PRON 15.95%\nTag start NOUN 14.1%\nTag start CONJ 4.975%\nTag start . 8.953%\nTag start NUM 1.657%\nTag start VERB 4.534%\nTag start X 0.0545%\nTag end . 38.16%\nTag end NOUN 0.3272%\nTag end NUM 0.5304%\nTag end VERB 0.05131%\nTag end ADJ 0.03745%\nTag end ADV 0.03565%\nTag end ADP 0.006044%\nTag end DET 0.01277%\nTag end CONJ 0.006549%\nTag end PRON 0.01016%\nTag end PRT 0.02928%\nTag end X 0.09141%\n"
],
[
"hmm_training_acc = accuracy(data.training_set.X, data.training_set.Y, basic_model)\nprint(\"training accuracy basic hmm model: {:.2f}%\".format(100 * hmm_training_acc))\n\nhmm_testing_acc = accuracy(data.testing_set.X, data.testing_set.Y, basic_model)\nprint(\"testing accuracy basic hmm model: {:.2f}%\".format(100 * hmm_testing_acc))\n\nassert hmm_training_acc > 0.97, \"Uh oh. Your HMM accuracy on the training set doesn't look right.\"\nassert hmm_testing_acc > 0.955, \"Uh oh. Your HMM accuracy on the testing set doesn't look right.\"\nHTML('<div class=\"alert alert-block alert-success\">Your HMM tagger accuracy looks correct! Congratulations, you\\'ve finished the project.</div>')",
"training accuracy basic hmm model: 97.54%\ntesting accuracy basic hmm model: 95.98%\n"
]
],
[
[
"### Example Decoding Sequences with the HMM Tagger",
"_____no_output_____"
]
],
[
[
"for key in data.testing_set.keys[:3]:\n print(\"Sentence Key: {}\\n\".format(key))\n print(\"Predicted labels:\\n-----------------\")\n print(simplify_decoding(data.sentences[key].words, basic_model))\n print()\n print(\"Actual labels:\\n--------------\")\n print(data.sentences[key].tags)\n print(\"\\n\")",
"Sentence Key: b100-28144\n\nPredicted labels:\n-----------------\n['CONJ', 'NOUN', 'NUM', '.', 'NOUN', 'NUM', '.', 'NOUN', 'NUM', '.', 'CONJ', 'NOUN', 'NUM', '.', '.', 'NOUN', '.', '.']\n\nActual labels:\n--------------\n('CONJ', 'NOUN', 'NUM', '.', 'NOUN', 'NUM', '.', 'NOUN', 'NUM', '.', 'CONJ', 'NOUN', 'NUM', '.', '.', 'NOUN', '.', '.')\n\n\nSentence Key: b100-23146\n\nPredicted labels:\n-----------------\n['PRON', 'VERB', 'DET', 'NOUN', 'ADP', 'ADJ', 'ADJ', 'NOUN', 'VERB', 'VERB', '.', 'ADP', 'VERB', 'DET', 'NOUN', 'ADP', 'NOUN', 'ADP', 'DET', 'NOUN', '.']\n\nActual labels:\n--------------\n('PRON', 'VERB', 'DET', 'NOUN', 'ADP', 'ADJ', 'ADJ', 'NOUN', 'VERB', 'VERB', '.', 'ADP', 'VERB', 'DET', 'NOUN', 'ADP', 'NOUN', 'ADP', 'DET', 'NOUN', '.')\n\n\nSentence Key: b100-35462\n\nPredicted labels:\n-----------------\n['DET', 'ADJ', 'NOUN', 'VERB', 'VERB', 'VERB', 'ADP', 'DET', 'ADJ', 'ADJ', 'NOUN', 'ADP', 'DET', 'ADJ', 'NOUN', '.', 'ADP', 'ADJ', 'NOUN', '.', 'CONJ', 'ADP', 'DET', 'NOUN', 'ADP', 'ADJ', 'ADJ', '.', 'ADJ', '.', 'CONJ', 'ADJ', 'NOUN', 'ADP', 'ADJ', 'NOUN', '.']\n\nActual labels:\n--------------\n('DET', 'ADJ', 'NOUN', 'VERB', 'VERB', 'VERB', 'ADP', 'DET', 'ADJ', 'ADJ', 'NOUN', 'ADP', 'DET', 'ADJ', 'NOUN', '.', 'ADP', 'ADJ', 'NOUN', '.', 'CONJ', 'ADP', 'DET', 'NOUN', 'ADP', 'ADJ', 'ADJ', '.', 'ADJ', '.', 'CONJ', 'ADJ', 'NOUN', 'ADP', 'ADJ', 'NOUN', '.')\n\n\n"
]
],
[
[
"\n## Finishing the project\n---\n\n<div class=\"alert alert-block alert-info\">\n**Note:** **SAVE YOUR NOTEBOOK**, then run the next cell to generate an HTML copy. You will zip & submit both this file and the HTML copy for review.\n</div>",
"_____no_output_____"
]
],
[
[
"!!jupyter nbconvert *.ipynb --to html",
"_____no_output_____"
]
],
[
[
"## Step 4: [Optional] Improving model performance\n---\nThere are additional enhancements that can be incorporated into your tagger that improve performance on larger tagsets where the data sparsity problem is more significant. The data sparsity problem arises because the same amount of data split over more tags means there will be fewer samples in each tag, and there will be more missing data tags that have zero occurrences in the data. The techniques in this section are optional.\n\n- [Laplace Smoothing](https://en.wikipedia.org/wiki/Additive_smoothing) (pseudocounts)\n Laplace smoothing is a technique where you add a small, non-zero value to all observed counts to offset for unobserved values.\n\n- Backoff Smoothing\n Another smoothing technique is to interpolate between n-grams for missing data. This method is more effective than Laplace smoothing at combatting the data sparsity problem. Refer to chapters 4, 9, and 10 of the [Speech & Language Processing](https://web.stanford.edu/~jurafsky/slp3/) book for more information.\n\n- Extending to Trigrams\n HMM taggers have achieved better than 96% accuracy on this dataset with the full Penn treebank tagset using an architecture described in [this](http://www.coli.uni-saarland.de/~thorsten/publications/Brants-ANLP00.pdf) paper. Altering your HMM to achieve the same performance would require implementing deleted interpolation (described in the paper), incorporating trigram probabilities in your frequency tables, and re-implementing the Viterbi algorithm to consider three consecutive states instead of two.\n\n### Obtain the Brown Corpus with a Larger Tagset\nRun the code below to download a copy of the brown corpus with the full NLTK tagset. You will need to research the available tagset information in the NLTK docs and determine the best way to extract the subset of NLTK tags you want to explore. If you write the following the format specified in Step 1, then you can reload the data using all of the code above for comparison.\n\nRefer to [Chapter 5](http://www.nltk.org/book/ch05.html) of the NLTK book for more information on the available tagsets.",
"_____no_output_____"
]
],
[
[
"import nltk\nfrom nltk import pos_tag, word_tokenize\nfrom nltk.corpus import brown\n\nnltk.download('brown')\ntraining_corpus = nltk.corpus.brown\ntraining_corpus.tagged_sents()[0]",
"[nltk_data] Downloading package brown to\n[nltk_data] /Users/luiscberrocal/nltk_data...\n[nltk_data] Package brown is already up-to-date!\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
e73f239de2c12e0cb7895a3ef2817ade3dc8519f | 675,015 | ipynb | Jupyter Notebook | word2vec-embeddings/Negative_Sampling_Exercise.ipynb | Joonsoo/udacity-deep-learning-2019 | 0eb1f130e1ebeb62bd035d4f657d8b772e4631c3 | [
"MIT"
] | null | null | null | word2vec-embeddings/Negative_Sampling_Exercise.ipynb | Joonsoo/udacity-deep-learning-2019 | 0eb1f130e1ebeb62bd035d4f657d8b772e4631c3 | [
"MIT"
] | 7 | 2019-12-16T21:54:38.000Z | 2022-02-10T00:10:37.000Z | word2vec-embeddings/Negative_Sampling_Exercise.ipynb | Joonsoo/udacity-deep-learning-2019 | 0eb1f130e1ebeb62bd035d4f657d8b772e4631c3 | [
"MIT"
] | null | null | null | 493.792977 | 614,832 | 0.930153 | [
[
[
"# Skip-gram Word2Vec\n\nIn this notebook, I'll lead you through using PyTorch to implement the [Word2Vec algorithm](https://en.wikipedia.org/wiki/Word2vec) using the skip-gram architecture. By implementing this, you'll learn about embedding words for use in natural language processing. This will come in handy when dealing with things like machine translation.\n\n## Readings\n\nHere are the resources I used to build this notebook. I suggest reading these either beforehand or while you're working on this material.\n\n* A really good [conceptual overview](http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/) of Word2Vec from Chris McCormick \n* [First Word2Vec paper](https://arxiv.org/pdf/1301.3781.pdf) from Mikolov et al.\n* [Neural Information Processing Systems, paper](http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf) with improvements for Word2Vec also from Mikolov et al.\n\n---\n## Word embeddings\n\nWhen you're dealing with words in text, you end up with tens of thousands of word classes to analyze; one for each word in a vocabulary. Trying to one-hot encode these words is massively inefficient because most values in a one-hot vector will be set to zero. So, the matrix multiplication that happens in between a one-hot input vector and a first, hidden layer will result in mostly zero-valued hidden outputs.\n\nTo solve this problem and greatly increase the efficiency of our networks, we use what are called **embeddings**. Embeddings are just a fully connected layer like you've seen before. We call this layer the embedding layer and the weights are embedding weights. We skip the multiplication into the embedding layer by instead directly grabbing the hidden layer values from the weight matrix. We can do this because the multiplication of a one-hot encoded vector with a matrix returns the row of the matrix corresponding the index of the \"on\" input unit.\n\n<img src='assets/lookup_matrix.png' width=50%>\n\nInstead of doing the matrix multiplication, we use the weight matrix as a lookup table. We encode the words as integers, for example \"heart\" is encoded as 958, \"mind\" as 18094. Then to get hidden layer values for \"heart\", you just take the 958th row of the embedding matrix. This process is called an **embedding lookup** and the number of hidden units is the **embedding dimension**.\n \nThere is nothing magical going on here. The embedding lookup table is just a weight matrix. The embedding layer is just a hidden layer. The lookup is just a shortcut for the matrix multiplication. The lookup table is trained just like any weight matrix.\n\nEmbeddings aren't only used for words of course. You can use them for any model where you have a massive number of classes. A particular type of model called **Word2Vec** uses the embedding layer to find vector representations of words that contain semantic meaning.",
"_____no_output_____"
],
[
"---\n## Word2Vec\n\nThe Word2Vec algorithm finds much more efficient representations by finding vectors that represent the words. These vectors also contain semantic information about the words.\n\n<img src=\"assets/context_drink.png\" width=40%>\n\nWords that show up in similar **contexts**, such as \"coffee\", \"tea\", and \"water\" will have vectors near each other. Different words will be further away from one another, and relationships can be represented by distance in vector space.\n\n\nThere are two architectures for implementing Word2Vec:\n>* CBOW (Continuous Bag-Of-Words) and \n* Skip-gram\n\n<img src=\"assets/word2vec_architectures.png\" width=60%>\n\nIn this implementation, we'll be using the **skip-gram architecture** with **negative sampling** because it performs better than CBOW and trains faster with negative sampling. Here, we pass in a word and try to predict the words surrounding it in the text. In this way, we can train the network to learn representations for words that show up in similar contexts.",
"_____no_output_____"
],
[
"---\n## Loading Data\n\nNext, we'll ask you to load in data and place it in the `data` directory\n\n1. Load the [text8 dataset](https://s3.amazonaws.com/video.udacity-data.com/topher/2018/October/5bbe6499_text8/text8.zip); a file of cleaned up *Wikipedia article text* from Matt Mahoney. \n2. Place that data in the `data` folder in the home directory.\n3. Then you can extract it and delete the archive, zip file to save storage space.\n\nAfter following these steps, you should have one file in your data directory: `data/text8`.",
"_____no_output_____"
]
],
[
[
"# read in the extracted text file \nwith open('data/text8') as f:\n text = f.read()\n\n# print out the first 100 characters\nprint(text[:100])",
" anarchism originated as a term of abuse first used against early working class radicals including t\n"
]
],
[
[
"## Pre-processing\n\nHere I'm fixing up the text to make training easier. This comes from the `utils.py` file. The `preprocess` function does a few things:\n>* It converts any punctuation into tokens, so a period is changed to ` <PERIOD> `. In this data set, there aren't any periods, but it will help in other NLP problems. \n* It removes all words that show up five or *fewer* times in the dataset. This will greatly reduce issues due to noise in the data and improve the quality of the vector representations. \n* It returns a list of words in the text.\n\nThis may take a few seconds to run, since our text file is quite large. If you want to write your own functions for this stuff, go for it!",
"_____no_output_____"
]
],
[
[
"import utils\n\n# get list of words\nwords = utils.preprocess(text)\nprint(words[:30])",
"['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans', 'culottes', 'of', 'the', 'french', 'revolution', 'whilst']\n"
],
[
"# print some stats about this word data\nprint(\"Total words in text: {}\".format(len(words)))\nprint(\"Unique words: {}\".format(len(set(words)))) # `set` removes any duplicate words",
"Total words in text: 16680599\nUnique words: 63641\n"
]
],
[
[
"### Dictionaries\n\nNext, I'm creating two dictionaries to convert words to integers and back again (integers to words). This is again done with a function in the `utils.py` file. `create_lookup_tables` takes in a list of words in a text and returns two dictionaries.\n>* The integers are assigned in descending frequency order, so the most frequent word (\"the\") is given the integer 0 and the next most frequent is 1, and so on. \n\nOnce we have our dictionaries, the words are converted to integers and stored in the list `int_words`.",
