
repo_id
stringlengths 15
89
| file_path
stringlengths 27
180
| content
stringlengths 1
2.23M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers简介
为 [PyTorch](https://pytorch.org/)、[TensorFlow](https://www.tensorflow.org/) 和 [JAX](https://jax.readthedocs.io/en/latest/) 打造的先进的机器学习工具.
🤗 Transformers 提供了可以轻松地下载并且训练先进的预训练模型的 API 和工具。使用预训练模型可以减少计算消耗和碳排放,并且节省从头训练所需要的时间和资源。这些模型支持不同模态中的常见任务,比如:
📝 **自然语言处理**:文本分类、命名实体识别、问答、语言建模、摘要、翻译、多项选择和文本生成。<br>
🖼️ **机器视觉**:图像分类、目标检测和语义分割。<br>
🗣️ **音频**:自动语音识别和音频分类。<br>
🐙 **多模态**:表格问答、光学字符识别、从扫描文档提取信息、视频分类和视觉问答。
🤗 Transformers 支持在 PyTorch、TensorFlow 和 JAX 上的互操作性. 这给在模型的每个阶段使用不同的框架带来了灵活性;在一个框架中使用几行代码训练一个模型,然后在另一个框架中加载它并进行推理。模型也可以被导出为 ONNX 和 TorchScript 格式,用于在生产环境中部署。
马上加入在 [Hub](https://huggingface.co/models)、[论坛](https://discuss.huggingface.co/) 或者 [Discord](https://discord.com/invite/JfAtkvEtRb) 上正在快速发展的社区吧!
## 如果你需要来自 Hugging Face 团队的个性化支持
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## 目录
这篇文档被组织为以下5个章节:
- **开始使用** 包含了库的快速上手和安装说明,便于配置和运行。
- **教程** 是一个初学者开始的好地方。本章节将帮助你获得你会用到的使用这个库的基本技能。
- **操作指南** 向你展示如何实现一个特定目标,比如为语言建模微调一个预训练模型或者如何创造并分享个性化模型。
- **概念指南** 对 🤗 Transformers 的模型,任务和设计理念背后的基本概念和思想做了更多的讨论和解释。
- **API 介绍** 描述了所有的类和函数:
- **MAIN CLASSES** 详述了配置(configuration)、模型(model)、分词器(tokenizer)和流水线(pipeline)这几个最重要的类。
- **MODELS** 详述了在这个库中和每个模型实现有关的类和函数。
- **INTERNAL HELPERS** 详述了内部使用的工具类和函数。
### 支持的模型
<!--This list is updated automatically from the README with _make fix-copies_. Do not update manually! -->
1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### 支持的框架
下表展示了库中对每个模型的支持情况,如是否具有 Python 分词器(表中的“Tokenizer slow”)、是否具有由 🤗 Tokenizers 库支持的快速分词器(表中的“Tokenizer fast”)、是否支持 Jax(通过
Flax)、PyTorch 与 TensorFlow。
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:-----------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| AltCLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| Audio Spectrogram Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| BioGpt | ✅ | ❌ | ✅ | ❌ | ❌ |
| BiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| BLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
| Chinese-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GIT | ❌ | ❌ | ✅ | ❌ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| GPT-Sw3 | ✅ | ✅ | ✅ | ✅ | ✅ |
| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Mask2Former | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormerSwin | ❌ | ❌ | ❌ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ✅ | ❌ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoBERTa-PreLayerNorm | ❌ | ❌ | ✅ | ✅ | ✅ |
| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| Swin2SR | ❌ | ❌ | ✅ | ❌ | ❌ |
| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TimeSformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| UPerNet | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViT Hybrid | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- End table-->
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/tflite.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 导出为 TFLite
[TensorFlow Lite](https://www.tensorflow.org/lite/guide) 是一个轻量级框架,用于资源受限的设备上,如手机、嵌入式系统和物联网(IoT)设备,部署机器学习模型。TFLite 旨在在计算能力、内存和功耗有限的设备上优化和高效运行模型。模型以一种特殊的高效可移植格式表示,其文件扩展名为 `.tflite`。
🤗 Optimum 通过 `exporters.tflite` 模块提供将 🤗 Transformers 模型导出至 TFLite 格式的功能。请参考 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/tflite/overview) 以获取支持的模型架构列表。
要将模型导出为 TFLite 格式,请安装所需的依赖项:
```bash
pip install optimum[exporters-tf]
```
请参阅 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model) 以查看所有可用参数,或者在命令行中查看帮助:
```bash
optimum-cli export tflite --help
```
运行以下命令,以从 🤗 Hub 导出模型的检查点(checkpoint),以 `bert-base-uncased` 为例:
```bash
optimum-cli export tflite --model bert-base-uncased --sequence_length 128 bert_tflite/
```
你应该能在日志中看到导出进度以及生成的 `model.tflite` 文件的保存位置,如下所示:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
上面的示例说明了从 🤗 Hub 导出检查点的过程。导出本地模型时,首先需要确保将模型的权重和分词器文件保存在同一目录(`local_path`)中。在使用 CLI(命令行)时,将 `local_path` 传递给 `model` 参数,而不是 🤗 Hub 上的检查点名称。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/perf_hardware.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 训练用的定制硬件
您用来运行模型训练和推断的硬件可能会对性能产生重大影响。要深入了解 GPU,务必查看 Tim Dettmer 出色的[博文](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/)。
让我们来看一些关于 GPU 配置的实用建议。
## GPU
当你训练更大的模型时,基本上有三种选择:
- 更大的 GPU
- 更多的 GPU
- 更多的 CPU 和 NVMe(通过[DeepSpeed-Infinity](main_classes/deepspeed#nvme-support)实现)
让我们从只有一块GPU的情况开始。
### 供电和散热
如果您购买了昂贵的高端GPU,请确保为其提供正确的供电和足够的散热。
**供电**:
一些高端消费者级GPU卡具有2个,有时甚至3个PCI-E-8针电源插口。请确保将与插口数量相同的独立12V PCI-E-8针线缆插入卡中。不要使用同一根线缆两端的2个分叉(也称为pigtail cable)。也就是说,如果您的GPU上有2个插口,您需要使用2条PCI-E-8针线缆连接电源和卡,而不是使用一条末端有2个PCI-E-8针连接器的线缆!否则,您无法充分发挥卡的性能。
每个PCI-E-8针电源线缆需要插入电源侧的12V轨上,并且可以提供最多150W的功率。
其他一些卡可能使用PCI-E-12针连接器,这些连接器可以提供最多500-600W的功率。
低端卡可能使用6针连接器,这些连接器可提供最多75W的功率。
此外,您需要选择具有稳定电压的高端电源。一些质量较低的电源可能无法为卡提供所需的稳定电压以发挥其最大性能。
当然,电源还需要有足够的未使用的瓦数来为卡供电。
**散热**:
当GPU过热时,它将开始降频,不会提供完整的性能。如果温度过高,可能会缩短GPU的使用寿命。
当GPU负载很重时,很难确定最佳温度是多少,但任何低于+80度的温度都是好的,越低越好,也许在70-75度之间是一个非常好的范围。降频可能从大约84-90度开始。但是除了降频外,持续的高温可能会缩短GPU的使用寿命。
接下来让我们看一下拥有多个GPU时最重要的方面之一:连接。
### 多GPU连接
如果您使用多个GPU,则卡之间的互连方式可能会对总训练时间产生巨大影响。如果GPU位于同一物理节点上,您可以运行以下代码:
```
nvidia-smi topo -m
```
它将告诉您GPU如何互连。在具有双GPU并通过NVLink连接的机器上,您最有可能看到类似以下内容:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X NV2 0-23 N/A
GPU1 NV2 X 0-23 N/A
```
在不同的机器上,如果没有NVLink,我们可能会看到:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X PHB 0-11 N/A
GPU1 PHB X 0-11 N/A
```
这个报告包括了这个输出:
```
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
```
因此,第一个报告`NV2`告诉我们GPU通过2个NVLink互连,而第二个报告`PHB`展示了典型的消费者级PCIe+Bridge设置。
检查你的设置中具有哪种连接类型。其中一些会使卡之间的通信更快(例如NVLink),而其他则较慢(例如PHB)。
根据使用的扩展解决方案的类型,连接速度可能会产生重大或较小的影响。如果GPU很少需要同步,就像在DDP中一样,那么较慢的连接的影响将不那么显著。如果GPU经常需要相互发送消息,就像在ZeRO-DP中一样,那么更快的连接对于实现更快的训练变得非常重要。
#### NVlink
[NVLink](https://en.wikipedia.org/wiki/NVLink)是由Nvidia开发的一种基于线缆的串行多通道近程通信链接。
每个新一代提供更快的带宽,例如在[Nvidia Ampere GA102 GPU架构](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf)中有这样的引述:
> Third-Generation NVLink®
> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
> (Note that 3-Way and 4-Way SLI configurations are not supported.)
所以,在`nvidia-smi topo -m`输出的`NVX`报告中获取到的更高的`X`值意味着更好的性能。生成的结果将取决于您的GPU架构。
让我们比较在小样本wikitext上训练gpt2语言模型的执行结果。
结果是:
| NVlink | Time |
| ----- | ---: |
| Y | 101s |
| N | 131s |
可以看到,NVLink使训练速度提高了约23%。在第二个基准测试中,我们使用`NCCL_P2P_DISABLE=1`告诉GPU不要使用NVLink。
这里是完整的基准测试代码和输出:
```bash
# DDP w/ NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
硬件: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
软件: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/hpo_train.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用Trainer API进行超参数搜索
🤗 Transformers库提供了一个优化过的[`Trainer`]类,用于训练🤗 Transformers模型,相比于手动编写自己的训练循环,这更容易开始训练。[`Trainer`]提供了超参数搜索的API。本文档展示了如何在示例中启用它。
## 超参数搜索后端
[`Trainer`] 目前支持四种超参数搜索后端:[optuna](https://optuna.org/),[sigopt](https://sigopt.com/),[raytune](https://docs.ray.io/en/latest/tune/index.html),[wandb](https://wandb.ai/site/sweeps)
在使用它们之前,您应该先安装它们作为超参数搜索后端。
```bash
pip install optuna/sigopt/wandb/ray[tune]
```
## 如何在示例中启用超参数搜索
定义超参数搜索空间,不同的后端需要不同的格式。
对于sigopt,请参阅sigopt [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter),它类似于以下内容:
```py
>>> def sigopt_hp_space(trial):
... return [
... {"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
... {
... "categorical_values": ["16", "32", "64", "128"],
... "name": "per_device_train_batch_size",
... "type": "categorical",
... },
... ]
```
对于optuna,请参阅optuna [object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py),它类似于以下内容:
```py
>>> def optuna_hp_space(trial):
... return {
... "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
... "per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
... }
```
Optuna提供了多目标HPO。您可以在`hyperparameter_search`中传递`direction`参数,并定义自己的`compute_objective`以返回多个目标值。在`hyperparameter_search`中将返回Pareto Front(`List[BestRun]`),您应该参考[test_trainer](https://github.com/huggingface/transformers/blob/main/tests/trainer/test_trainer.py)中的测试用例`TrainerHyperParameterMultiObjectOptunaIntegrationTest`。它类似于以下内容:
```py
>>> best_trials = trainer.hyperparameter_search(
... direction=["minimize", "maximize"],
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
对于raytune,可以参考raytune的[object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html),它类似于以下内容:
```py
>>> def ray_hp_space(trial):
... return {
... "learning_rate": tune.loguniform(1e-6, 1e-4),
... "per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
... }
```
对于wandb,可以参考wandb的[object_parameter](https://docs.wandb.ai/guides/sweeps/configuration),它类似于以下内容:
```py
>>> def wandb_hp_space(trial):
... return {
... "method": "random",
... "metric": {"name": "objective", "goal": "minimize"},
... "parameters": {
... "learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
... "per_device_train_batch_size": {"values": [16, 32, 64, 128]},
... },
... }
```
定义一个`model_init`函数并将其传递给[Trainer],作为示例:
```py
>>> def model_init(trial):
... return AutoModelForSequenceClassification.from_pretrained(
... model_args.model_name_or_path,
... from_tf=bool(".ckpt" in model_args.model_name_or_path),
... config=config,
... cache_dir=model_args.cache_dir,
... revision=model_args.model_revision,
... use_auth_token=True if model_args.use_auth_token else None,
... )
```
使用你的`model_init`函数、训练参数、训练和测试数据集以及评估函数创建一个[`Trainer`]。
```py
>>> trainer = Trainer(
... model=None,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... tokenizer=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
```
调用超参数搜索,获取最佳试验参数,后端可以是`"optuna"`/`"sigopt"`/`"wandb"`/`"ray"`。方向可以是`"minimize"`或`"maximize"`,表示是否优化更大或更低的目标。
您可以定义自己的compute_objective函数,如果没有定义,将调用默认的compute_objective,并将评估指标(如f1)之和作为目标值返回。
```py
>>> best_trial = trainer.hyperparameter_search(
... direction="maximize",
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
## 针对DDP微调的超参数搜索
目前,Optuna和Sigopt已启用针对DDP的超参数搜索。只有rank-zero进程会进行超参数搜索并将参数传递给其他进程。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/run_scripts.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用脚本进行训练
除了 🤗 Transformers [notebooks](./noteboks/README),还有示例脚本演示了如何使用[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch)、[TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow)或[JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax)训练模型以解决特定任务。
您还可以在这些示例中找到我们在[研究项目](https://github.com/huggingface/transformers/tree/main/examples/research_projects)和[遗留示例](https://github.com/huggingface/transformers/tree/main/examples/legacy)中使用过的脚本,这些脚本主要是由社区贡献的。这些脚本已不再被积极维护,需要使用特定版本的🤗 Transformers, 可能与库的最新版本不兼容。
示例脚本可能无法在初始配置下直接解决每个问题,您可能需要根据要解决的问题调整脚本。为了帮助您,大多数脚本都完全暴露了数据预处理的方式,允许您根据需要对其进行编辑。
如果您想在示例脚本中实现任何功能,请在[论坛](https://discuss.huggingface.co/)或[issue](https://github.com/huggingface/transformers/issues)上讨论,然后再提交Pull Request。虽然我们欢迎修复错误,但不太可能合并添加更多功能的Pull Request,因为这会降低可读性。
本指南将向您展示如何在[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization)和[TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization)中运行示例摘要训练脚本。除非另有说明,否则所有示例都可以在两个框架中工作。
## 设置
要成功运行示例脚本的最新版本,您必须在新虚拟环境中**从源代码安装 🤗 Transformers**:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
对于旧版本的示例脚本,请点击下面的切换按钮:
<details>
<summary>老版本🤗 Transformers示例 </summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
然后切换您clone的 🤗 Transformers 仓到特定的版本,例如v3.5.1:
```bash
git checkout tags/v3.5.1
```
在安装了正确的库版本后,进入您选择的版本的`example`文件夹并安装例子要求的环境:
```bash
pip install -r requirements.txt
```
## 运行脚本
<frameworkcontent>
<pt>
示例脚本从🤗 [Datasets](https://huggingface.co/docs/datasets/)库下载并预处理数据集。然后,脚本通过[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer)使用支持摘要任务的架构对数据集进行微调。以下示例展示了如何在[CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail)数据集上微调[T5-small](https://huggingface.co/t5-small)。由于T5模型的训练方式,它需要一个额外的`source_prefix`参数。这个提示让T5知道这是一个摘要任务。
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
示例脚本从 🤗 [Datasets](https://huggingface.co/docs/datasets/) 库下载并预处理数据集。然后,脚本使用 Keras 在支持摘要的架构上微调数据集。以下示例展示了如何在 [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) 数据集上微调 [T5-small](https://huggingface.co/t5-small)。T5 模型由于训练方式需要额外的 `source_prefix` 参数。这个提示让 T5 知道这是一个摘要任务。
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## 分布式训练和混合精度
[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) 支持分布式训练和混合精度,这意味着你也可以在脚本中使用它。要启用这两个功能,可以做如下设置:
- 添加 `fp16` 参数以启用混合精度。
- 使用 `nproc_per_node` 参数设置使用的GPU数量。
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
TensorFlow脚本使用[`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy)进行分布式训练,您无需在训练脚本中添加任何其他参数。如果可用,TensorFlow脚本将默认使用多个GPU。
## 在TPU上运行脚本
<frameworkcontent>
<pt>
张量处理单元(TPUs)是专门设计用于加速性能的。PyTorch使用[XLA](https://www.tensorflow.org/xla)深度学习编译器支持TPU(更多细节请参见[这里](https://github.com/pytorch/xla/blob/master/README.md))。要使用TPU,请启动`xla_spawn.py`脚本并使用`num_cores`参数设置要使用的TPU核心数量。
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
张量处理单元(TPUs)是专门设计用于加速性能的。TensorFlow脚本使用[`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy)在TPU上进行训练。要使用TPU,请将TPU资源的名称传递给`tpu`参数。
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## 基于🤗 Accelerate运行脚本
🤗 [Accelerate](https://huggingface.co/docs/accelerate) 是一个仅支持 PyTorch 的库,它提供了一种统一的方法来在不同类型的设置(仅 CPU、多个 GPU、多个TPU)上训练模型,同时保持对 PyTorch 训练循环的完全可见性。如果你还没有安装 🤗 Accelerate,请确保你已经安装了它:
> 注意:由于 Accelerate 正在快速发展,因此必须安装 git 版本的 accelerate 来运行脚本。
```bash
pip install git+https://github.com/huggingface/accelerate
```
你需要使用`run_summarization_no_trainer.py`脚本,而不是`run_summarization.py`脚本。🤗 Accelerate支持的脚本需要在文件夹中有一个`task_no_trainer.py`文件。首先运行以下命令以创建并保存配置文件:
```bash
accelerate config
```
检测您的设置以确保配置正确:
```bash
accelerate test
```
现在您可以开始训练模型了:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## 使用自定义数据集
摘要脚本支持自定义数据集,只要它们是CSV或JSON Line文件。当你使用自己的数据集时,需要指定一些额外的参数:
- `train_file` 和 `validation_file` 分别指定您的训练和验证文件的路径。
- `text_column` 是输入要进行摘要的文本。
- `summary_column` 是目标输出的文本。
使用自定义数据集的摘要脚本看起来是这样的:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## 测试脚本
通常,在提交整个数据集之前,最好先在较少的数据集示例上运行脚本,以确保一切按预期工作,因为完整数据集的处理可能需要花费几个小时的时间。使用以下参数将数据集截断为最大样本数:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
并非所有示例脚本都支持`max_predict_samples`参数。如果您不确定您的脚本是否支持此参数,请添加`-h`参数进行检查:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## 从checkpoint恢复训练
另一个有用的选项是从之前的checkpoint恢复训练。这将确保在训练中断时,您可以从之前停止的地方继续进行,而无需重新开始。有两种方法可以从checkpoint恢复训练。
第一种方法使用`output_dir previous_output_dir`参数从存储在`output_dir`中的最新的checkpoint恢复训练。在这种情况下,您应该删除`overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
第二种方法使用`resume_from_checkpoint path_to_specific_checkpoint`参数从特定的checkpoint文件夹恢复训练。
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## 分享模型
所有脚本都可以将您的最终模型上传到[Model Hub](https://huggingface.co/models)。在开始之前,请确保您已登录Hugging Face:
```bash
huggingface-cli login
```
然后,在脚本中添加`push_to_hub`参数。这个参数会创建一个带有您Hugging Face用户名和`output_dir`中指定的文件夹名称的仓库。
为了给您的仓库指定一个特定的名称,使用`push_to_hub_model_id`参数来添加它。该仓库将自动列出在您的命名空间下。
以下示例展示了如何上传具有特定仓库名称的模型:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/multilingual.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 用于推理的多语言模型
[[open-in-colab]]
🤗 Transformers 中有多种多语言模型,它们的推理用法与单语言模型不同。但是,并非*所有*的多语言模型用法都不同。一些模型,例如 [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) 就可以像单语言模型一样使用。本指南将向您展示如何使用不同用途的多语言模型进行推理。
## XLM
XLM 有十个不同的检查点,其中只有一个是单语言的。剩下的九个检查点可以归为两类:使用语言嵌入的检查点和不使用语言嵌入的检查点。
### 带有语言嵌入的 XLM
以下 XLM 模型使用语言嵌入来指定推理中使用的语言:
- `xlm-mlm-ende-1024` (掩码语言建模,英语-德语)
- `xlm-mlm-enfr-1024` (掩码语言建模,英语-法语)
- `xlm-mlm-enro-1024` (掩码语言建模,英语-罗马尼亚语)
- `xlm-mlm-xnli15-1024` (掩码语言建模,XNLI 数据集语言)
- `xlm-mlm-tlm-xnli15-1024` (掩码语言建模+翻译,XNLI 数据集语言)
- `xlm-clm-enfr-1024` (因果语言建模,英语-法语)
- `xlm-clm-ende-1024` (因果语言建模,英语-德语)
语言嵌入被表示一个张量,其形状与传递给模型的 `input_ids` 相同。这些张量中的值取决于所使用的语言,并由分词器的 `lang2id` 和 `id2lang` 属性识别。
在此示例中,加载 `xlm-clm-enfr-1024` 检查点(因果语言建模,英语-法语):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
分词器的 `lang2id` 属性显示了该模型的语言及其对应的id:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
接下来,创建一个示例输入:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size 为 1
```
将语言 id 设置为 `"en"` 并用其定义语言嵌入。语言嵌入是一个用 `0` 填充的张量,这个张量应该与 `input_ids` 大小相同。
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # 我们将其 reshape 为 (batch_size, sequence_length) 大小
>>> langs = langs.view(1, -1) # 现在的形状是 [1, sequence_length] (我们的 batch size 为 1)
```
现在,你可以将 `input_ids` 和语言嵌入传递给模型:
```py
>>> outputs = model(input_ids, langs=langs)
```
[run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) 脚本可以使用 `xlm-clm` 检查点生成带有语言嵌入的文本。
### 不带语言嵌入的 XLM
以下 XLM 模型在推理时不需要语言嵌入:
- `xlm-mlm-17-1280` (掩码语言建模,支持 17 种语言)
- `xlm-mlm-100-1280` (掩码语言建模,支持 100 种语言)
与之前的 XLM 检查点不同,这些模型用于通用句子表示。
## BERT
以下 BERT 模型可用于多语言任务:
- `bert-base-multilingual-uncased` (掩码语言建模 + 下一句预测,支持 102 种语言)
- `bert-base-multilingual-cased` (掩码语言建模 + 下一句预测,支持 104 种语言)
这些模型在推理时不需要语言嵌入。它们应该能够从上下文中识别语言并进行相应的推理。
## XLM-RoBERTa
以下 XLM-RoBERTa 模型可用于多语言任务:
- `xlm-roberta-base` (掩码语言建模,支持 100 种语言)
- `xlm-roberta-large` (掩码语言建模,支持 100 种语言)
XLM-RoBERTa 使用 100 种语言的 2.5TB 新创建和清理的 CommonCrawl 数据进行了训练。与之前发布的 mBERT 或 XLM 等多语言模型相比,它在分类、序列标记和问答等下游任务上提供了更强大的优势。
## M2M100
以下 M2M100 模型可用于多语言翻译:
- `facebook/m2m100_418M` (翻译)
- `facebook/m2m100_1.2B` (翻译)
在此示例中,加载 `facebook/m2m100_418M` 检查点以将中文翻译为英文。你可以在分词器中设置源语言:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
对文本进行分词:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
M2M100 强制将目标语言 id 作为第一个生成的标记,以进行到目标语言的翻译。在 `generate` 方法中将 `forced_bos_token_id` 设置为 `en` 以翻译成英语:
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
以下 MBart 模型可用于多语言翻译:
- `facebook/mbart-large-50-one-to-many-mmt` (一对多多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50-many-to-many-mmt` (多对多多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50-many-to-one-mmt` (多对一多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50` (多语言翻译,支持 50 种语言)
- `facebook/mbart-large-cc25`
在此示例中,加载 `facebook/mbart-large-50-many-to-many-mmt` 检查点以将芬兰语翻译为英语。 你可以在分词器中设置源语言:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
对文本进行分词:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
MBart 强制将目标语言 id 作为第一个生成的标记,以进行到目标语言的翻译。在 `generate` 方法中将 `forced_bos_token_id` 设置为 `en` 以翻译成英语:
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
如果你使用的是 `facebook/mbart-large-50-many-to-one-mmt` 检查点,则无需强制目标语言 id 作为第一个生成的令牌,否则用法是相同的。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/contributing.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 为 🤗 Transformers 做贡献
欢迎所有人为 🤗 Transformers 做出贡献,我们重视每个人的贡献。代码贡献并不是帮助社区的唯一途径。回答问题、帮助他人和改进文档也非常有价值。
宣传 🤗 Transformers 也会帮助我们!比如在博客文章里介绍一下这个库是如何帮助你完成了很棒的项目,每次它帮助你时都在 Twitter 上大声宣传,或者给这个代码仓库点⭐️来表示感谢。
无论你选择以哪种方式做出贡献,请注意并尊重我们的[行为准则](https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md)。
**本指南的灵感来源于 [scikit-learn贡献指南](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md) ,它令人印象深刻.**
## 做贡献的方法
有多种方法可以为 🤗 Transformers 做贡献:
* 修复现有代码中尚未解决的问题。
* 提交与 bug 或所需新功能相关的 issue。
* 实现新的模型。
* 为示例或文档做贡献。
如果你不知道从哪里开始,有一个特别的 [Good First Issue](https://github.com/huggingface/transformers/contribute) 列表。它会列出一些适合初学者的开放的 issues,并帮助你开始为开源项目做贡献。只需要在你想要处理的 issue 下发表评论就行。
如果想要稍微更有挑战性的内容,你也可以查看 [Good Second Issue](https://github.com/huggingface/transformers/labels/Good%20Second%20Issue) 列表。总的来说,如果你觉得自己知道该怎么做,就去做吧,我们会帮助你达到目标的!🚀
> 所有的贡献对社区来说都同样宝贵。🥰
## 修复尚未解决的问题
如果你发现现有代码中存在问题,并且已经想到了解决方法,请随时[开始贡献](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#create-a-pull-request) 并创建一个 Pull Request!
## 提交与 bug 相关的 issue 或功能请求
在提交与错误相关的 issue 或功能请求时,请尽量遵循下面的指南。这能让我们更容易迅速回复你,并提供良好的反馈意见。
### 你发现了 bug 吗?
🤗 Transformers 之所以强大可靠,要感谢用户报告了他们遇到的问题。
在提出issue之前,请你**确认该 bug 尚未被报告**(使用 GitHub 的 Issues 下面的搜索栏)。issue 也应该是与库本身的 bug 有关,而不是与你的代码有关。如果不确定 bug 是在你的代码中还是在库中,请先在[论坛](https://discuss.huggingface.co/)中询问。这有助于我们更快地解决与库相关的问题。
一旦你确认该 bug 尚未被报告,请在你的 issue 中包含以下信息,以便我们快速解决:
* 使用的**操作系统类型和版本**,以及 **Python**、**PyTorch** 和 **TensorFlow** 的版本。
* 一个简短、独立的代码片段,可以让我们在不到30秒内重现这个问题。
* 如果发生异常,请提供*完整的* traceback。
* 附上你认为可能有帮助的任何其他附加信息,如屏幕截图。
想要自动获取操作系统和软件版本,请运行以下命令:
```bash
transformers-cli env
```
你也可以从代码仓库的根目录下运行相同的命令:
```bash
python src/transformers/commands/transformers_cli.py env
```
### 你想要新功能吗?
如果你希望在 🤗 Transformers 中看到新功能,请提出一个 issue 并包含以下内容:
1. 这个新功能的*动机*是什么呢?是因为使用这个库时遇到了问题或者感到了某种不满吗?是因为你的项目需要这个功能吗?或者是你自己开发了某项内容,并且认为它可能会对社区有所帮助?
不管是什么,我们都很想听!
2. 请尽可能详细地描述你想要的功能。你告诉我们的越多,我们就能更好地帮助你。
3. 请提供一个*代码片段*,演示该功能的使用方法。
4. 如果这个功能与某篇论文相关,请包含链接。
如果你描述得足够清晰,那么在你创建 issue 时,我们已经完成了80%的工作。
我们已经添加了[模板](https://github.com/huggingface/transformers/tree/main/templates),可能有助于你提出 issue。
## 你想要实现一个新模型吗?
我们会持续发布新模型,如果你想要实现一个新模型,请提供以下信息:
* 模型的简要描述和论文链接。
* 如果实现是开源的,请提供实现的链接。
* 如果模型权重可用,请提供模型权重的链接。
如果你想亲自贡献模型,请告诉我们。让我们帮你把它添加到 🤗 Transformers!
我们已经添加了[详细的指南和模板](https://github.com/huggingface/transformers/tree/main/templates)来帮助你添加新模型。我们还有一个更技术性的指南,告诉你[如何将模型添加到 🤗 Transformers](https://huggingface.co/docs/transformers/add_new_model)。
## 你想要添加文档吗?
我们始终在寻求改进文档,使其更清晰准确。请告诉我们如何改进文档,比如拼写错误以及任何缺失、不清楚或不准确的内容。我们非常乐意进行修改,如果你有兴趣,我们也可以帮助你做出贡献!
有关如何生成、构建和编写文档的更多详细信息,请查看文档 [README](https://github.com/huggingface/transformers/tree/main/docs)。
## 创建 Pull Request
在开始编写任何代码之前,我们强烈建议你先搜索现有的 PR(Pull Request) 或 issue,以确保没有其他人已经在做同样的事情。如果你不确定,提出 issue 来获取反馈意见是一个好办法。
要为 🤗 Transformers 做贡献,你需要基本的 `git` 使用技能。虽然 `git` 不是一个很容易使用的工具,但它提供了非常全面的手册,在命令行中输入 `git --help` 并享受吧!如果你更喜欢书籍,[Pro Git](https://git-scm.com/book/en/v2)是一本很好的参考书。
要为 🤗 Transformers 做贡献,你需要 **[Python 3.8]((https://github.com/huggingface/transformers/blob/main/setup.py#L426))** 或更高版本。请按照以下步骤开始贡献:
1. 点击[仓库](https://github.com/huggingface/transformers)页面上的 **[Fork](https://github.com/huggingface/transformers/fork)** 按钮,这会在你的 GitHub 账号下拷贝一份代码。
2. 把派生仓库克隆到本地磁盘,并将基础仓库添加为远程仓库:
```bash
git clone [email protected]:<your Github handle>/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. 创建一个新的分支来保存你的更改:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
🚨 **不要**在 `main` 分支工作!
4. 在虚拟环境中运行以下命令来设置开发环境:
```bash
pip install -e ".[dev]"
```
如果在虚拟环境中已经安装了 🤗 Transformers,请先使用 `pip uninstall transformers` 卸载它,然后再用 `-e` 参数以可编辑模式重新安装。
根据你的操作系统,以及 Transformers 的可选依赖项数量的增加,可能会在执行此命令时出现失败。如果出现这种情况,请确保已经安装了你想使用的深度学习框架(PyTorch, TensorFlow 和 Flax),然后执行以下操作:
```bash
pip install -e ".[quality]"
```
大多数情况下,这些应该够用了。
5. 在你的分支上开发相关功能。
在编写代码时,请确保测试套件通过。用下面的方式运行受你的更改影响的测试:
```bash
pytest tests/<TEST_TO_RUN>.py
```
想了解更多关于测试的信息,请阅读[测试](https://huggingface.co/docs/transformers/testing)指南。
🤗 Transformers 使用 `black` 和 `ruff` 来保持代码风格的一致性。进行更改后,使用以下命令自动执行格式更正和代码验证:
```bash
make fixup
```
它已经被优化为仅适用于你创建的 PR 所修改过的文件。
如果想要逐个运行检查,可以使用以下命令:
```bash
make style
```
🤗 Transformers 还使用了 `ruff` 和一些自定义脚本来检查编码错误。虽然质量管理是通过 CI 进行的,但你也可以使用以下命令来运行相同的检查:
```bash
make quality
```
最后,我们有许多脚本来确保在添加新模型时不会忘记更新某些文件。你可以使用以下命令运行这些脚本:
```bash
make repo-consistency
```
想要了解有关这些检查及如何解决相关问题的更多信息,请阅读 [检查 Pull Request](https://huggingface.co/docs/transformers/pr_checks) 指南。
如果你修改了 `docs/source` 目录下的文档,请确保文档仍然能够被构建。这个检查也会在你创建 PR 时在 CI 中运行。如果要进行本地检查,请确保安装了文档构建工具:
```bash
pip install ".[docs]"
```
在仓库的根目录下运行以下命令:
```bash
doc-builder build transformers docs/source/en --build_dir ~/tmp/test-build
```
这将会在 `~/tmp/test-build` 文件夹中构建文档,你可以使用自己喜欢的编辑器查看生成的 Markdown 文件。当你创建 PR 时,也可以在GitHub上预览文档。
当你对修改满意后,使用 `git add` 把修改的文件添加到暂存区,然后使用 `git commit` 在本地记录你的更改:
```bash
git add modified_file.py
git commit
```
请记得写一个[好的提交信息](https://chris.beams.io/posts/git-commit/)来清晰地传达你所做的更改!
为了保持你的代码副本与原始仓库的最新状态一致,在你创建 PR *之前*或者在管理员要求的情况下,把你的分支在 `upstream/branch` 上进行 rebase:
```bash
git fetch upstream
git rebase upstream/main
```
把你的更改推送到你的分支:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
如果你已经创建了一个 PR,你需要使用 `--force` 参数进行强制推送。如果 PR 还没有被创建,你可以正常推送你的更改。
6. 现在你可以转到 GitHub 上你的账号下的派生仓库,点击 **Pull Request** 来创建一个 PR。 请确保勾选我们 [checklist](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#pull-request-checklist) 下的所有项目。准备好这些后,可以将你的更改发送给项目管理员进行审查。
7. 如果管理员要求你进行更改,别气馁,我们的核心贡献者也会经历相同的事情!请在你的本地分支上进行工作,并将更改推送到派生仓库,以便于每个人都可以在 PR 中看到你的更改。这样它们会自动出现在 PR 中。
### Pull request 的检查清单
☐ Pull request 的标题应该总结你的贡献内容。<br>
☐ 如果你的 Pull request 解决了一个issue,请在 Pull request 描述中提及该 issue 的编号,以确保它们被关联起来(这样查看 issue 的人就知道你正在处理它)。<br>
☐ 如果是正在进行中的工作,请在标题前加上 [WIP]。这有助于避免重复工作和区分哪些 PR 可以合并。<br>
☐ 确保可以通过现有的测试。<br>
☐ 如果添加了新功能,请同时添加对应的测试。<br>
- 如果添加一个新模型,请使用 `ModelTester.all_model_classes = (MyModel, MyModelWithLMHead,...)` 来触发通用测试。
- 如果你正在添加新的 `@slow` 测试,请确保通过以下检查:`RUN_SLOW=1 python -m pytest tests/models/my_new_model/test_my_new_model.py`
- 如果你正在添加一个新的分词器,请编写测试并确保通过以下检查:`RUN_SLOW=1 python -m pytest tests/models/{your_model_name}/test_tokenization_{your_model_name}.py`
- CircleCI 不会运行时间较长的测试,但 GitHub Actions 每晚会运行所有测试!<br>
☐ 所有公共 method 必须具有信息文档(比如 [`modeling_bert.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py))。<br>
☐ 由于代码仓库的体积正在迅速增长,请避免添加图像、视频和其他非文本文件,它们会增加仓库的负担。请使用 [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) 等 Hub 仓库来托管这些文件,并通过 URL 引用它们。我们建议将与文档相关的图片放置在以下仓库中:[huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images)。你可以在这个数据集仓库上创建一个 PR,并请求 Hugging Face 成员进行合并。
要了解更多有关在 Pull request 上运行的检查的信息,请查看我们的 [检查 Pull Request](https://huggingface.co/docs/transformers/pr_checks) 指南。
### 测试
包含了广泛的测试套件来测试库的行为和一些示例。库测试可以在 [tests](https://github.com/huggingface/transformers/tree/main/tests) 文件夹中找到,示例测试可以在 [examples](https://github.com/huggingface/transformers/tree/main/examples) 文件夹中找到。
我们喜欢使用 `pytest` 和 `pytest-xdist`,因为它运行更快。在仓库的根目录,指定一个*子文件夹的路径或测试文件*来运行测试。
```bash
python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
```
同样地,在 `examples` 目录,指定一个*子文件夹的路径或测试文件* 来运行测试。例如,以下命令会测试 PyTorch `examples` 目录中的文本分类子文件夹:
```bash
pip install -r examples/xxx/requirements.txt # 仅在第一次需要
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
```
实际上这就是我们的 `make test` 和 `make test-examples` 命令的实现方式(不包括 `pip install`)!
你也可以指定一个较小的测试集来仅测试特定功能。
默认情况下,会跳过时间较长的测试,但你可以将 `RUN_SLOW` 环境变量设置为 `yes` 来运行它们。这将下载以 GB 为单位的模型文件,所以确保你有足够的磁盘空间、良好的网络连接和足够的耐心!
<Tip warning={true}>
记得指定一个*子文件夹的路径或测试文件*来运行测试。否则你将会运行 `tests` 或 `examples` 文件夹中的所有测试,它会花费很长时间!
</Tip>
```bash
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
```
和时间较长的测试一样,还有其他环境变量在测试过程中,在默认情况下是未启用的:
- `RUN_CUSTOM_TOKENIZERS`: 启用自定义分词器的测试。
- `RUN_PT_FLAX_CROSS_TESTS`: 启用 PyTorch + Flax 整合的测试。
- `RUN_PT_TF_CROSS_TESTS`: 启用 TensorFlow + PyTorch 整合的测试。
更多环境变量和额外信息可以在 [testing_utils.py](src/transformers/testing_utils.py) 中找到。
🤗 Transformers 只是使用 `pytest` 作为测试运行程序,但测试套件本身没用任何与 `pytest` 相关的功能。
这意味着完全支持 `unittest` 。以下是如何使用 `unittest` 运行测试的方法:
```bash
python -m unittest discover -s tests -t . -v
python -m unittest discover -s examples -t examples -v
```
### 风格指南
🤗 Transformers 的文档遵循 [Google Python Style Guide](https://google.github.io/styleguide/pyguide.html)。请查看我们的 [文档编写指南](https://github.com/huggingface/transformers/tree/main/docs#writing-documentation---specification) 来获取更多信息。
### 在 Windows 上开发
在 Windows 上(除非你正在使用 [Windows Subsystem for Linux](https://learn.microsoft.com/en-us/windows/wsl/) 或 WSL),你需要配置 git 将 Windows 的 `CRLF` 行结束符转换为 Linux 的 `LF` 行结束符:
```bash
git config core.autocrlf input
```
在 Windows 上有一种方法可以运行 `make` 命令,那就是使用 MSYS2:
1. [下载 MSYS2](https://www.msys2.org/),假设已经安装在 `C:\msys64`。
2. 从命令行打开 `C:\msys64\msys2.exe` (可以在 **开始** 菜单中找到)。
3. 在 shell 中运行: `pacman -Syu` ,并使用 `pacman -S make` 安装 `make`。
4. 把 `C:\msys64\usr\bin` 添加到你的 PATH 环境变量中。
现在你可以在任何终端(Powershell、cmd.exe 等)中使用 `make` 命令了! 🎉
### 将派生仓库与上游主仓库(Hugging Face 仓库)同步
更新派生仓库的主分支时,请按照以下步骤操作。这是为了避免向每个上游 PR 添加参考注释,同时避免向参与这些 PR 的开发人员发送不必要的通知。
1. 可以的话,请避免使用派生仓库上的分支和 PR 来与上游进行同步,而是直接合并到派生仓库的主分支。
2. 如果确实需要一个 PR,在检查你的分支后,请按照以下步骤操作:
```bash
git checkout -b your-branch-for-syncing
git pull --squash --no-commit upstream main
git commit -m '<your message without GitHub references>'
git push --set-upstream origin your-branch-for-syncing
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/big_models.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 实例化大型模型
当你想使用一个非常大的预训练模型时,一个挑战是尽量减少对内存的使用。通常从PyTorch开始的工作流程如下:
1. 用随机权重创建你的模型。
2. 加载你的预训练权重。
3. 将这些预训练权重放入你的随机模型中。
步骤1和2都需要完整版本的模型在内存中,这在大多数情况下不是问题,但如果你的模型开始达到几个GB的大小,这两个副本可能会让你超出内存的限制。更糟糕的是,如果你使用`torch.distributed`来启动分布式训练,每个进程都会加载预训练模型并将这两个副本存储在内存中。
<Tip>
请注意,随机创建的模型使用“空”张量进行初始化,这些张量占用内存空间但不填充它(因此随机值是给定时间内该内存块中的任何内容)。在第3步之后,对未初始化的权重执行适合模型/参数种类的随机初始化(例如正态分布),以尽可能提高速度!
</Tip>
在本指南中,我们将探讨 Transformers 提供的解决方案来处理这个问题。请注意,这是一个积极开发的领域,因此这里解释的API在将来可能会略有变化。
## 分片checkpoints
自4.18.0版本起,占用空间超过10GB的模型检查点将自动分成较小的片段。在使用`model.save_pretrained(save_dir)`时,您最终会得到几个部分`checkpoints`(每个的大小都小于10GB)以及一个索引,该索引将参数名称映射到存储它们的文件。
您可以使用`max_shard_size`参数来控制分片之前的最大大小。为了示例的目的,我们将使用具有较小分片大小的普通大小的模型:让我们以传统的BERT模型为例。
```py
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-cased")
```
如果您使用 [`PreTrainedModel.save_pretrained`](模型预训练保存) 进行保存,您将得到一个新的文件夹,其中包含两个文件:模型的配置和权重:
```py
>>> import os
>>> import tempfile
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir)
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model.bin']
```
现在让我们使用最大分片大小为200MB:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
```
在模型配置文件最上方,我们可以看到三个不同的权重文件,以及一个`index.json`索引文件。这样的`checkpoint`可以使用`[~PreTrainedModel.from_pretrained]`方法完全重新加载:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... new_model = AutoModel.from_pretrained(tmp_dir)
```
对于大型模型来说,这样做的主要优点是在上述工作流程的步骤2中,每个`checkpoint`的分片在前一个分片之后加载,从而将内存中的内存使用限制在模型大小加上最大分片的大小。
在后台,索引文件用于确定`checkpoint`中包含哪些键以及相应的权重存储在哪里。我们可以像加载任何json一样加载该索引,并获得一个字典:
```py
>>> import json
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
... index = json.load(f)
>>> print(index.keys())
dict_keys(['metadata', 'weight_map'])
```
目前元数据仅包括模型的总大小。我们计划在将来添加其他信息:
```py
>>> index["metadata"]
{'total_size': 433245184}
```
权重映射是该索引的主要部分,它将每个参数的名称(通常在PyTorch模型的`state_dict`中找到)映射到存储该参数的文件:
```py
>>> index["weight_map"]
{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
...
```
如果您想直接在模型内部加载这样的分片`checkpoint`,而不使用 [`PreTrainedModel.from_pretrained`](就像您会为完整`checkpoint`执行 `model.load_state_dict()` 一样),您应该使用 [`modeling_utils.load_sharded_checkpoint`]:
```py
>>> from transformers.modeling_utils import load_sharded_checkpoint
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... load_sharded_checkpoint(model, tmp_dir)
```
## 低内存加载
分片`checkpoints`在上述工作流的第2步中降低了内存使用,但为了在低内存环境中使用该模型,我们建议使用基于 Accelerate 库的工具。
请阅读以下指南以获取更多信息:[使用 Accelerate 进行大模型加载](./main_classes/model#large-model-loading)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/transformers_agents.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Transformers Agents
<Tip warning={true}>
`Transformers Agents`是一个实验性的随时可能发生变化的API。由于API或底层模型可能发生变化,`agents`返回的结果也会有所不同。
</Tip>
Transformers版本`v4.29.0`基于`tools`和`agents`概念构建。您可以在[此Colab链接](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj)中进行测试。
简而言之,它在`Transformers`之上提供了一个自然语言API:我们定义了一组经过筛选的`tools`,并设计了一个`agents`来解读自然语言并使用这些工具。它具有很强的可扩展性;我们筛选了一些相关的`tools`,但我们将向您展示如何通过社区开发的`tool`轻松地扩展系统。
让我们从一些可以通过这个新API实现的示例开始。在处理多模态任务时它尤其强大,因此让我们快速试着生成图像并大声朗读文本。
```py
agent.run("Caption the following image", image=image)
```
| **输入** | **输出** |
|-----------------------------------------------------------------------------------------------------------------------------|-----------------------------------|
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/beaver.png" width=200> | A beaver is swimming in the water |
---
```py
agent.run("Read the following text out loud", text=text)
```
| **输入** | **输出** |
|-----------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| A beaver is swimming in the water | <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tts_example.wav" type="audio/wav"> your browser does not support the audio element. </audio>
---
```py
agent.run(
"In the following `document`, where will the TRRF Scientific Advisory Council Meeting take place?",
document=document,
)
```
| **输入** | **输出** |
|-----------------------------------------------------------------------------------------------------------------------------|----------------|
| <img src="https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/0/image/image.jpg" width=200> | ballroom foyer |
## 快速入门
要使用 `agent.run`,您需要实例化一个`agent`,它是一个大型语言模型(LLM)。我们支持OpenAI模型以及来自BigCode和OpenAssistant的开源替代方案。OpenAI模型性能更好(但需要您拥有OpenAI API密钥,因此无法免费使用),Hugging Face为BigCode和OpenAssistant模型提供了免费访问端点。
一开始请安装`agents`附加模块,以安装所有默认依赖项。
```bash
pip install transformers[agents]
```
要使用OpenAI模型,您可以在安装`openai`依赖项后实例化一个`OpenAiAgent`:
```bash
pip install openai
```
```py
from transformers import OpenAiAgent
agent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")
```
要使用BigCode或OpenAssistant,请首先登录以访问Inference API:
```py
from huggingface_hub import login
login("<YOUR_TOKEN>")
```
然后,实例化`agent`:
```py
from transformers import HfAgent
# Starcoder
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
# StarcoderBase
# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")
# OpenAssistant
# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
```
此示例使用了目前Hugging Face免费提供的推理API。如果你有自己的推理端点用于此模型(或其他模型),你可以用你的URL替换上面的URL。
<Tip>
StarCoder和OpenAssistant可以免费使用,并且在简单任务上表现出色。然而,当处理更复杂的提示时就不再有效。如果你遇到这样的问题,我们建议尝试使用OpenAI模型,尽管遗憾的是它不是开源的,但它在目前情况下表现更好。
</Tip>
现在,您已经可以开始使用了!让我们深入了解您现在可以使用的两个API。
### 单次执行(run)
单次执行方法是使用`agent`的 `~Agent.run`:
```py
agent.run("Draw me a picture of rivers and lakes.")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
它会自动选择适合您要执行的任务的`tool`(或`tools`),并以适当的方式运行它们。它可以在同一指令中执行一个或多个任务(尽管您的指令越复杂,`agent`失败的可能性就越大)。
```py
agent.run("Draw me a picture of the sea then transform the picture to add an island")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sea_and_island.png" width=200>
<br/>
每个 [`~Agent.run`] 操作都是独立的,因此您可以多次连续运行 [`~Agent.run`]并执行不同的任务。
请注意,您的 `agent` 只是一个大型语言模型,因此您略有变化的提示可能会产生完全不同的结果。重要的是尽可能清晰地解释您要执行的任务。我们在[这里](../en/custom_tools#writing-good-user-inputs)更深入地讨论了如何编写良好的提示。
如果您想在多次执行之间保持同一状态或向`agent`传递非文本对象,可以通过指定`agent`要使用的变量来实现。例如,您可以生成有关河流和湖泊的第一幅图像,并要求模型通过执行以下操作向该图片添加一个岛屿:
```python
picture = agent.run("Generate a picture of rivers and lakes.")
updated_picture = agent.run("Transform the image in `picture` to add an island to it.", picture=picture)
```
<Tip>
当模型无法理解您的请求和库中的工具时,这可能会有所帮助。例如:
```py
agent.run("Draw me the picture of a capybara swimming in the sea")
```
在这种情况下,模型可以以两种方式理解您的请求:
- 使用`text-to-image` 生成在大海中游泳的大水獭
- 或者,使用`text-to-image`生成大水獭,然后使用`image-transformation`工具使其在大海中游泳
如果您想强制使用第一种情景,可以通过将提示作为参数传递给它来实现:
```py
agent.run("Draw me a picture of the `prompt`", prompt="a capybara swimming in the sea")
```
</Tip>
### 基于交流的执行 (chat)
基于交流的执行(chat)方式是使用 [`~Agent.chat`]:
```py
agent.chat("Generate a picture of rivers and lakes")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
```py
agent.chat("Transform the picture so that there is a rock in there")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_and_beaver.png" width=200>
<br/>
当您希望在不同指令之间保持同一状态时,这会是一个有趣的方法。它更适合用于单个指令,而不是复杂的多步指令(`~Agent.run` 方法更适合处理这种情况)。
这种方法也可以接受参数,以便您可以传递非文本类型或特定提示。
### ⚠️ 远程执行
出于演示目的以便适用于所有设置,我们为发布版本的少数默认工具创建了远程执行器。这些工具是使用推理终端(inference endpoints)创建的。
目前我们已将其关闭,但为了了解如何自行设置远程执行器工具,我们建议阅读[自定义工具指南](./custom_tools)。
### 这里发生了什么?什么是`tools`,什么是`agents`?
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/diagram.png">
#### Agents
这里的`Agents`是一个大型语言模型,我们通过提示它以访问特定的工具集。
大型语言模型在生成小代码示例方面表现出色,因此这个API利用这一特点,通过提示LLM生成一个使用`tools`集合的小代码示例。然后,根据您给`Agents`的任务和`tools`的描述来完成此提示。这种方式让它能够访问工具的文档,特别是它们的期望输入和输出,以生成相关的代码。
#### Tools
`Tools`非常简单:它们是有名称和描述的单个函数。然后,我们使用这些`tools`的描述来提示代理。通过提示,我们向`agent`展示如何使用`tool`来执行查询语言中请求的操作。
这是使用全新`tools`而不是`pipelines`,因为`agent`编写的代码更好,具有非常原子化的`tools`。`pipelines`经常被重构,并且通常将多个任务合并为一个。`tools`旨在专注于一个非常简单的任务。
#### 代码执行?
然后,这段代码基于`tools`的输入被我们的小型Python解释器执行。我们听到你在后面大声呼喊“任意代码执行!”,但让我们解释为什么情况并非如此。
只能您提供的`tools`和打印函数可以被执行,因此您已经受到了执行的限制。如果仅限于 Hugging Face 工具,那么您应该是安全的。
然后,我们不允许任何属性查找或导入(无论如何都不需要将输入/输出传递给一小组函数),因此所有最明显的攻击(并且您需要提示LLM无论如何输出它们)不应该是一个问题。如果你想超级安全,你可以使用附加参数 return_code=True 执行 run() 方法,在这种情况下,`agent`将只返回要执行的代码,你可以决定是否执行。
如果`agent`生成的代码存在任何尝试执行非法操作的行为,或者代码中出现了常规Python错误,执行将停止。
### 一组经过精心筛选的`tools`
我们确定了一组可以赋予这些`agent`强大能力的`tools`。以下是我们在`transformers`中集成的`tools`的更新列表:
- **文档问答**:给定一个图像格式的文档(例如PDF),回答该文档上的问题([Donut](../en/model_doc/donut))
- **文本问答**:给定一段长文本和一个问题,回答文本中的问题([Flan-T5](../en/model_doc/flan-t5))
- **无条件图像字幕**:为图像添加字幕!([BLIP](../en/model_doc/blip))
- **图像问答**:给定一张图像,回答该图像上的问题([VILT](../en/model_doc/vilt))
- **图像分割**:给定一张图像和一个提示,输出该提示的分割掩模([CLIPSeg](../en/model_doc/clipseg))
- **语音转文本**:给定一个人说话的音频录音,将演讲内容转录为文本([Whisper](../en/model_doc/whisper))
- **文本转语音**:将文本转换为语音([SpeechT5](../en/model_doc/speecht5))
- **Zero-Shot文本分类**:给定一个文本和一个标签列表,确定文本最符合哪个标签([BART](../en/model_doc/bart))
- **文本摘要**:总结长文本为一两句话([BART](../en/model_doc/bart))
- **翻译**:将文本翻译为指定语言([NLLB](../en/model_doc/nllb))
这些`tools`已在transformers中集成,并且也可以手动使用,例如:
```py
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")
```
### 自定义工具
尽管我们确定了一组经过筛选的`tools`,但我们坚信,此实现提供的主要价值在于能够快速创建和共享自定义`tool`。
通过将工具的代码上传到Hugging Face空间或模型repository,您可以直接通过`agent`使用`tools`。我们已经添加了一些**与transformers无关**的`tools`到[`huggingface-tools`组织](https://huggingface.co/huggingface-tools)中:
- **文本下载器**:从Web URL下载文本
- **文本到图像**:根据提示生成图像,利用`stable diffusion`
- **图像转换**:根据初始图像和提示修改图像,利用`instruct pix2pix stable diffusion`
- **文本到视频**:根据提示生成小视频,利用`damo-vilab`
从一开始就一直在使用的文本到图像`tool`是一个远程`tool `,位于[*huggingface-tools/text-to-image*](https://huggingface.co/spaces/huggingface-tools/text-to-image)!我们将继续在此组织和其他组织上发布此类`tool`,以进一步增强此实现。
`agents`默认可以访问存储在[`huggingface-tools`](https://huggingface.co/huggingface-tools)上的`tools`。我们将在后续指南中解释如何编写和共享自定义`tools`,以及如何利用Hub上存在的任何自定义`tools`。
### 代码生成
到目前为止,我们已经展示了如何使用`agents`来为您执行操作。但是,`agents`仅使用非常受限Python解释器执行的代码。如果您希望在不同的环境中使用生成的代码,可以提示`agents`返回代码,以及`tools`的定义和准确的导入信息。
例如,以下指令
```python
agent.run("Draw me a picture of rivers and lakes", return_code=True)
```
返回以下代码
```python
from transformers import load_tool
image_generator = load_tool("huggingface-tools/text-to-image")
image = image_generator(prompt="rivers and lakes")
```
然后你就可以调整并执行代码
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/pipeline_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 推理pipeline
[`pipeline`] 让使用[Hub](https://huggingface.co/models)上的任何模型进行任何语言、计算机视觉、语音以及多模态任务的推理变得非常简单。即使您对特定的模态没有经验,或者不熟悉模型的源码,您仍然可以使用[`pipeline`]进行推理!本教程将教您:
- 如何使用[`pipeline`] 进行推理。
- 如何使用特定的`tokenizer`(分词器)或模型。
- 如何使用[`pipeline`] 进行音频、视觉和多模态任务的推理。
<Tip>
请查看[`pipeline`]文档以获取已支持的任务和可用参数的完整列表。
</Tip>
## Pipeline使用
虽然每个任务都有一个关联的[`pipeline`],但使用通用的抽象的[`pipeline`]更加简单,其中包含所有特定任务的`pipelines`。[`pipeline`]会自动加载一个默认模型和一个能够进行任务推理的预处理类。让我们以使用[`pipeline`]进行自动语音识别(ASR)或语音转文本为例。
1. 首先,创建一个[`pipeline`]并指定推理任务:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")
```
2. 将您的输入传递给[`pipeline`]。对于语音识别,这通常是一个音频输入文件:
```py
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
```
您没有得到您期望的结果?可以在Hub上查看一些[最受欢迎的自动语音识别模型](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending)
,看看是否可以获得更好的转录。
让我们尝试来自 OpenAI 的[Whisper large-v2](https://huggingface.co/openai/whisper-large) 模型。Whisperb比Wav2Vec2晚2年发布,使用接近10倍的数据进行了训练。因此,它在大多数下游基准测试上击败了Wav2Vec2。
它还具有预测标点和大小写的附加优势,而Wav2Vec2则无法实现这些功能。
让我们在这里尝试一下,看看它的表现如何:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
现在这个结果看起来更准确了!要进行深入的Wav2Vec2与Whisper比较,请参阅[音频变换器课程](https://huggingface.co/learn/audio-course/chapter5/asr_models)。
我们鼓励您在 Hub 上查看不同语言的模型,以及专业领域的模型等。您可以在Hub上直接查看并比较模型的结果,以确定是否适合或处理边缘情况是否比其他模型更好。如果您没有找到适用于您的用例的模型,您始终可以[训练](training)自己的模型!
如果您有多个输入,您可以将输入作为列表传递:
```py
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
```
`Pipelines`非常适合用于测试,因为从一个模型切换到另一个模型非常琐碎;但是,还有一些方法可以将它们优化后用于大型工作负载而不仅仅是测试。请查看以下指南,深入探讨如何迭代整个数据集或在Web服务器中使用`Pipelines`:
* [在数据集上使用流水线](#using-pipelines-on-a-dataset)
* [在Web服务器中使用流水线](./pipeline_webserver)
## 参数
[`pipeline`] 支持许多参数;有些是适用于特定任务的,而有些适用于所有`pipeline`。通常情况下,您可以在任何地方指定对应参数:
```py
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.
```
让我们查看其中的三个重要参数:
### 设备
如果您使用 `device=n`,`pipeline`会自动将模型放在指定的设备上。无论您使用PyTorch还是Tensorflow,这都可以工作。
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
```
如果模型对于单个GPU来说过于庞大,并且您正在使用PyTorch,您可以设置 `device_map="auto"` 以自动确定如何加载和存储模型权重。使用 `device_map` 参数需要安装🤗 [Accelerate](https://huggingface.co/docs/accelerate) 软件包:
```bash
pip install --upgrade accelerate
```
以下代码会自动在各个设备上加载和存储模型权重:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
```
请注意,如果传递了 `device_map="auto"`,在实例化您的 `pipeline` 时不需要添加 `device=device` 参数,否则可能会遇到一些意外的状况!
### 批量大小
默认情况下,`pipelines`不会进行批量推理,原因在[这里](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching)详细解释。因为批处理不一定更快,实际上在某些情况下可能会更慢。
但如果在您的用例中起作用,您可以使用:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)
```
以上代码会在提供的4个音频文件上运行`pipeline`,它会将它们以2个一组的批次传递给模型(模型在GPU上,此时批处理更有可能有所帮助),而您无需编写额外的代码。输出应始终与没有批处理时收到的结果相一致。它只是一种帮助您更快地使用`pipeline`的方式。
`pipeline`也可以减轻一些批处理的复杂性,因为对于某些`pipeline`,需要将单个项目(如长音频文件)分成多个部分以供模型处理。`pipeline`为您执行这种[*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching)。
### 任务特定参数
所有任务都提供了特定于任务的参数,这些参数提供额外的灵活性和选择,以帮助您完成工作。
例如,[`transformers.AutomaticSpeechRecognitionPipeline.__call__`] 方法具有一个 `return_timestamps` 参数,对于字幕视频似乎很有帮助:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
```
正如您所看到的,模型推断出了文本,还输出了各个句子发音的**时间**。
每个任务都有许多可用的参数,因此请查看每个任务的API参考,以了解您可以进行哪些调整!例如,[`~transformers.AutomaticSpeechRecognitionPipeline`] 具有 `chunk_length_s` 参数,对于处理非常长的音频文件(例如,为整部电影或长达一小时的视频配字幕)非常有帮助,这通常是模型无法单独处理的:
```python
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30, return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
{'text': " Chapter 16. I might have told you of the beginning of this liaison in a few lines, but I wanted you to see every step by which we came. I, too, agree to whatever Marguerite wished, Marguerite to be unable to live apart from me. It was the day after the evening...
```
如果您找不到一个真正有帮助的参数,欢迎[提出请求](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
## 在数据集上使用pipelines
`pipelines`也可以对大型数据集进行推理。我们建议使用迭代器来完成这一任务,这是最简单的方法:
```py
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
```
迭代器 `data()` 会产生每个结果,`pipelines`会自动识别输入为可迭代对象,并在GPU上处理数据的同时开始获取数据(在底层使用[DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader))。这一点非常重要,因为您不必为整个数据集分配内存,可以尽可能快地将数据传送到GPU。
由于批处理可以加速处理,因此在这里尝试调整 `batch_size` 参数可能会很有用。
迭代数据集的最简单方法就是从🤗 [Datasets](https://github.com/huggingface/datasets/) 中加载数据集:
```py
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
```
## 在Web服务器上使用pipelines
<Tip>
创建推理引擎是一个复杂的主题,值得有自己的页面。
</Tip>
[链接](./pipeline_webserver)
## 视觉流水线
对于视觉任务,使用[`pipeline`] 几乎是相同的。
指定您的任务并将图像传递给分类器。图像可以是链接、本地路径或base64编码的图像。例如,下面显示的是哪种品种的猫?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
## 文本流水线
对于NLP任务,使用[`pipeline`] 几乎是相同的。
```py
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
```
## 多模态流水线
[`pipeline`] 支持多个模态。例如,视觉问题回答(VQA)任务结合了文本和图像。请随意使用您喜欢的任何图像链接和您想要问关于该图像的问题。图像可以是URL或图像的本地路径。
例如,如果您使用这个[invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png):
```py
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
[{'score': 0.42515, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip>
要运行上面的示例,除了🤗 Transformers之外,您需要安装[`pytesseract`](https://pypi.org/project/pytesseract/)。
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
```
</Tip>
## 在大模型上使用🤗 `accelerate`和`pipeline`:
您可以轻松地使用🤗 `accelerate`在大模型上运行 `pipeline`!首先确保您已经使用 `pip install accelerate` 安装了 `accelerate`。
首先使用 `device_map="auto"` 加载您的模型!我们将在示例中使用 `facebook/opt-1.3b`。
```py
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
如果安装 `bitsandbytes` 并添加参数 `load_in_8bit=True`,您还可以传递8位加载的模型。
```py
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
请注意,您可以将`checkpoint `替换为任何支持大模型加载的Hugging Face模型,比如BLOOM!
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/quicktour.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 快速上手
[[open-in-colab]]
快来使用 🤗 Transformers 吧!无论你是开发人员还是日常用户,这篇快速上手教程都将帮助你入门并且向你展示如何使用 [`pipeline`] 进行推理,使用 [AutoClass](./model_doc/auto) 加载一个预训练模型和预处理器,以及使用 PyTorch 或 TensorFlow 快速训练一个模型。如果你是一个初学者,我们建议你接下来查看我们的教程或者[课程](https://huggingface.co/course/chapter1/1),来更深入地了解在这里介绍到的概念。
在开始之前,确保你已经安装了所有必要的库:
```bash
!pip install transformers datasets
```
你还需要安装喜欢的机器学习框架:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## Pipeline
<Youtube id="tiZFewofSLM"/>
使用 [`pipeline`] 是利用预训练模型进行推理的最简单的方式。你能够将 [`pipeline`] 开箱即用地用于跨不同模态的多种任务。来看看它支持的任务列表:
| **任务** | **描述** | **模态** | **Pipeline** |
|------------------------------|-----------------------------------|-----------------|-----------------------------------------------|
| 文本分类 | 为给定的文本序列分配一个标签 | NLP | pipeline(task="sentiment-analysis") |
| 文本生成 | 根据给定的提示生成文本 | NLP | pipeline(task="text-generation") |
| 命名实体识别 | 为序列里的每个 token 分配一个标签(人, 组织, 地址等等) | NLP | pipeline(task="ner") |
| 问答系统 | 通过给定的上下文和问题, 在文本中提取答案 | NLP | pipeline(task="question-answering") |
| 掩盖填充 | 预测出正确的在序列中被掩盖的token | NLP | pipeline(task="fill-mask") |
| 文本摘要 | 为文本序列或文档生成总结 | NLP | pipeline(task="summarization") |
| 文本翻译 | 将文本从一种语言翻译为另一种语言 | NLP | pipeline(task="translation") |
| 图像分类 | 为图像分配一个标签 | Computer vision | pipeline(task="image-classification") |
| 图像分割 | 为图像中每个独立的像素分配标签(支持语义、全景和实例分割) | Computer vision | pipeline(task="image-segmentation") |
| 目标检测 | 预测图像中目标对象的边界框和类别 | Computer vision | pipeline(task="object-detection") |
| 音频分类 | 给音频文件分配一个标签 | Audio | pipeline(task="audio-classification") |
| 自动语音识别 | 将音频文件中的语音提取为文本 | Audio | pipeline(task="automatic-speech-recognition") |
| 视觉问答 | 给定一个图像和一个问题,正确地回答有关图像的问题 | Multimodal | pipeline(task="vqa") |
创建一个 [`pipeline`] 实例并且指定你想要将它用于的任务,就可以开始了。你可以将 [`pipeline`] 用于任何一个上面提到的任务,如果想知道支持的任务的完整列表,可以查阅 [pipeline API 参考](./main_classes/pipelines)。不过, 在这篇教程中,你将把 [`pipeline`] 用在一个情感分析示例上:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
[`pipeline`] 会下载并缓存一个用于情感分析的默认的[预训练模型](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)和分词器。现在你可以在目标文本上使用 `classifier` 了:
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
如果你有不止一个输入,可以把所有输入放入一个列表然后传给[`pipeline`],它将会返回一个字典列表:
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
```
[`pipeline`] 也可以为任何你喜欢的任务遍历整个数据集。在下面这个示例中,让我们选择自动语音识别作为我们的任务:
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
加载一个你想遍历的音频数据集(查阅 🤗 Datasets [快速开始](https://huggingface.co/docs/datasets/quickstart#audio) 获得更多信息)。比如,加载 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 数据集:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
你需要确保数据集中的音频的采样率与 [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) 训练用到的音频的采样率一致:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
当调用 `"audio"` 列时, 音频文件将会自动加载并重采样。
从前四个样本中提取原始波形数组,将它作为列表传给 pipeline:
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FODING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE AP SO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I THURN A JOIN A COUNT']
```
对于输入非常庞大的大型数据集(比如语音或视觉),你会想到使用一个生成器,而不是一个将所有输入都加载进内存的列表。查阅 [pipeline API 参考](./main_classes/pipelines) 来获取更多信息。
### 在 pipeline 中使用另一个模型和分词器
[`pipeline`] 可以容纳 [Hub](https://huggingface.co/models) 中的任何模型,这让 [`pipeline`] 更容易适用于其他用例。比如,你想要一个能够处理法语文本的模型,就可以使用 Hub 上的标记来筛选出合适的模型。靠前的筛选结果会返回一个为情感分析微调的多语言的 [BERT 模型](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment),你可以将它用于法语文本:
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
使用 [`AutoModelForSequenceClassification`] 和 [`AutoTokenizer`] 来加载预训练模型和它关联的分词器(更多信息可以参考下一节的 `AutoClass`):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
使用 [`TFAutoModelForSequenceClassification`] 和 [`AutoTokenizer`] 来加载预训练模型和它关联的分词器(更多信息可以参考下一节的 `TFAutoClass`):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
在 [`pipeline`] 中指定模型和分词器,现在你就可以在法语文本上使用 `classifier` 了:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
如果你没有找到适合你的模型,就需要在你的数据上微调一个预训练模型了。查看 [微调教程](./training) 来学习怎样进行微调。最后,微调完模型后,考虑一下在 Hub 上与社区 [分享](./model_sharing) 这个模型,把机器学习普及到每一个人! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
在幕后,是由 [`AutoModelForSequenceClassification`] 和 [`AutoTokenizer`] 一起支持你在上面用到的 [`pipeline`]。[AutoClass](./model_doc/auto) 是一个能够通过预训练模型的名称或路径自动查找其架构的快捷方式。你只需要为你的任务选择合适的 `AutoClass` 和它关联的预处理类。
让我们回过头来看上一节的示例,看看怎样使用 `AutoClass` 来重现使用 [`pipeline`] 的结果。
### AutoTokenizer
分词器负责预处理文本,将文本转换为用于输入模型的数字数组。有多个用来管理分词过程的规则,包括如何拆分单词和在什么样的级别上拆分单词(在 [分词器总结](./tokenizer_summary) 学习更多关于分词的信息)。要记住最重要的是你需要实例化的分词器要与模型的名称相同, 来确保和模型训练时使用相同的分词规则。
使用 [`AutoTokenizer`] 加载一个分词器:
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
将文本传入分词器:
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
分词器返回了含有如下内容的字典:
* [input_ids](./glossary#input-ids):用数字表示的 token。
* [attention_mask](.glossary#attention-mask):应该关注哪些 token 的指示。
分词器也可以接受列表作为输入,并填充和截断文本,返回具有统一长度的批次:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
<Tip>
查阅[预处理](./preprocessing)教程来获得有关分词的更详细的信息,以及如何使用 [`AutoFeatureExtractor`] 和 [`AutoProcessor`] 来处理图像,音频,还有多模式输入。
</Tip>
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers 提供了一种简单统一的方式来加载预训练的实例. 这表示你可以像加载 [`AutoTokenizer`] 一样加载 [`AutoModel`]。唯一不同的地方是为你的任务选择正确的[`AutoModel`]。对于文本(或序列)分类,你应该加载[`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
通过 [任务摘要](./task_summary) 查找 [`AutoModel`] 支持的任务.
