
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
e7ca4c1ceee7f6841fea3b582321124c7a507db7 | 11,891 | ipynb | Jupyter Notebook | t81_558_class_08_3_keras_hyperparameters.ipynb | rserran/t81_558_deep_learning | ec312cc7a7cef207e55e382594455fe44bcdec11 | [
"Apache-2.0"
]
| null | null | null | t81_558_class_08_3_keras_hyperparameters.ipynb | rserran/t81_558_deep_learning | ec312cc7a7cef207e55e382594455fe44bcdec11 | [
"Apache-2.0"
]
| null | null | null | t81_558_class_08_3_keras_hyperparameters.ipynb | rserran/t81_558_deep_learning | ec312cc7a7cef207e55e382594455fe44bcdec11 | [
"Apache-2.0"
]
| null | null | null | 59.159204 | 526 | 0.686486 | [
[
[
"<a href=\"https://colab.research.google.com/github/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_08_3_keras_hyperparameters.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# T81-558: Applications of Deep Neural Networks\n**Module 8: Kaggle Data Sets**\n* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)\n* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).",
"_____no_output_____"
],
[
"# Module 8 Material\n\n* Part 8.1: Introduction to Kaggle [[Video]](https://www.youtube.com/watch?v=v4lJBhdCuCU&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_08_1_kaggle_intro.ipynb)\n* Part 8.2: Building Ensembles with Scikit-Learn and Keras [[Video]](https://www.youtube.com/watch?v=LQ-9ZRBLasw&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_08_2_keras_ensembles.ipynb)\n* **Part 8.3: How Should you Architect Your Keras Neural Network: Hyperparameters** [[Video]](https://www.youtube.com/watch?v=1q9klwSoUQw&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_08_3_keras_hyperparameters.ipynb)\n* Part 8.4: Bayesian Hyperparameter Optimization for Keras [[Video]](https://www.youtube.com/watch?v=sXdxyUCCm8s&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_08_4_bayesian_hyperparameter_opt.ipynb)\n* Part 8.5: Current Semester's Kaggle [[Video]](https://www.youtube.com/watch?v=PHQt0aUasRg&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_08_5_kaggle_project.ipynb)\n",
"_____no_output_____"
],
[
"# Google CoLab Instructions\n\nThe following code ensures that Google CoLab is running the correct version of TensorFlow.",
"_____no_output_____"
]
],
[
[
"# Startup CoLab\ntry:\n %tensorflow_version 2.x\n COLAB = True\n print(\"Note: using Google CoLab\")\nexcept:\n print(\"Note: not using Google CoLab\")\n COLAB = False\n\n\n# Nicely formatted time string\ndef hms_string(sec_elapsed):\n h = int(sec_elapsed / (60 * 60))\n m = int((sec_elapsed % (60 * 60)) / 60)\n s = sec_elapsed % 60\n return \"{}:{:>02}:{:>05.2f}\".format(h, m, s)",
"Note: not using Google CoLab\n"
]
],
[
[
"# Part 8.3: Architecting Network: Hyperparameters\n\nYou have probably noticed several hyperparameters introduced previously in this course that you need to choose for your neural network. The number of layers, neuron counts per layer, layer types, and activation functions are all choices you must make to optimize your neural network. Some of the categories of hyperparameters for you to choose from coming from the following list:\n\n* Number of Hidden Layers and Neuron Counts\n* Activation Functions\n* Advanced Activation Functions\n* Regularization: L1, L2, Dropout\n* Batch Normalization\n* Training Parameters\n\nThe following sections will introduce each of these categories for Keras. While I will provide some general guidelines for hyperparameter selection, no two tasks are the same. You will benefit from experimentation with these values to determine what works best for your neural network. In the next part, we will see how machine learning can select some of these values independently.\n\n## Number of Hidden Layers and Neuron Counts\n\nThe structure of Keras layers is perhaps the hyperparameters that most become aware of first. How many layers should you have? How many neurons are on each layer? What activation function and layer type should you use? These are all questions that come up when designing a neural network. There are many different [types of layer](https://keras.io/layers/core/) in Keras, listed here:\n\n* **Activation** - You can also add activation functions as layers. Using the activation layer is the same as specifying the activation function as part of a Dense (or other) layer type.\n* **ActivityRegularization** Used to add L1/L2 regularization outside of a layer. You can specify L1 and L2 as part of a Dense (or other) layer type.\n* **Dense** - The original neural network layer type. In this layer type, every neuron connects to the next layer. The input vector is one-dimensional, and placing specific inputs next does not affect each other. \n* **Dropout** - Dropout consists of randomly setting a fraction rate of input units to 0 at each update during training time, which helps prevent overfitting. Dropout only occurs during training.\n* **Flatten** - Flattens the input to 1D and does not affect the batch size.\n* **Input** - A Keras tensor is a tensor object from the underlying back end (Theano, TensorFlow, or CNTK), which we augment with specific attributes to build a Keras by knowing the inputs and outputs of the model.\n* **Lambda** - Wraps arbitrary expression as a Layer object.\n* **Masking** - Masks a sequence using a mask value to skip timesteps.\n* **Permute** - Permutes the input dimensions according to a given pattern. Useful for tasks such as connecting RNNs and convolutional networks.\n* **RepeatVector** - Repeats the input n times.\n* **Reshape** - Similar to Numpy reshapes.\n* **SpatialDropout1D** - This version performs the same function as Dropout; however, it drops entire 1D feature maps instead of individual elements. \n* **SpatialDropout2D** - This version performs the same function as Dropout; however, it drops entire 2D feature maps instead of individual elements\n* **SpatialDropout3D** - This version performs the same function as Dropout; however, it drops entire 3D feature maps instead of individual elements. \n\nThere is always trial and error for choosing a good number of neurons and hidden layers. Generally, the number of neurons on each layer will be larger closer to the hidden layer and smaller towards the output layer. This configuration gives the neural network a somewhat triangular or trapezoid appearance.\n\n## Activation Functions\n\nActivation functions are a choice that you must make for each layer. Generally, you can follow this guideline:\n* Hidden Layers - RELU\n* Output Layer - Softmax for classification, linear for regression.\n\nSome of the common activation functions in Keras are listed here:\n\n* **softmax** - Used for multi-class classification. Ensures all output neurons behave as probabilities and sum to 1.0.\n* **elu** - Exponential linear unit. Exponential Linear Unit or its widely known name ELU is a function that tends to converge cost to zero faster and produce more accurate results. Can produce negative outputs.\n* **selu** - Scaled Exponential Linear Unit (SELU), essentially **elu** multiplied by a scaling constant.\n* **softplus** - Softplus activation function. $log(exp(x) + 1)$ [Introduced](https://papers.nips.cc/paper/1920-incorporating-second-order-functional-knowledge-for-better-option-pricing.pdf) in 2001.\n* **softsign** Softsign activation function. $x / (abs(x) + 1)$ Similar to tanh, but not widely used.\n* **relu** - Very popular neural network activation function. Used for hidden layers, cannot output negative values. No trainable parameters.\n* **tanh** Classic neural network activation function, though often replaced by relu family on modern networks.\n* **sigmoid** - Classic neural network activation. Often used on output layer of a binary classifier.\n* **hard_sigmoid** - Less computationally expensive variant of sigmoid.\n* **exponential** - Exponential (base e) activation function.\n* **linear** - Pass-through activation function. Usually used on the output layer of a regression neural network.\n\nFor more information about Keras activation functions refer to the following:\n\n* [Keras Activation Functions](https://keras.io/activations/)\n* [Activation Function Cheat Sheets](https://ml-cheatsheet.readthedocs.io/en/latest/activation_functions.html)\n\n\n### Advanced Activation Functions\n\nHyperparameters are not changed when the neural network trains. You, the network designer, must define the hyperparameters. The neural network learns regular parameters during neural network training. Neural network weights are the most common type of regular parameter. The \"[advanced activation functions](https://keras.io/layers/advanced-activations/),\" as Keras call them, also contain parameters that the network will learn during training. These activation functions may give you better performance than RELU.\n\n* **LeakyReLU** - Leaky version of a Rectified Linear Unit. It allows a small gradient when the unit is not active, controlled by alpha hyperparameter.\n* **PReLU** - Parametric Rectified Linear Unit, learns the alpha hyperparameter. \n\n## Regularization: L1, L2, Dropout\n\n\n\n* [Keras Regularization](https://keras.io/regularizers/)\n* [Keras Dropout](https://keras.io/layers/core/)\n\n## Batch Normalization\n\n* [Keras Batch Normalization](https://keras.io/layers/normalization/)\n\n* Ioffe, S., & Szegedy, C. (2015). [Batch normalization: Accelerating deep network training by reducing internal covariate shift](https://arxiv.org/abs/1502.03167). *arXiv preprint arXiv:1502.03167*.\n\nNormalize the activations of the previous layer at each batch, i.e. applies a transformation that maintains the mean activation close to 0 and the activation standard deviation close to 1. Can allow learning rate to be larger.\n\n\n## Training Parameters\n\n* [Keras Optimizers](https://keras.io/optimizers/)\n\n* **Batch Size** - Usually small, such as 32 or so.\n* **Learning Rate** - Usually small, 1e-3 or so.\n\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7ca6150d7e814ce1d8647e3937909782e49b68a | 17,916 | ipynb | Jupyter Notebook | using_siam_unet.ipynb | danihae/bio-image-unet | 6cc74ec45ea5f03430920ae880e1e413db70e4fc | [
"MIT"
]
| 1 | 2021-10-04T15:58:47.000Z | 2021-10-04T15:58:47.000Z | using_siam_unet.ipynb | danihae/bio-image-unet | 6cc74ec45ea5f03430920ae880e1e413db70e4fc | [
"MIT"
]
| null | null | null | using_siam_unet.ipynb | danihae/bio-image-unet | 6cc74ec45ea5f03430920ae880e1e413db70e4fc | [
"MIT"
]
| null | null | null | 41.762238 | 679 | 0.58791 | [
[
[
"# Siamese U-Net Quickstart",
"_____no_output_____"
],
[
"## 1. Introduction\n\nThe Siamese U-Net is an improvement on the original U-Net architecture. It adds an additional additional encoder that encodes an additional frame other than the frame that we are trying to predict. See [this paper](https://pubmed.ncbi.nlm.nih.gov/31927473/). This repository contains an implementation of this network.\n\nIf you need help using a function, you can always try running `help(whichever_interesting_function)` or just look at the source code. If you need help using a class (one that is directly under the `biu.siam_unet` directory), trying to understand the examples in this notebook probably will be more helpful than finding the documentation of that function.\n\nIMPORTANT: Two packages that depend on your hardware need to be installed manually before running biu. To install CUDA 11.1 which is officially supported by PyTorch, navigate to [its installation page](https://developer.nvidia.com/cuda-11.1.1-download-archive) and follow the instructions onscreen. Because PyTorch depends on your CUDA installation version, it will need to be installed manually as well, through [the official PyTorch website](https://pytorch.org/get-started/locally/). Select the correct distribution of CUDA on this webpage and run the command in your terminal. biu doesn't depend on a specific version of CUDA and has been tested with PyTorch 1.7.0+.\n\nFinally, to import the Siamese U-Net package, write `import biu.siam_unet as unet`.",
"_____no_output_____"
],
[
"## 2. Data preparation\n\nBecause Siam UNet requires an additional input for training, we need to utilize an additional frame and use the appropriate dataloader for that. For the purpose of this notebook, I will call the frame which we are trying to infer \"current frame\", and the frame which is before the current frame the \"previous frame.\" ",
"_____no_output_____"
],
[
"#### If your input image is not a movie",
"_____no_output_____"
]
],
[
[
"from biu.siam_unet.helpers.generate_siam_unet_input_imgs import generate_coupled_image_from_self\nfrom pathlib import Path\nimport os\n\n# specify where the training data for vanilla u-net is located\ntraining_data_loc = '/home/longyuxi/Documents/mount/deeptissue_training/training_data/amnioserosa/yokogawa/image'\ntraining_data_loc = Path(training_data_loc)\n\n# create a separate folder for storing Siam-UNet input images\nsiam_training_data_loc = training_data_loc.parent / \"siam_image\"\nsiam_training_data_loc.mkdir(exist_ok=True)\n\n### multiprocessing accelerated, equivalent to \n## for img in training_data_loc.glob('*.tif'):\n## generate_coupled_image_from_self(str(img), str(siam_training_data_loc / img.name))\n\nimport multiprocessing\n\nimglist = training_data_loc.glob('*.tif')\ndef handle_image(img):\n generate_coupled_image_from_self(str(img), str(siam_training_data_loc / img.name))\n\np = multiprocessing.Pool(10)\n_ = p.map(handle_image, imglist)\n",
"_____no_output_____"
],
[
"import tifffile\na = tifffile.imread('/home/longyuxi/Documents/mount/deeptissue_training/training_data/leading_edge/eCad/image/00.tif')\nprint(a.shape)\n\ngenerate_coupled_image_from_self('/home/longyuxi/Documents/mount/deeptissue_training/training_data/leading_edge/eCad/image/00.tif', 'temp.tif')",
"_____no_output_____"
]
],
[
[
"#### If you know which frame you drew the label with",
"_____no_output_____"
],
[
"The dataloader in `siam_unet_cosh` takes an image that results from concatenating the previous frame with the current frame. If you already know which frame of which movie you want to train on, you can create this concatenated data using `generate_siam_unet_input_imgs.py`.",
"_____no_output_____"
]
],
[
[
"movie_dir = '/media/longyuxi/H is for HUGE/docmount backup/unet_pytorch/training_data/test_data/new_microscope/21B11-shgGFP-kin-18-bro4.tif' # change this\nframe = 10 # change this\nout_dir = './training_data/training_data/yokogawa/siam_data/image/' # change this\n\n\n\nfrom biu.siam_unet.helpers.generate_siam_unet_input_imgs import generate_coupled_image\n\ngenerate_coupled_image(movie_dir, frame, out_dir)",
"_____no_output_____"
]
],
[
[
"#### If you don't know which frame you drew the label with",
"_____no_output_____"
],
[
"If you have frames and labels, but you don't know which frame of which movie each frame comes from, you can use `find_frame_of_image`. This function takes your query and compares it against a list of tif files you specify through the parameter `search_space`.",
"_____no_output_____"
]
],
[
[
"image_name = f'./training_data/training_data/yokogawa/lateral_epidermis/image/83.tif'\n\nrazer_local_search_dir = '/media/longyuxi/H is for HUGE/docmount backup/all_movies'\ntifs_names = ['21B11-shgGFP-kin-18-bro4', '21B25_shgGFP_kin_1_Pos0', '21C04_shgGFP_kin_2_Pos4', '21C26_shgGFP_Pos12', '21D16_shgGFPkin_Pos7']\nsearch_space = [razer_local_search_dir + '/' + t + '.tif' for t in tifs_names]\n\nfrom biu.siam_unet.helpers.find_frame_of_image import find_frame_of_image\n\nfind_frame_of_image(image_name, search_space=search_space)\n",
"_____no_output_____"
]
],
[
[
"This function not only outputs what it finds to stdout, but also creates a machine readable output, location of which specified by `machine_readable_output_filename`, about which frames it is highly confident with at locating (i.e. an MSE of < 1000 and matching frame numbers). This output can further be used by `generate_siam_unet_input_images.py`.",
"_____no_output_____"
]
],
[
[
"from biu.siam_unet.helpers.generate_siam_unet_input_imgs import utilize_search_result\n\nutilize_search_result(f'./training_data/training_data/yokogawa/amnioserosa/search_result_mr.txt', f'./training_data/test_data/new_microscope', f'./training_data/training_data/yokogawa/amnioserosa/label/', f'./training_data/training_data/yokogawa/siam_amnioserosa_sanitize_test/')\n",
"_____no_output_____"
]
],
[
[
"Finally, organize the labels and images in a way similar to this shown. An example can be found at `training_data/lateral_epidermis/yokogawa_siam-u-net`",
"_____no_output_____"
],
[
"```\ntraining_data/lateral_epidermis/yokogawa_siam-u-net\n|\n├── image\n│ ├── 105.tif\n│ ├── 111.tif\n│ ├── 120.tif\n│ ├── 121.tif\n│ ├── 1.tif\n│ ├── 2.tif\n│ ├── 3.tif\n│ ├── 5.tif\n│ ├── 7.tif\n│ └── 83.tif\n└── label\n ├── 105.tif\n ├── 111.tif\n ├── 120.tif\n ├── 121.tif\n ├── 1.tif\n ├── 2.tif\n ├── 3.tif\n ├── 5.tif\n ├── 7.tif\n └── 83.tif\n```",
"_____no_output_____"
],
[
"## 3. Training",
"_____no_output_____"
],
[
"Training is simple. For example:",
"_____no_output_____"
]
],
[
[
"from biu.siam_unet import *\n\ndataset = 'amnioserosa/old_scope'\nbase_dir = '/home/longyuxi/Documents/mount/deeptissue_training/training_data/'\n\n# path to training data (images and labels with identical names in separate folders)\ndir_images = f'{base_dir}/{dataset}/siam_image/'\ndir_masks = f'{base_dir}/{dataset}/label/'\n\nprint('starting to create training dataset')\nprint(f'dir_images: {dir_images}')\nprint(f'dir_masks: {dir_masks}')\n# create training data set\ndata = DataProcess([dir_images, dir_masks], data_path='../delete_this_data', dilate_mask=0, aug_factor=10, create=True, invert=False, clip_threshold=(0.2, 99.8), dim_out=(256, 256), shiftscalerotate=(0, 0, 0))\n\nsave_dir = f'/home/longyuxi/Documents/mount/trained_networks_new_siam/siam/{dataset}'\n# create trainer\ntraining = Trainer(data ,num_epochs=500 ,batch_size=12, load_weights=False, lr=0.0001, n_filter=32, save_iter=True, save_dir=save_dir)\n\ntraining.start()\n",
"_____no_output_____"
]
],
[
[
"Note here that the value of the `n_filter` parameter is set to `32`. The network won't break with a different value of this, but you need to use the same value for the Predict part.",
"_____no_output_____"
],
[
"## 4. Predict",
"_____no_output_____"
],
[
"Predicting is simple as well. Just swap in the parameters",
"_____no_output_____"
]
],
[
[
"# load package\nfrom biu.siam_unet import *\nimport os\nos.nice(10)\nfrom biu.siam_unet.helpers import tif_to_mp4\n\nbase_dir = './'\nout_dir = f'{base_dir}/predicted_out'\nmodel = f'{base_dir}/models/siam_bce_amnio/model_epoch_100.pth'\n\ntif_file = f'{base_dir}/training_data/test_data/new_microscope/21C04_shgGFP_kin_2_Pos4.tif'\n\nresult_file = f'{out_dir}/siam_bce_amnio_100_epochs_21C04_shgGFP_kin_2_Pos4.tif'\nout_mp4_file = result_file[:-4] + '.mp4'\n\nprint('starting to predict file')\n# predict file \npredict = Predict(tif_file, result_file, model, invert=False, resize_dim=(512, 512), n_filter=32)\n# convert to mp4\ntif_to_mp4.convert_to_mp4(result_file, output_file=out_mp4_file, normalize_to_0_255=True)",
"_____no_output_____"
]
],
[
[
"Additionally, to evaluate the model's performance with different losses, one can also train the model across different models",
"_____no_output_____"
]
],
[
[
"\"\"\"\nFor each image in the training dataset, run siam unet to predict.\n\"\"\"\n\nfrom pathlib import *\n\nfrom biu.siam_unet import *\nimport glob\nimport logging\n\ndef predict_all_training_data(image_folder_prefix, model_folder_prefix, model_loss_functions, datasets, output_directory):\n image_folder_prefix = Path(image_folder_prefix)\n model_folder_prefix = Path(model_folder_prefix)\n datasets = [Path(d) for d in datasets]\n output_directory = Path(output_directory)\n for dataset in datasets:\n for model_loss_function in model_loss_functions:\n try:\n current_model = Path(model_folder_prefix / model_loss_function / dataset / 'model.pth')\n for image in glob.glob((str) (image_folder_prefix / dataset) + \"/image/*.tif\"):\n image_name = image.split('/')[-1]\n result_name = Path(output_directory / dataset / Path(image_name[:-4] + '_' + model_loss_function + '.tif'))\n _ = Predict(image, result_name, current_model, invert=False, n_filter=32)\n # _ = Predict(image, result_name, current_model, invert=False, resize_dim=None, n_filter=32)\n except:\n logging.error('{} in {} failed to execute'.format(model_loss_function, dataset))\n \n\nif __name__ == '__main__':\n # BEGIN Full dataset\n folders = [\"amnioserosa/yokogawa\", \"lateral_epidermis/40x\", \"lateral_epidermis/60x\", \"lateral_epidermis/yokogawa\", \"leading_edge/eCad\", \"leading_edge/myosin\", \"leading_edge/yokogawa_eCad\", \"nodes/old_scope\", \"nodes/yokogawa\"]\n model_loss_functions = ['siam_bce_dice','siam_logcoshtversky', 'siam_tversky', 'siam_logcoshtversky_08_02', 'siam_logcoshtversky_15_06', 'siam_logcoshtversky_02_08', \"siam_logcoshtversky_06_15\", 'siam_tversky_08_02', 'siam_tversky_15_06']\n # END Full dataset\n\n # BEGIN Toy dataset\n # folders = [\"lateral_epidermis/40x\"]\n # model_loss_functions = ['siam_bce_dice','siam_logcoshtversky', 'siam_tversky', 'siam_logcoshtversky_08_02', 'siam_logcoshtversky_15_06']\n # END Toy dataset\n\n predict_all_training_data(image_folder_prefix='/home/longyuxi/Documents/mount/deeptissue_training/training_data', model_loss_functions=model_loss_functions, model_folder_prefix='/home/longyuxi/Documents/mount/trained_networks', datasets=folders, output_directory='/home/longyuxi/Documents/mount/deeptissue_test/output_new_shape')",
"_____no_output_____"
]
],
[
[
"# Appendix: An annotated structure of the siam_unet package",
"_____no_output_____"
],
[
"Below is an annotated structure of the siam_unet package. Use `help(function)` to read the docstring of each function for a better understanding.\n\n```\nPackage Use\n\n.\n├── __init__.py\n├── data.py dataloader script\n├── siam_unet.py Siam U-Net model\n├── train.py training script\n├── losses.py loss functions\n├── predict.py prediction script\n├── helpers helper functions (usually not \n so useful except the \n ones mentioned in this notebook)\n \n│ ├── average_tifs.py averages a list of tiff files\n│ ├── create_pixel_value_histogram.py creates histograms for the \n pixel values in tif \n files. Useful for \n debugging during training\n│ ├── cuda_test.py tests cuda functionality\n│ ├── extract_frame_of_movie.py extract a certain frame of a \n tif movie \n│ ├── find_frame_of_image.py finds the frame number of \n a given query image \n within search_space.\n│ ├── generate_plain_image.py generates a plain image\n│ ├── generate_siam_unet_input_imgs.py generates a coupled image \n for Siam U-Net training\n│ ├── low_mem_tif_utils.py utilities for handling tif \n files with low memory \n usage\n│ ├── threshold_images.py thresholds each frame of a \n tif movie\n│ ├── tif_to_mp4.py uses ffmpeg to convert a tif \n movie to mp4\n│ └── util.py various utilities. see docstring\n\n```",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
e7ca853178a56a18ed2a526f79acd66dc42f0b36 | 8,345 | ipynb | Jupyter Notebook | DataAnalysis/Sessions.ipynb | schnorea/py-redis-mqtt-web | 0b2f4e16cdee0f7b897f5ae6c496565aef810f3f | [
"MIT"
]
| null | null | null | DataAnalysis/Sessions.ipynb | schnorea/py-redis-mqtt-web | 0b2f4e16cdee0f7b897f5ae6c496565aef810f3f | [
"MIT"
]
| null | null | null | DataAnalysis/Sessions.ipynb | schnorea/py-redis-mqtt-web | 0b2f4e16cdee0f7b897f5ae6c496565aef810f3f | [
"MIT"
]
| null | null | null | 26.832797 | 120 | 0.542361 | [
[
[
"import redis\nimport os\nimport matplotlib.pyplot as plt\nplt.ion()\n\n# Open Redis\nREDIS_IP_ADDRESS = os.getenv(\"REDIS_IP_ADDRESS\", \"localhost\")\nREDIS_PORT = int(os.getenv(\"REDIS_PORT\", \"6379\"))\n# Open connection to redis here and store the client as a property of this object\n \nredis_client = redis.Redis(host=REDIS_IP_ADDRESS, port=REDIS_PORT, db=0)",
"_____no_output_____"
],
[
"# Set the key\nkey = 'sim_ts'\n#key = 'web_ts'",
"_____no_output_____"
],
[
"# Get Range (zpopmax and min are destructive they pull the data out of the set)\nmax_d = redis_client.zpopmax(key)\n#print(max)\n\nmin_d = redis_client.zpopmin(key)\n#print(min)\n# Put them back\nmax_member = max_d[0][0]\nmax_score = max_d[0][1]\nredis_client.zadd(key, {max_member: max_score})\n\nmin_member = min_d[0][0]\nmin_score = min_d[0][1]\nredis_client.zadd(key, {min_member: min_score})\n\nprint(\"Min\",min_score,\"Max\",max_score)\n# Calculate the time interval\ndif_score = max_score - min_score\n# In milliseconds\nprint(\"Milliseconds\", dif_score)\n# Seconds\nseconds = dif_score/1000.0\nprint(\"Seconds\", seconds)\n# Minutes\nminutes = seconds/60\nprint(\"Minutes\", minutes)\n# Hours\nhours = minutes/60\nprint(\"Hours\", hours)",
"Min 1623440832070.0 Max 1623677465004.0\nMilliseconds 236632934.0\nSeconds 236632.934\nMinutes 3943.8822333333333\nHours 65.73137055555556\n"
],
[
"# One hour is how many ms\nms_hr = 60 * 60 * 1000\nprint(ms_hr)",
"3600000\n"
],
[
"import math\n# Calc Interactions Per Hour\nhour_blocks = math.floor(hours + 1)\ninteractions_per_hr = []\nfor h in range(hour_blocks):\n selection_min = min_score + (h * ms_hr)\n selection_max = ms_hr + selection_min\n\n results = redis_client.zrangebyscore(key, selection_min, selection_max)\n \n interactions_per_hr.append(len(results))\n ",
"_____no_output_____"
],
[
"# Plot\n#%matplotlib widget\n#import matplotlib.pyplot as plt\n%matplotlib widget\nx = list(range(len(interactions_per_hr)))\nplt.plot(x,interactions_per_hr)\nplt.show()",
"_____no_output_____"
],
[
"# Areas with a 120 second gap seperate \"sessions\"\nms_gap = 120 * 1000\n# Looking for gaps of this size using a similar technique as above.\nsteps = int(dif_score/ms_gap)\nprint(steps)\ngaps_location = []\nall_cnt = []\ngap_counter_list = []\ngap_counter = 0\nsession_counter_list = []\nsession_counter = 0\nsession_state = 0\nsession_length_list = []\nsession_length_counter = 0\nfor g in range(steps):\n selection_min = min_score + (g * ms_gap)\n selection_max = ms_gap + selection_min\n\n results = redis_client.zrangebyscore(key, selection_min, selection_max)\n all_cnt.append(len(results))\n \n if len(results) == 0:\n gaps_location.append([selection_min])\n if gap_counter < 10:\n gap_counter += 1\n # A sesssion may have ended\n if session_state == 1:\n session_counter += 1\n session_state = 0\n session_length_list.append(session_length_counter)\n session_length_counter = 0\n else:\n gap_counter = 0\n # A sesssion has started\n session_state = 1\n session_length_counter += 1\n \n gap_counter_list.append(gap_counter)\n session_counter_list.append(session_counter)\n\nprint(len(gaps_location))\n\ngap_cnt = len(gaps_location)\n\nprint(\"Percent gaps\", float(gap_cnt)/float(steps))\n\nx = list(range(len(all_cnt)))\nplt.rcParams['figure.figsize'] = [12, 8]\nplt.rcParams['figure.dpi'] = 100 # 200 e.g. is really fine, but slower\n\nprint(\"Number of sessions\",max(session_counter_list))\n\n%matplotlib widget\nplt.plot(x,all_cnt)\nplt.plot(x,gap_counter_list)\nplt.plot(x,session_counter_list)\nplt.show()\n",
"1971\n1872\nPercent gaps 0.9497716894977168\nNumber of sessions 74\n"
],
[
"\n\n\n%matplotlib widget\nx = session_length_list\nnum_bins = 5\nn, bins, patches = plt.hist(x, num_bins, facecolor='blue', alpha=0.5)\nplt.show()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7ca97cbea477b4639e21e74461a520d1f19c592 | 145,758 | ipynb | Jupyter Notebook | assignment/Meka-Rajitha/assign-03-rajithameka.ipynb | ml6973/Content | fc88831a9c6603a92afe7d610352e4848317b825 | [
"Apache-2.0"
]
| 22 | 2016-09-07T17:05:46.000Z | 2021-04-03T22:18:10.000Z | assignment/Meka-Rajitha/assign-03-rajithameka.ipynb | ml6973/Content | fc88831a9c6603a92afe7d610352e4848317b825 | [
"Apache-2.0"
]
| null | null | null | assignment/Meka-Rajitha/assign-03-rajithameka.ipynb | ml6973/Content | fc88831a9c6603a92afe7d610352e4848317b825 | [
"Apache-2.0"
]
| 25 | 2016-09-01T14:25:49.000Z | 2017-11-20T22:48:33.000Z | 120.262376 | 116,292 | 0.851109 | [
[
[
"import tensorflow as tf\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline\nfrom sklearn.cross_validation import train_test_split",
"_____no_output_____"
],
[
"data = pd.read_csv(\"https://raw.githubusercontent.com/ml6973/Course/master/code/data/intro_to_ann.csv\")\nX, y = np.array(data.ix[:,0:2]), np.array(data.ix[:,2:3])\nprint(X.shape, y.shape)\nX_train, X_test, y_train, y_test = train_test_split(X,y,test_size=1)\nprint(X_train.shape, X_test.shape, y_train.shape, y_test.shape)\nplt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.BuGn)",
"(500, 2) (500, 1)\n(499, 2) (1, 2) (499, 1) (1, 1)\n"
],
[
"epochs = 1000\nlearning_rate = 0.01\nhl_nodes = 5\nnum_features = 2\nnum_output = 1",
"_____no_output_____"
],
[
"x = tf.placeholder(tf.float32, [None, num_features])\ny_ = tf.placeholder(tf.float32, [None, num_output])\n\n# Create model\ndef multilayer_perceptron(x, weights, biases):\n # Hidden layer with sigmoid activation\n layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])\n layer_1 = tf.nn.softmax(layer_1)\n # Output layer with sigmoid activation\n out_layer = tf.matmul(layer_1, weights['out']) + biases['out']\n out_layer = tf.nn.sigmoid(out_layer)\n return out_layer",
"_____no_output_____"
],
[
"# Store layers weight & bias\nweights = {\n 'h1': tf.Variable(tf.random_normal([num_features, hl_nodes])),\n 'out': tf.Variable(tf.random_normal([hl_nodes, num_output]))\n}\nbiases = {\n 'b1': tf.Variable(tf.random_normal([hl_nodes])),\n 'out': tf.Variable(tf.random_normal([num_output]))\n}\n\n# Construct model\npred = multilayer_perceptron(x, weights, biases)\n",
"_____no_output_____"
],
[
"# Define loss and optimizer\ncross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(pred), reduction_indices=[1]))\noptimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)\n\n# Initializing the variables\ninit = tf.initialize_all_variables()",
"_____no_output_____"
],
[
"# Launch the graph\nwith tf.Session() as sess:\n sess.run(init)\n for i in range(epochs):\n sess.run([optimizer], feed_dict={x: X_train, y_: y_train})\n print(sess.run([cross_entropy], feed_dict={x: X_train, y_: y_train}))",
"[0.25093549]\n[0.25038719]\n[0.24984089]\n[0.24929652]\n[0.24875408]\n[0.24821357]\n[0.24767502]\n[0.24713837]\n[0.24660362]\n[0.24607077]\n[0.24553977]\n[0.2450107]\n[0.2444835]\n[0.24395816]\n[0.2434347]\n[0.24291307]\n[0.2423933]\n[0.24187531]\n[0.24135917]\n[0.2408448]\n[0.24033231]\n[0.2398216]\n[0.23931266]\n[0.23880547]\n[0.23830013]\n[0.23779652]\n[0.23729463]\n[0.23679456]\n[0.23629619]\n[0.23579955]\n[0.23530468]\n[0.2348115]\n[0.23432006]\n[0.23383027]\n[0.23334222]\n[0.23285584]\n[0.23237115]\n[0.23188813]\n[0.23140673]\n[0.23092709]\n[0.23044902]\n[0.22997266]\n[0.22949788]\n[0.22902475]\n[0.22855325]\n[0.22808336]\n[0.22761509]\n[0.2271484]\n[0.22668332]\n[0.22621979]\n[0.22575787]\n[0.22529756]\n[0.22483876]\n[0.22438155]\n[0.22392586]\n[0.22347176]\n[0.22301914]\n[0.22256812]\n[0.22211859]\n[0.22167057]\n[0.22122407]\n[0.22077911]\n[0.22033562]\n[0.21989362]\n[0.2194531]\n[0.21901405]\n[0.21857651]\n[0.21814041]\n[0.21770577]\n[0.21727262]\n[0.21684086]\n[0.21641059]\n[0.21598174]\n[0.2155543]\n[0.2151283]\n[0.21470368]\n[0.21428053]\n[0.2138588]\n[0.21343835]\n[0.21301942]\n[0.2126018]\n[0.21218558]\n[0.21177076]\n[0.21135727]\n[0.21094516]\n[0.21053441]\n[0.21012498]\n[0.2097169]\n[0.20931022]\n[0.2089048]\n[0.20850076]\n[0.20809802]\n[0.20769659]\n[0.20729648]\n[0.20689766]\n[0.20650014]\n[0.20610394]\n[0.205709]\n[0.20531535]\n[0.20492297]\n[0.20453186]\n[0.20414202]\n[0.20375347]\n[0.20336616]\n[0.20298006]\n[0.20259526]\n[0.20221168]\n[0.20182931]\n[0.20144819]\n[0.20106828]\n[0.2006896]\n[0.20031215]\n[0.19993591]\n[0.19956085]\n[0.19918697]\n[0.19881433]\n[0.19844285]\n[0.19807257]\n[0.19770344]\n[0.19733551]\n[0.19696872]\n[0.19660312]\n[0.19623868]\n[0.19587538]\n[0.19551323]\n[0.19515222]\n[0.19479236]\n[0.19443364]\n[0.19407605]\n[0.19371957]\n[0.19336422]\n[0.19300999]\n[0.19265683]\n[0.19230482]\n[0.1919539]\n[0.19160408]\n[0.19125536]\n[0.19090769]\n[0.19056115]\n[0.19021568]\n[0.1898713]\n[0.18952793]\n[0.18918565]\n[0.18884447]\n[0.18850428]\n[0.1881652]\n[0.18782715]\n[0.18749014]\n[0.18715419]\n[0.18681926]\n[0.18648535]\n[0.18615244]\n[0.18582062]\n[0.18548979]\n[0.18515998]\n[0.18483114]\n[0.18450335]\n[0.18417658]\n[0.18385078]\n[0.18352595]\n[0.18320216]\n[0.18287931]\n[0.18255743]\n[0.18223654]\n[0.18191665]\n[0.18159772]\n[0.18127979]\n[0.18096277]\n[0.18064672]\n[0.18033168]\n[0.18001752]\n[0.17970432]\n[0.17939207]\n[0.17908074]\n[0.17877038]\n[0.17846094]\n[0.1781524]\n[0.17784481]\n[0.17753816]\n[0.17723235]\n[0.17692757]\n[0.17662361]\n[0.17632057]\n[0.17601846]\n[0.17571722]\n[0.1754169]\n[0.17511743]\n[0.17481887]\n[0.17452121]\n[0.17422442]\n[0.17392851]\n[0.17363346]\n[0.17333929]\n[0.17304599]\n[0.17275357]\n[0.17246199]\n[0.17217124]\n[0.17188136]\n[0.17159234]\n[0.17130415]\n[0.17101683]\n[0.17073035]\n[0.1704447]\n[0.17015983]\n[0.16987586]\n[0.16959269]\n[0.16931036]\n[0.1690288]\n[0.16874813]\n[0.16846821]\n[0.16818914]\n[0.16791084]\n[0.1676334]\n[0.1673567]\n[0.16708082]\n[0.16680573]\n[0.16653147]\n[0.16625798]\n[0.16598524]\n[0.16571333]\n[0.16544215]\n[0.16517176]\n[0.16490221]\n[0.16463336]\n[0.16436528]\n[0.16409799]\n[0.16383146]\n[0.16356568]\n[0.16330065]\n[0.16303638]\n[0.16277285]\n[0.16251005]\n[0.16224805]\n[0.16198675]\n[0.16172619]\n[0.16146636]\n[0.16120727]\n[0.16094895]\n[0.16069129]\n[0.1604344]\n[0.16017821]\n[0.15992278]\n[0.159668]\n[0.15941396]\n[0.15916066]\n[0.15890802]\n[0.15865611]\n[0.15840493]\n[0.15815438]\n[0.1579046]\n[0.15765545]\n[0.15740702]\n[0.15715931]\n[0.15691225]\n[0.15666588]\n[0.1564202]\n[0.15617523]\n[0.15593088]\n[0.15568724]\n[0.15544425]\n[0.15520194]\n[0.15496029]\n[0.15471931]\n[0.15447897]\n[0.15423934]\n[0.15400031]\n[0.15376195]\n[0.15352423]\n[0.1532872]\n[0.15305081]\n[0.15281501]\n[0.15257992]\n[0.15234543]\n[0.1521116]\n[0.1518784]\n[0.15164579]\n[0.15141389]\n[0.15118256]\n[0.15095186]\n[0.1507218]\n[0.15049233]\n[0.15026352]\n[0.15003532]\n[0.14980771]\n[0.1495807]\n[0.14935432]\n[0.14912856]\n[0.14890341]\n[0.14867885]\n[0.14845487]\n[0.14823151]\n[0.14800873]\n[0.14778657]\n[0.14756498]\n[0.14734399]\n[0.14712358]\n[0.14690377]\n[0.14668448]\n[0.14646585]\n[0.14624776]\n[0.14603026]\n[0.14581335]\n[0.14559701]\n[0.14538123]\n[0.14516601]\n[0.14495136]\n[0.14473729]\n[0.14452377]\n[0.14431077]\n[0.14409837]\n[0.14388654]\n[0.14367524]\n[0.14346451]\n[0.14325434]\n[0.1430447]\n[0.14283559]\n[0.14262703]\n[0.14241906]\n[0.14221157]\n[0.14200465]\n[0.14179826]\n[0.14159238]\n[0.14138709]\n[0.14118229]\n[0.14097802]\n[0.14077426]\n[0.14057107]\n[0.14036837]\n[0.14016621]\n[0.1399646]\n[0.13976344]\n[0.13956283]\n[0.13936275]\n[0.13916317]\n[0.13896409]\n[0.13876553]\n[0.13856746]\n[0.13836992]\n[0.13817288]\n[0.13797635]\n[0.13778029]\n[0.13758475]\n[0.13738967]\n[0.13719514]\n[0.13700107]\n[0.1368075]\n[0.13661441]\n[0.13642183]\n[0.13622971]\n[0.13603809]\n[0.13584697]\n[0.13565628]\n[0.13546611]\n[0.13527639]\n[0.13508716]\n[0.13489842]\n[0.13471015]\n[0.13452235]\n[0.13433501]\n[0.13414814]\n[0.13396174]\n[0.13377579]\n[0.13359031]\n[0.1334053]\n[0.13322076]\n[0.13303666]\n[0.132853]\n[0.13266984]\n[0.13248709]\n[0.13230483]\n[0.13212299]\n[0.13194163]\n[0.1317607]\n[0.13158022]\n[0.13140017]\n[0.13122056]\n[0.13104139]\n[0.1308627]\n[0.13068441]\n[0.13050658]\n[0.13032918]\n[0.1301522]\n[0.12997565]\n[0.12979954]\n[0.12962388]\n[0.12944859]\n[0.12927379]\n[0.12909938]\n[0.12892543]\n[0.12875186]\n[0.12857872]\n[0.12840602]\n[0.12823373]\n[0.12806185]\n[0.12789041]\n[0.12771933]\n[0.12754871]\n[0.12737846]\n[0.12720865]\n[0.12703924]\n[0.12687026]\n[0.12670167]\n[0.12653345]\n[0.12636568]\n[0.12619828]\n[0.12603129]\n[0.12586471]\n[0.12569851]\n[0.12553275]\n[0.12536733]\n[0.12520234]\n[0.12503773]\n[0.1248735]\n[0.12470968]\n[0.12454624]\n[0.12438318]\n[0.12422053]\n[0.12405823]\n[0.12389633]\n[0.12373481]\n[0.12357368]\n[0.12341291]\n[0.12325253]\n[0.12309253]\n[0.1229329]\n[0.12277365]\n[0.12261478]\n[0.12245626]\n[0.12229814]\n[0.12214037]\n[0.12198297]\n[0.12182594]\n[0.12166928]\n[0.12151299]\n[0.12135705]\n[0.12120148]\n[0.12104627]\n[0.12089144]\n[0.12073692]\n[0.1205828]\n[0.12042902]\n[0.12027561]\n[0.12012253]\n[0.11996984]\n[0.1198175]\n[0.11966547]\n[0.11951382]\n[0.1193625]\n[0.11921153]\n[0.11906092]\n[0.11891066]\n[0.11876073]\n[0.11861115]\n[0.11846191]\n[0.11831304]\n[0.11816446]\n[0.11801624]\n[0.11786836]\n[0.11772081]\n[0.1175736]\n[0.11742672]\n[0.11728018]\n[0.11713398]\n[0.1169881]\n[0.11684257]\n[0.11669735]\n[0.11655247]\n[0.11640789]\n[0.11626365]\n[0.11611977]\n[0.11597618]\n[0.11583292]\n[0.11568999]\n[0.11554737]\n[0.11540506]\n[0.1152631]\n[0.11512142]\n[0.11498007]\n[0.11483905]\n[0.11469832]\n[0.11455792]\n[0.11441784]\n[0.11427808]\n[0.11413862]\n[0.11399946]\n[0.11386061]\n[0.11372207]\n[0.11358384]\n[0.11344592]\n[0.11330831]\n[0.11317099]\n[0.113034]\n[0.1128973]\n[0.11276088]\n[0.11262479]\n[0.11248898]\n[0.11235349]\n[0.11221829]\n[0.11208336]\n[0.11194877]\n[0.11181443]\n[0.11168042]\n[0.11154667]\n[0.11141326]\n[0.11128011]\n[0.11114725]\n[0.11101469]\n[0.11088242]\n[0.11075042]\n[0.11061873]\n[0.1104873]\n[0.11035619]\n[0.11022535]\n[0.11009478]\n[0.10996452]\n[0.10983451]\n[0.1097048]\n[0.10957537]\n[0.10944621]\n[0.10931735]\n[0.10918874]\n[0.10906041]\n[0.10893238]\n[0.10880461]\n[0.10867711]\n[0.10854989]\n[0.10842294]\n[0.10829626]\n[0.10816983]\n[0.10804371]\n[0.10791785]\n[0.10779223]\n[0.1076669]\n[0.10754186]\n[0.10741705]\n[0.10729251]\n[0.10716825]\n[0.10704425]\n[0.1069205]\n[0.10679702]\n[0.10667381]\n[0.10655086]\n[0.10642816]\n[0.10630573]\n[0.10618354]\n[0.10606162]\n[0.10593995]\n[0.10581855]\n[0.10569742]\n[0.10557652]\n[0.10545588]\n[0.10533549]\n[0.10521534]\n[0.10509546]\n[0.10497583]\n[0.10485642]\n[0.1047373]\n[0.10461842]\n[0.10449978]\n[0.10438138]\n[0.10426323]\n[0.10414535]\n[0.1040277]\n[0.10391027]\n[0.1037931]\n[0.10367618]\n[0.1035595]\n[0.10344306]\n[0.10332687]\n[0.1032109]\n[0.10309517]\n[0.1029797]\n[0.10286445]\n[0.10274947]\n[0.10263468]\n[0.10252015]\n[0.10240585]\n[0.10229178]\n[0.10217795]\n[0.10206436]\n[0.10195097]\n[0.10183786]\n[0.10172495]\n[0.10161228]\n[0.10149983]\n[0.10138763]\n[0.10127563]\n[0.10116387]\n[0.10105235]\n[0.10094105]\n[0.10082997]\n[0.10071912]\n[0.10060849]\n[0.10049808]\n[0.1003879]\n[0.10027794]\n[0.10016821]\n[0.1000587]\n[0.099949405]\n[0.099840336]\n[0.099731483]\n[0.099622853]\n[0.099514417]\n[0.099406227]\n[0.099298239]\n[0.099190466]\n[0.099082947]\n[0.098975591]\n[0.098868467]\n[0.098761573]\n[0.098654881]\n[0.098548405]\n[0.098442137]\n[0.098336071]\n[0.098230213]\n[0.098124586]\n[0.098019175]\n[0.097913951]\n[0.097808935]\n[0.097704127]\n[0.097599551]\n[0.097495161]\n[0.09739098]\n[0.097287007]\n[0.097183235]\n[0.097079679]\n[0.096976325]\n[0.096873157]\n[0.09677022]\n[0.096667454]\n[0.096564911]\n[0.096462555]\n[0.0963604]\n[0.096258461]\n[0.096156701]\n[0.096055165]\n[0.095953815]\n[0.095852666]\n[0.095751718]\n[0.095650956]\n[0.095550381]\n[0.095450014]\n[0.095349848]\n[0.095249869]\n[0.095150076]\n[0.095050484]\n[0.094951078]\n[0.094851889]\n[0.094752871]\n[0.094654061]\n[0.094555423]\n[0.094456971]\n[0.094358727]\n[0.094260655]\n[0.094162807]\n[0.094065115]\n[0.093967617]\n[0.093870305]\n[0.093773179]\n[0.093676254]\n[0.093579493]\n[0.093482919]\n[0.093386561]\n[0.093290359]\n[0.093194336]\n[0.093098506]\n[0.093002856]\n[0.092907406]\n[0.092812121]\n[0.092717014]\n[0.092622094]\n[0.092527352]\n[0.092432797]\n[0.09233842]\n[0.0922442]\n[0.092150196]\n[0.092056349]\n[0.091962673]\n[0.091869175]\n[0.091775864]\n[0.091682725]\n[0.091589764]\n[0.091496967]\n[0.091404349]\n[0.091311924]\n[0.091219656]\n[0.09112756]\n[0.091035619]\n[0.09094388]\n[0.090852298]\n[0.090760909]\n[0.090669669]\n[0.090578601]\n[0.090487696]\n[0.090396978]\n[0.090306409]\n[0.090216033]\n[0.090125814]\n[0.090035744]\n[0.089945875]\n[0.089856163]\n[0.089766592]\n[0.089677207]\n[0.089587986]\n[0.089498945]\n[0.089410037]\n[0.089321308]\n[0.08923275]\n[0.089144349]\n[0.089056119]\n[0.088968046]\n[0.088880122]\n[0.088792384]\n[0.088704795]\n[0.08861737]\n[0.088530093]\n[0.088442989]\n[0.088356033]\n[0.088269241]\n[0.088182613]\n[0.088096142]\n[0.088009804]\n[0.087923661]\n[0.087837681]\n[0.087751843]\n[0.087666146]\n[0.087580629]\n[0.087495252]\n[0.087410025]\n[0.087324962]\n[0.087240063]\n[0.087155297]\n[0.087070704]\n[0.086986244]\n[0.086901948]\n[0.086817794]\n[0.086733803]\n[0.086649962]\n[0.086566254]\n[0.086482711]\n[0.086399317]\n[0.086316071]\n[0.086232997]\n[0.086150043]\n[0.086067259]\n[0.085984617]\n[0.085902102]\n[0.085819766]\n[0.085737564]\n[0.085655503]\n[0.085573584]\n[0.085491821]\n[0.085410208]\n[0.085328728]\n[0.085247405]\n[0.085166231]\n[0.085085168]\n[0.085004292]\n[0.084923543]\n[0.084842928]\n[0.084762454]\n[0.084682129]\n[0.084601961]\n[0.084521912]\n[0.084442019]\n[0.084362268]\n[0.084282622]\n[0.084203161]\n[0.08412382]\n[0.084044628]\n[0.083965577]\n[0.083886653]\n[0.083807878]\n[0.083729237]\n[0.083650723]\n[0.083572373]\n[0.083494119]\n[0.083416052]\n[0.083338097]\n[0.083260268]\n[0.083182581]\n[0.083105028]\n[0.083027609]\n[0.082950324]\n[0.082873188]\n[0.082796186]\n[0.082719304]\n[0.082642555]\n[0.082565948]\n[0.082489483]\n[0.082413137]\n[0.082336925]\n[0.08226084]\n[0.082184896]\n[0.082109079]\n[0.082033388]\n[0.081957832]\n[0.081882402]\n[0.081807107]\n[0.081731938]\n[0.081656903]\n[0.081581995]\n[0.081507213]\n[0.081432559]\n[0.081358038]\n[0.081283629]\n[0.081209369]\n[0.081135213]\n[0.081061199]\n[0.080987327]\n[0.080913574]\n[0.080839932]\n[0.08076641]\n[0.080693044]\n[0.080619767]\n[0.080546632]\n[0.080473624]\n[0.080400728]\n[0.08032798]\n[0.080255322]\n[0.080182806]\n[0.080110416]\n[0.08003813]\n[0.079965986]\n[0.079893969]\n[0.079822063]\n[0.079750277]\n[0.079678617]\n[0.079607084]\n[0.079535641]\n[0.079464324]\n[0.079393156]\n[0.079322077]\n[0.079251148]\n[0.079180323]\n[0.079109617]\n[0.07903903]\n[0.078968577]\n[0.078898206]\n[0.078827985]\n[0.078757882]\n[0.078687869]\n[0.078617975]\n[0.078548215]\n[0.078478567]\n[0.078409038]\n[0.078339621]\n[0.078270316]\n[0.07820113]\n[0.078132063]\n[0.078063101]\n[0.077994257]\n[0.077925518]\n[0.077856906]\n[0.077788398]\n[0.077720009]\n[0.077651709]\n[0.077583559]\n[0.077515505]\n[0.077447556]\n[0.077379733]\n[0.077312008]\n[0.077244408]\n[0.077176906]\n[0.077109516]\n[0.077042229]\n[0.076975077]\n[0.076908022]\n[0.076841086]\n[0.07677424]\n[0.076707505]\n[0.076640896]\n[0.076574385]\n[0.076507986]\n[0.076441698]\n[0.076375499]\n[0.076309428]\n[0.07624346]\n[0.076177604]\n[0.076111853]\n[0.076046206]\n[0.075980648]\n[0.07591521]\n[0.075849891]\n[0.075784653]\n[0.075719558]\n[0.075654544]\n[0.075589627]\n[0.075524829]\n[0.075460121]\n[0.075395525]\n[0.07533104]\n[0.075266652]\n[0.075202361]\n[0.075138181]\n[0.075074106]\n[0.075010136]\n[0.074946262]\n[0.074882492]\n[0.07481882]\n[0.074755274]\n[0.07469181]\n[0.074628443]\n[0.074565172]\n[0.074502029]\n[0.074438952]\n[0.074376002]\n[0.074313134]\n[0.07425037]\n[0.074187711]\n[0.074125163]\n[0.074062712]\n[0.074000344]\n[0.073938072]\n[0.073875919]\n[0.073813848]\n[0.073751889]\n[0.073690012]\n[0.073628254]\n[0.073566556]\n[0.073504992]\n[0.073443502]\n[0.073382132]\n[0.073320828]\n[0.073259652]\n[0.073198557]\n[0.073137559]\n[0.073076658]\n[0.073015846]\n[0.072955139]\n[0.072894514]\n[0.072834]\n[0.072773576]\n[0.072713234]\n[0.072653003]\n[0.072592847]\n[0.07253281]\n[0.072472848]\n[0.07241299]\n[0.072353229]\n[0.072293535]\n[0.07223396]\n[0.072174467]\n[0.072115071]\n[0.072055764]\n[0.071996555]\n[0.071937434]\n[0.071878396]\n[0.071819469]\n[0.07176061]\n[0.071701854]\n[0.071643181]\n[0.071584612]\n[0.071526125]\n[0.071467735]\n[0.071409442]\n[0.071351215]\n[0.071293093]\n[0.071235046]\n[0.071177103]\n[0.071119241]\n[0.071061477]\n[0.07100378]\n[0.070946202]\n[0.070888683]\n[0.070831269]\n[0.070773944]\n[0.070716694]\n[0.070659555]\n[0.070602477]\n[0.070545502]\n[0.070488617]\n[0.070431814]\n[0.070375092]\n[0.070318453]\n[0.070261918]\n[0.070205435]\n[0.070149072]\n[0.070092782]\n[0.070036583]\n[0.069980465]\n[0.069924437]\n[0.069868475]\n[0.069812603]\n[0.069756828]\n[0.069701135]\n[0.069645509]\n[0.06958998]\n[0.06953454]\n[0.069479167]\n[0.069423884]\n[0.069368698]\n[0.069313571]\n[0.069258541]\n[0.069203593]\n[0.069148727]\n[0.069093943]\n[0.06903924]\n[0.068984613]\n[0.068930082]\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7ca99ec736a6e482b9679e860d54f8cd46f883e | 104,824 | ipynb | Jupyter Notebook | results-s3/Logs-distributed-Single-g2.2xlarge/raw-logs/run10-postprocessing-stage1-logs-data.ipynb | gakarak/DeepLearning_Frameworks_Benchmark | 23f1c5fa05195dc6f37fe6878da35b042bdab69e | [
"Apache-2.0"
]
| 3 | 2017-05-07T02:15:01.000Z | 2018-02-06T22:36:27.000Z | results-s3/Logs-distributed-Single-g2.2xlarge/raw-logs/run10-postprocessing-stage1-logs-data.ipynb | gakarak/DeepLearning_Frameworks_Benchmark | 23f1c5fa05195dc6f37fe6878da35b042bdab69e | [
"Apache-2.0"
]
| null | null | null | results-s3/Logs-distributed-Single-g2.2xlarge/raw-logs/run10-postprocessing-stage1-logs-data.ipynb | gakarak/DeepLearning_Frameworks_Benchmark | 23f1c5fa05195dc6f37fe6878da35b042bdab69e | [
"Apache-2.0"
]
| null | null | null | 545.958333 | 98,434 | 0.923367 | [
[
[
"%pylab inline\nimport pandas as pd",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"lstLogTypes=['Loss','Ex2Sec', 'Time2Batch']\nbatchSize=24\nlstNumGPUs=[1]\nlstNumNodesWK=[1,2,3,4,5]\nnumLogTypes=len(lstLogTypes)\nnumGPUs=len(lstNumGPUs)\nnumNodesWK=len(lstNumNodesWK)\nfoutCSV='results-g2.2xlarge.csv'\n##\ntotNum=numNodesWK*numGPUs\nlstCols=['numGPU', 'numWK', 'dt2Iter','numWKtot','Loss','LossV', 'Ex2Sec','Ex2SecV','Time2Batch','Time2BatchV']\ndata=np.zeros([totNum,len(lstCols)]) \ncnt=0\nfor ggi,gg in enumerate(lstNumGPUs):\n for nni,nn in enumerate(lstNumNodesWK):\n tmpRow=[]\n for tti,tt in enumerate(lstLogTypes):\n fnInp='log-Task1g-1PS-%dWK-%dGPU-%s.txt' % (nn,gg,tt)\n tdata=np.loadtxt(fnInp, dtype=np.float, delimiter=',')\n if tti==0:\n tdataTime=tdata[:,0]\n tdataIter=tdata[:,2]\n tdT=(tdataTime[-1]-tdataTime[0])/(tdataIter[-1]-tdataIter[0])/1000.\n tmpRow.append(gg)\n tmpRow.append(tdata[0,1]/gg)\n tmpRow.append(tdT)\n tmpRow.append(tdata[0,1])\n if tt=='Loss':\n tLossMean=np.mean(tdata[-1,3:])\n tLossVar =np.std(tdata[-1,3:])\n tmpRow.append(tLossMean)\n tmpRow.append(tLossVar)\n elif tt=='Ex2Sec':\n tmpVal=np.sum(tdata[:,3:],axis=1)\n tmpValMean=np.mean(tmpVal)\n tmpValVar=np.std(tmpVal)\n tmpRow.append(tmpValMean)\n tmpRow.append(tmpValVar)\n elif tt=='Time2Batch':\n tmpData=tdata[:,3:]\n tnum=tmpData.shape[1]\n tmpValMean=np.mean(tmpData)/tnum\n tmpValVar =np.std (tmpData)/tnum\n tmpRow.append(tmpValMean)\n tmpRow.append(tmpValVar)\n data[cnt,:]=np.array(tmpRow)\n cnt+=1\n##\ndataPD=pd.DataFrame(data,columns=lstCols)\ndataPD.to_csv(foutCSV,sep=',',index=False)",
"_____no_output_____"
],
[
"foutImage='plot-results-g2.8xlarge.png'\nplt.figure(figsize=(14,16))\ndataNumWK=dataPD['numWK']\n# (1) Total time\nplt.subplot(3,2,1)\nplt.plot(dataNumWK,dataPD['dt2Iter'],'-o',markersize=8,lineWidth=2.)\nplt.xlim((np.min(dataNumWK)-0.1,np.max(dataNumWK)+0.1))\nplt.xticks(dataNumWK.astype(np.int))\nplt.title('g2.2xlarge (1GPU): Total time per batch (%d)' % batchSize)\nplt.xlabel('#Worker-Nodes')\nplt.ylabel('Time (Sec)')\nplt.grid(True)\nplt.subplot(3,2,2)\nplt.plot(dataNumWK,dataPD['dt2Iter']/dataNumWK,'-o',markersize=8,lineWidth=2.)\nplt.xlim((np.min(dataNumWK)-0.1,np.max(dataNumWK)+0.1))\nplt.xticks(dataNumWK.astype(np.int))\nplt.title('g2.2xlarge (1GPU): Total time per batch (%d) Normed' % batchSize)\nplt.xlabel('#Worker-Nodes')\nplt.ylabel('Time (Sec)')\nplt.grid(True)\n# (2) Examples/Second\nplt.subplot(3,2,3)\nplt.plot(dataNumWK,dataPD['Ex2Sec'],'-o',markersize=8,lineWidth=2.)\nplt.xlim((np.min(dataNumWK)-0.1,np.max(dataNumWK)+0.1))\nplt.xticks(dataNumWK.astype(np.int))\nplt.title('g2.2xlarge (1GPU): Exampes/sec, batch=%d' % batchSize)\nplt.xlabel('#Worker-Nodes')\nplt.ylabel('#Examples/sec')\nplt.grid(True)\nplt.subplot(3,2,4)\nplt.plot(dataNumWK,dataPD['Ex2Sec']/dataNumWK,'-o',markersize=8,lineWidth=2.)\nplt.xlim((np.min(dataNumWK)-0.1,np.max(dataNumWK)+0.1))\nplt.xticks(dataNumWK.astype(np.int))\nplt.title('g2.2xlarge (1GPU): Exampes/sec Normed, batch=%d' % batchSize)\nplt.xlabel('#Worker-Nodes')\nplt.ylabel('#Examples/sec')\nplt.grid(True)\n# (3) Time for Batch\nplt.subplot(3,2,5)\nplt.plot(dataNumWK,dataPD['Time2Batch'],'-o',markersize=8,lineWidth=2.)\nplt.xlim((np.min(dataNumWK)-0.1,np.max(dataNumWK)+0.1))\nplt.xticks(dataNumWK.astype(np.int))\nplt.title('g2.2xlarge (1GPU): Time(s)/batch, batch=%d' % batchSize)\nplt.xlabel('#Worker-Nodes')\nplt.ylabel('Time(s)/batch')\nplt.grid(True)\nplt.subplot(3,2,6)\nplt.plot(dataNumWK,dataPD['Time2Batch']*dataNumWK,'-o',markersize=8,lineWidth=2.)\nplt.xlim((np.min(dataNumWK)-0.1,np.max(dataNumWK)+0.1))\nplt.xticks(dataNumWK.astype(np.int))\nplt.title('g2.2xlarge (1GPU): Time(s)/batch Normed, batch=%d' % batchSize)\nplt.xlabel('#Worker-Nodes')\nplt.ylabel('Time(s)/batch')\nplt.grid(True)\n#\nplt.savefig(foutImage)",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code"
]
]
|
e7ca9c8b999ffecb18795d315221905e9770180d | 6,760 | ipynb | Jupyter Notebook | evaluacion_leslytapia.ipynb | LESLYTAPIA/training-python-novice | d3c654cbb53aee4014e7224675d15acde2a416fc | [
"BSD-3-Clause"
]
| 1 | 2021-08-21T22:43:24.000Z | 2021-08-21T22:43:24.000Z | evaluacion_leslytapia.ipynb | LESLYTAPIA/training-python-novice | d3c654cbb53aee4014e7224675d15acde2a416fc | [
"BSD-3-Clause"
]
| null | null | null | evaluacion_leslytapia.ipynb | LESLYTAPIA/training-python-novice | d3c654cbb53aee4014e7224675d15acde2a416fc | [
"BSD-3-Clause"
]
| 7 | 2021-08-21T22:11:42.000Z | 2021-10-08T03:16:06.000Z | 31.737089 | 298 | 0.620118 | [
[
[
"## Evaluación\nCompleta lo que falta.\n",
"_____no_output_____"
]
],
[
[
"# instalacion\n!pip install pandas\n!pip install matplotlib\n!pip install pandas-datareader",
"_____no_output_____"
],
[
"# 1 importa las bibliotecas\nimport pandas as pd\nimport pandas_datareader.data as web\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"# 2. Establecer una fecha de inicio \"2020-01-01\" y una fecha de finalización \"2021-08-31\"\n\nstart_date = \n\nend_date = ",
"_____no_output_____"
],
[
"# 3.Usar el método del lector de datos para almacenar los datos\n# del precio de las acciones de facebook ('FB') en un DataFrame llamado data.\n# https://finance.yahoo.com/quote/FB/history?p=FB\ndata = web.DataReader(name='FB', data_source='yahoo', start=start_date, end=end_date)\ndata\n# La salida se ve igual a la que leemos en cualquier archivo CSV.",
"_____no_output_____"
],
[
"# 4. Explica el resultado.",
"_____no_output_____"
]
],
[
[
"\n* Entender los movimientos del precio, si suben o bajan.\n* Los precios de las acciones se mueven constantemente a lo largo del día de trading a medida que la oferta y la demanda de acciones cambian (precio mas alto o mas bajo). Cuando el mercado cierra, se registra el precio final de la acción.\n* EL precio de Apertura: Precio con el que un Valor inicia sus transacciones en una sesión bursátil. Normalmente este precio no tiene gran diferencia con el precio de cierre (salvo algun acontecimiento importante).\n* El precio de cierre: Es la última cotización que registró durante el día en el mercado bursátil de un determinado título financiero. Nos podemos referir a la acción de una empresa, un índice, la moneda local u otro activo similar.\n\n* El precio de cierre ajustado representa el precio de cierre preciso basado en acciones corporativas. Por ejemplo, si el precio de cierre de las acciones de la empresa ABC era de USD 21.90 pero se pagaron dividendos de 100 centimos por accion, el precio de cierre se ajustara a USD 20.90.\n\n* El volumen mide la cantidad de acciones que se han comprado y vendido en un periodo determinado para una accion en concreto en este caso (FB). Se debe analizar el volumen en relacion a los volumenes anteriores, si suben o bajan.",
"_____no_output_____"
]
],
[
[
"# 5. Muestre un resumen de la información básica sobre este DataFrame y sus datos \n# use la funcion dataFrame.info() y dataFrame.describe()\n",
"_____no_output_____"
],
[
"# 6. Devuelve las primeras 5 filas del DataFrame con dataFrame.head() o dataFrame.iloc[]\n",
"_____no_output_____"
],
[
"# 7. Seleccione solo las columnas 'Open','Close' y 'Volume' del DataFrame con dataFrame.loc\ndata.loc[:, ['', '', '']]",
"_____no_output_____"
],
[
"# Ver el rango de lo datos\ndata.index.min(), data.index.max()",
"_____no_output_____"
],
[
"# 8. Ahora grafica los datos de \"Close\" usando la biblioteca matplotlib en Python, \n# 9. Agrega title, marker, linestyle y color para mejorar la visualizacion\n\nclose = data['']\nax = close.plot(title='Facebook', linestyle='', color='')\nax.set_xlabel('')\nax.set_ylabel('')\nax.grid() #opcional\nplt.show()\n",
"_____no_output_____"
],
[
"# 10. Explica la grafica sencilla de linea",
"_____no_output_____"
]
],
[
[
"* Un gráfico de cierre es un tipo de gráfico que se utiliza normalmente para ilustrar los movimientos en el precio de un instrumento financiero a lo largo del tiempo.\n* El gráfico muestra los movimientos de la cotización de Facebook desde el 01/01/2020 hasta el 31/08/2021. La línea une los precios de cierre diarios, es decir, se relaciona con el precio al que cierra un acción en una jornada o rueda de bolsa. \n* Conocer el precio de cierre es importante porque este es el precio con el que iniciará la siguiente subasta de apertura de la cotización de la acción.",
"_____no_output_____"
],
[
"*Fuente:https://finance.yahoo.com/quote/FB/history?p=FB",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
]
|
e7caae1a33a26467c1e59a1b3506c59057c70ad9 | 15,006 | ipynb | Jupyter Notebook | KeyDistribution_BB84/KeyDistribution_BB84.ipynb | crazy4pi314/QuantumKatas | a4ddc1ed8e69e3a2162ed9d26cd66582cfada320 | [
"MIT"
]
| 1 | 2020-03-15T22:50:49.000Z | 2020-03-15T22:50:49.000Z | KeyDistribution_BB84/KeyDistribution_BB84.ipynb | crazy4pi314/QuantumKatas | a4ddc1ed8e69e3a2162ed9d26cd66582cfada320 | [
"MIT"
]
| null | null | null | KeyDistribution_BB84/KeyDistribution_BB84.ipynb | crazy4pi314/QuantumKatas | a4ddc1ed8e69e3a2162ed9d26cd66582cfada320 | [
"MIT"
]
| null | null | null | 34.576037 | 353 | 0.572838 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
e7cab50fb9a4ff3c40ecb5aad30c39933a627afb | 610,826 | ipynb | Jupyter Notebook | notebooks/metacal_proof_of_concept-Fourier.ipynb | andrevitorelli/autometacal | 97bce4f44780daf5cefcfadc5e3fcf9e2ce70b28 | [
"MIT"
]
| 4 | 2021-02-11T13:18:09.000Z | 2022-03-02T13:52:20.000Z | notebooks/metacal_proof_of_concept-Fourier.ipynb | andrevitorelli/autometacal | 97bce4f44780daf5cefcfadc5e3fcf9e2ce70b28 | [
"MIT"
]
| 36 | 2021-02-11T18:42:10.000Z | 2022-03-29T23:55:49.000Z | notebooks/metacal_proof_of_concept-Fourier.ipynb | andrevitorelli/autometacal | 97bce4f44780daf5cefcfadc5e3fcf9e2ce70b28 | [
"MIT"
]
| 1 | 2021-03-11T23:21:05.000Z | 2021-03-11T23:21:05.000Z | 1,120.781651 | 286,488 | 0.95854 | [
[
[
"%pylab inline\nimport galsim",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"gal_flux = 1.e5 # counts\ngal_r0 = 2.7 # arcsec\ng1 = 0.1 #\ng2 = 0.2 #\npixel_scale = 0.2 # arcsec / pixel\n\n\npsf_beta = 5 #\npsf_re = 1.0 # arcsec\n\n\n# Define the galaxy profile.\ngal = galsim.Exponential(flux=gal_flux, scale_radius=gal_r0)\n# To make sure that GalSim is not cheating, i.e. using the analytic formula of the light profile\n# when computing the affine transformation, it might be a good idea to instantiate the image as\n# an interpolated image.\n# We also make sure GalSim is using the same kind of interpolation as us (bilinear for TF)\ngal = galsim.InterpolatedImage(gal.drawImage(nx=256,ny=256, scale=pixel_scale),\n x_interpolant='linear')\n\n# Shear the galaxy by some value.\n# There are quite a few ways you can use to specify a shape.\n# q, beta Axis ratio and position angle: q = b/a, 0 < q < 1\n# e, beta Ellipticity and position angle: |e| = (1-q^2)/(1+q^2)\n# g, beta (\"Reduced\") Shear and position angle: |g| = (1-q)/(1+q)\n# eta, beta Conformal shear and position angle: eta = ln(1/q)\n# e1,e2 Ellipticity components: e1 = e cos(2 beta), e2 = e sin(2 beta)\n# g1,g2 (\"Reduced\") shear components: g1 = g cos(2 beta), g2 = g sin(2 beta)\n# eta1,eta2 Conformal shear components: eta1 = eta cos(2 beta), eta2 = eta sin(2 beta)\ngal0 = gal.shear(g1=g1, g2=g2)\n\npsf = galsim.Moffat(beta=psf_beta, flux=1., half_light_radius=psf_re)\n\ngal = galsim.Convolve([gal0, psf])",
"_____no_output_____"
],
[
"image_original = gal0.original.drawImage(nx=256,ny=256, scale=pixel_scale, method='no_pixel').array\nimage_shear = gal.drawImage(nx=256,ny=256,scale=pixel_scale, method='no_pixel', use_true_center=False).array",
"_____no_output_____"
],
[
"subplot(121)\nimshow(image_original, origin='lower')\ntitle('original galaxy')\nsubplot(122)\ntitle('after shear and PSF')\nimshow(image_shear, origin='lower')",
"_____no_output_____"
],
[
"import tensorflow as tf\n# let's try to do shape measurement using weigthed moments\nnx = 256\nny = 256\nXX=np.zeros((nx,ny))\nXY=np.zeros((nx,ny))\nYY=np.zeros((nx,ny))\nw = np.zeros((nx,ny))\nsigma=40\n\nfor i in range(0,nx):\n x=0.5+i-(nx)/2.0\n for j in range(0,ny):\n y=0.5+j-(ny)/2.0\n XX[i,j]=x*x\n XY[i,j]=x*y\n YY[i,j]=y*y\n w[i,j]=np.exp(-((x) ** 2 + (y) ** 2) /\n (2 * sigma ** 2))\n\ndef get_ellipticity(img):\n img = tf.convert_to_tensor(img, dtype=tf.float32)\n norm = tf.reduce_sum(w*img)\n Q11 = tf.reduce_sum(w*img*YY)/norm\n Q12 = tf.reduce_sum(w*img*XY)/norm\n Q21 = Q12\n Q22 = tf.reduce_sum(w*img*XX)/norm\n \n q1 = Q11 - Q22\n q2 = 2*Q12\n \n T= Q11 + Q22 + 2*tf.sqrt(Q11*Q22 - Q12**2)\n return q1/T, q2/T",
"_____no_output_____"
],
[
"get_ellipticity(image_shear+10*randn(256,256))",
"_____no_output_____"
],
[
"imshow(w*(image_shear+10*randn(256,256)))",
"_____no_output_____"
],
[
"noise = galsim.GaussianNoise().withVariance(10)\nobs_imag = gal.drawImage(nx=256,ny=256, scale=pixel_scale, method='no_pixel')\nnoise.applyTo(obs_imag)\n\n# Make noise image\nnoise_imag = galsim.Image(256,256, scale=pixel_scale)\nnoise.applyTo(noise_imag)\n\n# Building observed image object\nobs = galsim.InterpolatedImage(obs_imag)\nnos = galsim.InterpolatedImage(noise_imag)",
"_____no_output_____"
],
[
"# We draw the PSF image in Kspace at the correct resolution\nN = 256\nim_scale = pixel_scale\ninterp_factor=2\npadding_factor=2\nNk = N*interp_factor*padding_factor\nfrom galsim.bounds import _BoundsI\n\nbounds = _BoundsI(-Nk//2, Nk//2-1, -Nk//2, Nk//2-1)\n\nimpsf = psf.drawKImage(bounds=bounds,\n scale=2.*np.pi/(N*padding_factor* im_scale),\n recenter=False)\n\nipsf = galsim.Deconvolve(psf)\n\nimipsf = ipsf.drawKImage(bounds=bounds,\n scale=2.*np.pi/(N*padding_factor* im_scale),\n recenter=False)\n\nimgal = obs.drawKImage(bounds=bounds,\n scale=2.*np.pi/(N*padding_factor* im_scale),\n recenter=False)\n\nimnos = nos.drawKImage(bounds=bounds,\n scale=2.*np.pi/(N*padding_factor* im_scale),\n recenter=False)",
"_____no_output_____"
],
[
"tfimpsf = tf.convert_to_tensor(impsf.array, dtype=tf.complex64)\ntfimipsf = tf.convert_to_tensor(imipsf.array, dtype=tf.complex64)\ntfimgal = tf.convert_to_tensor(imgal.array, dtype=tf.complex64)\ntfimnos = tf.convert_to_tensor(imnos.array, dtype=tf.complex64)",
"_____no_output_____"
],
[
"tfimgal = tf.expand_dims(tfimgal ,0)\ntfimnos = tf.expand_dims(tfimnos ,0)\ntfimpsf = tf.expand_dims(tfimpsf ,0)\ntfimipsf = tf.expand_dims(tfimipsf ,0)\ntfimpsf = tf.signal.fftshift(tfimpsf,axes=2)[:,:,:1024//2+1]",
"_____no_output_____"
],
[
"import galflow as gf",
"_____no_output_____"
],
[
"# Deconvolve image\ntemp = tfimgal * tfimipsf\ntemp = tf.signal.fftshift(temp,axes=2)[:,:,:1024//2+1]\n# Reconvolve image\ntst2 = gf.kconvolve(temp, tfimpsf)[...,0]\ntst2 = tf.expand_dims(tf.signal.fftshift(tst2),-1)\ntst2 = tf.image.resize_with_crop_or_pad(tst2, 256, 256)",
"_____no_output_____"
],
[
"figure(figsize=[15,5])\nsubplot(131)\ntitle('input image')\nimshow(image_shear)\nsubplot(132)\ntitle('reconvolved image')\nimshow(tst2[0]); colorbar();\nsubplot(133)\ntitle('residuals image')\nimshow(((tst2[0,...,0] - obs_imag.array))); colorbar();",
"_____no_output_____"
],
[
"# Ok... so now can we make a poor man's metacal\ndef to_rfft(x):\n return tf.signal.fftshift(x,axes=2)[:,:,:1024//2+1]\n\[email protected]\ndef metacal_shear(gal_img, nos_img, inv_psf_img, psf_img, g1, g2):\n g1 = tf.reshape(tf.convert_to_tensor(g1, dtype=tf.float32), [-1])\n g2 = tf.reshape(tf.convert_to_tensor(g2, dtype=tf.float32), [-1])\n \n # Step1: remove observed psf\n img = gal_img * inv_psf_img\n imgn = nos_img * inv_psf_img\n \n # Step2: add shear layer\n img = gf.shear(tf.expand_dims(img,-1), g1, g2)[...,0]\n imgn = gf.shear(tf.expand_dims(imgn,-1), -g1, -g2)[...,0]\n \n # Step3: apply psf again\n img = gf.kconvolve(to_rfft(img), (psf_img))[...,0]\n img = tf.expand_dims(tf.signal.fftshift(img),-1)\n img = tf.image.resize_with_crop_or_pad(img, 256, 256)\n \n imgn = gf.kconvolve(to_rfft(imgn), (psf_img))[...,0]\n imgn = tf.expand_dims(tf.signal.fftshift(imgn),-1)\n imgn = tf.image.resize_with_crop_or_pad(imgn, 256, 256)\n \n # Adding the inversed sheared noise\n img += imgn\n \n # Step4: compute ellipticity\n return img, tf.stack(get_ellipticity(img[0,:,:,0] ))",
"_____no_output_____"
],
[
"i, res = metacal_shear(tfimgal, tfimnos, tfimipsf, tfimpsf, 0.05, 0.05)\nprint(\"measured shape\", res.numpy())\nfigure(figsize=[10,5])\nsubplot(121)\ntitle('input image')\nimshow(obs_imag.array)\nsubplot(122)\ntitle('metacal image')\nimshow(i[0,:,:,0])",
"measured shape [0.10150132 0.16835728]\n"
],
[
"res.numpy()",
"_____no_output_____"
],
[
"# True ellipticity: [0.1, 0.2]\[email protected]\ndef get_metacal_response(tfimgal, tfimnos, tfimipsf, tfimpsf):\n g = tf.zeros(2)\n with tf.GradientTape() as tape:\n tape.watch(g)\n # Measure ellipticity under metacal\n _, e = metacal_shear(tfimgal, tfimnos, tfimipsf, tfimpsf, g[0], g[1])\n # Compute response matrix\n R = tape.jacobian(e, g)\n return e, R",
"_____no_output_____"
],
[
"e,R = get_metacal_response(tfimgal, tfimnos, tfimipsf, tfimpsf)",
"WARNING:tensorflow:Using a while_loop for converting Roll\nWARNING:tensorflow:Using a while_loop for converting Roll\nWARNING:tensorflow:Using a while_loop for converting Roll\nWARNING:tensorflow:Using a while_loop for converting Roll\nWARNING:tensorflow:Using a while_loop for converting Addons>ResamplerGrad\nWARNING:tensorflow:Using a while_loop for converting Addons>ResamplerGrad\nWARNING:tensorflow:Using a while_loop for converting Roll\nWARNING:tensorflow:Using a while_loop for converting Roll\nWARNING:tensorflow:Using a while_loop for converting Roll\nWARNING:tensorflow:Using a while_loop for converting Roll\nWARNING:tensorflow:Using a while_loop for converting Addons>ResamplerGrad\nWARNING:tensorflow:Using a while_loop for converting Addons>ResamplerGrad\n"
],
[
"# Apply inverse response matrix :-D\ncalibrated_e = tf.linalg.inv(R) @ tf.reshape(e,[2,1])",
"_____no_output_____"
],
[
"print(\"measured ellipticity \", e.numpy())\nprint(\"calibrated ellipticity\", calibrated_e.numpy().squeeze())\nprint(\"true g1,g2 \",np.array([g1,g2]))",
"measured ellipticity [0.06872869 0.1395428 ]\ncalibrated ellipticity [0.0925119 0.21832576]\ntrue g1,g2 [0.1 0.2]\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cac4284d719fc23bb2ba8fcec6ec72f4e9a9b8 | 10,196 | ipynb | Jupyter Notebook | sagemaker-python-sdk/pytorch_cnn_cifar10/pytorch_local_mode_cifar10.ipynb | nigenda-amazon/amazon-sagemaker-examples | 4b172ee2e85daf2f0518236139b72940bc4135da | [
"Apache-2.0"
]
| 5 | 2019-01-19T23:53:35.000Z | 2022-01-29T14:04:31.000Z | sagemaker-python-sdk/pytorch_cnn_cifar10/pytorch_local_mode_cifar10.ipynb | nigenda-amazon/amazon-sagemaker-examples | 4b172ee2e85daf2f0518236139b72940bc4135da | [
"Apache-2.0"
]
| null | null | null | sagemaker-python-sdk/pytorch_cnn_cifar10/pytorch_local_mode_cifar10.ipynb | nigenda-amazon/amazon-sagemaker-examples | 4b172ee2e85daf2f0518236139b72940bc4135da | [
"Apache-2.0"
]
| 7 | 2020-03-04T22:23:51.000Z | 2021-07-13T14:05:46.000Z | 33.986667 | 557 | 0.616026 | [
[
[
"# PyTorch CIFAR-10 local training \n\n## Prerequisites\n\nThis notebook shows how to use the SageMaker Python SDK to run your code in a local container before deploying to SageMaker's managed training or hosting environments. This can speed up iterative testing and debugging while using the same familiar Python SDK interface. Just change your estimator's `train_instance_type` to `local` (or `local_gpu` if you're using an ml.p2 or ml.p3 notebook instance).\n\nIn order to use this feature, you'll need to install docker-compose (and nvidia-docker if training with a GPU).\n\n**Note: you can only run a single local notebook at one time.**",
"_____no_output_____"
]
],
[
[
"!/bin/bash ./setup.sh",
"_____no_output_____"
]
],
[
[
"## Overview\n\nThe **SageMaker Python SDK** helps you deploy your models for training and hosting in optimized, productions ready containers in SageMaker. The SageMaker Python SDK is easy to use, modular, extensible and compatible with TensorFlow, MXNet, PyTorch. This tutorial focuses on how to create a convolutional neural network model to train the [CIFAR-10 dataset](https://www.cs.toronto.edu/~kriz/cifar.html) using **PyTorch in local mode**.\n\n### Set up the environment\n\nThis notebook was created and tested on a single ml.p2.xlarge notebook instance.\n\nLet's start by specifying:\n\n- The S3 bucket and prefix that you want to use for training and model data. This should be within the same region as the Notebook Instance, training, and hosting.\n- The IAM role arn used to give training and hosting access to your data. See the documentation for how to create these. Note, if more than one role is required for notebook instances, training, and/or hosting, please replace the sagemaker.get_execution_role() with appropriate full IAM role arn string(s).",
"_____no_output_____"
]
],
[
[
"import sagemaker\n\nsagemaker_session = sagemaker.Session()\n\nbucket = sagemaker_session.default_bucket()\nprefix = 'sagemaker/DEMO-pytorch-cnn-cifar10'\n\nrole = sagemaker.get_execution_role()",
"_____no_output_____"
],
[
"import os\nimport subprocess\n\ninstance_type = \"local\"\n\ntry:\n if subprocess.call(\"nvidia-smi\") == 0:\n ## Set type to GPU if one is present\n instance_type = \"local_gpu\"\nexcept:\n pass\n\nprint(\"Instance type = \" + instance_type)",
"_____no_output_____"
]
],
[
[
"### Download the CIFAR-10 dataset",
"_____no_output_____"
]
],
[
[
"from utils_cifar import get_train_data_loader, get_test_data_loader, imshow, classes\n\ntrainloader = get_train_data_loader()\ntestloader = get_test_data_loader()",
"_____no_output_____"
]
],
[
[
"### Data Preview",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport torchvision, torch\n\n# get some random training images\ndataiter = iter(trainloader)\nimages, labels = dataiter.next()\n\n# show images\nimshow(torchvision.utils.make_grid(images))\n\n# print labels\nprint(' '.join('%9s' % classes[labels[j]] for j in range(4)))",
"_____no_output_____"
]
],
[
[
"### Upload the data\nWe use the ```sagemaker.Session.upload_data``` function to upload our datasets to an S3 location. The return value inputs identifies the location -- we will use this later when we start the training job.",
"_____no_output_____"
]
],
[
[
"inputs = sagemaker_session.upload_data(path='data', bucket=bucket, key_prefix='data/cifar10')",
"_____no_output_____"
]
],
[
[
"# Construct a script for training \nHere is the full code for the network model:",
"_____no_output_____"
]
],
[
[
"!pygmentize source/cifar10.py",
"_____no_output_____"
]
],
[
[
"## Script Functions\n\nSageMaker invokes the main function defined within your training script for training. When deploying your trained model to an endpoint, the model_fn() is called to determine how to load your trained model. The model_fn() along with a few other functions list below are called to enable predictions on SageMaker.\n\n### [Predicting Functions](https://github.com/aws/sagemaker-pytorch-containers/blob/master/src/sagemaker_pytorch_container/serving.py)\n* model_fn(model_dir) - loads your model.\n* input_fn(serialized_input_data, content_type) - deserializes predictions to predict_fn.\n* output_fn(prediction_output, accept) - serializes predictions from predict_fn.\n* predict_fn(input_data, model) - calls a model on data deserialized in input_fn.\n\nThe model_fn() is the only function that doesn't have a default implementation and is required by the user for using PyTorch on SageMaker. ",
"_____no_output_____"
],
[
"## Create a training job using the sagemaker.PyTorch estimator\n\nThe `PyTorch` class allows us to run our training function on SageMaker. We need to configure it with our training script, an IAM role, the number of training instances, and the training instance type. For local training with GPU, we could set this to \"local_gpu\". In this case, `instance_type` was set above based on your whether you're running a GPU instance.\n\nAfter we've constructed our `PyTorch` object, we fit it using the data we uploaded to S3. Even though we're in local mode, using S3 as our data source makes sense because it maintains consistency with how SageMaker's distributed, managed training ingests data.\n",
"_____no_output_____"
]
],
[
[
"from sagemaker.pytorch import PyTorch\n\ncifar10_estimator = PyTorch(entry_point='source/cifar10.py',\n role=role,\n framework_version='1.4.0',\n train_instance_count=1,\n train_instance_type=instance_type)\n\ncifar10_estimator.fit(inputs)",
"_____no_output_____"
]
],
[
[
"# Deploy the trained model to prepare for predictions\n\nThe deploy() method creates an endpoint (in this case locally) which serves prediction requests in real-time.",
"_____no_output_____"
]
],
[
[
"from sagemaker.pytorch import PyTorchModel\n\ncifar10_predictor = cifar10_estimator.deploy(initial_instance_count=1,\n instance_type=instance_type)",
"_____no_output_____"
]
],
[
[
"# Invoking the endpoint",
"_____no_output_____"
]
],
[
[
"# get some test images\ndataiter = iter(testloader)\nimages, labels = dataiter.next()\n\n# print images\nimshow(torchvision.utils.make_grid(images))\nprint('GroundTruth: ', ' '.join('%4s' % classes[labels[j]] for j in range(4)))\n\noutputs = cifar10_predictor.predict(images.numpy())\n\n_, predicted = torch.max(torch.from_numpy(np.array(outputs)), 1)\n\nprint('Predicted: ', ' '.join('%4s' % classes[predicted[j]]\n for j in range(4)))",
"_____no_output_____"
]
],
[
[
"# Clean-up\n\nDeleting the local endpoint when you're finished is important, since you can only run one local endpoint at a time.",
"_____no_output_____"
]
],
[
[
"cifar10_estimator.delete_endpoint()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7cacd2e41a399462127a83ec22bbc7d89fcac37 | 82,527 | ipynb | Jupyter Notebook | research/peq.ipynb | OscarDev/AutoEq | d0ad8ae003eff35740a4970ffb7b3bc6639b3433 | [
"MIT"
]
| 1 | 2020-06-26T16:27:40.000Z | 2020-06-26T16:27:40.000Z | research/peq.ipynb | spdebbarma/AutoEq | aa25ed8e8270c523893fadbda57e9811c65733f1 | [
"MIT"
]
| null | null | null | research/peq.ipynb | spdebbarma/AutoEq | aa25ed8e8270c523893fadbda57e9811c65733f1 | [
"MIT"
]
| null | null | null | 577.111888 | 78,752 | 0.944442 | [
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import os\nimport sys\nfrom pathlib import Path\nsys.path.insert(1, os.path.realpath(os.path.join(Path().absolute(), os.pardir)))",
"_____no_output_____"
],
[
"import numpy as np\nimport scipy\nimport matplotlib.pyplot as plt\nfrom frequency_response import FrequencyResponse\nfrom biquad import peaking, low_shelf, high_shelf, digital_coeffs\nfrom constants import ROOT_DIR",
"_____no_output_____"
],
[
"fns = {'PK': peaking, 'LS': low_shelf, 'HS': high_shelf}\nfs = 48000\nf = [20.0]\nwhile f[-1] < fs:\n f.append(f[-1]*2**(1/32))\nf = np.array(f)\n\ndef peq2fr(fc, q, gain, filts):\n c = np.zeros(f.shape)\n for i, filt in enumerate(filts):\n a0, a1, a2, b0, b1, b2 = fns[filt](fc[i], q[i], gain[i], fs=fs)\n c += digital_coeffs(f, fs, a0, a1, a2, b0, b1, b2)\n fr = FrequencyResponse(name='PEG', frequency=f, raw=c)\n return fr",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nfig.set_size_inches(16, 8)\n\nautoeq = peq2fr(\n [24, 322, 2947, 14388, 19893, 4419, 5501, 7712, 10169, 12622],\n [0.91, 2.34, 1.94, 1.35, 0.38, 4.45, 1.37, 3.23, 1.9, 4.29],\n [6.2, 3.4, -2.2, -9.1, -8.0, -5.0, 3.5, -5.7, 2.8, -3.2],\n ['PK'] * 10\n)\n\noratory1990 = peq2fr(\n [90, 200, 290, 2800, 3670, 4240, 5800, 7000, 8100, 11000],\n [0.9, 0.9, 1.8, 1.5, 4.5, 4.5, 3.5, 6.0, 5.0, 0.8],\n [2.8, -3.3, 4.5, -3.7, 2.7, -5.0, 2.8, -3.0, -4.6, -10.0],\n ['LS'] + ['PK'] * 8 + ['HS'],\n)\n\ndiff = FrequencyResponse(name='diff', frequency=f, raw=autoeq.raw - oratory1990.raw)\ndelta = np.mean(diff.raw[np.logical_and(f >= 100, f <= 10000)])\noratory1990.raw += delta\ndiff.raw = autoeq.raw - oratory1990.raw\n\nautoeq.plot_graph(fig=fig, ax=ax, show=False, color='C0')\noratory1990.plot_graph(fig=fig, ax=ax, show=False, color='C1')\ndiff.plot_graph(fig=fig, ax=ax, show=False, color='red')\n\nax.legend(['AutoEQ', 'Oratory1990', 'Difference'])\nax.set_ylim([-7, 7])\nax.set_title('Audio-Technica ATH-M50x\\nAutoEq vs oratory1990')\nplt.savefig('Audio-Technica ATH-M50x.png')\nplt.show()\n",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cad0359acc97f7ac4f220e820aa338ce886957 | 43,948 | ipynb | Jupyter Notebook | Wi20_content/SEDS/L5.Procedural_Python.ipynb | ShahResearchGroup/UWDIRECT.github.io | d4db958a6bfe151b6f7b1eb4772d8fd1b9bb0c3e | [
"BSD-3-Clause"
]
| 1 | 2021-01-26T19:55:02.000Z | 2021-01-26T19:55:02.000Z | Wi20_content/SEDS/L5.Procedural_Python.ipynb | ShahResearchGroup/UWDIRECT.github.io | d4db958a6bfe151b6f7b1eb4772d8fd1b9bb0c3e | [
"BSD-3-Clause"
]
| null | null | null | Wi20_content/SEDS/L5.Procedural_Python.ipynb | ShahResearchGroup/UWDIRECT.github.io | d4db958a6bfe151b6f7b1eb4772d8fd1b9bb0c3e | [
"BSD-3-Clause"
]
| null | null | null | 22.770984 | 376 | 0.528989 | [
[
[
"# Procedural programming in python\n\n## Topics\n* Tuples, lists and dictionaries\n* Flow control, part 1\n * If\n * For\n * range() function\n* Some hacky hack time\n* Flow control, part 2\n * Functions",
"_____no_output_____"
],
[
"<hr>",
"_____no_output_____"
],
[
"### Tuples\n\nLet's begin by creating a tuple called `my_tuple` that contains three elements.",
"_____no_output_____"
]
],
[
[
"my_tuple = ('I', 'like', 'cake')\nmy_tuple",
"_____no_output_____"
]
],
[
[
"Tuples are simple containers for data. They are ordered, meaining the order the elements are in when the tuple is created are preserved. We can get values from our tuple by using array indexing, similar to what we were doing with pandas.",
"_____no_output_____"
]
],
[
[
"my_tuple[0]",
"_____no_output_____"
]
],
[
[
"Recall that Python indexes start at 0. So the first element in a tuple is 0 and the last is array length - 1. You can also address from the `end` to the `front` by using negative (`-`) indexes, e.g.",
"_____no_output_____"
]
],
[
[
"my_tuple[-1]",
"_____no_output_____"
]
],
[
[
"You can also access a range of elements, e.g. the first two, the first three, by using the `:` to expand a range. This is called ``slicing``.",
"_____no_output_____"
]
],
[
[
"my_tuple[0:2]",
"_____no_output_____"
],
[
"my_tuple[0:3]",
"_____no_output_____"
]
],
[
[
"What do you notice about how the upper bound is referenced?",
"_____no_output_____"
],
[
"Without either end, the ``:`` expands to the entire list.",
"_____no_output_____"
]
],
[
[
"my_tuple[1:]",
"_____no_output_____"
],
[
"my_tuple[:-1]",
"_____no_output_____"
],
[
"my_tuple[:]",
"_____no_output_____"
]
],
[
[
"Tuples have a key feature that distinguishes them from other types of object containers in Python. They are _immutable_. This means that once the values are set, they cannot change.",
"_____no_output_____"
]
],
[
[
"my_tuple[2]",
"_____no_output_____"
]
],
[
[
"So what happens if I decide that I really prefer pie over cake?",
"_____no_output_____"
]
],
[
[
"#my_tuple[2] = 'pie'",
"_____no_output_____"
]
],
[
[
"Facts about tuples:\n* You can't add elements to a tuple. Tuples have no append or extend method.\n* You can't remove elements from a tuple. Tuples have no remove or pop method.\n* You can also use the in operator to check if an element exists in the tuple.\n\nSo then, what are the use cases of tuples? \n* Speed\n* `Write-protects` data that other pieces of code should not alter",
"_____no_output_____"
],
[
"You can alter the value of a tuple variable, e.g. change the tuple it holds, but you can't modify it.",
"_____no_output_____"
]
],
[
[
"my_tuple",
"_____no_output_____"
],
[
"my_tuple = ('I', 'love', 'pie')\nmy_tuple",
"_____no_output_____"
]
],
[
[
"There is a really handy operator ``in`` that can be used with tuples that will return `True` if an element is present in a tuple and `False` otherwise.",
"_____no_output_____"
]
],
[
[
"'love' in my_tuple",
"_____no_output_____"
]
],
[
[
"Finally, tuples can contain different types of data, not just strings.",
"_____no_output_____"
]
],
[
[
"import math\nmy_second_tuple = (42, 'Elephants', 'ate', math.pi)\nmy_second_tuple",
"_____no_output_____"
]
],
[
[
"Numerical operators work... Sort of. What happens when you add? \n\n``my_second_tuple + 'plus'``",
"_____no_output_____"
],
[
"Not what you expects? What about adding two tuples?",
"_____no_output_____"
]
],
[
[
"my_second_tuple + my_tuple",
"_____no_output_____"
]
],
[
[
"Other operators: -, /, *",
"_____no_output_____"
],
[
"### Questions about tuples before we move on?",
"_____no_output_____"
],
[
"<hr>\n\n### Lists\n\nLet's begin by creating a list called `my_list` that contains three elements.",
"_____no_output_____"
]
],
[
[
"my_list = ['I', 'like', 'cake']\nmy_list",
"_____no_output_____"
]
],
[
[
"At first glance, tuples and lists look pretty similar. Notice the lists use '[' and ']' instead of '(' and ')'. But indexing and refering to the first entry as 0 and the last as -1 still works the same.",
"_____no_output_____"
]
],
[
[
"my_list[0]",
"_____no_output_____"
],
[
"my_list[-1]",
"_____no_output_____"
],
[
"my_list[0:3]",
"_____no_output_____"
]
],
[
[
"Lists, however, unlike tuples, are mutable. ",
"_____no_output_____"
]
],
[
[
"my_list[2] = 'pie'\nmy_list",
"_____no_output_____"
]
],
[
[
"Multiple elements in the list can even be changed at once!",
"_____no_output_____"
]
],
[
[
"my_list[1:] = ['love', 'puppies']\nmy_list",
"_____no_output_____"
]
],
[
[
"You can still use the `in` operator.",
"_____no_output_____"
]
],
[
[
"'puppies' in my_list",
"_____no_output_____"
],
[
"'kittens' in my_list",
"_____no_output_____"
]
],
[
[
"So when to use a tuple and when to use a list?\n\n* Use a list when you will modify it after it is created?\n\nWays to modify a list? You have already seen by index. Let's start with an empty list.",
"_____no_output_____"
]
],
[
[
"my_new_list = []\nmy_new_list",
"_____no_output_____"
]
],
[
[
"We can add to the list using the append method on it.",
"_____no_output_____"
]
],
[
[
"my_new_list.append('Now')\nmy_new_list",
"_____no_output_____"
]
],
[
[
"We can use the `+` operator to create a longer list by adding the contents of two lists together.",
"_____no_output_____"
]
],
[
[
"my_new_list + my_list",
"_____no_output_____"
]
],
[
[
"One of the useful things to know about a list how many elements are in it. This can be found with the `len` function.",
"_____no_output_____"
]
],
[
[
"len(my_list)",
"_____no_output_____"
]
],
[
[
"Some other handy functions with lists:\n* max\n* min\n* cmp",
"_____no_output_____"
],
[
"Sometimes you have a tuple and you need to make it a list. You can `cast` the tuple to a list with ``list(my_tuple)``",
"_____no_output_____"
]
],
[
[
"list(my_tuple)",
"_____no_output_____"
]
],
[
[
"What in the above told us it was a list? \n\nYou can also use the ``type`` function to figure out the type.",
"_____no_output_____"
]
],
[
[
"type(tuple)",
"_____no_output_____"
],
[
"type(list(my_tuple))",
"_____no_output_____"
]
],
[
[
"There are other useful methods on lists, including:\n\n| methods | description |\n|---|---|\n| list.append(obj) | Appends object obj to list |\n| list.count(obj)| Returns count of how many times obj occurs in list |\n| list.extend(seq) | Appends the contents of seq to list |\n| list.index(obj) | Returns the lowest index in list that obj appears |\n| list.insert(index, obj) | Inserts object obj into list at offset index |\n| list.pop(obj=list[-1]) | Removes and returns last object or obj from list |\n| list.remove(obj) | Removes object obj from list |\n| list.reverse() | Reverses objects of list in place |\n| list.sort([func]) | Sort objects of list, use compare func, if given |\n\nTry some of them now.\n\n```\nmy_list.count('I')\nmy_list\n\nmy_list.append('I')\nmy_list\n\nmy_list.count('I')\nmy_list\n\n#my_list.index(42)\n\nmy_list.index('puppies')\nmy_list\n\nmy_list.insert(my_list.index('puppies'), 'furry')\nmy_list\n```",
"_____no_output_____"
]
],
[
[
"my_list.count('I')\nmy_list\n\nmy_list.append('I')\nmy_list\n\nmy_list.count('I')\nmy_list\n\n#my_list.index(42)\n\nmy_list.index('puppies')\nmy_list\n\nmy_list.insert(my_list.index('puppies'), 'furry')\nmy_list\n\nmy_list.pop()\nmy_list\n\nmy_list.remove('puppies')\nmy_list\n\nmy_list.append('cabbages')\nmy_list",
"_____no_output_____"
]
],
[
[
"### Any questions about lists before we move on?",
"_____no_output_____"
],
[
"<hr>\n\n### Dictionaries\n\nDictionaries are similar to tuples and lists in that they hold a collection of objects. Dictionaries, however, allow an additional indexing mode: keys. Think of a real dictionary where the elements in it are the definitions of the words and the keys to retrieve the entries are the words themselves.\n\n| word | definition |\n|------|------------|\n| tuple | An immutable collection of ordered objects |\n| list | A mutable collection of ordered objects |\n| dictionary | A mutable collection of named objects |\n\nLet's create this data structure now. Dictionaries, like tuples and elements use a unique referencing method, '{' and its evil twin '}'.",
"_____no_output_____"
]
],
[
[
"my_dict = { 'tuple' : 'An immutable collection of ordered objects',\n 'list' : 'A mutable collection of ordered objects',\n 'dictionary' : 'A mutable collection of objects' }\nmy_dict",
"_____no_output_____"
]
],
[
[
"We access items in the dictionary by name, e.g. ",
"_____no_output_____"
]
],
[
[
"my_dict['dictionary']",
"_____no_output_____"
]
],
[
[
"Since the dictionary is mutable, you can change the entries.",
"_____no_output_____"
]
],
[
[
"my_dict['dictionary'] = 'A mutable collection of named objects'\nmy_dict",
"_____no_output_____"
]
],
[
[
"Notice that ordering is not preserved!\n#### As of Python 3.7 the ordering is garunteed to be insertion order but that does not mean alphabetical or otherwise sorted.\n\nAnd we can add new items to the list.",
"_____no_output_____"
]
],
[
[
"my_dict['cabbage'] = 'Green leafy plant in the Brassica family'\nmy_dict",
"_____no_output_____"
]
],
[
[
"To delete an entry, we can't just set it to ``None``",
"_____no_output_____"
]
],
[
[
"my_dict['cabbage'] = None\nmy_dict",
"_____no_output_____"
]
],
[
[
"To delete it propery, we need to pop that specific entry.",
"_____no_output_____"
]
],
[
[
"my_dict.pop('cabbage', None)\nmy_dict",
"_____no_output_____"
]
],
[
[
"You can use other objects as names, but that is a topic for another time. You can mix and match key types, e.g.",
"_____no_output_____"
]
],
[
[
"my_new_dict = {}\nmy_new_dict[1] = 'One'\nmy_new_dict['42'] = 42\nmy_new_dict",
"_____no_output_____"
]
],
[
[
"You can get a list of keys in the dictionary by using the ``keys`` method.",
"_____no_output_____"
]
],
[
[
"my_dict.keys()",
"_____no_output_____"
]
],
[
[
"Similarly the contents of the dictionary with the ``items`` method.",
"_____no_output_____"
]
],
[
[
"my_dict.items()",
"_____no_output_____"
]
],
[
[
"We can use the keys list for fun stuff, e.g. with the ``in`` operator.",
"_____no_output_____"
]
],
[
[
"'dictionary' in my_dict.keys()",
"_____no_output_____"
]
],
[
[
"This is a synonym for `in my_dict`",
"_____no_output_____"
]
],
[
[
"'dictionary' in my_dict",
"_____no_output_____"
]
],
[
[
"Notice, it doesn't work for elements.",
"_____no_output_____"
]
],
[
[
"'A mutable collection of ordered objects' in my_dict",
"_____no_output_____"
]
],
[
[
"Other dictionary methods:\n\n| methods | description |\n|---|---|\n| dict.clear() | Removes all elements from dict |\n| dict.get(key, default=None) | For ``key`` key, returns value or ``default`` if key doesn't exist in dict | \n| dict.items() | Returns a list of dicts (key, value) tuple pairs | \n| dict.keys() | Returns a list of dictionary keys |\n| dict.setdefault(key, default=None) | Similar to get, but set the value of key if it doesn't exist in dict |\n| dict.update(dict2) | Add the key / value pairs in dict2 to dict |\n| dict.values | Returns a list of dictionary values|\n\nFeel free to experiment...",
"_____no_output_____"
],
[
"<hr>\n## Flow control\n\n<img src=\"https://docs.oracle.com/cd/B19306_01/appdev.102/b14261/lnpls008.gif\">Flow control figure</img>\n\nFlow control refers how to programs do loops, conditional execution, and order of functional operations. Let's start with conditionals, or the venerable ``if`` statement.\n\nLet's start with a simple list of instructors for these classes.",
"_____no_output_____"
]
],
[
[
"instructors = ['Dave', 'Jim', 'Dorkus the Clown']\ninstructors",
"_____no_output_____"
]
],
[
[
"### If\nIf statements can be use to execute some lines or block of code if a particular condition is satisfied. E.g. Let's print something based on the entries in the list.",
"_____no_output_____"
]
],
[
[
"if 'Dorkus the Clown' in instructors:\n print('#fakeinstructor')",
"_____no_output_____"
]
],
[
[
"Usually we want conditional logic on both sides of a binary condition, e.g. some action when ``True`` and some when ``False``",
"_____no_output_____"
]
],
[
[
"if 'Dorkus the Clown' in instructors:\n print('There are fake names for class instructors in your list!')\nelse:\n print(\"Nothing to see here\")",
"_____no_output_____"
]
],
[
[
"There is a special do nothing word: `pass` that skips over some arm of a conditional, e.g.",
"_____no_output_____"
]
],
[
[
"if 'Jim' in instructors:\n print(\"Congratulations! Jim is teaching, your class won't stink!\")\nelse:\n pass",
"_____no_output_____"
]
],
[
[
"_Note_: what have you noticed in this session about quotes? What is the difference between ``'`` and ``\"``?\n\n\nAnother simple example:",
"_____no_output_____"
]
],
[
[
"if True is False:\n print(\"I'm so confused\")\nelse:\n print(\"Everything is right with the world\")",
"_____no_output_____"
]
],
[
[
"It is always good practice to handle all cases explicity. `Conditional fall through` is a common source of bugs.\n\nSometimes we wish to test multiple conditions. Use `if`, `elif`, and `else`.",
"_____no_output_____"
]
],
[
[
"my_favorite = 'pie'\n\nif my_favorite is 'cake':\n print(\"He likes cake! I'll start making a double chocolate velvet cake right now!\")\nelif my_favorite is 'pie':\n print(\"He likes pie! I'll start making a cherry pie right now!\")\nelse:\n print(\"He likes \" + my_favorite + \". I don't know how to make that.\")",
"_____no_output_____"
]
],
[
[
"Conditionals can take ``and`` and ``or`` and ``not``. E.g.",
"_____no_output_____"
]
],
[
[
"my_favorite = 'pie'\n\nif my_favorite is 'cake' or my_favorite is 'pie':\n print(my_favorite + \" : I have a recipe for that!\")\nelse:\n print(\"Ew! Who eats that?\")",
"_____no_output_____"
]
],
[
[
"## For\n\nFor loops are the standard loop, though `while` is also common. For has the general form:\n```\nfor items in list:\n do stuff\n```\n\nFor loops and collections like tuples, lists and dictionaries are natural friends.",
"_____no_output_____"
]
],
[
[
"for instructor in instructors:\n print(instructor)",
"_____no_output_____"
]
],
[
[
"You can combine loops and conditionals:",
"_____no_output_____"
]
],
[
[
"for instructor in instructors:\n if instructor.endswith('Clown'):\n print(instructor + \" doesn't sound like a real instructor name!\")\n else:\n print(instructor + \" is so smart... all those gooey brains!\")",
"_____no_output_____"
]
],
[
[
"Dictionaries can use the `keys` method for iterating.",
"_____no_output_____"
]
],
[
[
"for key in my_dict.keys():\n if len(key) > 5:\n print(my_dict[key])",
"_____no_output_____"
]
],
[
[
"### range()\n\nSince for operates over lists, it is common to want to do something like:\n```\nNOTE: C-like\nfor (i = 0; i < 3; ++i) {\n print(i);\n}\n```\n\nThe Python equivalent is:\n\n```\nfor i in [0, 1, 2]:\n do something with i\n```\n\nWhat happens when the range you want to sample is big, e.g.\n```\nNOTE: C-like\nfor (i = 0; i < 1000000000; ++i) {\n print(i);\n}\n```\n\nThat would be a real pain in the rear to have to write out the entire list from 1 to 1000000000.\n\nEnter, the `range()` function. E.g.\n ```range(3) is [0, 1, 2]```",
"_____no_output_____"
]
],
[
[
"range(3)",
"_____no_output_____"
]
],
[
[
"Notice that Python (in the newest versions, e.g. 3+) has an object type that is a range. This saves memory and speeds up calculations vs. an explicit representation of a range as a list - but it can be automagically converted to a list on the fly by Python. To show the contents as a `list` we can use the type case like with the tuple above.\n\nSometimes, in older Python docs, you will see `xrange`. This used the range object back in Python 2 and `range` returned an actual list. Beware of this!",
"_____no_output_____"
]
],
[
[
"list(range(3))",
"_____no_output_____"
]
],
[
[
"Remember earlier with slicing, the syntax `:3` meant `[0, 1, 2]`? Well, the same upper bound philosophy applies here.\n",
"_____no_output_____"
]
],
[
[
"for index in range(3):\n instructor = instructors[index]\n if instructor.endswith('Clown'):\n print(instructor + \" doesn't sound like a real instructor name!\")\n else:\n print(instructor + \" is so smart... all those gooey brains!\")",
"_____no_output_____"
]
],
[
[
"This would probably be better written as",
"_____no_output_____"
]
],
[
[
"for index in range(len(instructors)):\n instructor = instructors[index]\n if instructor.endswith('Clown'):\n print(instructor + \" doesn't sound like a real instructor name!\")\n else:\n print(instructor + \" is so smart... all those gooey brains!\")",
"_____no_output_____"
]
],
[
[
"But in all, it isn't very Pythonesque to use indexes like that (unless you have another reason in the loop) and you would opt instead for the `instructor in instructors` form. \n\nMore often, you are doing something with the numbers that requires them to be integers, e.g. math.",
"_____no_output_____"
]
],
[
[
"sum = 0\nfor i in range(10):\n sum += i\nprint(sum)",
"_____no_output_____"
]
],
[
[
"#### For loops can be nested\n\n_Note_: for more on formatting strings, see: [https://pyformat.info](https://pyformat.info)",
"_____no_output_____"
]
],
[
[
"for i in range(1, 4):\n for j in range(1, 4):\n print('%d * %d = %d' % (i, j, i*j)) # Note string formatting here, %d means an integer",
"_____no_output_____"
]
],
[
[
"#### You can exit loops early if a condition is met:",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n if i == 4:\n break\ni",
"_____no_output_____"
]
],
[
[
"#### You can skip stuff in a loop with `continue`",
"_____no_output_____"
]
],
[
[
"sum = 0\nfor i in range(10):\n if (i == 5):\n continue\n else:\n sum += i\nprint(sum)",
"_____no_output_____"
]
],
[
[
"#### There is a unique language feature call ``for...else``",
"_____no_output_____"
]
],
[
[
"sum = 0\nfor i in range(10):\n sum += i\nelse:\n print('final i = %d, and sum = %d' % (i, sum))",
"_____no_output_____"
]
],
[
[
"#### You can iterate over letters in a string",
"_____no_output_____"
]
],
[
[
"my_string = \"DIRECT\"\nfor c in my_string:\n print(c)",
"_____no_output_____"
]
],
[
[
"<hr>\n## Hacky Hack Time with Ifs, Fors, Lists, and imports!\n\nObjective: Replace the `bash magic` bits for downloading the HCEPDB data and uncompressing it with Python code. Since the download is big, check if the zip file exists first before downloading it again. Then load it into a pandas dataframe.\n\nNotes:\n* The `os` package has tools for checking if a file exists: ``os.path.exists``\n```\nimport os\nfilename = 'HCEPDB_moldata.zip'\nif os.path.exists(filename):\n print(\"wahoo!\")\n```\n* Use the `requests` package to get the file given a url (got this from the requests docs)\n```\nimport requests\nurl = 'http://faculty.washington.edu/dacb/HCEPDB_moldata.zip'\nreq = requests.get(url)\nassert req.status_code == 200 # if the download failed, this line will generate an error\nwith open(filename, 'wb') as f:\n f.write(req.content)\n```\n* Use the `zipfile` package to decompress the file while reading it into `pandas`\n```\nimport pandas as pd\nimport zipfile\ncsv_filename = 'HCEPDB_moldata.csv'\nzf = zipfile.ZipFile(filename)\ndata = pd.read_csv(zf.open(csv_filename))\n```\n",
"_____no_output_____"
],
[
"### Now, use your code from above for the following URLs and filenames\n\n| URL | filename | csv_filename |\n|-----|----------|--------------|\n| http://faculty.washington.edu/dacb/HCEPDB_moldata_set1.zip | HCEPDB_moldata_set1.zip | HCEPDB_moldata_set1.csv |\n| http://faculty.washington.edu/dacb/HCEPDB_moldata_set2.zip | HCEPDB_moldata_set2.zip | HCEPDB_moldata_set2.csv |\n| http://faculty.washington.edu/dacb/HCEPDB_moldata_set3.zip | HCEPDB_moldata_set3.zip | HCEPDB_moldata_set3.csv |\n\nWhat pieces of the data structures and flow control that we talked about earlier can you use?",
"_____no_output_____"
],
[
"How did you solve this problem?",
"_____no_output_____"
],
[
"<hr>",
"_____no_output_____"
],
[
"### Functions\n\nFor loops let you repeat some code for every item in a list. Functions are similar in that they run the same lines of code for new values of some variable. They are different in that functions are not limited to looping over items.\n\nFunctions are a critical part of writing easy to read, reusable code.\n\nCreate a function like:\n```\ndef function_name (parameters):\n \"\"\"\n optional docstring\n \"\"\"\n function expressions\n return [variable]\n```\n\n_Note:_ Sometimes I use the word argument in place of parameter.\n\nHere is a simple example. It prints a string that was passed in and returns nothing.",
"_____no_output_____"
]
],
[
[
"def print_string(str):\n \"\"\"This prints out a string passed as the parameter.\"\"\"\n print(str)\n return",
"_____no_output_____"
]
],
[
[
"To call the function, use:\n```\nprint_string(\"Dave is awesome!\")\n```\n\n_Note:_ The function has to be defined before you can call it!",
"_____no_output_____"
]
],
[
[
"print_string(\"Dave is awesome!\")",
"_____no_output_____"
]
],
[
[
"If you don't provide an argument or too many, you get an error.",
"_____no_output_____"
],
[
"Parameters (or arguments) in Python are all passed by reference. This means that if you modify the parameters in the function, they are modified outside of the function.\n\nSee the following example:\n\n```\ndef change_list(my_list):\n \"\"\"This changes a passed list into this function\"\"\"\n my_list.append('four');\n print('list inside the function: ', my_list)\n return\n\nmy_list = [1, 2, 3];\nprint('list before the function: ', my_list)\nchange_list(my_list);\nprint('list after the function: ', my_list)\n```",
"_____no_output_____"
]
],
[
[
"def change_list(my_list):\n \"\"\"This changes a passed list into this function\"\"\"\n my_list.append('four');\n print('list inside the function: ', my_list)\n return\n\nmy_list = [1, 2, 3];\nprint('list before the function: ', my_list)\nchange_list(my_list);\nprint('list after the function: ', my_list)",
"list before the function: [1, 2, 3]\nlist inside the function: [1, 2, 3, 'four']\nlist after the function: [1, 2, 3, 'four']\n"
]
],
[
[
"Variables have scope: `global` and `local`\n\nIn a function, new variables that you create are not saved when the function returns - these are `local` variables. Variables defined outside of the function can be accessed but not changed - these are `global` variables, _Note_ there is a way to do this with the `global` keyword. Generally, the use of `global` variables is not encouraged, instead use parameters.\n\n```\nmy_global_1 = 'bad idea'\nmy_global_2 = 'another bad one'\nmy_global_3 = 'better idea'\n\ndef my_function():\n print(my_global)\n my_global_2 = 'broke your global, man!'\n global my_global_3\n my_global_3 = 'still a better idea'\n return\n \nmy_function()\nprint(my_global_2)\nprint(my_global_3)\n```",
"_____no_output_____"
],
[
"In general, you want to use parameters to provide data to a function and return a result with the `return`. E.g.\n\n```\ndef sum(x, y):\n my_sum = x + y\n return my_sum\n```\n\nIf you are going to return multiple objects, what data structure that we talked about can be used? Give and example below.",
"_____no_output_____"
],
[
"### Parameters have four different types:\n\n| type | behavior |\n|------|----------|\n| required | positional, must be present or error, e.g. `my_func(first_name, last_name)` |\n| keyword | position independent, e.g. `my_func(first_name, last_name)` can be called `my_func(first_name='Dave', last_name='Beck')` or `my_func(last_name='Beck', first_name='Dave')` |\n| default | keyword params that default to a value if not provided |\n",
"_____no_output_____"
]
],
[
[
"def print_name(first, last='the Clown'):\n print('Your name is %s %s' % (first, last))\n return",
"_____no_output_____"
]
],
[
[
"Play around with the above function.",
"_____no_output_____"
],
[
"Functions can contain any code that you put anywhere else including:\n* if...elif...else\n* for...else\n* while\n* other function calls",
"_____no_output_____"
]
],
[
[
"def print_name_age(first, last, age):\n print_name(first, last)\n print('Your age is %d' % (age))\n if age > 35:\n print('You are really old.')\n return",
"_____no_output_____"
],
[
"print_name_age(age=40, last='Beck', first='Dave')",
"_____no_output_____"
]
],
[
[
"#### How would you functionalize the above code for downloading, unzipping, and making a dataframe?",
"_____no_output_____"
],
[
"Once you have some code that is functionalized and not going to change, you can move it to a file that ends in `.py`, check it into version control, import it into your notebook and use it!\n\n",
"_____no_output_____"
],
[
"Homework:\nSave your functions to `hcepdb_utils.py`. Import the functions and use them to rewrite HW1. This will be laid out in the homework repo for HW2. Check the website.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
]
|
e7cad6c606af1c94e00e6edbbe0ecfaf522d673f | 262,972 | ipynb | Jupyter Notebook | figures/LINEAR_Example.ipynb | spencerwplovie/Lomb-Scargle-Copied | c7b83b0d79f03d3ecdec04f41ec1e1de85a486f7 | [
"CC-BY-4.0",
"BSD-3-Clause"
]
| 1 | 2018-10-02T01:02:43.000Z | 2018-10-02T01:02:43.000Z | figures/LINEAR_Example.ipynb | astrojuan/PracticalLombScargle | c7b83b0d79f03d3ecdec04f41ec1e1de85a486f7 | [
"CC-BY-4.0",
"BSD-3-Clause"
]
| null | null | null | figures/LINEAR_Example.ipynb | astrojuan/PracticalLombScargle | c7b83b0d79f03d3ecdec04f41ec1e1de85a486f7 | [
"CC-BY-4.0",
"BSD-3-Clause"
]
| null | null | null | 494.308271 | 74,296 | 0.933137 | [
[
[
"# Lomb-Scargle Example Dataset",
"_____no_output_____"
],
[
"## The Data\n\nFor simplicity, we download the data here and save locally",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ndef get_LINEAR_lightcurve(lcid):\n from astroML.datasets import fetch_LINEAR_sample\n LINEAR_sample = fetch_LINEAR_sample()\n data = pd.DataFrame(LINEAR_sample[lcid],\n columns=['t', 'mag', 'magerr'])\n data.to_csv('LINEAR_{0}.csv'.format(lcid), index=False)\n \n# Uncomment to download the data\n# get_LINEAR_lightcurve(lcid=11375941)",
"_____no_output_____"
],
[
"data = pd.read_csv('LINEAR_11375941.csv')\ndata.head()",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"(data.t.max() - data.t.min()) / 365.",
"_____no_output_____"
]
],
[
[
"## Visualizing the Data",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\n\nplt.style.use('seaborn-whitegrid')",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(8, 3))\nax.errorbar(data.t, data.mag, data.magerr,\n fmt='.k', ecolor='gray', capsize=0)\nax.set(xlabel='time (MJD)',\n ylabel='magnitude',\n title='LINEAR object 11375941')\nax.invert_yaxis()\n\nfig.savefig('fig01_LINEAR_data.pdf');",
"_____no_output_____"
],
[
"from astropy.stats import LombScargle\nls = LombScargle(data.t, data.mag, data.magerr)\nfrequency, power = ls.autopower(nyquist_factor=500,\n minimum_frequency=0.2)\n\nperiod_days = 1. / frequency\nperiod_hours = period_days * 24",
"_____no_output_____"
],
[
"best_period = period_days[np.argmax(power)]\n\nphase = (data.t / best_period) % 1\n\nprint(\"Best period: {0:.2f} hours\".format(24 * best_period))",
"Best period: 2.58 hours\n"
],
[
"fig, ax = plt.subplots(1, 2, figsize=(8, 3))\n\n# PSD has a _LOT_ of elements. Rasterize it so it can be displayed as PDF\nax[0].plot(period_days, power, '-k', rasterized=True)\n\nax[0].set(xlim=(0, 2.5), ylim=(0, 0.8),\n xlabel='Period (days)',\n ylabel='Lomb-Scargle Power',\n title='Lomb-Scargle Periodogram')\n\nax[1].errorbar(phase, data.mag, data.magerr,\n fmt='.k', ecolor='gray', capsize=0)\nax[1].set(xlabel='phase',\n ylabel='magnitude',\n title='Phased Data')\nax[1].invert_yaxis()\nax[1].text(0.02, 0.03, \"Period = {0:.2f} hours\".format(24 * best_period),\n transform=ax[1].transAxes)\n\ninset = fig.add_axes([0.25, 0.6, 0.2, 0.25])\ninset.plot(period_hours, power, '-k', rasterized=True)\ninset.xaxis.set_major_locator(plt.MultipleLocator(1))\ninset.yaxis.set_major_locator(plt.MultipleLocator(0.2))\ninset.set(xlim=(1, 5),\n xlabel='Period (hours)',\n ylabel='power')\n\nfig.savefig('fig02_LINEAR_PSD.pdf');",
"_____no_output_____"
]
],
[
[
"## Peak Precision\n\nEstimate peak precision by plotting the Bayesian periodogram peak and fitting a Gaussian to the peak (for simplicity, just do it by-eye):",
"_____no_output_____"
]
],
[
[
"f, P = ls.autopower(nyquist_factor=500,\n minimum_frequency=9.3,\n maximum_frequency=9.31,\n samples_per_peak=20,\n normalization='psd')\nP = np.exp(P)\nP /= P.max()\nh = 24. / f\n\nplt.plot(h, P, '-k')\nplt.fill(h, np.exp(-0.5 * (h - 2.58014) ** 2 / 0.00004 ** 2), color='gray', alpha=0.3)\nplt.xlim(2.58, 2.5803)",
"/Users/jakevdp/anaconda/envs/python3.5/lib/python3.5/site-packages/ipykernel/__main__.py:6: RuntimeWarning: overflow encountered in exp\n/Users/jakevdp/anaconda/envs/python3.5/lib/python3.5/site-packages/ipykernel/__main__.py:7: RuntimeWarning: invalid value encountered in true_divide\n"
]
],
[
[
"Looks like $2.58023 \\pm 0.00006$ hours",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(10, 3))\n\nphase_model = np.linspace(-0.5, 1.5, 100)\nbest_frequency = frequency[np.argmax(power)]\nmag_model = ls.model(phase_model / best_frequency, best_frequency)\n\nfor offset in [-1, 0, 1]:\n ax.errorbar(phase + offset, data.mag, data.magerr, fmt='.',\n color='gray', ecolor='lightgray', capsize=0);\nax.plot(phase_model, mag_model, '-k', lw=2)\nax.set(xlim=(-0.5, 1.5),\n xlabel='phase',\n ylabel='mag')\nax.invert_yaxis()\n\nfig.savefig('fig18_ls_model.pdf')",
"_____no_output_____"
],
[
"period_hours_bad = np.linspace(1, 6, 10001)\nfrequency_bad = 24 / period_hours_bad\npower_bad = ls.power(frequency_bad)\n\nmask = (period_hours > 1) & (period_hours < 6)\n\nfig, ax = plt.subplots(figsize=(10, 3))\nax.plot(period_hours[mask], power[mask], '-', color='lightgray',\n rasterized=True, label='Well-motivated frequency grid')\nax.plot(period_hours_bad, power_bad, '-k',\n rasterized=True, label='10,000 equally-spaced periods')\nax.grid(False)\nax.legend()\nax.set(xlabel='period (hours)',\n ylabel='Lomb-Scargle Power',\n title='LINEAR object 11375941')\n\nfig.savefig('fig19_LINEAR_coarse_grid.pdf')",
"_____no_output_____"
]
],
[
[
"## Required Grid Spacing",
"_____no_output_____"
]
],
[
[
"!head LINEAR_11375941.csv",
"t,mag,magerr\r\n52650.434545,15.969,0.035\r\n52650.44845,16.036,0.039\r\n52650.46242,15.99,0.035\r\n52650.476485,16.027,0.035\r\n52650.490443,15.675,0.03\r\n52666.464263,15.945,0.037\r\n52666.478719,15.97,0.035\r\n52666.493183,16.001,0.035\r\n52666.50771,15.829,0.031\r\n"
],
[
"n_digits = 6\nf_ny = 0.5 * 10 ** n_digits\nT = (data.t.max() - data.t.min())\nn_o = 5\n\ndelta_f = 1. / n_o / T\n\nprint(\"f_ny =\", f_ny)\nprint(\"T =\", T)\nprint(\"n_grid =\", f_ny / delta_f)",
"f_ny = 500000.0\nT = 1961.847365\nn_grid = 4904618412.5\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7cae3812ef87a5cd66cadee8c700a11ab58085d | 6,997 | ipynb | Jupyter Notebook | notebooks/users/SAMM-OSS/owaspsamm.ipynb | OpenSecuritySummit/jp-samm | 271fcb38b32f3d615ba560d44e75abc3a95a59db | [
"Apache-2.0"
]
| null | null | null | notebooks/users/SAMM-OSS/owaspsamm.ipynb | OpenSecuritySummit/jp-samm | 271fcb38b32f3d615ba560d44e75abc3a95a59db | [
"Apache-2.0"
]
| null | null | null | notebooks/users/SAMM-OSS/owaspsamm.ipynb | OpenSecuritySummit/jp-samm | 271fcb38b32f3d615ba560d44e75abc3a95a59db | [
"Apache-2.0"
]
| null | null | null | 28.67623 | 124 | 0.571388 | [
[
[
"# OWASP SAMM Open Security Summit Outcomes\n<img src=\"https://raw.githubusercontent.com/OWASP/samm/master/Supporting%20Resources/v2.0/LOGO-SAMM.png\" width=200/>",
"_____no_output_____"
],
[
"## Monday\n\n- Collected feedback from actual users in the sessions\n- Defined options for questions in the Measurement model \n <img src=\"https://files.slack.com/files-pri/TAULHPATC-FJWEV3N9Z/image.png\" />\n- Agreed to try out the options in smaller groups",
"_____no_output_____"
],
[
"## Tuesday\n\n\n### AM\n- Groups created questions \n https://1drv.ms/w/s!Ag3u_YTLhehYhbAMdHsC9cf73M58LA \n https://docs.google.com/spreadsheets/d/1Bcx7cUyFPGm796opIBh4YuPtlNPISBBwhmCq38uj8P0/edit?usp=sharing\n- Discussed questions format\n- Discussed scoring\n\n### PM1\n\nQuestions\n- 0-3\n- 0 is no\n- 1-3: to answer these you need to meet the criteria\n- Define criteria (called guidance in previous models)\n- Limit the number of questions to determine maturity\n- Criteria provides a standard of quality to achieve maturity level\n- Range of answers provides measure of coverage (completeness)\n\nAfter some heavy debate, we agreed on the measuring model.\n\nWriting guidelines\n- https://docs.google.com/presentation/d/1GK1fgbeq9fwEdVscjyr-kwPRE5jTf4VRR0-eTrDdYsc/edit?usp=sharing\n\n### PM2\n\nQuestions\n- Education & Guidance almost complete in GitHub in a .yaml file\n- Secure Deployment in GitHub in a .yaml file\n- Threat Assessment in a \"YAML\" file\n https://docs.google.com/document/d/1E-eUqwWnGRyyP91PydIGuhsmy5oaoVR05e5SDoWKh9o/edit?usp=sharing\n\n### EV1\n\nGitHub issues\n- 91\n- 111\n- 117\n- 118\n\nDiscussed process, visualization, tooling\n",
"_____no_output_____"
],
[
"## Wednesday\n\n\n### AM\n\n**Defined writing guidelines for questions and quality criteria** \n\n<img src=\"https://files.slack.com/files-pri/TAULHPATC-FKA0NMKQ8/image.png\" /> \n\n**Worked as a group to define one question** \n\n<img src=\"https://files.slack.com/files-pri/TAULHPATC-FK9C2GZSQ/image.png\" />\n\n### PM\n\n#### PM 1 & 2\n\n- Questions for Design, Security Architecture practice\n- Started mapping of ASVS to SAMM\n\n#### DevSecOps Session\n\n- Discussed the mapping from DSOMM to SAMM\n\n\n### Evening session\n\n\n#### GitHub issues\n\n**Restructure Secure Deployment Stream A**\n#123 \n\nsecure build - points for integrating security testing tools into the build pipeline\nsecure deploy - points for \nsecurity testing - are you doing it well even as a stand-alone practice? SAST or DAST well\n\nbuild is where you decide how you're going to record the integrity of what you're building\ndeploy is where you verify\n\n**Revise integrity checks in secure build and deployment**\n#124\n\nChange build to: \n1. E.g., Hash\n2. E.g., Code sign - proof is hard-linked to artifact - and auth'd\n3. Deterministic - build process itself has integrity (reproducible build)\n\nKeep deployment as it is, not requiring integrity verification.\n2. Verify integrity\n3. Verify signature\n\nFor both, use terms that are terminology-agnostic.\n\nHashing and code signing should be examples - describe their properties (e.g. hard linked to artifact)\n\n\n#### References\n\n\n**OWASP references**\n\nOnly reference Lab or Flaghsip projects\n\nAdd more details when using OWASP references.\n\nThey are part of the Additional documents, not the core model.\n\nAdd more details \n- name of the project\n- version\n- some other info that makes sense in the project\n\n**External references**\n\nIt could be a link to the DevSecOps maturity model.\n\nBe careful what you include because they imply endorsement.\n\nBe explicit about this: external references don't mean SAMM endorse them.\n\nThey are part of the Additional documents, not the core model.\n\n**SAMM references**\n\nAdd internal references in the core model.\n\nInclude \n- Business\n- function\n- practice\n- stream\n- level\n\nDependencies between business functions and streams\n\n#### Contributing to the SAMM project\n\nYan created a guidance document.\n\nhttps://owaspsamm.org/head/contributing-to-git/\n\n\n ",
"_____no_output_____"
],
[
"## Thursday\n\n### Measurement Model\n\n#### Questions report\n\nWe have a report where with all the questions from all the business functions.\n\nhttps://owaspsamm.org/head/question-report/\n\n#### Parallel editing\n\nWe worked on writing more questions for the model.\n\n### Process\n\n1. Define the objectives for the \n Business function | Practice | Stream| Maturity level\n2. Review\n3. Write the questions for the activities\n4. Write the quality criteria\n5. Review\n6. Write the description and description for the activity, including \n - examples\n - suggestions for how to do them\n - links to other activities\n",
"_____no_output_____"
]
]
]
| [
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
e7caf4be3c46bd02604afeb798a7db3dba200a02 | 55,575 | ipynb | Jupyter Notebook | Course1_week4_Building your Deep Neural Network - Step by Step v8.ipynb | korra0501/deeplearning.ai-coursera | 2cea7bb8aaedf08bfa762fb4b1ce651e0d1423be | [
"MIT"
]
| null | null | null | Course1_week4_Building your Deep Neural Network - Step by Step v8.ipynb | korra0501/deeplearning.ai-coursera | 2cea7bb8aaedf08bfa762fb4b1ce651e0d1423be | [
"MIT"
]
| null | null | null | Course1_week4_Building your Deep Neural Network - Step by Step v8.ipynb | korra0501/deeplearning.ai-coursera | 2cea7bb8aaedf08bfa762fb4b1ce651e0d1423be | [
"MIT"
]
| null | null | null | 37.729124 | 562 | 0.514206 | [
[
[
"# Building your Deep Neural Network: Step by Step\n\nWelcome to your week 4 assignment (part 1 of 2)! You have previously trained a 2-layer Neural Network (with a single hidden layer). This week, you will build a deep neural network, with as many layers as you want!\n\n- In this notebook, you will implement all the functions required to build a deep neural network.\n- In the next assignment, you will use these functions to build a deep neural network for image classification.\n\n**After this assignment you will be able to:**\n- Use non-linear units like ReLU to improve your model\n- Build a deeper neural network (with more than 1 hidden layer)\n- Implement an easy-to-use neural network class\n\n**Notation**:\n- Superscript $[l]$ denotes a quantity associated with the $l^{th}$ layer. \n - Example: $a^{[L]}$ is the $L^{th}$ layer activation. $W^{[L]}$ and $b^{[L]}$ are the $L^{th}$ layer parameters.\n- Superscript $(i)$ denotes a quantity associated with the $i^{th}$ example. \n - Example: $x^{(i)}$ is the $i^{th}$ training example.\n- Lowerscript $i$ denotes the $i^{th}$ entry of a vector.\n - Example: $a^{[l]}_i$ denotes the $i^{th}$ entry of the $l^{th}$ layer's activations).\n\nLet's get started!",
"_____no_output_____"
],
[
"## 1 - Packages\n\nLet's first import all the packages that you will need during this assignment. \n- [numpy](www.numpy.org) is the main package for scientific computing with Python.\n- [matplotlib](http://matplotlib.org) is a library to plot graphs in Python.\n- dnn_utils provides some necessary functions for this notebook.\n- testCases provides some test cases to assess the correctness of your functions\n- np.random.seed(1) is used to keep all the random function calls consistent. It will help us grade your work. Please don't change the seed. ",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport h5py\nimport matplotlib.pyplot as plt\nfrom testCases_v4 import *\nfrom dnn_utils_v2 import sigmoid, sigmoid_backward, relu, relu_backward\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots\nplt.rcParams['image.interpolation'] = 'nearest'\nplt.rcParams['image.cmap'] = 'gray'\n\n%load_ext autoreload\n%autoreload 2\n\nnp.random.seed(1)",
"C:\\Users\\korra\\Anaconda3\\lib\\site-packages\\h5py\\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n"
]
],
[
[
"## 2 - Outline of the Assignment\n\nTo build your neural network, you will be implementing several \"helper functions\". These helper functions will be used in the next assignment to build a two-layer neural network and an L-layer neural network. Each small helper function you will implement will have detailed instructions that will walk you through the necessary steps. Here is an outline of this assignment, you will:\n\n- Initialize the parameters for a two-layer network and for an $L$-layer neural network.\n- Implement the forward propagation module (shown in purple in the figure below).\n - Complete the LINEAR part of a layer's forward propagation step (resulting in $Z^{[l]}$).\n - We give you the ACTIVATION function (relu/sigmoid).\n - Combine the previous two steps into a new [LINEAR->ACTIVATION] forward function.\n - Stack the [LINEAR->RELU] forward function L-1 time (for layers 1 through L-1) and add a [LINEAR->SIGMOID] at the end (for the final layer $L$). This gives you a new L_model_forward function.\n- Compute the loss.\n- Implement the backward propagation module (denoted in red in the figure below).\n - Complete the LINEAR part of a layer's backward propagation step.\n - We give you the gradient of the ACTIVATE function (relu_backward/sigmoid_backward) \n - Combine the previous two steps into a new [LINEAR->ACTIVATION] backward function.\n - Stack [LINEAR->RELU] backward L-1 times and add [LINEAR->SIGMOID] backward in a new L_model_backward function\n- Finally update the parameters.\n\n<img src=\"images/final outline.png\" style=\"width:800px;height:500px;\">\n<caption><center> **Figure 1**</center></caption><br>\n\n\n**Note** that for every forward function, there is a corresponding backward function. That is why at every step of your forward module you will be storing some values in a cache. The cached values are useful for computing gradients. In the backpropagation module you will then use the cache to calculate the gradients. This assignment will show you exactly how to carry out each of these steps. ",
"_____no_output_____"
],
[
"## 3 - Initialization\n\nYou will write two helper functions that will initialize the parameters for your model. The first function will be used to initialize parameters for a two layer model. The second one will generalize this initialization process to $L$ layers.\n\n### 3.1 - 2-layer Neural Network\n\n**Exercise**: Create and initialize the parameters of the 2-layer neural network.\n\n**Instructions**:\n- The model's structure is: *LINEAR -> RELU -> LINEAR -> SIGMOID*. \n- Use random initialization for the weight matrices. Use `np.random.randn(shape)*0.01` with the correct shape.\n- Use zero initialization for the biases. Use `np.zeros(shape)`.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_parameters\n\ndef initialize_parameters(n_x, n_h, n_y):\n \"\"\"\n Argument:\n n_x -- size of the input layer\n n_h -- size of the hidden layer\n n_y -- size of the output layer\n \n Returns:\n parameters -- python dictionary containing your parameters:\n W1 -- weight matrix of shape (n_h, n_x)\n b1 -- bias vector of shape (n_h, 1)\n W2 -- weight matrix of shape (n_y, n_h)\n b2 -- bias vector of shape (n_y, 1)\n \"\"\"\n \n np.random.seed(1)\n \n ### START CODE HERE ### (≈ 4 lines of code)\n W1 = np.random.randn(n_h, n_x)*0.01\n b1 = np.zeros((n_h, 1))\n W2 = np.random.randn(n_y, n_h)*0.01\n b2 = np.zeros((n_y, 1))\n ### END CODE HERE ###\n \n assert(W1.shape == (n_h, n_x))\n assert(b1.shape == (n_h, 1))\n assert(W2.shape == (n_y, n_h))\n assert(b2.shape == (n_y, 1))\n \n parameters = {\"W1\": W1,\n \"b1\": b1,\n \"W2\": W2,\n \"b2\": b2}\n \n return parameters ",
"_____no_output_____"
],
[
"parameters = initialize_parameters(3,2,1)\nprint(\"W1 = \" + str(parameters[\"W1\"]))\nprint(\"b1 = \" + str(parameters[\"b1\"]))\nprint(\"W2 = \" + str(parameters[\"W2\"]))\nprint(\"b2 = \" + str(parameters[\"b2\"]))",
"W1 = [[ 0.01624345 -0.00611756 -0.00528172]\n [-0.01072969 0.00865408 -0.02301539]]\nb1 = [[0.]\n [0.]]\nW2 = [[ 0.01744812 -0.00761207]]\nb2 = [[0.]]\n"
]
],
[
[
"**Expected output**:\n \n<table style=\"width:80%\">\n <tr>\n <td> **W1** </td>\n <td> [[ 0.01624345 -0.00611756 -0.00528172]\n [-0.01072969 0.00865408 -0.02301539]] </td> \n </tr>\n\n <tr>\n <td> **b1**</td>\n <td>[[ 0.]\n [ 0.]]</td> \n </tr>\n \n <tr>\n <td>**W2**</td>\n <td> [[ 0.01744812 -0.00761207]]</td>\n </tr>\n \n <tr>\n <td> **b2** </td>\n <td> [[ 0.]] </td> \n </tr>\n \n</table>",
"_____no_output_____"
],
[
"### 3.2 - L-layer Neural Network\n\nThe initialization for a deeper L-layer neural network is more complicated because there are many more weight matrices and bias vectors. When completing the `initialize_parameters_deep`, you should make sure that your dimensions match between each layer. Recall that $n^{[l]}$ is the number of units in layer $l$. Thus for example if the size of our input $X$ is $(12288, 209)$ (with $m=209$ examples) then:\n\n<table style=\"width:100%\">\n\n\n <tr>\n <td> </td> \n <td> **Shape of W** </td> \n <td> **Shape of b** </td> \n <td> **Activation** </td>\n <td> **Shape of Activation** </td> \n <tr>\n \n <tr>\n <td> **Layer 1** </td> \n <td> $(n^{[1]},12288)$ </td> \n <td> $(n^{[1]},1)$ </td> \n <td> $Z^{[1]} = W^{[1]} X + b^{[1]} $ </td> \n <td> $(n^{[1]},209)$ </td> \n <tr>\n \n <tr>\n <td> **Layer 2** </td> \n <td> $(n^{[2]}, n^{[1]})$ </td> \n <td> $(n^{[2]},1)$ </td> \n <td>$Z^{[2]} = W^{[2]} A^{[1]} + b^{[2]}$ </td> \n <td> $(n^{[2]}, 209)$ </td> \n <tr>\n \n <tr>\n <td> $\\vdots$ </td> \n <td> $\\vdots$ </td> \n <td> $\\vdots$ </td> \n <td> $\\vdots$</td> \n <td> $\\vdots$ </td> \n <tr>\n \n <tr>\n <td> **Layer L-1** </td> \n <td> $(n^{[L-1]}, n^{[L-2]})$ </td> \n <td> $(n^{[L-1]}, 1)$ </td> \n <td>$Z^{[L-1]} = W^{[L-1]} A^{[L-2]} + b^{[L-1]}$ </td> \n <td> $(n^{[L-1]}, 209)$ </td> \n <tr>\n \n \n <tr>\n <td> **Layer L** </td> \n <td> $(n^{[L]}, n^{[L-1]})$ </td> \n <td> $(n^{[L]}, 1)$ </td>\n <td> $Z^{[L]} = W^{[L]} A^{[L-1]} + b^{[L]}$</td>\n <td> $(n^{[L]}, 209)$ </td> \n <tr>\n\n</table>\n\nRemember that when we compute $W X + b$ in python, it carries out broadcasting. For example, if: \n\n$$ W = \\begin{bmatrix}\n j & k & l\\\\\n m & n & o \\\\\n p & q & r \n\\end{bmatrix}\\;\\;\\; X = \\begin{bmatrix}\n a & b & c\\\\\n d & e & f \\\\\n g & h & i \n\\end{bmatrix} \\;\\;\\; b =\\begin{bmatrix}\n s \\\\\n t \\\\\n u\n\\end{bmatrix}\\tag{2}$$\n\nThen $WX + b$ will be:\n\n$$ WX + b = \\begin{bmatrix}\n (ja + kd + lg) + s & (jb + ke + lh) + s & (jc + kf + li)+ s\\\\\n (ma + nd + og) + t & (mb + ne + oh) + t & (mc + nf + oi) + t\\\\\n (pa + qd + rg) + u & (pb + qe + rh) + u & (pc + qf + ri)+ u\n\\end{bmatrix}\\tag{3} $$",
"_____no_output_____"
],
[
"**Exercise**: Implement initialization for an L-layer Neural Network. \n\n**Instructions**:\n- The model's structure is *[LINEAR -> RELU] $ \\times$ (L-1) -> LINEAR -> SIGMOID*. I.e., it has $L-1$ layers using a ReLU activation function followed by an output layer with a sigmoid activation function.\n- Use random initialization for the weight matrices. Use `np.random.randn(shape) * 0.01`.\n- Use zeros initialization for the biases. Use `np.zeros(shape)`.\n- We will store $n^{[l]}$, the number of units in different layers, in a variable `layer_dims`. For example, the `layer_dims` for the \"Planar Data classification model\" from last week would have been [2,4,1]: There were two inputs, one hidden layer with 4 hidden units, and an output layer with 1 output unit. Thus means `W1`'s shape was (4,2), `b1` was (4,1), `W2` was (1,4) and `b2` was (1,1). Now you will generalize this to $L$ layers! \n- Here is the implementation for $L=1$ (one layer neural network). It should inspire you to implement the general case (L-layer neural network).\n```python\n if L == 1:\n parameters[\"W\" + str(L)] = np.random.randn(layer_dims[1], layer_dims[0]) * 0.01\n parameters[\"b\" + str(L)] = np.zeros((layer_dims[1], 1))\n```",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_parameters_deep\n\ndef initialize_parameters_deep(layer_dims):\n \"\"\"\n Arguments:\n layer_dims -- python array (list) containing the dimensions of each layer in our network\n \n Returns:\n parameters -- python dictionary containing your parameters \"W1\", \"b1\", ..., \"WL\", \"bL\":\n Wl -- weight matrix of shape (layer_dims[l], layer_dims[l-1])\n bl -- bias vector of shape (layer_dims[l], 1)\n \"\"\"\n \n np.random.seed(3)\n parameters = {}\n L = len(layer_dims) # number of layers in the network\n\n for l in range(1, L):\n ### START CODE HERE ### (≈ 2 lines of code)\n parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) * 0.01\n parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))\n ### END CODE HERE ###\n \n assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))\n assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))\n\n \n return parameters",
"_____no_output_____"
],
[
"parameters = initialize_parameters_deep([5,4,3])\nprint(\"W1 = \" + str(parameters[\"W1\"]))\nprint(\"b1 = \" + str(parameters[\"b1\"]))\nprint(\"W2 = \" + str(parameters[\"W2\"]))\nprint(\"b2 = \" + str(parameters[\"b2\"]))",
"W1 = [[ 0.01788628 0.0043651 0.00096497 -0.01863493 -0.00277388]\n [-0.00354759 -0.00082741 -0.00627001 -0.00043818 -0.00477218]\n [-0.01313865 0.00884622 0.00881318 0.01709573 0.00050034]\n [-0.00404677 -0.0054536 -0.01546477 0.00982367 -0.01101068]]\nb1 = [[0.]\n [0.]\n [0.]\n [0.]]\nW2 = [[-0.01185047 -0.0020565 0.01486148 0.00236716]\n [-0.01023785 -0.00712993 0.00625245 -0.00160513]\n [-0.00768836 -0.00230031 0.00745056 0.01976111]]\nb2 = [[0.]\n [0.]\n [0.]]\n"
]
],
[
[
"**Expected output**:\n \n<table style=\"width:80%\">\n <tr>\n <td> **W1** </td>\n <td>[[ 0.01788628 0.0043651 0.00096497 -0.01863493 -0.00277388]\n [-0.00354759 -0.00082741 -0.00627001 -0.00043818 -0.00477218]\n [-0.01313865 0.00884622 0.00881318 0.01709573 0.00050034]\n [-0.00404677 -0.0054536 -0.01546477 0.00982367 -0.01101068]]</td> \n </tr>\n \n <tr>\n <td>**b1** </td>\n <td>[[ 0.]\n [ 0.]\n [ 0.]\n [ 0.]]</td> \n </tr>\n \n <tr>\n <td>**W2** </td>\n <td>[[-0.01185047 -0.0020565 0.01486148 0.00236716]\n [-0.01023785 -0.00712993 0.00625245 -0.00160513]\n [-0.00768836 -0.00230031 0.00745056 0.01976111]]</td> \n </tr>\n \n <tr>\n <td>**b2** </td>\n <td>[[ 0.]\n [ 0.]\n [ 0.]]</td> \n </tr>\n \n</table>",
"_____no_output_____"
],
[
"## 4 - Forward propagation module\n\n### 4.1 - Linear Forward \nNow that you have initialized your parameters, you will do the forward propagation module. You will start by implementing some basic functions that you will use later when implementing the model. You will complete three functions in this order:\n\n- LINEAR\n- LINEAR -> ACTIVATION where ACTIVATION will be either ReLU or Sigmoid. \n- [LINEAR -> RELU] $\\times$ (L-1) -> LINEAR -> SIGMOID (whole model)\n\nThe linear forward module (vectorized over all the examples) computes the following equations:\n\n$$Z^{[l]} = W^{[l]}A^{[l-1]} +b^{[l]}\\tag{4}$$\n\nwhere $A^{[0]} = X$. \n\n**Exercise**: Build the linear part of forward propagation.\n\n**Reminder**:\nThe mathematical representation of this unit is $Z^{[l]} = W^{[l]}A^{[l-1]} +b^{[l]}$. You may also find `np.dot()` useful. If your dimensions don't match, printing `W.shape` may help.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_forward\n\ndef linear_forward(A, W, b):\n \"\"\"\n Implement the linear part of a layer's forward propagation.\n\n Arguments:\n A -- activations from previous layer (or input data): (size of previous layer, number of examples)\n W -- weights matrix: numpy array of shape (size of current layer, size of previous layer)\n b -- bias vector, numpy array of shape (size of the current layer, 1)\n\n Returns:\n Z -- the input of the activation function, also called pre-activation parameter \n cache -- a python dictionary containing \"A\", \"W\" and \"b\" ; stored for computing the backward pass efficiently\n \"\"\"\n \n ### START CODE HERE ### (≈ 1 line of code)\n Z = np.dot(W, A) + b\n ### END CODE HERE ###\n \n assert(Z.shape == (W.shape[0], A.shape[1]))\n cache = (A, W, b)\n \n return Z, cache",
"_____no_output_____"
],
[
"A, W, b = linear_forward_test_case()\n\nZ, linear_cache = linear_forward(A, W, b)\nprint(\"Z = \" + str(Z))",
"Z = [[ 3.26295337 -1.23429987]]\n"
]
],
[
[
"**Expected output**:\n\n<table style=\"width:35%\">\n \n <tr>\n <td> **Z** </td>\n <td> [[ 3.26295337 -1.23429987]] </td> \n </tr>\n \n</table>",
"_____no_output_____"
],
[
"### 4.2 - Linear-Activation Forward\n\nIn this notebook, you will use two activation functions:\n\n- **Sigmoid**: $\\sigma(Z) = \\sigma(W A + b) = \\frac{1}{ 1 + e^{-(W A + b)}}$. We have provided you with the `sigmoid` function. This function returns **two** items: the activation value \"`a`\" and a \"`cache`\" that contains \"`Z`\" (it's what we will feed in to the corresponding backward function). To use it you could just call: \n``` python\nA, activation_cache = sigmoid(Z)\n```\n\n- **ReLU**: The mathematical formula for ReLu is $A = RELU(Z) = max(0, Z)$. We have provided you with the `relu` function. This function returns **two** items: the activation value \"`A`\" and a \"`cache`\" that contains \"`Z`\" (it's what we will feed in to the corresponding backward function). To use it you could just call:\n``` python\nA, activation_cache = relu(Z)\n```",
"_____no_output_____"
],
[
"For more convenience, you are going to group two functions (Linear and Activation) into one function (LINEAR->ACTIVATION). Hence, you will implement a function that does the LINEAR forward step followed by an ACTIVATION forward step.\n\n**Exercise**: Implement the forward propagation of the *LINEAR->ACTIVATION* layer. Mathematical relation is: $A^{[l]} = g(Z^{[l]}) = g(W^{[l]}A^{[l-1]} +b^{[l]})$ where the activation \"g\" can be sigmoid() or relu(). Use linear_forward() and the correct activation function.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_activation_forward\n\ndef linear_activation_forward(A_prev, W, b, activation):\n \"\"\"\n Implement the forward propagation for the LINEAR->ACTIVATION layer\n\n Arguments:\n A_prev -- activations from previous layer (or input data): (size of previous layer, number of examples)\n W -- weights matrix: numpy array of shape (size of current layer, size of previous layer)\n b -- bias vector, numpy array of shape (size of the current layer, 1)\n activation -- the activation to be used in this layer, stored as a text string: \"sigmoid\" or \"relu\"\n\n Returns:\n A -- the output of the activation function, also called the post-activation value \n cache -- a python dictionary containing \"linear_cache\" and \"activation_cache\";\n stored for computing the backward pass efficiently\n \"\"\"\n \n if activation == \"sigmoid\":\n # Inputs: \"A_prev, W, b\". Outputs: \"A, activation_cache\".\n ### START CODE HERE ### (≈ 2 lines of code)\n Z, linear_cache = linear_forward(A_prev, W, b)\n A, activation_cache = sigmoid(Z)\n ### END CODE HERE ###\n \n elif activation == \"relu\":\n # Inputs: \"A_prev, W, b\". Outputs: \"A, activation_cache\".\n ### START CODE HERE ### (≈ 2 lines of code)\n Z, linear_cache = linear_forward(A_prev, W, b)\n A, activation_cache = relu(Z)\n ### END CODE HERE ###\n \n assert (A.shape == (W.shape[0], A_prev.shape[1]))\n cache = (linear_cache, activation_cache)\n\n return A, cache",
"_____no_output_____"
],
[
"A_prev, W, b = linear_activation_forward_test_case()\n\nA, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = \"sigmoid\")\nprint(\"With sigmoid: A = \" + str(A))\n\nA, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = \"relu\")\nprint(\"With ReLU: A = \" + str(A))",
"With sigmoid: A = [[0.96890023 0.11013289]]\nWith ReLU: A = [[3.43896131 0. ]]\n"
]
],
[
[
"**Expected output**:\n \n<table style=\"width:35%\">\n <tr>\n <td> **With sigmoid: A ** </td>\n <td > [[ 0.96890023 0.11013289]]</td> \n </tr>\n <tr>\n <td> **With ReLU: A ** </td>\n <td > [[ 3.43896131 0. ]]</td> \n </tr>\n</table>\n",
"_____no_output_____"
],
[
"**Note**: In deep learning, the \"[LINEAR->ACTIVATION]\" computation is counted as a single layer in the neural network, not two layers. ",
"_____no_output_____"
],
[
"### d) L-Layer Model \n\nFor even more convenience when implementing the $L$-layer Neural Net, you will need a function that replicates the previous one (`linear_activation_forward` with RELU) $L-1$ times, then follows that with one `linear_activation_forward` with SIGMOID.\n\n<img src=\"images/model_architecture_kiank.png\" style=\"width:600px;height:300px;\">\n<caption><center> **Figure 2** : *[LINEAR -> RELU] $\\times$ (L-1) -> LINEAR -> SIGMOID* model</center></caption><br>\n\n**Exercise**: Implement the forward propagation of the above model.\n\n**Instruction**: In the code below, the variable `AL` will denote $A^{[L]} = \\sigma(Z^{[L]}) = \\sigma(W^{[L]} A^{[L-1]} + b^{[L]})$. (This is sometimes also called `Yhat`, i.e., this is $\\hat{Y}$.) \n\n**Tips**:\n- Use the functions you had previously written \n- Use a for loop to replicate [LINEAR->RELU] (L-1) times\n- Don't forget to keep track of the caches in the \"caches\" list. To add a new value `c` to a `list`, you can use `list.append(c)`.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: L_model_forward\n\ndef L_model_forward(X, parameters):\n \"\"\"\n Implement forward propagation for the [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID computation\n \n Arguments:\n X -- data, numpy array of shape (input size, number of examples)\n parameters -- output of initialize_parameters_deep()\n \n Returns:\n AL -- last post-activation value\n caches -- list of caches containing:\n every cache of linear_activation_forward() (there are L-1 of them, indexed from 0 to L-1)\n \"\"\"\n\n caches = []\n A = X\n L = len(parameters) // 2 # number of layers in the neural network\n \n # Implement [LINEAR -> RELU]*(L-1). Add \"cache\" to the \"caches\" list.\n for l in range(1, L):\n A_prev = A \n ### START CODE HERE ### (≈ 2 lines of code)\n A, cache = linear_activation_forward(A_prev, parameters['W'+str(l)], parameters['b'+str(l)], activation='relu')\n caches.append(cache)\n ### END CODE HERE ###\n \n # Implement LINEAR -> SIGMOID. Add \"cache\" to the \"caches\" list.\n ### START CODE HERE ### (≈ 2 lines of code)\n AL, cache = linear_activation_forward(A, parameters['W'+str(L)], parameters['b'+str(L)], activation='sigmoid')\n caches.append(cache)\n ### END CODE HERE ###\n \n assert(AL.shape == (1,X.shape[1]))\n \n return AL, caches",
"_____no_output_____"
],
[
"X, parameters = L_model_forward_test_case_2hidden()\nAL, caches = L_model_forward(X, parameters)\nprint(\"AL = \" + str(AL))\nprint(\"Length of caches list = \" + str(len(caches)))",
"AL = [[0.03921668 0.70498921 0.19734387 0.04728177]]\nLength of caches list = 3\n"
]
],
[
[
"<table style=\"width:50%\">\n <tr>\n <td> **AL** </td>\n <td > [[ 0.03921668 0.70498921 0.19734387 0.04728177]]</td> \n </tr>\n <tr>\n <td> **Length of caches list ** </td>\n <td > 3 </td> \n </tr>\n</table>",
"_____no_output_____"
],
[
"Great! Now you have a full forward propagation that takes the input X and outputs a row vector $A^{[L]}$ containing your predictions. It also records all intermediate values in \"caches\". Using $A^{[L]}$, you can compute the cost of your predictions.",
"_____no_output_____"
],
[
"## 5 - Cost function\n\nNow you will implement forward and backward propagation. You need to compute the cost, because you want to check if your model is actually learning.\n\n**Exercise**: Compute the cross-entropy cost $J$, using the following formula: $$-\\frac{1}{m} \\sum\\limits_{i = 1}^{m} (y^{(i)}\\log\\left(a^{[L] (i)}\\right) + (1-y^{(i)})\\log\\left(1- a^{[L](i)}\\right)) \\tag{7}$$\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_cost\n\ndef compute_cost(AL, Y):\n \"\"\"\n Implement the cost function defined by equation (7).\n\n Arguments:\n AL -- probability vector corresponding to your label predictions, shape (1, number of examples)\n Y -- true \"label\" vector (for example: containing 0 if non-cat, 1 if cat), shape (1, number of examples)\n\n Returns:\n cost -- cross-entropy cost\n \"\"\"\n \n m = Y.shape[1]\n\n # Compute loss from aL and y.\n ### START CODE HERE ### (≈ 1 lines of code)\n cost = -(1/m) * np.sum(np.multiply(Y, np.log(AL)) + np.multiply((1-Y), np.log(1-AL)))\n ### END CODE HERE ###\n \n cost = np.squeeze(cost) # To make sure your cost's shape is what we expect (e.g. this turns [[17]] into 17).\n assert(cost.shape == ())\n \n return cost",
"_____no_output_____"
],
[
"Y, AL = compute_cost_test_case()\n\nprint(\"cost = \" + str(compute_cost(AL, Y)))",
"cost = 0.41493159961539694\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n\n <tr>\n <td>**cost** </td>\n <td> 0.41493159961539694</td> \n </tr>\n</table>",
"_____no_output_____"
],
[
"## 6 - Backward propagation module\n\nJust like with forward propagation, you will implement helper functions for backpropagation. Remember that back propagation is used to calculate the gradient of the loss function with respect to the parameters. \n\n**Reminder**: \n<img src=\"images/backprop_kiank.png\" style=\"width:650px;height:250px;\">\n<caption><center> **Figure 3** : Forward and Backward propagation for *LINEAR->RELU->LINEAR->SIGMOID* <br> *The purple blocks represent the forward propagation, and the red blocks represent the backward propagation.* </center></caption>\n\n<!-- \nFor those of you who are expert in calculus (you don't need to be to do this assignment), the chain rule of calculus can be used to derive the derivative of the loss $\\mathcal{L}$ with respect to $z^{[1]}$ in a 2-layer network as follows:\n\n$$\\frac{d \\mathcal{L}(a^{[2]},y)}{{dz^{[1]}}} = \\frac{d\\mathcal{L}(a^{[2]},y)}{{da^{[2]}}}\\frac{{da^{[2]}}}{{dz^{[2]}}}\\frac{{dz^{[2]}}}{{da^{[1]}}}\\frac{{da^{[1]}}}{{dz^{[1]}}} \\tag{8} $$\n\nIn order to calculate the gradient $dW^{[1]} = \\frac{\\partial L}{\\partial W^{[1]}}$, you use the previous chain rule and you do $dW^{[1]} = dz^{[1]} \\times \\frac{\\partial z^{[1]} }{\\partial W^{[1]}}$. During the backpropagation, at each step you multiply your current gradient by the gradient corresponding to the specific layer to get the gradient you wanted.\n\nEquivalently, in order to calculate the gradient $db^{[1]} = \\frac{\\partial L}{\\partial b^{[1]}}$, you use the previous chain rule and you do $db^{[1]} = dz^{[1]} \\times \\frac{\\partial z^{[1]} }{\\partial b^{[1]}}$.\n\nThis is why we talk about **backpropagation**.\n!-->\n\nNow, similar to forward propagation, you are going to build the backward propagation in three steps:\n- LINEAR backward\n- LINEAR -> ACTIVATION backward where ACTIVATION computes the derivative of either the ReLU or sigmoid activation\n- [LINEAR -> RELU] $\\times$ (L-1) -> LINEAR -> SIGMOID backward (whole model)",
"_____no_output_____"
],
[
"### 6.1 - Linear backward\n\nFor layer $l$, the linear part is: $Z^{[l]} = W^{[l]} A^{[l-1]} + b^{[l]}$ (followed by an activation).\n\nSuppose you have already calculated the derivative $dZ^{[l]} = \\frac{\\partial \\mathcal{L} }{\\partial Z^{[l]}}$. You want to get $(dW^{[l]}, db^{[l]} dA^{[l-1]})$.\n\n<img src=\"images/linearback_kiank.png\" style=\"width:250px;height:300px;\">\n<caption><center> **Figure 4** </center></caption>\n\nThe three outputs $(dW^{[l]}, db^{[l]}, dA^{[l]})$ are computed using the input $dZ^{[l]}$.Here are the formulas you need:\n$$ dW^{[l]} = \\frac{\\partial \\mathcal{L} }{\\partial W^{[l]}} = \\frac{1}{m} dZ^{[l]} A^{[l-1] T} \\tag{8}$$\n$$ db^{[l]} = \\frac{\\partial \\mathcal{L} }{\\partial b^{[l]}} = \\frac{1}{m} \\sum_{i = 1}^{m} dZ^{[l](i)}\\tag{9}$$\n$$ dA^{[l-1]} = \\frac{\\partial \\mathcal{L} }{\\partial A^{[l-1]}} = W^{[l] T} dZ^{[l]} \\tag{10}$$\n",
"_____no_output_____"
],
[
"**Exercise**: Use the 3 formulas above to implement linear_backward().",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_backward\n\ndef linear_backward(dZ, cache):\n \"\"\"\n Implement the linear portion of backward propagation for a single layer (layer l)\n\n Arguments:\n dZ -- Gradient of the cost with respect to the linear output (of current layer l)\n cache -- tuple of values (A_prev, W, b) coming from the forward propagation in the current layer\n\n Returns:\n dA_prev -- Gradient of the cost with respect to the activation (of the previous layer l-1), same shape as A_prev\n dW -- Gradient of the cost with respect to W (current layer l), same shape as W\n db -- Gradient of the cost with respect to b (current layer l), same shape as b\n \"\"\"\n A_prev, W, b = cache\n m = A_prev.shape[1]\n\n ### START CODE HERE ### (≈ 3 lines of code)\n dW = (1/m) * np.dot(dZ, A_prev.T)\n db = (1/m) * np.sum(dZ, axis=1, keepdims=True)\n dA_prev = np.dot(W.T, dZ)\n ### END CODE HERE ###\n \n assert (dA_prev.shape == A_prev.shape)\n assert (dW.shape == W.shape)\n assert (db.shape == b.shape)\n \n return dA_prev, dW, db",
"_____no_output_____"
],
[
"# Set up some test inputs\ndZ, linear_cache = linear_backward_test_case()\n\ndA_prev, dW, db = linear_backward(dZ, linear_cache)\nprint (\"dA_prev = \"+ str(dA_prev))\nprint (\"dW = \" + str(dW))\nprint (\"db = \" + str(db))",
"dA_prev = [[ 0.51822968 -0.19517421]\n [-0.40506361 0.15255393]\n [ 2.37496825 -0.89445391]]\ndW = [[-0.10076895 1.40685096 1.64992505]]\ndb = [[0.50629448]]\n"
]
],
[
[
"**Expected Output**: \n\n<table style=\"width:90%\">\n <tr>\n <td> **dA_prev** </td>\n <td > [[ 0.51822968 -0.19517421]\n [-0.40506361 0.15255393]\n [ 2.37496825 -0.89445391]] </td> \n </tr> \n \n <tr>\n <td> **dW** </td>\n <td > [[-0.10076895 1.40685096 1.64992505]] </td> \n </tr> \n \n <tr>\n <td> **db** </td>\n <td> [[ 0.50629448]] </td> \n </tr> \n \n</table>\n\n",
"_____no_output_____"
],
[
"### 6.2 - Linear-Activation backward\n\nNext, you will create a function that merges the two helper functions: **`linear_backward`** and the backward step for the activation **`linear_activation_backward`**. \n\nTo help you implement `linear_activation_backward`, we provided two backward functions:\n- **`sigmoid_backward`**: Implements the backward propagation for SIGMOID unit. You can call it as follows:\n\n```python\ndZ = sigmoid_backward(dA, activation_cache)\n```\n\n- **`relu_backward`**: Implements the backward propagation for RELU unit. You can call it as follows:\n\n```python\ndZ = relu_backward(dA, activation_cache)\n```\n\nIf $g(.)$ is the activation function, \n`sigmoid_backward` and `relu_backward` compute $$dZ^{[l]} = dA^{[l]} * g'(Z^{[l]}) \\tag{11}$$. \n\n**Exercise**: Implement the backpropagation for the *LINEAR->ACTIVATION* layer.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_activation_backward\n\ndef linear_activation_backward(dA, cache, activation):\n \"\"\"\n Implement the backward propagation for the LINEAR->ACTIVATION layer.\n \n Arguments:\n dA -- post-activation gradient for current layer l \n cache -- tuple of values (linear_cache, activation_cache) we store for computing backward propagation efficiently\n activation -- the activation to be used in this layer, stored as a text string: \"sigmoid\" or \"relu\"\n \n Returns:\n dA_prev -- Gradient of the cost with respect to the activation (of the previous layer l-1), same shape as A_prev\n dW -- Gradient of the cost with respect to W (current layer l), same shape as W\n db -- Gradient of the cost with respect to b (current layer l), same shape as b\n \"\"\"\n linear_cache, activation_cache = cache\n \n if activation == \"relu\":\n ### START CODE HERE ### (≈ 2 lines of code)\n dZ = relu_backward(dA, activation_cache)\n dA_prev, dW, db = linear_backward(dZ, linear_cache)\n ### END CODE HERE ###\n \n elif activation == \"sigmoid\":\n ### START CODE HERE ### (≈ 2 lines of code)\n dZ = sigmoid_backward(dA, activation_cache)\n dA_prev, dW, db = linear_backward(dZ, linear_cache)\n ### END CODE HERE ###\n \n return dA_prev, dW, db",
"_____no_output_____"
],
[
"dAL, linear_activation_cache = linear_activation_backward_test_case()\n\ndA_prev, dW, db = linear_activation_backward(dAL, linear_activation_cache, activation = \"sigmoid\")\nprint (\"sigmoid:\")\nprint (\"dA_prev = \"+ str(dA_prev))\nprint (\"dW = \" + str(dW))\nprint (\"db = \" + str(db) + \"\\n\")\n\ndA_prev, dW, db = linear_activation_backward(dAL, linear_activation_cache, activation = \"relu\")\nprint (\"relu:\")\nprint (\"dA_prev = \"+ str(dA_prev))\nprint (\"dW = \" + str(dW))\nprint (\"db = \" + str(db))",
"sigmoid:\ndA_prev = [[ 0.11017994 0.01105339]\n [ 0.09466817 0.00949723]\n [-0.05743092 -0.00576154]]\ndW = [[ 0.10266786 0.09778551 -0.01968084]]\ndb = [[-0.05729622]]\n\nrelu:\ndA_prev = [[ 0.44090989 -0. ]\n [ 0.37883606 -0. ]\n [-0.2298228 0. ]]\ndW = [[ 0.44513824 0.37371418 -0.10478989]]\ndb = [[-0.20837892]]\n"
]
],
[
[
"**Expected output with sigmoid:**\n\n<table style=\"width:100%\">\n <tr>\n <td > dA_prev </td> \n <td >[[ 0.11017994 0.01105339]\n [ 0.09466817 0.00949723]\n [-0.05743092 -0.00576154]] </td> \n\n </tr> \n \n <tr>\n <td > dW </td> \n <td > [[ 0.10266786 0.09778551 -0.01968084]] </td> \n </tr> \n \n <tr>\n <td > db </td> \n <td > [[-0.05729622]] </td> \n </tr> \n</table>\n\n",
"_____no_output_____"
],
[
"**Expected output with relu:**\n\n<table style=\"width:100%\">\n <tr>\n <td > dA_prev </td> \n <td > [[ 0.44090989 0. ]\n [ 0.37883606 0. ]\n [-0.2298228 0. ]] </td> \n\n </tr> \n \n <tr>\n <td > dW </td> \n <td > [[ 0.44513824 0.37371418 -0.10478989]] </td> \n </tr> \n \n <tr>\n <td > db </td> \n <td > [[-0.20837892]] </td> \n </tr> \n</table>\n\n",
"_____no_output_____"
],
[