"_____no_output_____"
]
],
[
[
"vocab_to_int, int_to_vocab = utils.create_lookup_tables(words)\nint_words = [vocab_to_int[word] for word in words]\n\nprint(int_words[:30])",
"[5233, 3080, 11, 5, 194, 1, 3133, 45, 58, 155, 127, 741, 476, 10571, 133, 0, 27349, 1, 0, 102, 854, 2, 0, 15067, 58112, 1, 0, 150, 854, 3580]\n"
]
],
[
[
"## Subsampling\n\nWords that show up often such as \"the\", \"of\", and \"for\" don't provide much context to the nearby words. If we discard some of them, we can remove some of the noise from our data and in return get faster training and better representations. This process is called subsampling by Mikolov. For each word $w_i$ in the training set, we'll discard it with probability given by \n\n$$ P(w_i) = 1 - \\sqrt{\\frac{t}{f(w_i)}} $$\n\nwhere $t$ is a threshold parameter and $f(w_i)$ is the frequency of word $w_i$ in the total dataset.\n\n> Implement subsampling for the words in `int_words`. That is, go through `int_words` and discard each word given the probablility $P(w_i)$ shown above. Note that $P(w_i)$ is the probability that a word is discarded. Assign the subsampled data to `train_words`.",
"_____no_output_____"
]
],
[
[
"from collections import Counter\nimport random\nimport numpy as np\n\nthreshold = 1e-5\nword_counts = Counter(int_words)\n#print(list(word_counts.items())[0]) # dictionary of int_words, how many times they appear\n\ntotal_count = len(int_words)\nfreqs = {word: count/total_count for word, count in word_counts.items()}\np_drop = {word: 1 - np.sqrt(threshold/freqs[word]) for word in word_counts}\n# discard some frequent words, according to the subsampling equation\n# create a new list of words for training\ntrain_words = [word for word in int_words if random.random() < (1 - p_drop[word])]\n\nprint(train_words[:30])",
"[5233, 3080, 194, 3133, 741, 10571, 27349, 854, 15067, 58112, 854, 3580, 194, 190, 58, 10712, 1324, 104, 2731, 708, 2757, 567, 7088, 247, 5233, 248, 44611, 2877, 792, 2621]\n"
]
],
[
[
"## Making batches",
"_____no_output_____"
],
[
"Now that our data is in good shape, we need to get it into the proper form to pass it into our network. With the skip-gram architecture, for each word in the text, we want to define a surrounding _context_ and grab all the words in a window around that word, with size $C$. \n\nFrom [Mikolov et al.](https://arxiv.org/pdf/1301.3781.pdf): \n\n\"Since the more distant words are usually less related to the current word than those close to it, we give less weight to the distant words by sampling less from those words in our training examples... If we choose $C = 5$, for each training word we will select randomly a number $R$ in range $[ 1: C ]$, and then use $R$ words from history and $R$ words from the future of the current word as correct labels.\"\n\n> **Exercise:** Implement a function `get_target` that receives a list of words, an index, and a window size, then returns a list of words in the window around the index. Make sure to use the algorithm described above, where you chose a random number of words to from the window.\n\nSay, we have an input and we're interested in the idx=2 token, `741`: \n```\n[5233, 58, 741, 10571, 27349, 0, 15067, 58112, 3580, 58, 10712]\n```\n\nFor `R=2`, `get_target` should return a list of four values:\n```\n[5233, 58, 10571, 27349]\n```",
"_____no_output_____"
]
],
[
[
"def get_target(words, idx, window_size=5):\n ''' Get a list of words in a window around an index. '''\n \n R = np.random.randint(1, window_size+1)\n start = idx - R if (idx - R) > 0 else 0\n stop = idx + R\n target_words = words[start:idx] + words[idx+1:stop+1]\n \n return list(target_words)",
"_____no_output_____"
],
[
"# test your code!\n\n# run this cell multiple times to check for random window selection\nint_text = [i for i in range(10)]\nprint('Input: ', int_text)\nidx=5 # word index of interest\n\ntarget = get_target(int_text, idx=idx, window_size=5)\nprint('Target: ', target) # you should get some indices around the idx",
"Input: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\nTarget: [3, 4, 6, 7]\n"
]
],
[
[
"### Generating Batches \n\nHere's a generator function that returns batches of input and target data for our model, using the `get_target` function from above. The idea is that it grabs `batch_size` words from a words list. Then for each of those batches, it gets the target words in a window.",
"_____no_output_____"
]
],
[
[
"def get_batches(words, batch_size, window_size=5):\n ''' Create a generator of word batches as a tuple (inputs, targets) '''\n \n n_batches = len(words)//batch_size\n \n # only full batches\n words = words[:n_batches*batch_size]\n \n for idx in range(0, len(words), batch_size):\n x, y = [], []\n batch = words[idx:idx+batch_size]\n for ii in range(len(batch)):\n batch_x = batch[ii]\n batch_y = get_target(batch, ii, window_size)\n y.extend(batch_y)\n x.extend([batch_x]*len(batch_y))\n yield x, y\n ",
"_____no_output_____"
],
[
"int_text = [i for i in range(20)]\nx,y = next(get_batches(int_text, batch_size=4, window_size=5))\n\nprint('x\\n', x)\nprint('y\\n', y)",
"x\n [0, 0, 1, 1, 2, 2, 2, 3, 3, 3]\ny\n [1, 2, 0, 2, 0, 1, 3, 0, 1, 2]\n"
]
],
[
[
"---\n## Validation\n\nHere, I'm creating a function that will help us observe our model as it learns. We're going to choose a few common words and few uncommon words. Then, we'll print out the closest words to them using the cosine similarity: \n\n<img src=\"assets/two_vectors.png\" width=30%>\n\n$$\n\\mathrm{similarity} = \\cos(\\theta) = \\frac{\\vec{a} \\cdot \\vec{b}}{|\\vec{a}||\\vec{b}|}\n$$\n\n\nWe can encode the validation words as vectors $\\vec{a}$ using the embedding table, then calculate the similarity with each word vector $\\vec{b}$ in the embedding table. With the similarities, we can print out the validation words and words in our embedding table semantically similar to those words. It's a nice way to check that our embedding table is grouping together words with similar semantic meanings.",
"_____no_output_____"
]
],
[
[
"def cosine_similarity(embedding, valid_size=16, valid_window=100, device='cpu'):\n \"\"\" Returns the cosine similarity of validation words with words in the embedding matrix.\n Here, embedding should be a PyTorch embedding module.\n \"\"\"\n \n # Here we're calculating the cosine similarity between some random words and \n # our embedding vectors. With the similarities, we can look at what words are\n # close to our random words.\n \n # sim = (a . b) / |a||b|\n \n embed_vectors = embedding.weight\n \n # magnitude of embedding vectors, |b|\n magnitudes = embed_vectors.pow(2).sum(dim=1).sqrt().unsqueeze(0)\n \n # pick N words from our ranges (0,window) and (1000,1000+window). lower id implies more frequent \n valid_examples = np.array(random.sample(range(valid_window), valid_size//2))\n valid_examples = np.append(valid_examples,\n random.sample(range(1000,1000+valid_window), valid_size//2))\n valid_examples = torch.LongTensor(valid_examples).to(device)\n \n valid_vectors = embedding(valid_examples)\n similarities = torch.mm(valid_vectors, embed_vectors.t())/magnitudes\n \n return valid_examples, similarities",
"_____no_output_____"
]
],
[
[
"---\n# SkipGram model\n\nDefine and train the SkipGram model. \n> You'll need to define an [embedding layer](https://pytorch.org/docs/stable/nn.html#embedding) and a final, softmax output layer.\n\nAn Embedding layer takes in a number of inputs, importantly:\n* **num_embeddings** – the size of the dictionary of embeddings, or how many rows you'll want in the embedding weight matrix\n* **embedding_dim** – the size of each embedding vector; the embedding dimension\n\nBelow is an approximate diagram of the general structure of our network.\n<img src=\"assets/skip_gram_arch.png\" width=60%>\n\n>* The input words are passed in as batches of input word tokens. \n* This will go into a hidden layer of linear units (our embedding layer). \n* Then, finally into a softmax output layer. \n\nWe'll use the softmax layer to make a prediction about the context words by sampling, as usual.",
"_____no_output_____"
],
[
"---\n## Negative Sampling\n\nFor every example we give the network, we train it using the output from the softmax layer. That means for each input, we're making very small changes to millions of weights even though we only have one true example. This makes training the network very inefficient. We can approximate the loss from the softmax layer by only updating a small subset of all the weights at once. We'll update the weights for the correct example, but only a small number of incorrect, or noise, examples. This is called [\"negative sampling\"](http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf). \n\nThere are two modifications we need to make. First, since we're not taking the softmax output over all the words, we're really only concerned with one output word at a time. Similar to how we use an embedding table to map the input word to the hidden layer, we can now use another embedding table to map the hidden layer to the output word. Now we have two embedding layers, one for input words and one for output words. Secondly, we use a modified loss function where we only care about the true example and a small subset of noise examples.\n\n$$\n- \\large \\log{\\sigma\\left(u_{w_O}\\hspace{0.001em}^\\top v_{w_I}\\right)} -\n\\sum_i^N \\mathbb{E}_{w_i \\sim P_n(w)}\\log{\\sigma\\left(-u_{w_i}\\hspace{0.001em}^\\top v_{w_I}\\right)}\n$$\n\nThis is a little complicated so I'll go through it bit by bit. $u_{w_O}\\hspace{0.001em}^\\top$ is the embedding vector for our \"output\" target word (transposed, that's the $^\\top$ symbol) and $v_{w_I}$ is the embedding vector for the \"input\" word. Then the first term \n\n$$\\large \\log{\\sigma\\left(u_{w_O}\\hspace{0.001em}^\\top v_{w_I}\\right)}$$\n\nsays we take the log-sigmoid of the inner product of the output word vector and the input word vector. Now the second term, let's first look at \n\n$$\\large \\sum_i^N \\mathbb{E}_{w_i \\sim P_n(w)}$$ \n\nThis means we're going to take a sum over words $w_i$ drawn from a noise distribution $w_i \\sim P_n(w)$. The noise distribution is basically our vocabulary of words that aren't in the context of our input word. In effect, we can randomly sample words from our vocabulary to get these words. $P_n(w)$ is an arbitrary probability distribution though, which means we get to decide how to weight the words that we're sampling. This could be a uniform distribution, where we sample all words with equal probability. Or it could be according to the frequency that each word shows up in our text corpus, the unigram distribution $U(w)$. The authors found the best distribution to be $U(w)^{3/4}$, empirically. \n\nFinally, in \n\n$$\\large \\log{\\sigma\\left(-u_{w_i}\\hspace{0.001em}^\\top v_{w_I}\\right)},$$ \n\nwe take the log-sigmoid of the negated inner product of a noise vector with the input vector. \n\n<img src=\"assets/neg_sampling_loss.png\" width=50%>\n\nTo give you an intuition for what we're doing here, remember that the sigmoid function returns a probability between 0 and 1. The first term in the loss pushes the probability that our network will predict the correct word $w_O$ towards 1. In the second term, since we are negating the sigmoid input, we're pushing the probabilities of the noise words towards 0.",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torch import nn\nimport torch.optim as optim",
"_____no_output_____"
],
[
"class SkipGramNeg(nn.Module):\n def __init__(self, n_vocab, n_embed, noise_dist=None):\n super().__init__()\n \n self.n_vocab = n_vocab\n self.n_embed = n_embed\n self.noise_dist = noise_dist\n \n # define embedding layers for input and output words\n self.in_embed = nn.Embedding(n_vocab, n_embed)\n self.out_embed = nn.Embedding(n_vocab, n_embed)\n \n # Initialize both embedding tables with uniform distribution\n self.in_embed.weight.data.uniform_(-1, 1)\n self.out_embed.weight.data.uniform_(-1, 1)\n \n def forward_input(self, input_words):\n # return input vector embeddings\n return self.in_embed(input_words)\n \n def forward_output(self, output_words):\n # return output vector embeddings\n return self.out_embed(output_words)\n \n def forward_noise(self, batch_size, n_samples):\n \"\"\" Generate noise vectors with shape (batch_size, n_samples, n_embed)\"\"\"\n if self.noise_dist is None:\n # Sample words uniformly\n noise_dist = torch.ones(self.n_vocab)\n else:\n noise_dist = self.noise_dist\n \n # Sample words from our noise distribution\n noise_words = torch.multinomial(noise_dist,\n batch_size * n_samples,\n replacement=True)\n \n device = \"cuda\" if model.out_embed.weight.is_cuda else \"cpu\"\n noise_words = noise_words.to(device)\n \n ## TODO: get the noise embeddings\n # reshape the embeddings so that they have dims (batch_size, n_samples, n_embed)\n return self.out_embed(noise_words).view(batch_size, n_samples, self.n_embed)\n",
"_____no_output_____"
],
[