</Tip>
现在可以把预处理好的输入批次直接送进模型。你只需要通过 `**` 来解包字典:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
模型在 `logits` 属性输出最终的激活结果. 在 `logits` 上应用 softmax 函数来查询概率:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers 提供了一种简单统一的方式来加载预训练的实例。这表示你可以像加载 [`AutoTokenizer`] 一样加载 [`TFAutoModel`]。唯一不同的地方是为你的任务选择正确的 [`TFAutoModel`],对于文本(或序列)分类,你应该加载 [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
通过 [任务摘要](./task_summary) 查找 [`AutoModel`] 支持的任务.
</Tip>
现在通过直接将字典的键传给张量,将预处理的输入批次传给模型。
```py
>>> tf_outputs = tf_model(tf_batch)
```
模型在 `logits` 属性输出最终的激活结果。在 `logits` 上应用softmax函数来查询概率:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
所有 🤗 Transformers 模型(PyTorch 或 TensorFlow)在最终的激活函数(比如 softmax)*之前* 输出张量,
因为最终的激活函数常常与 loss 融合。模型的输出是特殊的数据类,所以它们的属性可以在 IDE 中被自动补全。模型的输出就像一个元组或字典(你可以通过整数、切片或字符串来索引它),在这种情况下,为 None 的属性会被忽略。
</Tip>
### 保存模型
<frameworkcontent>
<pt>
当你的模型微调完成,你就可以使用 [`PreTrainedModel.save_pretrained`] 把它和它的分词器保存下来:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
当你准备再次使用这个模型时,就可以使用 [`PreTrainedModel.from_pretrained`] 加载它了:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
当你的模型微调完成,你就可以使用 [`TFPreTrainedModel.save_pretrained`] 把它和它的分词器保存下来:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
当你准备再次使用这个模型时,就可以使用 [`TFPreTrainedModel.from_pretrained`] 加载它了:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
🤗 Transformers 有一个特别酷的功能,它能够保存一个模型,并且将它加载为 PyTorch 或 TensorFlow 模型。`from_pt` 或 `from_tf` 参数可以将模型从一个框架转换为另一个框架:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
## 自定义模型构建
你可以修改模型的配置类来改变模型的构建方式。配置指明了模型的属性,比如隐藏层或者注意力头的数量。当你从自定义的配置类初始化模型时,你就开始自定义模型构建了。模型属性是随机初始化的,你需要先训练模型,然后才能得到有意义的结果。
通过导入 [`AutoConfig`] 来开始,之后加载你想修改的预训练模型。在 [`AutoConfig.from_pretrained`] 中,你能够指定想要修改的属性,比如注意力头的数量:
```py
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
```
<frameworkcontent>
<pt>
使用 [`AutoModel.from_config`] 根据你的自定义配置创建一个模型:
```py
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
```
</pt>
<tf>
使用 [`TFAutoModel.from_config`] 根据你的自定义配置创建一个模型:
```py
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
```
</tf>
</frameworkcontent>
查阅 [创建一个自定义结构](./create_a_model) 指南获取更多关于构建自定义配置的信息。
## Trainer - PyTorch 优化训练循环
所有的模型都是标准的 [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module),所以你可以在任何典型的训练模型中使用它们。当你编写自己的训练循环时,🤗 Transformers 为 PyTorch 提供了一个 [`Trainer`] 类,它包含了基础的训练循环并且为诸如分布式训练,混合精度等特性增加了额外的功能。
取决于你的任务, 你通常可以传递以下的参数给 [`Trainer`]:
1. [`PreTrainedModel`] 或者 [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module):
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. [`TrainingArguments`] 含有你可以修改的模型超参数,比如学习率,批次大小和训练时的迭代次数。如果你没有指定训练参数,那么它会使用默认值:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="path/to/save/folder/",
... learning_rate=2e-5,
... per_device_train_batch_size=8,
... per_device_eval_batch_size=8,
... num_train_epochs=2,
... )
```
3. 一个预处理类,比如分词器,特征提取器或者处理器:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
4. 加载一个数据集:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
```
5. 创建一个给数据集分词的函数,并且使用 [`~datasets.Dataset.map`] 应用到整个数据集:
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"])
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
6. 用来从数据集中创建批次的 [`DataCollatorWithPadding`]:
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
现在把所有的类传给 [`Trainer`]:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
一切准备就绪后,调用 [`~Trainer.train`] 进行训练:
```py
>>> trainer.train() # doctest: +SKIP
```
<Tip>
对于像翻译或摘要这些使用序列到序列模型的任务,用 [`Seq2SeqTrainer`] 和 [`Seq2SeqTrainingArguments`] 来替代。
</Tip>
你可以通过子类化 [`Trainer`] 中的方法来自定义训练循环。这样你就可以自定义像损失函数,优化器和调度器这样的特性。查阅 [`Trainer`] 参考手册了解哪些方法能够被子类化。
另一个自定义训练循环的方式是通过[回调](./main_classes/callbacks)。你可以使用回调来与其他库集成,查看训练循环来报告进度或提前结束训练。回调不会修改训练循环。如果想自定义损失函数等,就需要子类化 [`Trainer`] 了。
## 使用 Tensorflow 训练
所有模型都是标准的 [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model),所以你可以通过 [Keras](https://keras.io/) API 实现在 Tensorflow 中训练。🤗 Transformers 提供了 [`~TFPreTrainedModel.prepare_tf_dataset`] 方法来轻松地将数据集加载为 `tf.data.Dataset`,这样你就可以使用 Keras 的 [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 和 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) 方法马上开始训练。
1. 使用 [`TFPreTrainedModel`] 或者 [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) 来开始:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. 一个预处理类,比如分词器,特征提取器或者处理器:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
3. 创建一个给数据集分词的函数
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"]) # doctest: +SKIP
```
4. 使用 [`~datasets.Dataset.map`] 将分词器应用到整个数据集,之后将数据集和分词器传给 [`~TFPreTrainedModel.prepare_tf_dataset`]。如果你需要的话,也可以在这里改变批次大小和是否打乱数据集:
```py
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
... dataset, batch_size=16, shuffle=True, tokenizer=tokenizer
... ) # doctest: +SKIP
```
5. 一切准备就绪后,调用 `compile` 和 `fit` 开始训练:
```py
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5))
>>> model.fit(dataset) # doctest: +SKIP
```
## 接下来做什么?
现在你已经完成了 🤗 Transformers 的快速上手教程,来看看我们的指南并且学习如何做一些更具体的事情,比如写一个自定义模型,为某个任务微调一个模型以及如何使用脚本来训练模型。如果你有兴趣了解更多 🤗 Transformers 的核心章节,那就喝杯咖啡然后来看看我们的概念指南吧!
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/performance.md
|
<!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 性能与可扩展性
训练大型transformer模型并将其部署到生产环境会面临各种挑战。
在训练过程中,模型可能需要比可用的GPU内存更多的资源,或者表现出较慢的训练速度。在部署阶段,模型可能在生产环境中难以处理所需的吞吐量。
本文档旨在帮助您克服这些挑战,并找到适合您使用场景的最佳设置。教程分为训练和推理部分,因为每个部分都有不同的挑战和解决方案。在每个部分中,您将找到针对不同硬件配置的单独指南,例如单GPU与多GPU用于训练或CPU与GPU用于推理。
将此文档作为您的起点,进一步导航到与您的情况匹配的方法。
## 训练
高效训练大型transformer模型需要使用加速器硬件,如GPU或TPU。最常见的情况是您只有一个GPU。您应用于单个GPU上提高训练效率的方法可以扩展到其他设置,如多个GPU。然而,也有一些特定于多GPU或CPU训练的技术。我们在单独的部分中介绍它们。
* [在单个GPU上进行高效训练的方法和工具](perf_train_gpu_one):从这里开始学习常见的方法,可以帮助优化GPU内存利用率、加快训练速度或两者兼备。
* [多GPU训练部分](perf_train_gpu_many):探索此部分以了解适用于多GPU设置的进一步优化方法,例如数据并行、张量并行和流水线并行。
* [CPU训练部分](perf_train_cpu):了解在CPU上的混合精度训练。
* [在多个CPU上进行高效训练](perf_train_cpu_many):了解分布式CPU训练。
* [使用TensorFlow在TPU上进行训练](perf_train_tpu_tf):如果您对TPU还不熟悉,请参考此部分,了解有关在TPU上进行训练和使用XLA的建议性介绍。
* [自定义硬件进行训练](perf_hardware):在构建自己的深度学习机器时查找技巧和窍门。
* [使用Trainer API进行超参数搜索](hpo_train)
## 推理
在生产环境中对大型模型进行高效推理可能与训练它们一样具有挑战性。在接下来的部分中,我们将详细介绍如何在CPU和单/多GPU设置上进行推理的步骤。
* [在单个CPU上进行推理](perf_infer_cpu)
* [在单个GPU上进行推理](perf_infer_gpu_one)
* [多GPU推理](perf_infer_gpu_one)
* [TensorFlow模型的XLA集成](tf_xla)
## 训练和推理
在这里,您将找到适用于训练模型或使用它进行推理的技巧、窍门和技巧。
* [实例化大型模型](big_models)
* [解决性能问题](debugging)
## 贡献
这份文档还远远没有完成,还有很多需要添加的内容,所以如果你有补充或更正的内容,请毫不犹豫地提交一个PR(Pull Request),或者如果你不确定,可以创建一个Issue,我们可以在那里讨论细节。
在做出贡献时,如果A比B更好,请尽量包含可重复的基准测试和(或)该信息来源的链接(除非它直接来自您)。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/custom_models.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 共享自定义模型
🤗 Transformers 库设计得易于扩展。每个模型的代码都在仓库给定的子文件夹中,没有进行抽象,因此你可以轻松复制模型代码文件并根据需要进行调整。
如果你要编写全新的模型,从头开始可能更容易。在本教程中,我们将向你展示如何编写自定义模型及其配置,以便可以在 Transformers 中使用它;以及如何与社区共享它(及其依赖的代码),以便任何人都可以使用,即使它不在 🤗 Transformers 库中。
我们将以 ResNet 模型为例,通过将 [timm 库](https://github.com/rwightman/pytorch-image-models) 的 ResNet 类封装到 [`PreTrainedModel`] 中来进行说明。
## 编写自定义配置
在深入研究模型之前,让我们首先编写其配置。模型的配置是一个对象,其中包含构建模型所需的所有信息。我们将在下一节中看到,模型只能接受一个 `config` 来进行初始化,因此我们很需要使该对象尽可能完整。
我们将采用一些我们可能想要调整的 ResNet 类的参数举例。不同的配置将为我们提供不同类型可能的 ResNet 模型。在确认其中一些参数的有效性后,我们只需存储这些参数。
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
编写自定义配置时需要记住的三个重要事项如下:
- 必须继承自 `PretrainedConfig`,
- `PretrainedConfig` 的 `__init__` 方法必须接受任何 kwargs,
- 这些 `kwargs` 需要传递给超类的 `__init__` 方法。
继承是为了确保你获得来自 🤗 Transformers 库的所有功能,而另外两个约束源于 `PretrainedConfig` 的字段比你设置的字段多。在使用 `from_pretrained` 方法重新加载配置时,这些字段需要被你的配置接受,然后传递给超类。
为你的配置定义 `model_type`(此处为 `model_type="resnet"`)不是必须的,除非你想使用自动类注册你的模型(请参阅最后一节)。
做完这些以后,就可以像使用库里任何其他模型配置一样,轻松地创建和保存配置。以下代码展示了如何创建并保存 resnet50d 配置:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
这行代码将在 `custom-resnet` 文件夹内保存一个名为 `config.json` 的文件。然后,你可以使用 `from_pretrained` 方法重新加载配置:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
你还可以使用 [`PretrainedConfig`] 类的任何其他方法,例如 [`~PretrainedConfig.push_to_hub`],直接将配置上传到 Hub。
## 编写自定义模型
有了 ResNet 配置后,就可以继续编写模型了。实际上,我们将编写两个模型:一个模型用于从一批图像中提取隐藏特征(类似于 [`BertModel`]),另一个模型适用于图像分类(类似于 [`BertForSequenceClassification`])。
正如之前提到的,我们只会编写一个松散的模型包装,以使示例保持简洁。在编写此类之前,只需要建立起块类型(block types)与实际块类(block classes)之间的映射。然后,通过将所有内容传递给ResNet类,从配置中定义模型:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
对用于进行图像分类的模型,我们只需更改前向方法:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
在这两种情况下,请注意我们如何继承 `PreTrainedModel` 并使用 `config` 调用了超类的初始化(有点像编写常规的torch.nn.Module)。设置 `config_class` 的那行代码不是必须的,除非你想使用自动类注册你的模型(请参阅最后一节)。
<Tip>
如果你的模型与库中的某个模型非常相似,你可以重用与该模型相同的配置。
</Tip>
你可以让模型返回任何你想要的内容,但是像我们为 `ResnetModelForImageClassification` 做的那样返回一个字典,并在传递标签时包含loss,可以使你的模型能够在 [`Trainer`] 类中直接使用。只要你计划使用自己的训练循环或其他库进行训练,也可以使用其他输出格式。
现在我们已经有了模型类,让我们创建一个:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
同样的,你可以使用 [`PreTrainedModel`] 的任何方法,比如 [`~PreTrainedModel.save_pretrained`] 或者 [`~PreTrainedModel.push_to_hub`]。我们将在下一节中使用第二种方法,并了解如何如何使用我们的模型的代码推送模型权重。但首先,让我们在模型内加载一些预训练权重。
在你自己的用例中,你可能会在自己的数据上训练自定义模型。为了快速完成本教程,我们将使用 resnet50d 的预训练版本。由于我们的模型只是它的包装,转移这些权重将会很容易:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
现在让我们看看,如何确保在执行 [`~PreTrainedModel.save_pretrained`] 或 [`~PreTrainedModel.push_to_hub`] 时,模型的代码被保存。
## 将代码发送到 Hub
<Tip warning={true}>
此 API 是实验性的,未来的发布中可能会有一些轻微的不兼容更改。
</Tip>
首先,确保你的模型在一个 `.py` 文件中完全定义。只要所有文件都位于同一目录中,它就可以依赖于某些其他文件的相对导入(目前我们还不为子模块支持此功能)。对于我们的示例,我们将在当前工作目录中名为 `resnet_model` 的文件夹中定义一个 `modeling_resnet.py` 文件和一个 `configuration_resnet.py` 文件。 配置文件包含 `ResnetConfig` 的代码,模型文件包含 `ResnetModel` 和 `ResnetModelForImageClassification` 的代码。
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
`__init__.py` 可以为空,它的存在只是为了让 Python 检测到 `resnet_model` 可以用作模块。
<Tip warning={true}>
如果从库中复制模型文件,你需要将文件顶部的所有相对导入替换为从 `transformers` 包中的导入。
</Tip>
请注意,你可以重用(或子类化)现有的配置/模型。
要与社区共享您的模型,请参照以下步骤:首先从新创建的文件中导入ResNet模型和配置:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
接下来,你需要告诉库,当使用 `save_pretrained` 方法时,你希望复制这些对象的代码文件,并将它们正确注册到给定的 Auto 类(特别是对于模型),只需要运行以下代码:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
请注意,对于配置(只有一个自动类 [`AutoConfig`]),不需要指定自动类,但对于模型来说情况不同。 你的自定义模型可能适用于许多不同的任务,因此你必须指定哪一个自动类适合你的模型。
接下来,让我们像之前一样创建配置和模型:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
现在要将模型推送到集线器,请确保你已登录。你看可以在终端中运行以下命令:
```bash
huggingface-cli login
```
或者在笔记本中运行以下代码:
```py
from huggingface_hub import notebook_login
notebook_login()
```
然后,可以这样将模型推送到自己的命名空间(或你所属的组织):
```py
resnet50d.push_to_hub("custom-resnet50d")
```
除了模型权重和 JSON 格式的配置外,这行代码也会复制 `custom-resnet50d` 文件夹内的模型以及配置的 `.py` 文件并将结果上传至 Hub。你可以在此[模型仓库](https://huggingface.co/sgugger/custom-resnet50d)中查看结果。
有关推推送至 Hub 方法的更多信息,请参阅[共享教程](model_sharing)。
## 使用带有自定义代码的模型
可以使用自动类(auto-classes)和 `from_pretrained` 方法,使用模型仓库里带有自定义代码的配置、模型或分词器文件。所有上传到 Hub 的文件和代码都会进行恶意软件扫描(有关更多信息,请参阅 [Hub 安全](https://huggingface.co/docs/hub/security#malware-scanning) 文档), 但你仍应查看模型代码和作者,以避免在你的计算机上执行恶意代码。 设置 `trust_remote_code=True` 以使用带有自定义代码的模型:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
我们强烈建议为 `revision` 参数传递提交哈希(commit hash),以确保模型的作者没有使用一些恶意的代码行更新了代码(除非您完全信任模型的作者)。
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
在 Hub 上浏览模型仓库的提交历史时,有一个按钮可以轻松复制任何提交的提交哈希。
## 将自定义代码的模型注册到自动类
如果你在编写一个扩展 🤗 Transformers 的库,你可能想要扩展自动类以包含您自己的模型。这与将代码推送到 Hub 不同,因为用户需要导入你的库才能获取自定义模型(与从 Hub 自动下载模型代码相反)。
只要你的配置 `model_type` 属性与现有模型类型不同,并且你的模型类有正确的 `config_class` 属性,你可以像这样将它们添加到自动类中:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
请注意,将自定义配置注册到 [`AutoConfig`] 时,使用的第一个参数需要与自定义配置的 `model_type` 匹配;而将自定义模型注册到任何自动模型类时,使用的第一个参数需要与 `config_class` 匹配。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/installation.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 安装
为你正在使用的深度学习框架安装 🤗 Transformers、设置缓存,并选择性配置 🤗 Transformers 以离线运行。
🤗 Transformers 已在 Python 3.6+、PyTorch 1.1.0+、TensorFlow 2.0+ 以及 Flax 上进行测试。针对你使用的深度学习框架,请参照以下安装说明进行安装:
* [PyTorch](https://pytorch.org/get-started/locally/) 安装说明。
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) 安装说明。
* [Flax](https://flax.readthedocs.io/en/latest/) 安装说明。
## 使用 pip 安装
你应该使用 [虚拟环境](https://docs.python.org/3/library/venv.html) 安装 🤗 Transformers。如果你不熟悉 Python 虚拟环境,请查看此 [教程](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。使用虚拟环境,你可以轻松管理不同项目,避免不同依赖项之间的兼容性问题。
首先,在项目目录中创建虚拟环境:
```bash
python -m venv .env
```
在 Linux 和 MacOs 系统中激活虚拟环境:
```bash
source .env/bin/activate
```
在 Windows 系统中激活虚拟环境:
```bash
.env/Scripts/activate
```
现在你可以使用以下命令安装 🤗 Transformers:
```bash
pip install transformers
```
若仅需 CPU 支持,可以使用单行命令方便地安装 🤗 Transformers 和深度学习库。例如,使用以下命令安装 🤗 Transformers 和 PyTorch:
```bash
pip install 'transformers[torch]'
```
🤗 Transformers 和 TensorFlow 2.0:
```bash
pip install 'transformers[tf-cpu]'
```
<Tip warning={true}>
M1 / ARM用户
在安装 TensorFlow 2.0 前,你需要安装以下库:
```
brew install cmake
brew install pkg-config
```
</Tip>
🤗 Transformers 和 Flax:
```bash
pip install 'transformers[flax]'
```
最后,运行以下命令以检查 🤗 Transformers 是否已被正确安装。该命令将下载一个预训练模型:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
然后打印标签以及分数:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## 源码安装
使用以下命令从源码安装 🤗 Transformers:
```bash
pip install git+https://github.com/huggingface/transformers
```
此命令下载的是最新的前沿 `main` 版本而不是最新的 `stable` 版本。`main` 版本适用于跟最新开发保持一致。例如,上次正式版发布带来的 bug 被修复了,但新版本尚未被推出。但是,这也说明 `main` 版本并不一定总是稳定的。我们努力保持 `main` 版本的可操作性,大多数问题通常在几个小时或一天以内就能被解决。如果你遇到问题,请提个 [Issue](https://github.com/huggingface/transformers/issues) 以便我们能更快修复。
运行以下命令以检查 🤗 Transformers 是否已被正确安装:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## 可编辑安装
如果你有下列需求,需要进行可编辑安装:
* 使用源码的 `main` 版本。
* 为 🤗 Transformers 贡献代码,需要测试代码中的更改。
使用以下命令克隆仓库并安装 🤗 Transformers:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
这些命令将会链接你克隆的仓库以及你的 Python 库路径。现在,Python 不仅会在正常的库路径中搜索库,也会在你克隆到的文件夹中进行查找。例如,如果你的 Python 包通常本应安装在 `~/anaconda3/envs/main/lib/python3.7/site-packages/` 目录中,在这种情况下 Python 也会搜索你克隆到的文件夹:`~/transformers/`。
<Tip warning={true}>
如果你想继续使用这个库,必须保留 `transformers` 文件夹。
</Tip>
现在,你可以使用以下命令,将你克隆的 🤗 Transformers 库轻松更新至最新版本:
```bash
cd ~/transformers/
git pull
```
你的 Python 环境将在下次运行时找到 `main` 版本的 🤗 Transformers。
## 使用 conda 安装
从 conda 的 `conda-forge` 频道安装:
```bash
conda install conda-forge::transformers
```
## 缓存设置
预训练模型会被下载并本地缓存到 `~/.cache/huggingface/hub`。这是由环境变量 `TRANSFORMERS_CACHE` 指定的默认目录。在 Windows 上,默认目录为 `C:\Users\username\.cache\huggingface\hub`。你可以按照不同优先级改变下述环境变量,以指定不同的缓存目录。
1. 环境变量(默认): `HUGGINGFACE_HUB_CACHE` 或 `TRANSFORMERS_CACHE`。
2. 环境变量 `HF_HOME`。
3. 环境变量 `XDG_CACHE_HOME` + `/huggingface`。
<Tip>
除非你明确指定了环境变量 `TRANSFORMERS_CACHE`,🤗 Transformers 将可能会使用较早版本设置的环境变量 `PYTORCH_TRANSFORMERS_CACHE` 或 `PYTORCH_PRETRAINED_BERT_CACHE`。
</Tip>
## 离线模式
🤗 Transformers 可以仅使用本地文件在防火墙或离线环境中运行。设置环境变量 `TRANSFORMERS_OFFLINE=1` 以启用该行为。
<Tip>
通过设置环境变量 `HF_DATASETS_OFFLINE=1` 将 [🤗 Datasets](https://huggingface.co/docs/datasets/) 添加至你的离线训练工作流程中。
</Tip>
例如,你通常会使用以下命令对外部实例进行防火墙保护的的普通网络上运行程序:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
在离线环境中运行相同的程序:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
现在脚本可以应该正常运行,而无需挂起或等待超时,因为它知道只应查找本地文件。
### 获取离线时使用的模型和分词器
另一种离线时使用 🤗 Transformers 的方法是预先下载好文件,然后在需要离线使用时指向它们的离线路径。有三种实现的方法:
* 单击 [Model Hub](https://huggingface.co/models) 用户界面上的 ↓ 图标下载文件。

* 使用 [`PreTrainedModel.from_pretrained`] 和 [`PreTrainedModel.save_pretrained`] 工作流程:
1. 预先使用 [`PreTrainedModel.from_pretrained`] 下载文件:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. 使用 [`PreTrainedModel.save_pretrained`] 将文件保存至指定目录:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. 现在,你可以在离线时从指定目录使用 [`PreTrainedModel.from_pretrained`] 重新加载你的文件:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* 使用代码用 [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) 库下载文件:
1. 在你的虚拟环境中安装 `huggingface_hub` 库:
```bash
python -m pip install huggingface_hub
```
2. 使用 [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) 函数将文件下载到指定路径。例如,以下命令将 `config.json` 文件从 [T0](https://huggingface.co/bigscience/T0_3B) 模型下载至你想要的路径:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
下载完文件并在本地缓存后,指定其本地路径以加载和使用该模型:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
请参阅 [如何从 Hub 下载文件](https://huggingface.co/docs/hub/how-to-downstream) 部分,获取有关下载存储在 Hub 上文件的更多详细信息。
</Tip>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/debugging.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 调试
## 多GPU网络问题调试
当使用`DistributedDataParallel`和多个GPU进行训练或推理时,如果遇到进程和(或)节点之间的互联问题,您可以使用以下脚本来诊断网络问题。
```bash
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
```
例如,要测试两个GPU之间的互联,请执行以下操作:
```bash
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
如果两个进程能够相互通信并分配GPU内存,它们各自将打印出 "OK" 状态。
对于更多的GPU或节点,可以根据脚本中的参数进行调整。
在诊断脚本内部,您将找到更多详细信息,甚至有关如何在SLURM环境中运行它的说明。
另一种级别的调试是添加 `NCCL_DEBUG=INFO` 环境变量,如下所示:
```bash
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
这将产生大量与NCCL相关的调试信息,如果发现有问题报告,您可以在线搜索以获取相关信息。或者,如果您不确定如何解释输出,可以在`issue`中分享日志文件。
## 下溢和上溢检测
<Tip>
目前,此功能仅适用于PyTorch。
</Tip>
<Tip>
对于多GPU训练,它需要使用DDP(`torch.distributed.launch`)。
</Tip>
<Tip>
此功能可以与任何基于`nn.Module`的模型一起使用。
</Tip>
如果您开始发现`loss=NaN`或模型因激活值或权重中的`inf`或`nan`而出现一些异常行为,就需要发现第一个下溢或上溢发生的地方以及导致它的原因。幸运的是,您可以通过激活一个特殊模块来自动进行检测。
如果您正在使用[`Trainer`],只需把以下内容:
```bash
--debug underflow_overflow
```
添加到常规命令行参数中,或在创建[`TrainingArguments`]对象时传递 `debug="underflow_overflow"`。
如果您正在使用自己的训练循环或其他Trainer,您可以通过以下方式实现相同的功能:
```python
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model)
```
[`debug_utils.DebugUnderflowOverflow`] 将`hooks`插入模型,紧跟在每次前向调用之后,进而测试输入和输出变量,以及相应模块的权重。一旦在激活值或权重的至少一个元素中检测到`inf`或`nan`,程序将执行`assert`并打印报告,就像这样(这是在`google/mt5-small`下使用fp16混合精度捕获的):
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output
[...]
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
由于篇幅原因,示例输出中间的部分已经被缩减。
第二列显示了绝对最大元素的值,因此,如果您仔细查看最后`frame`,输入和输出都在`1e4`的范围内。因此,在使用fp16混合精度进行训练时,最后一步发生了溢出(因为在`fp16`下,在`inf`之前的最大数字是`64e3`)。为了避免在`fp16`下发生溢出,激活值必须保持低于`1e4`,因为`1e4 * 1e4 = 1e8`,因此任何具有大激活值的矩阵乘法都会导致数值溢出。
在跟踪的开始处,您可以发现问题发生在哪个批次(这里的`Detected inf/nan during batch_number=0`表示问题发生在第一个批次)。
每个报告的`frame`都以声明相应模块的层信息为开头,说明这一`frame`是为哪个模块报告的。如果只看这个`frame`:
```
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
```
在这里,`encoder.block.2.layer.1.layer_norm` 表示它是编码器的第二个块中第一层的`layer norm`。而 `forward` 的具体调用是 `T5LayerNorm`。
让我们看看该报告的最后几个`frame`:
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
[...]
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
最后一个`frame`报告了`Dropout.forward`函数,第一个条目是唯一的输入,第二个条目是唯一的输出。您可以看到,它是从`DenseReluDense`类内的属性`dropout`中调用的。我们可以看到它发生在第2个块的第1层,也就是在第一个批次期间。最后,绝对最大的输入元素值为`6.27e+04`,输出也是`inf`。
您可以在这里看到,`T5DenseGatedGeluDense.forward`产生了输出激活值,其绝对最大值约为62.7K,非常接近fp16的上限64K。在下一个`frame`中,我们有`Dropout`对权重进行重新归一化,之后将某些元素归零,将绝对最大值推到了64K以上,导致溢出(`inf`)。
正如你所看到的,我们需要查看前面的`frame`, 从那里fp16数字开始变得非常大。
让我们将报告与`models/t5/modeling_t5.py`中的代码匹配:
```python
class T5DenseGatedGeluDense(nn.Module):
def __init__(self, config):
super().__init__()
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.gelu_act = ACT2FN["gelu_new"]
def forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
```
现在很容易看到`dropout`调用,以及所有之前的调用。
由于检测是在前向`hook`中进行的,这些报告将立即在每个`forward`返回后打印出来。
回到完整的报告,要采取措施并解决问题,我们需要往回看几个`frame`,在那里数字开始上升,并且最有可能切换到fp32模式以便在乘法或求和时数字不会溢出。当然,可能还有其他解决方案。例如,如果启用了`amp`,我们可以在将原始`forward`移到`helper wrapper`中后,暂时关闭它,如下所示:
```python
def _forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
import torch
def forward(self, hidden_states):
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)
```
由于自动检测器仅报告完整`frame`的输入和输出,一旦知道在哪里查找,您可能还希望分析特定`forward`函数的中间阶段。在这种情况下,您可以使用`detect_overflow`辅助函数将检测器放到希望的位置,例如:
```python
from debug_utils import detect_overflow
class T5LayerFF(nn.Module):
[...]
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
detect_overflow(forwarded_states, "after layer_norm")
forwarded_states = self.DenseReluDense(forwarded_states)
detect_overflow(forwarded_states, "after DenseReluDense")
return hidden_states + self.dropout(forwarded_states)
```
可以看到,我们添加了2个检测器,现在我们可以跟踪是否在`forwarded_states`中间的某个地方检测到了`inf`或`nan`。
实际上,检测器已经报告了这些,因为上面示例中的每个调用都是一个`nn.Module`,但假设如果您有一些本地的直接计算,这就是您将如何执行的方式。
此外,如果您在自己的代码中实例化调试器,您可以调整从其默认打印的`frame`数,例如:
```python
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
```
### 特定批次的绝对最小值和最大值跟踪
当关闭下溢/上溢检测功能, 同样的调试类可以用于批处理跟踪。
假设您想要监视给定批次的每个`forward`调用的所有成分的绝对最小值和最大值,并且仅对批次1和3执行此操作,您可以这样实例化这个类:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
```
现在,完整的批次1和3将以与下溢/上溢检测器相同的格式进行跟踪。
批次从0开始计数。
如果您知道程序在某个批次编号之后开始出现问题,那么您可以直接快进到该区域。以下是一个截取的配置示例输出:
```
*** Starting batch number=1 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.47e+04 input[0]
5.36e-05 7.92e+02 output
[...]
decoder.dropout Dropout
1.60e-07 2.27e+01 input[0]
0.00e+00 2.52e+01 output
decoder T5Stack
not a tensor output
lm_head Linear
1.01e-06 7.92e+02 weight
0.00e+00 1.11e+00 input[0]
6.06e-02 8.39e+01 output
T5ForConditionalGeneration
not a tensor output
*** Starting batch number=3 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.78e+04 input[0]
5.36e-05 7.92e+02 output
[...]
```
在这里,您将获得大量的`frame`被`dump` - 与您的模型中的前向调用一样多,它有可能符合也可能不符合您的要求,但有时对于调试目的来说,它可能比正常的调试器更容易使用。例如,如果问题开始发生在批次号150上,您可以`dump`批次149和150的跟踪,并比较数字开始发散的地方。
你还可以使用以下命令指定停止训练的批次号:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/preprocessing.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 预处理
[[open-in-colab]]
在您可以在数据集上训练模型之前,数据需要被预处理为期望的模型输入格式。无论您的数据是文本、图像还是音频,它们都需要被转换并组合成批量的张量。🤗 Transformers 提供了一组预处理类来帮助准备数据以供模型使用。在本教程中,您将了解以下内容:
* 对于文本,使用[分词器](./main_classes/tokenizer)(`Tokenizer`)将文本转换为一系列标记(`tokens`),并创建`tokens`的数字表示,将它们组合成张量。
* 对于语音和音频,使用[特征提取器](./main_classes/feature_extractor)(`Feature extractor`)从音频波形中提取顺序特征并将其转换为张量。
* 图像输入使用[图像处理器](./main_classes/image)(`ImageProcessor`)将图像转换为张量。
* 多模态输入,使用[处理器](./main_classes/processors)(`Processor`)结合了`Tokenizer`和`ImageProcessor`或`Processor`。
<Tip>
`AutoProcessor` **始终**有效的自动选择适用于您使用的模型的正确`class`,无论您使用的是`Tokenizer`、`ImageProcessor`、`Feature extractor`还是`Processor`。
</Tip>
在开始之前,请安装🤗 Datasets,以便您可以加载一些数据集来进行实验:
```bash
pip install datasets
```
## 自然语言处理
<Youtube id="Yffk5aydLzg"/>
处理文本数据的主要工具是[Tokenizer](main_classes/tokenizer)。`Tokenizer`根据一组规则将文本拆分为`tokens`。然后将这些`tokens`转换为数字,然后转换为张量,成为模型的输入。模型所需的任何附加输入都由`Tokenizer`添加。
<Tip>
如果您计划使用预训练模型,重要的是使用与之关联的预训练`Tokenizer`。这确保文本的拆分方式与预训练语料库相同,并在预训练期间使用相同的标记-索引的对应关系(通常称为*词汇表*-`vocab`)。
</Tip>
开始使用[`AutoTokenizer.from_pretrained`]方法加载一个预训练`tokenizer`。这将下载模型预训练的`vocab`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
然后将您的文本传递给`tokenizer`:
```py
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
>>> print(encoded_input)
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
`tokenizer`返回一个包含三个重要对象的字典:
* [input_ids](glossary#input-ids) 是与句子中每个`token`对应的索引。
* [attention_mask](glossary#attention-mask) 指示是否应该关注一个`token`。
* [token_type_ids](glossary#token-type-ids) 在存在多个序列时标识一个`token`属于哪个序列。
通过解码 `input_ids` 来返回您的输入:
```py
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
```
如您所见,`tokenizer`向句子中添加了两个特殊`token` - `CLS` 和 `SEP`(分类器和分隔符)。并非所有模型都需要特殊`token`,但如果需要,`tokenizer`会自动为您添加。
如果有多个句子需要预处理,将它们作为列表传递给`tokenizer`:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1]]}
```
### 填充
句子的长度并不总是相同,这可能会成为一个问题,因为模型输入的张量需要具有统一的形状。填充是一种策略,通过在较短的句子中添加一个特殊的`padding token`,以确保张量是矩形的。
将 `padding` 参数设置为 `True`,以使批次中较短的序列填充到与最长序列相匹配的长度:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
第一句和第三句因为较短,通过`0`进行填充,。
### 截断
另一方面,有时候一个序列可能对模型来说太长了。在这种情况下,您需要将序列截断为更短的长度。
将 `truncation` 参数设置为 `True`,以将序列截断为模型接受的最大长度:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
<Tip>
查看[填充和截断](./pad_truncation)概念指南,了解更多有关填充和截断参数的信息。
</Tip>
### 构建张量
最后,`tokenizer`可以返回实际输入到模型的张量。
将 `return_tensors` 参数设置为 `pt`(对于PyTorch)或 `tf`(对于TensorFlow):
<frameworkcontent>
<pt>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
>>> print(encoded_input)
{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
```
</pt>
<tf>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
>>> print(encoded_input)
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>,
'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
```
</tf>
</frameworkcontent>
## 音频
对于音频任务,您需要[feature extractor](main_classes/feature_extractor)来准备您的数据集以供模型使用。`feature extractor`旨在从原始音频数据中提取特征,并将它们转换为张量。
加载[MInDS-14](https://huggingface.co/datasets/PolyAI/minds14)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets教程](https://huggingface.co/docs/datasets/load_hub))以了解如何在音频数据集中使用`feature extractor`:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
访问 `audio` 列的第一个元素以查看输入。调用 `audio` 列会自动加载和重新采样音频文件:
```py
>>> dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 8000}
```
这会返回三个对象:
* `array` 是加载的语音信号 - 并在必要时重新采为`1D array`。
* `path` 指向音频文件的位置。
* `sampling_rate` 是每秒测量的语音信号数据点数量。
对于本教程,您将使用[Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)模型。查看模型卡片,您将了解到Wav2Vec2是在16kHz采样的语音音频数据上预训练的。重要的是,您的音频数据的采样率要与用于预训练模型的数据集的采样率匹配。如果您的数据的采样率不同,那么您需要对数据进行重新采样。
1. 使用🤗 Datasets的[`~datasets.Dataset.cast_column`]方法将采样率提升到16kHz:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
```
2. 再次调用 `audio` 列以重新采样音频文件:
```py
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
```
接下来,加载一个`feature extractor`以对输入进行标准化和填充。当填充文本数据时,会为较短的序列添加 `0`。相同的理念适用于音频数据。`feature extractor`添加 `0` - 被解释为静音 - 到`array` 。
使用 [`AutoFeatureExtractor.from_pretrained`] 加载`feature extractor`:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
将音频 `array` 传递给`feature extractor`。我们还建议在`feature extractor`中添加 `sampling_rate` 参数,以更好地调试可能发生的静音错误:
```py
>>> audio_input = [dataset[0]["audio"]["array"]]
>>> feature_extractor(audio_input, sampling_rate=16000)
{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
```
就像`tokenizer`一样,您可以应用填充或截断来处理批次中的可变序列。请查看这两个音频样本的序列长度:
```py
>>> dataset[0]["audio"]["array"].shape
(173398,)
>>> dataset[1]["audio"]["array"].shape
(106496,)
```
创建一个函数来预处理数据集,以使音频样本具有相同的长度。通过指定最大样本长度,`feature extractor`将填充或截断序列以使其匹配:
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays,
... sampling_rate=16000,
... padding=True,
... max_length=100000,
... truncation=True,
... )
... return inputs
```
将`preprocess_function`应用于数据集中的前几个示例:
```py
>>> processed_dataset = preprocess_function(dataset[:5])
```
现在样本长度是相同的,并且与指定的最大长度匹配。您现在可以将经过处理的数据集传递给模型了!
```py
>>> processed_dataset["input_values"][0].shape
(100000,)
>>> processed_dataset["input_values"][1].shape
(100000,)
```
## 计算机视觉
对于计算机视觉任务,您需要一个[ image processor](main_classes/image_processor)来准备数据集以供模型使用。图像预处理包括多个步骤将图像转换为模型期望输入的格式。这些步骤包括但不限于调整大小、标准化、颜色通道校正以及将图像转换为张量。
<Tip>
图像预处理通常遵循某种形式的图像增强。图像预处理和图像增强都会改变图像数据,但它们有不同的目的:
* 图像增强可以帮助防止过拟合并增加模型的鲁棒性。您可以在数据增强方面充分发挥创造性 - 调整亮度和颜色、裁剪、旋转、调整大小、缩放等。但要注意不要改变图像的含义。
* 图像预处理确保图像与模型预期的输入格式匹配。在微调计算机视觉模型时,必须对图像进行与模型训练时相同的预处理。
您可以使用任何您喜欢的图像增强库。对于图像预处理,请使用与模型相关联的`ImageProcessor`。
</Tip>
加载[food101](https://huggingface.co/datasets/food101)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets教程](https://huggingface.co/docs/datasets/load_hub))以了解如何在计算机视觉数据集中使用图像处理器:
<Tip>
因为数据集相当大,请使用🤗 Datasets的`split`参数加载训练集中的少量样本!
</Tip>
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101", split="train[:100]")
```
接下来,使用🤗 Datasets的[`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image)功能查看图像:
```py
>>> dataset[0]["image"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vision-preprocess-tutorial.png"/>
</div>
使用 [`AutoImageProcessor.from_pretrained`] 加载`image processor`:
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
首先,让我们进行图像增强。您可以使用任何您喜欢的库,但在本教程中,我们将使用torchvision的[`transforms`](https://pytorch.org/vision/stable/transforms.html)模块。如果您有兴趣使用其他数据增强库,请参阅[Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb)或[Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)中的示例。
1. 在这里,我们使用[`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html)将[`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html)和 [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html)变换连接在一起。请注意,对于调整大小,我们可以从`image_processor`中获取图像尺寸要求。对于一些模型,精确的高度和宽度需要被定义,对于其他模型只需定义`shortest_edge`。
```py
>>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
>>> size = (
... image_processor.size["shortest_edge"]
... if "shortest_edge" in image_processor.size
... else (image_processor.size["height"], image_processor.size["width"])
... )
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
```
2. 模型接受 [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) 作为输入。`ImageProcessor` 可以进行图像的标准化,并生成适当的张量。创建一个函数,将图像增强和图像预处理步骤组合起来处理批量图像,并生成 `pixel_values`:
```py
>>> def transforms(examples):
... images = [_transforms(img.convert("RGB")) for img in examples["image"]]
... examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
... return examples
```
<Tip>
在上面的示例中,我们设置`do_resize=False`,因为我们已经在图像增强转换中调整了图像的大小,并利用了适当的`image_processor`的`size`属性。如果您在图像增强期间不调整图像的大小,请将此参数排除在外。默认情况下`ImageProcessor`将处理调整大小。
如果希望将图像标准化步骤为图像增强的一部分,请使用`image_processor.image_mean`和`image_processor.image_std`。
</Tip>
3. 然后使用🤗 Datasets的[`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)在运行时应用这些变换:
```py
>>> dataset.set_transform(transforms)
```
4. 现在,当您访问图像时,您将注意到`image processor`已添加了 `pixel_values`。您现在可以将经过处理的数据集传递给模型了!
```py
>>> dataset[0].keys()
```
这是在应用变换后的图像样子。图像已被随机裁剪,并其颜色属性发生了变化。
```py
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> img = dataset[0]["pixel_values"]
>>> plt.imshow(img.permute(1, 2, 0))
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/preprocessed_image.png"/>
</div>
<Tip>
对于诸如目标检测、语义分割、实例分割和全景分割等任务,`ImageProcessor`提供了训练后处理方法。这些方法将模型的原始输出转换为有意义的预测,如边界框或分割地图。
</Tip>
### 填充
在某些情况下,例如,在微调[DETR](./model_doc/detr)时,模型在训练时应用了尺度增强。这可能导致批处理中的图像大小不同。您可以使用[`DetrImageProcessor.pad`]来指定自定义的`collate_fn`将图像批处理在一起。
```py
>>> def collate_fn(batch):
... pixel_values = [item["pixel_values"] for item in batch]
... encoding = image_processor.pad(pixel_values, return_tensors="pt")
... labels = [item["labels"] for item in batch]
... batch = {}
... batch["pixel_values"] = encoding["pixel_values"]
... batch["pixel_mask"] = encoding["pixel_mask"]
... batch["labels"] = labels
... return batch
```
## 多模态
对于涉及多模态输入的任务,您需要[processor](main_classes/processors)来为模型准备数据集。`processor`将两个处理对象-例如`tokenizer`和`feature extractor`-组合在一起。
加载[LJ Speech](https://huggingface.co/datasets/lj_speech)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets 教程](https://huggingface.co/docs/datasets/load_hub))以了解如何使用`processor`进行自动语音识别(ASR):
```py
>>> from datasets import load_dataset
>>> lj_speech = load_dataset("lj_speech", split="train")
```
对于ASR(自动语音识别),主要关注`audio`和`text`,因此可以删除其他列:
```py
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
```
现在查看`audio`和`text`列:
```py
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
>>> lj_speech[0]["text"]
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
```
请记住,您应始终[重新采样](preprocessing#audio)音频数据集的采样率,以匹配用于预训练模型数据集的采样率!
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
```
使用[`AutoProcessor.from_pretrained`]加载一个`processor`:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
```
1. 创建一个函数,用于将包含在 `array` 中的音频数据处理为 `input_values`,并将 `text` 标记为 `labels`。这些将是输入模型的数据:
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
... return example
```
2. 将 `prepare_dataset` 函数应用于一个示例:
```py
>>> prepare_dataset(lj_speech[0])
```
`processor`现在已经添加了 `input_values` 和 `labels`,并且采样率也正确降低为为16kHz。现在可以将处理后的数据集传递给模型!
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/create_a_model.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 创建自定义架构
[`AutoClass`](model_doc/auto) 自动推断模型架构并下载预训练的配置和权重。一般来说,我们建议使用 `AutoClass` 生成与检查点(checkpoint)无关的代码。希望对特定模型参数有更多控制的用户,可以仅从几个基类创建自定义的 🤗 Transformers 模型。这对于任何有兴趣学习、训练或试验 🤗 Transformers 模型的人可能特别有用。通过本指南,深入了解如何不通过 `AutoClass` 创建自定义模型。了解如何:
- 加载并自定义模型配置。
- 创建模型架构。
- 为文本创建慢速和快速分词器。
- 为视觉任务创建图像处理器。
- 为音频任务创建特征提取器。
- 为多模态任务创建处理器。
## 配置
[配置](main_classes/configuration) 涉及到模型的具体属性。每个模型配置都有不同的属性;例如,所有 NLP 模型都共享 `hidden_size`、`num_attention_heads`、 `num_hidden_layers` 和 `vocab_size` 属性。这些属性用于指定构建模型时的注意力头数量或隐藏层层数。
访问 [`DistilBertConfig`] 以更近一步了解 [DistilBERT](model_doc/distilbert),检查它的属性:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] 显示了构建基础 [`DistilBertModel`] 所使用的所有默认属性。所有属性都可以进行自定义,为实验创造了空间。例如,您可以将默认模型自定义为:
- 使用 `activation` 参数尝试不同的激活函数。
- 使用 `attention_dropout` 参数为 attention probabilities 使用更高的 dropout ratio。
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
预训练模型的属性可以在 [`~PretrainedConfig.from_pretrained`] 函数中进行修改:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
当你对模型配置满意时,可以使用 [`~PretrainedConfig.save_pretrained`] 来保存配置。你的配置文件将以 JSON 文件的形式存储在指定的保存目录中:
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
要重用配置文件,请使用 [`~PretrainedConfig.from_pretrained`] 进行加载:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
```
<Tip>
你还可以将配置文件保存为字典,甚至只保存自定义配置属性与默认配置属性之间的差异!有关更多详细信息,请参阅 [配置](main_classes/configuration) 文档。
</Tip>
## 模型
接下来,创建一个[模型](main_classes/models)。模型,也可泛指架构,定义了每一层网络的行为以及进行的操作。配置中的 `num_hidden_layers` 等属性用于定义架构。每个模型都共享基类 [`PreTrainedModel`] 和一些常用方法,例如调整输入嵌入的大小和修剪自注意力头。此外,所有模型都是 [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html)、[`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) 或 [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) 的子类。这意味着模型与各自框架的用法兼容。
<frameworkcontent>
<pt>
将自定义配置属性加载到模型中:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)
```
这段代码创建了一个具有随机参数而不是预训练权重的模型。在训练该模型之前,您还无法将该模型用于任何用途。训练是一项昂贵且耗时的过程。通常来说,最好使用预训练模型来更快地获得更好的结果,同时仅使用训练所需资源的一小部分。
使用 [`~PreTrainedModel.from_pretrained`] 创建预训练模型:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
```
当加载预训练权重时,如果模型是由 🤗 Transformers 提供的,将自动加载默认模型配置。然而,如果你愿意,仍然可以将默认模型配置的某些或者所有属性替换成你自己的配置:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
将自定义配置属性加载到模型中:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
这段代码创建了一个具有随机参数而不是预训练权重的模型。在训练该模型之前,您还无法将该模型用于任何用途。训练是一项昂贵且耗时的过程。通常来说,最好使用预训练模型来更快地获得更好的结果,同时仅使用训练所需资源的一小部分。
使用 [`~TFPreTrainedModel.from_pretrained`] 创建预训练模型:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
```
当加载预训练权重时,如果模型是由 🤗 Transformers 提供的,将自动加载默认模型配置。然而,如果你愿意,仍然可以将默认模型配置的某些或者所有属性替换成自己的配置:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### 模型头(Model heads)
此时,你已经有了一个输出*隐藏状态*的基础 DistilBERT 模型。隐藏状态作为输入传递到模型头以生成最终输出。🤗 Transformers 为每个任务提供不同的模型头,只要模型支持该任务(即,您不能使用 DistilBERT 来执行像翻译这样的序列到序列任务)。
<frameworkcontent>
<pt>
例如,[`DistilBertForSequenceClassification`] 是一个带有序列分类头(sequence classification head)的基础 DistilBERT 模型。序列分类头是池化输出之上的线性层。
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
通过切换到不同的模型头,可以轻松地将此检查点重复用于其他任务。对于问答任务,你可以使用 [`DistilBertForQuestionAnswering`] 模型头。问答头(question answering head)与序列分类头类似,不同点在于它是隐藏状态输出之上的线性层。
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</pt>
<tf>
例如,[`TFDistilBertForSequenceClassification`] 是一个带有序列分类头(sequence classification head)的基础 DistilBERT 模型。序列分类头是池化输出之上的线性层。
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
通过切换到不同的模型头,可以轻松地将此检查点重复用于其他任务。对于问答任务,你可以使用 [`TFDistilBertForQuestionAnswering`] 模型头。问答头(question answering head)与序列分类头类似,不同点在于它是隐藏状态输出之上的线性层。
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## 分词器
在将模型用于文本数据之前,你需要的最后一个基类是 [tokenizer](main_classes/tokenizer),它用于将原始文本转换为张量。🤗 Transformers 支持两种类型的分词器:
- [`PreTrainedTokenizer`]:分词器的Python实现
- [`PreTrainedTokenizerFast`]:来自我们基于 Rust 的 [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) 库的分词器。因为其使用了 Rust 实现,这种分词器类型的速度要快得多,尤其是在批量分词(batch tokenization)的时候。快速分词器还提供其他的方法,例如*偏移映射(offset mapping)*,它将标记(token)映射到其原始单词或字符。
这两种分词器都支持常用的方法,如编码和解码、添加新标记以及管理特殊标记。
<Tip warning={true}>
并非每个模型都支持快速分词器。参照这张 [表格](index#supported-frameworks) 查看模型是否支持快速分词器。
</Tip>
如果您训练了自己的分词器,则可以从*词表*文件创建一个分词器:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
请务必记住,自定义分词器生成的词表与预训练模型分词器生成的词表是不同的。如果使用预训练模型,则需要使用预训练模型的词表,否则输入将没有意义。 使用 [`DistilBertTokenizer`] 类创建具有预训练模型词表的分词器:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
```
使用 [`DistilBertTokenizerFast`] 类创建快速分词器:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
```
<Tip>
默认情况下,[`AutoTokenizer`] 将尝试加载快速标记生成器。你可以通过在 `from_pretrained` 中设置 `use_fast=False` 以禁用此行为。
</Tip>
## 图像处理器
图像处理器用于处理视觉输入。它继承自 [`~image_processing_utils.ImageProcessingMixin`] 基类。
要使用它,需要创建一个与你使用的模型关联的图像处理器。例如,如果你使用 [ViT](model_doc/vit) 进行图像分类,可以创建一个默认的 [`ViTImageProcessor`]:
```py
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
如果您不需要进行任何自定义,只需使用 `from_pretrained` 方法加载模型的默认图像处理器参数。
</Tip>
修改任何 [`ViTImageProcessor`] 参数以创建自定义图像处理器:
```py
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
## 特征提取器
特征提取器用于处理音频输入。它继承自 [`~feature_extraction_utils.FeatureExtractionMixin`] 基类,亦可继承 [`SequenceFeatureExtractor`] 类来处理音频输入。
要使用它,创建一个与你使用的模型关联的特征提取器。例如,如果你使用 [Wav2Vec2](model_doc/wav2vec2) 进行音频分类,可以创建一个默认的 [`Wav2Vec2FeatureExtractor`]:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
<Tip>
如果您不需要进行任何自定义,只需使用 `from_pretrained` 方法加载模型的默认特征提取器参数。
</Tip>
修改任何 [`Wav2Vec2FeatureExtractor`] 参数以创建自定义特征提取器:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 8000
}
```
## 处理器
对于支持多模式任务的模型,🤗 Transformers 提供了一个处理器类,可以方便地将特征提取器和分词器等处理类包装到单个对象中。例如,让我们使用 [`Wav2Vec2Processor`] 来执行自动语音识别任务 (ASR)。 ASR 将音频转录为文本,因此您将需要一个特征提取器和一个分词器。
创建一个特征提取器来处理音频输入:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
创建一个分词器来处理文本输入:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
将特征提取器和分词器合并到 [`Wav2Vec2Processor`] 中:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
通过两个基类 - 配置类和模型类 - 以及一个附加的预处理类(分词器、图像处理器、特征提取器或处理器),你可以创建 🤗 Transformers 支持的任何模型。 每个基类都是可配置的,允许你使用所需的特定属性。 你可以轻松设置模型进行训练或修改现有的预训练模型进行微调。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/serialization.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 导出为 ONNX
在生产环境中部署 🤗 Transformers 模型通常需要或者能够受益于,将模型导出为可在专门的运行时和硬件上加载和执行的序列化格式。
🤗 Optimum 是 Transformers 的扩展,可以通过其 `exporters` 模块将模型从 PyTorch 或 TensorFlow 导出为 ONNX 及 TFLite 等序列化格式。🤗 Optimum 还提供了一套性能优化工具,可以在目标硬件上以最高效率训练和运行模型。
本指南演示了如何使用 🤗 Optimum 将 🤗 Transformers 模型导出为 ONNX。有关将模型导出为 TFLite 的指南,请参考 [导出为 TFLite 页面](tflite)。
## 导出为 ONNX
[ONNX (Open Neural Network eXchange 开放神经网络交换)](http://onnx.ai) 是一个开放的标准,它定义了一组通用的运算符和一种通用的文件格式,用于表示包括 PyTorch 和 TensorFlow 在内的各种框架中的深度学习模型。当一个模型被导出为 ONNX时,这些运算符被用于构建计算图(通常被称为*中间表示*),该图表示数据在神经网络中的流动。
通过公开具有标准化运算符和数据类型的图,ONNX使得模型能够轻松在不同深度学习框架间切换。例如,在 PyTorch 中训练的模型可以被导出为 ONNX,然后再导入到 TensorFlow(反之亦然)。
导出为 ONNX 后,模型可以:
- 通过 [图优化(graph optimization)](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization) 和 [量化(quantization)](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/quantization) 等技术进行推理优化。
- 通过 [`ORTModelForXXX` 类](https://huggingface.co/docs/optimum/onnxruntime/package_reference/modeling_ort) 使用 ONNX Runtime 运行,它同样遵循你熟悉的 Transformers 中的 `AutoModel` API。
- 使用 [优化推理流水线(pipeline)](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/pipelines) 运行,其 API 与 🤗 Transformers 中的 [`pipeline`] 函数相同。
🤗 Optimum 通过利用配置对象提供对 ONNX 导出的支持。多种模型架构已经有现成的配置对象,并且配置对象也被设计得易于扩展以适用于其他架构。
现有的配置列表请参考 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/onnx/overview)。
有两种方式可以将 🤗 Transformers 模型导出为 ONNX,这里我们展示这两种方法:
- 使用 🤗 Optimum 的 CLI(命令行)导出。
- 使用 🤗 Optimum 的 `optimum.onnxruntime` 模块导出。
### 使用 CLI 将 🤗 Transformers 模型导出为 ONNX
要将 🤗 Transformers 模型导出为 ONNX,首先需要安装额外的依赖项:
```bash
pip install optimum[exporters]
```
请参阅 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) 以查看所有可用参数,或者在命令行中查看帮助:
```bash
optimum-cli export onnx --help
```
运行以下命令,以从 🤗 Hub 导出模型的检查点(checkpoint),以 `distilbert-base-uncased-distilled-squad` 为例:
```bash
optimum-cli export onnx --model distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
```
你应该能在日志中看到导出进度以及生成的 `model.onnx` 文件的保存位置,如下所示:
```bash
Validating ONNX model distilbert_base_uncased_squad_onnx/model.onnx...
-[✓] ONNX model output names match reference model (start_logits, end_logits)
- Validating ONNX Model output "start_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
- Validating ONNX Model output "end_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
The ONNX export succeeded and the exported model was saved at: distilbert_base_uncased_squad_onnx
```
上面的示例说明了从 🤗 Hub 导出检查点的过程。导出本地模型时,首先需要确保将模型的权重和分词器文件保存在同一目录(`local_path`)中。在使用 CLI 时,将 `local_path` 传递给 `model` 参数,而不是 🤗 Hub 上的检查点名称,并提供 `--task` 参数。你可以在 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/task_manager)中查看支持的任务列表。如果未提供 `task` 参数,将默认导出不带特定任务头的模型架构。
```bash
optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
```
生成的 `model.onnx` 文件可以在支持 ONNX 标准的 [许多加速引擎(accelerators)](https://onnx.ai/supported-tools.html#deployModel) 之一上运行。例如,我们可以使用 [ONNX Runtime](https://onnxruntime.ai/) 加载和运行模型,如下所示:
```python
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
>>> outputs = model(**inputs)
```
从 Hub 导出 TensorFlow 检查点的过程也一样。例如,以下是从 [Keras 组织](https://huggingface.co/keras-io) 导出纯 TensorFlow 检查点的命令:
```bash
optimum-cli export onnx --model keras-io/transformers-qa distilbert_base_cased_squad_onnx/
```
### 使用 `optimum.onnxruntime` 将 🤗 Transformers 模型导出为 ONNX
除了 CLI 之外,你还可以使用代码将 🤗 Transformers 模型导出为 ONNX,如下所示:
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> model_checkpoint = "distilbert_base_uncased_squad"
>>> save_directory = "onnx/"
>>> # 从 transformers 加载模型并将其导出为 ONNX
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
>>> tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
>>> # 保存 onnx 模型以及分词器
>>> ort_model.save_pretrained(save_directory)
>>> tokenizer.save_pretrained(save_directory)
```
### 导出尚未支持的架构的模型
如果你想要为当前无法导出的模型添加支持,请先检查 [`optimum.exporters.onnx`](https://huggingface.co/docs/optimum/exporters/onnx/overview) 是否支持该模型,如果不支持,你可以 [直接为 🤗 Optimum 贡献代码](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/contribute)。
### 使用 `transformers.onnx` 导出模型
<Tip warning={true}>
`tranformers.onnx` 不再进行维护,请如上所述,使用 🤗 Optimum 导出模型。这部分内容将在未来版本中删除。
</Tip>
要使用 `tranformers.onnx` 将 🤗 Transformers 模型导出为 ONNX,请安装额外的依赖项:
```bash
pip install transformers[onnx]
```
将 `transformers.onnx` 包作为 Python 模块使用,以使用现成的配置导出检查点:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
以上代码将导出由 `--model` 参数定义的检查点的 ONNX 图。传入任何 🤗 Hub 上或者存储与本地的检查点。生成的 `model.onnx` 文件可以在支持 ONNX 标准的众多加速引擎上运行。例如,使用 ONNX Runtime 加载并运行模型,如下所示:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
可以通过查看每个模型的 ONNX 配置来获取所需的输出名(例如 `["last_hidden_state"]`)。例如,对于 DistilBERT,可以用以下代码获取输出名称:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
从 Hub 导出 TensorFlow 检查点的过程也一样。导出纯 TensorFlow 检查点的示例代码如下:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
要导出本地存储的模型,请将模型的权重和分词器文件保存在同一目录中(例如 `local-pt-checkpoint`),然后通过将 `transformers.onnx` 包的 `--model` 参数指向该目录,将其导出为 ONNX:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/training.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 微调预训练模型
[[open-in-colab]]
使用预训练模型有许多显著的好处。它降低了计算成本,减少了碳排放,同时允许您使用最先进的模型,而无需从头开始训练一个。🤗 Transformers 提供了涉及各种任务的成千上万的预训练模型。当您使用预训练模型时,您需要在与任务相关的数据集上训练该模型。这种操作被称为微调,是一种非常强大的训练技术。在本教程中,您将使用您选择的深度学习框架来微调一个预训练模型:
* 使用 🤗 Transformers 的 [`Trainer`] 来微调预训练模型。
* 在 TensorFlow 中使用 Keras 来微调预训练模型。
* 在原生 PyTorch 中微调预训练模型。
<a id='data-processing'></a>
## 准备数据集
<Youtube id="_BZearw7f0w"/>
在您进行预训练模型微调之前,需要下载一个数据集并为训练做好准备。之前的教程向您展示了如何处理训练数据,现在您有机会将这些技能付诸实践!
首先,加载[Yelp评论](https://huggingface.co/datasets/yelp_review_full)数据集:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("yelp_review_full")
>>> dataset["train"][100]
{'label': 0,
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
正如您现在所知,您需要一个`tokenizer`来处理文本,包括填充和截断操作以处理可变的序列长度。如果要一次性处理您的数据集,可以使用 🤗 Datasets 的 [`map`](https://huggingface.co/docs/datasets/process#map) 方法,将预处理函数应用于整个数据集:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function(examples):
... return tokenizer(examples["text"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
```
如果愿意的话,您可以从完整数据集提取一个较小子集来进行微调,以减少训练所需的时间:
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
<a id='trainer'></a>
## 训练
此时,您应该根据您训练所用的框架来选择对应的教程章节。您可以使用右侧的链接跳转到您想要的章节 - 如果您想隐藏某个框架对应的所有教程内容,只需使用右上角的按钮!
<frameworkcontent>
<pt>
<Youtube id="nvBXf7s7vTI"/>
## 使用 PyTorch Trainer 进行训练
🤗 Transformers 提供了一个专为训练 🤗 Transformers 模型而优化的 [`Trainer`] 类,使您无需手动编写自己的训练循环步骤而更轻松地开始训练模型。[`Trainer`] API 支持各种训练选项和功能,如日志记录、梯度累积和混合精度。
首先加载您的模型并指定期望的标签数量。根据 Yelp Review [数据集卡片](https://huggingface.co/datasets/yelp_review_full#data-fields),您知道有五个标签:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
<Tip>
您将会看到一个警告,提到一些预训练权重未被使用,以及一些权重被随机初始化。不用担心,这是完全正常的!BERT 模型的预训练`head`被丢弃,并替换为一个随机初始化的分类`head`。您将在您的序列分类任务上微调这个新模型`head`,将预训练模型的知识转移给它。
</Tip>
### 训练超参数
接下来,创建一个 [`TrainingArguments`] 类,其中包含您可以调整的所有超参数以及用于激活不同训练选项的标志。对于本教程,您可以从默认的训练[超参数](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)开始,但随时可以尝试不同的设置以找到最佳设置。
指定保存训练检查点的位置:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer")
```
### 评估
[`Trainer`] 在训练过程中不会自动评估模型性能。您需要向 [`Trainer`] 传递一个函数来计算和展示指标。[🤗 Evaluate](https://huggingface.co/docs/evaluate/index) 库提供了一个简单的 [`accuracy`](https://huggingface.co/spaces/evaluate-metric/accuracy) 函数,您可以使用 [`evaluate.load`] 函数加载它(有关更多信息,请参阅此[快速入门](https://huggingface.co/docs/evaluate/a_quick_tour)):
```py
>>> import numpy as np
>>> import evaluate
>>> metric = evaluate.load("accuracy")
```
在 `metric` 上调用 [`~evaluate.compute`] 来计算您的预测的准确性。在将预测传递给 `compute` 之前,您需要将预测转换为`logits`(请记住,所有 🤗 Transformers 模型都返回对`logits`):
```py
>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... predictions = np.argmax(logits, axis=-1)
... return metric.compute(predictions=predictions, references=labels)
```
如果您希望在微调过程中监视评估指标,请在您的训练参数中指定 `evaluation_strategy` 参数,以在每个`epoch`结束时展示评估指标:
```py
>>> from transformers import TrainingArguments, Trainer
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
```
### 训练器
创建一个包含您的模型、训练参数、训练和测试数据集以及评估函数的 [`Trainer`] 对象:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
然后调用[`~transformers.Trainer.train`]以微调模型:
```py
>>> trainer.train()
```
</pt>
<tf>
<a id='keras'></a>
<Youtube id="rnTGBy2ax1c"/>
## 使用keras训练TensorFlow模型
您也可以使用 Keras API 在 TensorFlow 中训练 🤗 Transformers 模型!
### 加载用于 Keras 的数据
当您希望使用 Keras API 训练 🤗 Transformers 模型时,您需要将您的数据集转换为 Keras 可理解的格式。如果您的数据集很小,您可以将整个数据集转换为NumPy数组并传递给 Keras。在进行更复杂的操作之前,让我们先尝试这种方法。
首先,加载一个数据集。我们将使用 [GLUE benchmark](https://huggingface.co/datasets/glue) 中的 CoLA 数据集,因为它是一个简单的二元文本分类任务。现在只使用训练数据集。
```py
from datasets import load_dataset
dataset = load_dataset("glue", "cola")
dataset = dataset["train"] # Just take the training split for now
```
接下来,加载一个`tokenizer`并将数据标记为 NumPy 数组。请注意,标签已经是由 0 和 1 组成的`list`,因此我们可以直接将其转换为 NumPy 数组而无需进行分词处理!
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_data = tokenizer(dataset["sentence"], return_tensors="np", padding=True)
# Tokenizer returns a BatchEncoding, but we convert that to a dict for Keras
tokenized_data = dict(tokenized_data)
labels = np.array(dataset["label"]) # Label is already an array of 0 and 1
```
最后,加载、[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 和 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) 模型。请注意,Transformers 模型都有一个默认的与任务相关的损失函数,因此除非您希望自定义,否则无需指定一个损失函数:
```py
from transformers import TFAutoModelForSequenceClassification
from tensorflow.keras.optimizers import Adam
# Load and compile our model
model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased")
# Lower learning rates are often better for fine-tuning transformers
model.compile(optimizer=Adam(3e-5)) # No loss argument!
model.fit(tokenized_data, labels)
```
<Tip>
当您使用 `compile()` 编译模型时,无需传递损失参数!如果不指定损失参数,Hugging Face 模型会自动选择适合其任务和模型架构的损失函数。如果需要,您始终可以自己指定损失函数以覆盖默认配置。
</Tip>
这种方法对于较小的数据集效果很好,但对于较大的数据集,您可能会发现它开始变得有问题。为什么呢?因为分词后的数组和标签必须完全加载到内存中,而且由于 NumPy 无法处理“不规则”数组,因此每个分词后的样本长度都必须被填充到数据集中最长样本的长度。这将使您的数组变得更大,而所有这些`padding tokens`也会减慢训练速度!