"### 6.3 - L-Model Backward \n\nNow you will implement the backward function for the whole network. Recall that when you implemented the `L_model_forward` function, at each iteration, you stored a cache which contains (X,W,b, and z). In the back propagation module, you will use those variables to compute the gradients. Therefore, in the `L_model_backward` function, you will iterate through all the hidden layers backward, starting from layer $L$. On each step, you will use the cached values for layer $l$ to backpropagate through layer $l$. Figure 5 below shows the backward pass. \n\n\n<img src=\"images/mn_backward.png\" style=\"width:450px;height:300px;\">\n<caption><center> **Figure 5** : Backward pass </center></caption>\n\n** Initializing backpropagation**:\nTo backpropagate through this network, we know that the output is, \n$A^{[L]} = \\sigma(Z^{[L]})$. Your code thus needs to compute `dAL` $= \\frac{\\partial \\mathcal{L}}{\\partial A^{[L]}}$.\nTo do so, use this formula (derived using calculus which you don't need in-depth knowledge of):\n```python\ndAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) # derivative of cost with respect to AL\n```\n\nYou can then use this post-activation gradient `dAL` to keep going backward. As seen in Figure 5, you can now feed in `dAL` into the LINEAR->SIGMOID backward function you implemented (which will use the cached values stored by the L_model_forward function). After that, you will have to use a `for` loop to iterate through all the other layers using the LINEAR->RELU backward function. You should store each dA, dW, and db in the grads dictionary. To do so, use this formula : \n\n$$grads[\"dW\" + str(l)] = dW^{[l]}\\tag{15} $$\n\nFor example, for $l=3$ this would store $dW^{[l]}$ in `grads[\"dW3\"]`.\n\n**Exercise**: Implement backpropagation for the *[LINEAR->RELU] $\\times$ (L-1) -> LINEAR -> SIGMOID* model.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: L_model_backward\n\ndef L_model_backward(AL, Y, caches):\n \"\"\"\n Implement the backward propagation for the [LINEAR->RELU] * (L-1) -> LINEAR -> SIGMOID group\n \n Arguments:\n AL -- probability vector, output of the forward propagation (L_model_forward())\n Y -- true \"label\" vector (containing 0 if non-cat, 1 if cat)\n caches -- list of caches containing:\n every cache of linear_activation_forward() with \"relu\" (it's caches[l], for l in range(L-1) i.e l = 0...L-2)\n the cache of linear_activation_forward() with \"sigmoid\" (it's caches[L-1])\n \n Returns:\n grads -- A dictionary with the gradients\n grads[\"dA\" + str(l)] = ... \n grads[\"dW\" + str(l)] = ...\n grads[\"db\" + str(l)] = ... \n \"\"\"\n grads = {}\n L = len(caches) # the number of layers\n m = AL.shape[1]\n Y = Y.reshape(AL.shape) # after this line, Y is the same shape as AL\n \n # Initializing the backpropagation\n ### START CODE HERE ### (1 line of code)\n dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))\n ### END CODE HERE ###\n \n # Lth layer (SIGMOID -> LINEAR) gradients. Inputs: \"dAL, current_cache\". Outputs: \"grads[\"dAL-1\"], grads[\"dWL\"], grads[\"dbL\"]\n ### START CODE HERE ### (approx. 2 lines)\n current_cache = caches[L-1]\n grads[\"dA\" + str(L-1)], grads[\"dW\" + str(L)], grads[\"db\" + str(L)] = linear_activation_backward(dAL, current_cache,'sigmoid')\n ### END CODE HERE ###\n \n # Loop from l=L-2 to l=0\n for l in reversed(range(L-1)):\n # lth layer: (RELU -> LINEAR) gradients.\n # Inputs: \"grads[\"dA\" + str(l + 1)], current_cache\". Outputs: \"grads[\"dA\" + str(l)] , grads[\"dW\" + str(l + 1)] , grads[\"db\" + str(l + 1)] \n ### START CODE HERE ### (approx. 5 lines)\n current_cache = caches[l]\n dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads['dA'+str(l+1)], current_cache, 'relu')\n grads[\"dA\" + str(l)] = dA_prev_temp\n grads[\"dW\" + str(l + 1)] = dW_temp\n grads[\"db\" + str(l + 1)] = db_temp\n ### END CODE HERE ###\n\n return grads",
"_____no_output_____"
],
[
"AL, Y_assess, caches = L_model_backward_test_case()\ngrads = L_model_backward(AL, Y_assess, caches)\nprint_grads(grads)",
"dW1 = [[0.41010002 0.07807203 0.13798444 0.10502167]\n [0. 0. 0. 0. ]\n [0.05283652 0.01005865 0.01777766 0.0135308 ]]\ndb1 = [[-0.22007063]\n [ 0. ]\n [-0.02835349]]\ndA1 = [[ 0.12913162 -0.44014127]\n [-0.14175655 0.48317296]\n [ 0.01663708 -0.05670698]]\n"
]
],
[
[
"**Expected Output**\n\n<table style=\"width:60%\">\n \n <tr>\n <td > dW1 </td> \n <td > [[ 0.41010002 0.07807203 0.13798444 0.10502167]\n [ 0. 0. 0. 0. ]\n [ 0.05283652 0.01005865 0.01777766 0.0135308 ]] </td> \n </tr> \n \n <tr>\n <td > db1 </td> \n <td > [[-0.22007063]\n [ 0. ]\n [-0.02835349]] </td> \n </tr> \n \n <tr>\n <td > dA1 </td> \n <td > [[ 0.12913162 -0.44014127]\n [-0.14175655 0.48317296]\n [ 0.01663708 -0.05670698]] </td> \n\n </tr> \n</table>\n\n",
"_____no_output_____"
],
[
"### 6.4 - Update Parameters\n\nIn this section you will update the parameters of the model, using gradient descent: \n\n$$ W^{[l]} = W^{[l]} - \\alpha \\text{ } dW^{[l]} \\tag{16}$$\n$$ b^{[l]} = b^{[l]} - \\alpha \\text{ } db^{[l]} \\tag{17}$$\n\nwhere $\\alpha$ is the learning rate. After computing the updated parameters, store them in the parameters dictionary. ",
"_____no_output_____"
],
[
"**Exercise**: Implement `update_parameters()` to update your parameters using gradient descent.\n\n**Instructions**:\nUpdate parameters using gradient descent on every $W^{[l]}$ and $b^{[l]}$ for $l = 1, 2, ..., L$. \n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: update_parameters\n\ndef update_parameters(parameters, grads, learning_rate):\n \"\"\"\n Update parameters using gradient descent\n \n Arguments:\n parameters -- python dictionary containing your parameters \n grads -- python dictionary containing your gradients, output of L_model_backward\n \n Returns:\n parameters -- python dictionary containing your updated parameters \n parameters[\"W\" + str(l)] = ... \n parameters[\"b\" + str(l)] = ...\n \"\"\"\n \n L = len(parameters) // 2 # number of layers in the neural network\n\n # Update rule for each parameter. Use a for loop.\n ### START CODE HERE ### (≈ 3 lines of code)\n for l in range(L):\n parameters[\"W\" + str(l+1)] -= learning_rate * grads[\"dW\" + str(l+1)] \n parameters[\"b\" + str(l+1)] -= learning_rate * grads[\"db\" + str(l+1)] \n ### END CODE HERE ###\n return parameters",
"_____no_output_____"
],
[
"parameters, grads = update_parameters_test_case()\nparameters = update_parameters(parameters, grads, 0.1)\n\nprint (\"W1 = \"+ str(parameters[\"W1\"]))\nprint (\"b1 = \"+ str(parameters[\"b1\"]))\nprint (\"W2 = \"+ str(parameters[\"W2\"]))\nprint (\"b2 = \"+ str(parameters[\"b2\"]))",
"W1 = [[-0.59562069 -0.09991781 -2.14584584 1.82662008]\n [-1.76569676 -0.80627147 0.51115557 -1.18258802]\n [-1.0535704 -0.86128581 0.68284052 2.20374577]]\nb1 = [[-0.04659241]\n [-1.28888275]\n [ 0.53405496]]\nW2 = [[-0.55569196 0.0354055 1.32964895]]\nb2 = [[-0.84610769]]\n"
]
],
[
[
"**Expected Output**:\n\n<table style=\"width:100%\"> \n <tr>\n <td > W1 </td> \n <td > [[-0.59562069 -0.09991781 -2.14584584 1.82662008]\n [-1.76569676 -0.80627147 0.51115557 -1.18258802]\n [-1.0535704 -0.86128581 0.68284052 2.20374577]] </td> \n </tr> \n \n <tr>\n <td > b1 </td> \n <td > [[-0.04659241]\n [-1.28888275]\n [ 0.53405496]] </td> \n </tr> \n <tr>\n <td > W2 </td> \n <td > [[-0.55569196 0.0354055 1.32964895]]</td> \n </tr> \n \n <tr>\n <td > b2 </td> \n <td > [[-0.84610769]] </td> \n </tr> \n</table>\n",
"_____no_output_____"
],
[
"\n## 7 - Conclusion\n\nCongrats on implementing all the functions required for building a deep neural network! \n\nWe know it was a long assignment but going forward it will only get better. The next part of the assignment is easier. \n\nIn the next assignment you will put all these together to build two models:\n- A two-layer neural network\n- An L-layer neural network\n\nYou will in fact use these models to classify cat vs non-cat images!",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
]
|
e7cb1bec50f4b035ae3153fce4b7fd73b6dfdd75 | 158,393 | ipynb | Jupyter Notebook | Connect The Islands.ipynb | ac547/Connect-The-Islands | 8d8ebe6e4e5de409fd2a17a2cb9b63754b062219 | [
"MIT"
]
| null | null | null | Connect The Islands.ipynb | ac547/Connect-The-Islands | 8d8ebe6e4e5de409fd2a17a2cb9b63754b062219 | [
"MIT"
]
| null | null | null | Connect The Islands.ipynb | ac547/Connect-The-Islands | 8d8ebe6e4e5de409fd2a17a2cb9b63754b062219 | [
"MIT"
]
| null | null | null | 60.547783 | 58,728 | 0.664139 | [
[
[
"# <center> Data Structures and Algorithms </center>\n<center> Andres Castellano </center>\n<center> June 11, 2020 </center>\n",
"_____no_output_____"
],
[
"### <center> Mini Project 1 </center>",
"_____no_output_____"
]
],
[
[
"from google.colab import drive \ndrive.mount('/content/gdrive/')",
"_____no_output_____"
],
[
"%cd /content/gdrive/My\\ Drive/Mini-Project 1",
"_____no_output_____"
]
],
[
[
"**Step 1)** Construct a text file that follows the input specifications of the problem, i.e. it can serve\nas a sample input. Specifically, you should give an input file representing a 10x10 patch. The patch\nshould contain two or three islands, according to your choice. The shape of the islands can be\narbitrary, but try to be creative. The text file should be of the form firstname-lastname.txt.\nNotice that each cell in the patch is characterized by its coordinates. The top left coordinate is\n(0,0) and coordinate (i,j) is for the cell in the i-th row and j-th column.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"**Step 2)** Write a function that reads an input file with the given specifications and returns the list\nof the coordinates of the land points, i.e. the list of coordinates for the ‘X’ points.",
"_____no_output_____"
]
],
[
[
"f = open('andres-castellano.txt', 'r')",
"_____no_output_____"
],
[
"def Coordinates(file):\n \n \n ''' This function will return a list,\n where each element of the list is a list itself of coordinates for each test case in the file.\n In the case where the input file only contains 1 test case, the function will return a list of length 1.'''\n \n import re\n f.seek(0)\n coor = []\n \n num_cases = int(f.readlines(1)[0][0])\n print(\"Number of test cases is: {} \\n\".format(num_cases))\n \n \n for case in range(num_cases):\n print('For test case {} ... '.format(case+1))\n \n dims = re.findall('\\d+', f.readlines(1)[0])\n i = int(dims[0])\n j = int(dims[1])\n case_coor = []\n \n print('Dimensions are {0} by {1} \\n'.format(i,j))\n \n for ith in range(i):\n line = f.readlines(1)[0]\n for jth in range(j):\n if line[jth] == \"x\":\n #print(ith+1,jth+1)\n case_coor.append((ith+1,jth+1))\n #print(case_coor)\n coor.append(case_coor)\n \n return coor\n \n \n \n ",
"_____no_output_____"
],
[
"Coordinates(f)",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
]
],
[
[
"**Step 3)** Write a function CoordinateToNumber(i, j, m, n) that takes a coordinate (i, j) and\nmaps it to a unique number t in [0, mn − 1], which is then returned by the function.\n\nI'm assuming this step is directing us to create a function that takes a list of coordinates and generates unique identifiers for each coordinate within the list.",
"_____no_output_____"
]
],
[
[
"def CoordinateToNumber(coordinate_list=list,m=int,n=int):\n '''Returns a list for a list of coordinates as input,\n returns a tuple for a coordinate as input'''\n global T\n if len(coordinate_list) > m*n:\n raise Exception('Stop, too many coordinates for mXn')\n if type(coordinate_list) is tuple:\n T = {0 : coordinate_list}\n else:\n for value in enumerate(coordinate_list):\n T = dict(val for val in enumerate(coordinate_list))\n return T\n ",
"_____no_output_____"
],
[
"CoordinateToNumber(Coordinates(f)[0],10,10)",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
]
],
[
[
"**Step 4)** Write a function NumberToCoordinate(t, m, n) that takes a number t and returns the\ncorresponding coordinate. This function must be the inverse of CoordinateToNumber. That\nis, for all i, j, m, n we must have\n\nNumberToCoordinate(CoordinateToNumber(i, j, m, n), m, n) = (i, j)\n\nThe two steps above mean that besides its coordinates, each cell has its own unique identity\nnumber in [0, mn − 1]",
"_____no_output_____"
]
],
[
[
"def NumberToCoordinate(L=list,m=int,n=int):\n '''Returns a list size n of tuples for a list of inputs of size n'''\n coordinate_list = []\n for key in L:\n coordinate_list.append(T.get(key))\n return coordinate_list",
"_____no_output_____"
],
[
"NumberToCoordinate(CoordinateToNumber(Coordinates(f)[0],10,10),10,10)",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
]
],
[
[
"### Note 1:\n\nThe functions as defined above take as inputs iterable objects as seen above. However. All functions can also be called on specific coordinates.\n\nFor example:\n\nThe below code will call the identifier and coordinates of one single cell from test case 1.\n\n\n",
"_____no_output_____"
]
],
[
[
"Coordinates(f)[0][5] # Gets the 6th coordinate of test case 1.\n",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
],
[
"CoordinateToNumber(Coordinates(f)[0][5],10,10) # Gets the identifier and coordinates for the 6th coordinate of case 1.",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
],
[
"NumberToCoordinate(CoordinateToNumber(Coordinates(f)[0][5],10,10),10,10) \n",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
]
],
[
[
"The last line of code gets the coordinate from the correspondng identifier given to the coordinate 6 of test case 1.\nNote that Coordinates(f)[0][5] and NumberToCoordinate(CoordinateToNumber(Coordinates(f)[0][5])) should return\nthe same coordinate and it does.\n\n**Step 5)** Write a function Distance(t1, t2), where t1 and t2 are the identity numbers of two cells,\nand the output is the distance between them. The distance is the minimum number of connected\ncells that one has to traverse to go from t1 to t2. (Hint: Use function NumberToCoordinate for\nthis)",
"_____no_output_____"
]
],
[
[
"CoordinateToNumber(Coordinates(f)[0],10,10)",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
],
[
"def Distance(t1=int,t2=int):\n '''Returns a scalar representing the manhattan distance between two coordinates representing input identifiers t1 and t2. '''\n t1 = T[t1]\n t2 = T[t2]\n \n distance = abs(t2[1]-t1[1]) + abs(t2[0]-t1[0])\n \n return distance\n\nDistance(0,1) == abs(8-3)+abs(2-2)",
"_____no_output_____"
]
],
[
[
"\n\nRecall that in **Step 2** we wrote a function for finding the list of land cells. Let’s call\nthis function **FindLandCells**, and its output **LandCell_List**. This list of land cells can look\nlike this:\n\nLandCell List = [10, 11, 25, 12, 50, 51, 80, 81, 82]\n(this is only an example, it does not correspond to some specific input).\n",
"_____no_output_____"
]
],
[
[
"FindLandCells = CoordinateToNumber\nLandCell_List = CoordinateToNumber(Coordinates(f)[1],20,20)\nLandCell_List.keys()",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
]
],
[
[
"Now this lists can be further broken into islands. So, we have something that looks like this:\n\nIsland_List = [[10, 11, 12], [25], [50, 51], [80, 81, 82]]\n\nYou see how all the cells from the original list appear in the second data structure, which is a list\nof lists, with each list being an island. Observe how cells belonging to the same island (e.g. cell\n12), can be mixed up with other islands in LandCell List. In other words, one island’s cells do\nnot have to be in contiguous positions in LandCell List.\n\nIn this section we will write functions to help find the list of islands.\n\n**Step 6)** Write a function GenerateNeighbors(t1, n, m), that takes one cell number t1 (and also\nthe dimensions), and returns the numbers for the neighbors of t1 in the grid. Notice that t1 can\nhave 2, 3 or 4 neighbors.",
"_____no_output_____"
]
],
[
[
"CoordinateToNumber(Coordinates(f)[0],10,10)",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
],
[
"def GenerateNeighbors(t1=int,m=int,n=int):\n \n coordinates = T[t1]\n row_neighboors = []\n candidates = []\n \n row_candidates = [(coordinates[0],coordinates[1]-1),(coordinates[0],coordinates[1]+1)]\n [candidates.append(x) for x in row_candidates]\n \n \n col_candidates = [(coordinates[0]-1,coordinates[1]),(coordinates[0]+1,coordinates[1])]\n [candidates.append(x) for x in col_candidates]\n \n #return [x in T.values() for x in candidates]\n return sum([x in T.values() for x in candidates])\n ",
"_____no_output_____"
],
[
"GenerateNeighbors(2,10,10)",
"_____no_output_____"
]
],
[
[
"**Step 7)** Write a function ExploreIsland(t1, n, m). This function should start from cell t1,\nand construct a list of cells that are in the same island as t1. (Hint: t1 can add itself to a\ndictionary representing the island, and also its neighbors, then the neighbors should recursively\ndo the the same. But when new neighbors are inserted in the dictionary, we should first check if\nthey are already in it. The process should terminate when it’s not possible to add more cells to the\ndictionary, meaning that we found the island. Finally the function should return a list with the\ncells on the island)",
"_____no_output_____"
]
],
[
[
"FindLandCells = CoordinateToNumber\nLandCell_List = CoordinateToNumber(Coordinates(f)[0],10,10)\nLandCell_List.keys()",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
],
[
"def ExploreIsland(t1=int,m=int,n=int, neighbors=[]):\n \n coordinates = T[t1]\n candidates = []\n if neighbors == []:\n neighbors.append(t1)\n \n row_candidates = [(coordinates[0],coordinates[1]-1),(coordinates[0],coordinates[1]+1)]\n [candidates.append(x) for x in row_candidates]\n \n \n col_candidates = [(coordinates[0]-1,coordinates[1]),(coordinates[0]+1,coordinates[1])]\n [candidates.append(x) for x in col_candidates]\n \n print(\"\\nFor Land {0} with coordinates {1}, Candidates are {2} \".format(t1, coordinates, candidates))\n\n for x in candidates:\n print(\" ...Checking coordinates {} for land {}\".format(x,t1))\n if x in T.values():\n for key, value in T.items():\n if value == x and key in neighbors:\n print(\" Land {} already on Island with land {}! \".format(key,t1))\n if value == x and key not in neighbors:\n print(\" ...Adding land {} with coordinates {} to land {} \".format(key,x,t1))\n neighbors.append(key)\n print(\"\\nExploring land {}____________\\n\".format(key))\n ExploreIsland(key,m,n,neighbors)\n \n #print(\"Island consists of Lands {}\".format(neighbors)) \n return neighbors \n #neighbors.append()",
"_____no_output_____"
],
[
"ExploreIsland(10,10,10,neighbors=[])",
"\nFor Land 10 with coordinates (8, 5), Candidates are [(8, 4), (8, 6), (7, 5), (9, 5)] \n ...Checking coordinates (8, 4) for land 10\n ...Checking coordinates (8, 6) for land 10\n ...Adding land 11 with coordinates (8, 6) to land 10 \n\nExploring land 11____________\n\n\nFor Land 11 with coordinates (8, 6), Candidates are [(8, 5), (8, 7), (7, 6), (9, 6)] \n ...Checking coordinates (8, 5) for land 11\n Land 10 already on Island with land 11! \n ...Checking coordinates (8, 7) for land 11\n ...Checking coordinates (7, 6) for land 11\n ...Checking coordinates (9, 6) for land 11\n ...Checking coordinates (7, 5) for land 10\n ...Checking coordinates (9, 5) for land 10\n"
],
[
"FindLandCells = CoordinateToNumber\nLandCell_List = FindLandCells(Coordinates(f)[1],20,20)\nLandCell_List.keys()",
"Number of test cases is: 2 \n\nFor test case 1 ... \nDimensions are 10 by 10 \n\nFor test case 2 ... \nDimensions are 20 by 20 \n\n"
],
[
"ExploreIsland(0,20,20,neighbors=[])",
"\nFor Land 0 with coordinates (3, 10), Candidates are [(3, 9), (3, 11), (2, 10), (4, 10)] \n ...Checking coordinates (3, 9) for land 0\n ...Checking coordinates (3, 11) for land 0\n ...Adding land 1 with coordinates (3, 11) to land 0 \n\nExploring land 1____________\n\n\nFor Land 1 with coordinates (3, 11), Candidates are [(3, 10), (3, 12), (2, 11), (4, 11)] \n ...Checking coordinates (3, 10) for land 1\n Land 0 already on Island with land 1! \n ...Checking coordinates (3, 12) for land 1\n ...Adding land 2 with coordinates (3, 12) to land 1 \n\nExploring land 2____________\n\n\nFor Land 2 with coordinates (3, 12), Candidates are [(3, 11), (3, 13), (2, 12), (4, 12)] \n ...Checking coordinates (3, 11) for land 2\n Land 1 already on Island with land 2! \n ...Checking coordinates (3, 13) for land 2\n ...Adding land 3 with coordinates (3, 13) to land 2 \n\nExploring land 3____________\n\n\nFor Land 3 with coordinates (3, 13), Candidates are [(3, 12), (3, 14), (2, 13), (4, 13)] \n ...Checking coordinates (3, 12) for land 3\n Land 2 already on Island with land 3! \n ...Checking coordinates (3, 14) for land 3\n ...Checking coordinates (2, 13) for land 3\n ...Checking coordinates (4, 13) for land 3\n ...Adding land 7 with coordinates (4, 13) to land 3 \n\nExploring land 7____________\n\n\nFor Land 7 with coordinates (4, 13), Candidates are [(4, 12), (4, 14), (3, 13), (5, 13)] \n ...Checking coordinates (4, 12) for land 7\n ...Adding land 6 with coordinates (4, 12) to land 7 \n\nExploring land 6____________\n\n\nFor Land 6 with coordinates (4, 12), Candidates are [(4, 11), (4, 13), (3, 12), (5, 12)] \n ...Checking coordinates (4, 11) for land 6\n ...Adding land 5 with coordinates (4, 11) to land 6 \n\nExploring land 5____________\n\n\nFor Land 5 with coordinates (4, 11), Candidates are [(4, 10), (4, 12), (3, 11), (5, 11)] \n ...Checking coordinates (4, 10) for land 5\n ...Adding land 4 with coordinates (4, 10) to land 5 \n\nExploring land 4____________\n\n\nFor Land 4 with coordinates (4, 10), Candidates are [(4, 9), (4, 11), (3, 10), (5, 10)] \n ...Checking coordinates (4, 9) for land 4\n ...Checking coordinates (4, 11) for land 4\n Land 5 already on Island with land 4! \n ...Checking coordinates (3, 10) for land 4\n Land 0 already on Island with land 4! \n ...Checking coordinates (5, 10) for land 4\n ...Checking coordinates (4, 12) for land 5\n Land 6 already on Island with land 5! \n ...Checking coordinates (3, 11) for land 5\n Land 1 already on Island with land 5! \n ...Checking coordinates (5, 11) for land 5\n ...Checking coordinates (4, 13) for land 6\n Land 7 already on Island with land 6! \n ...Checking coordinates (3, 12) for land 6\n Land 2 already on Island with land 6! \n ...Checking coordinates (5, 12) for land 6\n ...Adding land 8 with coordinates (5, 12) to land 6 \n\nExploring land 8____________\n\n\nFor Land 8 with coordinates (5, 12), Candidates are [(5, 11), (5, 13), (4, 12), (6, 12)] \n ...Checking coordinates (5, 11) for land 8\n ...Checking coordinates (5, 13) for land 8\n ...Adding land 9 with coordinates (5, 13) to land 8 \n\nExploring land 9____________\n\n\nFor Land 9 with coordinates (5, 13), Candidates are [(5, 12), (5, 14), (4, 13), (6, 13)] \n ...Checking coordinates (5, 12) for land 9\n Land 8 already on Island with land 9! \n ...Checking coordinates (5, 14) for land 9\n ...Checking coordinates (4, 13) for land 9\n Land 7 already on Island with land 9! \n ...Checking coordinates (6, 13) for land 9\n ...Adding land 11 with coordinates (6, 13) to land 9 \n\nExploring land 11____________\n\n\nFor Land 11 with coordinates (6, 13), Candidates are [(6, 12), (6, 14), (5, 13), (7, 13)] \n ...Checking coordinates (6, 12) for land 11\n ...Adding land 10 with coordinates (6, 12) to land 11 \n\nExploring land 10____________\n\n\nFor Land 10 with coordinates (6, 12), Candidates are [(6, 11), (6, 13), (5, 12), (7, 12)] \n ...Checking coordinates (6, 11) for land 10\n ...Checking coordinates (6, 13) for land 10\n Land 11 already on Island with land 10! \n ...Checking coordinates (5, 12) for land 10\n Land 8 already on Island with land 10! \n ...Checking coordinates (7, 12) for land 10\n ...Adding land 14 with coordinates (7, 12) to land 10 \n\nExploring land 14____________\n\n\nFor Land 14 with coordinates (7, 12), Candidates are [(7, 11), (7, 13), (6, 12), (8, 12)] \n ...Checking coordinates (7, 11) for land 14\n ...Checking coordinates (7, 13) for land 14\n ...Adding land 15 with coordinates (7, 13) to land 14 \n\nExploring land 15____________\n\n\nFor Land 15 with coordinates (7, 13), Candidates are [(7, 12), (7, 14), (6, 13), (8, 13)] \n ...Checking coordinates (7, 12) for land 15\n Land 14 already on Island with land 15! \n ...Checking coordinates (7, 14) for land 15\n ...Checking coordinates (6, 13) for land 15\n Land 11 already on Island with land 15! \n ...Checking coordinates (8, 13) for land 15\n ...Adding land 19 with coordinates (8, 13) to land 15 \n\nExploring land 19____________\n\n\nFor Land 19 with coordinates (8, 13), Candidates are [(8, 12), (8, 14), (7, 13), (9, 13)] \n ...Checking coordinates (8, 12) for land 19\n ...Adding land 18 with coordinates (8, 12) to land 19 \n\nExploring land 18____________\n\n\nFor Land 18 with coordinates (8, 12), Candidates are [(8, 11), (8, 13), (7, 12), (9, 12)] \n ...Checking coordinates (8, 11) for land 18\n ...Checking coordinates (8, 13) for land 18\n Land 19 already on Island with land 18! \n ...Checking coordinates (7, 12) for land 18\n Land 14 already on Island with land 18! \n ...Checking coordinates (9, 12) for land 18\n ...Checking coordinates (8, 14) for land 19\n ...Checking coordinates (7, 13) for land 19\n Land 15 already on Island with land 19! \n ...Checking coordinates (9, 13) for land 19\n ...Checking coordinates (6, 12) for land 14\n Land 10 already on Island with land 14! \n ...Checking coordinates (8, 12) for land 14\n Land 18 already on Island with land 14! \n ...Checking coordinates (6, 14) for land 11\n ...Checking coordinates (5, 13) for land 11\n Land 9 already on Island with land 11! \n ...Checking coordinates (7, 13) for land 11\n Land 15 already on Island with land 11! \n ...Checking coordinates (4, 12) for land 8\n Land 6 already on Island with land 8! \n ...Checking coordinates (6, 12) for land 8\n Land 10 already on Island with land 8! \n ...Checking coordinates (4, 14) for land 7\n ...Checking coordinates (3, 13) for land 7\n Land 3 already on Island with land 7! \n ...Checking coordinates (5, 13) for land 7\n Land 9 already on Island with land 7! \n ...Checking coordinates (2, 12) for land 2\n ...Checking coordinates (4, 12) for land 2\n Land 6 already on Island with land 2! \n ...Checking coordinates (2, 11) for land 1\n ...Checking coordinates (4, 11) for land 1\n Land 5 already on Island with land 1! \n ...Checking coordinates (2, 10) for land 0\n ...Checking coordinates (4, 10) for land 0\n Land 4 already on Island with land 0! \n"
]
],
[
[
"**Step 8)** Write a function FindIslands that reads the list LandCell_List and converts its to\nIsland List as explained above. The idea for this step is to scan the list of land cells, and call\nrepeatedly the ExploreIsland function.",
"_____no_output_____"
]
],
[
[
"def FindIslands(LandCell_List=list):\n \n Island_List = []\n island = []\n checked = []\n \n for i in LandCell_List.keys():\n \n if i not in checked:\n \n print(\"Finding Islands Connected to Land {}\".format(i))\n \n island = ExploreIsland(i,20,20,neighbors=[])\n [checked.append(x) for x in island]\n print(\"Explored island {}, consists of {}:\".format(i, island))\n \n if len(island) < 1:\n Island_List.append([i])\n \n if island is not None:\n Island_List.append(island)\n else:\n next\n \n return Island_List",
"_____no_output_____"
],
[
"Island_List = FindIslands(LandCell_List)\n",
"Finding Islands Connected to Land 0\n\nFor Land 0 with coordinates (3, 10), Candidates are [(3, 9), (3, 11), (2, 10), (4, 10)] \n ...Checking coordinates (3, 9) for land 0\n ...Checking coordinates (3, 11) for land 0\n ...Adding land 1 with coordinates (3, 11) to land 0 \n\nExploring land 1____________\n\n\nFor Land 1 with coordinates (3, 11), Candidates are [(3, 10), (3, 12), (2, 11), (4, 11)] \n ...Checking coordinates (3, 10) for land 1\n Land 0 already on Island with land 1! \n ...Checking coordinates (3, 12) for land 1\n ...Adding land 2 with coordinates (3, 12) to land 1 \n\nExploring land 2____________\n\n\nFor Land 2 with coordinates (3, 12), Candidates are [(3, 11), (3, 13), (2, 12), (4, 12)] \n ...Checking coordinates (3, 11) for land 2\n Land 1 already on Island with land 2! \n ...Checking coordinates (3, 13) for land 2\n ...Adding land 3 with coordinates (3, 13) to land 2 \n\nExploring land 3____________\n\n\nFor Land 3 with coordinates (3, 13), Candidates are [(3, 12), (3, 14), (2, 13), (4, 13)] \n ...Checking coordinates (3, 12) for land 3\n Land 2 already on Island with land 3! \n ...Checking coordinates (3, 14) for land 3\n ...Checking coordinates (2, 13) for land 3\n ...Checking coordinates (4, 13) for land 3\n ...Adding land 7 with coordinates (4, 13) to land 3 \n\nExploring land 7____________\n\n\nFor Land 7 with coordinates (4, 13), Candidates are [(4, 12), (4, 14), (3, 13), (5, 13)] \n ...Checking coordinates (4, 12) for land 7\n ...Adding land 6 with coordinates (4, 12) to land 7 \n\nExploring land 6____________\n\n\nFor Land 6 with coordinates (4, 12), Candidates are [(4, 11), (4, 13), (3, 12), (5, 12)] \n ...Checking coordinates (4, 11) for land 6\n ...Adding land 5 with coordinates (4, 11) to land 6 \n\nExploring land 5____________\n\n\nFor Land 5 with coordinates (4, 11), Candidates are [(4, 10), (4, 12), (3, 11), (5, 11)] \n ...Checking coordinates (4, 10) for land 5\n ...Adding land 4 with coordinates (4, 10) to land 5 \n\nExploring land 4____________\n\n\nFor Land 4 with coordinates (4, 10), Candidates are [(4, 9), (4, 11), (3, 10), (5, 10)] \n ...Checking coordinates (4, 9) for land 4\n ...Checking coordinates (4, 11) for land 4\n Land 5 already on Island with land 4! \n ...Checking coordinates (3, 10) for land 4\n Land 0 already on Island with land 4! \n ...Checking coordinates (5, 10) for land 4\n ...Checking coordinates (4, 12) for land 5\n Land 6 already on Island with land 5! \n ...Checking coordinates (3, 11) for land 5\n Land 1 already on Island with land 5! \n ...Checking coordinates (5, 11) for land 5\n ...Checking coordinates (4, 13) for land 6\n Land 7 already on Island with land 6! \n ...Checking coordinates (3, 12) for land 6\n Land 2 already on Island with land 6! \n ...Checking coordinates (5, 12) for land 6\n ...Adding land 8 with coordinates (5, 12) to land 6 \n\nExploring land 8____________\n\n\nFor Land 8 with coordinates (5, 12), Candidates are [(5, 11), (5, 13), (4, 12), (6, 12)] \n ...Checking coordinates (5, 11) for land 8\n ...Checking coordinates (5, 13) for land 8\n ...Adding land 9 with coordinates (5, 13) to land 8 \n\nExploring land 9____________\n\n\nFor Land 9 with coordinates (5, 13), Candidates are [(5, 12), (5, 14), (4, 13), (6, 13)] \n ...Checking coordinates (5, 12) for land 9\n Land 8 already on Island with land 9! \n ...Checking coordinates (5, 14) for land 9\n ...Checking coordinates (4, 13) for land 9\n Land 7 already on Island with land 9! \n ...Checking coordinates (6, 13) for land 9\n ...Adding land 11 with coordinates (6, 13) to land 9 \n\nExploring land 11____________\n\n\nFor Land 11 with coordinates (6, 13), Candidates are [(6, 12), (6, 14), (5, 13), (7, 13)] \n ...Checking coordinates (6, 12) for land 11\n ...Adding land 10 with coordinates (6, 12) to land 11 \n\nExploring land 10____________\n\n\nFor Land 10 with coordinates (6, 12), Candidates are [(6, 11), (6, 13), (5, 12), (7, 12)] \n ...Checking coordinates (6, 11) for land 10\n ...Checking coordinates (6, 13) for land 10\n Land 11 already on Island with land 10! \n ...Checking coordinates (5, 12) for land 10\n Land 8 already on Island with land 10! \n ...Checking coordinates (7, 12) for land 10\n ...Adding land 14 with coordinates (7, 12) to land 10 \n\nExploring land 14____________\n\n\nFor Land 14 with coordinates (7, 12), Candidates are [(7, 11), (7, 13), (6, 12), (8, 12)] \n ...Checking coordinates (7, 11) for land 14\n ...Checking coordinates (7, 13) for land 14\n ...Adding land 15 with coordinates (7, 13) to land 14 \n\nExploring land 15____________\n\n\nFor Land 15 with coordinates (7, 13), Candidates are [(7, 12), (7, 14), (6, 13), (8, 13)] \n ...Checking coordinates (7, 12) for land 15\n Land 14 already on Island with land 15! \n ...Checking coordinates (7, 14) for land 15\n ...Checking coordinates (6, 13) for land 15\n Land 11 already on Island with land 15! \n ...Checking coordinates (8, 13) for land 15\n ...Adding land 19 with coordinates (8, 13) to land 15 \n\nExploring land 19____________\n\n\nFor Land 19 with coordinates (8, 13), Candidates are [(8, 12), (8, 14), (7, 13), (9, 13)] \n ...Checking coordinates (8, 12) for land 19\n ...Adding land 18 with coordinates (8, 12) to land 19 \n\nExploring land 18____________\n\n\nFor Land 18 with coordinates (8, 12), Candidates are [(8, 11), (8, 13), (7, 12), (9, 12)] \n ...Checking coordinates (8, 11) for land 18\n ...Checking coordinates (8, 13) for land 18\n Land 19 already on Island with land 18! \n ...Checking coordinates (7, 12) for land 18\n Land 14 already on Island with land 18! \n ...Checking coordinates (9, 12) for land 18\n ...Checking coordinates (8, 14) for land 19\n ...Checking coordinates (7, 13) for land 19\n Land 15 already on Island with land 19! \n ...Checking coordinates (9, 13) for land 19\n ...Checking coordinates (6, 12) for land 14\n Land 10 already on Island with land 14! \n ...Checking coordinates (8, 12) for land 14\n Land 18 already on Island with land 14! \n ...Checking coordinates (6, 14) for land 11\n ...Checking coordinates (5, 13) for land 11\n Land 9 already on Island with land 11! \n ...Checking coordinates (7, 13) for land 11\n Land 15 already on Island with land 11! \n ...Checking coordinates (4, 12) for land 8\n Land 6 already on Island with land 8! \n ...Checking coordinates (6, 12) for land 8\n Land 10 already on Island with land 8! \n ...Checking coordinates (4, 14) for land 7\n ...Checking coordinates (3, 13) for land 7\n Land 3 already on Island with land 7! \n ...Checking coordinates (5, 13) for land 7\n Land 9 already on Island with land 7! \n ...Checking coordinates (2, 12) for land 2\n ...Checking coordinates (4, 12) for land 2\n Land 6 already on Island with land 2! \n ...Checking coordinates (2, 11) for land 1\n ...Checking coordinates (4, 11) for land 1\n Land 5 already on Island with land 1! \n ...Checking coordinates (2, 10) for land 0\n ...Checking coordinates (4, 10) for land 0\n Land 4 already on Island with land 0! \nExplored island 0, consists of [0, 1, 2, 3, 7, 6, 5, 4, 8, 9, 11, 10, 14, 15, 19, 18]:\nFinding Islands Connected to Land 12\n\nFor Land 12 with coordinates (7, 3), Candidates are [(7, 2), (7, 4), (6, 3), (8, 3)] \n ...Checking coordinates (7, 2) for land 12\n ...Checking coordinates (7, 4) for land 12\n ...Adding land 13 with coordinates (7, 4) to land 12 \n\nExploring land 13____________\n\n\nFor Land 13 with coordinates (7, 4), Candidates are [(7, 3), (7, 5), (6, 4), (8, 4)] \n ...Checking coordinates (7, 3) for land 13\n Land 12 already on Island with land 13! \n ...Checking coordinates (7, 5) for land 13\n ...Checking coordinates (6, 4) for land 13\n ...Checking coordinates (8, 4) for land 13\n ...Adding land 17 with coordinates (8, 4) to land 13 \n\nExploring land 17____________\n\n\nFor Land 17 with coordinates (8, 4), Candidates are [(8, 3), (8, 5), (7, 4), (9, 4)] \n ...Checking coordinates (8, 3) for land 17\n ...Adding land 16 with coordinates (8, 3) to land 17 \n\nExploring land 16____________\n\n\nFor Land 16 with coordinates (8, 3), Candidates are [(8, 2), (8, 4), (7, 3), (9, 3)] \n ...Checking coordinates (8, 2) for land 16\n ...Checking coordinates (8, 4) for land 16\n Land 17 already on Island with land 16! \n ...Checking coordinates (7, 3) for land 16\n Land 12 already on Island with land 16! \n ...Checking coordinates (9, 3) for land 16\n ...Adding land 20 with coordinates (9, 3) to land 16 \n\nExploring land 20____________\n\n\nFor Land 20 with coordinates (9, 3), Candidates are [(9, 2), (9, 4), (8, 3), (10, 3)] \n ...Checking coordinates (9, 2) for land 20\n ...Checking coordinates (9, 4) for land 20\n ...Adding land 21 with coordinates (9, 4) to land 20 \n\nExploring land 21____________\n\n\nFor Land 21 with coordinates (9, 4), Candidates are [(9, 3), (9, 5), (8, 4), (10, 4)] \n ...Checking coordinates (9, 3) for land 21\n Land 20 already on Island with land 21! \n ...Checking coordinates (9, 5) for land 21\n ...Adding land 22 with coordinates (9, 5) to land 21 \n\nExploring land 22____________\n\n\nFor Land 22 with coordinates (9, 5), Candidates are [(9, 4), (9, 6), (8, 5), (10, 5)] \n ...Checking coordinates (9, 4) for land 22\n Land 21 already on Island with land 22! \n ...Checking coordinates (9, 6) for land 22\n ...Adding land 23 with coordinates (9, 6) to land 22 \n\nExploring land 23____________\n\n\nFor Land 23 with coordinates (9, 6), Candidates are [(9, 5), (9, 7), (8, 6), (10, 6)] \n ...Checking coordinates (9, 5) for land 23\n Land 22 already on Island with land 23! \n ...Checking coordinates (9, 7) for land 23\n ...Checking coordinates (8, 6) for land 23\n ...Checking coordinates (10, 6) for land 23\n ...Adding land 29 with coordinates (10, 6) to land 23 \n\nExploring land 29____________\n\n\nFor Land 29 with coordinates (10, 6), Candidates are [(10, 5), (10, 7), (9, 6), (11, 6)] \n ...Checking coordinates (10, 5) for land 29\n ...Adding land 28 with coordinates (10, 5) to land 29 \n\nExploring land 28____________\n\n\nFor Land 28 with coordinates (10, 5), Candidates are [(10, 4), (10, 6), (9, 5), (11, 5)] \n ...Checking coordinates (10, 4) for land 28\n ...Adding land 27 with coordinates (10, 4) to land 28 \n\nExploring land 27____________\n\n\nFor Land 27 with coordinates (10, 4), Candidates are [(10, 3), (10, 5), (9, 4), (11, 4)] \n ...Checking coordinates (10, 3) for land 27\n ...Adding land 26 with coordinates (10, 3) to land 27 \n\nExploring land 26____________\n\n\nFor Land 26 with coordinates (10, 3), Candidates are [(10, 2), (10, 4), (9, 3), (11, 3)] \n ...Checking coordinates (10, 2) for land 26\n ...Checking coordinates (10, 4) for land 26\n Land 27 already on Island with land 26! \n ...Checking coordinates (9, 3) for land 26\n Land 20 already on Island with land 26! \n ...Checking coordinates (11, 3) for land 26\n ...Adding land 32 with coordinates (11, 3) to land 26 \n\nExploring land 32____________\n\n\nFor Land 32 with coordinates (11, 3), Candidates are [(11, 2), (11, 4), (10, 3), (12, 3)] \n ...Checking coordinates (11, 2) for land 32\n ...Checking coordinates (11, 4) for land 32\n ...Adding land 33 with coordinates (11, 4) to land 32 \n\nExploring land 33____________\n\n\nFor Land 33 with coordinates (11, 4), Candidates are [(11, 3), (11, 5), (10, 4), (12, 4)] \n ...Checking coordinates (11, 3) for land 33\n Land 32 already on Island with land 33! \n ...Checking coordinates (11, 5) for land 33\n ...Checking coordinates (10, 4) for land 33\n Land 27 already on Island with land 33! \n ...Checking coordinates (12, 4) for land 33\n ...Adding land 39 with coordinates (12, 4) to land 33 \n\nExploring land 39____________\n\n\nFor Land 39 with coordinates (12, 4), Candidates are [(12, 3), (12, 5), (11, 4), (13, 4)] \n ...Checking coordinates (12, 3) for land 39\n ...Adding land 38 with coordinates (12, 3) to land 39 \n\nExploring land 38____________\n\n\nFor Land 38 with coordinates (12, 3), Candidates are [(12, 2), (12, 4), (11, 3), (13, 3)] \n ...Checking coordinates (12, 2) for land 38\n ...Checking coordinates (12, 4) for land 38\n Land 39 already on Island with land 38! \n ...Checking coordinates (11, 3) for land 38\n Land 32 already on Island with land 38! \n ...Checking coordinates (13, 3) for land 38\n ...Checking coordinates (12, 5) for land 39\n ...Checking coordinates (11, 4) for land 39\n Land 33 already on Island with land 39! \n ...Checking coordinates (13, 4) for land 39\n ...Checking coordinates (10, 3) for land 32\n Land 26 already on Island with land 32! \n ...Checking coordinates (12, 3) for land 32\n Land 38 already on Island with land 32! \n ...Checking coordinates (10, 5) for land 27\n Land 28 already on Island with land 27! \n ...Checking coordinates (9, 4) for land 27\n Land 21 already on Island with land 27! \n ...Checking coordinates (11, 4) for land 27\n Land 33 already on Island with land 27! \n ...Checking coordinates (10, 6) for land 28\n Land 29 already on Island with land 28! \n ...Checking coordinates (9, 5) for land 28\n Land 22 already on Island with land 28! \n ...Checking coordinates (11, 5) for land 28\n ...Checking coordinates (10, 7) for land 29\n ...Checking coordinates (9, 6) for land 29\n Land 23 already on Island with land 29! \n ...Checking coordinates (11, 6) for land 29\n ...Checking coordinates (8, 5) for land 22\n ...Checking coordinates (10, 5) for land 22\n Land 28 already on Island with land 22! \n ...Checking coordinates (8, 4) for land 21\n Land 17 already on Island with land 21! \n ...Checking coordinates (10, 4) for land 21\n Land 27 already on Island with land 21! \n ...Checking coordinates (8, 3) for land 20\n Land 16 already on Island with land 20! \n ...Checking coordinates (10, 3) for land 20\n Land 26 already on Island with land 20! \n ...Checking coordinates (8, 5) for land 17\n ...Checking coordinates (7, 4) for land 17\n Land 13 already on Island with land 17! \n ...Checking coordinates (9, 4) for land 17\n Land 21 already on Island with land 17! \n ...Checking coordinates (6, 3) for land 12\n ...Checking coordinates (8, 3) for land 12\n Land 16 already on Island with land 12! \nExplored island 12, consists of [12, 13, 17, 16, 20, 21, 22, 23, 29, 28, 27, 26, 32, 33, 39, 38]:\nFinding Islands Connected to Land 24\n\nFor Land 24 with coordinates (9, 16), Candidates are [(9, 15), (9, 17), (8, 16), (10, 16)] \n ...Checking coordinates (9, 15) for land 24\n ...Checking coordinates (9, 17) for land 24\n ...Adding land 25 with coordinates (9, 17) to land 24 \n\nExploring land 25____________\n\n\nFor Land 25 with coordinates (9, 17), Candidates are [(9, 16), (9, 18), (8, 17), (10, 17)] \n ...Checking coordinates (9, 16) for land 25\n Land 24 already on Island with land 25! \n ...Checking coordinates (9, 18) for land 25\n ...Checking coordinates (8, 17) for land 25\n ...Checking coordinates (10, 17) for land 25\n ...Adding land 31 with coordinates (10, 17) to land 25 \n\nExploring land 31____________\n\n\nFor Land 31 with coordinates (10, 17), Candidates are [(10, 16), (10, 18), (9, 17), (11, 17)] \n ...Checking coordinates (10, 16) for land 31\n ...Adding land 30 with coordinates (10, 16) to land 31 \n\nExploring land 30____________\n\n\nFor Land 30 with coordinates (10, 16), Candidates are [(10, 15), (10, 17), (9, 16), (11, 16)] \n ...Checking coordinates (10, 15) for land 30\n ...Checking coordinates (10, 17) for land 30\n Land 31 already on Island with land 30! \n ...Checking coordinates (9, 16) for land 30\n Land 24 already on Island with land 30! \n ...Checking coordinates (11, 16) for land 30\n ...Adding land 36 with coordinates (11, 16) to land 30 \n\nExploring land 36____________\n\n\nFor Land 36 with coordinates (11, 16), Candidates are [(11, 15), (11, 17), (10, 16), (12, 16)] \n ...Checking coordinates (11, 15) for land 36\n ...Adding land 35 with coordinates (11, 15) to land 36 \n\nExploring land 35____________\n\n\nFor Land 35 with coordinates (11, 15), Candidates are [(11, 14), (11, 16), (10, 15), (12, 15)] \n ...Checking coordinates (11, 14) for land 35\n ...Adding land 34 with coordinates (11, 14) to land 35 \n\nExploring land 34____________\n\n\nFor Land 34 with coordinates (11, 14), Candidates are [(11, 13), (11, 15), (10, 14), (12, 14)] \n ...Checking coordinates (11, 13) for land 34\n ...Checking coordinates (11, 15) for land 34\n Land 35 already on Island with land 34! \n ...Checking coordinates (10, 14) for land 34\n ...Checking coordinates (12, 14) for land 34\n ...Adding land 40 with coordinates (12, 14) to land 34 \n\nExploring land 40____________\n\n\nFor Land 40 with coordinates (12, 14), Candidates are [(12, 13), (12, 15), (11, 14), (13, 14)] \n ...Checking coordinates (12, 13) for land 40\n ...Checking coordinates (12, 15) for land 40\n ...Adding land 41 with coordinates (12, 15) to land 40 \n\nExploring land 41____________\n\n\nFor Land 41 with coordinates (12, 15), Candidates are [(12, 14), (12, 16), (11, 15), (13, 15)] \n ...Checking coordinates (12, 14) for land 41\n Land 40 already on Island with land 41! \n ...Checking coordinates (12, 16) for land 41\n ...Adding land 42 with coordinates (12, 16) to land 41 \n\nExploring land 42____________\n\n\nFor Land 42 with coordinates (12, 16), Candidates are [(12, 15), (12, 17), (11, 16), (13, 16)] \n ...Checking coordinates (12, 15) for land 42\n Land 41 already on Island with land 42! \n ...Checking coordinates (12, 17) for land 42\n ...Adding land 43 with coordinates (12, 17) to land 42 \n\nExploring land 43____________\n\n\nFor Land 43 with coordinates (12, 17), Candidates are [(12, 16), (12, 18), (11, 17), (13, 17)] \n ...Checking coordinates (12, 16) for land 43\n Land 42 already on Island with land 43! \n ...Checking coordinates (12, 18) for land 43\n ...Checking coordinates (11, 17) for land 43\n ...Adding land 37 with coordinates (11, 17) to land 43 \n\nExploring land 37____________\n\n\nFor Land 37 with coordinates (11, 17), Candidates are [(11, 16), (11, 18), (10, 17), (12, 17)] \n ...Checking coordinates (11, 16) for land 37\n Land 36 already on Island with land 37! \n ...Checking coordinates (11, 18) for land 37\n ...Checking coordinates (10, 17) for land 37\n Land 31 already on Island with land 37! \n ...Checking coordinates (12, 17) for land 37\n Land 43 already on Island with land 37! \n ...Checking coordinates (13, 17) for land 43\n ...Checking coordinates (11, 16) for land 42\n Land 36 already on Island with land 42! \n ...Checking coordinates (13, 16) for land 42\n ...Checking coordinates (11, 15) for land 41\n Land 35 already on Island with land 41! \n ...Checking coordinates (13, 15) for land 41\n ...Adding land 45 with coordinates (13, 15) to land 41 \n\nExploring land 45____________\n\n\nFor Land 45 with coordinates (13, 15), Candidates are [(13, 14), (13, 16), (12, 15), (14, 15)] \n ...Checking coordinates (13, 14) for land 45\n ...Adding land 44 with coordinates (13, 14) to land 45 \n\nExploring land 44____________\n\n\nFor Land 44 with coordinates (13, 14), Candidates are [(13, 13), (13, 15), (12, 14), (14, 14)] \n ...Checking coordinates (13, 13) for land 44\n ...Checking coordinates (13, 15) for land 44\n Land 45 already on Island with land 44! \n ...Checking coordinates (12, 14) for land 44\n Land 40 already on Island with land 44! \n ...Checking coordinates (14, 14) for land 44\n ...Adding land 46 with coordinates (14, 14) to land 44 \n\nExploring land 46____________\n\n\nFor Land 46 with coordinates (14, 14), Candidates are [(14, 13), (14, 15), (13, 14), (15, 14)] \n ...Checking coordinates (14, 13) for land 46\n ...Checking coordinates (14, 15) for land 46\n ...Adding land 47 with coordinates (14, 15) to land 46 \n\nExploring land 47____________\n\n\nFor Land 47 with coordinates (14, 15), Candidates are [(14, 14), (14, 16), (13, 15), (15, 15)] \n ...Checking coordinates (14, 14) for land 47\n Land 46 already on Island with land 47! \n ...Checking coordinates (14, 16) for land 47\n ...Checking coordinates (13, 15) for land 47\n Land 45 already on Island with land 47! \n ...Checking coordinates (15, 15) for land 47\n ...Checking coordinates (13, 14) for land 46\n Land 44 already on Island with land 46! \n ...Checking coordinates (15, 14) for land 46\n ...Checking coordinates (13, 16) for land 45\n ...Checking coordinates (12, 15) for land 45\n Land 41 already on Island with land 45! \n ...Checking coordinates (14, 15) for land 45\n Land 47 already on Island with land 45! \n ...Checking coordinates (11, 14) for land 40\n Land 34 already on Island with land 40! \n ...Checking coordinates (13, 14) for land 40\n Land 44 already on Island with land 40! \n ...Checking coordinates (11, 16) for land 35\n Land 36 already on Island with land 35! \n ...Checking coordinates (10, 15) for land 35\n ...Checking coordinates (12, 15) for land 35\n Land 41 already on Island with land 35! \n ...Checking coordinates (11, 17) for land 36\n Land 37 already on Island with land 36! \n ...Checking coordinates (10, 16) for land 36\n Land 30 already on Island with land 36! \n ...Checking coordinates (12, 16) for land 36\n Land 42 already on Island with land 36! \n ...Checking coordinates (10, 18) for land 31\n ...Checking coordinates (9, 17) for land 31\n Land 25 already on Island with land 31! \n ...Checking coordinates (11, 17) for land 31\n Land 37 already on Island with land 31! \n ...Checking coordinates (8, 16) for land 24\n ...Checking coordinates (10, 16) for land 24\n Land 30 already on Island with land 24! \nExplored island 24, consists of [24, 25, 31, 30, 36, 35, 34, 40, 41, 42, 43, 37, 45, 44, 46, 47]:\nFinding Islands Connected to Land 48\n\nFor Land 48 with coordinates (15, 7), Candidates are [(15, 6), (15, 8), (14, 7), (16, 7)] \n ...Checking coordinates (15, 6) for land 48\n ...Checking coordinates (15, 8) for land 48\n ...Adding land 49 with coordinates (15, 8) to land 48 \n\nExploring land 49____________\n\n\nFor Land 49 with coordinates (15, 8), Candidates are [(15, 7), (15, 9), (14, 8), (16, 8)] \n ...Checking coordinates (15, 7) for land 49\n Land 48 already on Island with land 49! \n ...Checking coordinates (15, 9) for land 49\n ...Checking coordinates (14, 8) for land 49\n ...Checking coordinates (16, 8) for land 49\n ...Adding land 51 with coordinates (16, 8) to land 49 \n\nExploring land 51____________\n\n\nFor Land 51 with coordinates (16, 8), Candidates are [(16, 7), (16, 9), (15, 8), (17, 8)] \n ...Checking coordinates (16, 7) for land 51\n ...Adding land 50 with coordinates (16, 7) to land 51 \n\nExploring land 50____________\n\n\nFor Land 50 with coordinates (16, 7), Candidates are [(16, 6), (16, 8), (15, 7), (17, 7)] \n ...Checking coordinates (16, 6) for land 50\n ...Checking coordinates (16, 8) for land 50\n Land 51 already on Island with land 50! \n ...Checking coordinates (15, 7) for land 50\n Land 48 already on Island with land 50! \n ...Checking coordinates (17, 7) for land 50\n ...Adding land 54 with coordinates (17, 7) to land 50 \n\nExploring land 54____________\n\n\nFor Land 54 with coordinates (17, 7), Candidates are [(17, 6), (17, 8), (16, 7), (18, 7)] \n ...Checking coordinates (17, 6) for land 54\n ...Checking coordinates (17, 8) for land 54\n ...Adding land 55 with coordinates (17, 8) to land 54 \n\nExploring land 55____________\n\n\nFor Land 55 with coordinates (17, 8), Candidates are [(17, 7), (17, 9), (16, 8), (18, 8)] \n ...Checking coordinates (17, 7) for land 55\n Land 54 already on Island with land 55! \n ...Checking coordinates (17, 9) for land 55\n ...Checking coordinates (16, 8) for land 55\n Land 51 already on Island with land 55! \n ...Checking coordinates (18, 8) for land 55\n ...Adding land 65 with coordinates (18, 8) to land 55 \n\nExploring land 65____________\n\n\nFor Land 65 with coordinates (18, 8), Candidates are [(18, 7), (18, 9), (17, 8), (19, 8)] \n ...Checking coordinates (18, 7) for land 65\n ...Adding land 64 with coordinates (18, 7) to land 65 \n\nExploring land 64____________\n\n\nFor Land 64 with coordinates (18, 7), Candidates are [(18, 6), (18, 8), (17, 7), (19, 7)] \n ...Checking coordinates (18, 6) for land 64\n ...Checking coordinates (18, 8) for land 64\n Land 65 already on Island with land 64! \n ...Checking coordinates (17, 7) for land 64\n Land 54 already on Island with land 64! \n ...Checking coordinates (19, 7) for land 64\n ...Adding land 74 with coordinates (19, 7) to land 64 \n\nExploring land 74____________\n\n\nFor Land 74 with coordinates (19, 7), Candidates are [(19, 6), (19, 8), (18, 7), (20, 7)] \n ...Checking coordinates (19, 6) for land 74\n ...Checking coordinates (19, 8) for land 74\n ...Adding land 75 with coordinates (19, 8) to land 74 \n\nExploring land 75____________\n\n\nFor Land 75 with coordinates (19, 8), Candidates are [(19, 7), (19, 9), (18, 8), (20, 8)] \n ...Checking coordinates (19, 7) for land 75\n Land 74 already on Island with land 75! \n ...Checking coordinates (19, 9) for land 75\n ...Checking coordinates (18, 8) for land 75\n Land 65 already on Island with land 75! \n ...Checking coordinates (20, 8) for land 75\n ...Checking coordinates (18, 7) for land 74\n Land 64 already on Island with land 74! \n ...Checking coordinates (20, 7) for land 74\n ...Checking coordinates (18, 9) for land 65\n ...Checking coordinates (17, 8) for land 65\n Land 55 already on Island with land 65! \n ...Checking coordinates (19, 8) for land 65\n Land 75 already on Island with land 65! \n ...Checking coordinates (16, 7) for land 54\n Land 50 already on Island with land 54! \n ...Checking coordinates (18, 7) for land 54\n Land 64 already on Island with land 54! \n ...Checking coordinates (16, 9) for land 51\n ...Checking coordinates (15, 8) for land 51\n Land 49 already on Island with land 51! \n ...Checking coordinates (17, 8) for land 51\n Land 55 already on Island with land 51! \n ...Checking coordinates (14, 7) for land 48\n ...Checking coordinates (16, 7) for land 48\n Land 50 already on Island with land 48! \nExplored island 48, consists of [48, 49, 51, 50, 54, 55, 65, 64, 74, 75]:\nFinding Islands Connected to Land 52\n\nFor Land 52 with coordinates (17, 3), Candidates are [(17, 2), (17, 4), (16, 3), (18, 3)] \n ...Checking coordinates (17, 2) for land 52\n ...Checking coordinates (17, 4) for land 52\n ...Adding land 53 with coordinates (17, 4) to land 52 \n\nExploring land 53____________\n\n\nFor Land 53 with coordinates (17, 4), Candidates are [(17, 3), (17, 5), (16, 4), (18, 4)] \n ...Checking coordinates (17, 3) for land 53\n Land 52 already on Island with land 53! \n ...Checking coordinates (17, 5) for land 53\n ...Checking coordinates (16, 4) for land 53\n ...Checking coordinates (18, 4) for land 53\n ...Adding land 63 with coordinates (18, 4) to land 53 \n\nExploring land 63____________\n\n\nFor Land 63 with coordinates (18, 4), Candidates are [(18, 3), (18, 5), (17, 4), (19, 4)] \n ...Checking coordinates (18, 3) for land 63\n ...Adding land 62 with coordinates (18, 3) to land 63 \n\nExploring land 62____________\n\n\nFor Land 62 with coordinates (18, 3), Candidates are [(18, 2), (18, 4), (17, 3), (19, 3)] \n ...Checking coordinates (18, 2) for land 62\n ...Checking coordinates (18, 4) for land 62\n Land 63 already on Island with land 62! \n ...Checking coordinates (17, 3) for land 62\n Land 52 already on Island with land 62! \n ...Checking coordinates (19, 3) for land 62\n ...Adding land 72 with coordinates (19, 3) to land 62 \n\nExploring land 72____________\n\n\nFor Land 72 with coordinates (19, 3), Candidates are [(19, 2), (19, 4), (18, 3), (20, 3)] \n ...Checking coordinates (19, 2) for land 72\n ...Checking coordinates (19, 4) for land 72\n ...Adding land 73 with coordinates (19, 4) to land 72 \n\nExploring land 73____________\n\n\nFor Land 73 with coordinates (19, 4), Candidates are [(19, 3), (19, 5), (18, 4), (20, 4)] \n ...Checking coordinates (19, 3) for land 73\n Land 72 already on Island with land 73! \n ...Checking coordinates (19, 5) for land 73\n ...Checking coordinates (18, 4) for land 73\n Land 63 already on Island with land 73! \n ...Checking coordinates (20, 4) for land 73\n ...Checking coordinates (18, 3) for land 72\n Land 62 already on Island with land 72! \n ...Checking coordinates (20, 3) for land 72\n ...Checking coordinates (18, 5) for land 63\n ...Checking coordinates (17, 4) for land 63\n Land 53 already on Island with land 63! \n ...Checking coordinates (19, 4) for land 63\n Land 73 already on Island with land 63! \n ...Checking coordinates (16, 3) for land 52\n ...Checking coordinates (18, 3) for land 52\n Land 62 already on Island with land 52! \nExplored island 52, consists of [52, 53, 63, 62, 72, 73]:\nFinding Islands Connected to Land 56\n\nFor Land 56 with coordinates (17, 11), Candidates are [(17, 10), (17, 12), (16, 11), (18, 11)] \n ...Checking coordinates (17, 10) for land 56\n ...Checking coordinates (17, 12) for land 56\n ...Adding land 57 with coordinates (17, 12) to land 56 \n\nExploring land 57____________\n\n\nFor Land 57 with coordinates (17, 12), Candidates are [(17, 11), (17, 13), (16, 12), (18, 12)] \n ...Checking coordinates (17, 11) for land 57\n Land 56 already on Island with land 57! \n ...Checking coordinates (17, 13) for land 57\n ...Checking coordinates (16, 12) for land 57\n ...Checking coordinates (18, 12) for land 57\n ...Adding land 67 with coordinates (18, 12) to land 57 \n\nExploring land 67____________\n\n\nFor Land 67 with coordinates (18, 12), Candidates are [(18, 11), (18, 13), (17, 12), (19, 12)] \n ...Checking coordinates (18, 11) for land 67\n ...Adding land 66 with coordinates (18, 11) to land 67 \n\nExploring land 66____________\n\n\nFor Land 66 with coordinates (18, 11), Candidates are [(18, 10), (18, 12), (17, 11), (19, 11)] \n ...Checking coordinates (18, 10) for land 66\n ...Checking coordinates (18, 12) for land 66\n Land 67 already on Island with land 66! \n ...Checking coordinates (17, 11) for land 66\n Land 56 already on Island with land 66! \n ...Checking coordinates (19, 11) for land 66\n ...Adding land 76 with coordinates (19, 11) to land 66 \n\nExploring land 76____________\n\n\nFor Land 76 with coordinates (19, 11), Candidates are [(19, 10), (19, 12), (18, 11), (20, 11)] \n ...Checking coordinates (19, 10) for land 76\n ...Checking coordinates (19, 12) for land 76\n ...Adding land 77 with coordinates (19, 12) to land 76 \n\nExploring land 77____________\n\n\nFor Land 77 with coordinates (19, 12), Candidates are [(19, 11), (19, 13), (18, 12), (20, 12)] \n ...Checking coordinates (19, 11) for land 77\n Land 76 already on Island with land 77! \n ...Checking coordinates (19, 13) for land 77\n ...Checking coordinates (18, 12) for land 77\n Land 67 already on Island with land 77! \n ...Checking coordinates (20, 12) for land 77\n ...Checking coordinates (18, 11) for land 76\n Land 66 already on Island with land 76! \n ...Checking coordinates (20, 11) for land 76\n ...Checking coordinates (18, 13) for land 67\n ...Checking coordinates (17, 12) for land 67\n Land 57 already on Island with land 67! \n ...Checking coordinates (19, 12) for land 67\n Land 77 already on Island with land 67! \n ...Checking coordinates (16, 11) for land 56\n ...Checking coordinates (18, 11) for land 56\n Land 66 already on Island with land 56! \nExplored island 56, consists of [56, 57, 67, 66, 76, 77]:\nFinding Islands Connected to Land 58\n\nFor Land 58 with coordinates (17, 16), Candidates are [(17, 15), (17, 17), (16, 16), (18, 16)] \n ...Checking coordinates (17, 15) for land 58\n ...Checking coordinates (17, 17) for land 58\n ...Adding land 59 with coordinates (17, 17) to land 58 \n\nExploring land 59____________\n\n\nFor Land 59 with coordinates (17, 17), Candidates are [(17, 16), (17, 18), (16, 17), (18, 17)] \n ...Checking coordinates (17, 16) for land 59\n Land 58 already on Island with land 59! \n ...Checking coordinates (17, 18) for land 59\n ...Adding land 60 with coordinates (17, 18) to land 59 \n\nExploring land 60____________\n\n\nFor Land 60 with coordinates (17, 18), Candidates are [(17, 17), (17, 19), (16, 18), (18, 18)] \n ...Checking coordinates (17, 17) for land 60\n Land 59 already on Island with land 60! \n ...Checking coordinates (17, 19) for land 60\n ...Adding land 61 with coordinates (17, 19) to land 60 \n\nExploring land 61____________\n\n\nFor Land 61 with coordinates (17, 19), Candidates are [(17, 18), (17, 20), (16, 19), (18, 19)] \n ...Checking coordinates (17, 18) for land 61\n Land 60 already on Island with land 61! \n ...Checking coordinates (17, 20) for land 61\n ...Checking coordinates (16, 19) for land 61\n ...Checking coordinates (18, 19) for land 61\n ...Adding land 71 with coordinates (18, 19) to land 61 \n\nExploring land 71____________\n\n\nFor Land 71 with coordinates (18, 19), Candidates are [(18, 18), (18, 20), (17, 19), (19, 19)] \n ...Checking coordinates (18, 18) for land 71\n ...Adding land 70 with coordinates (18, 18) to land 71 \n\nExploring land 70____________\n\n\nFor Land 70 with coordinates (18, 18), Candidates are [(18, 17), (18, 19), (17, 18), (19, 18)] \n ...Checking coordinates (18, 17) for land 70\n ...Adding land 69 with coordinates (18, 17) to land 70 \n\nExploring land 69____________\n\n\nFor Land 69 with coordinates (18, 17), Candidates are [(18, 16), (18, 18), (17, 17), (19, 17)] \n ...Checking coordinates (18, 16) for land 69\n ...Adding land 68 with coordinates (18, 16) to land 69 \n\nExploring land 68____________\n\n\nFor Land 68 with coordinates (18, 16), Candidates are [(18, 15), (18, 17), (17, 16), (19, 16)] \n ...Checking coordinates (18, 15) for land 68\n ...Checking coordinates (18, 17) for land 68\n Land 69 already on Island with land 68! \n ...Checking coordinates (17, 16) for land 68\n Land 58 already on Island with land 68! \n ...Checking coordinates (19, 16) for land 68\n ...Adding land 78 with coordinates (19, 16) to land 68 \n\nExploring land 78____________\n\n\nFor Land 78 with coordinates (19, 16), Candidates are [(19, 15), (19, 17), (18, 16), (20, 16)] \n ...Checking coordinates (19, 15) for land 78\n ...Checking coordinates (19, 17) for land 78\n ...Adding land 79 with coordinates (19, 17) to land 78 \n\nExploring land 79____________\n\n\nFor Land 79 with coordinates (19, 17), Candidates are [(19, 16), (19, 18), (18, 17), (20, 17)] \n ...Checking coordinates (19, 16) for land 79\n Land 78 already on Island with land 79! \n ...Checking coordinates (19, 18) for land 79\n ...Adding land 80 with coordinates (19, 18) to land 79 \n\nExploring land 80____________\n\n\nFor Land 80 with coordinates (19, 18), Candidates are [(19, 17), (19, 19), (18, 18), (20, 18)] \n ...Checking coordinates (19, 17) for land 80\n Land 79 already on Island with land 80! \n ...Checking coordinates (19, 19) for land 80\n ...Adding land 81 with coordinates (19, 19) to land 80 \n\nExploring land 81____________\n\n\nFor Land 81 with coordinates (19, 19), Candidates are [(19, 18), (19, 20), (18, 19), (20, 19)] \n ...Checking coordinates (19, 18) for land 81\n Land 80 already on Island with land 81! \n ...Checking coordinates (19, 20) for land 81\n ...Checking coordinates (18, 19) for land 81\n Land 71 already on Island with land 81! \n ...Checking coordinates (20, 19) for land 81\n ...Checking coordinates (18, 18) for land 80\n Land 70 already on Island with land 80! \n ...Checking coordinates (20, 18) for land 80\n ...Checking coordinates (18, 17) for land 79\n Land 69 already on Island with land 79! \n ...Checking coordinates (20, 17) for land 79\n ...Checking coordinates (18, 16) for land 78\n Land 68 already on Island with land 78! \n ...Checking coordinates (20, 16) for land 78\n ...Checking coordinates (18, 18) for land 69\n Land 70 already on Island with land 69! \n ...Checking coordinates (17, 17) for land 69\n Land 59 already on Island with land 69! \n ...Checking coordinates (19, 17) for land 69\n Land 79 already on Island with land 69! \n ...Checking coordinates (18, 19) for land 70\n Land 71 already on Island with land 70! \n ...Checking coordinates (17, 18) for land 70\n Land 60 already on Island with land 70! \n ...Checking coordinates (19, 18) for land 70\n Land 80 already on Island with land 70! \n ...Checking coordinates (18, 20) for land 71\n ...Checking coordinates (17, 19) for land 71\n Land 61 already on Island with land 71! \n ...Checking coordinates (19, 19) for land 71\n Land 81 already on Island with land 71! \n ...Checking coordinates (16, 18) for land 60\n ...Checking coordinates (18, 18) for land 60\n Land 70 already on Island with land 60! \n ...Checking coordinates (16, 17) for land 59\n ...Checking coordinates (18, 17) for land 59\n Land 69 already on Island with land 59! \n ...Checking coordinates (16, 16) for land 58\n ...Checking coordinates (18, 16) for land 58\n Land 68 already on Island with land 58! \nExplored island 58, consists of [58, 59, 60, 61, 71, 70, 69, 68, 78, 79, 80, 81]:\n"
],
[
"Island_List",
"_____no_output_____"
]
],
[
[
"**Step 9)** Write a function Island Distance(isl1, isl2), which takes two lists of cells representing\ntwo islands, and finds the distance of these two islands. For this you will need to compute the\nDistance function from Milestone 1.",
"_____no_output_____"
]
],
[
[
"def Island_Distance(isl1=list,isl2=list):\n \n x0 = 'nothing'\n \n for i in isl1:\n \n if GenerateNeighbors(i,m=int,n=int) > 3: #Landlocked Land\n next\n else:\n \n #print(\" Checking land {}\".format(i))\n for j in isl2:\n \n if GenerateNeighbors(j,m=int,n=int) >3: \n next\n else:\n \n #print(\"Measuring land {} to land {}\".format(i,j))\n \n x1 = Distance(i,j)\n \n if x0 == 'nothing':\n x0 = x1\n \n if x1 < x0:\n x0 = x1\n #print(\"\\nNew Shortest Lenght is {}\".format(x0))\n #print(\"\\nShortest distance is {}\\n\".format(x0))\n return x0\n \n ",
"_____no_output_____"
],
[
"Island_Distance(Island_List[0],Island_List[1])",
"_____no_output_____"
]
],
[
[
"**Step 10)** We will now construct a graph of islands. Consider an example for this. Suppose\nIsland List contains 3 islands. We will assign to each island a unique number in [0, 3). Then\nIsland Graph will be a list of the following form:\n\n<br>\n\n<center>[[0, 1, d(0, 1)], [0, 2, d(0, 2)], [1, 2, d(1, 2)]].</center>\n\n<br>\nHere d(i, j) is the distance between islands i and j, as computed with the function in Step 9. In\nother words, for each pair of islands, we have a triple consisting of the identities of the pair, and\ntheir distance. This is a complete weighted graph. The goal of this Step is to write a function\nIsland Graph that outputs this list.",
"_____no_output_____"
]
],
[
[
"def Island_Graph(Island_List=list):\n \n import sys, os\n \n # For n islands in Island list, enumerate island on [0,3)\n \n output = []\n skip = []\n global dums\n dums = dict(val for val in enumerate(Island_List))\n \n for i in dums.keys():\n #print(i)\n skip.append(i)\n \n for j in dums.keys():\n \n if i == j or j in skip:\n next\n #print(\"skipped\")\n \n else:\n \n #sys.stdout = open(os.devnull, 'w')\n \n y0 = [i,j,Island_Distance(dums[i],dums[j])]\n \n output.append(y0)\n \n #sys.stdout = sys.__stdout__\n \n #print(y0)\n \n \n #print(output)\n print(\"\\nLenght of output list is {}, \".format(len(output)),\n \"which makes sense for a list of size {}, \".format(len(Island_List)),\n \"Since {} times {} divided by 2 is {}.\".format(len(Island_List),\n len(Island_List)-1,\n int(len(Island_List)*(len(Island_List)-1))/2))\n \n \n return output\n \n ",
"_____no_output_____"
],
[
"fun = Island_Graph(Island_List)\nfun",
"\nLenght of output list is 21, which makes sense for a list of size 7, Since 7 times 6 divided by 2 is 21.0.\n"
]
],
[
[
"**Final Step** \n\nWe now have a data structure which is the adjacency list (with weights) of the graphs.\nTo connect all islands, we need to find a **minimum weight spanning tree** for this graph. I\nhave seen one algorithm for computing such a tree in class. However, for this project, I will\nuse the python library **networkx**.\n\n<a href=\" https://networkx.github.io/documentation/networkx-1.10/reference/generated/networkx.algorithms.mst.minimum_spanning_tree.html#networkx.algorithms.mst.minimum_spanning_\ntree \"> Here </a>is the documentation of a function that computes minimum weight spaning trees:\n\n\n\n",
"_____no_output_____"
]
],
[
[
"import networkx as nx",
"_____no_output_____"
],
[
"G = nx.Graph()",
"_____no_output_____"
],
[
"G.clear()\n\nfor i in range(len(fun)):\n print(fun[i][0],fun[i][1],fun[i][2])\n G.add_edge(fun[i][0],fun[i][1], weight=fun[i][2])\n ",
"0 1 7\n0 2 4\n0 3 11\n0 4 17\n0 5 9\n0 6 12\n1 2 9\n1 3 6\n1 4 5\n1 5 12\n1 6 17\n2 3 7\n2 4 13\n2 5 5\n2 6 4\n3 4 3\n3 5 3\n3 6 8\n4 5 7\n4 6 12\n5 6 4\n"
],
[
"mst = nx.tree.minimum_spanning_edges(G, algorithm='kruskal', data=False)",
"_____no_output_____"
],
[
"edgelist = list(mst)",
"_____no_output_____"
],
[
"sorted(sorted(e) for e in edgelist)",
"_____no_output_____"
],
[
"arbol = sorted(sorted(e) for e in edgelist)",
"_____no_output_____"
],
[
" nx.draw(G, with_labels=True, font_weight='bold')",
"_____no_output_____"
],
[
"EDGY = []\nfor item in edgelist:\n \n #print(item[0],item[1])\n \n i = item[0]\n j = item[1]\n \n #print(i)\n \n k = Island_Distance(Island_List[i],Island_List[j])\n \n EDGY.append(k)\n \n length = sum(EDGY)\n \nprint(length)\n",
"23\n"
],
[
"print(\"The minimum cost to build the bridges required to connect all the islands is {}.\".format(length))",
"The minimum cost to build the bridges required to connect all the islands is 23.\n"
]
],
[
[
"### Note:\n\nThe last part of the project was executed using the image and coordinates of the second patch on the text file.\n\n### End",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
]
|
e7cb1de34d87fb6fd2ecc6e259471e540480c722 | 178,014 | ipynb | Jupyter Notebook | Diabetes.ipynb | AryanMethil/Diabetes-KNN-vs-Naive-Bayes | f38f8f80a6ecff60b84cb940eee8f1a42359d382 | [
"MIT"
]
| 6 | 2020-10-27T17:50:24.000Z | 2021-02-21T07:31:05.000Z | Diabetes.ipynb | AryanMethil/Diabetes-KNN-vs-Naive-Bayes | f38f8f80a6ecff60b84cb940eee8f1a42359d382 | [
"MIT"
]
| null | null | null | Diabetes.ipynb | AryanMethil/Diabetes-KNN-vs-Naive-Bayes | f38f8f80a6ecff60b84cb940eee8f1a42359d382 | [
"MIT"
]
| null | null | null | 73.589913 | 23,526 | 0.567568 | [
[
[
"<a href=\"https://colab.research.google.com/github/AryanMethil/Diabetes-KNN-vs-Naive-Bayes/blob/main/Diabetes.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Mounted at /content/drive\n"
]
],
[
[
"# Dataset Exploration\n\n\n\n1. Head of dataset\n2. Check for null values (absent)\n3. Check for class imbalance (present - remove it by upsampling)\n\n\n",
"_____no_output_____"
]
],
[
[
"# Read the csv file\nimport pandas as pd\ndf=pd.read_csv('/content/drive/My Drive/Diabetes/diabetes.csv')\ndf.head()",
"_____no_output_____"
],
[
"# Print the null values of every column\ndf.isna().sum()\n",
"_____no_output_____"
],
[
"# Print class count to check for imbalance\ndf['Outcome'].value_counts()",
"_____no_output_____"
],
[
"from sklearn.utils import resample\ndf_majority = df[df.Outcome==0]\ndf_minority = df[df.Outcome==1]\n \n# Upsample minority class\ndf_minority_upsampled = resample(df_minority, \n replace=True, # sample with replacement\n n_samples=500, # to match majority class\n random_state=42) # reproducible results\n \n# Combine majority class with upsampled minority class\ndf = pd.concat([df_majority, df_minority_upsampled])\n\nprint(df['Outcome'].value_counts())",
"1 500\n0 500\nName: Outcome, dtype: int64\n"
]
],
[
[
"# Stratified K Folds Cross Validation",
"_____no_output_____"
]
],
[
[
"# Add a \"kfolds\" column which will indicate the validation set number\ndf['kfolds']=-1\n\n# Shuffle all the rows and then reset the index\ndf=df.sample(frac=1,random_state=42).reset_index(drop=True)\ndf.head()",
"_____no_output_____"
],
[
"from sklearn import model_selection\n\n# Create 5 sets of training,validation sets\nstrat_kf=model_selection.StratifiedKFold(n_splits=5)\n\n# .split() returns a list of 5 lists (corresponding to the n_splits value)\n# Each of these 5 lists consists of 2 lists. 1st one contains training set indices and 2nd one contains validation set indices\n# In a dataset of 10 data points, data 1 and 2 will be the validation in 1st fold, data 3 and 4 in the second fold and so on\n# 1st iteration of the for loop : trn_ = 3,4,5,6,7,8,9,10 and val_ = 1,2 and fold : 0\n# Assign 1st and 2nd row's kfolds value as 0 representing that they will be the validation points for 1st (0th) fold\n\nfor fold,(trn_,val_) in enumerate(strat_kf.split(X=df,y=df['Outcome'])):\n df.loc[val_,'kfolds']=fold\ndf.head()",
"_____no_output_____"
]
],
[
[
"# Scale the features using StandardScaler",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import StandardScaler\nscaler=StandardScaler()\ndf_2=pd.DataFrame(scaler.fit_transform(df),index=df.index,columns=df.columns)\n\n# Target column and kfolds column dont need to be scaled\ndf_2['Outcome']=df['Outcome']\ndf_2['kfolds']=df['kfolds']\ndf_2.head()",
"_____no_output_____"
]
],
[
[
"# Feature Selection\n\n1. KNN\n2. Naive Bayes",
"_____no_output_____"
]
],
[
[
"from sklearn import metrics\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"def run(fold,df,models,print_details=False):\n \n # Training and validation sets\n df_train=df[df['kfolds']!=fold].reset_index(drop=True)\n df_valid=df[df['kfolds']==fold].reset_index(drop=True)\n\n\n # x and y of training dataset\n x_train=df_train.drop('Outcome',axis=1).values\n y_train=df_train.Outcome.values\n\n # x and y of validation dataset\n x_valid=df_valid.drop('Outcome',axis=1).values\n y_valid=df_valid.Outcome.values\n\n # accuracy => will store accuracies of the models (same for confusion_matrices)\n accuracy=[]\n confusion_matrices=[]\n classification_report=[]\n\n for model_name,model_constructor in list(models.items()):\n clf=model_constructor\n clf.fit(x_train,y_train)\n\n # preds_train, preds_valid => predictions when training and validation x are fed into the trained model\n preds_train=clf.predict(x_train)\n preds_valid=clf.predict(x_valid)\n\n acc_train=metrics.accuracy_score(y_train,preds_train)\n acc_valid=metrics.accuracy_score(y_valid,preds_valid)\n conf_matrix=metrics.confusion_matrix(y_valid,preds_valid)\n class_report=metrics.classification_report(y_valid,preds_valid)\n\n accuracy.append(acc_valid)\n confusion_matrices.append(conf_matrix)\n classification_report.append(class_report)\n\n if(print_details==True):\n print(f'Model => {model_name} => Fold = {fold} => Training Accuracy = {acc_train} => Validation Accuracy = {acc_valid}')\n\n if(print_details==True):\n print('\\n--------------------------------------------------------------------------------------------\\n')\n \n return accuracy,confusion_matrices,classification_report",
"_____no_output_____"
]
],
[
[
"#### Greedy Feature Selection",
"_____no_output_____"
]
],
[
[
"def greedy_feature_selection(fold,df,models,target_name):\n\n # target_index => stores the index of the target variable in the dataset\n # kfolds_index => stores the index of kfolds column in the dataset\n target_index=df.columns.get_loc(target_name)\n kfolds_index=df.columns.get_loc('kfolds')\n\n # good_features => stores the indices of all the optimal features\n # best_scores => keeps track of the best scores \n good_features=[]\n best_scores=[]\n\n # df has X and y and a kfolds column. \n # no of features (no of columns in X) => total columns in df - 1 (there's 1 y) - 1 (there's 1 kfolds)\n num_features=df.shape[1]-2\n\n\n while True:\n\n # this_feature => the feature added to the already selected features to measure the effect of the former on the model\n # best_score => keeps track of the best score achieved while selecting features 1 at a time and checking its effect on the model\n this_feature=None\n best_score=0\n\n\n for feature in range(num_features):\n\n # if the feature is already in the good_features list, ignore and move ahead\n if feature in good_features:\n continue\n \n # add the currently selected feature to the already discovered good features\n selected_features=good_features+[feature]\n\n # all the selected features + target and kfolds column\n df_train=df.iloc[:, selected_features + [target_index,kfolds_index]]\n\n # fit the selected dataset to a model \n accuracy,confusion_matrices,classification_report=run(fold,df_train,models)\n\n # if any improvement is observed over the previous set of features\n if(accuracy[0]>best_score):\n this_feature=feature\n best_score=accuracy[0]\n \n if(this_feature!=None):\n good_features.append(this_feature)\n best_scores.append(best_score)\n \n if(len(best_scores)>2):\n if(best_scores[-1]<best_scores[-2]):\n break\n \n return best_scores[:-1] , df.iloc[:, good_features[:-1] + [target_index,kfolds_index]]\n\n \n",
"_____no_output_____"
]
],
[
[
"#### Recursive Feature Selection",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_selection import RFE\n\ndef recursive_feature_selection(df,models,n_features_to_select,target_name):\n X=df.drop(labels=[target_name,'kfolds'],axis=1).values\n y=df[target_name]\n kfolds=df.kfolds.values\n\n model_name,model_constructor=list(models.items())[0]\n\n rfe=RFE(\n estimator=model_constructor,\n n_features_to_select=n_features_to_select\n )\n\n try:\n rfe.fit(X,y)\n except RuntimeError:\n print(f\"{model_name} does not support feature importance... Returning original dataframe\\n\")\n return df\n else:\n X_transformed = rfe.transform(X)\n df_optimal=pd.DataFrame(data=[X,y,kfolds])\n return df_optimal",
"_____no_output_____"
],
[
"from sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.naive_bayes import MultinomialNB",
"_____no_output_____"
],
[
"print('Greedy Feature Selection : ')\nprint('\\n')\nmodels={'KNN': KNeighborsClassifier()}\nbest_scores,df_optimal_KNN=greedy_feature_selection(fold=4,df=df_2,models=models,target_name='Outcome')\nprint(df_optimal_KNN.head())\n\nprint('\\n')\nprint(\"Recursive Feature Selection : \")\nprint('\\n')\ndf_recursive_optimal_KNN=recursive_feature_selection(df=df_2,models=models,n_features_to_select=5,target_name='Outcome')\nprint(df_recursive_optimal_KNN.head())",
"Greedy Feature Selection : \n\n\n Glucose DiabetesPedigreeFunction Age Outcome kfolds\n0 -0.230248 -0.295300 -0.367793 1 0\n1 2.011697 -0.680386 0.579018 1 0\n2 -0.614581 -0.726229 0.923314 1 0\n3 -0.518498 -0.625373 0.665092 1 0\n4 0.250169 -0.255569 -1.142458 0 0\n\n\nRecursive Feature Selection : \n\n\nKNN does not support feature importance... Returning original dataframe\n\n Pregnancies Glucose BloodPressure ... Age Outcome kfolds\n0 -0.053578 -0.230248 -0.423269 ... -0.367793 1 0\n1 0.787960 2.011697 -0.111124 ... 0.579018 1 0\n2 1.068473 -0.614581 1.553653 ... 0.923314 1 0\n3 1.629498 -0.518498 -0.215172 ... 0.665092 1 0\n4 -1.175629 0.250169 0.409119 ... -1.142458 0 0\n\n[5 rows x 10 columns]\n"
],
[
"models={'Naive Bayes' : GaussianNB()}\nbest_scores,df_optimal_NB=greedy_feature_selection(fold=4,df=df_2,models=models,target_name='Outcome')\nprint(df_optimal_NB.head())\n\nprint('\\n')\ndf_recursive_optimal_NB=recursive_feature_selection(df=df_2,models=models,n_features_to_select=5,target_name='Outcome')\nprint(df_recursive_optimal_NB.head())",
" Glucose Pregnancies BMI Outcome kfolds\n0 -0.230248 -0.053578 -0.363725 1 0\n1 2.011697 0.787960 0.691889 1 0\n2 -0.614581 1.068473 1.430819 1 0\n3 -0.518498 1.629498 -0.007455 1 0\n4 0.250169 -1.175629 -0.007455 0 0\n\n\nNaive Bayes does not support feature importance... Returning original dataframe\n\n Pregnancies Glucose BloodPressure ... Age Outcome kfolds\n0 -0.053578 -0.230248 -0.423269 ... -0.367793 1 0\n1 0.787960 2.011697 -0.111124 ... 0.579018 1 0\n2 1.068473 -0.614581 1.553653 ... 0.923314 1 0\n3 1.629498 -0.518498 -0.215172 ... 0.665092 1 0\n4 -1.175629 0.250169 0.409119 ... -1.142458 0 0\n\n[5 rows x 10 columns]\n"
]
],
[
[
"# Hyperparameter Tuning in KNN",
"_____no_output_____"
],
[
"#### Manually finding the optimal value of n_neighbors parameter",
"_____no_output_____"
]
],
[
[
"# Find the optimal value of the n_neighbors parameter\n\nmodels={f'KNN_{i}':KNeighborsClassifier(n_neighbors=i) for i in range(2,31)}",
"_____no_output_____"
],
[
"# run the model only for fold number 4 ie the 5th fold\n\naccuracy,confusion_matrices,classification_report=run(fold=4,df=df_optimal_KNN,models=models,print_details=True)",
"Model => KNN_2 => Fold = 4 => Training Accuracy = 0.8825 => Validation Accuracy = 0.67\nModel => KNN_3 => Fold = 4 => Training Accuracy = 0.85 => Validation Accuracy = 0.705\nModel => KNN_4 => Fold = 4 => Training Accuracy = 0.8175 => Validation Accuracy = 0.725\nModel => KNN_5 => Fold = 4 => Training Accuracy = 0.81625 => Validation Accuracy = 0.765\nModel => KNN_6 => Fold = 4 => Training Accuracy = 0.8025 => Validation Accuracy = 0.705\nModel => KNN_7 => Fold = 4 => Training Accuracy = 0.7975 => Validation Accuracy = 0.735\nModel => KNN_8 => Fold = 4 => Training Accuracy = 0.79625 => Validation Accuracy = 0.71\nModel => KNN_9 => Fold = 4 => Training Accuracy = 0.77375 => Validation Accuracy = 0.745\nModel => KNN_10 => Fold = 4 => Training Accuracy = 0.785 => Validation Accuracy = 0.74\nModel => KNN_11 => Fold = 4 => Training Accuracy = 0.77625 => Validation Accuracy = 0.72\nModel => KNN_12 => Fold = 4 => Training Accuracy = 0.77875 => Validation Accuracy = 0.72\nModel => KNN_13 => Fold = 4 => Training Accuracy = 0.77625 => Validation Accuracy = 0.715\nModel => KNN_14 => Fold = 4 => Training Accuracy = 0.77875 => Validation Accuracy = 0.725\nModel => KNN_15 => Fold = 4 => Training Accuracy = 0.775 => Validation Accuracy = 0.725\nModel => KNN_16 => Fold = 4 => Training Accuracy = 0.77875 => Validation Accuracy = 0.705\nModel => KNN_17 => Fold = 4 => Training Accuracy = 0.77625 => Validation Accuracy = 0.7\nModel => KNN_18 => Fold = 4 => Training Accuracy = 0.7725 => Validation Accuracy = 0.7\nModel => KNN_19 => Fold = 4 => Training Accuracy = 0.77375 => Validation Accuracy = 0.705\nModel => KNN_20 => Fold = 4 => Training Accuracy = 0.77625 => Validation Accuracy = 0.69\nModel => KNN_21 => Fold = 4 => Training Accuracy = 0.7725 => Validation Accuracy = 0.695\nModel => KNN_22 => Fold = 4 => Training Accuracy = 0.7675 => Validation Accuracy = 0.7\nModel => KNN_23 => Fold = 4 => Training Accuracy = 0.76875 => Validation Accuracy = 0.7\nModel => KNN_24 => Fold = 4 => Training Accuracy = 0.755 => Validation Accuracy = 0.7\nModel => KNN_25 => Fold = 4 => Training Accuracy = 0.76 => Validation Accuracy = 0.715\nModel => KNN_26 => Fold = 4 => Training Accuracy = 0.7575 => Validation Accuracy = 0.735\nModel => KNN_27 => Fold = 4 => Training Accuracy = 0.765 => Validation Accuracy = 0.73\nModel => KNN_28 => Fold = 4 => Training Accuracy = 0.76 => Validation Accuracy = 0.74\nModel => KNN_29 => Fold = 4 => Training Accuracy = 0.765 => Validation Accuracy = 0.75\nModel => KNN_30 => Fold = 4 => Training Accuracy = 0.75 => Validation Accuracy = 0.745\n\n--------------------------------------------------------------------------------------------\n\n"
],
[
"x=[i for i in range(2,31)]\ny=accuracy\nplt.plot(x,y)\nplt.xlabel('Number of Nearest Neighbors')\nplt.ylabel('Accuracy Score')\nplt.title(\"Optimal n_neighbors value\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Using Grid Search to find optimal values of n_neighbors and p",
"_____no_output_____"
]
],
[
[
"from sklearn import model_selection\nfrom sklearn import metrics\n\ndef hyperparameter_tune_and_run(df,num_folds,models,target_name,param_grid,evaluation_metric,print_details=False):\n X=df.drop(labels=[target_name,'kfolds'],axis=1).values\n y=df[target_name]\n\n model_name,model_constructor=list(models.items())[0]\n\n model = model_selection.GridSearchCV(\n estimator = model_constructor,\n param_grid = param_grid,\n scoring = evaluation_metric,\n verbose = 10,\n cv = num_folds\n )\n\n model.fit(X,y)\n\n if(print_details==True):\n print(f\"Best score : {model.best_score_}\")\n\n print(\"Best parameters : \")\n best_parameters=model.best_estimator_.get_params()\n for param_name in sorted(param_grid.keys()):\n print(f\"\\t{param_name}: {best_parameters[param_name]}\")\n \n return model\n",
"_____no_output_____"
],
[
"models={'KNN': KNeighborsClassifier()}\nparam_grid = {\n \"n_neighbors\" : [i for i in range(2,31)],\n \"p\" : [2,3]\n}\nmodel = hyperparameter_tune_and_run(df=df_optimal_KNN,num_folds=5,models=models,target_name='Outcome',param_grid=param_grid,evaluation_metric=\"accuracy\",print_details=True)",
"Fitting 5 folds for each of 58 candidates, totalling 290 fits\n[CV] n_neighbors=2, p=2 ..............................................\n[CV] .................. n_neighbors=2, p=2, score=0.770, total= 0.0s\n[CV] n_neighbors=2, p=2 ..............................................\n[CV] .................. n_neighbors=2, p=2, score=0.730, total= 0.0s\n[CV] n_neighbors=2, p=2 ..............................................\n[CV] .................. n_neighbors=2, p=2, score=0.785, total= 0.0s\n[CV] n_neighbors=2, p=2 ..............................................\n[CV] .................. n_neighbors=2, p=2, score=0.755, total= 0.0s\n[CV] n_neighbors=2, p=2 ..............................................\n[CV] .................. n_neighbors=2, p=2, score=0.740, total= 0.0s\n[CV] n_neighbors=2, p=3 ..............................................\n[CV] .................. n_neighbors=2, p=3, score=0.775, total= 0.0s\n[CV] n_neighbors=2, p=3 ..............................................\n[CV] .................. n_neighbors=2, p=3, score=0.725, total= 0.0s\n[CV] n_neighbors=2, p=3 ..............................................\n[CV] .................. n_neighbors=2, p=3, score=0.790, total= 0.0s\n[CV] n_neighbors=2, p=3 ..............................................\n[CV] .................. n_neighbors=2, p=3, score=0.745, total= 0.0s\n[CV] n_neighbors=2, p=3 ..............................................\n[CV] .................. n_neighbors=2, p=3, score=0.745, total= 0.0s\n[CV] n_neighbors=3, p=2 ..............................................\n[CV] .................. n_neighbors=3, p=2, score=0.750, total= 0.0s\n[CV] n_neighbors=3, p=2 ..............................................\n[CV] .................. n_neighbors=3, p=2, score=0.750, total= 0.0s\n[CV] n_neighbors=3, p=2 ..............................................\n[CV] .................. n_neighbors=3, p=2, score=0.740, total= 0.0s\n[CV] n_neighbors=3, p=2 ..............................................\n[CV] .................. n_neighbors=3, p=2, score=0.755, total= 0.0s\n[CV] n_neighbors=3, p=2 ..............................................\n[CV] .................. n_neighbors=3, p=2, score=0.745, total= 0.0s\n[CV] n_neighbors=3, p=3 ..............................................\n[CV] .................. n_neighbors=3, p=3, score=0.745, total= 0.0s\n[CV] n_neighbors=3, p=3 ..............................................\n"
]
],
[
[
"# Comparison between KNN and NB\n\n1. Dataset when KNN was considered for feature selection\n2. Dataset when NB was considered for feature selection\n\n",
"_____no_output_____"
]
],
[
[
"# Compare between KNN and Naive Bayes\n\nmodels={\n 'KNN': KNeighborsClassifier(n_neighbors=12,p=3),\n 'Gaussian Naive Bayes': GaussianNB(),\n }",
"_____no_output_____"
],
[
"# accuracies => list of 5 lists. Each list will contain 3 values ie KNN accuracy, Gaussian Naive Bayes\n\naccuracies,confusion_matrices,classification_reports=[],[],[]\nfor f in range(5):\n accuracy,confusion_matrix,classification_report=run(f,df_optimal_KNN,models=models,print_details=True)\n accuracies.append(accuracy)\n confusion_matrices.append(confusion_matrix)\n classification_reports.append(classification_report)",
"Model => KNN => Fold = 0 => Training Accuracy = 0.75 => Validation Accuracy = 0.75\nModel => Gaussian Naive Bayes => Fold = 0 => Training Accuracy = 0.7125 => Validation Accuracy = 0.705\n\n--------------------------------------------------------------------------------------------\n\nModel => KNN => Fold = 1 => Training Accuracy = 0.74625 => Validation Accuracy = 0.755\nModel => Gaussian Naive Bayes => Fold = 1 => Training Accuracy = 0.7125 => Validation Accuracy = 0.725\n\n--------------------------------------------------------------------------------------------\n\nModel => KNN => Fold = 2 => Training Accuracy = 0.74875 => Validation Accuracy = 0.75\nModel => Gaussian Naive Bayes => Fold = 2 => Training Accuracy = 0.70875 => Validation Accuracy = 0.71\n\n--------------------------------------------------------------------------------------------\n\nModel => KNN => Fold = 3 => Training Accuracy = 0.7675 => Validation Accuracy = 0.755\nModel => Gaussian Naive Bayes => Fold = 3 => Training Accuracy = 0.71875 => Validation Accuracy = 0.7\n\n--------------------------------------------------------------------------------------------\n\nModel => KNN => Fold = 4 => Training Accuracy = 0.77 => Validation Accuracy = 0.725\nModel => Gaussian Naive Bayes => Fold = 4 => Training Accuracy = 0.7175 => Validation Accuracy = 0.715\n\n--------------------------------------------------------------------------------------------\n\n"
],
[
"print(accuracies)",
"[[0.75, 0.705], [0.755, 0.725], [0.75, 0.71], [0.755, 0.7], [0.725, 0.715]]\n"
],
[
"x_axis_labels=['Predicted Normal','Predicted Diabetic']\ny_axis_labels=['True Normal','True Diabetic']",
"_____no_output_____"
],
[
"import seaborn as sns\n\n# Heatmap of confusion matrix of 5th fold of KNN\n\nsns.heatmap(confusion_matrices[4][0],xticklabels=x_axis_labels,yticklabels=y_axis_labels,annot=True)\n",
"_____no_output_____"
],
[
"# Heatmap of confusion matrix of 5th fold of Naive Bayes\n\nsns.heatmap(confusion_matrices[4][1],xticklabels=x_axis_labels,yticklabels=y_axis_labels,annot=True)\n",
"_____no_output_____"
],
[
"# Classification report of 5th fold of KNN\n\nprint(\"KNN\")\nprint(classification_reports[4][0])",
"KNN\n precision recall f1-score support\n\n 0 0.75 0.67 0.71 100\n 1 0.70 0.78 0.74 100\n\n accuracy 0.73 200\n macro avg 0.73 0.73 0.72 200\nweighted avg 0.73 0.72 0.72 200\n\n"
],
[
"# Classification report of 5th fold of Naive Bayes\n\nprint(\"Naive Bayes\")\nprint(classification_reports[4][1])",
"Naive Bayes\n precision recall f1-score support\n\n 0 0.70 0.76 0.73 100\n 1 0.74 0.67 0.70 100\n\n accuracy 0.71 200\n macro avg 0.72 0.72 0.71 200\nweighted avg 0.72 0.71 0.71 200\n\n"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"accuracies,confusion_matrices,classification_reports=[],[],[]\nfor f in range(5):\n accuracy,confusion_matrix,classification_report=run(f,df_optimal_NB,models=models,print_details=True)\n accuracies.append(accuracy)\n confusion_matrices.append(confusion_matrix)\n classification_reports.append(classification_report)",
"Model => KNN => Fold = 0 => Training Accuracy = 0.77125 => Validation Accuracy = 0.7\nModel => Gaussian Naive Bayes => Fold = 0 => Training Accuracy = 0.74 => Validation Accuracy = 0.715\n\n--------------------------------------------------------------------------------------------\n\nModel => KNN => Fold = 1 => Training Accuracy = 0.77 => Validation Accuracy = 0.74\nModel => Gaussian Naive Bayes => Fold = 1 => Training Accuracy = 0.7325 => Validation Accuracy = 0.75\n\n--------------------------------------------------------------------------------------------\n\nModel => KNN => Fold = 2 => Training Accuracy = 0.7875 => Validation Accuracy = 0.73\nModel => Gaussian Naive Bayes => Fold = 2 => Training Accuracy = 0.7275 => Validation Accuracy = 0.76\n\n--------------------------------------------------------------------------------------------\n\nModel => KNN => Fold = 3 => Training Accuracy = 0.7725 => Validation Accuracy = 0.705\nModel => Gaussian Naive Bayes => Fold = 3 => Training Accuracy = 0.74625 => Validation Accuracy = 0.635\n\n--------------------------------------------------------------------------------------------\n\nModel => KNN => Fold = 4 => Training Accuracy = 0.78 => Validation Accuracy = 0.745\nModel => Gaussian Naive Bayes => Fold = 4 => Training Accuracy = 0.725 => Validation Accuracy = 0.76\n\n--------------------------------------------------------------------------------------------\n\n"
],
[
"import seaborn as sns\n\n# Heatmap of confusion matrix of 5th fold of KNN\n\nsns.heatmap(confusion_matrices[4][0],xticklabels=x_axis_labels,yticklabels=y_axis_labels,annot=True)",
"_____no_output_____"
],
[
"# Heatmap of confusion matrix of 5th fold of Naive Bayes\n\nsns.heatmap(confusion_matrices[4][1],xticklabels=x_axis_labels,yticklabels=y_axis_labels,annot=True)",
"_____no_output_____"
],
[
"# Classification report of 5th fold of KNN\n\nprint(\"KNN\")\nprint(classification_reports[4][0])",
"KNN\n precision recall f1-score support\n\n 0 0.76 0.71 0.74 100\n 1 0.73 0.78 0.75 100\n\n accuracy 0.74 200\n macro avg 0.75 0.74 0.74 200\nweighted avg 0.75 0.74 0.74 200\n\n"
],
[
"# Classification report of 5th fold of Naive Bayes\n\nprint(\"Naive Bayes\")\nprint(classification_reports[4][1])",
"Naive Bayes\n precision recall f1-score support\n\n 0 0.76 0.76 0.76 100\n 1 0.76 0.76 0.76 100\n\n accuracy 0.76 200\n macro avg 0.76 0.76 0.76 200\nweighted avg 0.76 0.76 0.76 200\n\n"
],
[
"",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cb24469168cb3da5460e96047ba559b2ba12d3 | 759,986 | ipynb | Jupyter Notebook | ipynb/bac_genome/priming_exp/priming_exp_info.ipynb | arischwartz/test | 87a8306a294f59b0eef992529ce900cea876c605 | [
"MIT"
]
| 2 | 2019-03-15T09:46:48.000Z | 2019-06-05T18:16:39.000Z | ipynb/bac_genome/priming_exp/priming_exp_info.ipynb | arischwartz/test | 87a8306a294f59b0eef992529ce900cea876c605 | [
"MIT"
]
| 1 | 2020-11-01T23:18:10.000Z | 2020-11-01T23:18:10.000Z | ipynb/bac_genome/priming_exp/priming_exp_info.ipynb | arischwartz/test | 87a8306a294f59b0eef992529ce900cea876c605 | [
"MIT"
]
| null | null | null | 370.544125 | 199,427 | 0.91852 | [
[
[
"# Getting info on Priming experiment dataset that's needed for modeling\n\n## Info:\n\n* __Which gradient(s) to simulate?__\n* For each gradient to simulate:\n * Infer total richness of starting community \n * Get distribution of total OTU abundances per fraction\n * Number of sequences per sample\n * Infer total abundance of each target taxon",
"_____no_output_____"
],
[
"# User variables",
"_____no_output_____"
]
],
[
[
"baseDir = '/home/nick/notebook/SIPSim/dev/priming_exp/'\nworkDir = os.path.join(baseDir, 'exp_info')\n\notuTableFile = '/var/seq_data/priming_exp/data/otu_table.txt'\notuTableSumFile = '/var/seq_data/priming_exp/data/otu_table_summary.txt'\n\nmetaDataFile = '/var/seq_data/priming_exp/data/allsample_metadata_nomock.txt'\n\n#otuRepFile = '/var/seq_data/priming_exp/otusn.pick.fasta'\n#otuTaxFile = '/var/seq_data/priming_exp/otusn_tax/otusn_tax_assignments.txt'\n#genomeDir = '/home/nick/notebook/SIPSim/dev/bac_genome1210/genomes/'",
"_____no_output_____"
]
],
[
[
"# Init",
"_____no_output_____"
]
],
[
[
"import glob",
"_____no_output_____"
],
[
"%load_ext rpy2.ipython",
"_____no_output_____"
],
[
"%%R\nlibrary(ggplot2)\nlibrary(dplyr)\nlibrary(tidyr)\nlibrary(gridExtra)\nlibrary(fitdistrplus)",
"/opt/anaconda/lib/python2.7/site-packages/rpy2/robjects/functions.py:106: UserWarning: \nAttaching package: ‘dplyr’\n\n\n res = super(Function, self).__call__(*new_args, **new_kwargs)\n/opt/anaconda/lib/python2.7/site-packages/rpy2/robjects/functions.py:106: UserWarning: The following objects are masked from ‘package:stats’:\n\n filter, lag\n\n\n res = super(Function, self).__call__(*new_args, **new_kwargs)\n/opt/anaconda/lib/python2.7/site-packages/rpy2/robjects/functions.py:106: UserWarning: The following objects are masked from ‘package:base’:\n\n intersect, setdiff, setequal, union\n\n\n res = super(Function, self).__call__(*new_args, **new_kwargs)\n/opt/anaconda/lib/python2.7/site-packages/rpy2/robjects/functions.py:106: UserWarning: Loading required package: grid\n\n res = super(Function, self).__call__(*new_args, **new_kwargs)\n"
],
[
"if not os.path.isdir(workDir):\n os.makedirs(workDir)",
"_____no_output_____"
]
],
[
[
"# Loading OTU table (filter to just bulk samples)",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n\ntbl = read.delim(otuTableFile, sep='\\t')\n\n# filter\ntbl = tbl %>%\n select(ends_with('.NA'))\n\ntbl %>% ncol %>% print\ntbl[1:4,1:4]",
"_____no_output_____"
],
[
"%%R\n\ntbl.h = tbl %>% \n gather('sample', 'count', 1:ncol(tbl)) %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F)\ntbl.h %>% head ",
"_____no_output_____"
]
],
[
[
"# Which gradient(s) to simulate?",
"_____no_output_____"
]
],
[
[
"%%R -w 900 -h 400\n\ntbl.h.s = tbl.h %>%\n group_by(sample) %>%\n summarize(total_count = sum(count)) %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F)\n\nggplot(tbl.h.s, aes(day, total_count, color=rep %>% as.character)) +\n geom_point() +\n facet_grid(isotope ~ treatment) +\n theme(\n text = element_text(size=16)\n )",
"_____no_output_____"
],
[
"%%R\ntbl.h.s$sample[grepl('700', tbl.h.s$sample)] %>% as.vector %>% sort",
"_____no_output_____"
]
],
[
[
"#### Notes\n\nSamples to simulate\n\n* Isotope:\n * 12C vs 13C\n* Treatment:\n * 700\n* Days:\n * 14\n * 28\n * 45\n ",
"_____no_output_____"
]
],
[
[
"%%R\n# bulk soil samples for gradients to simulate\n\nsamples.to.use = c(\n\"X12C.700.14.05.NA\",\n\"X12C.700.28.03.NA\",\n\"X12C.700.45.01.NA\",\n\"X13C.700.14.08.NA\",\n\"X13C.700.28.06.NA\",\n\"X13C.700.45.01.NA\"\n)",
"_____no_output_____"
]
],
[
[
"# Total richness of starting (bulk-soil) community\n\nMethod:\n\n* Total number of OTUs in OTU table (i.e., gamma richness)\n* Just looking at bulk soil samples",
"_____no_output_____"
],
[
"## Loading just bulk soil",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n\ntbl = read.delim(otuTableFile, sep='\\t')\n\n# filter\ntbl = tbl %>%\n select(ends_with('.NA'))\ntbl$OTUId = rownames(tbl)\n\ntbl %>% ncol %>% print\ntbl[1:4,1:4]",
"_____no_output_____"
],
[
"%%R\n\ntbl.h = tbl %>% \n gather('sample', 'count', 1:(ncol(tbl)-1)) %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F)\ntbl.h %>% head ",
"_____no_output_____"
],
[
"%%R -w 800\ntbl.s = tbl.h %>% \n filter(count > 0) %>%\n group_by(sample, isotope, treatment, day, rep, fraction) %>%\n summarize(n_taxa = n())\n\nggplot(tbl.s, aes(day, n_taxa, color=rep %>% as.character)) +\n geom_point() +\n facet_grid(isotope ~ treatment) +\n theme_bw() +\n theme(\n text = element_text(size=16),\n axis.text.x = element_blank()\n )",
"_____no_output_____"
],
[
"%%R -w 800 -h 350\n# filter to just target samples\n\ntbl.s.f = tbl.s %>% filter(sample %in% samples.to.use)\n\nggplot(tbl.s.f, aes(day, n_taxa, fill=rep %>% as.character)) +\n geom_bar(stat='identity') +\n facet_grid(. ~ isotope) +\n labs(y = 'Number of taxa') +\n theme_bw() +\n theme(\n text = element_text(size=16),\n axis.text.x = element_blank()\n )",
"_____no_output_____"
],
[
"%%R\nmessage('Bulk soil total observed richness: ')\n\ntbl.s.f %>% select(-fraction) %>% as.data.frame %>% print",
"_____no_output_____"
]
],
[
[
"### Number of taxa in all fractions corresponding to each bulk soil sample\n\n* Trying to see the difference between richness of bulk vs gradients (veil line effect)",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n# loading OTU table\ntbl = read.delim(otuTableFile, sep='\\t') %>%\n select(-ends_with('.NA'))\n\ntbl.h = tbl %>% \n gather('sample', 'count', 2:ncol(tbl)) %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F)\ntbl.h %>% head ",
"_____no_output_____"
],
[
"%%R\n# basename of fractions\nsamples.to.use.base = gsub('\\\\.[0-9]+\\\\.NA', '', samples.to.use)\n\nsamps = tbl.h$sample %>% unique\n\nfracs = sapply(samples.to.use.base, function(x) grep(x, samps, value=TRUE))\n\nfor (n in names(fracs)){\n n.frac = length(fracs[[n]])\n cat(n, '-->', 'Number of fraction samples: ', n.frac, '\\n')\n}",
"_____no_output_____"
],
[
"%%R\n# function for getting all OTUs in a sample\nn.OTUs = function(samples, otu.long){\n otu.long.f = otu.long %>%\n filter(sample %in% samples,\n count > 0) \n n.OTUs = otu.long.f$OTUId %>% unique %>% length\n return(n.OTUs)\n}\n\n\nnum.OTUs = lapply(fracs, n.OTUs, otu.long=tbl.h)\n\nnum.OTUs = do.call(rbind, num.OTUs) %>% as.data.frame\ncolnames(num.OTUs) = c('n_taxa')\nnum.OTUs$sample = rownames(num.OTUs)\nnum.OTUs",
"_____no_output_____"
],
[
"%%R\ntbl.s.f %>% as.data.frame",
"_____no_output_____"
],
[
"%%R \n# joining with bulk soil sample summary table\nnum.OTUs$data = 'fractions'\ntbl.s.f$data = 'bulk_soil'\ntbl.j = rbind(num.OTUs,\n tbl.s.f %>% ungroup %>% select(sample, n_taxa, data)) %>%\n mutate(isotope = gsub('X|\\\\..+', '', sample),\n sample = gsub('\\\\.[0-9]+\\\\.NA', '', sample))\ntbl.j",
"_____no_output_____"
],
[
"%%R -h 300 -w 800\n\nggplot(tbl.j, aes(sample, n_taxa, fill=data)) +\n geom_bar(stat='identity', position='dodge') +\n facet_grid(. ~ isotope, scales='free_x') +\n labs(y = 'Number of OTUs') +\n theme(\n text = element_text(size=16)\n # axis.text.x = element_text(angle=90)\n )",
"_____no_output_____"
]
],
[
[
"# Distribution of total sequences per fraction\n \n* Number of sequences per sample\n* Using all samples to assess this one\n* Just fraction samples\n\n__Method:__\n\n* Total number of sequences (total abundance) per sample",
"_____no_output_____"
],
[
"### Loading OTU table",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n\ntbl = read.delim(otuTableFile, sep='\\t')\n\n# filter\ntbl = tbl %>%\n select(-ends_with('.NA'))\n\ntbl %>% ncol %>% print\ntbl[1:4,1:4]",
"_____no_output_____"
],
[
"%%R\n\ntbl.h = tbl %>% \n gather('sample', 'count', 2:ncol(tbl)) %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F)\ntbl.h %>% head ",
"_____no_output_____"
],
[
"%%R -h 400\n\ntbl.h.s = tbl.h %>%\n group_by(sample) %>%\n summarize(total_seqs = sum(count))\n\n\np = ggplot(tbl.h.s, aes(total_seqs)) +\n theme_bw() +\n theme(\n text = element_text(size=16)\n )\np1 = p + geom_histogram(binwidth=200) \np2 = p + geom_density()\n\ngrid.arrange(p1,p2,ncol=1)",
"_____no_output_____"
]
],
[
[
"### Distribution fitting",
"_____no_output_____"
]
],
[
[
"%%R -w 700 -h 350\nplotdist(tbl.h.s$total_seqs)",
"_____no_output_____"
],
[
"%%R -w 450 -h 400\ndescdist(tbl.h.s$total_seqs, boot=1000)",
"_____no_output_____"
],
[
"%%R\nf.n = fitdist(tbl.h.s$total_seqs, 'norm')\nf.ln = fitdist(tbl.h.s$total_seqs, 'lnorm')\nf.ll = fitdist(tbl.h.s$total_seqs, 'logis')\n#f.c = fitdist(tbl.s$count, 'cauchy')\nf.list = list(f.n, f.ln, f.ll)\n\nplot.legend = c('normal', 'log-normal', 'logistic')\n\npar(mfrow = c(2,1))\ndenscomp(f.list, legendtext=plot.legend)\nqqcomp(f.list, legendtext=plot.legend)",
"_____no_output_____"
],
[
"%%R\n\ngofstat(list(f.n, f.ln, f.ll), fitnames=plot.legend)",
"_____no_output_____"
],
[
"%%R\nsummary(f.ln)",
"_____no_output_____"
]
],
[
[
"#### Notes:\n\n* best fit:\n * lognormal\n * mean = 10.113\n * sd = 1.192",
"_____no_output_____"
],
[
"## Does sample size correlate to buoyant density?",
"_____no_output_____"
],
[
"### Loading OTU table",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n\ntbl = read.delim(otuTableFile, sep='\\t')\n\n# filter\ntbl = tbl %>%\n select(-ends_with('.NA')) %>%\n select(-starts_with('X0MC'))\ntbl = tbl %>%\n gather('sample', 'count', 2:ncol(tbl)) %>%\n mutate(sample = gsub('^X', '', sample))\n\ntbl %>% head",
"_____no_output_____"
],
[
"%%R\n# summarize\n\ntbl.s = tbl %>%\n group_by(sample) %>%\n summarize(total_count = sum(count))\ntbl.s %>% head(n=3)",
"_____no_output_____"
]
],
[
[
"### Loading metadata",
"_____no_output_____"
]
],
[
[
"%%R -i metaDataFile\n\ntbl.meta = read.delim(metaDataFile, sep='\\t')\ntbl.meta %>% head(n=3)",
"_____no_output_____"
]
],
[
[
"### Determining association",
"_____no_output_____"
]
],
[
[
"%%R -w 700\n\ntbl.j = inner_join(tbl.s, tbl.meta, c('sample' = 'Sample')) \n\nggplot(tbl.j, aes(Density, total_count, color=rep)) +\n geom_point() +\n facet_grid(Treatment ~ Day)",
"_____no_output_____"
],
[
"%%R -w 600 -h 350\n\nggplot(tbl.j, aes(Density, total_count)) +\n geom_point(aes(color=Treatment)) +\n geom_smooth(method='lm') +\n labs(x='Buoyant density', y='Total sequences') +\n theme_bw() +\n theme(\n text = element_text(size=16)\n )",
"_____no_output_____"
]
],
[
[
"## Number of taxa along the gradient",
"_____no_output_____"
]
],
[
[
"%%R \n\ntbl.s = tbl %>%\n filter(count > 0) %>%\n group_by(sample) %>%\n summarize(n_taxa = sum(count > 0))\n\ntbl.j = inner_join(tbl.s, tbl.meta, c('sample' = 'Sample')) \ntbl.j %>% head(n=3)",
"_____no_output_____"
],
[
"%%R -w 900 -h 600\n\nggplot(tbl.j, aes(Density, n_taxa, fill=rep, color=rep)) +\n #geom_area(stat='identity', alpha=0.5, position='dodge') +\n geom_point() +\n geom_line() +\n labs(x='Buoyant density', y='Number of taxa') +\n facet_grid(Treatment ~ Day) +\n theme_bw() +\n theme( \n text = element_text(size=16),\n legend.position = 'none'\n )",
"_____no_output_____"
]
],
[
[
"#### Notes:\n\n* Many taxa out to the tails of the gradient.\n* It seems that the DNA fragments were quite diffuse in the gradients.",
"_____no_output_____"
],
[
"# Total abundance of each target taxon: bulk soil approach\n\n* Getting relative abundances from bulk soil samples\n * This has the caveat of likely undersampling richness vs using all gradient fraction samples.\n * i.e., veil line effect",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n# loading OTU table\ntbl = read.delim(otuTableFile, sep='\\t')\n\n# filter\ntbl = tbl %>%\n select(matches('OTUId'), ends_with('.NA'))\n\ntbl %>% ncol %>% print\ntbl[1:4,1:4]",
"_____no_output_____"
],
[
"%%R\n# long table format w/ selecting samples of interest\ntbl.h = tbl %>% \n gather('sample', 'count', 2:ncol(tbl)) %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F) %>%\n filter(sample %in% samples.to.use,\n count > 0) \ntbl.h %>% head ",
"_____no_output_____"
],
[
"%%R\nmessage('Number of samples: ', tbl.h$sample %>% unique %>% length)\nmessage('Number of OTUs: ', tbl.h$OTUId %>% unique %>% length)",
"_____no_output_____"
],
[
"%%R\n\ntbl.hs = tbl.h %>%\n group_by(OTUId) %>%\n summarize(\n total_count = sum(count),\n mean_count = mean(count),\n median_count = median(count),\n sd_count = sd(count)\n ) %>%\n filter(total_count > 0)\n\ntbl.hs %>% head",
"_____no_output_____"
]
],
[
[
"### For each sample, writing a table of OTU_ID and count",
"_____no_output_____"
]
],
[
[
"%%R -i workDir\nsetwd(workDir)\n\nsamps = tbl.h$sample %>% unique %>% as.vector\n\nfor(samp in samps){\n outFile = paste(c(samp, 'OTU.txt'), collapse='_')\n \n tbl.p = tbl.h %>% \n filter(sample == samp, count > 0)\n \n write.table(tbl.p, outFile, sep='\\t', quote=F, row.names=F)\n \n message('Table written: ', outFile)\n message(' Number of OTUs: ', tbl.p %>% nrow)\n }",
"_____no_output_____"
]
],
[
[
"# Making directories for simulations",
"_____no_output_____"
]
],
[
[
"p = os.path.join(workDir, '*_OTU.txt')\nfiles = glob.glob(p)\n\nbaseDir = os.path.split(workDir)[0]\nnewDirs = [os.path.split(x)[1].rstrip('.NA_OTU.txt') for x in files]\nnewDirs = [os.path.join(baseDir, x) for x in newDirs]\n\nfor newDir,f in zip(newDirs, files):\n if not os.path.isdir(newDir):\n print 'Making new directory: {}'.format(newDir)\n os.makedirs(newDir)\n else:\n print 'Directory exists: {}'.format(newDir)\n # symlinking file\n linkPath = os.path.join(newDir, os.path.split(f)[1])\n if not os.path.islink(linkPath):\n os.symlink(f, linkPath)",
"Directory exists: /home/nick/notebook/SIPSim/dev/priming_exp/X13C.700.28.06\nDirectory exists: /home/nick/notebook/SIPSim/dev/priming_exp/X12C.700.28.03\nDirectory exists: /home/nick/notebook/SIPSim/dev/priming_exp/X13C.700.14.08\nDirectory exists: /home/nick/notebook/SIPSim/dev/priming_exp/X13C.700.45.01\nDirectory exists: /home/nick/notebook/SIPSim/dev/priming_exp/X12C.700.45.01\nDirectory exists: /home/nick/notebook/SIPSim/dev/priming_exp/X12C.700.14.05\n"
]
],
[
[
"# Rank-abundance distribution for each sample",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n\ntbl = read.delim(otuTableFile, sep='\\t')\n\n# filter\ntbl = tbl %>%\n select(matches('OTUId'), ends_with('.NA'))\n\ntbl %>% ncol %>% print\ntbl[1:4,1:4]",
"_____no_output_____"
],
[
"%%R\n# long table format w/ selecting samples of interest\ntbl.h = tbl %>% \n gather('sample', 'count', 2:ncol(tbl)) %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F) %>%\n filter(sample %in% samples.to.use,\n count > 0) \ntbl.h %>% head ",
"_____no_output_____"
],
[
"%%R\n# ranks of relative abundances\n\ntbl.r = tbl.h %>%\n group_by(sample) %>%\n mutate(perc_rel_abund = count / sum(count) * 100,\n rank = row_number(-perc_rel_abund)) %>%\n unite(day_rep, day, rep, sep='-')\ntbl.r %>% as.data.frame %>% head(n=3)",
"_____no_output_____"
],
[
"%%R -w 900 -h 350\n\n\nggplot(tbl.r, aes(rank, perc_rel_abund)) +\n geom_point() +\n# labs(x='Buoyant density', y='Number of taxa') +\n facet_wrap(~ day_rep) +\n theme_bw() +\n theme( \n text = element_text(size=16),\n legend.position = 'none'\n )",
"_____no_output_____"
]
],
[
[
"## Taxon abundance range for each sample-fraction",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n\ntbl = read.delim(otuTableFile, sep='\\t')\n\n# filter\ntbl = tbl %>%\n select(-ends_with('.NA')) %>%\n select(-starts_with('X0MC'))\ntbl = tbl %>%\n gather('sample', 'count', 2:ncol(tbl)) %>%\n mutate(sample = gsub('^X', '', sample))\n\ntbl %>% head",
"_____no_output_____"
],
[
"%%R\n\ntbl.ar = tbl %>%\n #mutate(fraction = gsub('.+\\\\.', '', sample) %>% as.numeric) %>%\n #mutate(treatment = gsub('(.+)\\\\..+', '\\\\1', sample)) %>%\n group_by(sample) %>%\n mutate(rel_abund = count / sum(count)) %>% \n summarize(abund_range = max(rel_abund) - min(rel_abund)) %>%\n ungroup() %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F)\n\ntbl.ar %>% head(n=3)",
"_____no_output_____"
],
[
"%%R -w 800\n\ntbl.ar = tbl.ar %>%\n mutate(fraction = as.numeric(fraction))\n\nggplot(tbl.ar, aes(fraction, abund_range, fill=rep, color=rep)) +\n geom_point() +\n geom_line() +\n labs(x='Buoyant density', y='Range of relative abundance values') +\n facet_grid(treatment ~ day) +\n theme_bw() +\n theme( \n text = element_text(size=16),\n legend.position = 'none'\n )",
"_____no_output_____"
]
],
[
[
"# Total abundance of each target taxon: all fraction samples approach\n\n* Getting relative abundances from all fraction samples for the gradient\n * I will need to calculate (mean|max?) relative abundances for each taxon and then re-scale so that cumsum = 1",
"_____no_output_____"
]
],
[
[
"%%R -i otuTableFile\n# loading OTU table\ntbl = read.delim(otuTableFile, sep='\\t') %>%\n select(-ends_with('.NA'))\n\ntbl.h = tbl %>% \n gather('sample', 'count', 2:ncol(tbl)) %>%\n separate(sample, c('isotope','treatment','day','rep','fraction'), sep='\\\\.', remove=F)\ntbl.h %>% head ",
"_____no_output_____"
],
[
"%%R\n# basename of fractions\nsamples.to.use.base = gsub('\\\\.[0-9]+\\\\.NA', '', samples.to.use)\n\nsamps = tbl.h$sample %>% unique\n\nfracs = sapply(samples.to.use.base, function(x) grep(x, samps, value=TRUE))\n\nfor (n in names(fracs)){\n n.frac = length(fracs[[n]])\n cat(n, '-->', 'Number of fraction samples: ', n.frac, '\\n')\n}",
"_____no_output_____"
],
[
"%%R\n# function for getting mean OTU abundance from all fractions \nOTU.abund = function(samples, otu.long){\n otu.rel.abund = otu.long %>%\n filter(sample %in% samples,\n count > 0) %>%\n ungroup() %>%\n group_by(sample) %>%\n mutate(total_count = sum(count)) %>%\n ungroup() %>%\n mutate(perc_abund = count / total_count * 100) %>%\n group_by(OTUId) %>%\n summarize(mean_perc_abund = mean(perc_abund),\n median_perc_abund = median(perc_abund),\n max_perc_abund = max(perc_abund)) \n \n return(otu.rel.abund)\n}\n\n## calling function\notu.rel.abund = lapply(fracs, OTU.abund, otu.long=tbl.h)\notu.rel.abund = do.call(rbind, otu.rel.abund) %>% as.data.frame\notu.rel.abund$sample = gsub('\\\\.[0-9]+$', '', rownames(otu.rel.abund))\notu.rel.abund %>% head",
"_____no_output_____"
],
[
"%%R -h 600 -w 900\n# plotting\notu.rel.abund.l = otu.rel.abund %>%\n gather('abund_stat', 'value', mean_perc_abund, median_perc_abund, max_perc_abund)\n\notu.rel.abund.l$OTUId = reorder(otu.rel.abund.l$OTUId, -otu.rel.abund.l$value)\n\nggplot(otu.rel.abund.l, aes(OTUId, value, color=abund_stat)) +\n geom_point(shape='O', alpha=0.7) +\n scale_y_log10() +\n facet_grid(abund_stat ~ sample) +\n theme_bw() +\n theme(\n text = element_text(size=16),\n axis.text.x = element_blank(),\n legend.position = 'none'\n )",
"_____no_output_____"
]
],
[
[
"### For each sample, writing a table of OTU_ID and count",
"_____no_output_____"
]
],
[
[
"%%R -i workDir\nsetwd(workDir)\n\n\n\n# each sample is a file\nsamps = otu.rel.abund.l$sample %>% unique %>% as.vector\n\nfor(samp in samps){\n outFile = paste(c(samp, 'frac_OTU.txt'), collapse='_')\n \n tbl.p = otu.rel.abund %>% \n filter(sample == samp, mean_perc_abund > 0)\n \n write.table(tbl.p, outFile, sep='\\t', quote=F, row.names=F)\n \n cat('Table written: ', outFile, '\\n')\n cat(' Number of OTUs: ', tbl.p %>% nrow, '\\n')\n }",
"_____no_output_____"
]
],
[
[
"# A broader taxon distribution with increased abundance?\n\n* Overloading molecules at one spot in the gradient, leading to more diffusion?",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7cb35e7f858a22663244a78170407b4b31fc956 | 7,950 | ipynb | Jupyter Notebook | SuperdenseCoding/SuperdenseCoding.ipynb | samik-saha/QuantumKatas | b189fd7cb6b10734d67c42ae38e2c9cd73011274 | [
"MIT"
]
| 1 | 2020-10-23T10:11:56.000Z | 2020-10-23T10:11:56.000Z | SuperdenseCoding/SuperdenseCoding.ipynb | samik-saha/QuantumKatas | b189fd7cb6b10734d67c42ae38e2c9cd73011274 | [
"MIT"
]
| null | null | null | SuperdenseCoding/SuperdenseCoding.ipynb | samik-saha/QuantumKatas | b189fd7cb6b10734d67c42ae38e2c9cd73011274 | [
"MIT"
]
| null | null | null | 37.5 | 296 | 0.606038 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
e7cb65fc6c9d9013dbcb5c126fa05fb3aa462225 | 81,126 | ipynb | Jupyter Notebook | benchmark/synthetic.ipynb | DebolinaHalder/599 | 36b7a29f867e9a7ae0a13e8bcdd8d67e71233e48 | [
"MIT"
]
| null | null | null | benchmark/synthetic.ipynb | DebolinaHalder/599 | 36b7a29f867e9a7ae0a13e8bcdd8d67e71233e48 | [
"MIT"
]
| null | null | null | benchmark/synthetic.ipynb | DebolinaHalder/599 | 36b7a29f867e9a7ae0a13e8bcdd8d67e71233e48 | [
"MIT"
]
| null | null | null | 40,563 | 81,125 | 0.81477 | [
[
[
"import numpy as np\nimport pandas as pd\nfrom scipy.special import logit\nfrom fairforest import d_tree\nfrom fairforest import utils\nimport warnings\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"warnings.simplefilter(\"ignore\")\n",
"_____no_output_____"
],
[
"np.random.seed(0)",
"_____no_output_____"
],
[
"def NormalizeData(data):\n return (data - np.min(data)) / (np.max(data) - np.min(data))\n",
"_____no_output_____"
]
],
[
[
"Here Z ∼ binomial(1, 0.5) is the protected attribute. Features related to the protected attribute are sampled from X ∼ N(µ, I) with µ = 1 when Z = 0 and µ = 2 when Z = 1. Other features not related to the protected attribute Z are generated with µ = 0. First 4 features are correlated with z. The first 10 features are correlated with y according to a logistic regression model y = logit(β^TX) with β ∼ N(µβ, 0.1), where µβ = 5 for the first 6 features and µβ = 0 for all others.",
"_____no_output_____"
]
],
[
[
"z = np.zeros(1000)\nfor j in range(1000):\n z[j] = np.random.binomial(1,0.5)\nx_correlated = np.zeros((1000,4))\nx_uncorrelated = np.zeros((1000,16))\nfor j in range(16):\n for i in range (1000):\n if j < 4:\n x_correlated[i][j] = np.random.normal((z[i]*2 + 10), 1, 1)\n x_uncorrelated[i][j] = np.random.normal(0,1,1)\nx = np.concatenate((x_correlated,x_uncorrelated),axis=1)\nx = np.concatenate((x,np.reshape(z,(1000,1))),axis=1)\nb = np.zeros(21)\nnoise = np.random.normal(0,1,1000)\nfor i in range (10):\n b[i] = np.random.normal(5,0.1,1)\ny = logit(NormalizeData(np.dot(x,b)) + noise.T)\nfor i in range (len(y)):\n if y[i] > 0:\n y[i] = int(1)\n else:\n y[i] = int(0)\ncolumn = []\nfor i in range(21):\n column.append(str(i+1))\ndataframe = pd.DataFrame(x, columns = column)\n",
"_____no_output_____"
],
[
"model_dtree = d_tree.DecisionTree(20,0,'21',1)\nmodel_dtree.fit(dataframe,y)\n\n",
"build tree for node 0\nspliting\nspliting done\n14 -0.48628298355753774\nbuild tree for node 1\nspliting\nspliting done\n15 2.727706000881293\nbuild tree for node 3\nspliting\nspliting done\n19 1.026193998624007\nbuild tree for node 5\nspliting\nspliting done\n19 0.7957742535230151\nbuild tree for node 7\nspliting\nspliting done\n9 0.6667169329122717\nbuild tree for node 9\nspliting\nspliting done\n10 1.7739421109627675\nbuild tree for node 11\nspliting\nspliting done\n10 1.1021466604866685\nbuild tree for node 13\nspliting\nspliting done\n13 0.594388544400418\nbuild tree for node 15\nspliting\nspliting done\n17 2.005916952550997\nbuild tree for node 17\nspliting\nspliting done\n19 -2.283133218977109\nbuild tree for node 19\nonly one class for this node\nbuild tree for node 20\nspliting\nspliting done\n20 1.2572946822307274\nbuild tree for node 21\nspliting\nspliting done\n16 -1.7003388231534555\nbuild tree for node 23\nonly one class for this node\nbuild tree for node 24\nspliting\nspliting done\n16 0.641020457626244\nbuild tree for node 25\nspliting\nspliting done\n9 -0.5755189462992927\nbuild tree for node 27\nspliting\nspliting done\n6 1.2484865265384693\nbuild tree for node 29\nspliting\nspliting done\n1 11.206468061662111\nbuild tree for node 31\nspliting\nspliting done\n1 10.321177107105546\nbuild tree for node 33\nspliting\nspliting done\n1 9.211704378973865\nbuild tree for node 35\nspliting\nspliting done\n5 -0.7501546359835667\nbuild tree for node 37\nonly one class for this node\nbuild tree for node 38\nonly one class for this node\nbuild tree for node 36\nonly one class for this node\nbuild tree for node 34\nspliting\nspliting done\n6 -1.065662875693158\nbuild tree for node 39\nonly one class for this node\nbuild tree for node 40\nonly one class for this node\nbuild tree for node 32\nonly one class for this node\nbuild tree for node 30\nonly one class for this node\nbuild tree for node 28\nspliting\nspliting done\n20 1.0978308090659779\nbuild tree for node 41\nonly one class for this node\nbuild tree for node 42\nonly one class for this node\nbuild tree for node 26\nspliting\nspliting done\n9 0.06192719026914312\nbuild tree for node 43\nspliting\nspliting done\n1 11.935149546003732\nbuild tree for node 45\nspliting\nspliting done\n3 8.423894217789442\nbuild tree for node 47\nonly one class for this node\nbuild tree for node 48\nonly one class for this node\nbuild tree for node 46\nspliting\nspliting done\n1 12.579912786521087\nbuild tree for node 49\nonly one class for this node\nbuild tree for node 50\nonly one class for this node\nbuild tree for node 44\nonly one class for this node\nbuild tree for node 22\nonly one class for this node\nbuild tree for node 18\nonly one class for this node\nbuild tree for node 16\nspliting\nspliting done\n8 -0.46460138168827947\nbuild tree for node 51\nspliting\nspliting done\n3 9.972789818391131\nbuild tree for node 53\nonly one class for this node\nbuild tree for node 54\nspliting\nspliting done\n5 0.6780285289983785\nbuild tree for node 55\nonly one class for this node\nbuild tree for node 56\nspliting\nspliting done\n1 13.313292023608527\nbuild tree for node 57\nonly one class for this node\nbuild tree for node 58\nonly one class for this node\nbuild tree for node 52\nspliting\nspliting done\n1 13.376869974074538\nbuild tree for node 59\nonly one class for this node\nbuild tree for node 60\nspliting\nspliting done\n1 13.652287424641658\nbuild tree for node 61\nonly one class for this node\nbuild tree for node 62\nonly one class for this node\nbuild tree for node 14\nonly one class for this node\nbuild tree for node 12\nspliting\nspliting done\n4 10.594694743854149\nbuild tree for node 63\nonly one class for this node\nbuild tree for node 64\nspliting\nspliting done\n2 12.324079657075991\nbuild tree for node 65\nonly one class for this node\nbuild tree for node 66\nonly one class for this node\nbuild tree for node 10\nspliting\nspliting done\n1 11.68701983126488\nbuild tree for node 67\nspliting\nspliting done\n16 0.5023241217075542\nbuild tree for node 69\nspliting\nspliting done\n9 1.3755513673035433\nbuild tree for node 71\nspliting\nspliting done\n14 -1.5344775477424402\nbuild tree for node 73\nonly one class for this node\nbuild tree for node 74\nspliting\nspliting done\n18 1.708611151921764\nbuild tree for node 75\nonly one class for this node\nbuild tree for node 76\nonly one class for this node\nbuild tree for node 72\nspliting\nspliting done\n3 11.420131256673843\nbuild tree for node 77\nspliting\nspliting done\n1 10.108868077705525\nbuild tree for node 79\nspliting\nspliting done\n3 10.786360849004788\nbuild tree for node 81\nonly one class for this node\nbuild tree for node 82\nonly one class for this node\nbuild tree for node 80\nonly one class for this node\nbuild tree for node 78\nonly one class for this node\nbuild tree for node 70\nspliting\nspliting done\n4 9.402010438939815\nbuild tree for node 83\nonly one class for this node\nbuild tree for node 84\nonly one class for this node\nbuild tree for node 68\nspliting\nspliting done\n9 0.8332034995819015\nbuild tree for node 85\nspliting\nspliting done\n1 12.986435066872275\nbuild tree for node 87\nonly one class for this node\nbuild tree for node 88\nonly one class for this node\nbuild tree for node 86\nonly one class for this node\nbuild tree for node 8\nspliting\nspliting done\n8 0.8805099610248939\nbuild tree for node 89\nspliting\nspliting done\n14 -1.880249935220326\nbuild tree for node 91\nspliting\nspliting done\n1 11.002961387839068\nbuild tree for node 93\nonly one class for this node\nbuild tree for node 94\nonly one class for this node\nbuild tree for node 92\nonly one class for this node\nbuild tree for node 90\nonly one class for this node\nbuild tree for node 6\nspliting\nspliting done\n4 11.818298509926992\nbuild tree for node 95\nspliting\nspliting done\n12 1.6687198909031067\nbuild tree for node 97\nonly one class for this node\nbuild tree for node 98\nonly one class for this node\nbuild tree for node 96\nspliting\nspliting done\n8 0.3949089429740912\nbuild tree for node 99\nspliting\nspliting done\n1 12.720175730922666\nbuild tree for node 101\nonly one class for this node\nbuild tree for node 102\nonly one class for this node\nbuild tree for node 100\nonly one class for this node\nbuild tree for node 4\nonly one class for this node\nbuild tree for node 2\nspliting\nspliting done\n18 2.0570281678355835\nbuild tree for node 103\nspliting\nspliting done\n8 -0.24042679492595417\nbuild tree for node 105\nspliting\nspliting done\n4 8.308129458346738\nbuild tree for node 107\nspliting\nspliting done\n2 9.2962861036525\nbuild tree for node 109\nonly one class for this node\nbuild tree for node 110\nonly one class for this node\nbuild tree for node 108\nspliting\nspliting done\n8 -2.238934289983918\nbuild tree for node 111\nspliting\nspliting done\n18 -0.528479086853427\nbuild tree for node 113\nspliting\nspliting done\n1 10.107377529021235\nbuild tree for node 115\nonly one class for this node\nbuild tree for node 116\nonly one class for this node\nbuild tree for node 114\nonly one class for this node\nbuild tree for node 112\nspliting\nspliting done\n11 -1.116671339676862\nbuild tree for node 117\nspliting\nspliting done\n5 0.31810867089849865\nbuild tree for node 119\nspliting\nspliting done\n1 9.52631487657111\nbuild tree for node 121\nonly one class for this node\nbuild tree for node 122\nspliting\nspliting done\n12 2.0366096555590376\nbuild tree for node 123\nonly one class for this node\nbuild tree for node 124\nonly one class for this node\nbuild tree for node 120\nspliting\nspliting done\n5 0.8206806078404716\nbuild tree for node 125\nonly one class for this node\nbuild tree for node 126\nspliting\nspliting done\n4 11.224755309082102\nbuild tree for node 127\nonly one class for this node\nbuild tree for node 128\nonly one class for this node\nbuild tree for node 118\nspliting\nspliting done\n10 -1.1961182840383455\nbuild tree for node 129\nspliting\nspliting done\n6 0.02594498152573349\nbuild tree for node 131\nspliting\nspliting done\n19 0.594446850835741\nbuild tree for node 133\nonly one class for this node\nbuild tree for node 134\nonly one class for this node\nbuild tree for node 132\nonly one class for this node\nbuild tree for node 130\nspliting\nspliting done\n13 -2.518845418509098\nbuild tree for node 135\nspliting\nspliting done\n1 10.76958342203605\nbuild tree for node 137\nonly one class for this node\nbuild tree for node 138\nonly one class for this node\nbuild tree for node 136\nspliting\nspliting done\n1 8.155885375851463\nbuild tree for node 139\nspliting\nspliting done\n1 7.741662115753707\nbuild tree for node 141\nonly one class for this node\nbuild tree for node 142\nonly one class for this node\nbuild tree for node 140\nspliting\nspliting done\n15 -2.026116808492584\nbuild tree for node 143\nspliting\nspliting done\n3 10.486159406563804\nbuild tree for node 145\nonly one class for this node\nbuild tree for node 146\nonly one class for this node\nbuild tree for node 144\nspliting\nspliting done\n13 -1.0564421437860596\nbuild tree for node 147\nspliting\nspliting done\n10 0.8288206795207681\nbuild tree for node 149\nonly one class for this node\nbuild tree for node 150\nspliting\nspliting done\n3 11.438428377787869\nbuild tree for node 151\nonly one class for this node\nbuild tree for node 152\nonly one class for this node\nbuild tree for node 148\nspliting\nspliting done\n10 -0.7575924923100561\nbuild tree for node 153\nspliting\nspliting done\n7 -1.2879850696212989\nbuild tree for node 155\nonly one class for this node\nbuild tree for node 156\nspliting\nspliting done\n4 13.410308718837175\nbuild tree for node 157\nonly one class for this node\nbuild tree for node 158\nspliting\nspliting done\n1 11.905422028814233\nbuild tree for node 159\nonly one class for this node\nbuild tree for node 160\nonly one class for this node\nbuild tree for node 154\nonly one class for this node\nbuild tree for node 106\nspliting\nspliting done\n7 -1.1898053747140236\nbuild tree for node 161\nonly one class for this node\nbuild tree for node 162\nspliting\nspliting done\n5 2.713498968991537\nbuild tree for node 163\nspliting\nspliting done\n16 -2.539618066234551\nbuild tree for node 165\nonly one class for this node\nbuild tree for node 166\nspliting\nspliting done\n19 -1.0842623188960647\nbuild tree for node 167\nspliting\nspliting done\n3 8.273249089381032\nbuild tree for node 169\nonly one class for this node\nbuild tree for node 170\nspliting\nspliting done\n7 -1.1091236090919598\nbuild tree for node 171\nspliting\nspliting done\n4 10.752491555589776\nbuild tree for node 173\nonly one class for this node\nbuild tree for node 174\nonly one class for this node\nbuild tree for node 172\nspliting\nspliting done\n18 -1.4612525361794246\nbuild tree for node 175\nspliting\nspliting done\n2 10.38916568160802\nbuild tree for node 177\nonly one class for this node\nbuild tree for node 178\nonly one class for this node\nbuild tree for node 176\nonly one class for this node\nbuild tree for node 168\nspliting\nspliting done\n19 -1.0641573801921242\nbuild tree for node 179\nonly one class for this node\nbuild tree for node 180\nspliting\nspliting done\n14 0.8922056759889184\nbuild tree for node 181\nspliting\nspliting done\n16 2.088327487534671\nbuild tree for node 183\nspliting\nspliting done\n12 -1.046974445953249\nbuild tree for node 185\nspliting\nspliting done\n15 0.3806079375599444\nbuild tree for node 187\nspliting\nspliting done\n4 9.356322726537645\nbuild tree for node 189\nonly one class for this node\nbuild tree for node 190\nspliting\nspliting done\n3 12.874881358666828\nbuild tree for node 191\nonly one class for this node\nbuild tree for node 192\nonly one class for this node\nbuild tree for node 188\nonly one class for this node\nbuild tree for node 186\nspliting\nspliting done\n10 -2.1571752214275395\nbuild tree for node 193\nonly one class for this node\nbuild tree for node 194\nspliting\nspliting done\n4 8.53890819733801\nbuild tree for node 195\nspliting\nspliting done\n4 8.199662068840114\nbuild tree for node 197\nonly one class for this node\nbuild tree for node 198\nonly one class for this node\nbuild tree for node 196\nspliting\nspliting done\n11 -0.6890127255634545\nbuild tree for node 199\nspliting\nspliting done\n11 -0.7825682469456214\nbuild tree for node 201\nspliting\nspliting done\n8 0.5611826157617578\nbuild tree for node 203\nonly one class for this node\nbuild tree for node 204\nspliting\nspliting done\n6 -0.3034688381066008\nbuild tree for node 205\nonly one class for this node\nbuild tree for node 206\nspliting\nspliting done\n7 -0.010329327392823662\nbuild tree for node 207\nspliting\nspliting done\n11 -1.326878675333944\nbuild tree for node 209\nspliting\nspliting done\n1 12.658286272220781\nbuild tree for node 211\nonly one class for this node\nbuild tree for node 212\nonly one class for this node\nbuild tree for node 210\nonly one class for this node\nbuild tree for node 208\nonly one class for this node\nbuild tree for node 202\nspliting\nspliting done\n8 2.096548628604718\nbuild tree for node 213\nonly one class for this node\nbuild tree for node 214\nonly one class for this node\nbuild tree for node 200\nspliting\nspliting done\n19 -1.006309182433219\nbuild tree for node 215\nonly one class for this node\nbuild tree for node 216\nspliting\nspliting done\n20 -2.2234212143048806\nbuild tree for node 217\nonly one class for this node\nbuild tree for node 218\nspliting\nspliting done\n3 12.050009255133318\nbuild tree for node 219\nspliting\nspliting done\n2 8.428582633534116\nbuild tree for node 221\nspliting\nspliting done\n2 8.383636477616678\nbuild tree for node 223\nonly one class for this node\nbuild tree for node 224\nonly one class for this node\nbuild tree for node 222\nspliting\nspliting done\n13 -1.4134038181465653\nbuild tree for node 225\nspliting\nspliting done\n12 -0.8353485668443831\nbuild tree for node 227\nonly one class for this node\nbuild tree for node 228\nonly one class for this node\nbuild tree for node 226\nonly one class for this node\nbuild tree for node 220\nspliting\nspliting done\n7 -0.9834757201260955\nbuild tree for node 229\nonly one class for this node\nbuild tree for node 230\nspliting\nspliting done\n14 -0.3636846148603601\nbuild tree for node 231\nspliting\nspliting done\n1 12.952510811570342\nbuild tree for node 233\nonly one class for this node\nbuild tree for node 234\nonly one class for this node\nbuild tree for node 232\nspliting\nspliting done\n17 -1.453380736120219\nbuild tree for node 235\nonly one class for this node\nbuild tree for node 236\nspliting\nspliting done\n19 -0.3711549802905688\nbuild tree for node 237\nspliting\nspliting done\n5 0.5658479846786229\nbuild tree for node 239\nonly one class for this node\nbuild tree for node 240\nonly one class for this node\nbuild tree for node 238\nonly one class for this node\nbuild tree for node 184\nonly one class for this node\nbuild tree for node 182\nspliting\nspliting done\n2 8.51332055671438\nbuild tree for node 241\nonly one class for this node\nbuild tree for node 242\nspliting\nspliting done\n12 -0.0668863007916252\nbuild tree for node 243\nspliting\nspliting done\n10 1.947924660529866\nbuild tree for node 245\nspliting\nspliting done\n19 1.721289472624499\nbuild tree for node 247\nspliting\nspliting done\n18 -0.21926248977082352\nbuild tree for node 249\nspliting\nspliting done\n18 -0.5089059016723196\nbuild tree for node 251\nspliting\nspliting done\n4 13.209606791590588\nbuild tree for node 253\nonly one class for this node\nbuild tree for node 254\nonly one class for this node\nbuild tree for node 252\nonly one class for this node\nbuild tree for node 250\nonly one class for this node\nbuild tree for node 248\nonly one class for this node\nbuild tree for node 246\nonly one class for this node\nbuild tree for node 244\nspliting\nspliting done\n4 11.89596870069405\nbuild tree for node 255\nspliting\nspliting done\n4 11.222677444654341\nbuild tree for node 257\nspliting\nspliting done\n10 -0.1659768963518981\nbuild tree for node 259\nspliting\nspliting done\n1 9.051704626537415\nbuild tree for node 261\nonly one class for this node\nbuild tree for node 262\nonly one class for this node\nbuild tree for node 260\nspliting\nspliting done\n4 10.748693454893584\nbuild tree for node 263\nspliting\nspliting done\n15 1.9465421098549385\nbuild tree for node 265\nspliting\nspliting done\n17 1.0837076287539023\nbuild tree for node 267\nonly one class for this node\nbuild tree for node 268\nonly one class for this node\nbuild tree for node 266\nonly one class for this node\nbuild tree for node 264\nonly one class for this node\nbuild tree for node 258\nonly one class for this node\nbuild tree for node 256\nspliting\nspliting done\n4 13.745745738346791\nbuild tree for node 269\nonly one class for this node\nbuild tree for node 270\nonly one class for this node\nbuild tree for node 164\nonly one class for this node\nbuild tree for node 104\nspliting\nspliting done\n9 -1.3954378686501476\nbuild tree for node 271\nonly one class for this node\nbuild tree for node 272\nspliting\nspliting done\n10 0.7291138308462143\nbuild tree for node 273\nspliting\nspliting done\n10 -1.5498439370504378\nbuild tree for node 275\nonly one class for this node\nbuild tree for node 276\nonly one class for this node\nbuild tree for node 274\nonly one class for this node\n"
],
[
"fairness_importance = model_dtree._fairness_importance()",
"_____no_output_____"
],
[
"feature = []\nscore = []\nfor key, value in fairness_importance.items():\n print(key, value)\n feature.append(key)\n score.append((value))\nutils.draw_plot(feature,score,\"Results/Synthetic/eqop.pdf\")\n\n",
"1 0.01561942959001783\n2 0.15873015873015872\n3 0.12222222222222223\n4 0.09895577395577397\n5 0.031198686371100164\n6 -0.0378787878787879\n7 0.12727272727272726\n8 0.07899159663865545\n9 -0.014069264069264073\n10 -0.3595302445302445\n11 -0.21951219512195122\n12 0.0\n13 0.0\n14 0.07105263157894737\n15 0.0\n16 0.046153846153846156\n17 0.0\n18 -0.06944444444444443\n19 -0.06349206349206349\n20 0.0\n21 0\n"
],
[
"model_dtree_dp = d_tree.DecisionTree(20,0,'21',2)\nmodel_dtree_dp.fit(dataframe,y)\n\n",
"build tree for node 0\nspliting\nspliting done\n14 -0.48628298355753774\nbuild tree for node 1\nspliting\nspliting done\n15 2.727706000881293\nbuild tree for node 3\nspliting\nspliting done\n19 1.026193998624007\nbuild tree for node 5\nspliting\nspliting done\n19 0.7957742535230151\nbuild tree for node 7\nspliting\nspliting done\n9 0.6667169329122717\nbuild tree for node 9\nspliting\nspliting done\n10 1.7739421109627675\nbuild tree for node 11\nspliting\nspliting done\n10 1.1021466604866685\nbuild tree for node 13\nspliting\nspliting done\n13 0.594388544400418\nbuild tree for node 15\nspliting\nspliting done\n17 2.005916952550997\nbuild tree for node 17\nspliting\nspliting done\n19 -2.283133218977109\nbuild tree for node 19\nonly one class for this node\nbuild tree for node 20\nspliting\nspliting done\n20 1.2572946822307274\nbuild tree for node 21\nspliting\nspliting done\n16 -1.7003388231534555\nbuild tree for node 23\nonly one class for this node\nbuild tree for node 24\nspliting\nspliting done\n16 0.641020457626244\nbuild tree for node 25\nspliting\nspliting done\n9 -0.5755189462992927\nbuild tree for node 27\nspliting\nspliting done\n6 1.2484865265384693\nbuild tree for node 29\nspliting\nspliting done\n1 11.206468061662111\nbuild tree for node 31\nspliting\nspliting done\n1 10.321177107105546\nbuild tree for node 33\nspliting\nspliting done\n1 9.211704378973865\nbuild tree for node 35\nspliting\nspliting done\n5 -0.7501546359835667\nbuild tree for node 37\nonly one class for this node\nbuild tree for node 38\nonly one class for this node\nbuild tree for node 36\nonly one class for this node\nbuild tree for node 34\nspliting\nspliting done\n6 -1.065662875693158\nbuild tree for node 39\nonly one class for this node\nbuild tree for node 40\nonly one class for this node\nbuild tree for node 32\nonly one class for this node\nbuild tree for node 30\nonly one class for this node\nbuild tree for node 28\nspliting\nspliting done\n20 1.0978308090659779\nbuild tree for node 41\nonly one class for this node\nbuild tree for node 42\nonly one class for this node\nbuild tree for node 26\nspliting\nspliting done\n9 0.06192719026914312\nbuild tree for node 43\nspliting\nspliting done\n1 11.935149546003732\nbuild tree for node 45\nspliting\nspliting done\n3 8.423894217789442\nbuild tree for node 47\nonly one class for this node\nbuild tree for node 48\nonly one class for this node\nbuild tree for node 46\nspliting\nspliting done\n1 12.579912786521087\nbuild tree for node 49\nonly one class for this node\nbuild tree for node 50\nonly one class for this node\nbuild tree for node 44\nonly one class for this node\nbuild tree for node 22\nonly one class for this node\nbuild tree for node 18\nonly one class for this node\nbuild tree for node 16\nspliting\nspliting done\n8 -0.46460138168827947\nbuild tree for node 51\nspliting\nspliting done\n3 9.972789818391131\nbuild tree for node 53\nonly one class for this node\nbuild tree for node 54\nspliting\nspliting done\n5 0.6780285289983785\nbuild tree for node 55\nonly one class for this node\nbuild tree for node 56\nspliting\nspliting done\n1 13.313292023608527\nbuild tree for node 57\nonly one class for this node\nbuild tree for node 58\nonly one class for this node\nbuild tree for node 52\nspliting\nspliting done\n1 13.376869974074538\nbuild tree for node 59\nonly one class for this node\nbuild tree for node 60\nspliting\nspliting done\n1 13.652287424641658\nbuild tree for node 61\nonly one class for this node\nbuild tree for node 62\nonly one class for this node\nbuild tree for node 14\nonly one class for this node\nbuild tree for node 12\nspliting\nspliting done\n4 10.594694743854149\nbuild tree for node 63\nonly one class for this node\nbuild tree for node 64\nspliting\nspliting done\n2 12.324079657075991\nbuild tree for node 65\nonly one class for this node\nbuild tree for node 66\nonly one class for this node\nbuild tree for node 10\nspliting\nspliting done\n1 11.68701983126488\nbuild tree for node 67\nspliting\nspliting done\n16 0.5023241217075542\nbuild tree for node 69\nspliting\nspliting done\n9 1.3755513673035433\nbuild tree for node 71\nspliting\nspliting done\n14 -1.5344775477424402\nbuild tree for node 73\nonly one class for this node\nbuild tree for node 74\nspliting\nspliting done\n18 1.708611151921764\nbuild tree for node 75\nonly one class for this node\nbuild tree for node 76\nonly one class for this node\nbuild tree for node 72\nspliting\nspliting done\n3 11.420131256673843\nbuild tree for node 77\nspliting\nspliting done\n1 10.108868077705525\nbuild tree for node 79\nspliting\nspliting done\n3 10.786360849004788\nbuild tree for node 81\nonly one class for this node\nbuild tree for node 82\nonly one class for this node\nbuild tree for node 80\nonly one class for this node\nbuild tree for node 78\nonly one class for this node\nbuild tree for node 70\nspliting\nspliting done\n4 9.402010438939815\nbuild tree for node 83\nonly one class for this node\nbuild tree for node 84\nonly one class for this node\nbuild tree for node 68\nspliting\nspliting done\n9 0.8332034995819015\nbuild tree for node 85\nspliting\nspliting done\n1 12.986435066872275\nbuild tree for node 87\nonly one class for this node\nbuild tree for node 88\nonly one class for this node\nbuild tree for node 86\nonly one class for this node\nbuild tree for node 8\nspliting\nspliting done\n8 0.8805099610248939\nbuild tree for node 89\nspliting\nspliting done\n14 -1.880249935220326\nbuild tree for node 91\nspliting\nspliting done\n1 11.002961387839068\nbuild tree for node 93\nonly one class for this node\nbuild tree for node 94\nonly one class for this node\nbuild tree for node 92\nonly one class for this node\nbuild tree for node 90\nonly one class for this node\nbuild tree for node 6\nspliting\nspliting done\n4 11.818298509926992\nbuild tree for node 95\nspliting\nspliting done\n12 1.6687198909031067\nbuild tree for node 97\nonly one class for this node\nbuild tree for node 98\nonly one class for this node\nbuild tree for node 96\nspliting\nspliting done\n8 0.3949089429740912\nbuild tree for node 99\nspliting\nspliting done\n1 12.720175730922666\nbuild tree for node 101\nonly one class for this node\nbuild tree for node 102\nonly one class for this node\nbuild tree for node 100\nonly one class for this node\nbuild tree for node 4\nonly one class for this node\nbuild tree for node 2\nspliting\nspliting done\n18 2.0570281678355835\nbuild tree for node 103\nspliting\nspliting done\n8 -0.24042679492595417\nbuild tree for node 105\nspliting\nspliting done\n4 8.308129458346738\nbuild tree for node 107\nspliting\nspliting done\n2 9.2962861036525\nbuild tree for node 109\nonly one class for this node\nbuild tree for node 110\nonly one class for this node\nbuild tree for node 108\nspliting\nspliting done\n8 -2.238934289983918\nbuild tree for node 111\nspliting\nspliting done\n18 -0.528479086853427\nbuild tree for node 113\nspliting\nspliting done\n1 10.107377529021235\nbuild tree for node 115\nonly one class for this node\nbuild tree for node 116\nonly one class for this node\nbuild tree for node 114\nonly one class for this node\nbuild tree for node 112\nspliting\nspliting done\n11 -1.116671339676862\nbuild tree for node 117\nspliting\nspliting done\n5 0.31810867089849865\nbuild tree for node 119\nspliting\nspliting done\n1 9.52631487657111\nbuild tree for node 121\nonly one class for this node\nbuild tree for node 122\nspliting\nspliting done\n12 2.0366096555590376\nbuild tree for node 123\nonly one class for this node\nbuild tree for node 124\nonly one class for this node\nbuild tree for node 120\nspliting\nspliting done\n5 0.8206806078404716\nbuild tree for node 125\nonly one class for this node\nbuild tree for node 126\nspliting\nspliting done\n4 11.224755309082102\nbuild tree for node 127\nonly one class for this node\nbuild tree for node 128\nonly one class for this node\nbuild tree for node 118\nspliting\nspliting done\n10 -1.1961182840383455\nbuild tree for node 129\nspliting\nspliting done\n6 0.02594498152573349\nbuild tree for node 131\nspliting\nspliting done\n19 0.594446850835741\nbuild tree for node 133\nonly one class for this node\nbuild tree for node 134\nonly one class for this node\nbuild tree for node 132\nonly one class for this node\nbuild tree for node 130\nspliting\nspliting done\n13 -2.518845418509098\nbuild tree for node 135\nspliting\nspliting done\n1 10.76958342203605\nbuild tree for node 137\nonly one class for this node\nbuild tree for node 138\nonly one class for this node\nbuild tree for node 136\nspliting\nspliting done\n1 8.155885375851463\nbuild tree for node 139\nspliting\nspliting done\n1 7.741662115753707\nbuild tree for node 141\nonly one class for this node\nbuild tree for node 142\nonly one class for this node\nbuild tree for node 140\nspliting\nspliting done\n15 -2.026116808492584\nbuild tree for node 143\nspliting\nspliting done\n3 10.486159406563804\nbuild tree for node 145\nonly one class for this node\nbuild tree for node 146\nonly one class for this node\nbuild tree for node 144\nspliting\nspliting done\n13 -1.0564421437860596\nbuild tree for node 147\nspliting\nspliting done\n10 0.8288206795207681\nbuild tree for node 149\nonly one class for this node\nbuild tree for node 150\nspliting\nspliting done\n3 11.438428377787869\nbuild tree for node 151\nonly one class for this node\nbuild tree for node 152\nonly one class for this node\nbuild tree for node 148\nspliting\nspliting done\n10 -0.7575924923100561\nbuild tree for node 153\nspliting\nspliting done\n7 -1.2879850696212989\nbuild tree for node 155\nonly one class for this node\nbuild tree for node 156\nspliting\nspliting done\n4 13.410308718837175\nbuild tree for node 157\nonly one class for this node\nbuild tree for node 158\nspliting\nspliting done\n1 11.905422028814233\nbuild tree for node 159\nonly one class for this node\nbuild tree for node 160\nonly one class for this node\nbuild tree for node 154\nonly one class for this node\nbuild tree for node 106\nspliting\nspliting done\n7 -1.1898053747140236\nbuild tree for node 161\nonly one class for this node\nbuild tree for node 162\nspliting\nspliting done\n5 2.713498968991537\nbuild tree for node 163\nspliting\nspliting done\n16 -2.539618066234551\nbuild tree for node 165\nonly one class for this node\nbuild tree for node 166\nspliting\nspliting done\n19 -1.0842623188960647\nbuild tree for node 167\nspliting\nspliting done\n3 8.273249089381032\nbuild tree for node 169\nonly one class for this node\nbuild tree for node 170\nspliting\nspliting done\n7 -1.1091236090919598\nbuild tree for node 171\nspliting\nspliting done\n4 10.752491555589776\nbuild tree for node 173\nonly one class for this node\nbuild tree for node 174\nonly one class for this node\nbuild tree for node 172\nspliting\nspliting done\n18 -1.4612525361794246\nbuild tree for node 175\nspliting\nspliting done\n2 10.38916568160802\nbuild tree for node 177\nonly one class for this node\nbuild tree for node 178\nonly one class for this node\nbuild tree for node 176\nonly one class for this node\nbuild tree for node 168\nspliting\nspliting done\n19 -1.0641573801921242\nbuild tree for node 179\nonly one class for this node\nbuild tree for node 180\nspliting\nspliting done\n14 0.8922056759889184\nbuild tree for node 181\nspliting\nspliting done\n16 2.088327487534671\nbuild tree for node 183\nspliting\nspliting done\n12 -1.046974445953249\nbuild tree for node 185\nspliting\nspliting done\n15 0.3806079375599444\nbuild tree for node 187\nspliting\nspliting done\n4 9.356322726537645\nbuild tree for node 189\nonly one class for this node\nbuild tree for node 190\nspliting\nspliting done\n3 12.874881358666828\nbuild tree for node 191\nonly one class for this node\nbuild tree for node 192\nonly one class for this node\nbuild tree for node 188\nonly one class for this node\nbuild tree for node 186\nspliting\nspliting done\n10 -2.1571752214275395\nbuild tree for node 193\nonly one class for this node\nbuild tree for node 194\nspliting\nspliting done\n4 8.53890819733801\nbuild tree for node 195\nspliting\nspliting done\n4 8.199662068840114\nbuild tree for node 197\nonly one class for this node\nbuild tree for node 198\nonly one class for this node\nbuild tree for node 196\nspliting\nspliting done\n11 -0.6890127255634545\nbuild tree for node 199\nspliting\nspliting done\n11 -0.7825682469456214\nbuild tree for node 201\nspliting\nspliting done\n8 0.5611826157617578\nbuild tree for node 203\nonly one class for this node\nbuild tree for node 204\nspliting\nspliting done\n6 -0.3034688381066008\nbuild tree for node 205\nonly one class for this node\nbuild tree for node 206\nspliting\nspliting done\n7 -0.010329327392823662\nbuild tree for node 207\nspliting\nspliting done\n11 -1.326878675333944\nbuild tree for node 209\nspliting\nspliting done\n1 12.658286272220781\nbuild tree for node 211\nonly one class for this node\nbuild tree for node 212\nonly one class for this node\nbuild tree for node 210\nonly one class for this node\nbuild tree for node 208\nonly one class for this node\nbuild tree for node 202\nspliting\nspliting done\n8 2.096548628604718\nbuild tree for node 213\nonly one class for this node\nbuild tree for node 214\nonly one class for this node\nbuild tree for node 200\nspliting\nspliting done\n19 -1.006309182433219\nbuild tree for node 215\nonly one class for this node\nbuild tree for node 216\nspliting\nspliting done\n20 -2.2234212143048806\nbuild tree for node 217\nonly one class for this node\nbuild tree for node 218\nspliting\nspliting done\n3 12.050009255133318\nbuild tree for node 219\nspliting\nspliting done\n2 8.428582633534116\nbuild tree for node 221\nspliting\nspliting done\n2 8.383636477616678\nbuild tree for node 223\nonly one class for this node\nbuild tree for node 224\nonly one class for this node\nbuild tree for node 222\nspliting\nspliting done\n13 -1.4134038181465653\nbuild tree for node 225\nspliting\nspliting done\n12 -0.8353485668443831\nbuild tree for node 227\nonly one class for this node\nbuild tree for node 228\nonly one class for this node\nbuild tree for node 226\nonly one class for this node\nbuild tree for node 220\nspliting\nspliting done\n7 -0.9834757201260955\nbuild tree for node 229\nonly one class for this node\nbuild tree for node 230\nspliting\nspliting done\n14 -0.3636846148603601\nbuild tree for node 231\nspliting\nspliting done\n1 12.952510811570342\nbuild tree for node 233\nonly one class for this node\nbuild tree for node 234\nonly one class for this node\nbuild tree for node 232\nspliting\nspliting done\n17 -1.453380736120219\nbuild tree for node 235\nonly one class for this node\nbuild tree for node 236\nspliting\nspliting done\n19 -0.3711549802905688\nbuild tree for node 237\nspliting\nspliting done\n5 0.5658479846786229\nbuild tree for node 239\nonly one class for this node\nbuild tree for node 240\nonly one class for this node\nbuild tree for node 238\nonly one class for this node\nbuild tree for node 184\nonly one class for this node\nbuild tree for node 182\nspliting\nspliting done\n2 8.51332055671438\nbuild tree for node 241\nonly one class for this node\nbuild tree for node 242\nspliting\nspliting done\n12 -0.0668863007916252\nbuild tree for node 243\nspliting\nspliting done\n10 1.947924660529866\nbuild tree for node 245\nspliting\nspliting done\n19 1.721289472624499\nbuild tree for node 247\nspliting\nspliting done\n18 -0.21926248977082352\nbuild tree for node 249\nspliting\nspliting done\n18 -0.5089059016723196\nbuild tree for node 251\nspliting\nspliting done\n4 13.209606791590588\nbuild tree for node 253\nonly one class for this node\nbuild tree for node 254\nonly one class for this node\nbuild tree for node 252\nonly one class for this node\nbuild tree for node 250\nonly one class for this node\nbuild tree for node 248\nonly one class for this node\nbuild tree for node 246\nonly one class for this node\nbuild tree for node 244\nspliting\nspliting done\n4 11.89596870069405\nbuild tree for node 255\nspliting\nspliting done\n4 11.222677444654341\nbuild tree for node 257\nspliting\nspliting done\n10 -0.1659768963518981\nbuild tree for node 259\nspliting\nspliting done\n1 9.051704626537415\nbuild tree for node 261\nonly one class for this node\nbuild tree for node 262\nonly one class for this node\nbuild tree for node 260\nspliting\nspliting done\n4 10.748693454893584\nbuild tree for node 263\nspliting\nspliting done\n15 1.9465421098549385\nbuild tree for node 265\nspliting\nspliting done\n17 1.0837076287539023\nbuild tree for node 267\nonly one class for this node\nbuild tree for node 268\nonly one class for this node\nbuild tree for node 266\nonly one class for this node\nbuild tree for node 264\nonly one class for this node\nbuild tree for node 258\nonly one class for this node\nbuild tree for node 256\nspliting\nspliting done\n4 13.745745738346791\nbuild tree for node 269\nonly one class for this node\nbuild tree for node 270\nonly one class for this node\nbuild tree for node 164\nonly one class for this node\nbuild tree for node 104\nspliting\nspliting done\n9 -1.3954378686501476\nbuild tree for node 271\nonly one class for this node\nbuild tree for node 272\nspliting\nspliting done\n10 0.7291138308462143\nbuild tree for node 273\nspliting\nspliting done\n10 -1.5498439370504378\nbuild tree for node 275\nonly one class for this node\nbuild tree for node 276\nonly one class for this node\nbuild tree for node 274\nonly one class for this node\n"