"class NegativeSamplingLoss(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, input_vectors, output_vectors, noise_vectors):\n \n batch_size, embed_size = input_vectors.shape\n \n # Input vectors should be a batch of column vectors\n input_vectors = input_vectors.view(batch_size, embed_size, 1)\n \n # Output vectors should be a batch of row vectors\n output_vectors = output_vectors.view(batch_size, 1, embed_size)\n \n # bmm = batch matrix multiplication\n # correct log-sigmoid loss\n out_loss = torch.bmm(output_vectors, input_vectors).sigmoid().log()\n out_loss = out_loss.squeeze()\n \n # incorrect log-sigmoid loss\n noise_loss = torch.bmm(noise_vectors.neg(), input_vectors).sigmoid().log()\n noise_loss = noise_loss.squeeze().sum(1) # sum the losses over the sample of noise vectors\n\n # negate and sum correct and noisy log-sigmoid losses\n # return average batch loss\n return -(out_loss + noise_loss).mean()",
"_____no_output_____"
]
],
[
[
"### Training\n\nBelow is our training loop, and I recommend that you train on GPU, if available.",
"_____no_output_____"
]
],
[
[
"device = 'cuda' if torch.cuda.is_available() else 'cpu'\n\n# Get our noise distribution\n# Using word frequencies calculated earlier in the notebook\nword_freqs = np.array(sorted(freqs.values(), reverse=True))\nunigram_dist = word_freqs/word_freqs.sum()\nnoise_dist = torch.from_numpy(unigram_dist**(0.75)/np.sum(unigram_dist**(0.75)))\n\n# instantiating the model\nembedding_dim = 300\nmodel = SkipGramNeg(len(vocab_to_int), embedding_dim, noise_dist=noise_dist).to(device)\n\n# using the loss that we defined\ncriterion = NegativeSamplingLoss() \noptimizer = optim.Adam(model.parameters(), lr=0.003)\n\nprint_every = 1500\nsteps = 0\nepochs = 5\n\n# train for some number of epochs\nfor e in range(epochs):\n \n # get our input, target batches\n for input_words, target_words in get_batches(train_words, 512):\n steps += 1\n inputs, targets = torch.LongTensor(input_words), torch.LongTensor(target_words)\n inputs, targets = inputs.to(device), targets.to(device)\n \n # input, outpt, and noise vectors\n input_vectors = model.forward_input(inputs)\n output_vectors = model.forward_output(targets)\n noise_vectors = model.forward_noise(inputs.shape[0], 5)\n\n # negative sampling loss\n loss = criterion(input_vectors, output_vectors, noise_vectors)\n\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n # loss stats\n if steps % print_every == 0:\n print(\"Epoch: {}/{}\".format(e+1, epochs))\n print(\"Loss: \", loss.item()) # avg batch loss at this point in training\n valid_examples, valid_similarities = cosine_similarity(model.in_embed, device=device)\n _, closest_idxs = valid_similarities.topk(6)\n\n valid_examples, closest_idxs = valid_examples.to('cpu'), closest_idxs.to('cpu')\n for ii, valid_idx in enumerate(valid_examples):\n closest_words = [int_to_vocab[idx.item()] for idx in closest_idxs[ii]][1:]\n print(int_to_vocab[valid_idx.item()] + \" | \" + ', '.join(closest_words))\n print(\"...\\n\")",
"Epoch: 1/5\nLoss: 6.832333087921143\nwould | yard, mlb, aspartame, supports, magazine\nfrom | and, brown, falling, lenses, deposit\ncan | epistolary, ambitious, birds, bhutan, adherents\nin | of, the, one, republic, corinth\nsystem | yankees, simple, cueball, kemp, hague\ntwo | of, a, one, the, greeks\nthis | dictate, the, empire, sleepers, breaks\nthere | camps, stated, encyclop, printer, atzma\npolice | almoravid, trial, feeding, microscopy, artists\nocean | meteor, breaths, corners, poem, led\nversions | direct, gehrig, varied, albicans, nor\naccepted | removes, brock, lips, geometry, quickly\njoseph | the, architect, valine, installations, dennis\ninstitute | superiors, tragically, requiring, aragon, hiv\ndefense | the, witch, over, vila, neighborhood\nmagazine | forging, streets, would, pitch, exploded\n...\n\nEpoch: 1/5\nLoss: 5.065519332885742\npeople | bishop, used, payment, carolingian, one\nsee | have, hobart, the, defy, encountered\nworld | ratified, closest, photography, as, and\nwere | and, a, of, that, the\nfour | two, the, nine, five, zero\nis | the, of, to, are, and\nfive | two, four, nine, one, three\nhis | the, by, of, and, in\nhit | c, downstream, tighter, editorial, thoroughbred\nquestion | they, miraculously, meritocracy, gestalt, biomes\nsan | idf, of, granted, barak, violet\npre | wardens, scientifique, threatens, hips, blades\ntest | that, elders, subtlety, alg, lamport\nmathematics | exceeding, hohenzollern, register, japonica, limited\ncentre | pediatric, denying, franks, donaldson, alluvial\npope | hedley, it, folded, crypto, nitro\n...\n\nEpoch: 1/5\nLoss: 3.9132397174835205\nhowever | be, the, was, a, of\nknown | to, by, at, the, s\nat | the, of, by, and, one\nsuch | the, that, to, used, or\nthere | the, as, that, for, not\nfrom | the, to, of, in, which\nover | five, in, two, to, of\nwith | a, the, in, of, and\nsan | links, country, gamblers, kanto, violet\nbehind | lyric, sick, slash, abbasids, eva\narticles | lookout, shelter, physiology, april, bin\nroad | rosser, tv, assist, damietta, leitch\nanimals | prohibiting, spc, namek, an, rerun\negypt | lytton, death, attend, holt, blue\ngovernor | monogamy, flights, reform, shadowed, baldrick\ncreation | distributor, rectangle, indebted, talkin, glider\n...\n\nEpoch: 1/5\nLoss: 3.488314151763916\nwho | he, in, of, and, son\nuse | can, it, all, is, to\nunited | war, state, the, government, one\nby | in, and, a, to, of\nand | of, the, in, by, as\none | nine, three, five, four, seven\nfour | five, one, six, seven, eight\nduring | three, of, national, country, in\nbible | faith, do, earliest, ancient, to\npope | for, inspired, nuncio, made, greenfacts\nsan | cerf, embarked, almohad, six, granted\nocean | breaths, pacific, diazepam, provincial, ivan\npolice | trial, organization, german, ong, buyout\naccount | about, numbers, restored, case, pa\nchannel | embodiment, u, ministry, errol, editing\nmagazine | genre, original, being, technology, batter\n...\n\nEpoch: 1/5\nLoss: 3.3560147285461426\non | of, a, by, the, at\nbe | not, we, that, is, such\nmany | in, the, not, and, have\ncalled | the, and, as, a, in\nsee | as, in, english, is, the\nwhere | been, of, to, the, have\nsuch | to, of, be, and, is\nor | of, a, the, are, this\nshown | also, millay, described, earth, similar\ncost | monistic, rather, ability, reneged, power\nuniverse | god, perception, consciousness, intelligent, theory\nactive | have, power, the, against, any\ngrand | deaths, part, eight, six, births\nfreedom | states, power, did, part, school\nwoman | john, seven, live, band, he\nmean | anxiolytics, particular, hollow, if, heterogeneous\n...\n\nEpoch: 1/5\nLoss: 3.977637767791748\nsee | history, article, of, the, links\nyears | male, population, over, six, female\ncan | or, this, these, be, are\nbut | to, that, by, the, been\nstates | united, state, country, government, countries\nhowever | the, not, to, a, with\ntwo | zero, five, three, one, eight\nand | the, of, with, in, as\nwoman | her, king, married, mary, john\northodox | church, christians, christianity, christ, jewish\nunits | air, unit, force, forces, m\nbible | christ, testament, god, judaism, biblical\noperating | software, windows, systems, os, system\nengine | engines, models, fuel, design, system\nexistence | we, theory, sense, effect, human\ntaking | then, with, this, their, of\n...\n\nEpoch: 2/5\nLoss: 2.845167398452759\neight | five, one, four, six, zero\ntime | next, here, the, up, to\na | for, and, the, with, as\nfrom | the, in, and, other, of\nmay | or, but, have, be, the\nwith | a, the, to, that, in\nhas | the, as, in, many, also\nis | of, the, and, a, are\nfrac | x, equation, function, y, vector\nbbc | listing, news, march, day, birthday\nbill | career, robert, president, nine, director\ninstitute | university, schools, education, science, school\nparis | french, de, royal, france, composer\nunits | unit, per, supply, force, length\nmainly | until, among, age, as, europe\nshown | is, natural, non, if, containing\n...\n\nEpoch: 2/5\nLoss: 2.8011245727539062\nuse | with, similar, are, or, can\nfour | five, seven, eight, six, two\nwho | his, himself, him, to, took\nthe | to, that, of, with, and\nthree | six, one, five, two, seven\nthere | are, that, generally, is, certain\non | the, of, and, has, to\nhas | on, its, have, of, that\nnumerous | many, been, in, was, their\npolice | defense, executive, leader, troops, military\nassembly | election, elected, elections, president, legislative\nrunning | fast, speed, games, hit, run\ncost | control, costs, expected, reducing, increase\nparis | de, le, composer, france, museum\ncentre | buildings, city, located, southern, station\nengine | engines, speed, mechanical, fuel, wheel\n...\n\nEpoch: 2/5\nLoss: 2.6456174850463867\nhas | which, its, and, significant, other\nare | or, is, these, common, other\nbut | not, it, when, be, the\nits | which, the, or, non, of\nall | there, that, not, or, is\noften | their, such, many, aspects, particular\ns | one, nine, was, seven, david\nof | the, is, and, as, to\npolice | war, military, officers, wing, former\nmagazine | tv, movie, awards, award, best\nfile | files, code, program, unix, microsoft\ncost | costs, industry, prices, low, reducing\nocean | sea, atlantic, pacific, coast, mountains\npre | practices, cultures, celtic, greek, history\nquestion | we, idea, interpretation, that, particular\nbrother | son, father, sons, his, was\n...\n\nEpoch: 2/5\nLoss: 2.683985710144043\ncalled | is, and, of, in, are\nto | the, a, and, which, of\nthan | small, or, less, very, can\nknown | and, of, the, by, name\nup | down, they, around, at, with\nwill | must, you, be, does, exactly\nwhich | the, and, is, to, with\ns | nine, one, eight, five, in\nroad | train, miles, street, highway, area\nwriters | authors, science, literary, fiction, literature\nolder | females, male, size, pack, old\nprince | king, crown, son, emperor, throne\nexperience | effort, improve, memories, care, towards\nchannel | channels, cable, broadcast, stations, station\nnobel | prize, laureate, physicist, politician, chemist\nmarriage | divorce, married, husband, she, son\n...\n\nEpoch: 2/5\nLoss: 2.6408331394195557\nthat | to, not, him, but, by\nso | will, when, you, my, that\nstates | united, state, federal, commission, executive\nsix | seven, one, five, eight, three\nmost | and, the, traditional, from, by\nstate | states, district, city, virginia, administrative\nthis | their, be, the, often, many\nof | and, the, from, in, by\nlived | spent, maria, grew, whom, banks\nmainly | areas, region, small, from, ethnic\nexcept | is, it, or, teeth, appear\nexperience | pain, critical, credited, effort, artists\npressure | resulting, low, severe, cold, cooling\nadditional | require, used, or, automatically, requires\nsomething | you, know, isn, understand, want\nevent | events, victory, time, ever, visited\n...\n\nEpoch: 2/5\nLoss: 2.5087203979492188\nabout | book, source, account, interview, accessed\nas | and, the, in, of, also\ns | nine, the, was, six, film\nalso | the, for, see, with, as\nnine | one, seven, two, three, five\nwhich | the, is, a, this, called\nhistory | external, references, see, century, links\nuse | can, used, be, for, uses\nsquare | street, miles, tower, hill, avenue\nreport | news, org, security, commission, assessment\nheavy | metal, rock, tank, relatively, heavier\n"
]
],
[
[
"## Visualizing the word vectors\n\nBelow we'll use T-SNE to visualize how our high-dimensional word vectors cluster together. T-SNE is used to project these vectors into two dimensions while preserving local stucture. Check out [this post from Christopher Olah](http://colah.github.io/posts/2014-10-Visualizing-MNIST/) to learn more about T-SNE and other ways to visualize high-dimensional data.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport matplotlib.pyplot as plt\nfrom sklearn.manifold import TSNE",
"_____no_output_____"
],
[
"# getting embeddings from the embedding layer of our model, by name\nembeddings = model.in_embed.weight.to('cpu').data.numpy()",
"_____no_output_____"
],
[
"viz_words = 380\ntsne = TSNE()\nembed_tsne = tsne.fit_transform(embeddings[:viz_words, :])",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(16, 16))\nfor idx in range(viz_words):\n plt.scatter(*embed_tsne[idx, :], color='steelblue')\n plt.annotate(int_to_vocab[idx], (embed_tsne[idx, 0], embed_tsne[idx, 1]), alpha=0.7)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
e73f767668e2cc16fd64981da3d781b195b0b446 | 369,833 | ipynb | Jupyter Notebook | election.ipynb | mittshah2/Data-Analysis-Projects | ae04748f3a18ea012b78497885654e363adf753c | [
"MIT"
] | null | null | null | election.ipynb | mittshah2/Data-Analysis-Projects | ae04748f3a18ea012b78497885654e363adf753c | [
"MIT"
] | null | null | null | election.ipynb | mittshah2/Data-Analysis-Projects | ae04748f3a18ea012b78497885654e363adf753c | [
"MIT"
] | null | null | null | 149.24657 | 75,792 | 0.844514 | [
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as p\nimport seaborn as se\nse.set_style('whitegrid')\n%matplotlib inline",
"_____no_output_____"
],
[
"import requests as r\nfrom io import StringIO",
"_____no_output_____"