### 将数据加载为 tf.data.Dataset
如果您想避免训练速度减慢,可以将数据加载为 `tf.data.Dataset`。虽然您可以自己编写自己的 `tf.data` 流水线,但我们有两种方便的方法来实现这一点:
- [`~TFPreTrainedModel.prepare_tf_dataset`]:这是我们在大多数情况下推荐的方法。因为它是模型上的一个方法,它可以检查模型以自动确定哪些列可用作模型输入,并丢弃其他列以创建一个更简单、性能更好的数据集。
- [`~datasets.Dataset.to_tf_dataset`]:这个方法更低级,但当您希望完全控制数据集的创建方式时非常有用,可以通过指定要包括的确切 `columns` 和 `label_cols` 来实现。
在使用 [`~TFPreTrainedModel.prepare_tf_dataset`] 之前,您需要将`tokenizer`的输出添加到数据集作为列,如下面的代码示例所示:
```py
def tokenize_dataset(data):
# Keys of the returned dictionary will be added to the dataset as columns
return tokenizer(data["text"])
dataset = dataset.map(tokenize_dataset)
```
请记住,默认情况下,Hugging Face 数据集存储在硬盘上,因此这不会增加您的内存使用!一旦列已经添加,您可以从数据集中流式的传输批次数据,并为每个批次添加`padding tokens`,这与为整个数据集添加`padding tokens`相比,大大减少了`padding tokens`的数量。
```py
>>> tf_dataset = model.prepare_tf_dataset(dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer)
```
请注意,在上面的代码示例中,您需要将`tokenizer`传递给`prepare_tf_dataset`,以便它可以在加载批次时正确填充它们。如果数据集中的所有样本都具有相同的长度而且不需要填充,您可以跳过此参数。如果需要执行比填充样本更复杂的操作(例如,用于掩码语言模型的`tokens` 替换),则可以使用 `collate_fn` 参数,而不是传递一个函数来将样本列表转换为批次并应用任何所需的预处理。请查看我们的[示例](https://github.com/huggingface/transformers/tree/main/examples)或[笔记](https://huggingface.co/docs/transformers/notebooks)以了解此方法的实际操作。
一旦创建了 `tf.data.Dataset`,您可以像以前一样编译和训练模型:
```py
model.compile(optimizer=Adam(3e-5)) # No loss argument!
model.fit(tf_dataset)
```
</tf>
</frameworkcontent>
<a id='pytorch_native'></a>
## 在原生 PyTorch 中训练
<frameworkcontent>
<pt>
<Youtube id="Dh9CL8fyG80"/>
[`Trainer`] 负责训练循环,允许您在一行代码中微调模型。对于喜欢编写自己训练循环的用户,您也可以在原生 PyTorch 中微调 🤗 Transformers 模型。
现在,您可能需要重新启动您的`notebook`,或执行以下代码以释放一些内存:
```py
del model
del trainer
torch.cuda.empty_cache()
```
接下来,手动处理 `tokenized_dataset` 以准备进行训练。
1. 移除 text 列,因为模型不接受原始文本作为输入:
```py
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
```
2. 将 label 列重命名为 labels,因为模型期望参数的名称为 labels:
```py
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
```
3. 设置数据集的格式以返回 PyTorch 张量而不是`lists`:
```py
>>> tokenized_datasets.set_format("torch")
```
接着,创建一个先前展示的数据集的较小子集,以加速微调过程
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
### DataLoader
您的训练和测试数据集创建一个`DataLoader`类,以便可以迭代处理数据批次
```py
>>> from torch.utils.data import DataLoader
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
```
加载您的模型,并指定期望的标签数量:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
### Optimizer and learning rate scheduler
创建一个`optimizer`和`learning rate scheduler`以进行模型微调。让我们使用 PyTorch 中的 [AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) 优化器:
```py
>>> from torch.optim import AdamW
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
```
创建来自 [`Trainer`] 的默认`learning rate scheduler`:
```py
>>> from transformers import get_scheduler
>>> num_epochs = 3
>>> num_training_steps = num_epochs * len(train_dataloader)
>>> lr_scheduler = get_scheduler(
... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
... )
```
最后,指定 `device` 以使用 GPU(如果有的话)。否则,使用 CPU 进行训练可能需要几个小时,而不是几分钟。
```py
>>> import torch
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
>>> model.to(device)
```
<Tip>
如果没有 GPU,可以通过notebook平台如 [Colaboratory](https://colab.research.google.com/) 或 [SageMaker StudioLab](https://studiolab.sagemaker.aws/) 来免费获得云端GPU使用。
</Tip>
现在您已经准备好训练了!🥳
### 训练循环
为了跟踪训练进度,使用 [tqdm](https://tqdm.github.io/) 库来添加一个进度条,显示训练步数的进展:
```py
>>> from tqdm.auto import tqdm
>>> progress_bar = tqdm(range(num_training_steps))
>>> model.train()
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... outputs = model(**batch)
... loss = outputs.loss
... loss.backward()
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
### 评估
就像您在 [`Trainer`] 中添加了一个评估函数一样,当您编写自己的训练循环时,您需要做同样的事情。但与在每个`epoch`结束时计算和展示指标不同,这一次您将使用 [`~evaluate.add_batch`] 累积所有批次,并在最后计算指标。
```py
>>> import evaluate
>>> metric = evaluate.load("accuracy")
>>> model.eval()
>>> for batch in eval_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... with torch.no_grad():
... outputs = model(**batch)
... logits = outputs.logits
... predictions = torch.argmax(logits, dim=-1)
... metric.add_batch(predictions=predictions, references=batch["labels"])
>>> metric.compute()
```
</pt>
</frameworkcontent>
<a id='additional-resources'></a>
## 附加资源
更多微调例子可参考如下链接:
- [🤗 Transformers 示例](https://github.com/huggingface/transformers/tree/main/examples) 包含用于在 PyTorch 和 TensorFlow 中训练常见自然语言处理任务的脚本。
- [🤗 Transformers 笔记](notebooks) 包含针对特定任务在 PyTorch 和 TensorFlow 中微调模型的各种`notebook`。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/model_sharing.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 分享模型
最后两个教程展示了如何使用PyTorch、Keras和 🤗 Accelerate进行分布式设置来微调模型。下一步是将您的模型与社区分享!在Hugging Face,我们相信公开分享知识和资源,能实现人工智能的普及化,让每个人都能受益。我们鼓励您将您的模型与社区分享,以帮助他人节省时间和精力。
在本教程中,您将学习两种在[Model Hub](https://huggingface.co/models)上共享训练好的或微调的模型的方法:
- 通过编程将文件推送到Hub。
- 使用Web界面将文件拖放到Hub。
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
要与社区共享模型,您需要在[huggingface.co](https://huggingface.co/join)上拥有一个帐户。您还可以加入现有的组织或创建一个新的组织。
</Tip>
## 仓库功能
Model Hub上的每个仓库都像是一个典型的GitHub仓库。我们的仓库提供版本控制、提交历史记录以及可视化差异的能力。
Model Hub的内置版本控制基于git和[git-lfs](https://git-lfs.github.com/)。换句话说,您可以将一个模型视为一个仓库,从而实现更好的访问控制和可扩展性。版本控制允许使用*修订*方法来固定特定版本的模型,可以使用提交哈希值、标签或分支来标记。
因此,您可以通过`revision`参数加载特定的模型版本:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
... )
```
文件也可以轻松地在仓库中编辑,您可以查看提交历史记录以及差异:

## 设置
在将模型共享到Hub之前,您需要拥有Hugging Face的凭证。如果您有访问终端的权限,请在安装🤗 Transformers的虚拟环境中运行以下命令。这将在您的Hugging Face缓存文件夹(默认为`~/.cache/`)中存储您的`access token`:
```bash
huggingface-cli login
```
如果您正在使用像Jupyter或Colaboratory这样的`notebook`,请确保您已安装了[`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library)库。该库允许您以编程方式与Hub进行交互。
```bash
pip install huggingface_hub
```
然后使用`notebook_login`登录到Hub,并按照[这里](https://huggingface.co/settings/token)的链接生成一个token进行登录:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## 转换模型适用于所有框架
为确保您的模型可以被使用不同框架的人使用,我们建议您将PyTorch和TensorFlow `checkpoints`都转换并上传。如果您跳过此步骤,用户仍然可以从其他框架加载您的模型,但速度会变慢,因为🤗 Transformers需要实时转换`checkpoints`。
为另一个框架转换`checkpoints`很容易。确保您已安装PyTorch和TensorFlow(请参阅[此处](installation)的安装说明),然后在其他框架中找到适合您任务的特定模型。
<frameworkcontent>
<pt>
指定`from_tf=True`将checkpoint从TensorFlow转换为PyTorch。
```py
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
```
</pt>
<tf>
指定`from_pt=True`将checkpoint从PyTorch转换为TensorFlow。
```py
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
```
然后,您可以使用新的checkpoint保存您的新TensorFlow模型:
```py
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
```
</tf>
<jax>
如果模型在Flax中可用,您还可以将PyTorch checkpoint转换为Flax:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/to/awesome-name-you-picked", from_pt=True
... )
```
</jax>
</frameworkcontent>
## 在训练过程中推送模型
<frameworkcontent>
<pt>
<Youtube id="Z1-XMy-GNLQ"/>
将模型分享到Hub就像添加一个额外的参数或回调函数一样简单。请记住,在[微调教程](training)中,`TrainingArguments`类是您指定超参数和附加训练选项的地方。其中一项训练选项包括直接将模型推送到Hub的能力。在您的`TrainingArguments`中设置`push_to_hub=True`:
```py
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
```
像往常一样将您的训练参数传递给[`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
在您微调完模型后,在[`Trainer`]上调用[`~transformers.Trainer.push_to_hub`]将训练好的模型推送到Hub。🤗 Transformers甚至会自动将训练超参数、训练结果和框架版本添加到你的模型卡片中!
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
使用[`PushToHubCallback`]将模型分享到Hub。在[`PushToHubCallback`]函数中,添加以下内容:
- 一个用于存储模型的输出目录。
- 一个tokenizer。
- `hub_model_id`,即您的Hub用户名和模型名称。
```py
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
... )
```
将回调函数添加到 [`fit`](https://keras.io/api/models/model_training_apis/)中,然后🤗 Transformers 会将训练好的模型推送到 Hub:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
</tf>
</frameworkcontent>
## 使用`push_to_hub`功能
您可以直接在您的模型上调用`push_to_hub`来将其上传到Hub。
在`push_to_hub`中指定你的模型名称:
```py
>>> pt_model.push_to_hub("my-awesome-model")
```
这会在您的用户名下创建一个名为`my-awesome-model`的仓库。用户现在可以使用`from_pretrained`函数加载您的模型:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
```
如果您属于一个组织,并希望将您的模型推送到组织名称下,只需将其添加到`repo_id`中:
```py
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
```
`push_to_hub`函数还可以用于向模型仓库添加其他文件。例如,向模型仓库中添加一个`tokenizer`:
```py
>>> tokenizer.push_to_hub("my-awesome-model")
```
或者,您可能希望将您的微调后的PyTorch模型的TensorFlow版本添加进去:
```py
>>> tf_model.push_to_hub("my-awesome-model")
```
现在,当您导航到您的Hugging Face个人资料时,您应该看到您新创建的模型仓库。点击**文件**选项卡将显示您已上传到仓库的所有文件。
有关如何创建和上传文件到仓库的更多详细信息,请参考Hub文档[这里](https://huggingface.co/docs/hub/how-to-upstream)。
## 使用Web界面上传
喜欢无代码方法的用户可以通过Hugging Face的Web界面上传模型。访问[huggingface.co/new](https://huggingface.co/new)创建一个新的仓库:

从这里开始,添加一些关于您的模型的信息:
- 选择仓库的**所有者**。这可以是您本人或者您所属的任何组织。
- 为您的项目选择一个名称,该名称也将成为仓库的名称。
- 选择您的模型是公开还是私有。
- 指定您的模型的许可证使用情况。
现在点击**文件**选项卡,然后点击**添加文件**按钮将一个新文件上传到你的仓库。接着拖放一个文件进行上传,并添加提交信息。

## 添加模型卡片
为了确保用户了解您的模型的能力、限制、潜在偏差和伦理考虑,请在仓库中添加一个模型卡片。模型卡片在`README.md`文件中定义。你可以通过以下方式添加模型卡片:
* 手动创建并上传一个`README.md`文件。
* 在你的模型仓库中点击**编辑模型卡片**按钮。
可以参考DistilBert的[模型卡片](https://huggingface.co/distilbert-base-uncased)来了解模型卡片应该包含的信息类型。有关您可以在`README.md`文件中控制的更多选项的细节,例如模型的碳足迹或小部件示例,请参考文档[这里](https://huggingface.co/docs/hub/models-cards)。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/autoclass_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用AutoClass加载预训练实例
由于存在许多不同的Transformer架构,因此为您的checkpoint创建一个可用架构可能会具有挑战性。通过`AutoClass`可以自动推断并从给定的checkpoint加载正确的架构, 这也是🤗 Transformers易于使用、简单且灵活核心规则的重要一部分。`from_pretrained()`方法允许您快速加载任何架构的预训练模型,因此您不必花费时间和精力从头开始训练模型。生成这种与checkpoint无关的代码意味着,如果您的代码适用于一个checkpoint,它将适用于另一个checkpoint - 只要它们是为了类似的任务进行训练的 - 即使架构不同。
<Tip>
请记住,架构指的是模型的结构,而checkpoints是给定架构的权重。例如,[BERT](https://huggingface.co/bert-base-uncased)是一种架构,而`bert-base-uncased`是一个checkpoint。模型是一个通用术语,可以指代架构或checkpoint。
</Tip>
在这个教程中,学习如何:
* 加载预训练的分词器(`tokenizer`)
* 加载预训练的图像处理器(`image processor`)
* 加载预训练的特征提取器(`feature extractor`)
* 加载预训练的处理器(`processor`)
* 加载预训练的模型。
## AutoTokenizer
几乎所有的NLP任务都以`tokenizer`开始。`tokenizer`将您的输入转换为模型可以处理的格式。
使用[`AutoTokenizer.from_pretrained`]加载`tokenizer`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
然后按照如下方式对输入进行分词:
```py
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoImageProcessor
对于视觉任务,`image processor`将图像处理成正确的输入格式。
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
## AutoFeatureExtractor
对于音频任务,`feature extractor`将音频信号处理成正确的输入格式。
使用[`AutoFeatureExtractor.from_pretrained`]加载`feature extractor`:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
多模态任务需要一种`processor`,将两种类型的预处理工具结合起来。例如,[LayoutLMV2](model_doc/layoutlmv2)模型需要一个`image processo`来处理图像和一个`tokenizer`来处理文本;`processor`将两者结合起来。
使用[`AutoProcessor.from_pretrained`]加载`processor`:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
最后,`AutoModelFor`类让你可以加载给定任务的预训练模型(参见[这里](model_doc/auto)获取可用任务的完整列表)。例如,使用[`AutoModelForSequenceClassification.from_pretrained`]加载用于序列分类的模型:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
轻松地重复使用相同的checkpoint来为不同任务加载模型架构:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
<Tip warning={true}>
对于PyTorch模型,`from_pretrained()`方法使用`torch.load()`,它内部使用已知是不安全的`pickle`。一般来说,永远不要加载来自不可信来源或可能被篡改的模型。对于托管在Hugging Face Hub上的公共模型,这种安全风险在一定程度上得到了缓解,因为每次提交都会进行[恶意软件扫描](https://huggingface.co/docs/hub/security-malware)。请参阅[Hub文档](https://huggingface.co/docs/hub/security)以了解最佳实践,例如使用GPG进行[签名提交验证](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg)。
TensorFlow和Flax的checkpoints不受影响,并且可以在PyTorch架构中使用`from_tf`和`from_flax`关键字参数,通过`from_pretrained`方法进行加载,来绕过此问题。
</Tip>
一般来说,我们建议使用`AutoTokenizer`类和`AutoModelFor`类来加载预训练的模型实例。这样可以确保每次加载正确的架构。在下一个[教程](preprocessing)中,学习如何使用新加载的`tokenizer`, `image processor`, `feature extractor`和`processor`对数据集进行预处理以进行微调。
</pt>
<tf>
最后,`TFAutoModelFor`类允许您加载给定任务的预训练模型(请参阅[这里](model_doc/auto)获取可用任务的完整列表)。例如,使用[`TFAutoModelForSequenceClassification.from_pretrained`]加载用于序列分类的模型:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
轻松地重复使用相同的checkpoint来为不同任务加载模型架构:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
一般来说,我们推荐使用`AutoTokenizer`类和`TFAutoModelFor`类来加载模型的预训练实例。这样可以确保每次加载正确的架构。在下一个[教程](preprocessing)中,学习如何使用新加载的`tokenizer`, `image processor`, `feature extractor`和`processor`对数据集进行预处理以进行微调。
</tf>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers 简介
- local: quicktour
title: 快速上手
- local: installation
title: 安装
title: 开始使用
- sections:
- local: pipeline_tutorial
title: 使用pipelines进行推理
- local: autoclass_tutorial
title: 使用AutoClass编写可移植的代码
- local: preprocessing
title: 预处理数据
- local: training
title: 微调预训练模型
- local: run_scripts
title: 通过脚本训练模型
- local: accelerate
title: 使用🤗Accelerate进行分布式训练
- local: peft
title: 使用🤗 PEFT加载和训练adapters
- local: model_sharing
title: 分享您的模型
- local: transformers_agents
title: agents教程
- local: llm_tutorial
title: 使用LLMs进行生成
title: 教程
- sections:
- local: fast_tokenizers
title: 使用 🤗 Tokenizers 中的分词器
- local: multilingual
title: 使用多语言模型进行推理
- local: create_a_model
title: 使用特定于模型的 API
- local: custom_models
title: 共享自定义模型
- local: serialization
title: 导出为 ONNX
- local: tflite
title: 导出为 TFLite
title: 开发者指南
- sections:
- local: performance
title: 综述
- sections:
- local: perf_hardware
title: 用于训练的定制硬件
- local: hpo_train
title: 使用Trainer API 进行超参数搜索
title: 高效训练技术
- local: big_models
title: 实例化大模型
- local: debugging
title: 问题定位及解决
- local: tf_xla
title: TensorFlow模型的XLA集成
- local: perf_torch_compile
title: 使用 `torch.compile()` 优化推理
title: 性能和可扩展性
- sections:
- local: contributing
title: 如何为 🤗 Transformers 做贡献?
title: 贡献
- sections:
- local: task_summary
title: 🤗Transformers能做什么
- local: tokenizer_summary
title: 分词器的摘要
title: 概念指南
- sections:
- sections:
- local: main_classes/agent
title: Agents和工具
- local: main_classes/callback
title: Callbacks
- local: main_classes/configuration
title: Configuration
- local: main_classes/data_collator
title: Data Collator
- local: main_classes/keras_callbacks
title: Keras callbacks
- local: main_classes/logging
title: Logging
- local: main_classes/model
title: 模型
- local: main_classes/text_generation
title: 文本生成
- local: main_classes/onnx
title: ONNX
- local: main_classes/optimizer_schedules
title: Optimization
- local: main_classes/output
title: 模型输出
- local: main_classes/pipelines
title: Pipelines
- local: main_classes/processors
title: Processors
- local: main_classes/quantization
title: Quantization
- local: main_classes/tokenizer
title: Tokenizer
- local: main_classes/trainer
title: Trainer
- local: main_classes/deepspeed
title: DeepSpeed集成
- local: main_classes/feature_extractor
title: Feature Extractor
- local: main_classes/image_processor
title: Image Processor
title: 主要类
- sections:
- local: internal/modeling_utils
title: 自定义层和工具
- local: internal/pipelines_utils
title: pipelines工具
- local: internal/tokenization_utils
title: Tokenizers工具
- local: internal/trainer_utils
title: 训练器工具
- local: internal/generation_utils
title: 生成工具
- local: internal/image_processing_utils
title: 图像处理工具
- local: internal/audio_utils
title: 音频处理工具
- local: internal/file_utils
title: 通用工具
- local: internal/time_series_utils
title: 时序数据工具
title: 内部辅助工具
title: 应用程序接口 (API)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/accelerate.md
|
<!--版权2023年HuggingFace团队保留所有权利。
根据Apache许可证第2.0版(“许可证”)许可;除非符合许可证,否则您不得使用此文件。您可以在以下网址获取许可证的副本:
http://www.apache.org/licenses/LICENSE-2.0
除非适用法律要求或书面同意,否则按“按原样”分发的软件,无论是明示还是暗示的,都没有任何担保或条件。请参阅许可证以了解特定语言下的权限和限制。
⚠️ 请注意,本文件虽然使用Markdown编写,但包含了特定的语法,适用于我们的doc-builder(类似于MDX),可能无法在您的Markdown查看器中正常渲染。
-->
# 🤗 加速分布式训练
随着模型变得越来越大,并行性已经成为在有限硬件上训练更大模型和加速训练速度的策略,增加了数个数量级。在Hugging Face,我们创建了[🤗 加速](https://huggingface.co/docs/accelerate)库,以帮助用户在任何类型的分布式设置上轻松训练🤗 Transformers模型,无论是在一台机器上的多个GPU还是在多个机器上的多个GPU。在本教程中,了解如何自定义您的原生PyTorch训练循环,以启用分布式环境中的训练。
## 设置
通过安装🤗 加速开始:
```bash
pip install accelerate
```
然后导入并创建[`~accelerate.Accelerator`]对象。[`~accelerate.Accelerator`]将自动检测您的分布式设置类型,并初始化所有必要的训练组件。您不需要显式地将模型放在设备上。
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## 准备加速
下一步是将所有相关的训练对象传递给[`~accelerate.Accelerator.prepare`]方法。这包括您的训练和评估DataLoader、一个模型和一个优化器:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## 反向传播
最后一步是用🤗 加速的[`~accelerate.Accelerator.backward`]方法替换训练循环中的典型`loss.backward()`:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
如您在下面的代码中所见,您只需要添加四行额外的代码到您的训练循环中即可启用分布式训练!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## 训练
在添加了相关代码行后,可以在脚本或笔记本(如Colaboratory)中启动训练。
### 用脚本训练
如果您从脚本中运行训练,请运行以下命令以创建和保存配置文件:
```bash
accelerate config
```
然后使用以下命令启动训练:
```bash
accelerate launch train.py
```
### 用笔记本训练
🤗 加速还可以在笔记本中运行,如果您计划使用Colaboratory的TPU,则可在其中运行。将负责训练的所有代码包装在一个函数中,并将其传递给[`~accelerate.notebook_launcher`]:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
有关🤗 加速及其丰富功能的更多信息,请参阅[文档](https://huggingface.co/docs/accelerate)。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/tf_xla.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 用于 TensorFlow 模型的 XLA 集成
[[open-in-colab]]
加速线性代数,也称为XLA,是一个用于加速TensorFlow模型运行时间的编译器。从[官方文档](https://www.tensorflow.org/xla)中可以看到:
XLA(加速线性代数)是一种针对线性代数的特定领域编译器,可以在可能不需要更改源代码的情况下加速TensorFlow模型。
在TensorFlow中使用XLA非常简单——它包含在`tensorflow`库中,并且可以使用任何图创建函数中的`jit_compile`参数来触发,例如[`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs)。在使用Keras方法如`fit()`和`predict()`时,只需将`jit_compile`参数传递给`model.compile()`即可启用XLA。然而,XLA不仅限于这些方法 - 它还可以用于加速任何任意的`tf.function`。
在🤗 Transformers中,几个TensorFlow方法已经被重写为与XLA兼容,包括[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)、[T5](https://huggingface.co/docs/transformers/model_doc/t5)和[OPT](https://huggingface.co/docs/transformers/model_doc/opt)等文本生成模型,以及[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)等语音处理模型。
虽然确切的加速倍数很大程度上取决于模型,但对于🤗 Transformers中的TensorFlow文本生成模型,我们注意到速度提高了约100倍。本文档将解释如何在这些模型上使用XLA获得最大的性能。如果您有兴趣了解更多关于基准测试和我们在XLA集成背后的设计哲学的信息,我们还将提供额外的资源链接。
## 使用 XLA 运行 TensorFlow 函数
让我们考虑以下TensorFlow 中的模型:
```py
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)
```
上述模型接受维度为 `(10,)` 的输入。我们可以像下面这样使用模型进行前向传播:
```py
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)
```
为了使用 XLA 编译的函数运行前向传播,我们需要执行以下操作:
```py
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
```
`model`的默认`call()`函数用于编译XLA图。但如果你想将其他模型函数编译成XLA,也是可以的,如下所示:
```py
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
```
## 在🤗 Transformers库中使用XLA运行TensorFlow文本生成模型
要在🤗 Transformers中启用XLA加速生成,您需要安装最新版本的`transformers`。您可以通过运行以下命令来安装它:
```bash
pip install transformers --upgrade
```
然后您可以运行以下代码:
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
```
正如您所注意到的,在`generate()`上启用XLA只需要一行代码。其余部分代码保持不变。然而,上面的代码片段中有一些与XLA相关的注意事项。您需要了解这些注意事项,以充分利用XLA可能带来的性能提升。我们将在下面的部分讨论这些内容。
## 需要关注的注意事项
当您首次执行启用XLA的函数(如上面的`xla_generate()`)时,它将在内部尝试推断计算图,这是一个耗时的过程。这个过程被称为[“tracing”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing)。
您可能会注意到生成时间并不快。连续调用`xla_generate()`(或任何其他启用了XLA的函数)不需要再次推断计算图,只要函数的输入与最初构建计算图时的形状相匹配。对于具有固定输入形状的模态(例如图像),这不是问题,但如果您正在处理具有可变输入形状的模态(例如文本),则必须注意。
为了确保`xla_generate()`始终使用相同的输入形状,您可以在调用`tokenizer`时指定`padding`参数。
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
```
通过这种方式,您可以确保`xla_generate()`的输入始终具有它跟踪的形状,从而加速生成时间。您可以使用以下代码来验证这一点:
```py
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
```
在Tesla T4 GPU上,您可以期望如下的输出:
```bash
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms
```
第一次调用`xla_generate()`会因为`tracing`而耗时,但后续的调用会快得多。请注意,任何时候对生成选项的更改都会触发重新`tracing`,从而导致生成时间减慢。
在本文档中,我们没有涵盖🤗 Transformers提供的所有文本生成选项。我们鼓励您阅读文档以了解高级用例。
## 附加资源
以下是一些附加资源,如果您想深入了解在🤗 Transformers和其他库下使用XLA:
* [这个Colab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb) 提供了一个互动演示,让您可以尝试使用XLA兼容的编码器-解码器(例如[T5](https://huggingface.co/docs/transformers/model_doc/t5))和仅解码器(例如[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2))文本生成模型。
* [这篇博客文章](https://huggingface.co/blog/tf-xla-generate) 提供了XLA兼容模型的比较基准概述,以及关于在TensorFlow中使用XLA的友好介绍。
* [这篇博客文章](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) 讨论了我们在🤗 Transformers中为TensorFlow模型添加XLA支持的设计理念。
* 推荐用于更多学习XLA和TensorFlow图的资源:
* [XLA:面向机器学习的优化编译器](https://www.tensorflow.org/xla)
* [图和tf.function简介](https://www.tensorflow.org/guide/intro_to_graphs)
* [使用tf.function获得更好的性能](https://www.tensorflow.org/guide/function)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/llm_tutorial.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
## 使用LLMs进行生成
[[open-in-colab]]
LLMs,即大语言模型,是文本生成背后的关键组成部分。简单来说,它们包含经过大规模预训练的transformer模型,用于根据给定的输入文本预测下一个词(或更准确地说,下一个`token`)。由于它们一次只预测一个`token`,因此除了调用模型之外,您需要执行更复杂的操作来生成新的句子——您需要进行自回归生成。
自回归生成是在给定一些初始输入,通过迭代调用模型及其自身的生成输出来生成文本的推理过程,。在🤗 Transformers中,这由[`~generation.GenerationMixin.generate`]方法处理,所有具有生成能力的模型都可以使用该方法。
本教程将向您展示如何:
* 使用LLM生成文本
* 避免常见的陷阱
* 帮助您充分利用LLM下一步指导
在开始之前,请确保已安装所有必要的库:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
```
## 生成文本
一个用于[因果语言建模](tasks/language_modeling)训练的语言模型,将文本`tokens`序列作为输入,并返回下一个`token`的概率分布。
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
<figcaption>"LLM的前向传递"</figcaption>
</figure>
使用LLM进行自回归生成的一个关键方面是如何从这个概率分布中选择下一个`token`。这个步骤可以随意进行,只要最终得到下一个迭代的`token`。这意味着可以简单的从概率分布中选择最可能的`token`,也可以复杂的在对结果分布进行采样之前应用多种变换,这取决于你的需求。
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
<figcaption>"自回归生成迭代地从概率分布中选择下一个token以生成文本"</figcaption>
</figure>
上述过程是迭代重复的,直到达到某个停止条件。理想情况下,停止条件由模型决定,该模型应学会在何时输出一个结束序列(`EOS`)标记。如果不是这种情况,生成将在达到某个预定义的最大长度时停止。
正确设置`token`选择步骤和停止条件对于让你的模型按照预期的方式执行任务至关重要。这就是为什么我们为每个模型都有一个[~generation.GenerationConfig]文件,它包含一个效果不错的默认生成参数配置,并与您模型一起加载。
让我们谈谈代码!
<Tip>
如果您对基本的LLM使用感兴趣,我们高级的[`Pipeline`](pipeline_tutorial)接口是一个很好的起点。然而,LLMs通常需要像`quantization`和`token选择步骤的精细控制`等高级功能,这最好通过[`~generation.GenerationMixin.generate`]来完成。使用LLM进行自回归生成也是资源密集型的操作,应该在GPU上执行以获得足够的吞吐量。
</Tip>
首先,您需要加载模型。
```py
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
您将会注意到在`from_pretrained`调用中的两个标志:
- `device_map`确保模型被移动到您的GPU(s)上
- `load_in_4bit`应用[4位动态量化](main_classes/quantization)来极大地减少资源需求
还有其他方式来初始化一个模型,但这是一个开始使用LLM很好的起点。
接下来,你需要使用一个[tokenizer](tokenizer_summary)来预处理你的文本输入。
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
```
`model_inputs`变量保存着分词后的文本输入以及注意力掩码。尽管[`~generation.GenerationMixin.generate`]在未传递注意力掩码时会尽其所能推断出注意力掩码,但建议尽可能传递它以获得最佳结果。
在对输入进行分词后,可以调用[`~generation.GenerationMixin.generate`]方法来返回生成的`tokens`。生成的`tokens`应该在打印之前转换为文本。
```py
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, orange, purple, pink,'
```
最后,您不需要一次处理一个序列!您可以批量输入,这将在小延迟和低内存成本下显著提高吞吐量。您只需要确保正确地填充您的输入(详见下文)。
```py
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
'Portugal is a country in southwestern Europe, on the Iber']
```
就是这样!在几行代码中,您就可以利用LLM的强大功能。
## 常见陷阱
有许多[生成策略](generation_strategies),有时默认值可能不适合您的用例。如果您的输出与您期望的结果不匹配,我们已经创建了一个最常见的陷阱列表以及如何避免它们。
```py
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
### 生成的输出太短/太长
如果在[`~generation.GenerationConfig`]文件中没有指定,`generate`默认返回20个tokens。我们强烈建议在您的`generate`调用中手动设置`max_new_tokens`以控制它可以返回的最大新tokens数量。请注意,LLMs(更准确地说,仅[解码器模型](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt))也将输入提示作为输出的一部分返回。
```py
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
```
### 错误的生成模式
默认情况下,除非在[`~generation.GenerationConfig`]文件中指定,否则`generate`会在每个迭代中选择最可能的token(贪婪解码)。对于您的任务,这可能是不理想的;像聊天机器人或写作文章这样的创造性任务受益于采样。另一方面,像音频转录或翻译这样的基于输入的任务受益于贪婪解码。通过将`do_sample=True`启用采样,您可以在这篇[博客文章](https://huggingface.co/blog/how-to-generate)中了解更多关于这个话题的信息。
```py
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(42)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. Specifically, I am an indoor-only cat. I'
```
### 错误的填充位置
LLMs是[仅解码器](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)架构,意味着它们会持续迭代您的输入提示。如果您的输入长度不相同,则需要对它们进行填充。由于LLMs没有接受过从`pad tokens`继续训练,因此您的输入需要左填充。确保在生成时不要忘记传递注意力掩码!
```py
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails to capture the logic.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 33333333333'
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
```
### 错误的提示
一些模型和任务期望某种输入提示格式才能正常工作。当未应用此格式时,您将获得悄然的性能下降:模型能工作,但不如预期提示那样好。有关提示的更多信息,包括哪些模型和任务需要小心,可在[指南](tasks/prompting)中找到。让我们看一个使用[聊天模板](chat_templating)的聊天LLM示例:
```python
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
>>> model = AutoModelForCausalLM.from_pretrained(
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
... )
>>> set_seed(0)
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
>>> input_length = model_inputs.input_ids.shape[1]
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
"I'm not a thug, but i can tell you that a human cannot eat"
>>> # Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
>>> # a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)
>>> set_seed(0)
>>> messages = [
... {
... "role": "system",
... "content": "You are a friendly chatbot who always responds in the style of a thug",
... },
... {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
>>> input_length = model_inputs.shape[1]
>>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
'None, you thug. How bout you try to focus on more useful questions?'
>>> # As we can see, it followed a proper thug style 😎
```
## 更多资源
虽然自回归生成过程相对简单,但要充分利用LLM可能是一个具有挑战性的任务,因为很多组件复杂且密切关联。以下是帮助您深入了解LLM使用和理解的下一步:
### 高级生成用法
1. [指南](generation_strategies),介绍如何控制不同的生成方法、如何设置生成配置文件以及如何进行输出流式传输;
2. [指南](chat_templating),介绍聊天LLMs的提示模板;
3. [指南](tasks/prompting),介绍如何充分利用提示设计;
4. API参考文档,包括[`~generation.GenerationConfig`]、[`~generation.GenerationMixin.generate`]和[与生成相关的类](internal/generation_utils)。
### LLM排行榜
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), 侧重于开源模型的质量;
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), 侧重于LLM的吞吐量.
### 延迟、吞吐量和内存利用率
1. [指南](llm_tutorial_optimization),如何优化LLMs以提高速度和内存利用;
2. [指南](main_classes/quantization), 关于`quantization`,如bitsandbytes和autogptq的指南,教您如何大幅降低内存需求。
### 相关库
1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), 一个面向生产的LLM服务器;
2. [`optimum`](https://github.com/huggingface/optimum), 一个🤗 Transformers的扩展,优化特定硬件设备的性能
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/perf_torch_compile.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用 torch.compile() 优化推理
本指南旨在为使用[`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)在[🤗 Transformers中的计算机视觉模型](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending)中引入的推理速度提升提供一个基准。
## torch.compile 的优势
根据模型和GPU的不同,`torch.compile()`在推理过程中可以提高多达30%的速度。要使用`torch.compile()`,只需安装2.0及以上版本的`torch`即可。
编译模型需要时间,因此如果您只需要编译一次模型而不是每次推理都编译,那么它非常有用。
要编译您选择的任何计算机视觉模型,请按照以下方式调用`torch.compile()`:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
```
`compile()` 提供了多种编译模式,它们在编译时间和推理开销上有所不同。`max-autotune` 比 `reduce-overhead` 需要更长的时间,但会得到更快的推理速度。默认模式在编译时最快,但在推理时间上与 `reduce-overhead` 相比效率较低。在本指南中,我们使用了默认模式。您可以在[这里](https://pytorch.org/get-started/pytorch-2.0/#user-experience)了解更多信息。
我们在 PyTorch 2.0.1 版本上使用不同的计算机视觉模型、任务、硬件类型和数据批量大小对 `torch.compile` 进行了基准测试。
## 基准测试代码
以下是每个任务的基准测试代码。我们在推理之前”预热“GPU,并取300次推理的平均值,每次使用相同的图像。
### 使用 ViT 进行图像分类
```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
```
#### 使用 DETR 进行目标检测
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
```
#### 使用 Segformer 进行图像分割
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
```
以下是我们进行基准测试的模型列表。
**图像分类**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**图像分割**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**目标检测**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
下面是使用和不使用`torch.compile()`的推理持续时间可视化,以及每个模型在不同硬件和数据批量大小下的改进百分比。
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
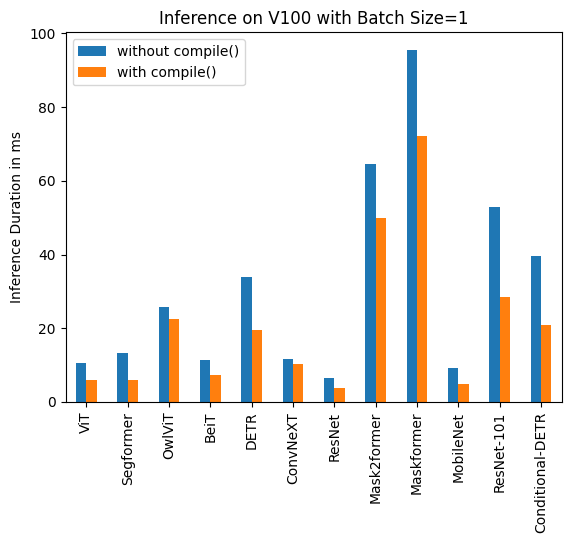
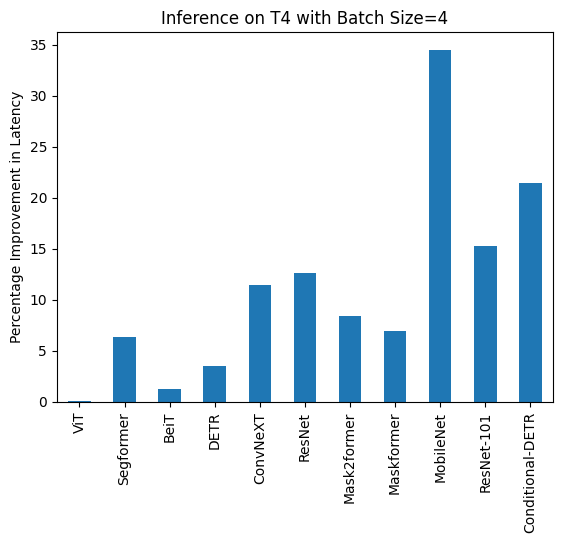
下面可以找到每个模型使用和不使用`compile()`的推理时间(毫秒)。请注意,OwlViT在大批量大小下会导致内存溢出。
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
我们还在 PyTorch Nightly 版本(2.1.0dev)上进行了基准测试,可以在[这里](https://download.pytorch.org/whl/nightly/cu118)找到 Nightly 版本的安装包,并观察到了未编译和编译模型的延迟性能改善。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## 降低开销
我们在 PyTorch Nightly 版本中为 A100 和 T4 进行了 `reduce-overhead` 编译模式的性能基准测试。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/pipelines_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# pipelines的工具
此页面列出了库为pipelines提供的所有实用程序功能。
其中大多数只有在您研究库中模型的代码时才有用。
## 参数处理
[[autodoc]] pipelines.ArgumentHandler
[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
## 数据格式
[[autodoc]] pipelines.PipelineDataFormat
[[autodoc]] pipelines.CsvPipelineDataFormat
[[autodoc]] pipelines.JsonPipelineDataFormat
[[autodoc]] pipelines.PipedPipelineDataFormat
## 实用函数
[[autodoc]] pipelines.PipelineException
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/image_processing_utils.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image Processors的工具
此页面列出了image processors使用的所有实用函数功能,主要是用于处理图像的功能变换。
其中大多数仅在您研究库中image processors的代码时有用。
## 图像转换
[[autodoc]] image_transforms.center_crop
[[autodoc]] image_transforms.center_to_corners_format
[[autodoc]] image_transforms.corners_to_center_format
[[autodoc]] image_transforms.id_to_rgb
[[autodoc]] image_transforms.normalize
[[autodoc]] image_transforms.pad
[[autodoc]] image_transforms.rgb_to_id
[[autodoc]] image_transforms.rescale
[[autodoc]] image_transforms.resize
[[autodoc]] image_transforms.to_pil_image
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/time_series_utils.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 时间序列工具
此页面列出了可用于时间序列类模型的所有实用函数和类。
其中大多数仅在您研究时间序列模型的代码,或希望添加到分布输出类集合时有用。
## 输出分布
[[autodoc]] time_series_utils.NormalOutput
[[autodoc]] time_series_utils.StudentTOutput
[[autodoc]] time_series_utils.NegativeBinomialOutput
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/audio_utils.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# `FeatureExtractors`的工具
此页面列出了音频 [`FeatureExtractor`] 可以使用的所有实用函数,以便使用常见的算法(如 *Short Time Fourier Transform* 或 *log mel spectrogram*)从原始音频中计算特殊特征。
其中大多数仅在您研究库中音频processors的代码时有用。
## 音频转换
[[autodoc]] audio_utils.hertz_to_mel
[[autodoc]] audio_utils.mel_to_hertz
[[autodoc]] audio_utils.mel_filter_bank
[[autodoc]] audio_utils.optimal_fft_length
[[autodoc]] audio_utils.window_function
[[autodoc]] audio_utils.spectrogram
[[autodoc]] audio_utils.power_to_db
[[autodoc]] audio_utils.amplitude_to_db
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/file_utils.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 通用工具
此页面列出了在`utils.py`文件中找到的所有Transformers通用实用函数。
其中大多数仅在您研究库中的通用代码时才有用。
## Enums和namedtuples(命名元组)
[[autodoc]] utils.ExplicitEnum
[[autodoc]] utils.PaddingStrategy
[[autodoc]] utils.TensorType
## 特殊的装饰函数
[[autodoc]] utils.add_start_docstrings
[[autodoc]] utils.add_start_docstrings_to_model_forward
[[autodoc]] utils.add_end_docstrings
[[autodoc]] utils.add_code_sample_docstrings
[[autodoc]] utils.replace_return_docstrings
## 特殊的属性
[[autodoc]] utils.cached_property
## 其他实用程序
[[autodoc]] utils._LazyModule
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/modeling_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 自定义层和工具
此页面列出了库使用的所有自定义层,以及它为模型提供的实用函数。
其中大多数只有在您研究库中模型的代码时才有用。
## Pytorch自定义模块
[[autodoc]] pytorch_utils.Conv1D
[[autodoc]] modeling_utils.PoolerStartLogits
- forward
[[autodoc]] modeling_utils.PoolerEndLogits
- forward
[[autodoc]] modeling_utils.PoolerAnswerClass
- forward
[[autodoc]] modeling_utils.SquadHeadOutput
[[autodoc]] modeling_utils.SQuADHead
- forward
[[autodoc]] modeling_utils.SequenceSummary
- forward
## PyTorch帮助函数
[[autodoc]] pytorch_utils.apply_chunking_to_forward
[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
[[autodoc]] pytorch_utils.prune_layer
[[autodoc]] pytorch_utils.prune_conv1d_layer
[[autodoc]] pytorch_utils.prune_linear_layer
## TensorFlow自定义层
[[autodoc]] modeling_tf_utils.TFConv1D
[[autodoc]] modeling_tf_utils.TFSequenceSummary
## TensorFlow loss 函数
[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
## TensorFlow帮助函数
[[autodoc]] modeling_tf_utils.get_initializer
[[autodoc]] modeling_tf_utils.keras_serializable
[[autodoc]] modeling_tf_utils.shape_list
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/generation_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 用于生成的工具
此页面列出了所有由 [`~generation.GenerationMixin.generate`],
[`~generation.GenerationMixin.greedy_search`],
[`~generation.GenerationMixin.contrastive_search`],
[`~generation.GenerationMixin.sample`],
[`~generation.GenerationMixin.beam_search`],
[`~generation.GenerationMixin.beam_sample`],
[`~generation.GenerationMixin.group_beam_search`], 和
[`~generation.GenerationMixin.constrained_beam_search`]使用的实用函数。
其中大多数仅在您研究库中生成方法的代码时才有用。
## 生成输出
[`~generation.GenerationMixin.generate`] 的输出是 [`~utils.ModelOutput`] 的一个子类的实例。这个输出是一种包含 [`~generation.GenerationMixin.generate`] 返回的所有信息数据结构,但也可以作为元组或字典使用。
这里是一个例子:
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
```
`generation_output` 的对象是 [`~generation.GenerateDecoderOnlyOutput`] 的一个实例,从该类的文档中我们可以看到,这意味着它具有以下属性:
- `sequences`: 生成的tokens序列
- `scores`(可选): 每个生成步骤的语言建模头的预测分数
- `hidden_states`(可选): 每个生成步骤模型的hidden states
- `attentions`(可选): 每个生成步骤模型的注意力权重
在这里,由于我们传递了 `output_scores=True`,我们具有 `scores` 属性。但我们没有 `hidden_states` 和 `attentions`,因为没有传递 `output_hidden_states=True` 或 `output_attentions=True`。
您可以像通常一样访问每个属性,如果该属性未被模型返回,则将获得 `None`。例如,在这里 `generation_output.scores` 是语言建模头的所有生成预测分数,而 `generation_output.attentions` 为 `None`。
当我们将 `generation_output` 对象用作元组时,它只保留非 `None` 值的属性。例如,在这里它有两个元素,`loss` 然后是 `logits`,所以
```python
generation_output[:2]
```
将返回元组`(generation_output.sequences, generation_output.scores)`。
当我们将`generation_output`对象用作字典时,它只保留非`None`的属性。例如,它有两个键,分别是`sequences`和`scores`。
我们在此记录所有输出类型。
### PyTorch
[[autodoc]] generation.GenerateDecoderOnlyOutput
[[autodoc]] generation.GenerateEncoderDecoderOutput
[[autodoc]] generation.GenerateBeamDecoderOnlyOutput
[[autodoc]] generation.GenerateBeamEncoderDecoderOutput
### TensorFlow
[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
[[autodoc]] generation.TFSampleEncoderDecoderOutput
[[autodoc]] generation.TFSampleDecoderOnlyOutput
[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
### FLAX
[[autodoc]] generation.FlaxSampleOutput
[[autodoc]] generation.FlaxGreedySearchOutput
[[autodoc]] generation.FlaxBeamSearchOutput
## LogitsProcessor
[`LogitsProcessor`] 可以用于修改语言模型头的预测分数以进行生成
### PyTorch
[[autodoc]] AlternatingCodebooksLogitsProcessor
- __call__
[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] EpsilonLogitsWarper
- __call__
[[autodoc]] EtaLogitsWarper
- __call__
[[autodoc]] ExponentialDecayLengthPenalty
- __call__
[[autodoc]] ForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] ForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] ForceTokensLogitsProcessor
- __call__
[[autodoc]] HammingDiversityLogitsProcessor
- __call__
[[autodoc]] InfNanRemoveLogitsProcessor
- __call__
[[autodoc]] LogitNormalization
- __call__
[[autodoc]] LogitsProcessor
- __call__
[[autodoc]] LogitsProcessorList
- __call__
[[autodoc]] LogitsWarper
- __call__
[[autodoc]] MinLengthLogitsProcessor
- __call__
[[autodoc]] MinNewTokensLengthLogitsProcessor
- __call__
[[autodoc]] NoBadWordsLogitsProcessor
- __call__
[[autodoc]] NoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] PrefixConstrainedLogitsProcessor
- __call__
[[autodoc]] RepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] SequenceBiasLogitsProcessor
- __call__
[[autodoc]] SuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] SuppressTokensLogitsProcessor
- __call__
[[autodoc]] TemperatureLogitsWarper
- __call__
[[autodoc]] TopKLogitsWarper
- __call__
[[autodoc]] TopPLogitsWarper
- __call__
[[autodoc]] TypicalLogitsWarper
- __call__
[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] WhisperTimeStampLogitsProcessor
- __call__
### TensorFlow
[[autodoc]] TFForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForceTokensLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessorList
- __call__
[[autodoc]] TFLogitsWarper
- __call__
[[autodoc]] TFMinLengthLogitsProcessor
- __call__
[[autodoc]] TFNoBadWordsLogitsProcessor
- __call__
[[autodoc]] TFNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] TFRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensLogitsProcessor
- __call__
[[autodoc]] TFTemperatureLogitsWarper
- __call__
[[autodoc]] TFTopKLogitsWarper
- __call__
[[autodoc]] TFTopPLogitsWarper
- __call__
### FLAX
[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForceTokensLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessorList
- __call__
[[autodoc]] FlaxLogitsWarper
- __call__
[[autodoc]] FlaxMinLengthLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensLogitsProcessor
- __call__
[[autodoc]] FlaxTemperatureLogitsWarper
- __call__
[[autodoc]] FlaxTopKLogitsWarper
- __call__
[[autodoc]] FlaxTopPLogitsWarper
- __call__
[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
- __call__
## StoppingCriteria
可以使用[`StoppingCriteria`]来更改停止生成的时间(除了EOS token以外的方法)。请注意,这仅适用于我们的PyTorch实现。
[[autodoc]] StoppingCriteria
- __call__
[[autodoc]] StoppingCriteriaList
- __call__
[[autodoc]] MaxLengthCriteria
- __call__
[[autodoc]] MaxTimeCriteria
- __call__
## Constraints
可以使用[`Constraint`]来强制生成结果包含输出中的特定tokens或序列。请注意,这仅适用于我们的PyTorch实现。
[[autodoc]] Constraint
[[autodoc]] PhrasalConstraint
[[autodoc]] DisjunctiveConstraint
[[autodoc]] ConstraintListState
## BeamSearch
[[autodoc]] BeamScorer
- process
- finalize
[[autodoc]] BeamSearchScorer
- process
- finalize
[[autodoc]] ConstrainedBeamSearchScorer
- process
- finalize
## Utilities
[[autodoc]] top_k_top_p_filtering
[[autodoc]] tf_top_k_top_p_filtering
## Streamers
[[autodoc]] TextStreamer
[[autodoc]] TextIteratorStreamer
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/tokenization_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tokenizers的工具
并保留格式:此页面列出了tokenizers使用的所有实用函数,主要是类
[`~tokenization_utils_base.PreTrained TokenizerBase`] 实现了常用方法之间的
[`PreTrained Tokenizer`] 和 [`PreTrained TokenizerFast`] 以及混合类
[`~tokenization_utils_base.SpecialTokens Mixin`]。
其中大多数只有在您研究库中tokenizers的代码时才有用。
## PreTrainedTokenizerBase
[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
- __call__
- all
## SpecialTokensMixin
[[autodoc]] tokenization_utils_base.SpecialTokensMixin
## Enums和namedtuples(命名元组)
[[autodoc]] tokenization_utils_base.TruncationStrategy
[[autodoc]] tokenization_utils_base.CharSpan
[[autodoc]] tokenization_utils_base.TokenSpan
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/internal/trainer_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer的工具
此页面列出了 [`Trainer`] 使用的所有实用函数。
其中大多数仅在您研究库中Trainer的代码时有用。
## 工具
[[autodoc]] EvalPrediction
[[autodoc]] IntervalStrategy
[[autodoc]] enable_full_determinism
[[autodoc]] set_seed
[[autodoc]] torch_distributed_zero_first
## Callbacks内部机制
[[autodoc]] trainer_callback.CallbackHandler
## 分布式评估
[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
## Trainer参数解析
[[autodoc]] HfArgumentParser
## Debug工具
[[autodoc]] debug_utils.DebugUnderflowOverflow
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/feature_extractor.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Feature Extractor
Feature Extractor负责为音频或视觉模型准备输入特征。这包括从序列中提取特征,例如,对音频文件进行预处理以生成Log-Mel频谱特征,以及从图像中提取特征,例如,裁剪图像文件,同时还包括填充、归一化和转换为NumPy、PyTorch和TensorFlow张量。
## FeatureExtractionMixin
[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
- from_pretrained
- save_pretrained
## SequenceFeatureExtractor
[[autodoc]] SequenceFeatureExtractor
- pad
## BatchFeature
[[autodoc]] BatchFeature
## ImageFeatureExtractionMixin
[[autodoc]] image_utils.ImageFeatureExtractionMixin
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/output.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 模型输出
所有模型的输出都是 [`~utils.ModelOutput`] 的子类的实例。这些是包含模型返回的所有信息的数据结构,但也可以用作元组或字典。
让我们看一个例子:
```python
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(**inputs, labels=labels)
```
`outputs` 对象是 [`~modeling_outputs.SequenceClassifierOutput`],如下面该类的文档中所示,它表示它有一个可选的 `loss`,一个 `logits`,一个可选的 `hidden_states` 和一个可选的 `attentions` 属性。在这里,我们有 `loss`,因为我们传递了 `labels`,但我们没有 `hidden_states` 和 `attentions`,因为我们没有传递 `output_hidden_states=True` 或 `output_attentions=True`。
<Tip>
当传递 `output_hidden_states=True` 时,您可能希望 `outputs.hidden_states[-1]` 与 `outputs.last_hidden_states` 完全匹配。然而,这并不总是成立。一些模型在返回最后的 hidden state时对其应用归一化或其他后续处理。
</Tip>
您可以像往常一样访问每个属性,如果模型未返回该属性,您将得到 `None`。在这里,例如,`outputs.loss` 是模型计算的损失,而 `outputs.attentions` 是 `None`。
当将我们的 `outputs` 对象视为元组时,它仅考虑那些没有 `None` 值的属性。例如这里它有两个元素,`loss` 和 `logits`,所以
```python
outputs[:2]
```
将返回元组 `(outputs.loss, outputs.logits)`。
将我们的 `outputs` 对象视为字典时,它仅考虑那些没有 `None` 值的属性。例如在这里它有两个键,分别是 `loss` 和 `logits`。
我们在这里记录了被多个类型模型使用的通用模型输出。特定输出类型在其相应的模型页面上有文档。
## ModelOutput
[[autodoc]] utils.ModelOutput
- to_tuple
## BaseModelOutput
[[autodoc]] modeling_outputs.BaseModelOutput
## BaseModelOutputWithPooling
[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
## BaseModelOutputWithCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
## BaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
## BaseModelOutputWithPast
[[autodoc]] modeling_outputs.BaseModelOutputWithPast
## BaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
## Seq2SeqModelOutput
[[autodoc]] modeling_outputs.Seq2SeqModelOutput
## CausalLMOutput
[[autodoc]] modeling_outputs.CausalLMOutput
## CausalLMOutputWithCrossAttentions
[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
## CausalLMOutputWithPast
[[autodoc]] modeling_outputs.CausalLMOutputWithPast
## MaskedLMOutput
[[autodoc]] modeling_outputs.MaskedLMOutput
## Seq2SeqLMOutput
[[autodoc]] modeling_outputs.Seq2SeqLMOutput
## NextSentencePredictorOutput
[[autodoc]] modeling_outputs.NextSentencePredictorOutput
## SequenceClassifierOutput
[[autodoc]] modeling_outputs.SequenceClassifierOutput
## Seq2SeqSequenceClassifierOutput
[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
## MultipleChoiceModelOutput
[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
## TokenClassifierOutput
[[autodoc]] modeling_outputs.TokenClassifierOutput
## QuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
## Seq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
## Seq2SeqSpectrogramOutput
[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
## SemanticSegmenterOutput
[[autodoc]] modeling_outputs.SemanticSegmenterOutput
## ImageClassifierOutput
[[autodoc]] modeling_outputs.ImageClassifierOutput
## ImageClassifierOutputWithNoAttention
[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
## DepthEstimatorOutput
[[autodoc]] modeling_outputs.DepthEstimatorOutput
## Wav2Vec2BaseModelOutput
[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
## XVectorOutput
[[autodoc]] modeling_outputs.XVectorOutput
## Seq2SeqTSModelOutput
[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
## Seq2SeqTSPredictionOutput
[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
## SampleTSPredictionOutput
[[autodoc]] modeling_outputs.SampleTSPredictionOutput
## TFBaseModelOutput
[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
## TFBaseModelOutputWithPooling
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
## TFBaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
## TFBaseModelOutputWithPast
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
## TFBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
## TFSeq2SeqModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
## TFCausalLMOutput
[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
## TFCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
## TFCausalLMOutputWithPast
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
## TFMaskedLMOutput
[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
## TFSeq2SeqLMOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
## TFNextSentencePredictorOutput
[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
## TFSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
## TFSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
## TFMultipleChoiceModelOutput
[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
## TFTokenClassifierOutput
[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
## TFQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
## TFSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
## FlaxBaseModelOutput
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
## FlaxBaseModelOutputWithPast
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
## FlaxBaseModelOutputWithPooling
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
## FlaxBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
## FlaxSeq2SeqModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
## FlaxCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
## FlaxMaskedLMOutput
[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
## FlaxSeq2SeqLMOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
## FlaxNextSentencePredictorOutput
[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
## FlaxSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
## FlaxSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
## FlaxMultipleChoiceModelOutput
[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
## FlaxTokenClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
## FlaxQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
## FlaxSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/text_generation.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Generation
每个框架都在它们各自的 `GenerationMixin` 类中实现了文本生成的 `generate` 方法:
- PyTorch [`~generation.GenerationMixin.generate`] 在 [`~generation.GenerationMixin`] 中实现。
- TensorFlow [`~generation.TFGenerationMixin.generate`] 在 [`~generation.TFGenerationMixin`] 中实现。
- Flax/JAX [`~generation.FlaxGenerationMixin.generate`] 在 [`~generation.FlaxGenerationMixin`] 中实现。
无论您选择哪个框架,都可以使用 [`~generation.GenerationConfig`] 类实例对 generate 方法进行参数化。有关生成方法的控制参数的完整列表,请参阅此类。
要了解如何检查模型的生成配置、默认值是什么、如何临时更改参数以及如何创建和保存自定义生成配置,请参阅 [文本生成策略指南](../generation_strategies)。该指南还解释了如何使用相关功能,如token流。
## GenerationConfig
[[autodoc]] generation.GenerationConfig
- from_pretrained
- from_model_config
- save_pretrained
## GenerationMixin
[[autodoc]] generation.GenerationMixin
- generate
- compute_transition_scores
- greedy_search
- sample
- beam_search
- beam_sample
- contrastive_search
- group_beam_search
- constrained_beam_search
## TFGenerationMixin
[[autodoc]] generation.TFGenerationMixin
- generate
- compute_transition_scores
## FlaxGenerationMixin
[[autodoc]] generation.FlaxGenerationMixin
- generate
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/logging.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Logging
🤗 Transformers拥有一个集中式的日志系统,因此您可以轻松设置库输出的日志详细程度。
当前库的默认日志详细程度为`WARNING`。
要更改日志详细程度,只需使用其中一个直接的setter。例如,以下是如何将日志详细程度更改为INFO级别的方法:
```python
import transformers
transformers.logging.set_verbosity_info()
```
您还可以使用环境变量`TRANSFORMERS_VERBOSITY`来覆盖默认的日志详细程度。您可以将其设置为以下级别之一:`debug`、`info`、`warning`、`error`、`critical`。例如:
```bash
TRANSFORMERS_VERBOSITY=error ./myprogram.py
```
此外,通过将环境变量`TRANSFORMERS_NO_ADVISORY_WARNINGS`设置为`true`(如*1*),可以禁用一些`warnings`。这将禁用[`logger.warning_advice`]记录的任何警告。例如:
```bash
TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
```
以下是如何在您自己的模块或脚本中使用与库相同的logger的示例:
```python
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
logger.info("INFO")
logger.warning("WARN")
```
此日志模块的所有方法都在下面进行了记录,主要的方法包括 [`logging.get_verbosity`] 用于获取logger当前输出日志详细程度的级别和 [`logging.set_verbosity`] 用于将详细程度设置为您选择的级别。按照顺序(从最不详细到最详细),这些级别(及其相应的整数值)为:
- `transformers.logging.CRITICAL` 或 `transformers.logging.FATAL`(整数值,50):仅报告最关键的errors。
- `transformers.logging.ERROR`(整数值,40):仅报告errors。
- `transformers.logging.WARNING` 或 `transformers.logging.WARN`(整数值,30):仅报告error和warnings。这是库使用的默认级别。
- `transformers.logging.INFO`(整数值,20):报告error、warnings和基本信息。
- `transformers.logging.DEBUG`(整数值,10):报告所有信息。
默认情况下,将在模型下载期间显示`tqdm`进度条。[`logging.disable_progress_bar`] 和 [`logging.enable_progress_bar`] 可用于禁止或启用此行为。
## `logging` vs `warnings`
Python有两个经常一起使用的日志系统:如上所述的`logging`,和对特定buckets中的警告进行进一步分类的`warnings`,例如,`FutureWarning`用于输出已经被弃用的功能或路径,`DeprecationWarning`用于指示即将被弃用的内容。
我们在`transformers`库中同时使用这两个系统。我们利用并调整了`logging`的`captureWarning`方法,以便通过上面的详细程度setters来管理这些警告消息。
对于库的开发人员,这意味着什么呢?我们应该遵循以下启发法则:
- 库的开发人员和依赖于`transformers`的库应优先使用`warnings`
- `logging`应该用于在日常项目中经常使用它的用户
以下是`captureWarnings`方法的参考。
[[autodoc]] logging.captureWarnings
## Base setters
[[autodoc]] logging.set_verbosity_error
[[autodoc]] logging.set_verbosity_warning
[[autodoc]] logging.set_verbosity_info
[[autodoc]] logging.set_verbosity_debug
## Other functions
[[autodoc]] logging.get_verbosity
[[autodoc]] logging.set_verbosity
[[autodoc]] logging.get_logger
[[autodoc]] logging.enable_default_handler
[[autodoc]] logging.disable_default_handler
[[autodoc]] logging.enable_explicit_format
[[autodoc]] logging.reset_format
[[autodoc]] logging.enable_progress_bar
[[autodoc]] logging.disable_progress_bar
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/configuration.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Configuration
基类[`PretrainedConfig`]实现了从本地文件或目录加载/保存配置的常见方法,或下载库提供的预训练模型配置(从HuggingFace的AWS S3库中下载)。
每个派生的配置类都实现了特定于模型的属性。所有配置类中共同存在的属性有:`hidden_size`、`num_attention_heads` 和 `num_hidden_layers`。文本模型进一步添加了 `vocab_size`。
## PretrainedConfig
[[autodoc]] PretrainedConfig
- push_to_hub
- all
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/processors.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Processors
在 Transformers 库中,processors可以有两种不同的含义:
- 为多模态模型,例如[Wav2Vec2](../model_doc/wav2vec2)(语音和文本)或[CLIP](../model_doc/clip)(文本和视觉)预处理输入的对象
- 在库的旧版本中用于预处理GLUE或SQUAD数据的已弃用对象。
## 多模态processors
任何多模态模型都需要一个对象来编码或解码将多个模态(包括文本、视觉和音频)组合在一起的数据。这由称为processors的对象处理,这些processors将两个或多个处理对象组合在一起,例如tokenizers(用于文本模态),image processors(用于视觉)和feature extractors(用于音频)。
这些processors继承自以下实现保存和加载功能的基类:
[[autodoc]] ProcessorMixin
## 已弃用的processors
所有processor都遵循与 [`~data.processors.utils.DataProcessor`] 相同的架构。processor返回一个 [`~data.processors.utils.InputExample`] 列表。这些 [`~data.processors.utils.InputExample`] 可以转换为 [`~data.processors.utils.InputFeatures`] 以供输送到模型。
[[autodoc]] data.processors.utils.DataProcessor
[[autodoc]] data.processors.utils.InputExample
[[autodoc]] data.processors.utils.InputFeatures
## GLUE
[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) 是一个基准测试,评估模型在各种现有的自然语言理解任务上的性能。它与论文 [GLUE: A multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7) 一同发布。
该库为以下任务提供了总共10个processor:MRPC、MNLI、MNLI(mismatched)、CoLA、SST2、STSB、QQP、QNLI、RTE 和 WNLI。
这些processor是:
- [`~data.processors.utils.MrpcProcessor`]
- [`~data.processors.utils.MnliProcessor`]
- [`~data.processors.utils.MnliMismatchedProcessor`]
- [`~data.processors.utils.Sst2Processor`]
- [`~data.processors.utils.StsbProcessor`]
- [`~data.processors.utils.QqpProcessor`]
- [`~data.processors.utils.QnliProcessor`]
- [`~data.processors.utils.RteProcessor`]
- [`~data.processors.utils.WnliProcessor`]
此外,还可以使用以下方法从数据文件加载值并将其转换为 [`~data.processors.utils.InputExample`] 列表。
[[autodoc]] data.processors.glue.glue_convert_examples_to_features
## XNLI
[跨语言NLI语料库(XNLI)](https://www.nyu.edu/projects/bowman/xnli/) 是一个评估跨语言文本表示质量的基准测试。XNLI是一个基于[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/)的众包数据集:”文本对“被标记为包含15种不同语言(包括英语等高资源语言和斯瓦希里语等低资源语言)的文本蕴涵注释。
它与论文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) 一同发布。
该库提供了加载XNLI数据的processor:
- [`~data.processors.utils.XnliProcessor`]
请注意,由于测试集上有“gold”标签,因此评估是在测试集上进行的。
使用这些processor的示例在 [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) 脚本中提供。
## SQuAD
[斯坦福问答数据集(SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) 是一个评估模型在问答上性能的基准测试。有两个版本,v1.1 和 v2.0。第一个版本(v1.1)与论文 [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) 一同发布。第二个版本(v2.0)与论文 [Know What You Don't Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822) 一同发布。
该库为两个版本各自提供了一个processor:
### Processors
这两个processor是:
- [`~data.processors.utils.SquadV1Processor`]
- [`~data.processors.utils.SquadV2Processor`]
它们都继承自抽象类 [`~data.processors.utils.SquadProcessor`]。
[[autodoc]] data.processors.squad.SquadProcessor
- all
此外,可以使用以下方法将 SQuAD 示例转换为可用作模型输入的 [`~data.processors.utils.SquadFeatures`]。
[[autodoc]] data.processors.squad.squad_convert_examples_to_features
这些processor以及前面提到的方法可以与包含数据的文件以及tensorflow_datasets包一起使用。下面给出了示例。
### Example使用
以下是使用processor以及使用数据文件的转换方法的示例:
```python
# Loading a V2 processor
processor = SquadV2Processor()
examples = processor.get_dev_examples(squad_v2_data_dir)
# Loading a V1 processor
processor = SquadV1Processor()
examples = processor.get_dev_examples(squad_v1_data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
使用 *tensorflow_datasets* 就像使用数据文件一样简单:
```python
# tensorflow_datasets only handle Squad V1.
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
另一个使用这些processor的示例在 [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) 脚本中提供。
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/pipelines.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines
pipelines是使用模型进行推理的一种简单方法。这些pipelines是抽象了库中大部分复杂代码的对象,提供了一个专用于多个任务的简单API,包括专名识别、掩码语言建模、情感分析、特征提取和问答等。请参阅[任务摘要](../task_summary)以获取使用示例。
有两种pipelines抽象类需要注意:
- [`pipeline`],它是封装所有其他pipelines的最强大的对象。
- 针对特定任务pipelines,适用于[音频](#audio)、[计算机视觉](#computer-vision)、[自然语言处理](#natural-language-processing)和[多模态](#multimodal)任务。
## pipeline抽象类
*pipeline*抽象类是对所有其他可用pipeline的封装。它可以像任何其他pipeline一样实例化,但进一步提供额外的便利性。
简单调用一个项目:
```python
>>> pipe = pipeline("text-classification")
>>> pipe("This restaurant is awesome")
[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
```
如果您想使用 [hub](https://huggingface.co) 上的特定模型,可以忽略任务,如果hub上的模型已经定义了该任务:
```python
>>> pipe = pipeline(model="roberta-large-mnli")
>>> pipe("This restaurant is awesome")
[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
```
要在多个项目上调用pipeline,可以使用*列表*调用它。
```python
>>> pipe = pipeline("text-classification")
>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9996669292449951}]
```
为了遍历整个数据集,建议直接使用 `dataset`。这意味着您不需要一次性分配整个数据集,也不需要自己进行批处理。这应该与GPU上的自定义循环一样快。如果不是,请随时提出issue。
```python
import datasets
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
from tqdm.auto import tqdm
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
dataset = datasets.load_dataset("superb", name="asr", split="test")
# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
for out in tqdm(pipe(KeyDataset(dataset, "file"))):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
为了方便使用,也可以使用生成器:
```python
from transformers import pipeline
pipe = pipeline("text-classification")
def data():
while True:
# This could come from a dataset, a database, a queue or HTTP request
# in a server
# Caveat: because this is iterative, you cannot use `num_workers > 1` variable
# to use multiple threads to preprocess data. You can still have 1 thread that
# does the preprocessing while the main runs the big inference
yield "This is a test"
for out in pipe(data()):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
[[autodoc]] pipeline
## Pipeline batching
所有pipeline都可以使用批处理。这将在pipeline使用其流处理功能时起作用(即传递列表或 `Dataset` 或 `generator` 时)。
```python
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
import datasets
dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
pipe = pipeline("text-classification", device=0)
for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
print(out)
# [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
# Exactly the same output as before, but the content are passed
# as batches to the model
```
<Tip warning={true}>
然而,这并不自动意味着性能提升。它可能是一个10倍的加速或5倍的减速,具体取决于硬件、数据和实际使用的模型。
主要是加速的示例:
</Tip>
```python
from transformers import pipeline
from torch.utils.data import Dataset
from tqdm.auto import tqdm
pipe = pipeline("text-classification", device=0)
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
return "This is a test"
dataset = MyDataset()
for batch_size in [1, 8, 64, 256]:
print("-" * 30)
print(f"Streaming batch_size={batch_size}")
for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
pass
```
```
# On GTX 970
------------------------------
Streaming no batching
100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
------------------------------
Streaming batch_size=64
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
------------------------------
Streaming batch_size=256
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
(diminishing returns, saturated the GPU)
```
主要是减速的示例:
```python
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
if i % 64 == 0:
n = 100
else:
n = 1
return "This is a test" * n
```
与其他句子相比,这是一个非常长的句子。在这种情况下,**整个**批次将需要400个tokens的长度,因此整个批次将是 [64, 400] 而不是 [64, 4],从而导致较大的减速。更糟糕的是,在更大的批次上,程序会崩溃。
```
------------------------------
Streaming no batching
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
------------------------------
Streaming batch_size=64
100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
------------------------------
Streaming batch_size=256
0%| | 0/1000 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/home/nicolas/src/transformers/test.py", line 42, in <module>
for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
....
q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
```
对于这个问题,没有好的(通用)解决方案,效果可能因您的用例而异。经验法则如下:
对于用户,一个经验法则是:
- **使用硬件测量负载性能。测量、测量、再测量。真实的数字是唯一的方法。**
- 如果受到延迟的限制(进行推理的实时产品),不要进行批处理。
- 如果使用CPU,不要进行批处理。
- 如果您在GPU上处理的是吞吐量(您希望在大量静态数据上运行模型),则:
- 如果对序列长度的大小没有概念("自然"数据),默认情况下不要进行批处理,进行测试并尝试逐渐添加,添加OOM检查以在失败时恢复(如果您不能控制序列长度,它将在某些时候失败)。
- 如果您的序列长度非常规律,那么批处理更有可能非常有趣,进行测试并推动它,直到出现OOM。
- GPU越大,批处理越有可能变得更有趣
- 一旦启用批处理,确保能够很好地处理OOM。
## Pipeline chunk batching
`zero-shot-classification` 和 `question-answering` 在某种意义上稍微特殊,因为单个输入可能会导致模型的多次前向传递。在正常情况下,这将导致 `batch_size` 参数的问题。
为了规避这个问题,这两个pipeline都有点特殊,它们是 `ChunkPipeline` 而不是常规的 `Pipeline`。简而言之:
```python
preprocessed = pipe.preprocess(inputs)
model_outputs = pipe.forward(preprocessed)
outputs = pipe.postprocess(model_outputs)
```
现在变成:
```python
all_model_outputs = []
for preprocessed in pipe.preprocess(inputs):
model_outputs = pipe.forward(preprocessed)
all_model_outputs.append(model_outputs)
outputs = pipe.postprocess(all_model_outputs)
```
这对您的代码应该是非常直观的,因为pipeline的使用方式是相同的。
这是一个简化的视图,因为Pipeline可以自动处理批次!这意味着您不必担心您的输入实际上会触发多少次前向传递,您可以独立于输入优化 `batch_size`。前面部分的注意事项仍然适用。
## Pipeline自定义
如果您想要重载特定的pipeline。
请随时为您手头的任务创建一个issue,Pipeline的目标是易于使用并支持大多数情况,因此 `transformers` 可能支持您的用例。
如果您想简单地尝试一下,可以:
- 继承您选择的pipeline
```python
class MyPipeline(TextClassificationPipeline):
def postprocess():
# Your code goes here
scores = scores * 100
# And here
my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
# or if you use *pipeline* function, then:
my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
```
这样就可以让您编写所有想要的自定义代码。
## 实现一个pipeline
[实现一个新的pipeline](../add_new_pipeline)
## 音频
可用于音频任务的pipeline包括以下几种。
### AudioClassificationPipeline
[[autodoc]] AudioClassificationPipeline
- __call__
- all
### AutomaticSpeechRecognitionPipeline
[[autodoc]] AutomaticSpeechRecognitionPipeline
- __call__
- all
### TextToAudioPipeline
[[autodoc]] TextToAudioPipeline
- __call__
- all
### ZeroShotAudioClassificationPipeline
[[autodoc]] ZeroShotAudioClassificationPipeline
- __call__
- all
## 计算机视觉
可用于计算机视觉任务的pipeline包括以下几种。
### DepthEstimationPipeline
[[autodoc]] DepthEstimationPipeline
- __call__
- all
### ImageClassificationPipeline
[[autodoc]] ImageClassificationPipeline
- __call__
- all
### ImageSegmentationPipeline
[[autodoc]] ImageSegmentationPipeline
- __call__
- all
### ImageToImagePipeline
[[autodoc]] ImageToImagePipeline
- __call__
- all
### ObjectDetectionPipeline
[[autodoc]] ObjectDetectionPipeline
- __call__
- all
### VideoClassificationPipeline
[[autodoc]] VideoClassificationPipeline
- __call__
- all
### ZeroShotImageClassificationPipeline
[[autodoc]] ZeroShotImageClassificationPipeline
- __call__
- all
### ZeroShotObjectDetectionPipeline
[[autodoc]] ZeroShotObjectDetectionPipeline
- __call__
- all
## 自然语言处理
可用于自然语言处理任务的pipeline包括以下几种。
### ConversationalPipeline
[[autodoc]] Conversation
[[autodoc]] ConversationalPipeline
- __call__
- all
### FillMaskPipeline
[[autodoc]] FillMaskPipeline
- __call__
- all
### NerPipeline
[[autodoc]] NerPipeline
See [`TokenClassificationPipeline`] for all details.