],
[
"fairness_importance_dp = model_dtree_dp._fairness_importance()",
"_____no_output_____"
],
[
"feature = []\nscore_dp = []\nfor key, value in fairness_importance_dp.items():\n print(key, value)\n feature.append(key)\n score_dp.append((value))\nutils.draw_plot(feature,score_dp,\"Results/Synthetic/DP.pdf\")\n",
"1 0.05463606492501176\n2 0.08063399942054912\n3 0.03650874685807248\n4 0.014060730152174945\n5 -0.08824841875175003\n6 0.13065760832304948\n7 -0.06566905482196113\n8 0.006551584716514561\n9 0.09270784624554147\n10 -0.1595238581244938\n11 -0.04018076053206942\n12 0.0980352987174192\n13 0.056451466659543474\n14 0.20194317565864095\n15 -0.1309365416097205\n16 -0.028460912064102194\n17 -0.009640649922612904\n18 -0.006704047581253221\n19 -0.0022898315096238847\n20 0.040568466549553345\n21 0\n"
],
[
"count_z0 = count_z1 = 0\ncount0 = count1 = 0\nz0 = z1 = 0\nfor i in range (1000):\n if y[i] == 0:\n count0+=1\n else:\n count1+=1\n if x[i][20] == 0:\n count_z0 += 1\n else:\n count_z1 +=1\n if x[i][20] == 0:\n z0+=1\n else:\n z1+=1\nprint(count0,count1, count_z0,count_z1,z0,z1)\n\n",
"809 191 104 87 498 502\n"
]
]
]
| [
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cb79a2bb1b4e984b7f7dd40b1d6b9ab5a375b9 | 218,991 | ipynb | Jupyter Notebook | annif.ipynb | CSCfi/annif-utils | 1769089cc11d3eafb968136aebfc56e55a18dd3a | [
"Apache-2.0"
]
| null | null | null | annif.ipynb | CSCfi/annif-utils | 1769089cc11d3eafb968136aebfc56e55a18dd3a | [
"Apache-2.0"
]
| null | null | null | annif.ipynb | CSCfi/annif-utils | 1769089cc11d3eafb968136aebfc56e55a18dd3a | [
"Apache-2.0"
]
| null | null | null | 175.052758 | 75,764 | 0.86299 | [
[
[
"",
"_____no_output_____"
],
[
"# Annif tutorial with Jupyter notebook",
"_____no_output_____"
],
[
"[Annif](https://annif.org/) is an open source subject indexing tool for new documents and aims to improve the discoverability of vast amount of electronic documents. \n\nIn order to accomplish automatic subject indexing task, annif uses ML/NLP algorithms to leverage existing training data in the form of subject vocabulary and metadata. For the purpose of a test use-case service of Annif at CSC, small subsets of yso-finna-theses records (i.e., yso-finna-small.tsv.gz file as provided by Annif tutorial dataset) from the [Finna.fi](https://www.finna.fi/?lng=en-gb) discovery serviceis are used. The backend models of this annif instance inculdes handful of different subject indexing algorithms namely, Maui, TF-IDF, ensemble and Omikuji (Parabel/Bonsai) methods. These models are trained in supercomputing (Puhti) environment using singularity container for Annif application. \n\nThis tutorial uses REST API calls to interact with a given Annif webserver which can be either [Annif webserver](https://api.annif.org/v1/ui/) hosted by national library of Finland or a [test case webserver](https://annif.rahtiapp.fi/v1/ui/) hosted by CSC ",
"_____no_output_____"
],
[
"## Learning Objectives\nUpon completion of this tutorial, you will be able to learn how to:\n - List available trained projects in a given annif webserver\n - Perform subject indexing with Annif using different projects (subject vocabularies and existing metadata)",
"_____no_output_____"
],
[
"## List all available projects from a given annif webserver\nAll available projects form annif webserver can be retrieved using Annif REST API GET call.\n \n>**Note**: One can make REST API call using the following *curl* command in command-line environment: curl -X GET --header 'Accept: application/json' 'https://annif.rahtiapp.fi/v1/projects' \n\nBelow is the python way of making REST API GET call to annif server and then converting the resulting json data in the form of a table",
"_____no_output_____"
]
],
[
[
"import requests\nimport json \nfrom pandas import json_normalize\nheaders = {'Accept': 'application/json'}\nbase_url='https://annif.rahtiapp.fi/v1/projects' # Annif webserver hosted by CSC \n#base_url='https://api.annif.org/v1/projects' # Annif webserver by NatLibFi\n\nresponse = requests.get(base_url, headers=headers)\nd=response.json() # print resulting json file: print(response.text) \njson_normalize(d['projects'])",
"_____no_output_____"
]
],
[
[
"## Perform subject indexing with Annif\nThere are mainly six types of projects in a test case example of [Annif](https://annif.rahtiapp.fi) hosted at CSC and it runs\non Rahti container cloud. Let's see how to get subject indexing with each of these projects here\n\n### 1. Perform subject indexing for your own text using YSO TFIDF project (projectid: yso-tfidf-en) \nThis can be accomplished using swagger API POST call\n> **Note**: Here is the curl command for subject indexing: curl -X POST --header 'Content-Type: application/x-www-form-urlencoded' --header 'Accept: application/json' -d 'text=frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary&limit=10' 'https://annif.rahtiapp.fi/v1/projects/yso-tfidf-en/suggest'\n\nBelow is the python approach:",
"_____no_output_____"
]
],
[
[
"projectid='yso-tfidf-en'\ntext='frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary'\nurl= base_url+ '/' + projectid +'/suggest'\ndata = {'text': text} \nheaders = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}\n\nresponse = requests.post(url, headers=headers, data=data)\nd=response.json() # print(response.text) \ndisplay(json_normalize(d['results']))\ndata=json_normalize(d['results'])\ndata.loc[:,['label','score','uri']].plot('label',kind='bar')",
"_____no_output_____"
]
],
[
[
"### 2. Perform subject indexing with YSO ensemble project (projectid:'yso-ensemble-en') \nThis can be accomplished using swagger API POST call\n> **Note**: curl command - curl -X POST --header 'Content-Type: application/x-www-form-urlencoded' --header 'Accept: application/json' -d 'text=frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary&limit=10' 'https://annif.rahtiapp.fi/v1/projects/yso-tfidf-en/suggest'\n\nUsing python: ",
"_____no_output_____"
]
],
[
[
"projectid='yso-ensemble-en'\ntext='frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary'\nurl= base_url+ '/' + projectid +'/suggest'\ndata = {'text': text} \nheaders = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}\n\nresponse = requests.post(url, headers=headers, data=data)\nd=response.json() # print(response.text) \ndisplay(json_normalize(d['results']))\ndata=json_normalize(d['results'])\ndata.loc[:,['label','score','uri']].plot('label',kind='bar')",
"_____no_output_____"
]
],
[
[
"### 3. Perform subject indexing with for your own text using project 'yso-maui-en' \nThis can be accomplished using swagger API POST call\n> **curl command**:curl -X POST --header 'Content-Type: application/x-www-form-urlencoded' --header 'Accept: application/json' -d 'text=frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary&limit=10' 'https://annif.rahtiapp.fi/v1/projects/yso-maui-en/suggest'\n \nUsing python approach:",
"_____no_output_____"
]
],
[
[
"projectid='yso-maui-en'\ntext='frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary'\nurl= base_url+ '/' + projectid +'/suggest'\ndata = {'text': text} \nheaders = { 'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}\nresponse = requests.post(url, headers=headers, data=data)\n\nd=response.json() # print(response.text) \ndisplay(json_normalize(d['results']))\ndata=json_normalize(d['results'])\ndata.loc[:,['label','score','uri']].plot('label',kind='bar')",
"_____no_output_____"
]
],
[
[
"### 4. Perform subject indexing for your own text using project 'yso-omikuji-parabel-en' \nThis can be accomplished using swagger API POST call\n>**curl command**: curl -X POST --header 'Content-Type: application/x-www-form-urlencoded' --header 'Accept: application/json' -d 'text=frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary&limit=10' 'https://annif.rahtiapp.fi/v1/projects/yso-omikuji-parabel-en/suggest'\n\nUsing python approach:",
"_____no_output_____"
]
],
[
[
"projectid='yso-omikuji-parabel-en'\ntext='frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary'\nurl= base_url+ '/' + projectid +'/suggest'\ndata = {'text': text} \nheaders = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}\nresponse = requests.post(url, headers=headers, data=data)\n\nd=response.json() # print(response.text) \ndisplay(json_normalize(d['results']))\ndata=json_normalize(d['results'])\ndata.loc[:,['label','score','uri']].plot('label',kind='bar')",
"_____no_output_____"
]
],
[
[
"### 5. Perform subject indexing for your own text using project 'yso-omikuji-bonsai-en' \nThis can be accomplished using swagger API POST call\n>**curl command**:curl -X POST --header 'Content-Type: application/x-www-form-urlencoded' --header 'Accept: application/json' -d 'text=frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary&limit=10' 'https://annif.rahtiapp.fi/v1/projects/yyso-omikuji-bonsai-en/suggest'\n\nUsing python approach:",
"_____no_output_____"
]
],
[
[
"projectid='yso-omikuji-bonsai-en'\ntext='frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary'\nurl= base_url+ '/' + projectid +'/suggest'\ndata = {'text': text} \nheaders = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}\n\nresponse = requests.post(url, headers=headers, data=data)\nd=response.json() # print(response.text) \ndisplay(json_normalize(d['results']))\ndata=json_normalize(d['results'])\ndata.loc[:,['label','score','uri']].plot('label',kind='bar')",
"_____no_output_____"
]
],
[
[
"### 6. Perform subject indexing for your own text using project 'yso-nn-ensemble-en' \nThis can be accomplished using swagger API POST call\n>**curl command**: curl -X POST --header 'Content-Type: application/x-www-form-urlencoded' --header 'Accept: application/json' -d 'text=frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary&limit=10' 'https://annif.rahtiapp.fi/v1/projects/yso-nn-ensemble-en/suggest'\n\nUsing python approach:",
"_____no_output_____"
]
],
[
[
"projectid='yso-nn-ensemble-en'\ntext='frequently occurring or otherwise salient terms in the document are matched with terms in the vocabulary'\nurl= base_url+ '/' + projectid +'/suggest'\ndata = {'text': text} \nheaders = { 'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}\nresponse = requests.post(url, headers=headers, data=data)\n\nd=response.json() \ndisplay(json_normalize(d['results']))\ndata=json_normalize(d['results'])\ndata.loc[:,['label','score','uri']].plot('label',kind='bar')",
"_____no_output_____"
]
],
[
[
"## References",
"_____no_output_____"
],
[
"1 Suominen, O., 2019. Annif: DIY automated subject indexing using multiple algorithms. LIBER Quarterly, 29(1), pp.1–25\n\n2 Annif github repositories: [CSC github](https://github.com/CSCfi/annif-utils) and [NatLibFi github](https://github.com/NatLibFi/Annif)\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
e7cb89b5fff19fffdf8a80322be4e5826d1b261b | 22,559 | ipynb | Jupyter Notebook | mpi.ipynb | craiggardner/jupyter_notebooks | 1343e4accacabbe93b0f15e80915cb5c92acd6da | [
"CC0-1.0"
]
| null | null | null | mpi.ipynb | craiggardner/jupyter_notebooks | 1343e4accacabbe93b0f15e80915cb5c92acd6da | [
"CC0-1.0"
]
| null | null | null | mpi.ipynb | craiggardner/jupyter_notebooks | 1343e4accacabbe93b0f15e80915cb5c92acd6da | [
"CC0-1.0"
]
| null | null | null | 25.037736 | 495 | 0.547719 | [
[
[
"# Several exercises: Jupyter Notebook, iPython and ipyparallel, and HPC MPICH\n\nThe content of this notebook is borrowed extensively from Daan Van Hauwermeiren, from his tutotial of ipyparallel, stored on github https://github.com/DaanVanHauwermeiren/ipyparallel-tutorial/blob/master/02-ipyparallel-tutorial-direct-interface.ipynb. Many adaptions have been made to accommodate this demonstration and this HPC MPI environment.\n\nPrior to running these steps in this notebook, the following details must\nbe completed outside the context of Jupyter, and generally will need to be \nfacilitated by a systems administator with appropriate rights and knowledge \nof HPC and MPI.\n\n 1) HPC and MPICH have been configured, with compute nodes running\n 2) Related to HPC and MPICH, an NFS/NIS environment exists to facilitate the 'scientist' user environment across all of the computing resources in the cluster\n 3) The ipyparallel client/engine environment must be configured and started that supports MPI/MPICH\n 4) Ensure that the \"IPython Cluster\" called \"mpi\" in the JupyterHub is running\n\nOnce the above details have been acomplished, import the IPython ipyparallel module and create a Client instance",
"_____no_output_____"
]
],
[
[
"# import the IPython ipyparallel module and create a Client instance\n# In this demonstration, an MPI-oriented client is created, referenced by the 'mpi' profile\n# There are 4 mpi engines that have been configured and running on 4 separate HPC compute nodes\nimport ipyparallel as ipp\nrc = ipp.Client(profile='mpi')\n\n# Show that there are engines running, responding\nrc.ids\n",
"_____no_output_____"
],
[
"# Create an ipyparallel object, constructed via list-access to the client:\n vobject = rc[:]",
"_____no_output_____"
]
],
[
[
"Python’s builtin map() functions allows a function to be applied to a sequence element-by-element. This type of code is typically trivial to parallelize. In fact, since IPython’s interface is all about functions anyway, you can just use the builtin map() with a RemoteFunction, or a vobject’s map() method.\n\ndo an arbitrary serial computation using just the power of the HPC head node, \n... and show how long it takes to compute",
"_____no_output_____"
]
],
[
[
"%%time\nserial_result = list(map(lambda x:x**2**2, range(30)))",
"CPU times: user 18 µs, sys: 3 µs, total: 21 µs\nWall time: 25.5 µs\n"
]
],
[
[
"Now do the same computation using the MPI compute nodes HPC cluster, \n... and show how long it takes",
"_____no_output_____"
]
],
[
[
"%%time\nparallel_result = vobject.map_sync(lambda x:x**2**2, range(30))",
"CPU times: user 176 ms, sys: 53.1 ms, total: 229 ms\nWall time: 334 ms\n"
],
[
"serial_result==parallel_result",
"_____no_output_____"
]
],
[
[
"# Remote function decorators\n\nRemote functions are just like normal functions, but when they are called, they execute on one or more engines, rather than locally. Here we will demonstrate the @parallel function decorator, which creates parallel functions that break up an element-wise operations and distribute them to remote workers. It also reconstructs the result from each worker as the result is returned.",
"_____no_output_____"
]
],
[
[
"# First, we'll enable blocking, which will be explored more throughly later. \n# In short, blocking will ensure that each task won't proceed until all the remotely distributed work is complete.\[email protected](block=True)\n\n# Define a function called \"getpid\" that ... well, you can see the description\ndef getpid():\n '''\n import library os and return the process number (pid) corresponding with\n the execution\n '''\n import os\n return os.getpid()",
"_____no_output_____"
],
[
"# Using our newly defined function, show the process id of the engine running on each compute node\ngetpid()",
"_____no_output_____"
]
],
[
[
"We'll use numpy to create some complicated (random) arrays, then use those arrays for some big computations that should benefit by some distributed HPC compute resources.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nA = np.random.random((64,48))",
"_____no_output_____"
],
[
"# Create a little function that can do the calculations as a distribution among multiple, parallel compute nodes\[email protected](block=True)\ndef pmul(A,B):\n return A*B",
"_____no_output_____"
]
],
[
[
"We want to be able to compare the amount of time it takes to do the calulation locally on the HPC head\nand the amount of time it takes to do the calculation among the distributed compute nodes\n\nFirst, do the calculation locally, then do it remotely",
"_____no_output_____"
]
],
[
[
"%%time\nC_local = A*A",
"CPU times: user 27 µs, sys: 6 µs, total: 33 µs\nWall time: 37.4 µs\n"
],
[
"%%time\nC_remote = pmul(A,A)",
"CPU times: user 20.3 ms, sys: 51 µs, total: 20.3 ms\nWall time: 23.8 ms\n"
],
[
"(C_local == C_remote).all()",
"_____no_output_____"
]
],
[
[
"Create a simple, new function that can be called locally but that will execute remotely, in parallel.\nIt's just a simple instruction that will \"echo\" the output of what is run on the remote worker",
"_____no_output_____"
]
],
[
[
"@vobject.parallel(block=True)\ndef echo(x):\n return str(x)",
"_____no_output_____"
],
[
"echo(range(5))",
"_____no_output_____"
],
[
"echo.map(range(5))",
"_____no_output_____"
]
],
[
[
"# Blocking execution\n\nIn blocking mode, the iPython ipyparallel object (called vobject in these examples; defined at the beginning of this notebook) submits the command to the controller, which places the command in the engines’ queues for execution. The apply() call then blocks until the engines are done executing the command.",
"_____no_output_____"
]
],
[
[
"# Show function names (on the remote worker) that beging with the string \"apply\"\n[x for x in dir(vobject) if x.startswith('apply')]",
"_____no_output_____"
],
[
"vobject.block = True\nvobject['a'] = 5\nvobject['b'] = 10\nvobject.apply(lambda x: a+b+x, 27)",
"_____no_output_____"
],
[
"vobject.block = False\nvobject.apply_sync(lambda x: a+b+x, 27)",
"_____no_output_____"
]
],
[
[
"Python commands can be executed as strings on specific engines by using a vobject’s execute method:",
"_____no_output_____"
]
],
[
[
"rc[::2].execute('c=a+b')",
"_____no_output_____"
],
[
"rc[1::2].execute('c=a-b')",
"_____no_output_____"
],
[
"vobject['c'] # shorthand for vobject.pull('c', block=True)",
"_____no_output_____"
]
],
[
[
"# Non-blocking execution\n\nIn non-blocking mode, apply() submits the command to be executed and then returns a AsyncResult object immediately. The AsyncResult object gives you a way of getting a result at a later time through its get() method.\n\nMore info on the AsyncResult object: http://ipyparallel.readthedocs.io/en/6.0.2/asyncresult.html#parallel-asyncresult\n\nThis allows you to quickly submit long running commands without blocking your local Python/IPython session:",
"_____no_output_____"
]
],
[
[
"# define our function\ndef wait(t):\n import time\n tic = time.time()\n time.sleep(t)\n return time.time()-tic",
"_____no_output_____"
],
[
"# In non-blocking mode\nar = vobject.apply_async(wait, 3)",
"_____no_output_____"
],
[
"# Now block for the result, and the output won't disply until after 3 seconds\nar.get()",
"_____no_output_____"
],
[
"# Again in non-blocking mode, with longer wait (10 seconds)\nar = vobject.apply_async(wait, 10)",
"_____no_output_____"
],
[
"# Poll to see if the result is ready\n# If you run this fast enough following the previous step, the output will be \"False\"\n# But if you wait for 10 seconds, before executing this step, the output will be \"True\"\nar.ready()",
"_____no_output_____"
],
[
"# ask for the result, but wait a maximum of 1 second:\nar.get(1)",
"_____no_output_____"
]
],
[
[
"Often, it is desirable to wait until a set of AsyncResult objects are done. For this, there is the method wait(). This method takes a tuple of AsyncResult objects (or msg_ids or indices to the client’s History), and blocks until all of the associated results are ready.\n\nIn proper Jupyter Notebook fashion, the step progress indicator will show as a '*' character until the instruction is completed. Output will not be displayed until the instruction is completed.",
"_____no_output_____"
]
],
[
[
"vobject.block=False\n# A trivial list of AsyncResults objects\npr_list = [vobject.apply_async(wait, 3) for i in range(10)]\n# Wait until all of the clients have completed the instruction\nvobject.wait(pr_list)\n# Then, their results are ready using get() or the `.r` attribute\npr_list[0].get()",
"_____no_output_____"
]
],
[
[
"# Scatter and gather\n\nSometimes it is useful to partition a sequence and push the partitions to different engines. In MPI language, this is know as scatter/gather and we follow that terminology. However, it is important to remember that in IPython’s Client class, scatter() is from the interactive IPython session to the engines and gather() is from the engines back to the interactive IPython session. For scatter/gather operations between engines, MPI, pyzmq, or some other direct interconnect should be used.",
"_____no_output_____"
]
],
[
[
"vobject.scatter('a',range(16))",
"_____no_output_____"
],
[
"vobject['a']",
"_____no_output_____"
],
[
"vobject.gather('a')",
"_____no_output_____"
]
],
[
[
"# parallel list comprehensions\n\nIn many cases list comprehensions are nicer than using the map function. While we don’t have fully parallel list comprehensions, it is simple to get the basic effect using scatter() and gather():\n\nThe %px magic executes a single Python command on the engines specified by the targets attribute of the view instance",
"_____no_output_____"
]
],
[
[
"vobject.scatter('x', range(64))\n#Parallel execution on engines: [0, 1, 2, 3]\n%px y = [i**10 for i in x]\ny = vobject.gather('y')\nprint(y.get()[-10:])",
"[210832519264920576, 253295162119140625, 303305489096114176, 362033331456891249, 430804206899405824, 511116753300641401, 604661760000000000, 713342911662882601, 839299365868340224, 984930291881790849]\n"
]
],
[
[
"# example: monte carlo approximation of pi\n\nA simple toy problem to get a handle on multiple engines is a Monte Carlo approximation of π.\n\nLet’s say we have a dartboard with a round target inscribed on a square board. If you threw darts randomly, and they land evenly distributed on the square board, how many darts would you expect to hit the target?",
"_____no_output_____"
]
],
[
[
"from random import random\nfrom math import pi\nvobject['random'] = random",
"_____no_output_____"
],
[
"def mcpi(nsamples):\n s = 0\n for i in range(nsamples):\n x = random()\n y = random()\n if x*x + y*y <= 1:\n s+=1\n return 4.*s/nsamples\n \ndef multi_mcpi(view, nsamples):\n p = len(view.targets)\n if nsamples % p:\n # ensure even divisibility\n nsamples += p - (nsamples%p)\n \n subsamples = nsamples//p\n \n ar = view.apply(mcpi, subsamples)\n return sum(ar)/p\n\ndef check_pi(tol=1e-5, step=10, verbose=False):\n guess = 0\n spi = pi\n steps = 0\n while abs(spi-guess)/spi > tol:\n for i in range(step):\n x = random()\n y = random()\n if x*x+y*y <= 1:\n guess += 4.\n steps += step\n spi = pi*steps\n if verbose:\n print(spi, guess, abs(spi-guess)/spi)\n return steps, guess/steps",
"_____no_output_____"
],
[
"%%time\nmcpi(int(1e9))\n# 1e7 means 10 to the 7th power. \"e\" stands for \"expontent\"",
"CPU times: user 5min 37s, sys: 0 ns, total: 5min 37s\nWall time: 5min 38s\n"
],
[
"%%time\nmulti_mcpi(vobject, int(1e9))",
"CPU times: user 21.4 ms, sys: 0 ns, total: 21.4 ms\nWall time: 872 ms\n"
],
[
"check_pi()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cb9c6c6e578bfa22408f4e5794cb5332546b2d | 90,545 | ipynb | Jupyter Notebook | time_series/pycaret/pycaret_ts_ccf.ipynb | ngupta23/medium_articles | 53dee1cec0677f1129d0f791be060b69a62a8214 | [
"MIT"
]
| 2 | 2021-11-20T16:13:42.000Z | 2021-11-20T16:13:43.000Z | time_series/pycaret/pycaret_ts_ccf.ipynb | ngupta23/medium_articles | 53dee1cec0677f1129d0f791be060b69a62a8214 | [
"MIT"
]
| null | null | null | time_series/pycaret/pycaret_ts_ccf.ipynb | ngupta23/medium_articles | 53dee1cec0677f1129d0f791be060b69a62a8214 | [
"MIT"
]
| 2 | 2021-11-23T07:59:10.000Z | 2021-11-26T13:32:26.000Z | 130.845376 | 45,760 | 0.503341 | [
[
[
"<a href=\"https://colab.research.google.com/github/ngupta23/medium_articles/blob/main/time_series/pycaret/pycaret_ts_ccf.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"def what_is_installed():\n import pycaret\n from pycaret import show_versions\n show_versions()\n\ntry:\n what_is_installed()\nexcept:\n !pip install pycaret-ts-alpha\n what_is_installed()",
"\nSystem:\n python: 3.7.12 (default, Jan 15 2022, 18:48:18) [GCC 7.5.0]\nexecutable: /usr/bin/python3\n machine: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic\n\nPython dependencies:\n pip: 21.1.3\n setuptools: 57.4.0\n pycaret: 3.0.0\n sklearn: 1.0.2\n sktime: 0.10.1\n statsmodels: 0.12.2\n numpy: 1.21.5\n scipy: 1.7.3\n pandas: 1.3.5\n matplotlib: 3.2.2\n plotly: 5.5.0\n joblib: 1.0.1\n numba: 0.55.1\n mlflow: 1.23.1\n lightgbm: 3.3.2\n xgboost: 0.90\n pmdarima: 1.8.5\n tbats: Installed but version unavailable\n prophet: Not installed\n tsfresh: Not installed\n"
],
[
"import numpy as np\nimport pandas as pd\nfrom pycaret.datasets import get_data\nfrom pycaret.time_series import TSForecastingExperiment",
"/usr/local/lib/python3.7/dist-packages/distributed/config.py:20: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.\n defaults = yaml.load(f)\n"
],
[
"#### Exogenous variables ----\ndata = pd.DataFrame({'a': np.random.randn(200), 'b': np.random.randn(200), 'c': np.random.randn(200)})\n\n#### Produce dependent variable based on exogenous variables ----\n# NOTE: Only dependent on 'a' and 'c' but not 'b'\ndata['y'] = data['a'].shift(4) + data['c'].shift(8)\ndata.dropna(inplace=True)\ndata.shape",
"_____no_output_____"
],
[
"#### Create Time Series Forecasting Experiment ----\nexp = TSForecastingExperiment()\nglobal_plot_settings = {\"renderer\": \"colab\"}\nexp.setup(data=data, target=\"y\", seasonal_period=1, fh=8, fig_kwargs=global_plot_settings, session_id=42)",
"_____no_output_____"
],
[
"exp.plot_model(plot=\"acf\")",
"_____no_output_____"
]
],
[
[
"**Not much to go by in terms of forecasting y just by itself (without exogenous variables)**",
"_____no_output_____"
]
],
[
[
"exp.plot_model(plot=\"ccf\")",
"_____no_output_____"
]
],
[
[
"**The relation 'y vs. a', and 'y vs. c' is clearly visible from the CCF plot. Also, the lack of relation 'y vs. b' is also visible.**\n\n**Interestingly, the relation 'y vs. y' is the same as the ACF plot (users should check the values to compare for themselves).**\n\n**From a modeling perspective, modelers should use 'a' and 'c' to model 'y' but not 'b' as it does not contain useful information.**",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7cbc2f231f936be8e03509e855a6b420c29bbd0 | 19,773 | ipynb | Jupyter Notebook | Q_Learning/Taxi_env.ipynb | alirezakazemipour/Q-Table-Numpy | e87a2819b4dd36c2768b2d7f3d5414a75dd8c10f | [
"MIT"
]
| 1 | 2022-03-01T20:22:43.000Z | 2022-03-01T20:22:43.000Z | Q_Learning/Taxi_env.ipynb | alirezakazemipour/Tabular_Reinforcement_Learning | e87a2819b4dd36c2768b2d7f3d5414a75dd8c10f | [
"MIT"
]
| null | null | null | Q_Learning/Taxi_env.ipynb | alirezakazemipour/Tabular_Reinforcement_Learning | e87a2819b4dd36c2768b2d7f3d5414a75dd8c10f | [
"MIT"
]
| null | null | null | 69.136364 | 11,908 | 0.785212 | [
[
[
"# Q-Learning\n> Off-Policy Temporal Difference Learning.\n",
"_____no_output_____"
]
],
[
[
"import gym\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom IPython.display import clear_output\nfrom time import sleep",
"_____no_output_____"
],
[
"env_name = \"Taxi-v3\"\nepsilon = 1\ndecay_rate = 0.001\nmin_epsilon = 0.01\nmax_episodes = 2500\nprint_interval = 100\ntest_episodes = 3\nlr = 0.4\ngamma = 0.99",
"_____no_output_____"
],
[
"env = gym.make(env_name)\nenv = gym.wrappers.Monitor(env, \"./vid\", force=True)\nn_states = env.observation_space.n\nn_actions = env.action_space.n\nprint(f\"Number of states: {n_states}\\n\"\n f\"Number of actions: {n_actions}\")",
"Number of states: 500\nNumber of actions: 6\n"
],
[
"q_table = np.zeros((n_states, n_actions))",
"_____no_output_____"
],
[
"def choose_action(state):\n global q_table\n if epsilon > np.random.uniform():\n action = env.action_space.sample()\n else:\n action = np.argmax(q_table[state, :])\n return action",
"_____no_output_____"
],
[
"def update_table(state, action, reward, done, next_state):\n global q_table\n q_table[state, action] += lr * (reward + gamma * np.max(q_table[next_state, :]) * (1 - done) - q_table[state, action])",
"_____no_output_____"
]
],
[
[
"## Pseudocode\n> <p align=\"center\">\n <img src=\"q_learning_psuedo.png\">\n </p> ",
"_____no_output_____"
]
],
[
[
"running_reward = []\nfor episode in range(1, 1 + max_episodes):\n state = env.reset()\n done = False \n episode_reward = 0\n while not done:\n action = choose_action(state)\n next_state, reward, done, _ = env.step(action)\n update_table(state, action, reward, done, next_state)\n \n episode_reward += reward\n if done:\n break\n state = next_state\n \n epsilon = epsilon - decay_rate if epsilon - decay_rate > min_epsilon else min_epsilon\n \n if episode == 1:\n running_reward.append(episode_reward)\n else:\n running_reward.append(0.99 * running_reward[-1] + 0.01 * episode_reward)\n if episode % print_interval == 0:\n print(f\"Ep:{episode}| \"\n f\"Ep_reward:{episode_reward}| \"\n f\"Running_reward:{running_reward[-1]:.3f}| \"\n f\"Epsilon:{epsilon:.3f}| \")",
"Ep:100| Ep_reward:-641| Running_reward:-775.473| Epsilon:0.900| \nEp:200| Ep_reward:-528| Running_reward:-683.087| Epsilon:0.800| \nEp:300| Ep_reward:-193| Running_reward:-449.210| Epsilon:0.700| \nEp:400| Ep_reward:-210| Running_reward:-258.769| Epsilon:0.600| \nEp:500| Ep_reward:-21| Running_reward:-136.564| Epsilon:0.500| \nEp:600| Ep_reward:-61| Running_reward:-77.223| Epsilon:0.400| \nEp:700| Ep_reward:0| Running_reward:-42.093| Epsilon:0.300| \nEp:800| Ep_reward:-13| Running_reward:-22.446| Epsilon:0.200| \nEp:900| Ep_reward:-16| Running_reward:-8.791| Epsilon:0.100| \nEp:1000| Ep_reward:4| Running_reward:0.143| Epsilon:0.010| \nEp:1100| Ep_reward:6| Running_reward:4.621| Epsilon:0.010| \nEp:1200| Ep_reward:-6| Running_reward:6.137| Epsilon:0.010| \nEp:1300| Ep_reward:5| Running_reward:6.853| Epsilon:0.010| \nEp:1400| Ep_reward:8| Running_reward:6.789| Epsilon:0.010| \nEp:1500| Ep_reward:10| Running_reward:7.398| Epsilon:0.010| \nEp:1600| Ep_reward:10| Running_reward:7.514| Epsilon:0.010| \nEp:1700| Ep_reward:12| Running_reward:7.549| Epsilon:0.010| \nEp:1800| Ep_reward:5| Running_reward:6.959| Epsilon:0.010| \nEp:1900| Ep_reward:10| Running_reward:7.380| Epsilon:0.010| \nEp:2000| Ep_reward:3| Running_reward:6.998| Epsilon:0.010| \nEp:2100| Ep_reward:5| Running_reward:7.054| Epsilon:0.010| \nEp:2200| Ep_reward:7| Running_reward:7.516| Epsilon:0.010| \nEp:2300| Ep_reward:11| Running_reward:7.473| Epsilon:0.010| \nEp:2400| Ep_reward:12| Running_reward:7.629| Epsilon:0.010| \nEp:2500| Ep_reward:12| Running_reward:7.828| Epsilon:0.010| \n"
],
[
"plt.figure()\nplt.style.use(\"ggplot\")\nplt.plot(np.arange(max_episodes), running_reward)\nplt.title(\"Running_reward\")",
"_____no_output_____"
],
[
"for episode in range(1, 1 + test_episodes):\n state = env.reset()\n done = False \n episode_reward = 0\n while not done:\n action = choose_action(state)\n next_state, reward, done, _ = env.step(action)\n env.render()\n clear_output(wait=True)\n sleep(0.2)\n episode_reward += reward\n if done:\n break\n state = next_state\n\n print(f\"Ep:{episode}| \"\n f\"Ep_reward:{episode_reward}| \")\n env.close()",
"Ep:3| Ep_reward:4| \n"
]
],
[
[
"## Demo\n<p align=\"center\">\n <img src=\"q_learning.gif\" width=150>\n</p> ",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
]
|
e7cbc9b8dbd343ade718dbde38323f0dfe9353ce | 52,495 | ipynb | Jupyter Notebook | Watercourse/Stationary freatic flow between two water courses above a semi-pervious layer (Wesseling).ipynb | tdmeij/GWF | 06d6f5a68950741282f17d1a6fc5ed54136160d3 | [
"MIT"
]
| null | null | null | Watercourse/Stationary freatic flow between two water courses above a semi-pervious layer (Wesseling).ipynb | tdmeij/GWF | 06d6f5a68950741282f17d1a6fc5ed54136160d3 | [
"MIT"
]
| null | null | null | Watercourse/Stationary freatic flow between two water courses above a semi-pervious layer (Wesseling).ipynb | tdmeij/GWF | 06d6f5a68950741282f17d1a6fc5ed54136160d3 | [
"MIT"
]
| null | null | null | 166.650794 | 44,188 | 0.89119 | [
[
[
"# Stationary freatic flow between two water courses above a semi-pervious layer (Wesseling)",
"_____no_output_____"
],
[
"<img src=\"Wesseling_profile_sketch.gif\" width=\"382\" height=\"267\" align=\"left\"/>",
"_____no_output_____"
],
[
"Constant precipitation N on a strip of land between two parallel water courses with water level hs causes a rise h(x) of the groundwater level that induces in a groundwater flow towards the water courses. The phreatic groundwater is separated from an aquifer below by a semi-pervious layer. The interaction between phreatic groundwater system and the aquifer is determined by the resistance c of the semi-pervious layer and the groundwater head H in the aquifer below. \n\nA solution was published by Wesseling & Wesseling (1984). A practical dicussion is provided by Van Drecht (1997, in Dutch)",
"_____no_output_____"
]
],
[
[
"import numpy as np\n%matplotlib inline\nimport matplotlib.pyplot as plt\nplt.style.use('seaborn-whitegrid')",
"_____no_output_____"
],
[
"def hx(x,L,hs,p,H,c,T):\n \"\"\"Return phreatic groundwater level h(x) between two water courses\n \n Parameters:\n x : numpy array\n Distance from centre of the water course (m)\n L : float\n Distance between the centre of both water courses (m)\n hs : float\n water level in the water courses (m)\n p : float\n precipitation (m/day)\n H : float\n groundwater head in the deep aquifer (m)\n c : float\n resistance of semi-pervious layer (day) \n T : float\n transmissivity of the deep aquifer (m2/day)\n\n Returns\n -------\n numpy array\n\n \"\"\"\n labda = np.sqrt(T*c)\n alpha = L / (2*labda)\n hx = hs + (H - hs + p*c)* (np.tanh(alpha) * np.sinh(x/labda) - np.cosh(x/labda) + 1)\n return hx",
"_____no_output_____"
],
[
"def qd(L,hs,p,H,c,T):\n \"\"\"Return groundwater discharge to water courses\"\"\"\n labda = np.sqrt(T*c)\n alpha = L / (2*labda)\n qd = ((H-hs)/c+p)*np.tanh(alpha)/alpha\n return qd\n\ndef qs(L,hs,p,H,c,T):\n \"\"\"Return groundwater seepage\"\"\"\n #labda = np.sqrt(T*c)\n #alpha = L / (2*labda)\n #qd = -p + ((H-hs)/c+p)*np.tanh(alpha)/alpha\n\n qs = -p + qd(L,hs,p,H,c,T)\n return qs\n",
"_____no_output_____"
],
[
"L = 400.\nhs = 0.0\np = 300./365./1000.\nH = 0.0\nc = 100000.\nT = 15.\nx = np.linspace(1,L/2,25)",
"_____no_output_____"
],
[
"# h0\np = 300./365./1000.\nH = 0.0\nc = 10.\nh0 = hx(x,L,hs,p,H,c,T)\nqd0 = qd(L,hs,p,H,c,T)\nqs0 = qs(L,hs,p,H,c,T)\n\n# h1\np = 300./365./1000.\nH = -0.025\nc = 10.\nh1 = hx(x,L,hs,p,H,c,T)\nqd1 = qd(L,hs,p,H,c,T)\nqs1 = qs(L,hs,p,H,c,T)\n\n# h2\np = 300./365./1000.\nH = 0.025\nc = 10.\nh2 = hx(x,L,hs,p,H,c,T)\nqd2 = qd(L,hs,p,H,c,T)\nqs2 = qs(L,hs,p,H,c,T)\n\n# h3\np = 7./1000.\nH = 0.0\nc = 10.\nh3 = hx(x,L,hs,p,H,c,T)\nqd3 = qd(L,hs,p,H,c,T)\nqs3 = qs(L,hs,p,H,c,T)\n\n# h4\np = 300./365./1000.\nH = 0.20\nc = 10.\nh4 = hx(x,L,hs,p,H,c,T)\nqd4 = qd(L,hs,p,H,c,T)\nqs4 = qs(L,hs,p,H,c,T)\n\n# h5\np = 7./1000.\nH = 0.20\nc = 10.\nh5 = hx(x,L,hs,p,H,c,T)\nqd5 = qd(L,hs,p,H,c,T)\nqs5 = qs(L,hs,p,H,c,T)\n",
"_____no_output_____"
],
[
"plt.rcParams['figure.figsize'] = [10, 7]\nfig, ax = plt.subplots()\n\n#4c4c4c gray\n#f65b00 orange\n#fabb01 yellow\n#0000FF dark blue\n#0080FF light blue\n\nax.plot(x, h0, '-', color='#0080FF', label='dH = 0, N = 0.8 mm/d');\nax.plot(x, h3, '-', color='#0000FF', label='dH = 0cm, N = 7 mm/d');\nax.plot(x, h1, '--', color='#0080FF', label='dH = -2.5cm, N = 0.8 mm/d');\nax.plot(x, h2, '--', color='#0080FF', label='dH = +2.5cm, N = 0.8 mm/d');\nax.plot(x, h4, '-', color='#fabb01', label='dH = +20cm, N = 0.8 mm/d');\nax.plot(x, h5, '-', color='#f65b00', label='dH = +20cm, N = 7 mm/d');\n\nax.set_ylim(-0.05, 0.3)\nax.set_xlim(0, L/2)\nax.set_xlabel('afstand tot de beek (m)',fontsize=11)\nax.set_ylabel('opbolling van het grondwater (m)', fontsize = 11)\n#ax.set_title('')\n#lg = ax.legend(loc=\"upper right\")\nax.grid(True)\n#legframe = plt.legend.get_frame()\n#lg.get_frame().set_alpha(0.5)\n#lg.get_frame().set_facecolor('white')\nax.legend(loc=\"upper right\", fancybox=True, frameon=True, facecolor='white', framealpha=1, )\n\nplt.show()",
"_____no_output_____"
],
[
"fig.savefig('wesseling_hx.png')",
"_____no_output_____"
],
[
"# slootafvoer\nfor q in [0.8/1000,7/1000,qd0,qd3,qd4,qd5]:\n m3dagkm = q*L*1000\n lsdkm = m3dagkm*1/86.4\n print(m3dagkm,lsdkm)",
"320.0 3.7037037037037033\n2800.0000000000005 32.40740740740741\n20.132792406436813 0.2330184306300557\n171.46428199482023 1.9845403008659748\n510.0307409630659 5.9031335759614105\n661.3622305514493 7.65465544619733\n"
],
[
"# kwelflux\nfor q in [0.8/1000,7/1000,qs0,qs3,qs4,qs5]:\n m3dagkm = q*L*1000\n lsdkm = m3dagkm*1/86.4\n print(m3dagkm,lsdkm)",
"320.0 3.7037037037037033\n2800.0000000000005 32.40740740740741\n-308.63433088123435 -3.5721566074216935\n-2628.53571800518 -30.422867106541435\n181.26361767539473 2.097958537909661\n-2138.637769448551 -24.752751961210077\n"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cbe3f6ca2c42b56f58df4a22eb96b9a74c8a39 | 31,984 | ipynb | Jupyter Notebook | getStarted/TextClassification/textClassification.ipynb | iamhimanshu0/Spark | 8a7ae0ac62c9ecb7175586ce28fa8e0b49a53b14 | [
"Apache-2.0"
]
| 1 | 2022-03-23T03:24:41.000Z | 2022-03-23T03:24:41.000Z | getStarted/TextClassification/textClassification.ipynb | iamhimanshu0/Spark | 8a7ae0ac62c9ecb7175586ce28fa8e0b49a53b14 | [
"Apache-2.0"
]
| null | null | null | getStarted/TextClassification/textClassification.ipynb | iamhimanshu0/Spark | 8a7ae0ac62c9ecb7175586ce28fa8e0b49a53b14 | [
"Apache-2.0"
]
| null | null | null | 27.763889 | 218 | 0.444097 | [
[
[
"## Text Classification with PySpark \n- Multiclass Text Classification\nTask\n- Predict the subject category given a course title or text",
"_____no_output_____"
]
],
[
[
"import pyspark\nfrom pyspark import SparkContext",
"_____no_output_____"
],
[
"sc = SparkContext(master='local[2]')",
"22/03/22 16:56:57 WARN Utils: Your hostname, iamhimanshu0 resolves to a loopback address: 127.0.1.1; using 192.168.43.239 instead (on interface wlo1)\n22/03/22 16:56:57 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address\nWARNING: An illegal reflective access operation has occurred\nWARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.1.2.jar) to constructor java.nio.DirectByteBuffer(long,int)\nWARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform\nWARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations\nWARNING: All illegal access operations will be denied in a future release\n22/03/22 16:56:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable\nUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.properties\nSetting default log level to \"WARN\".\nTo adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).\n"
],
[
"# lunch UI\nsc",
"_____no_output_____"
],
[
"# create spark seassion\nfrom pyspark.sql import SparkSession\n\nspark = SparkSession.builder.appName(\"Text Classifier\").getOrCreate()",
"_____no_output_____"
],
[
"# read the dataset and load\ndf = spark.read.csv('udemy.csv',header=True, inferSchema=True)\ndf.show(5)",
" \r"
],
[
"df.columns",
"_____no_output_____"
],
[
"df = df.select('course_title','subject')",
"_____no_output_____"
],
[
"df.show(5)",
"+--------------------+----------------+\n| course_title| subject|\n+--------------------+----------------+\n|Ultimate Investme...|Business Finance|\n|Complete GST Cour...|Business Finance|\n|Financial Modelin...|Business Finance|\n|Beginner to Pro -...|Business Finance|\n|How To Maximize Y...|Business Finance|\n+--------------------+----------------+\nonly showing top 5 rows\n\n"
],
[
"df.groupby('subject').count().sort(\"count\",ascending=False).show()",
"[Stage 23:=====================================================>(199 + 1) / 200]\r"
],
[
"# getting values count using pandas\n# df.toPandas()['subject'].value_counts()",
"_____no_output_____"
],
[
"# check for missing values\ndf.toPandas()['subject'].isnull().sum()",
"_____no_output_____"
],
[
"# drop missing values\ndf = df.dropna(subset= ['subject'])",
"_____no_output_____"
],
[
"# check for missing values\ndf.toPandas()['subject'].isnull().sum()",
"_____no_output_____"
],
[
"df.show(5)",
"+--------------------+----------------+\n| course_title| subject|\n+--------------------+----------------+\n|Ultimate Investme...|Business Finance|\n|Complete GST Cour...|Business Finance|\n|Financial Modelin...|Business Finance|\n|Beginner to Pro -...|Business Finance|\n|How To Maximize Y...|Business Finance|\n+--------------------+----------------+\nonly showing top 5 rows\n\n"
]
],
[
[
"### Feature Extraction\n\nbuild features \n+ count vectorizer\n+ tfIDF\n+ wordEmbeddings\n+ hashingTF\n+ etc...\n\nWe have 2 things in Pipeline stages\n- Transformer\n- Estimator\n\n**Transformer** (Data to Data)\n\nFunction that takes data and fit, transform them into augmented data or features\ni.e Extractors, Vectorizer, Scalers (Tokenizer, StopwordRemover, CountVectorizer, IDF)\n\n**Estimator** (Data to model)\n\nFunction that takes data as input and fit the data and produces a model we can use to predict\ni.e LogisticRegression",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import Tokenizer, StopWordsRemover, CountVectorizer, IDF, StringIndexer",
"_____no_output_____"
],
[
"# dir(pyspark.ml.feature)",
"_____no_output_____"
],
[
"# Stages for the pipeline\ntokenizer = Tokenizer(inputCol='course_title', outputCol='mytokens')\nstopwordRemover = StopWordsRemover(inputCol='mytokens',outputCol='filtered_tokens')\nvectorizer = CountVectorizer(inputCol='filtered_tokens',outputCol='rawFeatures')\nidf = IDF(inputCol='rawFeatures', outputCol='vectorizedFeatures')",
"_____no_output_____"
],
[
"# work on taget variable (subject)\n# label encoding/indexing\nlabelEncoder = StringIndexer(inputCol='subject',outputCol='label').fit(df)",
" \r"
],
[
"labelEncoder.transform(df).show(5)",
"+--------------------+----------------+-----+\n| course_title| subject|label|\n+--------------------+----------------+-----+\n|Ultimate Investme...|Business Finance| 1.0|\n|Complete GST Cour...|Business Finance| 1.0|\n|Financial Modelin...|Business Finance| 1.0|\n|Beginner to Pro -...|Business Finance| 1.0|\n|How To Maximize Y...|Business Finance| 1.0|\n+--------------------+----------------+-----+\nonly showing top 5 rows\n\n"
],
[
"# labelEncoder.labels\n# making dict to labels\nlabel_dict = {\n 'Web Development':0.0,\n 'Business Finance':1.0,\n 'Musical Instruments':2.0,\n 'Graphic Design':3.0\n}",
"_____no_output_____"
],
[
"df = labelEncoder.transform(df)\ndf.show(5)",
"+--------------------+----------------+-----+\n| course_title| subject|label|\n+--------------------+----------------+-----+\n|Ultimate Investme...|Business Finance| 1.0|\n|Complete GST Cour...|Business Finance| 1.0|\n|Financial Modelin...|Business Finance| 1.0|\n|Beginner to Pro -...|Business Finance| 1.0|\n|How To Maximize Y...|Business Finance| 1.0|\n+--------------------+----------------+-----+\nonly showing top 5 rows\n\n"
],
[
"# split dataset\n(train_df, test_df) = df.randomSplit((0.7,0.3),seed=42)",
"_____no_output_____"
],
[
"train_df.show(2)",
"+--------------------+-------------------+-----+\n| course_title| subject|label|\n+--------------------+-------------------+-----+\n|#1 Piano Hand Coo...|Musical Instruments| 2.0|\n|#10 Hand Coordina...|Musical Instruments| 2.0|\n+--------------------+-------------------+-----+\nonly showing top 2 rows\n\n"
],
[
"# machine learning model (Estimator) (data to model)\nfrom pyspark.ml.classification import LogisticRegression",
"_____no_output_____"
],
[
"lr = LogisticRegression(featuresCol='vectorizedFeatures',\n labelCol = 'label'\n )",
"_____no_output_____"
]
],
[
[
"### Building the pipeline\n",
"_____no_output_____"
]
],
[
[
"from pyspark.ml import Pipeline",
"_____no_output_____"
],
[
"pipeline = Pipeline(\n stages=[tokenizer, stopwordRemover, vectorizer, idf, lr]\n)",
"_____no_output_____"
],
[
"pipeline.stages",
"_____no_output_____"
],
[
"# model building\nlr_model = pipeline.fit(train_df)",
"22/03/22 17:36:47 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS\n22/03/22 17:36:47 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS\n"
],
[
"lr_model",
"_____no_output_____"
],
[
"# get predicction on test data\npredictions = lr_model.transform(test_df)",
"_____no_output_____"
],
[
"# predictions.show()\npredictions.columns",
"_____no_output_____"
],
[
"predictions.select('rawPrediction', 'probability','subject','label','prediction').show(10)",
"+--------------------+--------------------+-------------------+-----+----------+\n| rawPrediction| probability| subject|label|prediction|\n+--------------------+--------------------+-------------------+-----+----------+\n|[8.30964874634511...|[0.87877993991729...|Musical Instruments| 2.0| 0.0|\n|[-1.3744065857781...|[1.90975343878318...|Musical Instruments| 2.0| 2.0|\n|[0.60822716351824...|[3.28451283099288...|Musical Instruments| 2.0| 2.0|\n|[-1.0584564885297...|[3.70732079181542...| Business Finance| 1.0| 1.0|\n|[24.6296077836821...|[0.99999999906211...| Web Development| 0.0| 0.0|\n|[22.0136686708729...|[0.99999999049941...| Web Development| 0.0| 0.0|\n|[19.9225858177008...|[0.99999995276066...| Web Development| 0.0| 0.0|\n|[-5.7386799100009...|[5.78822181193782...|Musical Instruments| 2.0| 2.0|\n|[-19.060576929776...|[1.71813778453453...| Graphic Design| 3.0| 3.0|\n|[-2.4736166619785...|[1.84538870784594...|Musical Instruments| 2.0| 2.0|\n+--------------------+--------------------+-------------------+-----+----------+\nonly showing top 10 rows\n\n"
]
],
[
[
"### model evaluation\n+ Accuracy\n+ Precision\n+ F1Score\n+ etc",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.evaluation import MulticlassClassificationEvaluator",
"_____no_output_____"
],
[
"evaluator = MulticlassClassificationEvaluator(predictionCol='prediction',labelCol='label')",
"_____no_output_____"
],
[
"accuracy = evaluator.evaluate(predictions)\naccuracy*100",
"_____no_output_____"
],
[
"\"\"\"\nMethod 2:\n precision, f1score classification report\n\"\"\"\nfrom pyspark.mllib.evaluation import MulticlassMetrics",
"_____no_output_____"
],
[
"lr_metric = MulticlassMetrics(predictions['label','prediction'].rdd)",
" \r"
],
[
"print(\"Accuracy \", lr_metric.accuracy)\nprint(\"precision \", lr_metric.precision(1.0))\nprint(\"f1Score \", lr_metric.fMeasure(1.0))\nprint(\"recall \", lr_metric.recall(1.0))",
"Accuracy 0.9182509505703422\nprecision 0.9544159544159544\nf1Score 0.9178082191780822\nrecall 0.8839050131926122\n"
]
],
[
[
"#### Confusion matrix\n- convert to pandas\n- sklearn",
"_____no_output_____"
]
],
[
[
"y_true = predictions.select('label')\ny_true = y_true.toPandas()\n\ny_predict = predictions.select('prediction')\ny_predict = y_predict.toPandas()",
"_____no_output_____"
],
[
"from sklearn.metrics import confusion_matrix, classification_report",
"_____no_output_____"
],
[
"cm = confusion_matrix(y_true, y_predict)\ncm",
"_____no_output_____"
]
],
[
[
"#### making prediction on one sample\n+ sample as df\n+ apply pipeline",
"_____no_output_____"
]
],
[
[
"from pyspark.sql.types import StringType",
"_____no_output_____"
],
[
"exl = spark.createDataFrame([ \n (\"Building Machine Learning Apps with Python and PySpark\", StringType())\n], \n#column name\n['course_title']\n)\nexl.show()",
"+--------------------+---+\n| course_title| _2|\n+--------------------+---+\n|Building Machine ...| {}|\n+--------------------+---+\n\n"
],
[
"# show fill\nexl.show(truncate=False)",
"+------------------------------------------------------+---+\n|course_title |_2 |\n+------------------------------------------------------+---+\n|Building Machine Learning Apps with Python and PySpark|{} |\n+------------------------------------------------------+---+\n\n"
],
[
"# making prediction\nprediction_ex1 = lr_model.transform(exl)\nprediction_ex1.show(truncate=True)",
"+--------------------+---+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\n| course_title| _2| mytokens| filtered_tokens| rawFeatures| vectorizedFeatures| rawPrediction| probability|prediction|\n+--------------------+---+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\n|Building Machine ...| {}|[building, machin...|[building, machin...|(3669,[57,79,115,...|(3669,[57,79,115,...|[14.7174498131555...|[0.99999814636182...| 0.0|\n+--------------------+---+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\n\n"
],
[
"prediction_ex1.columns",
"_____no_output_____"
],
[
"prediction_ex1.select('course_title','rawPrediction','probability','prediction').show()",
"+--------------------+--------------------+--------------------+----------+\n| course_title| rawPrediction| probability|prediction|\n+--------------------+--------------------+--------------------+----------+\n|Building Machine ...|[14.7174498131555...|[0.99999814636182...| 0.0|\n+--------------------+--------------------+--------------------+----------+\n\n"
],
[
"label_dict",
"_____no_output_____"
],
[
"# save and load the model\nmodelPath = \"models/pyspark_lr_model\"\nlr_model.write().save(modelPath)",
" \r"
],
[
"# loading pickled model \nfrom pyspark.ml.pipeline import PipelineModel\n\npresistedModel =PipelineModel.load(modelPath)",
"_____no_output_____"
],
[
"# laodModel\n# making prediction\nloadModel = presistedModel.transform(exl)\nloadModel.show(truncate=True)",
"+--------------------+---+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\n| course_title| _2| mytokens| filtered_tokens| rawFeatures| vectorizedFeatures| rawPrediction| probability|prediction|\n+--------------------+---+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\n|Building Machine ...| {}|[building, machin...|[building, machin...|(3669,[57,79,115,...|(3669,[57,79,115,...|[14.7174498131555...|[0.99999814636182...| 0.0|\n+--------------------+---+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+----------+\n\n"
],
[
"loadModel.select('course_title','rawPrediction','probability','prediction').show()",
"+--------------------+--------------------+--------------------+----------+\n| course_title| rawPrediction| probability|prediction|\n+--------------------+--------------------+--------------------+----------+\n|Building Machine ...|[14.7174498131555...|[0.99999814636182...| 0.0|\n+--------------------+--------------------+--------------------+----------+\n\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cbe4b93e0e5264dc2e7c2bc2f34884e3fb6e90 | 32,972 | ipynb | Jupyter Notebook | 07-Text-Methods.ipynb | srijikabanerjee/demo2 | 8bd385a38a1b01f0402224e33be96baca56ac15b | [
"Apache-2.0"
]
| null | null | null | 07-Text-Methods.ipynb | srijikabanerjee/demo2 | 8bd385a38a1b01f0402224e33be96baca56ac15b | [
"Apache-2.0"
]
| null | null | null | 07-Text-Methods.ipynb | srijikabanerjee/demo2 | 8bd385a38a1b01f0402224e33be96baca56ac15b | [
"Apache-2.0"
]
| 1 | 2022-03-01T16:56:36.000Z | 2022-03-01T16:56:36.000Z | 29.651079 | 230 | 0.476889 | [
[
[
"___\n\n<a href='http://www.pieriandata.com'><img src='../Pierian_Data_Logo.png'/></a>\n___\n<center><em>Copyright by Pierian Data Inc.</em></center>\n<center><em>For more information, visit us at <a href='http://www.pieriandata.com'>www.pieriandata.com</a></em></center>",
"_____no_output_____"
],
[
"# Text Methods",
"_____no_output_____"
],
[
"A normal Python string has a variety of method calls available:",
"_____no_output_____"
]
],
[
[
"mystring = 'hello'",
"_____no_output_____"
],
[
"mystring.capitalize()",
"_____no_output_____"
],
[
"mystring.isdigit()",
"_____no_output_____"
],
[
"help(str)",
"Help on class str in module builtins:\n\nclass str(object)\n | str(object='') -> str\n | str(bytes_or_buffer[, encoding[, errors]]) -> str\n | \n | Create a new string object from the given object. If encoding or\n | errors is specified, then the object must expose a data buffer\n | that will be decoded using the given encoding and error handler.\n | Otherwise, returns the result of object.__str__() (if defined)\n | or repr(object).\n | encoding defaults to sys.getdefaultencoding().\n | errors defaults to 'strict'.\n | \n | Methods defined here:\n | \n | __add__(self, value, /)\n | Return self+value.\n | \n | __contains__(self, key, /)\n | Return key in self.\n | \n | __eq__(self, value, /)\n | Return self==value.\n | \n | __format__(self, format_spec, /)\n | Return a formatted version of the string as described by format_spec.\n | \n | __ge__(self, value, /)\n | Return self>=value.\n | \n | __getattribute__(self, name, /)\n | Return getattr(self, name).\n | \n | __getitem__(self, key, /)\n | Return self[key].\n | \n | __getnewargs__(...)\n | \n | __gt__(self, value, /)\n | Return self>value.\n | \n | __hash__(self, /)\n | Return hash(self).\n | \n | __iter__(self, /)\n | Implement iter(self).\n | \n | __le__(self, value, /)\n | Return self<=value.\n | \n | __len__(self, /)\n | Return len(self).\n | \n | __lt__(self, value, /)\n | Return self<value.\n | \n | __mod__(self, value, /)\n | Return self%value.\n | \n | __mul__(self, value, /)\n | Return self*value.\n | \n | __ne__(self, value, /)\n | Return self!=value.\n | \n | __repr__(self, /)\n | Return repr(self).\n | \n | __rmod__(self, value, /)\n | Return value%self.\n | \n | __rmul__(self, value, /)\n | Return value*self.\n | \n | __sizeof__(self, /)\n | Return the size of the string in memory, in bytes.\n | \n | __str__(self, /)\n | Return str(self).\n | \n | capitalize(self, /)\n | Return a capitalized version of the string.\n | \n | More specifically, make the first character have upper case and the rest lower\n | case.\n | \n | casefold(self, /)\n | Return a version of the string suitable for caseless comparisons.\n | \n | center(self, width, fillchar=' ', /)\n | Return a centered string of length width.\n | \n | Padding is done using the specified fill character (default is a space).\n | \n | count(...)\n | S.count(sub[, start[, end]]) -> int\n | \n | Return the number of non-overlapping occurrences of substring sub in\n | string S[start:end]. Optional arguments start and end are\n | interpreted as in slice notation.\n | \n | encode(self, /, encoding='utf-8', errors='strict')\n | Encode the string using the codec registered for encoding.\n | \n | encoding\n | The encoding in which to encode the string.\n | errors\n | The error handling scheme to use for encoding errors.\n | The default is 'strict' meaning that encoding errors raise a\n | UnicodeEncodeError. Other possible values are 'ignore', 'replace' and\n | 'xmlcharrefreplace' as well as any other name registered with\n | codecs.register_error that can handle UnicodeEncodeErrors.\n | \n | endswith(...)\n | S.endswith(suffix[, start[, end]]) -> bool\n | \n | Return True if S ends with the specified suffix, False otherwise.\n | With optional start, test S beginning at that position.\n | With optional end, stop comparing S at that position.\n | suffix can also be a tuple of strings to try.\n | \n | expandtabs(self, /, tabsize=8)\n | Return a copy where all tab characters are expanded using spaces.\n | \n | If tabsize is not given, a tab size of 8 characters is assumed.\n | \n | find(...)\n | S.find(sub[, start[, end]]) -> int\n | \n | Return the lowest index in S where substring sub is found,\n | such that sub is contained within S[start:end]. Optional\n | arguments start and end are interpreted as in slice notation.\n | \n | Return -1 on failure.\n | \n | format(...)\n | S.format(*args, **kwargs) -> str\n | \n | Return a formatted version of S, using substitutions from args and kwargs.\n | The substitutions are identified by braces ('{' and '}').\n | \n | format_map(...)\n | S.format_map(mapping) -> str\n | \n | Return a formatted version of S, using substitutions from mapping.\n | The substitutions are identified by braces ('{' and '}').\n | \n | index(...)\n | S.index(sub[, start[, end]]) -> int\n | \n | Return the lowest index in S where substring sub is found, \n | such that sub is contained within S[start:end]. Optional\n | arguments start and end are interpreted as in slice notation.\n | \n | Raises ValueError when the substring is not found.\n | \n | isalnum(self, /)\n | Return True if the string is an alpha-numeric string, False otherwise.\n | \n | A string is alpha-numeric if all characters in the string are alpha-numeric and\n | there is at least one character in the string.\n | \n | isalpha(self, /)\n | Return True if the string is an alphabetic string, False otherwise.\n | \n | A string is alphabetic if all characters in the string are alphabetic and there\n | is at least one character in the string.\n | \n | isascii(self, /)\n | Return True if all characters in the string are ASCII, False otherwise.\n | \n | ASCII characters have code points in the range U+0000-U+007F.\n | Empty string is ASCII too.\n | \n | isdecimal(self, /)\n | Return True if the string is a decimal string, False otherwise.\n | \n | A string is a decimal string if all characters in the string are decimal and\n | there is at least one character in the string.\n | \n | isdigit(self, /)\n | Return True if the string is a digit string, False otherwise.\n | \n | A string is a digit string if all characters in the string are digits and there\n | is at least one character in the string.\n | \n | isidentifier(self, /)\n | Return True if the string is a valid Python identifier, False otherwise.\n | \n | Use keyword.iskeyword() to test for reserved identifiers such as \"def\" and\n | \"class\".\n | \n | islower(self, /)\n | Return True if the string is a lowercase string, False otherwise.\n | \n | A string is lowercase if all cased characters in the string are lowercase and\n | there is at least one cased character in the string.\n | \n | isnumeric(self, /)\n | Return True if the string is a numeric string, False otherwise.\n | \n | A string is numeric if all characters in the string are numeric and there is at\n | least one character in the string.\n | \n | isprintable(self, /)\n | Return True if the string is printable, False otherwise.\n | \n | A string is printable if all of its characters are considered printable in\n | repr() or if it is empty.\n | \n | isspace(self, /)\n | Return True if the string is a whitespace string, False otherwise.\n | \n | A string is whitespace if all characters in the string are whitespace and there\n | is at least one character in the string.\n | \n | istitle(self, /)\n | Return True if the string is a title-cased string, False otherwise.\n | \n | In a title-cased string, upper- and title-case characters may only\n | follow uncased characters and lowercase characters only cased ones.\n | \n | isupper(self, /)\n | Return True if the string is an uppercase string, False otherwise.\n | \n | A string is uppercase if all cased characters in the string are uppercase and\n | there is at least one cased character in the string.\n | \n | join(self, iterable, /)\n | Concatenate any number of strings.\n | \n | The string whose method is called is inserted in between each given string.\n | The result is returned as a new string.\n | \n | Example: '.'.join(['ab', 'pq', 'rs']) -> 'ab.pq.rs'\n | \n | ljust(self, width, fillchar=' ', /)\n | Return a left-justified string of length width.\n | \n | Padding is done using the specified fill character (default is a space).\n | \n | lower(self, /)\n | Return a copy of the string converted to lowercase.\n | \n | lstrip(self, chars=None, /)\n | Return a copy of the string with leading whitespace removed.\n | \n | If chars is given and not None, remove characters in chars instead.\n | \n | partition(self, sep, /)\n | Partition the string into three parts using the given separator.\n | \n | This will search for the separator in the string. If the separator is found,\n | returns a 3-tuple containing the part before the separator, the separator\n | itself, and the part after it.\n | \n | If the separator is not found, returns a 3-tuple containing the original string\n | and two empty strings.\n | \n | replace(self, old, new, count=-1, /)\n | Return a copy with all occurrences of substring old replaced by new.\n | \n | count\n | Maximum number of occurrences to replace.\n | -1 (the default value) means replace all occurrences.\n | \n | If the optional argument count is given, only the first count occurrences are\n | replaced.\n | \n | rfind(...)\n | S.rfind(sub[, start[, end]]) -> int\n | \n | Return the highest index in S where substring sub is found,\n | such that sub is contained within S[start:end]. Optional\n | arguments start and end are interpreted as in slice notation.\n | \n | Return -1 on failure.\n | \n | rindex(...)\n | S.rindex(sub[, start[, end]]) -> int\n | \n | Return the highest index in S where substring sub is found,\n | such that sub is contained within S[start:end]. Optional\n | arguments start and end are interpreted as in slice notation.\n | \n | Raises ValueError when the substring is not found.\n | \n | rjust(self, width, fillchar=' ', /)\n | Return a right-justified string of length width.\n | \n | Padding is done using the specified fill character (default is a space).\n | \n | rpartition(self, sep, /)\n | Partition the string into three parts using the given separator.\n | \n | This will search for the separator in the string, starting at the end. If\n | the separator is found, returns a 3-tuple containing the part before the\n | separator, the separator itself, and the part after it.\n | \n | If the separator is not found, returns a 3-tuple containing two empty strings\n | and the original string.\n | \n | rsplit(self, /, sep=None, maxsplit=-1)\n | Return a list of the words in the string, using sep as the delimiter string.\n | \n | sep\n | The delimiter according which to split the string.\n | None (the default value) means split according to any whitespace,\n | and discard empty strings from the result.\n | maxsplit\n | Maximum number of splits to do.\n | -1 (the default value) means no limit.\n | \n | Splits are done starting at the end of the string and working to the front.\n | \n | rstrip(self, chars=None, /)\n | Return a copy of the string with trailing whitespace removed.\n | \n | If chars is given and not None, remove characters in chars instead.\n | \n | split(self, /, sep=None, maxsplit=-1)\n | Return a list of the words in the string, using sep as the delimiter string.\n | \n | sep\n | The delimiter according which to split the string.\n | None (the default value) means split according to any whitespace,\n | and discard empty strings from the result.\n | maxsplit\n | Maximum number of splits to do.\n | -1 (the default value) means no limit.\n | \n | splitlines(self, /, keepends=False)\n | Return a list of the lines in the string, breaking at line boundaries.\n | \n | Line breaks are not included in the resulting list unless keepends is given and\n | true.\n | \n | startswith(...)\n | S.startswith(prefix[, start[, end]]) -> bool\n | \n | Return True if S starts with the specified prefix, False otherwise.\n | With optional start, test S beginning at that position.\n | With optional end, stop comparing S at that position.\n | prefix can also be a tuple of strings to try.\n | \n | strip(self, chars=None, /)\n | Return a copy of the string with leading and trailing whitespace removed.\n | \n | If chars is given and not None, remove characters in chars instead.\n | \n | swapcase(self, /)\n | Convert uppercase characters to lowercase and lowercase characters to uppercase.\n | \n | title(self, /)\n | Return a version of the string where each word is titlecased.\n | \n | More specifically, words start with uppercased characters and all remaining\n | cased characters have lower case.\n | \n | translate(self, table, /)\n | Replace each character in the string using the given translation table.\n | \n | table\n | Translation table, which must be a mapping of Unicode ordinals to\n | Unicode ordinals, strings, or None.\n | \n | The table must implement lookup/indexing via __getitem__, for instance a\n | dictionary or list. If this operation raises LookupError, the character is\n | left untouched. Characters mapped to None are deleted.\n | \n | upper(self, /)\n | Return a copy of the string converted to uppercase.\n | \n | zfill(self, width, /)\n | Pad a numeric string with zeros on the left, to fill a field of the given width.\n | \n | The string is never truncated.\n | \n | ----------------------------------------------------------------------\n | Static methods defined here:\n | \n | __new__(*args, **kwargs) from builtins.type\n | Create and return a new object. See help(type) for accurate signature.\n | \n | maketrans(x, y=None, z=None, /)\n | Return a translation table usable for str.translate().\n | \n | If there is only one argument, it must be a dictionary mapping Unicode\n | ordinals (integers) or characters to Unicode ordinals, strings or None.\n | Character keys will be then converted to ordinals.\n | If there are two arguments, they must be strings of equal length, and\n | in the resulting dictionary, each character in x will be mapped to the\n | character at the same position in y. If there is a third argument, it\n | must be a string, whose characters will be mapped to None in the result.\n\n"
]
],
[
[
"# Pandas and Text\n\nPandas can do a lot more than what we show here. Full online documentation on things like advanced string indexing and regular expressions with pandas can be found here: https://pandas.pydata.org/docs/user_guide/text.html\n\n## Text Methods on Pandas String Column",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"names = pd.Series(['andrew','bobo','claire','david','4'])",
"_____no_output_____"
],
[
"names",
"_____no_output_____"
],
[
"names.str.capitalize()",
"_____no_output_____"
],
[
"names.str.isdigit()",
"_____no_output_____"
]
],
[
[
"## Splitting , Grabbing, and Expanding",
"_____no_output_____"
]
],
[
[
"tech_finance = ['GOOG,APPL,AMZN','JPM,BAC,GS']",
"_____no_output_____"
],
[
"len(tech_finance)",
"_____no_output_____"
],
[
"tickers = pd.Series(tech_finance)",
"_____no_output_____"
],
[
"tickers",
"_____no_output_____"
],
[
"tickers.str.split(',')",
"_____no_output_____"
],
[
"tickers.str.split(',').str[0]",
"_____no_output_____"
],
[
"tickers.str.split(',',expand=True)",
"_____no_output_____"
]
],
[
[
"## Cleaning or Editing Strings",
"_____no_output_____"
]
],
[
[
"messy_names = pd.Series([\"andrew \",\"bo;bo\",\" claire \"])",
"_____no_output_____"
],
[
"# Notice the \"mis-alignment\" on the right hand side due to spacing in \"andrew \" and \" claire \"\nmessy_names",
"_____no_output_____"
],
[
"messy_names.str.replace(\";\",\"\")",
"_____no_output_____"
],
[
"messy_names.str.strip()",
"_____no_output_____"
],
[
"messy_names.str.replace(\";\",\"\").str.strip()",
"_____no_output_____"
],
[
"messy_names.str.replace(\";\",\"\").str.strip().str.capitalize()",
"_____no_output_____"
]
],
[
[
"## Alternative with Custom apply() call",
"_____no_output_____"
]
],
[
[
"def cleanup(name):\n name = name.replace(\";\",\"\")\n name = name.strip()\n name = name.capitalize()\n return name",
"_____no_output_____"
],
[
"messy_names",
"_____no_output_____"
],
[
"messy_names.apply(cleanup)",
"_____no_output_____"
]
],
[
[
"## Which one is more efficient?",
"_____no_output_____"
]
],
[
[
"import timeit \n \n# code snippet to be executed only once \nsetup = '''\nimport pandas as pd\nimport numpy as np\nmessy_names = pd.Series([\"andrew \",\"bo;bo\",\" claire \"])\ndef cleanup(name):\n name = name.replace(\";\",\"\")\n name = name.strip()\n name = name.capitalize()\n return name\n'''\n \n# code snippet whose execution time is to be measured \nstmt_pandas_str = ''' \nmessy_names.str.replace(\";\",\"\").str.strip().str.capitalize()\n'''\n\nstmt_pandas_apply = '''\nmessy_names.apply(cleanup)\n'''\n\nstmt_pandas_vectorize='''\nnp.vectorize(cleanup)(messy_names)\n'''",
"_____no_output_____"
],
[
"timeit.timeit(setup = setup, \n stmt = stmt_pandas_str, \n number = 10000) ",
"_____no_output_____"
],
[
"timeit.timeit(setup = setup, \n stmt = stmt_pandas_apply, \n number = 10000) ",
"_____no_output_____"
],
[
"timeit.timeit(setup = setup, \n stmt = stmt_pandas_vectorize, \n number = 10000) ",
"_____no_output_____"
]
],
[
[
"Wow! While .str() methods can be extremely convienent, when it comes to performance, don't forget about np.vectorize()! Review the \"Useful Methods\" lecture for a deeper discussion on np.vectorize()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
]
|
e7cbe581a4a9ba62050dafaec962dcf38b6bc06e | 3,679 | ipynb | Jupyter Notebook | TX by county.ipynb | kirbs-/covid-19-dataset | 3427880186a03339abf82688581b7aab9fe5cb72 | [
"MIT"
]
| null | null | null | TX by county.ipynb | kirbs-/covid-19-dataset | 3427880186a03339abf82688581b7aab9fe5cb72 | [
"MIT"
]
| null | null | null | TX by county.ipynb | kirbs-/covid-19-dataset | 3427880186a03339abf82688581b7aab9fe5cb72 | [
"MIT"
]
| null | null | null | 25.548611 | 134 | 0.552868 | [
[
[
"Texas updates their data daily at noon CDT",
"_____no_output_____"
]
],
[
[
"from selenium import webdriver\nimport time\nimport pandas as pd\nimport pendulum\nimport re\nimport yaml\nfrom selenium.webdriver.chrome.options import Options\nchrome_options = Options()\n#chrome_options.add_argument(\"--disable-extensions\")\n#chrome_options.add_argument(\"--disable-gpu\")\n#chrome_options.add_argument(\"--no-sandbox) # linux only\nchrome_options.add_argument(\"--start-maximized\")\n# chrome_options.add_argument(\"--headless\")\nchrome_options.add_argument(\"user-agent=[Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:73.0) Gecko/20100101 Firefox/73.0]\")",
"_____no_output_____"
],
[
"with open('config.yaml', 'r') as f:\n config = yaml.safe_load(f.read())",
"_____no_output_____"
],
[
"state = 'TX'",
"_____no_output_____"
],
[
"scrape_timestamp = pendulum.now().strftime('%Y%m%d%H%M%S')",
"_____no_output_____"
],
[
"# MD positive cases by county\nurl = 'https://www.dshs.state.tx.us/news/updates.shtm#coronavirus'\nurl = 'https://txdshs.maps.arcgis.com/apps/opsdashboard/index.html#/ed483ecd702b4298ab01e8b9cafc8b83'",
"_____no_output_____"
],
[
"def fetch():\n driver = webdriver.Chrome('../20190611 - Parts recommendation/chromedriver', options=chrome_options)\n\n driver.get(url)\n time.sleep(5)\n\n datatbl = driver.find_element_by_class_name('feature-list')\n\n datatbl.find_elements_by_class_name('external-html')\n datatbl = datatbl.text.split('\\n')\n data = []\n for i in range(0, len(datatbl), 2):\n data.append([datatbl[i], datatbl[i+1]])\n\n page_source = driver.page_source\n driver.close()\n\n return pd.DataFrame(data, columns=['county','positive_cases']), page_source",
"_____no_output_____"
],
[
"def save(df, source):\n df.to_csv(f\"{config['data_folder']}/{state}_county_{scrape_timestamp}.txt\", sep='|', index=False)\n\n with open(f\"{config['data_source_backup_folder']}/{state}_county_{scrape_timestamp}.html\", 'w') as f:\n f.write(source)",
"_____no_output_____"
],
[
"def run():\n df, source = fetch()\n save(df, source)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cbfb1c412aa3728ea2018abeff19c4cef9c437 | 33,019 | ipynb | Jupyter Notebook | docs/source/recipes/convert_datasets.ipynb | pixta-dev/fiftyone | 7d1fa672a81547f2284704d24417e246bb071c0b | [
"Apache-2.0"
]
| null | null | null | docs/source/recipes/convert_datasets.ipynb | pixta-dev/fiftyone | 7d1fa672a81547f2284704d24417e246bb071c0b | [
"Apache-2.0"
]
| null | null | null | docs/source/recipes/convert_datasets.ipynb | pixta-dev/fiftyone | 7d1fa672a81547f2284704d24417e246bb071c0b | [
"Apache-2.0"
]
| null | null | null | 36.892737 | 369 | 0.520518 | [
[
[
"# Convert Dataset Formats\n\nThis recipe demonstrates how to use FiftyOne to convert datasets on disk between common formats.",
"_____no_output_____"
],
[
"## Setup\n",
"_____no_output_____"
],
[
"If you haven't already, install FiftyOne:",
"_____no_output_____"
]
],
[
[
"!pip install fiftyone",
"_____no_output_____"
],
[
"import fiftyone as fo",
"_____no_output_____"
]
],
[
[
"If the above import fails due to a `cv2` error, it is an issue with OpenCV in Colab environments. [Follow these instructions to resolve it.](https://github.com/voxel51/fiftyone/issues/1494#issuecomment-1003148448). ",
"_____no_output_____"
],
[
"This notebook contains bash commands. To run it as a notebook, you must install the [Jupyter bash kernel](https://github.com/takluyver/bash_kernel) via the command below.\n\nAlternatively, you can just copy + paste the code blocks into your shell.",
"_____no_output_____"
]
],
[
[
"pip install bash_kernel\npython -m bash_kernel.install",
"_____no_output_____"
]
],
[
[
"In this recipe we'll use the [FiftyOne Dataset Zoo](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/zoo_datasets.html) to download some open source datasets to work with.\n\nSpecifically, we'll need [TensorFlow](https://www.tensorflow.org/) and [TensorFlow Datasets](https://www.tensorflow.org/datasets) installed to [access the datasets](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/zoo_datasets.html#customizing-your-ml-backend):",
"_____no_output_____"
]
],
[
[
"pip install tensorflow tensorflow-datasets",
"_____no_output_____"
]
],
[
[
"## Download datasets\n\n",
"_____no_output_____"
],
[
"Download the test split of the [CIFAR-10 dataset](https://www.cs.toronto.edu/~kriz/cifar.html) from the [FiftyOne Dataset Zoo](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/zoo_datasets.html) using the command below:",
"_____no_output_____"
]
],
[
[
"# Download the test split of CIFAR-10\nfiftyone zoo datasets download cifar10 --split test",
"Downloading split 'test' to '~/fiftyone/cifar10/test'\nDownloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ~/fiftyone/cifar10/tmp-download/cifar-10-python.tar.gz\n170500096it [00:04, 35887670.65it/s] \nExtracting ~/fiftyone/cifar10/tmp-download/cifar-10-python.tar.gz to ~/fiftyone/cifar10/tmp-download\n 100% |███| 10000/10000 [5.2s elapsed, 0s remaining, 1.8K samples/s] \nDataset info written to '~/fiftyone/cifar10/info.json'\n"
]
],
[
[
"Download the validation split of the [KITTI dataset]( http://www.cvlibs.net/datasets/kitti) from the [FiftyOne Dataset Zoo](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/zoo_datasets.html) using the command below:",
"_____no_output_____"
]
],
[
[
"# Download the validation split of KITTI\nfiftyone zoo datasets download kitti --split validation",
"Split 'validation' already downloaded\n"
]
],
[
[
"## The fiftyone convert command",
"_____no_output_____"
],
[
"The [FiftyOne CLI](https://voxel51.com/docs/fiftyone/cli/index.html) provides a number of utilities for importing and exporting datasets in a variety of common (or custom) formats.\n\nSpecifically, the `fiftyone convert` command provides a convenient way to convert datasets on disk between formats by specifying the [fiftyone.types.Dataset](https://voxel51.com/docs/fiftyone/api/fiftyone.types.html#fiftyone.types.dataset_types.Dataset) type of the input and desired output.\n\nFiftyOne provides a collection of [builtin types](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#supported-formats) that you can use to read/write datasets in common formats out-of-the-box:",
"_____no_output_____"
],
[
"<div class=\"convert-recipes-table\">\n\n| Dataset format | Import Supported? | Export Supported? | Conversion Supported? |\n| ---------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------- | ----------------- | --------------------- |\n| [ImageDirectory](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#imagedirectory) | ✓ | ✓ | ✓ |\n| [VideoDirectory](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#videodirectory) | ✓ | ✓ | ✓ |\n| [FiftyOneImageClassificationDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#fiftyoneimageclassificationdataset) | ✓ | ✓ | ✓ |\n| [ImageClassificationDirectoryTree](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#imageclassificationdirectorytree) | ✓ | ✓ | ✓ |\n| [TFImageClassificationDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#tfimageclassificationdataset) | ✓ | ✓ | ✓ |\n| [FiftyOneImageDetectionDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#fiftyoneimagedetectiondataset) | ✓ | ✓ | ✓ |\n| [COCODetectionDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#cocodetectiondataset) | ✓ | ✓ | ✓ |\n| [VOCDetectionDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#vocdetectiondataset) | ✓ | ✓ | ✓ |\n| [KITTIDetectionDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#kittidetectiondataset) | ✓ | ✓ | ✓ |\n| [YOLODataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#yolodataset) | ✓ | ✓ | ✓ |\n| [TFObjectDetectionDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#tfobjectdetectiondataset) | ✓ | ✓ | ✓ |\n| [CVATImageDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#cvatimagedataset) | ✓ | ✓ | ✓ |\n| [CVATVideoDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#cvatvideodataset) | ✓ | ✓ | ✓ |\n| [FiftyOneImageLabelsDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#fiftyoneimagelabelsdataset) | ✓ | ✓ | ✓ |\n| [FiftyOneVideoLabelsDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#fiftyonevideolabelsdataset) | ✓ | ✓ | ✓ |\n| [BDDDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#bdddataset) | ✓ | ✓ | ✓ |\n\n</div>",
"_____no_output_____"
],
[
"In addition, you can define your own [custom dataset types](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#custom-formats) to read/write datasets in your own formats.\n\nThe usage of the `fiftyone convert` command is as follows:",
"_____no_output_____"
]
],
[
[
"fiftyone convert -h",
"usage: fiftyone convert [-h] [--input-dir INPUT_DIR] [--input-type INPUT_TYPE]\n [--output-dir OUTPUT_DIR] [--output-type OUTPUT_TYPE]\n\nConvert datasets on disk between supported formats.\n\n Examples::\n\n # Convert an image classification directory tree to TFRecords format\n fiftyone convert \\\n --input-dir /path/to/image-classification-directory-tree \\\n --input-type fiftyone.types.ImageClassificationDirectoryTree \\\n --output-dir /path/for/tf-image-classification-dataset \\\n --output-type fiftyone.types.TFImageClassificationDataset\n\n # Convert a COCO detection dataset to CVAT image format\n fiftyone convert \\\n --input-dir /path/to/coco-detection-dataset \\\n --input-type fiftyone.types.COCODetectionDataset \\\n --output-dir /path/for/cvat-image-dataset \\\n --output-type fiftyone.types.CVATImageDataset\n\noptional arguments:\n -h, --help show this help message and exit\n --input-dir INPUT_DIR\n the directory containing the dataset\n --input-type INPUT_TYPE\n the fiftyone.types.Dataset type of the input dataset\n --output-dir OUTPUT_DIR\n the directory to which to write the output dataset\n --output-type OUTPUT_TYPE\n the fiftyone.types.Dataset type to output\n"
]
],
[
[
"## Convert CIFAR-10 dataset",
"_____no_output_____"
],
[
"When you downloaded the test split of the CIFAR-10 dataset above, it was written to disk as a dataset in [fiftyone.types.FiftyOneImageClassificationDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#fiftyoneimageclassificationdataset) format.\n\nYou can verify this by printing information about the downloaded dataset:",
"_____no_output_____"
]
],
[
[
"fiftyone zoo datasets info cifar10",
"***** Dataset description *****\nThe CIFAR-10 dataset consists of 60000 32 x 32 color images in 10\n classes, with 6000 images per class. There are 50000 training images and\n 10000 test images.\n\n Dataset size:\n 132.40 MiB\n\n Source:\n https://www.cs.toronto.edu/~kriz/cifar.html\n \n***** Supported splits *****\ntest, train\n\n***** Dataset location *****\n~/fiftyone/cifar10\n\n***** Dataset info *****\n{\n \"name\": \"cifar10\",\n \"zoo_dataset\": \"fiftyone.zoo.datasets.torch.CIFAR10Dataset\",\n \"dataset_type\": \"fiftyone.types.dataset_types.FiftyOneImageClassificationDataset\",\n \"num_samples\": 10000,\n \"downloaded_splits\": {\n \"test\": {\n \"split\": \"test\",\n \"num_samples\": 10000\n }\n },\n \"classes\": [\n \"airplane\",\n \"automobile\",\n \"bird\",\n \"cat\",\n \"deer\",\n \"dog\",\n \"frog\",\n \"horse\",\n \"ship\",\n \"truck\"\n ]\n}\n"
]
],
[
[
"The snippet below uses `fiftyone convert` to convert the test split of the CIFAR-10 dataset to [fiftyone.types.ImageClassificationDirectoryTree](https://voxel51.com/docs/fiftyone/user_guide/export_datasets.html#imageclassificationdirectorytree) format, which stores classification datasets on disk in a directory tree structure with images organized per-class:\n\n```\n<dataset_dir>\n├── <classA>/\n│ ├── <image1>.<ext>\n│ ├── <image2>.<ext>\n│ └── ...\n├── <classB>/\n│ ├── <image1>.<ext>\n│ ├── <image2>.<ext>\n│ └── ...\n└── ...\n```",
"_____no_output_____"
]
],
[
[
"INPUT_DIR=$(fiftyone zoo datasets find cifar10 --split test)\nOUTPUT_DIR=/tmp/fiftyone/cifar10-dir-tree\n\nfiftyone convert \\\n --input-dir ${INPUT_DIR} --input-type fiftyone.types.FiftyOneImageClassificationDataset \\\n --output-dir ${OUTPUT_DIR} --output-type fiftyone.types.ImageClassificationDirectoryTree",
"Loading dataset from '~/fiftyone/cifar10/test'\nInput format 'fiftyone.types.dataset_types.FiftyOneImageClassificationDataset'\n 100% |███| 10000/10000 [4.2s elapsed, 0s remaining, 2.4K samples/s] \nImport complete\nExporting dataset to '/tmp/fiftyone/cifar10-dir-tree'\nExport format 'fiftyone.types.dataset_types.ImageClassificationDirectoryTree'\n 100% |███| 10000/10000 [6.2s elapsed, 0s remaining, 1.7K samples/s] \nExport complete\n"
]
],
[
[
"Let's verify that the conversion happened as expected:",
"_____no_output_____"
]
],
[
[
"ls -lah /tmp/fiftyone/cifar10-dir-tree/",
"total 0\ndrwxr-xr-x 12 voxel51 wheel 384B Jul 14 11:08 .\ndrwxr-xr-x 3 voxel51 wheel 96B Jul 14 11:08 ..\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 airplane\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 automobile\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 bird\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 cat\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 deer\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 dog\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 frog\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 horse\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 ship\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 truck\n"
],
[
"ls -lah /tmp/fiftyone/cifar10-dir-tree/airplane/ | head",
"total 8000\ndrwxr-xr-x 1002 voxel51 wheel 31K Jul 14 11:08 .\ndrwxr-xr-x 12 voxel51 wheel 384B Jul 14 11:08 ..\n-rw-r--r-- 1 voxel51 wheel 1.2K Jul 14 11:23 000004.jpg\n-rw-r--r-- 1 voxel51 wheel 1.1K Jul 14 11:23 000011.jpg\n-rw-r--r-- 1 voxel51 wheel 1.1K Jul 14 11:23 000022.jpg\n-rw-r--r-- 1 voxel51 wheel 1.3K Jul 14 11:23 000028.jpg\n-rw-r--r-- 1 voxel51 wheel 1.2K Jul 14 11:23 000045.jpg\n-rw-r--r-- 1 voxel51 wheel 1.2K Jul 14 11:23 000053.jpg\n-rw-r--r-- 1 voxel51 wheel 1.3K Jul 14 11:23 000075.jpg\n"
]
],
[
[
"Now let's convert the classification directory tree to [TFRecords](https://voxel51.com/docs/fiftyone/user_guide/export_datasets.html#tfimageclassificationdataset) format!",
"_____no_output_____"
]
],
[
[
"INPUT_DIR=/tmp/fiftyone/cifar10-dir-tree\nOUTPUT_DIR=/tmp/fiftyone/cifar10-tfrecords\n\nfiftyone convert \\\n --input-dir ${INPUT_DIR} --input-type fiftyone.types.ImageClassificationDirectoryTree \\\n --output-dir ${OUTPUT_DIR} --output-type fiftyone.types.TFImageClassificationDataset",
"Loading dataset from '/tmp/fiftyone/cifar10-dir-tree'\nInput format 'fiftyone.types.dataset_types.ImageClassificationDirectoryTree'\n 100% |███| 10000/10000 [4.0s elapsed, 0s remaining, 2.5K samples/s] \nImport complete\nExporting dataset to '/tmp/fiftyone/cifar10-tfrecords'\nExport format 'fiftyone.types.dataset_types.TFImageClassificationDataset'\n 0% ||--| 1/10000 [23.2ms elapsed, 3.9m remaining, 43.2 samples/s] 2020-07-14 11:24:15.187387: I tensorflow/core/platform/cpu_feature_guard.cc:143] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n2020-07-14 11:24:15.201384: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f83df428f60 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n2020-07-14 11:24:15.201405: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\n 100% |███| 10000/10000 [8.2s elapsed, 0s remaining, 1.3K samples/s] \nExport complete\n"
]
],
[
[
"Let's verify that the conversion happened as expected:",
"_____no_output_____"
]
],
[
[
"ls -lah /tmp/fiftyone/cifar10-tfrecords",
"total 29696\ndrwxr-xr-x 3 voxel51 wheel 96B Jul 14 11:24 .\ndrwxr-xr-x 4 voxel51 wheel 128B Jul 14 11:24 ..\n-rw-r--r-- 1 voxel51 wheel 14M Jul 14 11:24 tf.records\n"
]
],
[
[
"## Convert KITTI dataset",
"_____no_output_____"
],
[
"When you downloaded the validation split of the KITTI dataset above, it was written to disk as a dataset in [fiftyone.types.FiftyOneImageDetectionDataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/datasets.html#fiftyoneimagedetectiondataset) format.\n\nYou can verify this by printing information about the downloaded dataset:",
"_____no_output_____"
]
],
[
[
"fiftyone zoo datasets info kitti",
"***** Dataset description *****\nKITTI contains a suite of vision tasks built using an autonomous\n driving platform.\n\n The full benchmark contains many tasks such as stereo, optical flow, visual\n odometry, etc. This dataset contains the object detection dataset,\n including the monocular images and bounding boxes. The dataset contains\n 7481 training images annotated with 3D bounding boxes. A full description\n of the annotations can be found in the README of the object development kit\n on the KITTI homepage.\n\n Dataset size:\n 5.27 GiB\n\n Source:\n http://www.cvlibs.net/datasets/kitti\n \n***** Supported splits *****\ntest, train, validation\n\n***** Dataset location *****\n~/fiftyone/kitti\n\n***** Dataset info *****\n{\n \"name\": \"kitti\",\n \"zoo_dataset\": \"fiftyone.zoo.datasets.tf.KITTIDataset\",\n \"dataset_type\": \"fiftyone.types.dataset_types.FiftyOneImageDetectionDataset\",\n \"num_samples\": 423,\n \"downloaded_splits\": {\n \"validation\": {\n \"split\": \"validation\",\n \"num_samples\": 423\n }\n },\n \"classes\": [\n \"Car\",\n \"Van\",\n \"Truck\",\n \"Pedestrian\",\n \"Person_sitting\",\n \"Cyclist\",\n \"Tram\",\n \"Misc\"\n ]\n}\n"
]
],
[
[
"The snippet below uses `fiftyone convert` to convert the test split of the CIFAR-10 dataset to [fiftyone.types.COCODetectionDataset](https://voxel51.com/docs/fiftyone/user_guide/export_datasets.html#cocodetectiondataset) format, which writes the dataset to disk with annotations in [COCO format](https://cocodataset.org/#format-data).",
"_____no_output_____"
]
],
[
[
"INPUT_DIR=$(fiftyone zoo datasets find kitti --split validation)\nOUTPUT_DIR=/tmp/fiftyone/kitti-coco\n\nfiftyone convert \\\n --input-dir ${INPUT_DIR} --input-type fiftyone.types.FiftyOneImageDetectionDataset \\\n --output-dir ${OUTPUT_DIR} --output-type fiftyone.types.COCODetectionDataset",
"Loading dataset from '~/fiftyone/kitti/validation'\nInput format 'fiftyone.types.dataset_types.FiftyOneImageDetectionDataset'\n 100% |███████| 423/423 [1.2s elapsed, 0s remaining, 351.0 samples/s] \nImport complete\nExporting dataset to '/tmp/fiftyone/kitti-coco'\nExport format 'fiftyone.types.dataset_types.COCODetectionDataset'\n 100% |███████| 423/423 [4.4s elapsed, 0s remaining, 96.1 samples/s] \nExport complete\n"
]
],
[
[
"Let's verify that the conversion happened as expected:",
"_____no_output_____"
]
],
[
[
"ls -lah /tmp/fiftyone/kitti-coco/",
"total 880\ndrwxr-xr-x 4 voxel51 wheel 128B Jul 14 11:24 .\ndrwxr-xr-x 5 voxel51 wheel 160B Jul 14 11:24 ..\ndrwxr-xr-x 425 voxel51 wheel 13K Jul 14 11:24 data\n-rw-r--r-- 1 voxel51 wheel 437K Jul 14 11:24 labels.json\n"
],
[
"ls -lah /tmp/fiftyone/kitti-coco/data | head",
"total 171008\ndrwxr-xr-x 425 voxel51 wheel 13K Jul 14 11:24 .\ndrwxr-xr-x 4 voxel51 wheel 128B Jul 14 11:24 ..\n-rw-r--r-- 1 voxel51 wheel 195K Jul 14 11:24 000001.jpg\n-rw-r--r-- 1 voxel51 wheel 191K Jul 14 11:24 000002.jpg\n-rw-r--r-- 1 voxel51 wheel 167K Jul 14 11:24 000003.jpg\n-rw-r--r-- 1 voxel51 wheel 196K Jul 14 11:24 000004.jpg\n-rw-r--r-- 1 voxel51 wheel 224K Jul 14 11:24 000005.jpg\n-rw-r--r-- 1 voxel51 wheel 195K Jul 14 11:24 000006.jpg\n-rw-r--r-- 1 voxel51 wheel 177K Jul 14 11:24 000007.jpg\n"
],
[
"cat /tmp/fiftyone/kitti-coco/labels.json | python -m json.tool 2> /dev/null | head -20\necho \"...\"\ncat /tmp/fiftyone/kitti-coco/labels.json | python -m json.tool 2> /dev/null | tail -20",
"{\n \"info\": {\n \"year\": \"\",\n \"version\": \"\",\n \"description\": \"Exported from FiftyOne\",\n \"contributor\": \"\",\n \"url\": \"https://voxel51.com/fiftyone\",\n \"date_created\": \"2020-07-14T11:24:40\"\n },\n \"licenses\": [],\n \"categories\": [\n {\n \"id\": 0,\n \"name\": \"Car\",\n \"supercategory\": \"none\"\n },\n {\n \"id\": 1,\n \"name\": \"Cyclist\",\n \"supercategory\": \"none\"\n...\n \"area\": 4545.8,\n \"segmentation\": null,\n \"iscrowd\": 0\n },\n {\n \"id\": 3196,\n \"image_id\": 422,\n \"category_id\": 3,\n \"bbox\": [\n 367.2,\n 107.3,\n 36.2,\n 105.2\n ],\n \"area\": 3808.2,\n \"segmentation\": null,\n \"iscrowd\": 0\n }\n ]\n}\n"
]
],
[
[
"Now let's convert from COCO format to [CVAT Image format](https://voxel51.com/docs/fiftyone/user_guide/export_datasets.html#cvatimageformat) format!",
"_____no_output_____"
]
],
[
[
"INPUT_DIR=/tmp/fiftyone/kitti-coco\nOUTPUT_DIR=/tmp/fiftyone/kitti-cvat\n\nfiftyone convert \\\n --input-dir ${INPUT_DIR} --input-type fiftyone.types.COCODetectionDataset \\\n --output-dir ${OUTPUT_DIR} --output-type fiftyone.types.CVATImageDataset",
"Loading dataset from '/tmp/fiftyone/kitti-coco'\nInput format 'fiftyone.types.dataset_types.COCODetectionDataset'\n 100% |███████| 423/423 [2.0s elapsed, 0s remaining, 206.4 samples/s] \nImport complete\nExporting dataset to '/tmp/fiftyone/kitti-cvat'\nExport format 'fiftyone.types.dataset_types.CVATImageDataset'\n 100% |███████| 423/423 [1.3s elapsed, 0s remaining, 323.7 samples/s] \nExport complete\n"
]
],
[
[
"Let's verify that the conversion happened as expected:",
"_____no_output_____"
]
],
[
[
"ls -lah /tmp/fiftyone/kitti-cvat",
"total 584\ndrwxr-xr-x 4 voxel51 wheel 128B Jul 14 11:25 .\ndrwxr-xr-x 6 voxel51 wheel 192B Jul 14 11:25 ..\ndrwxr-xr-x 425 voxel51 wheel 13K Jul 14 11:25 data\n-rw-r--r-- 1 voxel51 wheel 289K Jul 14 11:25 labels.xml\n"
],
[
"cat /tmp/fiftyone/kitti-cvat/labels.xml | head -20\necho \"...\"\ncat /tmp/fiftyone/kitti-cvat/labels.xml | tail -20",
"<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<annotations>\n <version>1.1</version>\n <meta>\n <task>\n <size>423</size>\n <mode>annotation</mode>\n <labels>\n <label>\n <name>Car</name>\n <attributes>\n </attributes>\n </label>\n <label>\n <name>Cyclist</name>\n <attributes>\n </attributes>\n </label>\n <label>\n <name>Misc</name>\n...\n <box label=\"Pedestrian\" xtl=\"360\" ytl=\"116\" xbr=\"402\" ybr=\"212\">\n </box>\n <box label=\"Pedestrian\" xtl=\"396\" ytl=\"120\" xbr=\"430\" ybr=\"212\">\n </box>\n <box label=\"Pedestrian\" xtl=\"413\" ytl=\"112\" xbr=\"483\" ybr=\"212\">\n </box>\n <box label=\"Pedestrian\" xtl=\"585\" ytl=\"80\" xbr=\"646\" ybr=\"215\">\n </box>\n <box label=\"Pedestrian\" xtl=\"635\" ytl=\"94\" xbr=\"688\" ybr=\"212\">\n </box>\n <box label=\"Pedestrian\" xtl=\"422\" ytl=\"85\" xbr=\"469\" ybr=\"210\">\n </box>\n <box label=\"Pedestrian\" xtl=\"457\" ytl=\"93\" xbr=\"520\" ybr=\"213\">\n </box>\n <box label=\"Pedestrian\" xtl=\"505\" ytl=\"101\" xbr=\"548\" ybr=\"206\">\n </box>\n <box label=\"Pedestrian\" xtl=\"367\" ytl=\"107\" xbr=\"403\" ybr=\"212\">\n </box>\n </image>\n</annotations>"
]
],
[
[
"## Cleanup\n\nYou can cleanup the files generated by this recipe by running the command below:",
"_____no_output_____"
]
],
[
[
"rm -rf /tmp/fiftyone",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7cc02020f2e4ecf4d5ea3d2d9a682f35a28bf20 | 83,229 | ipynb | Jupyter Notebook | book/homework_1_solutions.ipynb | janash/python-analysis | c8769dcf7eb452b365207d24a6fb60d3f06e13cd | [
"BSD-3-Clause"
]
| null | null | null | book/homework_1_solutions.ipynb | janash/python-analysis | c8769dcf7eb452b365207d24a6fb60d3f06e13cd | [
"BSD-3-Clause"
]
| null | null | null | book/homework_1_solutions.ipynb | janash/python-analysis | c8769dcf7eb452b365207d24a6fb60d3f06e13cd | [
"BSD-3-Clause"
]
| 1 | 2022-02-26T03:08:17.000Z | 2022-02-26T03:08:17.000Z | 160.055769 | 26,924 | 0.869445 | [
[
[
"Session 1 Homework Solution\n=========================\nThis is the homework for the first session of the MolSSI Python Scripting Level 2 Workshop.\nThis homework is intended to give you practice with the material covered in the first session. \n\nGoals:\n - Utilize pandas to read in and work with the data in a csv file.\n - Utilize matplotlib to create plots and subplots of data stored in a pandas dataframe.\n - Utilize pandas to extract specific information from a dataframe.\n - Utilize matplotlib to construct a plot with multiple groups of data.\n\n## Exercise 1\nUsing the `PubChemElements_all.csv` file used during Session 1, create a plot of the Ionization Energy trend of the periodic table. The trend can be visualized by plotting the Ionization Energy of each element against it's Atomic Number. HINT: Use pandas to read in the csv file and plot the data using matplotlib.\n\n## Exercise 2\nCreate a pair of subplots comparing the Ionization Energy and Electronegativity trends. The Electronegativity trend can be plotted in the same way as the Ionization Energy, by plotting the Electronegativity of each element against it's Atomic Number.\n\n## Exercise 3 \nCreate a function that will assign a color coding to a particular Standard State of an element, i.e. red for gases, blue for solids, etc. Use the apply function from pandas to apply the function across the periodic table, creating a column of assigned colors. Create a pair of subplots utilizing the assigned color as the color of the marker:\n - Atomic Mass against the Melting point of each element\n - Ionization Energy against the Melting Point of each element",
"_____no_output_____"
],
[
"## Exercise 1 Solution",
"_____no_output_____"
]
],
[
[
"# Import necessary packages for the homework:\nimport os\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n# %matplotlib notebook",
"_____no_output_____"
],
[
"# Create a filepath to the periodic table csv file.\nfile_path = os.path.join(\"data\", \"PubChemElements_all.csv\")\n\n# Use pandas to read the csv file into a table.\ndf = pd.read_csv(file_path)",
"_____no_output_____"
],
[
"# Print the first 5 rows of the table to get a quick glance at its contents.\ndf.head()",
"_____no_output_____"
],
[
"# Create a simple scatter plot of the Ionization Energy vs the Atomic number of each element.\nion_fig, ion_ax = plt.subplots()\nion_ax.scatter('AtomicNumber', 'IonizationEnergy', data=df)\nion_ax.set_xlabel('Atomic Number')\nion_ax.set_ylabel('Ionization Energy')",
"_____no_output_____"
]
],
[
[
"## Exercise 2 Solution",
"_____no_output_____"
]
],
[
[
"# Create a set of subplots of the two trends: Ionization Energy and Electronegativity.\n\ncomparison_fig, comparison_ax = plt.subplots(1, 2)\n# Add the first subplot.\ncomparison_ax[0].scatter('AtomicNumber', 'IonizationEnergy', data=df)\ncomparison_ax[0].set_xlabel('Atomic Number')\ncomparison_ax[0].set_ylabel('Ionization')\n\n\n\ncomparison_fig.tight_layout()",
"_____no_output_____"
],
[
"# Add the second subplot.\ncomparison_ax[1].scatter('AtomicNumber', 'Electronegativity', data=df)\ncomparison_ax[1].set_xlabel('Atomic Number')\ncomparison_ax[1].set_ylabel('Electronegativity')",
"_____no_output_____"
],
[
"comparison_fig.tight_layout()\ncomparison_fig",
"_____no_output_____"
]
],
[
[
"## Exercise 3 Solution",
"_____no_output_____"
]
],
[
[
"# Determine possible states stored in the Dataframe\nstates = pd.unique(df['StandardState'])\nstates",
"_____no_output_____"
],
[
"# Create a function that returns a different color for each type of standard state.\ndef assign_state_color(standard_state):\n state_markers = {'Gas': 'r',\n 'Solid': 'b',\n 'Liquid': 'g',\n 'Expected to be a Solid': 'y',\n 'Expected to be a Gas': 'k'}\n return state_markers[standard_state]",
"_____no_output_____"
],
[
"# Apply the function to the dataframe, creating a new column.\ndf['StateMarker'] = df['StandardState'].apply(assign_state_color)",
"_____no_output_____"
],
[
"# Create a plot that uses the colors assigned to the table of the Atomic Mass vs the Melting Point.\nstate_fig, state_ax = plt.subplots(1, 2, figsize=(8,4))\nstate_ax[0].set_xlabel('Atomic Mass')\nstate_ax[0].set_ylabel('Melting Point')\n\n# Add each state as a separate scatter to the same subplot.\nfor state in states:\n dataframe = df[df['StandardState'] == state]\n line = state_ax[0].scatter('AtomicMass', 'MeltingPoint', data=dataframe, color=dataframe.iloc[0]['StateMarker'])\n line.set_label(state)\n\nstate_ax[1].set_xlabel('Ionization Energy')\nstate_ax[1].set_ylabel('Melting Point')\nfor state in states:\n dataframe = df[df['StandardState'] == state]\n line = state_ax[1].scatter('IonizationEnergy', 'MeltingPoint', data=dataframe, color=dataframe.iloc[0]['StateMarker'])\n line.set_label(state)\n\n# Create a legend\nstate_ax[1].legend(states)\n\n\nstate_fig.tight_layout()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7cc05d60ebfe2a55727c12373f3c029406d86fd | 27,497 | ipynb | Jupyter Notebook | lessons/00_Lesson00_QuickPythonIntro.ipynb | tobiassugandi/AeroPython | 18cca97ec5c0ef2c253565c3b98dcf9bbf2e4dee | [
"CC-BY-4.0",
"BSD-3-Clause"
]
| null | null | null | lessons/00_Lesson00_QuickPythonIntro.ipynb | tobiassugandi/AeroPython | 18cca97ec5c0ef2c253565c3b98dcf9bbf2e4dee | [
"CC-BY-4.0",
"BSD-3-Clause"
]
| null | null | null | lessons/00_Lesson00_QuickPythonIntro.ipynb | tobiassugandi/AeroPython | 18cca97ec5c0ef2c253565c3b98dcf9bbf2e4dee | [
"CC-BY-4.0",
"BSD-3-Clause"
]
| null | null | null | 26.984298 | 441 | 0.516602 | [
[
[
"###### Content provided under a Creative Commons Attribution license, CC-BY 4.0; code under BSD 3-Clause license. (c)2014 Lorena A. Barba. Thanks: Gilbert Forsyth and Olivier Mesnard, and NSF for support via CAREER award #1149784.",
"_____no_output_____"
],
[
"# Python Crash Course\n",
"_____no_output_____"
],
[
"Hello! This is a quick intro to numerical programming in Python to help you hit the ground running with the _AeroPython_ set of notebooks. (This intro is a modified version of the first notebook of the [_CFD Python_](http://lorenabarba.com/blog/cfd-python-12-steps-to-navier-stokes/) series by Prof. Lorena A. Barba, July 2013.)\n\nPython may already be installed on your computer (especially if you use OSX or a flavor of Linux). Even so, we recommend that you download and install the free [Anaconda Scientific Python](https://www.continuum.io/downloads) distribution. It makes it much easier to hit the ground running.\n\nYou will probably want to download a copy of this notebook, or the whole _AeroPython_ collection. We recommend that you then follow along each lesson, experimenting with the code in the notebooks, or typing the code into a separate Python interactive session.\n\nIf you decided to work on your local Python installation, you will have to navigate in the terminal to the folder that contains the .ipynb files. Then, to launch the notebook server, just type:\n\n`jupyter notebook`\n\nYou will get a new browser window or tab with a list of the notebooks available in that folder. Click on one and start working! ",
"_____no_output_____"
],
[
"## Libraries",
"_____no_output_____"
],
[
"Python is a high-level open-source language. But the *Python world* is inhabited by many packages or libraries that provide useful things like array operations, plotting functions, and much more. We can import libraries of functions to expand the capabilities of Python in our programs. \n\nOK! We'll start by importing a few libraries to help us out. First: our favorite library is **NumPy**, providing a bunch of useful array operations (similar to MATLAB). We will use it a lot! The second library we need is **Matplotlib**, a 2D plotting library which we will use to plot our results. \n\nThe following code will be at the top of most of your programs, so execute this cell first:",
"_____no_output_____"
]
],
[
[
"# <-- comments in python are denoted by the pound sign, like this one\n\nimport numpy # we import the array library\nfrom matplotlib import pyplot # import plotting library",
"_____no_output_____"
]
],
[
[
"We are importing one library named `numpy` and we are importing a module called `pyplot` of a big library called `matplotlib`. \n\nTo use a function belonging to one of these libraries, we have to tell Python where to look for it. For that, each function name is written following the library name, with a dot in between. \n\nSo if we want to use the NumPy function [`linspace()`](http://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html), which creates an array with equally spaced numbers between a start and end, we call it by writing:",
"_____no_output_____"
]
],
[
[
"myarray = numpy.linspace(0, 5, 10)\nprint(myarray)",
"[ 0. 0.55555556 1.11111111 1.66666667 2.22222222 2.77777778\n 3.33333333 3.88888889 4.44444444 5. ]\n"
]
],
[
[
"If we *don't* preface the `linspace()` function with `numpy`, **Python will throw an error**, because it doesn't know where to find this function. Try it:",
"_____no_output_____"
]
],
[
[
"myarray = linspace(0, 5, 10)",
"_____no_output_____"
]
],
[
[
"\nThe function [`linspace`()](http://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html) is very useful. Try it changing the input parameters!",
"_____no_output_____"
],
[
"##### Import style:",
"_____no_output_____"
],
[
"You will often see code snippets that use the following lines\n\n```Python\nimport numpy as np\nimport matplotlib.pyplot as plt\n```\n\nWhat's all of this `import-as` business? It's a way of creating a 'shortcut' to the NumPy library and the pyplot module. You will see it frequently as it is in common usage, but we prefer to keep out imports *explicit*. We think it helps with code readability. ",
"_____no_output_____"
],
[
"##### Pro tip:",
"_____no_output_____"
],
[
"Sometimes, you'll see people importing a whole library without assigning a shortcut for it (like `from numpy import *`). This saves typing but is sloppy and can get you in trouble. Best to get into good habits from the beginning!\n\nTo learn new functions available to you, visit the [NumPy Reference](http://docs.scipy.org/doc/numpy/reference/) page. If you are a proficient `Matlab` user, there is a wiki page that should prove helpful to you: [NumPy for Matlab Users](http://wiki.scipy.org/NumPy_for_Matlab_Users)",
"_____no_output_____"
],
[
"## Variables",
"_____no_output_____"
],
[
"Python doesn't require explicitly declared variable types, like C and other languages do. Just assign a variable and Python understands what you want:",
"_____no_output_____"
]
],
[
[
"a = 5 # a is an integer 5\nb = 'five' # b is a string of the word 'five'\nc = 5.0 # c is a floating point 5 ",
"_____no_output_____"
]
],
[
[
"Ask Python to tell you what type it has assigned to a given variable name like this:",
"_____no_output_____"
]
],
[
[
"type(a)",
"_____no_output_____"
],
[
"type(b)",
"_____no_output_____"
],
[
"type(c)",
"_____no_output_____"
]
],
[
[
"In Python 3, division between integers, floats, or a combination thereof produces a float with the correct value, to machine precision. For example,",
"_____no_output_____"
]
],
[
[
"14/a",
"_____no_output_____"
],
[
"14/c",
"_____no_output_____"
]
],
[
[
"both produce the same floating point number.",
"_____no_output_____"
],
[
"## Whitespace in Python",
"_____no_output_____"
],
[
"Python uses indents and whitespace to group statements together. For contrast, if you were to write a short loop in the C language, you might use:\n\n for (i = 0, i < 5, i++){\n printf(\"Hi! \\n\");\n }",
"_____no_output_____"
],
[
"Python does not use curly braces like C, it uses indentation instead; so the same program as above is written in Python as follows:",
"_____no_output_____"
]
],
[
[
"for i in range(5):\n print(\"Hi \\n\")",
"Hi \n\nHi \n\nHi \n\nHi \n\nHi \n\n"
]
],
[
[
"Did you notice the [`range()`](http://docs.python.org/release/1.5.1p1/tut/range.html) function? It is a neat built-in function of Python that gives you a list from an arithmetic progression.\n\nIf you have nested `for` loops, there is a further indent for the inner loop, like this:",
"_____no_output_____"
]
],
[
[
"for i in range(3):\n for j in range(3):\n print(i, j)\n \n print(\"This statement is within the i-loop, but not the j-loop\")",
"0 0\n0 1\n0 2\nThis statement is within the i-loop, but not the j-loop\n1 0\n1 1\n1 2\nThis statement is within the i-loop, but not the j-loop\n2 0\n2 1\n2 2\nThis statement is within the i-loop, but not the j-loop\n"
]
],
[
[
"## Slicing arrays",
"_____no_output_____"
],
[
"In NumPy, you can look at portions of arrays in the same way as in MATLAB, with a few extra tricks thrown in. Let's take an array of values from 1 to 5:",
"_____no_output_____"
]
],
[
[
"myvals = numpy.array([1, 2, 3, 4, 5])\nmyvals",
"_____no_output_____"
]
],
[
[
"Python uses a **zero-based index** (like C), which is [a good thing](http://www.cs.utexas.edu/~EWD/transcriptions/EWD08xx/EWD831.html). Knowing this, let's look at the first and last element in the array we have created above,",
"_____no_output_____"
]
],
[
[
"myvals[0], myvals[4]",
"_____no_output_____"
]
],
[
[
"There are 5 elements in the array `myvals`, but if we try to look at `myvals[5]`, Python will be unhappy and **throw an error**, as `myvals[5]` is actually calling the non-existent 6th element of that array.",
"_____no_output_____"
]
],
[
[
"myvals[5]",
"_____no_output_____"
]
],
[
[
"Arrays can also be *sliced*, grabbing a range of values. Let's look at the first three elements,",
"_____no_output_____"
]
],
[
[
"myvals[0:3]",
"_____no_output_____"
]
],
[
[
"Note here, the slice is inclusive on the front end and exclusive on the back, so the above command gives us the values of `myvals[0]`, `myvals[1]` and `myvals[2]`, but not `myvals[3]`.",
"_____no_output_____"
],
[
"## Assigning array variables",
"_____no_output_____"
],
[
"One of the strange little quirks/features in Python that often confuses people comes up when assigning and comparing arrays of values. Here is a quick example. Let's start by defining a 1-D array called $a$:",
"_____no_output_____"
]
],
[
[
"a = numpy.linspace(1,5,5)",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
]
],
[
[
"OK, so we have an array $a$, with the values 1 through 5. I want to make a copy of that array, called $b$, so I'll try the following:",
"_____no_output_____"
]
],
[
[
"b = a",
"_____no_output_____"
],
[
"b",
"_____no_output_____"
]
],
[
[
"Great. So $a$ has the values 1 through 5 and now so does $b$. Now that I have a backup of $a$, I can change its values without worrying about losing data (or so I may think!).",
"_____no_output_____"
]
],
[
[
"a[2] = 17",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
]
],
[
[
"Here, the 3rd element of $a$ has been changed to 17. Now let's check on $b$.",
"_____no_output_____"
]
],
[
[
"b",
"_____no_output_____"
]
],
[
[
"And that's how things go wrong! When you use a statement like `a = b`, rather than copying all the values of `a` into a new array called `b`, Python just creates an alias called `b` and tells it to route us to `a`. So if we change a value in `a`, then `b` will reflect that change (technically, this is called *assignment by reference*). If you want to make a true copy of the array, you have to tell Python to create a copy of `a`.",
"_____no_output_____"
]
],
[
[
"c = a.copy()",
"_____no_output_____"
]
],
[
[
"Now, we can try again to change a value in $a$ and see if the changes are also seen in $c$. ",
"_____no_output_____"
]
],
[
[
"a[2] = 3",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"c",
"_____no_output_____"
]
],
[
[
"OK, it worked! If the difference between `a = b` and `a = b.copy()` is unclear, you should read through this again. This issue will come back to haunt you otherwise.\n\n---",
"_____no_output_____"
],
[
"## Learn more",
"_____no_output_____"
],
[
"There are a lot of resources online to learn more about using NumPy and other libraries. Just for kicks, here we use IPython's feature for embedding videos to point you to a short video on YouTube on using NumPy arrays.",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\nYouTubeVideo('vWkb7VahaXQ')",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
]
],
[
[
"Please ignore the cell below. It just loads our style for the notebook.",
"_____no_output_____"
]
],
[
[
"from IPython.core.display import HTML\ndef css_styling(filepath):\n styles = open(filepath, 'r').read()\n return HTML(styles)\ncss_styling('../styles/custom.css')",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"code"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"code"
]
]
|
e7cc0719642f957d9b34a1355e6d223f78172d1b | 1,424 | ipynb | Jupyter Notebook | Assignment Day 9 q2.ipynb | gopi2650/letsupgrade-python | f74c6f647ec5f305e3105d4146cad1013db48719 | [
"Apache-2.0"
]
| null | null | null | Assignment Day 9 q2.ipynb | gopi2650/letsupgrade-python | f74c6f647ec5f305e3105d4146cad1013db48719 | [
"Apache-2.0"
]
| null | null | null | Assignment Day 9 q2.ipynb | gopi2650/letsupgrade-python | f74c6f647ec5f305e3105d4146cad1013db48719 | [
"Apache-2.0"
]
| null | null | null | 18.493506 | 47 | 0.426966 | [
[
[
"# Generator function to armstrong numbers",
"_____no_output_____"
]
],
[
[
"def genFunc(): \n start = 1 \n end = 1000\n \n for i in range(start, end + 1): \n if i >= 10:\n order = len(str(i)) \n sum = 0 \n temp = i\n while temp > 0:\n dig = temp % 10\n sum += dig ** order\n temp //= 10 \n if i == sum:\n yield i\n \nfor x in genFunc():\n print(x)",
"153\n370\n371\n407\n"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
]
]
|
e7cc088153953de84041f2b09f49a77dd62ab40c | 338,866 | ipynb | Jupyter Notebook | notebooks/rhys_v2.ipynb | Orion-51/jax-cosmo-paper | f7d986f9a1cccb50e644b7f80fbbd6ea5a03aecb | [
"MIT"
]
| null | null | null | notebooks/rhys_v2.ipynb | Orion-51/jax-cosmo-paper | f7d986f9a1cccb50e644b7f80fbbd6ea5a03aecb | [
"MIT"
]
| null | null | null | notebooks/rhys_v2.ipynb | Orion-51/jax-cosmo-paper | f7d986f9a1cccb50e644b7f80fbbd6ea5a03aecb | [
"MIT"
]
| null | null | null | 135.818036 | 95,956 | 0.816621 | [
[
[
"import numpy as np\nimport hmc\nimport hmc_v2# as hmc\n#import hmc_v3 as hmc\nimport matplotlib.pyplot as plt\nimport corner\nimport time\nimport sklearn.datasets as skld",
"_____no_output_____"
],
[
"plt.rcParams['figure.figsize'] = [10, 10]\n\nlimits = [(-40,40),(-40,40),(-40,40)]\nnparam = len(limits)\n\ncov = skld.make_spd_matrix(nparam)\n#cov = np.eye(nparam)*100\ninv_cov = np.linalg.inv(cov)\n",
"_____no_output_____"
],
[
"# def mock_posterior_and_gradient(p):\n# logP = -0.5 * np.sum(p**2)\n# logP_jacobian = p * (-1)\n# #mock_posterior_and_gradient.counter += 1\n# return logP, logP_jacobian",
"_____no_output_____"
],
[
"def mock_posterior_and_gradient(p):\n dlogL_dCl = - inv_cov @ p\n #j = theory_jacobian(p, *self.args).T\n logP = 0.5 * p.T @ dlogL_dCl\n #logP_jacobian = j @ dlogL_dCl\n #logP_jacobian = p * (-1)\n #mock_posterior_and_gradient.counter += 1\n return logP, dlogL_dCl",
"_____no_output_____"
],
[
"def run_hmc(n_it, filebase, epsilon, hmc, spit, cov):\n #rank = 5\n rank = nparam\n filename = f'{filebase}.{rank}.txt'\n #np.random.seed(100 + rank)\n #C = np.eye(nparam)\n # mass matrix\n sampler = hmc.HMC(mock_posterior_and_gradient, cov, epsilon, spit, limits)\n # first sample starts at fid\n fid_params = np.zeros(nparam)\n results = sampler.sample(n_it, fid_params)\n\n # continue\n #for i in range(n_it):\n # Save chain\n #chain = np.array(sampler.trace)\n #np.savetxt(filename, chain)\n\n # next round of samples\n #sampler.sample(n_it)\n \n #chain = np.array(sampler.paths)\n #anti_chain = np.array(sampler.anti_paths)\n \n #tr = np.array(sampler.trace)\n #np.savetxt(filename, chain)\n return sampler",
"_____no_output_____"
],
[
"start = time.time()\nnit = 1000\nprint(np.sqrt(cov))\nchain = run_hmc(nit*20, \"hmc_002_500\", 0.02, hmc, 5, cov)\nprint(\"%.2f\" %(time.time()-start))\nstart = time.time()\nchain2 = run_hmc(nit, \"hmc_002_500\", 0.02, hmc_v2, 0, cov)\nprint(\"%.2f\" %(time.time()-start))",
"<ipython-input-6-3ff71303c705>:3: RuntimeWarning: invalid value encountered in sqrt\n print(np.sqrt(cov))\n"
],
[
"#paths = np.array(chain.paths)\n#anti_paths = np.array(chain.anti_paths)\ntrace = np.array(chain.trace)\ntrace2 = np.array(chain2.trace)\n\ncalls = np.array(chain.ncall_list)\ncalls2 = np.array(chain2.ncall_list)",
"_____no_output_____"
],
[
"#plt.scatter(paths[:,0],paths[:,1],s=3)\n#plt.scatter(anti_paths[:,0],anti_paths[:,1],s=3)\n#plt.show()\n\n#plt.scatter(trace[:,0],trace[:,1],s=5)\n#plt.show()\n\nfigure = corner.corner(trace)\nfigure2 = corner.corner(trace2)",
"_____no_output_____"
],
[
"def plot_conv(trace,dim,botlim,toplim, hmc, cov, calls):\n STDs, means = [], []\n for i in range(trace.shape[0]):\n STD=np.std(trace[:i,dim])\n STDs.append(STD/np.sqrt(cov[dim,dim]))\n means.append(np.mean(trace[:i,dim]))\n plt.plot(calls, STDs, label=\"STD/sigma hmc %s\" %hmc)\n plt.plot(calls, means, label=\"mean hmc %s\" %hmc)\n plt.hlines([0,1],0,calls[-1],ls=\":\", color=\"k\")\n plt.legend()\n plt.title(\"Mean & STD vs L-calls for dim %.0f\" %dim)\n plt.ylim(botlim,toplim)\n \n print(np.std(trace[:,dim]))\n ",
"_____no_output_____"
],
[
"print(np.sqrt(cov))\n\nplot_conv(trace,2,-1,1.5,1, cov, calls)\nplot_conv(trace2,2,-1,1.5,2, cov, calls2)\nplt.show()",
"<ipython-input-10-93b47e9ea3d1>:1: RuntimeWarning: invalid value encountered in sqrt\n print(np.sqrt(cov))\n/opt/conda/lib/python3.8/site-packages/numpy/core/_methods.py:261: RuntimeWarning: Degrees of freedom <= 0 for slice\n ret = _var(a, axis=axis, dtype=dtype, out=out, ddof=ddof,\n/opt/conda/lib/python3.8/site-packages/numpy/core/_methods.py:221: RuntimeWarning: invalid value encountered in true_divide\n arrmean = um.true_divide(arrmean, div, out=arrmean, casting='unsafe',\n/opt/conda/lib/python3.8/site-packages/numpy/core/_methods.py:253: RuntimeWarning: invalid value encountered in double_scalars\n ret = ret.dtype.type(ret / rcount)\n/opt/conda/lib/python3.8/site-packages/numpy/core/fromnumeric.py:3419: RuntimeWarning: Mean of empty slice.\n return _methods._mean(a, axis=axis, dtype=dtype,\n/opt/conda/lib/python3.8/site-packages/numpy/core/_methods.py:188: RuntimeWarning: invalid value encountered in double_scalars\n ret = ret.dtype.type(ret / rcount)\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cc0a616d6a67e1c172c3690a5e0f4c127d1665 | 500,910 | ipynb | Jupyter Notebook | datascience/2018_10_27_anyway_data_trial_1.ipynb | neuhofmo/anyway_projects | 5e0ff6b32655abf79a31ad6c5d49ba0aadb94832 | [
"MIT"
]
| 5 | 2018-10-22T18:40:49.000Z | 2019-03-25T18:37:23.000Z | datascience/2018_10_27_anyway_data_trial_1.ipynb | neuhofmo/anyway_projects | 5e0ff6b32655abf79a31ad6c5d49ba0aadb94832 | [
"MIT"
]
| 6 | 2018-05-08T07:42:26.000Z | 2019-03-19T00:58:08.000Z | datascience/2018_10_27_anyway_data_trial_1.ipynb | neuhofmo/anyway_projects | 5e0ff6b32655abf79a31ad6c5d49ba0aadb94832 | [
"MIT"
]
| 11 | 2018-05-08T07:32:36.000Z | 2019-09-23T16:04:54.000Z | 119.20752 | 126,228 | 0.741956 | [
[
[
"import pandas as pd\nimport seaborn as sns\nimport os\nimport numpy as np",
"_____no_output_____"
],
[
"#df = pd.read_csv('data/involved_hebrew.csv.gz')\n#df.to_parquet('data/involved_hebrew.parquet')\ndf = pd.read_parquet('data/involved_hebrew.parquet')\nheb_cols = [c for c in df.columns if c.endswith('hebrew') or c.endswith('_name')]\nheb = df[heb_cols]\nd = df[[c for c in df.columns if not c in heb_cols]]",
"_____no_output_____"
],
[
"df.describe().T",
"_____no_output_____"
],
[
"df.dtypes",
"_____no_output_____"
],
[
"def color_pos_red(val, cutoff=0.85):\n return 'color: %s' % ('red' if val >=cutoff else 'grey')\nif not 'dcor' in globals():\n dcor = d.corr()\ndcor.style.applymap(color_pos_red)",
"_____no_output_____"
],
[
"from tqdm import tqdm\nsummary = []\nfor c in tqdm(df.columns, leave=False):\n try:\n summary.append([c, df[c].dropna().nunique(), df[c].count(), [x for x in df[c].dropna().unique()[0:5]]])\n except KeyError:\n print(c)\npd.DataFrame(summary, columns=['col', 'uniques','count', 'examples'])",
""
]
],
[
[
"# define categorical / numeric columns",
"_____no_output_____"
]
],
[
[
"d.hist(figsize=[20, 20], sharey=False, bins=50)\nd.hist(figsize=[20, 20], sharey=True)\nprint()",
"\n"
],
[
"col_identity = {'ignore': ['accident_id','provider_and_id','provider_code'],\n 'numeric' : ['license_acquiring_date', 'accident_year','accident_month'],\n 'category' : ['age_group', 'sex', 'vehicle_type', 'safety_measures', 'population_type', 'home_region', 'home_district', 'home_natural_area', 'home_municipal_status', 'home_residence_type', 'medical_type', 'safety_measures_use', 'car_id', 'involve_id']}\ncol_target = 'late_deceased'",
"_____no_output_____"
],
[
"if not 'data' in globals():\n data_fname = 'data/involved_hebrew_dummies.parquet'\n if os.path.isfile(data_fname):\n data = pd.read_parquet(data_fname)\n else:\n rel_cols = col_identity['category'] + col_identity['numeric']\n data = d[col_identity['numeric']].fillna(-1)\n data['license_acquiring_date'] = data['license_acquiring_date'].replace(0, -1)\n dummies = pd.get_dummies(d[col_identity['category']], columns=col_identity['category'], prefix_sep='==')\n data = pd.concat([dummies, data], axis=1)\n data.to_parquet(data_fname)\ndata.head()",
"_____no_output_____"
],
[
"y = d[col_target].fillna(0)\ny[y == 2] = 1\ny = y.astype(np.int16).values\nx = data.fillna(-1).values\n\ny.sum(), y.shape[0], x.shape",
"_____no_output_____"
]
],
[
[
"# balance the data and train forest of decision trees",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nfrom imblearn.ensemble import BalancedRandomForestClassifier # !!!!!! balanced!\nfrom sklearn.metrics import f1_score, precision_score, recall_score, balanced_accuracy_score\ndel df\nX_train, X_test, y_train, y_test = train_test_split(x, y, random_state=42, test_size=0.25)",
"_____no_output_____"
],
[
"print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)\nprint(\"%.4f, %.4f\"%(y_train.sum() / len(y_train), y_test.sum() / len(y_test)))",
"(1217887, 359) (405963, 359) (1217887,) (405963,)\n0.0023, 0.0024\n"
],
[
"brf = BalancedRandomForestClassifier(n_estimators=30, random_state=0)\nbrf.fit(X_train, y_train)",
"_____no_output_____"
],
[
"y_pred = brf.predict(X_test)\n\nprint('f1 score = %.3f'%(f1_score(y_test, y_pred, average='weighted')))\nprint('precision = %.3f'%(precision_score(y_test, y_pred, average='weighted')))\nprint('recall = %.3f'%(recall_score(y_test, y_pred, average='weighted')))\nprint('accuracy(balanced) = %.3f'%(balanced_accuracy_score(y_test, y_pred)))",
"f1 score = 0.902\nprecision = 0.997\nrecall = 0.825\naccuracy(balanced) = 0.823\n"
],
[
"importance = pd.DataFrame(list(zip(data.columns, brf.feature_importances_)), columns=['feature', 'importance']).sort_values('importance', ascending=False)\nimportance[0:20].style.bar()",
"_____no_output_____"
],
[
"if not os.path.isdir('models'): os.mkdir('models')\nfrom sklearn.externals import joblib\njoblib.dump(brf, 'models/2018_10_28_death_risk_balanced_RF_classifier_01.joblib')",
"_____no_output_____"
],
[
"import lime\n#eplain?",
"_____no_output_____"
],
[
"#see http://explained.ai/rf-importance/index.html",
"_____no_output_____"
],
[
"from sklearn.metrics import f1_score, precision_score, recall_score, balanced_accuracy_score\n\ndef metric(model, x, y):\n return balanced_accuracy_score(y, model.predict(x))\n\ndef permutation_importances(model, X_train, y_train):\n baseline = metric(model, X_train, y_train)\n imp = []\n for col in X_train.columns:\n save = X_train[col].copy()\n X_train[col] = np.random.permutation(X_train[col])\n m = metric(model, X_train, y_train)\n X_train[col] = save\n imp.append(baseline - m)\n return np.array(imp)\n\n#permutation_importances(brf, data, y_train)\n",
"_____no_output_____"
],
[
"d.groupby('accident_year').count()['accident_id'].plot(kind='bar')",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cc17bd2285fc2d78d77f20f3a492639a02c71c | 415,809 | ipynb | Jupyter Notebook | results/Temperature Control Plots.ipynb | ethanjli/punchcard-microfluidics | 28fdee65d7659b8f6e72b1e4bc44070514723485 | [
"BSD-3-Clause"
]
| 1 | 2021-12-03T16:04:32.000Z | 2021-12-03T16:04:32.000Z | results/Temperature Control Plots.ipynb | prakashlab/punchcard-microfluidics | 28fdee65d7659b8f6e72b1e4bc44070514723485 | [
"BSD-3-Clause"
]
| null | null | null | results/Temperature Control Plots.ipynb | prakashlab/punchcard-microfluidics | 28fdee65d7659b8f6e72b1e4bc44070514723485 | [
"BSD-3-Clause"
]
| null | null | null | 512.080049 | 137,084 | 0.931613 | [
[
[
"import scipy.ndimage as ndi # using version 1.2.1\nimport pandas as pd # using version 0.24.2\nimport matplotlib as mpl # using version 3.0.3\nfrom matplotlib import pyplot as plt\n\n# Uncomment to rebuild matplotlib's font cache so it can find a newly-installed font\n#import matplotlib.font_manager\n#mpl.font_manager._rebuild()\n\npd.set_option('display.max_rows', 10) # concise dataframe display\n\nmpl.rc(\n 'font',\n family=['Helvetica', 'Helvetica Neue', 'Helvetica Neue LT Std'],\n weight=500,\n size=24\n)\nmpl.rc(\n 'axes',\n titlesize=36,\n titleweight='medium',\n labelsize=36,\n labelweight='medium',\n titlepad=30,\n labelpad=20,\n linewidth=2,\n xmargin=0.01,\n ymargin=0.01\n)\nmpl.rc('xtick', labelsize=30)\nmpl.rc('xtick.major', pad=10, size=10, width=2)\nmpl.rc('ytick', labelsize=24)\nmpl.rc('ytick.major', pad=10, size=10, width=2)\nmpl.rc(\n 'legend',\n fontsize=30,\n handlelength=1,\n fancybox=False,\n borderpad=0.5,\n borderaxespad=0.05,\n framealpha=1\n)\nmpl.rc(\n 'figure',\n dpi=300,\n titlesize=36,\n titleweight='medium'\n)\nmpl.rc('savefig', dpi=300, transparent=True, bbox='tight')\nmpl.rc('pdf', fonttype=42) # TrueType fonts\n\nmpl.rc('lines', linewidth=5)",
"_____no_output_____"
]
],
[
[
"# Data Support",
"_____no_output_____"
]
],
[
[
"fan_smoothing_window = 60 # time width of smoothing wndow\n\ndef load_df(df_name):\n df = pd.read_csv(\n df_name,\n usecols=[0, 1, 2, 3, 4, 5, 6]\n )\n df.rename(index=str, columns={ # remove units for easier indexing\n 'Time (s)': 'Time',\n 'Temperature': 'Thermistor',\n 'Error (deg C)': 'Error',\n 'Setpoint Reached': 'Reached'\n }, inplace=True)\n df.dropna(how='all', inplace=True)\n df.index = pd.to_timedelta(df['Time'], unit='s') # set index to units of seconds\n df.Time = df.Time / 60 # set Time to units of minutes\n return df\n\ndef smooth_fan(df):\n df['FanSmooth'] = df.Fan.rolling(fan_smoothing_window, win_type='hamming').mean()",
"_____no_output_____"
]
],
[
[
"# Plotting Support",
"_____no_output_____"
]
],
[
[
"figure_width = 17.5\nfigure_temps_height = 4\nfigure_complete_height = 7.5\nfigure_complete_height_ratio = (3, 2)\nbox_width_shrink_factor = 0.875 # to fit the figure legend on the right\nylabel_position = -0.08\n\nmin_temp = 20\nmax_temp = 100\n\nlegend_location = 'center right'\n\nreached_color = 'gainsboro' # light gray\nsetpoint_color = 'tab:green'\nthermistor_color = 'tab:orange'\nfan_color = 'tab:blue'\nheater_color = 'tab:red'",
"_____no_output_____"
],
[
"def fig_temps(title):\n (fig, ax_temp) = plt.subplots(\n figsize=(figure_width, figure_temps_height)\n )\n ax_temp.set_title(title)\n return (fig, ax_temp)\n\ndef fig_complete(title):\n (fig, (ax_temp, ax_duties)) = plt.subplots(\n nrows=2, sharex=True,\n gridspec_kw={\n 'height_ratios': figure_complete_height_ratio\n },\n figsize=(figure_width, figure_complete_height)\n )\n ax_temp.set_title(title)\n return (fig, (ax_temp, ax_duties))\n\ndef plot_setpoint_reached(df, ax, label=True):\n legend_label = 'Reached\\nSetpoint'\n if not label:\n legend_label = '_' + legend_label # hide the label from the legend\n \n (groups, _) = ndi.label(df.Reached.values.tolist())\n df = pd.DataFrame({\n 'Time': df.Time,\n 'ReachedGroup': groups\n })\n result = (\n df\n .loc[df.ReachedGroup != 0]\n .groupby('ReachedGroup')['Time']\n .agg(['first', 'last'])\n )\n for (i, (group_start, group_end)) in enumerate(result.values.tolist()):\n ax.axvspan(group_start, group_end, facecolor=reached_color, label=legend_label)\n if i == 0:\n legend_label = '_' + legend_label # hide subsequent labels from the legend\n \n\ndef plot_temps(df, ax, label_x=True):\n ax.plot(df.Time, df.Setpoint, color=setpoint_color, label='Setpoint')\n ax.plot(df.Time, df.Thermistor, color=thermistor_color, label='Thermistor')\n \n ax.set_xlim([df.Time[0], df.Time[-1]])\n ax.set_ylim([min_temp, max_temp])\n \n if label_x:\n ax.set_xlabel('Time (min)')\n ax.set_ylabel('Temperature\\n(°C)')\n \ndef plot_efforts(df, ax):\n ax.plot(df.Time, df.FanSmooth, color=fan_color, label='Fan')\n ax.plot(df.Time, df.Heater, color=heater_color, label='Heater')\n \n ax.set_xlabel('Time (min)')\n ax.set_ylabel('Duty\\nCycle')\n\ndef shrink_ax_width(ax, shrink_factor):\n box = ax.get_position()\n ax.set_position([box.x0, box.y0, box.width * shrink_factor, box.height])\n\ndef fig_plot_complete(df, title):\n (fig, (ax_temp, ax_duties)) = fig_complete(title)\n \n plot_setpoint_reached(df, ax_temp)\n plot_temps(df, ax_temp, label_x=False)\n ax_temp.yaxis.set_label_coords(ylabel_position, 0.5)\n shrink_ax_width(ax_temp, box_width_shrink_factor)\n \n plot_setpoint_reached(df, ax_duties, label=False)\n plot_efforts(df, ax_duties)\n ax_duties.yaxis.set_label_coords(ylabel_position, 0.5)\n shrink_ax_width(ax_duties, box_width_shrink_factor)\n \n fig.legend(loc=legend_location)\n\ndef fig_plot_temps(df, title):\n (fig, ax_temp) = fig_temps(title)\n \n plot_setpoint_reached(df, ax_temp)\n plot_temps(df, ax_temp)\n ax_temp.yaxis.set_label_coords(ylabel_position, 0.5)\n shrink_ax_width(ax_temp, box_width_shrink_factor)\n \n fig.legend(loc=legend_location)",
"_____no_output_____"
]
],
[
[
"# Stepwise Sequence",
"_____no_output_____"
]
],
[
[
"df_stepwise = load_df('20190117 Thermal Subsystem Testing Data - Fifth Test.csv')\nsmooth_fan(df_stepwise)\ndf_stepwise",
"_____no_output_____"
],
[
"fig_plot_temps(df_stepwise, 'Stepwise Adjustment Control Sequence')\nplt.savefig('stepwise_control.pdf', format='pdf')\nplt.savefig('stepwise_control.png', format='png')",
"'HelveticaNeueLTStd_Md.otf' can not be subsetted into a Type 3 font. The entire font will be embedded in the output.\n'HelveticaNeueLTStd_Roman.otf' can not be subsetted into a Type 3 font. The entire font will be embedded in the output.\n'HelveticaNeueLTStd_Md.otf' can not be subsetted into a Type 3 font. The entire font will be embedded in the output.\n'HelveticaNeueLTStd_Roman.otf' can not be subsetted into a Type 3 font. The entire font will be embedded in the output.\n"
],
[
"fig_plot_complete(df_stepwise, 'Stepwise Control Sequence')",
"_____no_output_____"
]
],
[
[
"# Lysis Sequence",
"_____no_output_____"
]
],
[
[
"df_lysis = load_df('20190117 Thermal Subsystem Testing Data - Fourth Test.csv')\nsmooth_fan(df_lysis)\ndf_lysis",
"_____no_output_____"
],
[
"fig_plot_temps(df_lysis, 'Thermal Lysis Control Sequence')",
"_____no_output_____"
],
[
"fig_plot_complete(df_lysis, 'Thermal Lysis Control Sequence')\nplt.savefig('thermal_lysis.pdf', format='pdf')\nplt.savefig('thermal_lysis.png', format='png')",
"'HelveticaNeueLTStd_Md.otf' can not be subsetted into a Type 3 font. The entire font will be embedded in the output.\n'HelveticaNeueLTStd_Roman.otf' can not be subsetted into a Type 3 font. The entire font will be embedded in the output.\n'HelveticaNeueLTStd_Md.otf' can not be subsetted into a Type 3 font. The entire font will be embedded in the output.\n'HelveticaNeueLTStd_Roman.otf' can not be subsetted into a Type 3 font. The entire font will be embedded in the output.\n"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7cc2955007df2e6c8b1d36f3ced901a7cd49694 | 1,107 | ipynb | Jupyter Notebook | CodeChef/Chef and An Ideal Problem.ipynb | deepaksood619/Python-Competitive-Programming | c8353d732a372c2bc62f5f12169acc421e802d0c | [
"MIT"
]
| null | null | null | CodeChef/Chef and An Ideal Problem.ipynb | deepaksood619/Python-Competitive-Programming | c8353d732a372c2bc62f5f12169acc421e802d0c | [
"MIT"
]
| null | null | null | CodeChef/Chef and An Ideal Problem.ipynb | deepaksood619/Python-Competitive-Programming | c8353d732a372c2bc62f5f12169acc421e802d0c | [
"MIT"
]
| null | null | null | 18.762712 | 97 | 0.485998 | [
[
[
"import random\n\n# X - Chef pick a door\n# Y - host opens a door\n# Z - Chef should choose from remaining doors to maximize the probability of getting car\n\nlst = [1,2,3]\nX = random.choice(lst)\nprint(X)\nlst.remove(X)\nY = int(input())\nlst.remove(Y) # because it has goat\nZ = lst[0]\nprint(Z)",
"1\n2\n2\n3\n"
]
]
]
| [
"code"
]
| [
[
"code"
]
]
|
e7cc344072d9c84eaa82df891fc90b2d2d7a825a | 334,939 | ipynb | Jupyter Notebook | titanic/end-to-end-project-with-python.ipynb | MLVPRASAD/KaggleProjects | 379e062cf58d83ff57a456552bb956df68381fdd | [
"MIT"
]
| 2 | 2020-01-25T08:31:14.000Z | 2022-03-23T18:24:03.000Z | titanic/end-to-end-project-with-python.ipynb | MLVPRASAD/KaggleProjects | 379e062cf58d83ff57a456552bb956df68381fdd | [
"MIT"
]
| null | null | null | titanic/end-to-end-project-with-python.ipynb | MLVPRASAD/KaggleProjects | 379e062cf58d83ff57a456552bb956df68381fdd | [
"MIT"
]
| null | null | null | 88.188257 | 49,328 | 0.793177 | [
[
[
"## **Table of Contents:**\n* Introduction\n* The RMS Titanic\n* Import Libraries\n* Getting the Data\n* Data Exploration/Analysis\n* Data Preprocessing\n - Missing Data\n - Converting Features\n - Creating Categories\n - Creating new Features\n* Building Machine Learning Models\n - Training 8 different models\n - Which is the best model ?\n - K-Fold Cross Validation\n* Random Forest \n - What is Random Forest ?\n - Feature importance\n - Hyperparameter Tuning \n* Further Evaluation \n - Confusion Matrix\n - Precision and Recall \n - F-Score\n - Precision Recall Curve\n - ROC AUC Curve\n - ROC AUC Score\n* Submission\n* Summary",
"_____no_output_____"
],
[
"# **Introduction**\n\nIn this kernel I will go through the whole process of creating a machine learning model on the famous Titanic dataset, which is used by many people all over the world. It provides information on the fate of passengers on the Titanic, summarized according to economic status (class), sex, age and survival. In this challenge, we are asked to predict whether a passenger on the titanic would have been survived or not.",
"_____no_output_____"
],
[
"# **The RMS Titanic**\n\nRMS Titanic was a British passenger liner that sank in the North Atlantic Ocean in the early morning hours of 15 April 1912, after it collided with an iceberg during its maiden voyage from Southampton to New York City. There were an estimated 2,224 passengers and crew aboard the ship, and more than 1,500 died, making it one of the deadliest commercial peacetime maritime disasters in modern history. The RMS Titanic was the largest ship afloat at the time it entered service and was the second of three Olympic-class ocean liners operated by the White Star Line. The Titanic was built by the Harland and Wolff shipyard in Belfast. Thomas Andrews, her architect, died in the disaster.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"# **Import Libraries**",
"_____no_output_____"
]
],
[
[
"# linear algebra\nimport numpy as np \n\n# data processing\nimport pandas as pd \n\n# data visualization\nimport seaborn as sns\n%matplotlib inline\nfrom matplotlib import pyplot as plt\nfrom matplotlib import style\n\n# Algorithms\nfrom sklearn import linear_model\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.linear_model import Perceptron\nfrom sklearn.linear_model import SGDClassifier\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.svm import SVC, LinearSVC\nfrom sklearn.naive_bayes import GaussianNB",
"_____no_output_____"
]
],
[
[
"# **Getting the Data**",
"_____no_output_____"
]
],
[
[
"test_df = pd.read_csv(\"../input/test.csv\")\ntrain_df = pd.read_csv(\"../input/train.csv\")",
"_____no_output_____"
]
],
[
[
"# **Data Exploration/Analysis**",
"_____no_output_____"
]
],
[
[
"train_df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 891 entries, 0 to 890\nData columns (total 12 columns):\nPassengerId 891 non-null int64\nSurvived 891 non-null int64\nPclass 891 non-null int64\nName 891 non-null object\nSex 891 non-null object\nAge 714 non-null float64\nSibSp 891 non-null int64\nParch 891 non-null int64\nTicket 891 non-null object\nFare 891 non-null float64\nCabin 204 non-null object\nEmbarked 889 non-null object\ndtypes: float64(2), int64(5), object(5)\nmemory usage: 83.6+ KB\n"
]
],
[
[
"**The training-set has 891 examples and 11 features + the target variable (survived)**. 2 of the features are floats, 5 are integers and 5 are objects. Below I have listed the features with a short description:\n\n survival:\tSurvival\n PassengerId: Unique Id of a passenger.\n pclass:\tTicket class\t\n sex:\tSex\t\n Age:\tAge in years\t\n sibsp:\t# of siblings / spouses aboard the Titanic\t\n parch:\t# of parents / children aboard the Titanic\t\n ticket:\tTicket number\t\n fare:\tPassenger fare\t\n cabin:\tCabin number\t\n embarked:\tPort of Embarkation",
"_____no_output_____"
]
],
[
[
"train_df.describe()",
"_____no_output_____"
]
],
[
[
"Above we can see that **38% out of the training-set survived the Titanic**. We can also see that the passenger ages range from 0.4 to 80. On top of that we can already detect some features, that contain missing values, like the 'Age' feature.",
"_____no_output_____"
]
],
[
[
"train_df.head(15)",
"_____no_output_____"
]
],
[
[
"From the table above, we can note a few things. First of all, that we **need to convert a lot of features into numeric** ones later on, so that the machine learning algorithms can process them. Furthermore, we can see that the **features have widely different ranges**, that we will need to convert into roughly the same scale. We can also spot some more features, that contain missing values (NaN = not a number), that wee need to deal with.\n\n**Let's take a more detailed look at what data is actually missing:**",
"_____no_output_____"
]
],
[
[
"total = train_df.isnull().sum().sort_values(ascending=False)\npercent_1 = train_df.isnull().sum()/train_df.isnull().count()*100\npercent_2 = (round(percent_1, 1)).sort_values(ascending=False)\nmissing_data = pd.concat([total, percent_2], axis=1, keys=['Total', '%'])\nmissing_data.head(5)",
"_____no_output_____"
]
],
[
[
"The Embarked feature has only 2 missing values, which can easily be filled. It will be much more tricky, to deal with the 'Age' feature, which has 177 missing values. The 'Cabin' feature needs further investigation, but it looks like that we might want to drop it from the dataset, since 77 % of it are missing.",
"_____no_output_____"
]
],
[
[
"train_df.columns.values",
"_____no_output_____"
]
],
[
[
"Above you can see the 11 features + the target variable (survived). **What features could contribute to a high survival rate ?** \n\nTo me it would make sense if everything except 'PassengerId', 'Ticket' and 'Name' would be correlated with a high survival rate. ",
"_____no_output_____"
],
[
"**1. Age and Sex:**",
"_____no_output_____"
]
],
[
[
"survived = 'survived'\nnot_survived = 'not survived'\nfig, axes = plt.subplots(nrows=1, ncols=2,figsize=(10, 4))\nwomen = train_df[train_df['Sex']=='female']\nmen = train_df[train_df['Sex']=='male']\nax = sns.distplot(women[women['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[0], kde =False)\nax = sns.distplot(women[women['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[0], kde =False)\nax.legend()\nax.set_title('Female')\nax = sns.distplot(men[men['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[1], kde = False)\nax = sns.distplot(men[men['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[1], kde = False)\nax.legend()\n_ = ax.set_title('Male')",
"_____no_output_____"
]
],
[
[