],
[
"url = \"http://elections.huffingtonpost.com/pollster/2012-general-election-romney-vs-obama.csv\"\n\nsource=r.get(url).text\n\npoll_data=StringIO(source)\n\npoll=pd.read_csv(poll_data)",
"_____no_output_____"
],
[
"poll.head()",
"_____no_output_____"
],
[
"poll.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 586 entries, 0 to 585\nData columns (total 17 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Pollster 586 non-null object \n 1 Start Date 586 non-null object \n 2 End Date 586 non-null object \n 3 Entry Date/Time (ET) 586 non-null object \n 4 Number of Observations 564 non-null float64\n 5 Population 586 non-null object \n 6 Mode 586 non-null object \n 7 Obama 586 non-null float64\n 8 Romney 586 non-null float64\n 9 Undecided 423 non-null float64\n 10 Other 202 non-null float64\n 11 Pollster URL 586 non-null object \n 12 Source URL 584 non-null object \n 13 Partisan 586 non-null object \n 14 Affiliation 586 non-null object \n 15 Question Text 0 non-null float64\n 16 Question Iteration 586 non-null int64 \ndtypes: float64(6), int64(1), object(10)\nmemory usage: 78.0+ KB\n"
],
[
"poll.describe()",
"_____no_output_____"
],
[
"se.catplot(x='Affiliation',data=poll,kind='count')",
"_____no_output_____"
],
[
"se.catplot(x='Affiliation',hue='Population',data=poll,kind='count')\n#to check the genuineness of our data set. Most were neutral polls i.e not affiliated to any party",
"_____no_output_____"
],
[
"avg=pd.DataFrame(poll.mean(),columns=['Average'])\navg.drop('Number of Observations',axis=0,inplace=True)\navg.drop('Question Text',axis=0,inplace=True)\navg.drop('Question Iteration',axis=0,inplace=True)\navg",
"_____no_output_____"
],
[
"std=pd.DataFrame(poll.std())\nstd.drop('Number of Observations',axis=0,inplace=True)\nstd.drop('Question Text',axis=0,inplace=True)\nstd.drop('Question Iteration',axis=0,inplace=True)\nstd.columns=['Standard deviation']\nstd",
"_____no_output_____"
],
[
"avg.plot(kind='bar',figsize=(15,5),legend=False,yerr=std)",
"_____no_output_____"
],
[
"poll_avg=pd.concat([avg,std],axis=1)\npoll_avg",
"_____no_output_____"
],
[
"poll.plot(x='End Date',y=['Obama','Romney','Undecided'],linestyle='',marker='o',figsize=(15,5))",
"_____no_output_____"
],
[
"from datetime import datetime",
"_____no_output_____"
],
[
"poll['Difference']=(poll['Obama']-poll['Romney'])/100\npoll.head()",
"_____no_output_____"
],
[
"poll=poll.groupby(['Start Date'],as_index=False).mean()\npoll.head()",
"_____no_output_____"
],
[
"poll.plot(x='Start Date',y='Difference',figsize=(15,5),marker='o')",
"_____no_output_____"
],
[
"row_in=0\nxlimit=[]\n\nfor date in poll['Start Date']:\n if(date[0:7]=='2012-10'):\n xlimit.append(row_in)\n row_in=row_in+1\nprint(min(xlimit)) \nprint(max(xlimit))",
"325\n352\n"
],
[
"poll.plot(x='Start Date',y='Difference',figsize=(15,5),marker='o',xlim=(325,352))\n\n#Oct 3rd\np.axvline(x=325+2,linewidth=2,color='grey')\n#Oct 11th\np.axvline(x=325+10,linewidth=2,color='grey')\n#Oct 22nd\np.axvline(x=325+21,linewidth=2,color='grey')",
"_____no_output_____"
],
[
"donor=pd.read_csv('Election_Donor_Data.csv')",
"c:\\users\\mitts\\appdata\\local\\programs\\python\\python37\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3063: DtypeWarning: Columns (6) have mixed types.Specify dtype option on import or set low_memory=False.\n interactivity=interactivity, compiler=compiler, result=result)\n"
],
[
"donor.info()\n",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1001731 entries, 0 to 1001730\nData columns (total 16 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 cmte_id 1001731 non-null object \n 1 cand_id 1001731 non-null object \n 2 cand_nm 1001731 non-null object \n 3 contbr_nm 1001731 non-null object \n 4 contbr_city 1001712 non-null object \n 5 contbr_st 1001727 non-null object \n 6 contbr_zip 1001620 non-null object \n 7 contbr_employer 988002 non-null object \n 8 contbr_occupation 993301 non-null object \n 9 contb_receipt_amt 1001731 non-null float64\n 10 contb_receipt_dt 1001731 non-null object \n 11 receipt_desc 14166 non-null object \n 12 memo_cd 92482 non-null object \n 13 memo_text 97770 non-null object \n 14 form_tp 1001731 non-null object \n 15 file_num 1001731 non-null int64 \ndtypes: float64(1), int64(1), object(14)\nmemory usage: 122.3+ MB\n"
],
[
"donor.describe()",
"_____no_output_____"
],
[
"donor.head()",
"_____no_output_____"
],
[
"donor['contb_receipt_amt'].value_counts()",
"_____no_output_____"
],
[
"don_mean=donor['contb_receipt_amt'].mean()\ndon_std=donor['contb_receipt_amt'].std()\nprint('The average donation was',round(don_mean,2),'with a std of',round(don_std,2))",
"The average donation was 298.24 with a std of 3749.67\n"
],
[
"top_donor=np.array(donor['contb_receipt_amt'])\ntop_donor.sort()\ntop_donor=pd.Series(top_donor)\ntop_donor=top_donor[top_donor>0]\ntop_donor.value_counts().head(10)",
"_____no_output_____"
],
[
"common_don=top_donor[top_donor<2500]\ncommon_don.hist(bins=100)\n#It proves that our people donate in round figure more as there are peaks at rounded numbers",
"_____no_output_____"
],
[
"candidates=(donor['cand_nm'].unique())\ncandidates",
"_____no_output_____"
],
[
"# Dictionary of party affiliation\nparty_map = {'Bachmann, Michelle': 'Republican',\n 'Cain, Herman': 'Republican',\n 'Gingrich, Newt': 'Republican',\n 'Huntsman, Jon': 'Republican',\n 'Johnson, Gary Earl': 'Republican',\n 'McCotter, Thaddeus G': 'Republican',\n 'Obama, Barack': 'Democrat',\n 'Paul, Ron': 'Republican',\n 'Pawlenty, Timothy': 'Republican',\n 'Perry, Rick': 'Republican',\n \"Roemer, Charles E. 'Buddy' III\": 'Republican',\n 'Romney, Mitt': 'Republican',\n 'Santorum, Rick': 'Republican'}",
"_____no_output_____"
],
[
"donor['Party']=donor['cand_nm'].map(party_map)\ndonor.head()",
"_____no_output_____"
],
[
"donor=donor[donor['contb_receipt_amt']>0]",
"_____no_output_____"
],
[
"donor.groupby('cand_nm')['contb_receipt_amt'].count()\n#number of donations to a single candidate",
"_____no_output_____"
],
[
"round(donor.groupby('cand_nm')['contb_receipt_amt'].sum(),0)\n#sum of total donations to the candidates",
"_____no_output_____"
],
[
"(donor.groupby('cand_nm')['contb_receipt_amt'].sum()).plot(kind='bar',figsize=(15,5))",
"_____no_output_____"
],
[
"donor.groupby('Party')['contb_receipt_amt'].sum().plot(kind='bar',figsize=(15,5),legend=False)",
"_____no_output_____"
],
[
"occupation_contri=donor.pivot_table('contb_receipt_amt',index='contbr_occupation',columns='Party',aggfunc='sum')\noccupation_contri.head()",
"_____no_output_____"
],
[
"occupation_contri=occupation_contri[occupation_contri.sum(axis=1)>1000000]\noccupation_contri",
"_____no_output_____"
],
[
"occupation_contri.plot(kind='bar',figsize=(15,5))",
"_____no_output_____"
],
[
"occupation_contri.loc['CEO']=occupation_contri.loc['CEO']+occupation_contri.loc['C.E.O.']\noccupation_contri.drop(index='C.E.O.',inplace=True)",
"_____no_output_____"
],
[
"occupation_contri.plot(kind='bar',figsize=(15,5))",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73f87846c20bd166d143c3cc8253e3858603337 | 2,157 | ipynb | Jupyter Notebook | playbook/tactics/defense-evasion/T1578.003.ipynb | haresudhan/The-AtomicPlaybook | 447b1d6bca7c3750c5a58112634f6bac31aff436 | [
"MIT"
] | 8 | 2021-05-25T15:25:31.000Z | 2021-11-08T07:14:45.000Z | playbook/tactics/defense-evasion/T1578.003.ipynb | haresudhan/The-AtomicPlaybook | 447b1d6bca7c3750c5a58112634f6bac31aff436 | [
"MIT"
] | 1 | 2021-08-23T17:38:02.000Z | 2021-10-12T06:58:19.000Z | playbook/tactics/defense-evasion/T1578.003.ipynb | haresudhan/The-AtomicPlaybook | 447b1d6bca7c3750c5a58112634f6bac31aff436 | [
"MIT"
] | 2 | 2021-05-29T20:24:24.000Z | 2021-08-05T23:44:12.000Z | 47.933333 | 881 | 0.707 | [
[
[
"# T1578.003 - Delete Cloud Instance\nAn adversary may delete a cloud instance after they have performed malicious activities in an attempt to evade detection and remove evidence of their presence. Deleting an instance or virtual machine can remove valuable forensic artifacts and other evidence of suspicious behavior if the instance is not recoverable.\n\nAn adversary may also [Create Cloud Instance](https://attack.mitre.org/techniques/T1578/002) and later terminate the instance after achieving their objectives.(Citation: Mandiant M-Trends 2020)",
"_____no_output_____"
],
[
"## Atomic Tests:\nCurrently, no tests are available for this technique.",
"_____no_output_____"
],
[
"## Detection\nThe deletion of a new instance or virtual machine is a common part of operations within many cloud environments. Events should then not be viewed in isolation, but as part of a chain of behavior that could lead to other activities. For example, detecting a sequence of events such as the creation of an instance, mounting of a snapshot to that instance, and deletion of that instance by a new user account may indicate suspicious activity.\n\nIn AWS, CloudTrail logs capture the deletion of an instance in the <code>TerminateInstances</code> event, and in Azure the deletion of a VM may be captured in Azure activity logs.(Citation: AWS CloudTrail Search)(Citation: Azure Activity Logs) Google's Admin Activity audit logs within their Cloud Audit logs can be used to detect the usage of <code>gcloud compute instances delete</code> to delete a VM.(Citation: Cloud Audit Logs)",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
]
] |
e73f9188d673727d62b6ec835731d2672e9d025c | 862,769 | ipynb | Jupyter Notebook | 20211025/policyComparison.ipynb | dongxulee/lifeCycleRefine | 6ca9670dea50150aabe31f86578323cec0ab018c | [
"MIT"
] | null | null | null | 20211025/policyComparison.ipynb | dongxulee/lifeCycleRefine | 6ca9670dea50150aabe31f86578323cec0ab018c | [
"MIT"
] | null | null | null | 20211025/policyComparison.ipynb | dongxulee/lifeCycleRefine | 6ca9670dea50150aabe31f86578323cec0ab018c | [
"MIT"
] | null | null | null | 1,244.976912 | 74,880 | 0.958849 | [
[
[
"%pylab inline\nimport numpy as np\nimport pandas as pd\nmatplotlib.rcParams['figure.figsize'] = [16, 8]\nplt.rcParams.update({'font.size': 10})",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"housingDecisionBoundary_noRetirement",
"_____no_output_____"
],
[
"housingDecisionBoundary",
"_____no_output_____"
],
[
"ages = list(range(21, 50))\nhousingDecisionBoundary_noRetirement = np.load(\"H_boundary_full_model.npy\")\nhousingDecisionBoundary = np.load(\"H_boundary_without_401k_model.npy\")\nplt.title(\"Housing purchase behavior: wealth level decision boundary\")\nplt.plot(ages,housingDecisionBoundary_noRetirement,'*-', label = \"Model without 401k feature\")\nplt.plot(ages, housingDecisionBoundary,'*-', label = \"Model with 401k feature\")\nplt.xlabel(\"age level\")\nplt.ylabel(\"wealth level\")\nplt.legend()\nplt.savefig(\"housingDecisionBoundary\")",
"_____no_output_____"
],
[
"wealthGap = [5,10,15,20,25,30,35,40,50]\nfor wealthgap in wealthGap:\n plt.figure()\n plt.title(\"Investment Ratio\" + \"_\" + str(wealthgap))\n plt.plot(ages,np.load(\"investmentRatio_\" +str(wealthgap) + \".npy\"), label = \"withHousing\")\n plt.plot(ages,np.load(\"investmentRatio_without_housing\" +str(wealthgap) + \".npy\"), label = \"withoutHousing\")\n plt.legend()",
"_____no_output_____"
],
[
"wealthGap = [5,10,15,20,25,30,35,40,50]\nfor wealthgap in wealthGap:\n plt.figure() \n plt.title(\"Saving Ratio_\" + str(wealthgap))\n plt.plot(ages, np.load(\"savingRatio_\" +str(wealthgap) + \".npy\"), label = \"withHousing\")\n plt.plot(ages, np.load(\"savingRatio_without_housing\" +str(wealthgap) + \".npy\"), label = \"withoutHousing\")\n plt.legend()",
"_____no_output_____"
],
[
"investmentRatio = np.load(\"investmentRatio.npy\")\nsavingRatio = np.load(\"savingRatio.npy\")\ninvestmentRatio_3 = np.load(\"investmentRatio_3.npy\")\nsavingRatio_3 = np.load(\"savingRatio_3.npy\")\ninvestmentRatio_10 = np.load(\"investmentRatio_10.npy\")\nsavingRatio_10 = np.load(\"savingRatio_10.npy\")\ninvestmentRatio_20 = np.load(\"investmentRatio_20.npy\")\nsavingRatio_20 = np.load(\"savingRatio_20.npy\")\ninvestmentRatio_25 = np.load(\"investmentRatio_25.npy\")\nsavingRatio_25 = np.load(\"savingRatio_25.npy\")\ninvestmentRatio_30 = np.load(\"investmentRatio_30.npy\")\nsavingRatio_30 = np.load(\"savingRatio_30.npy\")\ninvestmentRatio_40 = np.load(\"investmentRatio_40.npy\")\nsavingRatio_40 = np.load(\"savingRatio_40.npy\")\ninvestmentRatio_50 = np.load(\"investmentRatio_50.npy\")\nsavingRatio_50 = np.load(\"savingRatio_50.npy\")\n# plt.plot(ages[:10], investmentRatio[:10], label = \"On the boundary\")\nplt.plot(ages[:10], investmentRatio_10[:10], label = \"On the boundary-10\")\nplt.plot(ages[:10], investmentRatio_20[:10], label = \"On the boundary-20\")\n# plt.plot(ages[:10], investmentRatio_40[:10], label = \"On the boundary-40\")\nplt.plot(ages[:10], investmentRatio_50[:10], label = \"On the boundary-50\")\nplt.legend(loc ='lower right')",
"_____no_output_____"
],
[
"plt.plot(ages, savingRatio_10, label = \"On the boundary-10\")\nplt.plot(ages, savingRatio_20, label = \"On the boundary-20\")\nplt.plot(ages, savingRatio_50, label = \"On the boundary-50\")\nplt.legend()",
"_____no_output_____"
],
[