### QuestionAnsweringPipeline
[[autodoc]] QuestionAnsweringPipeline
- __call__
- all
### SummarizationPipeline
[[autodoc]] SummarizationPipeline
- __call__
- all
### TableQuestionAnsweringPipeline
[[autodoc]] TableQuestionAnsweringPipeline
- __call__
### TextClassificationPipeline
[[autodoc]] TextClassificationPipeline
- __call__
- all
### TextGenerationPipeline
[[autodoc]] TextGenerationPipeline
- __call__
- all
### Text2TextGenerationPipeline
[[autodoc]] Text2TextGenerationPipeline
- __call__
- all
### TokenClassificationPipeline
[[autodoc]] TokenClassificationPipeline
- __call__
- all
### TranslationPipeline
[[autodoc]] TranslationPipeline
- __call__
- all
### ZeroShotClassificationPipeline
[[autodoc]] ZeroShotClassificationPipeline
- __call__
- all
## 多模态
可用于多模态任务的pipeline包括以下几种。
### DocumentQuestionAnsweringPipeline
[[autodoc]] DocumentQuestionAnsweringPipeline
- __call__
- all
### FeatureExtractionPipeline
[[autodoc]] FeatureExtractionPipeline
- __call__
- all
### ImageToTextPipeline
[[autodoc]] ImageToTextPipeline
- __call__
- all
### MaskGenerationPipeline
[[autodoc]] MaskGenerationPipeline
- __call__
- all
### VisualQuestionAnsweringPipeline
[[autodoc]] VisualQuestionAnsweringPipeline
- __call__
- all
## Parent class: `Pipeline`
[[autodoc]] Pipeline
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/image_processor.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image Processor
Image processor负责为视觉模型准备输入特征并后期处理处理它们的输出。这包括诸如调整大小、归一化和转换为PyTorch、TensorFlow、Flax和NumPy张量等转换。它还可能包括特定于模型的后期处理,例如将logits转换为分割掩码。
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
- from_pretrained
- save_pretrained
## BatchFeature
[[autodoc]] BatchFeature
## BaseImageProcessor
[[autodoc]] image_processing_utils.BaseImageProcessor
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/optimizer_schedules.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimization
`.optimization` 模块提供了:
- 一个带有固定权重衰减的优化器,可用于微调模型
- 继承自 `_LRSchedule` 多个调度器:
- 一个梯度累积类,用于累积多个批次的梯度
## AdamW (PyTorch)
[[autodoc]] AdamW
## AdaFactor (PyTorch)
[[autodoc]] Adafactor
## AdamWeightDecay (TensorFlow)
[[autodoc]] AdamWeightDecay
[[autodoc]] create_optimizer
## Schedules
### Learning Rate Schedules (Pytorch)
[[autodoc]] SchedulerType
[[autodoc]] get_scheduler
[[autodoc]] get_constant_schedule
[[autodoc]] get_constant_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_constant_schedule.png"/>
[[autodoc]] get_cosine_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_schedule.png"/>
[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_hard_restarts_schedule.png"/>
[[autodoc]] get_linear_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_linear_schedule.png"/>
[[autodoc]] get_polynomial_decay_schedule_with_warmup
[[autodoc]] get_inverse_sqrt_schedule
### Warmup (TensorFlow)
[[autodoc]] WarmUp
## Gradient Strategies
### GradientAccumulator (TensorFlow)
[[autodoc]] GradientAccumulator
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/quantization.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 量化 🤗 Transformers 模型
## AWQ集成
AWQ方法已经在[*AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration*论文](https://arxiv.org/abs/2306.00978)中引入。通过AWQ,您可以以4位精度运行模型,同时保留其原始性能(即没有性能降级),并具有比下面介绍的其他量化方法更出色的吞吐量 - 达到与纯`float16`推理相似的吞吐量。
我们现在支持使用任何AWQ模型进行推理,这意味着任何人都可以加载和使用在Hub上推送或本地保存的AWQ权重。请注意,使用AWQ需要访问NVIDIA GPU。目前不支持CPU推理。
### 量化一个模型
我们建议用户查看生态系统中不同的现有工具,以使用AWQ算法对其模型进行量化,例如:
- [`llm-awq`](https://github.com/mit-han-lab/llm-awq),来自MIT Han Lab
- [`autoawq`](https://github.com/casper-hansen/AutoAWQ),来自[`casper-hansen`](https://github.com/casper-hansen)
- Intel neural compressor,来自Intel - 通过[`optimum-intel`](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc)使用
生态系统中可能存在许多其他工具,请随时提出PR将它们添加到列表中。
目前与🤗 Transformers的集成仅适用于使用`autoawq`和`llm-awq`量化后的模型。大多数使用`auto-awq`量化的模型可以在🤗 Hub的[`TheBloke`](https://huggingface.co/TheBloke)命名空间下找到,要使用`llm-awq`对模型进行量化,请参阅[`llm-awq`](https://github.com/mit-han-lab/llm-awq/)的示例文件夹中的[`convert_to_hf.py`](https://github.com/mit-han-lab/llm-awq/blob/main/examples/convert_to_hf.py)脚本。
### 加载一个量化的模型
您可以使用`from_pretrained`方法从Hub加载一个量化模型。通过检查模型配置文件(`configuration.json`)中是否存在`quantization_config`属性,来进行确认推送的权重是量化的。您可以通过检查字段`quantization_config.quant_method`来确认模型是否以AWQ格式进行量化,该字段应该设置为`"awq"`。请注意,为了性能原因,默认情况下加载模型将设置其他权重为`float16`。如果您想更改这种设置,可以通过将`torch_dtype`参数设置为`torch.float32`或`torch.bfloat16`。在下面的部分中,您可以找到一些示例片段和notebook。
## 示例使用
首先,您需要安装[`autoawq`](https://github.com/casper-hansen/AutoAWQ)库
```bash
pip install autoawq
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
```
如果您首先将模型加载到CPU上,请确保在使用之前将其移动到GPU设备上。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id).to("cuda:0")
```
### 结合 AWQ 和 Flash Attention
您可以将AWQ量化与Flash Attention结合起来,得到一个既被量化又更快速的模型。只需使用`from_pretrained`加载模型,并传递`attn_implementation="flash_attention_2"`参数。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
```
### 基准测试
我们使用[`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark)库进行了一些速度、吞吐量和延迟基准测试。
请注意,在编写本文档部分时,可用的量化方法包括:`awq`、`gptq`和`bitsandbytes`。
基准测试在一台NVIDIA-A100实例上运行,使用[`TheBloke/Mistral-7B-v0.1-AWQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ)作为AWQ模型,[`TheBloke/Mistral-7B-v0.1-GPTQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ)作为GPTQ模型。我们还将其与`bitsandbytes`量化模型和`float16`模型进行了对比。以下是一些结果示例:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/forward_memory_plot.png">
</div>
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/generate_memory_plot.png">
</div>
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/generate_throughput_plot.png">
</div>
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/forward_latency_plot.png">
</div>
你可以在[此链接](https://github.com/huggingface/optimum-benchmark/tree/main/examples/running-mistrals)中找到完整的结果以及包版本。
从结果来看,AWQ量化方法是推理、文本生成中最快的量化方法,并且在文本生成的峰值内存方面属于最低。然而,对于每批数据,AWQ似乎有最大的前向延迟。
### Google colab 演示
查看如何在[Google Colab演示](https://colab.research.google.com/drive/1HzZH89yAXJaZgwJDhQj9LqSBux932BvY)中使用此集成!
### AwqConfig
[[autodoc]] AwqConfig
## `AutoGPTQ` 集成
🤗 Transformers已经整合了`optimum` API,用于对语言模型执行GPTQ量化。您可以以8、4、3甚至2位加载和量化您的模型,而性能无明显下降,并且推理速度更快!这受到大多数GPU硬件的支持。
要了解更多关于量化模型的信息,请查看:
- [GPTQ](https://arxiv.org/pdf/2210.17323.pdf)论文
- `optimum`关于GPTQ量化的[指南](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- 用作后端的[`AutoGPTQ`](https://github.com/PanQiWei/AutoGPTQ)库
### 要求
为了运行下面的代码,您需要安装:
- 安装最新版本的 `AutoGPTQ` 库
`pip install auto-gptq`
- 从源代码安装最新版本的`optimum`
`pip install git+https://github.com/huggingface/optimum.git`
- 从源代码安装最新版本的`transformers`
`pip install git+https://github.com/huggingface/transformers.git`
- 安装最新版本的`accelerate`库:
`pip install --upgrade accelerate`
请注意,目前GPTQ集成仅支持文本模型,对于视觉、语音或多模态模型可能会遇到预期以外结果。
### 加载和量化模型
GPTQ是一种在使用量化模型之前需要进行权重校准的量化方法。如果您想从头开始对transformers模型进行量化,生成量化模型可能需要一些时间(在Google Colab上对`facebook/opt-350m`模型量化约为5分钟)。
因此,有两种不同的情况下您可能想使用GPTQ量化模型。第一种情况是加载已经由其他用户在Hub上量化的模型,第二种情况是从头开始对您的模型进行量化并保存或推送到Hub,以便其他用户也可以使用它。
#### GPTQ 配置
为了加载和量化一个模型,您需要创建一个[`GPTQConfig`]。您需要传递`bits`的数量,一个用于校准量化的`dataset`,以及模型的`tokenizer`以准备数据集。
```python
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
```
请注意,您可以将自己的数据集以字符串列表形式传递到模型。然而,强烈建议您使用GPTQ论文中提供的数据集。
```python
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)
```
#### 量化
您可以通过使用`from_pretrained`并设置`quantization_config`来对模型进行量化。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
```
请注意,您需要一个GPU来量化模型。我们将模型放在cpu中,并将模块来回移动到gpu中,以便对其进行量化。
如果您想在使用 CPU 卸载的同时最大化 GPU 使用率,您可以设置 `device_map = "auto"`。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
```
请注意,不支持磁盘卸载。此外,如果由于数据集而内存不足,您可能需要在`from_pretrained`中设置`max_memory`。查看这个[指南](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map)以了解有关`device_map`和`max_memory`的更多信息。
<Tip warning={true}>
目前,GPTQ量化仅适用于文本模型。此外,量化过程可能会花费很多时间,具体取决于硬件性能(175B模型在NVIDIA A100上需要4小时)。请在Hub上检查是否有模型的GPTQ量化版本。如果没有,您可以在GitHub上提交需求。
</Tip>
### 推送量化模型到 🤗 Hub
您可以使用`push_to_hub`将量化模型像任何模型一样推送到Hub。量化配置将与模型一起保存和推送。
```python
quantized_model.push_to_hub("opt-125m-gptq")
tokenizer.push_to_hub("opt-125m-gptq")
```
如果您想在本地计算机上保存量化模型,您也可以使用`save_pretrained`来完成:
```python
quantized_model.save_pretrained("opt-125m-gptq")
tokenizer.save_pretrained("opt-125m-gptq")
```
请注意,如果您量化模型时想使用`device_map`,请确保在保存之前将整个模型移动到您的GPU或CPU之一。
```python
quantized_model.to("cpu")
quantized_model.save_pretrained("opt-125m-gptq")
```
### 从 🤗 Hub 加载一个量化模型
您可以使用`from_pretrained`从Hub加载量化模型。
请确保推送权重是量化的,检查模型配置对象中是否存在`quantization_config`属性。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq")
```
如果您想更快地加载模型,并且不需要分配比实际需要内存更多的内存,量化模型也使用`device_map`参数。确保您已安装`accelerate`库。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
```
### Exllama内核加快推理速度
保留格式:对于 4 位模型,您可以使用 exllama 内核来提高推理速度。默认情况下,它处于启用状态。您可以通过在 [`GPTQConfig`] 中传递 `use_exllama` 来更改此配置。这将覆盖存储在配置中的量化配置。请注意,您只能覆盖与内核相关的属性。此外,如果您想使用 exllama 内核,整个模型需要全部部署在 gpus 上。此外,您可以使用 版本 > 0.4.2 的 Auto-GPTQ 并传递 `device_map` = "cpu" 来执行 CPU 推理。对于 CPU 推理,您必须在 `GPTQConfig` 中传递 `use_exllama = False`。
```py
import torch
gptq_config = GPTQConfig(bits=4)
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)
```
随着 exllamav2 内核的发布,与 exllama 内核相比,您可以获得更快的推理速度。您只需在 [`GPTQConfig`] 中传递 `exllama_config={"version": 2}`:
```py
import torch
gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config = gptq_config)
```
请注意,目前仅支持 4 位模型。此外,如果您正在使用 peft 对量化模型进行微调,建议禁用 exllama 内核。
您可以在此找到这些内核的基准测试 [这里](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark)
#### 微调一个量化模型
在Hugging Face生态系统的官方支持下,您可以使用GPTQ进行量化后的模型进行微调。
请查看`peft`库了解更多详情。
### 示例演示
请查看 Google Colab [notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94ilkUFu6ZX4ceb?usp=sharing),了解如何使用GPTQ量化您的模型以及如何使用peft微调量化模型。
### GPTQConfig
[[autodoc]] GPTQConfig
## `bitsandbytes` 集成
🤗 Transformers 与 `bitsandbytes` 上最常用的模块紧密集成。您可以使用几行代码以 8 位精度加载您的模型。
自bitsandbytes的0.37.0版本发布以来,大多数GPU硬件都支持这一点。
在[LLM.int8()](https://arxiv.org/abs/2208.07339)论文中了解更多关于量化方法的信息,或者在[博客文章](https://huggingface.co/blog/hf-bitsandbytes-integration)中了解关于合作的更多信息。
自其“0.39.0”版本发布以来,您可以使用FP4数据类型,通过4位量化加载任何支持“device_map”的模型。
如果您想量化自己的 pytorch 模型,请查看 🤗 Accelerate 的[文档](https://huggingface.co/docs/accelerate/main/en/usage_guides/quantization)。
以下是您可以使用“bitsandbytes”集成完成的事情
### 通用用法
只要您的模型支持使用 🤗 Accelerate 进行加载并包含 `torch.nn.Linear` 层,您可以在调用 [`~PreTrainedModel.from_pretrained`] 方法时使用 `load_in_8bit` 或 `load_in_4bit` 参数来量化模型。这也应该适用于任何模态。
```python
from transformers import AutoModelForCausalLM
model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
model_4bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True)
```
默认情况下,所有其他模块(例如 `torch.nn.LayerNorm`)将被转换为 `torch.float16` 类型。但如果您想更改它们的 `dtype`,可以重载 `torch_dtype` 参数:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM
>>> model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, torch_dtype=torch.float32)
>>> model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
torch.float32
```
### FP4 量化
#### 要求
确保在运行以下代码段之前已完成以下要求:
- 最新版本 `bitsandbytes` 库
`pip install bitsandbytes>=0.39.0`
- 安装最新版本 `accelerate`
`pip install --upgrade accelerate`
- 安装最新版本 `transformers`
`pip install --upgrade transformers`
#### 提示和最佳实践
- **高级用法:** 请参考 [此 Google Colab notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf) 以获取 4 位量化高级用法和所有可选选项。
- **使用 `batch_size=1` 实现更快的推理:** 自 `bitsandbytes` 的 `0.40.0` 版本以来,设置 `batch_size=1`,您可以从快速推理中受益。请查看 [这些发布说明](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.40.0) ,并确保使用大于 `0.40.0` 的版本以直接利用此功能。
- **训练:** 根据 [QLoRA 论文](https://arxiv.org/abs/2305.14314),对于4位基模型训练(使用 LoRA 适配器),应使用 `bnb_4bit_quant_type='nf4'`。
- **推理:** 对于推理,`bnb_4bit_quant_type` 对性能影响不大。但是为了与模型的权重保持一致,请确保使用相同的 `bnb_4bit_compute_dtype` 和 `torch_dtype` 参数。
#### 加载 4 位量化的大模型
在调用 `.from_pretrained` 方法时使用 `load_in_4bit=True`,可以将您的内存使用量减少到大约原来的 1/4。
```python
# pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "bigscience/bloom-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_4bit=True)
```
<Tip warning={true}>
需要注意的是,一旦模型以 4 位量化方式加载,就无法将量化后的权重推送到 Hub 上。此外,您不能训练 4 位量化权重,因为目前尚不支持此功能。但是,您可以使用 4 位量化模型来训练额外参数,这将在下一部分中介绍。
</Tip>
### 加载 8 位量化的大模型
您可以通过在调用 `.from_pretrained` 方法时使用 `load_in_8bit=True` 参数,将内存需求大致减半来加载模型
```python
# pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "bigscience/bloom-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_8bit=True)
```
然后,像通常使用 `PreTrainedModel` 一样使用您的模型。
您可以使用 `get_memory_footprint` 方法检查模型的内存占用。
```python
print(model.get_memory_footprint())
```
通过这种集成,我们能够在较小的设备上加载大模型并运行它们而没有任何问题。
<Tip warning={true}>
需要注意的是,一旦模型以 8 位量化方式加载,除了使用最新的 `transformers` 和 `bitsandbytes` 之外,目前尚无法将量化后的权重推送到 Hub 上。此外,您不能训练 8 位量化权重,因为目前尚不支持此功能。但是,您可以使用 8 位量化模型来训练额外参数,这将在下一部分中介绍。
注意,`device_map` 是可选的,但设置 `device_map = 'auto'` 更适合用于推理,因为它将更有效地调度可用资源上的模型。
</Tip>
#### 高级用例
在这里,我们将介绍使用 FP4 量化的一些高级用例。
##### 更改计算数据类型
计算数据类型用于改变在进行计算时使用的数据类型。例如,hidden states可以是 `float32`,但为了加速,计算时可以被设置为 `bf16`。默认情况下,计算数据类型被设置为 `float32`。
```python
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
```
#### 使用 NF4(普通浮点数 4)数据类型
您还可以使用 NF4 数据类型,这是一种针对使用正态分布初始化的权重而适应的新型 4 位数据类型。要运行:
```python
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
```
#### 使用嵌套量化进行更高效的内存推理
我们还建议用户使用嵌套量化技术。从我们的经验观察来看,这种方法在不增加额外性能的情况下节省更多内存。这使得 llama-13b 模型能够在具有 1024 个序列长度、1 个批次大小和 4 个梯度累积步骤的 NVIDIA-T4 16GB 上进行 fine-tuning。
```python
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
```
### 将量化模型推送到🤗 Hub
您可以使用 `push_to_hub` 方法将量化模型推送到 Hub 上。这将首先推送量化配置文件,然后推送量化模型权重。
请确保使用 `bitsandbytes>0.37.2`(在撰写本文时,我们使用的是 `bitsandbytes==0.38.0.post1`)才能使用此功能。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m", device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
model.push_to_hub("bloom-560m-8bit")
```
<Tip warning={true}>
对大模型,强烈鼓励将 8 位量化模型推送到 Hub 上,以便让社区能够从内存占用减少和加载中受益,例如在 Google Colab 上加载大模型。
</Tip>
### 从🤗 Hub加载量化模型
您可以使用 `from_pretrained` 方法从 Hub 加载量化模型。请确保推送的权重是量化的,检查模型配置对象中是否存在 `quantization_config` 属性。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
```
请注意,在这种情况下,您不需要指定 `load_in_8bit=True` 参数,但需要确保 `bitsandbytes` 和 `accelerate` 已安装。
情注意,`device_map` 是可选的,但设置 `device_map = 'auto'` 更适合用于推理,因为它将更有效地调度可用资源上的模型。
### 高级用例
本节面向希望探索除了加载和运行 8 位模型之外还能做什么的进阶用户。
#### 在 `cpu` 和 `gpu` 之间卸载
此高级用例之一是能够加载模型并将权重分派到 `CPU` 和 `GPU` 之间。请注意,将在 CPU 上分派的权重 **不会** 转换为 8 位,因此会保留为 `float32`。此功能适用于想要适应非常大的模型并将模型分派到 GPU 和 CPU 之间的用户。
首先,从 `transformers` 中加载一个 [`BitsAndBytesConfig`],并将属性 `llm_int8_enable_fp32_cpu_offload` 设置为 `True`:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
```
假设您想加载 `bigscience/bloom-1b7` 模型,您的 GPU显存仅足够容纳除了`lm_head`外的整个模型。因此,您可以按照以下方式编写自定义的 device_map:
```python
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": 0,
"lm_head": "cpu",
"transformer.h": 0,
"transformer.ln_f": 0,
}
```
然后如下加载模型:
```python
model_8bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
device_map=device_map,
quantization_config=quantization_config,
)
```
这就是全部内容!享受您的模型吧!
#### 使用`llm_int8_threshold`
您可以使用 `llm_int8_threshold` 参数来更改异常值的阈值。“异常值”是一个大于特定阈值的`hidden state`值。
这对应于`LLM.int8()`论文中描述的异常检测的异常阈值。任何高于此阈值的`hidden state`值都将被视为异常值,对这些值的操作将在 fp16 中完成。值通常是正态分布的,也就是说,大多数值在 [-3.5, 3.5] 范围内,但有一些额外的系统异常值,对于大模型来说,它们的分布非常不同。这些异常值通常在区间 [-60, -6] 或 [6, 60] 内。Int8 量化对于幅度为 ~5 的值效果很好,但超出这个范围,性能就会明显下降。一个好的默认阈值是 6,但对于更不稳定的模型(小模型、微调)可能需要更低的阈值。
这个参数会影响模型的推理速度。我们建议尝试这个参数,以找到最适合您的用例的参数。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_threshold=10,
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
```
#### 跳过某些模块的转换
一些模型有几个需要保持未转换状态以确保稳定性的模块。例如,Jukebox 模型有几个 `lm_head` 模块需要跳过。使用 `llm_int8_skip_modules` 参数进行相应操作。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_skip_modules=["lm_head"],
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
```
#### 微调已加载为8位精度的模型
借助Hugging Face生态系统中适配器(adapters)的官方支持,您可以在8位精度下微调模型。这使得可以在单个Google Colab中微调大模型,例如`flan-t5-large`或`facebook/opt-6.7b`。请查看[`peft`](https://github.com/huggingface/peft)库了解更多详情。
注意,加载模型进行训练时无需传递`device_map`。它将自动将您的模型加载到GPU上。如果需要,您可以将设备映射为特定设备(例如`cuda:0`、`0`、`torch.device('cuda:0')`)。请注意,`device_map=auto`仅应用于推理。
### BitsAndBytesConfig
[[autodoc]] BitsAndBytesConfig
## 使用 🤗 `optimum` 进行量化
请查看[Optimum 文档](https://huggingface.co/docs/optimum/index)以了解更多关于`optimum`支持的量化方法,并查看这些方法是否适用于您的用例。
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/agent.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Agents和工具
<Tip warning={true}>
Transformers Agents是一个实验性的API,它随时可能发生变化。由于API或底层模型容易发生变化,因此由agents返回的结果可能会有所不同。
</Tip>
要了解更多关于agents和工具的信息,请确保阅读[介绍指南](../transformers_agents)。此页面包含底层类的API文档。
## Agents
我们提供三种类型的agents:[`HfAgent`]使用开源模型的推理端点,[`LocalAgent`]使用您在本地选择的模型,[`OpenAiAgent`]使用OpenAI封闭模型。
### HfAgent
[[autodoc]] HfAgent
### LocalAgent
[[autodoc]] LocalAgent
### OpenAiAgent
[[autodoc]] OpenAiAgent
### AzureOpenAiAgent
[[autodoc]] AzureOpenAiAgent
### Agent
[[autodoc]] Agent
- chat
- run
- prepare_for_new_chat
## 工具
### load_tool
[[autodoc]] load_tool
### Tool
[[autodoc]] Tool
### PipelineTool
[[autodoc]] PipelineTool
### RemoteTool
[[autodoc]] RemoteTool
### launch_gradio_demo
[[autodoc]] launch_gradio_demo
## Agent类型
Agents可以处理工具之间任何类型的对象;工具是多模态的,可以接受和返回文本、图像、音频、视频等类型。为了增加工具之间的兼容性,以及正确地在ipython(jupyter、colab、ipython notebooks等)中呈现这些返回值,我们实现了这些类型的包装类。
被包装的对象应该继续按照最初的行为方式运作;文本对象应该仍然像字符串一样运作,图像对象应该仍然像`PIL.Image`一样运作。
这些类型有三个特定目的:
- 对类型调用 `to_raw` 应该返回底层对象
- 对类型调用 `to_string` 应该将对象作为字符串返回:在`AgentText`的情况下可能是字符串,但在其他情况下可能是对象序列化版本的路径
- 在ipython内核中显示它应该正确显示对象
### AgentText
[[autodoc]] transformers.tools.agent_types.AgentText
### AgentImage
[[autodoc]] transformers.tools.agent_types.AgentImage
### AgentAudio
[[autodoc]] transformers.tools.agent_types.AgentAudio
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/trainer.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer
[`Trainer`] 类提供了一个 PyTorch 的 API,用于处理大多数标准用例的全功能训练。它在大多数[示例脚本](https://github.com/huggingface/transformers/tree/main/examples)中被使用。
<Tip>
如果你想要使用自回归技术在文本数据集上微调像 Llama-2 或 Mistral 这样的语言模型,考虑使用 [`trl`](https://github.com/huggingface/trl) 的 [`~trl.SFTTrainer`]。[`~trl.SFTTrainer`] 封装了 [`Trainer`],专门针对这个特定任务进行了优化,并支持序列打包、LoRA、量化和 DeepSpeed,以有效扩展到任何模型大小。另一方面,[`Trainer`] 是一个更通用的选项,适用于更广泛的任务。
</Tip>
在实例化你的 [`Trainer`] 之前,创建一个 [`TrainingArguments`],以便在训练期间访问所有定制点。
这个 API 支持在多个 GPU/TPU 上进行分布式训练,支持 [NVIDIA Apex](https://github.com/NVIDIA/apex) 的混合精度和 PyTorch 的原生 AMP。
[`Trainer`] 包含基本的训练循环,支持上述功能。如果需要自定义训练,你可以继承 `Trainer` 并覆盖以下方法:
- **get_train_dataloader** -- 创建训练 DataLoader。
- **get_eval_dataloader** -- 创建评估 DataLoader。
- **get_test_dataloader** -- 创建测试 DataLoader。
- **log** -- 记录观察训练的各种对象的信息。
- **create_optimizer_and_scheduler** -- 如果它们没有在初始化时传递,请设置优化器和学习率调度器。请注意,你还可以单独继承或覆盖 `create_optimizer` 和 `create_scheduler` 方法。
- **create_optimizer** -- 如果在初始化时没有传递,则设置优化器。
- **create_scheduler** -- 如果在初始化时没有传递,则设置学习率调度器。
- **compute_loss** - 计算单批训练输入的损失。
- **training_step** -- 执行一步训练。
- **prediction_step** -- 执行一步评估/测试。
- **evaluate** -- 运行评估循环并返回指标。
- **predict** -- 返回在测试集上的预测(如果有标签,则包括指标)。
<Tip warning={true}>
[`Trainer`] 类被优化用于 🤗 Transformers 模型,并在你在其他模型上使用时可能会有一些令人惊讶的结果。当在你自己的模型上使用时,请确保:
- 你的模型始终返回元组或 [`~utils.ModelOutput`] 的子类。
- 如果提供了 `labels` 参数,你的模型可以计算损失,并且损失作为元组的第一个元素返回(如果你的模型返回元组)。
- 你的模型可以接受多个标签参数(在 [`TrainingArguments`] 中使用 `label_names` 将它们的名称指示给 [`Trainer`]),但它们中没有一个应该被命名为 `"label"`。
</Tip>
以下是如何自定义 [`Trainer`] 以使用加权损失的示例(在训练集不平衡时很有用):
```python
from torch import nn
from transformers import Trainer
class CustomTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss (suppose one has 3 labels with different weights)
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
```
在 PyTorch [`Trainer`] 中自定义训练循环行为的另一种方法是使用 [callbacks](callback),这些回调可以检查训练循环状态(用于进度报告、在 TensorBoard 或其他 ML 平台上记录日志等)并做出决策(比如提前停止)。
## Trainer
[[autodoc]] Trainer - all
## Seq2SeqTrainer
[[autodoc]] Seq2SeqTrainer - evaluate - predict
## TrainingArguments
[[autodoc]] TrainingArguments - all
## Seq2SeqTrainingArguments
[[autodoc]] Seq2SeqTrainingArguments - all
## Checkpoints
默认情况下,[`Trainer`] 会将所有checkpoints保存在你使用的 [`TrainingArguments`] 中设置的 `output_dir` 中。这些checkpoints将位于名为 `checkpoint-xxx` 的子文件夹中,xxx 是训练的步骤。
从checkpoints恢复训练可以通过调用 [`Trainer.train`] 时使用以下任一方式进行:
- `resume_from_checkpoint=True`,这将从最新的checkpoint恢复训练。
- `resume_from_checkpoint=checkpoint_dir`,这将从指定目录中的特定checkpoint恢复训练。
此外,当使用 `push_to_hub=True` 时,你可以轻松将checkpoints保存在 Model Hub 中。默认情况下,保存在训练中间过程的checkpoints中的所有模型都保存在不同的提交中,但不包括优化器状态。你可以根据需要调整 [`TrainingArguments`] 的 `hub-strategy` 值:
- `"checkpoint"`: 最新的checkpoint也被推送到一个名为 last-checkpoint 的子文件夹中,让你可以通过 `trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")` 轻松恢复训练。
- `"all_checkpoints"`: 所有checkpoints都像它们出现在输出文件夹中一样被推送(因此你将在最终存储库中的每个文件夹中获得一个checkpoint文件夹)。
## Logging
默认情况下,[`Trainer`] 将对主进程使用 `logging.INFO`,对副本(如果有的话)使用 `logging.WARNING`。
可以通过 [`TrainingArguments`] 的参数覆盖这些默认设置,使用其中的 5 个 `logging` 级别:
- `log_level` - 用于主进程
- `log_level_replica` - 用于副本
此外,如果 [`TrainingArguments`] 的 `log_on_each_node` 设置为 `False`,则只有主节点将使用其主进程的日志级别设置,所有其他节点将使用副本的日志级别设置。
请注意,[`Trainer`] 将在其 [`Trainer.__init__`] 中分别为每个节点设置 `transformers` 的日志级别。因此,如果在创建 [`Trainer`] 对象之前要调用其他 `transformers` 功能,可能需要更早地设置这一点(请参见下面的示例)。
以下是如何在应用程序中使用的示例:
```python
[...]
logger = logging.getLogger(__name__)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
# set the main code and the modules it uses to the same log-level according to the node
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
trainer = Trainer(...)
```
然后,如果你只想在主节点上看到警告,并且所有其他节点不打印任何可能重复的警告,可以这样运行:
```bash
my_app.py ... --log_level warning --log_level_replica error
```
在多节点环境中,如果你也不希望每个节点的主进程的日志重复输出,你需要将上面的代码更改为:
```bash
my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
```
然后,只有第一个节点的主进程将以 "warning" 级别记录日志,主节点上的所有其他进程和其他节点上的所有进程将以 "error" 级别记录日志。
如果你希望应用程序尽可能”安静“,可以执行以下操作:
```bash
my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
```
(如果在多节点环境,添加 `--log_on_each_node 0`)
## 随机性
当从 [`Trainer`] 生成的checkpoint恢复训练时,程序会尽一切努力将 _python_、_numpy_ 和 _pytorch_ 的 RNG(随机数生成器)状态恢复为保存检查点时的状态,这样可以使“停止和恢复”式训练尽可能接近“非停止式”训练。
然而,由于各种默认的非确定性 PyTorch 设置,这可能无法完全实现。如果你想要完全确定性,请参阅[控制随机源](https://pytorch.org/docs/stable/notes/randomness)。正如文档中所解释的那样,使事物变得确定的一些设置(例如 `torch.backends.cudnn.deterministic`)可能会减慢速度,因此不能默认执行,但如果需要,你可以自行启用这些设置。
## 特定GPU选择
让我们讨论一下如何告诉你的程序应该使用哪些 GPU 以及使用的顺序。
当使用 [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) 且仅使用部分 GPU 时,你只需指定要使用的 GPU 数量。例如,如果你有 4 个 GPU,但只想使用前 2 个,可以执行以下操作:
```bash
python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
```
如果你安装了 [`accelerate`](https://github.com/huggingface/accelerate) 或 [`deepspeed`](https://github.com/microsoft/DeepSpeed),你还可以通过以下任一方法实现相同的效果:
```bash
accelerate launch --num_processes 2 trainer-program.py ...
```
```bash
deepspeed --num_gpus 2 trainer-program.py ...
```
你不需要使用 Accelerate 或 [Deepspeed 集成](Deepspeed) 功能来使用这些启动器。
到目前为止,你已经能够告诉程序要使用多少个 GPU。现在让我们讨论如何选择特定的 GPU 并控制它们的顺序。
以下环境变量可帮助你控制使用哪些 GPU 以及它们的顺序。
**`CUDA_VISIBLE_DEVICES`**
如果你有多个 GPU,想要仅使用其中的一个或几个 GPU,请将环境变量 `CUDA_VISIBLE_DEVICES` 设置为要使用的 GPU 列表。
例如,假设你有 4 个 GPU:0、1、2 和 3。要仅在物理 GPU 0 和 2 上运行,你可以执行以下操作:
```bash
CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
```
现在,PyTorch 将只看到 2 个 GPU,其中你的物理 GPU 0 和 2 分别映射到 `cuda:0` 和 `cuda:1`。
你甚至可以改变它们的顺序:
```bash
CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
```
这里,你的物理 GPU 0 和 2 分别映射到 `cuda:1` 和 `cuda:0`。
上面的例子都是针对 `DistributedDataParallel` 使用模式的,但同样的方法也适用于 [`DataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html):
```bash
CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
```
为了模拟没有 GPU 的环境,只需将此环境变量设置为空值,如下所示:
```bash
CUDA_VISIBLE_DEVICES= python trainer-program.py ...
```
与任何环境变量一样,你当然可以将其export到环境变量而不是将其添加到命令行,如下所示:
```bash
export CUDA_VISIBLE_DEVICES=0,2
python -m torch.distributed.launch trainer-program.py ...
```
这种方法可能会令人困惑,因为你可能会忘记之前设置了环境变量,进而不明白为什么会使用错误的 GPU。因此,在同一命令行中仅为特定运行设置环境变量是一种常见做法,正如本节大多数示例所示。
**`CUDA_DEVICE_ORDER`**
还有一个额外的环境变量 `CUDA_DEVICE_ORDER`,用于控制物理设备的排序方式。有两个选择:
1. 按 PCIe 总线 ID 排序(与 nvidia-smi 的顺序相匹配)- 这是默认选项。
```bash
export CUDA_DEVICE_ORDER=PCI_BUS_ID
```
2. 按 GPU 计算能力排序。
```bash
export CUDA_DEVICE_ORDER=FASTEST_FIRST
```
大多数情况下,你不需要关心这个环境变量,但如果你的设置不均匀,那么这将非常有用,例如,您的旧 GPU 和新 GPU 物理上安装在一起,但让速度较慢的旧卡排在运行的第一位。解决这个问题的一种方法是交换卡的位置。但如果不能交换卡(例如,如果设备的散热受到影响),那么设置 `CUDA_DEVICE_ORDER=FASTEST_FIRST` 将始终将较新、更快的卡放在第一位。但这可能会有点混乱,因为 `nvidia-smi` 仍然会按照 PCIe 顺序报告它们。
交换卡的顺序的另一种方法是使用:
```bash
export CUDA_VISIBLE_DEVICES=1,0
```
在此示例中,我们只使用了 2 个 GPU,但是当然,对于计算机上有的任何数量的 GPU,都适用相同的方法。
此外,如果你设置了这个环境变量,最好将其设置在 `~/.bashrc` 文件或其他启动配置文件中,然后就可以忘记它了。
## Trainer集成
[`Trainer`] 已经被扩展,以支持可能显著提高训练时间并适应更大模型的库。
目前,它支持第三方解决方案 [DeepSpeed](https://github.com/microsoft/DeepSpeed) 和 [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html),它们实现了论文 [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He](https://arxiv.org/abs/1910.02054) 的部分内容。
截至撰写本文,此提供的支持是新的且实验性的。尽管我们欢迎围绕 DeepSpeed 和 PyTorch FSDP 的issues,但我们不再支持 FairScale 集成,因为它已经集成到了 PyTorch 主线(参见 [PyTorch FSDP 集成](#pytorch-fully-sharded-data-parallel))。
<a id='zero-install-notes'></a>
### CUDA拓展安装注意事项
撰写时,Deepspeed 需要在使用之前编译 CUDA C++ 代码。
虽然所有安装问题都应通过 [Deepspeed](https://github.com/microsoft/DeepSpeed/issues) 的 GitHub Issues处理,但在构建依赖CUDA 扩展的任何 PyTorch 扩展时,可能会遇到一些常见问题。
因此,如果在执行以下操作时遇到与 CUDA 相关的构建问题:
```bash
pip install deepspeed
```
请首先阅读以下说明。
在这些说明中,我们提供了在 `pytorch` 使用 CUDA `10.2` 构建时应采取的操作示例。如果你的情况有所不同,请记得将版本号调整为您所需的版本。
#### 可能的问题 #1
尽管 PyTorch 自带了其自己的 CUDA 工具包,但要构建这两个项目,你必须在整个系统上安装相同版本的 CUDA。
例如,如果你在 Python 环境中使用 `cudatoolkit==10.2` 安装了 `pytorch`,你还需要在整个系统上安装 CUDA `10.2`。
确切的位置可能因系统而异,但在许多 Unix 系统上,`/usr/local/cuda-10.2` 是最常见的位置。当 CUDA 正确设置并添加到 `PATH` 环境变量时,可以通过执行以下命令找到安装位置:
```bash
which nvcc
```
如果你尚未在整个系统上安装 CUDA,请首先安装。你可以使用你喜欢的搜索引擎查找说明。例如,如果你使用的是 Ubuntu,你可能想搜索:[ubuntu cuda 10.2 install](https://www.google.com/search?q=ubuntu+cuda+10.2+install)。
#### 可能的问题 #2
另一个可能的常见问题是你可能在整个系统上安装了多个 CUDA 工具包。例如,你可能有:
```bash
/usr/local/cuda-10.2
/usr/local/cuda-11.0
```
在这种情况下,你需要确保 `PATH` 和 `LD_LIBRARY_PATH` 环境变量包含所需 CUDA 版本的正确路径。通常,软件包安装程序将设置这些变量以包含最新安装的版本。如果遇到构建失败的问题,且是因为在整个系统安装但软件仍找不到正确的 CUDA 版本,这意味着你需要调整这两个环境变量。
首先,你以查看它们的内容:
```bash
echo $PATH
echo $LD_LIBRARY_PATH
```
因此,您可以了解其中的内容。
`LD_LIBRARY_PATH` 可能是空的。
`PATH` 列出了可以找到可执行文件的位置,而 `LD_LIBRARY_PATH` 用于查找共享库。在这两种情况下,较早的条目优先于较后的条目。 `:` 用于分隔多个条目。
现在,为了告诉构建程序在哪里找到特定的 CUDA 工具包,请插入所需的路径,让其首先列出:
```bash
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
```
请注意,我们没有覆盖现有值,而是在前面添加新的值。
当然,根据需要调整版本号和完整路径。检查你分配的目录是否实际存在。`lib64` 子目录是各种 CUDA `.so` 对象(如 `libcudart.so`)的位置,这个名字可能在你的系统中是不同的,如果是,请调整以反映实际情况。
#### 可能的问题 #3
一些较旧的 CUDA 版本可能会拒绝使用更新的编译器。例如,你可能有 `gcc-9`,但 CUDA 可能需要 `gcc-7`。
有各种方法可以解决这个问题。
如果你可以安装最新的 CUDA 工具包,通常它应该支持更新的编译器。
或者,你可以在已经拥有的编译器版本之外安装较低版本,或者你可能已经安装了它但它不是默认的编译器,因此构建系统无法找到它。如果你已经安装了 `gcc-7` 但构建系统找不到它,以下操作可能会解决问题:
```bash
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
```
这里,我们正在从 `/usr/local/cuda-10.2/bin/gcc` 创建到 `gcc-7` 的软链接,由于 `/usr/local/cuda-10.2/bin/` 应该在 `PATH` 环境变量中(参见前一个问题的解决方案),它应该能够找到 `gcc-7`(和 `g++7`),然后构建将成功。
与往常一样,请确保编辑示例中的路径以匹配你的情况。
### PyTorch完全分片数据并行(FSDP)
为了加速在更大批次大小上训练庞大模型,我们可以使用完全分片的数据并行模型。这种数据并行范例通过对优化器状态、梯度和参数进行分片,实现了在更多数据和更大模型上的训练。要了解更多信息以及其优势,请查看[完全分片的数据并行博客](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)。我们已经集成了最新的PyTorch完全分片的数据并行(FSDP)训练功能。您只需通过配置启用它。
**FSDP支持所需的PyTorch版本**: PyTorch Nightly(或者如果你在发布后阅读这个,使用1.12.0版本,因为带有激活的FSDP的模型保存仅在最近的修复中可用。
**用法**:
- 如果你尚未使用过分布式启动器,确保你已经添加了它 `-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE`。
- **分片策略**:
- FULL_SHARD:在数据并行线程/GPU之间,对优化器状态、梯度和模型参数进行分片。
为此,请在命令行参数中添加 `--fsdp full_shard`。
- SHARD_GRAD_OP:在数据并行线程/GPU之间对优化器状态和梯度进行分片。
为此,请在命令行参数中添加 `--fsdp shard_grad_op`。
- NO_SHARD:不进行分片。为此,请在命令行参数中添加 `--fsdp no_shard`。
- 要将参数和梯度卸载到CPU,添加 `--fsdp "full_shard offload"` 或 `--fsdp "shard_grad_op offload"` 到命令行参数中。
- 要使用 `default_auto_wrap_policy` 自动递归地用FSDP包装层,请添加 `--fsdp "full_shard auto_wrap"` 或 `--fsdp "shard_grad_op auto_wrap"` 到命令行参数中。
- 要同时启用CPU卸载和自动包装层工具,请添加 `--fsdp "full_shard offload auto_wrap"` 或 `--fsdp "shard_grad_op offload auto_wrap"` 到命令行参数中。
- 其余的FSDP配置通过 `--fsdp_config <path_to_fsdp_config.json>` 传递。它可以是FSDP json配置文件的位置(例如,`fsdp_config.json`)或已加载的json文件作为 `dict`。
- 如果启用了自动包装,您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
- 对于基于transformer的自动包装策略,建议在配置文件中指定 `fsdp_transformer_layer_cls_to_wrap`。如果未指定,则默认值为 `model._no_split_modules`(如果可用)。这将指定要包装的transformer层类名(区分大小写),例如 [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] 等。这很重要,因为共享权重的子模块(例如,embedding层)不应最终出现在不同的FSDP包装单元中。使用此策略,每个包装的块将包含多头注意力和后面的几个MLP层。剩余的层,包括共享的embedding层,都将被方便地包装在同一个最外层的FSDP单元中。因此,对于基于transformer的模型,请使用这个方法。
- 对于基于大小的自动包装策略,请在配置文件中添加 `fsdp_min_num_params`。它指定了FSDP进行自动包装的最小参数数量。
- 可以在配置文件中指定 `fsdp_backward_prefetch`。它控制何时预取下一组参数。`backward_pre` 和 `backward_pos` 是可用的选项。有关更多信息,请参阅 `torch.distributed.fsdp.fully_sharded_data_parallel.BackwardPrefetch`
- 可以在配置文件中指定 `fsdp_forward_prefetch`。它控制何时预取下一组参数。如果是`"True"`,在执行前向传递时,FSDP明确地预取下一次即将发生的全局聚集。
- 可以在配置文件中指定 `limit_all_gathers`。如果是`"True"`,FSDP明确地同步CPU线程,以防止太多的进行中的全局聚集。
- 可以在配置文件中指定 `activation_checkpointing`。如果是`"True"`,FSDP activation checkpoint是一种通过清除某些层的激活值并在反向传递期间重新计算它们来减少内存使用的技术。实际上,这以更多的计算时间为代价减少了内存使用。
**需要注意几个注意事项**
- 它与 `generate` 不兼容,因此与所有seq2seq/clm脚本(翻译/摘要/clm等)中的 `--predict_with_generate` 不兼容。请参阅issue[#21667](https://github.com/huggingface/transformers/issues/21667)。
### PyTorch/XLA 完全分片数据并行
对于所有TPU用户,有个好消息!PyTorch/XLA现在支持FSDP。所有最新的完全分片数据并行(FSDP)训练都受支持。有关更多信息,请参阅[在云端TPU上使用FSDP扩展PyTorch模型](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/)和[PyTorch/XLA FSDP的实现](https://github.com/pytorch/xla/tree/master/torch_xla/distributed/fsdp)。使用它只需通过配置启用。
**需要的 PyTorch/XLA 版本以支持 FSDP**:>=2.0
**用法**:
传递 `--fsdp "full shard"`,同时对 `--fsdp_config <path_to_fsdp_config.json>` 进行以下更改:
- `xla` 应设置为 `True` 以启用 PyTorch/XLA FSDP。
- `xla_fsdp_settings` 的值是一个字典,存储 XLA FSDP 封装参数。完整的选项列表,请参见[此处](https://github.com/pytorch/xla/blob/master/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py)。
- `xla_fsdp_grad_ckpt`。当 `True` 时,在每个嵌套的 XLA FSDP 封装层上使用梯度checkpoint。该设置只能在将 xla 标志设置为 true,并通过 `fsdp_min_num_params` 或 `fsdp_transformer_layer_cls_to_wrap` 指定自动包装策略时使用。
- 您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
- 对于基于transformer的自动包装策略,建议在配置文件中指定 `fsdp_transformer_layer_cls_to_wrap`。如果未指定,默认值为 `model._no_split_modules`(如果可用)。这指定了要包装的transformer层类名列表(区分大小写),例如 [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] 等。这很重要,因为共享权重的子模块(例如,embedding层)不应最终出现在不同的FSDP包装单元中。使用此策略,每个包装的块将包含多头注意力和后面的几个MLP层。剩余的层,包括共享的embedding层,都将被方便地包装在同一个最外层的FSDP单元中。因此,对于基于transformer的模型,请使用这个方法。
- 对于基于大小的自动包装策略,请在配置文件中添加 `fsdp_min_num_params`。它指定了自动包装的 FSDP 的最小参数数量。
### 在 Mac 上使用 Trainer 进行加速的 PyTorch 训练
随着 PyTorch v1.12 版本的发布,开发人员和研究人员可以利用 Apple Silicon GPU 进行显著更快的模型训练。这使得可以在 Mac 上本地执行原型设计和微调等机器学习工作流程。Apple 的 Metal Performance Shaders(MPS)作为 PyTorch 的后端实现了这一点,并且可以通过新的 `"mps"` 设备来使用。
这将在 MPS 图形框架上映射计算图和神经图元,并使用 MPS 提供的优化内核。更多信息,请参阅官方文档 [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) 和 [MPS BACKEND](https://pytorch.org/docs/stable/notes/mps.html)。
<Tip warning={false}>
我们强烈建议在你的 MacOS 机器上安装 PyTorch >= 1.13(在撰写本文时为最新版本)。对于基于 transformer 的模型, 它提供与模型正确性和性能改进相关的重大修复。有关更多详细信息,请参阅[pytorch/pytorch#82707](https://github.com/pytorch/pytorch/issues/82707)。
</Tip>
**使用 Apple Silicon 芯片进行训练和推理的好处**
1. 使用户能够在本地训练更大的网络或批量数据。
2. 由于统一内存架构,减少数据检索延迟,并为 GPU 提供对完整内存存储的直接访问。从而提高端到端性能。
3. 降低与基于云的开发或需要额外本地 GPU 的成本。
**先决条件**:要安装带有 mps 支持的 torch,请按照这篇精彩的 Medium 文章操作 [GPU-Acceleration Comes to PyTorch on M1 Macs](https://medium.com/towards-data-science/gpu-acceleration-comes-to-pytorch-on-m1-macs-195c399efcc1)。
**用法**:
如果可用,`mps` 设备将默认使用,类似于使用 `cuda` 设备的方式。因此,用户无需采取任何操作。例如,您可以使用以下命令在 Apple Silicon GPU 上运行官方的 Glue 文本分类任务(从根文件夹运行):
```bash
export TASK_NAME=mrpc
python examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
**需要注意的一些注意事项**
1. 一些 PyTorch 操作尚未在 mps 中实现,将引发错误。解决此问题的一种方法是设置环境变量 `PYTORCH_ENABLE_MPS_FALLBACK=1`,它将把这些操作回退到 CPU 进行。然而,它仍然会抛出 UserWarning 信息。
2. 分布式设置 `gloo` 和 `nccl` 在 `mps` 设备上不起作用。这意味着当前只能使用 `mps` 设备类型的单个 GPU。
最后,请记住,🤗 `Trainer` 仅集成了 MPS 后端,因此如果你在使用 MPS 后端时遇到任何问题或有疑问,请在 [PyTorch GitHub](https://github.com/pytorch/pytorch/issues) 上提交问题。
## 通过 Accelerate Launcher 使用 Trainer
Accelerate 现在支持 Trainer。用户可以期待以下内容:
- 他们可以继续使用 Trainer 的迭代,如 FSDP、DeepSpeed 等,而无需做任何更改。
- 现在可以在 Trainer 中使用 Accelerate Launcher(建议使用)。
通过 Accelerate Launcher 使用 Trainer 的步骤:
1. 确保已安装 🤗 Accelerate,无论如何,如果没有它,你无法使用 `Trainer`。如果没有,请执行 `pip install accelerate`。你可能还需要更新 Accelerate 的版本:`pip install accelerate --upgrade`。
2. 运行 `accelerate config` 并填写问题。以下是一些加速配置的示例:
a. DDP 多节点多 GPU 配置:
```yaml
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 #change rank as per the node
main_process_ip: 192.168.20.1
main_process_port: 9898
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
b. FSDP 配置:
```yaml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: true
fsdp_offload_params: false
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
c. 指向文件的 DeepSpeed 配置:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /home/user/configs/ds_zero3_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
d. 使用 accelerate 插件的 DeepSpeed 配置:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
3. 使用accelerate配置文件参数或启动器参数以外的参数运行Trainer脚本。以下是一个使用上述FSDP配置从accelerate启动器运行`run_glue.py`的示例。
```bash
cd transformers
accelerate launch \
./examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
4. 你也可以直接使用`accelerate launch`的cmd参数。上面的示例将映射到:
```bash
cd transformers
accelerate launch --num_processes=2 \
--use_fsdp \
--mixed_precision=bf16 \
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
--fsdp_sharding_strategy=1 \
--fsdp_state_dict_type=FULL_STATE_DICT \
./examples/pytorch/text-classification/run_glue.py
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
有关更多信息,请参阅 🤗 Accelerate CLI 指南:[启动您的 🤗 Accelerate 脚本](https://huggingface.co/docs/accelerate/basic_tutorials/launch)。
已移动的部分:
[ <a href="./deepspeed#deepspeed-trainer-integration">DeepSpeed</a><a id="deepspeed"></a> | <a href="./deepspeed#deepspeed-installation">Installation</a><a id="installation"></a> | <a href="./deepspeed#deepspeed-multi-gpu">Deployment with multiple GPUs</a><a id="deployment-with-multiple-gpus"></a> | <a href="./deepspeed#deepspeed-one-gpu">Deployment with one GPU</a><a id="deployment-with-one-gpu"></a> | <a href="./deepspeed#deepspeed-notebook">Deployment in Notebooks</a><a id="deployment-in-notebooks"></a> | <a href="./deepspeed#deepspeed-config">Configuration</a><a id="configuration"></a> | <a href="./deepspeed#deepspeed-config-passing">Passing Configuration</a><a id="passing-configuration"></a> | <a href="./deepspeed#deepspeed-config-shared">Shared Configuration</a><a id="shared-configuration"></a> | <a href="./deepspeed#deepspeed-zero">ZeRO</a><a id="zero"></a> | <a href="./deepspeed#deepspeed-zero2-config">ZeRO-2 Config</a><a id="zero-2-config"></a> | <a href="./deepspeed#deepspeed-zero3-config">ZeRO-3 Config</a><a id="zero-3-config"></a> | <a href="./deepspeed#deepspeed-nvme">NVMe Support</a><a id="nvme-support"></a> | <a href="./deepspeed#deepspeed-zero2-zero3-performance">ZeRO-2 vs ZeRO-3 Performance</a><a id="zero-2-vs-zero-3-performance"></a> | <a href="./deepspeed#deepspeed-zero2-example">ZeRO-2 Example</a><a id="zero-2-example"></a> | <a href="./deepspeed#deepspeed-zero3-example">ZeRO-3 Example</a><a id="zero-3-example"></a> | <a href="./deepspeed#deepspeed-optimizer">Optimizer</a><a id="optimizer"></a> | <a href="./deepspeed#deepspeed-scheduler">Scheduler</a><a id="scheduler"></a> | <a href="./deepspeed#deepspeed-fp32">fp32 Precision</a><a id="fp32-precision"></a> | <a href="./deepspeed#deepspeed-amp">Automatic Mixed Precision</a><a id="automatic-mixed-precision"></a> | <a href="./deepspeed#deepspeed-bs">Batch Size</a><a id="batch-size"></a> | <a href="./deepspeed#deepspeed-grad-acc">Gradient Accumulation</a><a id="gradient-accumulation"></a> | <a href="./deepspeed#deepspeed-grad-clip">Gradient Clipping</a><a id="gradient-clipping"></a> | <a href="./deepspeed#deepspeed-weight-extraction">Getting The Model Weights Out</a><a id="getting-the-model-weights-out"></a>]
## 通过 NEFTune 提升微调性能
NEFTune 是一种提升聊天模型性能的技术,由 Jain 等人在论文“NEFTune: Noisy Embeddings Improve Instruction Finetuning” 中引入。该技术在训练过程中向embedding向量添加噪音。根据论文摘要:
> 使用 Alpaca 对 LLaMA-2-7B 进行标准微调,可以在 AlpacaEval 上达到 29.79%,而使用带有噪音embedding的情况下,性能提高至 64.69%。NEFTune 还在modern instruction数据集上大大优于基线。Evol-Instruct 训练的模型表现提高了 10%,ShareGPT 提高了 8%,OpenPlatypus 提高了 8%。即使像 LLaMA-2-Chat 这样通过 RLHF 进一步细化的强大模型,通过 NEFTune 的额外训练也能受益。
<div style="text-align: center">
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/neft-screenshot.png">
</div>
要在 `Trainer` 中使用它,只需在创建 `TrainingArguments` 实例时传递 `neftune_noise_alpha`。请注意,为了避免任何意外行为,NEFTune在训练后被禁止,以此恢复原始的embedding层。
```python
from transformers import Trainer, TrainingArguments
args = TrainingArguments(..., neftune_noise_alpha=0.1)
trainer = Trainer(..., args=args)
...
trainer.train()
```
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/model.md
|
<!--版权所有 2020 年 HuggingFace 团队。保留所有权利。
根据 Apache 许可证 2.0 版本许可,除非符合许可证的规定,否则您不得使用此文件。您可以在以下网址获取许可证的副本:
http://www.apache.org/licenses/LICENSE-2.0
除非适用法律要求或书面同意,否则依照许可证分发的软件是基于“原样”提供的,不附带任何明示或暗示的担保或条件。有关特定语言下权限的限制和限制,请参阅许可证。-->
# 模型
基类 [`PreTrainedModel`]、[`TFPreTrainedModel`] 和 [`FlaxPreTrainedModel`] 实现了从本地文件或目录加载/保存模型的常用方法,或者从库上提供的预训练模型配置(从 HuggingFace 的 AWS S3 存储库下载)加载模型。
[`PreTrainedModel`] 和 [`TFPreTrainedModel`] 还实现了一些所有模型共有的方法:
- 在向量词嵌入增加新词汇时调整输入标记(token)的大小
- 对模型的注意力头进行修剪。
其他的通用方法在 [`~modeling_utils.ModuleUtilsMixin`](用于 PyTorch 模型)和 [`~modeling_tf_utils.TFModuleUtilsMixin`](用于 TensorFlow 模型)中定义;文本生成方面的方法则定义在 [`~generation.GenerationMixin`](用于 PyTorch 模型)、[`~generation.TFGenerationMixin`](用于 TensorFlow 模型)和 [`~generation.FlaxGenerationMixin`](用于 Flax/JAX 模型)中。
## PreTrainedModel
[[autodoc]] PreTrainedModel
- push_to_hub
- all
<a id='from_pretrained-torch-dtype'></a>
### 大模型加载
在 Transformers 4.20.0 中,[`~PreTrainedModel.from_pretrained`] 方法已重新设计,以适应使用 [Accelerate](https://huggingface.co/docs/accelerate/big_modeling) 加载大型模型的场景。这需要您使用的 Accelerate 和 PyTorch 版本满足: Accelerate >= 0.9.0, PyTorch >= 1.9.0。除了创建完整模型,然后在其中加载预训练权重(这会占用两倍于模型大小的内存空间,一个用于随机初始化模型,一个用于预训练权重),我们提供了一种选项,将模型创建为空壳,然后只有在加载预训练权重时才实例化其参数。
您可以使用 `low_cpu_mem_usage=True` 激活此选项。首先,在 Meta 设备上创建模型(带有空权重),然后将状态字典加载到其中(在分片检查点的情况下逐片加载)。这样,最大使用的内存占用仅为模型的完整大小。
```python
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
```
此外,如果内存不足以放下加载整个模型(目前仅适用于推理),您可以直接将模型放置在不同的设备上。使用 `device_map="auto"`,Accelerate 将确定将每一层放置在哪个设备上,以最大化使用最快的设备(GPU),并将其余部分卸载到 CPU,甚至硬盘上(如果您没有足够的 GPU 内存 或 CPU 内存)。即使模型分布在几个设备上,它也将像您通常期望的那样运行。
在传递 `device_map` 时,`low_cpu_mem_usage` 会自动设置为 `True`,因此您不需要指定它:
```python
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
```
您可以通过 `hf_device_map` 属性来查看模型是如何在设备上分割的:
```python
t0pp.hf_device_map
{'shared': 0,
'decoder.embed_tokens': 0,
'encoder': 0,
'decoder.block.0': 0,
'decoder.block.1': 1,
'decoder.block.2': 1,
'decoder.block.3': 1,
'decoder.block.4': 1,
'decoder.block.5': 1,
'decoder.block.6': 1,
'decoder.block.7': 1,
'decoder.block.8': 1,
'decoder.block.9': 1,
'decoder.block.10': 1,
'decoder.block.11': 1,
'decoder.block.12': 1,
'decoder.block.13': 1,
'decoder.block.14': 1,
'decoder.block.15': 1,
'decoder.block.16': 1,
'decoder.block.17': 1,
'decoder.block.18': 1,
'decoder.block.19': 1,
'decoder.block.20': 1,
'decoder.block.21': 1,
'decoder.block.22': 'cpu',
'decoder.block.23': 'cpu',
'decoder.final_layer_norm': 'cpu',
'decoder.dropout': 'cpu',
'lm_head': 'cpu'}
```
您还可以按照相同的格式(一个层名称到设备的映射关系的字典)编写自己的设备映射规则。它应该将模型的所有参数映射到给定的设备上,如果该层的所有子模块都在同一设备上,您不必详细说明其中所有子模块的位置。例如,以下设备映射对于 T0pp 将正常工作(只要您有 GPU 内存):
```python
device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
```
另一种减少模型内存影响的方法是以较低精度的 dtype(例如 `torch.float16`)实例化它,或者使用下面介绍的直接量化技术。
### 模型实例化 dtype
在 PyTorch 下,模型通常以 `torch.float32` 格式实例化。如果尝试加载权重为 fp16 的模型,这可能会导致问题,因为它将需要两倍的内存。为了克服此限制,您可以使用 `torch_dtype` 参数显式传递所需的 `dtype`:
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
```
或者,如果您希望模型始终以最优的内存模式加载,则可以使用特殊值 `"auto"`,然后 `dtype` 将自动从模型的权重中推导出:
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
```
也可以通过以下方式告知从头开始实例化的模型要使用哪种 `dtype`:
```python
config = T5Config.from_pretrained("t5")
model = AutoModel.from_config(config)
```
由于 PyTorch 的设计,此功能仅适用于浮点类型。
## ModuleUtilsMixin
[[autodoc]] modeling_utils.ModuleUtilsMixin
TFPreTrainedModel
[[autodoc]] TFPreTrainedModel
- push_to_hub
- all
## TFModelUtilsMixin
[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
FlaxPreTrainedModel
[[autodoc]] FlaxPreTrainedModel
- push_to_hub
- all
## 推送到 Hub
[[autodoc]] utils.PushToHubMixin
## 分片检查点
[[autodoc]] modeling_utils.load_sharded_checkpoint
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/tokenizer.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tokenizer
tokenizer负责准备输入以供模型使用。该库包含所有模型的tokenizer。大多数tokenizer都有两种版本:一个是完全的 Python 实现,另一个是基于 Rust 库 [🤗 Tokenizers](https://github.com/huggingface/tokenizers) 的“Fast”实现。"Fast" 实现允许:
1. 在批量分词时显著提速
2. 在原始字符串(字符和单词)和token空间之间进行映射的其他方法(例如,获取包含给定字符的token的索引或与给定token对应的字符范围)。
基类 [PreTrainedTokenizer] 和 [PreTrained TokenizerFast] 实现了在模型输入中编码字符串输入的常用方法(见下文),并从本地文件或目录或从库提供的预训练的 tokenizer(从 HuggingFace 的 AWS S3 存储库下载)实例化/保存 python 和“Fast” tokenizer。它们都依赖于包含常用方法的 [`~tokenization_utils_base.PreTrainedTokenizerBase`]和[`~tokenization_utils_base.SpecialTokensMixin`]。
因此,[`PreTrainedTokenizer`] 和 [`PreTrainedTokenizerFast`] 实现了使用所有tokenizers的主要方法:
- 分词(将字符串拆分为子词标记字符串),将tokens字符串转换为id并转换回来,以及编码/解码(即标记化并转换为整数)。
- 以独立于底层结构(BPE、SentencePiece……)的方式向词汇表中添加新tokens。
- 管理特殊tokens(如mask、句首等):添加它们,将它们分配给tokenizer中的属性以便于访问,并确保它们在标记过程中不会被分割。
[`BatchEncoding`] 包含 [`~tokenization_utils_base.PreTrainedTokenizerBase`] 的编码方法(`__call__`、`encode_plus` 和 `batch_encode_plus`)的输出,并且是从 Python 字典派生的。当tokenizer是纯 Python tokenizer时,此类的行为就像标准的 Python 字典一样,并保存这些方法计算的各种模型输入(`input_ids`、`attention_mask` 等)。当分词器是“Fast”分词器时(即由 HuggingFace 的 [tokenizers 库](https://github.com/huggingface/tokenizers) 支持),此类还提供了几种高级对齐方法,可用于在原始字符串(字符和单词)与token空间之间进行映射(例如,获取包含给定字符的token的索引或与给定token对应的字符范围)。
## PreTrainedTokenizer
[[autodoc]] PreTrainedTokenizer
- __call__
- add_tokens
- add_special_tokens
- apply_chat_template
- batch_decode
- decode
- encode
- push_to_hub
- all
## PreTrainedTokenizerFast
[`PreTrainedTokenizerFast`] 依赖于 [tokenizers](https://huggingface.co/docs/tokenizers) 库。可以非常简单地将从 🤗 tokenizers 库获取的tokenizers加载到 🤗 transformers 中。查看 [使用 🤗 tokenizers 的分词器](../fast_tokenizers) 页面以了解如何执行此操作。
[[autodoc]] PreTrainedTokenizerFast
- __call__
- add_tokens
- add_special_tokens
- apply_chat_template
- batch_decode
- decode
- encode
- push_to_hub
- all
## BatchEncoding
[[autodoc]] BatchEncoding
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/deepspeed.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DeepSpeed集成
[DeepSpeed](https://github.com/microsoft/DeepSpeed)实现了[ZeRO论文](https://arxiv.org/abs/1910.02054)中描述的所有内容。目前,它提供对以下功能的全面支持:
1. 优化器状态分区(ZeRO stage 1)
2. 梯度分区(ZeRO stage 2)
3. 参数分区(ZeRO stage 3)
4. 自定义混合精度训练处理
5. 一系列基于CUDA扩展的快速优化器
6. ZeRO-Offload 到 CPU 和 NVMe
ZeRO-Offload有其自己的专门论文:[ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)。而NVMe支持在论文[ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)中进行了描述。
DeepSpeed ZeRO-2主要用于训练,因为它的特性对推理没有用处。
DeepSpeed ZeRO-3也可以用于推理,因为它允许将单个GPU无法加载的大模型加载到多个GPU上。
🤗 Transformers通过以下两种方式集成了[DeepSpeed](https://github.com/microsoft/DeepSpeed):
1. 通过[`Trainer`]集成核心的DeepSpeed功能。这是一种“为您完成一切”式的集成 - 您只需提供自定义配置文件或使用我们的模板配置文件。本文档的大部分内容都集中在这个功能上。
2. 如果您不使用[`Trainer`]并希望在自己的Trainer中集成DeepSpeed,那么像`from_pretrained`和`from_config`这样的核心功能函数将包括ZeRO stage 3及以上的DeepSpeed的基础部分,如`zero.Init`。要利用此功能,请阅读有关[非Trainer DeepSpeed集成](#nontrainer-deepspeed-integration)的文档。
集成的内容:
训练:
1. DeepSpeed ZeRO训练支持完整的ZeRO stages 1、2和3,以及ZeRO-Infinity(CPU和NVMe offload)。
推理:
1. DeepSpeed ZeRO推理支持ZeRO stage 3和ZeRO-Infinity。它使用与训练相同的ZeRO协议,但不使用优化器和学习率调度器,只有stage 3与推理相关。更多详细信息请参阅:[zero-inference](#zero-inference)。
此外还有DeepSpeed推理 - 这是一种完全不同的技术,它使用张量并行而不是ZeRO(即将推出)。
<a id='deepspeed-trainer-integration'></a>
## Trainer DeepSpeed 集成
<a id='deepspeed-installation'></a>
### 安装
通过pypi安装库:
```bash
pip install deepspeed
```
或通过 `transformers` 的 `extras`安装:
```bash
pip install transformers[deepspeed]
```
或在 [DeepSpeed 的 GitHub 页面](https://github.com/microsoft/deepspeed#installation) 和
[高级安装](https://www.deepspeed.ai/tutorials/advanced-install/) 中查找更多详细信息。
如果构建过程中仍然遇到问题,请首先确保阅读 [CUDA 扩展安装注意事项](trainer#cuda-extension-installation-notes)。
如果您没有预先构建扩展而是在运行时构建它们,而且您尝试了以上所有解决方案都无效,下一步可以尝试在安装之前预先构建扩展。
进行 DeepSpeed 的本地构建:
```bash
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log
```
如果您打算使用 NVMe offload,您还需要在上述说明中添加 `DS_BUILD_AIO=1`(并且还需要在系统范围内安装 *libaio-dev*)。
编辑 `TORCH_CUDA_ARCH_LIST` 以插入您打算使用的 GPU 卡的架构代码。假设您的所有卡都是相同的,您可以通过以下方式获取架构:
```bash
CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
```
因此,如果您得到 `8, 6`,则使用 `TORCH_CUDA_ARCH_LIST="8.6"`。如果您有多个不同的卡,您可以像这样列出所有卡 `TORCH_CUDA_ARCH_LIST="6.1;8.6"`。
如果您需要在多台机器上使用相同的设置,请创建一个二进制 wheel:
```bash
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 \
python setup.py build_ext -j8 bdist_wheel
```
它将生成类似于 `dist/deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl` 的文件,现在您可以在本地或任何其他机器上安装它,如 `pip install deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl`。
再次提醒确保调整 `TORCH_CUDA_ARCH_LIST` 以匹配目标架构。
您可以在[这里](https://developer.nvidia.com/cuda-gpus)找到完整的 NVIDIA GPU 列表及其对应的 **计算能力**(与此上下文中的架构相同)。
您可以使用以下命令检查 PyTorch 构建时使用的架构:
```bash
python -c "import torch; print(torch.cuda.get_arch_list())"
```
以下是如何查找已安装 GPU 中的一张卡的架构。例如,对于 GPU 0:
```bash
CUDA_VISIBLE_DEVICES=0 python -c "import torch; \
print(torch.cuda.get_device_properties(torch.device('cuda')))"
```
如果输出结果如下:
```bash
_CudaDeviceProperties(name='GeForce RTX 3090', major=8, minor=6, total_memory=24268MB, multi_processor_count=82)
```
然后您就知道这张卡的架构是 `8.6`。
您也可以完全省略 `TORCH_CUDA_ARCH_LIST`,然后构建程序将自动查询构建所在的 GPU 的架构。这可能与目标机器上的 GPU 不匹配,因此最好明确指定所需的架构。
如果尝试了所有建议的方法仍然遇到构建问题,请继续在 [Deepspeed](https://github.com/microsoft/DeepSpeed/issues)的 GitHub Issue 上提交问题。
<a id='deepspeed-multi-gpu'></a>
### 多GPU启用
为了启用DeepSpeed 集成,调整 [`Trainer`] 的命令行参数,添加一个新的参数 `--deepspeed ds_config.json`,其中 `ds_config.json` 是 DeepSpeed 配置文件,如文档 [这里](https://www.deepspeed.ai/docs/config-json/) 所述。文件命名由您决定。
建议使用 DeepSpeed 的 `add_config_arguments` 程序将必要的命令行参数添加到您的代码中。
有关更多信息,请参阅 [DeepSpeed 的参数解析](https://deepspeed.readthedocs.io/en/latest/initialize.html#argument-parsing) 文档。
在这里,您可以使用您喜欢的启动器。您可以继续使用 PyTorch 启动器:
```bash
torch.distributed.run --nproc_per_node=2 your_program.py <normal cl args> --deepspeed ds_config.json
```
或使用由 `deepspeed` 提供的启动器:
```bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json
```
正如您所见,这两个启动器的参数不同,但对于大多数需求,任何一个都可以满足工作需求。有关如何配置各个节点和 GPU 的完整详细信息,请查看 [此处](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node)。
当您使用 `deepspeed` 启动器并且希望使用所有可用的 GPU 时,您可以简单地省略 `--num_gpus` 标志。
以下是在 DeepSpeed 中启用使用所有可用 GPU情况下, 运行 `run_translation.py` 的示例:
```bash
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
请注意,在 DeepSpeed 文档中,您可能会看到 `--deepspeed --deepspeed_config ds_config.json` - 即两个与 DeepSpeed 相关的参数,但为简单起见,并且因为已经有很多参数要处理,我们将两者合并为一个单一参数。
有关一些实际使用示例,请参阅 [此帖](https://github.com/huggingface/transformers/issues/8771#issuecomment-759248400)。
<a id='deepspeed-one-gpu'></a>
### 单GPU启用
要使用一张 GPU 启用 DeepSpeed,调整 [`Trainer`] 的命令行参数如下:
```bash
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero2.json \
--model_name_or_path t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
这与多 GPU 的情况几乎相同,但在这里我们通过 `--num_gpus=1` 明确告诉 DeepSpeed 仅使用一张 GPU。默认情况下,DeepSpeed 启用给定节点上可以看到的所有 GPU。如果您一开始只有一张 GPU,那么您不需要这个参数。以下 [文档](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) 讨论了启动器的选项。
为什么要在仅使用一张 GPU 的情况下使用 DeepSpeed 呢?