"You can see that men have a high probability of survival when they are between 18 and 30 years old, which is also a little bit true for women but not fully. For women the survival chances are higher between 14 and 40.\n\nFor men the probability of survival is very low between the age of 5 and 18, but that isn't true for women. Another thing to note is that infants also have a little bit higher probability of survival.\n\nSince there seem to be **certain ages, which have increased odds of survival** and because I want every feature to be roughly on the same scale, I will create age groups later on.",
"_____no_output_____"
],
[
"**3. Embarked, Pclass and Sex:**",
"_____no_output_____"
]
],
[
[
"FacetGrid = sns.FacetGrid(train_df, row='Embarked', size=4.5, aspect=1.6)\nFacetGrid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette=None, order=None, hue_order=None )\nFacetGrid.add_legend()",
"/opt/conda/lib/python3.6/site-packages/seaborn/axisgrid.py:230: UserWarning: The `size` paramter has been renamed to `height`; please update your code.\n warnings.warn(msg, UserWarning)\n/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.\n return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval\n"
]
],
[
[
"Embarked seems to be correlated with survival, depending on the gender. \n\nWomen on port Q and on port S have a higher chance of survival. The inverse is true, if they are at port C. Men have a high survival probability if they are on port C, but a low probability if they are on port Q or S. \n\nPclass also seems to be correlated with survival. We will generate another plot of it below.",
"_____no_output_____"
],
[
"**4. Pclass:**",
"_____no_output_____"
]
],
[
[
"sns.barplot(x='Pclass', y='Survived', data=train_df)",
"/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.\n return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval\n"
]
],
[
[
"Here we see clearly, that Pclass is contributing to a persons chance of survival, especially if this person is in class 1. We will create another pclass plot below.",
"_____no_output_____"
]
],
[
[
"grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.2, aspect=1.6)\ngrid.map(plt.hist, 'Age', alpha=.5, bins=20)\ngrid.add_legend();",
"/opt/conda/lib/python3.6/site-packages/seaborn/axisgrid.py:230: UserWarning: The `size` paramter has been renamed to `height`; please update your code.\n warnings.warn(msg, UserWarning)\n"
]
],
[
[
"The plot above confirms our assumption about pclass 1, but we can also spot a high probability that a person in pclass 3 will not survive.",
"_____no_output_____"
],
[
"**5. SibSp and Parch:**\n\nSibSp and Parch would make more sense as a combined feature, that shows the total number of relatives, a person has on the Titanic. I will create it below and also a feature that sows if someone is not alone.",
"_____no_output_____"
]
],
[
[
"data = [train_df, test_df]\nfor dataset in data:\n dataset['relatives'] = dataset['SibSp'] + dataset['Parch']\n dataset.loc[dataset['relatives'] > 0, 'not_alone'] = 0\n dataset.loc[dataset['relatives'] == 0, 'not_alone'] = 1\n dataset['not_alone'] = dataset['not_alone'].astype(int)",
"_____no_output_____"
],
[
"train_df['not_alone'].value_counts()",
"_____no_output_____"
],
[
"axes = sns.factorplot('relatives','Survived', \n data=train_df, aspect = 2.5, )",
"/opt/conda/lib/python3.6/site-packages/seaborn/categorical.py:3666: UserWarning: The `factorplot` function has been renamed to `catplot`. The original name will be removed in a future release. Please update your code. Note that the default `kind` in `factorplot` (`'point'`) has changed `'strip'` in `catplot`.\n warnings.warn(msg)\n/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.\n return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval\n"
]
],
[
[
"Here we can see that you had a high probabilty of survival with 1 to 3 realitves, but a lower one if you had less than 1 or more than 3 (except for some cases with 6 relatives).",
"_____no_output_____"
],
[
"# **Data Preprocessing**",
"_____no_output_____"
],
[
"First, I will drop 'PassengerId' from the train set, because it does not contribute to a persons survival probability. I will not drop it from the test set, since it is required there for the submission",
"_____no_output_____"
]
],
[
[
"train_df = train_df.drop(['PassengerId'], axis=1)",
"_____no_output_____"
]
],
[
[
"## Missing Data:\n### Cabin:\nAs a reminder, we have to deal with Cabin (687), Embarked (2) and Age (177). \n\nFirst I thought, we have to delete the 'Cabin' variable but then I found something interesting. A cabin number looks like ‘C123’ and the **letter refers to the deck**. \n\nTherefore we’re going to extract these and create a new feature, that contains a persons deck. Afterwords we will convert the feature into a numeric variable. The missing values will be converted to zero.\n\nIn the picture below you can see the actual decks of the titanic, ranging from A to G.\n\n",
"_____no_output_____"
]
],
[
[
"import re\ndeck = {\"A\": 1, \"B\": 2, \"C\": 3, \"D\": 4, \"E\": 5, \"F\": 6, \"G\": 7, \"U\": 8}\ndata = [train_df, test_df]\n\nfor dataset in data:\n dataset['Cabin'] = dataset['Cabin'].fillna(\"U0\")\n dataset['Deck'] = dataset['Cabin'].map(lambda x: re.compile(\"([a-zA-Z]+)\").search(x).group())\n dataset['Deck'] = dataset['Deck'].map(deck)\n dataset['Deck'] = dataset['Deck'].fillna(0)\n dataset['Deck'] = dataset['Deck'].astype(int) ",
"_____no_output_____"
],
[
"# we can now drop the cabin feature\ntrain_df = train_df.drop(['Cabin'], axis=1)\ntest_df = test_df.drop(['Cabin'], axis=1)",
"_____no_output_____"
]
],
[
[
"### Age:\n\nNow we can tackle the issue with the age features missing values. I will create an array that contains random numbers, which are computed based on the mean age value in regards to the standard deviation and is_null.",
"_____no_output_____"
]
],
[
[
"data = [train_df, test_df]\n\nfor dataset in data:\n mean = train_df[\"Age\"].mean()\n std = test_df[\"Age\"].std()\n is_null = dataset[\"Age\"].isnull().sum()\n # compute random numbers between the mean, std and is_null\n rand_age = np.random.randint(mean - std, mean + std, size = is_null)\n # fill NaN values in Age column with random values generated\n age_slice = dataset[\"Age\"].copy()\n age_slice[np.isnan(age_slice)] = rand_age\n dataset[\"Age\"] = age_slice\n dataset[\"Age\"] = train_df[\"Age\"].astype(int)",
"_____no_output_____"
],
[
"train_df[\"Age\"].isnull().sum()",
"_____no_output_____"
]
],
[
[
"### Embarked:\n\nSince the Embarked feature has only 2 missing values, we will just fill these with the most common one.",
"_____no_output_____"
]
],
[
[
"train_df['Embarked'].describe()",
"_____no_output_____"
],
[
"common_value = 'S'\ndata = [train_df, test_df]\n\nfor dataset in data:\n dataset['Embarked'] = dataset['Embarked'].fillna(common_value)",
"_____no_output_____"
]
],
[
[
"## Converting Features:",
"_____no_output_____"
]
],
[
[
"train_df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 891 entries, 0 to 890\nData columns (total 13 columns):\nSurvived 891 non-null int64\nPclass 891 non-null int64\nName 891 non-null object\nSex 891 non-null object\nAge 891 non-null int64\nSibSp 891 non-null int64\nParch 891 non-null int64\nTicket 891 non-null object\nFare 891 non-null float64\nEmbarked 891 non-null object\nrelatives 891 non-null int64\nnot_alone 891 non-null int64\nDeck 891 non-null int64\ndtypes: float64(1), int64(8), object(4)\nmemory usage: 90.6+ KB\n"
]
],
[
[
"Above you can see that 'Fare' is a float and we have to deal with 4 categorical features: Name, Sex, Ticket and Embarked. Lets investigate and transfrom one after another.",
"_____no_output_____"
],
[
"### Fare:\n\nConverting \"Fare\" from float to int64, using the \"astype()\" function pandas provides:",
"_____no_output_____"
]
],
[
[
"data = [train_df, test_df]\n\nfor dataset in data:\n dataset['Fare'] = dataset['Fare'].fillna(0)\n dataset['Fare'] = dataset['Fare'].astype(int)",
"_____no_output_____"
]
],
[
[
"### Name:\nWe will use the Name feature to extract the Titles from the Name, so that we can build a new feature out of that.",
"_____no_output_____"
]
],
[
[
"data = [train_df, test_df]\ntitles = {\"Mr\": 1, \"Miss\": 2, \"Mrs\": 3, \"Master\": 4, \"Rare\": 5}\n\nfor dataset in data:\n # extract titles\n dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\\.', expand=False)\n # replace titles with a more common title or as Rare\n dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr',\\\n 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')\n dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')\n dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')\n dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')\n # convert titles into numbers\n dataset['Title'] = dataset['Title'].map(titles)\n # filling NaN with 0, to get safe\n dataset['Title'] = dataset['Title'].fillna(0)",
"_____no_output_____"
],
[
"train_df = train_df.drop(['Name'], axis=1)\ntest_df = test_df.drop(['Name'], axis=1)",
"_____no_output_____"
]
],
[
[
"### Sex:\n\nConvert 'Sex' feature into numeric.",
"_____no_output_____"
]
],
[
[
"genders = {\"male\": 0, \"female\": 1}\ndata = [train_df, test_df]\n\nfor dataset in data:\n dataset['Sex'] = dataset['Sex'].map(genders)",
"_____no_output_____"
]
],
[
[
"### Ticket:",
"_____no_output_____"
]
],
[
[
"train_df['Ticket'].describe()",
"_____no_output_____"
]
],
[
[
"Since the Ticket attribute has 681 unique tickets, it will be a bit tricky to convert them into useful categories. So we will drop it from the dataset.",
"_____no_output_____"
]
],
[
[
"train_df = train_df.drop(['Ticket'], axis=1)\ntest_df = test_df.drop(['Ticket'], axis=1)",
"_____no_output_____"
]
],
[
[
"### Embarked:\nConvert 'Embarked' feature into numeric.",
"_____no_output_____"
]
],
[
[
"ports = {\"S\": 0, \"C\": 1, \"Q\": 2}\ndata = [train_df, test_df]\n\nfor dataset in data:\n dataset['Embarked'] = dataset['Embarked'].map(ports)",
"_____no_output_____"
]
],
[
[
"## Creating Categories:\n\nWe will now create categories within the following features:\n\n### Age:\nNow we need to convert the 'age' feature. First we will convert it from float into integer. Then we will create the new 'AgeGroup\" variable, by categorizing every age into a group. Note that it is important to place attention on how you form these groups, since you don't want for example that 80% of your data falls into group 1.",
"_____no_output_____"
]
],
[
[
"data = [train_df, test_df]\nfor dataset in data:\n dataset['Age'] = dataset['Age'].astype(int)\n dataset.loc[ dataset['Age'] <= 11, 'Age'] = 0\n dataset.loc[(dataset['Age'] > 11) & (dataset['Age'] <= 18), 'Age'] = 1\n dataset.loc[(dataset['Age'] > 18) & (dataset['Age'] <= 22), 'Age'] = 2\n dataset.loc[(dataset['Age'] > 22) & (dataset['Age'] <= 27), 'Age'] = 3\n dataset.loc[(dataset['Age'] > 27) & (dataset['Age'] <= 33), 'Age'] = 4\n dataset.loc[(dataset['Age'] > 33) & (dataset['Age'] <= 40), 'Age'] = 5\n dataset.loc[(dataset['Age'] > 40) & (dataset['Age'] <= 66), 'Age'] = 6\n dataset.loc[ dataset['Age'] > 66, 'Age'] = 6",
"_____no_output_____"
],
[
"# let's see how it's distributed\ntrain_df['Age'].value_counts()",
"_____no_output_____"
]
],
[
[
"### Fare:\nFor the 'Fare' feature, we need to do the same as with the 'Age' feature. But it isn't that easy, because if we cut the range of the fare values into a few equally big categories, 80% of the values would fall into the first category. Fortunately, we can use sklearn \"qcut()\" function, that we can use to see, how we can form the categories.",
"_____no_output_____"
]
],
[
[
"train_df.head(10)",
"_____no_output_____"
],
[
"data = [train_df, test_df]\n\nfor dataset in data:\n dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0\n dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1\n dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2\n dataset.loc[(dataset['Fare'] > 31) & (dataset['Fare'] <= 99), 'Fare'] = 3\n dataset.loc[(dataset['Fare'] > 99) & (dataset['Fare'] <= 250), 'Fare'] = 4\n dataset.loc[ dataset['Fare'] > 250, 'Fare'] = 5\n dataset['Fare'] = dataset['Fare'].astype(int)",
"_____no_output_____"
]
],
[
[
"# Creating new Features\n\nI will add two new features to the dataset, that I compute out of other features.\n\n### 1. Age times Class",
"_____no_output_____"
]
],
[
[
"data = [train_df, test_df]\nfor dataset in data:\n dataset['Age_Class']= dataset['Age']* dataset['Pclass']",
"_____no_output_____"
]
],
[
[
"### 2. Fare per Person",
"_____no_output_____"
]
],
[
[
"for dataset in data:\n dataset['Fare_Per_Person'] = dataset['Fare']/(dataset['relatives']+1)\n dataset['Fare_Per_Person'] = dataset['Fare_Per_Person'].astype(int)",
"_____no_output_____"
],
[
"# Let's take a last look at the training set, before we start training the models.\ntrain_df.head(20)",
"_____no_output_____"
]
],
[
[
"# **Building Machine Learning Models**",
"_____no_output_____"
]
],
[
[
"X_train = train_df.drop(\"Survived\", axis=1)\nY_train = train_df[\"Survived\"]\nX_test = test_df.drop(\"PassengerId\", axis=1).copy()",
"_____no_output_____"
],
[
"# stochastic gradient descent (SGD) learning\nsgd = linear_model.SGDClassifier(max_iter=5, tol=None)\nsgd.fit(X_train, Y_train)\nY_pred = sgd.predict(X_test)\n\nsgd.score(X_train, Y_train)\n\nacc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)\n\n\nprint(round(acc_sgd,2,), \"%\")",
"47.03 %\n"
],
[
"# Random Forest\nrandom_forest = RandomForestClassifier(n_estimators=100)\nrandom_forest.fit(X_train, Y_train)\n\nY_prediction = random_forest.predict(X_test)\n\nrandom_forest.score(X_train, Y_train)\nacc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)\nprint(round(acc_random_forest,2,), \"%\")",
"92.48 %\n"
],
[
"# Logistic Regression\nlogreg = LogisticRegression()\nlogreg.fit(X_train, Y_train)\n\nY_pred = logreg.predict(X_test)\n\nacc_log = round(logreg.score(X_train, Y_train) * 100, 2)\nprint(round(acc_log,2,), \"%\")",
"81.37 %\n"
],
[
"# KNN\nknn = KNeighborsClassifier(n_neighbors = 3)\nknn.fit(X_train, Y_train)\n\nY_pred = knn.predict(X_test)\n\nacc_knn = round(knn.score(X_train, Y_train) * 100, 2)\nprint(round(acc_knn,2,), \"%\")",
"87.65 %\n"
],
[
"# Gaussian Naive Bayes\ngaussian = GaussianNB()\ngaussian.fit(X_train, Y_train)\n\nY_pred = gaussian.predict(X_test)\n\nacc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)\nprint(round(acc_gaussian,2,), \"%\")",
"78.23 %\n"
],
[
"# Perceptron\nperceptron = Perceptron(max_iter=5)\nperceptron.fit(X_train, Y_train)\n\nY_pred = perceptron.predict(X_test)\n\nacc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)\nprint(round(acc_perceptron,2,), \"%\")",
"81.59 %\n"
],
[
"# Linear SVC\nlinear_svc = LinearSVC()\nlinear_svc.fit(X_train, Y_train)\n\nY_pred = linear_svc.predict(X_test)\n\nacc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)\nprint(round(acc_linear_svc,2,), \"%\")",
"80.7 %\n"
],
[
"# Decision Tree\ndecision_tree = DecisionTreeClassifier()\ndecision_tree.fit(X_train, Y_train)\n\nY_pred = decision_tree.predict(X_test)\n\nacc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)\nprint(round(acc_decision_tree,2,), \"%\")",
"92.48 %\n"
]
],
[
[
"## Which is the best Model ?",
"_____no_output_____"
]
],
[
[
"results = pd.DataFrame({\n 'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression', \n 'Random Forest', 'Naive Bayes', 'Perceptron', \n 'Stochastic Gradient Decent', \n 'Decision Tree'],\n 'Score': [acc_linear_svc, acc_knn, acc_log, \n acc_random_forest, acc_gaussian, acc_perceptron, \n acc_sgd, acc_decision_tree]})\nresult_df = results.sort_values(by='Score', ascending=False)\nresult_df = result_df.set_index('Score')\nresult_df.head(9)",
"_____no_output_____"
]
],
[
[
"As we can see, the Random Forest classifier goes on the first place. But first, let us check, how random-forest performs, when we use cross validation. ",
"_____no_output_____"
],
[
"## K-Fold Cross Validation:\n\nK-Fold Cross Validation randomly splits the training data into **K subsets called folds**. Let's image we would split our data into 4 folds (K = 4). Our random forest model would be trained and evaluated 4 times, using a different fold for evaluation everytime, while it would be trained on the remaining 3 folds. \n\nThe image below shows the process, using 4 folds (K = 4). Every row represents one training + evaluation process. In the first row, the model get's trained on the first, second and third subset and evaluated on the fourth. In the second row, the model get's trained on the second, third and fourth subset and evaluated on the first. K-Fold Cross Validation repeats this process till every fold acted once as an evaluation fold.\n\n\n\n\nThe result of our K-Fold Cross Validation example would be an array that contains 4 different scores. We then need to compute the mean and the standard deviation for these scores. \n\nThe code below perform K-Fold Cross Validation on our random forest model, using 10 folds (K = 10). Therefore it outputs an array with 10 different scores.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score\nrf = RandomForestClassifier(n_estimators=100)\nscores = cross_val_score(rf, X_train, Y_train, cv=10, scoring = \"accuracy\")",
"_____no_output_____"
],
[
"print(\"Scores:\", scores)\nprint(\"Mean:\", scores.mean())\nprint(\"Standard Deviation:\", scores.std())",
"Scores: [0.77777778 0.83333333 0.73033708 0.84269663 0.87640449 0.82022472\n 0.80898876 0.7752809 0.85393258 0.88636364]\nMean: 0.8205339916014074\nStandard Deviation: 0.04622805870202012\n"
]
],
[
[
"This looks much more realistic than before. Our model has a average accuracy of 82% with a standard deviation of 4 %. The standard deviation shows us, how precise the estimates are . \n\nThis means in our case that the accuracy of our model can differ **+ -** 4%.\n\nI think the accuracy is still really good and since random forest is an easy to use model, we will try to increase it's performance even further in the following section.",
"_____no_output_____"
],
[
"# **Random Forest**\n\n## What is Random Forest ?\n\nRandom Forest is a supervised learning algorithm. Like you can already see from it’s name, it creates a forest and makes it somehow random. The „forest“ it builds, is an ensemble of Decision Trees, most of the time trained with the “bagging” method. The general idea of the bagging method is that a combination of learning models increases the overall result.\n\nTo say it in simple words: Random forest builds multiple decision trees and merges them together to get a more accurate and stable prediction.\n\nOne big advantage of random forest is, that it can be used for both classification and regression problems, which form the majority of current machine learning systems. With a few exceptions a random-forest classifier has all the hyperparameters of a decision-tree classifier and also all the hyperparameters of a bagging classifier, to control the ensemble itself. \n\nThe random-forest algorithm brings extra randomness into the model, when it is growing the trees. Instead of searching for the best feature while splitting a node, it searches for the best feature among a random subset of features. This process creates a wide diversity, which generally results in a better model. Therefore when you are growing a tree in random forest, only a random subset of the features is considered for splitting a node. You can even make trees more random, by using random thresholds on top of it, for each feature rather than searching for the best possible thresholds (like a normal decision tree does).\n\nBelow you can see how a random forest would look like with two trees:\n\n",
"_____no_output_____"
],
[
"## Feature Importance\n\nAnother great quality of random forest is that they make it very easy to measure the relative importance of each feature. Sklearn measure a features importance by looking at how much the treee nodes, that use that feature, reduce impurity on average (across all trees in the forest). It computes this score automaticall for each feature after training and scales the results so that the sum of all importances is equal to 1. We will acces this below:",
"_____no_output_____"
]
],
[
[
"importances = pd.DataFrame({'feature':X_train.columns,'importance':np.round(random_forest.feature_importances_,3)})\nimportances = importances.sort_values('importance',ascending=False).set_index('feature')",
"_____no_output_____"
],
[
"importances.head(15)",
"_____no_output_____"
],
[
"importances.plot.bar()",
"_____no_output_____"
]
],
[
[
"**Conclusion:**\n\nnot_alone and Parch doesn't play a significant role in our random forest classifiers prediction process. Because of that I will drop them from the dataset and train the classifier again. We could also remove more or less features, but this would need a more detailed investigation of the features effect on our model. But I think it's just fine to remove only Alone and Parch.",
"_____no_output_____"
]
],
[
[
"train_df = train_df.drop(\"not_alone\", axis=1)\ntest_df = test_df.drop(\"not_alone\", axis=1)\n\ntrain_df = train_df.drop(\"Parch\", axis=1)\ntest_df = test_df.drop(\"Parch\", axis=1)",
"_____no_output_____"
]
],
[
[
"**Training random forest again:**",
"_____no_output_____"
]
],
[
[
"# Random Forest\n\nrandom_forest = RandomForestClassifier(n_estimators=100, oob_score = True)\nrandom_forest.fit(X_train, Y_train)\nY_prediction = random_forest.predict(X_test)\n\nrandom_forest.score(X_train, Y_train)\n\nacc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)\nprint(round(acc_random_forest,2,), \"%\")",
"92.48 %\n"
]
],
[
[
"Our random forest model predicts as good as it did before. A general rule is that, **the more features you have, the more likely your model will suffer from overfitting** and vice versa. But I think our data looks fine for now and hasn't too much features.\n\nThere is also another way to evaluate a random-forest classifier, which is probably much more accurate than the score we used before. What I am talking about is the **out-of-bag samples** to estimate the generalization accuracy. I will not go into details here about how it works. Just note that out-of-bag estimate is as accurate as using a test set of the same size as the training set. Therefore, using the out-of-bag error estimate removes the need for a set aside test set.",
"_____no_output_____"
]
],
[
[
"print(\"oob score:\", round(random_forest.oob_score_, 4)*100, \"%\")",
"oob score: 81.82000000000001 %\n"
]
],
[
[
"Now we can start tuning the hyperameters of random forest. ",
"_____no_output_____"
],
[
"## Hyperparameter Tuning\n\nBelow you can see the code of the hyperparamter tuning for the parameters criterion, min_samples_leaf, min_samples_split and n_estimators. \n\nI put this code into a markdown cell and not into a code cell, because it takes a long time to run it. Directly underneeth it, I put a screenshot of the gridsearch's output.",
"_____no_output_____"
],
[
"param_grid = { \"criterion\" : [\"gini\", \"entropy\"], \n \"min_samples_leaf\" : [1, 5, 10, 25, 50, 70], \n \"min_samples_split\" : [2, 4, 10, 12, 16, 18, 25, 35], \n \"n_estimators\": [100, 400, 700, 1000, 1500]}\n\n\nfrom sklearn.model_selection import GridSearchCV, cross_val_score\n\nrf = RandomForestClassifier(n_estimators=100, max_features='auto', oob_score=True, random_state=1, n_jobs=-1)\n\nclf = GridSearchCV(estimator=rf, param_grid=param_grid,\n n_jobs=-1)\n\nclf.fit(X_train, Y_train) \n\nclf.best_params_\n\n",
"_____no_output_____"
],
[
"**Test new paramters:**",
"_____no_output_____"
]
],
[
[
"# Random Forest\nrandom_forest = RandomForestClassifier(criterion = \"gini\", \n min_samples_leaf = 1, \n min_samples_split = 10, \n n_estimators=100, \n max_features='auto', \n oob_score=True, \n random_state=1, \n n_jobs=-1)\n\nrandom_forest.fit(X_train, Y_train)\nY_prediction = random_forest.predict(X_test)\n\nrandom_forest.score(X_train, Y_train)\n\nprint(\"oob score:\", round(random_forest.oob_score_, 4)*100, \"%\")",
"oob score: 83.39 %\n"
]
],
[
[
"Now that we have a proper model, we can start evaluating it's performace in a more accurate way. Previously we only used accuracy and the oob score, which is just another form of accuracy. The problem is just, that it's more complicated to evaluate a classification model than a regression model. We will talk about this in the following section.",
"_____no_output_____"
],
[
"# **Further Evaluation**\n\n",
"_____no_output_____"
],
[
"## Confusion Matrix:",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_predict\nfrom sklearn.metrics import confusion_matrix\npredictions = cross_val_predict(random_forest, X_train, Y_train, cv=3)\nconfusion_matrix(Y_train, predictions)",
"_____no_output_____"
]
],
[
[
"The first row is about the not-survived-predictions: **493 passengers were correctly classified as not survived** (called true negatives) and **56 where wrongly classified as not survived** (false negatives).\n\nThe second row is about the survived-predictions: **93 passengers where wrongly classified as survived** (false positives) and **249 where correctly classified as survived** (true positives).\n\nA confusion matrix gives you a lot of information about how well your model does, but theres a way to get even more, like computing the classifiers precision.",
"_____no_output_____"
],
[
"## Precision and Recall:",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import precision_score, recall_score\n\nprint(\"Precision:\", precision_score(Y_train, predictions))\nprint(\"Recall:\",recall_score(Y_train, predictions))",
"Precision: 0.8013029315960912\nRecall: 0.7192982456140351\n"
]
],
[
[
"Our model predicts 81% of the time, a passengers survival correctly (precision). The recall tells us that it predicted the survival of 73 % of the people who actually survived. ",
"_____no_output_____"
],
[
"## F-Score\n\nYou can combine precision and recall into one score, which is called the F-score. The F-score is computed with the harmonic mean of precision and recall. Note that it assigns much more weight to low values. As a result of that, the classifier will only get a high F-score, if both recall and precision are high.",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import f1_score\nf1_score(Y_train, predictions)",
"_____no_output_____"
]
],
[
[
"There we have it, a 77 % F-score. The score is not that high, because we have a recall of 73%.\n\nBut unfortunately the F-score is not perfect, because it favors classifiers that have a similar precision and recall. This is a problem, because you sometimes want a high precision and sometimes a high recall. The thing is that an increasing precision, sometimes results in an decreasing recall and vice versa (depending on the threshold). This is called the precision/recall tradeoff. We will discuss this in the following section.\n",
"_____no_output_____"
],
[
"## Precision Recall Curve\n\nFor each person the Random Forest algorithm has to classify, it computes a probability based on a function and it classifies the person as survived (when the score is bigger the than threshold) or as not survived (when the score is smaller than the threshold). That's why the threshold plays an important part.\n\nWe will plot the precision and recall with the threshold using matplotlib:",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import precision_recall_curve\n\n# getting the probabilities of our predictions\ny_scores = random_forest.predict_proba(X_train)\ny_scores = y_scores[:,1]\n\nprecision, recall, threshold = precision_recall_curve(Y_train, y_scores)",
"_____no_output_____"
],
[
"def plot_precision_and_recall(precision, recall, threshold):\n plt.plot(threshold, precision[:-1], \"r-\", label=\"precision\", linewidth=5)\n plt.plot(threshold, recall[:-1], \"b\", label=\"recall\", linewidth=5)\n plt.xlabel(\"threshold\", fontsize=19)\n plt.legend(loc=\"upper right\", fontsize=19)\n plt.ylim([0, 1])\n\nplt.figure(figsize=(14, 7))\nplot_precision_and_recall(precision, recall, threshold)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Above you can clearly see that the recall is falling of rapidly at a precision of around 85%. Because of that you may want to select the precision/recall tradeoff before that - maybe at around 75 %.\n\nYou are now able to choose a threshold, that gives you the best precision/recall tradeoff for your current machine learning problem. If you want for example a precision of 80%, you can easily look at the plots and see that you would need a threshold of around 0.4. Then you could train a model with exactly that threshold and would get the desired accuracy.\n\n\nAnother way is to plot the precision and recall against each other:",
"_____no_output_____"
]
],
[
[
"def plot_precision_vs_recall(precision, recall):\n plt.plot(recall, precision, \"g--\", linewidth=2.5)\n plt.ylabel(\"recall\", fontsize=19)\n plt.xlabel(\"precision\", fontsize=19)\n plt.axis([0, 1.5, 0, 1.5])\n\nplt.figure(figsize=(14, 7))\nplot_precision_vs_recall(precision, recall)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## ROC AUC Curve\n\nAnother way to evaluate and compare your binary classifier is provided by the ROC AUC Curve. This curve plots the true positive rate (also called recall) against the false positive rate (ratio of incorrectly classified negative instances), instead of plotting the precision versus the recall.",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import roc_curve\n# compute true positive rate and false positive rate\nfalse_positive_rate, true_positive_rate, thresholds = roc_curve(Y_train, y_scores)",
"_____no_output_____"
],
[
"# plotting them against each other\ndef plot_roc_curve(false_positive_rate, true_positive_rate, label=None):\n plt.plot(false_positive_rate, true_positive_rate, linewidth=2, label=label)\n plt.plot([0, 1], [0, 1], 'r', linewidth=4)\n plt.axis([0, 1, 0, 1])\n plt.xlabel('False Positive Rate (FPR)', fontsize=16)\n plt.ylabel('True Positive Rate (TPR)', fontsize=16)\n\nplt.figure(figsize=(14, 7))\nplot_roc_curve(false_positive_rate, true_positive_rate)\nplt.show()",
"_____no_output_____"
]
],
[
[
"The red line in the middel represents a purely random classifier (e.g a coin flip) and therefore your classifier should be as far away from it as possible. Our Random Forest model seems to do a good job. \n\nOf course we also have a tradeoff here, because the classifier produces more false positives, the higher the true positive rate is. ",
"_____no_output_____"
],
[
"## ROC AUC Score\nThe ROC AUC Score is the corresponding score to the ROC AUC Curve. It is simply computed by measuring the area under the curve, which is called AUC. \n\nA classifiers that is 100% correct, would have a ROC AUC Score of 1 and a completely random classiffier would have a score of 0.5.",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import roc_auc_score\nr_a_score = roc_auc_score(Y_train, y_scores)\nprint(\"ROC-AUC-Score:\", r_a_score)",
"ROC-AUC-Score: 0.9424898007009023\n"
]
],
[
[
"Nice ! I think that score is good enough to submit the predictions for the test-set to the Kaggle leaderboard.",
"_____no_output_____"
],
[
"# **Submission**",
"_____no_output_____"
]
],
[
[
"submission = pd.DataFrame({\n \"PassengerId\": test_df[\"PassengerId\"],\n \"Survived\": Y_prediction\n })\nsubmission.to_csv('submission.csv', index=False)",
"_____no_output_____"
]
],
[
[
"# **Summary**\n\nThis project deepened my machine learning knowledge significantly and I strengthened my ability to apply concepts that I learned from textbooks, blogs and various other sources, on a different type of problem. This project had a heavy focus on the data preparation part, since this is what data scientists work on most of their time. \n\nI started with the data exploration where I got a feeling for the dataset, checked about missing data and learned which features are important. During this process I used seaborn and matplotlib to do the visualizations. During the data preprocessing part, I computed missing values, converted features into numeric ones, grouped values into categories and created a few new features. Afterwards I started training 8 different machine learning models, picked one of them (random forest) and applied cross validation on it. Then I explained how random forest works, took a look at the importance it assigns to the different features and tuned it's performace through optimizing it's hyperparameter values. Lastly I took a look at it's confusion matrix and computed the models precision, recall and f-score, before submitting my predictions on the test-set to the Kaggle leaderboard.\n\nBelow you can see a before and after picture of the train_df dataframe:\n\n\n\n\nOf course there is still room for improvement, like doing a more extensive feature engineering, by comparing and plotting the features against each other and identifying and removing the noisy features. Another thing that can improve the overall result on the kaggle leaderboard would be a more extensive hyperparameter tuning on several machine learning models. Of course you could also do some ensemble learning.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7cc380f3c9388e74da091cbd0d669cbd811c69c | 7,237 | ipynb | Jupyter Notebook | decision-trees/lenses-tree.ipynb | HectorJuarezL/machine-learning-codes | 8b3e5a81f9dfeeba51b8e4226b33a9849b55e588 | [
"MIT"
]
| null | null | null | decision-trees/lenses-tree.ipynb | HectorJuarezL/machine-learning-codes | 8b3e5a81f9dfeeba51b8e4226b33a9849b55e588 | [
"MIT"
]
| null | null | null | decision-trees/lenses-tree.ipynb | HectorJuarezL/machine-learning-codes | 8b3e5a81f9dfeeba51b8e4226b33a9849b55e588 | [
"MIT"
]
| null | null | null | 19.094987 | 87 | 0.44839 | [
[
[
"import trees\nmyDat,labels=trees.createDataSet()\nmyDat",
"_____no_output_____"
],
[
"trees.calcShannonEnt(myDat)",
"_____no_output_____"
],
[
"myDat[0][-1]='maybe'\nmyDat",
"_____no_output_____"
],
[
"trees.calcShannonEnt(myDat)",
"_____no_output_____"
],
[
"#Siguiente parte\n\nmyDat,labels=trees.createDataSet()\nmyDat\n",
"_____no_output_____"
],
[
"trees.splitDataSet(myDat,0,1)",
"_____no_output_____"
],
[
"trees.splitDataSet(myDat,0,0)",
"_____no_output_____"
],
[
"#Siguiente parte mas\n\nmyDat,labels=trees.createDataSet()\ntrees.chooseBestFeatureToSplit(myDat)",
"_____no_output_____"
],
[
"myDat",
"_____no_output_____"
],
[
"### espacio\nimport trees\nmyDat,labels=trees.createDataSet()\nlabels\n",
"_____no_output_____"
],
[
"myTree = trees.createTree(myDat,labels[:])\nmyTree",
"_____no_output_____"
],
[
"#myDat,labels=trees.createDataSet()\ntrees.classify(myTree,labels,[1,0])",
"_____no_output_____"
],
[
"trees.classify(myTree,labels,[1,1])",
"_____no_output_____"
],
[
"myTree",
"_____no_output_____"
],
[
"trees.storeTree(myTree,'classifierStorage.txt')\ntrees.grabTree('classifierStorage.txt')",
"_____no_output_____"
],
[
"fr=open('lenses.txt')\nlenses=[inst.strip().split('\\t') for inst in fr.readlines()]\nlensesLabels=['age', 'prescript', 'astigmatic', 'tearRate']\nlensesTree = trees.createTree(lenses,lensesLabels)\nlensesTree",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cc44d4d6d1a6eac3fd14935a0f3fe300863f40 | 87,026 | ipynb | Jupyter Notebook | m02_data_analysis/m02_c02_data_manipulation/m02_c02_data_manipulation.ipynb | Taz-Ricardo/mat281_portafolio | 03d9154ef7f383f5e42c4ce419f80c099a0ed162 | [
"MIT",
"BSD-3-Clause"
]
| null | null | null | m02_data_analysis/m02_c02_data_manipulation/m02_c02_data_manipulation.ipynb | Taz-Ricardo/mat281_portafolio | 03d9154ef7f383f5e42c4ce419f80c099a0ed162 | [
"MIT",
"BSD-3-Clause"
]
| null | null | null | m02_data_analysis/m02_c02_data_manipulation/m02_c02_data_manipulation.ipynb | Taz-Ricardo/mat281_portafolio | 03d9154ef7f383f5e42c4ce419f80c099a0ed162 | [
"MIT",
"BSD-3-Clause"
]
| null | null | null | 28.683586 | 503 | 0.415152 | [
[
[
"<img src=\"https://upload.wikimedia.org/wikipedia/commons/4/47/Logo_UTFSM.png\" width=\"200\" alt=\"utfsm-logo\" align=\"left\"/>\n\n# MAT281\n### Aplicaciones de la Matemática en la Ingeniería",
"_____no_output_____"
],
[
"## Módulo 02\n## Clase 02: Manipulación de Datos",
"_____no_output_____"
],
[
"## Objetivos\n\n* Comprender objetos de pandas\n* Poder realizar manipulación de datos",
"_____no_output_____"
],
[
"## Contenidos\n* [Introducción a Pandas](#pandas)\n* [Series](#series)\n* [DataFrames](#dataframes)",
"_____no_output_____"
],
[
"<a id='pandas'></a>\n## Introducción a Pandas",
"_____no_output_____"
],
[
"Desde el [repositorio](https://github.com/pandas-dev/pandas) oficial:\n\npandas is a Python package providing fast, flexible, and expressive data structures designed to make working with \"relational\" or \"labeled\" data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, **real world** data analysis in Python. Additionally, it has the broader goal of becoming **the most powerful and flexible open source data analysis / manipulation tool available in any language**. It is already well on its way towards this goal.",
"_____no_output_____"
],
[
"### Principales Características\n\n* Easy handling of missing data (represented as NaN) in floating point as well as non-floating point data\n* Size mutability: columns can be inserted and deleted from DataFrame and higher dimensional objects\n* Automatic and explicit data alignment: objects can be explicitly aligned to a set of labels, or the user can simply ignore the labels and let Series, DataFrame, etc. automatically align the data for you in computations\n* Powerful, flexible group by functionality to perform split-apply-combine operations on data sets, for both aggregating and transforming data\n* Make it easy to convert ragged, differently-indexed data in other Python and NumPy data structures into DataFrame objects\n* Intelligent label-based slicing, fancy indexing, and subsetting of large data sets\n* Intuitive merging and joining data sets\n* Flexible reshaping and pivoting of data sets\n* Hierarchical labeling of axes (possible to have multiple labels per tick)\n* Robust IO tools for loading data from flat files (CSV and delimited), Excel files, databases, and saving/loading data from the ultrafast HDF5 format\n* Time series-specific functionality: date range generation and frequency conversion, moving window statistics, moving window linear regressions, date shifting and lagging, etc.",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"pd.__version__",
"_____no_output_____"
]
],
[
[
"<a id='series'></a>\n## Series",
"_____no_output_____"
],
[
"Arreglos unidimensionales con etiquetas. Se puede pensar como una generalización de los diccionarios de Python.",
"_____no_output_____"
]
],
[
[
"pd.Series?",
"_____no_output_____"
]
],
[
[
"Para crear una instancia de una serie existen muchas opciones, las más comunes son:\n\n* A partir de una lista.\n* A partir de un _numpy.array_.\n* A partir de un diccionario.\n* A partir de un archivo (por ejemplo un csv).",
"_____no_output_____"
]
],
[
[
"my_serie = pd.Series(range(3, 33, 3))\nmy_serie",
"_____no_output_____"
],
[
"type(my_serie)",
"_____no_output_____"
],
[
"# Presiona TAB y sorpréndete con la cantidad de métodos y atributos que poseen!\n# my_serie.",
"_____no_output_____"
]
],
[
[
"Las series son arreglos unidemensionales que constan de _data_ e _index_.",
"_____no_output_____"
]
],
[
[
"# Data\nmy_serie.values",
"_____no_output_____"
],
[
"type(my_serie.values)",
"_____no_output_____"
],
[
"# Index\nmy_serie.index",
"_____no_output_____"
],
[
"type(my_serie.index)",
"_____no_output_____"
]
],
[
[
"¿Te fijaste que el index es de otra clase?",
"_____no_output_____"
],
[
"A diferencia de Numpy, pandas ofrece más flexibilidad para los valores e índices.",
"_____no_output_____"
]
],
[
[
"my_serie_2 = pd.Series(range(3, 33, 3), index=list('abcdefghij'))\nmy_serie_2",
"_____no_output_____"
]
],
[
[
"### Acceder a los valores de una",
"_____no_output_____"
]
],
[
[
"my_serie_2['b']",
"_____no_output_____"
],
[
"my_serie_2.loc['b']",
"_____no_output_____"
],
[
"my_serie_2.iloc[1]",
"_____no_output_____"
]
],
[
[
"```loc```?? ```iloc```??",
"_____no_output_____"
]
],
[
[
"# pd.Series.loc?",
"_____no_output_____"
]
],
[
[
"A modo de resumen:\n\n* ```loc``` es un método que hace referencia a las etiquetas (*labels*) del objeto .\n* ```iloc``` es un método que hace referencia posicional del objeto.",
"_____no_output_____"
],
[
"**Consejo**: Si quieres editar valores siempre utiliza ```loc``` y/o ```iloc```.",
"_____no_output_____"
]
],
[
[
"my_serie_2.loc['d'] = 1000",
"_____no_output_____"
],
[
"my_serie_2",
"_____no_output_____"
]
],
[
[
"¿Y si quiero escoger más de un valor?",
"_____no_output_____"
]
],
[
[
"my_serie_2.loc[\"b\":\"e\"] # Incluso retorna el último valor!",
"_____no_output_____"
],
[
"my_serie_2.iloc[1:5] # Incluso retorna el último valor!",
"_____no_output_____"
]
],
[
[
"Sorpresa! También puedes filtrar según condiciones!",
"_____no_output_____"
],
[
"En la mayoría de los tutoriales en internet encontrarás algo como lo siguiente:",
"_____no_output_____"
]
],
[
[
"my_serie_2[my_serie_2 % 2 == 0]",
"_____no_output_____"
]
],
[
[
"Lo siguiente se conoce como _mask_, y se basa en el siguiente hecho:",
"_____no_output_____"
]
],
[
[
"my_serie_2 % 2 == 0 # Retorna una serie con valores booleanos pero los mismos index!",
"_____no_output_____"
]
],
[
[
"Si es una serie resultante de otra operación, tendrás que guardarla en una variable para así tener el nombre y luego acceder a ella. La siguiente manera puede qeu sea un poco más verboso, pero te otorga más flexibilidad.",
"_____no_output_____"
]
],
[
[
"my_serie_2.loc[lambda s: s % 2 == 0]",
"_____no_output_____"
]
],
[
[
"Una función lambda es una función pequeña y anónima. Pueden tomar cualquer número de argumentos pero solo tienen una expresión.",
"_____no_output_____"
],
[
"### Trabajar con fechas",
"_____no_output_____"
],
[
"Pandas incluso permite que los index sean fechas! Por ejemplo, a continuación se crea una serie con las tendencia de búsqueda de *data science* en Google.",
"_____no_output_____"
]
],
[
[
"import os",
"_____no_output_____"
],
[
"ds_trend = pd.read_csv(os.path.join('data', 'dataScienceTrend.csv'), index_col=0, squeeze=True)",
"_____no_output_____"
],
[
"ds_trend.head(10)",
"_____no_output_____"
],
[
"ds_trend.tail(10)",
"_____no_output_____"
],
[
"ds_trend.dtype",
"_____no_output_____"
],
[
"ds_trend.index",
"_____no_output_____"
]
],
[
[
"**OJO!** Los valores del Index son _strings_ (_object_ es una generalización). ",
"_____no_output_____"
],
[
"**Solución:** _Parsear_ a elementos de fecha con la función ```pd.to_datetime()```.",
"_____no_output_____"
]
],
[
[
"# pd.to_datetime?",
"_____no_output_____"
],
[
"ds_trend.index = pd.to_datetime(ds_trend.index, format='%Y-%m-%d')",
"_____no_output_____"
],
[
"ds_trend.index",
"_____no_output_____"
]
],
[
[
"Para otros tipos de _parse_ puedes visitar la documentación [aquí](https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior).\n",
"_____no_output_____"
],
[
"La idea de los elementos de fecha es poder realizar operaciones que resulten naturales para el ser humano. Por ejemplo:",
"_____no_output_____"
]
],
[
[
"ds_trend.index.min()",
"_____no_output_____"
],
[
"ds_trend.index.max()",
"_____no_output_____"
],
[
"ds_trend.index.max() - ds_trend.index.min()",
"_____no_output_____"
]
],
[
[
"Volviendo a la Serie, podemos trabajar con todos sus elementos, por ejemplo, determinar rápidamente la máxima tendencia.",
"_____no_output_____"
]
],
[
[
"max_trend = ds_trend.max()\nmax_trend ",
"_____no_output_____"
]
],
[
[
"Para determinar el _index_ correspondiente al valor máximo usualmente se utilizan dos formas:\n\n* Utilizar una máscara (*mask*)\n* Utilizar métodos ya implementados",
"_____no_output_____"
]
],
[
[
"# Mask\nds_trend[ds_trend == max_trend]",
"_____no_output_____"
],
[
"# Built-in method\nds_trend.idxmax()",
"_____no_output_____"
]
],
[
[
"<a id='dataframes'></a>\n## DataFrames",
"_____no_output_____"
],
[
"Arreglo bidimensional y extensión natural de una serie. Podemos pensarlo como la generalización de un numpy.array.",
"_____no_output_____"
],
[
"Utilizando el dataset de los jugadores de la NBA la flexibilidad de pandas se hace mucho más visible. No es necesario que todos los elementos sean del mismo tipo!",
"_____no_output_____"
]
],
[
[
"player_data = pd.read_csv(os.path.join('data', 'player_data.csv'), index_col='name')\nplayer_data.head()",
"_____no_output_____"
],
[
"type(player_data)",
"_____no_output_____"
],
[
"player_data.info(memory_usage=True)",
"<class 'pandas.core.frame.DataFrame'>\nIndex: 4550 entries, Alaa Abdelnaby to Matt Zunic\nData columns (total 7 columns):\nyear_start 4550 non-null int64\nyear_end 4550 non-null int64\nposition 4549 non-null object\nheight 4549 non-null object\nweight 4544 non-null float64\nbirth_date 4519 non-null object\ncollege 4248 non-null object\ndtypes: float64(1), int64(2), object(4)\nmemory usage: 284.4+ KB\n"
],
[
"player_data.dtypes",
"_____no_output_____"
]
],
[
[
"Puedes pensar que un dataframe es una colección de series",
"_____no_output_____"
]
],
[
[
"player_data['birth_date'].head()",
"_____no_output_____"
],
[
"type(player_data['birth_date'])",
"_____no_output_____"
]
],
[
[
"### Exploración ",
"_____no_output_____"
]
],
[
[
"player_data.describe().T",
"_____no_output_____"
],
[
"player_data.describe(include='all').T",
"_____no_output_____"
],
[
"player_data.max()",
"_____no_output_____"
]
],
[
[
"Para extraer elementos lo más recomendable es el método loc.",
"_____no_output_____"
]
],
[
[
"player_data.loc['Zaid Abdul-Aziz', 'college']",
"_____no_output_____"
]
],
[
[
"Evita acceder con doble corchete",
"_____no_output_____"
]
],
[
[
"player_data['college']['Zaid Abdul-Aziz']",
"_____no_output_____"
]
],
[
[
"Aunque en ocasiones funcione, no se asegura que sea siempre así. [Más info aquí.](https://pandas.pydata.org/pandas-docs/stable/indexing.html#why-does-assignment-fail-when-using-chained-indexing)",
"_____no_output_____"
]
],
[
[
"player_data['position'].value_counts()",
"_____no_output_____"
]
],
[
[
"### Valores perdidos/nulos",
"_____no_output_____"
],
[
"Pandas ofrece herramientas para trabajar con valors nulos, pero es necesario conocerlas y saber aplicarlas. Por ejemplo, el método ```isnull()``` entrega un booleano si algún valor es nulo.",
"_____no_output_____"
],
[
"Por ejemplo: ¿Qué jugadores no tienen registrado su fecha de nacimiento?",
"_____no_output_____"
]
],
[
[
"player_data.index.shape",
"_____no_output_____"
],
[
"player_data.loc[lambda x: x['birth_date'].isnull()]",
"_____no_output_____"
]
],
[
[
"Si deseamos encontrar todas las filas que contengan por lo menos un valor nulo.",
"_____no_output_____"
]
],
[
[
"player_data.isnull()",
"_____no_output_____"
],
[
"# pd.DataFrame.any?",
"_____no_output_____"
],
[
"rows_null_mask = player_data.isnull().any(axis=1) # axis=1 hace referencia a las filas.\nrows_null_mask.head()",
"_____no_output_____"
],
[
"player_data[rows_null_mask].head()",
"_____no_output_____"
],
[
"player_data[rows_null_mask].shape",
"_____no_output_____"
]
],
[
[
"Para determinar aquellos que no tienen valors nulos el prodecimiento es similar.",
"_____no_output_____"
]
],
[
[
"player_data.loc[lambda x: x.notnull().all(axis=1)].head()",
"_____no_output_____"
]
],
[
[
"Pandas incluso ofrece opciones para eliminar elementos nulos!",
"_____no_output_____"
]
],
[
[
"pd.DataFrame.dropna?",
"_____no_output_____"
],
[
"# Cualquier registro con null\nprint(player_data.dropna().shape)\n# Filas con elementos nulos\nprint(player_data.dropna(axis=0).shape)\n# Columnas con elementos nulos\nprint(player_data.dropna(axis=1).shape)",
"(4213, 7)\n(4213, 7)\n(4550, 2)\n"
]
],
[
[
"## Resumen\n* Pandas posee una infinidad de herramientas para trabajar con datos, incluyendo la carga, manipulación, operaciones y filtrado de datos.\n* La documentación oficial (y StackOverflow) son tus mejores amigos.\n* La importancia está en darle sentido a los datos, no solo a coleccionarlos.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
e7cc4f9822a81eb4bc49eba7c5fb59d72fdf2a17 | 289,540 | ipynb | Jupyter Notebook | src/Trend.ipynb | sekR4/cryptoracle | 2541bb68cd5c533262d5e426196bd205d96b327a | [
"MIT"
]
| null | null | null | src/Trend.ipynb | sekR4/cryptoracle | 2541bb68cd5c533262d5e426196bd205d96b327a | [
"MIT"
]
| null | null | null | src/Trend.ipynb | sekR4/cryptoracle | 2541bb68cd5c533262d5e426196bd205d96b327a | [
"MIT"
]
| null | null | null | 692.679426 | 103,248 | 0.946197 | [
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom utils import get_ts",
"_____no_output_____"
],
[
"# Set Matplotlib defaults\nplt.style.use(\"seaborn-whitegrid\")\nplt.rc(\"figure\", autolayout=True, figsize=(11, 5))\nplt.rc(\n \"axes\",\n labelweight=\"bold\",\n labelsize=\"large\",\n titleweight=\"bold\",\n titlesize=14,\n titlepad=10,\n)\nplot_params = dict(\n color=\"0.75\",\n style=\".-\",\n markeredgecolor=\"0.25\",\n markerfacecolor=\"0.25\",\n legend=False,\n)\n%config InlineBackend.figure_format = 'retina'",
"_____no_output_____"
],
[
"df = get_ts(days=600)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"window = 365\nmin_periods = window // 2\n\nmoving_average = df.rolling(\n window=window, # x-days window\n center=True, # puts the average at the center of the window\n min_periods=min_periods, # choose about half the window size\n).mean() # compute the mean (could also do median, std, min, max, ...)\n\nax = df.plot(style=\".\", color=\"0.5\")\nmoving_average.plot(\n ax=ax, linewidth=3, title=f\"NEXO Prices - {window}-Days Moving Average\", legend=False,\n);",
"_____no_output_____"
],
[
"# https://www.kaggle.com/learn/time-series\nfrom statsmodels.tsa.deterministic import DeterministicProcess\n\ndp = DeterministicProcess(\n index=df.index, # dates from the training data\n constant=True, # dummy feature for the bias (y_intercept)\n order=1, # the time dummy (trend)\n drop=True, # drop terms if necessary to avoid collinearity\n)\n# `in_sample` creates features for the dates given in the `index` argument\nX = dp.in_sample()\n\nX.head()",
"_____no_output_____"
],
[
"from sklearn.linear_model import LinearRegression\n\ny = df[\"prices\"] # the target\n\n# The intercept is the same as the `const` feature from\n# DeterministicProcess. LinearRegression behaves badly with duplicated\n# features, so we need to be sure to exclude it here.\nmodel = LinearRegression(fit_intercept=False)\nmodel.fit(X, y)\n\ny_pred = pd.Series(model.predict(X), index=X.index)",
"_____no_output_____"
],
[
"ax = df.plot(style=\".\", color=\"0.5\", title=\"NEXO Prices - Linear Trend\")\n_ = y_pred.plot(ax=ax, linewidth=3, label=\"Trend\")",
"_____no_output_____"
]
],
[
[
"Even though the linear model looks quite different with the 365 days moving average and is obviously a bad fit, for simplicity and interpretability we'll continue working with it for now.",
"_____no_output_____"
]
],
[
[
"forecast_n_days = 30\nforecast_index = pd.date_range(df.index.max(), periods=forecast_n_days+1).tolist()[1:]\n\nX = dp.out_of_sample(steps=forecast_n_days,forecast_index=forecast_index)\ny_fore = pd.Series(model.predict(X), index=X.index)\n\ny_fore.head()",
"_____no_output_____"
],
[
"from datetime import datetime\n\nmin_date = datetime.strptime(\"2021-05\", '%Y-%m').date()\n\nax = df[df.index > min_date].plot(title=\"NEXO Price - Linear Trend Forecast\", **plot_params)\nax = y_pred[y_pred.index > min_date].plot(ax=ax, linewidth=3, label=\"Trend\")\nax = y_fore.plot(ax=ax, linewidth=3, label=\"Trend Forecast\", color=\"C3\")\n_ = ax.legend()",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7cc5ca35db2f88d7409b3a0f9f24b1b6f0aee14 | 3,669 | ipynb | Jupyter Notebook | dalle_back.ipynb | johnpaulbin/dalle-service | c88380d9701c0c77d2d4aa789dc5aa655ea7f550 | [
"MIT"
]
| 33 | 2021-06-06T22:35:21.000Z | 2022-01-28T17:44:22.000Z | dalle_back.ipynb | johnpaulbin/dalle-service | c88380d9701c0c77d2d4aa789dc5aa655ea7f550 | [
"MIT"
]
| 10 | 2021-06-06T22:37:14.000Z | 2021-12-05T05:31:12.000Z | dalle_back.ipynb | johnpaulbin/dalle-service | c88380d9701c0c77d2d4aa789dc5aa655ea7f550 | [
"MIT"
]
| 11 | 2021-06-08T15:24:41.000Z | 2022-03-17T19:58:09.000Z | 31.09322 | 230 | 0.515672 | [
[
[
"<a href=\"https://colab.research.google.com/github/rom1504/dalle-service/blob/master/dalle_back.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# **This colab allows users to inference and share released Dall-E Models.**\n\n# [Dall-E Service](https://github.com/rom1504/dalle-service) | [Models](https://github.com/robvanvolt/DALLE-models)\n\n*Colab created by mega b#6696*",
"_____no_output_____"
]
],
[
[
"#@title # **Setup, run this once**\nfrom IPython.display import clear_output\n!sudo apt-get -y install llvm-9-dev cmake\n!git clone https://github.com/microsoft/DeepSpeed.git /tmp/Deepspeed\n%cd /tmp/Deepspeed\n!DS_BUILD_SPARSE_ATTN=1 ./install.sh -r\n!npm install -g localtunnel\nclear_output()\n%cd /content/\n!pip install Flask==1.1.2 Flask-Cors==3.0.9 Flask-RESTful==0.3.8 dalle-pytorch tqdm\n!git clone https://github.com/rom1504/dalle-service.git\nclear_output()\nprint(\"Finished setup.\")",
"_____no_output_____"
],
[
"#@title # **Enter direct model download**\n#@markdown # Publicly released models are located [here](https://github.com/robvanvolt/DALLE-models).\n\nmodel_url = \"https://github.com/johnpaulbin/DALLE-models/releases/download/model/16L_64HD_8H_512I_128T_cc12m_cc3m_3E.pt\" #@param {type:\"string\"}\n\n!wget \"$model_url\" -O dalle_checkpoint.pt\n\n!echo '{\"good\": \"dalle_checkpoint.pt\"}' > model_paths.json\n\nclear_output()\n\nprint(\"Finished download.\")",
"_____no_output_____"
],
[
"#@title # **Start backend**\n#@markdown ## Copy the url it provides you, and you will be able to use it in https://rom1504.github.io/dalle-service\n\n#@markdown #### Example: https://rom1504.github.io/dalle-service?back=https://XXXX.loca.lt\n\nfrom threading import Thread\n\ndef app():\n !python dalle-service/back/dalle_service.py 8000\n\nif __name__ == '__main__':\n t1 = Thread(target = app)\n a = t1.start()\n !lt --port 8000",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7cc61372ff211b15eab202771574cb131204051 | 13,225 | ipynb | Jupyter Notebook | app/db/csv_check.ipynb | industArk/microservices_app | 8d312615c9c852605457927fdc9f4c1aa126d28e | [
"MIT"
]
| null | null | null | app/db/csv_check.ipynb | industArk/microservices_app | 8d312615c9c852605457927fdc9f4c1aa126d28e | [
"MIT"
]
| 7 | 2021-07-26T17:46:53.000Z | 2021-08-15T14:45:51.000Z | app/db/csv_check.ipynb | industArk/microservices_app | 8d312615c9c852605457927fdc9f4c1aa126d28e | [
"MIT"
]
| null | null | null | 34.620419 | 1,472 | 0.454367 | [
[
[
"import requests\nimport pandas as pd\nimport matplotlib as mpl\n\nurl = 'https://data.cityofnewyork.us/api/views/7yc5-fec2/rows.csv'\nurl_file = requests.get(url)\n\nprint('Status code:', url_file.status_code)",
"Status code: 200\n"
],
[
"dataset = pd.read_csv(url)\ndataset.head()",
"_____no_output_____"
],
[
"df = pd.DataFrame(dataset, columns=['School Name', 'Category', 'Total Enrollment', '#Female', '#Male'])\n\ndf.head()",
"_____no_output_____"
],
[
"df.columns = [title.lower().replace(\" \", \"_\").replace(\"#\", \"\") for title in df.columns]\ndf.columns",
"_____no_output_____"
],
[
"df.dtypes",
"_____no_output_____"
],
[
"df1 = df.dropna()\ndf.isnull().sum()",
"_____no_output_____"
],
[
"df1.isnull().sum()",
"_____no_output_____"
],
[
"df1 = df1.drop(df1[(df1.total_enrollment == 's') | (df1.female == 's') | (df1.male == 's')].index)",
"_____no_output_____"
],
[
"datatypes = {'school_name': str,\n 'category': str,\n 'total_enrollment': int,\n 'female': int,\n 'male': int}\n\ndf1 = df1.astype(datatypes)\ndf1.dtypes",
"_____no_output_____"
],
[
"df1.head()",
"_____no_output_____"
],
[
"df2 = pd.DataFrame(df1, columns=[\"school_name\"])\ndf2.drop_duplicates(inplace=True, ignore_index=True)\nlist(df2.columns)",
"_____no_output_____"
],
[
"df3 = pd.DataFrame(df1, columns=[\"category\"])\ndf3.drop_duplicates(inplace=True, ignore_index=True)\ndf3",
"_____no_output_____"
],
[
" columns_to_use_raw = [\n \"School Name\",\n \"Category\",\n \"Total Enrollment\",\n \"#Female\",\n \"#Male\",\n ]\n\ncolumns_to_use_final = [col.lower().replace(\" \", \"_\").replace(\"#\", \"\") for col in columns_to_use_raw]\n\ncolumns_to_use_final",
"_____no_output_____"
],
[
"COLUMNS = {\n \"School Name\": str,\n \"Category\": str,\n \"Total Enrollment\": int,\n \"#Female\": int,\n \"#Male\": int,\n}\n\ncolumns_to_use = [col.lower().replace(\" \", \"_\").replace(\"#\", \"\") for col in COLUMNS.keys()]\ndatatypes = {col.lower().replace(\" \", \"_\").replace(\"#\", \"\") : typ for (col, typ) in COLUMNS.items()}\ncolumns_to_use\ndatatypes",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cc662d830fd18d5335145d4be3c76c373472c4 | 15,050 | ipynb | Jupyter Notebook | QuickReference.ipynb | tomdonaldson/navo-workshop | 8fed3b476871f1e6283f211e2a141a3649a4534d | [
"BSD-3-Clause"
]
| null | null | null | QuickReference.ipynb | tomdonaldson/navo-workshop | 8fed3b476871f1e6283f211e2a141a3649a4534d | [
"BSD-3-Clause"
]
| null | null | null | QuickReference.ipynb | tomdonaldson/navo-workshop | 8fed3b476871f1e6283f211e2a141a3649a4534d | [
"BSD-3-Clause"
]
| 1 | 2021-05-27T01:29:38.000Z | 2021-05-27T01:29:38.000Z | 36.977887 | 462 | 0.61907 | [
[
[
"# 0. Setup\nPlease make sure your environment is set up according to the instructions here: https://github.com/NASA-NAVO/aas_workshop_2020_winter/blob/master/00_SETUP.md\n\nEnsure you have the latest version of the workshop material by updating your environment:\nTBD",
"_____no_output_____"
],
[
"# 1. Overview\nNASA services can be queried from Python in multiple ways.\n* Generic Virtual Observatory (VO) queries.\n * Call sequence is consistent, including for non-NASA resources.\n * Use the `pyvo` package: https://pyvo.readthedocs.io/en/latest/\n * Known issues/caveats: https://github.com/NASA-NAVO/aas_workshop_2020_winter/blob/master/KNOWN_ISSUES.md\n* Astroquery interfaces\n * Call sequences not quite as consistent, but follow similar patterns.\n * See https://astroquery.readthedocs.io/en/latest/\n * Informal Q&A session Tuesday, 5:30pm-6:30pm, NumFocus booth\n* Ad hoc archive-specific interfaces\n\n# 2. VO Services\nThis workshop will introduce 4 types of VO queries:\n* **VO Registry** - Discover what services are available worldwide\n* **Simple Cone Search** - Search for catalog object within a specified cone region\n* **Simple Image Access** - Search for image products within a spatial region\n* **Simple Spectral Access** - Search for spectral products within a spatial region\n* **Table Access** - SQL-like queries to databases\n\n## 2.1 Import Necessary Packages",
"_____no_output_____"
]
],
[
[
"# Generic VO access routines\nimport pyvo as vo\n\n# For specifying coordinates and angles\nfrom astropy.coordinates import SkyCoord\nfrom astropy.coordinates import Angle\nfrom astropy import units as u\n\n# For downloading files\nfrom astropy.utils.data import download_file\n\n# Ignore unimportant warnings\nimport warnings\nwarnings.filterwarnings('ignore', '.*Unknown element mirrorURL.*', vo.utils.xml.elements.UnknownElementWarning)",
"_____no_output_____"
]
],
[
[
"## 2.1 Look Up Services in VO Registry\nSimple example: Find Simple Cone Search (conesearch) services related to SWIFT.",
"_____no_output_____"
]
],
[
[
"services = vo.regsearch(servicetype='conesearch', keywords=['swift'])\nservices",
"_____no_output_____"
]
],
[
[
"### 2.1.1 Use different arguments/values to modify the simple example\n| Argument | Description | Examples |\n| :-----: | :----------- | :-------- |\n| **servicetype** | Type of service | `conesearch` or `scs` for **Simple Cone Search**<br> `image` or `sia` for **Simple Image Access**<br> `spectrum` or `ssa` for **Simple Spectral Access**<br> `table` or `tap` for **Table Access Protocol**|\n| **keyword** | List of one or more keyword(s) to match service's metadata. Both ORs and ANDs may be specified.<br><ul><li>(OR) A list of keywords match a service if **any** of the keywords match the service.</li><li>(AND) If a keyword contains multiple space-delimited words, **all** the words must match the metadata.</li></ul>| `['galex', 'swift']` matches 'galex' or 'swift'<br>`['hst survey']` matches services mentioning both 'hst' and 'survey' |\n| **waveband** | Resulting services have data in the specified waveband(s) | ‘radio’, ‘millimeter’, ‘infrared’, ‘optical’, ‘uv’, ‘euv’, ‘x-ray’ ‘gamma-ray’ |\n\n### 2.1.2 Inspect the results.\n#### Using pyvo\nAlthough not lists, `pyvo` results can be iterated over to see each individual result. The results are specialized based on the type of query, providing access to the important properties of the results. Some useful accessors with registry results are:\n* `short_name` - A short name\n* `res_title` - A more descriptive title\n* `res_description` - A more verbose description\n* `reference_url` - A link for more information\n* `ivoid` - A unique identifier for the service. Gives some indication of what organization is serving the data.",
"_____no_output_____"
]
],
[
[
"# Print the number of results and the 1st 4 short names and titles.\nprint(f'Number of results: {len(services)}\\n')\nfor s in list(services)[:4]: # (Treat services as list to get the subset of rows)\n print(f'{s.short_name} - {s.res_title}')",
"_____no_output_____"
]
],
[
[
"#### Filtering results\nOf the services we found, which one(s) have 'stsci.edu' in their unique identifier?",
"_____no_output_____"
]
],
[
[
"stsci_services = [s for s in services if 'stsci.edu' in s.ivoid]\nfor s in stsci_services:\n print (f'(STScI): {s.short_name} - {s.res_title}')",
"_____no_output_____"
]
],
[
[
"#### Using astropy\nWith the `to_table()` method, `pyvo` results can also be converted to Astropy `Table` objects which offer a variety of addional features. See http://docs.astropy.org/en/stable/table/ for more on working with Astropy Tables.",
"_____no_output_____"
]
],
[
[
"# Convert to an Astropy Table\nservices_table = services.to_table()\n\n# Print the column names and display 1st 3 rows with a subset of columns\nprint(f'\\nColumn Names:\\n{services_table.colnames}\\n') \nservices_table['short_name', 'res_title', 'res_description'][:3] ",
"_____no_output_____"
]
],
[
[
"## 2.2 Cone search\nExample: Find a cone search service for the USNO-B catalog and search it around M51 with a .1 degree radius. (More inspection could be done on the service list instead of blindly choosing the first service.) \n\nThe position (`pos`) is best specified with `SkyCoord` objects (see http://docs.astropy.org/en/stable/api/astropy.coordinates.SkyCoord.html). \n\nThe size of the region is specified with the `radius` keyword and may be decimal degrees or an Astropy `Angle` (http://docs.astropy.org/en/stable/api/astropy.coordinates.Angle.html#astropy.coordinates.Angle). ",
"_____no_output_____"
]
],
[
[
"m51_pos = SkyCoord.from_name(\"m51\")\nservices = vo.regsearch(servicetype='conesearch', keywords='usno-b')\nresults = services[0].search(pos=m51_pos, radius=0.1)\n# Astropy Table is useful for displaying cone search results.\nresults.to_table() ",
"_____no_output_____"
]
],
[
[
"## 2.3 Image search\nExample: Find an image search service for GALEX, and search it around coordinates 13:37:00.950,-29:51:55.51 (M83) with a radius of .2 degrees. Download the first file in the results.\n#### Find an image service",
"_____no_output_____"
]
],
[
[
"services = vo.regsearch(servicetype='image', keywords=['galex'])\nservices.to_table()['ivoid', 'short_name', 'res_title']",
"_____no_output_____"
]
],
[
[
"#### Search one of the services\nThe first service looks good. Search it!\n\nFor more details on using `SkyCoord` see http://docs.astropy.org/en/stable/api/astropy.coordinates.SkyCoord.html#astropy.coordinates.SkyCoord\n\n**NOTE**: For image searches, the size of the region is defined by the `size` keyword which is more like a diameter than a radius.",
"_____no_output_____"
]
],
[
[
"m83_pos = SkyCoord('13h37m00.950s -29d51m55.51s')\nresults = services[0].search(pos=m83_pos, size=.2)\n\n# We can look at the results.\nresults.to_table()",
"_____no_output_____"
]
],
[
[
"#### Download an image\nFor the first result, print the file format and download the file. If repeatedly executing this code, add `cache=True` to `download_file()` to prevent repeated downloads.\n\nSee `download_file()` documentation here: https://docs.astropy.org/en/stable/api/astropy.utils.data.download_file.html#astropy.utils.data.download_file",
"_____no_output_____"
]
],
[
[
"print(results[0].format)\nfile_name = download_file(results[0].getdataurl()) \nfile_name",
"_____no_output_____"
]
],
[
[
"## 2.4 Spectral search\nExample: Find a spectral service for x-ray data. Query it around Delta Ori with a search **diameter** of 10 arc minutes, and download the first data product. Note that the results table can be inspected for potentially useful columns.\n\nSpectral search is very similar to image search. In this example, note:\n* **`diameter`** defines the size of the search region\n* `waveband` used in `regsearch()`\n* Astropy `Angle` used to specify radius units other than degrees.",
"_____no_output_____"
]
],
[
[
"# Search for a spectrum search service that has x-ray data.\nservices = vo.regsearch(servicetype='spectrum', waveband='x-ray')\n\n# Assuming there are services and the first one is OK...\nresults = services[0].search(pos=SkyCoord.from_name(\"Delta Ori\"), \n diameter=Angle(10 * u.arcmin))\n\n# Assuming there are results, download the first file.\nprint(f'Title: {results[0].title}, Format: {results[0].format}')\nfile_name = download_file(results[0].getdataurl()) \nfile_name",
"_____no_output_____"
]
],
[
[
"## 2.5 Table search\nExample: Find the HEASARC Table Access Protocol (TAP) service, get some information about the available tables.",
"_____no_output_____"
]
],
[
[
"services = vo.regsearch(servicetype='tap', keywords=['heasarc'])\nprint(f'{len(services)} service(s) found.')\n# We found only one service. Print some info about the service and its tables.\nprint(f'{services[0].describe()}')\ntables = services[0].service.tables # Queries for details of the service's tables\nprint(f'{len(tables)} tables:')\nfor t in tables:\n print(f'{t.name:30s} - {t.description}') # A more succinct option than t.describe()",
"_____no_output_____"
]
],
[
[
"#### Column Information\nFor any table, we can list the column names and descriptions.",
"_____no_output_____"
]
],
[
[
"for c in tables['zcat'].columns:\n print(f'{c.name:30s} - {c.description}')",
"_____no_output_____"
]
],
[
[
"#### Perform a Query\nExample: Perform a cone search on the ZCAT catalog at M83 with a 1.0 degree radius.",
"_____no_output_____"
]
],
[
[
"coord = SkyCoord.from_name(\"m83\")\nquery = f'''\nSELECT ra, dec, Radial_Velocity, radial_velocity_error, bmag, morph_type FROM public.zcat as cat where \ncontains(point('ICRS',cat.ra,cat.dec),circle('ICRS',{coord.ra.deg},{coord.dec.deg},1.0))=1\n'''\nresults = services[0].service.run_async(query)\n\nresults.to_table()",
"_____no_output_____"
]
],
[
[
"# 3. Astroquery \nMany archives have Astroquery modules for data access, including:\n\n* [HEASARC Queries (astroquery.heasarc)](https://astroquery.readthedocs.io/en/latest/heasarc/heasarc.html)\n* [HITRAN Queries (astroquery.hitran)](https://astroquery.readthedocs.io/en/latest/hitran/hitran.html)\n* [IRSA Image Server program interface (IBE) Queries (astroquery.ibe)](https://astroquery.readthedocs.io/en/latest/ibe/ibe.html)\n* [IRSA Queries (astroquery.irsa)](https://astroquery.readthedocs.io/en/latest/irsa/irsa.html)\n* [IRSA Dust Extinction Service Queries (astroquery.irsa_dust)](https://astroquery.readthedocs.io/en/latest/irsa/irsa_dust.html)\n* [JPL Spectroscopy Queries (astroquery.jplspec)](https://astroquery.readthedocs.io/en/latest/jplspec/jplspec.html)\n* [MAST Queries (astroquery.mast)](https://astroquery.readthedocs.io/en/latest/mast/mast.html)\n* [NASA ADS Queries (astroquery.nasa_ads)](https://astroquery.readthedocs.io/en/latest/nasa_ads/nasa_ads.html)\n* [NED Queries (astroquery.ned)](https://astroquery.readthedocs.io/en/latest/ned/ned.html)\n\nFor more, see https://astroquery.readthedocs.io/en/latest/\n\n## 3.1 NED\nExample: Get an Astropy Table containing the objects from paper 2018ApJ...858...62K. For more on the API, see https://astroquery.readthedocs.io/en/latest/ned/ned.html ",
"_____no_output_____"
]
],
[
[
"from astroquery.ned import Ned\nobjects_in_paper = Ned.query_refcode('2018ApJ...858...62K')\nobjects_in_paper",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7cc668b7356c4db9c7719687331f904ad84964b | 920,116 | ipynb | Jupyter Notebook | Heart_Attack_Analysis_&_Classification_Dataset.ipynb | DivyaniMaharana/manim | 5cb605f8c5c330e514dbca2a6cdf820e56d29f5b | [
"MIT"
]
| null | null | null | Heart_Attack_Analysis_&_Classification_Dataset.ipynb | DivyaniMaharana/manim | 5cb605f8c5c330e514dbca2a6cdf820e56d29f5b | [
"MIT"
]
| null | null | null | Heart_Attack_Analysis_&_Classification_Dataset.ipynb | DivyaniMaharana/manim | 5cb605f8c5c330e514dbca2a6cdf820e56d29f5b | [
"MIT"
]
| null | null | null | 339.526199 | 769,102 | 0.894957 | [
[
[
"**About this dataset**\n\nAge : Age of the patient\n\nSex : Sex of the patient\n\nexang: exercise induced angina (1 = yes; 0 = no)\n\nca: number of major vessels (0-3)\n\ncp : Chest Pain type chest pain type\n\nValue 1: typical angina\n\n Value 2: atypical angina\n\nValue 3: non-anginal pain\n\nValue 4: asymptomatic\n\ntrtbps : resting blood pressure (in mm Hg)\n\nchol : cholestoral in mg/dl fetched via BMI sensor\n\nfbs : (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)\n\nrest_ecg : resting electrocardiographic results\n\n Value 0: normal\n\nValue 1: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV)\n\nValue 2: showing probable or definite left ventricular hypertrophy by Estes' criteria\n\n\n\nthalach : maximum heart rate achieved\n\ntarget : 0= less chance of heart attack 1= more chance of heart attack\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"data=pd.read_csv('/content/drive/MyDrive/dataset/heart_new.csv')\ndata",
"_____no_output_____"
],
[
"data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 304 entries, 0 to 303\nData columns (total 15 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 age 303 non-null float64\n 1 sex 303 non-null float64\n 2 cp 303 non-null float64\n 3 trtbps 303 non-null float64\n 4 chol 303 non-null float64\n 5 fbs 303 non-null float64\n 6 restecg 303 non-null float64\n 7 thalachh 303 non-null float64\n 8 exng 303 non-null float64\n 9 oldpeak 303 non-null float64\n 10 slp 303 non-null float64\n 11 caa 303 non-null float64\n 12 thall 303 non-null float64\n 13 O2Saturation 304 non-null float64\n 14 output 303 non-null float64\ndtypes: float64(15)\nmemory usage: 35.8 KB\n"
],
[
"data.describe()",
"_____no_output_____"
]
],
[
[
"Data Cleaning",
"_____no_output_____"
]
],
[
[
"data.isnull()",
"_____no_output_____"
],
[
"data.isnull().sum()",
"_____no_output_____"
],
[
"df=data.drop(axis=0,labels=303)\ndf",
"_____no_output_____"
],
[
"sns.heatmap(df.isnull())",
"_____no_output_____"
],
[
"df.isnull().sum()",
"_____no_output_____"
]
],
[
[
"EDA ",
"_____no_output_____"
]
],
[
[
"sns.boxplot(x='sex',y='cp',data=df)",
"_____no_output_____"
],
[
"sns.pairplot(df)",
"_____no_output_____"
],
[
"df.corr()",
"_____no_output_____"
],
[
"plt.figure(figsize=(8, 12))\nheatmap = sns.heatmap(df.corr()[['output']].sort_values(by='output', ascending=False), vmin=-1, vmax=1, annot=True, cmap='BrBG')\nheatmap.set_title('Features Correlating with output', fontdict={'fontsize':18}, pad=16);",
"_____no_output_____"
]
],
[
[
"DATA PREPROCESSING ",
"_____no_output_____"
]
],
[
[
"df",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"X=df.drop(['output'] , axis=1)\ny=df['output']",
"_____no_output_____"
],
[
"X.shape , y.shape",
"_____no_output_____"
],
[
"X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)",
"_____no_output_____"
],
[
"X_train.shape , y_train.shape",
"_____no_output_____"
],
[
"X_test.shape , y_test.shape",
"_____no_output_____"
],
[
"from sklearn.preprocessing import StandardScaler",
"_____no_output_____"
],
[
"sc=StandardScaler()\nX_train=sc.fit_transform(X_train)\nX_test=sc.fit_transform(X_test)",
"_____no_output_____"
],
[
"from sklearn.svm import SVC",
"_____no_output_____"
],
[
"svc=SVC(C=10, kernel='linear', degree=5)\nsvc.fit(X_train,y_train)",
"_____no_output_____"
],
[
"y_pred=svc.predict(X_test)\ny_pred",
"_____no_output_____"
],
[
"y_test",
"_____no_output_____"
],
[
"svc.score(X_test,y_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score",
"_____no_output_____"
],
[
"acc=accuracy_score(y_test,y_pred)\nacc",
"_____no_output_____"
],
[
"from sklearn.tree import DecisionTreeClassifier",
"_____no_output_____"
],
[
"dt=DecisionTreeClassifier()\ndt.fit(X_train,y_train)",
"_____no_output_____"
],
[
"dt.predict(X_test)",
"_____no_output_____"
],
[
"y_test",
"_____no_output_____"
],
[
"dt.score(X_test,y_test)",
"_____no_output_____"
],
[
"dt=DecisionTreeClassifier(criterion='gini',splitter='best',max_depth=1)\ndt.fit(X_train,y_train)",
"_____no_output_____"
],
[
"dt.predict(X_test)",
"_____no_output_____"
],
[
"dt.score(X_test,y_test)",
"_____no_output_____"
],
[
"import pickle",
"_____no_output_____"
],
[
"filename='heart attack analysis svc ml model.pkl'\npickle.dump(svc,open(filename,'wb'))\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cc7ba5af9f277ce12becb45beb6b28e5e125f8 | 121,719 | ipynb | Jupyter Notebook | notebooks/Morglorb-Peanut-Butter-SLSQP.ipynb | sekondusg/dunli | 9abb59bf96f3941db8e8c7b6acecd6551b23bace | [
"MIT"
]
| null | null | null | notebooks/Morglorb-Peanut-Butter-SLSQP.ipynb | sekondusg/dunli | 9abb59bf96f3941db8e8c7b6acecd6551b23bace | [
"MIT"
]
| null | null | null | notebooks/Morglorb-Peanut-Butter-SLSQP.ipynb | sekondusg/dunli | 9abb59bf96f3941db8e8c7b6acecd6551b23bace | [
"MIT"
]
| null | null | null | 181.129464 | 79,832 | 0.878639 | [
[
[
"# Introduction\n\nThis Morglorb recipe uses groupings of ingredients to try to cover nutritional requirements with enough overlap that a single ingredient with quality issues does not cause a failure for the whole recipe. An opimizer is used to find the right amount of each ingredient to fulfill the nutritional and practical requirements.\n\n# To Do\n\n* Nutrients without an upper limit should have the upper limit constraint removed\n* Add constraints for the NIH essential protein combinations as a limit\n* Add a radar graph for vitamins showing the boundry between RDI and UL\n* Add a radar graph for vitamins without an upper limit but showing the RDI\n* Add a radar graph for essential proteins showing the range between RDI and UL\n* Add a radar graph for essential proteins without an upper limit, but showing the RDI as the lower limit\n* Add a radar graph pair for non-essential proteins with the above UL and no UL pairing\n* Add equality constraints for at least energy, and macro nutrients if possible",
"_____no_output_____"
]
],
[
[
"# Import all of the helper libraries \n\nfrom scipy.optimize import minimize\nfrom scipy.optimize import Bounds\nfrom scipy.optimize import least_squares, lsq_linear, dual_annealing, minimize\nimport pandas as pd\nimport numpy as np\nimport os\nimport json\nfrom math import e, log, log10\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom ipysheet import from_dataframe, to_dataframe",
"_____no_output_____"
],
[
"#!pip install seaborn\n#!pip install ipysheet\n#!pip install ipywidgets",
"_____no_output_____"
],
[
"# Setup the notebook context\n\ndata_dir = '../data'\npd.set_option('max_columns', 70)",
"_____no_output_____"
]
],
[
[
"# Our Data\n\nThe [tables](https://docs.google.com/spreadsheets/d/104Y7kH4OzmfsM-v2MSEoc7cIgv0aAMT2sQLAmgkx8R8/edit#gid=442191411) containing our ingredients nutrition profile are held in Google Sheets.\nThe sheet names are \"Ingredients\" and \"Nutrition Profile\"",
"_____no_output_____"
]
],
[
[
"# Download our nutrition profile data from Google Sheets\n\ngoogle_spreadsheet_url = 'https://docs.google.com/spreadsheets/d/104Y7kH4OzmfsM-v2MSEoc7cIgv0aAMT2sQLAmgkx8R8/export?format=csv&id=104Y7kH4OzmfsM-v2MSEoc7cIgv0aAMT2sQLAmgkx8R8'\nnutrition_tab = '624419712'\ningredient_tab = '1812860789'\nnutrition_tab_url = f'{google_spreadsheet_url}&gid={nutrition_tab}'\ningredient_tab_url = f'{google_spreadsheet_url}&gid={ingredient_tab}'\n\nnutrition_profile_df = pd.read_csv(nutrition_tab_url, index_col=0, verbose=True)\nfor col in ['RDI', 'UL', 'Target Scale', 'Target', 'Weight']:\n nutrition_profile_df[col] = nutrition_profile_df[col].astype(float)\nnutrition_profile_df = nutrition_profile_df.transpose()\n\ningredients_df = pd.read_csv(ingredient_tab_url, index_col=0, verbose=True).transpose()\n\n# convert all values to float\nfor col in ingredients_df.columns:\n ingredients_df[col] = ingredients_df[col].astype(float)",
"Tokenization took: 0.04 ms\nType conversion took: 1.01 ms\nParser memory cleanup took: 0.00 ms\nTokenization took: 0.06 ms\nType conversion took: 1.29 ms\nParser memory cleanup took: 0.01 ms\n"
]
],
[
[
"# Problem Setup\n\nLet's cast our data into the from $\\vec{y} = A \\vec{x} + \\vec{b}$ where $A$ is our ingredients data, $\\vec{x}$ is the quantity of each ingredient for our recipe, and $\\vec{b}$ is the nutrition profile.\nThe problem to be solved is to find the quantity of each ingredient which will optimally satisfy the nutrition profile, or in our model, to minimize: $|A \\vec{x} - \\vec{b}|$.\n\nThere are some nutrients we only want to track, but not optimize. For example, we want to know how much cholesterol is contained in our recipe, but we don't want to constrain our result to obtain a specific amount of cholesterol as a goal. The full list of ingredients are named: A_full, and b_full. The values to optimized are named: A and b",
"_____no_output_____"
]
],
[
[
"b_full = nutrition_profile_df\nA_full = ingredients_df.transpose()\nA = ingredients_df.transpose()[nutrition_profile_df.loc['Report Only'] == False].astype(float)\n\nb_full = nutrition_profile_df.loc['Target']\nb = nutrition_profile_df.loc['Target'][nutrition_profile_df.loc['Report Only'] == False].astype(float)\nul = nutrition_profile_df.loc['UL'][nutrition_profile_df.loc['Report Only'] == False].astype(float)\nrdi = nutrition_profile_df.loc['RDI'][nutrition_profile_df.loc['Report Only'] == False].astype(float)\nweight = nutrition_profile_df.loc['Weight'][nutrition_profile_df.loc['Report Only'] == False]\nul_full = nutrition_profile_df.loc['UL']\nrdi_full = nutrition_profile_df.loc['RDI']",
"_____no_output_____"
],
[
"# Constrain ingredients before the optimization process. Many of the ingredients are required for non-nutritional purposes \n# or are being limited to enhance flavor\n#\n# The bounds units are in fractions of 100g / day, i.e.: 0.5 represents 50g / day, of the ingredient\n\n#bounds_df = pd.DataFrame(index=ingredients_df.index, data={'lower': 0.0, 'upper': np.inf})\nbounds_df = pd.DataFrame(index=ingredients_df.index, data={'lower': 0.0, 'upper': 1.0e6})\nbounds_df.loc['Guar gum'] = [1.5 * .01, 1.5 * .01 + .0001]\nbounds_df.loc['Xanthan Gum'] = [1.5 * .01, 1.5 * .01 + .0001]\nbounds_df.loc['Alpha-galactosidase enzyme (Beano)'] = [1.0, 1.0 + .0001]\nbounds_df.loc['Multivitamin'] = [1.0, 1.0 + .0001]\nbounds_df.loc['Corn flour, nixtamalized'] = [0, 1.0]\nbounds_df.loc['Whey protein'] = [0.0,0.15]\nbounds_df.loc['Ascorbic acid'] = [0.01, 0.01 + .0001]\nbounds_df.loc['Peanut butter'] = [0.70, 5.0]\nbounds_df.loc['Wheat bran, crude'] = [0.5, 5.0]\nbounds_df.loc['Flaxseed, fresh ground'] = [0.25, 5.0]\nbounds_df.loc['Choline Bitartrate'] = [0.0, 0.05]\nbounds_df.loc['Potassium chloride'] = [0.0, 0.15]\nlower = bounds_df.lower.values\nupper = bounds_df.upper.values\nlower.shape, upper.shape\nx0 = np.array(lower)\nbounds = pd.DataFrame( data = {'lower': lower, 'upper': upper}, dtype=float)",
"_____no_output_____"
],
[
"a = 100.; b = 2.; c = a; k = 10\na = 20.; b = 2.; c = a; k = 10\na = 10.; b = 0.1 ; c = a; k = 5\n#u0 = (rdi + np.log(rdi)); u0.name = 'u0'\n#u0 = rdi * (1 + log(a))\nu0 = rdi / (1 - log(k) / a)\nu1 = ul / (log(k) / c + 1)\n#u1 = ul - np.log(ul); u1.name = 'u1'\n\n#u = pd.concat([limits, pd.Series(y0,scale_limits.index, name='y0')], axis=1)\n\ndef obj(x):\n y0 = A.dot(x.transpose())\n obj_vec = (np.exp(a * (u0 - y0)/u0) + np.exp(b * (y0 - u0)/u0) + np.nan_to_num(np.exp(c * (y0 - u1)/u1))) * weight\n #print(f'obj_vec: {obj_vec[0]}, y0: {y0[0]}, u0: {u0[0]}')\n return(np.sum(obj_vec))\n \n#rdi[26], u0[26], u1[26], ul[26]\n#rdi[0:5], u0[0:5], u1[0:5], ul[0:5]\n#np.log(rdi)[26]\n#u1\n",
"_____no_output_____"
],
[
"solution = minimize(obj, x0, method='SLSQP', bounds=list(zip(lower, upper)), options = {'maxiter': 1000})\nsolution.success",
"/home/dennis/anaconda3/envs/dunli/lib/python3.7/site-packages/pandas/core/arraylike.py:358: RuntimeWarning: overflow encountered in exp\n result = getattr(ufunc, method)(*inputs, **kwargs)\n"
],
[
"A_full.dot(solution.x).astype(int)",
"_____no_output_____"
],
[
"# Scale the ingredient nutrient amounts for the given quantity of each ingredient given by the optimizer\nsolution_df = A_full.transpose().mul(solution.x, axis=0) # Scale each nutrient vector per ingredient by the amount of the ingredient\nsolution_df.insert(0, 'Quantity (g)', solution.x * 100) # Scale to 100 g since that is basis for the nutrient quantities\n\n# Add a row showing the sum of the scaled amount of each nutrient\ntotal = solution_df.sum()\ntotal.name = 'Total'\nsolution_df = solution_df.append(total)",
"_____no_output_____"
],
[
"# Plot the macro nutrient profile\n# The ratio of Calories for protein:carbohydrates:fat is 4:4:9 kcal/g\npc = solution_df['Protein (g)']['Total'] * 4.0\ncc = solution_df['Carbohydrates (g)']['Total'] * 4.0\nfc = solution_df['Total Fat (g)']['Total'] * 9.0\ntc = pc + cc + fc\np_pct = int(round(pc / tc * 100))\nc_pct = int(round(cc / tc * 100))\nf_pct = int(round(fc / tc * 100))\n(p_pct, c_pct, f_pct)\n# create data\nnames=f'Protein {p_pct}%', f'Carbohydrates {c_pct}%', f'Fat {f_pct}%', \nsize=[p_pct, c_pct, f_pct]\n \nfig = plt.figure(figsize=(10, 5))\n\nfig.add_subplot(1,2,1)\n# Create a circle for the center of the plot\nmy_circle=plt.Circle( (0,0), 0.5, color='white')\n\n# Give color names\ncmap = plt.get_cmap('Spectral')\nsm = plt.cm.ScalarMappable(cmap=cmap)\ncolors = ['yellow','orange','red']\nplt.pie(size, labels=names, colors=colors)\n\n#p=plt.gcf()\n#p.gca().add_artist(my_circle)\nfig.gca().add_artist(my_circle)\n#plt.show()\n\nfig.add_subplot(1,2,2)\nbarWidth = 1\nfs = [solution_df['Soluble Fiber (g)']['Total']]\nfi = [solution_df['Insoluble Fiber (g)']['Total']]\nplt.bar([0], fs, color='red', edgecolor='white', width=barWidth, label=['Soluble Fiber (g)'])\nplt.bar([0], fi, bottom=fs, color='yellow', edgecolor='white', width=barWidth, label=['Insoluble Fiber (g)'])\nplt.show()\n# Also show the Omega-3, Omega-6 ratio\n# Saturated:Monounsaturated:Polyunsaturated ratios",
"_____no_output_____"
],
[
"# Prepare data as a whole for plotting by normalizing and scaling\namounts = solution_df\ntotal = A_full.dot(solution.x) #solution_df.loc['Total']\n\n# Normalize as a ratio beyond RDI\nnorm = (total) / rdi_full\nnorm_ul = (ul_full) / rdi_full\n\nnuts = pd.concat([pd.Series(norm.values, name='value'), pd.Series(norm.index, name='name')], axis=1)",
"_____no_output_____"
],
[
"# Setup categories of nutrients and a common plotting function\nvitamins = ['Vitamin A (IU)','Vitamin B6 (mg)','Vitamin B12 (ug)','Vitamin C (mg)','Vitamin D (IU)',\n 'Vitamin E (IU)','Vitamin K (ug)','Thiamin (mg)','Riboflavin (mg)','Niacin (mg)','Folate (ug)','Pantothenic Acid (mg)','Biotin (ug)','Choline (mg)']\nminerals = ['Calcium (g)','Chloride (g)','Chromium (ug)','Copper (mg)','Iodine (ug)','Iron (mg)',\n 'Magnesium (mg)','Manganese (mg)','Molybdenum (ug)','Phosphorus (g)','Potassium (g)','Selenium (ug)','Sodium (g)','Sulfur (g)','Zinc (mg)']\nessential_aminoacids = ['Cystine (mg)','Histidine (mg)','Isoleucine (mg)','Leucine (mg)','Lysine (mg)',\n 'Methionine (mg)','Phenylalanine (mg)','Threonine (mg)','Tryptophan (mg)','Valine (mg)']\nother_aminoacids = ['Tyrosine (mg)','Arginine (mg)','Alanine (mg)','Aspartic acid (mg)','Glutamic acid (mg)','Glycine (mg)','Proline (mg)','Serine (mg)','Hydroxyproline (mg)']\n\ndef plot_group(nut_names, title):\n nut_names_short = [s.split(' (')[0] for s in nut_names] # Snip off the units from the nutrient names\n \n # Create a bar to indicate an upper limit \n ul_bar = (norm_ul * 1.04)[nut_names]\n ul_bar[ul_full[nut_names].isnull() == True] = 0\n \n # Create a bar to mask the UL bar so just the end is exposed\n ul_mask = norm_ul[nut_names]\n ul_mask[ul_full[nut_names].isnull() == True] = 0\n \n \n n = [] # normalized values for each bar\n for x, mx in zip(norm[nut_names], ul_mask.values):\n if mx == 0: # no upper limit\n if x < 1.0:\n n.append(1.0 - (x / 2.0))\n else:\n n.append(0.50)\n else:\n n.append(1.0 - (log10(x) / log10(mx)))\n clrs = sm.to_rgba(n, norm=False)\n \n g = sns.barplot(x=ul_bar.values, y=nut_names_short, color='red')\n g.set_xscale('log')\n sns.barplot(x=ul_mask.values, y=nut_names_short, color='white')\n bax = sns.barplot(x=norm[nut_names], y=nut_names_short, label=\"Total\", palette=clrs)\n \n # Add a legend and informative axis label\n g.set( ylabel=\"\",xlabel=\"Nutrient Mass / RDI (Red Band is UL)\", title=title)\n\n #sns.despine(left=True, bottom=True)",
"_____no_output_____"
],
[
"# Construct a group of bar charts for each nutrient group\n\n# Setup the colormap for each bar\ncmap = plt.get_cmap('Spectral')\nsm = plt.cm.ScalarMappable(cmap=cmap)\n\n#fig = plt.figure(figsize=plt.figaspect(3.))\nfig = plt.figure(figsize=(20, 20))\nfig.add_subplot(4, 1, 1)\nplot_group(vitamins,'Vitamin amounts relative to RDI')\nfig.add_subplot(4, 1, 2)\nplot_group(minerals,'Mineral amounts relative to RDI')\nfig.add_subplot(4, 1, 3)\nplot_group(essential_aminoacids,'Essential amino acid amounts relative to RDI')\nfig.add_subplot(4, 1, 4)\nplot_group(other_aminoacids,'Other amino acid amounts relative to RDI')\n\n#fig.show()\nfig.tight_layout()",
"_____no_output_____"
],
[
"#solu_amount = (solution_df['Quantity (g)'] * 14).astype(int)\npd.options.display.float_format = \"{:,.2f}\".format\nsolu_amount = solution_df['Quantity (g)']\nsolu_amount.index.name = 'Ingredient'\nsolu_amount.reset_index()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cc954d449323dd4f159f97cd1df2659492473e | 11,298 | ipynb | Jupyter Notebook | notebooks/0-computer-matching.ipynb | thbland/investigation-data-broker-lobbying | fa69b75c48595aa60b9f382ff06c6656237d94ff | [
"Unlicense"
]
| 8 | 2021-04-01T14:08:36.000Z | 2021-11-08T09:19:25.000Z | notebooks/0-computer-matching.ipynb | thezedwards/investigation-data-broker-lobbying | fa69b75c48595aa60b9f382ff06c6656237d94ff | [
"Unlicense"
]
| 1 | 2021-07-16T16:16:48.000Z | 2021-07-16T16:16:48.000Z | notebooks/0-computer-matching.ipynb | thezedwards/investigation-data-broker-lobbying | fa69b75c48595aa60b9f382ff06c6656237d94ff | [
"Unlicense"
]
| 5 | 2021-04-01T14:08:38.000Z | 2022-01-29T20:06:41.000Z | 27.289855 | 347 | 0.536467 | [
[
[
"import xml.etree.ElementTree as ET\nimport os\n\nimport pandas as pd\nfrom fuzzywuzzy import fuzz \nfrom fuzzywuzzy import process \nfrom tqdm.autonotebook import tqdm\nfrom pandarallel import pandarallel\n\ntqdm.pandas()\npandarallel.initialize(progress_bar=True)",
"INFO: Pandarallel will run on 4 workers.\nINFO: Pandarallel will use standard multiprocessing data transfer (pipe) to transfer data between the main process and workers.\n"
]
],
[
[
"### Load Data Brokers",
"_____no_output_____"
],
[
"Import CA data brokers list",
"_____no_output_____"
]
],
[
[
"fn = '../data/data_brokers/ca-data-brokers.csv'\ndf = pd.read_csv(fn)\ndf['state'] = 'CA'\nca = df[['Data Broker Name', 'Email Address', 'Website URL', 'Physical Address', 'state']].copy()\nca.rename(inplace=True, columns={\n 'Data Broker Name':'name',\n 'Email Address':'email',\n 'Website URL':'url',\n 'Physical Address':'address'\n})",
"_____no_output_____"
]
],
[
[
"Import VT data brokers list",
"_____no_output_____"
]
],
[
[
"fn = '../data/data_brokers/vt-data-brokers.csv'\ndf = pd.read_csv(fn)\ndf['state'] = \"VT\"\n\nvt = df[['Data Broker Name:','Address:', 'Email Address:', 'Primary Internet Address:', 'state']].copy()\nvt.rename(inplace=True, columns={\n 'Data Broker Name:':'name',\n 'Address:':'address',\n 'Email Address:':'email',\n 'Primary Internet Address:':'url'\n})",
"_____no_output_____"
]
],
[
[
"Merge the two",
"_____no_output_____"
]
],
[
[
"brokers = pd.concat([ca, vt])",
"_____no_output_____"
]
],
[
[
"Save as output",
"_____no_output_____"
]
],
[
[
"brokers.to_csv('../data/matching_process/brokers.csv', index=False)",
"_____no_output_____"
]
],
[
[
"### Load Lobbyist Clients",
"_____no_output_____"
]
],
[
[
"client_list = []\n\nfolder = '../data/lobbying/'\nfor path, dirs, files in os.walk(folder):\n for file in files:\n fullpath = os.path.join(path, file)\n if file.endswith(\".xml\"):\n with open(fullpath, \"rb\") as data:\n tree = ET.parse(data)\n root = tree.getroot()\n for filing in root.iter('Filing'):\n filing_info = filing.attrib\n for client in filing.iter('Client'):\n client_info = client.attrib\n info = {\n 'filing.id': filing_info['ID'],\n 'filing.period': filing_info['Period'],\n 'filing.year': filing_info['Year'],\n 'client.name': client_info['ClientName'],\n 'client.id': client_info['ClientID'],\n 'client.desc': client_info['GeneralDescription'],\n 'client.state': client_info['ClientState'],\n 'client.country': client_info['ClientCountry']\n }\n client_list.append(info)\n\ncf = pd.DataFrame(client_list)",
"_____no_output_____"
]
],
[
[
"Filter for just 2020 filings",
"_____no_output_____"
]
],
[
[
"clients = cf[cf['filing.year'] == '2020'].copy()",
"_____no_output_____"
]
],
[
[
"Add bridge to matches",
"_____no_output_____"
]
],
[
[
"clients['client.name.check'] = clients['client.name'].str.replace(\",\",\"\").str.replace(\".\",\"\").str.upper()",
"/Users/maddy/Documents/2021/markup/investigations-data-broker-lobbying/databrokers/lib/python3.7/site-packages/ipykernel_launcher.py:1: FutureWarning: The default value of regex will change from True to False in a future version. In addition, single character regular expressions will*not* be treated as literal strings when regex=True.\n \"\"\"Entry point for launching an IPython kernel.\n"
]
],
[
[
"Save as output",
"_____no_output_____"
]
],
[
[
"clients.to_csv('../data/matching_process/clients.csv', index=False)",
"_____no_output_____"
]
],
[
[
"### Guess Matches",
"_____no_output_____"
]
],
[
[
"brokers['name.check'] = brokers['name'].str.replace(\",\",\"\").str.replace(\".\",\"\").str.upper()",
"/Users/maddy/Documents/2021/markup/investigations-data-broker-lobbying/databrokers/lib/python3.7/site-packages/ipykernel_launcher.py:1: FutureWarning: The default value of regex will change from True to False in a future version. In addition, single character regular expressions will*not* be treated as literal strings when regex=True.\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"unique_clients = pd.DataFrame()\nunique_clients['client.name.check'] = clients['client.name.check'].unique()\n\nchoices = list(brokers['name.check'].unique())\nchoices.extend([\n 'EQUIFAX',\n 'EXPERIAN',\n 'X-MODE',\n 'IHS MARITIME & TRADE',\n 'ACXIOM',\n 'DELOITTE', \n 'PUBLICIS GROUP', \n 'ORACLE',\n 'ACCENTURE FEDERAL SERVICES',\n 'RELX',\n 'ELSEVIER',\n 'LIVERAMP',\n 'INMAR',\n 'EPSILON DATA'])\n\ndef guess(client):\n if client in choices:\n return client, 100\n pick, score = process.extractOne(client, choices)\n return pick, score",
"_____no_output_____"
]
],
[
[
"### First Pass: Data Broker Name List",
"_____no_output_____"
]
],
[
[
"unique_clients['guess'] = unique_clients['client.name.check'].parallel_apply(guess)",
"_____no_output_____"
],
[
"unique_clients[['guess.name', 'guess.confidence']] = unique_clients['guess'].apply(pd.Series)",
"_____no_output_____"
]
],
[
[
"### Export for Human Double-Checking",
"_____no_output_____"
]
],
[
[
"describe = unique_clients['guess.confidence'].describe()",
"_____no_output_____"
],
[
"guesses = unique_clients[unique_clients['guess.confidence'] > describe['75%']].sort_values(by='guess.confidence', ascending=False)\nguesses.to_csv('../data/matching_process/match-guesses.csv', index=False)",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7cc99bf97cb21abd1ebe532028377f863372c3e | 103,263 | ipynb | Jupyter Notebook | Course 8: Machine Learning with Python/The best classifier.ipynb | jonathanyeh0723/Coursera_IBM-Data-Science | e4c9850c96fd4cccba78db7d7df32ee3bed77f6c | [
"MIT"
]
| null | null | null | Course 8: Machine Learning with Python/The best classifier.ipynb | jonathanyeh0723/Coursera_IBM-Data-Science | e4c9850c96fd4cccba78db7d7df32ee3bed77f6c | [
"MIT"
]
| null | null | null | Course 8: Machine Learning with Python/The best classifier.ipynb | jonathanyeh0723/Coursera_IBM-Data-Science | e4c9850c96fd4cccba78db7d7df32ee3bed77f6c | [
"MIT"
]
| null | null | null | 40.686761 | 9,644 | 0.565711 | [
[
[
"<a href=\"https://www.bigdatauniversity.com\"><img src=\"https://ibm.box.com/shared/static/cw2c7r3o20w9zn8gkecaeyjhgw3xdgbj.png\" width=\"400\" align=\"center\"></a>\n\n<h1 align=\"center\"><font size=\"5\">Classification with Python</font></h1>",
"_____no_output_____"
],
[
"In this notebook we try to practice all the classification algorithms that we learned in this course.\n\nWe load a dataset using Pandas library, and apply the following algorithms, and find the best one for this specific dataset by accuracy evaluation methods.\n\nLets first load required libraries:",
"_____no_output_____"
]
],
[
[
"import itertools\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.ticker import NullFormatter\nimport pandas as pd\nimport numpy as np\nimport matplotlib.ticker as ticker\nfrom sklearn import preprocessing\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### About dataset",
"_____no_output_____"
],
[
"This dataset is about past loans. The __Loan_train.csv__ data set includes details of 346 customers whose loan are already paid off or defaulted. It includes following fields:\n\n| Field | Description |\n|----------------|---------------------------------------------------------------------------------------|\n| Loan_status | Whether a loan is paid off on in collection |\n| Principal | Basic principal loan amount at the |\n| Terms | Origination terms which can be weekly (7 days), biweekly, and monthly payoff schedule |\n| Effective_date | When the loan got originated and took effects |\n| Due_date | Since it’s one-time payoff schedule, each loan has one single due date |\n| Age | Age of applicant |\n| Education | Education of applicant |\n| Gender | The gender of applicant |",
"_____no_output_____"
],
[
"Lets download the dataset",
"_____no_output_____"
]
],
[
[
"#!wget -O loan_train.csv https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/loan_train.csv\npath='https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/loan_train.csv'",
"_____no_output_____"
]
],
[
[
"### Load Data From CSV File ",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(path)\ndf.head()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
]
],
[
[
"### Convert to date time object ",
"_____no_output_____"
]
],
[
[
"df['due_date'] = pd.to_datetime(df['due_date'])\ndf['effective_date'] = pd.to_datetime(df['effective_date'])\ndf.head()",
"_____no_output_____"
]
],
[
[
"# Data visualization and pre-processing\n\n",
"_____no_output_____"
],
[
"Let’s see how many of each class is in our data set ",
"_____no_output_____"
]
],
[
[
"df['loan_status'].value_counts()",
"_____no_output_____"
]
],
[
[
"260 people have paid off the loan on time while 86 have gone into collection \n",
"_____no_output_____"
],
[
"Lets plot some columns to underestand data better:",
"_____no_output_____"
]
],
[
[
"# notice: installing seaborn might takes a few minutes\n!conda install -c anaconda seaborn -y",
"Collecting package metadata (current_repodata.json): ...working... done\nSolving environment: ...working... done\n\n## Package Plan ##\n\n environment location: C:\\Users\\User\\anaconda3\n\n added / updated specs:\n - seaborn\n\n\nThe following packages will be downloaded:\n\n package | build\n ---------------------------|-----------------\n ca-certificates-2020.1.1 | 0 165 KB anaconda\n certifi-2020.4.5.1 | py37_0 159 KB anaconda\n conda-4.8.3 | py37_0 3.0 MB anaconda\n openssl-1.1.1 | he774522_0 5.7 MB anaconda\n seaborn-0.10.0 | py_0 161 KB anaconda\n ------------------------------------------------------------\n Total: 9.3 MB\n\nThe following packages will be UPDATED:\n\n openssl pkgs/main::openssl-1.1.1f-he774522_0 --> anaconda::openssl-1.1.1-he774522_0\n\nThe following packages will be SUPERSEDED by a higher-priority channel:\n\n ca-certificates pkgs/main --> anaconda\n certifi pkgs/main --> anaconda\n conda pkgs/main --> anaconda\n seaborn pkgs/main --> anaconda\n\n\n\nDownloading and Extracting Packages\n\nca-certificates-2020 | 165 KB | | 0% \nca-certificates-2020 | 165 KB | #####8 | 58% \nca-certificates-2020 | 165 KB | ########## | 100% \n\nseaborn-0.10.0 | 161 KB | | 0% \nseaborn-0.10.0 | 161 KB | ########## | 100% \n\ncertifi-2020.4.5.1 | 159 KB | | 0% \ncertifi-2020.4.5.1 | 159 KB | ########## | 100% \n\nopenssl-1.1.1 | 5.7 MB | | 0% \nopenssl-1.1.1 | 5.7 MB | 5 | 5% \nopenssl-1.1.1 | 5.7 MB | #4 | 15% \nopenssl-1.1.1 | 5.7 MB | ##5 | 25% \nopenssl-1.1.1 | 5.7 MB | ###2 | 33% \nopenssl-1.1.1 | 5.7 MB | ####1 | 42% \nopenssl-1.1.1 | 5.7 MB | ##### | 51% \nopenssl-1.1.1 | 5.7 MB | ######1 | 61% \nopenssl-1.1.1 | 5.7 MB | ######9 | 70% \nopenssl-1.1.1 | 5.7 MB | #######8 | 79% \nopenssl-1.1.1 | 5.7 MB | ########7 | 87% \nopenssl-1.1.1 | 5.7 MB | #########4 | 95% \nopenssl-1.1.1 | 5.7 MB | ########## | 100% \n\nconda-4.8.3 | 3.0 MB | | 0% \nconda-4.8.3 | 3.0 MB | #2 | 12% \nconda-4.8.3 | 3.0 MB | ###2 | 33% \nconda-4.8.3 | 3.0 MB | ####6 | 46% \nconda-4.8.3 | 3.0 MB | ######5 | 66% \nconda-4.8.3 | 3.0 MB | ########3 | 84% \nconda-4.8.3 | 3.0 MB | ########## | 100% \nPreparing transaction: ...working... done\nVerifying transaction: ...working... done\nExecuting transaction: ...working... done\n"
],
[
"import seaborn as sns\n\nbins = np.linspace(df.Principal.min(), df.Principal.max(), 10)\ng = sns.FacetGrid(df, col=\"Gender\", hue=\"loan_status\", palette=\"Set1\", col_wrap=2)\ng.map(plt.hist, 'Principal', bins=bins, ec=\"k\")\n\ng.axes[-1].legend()\nplt.show()",
"_____no_output_____"
],
[
"bins = np.linspace(df.age.min(), df.age.max(), 10)\ng = sns.FacetGrid(df, col=\"Gender\", hue=\"loan_status\", palette=\"Set1\", col_wrap=2)\ng.map(plt.hist, 'age', bins=bins, ec=\"k\")\n\ng.axes[-1].legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Pre-processing: Feature selection/extraction",
"_____no_output_____"
],
[
"### Lets look at the day of the week people get the loan ",
"_____no_output_____"
]
],
[
[
"df['dayofweek'] = df['effective_date'].dt.dayofweek\nbins = np.linspace(df.dayofweek.min(), df.dayofweek.max(), 10)\ng = sns.FacetGrid(df, col=\"Gender\", hue=\"loan_status\", palette=\"Set1\", col_wrap=2)\ng.map(plt.hist, 'dayofweek', bins=bins, ec=\"k\")\ng.axes[-1].legend()\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"We see that people who get the loan at the end of the week dont pay it off, so lets use Feature binarization to set a threshold values less then day 4 ",
"_____no_output_____"
]
],
[
[
"df['weekend'] = df['dayofweek'].apply(lambda x: 1 if (x>3) else 0)\ndf.head()",
"_____no_output_____"
]
],
[
[
"## Convert Categorical features to numerical values",
"_____no_output_____"
],
[
"Lets look at gender:",
"_____no_output_____"
]
],
[
[
"df.groupby(['Gender'])['loan_status'].value_counts(normalize=True)",
"_____no_output_____"
]
],
[
[
"86 % of female pay there loans while only 73 % of males pay there loan\n",
"_____no_output_____"
],
[
"Lets convert male to 0 and female to 1:\n",
"_____no_output_____"
]
],
[
[
"df['Gender'].replace(to_replace=['male','female'], value=[0,1],inplace=True)\ndf.head()",
"_____no_output_____"
]
],
[
[
"## One Hot Encoding \n#### How about education?",
"_____no_output_____"
]
],
[
[
"df.groupby(['education'])['loan_status'].value_counts(normalize=True)",
"_____no_output_____"
]
],
[
[
"#### Feature befor One Hot Encoding",
"_____no_output_____"
]
],
[
[
"df[['Principal','terms','age','Gender','education']].head()",
"_____no_output_____"
]
],
[
[
"#### Use one hot encoding technique to conver categorical varables to binary variables and append them to the feature Data Frame ",
"_____no_output_____"
]
],
[
[
"Feature = df[['Principal','terms','age','Gender','weekend']]\nFeature = pd.concat([Feature,pd.get_dummies(df['education'])], axis=1)\nFeature.drop(['Master or Above'], axis = 1,inplace=True)\nFeature.head()",
"_____no_output_____"
]
],
[
[
"### Feature selection",
"_____no_output_____"
],
[
"Lets defind feature sets, X:",
"_____no_output_____"
]
],
[
[
"X = Feature\nX[0:5]",
"_____no_output_____"
]
],
[
[
"What are our lables?",
"_____no_output_____"
]
],
[
[
"y = df['loan_status'].values\ny[0:5]",
"_____no_output_____"
]
],
[
[
"## Normalize Data ",
"_____no_output_____"
],
[
"Data Standardization give data zero mean and unit variance (technically should be done after train test split )",
"_____no_output_____"
]
],
[
[
"X= preprocessing.StandardScaler().fit(X).transform(X)\nX[0:5]",
"_____no_output_____"
]
],
[
[
"# Classification ",
"_____no_output_____"
],
[
"Now, it is your turn, use the training set to build an accurate model. Then use the test set to report the accuracy of the model\nYou should use the following algorithm:\n- K Nearest Neighbor(KNN)\n- Decision Tree\n- Support Vector Machine\n- Logistic Regression\n\n\n\n__ Notice:__ \n- You can go above and change the pre-processing, feature selection, feature-extraction, and so on, to make a better model.\n- You should use either scikit-learn, Scipy or Numpy libraries for developing the classification algorithms.\n- You should include the code of the algorithm in the following cells.",
"_____no_output_____"
],
[
"# K Nearest Neighbor(KNN)\nNotice: You should find the best k to build the model with the best accuracy. \n**warning:** You should not use the __loan_test.csv__ for finding the best k, however, you can split your train_loan.csv into train and test to find the best __k__.",
"_____no_output_____"
]
],
[
[
"#Importing library for KNN \nfrom sklearn.neighbors import KNeighborsClassifier\n\n# Train Test Split \nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=4)\nprint ('Train set:', X_train.shape, y_train.shape)\nprint ('Test set:', X_test.shape, y_test.shape)",
"Train set: (276, 8) (276,)\nTest set: (70, 8) (70,)\n"
],
[
"#Set initial k for prediction\nk = 4\n\n#Train Model and Predict \nneigh = KNeighborsClassifier(n_neighbors = k).fit(X_train,y_train)\nneigh\n\nyhat_KNN = neigh.predict(X_test)\nyhat_KNN",
"_____no_output_____"
],
[
"from sklearn import metrics\n\n#To check which k is the best to our model\nKs = 10\nmean_acc = np.zeros((Ks-1))\nstd_acc = np.zeros((Ks-1))\nConfustionMx = [];\nfor n in range(1,Ks):\n \n #Train Model and Predict \n neigh = KNeighborsClassifier(n_neighbors = n).fit(X_train,y_train)\n yhat_KNN=neigh.predict(X_test)\n mean_acc[n-1] = metrics.accuracy_score(y_test, yhat_KNN)\n\n \n std_acc[n-1]=np.std(yhat_KNN==y_test)/np.sqrt(yhat_KNN.shape[0])\n\nmean_acc\n\n#Print the best accuracy with k value\nprint( \"The best accuracy was with\", mean_acc.max(), \"with k=\", mean_acc.argmax()+1) \n\nprint(\"Train set Accuracy: \", metrics.accuracy_score(y_train, neigh.predict(X_train)))\nprint(\"Test set Accuracy: \", metrics.accuracy_score(y_test, yhat_KNN))",
"The best accuracy was with 0.7857142857142857 with k= 7\nTrain set Accuracy: 0.7898550724637681\nTest set Accuracy: 0.7571428571428571\n"
]
],
[
[
"# Decision Tree",
"_____no_output_____"
]
],
[
[
"#Import library of DecisionTreeClassifier\nfrom sklearn.tree import DecisionTreeClassifier",
"_____no_output_____"
],
[
"#Modeling\ndrugTree = DecisionTreeClassifier(criterion=\"entropy\", max_depth = 5)\ndrugTree # it shows the default parameters\ndrugTree.fit(X_train,y_train)",
"_____no_output_____"
],
[
"#Prediction\npredTree = drugTree.predict(X_test)\nprint (predTree [0:10])\nprint (y [0:10])",
"['COLLECTION' 'COLLECTION' 'PAIDOFF' 'PAIDOFF' 'PAIDOFF' 'PAIDOFF'\n 'COLLECTION' 'COLLECTION' 'PAIDOFF' 'PAIDOFF']\n['PAIDOFF' 'PAIDOFF' 'PAIDOFF' 'PAIDOFF' 'PAIDOFF' 'PAIDOFF' 'PAIDOFF'\n 'PAIDOFF' 'PAIDOFF' 'PAIDOFF']\n"
]
],
[
[
"# Support Vector Machine",
"_____no_output_____"
]
],
[
[
"#Importing library for SVM\nfrom sklearn import svm",
"_____no_output_____"
],
[
"#Modeling\nclf = svm.SVC(kernel='rbf')\nclf.fit(X_train, y_train) ",
"_____no_output_____"
],
[
"#Prediction\nyhat_SVM = clf.predict(X_test)\nyhat_SVM [0:5]",
"_____no_output_____"
]
],
[
[
"# Logistic Regression",
"_____no_output_____"
]
],
[
[
"#Importing library for Logistic Regression\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"#Modeling\nLR = LogisticRegression(C=0.01, solver='liblinear').fit(X_train,y_train)\nLR",
"_____no_output_____"
],
[
"#Prediction\nyhat_L = LR.predict(X_test)\n\nyhat_prob = LR.predict_proba(X_test)\nyhat_prob",
"_____no_output_____"
]
],
[
[
"# Model Evaluation using Test set",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import jaccard_similarity_score\nfrom sklearn.metrics import f1_score\nfrom sklearn.metrics import log_loss",
"_____no_output_____"
]
],
[
[
"First, download and load the test set:",
"_____no_output_____"
]
],
[
[
"#!wget -O loan_test.csv https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/loan_test.csv\nurl='https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/loan_test.csv'",
"_____no_output_____"
]
],
[
[
"### Load Test set for evaluation ",
"_____no_output_____"
]
],
[
[
"test_df = pd.read_csv(url)\ntest_df.head()",
"_____no_output_____"
],
[
"#Test set for y\ny_for_test=test_df[['loan_status']]\n\n\n#Feature\ntest_df['due_date'] = pd.to_datetime(test_df['due_date'])\ntest_df['effective_date'] = pd.to_datetime(test_df['effective_date'])\n\ntest_df['dayofweek'] = test_df['effective_date'].dt.dayofweek\ntest_df['weekend'] = test_df['dayofweek'].apply(lambda x: 1 if (x>3) else 0)\ntest_df['Gender'].replace(to_replace=['male','female'], value=[0,1],inplace=True)\n\ntest_df.shape\n\nFeature_T = test_df[['Principal','terms','age','Gender','weekend']]\n#pd_T=pd.get_dummies(test_df['education'])\nFeature_T = pd.concat([Feature_T,pd.get_dummies(test_df['education'])], axis=1)\nFeature_T.drop(['Master or Above'], axis = 1,inplace=True)\nFeature_T.head()\n\nFeature_T= preprocessing.StandardScaler().fit(Feature_T).transform(Feature_T)",
"_____no_output_____"
],
[
"#Using best k=8 for KNN\nneigh = KNeighborsClassifier(n_neighbors = 8).fit(X_train,y_train)\nyhat_KNN = neigh.predict(Feature_T)\n\n#Decision tree prediction using test set \nT_predTree = drugTree.predict(Feature_T)\n\n#SVM prediction using test set\nyhat_SVM = clf.predict(Feature_T)\n\n#Prediction\nyhat_L = LR.predict(Feature_T)\n#Evaluation for logistic log_loss\nyhat_prob = LR.predict_proba(Feature_T)\n\n#Evaluation for Jaccard index\nJ_KNN=jaccard_similarity_score(y_for_test, yhat_KNN)\nJ_Tree=jaccard_similarity_score(y_for_test, T_predTree)\nJ_SVM=jaccard_similarity_score(y_for_test, yhat_SVM)\nJ_L=jaccard_similarity_score(y_for_test, yhat_L)\n\n#Evaluation for F1-score\nf1_KNN=f1_score(y_for_test, yhat_KNN, average='weighted')\nf1_Tree=f1_score(y_for_test, T_predTree, average='weighted')\nf1_SVM=f1_score(y_for_test, yhat_SVM, average='weighted')\nf1_L=f1_score(y_for_test, yhat_L, average='weighted')\n\n#Evaluation for log_loss\nloglossL=log_loss(y_for_test, yhat_prob)",
"C:\\Users\\User\\anaconda3\\lib\\site-packages\\sklearn\\metrics\\_classification.py:664: FutureWarning: jaccard_similarity_score has been deprecated and replaced with jaccard_score. It will be removed in version 0.23. This implementation has surprising behavior for binary and multiclass classification tasks.\n FutureWarning)\n"
],
[
"row_index = ['KNN', 'Decision Tree', 'SVM','LogisticRegression']\ncolumn_index = ['Jaccard', 'F1-score', 'LogLoss']\nvalues=[[J_KNN,f1_KNN,'NA'],[J_Tree,f1_Tree,'NA'],[J_SVM,f1_SVM,'NA'],[J_L,f1_L,loglossL]]\ndf = pd.DataFrame(values, index=row_index, columns = column_index)\ndf",
"_____no_output_____"
]
],
[
[
"# Report\nYou should be able to report the accuracy of the built model using different evaluation metrics:",
"_____no_output_____"
],
[
"| Algorithm | Jaccard | F1-score | LogLoss |\n|--------------------|---------|----------|---------|\n| KNN | ? | ? | NA |\n| Decision Tree | ? | ? | NA |\n| SVM | ? | ? | NA |\n| LogisticRegression | ? | ? | ? |",
"_____no_output_____"
],
[
"<h2>Want to learn more?</h2>\n\nIBM SPSS Modeler is a comprehensive analytics platform that has many machine learning algorithms. It has been designed to bring predictive intelligence to decisions made by individuals, by groups, by systems – by your enterprise as a whole. A free trial is available through this course, available here: <a href=\"http://cocl.us/ML0101EN-SPSSModeler\">SPSS Modeler</a>\n\nAlso, you can use Watson Studio to run these notebooks faster with bigger datasets. Watson Studio is IBM's leading cloud solution for data scientists, built by data scientists. With Jupyter notebooks, RStudio, Apache Spark and popular libraries pre-packaged in the cloud, Watson Studio enables data scientists to collaborate on their projects without having to install anything. Join the fast-growing community of Watson Studio users today with a free account at <a href=\"https://cocl.us/ML0101EN_DSX\">Watson Studio</a>\n\n<h3>Thanks for completing this lesson!</h3>\n\n<h4>Author: <a href=\"https://ca.linkedin.com/in/saeedaghabozorgi\">Saeed Aghabozorgi</a></h4>\n<p><a href=\"https://ca.linkedin.com/in/saeedaghabozorgi\">Saeed Aghabozorgi</a>, PhD is a Data Scientist in IBM with a track record of developing enterprise level applications that substantially increases clients’ ability to turn data into actionable knowledge. He is a researcher in data mining field and expert in developing advanced analytic methods like machine learning and statistical modelling on large datasets.</p>\n\n<hr>\n\n<p>Copyright © 2018 <a href=\"https://cocl.us/DX0108EN_CC\">Cognitive Class</a>. This notebook and its source code are released under the terms of the <a href=\"https://bigdatauniversity.com/mit-license/\">MIT License</a>.</p>",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
]
|
e7cca48c2db967a83f4c6e67bd9e5679281d2ada | 426,732 | ipynb | Jupyter Notebook | 04 - Clustering.ipynb | jschevers/ml-basics | 54f598a5a9dd50993e2a19431af268b24e2eff11 | [
"MIT"
]
| null | null | null | 04 - Clustering.ipynb | jschevers/ml-basics | 54f598a5a9dd50993e2a19431af268b24e2eff11 | [
"MIT"
]
| null | null | null | 04 - Clustering.ipynb | jschevers/ml-basics | 54f598a5a9dd50993e2a19431af268b24e2eff11 | [
"MIT"
]
| null | null | null | 756.617021 | 72,916 | 0.688877 | [
[
[
"# Clustering\n\nIn contrast to *supervised* machine learning, *unsupervised* learning is used when there is no \"ground truth\" from which to train and validate label predictions. The most common form of unsupervised learning is *clustering*, which is simllar conceptually to *classification*, except that the the training data does not include known values for the class label to be predicted. Clustering works by separating the training cases based on similarities that can be determined from their feature values. Think of it this way; the numeric features of a given entity can be thought of as vector coordinates that define the entity's position in n-dimensional space. What a clustering model seeks to do is to identify groups, or *clusters*, of entities that are close to one another while being separated from other clusters.\n\nFor example, let's take a look at a dataset that contains measurements of different species of wheat seed.\n\n> **Citation**: The seeds dataset used in the this exercise was originally published by the Institute of Agrophysics of the Polish Academy of Sciences in Lublin, and can be downloaded from the UCI dataset repository (Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science).",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\n# load the training dataset\ndata = pd.read_csv('data/seeds.csv')\n\n# Display a random sample of 10 observations (just the features)\nfeatures = data[data.columns[0:6]]\nfeatures.sample(10)",
"_____no_output_____"
]
],
[
[
"As you can see, the dataset contains six data points (or *features*) for each instance (*observation*) of a seed. So you could interpret these as coordinates that describe each instance's location in six-dimensional space.\n\nNow, of course six-dimensional space is difficult to visualise in a three-dimensional world, or on a two-dimensional plot; so we'll take advantage of a mathematical technique called *Principal Component Analysis* (PCA) to analyze the relationships between the features and summarize each observation as coordinates for two principal components - in other words, we'll translate the six-dimensional feature values into two-dimensional coordinates.",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import MinMaxScaler\nfrom sklearn.decomposition import PCA\n\n# Normalize the numeric features so they're on the same scale\nscaled_features = MinMaxScaler().fit_transform(features[data.columns[0:6]])\n\n# Get two principal components\npca = PCA(n_components = 2).fit(scaled_features)\nfeatures_2d = pca.transform(scaled_features)\nfeatures_2d[0:10]",
"_____no_output_____"
],
[
"#js: complete decomposition\npca = PCA().fit(scaled_features)",
"_____no_output_____"
],
[
"#js\nprint(pca.explained_variance_)\nprint(pca.explained_variance_ratio_)",
"[2.92954741e-01 4.40885796e-02 2.84860612e-02 1.22253823e-03\n 3.91072778e-04 6.81063524e-05]\n[7.97782915e-01 1.20063309e-01 7.75740747e-02 3.32925184e-03\n 1.06498082e-03 1.85469210e-04]\n"
],
[
"#js: cumulative explain variance ratio\npca.explained_variance_ratio_.cumsum()",
"_____no_output_____"
],
[
"#js: how many components do I need if I want alleast 95% of the variance to be explained\npca = PCA(.95)\npca.fit(scaled_features)\npca.n_components_",
"_____no_output_____"
]
],
[
[
"Now that we have the data points translated to two dimensions, we can visualize them in a plot:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\n%matplotlib inline\n\nplt.scatter(features_2d[:,0],features_2d[:,1])\nplt.xlabel('Dimension 1')\nplt.ylabel('Dimension 2')\nplt.title('Data')\nplt.show()",
"_____no_output_____"
]
],
[
[
"Hopefully you can see at least two, arguably three, reasonably distinct groups of data points; but here lies one of the fundamental problems with clustering - without known class labels, how do you know how many clusters to separate your data into?\n\nOne way we can try to find out is to use a data sample to create a series of clustering models with an incrementing number of clusters, and measure how tightly the data points are grouped within each cluster. A metric often used to measure this tightness is the *within cluster sum of squares* (WCSS), with lower values meaning that the data points are closer. You can then plot the WCSS for each model.",
"_____no_output_____"
]
],
[
[
"#importing the libraries\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom sklearn.cluster import KMeans\n%matplotlib inline\n\n# Create 10 models with 1 to 10 clusters\nwcss = []\nfor i in range(1, 11):\n kmeans = KMeans(n_clusters = i)\n # Fit the data points\n kmeans.fit(features.values)\n # kmeans.fit(scaled_features) # why not on these?\n # Get the WCSS (inertia) value\n wcss.append(kmeans.inertia_)\n \n#Plot the WCSS values onto a line graph\nplt.plot(range(1, 11), wcss)\nplt.title('WCSS by Clusters')\nplt.xlabel('Number of clusters')\nplt.ylabel('WCSS')\nplt.show()",
"_____no_output_____"
]
],
[
[
"The plot shows a large reduction in WCSS (so greater *tightness*) as the number of clusters increases from one to two, and a further noticable reduction from two to three clusters. After that, the reduction is less pronounced, resulting in an \"elbow\" in the chart at around three clusters. This is a good indication that there are two to three reasonably well separated clusters of data points.\n\n## K-Means Clustering\n\nThe algorithm we used to create our test clusters is *K-Means*. This is a commonly used clustering algorithm that separates a dataset into *K* clusters of equal variance. The number of clusters, *K*, is user defined. The basic algorithm has the following steps:\n\n1. A set of K centroids are randomly chosen.\n2. Clusters are formed by assigning the data points to their closest centroid.\n3. The means of each cluster is computed and the centroid is moved to the mean.\n4. Steps 2 and 3 are repeated until a stopping criteria is met. Typically, the algorithm terminates when each new iteration results in negligable movement of centroids and the clusters become static.\n5. When the clusters stop changing, the algorithm has *converged*, defining the locations of the clusters - note that the random starting point for the centroids means that re-running the algorithm could result in slightly different clusters, so training usually involves multiple iterations, reinitializing the centroids each time, and the model with the best WCSS is selected.\n\nLet's try using K-Means on our seeds data with a K value of 3.",
"_____no_output_____"
]
],
[
[
"from sklearn.cluster import KMeans\n\n# Create a model based on 3 centroids\nmodel = KMeans(n_clusters=3, init='k-means++', n_init=100, max_iter=1000)\n# Fit to the data and predict the cluster assignments for each data point\nkm_clusters = model.fit_predict(features.values)\n# View the cluster assignments\nkm_clusters",
"_____no_output_____"
]
],
[
[
"Let's see those cluster assignments with the two-dimensional data points.",
"_____no_output_____"
]
],
[
[
"def plot_clusters(samples, clusters):\n col_dic = {0:'blue',1:'green',2:'orange'}\n mrk_dic = {0:'*',1:'x',2:'+'}\n colors = [col_dic[x] for x in clusters]\n markers = [mrk_dic[x] for x in clusters]\n for sample in range(len(clusters)):\n plt.scatter(samples[sample][0], samples[sample][1], color = colors[sample], marker=markers[sample], s=100)\n plt.xlabel('Dimension 1')\n plt.ylabel('Dimension 2')\n plt.title('Assignments')\n plt.show()\n\nplot_clusters(features_2d, km_clusters)",
"_____no_output_____"
]
],
[
[
"Hopefully, the the data has been separated into three distinct clusters.\n\nSo what's the practical use of clustering? In some cases, you may have data that you need to group into distict clusters without knowing how many clusters there are or what they indicate. For example a marketing organization might want to separate customers into distinct segments, and then investigate how those segments exhibit different purchasing behaviors.\n\nSometimes, clustering is used as an initial step towards creating a classification model. You start by identifying distinct groups of data points, and then assign class labels to those clusters. You can then use this labelled data to train a classification model.\n\nIn the case of the seeds data, the different species of seed are already known and encoded as 0 (*Kama*), 1 (*Rosa*), or 2 (*Canadian*), so we can use these identifiers to compare the species classifications to the clusters identified by our unsupervised algorithm",
"_____no_output_____"
]
],
[
[
"seed_species = data[data.columns[7]]\nplot_clusters(features_2d, seed_species.values)",
"_____no_output_____"
]
],
[
[
"There may be some differences between the cluster assignments and class labels, but the K-Means model should have done a reasonable job of clustering the observations so that seeds of the same species are generally in the same cluster.",
"_____no_output_____"
],
[
"## Hierarchical Clustering\n\nHierarchical clustering methods make fewer distributional assumptions when compared to K-means methods. However, K-means methods are generally more scalable, sometimes very much so.\n\nHierarchical clustering creates clusters by either a *divisive* method or *agglomerative* method. The divisive method is a \"top down\" approach starting with the entire dataset and then finding partitions in a stepwise manner. Agglomerative clustering is a \"bottom up** approach. In this lab you will work with agglomerative clustering which roughly works as follows:\n\n1. The linkage distances between each of the data points is computed.\n2. Points are clustered pairwise with their nearest neighbor.\n3. Linkage distances between the clusters are computed.\n4. Clusters are combined pairwise into larger clusters.\n5. Steps 3 and 4 are repeated until all data points are in a single cluster.\n\nThe linkage function can be computed in a number of ways:\n- Ward linkage measures the increase in variance for the clusters being linked,\n- Average linkage uses the mean pairwise distance between the members of the two clusters,\n- Complete or Maximal linkage uses the maximum distance between the members of the two clusters.\n\nSeveral different distance metrics are used to compute linkage functions:\n- Euclidian or l2 distance is the most widely used. This metric is only choice for the Ward linkage method.\n- Manhattan or l1 distance is robust to outliers and has other interesting properties.\n- Cosine similarity, is the dot product between the location vectors divided by the magnitudes of the vectors. Notice that this metric is a measure of similarity, whereas the other two metrics are measures of difference. Similarity can be quite useful when working with data such as images or text documents.\n\n### Agglomerative Clustering\n\nLet's see an example of clustering the seeds data using an agglomerative clustering algorithm.",
"_____no_output_____"
]
],
[
[
"from sklearn.cluster import AgglomerativeClustering\n\nagg_model = AgglomerativeClustering(n_clusters=3)\nagg_clusters = agg_model.fit_predict(features.values)\nagg_clusters",
"_____no_output_____"
]
],
[
[
"So what do the agglomerative cluster assignments look like?",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\n%matplotlib inline\n\ndef plot_clusters(samples, clusters):\n col_dic = {0:'blue',1:'green',2:'orange'}\n mrk_dic = {0:'*',1:'x',2:'+'}\n colors = [col_dic[x] for x in clusters]\n markers = [mrk_dic[x] for x in clusters]\n for sample in range(len(clusters)):\n plt.scatter(samples[sample][0], samples[sample][1], color = colors[sample], marker=markers[sample], s=100)\n plt.xlabel('Dimension 1')\n plt.ylabel('Dimension 2')\n plt.title('Assignments')\n plt.show()\n\nplot_clusters(features_2d, agg_clusters)\n",
"_____no_output_____"
]
],
[
[
"## Further Reading\n\nTo learn more about clustering with scikit-learn, see the [scikit-learn documentation](https://scikit-learn.org/stable/modules/clustering.html).\n\n## Further Reading\n\nTo learn more about the Python packages you explored in this notebook, see the following documentation:\n\n- [NumPy](https://numpy.org/doc/stable/)\n- [Pandas](https://pandas.pydata.org/pandas-docs/stable/)\n- [Matplotlib](https://matplotlib.org/contents.html)\n\n## Challenge: Cluster Unlabelled Data\n\nNow that you've seen how to create a clustering model, why not try for yourself? You'll find a clustering challenge in the [/challenges/04 - Clustering Challenge.ipynb](./challenges/04%20-%20Clustering%20Challenge.ipynb) notebook!\n\n> **Note**: The time to complete this optional challenge is not included in the estimated time for this exercise - you can spend as little or as much time on it as you like!",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7cca5acc19acd52bf301e245699ec115ae4f0f4 | 4,183 | ipynb | Jupyter Notebook | Notebooks/Batch Process and Sliding Windows.ipynb | agbs2k8/python_FAQ | 90d51f02b21ed22dc67e8ba298783894462bd7a0 | [
"MIT"
]
| 1 | 2020-03-06T16:18:16.000Z | 2020-03-06T16:18:16.000Z | Notebooks/Batch Process and Sliding Windows.ipynb | agbs2k8/python_FAQ | 90d51f02b21ed22dc67e8ba298783894462bd7a0 | [
"MIT"
]
| null | null | null | Notebooks/Batch Process and Sliding Windows.ipynb | agbs2k8/python_FAQ | 90d51f02b21ed22dc67e8ba298783894462bd7a0 | [
"MIT"
]
| null | null | null | 24.751479 | 227 | 0.497251 | [
[
[
"These are a couple of functions I've always kept handy because I end up using them more often than I even expect. They both work off of an iterable, so I'll define one here to use as an example:",
"_____no_output_____"
]
],
[
[
"my_iter = [x for x in range(20)]",
"_____no_output_____"
]
],
[
[
"# Batch Processing\n\nThis is a function that will yield small subsets of an iterable and allow you to work with smaller parts at once. I've used this when I have too much data to process all of it at once, so I could process it in chuncks. ",
"_____no_output_____"
]
],
[
[
"def batch(iterable, n: int = 1):\n \"\"\"\n Return a dataset in batches (no overlap)\n :param iterable: the item to be returned in segments\n :param n: length of the segments\n :return: generator of portions of the original data\n \"\"\"\n for ndx in range(0, len(iterable), n):\n yield iterable[ndx:max(ndx+n, 1)]",
"_____no_output_____"
],
[
"for this_batch in batch(my_iter, 3):\n print(this_batch)",
"[0, 1, 2]\n[3, 4, 5]\n[6, 7, 8]\n[9, 10, 11]\n[12, 13, 14]\n[15, 16, 17]\n[18, 19]\n"
]
],
[
[
"You can see that it just split my iterable up into smaller parts. It still gave me back all of it, and did not repeat any portions.\n\n# Sliding Window\n\nDifferent from the batch, this gives me overlapping sections of the iterable. You define a window size, and it will give you back each window, in order of that size.",
"_____no_output_____"
]
],
[
[
"from itertools import islice\n\n\ndef window(sequence, n: int = 5):\n \"\"\"\n Returns a sliding window of width n over the iterable sequence\n :param sequence: iterable to yield segments from\n :param n: number of items in the window\n :return: generator of windows\n \"\"\"\n _it = iter(sequence)\n result = tuple(islice(_it, n))\n if len(result) == n:\n yield result\n for element in _it:\n result = result[1:] + (element,)\n yield result",
"_____no_output_____"
],
[
"for this_window in window(my_iter, 4):\n print(this_window)",
"(0, 1, 2, 3)\n(1, 2, 3, 4)\n(2, 3, 4, 5)\n(3, 4, 5, 6)\n(4, 5, 6, 7)\n(5, 6, 7, 8)\n(6, 7, 8, 9)\n(7, 8, 9, 10)\n(8, 9, 10, 11)\n(9, 10, 11, 12)\n(10, 11, 12, 13)\n(11, 12, 13, 14)\n(12, 13, 14, 15)\n(13, 14, 15, 16)\n(14, 15, 16, 17)\n(15, 16, 17, 18)\n(16, 17, 18, 19)\n"
]
],
[
[
"It's as easy as that!",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
e7ccaf50e9624b017aa2b594671c66584c0663b0 | 3,739 | ipynb | Jupyter Notebook | examples_en/tutorial001_qubo_en.ipynb | mori388/annealing | 501d70b98784b95ed760a4fe5798925bfd72f31d | [
"Apache-2.0"
]
| 1 | 2021-06-25T06:54:14.000Z | 2021-06-25T06:54:14.000Z | examples_en/tutorial001_qubo_en.ipynb | mori388/annealing | 501d70b98784b95ed760a4fe5798925bfd72f31d | [
"Apache-2.0"
]
| null | null | null | examples_en/tutorial001_qubo_en.ipynb | mori388/annealing | 501d70b98784b95ed760a4fe5798925bfd72f31d | [
"Apache-2.0"
]
| null | null | null | 22.524096 | 255 | 0.425515 | [
[
[
"#QUBO and basic calculation",
"_____no_output_____"
],
[
"Here we are going to check the way how to create QUBO matrix and solve it.\n",
"_____no_output_____"
],
[
"First we prepare the wildqat sdk and create an instance.",
"_____no_output_____"
]
],
[
[
"import wildqat as wq\na = wq.opt()",
"_____no_output_____"
]
],
[
[
"Next we make a matrix called QUBO like below.",
"_____no_output_____"
]
],
[
[
"a.qubo = [[4,-4,-4],[0,4,-4],[0,0,4]]\n",
"_____no_output_____"
]
],
[
[
"And then calculate with algorithm. This time we use SA algorithm to solve the matrix.",
"_____no_output_____"
]
],
[
[
"a.sa()",
"1.412949800491333\n"
]
],
[
[
"And we got the result. Upper value show the time to aquire the result. The array is the list of result of the bit. The QUBO matrix once converted to Ising Model so called Jij matrix. If we want to check it we can easily aquire is by printing a.J",
"_____no_output_____"
]
],
[
[
"print(a.J)",
"[[0, -1, -1], [0, 0, -1], [0, 0, 0]]\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7ccb25e3e97a03d9b349008d6c275791452e67d | 10,653 | ipynb | Jupyter Notebook | docs/source/user_guide/component_graphs.ipynb | peterataylor/evalml | 917f07845c4a319bb08c7aaa8df9e09623df11c8 | [
"BSD-3-Clause"
]
| 454 | 2020-09-25T15:36:06.000Z | 2022-03-30T04:48:49.000Z | docs/source/user_guide/component_graphs.ipynb | peterataylor/evalml | 917f07845c4a319bb08c7aaa8df9e09623df11c8 | [
"BSD-3-Clause"
]
| 2,175 | 2020-09-25T17:05:45.000Z | 2022-03-31T19:54:54.000Z | docs/source/user_guide/component_graphs.ipynb | isabella232/evalml | 5b372d0dfac05ff9b7e41eb494a9df1bf2da4a9d | [
"BSD-3-Clause"
]
| 66 | 2020-09-25T18:46:27.000Z | 2022-03-02T18:33:30.000Z | 38.738182 | 572 | 0.624988 | [
[
[
"# Component Graphs\n\nEvalML component graphs represent and describe the flow of data in a collection of related components. A component graph is comprised of nodes representing components, and edges between pairs of nodes representing where the inputs and outputs of each component should go. It is the backbone of the features offered by the EvalML [pipeline](pipelines.ipynb), but is also a powerful data structure on its own. EvalML currently supports component graphs as linear and [directed acyclic graphs (DAG)](https://en.wikipedia.org/wiki/Directed_acyclic_graph).",
"_____no_output_____"
],
[
"## Defining a Component Graph\n\nComponent graphs can be defined by specifying the dictionary of components and edges that describe the graph.\n\nIn this dictionary, each key is a reference name for a component. Each corresponding value is a list, where the first element is the component itself, and the remaining elements are the input edges that should be connected to that component. The component as listed in the value can either be the component object itself or its string name.\n\nThis stucture is very similar to that of [Dask computation graphs](https://docs.dask.org/en/latest/spec.html).\n\n\nFor example, in the code example below, we have a simple component graph made up of two components: an Imputer and a Random Forest Classifer. The names used to reference these two components are given by the keys, \"My Imputer\" and \"RF Classifier\" respectively. Each value in the dictionary is a list where the first element is the component corresponding to the component name, and the remaining elements are the inputs, e.g. \"My Imputer\" represents an Imputer component which has inputs \"X\" (the original features matrix) and \"y\" (the original target).\n\nFeature edges are specified as `\"X\"` or `\"{component_name}.x\"`. For example, `{\"My Component\": [MyComponent, \"Imputer.x\", ...]}` indicates that we should use the feature output of the `Imputer` as as part of the feature input for MyComponent. Similarly, target edges are specified as `\"y\"` or `\"{component_name}.y\". {\"My Component\": [MyComponent, \"Target Imputer.y\", ...]}` indicates that we should use the target output of the `Target Imputer` as a target input for MyComponent.\n\nEach component can have a number of feature inputs, but can only have one target input. All input edges must be explicitly defined.",
"_____no_output_____"
],
[
"Using a real example, we define a simple component graph consisting of three nodes: an Imputer (\"My Imputer\"), an One-Hot Encoder (\"OHE\"), and a Random Forest Classifier (\"RF Classifier\"). \n\n- \"My Imputer\" takes the original X as a features input, and the original y as the target input\n- \"OHE\" also takes the original X as a features input, and the original y as the target input\n- \"RF Classifer\" takes the concatted feature outputs from \"My Imputer\" and \"OHE\" as a features input, and the original y as the target input.",
"_____no_output_____"
]
],
[
[
"from evalml.pipelines import ComponentGraph\n\ncomponent_dict = {\n 'My Imputer': ['Imputer', 'X', 'y'],\n 'OHE': ['One Hot Encoder', 'X', 'y'],\n 'RF Classifier': ['Random Forest Classifier', 'My Imputer.x', 'OHE.x', 'y'] # takes in multiple feature inputs\n}\ncg_simple = ComponentGraph(component_dict)",
"_____no_output_____"
]
],
[
[
"All component graphs must end with one final or terminus node. This can either be a transformer or an estimator. Below, the component graph is invalid because has two terminus nodes: the \"RF Classifier\" and the \"EN Classifier\".",
"_____no_output_____"
]
],
[
[
"# Can't instantiate a component graph with more than one terminus node (here: RF Classifier, EN Classifier)\ncomponent_dict = {\n 'My Imputer': ['Imputer', 'X', 'y'],\n 'RF Classifier': ['Random Forest Classifier', 'My Imputer.x', 'y'],\n 'EN Classifier': ['Elastic Net Classifier', 'My Imputer.x', 'y']\n}",
"_____no_output_____"
]
],
[
[
"Once we have defined a component graph, we can instantiate the graph with specific parameter values for each component using `.instantiate(parameters)`. All components in a component graph must be instantiated before fitting, transforming, or predicting.\n\nBelow, we instantiate our graph and set the value of our Imputer's `numeric_impute_strategy` to \"most_frequent\".",
"_____no_output_____"
]
],
[
[
"cg_simple.instantiate({'My Imputer': {'numeric_impute_strategy': 'most_frequent'}})",
"_____no_output_____"
]
],
[
[
"## Components in the Component Graph\n\nYou can use `.get_component(name)` and provide the unique component name to access any component in the component graph. Below, we can grab our Imputer component and confirm that `numeric_impute_strategy` has indeed been set to \"most_frequent\".",
"_____no_output_____"
]
],
[
[
"cg_simple.get_component('My Imputer')",
"_____no_output_____"
]
],
[
[
"You can also `.get_inputs(name)` and provide the unique component name to to retrieve all inputs for that component.\n\nBelow, we can grab our 'RF Classifier' component and confirm that we use `\"My Imputer.x\"` as our features input and `\"y\"` as target input.",
"_____no_output_____"
]
],
[
[
"cg_simple.get_inputs('RF Classifier')",
"_____no_output_____"
]
],
[
[
"## Component Graph Computation Order\n\nUpon initalization, each component graph will generate a topological order. We can access this generated order by calling the `.compute_order` attribute. This attribute is used to determine the order that components should be evaluated during calls to `fit` and `transform`.",
"_____no_output_____"
]
],
[
[
"cg_simple.compute_order",
"_____no_output_____"
]
],
[
[
"## Visualizing Component Graphs\n\n",
"_____no_output_____"
],
[
"We can get more information about an instantiated component graph by calling `.describe()`. This method will pretty-print each of the components in the graph and its parameters.",
"_____no_output_____"
]
],
[
[
"# Using a more involved component graph with more complex edges\ncomponent_dict = {\n \"Imputer\": [\"Imputer\", \"X\", \"y\"],\n \"Target Imputer\": [\"Target Imputer\", \"X\", \"y\"],\n \"OneHot_RandomForest\": [\"One Hot Encoder\", \"Imputer.x\", \"Target Imputer.y\"],\n \"OneHot_ElasticNet\": [\"One Hot Encoder\", \"Imputer.x\", \"y\"],\n \"Random Forest\": [\"Random Forest Classifier\", \"OneHot_RandomForest.x\", \"y\"],\n \"Elastic Net\": [\"Elastic Net Classifier\", \"OneHot_ElasticNet.x\", \"Target Imputer.y\"],\n \"Logistic Regression\": [\n \"Logistic Regression Classifier\",\n \"Random Forest.x\",\n \"Elastic Net.x\",\n \"y\",\n ],\n}\ncg_with_estimators = ComponentGraph(component_dict)\ncg_with_estimators.instantiate({})\ncg_with_estimators.describe()",
"_____no_output_____"
]
],
[
[
"We can also visualize a component graph by calling `.graph()`.",
"_____no_output_____"
]
],
[
[
"cg_with_estimators.graph()",
"_____no_output_____"
]
],
[
[
"## Component graph methods\n\nSimilar to the pipeline structure, we can call `fit`, `transform` or `predict`. \n\nWe can also call `fit_features` which will fit all but the final component and `compute_final_component_features` which will transform all but the final component. These two methods may be useful in cases where you want to understand what transformed features are being passed into the last component.",
"_____no_output_____"
]
],
[
[
"from evalml.demos import load_breast_cancer\n\nX, y = load_breast_cancer()\ncomponent_dict = {\n 'My Imputer': ['Imputer', 'X', 'y'],\n 'OHE': ['One Hot Encoder', 'My Imputer.x', 'y']\n}\ncg_with_final_transformer = ComponentGraph(component_dict)\ncg_with_final_transformer.instantiate({})\ncg_with_final_transformer.fit(X, y)\n\n# We can call `transform` for ComponentGraphs with a final transformer\ncg_with_final_transformer.transform(X, y)",
"_____no_output_____"
],
[
"cg_with_estimators.fit(X, y)\n\n# We can call `predict` for ComponentGraphs with a final transformer\ncg_with_estimators.predict(X)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7ccd4675e958e8d319cfba807b169a2e64309b9 | 5,350 | ipynb | Jupyter Notebook | user_recommendation.ipynb | beloshh/team_python | a26606bb96334d6a93412bede09082038e4060e7 | [
"MIT"
]
| 1 | 2020-04-11T19:37:59.000Z | 2020-04-11T19:37:59.000Z | user_recommendation.ipynb | beloshh/team_python | a26606bb96334d6a93412bede09082038e4060e7 | [
"MIT"
]
| null | null | null | user_recommendation.ipynb | beloshh/team_python | a26606bb96334d6a93412bede09082038e4060e7 | [
"MIT"
]
| null | null | null | 30.05618 | 111 | 0.586729 | [
[
[
"#import libraries\nimport pandas as pd\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.metrics.pairwise import linear_kernel",
"_____no_output_____"
],
[
"#reading the csv file\nds = pd.read_json(\"json_data/lucid_table_users.json\")\n#renaming the empty rows with space\nds = ds.fillna(' ')",
"_____no_output_____"
],
[
"#analyzing the words in the column and removing common stop words, calculating the cosine similarities\ntf = TfidfVectorizer(analyzer='word', ngram_range=(1, 3), min_df=0, stop_words='english')\ntfidf_matrix = tf.fit_transform(ds['short_bio'])\n\ncosine_similarities = linear_kernel(tfidf_matrix, tfidf_matrix)\n\nresults = {}\n\nfor idx, row in ds.iterrows():\n similar_indices = cosine_similarities[idx].argsort()[:-100:-1]\n similar_items = [(cosine_similarities[idx][i], ds['id'][i]) for i in similar_indices]\n\n results[row['id']] = similar_items[1:]\n \nprint('done!')\n",
"done!\n"
],
[
"def item(id):\n return ds.loc[ds['id'] == id]['short_bio'].tolist()[0].split(' - ')[0]\n\n# a function that reads the results out of the column and the amount of results wanted.\ndef recommend(item_id, num):\n print(\"Recommending \" + str(num) + \" people similar to \" + item(item_id) + \"...\")\n print(\"-------\")\n recs = results[item_id][:num]\n for rec in recs:\n print(\"Recommended: \" + item(rec[1]) + \" (score:\" + str(rec[0]) + \")\")\n",
"_____no_output_____"
],
[
"#item_id is the number of the item in the column, num is te number of results to be displayed\nrecommend(item_id=1, num=20)",
"Recommending 20 people similar to Software Developer | DevOPs Engineer...\n-------\nRecommended: | Software Developer | DevOps Engineer | @linuxjobber (score:0.8005910040856886)\nRecommended: Software developer (score:0.3537003554834601)\nRecommended: Software Developer (score:0.3537003554834601)\nRecommended: Software Developer (score:0.3537003554834601)\nRecommended: Am a software developer (score:0.3537003554834601)\nRecommended: Software developer (score:0.3537003554834601)\nRecommended: Software Developer (score:0.3537003554834601)\nRecommended: Software Developer (score:0.3537003554834601)\nRecommended: Software developer (score:0.3537003554834601)\nRecommended: Software Developer (score:0.3537003554834601)\nRecommended: Software Developer (score:0.3537003554834601)\nRecommended: An engineer (score:0.2339796470705172)\nRecommended: Engineer (score:0.2339796470705172)\nRecommended: Software Engineer (score:0.23150932898479748)\nRecommended: Software engineer (score:0.23150932898479748)\nRecommended: Software Engineer...Here and there (score:0.23150932898479748)\nRecommended: I'm a software and how do I engineer (score:0.23150932898479748)\nRecommended: Software Engineer (score:0.23150932898479748)\nRecommended: Software Engineer (score:0.23150932898479748)\nRecommended: Software Engineer (score:0.23150932898479748)\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7ccdb1be6ea6d9d70b7aece0261918fae4b3f04 | 12,441 | ipynb | Jupyter Notebook | Prep_materials/Python and pandas basics solutions.ipynb | lgfunderburk/hackathon | 17cb276e9a9f2d897904073bb600d9311d4adad1 | [
"CC-BY-4.0"
]
| null | null | null | Prep_materials/Python and pandas basics solutions.ipynb | lgfunderburk/hackathon | 17cb276e9a9f2d897904073bb600d9311d4adad1 | [
"CC-BY-4.0"
]
| null | null | null | Prep_materials/Python and pandas basics solutions.ipynb | lgfunderburk/hackathon | 17cb276e9a9f2d897904073bb600d9311d4adad1 | [
"CC-BY-4.0"
]
| null | null | null | 23.473585 | 158 | 0.539828 | [
[
[
"",
"_____no_output_____"
],
[
"# Basics of Python\nThis notebook will provide basics of python and introduction to DataFrames.\n\nTo enter code in Colab we are going to use **Code Cells**. \nClick on `+Code` in the top left corner (or in between cells) to create a new Code cell.",
"_____no_output_____"
]
],
[
[
"# Anything in a code cell after a pound sign is a comment! \n# You can type anything here and it will not be excecuted \n\n# Variables are defined with an equals sign (=)\n\nmy_variable = 10 # You cannot put spaces in variable names. \nother_variable = \"some text\" # variables need not be numbers!\n\n# Print will output our variables below the cell\nprint(my_variable, other_variable)",
"_____no_output_____"
],
[
"# Variables are also shared between cells. You can also pring words and sentences directly. \nprint(my_variable, other_variable, \"We can print text directly in quotes\")",
"_____no_output_____"
],
[
"# You can do mathematical operations in python\n\nx = 5\ny = 10\n\nadd = x + y\nsubtract = x - y\nmultiply = x * y\ndivide = x/y\n\nprint(add, subtract, multiply, divide)",
"_____no_output_____"
]
],
[
[
"---\n### Exercise 1\n\n1. In the cell below, assign variable **z** to your name and run the cell. \n2. In the cell below, write a comment on the same line where you define z. Run the cell to make sure the comment is not changing anything.\n---\n",
"_____no_output_____"
]
],
[
[
"## Enter your code in the line below\nz = \"your name here\"\n\n##\n\nprint(z, \"is loving Python!\")",
"_____no_output_____"
]
],
[
[
"# Basics of DataFrames and pandas",
"_____no_output_____"
],
[
"**DataFrame** - two-dimentional data structure, similar to a table or a spreadsheet.\n\nIn Python there is a library of pre-defined functions to work with DataFrames - **pandas**.",
"_____no_output_____"
]
],
[
[
"#load \"pandas\" library under short name \"pd\"\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
"To read file in csv format the **read_csv()** function is used, it can read a file or a file from a URL.",
"_____no_output_____"
]
],
[
[