"investmentRatio = np.load(\"investmentRatio.npy\")\nsavingRatio = np.load(\"savingRatio.npy\")\ninvestmentRatio_without_housing = np.load(\"investmentRatio_without_housing.npy\")\nsavingRatio_without_housing = np.load(\"savingRatio_without_housing.npy\")\ninvestmentRatio_without_401k = np.load(\"investmentRatio_without_retirement.npy\")\nsavingRatio_without_401k = np.load(\"savingRatio_without_retirement.npy\")",
"_____no_output_____"
],
[
"plt.title(\"owner_to_be agent's decision rules on investment ratio across models\")\nplt.plot(ages, investmentRatio, label = \"Model with both housing and 401k\")\nplt.plot(ages, investmentRatio_without_401k, label = \"Model without 401k\")\nplt.plot(ages, investmentRatio_without_housing, label = \"Model without housing\")\nplt.xlabel(\"age level\")\nplt.ylabel(\"ratio\")\nplt.legend()\nplt.savefig(\"investmentRatioForOwner_to_be\")",
"_____no_output_____"
],
[
"plt.title(\"owner_to_be agent's decision rules on saving ratio across models\")\nplt.plot(ages, savingRatio, label = \"Model with both housing and 401k\")\nplt.plot(ages, savingRatio_without_401k, label = \"Model without 401k\")\nplt.plot(ages, savingRatio_without_housing, label = \"Model without housing\")\nplt.xlabel(\"age level\")\nplt.ylabel(\"ratio\")\nplt.legend()\nplt.savefig(\"savingRatioForOwner_to_be\")",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73f9c5a65c87a9335a51831b14ffc89eb739b91 | 73,621 | ipynb | Jupyter Notebook | experiments/hypersingular_accuracy.ipynb | tbenthompson/tectosaur2 | 02cd56ab7e63e36afc4a10db17072076541aab77 | [
"MIT"
] | 1 | 2021-06-18T18:02:55.000Z | 2021-06-18T18:02:55.000Z | experiments/hypersingular_accuracy.ipynb | tbenthompson/tectosaur2 | 02cd56ab7e63e36afc4a10db17072076541aab77 | [
"MIT"
] | null | null | null | experiments/hypersingular_accuracy.ipynb | tbenthompson/tectosaur2 | 02cd56ab7e63e36afc4a10db17072076541aab77 | [
"MIT"
] | 1 | 2021-07-14T19:47:00.000Z | 2021-07-14T19:47:00.000Z | 94.265045 | 34,574 | 0.808954 | [
[
[
"\\begin{equation}\n\\int_{S} K(x, y) y_2 dy\n\\end{equation}",
"_____no_output_____"
],
[
"Ideas:\n* there could be a bug in adaptive.hpp\n* maybe recursive subdivision is better than gauss-kronrod for this type of problem.\n* ~~kahan summation might be necessary. perhaps the adding and subtracting of the error causes problems?~~\n* align the python numpy kernels with the nearfield.cpp kernels.",
"_____no_output_____"
]
],
[
[
"from tectosaur2.nb_config import setup\nsetup()\n\nimport numpy as np\nfrom tectosaur2 import gauss_rule, integrate_term\nfrom tectosaur2.mesh import unit_circle\nfrom tectosaur2.laplace2d import hypersingular\nfrom tectosaur2.global_qbx import global_qbx_self\nquad_rule = gauss_rule(10)\ncircle = unit_circle(quad_rule)\ncircle.n_panels\n\ngmats = []\ngvecs = []\nv = np.cos(circle.pts[:,1])\nps = np.arange(3, 8)\nfor p in ps:\n gmat, report = global_qbx_self(hypersingular, circle, p, 1.0, 10, return_report=True)\n gmats.append(gmat)\n gvecs.append(gmat[:,:,:,0].dot(v))\nlmat, lreport = integrate_term(hypersingular, circle.pts, circle, safety_mode=True, return_report=True)\nlvec = lmat[:,:,:,0].dot(v)\n\nprint(np.max(np.abs(lvec - gvecs[-1])))",
"2.4279452615072472e-09\n"
],
[
"lmat, lreport = integrate_term(hypersingular, circle.pts, circle, return_report=True)\nlvec = lmat[:,:,:,0].dot(v)\nprint(np.max(np.abs(lvec - gvecs[-1])))",
"1.20824183991175e-11\n"
],
[
"for i in range(1, ps.shape[0]):\n print('\\n', i)\n print(np.max(np.abs(gmats[i] - gmat[i - 1])))\n print(np.max(np.abs(gvecs[i] - gvecs[i - 1])))",
"\n 1\n4.657536261689784\n8.12064950692637e-05\n\n 2\n5.704405858601769\n7.705862049567358e-07\n\n 3\n8.12835335669428\n3.9674554669355544e-08\n\n 4\n9.690547112513867\n2.4950611021701263e-10\n"
]
],
[
[
"# Analytic comparison \n\nLet's use the analytic solution for stress for slip on a line segment in a fullspace extending from y = -1 to y = 1. From page 35 of the Segall book. ",
"_____no_output_____"
]
],
[
[
"import sympy as sp\nimport matplotlib.pyplot as plt\nfrom tectosaur2 import panelize_symbolic_surface, pts_grid\nt = sp.var('t')\nfault = panelize_symbolic_surface(t, 0*t, t, quad_rule, n_panels=1)",
"_____no_output_____"
],
[
"def analytical_stress(obsx, obsy):\n rp = obsx ** 2 + (obsy + 1) ** 2\n ri = obsx ** 2 + (obsy - 1) ** 2\n sxz = -(1.0 / (2 * np.pi)) * (((obsy + 1) / rp) - ((obsy - 1) / ri))\n syz = (1.0 / (2 * np.pi)) * ((obsx / rp) - (obsx / ri))\n return sxz, syz",
"_____no_output_____"
],
[
"def run(zoomx, zoomy):\n nobs = 200\n xs = np.linspace(*zoomx, nobs)\n ys = np.linspace(*zoomy, nobs)\n obs_pts = pts_grid(xs, ys)\n obsx = obs_pts[:, 0]\n obsy = obs_pts[:, 1]\n\n sing = np.array([(0,-1), (0, 1)])\n stress_mat, report = integrate_term(hypersingular, obs_pts, fault, singularities=sing, return_report=True)\n interior_stress = stress_mat[:,:,:,0].sum(axis=2)\n analytical_sxz, analytical_syz = analytical_stress(obsx, obsy)\n interior_sxz = interior_stress[:,0]\n interior_syz = interior_stress[:,1]\n import warnings\n with warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n sxz_err = np.log10(np.abs(interior_sxz - analytical_sxz))\n syz_err = np.log10(np.abs(interior_syz - analytical_syz))\n plt.figure(figsize=(12, 8))\n\n plots = [\n (\"analytical_sxz\", \"$\\sigma_{xz}$\"),\n (\"analytical_syz\", \"$\\sigma_{yz}$\"),\n (\"sxz_err\", r\"$\\log_{10}|\\sigma_{xz,\\textrm{BIE}} - \\sigma_{xz,\\textrm{analytic}}|$\"),\n (\"syz_err\", r\"$\\log_{10}|\\sigma_{yz,\\textrm{BIE}} - \\sigma_{yz,\\textrm{analytic}}|$\")\n ]\n for i, (k, title) in enumerate(plots):\n plt.subplot(2, 2, 1 + i)\n plt.title(title)\n v = locals()[k].reshape((nobs, nobs))\n v2d = v.reshape((nobs, nobs))\n if i < 2:\n levels = np.linspace(-0.5, 0.5, 11)\n else:\n levels = np.linspace(-14, -1, 14)\n cntf = plt.contourf(xs, ys, v2d, levels=levels, extend=\"both\")\n plt.contour(\n xs,\n ys,\n v2d,\n colors=\"k\",\n linestyles=\"-\",\n linewidths=0.5,\n levels=levels,\n extend=\"both\",\n )\n plt.colorbar(cntf)\n # plt.xlim([-0.01, 0.01])\n # plt.ylim([-0.02, 0.0])\n\n plt.tight_layout()\n plt.show()\n",
"_____no_output_____"
],
[
"\n# run([-2, 2], [-2, 2])\n# run([-0.5, 0.5], [0.5, 1.5])\n# run([-0.1, 0.1], [0.9, 1.1])\n# run([-0.003, 0.003], [0.997, 1.003])",
"_____no_output_____"
],
[
"xs = np.linspace(-0.003, 0.003, 100)\nys = [1.001] * xs.shape[0] \nobs_pts = np.array([xs, ys]).T.copy()\nsing = np.array([(0,-1), (0, 1)])\nstress_mat, report = integrate_term(hypersingular, obs_pts, fault, safety_mode=True, singularities=sing, return_report=True)\ninterior_stress = stress_mat[:,:,:,0].sum(axis=2)\nanalytical_sxz, analytical_syz = analytical_stress(obs_pts[:,0], obs_pts[:,1])\ninterior_sxz = interior_stress[:,0]\ninterior_syz = interior_stress[:,1]\nimport warnings\nwith warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n sxz_err = np.log10(np.abs(interior_sxz - analytical_sxz))\n syz_err = np.log10(np.abs(interior_syz - analytical_syz))",
"/Users/tbent/Dropbox/active/eq/tectosaur2/tectosaur2/integrate.py:206: UserWarning: Some integrals failed to converge during adaptive integration. This an indication of a problem in either the integration or the problem formulation.\n warnings.warn(\n"
],
[
"report.keys()",
"_____no_output_____"
],
[
"report['p']",
"_____no_output_____"
],
[
"report['qbx_integration_error']",
"_____no_output_____"
],
[
"report['exp_centers'][:, 1]",
"_____no_output_____"
],
[
"plt.plot(xs, sxz_err, 'bo')\nplt.plot(xs, report['exp_centers'][:, 0] * 1000 - 10)\nplt.plot(xs, (report['exp_centers'][:, 1] - 1) * 1000 - 10)\nplt.show()",
"_____no_output_____"
],
[
"from tectosaur2.laplace2d import Hypersingular\nys = np.linspace(1.0, 1.00005, 2)\nxs = [0.0] * ys.shape[0] \nobs_pts = np.array([xs, ys]).T.copy()\nsing = np.array([(0,-1), (0, 1)])\nstress_mat, report = integrate_term(Hypersingular(d_qbx=0), obs_pts, fault, safety_mode=True, singularities=sing, return_report=True)\ninterior_stress = stress_mat[:,:,:,0].sum(axis=2)\nanalytical_sxz, analytical_syz = analytical_stress(obs_pts[:,0], obs_pts[:,1])\ninterior_sxz = interior_stress[:,0]\ninterior_syz = interior_stress[:,1]\nimport warnings\nwith warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n sxz_err = np.log10(np.abs(interior_sxz - analytical_sxz))\n syz_err = np.log10(np.abs(interior_syz - analytical_syz))",
"/Users/tbent/Dropbox/active/eq/tectosaur2/tectosaur2/integrate.py:287: UserWarning: Some integrals failed to converge during adaptive integration. This an indication of a problem in either the integration or the problem formulation.\n warnings.warn(\n/var/folders/mt/cmys2v_143q1kpcrdt5wcdyr0000gn/T/ipykernel_73562/2211585198.py:4: RuntimeWarning: invalid value encountered in true_divide\n sxz = -(1.0 / (2 * np.pi)) * (((obsy + 1) / rp) - ((obsy - 1) / ri))\n/var/folders/mt/cmys2v_143q1kpcrdt5wcdyr0000gn/T/ipykernel_73562/2211585198.py:5: RuntimeWarning: invalid value encountered in true_divide\n syz = (1.0 / (2 * np.pi)) * ((obsx / rp) - (obsx / ri))\n"
],
[
"plt.plot(ys, sxz_err, 'bo')\nplt.show()\n# plt.plot(ys, report['exp_rs'])\n# plt.show()",
"_____no_output_____"
],
[
"correct = analytical_sxz[1]\ntct_val = interior_sxz[1]",
"_____no_output_____"
],
[
"report['nearfield_n_subsets']",
"_____no_output_____"
],
[
"report['nearfield_integration_error']",
"_____no_output_____"
],
[
"interior_sxz[1]",
"_____no_output_____"
],
[
"from tectosaur2.laplace2d import Hypersingular\nop = obs_pts[1:]\n# op = report['exp_centers'][50:51]\nkernel = Hypersingular()\ndef integrand(srcy):\n src_normals = np.zeros((srcy.shape[0], 2))\n src_normals[:,0] = -1\n entry = kernel.kernel(op, np.array([0*srcy, srcy]).T.copy(), src_normals)\n return entry[0,0,:,0]\n\ngrule = gauss_rule(8)\ndef simple_quad(domain):\n xs = domain[0] + (domain[1] - domain[0]) * ((grule[0] + 1) * 0.5)\n ws = (domain[1] - domain[0]) * 0.5 * grule[1]\n return np.sum(integrand(xs) * ws)\n\ndef recursive_quad(domain, tol, base_value=None):\n if base_value is None:\n base_value = simple_quad(domain)\n center = (domain[0] + domain[1]) * 0.5\n ldom = [domain[0], center]\n lval = simple_quad(ldom)\n\n rdom = [center, domain[1]]\n rval = simple_quad(rdom)\n better_value = lval + rval\n err = np.abs(better_value - base_value)\n if err < tol:\n return better_value, 2, err\n else:\n left = recursive_quad(ldom, tol, lval)\n right = recursive_quad(rdom, tol, rval)\n return left[0] + right[0], left[1] + right[1], left[2] + right[2]\n\nval, n_integrals, err = recursive_quad([-1, 1], 1e-12)\nval, val - correct, val - tct_val, n_integrals, err",
"_____no_output_____"
],
[
"import quadpy\nkronrod_n = 10\nkronrod_rule = quadpy.c1.gauss_kronrod(kronrod_n)\nkronrod_qx = kronrod_rule.points\nkronrod_qw = kronrod_rule.weights\ngauss_r = quadpy.c1.gauss_legendre(kronrod_n)\ngauss_qx = gauss_r.points\nkronrod_qw_gauss = gauss_r.weights\n\nimport heapq\ndef gk_quad(domain):\n gxs = domain[0] + (domain[1] - domain[0]) * ((gauss_qx + 1) * 0.5)\n gws = (domain[1] - domain[0]) * 0.5 * kronrod_qw_gauss\n kxs = domain[0] + (domain[1] - domain[0]) * ((kronrod_qx + 1) * 0.5)\n kws = (domain[1] - domain[0]) * 0.5 * kronrod_qw\n est1 = np.sum(integrand(gxs) * gws)\n est2 = np.sum(integrand(kxs) * kws)\n return est1, est2, np.abs(est2 - est1)\n\ndef priority_quad(tol):\n low_est, est, err = gk_quad([-1, 1])\n\n queue = []\n heapq.heappush(queue, (-err, est, -1, 1))\n\n for i in range(1000):\n cur_integral = heapq.heappop(queue)\n midpt = (cur_integral[2] + cur_integral[3]) * 0.5\n left = gk_quad([cur_integral[2], midpt])\n right = gk_quad([midpt, cur_integral[3]])\n err += cur_integral[0] + left[2] + right[2]\n est += -cur_integral[1] + left[1] + right[1]\n heapq.heappush(queue, (-left[2], left[1], cur_integral[2], midpt))\n heapq.heappush(queue, (-right[2], right[1], midpt, cur_integral[3]))\n if err < tol:\n break\n return est, i, err\n\nval, n_integrals, err = priority_quad(1e-12)\nval, val - correct, val - tct_val, n_integrals, err",
"_____no_output_____"
],
[
"def kahan_update(kv, a):\n y = a - kv[1]\n t = kv[0] + y\n kv[1] = (t - kv[0]) - y\n kv[0] = t\n\n\ndef exact_quad(domain):\n rp = op[:, 0] ** 2 + (op[:, 1] - domain[0]) ** 2\n ri = op[:, 0] ** 2 + (op[:, 1] - domain[1]) ** 2\n sxz = -(1.0 / (2 * np.pi)) * (\n ((op[:, 1] - domain[0]) / rp) - ((op[:, 1] - domain[1]) / ri)\n )\n return sxz, sxz, 0\n\n\ndef kahan_priority_quad(tol, exact=False, kahan=False):\n quad_fnc = exact_quad if exact else gk_quad\n low_est, est_, err_ = quad_fnc([-1, 1])\n est = [est_, 0]\n err = [err_, 0]\n\n queue = []\n heapq.heappush(queue, (-err[0], est[0], -1, 1))\n\n for i in range(1000):\n\n cur_integral = heapq.heappop(queue)\n midpt = (cur_integral[2] + cur_integral[3]) * 0.5\n left = quad_fnc([cur_integral[2], midpt])\n right = quad_fnc([midpt, cur_integral[3]])\n\n if kahan:\n kahan_update(err, cur_integral[0])\n kahan_update(err, left[2])\n kahan_update(err, right[2])\n\n kahan_update(est, -cur_integral[1])\n kahan_update(est, left[1])\n kahan_update(est, right[1])\n else:\n err[0] += cur_integral[0] + left[2] + right[2]\n est[0] += -cur_integral[1] + left[1] + right[1]\n\n heapq.heappush(queue, (-left[2], left[1], cur_integral[2], midpt))\n heapq.heappush(queue, (-right[2], right[1], midpt, cur_integral[3]))\n\n if err[0] < tol:\n break\n return est[0] + est[1], i, err[0] + err[1]\n\n",