1. 它具有 ZeRO-offload 功能,可以将一些计算和内存委托给主机的 CPU 和 内存,从而为模型的需求保留更多 GPU 资源 - 例如更大的批处理大小,或启用正常情况下无法容纳的非常大模型。
2. 它提供了智能的 GPU 内存管理系统,最小化内存碎片,这再次允许您容纳更大的模型和数据批次。
虽然接下来我们将详细讨论配置,但在单个 GPU 上通过 DeepSpeed 实现巨大性能提升的关键是在配置文件中至少有以下配置:
```json
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true
}
}
```
这会启用`optimizer offload `和一些其他重要功能。您可以尝试不同的buffer大小,有关详细信息,请参见下面的讨论。
关于这种启用类型的实际使用示例,请参阅 [此帖](https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685)。
您还可以尝试使用本文后面进一步解释的支持`CPU 和 NVMe offload`功能的ZeRO-3 。
<!--- TODO: Benchmark whether we can get better performance out of ZeRO-3 vs. ZeRO-2 on a single GPU, and then
recommend ZeRO-3 config as starting one. -->
注意:
- 如果您需要在特定的 GPU 上运行,而不是 GPU 0,则无法使用 `CUDA_VISIBLE_DEVICES` 来限制可用 GPU 的可见范围。相反,您必须使用以下语法:
```bash
deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py ...
```
在这个例子中,我们告诉 DeepSpeed 使用 GPU 1(第二个 GPU)。
<a id='deepspeed-multi-node'></a>
### 多节点启用
这一部分的信息不仅适用于 DeepSpeed 集成,也适用于任何多节点程序。但 DeepSpeed 提供了一个比其他启动器更易于使用的 `deepspeed` 启动器,除非您在 SLURM 环境中。
在本节,让我们假设您有两个节点,每个节点有 8 张 GPU。您可以通过 `ssh hostname1` 访问第一个节点,通过 `ssh hostname2` 访问第二个节点,两者必须能够在本地通过 ssh 无密码方式相互访问。当然,您需要将这些主机(节点)名称重命名为您实际使用的主机名称。
#### torch.distributed.run启动器
例如,要使用 `torch.distributed.run`,您可以执行以下操作:
```bash
python -m torch.distributed.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
--master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
```
您必须 ssh 到每个节点,并在每个节点上运行相同的命令!不用担心,启动器会等待两个节点同步完成。
有关更多信息,请参阅 [torchrun](https://pytorch.org/docs/stable/elastic/run.html)。顺便说一下,这也是替代了几个 PyTorch 版本前的 `torch.distributed.launch` 的启动器。
#### deepspeed启动器
要改用 `deepspeed` 启动器,首先需要创建一个 `hostfile` 文件:
```
hostname1 slots=8
hostname2 slots=8
```
然后,您可以这样启动:
```bash
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
```
与 `torch.distributed.run` 启动器不同,`deepspeed` 将自动在两个节点上启动此命令!
更多信息,请参阅[资源配置(多节点)](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node)。
#### 在 SLURM 环境中启动
在 SLURM 环境中,可以采用以下方法。以下是一个 SLURM 脚本 `launch.slurm`,您需要根据您的具体 SLURM 环境进行调整。
```bash
#SBATCH --job-name=test-nodes # name
#SBATCH --nodes=2 # nodes
#SBATCH --ntasks-per-node=1 # crucial - only 1 task per dist per node!
#SBATCH --cpus-per-task=10 # number of cores per tasks
#SBATCH --gres=gpu:8 # number of gpus
#SBATCH --time 20:00:00 # maximum execution time (HH:MM:SS)
#SBATCH --output=%x-%j.out # output file name
export GPUS_PER_NODE=8
export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
export MASTER_PORT=9901
srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
--nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
--master_addr $MASTER_ADDR --master_port $MASTER_PORT \
your_program.py <normal cl args> --deepspeed ds_config.json'
```
剩下的就是运行它:
```bash
sbatch launch.slurm
```
`srun` 将负责在所有节点上同时启动程序。
#### 使用非共享文件系统
默认情况下,DeepSpeed 假定多节点环境使用共享存储。如果不是这种情况,每个节点只能看到本地文件系统,你需要调整配置文件,包含一个 [`checkpoint` 部分](https://www.deepspeed.ai/docs/config-json/#checkpoint-options)并设置如下选项:
```json
{
"checkpoint": {
"use_node_local_storage": true
}
}
```
或者,你还可以使用 [`Trainer`] 的 `--save_on_each_node` 参数,上述配置将自动添加。
<a id='deepspeed-notebook'></a>
### 在Notebooks启用
在将`notebook cells`作为脚本运行的情况下,问题在于没有正常的 `deepspeed` 启动器可依赖,因此在某些设置下,我们必须仿真运行它。
如果您只使用一个 GPU,以下是如何调整notebook中的训练代码以使用 DeepSpeed。
```python
# DeepSpeed requires a distributed environment even when only one process is used.
# This emulates a launcher in the notebook
import os
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "9994" # modify if RuntimeError: Address already in use
os.environ["RANK"] = "0"
os.environ["LOCAL_RANK"] = "0"
os.environ["WORLD_SIZE"] = "1"
# Now proceed as normal, plus pass the deepspeed config file
training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
trainer = Trainer(...)
trainer.train()
```
注意:`...` 代表您传递给函数的正常参数。
如果要使用多于一个 GPU,您必须在 DeepSpeed 中使用多进程环境。也就是说,您必须使用专门的启动器来实现这一目的,而不能通过仿真本节开头呈现的分布式环境来完成。
如果想要在notebook中动态创建配置文件并保存在当前目录,您可以在一个专用的cell中使用:
```python no-style
%%bash
cat <<'EOT' > ds_config_zero3.json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
EOT
```
如果训练脚本在一个普通文件中而不是在notebook cells中,您可以通过笔记本中的 shell 正常启动 `deepspeed`。例如,要使用 `run_translation.py`,您可以这样启动:
```python no-style
!git clone https://github.com/huggingface/transformers
!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
```
或者使用 `%%bash` 魔术命令,您可以编写多行代码,用于运行 shell 程序:
```python no-style
%%bash
git clone https://github.com/huggingface/transformers
cd transformers
deepspeed examples/pytorch/translation/run_translation.py ...
```
在这种情况下,您不需要本节开头呈现的任何代码。
注意:虽然 `%%bash` 魔术命令很方便,但目前它会缓冲输出,因此在进程完成之前您看不到日志。
<a id='deepspeed-config'></a>
### 配置
有关可以在 DeepSpeed 配置文件中使用的完整配置选项的详细指南,请参阅[以下文档](https://www.deepspeed.ai/docs/config-json/)。
您可以在 [DeepSpeedExamples 仓库](https://github.com/microsoft/DeepSpeedExamples)中找到解决各种实际需求的数十个 DeepSpeed 配置示例。
```bash
git clone https://github.com/microsoft/DeepSpeedExamples
cd DeepSpeedExamples
find . -name '*json'
```
延续上面的代码,假设您要配置 Lamb 优化器。那么您可以通过以下方式在示例的 `.json` 文件中进行搜索:
```bash
grep -i Lamb $(find . -name '*json')
```
还可以在[主仓](https://github.com/microsoft/DeepSpeed)中找到更多示例。
在使用 DeepSpeed 时,您总是需要提供一个 DeepSpeed 配置文件,但是一些配置参数必须通过命令行进行配置。您将在本指南的剩余章节找到这些细微差别。
为了了解 DeepSpeed 配置文件,这里有一个激活 ZeRO stage 2 功能的示例,包括优化器状态的 CPU offload,使用 `AdamW` 优化器和 `WarmupLR` 调度器,并且如果传递了 `--fp16` 参数将启用混合精度训练:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
}
```
当您执行程序时,DeepSpeed 将把它从 [`Trainer`] 收到的配置日志输出到console,因此您可以看到传递给它的最终配置。
<a id='deepspeed-config-passing'></a>
### 传递配置
正如本文档讨论的那样,通常将 DeepSpeed 配置作为指向 JSON 文件的路径传递,但如果您没有使用命令行界面配置训练,而是通过 [`TrainingArguments`] 实例化 [`Trainer`],那么对于 `deepspeed` 参数,你可以传递一个嵌套的 `dict`。这使您能够即时创建配置,而无需在将其传递给 [`TrainingArguments`] 之前将其写入文件系统。
总结起来,您可以这样做:
```python
TrainingArguments(..., deepspeed="/path/to/ds_config.json")
```
或者:
```python
ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
TrainingArguments(..., deepspeed=ds_config_dict)
```
<a id='deepspeed-config-shared'></a>
### 共享配置
<Tip warning={true}>
这一部分是必读的。
</Tip>
一些配置值对于 [`Trainer`] 和 DeepSpeed 正常运行都是必需的,因此,为了防止定义冲突及导致的难以检测的错误,我们选择通过 [`Trainer`] 命令行参数配置这些值。
此外,一些配置值是基于模型的配置自动派生的,因此,与其记住手动调整多个值,最好让 [`Trainer`] 为您做大部分配置。
因此,在本指南的其余部分,您将找到一个特殊的配置值:`auto`,当设置时将自动将参数替换为正确或最有效的值。请随意选择忽略此建议或显式设置该值,在这种情况下,请务必确保 [`Trainer`] 参数和 DeepSpeed 配置保持一致。例如,您是否使用相同的学习率、批量大小或梯度累积设置?如果这些不匹配,训练可能以非常难以检测的方式失败。请重视该警告。
还有一些参数是仅适用于 DeepSpeed 的,并且这些参数必须手动设置以适应您的需求。
在您自己的程序中,如果您想要作为主动修改 DeepSpeed 配置并以此配置 [`TrainingArguments`],您还可以使用以下方法。步骤如下:
1. 创建或加载要用作主配置的 DeepSpeed 配置
2. 根据这些参数值创建 [`TrainingArguments`] 对象
请注意,一些值,比如 `scheduler.params.total_num_steps`,是在 [`Trainer`] 的 `train` 过程中计算的,但当然您也可以自己计算这些值。
<a id='deepspeed-zero'></a>
### ZeRO
[Zero Redundancy Optimizer (ZeRO)](https://www.deepspeed.ai/tutorials/zero/) 是 DeepSpeed 的工作核心。它支持3个不同级别(stages)的优化。Stage 1 对于扩展性来说不是很有趣,因此本文档重点关注Stage 2和Stage 3。Stage 3通过最新的 ZeRO-Infinity 进一步改进。你可以在 DeepSpeed 文档中找到更详细的信息。
配置文件的 `zero_optimization` 部分是最重要的部分([文档](https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training)),因为在这里您定义了要启用哪些 ZeRO stages 以及如何配置它们。您可以在 DeepSpeed 文档中找到每个参数的解释。
这一部分必须通过 DeepSpeed 配置文件单独配置 - [`Trainer`] 不提供相应的命令行参数。
注意:目前 DeepSpeed 不验证参数名称,因此如果您拼错了任何参数,它将使用拼写错误的参数的默认设置。您可以观察 DeepSpeed 引擎启动日志消息,看看它将使用哪些值。
<a id='deepspeed-zero2-config'></a>
#### ZeRO-2 配置
以下是 ZeRO stage 2 的配置示例:
```json
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true
}
}
```
**性能调优:**
- 启用 `offload_optimizer` 应该减少 GPU 内存使用(需要 `"stage": 2`)。
- `"overlap_comm": true` 通过增加 GPU 内存使用来降低all-reduce 的延迟。 `overlap_comm` 使用了 `allgather_bucket_size` 和 `reduce_bucket_size` 值的4.5倍。因此,如果它们设置为 `5e8`,这将需要一个9GB的内存占用(`5e8 x 2Bytes x 2 x 4.5`)。因此,如果您的 GPU 内存为8GB或更小,为了避免出现OOM错误,您需要将这些参数减小到约 `2e8`,这将需要3.6GB。如果您的 GPU 容量更大,当您开始遇到OOM时,你可能也需要这样做。
- 当减小这些buffers时,您以更慢的通信速度来换取更多的 GPU 内存。buffers大小越小,通信速度越慢,GPU 可用于其他任务的内存就越多。因此,如果更大的批处理大小很重要,那么稍微减慢训练时间可能是一个很好的权衡。
此外,`deepspeed==0.4.4` 添加了一个新选项 `round_robin_gradients`,您可以通过以下方式启用:
```json
{
"zero_optimization": {
"round_robin_gradients": true
}
}
```
这是一个用于 CPU offloading 的stage 2优化,通过细粒度梯度分区在 ranks 之间并行复制到 CPU 内存,从而实现了性能的提升。性能优势随着梯度累积步骤(在优化器步骤之间进行更多复制)或 GPU 数量(增加并行性)增加而增加。
<a id='deepspeed-zero3-config'></a>
#### ZeRO-3 配置
以下是 ZeRO stage 3的配置示例:
```json
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
如果您因为你的模型或激活值超过 GPU 内存而遇到OOM问题,并且您有未使用的 CPU 内存,可以通股票使用 `"device": "cpu"` 将优化器状态和参数卸载到 CPU 内存中,来解决这个限制。如果您不想卸载到 CPU 内存,可以在 `device` 条目中使用 `none` 代替 `cpu`。将优化器状态卸载到 NVMe 上会在后面进一步讨论。
通过将 `pin_memory` 设置为 `true` 启用固定内存。此功能会以减少可用于其他进程的内存为代价来提高吞吐量。固定内存被分配给特定请求它的进程,通常比普通 CPU 内存访问速度更快。
**性能调优:**
- `stage3_max_live_parameters`: `1e9`
- `stage3_max_reuse_distance`: `1e9`
如果遇到OOM问题,请减小 `stage3_max_live_parameters` 和 `stage3_max_reuse_distance`。它们对性能的影响应该很小,除非您正在进行激活值checkpointing。`1e9` 大约会消耗 ~2GB。内存由 `stage3_max_live_parameters` 和 `stage3_max_reuse_distance` 共享,所以它不是叠加的,而是总共2GB。
`stage3_max_live_parameters` 是在任何给定时间要在 GPU 上保留多少个完整参数的上限。"reuse distance" 是我们用来确定参数在将来何时会再次使用的度量标准,我们使用 `stage3_max_reuse_distance` 来决定是丢弃参数还是保留参数。如果一个参数在不久的将来(小于 `stage3_max_reuse_distance`)将被再次使用,那么我们将其保留以减少通信开销。这在启用激活值checkpoing时非常有用,其中我们以单层粒度进行前向重计算和反向传播,并希望在反向传播期间保留前向重计算中的参数。
以下配置值取决于模型的隐藏大小:
- `reduce_bucket_size`: `hidden_size*hidden_size`
- `stage3_prefetch_bucket_size`: `0.9 * hidden_size * hidden_size`
- `stage3_param_persistence_threshold`: `10 * hidden_size`
因此,将这些值设置为 `auto`,[`Trainer`] 将自动分配推荐的参数值。当然,如果您愿意,也可以显式设置这些值。
`stage3_gather_16bit_weights_on_model_save` 在模型保存时启用模型的 fp16 权重整合。对于大模型和多个 GPU,无论是在内存还是速度方面,这都是一项昂贵的操作。目前如果计划恢复训练,这是必需的。请注意未来的更新可能会删除此限制并让使用更加灵活。
如果您从 ZeRO-2 配置迁移,请注意 `allgather_partitions`、`allgather_bucket_size` 和 `reduce_scatter` 配置参数在 ZeRO-3 中不被使用。如果保留这些配置文件,它们将被忽略。
- `sub_group_size`: `1e9`
`sub_group_size` 控制在优化器步骤期间更新参数的粒度。参数被分组到大小为 `sub_group_size` 的桶中,每个桶逐个更新。在 ZeRO-Infinity 中与 NVMe offload一起使用时,`sub_group_size` 控制了在优化器步骤期间在 NVMe 和 CPU 内存之间移动模型状态的粒度。这可以防止非常大的模型耗尽 CPU 内存。
当不使用 NVMe offload时,可以将 `sub_group_size` 保留为其默认值 *1e9*。在以下情况下,您可能需要更改其默认值:
1. 在优化器步骤中遇到OOM:减小 `sub_group_size` 以减少临时buffers的内存利用
2. 优化器步骤花费很长时间:增加 `sub_group_size` 以提高由于增加的数据buffers而导致的带宽利用率。
#### ZeRO-0 配置
请注意,我们将 Stage 0 和 1 放在最后,因为它们很少使用。
Stage 0 禁用了所有类型的分片,只是将 DeepSpeed 作为 DDP 使用。您可以通过以下方式启用:
```json
{
"zero_optimization": {
"stage": 0
}
}
```
这将实质上禁用 ZeRO,而无需更改其他任何内容。
#### ZeRO-1 配置
Stage 1 等同于 Stage 2 减去梯度分片。您可以尝试使用以下配置,仅对优化器状态进行分片,以稍微加速:
```json
{
"zero_optimization": {
"stage": 1
}
}
```
<a id='deepspeed-nvme'></a>
### NVMe 支持
ZeRO-Infinity 通过使用 NVMe 内存扩展 GPU 和 CPU 内存,从而允许训练非常大的模型。由于智能分区和平铺算法,在offload期间每个 GPU 需要发送和接收非常小量的数据,因此 NVMe 被证明适用于训练过程中提供更大的总内存池。ZeRO-Infinity 需要启用 ZeRO-3。
以下配置示例启用 NVMe 来offload优化器状态和参数:
```json
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 5,
"buffer_size": 1e8,
"max_in_cpu": 1e9
},
"aio": {
"block_size": 262144,
"queue_depth": 32,
"thread_count": 1,
"single_submit": false,
"overlap_events": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
}
```
您可以选择将优化器状态和参数都卸载到 NVMe,也可以只选择其中一个,或者都不选择。例如,如果您有大量的 CPU 内存可用,只卸载到 CPU 内存训练速度会更快(提示:"device": "cpu")。
这是有关卸载 [优化器状态](https://www.deepspeed.ai/docs/config-json/#optimizer-offloading) 和 [参数](https://www.deepspeed.ai/docs/config-json/#parameter-offloading) 的完整文档。
确保您的 `nvme_path` 实际上是一个 NVMe,因为它与普通硬盘或 SSD 一起工作,但速度会慢得多。快速可扩展的训练是根据现代 NVMe 传输速度设计的(截至本文撰写时,可以达到 ~3.5GB/s 读取,~3GB/s 写入的峰值速度)。
为了找出最佳的 `aio` 配置块,您必须在目标设置上运行一个基准测试,具体操作请参见[说明](https://github.com/microsoft/DeepSpeed/issues/998)。
<a id='deepspeed-zero2-zero3-performance'></a>
#### ZeRO-2 和 ZeRO-3 性能对比
如果其他一切都配置相同,ZeRO-3 可能比 ZeRO-2 慢,因为前者除了 ZeRO-2 的操作外,还必须收集模型权重。如果 ZeRO-2 满足您的需求,而且您不需要扩展到几个 GPU 以上,那么您可以选择继续使用它。重要的是要理解,ZeRO-3 以速度为代价实现了更高的可扩展性。
可以调整 ZeRO-3 配置使其性能接近 ZeRO-2:
- 将 `stage3_param_persistence_threshold` 设置为一个非常大的数字 - 大于最大的参数,例如 `6 * hidden_size * hidden_size`。这将保留参数在 GPU 上。
- 关闭 `offload_params`,因为 ZeRO-2 没有这个选项。
即使不更改 `stage3_param_persistence_threshold`,仅将 `offload_params` 关闭,性能可能会显著提高。当然,这些更改将影响您可以训练的模型的大小。因此,这些更改可根据需求帮助您在可扩展性和速度之间进行权衡。
<a id='deepspeed-zero2-example'></a>
#### ZeRO-2 示例
这是一个完整的 ZeRO-2 自动配置文件 `ds_config_zero2.json`:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
这是一个完整的手动设置的启用所有功能的 ZeRO-2 配置文件。主要是为了让您看到典型的参数值是什么样的,但我们强烈建议使用其中包含多个 `auto` 设置的配置文件。
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
<a id='deepspeed-zero3-example'></a>
#### ZeRO-3 示例
这是一个完整的 ZeRO-3 自动配置文件 `ds_config_zero3.json`:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
这是一个完整的 手动设置的启用所有功能的ZeRO-3 配置文件。主要是为了让您看到典型的参数值是什么样的,但我们强烈建议使用其中包含多个 `auto` 设置的配置文件。
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 1e6,
"stage3_prefetch_bucket_size": 0.94e6,
"stage3_param_persistence_threshold": 1e4,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
#### 如何选择最佳性能的ZeRO Stage和 offloads
了解了这些不同stages后,现在您需要决定使用哪个stage。本节将尝试回答这个问题。
通常,以下规则适用:
- 速度方面(左边比右边快)
stage 0(DDP) > stage 1 > stage 2 > stage 2 + offload > stage 3 > stage3 + offload
- GPU内存使用方面(右边比左边更节省GPU内存)
stage 0(DDP) < stage 1 < stage 2 < stage 2 + offload < stage 3 < stage 3 + offload
所以,当您希望在尽量使用较少数量的GPU的同时获得最快的执行速度时,可以按照以下步骤进行。我们从最快的方法开始,如果遇到GPU内存溢出,然后切换到下一个速度较慢但使用的GPU内存更少的方法。以此类推。
首先,将批量大小设置为1(您始终可以使用梯度累积来获得任何所需的有效批量大小)。
1. 启用 `--gradient_checkpointing 1`(HF Trainer)或直接 `model.gradient_checkpointing_enable()` - 如果发生OOM(Out of Memory),则执行以下步骤。
2. 首先尝试 ZeRO stage 2。如果发生OOM,则执行以下步骤。
3. 尝试 ZeRO stage 2 + `offload_optimizer` - 如果发生OOM,则执行以下步骤。
4. 切换到 ZeRO stage 3 - 如果发生OOM,则执行以下步骤。
5. 启用 `offload_param` 到 `cpu` - 如果发生OOM,则执行以下步骤。
6. 启用 `offload_optimizer` 到 `cpu` - 如果发生OOM,则执行以下步骤。
7. 如果仍然无法适应批量大小为1,请首先检查各种默认值并尽可能降低它们。例如,如果使用 `generate` 并且不使用宽搜索束,将其缩小,因为它会占用大量内存。
8. 绝对要使用混合半精度而非fp32 - 在Ampere及更高的GPU上使用bf16,在旧的GPU体系结构上使用fp16。
9. 如果仍然发生OOM,可以添加更多硬件或启用ZeRO-Infinity - 即切换 `offload_param` 和 `offload_optimizer` 到 `nvme`。您需要确保它是非常快的NVMe。作为趣闻,我曾经能够在一个小型GPU上使用BLOOM-176B进行推理,使用了ZeRO-Infinity,尽管速度非常慢。但它奏效了!
当然,您也可以按相反的顺序进行这些步骤,从最节省GPU内存的配置开始,然后逐步反向进行,或者尝试进行二分法。
一旦您的批量大小为1不会导致OOM,就测量您的有效吞吐量。
接下来尝试将批量大小增加到尽可能大,因为批量大小越大,GPU的效率越高,特别是在它们乘法运算的矩阵很大时。
现在性能优化游戏开始了。您可以关闭一些offload特性,或者降低ZeRO stage,并增加/减少批量大小,再次测量有效吞吐量。反复尝试,直到满意为止。
不要花费太多时间,但如果您即将开始一个为期3个月的训练 - 请花几天时间找到吞吐量方面最有效的设置。这样您的训练成本将最低,而且您会更快地完成训练。在当前快节奏的机器学习世界中,如果您花费一个额外的月份来训练某样东西,你很可能会错过一个黄金机会。当然,这只是我分享的一种观察,我并不是在催促你。在开始训练BLOOM-176B之前,我花了2天时间进行这个过程,成功将吞吐量从90 TFLOPs提高到150 TFLOPs!这一努力为我们节省了一个多月的训练时间。
这些注释主要是为训练模式编写的,但它们在推理中也应该大部分适用。例如,在推理中,Gradient Checkpointing 是无用的,因为它只在训练过程中有用。此外,我们发现,如果你正在进行多GPU推理并且不使用 [DeepSpeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/),[Accelerate](https://huggingface.co/blog/bloom-inference-pytorch-scripts) 应该提供更优越的性能。
其他与性能相关的快速注释:
- 如果您从头开始训练某个模型,请尽量确保张量的形状可以被16整除(例如隐藏层大小)。对于批量大小,至少尝试可被2整除。如果您想从GPU中挤取更高性能,还有一些硬件特定的[wave和tile量化](https://developer.nvidia.com/blog/optimizing-gpu-performance-tensor-cores/)的可整除性。
### Activation Checkpointing 或 Gradient Checkpointing
Activation Checkpointing和Gradient Checkpointing是指相同方法的两个不同术语。这确实让人感到困惑,但事实就是这样。
Gradient Checkpointing允许通过牺牲速度来换取GPU内存,这要么使您能够克服GPU内存溢出,要么增加批量大小来获得更好的性能。
HF Transformers 模型对DeepSpeed的Activation Checkpointing一无所知,因此如果尝试在DeepSpeed配置文件中启用该功能,什么都不会发生。
因此,您有两种方法可以利用这个非常有益的功能:
1. 如果您想使用 HF Transformers 模型,你可以使用 `model.gradient_checkpointing_enable()` 或在 HF Trainer 中使用 `--gradient_checkpointing`,它会自动为您启用这个功能。在这里使用了 `torch.utils.checkpoint`。
2. 如果您编写自己的模型并希望使用DeepSpeed的Activation Checkpointing,可以使用[规定的API](https://deepspeed.readthedocs.io/en/latest/activation-checkpointing.html)。您还可以使用 HF Transformers 的模型代码,将 `torch.utils.checkpoint` 替换为 DeepSpeed 的API。后者更灵活,因为它允许您将前向激活值卸载到CPU内存,而不是重新计算它们。
### Optimizer 和 Scheduler
只要你不启用 `offload_optimizer`,您可以混合使用DeepSpeed和HuggingFace的调度器和优化器,但有一个例外,即不要使用HuggingFace调度器和DeepSpeed优化器的组合:
| Combos | HF Scheduler | DS Scheduler |
|:-------------|:-------------|:-------------|
| HF Optimizer | Yes | Yes |
| DS Optimizer | No | Yes |
在启用 `offload_optimizer` 的情况下,可以使用非DeepSpeed优化器,只要该优化器具有CPU和GPU的实现(除了LAMB)。
<a id='deepspeed-optimizer'></a>
#### Optimizer
DeepSpeed的主要优化器包括Adam、AdamW、OneBitAdam和Lamb。这些优化器已经与ZeRO进行了彻底的测试,因此建议使用它们。然而,也可以导入`torch`中的其他优化器。完整的文档在[这里](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters)。
如果在配置文件中不配置`optimizer`条目,[`Trainer`] 将自动将其设置为 `AdamW`,并使用提供的值或以下命令行参数的默认值:`--learning_rate`、`--adam_beta1`、`--adam_beta2`、`--adam_epsilon` 和 `--weight_decay`。
以下是`AdamW` 的自动配置示例:
```json
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
}
}
```
请注意,命令行参数将设置配置文件中的值。这是为了有一个明确的值来源,并避免在不同地方设置学习率等值时难以找到的错误。命令行参数配置高于其他。被覆盖的值包括:
- `lr` 的值为 `--learning_rate`
- `betas` 的值为 `--adam_beta1 --adam_beta2`
- `eps` 的值为 `--adam_epsilon`
- `weight_decay` 的值为 `--weight_decay`
因此,请记住在命令行上调整共享的超参数。
您也可以显式地设置这些值:
```json
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": 0.001,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
}
}
```
但在这种情况下,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
如果您想使用上面未列出的其他优化器,您将不得不将其添加到顶层配置中。
```json
{
"zero_allow_untested_optimizer": true
}
```
类似于 `AdamW`,您可以配置其他官方支持的优化器。只是记住这些可能有不同的配置值。例如,对于Adam,您可能需要将 `weight_decay` 设置在 `0.01` 左右。
此外,当与DeepSpeed的CPU Adam优化器一起使用时,offload的效果最好。如果您想在offload时使用不同的优化器,自 `deepspeed==0.8.3` 起,您还需要添加:
```json
{
"zero_force_ds_cpu_optimizer": false
}
```
到顶层配置中。
<a id='deepspeed-scheduler'></a>
#### Scheduler
DeepSpeed支持`LRRangeTest`、`OneCycle`、`WarmupLR`和`WarmupDecayLR`学习率调度器。完整文档在[这里](https://www.deepspeed.ai/docs/config-json/#scheduler-parameters)。
以下是🤗 Transformers 和 DeepSpeed 之间的调度器重叠部分:
- 通过 `--lr_scheduler_type constant_with_warmup` 实现 `WarmupLR`
- 通过 `--lr_scheduler_type linear` 实现 `WarmupDecayLR`。这也是 `--lr_scheduler_type` 的默认值,因此,如果不配置调度器,这将是默认配置的调度器。
如果在配置文件中不配置 `scheduler` 条目,[`Trainer`] 将使用 `--lr_scheduler_type`、`--learning_rate` 和 `--warmup_steps` 或 `--warmup_ratio` 的值来配置其🤗 Transformers 版本。
以下是 `WarmupLR` 的自动配置示例:
```json
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
```
由于使用了 *"auto"*,[`Trainer`] 的参数将在配置文件中设置正确的值。这是为了有一个明确的值来源,并避免在不同地方设置学习率等值时难以找到的错误。命令行配置高于其他。被设置的值包括:
- `warmup_min_lr` 的值为 `0`。
- `warmup_max_lr` 的值为 `--learning_rate`。
- `warmup_num_steps` 的值为 `--warmup_steps`(如果提供)。否则,将使用 `--warmup_ratio` 乘以训练步骤的数量,并四舍五入。
- `total_num_steps` 的值为 `--max_steps` 或者如果没有提供,将在运行时根据环境、数据集的大小和其他命令行参数(对于 `WarmupDecayLR` 来说需要)自动推导。
当然,您可以接管任何或所有的配置值,并自行设置这些值:
```json
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
}
}
```
但在这种情况下,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
例如,对于 `WarmupDecayLR`,您可以使用以下条目:
```json
{
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"last_batch_iteration": -1,
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
```
然后,`total_num_steps`、`warmup_max_lr`、`warmup_num_steps` 和 `total_num_steps` 将在加载时设置。
<a id='deepspeed-fp32'></a>
### fp32精度
DeepSpeed支持完整的fp32和fp16混合精度。
由于fp16混合精度具有更小的内存需求和更快的速度,唯一不使用它的时候是当您使用的模型在这种训练模式下表现不佳时。通常,当模型没有在fp16混合精度下进行预训练时(例如,bf16预训练模型经常出现这种情况),会出现这种情况。这样的模型可能会发生溢出或下溢,导致 `NaN` 损失。如果是这种情况,那么您将希望使用完整的fp32模式,通过显式禁用默认启用的fp16混合精度模式:
```json
{
"fp16": {
"enabled": false,
}
}
```
如果您使用基于Ampere架构的GPU,PyTorch版本1.7及更高版本将自动切换到使用更高效的tf32格式进行一些操作,但结果仍将以fp32格式呈现。有关详细信息和基准测试,请参见[TensorFloat-32(TF32) on Ampere devices](https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)。如果出于某种原因您不希望使用它,该文档包括有关如何禁用此自动转换的说明。
在🤗 Trainer中,你可以使用 `--tf32` 来启用它,或使用 `--tf32 0` 或 `--no_tf32` 来禁用它。默认情况下,使用PyTorch的默认设置。
<a id='deepspeed-amp'></a>
### 自动混合精度
您可以使用自动混合精度,可以选择使用类似 PyTorch AMP 的方式,也可以选择使用类似 Apex 的方式:
### fp16
要配置PyTorch AMP-like 的 fp16(float16) 模式,请设置:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
并且,[`Trainer`]将根据`args.fp16_backend`的值自动启用或禁用它。其余的配置值由您决定。
当传递`--fp16 --fp16_backend amp`或`--fp16_full_eval`命令行参数时,此模式将被启用。
您也可以显式地启用/禁用此模式:
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
但是之后您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
以下是[相关文档](https://www.deepspeed.ai/docs/config-json/#fp16-training-options)
### bf16
如果需要使用bfloat16而不是fp16,那么可以使用以下配置部分:
```json
{
"bf16": {
"enabled": "auto"
}
}
```
bf16具有与fp32相同的动态范围,因此不需要损失缩放。
当传递`--bf16`或`--bf16_full_eval`命令行参数时,启用此模式。
您还可以显式地启用/禁用此模式:
```json
{
"bf16": {
"enabled": true
}
}
```
<Tip>
在`deepspeed==0.6.0`版本中,bf16支持是新的实验性功能。
如果您启用了bf16来进行[梯度累积](#gradient-accumulation),您需要意识到它会以bf16累积梯度,这可能不是您想要的,因为这种格式的低精度可能会导致lossy accumulation。
修复这个问题的工作正在努力进行,同时提供了使用更高精度的`dtype`(fp16或fp32)的选项。
</Tip>
### NCCL集合
在训练过程中,有两种数据类型:`dtype`和用于通信收集操作的`dtype`,如各种归约和收集/分散操作。
所有的gather/scatter操作都是在数据相同的`dtype`中执行的,所以如果您正在使用bf16的训练模式,那么它将在bf16中进行gather操作 - gather操作是非损失性的。
各种reduce操作可能会是非常损失性的,例如当梯度在多个gpu上平均时,如果通信是在fp16或bf16中进行的,那么结果可能是有损失性的 - 因为当在一个低精度中添加多个数字时,结果可能不是精确的。更糟糕的是,bf16比fp16具有更低的精度。通常,当平均梯度时,损失最小,这些梯度通常非常小。因此,对于半精度训练,默认情况下,fp16被用作reduction操作的默认值。但是,您可以完全控制这个功能,如果你选择的话,您可以添加一个小的开销,并确保reductions将使用fp32作为累积数据类型,只有当结果准备好时,它才会降级到您在训练中使用的半精度`dtype`。
要覆盖默认设置,您只需添加一个新的配置条目:
```json
{
"communication_data_type": "fp32"
}
```
根据这个信息,有效的值包括"fp16"、"bfp16"和"fp32"。
注意:在stage zero 3中,bf16通信数据类型存在一个bug,该问题已在`deepspeed==0.8.1`版本中得到修复。
### apex
配置apex AMP-like模式:
```json
"amp": {
"enabled": "auto",
"opt_level": "auto"
}
```
并且,[`Trainer`]将根据`args.fp16_backend`和`args.fp16_opt_level`的值自动配置它。
当传递`--fp16 --fp16_backend apex --fp16_opt_level 01`命令行参数时,此模式将被启用。
您还可以显式配置此模式:
```json
{
"amp": {
"enabled": true,
"opt_level": "O1"
}
}
```
但是,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
这里是[文档](https://www.deepspeed.ai/docs/config-json/#automatic-mixed-precision-amp-training-options)
<a id='deepspeed-bs'></a>
### Batch Size
配置batch size可以使用如下参数:
```json
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto"
}
```
并且,[`Trainer`]将自动将`train_micro_batch_size_per_gpu`设置为`args.per_device_train_batch_size`的值,并将`train_batch_size`设置为`args.world_size * args.per_device_train_batch_size * args.gradient_accumulation_steps`。
您也可以显式设置这些值:
```json
{
"train_batch_size": 12,
"train_micro_batch_size_per_gpu": 4
}
```
但是,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
<a id='deepspeed-grad-acc'></a>
### Gradient Accumulation
配置gradient accumulation设置如下:
```json
{
"gradient_accumulation_steps": "auto"
}
```
并且,[`Trainer`]将自动将其设置为`args.gradient_accumulation_steps`的值。
您也可以显式设置这个值:
```json
{
"gradient_accumulation_steps": 3
}
```
但是,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
<a id='deepspeed-grad-clip'></a>
### Gradient Clipping
配置gradient clipping如下:
```json
{
"gradient_clipping": "auto"
}
```
并且,[`Trainer`]将自动将其设置为`args.max_grad_norm`的值。
您也可以显式设置这个值:
```json
{
"gradient_clipping": 1.0
}
```
但是,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
<a id='deepspeed-weight-extraction'></a>
### 获取模型权重
只要您继续使用DeepSpeed进行训练和恢复,您就不需要担心任何事情。DeepSpeed在其自定义检查点优化器文件中存储fp32主权重,这些文件是`global_step*/*optim_states.pt`(这是glob模式),并保存在正常的checkpoint下。
**FP16权重:**
当模型保存在ZeRO-2下时,您最终会得到一个包含模型权重的普通`pytorch_model.bin`文件,但它们只是权重的fp16版本。
在ZeRO-3下,事情要复杂得多,因为模型权重分布在多个GPU上,因此需要`"stage3_gather_16bit_weights_on_model_save": true`才能让`Trainer`保存fp16版本的权重。如果这个设置是`False`,`pytorch_model.bin`将不会被创建。这是因为默认情况下,DeepSpeed的`state_dict`包含一个占位符而不是实际的权重。如果我们保存这个`state_dict`,就无法再加载它了。
```json
{
"zero_optimization": {
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
**FP32权重:**
虽然fp16权重适合恢复训练,但如果您完成了模型的微调并希望将其上传到[models hub](https://huggingface.co/models)或传递给其他人,您很可能想要获取fp32权重。这最好不要在训练期间完成,因为这需要大量内存,因此最好在训练完成后离线进行。但是,如果需要并且有充足的空闲CPU内存,可以在相同的训练脚本中完成。以下部分将讨论这两种方法。
**实时FP32权重恢复:**
如果您的模型很大,并且在训练结束时几乎没有剩余的空闲CPU内存,这种方法可能不起作用。
如果您至少保存了一个检查点,并且想要使用最新的一个,可以按照以下步骤操作:
```python
from transformers.trainer_utils import get_last_checkpoint
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = get_last_checkpoint(trainer.args.output_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
如果您在使用`--load_best_model_at_end`类:*~transformers.TrainingArguments*参数(用于跟踪最佳
检查点),那么你可以首先显式地保存最终模型,然后再执行相同的操作:
```python
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = os.path.join(trainer.args.output_dir, "checkpoint-final")
trainer.deepspeed.save_checkpoint(checkpoint_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
<Tip>
注意,一旦运行了`load_state_dict_from_zero_checkpoint`,该模型将不再可以在相同的应用程序的DeepSpeed上下文中使用。也就是说,您需要重新初始化deepspeed引擎,因为`model.load_state_dict(state_dict)`会从其中移除所有的DeepSpeed相关点。所以您只能训练结束时这样做。
</Tip>
当然,您不必使用类:*~transformers.Trainer*,您可以根据你的需求调整上面的示例。
如果您出于某种原因想要更多的优化,您也可以提取权重的fp32 `state_dict`并按照以下示例进行操作:
```python
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) # already on cpu
model = model.cpu()
model.load_state_dict(state_dict)
```
**离线FP32权重恢复:**
DeepSpeed会创建一个特殊的转换脚本`zero_to_fp32.py`,并将其放置在checkpoint文件夹的顶层。使用此脚本,您可以在任何时候提取权重。该脚本是独立的,您不再需要配置文件或`Trainer`来执行提取操作。
假设您的checkpoint文件夹如下所示:
```bash
$ ls -l output_dir/checkpoint-1/
-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
```
在这个例子中,只有一个DeepSpeed检查点子文件夹*global_step1*。因此,要重构fp32权重,只需运行:
```bash
python zero_to_fp32.py . pytorch_model.bin
```
这就是它。`pytorch_model.bin`现在将包含从多个GPUs合并的完整的fp32模型权重。
该脚本将自动能够处理ZeRO-2或ZeRO-3 checkpoint。
`python zero_to_fp32.py -h`将为您提供使用细节。
该脚本将通过文件`latest`的内容自动发现deepspeed子文件夹,在当前示例中,它将包含`global_step1`。
注意:目前该脚本需要2倍于最终fp32模型权重的通用内存。
### ZeRO-3 和 Infinity Nuances
ZeRO-3与ZeRO-2有很大的不同,主要是因为它的参数分片功能。
ZeRO-Infinity进一步扩展了ZeRO-3,以支持NVMe内存和其他速度和可扩展性改进。
尽管所有努力都是为了在不需要对模型进行任何特殊更改的情况下就能正常运行,但在某些情况下,您可能需要以下信息。
#### 构建大模型
DeepSpeed/ZeRO-3可以处理参数量达到数万亿的模型,这些模型可能无法适应现有的内存。在这种情况下,如果您还是希望初始化更快地发生,可以使用*deepspeed.zero.Init()*上下文管理器(也是一个函数装饰器)来初始化模型,如下所示:
```python
from transformers import T5ForConditionalGeneration, T5Config
import deepspeed
with deepspeed.zero.Init():
config = T5Config.from_pretrained("t5-small")
model = T5ForConditionalGeneration(config)
```
如您所见,这会为您随机初始化一个模型。
如果您想使用预训练模型,`model_class.from_pretrained`将在`is_deepspeed_zero3_enabled()`返回`True`的情况下激活此功能,目前这是通过传递的DeepSpeed配置文件中的ZeRO-3配置部分设置的。因此,在调用`from_pretrained`之前,您必须创建**TrainingArguments**对象。以下是可能的顺序示例:
```python
from transformers import AutoModel, Trainer, TrainingArguments
training_args = TrainingArguments(..., deepspeed=ds_config)
model = AutoModel.from_pretrained("t5-small")
trainer = Trainer(model=model, args=training_args, ...)
```
如果您使用的是官方示例脚本,并且命令行参数中包含`--deepspeed ds_config.json`且启用了ZeRO-3配置,那么一切都已经为您准备好了,因为这是示例脚本的编写方式。
注意:如果模型的fp16权重无法适应单个GPU的内存,则必须使用此功能。
有关此方法和其他相关功能的完整详细信息,请参阅[构建大模型](https://deepspeed.readthedocs.io/en/latest/zero3.html#constructing-massive-models)。
此外,在加载fp16预训练模型时,您希望`from_pretrained`使用`torch_dtype=torch.float16`。详情请参见[from_pretrained-torch-dtype](#from_pretrained-torch-dtype)。
#### 参数收集
在多个GPU上使用ZeRO-3时,没有一个GPU拥有所有参数,除非它是当前执行层的参数。因此,如果您需要一次访问所有层的所有参数,有一个特定的方法可以实现。
您可能不需要它,但如果您需要,请参考[参数收集](https://deepspeed.readthedocs.io/en/latest/zero3.html#manual-parameter-coordination)。
然而,我们在多个地方确实使用了它,其中一个例子是在`from_pretrained`中加载预训练模型权重。我们一次加载一层,然后立即将其分区到所有参与的GPU上,因为对于非常大的模型,无法在一个GPU上一次性加载并将其分布到多个GPU上,因为内存限制。
此外,在ZeRO-3下,如果您编写自己的代码并遇到看起来像这样的模型参数权重:
```python
tensor([1.0], device="cuda:0", dtype=torch.float16, requires_grad=True)
```
强调`tensor([1.])`,或者如果您遇到一个错误,它说参数的大小是`1`,而不是某个更大的多维形状,这意味着参数被划分了,你看到的是一个ZeRO-3占位符。
<a id='deepspeed-zero-inference'></a>
### ZeRO 推理
"ZeRO 推断" 使用与 "ZeRO-3 训练" 相同的配置。您只需要去掉优化器和调度器部分。实际上,如果您希望与训练共享相同的配置文件,您可以将它们保留在配置文件中,它们只会被忽略。
您只需要传递通常的[`TrainingArguments`]参数。例如:
```bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.json
```
唯一的重要事情是您需要使用ZeRO-3配置,因为ZeRO-2对于推理没有任何优势,因为只有ZeRO-3才对参数进行分片,而ZeRO-1则对梯度和优化器状态进行分片。
以下是在DeepSpeed下运行`run_translation.py`启用所有可用GPU的示例:
```bash
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small --output_dir output_dir \
--do_eval --max_eval_samples 50 --warmup_steps 50 \
--max_source_length 128 --val_max_target_length 128 \
--overwrite_output_dir --per_device_eval_batch_size 4 \
--predict_with_generate --dataset_config "ro-en" --fp16 \
--source_lang en --target_lang ro --dataset_name wmt16 \
--source_prefix "translate English to Romanian: "
```
由于在推理阶段,优化器状态和梯度不需要额外的大量内存,您应该能够将更大的批次和/或序列长度放到相同的硬件上。
此外,DeepSpeed目前正在开发一个名为Deepspeed-Inference的相关产品,它与ZeRO技术无关,而是使用张量并行来扩展无法适应单个GPU的模型。这是一个正在进行的工作,一旦该产品完成,我们将提供集成。
### 内存要求
由于 DeepSpeed ZeRO 可以将内存卸载到 CPU(和 NVMe),该框架提供了一些工具,允许根据使用的 GPU 数量告知将需要多少 CPU 和 GPU 内存。
让我们估计在单个GPU上微调"bigscience/T0_3B"所需的内存:
```bash
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 1 GPU per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
```
因此,您可以将模型拟合在单个80GB的GPU上,不进行CPU offload,或者使用微小的8GB GPU,但需要约60GB的CPU内存。(请注意,这仅是参数、优化器状态和梯度所需的内存 - 您还需要为CUDA内核、激活值和临时变量分配更多的内存。)
然后,这是成本与速度的权衡。购买/租用较小的 GPU(或较少的 GPU,因为您可以使用多个 GPU 进行 Deepspeed ZeRO)。但这样会更慢,因此即使您不关心完成某项任务的速度,减速也直接影响 GPU 使用的持续时间,从而导致更大的成本。因此,请进行实验并比较哪种方法效果最好。
如果您有足够的GPU内存,请确保禁用CPU/NVMe卸载,因为这会使所有操作更快。
例如,让我们重复相同的操作,使用2个GPU:
```bash
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=2, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 2 GPUs per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.74GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=1
31.11GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=0
```
所以,您需要2个32GB或更高的GPU,且不进行CPU卸载。
如需了解更多信息,请参阅[内存估算器](https://deepspeed.readthedocs.io/en/latest/memory.html)。
### 归档Issues
请按照以下步骤提交问题,以便我们能够迅速找到问题并帮助您解除工作阻塞。
在您的报告中,请始终包括以下内容:
1. 完整的Deepspeed配置文件
2. 如果使用了[`Trainer`],则包括命令行参数;如果自己编写了Trainer设置,则包括[`TrainingArguments`]参数。请不要导出[`TrainingArguments`],因为它有几十个与问题无关的条目。
3. 输出:
```bash
python -c 'import torch; print(f"torch: {torch.__version__}")'
python -c 'import transformers; print(f"transformers: {transformers.__version__}")'
python -c 'import deepspeed; print(f"deepspeed: {deepspeed.__version__}")'
```
4. 如果可能,请包含一个Google Colab notebook链接,我们可以使用它来重现问题。您可以使用这个[notebook](https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb)作为起点。
5. 除非不可能,否则请始终使用标准数据集,而不是自定义数据集。
6. 如果可能,尝试使用现有[示例](https://github.com/huggingface/transformers/tree/main/examples/pytorch)之一来重现问题。
需要考虑的因素:
- Deepspeed通常不是问题的原因。
一些已提交的问题被证明与Deepspeed无关。也就是说,一旦将Deepspeed从设置中移除,问题仍然存在。
因此,如果问题明显与DeepSpeed相关,例如您可以看到有一个异常并且可以看到DeepSpeed模块涉及其中,请先重新测试没有DeepSpeed的设置。只有当问题仍然存在时,才向Deepspeed提供所有必需的细节。
- 如果您明确问题是在Deepspeed核心中而不是集成部分,请直接向[Deepspeed](https://github.com/microsoft/DeepSpeed/)提交问题。如果您不确定,请不要担心,无论使用哪个issue跟踪问题都可以,一旦您发布问题,我们会弄清楚并将其重定向到另一个issue跟踪(如果需要的话)。
### Troubleshooting
#### 启动时`deepspeed`进程被终止,没有回溯
如果启动时`deepspeed`进程被终止,没有回溯,这通常意味着程序尝试分配的CPU内存超过了系统的限制或进程被允许分配的内存,操作系统内核杀死了该进程。这是因为您的配置文件很可能将`offload_optimizer`或`offload_param`或两者都配置为卸载到`cpu`。如果您有NVMe,可以尝试在ZeRO-3下卸载到NVMe。这里是如何[估计特定模型所需的内存](https://deepspeed.readthedocs.io/en/latest/memory.html)。
#### 训练和/或评估/预测loss为`NaN`
这种情况通常发生在使用bf16混合精度模式预训练的模型试图在fp16(带或不带混合精度)下使用时。大多数在TPU上训练的模型以及由谷歌发布的模型都属于这个类别(例如,几乎所有基于t5的模型)。在这种情况下,解决方案是要么使用fp32,要么在支持的情况下使用bf16(如TPU、Ampere GPU或更新的版本)。
另一个问题可能与使用fp16有关。当您配置此部分时:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
并且您在日志中看到Deepspeed报告`OVERFLOW`如下
```
0%| | 0/189 [00:00<?, ?it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 262144
1%|▌ | 1/189 [00:00<01:26, 2.17it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 131072.0
1%|█▏
[...]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
14%|████████████████▌ | 27/189 [00:14<01:13, 2.21it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▏ | 28/189 [00:14<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▊ | 29/189 [00:15<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
[...]
```
这意味着Deepspeed损失缩放器无法找到一个克服损失溢出的缩放系数。
在这种情况下,通常需要提高`initial_scale_power`的值。将其设置为`"initial_scale_power": 32`通常会解决问题。
### 注意事项
- 尽管 DeepSpeed 有一个可安装的 PyPI 包,但强烈建议从源代码安装它,以最好地匹配您的硬件,如果您需要启用某些功能,如 1-bit Adam,这些功能在 pypi 发行版中不可用。
- 您不必使用🤗 Transformers的 [`Trainer`] 来使用 DeepSpeed - 您可以使用任何模型与自己的训练器,您还需要根据 [DeepSpeed 集成说明](https://www.deepspeed.ai/getting-started/#writing-deepspeed-models) 调整后者。
## Non-Trainer Deepspeed集成
当`Trainer`没有被使用时,`~integrations.HfDeepSpeedConfig`被用来将Deepspeed集成到huggingface的Transformers核心功能中。它唯一做的事情就是在`from_pretrained`调用期间处理Deepspeed ZeRO-3参数收集和将模型自动分割到多个GPU上。除此之外,您需要自己完成其他所有工作。
当使用`Trainer`时,所有事情都自动得到了处理。
当不使用`Trainer`时,为了高效地部署Deepspeed ZeRO-3,您必须在实例化模型之前实例化`~integrations.HfDeepSpeedConfig`对象并保持该对象活跃。
如果您正在使用Deepspeed ZeRO-1或ZeRO-2,您根本不需要使用`HfDeepSpeedConfig`。
以预训练模型为例:
```python
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
model = AutoModel.from_pretrained("gpt2")
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
或者以非预训练模型为例:
```python
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel, AutoConfig
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
config = AutoConfig.from_pretrained("gpt2")
model = AutoModel.from_config(config)
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
请注意,如果您没有使用[`Trainer`]集成,您完全需要自己动手。基本上遵循[Deepspeed](https://www.deepspeed.ai/)网站上的文档。同时,您必须显式配置配置文件 - 不能使用`"auto"`值,而必须放入实际值。
## HfDeepSpeedConfig
[[autodoc]] integrations.HfDeepSpeedConfig
- all
### 自定义DeepSpeed ZeRO推理
以下是一个示例,演示了在无法将模型放入单个 GPU 时如果不使用[Trainer]进行 DeepSpeed ZeRO 推理 。该解决方案包括使用额外的 GPU 或/和将 GPU 内存卸载到 CPU 内存。
这里要理解的重要细微差别是,ZeRO的设计方式可以让您在不同的GPU上并行处理不同的输入。
这个例子有很多注释,并且是自文档化的。
请确保:
1. 如果您有足够的GPU内存(因为这会减慢速度),禁用CPU offload。
2. 如果您拥有Ampere架构或更新的GPU,启用bf16以加快速度。如果您没有这种硬件,只要不使用任何在bf16混合精度下预训练的模型(如大多数t5模型),就可以启用fp16。否则这些模型通常在fp16中溢出,您会看到输出无效结果。
```python
#!/usr/bin/env python
# This script demonstrates how to use Deepspeed ZeRO in an inference mode when one can't fit a model
# into a single GPU
#
# 1. Use 1 GPU with CPU offload
# 2. Or use multiple GPUs instead
#
# First you need to install deepspeed: pip install deepspeed
#
# Here we use a 3B "bigscience/T0_3B" model which needs about 15GB GPU RAM - so 1 largish or 2
# small GPUs can handle it. or 1 small GPU and a lot of CPU memory.
#
# To use a larger model like "bigscience/T0" which needs about 50GB, unless you have an 80GB GPU -
# you will need 2-4 gpus. And then you can adapt the script to handle more gpus if you want to
# process multiple inputs at once.
#
# The provided deepspeed config also activates CPU memory offloading, so chances are that if you
# have a lot of available CPU memory and you don't mind a slowdown you should be able to load a
# model that doesn't normally fit into a single GPU. If you have enough GPU memory the program will
# run faster if you don't want offload to CPU - so disable that section then.
#
# To deploy on 1 gpu:
#
# deepspeed --num_gpus 1 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=1 t0.py
#
# To deploy on 2 gpus:
#
# deepspeed --num_gpus 2 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=2 t0.py
from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
from transformers.integrations import HfDeepSpeedConfig
import deepspeed
import os
import torch
os.environ["TOKENIZERS_PARALLELISM"] = "false" # To avoid warnings about parallelism in tokenizers
# distributed setup
local_rank = int(os.getenv("LOCAL_RANK", "0"))
world_size = int(os.getenv("WORLD_SIZE", "1"))
torch.cuda.set_device(local_rank)
deepspeed.init_distributed()
model_name = "bigscience/T0_3B"
config = AutoConfig.from_pretrained(model_name)
model_hidden_size = config.d_model
# batch size has to be divisible by world_size, but can be bigger than world_size
train_batch_size = 1 * world_size
# ds_config notes
#
# - enable bf16 if you use Ampere or higher GPU - this will run in mixed precision and will be
# faster.
#
# - for older GPUs you can enable fp16, but it'll only work for non-bf16 pretrained models - e.g.
# all official t5 models are bf16-pretrained
#
# - set offload_param.device to "none" or completely remove the `offload_param` section if you don't
# - want CPU offload
#
# - if using `offload_param` you can manually finetune stage3_param_persistence_threshold to control
# - which params should remain on gpus - the larger the value the smaller the offload size
#
# For indepth info on Deepspeed config see
# https://huggingface.co/docs/transformers/main/main_classes/deepspeed
# keeping the same format as json for consistency, except it uses lower case for true/false
# fmt: off
ds_config = {
"fp16": {
"enabled": False
},
"bf16": {
"enabled": False
},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": True
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_bucket_size": model_hidden_size * model_hidden_size,
"stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
"stage3_param_persistence_threshold": 10 * model_hidden_size
},
"steps_per_print": 2000,
"train_batch_size": train_batch_size,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": False
}
# fmt: on
# next line instructs transformers to partition the model directly over multiple gpus using
# deepspeed.zero.Init when model's `from_pretrained` method is called.
#
# **it has to be run before loading the model AutoModelForSeq2SeqLM.from_pretrained(model_name)**
#
# otherwise the model will first be loaded normally and only partitioned at forward time which is
# less efficient and when there is little CPU RAM may fail
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
# now a model can be loaded.
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# initialise Deepspeed ZeRO and store only the engine object
ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
ds_engine.module.eval() # inference
# Deepspeed ZeRO can process unrelated inputs on each GPU. So for 2 gpus you process 2 inputs at once.
# If you use more GPUs adjust for more.
# And of course if you have just one input to process you then need to pass the same string to both gpus
# If you use only one GPU, then you will have only rank 0.
rank = torch.distributed.get_rank()
if rank == 0:
text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
elif rank == 1:
text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
with torch.no_grad():
outputs = ds_engine.module.generate(inputs, synced_gpus=True)
text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"rank{rank}:\n in={text_in}\n out={text_out}")
```
让我们保存它为 `t0.py`并运行:
```
$ deepspeed --num_gpus 2 t0.py
rank0:
in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
out=Positive
rank1:
in=Is this review positive or negative? Review: this is the worst restaurant ever
out=negative
```
这是一个非常基本的例子,您需要根据自己的需求进行修改。
### `generate` 的差异
在使用ZeRO stage 3的多GPU时,需要通过调用`generate(..., synced_gpus=True)`来同步GPU。如果一个GPU在其它GPU之前完成生成,整个系统将挂起,因为其他GPU无法从停止生成的GPU接收权重分片。
从`transformers>=4.28`开始,如果没有明确指定`synced_gpus`,检测到这些条件后它将自动设置为`True`。但如果您需要覆盖`synced_gpus`的值,仍然可以这样做。
## 测试 DeepSpeed 集成
如果您提交了一个涉及DeepSpeed集成的PR,请注意我们的CircleCI PR CI设置没有GPU,因此我们只在另一个CI夜间运行需要GPU的测试。因此,如果您在PR中获得绿色的CI报告,并不意味着DeepSpeed测试通过。
要运行DeepSpeed测试,请至少运行以下命令:
```
RUN_SLOW=1 pytest tests/deepspeed/test_deepspeed.py
```
如果你更改了任何模型或PyTorch示例代码,请同时运行多模型测试。以下将运行所有DeepSpeed测试:
```
RUN_SLOW=1 pytest tests/deepspeed
```
## 主要的DeepSpeed资源
- [项目GitHub](https://github.com/microsoft/deepspeed)
- [使用文档](https://www.deepspeed.ai/getting-started/)
- [API文档](https://deepspeed.readthedocs.io/en/latest/index.html)
- [博客文章](https://www.microsoft.com/en-us/research/search/?q=deepspeed)
论文:
- [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/abs/1910.02054)
- [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)
- [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)
最后,请记住,HuggingFace [`Trainer`]仅集成了DeepSpeed,因此如果您在使用DeepSpeed时遇到任何问题或疑问,请在[DeepSpeed GitHub](https://github.com/microsoft/DeepSpeed/issues)上提交一个issue。
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/callback.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Callbacks
Callbacks可以用来自定义PyTorch [Trainer]中训练循环行为的对象(此功能尚未在TensorFlow中实现),该对象可以检查训练循环状态(用于进度报告、在TensorBoard或其他ML平台上记录日志等),并做出决策(例如提前停止)。
Callbacks是“只读”的代码片段,除了它们返回的[TrainerControl]对象外,它们不能更改训练循环中的任何内容。对于需要更改训练循环的自定义,您应该继承[Trainer]并重载您需要的方法(有关示例,请参见[trainer](trainer))。
默认情况下,`TrainingArguments.report_to` 设置为"all",然后[Trainer]将使用以下callbacks。
- [`DefaultFlowCallback`],它处理默认的日志记录、保存和评估行为
- [`PrinterCallback`] 或 [`ProgressCallback`],用于显示进度和打印日志(如果通过[`TrainingArguments`]停用tqdm,则使用第一个函数;否则使用第二个)。
- [`~integrations.TensorBoardCallback`],如果TensorBoard可访问(通过PyTorch版本 >= 1.4 或者 tensorboardX)。
- [`~integrations.WandbCallback`],如果安装了[wandb](https://www.wandb.com/)。
- [`~integrations.CometCallback`],如果安装了[comet_ml](https://www.comet.ml/site/)。
- [`~integrations.MLflowCallback`],如果安装了[mlflow](https://www.mlflow.org/)。
- [`~integrations.NeptuneCallback`],如果安装了[neptune](https://neptune.ai/)。
- [`~integrations.AzureMLCallback`],如果安装了[azureml-sdk](https://pypi.org/project/azureml-sdk/)。
- [`~integrations.CodeCarbonCallback`],如果安装了[codecarbon](https://pypi.org/project/codecarbon/)。
- [`~integrations.ClearMLCallback`],如果安装了[clearml](https://github.com/allegroai/clearml)。
- [`~integrations.DagsHubCallback`],如果安装了[dagshub](https://dagshub.com/)。
- [`~integrations.FlyteCallback`],如果安装了[flyte](https://flyte.org/)。
- [`~integrations.DVCLiveCallback`],如果安装了[dvclive](https://dvc.org/doc/dvclive)。
如果安装了一个软件包,但您不希望使用相关的集成,您可以将 `TrainingArguments.report_to` 更改为仅包含您想要使用的集成的列表(例如 `["azure_ml", "wandb"]`)。
实现callbacks的主要类是[`TrainerCallback`]。它获取用于实例化[`Trainer`]的[`TrainingArguments`],可以通过[`TrainerState`]访问该Trainer的内部状态,并可以通过[`TrainerControl`]对训练循环执行一些操作。
## 可用的Callbacks
这里是库里可用[`TrainerCallback`]的列表:
[[autodoc]] integrations.CometCallback
- setup
[[autodoc]] DefaultFlowCallback
[[autodoc]] PrinterCallback
[[autodoc]] ProgressCallback
[[autodoc]] EarlyStoppingCallback
[[autodoc]] integrations.TensorBoardCallback
[[autodoc]] integrations.WandbCallback
- setup
[[autodoc]] integrations.MLflowCallback
- setup
[[autodoc]] integrations.AzureMLCallback
[[autodoc]] integrations.CodeCarbonCallback
[[autodoc]] integrations.NeptuneCallback
[[autodoc]] integrations.ClearMLCallback
[[autodoc]] integrations.DagsHubCallback
[[autodoc]] integrations.FlyteCallback
[[autodoc]] integrations.DVCLiveCallback
- setup
## TrainerCallback
[[autodoc]] TrainerCallback
以下是如何使用PyTorch注册自定义callback的示例:
[`Trainer`]:
```python
class MyCallback(TrainerCallback):
"A callback that prints a message at the beginning of training"
def on_train_begin(self, args, state, control, **kwargs):
print("Starting training")
trainer = Trainer(
model,
args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[MyCallback], # We can either pass the callback class this way or an instance of it (MyCallback())
)
```
注册callback的另一种方式是调用 `trainer.add_callback()`,如下所示:
```python
trainer = Trainer(...)
trainer.add_callback(MyCallback)
# Alternatively, we can pass an instance of the callback class
trainer.add_callback(MyCallback())
```
## TrainerState
[[autodoc]] TrainerState
## TrainerControl
[[autodoc]] TrainerControl
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/keras_callbacks.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Keras callbacks
在Keras中训练Transformers模型时,有一些库特定的callbacks函数可用于自动执行常见任务:
## KerasMetricCallback
[[autodoc]] KerasMetricCallback
## PushToHubCallback
[[autodoc]] PushToHubCallback
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/data_collator.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Data Collator
Data collators是一个对象,通过使用数据集元素列表作为输入来形成一个批次。这些元素与 `train_dataset` 或 `eval_dataset` 的元素类型相同。
为了能够构建批次,Data collators可能会应用一些预处理(比如填充)。其中一些(比如[`DataCollatorForLanguageModeling`])还会在形成的批次上应用一些随机数据增强(比如随机掩码)。
在[示例脚本](../examples)或[示例notebooks](../notebooks)中可以找到使用的示例。
## Default data collator
[[autodoc]] data.data_collator.default_data_collator
## DefaultDataCollator
[[autodoc]] data.data_collator.DefaultDataCollator
## DataCollatorWithPadding
[[autodoc]] data.data_collator.DataCollatorWithPadding
## DataCollatorForTokenClassification
[[autodoc]] data.data_collator.DataCollatorForTokenClassification
## DataCollatorForSeq2Seq
[[autodoc]] data.data_collator.DataCollatorForSeq2Seq
## DataCollatorForLanguageModeling
[[autodoc]] data.data_collator.DataCollatorForLanguageModeling
- numpy_mask_tokens
- tf_mask_tokens
- torch_mask_tokens
## DataCollatorForWholeWordMask
[[autodoc]] data.data_collator.DataCollatorForWholeWordMask
- numpy_mask_tokens
- tf_mask_tokens
- torch_mask_tokens
## DataCollatorForPermutationLanguageModeling
[[autodoc]] data.data_collator.DataCollatorForPermutationLanguageModeling
- numpy_mask_tokens
- tf_mask_tokens
- torch_mask_tokens
| 0 |
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/onnx.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 导出 🤗 Transformers 模型到 ONNX
🤗 Transformers提供了一个`transformers.onnx`包,通过利用配置对象,您可以将模型checkpoints转换为ONNX图。
有关更多详细信息,请参阅导出 🤗 Transformers 模型的[指南](../serialization)。
## ONNX Configurations
我们提供了三个抽象类,取决于您希望导出的模型架构类型:
* 基于编码器的模型继承 [`~onnx.config.OnnxConfig`]
* 基于解码器的模型继承 [`~onnx.config.OnnxConfigWithPast`]
* 编码器-解码器模型继承 [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
### OnnxConfig
[[autodoc]] onnx.config.OnnxConfig
### OnnxConfigWithPast
[[autodoc]] onnx.config.OnnxConfigWithPast
### OnnxSeq2SeqConfigWithPast
[[autodoc]] onnx.config.OnnxSeq2SeqConfigWithPast
## ONNX Features
每个ONNX配置与一组 _特性_ 相关联,使您能够为不同类型的拓扑结构或任务导出模型。
### FeaturesManager
[[autodoc]] onnx.features.FeaturesManager
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers
Machine Learning allo stato dell'arte per PyTorch, TensorFlow e JAX.