"#we have csv file stored in the cloud - it is 10 rows of data related to Titanic\nurl = \"https://swift-yeg.cloud.cybera.ca:8080/v1/AUTH_d22d1e3f28be45209ba8f660295c84cf/hackaton/titanic_short.csv\"\n\n#read csv file from url and save it as dataframe\ntitanic = pd.read_csv(url)",
"_____no_output_____"
],
[
"#shape shows number of rows and number of columns\ntitanic.shape",
"_____no_output_____"
]
],
[
[
"## Basic operations with DataFrames ",
"_____no_output_____"
],
[
"### Select rows/colums by name and index",
"_____no_output_____"
]
],
[
[
"#Getting column names\ntitanic.columns",
"_____no_output_____"
],
[
"#Selecting one column\ntitanic[['survived']]",
"_____no_output_____"
],
[
"#Selecting multiple columns\ntitanic[['survived','age']] ",
"_____no_output_____"
],
[
"#Selecting first 5 rows\n#try changin to head(10) or head(2)\ntitanic.head()",
"_____no_output_____"
],
[
"#Getting index (row names) - note that row names start at 0\ntitanic.index.tolist()",
"_____no_output_____"
],
[
"#Selecting one row\ntitanic.iloc[[2]]\n#(it's row 3, remember row number start at zero)",
"_____no_output_____"
],
[
"#Selecting multiple rows(rows 2 and 5):\ntitanic.iloc[[2,5]]",
"_____no_output_____"
],
[
"#Selecting rows and columns:\ntitanic[['survived','age']].iloc[[2,5]]",
"_____no_output_____"
]
],
[
[
"---\n### Exercise 2\n\n1. In the cell below, uncomment the code\n2. Change \"column1\", \"column2\", and \"column3\" to \"fare\", \"age\", and \"class\" to get these 3 columns\n\n---",
"_____no_output_____"
]
],
[
[
"#titanic[[\"column1\",\"column2\",\"column3\"]]",
"_____no_output_____"
]
],
[
[
"### Add a new column using existing one",
"_____no_output_____"
]
],
[
[
"#creating new column - age in months by multiplying \"age\" column by 12\ntitanic['age_months'] = titanic['age']*12\n\n#look at the very last column 'age_months'\ntitanic",
"_____no_output_____"
]
],
[
[
"### Select specific colums by condition",
"_____no_output_____"
]
],
[
[
"#create a condition: for example sex equals female\ncondition = titanic['sex']==\"female\" #note == sign checks rather than assigns\n\ncondition #it shows True for rows where sex is equal to female",
"_____no_output_____"
],
[
"#select only rows where condition is True (all female)\ntitanic[condition]",
"_____no_output_____"
],
[
"#other examples of conditions:\n\n#Not equal\ncondition1 = titanic['sex']!=\"female\"\n\n#equal to one value in the list\ncondition2 = titanic['class'].isin([\"First\",\"Second\"])\n\n#Multiple conditions - \"and\" (sex is \"female\" and class id \"First\")\ncondition3 = (titanic['sex']==\"female\") & (titanic['class']==\"First\")\n\n#Multiple conditions - \"or\" (sex is \"female\" or class id \"First\")\ncondition4 = (titanic['sex']==\"female\") | (titanic['class']==\"First\")",
"_____no_output_____"
]
],
[
[
"---\n### Exercise 3\n\n1. Change the cell below to subset data where sex is \"female\" and embark_town is \"Cherbourg\"\n\n---",
"_____no_output_____"
]
],
[
[
"condition5 = (titanic['sex']==\"female\") | (titanic['class']==\"First\") #change the condition here\n\n\ntitanic[condition5]",
"_____no_output_____"
]
],
[
[
"### Sorting ",
"_____no_output_____"
]
],
[
[
"#sorting by pclass - note the ascending paramater, try changing it to False\ntitanic.sort_values(\"pclass\", ascending=True)",
"_____no_output_____"
],
[
"#sort by two columns - first by pclass and then by age\ntitanic.sort_values([\"pclass\",\"age\"])",
"_____no_output_____"
]
],
[
[
"### Grouping and calculating summaries on groups",
"_____no_output_____"
]
],
[
[
"#split data into groups based on all unique values in \"survived\" column - \n#first group is survived(1), second groups is not survived(0)\n\n#calculate average(mean) for every column for both groups\ntitanic.groupby(\"survived\").mean()",
"_____no_output_____"
],
[
"#another operations you can do on groups are\n# min(), max(), sum()",
"_____no_output_____"
],
[
"#you can do multiple operations at once using agg() function\ntitanic.groupby(\"survived\").agg([\"mean\",\"max\"])",
"_____no_output_____"
]
],
[
[
"---\n### Exercise 4\n\n1. Modify the cell below to calculate **max()** for every column grouped by \"class\"\n---",
"_____no_output_____"
]
],
[
[
"titanic.groupby(\"survived\").mean() ##modify this cell",
"_____no_output_____"
]
],
[
[
"### Calculating number of rows by group",
"_____no_output_____"
]
],
[
[
"#using size() function to calculate number of rows by group\nrow_counts = titanic.groupby(\"sex\").size()\n\n#create new column \"count\" - to store row numbers\nrow_counts = row_counts.reset_index(name=\"count\")\n\nrow_counts",
"_____no_output_____"
]
],
[
[
"---\n### Exercise 5\n\n1. Calculate the number of rows grouped by column \"who\"\n---",
"_____no_output_____"
],
[
"Addtional resources for Pandas and DataFrames can be found [here](https://www.datacamp.com/community/tutorials/pandas-tutorial-dataframe-python) and \n[here](https://www.kaggle.com/grroverpr/pandas-cheatsheet).",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
]
|
e7ccf0fb1a7f543377e9d8ac52406cc222bf9324 | 63,289 | ipynb | Jupyter Notebook | tsa/src/jupyter/python/welchbishopkalmanfilteringtutorial.ipynb | mikimaus78/ml_monorepo | b2c2627ff0e86e27f6829170d0dac168d8e5783b | [
"BSD-3-Clause"
]
| 51 | 2019-02-01T19:43:37.000Z | 2022-03-16T09:07:03.000Z | tsa/src/jupyter/python/welchbishopkalmanfilteringtutorial.ipynb | mikimaus78/ml_monorepo | b2c2627ff0e86e27f6829170d0dac168d8e5783b | [
"BSD-3-Clause"
]
| 2 | 2019-02-23T18:54:22.000Z | 2019-11-09T01:30:32.000Z | tsa/src/jupyter/python/welchbishopkalmanfilteringtutorial.ipynb | mikimaus78/ml_monorepo | b2c2627ff0e86e27f6829170d0dac168d8e5783b | [
"BSD-3-Clause"
]
| 35 | 2019-02-08T02:00:31.000Z | 2022-03-01T23:17:00.000Z | 310.240196 | 33,136 | 0.9176 | [
[
[
"# Univariate Process Kalman Filtering Example\n\nIn this Jypyter notebook we implement the example given on pages 11-15 of [An Introduction to the Kalman Filter](http://www.cs.unc.edu/~welch/kalman/kalmanIntro.html) by Greg Welch and Gary Bishop. It is written in the spirit of Andrew Straw's [SciPy cookbook](http://scipy-cookbook.readthedocs.io/items/KalmanFiltering.html). Our aim is to show how one can use the higher-level TSA routines in this simple setting.",
"_____no_output_____"
]
],
[
[
"import os, sys\nsys.path.append(os.path.abspath('../../main/python'))",
"_____no_output_____"
],
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\nfrom thalesians.tsa.distrs import NormalDistr as N\nimport thalesians.tsa.filtering as filtering\nimport thalesians.tsa.filtering.kalman as kalman\nimport thalesians.tsa.processes as proc\nimport thalesians.tsa.pypes as pypes\nimport thalesians.tsa.random as rnd\nimport thalesians.tsa.simulation as sim",
"_____no_output_____"
],
[
"%matplotlib inline\nplt.rcParams['figure.figsize'] = (16, 10)",
"_____no_output_____"
],
[
"rnd.random_state(np.random.RandomState(seed=42), force=True)",
"_____no_output_____"
],
[
"pype = pypes.Pype(pypes.Direction.OUTGOING, name='FILTER', port=5758)",
"_____no_output_____"
],
[
"n = 100 # number of itrations\nx = -0.37727 # true value\nz = np.random.normal(x, .1, size=n) # observations (normal about x, sd=0.1)\nposteriors = np.zeros(n) # a posteri estimate of x\nP = np.zeros(n) # a posteri error estimate\npriors = np.zeros(n) # a priori estimate of x\nPminus = np.zeros(n) # a priori error estimate\nP[0] = 1.0\n\nQ = 1e-5 # process variance\nR = 0.1**2 # estimate of measurement variance (change to see the effect)\n\n# Instantiate the process\nW = proc.WienerProcess(mean=0, vol=Q)\n\n# Insantiate the filter\nkf = kalman.KalmanFilter(time=0, state_distr=N(0.,1.), process=W, pype=pype)\nobservable = kf.create_named_observable('noisy observation', kalman.KalmanFilterObsModel.create(1.), W)\n\n\nfor k in range(0, n):\n prior = observable.predict(k)\n P[k] = prior.distr.cov[0][0]\n obs = observable.observe(time=k, obs=N(z[k], R), true_value=x)\n posterior = observable.predict(k)\n posteriors[k] = posterior.distr.mean[0][0]",
"_____no_output_____"
],
[
"plt.figure()\nplt.plot(z, 'k+', label='noisy measurements')\nplt.plot(posteriors, 'b-', label='a posteri estimate')\nplt.axhline(x, color='g', label='truth value')\nplt.legend()\nplt.title('Estimate vs. iteration step', fontweight='bold')\nplt.xlabel('Iteration')\nplt.ylabel('Voltage')\n\nplt.figure()\nplt.plot(P[1:], label='a priori error estimate')\nplt.title('Estimated $\\it{\\mathbf{a \\ priori}}$ error vs. iteration step', fontweight='bold')\nplt.xlabel('Iteration')\nplt.ylabel('$(Voltage)^2$')\nplt.ylim([0, 0.015])\nplt.show()\n\n",
"_____no_output_____"
],
[
"pype.close()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7ccf29ff8af463406120f869b591cb083cf70d4 | 65,506 | ipynb | Jupyter Notebook | doc2vec/Word2Vec to cyber security data.ipynb | sagar1993/NLP_cyber_security | 1e2aa2b4ae16316bc02d2fd6c84c31e721e947e5 | [
"MIT"
]
| 5 | 2019-11-07T10:00:26.000Z | 2021-05-08T20:11:51.000Z | doc2vec/Word2Vec to cyber security data.ipynb | sagar1993/NLP_cyber_security | 1e2aa2b4ae16316bc02d2fd6c84c31e721e947e5 | [
"MIT"
]
| null | null | null | doc2vec/Word2Vec to cyber security data.ipynb | sagar1993/NLP_cyber_security | 1e2aa2b4ae16316bc02d2fd6c84c31e721e947e5 | [
"MIT"
]
| 2 | 2019-11-08T02:53:06.000Z | 2021-05-30T03:50:11.000Z | 35.834792 | 214 | 0.482963 | [
[
[
"## - Combine all data ",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom os import listdir\n\npath = '../data/'\nfiles = listdir('../data/')\ndf = pd.DataFrame(columns=[\"url\", \"query\", \"text\"])\n\nfor f in files:\n temp = pd.read_csv(path + f)\n if 'article-name' in temp.columns:\n temp.rename(columns={'article-name':'name','article-url':'url','content':'text','keyword':'query'}, inplace=True)\n if len(temp) < 1:\n continue\n df = df.append(temp)\ndf.drop(['Unnamed: 0', 'name'], inplace=True, axis=1)",
"_____no_output_____"
]
],
[
[
"## - data preprocessing\n 1. stop word removal\n 2. lower case letters\n 3. non ascii character removal",
"_____no_output_____"
]
],
[
[
"from nltk.corpus import stopwords\nimport re\nstop = stopwords.words('english')\n\ndef normalize_text(text):\n norm_text = text.lower()\n # Replace breaks with spaces\n norm_text = norm_text.replace('<br />', ' ')\n # Pad punctuation with spaces on both sides\n norm_text = re.sub(r\"([\\.\\\",\\(\\)!\\?;:])\", \" \\\\1 \", norm_text)\n return norm_text\n\ndef remove_stop_words(text):\n return \" \".join([item.lower() for item in text.split() if item not in stop])\n\ndef remove_non_ascii(text):\n return ''.join([\"\" if ord(i) < 32 or ord(i) > 126 else i for i in text])\n\ndf['text'] = df['text'].apply(remove_non_ascii)\ndf['text'] = df['text'].apply(normalize_text)\ndf['text'] = df['text'].apply(remove_stop_words)\ndf[\"text\"] = df['text'].str.replace('[^\\w\\s]','')",
"_____no_output_____"
]
],
[
[
"## - a simple word2vec model\n In this section we apply simple word to vec model to tokenized data.",
"_____no_output_____"
]
],
[
[
"from gensim.models import Word2Vec\nfrom nltk import word_tokenize",
"_____no_output_____"
],
[
"df['tokenized_text'] = df.apply(lambda row: word_tokenize(row['text']), axis=1)",
"_____no_output_____"
],
[
"model = Word2Vec(df['tokenized_text'], size=100)",
"_____no_output_____"
],
[
"for num in [1, 3, 5, 10, 12, 16, 17, 18, 19, 28, 29, 30, 32, 33, 34, 37, 38]:\n term = \"apt%s\"%str(num)\n if term in model.wv.vocab:\n print(\"Most similar words for %s\"%term)\n for t in model.most_similar(term): print(t)\n print('\\n')",
"Most similar words for apt1\n('mandiant', 0.9992831349372864)\n('according', 0.9988211989402771)\n('china', 0.9986724257469177)\n('defense', 0.9986507892608643)\n('kaspersky', 0.9986412525177002)\n('iranian', 0.9985784888267517)\n('military', 0.9983772039413452)\n('lab', 0.9978839159011841)\n('detected', 0.997614860534668)\n('published', 0.997364342212677)\n\n\nMost similar words for apt3\n('strontium', 0.9977763891220093)\n('cozy', 0.9963721036911011)\n('tracked', 0.9958826899528503)\n('team', 0.994817852973938)\n('also', 0.9941498041152954)\n('menupass', 0.9935141205787659)\n('linked', 0.9934953451156616)\n('axiom', 0.9930843114852905)\n('chinalinked', 0.9929003715515137)\n('behind', 0.9923593997955322)\n\n\nMost similar words for apt10\n('apt37', 0.9996817111968994)\n('sophisticated', 0.9994451403617859)\n('naikon', 0.9994421601295471)\n('overlap', 0.999294638633728)\n('entities', 0.9992740154266357)\n('micro', 0.9989956021308899)\n('noticed', 0.9988883137702942)\n('tracks', 0.9988324642181396)\n('primarily', 0.9988023042678833)\n('associated', 0.9987926483154297)\n\n\nMost similar words for apt17\n('vietnamese', 0.9984132051467896)\n('hellsing', 0.9982680082321167)\n('netherlands', 0.9982122182846069)\n('turla', 0.9981800317764282)\n('aligns', 0.99793940782547)\n('region', 0.997829258441925)\n('continues', 0.9977688193321228)\n('operating', 0.9977645874023438)\n('variety', 0.9977619647979736)\n('aware', 0.9976860284805298)\n\n\nMost similar words for apt28\n('sofacy', 0.9984127283096313)\n('bear', 0.9978348612785339)\n('known', 0.9976195096969604)\n('fancy', 0.9963506460189819)\n('storm', 0.9960793256759644)\n('apt', 0.995140790939331)\n('pawn', 0.9940293431282043)\n('sednit', 0.9939311742782593)\n('tsar', 0.9931427240371704)\n('actor', 0.9903273582458496)\n\n\nMost similar words for apt29\n('sandworm', 0.9979566335678101)\n('2010', 0.9978185892105103)\n('including', 0.9976153373718262)\n('observed', 0.9976032972335815)\n('overview', 0.9973697662353516)\n('spotted', 0.9972324371337891)\n('aimed', 0.9965631365776062)\n('2007', 0.9963749647140503)\n('buckeye', 0.9962424039840698)\n('aka', 0.9962256550788879)\n\n\nMost similar words for apt30\n('companies', 0.998908281326294)\n('prolific', 0.9988271594047546)\n('variety', 0.9987081289291382)\n('expanded', 0.9986468553543091)\n('focuses', 0.9986134767532349)\n('continues', 0.998511552810669)\n('connected', 0.9984531402587891)\n('detailed', 0.9984067678451538)\n('interests', 0.9984041452407837)\n('actively', 0.9984041452407837)\n\n\nMost similar words for apt32\n('continues', 0.9995431900024414)\n('region', 0.9994964003562927)\n('ties', 0.9994940757751465)\n('destructive', 0.999233067035675)\n('interests', 0.9991957545280457)\n('europe', 0.9991946220397949)\n('dukes', 0.9991874098777771)\n('mainly', 0.9991647005081177)\n('countries', 0.9991510510444641)\n('apt38', 0.9991440176963806)\n\n\nMost similar words for apt33\n('multiple', 0.9996379613876343)\n('japanese', 0.9994475841522217)\n('revealed', 0.9994279146194458)\n('involved', 0.9992635250091553)\n('south', 0.9992367029190063)\n('2009', 0.998937726020813)\n('responsible', 0.9989287257194519)\n('evidence', 0.9987417459487915)\n('associated', 0.9987338781356812)\n('determined', 0.9987262487411499)\n\n\nMost similar words for apt34\n('shift', 0.9994713068008423)\n('particularly', 0.9993870258331299)\n('continue', 0.9993187785148621)\n('indicate', 0.9992826581001282)\n('crew', 0.9991933703422546)\n('consistent', 0.999139666557312)\n('palo', 0.999091625213623)\n('august', 0.9990721344947815)\n('added', 0.9990265369415283)\n('provided', 0.9990137815475464)\n\n\nMost similar words for apt37\n('apt10', 0.9996817111968994)\n('sophisticated', 0.9993605017662048)\n('entities', 0.9991942048072815)\n('overlap', 0.9991032481193542)\n('naikon', 0.9991011619567871)\n('micro', 0.9990009069442749)\n('primarily', 0.9989291429519653)\n('associated', 0.9988642930984497)\n('highly', 0.9987080097198486)\n('noticed', 0.9986851811408997)\n\n\nMost similar words for apt38\n('continues', 0.9994156956672668)\n('individuals', 0.9993045330047607)\n('early', 0.9992733001708984)\n('turla', 0.9992636442184448)\n('stone', 0.9992102980613708)\n('experts', 0.9991610050201416)\n('europe', 0.9991508722305298)\n('apt32', 0.9991441965103149)\n('kitten', 0.9991305470466614)\n('region', 0.9991227388381958)\n\n\n"
]
],
[
[
"### here we got one interesting result for apt17 as apt28\n but for all other word2vec results we observe that we are getting names like malware, attackers, groups, backdoor in the most similar items. \n It might be the case that the names of attacker groups are ommited because they are phrases instead simple words.",
"_____no_output_____"
],
[
"## - word2vec with bigram phrases\n here we try to find bigram phrases from the dataset and apply word2vec model to it",
"_____no_output_____"
]
],
[
[
"from gensim.models import Phrases\nfrom collections import Counter",
"_____no_output_____"
],
[
"bigram = Phrases()",
"_____no_output_____"
],
[
"bigram.add_vocab(df['tokenized_text'])",
"_____no_output_____"
],
[
"bigram_counter = Counter()\nfor key in bigram.vocab.keys():\n if len(key.split(\"_\")) > 1:\n bigram_counter[key] += bigram.vocab[key]\n\nfor key, counts in bigram_counter.most_common(20):\n print '{0: <20} {1}'.format(key.encode(\"utf-8\"), counts)",
"cyber_security 353\nsecurity_conference 334\nics_cyber 334\ndocument_getelementsbytagname 163\ncomjsplusone_js 163\nconference_singapore 163\ngoogle_comjsplusone 163\nscript_0 163\nciso_forum 163\nforum_half 163\ndocument_createelement 163\npo_src 163\napis_google 163\ntextjavascript_po 163\ntype_textjavascript 163\npo_async 163\nvar_po 163\nparentnode_insertbefore 163\nasync_true 163\npo_type 163\n"
],
[
"bigram_model = Word2Vec(bigram[df['tokenized_text']], size=100)",
"_____no_output_____"
],
[
"for num in [1, 3, 5, 10, 12, 16, 17, 18, 19, 28, 29, 30, 32, 33, 34, 37, 38]:\n term = \"apt%s\"%str(num)\n if term in bigram_model.wv.vocab:\n print(\"Most similar words for %s\"%term)\n for t in bigram_model.most_similar(term): print(t)\n print('\\n')",
"Most similar words for apt1\n(u'different', 0.99991774559021)\n(u'likely', 0.9999154806137085)\n(u'well', 0.9999152421951294)\n(u'says', 0.9999047517776489)\n(u'multiple', 0.9999043941497803)\n(u'threat_actors', 0.9998949766159058)\n(u'network', 0.9998934268951416)\n(u'according', 0.9998912811279297)\n(u'compromised', 0.9998894929885864)\n(u'related', 0.999876856803894)\n\n\nMost similar words for apt3\n(u'actor', 0.9998462796211243)\n(u'described', 0.9998243451118469)\n(u'also_known', 0.9998069405555725)\n(u'actors', 0.9997928738594055)\n(u'recently', 0.9997922778129578)\n(u'experts', 0.999782919883728)\n(u'apt29', 0.9997620582580566)\n(u'identified', 0.9997564554214478)\n(u'two', 0.9997557401657104)\n(u'domains', 0.9997459650039673)\n\n\nMost similar words for apt10\n(u'time', 0.999898374080658)\n(u'analysis', 0.9998810291290283)\n(u'u', 0.9998781681060791)\n(u'version', 0.9998765587806702)\n(u'based', 0.9998717308044434)\n(u'provided', 0.9998701810836792)\n(u'least', 0.9998694658279419)\n(u'mandiant', 0.9998666644096375)\n(u'governments', 0.9998637437820435)\n(u'apt32', 0.9998601675033569)\n\n\nMost similar words for apt17\n(u'connections', 0.9996646642684937)\n(u'email', 0.9996588230133057)\n(u'find', 0.9996576905250549)\n(u'across', 0.9996559023857117)\n(u'order', 0.9996424913406372)\n(u'web', 0.9996327757835388)\n(u'user', 0.9996271133422852)\n(u'connection', 0.9996263980865479)\n(u'key', 0.9996225833892822)\n(u'shows', 0.9996156096458435)\n\n\nMost similar words for apt28\n(u'fireeye', 0.9996447563171387)\n(u'using', 0.999575138092041)\n(u'targeted', 0.9995599985122681)\n(u'sofacy', 0.9995203614234924)\n(u'known', 0.9995172619819641)\n(u'tools', 0.9993760585784912)\n(u'spotted', 0.9993688464164734)\n(u'researchers', 0.9991514086723328)\n(u'report', 0.9991289973258972)\n(u'also', 0.9991098046302795)\n\n\nMost similar words for apt29\n(u'recently', 0.9998775720596313)\n(u'however', 0.9998724460601807)\n(u'actors', 0.9998624920845032)\n(u'two', 0.999857485294342)\n(u'vulnerabilities', 0.9998537302017212)\n(u'identified', 0.9998456835746765)\n(u'first', 0.9998396635055542)\n(u'described', 0.9998297691345215)\n(u'leveraged', 0.999822735786438)\n(u'seen', 0.9998195767402649)\n\n\nMost similar words for apt30\n(u'research', 0.999484658241272)\n(u'published', 0.9994805455207825)\n(u'noted', 0.9994770288467407)\n(u'fireeye_said', 0.9994675517082214)\n(u'account', 0.9994667768478394)\n(u'provide', 0.9994657039642334)\n(u'command_control', 0.9994556903839111)\n(u'splm', 0.9994515776634216)\n(u'c2', 0.9994462728500366)\n(u'2013', 0.9994445443153381)\n\n\nMost similar words for apt32\n(u'techniques', 0.9999111890792847)\n(u'additional', 0.9999087452888489)\n(u'analysis', 0.9999069571495056)\n(u'many', 0.9999059438705444)\n(u'companies', 0.9998983144760132)\n(u'based', 0.9998965263366699)\n(u'part', 0.9998964071273804)\n(u'backdoors', 0.999894380569458)\n(u'mandiant', 0.9998939037322998)\n(u'another', 0.9998925924301147)\n\n\nMost similar words for apt33\n(u'mandiant', 0.9999130368232727)\n(u'year', 0.9999092221260071)\n(u'techniques', 0.9998992681503296)\n(u'tracked', 0.999896764755249)\n(u'team', 0.9998966455459595)\n(u'last_year', 0.9998915195465088)\n(u'part', 0.9998914003372192)\n(u'military', 0.9998868703842163)\n(u'chinese', 0.9998816251754761)\n(u'threat', 0.9998784065246582)\n\n\nMost similar words for apt34\n(u'services', 0.9997851848602295)\n(u'targeted_attacks', 0.9997463226318359)\n(u'example', 0.9997448325157166)\n(u'called', 0.999743640422821)\n(u'available', 0.9997414946556091)\n(u'able', 0.9997405409812927)\n(u'activities', 0.999738335609436)\n(u'2018', 0.9997329711914062)\n(u'make', 0.9997280836105347)\n(u'details', 0.9997265934944153)\n\n\nMost similar words for apt37\n(u'flaw', 0.999801754951477)\n(u'2014', 0.9997944831848145)\n(u'2013', 0.9997936487197876)\n(u'efforts', 0.999792754650116)\n(u'made', 0.9997915625572205)\n(u'designed', 0.9997785091400146)\n(u'list', 0.9997777938842773)\n(u'media', 0.9997776746749878)\n(u'make', 0.9997761845588684)\n(u'attribution', 0.9997747540473938)\n\n\nMost similar words for apt38\n(u'command_control', 0.99981290102005)\n(u'attribution', 0.9997984170913696)\n(u'media', 0.9997962117195129)\n(u'activities', 0.9997954368591309)\n(u'2014', 0.9997861385345459)\n(u'software', 0.9997845888137817)\n(u'see', 0.9997791051864624)\n(u'research', 0.999776303768158)\n(u'designed', 0.9997758865356445)\n(u'even', 0.9997751712799072)\n\n\n"
]
],
[
[
"### After applying bigram phrases still we cannot see the desired results. ",
"_____no_output_____"
],
[
"## Word2Vec model topic by topic using bigram phrases",
"_____no_output_____"
]
],
[
[
"df_doc = df[['query', 'text']]",
"_____no_output_____"
],
[
"df_doc",
"_____no_output_____"
],
[
"df_doc = df_doc.groupby(['query'],as_index=False).first()",
"_____no_output_____"
],
[
"df_doc",
"_____no_output_____"
],
[
"from nltk.corpus import stopwords\nimport re\nstop = stopwords.words('english') + ['fireeye', 'crowdstrike', 'symantec', 'rapid7', 'securityweek', 'kaspersky']\n\ndef normalize_text(text):\n norm_text = text.lower()\n # Replace breaks with spaces\n norm_text = norm_text.replace('<br />', ' ')\n # Pad punctuation with spaces on both sides\n norm_text = re.sub(r\"([\\.\\\",\\(\\)!\\?;:])\", \" \\\\1 \", norm_text)\n return norm_text\n\ndef remove_stop_words(text):\n return \" \".join([item.lower() for item in text.split() if item not in stop])\n\ndef remove_non_ascii(text):\n return ''.join([\"\" if ord(i) < 32 or ord(i) > 126 else i for i in text])\n\ndf_doc['text'] = df_doc['text'].apply(remove_non_ascii)\ndf_doc['text'] = df_doc['text'].apply(normalize_text)\ndf_doc['text'] = df_doc['text'].apply(remove_stop_words)\ndf_doc[\"text\"] = df_doc['text'].str.replace('[^\\w\\s]','')",
"_____no_output_____"
],
[
"df_doc",
"_____no_output_____"
],
[
"df_doc['tokenized_text'] = df_doc.apply(lambda row: word_tokenize(row['text']), axis=1)",
"_____no_output_____"
],
[
"df_doc",
"_____no_output_____"
],
[
"from gensim.models import Phrases\nfrom collections import Counter",
"_____no_output_____"
],
[
"for num in ['APT1', 'APT10', 'APT12', 'APT15', 'APT16', 'APT17', 'APT18', 'APT27', 'APT28', 'APT29', 'APT3', 'APT30', 'APT32', 'APT33', 'APT34', 'APT35', 'APT37', 'APT38']:\n temp = df_doc[df_doc['query'] == num]\n print(temp.shape)\n if temp.shape[0] == 0:\n continue\n bigram = Phrases()\n \n bigram.add_vocab(temp['tokenized_text'])\n \n bigram_model = Word2Vec(bigram[temp['tokenized_text']], size=100)\n \n term = num.lower()\n if term in bigram_model.wv.vocab:\n print(\"Most similar words for %s\"%term)\n for t in bigram_model.most_similar(term, topn=20): print(t)\n print('\\n')",
"(1, 3)\n(1, 3)\n(1, 3)\n(1, 3)\n(1, 3)\n(1, 3)\nMost similar words for apt17\n(u'threat', 0.1114407628774643)\n\n\n(1, 3)\n(1, 3)\n"
],
[
"num = 38\ntemp = df_doc[df_doc['query'] == 'APT%s'%num]\nbigram = Phrases()\n\nbigram.add_vocab(temp['tokenized_text'])",
"_____no_output_____"
],
[
"bigram_model = Word2Vec(bigram[temp['tokenized_text']], size=100)\n\nterm = 'apt%s'%num\nif term in bigram_model.wv.vocab:\n print(\"Most similar words for %s\"%term)\n for t in bigram_model.most_similar(term, topn=20): print(t)\n print('\\n')",
"Most similar words for apt38\n(u'used', 0.20620612800121307)\n(u'group', 0.14802813529968262)\n(u'operations', 0.135009765625)\n(u'victim', 0.061795078217983246)\n(u'swift', 0.05330579727888107)\n(u'transactions', 0.04159824922680855)\n(u'organizations', 0.04043135046958923)\n(u'systems', -0.006069064140319824)\n(u'access', -0.02243630588054657)\n(u'malware', -0.03157751262187958)\n(u'activity', -0.07716790586709976)\n(u'tools', -0.08170446008443832)\n(u'north_korean', -0.09251955151557922)\n(u'financial', -0.11650492250919342)\n\n\n"
],
[
"temp.shape",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cd004f21629bc71a6330902ecc2e92f721f164 | 941,960 | ipynb | Jupyter Notebook | Logistic Regression/17.4 Logistic Regression Project.ipynb | CommunityOfCoders/ML_Workshop_Teachers | 7673e2960f21a08bed586bfd3ead5a8d82add884 | [
"BSD-3-Clause"
]
| 7 | 2020-01-24T23:20:22.000Z | 2022-03-14T17:10:25.000Z | 17. Logistic Regression/17.4 Logistic Regression Project.ipynb | itsmerohit1/ml_bootcamp_udemy | e60b6415402be99e7a97fcec32b09febf0e92518 | [
"MIT"
]
| 2 | 2019-03-22T17:25:00.000Z | 2019-03-23T09:50:19.000Z | 17. Logistic Regression/17.4 Logistic Regression Project.ipynb | itsmerohit1/ml_bootcamp_udemy | e60b6415402be99e7a97fcec32b09febf0e92518 | [
"MIT"
]
| 8 | 2019-04-28T20:14:54.000Z | 2021-08-29T08:36:11.000Z | 674.756447 | 344,156 | 0.939201 | [
[
[
"# Logistic Regression Project \n\nIn this project we will be working with a fake advertising data set, indicating whether or not a particular internet user clicked on an Advertisement. We will try to create a model that will predict whether or not they will click on an ad based off the features of that user.\n\nThis data set contains the following features:\n\n* 'Daily Time Spent on Site': consumer time on site in minutes\n* 'Age': cutomer age in years\n* 'Area Income': Avg. Income of geographical area of consumer\n* 'Daily Internet Usage': Avg. minutes a day consumer is on the internet\n* 'Ad Topic Line': Headline of the advertisement\n* 'City': City of consumer\n* 'Male': Whether or not consumer was male\n* 'Country': Country of consumer\n* 'Timestamp': Time at which consumer clicked on Ad or closed window\n* 'Clicked on Ad': 0 or 1 indicated clicking on Ad\n\n## Import Libraries\n\n**Import a few libraries you think you'll need (Or just import them as you go along!)**",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n%matplotlib inline",
"_____no_output_____"
],
[
"import warnings\nwarnings.filterwarnings(\"ignore\")",
"_____no_output_____"
]
],
[
[
"## Get the Data\n**Read in the advertising.csv file and set it to a data frame called ad_data.**",
"_____no_output_____"
]
],
[
[
"ad_data = pd.read_csv(\"advertising.csv\")",
"_____no_output_____"
]
],
[
[
"**Check the head of ad_data**",
"_____no_output_____"
]
],
[
[
"ad_data.head()",
"_____no_output_____"
]
],
[
[
"** Use info and describe() on ad_data**",
"_____no_output_____"
]
],
[
[
"ad_data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1000 entries, 0 to 999\nData columns (total 10 columns):\nDaily Time Spent on Site 1000 non-null float64\nAge 1000 non-null int64\nArea Income 1000 non-null float64\nDaily Internet Usage 1000 non-null float64\nAd Topic Line 1000 non-null object\nCity 1000 non-null object\nMale 1000 non-null int64\nCountry 1000 non-null object\nTimestamp 1000 non-null object\nClicked on Ad 1000 non-null int64\ndtypes: float64(3), int64(3), object(4)\nmemory usage: 78.2+ KB\n"
],
[
"ad_data.describe()",
"_____no_output_____"
]
],
[
[
"## Exploratory Data Analysis\n\nLet's use seaborn to explore the data!\n\nTry recreating the plots shown below!\n\n** Create a histogram of the Age**",
"_____no_output_____"
]
],
[
[
"sns.set_style('whitegrid')\nad_data['Age'].hist(bins=30)\nplt.xlabel(\"Age\")",
"_____no_output_____"
]
],
[
[
"**Create a jointplot showing Area Income versus Age.**",
"_____no_output_____"
]
],
[
[
"sns.jointplot(x='Age',y='Area Income',data=ad_data)",
"_____no_output_____"
]
],
[
[
"**Create a jointplot showing the kde distributions of Daily Time spent on site vs. Age.**",
"_____no_output_____"
]
],
[
[
"sns.jointplot(x='Age',y='Daily Time Spent on Site',data=ad_data,color='red',kind='kde')",
"_____no_output_____"
]
],
[
[
"** Create a jointplot of 'Daily Time Spent on Site' vs. 'Daily Internet Usage'**",
"_____no_output_____"
]
],
[
[
"sns.jointplot(x=\"Daily Time Spent on Site\",y=\"Daily Internet Usage\",data=ad_data,color='green')",
"_____no_output_____"
]
],
[
[
"** Finally, create a pairplot with the hue defined by the 'Clicked on Ad' column feature.**",
"_____no_output_____"
]
],
[
[
"sns.pairplot(ad_data,hue='Clicked on Ad',palette='bwr')",
"_____no_output_____"
]
],
[
[
"# Logistic Regression\n\nNow it's time to do a train test split, and train our model!\n\nYou'll have the freedom here to choose columns that you want to train on!",
"_____no_output_____"
],
[
"** Split the data into training set and testing set using train_test_split**",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"X = ad_data[['Daily Time Spent on Site', 'Age', 'Area Income','Daily Internet Usage', 'Male']]\ny = ad_data['Clicked on Ad']",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.33,random_state = 42)",
"_____no_output_____"
]
],
[
[
"** Train and fit a logistic regression model on the training set.**",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LogisticRegression",
"_____no_output_____"
],
[
"logmodel = LogisticRegression()",
"_____no_output_____"
],
[
"logmodel.fit(X_train,y_train)",
"_____no_output_____"
]
],
[
[
"## Predictions and Evaluations\n** Now predict values for the testing data.**",
"_____no_output_____"
]
],
[
[
"predictions = logmodel.predict(X_test)",
"_____no_output_____"
]
],
[
[
"** Create a classification report for the model.**",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import classification_report",
"_____no_output_____"
],
[
"print(classification_report(y_test,predictions))",
" precision recall f1-score support\n\n 0 0.87 0.96 0.91 162\n 1 0.96 0.86 0.91 168\n\n micro avg 0.91 0.91 0.91 330\n macro avg 0.91 0.91 0.91 330\nweighted avg 0.91 0.91 0.91 330\n\n"
],
[
"from sklearn.metrics import confusion_matrix\nconfusion_matrix(y_test,predictions)",
"_____no_output_____"
]
],
[
[
"## Great Job!",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
]
|
e7cd01e18bb743f91f57b8f0069e8ca3de8f9d24 | 140,475 | ipynb | Jupyter Notebook | notebooks/Modelling_Forecast.ipynb | MayuriKalokhe/Data_Science_Covid-19 | e4bd99ddb2d6b2467991867bfa8a658804689d9f | [
"MIT"
]
| null | null | null | notebooks/Modelling_Forecast.ipynb | MayuriKalokhe/Data_Science_Covid-19 | e4bd99ddb2d6b2467991867bfa8a658804689d9f | [
"MIT"
]
| null | null | null | notebooks/Modelling_Forecast.ipynb | MayuriKalokhe/Data_Science_Covid-19 | e4bd99ddb2d6b2467991867bfa8a658804689d9f | [
"MIT"
]
| null | null | null | 49.237645 | 38,484 | 0.550368 | [
[
[
"# Forecasting - Facebook Prophet",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\n%matplotlib inline\nmpl.rcParams['figure.figsize'] = (16, 10)\npd.set_option('display.max_rows', 500)\n\nimport plotly.graph_objects as go",
"_____no_output_____"
],
[
"#from fbprophet import Prophet ",
"_____no_output_____"
],
[
"%matplotlib inline\nplt.style.use('fivethirtyeight')",
"_____no_output_____"
],
[
"#def mean_absolute_percentage_error(y_true, y_pred): \n # y_true, y_pred = np.array(y_true), np.array(y_pred)\n # return np.mean(np.abs((y_true - y_pred) / y_true)) * 100",
"_____no_output_____"
]
],
[
[
"## Trivial Forecast (rolling mean)",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame({'X': np.arange(0,10)}) # generate an input df\ndf['y']=df.rolling(3).mean()\ndf",
"_____no_output_____"
],
[
"#trying over small data set first\ndf_new = pd.read_csv('../data/processed/COVID_small_flat_table.csv',sep=';')\ndf=df_new[['date','India']]\ndf=df.rename(columns={'date': 'ds',\n 'India': 'y'})",
"_____no_output_____"
],
[
"ax = df.set_index('ds').plot(figsize=(12, 8),\n logy=True)\nax.set_ylabel('Daily Number of confimed cases')\nax.set_xlabel('Date')\n\nplt.show()\n",
"_____no_output_____"
],
[
"my_model = Prophet(interval_width=0.95) #changing uncertainty interval to 95% \n#my_model = Prophet(growth='logistic')",
"_____no_output_____"
],
[
"#df['cap']=1000000\nmy_model.fit(df)",
"_____no_output_____"
],
[
"#adding more date vectors (to predict) to the existing dataframe\nfuture_dates = my_model.make_future_dataframe(periods=7, freq='D')\n#future_dates['cap']=1000000. # only mandatory for the logistic model\nfuture_dates.tail()",
"_____no_output_____"
],
[
"forecast = my_model.predict(future_dates)",
"_____no_output_____"
],
[
"my_model.plot(forecast,uncertainty=True ); ",
"_____no_output_____"
],
[
"#plotting the same in plotly to overcome fbprophet rendering drawbank\nimport plotly.offline as py\nfrom fbprophet.plot import plot_plotly\n\nfig = plot_plotly(my_model, forecast) \n\nfig.update_layout(\n width=1024,\n height=900,\n xaxis_title=\"Time\",\n yaxis_title=\"Confirmed infected people (source johns hopkins csse, log-scale)\",\n)\nfig.update_yaxes(type=\"log\",range=[1.1,5.5])\npy.iplot(fig)",
"_____no_output_____"
],
[
"forecast.sort_values(by='ds').head() #checking what information we get from this prediction model",
"_____no_output_____"
],
[
"my_model.plot_components(forecast); #decomsing the prediction model for treand and seasonal pattern",
"_____no_output_____"
],
[
"#to get better visualization of the trend, plotting the graph from the data frame data directly\nforecast[['ds','trend']].set_index('ds').plot(figsize=(12, 8),logy=True)",
"_____no_output_____"
]
],
[
[
"## Cross Validation",
"_____no_output_____"
]
],
[
[
"from fbprophet.diagnostics import cross_validation\ndf_cv = cross_validation(my_model, \n initial='40 days', # we take the first 40 days for training\n period='1 days', # every days a new prediction run\n horizon = '7 days') #we predict 7days into the future",
"_____no_output_____"
],
[
"df_cv.sort_values(by=['cutoff','ds'])[0:14]\ndf_cv.head()",
"_____no_output_____"
],
[
"from fbprophet.diagnostics import performance_metrics\ndf_p = performance_metrics(df_cv)\n#to understand the error between actual and predicted value",
"_____no_output_____"
],
[
"df_p",
"_____no_output_____"
],
[
"from fbprophet.plot import plot_cross_validation_metric\nfig = plot_cross_validation_metric(df_cv, metric='mape',)",
"_____no_output_____"
]
],
[
[
"## Diagonalplot",
"_____no_output_____"
]
],
[
[
"## to understand comparison/under and over estimation wrt. actual values\nhorizon='7 days'\ndf_cv['horizon']=df_cv.ds-df_cv.cutoff\n\ndate_vec=df_cv[df_cv['horizon']==horizon]['ds']\ny_hat=df_cv[df_cv['horizon']==horizon]['yhat']\ny=df_cv[df_cv['horizon']==horizon]['y']",
"_____no_output_____"
],
[
"df_cv_7=df_cv[df_cv['horizon']==horizon]\ndf_cv_7.tail()",
"_____no_output_____"
],
[
"type(df_cv['horizon'][0])",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1)\n\n\nax.plot(np.arange(max(y)),np.arange(max(y)),'--',label='diagonal')\nax.plot(y,y_hat,'-',label=horizon) # horizon is a np.timedelta objct\n\nax.set_title('Diagonal Plot')\nax.set_ylim(10, max(y))\n\nax.set_xlabel('truth: y')\nax.set_ylabel('prediciton: y_hat')\nax.set_yscale('log')\n\nax.set_xlim(10, max(y))\nax.set_xscale('log')\nax.legend(loc='best',\n prop={'size': 16});",
"_____no_output_____"
]
],
[
[
"## Trivial Forecast",
"_____no_output_____"
]
],
[
[
"def mean_absolute_percentage_error(y_true, y_pred): \n ''' MAPE calculation '''\n y_true, y_pred = np.array(y_true), np.array(y_pred)\n return np.mean(np.abs((y_true - y_pred) / y_true)) * 100",
"_____no_output_____"
],
[
"parse_dates=['date']\ndf_all = pd.read_csv('../data/processed/COVID_small_flat_table.csv',sep=';',parse_dates=parse_dates)\ndf_trivial=df_all[['date','Germany']]\ndf_trivial=df_trivial.rename(columns={'date': 'ds',\n 'Germany': 'y'})",
"_____no_output_____"
],
[
"df_trivial['y_mean_r3']=df_trivial.y.rolling(3).mean()",
"_____no_output_____"
],
[
"df_trivial['cutoff']=df_trivial['ds'].shift(7)\ndf_trivial['y_hat']=df_trivial['y_mean_r3'].shift(7)\ndf_trivial['horizon']=df_trivial['ds']-df_trivial['cutoff']\nprint('MAPE: '+str(mean_absolute_percentage_error(df_trivial['y_hat'].iloc[12:,], df_trivial['y'].iloc[12:,])))\ndf_trivial",
"MAPE: 134.06143093647987\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7cd0ddb92a48cf56014283cc502a39ff5e8d41e | 94,992 | ipynb | Jupyter Notebook | us-deaths.ipynb | mkudija/US-Causes-of-Death | aa353817a8bab434b98b3e5f67e18f627a2f58f0 | [
"MIT"
]
| null | null | null | us-deaths.ipynb | mkudija/US-Causes-of-Death | aa353817a8bab434b98b3e5f67e18f627a2f58f0 | [
"MIT"
]
| null | null | null | us-deaths.ipynb | mkudija/US-Causes-of-Death | aa353817a8bab434b98b3e5f67e18f627a2f58f0 | [
"MIT"
]
| null | null | null | 424.071429 | 48,793 | 0.928636 | [
[
[
"# Causes of Death in the United States (2011)\nTo visualize the causes of death in the United States, we look at data from the [Centers for Disease Control](http://www.cdc.gov/).\n\nTo get the most recent information, we start with [data from 2015 (PDF)](http://www.cdc.gov/nchs/data/hus/hus15.pdf#019). Table 7 inclues data on the number of legal abortions (699,000 in 2012, the latest year with data available from the CDC). CDC abortion data for 2012 is also given here: [Web](http://www.cdc.gov/reproductivehealth/data_stats/abortion.htm) and [Excel](http://www.cdc.gov/reproductivehealth/data_stats/excel/abortions_2012.xls)\n\nThe Guttmacher Institute also provides and analyzes abortion data. According to the institute's webpage:\n\n>The Guttmacher Institute is a primary source for research and policy analysis on abortion in the United States. In many cases, Guttmacher’s data are more comprehensive than state and federal government sources. The Institute’s work examines the incidence of abortion, access to care and barriers to obtaining services, factors underlying women’s decisions to terminate a pregnancy, characteristics of women who have abortions and the conditions under which women obtain them.\"[[1]](https://www.guttmacher.org/united-states/abortion)\n\nThe Guttmacher Institute [September 2016 Fact Sheet](https://www.guttmacher.org/fact-sheet/induced-abortion-united-states?gclid=CjwKEAjw1qHABRDU9qaXs4rtiS0SJADNzJisAvv0VPSG-35GEPayoftb1RwZuF8heovbdZz0u1ns-xoC0cjw_wcB#7) indicates that **1.06 million** abortions were performed in 2011. This number is also reported by the CDC in the [2015 document cited above](http://www.cdc.gov/nchs/data/hus/hus15.pdf#019). \n\nThe goal is to compare abortion with other leading causes of death in the United States. We will use the figure of 1.06 million abortions in 2011 reported by the Guttmacher Institute. Data for other causes of death in 2011 data is available from the CDC here: [Deaths: Final Data for 2011 (PDF)](http://www.cdc.gov/nchs/data/nvsr/nvsr63/nvsr63_03.pdf)\n\n\n\n",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport pandas as pd\nfrom altair import *\n\ndf = pd.read_excel('2011_causes_of_death.xlsx')\ndf.head()",
"_____no_output_____"
],
[
"df = df.ix[1:]\n\ndf.plot(kind=\"bar\",x=df[\"Cause\"],\n title=\"United SttCauses of Death\",\n legend=False)",
"_____no_output_____"
],
[
"c = Chart(df).mark_bar().encode(\n x=X('Number:Q',axis=Axis(title='2011 Deaths')),\n y=Y('Cause:O', sort=SortField(field='Number', order='descending', op='sum'))\n)\nc",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7cd10902d051a5f653038d424661a7a3fa7b701 | 210,539 | ipynb | Jupyter Notebook | mxnet-week3/HW3/.ipynb_checkpoints/Homework3-checkpoint.ipynb | FanW123/MXNET-project | 1c09285b9d4e29082dab04524912b42fa032f8c6 | [
"MIT"
]
| null | null | null | mxnet-week3/HW3/.ipynb_checkpoints/Homework3-checkpoint.ipynb | FanW123/MXNET-project | 1c09285b9d4e29082dab04524912b42fa032f8c6 | [
"MIT"
]
| null | null | null | mxnet-week3/HW3/.ipynb_checkpoints/Homework3-checkpoint.ipynb | FanW123/MXNET-project | 1c09285b9d4e29082dab04524912b42fa032f8c6 | [
"MIT"
]
| null | null | null | 87.944444 | 8,122 | 0.629912 | [
[
[
"import mxnet as mx \nfrom importlib import import_module\nimport cv2\nimport matplotlib.pyplot as plt \nimport numpy as np ",
"_____no_output_____"
],
[
"# 1. data reading\n# labels in order: \n\"\"\"\n0 airplane\n1 automobile\n2 bird\n3 cat\n4 deer\n5 dog\n6 frog\n7 horse\n8 ship\n9 truck\n\"\"\"\n\ndef get_cifar10():\n # TODO fill all the blanks \n # Hint\n # rgb mean default: '123.68,116.779,103.939',\n # pad size: whatever you think is valid, pad to 32 is good \n # image shape: the image shape feed into the network, e.g. (3,224,224)')\n # num-classes: the number of classes\n # num-examples: the number of training examples, 50000 :)\n # data-nthreads: default=4,number of threads for data decoding, how many cpus do you have\n # dtype: default is float32, can be data type: float32 or float16')\n train = mx.io.ImageRecordIter(\n path_imgrec = \"./cifar10_train.rec\",\n label_width = 1,\n mean_r = 123.68,\n mean_g = 116.779,\n mean_b = 103.939,\n data_name = 'data',\n label_name = 'softmax_label',\n data_shape = (3, 28, 28),\n batch_size = 64,\n pad = 0,\n fill_value = 127,\n preprocess_threads = 4,\n shuffle = True)\n val = mx.io.ImageRecordIter(\n path_imgrec = \"./cifar10_val.rec\",\n label_width = 1,\n mean_r = 123.68,\n mean_g = 116.779,\n mean_b = 103.939,\n data_name = 'data',\n label_name = 'softmax_label',\n data_shape = (3, 28, 28),\n batch_size = 64,\n pad = 0,\n fill_value = 127,\n preprocess_threads = 4,\n shuffle = False)\n return train, val\n\ntrain, val = get_cifar10()",
"<mxnet.io.MXDataIter object at 0x116009ed0>\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\n<mxnet.io.MXDataIter object at 0x115c29810>\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\n<type 'numpy.ndarray'>\n<type 'numpy.ndarray'>\nRandomly pick a picture form a batch:\n"
],
[
"# TODO write the script to look what is inside train and val\n# Check the image size, and label \n# Question? check MXNET_course/mxnet-week3/cifar10/step_by_step_debug.ipynb\ndef check_dataset(dataset):\n print (dataset)\n i=0\n for each in dataset:\n i+=1\n if i>5:\n break\n print each\n\n batch_numpy = each.data[0].asnumpy()\n label_numpy = each.label[0].asnumpy()\n print (type(batch_numpy))\n print (type(label_numpy))\n \n #show img\n randidx = np.random.randint(0,dataset.batch_size)\n img = batch_numpy[randidx]\n #Remove single-dimensional entries from the shape of an array, and sum array elements over axis 0.\n img = np.squeeze(img).sum(axis=0) \n plt.imshow(img, cmap='gray')\n plt.show()\n \nprint(\"Training image: {}\".format(train))\ncheck_dataset(train)\n\nprint(\"\")\nprint(\"Validation image: {}\".format(val))\ncheck_dataset(val)",
"Training image: <mxnet.io.MXDataIter object at 0x116009ed0>\n<mxnet.io.MXDataIter object at 0x116009ed0>\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\nDataBatch: data shapes: [(64L, 3L, 28L, 28L)] label shapes: [(64L,)]\n<type 'numpy.ndarray'>\n<type 'numpy.ndarray'>\n"
],
[
"# 2 model getting \n# TODO read through resnet.py file for understanding\ndef get_resnet():\n net = import_module('resnet')\n sym = net.get_symbol(10,20,\"3,28,28\")\n return sym \nsym = get_resnet()\n\n# TODO \n# 1. Plot and visualize the network. Put your comments about its architecture (why bottlenet)\nmx.viz.plot_network(sym,hide_weights=True,save_format='pdf',title='resnet8')",
"_____no_output_____"
],
[
"# 2. List all weight and output (Question? check MXNET_course/mxnet-week3/cifar10/step_by_step_debug.ipynb)\n\n#check_point = mx.callback.do_checkpoint(model_prefix)\narg_name = sym.list_arguments()\nout_name = sym.list_outputs()\nprint(\"All the weights:\")\nprint (arg_name)\nprint(\"\")\nprint(\"All the output:\")\nprint (out_name)\n\n",
"All the weights:\n['data', 'bn_data_gamma', 'bn_data_beta', 'conv0_weight', 'stage1_unit1_bn1_gamma', 'stage1_unit1_bn1_beta', 'stage1_unit1_conv1_weight', 'stage1_unit1_bn2_gamma', 'stage1_unit1_bn2_beta', 'stage1_unit1_conv2_weight', 'stage1_unit1_sc_weight', 'stage1_unit2_bn1_gamma', 'stage1_unit2_bn1_beta', 'stage1_unit2_conv1_weight', 'stage1_unit2_bn2_gamma', 'stage1_unit2_bn2_beta', 'stage1_unit2_conv2_weight', 'stage1_unit3_bn1_gamma', 'stage1_unit3_bn1_beta', 'stage1_unit3_conv1_weight', 'stage1_unit3_bn2_gamma', 'stage1_unit3_bn2_beta', 'stage1_unit3_conv2_weight', 'stage2_unit1_bn1_gamma', 'stage2_unit1_bn1_beta', 'stage2_unit1_conv1_weight', 'stage2_unit1_bn2_gamma', 'stage2_unit1_bn2_beta', 'stage2_unit1_conv2_weight', 'stage2_unit1_sc_weight', 'stage2_unit2_bn1_gamma', 'stage2_unit2_bn1_beta', 'stage2_unit2_conv1_weight', 'stage2_unit2_bn2_gamma', 'stage2_unit2_bn2_beta', 'stage2_unit2_conv2_weight', 'stage2_unit3_bn1_gamma', 'stage2_unit3_bn1_beta', 'stage2_unit3_conv1_weight', 'stage2_unit3_bn2_gamma', 'stage2_unit3_bn2_beta', 'stage2_unit3_conv2_weight', 'stage3_unit1_bn1_gamma', 'stage3_unit1_bn1_beta', 'stage3_unit1_conv1_weight', 'stage3_unit1_bn2_gamma', 'stage3_unit1_bn2_beta', 'stage3_unit1_conv2_weight', 'stage3_unit1_sc_weight', 'stage3_unit2_bn1_gamma', 'stage3_unit2_bn1_beta', 'stage3_unit2_conv1_weight', 'stage3_unit2_bn2_gamma', 'stage3_unit2_bn2_beta', 'stage3_unit2_conv2_weight', 'stage3_unit3_bn1_gamma', 'stage3_unit3_bn1_beta', 'stage3_unit3_conv1_weight', 'stage3_unit3_bn2_gamma', 'stage3_unit3_bn2_beta', 'stage3_unit3_conv2_weight', 'bn1_gamma', 'bn1_beta', 'fc1_weight', 'fc1_bias', 'softmax_label']\n\nAll the output:\n['softmax_output']\n"
],
[
"net_arguments = sym.list_arguments()\nnet_outputs = sym.list_outputs()\nprint(\"Network arguments:\")\nprint(net_arguments)\n\nprint(\"\")\nprint(\"Network Outputs:\")\nprint(net_outputs)",
"_____no_output_____"
],
[
"# 3 sanity check random image inference\nimg1 = cv2.imread(\"frog.jpg\")\nimg1 = cv2.resize(img1,(28,28))# you need to pad it if you do padding for you nework\nplt.imshow(img1)\nplt.show()\nprint type(img1)\nimg1 = img1.transpose((2,0,1)).reshape((1,3,28,28))\nprint img1.shape\n\nimg2 = cv2.imread(\"frog2.jpg\")\nimg2 = cv2.resize(img2,(28,28))# you need to pad it if you do padding for you nework\nplt.imshow(img2)\nplt.show()\nprint type(img2)\nimg2 = img2.transpose((2,0,1)).reshape((1,3,28,28))\nprint img2.shape\n\nimg = np.vstack([img1,img2])\nprint \"The very small training dataset contain: \", img.shape\n\n# TODO: figure out how to convert numpy array to mx.nd.array\nimg_mxnd = mx.nd.array(???)\nlabel_mxnd = mx.nd.array(ctx=mx.cpu(), source_array=np.asarray([6,6])) # 6 is frog\nimg_itr = mx.io.NDArrayIter(???) # Hint the name should \"data\" and softmax_label\nprint \"small dataset is: \", type(img_itr)\nfor each in img_itr:\n print each\n\n# TODO bind the random img to network \n# question? check mxnet-week3/cifar10/train_cifar10.py\nmod = mx.mod.Module(???)\nmod.bind(img_itr.provide_data,img_itr.provide_label)\nmod.init_params(???) \n\n# run forward perdiction \n# TODO fill the mod.predict \n# check mod.predict\nout = mod.predict(???)",
"_____no_output_____"
],
[
"print np.argmax(out.asnumpy(),axis=1)",
"_____no_output_____"
],
[
"# 4 overfit small dataset \n# TODO fill all ???\nmod.init_params(???) \nmod.init_optimizer(???) \n# run forward perdiction\nmetric = mx.metric.create('acc')\n\nfor epoch in range(5):\n img_itr.reset()\n metric.reset()\n for batch in img_itr:\n mod.forward(batch, is_train=True)\n mod.update_metric(metric, batch.label)\n mod.backward()\n mod.update()\n print ('Epoch {}, Train {}'.format(epoch, metric.get()))\n # You should get 100% accuacy on these two images\n",
"_____no_output_____"
],
[
"# 5 (optional) train cifar10 on resnet(~epoch) if you have GPU. Build the training script from week2",
"_____no_output_____"
],
[
"# 6 (optional) Wild test on your model ",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cd188953032cb0788d5ccce3e0a5aa2a5eb02d | 15,240 | ipynb | Jupyter Notebook | speakers/Stuart Williams/PyCon-2018-Python-Epiphanies/Python-Epiphanies-7-Iterators-and-Generators.ipynb | gitter-badger/awesome-pycon-notes | b2943736c42193685290bf183523945da2c7d72e | [
"MIT"
]
| null | null | null | speakers/Stuart Williams/PyCon-2018-Python-Epiphanies/Python-Epiphanies-7-Iterators-and-Generators.ipynb | gitter-badger/awesome-pycon-notes | b2943736c42193685290bf183523945da2c7d72e | [
"MIT"
]
| null | null | null | speakers/Stuart Williams/PyCon-2018-Python-Epiphanies/Python-Epiphanies-7-Iterators-and-Generators.ipynb | gitter-badger/awesome-pycon-notes | b2943736c42193685290bf183523945da2c7d72e | [
"MIT"
]
| null | null | null | 17.971698 | 81 | 0.436942 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
e7cd1ea594d3dde30e17dc9304abb8dff69c7140 | 578,715 | ipynb | Jupyter Notebook | monte-carlo/Monte_Carlo.ipynb | dmitrylosev/deep-reinforcement-learning | b01da45c3019bd4c8c5203d4d69c2f0ca193a7bc | [
"MIT"
]
| 1 | 2018-07-25T07:49:48.000Z | 2018-07-25T07:49:48.000Z | monte-carlo/Monte_Carlo.ipynb | uniquenessrising/deep-reinforcement-learning | b01da45c3019bd4c8c5203d4d69c2f0ca193a7bc | [
"MIT"
]
| null | null | null | monte-carlo/Monte_Carlo.ipynb | uniquenessrising/deep-reinforcement-learning | b01da45c3019bd4c8c5203d4d69c2f0ca193a7bc | [
"MIT"
]
| null | null | null | 1,173.864097 | 276,248 | 0.956236 | [
[
[
"# Monte Carlo Methods\n\nIn this notebook, you will write your own implementations of many Monte Carlo (MC) algorithms. \n\nWhile we have provided some starter code, you are welcome to erase these hints and write your code from scratch.\n\n### Part 0: Explore BlackjackEnv\n\nWe begin by importing the necessary packages.",
"_____no_output_____"
]
],
[
[
"import sys\nimport gym\nimport numpy as np\nfrom collections import defaultdict\n\nfrom plot_utils import plot_blackjack_values, plot_policy",
"_____no_output_____"
]
],
[
[
"Use the code cell below to create an instance of the [Blackjack](https://github.com/openai/gym/blob/master/gym/envs/toy_text/blackjack.py) environment.",
"_____no_output_____"
]
],
[
[
"env = gym.make('Blackjack-v0')",
"_____no_output_____"
]
],
[
[
"Each state is a 3-tuple of:\n- the player's current sum $\\in \\{0, 1, \\ldots, 31\\}$,\n- the dealer's face up card $\\in \\{1, \\ldots, 10\\}$, and\n- whether or not the player has a usable ace (`no` $=0$, `yes` $=1$).\n\nThe agent has two potential actions:\n\n```\n STICK = 0\n HIT = 1\n```\nVerify this by running the code cell below.",
"_____no_output_____"
]
],
[
[
"print(env.observation_space)\nprint(env.action_space)",
"Tuple(Discrete(32), Discrete(11), Discrete(2))\nDiscrete(2)\n"
]
],
[
[
"Execute the code cell below to play Blackjack with a random policy. \n\n(_The code currently plays Blackjack three times - feel free to change this number, or to run the cell multiple times. The cell is designed for you to get some experience with the output that is returned as the agent interacts with the environment._)",
"_____no_output_____"
]
],
[
[
"for i_episode in range(3):\n state = env.reset()\n while True:\n print(state)\n action = env.action_space.sample()\n state, reward, done, info = env.step(action)\n if done:\n print('End game! Reward: ', reward)\n print('You won :)\\n') if reward > 0 else print('You lost :(\\n')\n break",
"(17, 2, False)\nEnd game! Reward: -1\nYou lost :(\n\n(20, 5, False)\nEnd game! Reward: -1\nYou lost :(\n\n(20, 7, False)\nEnd game! Reward: 1.0\nYou won :)\n\n"
]
],
[
[
"### Part 1: MC Prediction\n\nIn this section, you will write your own implementation of MC prediction (for estimating the action-value function). \n\nWe will begin by investigating a policy where the player _almost_ always sticks if the sum of her cards exceeds 18. In particular, she selects action `STICK` with 80% probability if the sum is greater than 18; and, if the sum is 18 or below, she selects action `HIT` with 80% probability. The function `generate_episode_from_limit_stochastic` samples an episode using this policy. \n\nThe function accepts as **input**:\n- `bj_env`: This is an instance of OpenAI Gym's Blackjack environment.\n\nIt returns as **output**:\n- `episode`: This is a list of (state, action, reward) tuples (of tuples) and corresponds to $(S_0, A_0, R_1, \\ldots, S_{T-1}, A_{T-1}, R_{T})$, where $T$ is the final time step. In particular, `episode[i]` returns $(S_i, A_i, R_{i+1})$, and `episode[i][0]`, `episode[i][1]`, and `episode[i][2]` return $S_i$, $A_i$, and $R_{i+1}$, respectively.",
"_____no_output_____"
]
],
[
[
"def generate_episode_from_limit_stochastic(bj_env):\n episode = []\n state = bj_env.reset()\n while True:\n probs = [0.8, 0.2] if state[0] > 18 else [0.2, 0.8]\n action = np.random.choice(np.arange(2), p=probs)\n next_state, reward, done, info = bj_env.step(action)\n episode.append((state, action, reward))\n state = next_state\n if done:\n break\n return episode",
"_____no_output_____"
]
],
[
[
"Execute the code cell below to play Blackjack with the policy. \n\n(*The code currently plays Blackjack three times - feel free to change this number, or to run the cell multiple times. The cell is designed for you to gain some familiarity with the output of the `generate_episode_from_limit_stochastic` function.*)",
"_____no_output_____"
]
],
[
[
"for i in range(3):\n print(generate_episode_from_limit_stochastic(env))",
"[((17, 2, True), 0, 1.0)]\n[((17, 5, False), 1, 0), ((18, 5, False), 1, 0), ((20, 5, False), 1, -1)]\n[((10, 9, False), 0, -1.0)]\n"
]
],
[
[
"Now, you are ready to write your own implementation of MC prediction. Feel free to implement either first-visit or every-visit MC prediction; in the case of the Blackjack environment, the techniques are equivalent.\n\nYour algorithm has three arguments:\n- `env`: This is an instance of an OpenAI Gym environment.\n- `num_episodes`: This is the number of episodes that are generated through agent-environment interaction.\n- `generate_episode`: This is a function that returns an episode of interaction.\n- `gamma`: This is the discount rate. It must be a value between 0 and 1, inclusive (default value: `1`).\n\nThe algorithm returns as output:\n- `Q`: This is a dictionary (of one-dimensional arrays) where `Q[s][a]` is the estimated action value corresponding to state `s` and action `a`.",
"_____no_output_____"
]
],
[
[
"def mc_prediction_q(env, num_episodes, generate_episode, gamma=1.0):\n # initialize empty dictionaries of arrays\n returns_sum = defaultdict(lambda: np.zeros(env.action_space.n))\n N = defaultdict(lambda: np.zeros(env.action_space.n))\n Q = defaultdict(lambda: np.zeros(env.action_space.n))\n # loop over episodes\n for i_episode in range(1, num_episodes+1):\n # monitor progress\n if i_episode % 1000 == 0:\n print(\"\\rEpisode {}/{}.\".format(i_episode, num_episodes), end=\"\")\n sys.stdout.flush()\n \n episode = generate_episode(env)\n states, actions, rewards = zip(*episode)\n discounts = np.array([gamma**i for i in range(len(episode))])\n for i, (state, action, reward) in enumerate(episode):\n returns_sum[state][action] += sum(rewards[i:]*discounts[:len(rewards)-i])\n N[state][action] += 1\n Q[state][action] = returns_sum[state][action]/N[state][action]\n \n return Q",
"_____no_output_____"
]
],
[
[
"Use the cell below to obtain the action-value function estimate $Q$. We have also plotted the corresponding state-value function.\n\nTo check the accuracy of your implementation, compare the plot below to the corresponding plot in the solutions notebook **Monte_Carlo_Solution.ipynb**.",
"_____no_output_____"
]
],
[
[
"# obtain the action-value function\nQ = mc_prediction_q(env, 500000, generate_episode_from_limit_stochastic)\n\n# obtain the corresponding state-value function\nV_to_plot = dict((k,(k[0]>18)*(np.dot([0.8, 0.2],v)) + (k[0]<=18)*(np.dot([0.2, 0.8],v))) \\\n for k, v in Q.items())\n\n# plot the state-value function\nplot_blackjack_values(V_to_plot)",
"Episode 500000/500000."
]
],
[
[
"### Part 2: MC Control\n\nIn this section, you will write your own implementation of constant-$\\alpha$ MC control. \n\nYour algorithm has four arguments:\n- `env`: This is an instance of an OpenAI Gym environment.\n- `num_episodes`: This is the number of episodes that are generated through agent-environment interaction.\n- `alpha`: This is the step-size parameter for the update step.\n- `gamma`: This is the discount rate. It must be a value between 0 and 1, inclusive (default value: `1`).\n\nThe algorithm returns as output:\n- `Q`: This is a dictionary (of one-dimensional arrays) where `Q[s][a]` is the estimated action value corresponding to state `s` and action `a`.\n- `policy`: This is a dictionary where `policy[s]` returns the action that the agent chooses after observing state `s`.\n\n(_Feel free to define additional functions to help you to organize your code._)",
"_____no_output_____"
]
],
[
[
"def epsilon_soft_policy(Qs, epsilon, nA):\n policy = np.ones(nA)*epsilon/nA\n Q_arg_max = np.argmax(Qs)\n policy[Q_arg_max] = 1 - epsilon + epsilon/nA\n return policy\n\ndef generate_episode_with_Q(env, Q, epsilon, nA):\n episode = []\n state = env.reset()\n while True:\n probs = epsilon_soft_policy(Q[state], epsilon, nA)\n action = np.random.choice(np.arange(nA), p=probs) if state in Q else env.action_space.sample()\n next_state, reward, done, info = env.step(action)\n episode.append((state, action, reward))\n state = next_state\n if done:\n break\n return episode\n\ndef update_Q(Q, episode, alpha, gamma):\n states, actions, rewards = zip(*episode)\n discounts = np.array([gamma**i for i in range(len(episode))])\n for i, (state, action, reward) in enumerate(episode):\n Q_prev = Q[state][action]\n Q[state][action] = Q_prev + alpha*(sum(rewards[i:]*discounts[:len(rewards)-i]) - Q_prev)\n return Q",
"_____no_output_____"
],
[
"def mc_control(env, num_episodes, alpha, gamma=1.0, epsilon_start=1.0, epsilon_decay=0.99999, epsilon_min=0.05):\n nA = env.action_space.n\n # initialize empty dictionary of arrays\n Q = defaultdict(lambda: np.zeros(nA))\n epsilon = epsilon_start\n # loop over episodes\n for i_episode in range(1, num_episodes+1):\n # monitor progress\n if i_episode % 1000 == 0:\n print(\"\\rEpisode {}/{}.\".format(i_episode, num_episodes), end=\"\")\n sys.stdout.flush()\n \n epsilon = max(epsilon*epsilon_decay, epsilon_min)\n episode = generate_episode_with_Q(env, Q, epsilon, nA)\n Q = update_Q(Q, episode, alpha, gamma)\n policy = dict((key, np.argmax(value)) for key, value in Q.items())\n \n return policy, Q",
"_____no_output_____"
]
],
[
[
"Use the cell below to obtain the estimated optimal policy and action-value function. Note that you should fill in your own values for the `num_episodes` and `alpha` parameters.",
"_____no_output_____"
]
],
[
[
"# obtain the estimated optimal policy and action-value function\npolicy, Q = mc_control(env, 500000, 1/50)",
"Episode 500000/500000."
]
],
[
[
"Next, we plot the corresponding state-value function.",
"_____no_output_____"
]
],
[
[
"# obtain the corresponding state-value function\nV = dict((k,np.max(v)) for k, v in Q.items())\n\n# plot the state-value function\nplot_blackjack_values(V)",
"_____no_output_____"
]
],
[
[
"Finally, we visualize the policy that is estimated to be optimal.",
"_____no_output_____"
]
],
[
[
"# plot the policy\nplot_policy(policy)",
"_____no_output_____"
]
],
[
[
"The **true** optimal policy $\\pi_*$ can be found in Figure 5.2 of the [textbook](http://go.udacity.com/rl-textbook) (and appears below). Compare your final estimate to the optimal policy - how close are you able to get? If you are not happy with the performance of your algorithm, take the time to tweak the decay rate of $\\epsilon$, change the value of $\\alpha$, and/or run the algorithm for more episodes to attain better results.\n\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7cd28d052ce368824825f7c17cfc4212134e294 | 195,042 | ipynb | Jupyter Notebook | figure_04.ipynb | tjjlemaire/JNE1685 | 99bd0344ce828eefd6cf1f7b98bcea1767fe468e | [
"MIT"
]
| null | null | null | figure_04.ipynb | tjjlemaire/JNE1685 | 99bd0344ce828eefd6cf1f7b98bcea1767fe468e | [
"MIT"
]
| null | null | null | figure_04.ipynb | tjjlemaire/JNE1685 | 99bd0344ce828eefd6cf1f7b98bcea1767fe468e | [
"MIT"
]
| null | null | null | 898.81106 | 70,628 | 0.956097 | [
[
[
"# Figure 4 - Effective variables\n\nCreate the figure panels describing the model's effective variables dependencies on US frequency, US amplitude and sonophore radius.",
"_____no_output_____"
],
[
"### Imports",
"_____no_output_____"
]
],
[
[
"import os\nimport matplotlib.pyplot as plt\nfrom PySONIC.plt import plotEffectiveVariables\nfrom PySONIC.utils import logger\nfrom PySONIC.neurons import getPointNeuron\nfrom utils import saveFigsAsPDF",
"_____no_output_____"
]
],
[
[
"### Plot parameters",
"_____no_output_____"
]
],
[
[
"figindex = 4\nfs = 12\nlw = 2\nps = 15\nfigs = {}",
"_____no_output_____"
]
],
[
[
"### Simulation parameters",
"_____no_output_____"
]
],
[
[
"pneuron = getPointNeuron('RS')\na = 32e-9 # m\nFdrive = 500e3 # Hz\nAdrive = 50e3 # Pa",
"_____no_output_____"
]
],
[
[
"## Panel A: dependence on acoustic amplitude",
"_____no_output_____"
]
],
[
[
"fig = plotEffectiveVariables(pneuron, a=a, f=Fdrive, cmap='Oranges', zscale='log')\nfigs['a'] = fig",
"_____no_output_____"
]
],
[
[
"## Panel B: dependence on US frequency",
"_____no_output_____"
]
],
[
[
"fig = plotEffectiveVariables(pneuron, a=a, A=Adrive, cmap='Greens', zscale='log')\nfigs['b'] = fig",
" 28/04/2020 22:17:14: Rounding f value (4000000.000000001) to interval upper bound (4000000.0)"
]
],
[
[
"## Panel C: dependence on sonophore radius",
"_____no_output_____"
]
],
[
[
"fig = plotEffectiveVariables(pneuron, f=Fdrive, A=Adrive, cmap='Blues', zscale='log')\nfigs['c'] = fig",
"_____no_output_____"
]
],
[
[
"### Save figure panels\n\nSave figure panels as **pdf** in the *figs* sub-folder:",
"_____no_output_____"
]
],
[
[
"saveFigsAsPDF(figs, figindex)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7cd2a000d2aa0630d5e6c9ace50d0acbb78ea6a | 198,338 | ipynb | Jupyter Notebook | Notebooks/.ipynb_checkpoints/Character Segmentation Model -checkpoint.ipynb | swapnilmarathe007/Handwriting-Recognition | 1c0430ec528573a2022d5059ef20243c39980776 | [
"MIT"
]
| null | null | null | Notebooks/.ipynb_checkpoints/Character Segmentation Model -checkpoint.ipynb | swapnilmarathe007/Handwriting-Recognition | 1c0430ec528573a2022d5059ef20243c39980776 | [
"MIT"
]
| null | null | null | Notebooks/.ipynb_checkpoints/Character Segmentation Model -checkpoint.ipynb | swapnilmarathe007/Handwriting-Recognition | 1c0430ec528573a2022d5059ef20243c39980776 | [
"MIT"
]
| null | null | null | 143.307803 | 85,860 | 0.894095 | [
[
[
"import numpy as np\nimport cv2 \nimport matplotlib.pyplot as plt\n%matplotlib inline\nimage_name = \"wipro.png\"",
"_____no_output_____"
],
[
"# image_location = \"test_img/cat.png\"\n# image_location = \"test_img/reverse.png\"\n# image_location = \"test_img/place.png\"\n# image_location = \"test_img/cts.png\"\nimage_location = \"test_img/\"+image_name\nimg = cv2.imread(image_location,0)\n\n",
"_____no_output_____"
],
[
"plt.imshow(img)",
"_____no_output_____"
]
],
[
[
"# Thresh - Binary \n",
"_____no_output_____"
]
],
[
[
"res , thresh = cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV)\nplt.imshow(thresh)",
"_____no_output_____"
]
],
[
[
"# Skeletonize",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport cv2\nfrom imutils import resize\nfrom imutils.contours import sort_contours\n\nfrom skimage.morphology import skeletonize as skl\n\n# path = 'test_img/cat.png'\n# path = \"test_img/place.png\"\n# path = \"test_img/cts.png\"\npath = \"test_img/\"+image_name\n# path = 'test_img/reverse.png'\nimg = cv2.imread(path, 0)\n# Some smoothing to get rid of the noise\n# img = cv2.bilateralFilter(img, 5, 35, 10)\nimg = cv2.GaussianBlur(img, (3, 3), 3)\n# img = resize(img, width=700)\n\n# Preprocessing to get the shapes\nth = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,\n cv2.THRESH_BINARY, 35, 11)\n# Invert to hightligth the shape\nth = cv2.bitwise_not(th)\n\n# Text has mostly vertical and right-inclined lines. This kernel seems to\n# work quite well\nkernel = np.array([[0, 1, 1],\n [0, 1, 0],\n [1, 1, 0]], dtype='uint8')\n\nth = cv2.morphologyEx(th, cv2.MORPH_CLOSE, kernel)\n\ncv2.imshow('mask', th)\ncv2.waitKey(0)\n\n\n#def contour_sorter(contours):\n# '''Sort the contours by multiplying the y-coordinate and sorting first by\n# x, then by y-coordinate.'''\n# boxes = [cv2.boundingRect(c) for c in contours]\n# cnt = [4*y, x for y, x, , _, _ in ]\n\n# Skeletonize the shapes\n# Skimage function takes image with either True, False or 0,1\n# and returns and image with values 0, 1.\nth = th == 255\nth = skl(th)\nth = th.astype(np.uint8)*255\n\n# Find contours of the skeletons\n_, contours, _ = cv2.findContours(th.copy(), cv2.RETR_EXTERNAL,\n cv2.CHAIN_APPROX_NONE)\n# Sort the contours left-to-rigth\ncontours, _ = sort_contours(contours, )\n#\n# Sort them again top-to-bottom\n\n\ndef skeleton_endpoints(skel):\n # Function source: https://stackoverflow.com/questions/26537313/\n # how-can-i-find-endpoints-of-binary-skeleton-image-in-opencv\n # make out input nice, possibly necessary\n skel = skel.copy()\n skel[skel != 0] = 1\n skel = np.uint8(skel)\n\n # apply the convolution\n kernel = np.uint8([[1, 1, 1],\n [1, 10, 1],\n [1, 1, 1]])\n src_depth = -1\n filtered = cv2.filter2D(skel, src_depth,kernel)\n\n # now look through to find the value of 11\n # this returns a mask of the endpoints, but if you just want the\n # coordinates, you could simply return np.where(filtered==11)\n out = np.zeros_like(skel)\n out[np.where(filtered == 11)] = 1\n rows, cols = np.where(filtered == 11)\n coords = list(zip(cols, rows))\n return coords\n\n# List for endpoints\nendpoints = []\n# List for (x, y) coordinates of the skeletons\nskeletons = []\n\n\n\nfor contour in contours:\n if cv2.arcLength(contour, True) > 100:\n # Initialize mask\n mask = np.zeros(img.shape, np.uint8)\n # Bounding rect of the contour\n x, y, w, h = cv2.boundingRect(contour)\n mask[y:y+h, x:x+w] = 255\n # Get only the skeleton in the mask area\n mask = cv2.bitwise_and(mask, th)\n # Take the coordinates of the skeleton points\n rows, cols = np.where(mask == 255)\n # Add the coordinates to the list\n skeletons.append(list(zip(cols, rows)))\n \n\n # Find the endpoints for the shape and update a list\n eps = skeleton_endpoints(mask)\n endpoints.append(eps)\n\n # Draw the endpoints\n# [cv2.circle(th, ep, 5, 255, 1) for ep in eps]\n cv2.imshow('mask', mask)\n cv2.waitKey(500)\n# cv2.imwrite(\"res/l_cat.png\",th)# Stack the original and modified\n# cv2.imwrite(\"res/l_reverse.png\",th)# Stack the original and modified\n# cv2.imwrite(\"res/l_place.png\",th)# Stack the original and modified\n# cv2.imwrite(\"res/l_cts.png\",th)# Stack the original and modified\ncv2.imwrite(\"res/l_\"+image_name+\".png\",th)# Stack the original and modified\n\nth = resize(np.hstack((img, th)), 1200)\n\n\n# cv2.waitKey(50)\n\n# TODO\n# Walk the points using the endpoints by minimizing the walked distance\n# Points in between can be used many times, endpoints only once\ncv2.imshow('mask', th)\ncv2.waitKey(0)\ncv2.destroyAllWindows()\n",
"_____no_output_____"
],
[
"# skel_img = cv2.imread(\"res/l_cat.png\",0)\n# skel_img = cv2.imread(\"res/l_place.png\",0)\n# skel_img = cv2.imread(\"res/l_cts.png\",0)\nskel_img = cv2.imread(\"res/l_\"+image_name+\".png\",0)\n# skel_img = cv2.imread(\"res/l_reverse.png\",0)\nplt.imshow(skel_img)",
"_____no_output_____"
]
],
[
[
"# Turn to transpose ",
"_____no_output_____"
]
],
[
[
"trnspse_img = np.transpose(skel_img)",
"_____no_output_____"
],
[
"plt.imshow(trnspse_img)",
"_____no_output_____"
]
],
[
[
"# Calculate the median of the word",
"_____no_output_____"
]
],
[
[
"up = []\ndown = []\nfor val in trnspse_img:\n temp = []\n for i , value in enumerate(val):\n if(value>0):\n temp.append(i)\n try:\n up.append(temp[0])\n down.append(temp[-1])\n except : \n pass\n ",
"_____no_output_____"
],
[
"up_avg = sum(up)//len(up)\nprint (up_avg)",
"130\n"
],
[
"down_avg = sum(down) // len(down)\nprint (down_avg)",
"161\n"
],
[
"median = ( up_avg + down_avg ) // 2\nprint (median)",
"145\n"
],
[
"copy_of_original = skel_img.copy()\nplt.imshow(copy_of_original)",
"_____no_output_____"
]
],
[
[
"# Draw line in median in copy ",
"_____no_output_____"
]
],
[
[
"copy_of_original[median] = [255] * len(copy_of_original[median])",
"_____no_output_____"
],
[
"plt.imshow(copy_of_original)",
"_____no_output_____"
],
[
"# Transpose look of median drawn image \nplt.imshow(np.transpose(copy_of_original))",
"_____no_output_____"
],
[
"# checking from down till median for single 255 and sum of that val == 255 \nsp_list = [] # Segmentation Points\nfor i , val in enumerate(trnspse_img):\n if (sum(val[median:]) == 255 and sum(val) == 255):\n sp_list.append(i)",
"_____no_output_____"
],
[
"#from Top to bottom \n# checking from down till median for single 255 and sum of that val == 255 \nsp_list_t = [] # Segmentation Points\nfor i , val in enumerate(trnspse_img):\n if (sum(val[:median]) == 255 and sum(val) == 255):\n sp_list_t.append(i)",
"_____no_output_____"
],
[
"# print(sp_list_t)",
"_____no_output_____"
],
[
"print (sp_list)",
"[193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 274, 276, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330, 384, 385, 386, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 402, 403, 419, 421, 425, 426, 427, 428, 429, 431, 433, 434, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 502, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 518, 519, 520, 521, 522, 523, 524, 525, 526, 527, 528, 529, 530]\n"
]
],
[
[
"# To find Consecutive elements ",
"_____no_output_____"
]
],
[
[
"def consecutive(data, stepsize=1):\n return np.split(data, np.where(np.diff(data) != stepsize)[0]+1)",
"_____no_output_____"
],
[
"res_list = consecutive(sp_list)",
"_____no_output_____"
],
[
"# from Top\nres_list_t = consecutive(sp_list_t)",
"_____no_output_____"
],
[
"for lst in res_list:\n print (lst)",
"[193 194 195 196 197 198 199 200 201 202 203 204 205 206]\n[249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266\n 267 268 269 270 271 272]\n[274]\n[276]\n[311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328\n 329 330]\n[384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399]\n[402 403]\n[419]\n[421]\n[425 426 427 428 429]\n[431]\n[433 434]\n[463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480\n 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498\n 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516\n 517 518 519 520 521 522 523 524 525 526 527 528 529 530]\n"
],
[
"#from Top\nfor lst in res_list_t:\n print (lst)",
"[85 86]\n[277 278 279 280 281 282]\n[335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352\n 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370\n 371]\n[373]\n[416]\n"
],
[
"avg_of_blocks = []\n#from top\navg_of_blocks_t = []",
"_____no_output_____"
],
[
"for lst in res_list:\n# if(len(lst) > 7):\n avg_of_blocks.append(sum(lst)//len(lst))",
"_____no_output_____"
],
[
"\n\n\n",
"_____no_output_____"
],
[
"print(avg_of_blocks_t)",
"[]\n"
],
[
"#from Top\nfor lst in res_list_t:\n# if(len(lst) > ):\n avg_of_blocks_t.append(sum(lst)//len(lst))",
"_____no_output_____"
],
[
"# Saving splliting of u , v, w \nnew_avg_block = []\nnew_avg_block.append(avg_of_blocks[0])\n\n\n\n\nfor i , val in enumerate(avg_of_blocks):\n try:\n temp = (avg_of_blocks[i+1]-avg_of_blocks[i])\n if(temp > 60):\n new_avg_block.append(avg_of_blocks[i+1])\n except:\n pass",
"_____no_output_____"
],
[
"#from Top\n# Saving splliting of m , n , h , \nnew_avg_block_t = []\nnew_avg_block_t.append(avg_of_blocks_t[0])\nfor i , val in enumerate(avg_of_blocks_t):\n try:\n temp = (avg_of_blocks_t[i+1]-avg_of_blocks_t[i])\n if(temp > 60):\n new_avg_block_t.append(avg_of_blocks_t[i+1])\n except:\n pass",
"_____no_output_____"
],
[
"print (new_avg_block)",
"[199, 260, 391, 496]\n"
],
[
"print (new_avg_block_t)",
"[85, 279, 353]\n"
]
],
[
[
"# This is a new way of hacking",
"_____no_output_____"
]
],
[
[
"combine_copy = skel_img.copy()\nplt.imshow(combine_copy)",
"_____no_output_____"
],
[
"new_combined_list = [] + new_avg_block\nfor val in new_avg_block_t:\n for i , vl in enumerate(new_avg_block):\n try:\n if(val-vl > 80 and new_avg_block[i+1]-val > 80):\n new_combined_list.append(val)\n break\n except:\n pass\n ",
"_____no_output_____"
],
[
"new_combined_list = sorted(new_combined_list)",
"_____no_output_____"
],
[
"new_transpose_copy = np.transpose(combine_copy)",
"_____no_output_____"
],
[
"plt.imshow(new_transpose_copy)",
"_____no_output_____"
],
[
"for val in new_combined_list:\n new_transpose_copy[val] = [255] * len(new_transpose_copy[val])\nplt.imshow(new_transpose_copy)",
"_____no_output_____"
],
[
"# cv2.imwrite(\"res/res_cts_combined.png\",np.transpose(new_transpose_copy))\ncv2.imwrite(\"res/res_\"+image_name+\"_combined.png\",np.transpose(new_transpose_copy))\n# cv2.imwrite(\"res/res_place_combined.png\",np.transpose(new_transpose_copy))",
"_____no_output_____"
]
],
[
[
"# Tried but not working ",
"_____no_output_____"
]
],
[
[
"transpose_of_copy = np.transpose(copy_of_original)",
"_____no_output_____"
],
[
"#for top\ntranspose_of_copy_t = np.transpose(copy_of_original)",
"_____no_output_____"
],
[
"plt.imshow(transpose_of_copy)",
"_____no_output_____"
],
[
"plt.imshow(transpose_of_copy_t)",
"_____no_output_____"
],
[
"# for val in avg_of_blocks:\n# transpose_of_copy[val] = [255] * len(transpose_of_copy[val])\nfor val in new_avg_block:\n transpose_of_copy[val] = [255] * len(transpose_of_copy[val])",
"_____no_output_____"
],
[
"#from Top\n# for val in avg_of_blocks:\n# transpose_of_copy[val] = [255] * len(transpose_of_copy[val])\nfor val in new_avg_block_t:\n transpose_of_copy_t[val] = [255] * len(transpose_of_copy_t[val])",
"_____no_output_____"
],
[
"plt.imshow(transpose_of_copy)",
"_____no_output_____"
],
[
"plt.imshow(transpose_of_copy_t)",
"_____no_output_____"
],
[
"plt.imshow(np.transpose(transpose_of_copy))",
"_____no_output_____"
],
[
"plt.imshow(np.transpose(transpose_of_copy_t))",
"_____no_output_____"
],
[
"# cv2.imwrite(\"res/res_reverse.png\",np.transpose(transpose_of_copy))\n# cv2.imwrite(\"res/res_place.png\",np.transpose(transpose_of_copy))\n# cv2.imwrite(\"res/res_cts.png\",np.transpose(transpose_of_copy))\ncv2.imwrite(\"res/res_\"+image_name+\".png\",np.transpose(transpose_of_copy))",
"_____no_output_____"
],
[
"#from Top\n# cv2.imwrite(\"res/res_reverse.png\",np.transpose(transpose_of_copy))\n# cv2.imwrite(\"res/res_place.png\",np.transpose(transpose_of_copy))\ncv2.imwrite(\"res/res_\"+image_name+\"_t.png\",np.transpose(transpose_of_copy_t))",
"_____no_output_____"
],
[
"# Checking for a way to save u, v, w\n\nprint (avg_of_blocks)\nprint (new_avg_block)",
"[199, 260, 274, 276, 320, 391, 402, 419, 421, 427, 431, 433, 496]\n[199, 260, 391, 496]\n"
],
[
"#checking diff between next and this \nfor i , val in enumerate(avg_of_blocks):\n try:\n print (avg_of_blocks[i+1]-avg_of_blocks[i])\n except:\n pass\n ",
"61\n14\n2\n44\n71\n11\n17\n2\n6\n4\n2\n63\n"
],
[
"#checking diff between next and this \nfor i , val in enumerate(new_avg_block):\n try:\n print (new_avg_block[i+1]-new_avg_block[i])\n except:\n pass\n ",
"61\n131\n105\n"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cd323f87e802fa3324a80e2aa876e6f2db9cb8 | 81,267 | ipynb | Jupyter Notebook | CNNResults/project_cnn_full_hyperparam_run_30_12.ipynb | ruizhi92/EE239AS_Project | 9b9bc46a45d75f4778ba945e1b6c6221276c4a35 | [
"MIT"
]
| 15 | 2019-05-11T02:35:09.000Z | 2022-03-22T09:17:28.000Z | CNNResults/project_cnn_full_hyperparam_run_30_12.ipynb | ruizhi92/EE239AS_Project | 9b9bc46a45d75f4778ba945e1b6c6221276c4a35 | [
"MIT"
]
| 1 | 2020-09-23T11:05:22.000Z | 2020-09-23T13:40:01.000Z | CNNResults/project_cnn_full_hyperparam_run_30_12.ipynb | ruizhi92/EE239AS_Project | 9b9bc46a45d75f4778ba945e1b6c6221276c4a35 | [
"MIT"
]
| 9 | 2018-03-14T23:48:03.000Z | 2022-02-05T13:13:16.000Z | 240.434911 | 68,772 | 0.899147 | [
[
[
"import torch\nimport torch.utils.data\nfrom torch.autograd import Variable\nimport torch.nn as nn\nimport torch.optim as optim\nimport numpy as np\nimport h5py\nfrom data_utils import get_data\nimport matplotlib.pyplot as plt\nfrom solver_pytorch import Solver",
"_____no_output_____"
],
[
"# Load data from all .mat files, combine them, eliminate EOG signals, shuffle and \n# seperate training data, validation data and testing data.\n# Also do mean subtraction on x.\n\ndata = get_data('../project_datasets',num_validation=100, num_test=100)\nfor k in data.keys():\n print('{}: {} '.format(k, data[k].shape))",
"X_train: (2358, 22, 1000) \ny_train: (2358,) \nX_val: (100, 22, 1000) \ny_val: (100,) \nX_test: (100, 22, 1000) \ny_test: (100,) \n"
],
[
"# class flatten to connect to FC layer\nclass Flatten(nn.Module):\n def forward(self, x):\n N, C, H = x.size() # read in N, C, H\n return x.view(N, -1)",
"_____no_output_____"
],
[
"# turn x and y into torch type tensor\n\ndtype = torch.FloatTensor\n\nX_train = Variable(torch.Tensor(data.get('X_train'))).type(dtype)\ny_train = Variable(torch.Tensor(data.get('y_train'))).type(torch.IntTensor)\nX_val = Variable(torch.Tensor(data.get('X_val'))).type(dtype)\ny_val = Variable(torch.Tensor(data.get('y_val'))).type(torch.IntTensor)\nX_test = Variable(torch.Tensor(data.get('X_test'))).type(dtype)\ny_test = Variable(torch.Tensor(data.get('y_test'))).type(torch.IntTensor)",
"_____no_output_____"
],
[
"# train a 1D convolutional neural network\n# optimize hyper parameters\nbest_model = None\nparameters =[] # a list of dictionaries\nparameter = {} # a dictionary\nbest_params = {} # a dictionary\nbest_val_acc = 0.0\n\n# hyper parameters in model\nfilter_nums = [30]\n\nfilter_sizes = [12]\npool_sizes = [4]\n\n# hyper parameters in solver\nbatch_sizes = [100]\nlrs = [5e-4]\n\nfor filter_num in filter_nums:\n for filter_size in filter_sizes:\n for pool_size in pool_sizes:\n linear_size = int((X_test.shape[2]-filter_size)/4)+1\n linear_size = int((linear_size-pool_size)/pool_size)+1\n linear_size *= filter_num\n for batch_size in batch_sizes:\n for lr in lrs:\n model = nn.Sequential(\n nn.Conv1d(22, filter_num, kernel_size=filter_size, stride=4),\n nn.ReLU(inplace=True),\n nn.Dropout(p=0.5),\n nn.BatchNorm1d(num_features=filter_num),\n nn.MaxPool1d(kernel_size=pool_size, stride=pool_size),\n Flatten(),\n nn.Linear(linear_size, 20),\n nn.ReLU(inplace=True),\n nn.Linear(20, 4)\n )\n\n model.type(dtype)\n\n solver = Solver(model, data,\n lr = lr, batch_size=batch_size,\n verbose=True, print_every=50)\n\n solver.train()\n\n # save training results and parameters of neural networks\n parameter['filter_num'] = filter_num\n parameter['filter_size'] = filter_size\n parameter['pool_size'] = pool_size\n parameter['batch_size'] = batch_size\n parameter['lr'] = lr\n parameters.append(parameter)\n\n print('Accuracy on the validation set: ', solver.best_val_acc)\n print('parameters of the best model:')\n print(parameter)\n\n if solver.best_val_acc > best_val_acc:\n best_val_acc = solver.best_val_acc\n best_model = model\n best_solver = solver\n best_params = parameter\n \n\n",
"(Iteration 1 / 1150) loss: 1.411448\n(Epoch 0 / 50) train acc: 0.254029; val_acc: 0.310000\n(Epoch 1 / 50) train acc: 0.365564; val_acc: 0.310000\n(Epoch 2 / 50) train acc: 0.424936; val_acc: 0.300000\n(Iteration 51 / 1150) loss: 1.234196\n(Epoch 3 / 50) train acc: 0.489822; val_acc: 0.400000\n(Epoch 4 / 50) train acc: 0.518660; val_acc: 0.440000\n(Iteration 101 / 1150) loss: 1.073403\n(Epoch 5 / 50) train acc: 0.569126; val_acc: 0.400000\n(Epoch 6 / 50) train acc: 0.600933; val_acc: 0.440000\n(Iteration 151 / 1150) loss: 0.911245\n(Epoch 7 / 50) train acc: 0.625106; val_acc: 0.510000\n(Epoch 8 / 50) train acc: 0.678965; val_acc: 0.540000\n(Iteration 201 / 1150) loss: 0.858946\n(Epoch 9 / 50) train acc: 0.691688; val_acc: 0.510000\n(Epoch 10 / 50) train acc: 0.706531; val_acc: 0.580000\n(Iteration 251 / 1150) loss: 0.733024\n(Epoch 11 / 50) train acc: 0.726463; val_acc: 0.520000\n(Epoch 12 / 50) train acc: 0.744275; val_acc: 0.590000\n(Epoch 13 / 50) train acc: 0.751060; val_acc: 0.550000\n(Iteration 301 / 1150) loss: 0.709640\n(Epoch 14 / 50) train acc: 0.754453; val_acc: 0.590000\n(Epoch 15 / 50) train acc: 0.787532; val_acc: 0.600000\n(Iteration 351 / 1150) loss: 0.556629\n(Epoch 16 / 50) train acc: 0.789228; val_acc: 0.580000\n(Epoch 17 / 50) train acc: 0.807888; val_acc: 0.650000\n(Iteration 401 / 1150) loss: 0.567066\n(Epoch 18 / 50) train acc: 0.801103; val_acc: 0.600000\n(Epoch 19 / 50) train acc: 0.803223; val_acc: 0.540000\n(Iteration 451 / 1150) loss: 0.505823\n(Epoch 20 / 50) train acc: 0.811281; val_acc: 0.630000\n(Epoch 21 / 50) train acc: 0.823155; val_acc: 0.610000\n(Iteration 501 / 1150) loss: 0.489713\n(Epoch 22 / 50) train acc: 0.806616; val_acc: 0.560000\n(Epoch 23 / 50) train acc: 0.847752; val_acc: 0.650000\n(Iteration 551 / 1150) loss: 0.456655\n(Epoch 24 / 50) train acc: 0.834182; val_acc: 0.640000\n(Epoch 25 / 50) train acc: 0.827820; val_acc: 0.640000\n(Epoch 26 / 50) train acc: 0.854114; val_acc: 0.650000\n(Iteration 601 / 1150) loss: 0.317949\n(Epoch 27 / 50) train acc: 0.839271; val_acc: 0.610000\n(Epoch 28 / 50) train acc: 0.857506; val_acc: 0.630000\n(Iteration 651 / 1150) loss: 0.294298\n(Epoch 29 / 50) train acc: 0.873198; val_acc: 0.670000\n(Epoch 30 / 50) train acc: 0.870229; val_acc: 0.600000\n(Iteration 701 / 1150) loss: 0.278005\n(Epoch 31 / 50) train acc: 0.874894; val_acc: 0.690000\n(Epoch 32 / 50) train acc: 0.887193; val_acc: 0.660000\n(Iteration 751 / 1150) loss: 0.309959\n(Epoch 33 / 50) train acc: 0.888889; val_acc: 0.650000\n(Epoch 34 / 50) train acc: 0.892706; val_acc: 0.690000\n(Iteration 801 / 1150) loss: 0.275150\n(Epoch 35 / 50) train acc: 0.890585; val_acc: 0.620000\n(Epoch 36 / 50) train acc: 0.899491; val_acc: 0.640000\n(Iteration 851 / 1150) loss: 0.273157\n(Epoch 37 / 50) train acc: 0.903732; val_acc: 0.660000\n(Epoch 38 / 50) train acc: 0.891009; val_acc: 0.580000\n(Epoch 39 / 50) train acc: 0.902460; val_acc: 0.650000\n(Iteration 901 / 1150) loss: 0.279389\n(Epoch 40 / 50) train acc: 0.899915; val_acc: 0.600000\n(Epoch 41 / 50) train acc: 0.912638; val_acc: 0.610000\n(Iteration 951 / 1150) loss: 0.309685\n(Epoch 42 / 50) train acc: 0.915182; val_acc: 0.550000\n(Epoch 43 / 50) train acc: 0.890585; val_acc: 0.610000\n(Iteration 1001 / 1150) loss: 0.279289\n(Epoch 44 / 50) train acc: 0.910941; val_acc: 0.580000\n(Epoch 45 / 50) train acc: 0.909669; val_acc: 0.660000\n(Iteration 1051 / 1150) loss: 0.321960\n(Epoch 46 / 50) train acc: 0.911366; val_acc: 0.610000\n(Epoch 47 / 50) train acc: 0.913062; val_acc: 0.580000\n(Iteration 1101 / 1150) loss: 0.203777\n(Epoch 48 / 50) train acc: 0.927905; val_acc: 0.650000\n(Epoch 49 / 50) train acc: 0.920271; val_acc: 0.670000\n(Epoch 50 / 50) train acc: 0.922392; val_acc: 0.640000\nAccuracy on the validation set: 0.69\nparameters of the best model:\n{'filter_num': 30, 'filter_size': 12, 'pool_size': 4, 'batch_size': 100, 'lr': 0.0005}\n"
],
[
"# Plot the loss function and train / validation accuracies of the best model\nplt.subplot(2,1,1)\nplt.plot(best_solver.loss_history)\nplt.title('Training loss history')\nplt.xlabel('Iteration')\nplt.ylabel('Training loss')\n\nplt.subplot(2,1,2)\nplt.plot(best_solver.train_acc_history, '-o', label='train accuracy')\nplt.plot(best_solver.val_acc_history, '-o', label='validation accuracy')\nplt.xlabel('Iteration')\nplt.ylabel('Accuracies')\nplt.legend(loc='upper center', ncol=4)\n\nplt.gcf().set_size_inches(10, 10)\nplt.show()\n\nprint('Accuracy on the validation set: ', best_val_acc)\nprint('parameters of the best model:')\nprint(best_params)",
"_____no_output_____"
],
[
"# test set\ny_test_pred = model(X_test)\n \n_, y_pred = torch.max(y_test_pred,1)\ntest_accu = np.mean(y_pred.data.numpy() == y_test.data.numpy())\nprint('Test accuracy', test_accu, '\\n') ",
"Test accuracy 0.59 \n\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cd328509a90b693bda6d05f674a7532a3e376e | 439,895 | ipynb | Jupyter Notebook | handson-ml/8_Dimensionality Reduction.ipynb | Luoyayu/Machine-Learning | 24cd81680cf901f3bf35d19f6cbae7df16b5e547 | [
"MIT"
]
| null | null | null | handson-ml/8_Dimensionality Reduction.ipynb | Luoyayu/Machine-Learning | 24cd81680cf901f3bf35d19f6cbae7df16b5e547 | [
"MIT"
]
| null | null | null | handson-ml/8_Dimensionality Reduction.ipynb | Luoyayu/Machine-Learning | 24cd81680cf901f3bf35d19f6cbae7df16b5e547 | [
"MIT"
]
| null | null | null | 342.86438 | 246,064 | 0.917276 | [
[
[
"两种降维的途径:投影$(projection)$和流形学习$(Manifold\\ Learning)$ \n三种降维的技术:$PCA, Kernel\\ PCA, LLE$",
"_____no_output_____"
]
],
[
[
"# 2D\nimport numpy as np\np = 0\nfor it in range(100001):\n x1, y1 = np.random.ranf(), np.random.ranf()\n x2, y2 = np.random.ranf(), np.random.ranf()\n p += np.sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2)\nprint(1.0 * p / 100000)",
"0.5215003291824485\n"
],
[
"# 3D\np = 0\nfor it in range(100001):\n x1, y1, z1 = np.random.ranf(), np.random.ranf(), np.random.ranf()\n x2, y2, z2 = np.random.ranf(), np.random.ranf(), np.random.ranf()\n p += np.sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2 + (z1-z2) ** 2)\nprint(1.0 * p / 100000)",
"0.6608013968282513\n"
],
[
"# 7D\np = 0\nfor it in range(100001):\n (x1, y1, z1, a1, b1, c1, d1, e1) = (np.random.ranf(), np.random.ranf(), np.random.ranf(), np.random.ranf(), \n np.random.ranf(), np.random.ranf(), np.random.ranf(), np.random.ranf())\n (x2, y2, z2, a2, b2, c2, d2, e2) = (np.random.ranf(), np.random.ranf(), np.random.ranf(), np.random.ranf(), \n np.random.ranf(), np.random.ranf(), np.random.ranf(), np.random.ranf())\n p += np.sqrt((x1-x2)**2+(y1-y2)**2+(z1-z2)**2+(a1-a2)**2 +(b1-b2)**2+(c1-c2)**2+(d1-d2)**2+(e1-e2)**2)\nprint(1.0 * p / 100000)",
"1.1286641926694834\n"
]
],
[
[
"由上述计算可知,当维数增加时,hypercube中两点距离变大,当维数为1e6时,avg_dis=408.25,可知在高维空间内数据点间隔较大,分布非常稀疏, \n这意味着遇到的new instace 也可能距离所有的train instances很远, 从而导致预测相比低维空间不可靠, 通常表现为overfitting, 因为模型做了很强的外推。一种直观的解决方法是增大数据密度然而显然这是不切实际的。",
"_____no_output_____"
],
[
"## Main Approaches for Dimensionality Reduction",
"_____no_output_____"
],
[
"### Projection 投影法\n投影法基于这样的事实:虽然数据是多维度的,但是数据之间强关联性或者某类特征为常量,这样产生的数据集就很有可能仅仅lie with很低的维度,比如下面的3D数据",
"_____no_output_____"
],
[
"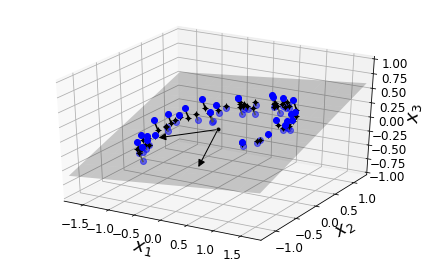",
"_____no_output_____"
],
[
"可以看出数据仅在灰色平面上, 因此我们可以做这样的降维处理 \n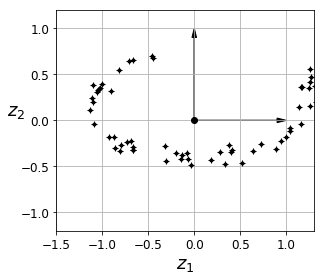",
"_____no_output_____"
],
[
"但是不是所有的数据集合都是可以简单通过投影进行降维的,对于Swiss roll dataset,我们希望能有更好的方法降低维度",
"_____no_output_____"
],
[
"#### Swiss rollm",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import make_swiss_roll\nimport matplotlib.pylab as plt\nfrom mpl_toolkits.mplot3d import Axes3D\nX, t = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)",
"_____no_output_____"
],
[
"axes = [-11.5, 14, -2, 23, -12, 15]\n\nfig = plt.figure(figsize=(10, 10))\nax = fig.add_subplot(111, projection='3d')\n\nax.scatter(X[:, 0], X[:, 1], X[:, 2], c=t, cmap=plt.cm.hot) # 绘点\nax.view_init(10, -70) # 视角\nax.set_xlim(axes[0:2])\nax.set_ylim(axes[2:4])\nax.set_zlim(axes[4:6])\nplt.show()",
"_____no_output_____"
]
],
[
[
"我们应该把瑞士卷拉开展平在2D上,而不是直接拍平",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(18, 6))\nplt.subplot(121)\nplt.scatter(X[:, 0], X[:, 1], c=t, cmap=plt.cm.hot)\nplt.axis('off')\nplt.subplot(122)\nplt.scatter(t, X[:,1], c=t, cmap=plt.cm.hot)\nplt.axis('off')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Manifold Learning",
"_____no_output_____"
],
[
"所谓流形是指d维的超平面在更高的n维空间被bent,twist, 比如上面的右图其在作为2D平面在3D空间被roll后形成了3D瑞士卷",
"_____no_output_____"
],
[
"### PCA \nPrincipal Component Analysis",
"_____no_output_____"
]
],
[
[
"np.random.seed(4)\nm = 60\nw1, w2 = 0.1, 0.3\nnoise = 0.1\n\nangles = np.random.rand(m) * 3 * np.pi / 2 - 0.5\nX = np.empty((m, 3))\nX[:, 0] = np.cos(angles) + np.sin(angles)/2 + noise * np.random.randn(m) / 2\nX[:, 1] = np.sin(angles) * 0.7 + noise * np.random.randn(m) / 2\nX[:, 2] = X[:, 0] * w1 + X[:, 1] * w2 + noise * np.random.randn(m)",
"_____no_output_____"
]
],
[
[
"### Principal Component(PCs)",
"_____no_output_____"
]
],
[
[
"# 使用SVD(奇异值分解)求主成分PCs\nimport numpy as np\nX_centered = X - X.mean(axis=0)\nU, s, V = np.linalg.svd(X_centered)\nc1 = V[:, 0]\nc2 = V[:, 1]\nc1, c2 # PCs",
"_____no_output_____"
],
[
"c1.dot(c2) # 正交",
"_____no_output_____"
],
[
"W2 = V.T[:, :2]\nX2D = X_centered.dot(W2)",
"_____no_output_____"
],
[
"from sklearn.decomposition import PCA\npca = PCA(n_components = 2)\nX2D = pca.fit_transform(X) # automatic centering",
"_____no_output_____"
],
[
"print(pca.explained_variance_ratio_) # 可解释方差比, 反映了特征所在轴的方差占比",
"[0.84248607 0.14631839]\n"
]
],
[
[
"### Choose the Right Number of Dimensions ",
"_____no_output_____"
]
],
[
[
"# 假设我们要求降维后的数据保存95%的信息\npca = PCA()\npca.fit(X)\ncumsum = np.cumsum(pca.explained_variance_ratio_) # 前缀和cumsum\nd = np.argmax(cumsum >= 0.95) + 1\nprint(d, cumsum[d-1])\npca = PCA(n_components=d) # or n_components = 0.95",
"2 0.988804464429311\n"
]
],
[
[
"### PCA for Compression",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import fetch_mldata\nfrom sklearn.model_selection import train_test_split\nimport matplotlib\nmnist = fetch_mldata(\"mnist original\")\n\nX = mnist['data']\ny = mnist['target']\nX_train, X_test, y_train, y_test = train_test_split(X, y)\ndef plot_digit(flat, size=28):\n img = flat.reshape(size, size)\n plt.imshow(img, cmap=matplotlib.cm.binary, interpolation='nearest')\ns = 5555\nsome_digit = X_train[s]\nplt.figure(figsize=(12,6))\nplt.subplot(221)\nplt.title('number <{}>'.format(int(y[s])))\nplot_digit(some_digit)\nplt.subplot(222)\npca = PCA(n_components=169)\nX_reduced = pca.fit_transform(X_train)\nX_recoverd = pca.inverse_transform(X_reduced)\nplot_digit(X_recoverd[s]) # 绘制解压图像\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Incremental PCA",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook\nfrom sklearn.decomposition import IncrementalPCA\nimport numpy as np\nn_batchs = 100\ninc_pac = path = IncrementalPCA(n_components=169)\nfor X_batch in np.array_split(X_train, n_batchs):\n inc_pac.partial_fit(X_batch)\nX_mnist_reduced = inc_pac.fit_transform(X_train)\nX_mnist_recoverd = inc_pac.inverse_transform(X_mnist_reduced)\nplot_digit(X_mnist_recoverd[s])",
"_____no_output_____"
],
[
"import cv2 as cv\nimg = cv.imread('/Users/hu-osx/Desktop/ER.jpg')\nimg = cv.cvtColor(img, cv.COLOR_BGR2RGB) \nplt.imshow(img)\nplt.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7cd339227d0fa3c07ab869286a7a62393c27fa5 | 375,226 | ipynb | Jupyter Notebook | code/phase0/1.2.Train_Keras_Local_Script_Mode.ipynb | gonsoomoon-ml/SageMaker-Tensorflow-Step-By-Step | 132589a2544bd5d99cb494d871195195d1dcec5c | [
"MIT"
]
| 1 | 2022-03-02T07:52:55.000Z | 2022-03-02T07:52:55.000Z | code/phase0/1.2.Train_Keras_Local_Script_Mode.ipynb | gonsoomoon-ml/SageMaker-Tensorflow-Step-By-Step | 132589a2544bd5d99cb494d871195195d1dcec5c | [
"MIT"
]
| null | null | null | code/phase0/1.2.Train_Keras_Local_Script_Mode.ipynb | gonsoomoon-ml/SageMaker-Tensorflow-Step-By-Step | 132589a2544bd5d99cb494d871195195d1dcec5c | [
"MIT"
]
| 1 | 2022-03-02T01:19:38.000Z | 2022-03-02T01:19:38.000Z | 466.119255 | 41,122 | 0.671062 | [
[
[
"# [Module 1.2] 세이지 메이커 로컬 모드 및 스크립트 모드로 훈련\n\n본 워크샵의 모든 노트북은 **<font color=\"red\">conda_tensorflow2_p36</font>** 를 사용합니다.\n\n이 노트북은 아래와 같은 작업을 합니다.\n- 1. 기본 환경 세팅 \n- 2. 노트북에서 세이지 메이커 스크립트 모드 스타일로 코드 변경\n- 3. 세이지 메이커 스크립트 모드 스타일로 코드 실행 (실제로 세이지 메이커 사용 안함)\n- 4. 세이지 메이커 로컬 모드로 훈련\n- 5. 세이지 메이커의 호스트 모드로 훈련\n- 6. 모델 아티펙트 경로 저장\n\n## 참고:\n- 이 페이지를 보시면 Cifar10 데이터 설명 및 기본 모델 훈련이 있습니다. --> [Train a Keras Sequential Model (TensorFlow 2.0)](https://github.com/daekeun-ml/tensorflow-in-sagemaker-workshop/blob/master/0_Running_TensorFlow_In_SageMaker_tf2.ipynb)\n - 메인 깃 리파지토리: [SageMaker Workshop: Tensorflow-Keras 모델을 Amazon SageMaker에서 학습하기](https://github.com/daekeun-ml/tensorflow-in-sagemaker-workshop)\n\n---",
"_____no_output_____"
],
[
"# 1. 기본 환경 세팅\n사용하는 패키지는 import 시점에 다시 재로딩 합니다.",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import sagemaker\n\nsagemaker_session = sagemaker.Session()\n\nbucket = sagemaker_session.default_bucket()\nprefix = \"sagemaker/DEMO-pytorch-cnn-cifar10\"\n\nrole = sagemaker.get_execution_role()\n",
"_____no_output_____"
],
[
"import tensorflow as tf\nprint(\"tensorflow version: \", tf.__version__)",
"tensorflow version: 2.4.1\n"
],
[
"%store -r train_dir\n%store -r validation_dir\n%store -r eval_dir\n%store -r data_dir",
"_____no_output_____"
]
],
[
[
"# 2. 노트북에서 세이지 메이커 스크립트 모드 스타일로 코드 변경\n- 이 페이지를 보시면 기본 코드를 세이지 메이커 스크립트 모드로 변경하는 내용이 있습니다.\n - [Train a Keras Sequential Model (TensorFlow 2.0)](https://github.com/daekeun-ml/tensorflow-in-sagemaker-workshop/blob/master/0_Running_TensorFlow_In_SageMaker_tf2.ipynb)\n\n\n- 아래의 `# !pygmentize src/cifar10_keras_sm_tf2.py` 의 주석을 제거하시고 보시면 실제 변경된 코드가 있습니다.\n",
"_____no_output_____"
]
],
[
[
"# !pygmentize src/cifar10_keras_sm_tf2.py",
"_____no_output_____"
]
],
[
[
"# 3. 세이지 메이커 스크립트 모드 스타일로 코드 실행 (실제로 세이지 메이커 사용 안함)\n\n테스트를 위해 위와 동일한 명령(command)으로 새 스크립트를 실행하고, 예상대로 실행되는지 확인합니다. <br>\nSageMaker TensorFlow API 호출 시에 환경 변수들은 자동으로 넘겨기지만, 로컬 주피터 노트북에서 테스트 시에는 수동으로 환경 변수들을 지정해야 합니다. (아래 예제 코드를 참조해 주세요.)\n\n```python\n%env SM_MODEL_DIR=./logs\n```",
"_____no_output_____"
]
],
[
[
"print(\"train_dir: \", train_dir)\nprint(\"validation_dir: \", validation_dir)\nprint(\"eval_dir: \", eval_dir)",
"train_dir: data/cifar10/train\nvalidation_dir: data/cifar10/validation\neval_dir: data/cifar10/eval\n"
],
[
"%%time\n!mkdir -p logs \n\n# Number of GPUs on this machine\n%env SM_NUM_GPUS=1\n# Where to save the model\n%env SM_MODEL_DIR=./logs\n\n!python src/cifar10_keras_sm_tf2.py --model_dir ./logs \\\n --train {train_dir} \\\n --validation {validation_dir} \\\n --eval {eval_dir} \\\n --epochs 1\n!rm -rf logs",
"env: SM_NUM_GPUS=1\nenv: SM_MODEL_DIR=./logs\nargs: \n Namespace(batch_size=128, epochs=1, eval='data/cifar10/eval', learning_rate=0.001, model_dir='./logs', model_output_dir='./logs', momentum=0.9, optimizer='adam', train='data/cifar10/train', validation='data/cifar10/validation', weight_decay=0.0002)\n312/312 [==============================] - 76s 237ms/step - loss: 2.2003 - accuracy: 0.2331 - val_loss: 1.8217 - val_accuracy: 0.3403\nINFO:tensorflow:Assets written to: ./logs/1/assets\nINFO:tensorflow:Assets written to: ./logs/1/assets\nCPU times: user 2.05 s, sys: 316 ms, total: 2.37 s\nWall time: 1min 27s\n"
]
],
[
[
"# 4. 세이지 메이커 로컬 모드로 훈련\n\n본격적으로 학습을 시작하기 전에 로컬 모드를 사용하여 디버깅을 먼저 수행합니다. 로컬 모드는 학습 인스턴스를 생성하는 과정이 없이 로컬 인스턴스로 컨테이너를 가져온 후 곧바로 학습을 수행하기 때문에 코드를 보다 신속히 검증할 수 있습니다.\n\nAmazon SageMaker Python SDK의 로컬 모드는 TensorFlow 또는 MXNet estimator서 단일 인자값을 변경하여 CPU (단일 및 다중 인스턴스) 및 GPU (단일 인스턴스) SageMaker 학습 작업을 에뮬레이션(enumlate)할 수 있습니다. \n\n로컬 모드 학습을 위해서는 docker-compose 또는 nvidia-docker-compose (GPU 인스턴스인 경우)의 설치가 필요합니다. 아래 코드 셀을 통해 본 노트북 환경에 docker-compose 또는 nvidia-docker-compose를 설치하고 구성합니다. \n \n로컬 모드의 학습을 통해 여러분의 코드가 현재 사용 중인 하드웨어를 적절히 활용하고 있는지 확인하기 위한 GPU 점유와 같은 지표(metric)를 쉽게 모니터링할 수 있습니다.",
"_____no_output_____"
]
],
[
[
"!wget -q https://raw.githubusercontent.com/aws-samples/amazon-sagemaker-script-mode/master/local_mode_setup.sh\n!wget -q https://raw.githubusercontent.com/aws-samples/amazon-sagemaker-script-mode/master/daemon.json \n!/bin/bash ./local_mode_setup.sh",
"nvidia-docker2 already installed. We are good to go!\nSageMaker instance route table setup is ok. We are good to go.\nSageMaker instance routing for Docker is ok. We are good to go!\n"
]
],
[
[
"### 로컬 모드로 훈련 실행\n- 아래의 두 라인이 로컬모드로 훈련을 지시 합니다.\n```python\n instance_type=instance_type, # local_gpu or local 지정\n session = sagemaker.LocalSession(), # 로컬 세션을 사용합니다.\n```",
"_____no_output_____"
],
[
"#### 로컬의 GPU, CPU 여부로 instance_type 결정",
"_____no_output_____"
]
],
[
[
"import os\nimport subprocess\n\n\ninstance_type = \"local_gpu\" # GPU 사용을 가정 합니다. CPU 사용시에 'local' 로 정의 합니다.\n\nprint(\"Instance type = \" + instance_type)",
"Instance type = local_gpu\n"
]
],
[
[
"학습 작업을 시작하기 위해 `estimator.fit() ` 호출 시, Amazon ECR에서 Amazon SageMaker TensorFlow 컨테이너를 로컬 노트북 인스턴스로 다운로드합니다.\n\n`sagemaker.tensorflow` 클래스를 사용하여 SageMaker Python SDK의 Tensorflow Estimator 인스턴스를 생성합니다.\n인자값으로 하이퍼파라메터와 다양한 설정들을 변경할 수 있습니다.\n\n\n자세한 내용은 [documentation](https://sagemaker.readthedocs.io/en/stable/using_tf.html#training-with-tensorflow-estimator)을 확인하시기 바랍니다.",
"_____no_output_____"
]
],
[
[
"from sagemaker.tensorflow import TensorFlow\nestimator = TensorFlow(base_job_name='cifar10',\n entry_point='cifar10_keras_sm_tf2.py',\n source_dir='src',\n role=role,\n framework_version='2.4.1',\n py_version='py37',\n script_mode=True,\n hyperparameters={'epochs' : 1},\n train_instance_count=1, \n train_instance_type= instance_type)",
"train_instance_type has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\ntrain_instance_count has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\ntrain_instance_type has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\n"
],
[
"%%time\nestimator.fit({'train': f'file://{train_dir}',\n 'validation': f'file://{validation_dir}',\n 'eval': f'file://{eval_dir}'})",
"Creating roqiryt46i-algo-1-jt4ft ... \nCreating roqiryt46i-algo-1-jt4ft ... done\nAttaching to roqiryt46i-algo-1-jt4ft\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:34.729714: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:34.729908: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:34.734209: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:34.771766: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:36,568 sagemaker-training-toolkit INFO Imported framework sagemaker_tensorflow_container.training\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:36,940 sagemaker-training-toolkit INFO Invoking user script\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m Training Env:\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m {\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"additional_framework_parameters\": {},\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"channel_input_dirs\": {\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"train\": \"/opt/ml/input/data/train\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"validation\": \"/opt/ml/input/data/validation\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"eval\": \"/opt/ml/input/data/eval\"\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m },\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"current_host\": \"algo-1-jt4ft\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"framework_module\": \"sagemaker_tensorflow_container.training:main\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"hosts\": [\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"algo-1-jt4ft\"\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m ],\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"hyperparameters\": {\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"epochs\": 1,\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"model_dir\": \"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/model\"\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m },\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"input_config_dir\": \"/opt/ml/input/config\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"input_data_config\": {\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"train\": {\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"TrainingInputMode\": \"File\"\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m },\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"validation\": {\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"TrainingInputMode\": \"File\"\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m },\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"eval\": {\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"TrainingInputMode\": \"File\"\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m }\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m },\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"input_dir\": \"/opt/ml/input\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"is_master\": true,\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"job_name\": \"cifar10-2021-10-11-09-53-58-320\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"log_level\": 20,\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"master_hostname\": \"algo-1-jt4ft\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"model_dir\": \"/opt/ml/model\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"module_dir\": \"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/source/sourcedir.tar.gz\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"module_name\": \"cifar10_keras_sm_tf2\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"network_interface_name\": \"eth0\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"num_cpus\": 8,\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"num_gpus\": 1,\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"output_data_dir\": \"/opt/ml/output/data\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"output_dir\": \"/opt/ml/output\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"output_intermediate_dir\": \"/opt/ml/output/intermediate\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"resource_config\": {\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"current_host\": \"algo-1-jt4ft\",\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"hosts\": [\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"algo-1-jt4ft\"\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m ]\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m },\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \"user_entry_point\": \"cifar10_keras_sm_tf2.py\"\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m }\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m Environment variables:\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_HOSTS=[\"algo-1-jt4ft\"]\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_NETWORK_INTERFACE_NAME=eth0\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_HPS={\"epochs\":1,\"model_dir\":\"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/model\"}\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_USER_ENTRY_POINT=cifar10_keras_sm_tf2.py\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_FRAMEWORK_PARAMS={}\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_RESOURCE_CONFIG={\"current_host\":\"algo-1-jt4ft\",\"hosts\":[\"algo-1-jt4ft\"]}\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_INPUT_DATA_CONFIG={\"eval\":{\"TrainingInputMode\":\"File\"},\"train\":{\"TrainingInputMode\":\"File\"},\"validation\":{\"TrainingInputMode\":\"File\"}}\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_OUTPUT_DATA_DIR=/opt/ml/output/data\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_CHANNELS=[\"eval\",\"train\",\"validation\"]\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_CURRENT_HOST=algo-1-jt4ft\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_MODULE_NAME=cifar10_keras_sm_tf2\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_LOG_LEVEL=20\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_FRAMEWORK_MODULE=sagemaker_tensorflow_container.training:main\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_INPUT_DIR=/opt/ml/input\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_INPUT_CONFIG_DIR=/opt/ml/input/config\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_OUTPUT_DIR=/opt/ml/output\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_NUM_CPUS=8\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_NUM_GPUS=1\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_MODEL_DIR=/opt/ml/model\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_MODULE_DIR=s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/source/sourcedir.tar.gz\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_TRAINING_ENV={\"additional_framework_parameters\":{},\"channel_input_dirs\":{\"eval\":\"/opt/ml/input/data/eval\",\"train\":\"/opt/ml/input/data/train\",\"validation\":\"/opt/ml/input/data/validation\"},\"current_host\":\"algo-1-jt4ft\",\"framework_module\":\"sagemaker_tensorflow_container.training:main\",\"hosts\":[\"algo-1-jt4ft\"],\"hyperparameters\":{\"epochs\":1,\"model_dir\":\"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/model\"},\"input_config_dir\":\"/opt/ml/input/config\",\"input_data_config\":{\"eval\":{\"TrainingInputMode\":\"File\"},\"train\":{\"TrainingInputMode\":\"File\"},\"validation\":{\"TrainingInputMode\":\"File\"}},\"input_dir\":\"/opt/ml/input\",\"is_master\":true,\"job_name\":\"cifar10-2021-10-11-09-53-58-320\",\"log_level\":20,\"master_hostname\":\"algo-1-jt4ft\",\"model_dir\":\"/opt/ml/model\",\"module_dir\":\"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/source/sourcedir.tar.gz\",\"module_name\":\"cifar10_keras_sm_tf2\",\"network_interface_name\":\"eth0\",\"num_cpus\":8,\"num_gpus\":1,\"output_data_dir\":\"/opt/ml/output/data\",\"output_dir\":\"/opt/ml/output\",\"output_intermediate_dir\":\"/opt/ml/output/intermediate\",\"resource_config\":{\"current_host\":\"algo-1-jt4ft\",\"hosts\":[\"algo-1-jt4ft\"]},\"user_entry_point\":\"cifar10_keras_sm_tf2.py\"}\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_USER_ARGS=[\"--epochs\",\"1\",\"--model_dir\",\"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/model\"]\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_CHANNEL_TRAIN=/opt/ml/input/data/train\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_CHANNEL_VALIDATION=/opt/ml/input/data/validation\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_CHANNEL_EVAL=/opt/ml/input/data/eval\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_HP_EPOCHS=1\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m SM_HP_MODEL_DIR=s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/model\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m PYTHONPATH=/opt/ml/code:/usr/local/bin:/usr/local/lib/python37.zip:/usr/local/lib/python3.7:/usr/local/lib/python3.7/lib-dynload:/usr/local/lib/python3.7/site-packages\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m Invoking script with the following command:\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m /usr/local/bin/python3.7 cifar10_keras_sm_tf2.py --epochs 1 --model_dir s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/model\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m args: \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m Namespace(batch_size=128, epochs=1, eval='/opt/ml/input/data/eval', learning_rate=0.001, model_dir='s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-53-58-320/model', model_output_dir='/opt/ml/model', momentum=0.9, optimizer='adam', train='/opt/ml/input/data/train', validation='/opt/ml/input/data/validation', weight_decay=0.0002)\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m [2021-10-11 09:57:41.223 a4d4778958f9:37 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m [2021-10-11 09:57:41.329 a4d4778958f9:37 INFO profiler_config_parser.py:102] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.\n312/312 [==============================] - 9s 14ms/step - loss: 2.1226 - accuracy: 0.2532 - val_loss: 1.8308 - val_accuracy: 0.3635\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:37.091032: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:37.091215: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:37.132764: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:52.594222: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m INFO:tensorflow:Assets written to: /opt/ml/model/1/assets\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m INFO:tensorflow:Assets written to: /opt/ml/model/1/assets\n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m \n\u001b[36mroqiryt46i-algo-1-jt4ft |\u001b[0m 2021-10-11 09:57:56,497 sagemaker-training-toolkit INFO Reporting training SUCCESS\n\u001b[36mroqiryt46i-algo-1-jt4ft exited with code 0\n\u001b[0mAborting on container exit...\n===== Job Complete =====\nCPU times: user 1.07 s, sys: 126 ms, total: 1.19 s\nWall time: 4min\n"
]
],
[
[
"## ECR 로 부터 로컬에 다운로드된 도커 이미지 확인",
"_____no_output_____"
]
],
[
[
"! docker image ls",
"REPOSITORY TAG IMAGE ID CREATED SIZE\n763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training 2.4.1-gpu-py37 8467bc1c5070 5 months ago 8.91GB\n"
]
],
[
[
"# 5. 세이지 메이커의 호스트 모드로 훈련",
"_____no_output_____"
],
[
"### 데이터 세트를 S3에 업로드\n\n- 로컬에 저장되어 있는 데이터를 S3 로 업로드하여 사용합니다.",
"_____no_output_____"
]
],
[
[
"dataset_location = sagemaker_session.upload_data(path=data_dir, key_prefix='data/DEMO-cifar10')\ndisplay(dataset_location)",
"_____no_output_____"
],
[
"from sagemaker.tensorflow import TensorFlow\nestimator = TensorFlow(base_job_name='cifar10',\n entry_point='cifar10_keras_sm_tf2.py',\n source_dir='src',\n role=role,\n framework_version='2.4.1',\n py_version='py37',\n script_mode=True, \n hyperparameters={'epochs': 5},\n train_instance_count=1, \n train_instance_type='ml.p2.8xlarge')",
"train_instance_type has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\ntrain_instance_count has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\ntrain_instance_type has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\n"
]
],
[
[
"## SageMaker Host Mode 로 훈련\n- `cifar10_estimator.fit(inputs, wait=False)`\n - 입력 데이터를 inputs로서 S3 의 경로를 제공합니다.\n - wait=False 로 지정해서 async 모드로 훈련을 실행합니다. \n - 실행 경과는 아래의 cifar10_estimator.logs() 에서 확인 합니다.",
"_____no_output_____"
]
],
[
[
"%%time\nestimator.fit({'train':'{}/train'.format(dataset_location),\n 'validation':'{}/validation'.format(dataset_location),\n 'eval':'{}/eval'.format(dataset_location)}, wait=False)",
"CPU times: user 64.4 ms, sys: 0 ns, total: 64.4 ms\nWall time: 320 ms\n"
],
[
"estimator.logs()",
"2021-10-11 10:10:06 Starting - Starting the training job...\n2021-10-11 10:10:29 Starting - Launching requested ML instancesProfilerReport-1633947005: InProgress\n............\n2021-10-11 10:12:29 Starting - Preparing the instances for training.........\n2021-10-11 10:14:02 Downloading - Downloading input data\n2021-10-11 10:14:02 Training - Downloading the training image..................\n2021-10-11 10:17:00 Training - Training image download completed. Training in progress.\u001b[34m2021-10-11 10:17:01.282337: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\u001b[0m\n\u001b[34m2021-10-11 10:17:01.288520: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.\u001b[0m\n\u001b[34m2021-10-11 10:17:01.384938: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0\u001b[0m\n\u001b[34m2021-10-11 10:17:01.489458: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\u001b[0m\n\u001b[34m2021-10-11 10:17:06,008 sagemaker-training-toolkit INFO Imported framework sagemaker_tensorflow_container.training\u001b[0m\n\u001b[34m2021-10-11 10:17:06,769 sagemaker-training-toolkit INFO Invoking user script\n\u001b[0m\n\u001b[34mTraining Env:\n\u001b[0m\n\u001b[34m{\n \"additional_framework_parameters\": {},\n \"channel_input_dirs\": {\n \"eval\": \"/opt/ml/input/data/eval\",\n \"validation\": \"/opt/ml/input/data/validation\",\n \"train\": \"/opt/ml/input/data/train\"\n },\n \"current_host\": \"algo-1\",\n \"framework_module\": \"sagemaker_tensorflow_container.training:main\",\n \"hosts\": [\n \"algo-1\"\n ],\n \"hyperparameters\": {\n \"model_dir\": \"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-58-44-104/model\",\n \"epochs\": 5\n },\n \"input_config_dir\": \"/opt/ml/input/config\",\n \"input_data_config\": {\n \"eval\": {\n \"TrainingInputMode\": \"File\",\n \"S3DistributionType\": \"FullyReplicated\",\n \"RecordWrapperType\": \"None\"\n },\n \"validation\": {\n \"TrainingInputMode\": \"File\",\n \"S3DistributionType\": \"FullyReplicated\",\n \"RecordWrapperType\": \"None\"\n },\n \"train\": {\n \"TrainingInputMode\": \"File\",\n \"S3DistributionType\": \"FullyReplicated\",\n \"RecordWrapperType\": \"None\"\n }\n },\n \"input_dir\": \"/opt/ml/input\",\n \"is_master\": true,\n \"job_name\": \"cifar10-2021-10-11-10-10-05-339\",\n \"log_level\": 20,\n \"master_hostname\": \"algo-1\",\n \"model_dir\": \"/opt/ml/model\",\n \"module_dir\": \"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-10-10-05-339/source/sourcedir.tar.gz\",\n \"module_name\": \"cifar10_keras_sm_tf2\",\n \"network_interface_name\": \"eth0\",\n \"num_cpus\": 32,\n \"num_gpus\": 8,\n \"output_data_dir\": \"/opt/ml/output/data\",\n \"output_dir\": \"/opt/ml/output\",\n \"output_intermediate_dir\": \"/opt/ml/output/intermediate\",\n \"resource_config\": {\n \"current_host\": \"algo-1\",\n \"hosts\": [\n \"algo-1\"\n ],\n \"network_interface_name\": \"eth0\"\n },\n \"user_entry_point\": \"cifar10_keras_sm_tf2.py\"\u001b[0m\n\u001b[34m}\n\u001b[0m\n\u001b[34mEnvironment variables:\n\u001b[0m\n\u001b[34mSM_HOSTS=[\"algo-1\"]\u001b[0m\n\u001b[34mSM_NETWORK_INTERFACE_NAME=eth0\u001b[0m\n\u001b[34mSM_HPS={\"epochs\":5,\"model_dir\":\"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-58-44-104/model\"}\u001b[0m\n\u001b[34mSM_USER_ENTRY_POINT=cifar10_keras_sm_tf2.py\u001b[0m\n\u001b[34mSM_FRAMEWORK_PARAMS={}\u001b[0m\n\u001b[34mSM_RESOURCE_CONFIG={\"current_host\":\"algo-1\",\"hosts\":[\"algo-1\"],\"network_interface_name\":\"eth0\"}\u001b[0m\n\u001b[34mSM_INPUT_DATA_CONFIG={\"eval\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"train\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"validation\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}}\u001b[0m\n\u001b[34mSM_OUTPUT_DATA_DIR=/opt/ml/output/data\u001b[0m\n\u001b[34mSM_CHANNELS=[\"eval\",\"train\",\"validation\"]\u001b[0m\n\u001b[34mSM_CURRENT_HOST=algo-1\u001b[0m\n\u001b[34mSM_MODULE_NAME=cifar10_keras_sm_tf2\u001b[0m\n\u001b[34mSM_LOG_LEVEL=20\u001b[0m\n\u001b[34mSM_FRAMEWORK_MODULE=sagemaker_tensorflow_container.training:main\u001b[0m\n\u001b[34mSM_INPUT_DIR=/opt/ml/input\u001b[0m\n\u001b[34mSM_INPUT_CONFIG_DIR=/opt/ml/input/config\u001b[0m\n\u001b[34mSM_OUTPUT_DIR=/opt/ml/output\u001b[0m\n\u001b[34mSM_NUM_CPUS=32\u001b[0m\n\u001b[34mSM_NUM_GPUS=8\u001b[0m\n\u001b[34mSM_MODEL_DIR=/opt/ml/model\u001b[0m\n\u001b[34mSM_MODULE_DIR=s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-10-10-05-339/source/sourcedir.tar.gz\u001b[0m\n\u001b[34mSM_TRAINING_ENV={\"additional_framework_parameters\":{},\"channel_input_dirs\":{\"eval\":\"/opt/ml/input/data/eval\",\"train\":\"/opt/ml/input/data/train\",\"validation\":\"/opt/ml/input/data/validation\"},\"current_host\":\"algo-1\",\"framework_module\":\"sagemaker_tensorflow_container.training:main\",\"hosts\":[\"algo-1\"],\"hyperparameters\":{\"epochs\":5,\"model_dir\":\"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-58-44-104/model\"},\"input_config_dir\":\"/opt/ml/input/config\",\"input_data_config\":{\"eval\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"train\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"validation\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}},\"input_dir\":\"/opt/ml/input\",\"is_master\":true,\"job_name\":\"cifar10-2021-10-11-10-10-05-339\",\"log_level\":20,\"master_hostname\":\"algo-1\",\"model_dir\":\"/opt/ml/model\",\"module_dir\":\"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-10-10-05-339/source/sourcedir.tar.gz\",\"module_name\":\"cifar10_keras_sm_tf2\",\"network_interface_name\":\"eth0\",\"num_cpus\":32,\"num_gpus\":8,\"output_data_dir\":\"/opt/ml/output/data\",\"output_dir\":\"/opt/ml/output\",\"output_intermediate_dir\":\"/opt/ml/output/intermediate\",\"resource_config\":{\"current_host\":\"algo-1\",\"hosts\":[\"algo-1\"],\"network_interface_name\":\"eth0\"},\"user_entry_point\":\"cifar10_keras_sm_tf2.py\"}\u001b[0m\n\u001b[34mSM_USER_ARGS=[\"--epochs\",\"5\",\"--model_dir\",\"s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-58-44-104/model\"]\u001b[0m\n\u001b[34mSM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate\u001b[0m\n\u001b[34mSM_CHANNEL_EVAL=/opt/ml/input/data/eval\u001b[0m\n\u001b[34mSM_CHANNEL_VALIDATION=/opt/ml/input/data/validation\u001b[0m\n\u001b[34mSM_CHANNEL_TRAIN=/opt/ml/input/data/train\u001b[0m\n\u001b[34mSM_HP_MODEL_DIR=s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-58-44-104/model\u001b[0m\n\u001b[34mSM_HP_EPOCHS=5\u001b[0m\n\u001b[34mPYTHONPATH=/opt/ml/code:/usr/local/bin:/usr/local/lib/python37.zip:/usr/local/lib/python3.7:/usr/local/lib/python3.7/lib-dynload:/usr/local/lib/python3.7/site-packages\n\u001b[0m\n\u001b[34mInvoking script with the following command:\n\u001b[0m\n\u001b[34m/usr/local/bin/python3.7 cifar10_keras_sm_tf2.py --epochs 5 --model_dir s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-58-44-104/model\n\n\u001b[0m\n\u001b[34margs: \n Namespace(batch_size=128, epochs=5, eval='/opt/ml/input/data/eval', learning_rate=0.001, model_dir='s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-09-58-44-104/model', model_output_dir='/opt/ml/model', momentum=0.9, optimizer='adam', train='/opt/ml/input/data/train', validation='/opt/ml/input/data/validation', weight_decay=0.0002)\u001b[0m\n\u001b[34m[2021-10-11 10:17:17.171 ip-10-0-206-213.ec2.internal:82 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None\u001b[0m\n\u001b[34m[2021-10-11 10:17:17.324 ip-10-0-206-213.ec2.internal:82 INFO profiler_config_parser.py:102] User has disabled profiler.\u001b[0m\n\u001b[34m[2021-10-11 10:17:17.701 ip-10-0-206-213.ec2.internal:82 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.\u001b[0m\n\u001b[34m[2021-10-11 10:17:17.701 ip-10-0-206-213.ec2.internal:82 INFO hook.py:199] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.\u001b[0m\n\u001b[34m[2021-10-11 10:17:17.702 ip-10-0-206-213.ec2.internal:82 INFO hook.py:253] Saving to /opt/ml/output/tensors\u001b[0m\n\u001b[34m[2021-10-11 10:17:17.702 ip-10-0-206-213.ec2.internal:82 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.\u001b[0m\n\u001b[34mEpoch 1/5\u001b[0m\n\u001b[34m[2021-10-11 10:17:17.751 ip-10-0-206-213.ec2.internal:82 INFO hook.py:413] Monitoring the collections: metrics, sm_metrics, losses\u001b[0m\n\u001b[34m#015 1/312 [..............................] - ETA: 59:33 - loss: 4.1698 - accuracy: 0.0547#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 2/312 [..............................] - ETA: 1:52 - loss: 3.9593 - accuracy: 0.0703 #010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 3/312 [..............................] - ETA: 1:16 - loss: 3.8742 - accuracy: 0.0764#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 4/312 [..............................] - ETA: 1:03 - loss: 3.8124 - accuracy: 0.0817#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 5/312 [..............................] - ETA: 53s - loss: 3.7526 - accuracy: 0.0869 #010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 6/312 [..............................] - ETA: 47s - loss: 3.6985 - accuracy: 0.0907#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 7/312 [..............................] - ETA: 42s - loss: 3.6438 - accuracy: 0.0938#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 8/312 [..............................] - ETA: 39s - loss: 3.5947 - accuracy: 0.0966#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 10/312 [..............................] - ETA: 33s - loss: 3.5067 - accuracy: 0.1011#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 12/312 [>.............................] - ETA: 29s - loss: 3.4288 - accuracy: 0.1060#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 14/312 [>.............................] - ETA: 26s - loss: 3.3607 - accuracy: 0.1106#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 16/312 [>.............................] - ETA: 23s - loss: 3.2987 - accuracy: 0.1144#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 18/312 [>.............................] - ETA: 21s - loss: 3.2426 - accuracy: 0.1180#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 20/312 [>.............................] - ETA: 20s - loss: 3.1924 - accuracy: 0.1211#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 22/312 [=>............................] - ETA: 19s - loss: 3.1469 - accuracy: 0.1240#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 24/312 [=>............................] - ETA: 18s - loss: 3.1051 - accuracy: 0.1268#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 26/312 [=>............................] - ETA: 17s - loss: 3.0664 - accuracy: 0.1296#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 28/312 [=>............................] - ETA: 16s - loss: 3.0311 - accuracy: 0.1323#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 30/312 [=>............................] - ETA: 15s - loss: 2.9987 - accuracy: 0.1349#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 32/312 [==>...........................] - ETA: 15s - loss: 2.9686 - accuracy: 0.1373#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 34/312 [==>...........................] - ETA: 14s - loss: 2.9405 - accuracy: 0.1396#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 36/312 [==>...........................] - ETA: 14s - loss: 2.9142 - accuracy: 0.1418#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 38/312 [==>...........................] - ETA: 13s - loss: 2.8898 - accuracy: 0.1439#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 40/312 [==>...........................] - ETA: 13s - loss: 2.8670 - accuracy: 0.1459#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 42/312 [===>..........................] - ETA: 12s - loss: 2.8454 - accuracy: 0.1479#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 44/312 [===>..........................] - ETA: 12s - loss: 2.8251 - accuracy: 0.1497#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 46/312 [===>..........................] - ETA: 12s - loss: 2.8058 - accuracy: 0.1515#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 48/312 [===>..........................] - ETA: 12s - loss: 2.7876 - accuracy: 0.1531#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 50/312 [===>..........................] - ETA: 11s - loss: 2.7702 - accuracy: 0.1548#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 52/312 [====>.........................] - ETA: 11s - loss: 2.7537 - accuracy: 0.1564#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 54/312 [====>.........................] - ETA: 11s - loss: 2.7379 - accuracy: 0.1580#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 56/312 [====>.........................] - ETA: 11s - loss: 2.7228 - accuracy: 0.1596#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 58/312 [====>.........................] - ETA: 10s - loss: 2.7084 - accuracy: 0.1612#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 60/312 [====>.........................] - ETA: 10s - loss: 2.6945 - accuracy: 0.1627#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 62/312 [====>.........................] - ETA: 10s - loss: 2.6812 - accuracy: 0.1640#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 64/312 [=====>........................] - ETA: 10s - loss: 2.6683 - accuracy: 0.1654#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 66/312 [=====>........................] - ETA: 10s - loss: 2.6559 - accuracy: 0.1667#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 68/312 [=====>........................] - ETA: 9s - loss: 2.6440 - accuracy: 0.1679 #010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 70/312 [=====>........................] - ETA: 9s - loss: 2.6326 - accuracy: 0.1692#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 72/312 [=====>........................] - ETA: 9s - loss: 2.6216 - accuracy: 0.1704#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 74/312 [======>.......................] - ETA: 9s - loss: 2.6110 - accuracy: 0.1716#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 76/312 [======>.......................] - ETA: 9s - loss: 2.6007 - accuracy: 0.1727#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 78/312 [======>.......................] - ETA: 9s - loss: 2.5908 - accuracy: 0.1738#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 80/312 [======>.......................] - ETA: 9s - loss: 2.5811 - accuracy: 0.1749#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 82/312 [======>.......................] - ETA: 8s - loss: 2.5718 - accuracy: 0.1760#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 84/312 [=======>......................] - ETA: 8s - loss: 2.5627 - accuracy: 0.1771#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 86/312 [=======>......................] - ETA: 8s - loss: 2.5540 - accuracy: 0.1782#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 88/312 [=======>......................] - ETA: 8s - loss: 2.5455 - accuracy: 0.1792#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 90/312 [=======>......................] - ETA: 8s - loss: 2.5373 - accuracy: 0.1802#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 92/312 [=======>......................] - ETA: 8s - loss: 2.5293 - accuracy: 0.1812#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 94/312 [========>.....................] - ETA: 8s - loss: 2.5216 - accuracy: 0.1822#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 96/312 [========>.....................] - ETA: 8s - loss: 2.5140 - accuracy: 0.1831#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 98/312 [========>.....................] - ETA: 7s - loss: 2.5066 - accuracy: 0.1840#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015100/312 [========>.....................] - ETA: 7s - loss: 2.4994 - accuracy: 0.1849#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015102/312 [========>.....................] - ETA: 7s - loss: 2.4924 - accuracy: 0.1858#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015104/312 [=========>....................] - ETA: 7s - loss: 2.4855 - accuracy: 0.1868#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015106/312 [=========>....................] - ETA: 7s - loss: 2.4788 - accuracy: 0.1877#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015108/312 [=========>....................] - ETA: 7s - loss: 2.4722 - accuracy: 0.1885#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015110/312 [=========>....................] - ETA: 7s - loss: 2.4658 - accuracy: 0.1894#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015112/312 [=========>....................] - ETA: 7s - loss: 2.4596 - accuracy: 0.1903#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015114/312 [=========>....................] - ETA: 7s - loss: 2.4535 - accuracy: 0.1911#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015116/312 [==========>...................] - ETA: 7s - loss: 2.4475 - accuracy: 0.1920#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015118/312 [==========>...................] - ETA: 6s - loss: 2.4417 - accuracy: 0.1928#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015120/312 [==========>...................] - ETA: 6s - loss: 2.4359 - accuracy: 0.1936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015122/312 [==========>...................] - ETA: 6s - loss: 2.4303 - accuracy: 0.1944#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015124/312 [==========>...................] - ETA: 6s - loss: 2.4248 - accuracy: 0.1952#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015126/312 [===========>..................] - ETA: 6s - loss: 2.4194 - accuracy: 0.1960#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015128/312 [===========>..................] - ETA: 6s - loss: 2.4141 - accuracy: 0.1968#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015130/312 [===========>..................] - ETA: 6s - loss: 2.4089 - accuracy: 0.1976#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015132/312 [===========>..................] - ETA: 6s - loss: 2.4037 - accuracy: 0.1984#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015134/312 [===========>..................] - ETA: 6s - loss: 2.3988 - accuracy: 0.1992#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015136/312 [============>.................] - ETA: 6s - loss: 2.3938 - accuracy: 0.1999#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015138/312 [============>.................] - ETA: 6s - loss: 2.3890 - accuracy: 0.2007#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015140/312 [============>.................] - ETA: 5s - loss: 2.3843 - accuracy: 0.2014#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015142/312 [============>.................] - ETA: 5s - loss: 2.3796 - accuracy: 0.2022#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015144/312 [============>.................] - ETA: 5s - loss: 2.3750 - accuracy: 0.2029#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015146/312 [=============>................] - ETA: 5s - loss: 2.3705 - accuracy: 0.2036#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015148/312 [=============>................] - ETA: 5s - loss: 2.3661 - accuracy: 0.2043#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015150/312 [=============>................] - ETA: 5s - loss: 2.3617 - accuracy: 0.2050#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015152/312 [=============>................] - ETA: 5s - loss: 2.3574 - accuracy: 0.2057#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015154/312 [=============>................] - ETA: 5s - loss: 2.3532 - accuracy: 0.2064#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015156/312 [==============>...............] - ETA: 5s - loss: 2.3490 - accuracy: 0.2071#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015158/312 [==============>...............] - ETA: 5s - loss: 2.3449 - accuracy: 0.2078#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015160/312 [==============>...............] - ETA: 5s - loss: 2.3408 - accuracy: 0.2085#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015162/312 [==============>...............] - ETA: 5s - loss: 2.3368 - accuracy: 0.2091#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015164/312 [==============>...............] - ETA: 5s - loss: 2.3328 - accuracy: 0.2098#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015166/312 [==============>...............] - ETA: 4s - loss: 2.3289 - accuracy: 0.2105#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015168/312 [===============>..............] - ETA: 4s - loss: 2.3251 - accuracy: 0.2111#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015170/312 [===============>..............] - ETA: 4s - loss: 2.3213 - accuracy: 0.2118#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015172/312 [===============>..............] - ETA: 4s - loss: 2.3176 - accuracy: 0.2124#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015174/312 [===============>..............] - ETA: 4s - loss: 2.3139 - accuracy: 0.2131#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015176/312 [===============>..............] - ETA: 4s - loss: 2.3102 - accuracy: 0.2137#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015178/312 [================>.............] - ETA: 4s - loss: 2.3066 - accuracy: 0.2144#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015180/312 [================>.............] - ETA: 4s - loss: 2.3031 - accuracy: 0.2150#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015182/312 [================>.............] - ETA: 4s - loss: 2.2996 - accuracy: 0.2156#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015184/312 [================>.............] - ETA: 4s - loss: 2.2961 - accuracy: 0.2163#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015186/312 [================>.............] - ETA: 4s - loss: 2.2927 - accu\u001b[0m\n\u001b[34mracy: 0.2169#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015188/312 [=================>............] - ETA: 4s - loss: 2.2893 - accuracy: 0.2175#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015190/312 [=================>............] - ETA: 4s - loss: 2.2860 - accuracy: 0.2181#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015192/312 [=================>............] - ETA: 3s - loss: 2.2827 - accuracy: 0.2188#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015194/312 [=================>............] - ETA: 3s - loss: 2.2794 - accuracy: 0.2194#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015196/312 [=================>............] - ETA: 3s - loss: 2.2762 - accuracy: 0.2200#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015198/312 [==================>...........] - ETA: 3s - loss: 2.2730 - accuracy: 0.2206#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015200/312 [==================>...........] - ETA: 3s - loss: 2.2699 - accuracy: 0.2212#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015202/312 [==================>...........] - ETA: 3s - loss: 2.2668 - accuracy: 0.2218#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015204/312 [==================>...........] - ETA: 3s - loss: 2.2637 - accuracy: 0.2224#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015206/312 [==================>...........] - ETA: 3s - loss: 2.2607 - accuracy: 0.2230#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015208/312 [===================>..........] - ETA: 3s - loss: 2.2577 - accuracy: 0.2236#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015210/312 [===================>..........] - ETA: 3s - loss: 2.2547 - accuracy: 0.2242#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015212/312 [===================>..........] - ETA: 3s - loss: 2.2518 - accuracy: 0.2247#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015214/312 [===================>..........] - ETA: 3s - loss: 2.2489 - accuracy: 0.2253#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015216/312 [===================>..........] - ETA: 3s - loss: 2.2460 - accuracy: 0.2259#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015218/312 [===================>..........] - ETA: 3s - loss: 2.2432 - accuracy: 0.2264#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015220/312 [====================>.........] - ETA: 3s - loss: 2.2404 - accuracy: 0.2270#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015222/312 [====================>.........] - ETA: 2s - loss: 2.2376 - accuracy: 0.2276#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015224/312 [====================>.........] - ETA: 2s - loss: 2.2349 - accuracy: 0.2281#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015226/312 [====================>.........] - ETA: 2s - loss: 2.2322 - accuracy: 0.2287#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015228/312 [====================>.........] - ETA: 2s - loss: 2.2295 - accuracy: 0.2292#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015230/312 [=====================>........] - ETA: 2s - loss: 2.2268 - accuracy: 0.2298#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015232/312 [=====================>........] - ETA: 2s - loss: 2.2242 - accuracy: 0.2304#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015234/312 [=====================>........] - ETA: 2s - loss: 2.2216 - accuracy: 0.2309#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015236/312 [=====================>........] - ETA: 2s - loss: 2.2190 - accuracy: 0.2315#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015238/312 [=====================>........] - ETA: 2s - loss: 2.2164 - accuracy: 0.2320#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015240/312 [======================>.......] - ETA: 2s - loss: 2.2139 - accuracy: 0.2326#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015242/312 [======================>.......] - ETA: 2s - loss: 2.2113 - accuracy: 0.2331#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015244/312 [======================>.......] - ETA: 2s - loss: 2.2088 - accuracy: 0.2337#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015246/312 [======================>.......] - ETA: 2s - loss: 2.2064 - accuracy: 0.2342#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015248/312 [======================>.......] - ETA: 2s - loss: 2.2039 - accuracy: 0.2347#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015250/312 [=======================>......] - ETA: 1s - loss: 2.2014 - accuracy: 0.2353#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015252/312 [=======================>......] - ETA: 1s - loss: 2.1990 - accuracy: 0.2358#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015254/312 [=======================>......] - ETA: 1s - loss: 2.1966 - accuracy: 0.2364#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015256/312 [=======================>......] - ETA: 1s - loss: 2.1942 - accuracy: 0.2369#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015258/312 [=======================>......] - ETA: 1s - loss: 2.1918 - accuracy: 0.2374#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015260/312 [========================>.....] - ETA: 1s - loss: 2.1895 - accuracy: 0.2380#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015262/312 [========================>.....] - ETA: 1s - loss: 2.1872 - accuracy: 0.2385#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015264/312 [========================>.....] - ETA: 1s - loss: 2.1848 - accuracy: 0.2390#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015266/312 [========================>.....] - ETA: 1s - loss: 2.1826 - accuracy: 0.2395#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015268/312 [========================>.....] - ETA: 1s - loss: 2.1803 - accuracy: 0.2401#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015270/312 [========================>.....] - ETA: 1s - loss: 2.1780 - accuracy: 0.2406#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015272/312 [=========================>....] - ETA: 1s - loss: 2.1758 - accuracy: 0.2411#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015274/312 [=========================>....] - ETA: 1s - loss: 2.1736 - accuracy: 0.2416#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015276/312 [=========================>....] - ETA: 1s - loss: 2.1714 - accuracy: 0.2421#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015278/312 [=========================>....] - ETA: 1s - loss: 2.1693 - accuracy: 0.2426#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015280/312 [=========================>....] - ETA: 1s - loss: 2.1671 - accuracy: 0.2431#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015282/312 [==========================>...] - ETA: 0s - loss: 2.1650 - accuracy: 0.2436#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015284/312 [==========================>...] - ETA: 0s - loss: 2.1629 - accuracy: 0.2441#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015286/312 [==========================>...] - ETA: 0s - loss: 2.1608 - accuracy: 0.2446#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015288/312 [==========================>...] - ETA: 0s - loss: 2.1587 - accuracy: 0.2451#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015290/312 [==========================>...] - ETA: 0s - loss: 2.1566 - accuracy: 0.2456#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015292/312 [===========================>..] - ETA: 0s - loss: 2.1545 - accuracy: 0.2461#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015294/312 [===========================>..] - ETA: 0s - loss: 2.1525 - accuracy: 0.2465#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015296/312 [===========================>..] - ETA: 0s - loss: 2.1505 - accuracy: 0.2470#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015298/312 [===========================>..] - ETA: 0s - loss: 2.1485 - accuracy: 0.2475#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015300/312 [===========================>..] - ETA: 0s - loss: 2.1465 - accuracy: 0.2480#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015302/312 [============================>.] - ETA: 0s - loss: 2.1445 - accuracy: 0.2485#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015304/312 [============================>.] - ETA: 0s - loss: 2.1425 - accuracy: 0.2489#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015306/312 [============================>.] - ETA: 0s - loss: 2.1405 - accuracy: 0.2494#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015308/312 [============================>.] - ETA: 0s - loss: 2.1386 - accuracy: 0.2499#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015310/312 [============================>.] - ETA: 0s - loss: 2.1366 - accuracy: 0.2504#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015312/312 [==============================] - ETA: 0s - loss: 2.1347 - accuracy: 0.2508#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015312/312 [==============================] - 23s 36ms/step - loss: 2.1338 - accuracy: 0.2511 - val_loss: 1.6756 - val_accuracy: 0.4084\u001b[0m\n\u001b[34mEpoch 2/5\u001b[0m\n\u001b[34m#015 1/312 [..............................] - ETA: 8s - loss: 1.5448 - accuracy: 0.4531#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 3/312 [..............................] - ETA: 8s - loss: 1.5196 - accuracy: 0.4449#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 5/312 [..............................] - ETA: 8s - loss: 1.5302 - accuracy: 0.4390#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 7/312 [..............................] - ETA: 8s - loss: 1.5383 - accuracy: 0.4368#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 9/312 [..............................] - ETA: 8s - loss: 1.5405 - accuracy: 0.4357#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 11/312 [>.............................] - ETA: 8s - loss: 1.5429 - accuracy: 0.4337#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 13/312 [>.............................] - ETA: 8s - loss: 1.5443 - accuracy: 0.4326#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 15/312 [>.............................] - ETA: 8s - loss: 1.5469 - accuracy: 0.4309#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 17/312 [>.............................] - ETA: 8s - loss: 1.5479 - accuracy: 0.4302#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 19/312 [>.............................] - ETA: 8s - loss: 1.5485 - accuracy: 0.4298#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 21/312 [=>............................] - ETA: 8s - loss: 1.5486 - accuracy: 0.4293#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 23/312 [=>............................] - ETA: 8s - loss: 1.5479 - accuracy: 0.4290#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 25/312 [=>............................] - ETA: 8s - loss: 1.5468 - accuracy: 0.4288#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 27/312 [=>............................] - ETA: 8s - loss: 1.5458 - accuracy: 0.4288#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 29/312 [=>............................] - ETA: 8s - loss: 1.5446 - accuracy: 0.4292#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 