"_____no_output_____"
],
[
"\nval, n_integrals, err = kahan_priority_quad(1e-13, exact=True, kahan=False)\nval, val - correct, val - tct_val, n_integrals, err\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73f9d40ed9b2bbe7777e9e1eba9bb2832ba0536 | 3,223 | ipynb | Jupyter Notebook | CSE 250A/hw4/Code/Code.ipynb | vnnsrk/UCSD | 0bce6729b6f3940d51065944125abeead3f413a6 | [
"Apache-2.0"
] | 3 | 2018-11-17T06:19:41.000Z | 2021-08-18T07:28:06.000Z | CSE 250A/hw4/Code/Code.ipynb | vnnsrk/UCSD | 0bce6729b6f3940d51065944125abeead3f413a6 | [
"Apache-2.0"
] | null | null | null | CSE 250A/hw4/Code/Code.ipynb | vnnsrk/UCSD | 0bce6729b6f3940d51065944125abeead3f413a6 | [
"Apache-2.0"
] | 3 | 2019-10-15T12:43:32.000Z | 2021-09-23T23:09:14.000Z | 18.738372 | 65 | 0.458269 | [
[
[
"import math\nimport numpy as np",
"_____no_output_____"
],
[
"f = open('nasdaq00.txt','r')\np0 = [float(k) for k in f.read().split('\\n')]\nf.close()\nf = open('nasdaq01.txt','r')\np1 = [float(k) for k in f.read().split('\\n')]\nf.close()",
"_____no_output_____"
],
[
"b = list()\nx = list()\nfor i in range(3,len(p0)):\n b.append(p0[i])\n x.append([p0[i-1],p0[i-2],p0[i-3]])\nb=np.array(b)\nx=np.matrix(x)",
"_____no_output_____"
],
[
"pinvx = np.linalg.pinv(x)\ncoeff = pinvx.dot(b)",
"_____no_output_____"
],
[
"a = np.array(coeff)[0][0]\nb = np.array(coeff)[0][1]\nc = np.array(coeff)[0][2]\nprint a,b,c",
"0.950673366139 0.015601330776 0.0318956851587\n"
],
[
"err0 = 0.0\nfor i in range(3,len(p0)):\n err0+=(a*p0[i-1] + b*p0[i-2] + c*p0[i-3] - p0[i])**2\nerr0/=(len(p0)-3)*1.0",
"_____no_output_____"
],
[
"err1 = 0.0\nfor i in range(3,len(p1)):\n err1+=(a*p1[i-1] + b*p1[i-2] + c*p1[i-3] - p1[i])**2\nerr1/=(len(p1)-3)*1.0",
"_____no_output_____"
],
[
"err0",
"_____no_output_____"
],
[
"err1",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73f9d8c422a08109ba35e1d0f11f25fa678dfe5 | 63,402 | ipynb | Jupyter Notebook | text-classification/72.transfer-learning-xlnet-large.ipynb | huseinzol05/Tensorflow-NLP-Models | 0741216aa8235e1228b3de7903cc36d73f8f2b45 | [
"MIT"
] | 1,705 | 2018-11-03T17:34:22.000Z | 2022-03-29T04:30:01.000Z | text-classification/72.transfer-learning-xlnet-large.ipynb | eridgd/NLP-Models-Tensorflow | d46e746cd038f25e8ee2df434facbe12e31576a1 | [
"MIT"
] | 26 | 2019-03-16T17:23:00.000Z | 2021-10-08T08:06:09.000Z | text-classification/72.transfer-learning-xlnet-large.ipynb | eridgd/NLP-Models-Tensorflow | d46e746cd038f25e8ee2df434facbe12e31576a1 | [
"MIT"
] | 705 | 2018-11-03T17:34:25.000Z | 2022-03-24T02:29:14.000Z | 56.608929 | 386 | 0.625453 | [
[
[
"# !wget https://storage.googleapis.com/xlnet/released_models/cased_L-24_H-1024_A-16.zip\n# !unzip cased_L-24_H-1024_A-16.zip\n# !wget https://raw.githubusercontent.com/huseinzol05/NLP-Models-Tensorflow/master/text-classification/utils.py",
"_____no_output_____"
],
[
"import xlnet\nimport numpy as np\nimport tensorflow as tf\nfrom tqdm import tqdm\nimport model_utils",
"_____no_output_____"
],
[
"import sentencepiece as spm\nfrom prepro_utils import preprocess_text, encode_ids\n\nsp_model = spm.SentencePieceProcessor()\nsp_model.Load('xlnet_cased_L-24_H-1024_A-16/spiece.model')",
"_____no_output_____"
],
[
"from utils import *\nfrom sklearn.cross_validation import train_test_split\n\ntrainset = sklearn.datasets.load_files(container_path = 'data', encoding = 'UTF-8')\ntrainset.data, trainset.target = separate_dataset(trainset,1.0)\nprint (trainset.target_names)\nprint (len(trainset.data))\nprint (len(trainset.target))",
"/home/jupyter/.local/lib/python3.6/site-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.\n \"This module will be removed in 0.20.\", DeprecationWarning)\n"
],
[
"from prepro_utils import preprocess_text, encode_ids\n\ndef tokenize_fn(text):\n text = preprocess_text(text, lower= False)\n return encode_ids(sp_model, text)",
"_____no_output_____"
],
[
"MAX_SEQ_LENGTH = 128\n\nSEG_ID_A = 0\nSEG_ID_B = 1\nSEG_ID_CLS = 2\nSEG_ID_SEP = 3\nSEG_ID_PAD = 4\n\nspecial_symbols = {\n \"<unk>\" : 0,\n \"<s>\" : 1,\n \"</s>\" : 2,\n \"<cls>\" : 3,\n \"<sep>\" : 4,\n \"<pad>\" : 5,\n \"<mask>\" : 6,\n \"<eod>\" : 7,\n \"<eop>\" : 8,\n}\n\nVOCAB_SIZE = 32000\nUNK_ID = special_symbols[\"<unk>\"]\nCLS_ID = special_symbols[\"<cls>\"]\nSEP_ID = special_symbols[\"<sep>\"]\nMASK_ID = special_symbols[\"<mask>\"]\nEOD_ID = special_symbols[\"<eod>\"]\n\ninput_ids, input_masks, segment_ids = [], [], []\n\nfor text in tqdm(trainset.data):\n tokens_a = tokenize_fn(text)\n if len(tokens_a) > MAX_SEQ_LENGTH - 2:\n tokens_a = tokens_a[:(MAX_SEQ_LENGTH - 2)]\n \n tokens = []\n segment_id = []\n for token in tokens_a:\n tokens.append(token)\n segment_id.append(SEG_ID_A)\n tokens.append(SEP_ID)\n segment_id.append(SEG_ID_A)\n tokens.append(CLS_ID)\n segment_id.append(SEG_ID_CLS)\n \n input_id = tokens\n input_mask = [0] * len(input_id)\n if len(input_id) < MAX_SEQ_LENGTH:\n delta_len = MAX_SEQ_LENGTH - len(input_id)\n input_id = [0] * delta_len + input_id\n input_mask = [1] * delta_len + input_mask\n segment_id = [SEG_ID_PAD] * delta_len + segment_id\n \n input_ids.append(input_id)\n input_masks.append(input_mask)\n segment_ids.append(segment_id)",
"100%|██████████| 10662/10662 [00:01<00:00, 9333.88it/s]\n"
],
[
"kwargs = dict(\n is_training=True,\n use_tpu=False,\n use_bfloat16=False,\n dropout=0,\n dropatt=0,\n init='normal',\n init_range=0.1,\n init_std=0.02,\n clamp_len=-1)\n\nxlnet_parameters = xlnet.RunConfig(**kwargs)\nxlnet_config = xlnet.XLNetConfig(json_path='xlnet_cased_L-24_H-1024_A-16/xlnet_config.json')",
"_____no_output_____"
],
[
"epoch = 10\nbatch_size = 10\nwarmup_proportion = 0.1\nnum_train_steps = int(len(input_ids) / batch_size * epoch)\nnum_warmup_steps = int(num_train_steps * warmup_proportion)\nprint(num_train_steps, num_warmup_steps)\n\ntraining_parameters = dict(\n decay_method = 'poly',\n train_steps = num_train_steps,\n learning_rate = 2e-5,\n warmup_steps = num_warmup_steps,\n min_lr_ratio = 0.0,\n weight_decay = 0.00,\n adam_epsilon = 1e-8,\n num_core_per_host = 1,\n lr_layer_decay_rate = 1,\n use_tpu=False,\n use_bfloat16=False,\n dropout=0.0,\n dropatt=0.0,\n init='normal',\n init_range=0.1,\n init_std=0.02,\n clip = 1.0,\n clamp_len=-1,)",
"10662 1066\n"
],
[
"class Parameter:\n def __init__(self, decay_method, warmup_steps, weight_decay, adam_epsilon, \n num_core_per_host, lr_layer_decay_rate, use_tpu, learning_rate, train_steps,\n min_lr_ratio, clip, **kwargs):\n self.decay_method = decay_method\n self.warmup_steps = warmup_steps\n self.weight_decay = weight_decay\n self.adam_epsilon = adam_epsilon\n self.num_core_per_host = num_core_per_host\n self.lr_layer_decay_rate = lr_layer_decay_rate\n self.use_tpu = use_tpu\n self.learning_rate = learning_rate\n self.train_steps = train_steps\n self.min_lr_ratio = min_lr_ratio\n self.clip = clip\n \ntraining_parameters = Parameter(**training_parameters)",
"_____no_output_____"
],
[
"class Model:\n def __init__(\n self,\n dimension_output,\n learning_rate = 2e-5,\n ):\n self.X = tf.placeholder(tf.int32, [None, None])\n self.segment_ids = tf.placeholder(tf.int32, [None, None])\n self.input_masks = tf.placeholder(tf.float32, [None, None])\n self.Y = tf.placeholder(tf.int32, [None])\n \n xlnet_model = xlnet.XLNetModel(\n xlnet_config=xlnet_config,\n run_config=xlnet_parameters,\n input_ids=tf.transpose(self.X, [1, 0]),\n seg_ids=tf.transpose(self.segment_ids, [1, 0]),\n input_mask=tf.transpose(self.input_masks, [1, 0]))\n \n summary = xlnet_model.get_pooled_out(\"last\", True)\n print(summary)\n \n self.logits = tf.layers.dense(summary, dimension_output)\n \n self.cost = tf.reduce_mean(\n tf.nn.sparse_softmax_cross_entropy_with_logits(\n logits = self.logits, labels = self.Y\n )\n )\n \n self.optimizer, self.learning_rate, _ = model_utils.get_train_op(training_parameters, self.cost)\n \n correct_pred = tf.equal(\n tf.argmax(self.logits, 1, output_type = tf.int32), self.Y\n )\n self.accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))",
"_____no_output_____"
],
[
"dimension_output = 2\nlearning_rate = 2e-5\n\ntf.reset_default_graph()\nsess = tf.InteractiveSession()\nmodel = Model(\n dimension_output,\n learning_rate\n)\n\nsess.run(tf.global_variables_initializer())",
"INFO:tensorflow:memory input None\nINFO:tensorflow:Use float type <dtype: 'float32'>\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nColocations handled automatically by placer.\nWARNING:tensorflow:From /home/jupyter/xlnet/modeling.py:533: dropout (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse keras.layers.dropout instead.\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/layers/core.py:143: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.\n\nWARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.\nFor more information, please see:\n * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md\n * https://github.com/tensorflow/addons\nIf you depend on functionality not listed there, please file an issue.\n\nWARNING:tensorflow:From /home/jupyter/xlnet/modeling.py:67: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse keras.layers.dense instead.\nTensor(\"model_1/sequnece_summary/summary/Tanh:0\", shape=(?, 1024), dtype=float32)\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/training/learning_rate_decay_v2.py:321: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nDeprecated in favor of operator or tf.math.divide.\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.cast instead.\n"
],
[
"def get_assignment_map_from_checkpoint(tvars, init_checkpoint):\n \"\"\"Compute the union of the current variables and checkpoint variables.\"\"\"\n assignment_map = {}\n initialized_variable_names = {}\n\n name_to_variable = collections.OrderedDict()\n for var in tvars:\n name = var.name\n m = re.match('^(.*):\\\\d+$', name)\n if m is not None:\n name = m.group(1)\n name_to_variable[name] = var\n\n init_vars = tf.train.list_variables(init_checkpoint)\n\n assignment_map = collections.OrderedDict()\n for x in init_vars:\n (name, var) = (x[0], x[1])\n if name not in name_to_variable:\n continue\n assignment_map[name] = name_to_variable[name]\n initialized_variable_names[name] = 1\n initialized_variable_names[name + ':0'] = 1\n\n return (assignment_map, initialized_variable_names)",
"_____no_output_____"
],
[
"tvars = tf.trainable_variables()\ntvars",
"_____no_output_____"
],
[
"initialized_variable_names = {}\ncheckpoint = 'xlnet_cased_L-24_H-1024_A-16/xlnet_model.ckpt'\nassignment_map, initialized_variable_names = get_assignment_map_from_checkpoint(tvars, \n checkpoint)",
"_____no_output_____"
],
[
"saver = tf.train.Saver(var_list = assignment_map)\nsaver.restore(sess, checkpoint)",
"WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/training/saver.py:1266: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse standard file APIs to check for files with this prefix.\nINFO:tensorflow:Restoring parameters from xlnet_cased_L-24_H-1024_A-16/xlnet_model.ckpt\n"
],
[
"from sklearn.cross_validation import train_test_split\n\ntrain_input_ids, test_input_ids, train_input_masks, test_input_masks, train_segment_ids, test_segment_ids, train_Y, test_Y = train_test_split(\n input_ids, input_masks, segment_ids, trainset.target, test_size = 0.2\n)",
"_____no_output_____"
],
[
"from tqdm import tqdm\nimport time\n\nEARLY_STOPPING, CURRENT_CHECKPOINT, CURRENT_ACC, EPOCH = 3, 0, 0, 0\n\nwhile True:\n lasttime = time.time()\n if CURRENT_CHECKPOINT == EARLY_STOPPING:\n print('break epoch:%d\\n' % (EPOCH))\n break\n\n train_acc, train_loss, test_acc, test_loss = 0, 0, 0, 0\n pbar = tqdm(\n range(0, len(train_input_ids), batch_size), desc = 'train minibatch loop'\n )\n for i in pbar:\n index = min(i + batch_size, len(train_input_ids))\n batch_x = train_input_ids[i: index]\n batch_masks = train_input_masks[i: index]\n batch_segment = train_segment_ids[i: index]\n batch_y = train_Y[i: index]\n acc, cost, _ = sess.run(\n [model.accuracy, model.cost, model.optimizer],\n feed_dict = {\n model.Y: batch_y,\n model.X: batch_x,\n model.segment_ids: batch_segment,\n model.input_masks: batch_masks\n },\n )\n assert not np.isnan(cost)\n train_loss += cost\n train_acc += acc\n pbar.set_postfix(cost = cost, accuracy = acc)\n \n pbar = tqdm(range(0, len(test_input_ids), batch_size), desc = 'test minibatch loop')\n for i in pbar:\n index = min(i + batch_size, len(test_input_ids))\n batch_x = test_input_ids[i: index]\n batch_masks = test_input_masks[i: index]\n batch_segment = test_segment_ids[i: index]\n batch_y = test_Y[i: index]\n acc, cost = sess.run(\n [model.accuracy, model.cost],\n feed_dict = {\n model.Y: batch_y,\n model.X: batch_x,\n model.segment_ids: batch_segment,\n model.input_masks: batch_masks\n },\n )\n test_loss += cost\n test_acc += acc\n pbar.set_postfix(cost = cost, accuracy = acc)\n\n train_loss /= len(train_input_ids) / batch_size\n train_acc /= len(train_input_ids) / batch_size\n test_loss /= len(test_input_ids) / batch_size\n test_acc /= len(test_input_ids) / batch_size\n\n if test_acc > CURRENT_ACC:\n print(\n 'epoch: %d, pass acc: %f, current acc: %f'\n % (EPOCH, CURRENT_ACC, test_acc)\n )\n CURRENT_ACC = test_acc\n CURRENT_CHECKPOINT = 0\n else:\n CURRENT_CHECKPOINT += 1\n \n print('time taken:', time.time() - lasttime)\n print(\n 'epoch: %d, training loss: %f, training acc: %f, valid loss: %f, valid acc: %f\\n'\n % (EPOCH, train_loss, train_acc, test_loss, test_acc)\n )\n EPOCH += 1",