🤗 Transformers fornisce delle API per scaricare in modo semplice e allenare modelli pre-allenati allo stato dell'arte. L'utilizzo di modelli pre-allenati può ridurre i tuoi costi computazionali, l'impatto ambientale, e farti risparmiare il tempo che utilizzeresti per allenare un modello da zero. I modelli possono essere utilizzati in diverse modalità come ad esempio:
* 📝 Testo: classificazione del testo, estrazione delle informazioni, rispondere a domande, riassumere, traduzione e generazione del testo in più di 100 lingue.
* 🖼️ Immagini: classificazione di immagini, rilevazione di oggetti e segmentazione.
* 🗣️ Audio: riconoscimento vocale e classificazione dell'audio.
* 🐙 Multimodale: rispondere a domande inerenti dati tabulari, riconoscimento ottico dei caratteri, estrazione di informazioni a partire da documenti scannerizzati, classificazione di video e risposta visuale a domande.
La nostra libreria supporta un'integrazione perfetta tra tre delle librerie per il deep learning più popolari: [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) e [JAX](https://jax.readthedocs.io/en/latest/). Allena il tuo modello in tre righe di codice in un framework, e caricalo per l'inferenza in un altro.
Ogni architettura di 🤗 Transformers è definita in un modulo Python indipendente così da poter essere personalizzata in modo semplice per la ricerca e gli esperimenti.
## Se stai cercando supporto personalizzato dal team di Hugging Face
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://huggingface.co/front/thumbnails/support.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## Contenuti
La documentazione è organizzata in cinque parti:
- **INIZIARE** contiene un tour rapido e le istruzioni di installazione per cominciare ad utilizzare 🤗 Transformers.
- **TUTORIALS** è un buon posto da cui iniziare se per te la nostra libreria è nuova. Questa sezione ti aiuterà ad acquisire le competenze basilari di cui hai bisogno per iniziare ad utilizzare 🤗 Transformers.
- **GUIDE PRATICHE** ti mostrerà come raggiungere obiettivi specifici come fare fine-tuning di un modello pre-allenato per la modellizzazione del linguaggio o come creare una testa per un modello personalizzato.
- **GUIDE CONCETTUALI** fornisce discussioni e spiegazioni dei concetti sottostanti alle idee dietro ai modelli, compiti, e la filosofia di progettazione di 🤗 Transformers.
- **API** descrive ogni classe e funzione, raggruppate in:
- **CLASSI PRINCIPALI** per le classi principali che espongono le API importanti della libreria.
- **MODELLI** per le classi e le funzioni relative ad ogni modello implementato all'interno della libreria.
- **HELPERS INTERNI** per le classi e le funzioni che utilizziamo internamente.
La libreria attualmente contiene implementazioni in JAX, PyTorch e TensorFlow, pesi di modelli pre-allenati, script di utilizzo e strumenti di conversione per i seguenti modelli.
### Modelli supportati
<!--This list is updated automatically from the README with _make fix-copies_. Do not update manually! -->
1. **[ALBERT](model_doc/albert)** (da Google Research e l'Istituto Tecnologico di Chicago) rilasciato con il paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), da Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[ALIGN](model_doc/align)** (from Google Research) rilasciato con il paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) da Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
1. **[BART](model_doc/bart)** (da Facebook) rilasciato con il paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) da Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov e Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (da politecnico di École) rilasciato con il paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) da Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (da VinAI Research) rilasciato con il paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) da Nguyen Luong Tran, Duong Minh Le e Dat Quoc Nguyen.
1. **[BEiT](model_doc/beit)** (da Microsoft) rilasciato con il paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) da Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](model_doc/bert)** (da Google) rilasciato con il paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) da Jacob Devlin, Ming-Wei Chang, Kenton Lee e Kristina Toutanova.
1. **[BERTweet](model_doc/bertweet)** (da VinAI Research) rilasciato con il paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) da Dat Quoc Nguyen, Thanh Vu e Anh Tuan Nguyen.
1. **[BERT For Sequence Generation](model_doc/bert-generation)** (da Google) rilasciato con il paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) da Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BigBird-RoBERTa](model_doc/big_bird)** (da Google Research) rilasciato con il paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) da Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (v Google Research) rilasciato con il paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) da Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[Blenderbot](model_doc/blenderbot)** (da Facebook) rilasciato con il paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) da Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (da Facebook) rilasciato con il paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) da Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BORT](model_doc/bort)** (da Alexa) rilasciato con il paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) da Adrian de Wynter e Daniel J. Perry.
1. **[ByT5](model_doc/byt5)** (da Google Research) rilasciato con il paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) da Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (da Inria/Facebook/Sorbonne) rilasciato con il paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) da Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah e Benoît Sagot.
1. **[CANINE](model_doc/canine)** (da Google Research) rilasciato con il paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) da Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[ConvNeXT](model_doc/convnext)** (da Facebook AI) rilasciato con il paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) da Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](model_doc/convnextv2)** (da Facebook AI) rilasciato con il paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) da Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CLIP](model_doc/clip)** (da OpenAI) rilasciato con il paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) da Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[ConvBERT](model_doc/convbert)** (da YituTech) rilasciato con il paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) da Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[CPM](model_doc/cpm)** (dalla Università di Tsinghua) rilasciato con il paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) da Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](model_doc/ctrl)** (da Salesforce) rilasciato con il paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) da Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong e Richard Socher.
1. **[CvT](model_doc/cvt)** (da Microsoft) rilasciato con il paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) da Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
1. **[Data2Vec](model_doc/data2vec)** (da Facebook) rilasciato con il paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) da Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](model_doc/deberta)** (da Microsoft) rilasciato con il paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) da Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](model_doc/deberta-v2)** (da Microsoft) rilasciato con il paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) da Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](model_doc/decision_transformer)** (da Berkeley/Facebook/Google) rilasciato con il paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) da Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[DiT](model_doc/dit)** (da Microsoft Research) rilasciato con il paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) da Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[DeiT](model_doc/deit)** (da Facebook) rilasciato con il paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) da Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DETR](model_doc/detr)** (da Facebook) rilasciato con il paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) da Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](model_doc/dialogpt)** (da Microsoft Research) rilasciato con il paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) da Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DistilBERT](model_doc/distilbert)** (da HuggingFace), rilasciato assieme al paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) da Victor Sanh, Lysandre Debut e Thomas Wolf. La stessa tecnica è stata applicata per comprimere GPT2 in [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa in [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT in [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DPR](model_doc/dpr)** (da Facebook) rilasciato con il paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) da Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, e Wen-tau Yih.
1. **[DPT](master/model_doc/dpt)** (da Intel Labs) rilasciato con il paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) da René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
1. **[EncoderDecoder](model_doc/encoder-decoder)** (da Google Research) rilasciato con il paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) da Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ELECTRA](model_doc/electra)** (da Google Research/Stanford University) rilasciato con il paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) da Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[FlauBERT](model_doc/flaubert)** (da CNRS) rilasciato con il paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) da Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FLAVA](model_doc/flava)** (da Facebook AI) rilasciato con il paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) da Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, e Douwe Kiela.
1. **[FNet](model_doc/fnet)** (da Google Research) rilasciato con il paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) da James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[Funnel Transformer](model_doc/funnel)** (da CMU/Google Brain) rilasciato con il paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) da Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GLPN](model_doc/glpn)** (da KAIST) rilasciato con il paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) da Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (da OpenAI) rilasciato con il paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) da Alec Radford, Karthik Narasimhan, Tim Salimans e Ilya Sutskever.
1. **[GPT-2](model_doc/gpt2)** (da OpenAI) rilasciato con il paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) da Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** e Ilya Sutskever**.
1. **[GPT-J](model_doc/gptj)** (da EleutherAI) rilasciato nel repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) da Ben Wang e Aran Komatsuzaki.
1. **[GPT Neo](model_doc/gpt_neo)** (da EleutherAI) rilasciato nel repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) da Sid Black, Stella Biderman, Leo Gao, Phil Wang e Connor Leahy.
1. **[GPT NeoX](model_doc/gpt_neox)** (da EleutherAI) rilasciato con il paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) da Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[Hubert](model_doc/hubert)** (da Facebook) rilasciato con il paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) da Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](model_doc/ibert)** (da Berkeley) rilasciato con il paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) da Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (da OpenAI) rilasciato con il paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) da Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[LayoutLM](model_doc/layoutlm)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) da Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](model_doc/layoutlmv2)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) da Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](model_doc/layoutlmv3)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) da Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](model_doc/layoutlxlm)** (da Microsoft Research Asia) rilasciato con il paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) da Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (da AllenAI) rilasciato con il paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) da Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[Longformer](model_doc/longformer)** (da AllenAI) rilasciato con il paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) da Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LUKE](model_doc/luke)** (da Studio Ousia) rilasciato con il paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) da Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[mLUKE](model_doc/mluke)** (da Studio Ousia) rilasciato con il paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) da Ryokan Ri, Ikuya Yamada, e Yoshimasa Tsuruoka.
1. **[LXMERT](model_doc/lxmert)** (da UNC Chapel Hill) rilasciato con il paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) da Hao Tan e Mohit Bansal.
1. **[M2M100](model_doc/m2m_100)** (da Facebook) rilasciato con il paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) da Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Modello di machine learning per le traduzioni allenato utilizzando i dati [OPUS](http://opus.nlpl.eu/) di Jörg Tiedemann. Il [Framework Marian](https://marian-nmt.github.io/) è stato sviluppato dal Microsoft Translator Team.
1. **[Mask2Former](model_doc/mask2former)** (da FAIR e UIUC) rilasciato con il paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) da Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](model_doc/maskformer)** (da Meta e UIUC) rilasciato con il paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) da Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MBart](model_doc/mbart)** (da Facebook) rilasciato con il paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) da Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[MBart-50](model_doc/mbart)** (da Facebook) rilasciato con il paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) da Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[Megatron-BERT](model_doc/megatron-bert)** (da NVIDIA) rilasciato con il paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) da Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper e Bryan Catanzaro.
1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (da NVIDIA) rilasciato con il paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) da Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper e Bryan Catanzaro.
1. **[MPNet](model_doc/mpnet)** (da Microsoft Research) rilasciato con il paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) da Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MT5](model_doc/mt5)** (da Google AI) rilasciato con il paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) da Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[Nyströmformer](model_doc/nystromformer)** (dalla Università del Wisconsin - Madison) rilasciato con il paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) da Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](model_doc/oneformer)** (da SHI Labs) rilasciato con il paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) da Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[OPT](master/model_doc/opt)** (da Meta AI) rilasciato con il paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) da Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[Pegasus](model_doc/pegasus)** (da Google) rilasciato con il paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) da Jingqing Zhang, Yao Zhao, Mohammad Saleh e Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (da Deepmind) rilasciato con il paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) da Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (da VinAI Research) rilasciato con il paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) da Dat Quoc Nguyen e Anh Tuan Nguyen.
1. **[PLBart](model_doc/plbart)** (da UCLA NLP) rilasciato con il paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) da Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](model_doc/poolformer)** (da Sea AI Labs) rilasciato con il paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) da Yu, Weihao e Luo, Mi e Zhou, Pan e Si, Chenyang e Zhou, Yichen e Wang, Xinchao e Feng, Jiashi e Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (da Microsoft Research) rilasciato con il paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) da Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang e Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (da NVIDIA) rilasciato con il paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) da Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev e Paulius Micikevicius.
1. **[REALM](model_doc/realm.html)** (da Google Research) rilasciato con il paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) da Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat e Ming-Wei Chang.
1. **[Reformer](model_doc/reformer)** (da Google Research) rilasciato con il paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) da Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RemBERT](model_doc/rembert)** (da Google Research) rilasciato con il paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) da Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[RegNet](model_doc/regnet)** (da META Platforms) rilasciato con il paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) da Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[ResNet](model_doc/resnet)** (da Microsoft Research) rilasciato con il paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) da Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](model_doc/roberta)** (da Facebook), rilasciato assieme al paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) da Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoFormer](model_doc/roformer)** (da ZhuiyiTechnology), rilasciato assieme al paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) da Jianlin Su e Yu Lu e Shengfeng Pan e Bo Wen e Yunfeng Liu.
1. **[SegFormer](model_doc/segformer)** (da NVIDIA) rilasciato con il paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) da Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[SEW](model_doc/sew)** (da ASAPP) rilasciato con il paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) da Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](model_doc/sew_d)** (da ASAPP) rilasciato con il paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) da Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (da Facebook), rilasciato assieme al paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) da Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (da Facebook), rilasciato assieme al paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) da Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](model_doc/splinter)** (dalla Università di Tel Aviv), rilasciato assieme al paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) da Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBert](model_doc/squeezebert)** (da Berkeley) rilasciato con il paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) da Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, e Kurt W. Keutzer.
1. **[Swin Transformer](model_doc/swin)** (da Microsoft) rilasciato con il paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) da Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[T5](model_doc/t5)** (da Google AI) rilasciato con il paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) da Colin Raffel e Noam Shazeer e Adam Roberts e Katherine Lee e Sharan Narang e Michael Matena e Yanqi Zhou e Wei Li e Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (da Google AI) rilasciato nel repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) da Colin Raffel e Noam Shazeer e Adam Roberts e Katherine Lee e Sharan Narang e Michael Matena e Yanqi Zhou e Wei Li e Peter J. Liu.
1. **[TAPAS](model_doc/tapas)** (da Google AI) rilasciato con il paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) da Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno e Julian Martin Eisenschlos.
1. **[TAPEX](model_doc/tapex)** (da Microsoft Research) rilasciato con il paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) da Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (dall'Università della California a Berkeley) rilasciato con il paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) da Michael Janner, Qiyang Li, Sergey Levine
1. **[Transformer-XL](model_doc/transfo-xl)** (da Google/CMU) rilasciato con il paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) da Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](model_doc/trocr)** (da Microsoft), rilasciato assieme al paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) da Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[UniSpeech](model_doc/unispeech)** (da Microsoft Research) rilasciato con il paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) da Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (da Microsoft Research) rilasciato con il paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) da Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[VAN](model_doc/van)** (dalle Università di Tsinghua e Nankai) rilasciato con il paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) da Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[ViLT](model_doc/vilt)** (da NAVER AI Lab/Kakao Enterprise/Kakao Brain) rilasciato con il paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) da Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (da Google AI) rilasciato con il paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) da Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[ViTMAE](model_doc/vit_mae)** (da Meta AI) rilasciato con il paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) da Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[VisualBERT](model_doc/visual_bert)** (da UCLA NLP) rilasciato con il paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) da Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[WavLM](model_doc/wavlm)** (da Microsoft Research) rilasciato con il paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) da Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Wav2Vec2](model_doc/wav2vec2)** (da Facebook AI) rilasciato con il paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) da Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (da Facebook AI) rilasciato con il paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) da Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[XGLM](model_doc/xglm)** (da Facebook AI) rilasciato con il paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) da Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](model_doc/xlm)** (v Facebook) rilasciato assieme al paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) da Guillaume Lample e Alexis Conneau.
1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (da Microsoft Research) rilasciato con il paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) da Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang e Ming Zhou.
1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (da Facebook AI), rilasciato assieme al paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) da Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer e Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (da Facebook AI), rilasciato assieme al paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) da Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLNet](model_doc/xlnet)** (da Google/CMU) rilasciato con il paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) da Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (da Facebook AI) rilasciato con il paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) da Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[XLS-R](model_doc/xls_r)** (da Facebook AI) rilasciato con il paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) da Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[YOLOS](model_doc/yolos)** (dalla Università della scienza e tecnologia di Huazhong) rilasciato con il paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) da Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](model_doc/yoso)** (dall'Università del Wisconsin - Madison) rilasciato con il paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) da Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Framework supportati
La tabella seguente rappresenta il supporto attuale nella libreria per ognuno di questi modelli, si può identificare se questi hanno un Python
tokenizer (chiamato "slow"). Un tokenizer "fast" supportato dalla libreria 🤗 Tokenizers, e se hanno supporto in Jax (via Flax), PyTorch, e/o TensorFlow.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| CvT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| Flava | ❌ | ❌ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| MegatronBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| mT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Nystromformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| Realm | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| SegFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin | ❌ | ❌ | ✅ | ✅ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| VisualBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- End table-->
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_train_cpu_many.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Addestramento effciente su multiple CPU
Quando l'addestramento su una singola CPU è troppo lento, possiamo usare CPU multiple. Quasta guida si concentra su DDP basato su PyTorch abilitando l'addetramento distribuito su CPU in maniera efficiente.
## Intel® oneCCL Bindings per PyTorch
[Intel® oneCCL](https://github.com/oneapi-src/oneCCL) (collective communications library) è una libreria per l'addestramento efficiente del deep learning in distribuito e implementa collettivi come allreduce, allgather, alltoall. Per maggiori informazioni su oneCCL, fai riferimento a [oneCCL documentation](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html) e [oneCCL specification](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html).
Il modulo `oneccl_bindings_for_pytorch` (`torch_ccl` precedentemente alla versione 1.12) implementa PyTorch C10D ProcessGroup API e può essere caricato dinamicamente com external ProcessGroup e funziona solo su piattaforma Linux al momento.
Qui trovi informazioni più dettagliate per [oneccl_bind_pt](https://github.com/intel/torch-ccl).
### Intel® oneCCL Bindings per l'installazione PyTorch:
I file wheel sono disponibili per le seguenti versioni di Python:
| Extension Version | Python 3.6 | Python 3.7 | Python 3.8 | Python 3.9 | Python 3.10 |
| :---------------: | :--------: | :--------: | :--------: | :--------: | :---------: |
| 1.13.0 | | √ | √ | √ | √ |
| 1.12.100 | | √ | √ | √ | √ |
| 1.12.0 | | √ | √ | √ | √ |
| 1.11.0 | | √ | √ | √ | √ |
| 1.10.0 | √ | √ | √ | √ | |
```bash
pip install oneccl_bind_pt=={pytorch_version} -f https://developer.intel.com/ipex-whl-stable-cpu
```
dove `{pytorch_version}` deve essere la tua versione di PyTorch, per l'stanza 1.13.0.
Verifica altri approcci per [oneccl_bind_pt installation](https://github.com/intel/torch-ccl).
Le versioni di oneCCL e PyTorch devono combaciare.
<Tip warning={true}>
oneccl_bindings_for_pytorch 1.12.0 prebuilt wheel does not work with PyTorch 1.12.1 (it is for PyTorch 1.12.0)
PyTorch 1.12.1 should work with oneccl_bindings_for_pytorch 1.12.100
</Tip>
## Intel® MPI library
Usa questa implementazione basata su standard MPI per fornire una architettura flessibile, efficiente, scalabile su cluster per Intel®. Questo componente è parte di Intel® oneAPI HPC Toolkit.
oneccl_bindings_for_pytorch è installato insieme al set di strumenti MPI. Necessità di reperire l'ambiente prima di utilizzarlo.
per Intel® oneCCL >= 1.12.0
```bash
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
```
per Intel® oneCCL con versione < 1.12.0
```bash
torch_ccl_path=$(python -c "import torch; import torch_ccl; import os; print(os.path.abspath(os.path.dirname(torch_ccl.__file__)))")
source $torch_ccl_path/env/setvars.sh
```
#### Installazione IPEX:
IPEX fornisce ottimizzazioni delle prestazioni per l'addestramento della CPU sia con Float32 che con BFloat16; puoi fare riferimento a [single CPU section](./perf_train_cpu).
Il seguente "Utilizzo in Trainer" prende come esempio mpirun nella libreria Intel® MPI.
## Utilizzo in Trainer
Per abilitare l'addestramento distribuito multi CPU nel Trainer con il ccl backend, gli utenti devono aggiungere **`--ddp_backend ccl`** negli argomenti del comando.
Vediamo un esempio per il [question-answering example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
Il seguente comando abilita due processi sul nodo Xeon, con un processo in esecuzione per ogni socket. Le variabili OMP_NUM_THREADS/CCL_WORKER_COUNT possono essere impostate per una prestazione ottimale.
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=127.0.0.1
mpirun -n 2 -genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex
```
Il seguente comando abilita l'addestramento per un totale di quattro processi su due Xeon (node0 e node1, prendendo node0 come processo principale), ppn (processes per node) è impostato a 2, on un processo in esecuzione per ogni socket. Le variabili OMP_NUM_THREADS/CCL_WORKER_COUNT possono essere impostate per una prestazione ottimale.
In node0, è necessario creare un file di configurazione che contenga gli indirizzi IP di ciascun nodo (per esempio hostfile) e passare il percorso del file di configurazione come parametro.
```shell script
cat hostfile
xxx.xxx.xxx.xxx #node0 ip
xxx.xxx.xxx.xxx #node1 ip
```
A questo punto, esegui il seguente comando nel nodo0 e **4DDP** sarà abilitato in node0 e node1 con BF16 auto mixed precision:
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
mpirun -f hostfile -n 4 -ppn 2 \
-genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex \
--bf16
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_hardware.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Hardware ottimizzato per l'addestramento
L'hardware utilizzato per eseguire l'addestramento del modello e l'inferenza può avere un grande effetto sulle prestazioni. Per un analisi approfondita delle GPUs, assicurati di dare un'occhiata all'eccellente [blog post](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/) di Tim Dettmer.
Diamo un'occhiata ad alcuni consigli pratici per la configurazione della GPU.
## GPU
Quando si addestrano modelli più grandi ci sono essenzialmente tre opzioni:
- GPUs piu' grandi
- Piu' GPUs
- Piu' CPU e piu' NVMe (scaricato da [DeepSpeed-Infinity](main_classes/deepspeed#nvme-support))
Iniziamo dal caso in cui ci sia una singola GPU.
### Potenza e Raffreddamento
Se hai acquistato una costosa GPU di fascia alta, assicurati di darle la potenza corretta e un raffreddamento sufficiente.
**Potenza**:
Alcune schede GPU consumer di fascia alta hanno 2 e talvolta 3 prese di alimentazione PCI-E a 8 pin. Assicurati di avere tanti cavi PCI-E a 8 pin indipendenti da 12 V collegati alla scheda quante sono le prese. Non utilizzare le 2 fessure a un'estremità dello stesso cavo (noto anche come cavo a spirale). Cioè se hai 2 prese sulla GPU, vuoi 2 cavi PCI-E a 8 pin che vanno dall'alimentatore alla scheda e non uno che abbia 2 connettori PCI-E a 8 pin alla fine! In caso contrario, non otterrai tutte le prestazioni ufficiali.
Ciascun cavo di alimentazione PCI-E a 8 pin deve essere collegato a una guida da 12 V sul lato dell'alimentatore e può fornire fino a 150 W di potenza.
Alcune altre schede possono utilizzare connettori PCI-E a 12 pin e questi possono fornire fino a 500-600 W di potenza.
Le schede di fascia bassa possono utilizzare connettori a 6 pin, che forniscono fino a 75 W di potenza.
Inoltre vuoi un alimentatore (PSU) di fascia alta che abbia una tensione stabile. Alcuni PSU di qualità inferiore potrebbero non fornire alla scheda la tensione stabile di cui ha bisogno per funzionare al massimo.
E ovviamente l'alimentatore deve avere abbastanza Watt inutilizzati per alimentare la scheda.
**Raffreddamento**:
Quando una GPU si surriscalda, inizierà a rallentare e non fornirà le prestazioni mssimali e potrebbe persino spegnersi se diventasse troppo calda.
È difficile dire l'esatta temperatura migliore a cui aspirare quando una GPU è molto caricata, ma probabilmente qualsiasi cosa al di sotto di +80°C va bene, ma più bassa è meglio - forse 70-75°C è un intervallo eccellente in cui trovarsi. È probabile che il rallentamento inizi a circa 84-90°C. Ma oltre alla limitazione delle prestazioni, una temperatura molto elevata prolungata è probabile che riduca la durata di una GPU.
Diamo quindi un'occhiata a uno degli aspetti più importanti quando si hanno più GPU: la connettività.
### Connettività multi-GPU
Se utilizzi più GPU, il modo in cui le schede sono interconnesse può avere un enorme impatto sul tempo totale di allenamento. Se le GPU si trovano sullo stesso nodo fisico, puoi eseguire:
```
nvidia-smi topo -m
```
e ti dirà come sono interconnesse le GPU. Su una macchina con doppia GPU e collegata a NVLink, molto probabilmente vedrai qualcosa del tipo:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X NV2 0-23 N/A
GPU1 NV2 X 0-23 N/A
```
su una macchina diversa senza NVLink potremmo vedere:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X PHB 0-11 N/A
GPU1 PHB X 0-11 N/A
```
Il rapporto include questa legenda:
```
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
```
Quindi il primo rapporto `NV2` ci dice che le GPU sono interconnesse con 2 NVLinks e nel secondo report `PHB` abbiamo una tipica configurazione PCIe+Bridge a livello di consumatore.
Controlla che tipo di connettività hai sulla tua configurazione. Alcuni di questi renderanno la comunicazione tra le carte più veloce (es. NVLink), altri più lenta (es. PHB).
A seconda del tipo di soluzione di scalabilità utilizzata, la velocità di connettività potrebbe avere un impatto maggiore o minore. Se le GPU devono sincronizzarsi raramente, come in DDP, l'impatto di una connessione più lenta sarà meno significativo. Se le GPU devono scambiarsi messaggi spesso, come in ZeRO-DP, una connettività più veloce diventa estremamente importante per ottenere un addestramento più veloce.
#### NVlink
[NVLink](https://en.wikipedia.org/wiki/NVLink) è un collegamento di comunicazione a corto raggio multilinea seriale basato su cavo sviluppato da Nvidia.
Ogni nuova generazione fornisce una larghezza di banda più veloce, ad es. ecco una citazione da [Nvidia Ampere GA102 GPU Architecture](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf):
> Third-Generation NVLink®
> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
> (Note that 3-Way and 4-Way SLI configurations are not supported.)
Quindi più `X` si ottiene nel rapporto di `NVX` nell'output di `nvidia-smi topo -m`, meglio è. La generazione dipenderà dall'architettura della tua GPU.
Confrontiamo l'esecuzione di un training del modello di linguaggio gpt2 su un piccolo campione di wikitext
I risultati sono:
| NVlink | Time |
| ----- | ---: |
| Y | 101s |
| N | 131s |
Puoi vedere che NVLink completa l'addestramento circa il 23% più velocemente. Nel secondo benchmark utilizziamo `NCCL_P2P_DISABLE=1` per dire alle GPU di non utilizzare NVLink.
Ecco il codice benchmark completo e gli output:
```bash
# DDP w/ NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/run_scripts.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Addestramento con script
Insieme ai [notebooks](./noteboks/README) 🤗 Transformers, ci sono anche esempi di script che dimostrano come addestrare un modello per un task con [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), o [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
Troverai anche script che abbiamo usato nei nostri [progetti di ricerca](https://github.com/huggingface/transformers/tree/main/examples/research_projects) e [precedenti esempi](https://github.com/huggingface/transformers/tree/main/examples/legacy) a cui contribuisce per lo più la comunità. Questi script non sono attivamente mantenuti e richiedono una specifica versione di 🤗 Transformers che sarà molto probabilmente incompatibile con l'ultima versione della libreria.
Non è dato per scontato che gli script di esempio funzionino senza apportare modifiche per ogni problema, bensì potrebbe essere necessario adattare lo script al tuo caso specifico. Per aiutarti in ciò, la maggioranza degli script espone le modalità di pre-processamento dei dati, consentendoti di modificare lo script come preferisci.
Per qualsiasi feature che vorresti implementare in uno script d'esempio, per favore discutine nel [forum](https://discuss.huggingface.co/) o in un'[issue](https://github.com/huggingface/transformers/issues) prima di inviare una Pull Request. Mentre accogliamo con piacere la correzione di bug, è più improbabile che faremo la stessa con una PR che aggiunge funzionalità sacrificando la leggibilità.
Questa guida ti mostrerà come eseguire uno script di esempio relativo al task di summarization in [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) e [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). Tutti gli esempi funzioneranno con entrambi i framework a meno che non sia specificato altrimenti.
## Installazione
Per eseguire con successo l'ultima versione degli script di esempio, devi **installare 🤗 Transformers dalla fonte** in un nuovo ambiente virtuale:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
Per le precedenti versioni degli script di esempio, clicca sul pulsante di seguito:
<details>
<summary>Esempi per versioni precedenti di 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Successivamente, cambia la tua attuale copia di 🤗 Transformers specificandone la versione, ad esempio v3.5.1:
```bash
git checkout tags/v3.5.1
```
Dopo aver configurato correttamente la versione della libreria, naviga nella cartella degli esempi di tua scelta e installa i requisiti:
```bash
pip install -r requirements.txt
```
## Esegui uno script
<frameworkcontent>
<pt>
Lo script di esempio scarica e pre-processa un dataset dalla libreria 🤗 [Datasets](https://huggingface.co/docs/datasets/). Successivamente, lo script esegue il fine-tuning su un dataset usando il [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) su un'architettura che supporta la summarization. Il seguente esempio mostra come eseguire il fine-tuning di [T5-small](https://huggingface.co/t5-small) sul dataset [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). Il modello T5 richiede un parametro addizionale `source_prefix` a causa del modo in cui è stato addestrato. Questo prefisso permette a T5 di sapere che si tratta di un task di summarization.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Lo script di esempio scarica e pre-processa un dataset dalla libreria 🤗 [Datasets](https://huggingface.co/docs/datasets/). Successivamente, lo script esegue il fine-tuning su un dataset usando Keras su un'architettura che supporta la summarization. Il seguente esempio mostra come eseguire il fine-tuning di [T5-small](https://huggingface.co/t5-small) sul dataset [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). Il modello T5 richiede un parametro addizionale `source_prefix` a causa del modo in cui è stato addestrato. Questo prefisso permette a T5 di sapere che si tratta di un task di summarization.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Addestramento distribuito e precisione mista
Il [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supporta l'addestramento distribuito e la precisione mista, che significa che puoi anche usarla in uno script. Per abilitare entrambe le funzionalità:
- Aggiunto l'argomento `fp16` per abilitare la precisione mista.
- Imposta un numero di GPU da usare con l'argomento `nproc_per_node`.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Gli script TensorFlow utilizzano una [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) per il training distribuito e non devi aggiungere alcun argomento addizionale allo script di training. Lo script TensorFlow userà multiple GPU in modo predefinito se quest'ultime sono disponibili:
## Esegui uno script su TPU
<frameworkcontent>
<pt>
Le Tensor Processing Units (TPU) sono state progettate per migliorare le prestazioni. PyTorch supporta le TPU con il compilatore per deep learning [XLA](https://www.tensorflow.org/xla) (guarda [questo link](https://github.com/pytorch/xla/blob/master/README.md) per maggiori dettagli). Per usare una TPU, avvia lo script `xla_spawn.py` e usa l'argomento `num_cores` per impostare il numero di core TPU che intendi usare.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Le Tensor Processing Units (TPU) sono state progettate per migliorare le prestazioni. Gli script TensorFlow utilizzano una [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) per eseguire l'addestramento su TPU. Per usare una TPU, passa il nome della risorsa TPU all'argomento `tpu`.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Esegui uno script con 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) è una libreria compatibile solo con PyTorch che offre un metodo unificato per addestrare modelli su diverse tipologie di configurazioni (CPU, multiple GPU, TPU) mantenendo una completa visibilità rispetto al ciclo di training di PyTorch. Assicurati di aver effettuato l'installazione di 🤗 Accelerate, nel caso non lo avessi fatto:
> Nota: dato che Accelerate è in rapido sviluppo, è necessario installare la versione proveniente da git per eseguire gli script:
```bash
pip install git+https://github.com/huggingface/accelerate
```
Invece che usare lo script `run_summarization.py`, devi usare lo script `run_summarization_no_trainer.py`. Gli script supportati in 🤗 Accelerate avranno un file chiamato `task_no_trainer.py` nella rispettiva cartella. Per iniziare, esegui il seguente comando per creare e salvare un file di configurazione:
```bash
accelerate config
```
Testa la tua configurazione per assicurarti della sua correttezza:
```bash
accelerate test
```
Ora sei pronto per avviare l'addestramento:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Uso di un dataset personalizzato
Lo script di summarization supporta dataset personalizzati purché siano file CSV o JSON Line. Quando usi il tuo dataset, devi specificare diversi argomenti aggiuntivi:
- `train_file` e `validation_file` specificano dove si trovano i file di addestramento e validazione.
- `text_column` è il file di input da riassumere.
- `summary_column` è il file di destinazione per l'output.
Uno script di summarization usando un dataset personalizzato sarebbe simile a questo:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Testare uno script
È spesso una buona idea avviare il tuo script su un numero inferiore di esempi tratti dal dataset, per assicurarti che tutto funzioni come previsto prima di eseguire lo script sull'intero dataset, che potrebbe necessitare di ore. Usa i seguenti argomenti per limitare il dataset ad un massimo numero di esempi:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Non tutti gli esempi di script supportano l'argomento `max_predict_samples`. Se non sei sicuro circa il supporto di questo argomento da parte del tuo script, aggiungi l'argomento `-h` per controllare:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Riavviare addestramento da un checkpoint
Un'altra utile opzione è riavviare un addestramento da un checkpoint precedente. Questo garantirà che tu possa riprendere da dove hai interrotto senza ricominciare se l'addestramento viene interrotto. Ci sono due metodi per riavviare l'addestramento da un checkpoint:
Il primo metodo usa l'argomento `output_dir previous_output_dir` per riavviare l'addestramento dall'ultima versione del checkpoint contenuto in `output_dir`. In questo caso, dovresti rimuovere `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
Il secondo metodo usa l'argomento `resume_from_checkpoint path_to_specific_checkpoint` per riavviare un addestramento da una specifica cartella di checkpoint.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Condividi il tuo modello
Tutti gli script possono caricare il tuo modello finale al [Model Hub](https://huggingface.co/models). Prima di iniziare, assicurati di aver effettuato l'accesso su Hugging Face:
```bash
huggingface-cli login
```
Poi, aggiungi l'argomento `push_to_hub` allo script. Questo argomento consentirà di creare un repository con il tuo username Hugging Face e la cartella specificata in `output_dir`.
Per dare uno specifico nome al repository, usa l'argomento `push_to_hub_model_id`. Il repository verrà automaticamente elencata sotto al tuo namespace.
Il seguente esempio mostra come caricare un modello specificando il nome del repository:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/multilingual.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Modelli multilingue per l'inferenza
[[open-in-colab]]
Ci sono diversi modelli multilingue in 🤗 Transformers, e il loro utilizzo per l'inferenza differisce da quello dei modelli monolingua. Non *tutti* gli utilizzi dei modelli multilingue sono però diversi. Alcuni modelli, come [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased), possono essere usati come un modello monolingua. Questa guida ti mostrerà come utilizzare modelli multilingue che utilizzano un modo diverso per fare l'inferenza.
## XLM
XLM ha dieci diversi checkpoint, di cui solo uno è monolingua. I nove checkpoint rimanenti possono essere suddivisi in due categorie: i checkpoint che utilizzano i language embeddings e quelli che non li utilizzano.
### XLM con language embeddings
I seguenti modelli XLM utilizzano gli embeddings linguistici per specificare la lingua utilizzata per l'inferenza:
- `xlm-mlm-ende-1024` (Modellazione mascherata del linguaggio (Masked language modeling, in inglese), Inglese-Tedesco)
- `xlm-mlm-enfr-1024` (Modellazione mascherata del linguaggio, Inglese-Francese)
- `xlm-mlm-enro-1024` (Modellazione mascherata del linguaggio, Inglese-Rumeno)
- `xlm-mlm-xnli15-1024` (Modellazione mascherata del linguaggio, lingue XNLI)
- `xlm-mlm-tlm-xnli15-1024` (Modellazione mascherata del linguaggio + traduzione, lingue XNLI)
- `xlm-clm-enfr-1024` (Modellazione causale del linguaggio, Inglese-Francese)
- `xlm-clm-ende-1024` (Modellazione causale del linguaggio, Inglese-Tedesco)
Gli embeddings linguistici sono rappresentati come un tensore delle stesse dimensioni dell' `input_ids` passato al modello. I valori in questi tensori dipendono dal linguaggio usato e sono identificati dagli attributi `lang2id` e `id2lang` del tokenizer.
In questo esempio, carica il checkpoint `xlm-clm-enfr-1024` (Modellazione causale del linguaggio, Inglese-Francese):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
L'attributo `lang2id` del tokenizer mostra il linguaggio del modello e il suo ids:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
Poi, crea un esempio di input:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
```
Imposta l'id del linguaggio a `"en"` e usalo per definire il language embedding. Il language embedding è un tensore riempito con `0` perché questo è il language id per l'inglese. Questo tensore dovrebbe avere la stessa dimensione di `input_ids`.
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
```
Adesso puoi inserire `input_ids` e language embedding nel modello:
```py
>>> outputs = model(input_ids, langs=langs)
```
Lo script [run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) può generare testo tramite i language embeddings usando i checkpoints `xlm-clm`.
### XLM senza language embeddings
I seguenti modelli XLM non richiedono l'utilizzo dei language embeddings per fare inferenza:
- `xlm-mlm-17-1280` (Modellazione mascherata del linguaggio, 17 lingue)
- `xlm-mlm-100-1280` (Modellazione mascherata del linguaggio, 100 lingue)
Questi modelli sono utilizzati per rappresentazioni generiche di frasi, a differenza dei precedenti checkpoints XML.
## BERT
Il seguente modello BERT può essere usato per compiti multilingue:
- `bert-base-multilingual-uncased` (Modellazione mascherata del linguaggio + Previsione della prossima frase, 102 lingue)
- `bert-base-multilingual-cased` (Modellazione mascherata del linguaggio + Previsione della prossima frase, 104 lingue)
Questi modelli non richiedono language embeddings per fare inferenza. Riescono ad identificare il linguaggio dal contesto e inferire di conseguenza.
## XLM-RoBERTa
Il seguente modello XLM-RoBERTa può essere usato per compiti multilingue:
- `xlm-roberta-base` (Modellazione mascherata del linguaggio, 100 lingue)
- `xlm-roberta-large` (Modellazione mascherata del linguaggio, 100 lingue)
XLM-RoBERTa è stato addestrato su 2.5TB di dati CommonCrawl appena creati e puliti in 100 lingue. Offre notevoli vantaggi rispetto ai modelli multilingue rilasciati in precedenza, come mBERT o XLM, in compiti come la classificazione, l'etichettatura delle sequenze e la risposta alle domande.
## M2M100
Il seguente modello M2M100 può essere usato per compiti multilingue:
- `facebook/m2m100_418M` (Traduzione)
- `facebook/m2m100_1.2B` (Traduzione)
In questo esempio, carica il checkpoint `facebook/m2m100_418M` per tradurre dal cinese all'inglese. Puoi impostare la lingua di partenza nel tokenizer:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
Applica il tokenizer al testo:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
M2M100 forza l'id della lingua obiettivo come primo token generato per tradurre nella lingua obiettivo. Imposta il parametro `forced_bos_token_id` a `en` nel metodo `generate` per tradurre in inglese:
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
Il seguente modello MBart può essere usato per compiti multilingue:
- `facebook/mbart-large-50-one-to-many-mmt` (Traduzione automatica multilingue uno-a-molti, 50 lingue)
- `facebook/mbart-large-50-many-to-many-mmt` (Traduzione automatica multilingue molti-a-molti, 50 lingue)
- `facebook/mbart-large-50-many-to-one-mmt` (Traduzione automatica multilingue molti-a-uno, 50 lingue)
- `facebook/mbart-large-50` (Traduzione multilingue, 50 lingue)
- `facebook/mbart-large-cc25`
In questo esempio, carica il checkpoint `facebook/mbart-large-50-many-to-many-mmt` per tradurre dal finlandese all'inglese. Puoi impostare la lingua di partenza nel tokenizer:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
Applica il tokenizer sul testo:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
MBart forza l'id della lingua obiettivo come primo token generato per tradurre nella lingua obiettivo. Imposta il parametro `forced_bos_token_id` a `en` nel metodo `generate` per tradurre in inglese:
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
Se stai usando il checkpoint `facebook/mbart-large-50-many-to-one-mmt`, non hai bisogno di forzare l'id della lingua obiettivo come primo token generato altrimenti l'uso è lo stesso.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/big_models.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Istanziare un big model
Quando vuoi utilizzare un modello preaddestrato (pretrained) molto grande, una sfida è minimizzare l'uso della RAM. Il workflow classico
in PyTorch è:
1. Crea il tuo modello con pesi casuali (random weights).
2. Carica i tuoi pesi preaddestrati.
3. Inserisci i pesi preaddestrati nel tuo modello casuale.
I passi 1 e 2 una versione completa del modello in memoria, in molti casi non è un problema, ma se il modello inizia a pesare diversi GigaBytes, queste due copie possono sturare la nostra RAM. Ancora peggio, se stai usando `torch.distributed` per seguire l'addestramento (training) in distribuito, ogni processo caricherà il modello preaddestrato e memorizzerà queste due copie nella RAM.
<Tip>
Nota che il modello creato casualmente è inizializzato con tensori "vuoti", che occupano spazio in memoria ma senza riempirlo (quindi i valori casuali sono quelli che si trovavano in questa porzione di memoria in un determinato momento). L'inizializzazione casuale che segue la distribuzione appropriata per il tipo di modello/parametri istanziato (come la distribuzione normale per le istanze) è eseguito solo dopo il passaggio 3 sui pesi non inizializzati, per essere più rapido possibile!
</Tip>
In questa guida, esploreremo le soluzioni che Transformers offre per affrontare questo problema. C'è da tenere in conto che questa è un'area in cui si sta attualmente sviluppando, quindi le API spiegate qui possono variare velocemente in futuro.
## Checkpoints condivisi
Dalla versione 4.18.0, i checkpoints dei modelli che occupano più di 10GB di spazio vengono automaticamente frammentati in più parti. Per quanto riguarda la possibilità di avere un unico checkpoint quando si utilizza `model.save_pretrained(save_dir)`, si hanno diversi checkpoint parziali (ognuno con dimensione < 10GB) e un indice che mappa i nomi dei parametri ai file in cui sono memorizzati.
Puoi controllare la dimensione massima dopo la frammentazione con il parametro `max_shard_size`, nel prossimo esempio, useremo modelli di dimensioni normali con frammenti di piccoli dimensioni: prendiamo un modello BERT classico.
```py
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-cased")
```
Se tu salvi usando [`~PreTrainedModel.save_pretrained`], avrai una nuova cartella con due file: il config del modello e i suoi pesi:
```py
>>> import os
>>> import tempfile
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir)
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model.bin']
```
Adesso usiamo una dimensione massima di frammentazione di 200MB:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
```
In aggiunta alla configurazione del modello, vediamo tre differenti file dei pesi, e un file `index.json` che è il nostro indice. Un checkpoint può essere ricaricato totalmente usando il metodo [`~PreTrainedModel.from_pretrained`]:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... new_model = AutoModel.from_pretrained(tmp_dir)
```
Il vantaggio principale di applicare questo metodo per modelli grandi è che durante il passo 2 del workflow illustrato in precedenza, ogni frammento del checkpoint viene caricato dopo il precedente, limitando l'utilizzo della RAM alla dimensione del modello più la dimensione del frammento più grande.
Dietro le quinte, il file indice è utilizzato per determinare quali chiavi sono nel checkpoint, e dove i corrispondenti pesi sono memorizzati. Possiamo caricare l'indice come un qualsiasi json e ottenere un dizionario:
```py
>>> import json
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
... index = json.load(f)
>>> print(index.keys())
dict_keys(['metadata', 'weight_map'])
```
I metadati consistono solo nella dimensione totale del modello per ora. Abbiamo in programma di aggiungere altre informazioni in futuro:
```py
>>> index["metadata"]
{'total_size': 433245184}
```
La mappa dei pesi è la parte principale di questo indice, che mappa ogni nome dei parametri (si trova solitamente nei modelli PyTorch come `state_dict`) al file in cui è memorizzato:
```py
>>> index["weight_map"]
{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
...
```
Se vuoi caricare direttamente un checkpoint frammentato in un modello senza usare [`~PreTrainedModel.from_pretrained`] (come si farebbe con `model.load_state_dict()` per un checkpoint completo) devi usare [`~modeling_utils.load_sharded_checkpoint`]:
```py
>>> from transformers.modeling_utils import load_sharded_checkpoint
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... load_sharded_checkpoint(model, tmp_dir)
```
## Caricamento low memory
Frammentare i checkpoint l'utilizzo di memoria al passo 2 del workflow citato in precedenza, ma per utilizzare questo modello in un ambiente con poca memoria, consigliamo di utilizzare i nostri strumenti basati sulla libreria Accelerate.
Per ulteriori informazioni, leggere la seguente guida: [Large model loading using Accelerate](./main_classes/model#large-model-loading)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/pipeline_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipeline per l'inferenza
La [`pipeline`] rende semplice usare qualsiasi modello dal [Model Hub](https://huggingface.co/models) per fare inferenza su diversi compiti come generazione del testo, segmentazione di immagini e classificazione di audio. Anche se non hai esperienza con una modalità specifica o non comprendi bene il codice che alimenta i modelli, è comunque possibile utilizzarli con l'opzione [`pipeline`]! Questa esercitazione ti insegnerà a:
* Usare una [`pipeline`] per fare inferenza.
* Usare uno specifico tokenizer o modello.
* Usare una [`pipeline`] per compiti che riguardano audio e video.
<Tip>
Dai un'occhiata alla documentazione di [`pipeline`] per una lista completa dei compiti supportati.
</Tip>
## Utilizzo della Pipeline
Nonostante ogni compito abbia una [`pipeline`] associata, è più semplice utilizzare l'astrazione generica della [`pipeline`] che contiene tutte quelle specifiche per ogni mansione. La [`pipeline`] carica automaticamente un modello predefinito e un tokenizer in grado di fare inferenza per il tuo compito.
1. Inizia creando una [`pipeline`] e specificando il compito su cui fare inferenza:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation")
```
2. Inserisci il testo in input nella [`pipeline`]:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
... ) # doctest: +SKIP
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
```
Se hai più di un input, inseriscilo in una lista:
```py
>>> generator(
... [
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
... ]
... ) # doctest: +SKIP
```
Qualsiasi parametro addizionale per il tuo compito può essere incluso nella [`pipeline`]. La mansione `text-generation` ha un metodo [`~generation.GenerationMixin.generate`] con diversi parametri per controllare l'output. Ad esempio, se desideri generare più di un output, utilizza il parametro `num_return_sequences`:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... num_return_sequences=2,
... ) # doctest: +SKIP
```
### Scegliere modello e tokenizer
La [`pipeline`] accetta qualsiasi modello dal [Model Hub](https://huggingface.co/models). Ci sono tag nel Model Hub che consentono di filtrare i modelli per attività. Una volta che avrai scelto il modello appropriato, caricalo usando la corrispondente classe `AutoModelFor` e [`AutoTokenizer`]. Ad esempio, carica la classe [`AutoModelForCausalLM`] per un compito di causal language modeling:
```py
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
```
Crea una [`pipeline`] per il tuo compito, specificando il modello e il tokenizer che hai caricato:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
```
Inserisci il testo di input nella [`pipeline`] per generare del testo:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
... ) # doctest: +SKIP
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
```
## Audio pipeline
La flessibilità della [`pipeline`] fa si che possa essere estesa ad attività sugli audio.
Per esempio, classifichiamo le emozioni in questo clip audio:
```py
>>> from datasets import load_dataset
>>> import torch
>>> torch.manual_seed(42) # doctest: +IGNORE_RESULT
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> audio_file = ds[0]["audio"]["path"]
```
Trova un modello per la [classificazione audio](https://huggingface.co/models?pipeline_tag=audio-classification) sul Model Hub per eseguire un compito di riconoscimento automatico delle emozioni e caricalo nella [`pipeline`]:
```py
>>> from transformers import pipeline
>>> audio_classifier = pipeline(
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
Inserisci il file audio nella [`pipeline`]:
```py
>>> preds = audio_classifier(audio_file)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.1315, 'label': 'calm'}, {'score': 0.1307, 'label': 'neutral'}, {'score': 0.1274, 'label': 'sad'}, {'score': 0.1261, 'label': 'fearful'}, {'score': 0.1242, 'label': 'happy'}]
```
## Vision pipeline
Infine, usare la [`pipeline`] per le attività sulle immagini è praticamente la stessa cosa.
Specifica la tua attività e inserisci l'immagine nel classificatore. L'immagine può essere sia un link che un percorso sul tuo pc in locale. Per esempio, quale specie di gatto è raffigurata qui sotto?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(task="image-classification")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/quicktour.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Quick tour
[[open-in-colab]]
Entra in azione con 🤗 Transformers! Inizia utilizzando [`pipeline`] per un'inferenza veloce, carica un modello pre-allenato e un tokenizer con una [AutoClass](./model_doc/auto) per risolvere i tuoi compiti legati a testo, immagini o audio.
<Tip>
Tutti gli esempi di codice presenti in questa documentazione hanno un pulsante in alto a sinistra che permette di selezionare tra PyTorch e TensorFlow. Se
questo non è presente, ci si aspetta che il codice funzioni per entrambi i backend senza alcun cambiamento.
</Tip>
## Pipeline
[`pipeline`] è il modo più semplice per utilizzare un modello pre-allenato per un dato compito.
<Youtube id="tiZFewofSLM"/>
La [`pipeline`] supporta molti compiti comuni:
**Testo**:
* Analisi del Sentimento (Sentiment Analysis, in inglese): classifica la polarità di un testo dato.
* Generazione del Testo (Text Generation, in inglese): genera del testo a partire da un dato input.
* Riconoscimento di Entità (Name Entity Recognition o NER, in inglese): etichetta ogni parola con l'entità che questa rappresenta (persona, data, luogo, ecc.).
* Rispondere a Domande (Question answering, in inglese): estrae la risposta da un contesto, dato del contesto e una domanda.
* Riempimento di Maschere (Fill-mask, in inglese): riempie gli spazi mancanti in un testo che ha parole mascherate.
* Riassumere (Summarization, in inglese): genera una sintesi di una lunga sequenza di testo o di un documento.
* Traduzione (Translation, in inglese): traduce un testo in un'altra lingua.
* Estrazione di Caratteristiche (Feature Extraction, in inglese): crea un tensore che rappresenta un testo.
**Immagini**:
* Classificazione di Immagini (Image Classification, in inglese): classifica un'immagine.
* Segmentazione di Immagini (Image Segmentation, in inglese): classifica ogni pixel di un'immagine.
* Rilevazione di Oggetti (Object Detection, in inglese): rileva oggetti all'interno di un'immagine.
**Audio**:
* Classificazione di Audio (Audio Classification, in inglese): assegna un'etichetta ad un segmento di audio dato.
* Riconoscimento Vocale Automatico (Automatic Speech Recognition o ASR, in inglese): trascrive il contenuto di un audio dato in un testo.
<Tip>
Per maggiori dettagli legati alla [`pipeline`] e ai compiti ad essa associati, fai riferimento alla documentazione [qui](./main_classes/pipelines).
</Tip>
### Utilizzo della Pipeline
Nel seguente esempio, utilizzerai la [`pipeline`] per l'analisi del sentimento.
Installa le seguenti dipendenze se non lo hai già fatto:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
Importa [`pipeline`] e specifica il compito che vuoi completare:
```py
>>> from transformers import pipeline
>>> classificatore = pipeline("sentiment-analysis", model="MilaNLProc/feel-it-italian-sentiment")
```
La pipeline scarica e salva il [modello pre-allenato](https://huggingface.co/MilaNLProc/feel-it-italian-sentiment) e il tokenizer per l'analisi del sentimento. Se non avessimo scelto un modello, la pipeline ne avrebbe scelto uno di default. Ora puoi utilizzare il `classifier` sul tuo testo obiettivo:
```py
>>> classificatore("Siamo molto felici di mostrarti la libreria 🤗 Transformers.")
[{'label': 'positive', 'score': 0.9997}]
```
Per più di una frase, passa una lista di frasi alla [`pipeline`] la quale restituirà una lista di dizionari:
```py
>>> risultati = classificatore(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."]
... )
>>> for risultato in risultati:
... print(f"etichetta: {risultato['label']}, con punteggio: {round(risultato['score'], 4)}")
etichetta: positive, con punteggio: 0.9998
etichetta: negative, con punteggio: 0.9998
```
La [`pipeline`] può anche iterare su un dataset intero. Inizia installando la libreria [🤗 Datasets](https://huggingface.co/docs/datasets/):
```bash
pip install datasets
```
Crea una [`pipeline`] con il compito che vuoi risolvere e con il modello che vuoi utilizzare.
```py
>>> import torch
>>> from transformers import pipeline
>>> riconoscitore_vocale = pipeline(
... "automatic-speech-recognition", model="radiogroup-crits/wav2vec2-xls-r-1b-italian-doc4lm-5gram"
... )
```
Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="it-IT", split="train") # doctest: +IGNORE_RESULT
```
Dobbiamo assicurarci che la frequenza di campionamento del set di dati corrisponda alla frequenza di campionamento con cui è stato addestrato `radiogroup-crits/wav2vec2-xls-r-1b-italian-doc4lm-5gram`.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=riconoscitore_vocale.feature_extractor.sampling_rate))
```
I file audio vengono caricati automaticamente e ri-campionati quando chiamiamo la colonna "audio".
Estraiamo i vettori delle forme d'onda grezze delle prime 4 osservazioni e passiamoli come lista alla pipeline:
```py
>>> risultato = riconoscitore_vocale(dataset[:4]["audio"])
>>> print([d["text"] for d in risultato])
['dovrei caricare dei soldi sul mio conto corrente', 'buongiorno e senza vorrei depositare denaro sul mio conto corrente come devo fare per cortesia', 'sì salve vorrei depositare del denaro sul mio conto', 'e buon pomeriggio vorrei depositare dei soldi sul mio conto bancario volleo sapere come posso fare se e posso farlo online ed un altro conto o andandoo tramite bancomut']
```
Per un dataset più grande dove gli input sono di dimensione maggiore (come nel parlato/audio o nella visione), dovrai passare un generatore al posto di una lista che carica tutti gli input in memoria. Guarda la [documentazione della pipeline](./main_classes/pipelines) per maggiori informazioni.
### Utilizzare un altro modello e tokenizer nella pipeline
La [`pipeline`] può ospitare qualsiasi modello del [Model Hub](https://huggingface.co/models), rendendo semplice l'adattamento della [`pipeline`] per altri casi d'uso. Per esempio, se si vuole un modello capace di trattare testo in francese, usa i tag presenti nel Model Hub in modo da filtrare per ottenere un modello appropriato. Il miglior risultato filtrato restituisce un modello multi-lingua [BERT model](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) fine-tuned per l'analisi del sentimento. Ottimo, utilizziamo questo modello!
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Usa [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] per caricare il modello pre-allenato e il suo tokenizer associato (maggiori informazioni su una `AutoClass` in seguito):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Usa [`TFAutoModelForSequenceClassification`] e [`AutoTokenizer`] per caricare il modello pre-allenato e il suo tokenizer associato (maggiori informazioni su una `TFAutoClass` in seguito):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Poi puoi specificare il modello e il tokenizer nella [`pipeline`], e applicare il `classifier` sul tuo testo obiettivo:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Se non riesci a trovare un modello per il tuo caso d'uso, dovrai fare fine-tuning di un modello pre-allenato sui tuoi dati. Dai un'occhiata al nostro tutorial [fine-tuning tutorial](./training) per imparare come. Infine, dopo che hai completato il fine-tuning del tuo modello pre-allenato, considera per favore di condividerlo (vedi il tutorial [qui](./model_sharing)) con la comunità sul Model Hub per democratizzare l'NLP! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Al suo interno, le classi [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] lavorano assieme per dare potere alla [`pipeline`]. Una [AutoClass](./model_doc/auto) è una scorciatoia che automaticamente recupera l'architettura di un modello pre-allenato a partire dal suo nome o path. Hai solo bisogno di selezionare la `AutoClass` appropriata per il tuo compito e il suo tokenizer associato con [`AutoTokenizer`].
Ritorniamo al nostro esempio e vediamo come puoi utilizzare la `AutoClass` per replicare i risultati della [`pipeline`].
### AutoTokenizer
Un tokenizer è responsabile dell'elaborazione del testo in modo da trasformarlo in un formato comprensibile dal modello. Per prima cosa, il tokenizer dividerà il testo in parole chiamate *token*. Ci sono diverse regole che governano il processo di tokenizzazione, tra cui come dividere una parola e a quale livello (impara di più sulla tokenizzazione [qui](./tokenizer_summary)). La cosa più importante da ricordare comunque è che hai bisogno di inizializzare il tokenizer con lo stesso nome del modello in modo da assicurarti che stai utilizzando le stesse regole di tokenizzazione con cui il modello è stato pre-allenato.
Carica un tokenizer con [`AutoTokenizer`]:
```py
>>> from transformers import AutoTokenizer
>>> nome_del_modello = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(nome_del_modello)
```
Dopodiché, il tokenizer converte i token in numeri in modo da costruire un tensore come input del modello. Questo è conosciuto come il *vocabolario* del modello.
Passa il tuo testo al tokenizer:
```py
>>> encoding = tokenizer("Siamo molto felici di mostrarti la libreria 🤗 Transformers.")
>>> print(encoding)
{'input_ids': [101, 56821, 10132, 14407, 13019, 13007, 10120, 47201, 10330, 10106, 91686, 100, 58263, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
Il tokenizer restituirà un dizionario contenente:
* [input_ids](./glossary#input-ids): rappresentazioni numeriche dei tuoi token.
* [attention_mask](.glossary#attention-mask): indica quali token devono essere presi in considerazione.
Come con la [`pipeline`], il tokenizer accetterà una lista di input. In più, il tokenizer può anche completare (pad, in inglese) e troncare il testo in modo da restituire un lotto (batch, in inglese) di lunghezza uniforme:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
Leggi il tutorial sul [preprocessing](./preprocessing) per maggiori dettagli sulla tokenizzazione.
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers fornisce un metodo semplice e unificato per caricare istanze pre-allenate. Questo significa che puoi caricare un [`AutoModel`] come caricheresti un [`AutoTokenizer`]. L'unica differenza è selezionare l'[`AutoModel`] corretto per il compito di interesse. Dato che stai facendo classificazione di testi, o sequenze, carica [`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Guarda il [task summary](./task_summary) per sapere quale classe di [`AutoModel`] utilizzare per quale compito.
</Tip>
Ora puoi passare il tuo lotto di input pre-processati direttamente al modello. Devi solo spacchettare il dizionario aggiungendo `**`:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
Il modello produrrà le attivazioni finali nell'attributo `logits`. Applica la funzione softmax a `logits` per ottenere le probabilità:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0041, 0.0037, 0.0203, 0.2005, 0.7713],
[0.3766, 0.3292, 0.1832, 0.0558, 0.0552]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers fornisce un metodo semplice e unificato per caricare istanze pre-allenate. Questo significa che puoi caricare un [`TFAutoModel`] come caricheresti un [`AutoTokenizer`]. L'unica differenza è selezionare il [`TFAutoModel`] corretto per il compito di interesse. Dato che stai facendo classificazione di testi, o sequenze, carica [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> nome_del_modello = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(nome_del_modello)
```
<Tip>
Guarda il [task summary](./task_summary) per sapere quale classe di [`AutoModel`] utilizzare per quale compito.
</Tip>
Ora puoi passare il tuo lotto di input pre-processati direttamente al modello passando le chiavi del dizionario al tensore:
```py
>>> tf_outputs = tf_model(tf_batch)
```
Il modello produrrà le attivazioni finali nell'attributo `logits`. Applica la funzione softmax a `logits` per ottenere le probabilità:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
Tutti i modelli di 🤗 Transformers (PyTorch e TensorFlow) restituiscono i tensori *prima* della funzione finale
di attivazione (come la softmax) perché la funzione di attivazione finale viene spesso unita a quella di perdita.
</Tip>
I modelli sono [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) o [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) standard così puoi utilizzarli all'interno del tuo training loop usuale. Tuttavia, per rendere le cose più semplici, 🤗 Transformers fornisce una classe [`Trainer`] per PyTorch che aggiunge delle funzionalità per l'allenamento distribuito, precisione mista, e altro ancora. Per TensorFlow, puoi utilizzare il metodo `fit` di [Keras](https://keras.io/). Fai riferimento al [tutorial per il training](./training) per maggiori dettagli.
<Tip>
Gli output del modello di 🤗 Transformers sono delle dataclasses speciali in modo che i loro attributi vengano auto-completati all'interno di un IDE.
Gli output del modello si comportano anche come una tupla o un dizionario (ad esempio, puoi indicizzare con un intero, una slice o una stringa) nel qual caso gli attributi che sono `None` vengono ignorati.
</Tip>
### Salva un modello
<frameworkcontent>
<pt>
Una volta completato il fine-tuning del tuo modello, puoi salvarlo con il suo tokenizer utilizzando [`PreTrainedModel.save_pretrained`]:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Quando desideri utilizzare il tuo modello nuovamente, puoi ri-caricarlo con [`PreTrainedModel.from_pretrained`]:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Una volta completato il fine-tuning del tuo modello, puoi salvarlo con il suo tokenizer utilizzando [`TFPreTrainedModel.save_pretrained`]:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Quando desideri utilizzare il tuo modello nuovamente, puoi ri-caricarlo con [`TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Una caratteristica particolarmente interessante di 🤗 Transformers è la sua abilità di salvare un modello e ri-caricarlo sia come modello di PyTorch che di TensorFlow. I parametri `from_pt` o `from_tf` possono convertire un modello da un framework all'altro:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_infer_cpu.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Inferenza Efficiente su CPU
Questa guida si concentra sull'inferenza di modelli di grandi dimensioni in modo efficiente sulla CPU.
## `BetterTransformer` per inferenza più rapida
Abbiamo integrato di recente `BetterTransformer` per fare inferenza più rapidamente con modelli per testi, immagini e audio. Visualizza la documentazione sull'integrazione [qui](https://huggingface.co/docs/optimum/bettertransformer/overview) per maggiori dettagli.
## PyTorch JIT-mode (TorchScript)
TorchScript è un modo di creare modelli serializzabili e ottimizzabili da codice PyTorch. Ogni programmma TorchScript può esere salvato da un processo Python e caricato in un processo dove non ci sono dipendenze Python.
Comparandolo con l'eager mode di default, jit mode in PyTorch normalmente fornisce prestazioni migliori per l'inferenza del modello da parte di metodologie di ottimizzazione come la operator fusion.
Per una prima introduzione a TorchScript, vedi la Introduction to [PyTorch TorchScript tutorial](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html#tracing-modules).
### IPEX Graph Optimization con JIT-mode
Intel® Extension per PyTorch fornnisce ulteriori ottimizzazioni in jit mode per i modelli della serie Transformers. Consigliamo vivamente agli utenti di usufruire dei vantaggi di Intel® Extension per PyTorch con jit mode. Alcuni operator patterns usati fequentemente dai modelli Transformers models sono già supportati in Intel® Extension per PyTorch con jit mode fusions. Questi fusion patterns come Multi-head-attention fusion, Concat Linear, Linear+Add, Linear+Gelu, Add+LayerNorm fusion and etc. sono abilitati e hanno buone performance. I benefici della fusion è fornito agli utenti in modo trasparente. In base alle analisi, il ~70% dei problemi più popolari in NLP question-answering, text-classification, and token-classification possono avere benefici sulle performance grazie ai fusion patterns sia per Float32 precision che per BFloat16 Mixed precision.
Vedi maggiori informazioni per [IPEX Graph Optimization](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html).
#### Installazione di IPEX
I rilasci di IPEX seguono PyTorch, verifica i vari approcci per [IPEX installation](https://intel.github.io/intel-extension-for-pytorch/).
### Utilizzo del JIT-mode
Per abilitare JIT-mode in Trainer per evaluation e prediction, devi aggiungere `jit_mode_eval` negli argomenti di Trainer.
<Tip warning={true}>
per PyTorch >= 1.14.0. JIT-mode potrebe giovare a qualsiasi modello di prediction e evaluaion visto che il dict input è supportato in jit.trace
per PyTorch < 1.14.0. JIT-mode potrebbe giovare ai modelli il cui ordine dei parametri corrisponde all'ordine delle tuple in ingresso in jit.trace, come i modelli per question-answering.
Nel caso in cui l'ordine dei parametri seguenti non corrisponda all'ordine delle tuple in ingresso in jit.trace, come nei modelli di text-classification, jit.trace fallirà e lo cattureremo con una eccezione al fine di renderlo un fallback. Il logging è usato per notificare gli utenti.
</Tip>
Trovi un esempo con caso d'uso in [Transformers question-answering](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
- Inference using jit mode on CPU:
<pre>python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
<b>--jit_mode_eval </b></pre>
- Inference with IPEX using jit mode on CPU:
<pre>python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
<b>--use_ipex \</b>
<b>--jit_mode_eval</b></pre>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/converting_tensorflow_models.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convertire checkpoint di Tensorflow
È disponibile un'interfaccia a linea di comando per convertire gli originali checkpoint di Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM
in modelli che possono essere caricati utilizzando i metodi `from_pretrained` della libreria.
<Tip>
A partire dalla versione 2.3.0 lo script di conversione è parte di transformers CLI (**transformers-cli**), disponibile in ogni installazione
di transformers >=2.3.0.
La seguente documentazione riflette il formato dei comandi di **transformers-cli convert**.
</Tip>
## BERT
Puoi convertire qualunque checkpoint Tensorflow di BERT (in particolare
[i modeli pre-allenati rilasciati da Google](https://github.com/google-research/bert#pre-trained-models))
in un file di salvataggio Pytorch utilizzando lo script
[convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py).
Questo CLI prende come input un checkpoint di Tensorflow (tre files che iniziano con `bert_model.ckpt`) ed il relativo
file di configurazione (`bert_config.json`), crea un modello Pytorch per questa configurazione, carica i pesi dal
checkpoint di Tensorflow nel modello di Pytorch e salva il modello che ne risulta in un file di salvataggio standard di Pytorch che
può essere importato utilizzando `from_pretrained()` (vedi l'esempio nel
[quicktour](quicktour) , [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py) ).
Devi soltanto lanciare questo script di conversione **una volta** per ottenere un modello Pytorch. Dopodichè, potrai tralasciare
il checkpoint di Tensorflow (i tre files che iniziano con `bert_model.ckpt`), ma assicurati di tenere il file di configurazione
(`bert_config.json`) ed il file di vocabolario (`vocab.txt`) in quanto queste componenti sono necessarie anche per il modello di Pytorch.
Per lanciare questo specifico script di conversione avrai bisogno di un'installazione di Tensorflow e di Pytorch
(`pip install tensorflow`). Il resto della repository richiede soltanto Pytorch.
Questo è un esempio del processo di conversione per un modello `BERT-Base Uncased` pre-allenato:
```bash
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
transformers-cli convert --model_type bert \
--tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
--config $BERT_BASE_DIR/bert_config.json \
--pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
```
Puoi scaricare i modelli pre-allenati di Google per la conversione [qua](https://github.com/google-research/bert#pre-trained-models).
## ALBERT
Per il modello ALBERT, converti checkpoint di Tensoflow in Pytorch utilizzando lo script
[convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py).
Il CLI prende come input un checkpoint di Tensorflow (tre files che iniziano con `model.ckpt-best`) e i relativi file di
configurazione (`albert_config.json`), dopodichè crea e salva un modello Pytorch. Per lanciare questa conversione
avrai bisogno di un'installazione di Tensorflow e di Pytorch.
Ecco un esempio del procedimento di conversione di un modello `ALBERT Base` pre-allenato:
```bash
export ALBERT_BASE_DIR=/path/to/albert/albert_base
transformers-cli convert --model_type albert \
--tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
--config $ALBERT_BASE_DIR/albert_config.json \
--pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
```
Puoi scaricare i modelli pre-allenati di Google per la conversione [qui](https://github.com/google-research/albert#pre-trained-models).