31/312 [=>............................] - ETA: 8s - loss: 1.5431 - accuracy: 0.4296#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 33/312 [==>...........................] - ETA: 8s - loss: 1.5417 - accuracy: 0.4301#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 35/312 [==>...........................] - ETA: 8s - loss: 1.5404 - accuracy: 0.4305#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 37/312 [==>...........................] - ETA: 7s - loss: 1.5391 - accuracy: 0.4309#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 39/312 [==>...........................] - ETA: 7s - loss: 1.5379 - accuracy: 0.4313#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 41/312 [==>...........................] - ETA: 7s - loss: 1.5367 - accuracy: 0.4316#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 43/312 [===>..........................] - ETA: 7s - loss: 1.5359 - accuracy: 0.4319#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 45/312 [===>..........................] - ETA: 7s - loss: 1.5351 - accuracy: 0.4322#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 47/312 [===>..........................] - ETA: 7s - loss: 1.5342 - accuracy: 0.4325#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 49/312 [===>..........................] - ETA: 7s - loss: 1.5336 - accuracy: 0.4328#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 51/312 [===>..........................] - ETA: 7s - loss: 1.5330 - accuracy: 0.4331#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 53/312 [====>.........................] - ETA: 7s - loss: 1.5324 - accuracy: 0.4333#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 55/312 [====>.........................] - ETA: 7s - loss: 1.5318 - accuracy: 0.4335#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 57/312 [====>.........................] - ETA: 7s - loss: 1.5313 - accuracy: 0.4338#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 59/312 [====>.........................] - ETA: 7s - loss: 1.5307 - accuracy: 0.4340#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 61/312 [====>.........................] - ETA: 7s - loss: 1.5302 - accuracy: 0.4342#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 63/312 [=====>........................] - ETA: 7s - loss: 1.5297 - accuracy: 0.4344#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 65/312 [=====>........................] - ETA: 7s - loss: 1.5292 - accuracy: 0.4346#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 67/312 [=====>........................] - ETA: 7s - loss: 1.5288 - accuracy: 0.4347#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 69/312 [=====>........................] - ETA: 7s - loss: 1.5284 - accuracy: 0.4349#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 71/312 [=====>........................] - ETA: 7s - loss: 1.5280 - accuracy: 0.4351#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 73/312 [======>.......................] - ETA: 6s - loss: 1.5277 - accuracy: 0.4353#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 75/312 [======>.......................] - ETA: 6s - loss: 1.5273 - accuracy: 0.4355#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 77/312 [======>.......................] - ETA: 6s - loss: 1.5269 - accuracy: 0.4357#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 79/312 [======>.......................] - ETA: 6s - loss: 1.5265 - accuracy: 0.4359#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 81/312 [======>.......................] - ETA: 6s - loss: 1.5261 - accuracy: 0.4361#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 83/312 [======>.......................] - ETA: 6s - loss: 1.5256 - accuracy: 0.4363#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 85/312 [=======>......................] - ETA: 6s - loss: 1.5251 - accuracy: 0.4366#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 87/312 [=======>......................] - ETA: 6s - loss: 1.5247 - accuracy: 0.4368#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 89/312 [=======>......................] - ETA: 6s - loss: 1.5242 - accuracy: 0.4370#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 91/312 [=======>......................] - ETA: 6s - loss: 1.5238 - accuracy: 0.4373#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 93/312 [=======>......................] - ETA: 6s - loss: 1.5234 - accuracy: 0.4375#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 95/312 [========>.....................] - ETA: 6s - loss: 1.5231 - accuracy: 0.4377#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 97/312 [========>.....................] - ETA: 6s - loss: 1.5227 - accuracy: 0.4379#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 99/312 [========>.....................] - ETA: 6s - loss: 1.5223 - accuracy: 0.4382#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015101/312 [========>.....................] - ETA: 6s - loss: 1.5218 - accuracy: 0.4384#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015103/312 [========>.....................] - ETA: 6s - loss: 1.5214 - accuracy: 0.4386#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015105/312 [=========>....................] - ETA: 6s - loss: 1.5210 - accuracy: 0.4389#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015107/312 [=========>....................] - ETA: 5s - loss: 1.5206 - accuracy: 0.4391#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015109/312 [=========>....................] - ETA: 5s - loss: 1.5201 - accuracy: 0.4393#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015111/312 [=========>....................] - ETA: 5s - loss: 1.5197 - accuracy: 0.4396#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015113/312 [=========>....................] - ETA: 5s - loss: 1.5192 - accuracy: 0.4398#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015115/312 [==========>...................] - ETA: 5s - loss: 1.5188 - accuracy: 0.4401#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015117/312 [==========>...................] - ETA: 5s - loss: 1.5183 - accuracy: 0.4403#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015119/312 [==========>...................] - ETA: 5s - loss: 1.5178 - accuracy: 0.4406#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015121/312 [==========>...................] - ETA: 5s - loss: 1.5174 - accuracy: 0.4408#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015123/312 [==========>...................] - ETA: 5s - loss: 1.5169 - accuracy: 0.4410#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015125/312 [===========>..................] - ETA: 5s - loss: 1.5164 - accuracy: 0.4413#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015127/312 [===========>..................] - ETA: 5s - loss: 1.5159 - accuracy: 0.4415#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015129/312 [===========>..................] - ETA: 5s - loss: 1.5154 - accuracy: 0.4417#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015131/312 [===========>..................] - ETA: 5s - loss: 1.5150 - accuracy: 0.4420#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015133/312 [===========>..................] - ETA: 5s - loss: 1.5145 - accuracy: 0.4422#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015135/312 [===========>..................] - ETA: 5s - loss: 1.5140 - accuracy: 0.4424#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015137/312 [============>.................] - ETA: 5s - loss: 1.5136 - accuracy: 0.4426#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015139/312 [============>.................] - ETA: 5s - loss: 1.5131 - accuracy: 0.4428#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015141/312 [============>.................] - ETA: 4s - loss: 1.5127 - accuracy: 0.4430#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015143/312 [============>.................] - ETA: 4s - loss: 1.5122 - accuracy: 0.4432#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015145/312 [============>.................] - ETA: 4s - loss: 1.5118 - accuracy: 0.4434#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015147/312 [=============>................] - ETA: 4s - loss: 1.5114 - accuracy: 0.4436#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015149/312 [=============>................] - ETA: 4s - loss: 1.5110 - accuracy: 0.4438#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015151/312 [=============>................] - ETA: 4s - loss: 1.5105 - accuracy: 0.4440#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015153/312 [=============>................] - ETA: 4s - loss: 1.5101 - accuracy: 0.4442#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015155/312 [=============>................] - ETA: 4s - loss: 1.5096 - accuracy: 0.4444#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015157/312 [==============>...............] - ETA: 4s - loss: 1.5091 - accuracy: 0.4446#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015159/312 [==============>...............] - ETA: 4s - loss: 1.5087 - accuracy: 0.4448#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015161/312 [==============>...............] - ETA: 4s - loss: 1.5082 - accuracy: 0.4450#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015163/312 [==============>...............] - ETA: 4s - loss: 1.5078 - accuracy: 0.4452#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015165/312 [==============>...............] - ETA: 4s - loss: 1.5073 - accuracy: 0.4454#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015167/312 [===============>..............] - ETA: 4s - loss: 1.5069 - accuracy: 0.4456#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015169/312 [===============>..............] - ETA: 4s - loss: 1.5064 - accuracy: 0.4458#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015171/312 [===============>..............] - ETA: 4s - loss: 1.5060 - accuracy: 0.4460#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015173/312 [===============>..............] - ETA: 4s - loss: 1.5056 - accuracy: 0.4462#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015175/312 [===============>..............] - ETA: 3s - loss: 1.5051 - accuracy: 0.4464#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015177/312 [================>.............] - ETA: 3s - loss: 1.5047 - accuracy: 0.4466#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015179/312 [================>.............] - ETA: 3s - loss: 1.5042 - accuracy: 0.4468#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015181/312 [================>.............] - ETA: 3s - loss: 1.5038 - accuracy: 0.4470#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015183/312 [================>.............] - ETA: 3s - loss: 1.5033 - accuracy: 0.4472#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015185/312 [================>.............] - ETA: 3s - loss: 1.5029 - accuracy: 0.4474#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015187/312 [================>.............] - ETA: 3s - loss: 1.5025 - accuracy: 0.4476#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015189/312 [=================>............] - ETA: 3s - loss: 1.5020 - accuracy: 0.4477#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015191/312 [=================>............] - ETA: 3s - loss: 1.5016 - accuracy: 0.4479#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015193/312 [=================>............] - ETA: 3s - loss: 1.5012 - accuracy: 0.4481#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010\u001b[0m\n\u001b[34m#010#010#010#010#010#010#010#010#010#015195/312 [=================>............] - ETA: 3s - loss: 1.5008 - accuracy: 0.4483#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015197/312 [=================>............] - ETA: 3s - loss: 1.5004 - accuracy: 0.4485#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015199/312 [==================>...........] - ETA: 3s - loss: 1.5000 - accuracy: 0.4487#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015201/312 [==================>...........] - ETA: 3s - loss: 1.4995 - accuracy: 0.4489#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015203/312 [==================>...........] - ETA: 3s - loss: 1.4991 - accuracy: 0.4491#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015205/312 [==================>...........] - ETA: 3s - loss: 1.4987 - accuracy: 0.4493#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015207/312 [==================>...........] - ETA: 3s - loss: 1.4983 - accuracy: 0.4495#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015209/312 [===================>..........] - ETA: 2s - loss: 1.4979 - accuracy: 0.4497#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015211/312 [===================>..........] - ETA: 2s - loss: 1.4975 - accuracy: 0.4499#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015213/312 [===================>..........] - ETA: 2s - loss: 1.4971 - accuracy: 0.4500#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015215/312 [===================>..........] - ETA: 2s - loss: 1.4967 - accuracy: 0.4502#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015217/312 [===================>..........] - ETA: 2s - loss: 1.4963 - accuracy: 0.4504#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015219/312 [====================>.........] - ETA: 2s - loss: 1.4959 - accuracy: 0.4506#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015221/312 [====================>.........] - ETA: 2s - loss: 1.4955 - accuracy: 0.4508#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015223/312 [====================>.........] - ETA: 2s - loss: 1.4950 - accuracy: 0.4510#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015225/312 [====================>.........] - ETA: 2s - loss: 1.4946 - accuracy: 0.4512#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015227/312 [====================>.........] - ETA: 2s - loss: 1.4942 - accuracy: 0.4514#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015229/312 [=====================>........] - ETA: 2s - loss: 1.4938 - accuracy: 0.4516#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015231/312 [=====================>........] - ETA: 2s - loss: 1.4934 - accuracy: 0.4518#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015233/312 [=====================>........] - ETA: 2s - loss: 1.4929 - accuracy: 0.4520#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015235/312 [=====================>........] - ETA: 2s - loss: 1.4925 - accuracy: 0.4522#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015237/312 [=====================>........] - ETA: 2s - loss: 1.4921 - accuracy: 0.4524#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015239/312 [=====================>........] - ETA: 2s - loss: 1.4917 - accuracy: 0.4526#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015241/312 [======================>.......] - ETA: 2s - loss: 1.4913 - accuracy: 0.4527#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015243/312 [======================>.......] - ETA: 2s - loss: 1.4908 - accuracy: 0.4529#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015245/312 [======================>.......] - ETA: 1s - loss: 1.4904 - accuracy: 0.4531#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015247/312 [======================>.......] - ETA: 1s - loss: 1.4900 - accuracy: 0.4533#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015249/312 [======================>.......] - ETA: 1s - loss: 1.4896 - accuracy: 0.4535#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015251/312 [=======================>......] - ETA: 1s - loss: 1.4893 - accuracy: 0.4536#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015253/312 [=======================>......] - ETA: 1s - loss: 1.4889 - accuracy: 0.4538#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015255/312 [=======================>......] - ETA: 1s - loss: 1.4885 - accuracy: 0.4540#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015257/312 [=======================>......] - ETA: 1s - loss: 1.4881 - accuracy: 0.4542#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015259/312 [=======================>......] - ETA: 1s - loss: 1.4878 - accuracy: 0.4543#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015261/312 [========================>.....] - ETA: 1s - loss: 1.4874 - accuracy: 0.4545#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015263/312 [========================>.....] - ETA: 1s - loss: 1.4871 - accuracy: 0.4546#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015265/312 [========================>.....] - ETA: 1s - loss: 1.4867 - accuracy: 0.4548#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015267/312 [========================>.....] - ETA: 1s - loss: 1.4863 - accuracy: 0.4550#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015269/312 [========================>.....] - ETA: 1s - loss: 1.4860 - accuracy: 0.4551#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015271/312 [=========================>....] - ETA: 1s - loss: 1.4856 - accuracy: 0.4553#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015273/312 [=========================>....] - ETA: 1s - loss: 1.4852 - accuracy: 0.4555#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015275/312 [=========================>....] - ETA: 1s - loss: 1.4848 - accuracy: 0.4556#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015277/312 [=========================>....] - ETA: 1s - loss: 1.4845 - accuracy: 0.4558#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015279/312 [=========================>....] - ETA: 0s - loss: 1.4841 - accuracy: 0.4560#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015281/312 [==========================>...] - ETA: 0s - loss: 1.4837 - accuracy: 0.4561#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015283/312 [==========================>...] - ETA: 0s - loss: 1.4833 - accuracy: 0.4563#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015285/312 [==========================>...] - ETA: 0s - loss: 1.4829 - accuracy: 0.4565#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015287/312 [==========================>...] - ETA: 0s - loss: 1.4825 - accuracy: 0.4567#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015289/312 [==========================>...] - ETA: 0s - loss: 1.4821 - accuracy: 0.4568#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015291/312 [==========================>...] - ETA: 0s - loss: 1.4818 - accuracy: 0.4570#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015293/312 [===========================>..] - ETA: 0s - loss: 1.4814 - accuracy: 0.4572#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015295/312 [===========================>..] - ETA: 0s - loss: 1.4810 - accuracy: 0.4573#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015297/312 [===========================>..] - ETA: 0s - loss: 1.4806 - accuracy: 0.4575#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015299/312 [===========================>..] - ETA: 0s - loss: 1.4802 - accuracy: 0.4577#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015301/312 [===========================>..] - ETA: 0s - loss: 1.4798 - accuracy: 0.4578#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015303/312 [============================>.] - ETA: 0s - loss: 1.4794 - accuracy: 0.4580#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015305/312 [============================>.] - ETA: 0s - loss: 1.4790 - accuracy: 0.4582#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015307/312 [============================>.] - ETA: 0s - loss: 1.4786 - accuracy: 0.4583#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015309/312 [============================>.] - ETA: 0s - loss: 1.4782 - accuracy: 0.4585#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015311/312 [============================>.] - ETA: 0s - loss: 1.4778 - accuracy: 0.4587#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015312/312 [==============================] - 10s 31ms/step - loss: 1.4774 - accuracy: 0.4588 - val_loss: 1.4685 - val_accuracy: 0.4654\u001b[0m\n\u001b[34mEpoch 3/5\u001b[0m\n\u001b[34m#015 1/312 [..............................] - ETA: 9s - loss: 1.5111 - accuracy: 0.4453#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 3/312 [..............................] - ETA: 8s - loss: 1.3716 - accuracy: 0.5052#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 5/312 [..............................] - ETA: 8s - loss: 1.3366 - accuracy: 0.5173#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 7/312 [..............................] - ETA: 8s - loss: 1.3296 - accuracy: 0.5200#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 9/312 [..............................] - ETA: 8s - loss: 1.3249 - accuracy: 0.5226#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 11/312 [>.............................] - ETA: 8s - loss: 1.3181 - accuracy: 0.5257#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 13/312 [>.............................] - ETA: 8s - loss: 1.3125 - accuracy: 0.5273#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 15/312 [>.............................] - ETA: 8s - loss: 1.3086 - accuracy: 0.5280#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 17/312 [>.............................] - ETA: 8s - loss: 1.3068 - accuracy: 0.5284#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 19/312 [>.............................] - ETA: 8s - loss: 1.3045 - accuracy: 0.5292#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 21/312 [=>............................] - ETA: 8s - loss: 1.3030 - accuracy: 0.5298#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 23/312 [=>............................] - ETA: 8s - loss: 1.3009 - accuracy: 0.5306#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 25/312 [=>............................] - ETA: 8s - loss: 1.2990 - accuracy: 0.5316#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 27/312 [=>............................] - ETA: 8s - loss: 1.2972 - accuracy: 0.5326#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 29/312 [=>............................] - ETA: 8s - loss: 1.2955 - accuracy: 0.5336#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 31/312 [=>............................] - ETA: 8s - loss: 1.2938 - accuracy: 0.5347#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 33/312 [==>...........................] - ETA: 8s - loss: 1.2927 - accuracy: 0.5353#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 35/312 [==>...........................] - ETA: 8s - loss: 1.2918 - accuracy: 0.5358#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 37/312 [==>...........................] - ETA: 8s - loss: 1.2912 - accuracy: 0.5361#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 39/312 [==>...........................] - ETA: 7s - loss: 1.2906 - accuracy: 0.5364#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 41/312 [==>...........................] - ETA: 7s - loss: 1.2899 - accuracy: 0.5367#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 43/312 [===>..........................] - ETA: 7s - loss: 1.2893 - accuracy: 0.5370#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 45/312 [===>..........................] - ETA: 7s - loss: 1.2888 - accuracy: 0.5372#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 47/312 [===>..........................] - ETA: 7s - loss: 1.2883 - accuracy: 0.5373#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 49/312 [===>..........................] - ETA: 7s - loss: 1.2879 - accuracy: 0.5374#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 51/312 [===>..........................] - ETA: 7s - loss: 1.2877 - accuracy: 0.5374#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 53/312 [====>.........................] - ETA: 7s - loss: 1.2873 - accuracy: 0.5375#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 55/312 [====>.........................] - ETA: 7s - loss: 1.2869 - accuracy: 0.5375#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 57/312 [====>.........................] - ETA: 7s - loss: 1.2865 - accuracy: 0.5375#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 59/312 [====>.........................] - ETA: 7s - loss: 1.2859 - accuracy: 0.5376#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 61/312 [====>.........................] - ETA: 7s - loss: 1.2852 - accuracy: 0.5377#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 63/312 [=====>........................] - ETA: 7s - loss: 1.2845 - accuracy: 0.5378#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 65/312 [=====>........................] - ETA: 7s - loss: 1.2837 - accuracy: 0.5379#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 67/312 [=====>........................] - ETA: 7s - loss: 1.2831 - accuracy: 0.5380#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 69/312 [=====>........................] - ETA: 7s - loss: 1.2824 - accuracy: 0.5382#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 71/312 [=====>........................] - ETA: 7s - loss: 1.2817 - accuracy: 0.5384#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 73/312 [======>.......................] - ETA: 6s - loss: 1.2812 - accuracy: 0.5385#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 75/312 [======>.......................] - ETA: 6s - loss: 1.2808 - accuracy: 0.5386#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 77/312 [======>.......................] - ETA: 6s - loss: 1.2804 - accuracy: 0.5387#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 79/312 [======>.......................] - ETA: 6s - loss: 1.2799 - accuracy: 0.5389#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 81/312 [======>.......................] - ETA: 6s - loss: 1.2796 - accuracy: 0.5390#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 83/312 [======>.......................] - ETA: 6s - loss: 1.2792 - accuracy: 0.5391#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 85/312 [=======>......................] - ETA: 6s - loss: 1.2789 - accuracy: 0.5392#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 87/312 [=======>......................] - ETA: 6s - loss: 1.2785 - accuracy: 0.5393#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 89/312 [=======>......................] - ETA: 6s - loss: 1.2782 - accuracy: 0.5394#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 91/312 [=======>......................] - ETA: 6s - loss: 1.2778 - accuracy: 0.5395#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 93/312 [=======>......................] - ETA: 6s - loss: 1.2775 - accuracy: 0.5396#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 95/312 [========>.....................] - ETA: 6s - loss: 1.2772 - accuracy: 0.5397#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 97/312 [========>.....................] - ETA: 6s - loss: 1.2769 - accuracy: 0.5398#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 99/312 [========>.....................] - ETA: 6s - loss: 1.2765 - accuracy: 0.5399#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015101/312 [========>.....................] - ETA: 6s - loss: 1.2762 - accuracy: 0.5400#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015103/312 [========>.....................] - ETA: 6s - loss: 1.2759 - accuracy: 0.5400#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015105/312 [=========>....................] - ETA: 6s - loss: 1.2755 - accuracy: 0.5401#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015107/312 [=========>....................] - ETA: 5s - loss: 1.2752 - accuracy: 0.5402#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015109/312 [=========>....................] - ETA: 5s - loss: 1.2749 - accuracy: 0.5402#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015111/312 [=========>....................] - ETA: 5s - loss: 1.2746 - accuracy: 0.5403#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015113/312 [=========>....................] - ETA: 5s - loss: 1.2743 - accuracy: 0.5404#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015115/312 [==========>...................] - ETA: 5s - loss: 1.2739 - accuracy: 0.5404#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015117/312 [==========>...................] - ETA: 5s - loss: 1.2736 - accuracy: 0.5405#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015119/312 [==========>...................] - ETA: 5s - loss: 1.2733 - accuracy: 0.5406#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015121/312 [==========>...................] - ETA: 5s - loss: 1.2730 - accuracy: 0.5406#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015123/312 [==========>...................] - ETA: 5s - loss: 1.2727 - accuracy: 0.5407#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015125/312 [===========>..................] - ETA: 5s - loss: 1.2724 - accuracy: 0.5407#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015127/312 [===========>..................] - ETA: 5s - loss: 1.2721 - accuracy: 0.5408#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015129/312 [===========>..................] - ETA: 5s - loss: 1.2718 - accuracy: 0.5409#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015131/312 [===========>..................] - ETA: 5s - loss: 1.2716 - accuracy: 0.5409#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015133/312 [===========>..................] - ETA: 5s - loss: 1.2713 - accuracy: 0.5410#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015135/312 [===========>..................] - ETA: 5s - loss: 1.2711 - accuracy: 0.5411#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015137/312 [============>.................] - ETA: 5s - loss: 1.2709 - accuracy: 0.5411#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015139/312 [============>.................] - ETA: 5s - loss: 1.2707 - accuracy: 0.5412#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015141/312 [============>.................] - ETA: 4s - loss: 1.2704 - accuracy: 0.5413#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015143/312 [============>.................] - ETA: 4s - loss: 1.2702 - accuracy: 0.5413#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015145/312 [============>.................] - ETA: 4s - loss: 1.2701 - accuracy: 0.5414#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015147/312 [=============>................] - ETA: 4s - loss: 1.2699 - accuracy: 0.5414#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015149/312 [=============>................] - ETA: 4s - loss: 1.2697 - accuracy: 0.5415#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015151/312 [=============>................] - ETA: 4s - loss: 1.2695 - accuracy: 0.5416#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015153/312 [=============>................] - ETA: 4s - loss: 1.2693 - accuracy: 0.5416#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015155/312 [=============>................] - ETA: 4s - loss: 1.2692 - accuracy: 0.5417#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015157/312 [==============>...............] - ETA: 4s - loss: 1.2690 - accuracy: 0.5418#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015159/312 [==============>...............] - ETA: 4s - loss: 1.2688 - accuracy: 0.5418#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015161/312 [==============>...............] - ETA: 4s - loss: 1.2687 - accuracy: 0.5419#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015163/312 [==============>...............] - ETA: 4s - loss: 1.2685 - accuracy: 0.5419#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015165/312 [==============>...............] - ETA: 4s - loss: 1.2684 - accuracy: 0.5420#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015167/312 [===============>..............] - ETA: 4s - loss: 1.2683 - accuracy: 0.5420#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015169/312 [===============>..............] - ETA: 4s - loss: 1.2682 - accuracy: 0.5421#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015171/312 [===============>..............] - ETA: 4s - loss: 1.2680 - accuracy: 0.5421#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015173/312 [===============>..............] - ETA: 4s - loss: 1.2679 - accuracy: 0.5422#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015175/312 [===============>..............] - ETA: 3s - loss: 1.2677 - accuracy: 0.5422#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015177/312 [================>.............] - ETA: 3s - loss: 1.2676 - accuracy: 0.5423#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015179/312 [================>.............] - ETA: 3s - loss: 1.2674 - accuracy: 0.5424#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015181/312 [================>.............] - ETA: 3s - loss: 1.2673 - accuracy: 0.5424#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015183/312 [================>.............] - ETA: 3s - loss: 1.2672 - accuracy: 0.5425#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015185/312 [================>.............] - ETA: 3s - loss: 1.2670 - accuracy: 0.5425#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015187/312 [================>.............] - ETA: 3s - loss: 1.2669 - accuracy: 0.5426#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015189/312 [=================>............] - ETA: 3s - loss: 1.2667 - accuracy: 0.5427#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015191/312 [=================>............] - ETA: 3s - loss: 1.2666 - accuracy: 0.5427#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015193/312 [=================>............] - ETA: 3s - loss: 1.2664 - accuracy: 0.5428#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010\u001b[0m\n\u001b[34m#010#010#010#010#010#010#010#010#010#015195/312 [=================>............] - ETA: 3s - loss: 1.2663 - accuracy: 0.5429#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015197/312 [=================>............] - ETA: 3s - loss: 1.2661 - accuracy: 0.5430#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015199/312 [==================>...........] - ETA: 3s - loss: 1.2659 - accuracy: 0.5430#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015201/312 [==================>...........] - ETA: 3s - loss: 1.2658 - accuracy: 0.5431#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015203/312 [==================>...........] - ETA: 3s - loss: 1.2656 - accuracy: 0.5432#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015205/312 [==================>...........] - ETA: 3s - loss: 1.2654 - accuracy: 0.5433#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015207/312 [==================>...........] - ETA: 3s - loss: 1.2653 - accuracy: 0.5433#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015209/312 [===================>..........] - ETA: 2s - loss: 1.2651 - accuracy: 0.5434#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015211/312 [===================>..........] - ETA: 2s - loss: 1.2650 - accuracy: 0.5435#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015213/312 [===================>..........] - ETA: 2s - loss: 1.2648 - accuracy: 0.5436#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015215/312 [===================>..........] - ETA: 2s - loss: 1.2646 - accuracy: 0.5436#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015217/312 [===================>..........] - ETA: 2s - loss: 1.2644 - accuracy: 0.5437#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015219/312 [====================>.........] - ETA: 2s - loss: 1.2642 - accuracy: 0.5438#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015221/312 [====================>.........] - ETA: 2s - loss: 1.2641 - accuracy: 0.5439#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015223/312 [====================>.........] - ETA: 2s - loss: 1.2639 - accuracy: 0.5440#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015225/312 [====================>.........] - ETA: 2s - loss: 1.2637 - accuracy: 0.5441#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015227/312 [====================>.........] - ETA: 2s - loss: 1.2635 - accuracy: 0.5441#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015229/312 [=====================>........] - ETA: 2s - loss: 1.2633 - accuracy: 0.5442#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015231/312 [=====================>........] - ETA: 2s - loss: 1.2631 - accuracy: 0.5443#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015233/312 [=====================>........] - ETA: 2s - loss: 1.2629 - accuracy: 0.5444#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015235/312 [=====================>........] - ETA: 2s - loss: 1.2627 - accuracy: 0.5445#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015237/312 [=====================>........] - ETA: 2s - loss: 1.2625 - accuracy: 0.5446#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015239/312 [=====================>........] - ETA: 2s - loss: 1.2623 - accuracy: 0.5447#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015241/312 [======================>.......] - ETA: 2s - loss: 1.2621 - accuracy: 0.5447#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015243/312 [======================>.......] - ETA: 2s - loss: 1.2619 - accuracy: 0.5448#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015245/312 [======================>.......] - ETA: 1s - loss: 1.2617 - accuracy: 0.5449#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015247/312 [======================>.......] - ETA: 1s - loss: 1.2615 - accuracy: 0.5450#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015249/312 [======================>.......] - ETA: 1s - loss: 1.2613 - accuracy: 0.5451#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015251/312 [=======================>......] - ETA: 1s - loss: 1.2611 - accuracy: 0.5451#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015253/312 [=======================>......] - ETA: 1s - loss: 1.2609 - accuracy: 0.5452#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015255/312 [=======================>......] - ETA: 1s - loss: 1.2608 - accuracy: 0.5453#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015257/312 [=======================>......] - ETA: 1s - loss: 1.2606 - accuracy: 0.5454#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015259/312 [=======================>......] - ETA: 1s - loss: 1.2604 - accuracy: 0.5454#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015261/312 [========================>.....] - ETA: 1s - loss: 1.2602 - accuracy: 0.5455#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015263/312 [========================>.....] - ETA: 1s - loss: 1.2600 - accuracy: 0.5456#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015265/312 [========================>.....] - ETA: 1s - loss: 1.2598 - accuracy: 0.5457#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015267/312 [========================>.....] - ETA: 1s - loss: 1.2596 - accuracy: 0.5457#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015269/312 [========================>.....] - ETA: 1s - loss: 1.2594 - accuracy: 0.5458#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015271/312 [=========================>....] - ETA: 1s - loss: 1.2592 - accuracy: 0.5459#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015273/312 [=========================>....] - ETA: 1s - loss: 1.2590 - accuracy: 0.5460#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015275/312 [=========================>....] - ETA: 1s - loss: 1.2588 - accuracy: 0.5461#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015277/312 [=========================>....] - ETA: 1s - loss: 1.2586 - accuracy: 0.5461#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015279/312 [=========================>....] - ETA: 0s - loss: 1.2584 - accuracy: 0.5462#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015281/312 [==========================>...] - ETA: 0s - loss: 1.2583 - accuracy: 0.5463#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015283/312 [==========================>...] - ETA: 0s - loss: 1.2581 - accuracy: 0.5463#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015285/312 [==========================>...] - ETA: 0s - loss: 1.2579 - accuracy: 0.5464#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015287/312 [==========================>...] - ETA: 0s - loss: 1.2577 - accuracy: 0.5465#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015289/312 [==========================>...] - ETA: 0s - loss: 1.2575 - accuracy: 0.5466#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015291/312 [==========================>...] - ETA: 0s - loss: 1.2574 - accuracy: 0.5466#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015293/312 [===========================>..] - ETA: 0s - loss: 1.2572 - accuracy: 0.5467#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015295/312 [===========================>..] - ETA: 0s - loss: 1.2570 - accuracy: 0.5468#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015297/312 [===========================>..] - ETA: 0s - loss: 1.2568 - accuracy: 0.5468#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015299/312 [===========================>..] - ETA: 0s - loss: 1.2567 - accuracy: 0.5469#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015301/312 [===========================>..] - ETA: 0s - loss: 1.2565 - accuracy: 0.5470#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015303/312 [============================>.] - ETA: 0s - loss: 1.2563 - accuracy: 0.5470#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015305/312 [============================>.] - ETA: 0s - loss: 1.2561 - accuracy: 0.5471#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015307/312 [============================>.] - ETA: 0s - loss: 1.2560 - accuracy: 0.5472#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015309/312 [============================>.] - ETA: 0s - loss: 1.2558 - accuracy: 0.5472#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015311/312 [============================>.] - ETA: 0s - loss: 1.2556 - accuracy: 0.5473#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015312/312 [==============================] - 10s 32ms/step - loss: 1.2554 - accuracy: 0.5474 - val_loss: 1.1826 - val_accuracy: 0.5735\u001b[0m\n\u001b[34mEpoch 4/5\u001b[0m\n\u001b[34m#015 1/312 [..............................] - ETA: 9s - loss: 1.2226 - accuracy: 0.6016#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 3/312 [..............................] - ETA: 9s - loss: 1.1838 - accuracy: 0.5929#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 5/312 [..............................] - ETA: 8s - loss: 1.1707 - accuracy: 0.5983#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 7/312 [..............................] - ETA: 8s - loss: 1.1572 - accuracy: 0.6042#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 9/312 [..............................] - ETA: 8s - loss: 1.1505 - accuracy: 0.6048#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 11/312 [>.............................] - ETA: 8s - loss: 1.1437 - accuracy: 0.6058#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 13/312 [>.............................] - ETA: 8s - loss: 1.1407 - accuracy: 0.6057#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 15/312 [>.............................] - ETA: 8s - loss: 1.1392 - accuracy: 0.6056#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 17/312 [>.............................] - ETA: 8s - loss: 1.1393 - accuracy: 0.6049#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 19/312 [>.............................] - ETA: 8s - loss: 1.1392 - accuracy: 0.6042#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 21/312 [=>............................] - ETA: 8s - loss: 1.1388 - accuracy: 0.6037#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 23/312 [=>............................] - ETA: 8s - loss: 1.1381 - accuracy: 0.6034#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 25/312 [=>............................] - ETA: 8s - loss: 1.1372 - accuracy: 0.6034#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 27/312 [=>............................] - ETA: 8s - loss: 1.1361 - accuracy: 0.6036#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 29/312 [=>............................] - ETA: 8s - loss: 1.1360 - accuracy: 0.6035#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 31/312 [=>............................] - ETA: 8s - loss: 1.1362 - accuracy: 0.6032#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 33/312 [==>...........................] - ETA: 8s - loss: 1.1364 - accuracy: 0.6028#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 35/312 [==>...........................] - ETA: 8s - loss: 1.1369 - accuracy: 0.6022#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 37/312 [==>...........................] - ETA: 7s - loss: 1.1374 - accuracy: 0.6016#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 39/312 [==>...........................] - ETA: 7s - loss: 1.1376 - accuracy: 0.6011#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 41/312 [==>...........................] - ETA: 7s - loss: 1.1376 - accuracy: 0.6007#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 43/312 [===>..........................] - ETA: 7s - loss: 1.1375 - accuracy: 0.6003#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 45/312 [===>..........................] - ETA: 7s - loss: 1.1374 - accuracy: 0.6000#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 47/312 [===>..........................] - ETA: 7s - loss: 1.1373 - accuracy: 0.5996#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 49/312 [===>..........................] - ETA: 7s - loss: 1.1374 - accuracy: 0.5993#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 51/312 [===>..........................] - ETA: 7s - loss: 1.1376 - accuracy: 0.5988#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 53/312 [====>.........................] - ETA: 7s - loss: 1.1378 - accuracy: 0.5984#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 55/312 [====>.........................] - ETA: 7s - loss: 1.1380 - accuracy: 0.5980#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 57/312 [====>.........................] - ETA: 7s - loss: 1.1383 - accuracy: 0.5975#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 59/312 [====>.........................] - ETA: 7s - loss: 1.1386 - accuracy: 0.5971#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 61/312 [====>.........................] - ETA: 7s - loss: 1.1388 - accuracy: 0.5967#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 63/312 [=====>........................] - ETA: 7s - loss: 1.1390 - accuracy: 0.5964#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 65/312 [=====>........................] - ETA: 7s - loss: 1.1392 - accuracy: 0.5961#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 67/312 [=====>........................] - ETA: 7s - loss: 1.1394 - accuracy: 0.5958#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 69/312 [=====>........................] - ETA: 7s - loss: 1.1396 - accuracy: 0.5955#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 71/312 [=====>........................] - ETA: 7s - loss: 1.1398 - accuracy: 0.5953#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 73/312 [======>.......................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5951#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 75/312 [======>.......................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5949#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 77/312 [======>.......................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5948#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 79/312 [======>.......................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5946#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 81/312 [======>.......................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5945#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 83/312 [======>.......................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5944#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 85/312 [=======>......................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5943#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 87/312 [=======>......................] - ETA: 6s - loss: 1.1400 - accuracy: 0.5942#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 89/312 [=======>......................] - ETA: 6s - loss: 1.1400 - accuracy: 0.5941#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 91/312 [=======>......................] - ETA: 6s - loss: 1.1400 - accuracy: 0.5940#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 93/312 [=======>......................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5940#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 95/312 [========>.....................] - ETA: 6s - loss: 1.1399 - accuracy: 0.5939#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 97/312 [========>.....................] - ETA: 6s - loss: 1.1398 - accuracy: 0.5938#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 99/312 [========>.....................] - ETA: 6s - loss: 1.1398 - accuracy: 0.5938#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015101/312 [========>.....................] - ETA: 6s - loss: 1.1397 - accuracy: 0.5938#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015103/312 [========>.....................] - ETA: 6s - loss: 1.1396 - accuracy: 0.5937#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015105/312 [=========>....................] - ETA: 6s - loss: 1.1396 - accuracy: 0.5937#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015107/312 [=========>....................] - ETA: 5s - loss: 1.1396 - accuracy: 0.5937#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015109/312 [=========>....................] - ETA: 5s - loss: 1.1395 - accuracy: 0.5937#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015111/312 [=========>....................] - ETA: 5s - loss: 1.1394 - accuracy: 0.5936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015113/312 [=========>....................] - ETA: 5s - loss: 1.1394 - accuracy: 0.5936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015115/312 [==========>...................] - ETA: 5s - loss: 1.1393 - accuracy: 0.5936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015117/312 [==========>...................] - ETA: 5s - loss: 1.1393 - accuracy: 0.5936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015119/312 [==========>...................] - ETA: 5s - loss: 1.1392 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015121/312 [==========>...................] - ETA: 5s - loss: 1.1392 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015123/312 [==========>...................] - ETA: 5s - loss: 1.1391 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015125/312 [===========>..................] - ETA: 5s - loss: 1.1391 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015127/312 [===========>..................] - ETA: 5s - loss: 1.1390 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015129/312 [===========>..................] - ETA: 5s - loss: 1.1390 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015131/312 [===========>..................] - ETA: 5s - loss: 1.1389 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015133/312 [===========>..................] - ETA: 5s - loss: 1.1388 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015135/312 [===========>..................] - ETA: 5s - loss: 1.1388 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015137/312 [============>.................] - ETA: 5s - loss: 1.1387 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015139/312 [============>.................] - ETA: 5s - loss: 1.1386 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015141/312 [============>.................] - ETA: 5s - loss: 1.1385 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015143/312 [============>.................] - ETA: 4s - loss: 1.1384 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015145/312 [============>.................] - ETA: 4s - loss: 1.1383 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015147/312 [=============>................] - ETA: 4s - loss: 1.1382 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015149/312 [=============>................] - ETA: 4s - loss: 1.1380 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015151/312 [=============>................] - ETA: 4s - loss: 1.1379 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015153/312 [=============>................] - ETA: 4s - loss: 1.1378 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015155/312 [=============>................] - ETA: 4s - loss: 1.1377 - accuracy: 0.5934#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015157/312 [==============>...............] - ETA: 4s - loss: 1.1376 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015159/312 [==============>...............] - ETA: 4s - loss: 1.1375 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015161/312 [==============>...............] - ETA: 4s - loss: 1.1374 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015163/312 [==============>...............] - ETA: 4s - loss: 1.1373 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015165/312 [==============>...............] - ETA: 4s - loss: 1.1371 - accuracy: 0.5935#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015167/312 [===============>..............] - ETA: 4s - loss: 1.1370 - accuracy: 0.5936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015169/312 [===============>..............] - ETA: 4s - loss: 1.1368 - accuracy: 0.5936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015171/312 [===============>..............] - ETA: 4s - loss: 1.1366 - accuracy: 0.5936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015173/312 [===============>..............] - ETA: 4s - loss: 1.1365 - accuracy: 0.5936#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015175/312 [===============>..............] - ETA: 4s - loss: 1.1363 - accuracy: 0.5937#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015177/312 [================>.............] - ETA: 3s - loss: 1.1361 - accuracy: 0.5937#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015179/312 [================>.............] - ETA: 3s - loss: 1.1359 - accuracy: 0.5937#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015181/312 [================>.............] - ETA: 3s - loss: 1.1357 - accuracy: 0.5938#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015183/312 [================>.............] - ETA: 3s - loss: 1.1355 - accuracy: 0.5938#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015185/312 [================>.............] - ETA: 3s - loss: 1.1353 - accuracy: 0.5939#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015187/312 [================>.............] - ETA: 3s - loss: 1.1351 - accuracy: 0.5939#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015189/312 [=================>............] - ETA: 3s - loss: 1.1349 - accuracy: 0.5939#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015191/312 [=================>............] - ETA: 3s - loss: 1.1348 - accuracy: 0.5940#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015193/312 [=================>............] - ETA: 3s - loss: 1.1346 - accuracy: 0.5940#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010\u001b[0m\n\u001b[34m#010#010#010#010#010#010#010#010#010#015195/312 [=================>............] - ETA: 3s - loss: 1.1344 - accuracy: 0.5941#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015197/312 [=================>............] - ETA: 3s - loss: 1.1342 - accuracy: 0.5941#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015199/312 [==================>...........] - ETA: 3s - loss: 1.1340 - accuracy: 0.5942#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015201/312 [==================>...........] - ETA: 3s - loss: 1.1338 - accuracy: 0.5942#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015203/312 [==================>...........] - ETA: 3s - loss: 1.1337 - accuracy: 0.5943#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015205/312 [==================>...........] - ETA: 3s - loss: 1.1335 - accuracy: 0.5943#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015207/312 [==================>...........] - ETA: 3s - loss: 1.1333 - accuracy: 0.5944#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015209/312 [===================>..........] - ETA: 3s - loss: 1.1331 - accuracy: 0.5944#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015211/312 [===================>..........] - ETA: 2s - loss: 1.1330 - accuracy: 0.5944#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015213/312 [===================>..........] - ETA: 2s - loss: 1.1328 - accuracy: 0.5945#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015215/312 [===================>..........] - ETA: 2s - loss: 1.1326 - accuracy: 0.5945#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015217/312 [===================>..........] - ETA: 2s - loss: 1.1324 - accuracy: 0.5946#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015219/312 [====================>.........] - ETA: 2s - loss: 1.1322 - accuracy: 0.5946#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015221/312 [====================>.........] - ETA: 2s - loss: 1.1320 - accuracy: 0.5947#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015223/312 [====================>.........] - ETA: 2s - loss: 1.1318 - accuracy: 0.5947#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015225/312 [====================>.........] - ETA: 2s - loss: 1.1317 - accuracy: 0.5948#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015227/312 [====================>.........] - ETA: 2s - loss: 1.1315 - accuracy: 0.5948#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015229/312 [=====================>........] - ETA: 2s - loss: 1.1313 - accuracy: 0.5949#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015231/312 [=====================>........] - ETA: 2s - loss: 1.1311 - accuracy: 0.5949#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015233/312 [=====================>........] - ETA: 2s - loss: 1.1309 - accuracy: 0.5950#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015235/312 [=====================>........] - ETA: 2s - loss: 1.1307 - accuracy: 0.5950#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015237/312 [=====================>........] - ETA: 2s - loss: 1.1305 - accuracy: 0.5951#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015239/312 [=====================>........] - ETA: 2s - loss: 1.1303 - accuracy: 0.5951#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015241/312 [======================>.......] - ETA: 2s - loss: 1.1301 - accuracy: 0.5952#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015243/312 [======================>.......] - ETA: 2s - loss: 1.1300 - accuracy: 0.5952#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015245/312 [======================>.......] - ETA: 1s - loss: 1.1298 - accuracy: 0.5953#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015247/312 [======================>.......] - ETA: 1s - loss: 1.1296 - accuracy: 0.5954#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015249/312 [======================>.......] - ETA: 1s - loss: 1.1294 - accuracy: 0.5954#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015251/312 [=======================>......] - ETA: 1s - loss: 1.1292 - accuracy: 0.5955#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015253/312 [=======================>......] - ETA: 1s - loss: 1.1290 - accuracy: 0.5955#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015255/312 [=======================>......] - ETA: 1s - loss: 1.1289 - accuracy: 0.5956#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015257/312 [=======================>......] - ETA: 1s - loss: 1.1287 - accuracy: 0.5956#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015259/312 [=======================>......] - ETA: 1s - loss: 1.1285 - accuracy: 0.5957#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015261/312 [========================>.....] - ETA: 1s - loss: 1.1283 - accuracy: 0.5957#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015263/312 [========================>.....] - ETA: 1s - loss: 1.1281 - accuracy: 0.5958#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015265/312 [========================>.....] - ETA: 1s - loss: 1.1280 - accuracy: 0.5958#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015267/312 [========================>.....] - ETA: 1s - loss: 1.1278 - accuracy: 0.5959#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015269/312 [========================>.....] - ETA: 1s - loss: 1.1276 - accuracy: 0.5959#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015271/312 [=========================>....] - ETA: 1s - loss: 1.1274 - accuracy: 0.5960#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015273/312 [=========================>....] - ETA: 1s - loss: 1.1272 - accuracy: 0.5961#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015275/312 [=========================>....] - ETA: 1s - loss: 1.1270 - accuracy: 0.5961#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015277/312 [=========================>....] - ETA: 1s - loss: 1.1269 - accuracy: 0.5962#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015279/312 [=========================>....] - ETA: 0s - loss: 1.1267 - accuracy: 0.5962#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015281/312 [==========================>...] - ETA: 0s - loss: 1.1265 - accuracy: 0.5963#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015283/312 [==========================>...] - ETA: 0s - loss: 1.1263 - accuracy: 0.5963#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015285/312 [==========================>...] - ETA: 0s - loss: 1.1261 - accuracy: 0.5964#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015287/312 [==========================>...] - ETA: 0s - loss: 1.1260 - accuracy: 0.5964#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015289/312 [==========================>...] - ETA: 0s - loss: 1.1258 - accuracy: 0.5965#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015291/312 [==========================>...] - ETA: 0s - loss: 1.1256 - accuracy: 0.5966#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015293/312 [===========================>..] - ETA: 0s - loss: 1.1254 - accuracy: 0.5966#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015295/312 [===========================>..] - ETA: 0s - loss: 1.1252 - accuracy: 0.5967#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015297/312 [===========================>..] - ETA: 0s - loss: 1.1250 - accuracy: 0.5967#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015299/312 [===========================>..] - ETA: 0s - loss: 1.1248 - accuracy: 0.5968#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015301/312 [===========================>..] - ETA: 0s - loss: 1.1246 - accuracy: 0.5969#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015303/312 [============================>.] - ETA: 0s - loss: 1.1245 - accuracy: 0.5969#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015305/312 [============================>.] - ETA: 0s - loss: 1.1243 - accuracy: 0.5970#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015307/312 [============================>.] - ETA: 0s - loss: 1.1241 - accuracy: 0.5970#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015309/312 [============================>.] - ETA: 0s - loss: 1.1239 - accuracy: 0.5971#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015311/312 [============================>.] - ETA: 0s - loss: 1.1237 - accuracy: 0.5972#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015312/312 [==============================] - 10s 32ms/step - loss: 1.1236 - accuracy: 0.5972 - val_loss: 1.1507 - val_accuracy: 0.5925\u001b[0m\n\u001b[34mEpoch 5/5\u001b[0m\n\u001b[34m#015 1/312 [..............................] - ETA: 8s - loss: 1.1089 - accuracy: 0.5703#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 3/312 [..............................] - ETA: 9s - loss: 1.0939 - accuracy: 0.5924#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 5/312 [..............................] - ETA: 8s - loss: 1.0874 - accuracy: 0.5989#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 7/312 [..............................] - ETA: 8s - loss: 1.0759 - accuracy: 0.6038#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 9/312 [..............................] - ETA: 8s - loss: 1.0646 - accuracy: 0.6089#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 11/312 [>.............................] - ETA: 8s - loss: 1.0546 - accuracy: 0.6136#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 13/312 [>.............................] - ETA: 8s - loss: 1.0504 - accuracy: 0.6157#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 15/312 [>.............................] - ETA: 8s - loss: 1.0502 - accuracy: 0.6167#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 17/312 [>.............................] - ETA: 8s - loss: 1.0492 - accuracy: 0.6178#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 19/312 [>.............................] - ETA: 8s - loss: 1.0478 - accuracy: 0.6189#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 21/312 [=>............................] - ETA: 8s - loss: 1.0466 - accuracy: 0.6197#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 23/312 [=>............................] - ETA: 8s - loss: 1.0456 - accuracy: 0.6204#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 25/312 [=>............................] - ETA: 8s - loss: 1.0443 - accuracy: 0.6212#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 27/312 [=>............................] - ETA: 8s - loss: 1.0431 - accuracy: 0.6219#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 29/312 [=>............................] - ETA: 8s - loss: 1.0419 - accuracy: 0.6226#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 31/312 [=>............................] - ETA: 8s - loss: 1.0412 - accuracy: 0.6232#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 33/312 [==>...........................] - ETA: 8s - loss: 1.0409 - accuracy: 0.6237#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 35/312 [==>...........................] - ETA: 8s - loss: 1.0405 - accuracy: 0.6241#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 37/312 [==>...........................] - ETA: 8s - loss: 1.0402 - accuracy: 0.6245#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 39/312 [==>...........................] - ETA: 7s - loss: 1.0398 - accuracy: 0.6248#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 41/312 [==>...........................] - ETA: 7s - loss: 1.0393 - accuracy: 0.6251#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 43/312 [===>..........................] - ETA: 7s - loss: 1.0390 - accuracy: 0.6253#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 45/312 [===>..........................] - ETA: 7s - loss: 1.0387 - accuracy: 0.6255#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 47/312 [===>..........................] - ETA: 7s - loss: 1.0384 - accuracy: 0.6256#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 49/312 [===>..........................] - ETA: 7s - loss: 1.0384 - accuracy: 0.6256#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 51/312 [===>..........................] - ETA: 7s - loss: 1.0385 - accuracy: 0.6256#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 53/312 [====>.........................] - ETA: 7s - loss: 1.0386 - accuracy: 0.6257#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 55/312 [====>.........................] - ETA: 7s - loss: 1.0386 - accuracy: 0.6257#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 57/312 [====>.........................] - ETA: 7s - loss: 1.0387 - accuracy: 0.6258#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 59/312 [====>.........................] - ETA: 7s - loss: 1.0388 - accuracy: 0.6258#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 61/312 [====>.........................] - ETA: 7s - loss: 1.0389 - accuracy: 0.6258#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 63/312 [=====>........................] - ETA: 7s - loss: 1.0389 - accuracy: 0.6258#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 65/312 [=====>........................] - ETA: 7s - loss: 1.0389 - accuracy: 0.6258#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 67/312 [=====>........................] - ETA: 7s - loss: 1.0389 - accuracy: 0.6259#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 69/312 [=====>........................] - ETA: 7s - loss: 1.0388 - accuracy: 0.6260#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 71/312 [=====>........................] - ETA: 7s - loss: 1.0387 - accuracy: 0.6260#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 73/312 [======>.......................] - ETA: 6s - loss: 1.0385 - accuracy: 0.6261#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 75/312 [======>.......................] - ETA: 6s - loss: 1.0384 - accuracy: 0.6262#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 77/312 [======>.......................] - ETA: 6s - loss: 1.0383 - accuracy: 0.6263#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 79/312 [======>.......................] - ETA: 6s - loss: 1.0381 - accuracy: 0.6264#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 81/312 [======>.......................] - ETA: 6s - loss: 1.0380 - accuracy: 0.6264#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 83/312 [======>.......................] - ETA: 6s - loss: 1.0379 - accuracy: 0.6265#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 85/312 [=======>......................] - ETA: 6s - loss: 1.0377 - accuracy: 0.6266#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 87/312 [=======>......................] - ETA: 6s - loss: 1.0376 - accuracy: 0.6266#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 89/312 [=======>......................] - ETA: 6s - loss: 1.0375 - accuracy: 0.6266#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 91/312 [=======>......................] - ETA: 6s - loss: 1.0374 - accuracy: 0.6267#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 93/312 [=======>......................] - ETA: 6s - loss: 1.0373 - accuracy: 0.6267#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 95/312 [========>.....................] - ETA: 6s - loss: 1.0371 - accuracy: 0.6268#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 97/312 [========>.....................] - ETA: 6s - loss: 1.0370 - accuracy: 0.6268#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 99/312 [========>.....................] - ETA: 6s - loss: 1.0369 - accuracy: 0.6268#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015101/312 [========>.....................] - ETA: 6s - loss: 1.0368 - accuracy: 0.6268#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015103/312 [========>.....................] - ETA: 6s - loss: 1.0367 - accuracy: 0.6269#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015105/312 [=========>....................] - ETA: 6s - loss: 1.0367 - accuracy: 0.6269#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015107/312 [=========>....................] - ETA: 5s - loss: 1.0366 - accuracy: 0.6269#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015109/312 [=========>....................] - ETA: 5s - loss: 1.0365 - accuracy: 0.6269#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015111/312 [=========>....................] - ETA: 5s - loss: 1.0364 - accuracy: 0.6270#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015113/312 [=========>....................] - ETA: 5s - loss: 1.0363 - accuracy: 0.6270#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015115/312 [==========>...................] - ETA: 5s - loss: 1.0361 - accuracy: 0.6271#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015117/312 [==========>...................] - ETA: 5s - loss: 1.0359 - accuracy: 0.6271#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015119/312 [==========>...................] - ETA: 5s - loss: 1.0358 - accuracy: 0.6271#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015121/312 [==========>...................] - ETA: 5s - loss: 1.0355 - accuracy: 0.6272#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015123/312 [==========>...................] - ETA: 5s - loss: 1.0354 - accuracy: 0.6273#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015125/312 [===========>..................] - ETA: 5s - loss: 1.0352 - accuracy: 0.6273#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015127/312 [===========>..................] - ETA: 5s - loss: 1.0350 - accuracy: 0.6274#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015129/312 [===========>..................] - ETA: 5s - loss: 1.0348 - accuracy: 0.6275#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015131/312 [===========>..................] - ETA: 5s - loss: 1.0346 - accuracy: 0.6276#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015133/312 [===========>..................] - ETA: 5s - loss: 1.0344 - accuracy: 0.6277#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015135/312 [===========>..................] - ETA: 5s - loss: 1.0342 - accuracy: 0.6277#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015137/312 [============>.................] - ETA: 5s - loss: 1.0340 - accuracy: 0.6278#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015139/312 [============>.................] - ETA: 5s - loss: 1.0338 - accuracy: 0.6279#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015141/312 [============>.................] - ETA: 4s - loss: 1.0336 - accuracy: 0.6279#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015143/312 [============>.................] - ETA: 4s - loss: 1.0334 - accuracy: 0.6280#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015145/312 [============>.................] - ETA: 4s - loss: 1.0333 - accuracy: 0.6281#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015147/312 [=============>................] - ETA: 4s - loss: 1.0331 - accuracy: 0.6281#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015149/312 [=============>................] - ETA: 4s - loss: 1.0329 - accuracy: 0.6282#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015151/312 [=============>................] - ETA: 4s - loss: 1.0327 - accuracy: 0.6282#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015153/312 [=============>................] - ETA: 4s - loss: 1.0325 - accuracy: 0.6283#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015155/312 [=============>................] - ETA: 4s - loss: 1.0323 - accuracy: 0.6284#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015157/312 [==============>...............] - ETA: 4s - loss: 1.0321 - accuracy: 0.6284#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015159/312 [==============>...............] - ETA: 4s - loss: 1.0319 - accuracy: 0.6285#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015161/312 [==============>...............] - ETA: 4s - loss: 1.0317 - accuracy: 0.6285#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015163/312 [==============>...............] - ETA: 4s - loss: 1.0315 - accuracy: 0.6286#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015165/312 [==============>...............] - ETA: 4s - loss: 1.0313 - accuracy: 0.6286#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015167/312 [===============>..............] - ETA: 4s - loss: 1.0311 - accuracy: 0.6287#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015169/312 [===============>..............] - ETA: 4s - loss: 1.0309 - accuracy: 0.6287#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015171/312 [===============>..............] - ETA: 4s - loss: 1.0308 - accuracy: 0.6288#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015173/312 [===============>..............] - ETA: 4s - loss: 1.0306 - accuracy: 0.6288#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015175/312 [===============>..............] - ETA: 3s - loss: 1.0305 - accuracy: 0.6289#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015177/312 [================>.............] - ETA: 3s - loss: 1.0303 - accuracy: 0.6289#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015179/312 [================>.............] - ETA: 3s - loss: 1.0302 - accuracy: 0.6289#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015181/312 [================>.............] - ETA: 3s - loss: 1.0300 - accuracy: 0.6290#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015183/312 [================>.............] - ETA: 3s - loss: 1.0299 - accuracy: 0.6290#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015185/312 [================>.............] - ETA: 3s - loss: 1.0297 - accuracy: 0.6291#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015187/312 [================>.............] - ETA: 3s - loss: 1.0296 - accuracy: 0.6291#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015189/312 [=================>............] - ETA: 3s - loss: 1.0294 - accuracy: 0.6292#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015191/312 [=================>............] - ETA: 3s - loss: 1.0292 - accuracy: 0.6292#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015193/312 [=================>............] - ETA: 3s - loss: 1.0291 - accuracy: 0.6293#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010\u001b[0m\n\u001b[34m#010#010#010#010#010#010#010#010#010#015195/312 [=================>............] - ETA: 3s - loss: 1.0289 - accuracy: 0.6293#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015197/312 [=================>............] - ETA: 3s - loss: 1.0288 - accuracy: 0.6294#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015199/312 [==================>...........] - ETA: 3s - loss: 1.0286 - accuracy: 0.6294#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015201/312 [==================>...........] - ETA: 3s - loss: 1.0285 - accuracy: 0.6295#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015203/312 [==================>...........] - ETA: 3s - loss: 1.0283 - accuracy: 0.6296#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015205/312 [==================>...........] - ETA: 3s - loss: 1.0281 - accuracy: 0.6296#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015207/312 [==================>...........] - ETA: 3s - loss: 1.0280 - accuracy: 0.6297#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015209/312 [===================>..........] - ETA: 2s - loss: 1.0279 - accuracy: 0.6297#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015211/312 [===================>..........] - ETA: 2s - loss: 1.0277 - accuracy: 0.6298#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015213/312 [===================>..........] - ETA: 2s - loss: 1.0276 - accuracy: 0.6298#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015215/312 [===================>..........] - ETA: 2s - loss: 1.0275 - accuracy: 0.6299#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015217/312 [===================>..........] - ETA: 2s - loss: 1.0273 - accuracy: 0.6299#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015219/312 [====================>.........] - ETA: 2s - loss: 1.0272 - accuracy: 0.6300#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015221/312 [====================>.........] - ETA: 2s - loss: 1.0271 - accuracy: 0.6300#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015223/312 [====================>.........] - ETA: 2s - loss: 1.0270 - accuracy: 0.6301#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015225/312 [====================>.........] - ETA: 2s - loss: 1.0268 - accuracy: 0.6302#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015227/312 [====================>.........] - ETA: 2s - loss: 1.0267 - accuracy: 0.6302#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015229/312 [=====================>........] - ETA: 2s - loss: 1.0266 - accuracy: 0.6303#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015231/312 [=====================>........] - ETA: 2s - loss: 1.0264 - accuracy: 0.6303#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015233/312 [=====================>........] - ETA: 2s - loss: 1.0263 - accuracy: 0.6304#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015235/312 [=====================>........] - ETA: 2s - loss: 1.0262 - accuracy: 0.6304#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015237/312 [=====================>........] - ETA: 2s - loss: 1.0260 - accuracy: 0.6305#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015239/312 [=====================>........] - ETA: 2s - loss: 1.0259 - accuracy: 0.6306#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015241/312 [======================>.......] - ETA: 2s - loss: 1.0257 - accuracy: 0.6306#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015243/312 [======================>.......] - ETA: 2s - loss: 1.0256 - accuracy: 0.6307#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015245/312 [======================>.......] - ETA: 1s - loss: 1.0254 - accuracy: 0.6307#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015247/312 [======================>.......] - ETA: 1s - loss: 1.0253 - accuracy: 0.6308#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015249/312 [======================>.......] - ETA: 1s - loss: 1.0251 - accuracy: 0.6309#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015251/312 [=======================>......] - ETA: 1s - loss: 1.0250 - accuracy: 0.6309#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015253/312 [=======================>......] - ETA: 1s - loss: 1.0248 - accuracy: 0.6310#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015255/312 [=======================>......] - ETA: 1s - loss: 1.0247 - accuracy: 0.6311#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015257/312 [=======================>......] - ETA: 1s - loss: 1.0245 - accuracy: 0.6311#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015259/312 [=======================>......] - ETA: 1s - loss: 1.0243 - accuracy: 0.6312#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015261/312 [========================>.....] - ETA: 1s - loss: 1.0242 - accuracy: 0.6313#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015263/312 [========================>.....] - ETA: 1s - loss: 1.0240 - accuracy: 0.6313#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015265/312 [========================>.....] - ETA: 1s - loss: 1.0239 - accuracy: 0.6314#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015267/312 [========================>.....] - ETA: 1s - loss: 1.0237 - accuracy: 0.6314#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015269/312 [========================>.....] - ETA: 1s - loss: 1.0236 - accuracy: 0.6315#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015271/312 [=========================>....] - ETA: 1s - loss: 1.0235 - accuracy: 0.6316#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015273/312 [=========================>....] - ETA: 1s - loss: 1.0233 - accuracy: 0.6316#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015275/312 [=========================>....] - ETA: 1s - loss: 1.0232 - accuracy: 0.6317#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015277/312 [=========================>....] - ETA: 1s - loss: 1.0230 - accuracy: 0.6317#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015279/312 [=========================>....] - ETA: 0s - loss: 1.0229 - accuracy: 0.6318#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015281/312 [==========================>...] - ETA: 0s - loss: 1.0227 - accuracy: 0.6319#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015283/312 [==========================>...] - ETA: 0s - loss: 1.0226 - accuracy: 0.6319#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015285/312 [==========================>...] - ETA: 0s - loss: 1.0224 - accuracy: 0.6320#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015287/312 [==========================>...] - ETA: 0s - loss: 1.0223 - accuracy: 0.6321#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015289/312 [==========================>...] - ETA: 0s - loss: 1.0221 - accuracy: 0.6321#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015291/312 [==========================>...] - ETA: 0s - loss: 1.0220 - accuracy: 0.6322#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015293/312 [===========================>..] - ETA: 0s - loss: 1.0219 - accuracy: 0.6323#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015295/312 [===========================>..] - ETA: 0s - loss: 1.0217 - accuracy: 0.6323#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015297/312 [===========================>..] - ETA: 0s - loss: 1.0216 - accuracy: 0.6324#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015299/312 [===========================>..] - ETA: 0s - loss: 1.0214 - accuracy: 0.6325#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015301/312 [===========================>..] - ETA: 0s - loss: 1.0213 - accuracy: 0.6325#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015303/312 [============================>.] - ETA: 0s - loss: 1.0211 - accuracy: 0.6326#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015305/312 [============================>.] - ETA: 0s - loss: 1.0210 - accuracy: 0.6326#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015307/312 [============================>.] - ETA: 0s - loss: 1.0208 - accuracy: 0.6327#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015309/312 [============================>.] - ETA: 0s - loss: 1.0207 - accuracy: 0.6328#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015311/312 [============================>.] - ETA: 0s - loss: 1.0205 - accuracy: 0.6328#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015312/312 [==============================] - 10s 31ms/step - loss: 1.0204 - accuracy: 0.6329 - val_loss: 0.9505 - val_accuracy: 0.6659\u001b[0m\n\n2021-10-11 10:18:41 Uploading - Uploading generated training model\n2021-10-11 10:18:41 Completed - Training job completed\n\u001b[34m2021-10-11 10:17:06.915955: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\u001b[0m\n\u001b[34m2021-10-11 10:17:06.916101: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.\u001b[0m\n\u001b[34m2021-10-11 10:17:06.957001: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\u001b[0m\n\u001b[34mWARNING:tensorflow:Callback method `on_test_batch_end` is slow compared to the batch time (batch time: 0.0027s vs `on_test_batch_end` time: 0.0055s). Check your callbacks.\u001b[0m\n\u001b[34mWARNING:tensorflow:Callback method `on_test_batch_end` is slow compared to the batch time (batch time: 0.0027s vs `on_test_batch_end` time: 0.0055s). Check your callbacks.\u001b[0m\n\u001b[34m2021-10-11 10:18:22.170449: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.\u001b[0m\n\u001b[34mINFO:tensorflow:Assets written to: /opt/ml/model/1/assets\u001b[0m\n\u001b[34mINFO:tensorflow:Assets written to: /opt/ml/model/1/assets\n\u001b[0m\n\u001b[34m2021-10-11 10:18:27,253 sagemaker-training-toolkit INFO Reporting training SUCCESS\u001b[0m\nTraining seconds: 293\nBillable seconds: 293\n"
]
],
[
[
"# 6. 모델 아티펙트 저장\n- S3 에 저장된 모델 아티펙트를 저장하여 추론시 사용합니다.",
"_____no_output_____"
]
],
[
[
"keras_script_artifact_path = estimator.model_data\nprint(\"script_artifact_path: \", keras_script_artifact_path)\n\n%store keras_script_artifact_path",
"script_artifact_path: s3://sagemaker-us-east-1-227612457811/cifar10-2021-10-11-10-10-05-339/output/model.tar.gz\nStored 'keras_script_artifact_path' (str)\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7cd5802360d8f541c03111de76ab7c04d40e635 | 176,065 | ipynb | Jupyter Notebook | lab/notebooks_phase2/AddModel_simpleB_b5.ipynb | felipessalvatore/ContraQA | 6c4eb599df4c9a1dc3ac4250598e8b1b7cc1169d | [
"MIT"
]
| 1 | 2020-09-11T15:32:15.000Z | 2020-09-11T15:32:15.000Z | lab/notebooks_phase2/AddModel_simpleB_b5.ipynb | felipessalvatore/ContraQA | 6c4eb599df4c9a1dc3ac4250598e8b1b7cc1169d | [
"MIT"
]
| null | null | null | lab/notebooks_phase2/AddModel_simpleB_b5.ipynb | felipessalvatore/ContraQA | 6c4eb599df4c9a1dc3ac4250598e8b1b7cc1169d | [
"MIT"
]
| null | null | null | 108.214505 | 27,204 | 0.816653 | [
[
[
"# Add model: translation attention ecoder-decocer over the b4 dataset",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torchtext import data\nimport pandas as pd\nimport unicodedata\nimport string\nimport re\nimport random\nimport copy\nfrom contra_qa.plots.functions import simple_step_plot, plot_confusion_matrix\nimport matplotlib.pyplot as plt\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nfrom nltk.translate.bleu_score import sentence_bleu\n\n\n% matplotlib inline",
"_____no_output_____"
],
[
"import time\nimport math\n\n\ndef asMinutes(s):\n m = math.floor(s / 60)\n s -= m * 60\n return '%dm %ds' % (m, s)\n\n\ndef timeSince(since):\n now = time.time()\n s = now - since\n return '%s' % asMinutes(s)",
"_____no_output_____"
]
],
[
[
"### Preparing data",
"_____no_output_____"
]
],
[
[
"df2 = pd.read_csv(\"data/boolean5_train.csv\")\ndf2_test = pd.read_csv(\"data/boolean5_test.csv\")\n\ndf2[\"text\"] = df2[\"sentence1\"] + df2[\"sentence2\"] \ndf2_test[\"text\"] = df2_test[\"sentence1\"] + df2_test[\"sentence2\"] \n\nall_sentences = list(df2.text.values) + list(df2_test.text.values)\n\ndf2train = df2.iloc[:8500]\ndf2valid = df2.iloc[8500:]",
"_____no_output_____"
],
[
"df2train.tail()",
"_____no_output_____"
],
[
"SOS_token = 0\nEOS_token = 1\n\nclass Lang:\n def __init__(self, name):\n self.name = name\n self.word2index = {}\n self.word2count = {}\n self.index2word = {0: \"SOS\", 1: \"EOS\"}\n self.n_words = 2 # Count SOS and EOS\n\n def addSentence(self, sentence):\n for word in sentence.split(' '):\n self.addWord(word)\n\n def addWord(self, word):\n if word not in self.word2index:\n self.word2index[word] = self.n_words\n self.word2count[word] = 1\n self.index2word[self.n_words] = word\n self.n_words += 1\n else:\n self.word2count[word] += 1",
"_____no_output_____"
],
[
"# Turn a Unicode string to plain ASCII, thanks to\n# http://stackoverflow.com/a/518232/2809427\ndef unicodeToAscii(s):\n return ''.join(\n c for c in unicodedata.normalize('NFD', s)\n if unicodedata.category(c) != 'Mn')\n\n# Lowercase, trim, and remove non-letter characters\n\ndef normalizeString(s):\n s = unicodeToAscii(s.lower().strip())\n s = re.sub(r\"([.!?])\", r\" \\1\", s)\n s = re.sub(r\"[^a-zA-Z.!?]+\", r\" \", s)\n return s\n\n\nexample = \"ddddda'''~~çãpoeéééééÈ'''#$$##@!@!@AAS@#12323fdf\"\nprint(\"Before:\", example)\nprint()\nprint(\"After:\", normalizeString(example))",
"Before: ddddda'''~~çãpoeéééééÈ'''#$$##@!@!@AAS@#12323fdf\n\nAfter: ddddda capoeeeeeee ! ! aas fdf\n"
],
[
"pairs_A = list(zip(list(df2train.sentence1.values), list(df2train.and_A.values)))\npairs_B = list(zip(list(df2train.sentence1.values), list(df2train.and_B.values)))\npairs_A = [(normalizeString(s1), normalizeString(s2)) for s1, s2 in pairs_A]\npairs_B = [(normalizeString(s1), normalizeString(s2)) for s1, s2 in pairs_B]\npairs_A_val = list(zip(list(df2valid.sentence1.values), list(df2valid.and_A.values)))\npairs_B_val = list(zip(list(df2valid.sentence1.values), list(df2valid.and_B.values)))\npairs_A_val = [(normalizeString(s1), normalizeString(s2)) for s1, s2 in pairs_A_val]\npairs_B_val = [(normalizeString(s1), normalizeString(s2)) for s1, s2 in pairs_B_val]\n",
"_____no_output_____"
],
[
"all_text_pairs = zip(all_sentences, all_sentences)\nall_text_pairs = [(normalizeString(s1), normalizeString(s2)) for s1, s2 in all_text_pairs]",
"_____no_output_____"
],
[
"def readLangs(lang1, lang2, pairs, reverse=False):\n # Reverse pairs, make Lang instances\n if reverse:\n pairs = [tuple(reversed(p)) for p in pairs]\n input_lang = Lang(lang2)\n output_lang = Lang(lang1)\n else:\n input_lang = Lang(lang1)\n output_lang = Lang(lang2)\n\n return input_lang, output_lang, pairs",
"_____no_output_____"
],
[
"f = lambda x: len(x.split(\" \"))\n\nMAX_LENGTH = np.max(list(map(f, all_sentences)))",
"_____no_output_____"
],
[
"MAX_LENGTH = 20\ndef filterPair(p):\n cond1 = len(p[0].split(' ')) < MAX_LENGTH\n cond2 = len(p[1].split(' ')) < MAX_LENGTH \n return cond1 and cond2\n\ndef filterPairs(pairs):\n return [pair for pair in pairs if filterPair(pair)]\n",
"_____no_output_____"
],
[
"def prepareData(lang1, lang2, pairs, reverse=False):\n input_lang, output_lang, pairs = readLangs(lang1, lang2, pairs, reverse)\n print(\"Read %s sentence pairs\" % len(pairs))\n pairs = filterPairs(pairs)\n print(\"Trimmed to %s sentence pairs\" % len(pairs))\n print(\"Counting words...\")\n for pair in pairs:\n input_lang.addSentence(pair[0])\n output_lang.addSentence(pair[1])\n print(\"Counted words:\")\n print(input_lang.name, input_lang.n_words)\n print(output_lang.name, output_lang.n_words)\n return input_lang, output_lang, pairs",
"_____no_output_____"
],
[
"_, _, training_pairs_A = prepareData(\"eng_enc\",\n \"eng_dec\",\n pairs_A)\n\nprint()\n\n\ninput_lang, _, _ = prepareData(\"eng_enc\",\n \"eng_dec\",\n all_text_pairs)\n\noutput_lang = copy.deepcopy(input_lang)\n\nprint()\n\nprint()\n_, _, valid_pairs_A = prepareData(\"eng_enc\",\n \"eng_dec\",\n pairs_A_val)",
"Read 8500 sentence pairs\nTrimmed to 8500 sentence pairs\nCounting words...\nCounted words:\neng_enc 773\neng_dec 772\n\nRead 11000 sentence pairs\nTrimmed to 11000 sentence pairs\nCounting words...\nCounted words:\neng_enc 776\neng_dec 776\n\n\nRead 1500 sentence pairs\nTrimmed to 1500 sentence pairs\nCounting words...\nCounted words:\neng_enc 701\neng_dec 700\n"
],
[
"_, _, training_pairs_B = prepareData(\"eng_enc\",\n \"eng_dec\",\n pairs_B)\nprint()\n_, _, valid_pairs_B = prepareData(\"eng_enc\",\n \"eng_dec\",\n pairs_B_val)",
"Read 8500 sentence pairs\nTrimmed to 8500 sentence pairs\nCounting words...\nCounted words:\neng_enc 773\neng_dec 772\n\nRead 1500 sentence pairs\nTrimmed to 1500 sentence pairs\nCounting words...\nCounted words:\neng_enc 701\neng_dec 700\n"
]
],
[
[
"### sentences 2 tensors",
"_____no_output_____"
]
],
[
[
"def indexesFromSentence(lang, sentence):\n return [lang.word2index[word] for word in sentence.split(' ')]",
"_____no_output_____"
],
[
"def tensorFromSentence(lang, sentence):\n indexes = indexesFromSentence(lang, sentence)\n indexes.append(EOS_token)\n return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)",
"_____no_output_____"
],
[
"def tensorsFromPair(pair):\n input_tensor = tensorFromSentence(input_lang, pair[0])\n target_tensor = tensorFromSentence(output_lang, pair[1])\n return (input_tensor, target_tensor)",
"_____no_output_____"
],
[
"def tensorsFromTriple(triple):\n input_tensor = tensorFromSentence(input_lang, triple[0])\n target_tensor = tensorFromSentence(output_lang, triple[1])\n label_tensor = torch.tensor(triple[2], dtype=torch.long).view((1))\n return (input_tensor, target_tensor, label_tensor)",
"_____no_output_____"
]
],
[
[
"### models",
"_____no_output_____"
]
],
[
[
"class EncoderRNN(nn.Module):\n def __init__(self, input_size, hidden_size):\n super(EncoderRNN, self).__init__()\n self.hidden_size = hidden_size\n self.embedding = nn.Embedding(input_size, hidden_size)\n self.gru = nn.GRU(hidden_size, hidden_size)\n\n def forward(self, input, hidden):\n embedded = self.embedding(input).view(1, 1, -1)\n output = embedded\n output, hidden = self.gru(output, hidden)\n return output, hidden\n\n def initHidden(self):\n return torch.zeros(1, 1, self.hidden_size, device=device)",
"_____no_output_____"
],
[
"class AttnDecoderRNN(nn.Module):\n def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):\n super(AttnDecoderRNN, self).__init__()\n self.hidden_size = hidden_size\n self.output_size = output_size\n self.dropout_p = dropout_p\n self.max_length = max_length\n\n self.embedding = nn.Embedding(self.output_size, self.hidden_size)\n self.attn = nn.Linear(self.hidden_size * 2, self.max_length)\n self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)\n self.dropout = nn.Dropout(self.dropout_p)\n self.gru = nn.GRU(self.hidden_size, self.hidden_size)\n self.out = nn.Linear(self.hidden_size, self.output_size)\n\n def forward(self, input, hidden, encoder_outputs):\n embedded = self.embedding(input).view(1, 1, -1)\n embedded = self.dropout(embedded)\n\n attn_weights = F.softmax(\n self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)\n attn_applied = torch.bmm(attn_weights.unsqueeze(0),\n encoder_outputs.unsqueeze(0))\n output = torch.cat((embedded[0], attn_applied[0]), 1)\n output = self.attn_combine(output).unsqueeze(0)\n\n output = F.relu(output)\n output, hidden = self.gru(output, hidden)\n\n output = F.log_softmax(self.out(output[0]), dim=1)\n return output, hidden, attn_weights\n\n def initHidden(self):\n return torch.zeros(1, 1, self.hidden_size, device=device)",
"_____no_output_____"
],
[
"hidden_size = 256\neng_enc_v_size = input_lang.n_words\neng_dec_v_size = output_lang.n_words",
"_____no_output_____"
],
[
"input_lang.n_words",
"_____no_output_____"
],
[
"encoderA = EncoderRNN(eng_enc_v_size, hidden_size)\ndecoderA = AttnDecoderRNN(hidden_size, eng_dec_v_size)\nencoderA.load_state_dict(torch.load(\"b5_encoder1_att.pkl\"))\ndecoderA.load_state_dict(torch.load(\"b5_decoder1_att.pkl\"))",
"_____no_output_____"
],
[
"encoderB = EncoderRNN(eng_enc_v_size, hidden_size)\ndecoderB = AttnDecoderRNN(hidden_size, eng_dec_v_size)\nencoderB.load_state_dict(torch.load(\"b5_encoder2_att.pkl\"))\ndecoderB.load_state_dict(torch.load(\"b5_decoder2_att.pkl\"))",
"_____no_output_____"
]
],
[
[
"## translating",
"_____no_output_____"
]
],
[
[
"def translate(encoder,\n decoder,\n sentence,\n max_length=MAX_LENGTH):\n with torch.no_grad():\n input_tensor = tensorFromSentence(input_lang, sentence)\n input_length = input_tensor.size()[0]\n encoder_hidden = encoder.initHidden()\n\n encoder_outputs = torch.zeros(\n max_length, encoder.hidden_size, device=device)\n\n for ei in range(input_length):\n encoder_output, encoder_hidden = encoder(input_tensor[ei],\n encoder_hidden)\n encoder_outputs[ei] += encoder_output[0, 0]\n\n decoder_input = torch.tensor([[SOS_token]], device=device) # SOS\n\n decoder_hidden = encoder_hidden\n\n decoded_words = []\n\n for di in range(max_length):\n decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)\n _, topone = decoder_output.data.topk(1)\n if topone.item() == EOS_token:\n decoded_words.append('<EOS>')\n break\n else:\n decoded_words.append(output_lang.index2word[topone.item()])\n\n decoder_input = topone.squeeze().detach()\n\n return \" \".join(decoded_words)",
"_____no_output_____"
]
],
[
[
"## translation of a trained model: and A",
"_____no_output_____"
]
],
[
[
"for t in training_pairs_A[0:3]:\n print(\"input_sentence : \" + t[0])\n neural_translation = translate(encoderA,\n decoderA,\n t[0],\n max_length=MAX_LENGTH)\n print(\"neural translation : \" + neural_translation)\n reference = t[1] + ' <EOS>'\n print(\"reference translation : \" + reference)\n reference = reference.split(\" \")\n candidate = neural_translation.split(\" \")\n score = sentence_bleu([reference], candidate)\n print(\"blue score = {:.2f}\".format(score))\n print()",
"input_sentence : jeffery created a silly and vast work of art\nneural translation : brenda created a blue work of art <EOS>\nreference translation : jeffery created a silly work of art <EOS>\nblue score = 0.41\n\ninput_sentence : hilda created a zealous and better work of art\nneural translation : brenda created a pitiful work of art <EOS>\nreference translation : hilda created a zealous work of art <EOS>\nblue score = 0.41\n\ninput_sentence : cheryl created an ugly and obedient work of art\nneural translation : brenda created an ugly work of art <EOS>\nreference translation : cheryl created an ugly work of art <EOS>\nblue score = 0.84\n\n"
]
],
[
[
"## translation of a trained model: and B",
"_____no_output_____"
]
],
[
[
"for t in training_pairs_B[0:3]:\n print(\"input_sentence : \" + t[0])\n neural_translation = translate(encoderB,\n decoderB,\n t[0],\n max_length=MAX_LENGTH)\n print(\"neural translation : \" + neural_translation)\n reference = t[1] + ' <EOS>'\n print(\"reference translation : \" + reference)\n reference = reference.split(\" \")\n candidate = neural_translation.split(\" \")\n score = sentence_bleu([reference], candidate)\n print(\"blue score = {:.2f}\".format(score))\n print()",
"input_sentence : jeffery created a silly and vast work of art\nneural translation : marion created a vast work of art <EOS>\nreference translation : jeffery created a vast work of art <EOS>\nblue score = 0.84\n\ninput_sentence : hilda created a zealous and better work of art\nneural translation : marion created a better work of art <EOS>\nreference translation : hilda created a better work of art <EOS>\nblue score = 0.84\n\ninput_sentence : cheryl created an ugly and obedient work of art\nneural translation : jessie created an obedient work of art <EOS>\nreference translation : cheryl created an obedient work of art <EOS>\nblue score = 0.84\n\n"
]
],
[
[
"## Defining the And model\n\nmodel inner working:\n\n- $s_1$ is the first sentence (e.g., 'penny is thankful and naomi is alive')\n\n- $s_2$ is the second sentence (e.g., 'penny is not alive')\n\n- $h_A = dec_{A}(enc_{A}(s_1, \\vec{0}))$\n\n- $h_B = dec_{B}(enc_{B}(s_1, \\vec{0}))$\n\n- $h_{inf} = \\sigma (W[h_A ;h_B] + b)$\n\n- $e = enc_{A}(s_2, h_{inf})$\n\n- $\\hat{y} = softmax(We + b)$",
"_____no_output_____"
]
],
[
[
"class AndModel(nn.Module):\n def __init__(self,\n encoderA,\n decoderA,\n encoderB,\n decoderB,\n hidden_size,\n output_size,\n max_length,\n input_lang,\n target_lang,\n SOS_token=0,\n EOS_token=1):\n super(AndModel, self).__init__()\n self.max_length = max_length\n self.hidden_size = hidden_size\n self.output_size = output_size\n self.encoderA = encoderA\n self.decoderA = decoderA\n self.encoderB = encoderB\n self.decoderB = decoderB\n self.input_lang = input_lang\n self.target_lang = target_lang\n self.SOS_token = SOS_token\n self.EOS_token = EOS_token\n self.fc_inf = nn.Linear(hidden_size * 2, hidden_size)\n self.fc_out = nn.Linear(hidden_size, output_size)\n \n \n def encode(self,\n sentence,\n encoder,\n is_tensor,\n hidden=None):\n if not is_tensor:\n input_tensor = tensorFromSentence(self.input_lang, sentence)\n else:\n input_tensor = sentence\n\n input_length = input_tensor.size()[0]\n \n if hidden is None:\n encoder_hidden = encoder.initHidden()\n else:\n encoder_hidden = hidden\n \n encoder_outputs = torch.zeros(self.max_length,\n encoder.hidden_size,\n device=device)\n \n for ei in range(input_length):\n encoder_output, encoder_hidden = encoder(input_tensor[ei],\n encoder_hidden)\n encoder_outputs[ei] += encoder_output[0, 0]\n \n self.encoder_outputs = encoder_outputs\n\n return encoder_hidden\n \n \n def decode(self,\n tensor,\n decoder,\n out_tensor):\n \n decoder_input = torch.tensor([[self.SOS_token]], device=device)\n decoder_hidden = tensor\n decoded_words = []\n\n for di in range(self.max_length):\n decoder_output, decoder_hidden, decoder_attention = decoder(\n decoder_input, decoder_hidden, self.encoder_outputs)\n _, topone = decoder_output.data.topk(1)\n if topone.item() == self.EOS_token:\n decoded_words.append('<EOS>')\n break\n else:\n decoded_words.append(self.target_lang.index2word[topone.item()])\n\n decoder_input = topone.squeeze().detach()\n \n if not out_tensor:\n output = \" \".join(decoded_words)\n else:\n output = decoder_hidden\n\n return output\n \n def sen2vec(self, sentence, encoder, decoder, is_tensor, out_tensor):\n encoded = self.encode(sentence, encoder, is_tensor)\n vec = self.decode(encoded, decoder, out_tensor)\n return vec\n \n def sen2vecA(self, sentence, is_tensor):\n encoded = self.encode(sentence, self.encoderA, is_tensor)\n vec = self.decode(encoded, self.decoderA, out_tensor=True)\n return vec\n \n def sen2vecB(self, sentence, is_tensor):\n encoded = self.encode(sentence, self.encoderB, is_tensor)\n vec = self.decode(encoded, self.decoderB, out_tensor=True)\n return vec\n \n def forward(self, s1, s2):\n hA = self.sen2vecA(s1, is_tensor=True)\n hB = self.sen2vecB(s1, is_tensor=True)\n# h_inf = torch.cat([hA, hB], dim=2).squeeze(1)\n# h_inf = torch.sigmoid(self.fc_inf(h_inf))\n# h_inf = h_inf.view((1, h_inf.shape[0], h_inf.shape[1])) \n h_inf = hA\n e = self.encode(s2,\n self.encoderA,\n hidden=h_inf,\n is_tensor=True)\n output = self.fc_out(e).squeeze(1)\n \n return output\n \n\n def predict(self, s1, s2):\n out = self.forward(s1, s2)\n softmax = nn.Softmax(dim=1)\n out = softmax(out)\n indices = torch.argmax(out, 1)\n return indices\n\n \n",
"_____no_output_____"
],
[
"addmodel = AndModel(encoderA,\n decoderA,\n encoderB,\n decoderB,\n hidden_size=256,\n output_size=2,\n max_length=MAX_LENGTH,\n input_lang=input_lang,\n target_lang=output_lang)",
"_____no_output_____"
]
],
[
[
"Test encoding decoding",
"_____no_output_____"
]
],
[
[
"for ex in training_pairs_B[0:3]:\n print(\"===========\")\n ex = ex[0]\n print(\"s1:\\n\")\n print(ex)\n print()\n\n \n ex_A = addmodel.sen2vec(ex,\n addmodel.encoderA,\n addmodel.decoderA,\n is_tensor=False,\n out_tensor=False)\n \n ex_B = addmodel.sen2vec(ex,\n addmodel.encoderB,\n addmodel.decoderB,\n is_tensor=False,\n out_tensor=False)\n\n print(\"inference A:\\n\")\n print(ex_A)\n print()\n print(\"inference B:\\n\")\n print(ex_B)",
"===========\ns1:\n\njeffery created a silly and vast work of art\n\ninference A:\n\nbrenda created a blue work of art <EOS>\n\ninference B:\n\nmarion created a vast work of art <EOS>\n===========\ns1:\n\nhilda created a zealous and better work of art\n\ninference A:\n\nbrenda created a pitiful work of art <EOS>\n\ninference B:\n\nmarion created a better work of art <EOS>\n===========\ns1:\n\ncheryl created an ugly and obedient work of art\n\ninference A:\n\nbrenda created an ugly work of art <EOS>\n\ninference B:\n\njessie created an obedient work of art <EOS>\n"
],
[
"for ex in training_pairs_B[0:1]:\n print(\"===========\")\n ex = ex[0]\n print(\"s1:\\n\")\n print(ex)\n print()\n\n ex_A = addmodel.sen2vecA(ex,is_tensor=False)\n ex_B = addmodel.sen2vecB(ex,is_tensor=False)\n \n print(ex_A)\n print()\n print(ex_B)",
"===========\ns1:\n\njeffery created a silly and vast work of art\n\ntensor([[[ 0.4644, -0.9722, -0.9057, 0.7538, 0.9068, 0.3098, 0.9091,\n 0.0894, -0.4915, 0.9366, -0.9717, 0.9378, 0.0168, -0.7900,\n -0.8559, -0.5751, 0.9745, -0.9347, -0.9504, 0.9526, 0.6295,\n 0.9573, 0.9876, 0.2444, 0.9188, 0.9903, 0.9832, 0.4486,\n 0.8237, 0.2145, -0.8022, -0.8897, 0.9811, 0.8324, -0.9019,\n 0.9322, 0.9126, -0.3876, -0.8967, 0.7525, -0.2460, -0.7099,\n 0.9754, -0.1871, -0.9535, 0.1064, 0.3144, -0.9186, 0.0988,\n -0.9124, 0.4662, 0.8515, 0.9006, 0.7455, -0.1537, -0.5813,\n 0.9617, 0.9486, 0.9551, -0.9615, -0.9407, -0.8111, -0.9703,\n -0.9494, -0.7786, -0.9295, 0.6681, 0.6450, -0.9574, -0.9312,\n -0.7870, 0.6602, 0.9516, 0.7669, 0.9888, 0.0739, -0.9854,\n 0.5087, -0.5664, -0.8989, 0.6182, -0.5060, 0.9512, -0.8433,\n -0.9600, -0.3974, -0.9314, -0.3198, 0.8349, -0.9792, -0.6238,\n -0.9714, -0.6386, -0.7133, -0.4722, 0.8459, 0.9795, -0.8968,\n -0.8265, 0.9910, 0.0543, 0.9317, -0.7925, -0.8815, 0.5672,\n -0.8361, 0.4211, -0.9909, 0.8822, -0.9979, -0.0763, 0.9339,\n 0.2516, -0.9539, -0.7562, 0.5102, -0.8825, -0.9316, -0.1524,\n -0.8968, 0.4289, 0.3486, -0.9265, 0.9527, 0.8994, -0.8939,\n 0.8025, -0.1173, -0.4432, -0.9620, -0.7479, 0.9700, 0.9170,\n -0.7579, 0.1905, 0.4195, 0.9963, 0.4132, 0.9882, -0.9976,\n -0.9233, 0.3337, 0.9922, -0.4225, -0.9452, -0.1976, 0.8840,\n 0.7183, -0.9868, 0.9724, -0.5853, 0.7327, 0.9578, -0.7729,\n 0.9189, 0.9609, -0.9378, 0.7782, 0.0493, 0.9077, -0.8714,\n -0.9009, 0.9845, 0.9972, 0.7458, 0.9317, -0.8661, -0.8904,\n -0.7382, 0.9512, 0.8908, -0.3146, 0.9862, 0.9856, -0.9323,\n -0.9566, 0.1387, -0.9501, 0.7654, -0.0156, -0.9104, 0.7189,\n -0.9099, 0.6207, 0.8960, 0.3893, -0.9541, 0.9814, -0.9655,\n -0.0350, -0.8892, -0.5666, 0.9734, 0.9237, 0.0827, 0.3984,\n 0.9564, 0.5412, -0.9954, -0.6801, 0.9831, -0.9863, -0.6405,\n -0.9171, 0.7795, 0.9917, -0.9963, -0.8782, 0.0064, -0.9136,\n 0.5680, 0.9299, 0.3436, -0.9500, -0.8213, 0.0745, -0.7070,\n 0.5790, -0.9275, -0.7071, 0.6410, -0.9189, -0.0683, 0.8072,\n -0.5207, 0.8435, -0.9175, -0.2262, 0.9342, 0.8970, -0.9730,\n 0.9980, -0.4931, 0.8275, 0.7794, -0.8533, 0.9565, 0.7656,\n -0.5152, 0.9490, -0.0400, -0.9140, 0.8791, -0.9007, -0.3982,\n 0.7099, -0.6294, 0.9956, 0.2133, 0.5328, -0.9845, -0.6610,\n 0.8029, -0.6777, 0.7187, 0.9749]]], grad_fn=<ViewBackward>)\n\ntensor([[[ 0.6615, 0.4582, -0.3529, 0.3883, 0.8898, 0.9835, -0.9318,\n -0.9953, -0.5572, -0.8072, -0.5363, -0.2770, 0.9027, -0.8874,\n -0.8490, 0.7664, -0.6025, -0.5675, 0.6740, 0.0966, 0.7467,\n 0.3790, -0.9043, -0.9954, -0.7201, 0.4530, -0.9078, 0.5072,\n 0.8245, 0.0386, 0.9160, 0.9547, 0.9117, 0.8145, 0.9097,\n 0.4660, -0.8212, -0.8764, 0.0393, 0.9056, -0.6156, 0.5918,\n 0.8990, 0.9296, 0.7971, 0.1950, 0.1816, 0.4875, -0.9814,\n -0.6117, -0.2696, -0.4585, 0.7613, 0.4128, 0.4253, 0.5772,\n -0.9019, -0.8445, -0.9694, 0.9440, -0.8485, -0.9688, -0.5849,\n 0.9885, 0.0945, -0.3347, -0.8407, -0.7439, 0.2858, 0.9726,\n -0.8819, -0.8911, -0.3457, 0.7206, 0.8988, 0.4795, -0.8596,\n -0.2631, 0.9629, -0.9233, 0.9698, 0.7264, -0.6762, 0.9699,\n 0.7045, 0.4429, -0.8915, -0.9931, -0.9532, 0.8265, -0.8531,\n -0.9246, -0.9338, -0.8120, 0.6927, -0.7688, -0.3324, 0.9036,\n -0.9766, 0.3356, -0.9172, 0.9710, 0.9056, 0.9097, 0.1455,\n 0.2179, -0.9179, -0.0581, -0.9391, -0.8471, 0.2385, 0.9803,\n -0.2567, -0.9456, -0.2850, 0.8889, 0.8944, -0.9299, -0.9161,\n 0.9862, 0.9083, -0.1389, 0.7331, -0.8274, 0.7694, 0.0994,\n 0.6560, -0.8085, -0.9592, 0.9898, 0.9130, 0.9604, 0.9853,\n -0.9923, 0.8573, 0.9787, -0.6147, -0.7737, 0.7847, 0.4209,\n 0.9887, -0.5735, -0.9480, -0.9688, -0.3823, 0.9989, 0.9071,\n 0.9209, -0.9526, -0.8558, 0.0902, -0.9587, 0.7146, 0.3887,\n -0.2046, 0.2078, -0.9870, -0.9293, -0.0651, -0.9996, -0.2286,\n 0.0578, -0.9392, -0.7300, -0.8576, -0.7765, 0.0129, 0.7315,\n 0.6571, 0.9645, -0.9898, -0.5196, 0.9585, 0.9854, -0.9233,\n 0.7673, 0.9414, -0.9542, 0.3871, 0.4715, 0.9590, 0.4332,\n 0.5533, 0.9215, 0.8621, -0.3737, 0.3130, 0.8968, 0.6553,\n 0.9330, 0.7565, 0.9171, -0.7824, 0.8033, 0.1752, -0.9886,\n -0.5231, 0.9803, -0.9882, 0.9184, 0.9164, -0.2441, -0.7554,\n -0.9923, -0.8666, 0.5993, -0.7666, -0.9574, 0.9897, 0.0541,\n 0.9600, 0.7957, 0.9174, 0.9179, -0.9102, -0.2108, 0.3522,\n 0.3103, 0.9984, 0.9764, 0.0113, -0.9748, -0.4972, 0.9376,\n 0.4760, -0.8904, 0.7479, -0.1873, 0.5813, 0.0032, 0.2378,\n -0.3897, -0.6759, -0.9147, -0.5263, -0.4794, -0.5709, -0.8770,\n -0.9470, -0.9841, 0.6973, -0.7847, -0.4216, 0.9860, 0.9336,\n -0.9987, -0.9837, 0.9954, 0.8327, -0.9373, -0.9950, 0.9719,\n 0.6154, -0.7480, -0.8410, -0.7041]]], grad_fn=<ViewBackward>)\n"
],
[
"train_triples = zip(list(df2train.sentence1.values), list(df2train.sentence2.values), list(df2train.label.values))\ntrain_triples = [(normalizeString(s1), normalizeString(s2), l) for s1, s2, l in train_triples]\ntrain_triples_t = [tensorsFromTriple(t) for t in train_triples]",
"_____no_output_____"
],
[
"train_triples = zip(list(df2train.sentence1.values), list(df2train.sentence2.values), list(df2train.label.values))\ntrain_triples = [(normalizeString(s1), normalizeString(s2), l) for s1, s2, l in train_triples]\ntrain_triples_t = [tensorsFromTriple(t) for t in train_triples]",
"_____no_output_____"
],
[
"valid_triples = zip(list(df2valid.sentence1.values), list(df2valid.sentence2.values), list(df2valid.label.values))\nvalid_triples = [(normalizeString(s1), normalizeString(s2), l) for s1, s2, l in valid_triples]\nvalid_triples_t = [tensorsFromTriple(t) for t in valid_triples]",
"_____no_output_____"
],
[
"len(valid_triples_t)",
"_____no_output_____"
],
[
"test_triples = zip(list(df2_test.sentence1.values), list(df2_test.sentence2.values), list(df2_test.label.values))\ntest_triples = [(normalizeString(s1), normalizeString(s2), l) for s1, s2, l in test_triples]\ntest_triples_t = [tensorsFromTriple(t) for t in test_triples]",
"_____no_output_____"
],
[
"example = train_triples[0]\nprint(example)\nexample_t = train_triples_t[0]\nprint(example_t)",
"('jeffery created a silly and vast work of art', 'jeffery didn t create a silly work of art', 1)\n(tensor([[ 2],\n [ 3],\n [ 4],\n [ 5],\n [ 6],\n [ 7],\n [ 8],\n [ 9],\n [10],\n [ 1]]), tensor([[ 2],\n [11],\n [12],\n [13],\n [ 4],\n [ 5],\n [ 8],\n [ 9],\n [10],\n [ 1]]), tensor([1]))\n"
]
],
[
[
"## Prediction BEFORE training",
"_____no_output_____"
]
],
[
[
"n_iters = 100\ntraining_pairs_little = [random.choice(train_triples_t) for i in range(n_iters)]\npredictions = []\nlabels = []\n\nfor i in range(n_iters):\n s1, s2, label = training_pairs_little[i]\n pred = addmodel.predict(s1, s2)\n label = label.item()\n pred = pred.item()\n predictions.append(pred)\n labels.append(label)\n\nplot_confusion_matrix(labels,\n predictions,\n classes=[\"no\", \"yes\"],\n path=\"confusion_matrix.png\")",
"_____no_output_____"
]
],
[
[
"### Training functions",
"_____no_output_____"
]
],
[
[
"def CEtrain(s1_tensor,\n s2_tensor,\n label,\n model,\n optimizer,\n criterion):\n \n model.train()\n optimizer.zero_grad()\n logits = model(s1_tensor, s2_tensor)\n loss = criterion(logits, label)\n loss.backward()\n optimizer.step()\n return loss",
"_____no_output_____"
]
],
[
[
"Test CEtrain",
"_____no_output_____"
]
],
[
[
"CE = nn.CrossEntropyLoss()\naddmodel_opt = torch.optim.SGD(addmodel.parameters(), lr= 0.3)\n\nloss = CEtrain(s1_tensor=example_t[0],\n s2_tensor=example_t[1],\n label=example_t[2],\n model=addmodel,\n optimizer=addmodel_opt,\n criterion=CE)\nassert type(loss.item()) == float ",
"_____no_output_____"
]
],
[
[
"## Little example of training",
"_____no_output_____"
]
],
[
[
"epochs = 10\nlearning_rate = 0.1\n\nCE = nn.CrossEntropyLoss()\n\nencoderA = EncoderRNN(eng_enc_v_size, hidden_size)\ndecoderA = AttnDecoderRNN(hidden_size, eng_dec_v_size)\nencoderA.load_state_dict(torch.load(\"b5_encoder1_att.pkl\"))\ndecoderA.load_state_dict(torch.load(\"b5_decoder1_att.pkl\"))\nencoderB = EncoderRNN(eng_enc_v_size, hidden_size)\ndecoderB = AttnDecoderRNN(hidden_size, eng_dec_v_size)\nencoderB.load_state_dict(torch.load(\"b5_encoder2_att.pkl\"))\ndecoderB.load_state_dict(torch.load(\"b5_decoder2_att.pkl\"))\n\naddmodel = AndModel(encoderA,\n decoderA,\n encoderB,\n decoderB,\n hidden_size=256,\n output_size=2,\n max_length=MAX_LENGTH,\n input_lang=input_lang,\n target_lang=output_lang)\n\n\n\n# # for model in [encoderA, decoderA, encoderB, decoderB]:\n# for model in [encoderB, decoderB]:\n# for param in model.parameters():\n# param.requires_grad = False\n\n# addmodel_opt = torch.optim.SGD(addmodel.parameters(), lr= learning_rate)\naddmodel_opt = torch.optim.Adagrad(addmodel.parameters(), lr= learning_rate)\n# addmodel_opt = torch.optim.Adadelta(addmodel.parameters(), lr= learning_rate)\n# addmodel_opt = torch.optim.Adam(addmodel.parameters(), lr= learning_rate)\n# addmodel_opt = torch.optim.SparseAdam(addmodel.parameters(), lr= learning_rate)\n# addmodel_opt = torch.optim.RMSprop(addmodel.parameters(), lr= learning_rate)\n\n\n\n\n\nlosses_per_epoch = []\n\nfor i in range(epochs):\n losses = []\n start = time.time()\n n_iters = 1000\n training_pairs_little = [random.choice(train_triples_t) for i in range(n_iters)]\n for t in training_pairs_little:\n s1, s2, label = t \n loss = CEtrain(s1_tensor=s1,\n s2_tensor=s2,\n label=label,\n model=addmodel,\n optimizer=addmodel_opt,\n criterion=CE)\n losses.append(loss.item())\n mean_loss = np.mean(losses)\n losses_per_epoch.append(mean_loss)\n print(\"epoch {}/{}\".format(i+1, epochs), timeSince(start), \"mean loss = {:.2f}\".format(mean_loss))\n\nsimple_step_plot([losses_per_epoch],\n \"loss\",\n \"loss example ({} epochs)\".format(epochs),\n \"loss_example.png\",\n figsize=(15,4))",
"epoch 1/10 0m 59s mean loss = 1.36\nepoch 2/10 0m 58s mean loss = 0.87\nepoch 3/10 1m 2s mean loss = 0.85\nepoch 4/10 0m 59s mean loss = 0.82\nepoch 5/10 0m 54s mean loss = 0.80\nepoch 6/10 0m 53s mean loss = 0.78\nepoch 7/10 0m 50s mean loss = 0.77\nepoch 8/10 0m 59s mean loss = 0.77\nepoch 9/10 0m 53s mean loss = 0.76\nepoch 10/10 0m 52s mean loss = 0.77\n"
]
],
[
[
"## Prediction AFTER training",
"_____no_output_____"
]
],
[
[
"n_iters = 100\ntraining_pairs_little = [random.choice(train_triples_t) for i in range(n_iters)]\npredictions = []\nlabels = []\n\nfor i in range(n_iters):\n s1, s2, label = training_pairs_little[i]\n pred = addmodel.predict(s1, s2)\n label = label.item()\n pred = pred.item()\n predictions.append(pred)\n labels.append(label)\n\nplot_confusion_matrix(labels,\n predictions,\n classes=[\"no\", \"yes\"],\n path=\"confusion_matrix.png\")",
"_____no_output_____"
],
[
"n_iters = len(valid_triples_t)\nvalid_pairs_little = [random.choice(valid_triples_t) for i in range(n_iters)]\npredictions = []\nlabels = []\n\nfor i in range(n_iters):\n s1, s2, label = valid_pairs_little[i]\n pred = addmodel.predict(s1, s2)\n label = label.item()\n pred = pred.item()\n predictions.append(pred)\n labels.append(label)\n\nplot_confusion_matrix(labels,\n predictions,\n classes=[\"no\", \"yes\"],\n path=\"confusion_matrix.png\")",
"_____no_output_____"
],
[
"torch.save(addmodel.state_dict(), \"b5_simpleB.pkl\")",
"_____no_output_____"
],
[
"n_iters = len(test_triples_t)\ntest_pairs_little = [random.choice(test_triples_t) for i in range(n_iters)]\npredictions = []\nlabels = []\n\nfor i in range(n_iters):\n s1, s2, label = test_pairs_little[i]\n pred = addmodel.predict(s1, s2)\n label = label.item()\n pred = pred.item()\n predictions.append(pred)\n labels.append(label)\n\nplot_confusion_matrix(labels,\n predictions,\n classes=[\"no\", \"yes\"],\n path=\"confusion_matrix.png\")",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7cd7805ca595e5a8ce12f9a7d346381ea73a10a | 816,071 | ipynb | Jupyter Notebook | suavizado/suavizado.ipynb | mcd-unison/ing-caracteristicas-2020 | 993cbc814defb2d8381726f68d311ecba55406e7 | [
"MIT"
]
| 1 | 2020-08-14T02:30:03.000Z | 2020-08-14T02:30:03.000Z | suavizado/suavizado.ipynb | mcd-unison/ing-caracteristicas | 993cbc814defb2d8381726f68d311ecba55406e7 | [
"MIT"
]
| null | null | null | suavizado/suavizado.ipynb | mcd-unison/ing-caracteristicas | 993cbc814defb2d8381726f68d311ecba55406e7 | [
"MIT"
]
| 12 | 2020-08-15T17:21:19.000Z | 2020-11-28T17:15:21.000Z | 42.185112 | 59,447 | 0.48863 | [
[
[
"\n\n# Ingeniería de características\n\n## Suavizado de series de tiempo\n\n#### [Julio Waissman Vilanova]([email protected])\n\nVamos a ver diferentes tipos y formas de suavisar curvas. Para esto, vamos a utilizar como serie de tiempo la serie de casos confirmados por COVID-19 recabados y mantenidos por [Luis Armando Moreno](http://www.luisarmandomoreno.com), los cuales se pueden descargar [aquí](https://onedrive.live.com/download.aspx?resid=5ADDF6870413EAC9!40221&authkey=!AHWUE_EQfhvGRm4).\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport statsmodels.api as sm\nimport plotly.graph_objects as go\nimport plotly.express as px\n\n\nconfirmados = pd.read_csv(\n \"Casosdiarios.csv\", \n engine=\"python\",\n parse_dates=['Fecha']\n)[['Fecha', 'CASOS']] \\\n .groupby(\"Fecha\") \\\n .sum() \\\n .diff() + 1\n\n\nfig = px.scatter(\n confirmados,\n y=\"CASOS\"\n).update_layout(\n title='Casos confirmados de COVID-10 en Sonora',\n hovermode=\"x\"\n).show()",
"_____no_output_____"
]
],
[
[
"### Suavizado por medias moviles\n\nEl suavizado por media movil utiliza una ventana de tiempo en los datos para suavizar. La ventana de tiempo debe de tener sentido para los datos, pero se puede jugar con ella. \n\nPara esto se usa el método `rolling` el cual se puede usar con otros tipos de funciones.\n",
"_____no_output_____"
]
],
[
[
"confirmados[\"ma 3\"] = confirmados.CASOS.rolling(window=3, center=True).mean()\nconfirmados[\"ma 7\"] = confirmados.CASOS.rolling(window=7, center=True).mean()\nconfirmados[\"ma 14\"] = confirmados.CASOS.rolling(window=14, center=True).mean()\n\nfig = go.Figure(\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"CASOS\"],\n mode='markers',\n name=\"Real\"\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"ma 3\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"MA 3 días\"\n).add_scatter(\n x=confirmados.index, \n y=confirmados[\"ma 7\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"MA 7 días\"\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"ma 14\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"MA 14 días\"\n).update_layout(\n title='Casos confirmados de COVID-10 en Sonora',\n hovermode=\"x unified\"\n).show()",
"_____no_output_____"
]
],
[
[
"### Medianas moviles exponenciales\n",
"_____no_output_____"
]
],
[
[
"confirmados[\"mm 3\"] = confirmados.CASOS.rolling(window=3, center=True).median()\nconfirmados[\"mm 7\"] = confirmados.CASOS.rolling(window=7, center=True).median()\nconfirmados[\"mm 14\"] = confirmados.CASOS.rolling(window=14, center=True).median()\n\nfig = go.Figure(\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"CASOS\"],\n mode='markers',\n name=\"Real\"\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"mm 3\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"MM 3 días\"\n).add_scatter(\n x=confirmados.index, \n y=confirmados[\"mm 7\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"MM 7 días\"\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"mm 14\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"MM 14 días\"\n).update_layout(\n title='Casos confirmados de COVID-10 en Sonora',\n hovermode=\"x\"\n).show()",
"_____no_output_____"
]
],
[
[
"### Medias moviles exponenciales",
"_____no_output_____"
]
],
[
[
"confirmados[\"ewm 3\"] = confirmados.CASOS.ewm(span=3).mean()\nconfirmados[\"ewm 7\"] = confirmados.CASOS.ewm(span=7).mean()\nconfirmados[\"ewm 14\"] = confirmados.CASOS.ewm(span=14).mean()\n\nfig = go.Figure(\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"CASOS\"],\n mode='markers',\n name=\"Real\"\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"ewm 3\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"EWM 3 días\"\n).add_scatter(\n x=confirmados.index, \n y=confirmados[\"ewm 7\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"EWM 7 días\"\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"ewm 14\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"EWM 14 días\"\n).update_layout(\n title='Casos confirmados de COVID-10 en Sonora'\n).show()",
"_____no_output_____"
]
],
[
[
"### LOWESS\n",
"_____no_output_____"
]
],
[
[
"lowess = sm.nonparametric.lowess\n\nl1 = lowess(confirmados.CASOS, confirmados.index, frac=1/5)\nl2 = lowess(confirmados.CASOS, confirmados.index, frac=1/10)\nl3 = lowess(confirmados.CASOS, confirmados.index, frac=1/20)\n\nfig = go.Figure(\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"CASOS\"],\n mode='markers',\n name=\"Real\"\n).add_scatter(\n x=confirmados.index[1:],\n y=l1[:,1],\n hovertemplate=\"%{y:.1f}\",\n name=\"LOWESS 1/5\"\n).add_scatter(\n x=confirmados.index[1:], \n y=l2[:,1],\n hovertemplate=\"%{y:.1f}\",\n name=\"LOWESS 1/10\"\n).add_scatter(\n x=confirmados.index[1:],\n y=l3[:,1],\n hovertemplate=\"%{y:.1f}\",\n name=\"LOWESS 1/20\"\n).update_layout(\n title='Casos confirmados de COVID-10 en Sonora',\n hovermode=\"x\"\n).show()\n\n",
"_____no_output_____"
],
[
"fig = go.Figure(\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"CASOS\"],\n mode='markers',\n name=\"Real\"\n).add_scatter(\n x=confirmados.index[1:],\n y=l2[:,0],\n hovertemplate=\"%{y:.1f}\",\n name=\"LOWESS 1/5\"\n).add_scatter(\n x=confirmados.index[1:], \n y=l2[:,1],\n hovertemplate=\"%{y:.1f}\",\n name=\"LOWESS 1/10\"\n).update_layout(\n title='Casos confirmados de COVID-10 en Sonora',\n hovermode=\"x\"\n).show()\n\n\n",
"_____no_output_____"
],
[
"fig = go.Figure(\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"CASOS\"],\n mode='markers',\n name=\"Real\"\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"ma 7\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"MA 7 días\"\n).add_scatter(\n x=confirmados.index, \n y=confirmados[\"mm 7\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"MM 7 días\"\n).add_scatter(\n x=confirmados.index,\n y=confirmados[\"ewm 7\"],\n hovertemplate=\"%{y:.1f}\",\n name=\"EWM 7 días\"\n).add_scatter(\n x=confirmados.index[1:],\n y=l2[:,1],\n hovertemplate=\"%{y:.1f}\",\n name=\"LOWESS 1/10\"\n).update_layout(\n title='Casos confirmados de COVID-10 en Sonora',\n hovermode=\"x\"\n).show()\n\n\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7cd81b20f48e014fea827af1ce98fd8b8a62062 | 1,815 | ipynb | Jupyter Notebook | Queries/Addl Queries/retiring_titles_rev2.ipynb | honoruru/Pewlett-Hackard-Analysis | a083916ffb2c25f18d9251a233962d0555de14bb | [
"MIT"
]
| null | null | null | Queries/Addl Queries/retiring_titles_rev2.ipynb | honoruru/Pewlett-Hackard-Analysis | a083916ffb2c25f18d9251a233962d0555de14bb | [
"MIT"
]
| null | null | null | Queries/Addl Queries/retiring_titles_rev2.ipynb | honoruru/Pewlett-Hackard-Analysis | a083916ffb2c25f18d9251a233962d0555de14bb | [
"MIT"
]
| null | null | null | 24.863014 | 67 | 0.558678 | [
[
[
"--Create retirement_titles\nSELECT e.emp_no,\n\t e.first_name,\n\t e.last_name,\n\t t.title,\n\t t.from_date,\n\t t.to_date,\n\t dp.dept_name\nINTO retirement_titles_rev2\nFROM employees AS e\nINNER JOIN titles AS t\n\tON (e.emp_no = t.emp_no)\nJOIN dept_emp AS de\n\tON (e.emp_no = de.emp_no)\nJOIN departments AS dp\n \tON (de.dept_no = dp.dept_no)\nWHERE (e.birth_date BETWEEN '1952-01-01' AND '1955-12-31')\n\tAND (de.to_date = '9999-01-01')\nORDER BY e.emp_no ASC;\n\nSELECT * FROM retirement_titles_rev2\n\n-- Use Distinct with Orderby to remove duplicate rows\nSELECT DISTINCT ON (emp_no) emp_no,\n\tfirst_name,\n\tlast_name,\n\ttitle,\n\tdept_name\nINTO unique_titles_rev2\nFROM retirement_titles_rev2\nORDER BY emp_no, to_date DESC;\n\n--Retiring Titles\nSELECT COUNT(title) AS \"count\", title, dept_name\nINTO retiring_titles_rev2\nFROM unique_titles_rev2\nGROUP BY title, dept_name\nORDER BY \"count\" DESC;",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code"
]
]
|
e7cd972be95173b8391170dde8a9a04cb5a7698d | 268,068 | ipynb | Jupyter Notebook | src/solutions/feature_engineering_solutions.ipynb | crawles/data-science-training | 5f5077faee792578f3d7ff3727576492354f1156 | [
"MIT"
]
| 5 | 2017-06-21T22:33:38.000Z | 2020-05-25T20:46:06.000Z | src/solutions/feature_engineering_solutions.ipynb | crawles/data-science-training | 5f5077faee792578f3d7ff3727576492354f1156 | [
"MIT"
]
| null | null | null | src/solutions/feature_engineering_solutions.ipynb | crawles/data-science-training | 5f5077faee792578f3d7ff3727576492354f1156 | [
"MIT"
]
| 3 | 2017-06-21T22:35:35.000Z | 2018-08-02T15:42:50.000Z | 42.036694 | 1,404 | 0.362956 | [
[
[
"%run ../db.ipynb\n%config SQL.notify_result = False",
"The sql_magic extension is already loaded. To reload it, use:\n %reload_ext sql_magic\n"
],
[
"%read_sql SET search_path TO ds_training_wnv;",
"Query started at 02:52:56 PM EDT; Query executed in 0.00 m"
],
[
"input_table = 'wnv_train'",
"_____no_output_____"
],
[
"%%read_sql _df\nSELECT *\nFROM {input_table} \nLIMIT 10",
"Query started at 02:52:57 PM EDT; Query executed in 0.00 m"
]
],
[
[
"# Casting as a date type",
"_____no_output_____"
]
],
[
[
"%%read_sql\nSELECT date::date\nFROM wnv_train\nLIMIT 10",
"Query started at 02:52:58 PM EDT; Query executed in 0.00 m"
]
],
[
[
"# Extracting year, month, and day from a date",
"_____no_output_____"
]
],
[
[
"input_table = 'wnv_train'\noutput_table = 'wnv_train_ts'",
"_____no_output_____"
],
[
"%%read_sql\nDROP TABLE if EXISTS {output_table};\nCREATE TABLE {output_table}\nAS\nWITH wnv_train_dates AS (\n SELECT date::date date_ts, *\n FROM {input_table} \n )\nSELECT extract(year from date_ts)::int AS year,\n extract(month from date_ts)::int AS month,\n extract(day from date_ts)::int AS day,\n extract(doy from date_ts)::int AS day_of_year,\n *\nFROM wnv_train_dates",
"Query started at 02:52:59 PM EDT; Query executed in 0.00 mQuery started at 02:52:59 PM EDT; Query executed in 0.00 m"
],
[
"%read_sql SELECT * FROM {output_table} LIMIT 10",
"Query started at 02:52:59 PM EDT; Query executed in 0.00 m"
]
],
[
[
"# Aggregate to Trap, Species, Level \n\nWe are asked to predict for a given day, trap, and species, predict the presence of West Nile Virus in mosquitoes.",
"_____no_output_____"
]
],
[
[
"input_table = 'wnv_train_ts'\noutput_table = 'wnv_train_agg'",
"_____no_output_____"
],
[
"%%read_sql\nDROP TABLE IF EXISTS {output_table};\nCREATE TABLE {output_table}\nAS\nSELECT date_ts,year,month,day,day_of_year,trap,latitude,longitude,species,\n SUM(NumMosquitos)::int total_num_mosquitos,\n MAX(WnvPresent) wnv_present\nFROM {input_table}\nGROUP BY date_ts,year,month,day,day_of_year,trap,latitude,longitude,species",
"Query started at 02:52:59 PM EDT; Query executed in 0.00 mQuery started at 02:52:59 PM EDT; Query executed in 0.00 m"
],
[
"%%read_sql\nSELECT *\nFROM {output_table}",
"Query started at 02:53:00 PM EDT; Query executed in 0.00 m"
]
],
[
[
"# Categorical Variable Enconding ",
"_____no_output_____"
]
],
[
[
"input_table = 'wnv_train_agg' \noutput_table = 'wnv_train_agg_dummy' ",
"_____no_output_____"
],
[
"df = %read_sql SELECT species FROM {input_table}",
"Query started at 02:53:00 PM EDT; Query executed in 0.00 m"
],
[
"import re\nspecies = ['CULEX PIPIENS/RESTUANS',\n 'CULEX RESTUANS',\n 'CULEX PIPIENS',\n 'CULEX TERRITANS',\n 'CULEX SALINARIUS',\n 'CULEX TARSALIS',\n 'CULEX ERRATICUS']\ndef _clean_dummy_val( cval):\n \"\"\"For creating dummy variable columns, we need to remove special characters in values\"\"\"\n cval_clean = cval.replace(' ','_').replace('-','_').replace('\"','').replace(\"'\",'')\n return re.sub('[^a-zA-Z\\d\\s:]', '_', cval_clean)\ndef to_dummy(c, c_value):\n c_val_clean = _clean_dummy_val(c_value)\n return \"CAST({c}='{c_value}' AS int) AS {c}_{c_val_clean}\".format(c=c,\n c_value = c_value,\n c_val_clean = c_val_clean\n )\n\ncols = %read_sql SELECT * FROM {input_table} LIMIT 0\ncols = cols.columns.tolist()\ncols.remove('species')\nsql = cols + [to_dummy('species', c) for c in species]\nsql_str = ',\\n'.join(sql)",
"Query started at 02:53:12 PM EDT; Query executed in 0.00 m"
],
[
"%%read_sql\nDROP TABLE IF EXISTS {output_table};\nCREATE TABLE {output_table}\nAS\nSELECT {sql_str}\nFROM {input_table};",
"Query started at 02:53:32 PM EDT; Query executed in 0.00 mQuery started at 02:53:32 PM EDT; Query executed in 0.00 m"
],
[
"%read_sql SELECT madlib.create_indicator_variables()",
"Query started at 02:53:07 PM EDT"
],
[
"%%read_sql\nDROP TABLE IF EXISTS {output_table};\nSELECT madlib.create_indicator_variables('{input_table}',\n '{output_table}',\n 'species')",
"Query started at 02:53:01 PM EDT; Query executed in 0.00 mQuery started at 02:53:01 PM EDT"
],
[
"%read_sql SELECT * FROM {output_table}",
"Query started at 02:54:09 PM EDT; Query executed in 0.00 m"
]
],
[
[
"# Weather Data",
"_____no_output_____"
],
[
"# Data Cleansing and Missing Values\n\nNeed to remove whitespace and replace characters with empty",
"_____no_output_____"
]
],
[
[
"input_table = 'wnv_weather' \noutput_table = 'wnv_trimmed'",
"_____no_output_____"
],
[
"df = %read_sql SELECT * FROM wnv_weather\ndf.dtypes",
"Query started at 03:08:37 PM EDT; Query executed in 0.00 m"
]
],
[
[
"# Trim White Space",
"_____no_output_____"
]
],
[
[
"%%read_sql\nDROP TABLE IF EXISTS {output_table};\nCREATE TEMP TABLE {output_table}\nAS\nSELECT *,\n trim(avgspeed) avgspeed_trimmed,\n trim(preciptotal) preciptotal_trimmed,\n/* trim(tmin) tmin_trimmed, */\n trim(tavg) tavg_trimmed\n/* trim(tmax) tmax_trimmed */\nFROM {input_table}",
"Query started at 03:08:38 PM EDT; Query executed in 0.00 mQuery started at 03:08:38 PM EDT; Query executed in 0.00 m"
],
[
"%read_sql SELECT * FROM wnv_trimmed",
"Query started at 03:09:27 PM EDT; Query executed in 0.00 m"
],
[
"conn.commit()",
"_____no_output_____"
]
],
[
[
"# Replacing Missing Variables",
"_____no_output_____"
]
],
[
[
"input_table = 'wnv_trimmed'\noutput_table = 'wnv_weather_clean'",
"_____no_output_____"
],
[
"%%read_sql \nDROP TABLE IF EXISTS {output_table};\nCREATE TABLE {output_table}\nAS\nSELECT date,\n CAST(regexp_replace(avgspeed_trimmed, '^[^\\d.]+$', '0') AS float) AS avgspeed,\n CAST(regexp_replace(preciptotal_trimmed, '^[^\\d.]+$', '0') AS float) AS preciptotal,\n CAST(regexp_replace(tavg_trimmed, '^[^\\\\d.]+$'::text, '0') AS float) AS tavg,\n tmin,\n tmax\nFROM {input_table}",
"Query started at 03:15:26 PM EDT; Query executed in 0.00 mQuery started at 03:15:26 PM EDT; Query executed in 0.00 m"
]
],
[
[
"# Create weather date features (same as for station data)\n\nThis analysis is the same as used for the station data so we have filled it in.",
"_____no_output_____"
]
],
[
[
"input_table = 'wnv_weather_clean'\noutput_table = 'wnv_weather_ts'",
"_____no_output_____"
],
[
"%%read_sql\nDROP TABLE if EXISTS {output_table};\nCREATE TABLE {output_table}\nAS\nWITH wnv_weather_dates AS (\n SELECT date::date date_ts, *\n FROM {input_table} \n )\nSELECT extract(year from date_ts)::int AS year,\n extract(month from date_ts)::int AS month,\n extract(day from date_ts)::int AS day,\n extract(doy from date_ts)::int AS day_of_year,\n *\nFROM wnv_weather_dates",
"Query started at 03:15:29 PM EDT; Query executed in 0.00 mQuery started at 03:15:29 PM EDT; Query executed in 0.00 m"
],
[
"%%read_sql\nSELECT *\nFROM {output_table}\nLIMIT 10",
"Query started at 03:15:30 PM EDT; Query executed in 0.00 m"
]
],
[
[
"# Compute Weather Averages",
"_____no_output_____"
]
],
[
[
"input_table = 'wnv_weather_ts'\noutput_table = 'wnv_weather_rolling'",
"_____no_output_____"
],
[
"%%read_sql\nDROP TABLE IF EXISTS {output_table};\nCREATE TABLE {output_table}\nAS\nSELECT date_ts,\n avg(avgspeed) OVER (ORDER BY date_ts RANGE BETWEEN 7 PRECEDING AND CURRENT ROW),\n avg(preciptotal) OVER (ORDER BY date_ts RANGE BETWEEN 7 PRECEDING AND CURRENT ROW) AS preciptotal7,\n avg(tmin) OVER (ORDER BY date_ts RANGE BETWEEN 7 PRECEDING AND CURRENT ROW) AS tmin7,\n avg(tavg) OVER (ORDER BY date_ts RANGE BETWEEN 7 PRECEDING AND CURRENT ROW) AS tavg7,\n avg(tmax) OVER (ORDER BY date_ts RANGE BETWEEN 7 PRECEDING AND CURRENT ROW) AS tmax7\nFROM {input_table}\nORDER BY date_ts",
"Query started at 03:15:35 PM EDT; Query executed in 0.00 mQuery started at 03:15:35 PM EDT"
],
[
"%%read_sql\nSELECT *\nFROM {output_table}\nLIMIT 10",
"Query started at 03:52:39 PM Eastern Daylight Time\nQuery executed in 0.00 m\n"
]
],
[
[
"# Putting it All Together: Join weather data and mosquito station data",
"_____no_output_____"
]
],
[
[
"station_table = 'wnv_train_agg_dummy'\nweather_table = 'wnv_weather_rolling'\noutput_table = 'wnv_features'",
"_____no_output_____"
],
[
"df = %read_sql SELECT * FROM {station_table} LIMIT 10\ndf.columns.tolist()",
"Query started at 04:11:07 PM Eastern Daylight Time\nQuery executed in 0.00 m\n"
],
[
"%%read_sql\nDROP TABLE IF EXISTS {output_table};\nCREATE TABLE {output_table}\nAS\nSELECT row_number() OVER () as id, *\nFROM {station_table}\nINNER JOIN {weather_table}\nUSING (date_ts);",
"Query started at 04:06:31 PM Eastern Daylight Time\nQuery executed in 0.00 m\nQuery started at 04:06:31 PM Eastern Daylight Time\nQuery executed in 0.06 m\n"
],
[
"print(1)",
"1\n"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7cdb8885e137a20dd02690d9c7105f8f072b965 | 72,493 | ipynb | Jupyter Notebook | libro_optimizacion/temas/I.computo_cientifico/1.5/Definicion_de_funcion_continuidad_derivada.ipynb | vserranoc/analisis-numerico-computo-cientifico | 336304bf713695df643460b1467bad7cc12141ae | [
"Apache-2.0"
]
| null | null | null | libro_optimizacion/temas/I.computo_cientifico/1.5/Definicion_de_funcion_continuidad_derivada.ipynb | vserranoc/analisis-numerico-computo-cientifico | 336304bf713695df643460b1467bad7cc12141ae | [
"Apache-2.0"
]
| null | null | null | libro_optimizacion/temas/I.computo_cientifico/1.5/Definicion_de_funcion_continuidad_derivada.ipynb | vserranoc/analisis-numerico-computo-cientifico | 336304bf713695df643460b1467bad7cc12141ae | [
"Apache-2.0"
]
| null | null | null | 24.302045 | 579 | 0.423931 | [
[
[
"(FCD)=",
"_____no_output_____"
],
[
"# 1.5 Definición de función, continuidad y derivada",
"_____no_output_____"
],
[
"```{admonition} Notas para contenedor de docker:\n\nComando de docker para ejecución de la nota de forma local:\n\nnota: cambiar `<ruta a mi directorio>` por la ruta de directorio que se desea mapear a `/datos` dentro del contenedor de docker y `<versión imagen de docker>` por la versión más actualizada que se presenta en la documentación.\n\n`docker run --rm -v <ruta a mi directorio>:/datos --name jupyterlab_optimizacion -p 8888:8888 -d palmoreck/jupyterlab_optimizacion:<versión imagen de docker>`\n\npassword para jupyterlab: `qwerty`\n\nDetener el contenedor de docker:\n\n`docker stop jupyterlab_optimizacion`\n\nDocumentación de la imagen de docker `palmoreck/jupyterlab_optimizacion:<versión imagen de docker>` en [liga](https://github.com/palmoreck/dockerfiles/tree/master/jupyterlab/optimizacion).\n\n```",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"Nota generada a partir de la [liga1](https://www.dropbox.com/s/jfrxanjls8kndjp/Diferenciacion_e_Integracion.pdf?dl=0), [liga2](https://www.dropbox.com/s/mmd1uzvwhdwsyiu/4.3.2.Teoria_de_convexidad_Funciones_convexas.pdf?dl=0) e inicio de [liga3](https://www.dropbox.com/s/ko86cce1olbtsbk/4.3.1.Teoria_de_convexidad_Conjuntos_convexos.pdf?dl=0).",
"_____no_output_____"
],
[
"```{admonition} Al final de esta nota el y la lectora:\n:class: tip\n\n* Aprenderá las definiciones de función y derivada de una función en algunos casos de interés para el curso. En específico el caso de derivada direccional es muy importante.\n\n* Aprenderá que el gradiente y Hessiana de una función son un vector y una matriz de primeras (información de primer orden) y segundas derivadas (información de segundo orden) respectivamente.\n\n* Aprenderá algunas fórmulas utilizadas con el operador nabla de diferenciación.\n\n\n* Aprenderá la diferencia entre el cálculo algebraico o simbólico y el numérico vía el paquete *SymPy*.\n\n```",
"_____no_output_____"
],
[
"## Función",
"_____no_output_____"
],
[
"```{admonition} Definición\n\nUna función, $f$, es una regla de correspondencia entre un conjunto nombrado dominio y otro conjunto nombrado codominio.\n```",
"_____no_output_____"
],
[
"### Notación\n\n$f: A \\rightarrow B$ es una función de un conjunto $\\text{dom}f \\subseteq A$ en un conjunto $B$.\n\n```{admonition} Observación\n:class: tip\n\n$\\text{dom}f$ (el dominio de $f$) puede ser un subconjunto propio de $A$, esto es, algunos elementos de $A$ y otros no, son mapeados a elementos de $B$.\n```",
"_____no_output_____"
],
[
"En lo que sigue se considera al espacio $\\mathbb{R}^n$ y se asume que conjuntos y subconjuntos están en este espacio.\n",
"_____no_output_____"
],
[
"(CACCI)=",
"_____no_output_____"
],
[
"### Conjunto abierto, cerrado, cerradura e interior",
"_____no_output_____"
],
[
"```{margin} \n\nUn punto $x$ se nombra **punto límite** de un conjunto $X$, si existe una sucesión $\\{x_k\\} \\subset X$ que converge a $x$. El conjunto de puntos límites se nombra **cerradura** o *closure* de $X$ y se denota como $\\text{cl}X$. \n\nUn conjunto $X$ se nombra **cerrado** si es igual a su cerradura.\n\n```",
"_____no_output_____"
],
[
"```{admonition} Definición\n\nEl interior de un conjunto $X$ es el conjunto de **puntos interiores**: un punto $x$ de un conjunto $X$ se llama interior si existe una **vecindad** de $x$ (conjunto abierto\\* que contiene a $x$) contenida en $X$.\n\n\\*Un conjunto $X$ se dice que es **abierto** si $\\forall x \\in X$ existe una bola abierta\\* centrada en $x$ y contenida en $X$. Es equivalente escribir que $X$ es **abierto** si su complemento $\\mathbb{R}^n \\ X$ es cerrado.\n\n\\*Una **bola abierta** con radio $\\epsilon>0$ y centrada en $x$ es el conjunto: $B_\\epsilon(x) =\\{y \\in \\mathbb{R}^n : ||y-x|| < \\epsilon\\}$. Ver {ref}`Ejemplos de gráficas de normas en el plano <EGNP>` para ejemplos de bolas abiertas en el plano.\n```",
"_____no_output_____"
],
[
"En lo siguiente $\\text{intdom}f$ es el **interior** del dominio de $f$. ",
"_____no_output_____"
],
[
"## Continuidad",
"_____no_output_____"
],
[
"```{admonition} Definición\n\n$f: \\mathbb{R}^n \\rightarrow \\mathbb{R}^m$ es continua en $x \\in \\text{dom}f$ si $\\forall \\epsilon >0 \\exists \\delta > 0$ tal que:\n\n$$y \\in \\text{dom}f, ||y-x||_2 \\leq \\delta \\implies ||f(y)-f(x)||_2 \\leq \\epsilon$$\n\n```",
"_____no_output_____"
],
[
"```{admonition} Comentarios\n\n* $f$ continua en un punto $x$ del dominio de $f$ entonces $f(y)$ es arbitrariamente cercana a $f(x)$ para $y$ en el dominio de $f$ cercana a $x$.\n\n* Otra forma de definir que $f$ sea continua en $x \\in \\text{dom}f$ es con sucesiones y límites: si $\\{x_i\\}_{i \\in \\mathbb{N}} \\subseteq \\text{dom}f$ es una sucesión de puntos en el dominio de $f$ que converge a $x \\in \\text{dom}f$, $\\displaystyle \\lim_{i \\rightarrow \\infty}x_i = x$, y $f$ es continua en $x$ entonces la sucesión $\\{f(x_i)\\}_{i \\in \\mathbb{N}}$ converge a $f(x)$: $\\displaystyle \\lim_{i \\rightarrow \\infty}f(x_i) = f(x) = f \\left(\\displaystyle \\lim_{i \\rightarrow \\infty} x_i \\right )$.\n```",
"_____no_output_____"
],
[
"### Notación\n\n$\\mathcal{C}([a,b])=\\{\\text{funciones } f:\\mathbb{R} \\rightarrow \\mathbb{R} \\text{ continuas en el intervalo [a,b]}\\}$ y $\\mathcal{C}(\\text{dom}f) = \\{\\text{funciones } f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^m \\text{ continuas en su dominio}\\}$.\n",
"_____no_output_____"
],
[
"## Función Diferenciable",
"_____no_output_____"
],
[
"### Caso $f: \\mathbb{R} \\rightarrow \\mathbb{R}$",
"_____no_output_____"
],
[
"```{admonition} Definición\n\n$f$ es diferenciable en $x_0 \\in (a,b)$ si $\\displaystyle \\lim_{x \\rightarrow x_0} \\frac{f(x)-f(x_0)}{x-x_0}$ existe y escribimos:\n\n$$f^{(1)}(x_0) = \\displaystyle \\lim_{x \\rightarrow x_0} \\frac{f(x)-f(x_0)}{x-x_0}.$$\n```",
"_____no_output_____"
],
[
"$f$ es diferenciable en $[a,b]$ si es diferenciable en cada punto de $[a,b]$. Análogamente definiendo la variable $h=x-x_0$ se tiene:\n",
"_____no_output_____"
],
[
"$f^{(1)}(x_0) = \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f(x_0+h)-f(x_0)}{h}$ que típicamente se escribe como:\n\n$$f^{(1)}(x) = \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f(x+h)-f(x)}{h}.$$",
"_____no_output_____"
],
[
"```{admonition} Comentario\n\nSi $f$ es diferenciable en $x_0$ entonces $f(x) \\approx f(x_0) + f^{(1)}(x_0)(x-x_0)$. Gráficamente:\n\n<img src=\"https://dl.dropboxusercontent.com/s/3t13ku6pk1pjwxo/f_diferenciable.png?dl=0\" heigth=\"500\" width=\"500\">\n```",
"_____no_output_____"
],
[
"Como las derivadas también son funciones tenemos una notación para las derivadas que son continuas:",
"_____no_output_____"
],
[
"### Notación\n\n$\\mathcal{C}^n([a,b])=\\{\\text{funciones } f:\\mathbb{R} \\rightarrow \\mathbb{R} \\text{ con } n \\text{ derivadas continuas en el intervalo [a,b]}\\}$.\n",
"_____no_output_____"
],
[
"En Python podemos utilizar el paquete [SymPy](https://www.sympy.org/en/index.html) para calcular límites y derivadas de forma **simbólica** (ver [sympy/calculus](https://docs.sympy.org/latest/tutorial/calculus.html)) que es diferente al cálculo **numérico** que se revisa en {ref}`Polinomios de Taylor y diferenciación numérica <PTDN>`.",