"train minibatch loop: 100%|██████████| 853/853 [05:52<00:00, 2.51it/s, accuracy=0.889, cost=0.22]\ntest minibatch loop: 100%|██████████| 214/214 [00:31<00:00, 6.80it/s, accuracy=0.667, cost=0.857]\ntrain minibatch loop: 0%| | 0/853 [00:00<?, ?it/s]"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73f9e1a20dd3328107deac1ad4003c47550608e | 220,808 | ipynb | Jupyter Notebook | remote_sensing/python/Local_Jupyter_NoteBooks/scratches_to_experiment/0_smoothing.ipynb | HNoorazar/Kirti | fb7108dac1190774bd90a527aaa8a3cb405f127d | [
"MIT"
] | null | null | null | remote_sensing/python/Local_Jupyter_NoteBooks/scratches_to_experiment/0_smoothing.ipynb | HNoorazar/Kirti | fb7108dac1190774bd90a527aaa8a3cb405f127d | [
"MIT"
] | null | null | null | remote_sensing/python/Local_Jupyter_NoteBooks/scratches_to_experiment/0_smoothing.ipynb | HNoorazar/Kirti | fb7108dac1190774bd90a527aaa8a3cb405f127d | [
"MIT"
] | null | null | null | 208.703214 | 47,256 | 0.901204 | [
[
[
"We are writing this notebook as first scratch of smoothing stuff to do double cropping classification.\n\nThis notebook will eventually be running on Colab. And hopefully we can maitain a .py script in sublime editor.",
"_____no_output_____"
],
[
"# import libraries",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport geopandas as gpd\nimport sys\nfrom IPython.display import Image\nfrom shapely.geometry import Point, Polygon\nfrom math import factorial\nimport datetime\nimport time\nimport scipy\n\nimport numpy as np\nimport statsmodels.api as sm\n\nfrom statsmodels.sandbox.regression.predstd import wls_prediction_std\nfrom sklearn.linear_model import LinearRegression\nfrom patsy import cr\n\nfrom pprint import pprint\nimport matplotlib.pyplot as plt\nimport seaborn as sb\n%matplotlib inline",
"_____no_output_____"
],
[
"\nimport sys\n# search path for modules\n# look @ https://stackoverflow.com/questions/67631/how-to-import-a-module-given-the-full-path\nsys.path.append('/Users/hn/Documents/00_GitHub/Ag/remote_sensing/python/')\nimport remote_sensing_core as remote_core\n",
"_____no_output_____"
]
],
[
[
"# Extensive peak detect",
"_____no_output_____"
],
[
"## Define directories\nHere we can define data or core.py directories",
"_____no_output_____"
]
],
[
[
"data_dir = \"/Users/hn/Documents/01_research_data/Ag_check_point/remote_sensing/01_NDVI_TS/Grant/\"",
"_____no_output_____"
]
],
[
[
"## Define some parameters",
"_____no_output_____"
]
],
[
[
"file_names = [\"Grant_2018_TS.csv\"]",
"_____no_output_____"
]
],
[
[
"## Read Data",
"_____no_output_____"
]
],
[
[
"file_N = file_names[0]\ngrant_2018 = pd.read_csv(data_dir + file_N)",
"_____no_output_____"
],
[
"print (\"The data before cleaning is of size\", str(grant_2018.shape))\ngrant_2018 = remote_core.initial_clean(grant_2018)\nprint (\"The data after cleaning is of size\", str(grant_2018.shape))",
"The data before cleaning is of size (385, 24)\nThe data after cleaning is of size (378, 23)\n"
],
[
"# Count distict values, use nunique:\npprint (grant_2018['geo'].nunique())\n\n# Count only non-null values, use count:\nprint (grant_2018['geo'].count())\n\n# Count total values including null values, use size attribute:\nprint (grant_2018['geo'].size)",
"7\n378\n378\n"
]
],
[
[
"#### List of unique polygons",
"_____no_output_____"
]
],
[
[
"polygon_list = grant_2018['geo'].unique()",
"_____no_output_____"
]
],
[
[
"# Pick one of the polygons and test the smoothing methods",
"_____no_output_____"
]
],
[
[
"grant_2018_first_field = grant_2018[grant_2018['geo']==polygon_list[1]]\ngrant_2018_first_field = remote_core.order_by_doy(grant_2018_first_field)\nprint(grant_2018_first_field.shape)\nprint(type(grant_2018_first_field))\ngrant_2018_first_field.head(2)",
"(54, 23)\n<class 'pandas.core.frame.DataFrame'>\n"
],
[
"# ax = plt.gca()\n# grant_2018_first_field.plot(kind='line',x='doy',y='NDVI',ax=ax)\n# plt.show();\nsb.set();\nplot = sb.scatterplot(x=\"doy\", y=\"NDVI\", data=grant_2018_first_field)\nplot = plot.set(title = 'NDVI in the first region in Grant county over 2018');",
"_____no_output_____"
],
[
"X = grant_2018_first_field['doy']\ny = grant_2018_first_field['NDVI']",
"_____no_output_____"
]
],
[
[
"### 1. Weighted Least Square",
"_____no_output_____"
]
],
[
[
"# print(res_wls.summary())",
"_____no_output_____"
]
],
[
[
"res_wls = sm.WLS(endog=y, exog=X, weights=y**(2)).fit()\nprint (res_wls.params)\n\nprstd, iv_l, iv_u = wls_prediction_std(res_wls)\nprstd, iv_l, iv_u = wls_prediction_std(res_wls)\n\nfig, ax = plt.subplots(figsize=(8,6));\nax.plot(X, y, 'o', label=\"Data\");\n\n# WLS\nax.plot(X, res_wls.fittedvalues, 'g--.', label=\"WLS fitted values\")\n# ax.plot(X, iv_u, 'g--', label=\"WLS\")\n# ax.plot(X, iv_l, 'g--')\nax.legend(loc=\"best\");",
"_____no_output_____"
]
],
[
[
"### Locally weighted regression\n - The [documentation page](https://www.statsmodels.org/stable/generated/statsmodels.nonparametric.smoothers_lowess.lowess.html) from stats model package\n \nIn the following the parameters are:\n\n - `frac`: Between 0 and 1. The fraction of the data used when estimating each y-value.\n - `itint`: The number of residual-based reweightings to perform.",
"_____no_output_____"
]
],
[
[
"lowess = sm.nonparametric.lowess\nLWLS_1 = lowess(endog=y, exog=X, frac= 1./3, it=0)\nLWLS_2 = lowess(endog=y, exog=X, frac= 1./3)\nLWLS_3 = lowess(endog=y, exog=X, frac= 1./3, it=5)\n# predict_3 = lowess(endog=y, exog=X)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(8,6));\nax.plot(X, y, 'o', label=\"Data\");\n\nax.plot(X, LWLS_1[:, 1], 'g--.', label=\"predict_1\")\nax.plot(X, LWLS_2[:, 1], 'r--.', label=\"predict_2\")\nax.plot(X, LWLS_3[:, 1], 'b--.', label=\"predict_3\")\nax.legend(loc=\"best\");",
"_____no_output_____"
]
],
[
[
"## Savitzky Golay filtering",
"_____no_output_____"
]
],
[
[
"smoothed_by_Savitzky = remote_core.savitzky_golay(y, window_size=5, order=1)\nfig, ax = plt.subplots(figsize=(8,6));\nax.plot(X, y, 'o', label=\"Data\");\n\nax.plot(X, LWLS_1[:, 1], 'g--.', label=\"predict_1 by LWLS\")\nax.plot(X, LWLS_2[:, 1], 'r--.', label=\"predict_2 by LWLS\")\nax.plot(X, LWLS_3[:, 1], 'b--.', label=\"predict_3 by LWLS\")\nax.plot(X, smoothed_by_Savitzky, 'k--.', label=\"smoothed_by_Savitzky\")\nax.legend(loc=\"best\");",
"_____no_output_____"
]
],
[
[
"## Gaussian Filtering/convolution \n[Documentation page](https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.gaussian_filter.html)",
"_____no_output_____"
]
],
[
[
"gaussian_smoothed = scipy.ndimage.gaussian_filter(input=y, sigma=2.5, order=0)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(8,6));\nax.plot(X, y, 'o', label=\"Data\");\n\nax.plot(X, LWLS_1[:, 1], 'g--.', label=\"predict_1 by LWLS\")\nax.plot(X, LWLS_3[:, 1], 'b--.', label=\"predict_3 by LWLS\")\nax.plot(X, smoothed_by_Savitzky, 'k--.', label=\"Savitzky\")\nax.plot(X, gaussian_smoothed, 'r--.', label=\"Gaussian\")\nax.legend(loc=\"best\");",
"_____no_output_____"
]
],
[
[
"## Spline Smooothing",
"_____no_output_____"
]
],
[
[
"freedom_df = 7\n\n# Generate spline basis with 10 degrees of freedom\nx_basis = cr(X, df=freedom_df, constraints='center')\n\n# Fit model to the data\nmodel = LinearRegression().fit(x_basis, y)\n\n# Get estimates\ny_hat = model.predict(x_basis)\n",
"_____no_output_____"
]
],
[
[
"#### Plot smoothing spline result",
"_____no_output_____"
]
],
[
[
"plt.scatter(X, y, s=7)\nplt.plot(X, y_hat, 'r', label=\"smoothing spline result\");\nplt.title(f'Natural cubic spline with {freedom_df} degrees of freedom');",
"_____no_output_____"
],
[
"# find peaks\npeaks_LWLS_1 = remote_core.peakdetect(LWLS_1[:, 1], lookahead = 10, delta=0)\nmax_peaks = peaks_LWLS_1[0]\npeaks_LWLS_1 = remote_core.form_xs_ys_from_peakdetect(max_peak_list = max_peaks, doy_vect=X)\n\npeaks_spline = remote_core.peakdetect(y_hat, lookahead = 10, delta=0)\nmax_peaks = peaks_spline[0]\npeaks_spline = remote_core.form_xs_ys_from_peakdetect(max_peak_list = max_peaks, doy_vect=X)",
"_____no_output_____"
]
],
[
[
"### Plot peaks",
"_____no_output_____"
]
],
[
[
"plt.scatter(X, y, s=7);\nplt.scatter(peaks_LWLS_1[0], peaks_LWLS_1[1], s=100, c='g', marker='*');\nplt.scatter(peaks_spline[0], peaks_spline[1], s=100, c='c', marker='*');\nplt.plot(X, y_hat, 'r');\nplt.title(f'Natural cubic spline with {freedom_df} degrees of freedom \\n and peak point in red');",
"_____no_output_____"
]
],
[
[
"def peakdet(v, delta, x = None):\n #\n # https://gist.github.com/endolith/250860\n # \n \"\"\"\n Converted from MATLAB script at http://billauer.co.il/peakdet.html\n \n Returns two arrays\n \n function [maxtab, mintab]=peakdet(v, delta, x)\n %PEAKDET Detect peaks in a vector\n % [MAXTAB, MINTAB] = PEAKDET(V, DELTA) finds the local\n % maxima and minima (\"peaks\") in the vector V.\n % MAXTAB and MINTAB consists of two columns. Column 1\n % contains indices in V, and column 2 the found values.\n % \n % With [MAXTAB, MINTAB] = PEAKDET(V, DELTA, X) the indices\n % in MAXTAB and MINTAB are replaced with the corresponding\n % X-values.\n %\n % A point is considered a maximum peak if it has the maximal\n % value, and was preceded (to the left) by a value lower by\n % DELTA.\n \n % Eli Billauer, 3.4.05 (Explicitly not copyrighted).\n % This function is released to the public domain; Any use is allowed.\n \n \"\"\"\n maxtab = []\n mintab = []\n \n if x is None:\n x = np.arange(len(v))\n \n v = np.asarray(v)\n \n if len(v) != len(x):\n sys.exit('Input vectors v and x must have same length')\n \n if not np.isscalar(delta):\n sys.exit('Input argument delta must be a scalar')\n \n if delta <= 0:\n sys.exit('Input argument delta must be positive')\n \n mn, mx = np.Inf, -np.Inf\n mnpos, mxpos = np.NaN, np.NaN\n \n lookformax = True\n \n for i in np.arange(len(v)):\n this = v[i]\n if this > mx:\n mx = this\n mxpos = x[i]\n if this < mn:\n mn = this\n mnpos = x[i]\n \n if lookformax:\n if this < mx-delta:\n maxtab.append((mxpos, mx))\n mn = this\n mnpos = x[i]\n lookformax = False\n else:\n if this > mn+delta:\n mintab.append((mnpos, mn))\n mx = this\n mxpos = x[i]\n lookformax = True\n\n return np.array(maxtab), np.array(mintab)",
"_____no_output_____"
]
],
[
[
"# ax = plt.gca()\n# grant_2018_first_field.plot(kind='line',x='doy',y='NDVI',ax=ax)\n# plt.show();\nsb.set();\nplot = sb.scatterplot(x=\"doy\", y=\"NDVI\", data=grant_2018_first_field)\nplot = plot.plot(X, y_hat, 'r', label=\"smoothing spline result\");\n# plot = plot.set(title = 'NDVI in the first region in Grant county over 2018');",
"_____no_output_____"
],
[
"import numpy as np\nfrom scipy.optimize import curve_fit\nimport pylab\n\nx0, A, gamma = 12, 3, 5\n\nn = 200\nx = np.linspace(1, 20, n)\nyexact = A * gamma**2 / (gamma**2 + (x-x0)**2)\n\n# Add some noise with a sigma of 0.5 apart from a particularly noisy region\n# near x0 where sigma is 3\nsigma = np.ones(n)*0.5\nsigma[np.abs(x-x0+1)<1] = 3\nnoise = np.random.randn(n) * sigma\ny = yexact + noise\n\ndef f(x, x0, A, gamma):\n \"\"\" The Lorentzian entered at x0 with amplitude A and HWHM gamma. \"\"\"\n return A *gamma**2 / (gamma**2 + (x-x0)**2)\n\ndef rms(y, yfit):\n return np.sqrt(np.sum((y-yfit)**2))\n\n# Unweighted fit\np0 = 10, 4, 2\npopt, pcov = curve_fit(f, x, y, p0)\nyfit = f(x, *popt)\nprint('Unweighted fit parameters:', popt)\nprint('Covariance matrix:'); print(pcov)\nprint('rms error in fit:', rms(yexact, yfit))\nprint()\n\n# Weighted fit\npopt2, pcov2 = curve_fit(f, x, y, p0, sigma=sigma, absolute_sigma=True)\nyfit2 = f(x, *popt2)\nprint('Weighted fit parameters:', popt2)\nprint('Covariance matrix:'); print(pcov2)\nprint('rms error in fit:', rms(yexact, yfit2))\n\npylab.plot(x, yexact, label='Exact')\npylab.plot(x, y, 'o', label='Noisy data')\npylab.plot(x, yfit, label='Unweighted fit')\npylab.plot(x, yfit2, label='Weighted fit')\npylab.ylim(-1,4)\npylab.legend(loc='best')\npylab.show()",
"_____no_output_____"
],
[
"# generate random data\nnp.random.seed(24)\nx = np.random.uniform(-5,5,25)\nϵ = 2*np.random.randn(25)\ny = 2*x+ϵ\n\n# alternate error as a function of x\nϵ2 = ϵ*(x+5)\ny2 = 2*x+ϵ2\nsns.regplot(x,y);\nsns.regplot(x,y2);\n\n\n# add a strong outlier for high x\nx_high = np.append(x,5)\ny_high = np.append(y2,160)\n# add a strong outlier for low x\nx_low = np.append(x,-4)\ny_low = np.append(y2,160) ",
"_____no_output_____"
],
[