## OpenAI GPT
Ecco un esempio del processo di conversione di un modello OpenAI GPT pre-allenato, assumendo che il tuo checkpoint di NumPy
sia salvato nello stesso formato dei modelli pre-allenati OpenAI (vedi [qui](https://github.com/openai/finetune-transformer-lm)):
```bash
export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
transformers-cli convert --model_type gpt \
--tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT_CONFIG] \
[--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
```
## OpenAI GPT-2
Ecco un esempio del processo di conversione di un modello OpenAI GPT-2 pre-allenato (vedi [qui](https://github.com/openai/gpt-2)):
```bash
export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/gpt2/pretrained/weights
transformers-cli convert --model_type gpt2 \
--tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT2_CONFIG] \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
## XLNet
Ecco un esempio del processo di conversione di un modello XLNet pre-allenato:
```bash
export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
transformers-cli convert --model_type xlnet \
--tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
--config $TRANSFO_XL_CONFIG_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--finetuning_task_name XLNET_FINETUNED_TASK] \
```
## XLM
Ecco un esempio del processo di conversione di un modello XLM pre-allenato:
```bash
export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
transformers-cli convert --model_type xlm \
--tf_checkpoint $XLM_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT
[--config XML_CONFIG] \
[--finetuning_task_name XML_FINETUNED_TASK]
```
## T5
Ecco un esempio del processo di conversione di un modello T5 pre-allenato:
```bash
export T5=/path/to/t5/uncased_L-12_H-768_A-12
transformers-cli convert --model_type t5 \
--tf_checkpoint $T5/t5_model.ckpt \
--config $T5/t5_config.json \
--pytorch_dump_output $T5/pytorch_model.bin
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/custom_models.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Condividere modelli personalizzati
La libreria 🤗 Transformers è studiata per essere facilmente estendibile. Il codice di ogni modello è interamente
situato in una sottocartella del repository senza alcuna astrazione, perciò puoi facilmente copiare il file di un
modello e modificarlo in base ai tuoi bisogni.
Se stai scrivendo un nuovo modello, potrebbe essere più semplice iniziare da zero. In questo tutorial, ti mostreremo
come scrivere un modello personalizzato e la sua configurazione in modo che possa essere utilizzato all’interno di
Transformers, e come condividerlo con la community (assieme al relativo codice) così che tutte le persone possano usarlo, anche
se non presente nella libreria 🤗 Transformers.
Illustriamo tutto questo su un modello ResNet, avvolgendo la classe ResNet della
[libreria timm](https://github.com/rwightman/pytorch-image-models) in un [`PreTrainedModel`].
## Scrivere una configurazione personalizzata
Prima di iniziare a lavorare al modello, scriviamone la configurazione. La configurazione di un modello è un oggetto
che contiene tutte le informazioni necessarie per la build del modello. Come vedremo nella prossima sezione, il
modello può soltanto essere inizializzato tramite `config`, per cui dovremo rendere tale oggetto più completo possibile.
Nel nostro esempio, prenderemo un paio di argomenti della classe ResNet che potremmo voler modificare.
Configurazioni differenti ci daranno quindi i differenti possibili tipi di ResNet. Salveremo poi questi argomenti,
dopo averne controllato la validità.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
Le tre cose più importanti da ricordare quando scrivi le tue configurazioni sono le seguenti:
- Devi ereditare da `Pretrainedconfig`,
- Il metodo `__init__` del tuo `Pretrainedconfig` deve accettare i kwargs,
- I `kwargs` devono essere passati alla superclass `__init__`
L’eredità è importante per assicurarsi di ottenere tutte le funzionalità della libreria 🤗 transformers,
mentre gli altri due vincoli derivano dal fatto che un `Pretrainedconfig` ha più campi di quelli che stai settando.
Quando ricarichi una config da un metodo `from_pretrained`, questi campi devono essere accettati dalla tua config e
poi inviati alla superclasse.
Definire un `model_type` per la tua configurazione (qua `model_type = “resnet”`) non è obbligatorio, a meno che tu
non voglia registrare il modello con le classi Auto (vedi l'ultima sezione).
Una volta completato, puoi facilmente creare e salvare la tua configurazione come faresti con ogni altra configurazione
di modelli della libreria. Ecco come possiamo creare la config di un resnet50d e salvarlo:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
Questo salverà un file chiamato `config.json` all'interno della cartella `custom-resnet`. Potrai poi ricaricare la tua
config con il metodo `from_pretrained`.
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
Puoi anche usare qualunque altro metodo della classe [`PretrainedConfig`], come [`~PretrainedConfig.push_to_hub`]
per caricare direttamente la tua configurazione nell'hub.
## Scrivere un modello personalizzato
Ora che abbiamo la nostra configurazione ResNet, possiamo continuare a scrivere il modello. In realtà, ne scriveremo
due: uno che estrae le features nascoste da una batch di immagini (come [`BertModel`]) e uno che è utilizzabile per
la classificazione di immagini (come [`BertModelForSequenceClassification`]).
Come abbiamo menzionato in precedenza, scriveremo soltanto un wrapper del modello, per mantenerlo semplice ai fini di
questo esempio. L'unica cosa che dobbiamo fare prima di scrivere questa classe è una mappatura fra i tipi di blocco e
le vere classi dei blocchi. Successivamente il modello è definito tramite la configurazione, passando tutto quanto alla
classe `ResNet`.
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
Per il modello che classificherà le immagini, cambiamo soltanto il metodo forward:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
Nota come, in entrambi i casi, ereditiamo da `PreTrainedModel` e chiamiamo l'inizializzazione della superclasse
con il metodo `config` (un po' come quando scrivi un normale `torch.nn.Module`). La riga che imposta la `config_class`
non è obbligatoria, a meno che tu non voglia registrare il modello con le classi Auto (vedi l'ultima sezione).
<Tip>
Se il tuo modello è molto simile a un modello all'interno della libreria, puoi ri-usare la stessa configurazione di quel modello.
</Tip>
Puoi fare in modo che il tuo modello restituisca in output qualunque cosa tu voglia, ma far restituire un dizionario
come abbiamo fatto per `ResnetModelForImageClassification`, con la funzione di perdita inclusa quando vengono passate le labels,
renderà il tuo modello direttamente utilizzabile all'interno della classe [`Trainer`]. Utilizzare altri formati di output va bene
se hai in progetto di utilizzare un tuo loop di allenamento, o se utilizzerai un'altra libreria per l'addestramento.
Ora che abbiamo la classe del nostro modello, creiamone uno:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Ribadiamo, puoi usare qualunque metodo dei [`PreTrainedModel`], come [`~PreTrainedModel.save_pretrained`] o
[`~PreTrainedModel.push_to_hub`]. Utilizzeremo quest'ultimo nella prossima sezione, e vedremo come caricare i pesi del
modello assieme al codice del modello stesso. Ma prima, carichiamo alcuni pesi pre-allenati all'interno del nostro modello.
Nel tuo caso specifico, probabilmente allenerai il tuo modello sui tuoi dati. Per velocizzare in questo tutorial,
utilizzeremo la versione pre-allenata del resnet50d. Dato che il nostro modello è soltanto un wrapper attorno a quel modello,
sarà facile trasferirne i pesi:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Vediamo adesso come assicurarci che quando facciamo [`~PreTrainedModel.save_pretrained`] o [`~PreTrainedModel.push_to_hub`],
il codice del modello venga salvato.
## Inviare il codice all'Hub
<Tip warning={true}>
Questa API è sperimentale e potrebbe avere alcuni cambiamenti nei prossimi rilasci.
</Tip>
Innanzitutto, assicurati che il tuo modello sia completamente definito in un file `.py`. Può sfruttare import relativi
ad altri file, purchè questi siano nella stessa directory (non supportiamo ancora sotto-moduli per questa funzionalità).
Per questo esempio, definiremo un file `modeling_resnet.py` e un file `configuration_resnet.py` in una cartella dell'attuale
working directory chiamata `resnet_model`. Il file configuration contiene il codice per `ResnetConfig` e il file modeling
contiene il codice di `ResnetModel` e `ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
Il file `__init__.py` può essere vuoto, serve solo perchè Python capisca che `resnet_model` può essere utilizzato come un modulo.
<Tip warning={true}>
Se stai copiando i file relativi alla modellazione della libreria, dovrai sostituire tutti gli import relativi in cima al file con import del
pacchetto `transformers`.
</Tip>
Nota che puoi ri-utilizzare (o usare come sottoclassi) un modello/configurazione esistente.
Per condividere il tuo modello con la community, segui questi passi: prima importa il modello ResNet e la sua configurazione
dai nuovi file creati:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Dopodichè dovrai dire alla libreria che vuoi copiare i file con il codice di quegli oggetti quando utilizzi il metodo
`save_pretrained` e registrarli in modo corretto con una Auto classe (specialmente per i modelli). Utilizza semplicemente:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Nota che non c'è bisogno di specificare una Auto classe per la configurazione (c'è solo una Auto classe per le configurazioni,
[`AutoConfig`], ma è diversa per i modelli). Il tuo modello personalizato potrebbe essere utilizzato per diverse tasks,
per cui devi specificare quale delle classi Auto è quella corretta per il tuo modello.
Successivamente, creiamo i modelli e la config come abbiamo fatto in precedenza:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Adesso, per inviare il modello all'Hub, assicurati di aver effettuato l'accesso. Lancia dal tuo terminale:
```bash
huggingface-cli login
```
O da un notebook:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Potrai poi inviare il tutto sul tuo profilo (o di un'organizzazione di cui fai parte) in questo modo:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
Oltre ai pesi del modello e alla configurazione in formato json, questo ha anche copiato i file `.py` modeling e
configuration all'interno della cartella `custom-resnet50d` e ha caricato i risultati sull'Hub. Puoi controllare
i risultati in questa [model repo](https://huggingface.co/sgugger/custom-resnet50d).
Puoi controllare il tutorial di condivisione [tutorial di condivisione](model_sharing) per più informazioni sul
metodo con cui inviare all'Hub.
## Usare un modello con codice personalizzato
Puoi usare ogni configurazione, modello o tokenizer con file di codice personalizzati nella sua repository
con le classi Auto e il metodo `from_pretrained`. Tutti i files e il codice caricati sull'Hub sono scansionati da malware
(fai riferimento alla documentazione [Hub security](https://huggingface.co/docs/hub/security#malware-scanning) per più informazioni),
ma dovresti comunque assicurarti dell'affidabilità del codice e dell'autore per evitare di eseguire codice dannoso sulla tua macchina.
Imposta `trust_remote_code=True` per usare un modello con codice personalizzato:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
Inoltre, raccomandiamo fortemente di passare un hash del commit come `revision` per assicurarti che le autrici o gli autori del modello
non abbiano modificato il codice con alcune nuove righe dannose (a meno che non ti fidi completamente della fonte):
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Nota che quando cerchi la storia dei commit della repo del modello sull'Hub, c'è un bottone con cui facilmente copiare il
commit hash di ciascun commit.
## Registrare un modello con codice personalizzato nelle classi Auto
Se stai scrivendo una libreria che estende 🤗 Transformers, potresti voler estendere le classi Auto per includere il tuo modello.
Questo è diverso dall'inviare codice nell'Hub: gli utenti dovranno importare la tua libreria per ottenere il modello personalizzato
(anzichè scaricare automaticamente il modello dall'Hub).
Finchè il tuo file di configurazione ha un attributo `model_type` diverso dai model types esistenti, e finchè le tue
classi modello hanno i corretti attributi `config_class`, potrai semplicemente aggiungerli alle classi Auto come segue:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Nota che il primo argomento utilizzato quando registri la configurazione di un modello personalizzato con [`AutoConfig`]
deve corrispondere al `model_type` della tua configurazione personalizzata, ed il primo argomento utilizzato quando
registri i tuoi modelli personalizzati in una qualunque classe Auto del modello deve corrispondere alla `config_class`
di quei modelli.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/installation.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installazione
Installa 🤗 Transformers per qualsiasi libreria di deep learning con cui stai lavorando, imposta la tua cache, e opzionalmente configura 🤗 Transformers per l'esecuzione offline.
🤗 Transformers è testato su Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Segui le istruzioni di installazione seguenti per la libreria di deep learning che stai utilizzando:
* [PyTorch](https://pytorch.org/get-started/locally/) istruzioni di installazione.
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) istruzioni di installazione.
* [Flax](https://flax.readthedocs.io/en/latest/) istruzioni di installazione.
## Installazione con pip
Puoi installare 🤗 Transformers in un [ambiente virtuale](https://docs.python.org/3/library/venv.html). Se non sei familiare con gli ambienti virtuali in Python, dai un'occhiata a questa [guida](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Un ambiente virtuale rende più semplice la gestione di progetti differenti, evitando problemi di compatibilità tra dipendenze.
Inizia creando un ambiente virtuale nella directory del tuo progetto:
```bash
python -m venv .env
```
Attiva l'ambiente virtuale:
```bash
source .env/bin/activate
```
Ora puoi procedere con l'installazione di 🤗 Transformers eseguendo il comando seguente:
```bash
pip install transformers
```
Per il solo supporto della CPU, puoi installare facilmente 🤗 Transformers e una libreria di deep learning in solo una riga. Ad esempio, installiamo 🤗 Transformers e PyTorch con:
```bash
pip install transformers[torch]
```
🤗 Transformers e TensorFlow 2.0:
```bash
pip install transformers[tf-cpu]
```
🤗 Transformers e Flax:
```bash
pip install transformers[flax]
```
Infine, verifica se 🤗 Transformers è stato installato in modo appropriato eseguendo il seguente comando. Questo scaricherà un modello pre-allenato:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Dopodiché stampa l'etichetta e il punteggio:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Installazione dalla fonte
Installa 🤗 Transformers dalla fonte con il seguente comando:
```bash
pip install git+https://github.com/huggingface/transformers
```
Questo comando installa la versione `main` più attuale invece dell'ultima versione stabile. Questo è utile per stare al passo con gli ultimi sviluppi. Ad esempio, se un bug è stato sistemato da quando è uscita l'ultima versione ufficiale ma non è stata ancora rilasciata una nuova versione. Tuttavia, questo significa che questa versione `main` può non essere sempre stabile. Ci sforziamo per mantenere la versione `main` operativa, e la maggior parte dei problemi viene risolta in poche ore o in un giorno. Se riscontri un problema, per favore apri una [Issue](https://github.com/huggingface/transformers/issues) così possiamo sistemarlo ancora più velocemente!
Controlla se 🤗 Transformers è stata installata in modo appropriato con il seguente comando:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Installazione modificabile
Hai bisogno di un'installazione modificabile se vuoi:
* Usare la versione `main` del codice dalla fonte.
* Contribuire a 🤗 Transformers e hai bisogno di testare i cambiamenti nel codice.
Clona il repository e installa 🤗 Transformers con i seguenti comandi:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
Questi comandi collegheranno la cartella in cui è stato clonato il repository e i path delle librerie Python. Python guarderà ora all'interno della cartella clonata, oltre ai normali path delle librerie. Per esempio, se i tuoi pacchetti Python sono installati tipicamente in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python cercherà anche nella cartella clonata: `~/transformers/`.
<Tip warning={true}>
Devi tenere la cartella `transformers` se vuoi continuare ad utilizzare la libreria.
</Tip>
Ora puoi facilmente aggiornare il tuo clone all'ultima versione di 🤗 Transformers con il seguente comando:
```bash
cd ~/transformers/
git pull
```
Il tuo ambiente Python troverà la versione `main` di 🤗 Transformers alla prossima esecuzione.
## Installazione con conda
Installazione dal canale conda `conda-forge`:
```bash
conda install conda-forge::transformers
```
## Impostazione della cache
I modelli pre-allenati sono scaricati e memorizzati localmente nella cache in: `~/.cache/huggingface/transformers/`. Questa è la directory di default data dalla variabile d'ambiente della shell `TRANSFORMERS_CACHE`. Su Windows, la directory di default è data da `C:\Users\username\.cache\huggingface\transformers`. Puoi cambiare le variabili d'ambiente della shell indicate in seguito, in ordine di priorità, per specificare una directory differente per la cache:
1. Variabile d'ambiente della shell (default): `TRANSFORMERS_CACHE`.
2. Variabile d'ambiente della shell: `HF_HOME` + `transformers/`.
3. Variabile d'ambiente della shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
<Tip>
🤗 Transformers utilizzerà le variabili d'ambiente della shell `PYTORCH_TRANSFORMERS_CACHE` o `PYTORCH_PRETRAINED_BERT_CACHE` se si proviene da un'iterazione precedente di questa libreria e sono state impostate queste variabili d'ambiente, a meno che non si specifichi la variabile d'ambiente della shell `TRANSFORMERS_CACHE`.
</Tip>
## Modalità Offline
🤗 Transformers può essere eseguita in un ambiente firewalled o offline utilizzando solo file locali. Imposta la variabile d'ambiente `TRANSFORMERS_OFFLINE=1` per abilitare questo comportamento.
<Tip>
Aggiungi [🤗 Datasets](https://huggingface.co/docs/datasets/) al tuo flusso di lavoro offline di training impostando la variabile d'ambiente `HF_DATASETS_OFFLINE=1`.
</Tip>
Ad esempio, in genere si esegue un programma su una rete normale, protetta da firewall per le istanze esterne, con il seguente comando:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Esegui lo stesso programma in un'istanza offline con:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Lo script viene ora eseguito senza bloccarsi o attendere il timeout, perché sa di dover cercare solo file locali.
### Ottenere modelli e tokenizer per l'uso offline
Un'altra opzione per utilizzare offline 🤗 Transformers è scaricare i file in anticipo, e poi puntare al loro path locale quando hai la necessità di utilizzarli offline. Ci sono tre modi per fare questo:
* Scarica un file tramite l'interfaccia utente sul [Model Hub](https://huggingface.co/models) premendo sull'icona ↓.

* Utilizza il flusso [`PreTrainedModel.from_pretrained`] e [`PreTrainedModel.save_pretrained`]:
1. Scarica i tuoi file in anticipo con [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Salva i tuoi file in una directory specificata con [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./il/tuo/path/bigscience_t0")
>>> model.save_pretrained("./il/tuo/path/bigscience_t0")
```
3. Ora quando sei offline, carica i tuoi file con [`PreTrainedModel.from_pretrained`] dalla directory specificata:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./il/tuo/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./il/tuo/path/bigscience_t0")
```
* Scarica in maniera programmatica i file con la libreria [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
1. Installa la libreria `huggingface_hub` nel tuo ambiente virtuale:
```bash
python -m pip install huggingface_hub
```
2. Utilizza la funzione [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) per scaricare un file in un path specifico. Per esempio, il seguente comando scarica il file `config.json` dal modello [T0](https://huggingface.co/bigscience/T0_3B) nel path che desideri:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./il/tuo/path/bigscience_t0")
```
Una volta che il tuo file è scaricato e salvato in cache localmente, specifica il suo path locale per caricarlo e utilizzarlo:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./il/tuo/path/bigscience_t0/config.json")
```
<Tip>
Fai riferimento alla sezione [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream) per avere maggiori dettagli su come scaricare modelli presenti sull Hub.
</Tip>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/migration.md
|
<!---
Copyright 2020 The HuggingFace Team. Tutti i diritti riservati.
Concesso in licenza in base alla Licenza Apache, Versione 2.0 (la "Licenza");
non è possibile utilizzare questo file se non in conformità con la Licenza.
È possibile ottenere una copia della Licenza all'indirizzo
http://www.apache.org/licenses/LICENSE-2.0
A meno che non sia richiesto dalla legge applicabile o concordato per iscritto, il software
distribuito con la Licenza è distribuito su BASE "COSÌ COM'È",
SENZA GARANZIE O CONDIZIONI DI ALCUN TIPO, espresse o implicite.
Per la lingua specifica vedi la Licenza che regola le autorizzazioni e
le limitazioni ai sensi della STESSA.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Migrazione da pacchetti precedenti
## Migrazione da transformers `v3.x` a `v4.x`
Un paio di modifiche sono state introdotte nel passaggio dalla versione 3 alla versione 4. Di seguito è riportato un riepilogo delle
modifiche previste:
#### 1. AutoTokenizer e pipeline ora utilizzano tokenizer veloci (rust) per impostazione predefinita.
I tokenizer python e rust hanno all'incirca le stesse API, ma i tokenizer rust hanno un set di funzionalità più completo.
Ciò introduce due modifiche sostanziali:
- La gestione dei token in overflow tra i tokenizer Python e Rust è diversa.
- I tokenizers di rust non accettano numeri interi nei metodi di codifica.
##### Come ottenere lo stesso comportamento di v3.x in v4.x
- Le pipeline ora contengono funzionalità aggiuntive pronte all'uso. Vedi la [pipeline di classificazione dei token con il flag `grouped_entities`](main_classes/pipelines#transformers.TokenClassificationPipeline).
- Gli auto-tokenizer ora restituiscono tokenizer rust. Per ottenere invece i tokenizer python, l'utente deve usare il flag `use_fast` impostandolo `False`:
Nella versione `v3.x`:
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
per ottenere lo stesso nella versione `v4.x`:
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
```
#### 2. SentencePiece è stato rimosso dalle dipendenze richieste
Il requisito sulla dipendenza SentencePiece è stato rimosso da `setup.py`. È stato fatto per avere un canale su anaconda cloud senza basarsi su `conda-forge`. Ciò significa che i tokenizer che dipendono dalla libreria SentencePiece non saranno disponibili con un'installazione standard di `transformers`.
Ciò include le versioni **lente** di:
- `XLNetTokenizer`
- `AlbertTokenizer`
- `CamembertTokenizer`
- `MBartTokenizer`
- `PegasusTokenizer`
- `T5Tokenizer`
- `ReformerTokenizer`
- `XLMRobertaTokenizer`
##### Come ottenere lo stesso comportamento della v3.x nella v4.x
Per ottenere lo stesso comportamento della versione `v3.x`, devi installare anche `sentencepiece`:
Nella versione `v3.x`:
```bash
pip install transformers
```
per ottenere lo stesso nella versione `v4.x`:
```bash
pip install transformers[sentencepiece]
```
o
```bash
pip install transformers stentencepiece
```
#### 3. L'architettura delle repo è stato aggiornata in modo che ogni modello abbia la propria cartella
Con l’aggiunta di nuovi modelli, il numero di file nella cartella `src/transformers` continua a crescere e diventa più difficile navigare e capire. Abbiamo fatto la scelta di inserire ogni modello e i file che lo accompagnano nelle proprie sottocartelle.
Si tratta di una modifica sostanziale in quanto l'importazione di layer intermedi utilizzando direttamente il modulo di un modello deve essere eseguita tramite un percorso diverso.
##### Come ottenere lo stesso comportamento della v3.x nella v4.x
Per ottenere lo stesso comportamento della versione `v3.x`, devi aggiornare il percorso utilizzato per accedere ai layer.
Nella versione `v3.x`:
```bash
from transformers.modeling_bert import BertLayer
```
per ottenere lo stesso nella versione `v4.x`:
```bash
from transformers.models.bert.modeling_bert import BertLayer
```
#### 4. Impostare l'argomento `return_dict` su `True` per impostazione predefinita
L'[argomento `return_dict`](main_classes/output) abilita la restituzione di oggetti python dict-like contenenti gli output del modello, invece delle tuple standard. Questo oggetto è self-documented poiché le chiavi possono essere utilizzate per recuperare valori, comportandosi anche come una tupla e gli utenti possono recuperare oggetti per indexing o slicing.
Questa è una modifica sostanziale poiché la tupla non può essere decompressa: `value0, value1 = outputs` non funzionerà.
##### Come ottenere lo stesso comportamento della v3.x nella v4.x
Per ottenere lo stesso comportamento della versione `v3.x`, specifica l'argomento `return_dict` come `False`, sia nella configurazione del modello che nel passaggio successivo.
Nella versione `v3.x`:
```bash
model = BertModel.from_pretrained("bert-base-cased")
outputs = model(**inputs)
```
per ottenere lo stesso nella versione `v4.x`:
```bash
model = BertModel.from_pretrained("bert-base-cased")
outputs = model(**inputs, return_dict=False)
```
o
```bash
model = BertModel.from_pretrained("bert-base-cased", return_dict=False)
outputs = model(**inputs)
```
#### 5. Rimozione di alcuni attributi deprecati
Gli attributi sono stati rimossi se deprecati da almeno un mese. L'elenco completo degli attributi obsoleti è disponibile in [#8604](https://github.com/huggingface/transformers/pull/8604).
Ecco un elenco di questi attributi/metodi/argomenti e quali dovrebbero essere le loro sostituzioni:
In diversi modelli, le etichette diventano coerenti con gli altri modelli:
- `masked_lm_labels` diventa `labels` in `AlbertForMaskedLM` e `AlbertForPreTraining`.
- `masked_lm_labels` diventa `labels` in `BertForMaskedLM` e `BertForPreTraining`.
- `masked_lm_labels` diventa `labels` in `DistilBertForMaskedLM`.
- `masked_lm_labels` diventa `labels` in `ElectraForMaskedLM`.
- `masked_lm_labels` diventa `labels` in `LongformerForMaskedLM`.
- `masked_lm_labels` diventa `labels` in `MobileBertForMaskedLM`.
- `masked_lm_labels` diventa `labels` in `RobertaForMaskedLM`.
- `lm_labels` diventa `labels` in `BartForConditionalGeneration`.
- `lm_labels` diventa `labels` in `GPT2DoubleHeadsModel`.
- `lm_labels` diventa `labels` in `OpenAIGPTDoubleHeadsModel`.
- `lm_labels` diventa `labels` in `T5ForConditionalGeneration`.
In diversi modelli, il meccanismo di memorizzazione nella cache diventa coerente con gli altri:
- `decoder_cached_states` diventa `past_key_values` in tutti i modelli BART-like, FSMT e T5.
- `decoder_past_key_values` diventa `past_key_values` in tutti i modelli BART-like, FSMT e T5.
- `past` diventa `past_key_values` in tutti i modelli CTRL.
- `past` diventa `past_key_values` in tutti i modelli GPT-2.
Per quanto riguarda le classi tokenizer:
- L'attributo tokenizer `max_len` diventa `model_max_length`.
- L'attributo tokenizer `return_lengths` diventa `return_length`.
- L'argomento di codifica del tokenizer `is_pretokenized` diventa `is_split_into_words`.
Per quanto riguarda la classe `Trainer`:
- L'argomento `tb_writer` di `Trainer` è stato rimosso in favore della funzione richiamabile `TensorBoardCallback(tb_writer=...)`.
- L'argomento `prediction_loss_only` di `Trainer` è stato rimosso in favore dell'argomento di classe `args.prediction_loss_only`.
- L'attributo `data_collator` di `Trainer` sarà richiamabile.
- Il metodo `_log` di `Trainer` è deprecato a favore di `log`.
- Il metodo `_training_step` di `Trainer` è deprecato a favore di `training_step`.
- Il metodo `_prediction_loop` di `Trainer` è deprecato a favore di `prediction_loop`.
- Il metodo `is_local_master` di `Trainer` è deprecato a favore di `is_local_process_zero`.
- Il metodo `is_world_master` di `Trainer` è deprecato a favore di `is_world_process_zero`.
Per quanto riguarda la classe `TrainingArguments`:
- L'argomento `evaluate_during_training` di `TrainingArguments` è deprecato a favore di `evaluation_strategy`.
Per quanto riguarda il modello Transfo-XL:
- L'attributo di configurazione `tie_weight` di Transfo-XL diventa `tie_words_embeddings`.
- Il metodo di modellazione `reset_length` di Transfo-XL diventa `reset_memory_length`.
Per quanto riguarda le pipeline:
- L'argomento `topk` di `FillMaskPipeline` diventa `top_k`.
## Passaggio da pytorch-transformers a 🤗 Transformers
Ecco un breve riepilogo di ciò a cui prestare attenzione durante il passaggio da `pytorch-transformers` a 🤗 Transformers.
### L’ordine posizionale di alcune parole chiave di input dei modelli (`attention_mask`, `token_type_ids`...) è cambiato
Per usare Torchscript (vedi #1010, #1204 e #1195) l'ordine specifico delle **parole chiave di input** di alcuni modelli (`attention_mask`, `token_type_ids`...) è stato modificato.
Se inizializzavi i modelli usando parole chiave per gli argomenti, ad esempio `model(inputs_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)`, questo non dovrebbe causare alcun cambiamento.
Se inizializzavi i modelli con input posizionali per gli argomenti, ad esempio `model(inputs_ids, attention_mask, token_type_ids)`, potrebbe essere necessario ricontrollare l'ordine esatto degli argomenti di input.
## Migrazione da pytorch-pretrained-bert
Ecco un breve riepilogo di ciò a cui prestare attenzione durante la migrazione da `pytorch-pretrained-bert` a 🤗 Transformers
### I modelli restituiscono sempre `tuple`
La principale modifica di rilievo durante la migrazione da `pytorch-pretrained-bert` a 🤗 Transformers è che il metodo dei modelli di previsione dà sempre una `tupla` con vari elementi a seconda del modello e dei parametri di configurazione.
Il contenuto esatto delle tuple per ciascun modello è mostrato in dettaglio nelle docstring dei modelli e nella [documentazione](https://huggingface.co/transformers/).
In quasi tutti i casi, andrà bene prendendo il primo elemento dell'output come quello che avresti precedentemente utilizzato in `pytorch-pretrained-bert`.
Ecco un esempio di conversione da `pytorch-pretrained-bert`
a 🤗 Transformers per un modello di classificazione `BertForSequenceClassification`:
```python
# Carichiamo il nostro modello
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
# Se usavi questa riga in pytorch-pretrained-bert :
loss = model(input_ids, labels=labels)
# Ora usa questa riga in 🤗 Transformers per estrarre la perdita dalla tupla di output:
outputs = model(input_ids, labels=labels)
loss = outputs[0]
# In 🤗 Transformers puoi anche avere accesso ai logit:
loss, logits = outputs[:2]
# Ed anche agli attention weight se configuri il modello per restituirli (e anche altri output, vedi le docstring e la documentazione)
model = BertForSequenceClassification.from_pretrained(" bert-base-uncased", output_attentions=True)
outputs = model(input_ids, labels=labels)
loss, logits, attentions = outputs
```
### Serializzazione
Modifica sostanziale nel metodo `from_pretrained()`:
1. I modelli sono ora impostati in modalità di valutazione in maniera predefinita quando usi il metodo `from_pretrained()`. Per addestrarli non dimenticare di riportarli in modalità di addestramento (`model.train()`) per attivare i moduli di dropout.
2. Gli argomenti aggiuntivi `*inputs` e `**kwargs` forniti al metodo `from_pretrained()` venivano passati direttamente al metodo `__init__()` della classe sottostante del modello. Ora sono usati per aggiornare prima l'attributo di configurazione del modello, che può non funzionare con le classi del modello derivate costruite basandosi sui precedenti esempi di `BertForSequenceClassification`. Più precisamente, gli argomenti posizionali `*inputs` forniti a `from_pretrained()` vengono inoltrati direttamente al metodo `__init__()` del modello mentre gli argomenti keyword `**kwargs` (i) che corrispondono agli attributi della classe di configurazione, vengono utilizzati per aggiornare tali attributi (ii) che non corrispondono ad alcun attributo della classe di configurazione, vengono inoltrati al metodo `__init__()`.
Inoltre, sebbene non si tratti di una modifica sostanziale, i metodi di serializzazione sono stati standardizzati e probabilmente dovresti passare al nuovo metodo `save_pretrained(save_directory)` se prima usavi qualsiasi altro metodo di serializzazione.
Ecco un esempio:
```python
### Carichiamo un modello e un tokenizer
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
### Facciamo fare alcune cose al nostro modello e tokenizer
# Es: aggiungiamo nuovi token al vocabolario e agli embending del nostro modello
tokenizer.add_tokens(["[SPECIAL_TOKEN_1]", "[SPECIAL_TOKEN_2]"])
model.resize_token_embeddings(len(tokenizer))
# Alleniamo il nostro modello
train(model)
### Ora salviamo il nostro modello e il tokenizer in una cartella
model.save_pretrained("./my_saved_model_directory/")
tokenizer.save_pretrained("./my_saved_model_directory/")
### Ricarichiamo il modello e il tokenizer
model = BertForSequenceClassification.from_pretrained("./my_saved_model_directory/")
tokenizer = BertTokenizer.from_pretrained("./my_saved_model_directory/")
```
### Ottimizzatori: BertAdam e OpenAIAdam ora sono AdamW, lo scheduling è quello standard PyTorch
I due ottimizzatori precedenti inclusi, `BertAdam` e `OpenAIAdam`, sono stati sostituiti da un singolo `AdamW` che presenta alcune differenze:
- implementa solo la correzione del weights decay,
- lo scheduling ora è esterno (vedi sotto),
- anche il gradient clipping ora è esterno (vedi sotto).
Il nuovo ottimizzatore `AdamW` corrisponde alle API di `Adam` di PyTorch e ti consente di utilizzare metodi PyTorch o apex per lo scheduling e il clipping.
Lo scheduling è ora standard [PyTorch learning rate schedulers](https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate) e non fanno più parte dell'ottimizzatore.
Ecco un esempio di linear warmup e decay con `BertAdam` e con `AdamW`:
```python
# Parametri:
lr = 1e-3
max_grad_norm = 1.0
num_training_steps = 1000
num_warmup_steps = 100
warmup_proportion = float( num_warmup_steps) / float(num_training_steps) # 0.1
### In precedenza l'ottimizzatore BertAdam veniva istanziato in questo modo:
optimizer = BertAdam(
model.parameters(),
lr=lr,
schedule="warmup_linear",
warmup=warmup_proportion,
num_training_steps=num_training_steps,
)
### e usato in questo modo:
for batch in train_data:
loss = model(batch)
loss.backward()
optimizer.step()
### In 🤗 Transformers, ottimizzatore e schedule sono divisi e usati in questo modo:
optimizer = AdamW(
model.parameters(), lr=lr, correct_bias=False
) # Per riprodurre il comportamento specifico di BertAdam impostare correct_bias=False
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps
) # PyTorch scheduler
### e va usato così:
for batch in train_data:
loss = model(batch)
loss.backward()
torch.nn.utils.clip_grad_norm_(
model.parameters(), max_grad_norm
) # Gradient clipping non è più in AdamW (quindi puoi usare amp senza problemi)
optimizer.step()
scheduler.step()
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_train_tpu.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Addestramento su TPU
<Tip>
Nota: Molte delle strategie introdotte nella [sezione sulla GPU singola](perf_train_gpu_one) (come mixed precision training o gradient accumulation) e [sezione multi-GPU](perf_train_gpu_many) sono generiche e applicabili all'addestramento di modelli in generale quindi assicurati di dargli un'occhiata prima di immergerti in questa sezione.
</Tip>
Questo documento sarà presto completato con informazioni su come effettuare la formazione su TPU.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/debugging.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Debugging
## Debug dei problemi di rete multi-GPU
Quando addestri o fai inferenza con `DistributedDataParallel` e GPU multiple, se si verificano problemi di intercomunicazione tra processi e/o nodi, puoi utilizzare il seguente script per diagnosticare i problemi della rete.
```bash
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
```
Per esempio per testare come 2 GPU interagiscono fai:
```bash
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
Se entrambi i processi sono in grado di comunicare tra loro e di allocare la memoria della GPU, ciascuno di essi stamperà lo stato OK.
Per più GPU o nodi adatta gli argumenti nello script.
All'interno dello script di diagnostica troverai molti altri dettagli e anche una guida per eseguirlo in ambiente SLURM.
Un livello di debug superiore è aggiungere la variabile d'ambiente `NCCL_DEBUG=INFO` come di seguito:
```bash
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
In questo modo si scaricano molte informazioni di debug relative a NCCL, che puoi cercare online in caso di problemi. Oppure, se non hai la sicurezza di come interpretare l'output, puoi condividere il file di log in una Issue.
## Rilevamento di Underflow e Overflow
<Tip>
Questa funzionalità al momento è disponibile solo per PyTorch.
</Tip>
<Tip>
Per addestramento multi-GPU richiede DDP (`torch.distributed.launch`).
</Tip>
<Tip>
Questa funzionalità può essere usata con modelli basati su `nn.Module`.
</Tip>
Se inizi a ottenere `loss=NaN` o il modello presenta qualche altro comportamento anomalo a causa di valori `inf` o `nan` in
attivazioni o nei pesi, è necessario scoprire dove si verifica il primo underflow o overflow e cosa lo ha determinato. Fortunatamente
è possibile farlo facilmente attivando un modulo speciale che effettuerà il rilevamento automaticamente.
Se stai usando [`Trainer`], hai bisogno di aggiungere solo:
```bash
--debug underflow_overflow
```
ai normali argomenti della riga di comando, o passa `debug="underflow_overflow"` quando viene creato l'oggetto
[`TrainingArguments`].
Se stai usando il tuo ciclo di allenamento o un altro trainer, puoi ottenere lo stesso risultato con:
```python
from .debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model)
```
[`~debug_utils.DebugUnderflowOverflow`] inserisce dei ganci nel modello che dopo ogni chiamata
testeranno le variabili di ingresso e di uscita e anche i pesi del modulo corrispondente. Non appena viene rilevato `inf` o
o `nan` in almeno un elemento delle attivazioni o dei pesi, il programma lo notifica e stampa un rapporto come il seguente (questo è stato rilevato con `google/mt5-small` sotto fp16 mixed precision):
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output
[...]
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
L'output di esempio è stato tagliato al centro per brevità.
La seconda colonna mostra il valore dell'elemento più grande in assoluto,così se osserviamo da vicino gli ultimi istanti,
input e output sono nel range di `1e4`. Questo addestramento è stato eseguito con una mixed precision fp16 e l'ultimo passo usciva fuori (sotto `fp16` il valore più grande prima di `inf` è `64e3`). Per evitare overflows sotto `fp16` le attivazionioni devono rimanere molto al di sotto di `1e4`, perché `1e4 * 1e4 = 1e8` quindi qualsiasi moltiplicazione di matrice con grandi attivazioni porterà a una condizione di overflow numerico.
All'inizio della traccia è possibile scoprire a quale lotto si è verificato il problema (questo `Detected inf/nan during batch_number=0` significa che il problema si è verificato nel primo lotto).
Ogni frame segnalato inizia dichiarando la voce completamente qualificata per il modulo corrispondente per il quale il frame è stato segnalato.
Se osserviamo il seguente frame:
```
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
```
Questo, `encoder.block.2.layer.1.layer_norm` indica che si tratta di un layer norm nel primo layer, del secondo blocco dell'encoder. E le chiamata specifica di `forward` è `T5LayerNorm`.
Osserviamo gli ultimi frame del report:
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
[...]
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
L'ultimo frame report per la funzione `Dropout.forward` con la prima voce per l'unico input e la seconda per l'unico output. Si può notare che è stato richiamato da un attibuto `dropout` dentro la classe `DenseReluDense`. Si può notare che ciò è avvenuto durante il primo strato, del 2° blocco, durante il primissimo lotto. Infine, gli elementi di input più grandi in assoluto sono stati `6.27e+04` e l'equivalente per l'output era `inf`.
Puoi vedere qui, che `T5DenseGatedGeluDense.forward` risulta in output activations, il cui valore massimo assoluto era circa 62,7K, che è molto vicino al limite massimo di 64K di fp16. Nel prossimo frame abbiamo `Dropout` che rinormalizza i pesi, dopo aver azzerato alcuni elementi, il che spinge il valore massimo assoluto a più di 64K e si verifica un overflow.(`inf`).
Come puoi notare, è nei frames precedenti che occorre esaminare quando i numeri iniziano a diventare molto grandi per i valori fp16.
Confrontiamo il report al codice `models/t5/modeling_t5.py`:
```python
class T5DenseGatedGeluDense(nn.Module):
def __init__(self, config):
super().__init__()
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.gelu_act = ACT2FN["gelu_new"]
def forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
```
Ora è facile vedere la chiamata `dropout`, e tutte le chiamate precedenti.
Poiché il rilevamento avviene in un avanzamento (forward hook in eng.), i rapporti vengono creati immeditamente dopo ogni rientro da `forward` (forward returns in eng.).
Tornando al rapporto completo, per agire e risolvere il problema, dobbiamo andare qualche frame più in alto, dove i numeri hanno iniziato a salire, e probabilmente passare alla modalità `fp32`, in modo che i numeri non trabocchino quando vengono moltiplicati o sommati. Naturalmente, potrebbero esserci altre soluzioni. Per esempio, potremmo spegnere temporanemante `amp` se è abilitato, successivamente spostare `forward` in un helper wrapper, come:
```python
def _forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
import torch
def forward(self, hidden_states):
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)
```
Poiché il rilevatore automatico riporta solo gli ingressi e le uscite di fotogrammi completi, una volta che si sa dove cercare, si può
analizzare anche le fasi intermedie di una specifica funzione `forward`. In alcuni casi puoi usare la funzione di supporto `detect_overflow` per indirizzare il rilevatore dove preferisci, ad esempio:
```python
from debug_utils import detect_overflow
class T5LayerFF(nn.Module):
[...]
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
detect_overflow(forwarded_states, "after layer_norm")
forwarded_states = self.DenseReluDense(forwarded_states)
detect_overflow(forwarded_states, "after DenseReluDense")
return hidden_states + self.dropout(forwarded_states)
```
Si può vedere che abbiamo aggiunto 2 di questi e ora teniamo traccia se `inf` o `nan` per `forwarded_states` è stato rilevato
da qualche parte.
In realtà, il rilevatore li riporta già, perché ciascuna delle chiamate nell'esempio precedente è un `nn.Module`, ma
diciamo che se avessimo dei calcoli diretti locali, questo è il modo in cui lo faremmo.
Inoltre, se si istanzia il debugger nel proprio codice, è possibile modificare il numero di fotogrammi stampati rispetto a
predefinito, ad esempio.:
```python
from .debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
```
### Tracciamento della mistura assoluta del lotto specifico e del valore massimo
La stessa classe di debug può essere utilizzata per il tracciamento per-batch con la funzione di rilevamento di underflow/overflow disattivata.
Supponiamo di voler osservare i valori minimi e massimi assoluti per tutti gli ingredienti di ogni chiamata `forward` di un dato lotto.
lotto, e che lo si voglia fare solo per i lotti 1 e 3. Si istanzia questa classe come:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
```
Ora i batch completi 1 e 3 saranno tracciati utilizzando lo stesso formato del rilevatore di underflow/overflow.
I batches sono 0-indexed.
Questo è utile se si sa che il programma inizia a comportarsi male dopo un certo numero di batch, in modo da poter avanzare velocemente fino a quell'area.
direttamente a quell'area. Ecco un esempio di output troncato per questa configurazione:
```
*** Starting batch number=1 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.47e+04 input[0]
5.36e-05 7.92e+02 output
[...]
decoder.dropout Dropout
1.60e-07 2.27e+01 input[0]
0.00e+00 2.52e+01 output
decoder T5Stack
not a tensor output
lm_head Linear
1.01e-06 7.92e+02 weight
0.00e+00 1.11e+00 input[0]
6.06e-02 8.39e+01 output
T5ForConditionalGeneration
not a tensor output
*** Starting batch number=3 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.78e+04 input[0]
5.36e-05 7.92e+02 output
[...]
```
Qui verrà scaricato un numero enorme di fotogrammi, tanti quanti sono le chiamate in avanti nel modello, quindi può essere o non essere quello che volete, ma a volte può essere più utile usarlo di un classico debugger. Per esempio, se il problema inizia a verificarsi a partire dal lotto numero 150. Quindi è possibile scaricare le tracce dei lotti 149 e 150 e confrontare i punti in cui i numeri hanno iniziato a divergere.
È inoltre possibile specificare il numero di batch dopo il quale interrompere l'addestramento, con:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/preprocessing.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Preprocess
[[open-in-colab]]
Prima di poter usare i dati in un modello, bisogna processarli in un formato accettabile per quest'ultimo. Un modello non comprende il testo grezzo, le immagini o l'audio. Bisogna convertire questi input in numeri e assemblarli all'interno di tensori. In questa esercitazione, tu potrai:
* Preprocessare dati testuali con un tokenizer.
* Preprocessare immagini o dati audio con un estrattore di caratteristiche.
* Preprocessare dati per attività multimodali mediante un processore.
## NLP
<Youtube id="Yffk5aydLzg"/>
Lo strumento principale per processare dati testuali è un [tokenizer](main_classes/tokenizer). Un tokenizer inizia separando il testo in *tokens* secondo una serie di regole. I tokens sono convertiti in numeri, questi vengono utilizzati per costruire i tensori di input del modello. Anche altri input addizionali se richiesti dal modello vengono aggiunti dal tokenizer.
<Tip>
Se stai pensando si utilizzare un modello preaddestrato, è importante utilizzare il tokenizer preaddestrato associato. Questo assicura che il testo sia separato allo stesso modo che nel corpus usato per l'addestramento, e venga usata la stessa mappatura tokens-to-index (solitamente indicato come il *vocabolario*) come nel preaddestramento.
</Tip>
Iniziamo subito caricando un tokenizer preaddestrato con la classe [`AutoTokenizer`]. Questo scarica il *vocabolario* usato quando il modello è stato preaddestrato.
### Tokenize
Carica un tokenizer preaddestrato con [`AutoTokenizer.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
Poi inserisci le tue frasi nel tokenizer:
```py
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
>>> print(encoded_input)
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
Il tokenizer restituisce un dizionario contenente tre oggetti importanti:
* [input_ids](glossary#input-ids) sono gli indici che corrispondono ad ogni token nella frase.
* [attention_mask](glossary#attention-mask) indicata se un token deve essere elaborato o no.
* [token_type_ids](glossary#token-type-ids) identifica a quale sequenza appartiene un token se è presente più di una sequenza.
Si possono decodificare gli `input_ids` per farsi restituire l'input originale:
```py
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
```
Come si può vedere, il tokenizer aggiunge due token speciali - `CLS` e `SEP` (classificatore e separatore) - alla frase. Non tutti i modelli hanno bisogno dei token speciali, ma se servono, il tokenizer li aggiungerà automaticamente.
Se ci sono più frasi che vuoi processare, passale come una lista al tokenizer:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1]]}
```
### Pad
Questo è un argomento importante. Quando processi un insieme di frasi potrebbero non avere tutte la stessa lunghezza. Questo è un problema perchè i tensori, in input del modello, devono avere dimensioni uniformi. Il padding è una strategia per assicurarsi che i tensori siano rettangolari aggiungendo uno speciale *padding token* alle frasi più corte.
Imposta il parametro `padding` a `True` per imbottire le frasi più corte nel gruppo in modo che combacino con la massima lunghezza presente:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
Nota che il tokenizer aggiunge alle sequenze degli `0` perchè sono troppo corte!
### Truncation
L'altra faccia della medaglia è che avolte le sequenze possono essere troppo lunghe per essere gestite dal modello. In questo caso, avrai bisogno di troncare la sequenza per avere una lunghezza minore.
Imposta il parametro `truncation` a `True` per troncare una sequenza alla massima lunghezza accettata dal modello:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
### Costruire i tensori
Infine, vuoi che il tokenizer restituisca i tensori prodotti dal modello.
Imposta il parametro `return_tensors` su `pt` per PyTorch, o `tf` per TensorFlow:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch, padding=True, truncation=True, return_tensors="pt")
>>> print(encoded_input)
{'input_ids': tensor([[ 101, 153, 7719, 21490, 1122, 1114, 9582, 1623, 102],
[ 101, 5226, 1122, 9649, 1199, 2610, 1236, 102, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0]])}
===PT-TF-SPLIT===
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch, padding=True, truncation=True, return_tensors="tf")
>>> print(encoded_input)
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[ 101, 153, 7719, 21490, 1122, 1114, 9582, 1623, 102],
[ 101, 5226, 1122, 9649, 1199, 2610, 1236, 102, 0]],
dtype=int32)>,
'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0]], dtype=int32)>}
```
## Audio
Gli input audio sono processati in modo differente rispetto al testo, ma l'obiettivo rimane lo stesso: creare sequenze numeriche che il modello può capire. Un [estrattore di caratteristiche](main_classes/feature_extractor) è progettato con lo scopo preciso di estrarre caratteristiche da immagini o dati audio grezzi e convertirli in tensori. Prima di iniziare, installa 🤗 Datasets per caricare un dataset audio e sperimentare:
```bash
pip install datasets
```
Carica il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) (vedi il 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) per avere maggiori dettagli su come caricare un dataset):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
Accedi al primo elemento della colonna `audio` per dare uno sguardo all'input. Richiamando la colonna `audio` sarà caricato automaticamente e ricampionato il file audio:
```py
>>> dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 8000}
```
Questo restituisce tre oggetti:
* `array` è il segnale vocale caricato - e potenzialmente ricampionato - come vettore 1D.
* `path` il percorso del file audio.
* `sampling_rate` si riferisce al numero di campioni del segnale vocale misurati al secondo.
### Ricampionamento
Per questo tutorial, puoi usare il modello [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base). Come puoi vedere dalla model card, il modello Wav2Vec2 è preaddestrato su un campionamento vocale a 16kHz.È importante che la frequenza di campionamento dei tuoi dati audio combaci con la frequenza di campionamento del dataset usato per preaddestrare il modello. Se la frequenza di campionamento dei tuoi dati non è uguale dovrai ricampionare i tuoi dati audio.
Per esempio, il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) ha una frequenza di campionamento di 8000kHz. Utilizzando il modello Wav2Vec2 su questo dataset, alzala a 16kHz:
```py
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
>>> dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 8000}
```
1. Usa il metodo di 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.cast_column) per alzare la frequenza di campionamento a 16kHz:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
```
2. Carica il file audio:
```py
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
```
Come puoi notare, la `sampling_rate` adesso è 16kHz!
### Feature extractor
Il prossimo passo è caricare un estrattore di caratteristiche per normalizzare e fare padding sull'input. Quando applichiamo il padding sui dati testuali, uno `0` è aggiunto alle sequenze più brevi. La stessa idea si applica ai dati audio, l'estrattore di caratteristiche per gli audio aggiungerà uno `0` - interpretato come silenzio - agli `array`.
Carica l'estrattore delle caratteristiche con [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
Inserisci l' `array` audio nell'estrattore delle caratteristiche. Noi raccomandiamo sempre di aggiungere il parametro `sampling_rate` nell'estrattore delle caratteristiche per correggere meglio qualche errore, dovuto ai silenzi, che potrebbe verificarsi.
```py
>>> audio_input = [dataset[0]["audio"]["array"]]
>>> feature_extractor(audio_input, sampling_rate=16000)
{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
```
### Pad e truncate
Come per il tokenizer, puoi applicare le operazioni padding o truncation per manipolare sequenze di variabili a lotti. Dai uno sguaro alla lunghezza delle sequenze di questi due campioni audio:
```py
>>> dataset[0]["audio"]["array"].shape
(173398,)
>>> dataset[1]["audio"]["array"].shape
(106496,)
```
Come puoi vedere, il primo campione ha una sequenza più lunga del secondo. Crea una funzione che preprocesserà il dataset. Specifica una lunghezza massima del campione, e l'estrattore di features si occuperà di riempire o troncare la sequenza per coincidervi:
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays,
... sampling_rate=16000,
... padding=True,
... max_length=100000,
... truncation=True,
... )
... return inputs
```
Applica la funzione ai primi esempi nel dataset:
```py
>>> processed_dataset = preprocess_function(dataset[:5])
```
Adesso guarda la lunghezza dei campioni elaborati:
```py
>>> processed_dataset["input_values"][0].shape
(100000,)
>>> processed_dataset["input_values"][1].shape
(100000,)
```
La lunghezza dei campioni adesso coincide con la massima lunghezza impostata nelle funzione.
## Vision
Un estrattore di caratteristiche si può usare anche per processare immagini e per compiti di visione. Ancora una volta, l'obiettivo è convertire l'immagine grezza in un lotto di tensori come input.
Carica il dataset [food101](https://huggingface.co/datasets/food101) per questa esercitazione. Usa il parametro `split` di 🤗 Datasets per caricare solo un piccolo campione dal dataset di addestramento poichè il set di dati è molto grande:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101", split="train[:100]")
```
Secondo passo, dai uno sguardo alle immagini usando la caratteristica [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) di 🤗 Datasets:
```py
>>> dataset[0]["image"]
```

### Feature extractor
Carica l'estrattore di caratteristiche [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
```
### Data augmentation
Per le attività di visione, è usuale aggiungere alcuni tipi di data augmentation alle immagini come parte del preprocessing. Puoi aggiungere augmentations con qualsiasi libreria che preferisci, ma in questa esercitazione, userai il modulo [`transforms`](https://pytorch.org/vision/stable/transforms.html) di torchvision.
1. Normalizza l'immagine e usa [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) per concatenare alcune trasformazioni - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) e [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - insieme:
```py
>>> from torchvision.transforms import Compose, Normalize, RandomResizedCrop, ColorJitter, ToTensor
>>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
>>> _transforms = Compose(
... [RandomResizedCrop(feature_extractor.size), ColorJitter(brightness=0.5, hue=0.5), ToTensor(), normalize]
... )
```
2. Il modello accetta [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) come input. Questo valore è generato dall'estrattore di caratteristiche. Crea una funzione che genera `pixel_values` dai transforms:
```py
>>> def transforms(examples):
... examples["pixel_values"] = [_transforms(image.convert("RGB")) for image in examples["image"]]
... return examples
```
3. Poi utilizza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)per applicare al volo la trasformazione:
```py
>>> dataset.set_transform(transforms)
```
4. Adesso quando accedi all'immagine, puoi notare che l'estrattore di caratteristiche ha aggiunto `pixel_values` allo schema di input:
```py
>>> dataset[0]["image"]
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F1A7B0630D0>,
'label': 6,
'pixel_values': tensor([[[ 0.0353, 0.0745, 0.1216, ..., -0.9922, -0.9922, -0.9922],
[-0.0196, 0.0667, 0.1294, ..., -0.9765, -0.9843, -0.9922],
[ 0.0196, 0.0824, 0.1137, ..., -0.9765, -0.9686, -0.8667],
...,
[ 0.0275, 0.0745, 0.0510, ..., -0.1137, -0.1216, -0.0824],
[ 0.0667, 0.0824, 0.0667, ..., -0.0588, -0.0745, -0.0980],
[ 0.0353, 0.0353, 0.0431, ..., -0.0039, -0.0039, -0.0588]],
[[ 0.2078, 0.2471, 0.2863, ..., -0.9451, -0.9373, -0.9451],
[ 0.1608, 0.2471, 0.3098, ..., -0.9373, -0.9451, -0.9373],
[ 0.2078, 0.2706, 0.3020, ..., -0.9608, -0.9373, -0.8275],
...,
[-0.0353, 0.0118, -0.0039, ..., -0.2392, -0.2471, -0.2078],
[ 0.0196, 0.0353, 0.0196, ..., -0.1843, -0.2000, -0.2235],
[-0.0118, -0.0039, -0.0039, ..., -0.0980, -0.0980, -0.1529]],
[[ 0.3961, 0.4431, 0.4980, ..., -0.9216, -0.9137, -0.9216],
[ 0.3569, 0.4510, 0.5216, ..., -0.9059, -0.9137, -0.9137],
[ 0.4118, 0.4745, 0.5216, ..., -0.9137, -0.8902, -0.7804],
...,
[-0.2314, -0.1922, -0.2078, ..., -0.4196, -0.4275, -0.3882],
[-0.1843, -0.1686, -0.2000, ..., -0.3647, -0.3804, -0.4039],
[-0.1922, -0.1922, -0.1922, ..., -0.2941, -0.2863, -0.3412]]])}
```
Di seguito come si vede l'immagine dopo la fase di preprocessing. Come ci si aspetterebbe dalle trasformazioni applicate, l'immagine è stata ritagliata in modo casuale e le proprietà del colore sono diverse.
```py
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> img = dataset[0]["pixel_values"]
>>> plt.imshow(img.permute(1, 2, 0))
```

## Multimodal
Per attività multimodali userai una combinazione di tutto quello che hai imparato poco fa e applicherai le tue competenze alla comprensione automatica del parlato (Automatic Speech Recognition - ASR). Questo significa che avrai bisogno di:
* Un estrattore delle caratteristiche per processare i dati audio.
* Il Tokenizer per processare i testi.
Ritorna sul datasere [LJ Speech](https://huggingface.co/datasets/lj_speech):
```py
>>> from datasets import load_dataset
>>> lj_speech = load_dataset("lj_speech", split="train")
```
Visto che sei interessato solo alle colonne `audio` e `text`, elimina tutte le altre:
```py
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
```
Adesso guarda le colonne `audio` e `text`:
```py
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
>>> lj_speech[0]["text"]
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
```
Ricorda dalla sezione precedente sull'elaborazione dei dati audio, tu dovresti sempre [ricampionare](preprocessing#audio) la frequenza di campionamento dei tuoi dati audio per farla coincidere con quella del dataset usato dal modello preaddestrato:
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
```
### Processor
Un processor combina un estrattore di caratteristiche e un tokenizer. Carica un processor con [`AutoProcessor.from_pretrained]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
```
1. Crea una funzione che processi i dati audio in `input_values`, e tokenizza il testo in `labels`. Questi sono i tuoi input per il modello:
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
... return example
```
2. Applica la funzione `prepare_dataset` ad un campione:
```py
>>> prepare_dataset(lj_speech[0])
```
Nota che il processor ha aggiunto `input_values` e `labels`. La frequenza di campionamento è stata corretta riducendola a 16kHz.
Fantastico, ora dovresti essere in grado di preelaborare i dati per qualsiasi modalità e persino di combinare modalità diverse! Nella prossima esercitazione, impareremo a mettere a punto un modello sui dati appena pre-elaborati.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/add_new_pipeline.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Come creare una pipeline personalizzata?
In questa guida, scopriremo come creare una pipeline personalizzata e condividerla sull' [Hub](https://hf.co/models) o aggiungerla nella libreria
Transformers.
Innanzitutto, è necessario decidere gli input grezzi che la pipeline sarà in grado di accettare. Possono essere strings, raw bytes,
dictionaries o qualsiasi cosa sia l'input desiderato più probabile. Cerca di mantenere questi input il più possibile in Python
in quanto facilita la compatibilità (anche con altri linguaggi tramite JSON). Questi saranno gli `inputs` della
pipeline (`preprocess`).
Poi definire gli `outputs`. Stessa strategia degli `inputs`. Più è seplice e meglio è. Questi saranno gli output del metodo
`postprocess`.
Si parte ereditando la classe base `Pipeline`. con i 4 metodi che bisogna implementare `preprocess`,
`_forward`, `postprocess` e `_sanitize_parameters`.
```python
from transformers import Pipeline
class MyPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
return preprocess_kwargs, {}, {}
def preprocess(self, inputs, maybe_arg=2):
model_input = Tensor(inputs["input_ids"])
return {"model_input": model_input}
def _forward(self, model_inputs):
# model_inputs == {"model_input": model_input}
outputs = self.model(**model_inputs)
# Maybe {"logits": Tensor(...)}
return outputs
def postprocess(self, model_outputs):
best_class = model_outputs["logits"].softmax(-1)
return best_class
```
La struttura di questa suddivisione consiste nel supportare in modo relativamente continuo CPU/GPU, supportando allo stesso tempo l'esecuzione di
pre/postelaborazione sulla CPU su thread diversi.
`preprocess` prenderà gli input originariamente definiti e li trasformerà in qualcosa di alimentabile dal modello. Potrebbe
contenere più informazioni e di solito è un `Dict`.
`_forward` è il dettaglio dell'implementazione e non è destinato a essere chiamato direttamente. `forward` è il metodo preferito per assicurarsi che tutto funzioni correttamente perchè contiene delle slavaguardie. Se qualcosa è
è collegato a un modello reale, appartiene al metodo `_forward`, tutto il resto è nel preprocess/postprocess.
`postprocess` prende l'otput di `_forward` e lo trasforma nell'output finale che era stato deciso in precedenza.
`_sanitize_parameters` esiste per consentire agli utenti di passare i parametri ogni volta che desiderano sia a inizialization time `pipeline(...., maybe_arg=4)` che al call time `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`.
`_sanitize_parameters` ritorna 3 dicts di kwargs che vengono passati direttamente a `preprocess`,
`_forward` e `postprocess`. Non riempire nulla se il chiamante non ha chiamato con alcun parametro aggiuntivo. Questo
consente di mantenere gli argomenti predefiniti nella definizione della funzione, che è sempre più "naturale".
Un esempio classico potrebbe essere l'argomento `top_k` nel post processing dei classification tasks.
```python
>>> pipe = pipeline("my-new-task")
>>> pipe("This is a test")
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
>>> pipe("This is a test", top_k=2)
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
```
In order to achieve that, we'll update our `postprocess` method with a default parameter to `5`. and edit
`_sanitize_parameters` to allow this new parameter.
```python
def postprocess(self, model_outputs, top_k=5):
best_class = model_outputs["logits"].softmax(-1)
# Add logic to handle top_k
return best_class
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
postprocess_kwargs = {}
if "top_k" in kwargs:
postprocess_kwargs["top_k"] = kwargs["top_k"]
return preprocess_kwargs, {}, postprocess_kwargs
```
Cercare di mantenere gli input/output molto semplici e idealmente serializzabili in JSON, in quanto ciò rende l'uso della pipeline molto facile
senza richiedere agli utenti di comprendere nuovi tipi di oggetti. È anche relativamente comune supportare molti tipi di argomenti
per facilitarne l'uso (ad esempio file audio, possono essere nomi di file, URL o byte puri).
## Aggiungilo alla lista dei tasks supportati
Per registrar il tuo `new-task` alla lista dei tasks supportati, devi aggiungerlo al `PIPELINE_REGISTRY`:
```python
from transformers.pipelines import PIPELINE_REGISTRY
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
)
```
Puoi specificare il modello di default che desideri, in questo caso dovrebbe essere accompagnato da una revisione specifica (che può essere il nome di un branch o l'hash di un commit, in questo caso abbiamo preso `"abcdef"`) e anche dal type:
```python
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
default={"pt": ("user/awesome_model", "abcdef")},
type="text", # current support type: text, audio, image, multimodal
)
```
## Condividi la tua pipeline sull'Hub
Per condividere la tua pipeline personalizzata sull'Hub, devi solo salvare il codice della tua sottoclasse `Pipeline` in un file
python. Per esempio, supponiamo di voler utilizzare una pipeline personalizzata per la classificazione delle coppie di frasi come la seguente:
```py
import numpy as np
from transformers import Pipeline
def softmax(outputs):
maxes = np.max(outputs, axis=-1, keepdims=True)
shifted_exp = np.exp(outputs - maxes)
return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
class PairClassificationPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "second_text" in kwargs:
preprocess_kwargs["second_text"] = kwargs["second_text"]
return preprocess_kwargs, {}, {}
def preprocess(self, text, second_text=None):
return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
def _forward(self, model_inputs):
return self.model(**model_inputs)
def postprocess(self, model_outputs):
logits = model_outputs.logits[0].numpy()
probabilities = softmax(logits)
best_class = np.argmax(probabilities)
label = self.model.config.id2label[best_class]
score = probabilities[best_class].item()
logits = logits.tolist()
return {"label": label, "score": score, "logits": logits}
```
L'implementazione è agnostica al framework, e lavorerà sia con modelli PyTorch che con TensorFlow. Se l'abbiamo salvato in un file chiamato `pair_classification.py`, può essere successivamente importato e registrato in questo modo:
```py
from pair_classification import PairClassificationPipeline
from transformers.pipelines import PIPELINE_REGISTRY
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
PIPELINE_REGISTRY.register_pipeline(
"pair-classification",
pipeline_class=PairClassificationPipeline,
pt_model=AutoModelForSequenceClassification,
tf_model=TFAutoModelForSequenceClassification,
)
```
Una volta fatto, possiamo usarla con un modello pretrained. L'istanza `sgugger/finetuned-bert-mrpc` è stata
fine-tuned sul dataset MRPC, che classifica le coppie di frasi come parafrasi o no.
```py
from transformers import pipeline
classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
```
Successivamente possiamo condividerlo sull'Hub usando il metodo `save_pretrained` in un `Repository`:
```py
from huggingface_hub import Repository
repo = Repository("test-dynamic-pipeline", clone_from="{your_username}/test-dynamic-pipeline")
classifier.save_pretrained("test-dynamic-pipeline")
repo.push_to_hub()
```
Questo codice copierà il file dove è stato definitp `PairClassificationPipeline` all'interno della cartella `"test-dynamic-pipeline"`,
insieme al salvataggio del modello e del tokenizer della pipeline, prima di pushare il tutto nel repository
`{your_username}/test-dynamic-pipeline`. Dopodiché chiunque potrà utilizzarlo, purché fornisca l'opzione
`trust_remote_code=True`:
```py
from transformers import pipeline
classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
```
## Aggiungere la pipeline a Transformers
Se vuoi contribuire con la tua pipeline a Transformers, dovrai aggiungere un modulo nel sottomodulo `pipelines`
con il codice della tua pipeline, quindi aggiungilo all'elenco dei tasks definiti in `pipelines/__init__.py`.
Poi hai bisogno di aggiungere i test. Crea un nuovo file `tests/test_pipelines_MY_PIPELINE.py` con esempi ed altri test.
La funzione `run_pipeline_test` sarà molto generica e su piccoli modelli casuali su ogni possibile
architettura, come definito da `model_mapping` e `tf_model_mapping`.
Questo è molto importante per testare la compatibilità futura, nel senso che se qualcuno aggiunge un nuovo modello di
`XXXForQuestionAnswering` allora il test della pipeline tenterà di essere eseguito su di esso. Poiché i modelli sono casuali, è
è impossibile controllare i valori effettivi, per questo esiste un aiuto `ANY` che tenterà solamente di far corrispondere l'output della pipeline TYPE.
Hai anche *bisogno* di implementare 2 (idealmente 4) test.
- `test_small_model_pt` : Definire 1 piccolo modello per questa pipeline (non importa se i risultati non hanno senso)
e testare i risultati della pipeline. I risultati dovrebbero essere gli stessi di `test_small_model_tf`.
- `test_small_model_tf` : Definire 1 piccolo modello per questa pipeline (non importa se i risultati non hanno senso)
e testare i risultati della pipeline. I risultati dovrebbero essere gli stessi di `test_small_model_pt`.
- `test_large_model_pt` (`optional`): Testare la pipeline su una pipeline reale in cui i risultati dovrebbero avere
senso. Questi test sono lenti e dovrebbero essere contrassegnati come tali. In questo caso l'obiettivo è mostrare la pipeline e assicurarsi che non ci siano derive nelle versioni future
- `test_large_model_tf` (`optional`): Testare la pipeline su una pipeline reale in cui i risultati dovrebbero avere
senso. Questi test sono lenti e dovrebbero essere contrassegnati come tali. In questo caso l'obiettivo è mostrare la pipeline e assicurarsi
che non ci siano derive nelle versioni future
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/create_a_model.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Crea un'architettura personalizzata
Una [`AutoClass`](model_doc/auto) deduce automaticamente il modello dell'architettura e scarica la configurazione e i pesi pre-allenati. Generalmente, noi consigliamo di usare un `AutoClass` per produrre un codice indipendente dal checkpoint. Ma gli utenti che desiderano un controllo maggiore su parametri specifici del modello possono creare un modello 🤗 Transformers personalizzato da poche classi base. Questo potrebbe essere particolarmente utile per qualunque persona sia interessata nel studiare, allenare o sperimentare con un modello 🤗 Transformers. In questa guida, approfondisci la creazione di un modello personalizzato senza `AutoClass`. Impara come:
- Caricare e personalizzare una configurazione del modello.
- Creare un'architettura modello.
- Creare un tokenizer lento e veloce per il testo.
- Creare un estrattore di caratteristiche per attività riguardanti audio o immagini.
- Creare un processore per attività multimodali.
## Configurazione
Una [configurazione](main_classes/configuration) si riferisce agli attributi specifici di un modello. Ogni configurazione del modello ha attributi diversi; per esempio, tutti i modelli npl hanno questi attributi in comune `hidden_size`, `num_attention_heads`, `num_hidden_layers` e `vocab_size`. Questi attributi specificano il numero di attention heads o strati nascosti con cui costruire un modello.
Dai un'occhiata più da vicino a [DistilBERT](model_doc/distilbert) accedendo a [`DistilBertConfig`] per ispezionare i suoi attributi:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] mostra tutti gli attributi predefiniti usati per costruire una base [`DistilBertModel`]. Tutti gli attributi sono personalizzabili, creando uno spazio per sperimentare. Per esempio, puoi configurare un modello predefinito per:
- Provare un funzione di attivazione diversa con il parametro `activation`.
- Utilizzare tasso di drop out più elevato per le probalità di attention con il parametro `attention_dropout`.
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
Nella funzione [`~PretrainedConfig.from_pretrained`] possono essere modificati gli attributi del modello pre-allenato:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Quando la configurazione del modello ti soddisfa, la puoi salvare con [`~PretrainedConfig.save_pretrained`]. Il file della tua configurazione è memorizzato come file JSON nella save directory specificata:
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
Per riutilizzare la configurazione del file, caricalo con [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
```
<Tip>
Puoi anche salvare il file di configurazione come dizionario oppure come la differenza tra gli attributi della tua configurazione personalizzata e gli attributi della configurazione predefinita! Guarda la documentazione [configuration](main_classes/configuration) per più dettagli.
</Tip>
## Modello
Il prossimo passo e di creare [modello](main_classes/models). Il modello - vagamente riferito anche come architettura - definisce cosa ogni strato deve fare e quali operazioni stanno succedendo. Attributi come `num_hidden_layers` provenienti dalla configurazione sono usati per definire l'architettura. Ogni modello condivide la classe base [`PreTrainedModel`] e alcuni metodi comuni come il ridimensionamento degli input embeddings e la soppressione delle self-attention heads . Inoltre, tutti i modelli sono la sottoclasse di [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html). Cio significa che i modelli sono compatibili con l'uso di ciascun di framework.