"_____no_output_____"
],
[
"### Ejemplo\n",
"_____no_output_____"
]
],
[
[
"import sympy",
"_____no_output_____"
]
],
[
[
"**Límite de $\\frac{\\cos(x+h) - \\cos(x)}{h}$ para $h \\rightarrow 0$:**",
"_____no_output_____"
]
],
[
[
"x, h = sympy.symbols(\"x, h\")",
"_____no_output_____"
],
[
"quotient = (sympy.cos(x+h) - sympy.cos(x))/h",
"_____no_output_____"
],
[
"sympy.pprint(sympy.limit(quotient, h, 0))",
"-sin(x)\n"
]
],
[
[
"Lo anterior corresponde a la **derivada de $\\cos(x)$**:",
"_____no_output_____"
]
],
[
[
"x = sympy.Symbol('x')",
"_____no_output_____"
],
[
"sympy.pprint(sympy.cos(x).diff(x))",
"-sin(x)\n"
]
],
[
[
"**Si queremos evaluar la derivada podemos usar:**",
"_____no_output_____"
]
],
[
[
"sympy.pprint(sympy.cos(x).diff(x).subs(x,sympy.pi/2))",
"-1\n"
],
[
"sympy.pprint(sympy.Derivative(sympy.cos(x), x))",
"d \n──(cos(x))\ndx \n"
],
[
"sympy.pprint(sympy.Derivative(sympy.cos(x), x).doit_numerically(sympy.pi/2))",
"-1.00000000000000\n"
]
],
[
[
"### Caso $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}^m$",
"_____no_output_____"
],
[
"```{admonition} Definición\n\n$f$ es diferenciable en $x \\in \\text{intdom}f$ si existe una matriz $Df(x) \\in \\mathbb{R}^{m\\times n}$ tal que:\n\n$$\\displaystyle \\lim_{z \\rightarrow x, z \\neq x} \\frac{||f(z)-f(x)-Df(x)(z-x)||_2}{||z-x||_2} = 0, z \\in \\text{dom}f$$\n\nen este caso $Df(x)$ se llama la derivada de $f$ en $x$.\n```",
"_____no_output_____"
],
[
"```{admonition} Observación\n:class: tip\n\nSólo puede existir a lo más una matriz que satisfaga el límite anterior.\n```\n",
"_____no_output_____"
],
[
"```{margin}\n\nUna función afín es de la forma $h(x) = Ax+b$ con $A \\in \\mathbb{R}^{p \\times n}$ y $b \\in \\mathbb{R}^p$. Ver [Affine_transformation](https://en.wikipedia.org/wiki/Affine_transformation)\n\n```",
"_____no_output_____"
],
[
"```{admonition} Comentarios:\n\n* $Df(x)$ también es llamada la **Jacobiana** de $f$.\n\n* Se dice que $f$ es diferenciable si $\\text{dom}f$ es abierto y es diferenciable en cada punto de $\\text{dom}f.$\n\n* La función: $f(x) + Df(x)(z-x)$ es afín y se le llama **aproximación de orden $1$** de $f$ en $x$ (o también cerca de $x$). Para $z$ cercana a $x$ ésta aproximación es cercana a $f(z)$.\n\n* $Df(x)$ puede encontrarse con la definición de límite anterior o con las derivadas parciales: $Df(x)_{ij} = \\frac{\\partial f_i(x)}{\\partial x_j}, i=1,\\dots,m, j=1,\\dots,n$ definidas como:\n\n$$\\frac{\\partial f_i(x)}{\\partial x_j} = \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f_i(x+he_j)-f_i(x)}{h}$$\n\ndonde: $f_i : \\mathbb{R}^n \\rightarrow \\mathbb{R}$, $i=1,\\dots,m,j=1,\\dots,n$ y $e_j$ $j$-ésimo vector canónico que tiene un número $1$ en la posición $j$ y $0$ en las entradas restantes.\n\n* Si $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}, Df(x) \\in \\mathbb{R}^{1\\times n}$, su transpuesta se llama **gradiente**, se denota $\\nabla f(x)$, es una función $\\nabla f : \\mathbb{R}^n \\rightarrow \\mathbb{R}^n$, recibe un vector y devuelve un vector columna y sus componentes son derivadas parciales: \n\n$$\\nabla f(x) = Df(x)^T = \n \\left[ \\begin{array}{c}\n \\frac{\\partial f(x)}{\\partial x_1}\\\\\n \\vdots\\\\\n \\frac{\\partial f(x)}{\\partial x_n}\n \\end{array}\n \\right] = \\left[ \n \\begin{array}{c} \n \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f(x+he_1) - f(x)}{h}\\\\\n \\vdots\\\\\n \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f(x+he_n) - f(x)}{h}\n \\end{array}\n \\right] \\in \\mathbb{R}^{n\\times 1}.$$\n \n* En este contexto, la aproximación de primer orden a $f$ en $x$ es: $f(x) + \\nabla f(x)^T(z-x)$ para $z$ cercana a $x$.\n```",
"_____no_output_____"
],
[
"### Notación\n\n$\\mathcal{C}^n(\\text{dom}f) = \\{\\text{funciones } f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^m \\text{ con } n \\text{ derivadas continuas en su dominio}\\}$.\n",
"_____no_output_____"
],
[
"### Ejemplo\n\n$f : \\mathbb{R}^2 \\rightarrow \\mathbb{R}^2$ dada por:\n\n$$f(x) = \n\\left [ \n\\begin{array}{c}\nx_1x_2 + x_2^2\\\\\nx_1^2 + 2x_1x_2 + x_2^2\\\\\n\\end{array}\n\\right ]\n$$\n\ncon $x = (x_1, x_2)^T$. Calcular la derivada de $f$.\n",
"_____no_output_____"
]
],
[
[
"x1, x2 = sympy.symbols(\"x1, x2\")",
"_____no_output_____"
]
],
[
[
"**Definimos funciones $f_1, f_2$ que son componentes del vector $f(x)$**.",
"_____no_output_____"
]
],
[
[
"f1 = x1*x2 + x2**2",
"_____no_output_____"
],
[
"sympy.pprint(f1)",
" 2\nx₁⋅x₂ + x₂ \n"
],
[
"f2 = x1**2 + x2**2 + 2*x1*x2",
"_____no_output_____"
],
[
"sympy.pprint(f2)",
" 2 2\nx₁ + 2⋅x₁⋅x₂ + x₂ \n"
]
],
[
[
"**Derivadas parciales:**",
"_____no_output_____"
],
[
"Para $f_1(x) = x_1x_2 + x_2^2$:",
"_____no_output_____"
],
[
"```{margin}\n\n**Derivada parcial de $f_1$ respecto a $x_1$.**\n```",
"_____no_output_____"
]
],
[
[
"df1_x1 = f1.diff(x1)",
"_____no_output_____"
],
[
"sympy.pprint(df1_x1)",
"x₂\n"
]
],
[
[
"```{margin}\n\n**Derivada parcial de $f_1$ respecto a $x_2$.**\n```",
"_____no_output_____"
]
],
[
[
"df1_x2 = f1.diff(x2)",
"_____no_output_____"
],
[
"sympy.pprint(df1_x2)",
"x₁ + 2⋅x₂\n"
]
],
[
[
"Para $f_2(x) = x_1^2 + 2x_1 x_2 + x_2^2$:",
"_____no_output_____"
],
[
"```{margin}\n\n**Derivada parcial de $f_2$ respecto a $x_1$.**\n```",
"_____no_output_____"
]
],
[
[
"df2_x1 = f2.diff(x1)",
"_____no_output_____"
],
[
"sympy.pprint(df2_x1)",
"2⋅x₁ + 2⋅x₂\n"
]
],
[
[
"```{margin}\n\n**Derivada parcial de $f_2$ respecto a $x_2$.**\n```",
"_____no_output_____"
]
],
[
[
"df2_x2 = f2.diff(x2)",
"_____no_output_____"
],
[
"sympy.pprint(df2_x2)",
"2⋅x₁ + 2⋅x₂\n"
]
],
[
[
"**Entonces la derivada es:**",
"_____no_output_____"
],
[
"$$Df(x) = \n\\left [\n\\begin{array}{cc}\nx_2 & x_1+2x_2\\\\\n2x_1 + 2x_2 & 2x_1+2x_2\n\\end{array}\n\\right ]\n$$",
"_____no_output_____"
],
[
"**Otra opción más fácil es utilizando [Matrices](https://docs.sympy.org/latest/tutorial/matrices.html):**",
"_____no_output_____"
]
],
[
[
"f = sympy.Matrix([f1, f2])",
"_____no_output_____"
],
[
"sympy.pprint(f)",
"⎡ 2 ⎤\n⎢ x₁⋅x₂ + x₂ ⎥\n⎢ ⎥\n⎢ 2 2⎥\n⎣x₁ + 2⋅x₁⋅x₂ + x₂ ⎦\n"
]
],
[
[
"```{margin} \n\n**Jacobiana de $f$**\n``` ",
"_____no_output_____"
]
],
[
[
"sympy.pprint(f.jacobian([x1, x2]))",
"⎡ x₂ x₁ + 2⋅x₂ ⎤\n⎢ ⎥\n⎣2⋅x₁ + 2⋅x₂ 2⋅x₁ + 2⋅x₂⎦\n"
]
],
[
[
"**Para evaluar por ejemplo en $(x_1, x_2)^T = (0, 1)^T$:**",
"_____no_output_____"
]
],
[
[
"d = f.jacobian([x1, x2])",
"_____no_output_____"
],
[
"sympy.pprint(d.subs([(x1, 0), (x2, 1)]))",
"⎡1 2⎤\n⎢ ⎥\n⎣2 2⎦\n"
]
],
[
[
"## Regla de la cadena",
"_____no_output_____"
],
[
"```{admonition} Definición\n\nSi $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^m$ es diferenciable en $x\\in \\text{intdom}f$ y $g:\\mathbb{R}^m \\rightarrow \\mathbb{R}^p$ es diferenciable en $f(x)\\in \\text{intdom}g$, se define la composición $h:\\mathbb{R}^n \\rightarrow \\mathbb{R}^p$ por $h(z) = g(f(z))$, la cual es diferenciable en $x$, con derivada:\n\n$$Dh(x)=Dg(f(x))Df(x)\\in \\mathbb{R}^{p\\times n}.$$\n```",
"_____no_output_____"
],
[
"(EJ1)=",
"_____no_output_____"
],
[
"### Ejemplo\n\nSean $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}$, $g:\\mathbb{R} \\rightarrow \\mathbb{R}$, $h:\\mathbb{R}^n \\rightarrow \\mathbb{R}$ con $h(z) = g(f(z))$ entonces: \n\n$$Dh(x) = Dg(f(x))Df(x) = \\frac{dg(f(x))}{dx}\\nabla f(x)^T \\in \\mathbb{R}^{1\\times n}$$\n\ny la transpuesta de $Dh(x)$ es: $\\nabla h(x) = Dh(x)^T = \\frac{dg(f(x))}{dx} \\nabla f(x) \\in \\mathbb{R}^{n\\times 1}$.\n",
"_____no_output_____"
],
[
"### Ejemplo\n\n$f(x) = \\cos(x), g(x)=\\sin(x)$ por lo que $h(x) = \\sin(\\cos(x))$. Calcular la derivada de $h$.\n",
"_____no_output_____"
]
],
[
[
"x = sympy.Symbol('x')",
"_____no_output_____"
],
[
"f = sympy.cos(x)",
"_____no_output_____"
],
[
"sympy.pprint(f)",
"cos(x)\n"
],
[
"g = sympy.sin(x)",
"_____no_output_____"
],
[
"sympy.pprint(g)",
"sin(x)\n"
],
[
"h = g.subs(x, f)",
"_____no_output_____"
],
[
"sympy.pprint(h)",
"sin(cos(x))\n"
],
[
"sympy.pprint(h.diff(x))",
"-sin(x)⋅cos(cos(x))\n"
]
],
[
[
"**Otras formas para calcular la derivada de la composición $h$:**",
"_____no_output_____"
]
],
[
[
"g = sympy.sin",
"_____no_output_____"
],
[
"h = g(f)",
"_____no_output_____"
],
[
"sympy.pprint(h.diff(x))",
"-sin(x)⋅cos(cos(x))\n"
],
[
"h = sympy.sin(f)",
"_____no_output_____"
],
[
"sympy.pprint(h.diff(x))",
"-sin(x)⋅cos(cos(x))\n"
]
],
[
[
"### Ejemplo\n\n$f(x) = x_1 + \\frac{1}{x_2}, g(x) = e^x$ por lo que $h(x) = e^{x_1 + \\frac{1}{x_2}}$. Calcular la derivada de $h$.",
"_____no_output_____"
]
],
[
[
"x1, x2 = sympy.symbols(\"x1, x2\")",
"_____no_output_____"
],
[
"f = x1 + 1/x2",
"_____no_output_____"
],
[
"sympy.pprint(f)",
" 1 \nx₁ + ──\n x₂\n"
],
[
"g = sympy.exp",
"_____no_output_____"
],
[
"sympy.pprint(g)",
"exp\n"
],
[
"h = g(f)",
"_____no_output_____"
],
[
"sympy.pprint(h)",
" 1 \n x₁ + ──\n x₂\nℯ \n"
]
],
[
[
"```{margin}\n\n**Derivada parcial de $h$ respecto a $x_1$.**\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(h.diff(x1))",
" 1 \n x₁ + ──\n x₂\nℯ \n"
]
],
[
[
"```{margin}\n\n**Derivada parcial de $h$ respecto a $x_2$.**\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(h.diff(x2))",
" 1 \n x₁ + ── \n x₂ \n-ℯ \n──────────\n 2 \n x₂ \n"
]
],
[
[
"**Otra forma para calcular el gradiente de $h$ (derivada de $h$) es utilizando [how-to-get-the-gradient-and-hessian-sympy](https://stackoverflow.com/questions/39558515/how-to-get-the-gradient-and-hessian-sympy):**",
"_____no_output_____"
]
],
[
[
"from sympy.tensor.array import derive_by_array",
"_____no_output_____"
],
[
"sympy.pprint(derive_by_array(h, (x1, x2)))",
"⎡ 1 ⎤\n⎢ 1 x₁ + ── ⎥\n⎢ x₁ + ── x₂ ⎥\n⎢ x₂ -ℯ ⎥\n⎢ℯ ──────────⎥\n⎢ 2 ⎥\n⎣ x₂ ⎦\n"
]
],
[
[
"(CP1)=",
"_____no_output_____"
],
[
"### Caso particular\n\nSean:\n\n* $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}^m$, $f(x) = Ax +b$ con $A \\in \\mathbb{R}^{m\\times n},b \\in \\mathbb{R}^m$,\n\n* $g:\\mathbb{R}^m \\rightarrow \\mathbb{R}^p$, \n\n* $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}^p$, $h(x)=g(f(x))=g(Ax+b)$ con $\\text{dom}h=\\{z \\in \\mathbb{R}^n | Az+b \\in \\text{dom}g\\}$ entonces:\n\n$$Dh(x) = Dg(f(x))Df(x)=Dg(Ax+b)A.$$",
"_____no_output_____"
],
[
"```{admonition} Observación\n:class: tip\n\nSi $p=1$, $g: \\mathbb{R}^m \\rightarrow \\mathbb{R}$, $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}$ se tiene:\n\n$$\\nabla h(x) = Dh(x)^T = A^TDg(Ax+b)^T=A^T\\nabla g(Ax+b) \\in \\mathbb{R}^{n\\times 1}.$$\n\n```",
"_____no_output_____"
],
[
"(EJRestriccionALinea)=",
"_____no_output_____"
],
[
"### Ejemplo\n\nEste caso particular considera un caso importante en el que se tienen funciones restringidas a una línea. Si $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}$, $g: \\mathbb{R} \\rightarrow \\mathbb{R}$ está dada por $g(t) = f(x+tv)$ con $x, v \\in \\mathbb{R}^n$ y $t \\in \\mathbb{R}$, entonces escribimos que $g$ es $f$ pero restringida a la línea $x+tv$. La derivada de $g$ es:\n\n$$Dg(t) = \\nabla f(x+tv)^T v.$$\n\nEl escalar $Dg(0) = \\nabla f(x)^Tv$ se llama **derivada direccional** de $f$ en $x$ en la dirección $v$. Un dibujo en el que se considera $\\Delta x: = v$:\n\n<img src=\"https://dl.dropboxusercontent.com/s/18udjmzmmd7drrz/line_search_backtracking_1.png?dl=0\" heigth=\"300\" width=\"300\">\n\n",
"_____no_output_____"
],
[
"Como ejemplo considérese $f(x) = x_1 ^2 + x_2^2$ con $x=(x_1, x_2)^T$ y $g(t) = f(x+tv)$ para $v=(v_1, v_2)^T$ vector fijo y $t \\in \\mathbb{R}$. Calcular $Dg(t)$.",
"_____no_output_____"
],
[
"**Primera opción**",
"_____no_output_____"
]
],
[
[
"x1, x2 = sympy.symbols(\"x1, x2\")",
"_____no_output_____"
],
[
"f = x1**2 + x2**2",
"_____no_output_____"
],
[
"sympy.pprint(f)",
" 2 2\nx₁ + x₂ \n"
],
[
"t = sympy.Symbol('t')\nv1, v2 = sympy.symbols(\"v1, v2\")",
"_____no_output_____"
],
[
"new_args_for_f_function = {\"x1\": x1+t*v1, \"x2\": x2 + t*v2}",
"_____no_output_____"
],
[
"g = f.subs(new_args_for_f_function)",
"_____no_output_____"
],
[
"sympy.pprint(g)",
" 2 2\n(t⋅v₁ + x₁) + (t⋅v₂ + x₂) \n"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $t$: $Dg(t)=\\nabla f(x+tv)^T v$.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(g.diff(t))",
"2⋅v₁⋅(t⋅v₁ + x₁) + 2⋅v₂⋅(t⋅v₂ + x₂)\n"
]
],
[
[
"**Segunda opción para calcular la derivada utilizando vectores:**",
"_____no_output_____"
]
],
[
[
"x = sympy.Matrix([x1, x2])",
"_____no_output_____"
],
[
"sympy.pprint(x)",
"⎡x₁⎤\n⎢ ⎥\n⎣x₂⎦\n"
],
[
"v = sympy.Matrix([v1, v2])",
"_____no_output_____"
],
[
"new_arg_f_function = x+t*v",
"_____no_output_____"
],
[
"sympy.pprint(new_arg_f_function)",
"⎡t⋅v₁ + x₁⎤\n⎢ ⎥\n⎣t⋅v₂ + x₂⎦\n"
],
[
"mapping_for_g_function = {\"x1\": new_arg_f_function[0], \n \"x2\": new_arg_f_function[1]}",
"_____no_output_____"
],
[
"g = f.subs(mapping_for_g_function)",
"_____no_output_____"
],
[
"sympy.pprint(g)",
" 2 2\n(t⋅v₁ + x₁) + (t⋅v₂ + x₂) \n"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $t$: $Dg(t)=\\nabla f(x+tv)^T v$.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(g.diff(t))",
"2⋅v₁⋅(t⋅v₁ + x₁) + 2⋅v₂⋅(t⋅v₂ + x₂)\n"
]
],
[
[
"**Tercera opción definiendo a la función $f$ a partir de $x$ symbol Matrix:**",
"_____no_output_____"
]
],
[
[
"sympy.pprint(x)",
"⎡x₁⎤\n⎢ ⎥\n⎣x₂⎦\n"
],
[
"f = x[0]**2 + x[1]**2",
"_____no_output_____"
],
[
"sympy.pprint(f)",
" 2 2\nx₁ + x₂ \n"
],
[
"sympy.pprint(new_arg_f_function)",
"⎡t⋅v₁ + x₁⎤\n⎢ ⎥\n⎣t⋅v₂ + x₂⎦\n"
],
[
"g = f.subs({\"x1\": new_arg_f_function[0], \n \"x2\": new_arg_f_function[1]})",
"_____no_output_____"
],
[
"sympy.pprint(g)",
" 2 2\n(t⋅v₁ + x₁) + (t⋅v₂ + x₂) \n"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $t$: $Dg(t)=\\nabla f(x+tv)^T v$.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(g.diff(t))",
"2⋅v₁⋅(t⋅v₁ + x₁) + 2⋅v₂⋅(t⋅v₂ + x₂)\n"
]
],
[
[
"**En lo siguiente se utiliza [derive-by_array](https://docs.sympy.org/latest/modules/tensor/array.html#derivatives-by-array), [how-to-get-the-gradient-and-hessian-sympy](https://stackoverflow.com/questions/39558515/how-to-get-the-gradient-and-hessian-sympy) para mostrar cómo se puede hacer un producto punto con SymPy**",
"_____no_output_____"
]
],
[
[
"sympy.pprint(derive_by_array(f, x))",
"⎡2⋅x₁⎤\n⎢ ⎥\n⎣2⋅x₂⎦\n"
],
[
"sympy.pprint(derive_by_array(f, x).subs({\"x1\": new_arg_f_function[0], \n \"x2\": new_arg_f_function[1]}))",
"⎡2⋅t⋅v₁ + 2⋅x₁⎤\n⎢ ⎥\n⎣2⋅t⋅v₂ + 2⋅x₂⎦\n"
],
[
"gradient_f_new_arg = derive_by_array(f, x).subs({\"x1\": new_arg_f_function[0], \n \"x2\": new_arg_f_function[1]})\n",
"_____no_output_____"
],
[
"sympy.pprint(v)",
"⎡v₁⎤\n⎢ ⎥\n⎣v₂⎦\n"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $t$: $Dg(t)=\\nabla f(x+tv)^T v = v^T \\nabla f(x + tv)$.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(v.dot(gradient_f_new_arg))",
"v₁⋅(2⋅t⋅v₁ + 2⋅x₁) + v₂⋅(2⋅t⋅v₂ + 2⋅x₂)\n"
]
],
[
[
"(EJ2)=",
"_____no_output_____"
],
[
"### Ejemplo\n\nSi $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}$ dada por $h(x) = \\log \\left( \\displaystyle \\sum_{i=1}^m \\exp(a_i^Tx+b_i) \\right)$ con $x\\in \\mathbb{R}^n,a_i\\in \\mathbb{R}^n \\forall i=1,\\dots,m$ y $b_i \\in \\mathbb{R} \\forall i=1,\\dots,m$ entonces: \n\n$$\nDh(x)=\\left(\\displaystyle \\sum_{i=1}^m\\exp(a_i^Tx+b_i) \\right)^{-1}\\left[ \\begin{array}{c}\n \\exp(a_1^Tx+b_1)\\\\\n \\vdots\\\\\n \\exp(a_m^Tx+b_m)\n \\end{array}\n \\right]^TA=(1^Tz)^{-1}z^TA\n$$\n\ndonde: $A=(a_i)_{i=1}^m \\in \\mathbb{R}^{m\\times n}, b \\in \\mathbb{R}^m$, $z=\\left[ \\begin{array}{c}\n \\exp(a_1^Tx+b_1)\\\\\n \\vdots\\\\\n \\exp(a_m^Tx+b_m)\n \\end{array}\\right]$. Por lo tanto $\\nabla h(x) = (1^Tz)^{-1}A^Tz$.\n \n\nEn este ejemplo $Dh(x) = Dg(f(x))Df(x)$ con:\n\n* $h(x)=g(f(x))$,\n\n* $g: \\mathbb{R}^m \\rightarrow \\mathbb{R}$ dada por $g(y)=\\log \\left( \\displaystyle \\sum_{i=1}^m \\exp(y_i) \\right )$,\n\n* $f(x)=Ax+b.$ \n",
"_____no_output_____"
],
[
"Para lo siguiente se utilizó como referencias: [liga1](https://stackoverflow.com/questions/41581002/how-to-derive-with-respect-to-a-matrix-element-with-sympy), [liga2](https://docs.sympy.org/latest/modules/tensor/indexed.html), [liga3](https://stackoverflow.com/questions/37705571/sum-over-matrix-entries-in-sympy-1-0-with-python-3-5), [liga4](https://docs.sympy.org/latest/modules/tensor/array.html), [liga5](https://docs.sympy.org/latest/modules/concrete.html), [liga6](https://stackoverflow.com/questions/51723550/summation-over-a-sympy-array).",
"_____no_output_____"
]
],
[
[
"m = sympy.Symbol('m')\nn = sympy.Symbol('n')",
"_____no_output_____"
]
],
[
[
"```{margin} \n\nVer [indexed](https://docs.sympy.org/latest/modules/tensor/indexed.html)\n\n```",
"_____no_output_____"
]
],
[
[
"y = sympy.IndexedBase('y')",
"_____no_output_____"
],
[
"i = sympy.Symbol('i') #for index of sum",
"_____no_output_____"
],
[
"g = sympy.log(sympy.Sum(sympy.exp(y[i]), (i, 1, m)))",
"_____no_output_____"
]
],
[
[
"```{margin} \n\n**Esta función es la que queremos derivar.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(g)",
" ⎛ m ⎞\n ⎜ ___ ⎟\n ⎜ ╲ ⎟\n ⎜ ╲ y[i]⎟\nlog⎜ ╱ ℯ ⎟\n ⎜ ╱ ⎟\n ⎜ ‾‾‾ ⎟\n ⎝i = 1 ⎠\n"
]
],
[
[
"**Para un caso de $m=3$ en la función $g$ se tiene:**",
"_____no_output_____"
]
],
[
[
"y1, y2, y3 = sympy.symbols(\"y1, y2, y3\")",
"_____no_output_____"
],
[
"g_m_3 = sympy.log(sympy.exp(y1) + sympy.exp(y2) + sympy.exp(y3))",
"_____no_output_____"
],
[
"sympy.pprint(g_m_3)",
" ⎛ y₁ y₂ y₃⎞\nlog⎝ℯ + ℯ + ℯ ⎠\n"
]
],
[
[
"```{margin} \n\nVer [derive-by_array](https://docs.sympy.org/latest/modules/tensor/array.html#derivatives-by-array)\n\n```",
"_____no_output_____"
]
],
[
[
"dg_m_3 = derive_by_array(g_m_3, [y1, y2, y3])",
"_____no_output_____"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $y_1, y_2, y_3$.** \n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(dg_m_3)",
"⎡ y₁ y₂ y₃ ⎤\n⎢ ℯ ℯ ℯ ⎥\n⎢─────────────── ─────────────── ───────────────⎥\n⎢ y₁ y₂ y₃ y₁ y₂ y₃ y₁ y₂ y₃⎥\n⎣ℯ + ℯ + ℯ ℯ + ℯ + ℯ ℯ + ℯ + ℯ ⎦\n"
]
],
[
[
"```{margin} \n\nVer [Kronecker delta](https://en.wikipedia.org/wiki/Kronecker_delta)\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(derive_by_array(g, [y[1], y[2], y[3]]))",
"⎡ m m m ⎤\n⎢ ____ ____ ____ ⎥\n⎢ ╲ ╲ ╲ ⎥\n⎢ ╲ ╲ ╲ ⎥\n⎢ ╲ y[i] ╲ y[i] ╲ y[i] ⎥\n⎢ ╱ ℯ ⋅δ ╱ ℯ ⋅δ ╱ ℯ ⋅δ ⎥\n⎢ ╱ 1,i ╱ 2,i ╱ 3,i⎥\n⎢ ╱ ╱ ╱ ⎥\n⎢ ‾‾‾‾ ‾‾‾‾ ‾‾‾‾ ⎥\n⎢i = 1 i = 1 i = 1 ⎥\n⎢──────────────── ──────────────── ────────────────⎥\n⎢ m m m ⎥\n⎢ ___ ___ ___ ⎥\n⎢ ╲ ╲ ╲ ⎥\n⎢ ╲ y[i] ╲ y[i] ╲ y[i] ⎥\n⎢ ╱ ℯ ╱ ℯ ╱ ℯ ⎥\n⎢ ╱ ╱ ╱ ⎥\n⎢ ‾‾‾ ‾‾‾ ‾‾‾ ⎥\n⎣ i = 1 i = 1 i = 1 ⎦\n"
]
],
[
[
"**Para la composición $h(x) = g(f(x))$ se utilizan las siguientes celdas:**",
"_____no_output_____"
],
[
"```{margin} \n\nVer [indexed](https://docs.sympy.org/latest/modules/tensor/indexed.html)\n```",
"_____no_output_____"
]
],
[
[
"A = sympy.IndexedBase('A')\nx = sympy.IndexedBase('x')",
"_____no_output_____"
],
[
"j = sympy.Symbol('j')",
"_____no_output_____"
],
[
"b = sympy.IndexedBase('b')",
"_____no_output_____"
],
[
"#we want something like:\nsympy.pprint(sympy.exp(sympy.Sum(A[i, j]*x[j], (j, 1, n)) + b[i]))",
" n \n ___ \n ╲ \n ╲ \n b[i] + ╱ A[i, j]⋅x[j]\n ╱ \n ‾‾‾ \n j = 1 \nℯ \n"
],
[
"#better if we split each step:\narg_sum = A[i, j]*x[j]",
"_____no_output_____"
],
[
"sympy.pprint(arg_sum)",
"A[i, j]⋅x[j]\n"
],
[
"arg_exp = sympy.Sum(arg_sum, (j, 1, n)) + b[i]",
"_____no_output_____"
],
[
"sympy.pprint(arg_exp)",
" n \n ___ \n ╲ \n ╲ \nb[i] + ╱ A[i, j]⋅x[j]\n ╱ \n ‾‾‾ \n j = 1 \n"
],
[
"sympy.pprint(sympy.exp(arg_exp))",
" n \n ___ \n ╲ \n ╲ \n b[i] + ╱ A[i, j]⋅x[j]\n ╱ \n ‾‾‾ \n j = 1 \nℯ \n"
],
[
"arg_2_sum = sympy.exp(arg_exp)",
"_____no_output_____"
],
[
"sympy.pprint(sympy.Sum(arg_2_sum, (i, 1, m)))",
" m \n_______ \n╲ \n ╲ \n ╲ n \n ╲ ___ \n ╲ ╲ \n ╲ ╲ \n ╱ b[i] + ╱ A[i, j]⋅x[j]\n ╱ ╱ \n ╱ ‾‾‾ \n ╱ j = 1 \n ╱ ℯ \n╱ \n‾‾‾‾‾‾‾ \n i = 1 \n"
],
[
"h = sympy.log(sympy.Sum(arg_2_sum, (i, 1, m))) \n#complex expression: sympy.log(sympy.Sum(sympy.exp(sympy.Sum(A[i, j]*x[j], (j, 1, n)) + b[i]), (i, 1, m)))",
"_____no_output_____"
],
[
"sympy.pprint(h)",
" ⎛ m ⎞\n ⎜_______ ⎟\n ⎜╲ ⎟\n ⎜ ╲ ⎟\n ⎜ ╲ n ⎟\n ⎜ ╲ ___ ⎟\n ⎜ ╲ ╲ ⎟\n ⎜ ╲ ╲ ⎟\nlog⎜ ╱ b[i] + ╱ A[i, j]⋅x[j]⎟\n ⎜ ╱ ╱ ⎟\n ⎜ ╱ ‾‾‾ ⎟\n ⎜ ╱ j = 1 ⎟\n ⎜ ╱ ℯ ⎟\n ⎜╱ ⎟\n ⎜‾‾‾‾‾‾‾ ⎟\n ⎝ i = 1 ⎠\n"
]
],
[
[
"```{margin} \n\n**Derivada de $h$ respecto a $x_1$.**\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(h.diff(x[1]))",
" m \n________ \n╲ \n ╲ n \n ╲ ___ \n ╲ ╲ \n ╲ ╲ \n ╲ b[i] + ╱ A[i, j]⋅x[j] n \n ╲ ╱ ___ \n ╱ ‾‾‾ ╲ \n ╱ j = 1 ╲ δ ⋅A[i, j]\n ╱ ℯ ⋅ ╱ 1,j \n ╱ ╱ \n ╱ ‾‾‾ \n ╱ j = 1 \n╱ \n‾‾‾‾‾‾‾‾ \n i = 1 \n──────────────────────────────────────────────────────\n m \n _______ \n ╲ \n ╲ \n ╲ n \n ╲ ___ \n ╲ ╲ \n ╲ ╲ \n ╱ b[i] + ╱ A[i, j]⋅x[j] \n ╱ ╱ \n ╱ ‾‾‾ \n ╱ j = 1 \n ╱ ℯ \n ╱ \n ‾‾‾‾‾‾‾ \n i = 1 \n"
]
],
[
[
"```{margin} \n\nVer [Kronecker delta](https://en.wikipedia.org/wiki/Kronecker_delta)\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(derive_by_array(h, [x[1]])) #we can use also: derive_by_array(h, [x[1], x[2], x[3]]",
"⎡ m ⎤\n⎢________ ⎥\n⎢╲ ⎥\n⎢ ╲ n ⎥\n⎢ ╲ ___ ⎥\n⎢ ╲ ╲ ⎥\n⎢ ╲ ╲ ⎥\n⎢ ╲ b[i] + ╱ A[i, j]⋅x[j] n ⎥\n⎢ ╲ ╱ ___ ⎥\n⎢ ╱ ‾‾‾ ╲ ⎥\n⎢ ╱ j = 1 ╲ δ ⋅A[i, j]⎥\n⎢ ╱ ℯ ⋅ ╱ 1,j ⎥\n⎢ ╱ ╱ ⎥\n⎢ ╱ ‾‾‾ ⎥\n⎢ ╱ j = 1 ⎥\n⎢╱ ⎥\n⎢‾‾‾‾‾‾‾‾ ⎥\n⎢ i = 1 ⎥\n⎢──────────────────────────────────────────────────────⎥\n⎢ m ⎥\n⎢ _______ ⎥\n⎢ ╲ ⎥\n⎢ ╲ ⎥\n⎢ ╲ n ⎥\n⎢ ╲ ___ ⎥\n⎢ ╲ ╲ ⎥\n⎢ ╲ ╲ ⎥\n⎢ ╱ b[i] + ╱ A[i, j]⋅x[j] ⎥\n⎢ ╱ ╱ ⎥\n⎢ ╱ ‾‾‾ ⎥\n⎢ ╱ j = 1 ⎥\n⎢ ╱ ℯ ⎥\n⎢ ╱ ⎥\n⎢ ‾‾‾‾‾‾‾ ⎥\n⎣ i = 1 ⎦\n"
]
],
[
[
"```{admonition} Pregunta\n:class: tip\n\n¿Se puede resolver este ejercicio con [Matrix Symbol](https://docs.sympy.org/latest/modules/matrices/expressions.html)?\n```",
"_____no_output_____"
],
[
"```{admonition} Ejercicio\n:class: tip\n\nVerificar que lo obtenido con SymPy es igual a lo desarrollado en \"papel\" al inicio del {ref}`Ejemplo <EJ2>`\n```",
"_____no_output_____"
],
[
"## Segunda derivada de una función $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}$.",
"_____no_output_____"
],
[
"```{admonition} Definición\n\nSea $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}$. La segunda derivada o matriz **Hessiana** de $f$ en $x \\in \\text{intdom}f$ existe si $f$ es dos veces diferenciable en $x$, se denota $\\nabla^2f(x)$ y sus componentes son segundas derivadas parciales:\n\n$$\\nabla^2f(x) = \\left[\\begin{array}{cccc}\n\\frac{\\partial^2f(x)}{\\partial x_1^2} &\\frac{\\partial^2f(x)}{\\partial x_2 \\partial x_1}&\\dots&\\frac{\\partial^2f(x)}{\\partial x_n \\partial x_1}\\\\\n\\frac{\\partial^2f(x)}{\\partial x_1 \\partial x_2} &\\frac{\\partial^2f(x)}{\\partial x_2^2} &\\dots&\\frac{\\partial^2f(x)}{\\partial x_n \\partial x_2}\\\\\n\\vdots &\\vdots& \\ddots&\\vdots\\\\\n\\frac{\\partial^2f(x)}{\\partial x_1 \\partial x_n} &\\frac{\\partial^2f(x)}{\\partial x_2 \\partial x_n}&\\dots&\\frac{\\partial^2f(x)}{\\partial x_n^2} \\\\\n\\end{array}\n\\right]\n$$\n```",
"_____no_output_____"
],
[
"```{admonition} Comentarios:\n\n* La aproximación de segundo orden a $f$ en $x$ (o también para puntos cercanos a $x$) es la función cuadrática en la variable $z$:\n\n$$f(x) + \\nabla f(x)^T(z-x)+\\frac{1}{2}(z-x)^T\\nabla^2f(x)(z-x)$$\n\n* Se cumple:\n\n$$\\displaystyle \\lim_{z \\rightarrow x, z \\neq x} \\frac{|f(z)-[f(x)+\\nabla f(x)^T(z-x)+\\frac{1}{2}(z-x)^T\\nabla^2f(x)(z-x)]|}{||z-x||_2} = 0, z \\in \\text{dom}f$$\n\n* Se tiene lo siguiente:\n\n * $\\nabla f$ es una función nombrada *gradient mapping* (o simplemente gradiente).\n\n * $\\nabla f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^n$ tiene regla de correspondencia $\\nabla f(x)$ (evaluar en $x$ la matriz $Df(\\cdot)^T$).\n\n * Se dice que $f$ es dos veces diferenciable en $\\text{dom}f$ si $\\text{dom}f$ es abierto y $f$ es dos veces diferenciable en cada punto de $x$.\n \n * $D\\nabla f(x) = \\nabla^2f(x)$ para $x \\in \\text{intdom}f$.\n \n * $\\nabla ^2 f(x) : \\mathbb{R}^n \\rightarrow \\mathbb{R}^{n \\times n}$.\n \n * Si $f \\in \\mathcal{C}^2(\\text{dom}f)$ entonces la Hessiana es una matriz simétrica.\n \n```",
"_____no_output_____"
],
[
"## Regla de la cadena para la segunda derivada",
"_____no_output_____"
],
[
"(CP2)=",
"_____no_output_____"
],
[
"### Caso particular",
"_____no_output_____"
],
[
"Sean:\n\n* $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}$, \n\n* $g:\\mathbb{R} \\rightarrow \\mathbb{R}$, \n\n* $h:\\mathbb{R}^n \\rightarrow \\mathbb{R}$ con $h(x) = g(f(x))$, entonces: \n\n$$\\nabla^2h(x) = D\\nabla h(x)$$ \n\n",
"_____no_output_____"
],
[
"```{margin} \n\nVer {ref}`Ejemplo 1 de la regla de la cadena <EJ1>` \n\n```",
"_____no_output_____"
],
[
"\ny \n\n$$\\nabla h(x)=Dh(x)^T = (Dg(f(x))Df(x))^T=\\frac{dg(f(x))}{dx}\\nabla f(x)$$\n",
"_____no_output_____"
],
[
"por lo que:\n\n$$\n\\begin{eqnarray}\n\\nabla^2 h(x) &=& D\\nabla h(x) \\nonumber \\\\\n&=& D \\left(\\frac{dg(f(x))}{dx}\\nabla f(x)\\right) \\nonumber \\\\\n&=& \\frac{dg(f(x))}{dx}\\nabla^2 f(x)+\\left(\\frac{d^2g(f(x))}{dx}\\nabla f(x) \\nabla f(x)^T \\right)^T \\nonumber \\\\\n&=& \\frac{dg(f(x))}{dx}\\nabla^2 f(x)+\\frac{d^2g(f(x))}{dx} \\nabla f(x) \\nabla f(x)^T \\nonumber\n\\end{eqnarray}\n$$",
"_____no_output_____"
],
[
"(CP3)=",
"_____no_output_____"
],
[
"### Caso particular",
"_____no_output_____"
],
[
"Sean:\n\n* $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^m, f(x) = Ax+b$ con $A \\in \\mathbb{R}^{m\\times n}$, $b \\in \\mathbb{R}^m$,\n\n* $g:\\mathbb{R}^m \\rightarrow \\mathbb{R}^p$,\n\n* $h:\\mathbb{R}^n \\rightarrow \\mathbb{R}^p$, $h(x) = g(f(x)) = g(Ax+b)$ con $\\text{dom}h=\\{z \\in \\mathbb{R}^n | Az+b \\in \\text{dom}g\\}$ entonces:\n",
"_____no_output_____"
],
[
"```{margin}\n\nVer {ref}`Caso particular <CP1>` para la expresión de la derivada.\n```",
"_____no_output_____"
],
[
"$$Dh(x)^T = Dg(f(x))Df(x) = Dg(Ax+b)A.$$\n",
"_____no_output_____"
],
[
"```{admonition} Observación\n:class: tip\n\nSi $p=1$, $g: \\mathbb{R}^m \\rightarrow \\mathbb{R}$, $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}$ se tiene: \n\n$$\\nabla^2h(x) = D \\nabla h(x) = A^T \\nabla^2g(Ax+b)A.$$\n\n```",
"_____no_output_____"
],
[
"### Ejemplo",
"_____no_output_____"
],
[
"```{margin}\n\nVer {ref}`Ejemplo <EJRestriccionALinea>`\n\n```",
"_____no_output_____"
],
[
"Si $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}$, $g: \\mathbb{R} \\rightarrow \\mathbb{R}$ está dada por $g(t) = f(x+tv)$ con $x,v \\in \\mathbb{R}^n, t \\in \\mathbb{R}$, esto es, $g$ es $f$ pero restringida a la línea $\\{x+tv|t \\in \\mathbb{R}\\}$ , entonces:\n\n$$Dg(t) = Df(x+tv)v = \\nabla f(x+tv)^Tv$$\n\nPor lo que:",
"_____no_output_____"
],
[
"$$\\nabla ^2g(t) = D\\nabla f(x+tv)^Tv=v^T\\nabla^2f(x+tv)v.$$",
"_____no_output_____"
],
[
"### Ejemplo",
"_____no_output_____"
],
[
"```{margin}\n\nVer {ref}`Ejemplo <EJ2>`\n\n```",
"_____no_output_____"
],
[
"Si $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}, h(x) = \\log \\left( \\displaystyle \\sum_{i=1}^m \\exp(a_i^Tx+b_i)\\right)$ con $x \\in \\mathbb{R}^n, a_i \\in \\mathbb{R}^n \\forall i=1,\\dots,m$ y $b_i \\in \\mathbb{R} \\forall i=1,\\dots,m$. \n\nComo se desarrolló anteriormente $\\nabla h(x) = (1^Tz)^{-1}A^Tz$ con $z=\\left[ \\begin{array}{c}\n \\exp(a_1^Tx+b_1)\\\\\n \\vdots\\\\\n \\exp(a_m^Tx+b_m)\n \\end{array}\\right]$ y $A=(a_i)_{i=1}^m \\in \\mathbb{R}^{m\\times n}.$\n\n",
"_____no_output_____"
],
[
"Por lo que \n\n$$\\nabla^2 h(x) = D\\nabla h(x) = A^T \\nabla^2g(Ax+b)A$$ ",
"_____no_output_____"
],
[
"```{margin}\n\n$\\nabla^2 g(y)$ se obtiene de acuerdo a {ref}`Caso particular <CP2>` tomando $\\log:\\mathbb{R} \\rightarrow \\mathbb{R}, \\displaystyle \\sum_{i=1}^m \\exp(y_i): \\mathbb{R}^m \\rightarrow \\mathbb{R}$\n\n```",
"_____no_output_____"
],
[
"donde: $\\nabla^2g(y)=(1^Ty)^{-1}\\text{diag}(y)-(1^Ty)^{-2}yy^T$.\n \n ",
"_____no_output_____"
],
[
"$$\\therefore \\nabla^2 h(x) = A^T\\left[(1^Tz)^{-1}\\text{diag}(z)-(1^Tz)^{-2}zz^T \\right]A$$\n\ny $\\text{diag}(c)$ es una matriz diagonal con elementos en su diagonal iguales a las entradas del vector $c$.",
"_____no_output_____"
],
[
"```{admonition} Ejercicio\n:class: tip\n\nVerificar con el paquete de SymPy las expresiones para la segunda derivada de los dos ejemplos anteriores.\n\n```",
"_____no_output_____"
],
[
"## Tablita útil para fórmulas de diferenciación con el operador $\\nabla$",
"_____no_output_____"
],
[
"Sean $f,g:\\mathbb{R}^n \\rightarrow \\mathbb{R}$ con $f,g \\in \\mathcal{C}^2$ respectivamente en sus dominios y $\\alpha_1, \\alpha_2 \\in \\mathbb{R}$, $A \\in \\mathbb{R}^{n \\times n}$, $b \\in \\mathbb{R}^n$ son fijas. Diferenciando con respecto a la variable $x \\in \\mathbb{R}^n$ se tiene:",
"_____no_output_____"
],
[
"| | |\n|:--:|:--:|\n|linealidad | $\\nabla(\\alpha_1 f(x) + \\alpha_2 g(x)) = \\alpha_1 \\nabla f(x) + \\alpha_2 \\nabla g(x)$|\n|producto | $\\nabla(f(x)g(x)) = \\nabla f(x) g(x) + f(x) \\nabla g(x)$|\n|producto punto|$\\nabla(b^Tx) = b$ \n|cuadrático|$\\nabla(x^TAx) = 2(A+A^T)x$|\n|segunda derivada| $\\nabla^2(Ax)=A$|",
"_____no_output_____"
],
[
"## Comentario respecto al cómputo simbólico o algebraico y númerico",
"_____no_output_____"
],
[
"\nSi bien el cómputo simbólico o algebraico nos ayuda a calcular las expresiones para las derivadas evitando los problemas de errores por redondeo que se revisarán en {ref}`Polinomios de Taylor y diferenciación numérica <PTDN>`, la complejidad de las expresiones que internamente se manejan es ineficiente vs el cómputo numérico, ver [Computer science aspects of computer algebra](https://en.wikipedia.org/wiki/Computer_algebra#Computer_science_aspects) y [GNU_Multiple_Precision_Arithmetic_Library](https://en.wikipedia.org/wiki/GNU_Multiple_Precision_Arithmetic_Library).\n",
"_____no_output_____"
],
[
"Como ejemplo de la precisión arbitraria que se puede manejar con el cómputo simbólico o algebraico vs el {ref}`Sistema en punto flotante <SPF>` considérese el cálculo siguiente:",
"_____no_output_____"
]
],
[
[
"eps = 1-3*(4/3-1)",
"_____no_output_____"
],
[
"print(\"{:0.16e}\".format(eps))",
"_____no_output_____"
],
[
"eps_sympy = 1-3*(sympy.Rational(4,3)-1)",
"_____no_output_____"
],
[
"print(\"{:0.16e}\".format(float(eps_sympy)))",
"_____no_output_____"
]
],
[
[
"```{admonition} Ejercicios\n:class: tip\n\n1.Resuelve los ejercicios y preguntas de la nota.\n```",
"_____no_output_____"
],
[
"**Referencias**\n\n1. S. P. Boyd, L. Vandenberghe, Convex Optimization. Cambridge University Press, 2004.\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
]
|
e7cdbdd2f4e4cd15d32c56a6246bd1140db25d5a | 399,394 | ipynb | Jupyter Notebook | mobile_data_00.ipynb | ugursakarya0707/Data-Visualization-with-Jupyter-Notebook | 61bebc0545b98b13f3ceba443883efba2781a820 | [
"MIT"
]
| null | null | null | mobile_data_00.ipynb | ugursakarya0707/Data-Visualization-with-Jupyter-Notebook | 61bebc0545b98b13f3ceba443883efba2781a820 | [
"MIT"
]
| null | null | null | mobile_data_00.ipynb | ugursakarya0707/Data-Visualization-with-Jupyter-Notebook | 61bebc0545b98b13f3ceba443883efba2781a820 | [
"MIT"
]
| null | null | null | 469.875294 | 135,476 | 0.932277 | [
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nmobile = pd.read_csv(r\"C:\\Users\\uguur\\OneDrive\\Masaüstü\\visulation\\kaggle-datasets\\train.csv\")",
"_____no_output_____"
],
[
"mobile.head()",
"_____no_output_____"
],
[
"mobile.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 2000 entries, 0 to 1999\nData columns (total 21 columns):\nbattery_power 2000 non-null int64\nblue 2000 non-null int64\nclock_speed 2000 non-null float64\ndual_sim 2000 non-null int64\nfc 2000 non-null int64\nfour_g 2000 non-null int64\nint_memory 2000 non-null int64\nm_dep 2000 non-null float64\nmobile_wt 2000 non-null int64\nn_cores 2000 non-null int64\npc 2000 non-null int64\npx_height 2000 non-null int64\npx_width 2000 non-null int64\nram 2000 non-null int64\nsc_h 2000 non-null int64\nsc_w 2000 non-null int64\ntalk_time 2000 non-null int64\nthree_g 2000 non-null int64\ntouch_screen 2000 non-null int64\nwifi 2000 non-null int64\nprice_range 2000 non-null int64\ndtypes: float64(2), int64(19)\nmemory usage: 328.2 KB\n"
],
[
"corr = mobile.corr()\nfig = plt.figure(figsize = (10,7))\na = sns.heatmap(corr , cmap =\"Purples\")\na.set_title(\"Korrelasyon Dağılımı\");",
"_____no_output_____"
],
[
"mobile[\"price_range\"].value_counts(normalize=True)",
"_____no_output_____"
],
[
"rangee=mobile[\"price_range\"].value_counts(normalize=True)\nprint(rangee)",
"3 0.25\n2 0.25\n1 0.25\n0 0.25\nName: price_range, dtype: float64\n"
],
[
"price_range_level = ['Premium','Cheap',\"Expensive\",\"Avangard\"]\nrangee =mobile[\"price_range\"].value_counts(normalize=True)\nfig1, ax1 = plt.subplots()\nax1.pie(rangee, labels=price_range_level, shadow=True, startangle=90, autopct='%1.1f%%');",
"_____no_output_____"
],
[
"wifi=mobile[\"wifi\"].value_counts(normalize=True)\nprint(wifi)",
"1 0.507\n0 0.493\nName: wifi, dtype: float64\n"
],
[
"have_Wifi = ['Wifi-Supported','Not Supported']\nwifi=mobile[\"wifi\"].value_counts(normalize=True)\nfig1, ax1 = plt.subplots()\nax1.pie(wifi, labels=have_Wifi, shadow=True, startangle=90, autopct='%1.1f%%');",
"_____no_output_____"
],
[
"high_price_range = mobile[\"price_range\"].isin([\"2\",\"3\"])\nmobile[high_price_range].head()",
"_____no_output_____"
],
[
"corr = mobile[high_price_range].corr()\nfig = plt.figure(figsize = (10,7))\na = sns.heatmap(corr , cmap =\"Purples\")\na.set_title(\"expensive phones distributions\");",
"_____no_output_____"
],
[
"sns.distplot(mobile[\"ram\"],kde=False,bins=10);",
"_____no_output_____"
],
[
"sns.swarmplot(mobile[\"price_range\"],mobile[\"ram\"]);\nplt.show()",
"_____no_output_____"
],
[
"sns.barplot(mobile['price_range'],mobile[\"ram\"]);",
"_____no_output_____"
],
[
"sns.swarmplot(mobile['price_range'],mobile['px_height']);\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,6))\nplt.hist(mobile['fc'],rwidth=15,alpha=0.7,color='red',bins=15,edgecolor='green') \nplt.xlabel('price_range') \nplt.ylabel('battery_power') \nplt.title('Mobile Price Classification') \nplt.show();",
"_____no_output_____"
],
[
"plt.figure(figsize = (10,6))\nsns.countplot(data = mobile,x = \"price_range\", hue = 'dual_sim',color=\"blue\")\nplt.title(\"Amount of Dual Sim Phones for each Price Range Level\")\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize = (10,6))\nsns.countplot(data=mobile,x = \"price_range\", hue = 'touch_screen',color=\"blue\")\nplt.title(\"Amount of Touch Screen Phones for each Price Range Level\")\nplt.show()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cdc82a77f20b0e1e8758fd1e87b7a845acd837 | 19,544 | ipynb | Jupyter Notebook | CEBD_1260_MikeD'Itri_IsraelPhiri_PRoject_Nov_23.ipynb | mikeditri/CEBD_1260_Machine_learning_Project | a7cc1798df34e25c57988deb1832c07e147cff2d | [
"MIT"
]
| null | null | null | CEBD_1260_MikeD'Itri_IsraelPhiri_PRoject_Nov_23.ipynb | mikeditri/CEBD_1260_Machine_learning_Project | a7cc1798df34e25c57988deb1832c07e147cff2d | [
"MIT"
]
| null | null | null | CEBD_1260_MikeD'Itri_IsraelPhiri_PRoject_Nov_23.ipynb | mikeditri/CEBD_1260_Machine_learning_Project | a7cc1798df34e25c57988deb1832c07e147cff2d | [
"MIT"
]
| null | null | null | 26.16332 | 125 | 0.46183 | [
[
[
"import numpy as np \nimport pandas as pd \nimport os\nimport gc\nimport seaborn as sns # for plotting graphs\nimport matplotlib.pyplot as plt # for plotting graphs aswell\nimport glob\nfrom datetime import datetime\nfrom sklearn.model_selection import train_test_split \nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn import preprocessing\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.preprocessing import LabelEncoder\nfrom scipy.sparse import coo_matrix, hstack\n%matplotlib inline\n\n",
"_____no_output_____"
],
[
"# to display maximum rows and columns\npd.set_option('display.max_rows', None)\npd.set_option('display.max_columns', None)\n",
"_____no_output_____"
],
[
"# function to set all numerical data to int16 or float16, to save on memory use\ndef dtype_conver(Dataframe):\n for col in Dataframe:\n if Dataframe[col].dtype == 'float32' or 'float64':\n Dataframe[col] = Dataframe[col].astype(np.float16)\n if Dataframe[col].dtype == 'int8' or 'int32' or 'float64':\n Dataframe[col] = Dataframe[col].astype(np.int16)",
"_____no_output_____"
],
[
"# Read in filepath \nDATA_PATH = r'C:/Users/t891199/Desktop/Big_Data_Diploma/CEBD_1260_Machine_learning/Data Files/Class_3/'\nfile_name = os.path.join(DATA_PATH,'train.csv')\n",
"_____no_output_____"
],
[
"# pandas reads in csv file using filepath\nold_train_df = pd.read_csv(file_name)\nprint(old_train_df.shape)\n#original_quote_date is time-series",
"(260753, 299)\n"
],
[
"#Feature Engineering\nold_train_df['Original_Quote_Date'] = pd.to_datetime(old_train_df['Original_Quote_Date'])\nold_train_df['year'] = old_train_df['Original_Quote_Date'].dt.year\nold_train_df['month'] = old_train_df['Original_Quote_Date'].dt.month\nold_train_df['day'] = old_train_df['Original_Quote_Date'].dt.day",
"_____no_output_____"
],
[
"train_df = old_train_df.drop([\"Original_Quote_Date\"], axis = 1)\n# lets see how many NaN or Null values are in each column\nnan_info = pd.DataFrame(train_df.isnull().sum()).reset_index()\nnan_info.columns = ['col','nan_cnt']\n",
"_____no_output_____"
],
[
"#sort them in descending order and print 1st 10\nnan_info.sort_values(by = 'nan_cnt',ascending=False,inplace=True)\nnan_info.head(10)",
"_____no_output_____"
],
[
"# extract column names with NaNs and Nulls\n# numerical cols with missing values\nnum_cols_with_missing = ['PersonalField84','PropertyField29']\n\n",
"_____no_output_____"
],
[
"#boolean type cols with missing values\nbool_cols_with_missing = ['PropertyField3','PropertyField4','PersonalField7','PropertyField32',\n 'PropertyField34','PropertyField36','PropertyField38']\n",
"_____no_output_____"
],
[
"# fill in null and NaN values with 'U' in boolean type cols ( 'Y','N')\nfor cols in bool_cols_with_missing:\n train_df[cols].fillna('U',inplace=True)\n\n",
"_____no_output_____"
],
[
"# fill in null and NaN values with -1 in numerical missing values\nfor cols in num_cols_with_missing:\n train_df[cols].fillna(-1, inplace=True)\n",
"_____no_output_____"
],
[
"# define target\ny = old_train_df[\"QuoteConversion_Flag\"].values",
"_____no_output_____"
],
[
"# drop target column from data\nX = train_df.drop([\"QuoteConversion_Flag\"], axis = 1)\n",
"_____no_output_____"
],
[
"#QuoteNumber setting as index\nX = X.set_index(\"QuoteNumber\")\n\n",
"_____no_output_____"
],
[
"# select all columns that are categorical i.e with unique categories less than 40 in our case\nX_for_ohe = [cols for cols in X.columns if X[cols].nunique() < 40 or X[cols].dtype in['object']]\nX_not_ohe = [cols for cols in X.columns if X[cols].nunique() > 40 and X[cols].dtype not in['object']]\n",
"_____no_output_____"
],
[
"#numerical column that we will not encode\nX[X_not_ohe].head()\n",
"_____no_output_____"
],
[
"#to keep track of our columns, how many are remaining after we removed 4 so far?\nlen(X_for_ohe)",
"_____no_output_____"
],
[
"nan_info = pd.DataFrame(X[X_for_ohe].isnull().sum()).reset_index()\nnan_info.columns = ['col','nan_cnt']",
"_____no_output_____"
],
[
"#sort them in descending order and print 1st 10\nnan_info.sort_values(by = 'nan_cnt',ascending=False,inplace=True)\nnan_info.head(10)",
"_____no_output_____"
],
[
"# These are columns that need to be picked through, they seem to have all kinds of strange data in them! \n#X_try = X[X_for_ohe].drop(['PropertyField3','PropertyField4','PropertyField32','PropertyField34','PropertyField36',\n# 'PropertyField38','PersonalField7','PersonalField4A',\n# 'PersonalField4B'], axis = 1)\n",
"_____no_output_____"
],
[
"# import OneHotEncoder\nfrom sklearn.preprocessing import OneHotEncoder\nohe = OneHotEncoder(categories = 'auto',sparse=True)\n",
"_____no_output_____"
],
[
"# apply OneHotEncoder on categorical feature columns\nX_ohe = ohe.fit_transform(X[X_for_ohe])\n",
"_____no_output_____"
],
[
"# we are pretty much done for now here, apparently we can set 'sparse = True' in OneHotEncoder and we get a \n#csr_matrix. I left it as false so that you can see the sparse matrix\nX_ohe\n",
"_____no_output_____"
],
[
"X_ohe.shape",
"_____no_output_____"
],
[
"X['SalesField8'].shape",
"_____no_output_____"
],
[
"#always separate test data from the rest\nX_rem,X_test,y_rem,y_test = train_test_split(X_ohe,y,test_size=0.2,random_state=1)\n\n#separate validation data from training data\nX_train,X_val,y_train,y_val = train_test_split(X_rem,y_rem,test_size=0.25,random_state=1)",
"_____no_output_____"
],
[
"clf = RandomForestClassifier(n_estimators=100, max_depth=2,random_state=0)",
"_____no_output_____"
],
[
"clf.fit(X_train,y_train)",
"_____no_output_____"
],
[
"print(clf.feature_importances_)",
"[0. 0.0019476 0. ... 0. 0. 0. ]\n"
],
[
"y_pred = clf.predict(X_val)",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7ce06258af22c9d51f172de9dd907a1128d0270 | 5,986 | ipynb | Jupyter Notebook | docs/doit.ipynb | marimeireles/jupyterlite | 65c9304cf89d311b8a48f227a0cbb2b7f50cf4bd | [
"BSD-3-Clause"
]
| null | null | null | docs/doit.ipynb | marimeireles/jupyterlite | 65c9304cf89d311b8a48f227a0cbb2b7f50cf4bd | [
"BSD-3-Clause"
]
| null | null | null | docs/doit.ipynb | marimeireles/jupyterlite | 65c9304cf89d311b8a48f227a0cbb2b7f50cf4bd | [
"BSD-3-Clause"
]
| null | null | null | 26.026087 | 223 | 0.567658 | [
[
[
"# doit\n\n> _The use of `doit` is an implementation detail, and is subject to change!_\n\nUnder the hood, the [CLI](./cli.ipynb) is powered by [doit](https://github.com/pydoit/doit), a lightweight task engine in python comparable to `make`.",
"_____no_output_____"
],
[
"## Using Tasks with the API",
"_____no_output_____"
]
],
[
[
"import os, pathlib, tempfile, shutil, atexit, hashlib, pandas\nfrom IPython.display import *\nfrom IPython import get_ipython # needed for `jupyter_execute` because magics?\nimport IPython\nif \"TMP_DIR\" not in globals():\n TMP_DIR = pathlib.Path(tempfile.mkdtemp(prefix=\"_my_lite_dir_\"))\n def clean():\n shutil.rmtree(TMP_DIR)\n atexit.register(clean)\nos.chdir(TMP_DIR)\nprint(pathlib.Path.cwd())",
"/tmp/_my_lite_dir_pskl3egv\n"
]
],
[
[
"The `LiteManager` collects all the tasks from _Addons_, and can optionally accept a `task_prefix` in case you need to integrate with existing tasks.",
"_____no_output_____"
]
],
[
[
"from jupyterlite.manager import LiteManager\nmanager = LiteManager(\n task_prefix=\"lite_\"\n)\nmanager.initialize()\nmanager.doit_run(\"lite_status\")",
"lite_static:jupyter-lite.json\n. lite_pre_status:lite_static:jupyter-lite.json\n tarball: jupyterlite-app-0.1.0-alpha.5.tgz 18MB\n output: /tmp/_my_lite_dir_pskl3egv/_output\n lite dir: /tmp/_my_lite_dir_pskl3egv\n apps: ('lab', 'retro')\nlite_archive:archive\nlite_contents:contents\nlite_lite:jupyter-lite.json\nlite_serve:contents\nlite_settings:overrides\n. lite_status:lite_archive:archive\n. lite_status:lite_contents:contents\n contents: 0 files\n. lite_status:lite_lite:jupyter-lite.json\n. lite_status:lite_serve:contents\n will serve 8000 with: tornado\n. lite_status:lite_settings:overrides\n overrides.json: 0\n"
]
],
[
[
"## Custom Tasks and `%doit`\n\n`doit` offers an IPython [magic](https://ipython.readthedocs.io/en/stable/interactive/magics.html), enabled with an extension. This can be combined to create highly reactive build tools for creating very custom sites.",
"_____no_output_____"
]
],
[
[
"%reload_ext doit",
"_____no_output_____"
]
],
[
[
"It works against the `__main__` namespace, which won't have anything by default.",
"_____no_output_____"
]
],
[
[
"%doit list",
"_____no_output_____"
]
],
[
[
"All the JupyterLite tasks can be added by updating `__main__` via `globals`",
"_____no_output_____"
]
],
[
[
"globals().update(manager._doit_tasks)",
"_____no_output_____"
]
],
[
[
"Now when a new task is created, it can reference other tasks and targets.",
"_____no_output_____"
]
],
[
[
"def task_hello():\n return dict(\n actions=[lambda: print(\"HELLO!\")],\n task_dep=[\"lite_post_status\"]\n )",
"_____no_output_____"
],
[
"%doit -v2 hello",
"lite_static:jupyter-lite.json\n. lite_pre_status:lite_static:jupyter-lite.json\n tarball: jupyterlite-app-0.1.0-alpha.5.tgz 18MB\n output: /tmp/_my_lite_dir_pskl3egv/_output\n lite dir: /tmp/_my_lite_dir_pskl3egv\n apps: ('lab', 'retro')\n. hello\nHELLO!\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7ce074d867cba1acf7b61cb59c24f6efe76fbca | 511,843 | ipynb | Jupyter Notebook | Vol Surfaces Webinar.ipynb | Refinitiv-API-Samples/Article.RDPLibrary.Python.VolatilitySurfaces_Curves | ddeba3c8778ff6dd59ebf4533b5f8c9f4dd117fe | [
"Apache-2.0"
]
| 3 | 2020-09-03T16:55:16.000Z | 2020-12-21T10:42:16.000Z | Vol Surfaces Webinar.ipynb | Refinitiv-API-Samples/Article.RDPLibrary.Python.VolatilitySurfaces_Curves | ddeba3c8778ff6dd59ebf4533b5f8c9f4dd117fe | [
"Apache-2.0"
]
| null | null | null | Vol Surfaces Webinar.ipynb | Refinitiv-API-Samples/Article.RDPLibrary.Python.VolatilitySurfaces_Curves | ddeba3c8778ff6dd59ebf4533b5f8c9f4dd117fe | [
"Apache-2.0"
]
| 3 | 2020-12-21T10:42:22.000Z | 2021-11-21T05:41:37.000Z | 190.986194 | 86,496 | 0.86338 | [
[
[
"# Instrument Pricing Analytics - Volatility Surfaces",
"_____no_output_____"
],
[
"#### Initialisation\n\nFirst thing I need to do is import my libraries and then run my scripts to define my helper functions. \nAs you will note I am importing the Refinitiv Data Platform library which will be my main interface to the Platform - as well as few of the most commonly used Python libraries.\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport requests\nimport numpy as np\nimport json\nimport refinitiv.dataplatform as rdp\n\n%run -i c:/Refinitiv/credentials.ipynb\n%run ./plotting_helper.ipynb",
"_____no_output_____"
]
],
[
[
"### Connect to the Refintiv Data Platform\nI am using my helper functions to establish a connection the Platform by requesting a session and opening it.",
"_____no_output_____"
]
],
[
[
"session = rdp.PlatformSession(\n get_app_key(),\n rdp.GrantPassword(\n username = get_rdp_login(),\n password = get_rdp_password()\n )\n)\nsession.open()",
"_____no_output_____"
]
],
[
[
"## Endpoint Interface\n\nUsing the Endpoint interface to request IPA content is fairly straighforward\n1. Identify the required IPA Endpoint (URL)\n2. Use the Endpoint Interface to send a request to the Endpoint\n3. Decode the response and extract the IPA data\n\n### Identifying the Surfaces Endpoint\nTo ascertain the Endpoint, we can use the Refinitiv Data Platform's <a href=\"http://api.refinitiv.com/\" target=\"_blank\">API Playground</a> - an interactive documentation site you can access once you have a valid Refinitiv Data Platform account.\n",
"_____no_output_____"
]
],
[
[
"vs_endpoint = rdp.Endpoint(session, \n \"https://api.refinitiv.com/data/quantitative-analytics-curves-and-surfaces/v1/surfaces\")",
"_____no_output_____"
]
],
[
[
"#### Build our JSON Request\n\nUsing the reference documentation or by referring to the example queries shown on the above API playground page, I can build up my Request. \n\nCurrently there are four Underlying Types of Volatility Surface supported:\n* Eti : exchange-traded instruments like equities, equity indices, and futures.\n* Fx : Fx instruments.\n* Swaption : Rate swaptions volatility cube.\n* Cap : Rate caps volatilities\n\nFor example the JSON request below, will allow me to generate Volatility Surfaces:\n* for Renault, Peugeot, BMW and VW\n* express the axes in Dates and Moneyness\n* and return the data in a matrix format\n\n\nNote from the request below, how I can obtain data for multiple entities in a single request.\n",
"_____no_output_____"
]
],
[
[
"eti_request_body={\n \"universe\": [\n { \"surfaceTag\": \"RENAULT\",\n \"underlyingType\": \"Eti\",\n \"underlyingDefinition\": {\n \"instrumentCode\": \"RENA.PA\"\n },\n \"surfaceParameters\": {\n \"xAxis\": \"Date\",\n \"yAxis\": \"Moneyness\",\n \"timeStamp\":\"Close\"\n },\n \"surfaceLayout\": { \"format\": \"Matrix\" }\n },\n { \"surfaceTag\": \"PEUGEOT\",\n \"underlyingType\": \"Eti\",\n \"underlyingDefinition\": {\n \"instrumentCode\": \"PEUP.PA\"\n },\n \"surfaceParameters\": {\n \"xAxis\": \"Date\",\n \"yAxis\": \"Moneyness\",\n \"timeStamp\":\"Close\"\n },\n \"surfaceLayout\": {\"format\": \"Matrix\" }\n },\n { \"surfaceTag\": \"BMW\",\n \"underlyingType\": \"Eti\",\n \"underlyingDefinition\": {\n \"instrumentCode\": \"BMWG.DE\"\n },\n \"surfaceParameters\": {\n \"xAxis\": \"Date\",\n \"yAxis\": \"Moneyness\",\n \"timeStamp\":\"Close\"\n },\n \"surfaceLayout\": {\"format\": \"Matrix\" }\n },\n { \"surfaceTag\": \"VW\",\n \"underlyingType\": \"Eti\",\n \"underlyingDefinition\": {\n \"instrumentCode\": \"VOWG_p.DE\"\n },\n \"surfaceParameters\": {\n \"xAxis\": \"Date\",\n \"yAxis\": \"Moneyness\",\n \"timeStamp\":\"Close\"\n },\n \"surfaceLayout\": {\"format\": \"Matrix\" }\n }]\n}\n",
"_____no_output_____"
]
],
[
[
"I then send the request to the Platform using the instance of Endpoint interface I created:",
"_____no_output_____"
]
],
[
[
"eti_response = vs_endpoint.send_request(\n method = rdp.Endpoint.RequestMethod.POST,\n body_parameters = eti_request_body\n)\nprint(json.dumps(eti_response.data.raw, indent=2))",
"{\n \"data\": [\n {\n \"surfaceTag\": \"RENAULT\",\n \"surface\": [\n [\n null,\n \"0.5\",\n \"0.6\",\n \"0.7\",\n \"0.75\",\n \"0.8\",\n \"0.85\",\n \"0.9\",\n \"0.95\",\n \"0.975\",\n \"1\",\n \"1.025\",\n \"1.05\",\n \"1.1\",\n \"1.15\",\n \"1.2\",\n \"1.25\",\n \"1.3\",\n \"1.4\",\n \"1.5\"\n ],\n [\n \"2021-09-17\",\n 147.08419792403998,\n 124.887128486199,\n 102.502608735503,\n 90.7725390709383,\n 78.3224754024164,\n 64.7347605843219,\n 49.5452700945521,\n 34.7540272345762,\n 31.4667054231154,\n 32.0453039114781,\n 34.512655172437704,\n 37.541128880630296,\n 43.6039134806104,\n 49.0859621495022,\n 53.9581726356531,\n 58.3160482626392,\n 62.25107287197859,\n 69.1277973238572,\n 74.9979157202164\n ],\n [\n \"2021-10-15\",\n 53.069388222896194,\n 48.5924854712817,\n 44.4596013501265,\n 42.481538137102596,\n 40.545928644530996,\n 38.642879888308,\n 36.764926387466204,\n 34.910013376827095,\n 33.995033240751596,\n 33.0976677871358,\n 32.243729081637,\n 31.5385617522967,\n 32.9317587757963,\n 36.540667097254,\n 39.8547710463726,\n 42.8206310435714,\n 45.4972388560462,\n 50.1755078982006,\n 54.1734706301841\n ],\n [\n \"2021-11-19\",\n 51.010168194334305,\n 47.2586137425893,\n 43.8369524931666,\n 42.215783288497,\n 40.6407820868742,\n 39.1035551143142,\n 37.5966976300453,\n 36.113513046636804,\n 35.3788420621087,\n 34.6477842934691,\n 33.9196052012799,\n 33.4083257579711,\n 33.970220758767496,\n 34.4985849874748,\n 34.9969846589742,\n 35.4684559278907,\n 35.915604065343,\n 36.745644518348705,\n 37.5018840990136\n ],\n [\n \"2021-12-17\",\n 57.233242294493905,\n 51.164053019880896,\n 45.701088650208,\n 43.1961463100387,\n 40.8664673512826,\n 38.7492162510077,\n 36.8984869723095,\n 35.3826377109506,\n 34.773166630264605,\n 34.2737384577619,\n 33.8906209420233,\n 33.6275219669106,\n 33.460272549395796,\n 33.7371002456965,\n 34.3813221293777,\n 35.298242246575,\n 36.3977365918439,\n 38.8705864290812,\n 41.4290579735572\n ],\n [\n \"2022-03-18\",\n 44.6596592255869,\n 42.0460856501159,\n 39.7202965404191,\n 38.644801723719105,\n 37.622080867111,\n 36.6519175260592,\n 35.7389270526863,\n 34.896264117111905,\n 34.5095990171748,\n 34.1537003957255,\n 33.8373185227046,\n 33.5720427853049,\n 33.2482704002882,\n 33.2492925176735,\n 33.5159983803838,\n 33.928850537993796,\n 34.4042590290927,\n 35.3962100605949,\n 36.3580111985554\n ],\n [\n \"2022-06-17\",\n 49.1870500594481,\n 44.9031179692494,\n 41.2680211636964,\n 39.69311034954,\n 38.288670999534006,\n 37.0639050681352,\n 36.0273893913099,\n 35.184454053269995,\n 34.8357727616879,\n 34.5348824790694,\n 34.2806770212382,\n 34.0716215264747,\n 33.7809379861908,\n 33.6439199904793,\n 33.6387371081713,\n 33.7429317144256,\n 33.9352165833992,\n 34.5107887236788,\n 35.2464953006523\n ],\n [\n \"2022-12-16\",\n 45.915430866261296,\n 41.568666875793696,\n 38.0589155632095,\n 36.7374739303178,\n 35.756679762792,\n 35.092477323812396,\n 34.6758141327614,\n 34.431121339744294,\n 34.354025406618796,\n 34.2993866650758,\n 34.2628112321313,\n 34.2407940558594,\n 34.229839222543504,\n 34.2502985967091,\n 34.291723154303796,\n 34.3472511126111,\n 34.412282078027204,\n 34.559230167779,\n 34.7171235514547\n ]\n ]\n },\n {\n \"surfaceTag\": \"PEUGEOT\",\n \"error\": {\n \"id\": \"232f6765-a920-4584-8b54-77f39b315da1/388f77ae-866e-44fe-989f-b954595da7f6\",\n \"status\": \"Error\",\n \"message\": \"Unknown underlying : PEUP.PA@RIC\",\n \"code\": \"VolSurf.10008\"\n }\n },\n {\n \"surfaceTag\": \"BMW\",\n \"surface\": [\n [\n null,\n \"0.5\",\n \"0.6\",\n \"0.7\",\n \"0.75\",\n \"0.8\",\n \"0.85\",\n \"0.9\",\n \"0.95\",\n \"0.975\",\n \"1\",\n \"1.025\",\n \"1.05\",\n \"1.1\",\n \"1.15\",\n \"1.2\",\n \"1.25\",\n \"1.3\",\n \"1.4\",\n \"1.5\"\n ],\n [\n \"2021-09-17\",\n 116.845285831284,\n 98.4955466076639,\n 79.8759711420056,\n 70.0693756839943,\n 59.648390837661005,\n 48.3928694609162,\n 36.659259523477,\n 27.8917636007667,\n 26.112867383184202,\n 25.7473437323123,\n 26.2111895589014,\n 27.1032791041882,\n 29.3810577196575,\n 31.7834555215809,\n 34.0931448372836,\n 36.2565214779287,\n 38.268806180789596,\n 41.8833019536874,\n 45.039930489630194\n ],\n [\n \"2021-10-15\",\n 66.4722438122797,\n 57.5692211952808,\n 48.8876367694066,\n 44.526206198251,\n 40.106867647071894,\n 35.6199006830361,\n 31.124524575682,\n 26.8858686281106,\n 25.0663745235899,\n 23.6223245491879,\n 22.6790698362936,\n 22.2830851870678,\n 22.838913504619,\n 24.3941728766485,\n 26.2802553341711,\n 28.2041512791805,\n 30.05887196084,\n 33.4545816221734,\n 36.4385434208208\n ],\n [\n \"2021-11-19\",\n 59.6548040147561,\n 51.676797795483594,\n 43.9545932082731,\n 40.1290827936518,\n 36.334848434780795,\n 32.647505885872405,\n 29.271374496206498,\n 26.5607752421821,\n 25.5533213548146,\n 24.7846805441186,\n 24.2280587712883,\n 23.8449233153254,\n 23.4499564127721,\n 23.364860568818898,\n 23.4512533780394,\n 23.6332095618005,\n 23.8686642855439,\n 24.4137497636682,\n 24.988755094251598\n ],\n [\n \"2021-12-17\",\n 57.000970257372096,\n 49.1530128772988,\n 41.6746242855461,\n 38.061545312743,\n 34.582295989538494,\n 31.342785189096702,\n 28.528564514887698,\n 26.3775814320784,\n 25.611275627130297,\n 25.061410076782497,\n 24.7181541429707,\n 24.560415940794698,\n 24.6897568420552,\n 25.2279090586339,\n 26.000041490541097,\n 26.891655530662,\n 27.8339749368404,\n 29.7296077956909,\n 31.538236502954497\n ],\n [\n \"2022-03-18\",\n 34.6517801480973,\n 33.025354724913605,\n 31.6136221315428,\n 30.9749328298299,\n 30.377048394941504,\n 29.818577916088003,\n 29.299317389159,\n 28.8202403595205,\n 28.5963970847672,\n 28.383495230161,\n 28.181976544217203,\n 27.9923398485676,\n 27.6509074086288,\n 27.363675150843903,\n 27.1345570901111,\n 26.9657285226333,\n 26.8565726713302,\n 26.799338623303896,\n 26.9072105062878\n ],\n [\n \"2022-06-17\",\n 41.7685383611724,\n 35.765823375570896,\n 31.4025984950861,\n 29.843831526977,\n 28.6450177020749,\n 27.743950355993903,\n 27.078791153078203,\n 26.5958597181018,\n 26.4088241855986,\n 26.251943454376097,\n 26.1213386702238,\n 26.0136362793075,\n 25.855616826955703,\n 25.7588339299166,\n 25.708958559441502,\n 25.6951736343913,\n 25.7092656860147,\n 25.7974083262819,\n 25.9384282659597\n ],\n [\n \"2022-12-16\",\n 32.4567965023246,\n 30.3259923139122,\n 28.465159965014802,\n 27.6227740152669,\n 26.836305731271498,\n 26.1059801603091,\n 25.433785668915498,\n 24.8234563051983,\n 24.5431246580115,\n 24.2804200751625,\n 24.0362566646918,\n 23.8116193408349,\n 23.4250812803751,\n 23.1291124084223,\n 22.9310563772648,\n 22.8357291149445,\n 22.8439015971646,\n 23.1491439341391,\n 23.763006647344103\n ],\n [\n \"2023-06-16\",\n 32.8275913709902,\n 29.825454499724902,\n 27.1644029353807,\n 26.069388721946602,\n 25.3369159794596,\n 25.0224640729829,\n 24.9362882169239,\n 24.9393990255266,\n 24.9561139814056,\n 24.9784593215957,\n 25.004568455885902,\n 25.0332082655576,\n 25.0949882246438,\n 25.1596879533267,\n 25.2252008561141,\n 25.290393165269297,\n 25.354639439640604,\n 25.4790779043358,\n 25.5973370893097\n ]\n ]\n },\n {\n \"surfaceTag\": \"VW\",\n \"surface\": [\n [\n null,\n \"0.5\",\n \"0.6\",\n \"0.7\",\n \"0.75\",\n \"0.8\",\n \"0.85\",\n \"0.9\",\n \"0.95\",\n \"0.975\",\n \"1\",\n \"1.025\",\n \"1.05\",\n \"1.1\",\n \"1.15\",\n \"1.2\",\n \"1.25\",\n \"1.3\",\n \"1.4\",\n \"1.5\"\n ],\n [\n \"2021-09-17\",\n 114.9314664709,\n 95.9894396686403,\n 76.6135440169291,\n 66.3472579190723,\n 55.4554726431587,\n 44.0344023956383,\n 33.7968257283678,\n 28.6851007510666,\n 28.1593306280496,\n 28.425046914714404,\n 29.140319709019202,\n 30.0946506746575,\n 32.2895785056828,\n 34.5475040494519,\n 36.7228908488976,\n 38.773967692826,\n 40.6945799450279,\n 44.1729901278008,\n 47.236493355838\n ],\n [\n \"2021-10-15\",\n 57.375246904915,\n 49.7825190662113,\n 42.5110323707841,\n 38.9611462854511,\n 35.4972590663025,\n 32.2134120429363,\n 29.3269545789032,\n 27.220565532367402,\n 26.593124698883102,\n 26.2860116277915,\n 26.284168490728398,\n 26.542959907222002,\n 27.6095695147525,\n 29.073599537630702,\n 30.678396354383196,\n 32.2960412468414,\n 33.8690560728042,\n 36.8038642621664,\n 39.4408213508689\n ],\n [\n \"2021-11-19\",\n 40.5164104901332,\n 37.5595161431696,\n 34.8643942746955,\n 33.5881627181228,\n 32.3487808701543,\n 31.1396611441992,\n 29.9550064044728,\n 28.789590185127402,\n 28.212574963201497,\n 27.6385789383842,\n 27.072623752272403,\n 27.4596183067678,\n 28.191684121696696,\n 28.8738666327561,\n 29.512238570718203,\n 30.111833833553497,\n 30.676872532730897,\n 31.7170519014931,\n 32.6556679383878\n ],\n [\n \"2021-12-17\",\n 55.608286147016194,\n 46.3040334948096,\n 40.4869770451672,\n 38.7152177248228,\n 37.488555251203195,\n 36.660398926279804,\n 36.117712281089794,\n 35.7785936997772,\n 35.666533484297204,\n 35.5851259433475,\n 35.5297584981015,\n 35.4965526522386,\n 35.4840584191147,\n 35.5270834682839,\n 35.6107986288532,\n 35.7243885274329,\n 35.8598807184815,\n 36.1743109491648,\n 36.522097375719596\n ],\n [\n \"2022-03-18\",\n 36.218856024754,\n 34.6807394151219,\n 33.324940583323794,\n 32.6999237680908,\n 32.1042464631892,\n 31.534446006490903,\n 30.987629291031897,\n 30.4613523293718,\n 30.2052526732421,\n 29.9535301598657,\n 29.7059690407111,\n 29.6409172737924,\n 31.121220791685,\n 32.472724324283,\n 33.7159724734816,\n 34.8668336413211,\n 35.9378533093031,\n 37.8789782799983,\n 39.600689996803\n ],\n [\n \"2022-06-17\",\n 40.6967382519956,\n 38.311602443083395,\n 36.1725087878902,\n 35.1730025482411,\n 34.2116033179677,\n 33.2832220760772,\n 32.3835544387683,\n 31.5089096515214,\n 31.0799529653275,\n 30.656082115330403,\n 30.236956333202503,\n 29.8222549207731,\n 29.0050062933094,\n 29.462628985363796,\n 30.1645965867815,\n 30.822896827282996,\n 31.442397039942797,\n 32.580810970083604,\n 33.6060043256551\n ],\n [\n \"2022-12-16\",\n 38.1576610298997,\n 36.1560428699018,\n 34.3728829559457,\n 33.5441055270122,\n 32.7498556584893,\n 31.985813170711403,\n 31.2483497326988,\n 30.5343812634024,\n 30.1853648866574,\n 29.841257308345497,\n 29.501781160512902,\n 29.166676726352396,\n 28.5086227430281,\n 28.1754694907583,\n 28.835064113784497,\n 29.4538568882352,\n 30.0363718203165,\n 31.107276612058598,\n 32.0721402018659\n ],\n [\n \"2023-06-16\",\n 39.3045381949598,\n 37.2057489339186,\n 35.3341218932086,\n 34.4635311488169,\n 33.6287516786616,\n 32.8252654304549,\n 32.0492747228427,\n 31.2975482300669,\n 30.9299001178461,\n 30.5673054909468,\n 30.209472801624198,\n 29.8561287927744,\n 29.161894864456002,\n 28.482721133135403,\n 28.005970047486002,\n 28.5473004789567,\n 29.057899229047703,\n 29.998966102327202,\n 30.8492854578305\n ],\n [\n \"2025-12-19\",\n 39.6026078187924,\n 36.8041510266428,\n 34.2602356279919,\n 33.058316528484696,\n 31.8930279193662,\n 30.7582320458014,\n 29.648578883315203,\n 28.5593035829799,\n 28.0209387344818,\n 27.4860669744102,\n 26.9541910066398,\n 26.4248249083007,\n 25.371716824556202,\n 24.3229682621768,\n 23.2748105524925,\n 22.223454158775798,\n 21.1653611786271,\n 19.459881926613,\n 20.043464945436902\n ]\n ]\n }\n ]\n}\n"
]
],
[
[
"Once I get the response back, I extract the payload and use the Matplotlib library to plot my surface. For example, below I extract and plot the Volatility Surface data for 'VW'.",
"_____no_output_____"
]
],
[
[
"surfaces = eti_response.data.raw['data']\nplot_surface(surfaces, 'VW')",
"_____no_output_____"
]
],
[
[
"### Smile Curve\nI can also use the same surfaces response data to plot a Smile Curve.\n\nFor example, to compare the volatility smiles of the 4 equities at the chosen expiry time (where the maturity value of 1 is the first expiry):",
"_____no_output_____"
]
],
[
[
"plot_smile(surfaces, 1)",
"_____no_output_____"
]
],
[
[
"### Volatility Terms\nWe can also use the same surfaces response data to plot the Term Structure (the full code for all the plots can be found in the plotting_helper file)\n\nLet the user to choose the Moneyness index - **integer value** - to use for the chart:",
"_____no_output_____"
]
],
[
[
"moneyness=1 \nplot_term_volatility(surfaces, moneyness)",
"_____no_output_____"
]
],
[
[
"### Equity Volatility Surface - advanced usage\n\nLet's dig deeper into some advanced parameters for ETI volaitlity surfaces.\n\nThe request is highly configurable and the various parameters & options are listed on the API playground. For example, the options are :\n* Timestamp : Default, Close, Settle\n* Volatility Model : SVI or SSVI (Surface SVI)\n* Input : Quoted or Implied\n",
"_____no_output_____"
]
],
[
[
"eti_advanced_request_body={\n \"universe\": [\n { \"surfaceTag\": \"ANZ\",\n \"underlyingType\": \"Eti\",\n \"underlyingDefinition\": {\n \"instrumentCode\": \"ANZ.AX\"\n },\n \"surfaceParameters\": {\n \"timestamp\" :\"Close\",\n \"volatilityModel\": \"SSVI\",\n \"inputVolatilityType\": \"Quoted\",\n \"xAxis\": \"Date\",\n \"yAxis\": \"Moneyness\"\n },\n \"surfaceLayout\": { \"format\": \"Matrix\" }\n }]\n}\n\neti_advanced_response = vs_endpoint.send_request(\n method = rdp.Endpoint.RequestMethod.POST,\n body_parameters = eti_advanced_request_body\n)\n\nprint(json.dumps(eti_advanced_response.data.raw, indent=2))",
"{\n \"data\": [\n {\n \"surfaceTag\": \"ANZ\",\n \"surface\": [\n [\n null,\n \"0.5\",\n \"0.6\",\n \"0.7\",\n \"0.75\",\n \"0.8\",\n \"0.85\",\n \"0.9\",\n \"0.95\",\n \"0.975\",\n \"1\",\n \"1.025\",\n \"1.05\",\n \"1.1\",\n \"1.15\",\n \"1.2\",\n \"1.25\",\n \"1.3\",\n \"1.4\",\n \"1.5\"\n ],\n [\n \"2021-09-16\",\n 44.215580320551,\n 39.384400912296705,\n 34.7800228493512,\n 32.5086783876381,\n 30.229884187990702,\n 27.920386602104003,\n 25.5524713455681,\n 23.0902099740693,\n 21.8086373419636,\n 20.4825037874273,\n 19.1006636259614,\n 17.648210352753598,\n 15.2912919064396,\n 15.333638881446602,\n 15.3750705984084,\n 15.4147805281901,\n 15.452858085471599,\n 15.524573298155001,\n 15.591053307580099\n ],\n [\n \"2021-10-21\",\n 40.268373906731505,\n 35.971852044603295,\n 31.8907446318008,\n 29.8841717706608,\n 27.876707178773902,\n 25.8493687163475,\n 23.78017277318,\n 21.641567407859,\n 20.535071232697398,\n 19.3959478810723,\n 18.216486708197,\n 16.9867351771227,\n 15.0192370013619,\n 15.0544493472079,\n 15.0887087652118,\n 15.121543021561001,\n 15.153035690817502,\n 15.2123773500846,\n 15.267422836358\n ],\n [\n \"2021-11-18\",\n 38.891959445774695,\n 34.7764395122118,\n 30.8717117027911,\n 28.953996753112897,\n 27.0372424180578,\n 25.103775279093398,\n 23.133323782130898,\n 21.1007671885408,\n 20.051133465927702,\n 18.9722802862759,\n 17.8574083657368,\n 16.69783501446,\n 14.8502496869929,\n 14.883359077157701,\n 14.915450686012798,\n 14.9462016862988,\n 14.975696862606998,\n 15.031280594443,\n 15.0828488985881\n ],\n [\n \"2021-12-16\",\n 37.9683249064433,\n 33.9729760324035,\n 30.1851625381529,\n 28.326252330969897,\n 26.469443329715,\n 24.597898423086402,\n 22.6924292580793,\n 20.7294358633867,\n 19.716981241133798,\n 18.6774245726983,\n 17.6045170857599,\n 16.490332938911102,\n 14.7196777513595,\n 14.7514649589374,\n 14.782175339061299,\n 14.8115974438598,\n 14.8398178007343,\n 14.8930020874205,\n 14.9423491713074\n ],\n [\n \"2022-01-20\",\n 37.1335353956471,\n 33.2473570108961,\n 29.5657755076431,\n 27.7603010232178,\n 25.9579627277524,\n 24.1426774209663,\n 22.296229600496,\n 20.39637807934,\n 19.4176433110459,\n 18.4136971680357,\n 17.378773173444902,\n 16.3056031300525,\n 14.604227916297798,\n 14.634834433150301,\n 14.6643046880924,\n 14.692533084512899,\n 14.719608065553599,\n 14.770636108223101,\n 14.817986691757701\n ],\n [\n \"2022-02-17\",\n 36.6200786297623,\n 32.8024623820977,\n 29.1877209113227,\n 27.4159216924563,\n 25.6479526407429,\n 23.868212725756,\n 22.059109453855598,\n 20.1992714910722,\n 19.2419301605687,\n 18.260593736133902,\n 17.249801854361298,\n 16.2027018988401,\n 14.545367762292999,\n 14.575221007484402,\n 14.6039028780167,\n 14.631372576920802,\n 14.6577196210635,\n 14.707377296836398,\n 14.753459024798099\n ],\n [\n \"2022-03-17\",\n 36.1987677775504,\n 32.4391220476939,\n 28.8810487583197,\n 27.1378685935572,\n 25.399162367132,\n 23.6497494730486,\n 21.8725826467905,\n 20.0470533340941,\n 19.1080942880255,\n 18.146214522521,\n 17.1562214288044,\n 16.131625162074002,\n 14.5123765139664,\n 14.5415710123286,\n 14.5695699302906,\n 14.596382850651901,\n 14.622099884802001,\n 14.6705717125003,\n 14.715555545683301\n ],\n [\n \"2022-06-16\",\n 35.228003490300104,\n 31.614150937188,\n 28.1996528929695,\n 26.529451972484804,\n 24.865735191124898,\n 23.1944664605749,\n 21.5000962827198,\n 19.7641222449269,\n 18.873410736636,\n 17.9627976420532,\n 17.0278270774212,\n 16.063004470001,\n 14.545423371757698,\n 14.5727944279693,\n 14.5989603613333,\n 14.624014605642998,\n 14.6480458816378,\n 14.6933461294565,\n 14.7353945653852\n ],\n [\n \"2022-09-15\",\n 34.6155015055886,\n 31.1117641037652,\n 27.8070770596431,\n 26.1932886040008,\n 24.587995237156502,\n 22.9781268833767,\n 21.349409929778602,\n 19.685141538644498,\n 18.833349933457598,\n 17.9642997421071,\n 17.0741548203317,\n 16.1582526961339,\n 14.7243025202511,\n 14.750073947352698,\n 14.7747203344747,\n 14.798322942691499,\n 14.8209646137536,\n 14.8636524632119,\n 14.9032841561248\n ],\n [\n \"2022-12-15\",\n 34.2029802947993,\n 30.7898415587424,\n 27.576442313314498,\n 26.009940043882,\n 24.453903158529698,\n 22.896109001181,\n 21.3234042782336,\n 19.720659497893102,\n 18.902388182044,\n 18.0692110770993,\n 17.2178185982692,\n 16.344249530721598,\n 14.9826594152141,\n 15.0069589398063,\n 15.0302838891618,\n 15.052629775604402,\n 15.0740699962055,\n 15.1145006616754,\n 15.1520448352742\n ],\n [\n \"2023-03-16\",\n 33.9128002270195,\n 30.5773479856755,\n 27.442787061818702,\n 25.9173395397919,\n 24.4042147556661,\n 22.891932493095197,\n 21.3683164963514,\n 19.8195973627979,\n 19.0307816691092,\n 18.229122789976802,\n 17.411750740203598,\n 16.5752851060859,\n 15.276893298893098,\n 15.299828594837,\n 15.321995299260799,\n 15.3432448022779,\n 15.363638246876398,\n 15.4021035328229,\n 15.4378304315921\n ],\n [\n \"2023-06-15\",\n 33.700997234424804,\n 30.4336238110701,\n 27.3684495461472,\n 25.879237926780302,\n 24.4040475094587,\n 22.9320435137161,\n 21.4518926344678,\n 19.950986147035298,\n 19.1882057777644,\n 18.4143630208485,\n 17.6269497955623,\n 16.8230609791982,\n 15.579878690246199,\n 15.6015476608239,\n 15.6226990147947,\n 15.6429922882934,\n 15.6624740911848,\n 15.6992288627604,\n 15.7333744766756\n ],\n [\n \"2023-12-21\",\n 33.406368886015805,\n 30.257402243593802,\n 27.313206500552102,\n 25.887235940069296,\n 24.4782488172535,\n 23.0764831627008,\n 21.67198757769,\n 20.2540233847856,\n 19.5362361161057,\n 18.810296872019,\n 18.0742528201199,\n 17.3259263469246,\n 16.1761589819322,\n 16.1954610987016,\n 16.2148820701821,\n 16.2335604030759,\n 16.251506612858897,\n 16.2853837864848,\n 16.3168704283149\n ],\n [\n \"2024-06-20\",\n 33.2199288041686,\n 30.162983150063898,\n 27.3127374892735,\n 25.9357910864233,\n 24.5780143391923,\n 23.2304099686929,\n 21.8839925630813,\n 20.5293014236692,\n 19.8456265838656,\n 19.155819273184697,\n 18.458286291441002,\n 17.751326467616,\n 16.6704569809582,\n 16.6877294529446,\n 16.705854547663602,\n 16.7233419028153,\n 16.740160881573498,\n 16.7719306658501,\n 16.8014720087808\n ]\n ]\n }\n ]\n}\n"
]
],
[
[
"Once again, I extract the payload and plot my surface for 'ANZ'.",
"_____no_output_____"
]
],
[
[
"surfaces = eti_advanced_response.data.raw['data']\nplot_surface(surfaces, 'ANZ')",
"_____no_output_____"
]
],
[
[
"### Equity Volatility Surface - Weights and Goodness of Fit\nIn this section, I will apply my own weights per moneyness range and check the goodness of fit.\n\nI will keep the same ANZ request and simply add my weighting assumptions:\n* Options with moneyness below 50% will have a 0.5 weight\n* Options with moneyness above 150% will have a 0.1 weight\n* All other options will have a higher weight of 1",
"_____no_output_____"
]
],
[
[
"eti_weights_request_body={\n \"universe\": [\n { \"surfaceTag\": \"ANZ_withWeights\",\n \"underlyingType\": \"Eti\",\n \"underlyingDefinition\": {\n \"instrumentCode\": \"ANZ.AX\"\n },\n \"surfaceParameters\": {\n \"timestamp\" :\"Close\",\n \"volatilityModel\": \"SSVI\",\n \"inputVolatilityType\": \"Quoted\",\n \"xAxis\": \"Date\",\n \"yAxis\": \"Moneyness\",\n \"weights\":[\n {\n \"minMoneyness\": 0,\n \"maxMoneyness\": 50,\n \"weight\":0.5\n },\n {\n \"minMoneyness\": 50,\n \"maxMoneyness\": 150,\n \"weight\":1\n },\n {\n \"minMoneyness\": 150,\n \"maxMoneyness\": 200,\n \"weight\":0.1\n }\n ]\n },\n \"surfaceLayout\": { \"format\": \"Matrix\" }\n }],\n \"outputs\":[\"GoodnessOfFit\"]\n}\n\neti_weights_response = vs_endpoint.send_request(\n method = rdp.Endpoint.RequestMethod.POST,\n body_parameters = eti_weights_request_body\n)\n\nprint(json.dumps(eti_weights_response.data.raw, indent=2))",
"{\n \"data\": [\n {\n \"surfaceTag\": \"ANZ_withWeights\",\n \"surface\": [\n [\n null,\n \"0.5\",\n \"0.6\",\n \"0.7\",\n \"0.75\",\n \"0.8\",\n \"0.85\",\n \"0.9\",\n \"0.95\",\n \"0.975\",\n \"1\",\n \"1.025\",\n \"1.05\",\n \"1.1\",\n \"1.15\",\n \"1.2\",\n \"1.25\",\n \"1.3\",\n \"1.4\",\n \"1.5\"\n ],\n [\n \"2021-09-16\",\n 41.315495980594,\n 36.5253696257479,\n 31.9557391811034,\n 29.7066013809671,\n 27.4616980356841,\n 25.21142782207,\n 22.955576812435798,\n 20.7162815042377,\n 19.622718689895997,\n 18.567888134949502,\n 17.5775937193865,\n 16.6857223980305,\n 15.341115919464501,\n 14.697517905566801,\n 14.6353291667322,\n 14.9195722795092,\n 15.3757115326768,\n 16.4633953668468,\n 17.5669389175231\n ],\n [\n \"2021-10-21\",\n 39.2216136397337,\n 34.9053691465696,\n 30.8014355515297,\n 28.784657807506196,\n 26.7709705639395,\n 24.746975102867598,\n 22.7029205976156,\n 20.640398334469403,\n 19.6113748452545,\n 18.5985504642363,\n 17.6261663110522,\n 16.736705373379902,\n 15.4613134233612,\n 15.0815716957889,\n 15.296007593521798,\n 15.745802217226402,\n 16.2706501587475,\n 17.340326001204,\n 18.3435460478668\n ],\n [\n \"2021-11-18\",\n 38.4879008299554,\n 34.336970894388,\n 30.3956066199626,\n 28.460069716193697,\n 26.527366963999,\n 24.582741108212698,\n 22.6126310522936,\n 20.608891124493102,\n 19.5970809197701,\n 18.587251245453,\n 17.597944504141598,\n 16.6702666012245,\n 15.3495873875858,\n 15.120927801956,\n 15.4805111757866,\n 15.9999209070145,\n 16.549095179661798,\n 17.6098672787138,\n 18.5778725146864\n ],\n [\n \"2021-12-16\",\n 37.9421552195927,\n 33.8967820017211,\n 30.058448285781804,\n 28.1741232811926,\n 26.2923152867652,\n 24.3974523231311,\n 22.4735859008732,\n 20.5060037486518,\n 19.5035864126491,\n 18.4917955640797,\n 17.481717428622503,\n 16.5058493057563,\n 15.0904046395378,\n 15.017818880622,\n 15.495270302042,\n 16.0612941366775,\n 16.625046521395202,\n 17.6794544788745,\n 18.6260000483635\n ],\n [\n \"2022-01-20\",\n 37.3835012373585,\n 33.4281074436749,\n 29.6768122022955,\n 27.8355001522332,\n 25.9963450153757,\n 24.1432266747749,\n 22.2584732386441,\n 20.322326768409802,\n 19.3286585851551,\n 18.3156791623199,\n 17.2854951686495,\n 16.2531868023427,\n 14.6565299587187,\n 14.8132154528031,\n 15.401932877930099,\n 16.0033180223134,\n 16.576265590456497,\n 17.6230741598152,\n 18.5517072680784\n ],\n [\n \"2022-02-17\",\n 37.0007651293515,\n 33.0983426411029,\n 29.3979609599716,\n 27.5817498352298,\n 25.7675325827609,\n 23.939025913978902,\n 22.0779017645407,\n 20.1622872399854,\n 19.175882474317,\n 18.1655555713383,\n 17.128266780597002,\n 16.0656116783051,\n 14.2743924445729,\n 14.6522640152314,\n 15.296674591237,\n 15.911533679693601,\n 16.4861525458593,\n 17.5256530997815,\n 18.4432108427342\n ],\n [\n \"2022-03-17\",\n 36.6623223233816,\n 32.8026300286961,\n 29.1432592264402,\n 27.347317795327402,\n 25.5533658093529,\n 23.7451496212653,\n 21.9041716998503,\n 20.0077629171988,\n 19.0298235218302,\n 18.0259984327897,\n 16.9906499939984,\n 15.917411127183101,\n 13.8971864807301,\n 14.5244653349413,\n 15.1929486734354,\n 15.8104834138289,\n 16.3825985486068,\n 17.4130396182272,\n 18.3206453265016\n ],\n [\n \"2022-06-16\",\n 35.7981299103931,\n 32.0402253847461,\n 28.479548009001697,\n 26.7332680279399,\n 24.9901480877225,\n 23.234986231792902,\n 21.450993940889198,\n 19.6188782019596,\n 18.6780967321083,\n 17.717576791242802,\n 16.7369373797048,\n 15.744201213013302,\n 14.153759189612899,\n 14.397934872577501,\n 14.9822915357957,\n 15.557797789094,\n 16.1008147159367,\n 17.0887478823804,\n 17.9639317693529\n ],\n [\n \"2022-09-15\",\n 35.1928667394721,\n 31.510481828563304,\n 28.025437226183804,\n 26.3187608179081,\n 24.6178859894785,\n 22.9095311849001,\n 21.1804756860674,\n 19.419181070171,\n 18.5251453175884,\n 17.6253264978474,\n 16.7298296280421,\n 15.8674145279838,\n 14.622898901585902,\n 14.5650924807574,\n 14.985718819157201,\n 15.4830648084742,\n 15.9790947680092,\n 16.909654808757598,\n 17.748194381643\n ],\n [\n \"2022-12-15\",\n 34.7541235732357,\n 31.1352217455262,\n 27.7158653133326,\n 26.044758285894197,\n 24.3829485151109,\n 22.7194174134355,\n 21.0450859568991,\n 19.356920755831002,\n 18.5116767098232,\n 17.6741146203684,\n 16.8606158678916,\n 16.1053956508601,\n 15.042153968583499,\n 14.8492685844727,\n 15.1292418160549,\n 15.5442022984051,\n 15.988113038310301,\n 16.8549474192877,\n 17.6539529570262\n ],\n [\n \"2023-03-16\",\n 34.4234931856566,\n 30.860569709735604,\n 27.500607009271498,\n 25.862409265998398,\n 24.2373831716031,\n 22.6168130391744,\n 20.9956746695873,\n 19.3785961778735,\n 18.5797928497816,\n 17.79922451453,\n 17.0554751724925,\n 16.3807130700788,\n 15.4305604921757,\n 15.1691090433219,\n 15.343637612518702,\n 15.684236042331301,\n 16.0775185033467,\n 16.880293959407,\n 17.6392531557133\n ],\n [\n \"2023-06-15\",\n 34.1652414557869,\n 30.6527349359139,\n 27.347255703781,\n 25.7397136027552,\n 24.1493073838355,\n 22.5695090459534,\n 20.998966761461,\n 19.4486130256881,\n 18.6921511806067,\n 17.9615475201608,\n 17.2752971300539,\n 16.661415384387098,\n 15.790032199648198,\n 15.4906764716507,\n 15.5875608964465,\n 15.8646795338133,\n 16.2115534276183,\n 16.9531162016424,\n 17.6730760367693\n ],\n [\n \"2023-12-21\",\n 33.7740848149711,\n 30.352948025053,\n 27.148082580009902,\n 25.597950570549,\n 24.0728714220735,\n 22.5702436871798,\n 21.094789304787,\n 19.6663052182271,\n 18.9838414025144,\n 18.3363418559689,\n 17.7395360677505,\n 17.213237339050398,\n 16.4500190903426,\n 16.1146145763006,\n 16.1067900559485,\n 16.2832105494534,\n 16.5494140529078,\n 17.1777200022157,\n 17.8229296610213\n ],\n [\n \"2024-06-20\",\n 33.5104252876891,\n 30.164560454337202,\n 27.0439388514777,\n 25.542360144188,\n 24.0726953908179,\n 22.6352872647925,\n 21.2388751890971,\n 19.9076997493886,\n 19.281316057188,\n 18.693649360439597,\n 18.157381347932102,\n 17.686764339106702,\n 16.991213733526,\n 16.6437823715975,\n 16.5762128926257,\n 16.6848853641344,\n 16.8910800025105,\n 17.4284478971494,\n 18.0106492386048\n ]\n ],\n \"goodnessOfFit\": [\n [\n \"Expiry\",\n \"Is Calibrated\",\n \"Average Spread Explained\",\n \"Min Strike\",\n \"Max Strike\"\n ],\n [\n \"2021-09-16\",\n 1,\n -0.0236784532251888,\n 25.0,\n 32.0\n ],\n [\n \"2021-10-21\",\n 1,\n 0.7659749064959646,\n 20.0,\n 33.0\n ],\n [\n \"2021-11-18\",\n 1,\n 0.660221662992283,\n 22.0,\n 33.0\n ],\n [\n \"2021-12-16\",\n 1,\n 0.8037144814184869,\n 14.5,\n 36.0\n ],\n [\n \"2022-01-20\",\n 1,\n 0.7231027163746602,\n 23.5,\n 33.0\n ],\n [\n \"2022-02-17\",\n 1,\n 0.670650304907773,\n 24.5,\n 32.0\n ],\n [\n \"2022-03-17\",\n 1,\n 0.8559676539236349,\n 13.0,\n 33.0\n ],\n [\n \"2022-06-16\",\n 1,\n 0.7625571978107928,\n 12.0,\n 37.0\n ],\n [\n \"2022-09-15\",\n 1,\n 0.8282767342491224,\n 13.5,\n 34.0\n ],\n [\n \"2022-12-15\",\n 1,\n 0.86728339986809,\n 10.0,\n 34.0\n ],\n [\n \"2023-03-16\",\n 1,\n 0.7068975659007458,\n 23.0,\n 34.0\n ],\n [\n \"2023-06-15\",\n 1,\n 0.7289880741072924,\n 13.5,\n 34.0\n ],\n [\n \"2023-12-21\",\n 1,\n 0.6232327789069758,\n 19.0,\n 34.0\n ],\n [\n \"2024-06-20\",\n 1,\n 0.5356213655234314,\n 23.0,\n 34.0\n ]\n ]\n }\n ]\n}\n"
]
],
[
[
"Once again, I extract the payload and plot my new surface for 'ANZ'",
"_____no_output_____"
]
],
[
[
"surfaces = eti_weights_response.data.raw['data']\nplot_surface(surfaces, 'ANZ_withWeights')",
"_____no_output_____"
]
],
[
[
"Since we changed the weights, I might want to view the Goodness Of Fit for this new generated surface.",
"_____no_output_____"
]
],
[
[
"pd.DataFrame(data=surfaces[0][\"goodnessOfFit\"])",
"_____no_output_____"
]
],
[
[
"### FX Volatility Surface\nI can also use the same IPA Endpoint to request FX Volatility Surfaces \n\nFor example the request below, will allow me to generate an FX volatility surface:\n\nfor USDSGD cross rates \nexpress the axes in Dates and Delta \nand return the data in a matrix format \n\nAs I mentioned earlier, the request is configurable and the parameters & options are listed on the API playground. \nFor example, some of the parameters I could have used and their current options:\n\n* Volatility Model : SVI, SABR or CubicSpline\n* Axes : Delta/Strike and Tenor/Date\n* Data format : Matrix or List\n\nThe ***calculationDate*** defaults to today's date and can be overridden - as I have done below: \n",
"_____no_output_____"
]
],
[
[
"fx_request_body={\n \"universe\": [\n {\n \"underlyingType\": \"Fx\",\n \"surfaceTag\": \"FxVol-USDSGD\",\n \"underlyingDefinition\": {\n \"fxCrossCode\": \"USDSGD\"\n },\n \"surfaceLayout\": {\n \"format\": \"Matrix\",\n \"yValues\": [ \"-0.1\",\"-0.15\",\"-0.2\",\"-0.25\",\"-0.3\",\"-0.35\",\"-0.4\",\"-0.45\",\"0.5\",\"0.45\",\"0.4\",\"0.35\",\"0.3\",\"0.25\",\"0.2\",\"0.15\",\"0.1\"]\n },\n \"surfaceParameters\": {\n \"xAxis\": \"Date\",\n \"yAxis\": \"Delta\",\n \"calculationDate\": \"2018-08-20T00:00:00Z\",\n \"returnAtm\": \"False\",\n }\n }\n ]\n}\n\nfx_response = vs_endpoint.send_request(\n method = rdp.Endpoint.RequestMethod.POST,\n body_parameters = fx_request_body\n)\n\nprint(json.dumps(fx_response.data.raw, indent=2))",
"{\n \"data\": [\n {\n \"surfaceTag\": \"FxVol-USDSGD\",\n \"surface\": [\n [\n null,\n -0.1,\n -0.15,\n -0.2,\n -0.25,\n -0.3,\n -0.35,\n -0.4,\n -0.45,\n 0.5,\n 0.45,\n 0.4,\n 0.35,\n 0.3,\n 0.25,\n 0.2,\n 0.15,\n 0.1\n ],\n [\n \"2018-08-27T00:00:00Z\",\n 4.974518945137208,\n 4.9247903047436346,\n 4.895074247096458,\n 4.877100340780957,\n 4.867337079224067,\n 4.864070228079728,\n 4.866473476189378,\n 4.874251953956021,\n 4.887496247068092,\n 4.907066584956367,\n 4.9337187499424795,\n 4.96900763257067,\n 5.0154418883190885,\n 5.077176643403251,\n 5.161547115598151,\n 5.2829683285775895,\n 5.475356718910382\n ],\n [\n \"2018-09-20T00:00:00Z\",\n 4.838527122989458,\n 4.843787440893674,\n 4.85126411709241,\n 4.862869538975778,\n 4.88174669231309,\n 4.911209267581311,\n 4.951400201648122,\n 4.999152668623619,\n 5.051421974374983,\n 5.109240579052077,\n 5.170386918643754,\n 5.235417623568648,\n 5.30553223129875,\n 5.382727225421624,\n 5.470338334976124,\n 5.574467589409287,\n 5.708360109968956\n ],\n [\n \"2018-10-19T00:00:00Z\",\n 4.976602059455342,\n 4.984217546752533,\n 4.994602710984536,\n 5.009816191457399,\n 5.032864816536398,\n 5.06678549938586,\n 5.112211026548413,\n 5.16680385348491,\n 5.227436144759485,\n 5.296726810289366,\n 5.370770734168017,\n 5.45009246134266,\n 5.53608229396217,\n 5.631174279062314,\n 5.73951487958861,\n 5.868753028874092,\n 6.035558088853484\n ],\n [\n \"2018-11-21T00:00:00Z\",\n 4.899023926398146,\n 4.9066510729213935,\n 4.91712311166735,\n 4.932687503516131,\n 4.956893271086363,\n 4.993804532150235,\n 5.044788813051125,\n 5.107081015495158,\n 5.176479804937106,\n 5.257104928631679,\n 5.343340755265668,\n 5.435785785387591,\n 5.536087471886052,\n 5.647131379255422,\n 5.773827458832362,\n 5.925229487531591,\n 6.121074812610049\n ],\n [\n \"2019-02-21T00:00:00Z\",\n 4.882792528557175,\n 4.88443065902285,\n 4.889861934685688,\n 4.900608319229801,\n 4.920051264997402,\n 4.953708959523724,\n 5.006726143183973,\n 5.078668144684444,\n 5.163100927677579,\n 5.267708752609406,\n 5.38151275127147,\n 5.504690853542167,\n 5.639233246500674,\n 5.789007148254301,\n 5.960769320383284,\n 6.167089945185912,\n 6.435476838213143\n ],\n [\n \"2019-05-21T00:00:00Z\",\n 4.921136276223659,\n 4.928211628073138,\n 4.93731525310799,\n 4.950024671162654,\n 4.96907049170929,\n 4.999157002578717,\n 5.046672648889839,\n 5.115603260797006,\n 5.201436067968562,\n 5.315685339215837,\n 5.443024281808281,\n 5.582535265823437,\n 5.735976174505293,\n 5.907576608724943,\n 6.105067580198182,\n 6.343023555317753,\n 6.653477186893951\n ],\n [\n \"2019-08-21T00:00:00Z\",\n 4.986184898093804,\n 4.974531372775044,\n 4.976443944311139,\n 4.989812066716617,\n 5.014724679375405,\n 5.052169096551939,\n 5.103414322320825,\n 5.169558360792649,\n 5.248596169645055,\n 5.360589621598737,\n 5.493973399909737,\n 5.649978399602314,\n 5.831353145811134,\n 6.043543286008076,\n 6.2968106631478475,\n 6.611247441333315,\n 7.032021277180051\n ],\n [\n \"2020-08-20T00:00:00Z\",\n 5.310322240047066,\n 5.209752269547287,\n 5.1604849810684295,\n 5.146492315706495,\n 5.1606186465052595,\n 5.198656911965351,\n 5.257509815184085,\n 5.334636041614901,\n 5.421433548361906,\n 5.553255563972978,\n 5.706954087994622,\n 5.883821344089949,\n 6.08731438569529,\n 6.324022026284657,\n 6.605884708786896,\n 6.955774374718987,\n 7.42459700544887\n ]\n ]\n }\n ]\n}\n"
]
],
[
[
"Once again, I extract the payload and plot my surface - below I extract and plot the Volatility Surface for 'Singapore Dollar / US Dollar'.",
"_____no_output_____"
]
],
[
[
"fx_surfaces = fx_response.data.raw['data']\nplot_surface(fx_surfaces, 'FxVol-USDSGD', True)",
"_____no_output_____"
]
],
[
[
"### Let's use the Surfaces to price OTC options\nNow that we know how to build a surface, we will see how we can use them to price OTC contracts.",
"_____no_output_____"
]
],
[
[
"fc_endpoint = rdp.Endpoint(session, \n \"https://api.refinitiv.com/data/quantitative-analytics/v1/financial-contracts\")",
"_____no_output_____"
]
],
[
[
"In the request below, I will price two OTC 'BNPP' options: ",
"_____no_output_____"
]
],
[
[
"option_request_body = {\n \"fields\": [\"InstrumentTag\",\"ExerciseType\",\"OptionType\",\"ExerciseStyle\",\"EndDate\",\"StrikePrice\",\\\n \"MarketValueInDealCcy\",\"VolatilityPercent\",\"DeltaPercent\",\"ErrorMessage\"],\n \n \"universe\":[{\n \n \"instrumentType\": \"Option\",\n \"instrumentDefinition\": {\n \"instrumentTag\" :\"BNPP 15Jan 20\",\n \"underlyingType\": \"Eti\",\n \"strike\": 20,\n \"endDate\": \"2022-01-15\",\n \"callPut\": \"Call\",\n \"underlyingDefinition\": {\n \"instrumentCode\": \"BNPP.PA\"\n }\n }\n },\n {\n \"instrumentType\": \"Option\",\n \"instrumentDefinition\": {\n \"instrumentTag\" :\"BNPP 15Jan 21\",\n \"underlyingType\": \"Eti\",\n \"strike\": 21,\n \"endDate\": \"2022-01-15\",\n \"callPut\": \"Call\",\n \"underlyingDefinition\": {\n \"instrumentCode\": \"BNPP.PA\"\n }\n }\n }], \n\n \"pricingParameters\": {\n \"timeStamp\" : \"Close\"\n },\n \n \"outputs\": [\"Data\",\"Headers\"]\n}\n\nfc_response = fc_endpoint.send_request(\n method = rdp.Endpoint.RequestMethod.POST,\n body_parameters = option_request_body\n)\n\nprint(json.dumps(fc_response.data.raw, indent=2))",
"{\n \"headers\": [\n {\n \"type\": \"String\",\n \"name\": \"InstrumentTag\"\n },\n {\n \"type\": \"String\",\n \"name\": \"ExerciseType\"\n },\n {\n \"type\": \"String\",\n \"name\": \"OptionType\"\n },\n {\n \"type\": \"String\",\n \"name\": \"ExerciseStyle\"\n },\n {\n \"type\": \"DateTime\",\n \"name\": \"EndDate\"\n },\n {\n \"type\": \"Float\",\n \"name\": \"StrikePrice\"\n },\n {\n \"type\": \"Float\",\n \"name\": \"MarketValueInDealCcy\"\n },\n {\n \"type\": \"Float\",\n \"name\": \"VolatilityPercent\"\n },\n {\n \"type\": \"Float\",\n \"name\": \"DeltaPercent\"\n },\n {\n \"type\": \"String\",\n \"name\": \"ErrorMessage\"\n }\n ],\n \"data\": [\n [\n \"BNPP 15Jan 20\",\n \"CALL\",\n \"Vanilla\",\n \"EURO\",\n \"2022-01-15T00:00:00Z\",\n 20.0,\n 33.2436109507395,\n 66.1570977665748,\n 0.995876780083118,\n \"\"\n ],\n [\n \"BNPP 15Jan 21\",\n \"CALL\",\n \"Vanilla\",\n \"EURO\",\n \"2022-01-15T00:00:00Z\",\n 21.0,\n 32.2483255576552,\n 64.587446946523,\n 0.994970528423083,\n \"\"\n ]\n ]\n}\n"
],
[
"headers_name = [h['name'] for h in fc_response.data.raw['headers']]\npd.DataFrame(data=fc_response.data.raw['data'], columns=headers_name)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7ce1ca9cafa252332fe83496e63c898a18abb86 | 20,961 | ipynb | Jupyter Notebook | corpus.ipynb | walshbr/humanists-nlp-cookbook | 9f533db2de91c992ea6d4295f2ea0b426346fac4 | [
"CC-BY-4.0"
]
| 34 | 2019-02-28T15:54:38.000Z | 2022-01-13T17:49:59.000Z | .ipynb_checkpoints/corpus-checkpoint.ipynb | walshbr/humanists-nlp-cookbook | 9f533db2de91c992ea6d4295f2ea0b426346fac4 | [
"CC-BY-4.0"
]
| 1 | 2020-09-21T11:04:09.000Z | 2020-09-21T11:04:09.000Z | .ipynb_checkpoints/corpus-checkpoint.ipynb | walshbr/humanists-nlp-cookbook | 9f533db2de91c992ea6d4295f2ea0b426346fac4 | [
"CC-BY-4.0"
]
| 6 | 2020-09-14T16:55:17.000Z | 2022-01-13T17:50:01.000Z | 45.37013 | 845 | 0.620199 | [
[
[
"# Creating a Pipeline using a Corpus Class\n\nWhen working with a corpus of texts it can quickly become confusing to keep track of which step in an NLP pipeline you are on. Say you want to run a Frequency Distribution, did you remember to tokenize the text? To pull out the stopwords? While this is simple enough if you are working with a small group of texts in a discrete timeperiod, this quickly becomes challenging when working with a large body of texts or when working over a longer period of time. Matters become more complicated if you want to switch between corpus-level analysis and text-level analysis. The realities of your project may quickly mean that manually performing each step in your pipeline becomes redundant, hard to keep track of, or a waste of time. This is where objects and classes can come in. \n\nThis can get confusing so we'll start with an example. I own a cat. Cats have certain qualities:\n\n* furry\n* color\n* four legs\n* personality\n\nAnd they do certain things:\n\n* eat\n* sleep\n* scratch\n* generally enrich the lives of all around them\n\nAny one cat might be different than another. Your cat might not have fur. It might have fewer than four legs. It might not enrich your life (hard to believe). What we have here is a set of characteristics and verbs that describe the thing that is a cat. Not all cats, but one type of cat. \n\nOne more example. Consider a house. We might assume that it has certain qualities: \n\n* a roof\n* a front door\n* walls\n* a window\n\nAnd you can do certain things to, with, or in a house:\n\n* open the front door\n* sell it\n* paint a wall\n\nYou could debate these features and these actions, particularly their regional and socioeconomic specificity. Not all houses look like this. It's perhaps better to think of these lists as the template for a certain kind of house rather than all houses. \n\n**Object-oriented programming** is a way of organizing your code into patterns like this, separating the qualities of your data (its \"attributes\") from the instructions for things you want to execute on those attributes (its \"methods\"). The result is that, rather than thinking of your code as a directional sequence of events, we are instead thinking about the underlying collections of data and the characteristics that define them. And we arrange the code itself accordingly. To take a more technical example, you might consider an Email object. \n\n**Email Object**\n\nAttributes\n\n* has a sender\n* has a date\n* has a body\n* may have some attachments\n\nMethods\n\n* can be sent\n* can be received\n* can be trashed\n\nIt is not too difficult to imagine associated pieces of code meant to store these pieces of information or to do each of these particular things. You might have a funtion that defines the sender of an email based on some input, and you might have another that looks to a mail server to send out that note when instructed to do so. Ultimately, thinking in objects allows you to more easily organize text-level and corpus-level functions, is easier to grasp when working at scale, and allows you to store your parameters so they can be imported as a module (a file that contains Python definitions and statements). There are other ways of organizing your code, with their own sets of advantages and disadvantages, but this particular way can often help humanists better grasp what they are working on. \n\nTo go back to our house example, if the house is the object then a **class** is the blueprint for how one of those objects is built. A class is the template that we write in Python that helps to pull everything together using the attributes and methods we specify. Classes can be as simple or as complex as you want them to be. In the following template, we will define a \"Corpus\" class as well as a \"Text\" class and assign to each class the different attributes we want it to contain and sample methods that might commonly be executed within an NLP project on those attributes. You might want to create your own classes for different use cases. But we find that thinking about corpus and the individual texts within it as distinct texts can be a helpful way to organize things. In the example below, we describe our corpus like so:\n\n**Corpus Object**\n\nAttributes\n\n* has a corresponding directory\n* has a series of filenames corresponding to the text files contained within that folder\n* has a list of stopwords associated with it\n* contains many different Text objects\n\nAnd we describe our texts like so:\n\n**Text Object**\n\nAttributes\n\n* has a filename associated with it\n* has a raw version of the text\n* has a tokenized version\n* has a cleaned tokenized version\n* has an NLTK version of the text for some quick functionality\n\nMethods\n\n* the text can be converted from a file into a raw version\n* the raw version can be tokenized\n\nAnd so on. \n\nIn what follows below, the two large code blocks contain our classes. This script could be saved as a file in your working directory and updated as neccessary. The subsequent code block allows us to import the script directly into the Python interpreter to play with our classes directly. Working with classes in the way we describe below enables you to move back-and-forth between modifying your code and interacting with it within the interpreter.",
"_____no_output_____"
]
],
[
[
"import os\nimport nltk\nimport string\n\n\nclass Corpus(object):\n # rather than enter the data bit by bit, we create a constructor that takes in the data at one time\n # all the attributes we want the class to have follow the __init__ syntax\n def __init__(self, corpus_dir):\n # all the attributes we want the class to have\n self.dir = corpus_dir # where corpus_dir is - the corpus' filepath\n # classes may contain functions we define ourselves, the all_files() function is defined below\n self.filenames = self.all_files()\n # this attribute calls nltk's built in English stopwords list and supplements it with punctuation and some extra characters we defined. \n self.stopwords = nltk.corpus.stopwords.words('english') + [char for char in string.punctuation] + ['``', \"''\"]\n self.texts = [Text(fn, self.stopwords) for fn in self.filenames]\n\n def all_files(self):\n \"\"\"given a directory, return the filenames in it\"\"\"\n texts = []\n for (root, _, files) in os.walk(self.dir):\n for fn in files:\n print(fn)\n if fn[0] == '.': # ignore dot files\n pass\n else:\n path = os.path.join(root, fn)\n texts.append(path)\n return texts\n\n# the Text class works the same as the Corpus, but will contain text-level only attributes\nclass Text(object):\n # now create the blueprint for our text object\n def __init__(self, fn, stopwords):\n # given a filename, store it\n self.filename = fn\n # a text has raw_text associated with it\n self.raw_text = self.get_text()\n # a text has raw tokens\n self.raw_tokens = nltk.word_tokenize(self.raw_text)\n # a text will have a clean version of those tokens\n self.cleaned_tokens = self.clean_tokens(stopwords)\n # we also want, in this case, to make an NLTK text object\n self.nltk_text = nltk.Text(self.cleaned_tokens)\n \n def get_text(self):\n with open(self.filename) as fin:\n return fin.read()\n \n def clean_tokens(self, stopwords):\n return [token.lower() for token in self.raw_tokens if token not in stopwords]\n \n# this is what runs if you run the file as a one-off event - $ python3 class_practice.py\ndef main():\n corpus_dir = 'corpus/sonnets/'\n print('As mentioned above, this output presents as though it is being run from the command line.') # anything that you might want to jump to, such as a graph, FreqDist, etc. would go here\n\n# this allows you to import the classes as a module. it uses the special built-in variable __name__ set to the value \"__main__\" if the module is being run as the main program\nif __name__ == \"__main__\":\n main()",
"As mentioned above, this output presents as though it is being run from the command line.\n"
]
],
[
[
"The payoff of organzing your project within classes is that you can run them as a module from the interpreter or as a Python file from the terminal. For the remainder of this section, we have inserted the above code into a file called file class_practice.py. The following code blocks show how you might go about importing the class and working with it in the terminal. \n\nTo work with our class in the Python in the interpreter, we first import our script and instantiate our Corpus class.",
"_____no_output_____"
]
],
[
[
"# import the script as a module--file name without the extension\nimport class_practice \n\n# store the path to the corpus directory\ncorpus_dir = \"corpus/sonnets/\"\n# create a new corpus using our class template\nthis_corpus = class_practice.Corpus(corpus_dir)\n\n# now we can access elements of our corpus by accessing this_corpus\nprint(this_corpus.dir) # will show the directory of the corpus\nprint(this_corpus.filenames) # returns all the filenames in the corpus\n\n# to work with the text class, instantiate the particular text you want to use\n",
"corpus/sonnets/\n['corpus/sonnets/sonnet_two.txt', 'corpus/sonnets/sonnet_five.txt', 'corpus/sonnets/sonnet_four.txt', 'corpus/sonnets/sonnets_three.txt', 'corpus/sonnets/sonnet_one.txt']\n"
]
],
[
[
"Now that our corpus is in the interpreter, we can confirm that it contains many texts:",
"_____no_output_____"
]
],
[
[
"this_corpus.texts",
"_____no_output_____"
]
],
[
[
"That is a little confusing. As a humanist, we might expect to see the titles of the text or something similar. But we haven't told our class anything like that. Instead, our corpus points to particular texts, represented by their locations in our computer's memory. But, since this is just a list, we can pull out individual texts like you would any other item in a list:",
"_____no_output_____"
]
],
[
[
"first_text = this_corpus.texts[0]\n\n# from here, any of our text level attributes will be available to us:\nprint(first_text.filename)\nprint(first_text.raw_text)",
"corpus/sonnets/sonnet_two.txt\nWhen forty winters shall besiege thy brow,\nAnd dig deep trenches in thy beauty's field,\nThy youth's proud livery so gazed on now,\nWill be a totter'd weed of small worth held:\nThen being asked, where all thy beauty lies,\nWhere all the treasure of thy lusty days;\nTo say, within thine own deep sunken eyes,\nWere an all-eating shame, and thriftless praise.\nHow much more praise deserv'd thy beauty's use,\nIf thou couldst answer 'This fair child of mine\nShall sum my count, and make my old excuse,'\nProving his beauty by succession thine!\nThis were to be new made when thou art old,\nAnd see thy blood warm when thou feel'st it cold.\n\n"
]
],
[
[
"We could loop over our corpus to pull out information from each text:",
"_____no_output_____"
]
],
[
[
"for text in this_corpus.texts:\n print(text.filename)\n \n# get the first few characters from each line\nfor text in this_corpus.texts:\n print(text.raw_text[0:40])",
"corpus/sonnets/sonnet_two.txt\ncorpus/sonnets/sonnet_five.txt\ncorpus/sonnets/sonnet_four.txt\ncorpus/sonnets/sonnets_three.txt\ncorpus/sonnets/sonnet_one.txt\nWhen forty winters shall besiege thy bro\nThose hours, that with gentle work did f\nUnthrifty loveliness, why dost thou spen\nLook in thy glass and tell the face thou\nFROM fairest creatures we desire increas\n"
]
],
[
[
"Depending on how complex you've made your Text class, you can get to some interesting analysis right away. Here, we take advantage of the fact that we use NLTK's more robust Text class to look at the top words in each text. Even though both this small example and NLTK both have created classes named \"Text\", they contain different functions. ",
"_____no_output_____"
]
],
[
[
"for text in this_corpus.texts:\n print(text.nltk_text.vocab().most_common(10))\n print('=======')",
"[('thy', 7), ('beauty', 4), (\"'s\", 3), ('thou', 3), ('shall', 2), ('and', 2), ('deep', 2), (\"'d\", 2), ('thine', 2), ('praise', 2)]\n=======\n[('beauty', 3), ('every', 2), ('doth', 2), ('summer', 2), ('winter', 2), (\"'s\", 2), ('those', 1), ('hours', 1), ('gentle', 1), ('work', 1)]\n=======\n[('thy', 6), ('thou', 5), ('dost', 4), ('self', 4), ('thee', 3), ('beauty', 2), (\"'s\", 2), ('nature', 2), ('then', 2), ('canst', 2)]\n=======\n[('thou', 6), ('thy', 4), ('glass', 2), ('face', 2), ('time', 2), ('whose', 2), ('mother', 2), ('thee', 2), ('thine', 2), ('look', 1)]\n=======\n[('thy', 4), (\"'s\", 3), ('world', 3), ('might', 2), ('but', 2), ('tender', 2), ('thou', 2), ('thine', 2), ('and', 2), ('from', 1)]\n=======\n"
]
],
[
[
"Theoretically, the process is agnostic of what texts are actually in the corpus folder. So you could use this as a starting point for analysis without having to reinvent the wheel each time. We could, for example, create a new corpus from a different set of texts and quickly grab the most common words from those texts. Let's do this with a small Woolf corpus.",
"_____no_output_____"
]
],
[
[
"corpus_dir = \"corpus/woolf/\"\nnew_corpus = class_practice.Corpus(corpus_dir)\nprint(new_corpus.texts)\nfor text in new_corpus.texts:\n print(text.filename)\n print(text.nltk_text.vocab().most_common(10))\n print('======')",
"[<class_practice.Text object at 0x10d2e0310>, <class_practice.Text object at 0x12a02f910>, <class_practice.Text object at 0x12a2815b0>]\ncorpus/woolf/1922_jacobs_room.txt\n[('--', 546), ('said', 425), (\"'s\", 411), ('jacob', 390), ('the', 360), ('one', 291), ('i', 236), ('mrs.', 225), ('like', 165), ('but', 153)]\n======\ncorpus/woolf/1915_the_voyage_out.txt\n[('i', 1609), (\"'s\", 1007), ('--', 976), ('said', 874), ('one', 801), ('she', 646), ('rachel', 579), ('the', 531), (\"n't\", 513), ('mrs.', 437)]\n======\ncorpus/woolf/1919_night_and_day.txt\n[('i', 1967), ('katharine', 1193), (\"'s\", 1139), ('she', 935), ('--', 841), ('said', 796), ('one', 774), (\"n't\", 720), ('he', 615), ('upon', 582)]\n======\n"
]
],
[
[
"We don't have to rework all of the basic details of what a corpus looks like. And, looking at these results, we might very quickly notice some changes we want to make to our pipeline! Thanks to how we've organized things, this should not be too challenging. However, this reproducibility is also a potential challenge. Each corpus is different and likely to present its own difficulties. For example, if we wanted to use a TEI-encoded text, this class would not be able to accommodate such a thing. But organizing things with classes means that we could add that to our pipeline fairly easily if we wished. ",
"_____no_output_____"
],
[
"## A Note on Making Changes while working in the Terminal",
"_____no_output_____"
],
[
"As you make changes to your class_practice.py file, it's important to know how these changes will or will not be represented in your working copy of the objects you've created. If, as suggested above, you are working with a class to examine your corpus in the terminal, you must be mindful of one extra step. Once you import your module and create a new instance of your class, any changes to the underlying files for that work will not be represented in the terminal. In order to update your object with new changes, you have to re-import the module into python and re-instantiate your classes. This makes sure you are running the most up-to-date version of your file. You would do that like so, using the above example:",
"_____no_output_____"
]
],
[
[
"import importlib\n\nimportlib.reload(class_practice)\n\n#re-instantiate the corpus or text\nthis_corpus = class_practice.Corpus(corpus_dir)",
"_____no_output_____"
]
],
[
[
"importlib allows us to reload our module, and we then refresh our this_corpus variable with the most recent version of the Corpus class. Using a class in this way using the terminal can allow you to test particular features of your corpus as you develop your full pipeline.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7ce1cc4b74e008cb1f26757218c150326b84c4f | 5,409 | ipynb | Jupyter Notebook | notebooks/Outlier-Detection.ipynb | mpff/hpa-single-cell-classification | 30521ff5e755fb4a02b17ff4bdd5451574dd7ef1 | [
"BSD-3-Clause"
]
| null | null | null | notebooks/Outlier-Detection.ipynb | mpff/hpa-single-cell-classification | 30521ff5e755fb4a02b17ff4bdd5451574dd7ef1 | [
"BSD-3-Clause"
]
| null | null | null | notebooks/Outlier-Detection.ipynb | mpff/hpa-single-cell-classification | 30521ff5e755fb4a02b17ff4bdd5451574dd7ef1 | [
"BSD-3-Clause"
]
| null | null | null | 24.147321 | 113 | 0.544648 | [
[
[
"# Outlier Detection\n\nThe goal is to remove outlier cells from the ```hpacellseg``` output.\n\nOutliers on the training set:\n* (Shape) Cells where the minimum bounding rectangle has a (h,w) ratio outside of 95% of the data range.\n* (Shape) Cells that are very large compared to the image size or the other cells in the image. (?)\n* (Shape) TBD: Cells where the nucleus is outside 95% quantile to distance to center. (deformed cells?)\n* (Color) Cells that have atypical mean and std in their image channels.\n* (Position) Cells that are touching the edge of the image.\n* (Position) TBD: Cells where the nucleus is missing, or intersecting with the edge of the image.\n\nOutliers on the testing set:\n* (Position) TBD: Cells where the nucleus is missing, or intersecting with the edge of the image.",
"_____no_output_____"
]
],
[
[
"import os\nimport importlib\n\nimport numpy\nimport pandas\nimport sklearn\nimport matplotlib.pyplot as plt\n\nimport cv2\nimport skimage\nimport pycocotools\n\nimport json\nimport ast\n\nimport src.utils\nimportlib.reload(src.utils)\n\nfrom tqdm import tqdm\nimport multiprocessing, logging\nfrom joblib import Parallel, delayed",
"_____no_output_____"
],
[
"train = pandas.read_csv(\"./data/train_cells.csv\")\ntrain.head()",
"_____no_output_____"
]
],
[
[
"Functions for parsing precomputed and compressed train and test dataset rles.",
"_____no_output_____"
]
],
[
[
"def get_rle_from_df(row):\n string = row.RLEmask\n h = row.ImageHeight\n w = row.ImageWidth\n rle = src.utils.decode_b64_string(string, h, w)\n return rle\n \ndef get_mask_from_rle(rle):\n mask = pycocotools._mask.decode([rle])[:,:,0]\n return mask",
"_____no_output_____"
],
[
"rles = train.apply(get_rle_from_df, axis=1)\nrles.head()",
"_____no_output_____"
],
[
"rles.head()",
"_____no_output_____"
],
[
"masks = rles.apply(get_mask_from_rle)\nmasks.head()",
"_____no_output_____"
]
],
[
[
"### Generate Outlier Metrics\nCalculate the **bounding box**.",
"_____no_output_____"
]
],
[
[
"def get_bbox_from_rle(rle):\n \"\"\"x,y = bottom left!\"\"\"\n bbox = pycocotools._mask.toBbox([encoded_mask])[0]\n x, y, w, h = (int(l) for l in bbox)\n return x, y, w, h",
"_____no_output_____"
]
],
[
[
"Calculate the **minimum bounding rectangle** (rotated bounding box).",
"_____no_output_____"
]
],
[
[
"def get_mbr_from_mask(mask):\n return x, y, l1, l2, phi",
"_____no_output_____"
],
[
"def get_hw_from_mbr(mbr):\n return h, w",
"_____no_output_____"
],
[
"if not n_workers: n_workers=num_cores\nprocessed_list = Parallel(n_jobs=int(n_workers))(\n delayed(segment_image)(i, segmentator, images_frame, test) for i in tqdm(images)\n )",
"_____no_output_____"
],
[
"touch = train.touches.apply(ast.literal_eval)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7ce241c7823124f3a940a440745c0234dfc2d57 | 13,387 | ipynb | Jupyter Notebook | RL using Dynamic Programming.ipynb | SanketAgrawal/ReinforcementLearning | 2bb11cc22631107f0b0ddad3a96b62f31edd16a4 | [
"Apache-2.0"
]
| 1 | 2020-05-24T18:31:17.000Z | 2020-05-24T18:31:17.000Z | RL using Dynamic Programming.ipynb | SanketAgrawal/ReinforcementLearning | 2bb11cc22631107f0b0ddad3a96b62f31edd16a4 | [
"Apache-2.0"
]
| null | null | null | RL using Dynamic Programming.ipynb | SanketAgrawal/ReinforcementLearning | 2bb11cc22631107f0b0ddad3a96b62f31edd16a4 | [
"Apache-2.0"
]
| null | null | null | 32.571776 | 108 | 0.410249 | [
[
[
"import numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"class GridWorld:\n \n def __init__(self, n, terminal_state, inplace = False, policy_iteration = True, verbose=False):\n \n self.grid_size = n\n self.terminal_state = terminal_state\n self.inplace = inplace\n self.policy_iteration = policy_iteration\n self.verbose = verbose\n self.gamma = 0.1\n \n self.vt = np.zeros((self.grid_size, self.grid_size))\n if not self.inplace:\n self.vt1 = np.zeros((self.grid_size, self.grid_size))\n \n self.actions = [(0,-1), (0, 1), (-1,0), (1, 0)]# Left, Right, Up, Down\n\n #Equi-probable action selection at each state for all actions\n self.policy = np.random.randint(1,4,size = (self.grid_size, self.grid_size))\n \n print(\"Initial V\", *self.vt, sep='\\n',end='\\n\\n')\n print(\"Initial Policy\", *self.policy, sep='\\n',end='\\n\\n')\n \n if self.verbose:\n print(\"Shape of V\", self.vt.shape)\n print(\"Shape of Policy\", self.policy.shape)\n \n def _get_reward(self, x, y):\n if x==self.terminal_state[0] and y==self.terminal_state[1]:\n return 3\n return -1\n \n def _get_next_state(self, x, y, a):\n \n if x+a[0]!=-1 and x+a[0]!=self.grid_size:\n x = x + a[0]\n if y+a[1]!=-1 and y+a[1]!=self.grid_size:\n y = y + a[1]\n \n return x,y\n \n def play(self, epochs = 10, threshold = 0.1):\n \n if self.policy_iteration:\n res = self._play_policy_iteration(epochs, threshold)\n print(\"Final Policy:\")\n print(*self.policy, sep = '\\n', end = '\\n\\n')\n print(\"Final Value Function:\")\n print(*self.vt, sep = '\\n', end = '\\n\\n')\n return res\n \n else:\n res = self._play_value_iteration(epochs, threshold)\n print(\"Final Policy:\")\n print(*self.policy, sep = '\\n', end = '\\n\\n')\n print(\"Final Value Function:\")\n print(*self.vt, sep = '\\n', end = '\\n\\n')\n return res\n \n def _play_policy_iteration(self, epochs, threshold):\n \n \n iters = 0\n while True:\n \n iters+=1\n \n #Policy Evaluation:\n# for _ in range(iters):\n diff = 0\n for i in range(self.grid_size):\n for j in range(self.grid_size):\n\n old_V = self.vt[i, j]\n action = self.actions[self.policy[i,j]]\n new_x, new_y = self._get_next_state(i,j,action)\n reward = self._get_reward(new_x, new_y)\n\n if self.inplace:\n self.vt[i,j] = 0.25*(reward + self.gamma * self.vt[new_x, new_y])\n diff+= abs(old_V-self.vt[i,j])\n else:\n self.vt1[i,j] = 0.25*(reward + self.gamma * self.vt[new_x, new_y])\n diff+= abs(old_V-self.vt1[i,j])\n\n if not self.inplace:\n self.vt = np.array(self.vt1)\n \n# if diff <= threshold:\n# break\n \n if self.verbose and not self.inplace:\n print(\"Ids of Vt and Vt+1\", id(self.vt), id(self.vt1))\n \n if self.verbose:\n print(\"Value function at iter:\", iters)\n print(*self.vt, sep = '\\n', end = '\\n\\n')\n \n #Policy Improvement:\n for i in range(self.grid_size):\n for j in range(self.grid_size):\n \n best_action = -1\n best_value = -10\n for k, a in enumerate(self.actions):\n \n new_x, new_y = self._get_next_state(i,j,a)\n reward = self._get_reward(new_x, new_y)\n if best_value< (0.25*(reward + self.gamma*self.vt[new_x, new_y])):\n best_value = (0.25*(reward + self.gamma*self.vt[new_x, new_y]))\n best_action = k\n \n self.policy[i,j] = best_action\n \n if self.verbose:\n print(\"Policy at iter:\", iters)\n print(*self.policy, sep = '\\n', end = '\\n\\n')\n \n if epochs==iters or diff<=threshold:\n return diff, iters\n\n def _play_value_iteration(self, epochs, threshold):\n \n \n iters = 0\n while True:\n \n diff = 0\n for i in range(self.grid_size):\n for j in range(self.grid_size):\n \n old_V = self.vt[i, j]\n best_action = -1\n best_value = -10\n for k, a in enumerate(self.actions):\n \n new_x, new_y = self._get_next_state(i,j,a)\n reward = self._get_reward(new_x, new_y)\n if best_value< (0.25*(reward + self.gamma*self.vt[new_x, new_y])):\n best_value = (0.25*(reward + self.gamma*self.vt[new_x, new_y]))\n best_action = k\n \n if self.inplace:\n self.vt[i,j] = best_value\n diff+= abs(old_V-self.vt[i,j])\n else:\n self.vt1[i,j] = best_value\n diff+= abs(old_V-self.vt1[i,j])\n \n self.policy[i,j] = best_action\n \n iters+=1\n \n if not self.inplace:\n self.vt = np.array(self.vt1)\n \n if self.verbose and not self.inplace: \n print(\"Ids of Vt and Vt+1\", id(self.vt), id(self.vt1))\n \n if self.verbose:\n print(\"Value function at iter:\", iters)\n print(*self.vt, sep = '\\n', end = '\\n\\n')\n \n if self.verbose:\n print(\"Policy at iter:\", iters)\n print(*self.policy, sep = '\\n', end = '\\n\\n')\n \n if epochs==iters or diff<=threshold:\n return diff, iters\n",
"_____no_output_____"
]
],
[
[
"# Policy Iteration",
"_____no_output_____"
]
],
[
[
"#Inplace\ngame = GridWorld(4, (2,1), inplace=True, policy_iteration = True)\nprint(game.play(epochs=50, threshold=0.00000000000001))",
"Initial V\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n\nInitial Policy\n[2 3 1 3]\n[2 2 2 3]\n[2 3 3 2]\n[1 2 1 1]\n\nFinal Policy:\n[1 3 0 0]\n[1 3 0 0]\n[1 0 0 0]\n[1 2 0 0]\n\nFinal Value Function:\n[-0.25578487 -0.23139462 -0.25578487 -0.25639462]\n[-0.23139462 0.74421513 -0.23139462 -0.25578487]\n[ 0.74421513 -0.23139462 0.74421513 -0.23139462]\n[-0.23139462 0.74421513 -0.23139462 -0.25578487]\n\n(1.1102230246251565e-16, 8)\n"
],
[
"game = GridWorld(4, (2,1), inplace=False, policy_iteration = True)\nprint(game.play(epochs=50, threshold=0.00000000000001))",
"Initial V\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n\nInitial Policy\n[3 2 1 1]\n[1 2 2 2]\n[3 3 3 3]\n[3 3 1 1]\n\nFinal Policy:\n[1 3 0 0]\n[1 3 0 0]\n[1 0 0 0]\n[1 2 0 0]\n\nFinal Value Function:\n[-0.25578487 -0.23139462 -0.25578487 -0.25639462]\n[-0.23139462 0.74421513 -0.23139462 -0.25578487]\n[ 0.74421513 -0.23139462 0.74421513 -0.23139462]\n[-0.23139462 0.74421513 -0.23139462 -0.25578487]\n\n(8.881784197001252e-16, 12)\n"
]
],
[
[
"# Value Iteration",
"_____no_output_____"
]
],
[
[
"#Inplace\ngame = GridWorld(4, (2,1), inplace=True, policy_iteration = False)\nprint(game.play(epochs=50, threshold=0.00000000000001))",
"Initial V\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n\nInitial Policy\n[1 3 2 2]\n[3 2 1 2]\n[2 1 3 3]\n[1 2 3 2]\n\nFinal Policy:\n[1 3 0 0]\n[1 3 0 0]\n[1 0 0 0]\n[1 2 0 0]\n\nFinal Value Function:\n[-0.25578487 -0.23139462 -0.25578487 -0.25639462]\n[-0.23139462 0.74421513 -0.23139462 -0.25578487]\n[ 0.74421513 -0.23139462 0.74421513 -0.23139462]\n[-0.23139462 0.74421513 -0.23139462 -0.25578487]\n\n(8.881784197001252e-16, 7)\n"
],
[
"game = GridWorld(4, (2,1), inplace=False, policy_iteration = False)\nprint(game.play(epochs=50, threshold=0.00000000000001))",
"Initial V\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n[0. 0. 0. 0.]\n\nInitial Policy\n[2 2 2 3]\n[1 2 3 2]\n[3 1 2 2]\n[3 2 2 3]\n\nFinal Policy:\n[1 3 0 0]\n[1 3 0 0]\n[1 0 0 0]\n[1 2 0 0]\n\nFinal Value Function:\n[-0.25578487 -0.23139462 -0.25578487 -0.25639462]\n[-0.23139462 0.74421513 -0.23139462 -0.25578487]\n[ 0.74421513 -0.23139462 0.74421513 -0.23139462]\n[-0.23139462 0.74421513 -0.23139462 -0.25578487]\n\n(6.38378239159465e-16, 11)\n"
]
],
[
[
"## The results clearly shows that inplace updation along with the Value Iteration converges fastest.",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
e7ce4862d86351d72d0769918128cf4aca6ef782 | 6,899 | ipynb | Jupyter Notebook | graphs/graphs.ipynb | gpetepg/simple_algos | b018a8adf4ee6bfa5eb46eba1c59fb3a75e8ad95 | [
"MIT"
]
| null | null | null | graphs/graphs.ipynb | gpetepg/simple_algos | b018a8adf4ee6bfa5eb46eba1c59fb3a75e8ad95 | [
"MIT"
]
| null | null | null | graphs/graphs.ipynb | gpetepg/simple_algos | b018a8adf4ee6bfa5eb46eba1c59fb3a75e8ad95 | [
"MIT"
]
| null | null | null | 19.655271 | 99 | 0.441513 | [
[
[
"import collections\n\nMatchResult = collections.namedtuple(\"MatchResult\", (\"winning_team\", \"losing_team\"))\n\ndef can_team_a_beat_team_b(matches, team_a, team_b): \n return is_reachable_dfs(build_graph(), team_a, team_b)\n\ndef build_graph():\n graph = collections.defaultdict(set)\n for match in matches:\n graph[match.winning_team].add(match.losing_team)\n return graph\n\ndef is_reachable_dfs(graph, curr, dest, visited=set()):\n if curr == dest:\n return True\n elif curr in visited or curr not in graph: \n return False\n visited.add(curr)\n return any(is_reachable_dfs(graph, team, dest) for team in graph[curr])",
"_____no_output_____"
],
[
"match1 = MatchResult(\"a\", \"b\")\nmatch2 = MatchResult(\"b\", \"e\")\nmatch3 = MatchResult(\"c\", \"d\")\nmatch4 = MatchResult(\"e\", \"b\")\nmatch5 = MatchResult(\"b\", \"a\")\nmatch6 = MatchResult(\"a\", \"c\")\nmatch7 = MatchResult(\"d\", \"b\")\n\nmatches = [match1, match2, match3, match4, match5, match6, match7]\n\ncan_team_a_beat_team_b(matches, \"a\", \"e\")",
"_____no_output_____"
],
[
"graph = collections.defaultdict(set)\nfor match in matches:\n graph[match.winning_team].add(match.losing_team)\n \ngraph",
"_____no_output_____"
],
[
"match1",
"_____no_output_____"
],
[
"can_team_a_beat_team_b()",
"_____no_output_____"
],
[
"any([True, False, False])",
"_____no_output_____"
],
[
"paths = [[1,2],[2,3],[3,4],[4,1],[1,3],[2,4]]\n\ng = collections.defaultdict(list)\nfor x, y in paths:\n g[x].append(y)\n g[y].append(x)",
"_____no_output_____"
],
[
"import pprint as pp\n\npp.pprint(g)",
"defaultdict(<class 'list'>,\n {1: [2, 4, 3],\n 2: [1, 3, 4],\n 3: [2, 4, 1],\n 4: [3, 1, 2]})\n"
],
[
"{\n 1: 2, 3\n 2: 3, 4\n 3: 4\n 4: 1\n}",
"_____no_output_____"
],
[
"paths = [[1,2],[2,3],[3,4],[4,1],[1,3],[2,4]]\n\nd = {}\nfor x, y in paths:\n d[x] = y\n d[y] = x",
"_____no_output_____"
],
[
"d",
"_____no_output_____"
],
[
"d[1]",
"_____no_output_____"
],
[
"d[2]",
"_____no_output_____"
],
[
"d[1] = [2,4,3]\nd[2] = [1,3,4]\n...",
"_____no_output_____"
],
[
"import collections\nddlist = collections.defaultdict(list)\n\nddlist[2].append(5)",
"_____no_output_____"
],
[
"ddlist",
"_____no_output_____"
],
[
"import collections\nddset = collections.defaultdict(set)\n\nddset[1].add((1,2))\nddset[2].add((\"a\",\"b\"))\nddset[2].add((\"c\",\"d\"))",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7ce4c1449d403618194ad0f3d7a84c816ca6ae1 | 512,471 | ipynb | Jupyter Notebook | geocoding_yandex_api.ipynb | skaryaeva/urban_studies_notebooks | e1b465320bb237eadb6a33dda27c747f995f884d | [
"MIT"
]
| null | null | null | geocoding_yandex_api.ipynb | skaryaeva/urban_studies_notebooks | e1b465320bb237eadb6a33dda27c747f995f884d | [
"MIT"
]
| null | null | null | geocoding_yandex_api.ipynb | skaryaeva/urban_studies_notebooks | e1b465320bb237eadb6a33dda27c747f995f884d | [
"MIT"
]
| null | null | null | 2,361.617512 | 507,036 | 0.960831 | [
[
[
"## Yandex geocoding API\n\nThis notebook works with [Yandex Geocoding API](https://tech.yandex.ru/maps/geocoder/doc/desc/concepts/about-docpage/), you have to get an API key to replicate the process.\n\nFree limit for HTTP GET request is now only 1000 addresses per day. \n\n[Open data about housing](https://www.reformagkh.ru/opendata?gid=2353101&cids=house_management&page=1&pageSize=10) is used for the example. ",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport requests\n\nimport geopandas as gpd\nfrom pyproj import CRS\nfrom shapely import wkt\n\nimport matplotlib.pyplot as plt\nimport contextily as ctx\n\nimport warnings\nwarnings.filterwarnings(\"ignore\")",
"_____no_output_____"
],
[
"# reading api keys\napi_keys = pd.read_excel('../api_keys.xlsx')\napi_keys.set_index('key_name', inplace=True)\n\n# API Yandex organization search\ngeocoding_api_key = api_keys.loc['yandex_geocoding']['key']",
"_____no_output_____"
],
[
"# importing housing data\ntab = pd.read_csv('./input_data/opendata_reform_tatarstan.csv', sep = ';')\n\n# selecting a city with a number of houses within our geocoder limit\ndf_sample = tab[tab['formalname_city']=='Верхний Услон']\nlen(df_sample)",
"_____no_output_____"
],
[
"URL = 'https://geocode-maps.yandex.ru/1.x'\n\n# retrieving the coordinates in wkt format\n\ndef geocode(address):\n params = { \n \"geocode\" : address, \n \"apikey\": geocoding_api_key,\n \"format\": \"json\"\n }\n response = requests.get(URL, params=params)\n response_json = response.json()\n try:\n point = response_json['response']['GeoObjectCollection']['featureMember'][0]['GeoObject']['Point']['pos'] \n wkt_point = 'POINT ({})'.format(point)\n \n return wkt_point\n \n except Exception as e:\n print(\"for address\", address)\n print(\"result is\", response_json)\n print(\"which raises\", e)\n return \"\"",
"_____no_output_____"
],
[
"# applying geocoding\ndf_sample['coordinates'] = df_sample['address'].apply(geocode)",
"_____no_output_____"
],
[
"# shapely wkt submodule to parse wkt format\n\ndef wkt_loads(x):\n try:\n return wkt.loads(x)\n except Exception:\n return None\n \ndf_sample['coords_wkt'] = df_sample['coordinates'].apply(wkt_loads)\ndf_sample = df_sample.dropna(subset=['coords_wkt'])\n\nprint ('Number of geocoded houses - ', len(df_sample))",
"Number of geocoded houses - 39\n"
],
[
"# transform to geodataframe\nhousing_sample = gpd.GeoDataFrame(df_sample, geometry='coords_wkt')\nhousing_sample = housing_sample.set_crs(epsg=4326)",
"_____no_output_____"
],
[
"# write the result to Shapefile\nhousing_sample.to_file('./output/housing_test.shp')",
"_____no_output_____"
],
[
"# Control figure size in here\nfig, ax = plt.subplots(figsize=(15,15))\n\n# Plot the data\nhousing_sample.to_crs(epsg=3857).plot(ax=ax)\n\n# Add basemap with basic OpenStreetMap visualization\nctx.add_basemap(ax, source=ctx.providers.OpenStreetMap.Mapnik)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7ce4f7312f8c3fbfe8026fa9f13bb6855173f8f | 2,230 | ipynb | Jupyter Notebook | 2048 GAME PROJECT/CONSTANTS.ipynb | ROZZ01/Hacktoberfest-1 | dbe68f44f8727dd76a66fffa4f8c5616384b998f | [
"MIT"
]
| null | null | null | 2048 GAME PROJECT/CONSTANTS.ipynb | ROZZ01/Hacktoberfest-1 | dbe68f44f8727dd76a66fffa4f8c5616384b998f | [
"MIT"
]
| null | null | null | 2048 GAME PROJECT/CONSTANTS.ipynb | ROZZ01/Hacktoberfest-1 | dbe68f44f8727dd76a66fffa4f8c5616384b998f | [
"MIT"
]
| 1 | 2020-09-30T18:53:05.000Z | 2020-09-30T18:53:05.000Z | 29.733333 | 92 | 0.402242 | [
[
[
"SIZE = 400\nGRID_LEN = 4\nGRID_PADDING = 10\n\nBACKGROUND_COLOR_GAME = \"#92877d\"\nBACKGROUND_COLOR_CELL_EMPTY = \"#9e948a\"\n\nBACKGROUND_COLOR_DICT = {2: \"#eee4da\", 4: \"#ede0c8\", 8: \"#f2b179\",\n 16: \"#f59563\", 32: \"#f67c5f\", 64: \"#f65e3b\",\n 128: \"#edcf72\", 256: \"#edcc61\", 512: \"#edc850\",\n 1024: \"#edc53f\", 2048: \"#edc22e\",\n\n 4096: \"#eee4da\", 8192: \"#edc22e\", 16384: \"#f2b179\",\n 32768: \"#f59563\", 65536: \"#f67c5f\", }\n\nCELL_COLOR_DICT = {2: \"#776e65\", 4: \"#776e65\", 8: \"#f9f6f2\", 16: \"#f9f6f2\",\n 32: \"#f9f6f2\", 64: \"#f9f6f2\", 128: \"#f9f6f2\",\n 256: \"#f9f6f2\", 512: \"#f9f6f2\", 1024: \"#f9f6f2\",\n 2048: \"#f9f6f2\",\n\n 4096: \"#776e65\", 8192: \"#f9f6f2\", 16384: \"#776e65\",\n 32768: \"#776e65\", 65536: \"#f9f6f2\", }\n\nFONT = (\"Verdana\", 40, \"bold\")\n\n\nKEY_UP_ALT = \"\\'\\\\uf700\\'\"\nKEY_DOWN_ALT = \"\\'\\\\uf701\\'\"\nKEY_LEFT_ALT = \"\\'\\\\uf702\\'\"\nKEY_RIGHT_ALT = \"\\'\\\\uf703\\'\"\n\nKEY_UP = \"'w'\"\nKEY_DOWN = \"'s'\"\nKEY_LEFT = \"'a'\"\nKEY_RIGHT = \"'d'\"\nKEY_BACK = \"'b'\"\n\nKEY_J = \"'j'\"\nKEY_K = \"'k'\"\nKEY_L = \"'l'\"\nKEY_H = \"'h'\"",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code"
]
]
|
e7ce56a8c81f4f58b9535605a83d0617609b1c79 | 37,974 | ipynb | Jupyter Notebook | 1_code/10_results_model_performance.ipynb | lindenmp/normative_neurodev_cs_t1 | 06e006224c747394bd2c6fc42efddf83f0949fac | [
"MIT"
]
| 1 | 2020-06-15T18:43:47.000Z | 2020-06-15T18:43:47.000Z | 1_code/10_results_model_performance.ipynb | lindenmp/normative_neurodev_cs_t1 | 06e006224c747394bd2c6fc42efddf83f0949fac | [
"MIT"
]
| 6 | 2020-09-15T22:03:06.000Z | 2022-03-12T00:48:32.000Z | 1_code/10_results_model_performance.ipynb | lindenmp/normative_neurodev_cs_t1 | 06e006224c747394bd2c6fc42efddf83f0949fac | [
"MIT"
]
| 1 | 2020-07-01T16:01:43.000Z | 2020-07-01T16:01:43.000Z | 55.355685 | 14,860 | 0.670827 | [
[
[
"# Essentials\nimport os, sys, glob\nimport pandas as pd\nimport numpy as np\nimport nibabel as nib\nimport scipy.io as sio\n\n# Stats\nimport scipy as sp\nfrom scipy import stats\nimport statsmodels.api as sm\nimport pingouin as pg\n\n# Plotting\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nplt.rcParams['svg.fonttype'] = 'none'",
"_____no_output_____"
],
[
"from matplotlib.ticker import FormatStrFormatter",
"_____no_output_____"
],
[
"sys.path.append('/Users/lindenmp/Google-Drive-Penn/work/research_projects/normative_neurodev_cs_t1/1_code/')\nfrom func import set_proj_env, my_get_cmap, get_fdr_p, get_exact_p, get_fdr_p_df",
"_____no_output_____"
],
[
"train_test_str = 'train_test'\nexclude_str = 't1Exclude' # 't1Exclude' 'fsFinalExclude'\nparc_str = 'schaefer' # 'schaefer' 'lausanne'\nparc_scale = 400 # 200 400 | 60 125 250\nparcel_names, parcel_loc, drop_parcels, num_parcels, yeo_idx, yeo_labels = set_proj_env(exclude_str = exclude_str, parc_str = parc_str, parc_scale = parc_scale)",
"_____no_output_____"
],
[
"# output file prefix\noutfile_prefix = exclude_str+'_'+parc_str+'_'+str(parc_scale)+'_'\noutfile_prefix",
"_____no_output_____"
]
],
[
[
"### Setup directory variables",
"_____no_output_____"
]
],
[
[
"print(os.environ['PIPELINEDIR'])\nif not os.path.exists(os.environ['PIPELINEDIR']): os.makedirs(os.environ['PIPELINEDIR'])",
"/Users/lindenmp/Google-Drive-Penn/work/research_projects/normative_neurodev_cs_t1/2_pipeline\n"
],
[
"figdir = os.path.join(os.environ['OUTPUTDIR'], 'figs')\nprint(figdir)\nif not os.path.exists(figdir): os.makedirs(figdir)",
"/Users/lindenmp/Google-Drive-Penn/work/research_projects/normative_neurodev_cs_t1/3_output/figs\n"
],
[
"phenos = ['Overall_Psychopathology','Psychosis_Positive','Psychosis_NegativeDisorg','AnxiousMisery','Externalizing','Fear']\nphenos_short = ['Ov. Psych.', 'Psy. (pos.)', 'Psy. (neg.)', 'Anx.-mis.', 'Ext.', 'Fear']\nphenos_label = ['Overall psychopathology','Psychosis (positive)','Psychosis (negative)','Anxious-misery','Externalizing','Fear']\n\nprint(phenos)\n\nmetrics = ['ct', 'vol']\nmetrics_label = ['Thickness', 'Volume']\n\nalgs = ['rr',]\nscores = ['corr', 'rmse', 'mae']\nseeds = np.arange(0,100)",
"['Overall_Psychopathology', 'Psychosis_Positive', 'Psychosis_NegativeDisorg', 'AnxiousMisery', 'Externalizing', 'Fear']\n"
],
[
"num_algs = len(algs)\nnum_metrics = len(metrics)\nnum_phenos = len(phenos)\nnum_scores = len(scores)",
"_____no_output_____"
]
],
[
[
"## Setup plots",
"_____no_output_____"
]
],
[
[
"if not os.path.exists(figdir): os.makedirs(figdir)\nos.chdir(figdir)\nsns.set(style='white', context = 'paper', font_scale = 0.8)\ncmap = my_get_cmap('psych_phenos')",
"_____no_output_____"
]
],
[
[
"## Load data",
"_____no_output_____"
]
],
[
[
"def load_data(indir, phenos, alg, score, metric):\n\n accuracy_mean = np.zeros((100, len(phenos)))\n accuracy_std = np.zeros((100, len(phenos)))\n y_pred_var = np.zeros((100, len(phenos)))\n p_vals = pd.DataFrame(columns = phenos)\n sig_points = pd.DataFrame(columns = phenos)\n\n for p, pheno in enumerate(phenos):\n accuracy_mean[:,p] = np.loadtxt(os.path.join(indir, alg + '_' + score + '_' + metric + '_' + pheno, 'accuracy_mean.txt'))\n accuracy_std[:,p] = np.loadtxt(os.path.join(indir, alg + '_' + score + '_' + metric + '_' + pheno, 'accuracy_std.txt'))\n\n y_pred_out_repeats = np.loadtxt(os.path.join(indir, alg + '_' + score + '_' + metric + '_' + pheno, 'y_pred_out_repeats.txt'))\n y_pred_var[:,p] = y_pred_out_repeats.var(axis = 0)\n\n in_file = os.path.join(indir, alg + '_' + score + '_' + metric + '_' + pheno, 'permuted_acc.txt')\n if os.path.isfile(in_file):\n permuted_acc = np.loadtxt(in_file)\n acc = np.mean(accuracy_mean[:,p])\n p_vals.loc[metric,pheno] = np.sum(permuted_acc >= acc) / len(permuted_acc)\n sig_points.loc[metric,pheno] = np.percentile(permuted_acc,95)\n\n# if score == 'rmse' or score == 'mae':\n# accuracy_mean = np.abs(accuracy_mean)\n# accuracy_std = np.abs(accuracy_std)\n\n return accuracy_mean, accuracy_std, y_pred_var, p_vals, sig_points",
"_____no_output_____"
],
[
"s = 0; score = scores[s]; print(score)\na = 0; alg = algs[a]; print(alg)\nm = 1; metric = metrics[m]; print(metric)",
"corr\nrr\nvol\n"
],
[
"covs = ['ageAtScan1_Years', 'sex_adj']\n# covs = ['ageAtScan1_Years', 'sex_adj', 'medu1']\n\n# predictiondir = os.path.join(os.environ['PIPELINEDIR'], '8_prediction', 'out', outfile_prefix)\npredictiondir = os.path.join(os.environ['PIPELINEDIR'], '8_prediction_fixedpcs', 'out', outfile_prefix)\nprint(predictiondir)\n\nmodeldir = predictiondir+'predict_symptoms_rcv_nuis_'+'_'.join(covs)\nprint(modeldir)",
"/Users/lindenmp/Google-Drive-Penn/work/research_projects/normative_neurodev_cs_t1/2_pipeline/8_prediction_fixedpcs/out/t1Exclude_schaefer_400_\n/Users/lindenmp/Google-Drive-Penn/work/research_projects/normative_neurodev_cs_t1/2_pipeline/8_prediction_fixedpcs/out/t1Exclude_schaefer_400_predict_symptoms_rcv_nuis_ageAtScan1_Years_sex_adj\n"
]
],
[
[
"## Load whole-brain results",
"_____no_output_____"
]
],
[
[
"accuracy_mean, accuracy_std, _, p_vals, sig_points = load_data(modeldir, phenos, alg, score, metric)\np_vals = get_fdr_p_df(p_vals)\np_vals[p_vals < 0.05]",
"_____no_output_____"
],
[
"accuracy_mean_z, accuracy_std_z, _, p_vals_z, sig_points_z = load_data(modeldir+'_z', phenos, alg, score, metric)\np_vals_z = get_fdr_p_df(p_vals_z)\np_vals_z[p_vals_z < 0.05]",
"_____no_output_____"
]
],
[
[
"### Plot",
"_____no_output_____"
]
],
[
[
"stats = pd.DataFrame(index = phenos, columns = ['meanx', 'meany', 'test_stat', 'pval'])\nfor i, pheno in enumerate(phenos): \n\n df = pd.DataFrame(columns = ['model','pheno'])\n for model in ['wb','wbz']:\n df_tmp = pd.DataFrame(columns = df.columns)\n if model == 'wb':\n df_tmp.loc[:,'score'] = accuracy_mean[:,i]\n elif model == 'wbz':\n df_tmp.loc[:,'score'] = accuracy_mean_z[:,i]\n df_tmp.loc[:,'pheno'] = pheno\n df_tmp.loc[:,'model'] = model\n\n df = pd.concat((df, df_tmp), axis = 0)\n \n x = df.loc[df.loc[:,'model'] == 'wb','score']\n y = df.loc[df.loc[:,'model'] == 'wbz','score']\n stats.loc[pheno,'meanx'] = np.round(np.mean(x),3)\n stats.loc[pheno,'meany'] = np.round(np.mean(y),3)\n stats.loc[pheno,'test_stat'] = stats.loc[pheno,'meanx']-stats.loc[pheno,'meany']\n stats.loc[pheno,'pval'] = get_exact_p(x, y)\n \nstats.loc[:,'pval_corr'] = get_fdr_p(stats.loc[:,'pval'])\nstats.loc[:,'sig'] = stats.loc[:,'pval_corr'] < 0.05\n\nstats",
"_____no_output_____"
],
[
"sig_points_plot = (sig_points + sig_points_z)/2\nidx = np.argsort(accuracy_mean_z.mean(axis = 0))[::-1][:]\nif metric == 'ct':\n idx = np.array([5, 1, 0, 3, 4, 2])\nelif metric == 'vol':\n idx = np.array([0, 1, 5, 4, 2, 3])\n\nf, ax = plt.subplots(len(phenos),1)\nf.set_figwidth(2.25)\nf.set_figheight(4)\n\n# for i, pheno in enumerate(phenos):\nfor i, ii in enumerate(idx):\n pheno = phenos[ii]\n for model in ['wb','wbz']:\n# ax[i].axvline(x=sig_points_plot.values.mean(), ymax=1.2, clip_on=False, color='gray', alpha=0.5, linestyle='--', linewidth=1.5)\n# if i == 0:\n# ax[i].text(sig_points_plot.values.mean(), 40, '$p$ < 0.05', fontweight=\"regular\", color='gray',\n# ha=\"left\", va=\"center\", rotation=270)\n\n if model == 'wb':\n if p_vals.loc[:,pheno].values[0]<.05:\n sns.kdeplot(x=accuracy_mean[:,ii], ax=ax[i], bw_adjust=.75, clip_on=False, color=cmap[ii], alpha=0.5, linewidth=2)\n # add point estimate\n ax[i].axvline(x=accuracy_mean[:,ii].mean(), ymax=0.25, clip_on=False, color=cmap[ii], linewidth=2)\n else:\n sns.kdeplot(x=accuracy_mean[:,ii], ax=ax[i], bw_adjust=.75, clip_on=False, color=cmap[ii], linewidth=.25)\n # add point estimate\n ax[i].axvline(x=accuracy_mean[:,ii].mean(), ymax=0.25, clip_on=False, color=cmap[ii], linewidth=0.5)\n \n# ax[i].axvline(x=sig_points.loc[:,pheno].values[0], ymax=1, clip_on=False, color='gray', alpha=0.5, linestyle='--', linewidth=1.5)\n elif model == 'wbz':\n if p_vals_z.loc[:,pheno].values[0]<.05:\n sns.kdeplot(x=accuracy_mean_z[:,ii], ax=ax[i], bw_adjust=.75, clip_on=False, color=cmap[ii], alpha=0.75, linewidth=0, fill=True)\n# sns.kdeplot(x=accuracy_mean_z[:,ii], ax=ax[i], bw_adjust=.75, clip_on=False, color=\"w\", alpha=1, linewidth=1)\n # add point estimate\n ax[i].axvline(x=accuracy_mean_z[:,ii].mean(), ymax=0.25, clip_on=False, color='w', linewidth=2)\n else:\n sns.kdeplot(x=accuracy_mean_z[:,ii], ax=ax[i], bw_adjust=.75, clip_on=False, color=cmap[ii], alpha=0.2, linewidth=0, fill=True)\n# sns.kdeplot(x=accuracy_mean_z[:,ii], ax=ax[i], bw_adjust=.75, clip_on=False, color=\"w\", alpha=1, linewidth=1)\n # add point estimate\n ax[i].axvline(x=accuracy_mean_z[:,ii].mean(), ymax=0.25, clip_on=False, color='w', linewidth=1)\n# ax[i].axvline(x=sig_points_z.loc[:,pheno].values[0], ymax=1, clip_on=False, color='gray', alpha=0.5, linestyle='--', linewidth=1.5)\n# ax[i].text(sig_points_z.loc[:,pheno].values[0], 40, '$p$<.05', fontweight=\"regular\", color='gray',\n# ha=\"left\", va=\"bottom\", rotation=270)\n\n # note between model significant performance difference\n if stats.loc[pheno,'sig']:\n ax[i].plot([accuracy_mean[:,ii].mean(),accuracy_mean_z[:,ii].mean()],[ax[i].get_ylim()[1],ax[i].get_ylim()[1]], color='gray', linewidth=1)\n# ax[i].text(accuracy_mean[:,ii].mean()+[accuracy_mean_z[:,ii].mean()-accuracy_mean[:,ii].mean()],\n# ax[i].get_ylim()[1], '$p$<.05', fontweight=\"regular\", color='gray', ha=\"left\", va=\"center\")\n# ax[i].axvline(x=accuracy_mean[:,ii].mean(), ymin=ax[i].get_ylim()[1], clip_on=False, color='gray', linewidth=1)\n# ax[i].axvline(x=accuracy_mean_z[:,ii].mean(), ymin=ax[i].get_ylim()[1], clip_on=False, color='gray', linewidth=1)\n# ax[i].axhline(y=25, linewidth=2, xmin=accuracy_mean[:,ii].mean(), xmax=accuracy_mean_z[:,ii].mean(), color = 'gray')\n# ax[i].axhline(y=25, linewidth=2, color = 'black')\n\n if score == 'corr':\n ax[i].set_xlim([accuracy_mean_z.min(),\n accuracy_mean_z.max()])\n\n ax[i].axhline(y=0, linewidth=2, clip_on=False, color=cmap[ii])\n\n for spine in ax[i].spines.values():\n spine.set_visible(False)\n ax[i].set_ylabel('')\n ax[i].set_yticklabels([])\n ax[i].set_yticks([])\n# if score == 'corr':\n# if i != len(idx)-1:\n# ax[i].set_xticklabels([])\n\n if i == len(idx)-1:\n if score == 'corr': ax[i].set_xlabel('corr(y_true,y_pred)')\n elif score == 'rmse': ax[i].set_xlabel('neg[RMSE] (higher = better)')\n elif score == 'mae': ax[i].set_xlabel('neg[MAE] (higher = better)')\n\n ax[i].tick_params(pad = -2)\n\n if score == 'corr':\n ax[i].text(0, 0.75, phenos_label[ii], fontweight=\"regular\", color=cmap[ii],\n ha=\"left\", va=\"center\", transform=ax[i].transAxes)\n\nf.subplots_adjust(hspace=1)\n# f.suptitle(alg+'_'+score+'_'+metric+' | '+'_'.join(covs))\nf.savefig(outfile_prefix+'performance_comparison_'+alg+'_'+score+'_'+metric+'.svg', dpi = 600, bbox_inches = 'tight')",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7ce793a64a7fab12e368c8ab828186aad52e6b2 | 665,378 | ipynb | Jupyter Notebook | notebooks/commute.ipynb | moorissa/geocoders | f294e1a4473a0487bd2bc09fb9aad0fd6d6abcb4 | [
"MIT"
]
| null | null | null | notebooks/commute.ipynb | moorissa/geocoders | f294e1a4473a0487bd2bc09fb9aad0fd6d6abcb4 | [
"MIT"
]
| null | null | null | notebooks/commute.ipynb | moorissa/geocoders | f294e1a4473a0487bd2bc09fb9aad0fd6d6abcb4 | [
"MIT"
]
| null | null | null | 653.612967 | 218,588 | 0.928176 | [
[
[
"%matplotlib inline\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nfig = plt.rcParams[\"figure.figsize\"]\nfig[0] = 10\nfig[1] = 6",
"_____no_output_____"
],
[
"df1 = pd.read_csv('../data/commutedata_sum.csv')\ndf1.head()",
"_____no_output_____"
],
[
"df = pd.read_csv('../data/commutedata_travel.csv')\ndf.head()",
"_____no_output_____"
],
[
"df['percent_leaving']=df['outofcounty_commuters']/df['total_commuters']",
"_____no_output_____"
],
[
"df1.dtypes\nprint(min(df1['percent_leaving']))\nprint(max(df1['percent_leaving']))",
"0.008253132\n0.51018187\n"
],
[
"fig = plt.figure(figsize=(18, 6))\n# binwidth = np.linspace(0,0.6,0.04)\n\nax1 = fig.add_subplot(121)\nax1.hist(df1['percent_leaving'],color='orange',edgecolor=\"white\")\nax1.set_title('Commute Rate Histogram')\nax1.set_ylabel('Frequency')\nax1.set_xlabel('Commute Rate')\n\nax2 = fig.add_subplot(122)\nax2.boxplot(df1['percent_leaving'])\nax2.set_title('Commute Rate Boxplot')\nax2.set_ylabel('Commute Rate')\nax2.set_xlabel('')\n\nplt.show()",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(18, 6))\n\nax1 = fig.add_subplot(122)\nax1.boxplot(df1['percent_leaving'])\nax1.set_title('Commute Rate Boxplot')\nax1.set_ylabel('Commute Rate')\nax1.set_xlabel('')\n\ndf['incounty_commuters'] = df['total_commuters']-df['outofcounty_commuters']\n\nax2 = fig.add_subplot(121)\nax2.scatter(df['outofcounty_commuters'],df['incounty_commuters'],alpha=0.35,color='r')\nax2.set_title('In-County Commuters v. Out-of-County Commuters')\nax2.set_ylabel('In-County Commuters')\nax2.set_xlabel('Out of County Commuters')\n\nplt.show()",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"import seaborn as sns\n\n# sns.plt.title('Ratings by Network Histogram') \nsns.set(style=\"darkgrid\", color_codes=True)\ng = sns.FacetGrid(df, col=\"travel_mode\",legend_out=False,size=4, aspect=1, margin_titles=True)\ng = g.map(plt.hist, \"percent_leaving\", color=\"orange\")\n\n# sns.plt.title(\"Out-of-County Commuters by Travel Modes\")\n# g.set_xlabel(\"Total Out-of-County Commuters\")\n# g.set_ylabel(\"Travel Mode\")\ng.axes[0,0].set_xlabel('Commute Rate')\ng.axes[0,1].set_xlabel('Commute Rate')\ng.axes[0,2].set_xlabel('Commute Rate')\ng.axes[0,3].set_xlabel('Commute Rate')\nplt.subplots_adjust(top=0.8)\ng.fig.suptitle('Commute Rate Histograms by Travel Mode')\nsns.plt.show()",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\", color_codes=True)\ng = sns.FacetGrid(df, col=\"travel_mode\",legend_out=False,size=4, aspect=1)\ng = g.map(plt.hist, \"total_commuters\", color=\"green\")\nsns.plt.show()",
"_____no_output_____"
],
[
"df.boxplot('total_commuters', by='travel_mode', figsize=(7, 8))",
"_____no_output_____"
],
[
"sns.set(style=\"ticks\", palette=\"muted\", color_codes=True)\n\nax = sns.boxplot(x=\"total_commuters\", y=\"travel_mode\", data=df,\n whis=np.inf, color=\"c\")\n\nsns.stripplot(x=\"total_commuters\", y=\"travel_mode\", data=df,\n jitter=True, size=3, color=\".3\", linewidth=0)\n\n\n# Make the quantitative axis logarithmic\nax.set_xscale(\"log\")\nsns.despine(trim=True)",
"_____no_output_____"
],
[
"sns.set(style=\"ticks\", palette=\"muted\", color_codes=True)\nax = sns.boxplot(x=\"outofcounty_commuters\", y=\"travel_mode\", data=df,\n whis=np.inf, color=\"c\")\nsns.stripplot(x=\"outofcounty_commuters\", y=\"travel_mode\", data=df,\n jitter=True, size=3, color=\".3\", linewidth=0)\nax.set_title(\"Out-of-County Commuters by Travel Modes\")\nax.set_xlabel(\"Total Out-of-County Commuters\")\nax.set_ylabel(\"Travel Mode\")\nax.set_xscale(\"log\")\nsns.despine(trim=True)",
"_____no_output_____"
],
[
"sns.set(style=\"ticks\", palette=\"muted\", color_codes=True)\n\nax = sns.boxplot(x=\"percent_leaving\", y=\"travel_mode\", data=df,\n whis=np.inf, color=\"c\")\n\nsns.stripplot(x=\"percent_leaving\", y=\"travel_mode\", data=df,\n jitter=True, size=3, color=\".3\", linewidth=0)\n\n\n# Make the quantitative axis logarithmic\nax.set_xscale(\"log\")\nsns.despine(trim=True)",
"_____no_output_____"
],
[
"df_carpooled = df.loc[df['travel_mode'] == 'Car, truck, or van: Carpooled']\ndf_alone = df.loc[df['travel_mode'] == 'Car, truck, or van: Drove alone']\ndf_other = df.loc[df['travel_mode'] == 'Other travel mode']\ndf_public = df.loc[df['travel_mode'] == 'Public transportation']",
"_____no_output_____"
],
[
"from matplotlib import pyplot\n\nfig, ax = pyplot.subplots(figsize=(11.7, 10))\nshow_group = df[['state','percent_leaving']].groupby('state')\nratings_group = show_group.mean()\nmy_plot = ratings_group.sort(columns='percent_leaving',ascending=True)\nmy_plot = my_plot.plot(ax=ax,kind='barh',legend=None,color='salmon',title=\"Commute Rate by State\")\n\nmy_plot.set_ylabel(\"State\")\nmy_plot.set_xlabel(\"Commute Rate\")\nplt.show()",
"/Users/moorissatjokro/anaconda/lib/python3.6/site-packages/ipykernel/__main__.py:6: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)\n"
],
[
"fig = plt.figure(figsize=(11.7, 17))\n\nax1 = fig.add_subplot(221)\nshow_group = df_carpooled[['state','percent_leaving']].groupby('state')\nratings_group = show_group.mean()\nmy_plot = ratings_group.sort(columns='percent_leaving',ascending=True)\nmy_plot = my_plot.plot(ax=ax1,kind='barh',legend=None,color='lightblue',title=\"Carpooled (Car, Truck, or Van)\")\nmy_plot.set_xlim([0,0.78])\nmy_plot.set_ylabel(\"State\")\nmy_plot.set_xlabel(\"Commute Rate\")\n\nax2 = fig.add_subplot(222)\nshow_group = df_alone[['state','percent_leaving']].groupby('state')\nratings_group = show_group.mean()\nmy_plot = ratings_group.sort(columns='percent_leaving',ascending=True)\nmy_plot = my_plot.plot(ax=ax2,kind='barh',legend=None,color='lightgreen',title=\"Drove Alone (Car, Truck, or Van)\")\nmy_plot.set_xlim([0,0.78])\nmy_plot.set_ylabel(\"State\")\nmy_plot.set_xlabel(\"Commute Rate\")\n\nax3 = fig.add_subplot(223)\nshow_group = df_other[['state','percent_leaving']].groupby('state')\nratings_group = show_group.mean()\nmy_plot = ratings_group.sort(columns='percent_leaving',ascending=True)\nmy_plot = my_plot.plot(ax=ax3,kind='barh',legend=None,color='orange',title=\"Other Modes\")\nmy_plot.set_xlim([0,0.78])\nmy_plot.set_ylabel(\"State\")\nmy_plot.set_xlabel(\"Commute Rate\")\n\nax4 = fig.add_subplot(224)\nshow_group = df_public[['state','percent_leaving']].groupby('state')\nratings_group = show_group.mean()\nmy_plot = ratings_group.sort(columns='percent_leaving',ascending=True)\nmy_plot = my_plot.plot(ax=ax4,kind='barh',legend=None,color='pink',title=\"Public Transportation\")\nmy_plot.set_ylabel(\"State\")\nmy_plot.set_xlabel(\"Commute Rate\")\nmy_plot.set_xlim([0,0.78])\n\nfig.tight_layout()\nplt.show()",
"/Users/moorissatjokro/anaconda/lib/python3.6/site-packages/ipykernel/__main__.py:6: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)\n/Users/moorissatjokro/anaconda/lib/python3.6/site-packages/ipykernel/__main__.py:15: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)\n/Users/moorissatjokro/anaconda/lib/python3.6/site-packages/ipykernel/__main__.py:24: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)\n/Users/moorissatjokro/anaconda/lib/python3.6/site-packages/ipykernel/__main__.py:33: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)\n"
],
[
"df.isnull().values.any()",
"_____no_output_____"
],
[
"df2 = pd.read_csv('../data/Table2_ACSCommutingFlow.csv',encoding='ISO-8859-1')\ndf2.head()",
"_____no_output_____"
],
[
"df2.isnull().values.any()",
"_____no_output_____"
],
[
"import missingno as msno\n%matplotlib inline\nmsno.matrix(df2.sample(1000))",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cedb2022a6ed409407cbda70974c300cd7f2df | 36,407 | ipynb | Jupyter Notebook | fuzzywuzzy match geo and turnstile.ipynb | Lwaggaman/EDA_Project | 0e1d47b82dc7b5ca1b7b5c69de8fdb4b7469e7eb | [
"SGI-B-2.0"
]
| null | null | null | fuzzywuzzy match geo and turnstile.ipynb | Lwaggaman/EDA_Project | 0e1d47b82dc7b5ca1b7b5c69de8fdb4b7469e7eb | [
"SGI-B-2.0"
]
| null | null | null | fuzzywuzzy match geo and turnstile.ipynb | Lwaggaman/EDA_Project | 0e1d47b82dc7b5ca1b7b5c69de8fdb4b7469e7eb | [
"SGI-B-2.0"
]
| null | null | null | 31.741064 | 135 | 0.420331 | [
[
[
"from fuzzywuzzy import fuzz\nfrom fuzzywuzzy import process\nimport pandas as pd\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"stations_geo = pd.read_csv('Data/raw/stations_loc.csv', usecols=['NAME', 'the_geom'])\nzip_by_station = pd.read_csv('Data/raw/zips.csv', dtype={'zip_code':'object'}, names=['STATION','ZIP'])\nzip_by_borough = pd.read_csv('Data/raw/zip_by_borough.csv', dtype={'ZIP':'object'})\nturnstile_stations = pd.read_csv('Data/Processed/unique_mta_stations.csv',index_col=0)",
"_____no_output_____"
],
[
"#We have geo data for 473 stations, but some have more than one set of coords, \n#so we'll only consider 355\nstations_geo = stations_geo.drop_duplicates(subset=('NAME'), keep='last').reset_index(drop=True)",
"_____no_output_____"
],
[
"# zip_by_station contains name matches for the stations in tursntile data, but I want to add \n# the ones the author dropped in case I can match them to geo data I acquired.\nstations_zip = turnstile_stations.merge(zip_by_station, on='STATION', how='left')\n\n# Add borough column for easy filtering later\nstation_borough = stations_zip.merge(zip_by_borough, on='ZIP', how='left').drop_duplicates(subset=['STATION','ZIP','BOROUGH'])\n\n#These stations have either been matched to worng zips outside or NYC or have been dropped\n##station_borough[station_borough.BOROUGH.isna()] \n#I'll try to match some of these if I have time later\n#station_borough.dropna(subset=['BOROUGH'], inplace=True) #None of these zips are in NYC, so I'll drop them\n#brook_manh = station_borough[(station_borough.BOROUGH=='Brooklyn')|(station_borough.BOROUGH=='Manhattan')]",
"_____no_output_____"
],
[
"geo_test = stations_geo.copy(deep=True)\nstation_test = station_borough.copy(deep=True)",
"_____no_output_____"
],
[