"# reshape for compatibility\nX_low = x_low.reshape(-1, 1)\nX_high = x_high.reshape(-1, 1)\n\n# calculate weights for sets with low and high outlier\nsample_weights_low = [1/(x+5) for x in x_low]\nsample_weights_high = [1/(x+5) for x in x_high] \n\n# ---------\n\n\n# import and fit an OLS model, check coefficients\nfrom sklearn.linear_model import LinearRegression\nmodel = LinearRegression()\nmodel.fit(X_low, y_low)\n# fit WLS using sample_weights\nWLS = LinearRegression()\nWLS.fit(X_low, y_low, sample_weight=sample_weights_low)\nprint(model.intercept_, model.coef_)\nprint('WLS')\nprint(WLS.intercept_, WLS.coef_)\n# run this yourself, don't trust every result you see online =)",
"_____no_output_____"
],
[
"#\n# double logistic \n#\nimport numpy as np\nimport math\nimport matplotlib.pyplot as plt\nfrom scipy.optimize import minimize\n\nimport ad\n\n\ndef double_logistic_array(params,timeArr):\n phenology=[]\n for time in timeArr:\n phenology.append(double_logistic(params,time))\n return np.array(phenology)\n\ndef double_logistic(params,time):\n \"\"\"Generate a double logistic curve similar \n to those of the MODIS phenology product\n \n k1 --- curvature parmeter for first half of season\n k2 --- curvature parmeter for second half of season\n t01 --- timing parmeter for first half of season\n t02 --- timing parmeter for second half of season\n c --- minimum LAI/NDVI etc\n d --- maximum LAI/NDVI etc\n \n time --- time valueto evaluate the function \n \"\"\"\n k1 =params[0]\n k2 =params[1]\n t01 =params[2]\n t02 =params[3]\n c =params[4]\n d =params[5]\n lgstc1=(c-d)/(1.+math.exp(k1*(time-t01)))+d \n lgstc2=(d-c)/(1.+math.exp(k2*(time-t02)))+c\n return np.min([lgstc1,lgstc2])\n \ndef genSynthObs(params,freq=10,stddev=0.3,cloud=0.0):\n \n time_arr=[]\n synth_obs=[]\n for t in range(0,366,freq):\n if np.random.rand()<cloud:\n continue\n time_arr.append(t)\n obs=double_logistic(params,t)\n obs=obs+np.random.normal(0.,stddev)\n synth_obs.append(obs)\n \n return np.array(synth_obs),np.array(time_arr)\n\n\ndef rmse(params,obs,obs_time):\n model=double_logistic_array(params,obs_time)\n return np.sqrt(np.sum((model-obs)**2)/float(len(obs_time)))\n \ndef solver(params,obs,obs_time,costFunction):\n costGradient, costHessian=ad.gh(costFunction)\n return minimize(costFunction,\\\n params,\\\n args=(obs,obs_time),\\\n method='L-BFGS-B',\\\n jac=costGradient,\\\n options={'gtol': 1e-10})\n \n \n \nif __name__==\"__main__\":\n\n time_arr=np.arange(366)\n \n params=np.zeros(6)\n params[0]=0.1\n params[1]=0.5\n params[2]=100\n params[3]=290\n params[4]=0.1\n params[5]=2.5\n \n phenology=double_logistic_array(params,time_arr)\n synth_obs, obs_times=genSynthObs(params,freq=10,stddev=0.25,cloud=0.5)\n \n s=solver(params,synth_obs,obs_times,rmse)\n \n retrieval=double_logistic_array(s.x,time_arr)\n \n plt.plot(time_arr,phenology, label=\"truth\")\n plt.plot(obs_times,synth_obs,\"o\", label=\"obs\")\n plt.plot(time_arr,retrieval, label=\"retrieved\")\n\n plt.xlabel(\"Day of year\")\n plt.ylabel(\"LAI (-)\")\n plt.ylim([0,3.0])\n plt.legend()\n # plt.show()\n # plt.savefig(\"phenology_example.png\")",
"_____no_output_____"
],
[
"params",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"raw",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"raw",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"raw"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"raw"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
e73fa76066c3656b8703f78db5bce5034f706a98 | 282,127 | ipynb | Jupyter Notebook | Scratch/ha_time_series_v1.1.ipynb | HassanAlam55/TimeSeriesHW-10 | a178cc7b2eac2c5c3590fbdbbc2c3a314ba14495 | [
"MIT"
] | null | null | null | Scratch/ha_time_series_v1.1.ipynb | HassanAlam55/TimeSeriesHW-10 | a178cc7b2eac2c5c3590fbdbbc2c3a314ba14495 | [
"MIT"
] | null | null | null | Scratch/ha_time_series_v1.1.ipynb | HassanAlam55/TimeSeriesHW-10 | a178cc7b2eac2c5c3590fbdbbc2c3a314ba14495 | [
"MIT"
] | null | null | null | 187.211015 | 71,048 | 0.865036 | [
[
[
"import numpy as np\nimport pandas as pd\nfrom pathlib import Path\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# Return Forecasting: Read Historical Daily Yen Futures Data\nIn this notebook, you will load historical Dollar-Yen exchange rate futures data and apply time series analysis and modeling to determine whether there is any predictable behavior.",
"_____no_output_____"
]
],
[
[
"# Futures contract on the Yen-dollar exchange rate:\n# This is the continuous chain of the futures contracts that are 1 month to expiration\nyen_futures = pd.read_csv(\n Path(\"yen.csv\"), index_col=\"Date\", infer_datetime_format=True, parse_dates=True\n)\nyen_futures.head()",
"_____no_output_____"
],
[
"# Trim the dataset to begin on January 1st, 1990\nyen_futures = yen_futures.loc[\"1990-01-01\":, :]\nyen_futures.head()",
"_____no_output_____"
]
],
[
[
" # Return Forecasting: Initial Time-Series Plotting",
"_____no_output_____"
],
[
" Start by plotting the \"Settle\" price. Do you see any patterns, long-term and/or short?",
"_____no_output_____"
]
],
[
[
"# Plot just the \"Settle\" column from the dataframe:\n# YOUR CODE HERE!\nyen_futures['Settle'].plot(figsize=(12, 8))",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"# Decomposition Using a Hodrick-Prescott Filter",
"_____no_output_____"
],
[
" Using a Hodrick-Prescott Filter, decompose the Settle price into a trend and noise.",
"_____no_output_____"
]
],
[
[
"import statsmodels.api as sm\n\n# Apply the Hodrick-Prescott Filter by decomposing the \"Settle\" price into two separate series:\n# YOUR CODE HERE!\n\nts_noise, ts_trend = sm.tsa.filters.hpfilter(yen_futures['Settle'])\n",
"_____no_output_____"
],
[
"# Create a dataframe of just the settle price, and add columns for \"noise\" and \"trend\" series from above:\n# YOUR CODE HERE!\n\nset_price = yen_futures[['Settle']].copy()\nset_price['noise'] = ts_noise\nset_price['trend'] = ts_trend\nset_price.head(5)",
"_____no_output_____"
],
[
"# Plot the Settle Price vs. the Trend for 2015 to the present\n# YOUR CODE HERE!\n\nset_price['Settle'].loc['2015':].plot(figsize=(12, 8))\nset_price['trend'].loc['2015':].plot()",
"_____no_output_____"
],
[
"# Plot the Settle Noise\n# YOUR CODE HERE!\nset_price['noise'].plot(figsize=(12, 8))",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"# Forecasting Returns using an ARMA Model",
"_____no_output_____"
],
[
"Using futures Settle *Returns*, estimate an ARMA model\n\n1. ARMA: Create an ARMA model and fit it to the returns data. Note: Set the AR and MA (\"p\" and \"q\") parameters to p=2 and q=1: order=(2, 1).\n2. Output the ARMA summary table and take note of the p-values of the lags. Based on the p-values, is the model a good fit (p < 0.05)?\n3. Plot the 5-day forecast of the forecasted returns (the results forecast from ARMA model)",
"_____no_output_____"
]
],
[
[
"# Create a series using \"Settle\" price percentage returns, drop any nan\"s, and check the results:\n# (Make sure to multiply the pct_change() results by 100)\n# In this case, you may have to replace inf, -inf values with np.nan\"s\nreturns = (yen_futures[[\"Settle\"]].pct_change() * 100)\nreturns = returns.replace(-np.inf, np.nan).dropna()\nreturns.tail()",
"_____no_output_____"
],
[
"import statsmodels.api as sm\n\n# Estimate and ARMA model using statsmodels (use order=(2, 1))\n# YOUR CODE HERE!\nfrom statsmodels.tsa.arima_model import ARMA\n# from statsmodels.tsa.arima_model.ARMA import ARMA\nmodel = ARMA(returns.values, order=(2,1))\n# Fit the model and assign it to a variable called results\n# YOUR CODE HERE!\nresults = model.fit()",
"C:\\Users\\Hassan\\Anaconda3\\envs\\pyvizenv\\lib\\site-packages\\statsmodels\\tsa\\arima_model.py:472: FutureWarning: \nstatsmodels.tsa.arima_model.ARMA and statsmodels.tsa.arima_model.ARIMA have\nbeen deprecated in favor of statsmodels.tsa.arima.model.ARIMA (note the .\nbetween arima and model) and\nstatsmodels.tsa.SARIMAX. These will be removed after the 0.12 release.\n\nstatsmodels.tsa.arima.model.ARIMA makes use of the statespace framework and\nis both well tested and maintained.\n\nTo silence this warning and continue using ARMA and ARIMA until they are\nremoved, use:\n\nimport warnings\nwarnings.filterwarnings('ignore', 'statsmodels.tsa.arima_model.ARMA',\n FutureWarning)\nwarnings.filterwarnings('ignore', 'statsmodels.tsa.arima_model.ARIMA',\n FutureWarning)\n\n warnings.warn(ARIMA_DEPRECATION_WARN, FutureWarning)\n"
],
[
"# Output model summary results:\n# YOUR CODE HERE!\nresults.summary()",
"_____no_output_____"
],
[
"# Plot the 5 Day Returns Forecast\n# YOUR CODE HERE!\npd.DataFrame(results.forecast(steps=5)[0]).plot(title=\"5 Day Returns Forecast\")",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"# Forecasting the Settle Price using an ARIMA Model",
"_____no_output_____"
],
[
" 1. Using the *raw* Yen **Settle Price**, estimate an ARIMA model.\n 1. Set P=5, D=1, and Q=1 in the model (e.g., ARIMA(df, order=(5,1,1))\n 2. P= # of Auto-Regressive Lags, D= # of Differences (this is usually =1), Q= # of Moving Average Lags\n 2. Output the ARIMA summary table and take note of the p-values of the lags. Based on the p-values, is the model a good fit (p < 0.05)?\n 3. Construct a 5 day forecast for the Settle Price. What does the model forecast will happen to the Japanese Yen in the near term?",
"_____no_output_____"
]
],
[
[
"from statsmodels.tsa.arima_model import ARIMA\n\n# Estimate and ARIMA Model:\n# Hint: ARIMA(df, order=(p, d, q))\n# YOUR CODE HERE!\nmodel = ARIMA(yen_futures['Settle'], order=(5, 1, 1))\n# Fit the model\n# YOUR CODE HERE!\nresults = model.fit()",
"C:\\Users\\Hassan\\Anaconda3\\envs\\pyvizenv\\lib\\site-packages\\statsmodels\\tsa\\arima_model.py:472: FutureWarning: \nstatsmodels.tsa.arima_model.ARMA and statsmodels.tsa.arima_model.ARIMA have\nbeen deprecated in favor of statsmodels.tsa.arima.model.ARIMA (note the .\nbetween arima and model) and\nstatsmodels.tsa.SARIMAX. These will be removed after the 0.12 release.\n\nstatsmodels.tsa.arima.model.ARIMA makes use of the statespace framework and\nis both well tested and maintained.\n\nTo silence this warning and continue using ARMA and ARIMA until they are\nremoved, use:\n\nimport warnings\nwarnings.filterwarnings('ignore', 'statsmodels.tsa.arima_model.ARMA',\n FutureWarning)\nwarnings.filterwarnings('ignore', 'statsmodels.tsa.arima_model.ARIMA',\n FutureWarning)\n\n warnings.warn(ARIMA_DEPRECATION_WARN, FutureWarning)\nC:\\Users\\Hassan\\Anaconda3\\envs\\pyvizenv\\lib\\site-packages\\statsmodels\\tsa\\base\\tsa_model.py:583: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.\n ' ignored when e.g. forecasting.', ValueWarning)\nC:\\Users\\Hassan\\Anaconda3\\envs\\pyvizenv\\lib\\site-packages\\statsmodels\\tsa\\base\\tsa_model.py:583: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.\n ' ignored when e.g. forecasting.', ValueWarning)\n"
],
[
"# Output model summary results:\nresults.summary()",
"_____no_output_____"
],
[
"# Plot the 5 Day Price Forecast\n# YOUR CODE HERE!\npd.DataFrame(results.forecast(steps=5)[0]).plot(title=\"5 Day Future Price Forecast\")",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"# Volatility Forecasting with GARCH\n\nRather than predicting returns, let's forecast near-term **volatility** of Japanese Yen futures returns. Being able to accurately predict volatility will be extremely useful if we want to trade in derivatives or quantify our maximum loss.\n \nUsing futures Settle *Returns*, estimate an GARCH model\n\n1. GARCH: Create an GARCH model and fit it to the returns data. Note: Set the parameters to p=2 and q=1: order=(2, 1).\n2. Output the GARCH summary table and take note of the p-values of the lags. Based on the p-values, is the model a good fit (p < 0.05)?\n3. Plot the 5-day forecast of the volatility.",
"_____no_output_____"
]
],
[
[
"from arch import arch_model",
"_____no_output_____"
],
[
"# Estimate a GARCH model:\n# YOUR CODE HERE!\nmodel = arch_model(returns, mean=\"Zero\", vol=\"GARCH\", p=2, q=1)\n# Fit the model\n# YOUR CODE HERE!\nres = model.fit(disp=\"off\")",
"_____no_output_____"
],
[
"# Summarize the model results\n# YOUR CODE HERE!\nres.summary()",
"_____no_output_____"
],
[
"# Find the last day of the dataset\nlast_day = returns.index.max().strftime('%Y-%m-%d')\nlast_day",
"_____no_output_____"
],
[
"# Create a 5 day forecast of volatility\nforecast_horizon = 5\n# Start the forecast using the last_day calculated above\n# YOUR CODE HERE!\nforecasts = res.forecast(start=last_day, horizon=forecast_horizon, reindex = True)\nforecasts",
"_____no_output_____"
],
[
"# Annualize the forecast\nintermediate = np.sqrt(forecasts.variance.dropna() * 252)\nintermediate.head()",
"_____no_output_____"
],
[
"# Transpose the forecast so that it is easier to plot\nfinal = intermediate.dropna().T\nfinal.head()",
"_____no_output_____"
],
[
"# Plot the final forecast\n# YOUR CODE HERE!\nfinal.plot(title=\"5 Day Future Price Forecast\")",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"# Conclusions",
"_____no_output_____"
],
[
"Based on your time series analysis, would you buy the yen now?\n\nIs the risk of the yen expected to increase or decrease?\n\nBased on the model evaluation, would you feel confident in using these models for trading?",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.