"#stations_zip.info() #We have turnstile data for only 379 stations\n#We have geo data for 473 stations, but some have more than one set of coords, \n#so we'll only consider 355\n#stations_geo.info() \n#stations_geo = stations_geo.drop_duplicates(subset=['NAME'], keep='last').reset_index(drop=True)\nstations_geo.head()",
"_____no_output_____"
],
[
"# Edit station names in geo data to try to match turnstile data\n# I want to remove the ordinal indicators from the names in the geo data, I will apply it before capitalizing\n# to avoid deleting the street indicators ('St') and other data that are not ord indicators\n\nstations_geo['NAME'] = (stations_geo.NAME.str.replace(' -','-')\n .str.replace('- ','-')\n .str.strip())\nstation_borough['STATION'] = (station_borough.STATION.str.strip().str.replace('AVE','AV')\n .str.replace('STREET','ST').str.replace('COLLEGE','CO')\n .str.replace('SQUARE','SQ').replace('STS','ST').replace('/','-'))\n\n# I will use fuzzywuzzy, but it's not very accurate with the numbered streets so I will treat them separately.\nstations_geo['NUMBER'] = stations_geo.NAME.apply(lambda x: True if True in [char.isdigit() for char in x] else False)\n\n\n#geo stations WITH numbers\nstations_geo_nr = stations_geo[stations_geo.NUMBER==True]\nstations_geo_nr['NAME'] = (stations_geo_nr.NAME.apply(lambda x: x.replace('th','').replace('1st','1')\n .replace('2nd','2').replace('3rd','3')\n .upper().replace('STS','ST')\n .replace('AVE','AV').replace('STREET','ST')\n .replace('COLLEGE','CO').replace('SQUARE','SQ')\n .replace('LOWER EAST SIDE','').strip()))\nstations_geo_no_nr = stations_geo[stations_geo.NUMBER==False]\nstations_geo_no_nr['NAME'] = stations_geo_no_nr.NAME.apply(lambda x: x.upper().replace('STS','ST')\n .replace('AVE','AV').replace('STREET','ST')\n .replace('COLLEGE','CO').replace('SQUARE','SQ')\n .strip())\n\n\n\n# do merge\nnew_stations_geo = pd.concat([stations_geo_no_nr, stations_geo_nr])\nmerged = station_borough.merge(new_stations_geo, left_on='STATION', right_on='NAME', how='outer')\n\n\n# retrieve unmerged\nunmerged_geo = (merged[(merged.NAME.notna())&(merged.STATION.isna())]\n .reset_index(drop=True).drop(['ZIP','STATION','BOROUGH','NUMBER'], axis=1,errors='ignore'))\nunmerged_station = (merged[(merged.STATION.notna())&(merged.NAME.isna())]\n .reset_index(drop=True).drop(['NAME','the_geom','NUMNER'], axis=1, errors='ignore'))\nunmerged_station = unmerged_station[~unmerged_station.STATION.isin(['2 AV','5 AV'])]",
"_____no_output_____"
],
[
"match1 = []\nscore1 = []\n\nmatch2 = []\nscore2 = []\n\nmatch3 = []\nscore3 = []\n\n\nfor i in unmerged_geo.NAME:\n ratio = process.extract( i, unmerged_station.STATION, limit=1)\n match1.append(ratio[0][0])\n score1.append(ratio[0][1])\n \nfor i in unmerged_geo.NAME:\n ratio = process.extract( i, unmerged_station.STATION, limit=1, scorer=fuzz.partial_ratio)\n match2.append(ratio[0][0])\n score2.append(ratio[0][1])\n \nfor i in unmerged_geo.NAME:\n ratio = process.extract( i, unmerged_station.STATION, limit=1, scorer=fuzz.token_set_ratio)\n match3.append(ratio[0][0])\n score3.append(ratio[0][1]) \n\nunmerged_geo['MATCH1'] = pd.Series(match1)\nunmerged_geo['SCORE1'] = pd.Series(score1)\n\nunmerged_geo['MATCH2'] = pd.Series(match2)\nunmerged_geo['SCORE2'] = pd.Series(score2)\n\nunmerged_geo['MATCH3'] = pd.Series(match3)\nunmerged_geo['SCORE3'] = pd.Series(score3)",
"_____no_output_____"
],
[
"#unmerged_geo.sort_values('SCORE2').head(25) ##TOKEN_SET_RATIO IS THE WAY TO GO.\nunmerged_geo.drop(['MATCH1','SCORE1','MATCH2','SCORE2'], axis=1, inplace=True)\nnew_merged_geo = (unmerged_geo[unmerged_geo.SCORE3>70]\n .merge(unmerged_station, left_on='MATCH3', right_on='STATION', how='inner'))\n\nnew_merged_geo.drop(['MATCH3','SCORE3'], axis=1, inplace=True)\n\ntotal_merged = pd.concat([new_merged_geo, merged[(merged.NAME.notna())&(merged.STATION.notna())]])\ntotal_merged = total_merged.drop_duplicates(subset='STATION').drop(['NUMBER'], axis=1) \n#add the stations we don't have geo data for, since their zip code is still usefull\nfinal_stations = pd.concat([total_merged, station_borough[~station_borough.STATION.isin(total_merged.STATION)]])\nfinal_stations.reset_index(drop=True, inplace=True) ",
"_____no_output_____"
],
[
"final_stations.loc[100,'STATION'] = '2 AV'\nfinal_stations.loc[100,'ZIP'] = '10003'\nfinal_stations.loc[100,'BOROUGH'] = 'Manhattan'\nfinal_stations.loc[131,'the_geom'] = 'POINT (-73.98177094440949 40.690648119969794)'\nfinal_stations.loc[157,'the_geom'] = 'POINT (-73.95024799996972 40.71407200064717)'\nfinal_stations.loc[95,'the_geom'] = 'POINT (-73.97334700047045 40.764510999755284)'",
"_____no_output_____"
],
[
"(final_stations.loc[:,['STATION','ZIP','BOROUGH','the_geom']]\n .to_csv('Data/Processed/zip_boro_geo.csv', index=False))",
"_____no_output_____"
]
],
[
[
"#### Code for comparison tests",
"_____no_output_____"
]
],
[
[
"final_stations[final_stations.ZIP=='10019']",
"_____no_output_____"
],
[
"final_stations[final_stations.STATION=='5 AV']",
"_____no_output_____"
],
[
"final_stations[final_stations.STATION.str.contains('5 AV')]",
"_____no_output_____"
],
[
"final_stations.dropna(subset=['NAME'])[final_stations.dropna(subset=['NAME']).NAME.str.contains('2 AV')]",
"_____no_output_____"
],
[
"station_test[station_test.STATION.str.contains('5 AV')]",
"_____no_output_____"
],
[
"geo_test[geo_test.NAME.str.contains('7th Ave')]",
"_____no_output_____"
],
[
"stations_geo_nr[stations_geo_nr.NAME.str.contains('7 AV')]",
"_____no_output_____"
],
[
"station_borough[station_borough.STATION.str.contains('/')]",
"_____no_output_____"
],
[
"unmerged_station[unmerged_station.STATION.str.contains('2 AV')]",
"_____no_output_____"
],
[
"stations_geo[stations_geo.NAME.str.contains('AVE')]",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cedd67e29717b631ed0c790b015888a1a423de | 615,022 | ipynb | Jupyter Notebook | examples/.ipynb_checkpoints/example-checkpoint.ipynb | sLakshmiprasad/advanced-lane-lines | a4f283bb27485cf649b4366df92538c45f854ba6 | [
"MIT"
]
| null | null | null | examples/.ipynb_checkpoints/example-checkpoint.ipynb | sLakshmiprasad/advanced-lane-lines | a4f283bb27485cf649b4366df92538c45f854ba6 | [
"MIT"
]
| null | null | null | examples/.ipynb_checkpoints/example-checkpoint.ipynb | sLakshmiprasad/advanced-lane-lines | a4f283bb27485cf649b4366df92538c45f854ba6 | [
"MIT"
]
| null | null | null | 4,046.197368 | 610,480 | 0.963666 | [
[
[
"## Advanced Lane Finding Project\n\nThe goals / steps of this project are the following:\n\n* Compute the camera calibration matrix and distortion coefficients given a set of chessboard images.\n* Apply a distortion correction to raw images.\n* Use color transforms, gradients, etc., to create a thresholded binary image.\n* Apply a perspective transform to rectify binary image (\"birds-eye view\").\n* Detect lane pixels and fit to find the lane boundary.\n* Determine the curvature of the lane and vehicle position with respect to center.\n* Warp the detected lane boundaries back onto the original image.\n* Output visual display of the lane boundaries and numerical estimation of lane curvature and vehicle position.\n\n---\n## First, I'll compute the camera calibration using chessboard images",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport cv2\nimport glob\nimport matplotlib.pyplot as plt\n%matplotlib qt\n\n# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)\nobjp = np.zeros((6*9,3), np.float32)\nobjp[:,:2] = np.mgrid[0:9,0:6].T.reshape(-1,2)\n\n# Arrays to store object points and image points from all the images.\nobjpoints = [] # 3d points in real world space\nimgpoints = [] # 2d points in image plane.\n\n# Make a list of calibration images\nimages = glob.glob('../camera_cal/calibration*.jpg')\n\n# Step through the list and search for chessboard corners\nfor fname in images:\n img = cv2.imread(fname)\n gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\n\n # Find the chessboard corners\n ret, corners = cv2.findChessboardCorners(gray, (9,6),None)\n\n # If found, add object points, image points\n if ret == True:\n objpoints.append(objp)\n imgpoints.append(corners)\n\n # Draw and display the corners\n img = cv2.drawChessboardCorners(img, (9,6), corners, ret)\n cv2.imshow('img',img)\n cv2.waitKey(500)\n\ncv2.destroyAllWindows()",
"_____no_output_____"
]
],
[
[
"## Calibrate the camera using the objpoints and imgpoints\n",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimg = cv2.imread('../test_images/test2.jpg')\nimg_size = (img.shape[1], img.shape[0])\nret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, img_size,None,None)\ndst = cv2.undistort(img, mtx, dist, None, mtx)\n\nf, (ax1, ax2) = plt.subplots(1, 2, figsize=(20,10))\nax1.imshow(img)\nax1.set_title('Original Image', fontsize=30)\nax2.imshow(dst)\nax2.set_title('Undistorted Image', fontsize=30)",
"Camera calibration matrix [[1.15777942e+03 0.00000000e+00 6.67111050e+02]\n [0.00000000e+00 1.15282305e+03 3.86129068e+02]\n [0.00000000e+00 0.00000000e+00 1.00000000e+00]]\nDistortion coefficient [[-0.24688832 -0.02372817 -0.00109843 0.00035105 -0.00259133]]\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7cef2414d14f61bdd07d2bd4de5a08c5749d0cb | 159,556 | ipynb | Jupyter Notebook | .ipynb_checkpoints/(200818) 2.-checkpoint.ipynb | Adrian123K/tensor | f5cb9bbb8b98d3ca52356454b1c6adf2851ed507 | [
"MIT"
]
| null | null | null | .ipynb_checkpoints/(200818) 2.-checkpoint.ipynb | Adrian123K/tensor | f5cb9bbb8b98d3ca52356454b1c6adf2851ed507 | [
"MIT"
]
| null | null | null | .ipynb_checkpoints/(200818) 2.-checkpoint.ipynb | Adrian123K/tensor | f5cb9bbb8b98d3ca52356454b1c6adf2851ed507 | [
"MIT"
]
| null | null | null | 51.88813 | 43,652 | 0.613032 | [
[
[
"## <b>■ 딥러닝 복습</b>\n 1장. numpy\n 2장. 퍼셉트론\n 3장. 3층 신경망 구현\n 4장. 2층 신경망 구현(수치미분)\n 5장. 2층 신경망 구현(오차역전파) tensorflow 1.x -> tensorflow 2.x\n --------------------------------------------------------------------\n 6장. 신경망 학습시키는 기술들\n 7장. CNN을 이용한 신경망 구현\n -------------------------------------------------------------------- 자전거 타는 법\n\n 6장. 신경망 학습시키는 기술들\n 1. 언더피팅 방지하는 방법\n - 가중치 초기값 선정\n ① Xavier\n ② He\n - 배치 정규화\n 2. 오버피팅 방지하는 방법\n### <b>■ 텐서플로우로 가중치 초기값 선정하는 방법</b>\n 1. Xavier\n\n\n$$ {{1} \\over {\\sqrt{n}}} \\cdot \\rm{np.random.randn(r,c)}$$",
"_____no_output_____"
]
],
[
[
"W1 = tf.get_variable(name='W1', shape=[784,50], initializer = tf.contrib.layers.xavier_initializer())",
"_____no_output_____"
]
],
[
[
" 2. He 가중치 초기값 구성\n$$ \\sqrt{{{2} \\over {n}}} \\cdot \\rm{np.random.randn(r,c)} $$",
"_____no_output_____"
]
],
[
[
"W1 = tf.get_variable(name=\"W1\", shape=[784,50], initializer = tf.contrib.layers.variance_scaling_initializer())",
"_____no_output_____"
]
],
[
[
"#### 예제1. 어제 마지막 문제로 만들었던 텐서 플로우로 구현한 신경망 코드에 가중치 초기값을 xavier로 해서 구현하시오",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\ntf.reset_default_graph()\n\n# 은닉1층\nx = tf.placeholder('float',[None,784])\nW1 = tf.get_variable(name='W1', shape=[784,50], initializer = tf.contrib.layers.xavier_initializer())\nb1 = tf.Variable(tf.ones([1,50]))\n\ny = tf.matmul(x, W1) + b1\ny_hat = tf.nn.relu(y)\n\n# 출력층\nW2 = tf.get_variable(name='W2', shape=[50,10], initializer = tf.contrib.layers.xavier_initializer())\nb2 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y_hat,W2) + b2\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\n# 그래프 실행\nsess = tf.Session()\nsess.run(init)\n\nfor i in range(1,601*20):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n batch_x_test, batch_y_test = mnist.test.next_batch(100)\n sess.run(train, feed_dict={x:batch_xs, y_onehot:batch_ys})\n if not i % 600:\n print(i//600,\"에폭 훈련데이터 정확도 : \",sess.run(accuracy, feed_dict={x:batch_xs, y_onehot:batch_ys}),\"\\t\",\"테스트 데이터 정확도:\", sess.run(accuracy, feed_dict={x:batch_x_test, y_onehot:batch_y_test}))",
"WARNING:tensorflow:From <ipython-input-9-a5d4a56c599c>:6: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use alternatives such as official/mnist/dataset.py from tensorflow/models.\nWARNING:tensorflow:From C:\\Users\\knitwill\\anaconda3\\lib\\site-packages\\tensorflow\\contrib\\learn\\python\\learn\\datasets\\mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease write your own downloading logic.\nWARNING:tensorflow:From C:\\Users\\knitwill\\anaconda3\\lib\\site-packages\\tensorflow\\contrib\\learn\\python\\learn\\datasets\\mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use tf.data to implement this functionality.\nExtracting MNIST_data/train-images-idx3-ubyte.gz\nWARNING:tensorflow:From C:\\Users\\knitwill\\anaconda3\\lib\\site-packages\\tensorflow\\contrib\\learn\\python\\learn\\datasets\\mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use tf.data to implement this functionality.\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nWARNING:tensorflow:From C:\\Users\\knitwill\\anaconda3\\lib\\site-packages\\tensorflow\\contrib\\learn\\python\\learn\\datasets\\mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use tf.one_hot on tensors.\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\nWARNING:tensorflow:From C:\\Users\\knitwill\\anaconda3\\lib\\site-packages\\tensorflow\\contrib\\learn\\python\\learn\\datasets\\mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use alternatives such as official/mnist/dataset.py from tensorflow/models.\n{1} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.92\n{2} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.98\n{3} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.99\n{4} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.94\n{5} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.97\n{6} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n{7} 에폭 훈련데이터 정확도 : 0.96 \t 테스트 데이터 정확도: 0.97\n{8} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.95\n{9} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.96\n{10} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.98\n{11} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.95\n{12} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.96\n{13} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.97\n{14} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.95\n{15} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.94\n{16} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.96\n{17} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n{18} 에폭 훈련데이터 정확도 : 0.97 \t 테스트 데이터 정확도: 0.97\n{19} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n{20} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 1.0\n"
]
],
[
[
"### ※ 문제137. 이번에는 가중치 초기값을 He로 해서 수행하시오",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 은닉1층\nx = tf.placeholder('float',[None,784])\nW1 = tf.get_variable(name=\"W1\", shape=[784,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb1 = tf.Variable(tf.ones([1,50]))\n\ny = tf.matmul(x, W1) + b1\ny_hat = tf.nn.relu(y)\n\n# 출력층\nW2 = tf.get_variable(name=\"W2\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb2 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y_hat,W2) + b2\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\n# 그래프 실행\nsess = tf.Session()\nsess.run(init)\n\nfor i in range(1,601*20):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n batch_x_test, batch_y_test = mnist.test.next_batch(100)\n sess.run(train, feed_dict={x:batch_xs, y_onehot:batch_ys})\n if not i % 600:\n print(i//600,\"에폭 훈련데이터 정확도 : \",sess.run(accuracy, feed_dict={x:batch_xs, y_onehot:batch_ys}),\"\\t\",\"테스트 데이터 정확도:\", sess.run(accuracy, feed_dict={x:batch_x_test, y_onehot:batch_y_test}))",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n{1} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.96\n{2} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 1.0\n{3} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n{4} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.99\n{5} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n{6} 에폭 훈련데이터 정확도 : 0.97 \t 테스트 데이터 정확도: 0.93\n{7} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.98\n{8} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.97\n{9} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.97\n{10} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.98\n{11} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n{12} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n{13} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.95\n{14} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n{15} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n{16} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.96\n{17} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n{18} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n{19} 에폭 훈련데이터 정확도 : 0.97 \t 테스트 데이터 정확도: 0.97\n{20} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.96\n"
]
],
[
[
"### ※ 문제138. 위의 2층 신경망을 3층 신경망으로 변경하시오\n 기존층 : 입력층 -------> 은닉1층 ------> 출력층\n 784 100 10\n 변경후 : 입력층 -------> 은닉1층 ------> 은닉2층 -------> 출력층\n 784 100 50 10",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 은닉1층\nx = tf.placeholder('float',[None,784])\nW1 = tf.get_variable(name=\"W1\", shape=[784,100], initializer = tf.contrib.layers.variance_scaling_initializer())\nb1 = tf.Variable(tf.ones([1,100]))\n\ny = tf.matmul(x, W1) + b1\ny_hat = tf.nn.relu(y)\n\n# 은닉2층\nW2 = tf.get_variable(name=\"W2\", shape=[100,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb2 = tf.Variable(tf.ones([1,50]))\n\ny2 = tf.matmul(y_hat,W2) + b2\ny2_hat = tf.nn.relu(y2)\n\n# 출력층\nW3 = tf.get_variable(name=\"W3\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb3 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y2_hat,W3) + b3\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\n# 그래프 실행\nsess = tf.Session()\nsess.run(init)\n\nfor i in range(1,601*20):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n batch_x_test, batch_y_test = mnist.test.next_batch(100)\n sess.run(train, feed_dict={x:batch_xs, y_onehot:batch_ys})\n if not i % 600:\n print(i//600,\"에폭 훈련데이터 정확도 : \",sess.run(accuracy, feed_dict={x:batch_xs, y_onehot:batch_ys}),\"\\t\",\"테스트 데이터 정확도:\", sess.run(accuracy, feed_dict={x:batch_x_test, y_onehot:batch_y_test}))",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n{1} 에폭 훈련데이터 정확도 : 0.91 \t 테스트 데이터 정확도: 0.95\n{2} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.97\n{3} 에폭 훈련데이터 정확도 : 0.97 \t 테스트 데이터 정확도: 0.98\n{4} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.93\n{5} 에폭 훈련데이터 정확도 : 0.97 \t 테스트 데이터 정확도: 0.97\n{6} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.96\n{7} 에폭 훈련데이터 정확도 : 0.97 \t 테스트 데이터 정확도: 0.96\n{8} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.96\n{9} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.96\n{10} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.97\n{11} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.97\n{12} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n{13} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n{14} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n{15} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.94\n{16} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.93\n{17} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.98\n{18} 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.98\n{19} 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.96\n{20} 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n"
]
],
[
[
"### <b>■ 텐서 플로우로 배치 정규화 구현하는 방법</b>\n 배치 정규화 - 신경망 학습시 가중치 값의 데이터가 골고루 분산될 수 있도록 강제화 하는 장치\n 층이 깊어져도 가중치의 정규분포를 계속 유지할 수 있도록 층마다 강제화 하는 장치\n \n```python\nbatch_z1 = tf.contrib.layers.batch_norm(z1, True)\n```\n Affine1 ------> 배치 정규화 ------> ReLU\n (z1)\n \n#### 예제1. 지금까지 완성한 신경망에 배치 정규화를 은닉 1층에 구현하시오",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 은닉1층\nx = tf.placeholder('float',[None,784])\nW1 = tf.get_variable(name=\"W1\", shape=[784,100], initializer = tf.contrib.layers.variance_scaling_initializer())\nb1 = tf.Variable(tf.ones([1,100]))\n\ny1 = tf.matmul(x, W1) + b1\n\nbatch_y1 = tf.contrib.layers.batch_norm(y1, True)\n\ny1_hat = tf.nn.relu(batch_y1)\n\n# 은닉2층\nW2 = tf.get_variable(name=\"W2\", shape=[100,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb2 = tf.Variable(tf.ones([1,50]))\n\ny2 = tf.matmul(y1_hat,W2) + b2\ny2_hat = tf.nn.relu(y2)\n\n# 출력층\nW3 = tf.get_variable(name=\"W3\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb3 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y2_hat,W3) + b3\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\n# 그래프 실행\nsess = tf.Session()\nsess.run(init)\n\nfor i in range(1,601*20):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n batch_x_test, batch_y_test = mnist.test.next_batch(100)\n sess.run(train, feed_dict={x:batch_xs, y_onehot:batch_ys})\n if not i % 600:\n print(i//600,\"에폭 훈련데이터 정확도 : \",sess.run(accuracy, feed_dict={x:batch_xs, y_onehot:batch_ys}),\"\\t\",\"테스트 데이터 정확도:\", sess.run(accuracy, feed_dict={x:batch_x_test, y_onehot:batch_y_test}))",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n1 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.97\n2 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n3 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.98\n4 에폭 훈련데이터 정확도 : 0.96 \t 테스트 데이터 정확도: 0.98\n5 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n6 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n7 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.94\n8 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.94\n9 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n10 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n11 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.98\n12 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n13 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.93\n14 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n15 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.95\n16 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 1.0\n17 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n18 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n19 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 1.0\n20 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n"
]
],
[
[
"### ※ 문제139. 은닉 2층에도 배치 정규화를 적용하시오",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 은닉1층\nx = tf.placeholder('float',[None,784])\nW1 = tf.get_variable(name=\"W1\", shape=[784,100], initializer = tf.contrib.layers.variance_scaling_initializer())\nb1 = tf.Variable(tf.ones([1,100]))\n\ny1 = tf.matmul(x, W1) + b1\n\nbatch_y1 = tf.contrib.layers.batch_norm(y1, True)\n\ny1_hat = tf.nn.relu(batch_y1)\n\n# 은닉2층\nW2 = tf.get_variable(name=\"W2\", shape=[100,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb2 = tf.Variable(tf.ones([1,50]))\n\ny2 = tf.matmul(y1_hat,W2) + b2\n\nbatch_y2 = tf.contrib.layers.batch_norm(y2, True)\n\ny2_hat = tf.nn.relu(batch_y2)\n\n# 출력층\nW3 = tf.get_variable(name=\"W3\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb3 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y2_hat,W3) + b3\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\n# 그래프 실행\nsess = tf.Session()\nsess.run(init)\n\nfor i in range(1,601*20):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n batch_x_test, batch_y_test = mnist.test.next_batch(100)\n sess.run(train, feed_dict={x:batch_xs, y_onehot:batch_ys})\n if not i % 600:\n print(i//600,\"에폭 훈련데이터 정확도 : \",sess.run(accuracy, feed_dict={x:batch_xs, y_onehot:batch_ys}),\"\\t\",\"테스트 데이터 정확도:\", sess.run(accuracy, feed_dict={x:batch_x_test, y_onehot:batch_y_test}))",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n1 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.99\n2 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 0.96\n3 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.95\n4 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n5 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n6 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n7 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.97\n8 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n9 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.99\n10 에폭 훈련데이터 정확도 : 0.98 \t 테스트 데이터 정확도: 0.97\n11 에폭 훈련데이터 정확도 : 0.99 \t 테스트 데이터 정확도: 1.0\n12 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n13 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n14 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n15 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 1.0\n16 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.98\n17 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n18 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n19 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n20 에폭 훈련데이터 정확도 : 1.0 \t 테스트 데이터 정확도: 0.97\n"
],
[
"\nimport tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 입력층\nx = tf.placeholder('float',[None,784])\nx1 = tf.reshape(x,[-1,28,28,1]) # 흑백사진, 1층, batch 개수를 모르므로 -1. 2차원 -> 4차원으로 변경\n\n# Convolution 1층\nW1 = tf.Variable(tf.random_normal([5,5,1,32], stddev=0.01)) # 필터 32개 생성\nb1 = tf.Variable(tf.ones([32])) # 숫자 1로 채워진 bias 생성\ny1 = tf.nn.conv2d(x1, W1, strides=[1,1,1,1], padding='SAME')\ny1 = y1 + b1\ny1 = tf.nn.relu(y1)\ny1 = tf.nn.max_pool(y1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME') # ksize : 필터 사이즈\ny1 = tf.reshape(y1, [-1,14*14*32]) # y1 4차원 -> 2차원\n\n# 완전연결계층 1층 (2층)\nW2 = tf.get_variable(name=\"W2\", shape=[14*14*32,100], initializer = tf.contrib.layers.variance_scaling_initializer())\nb2 = tf.Variable(tf.ones([1,100]))\n\ny2 = tf.matmul(y1, W2) + b2\n\nbatch_y2 = tf.contrib.layers.batch_norm(y2, True)\n\ny2_hat = tf.nn.relu(batch_y2)\n\n# 완전연결계층 2층 (3층)\nW3 = tf.get_variable(name=\"W3\", shape=[100,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb3 = tf.Variable(tf.ones([1,50]))\n\ny3 = tf.matmul(y2_hat, W3) + b3\n\nbatch_y3 = tf.contrib.layers.batch_norm(y3, True)\n\ny3_hat = tf.nn.relu(batch_y3)\n\n# 출력층 (4층)\nW4 = tf.get_variable(name=\"W4\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb4 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y3_hat,W4) + b4\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\n# 그래프 실행\nsess = tf.Session()\nsess.run(init)\n\nfor i in range(1,601*20):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n batch_x_test, batch_y_test = mnist.test.next_batch(100)\n sess.run(train, feed_dict={x:batch_xs, y_onehot:batch_ys})\n if not i % 600:\n print(i//600,\"에폭 훈련데이터 정확도 : \",sess.run(accuracy, feed_dict={x:batch_xs, y_onehot:batch_ys}),\"\\t\",\"테스트 데이터 정확도:\", sess.run(accuracy, feed_dict={x:batch_x_test, y_onehot:batch_y_test}))\n",
"_____no_output_____"
]
],
[
[
"### <b>■ 텐서 플로우로 dropout 적용하는 방법</b>\n 드롭아웃(dropout) 사용해야하는 이유 - 오버피팅 방지\n 구현 예시\n```python \nkeep_prob = tf.placeholder('float')\n 0.8 -> 전체 뉴런 중 80%만 남기고 20% 랜덤으로 삭제\n 1.0 -> 모든 뉴런을 그대로 남겨둔다\ny3_drop = tf.nn.dropout(y3, keep_prob)\n```\n 훈련할 때는 뉴런을 삭제하고 테스트 할 때는 뉴런을 삭제하지 않으려고 keep_prob로 남겨둠",
"_____no_output_____"
]
],
[
[
"\nimport tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 입력층\nx = tf.placeholder('float',[None,784])\nx1 = tf.reshape(x,[-1,28,28,1]) # 흑백사진, 1층, batch 개수를 모르므로 -1. 2차원 -> 4차원으로 변경\n\n# Convolution 1층\nW1 = tf.Variable(tf.random_normal([5,5,1,32], stddev=0.01)) # 필터 32개 생성\nb1 = tf.Variable(tf.ones([32])) # 숫자 1로 채워진 bias 생성\ny1 = tf.nn.conv2d(x1, W1, strides=[1,1,1,1], padding='SAME')\ny1 = y1 + b1\ny1 = tf.nn.relu(y1)\ny1 = tf.nn.max_pool(y1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME') # ksize : 필터 사이즈\ny1 = tf.reshape(y1, [-1,14*14*32]) # y1 4차원 -> 2차원\n\n# 완전연결계층 1층 (2층)\nW2 = tf.get_variable(name=\"W2\", shape=[14*14*32,100], initializer = tf.contrib.layers.variance_scaling_initializer())\nb2 = tf.Variable(tf.ones([1,100]))\n\ny2 = tf.matmul(y1, W2) + b2\n\nbatch_y2 = tf.contrib.layers.batch_norm(y2, True)\n\ny2_hat = tf.nn.relu(batch_y2)\n\n# drop out\nkeep_prob = tf.placeholder('float')\ny2_hat_drop = tf.nn.dropout(y2_hat, keep_prob)\n\n# 완전연결계층 2층 (3층)\nW3 = tf.get_variable(name=\"W3\", shape=[100,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb3 = tf.Variable(tf.ones([1,50]))\n\ny3 = tf.matmul(y2_hat_drop, W3) + b3\n\nbatch_y3 = tf.contrib.layers.batch_norm(y3, True)\n\ny3_hat = tf.nn.relu(batch_y3)\n\n# 출력층 (4층)\nW4 = tf.get_variable(name=\"W4\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb4 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y3_hat,W4) + b4\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\n# 그래프 실행\nsess = tf.Session()\nsess.run(init)\n\nfor i in range(1,601*20):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n batch_x_test, batch_y_test = mnist.test.next_batch(100)\n sess.run(train, feed_dict={x:batch_xs, y_onehot:batch_ys})\n if not i % 600:\n print(i//600,\"에폭 훈련데이터 정확도 : \",sess.run(accuracy, feed_dict={x:batch_xs, y_onehot:batch_ys}),\"\\t\",\"테스트 데이터 정확도:\", sess.run(accuracy, feed_dict={x:batch_x_test, y_onehot:batch_y_test}))\n",
"_____no_output_____"
],
[
"\nimport tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 입력층\nx = tf.placeholder('float',[None,784])\nx1 = tf.reshape(x,[-1,28,28,1]) # 흑백사진, 1층, batch 개수를 모르므로 -1. 2차원 -> 4차원으로 변경\n\n# Convolution 1층\nW1 = tf.Variable(tf.random_normal([5,5,1,32], stddev=0.01)) # 필터 32개 생성\nb1 = tf.Variable(tf.ones([32])) # 숫자 1로 채워진 bias 생성\ny1 = tf.nn.conv2d(x1, W1, strides=[1,1,1,1], padding='SAME')\ny1 = y1 + b1\ny1 = tf.nn.relu(y1)\ny1 = tf.nn.max_pool(y1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME') # ksize : 필터 사이즈\ny1 = tf.reshape(y1, [-1,14*14*32]) # y1 4차원 -> 2차원\n\n# 완전연결계층 1층 (2층)\nW2 = tf.get_variable(name=\"W2\", shape=[14*14*32,100], initializer = tf.contrib.layers.variance_scaling_initializer())\nb2 = tf.Variable(tf.ones([1,100]))\n\ny2 = tf.matmul(y1, W2) + b2\n\nbatch_y2 = tf.contrib.layers.batch_norm(y2, True)\n\ny2_hat = tf.nn.relu(batch_y2)\n\n# drop out\nkeep_prob = tf.placeholder('float')\ny2_hat_drop = tf.nn.dropout(y2_hat, keep_prob)\n\n# 완전연결계층 2층 (3층)\nW3 = tf.get_variable(name=\"W3\", shape=[100,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb3 = tf.Variable(tf.ones([1,50]))\n\ny3 = tf.matmul(y2_hat_drop, W3) + b3\n\nbatch_y3 = tf.contrib.layers.batch_norm(y3, True)\n\ny3_hat = tf.nn.relu(batch_y3)\n\n# 출력층 (4층)\nW4 = tf.get_variable(name=\"W4\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb4 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y3_hat,W4) + b4\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\ntrain_acc_list = []\ntest_acc_list = []\n\n# 그래프 실행\nwith tf.Session() as sess:\n sess.run(init)\n for j in range(20):\n for i in range(600):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n test_xs, test_ys = mnist.test.next_batch(100)\n\n sess.run(train, feed_dict={x: batch_xs, y_onehot: batch_ys, keep_prob: 0.9})\n \n if i == 0: # 1에폭마다 정확도 확인\n train_acc = sess.run(accuracy, feed_dict={x: batch_xs, y_onehot: batch_ys, keep_prob: 1.0}) # 훈련 데이터의 정확도 \n test_acc = sess.run(accuracy, feed_dict={x: test_xs, y_onehot: test_ys, keep_prob: 1.0}) # 테스트 데이터의 정확도\n\n # 그래프용 리스트에 정확도 담기\n train_acc_list.append(train_acc) \n test_acc_list.append(test_acc)\n\n print('훈련', str(j + 1) + '에폭 정확도 :', train_acc)\n print('테스트', str(j + 1) + '에폭 정확도 :', test_acc)\n print('-----------------------------------------------')",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\nWARNING:tensorflow:From <ipython-input-15-159da87ef0a0>:38: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.\n훈련 1에폭 정확도 : 0.65\n테스트 1에폭 정확도 : 0.46\n-----------------------------------------------\n훈련 2에폭 정확도 : 0.99\n테스트 2에폭 정확도 : 0.98\n-----------------------------------------------\n훈련 3에폭 정확도 : 0.98\n테스트 3에폭 정확도 : 0.99\n-----------------------------------------------\n훈련 4에폭 정확도 : 1.0\n테스트 4에폭 정확도 : 0.98\n-----------------------------------------------\n훈련 5에폭 정확도 : 0.99\n테스트 5에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 6에폭 정확도 : 0.98\n테스트 6에폭 정확도 : 0.98\n-----------------------------------------------\n훈련 7에폭 정확도 : 1.0\n테스트 7에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 8에폭 정확도 : 0.99\n테스트 8에폭 정확도 : 0.98\n-----------------------------------------------\n훈련 9에폭 정확도 : 1.0\n테스트 9에폭 정확도 : 0.98\n-----------------------------------------------\n훈련 10에폭 정확도 : 1.0\n테스트 10에폭 정확도 : 1.0\n-----------------------------------------------\n"
]
],
[
[
"### <b>■ 훈련과 테스트 데이터의 정확도가 시각화 될 수 있도록 코드를 추가 </b>",
"_____no_output_____"
]
],
[
[
"\nimport tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 입력층\nx = tf.placeholder('float',[None,784])\nx1 = tf.reshape(x,[-1,28,28,1]) # 흑백사진, 1층, batch 개수를 모르므로 -1. 2차원 -> 4차원으로 변경\n\n# Convolution 1층\nW1 = tf.Variable(tf.random_normal([5,5,1,32], stddev=0.01)) # 필터 32개 생성\nb1 = tf.Variable(tf.ones([32])) # 숫자 1로 채워진 bias 생성\ny1 = tf.nn.conv2d(x1, W1, strides=[1,1,1,1], padding='SAME')\ny1 = y1 + b1\ny1 = tf.nn.relu(y1)\ny1 = tf.nn.max_pool(y1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME') # ksize : 필터 사이즈\ny1 = tf.reshape(y1, [-1,14*14*32]) # y1 4차원 -> 2차원\n\n# 완전연결계층 1층 (2층)\nW2 = tf.get_variable(name=\"W2\", shape=[14*14*32,100], initializer = tf.contrib.layers.variance_scaling_initializer())\nb2 = tf.Variable(tf.ones([1,100]))\n\ny2 = tf.matmul(y1, W2) + b2\n\nbatch_y2 = tf.contrib.layers.batch_norm(y2, True)\n\ny2_hat = tf.nn.relu(batch_y2)\n\n# drop out\nkeep_prob = tf.placeholder('float')\ny2_hat_drop = tf.nn.dropout(y2_hat, keep_prob)\n\n# 완전연결계층 2층 (3층)\nW3 = tf.get_variable(name=\"W3\", shape=[100,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb3 = tf.Variable(tf.ones([1,50]))\n\ny3 = tf.matmul(y2_hat_drop, W3) + b3\n\nbatch_y3 = tf.contrib.layers.batch_norm(y3, True)\n\ny3_hat = tf.nn.relu(batch_y3)\n\n# 출력층 (4층)\nW4 = tf.get_variable(name=\"W4\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb4 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y3_hat,W4) + b4\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\ntrain_acc_list = []\ntest_acc_list = []\n\n# 그래프 실행\nwith tf.Session() as sess:\n sess.run(init)\n for j in range(10):\n for i in range(600):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n test_xs, test_ys = mnist.test.next_batch(100)\n\n sess.run(train, feed_dict={x: batch_xs, y_onehot: batch_ys, keep_prob: 0.9})\n \n if i == 0: # 1에폭마다 정확도 확인\n train_acc = sess.run(accuracy, feed_dict={x: batch_xs, y_onehot: batch_ys, keep_prob: 1.0}) # 훈련 데이터의 정확도 \n test_acc = sess.run(accuracy, feed_dict={x: test_xs, y_onehot: test_ys, keep_prob: 1.0}) # 테스트 데이터의 정확도\n\n # 그래프용 리스트에 정확도 담기\n train_acc_list.append(train_acc) \n test_acc_list.append(test_acc)\n\n print('훈련', str(j + 1) + '에폭 정확도 :', train_acc)\n print('테스트', str(j + 1) + '에폭 정확도 :', test_acc)\n print('-----------------------------------------------')\n \n# 그래프 작성\nimport matplotlib.pyplot as plt\nplt.rcParams['figure.figsize'] = (20,10)\nplt.rcParams.update({'font.size':20})\n\nmarkers = {'train': 'o', 'test': 's'}\nx = np.arange(len(train_acc_list))\n\nplt.plot()\nplt.plot(x, train_acc_list, label='train acc')\nplt.plot(x, test_acc_list, label='test acc', linestyle='--')\nplt.xlabel(\"epochs\")\nplt.ylabel(\"accuracy\")\nplt.ylim(min(min(train_acc_list),min(test_acc_list))-0.1, 1.005)\nplt.legend(loc='lower right')\nplt.show()\n",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n훈련 1에폭 정확도 : 0.65\n테스트 1에폭 정확도 : 0.42\n-----------------------------------------------\n훈련 2에폭 정확도 : 0.99\n테스트 2에폭 정확도 : 0.99\n-----------------------------------------------\n훈련 3에폭 정확도 : 1.0\n테스트 3에폭 정확도 : 0.99\n-----------------------------------------------\n훈련 4에폭 정확도 : 1.0\n테스트 4에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 5에폭 정확도 : 1.0\n테스트 5에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 6에폭 정확도 : 1.0\n테스트 6에폭 정확도 : 0.99\n-----------------------------------------------\n훈련 7에폭 정확도 : 0.99\n테스트 7에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 8에폭 정확도 : 0.98\n테스트 8에폭 정확도 : 0.99\n-----------------------------------------------\n훈련 9에폭 정확도 : 1.0\n테스트 9에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 10에폭 정확도 : 1.0\n테스트 10에폭 정확도 : 0.99\n-----------------------------------------------\n"
]
],
[
[
"### ※ 문제140. 위의 CNN 신경망을 아래와 같이 구현하시오\n 변경 전 : 입력층 ----> Conv1 ----> pooling ----> FC1층 ----> FC2층 ----> 출력층\n 784 32 100 50 10\n 변경 후 : 입력층 ----> Conv1 ----> pooling ----> Conv2 ----> pooling ----> FC1층 ----> FC2층 ----> 출력층\n 784 32 64 100 50 10",
"_____no_output_____"
]
],
[
[
"\nimport tensorflow as tf\nimport numpy as np\nimport warnings\nimport os\nfrom tensorflow.examples.tutorials.mnist import input_data\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nwarnings.filterwarnings('ignore')\n\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\n\ntf.reset_default_graph() # 텐서 그래프 초기화 하는 코드\n\n# 입력층\nx = tf.placeholder('float',[None,784])\nx1 = tf.reshape(x,[-1,28,28,1]) # 흑백사진, 1층, batch 개수를 모르므로 -1. 2차원 -> 4차원으로 변경\n\n# Convolution 1층\nW1 = tf.Variable(tf.random_normal([5,5,1,32], stddev=0.01)) # 필터 32개 생성\nb1 = tf.Variable(tf.ones([32])) # 숫자 1로 채워진 bias 생성\ny1 = tf.nn.conv2d(x1, W1, strides=[1,1,1,1], padding='SAME') + b1\ny1 = tf.nn.relu(y1)\ny1 = tf.nn.max_pool(y1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME') # ksize : 필터 사이즈\n# y1 = tf.reshape(y1, [-1,14*14*32]) # y1 4차원 -> 2차원\n\n# Convolution 2층\nW2 = tf.Variable(tf.random_normal([5,5,32,64], stddev=0.01)) \nb2 = tf.Variable(tf.ones([64])) # 숫자 1로 채워진 bias 생성\ny2 = tf.nn.conv2d(y1, W2, strides=[1,1,1,1], padding='SAME') + b2\ny2 = tf.nn.relu(y2)\ny2 = tf.nn.max_pool(y2, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME') \ny2 = tf.reshape(y2, [-1,7*7*64]) # y1 4차원 -> 2차원\n\n# 완전연결계층 1층 (2층)\nW3 = tf.get_variable(name=\"W3\", shape=[7*7*64,100], initializer = tf.contrib.layers.variance_scaling_initializer())\nb3 = tf.Variable(tf.ones([1,100]))\n\ny3 = tf.matmul(y2, W3) + b3\n\nbatch_y2 = tf.contrib.layers.batch_norm(y3, True)\n\ny2_hat = tf.nn.relu(batch_y2)\n\n# drop out\nkeep_prob = tf.placeholder('float')\ny2_hat_drop = tf.nn.dropout(y2_hat, keep_prob)\n\n# 완전연결계층 2층 (3층)\nW4 = tf.get_variable(name=\"W4\", shape=[100,50], initializer = tf.contrib.layers.variance_scaling_initializer())\nb4 = tf.Variable(tf.ones([1,50]))\n\ny4 = tf.matmul(y2_hat_drop, W4) + b4\n\nbatch_y3 = tf.contrib.layers.batch_norm(y4, True)\n\ny3_hat = tf.nn.relu(batch_y3)\n\n# 출력층 (4층)\nW5 = tf.get_variable(name=\"W5\", shape=[50,10], initializer = tf.contrib.layers.variance_scaling_initializer())\nb5 = tf.Variable(tf.ones([1,10]))\n\nz = tf.matmul(y3_hat,W5) + b5\nz_hat = tf.nn.softmax(z)\ny_predict = tf.argmax(z_hat, axis=1)\n\n# 정확도 확인\ny_onehot = tf.placeholder('float',[None,10]) # 정답 데이터를 담을 배열\ny_label = tf.argmax(y_onehot, axis=1)\n\ncorrection_prediction = tf.equal(y_predict, y_label)\naccuracy = tf.reduce_mean(tf.cast(correction_prediction,'float'))\n\n# 오차 확인\nloss = -tf.reduce_sum(y_onehot * tf.log(z_hat+0.0000001), axis=1)\nrs = tf.reduce_mean(loss)\n\n# 학습\noptimizer = tf.train.AdamOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(loss)\n\n# 변수 초기화\ninit = tf.global_variables_initializer()\n\ntrain_acc_list = []\ntest_acc_list = []\n\n# 그래프 실행\nwith tf.Session() as sess:\n sess.run(init)\n for j in range(10):\n for i in range(600):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n test_xs, test_ys = mnist.test.next_batch(100)\n\n sess.run(train, feed_dict={x: batch_xs, y_onehot: batch_ys, keep_prob: 0.9})\n \n if i == 0: # 1에폭마다 정확도 확인\n train_acc = sess.run(accuracy, feed_dict={x: batch_xs, y_onehot: batch_ys, keep_prob: 1.0}) # 훈련 데이터의 정확도 \n test_acc = sess.run(accuracy, feed_dict={x: test_xs, y_onehot: test_ys, keep_prob: 1.0}) # 테스트 데이터의 정확도\n\n # 그래프용 리스트에 정확도 담기\n train_acc_list.append(train_acc) \n test_acc_list.append(test_acc)\n\n print('훈련', str(j + 1) + '에폭 정확도 :', train_acc)\n print('테스트', str(j + 1) + '에폭 정확도 :', test_acc)\n print('-----------------------------------------------')\n \n# # 그래프 작성\n# import matplotlib.pyplot as plt\n# plt.rcParams['figure.figsize'] = (20,10)\n# plt.rcParams.update({'font.size':20})\n\n# markers = {'train': 'o', 'test': 's'}\n# x = np.arange(len(train_acc_list))\n\n# plt.plot()\n# plt.plot(x, train_acc_list, label='train acc')\n# plt.plot(x, test_acc_list, label='test acc', linestyle='--')\n# plt.xlabel(\"epochs\")\n# plt.ylabel(\"accuracy\")\n# plt.ylim(min(min(train_acc_list),min(test_acc_list))-0.1, 1.005)\n# plt.legend(loc='lower right')\n# plt.show()\n",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n훈련 1에폭 정확도 : 0.5\n테스트 1에폭 정확도 : 0.21\n-----------------------------------------------\n훈련 2에폭 정확도 : 1.0\n테스트 2에폭 정확도 : 0.98\n-----------------------------------------------\n훈련 3에폭 정확도 : 0.99\n테스트 3에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 4에폭 정확도 : 0.99\n테스트 4에폭 정확도 : 0.98\n-----------------------------------------------\n훈련 5에폭 정확도 : 0.99\n테스트 5에폭 정확도 : 0.98\n-----------------------------------------------\n훈련 6에폭 정확도 : 0.99\n테스트 6에폭 정확도 : 0.97\n-----------------------------------------------\n훈련 7에폭 정확도 : 0.99\n테스트 7에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 8에폭 정확도 : 1.0\n테스트 8에폭 정확도 : 0.99\n-----------------------------------------------\n훈련 9에폭 정확도 : 1.0\n테스트 9에폭 정확도 : 1.0\n-----------------------------------------------\n훈련 10에폭 정확도 : 1.0\n테스트 10에폭 정확도 : 0.98\n-----------------------------------------------\n"
]
],
[
[
"### <b>■ cifar10 데이터를 이용한 신경망 구성</b>\n cifar10은 총 6만 개의 데이터 셋으로 이루어져 있으며 그 중 5만 개가 훈련데이터, 1만 개가 테스트 데이터\n class는 비행기부터 트럭까지 총 10개\n 1. 비행기\n 2. 자동차\n 3. 새\n 4. 고양이\n 5. 사슴\n 6. 강아지\n 7. 개구리\n 8. 말\n 9. 배\n 10. 트럭\n### <b>■ 신경망 구현 홈페이지를 만들려면 필요한 코드</b>\n 1. 사진 데이터를 신경망에 로드하는 코드들\n 2. 사진 이미지를 분류하는 신경망 코드 --> 구글\n 3. 홈페이지 구축하는 코드(RShiny)\n \n### <b>■ 1. 사진 데이터를 신경망에 로드하는 코드들</b>\n#### 예제1. 사진을 불러와서 아래와 같이 이미지 이름을 출력하는 함수를 생성",
"_____no_output_____"
]
],
[
[
"import os\n\n\ndef image_load(path):\n file_list = os.listdir(path)\n return file_list\n\n\ntrain_image = 'd:/tensor/cifar10/train100/'\nprint(image_load(train_image))",
"['1.png', '10.png', '100.png', '11.png', '12.png', '13.png', '14.png', '15.png', '16.png', '17.png', '18.png', '19.png', '2.png', '20.png', '21.png', '22.png', '23.png', '24.png', '25.png', '26.png', '27.png', '28.png', '29.png', '3.png', '30.png', '31.png', '32.png', '33.png', '34.png', '35.png', '36.png', '37.png', '38.png', '39.png', '4.png', '40.png', '41.png', '42.png', '43.png', '44.png', '45.png', '46.png', '47.png', '48.png', '49.png', '5.png', '50.png', '51.png', '52.png', '53.png', '54.png', '55.png', '56.png', '57.png', '58.png', '59.png', '6.png', '60.png', '61.png', '62.png', '63.png', '64.png', '65.png', '66.png', '67.png', '68.png', '69.png', '7.png', '70.png', '71.png', '72.png', '73.png', '74.png', '75.png', '76.png', '77.png', '78.png', '79.png', '8.png', '80.png', '81.png', '82.png', '83.png', '84.png', '85.png', '86.png', '87.png', '88.png', '89.png', '9.png', '90.png', '91.png', '92.png', '93.png', '94.png', '95.png', '96.png', '97.png', '98.png', '99.png']\n"
]
],
[
[
"#### 예제2. 위의 결과에서 .png는 빼고 숫자만 출력되게 하시오",
"_____no_output_____"
]
],
[
[
"import os\nimport re\n\ndef image_load(path):\n file_list = os.listdir(path)\n file_name = []\n for i in file_list:\n name = re.sub('[^0-9]','',i)\n file_name.append(name)\n \n return file_name\n\ntrain_image = 'd:/tensor/cifar10/train100/'\nprint(image_load(train_image))",
"['1', '10', '100', '11', '12', '13', '14', '15', '16', '17', '18', '19', '2', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '3', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '4', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '5', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '6', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '7', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '8', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '9', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99']\n"
]
],
[
[
"#### 예제3. 위의 결과를 정렬해서 출력하시오",
"_____no_output_____"
]
],
[
[
"import os\nimport re\n\n\ndef image_load(path):\n file_list = os.listdir(path)\n file_name = []\n for i in file_list:\n file_name.append(int(re.sub('[^0-9]', '', i)))\n\n file_name.sort()\n\n return file_name\n\n\ntrain_image = 'd:/tensor/cifar10/train100/'\nprint(image_load(train_image))",
"[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100]\n"
]
],
[
[
"#### 예제4. 위의 출력된 결과에서 다시 .png를 붙여서 아래와 같이 출력되게 하시오",
"_____no_output_____"
]
],
[
[
"import os\nimport re\n\n\ndef image_load(path):\n file_list = os.listdir(path)\n\n file_name = []\n for i in file_list:\n file_name.append(int(re.sub('[^0-9]', '', i)))\n\n file_name.sort()\n\n file_res = []\n for i in file_name:\n file_res.append(str(i)+'.png')\n\n return file_res\n\n\ntrain_image = 'd:/tensor/cifar10/train100/'\nprint(image_load(train_image))",
"['1.png', '2.png', '3.png', '4.png', '5.png', '6.png', '7.png', '8.png', '9.png', '10.png', '11.png', '12.png', '13.png', '14.png', '15.png', '16.png', '17.png', '18.png', '19.png', '20.png', '21.png', '22.png', '23.png', '24.png', '25.png', '26.png', '27.png', '28.png', '29.png', '30.png', '31.png', '32.png', '33.png', '34.png', '35.png', '36.png', '37.png', '38.png', '39.png', '40.png', '41.png', '42.png', '43.png', '44.png', '45.png', '46.png', '47.png', '48.png', '49.png', '50.png', '51.png', '52.png', '53.png', '54.png', '55.png', '56.png', '57.png', '58.png', '59.png', '60.png', '61.png', '62.png', '63.png', '64.png', '65.png', '66.png', '67.png', '68.png', '69.png', '70.png', '71.png', '72.png', '73.png', '74.png', '75.png', '76.png', '77.png', '78.png', '79.png', '80.png', '81.png', '82.png', '83.png', '84.png', '85.png', '86.png', '87.png', '88.png', '89.png', '90.png', '91.png', '92.png', '93.png', '94.png', '95.png', '96.png', '97.png', '98.png', '99.png', '100.png']\n"
]
],
[
[
"#### 예제5. 이미지 이름 앞에 절대 경로가 아래처럼 붙게 하시오\n ['d:/tensor/cifar10/train100/1.png','d:/tensor/cifar10/train100/2.png',...,'d:/tensor/cifar10/train100/100.png']",
"_____no_output_____"
]
],
[
[
"import os\nimport re\n\n\ndef image_load(path):\n file_list = os.listdir(path)\n\n file_name = []\n for i in file_list:\n file_name.append(int(re.sub('[^0-9]', '', i)))\n\n file_name.sort()\n\n file_res = []\n for i in file_name:\n file_res.append(path+str(i)+'.png')\n\n return file_res\n\n\ntrain_image = 'd:/tensor/cifar10/train100/'\nprint(image_load(train_image))",
"['d:/tensor/cifar10/train100/1.png', 'd:/tensor/cifar10/train100/2.png', 'd:/tensor/cifar10/train100/3.png', 'd:/tensor/cifar10/train100/4.png', 'd:/tensor/cifar10/train100/5.png', 'd:/tensor/cifar10/train100/6.png', 'd:/tensor/cifar10/train100/7.png', 'd:/tensor/cifar10/train100/8.png', 'd:/tensor/cifar10/train100/9.png', 'd:/tensor/cifar10/train100/10.png', 'd:/tensor/cifar10/train100/11.png', 'd:/tensor/cifar10/train100/12.png', 'd:/tensor/cifar10/train100/13.png', 'd:/tensor/cifar10/train100/14.png', 'd:/tensor/cifar10/train100/15.png', 'd:/tensor/cifar10/train100/16.png', 'd:/tensor/cifar10/train100/17.png', 'd:/tensor/cifar10/train100/18.png', 'd:/tensor/cifar10/train100/19.png', 'd:/tensor/cifar10/train100/20.png', 'd:/tensor/cifar10/train100/21.png', 'd:/tensor/cifar10/train100/22.png', 'd:/tensor/cifar10/train100/23.png', 'd:/tensor/cifar10/train100/24.png', 'd:/tensor/cifar10/train100/25.png', 'd:/tensor/cifar10/train100/26.png', 'd:/tensor/cifar10/train100/27.png', 'd:/tensor/cifar10/train100/28.png', 'd:/tensor/cifar10/train100/29.png', 'd:/tensor/cifar10/train100/30.png', 'd:/tensor/cifar10/train100/31.png', 'd:/tensor/cifar10/train100/32.png', 'd:/tensor/cifar10/train100/33.png', 'd:/tensor/cifar10/train100/34.png', 'd:/tensor/cifar10/train100/35.png', 'd:/tensor/cifar10/train100/36.png', 'd:/tensor/cifar10/train100/37.png', 'd:/tensor/cifar10/train100/38.png', 'd:/tensor/cifar10/train100/39.png', 'd:/tensor/cifar10/train100/40.png', 'd:/tensor/cifar10/train100/41.png', 'd:/tensor/cifar10/train100/42.png', 'd:/tensor/cifar10/train100/43.png', 'd:/tensor/cifar10/train100/44.png', 'd:/tensor/cifar10/train100/45.png', 'd:/tensor/cifar10/train100/46.png', 'd:/tensor/cifar10/train100/47.png', 'd:/tensor/cifar10/train100/48.png', 'd:/tensor/cifar10/train100/49.png', 'd:/tensor/cifar10/train100/50.png', 'd:/tensor/cifar10/train100/51.png', 'd:/tensor/cifar10/train100/52.png', 'd:/tensor/cifar10/train100/53.png', 'd:/tensor/cifar10/train100/54.png', 'd:/tensor/cifar10/train100/55.png', 'd:/tensor/cifar10/train100/56.png', 'd:/tensor/cifar10/train100/57.png', 'd:/tensor/cifar10/train100/58.png', 'd:/tensor/cifar10/train100/59.png', 'd:/tensor/cifar10/train100/60.png', 'd:/tensor/cifar10/train100/61.png', 'd:/tensor/cifar10/train100/62.png', 'd:/tensor/cifar10/train100/63.png', 'd:/tensor/cifar10/train100/64.png', 'd:/tensor/cifar10/train100/65.png', 'd:/tensor/cifar10/train100/66.png', 'd:/tensor/cifar10/train100/67.png', 'd:/tensor/cifar10/train100/68.png', 'd:/tensor/cifar10/train100/69.png', 'd:/tensor/cifar10/train100/70.png', 'd:/tensor/cifar10/train100/71.png', 'd:/tensor/cifar10/train100/72.png', 'd:/tensor/cifar10/train100/73.png', 'd:/tensor/cifar10/train100/74.png', 'd:/tensor/cifar10/train100/75.png', 'd:/tensor/cifar10/train100/76.png', 'd:/tensor/cifar10/train100/77.png', 'd:/tensor/cifar10/train100/78.png', 'd:/tensor/cifar10/train100/79.png', 'd:/tensor/cifar10/train100/80.png', 'd:/tensor/cifar10/train100/81.png', 'd:/tensor/cifar10/train100/82.png', 'd:/tensor/cifar10/train100/83.png', 'd:/tensor/cifar10/train100/84.png', 'd:/tensor/cifar10/train100/85.png', 'd:/tensor/cifar10/train100/86.png', 'd:/tensor/cifar10/train100/87.png', 'd:/tensor/cifar10/train100/88.png', 'd:/tensor/cifar10/train100/89.png', 'd:/tensor/cifar10/train100/90.png', 'd:/tensor/cifar10/train100/91.png', 'd:/tensor/cifar10/train100/92.png', 'd:/tensor/cifar10/train100/93.png', 'd:/tensor/cifar10/train100/94.png', 'd:/tensor/cifar10/train100/95.png', 'd:/tensor/cifar10/train100/96.png', 'd:/tensor/cifar10/train100/97.png', 'd:/tensor/cifar10/train100/98.png', 'd:/tensor/cifar10/train100/99.png', 'd:/tensor/cifar10/train100/100.png']\n"
]
],
[
[
"#### 예제6. cv2.imread 함수를 이용해서 이미지를 숫자로 변경하시오",
"_____no_output_____"
]
],
[
[
"import os\nimport re\nimport numpy as np\nimport cv2\n\ndef image_load(path):\n file_list = os.listdir(path)\n\n file_name = []\n for i in file_list:\n file_name.append(int(re.sub('[^0-9]', '', i)))\n\n file_name.sort()\n\n file_res = []\n for j in file_name:\n file_res.append(path+str(j)+'.png')\n \n image = []\n for k in file_res:\n image.append(cv2.imread(k))\n\n return np.array(image)\n\n\ntrain_image = 'd:/tensor/cifar10/train100/'\nprint(image_load(train_image))",
"[[[[ 63 62 59]\n [ 45 46 43]\n [ 43 48 50]\n ...\n [108 132 158]\n [102 125 152]\n [103 124 148]]\n\n [[ 20 20 16]\n [ 0 0 0]\n [ 0 8 18]\n ...\n [ 55 88 123]\n [ 50 83 119]\n [ 57 87 122]]\n\n [[ 21 24 25]\n [ 0 7 16]\n [ 8 27 49]\n ...\n [ 50 84 118]\n [ 50 84 120]\n [ 42 73 109]]\n\n ...\n\n [[ 96 170 208]\n [ 34 153 201]\n [ 26 161 198]\n ...\n [ 70 133 160]\n [ 7 31 56]\n [ 20 34 53]]\n\n [[ 96 139 180]\n [ 42 123 173]\n [ 30 144 186]\n ...\n [ 94 148 184]\n [ 34 62 97]\n [ 34 53 83]]\n\n [[116 144 177]\n [ 94 129 168]\n [ 87 142 179]\n ...\n [140 184 216]\n [ 84 118 151]\n [ 72 92 123]]]\n\n\n [[[187 177 154]\n [136 137 126]\n [ 95 104 105]\n ...\n [ 71 95 91]\n [ 71 90 87]\n [ 70 81 79]]\n\n [[169 160 140]\n [154 153 145]\n [118 125 125]\n ...\n [ 78 99 96]\n [ 62 80 77]\n [ 61 73 71]]\n\n [[164 155 140]\n [149 146 139]\n [112 115 115]\n ...\n [ 64 82 79]\n [ 55 70 68]\n [ 55 69 67]]\n\n ...\n\n [[166 167 175]\n [160 154 156]\n [170 160 154]\n ...\n [ 36 34 42]\n [ 57 53 61]\n [ 91 83 93]]\n\n [[128 154 165]\n [130 152 156]\n [142 161 159]\n ...\n [ 96 93 103]\n [120 114 123]\n [131 121 131]]\n\n [[120 148 163]\n [122 148 158]\n [133 156 163]\n ...\n [139 133 143]\n [142 134 143]\n [144 133 143]]]\n\n\n [[[255 255 255]\n [253 253 253]\n [253 253 253]\n ...\n [253 253 253]\n [253 253 253]\n [253 253 253]]\n\n [[255 255 255]\n [255 255 255]\n [255 255 255]\n ...\n [255 255 255]\n [255 255 255]\n [255 255 255]]\n\n [[255 255 255]\n [254 254 254]\n [254 254 254]\n ...\n [254 254 254]\n [254 254 254]\n [254 254 254]]\n\n ...\n\n [[112 120 113]\n [111 118 111]\n [106 112 105]\n ...\n [ 80 81 72]\n [ 79 80 72]\n [ 79 80 72]]\n\n [[110 118 111]\n [104 111 104]\n [ 98 106 99]\n ...\n [ 73 75 68]\n [ 75 76 70]\n [ 82 84 78]]\n\n [[105 113 106]\n [ 98 106 99]\n [ 94 102 95]\n ...\n [ 83 85 78]\n [ 83 85 79]\n [ 84 86 80]]]\n\n\n ...\n\n\n [[[ 27 44 33]\n [ 31 44 29]\n [ 34 45 32]\n ...\n [221 197 157]\n [216 199 162]\n [213 194 160]]\n\n [[ 24 40 25]\n [ 27 40 24]\n [ 29 36 23]\n ...\n [227 209 174]\n [217 199 167]\n [220 198 165]]\n\n [[ 47 56 55]\n [ 46 56 47]\n [ 52 61 53]\n ...\n [165 162 129]\n [133 137 110]\n [154 153 123]]\n\n ...\n\n [[ 60 97 106]\n [ 58 91 103]\n [ 53 100 85]\n ...\n [ 52 91 78]\n [ 36 64 54]\n [ 31 56 44]]\n\n [[ 59 91 97]\n [ 57 97 92]\n [ 61 108 88]\n ...\n [ 59 107 96]\n [ 47 94 81]\n [ 41 88 71]]\n\n [[ 91 119 106]\n [115 141 128]\n [137 158 142]\n ...\n [ 63 108 100]\n [ 47 94 81]\n [ 40 90 71]]]\n\n\n [[[ 59 77 90]\n [ 64 81 94]\n [ 65 81 87]\n ...\n [ 35 44 46]\n [ 38 45 53]\n [ 38 46 57]]\n\n [[ 68 92 96]\n [ 63 84 101]\n [ 66 80 95]\n ...\n [ 44 51 60]\n [ 50 60 72]\n [ 45 56 71]]\n\n [[ 66 87 85]\n [ 75 102 113]\n [ 76 101 115]\n ...\n [ 57 84 90]\n [ 60 87 96]\n [ 55 79 91]]\n\n ...\n\n [[ 88 105 102]\n [ 47 69 61]\n [ 53 74 69]\n ...\n [ 95 142 157]\n [ 94 137 152]\n [ 95 152 169]]\n\n [[ 69 96 101]\n [ 52 66 69]\n [ 53 68 64]\n ...\n [100 125 131]\n [ 91 117 123]\n [ 79 109 115]]\n\n [[ 61 86 91]\n [ 58 72 78]\n [ 68 86 87]\n ...\n [ 85 126 135]\n [ 81 116 120]\n [ 80 96 102]]]\n\n\n [[[ 44 64 62]\n [ 26 50 50]\n [ 19 44 46]\n ...\n [ 69 172 167]\n [ 76 184 183]\n [ 72 136 137]]\n\n [[ 37 65 63]\n [ 26 53 55]\n [ 27 50 52]\n ...\n [ 61 169 163]\n [ 75 174 171]\n [ 77 146 145]]\n\n [[ 36 62 58]\n [ 37 66 64]\n [ 37 60 56]\n ...\n [ 62 155 153]\n [ 64 154 150]\n [ 57 128 123]]\n\n ...\n\n [[ 99 135 172]\n [ 84 110 143]\n [ 42 56 130]\n ...\n [ 56 75 94]\n [ 86 108 141]\n [ 81 105 139]]\n\n [[117 146 183]\n [ 95 118 150]\n [ 44 64 80]\n ...\n [ 60 72 81]\n [ 98 118 135]\n [110 125 143]]\n\n [[144 174 209]\n [123 151 182]\n [ 83 109 139]\n ...\n [ 47 54 59]\n [111 119 130]\n [160 156 169]]]]\n"
]
],
[
[
"### <b>■ 데이터를 신경망에 로드하기 위해 필요한 총 4개의 함수</b>\n 1. image_load : 데이터를 숫자로 변환하는 함수\n 2. label_load : 정답 숫자를 one hot encoding하는 함수\n 3. next_batch : 배치 단위로 데이터 가져오는 함수\n 4. shuffle_batch : 이미지 데이터를 shuffle 하는 함수 ",
"_____no_output_____"
],
[
"#### 예제8. train_label.csv의 숫자를 출력하는 함수를 만드시오",
"_____no_output_____"
]
],
[
[
"train_label = 'd:/tensor/cifar10/train_label.csv'\n\nimport csv\n\ndef label_load(path):\n file = open(path) \n label_data = csv.reader(file)\n \n label_list = [] \n for i in label_data:\n label_list.append(i)\n \n return label_list\nprint(label_load(train_label))",
"50000\n"
]
],
[
[
"#### 예제9. 위의 결과가 문자가 아니라 숫자로 출력되게 하시오",
"_____no_output_____"
]
],
[
[
"train_label = 'd:/tensor/cifar10/train_label.csv'\n\nimport csv\nimport numpy as np\n\ndef label_load(path):\n file = open(path) \n label_data = csv.reader(file)\n \n label_list = [] \n for i in label_data:\n label_list.append(i)\n \n label = np.array(label_list).astype(int)\n \n return label\nprint(label_load(train_label))",
"[[6]\n [9]\n [9]\n ...\n [9]\n [1]\n [1]]\n"
]
],
[
[
"#### 예제10. 아래의 결과를 출력하시오\n [0 0 0 1 0 0 0 0 0 0]",
"_____no_output_____"
]
],
[
[
"import numpy as np\nprint(np.eye(10)[4])",
"[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]\n"
]
],
[
[
"#### 예제11. 위의 np.eye를 가지고 예제 9에서 출력하고 있는 숫자들이 아래와 같이 one hot encoding된 숫자로 출력되게 하시오\n [0 0 0 1 0 0 0 0 0 0]\n [0 0 1 0 0 0 0 0 0 0]\n [1 0 0 0 0 0 0 0 0 0]\n [0 0 0 0 0 0 0 1 0 0]\n ...",
"_____no_output_____"
]
],
[
[
"train_label = 'd:/tensor/cifar10/train_label.csv'\n\nimport csv\nimport numpy as np\n\ndef label_load(path):\n file = open(path) \n label_data = csv.reader(file)\n \n label_list = [] \n for i in label_data:\n label_list.append(i)\n \n label = np.eye(10)[np.array(label_list).astype(int)]\n \n return label\n\nprint(label_load(train_label))",
"[[[0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 1.]]\n\n [[0. 0. 0. ... 0. 0. 1.]]\n\n ...\n\n [[0. 0. 0. ... 0. 0. 1.]]\n\n [[0. 1. 0. ... 0. 0. 0.]]\n\n [[0. 1. 0. ... 0. 0. 0.]]]\n"
]
],
[
[
"#### 예제12. 위의 결과는 3차원인데 신경망에서 라벨을 사용하려면 2차원이어야 하므로 차원을 2차원으로 축소시켜서 출력하시오",
"_____no_output_____"
]
],
[
[
"train_label = 'd:/tensor/cifar10/train_label.csv'\n\nimport csv\nimport numpy as np\n\ndef label_load(path):\n file = open(path) \n label_data = csv.reader(file)\n \n label_list = [] \n for i in label_data:\n label_list.append(i)\n \n label = np.eye(10)[np.array(label_list).astype(int)].reshape(-1,10)\n \n return label\n\nprint(label_load(train_label))",
"[[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 1.]\n [0. 0. 0. ... 0. 0. 1.]\n ...\n [0. 0. 0. ... 0. 0. 1.]\n [0. 1. 0. ... 0. 0. 0.]\n [0. 1. 0. ... 0. 0. 0.]]\n"
]
],
[
[
"#### 예제13. 지금까지 만든 두 개의 함수 image_load와 label_load를 loader2.py라는 파이썬 코드에 저장하고 아래와 같이 loader2.py를 import한 후에 cifar10 전체 데이터를 로드하는 코드를 구현하시오",
"_____no_output_____"
]
],
[
[
"import loader2\n\ntrain_image='D:/tensor/cifar10/train/'\ntrain_label = 'D:/tensor/cifar10/train_label.csv'\ntest_image='D:/tensor/cifar10/test/'\ntest_label = 'D:/tensor/cifar10/test_label.csv'\n\n\ntrainX = loader2.image_load(train_image)\ntrainY = loader2.label_load(train_label)\ntestX = loader2.image_load(test_image)\ntestY = loader2.label_load(test_label)\n\nprint ( trainX.shape)\nprint ( trainY.shape)\nprint ( testX.shape)\nprint ( testY.shape)",
"(50000, 32, 32, 3)\n(50000, 10)\n(10000, 32, 32, 3)\n(10000, 10)\n"
]
],
[
[
"#### 예제14. 신경망에 100장씩 데이터를 로드할 수 있도록 아래와 같이 next_batch 함수를 생성하시오",
"_____no_output_____"
]
],
[
[
"import loader2\n\ndef next_batch(data1, data2, init, final):\n return data1[init:final], data2[init:final]\n\ntest_image = 'D:/tensor/cifar10/test/'\ntest_label = 'D:/tensor/cifar10/test_label.csv'\n\ntestX = loader2.image_load(test_image)\ntestY = loader2.label_load(test_label)\n\nprint(next_batch(testX, testY, 0 ,100))",
"(array([[[[ 49, 112, 158],\n [ 47, 111, 159],\n [ 51, 116, 165],\n ...,\n [ 36, 95, 137],\n [ 36, 91, 126],\n [ 33, 85, 116]],\n\n [[ 51, 112, 152],\n [ 40, 110, 151],\n [ 45, 114, 159],\n ...,\n [ 31, 95, 136],\n [ 32, 91, 125],\n [ 34, 88, 119]],\n\n [[ 47, 110, 151],\n [ 33, 109, 151],\n [ 36, 111, 158],\n ...,\n [ 34, 98, 139],\n [ 34, 95, 130],\n [ 33, 89, 120]],\n\n ...,\n\n [[177, 124, 68],\n [148, 100, 42],\n [137, 88, 31],\n ...,\n [146, 97, 38],\n [108, 64, 13],\n [127, 85, 40]],\n\n [[168, 116, 61],\n [148, 102, 49],\n [132, 85, 35],\n ...,\n [130, 82, 26],\n [126, 82, 29],\n [107, 64, 20]],\n\n [[160, 107, 54],\n [149, 105, 56],\n [132, 89, 45],\n ...,\n [124, 77, 24],\n [129, 84, 34],\n [110, 67, 21]]],\n\n\n [[[235, 235, 235],\n [231, 231, 231],\n [232, 232, 232],\n ...,\n [233, 233, 233],\n [233, 233, 233],\n [232, 232, 232]],\n\n [[238, 238, 238],\n [235, 235, 235],\n [235, 235, 235],\n ...,\n [236, 236, 236],\n [236, 236, 236],\n [235, 235, 235]],\n\n [[237, 237, 237],\n [234, 234, 234],\n [234, 234, 234],\n ...,\n [235, 235, 235],\n [235, 235, 235],\n [234, 234, 234]],\n\n ...,\n\n [[ 89, 99, 87],\n [ 37, 51, 43],\n [ 11, 23, 19],\n ...,\n [179, 184, 169],\n [193, 197, 182],\n [201, 202, 188]],\n\n [[ 82, 96, 82],\n [ 36, 57, 46],\n [ 22, 44, 36],\n ...,\n [183, 189, 174],\n [196, 200, 185],\n [200, 202, 187]],\n\n [[ 83, 101, 85],\n [ 48, 75, 62],\n [ 38, 67, 58],\n ...,\n [178, 183, 168],\n [191, 195, 180],\n [199, 200, 186]]],\n\n\n [[[222, 190, 158],\n [218, 187, 158],\n [194, 166, 139],\n ...,\n [234, 231, 228],\n [243, 239, 237],\n [246, 241, 238]],\n\n [[229, 200, 170],\n [226, 199, 172],\n [201, 176, 151],\n ...,\n [236, 232, 232],\n [250, 246, 246],\n [251, 247, 246]],\n\n [[225, 201, 174],\n [222, 200, 176],\n [199, 179, 157],\n ...,\n [232, 229, 230],\n [251, 249, 250],\n [247, 244, 245]],\n\n ...,\n\n [[ 45, 40, 31],\n [ 44, 39, 30],\n [ 40, 35, 26],\n ...,\n [ 46, 40, 37],\n [ 14, 13, 9],\n [ 5, 7, 4]],\n\n [[ 39, 34, 23],\n [ 43, 38, 27],\n [ 41, 36, 25],\n ...,\n [ 24, 20, 19],\n [ 3, 6, 4],\n [ 3, 7, 5]],\n\n [[ 47, 41, 28],\n [ 50, 43, 30],\n [ 52, 45, 32],\n ...,\n [ 8, 6, 5],\n [ 3, 5, 4],\n [ 7, 8, 7]]],\n\n\n ...,\n\n\n [[[149, 135, 132],\n [150, 137, 133],\n [151, 139, 135],\n ...,\n [151, 138, 130],\n [152, 137, 130],\n [152, 137, 130]],\n\n [[152, 140, 138],\n [153, 141, 139],\n [153, 141, 139],\n ...,\n [153, 140, 133],\n [153, 139, 132],\n [153, 138, 131]],\n\n [[151, 140, 139],\n [151, 140, 139],\n [153, 141, 141],\n ...,\n [151, 139, 132],\n [151, 138, 131],\n [151, 137, 131]],\n\n ...,\n\n [[ 17, 38, 23],\n [ 10, 33, 19],\n [ 18, 38, 25],\n ...,\n [145, 137, 135],\n [145, 138, 135],\n [145, 137, 135]],\n\n [[ 13, 30, 17],\n [ 11, 26, 14],\n [ 12, 30, 17],\n ...,\n [146, 138, 137],\n [146, 138, 137],\n [146, 138, 137]],\n\n [[ 8, 24, 13],\n [ 10, 24, 13],\n [ 10, 25, 14],\n ...,\n [144, 136, 134],\n [143, 136, 134],\n [143, 136, 134]]],\n\n\n [[[255, 255, 255],\n [255, 255, 255],\n [255, 255, 255],\n ...,\n [255, 255, 255],\n [255, 255, 255],\n [255, 255, 255]],\n\n [[255, 255, 255],\n [254, 254, 254],\n [254, 254, 254],\n ...,\n [254, 254, 254],\n [254, 254, 254],\n [254, 254, 254]],\n\n [[255, 255, 255],\n [254, 254, 254],\n [255, 255, 255],\n ...,\n [255, 255, 255],\n [255, 255, 255],\n [255, 255, 255]],\n\n ...,\n\n [[255, 255, 255],\n [254, 254, 254],\n [255, 255, 255],\n ...,\n [255, 255, 255],\n [255, 255, 255],\n [255, 255, 255]],\n\n [[255, 255, 255],\n [254, 254, 254],\n [255, 255, 255],\n ...,\n [255, 255, 255],\n [255, 255, 255],\n [255, 255, 255]],\n\n [[255, 255, 255],\n [254, 254, 254],\n [255, 255, 255],\n ...,\n [255, 255, 255],\n [255, 255, 255],\n [255, 255, 255]]],\n\n\n [[[238, 233, 234],\n [241, 237, 238],\n [242, 238, 239],\n ...,\n [247, 244, 246],\n [249, 246, 248],\n [251, 248, 249]],\n\n [[233, 228, 229],\n [236, 231, 232],\n [237, 232, 233],\n ...,\n [245, 242, 244],\n [247, 244, 246],\n [248, 246, 248]],\n\n [[236, 230, 231],\n [238, 232, 233],\n [238, 232, 233],\n ...,\n [250, 248, 250],\n [251, 249, 251],\n [252, 251, 252]],\n\n ...,\n\n [[ 55, 75, 115],\n [ 55, 72, 107],\n [ 56, 71, 106],\n ...,\n [151, 198, 226],\n [128, 176, 212],\n [131, 181, 217]],\n\n [[ 55, 74, 113],\n [ 55, 70, 103],\n [ 55, 69, 99],\n ...,\n [138, 191, 215],\n [128, 182, 206],\n [129, 177, 207]],\n\n [[ 54, 71, 106],\n [ 57, 72, 105],\n [ 56, 72, 103],\n ...,\n [125, 178, 203],\n [137, 193, 213],\n [127, 178, 199]]]], dtype=uint8), array([[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],\n [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.]]))\n"
]
],
[
[
"#### 예제15. 아래와 같이 shuffle_batch 함수를 만들고 loader2.py에 추가시키시오",
"_____no_output_____"
]
],
[
[
"def shuffle_batch(data_list, label):\n x = np.arange(len(data_list))\n np.random.shuffle(x)\n \n data_list2 = data_list[x]\n label2 = label[x]\n \n return data_list2, label2",
"_____no_output_____"
],
[
"import loader2\n\ntest_image = 'D:/tensor/cifar10/test/'\ntest_label = 'D:/tensor/cifar10/test_label.csv'\n\ntestX = loader2.image_load(test_image)\ntestY = loader2.label_load(test_label)\n\nprint(loader2.shuffle_batch(testX, testY))",
"_____no_output_____"
]
],
[
[
"### ※ 문제141. (오늘의 마지막 문제) 4개의 함수를 모두 loader2.py에 넣고 내일 옥스포드에서 설계한 vgg 신경망에 넣기 위해 아래와 같이 실행되게 하시오\n```python\nimport loader2\n\ntrain_image='D:/tensor/cifar10/train/'\ntrain_label = 'D:/tensor/cifar10/train_label.csv'\ntest_image='D:/tensor/cifar10/test/'\ntest_label = 'D:/tensor/cifar10/test_label.csv'\n\n\ntrainX = loader2.image_load(train_image)\ntrainY = loader2.label_load(train_label)\ntestX = loader2.image_load(test_image)\ntestY = loader2.label_load(test_label)\n\ntestX, testY = loader2.shuffle_batch(testX, testY)\nprint(loader2.next_batch(testX, testY, 0, 100))\n```",
"_____no_output_____"
]
],
[
[
"import loader2\n\ntrain_image='D:/tensor/cifar10/train/'\ntrain_label = 'D:/tensor/cifar10/train_label.csv'\ntest_image='D:/tensor/cifar10/test/'\ntest_label = 'D:/tensor/cifar10/test_label.csv'\n\n\ntrainX = loader2.image_load(train_image)\ntrainY = loader2.label_load(train_label)\ntestX = loader2.image_load(test_image)\ntestY = loader2.label_load(test_label)\n\ntestX, testY = loader2.shuffle_batch(testX, testY)\nprint(loader2.next_batch(testX, testY, 0, 100))",
"_____no_output_____"
]
],
[
[
"### <b>■ 훈련시킨 가중치와 바이어스를 pickle 파일로 내리는 코드</b>",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7cefe78c003245ae8a56125cd29306e68a9b71f | 858,682 | ipynb | Jupyter Notebook | pymc_stuff.ipynb | Rmloong/movie-revenue-predictor | 702e16aec92ac13f47f655950e63bdacf1783200 | [
"MIT"
]
| 1 | 2018-05-31T01:21:14.000Z | 2018-05-31T01:21:14.000Z | pymc_stuff.ipynb | Rmloong/movie-revenue-predictor | 702e16aec92ac13f47f655950e63bdacf1783200 | [
"MIT"
]
| null | null | null | pymc_stuff.ipynb | Rmloong/movie-revenue-predictor | 702e16aec92ac13f47f655950e63bdacf1783200 | [
"MIT"
]
| null | null | null | 73.922348 | 344,468 | 0.71876 | [
[
[
"import scipy.stats as scs\nimport pymc3 as pm\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\n%matplotlib inline\n",
"_____no_output_____"
],
[
"mu_actual = 5\nsigma_actual = 2\ndata = scs.norm(mu_actual, sigma_actual).rvs(10)",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
],
[
"data.mean()",
"_____no_output_____"
],
[
"data.std()",
"_____no_output_____"
],
[
"with pm.Model() as model_normal:\n # prior\n mu = pm.Uniform(\"mu\", 0, 10)\n # likelihood\n observed = pm.Normal(\"observed\", mu, 2, observed=data)",
"_____no_output_____"
],
[
"with model_normal:\n estimate = pm.find_MAP()\nestimate",
"logp = -24.118, ||grad|| = 1.3767: 100%|██████████| 6/6 [00:00<00:00, 1145.31it/s]\n"
],
[
"with model_normal:\n trace = pm.sample(10000)",
"Auto-assigning NUTS sampler...\nInitializing NUTS using jitter+adapt_diag...\nMultiprocess sampling (4 chains in 4 jobs)\nNUTS: [mu_interval__]\n100%|██████████| 10500/10500 [00:04<00:00, 2368.98it/s]\n"
],
[
"fig, ax = plt.subplots()\nax.hist(trace['mu'], bins=50)\nplt.show()",
"_____no_output_____"
],
[
"df_scores = pd.read_csv('data/scores.csv')",
"_____no_output_____"
],
[
"df_scores.head()",
"_____no_output_____"
],
[
"df_scores.score.describe()",
"_____no_output_____"
],
[
"df_scores.groupby('group').mean()",
"_____no_output_____"
],
[
"with pm.Model() as model_scores:\n mu = pm.Uniform('mu', 0, 1)\n sigma = pm.HalfNormal('sigma', 1)\n sd = pm.HalfNormal('sd', 1)\n eta1 = pm.Normal('eta1', mu, sigma)\n eta2 = pm.Normal('eta2', mu, sigma)\n eta3 = pm.Normal('eta3', mu, sigma)\n eta4 = pm.Normal('eta4', mu, sigma)\n eta5 = pm.Normal('eta5', mu, sigma)\n obs1 = pm.Normal('obs1', eta1, sd, observed=df_scores[df_scores.group==1].values)\n obs2 = pm.Normal('obs2', eta2, sd, observed=df_scores[df_scores.group==2].values)\n obs3 = pm.Normal('obs3', eta3, sd, observed=df_scores[df_scores.group==3].values)\n obs4 = pm.Normal('obs4', eta4, sd, observed=df_scores[df_scores.group==4].values)\n obs5 = pm.Normal('obs5', eta5, sd, observed=df_scores[df_scores.group==5].values)\n\n",
"_____no_output_____"
],
[
"df_scores.mean()",
"_____no_output_____"
],
[
"df_scores[df_scores.group==5].mean()",
"_____no_output_____"
],
[
"with model_scores:\n trace = pm.sample(10000)",
"Auto-assigning NUTS sampler...\nInitializing NUTS using jitter+adapt_diag...\nMultiprocess sampling (4 chains in 4 jobs)\nNUTS: [eta5, eta4, eta3, eta2, eta1, sd_log__, sigma_log__, mu_interval__]\n100%|██████████| 10500/10500 [00:21<00:00, 497.65it/s]\nThere were 1 divergences after tuning. Increase `target_accept` or reparameterize.\n"
],
[
"pm.traceplot(trace)",
"_____no_output_____"
],
[
"list(trace)",
"_____no_output_____"
],
[
"probs= np.ones(10)/10\nsd=3",
"_____no_output_____"
],
[
"datum = 6\n\nfor i in range(10):\n probs[i] *= scs.norm(i, sd).pdf(datum)\nprobs /= probs.sum()\n\nfor i in range(0,10):\n print(\"The probability of N({0}, {1}) being correct is {3:6.4f}\"\n .format(i, sd, datum, probs[i]))\n\nfig, ax = plt.subplots()\nax.bar(range(10), probs)\nax.set_xlabel('hypothesized mean')\nax.set_ylabel('posterior probability')\nplt.show()",
"The probability of N(0, 3) being correct is 0.0208\nThe probability of N(1, 3) being correct is 0.0383\nThe probability of N(2, 3) being correct is 0.0632\nThe probability of N(3, 3) being correct is 0.0933\nThe probability of N(4, 3) being correct is 0.1231\nThe probability of N(5, 3) being correct is 0.1455\nThe probability of N(6, 3) being correct is 0.1538\nThe probability of N(7, 3) being correct is 0.1455\nThe probability of N(8, 3) being correct is 0.1231\nThe probability of N(9, 3) being correct is 0.0933\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cf077ff611e3ea39519e817ebbe2fbe21c2a3e | 452,399 | ipynb | Jupyter Notebook | section_graph_slam/graphbasedslam_2d_sensor1.ipynb | kentaroy47/LNPR_BOOK_CODES | f0d1bef336423ebdf04539ce833f0ce4cffc51f5 | [
"MIT"
]
| null | null | null | section_graph_slam/graphbasedslam_2d_sensor1.ipynb | kentaroy47/LNPR_BOOK_CODES | f0d1bef336423ebdf04539ce833f0ce4cffc51f5 | [
"MIT"
]
| null | null | null | section_graph_slam/graphbasedslam_2d_sensor1.ipynb | kentaroy47/LNPR_BOOK_CODES | f0d1bef336423ebdf04539ce833f0ce4cffc51f5 | [
"MIT"
]
| null | null | null | 207.617715 | 181,011 | 0.866403 | [
[
[
"import sys \nsys.path.append('../scripts/')\nfrom kf import * #誤差楕円を描くのに利用",
"_____no_output_____"
],
[
"def make_ax(): #axisの準備\n fig = plt.figure(figsize=(4,4))\n ax = fig.add_subplot(111)\n ax.set_aspect('equal')\n ax.set_xlim(-5,5) \n ax.set_ylim(-5,5) \n ax.set_xlabel(\"X\",fontsize=10) \n ax.set_ylabel(\"Y\",fontsize=10) \n return ax\n\ndef draw_trajectory(xs, ax): #軌跡の描画\n poses = [xs[s] for s in range(len(xs))]\n ax.scatter([e[0] for e in poses], [e[1] for e in poses], s=5, marker=\".\", color=\"black\")\n ax.plot([e[0] for e in poses], [e[1] for e in poses], linewidth=0.5, color=\"black\")\n \ndef draw_observations(xs, zlist, ax): #センサ値の描画\n for s in range(len(xs)):\n if s not in zlist:\n continue\n \n for obs in zlist[s]:\n x, y, theta = xs[s]\n ell, phi = obs[1][0], obs[1][1]\n mx = x + ell*math.cos(theta + phi)\n my = y + ell*math.sin(theta + phi)\n ax.plot([x,mx], [y,my], color=\"pink\", alpha=0.5)\n \ndef draw_edges(edges, ax):\n for e in edges:\n ax.plot([e.x1[0], e.x2[0]], [e.x1[1] ,e.x2[1]], color=\"red\", alpha=0.5)\n \ndef draw_landmarks(ms, ax): \n ax.scatter([ms[k][0] for k in ms], [ms[k][1] for k in ms], s=100, marker=\"*\", color=\"blue\", zorder=100)\n \ndef draw(xs, zlist, edges, ms={}): #ms追加\n ax = make_ax()\n draw_observations(xs, zlist, ax)\n draw_trajectory(xs, ax)\n draw_landmarks(ms, ax) #追加\n plt.show()",
"_____no_output_____"
],
[
"def read_data(): ###graphbasedslam_2d_sensor_readdata\n hat_xs = {} \n zlist = {} \n delta = 0.0\n us = {}\n\n with open(\"log2.txt\") as f: #log2.txtに変えておく\n for line in f.readlines():\n tmp = line.rstrip().split()\n\n step = int(tmp[1])\n if tmp[0] == \"x\": \n hat_xs[step] = np.array([float(tmp[2]), float(tmp[3]), float(tmp[4])]).T\n elif tmp[0] == \"z\": \n if step not in zlist: \n zlist[step] = []\n zlist[step].append((int(tmp[2]), np.array([float(tmp[3]), float(tmp[4])]).T)) #変更。ψを読み込まないように\n elif tmp[0] == \"delta\": \n delta = float(tmp[1])\n elif tmp[0] == \"u\":\n us[step] = np.array([float(tmp[2]), float(tmp[3])]).T \n \n return hat_xs, zlist, us, delta #us, deltaも返す",
"_____no_output_____"
],
[
"class ObsEdge: ###graphbasedslam_2d_sensor_obsedge\n def __init__(self, t1, t2, z1, z2, xs, sensor_noise_rate=[0.14, 0.05]): #ψの標準偏差を削除\n assert z1[0] == z2[0] \n\n self.t1, self.t2 = t1, t2 \n self.x1, self.x2 = xs[t1], xs[t2]\n self.z1, self.z2 = z1[1], z2[1]\n \n s1 = math.sin(self.x1[2] + self.z1[1]) \n c1 = math.cos(self.x1[2] + self.z1[1])\n s2 = math.sin(self.x2[2] + self.z2[1])\n c2 = math.cos(self.x2[2] + self.z2[1])\n\n ##誤差の計算##\n hat_e = self.x2[0:2] - self.x1[0:2] + np.array([ #self.x2とself.x1は上の2行だけを使う\n self.z2[0]*c2 - self.z1[0]*c1, \n self.z2[0]*s2 - self.z1[0]*s1\n ]) #ψに関する行列の行と、正規化していた行を削除。\n \n ##精度行列の作成## \n Q1 = np.diag([(self.z1[0]*sensor_noise_rate[0])**2, sensor_noise_rate[1]**2]) #ψの分散を削除\n R1 = - np.array([[c1, -self.z1[0]*s1],\n [s1, self.z1[0]*c1]]) #3行目、3列目を削除\n \n Q2 = np.diag([(self.z2[0]*sensor_noise_rate[0])**2, sensor_noise_rate[1]**2]) #ψの分散を削除\n R2 = np.array([[c2, -self.z2[0]*s2],\n [s2, self.z2[0]*c2]]) #3行目、3列目を削除\n \n Sigma = R1.dot(Q1).dot(R1.T) + R2.dot(Q2).dot(R2.T)\n Omega = np.linalg.inv(Sigma) #2x2行列になる\n \n ##大きな精度行列と係数ベクトルの各部分を計算##\n B1 = - np.array([[1, 0, -self.z1[0]*s1],\n [0, 1, self.z1[0]*c1]]) #3行目を削除\n B2 = np.array([[1, 0, -self.z2[0]*s2],\n [0, 1, self.z2[0]*c2]]) #3行目を削除\n \n self.omega_upperleft = B1.T.dot(Omega).dot(B1) #ここは計算すると3x3行列のままになる\n self.omega_upperright = B1.T.dot(Omega).dot(B2)\n self.omega_bottomleft = B2.T.dot(Omega).dot(B1)\n self.omega_bottomright = B2.T.dot(Omega).dot(B2)\n \n self.xi_upper = - B1.T.dot(Omega).dot(hat_e) #ここも計算すると3次元縦ベクトルのままになる\n self.xi_bottom = - B2.T.dot(Omega).dot(hat_e)",
"_____no_output_____"
],
[
"class MotionEdge:\n def __init__(self, t1, t2, xs, us, delta, motion_noise_stds={\"nn\":0.19, \"no\":0.001, \"on\":0.13, \"oo\":0.2}):\n self.t1, self.t2 = t1, t2 #時刻の記録\n self.hat_x1, self.hat_x2 = xs[t1], xs[t2] #各時刻の姿勢\n\n nu, omega = us[t2]\n if abs(omega) < 1e-5: omega = 1e-5 #ゼロにすると式が変わるので避ける\n\n M = matM(nu, omega, delta, motion_noise_stds)\n A = matA(nu, omega, delta, self.hat_x1[2])\n F = matF(nu, omega, delta, self.hat_x1[2])\n \n self.Omega = np.linalg.inv(A.dot(M).dot(A.T) + np.eye(3)*0.0001) #標準偏差0.01の雑音を足す\n \n self.omega_upperleft = F.T.dot(self.Omega).dot(F)\n self.omega_upperright = -F.T.dot(self.Omega)\n self.omega_bottomleft = - self.Omega.dot(F)\n self.omega_bottomright = self.Omega\n \n x2 = IdealRobot.state_transition(nu, omega, delta, self.hat_x1)\n self.xi_upper = F.T.dot(self.Omega).dot(self.hat_x2 - x2)\n self.xi_bottom = -self.Omega.dot(self.hat_x2 - x2)",
"_____no_output_____"
],
[
"import itertools \ndef make_edges(hat_xs, zlist):\n landmark_keys_zlist = {}\n\n for step in zlist: \n for z in zlist[step]:\n landmark_id = z[0]\n if landmark_id not in landmark_keys_zlist: \n landmark_keys_zlist[landmark_id] = []\n\n landmark_keys_zlist[landmark_id].append((step, z))\n \n edges = []\n for landmark_id in landmark_keys_zlist:\n step_pairs = list(itertools.combinations(landmark_keys_zlist[landmark_id], 2))\n edges += [ObsEdge(xz1[0], xz2[0], xz1[1], xz2[1], hat_xs) for xz1, xz2 in step_pairs]\n \n return edges, landmark_keys_zlist #ランドマークをキーにしたリストlandmark_keys_zlistも返す",
"_____no_output_____"
],
[
"def add_edge(edge, Omega, xi): \n f1, f2 = edge.t1*3, edge.t2*3\n t1 ,t2 = f1 + 3, f2 + 3\n Omega[f1:t1, f1:t1] += edge.omega_upperleft\n Omega[f1:t1, f2:t2] += edge.omega_upperright\n Omega[f2:t2, f1:t1] += edge.omega_bottomleft\n Omega[f2:t2, f2:t2] += edge.omega_bottomright\n xi[f1:t1] += edge.xi_upper\n xi[f2:t2] += edge.xi_bottom",
"_____no_output_____"
],
[
"hat_xs, zlist, us, delta = read_data() \ndim = len(hat_xs)*3\n\nfor n in range(1, 10000): \n ##エッジ、大きな精度行列、係数ベクトルの作成##\n edges, _ = make_edges(hat_xs, zlist) #返す変数が2つになるので「_」で合わせる\n\n for i in range(len(hat_xs)-1): #行動エッジの追加\n edges.append(MotionEdge(i, i+1, hat_xs, us, delta))\n \n Omega = np.zeros((dim, dim))\n xi = np.zeros(dim)\n Omega[0:3, 0:3] += np.eye(3)*1000000\n\n ##軌跡を動かす量(差分)の計算##\n for e in edges:\n add_edge(e, Omega, xi) \n\n delta_xs = np.linalg.inv(Omega).dot(xi) \n \n ##推定値の更新##\n for i in range(len(hat_xs)):\n hat_xs[i] += delta_xs[i*3:(i+1)*3] \n \n ##終了判定##\n diff = np.linalg.norm(delta_xs) \n print(\"{}回目の繰り返し: {}\".format(n, diff))\n if diff < 0.01:\n draw(hat_xs, zlist, edges)\n break",
"1回目の繰り返し: 13.492560155627253\n2回目の繰り返し: 1.700645583006014\n3回目の繰り返し: 0.5338784221459197\n4回目の繰り返し: 0.7126024349338206\n5回目の繰り返し: 0.2558521895167307\n6回目の繰り返し: 0.4280548681130588\n7回目の繰り返し: 0.3285468026462249\n8回目の繰り返し: 0.3464070357286495\n9回目の繰り返し: 0.3155859816304509\n10回目の繰り返し: 0.3062023591668455\n11回目の繰り返し: 0.288736306925775\n12回目の繰り返し: 0.2755458714695215\n13回目の繰り返し: 0.26143729559985407\n14回目の繰り返し: 0.24855839580259456\n15回目の繰り返し: 0.2359890454868832\n16回目の繰り返し: 0.22408885586192925\n17回目の繰り返し: 0.21268313273828418\n18回目の繰り返し: 0.20181950846547195\n19回目の繰り返し: 0.19145272606076325\n20回目の繰り返し: 0.18157611416930722\n21回目の繰り返し: 0.17216695249168373\n22回目の繰り返し: 0.16320933908300836\n23回目の繰り返し: 0.1546847724330825\n24回目の繰り返し: 0.1465761625882024\n25回目の繰り返し: 0.13886624009687915\n26回目の繰り返し: 0.1315382853822019\n27回目の繰り返し: 0.12457588177946163\n28回目の繰り返し: 0.11796306506635612\n29回目の繰り返し: 0.11168429902825051\n30回目の繰り返し: 0.10572451526548908\n31回目の繰り返し: 0.10006911893983723\n32回目の繰り返し: 0.09470400215295642\n33回目の繰り返し: 0.08961554835080779\n34回目の繰り返し: 0.08479063536446357\n35回目の繰り返し: 0.08021663457307102\n36回目の繰り返し: 0.07588140782781967\n37回目の繰り返し: 0.0717733020061498\n38回目の繰り返し: 0.06788114174446193\n39回目の繰り返し: 0.06419422056797343\n40回目の繰り返し: 0.06070229072992797\n41回目の繰り返し: 0.057395551986686055\n42回目の繰り返し: 0.05426463953322334\n43回目の繰り返し: 0.05130061128622012\n44回目の繰り返し: 0.048494934683569725\n45回目の繰り返し: 0.04583947314652989\n46回目の繰り返し: 0.043326472330731704\n47回目の繰り返し: 0.0409485462772818\n48回目の繰り返し: 0.038698663556279385\n49回目の繰り返し: 0.036570133485268504\n50回目の繰り返し: 0.03455659248797129\n51回目の繰り返し: 0.0326519906531846\n52回目の繰り返し: 0.03085057853914102\n53回目の繰り返し: 0.029146894262174747\n54回目の繰り返し: 0.027535750903023522\n55回目の繰り返し: 0.026012224252083264\n56回目の繰り返し: 0.024571640915472787\n57回目の繰り返し: 0.023209566795282674\n58回目の繰り返し: 0.021921795951274952\n59回目の繰り返し: 0.020704339854333936\n60回目の繰り返し: 0.019553417029613288\n61回目の繰り返し: 0.01846544309362543\n62回目の繰り返し: 0.017437021179615524\n63回目の繰り返し: 0.01646493274967522\n64回目の繰り返し: 0.015546128785707027\n65回目の繰り返し: 0.014677721353758163\n66回目の繰り返し: 0.013856975531884167\n67回目の繰り返し: 0.013081301694076475\n68回目の繰り返し: 0.012348248139214974\n69回目の繰り返し: 0.01165549405504262\n70回目の繰り返し: 0.011000842807370927\n71回目の繰り返し: 0.01038221554184009\n72回目の繰り返し: 0.009797645089201668\n"
],
[
"_, zlist_landmark = make_edges(hat_xs, zlist) \nzlist_landmark",
"_____no_output_____"
],
[
"class MapEdge: ###graphbasedslam_2d_sensor_mapedge\n def __init__(self, t, z, head_t, head_z, xs, sensor_noise_rate=[0.14, 0.05]): #センサの雑音モデルを削除\n self.x = xs[t]\n self.z = z\n \n self.m = self.x[0:2] + np.array([z[0]*math.cos(self.x[2] + z[1]), z[0]*math.sin(self.x[2] + z[1])]).T #3行目削除\n \n ##精度行列の計算## \n Q1 = np.diag([(self.z[0]*sensor_noise_rate[0])**2, sensor_noise_rate[1]**2]) #ψの分散を削除\n \n s1 = math.sin(self.x[2] + self.z[1]) \n c1 = math.cos(self.x[2] + self.z[1])\n R = np.array([[-c1, self.z[0]*s1],\n [-s1,-self.z[0]*c1]]) #3行目、3列目を削除\n \n self.Omega = R.dot(Q1).dot(R.T) #2x2行列になる\n self.xi = self.Omega.dot(self.m) #2次元ベクトルになる",
"_____no_output_____"
],
[
"ms = {}###graphbasedslam_2d_sensor_mapexec\nfor landmark_id in zlist_landmark:\n edges = []\n head_z = zlist_landmark[landmark_id][0]\n for z in zlist_landmark[landmark_id]:\n edges.append(MapEdge(z[0], z[1][1], head_z[0], head_z[1][1], hat_xs))\n \n Omega = np.zeros((2,2)) #2x2に\n xi = np.zeros(2) #2次元に\n for e in edges:\n Omega += e.Omega\n xi += e.xi\n \n ms[landmark_id] = np.mean([e.m for e in edges], axis=0)\n \ndraw(hat_xs, zlist, edges, ms)",
"_____no_output_____"
],
[
"actual_pos = [(-4,2), (2,-3), (3,3), (0,4), (1,1), (-3,-1)]\nms",
"_____no_output_____"
],
[
"from decimal import Decimal, ROUND_HALF_UP\ndef distance(landmark_id, ref_id1, ref_id2, ms):\n m, ref_m1, ref_m2 = ms[landmark_id], ms[ref_id1], ms[ref_id2]\n d = math.sqrt( (m[0]-ref_m1[0])**2 + (m[1]-ref_m1[1])**2 )\n ang = math.atan2(m[1] - ref_m1[1], m[0] - ref_m1[0]) - math.atan2(ref_m2[1] - ref_m1[1], ref_m2[0] - ref_m1[0])\n return Decimal(d).quantize(Decimal(\"0.01\"), rounding=ROUND_HALF_UP), Decimal(ang/math.pi*180).quantize(Decimal(\"0.1\"), rounding=ROUND_HALF_UP)",
"_____no_output_____"
],
[
"for i in range(1,6):\n d, ang = distance(i, 0, 1, ms)\n true_d, true_ang = distance(i, 0, 1, actual_pos)\n print(i, true_d, true_ang, d, ang, d - true_d, ang - true_ang)",
"1 7.81 0.0 8.20 0.0 0.39 0.0\n2 7.07 47.9 7.33 46.8 0.26 -1.1\n3 4.47 66.4 4.59 67.1 0.12 0.7\n4 5.10 28.5 5.28 28.2 0.18 -0.3\n5 3.16 -31.8 3.16 -31.7 0.00 0.1\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cf0c3d5c90216ddab6fc040b55afb696669c10 | 26,915 | ipynb | Jupyter Notebook | write_and_test/visualize.ipynb | liuandrew/training-rl-algo | ca56d65209de0bf88ac1e1db2269bb7daac4da47 | [
"MIT"
]
| null | null | null | write_and_test/visualize.ipynb | liuandrew/training-rl-algo | ca56d65209de0bf88ac1e1db2269bb7daac4da47 | [
"MIT"
]
| null | null | null | write_and_test/visualize.ipynb | liuandrew/training-rl-algo | ca56d65209de0bf88ac1e1db2269bb7daac4da47 | [
"MIT"
]
| null | null | null | 269.15 | 24,556 | 0.928181 | [
[
[
"from baselines.common import plot_util as pu",
"_____no_output_____"
]
],
[
[
"If you want to average results for multiple seeds, LOG_DIRS must contain subfolders in the following format: ```<name_exp0>-0```, ```<name_exp0>-1```, ```<name_exp1>-0```, ```<name_exp1>-1```. Where names correspond to experiments you want to compare separated with random seeds by dash.",
"_____no_output_____"
]
],
[
[
"LOG_DIRS = 'logs/reacher/'\n# Uncomment below to see the effect of the timit limits flag\n# LOG_DIRS = 'time_limit_logs/reacher'",
"_____no_output_____"
],
[
"results = pu.load_results(LOG_DIRS)",
"/home/kostrikov/GitHub/baselines/baselines/bench/monitor.py:163: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n df.headers = headers # HACK to preserve backwards compatibility\n"
],
[
"fig = pu.plot_results(results, average_group=True, split_fn=lambda _: '', shaded_std=False)",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7cf0fcce91e1c74dbb30083023a0eabaf7a33fb | 2,895 | ipynb | Jupyter Notebook | notebooks/nl-be/Output - Buzzer (Piezo).ipynb | RaspberryJamBe/IPythonNotebooks | f827fa4c5e85a4c629269954a704000201435e71 | [
"CC0-1.0"
]
| null | null | null | notebooks/nl-be/Output - Buzzer (Piezo).ipynb | RaspberryJamBe/IPythonNotebooks | f827fa4c5e85a4c629269954a704000201435e71 | [
"CC0-1.0"
]
| null | null | null | notebooks/nl-be/Output - Buzzer (Piezo).ipynb | RaspberryJamBe/IPythonNotebooks | f827fa4c5e85a4c629269954a704000201435e71 | [
"CC0-1.0"
]
| null | null | null | 20.978261 | 59 | 0.477029 | [
[
[
"<img src=\"Piezo01.png\" height=\"300\" />",
"_____no_output_____"
]
],
[
[
"import RPi.GPIO as GPIO\nGPIO.setmode(GPIO.BCM)\n\nBUZZ_PIN = 18\nGPIO.setup(BUZZ_PIN, GPIO.OUT)\nGPIO.output(BUZZ_PIN,False)",
"_____no_output_____"
],
[
"def hold(j):\n for k in range(1,j):\n pass\n\ndef fire():\n for j in range(1,1100):\n GPIO.output(BUZZ_PIN,True)\n hold(j)\n GPIO.output(BUZZ_PIN,False)\n hold(j)\n\ntry:\n while True:\n print(\".\"),\n fire()\nexcept KeyboardInterrupt:\n print(\"Uitvoering onderbroken\")\n GPIO.output(BUZZ_PIN,False)",
"_____no_output_____"
],
[
"import time\n\ndef buzz(pitch, duration):\n period = 1.0 / pitch\n delay = period / 2\n cycles = int(duration * pitch)\n for i in range(cycles):\n last_time = time.time()\n GPIO.output(BUZZ_PIN, True)\n while time.time() < last_time + delay:\n pass\n GPIO.output(BUZZ_PIN, False)\n while time.time() < last_time + 2 * delay:\n pass",
"_____no_output_____"
],
[
"try:\n for pitch in range(500,10000,500):\n print(\".\"),\n buzz(pitch, duration = 0.5)\nexcept KeyboardInterrupt:\n print(\"Uitvoering onderbroken\")\n GPIO.output(BUZZ_PIN,False)",
"_____no_output_____"
],
[
"GPIO.cleanup()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cf1a2ca083481bc88f6f1675f2afeae0bf8f79 | 219,268 | ipynb | Jupyter Notebook | BellCurve.ipynb | 4dsolutions/ONLC_XPYS | c4f6e85dce61f4c3de72c3563bf1669fba66f6bf | [
"MIT"
]
| null | null | null | BellCurve.ipynb | 4dsolutions/ONLC_XPYS | c4f6e85dce61f4c3de72c3563bf1669fba66f6bf | [
"MIT"
]
| null | null | null | BellCurve.ipynb | 4dsolutions/ONLC_XPYS | c4f6e85dce61f4c3de72c3563bf1669fba66f6bf | [
"MIT"
]
| null | null | null | 219.487487 | 24,088 | 0.904017 | [
[
[
"# Gaussian Distribution (Normal or Bell Curve)",
"_____no_output_____"
],
[
"Think of a Jupyter Notebook file as a Python script, but with comments given the seriousness they deserve, meaning inserted Youtubes if necessary. We also adopt a more conversational style with the reader, and with Python, pausing frequently to take stock, because we're telling a story.\n\nOne might ask, what is the benefit of computer programs if we read through them this slowly? Isn't the whole point that they run blazingly fast, and nobody needs to read them except those tasked with maintaining them, the programmer cast?\n\nFirst, lets point out the obvious: even when reading slowly, we're not keeping Python from doing its part as fast as it can, and what it does would have taken a single human ages to do, and would have occupied a team of secretaries for ages. Were you planning to pay them? Python effectively puts a huge staff at your disposal, ready to do your bidding. But that doesn't let you off the hook. They need to be managed, told what to do.\n\nHere's what you'll find at the top of your average script. A litany of players, a congress of agents, need to be assembled and made ready for the job at hand. But don't worry, as you remember to include necessary assets, add them at will as you need them. We rehearse the script over and over while building it. Nobody groans, except maybe you, when the director says \"take it from the top\" once again.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport scipy.stats as st\nimport matplotlib.pyplot as plt\nimport math",
"_____no_output_____"
]
],
[
[
"You'll be glad to have np.linspace as a friend, as so often you know exactly what the upper and lower bounds, of a domain, might be. You'll be computing a range. Do you remember these terms from high school? A domain is like a pile of cannon balls that we feed to our cannon, which them fires them, testing our knowledge of ballistics. It traces a parabola. We plot that in our tables. A lot of mathematics traces to developing tables for battle field use. Leonardo da Vinci, a great artist, was also an architect of defensive fortifications.\n\nAnyway, np.linspace lets to give exactly the number of points you would like of this linear one dimensional array space, as a closed set, meaning -5 and 5 are included, the minimum and maximum you specify. Ask for a healthy number of points, as points are cheap. All they require is memory. But then it's up to you not to overdo things. Why waste CPU cycles on way too many points?\n\nI bring up this niggling detail about points as a way of introducing what they're calling \"hyperparameters\" in Machine Learning, meaning settings or values that come from outside the data, so also \"metadata\" in some ways. You'll see in other notebooks how we might pick a few hyperparameters and ask scikit-learn to try all combinations of same.\n\nHere's what you'll be saying then:\n\nfrom sklearn.model_selection import GridSearchCV #CV = cross-validation",
"_____no_output_____"
]
],
[
[
"domain = np.linspace(-5, 5, 100)",
"_____no_output_____"
]
],
[
[
"I know mu sounds like \"mew\", the sound a kitten makes, and that's sometimes insisted upon by sticklers, for when we have a continuous function, versus one that's discrete. Statisticians make a big deal about the difference between digital and analog, where the former is seen as a \"sampling\" of the latter. Complete data may be an impossibility. We're always stuck with something digital trying to approximate something analog, or so it seems. Turn that around in your head sometimes: we smooth it over as an approximation, because a discrete treatment would require too high a level of precision.\n\nThe sticklers say \"mu\" for continuous, but \"x-bar\" (an x with a bar over it) for plain old \"average\" of discrete sets. I don't see this conventions holding water necessarily, for one thing because it's inconvenient to always reach for the most fancy typography. Python does have full access to Unicode, and to LaTex, but do we have to bother? Lets leave that question for another day and move on to...\n\n## The Guassian (Binomial if Discrete)",
"_____no_output_____"
]
],
[
[
"mu = 0 # might be x-bar if discrete\nsigma = 1 # standard deviation, more below",
"_____no_output_____"
]
],
[
[
"What we have here (below) is a typical Python numeric function, although it does get its pi from numpy instead of math. That won't matter. The sigma and mu in this function are globals and set above. Some LaTex would be in order here, I realize. Let me scavange the internet for something appropriate...\n\n$pdf(x,\\mu,\\sigma) = \\frac{1}{ \\sigma \\sqrt{2 \\pi}} e^{\\left(-\\frac{{\\left(\\mu - x\\right)}^{2}}{2 \\, \\sigma^{2}}\\right)}$\n\nUse of dollar signs is key.\n\nHere's another way, in a code cell instead of a Markdown cell.",
"_____no_output_____"
]
],
[
[
"from IPython.display import display, Latex\n\nltx = '$ pdf(x,\\\\mu,\\\\sigma) = \\\\frac{1}{ \\\\sigma' + \\\n '\\\\sqrt{2 \\\\pi}} e^{\\\\left(-\\\\frac{{\\\\left(\\\\mu - ' + \\\n 'x\\\\right)}^{2}}{2 \\\\, \\\\sigma^{2}}\\\\right)} $'\ndisplay(Latex(ltx))",
"_____no_output_____"
]
],
[
[
"I'm really tempted to try out [PrettyPy](https://github.com/charliekawczynski/prettyPy).",
"_____no_output_____"
]
],
[
[
"def g(x):\n return (1/(sigma * math.sqrt(2 * np.pi))) * math.exp(-0.5 * ((mu - x)/sigma)**2)",
"_____no_output_____"
]
],
[
[
"What I do below is semi-mysterious, and something I'd like to get to in numpy in more detail. The whole idea behind numpy is every function, or at least the unary ones, are vectorized, meaning the work element-wise through every cell, with no need for any for loops.\n\nMy Gaussian formula above won't natively understand how to have relations with a numpy array, unless we store it in vectorized form. I'm not claiming this will make it run any faster than under the control of for loops, we can test that. Even without a speedup, here we have a recipe for shortening our code.\n\nAs many have proclaimed around numpy: one of its primary benefits is it allows one to \"lose the loops\".",
"_____no_output_____"
]
],
[
[
"%timeit vg = np.vectorize(g)",
"The slowest run took 5.55 times longer than the fastest. This could mean that an intermediate result is being cached.\n100000 loops, best of 3: 4.1 µs per loop\n"
]
],
[
[
"At any rate, this way, with a list comprehension, is orders of magnitude slower:",
"_____no_output_____"
]
],
[
[
"%timeit vg2 = np.array([g(x) for x in domain])",
"1000 loops, best of 3: 263 µs per loop\n"
],
[
"vg = np.vectorize(g)",
"_____no_output_____"
],
[
"%matplotlib inline\n%timeit plt.plot(domain, vg(domain))",
"The slowest run took 89.97 times longer than the fastest. This could mean that an intermediate result is being cached.\n1 loop, best of 3: 2.49 ms per loop\n"
]
],
[
[
"I bravely built my own version of the Gaussian distribution, a continuous function (any real number input is OK, from negative infinity to infinity, but not those (keep it in between). The thing about a Gaussian is you can shrink it and grow it while keeping the curve itself, self similar. Remember \"hyperparamters\"? They control the shape. We should be sure to play around with those parameters.\n\nOf course the stats.norm section of scipy comes pre-equipped with the same PDF (probability distribution function). You'll see this curve called many things in the literature.",
"_____no_output_____"
]
],
[
[
"%timeit plt.plot(domain, st.norm.pdf(domain))",
"The slowest run took 28.99 times longer than the fastest. This could mean that an intermediate result is being cached.\n100 loops, best of 3: 2.7 ms per loop\n"
],
[
"mu = 0\nsigma = math.sqrt(0.2)\nplt.plot(domain, vg(domain), color = 'blue')\nsigma = math.sqrt(1)\nplt.plot(domain, vg(domain), color = 'red')\nsigma = math.sqrt(5)\nplt.plot(domain, vg(domain), color = 'orange')\nmu = -2\nsigma = math.sqrt(.5)\nplt.plot(domain, vg(domain), color = 'green')\nplt.title(\"Gaussian Distributions\")",
"_____no_output_____"
]
],
[
[
"[see Wikipedia figure](https://en.wikipedia.org/wiki/Gaussian_function#Properties)\n\nThese are Gaussian PDFs or Probability Density Functions.\n\n68.26% of values happen within -1 and 1.",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\nYouTubeVideo(\"xgQhefFOXrM\")",
"_____no_output_____"
],
[
"a = st.norm.cdf(-1) # Cumulative distribution function\nb = st.norm.cdf(1)\nb - a",
"_____no_output_____"
],
[
"a = st.norm.cdf(-2)\nb = st.norm.cdf(2)\nb - a",
"_____no_output_____"
],
[
"# 99.73% is more correct than 99.72% \na = st.norm.cdf(-3)\nb = st.norm.cdf(3)\nb - a",
"_____no_output_____"
],
[
"# 95%\na = st.norm.cdf(-1.96)\nb = st.norm.cdf(1.96)\nb - a",
"_____no_output_____"
],
[
"# 99% \na = st.norm.cdf(-2.58)\nb = st.norm.cdf(2.58)\nb - a",
"_____no_output_____"
],
[
"from IPython.display import YouTubeVideo\nYouTubeVideo(\"zZWd56VlN7w\")",
"_____no_output_____"
]
],
[
[
"What are the chances a value is less than -1.32?",
"_____no_output_____"
]
],
[
[
"st.norm.cdf(-1.32)",
"_____no_output_____"
]
],
[
[
"What are the chances a value is between -0.21 and 0.85?",
"_____no_output_____"
]
],
[
[
"1 - st.norm.sf(-0.21) # filling in from the right (survival function)",
"_____no_output_____"
],
[
"a = st.norm.cdf(0.85) # filling in from the left\na",
"_____no_output_____"
],
[
"b = st.norm.cdf(-0.21) # from the left\nb",
"_____no_output_____"
],
[
"a-b # getting the difference (per the Youtube)",
"_____no_output_____"
]
],
[
[
"Lets plot the integral of the Bell Curve. This curve somewhat describes the temporal pattern whereby a new technology is adopted, first by early adopters, then comes the bandwagon effect, then come the stragglers. Not the every technology gets adopted in this way. Only some do.",
"_____no_output_____"
]
],
[
[
"plt.plot(domain, st.norm.cdf(domain))",
"_____no_output_____"
]
],
[
[
"[Standard Deviation](https://en.wikipedia.org/wiki/Standard_deviation)\n\nAbove is the Bell Curve integral.\n\nRemember the derivative is obtain from small differences: (f(x+h) - f(x))/x\n\nGiven x is our entire domain and operations are vectorized, it's easy enough to plot said derivative.",
"_____no_output_____"
]
],
[
[
"x = st.norm.cdf(domain)\ndiff = st.norm.cdf(domain + 0.01)\nplt.plot(domain, (diff-x)/0.01)",
"_____no_output_____"
],
[
"x = st.norm.pdf(domain)\ndiff = st.norm.pdf(domain + 0.01)\nplt.plot(domain, (diff-x)/0.01)",
"_____no_output_____"
],
[
"x = st.norm.pdf(domain)\nplt.plot(domain, x, color = \"red\")\n\nx = st.norm.pdf(domain)\ndiff = st.norm.pdf(domain + 0.01)\nplt.plot(domain, (diff-x)/0.01, color = \"blue\")",
"_____no_output_____"
]
],
[
[
"# Integrating the Gaussian\n\nApparently there's no closed form, however sympy is able to do an integration somehow.",
"_____no_output_____"
]
],
[
[
"from sympy import var, Lambda, integrate, sqrt, pi, exp, latex\n\nfig = plt.gcf()\nfig.set_size_inches(8,5)\nvar('a b x sigma mu')\npdf = Lambda((x,mu,sigma),\n (1/(sigma * sqrt(2*pi)) * exp(-(mu-x)**2 / (2*sigma**2)))\n)\ncdf = Lambda((a,b,mu,sigma),\n integrate(\n pdf(x,mu,sigma),(x,a,b)\n )\n)\ndisplay(Latex('$ cdf(a,b,\\mu,\\sigma) = ' + latex(cdf(a,b,mu,sigma)) + '$'))",
"_____no_output_____"
]
],
[
[
"Lets stop right here and note the pdf and cdf have been defined, using sympy's Lambda and integrate, and the cdf will be fed a lot of data, one hundred points, along with mu and sigma. Then it's simply a matter of plotting.\n\nWhat's amazing is our ability to get something from sympy that works to give a cdf, independently of scipy.stats.norm.",
"_____no_output_____"
]
],
[
[
"x = np.linspace(50,159,100)\ny = np.array([cdf(-1e99,v,100,15) for v in x],dtype='float')\nplt.grid(True)\nplt.title('Cumulative Distribution Function')\nplt.xlabel('IQ')\nprint(type(plt.xlabel))\nplt.ylabel('Y')\nplt.text(65,.75,'$\\mu = 100$',fontsize=16)\nplt.text(65,.65,'$\\sigma = 15$',fontsize=16)\nplt.plot(x,y,color='gray')\nplt.fill_between(x,y,0,color='#c0f0c0')\nplt.show()",
"<class 'function'>\n"
]
],
[
[
"The above is truly a testament to Python's power, or the Python ecosystem's power. We've brought in sympy, able to do symbolic integration, and talk LaTeX at the same time. That's impressive. Here's [the high IQ source](https://arachnoid.com/IPython/normal_distribution.html) for the original version of the above code.\n\nThere's no indefinite integral of the Gaussian, but there's a definite one. sympy comes with its own generic sympy.stats.cdf function which produces Lambdas (symbolic expressions) when used to integrate different types of probability spaces, such as Normal (a continuous PDF). It also accepts discrete PMFs as well.\n\n<pre>\nExamples\n========\n \n>>> from sympy.stats import density, Die, Normal, cdf\n>>> from sympy import Symbol\n \n>>> D = Die('D', 6)\n>>> X = Normal('X', 0, 1)\n \n>>> density(D).dict\n{1: 1/6, 2: 1/6, 3: 1/6, 4: 1/6, 5: 1/6, 6: 1/6}\n>>> cdf(D)\n{1: 1/6, 2: 1/3, 3: 1/2, 4: 2/3, 5: 5/6, 6: 1}\n>>> cdf(3*D, D > 2)\n{9: 1/4, 12: 1/2, 15: 3/4, 18: 1}\n \n>>> cdf(X)\nLambda(_z, -erfc(sqrt(2)*_z/2)/2 + 1)\n</pre> ",
"_____no_output_____"
],
[
"## LAB: convert the Normal Distribution Below to IQ Curve...\n\n\nThat means domain is 0-200, standard deviation 15, mean = 100.",
"_____no_output_____"
]
],
[
[
"domain = np.linspace(0, 200, 3000)\nIQ = st.norm.pdf(domain, 100, 15)\nplt.plot(domain, IQ, color = \"red\")",
"_____no_output_____"
],
[
"domain = np.linspace(0, 200, 3000)\nmu = 100\nsigma = 15\nIQ = vg(domain)\nplt.plot(domain, IQ, color = \"green\")",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
]
|
e7cf247523d03193413fd267e46093ea094f6e40 | 3,680 | ipynb | Jupyter Notebook | connection.ipynb | Db2-DTE-POC/db2v11 | 9dcb1a0e0de1a593baab71da7ff31176bba15bcb | [
"Apache-2.0"
]
| null | null | null | connection.ipynb | Db2-DTE-POC/db2v11 | 9dcb1a0e0de1a593baab71da7ff31176bba15bcb | [
"Apache-2.0"
]
| null | null | null | connection.ipynb | Db2-DTE-POC/db2v11 | 9dcb1a0e0de1a593baab71da7ff31176bba15bcb | [
"Apache-2.0"
]
| null | null | null | 27.058824 | 311 | 0.589402 | [
[
[
"# Db2 Connection Document",
"_____no_output_____"
],
[
"This notebook contains the connect statement that will be used for connecting to Db2. The typical way of connecting to Db2 within a notebooks it to run the db2 notebook (`db2.ipynb`) and then issue the `%sql connect` statement:\n```sql\n%run db2.ipynb\n%sql connect to sample user ...\n```\n\nRather than having to change the connect statement in every notebook, this one file can be changed and all of the other notebooks will use the value in here. Note that if you do reset a connection within a notebook, you will need to issue the `CONNECT` command again or run this notebook to re-connect.\n\nThe `db2.ipynb` file is still used at the beginning of all notebooks to highlight the fact that we are using special code to allow Db2 commands to be issues from within Jupyter Notebooks.",
"_____no_output_____"
],
[
"### Connect to Db2\nThis code will connect to Db2 locally.",
"_____no_output_____"
]
],
[
[
"%sql CONNECT TO SAMPLE USER DB2INST1 USING db2inst1 HOST localhost PORT 50000",
"_____no_output_____"
]
],
[
[
"### Check that the EMPLOYEE and DEPARTMENT table exist\nA lot of the examples depend on these two tables existing in the database. These tables will be created for you if they don't already exist. Note that they will not overwrite the existing Db2 samples tables.",
"_____no_output_____"
]
],
[
[
"if sqlcode == 0:\n %sql -sampledata",
"_____no_output_____"
]
],
[
[
"### Code for Refreshing Slideware and Youtube Videos in a Notebook",
"_____no_output_____"
]
],
[
[
"%%javascript\nwindow.findCellIndicesByTag = function findCellIndicesByTag(tagName) {\n return (Jupyter.notebook.get_cells()\n .filter(\n ({metadata: {tags}}) => tags && tags.includes(tagName)\n )\n .map((cell) => Jupyter.notebook.find_cell_index(cell))\n );\n};\n\nwindow.refresh = function runPlotCells() {\n var c = window.findCellIndicesByTag('refresh');\n Jupyter.notebook.execute_cells(c);\n};",
"_____no_output_____"
]
],
[
[
"Run through all of the cells and refresh everything that has a **refresh** tag in it.",
"_____no_output_____"
]
],
[
[
"from IPython.display import Javascript\ndisplay(Javascript(\"window.refresh()\"))",
"_____no_output_____"
]
],
[
[
"#### Credits: IBM 2019, George Baklarz [[email protected]]",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7cf2b096efea00fba02c5c0bd9c742759b606bb | 4,631 | ipynb | Jupyter Notebook | samples/mandelbrot/mandelbrot_performance_test.ipynb | zerweck/doAzureParallel | aa10f12fce59d6c5cdd32f9b2fa933a50125fbd6 | [
"MIT"
]
| 127 | 2017-03-17T10:50:53.000Z | 2021-10-15T00:15:32.000Z | samples/mandelbrot/mandelbrot_performance_test.ipynb | zerweck/doAzureParallel | aa10f12fce59d6c5cdd32f9b2fa933a50125fbd6 | [
"MIT"
]
| 281 | 2017-03-02T09:22:11.000Z | 2021-05-19T16:49:42.000Z | samples/mandelbrot/mandelbrot_performance_test.ipynb | zerweck/doAzureParallel | aa10f12fce59d6c5cdd32f9b2fa933a50125fbd6 | [
"MIT"
]
| 61 | 2017-02-16T20:58:07.000Z | 2022-01-14T11:57:34.000Z | 4,631 | 4,631 | 0.673721 | [
[
[
"# Performance Testing with Computing the Mandlebrot Set",
"_____no_output_____"
],
[
"This sample was executed on a DSVM on a Standard_D2_v2 in Azure. \n\nThis code below also uses a few other cluster config files titled: \n- \"10_core_cluster.json\" \n- \"20_core_cluster.json\"\n- \"40_core_cluster.json\"\n- \"80_core_cluster.json\"\n\nEach of the cluster config files above are used by the doAzureParallel package. They all define static clusters (minNodes = maxNodes) and use the Standard_F2 VM size. ",
"_____no_output_____"
],
[
"Install package dependencies for doAzureParallel",
"_____no_output_____"
]
],
[
[
"install.packages(c('httr','rjson','RCurl','digest','foreach','iterators','devtools','curl','jsonlite','mime'))",
"_____no_output_____"
]
],
[
[
"Install doAzureParallel and rAzureBatch from github",
"_____no_output_____"
]
],
[
[
"library(devtools)\ninstall_github(\"Azure/rAzureBatch\")\ninstall_github(\"Azure/doAzureParallel\")",
"_____no_output_____"
]
],
[
[
"Install *microbenchmark* package and other utilities",
"_____no_output_____"
]
],
[
[
"install.packages(\"microbenchmark\")\nlibrary(microbenchmark)\nlibrary(reshape2)\nlibrary(ggplot2)",
"_____no_output_____"
]
],
[
[
"Define function to compute the mandlebrot set.",
"_____no_output_____"
]
],
[
[
"vmandelbrot <- function(xvec, y0, lim)\n{\n mandelbrot <- function(x0,y0,lim)\n {\n x <- x0; y <- y0\n iter <- 0\n while (x^2 + y^2 < 4 && iter < lim)\n {\n xtemp <- x^2 - y^2 + x0\n y <- 2 * x * y + y0\n x <- xtemp\n iter <- iter + 1\n }\n iter\n }\n \n unlist(lapply(xvec, mandelbrot, y0=y0, lim=lim))\n}",
"_____no_output_____"
]
],
[
[
"The local execution is performed on a single Standard_D2_V2 DSVM in Azure. We use the doParallel package and use both cores for this performance test",
"_____no_output_____"
]
],
[
[
"localExecution <- function() {\n print(\"doParallel\")\n library(doParallel)\n cl<-makeCluster(2)\n registerDoParallel(cl)\n \n x.in <- seq(-2, 1.5, length.out=1080)\n y.in <- seq(-1.5, 1.5, length.out=1080)\n m <- 1000\n mset <- foreach(i=y.in, .combine=rbind, .export = \"vmandelbrot\") %dopar% vmandelbrot(x.in, i, m)\n}",
"_____no_output_____"
]
],
[
[
"The Azure Execution takes in a pool_config JSON file and will use doAzureParallel.",
"_____no_output_____"
]
],
[
[
"azureExecution <- function(pool_config) {\n print(\"doAzureParallel\")\n library(doAzureParallel)\n pool <- doAzureParallel::makeCluster(pool_config)\n registerDoAzureParallel(pool)\n \n x.in <- seq(-2, 1.5, length.out=1080)\n y.in <- seq(-1.5, 1.5, length.out=1080)\n m <- 1000\n mset <- foreach(i=y.in, .combine=rbind, .options.azure = list(chunkSize=10), .export = \"vmandelbrot\") %dopar% vmandelbrot(x.in, i, m)\n}",
"_____no_output_____"
]
],
[
[
"Using the *microbenchmark* package, we test the difference in performance when running the same code to calculate the mandlebrot set on a single machine (localExecution), a cluster of 10 cores, a cluster of 20 cores, and finally a cluster of 40 cores.",
"_____no_output_____"
]
],
[
[
"op <- microbenchmark(\n doParLocal=localExecution(),\n doParAzure_10cores=azureExecution(\"10_core_cluster.json\"),\n doParAzure_20cores=azureExecution(\"20_core_cluster.json\"),\n doParAzure_40cores=azureExecution(\"40_core_cluster.json\"),\n times=5L)",
"_____no_output_____"
],
[
"print(op)",
"_____no_output_____"
],
[
"plot(op)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7cf2e8b0fb0a577a4276241108405f6a8f24fa4 | 46,607 | ipynb | Jupyter Notebook | lab9/lab9.ipynb | YgLK/ML | 1a8fd7857e6ef93bf85ce84e0c99d48dd9d38394 | [
"MIT"
]
| null | null | null | lab9/lab9.ipynb | YgLK/ML | 1a8fd7857e6ef93bf85ce84e0c99d48dd9d38394 | [
"MIT"
]
| null | null | null | lab9/lab9.ipynb | YgLK/ML | 1a8fd7857e6ef93bf85ce84e0c99d48dd9d38394 | [
"MIT"
]
| null | null | null | 52.722851 | 22,944 | 0.72193 | [
[
[
"from sklearn.datasets import load_iris \nimport pandas as pd\nimport numpy as np\nimport pickle\n\nfrom sklearn.linear_model import Perceptron\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import accuracy_score",
"_____no_output_____"
],
[
"# method used for saving object as pickle\ndef save_object_as_pickle(obj, filename):\n with open(filename, 'wb') as file:\n pickle.dump(obj, file, pickle.HIGHEST_PROTOCOL)",
"_____no_output_____"
]
],
[
[
"### Load the data",
"_____no_output_____"
]
],
[
[
"iris = load_iris(as_frame=True)",
"_____no_output_____"
],
[
"pd.concat([iris.data, iris.target], axis=1).plot.scatter(\n x='petal length (cm)',\n y='petal width (cm)',\n c='target',\n colormap='viridis'\n)",
"_____no_output_____"
],
[
"iris.data",
"_____no_output_____"
],
[
"X = iris.data[['petal length (cm)','petal width (cm)']]\ny = iris.target",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test= train_test_split(X, y, test_size=0.2)",
"_____no_output_____"
],
[
"y_train_0 = (y_train == 0).astype(int)\ny_test_0 = (y_test == 0).astype(int)",
"_____no_output_____"
]
],
[
[
"#### for 0 target value",
"_____no_output_____"
]
],
[
[
"# for 0 target value\nper_clf_0 = Perceptron()\nper_clf_0.fit(X_train, y_train_0)",
"_____no_output_____"
],
[
"y_pred_train_0 = per_clf_0.predict(X_train)\ny_pred_test_0 = per_clf_0.predict(X_test)",
"_____no_output_____"
],
[
"acc_train_0 = accuracy_score(y_train_0, y_pred_train_0)\nacc_test_0 = accuracy_score(y_test_0, y_pred_test_0)\nprint(\"acc_train_0\", acc_train_0)\nprint(\"acc_test_0\", acc_test_0)",
"acc_train_0 1.0\nacc_test_0 1.0\n"
]
],
[
[
"#### for 1 target value",
"_____no_output_____"
]
],
[
[
"y_train_1 = (y_train == 1).astype(int)\ny_test_1 = (y_test == 1).astype(int)",
"_____no_output_____"
],
[
"# for 1 target value\nper_clf_1 = Perceptron()\nper_clf_1.fit(X_train, y_train_1)",
"_____no_output_____"
],
[
"y_pred_train_1 = per_clf_1.predict(X_train)\ny_pred_test_1 = per_clf_1.predict(X_test)",
"_____no_output_____"
],
[
"acc_train_1 = accuracy_score(y_train_1, y_pred_train_1)\nacc_test_1 = accuracy_score(y_test_1, y_pred_test_1)\nprint(\"acc_train_1\", acc_train_1)\nprint(\"acc_test_1\", acc_test_1)",
"acc_train_1 0.6666666666666666\nacc_test_1 0.6666666666666666\n"
]
],
[
[
"#### for 2 target value",
"_____no_output_____"
]
],
[
[
"y_train_2 = (y_train == 2).astype(int)\ny_test_2 = (y_test == 2).astype(int)",
"_____no_output_____"
],
[
"# for 2 target value\nper_clf_2 = Perceptron()\nper_clf_2.fit(X_train, y_train_2)",
"_____no_output_____"
],
[
"y_pred_train_2 = per_clf_2.predict(X_train)\ny_pred_test_2 = per_clf_2.predict(X_test)",
"_____no_output_____"
],
[
"acc_train_2 = accuracy_score(y_train_2, y_pred_train_2)\nacc_test_2 = accuracy_score(y_test_2, y_pred_test_2)\nprint(\"acc_train_2\", acc_train_2)\nprint(\"acc_test_2\", acc_test_2)",
"acc_train_2 0.825\nacc_test_2 0.8666666666666667\n"
]
],
[
[
"#### weights",
"_____no_output_____"
]
],
[
[
"print(\"0: bias weight\", per_clf_0.intercept_)\nprint(\"Input weights (w1, w2): \", per_clf_0.coef_)",
"0: bias weight [9.]\nInput weights (w1, w2): [[-2.1 -3.1]]\n"
],
[
"print(\"1: bias weight\", per_clf_1.intercept_)\nprint(\"Input weights (w1, w2): \", per_clf_1.coef_)",
"1: bias weight [-8.]\nInput weights (w1, w2): [[ 4.6 -22.7]]\n"
],
[
"print(\"0: bias weight\", per_clf_2.intercept_)\nprint(\"Input weights (w1, w2): \", per_clf_2.coef_)",
"0: bias weight [-39.]\nInput weights (w1, w2): [[ 0.8 27.3]]\n"
]
],
[
[
"#### Save accuracy lists and weight tuple in the pickles",
"_____no_output_____"
]
],
[
[
"# accuracy\nper_acc = [(acc_train_0, acc_test_0), (acc_train_1, acc_test_1), (acc_train_2, acc_test_2)]\nfilename = \"per_acc.pkl\"\nsave_object_as_pickle(per_acc, filename)\nprint(\"per_acc\\n\", per_acc)",
"per_acc\n [(1.0, 1.0), (0.6666666666666666, 0.6666666666666666), (0.825, 0.8666666666666667)]\n"
],
[
"# weights\nper_wght = [(per_clf_0.intercept_[0], per_clf_0.coef_[0][0], per_clf_0.coef_[0][1]), (per_clf_1.intercept_[0], per_clf_1.coef_[0][0], per_clf_1.coef_[0][1]), (per_clf_2.intercept_[0], per_clf_2.coef_[0][0], per_clf_2.coef_[0][1])]\nfilename = \"per_wght.pkl\"\nsave_object_as_pickle(per_wght, filename)\nprint(\"per_wght\\n\", per_wght)",
"per_wght\n [(9.0, -2.0999999999999988, -3.0999999999999996), (-8.0, 4.600000000000016, -22.699999999999974), (-39.0, 0.7999999999999883, 27.30000000000003)]\n"
]
],
[
[
"### Perceptron, XOR",
"_____no_output_____"
]
],
[
[
" X = np.array([[0, 0],\n [0, 1],\n [1, 0],\n [1, 1]])\ny = np.array([0,\n 1, \n 1, \n 0])",
"_____no_output_____"
],
[
"per_clf_xor = Perceptron()\nper_clf_xor.fit(X, y)",
"_____no_output_____"
],
[
"pred_xor = per_clf_xor.predict(X)\nxor_acc = accuracy_score(y, pred_xor)\n\nprint(\"xor_accuracy:\", xor_acc)",
"xor_accuracy: 0.5\n"
],
[
"print(\"XOR: bias weight\", per_clf_xor.intercept_)\nprint(\"Input weights (w1, w2): \", per_clf_xor.coef_)",
"XOR: bias weight [0.]\nInput weights (w1, w2): [[0. 0.]]\n"
]
],
[
[
"### 2nd Perceprton, XOR",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom tensorflow import keras",
"_____no_output_____"
],
[
"while True:\n model = keras.models.Sequential()\n\n model.add(keras.layers.Dense(2, activation=\"relu\", input_dim=2))\n model.add(keras.layers.Dense(1, activation=\"sigmoid\"))\n\n model.compile(loss=tf.keras.losses.BinaryCrossentropy(), \n optimizer=tf.keras.optimizers.Adam(learning_rate=0.085), \n metrics=[\"binary_accuracy\"])\n\n history = model.fit(X, y, epochs=100, verbose=False)\n predict_prob=model.predict(X)\n print(predict_prob)\n print(history.history['binary_accuracy'][-1])\n if predict_prob[0] < 0.1 and predict_prob[1] > 0.9 and predict_prob[2] > 0.9 and predict_prob[3] < 0.1:\n weights = model.get_weights()\n break",
"[[0.33351305]\n [0.999105 ]\n [0.33351305]\n [0.33351305]]\n0.75\n[[0.33357185]\n [0.9995415 ]\n [0.33357185]\n [0.33357185]]\n0.75\nWARNING:tensorflow:5 out of the last 5 calls to <function Model.make_predict_function.<locals>.predict_function at 0x0000013C7743D430> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.\n[[0.4994214 ]\n [0.9989133 ]\n [0.4994214 ]\n [0.00138384]]\n0.75\nWARNING:tensorflow:6 out of the last 6 calls to <function Model.make_predict_function.<locals>.predict_function at 0x0000013C7E32BCA0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.\n[[0.6631104 ]\n [0.6631104 ]\n [0.6631104 ]\n [0.01176086]]\n0.75\n[[0.3341035 ]\n [0.3341035 ]\n [0.99895394]\n [0.3341035 ]]\n0.75\n[[0.5001977]\n [0.9983003]\n [0.5001977]\n [0.0029591]]\n0.75\n[[0.6626212 ]\n [0.6626212 ]\n [0.6626212 ]\n [0.00670475]]\n0.75\n[[0.01517117]\n [0.9965296 ]\n [0.99731755]\n [0.01517117]]\n1.0\n"
]
],
[
[
"### Save data to pickle",
"_____no_output_____"
]
],
[
[
"print(\"weights\\n\", weights)",
"weights\n [array([[2.8713741, 2.8880954],\n [2.865467 , 2.8870766]], dtype=float32), array([-2.8651741e+00, -1.7966949e-03], dtype=float32), array([[-5.7537994],\n [ 2.6404846]], dtype=float32), array([-3.0722845], dtype=float32)]\n"
],
[
"filename = \"mlp_xor_weights.pkl\"\nsave_object_as_pickle(weights, filename)",
"_____no_output_____"
]
],
[
[
"### Check saved Pickles contents",
"_____no_output_____"
]
],
[
[
"# check if pickles' contents are saved correctly\n\nprint(\"per_acc.pkl\\n\", pd.read_pickle(\"per_acc.pkl\"), \"\\n\")\nprint(\"per_wght.pkl\\n\", pd.read_pickle(\"per_wght.pkl\"), \"\\n\")\nprint(\"mlp_xor_weights.pkl\\n\", pd.read_pickle(\"mlp_xor_weights.pkl\"), \"\\n\")",
"per_acc.pkl\n [(1.0, 1.0), (0.6666666666666666, 0.6666666666666666), (0.825, 0.8666666666666667)] \n\nper_wght.pkl\n [(9.0, -2.0999999999999988, -3.0999999999999996), (-8.0, 4.600000000000016, -22.699999999999974), (-39.0, 0.7999999999999883, 27.30000000000003)] \n\nmlp_xor_weights.pkl\n [array([[2.8713741, 2.8880954],\n [2.865467 , 2.8870766]], dtype=float32), array([-2.8651741e+00, -1.7966949e-03], dtype=float32), array([[-5.7537994],\n [ 2.6404846]], dtype=float32), array([-3.0722845], dtype=float32)] \n\n"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7cf35f5eddaba2686965ae04320d7cfa5b86c76 | 9,355 | ipynb | Jupyter Notebook | chapter-4/section4.ipynb | NaiveXu/latex-cookbook | ff5596d7c76de8fc39f008e29fc6dc97805c6336 | [
"MIT"
]
| 283 | 2021-03-29T14:49:24.000Z | 2022-03-31T14:34:38.000Z | chapter-4/section4.ipynb | Hi1993Ryan/latex-cookbook | ba6b84e245982254958afa39b788cdf272009a3f | [
"MIT"
]
| null | null | null | chapter-4/section4.ipynb | Hi1993Ryan/latex-cookbook | ba6b84e245982254958afa39b788cdf272009a3f | [
"MIT"
]
| 57 | 2021-04-20T15:55:45.000Z | 2022-03-31T06:58:12.000Z | 35.169173 | 310 | 0.474826 | [
[
[
"## 4.4 微积分\n\n事实上,数学公式的范畴极为广泛,我们所熟知的大学数学课程中,微积分、线性代数、概率论与数理统计中数学表达式的符号系统均大不相同。本节将主要介绍如何使用LaTeX对微积分中的数学表达式进行书写和编译。\n\n### 4.4.1 极限\n\n求极限是整个微积分中的基石,例如$\\lim_{x\\to 2}x^{2}$对应的LaTeX代码为`$\\lim_{x\\to 2}x^{2}$`。\n\n【**例4-37**】书写以下求极限的表达式:\n\n$$\\lim_{x\\to-\\infty}\\frac{3x^{2}-2}{3x-2x^{2}}=\\lim_{x\\to-\\infty}\\frac{x^{2}\\left(3-\\frac{2}{x^{2}}\\right)}{x^{2}\\left(\\frac{3}{x}-2\\right)}=\\lim_{x\\to-\\infty}\\frac{3-\\frac{2}{x^{2}}}{\\frac{3}{x}-2}=-\\frac{3}{2}$$\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$\\lim_{x\\to-\\infty}\\frac{3x^{2}-2}{3x-2x^{2}}=\\lim_{x\\to-\\infty}\\frac{x^{2}\\left(3-\\frac{2}{x^{2}}\\right)}{x^{2}\\left(\\frac{3}{x}-2\\right)}=\\lim_{x\\to-\\infty}\\frac{3-\\frac{2}{x^{2}}}{\\frac{3}{x}-2}=-\\frac{3}{2}$$\n\n\\end{document}\n```\n\n【**例4-38**】书写极限$\\lim_{\\Delta t\\to0}\\frac{s(t+\\Delta t)+s(t)}{\\Delta t}$和$\\displaystyle{\\lim_{\\Delta t\\to0}\\frac{s(t+\\Delta t)+s(t)}{\\Delta t}}$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$\\lim_{\\Delta t\\to0}\\frac{s(t+\\Delta t)+s(t)}{\\Delta t}$ \\& $\\displaystyle{\\lim_{\\Delta t\\to0}\\frac{s(t+\\Delta t)+s(t)}{\\Delta t}}$\n\n\\end{document}\n```",
"_____no_output_____"
],
[
"### 4.4.2 导数\n\n在微积分中,给定函数$f(x)$后,我们能够将其导数定义为\n\n$$f^\\prime(a)=\\lim_{x\\to a}\\frac{f(x)-f(a)}{x-a}$$\n\n用LaTeX书写这条公式为`$$f^\\prime(a)=\\lim_{x\\to a}\\frac{f(x)-f(a)}{x-a}$$`,有时候,为了让分数的形式在直观上不显得过大,可以用`$$f^\\prime(a)=\\lim\\limits_{x\\to a}\\frac{f(x)-f(a)}{x-a}$$`,其中,`\\lim`和`\\limits`两个命令需要配合使用。\n\n需要注意的是,`f^\\prime(x)`中的`\\prime`命令是标准写法,有时候也可以写作`f'(x)`。\n\n【**例4-39**】书写导数的定义$f^\\prime(x)=\\lim_{\\Delta x\\to 0}\\frac{f(x+\\Delta x)-f(x)}{\\Delta x}$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$f^\\prime(x)=\\lim_{\\Delta x\\to 0}\\frac{f(x+\\Delta x)-f(x)}{\\Delta x}$$\n\n\\end{document}\n```\n\n【**例4-40**】书写函数$f(x)=3x^{5}+2x^{3}+1$的导数$f^\\prime(x)=15x^{4}+6x^{2}$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$f^\\prime(x)=15x^{4}+6x^{2}$$\n\n\\end{document}\n```\n\n微分在微积分中举足轻重,`\\mathrm{d}`为微分符号$\\mathrm{d}$的命令,一般而言,微分的标准写法为$\\frac{\\mathrm{d}^{n}}{\\mathrm{d}x^{n}}f(x)$。\n\n【**例4-41**】书写微分$\\frac{\\mathrm{d}}{\\mathrm{d}x}f(x)=15x^{4}+6x^{2}$、$\\frac{\\mathrm{d}^{2}}{\\mathrm{d}^{2}x}f(x)=60x^{3}+12x$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$\\frac{\\mathrm{d}}{\\mathrm{d}x}f(x)=15x^{4}+6x^{2}$$\n$$\\frac{\\mathrm{d}^{2}}{\\mathrm{d}^{2}x}f(x)=60x^{3}+12x$$\n\n\\end{document}\n```\n\n在微积分中,偏微分符号$\\partial$的命令为`\\partial`,对于任意函数$f(x,y)$,偏微分的标准写法为$\\frac{\\partial^{n}}{\\partial x^{n}}f(x,y)$或$\\frac{\\partial^{n}}{\\partial y^{n}}f(x,y)$。\n\n【**例4-42**】书写函数$f(x,y)=3x^{5}y^{2}+2x^{3}y+1$的偏微分$\\frac{\\partial}{\\partial x}f(x,y)=15x^{4}y^{2}+6x^{2}y$和$\\frac{\\partial}{\\partial y}f(x,y)=6x^{5}y+2x^{3}$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$\\frac{\\partial}{\\partial x}f(x,y)=15x^{4}y^{2}+6x^{2}y$$\n$$\\frac{\\partial}{\\partial y}f(x,y)=6x^{5}y+2x^{3}$$\n\n\\end{document}\n```\n\n【**例4-43**】书写偏导数$z=\\mu\\,\\frac{\\partial y}{\\partial x}\\bigg|_{x=0}$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$z=\\mu\\,\\frac{\\partial y}{\\partial x}\\bigg|_{x=0}$$\n\n\\end{document}\n```\n",
"_____no_output_____"
],
[
"### 4.4.3 积分\n\n积分的标准写法为$\\int_{a}^{b}f(x)\\,\\mathrm{d}x$,代码为`\\int_{a}^{b}f(x)\\,\\mathrm{d}x`,其中,`\\int`表示积分,是英文单词integral的缩写形式,使用`\\,`的目的是引入一个空格。\n\n【**例4-44**】书写积分$\\int\\frac{\\mathrm{d}x}{\\sqrt{a^{2}+x^{2}}}=\\frac{1}{a}\\arcsin\\left(\\frac{x}{a}\\right)+C$和$\\int\\tan^{2}x\\,\\mathrm{d}x=\\tan x-x+C$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$\\int\\frac{\\mathrm{d}x}{\\sqrt{a^{2}+x^{2}}}=\\frac{1}{a}\\arcsin\\left(\\frac{x}{a}\\right)+C$$\n$$\\int\\tan^{2}x\\,\\mathrm{d}x=\\tan x-x+C$$\n\n\\end{document}\n```\n\n【**例4-45**】书写积分$\\int_{a}^{b}\\left[\\lambda_{1}f_{1}(x)+\\lambda_{2}f_{2}(x)\\right]\\,\\mathrm{d}x=\\lambda_{1}\\int_{a}^{b}f_{1}(x)\\,\\mathrm{d}x+\\lambda_{2}\\int_{a}^{b}f_{2}(x)\\,\\mathrm{d}x$和$\\int_{a}^{b}f(x)\\,\\mathrm{d}x=\\int_{a}^{c}f(x)\\,\\mathrm{d}x+\\int_{c}^{b}f(x)\\,\\mathrm{d}x$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$\\int_{a}^{b}\\left[\\lambda_{1}f_{1}(x)+\\lambda_{2}f_{2}(x)\\right]\\,\\mathrm{d}x=\\lambda_{1}\\int_{a}^{b}f_{1}(x)\\,\\mathrm{d}x+\\lambda_{2}\\int_{a}^{b}f_{2}(x)\\,\\mathrm{d}x$$\n$$\\int_{a}^{b}f(x)\\,\\mathrm{d}x=\\int_{a}^{c}f(x)\\,\\mathrm{d}x+\\int_{c}^{b}f(x)\\,\\mathrm{d}x$$\n\n\\end{document}\n```\n\n【**例4-46**】书写积分\n\n\\begin{equation}\n\\begin{aligned}\nV &=2\\pi\\int_{0}^{1} x\\left[1-(x-1)^{2}\\right]\\,\\mathrm{d}x \\\\\n&=2\\pi\\int_{0}^{2}\\left[-x^{3}+2 x^{2}\\right]\\,\\mathrm{d}x \\\\\n&=2\\pi\\left[-\\frac{1}{4} x^{4}+\\frac{2}{3} x^{3}\\right]_{0}^{2} \\\\\n&=8\\pi/3\n\\end{aligned}\n\\end{equation}\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n\\begin{equation}\n\\begin{aligned}\nV&=2\\pi\\int_{0}^{1} x\\left\\{1-(x-1)^{2}\\right\\}\\,\\mathrm{d}x \\\\\n&=2\\pi\\int_{0}^{2}\\left\\{-x^{3}+2 x^{2}\\right\\}\\,\\mathrm{d}x \\\\\n&=2\\pi\\left[-\\frac{1}{4} x^{4}+\\frac{2}{3} x^{3}\\right]_{0}^{2} \\\\\n&=8\\pi/3\n\\end{aligned}\n\\end{equation}\n\n\\end{document}\n```\n\n上述介绍的都是一重积分,在微积分课程中,还有二重积分、三重积分等,对于一重积分,LaTeX提供的基本命令为`\\int`,二重积分为`\\iint`,三重积分为`\\iiint`、四重积分为`\\iiiint`,当积分为五重或以上时,一般使用`\\idotsint`,即$\\idotsint$。\n\n【**例4-47**】书写积分$\\iint\\limits_{D}f(x,y)\\,\\mathrm{d}\\sigma$和$\\iiint\\limits_{\\Omega}\\left(x^{2}+y^{2}+z^{2}\\right)\\,\\mathrm{d}v$。\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n$$\\iint\\limits_{D}f(x,y)\\,\\mathrm{d}\\sigma$$\n$$\\iiint\\limits_{\\Omega}\\left(x^{2}+y^{2}+z^{2}\\right)\\,\\mathrm{d}v$$\n\n\\end{document}\n```\n\n在积分中,有一种特殊的积分符号是在标准的积分符号上加上一个圈,可用来表示计算曲线曲面积分,即$\\oint_{C}f(x)\\,\\mathrm{d}x+g(y)\\,\\mathrm{d}y$,代码为`\\oint_{C}f(x)\\,\\mathrm{d}x+g(y)\\,\\mathrm{d}y`。",
"_____no_output_____"
],
[
"### 练习题\n\n> 打开LaTeX在线系统[https://www.overleaf.com](https://www.overleaf.com/project)或本地安装好的LaTeX编辑器,创建名为LaTeX_practice的项目,并同时新建一个以`.tex`为拓展名的源文件,完成以下几道练习题。\n\n[1] 书写泰勒展开式\n\n\\begin{equation}\n\\begin{aligned}\nf\\left(x\\right)=&\\frac{f\\left(x_{0}\\right)}{0!}+\\frac{f'\\left(x_{0}\\right)}{1!}\\left(x-x_{0}\\right)^{2} \\\\\n&+\\cdots+\\frac{f^{\\left(n\\right)}\\left(x_{0}\\right)}{n!}\\left(x-x_{0}\\right)^{n}+R_{n}\\left(x\\right)\n\\end{aligned}\n\\end{equation}\n\n```tex\n\\documentclass[12pt]{article}\n\\begin{document}\n\n\\begin{equation}\n\\begin{aligned}\n% 在此处书写公式\n\\end{aligned}\n\\end{equation}\n\n\\end{document}\n```",
"_____no_output_____"
],
[
"【回放】[**4.3 希腊字母**](https://nbviewer.jupyter.org/github/xinychen/latex-cookbook/blob/main/chapter-4/section3.ipynb)\n\n【继续】[**4.5 线性代数**](https://nbviewer.jupyter.org/github/xinychen/latex-cookbook/blob/main/chapter-4/section5.ipynb)",
"_____no_output_____"
],
[
"### License\n\n<div class=\"alert alert-block alert-danger\">\n<b>This work is released under the MIT license.</b>\n</div>",
"_____no_output_____"
]
]
]
| [
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
e7cf458b1066f01f6729ee273db12af4511b60d9 | 23,610 | ipynb | Jupyter Notebook | analysis/spheroid/20190703-sta-titration/exp.ipynb | hammerlab/spheroid | cc6a6677595a3cf176a3b7d91d23d42d0e47e0bb | [
"Apache-2.0"
]
| null | null | null | analysis/spheroid/20190703-sta-titration/exp.ipynb | hammerlab/spheroid | cc6a6677595a3cf176a3b7d91d23d42d0e47e0bb | [
"Apache-2.0"
]
| null | null | null | analysis/spheroid/20190703-sta-titration/exp.ipynb | hammerlab/spheroid | cc6a6677595a3cf176a3b7d91d23d42d0e47e0bb | [
"Apache-2.0"
]
| null | null | null | 30.464516 | 97 | 0.352817 | [
[
[
"import pandas as pd\nimport numpy as np\nimport os.path as osp\n%load_ext dotenv\n%dotenv env.sh\n%run -m cytokit_nb.keyence",
"_____no_output_____"
],
[
"df = pd.read_csv('experiments-base.csv')\ndf",
"_____no_output_____"
],
[
"grids = ['XY01', 'XY02', 'XY03']\n\ndef add_info(r, grid):\n path = osp.join(os.environ['EXP_GROUP_RAW_DIR'], r['dir'], grid)\n info = analyze_keyence_dataset(path)\n assert info['z_pitch'].nunique() == 1\n base_conf = 'experiment.yaml'\n if r['dir'] == '4uMsta-grids':\n base_conf = 'experiment_cy5last.yaml'\n return r.append(pd.Series({\n 'grid': grid,\n 'z_pitch': info['z_pitch'].iloc[0],\n 'n_tiles': info['tile'].nunique(),\n 'n_z': info['z'].nunique(),\n 'n_ch': info['ch'].nunique(),\n 'chs': tuple(sorted(info['ch'].unique())),\n 'conf': base_conf\n })).sort_index()\n\ndfi = pd.DataFrame([\n add_info(r, grid=g)\n for _, r in df.iterrows()\n for g in grids\n])\ndfi.head()",
"_____no_output_____"
],
[
"dfi['chs'].unique()",
"_____no_output_____"
],
[
"dfi[dfi['chs'] == ('1', '3', '4')]",
"_____no_output_____"
],
[
"dfi[['name', 'grid', 'n_z']]",
"_____no_output_____"
],
[
"assert dfi['n_ch'].nunique() == 1\nassert dfi['z_pitch'].nunique() == 1\nassert dfi['n_tiles'].nunique() == 1",
"_____no_output_____"
],
[
"dfe = dfi.copy()\ndfe = dfe.rename(columns={'name': 'cond'})\ndfe = dfe.drop('chs', axis=1)\ndfe.insert(0, 'name', dfe.apply(lambda r: '{}-{}'.format(r['cond'], r['grid']), axis=1))\ndfe.head()",
"_____no_output_____"
],
[
"dfe.to_csv('experiments.csv', index=False)",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cf529f7a73c921953d218f019c21622dfbc910 | 549,519 | ipynb | Jupyter Notebook | analysis/Jeran/.ipynb_checkpoints/EDA-checkpoint.ipynb | data301-2020-winter1/course-project-group_6019 | 7fdfd1aa7a7b5f99f03ec719fb94a9b200356859 | [
"MIT"
]
| null | null | null | analysis/Jeran/.ipynb_checkpoints/EDA-checkpoint.ipynb | data301-2020-winter1/course-project-group_6019 | 7fdfd1aa7a7b5f99f03ec719fb94a9b200356859 | [
"MIT"
]
| 1 | 2020-11-26T02:50:09.000Z | 2020-11-26T02:50:20.000Z | analysis/Jeran/.ipynb_checkpoints/EDA-checkpoint.ipynb | data301-2020-winter1/course-project-group_6019 | 7fdfd1aa7a7b5f99f03ec719fb94a9b200356859 | [
"MIT"
]
| null | null | null | 355.445666 | 174,772 | 0.902409 | [
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport sys, os\nsys.path.insert(0, os.path.abspath('..')) \nimport Project_Functions as pf\n\ndata = pf.load_data()\nClean_Data = pf.load_and_process()\npf.basics(data)",
" Team Full Name Overall Rating Position Age Speed \\\n0 Rams Aaron Donald 99 RE 29 82 \n1 Patriots Stephon Gilmore 99 CB 29 92 \n2 Panthers Christian McCaffrey 99 HB 24 92 \n3 Chiefs Patrick Mahomes 99 QB 24 81 \n4 Saints Michael Thomas 99 WR 27 89 \n\n Acceleration Awareness Agility Strength ... Jersey Number \\\n0 90 99 86 99 ... 99 \n1 94 99 94 70 ... 24 \n2 93 97 97 72 ... 22 \n3 87 97 88 69 ... 15 \n4 92 99 92 77 ... 13 \n\n Total Salary Signing Bonus Archetype \\\n0 $101,892,000.00 $40,000,000.00 DE_PowerRusher \n1 $33,550,000.00 $31,450,000.00 CB_MantoMan \n2 $45,840,000.00 $32,190,000.00 HB_ReceivingBack \n3 $6,840,000.00 $34,420,000.00 QB_Improviser \n4 $62,750,000.00 $35,130,000.00 WR_RouteRunner \n\n Running Style Years Pro Height Weight Birthdate College \n0 Default Stride Loose 6 73 280 5/23/1991 Pittsburgh \n1 Default 8 73 202 9/19/1990 South Carolina \n2 Short Stride Default 3 71 205 6/7/1996 Stanford \n3 Default 3 75 230 9/17/1995 Texas Tech \n4 Default 4 75 212 3/3/1993 Ohio State \n\n[5 rows x 69 columns]\n(2293, 69)\nIndex(['Team', 'Full Name', 'Overall Rating', 'Position', 'Age', 'Speed',\n 'Acceleration', 'Awareness', 'Agility', 'Strength', 'Throw Power',\n 'Throw On The Run', 'Throw Under Pressure', 'Throw Accuracy Short',\n 'Throw Accuracy Mid', 'Throw Accuracy Deep', 'Release',\n 'Ball Carrier Vision', 'Stamina', 'Carrying', 'Play Action', 'Pursuit',\n 'Play Recognition', 'Short Route Running', 'Medium Route Running',\n 'Deep Route Running', 'Catch In Traffic', 'Catching', 'Spin Move',\n 'Finesse Moves', 'Spectacular Catch', 'Jumping', 'Tackle',\n 'Zone Coverage', 'Man Coverage', 'Trucking', 'Juke Move', 'Break Sack',\n 'Toughness', 'Stiff Arm', 'Power Moves', 'Lead Blocking',\n 'Run Block Power', 'Run Blocking', 'Hit Power', 'Pass Block Finesse',\n 'Pass Block Power', 'Pass Blocking', 'Impact Blocking', 'Kick Return',\n 'Kick Accuracy', 'Break Tackle', 'Kick Power', 'Change Of Direction',\n 'Press', 'Block Shedding', 'Run Block Finesse', 'Injury',\n 'Player Handedness', 'Jersey Number', ' Total Salary ',\n ' Signing Bonus ', 'Archetype', 'Running Style', 'Years Pro', 'Height',\n 'Weight', 'Birthdate', 'College'],\n dtype='object')\n"
],
[
"data.describe(exclude=[np.number])",
"_____no_output_____"
],
[
"if len(data[data.duplicated()]) > 0:\n print(\"No. of duplicated entries: \", len(data[data.duplicated()]))\n print(data[data.duplicated(keep=False)].sort_values(by=list(data.columns)).head())\nelse:\n print(\"No duplicated entries found\")",
"No duplicated entries found\n"
],
[
"data.describe().T",
"_____no_output_____"
],
[
"data.describe(include=[np.number])",
"_____no_output_____"
],
[
"data.hist(bins=10, figsize=(25,25))",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize = (25, 25))\nsns.heatmap(data.corr(), cmap = 'crest', linewidths = .01)",
"_____no_output_____"
],
[
"data.boxplot(vert = False, figsize = (25,25))",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cf54a60582262538f56bfaffd72d2f26331065 | 6,347 | ipynb | Jupyter Notebook | writeups/rice/rice.ipynb | kdmurray91/kwip-experiments | 7a8e8778e0f5ae39d2dd123d9e4216a475d62ba0 | [
"MIT"
]
| 1 | 2020-07-07T04:50:20.000Z | 2020-07-07T04:50:20.000Z | writeups/rice/rice.ipynb | kdmurray91/kwip-experiments | 7a8e8778e0f5ae39d2dd123d9e4216a475d62ba0 | [
"MIT"
]
| null | null | null | writeups/rice/rice.ipynb | kdmurray91/kwip-experiments | 7a8e8778e0f5ae39d2dd123d9e4216a475d62ba0 | [
"MIT"
]
| null | null | null | 26.119342 | 192 | 0.490153 | [
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport scipy.stats as spstats\nfrom skbio import DistanceMatrix\nimport json\nfrom glob import glob\nimport rpy2\nimport pandas as pd\nfrom collections import defaultdict\n\n\n%matplotlib inline\n%load_ext rpy2.ipython\n#%config InlineBackend.figure_format = 'svg'\n%config InlineBackend.rc = {'font.size': 10, 'figure.figsize': (8.0, 8.0), 'figure.facecolor': 'white', 'savefig.dpi': 72, 'figure.subplot.bottom': 0.125, 'figure.edgecolor': 'white'}\n\nwith open(\"sample-run.json\") as fh:\n samples = json.load(fh)",
"_____no_output_____"
],
[
"def make_trumat():\n arr = np.zeros((96, 96))\n for x in range(2):\n for y in range(2):\n for j in range(x * 48, (x+1) * 48):\n for k in range(y * 48, (y+1) * 48):\n if x == y:\n arr[j, k] = 2\n else:\n arr[j, k] = 4\n for i in range(16):\n st = i * 6\n sp = st + 6\n for j in range(st, sp):\n for k in range(st, sp):\n if j == k:\n arr[j, k] = 0\n else:\n arr[j, k] = 1\n return arr",
"_____no_output_____"
],
[
"plt.imshow(make_trumat(), interpolation='none')\ntruth = DistanceMatrix(make_trumat()).condensed_form()",
"_____no_output_____"
],
[
"def reorder_matrix(mat, metad):\n ids = mat.ids\n g2s = defaultdict(list)\n for group, samples in metad.items():\n for sample in samples.values():\n for run in sample:\n g2s[group].append(run)\n neworder = []\n for grp in ['Indica', 'Japonica']:\n neworder.extend(list(sorted(g2s[grp])))\n assert(set(neworder) == set(ids))\n return mat.filter(neworder)",
"_____no_output_____"
],
[
"scores = []\n\nfor i in range(2, 102):\n wipf = \"kwip/3krice_set_{:03d}_wip.dist\".format(i)\n ipf = \"kwip/3krice_set_{:03d}_ip.dist\".format(i)\n mdf = \"metadata/3krice_set_{:03d}.txt.json\".format(i)\n try:\n wip = DistanceMatrix.read(wipf)\n ip = DistanceMatrix.read(ipf)\n with open(mdf) as fh:\n metad = json.load(fh)\n except Exception as e:\n print(str(e))\n print(\"skipping *{:03d}*\".format(i))\n continue\n wip = reorder_matrix(wip, metad)\n ip = reorder_matrix(ip, metad)\n if i <= 10:\n wip.plot()\n wipr, _ = spstats.pearsonr(truth, wip.condensed_form())\n ipr, _ = spstats.pearsonr(truth, ip.condensed_form())\n wips, _ = spstats.spearmanr(truth, wip.condensed_form())\n ips, _ = spstats.spearmanr(truth, ip.condensed_form())\n scores.append((wipr, ipr, wips, ips))",
"_____no_output_____"
],
[
"scoremat = pd.DataFrame(np.array(scores), columns=('WIPpearson', \"IPpearson\", \"WIP\", \"IP\"))",
"_____no_output_____"
],
[
"%%R -i scoremat\nlibrary(tidyr)\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(reshape2)\nsummary(scoremat)\n\nscoremat = scoremat %>%\n select(WIP, IP)\n\nsm.melt = melt(scoremat, value.name=\"r\", variable.name='Metric')\nprint(summary(sm.melt))\n\nt.test(scoremat$WIP, scoremat$IP, paired=T)",
"_____no_output_____"
],
[
"%%R\n\np = ggplot(sm.melt, aes(x=Metric, y=r)) +\n geom_violin(aes(fill=Metric)) +\n ylab(\"Spearman's rho\") +\n ylim(0, 1) +\n theme_bw()\n\nprint(p)\npdf(\"replicate-correlation.pdf\", width=3, height=4)\nprint(p)\ndev.off()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cf612bbff2da366ee4015137522bb1db41ab86 | 38,554 | ipynb | Jupyter Notebook | wandb/run-20210519_093746-2wg641lq/tmp/code/00-main.ipynb | Programmer-RD-AI/Weather-Clf-V2 | 1c2acf4f5ddb6c7f35c1d814f40a8eb8b13ab62f | [
"Apache-2.0"
]
| 1 | 2021-05-19T17:24:40.000Z | 2021-05-19T17:24:40.000Z | wandb/run-20210519_093746-2wg641lq/tmp/code/00-main.ipynb | Programmer-RD-AI/Weather-Clf | 1c2acf4f5ddb6c7f35c1d814f40a8eb8b13ab62f | [
"Apache-2.0"
]
| null | null | null | wandb/run-20210519_093746-2wg641lq/tmp/code/00-main.ipynb | Programmer-RD-AI/Weather-Clf | 1c2acf4f5ddb6c7f35c1d814f40a8eb8b13ab62f | [
"Apache-2.0"
]
| null | null | null | 31.86281 | 546 | 0.499767 | [
[
[
"test_index = 0",
"_____no_output_____"
]
],
[
[
"#### testing",
"_____no_output_____"
]
],
[
[
"from load_data import *",
"_____no_output_____"
],
[
"# load_data()",
"_____no_output_____"
]
],
[
[
"## Loading the data",
"_____no_output_____"
]
],
[
[
"from load_data import *",
"_____no_output_____"
],
[
"X_train,X_test,y_train,y_test = load_data()",
"4\nOpenCV(4.5.1) /tmp/pip-req-build-hj027r8z/opencv/modules/imgproc/src/resize.cpp:4051: error: (-215:Assertion failed) !ssize.empty() in function 'resize'\n\n./data/data/Shine/shine131.jpg\nOpenCV(4.5.1) /tmp/pip-req-build-hj027r8z/opencv/modules/imgproc/src/resize.cpp:4051: error: (-215:Assertion failed) !ssize.empty() in function 'resize'\n\n./data/data/Rain/rain141.jpg\n"
],
[
"len(X_train),len(y_train)",
"_____no_output_____"
],
[
"len(X_test),len(y_test)",
"_____no_output_____"
]
],
[
[
"## Test Modelling",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torch.optim as optim\nimport torch.nn.functional as F",
"_____no_output_____"
],
[
"class Test_Model(nn.Module):\n def __init__(self) -> None:\n super().__init__()\n self.c1 = nn.Conv2d(1,64,5)\n self.c2 = nn.Conv2d(64,128,5)\n self.c3 = nn.Conv2d(128,256,5)\n self.fc4 = nn.Linear(256*10*10,256)\n self.fc6 = nn.Linear(256,128)\n self.fc5 = nn.Linear(128,4)\n \n def forward(self,X):\n preds = F.max_pool2d(F.relu(self.c1(X)),(2,2))\n preds = F.max_pool2d(F.relu(self.c2(preds)),(2,2))\n preds = F.max_pool2d(F.relu(self.c3(preds)),(2,2))\n# print(preds.shape)\n preds = preds.view(-1,256*10*10)\n preds = F.relu(self.fc4(preds))\n preds = F.relu(self.fc6(preds))\n preds = self.fc5(preds)\n return preds",
"_____no_output_____"
],
[
"device = torch.device('cuda')",
"_____no_output_____"
],
[
"BATCH_SIZE = 32",
"_____no_output_____"
],
[
"IMG_SIZE = 112",
"_____no_output_____"
],
[
"model = Test_Model().to(device)\noptimizer = optim.SGD(model.parameters(),lr=0.1)\ncriterion = nn.CrossEntropyLoss()",
"_____no_output_____"
],
[
"EPOCHS = 125",
"_____no_output_____"
],
[
"from tqdm import tqdm",
"_____no_output_____"
],
[
"PROJECT_NAME = 'Weather-Clf'",
"_____no_output_____"
],
[
"import wandb",
"_____no_output_____"
],
[
"test_index += 1\nwandb.init(project=PROJECT_NAME,name=f'test')\nfor _ in tqdm(range(EPOCHS)):\n for i in range(0,len(X_train),BATCH_SIZE):\n X_batch = X_train[i:i+BATCH_SIZE].view(-1,1,112,112).to(device)\n y_batch = y_train[i:i+BATCH_SIZE].to(device)\n model.to(device)\n preds = model(X_batch.float())\n preds.to(device)\n loss = criterion(preds,torch.tensor(y_batch,dtype=torch.long))\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n wandb.log({'loss':loss.item()})\nwandb.finish()",
"_____no_output_____"
],
[
"# for index in range(10):\n# print(torch.argmax(preds[index]))\n# print(y_batch[index])\n# print('\\n')",
"_____no_output_____"
],
[
"class Test_Model(nn.Module):\n def __init__(self):\n super().__init__()\n self.conv1 = nn.Conv2d(1,16,5)\n self.conv2 = nn.Conv2d(16,32,5)\n self.conv3 = nn.Conv2d(32,64,5)\n self.fc1 = nn.Linear(64*10*10,16)\n self.fc2 = nn.Linear(16,32)\n self.fc3 = nn.Linear(32,64)\n self.fc4 = nn.Linear(64,32)\n self.fc5 = nn.Linear(32,6)\n \n def forward(self,X):\n preds = F.max_pool2d(F.relu(self.conv1(X)),(2,2))\n preds = F.max_pool2d(F.relu(self.conv2(preds)),(2,2))\n preds = F.max_pool2d(F.relu(self.conv3(preds)),(2,2))\n# print(preds.shape)\n preds = preds.view(-1,64*10*10)\n preds = F.relu(self.fc1(preds))\n preds = F.relu(self.fc2(preds))\n preds = F.relu(self.fc3(preds))\n preds = F.relu(self.fc4(preds))\n preds = F.relu(self.fc5(preds))\n return preds",
"_____no_output_____"
],
[
"model = Test_Model().to(device)\noptimizer = optim.SGD(model.parameters(),lr=0.1)\ncriterion = nn.CrossEntropyLoss()",
"_____no_output_____"
],
[
"# test_index += 1\n# wandb.init(project=PROJECT_NAME,name=f'test-{test_index}')\n# for _ in tqdm(range(EPOCHS)):\n# for i in range(0,len(X_train),BATCH_SIZE):\n# X_batch = X_train[i:i+BATCH_SIZE].view(-1,1,112,112).to(device)\n# y_batch = y_train[i:i+BATCH_SIZE].to(device)\n# model.to(device)\n# preds = model(X_batch.float())\n# preds.to(device)\n# loss = criterion(preds,torch.tensor(y_batch,dtype=torch.long))\n# optimizer.zero_grad()\n# loss.backward()\n# optimizer.step()\n# wandb.log({'loss':loss.item()})\n# wandb.finish()",
"_____no_output_____"
]
],
[
[
"## Modelling",
"_____no_output_____"
]
],
[
[
"class Test_Model(nn.Module):\n def __init__(self,conv1_output=16,conv2_output=32,conv3_output=64,fc1_output=16,fc2_output=32,fc3_output=64,activation=F.relu):\n super().__init__()\n self.conv3_output = conv3_output\n self.conv1 = nn.Conv2d(1,conv1_output,5)\n self.conv2 = nn.Conv2d(conv1_output,conv2_output,5)\n self.conv3 = nn.Conv2d(conv2_output,conv3_output,5)\n self.fc1 = nn.Linear(conv3_output*10*10,fc1_output)\n self.fc2 = nn.Linear(fc1_output,fc2_output)\n self.fc3 = nn.Linear(fc2_output,fc3_output)\n self.fc4 = nn.Linear(fc3_output,fc2_output)\n self.fc5 = nn.Linear(fc2_output,6)\n self.activation = activation\n \n def forward(self,X):\n preds = F.max_pool2d(self.activation(self.conv1(X)),(2,2))\n preds = F.max_pool2d(self.activation(self.conv2(preds)),(2,2))\n preds = F.max_pool2d(self.activation(self.conv3(preds)),(2,2))\n# print(preds.shape)\n preds = preds.view(-1,self.conv3_output*10*10)\n preds = self.activation(self.fc1(preds))\n preds = self.activation(self.fc2(preds))\n preds = self.activation(self.fc3(preds))\n preds = self.activation(self.fc4(preds))\n preds = self.activation(self.fc5(preds))\n return preds",
"_____no_output_____"
],
[
"# conv1_output = 32\n\n# conv2_output\n# conv3_output\n# fc1_output\n# fc2_output\n# fc3_output\n# activation\n# optimizer\n# loss\n# lr\n# num of epochs",
"_____no_output_____"
],
[
"def get_loss(criterion,y,model,X):\n model.to('cpu')\n preds = model(X.view(-1,1,112,112).to('cpu').float())\n preds.to('cpu')\n loss = criterion(preds,torch.tensor(y,dtype=torch.long).to('cpu'))\n loss.backward()\n return loss.item()",
"_____no_output_____"
],
[
"def test(net,X,y):\n device = 'cpu'\n net.to(device)\n correct = 0\n total = 0\n net.eval()\n with torch.no_grad():\n for i in range(len(X)):\n real_class = torch.argmax(y[i]).to(device)\n net_out = net(X[i].view(-1,1,112,112).to(device).float())\n net_out = net_out[0]\n predictied_class = torch.argmax(net_out)\n if predictied_class == real_class:\n correct += 1\n total += 1\n net.train()\n net.to('cuda')\n return round(correct/total,3)",
"_____no_output_____"
],
[
"EPOCHS = 3",
"_____no_output_____"
],
[
"conv3_outputs = [16,32,64,128]\nfor conv3_output in conv3_outputs:\n wandb.init(project=PROJECT_NAME,name=f'conv3_output-{conv3_output}')\n model = Test_Model(conv1_output=32,conv2_output=8,conv3_output=conv3_output).to(device)\n optimizer = optim.SGD(model.parameters(),lr=0.1)\n criterion = nn.CrossEntropyLoss()\n for _ in tqdm(range(EPOCHS)):\n for i in range(0,len(X_train),BATCH_SIZE):\n X_batch = X_train[i:i+BATCH_SIZE].view(-1,1,112,112).to(device)\n y_batch = y_train[i:i+BATCH_SIZE].to(device)\n model.to(device)\n preds = model(X_batch.float())\n preds.to(device)\n loss = criterion(preds,torch.tensor(y_batch,dtype=torch.long))\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n wandb.log({'loss':get_loss(criterion,y_train,model,X_train),'accuracy':test(model,X_train,y_train),'val_accuracy':test(model,X_test,y_test),'val_loss':get_loss(criterion,y_test,model,X_test)})\n for index in range(10):\n print(torch.argmax(preds[index]))\n print(y_batch[index])\n print('\\n')\n wandb.finish()",
"\u001b[34m\u001b[1mwandb\u001b[0m: Currently logged in as: \u001b[33mranuga-d\u001b[0m (use `wandb login --relogin` to force relogin)\n"
],
[
"# conv2_outputs = [8,16,32,64]\n# for conv2_output in conv2_outputs:\n# wandb.init(project=PROJECT_NAME,name=f'conv2_output-{conv2_output}')\n# model = Test_Model(conv1_output=32,conv2_output=conv2_output).to(device)\n# optimizer = optim.SGD(model.parameters(),lr=0.1)\n# criterion = nn.CrossEntropyLoss()\n# for _ in tqdm(range(EPOCHS)):\n# for i in range(0,len(X_train),BATCH_SIZE):\n# X_batch = X_train[i:i+BATCH_SIZE].view(-1,1,112,112).to(device)\n# y_batch = y_train[i:i+BATCH_SIZE].to(device)\n# model.to(device)\n# preds = model(X_batch.float())\n# preds.to(device)\n# loss = criterion(preds,torch.tensor(y_batch,dtype=torch.long))\n# optimizer.zero_grad()\n# loss.backward()\n# optimizer.step()\n# wandb.log({'loss':get_loss(criterion,y_train,model,X_train),'accuracy':test(model,X_train,y_train),'val_accuracy':test(model,X_test,y_test),'val_loss':get_loss(criterion,y_test,model,X_test)})\n# for index in range(10):\n# print(torch.argmax(preds[index]))\n# print(y_batch[index])\n# print('\\n')\n# wandb.finish()",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cf754777c56d7f3e5e3fa268f6933714dd89ee | 32,106 | ipynb | Jupyter Notebook | 7 Data Visualization - Matplotlib/BasicPloting.ipynb | sadamarif/Basic-50-ML | 4b30228cb2a30c85864683c685205c1cc8a84461 | [
"MIT"
]
| null | null | null | 7 Data Visualization - Matplotlib/BasicPloting.ipynb | sadamarif/Basic-50-ML | 4b30228cb2a30c85864683c685205c1cc8a84461 | [
"MIT"
]
| null | null | null | 7 Data Visualization - Matplotlib/BasicPloting.ipynb | sadamarif/Basic-50-ML | 4b30228cb2a30c85864683c685205c1cc8a84461 | [
"MIT"
]
| null | null | null | 156.614634 | 11,208 | 0.908148 | [
[
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"%matplotlib inline",
"_____no_output_____"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"x= np.linspace(0, 5, 11)\ny= x ** 2",
"_____no_output_____"
],
[
"x",
"_____no_output_____"
],
[
"y",
"_____no_output_____"
],
[
"plt.plot(x,y)",
"_____no_output_____"
],
[
"plt.xlabel('X Axis')\nplt.ylabel('Y Axis')\nplt.title('Some Title')",
"_____no_output_____"
],
[
"#Create SubPlot with Colors\nplt.subplot(2,1,1)\nplt.plot(x,y, 'r')#Red Color\n\nplt.subplot(2,1,2)\nplt.plot(y,x, 'b')#Blue Color\nplt.show()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7cf77204cc5e10493998e49e2a31f488d39e0c3 | 64,777 | ipynb | Jupyter Notebook | EmployeeSQL/Analysis.ipynb | Kennydao/sql-challenge | 68247dd0bdfb7313aa06a2248b41b14825af3136 | [
"ADSL"
]
| null | null | null | EmployeeSQL/Analysis.ipynb | Kennydao/sql-challenge | 68247dd0bdfb7313aa06a2248b41b14825af3136 | [
"ADSL"
]
| null | null | null | EmployeeSQL/Analysis.ipynb | Kennydao/sql-challenge | 68247dd0bdfb7313aa06a2248b41b14825af3136 | [
"ADSL"
]
| null | null | null | 264.395918 | 40,528 | 0.932136 | [
[
[
"# import sqlalchemy\nfrom sqlalchemy import create_engine\n\n# import dependencies\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"# import parameters\nfrom config import username, password",
"_____no_output_____"
],
[
"# initialize parameter \n\nengine = create_engine(f'postgresql://{username}:{password}@localhost/Employees_db')",
"_____no_output_____"
],
[
"# reading data from SQL database\n\nemp_df = pd.read_sql('Select * From employees', engine)\n#emp_df.head()",
"_____no_output_____"
],
[
"# reading salaries table from Sql db\n\nsal_df = pd.read_sql('Select * From salaries', engine)\n#sal_df.head()",
"_____no_output_____"
],
[
"# ploting histogram chart\n\nplt.figure(figsize=(18,6))\n\nsns.distplot(sal_df.salary, bins = 100, color = 'blue');\nplt.grid()\nplt.title('Distribution of Salary')\n\nplt.savefig('output/sal_dist.png')\nplt.show()",
"_____no_output_____"
],
[
"# reading title table from Sql db\n\ntit_df = pd.read_sql('Select * From titles', engine)\n#tit_df.head()",
"_____no_output_____"
],
[
"# rename colume title_id to emp_title for merging\n\nti_df = tit_df.rename(columns={'title_id':'emp_title'}, inplace=True)",
"_____no_output_____"
],
[
"# merging dataframe to calulate average salary by title\n\nemp_sal_df = pd.merge(emp_df, sal_df, how='left', on = 'emp_no' )\n#emp_sal_df.head()",
"_____no_output_____"
],
[
"# merging with titles table to get title name\n\nemp_sal_tit_df = pd.merge(emp_sal_df, tit_df, how = 'left', on = 'emp_title')\n#emp_sal_tit_df.head()",
"_____no_output_____"
],
[
"# calculing and storing average salary data\n\navg_sal_df = emp_sal_tit_df.groupby('title').mean()\navg_sal_df.reset_index(inplace=True)",
"_____no_output_____"
],
[
"# seting figure size\nplt.figure(figsize=(20,8))\n\n# assign value to x, y axis\nx_axis = avg_sal_df.index\ny_axis = avg_sal_df.salary\n\n# seting xticklabel\nplt.xticks(x_axis, avg_sal_df.title)\nplt.xticks(rotation=45,horizontalalignment='right', fontweight='light', fontsize='xx-large');\n\n# giving title to chart\nplt.xlabel('Title')\nplt.ylabel('Salary')\nplt.title('Average Salary By Title')\n\nplt.bar(x_axis, y_axis, color='blue', alpha=0.5, align=\"center\")\n\n# saving to file\nplt.savefig('output/avg_sal_by_title.png')\n\nplt.show()",
"_____no_output_____"
],
[
"# details info about employee, whose ID number is 499942 :))\nprint(emp_df[emp_df.emp_no == 499942])",
" emp_no emp_title birth_day first_name last_name sex hire_date\n168736 499942 e0004 1963-01-10 April Foolsday F 1997-02-10\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.