<frameworkcontent>
<pt>
Carica gli attributi della tua configurazione personalizzata nel modello:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> model = DistilBertModel(my_config)
```
Questo crea modelli con valori casuali invece di pesi pre-allenati. Non sarai in grado di usare questo modello per niente di utile finché non lo alleni. L'allenamento è un processo costoso e che richiede tempo . Generalmente è meglio usare un modello pre-allenato per ottenere risultati migliori velocemente, utilizzando solo una frazione delle risorse neccesarie per l'allenamento.
Crea un modello pre-allenato con [`~PreTrainedModel.from_pretrained`]:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
```
Quando carichi pesi pre-allenati, la configurazione del modello predefinito è automaticamente caricata se il modello è fornito da 🤗 Transformers. Tuttavia, puoi ancora sostituire gli attributi - alcuni o tutti - di configurazione del modello predefinito con i tuoi se lo desideri:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
Carica gli attributi di configurazione personalizzati nel modello:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
Questo crea modelli con valori casuali invece di pesi pre-allenati. Non sarai in grado di usare questo modello per niente di utile finché non lo alleni. L'allenamento è un processo costoso e che richiede tempo . Generalmente è meglio usare un modello pre-allenato per ottenere risultati migliori velocemente, utilizzando solo una frazione delle risorse neccesarie per l'allenamento.
Crea un modello pre-allenoto con [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
```
Quando carichi pesi pre-allenati, la configurazione del modello predefinito è automaticamente caricato se il modello è fornito da 🤗 Transformers. Tuttavia, puoi ancora sostituire gli attributi - alcuni o tutti - di configurazione del modello predefinito con i tuoi se lo desideri:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Model head
A questo punto, hai un modello DistilBERT base i cui output sono gli *hidden states* (in italiano stati nascosti). Gli stati nascosti sono passati come input a un model head per produrre l'output finale. 🤗 Transformers fornisce un model head diverso per ogni attività fintanto che il modello supporta l'attività (i.e., non puoi usare DistilBERT per un attività sequence-to-sequence come la traduzione).
<frameworkcontent>
<pt>
Per esempio, [`DistilBertForSequenceClassification`] è un modello DistilBERT base con una testa di classificazione per sequenze. La sequenza di classificazione head è uno strato lineare sopra gli output ragruppati.
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Riutilizza facilmente questo checkpoint per un'altra attività passando ad un model head differente. Per un attività di risposta alle domande, utilizzerai il model head [`DistilBertForQuestionAnswering`]. La head per compiti di question answering è simile alla classificazione di sequenza head tranne per il fatto che è uno strato lineare sopra l'output degli stati nascosti (hidden states in inglese)
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</pt>
<tf>
Per esempio, [`TFDistilBertForSequenceClassification`] è un modello DistilBERT base con classificazione di sequenza head. La classificazione di sequenza head è uno strato lineare sopra gli output raggruppati.
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Riutilizza facilmente questo checkpoint per un altra attività passando ad un modello head diverso. Per un attività di risposta alle domande, utilizzerai il model head [`TFDistilBertForQuestionAnswering`]. Il head di risposta alle domande è simile alla sequenza di classificazione head tranne per il fatto che è uno strato lineare sopra l'output degli stati nascosti (hidden states in inglese)
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
L'ultima classe base di cui hai bisogno prima di utilizzare un modello per i dati testuali è un [tokenizer](main_classes/tokenizer) per convertire il testo grezzo in tensori. Ci sono due tipi di tokenizer che puoi usare con 🤗 Transformers:
- [`PreTrainedTokenizer`]: un'implementazione Python di un tokenizer.
- [`PreTrainedTokenizerFast`]: un tokenizer dalla nostra libreria [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) basata su Rust. Questo tipo di tokenizer è significativamente più veloce, specialmente durante la batch tokenization, grazie alla sua implementazione Rust. Il tokenizer veloce offre anche metodi aggiuntivi come *offset mapping* che associa i token alle loro parole o caratteri originali.
Entrambi i tokenizer supportano metodi comuni come la codifica e la decodifica, l'aggiunta di nuovi token e la gestione di token speciali.
<Tip warning={true}>
Non tutti i modelli supportano un tokenizer veloce. Dai un'occhiata a questo [tabella](index#supported-frameworks) per verificare se un modello ha il supporto per tokenizer veloce.
</Tip>
Se hai addestrato il tuo tokenizer, puoi crearne uno dal tuo file *vocabolario*:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
È importante ricordare che il vocabolario di un tokenizer personalizzato sarà diverso dal vocabolario generato dal tokenizer di un modello preallenato. È necessario utilizzare il vocabolario di un modello preallenato se si utilizza un modello preallenato, altrimenti gli input non avranno senso. Crea un tokenizer con il vocabolario di un modello preallenato con la classe [`DistilBertTokenizer`]:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
```
Crea un tokenizer veloce con la classe [`DistilBertTokenizerFast`]:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
```
<Tip>
Per l'impostazione predefinita, [`AutoTokenizer`] proverà a caricare un tokenizer veloce. Puoi disabilitare questo comportamento impostando `use_fast=False` in `from_pretrained`.
</Tip>
## Estrattore Di Feature
Un estrattore di caratteristiche (feature in inglese) elabora input audio o immagini. Eredita dalla classe [`~feature_extraction_utils.FeatureExtractionMixin`] base e può anche ereditare dalla classe [`ImageFeatureExtractionMixin`] per l'elaborazione delle caratteristiche dell'immagine o dalla classe [`SequenceFeatureExtractor`] per l'elaborazione degli input audio.
A seconda che tu stia lavorando a un'attività audio o visiva, crea un estrattore di caratteristiche associato al modello che stai utilizzando. Ad esempio, crea un [`ViTFeatureExtractor`] predefinito se stai usando [ViT](model_doc/vit) per la classificazione delle immagini:
```py
>>> from transformers import ViTFeatureExtractor
>>> vit_extractor = ViTFeatureExtractor()
>>> print(vit_extractor)
ViTFeatureExtractor {
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
Se non stai cercando alcuna personalizzazione, usa il metodo `from_pretrained` per caricare i parametri di default dell'estrattore di caratteristiche di un modello.
</Tip>
Modifica uno qualsiasi dei parametri [`ViTFeatureExtractor`] per creare il tuo estrattore di caratteristiche personalizzato:
```py
>>> from transformers import ViTFeatureExtractor
>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTFeatureExtractor {
"do_normalize": false,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
Per gli input audio, puoi creare un [`Wav2Vec2FeatureExtractor`] e personalizzare i parametri in modo simile:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
## Processore
Per modelli che supportano attività multimodali, 🤗 Transformers offre una classe di processore che racchiude comodamente un estrattore di caratteristiche e un tokenizer in un unico oggetto. Ad esempio, utilizziamo [`Wav2Vec2Processor`] per un'attività di riconoscimento vocale automatico (ASR). ASR trascrive l'audio in testo, quindi avrai bisogno di un estrattore di caratteristiche e di un tokenizer.
Crea un estrattore di feature per gestire gli input audio:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
Crea un tokenizer per gestire gli input di testo:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
Combinare l'estrattore di caratteristiche e il tokenizer in [`Wav2Vec2Processor`]:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Con due classi di base - configurazione e modello - e una classe di preelaborazione aggiuntiva (tokenizer, estrattore di caratteristiche o processore), puoi creare qualsiasi modello supportato da 🤗 Transformers. Ognuna di queste classi base è configurabile, consentendoti di utilizzare gli attributi specifici che desideri. È possibile impostare facilmente un modello per l'addestramento o modificare un modello preallenato esistente per la messa a punto.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/serialization.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Esporta modelli 🤗 Transformers
Se devi implementare 🤗 modelli Transformers in ambienti di produzione, noi
consigliamo di esportarli in un formato serializzato che può essere caricato ed eseguito
su runtime e hardware specializzati. In questa guida ti mostreremo come farlo
esporta 🤗 Modelli Transformers in due formati ampiamente utilizzati: ONNX e TorchScript.
Una volta esportato, un modello può essere ottimizato per l'inferenza tramite tecniche come
la quantizzazione e soppressione. Se sei interessato a ottimizzare i tuoi modelli per l'esecuzione
con la massima efficienza, dai un'occhiata a [🤗 Optimum
library](https://github.com/huggingface/optimum).
## ONNX
Il progetto [ONNX (Open Neural Network eXchange)](http://onnx.ai) Il progetto onnx è un open
standard che definisce un insieme comune di operatori e un formato di file comune a
rappresentano modelli di deep learning in un'ampia varietà di framework, tra cui
PyTorch e TensorFlow. Quando un modello viene esportato nel formato ONNX, questi
operatori sono usati per costruire un grafico computazionale (often called an
_intermediate representation_) che rappresenta il flusso di dati attraverso la
rete neurale.
Esponendo un grafico con operatori e tipi di dati standardizzati, ONNX rende
più facile passare da un framework all'altro. Ad esempio, un modello allenato in PyTorch può
essere esportato in formato ONNX e quindi importato in TensorFlow (e viceversa).
🤗 Transformers fornisce un pacchetto `transformers.onnx` che ti consente di
convertire i checkpoint del modello in un grafico ONNX sfruttando gli oggetti di configurazione.
Questi oggetti di configurazione sono già pronti per una serie di architetture di modelli,
e sono progettati per essere facilmente estensibili ad altre architetture.
Le configurazioni pronte includono le seguenti architetture:
<!--This table is automatically generated by `make fix-copies`, do not fill manually!-->
- ALBERT
- BART
- BEiT
- BERT
- BigBird
- BigBird-Pegasus
- Blenderbot
- BlenderbotSmall
- CamemBERT
- ConvBERT
- Data2VecText
- Data2VecVision
- DeiT
- DistilBERT
- ELECTRA
- FlauBERT
- GPT Neo
- GPT-J
- I-BERT
- LayoutLM
- M2M100
- Marian
- mBART
- MobileBERT
- OpenAI GPT-2
- Perceiver
- PLBart
- RoBERTa
- RoFormer
- SqueezeBERT
- T5
- ViT
- XLM
- XLM-RoBERTa
- XLM-RoBERTa-XL
Nelle prossime due sezioni, ti mostreremo come:
* Esporta un modello supportato usando il pacchetto `transformers.onnx`.
* Esporta un modello personalizzato per un'architettura non supportata.
### Esportazione di un modello in ONNX
Per esportare un modello 🤗 Transformers in ONNX, dovrai prima installarne alcune
dipendenze extra:
```bash
pip install transformers[onnx]
```
Il pacchetto `transformers.onnx` può essere usato come modulo Python:
```bash
python -m transformers.onnx --help
usage: Hugging Face Transformers ONNX exporter [-h] -m MODEL [--feature {causal-lm, ...}] [--opset OPSET] [--atol ATOL] output
positional arguments:
output Path indicating where to store generated ONNX model.
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Model ID on huggingface.co or path on disk to load model from.
--feature {causal-lm, ...}
The type of features to export the model with.
--opset OPSET ONNX opset version to export the model with.
--atol ATOL Absolute difference tolerance when validating the model.
```
L'esportazione di un checkpoint utilizzando una configurazione già pronta può essere eseguita come segue:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
che dovrebbe mostrare i seguenti log:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'last_hidden_state'})
- Validating ONNX Model output "last_hidden_state":
-[✓] (2, 8, 768) matches (2, 8, 768)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Questo esporta un grafico ONNX del checkpoint definito dall'argomento `--model`.
In questo esempio è `distilbert-base-uncased`, ma può essere qualsiasi checkpoint
Hugging Face Hub o uno memorizzato localmente.
Il file risultante `model.onnx` può quindi essere eseguito su uno dei [tanti
acceleratori](https://onnx.ai/supported-tools.html#deployModel) che supportano il
lo standard ONNX. Ad esempio, possiamo caricare ed eseguire il modello con [ONNX
Runtime](https://onnxruntime.ai/) come segue:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
I nomi di output richiesti (cioè `["last_hidden_state"]`) possono essere ottenuti
dando un'occhiata alla configurazione ONNX di ogni modello. Ad esempio, per
DistilBERT abbiamo:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
Il processo è identico per i checkpoint TensorFlow sull'hub. Ad esempio, noi
possiamo esportare un checkpoint TensorFlow puro da [Keras
organizzazione](https://huggingface.co/keras-io) come segue:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
Per esportare un modello memorizzato localmente, devi disporre dei pesi del modello
e file tokenizer memorizzati in una directory. Ad esempio, possiamo caricare e salvare un
checkpoint come segue:
<frameworkcontent>
<pt>
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> # Load tokenizer and PyTorch weights form the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-pt-checkpoint")
>>> pt_model.save_pretrained("local-pt-checkpoint")
```
Una volta salvato il checkpoint, possiamo esportarlo su ONNX puntando l'argomento `--model`
del pacchetto `transformers.onnx` nella directory desiderata:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
</pt>
<tf>
```python
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> # Load tokenizer and TensorFlow weights from the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-tf-checkpoint")
>>> tf_model.save_pretrained("local-tf-checkpoint")
```
Once the checkpoint is saved, we can export it to ONNX by pointing the `--model`
argument of the `transformers.onnx` package to the desired directory:
```bash
python -m transformers.onnx --model=local-tf-checkpoint onnx/
```
</tf>
</frameworkcontent>
### Selezione delle caratteristiche per diverse topologie di modello
Ogni configurazione già pronta viene fornita con una serie di _caratteristiche_ che ti consentono di
esportare modelli per diversi tipi di topologie o attività. Come mostrato nella tabella
di seguito, ogni caratteristica è associata a una diversa Auto Class:
| Caratteristica | Auto Class |
| ------------------------------------ | ------------------------------------ |
| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
| `default`, `default-with-past` | `AutoModel` |
| `masked-lm` | `AutoModelForMaskedLM` |
| `question-answering` | `AutoModelForQuestionAnswering` |
| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
| `sequence-classification` | `AutoModelForSequenceClassification` |
| `token-classification` | `AutoModelForTokenClassification` |
Per ciascuna configurazione, puoi trovare l'elenco delle funzionalità supportate tramite il
`FeaturesManager`. Ad esempio, per DistilBERT abbiamo:
```python
>>> from transformers.onnx.features import FeaturesManager
>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
>>> print(distilbert_features)
["default", "masked-lm", "causal-lm", "sequence-classification", "token-classification", "question-answering"]
```
Puoi quindi passare una di queste funzionalità all'argomento `--feature` nel
pacchetto `transformers.onnx`. Ad esempio, per esportare un modello di classificazione del testo
possiamo scegliere un modello ottimizzato dall'Hub ed eseguire:
```bash
python -m transformers.onnx --model=distilbert-base-uncased-finetuned-sst-2-english \
--feature=sequence-classification onnx/
```
che visualizzerà i seguenti registri:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'logits'})
- Validating ONNX Model output "logits":
-[✓] (2, 2) matches (2, 2)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Puoi notare che in questo caso, i nomi di output del modello ottimizzato sono
`logits` invece di `last_hidden_state` che abbiamo visto con il
checkpoint `distilbert-base-uncased` precedente. Questo è previsto dal
modello ottimizato visto che ha una testa di e.
<Tip>
Le caratteristiche che hanno un suffisso `wtih-past` (ad es. `causal-lm-with-past`)
corrispondono a topologie di modello con stati nascosti precalcolati (chiave e valori
nei blocchi di attenzione) che possono essere utilizzati per la decodifica autoregressiva veloce.
</Tip>
### Esportazione di un modello per un'architettura non supportata
Se desideri esportare un modello la cui architettura non è nativamente supportata dalla
libreria, ci sono tre passaggi principali da seguire:
1. Implementare una configurazione ONNX personalizzata.
2. Esportare il modello in ONNX.
3. Convalidare gli output di PyTorch e dei modelli esportati.
In questa sezione, vedremo come DistilBERT è stato implementato per mostrare cosa è
coinvolto in ogni passaggio.
#### Implementazione di una configurazione ONNX personalizzata
Iniziamo con l'oggetto di configurazione ONNX. Forniamo tre classi
astratte da cui ereditare, a seconda del tipo di archittettura
del modello che desideri esportare:
* I modelli basati su encoder ereditano da [`~onnx.config.OnnxConfig`]
* I modelli basati su decoder ereditano da [`~onnx.config.OnnxConfigWithPast`]
* I modelli encoder-decoder ereditano da[`~onnx.config.OnnxSeq2SeqConfigWithPast`]
<Tip>
Un buon modo per implementare una configurazione ONNX personalizzata è guardare l'implementazione
esistente nel file `configuration_<model_name>.py` di un'architettura simile.
</Tip>
Poiché DistilBERT è un modello basato su encoder, la sua configurazione eredita da
`OnnxConfig`:
```python
>>> from typing import Mapping, OrderedDict
>>> from transformers.onnx import OnnxConfig
>>> class DistilBertOnnxConfig(OnnxConfig):
... @property
... def inputs(self) -> Mapping[str, Mapping[int, str]]:
... return OrderedDict(
... [
... ("input_ids", {0: "batch", 1: "sequence"}),
... ("attention_mask", {0: "batch", 1: "sequence"}),
... ]
... )
```
Ogni oggetto di configurazione deve implementare la proprietà `inputs` e restituire una
mappatura, dove ogni chiave corrisponde a un input previsto e ogni valore
indica l'asse di quell'input. Per DistilBERT, possiamo vedere che sono richiesti
due input: `input_ids` e `attention_mask`. Questi inputs hanno la stessa forma di
`(batch_size, sequence_length)` per questo motivo vediamo gli stessi assi usati nella
configurazione.
<Tip>
Puoi notare che la proprietà `inputs` per `DistilBertOnnxConfig` restituisce un
`OrdinatoDict`. Ciò garantisce che gli input corrispondano alla loro posizione
relativa all'interno del metodo `PreTrainedModel.forward()` durante il tracciamento del grafico.
Raccomandiamo di usare un `OrderedDict` per le proprietà `inputs` e `outputs`
quando si implementano configurazioni ONNX personalizzate.
</Tip>
Dopo aver implementato una configurazione ONNX, è possibile istanziarla
fornendo alla configurazione del modello base come segue:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config = DistilBertOnnxConfig(config)
```
L'oggetto risultante ha diverse proprietà utili. Ad esempio è possibile visualizzare il
Set operatore ONNX che verrà utilizzato durante l'esportazione:
```python
>>> print(onnx_config.default_onnx_opset)
11
```
È inoltre possibile visualizzare gli output associati al modello come segue:
```python
>>> print(onnx_config.outputs)
OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"})])
```
Puoi notare che la proprietà degli output segue la stessa struttura degli input; esso
restituisce un `OrderedDict` di output con nome e le loro forme. La struttura di output
è legato alla scelta della funzione con cui viene inizializzata la configurazione.
Per impostazione predefinita, la configurazione ONNX viene inizializzata con la funzione 'predefinita'
che corrisponde all'esportazione di un modello caricato con la classe `AutoModel`. Se tu
desideri esportare una topologia di modello diversa, è sufficiente fornire una funzionalità diversa a
l'argomento `task` quando inizializzi la configurazione ONNX. Ad esempio, se
volevamo esportare DistilBERT con una testa di classificazione per sequenze, potremmo
usare:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config_for_seq_clf = DistilBertOnnxConfig(config, task="sequence-classification")
>>> print(onnx_config_for_seq_clf.outputs)
OrderedDict([('logits', {0: 'batch'})])
```
<Tip>
Tutte le proprietà e i metodi di base associati a [`~onnx.config.OnnxConfig`] e le
altre classi di configurazione possono essere sovrascritte se necessario. Guarda
[`BartOnnxConfig`] per un esempio avanzato.
</Tip>
#### Esportazione del modello
Una volta implementata la configurazione ONNX, il passaggio successivo consiste nell'esportare il
modello. Qui possiamo usare la funzione `export()` fornita dal
pacchetto `transformers.onnx`. Questa funzione prevede la configurazione ONNX, insieme
con il modello base e il tokenizer e il percorso per salvare il file esportato:
```python
>>> from pathlib import Path
>>> from transformers.onnx import export
>>> from transformers import AutoTokenizer, AutoModel
>>> onnx_path = Path("model.onnx")
>>> model_ckpt = "distilbert-base-uncased"
>>> base_model = AutoModel.from_pretrained(model_ckpt)
>>> tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
>>> onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
```
Gli `onnx_inputs` e `onnx_outputs` restituiti dalla funzione `export()` sono
liste di chiavi definite nelle proprietà di `input` e `output` della
configurazione. Una volta esportato il modello, puoi verificare che il modello sia ben
formato come segue:
```python
>>> import onnx
>>> onnx_model = onnx.load("model.onnx")
>>> onnx.checker.check_model(onnx_model)
```
<Tip>
Se il tuo modello è più largo di 2 GB, vedrai che molti file aggiuntivi sono
creati durante l'esportazione. Questo è _previsto_ perché ONNX utilizza [Protocol
Buffer](https://developers.google.com/protocol-buffers/) per memorizzare il modello e
questi hanno un limite di dimensione 2 GB. Vedi la [Documentazione
ONNX](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md)
per istruzioni su come caricare modelli con dati esterni.
</Tip>
#### Convalida degli output del modello
Il passaggio finale consiste nel convalidare gli output dal modello di base e quello esportato
corrispondere entro una soglia di tolleranza assoluta. Qui possiamo usare la
Funzione `validate_model_outputs()` fornita dal pacchetto `transformers.onnx`
come segue:
```python
>>> from transformers.onnx import validate_model_outputs
>>> validate_model_outputs(
... onnx_config, tokenizer, base_model, onnx_path, onnx_outputs, onnx_config.atol_for_validation
... )
```
Questa funzione usa il metodo `OnnxConfig.generate_dummy_inputs()` per generare
input per il modello di base e quello esportato e la tolleranza assoluta può essere
definita nella configurazione. Generalmente troviamo una corrispondenza numerica nell'intervallo da 1e-6
a 1e-4, anche se è probabile che qualsiasi cosa inferiore a 1e-3 vada bene.
### Contribuire con una nuova configurazione a 🤗 Transformers
Stiamo cercando di espandere l'insieme di configurazioni già pronte e di accettare
contributi della community! Se vuoi contribuire con la tua aggiunta
nella libreria, dovrai:
* Implementare la configurazione ONNX nella corrispondente `configuration file
_<model_name>.py`
* Includere l'architettura del modello e le funzioni corrispondenti in [`~onnx.features.FeatureManager`]
* Aggiungere la tua architettura del modello ai test in `test_onnx_v2.py`
Scopri come stato contribuito la configurazione per [IBERT]
(https://github.com/huggingface/transformers/pull/14868/files) per
avere un'idea di cosa è coinvolto.
## TorchScript
<Tip>
Questo è l'inizio dei nostri esperimenti con TorchScript e stiamo ancora esplorando le sue capacità con
modelli con variable-input-size. È una nostra priorità e approfondiremo le nostre analisi nelle prossime versioni,
con più esempi di codici, un'implementazione più flessibile e benchmark che confrontano i codici basati su Python con quelli compilati con
TorchScript.
</Tip>
Secondo la documentazione di Pytorch: "TorchScript è un modo per creare modelli serializzabili e ottimizzabili da codice
Pytorch". I due moduli di Pytorch [JIT e TRACE](https://pytorch.org/docs/stable/jit.html) consentono allo sviluppatore di esportare
il loro modello da riutilizzare in altri programmi, come i programmi C++ orientati all'efficienza.
Abbiamo fornito un'interfaccia che consente l'esportazione di modelli 🤗 Transformers in TorchScript in modo che possano essere riutilizzati
in un ambiente diverso rispetto a un programma Python basato su Pytorch. Qui spieghiamo come esportare e utilizzare i nostri modelli utilizzando
TorchScript.
Esportare un modello richiede due cose:
- Un passaggio in avanti con input fittizzi.
- Istanziazione del modello con flag `torchscript`.
Queste necessità implicano diverse cose a cui gli sviluppatori dovrebbero prestare attenzione. Questi dettagli mostrati sotto.
### Flag TorchScript e pesi legati
Questo flag è necessario perché la maggior parte dei modelli linguistici in questo repository hanno pesi legati tra il loro
strato "Embedding" e lo strato "Decoding". TorchScript non consente l'esportazione di modelli che hanno pesi
legati, quindi è necessario prima slegare e clonare i pesi.
Ciò implica che i modelli istanziati con il flag `torchscript` hanno il loro strato `Embedding` e strato `Decoding`
separato, il che significa che non dovrebbero essere addestrati in futuro. L'allenamento de-sincronizza i due
strati, portando a risultati inaspettati.
Questo non è il caso per i modelli che non hanno una testa del modello linguistico, poiché quelli non hanno pesi legati. Questi modelli
può essere esportato in sicurezza senza il flag `torchscript`.
### Input fittizi e standard lengths
Gli input fittizzi sono usati per fare un modello passaggio in avanti . Mentre i valori degli input si propagano attraverso i strati,
Pytorch tiene traccia delle diverse operazioni eseguite su ciascun tensore. Queste operazioni registrate vengono quindi utilizzate per
creare la "traccia" del modello.
La traccia viene creata relativamente alle dimensioni degli input. È quindi vincolato dalle dimensioni dell'input
fittizio e non funzionerà per altre lunghezze di sequenza o dimensioni batch. Quando si proverà con una dimensione diversa, ci sarà errore
come:
`La dimensione espansa del tensore (3) deve corrispondere alla dimensione esistente (7) nella dimensione non singleton 2`
will be raised. Si consiglia pertanto di tracciare il modello con una dimensione di input fittizia grande almeno quanto il più grande
input che verrà fornito al modello durante l'inferenza. È possibile eseguire il padding per riempire i valori mancanti. Il modello
sarà tracciato con una grande dimensione di input, tuttavia, anche le dimensioni della diverse matrici saranno grandi,
risultando in più calcoli.
Si raccomanda di prestare attenzione al numero totale di operazioni eseguite su ciascun input e di seguire da vicino le prestazioni
durante l'esportazione di modelli di sequenza-lunghezza variabili.
### Usare TorchSscript in Python
Di seguito è riportato un esempio, che mostra come salvare, caricare modelli e come utilizzare la traccia per l'inferenza.
#### Salvare un modello
Questo frammento di codice mostra come usare TorchScript per esportare un `BertModel`. Qui il `BertModel` è istanziato secondo
una classe `BertConfig` e quindi salvato su disco con il nome del file `traced_bert.pt`
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
#### Caricare un modello
Questo frammento di codice mostra come caricare il `BertModel` che era stato precedentemente salvato su disco con il nome `traced_bert.pt`.
Stiamo riutilizzando il `dummy_input` precedentemente inizializzato.
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
#### Utilizzare un modello tracciato per l'inferenza
Usare il modello tracciato per l'inferenza è semplice come usare il suo metodo dunder `__call__`:
```python
traced_model(tokens_tensor, segments_tensors)
```
###Implementare modelli HuggingFace TorchScript su AWS utilizzando Neuron SDK
AWS ha introdotto [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/)
famiglia di istanze per l'inferenza di machine learning a basso costo e ad alte prestazioni nel cloud.
Le istanze Inf1 sono alimentate dal chip AWS Inferentia, un acceleratore hardware personalizzato,
specializzato in carichi di lavoro di inferenza di deep learning.
[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#)
è l'SDK per Inferentia che supporta il tracciamento e l'ottimizzazione dei modelli transformers per
distribuzione su Inf1. L'SDK Neuron fornisce:
1. API di facile utilizzo con una riga di modifica del codice per tracciare e ottimizzare un modello TorchScript per l'inferenza nel cloud.
2. Ottimizzazioni delle prestazioni pronte all'uso per [miglioramento dei costi-prestazioni](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>)
3. Supporto per i modelli di trasformatori HuggingFace costruiti con [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
o [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
#### Implicazioni
Modelli Transformers basati su architettura [BERT (Bidirectional Encoder Representations from Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert),
o sue varianti come [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert)
e [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta)
funzioneranno meglio su Inf1 per attività non generative come la question answering estrattive,
Classificazione della sequenza, Classificazione dei token. In alternativa, generazione di testo
le attività possono essere adattate per essere eseguite su Inf1, secondo questo [tutorial AWS Neuron MarianMT](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
Ulteriori informazioni sui modelli che possono essere convertiti fuori dagli schemi su Inferentia possono essere
trovati nella [sezione Model Architecture Fit della documentazione Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia).
#### Dipendenze
L'utilizzo di AWS Neuron per convertire i modelli richiede le seguenti dipendenze e l'ambiente:
* A [Neuron SDK environment](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide),
which comes pre-configured on [AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
#### Convertire un modello per AWS Neuron
Usando lo stesso script come in [Usando TorchScipt in Python](https://huggingface.co/docs/transformers/main/en/serialization#using-torchscript-in-python)
per tracciare un "BertModel", importi l'estensione del framework `torch.neuron` per accedere
i componenti di Neuron SDK tramite un'API Python.
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
E modificare solo la riga di codice di traccia
Da:
```python
torch.jit.trace(model, [tokens_tensor, segments_tensors])
```
A:
```python
torch.neuron.trace(model, [token_tensor, segments_tensors])
```
Questa modifica consente a Neuron SDK di tracciare il modello e ottimizzarlo per l'esecuzione nelle istanze Inf1.
Per ulteriori informazioni sulle funzionalità, gli strumenti, i tutorial di esempi e gli ultimi aggiornamenti di AWS Neuron SDK,
consultare la [documentazione AWS NeuronSDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/_config.py
|
# docstyle-ignore
INSTALL_CONTENT = """
# Installazione di Transformers
! pip install transformers datasets
# Per installare dalla fonte invece dell'ultima versione rilasciata, commenta il comando sopra e
# rimuovi la modalità commento al comando seguente.
# ! pip install git+https://github.com/huggingface/transformers.git
"""
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
black_avoid_patterns = {
"{processor_class}": "FakeProcessorClass",
"{model_class}": "FakeModelClass",
"{object_class}": "FakeObjectClass",
}
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/community.md
|
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Comunità
Questa pagina raggruppa le risorse sviluppate dalla comunità riguardo 🤗 Transformers.
## Risorse della comunità:
| Risorsa | Descrizione | Autore |
|:----------|:-------------|------:|
| [Glossario delle Flashcards di Transformers](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | Un insieme di flashcards basate sul [glossario della documentazione di Transformers](glossary), creato in un formato tale da permettere un facile apprendimento e revisione usando [Anki](https://apps.ankiweb.net/), un'applicazione open-source e multi-piattaforma, specificatamente progettata per ricordare informazioni nel lungo termine. Guarda questo [video introduttivo su come usare le flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
## Notebook della comunità:
| Notebook | Descrizione | Autore | |
|:----------|:-------------|:-------------|------:|
| [Fine-tuning di un Transformer pre-addestrato, al fine di generare testi di canzoni](https://github.com/AlekseyKorshuk/huggingartists) | Come generare testi di canzoni nello stile del vostro artista preferito attraverso il fine-tuning di un modello GPT-2. | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
| [Addestramento di T5 in Tensorflow 2 ](https://github.com/snapthat/TF-T5-text-to-text) | Come addestrare T5 per qualsiasi attività usando Tensorflow 2. Questo notebook mostra come risolvere l'attività di "Question Answering" usando Tensorflow 2 e SQUAD. | [Muhammad Harris](https://github.com/HarrisDePerceptron) |[](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
| [Addestramento di T5 con TPU](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | Come addestrare T5 su SQUAD con Transformers e NLP. | [Suraj Patil](https://github.com/patil-suraj) |[](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
| [Fine-tuning di T5 per la classificazione e scelta multipla](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | Come effettuare il fine-tuning di T5 per le attività di classificazione a scelta multipla - usando un formato testo-a-testo - con PyTorch Lightning. | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
| [Fine-tuning di DialoGPT su nuovi dataset e lingue](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | Come effettuare il fine-tuning di un modello DialoGPT su un nuovo dataset per chatbots conversazionali open-dialog. | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
| [Modellamento di una lunga sequenza con Reformer](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | Come addestrare su sequenze di lunghezza fino a 500 mila token con Reformer. | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
| [Fine-tuning di BART per riassumere testi](https://github.com/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) | Come effettuare il fine-tuning di BART per riassumere testi con fastai usando blurr. | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) |
| [Fine-tuning di un Transformer pre-addestrato su tweet](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | Come generare tweet nello stile del tuo account Twitter preferito attraverso il fine-tuning di un modello GPT-2. | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
| [Ottimizzazione di modelli 🤗 Hugging Face con Weights & Biases](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | Un tutorial completo che mostra l'integrazione di W&B con Hugging Face. | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
| [Longformer pre-addestrato](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | Come costruire una versione "long" degli esistenti modelli pre-addestrati. | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
| [Fine-tuning di Longformer per QA](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | Come effettuare il fine-tuning di un modello longformer per un task di QA.| [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
| [Valutazione di modelli con 🤗NLP](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | Come valutare longformer su TriviaQA con `NLP`. | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
| [Fine-tuning di T5 per Sentiment Span Extraction](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | Come effettuare il fine-tuning di T5 per la sentiment span extraction - usando un formato testo-a-testo - con PyTorch Lightning. | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
| [Fine-tuning di DistilBert per la classificazione multi-classe](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | Come effettuare il fine-tuning di DistilBert per la classificazione multi-classe con PyTorch. | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
|[Fine-tuning di BERT per la classificazione multi-etichetta](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|Come effettuare il fine-tuning di BERT per la classificazione multi-etichetta con PyTorch. |[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
|[Accelerazione del fine-tuning con il Dynamic Padding / Bucketing](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)| Come velocizzare il fine-tuning di un fattore 2X usando il dynamic padding / bucketing. |[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
|[Pre-addestramento di Reformer per Masked Language Modeling](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| Come addestrare un modello Reformer usando livelli di self-attention bi-direzionali.| [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
|[Espansione e fine-tuning di Sci-BERT](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| Come incrementare il vocabolario di un modello SciBERT - pre-addestrato da AllenAI sul dataset CORD - e crearne una pipeline. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
|[Fine-tuning di BlenderBotSmall per riassumere testi usando Trainer API](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| Come effettuare il fine-tuning di BlenderBotSmall per riassumere testi su un dataset personalizzato, usando Trainer API. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
|[Fine-tuning di Electra e interpretazione con Integrated Gradients](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | Come effettuare il fine-tuning di Electra per l'analisi dei sentimenti e intepretare le predizioni con Captum Integrated Gradients. | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
|[Fine-tuning di un modello GPT-2 non inglese con la classe Trainer](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | Come effettuare il fine-tuning di un modello GPT-2 non inglese con la classe Trainer. | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
|[Fine-tuning di un modello DistilBERT per la classficazione multi-etichetta](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | Come effettuare il fine-tuning di un modello DistilBERT per l'attività di classificazione multi-etichetta. | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
|[Fine-tuning di ALBERT per la classifcazione di coppie di frasi](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) | Come effettuare il fine-tuning di un modello ALBERT - o un altro modello BERT-based - per l'attività di classificazione di coppie di frasi. | [Nadir El Manouzi](https://github.com/NadirEM) | [](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
|[Fine-tuning di Roberta per l'analisi di sentimenti](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) | Come effettuare il fine-tuning di un modello Roberta per l'analisi di sentimenti. | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
|[Valutazione di modelli che generano domande](https://github.com/flexudy-pipe/qugeev) | Quanto sono accurante le risposte alle domande generate dal tuo modello transformer seq2seq? | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
|[Classificazione di testo con DistilBERT e Tensorflow](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | Come effettuare il fine-tuning di DistilBERT per la classificazione di testo in TensorFlow. | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
|[Utilizzo di BERT per riassumere testi con un modello Encoder-Decoder su CNN/Dailymail](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | Come avviare "a caldo" un *EncoderDecoderModel* attraverso l'utilizzo di un checkpoint *bert-base-uncased* per riassumere testi su CNN/Dailymail. | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
|[Utilizzo di RoBERTa per riassumere testi con un modello Encoder-Decoder su BBC XSum](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | Come avviare "a caldo" un *EncoderDecoderModel* (condiviso) attraverso l'utilizzo di un checkpoint *roberta-base* per riassumere testi su BBC/XSum. | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
|[Fine-tuning di TAPAS su Sequential Question Answering (SQA)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | Come effettuare il fine-tuning di un modello *TapasForQuestionAnswering* attraverso l'utilizzo di un checkpoint *tapas-base* sul dataset Sequential Question Answering (SQA). | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
|[Valutazione di TAPAS su Table Fact Checking (TabFact)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | Come valutare un modello *TapasForSequenceClassification* - fine-tuned con un checkpoint *tapas-base-finetuned-tabfact* - usando una combinazione delle librerie 🤗 datasets e 🤗 transformers. | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
|[Fine-tuning di mBART per la traduzione](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | Come effettuare il fine-tuning di mBART usando Seq2SeqTrainer per la traduzione da hindi a inglese.| [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
|[Fine-tuning di LayoutLM su FUNSD (un dataset per la comprensione della forma)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | Come effettuare il fine-tuning di un modello *LayoutLMForTokenClassification* sul dataset FUNSD per l'estrazione di informazioni da documenti scannerizzati.| [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
|[Fine-tuning di DistilGPT2 e generazione di testo](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | Come effettuare il fine-tuning di DistilGPT2 e generare testo. | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
|[Fine-tuning di LED fino a 8 mila token](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | Come effettuare il fine-tuning di LED su PubMed per riassumere "lunghi" testi. | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
|[Valutazione di LED su Arxiv](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | Come valutare efficacemente LED sull'attività di riassumere "lunghi" testi. | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
|[Fine-tuning di LayoutLM su RVL-CDIP, un dataset per la classificazione di documenti (immagini)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | Come effettuare il fine-tuning di un modello *LayoutLMForSequenceClassification* sul dataset RVL-CDIP per la classificazione di documenti scannerizzati. | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
|[Decodifica Wav2Vec2 CTC con variazioni di GPT2](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | Come decodificare sequenze CTC, variate da modelli di linguaggio. | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)
|[Fine-tuning di BART per riassumere testi in due lingue con la classe Trainer](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | Come effettuare il fine-tuning di BART per riassumere testi in due lingue usando la classe Trainer. | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
|[Valutazione di Big Bird su Trivia QA](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | Come valutare BigBird su question answering di "lunghi" documenti attraverso Trivia QA. | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
| [Creazione di sottotitoli per video usando Wav2Vec2](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | Come creare sottotitoli per qualsiasi video di YouTube trascrivendo l'audio con Wav2Vec. | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
| [Fine-tuning di Vision Transformer su CIFAR-10 usando PyTorch Lightning](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | Come effettuare il fine-tuning di Vision Transformer (ViT) su CIFAR-10 usando HuggingFace Transformers, Datasets e PyTorch Lightning.| [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
| [Fine-tuning di Vision Transformer su CIFAR-10 usando 🤗 Trainer](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | Come effettuare il fine-tuning di Vision Transformer (ViT) su CIFAR-10 usando HuggingFace Transformers, Datasets e 🤗 Trainer. | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
| [Valutazione di LUKE su Open Entity, un dataset di entity typing](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | Come valutare un modello *LukeForEntityClassification* sul dataset Open Entity. | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
| [Valutazione di LUKE su TACRED, un dataset per l'estrazione di relazioni](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | Come valutare un modello *LukeForEntityPairClassification* sul dataset TACRED. | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
| [Valutazione di LUKE su CoNLL-2003, un importante benchmark NER](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | Come valutare un modello *LukeForEntitySpanClassification* sul dataset CoNLL-2003. | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
| [Valutazione di BigBird-Pegasus su dataset PubMed](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | Come valutare un modello *BigBirdPegasusForConditionalGeneration* su dataset PubMed. | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
| [Classificazione di emozioni dal discorso con Wav2Vec2](https://github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) | Come utilizzare un modello pre-addestrato Wav2Vec2 per la classificazione di emozioni sul dataset MEGA. | [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
| [Rilevamento oggetti in un'immagine con DETR](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | Come usare un modello addestrato *DetrForObjectDetection* per rilevare oggetti in un'immagine e visualizzare l'attention. | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
| [Fine-tuning di DETR su un dataset personalizzato per rilevare oggetti](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | Come effettuare fine-tuning di un modello *DetrForObjectDetection* su un dataset personalizzato per rilevare oggetti. | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
| [Fine-tuning di T5 per Named Entity Recognition](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | Come effettuare fine-tunining di *T5* per un'attività di Named Entity Recognition. | [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/training.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fine-tuning di un modello pre-addestrato
[[open-in-colab]]
Ci sono benefici significativi nell'usare un modello pre-addestrato. Si riducono i costi computazionali, l'impronta di carbonio e ti consente di usare modelli stato dell'arte senza doverli addestrare da zero. 🤗 Transformers consente l'accesso a migliaia di modelli pre-addestrati per un'ampia gamma di compiti. Quando usi un modello pre-addestrato, lo alleni su un dataset specifico per il tuo compito. Questo è conosciuto come fine-tuning, una tecnica di addestramento incredibilmente potente. In questa esercitazione, potrai fare il fine-tuning di un modello pre-addestrato, con un framework di deep learning a tua scelta:
* Fine-tuning di un modello pre-addestrato con 🤗 Transformers [`Trainer`].
* Fine-tuning di un modello pre-addestrato in TensorFlow con Keras.
* Fine-tuning di un modello pre-addestrato con PyTorch.
<a id='data-processing'></a>
## Preparare un dataset
<Youtube id="_BZearw7f0w"/>
Prima di poter fare il fine-tuning di un modello pre-addestrato, scarica un dataset e preparalo per l'addestramento. La precedente esercitazione ti ha mostrato come processare i dati per l'addestramento e adesso hai l'opportunità di metterti alla prova!
Inizia caricando il dataset [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full):
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("yelp_review_full")
>>> dataset["train"][100]
{'label': 0,
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
Come già sai, hai bisogno di un tokenizer per processare il testo e includere una strategia di padding e truncation per gestire sequenze di lunghezza variabile. Per processare il dataset in un unico passo, usa il metodo [`map`](https://huggingface.co/docs/datasets/process#map) di 🤗 Datasets che applica la funzione di preprocessing all'intero dataset:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function(examples):
... return tokenizer(examples["text"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
```
Se vuoi, puoi creare un sottoinsieme più piccolo del dataset per il fine-tuning così da ridurre il tempo necessario:
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
<a id='trainer'></a>
## Addestramento
<frameworkcontent>
<pt>
<Youtube id="nvBXf7s7vTI"/>
🤗 Transformers mette a disposizione la classe [`Trainer`] ottimizzata per addestrare modelli 🤗 Transformers, rendendo semplice iniziare l'addestramento senza scrivere manualmente il tuo ciclo di addestramento. L'API [`Trainer`] supporta un'ampia gamma di opzioni e funzionalità di addestramento come logging, gradient accumulation e mixed precision.
Inizia caricando il tuo modello e specificando il numero di etichette (labels) attese. Nel dataset Yelp Review [dataset card](https://huggingface.co/datasets/yelp_review_full#data-fields), sai che ci sono cinque etichette:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
<Tip>
Potresti vedere un warning dato che alcuni dei pesi pre-addestrati non sono stati utilizzati e altri pesi sono stati inizializzati casualmente. Non preoccuparti, è completamente normale! L'head pre-addestrata del modello BERT viene scartata e rimpiazzata da una classification head inizializzata casualmente. Farai il fine-tuning di questa nuova head del modello sul tuo compito di classificazione, trasferendogli la conoscenza del modello pre-addestrato.
</Tip>
### Iperparametri per il training
Successivamente, crea una classe [`TrainingArguments`] contenente tutti gli iperparametri che si possono regore nonché le variabili per attivare le differenti opzioni di addestramento. Per questa esercitazione puoi iniziare con gli [iperparametri](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) di ddestramento predefiniti, ma sentiti libero di sperimentare per trovare la configurazione ottimale per te.
Specifica dove salvare i checkpoints del tuo addestramento:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer")
```
### Metriche
[`Trainer`] non valuta automaticamente le performance del modello durante l'addestramento. Dovrai passare a [`Trainer`] una funzione che calcola e restituisce le metriche. La libreria 🤗 Datasets mette a disposizione una semplice funzione [`accuracy`](https://huggingface.co/metrics/accuracy) che puoi caricare con la funzione `load_metric` (guarda questa [esercitazione](https://huggingface.co/docs/datasets/metrics) per maggiori informazioni):
```py
>>> import numpy as np
>>> from datasets import load_metric
>>> metric = load_metric("accuracy")
```
Richiama `compute` su `metric` per calcolare l'accuratezza delle tue previsioni. Prima di passare le tue previsioni a `compute`, hai bisogno di convertirle in logits (ricorda che tutti i modelli 🤗 Transformers restituiscono logits):
```py
>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... predictions = np.argmax(logits, axis=-1)
... return metric.compute(predictions=predictions, references=labels)
```
Se preferisci monitorare le tue metriche di valutazione durante il fine-tuning, specifica il parametro `evaluation_strategy` nei tuoi training arguments per restituire le metriche di valutazione ad ogni epoca di addestramento:
```py
>>> from transformers import TrainingArguments, Trainer
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
```
### Trainer
Crea un oggetto [`Trainer`] col tuo modello, training arguments, dataset di training e test, e funzione di valutazione:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
Poi metti a punto il modello richiamando [`~transformers.Trainer.train`]:
```py
>>> trainer.train()
```
</pt>
<tf>
<a id='keras'></a>
<Youtube id="rnTGBy2ax1c"/>
I modelli 🤗 Transformers supportano anche l'addestramento in TensorFlow usando l'API di Keras.
### Convertire dataset nel formato per TensorFlow
Il [`DefaultDataCollator`] assembla tensori in lotti su cui il modello si addestrerà. Assicurati di specificare di restituire tensori per TensorFlow in `return_tensors`:
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
```
<Tip>
[`Trainer`] usa [`DataCollatorWithPadding`] in maniera predefinita in modo da non dover specificare esplicitamente un collettore di dati.
</Tip>
Successivamente, converti i datasets tokenizzati in TensorFlow datasets con il metodo [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specifica il tuo input in `columns` e le tue etichette in `label_cols`:
```py
>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
... columns=["attention_mask", "input_ids", "token_type_ids"],
... label_cols=["labels"],
... shuffle=True,
... collate_fn=data_collator,
... batch_size=8,
... )
>>> tf_validation_dataset = small_eval_dataset.to_tf_dataset(
... columns=["attention_mask", "input_ids", "token_type_ids"],
... label_cols=["labels"],
... shuffle=False,
... collate_fn=data_collator,
... batch_size=8,
... )
```
### Compilazione e addestramento
Carica un modello TensorFlow col numero atteso di etichette:
```py
>>> import tensorflow as tf
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
Poi compila e fai il fine-tuning del tuo modello usando [`fit`](https://keras.io/api/models/model_training_apis/) come faresti con qualsiasi altro modello di Keras:
```py
>>> model.compile(
... optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
... loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
... metrics=tf.metrics.SparseCategoricalAccuracy(),
... )
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
```
</tf>
</frameworkcontent>
<a id='pytorch_native'></a>
## Addestramento in PyTorch nativo
<frameworkcontent>
<pt>
<Youtube id="Dh9CL8fyG80"/>
[`Trainer`] si occupa del ciclo di addestramento e ti consente di mettere a punto un modello con una sola riga di codice. Per chi preferisse scrivere un proprio ciclo di addestramento personale, puoi anche fare il fine-tuning di un modello 🤗 Transformers in PyTorch nativo.
A questo punto, potresti avere bisogno di riavviare il tuo notebook o eseguire il seguente codice per liberare un po' di memoria:
```py
del model
del pytorch_model
del trainer
torch.cuda.empty_cache()
```
Successivamente, postprocessa manualmente il `tokenized_dataset` per prepararlo ad essere allenato.
1. Rimuovi la colonna `text` perché il modello non accetta testo grezzo come input:
```py
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
```
2. Rinomina la colonna `label` in `labels` perché il modello si aspetta che questo argomento si chiami `labels`:
```py
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
```
3. Imposta il formato del dataset per farti restituire tensori di PyTorch all'interno delle liste:
```py
>>> tokenized_datasets.set_format("torch")
```
Poi crea un piccolo sottocampione del dataset come visto precedentemente per velocizzare il fine-tuning:
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
### DataLoader
Crea un `DataLoader` per i tuoi datasets di train e test così puoi iterare sui lotti di dati:
```py
>>> from torch.utils.data import DataLoader
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
```
Carica il tuo modello con il numero atteso di etichette:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
### Ottimizzatore e learning rate scheduler
Crea un ottimizzatore e il learning rate scheduler per fare il fine-tuning del modello. Usa l'ottimizzatore [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) di PyTorch:
```py
>>> from torch.optim import AdamW
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
```
Crea il learning rate scheduler predefinito da [`Trainer`]:
```py
>>> from transformers import get_scheduler
>>> num_epochs = 3
>>> num_training_steps = num_epochs * len(train_dataloader)
>>> lr_scheduler = get_scheduler(
... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
... )
```
Infine specifica come `device` da usare una GPU se ne hai una. Altrimenti, l'addestramento su una CPU può richiedere diverse ore invece di un paio di minuti.
```py
>>> import torch
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
>>> model.to(device)
```
<Tip>
Ottieni l'accesso gratuito a una GPU sul cloud se non ne possiedi una usando un notebook sul web come [Colaboratory](https://colab.research.google.com/) o [SageMaker StudioLab](https://studiolab.sagemaker.aws/).
</Tip>
Ottimo, adesso possiamo addestrare! 🥳
### Training loop
Per tenere traccia dei tuoi progressi durante l'addestramento, usa la libreria [tqdm](https://tqdm.github.io/) per aggiungere una progress bar sopra il numero dei passi di addestramento:
```py
>>> from tqdm.auto import tqdm
>>> progress_bar = tqdm(range(num_training_steps))
>>> model.train()
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... outputs = model(**batch)
... loss = outputs.loss
... loss.backward()
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
### Metriche
Proprio come è necessario aggiungere una funzione di valutazione del [`Trainer`], è necessario fare lo stesso quando si scrive il proprio ciclo di addestramento. Ma invece di calcolare e riportare la metrica alla fine di ogni epoca, questa volta accumulerai tutti i batch con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch) e calcolerai la metrica alla fine.
```py
>>> metric = load_metric("accuracy")
>>> model.eval()
>>> for batch in eval_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... with torch.no_grad():
... outputs = model(**batch)
... logits = outputs.logits
... predictions = torch.argmax(logits, dim=-1)
... metric.add_batch(predictions=predictions, references=batch["labels"])
>>> metric.compute()
```
</pt>
</frameworkcontent>
<a id='additional-resources'></a>
## Altre risorse
Per altri esempi sul fine-tuning, fai riferimento a:
- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) include scripts per addestrare compiti comuni di NLP in PyTorch e TensorFlow.
- [🤗 Transformers Notebooks](notebooks) contiene diversi notebooks su come mettere a punto un modello per compiti specifici in PyTorch e TensorFlow.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_infer_gpu_many.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Inferenza Efficiente su GPU Multiple
Questo documento contiene informazioni su come fare inferenza in maniera efficiente su GPU multiple.
<Tip>
Nota: Un setup con GPU multiple può utilizzare la maggior parte delle strategie descritte nella [sezione con GPU singola](./perf_infer_gpu_one). Tuttavia, è necessario conoscere delle tecniche semplici che possono essere utilizzate per un risultato migliore.
</Tip>
## `BetterTransformer` per inferenza più rapida
Abbiamo recentemente integrato `BetterTransformer` per inferenza più rapida su multi-GPU per modelli su testo, immagini e audio. Controlla il documento con queste integrazioni [qui](https://huggingface.co/docs/optimum/bettertransformer/overview) per maggiori dettagli.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/model_sharing.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Condividi un modello
Gli ultimi due tutorial ti hanno mostrato come puoi fare fine-tuning di un modello con PyTorch, Keras e 🤗 Accelerate per configurazioni distribuite. Il prossimo passo è quello di condividere il tuo modello con la community! In Hugging Face, crediamo nella condivisione della conoscenza e delle risorse in modo da democratizzare l'intelligenza artificiale per chiunque. Ti incoraggiamo a considerare di condividere il tuo modello con la community per aiutare altre persone a risparmiare tempo e risorse.
In questo tutorial, imparerai due metodi per la condivisione di un modello trained o fine-tuned nel [Model Hub](https://huggingface.co/models):
- Condividi in modo programmatico i tuoi file nell'Hub.
- Trascina i tuoi file nell'Hub mediante interfaccia grafica.
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
Per condividere un modello con la community, hai bisogno di un account su [huggingface.co](https://huggingface.co/join). Puoi anche unirti ad un'organizzazione esistente o crearne una nuova.
</Tip>
## Caratteristiche dei repository
Ogni repository nel Model Hub si comporta come un tipico repository di GitHub. I nostri repository offrono il versionamento, la cronologia dei commit, e la possibilità di visualizzare le differenze.
Il versionamento all'interno del Model Hub è basato su git e [git-lfs](https://git-lfs.github.com/). In altre parole, puoi trattare un modello come un unico repository, consentendo un maggiore controllo degli accessi e maggiore scalabilità. Il controllo delle versioni consente *revisions*, un metodo per appuntare una versione specifica di un modello con un hash di commit, un tag o un branch.
Come risultato, puoi caricare una specifica versione di un modello con il parametro `revision`:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # nome di un tag, di un branch, o commit hash
... )
```
Anche i file possono essere modificati facilmente in un repository ed è possibile visualizzare la cronologia dei commit e le differenze:

## Configurazione
Prima di condividere un modello nell'Hub, hai bisogno delle tue credenziali di Hugging Face. Se hai accesso ad un terminale, esegui il seguente comando nell'ambiente virtuale in cui è installata la libreria 🤗 Transformers. Questo memorizzerà il tuo token di accesso nella cartella cache di Hugging Face (di default `~/.cache/`):
```bash
huggingface-cli login
```
Se stai usando un notebook come Jupyter o Colaboratory, assicurati di avere la libreria [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library) installata. Questa libreria ti permette di interagire in maniera programmatica con l'Hub.
```bash
pip install huggingface_hub
```
Utilizza `notebook_login` per accedere all'Hub, e segui il link [qui](https://huggingface.co/settings/token) per generare un token con cui effettuare il login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Converti un modello per tutti i framework
Per assicurarti che il tuo modello possa essere utilizzato da persone che lavorano con un framework differente, ti raccomandiamo di convertire e caricare il tuo modello sia con i checkpoint di PyTorch che con quelli di TensorFlow. Anche se è possibile caricare il modello da un framework diverso, se si salta questo passaggio, il caricamento sarà più lento perché 🤗 Transformers ha bisogno di convertire i checkpoint al momento.
Convertire un checkpoint per un altro framework è semplice. Assicurati di avere PyTorch e TensorFlow installati (vedi [qui](installation) per le istruzioni d'installazione), e poi trova il modello specifico per il tuo compito nell'altro framework.
<frameworkcontent>
<pt>
Specifica `from_tf=True` per convertire un checkpoint da TensorFlow a PyTorch:
```py
>>> pt_model = DistilBertForSequenceClassification.from_pretrained(
... "path/verso/il-nome-magnifico-che-hai-scelto", from_tf=True
... )
>>> pt_model.save_pretrained("path/verso/il-nome-magnifico-che-hai-scelto")
```
</pt>
<tf>
Specifica `from_pt=True` per convertire un checkpoint da PyTorch a TensorFlow:
```py
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained(
... "path/verso/il-nome-magnifico-che-hai-scelto", from_pt=True
... )
```
Poi puoi salvare il tuo nuovo modello in TensorFlow con il suo nuovo checkpoint:
```py
>>> tf_model.save_pretrained("path/verso/il-nome-magnifico-che-hai-scelto")
```
</tf>
<jax>
Se un modello è disponibile in Flax, puoi anche convertire un checkpoint da PyTorch a Flax:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/verso/il-nome-magnifico-che-hai-scelto", from_pt=True
... )
```
</jax>
</frameworkcontent>
## Condividi un modello durante il training
<frameworkcontent>
<pt>
<Youtube id="Z1-XMy-GNLQ"/>
Condividere un modello nell'Hub è tanto semplice quanto aggiungere un parametro extra o un callback. Ricorda dal [tutorial sul fine-tuning](training), la classe [`TrainingArguments`] è dove specifichi gli iperparametri e le opzioni addizionali per l'allenamento. Una di queste opzioni di training include l'abilità di condividere direttamente un modello nell'Hub. Imposta `push_to_hub=True` in [`TrainingArguments`]:
```py
>>> training_args = TrainingArguments(output_dir="il-mio-bellissimo-modello", push_to_hub=True)
```
Passa gli argomenti per il training come di consueto al [`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
Dopo aver effettuato il fine-tuning del tuo modello, chiama [`~transformers.Trainer.push_to_hub`] sul [`Trainer`] per condividere il modello allenato nell'Hub. 🤗 Transformers aggiungerà in modo automatico persino gli iperparametri, i risultati del training e le versioni del framework alla scheda del tuo modello (model card, in inglese)!
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
Condividi un modello nell'Hub con [`PushToHubCallback`]. Nella funzione [`PushToHubCallback`], aggiungi:
- Una directory di output per il tuo modello.
- Un tokenizer.
- L'`hub_model_id`, che è il tuo username sull'Hub e il nome del modello.
```py
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./il_path_dove_salvare_il_tuo_modello",
... tokenizer=tokenizer,
... hub_model_id="il-tuo-username/il-mio-bellissimo-modello",
... )
```
Aggiungi il callback a [`fit`](https://keras.io/api/models/model_training_apis/), e 🤗 Transformers caricherà il modello allenato nell'Hub:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
</tf>
</frameworkcontent>
## Utilizzare la funzione `push_to_hub`
Puoi anche chiamare `push_to_hub` direttamente sul tuo modello per caricarlo nell'Hub.
Specifica il nome del tuo modello in `push_to_hub`:
```py
>>> pt_model.push_to_hub("il-mio-bellissimo-modello")
```
Questo crea un repository sotto il proprio username con il nome del modello `il-mio-bellissimo-modello`. Ora chiunque può caricare il tuo modello con la funzione `from_pretrained`:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("il-tuo-username/il-mio-bellissimo-modello")
```
Se fai parte di un'organizzazione e vuoi invece condividere un modello sotto il nome dell'organizzazione, aggiungi il parametro `organization`:
```py
>>> pt_model.push_to_hub("il-mio-bellissimo-modello", organization="la-mia-fantastica-org")
```
La funzione `push_to_hub` può essere anche utilizzata per aggiungere altri file al repository del modello. Per esempio, aggiungi un tokenizer ad un repository di un modello:
```py
>>> tokenizer.push_to_hub("il-mio-bellissimo-modello")
```
O magari potresti voler aggiungere la versione di TensorFlow del tuo modello PyTorch a cui hai fatto fine-tuning:
```py
>>> tf_model.push_to_hub("il-mio-bellissimo-modello")
```
Ora quando navighi nel tuo profilo Hugging Face, dovresti vedere il tuo repository del modello appena creato. Premendo sulla scheda **Files** vengono visualizzati tutti i file caricati nel repository.
Per maggiori dettagli su come creare e caricare file ad un repository, fai riferimento alla documentazione [qui](https://huggingface.co/docs/hub/how-to-upstream).
## Carica un modello utilizzando l'interfaccia web
Chi preferisce un approccio senza codice può caricare un modello tramite l'interfaccia web dell'hub. Visita [huggingface.co/new](https://huggingface.co/new) per creare un nuovo repository:

Da qui, aggiungi alcune informazioni sul tuo modello:
- Seleziona il/la **owner** del repository. Puoi essere te o qualunque organizzazione di cui fai parte.
- Scegli un nome per il tuo modello, il quale sarà anche il nome del repository.
- Scegli se il tuo modello è pubblico o privato.
- Specifica la licenza utilizzata per il tuo modello.
Ora premi sulla scheda **Files** e premi sul pulsante **Add file** per caricare un nuovo file al tuo repository. Trascina poi un file per caricarlo e aggiungere un messaggio di commit.

## Aggiungi una scheda del modello
Per assicurarti che chiunque possa comprendere le abilità, limitazioni, i potenziali bias e le considerazioni etiche del tuo modello, per favore aggiungi una scheda del modello (model card, in inglese) al tuo repository. La scheda del modello è definita nel file `README.md`. Puoi aggiungere una scheda del modello:
* Creando manualmente e caricando un file `README.md`.
* Premendo sul pulsante **Edit model card** nel repository del tuo modello.
Dai un'occhiata alla [scheda del modello](https://huggingface.co/distilbert-base-uncased) di DistilBert per avere un buon esempio del tipo di informazioni che una scheda di un modello deve includere. Per maggiori dettagli legati ad altre opzioni che puoi controllare nel file `README.md`, come l'impatto ambientale o widget di esempio, fai riferimento alla documentazione [qui](https://huggingface.co/docs/hub/models-cards).
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/add_new_model.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Come aggiungere un modello a 🤗 Transformers?
Aggiungere un nuovo modello é spesso difficile e richiede una profonda conoscenza della libreria 🤗 Transformers e anche
della repository originale del modello. A Hugging Face cerchiamo di dare alla community sempre piú poteri per aggiungere
modelli independentemente. Quindi, per alcuni nuovi modelli che la community vuole aggiungere a 🤗 Transformers, abbiamo
creato una specifica *call-for-model-addition* che spiega passo dopo passo come aggiungere il modello richiesto. Con
questo *call-for-model-addition* vogliamo insegnare a volenterosi e esperti collaboratori della community come implementare
un modello in 🤗 Transformers.
Se questo é qualcosa che può interessarvi, siete liberi di controllare l'attuale “calls-for-model-addition” [qui](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model/open_model_proposals/README.md)
e contattarci.
Se il modello sarà selezionato, allora potrete lavorare insieme a un membro di Hugging Face per integrare il modello in 🤗
Transformers. Così facendo, ci guadagnerai in una comprensione totale, sia teorica che pratica, del modello proposto. Inoltre,
sarai l'artefice di un importante contributo open-source a 🤗 Transformers. Durante l'implementazione avrai l'opportunità di:
- ottenere più comprensione delle best practices in open-source
- capire i principi di design di una della librerie NLP più popolari
- capire come efficientemente testare complessi modelli NLP
- capire come integrare utilit Python come `black`, `ruff`, `make fix-copies` in una libreria per garantire sempre di avere un codice leggibile e pulito
Siamo anche contenti se vuoi aggiungere un modello che non può essere trovato nella cartella “calls-for-model-addition”.
Le seguenti sezioni spiegano in dettaglio come aggiungere un nuovo modello. Può anche essere molto utile controllare modelli
già aggiunti [qui](https://github.com/huggingface/transformers/pulls?q=is%3Apr+label%3A%22PR+for+Model+Addition%22+is%3Aclosed),
per capire se richiamano il modello che vorreste aggiungere.
Per cominciare, vediamo una panoramica general della libreria Transformers.
## Panoramica generale su 🤗 Transformers
Prima di tutto, vediamo in generale 🤗 Transformers. 🤗 Transformers é una libreria molto strutturata, quindi
puà essere che a volte ci sia un disaccordo con alcune filosofie della libreria o scelte di design. Dalla nostra esperienza,
tuttavia, abbiamo trovato che le scelte fondamentali di design della libreria sono cruciali per usare 🤗 Transformers efficacemente
su larga scala, mantenendo i costi a un livello accettabile.
Un buon primo punto di partenza per capire al meglio la libreria é leggere la [documentazione sulla nostra filosofia](filosofia)
Da qui, ci sono alcune scelte sul modo di lavorare che cerchiamo di applicare a tutti i modelli:
- La composizione é generalmente favorita sulla sovra-astrazione
- Duplicare il codice non é sempre male, soprattutto se migliora notevolmente la leggibilità e accessibilità del modello
- Tutti i files creati per il nuovo modello devono il piu possibile "compatti". Questo vuol dire che quando qualcuno leggerá il codice
di uno specifico modello, potrá vedere solo il corrispettivo file `modeling_....py` senza avere multiple dipendenze.
La cosa piú importante, é che consideriamo la libreria non solo un mezzo per dare un prodotto, *per esempio* dare la possibilità
di usare BERT per inferenza, ma é anche il prodotto reale che noi vogliamo migliorare sempre più. Quindi, quando aggiungi
un modello, non sei solo la persona che userà il modello, ma rappresenti anche tutti coloro che leggeranno,
cercheranno di capire e modificare il tuo modello.
Tenendo questi principi in mente, immergiamoci nel design generale della libreria.
### Panoramica sui modelli
Per aggiungere con successo un modello, é importante capire l'interazione tra il tuo modello e la sua configurazione,
[`PreTrainedModel`], e [`PretrainedConfig`]. Per dare un esempio, chiameremo il modello da aggiungere a 🤗 Transformers
`BrandNewBert`.
Diamo un'occhiata:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_overview.png"/>
Come potete vedere, ci basiamo sull'ereditarietà in 🤗 Transformers, tenendo però il livello di astrazione a un minimo
assoluto. Non ci sono mai più di due livelli di astrazione per ogni modello nella libreria. `BrandNewBertModel` eredita
da `BrandNewBertPreTrainedModel` che, a sua volta, eredita da [`PreTrainedModel`] - semplice no?
Come regola generale, vogliamo essere sicuri che un nuovo modello dipenda solo da [`PreTrainedModel`]. Le funzionalità
importanti che sono automaticamente conferite a ogni nuovo modello sono [`~PreTrainedModel.from_pretrained`]
e [`~PreTrainedModel.save_pretrained`], che sono usate per serializzazione e deserializzazione. Tutte le altre importanti
funzionalità, come ad esempio `BrandNewBertModel.forward` devono essere definite completamente nel nuovo script
`modeling_brand_new_bert.py`. Inoltre, vogliamo essere sicuri che un modello con uno specifico head layer, come
`BrandNewBertForMaskedLM` non erediti da `BrandNewBertModel`, ma piuttosto usi `BrandNewBertModel`
come componente che può essere chiamata nel passaggio forward per mantenere il livello di astrazione basso. Ogni
nuovo modello richieste una classe di configurazione, chiamata `BrandNewBertConfig`. Questa configurazione é sempre
mantenuta come un attributo in [`PreTrainedModel`], e quindi può essere accessibile tramite l'attributo `config`
per tutte le classi che ereditano da `BrandNewBertPreTrainedModel`:
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # il modello ha accesso al suo config
```
Analogamente al modello, la configurazione eredita le funzionalità base di serializzazione e deserializzazione da
[`PretrainedConfig`]. É da notare che la configurazione e il modello sono sempre serializzati in due formati differenti -
il modello é serializzato in un file *pytorch_model.bin* mentre la configurazione con *config.json*. Chiamando
[`~PreTrainedModel.save_pretrained`] automaticamente chiamerà [`~PretrainedConfig.save_pretrained`], cosicché sia il
modello che la configurazione siano salvati.
### Stile per il codice
Quando codifichi un nuovo modello, tieni presente che Transformers ha una sua struttura di fondo come libreria, perciò
ci sono alcuni fatti da considerare su come scrivere un codice :-)
1. Il forward pass del tuo modello dev'essere scritto completamente nel file del modello, mentre dev'essere indipendente
da altri modelli nella libreria. Se vuoi riutilizzare un blocco di codice da un altro modello, copia e incolla il codice con un commento `# Copied from` in cima al codice (guarda [qui](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
per un ottimo esempio).
2. Il codice dev'essere interamente comprensibile, anche da persone che non parlano in inglese. Questo significa che le
variabili devono avere un nome descrittivo e bisogna evitare abbreviazioni. Per esempio, `activation` é molto meglio
che `act`. Le variabili con una lettera sono da evitare fortemente, almeno che non sia per un indce in un for loop.
3. Generamente é meglio avere un codice esplicito e piú lungo che un codice corto e magico.
4. Evita di subclassare `nn.Sequential` in Pytorch, puoi subclassare `nn.Module` e scrivere il forward pass, cosicché
chiunque può effettuare debug sul tuo codice, aggiungendo print o breaking points.
5. La tua function-signature dev'essere type-annoted. Per il resto, é meglio preferire variabili con un nome accettabile
piuttosto che annotazioni per aumentare la comprensione e leggibilità del codice.
### Panoramica sui tokenizers
Questa sezione sarà creata al piu presto :-(
## Aggiungere un modello a 🤗 Transformers passo dopo passo
Ci sono differenti modi per aggiungere un modello a Hugging Face. Qui trovi una lista di blog posts da parte della community su come aggiungere un modello:
1. [Aggiungere GPT2](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) scritto da [Thomas](https://huggingface.co/thomwolf)
2. [Aggiungere WMT19 MT](https://huggingface.co/blog/porting-fsmt) scritto da [Stas](https://huggingface.co/stas)
Per esperienza, possiamo dirti che quando si aggiunge un modello é meglio tenere a mente le seguenti considerazioni:
- Non sfondare una porta giá aperta! La maggior parte del codice che aggiungerai per un nuovo modello 🤗 Transformers
esiste già da qualche parte in 🤗 Transformers. Prendi un po' di tempo per trovare codici simili in modelli e tokenizers esistenti e fare un copia-incolla. Ricorda che [grep](https://www.gnu.org/software/grep/) e [rg](https://github.com/BurntSushi/ripgrep) sono tuoi buoni amici. Inoltre, ricorda che puó essere molto probabile che il tokenizer per il tuo modello sia basato sull'implementazione di un altro modello, e il codice del tuo modello stesso su un altro ancora. *Per esempio* il modello FSMT é basato su BART, mentre il tokenizer di FSMT é basato su XLM.
- Ricorda che qui é piu una sfida ingegneristica che scientifica. Spendi piú tempo per create un efficiente ambiente di debugging piuttosto che cercare di capire tutti gli aspetti teorici dell'articolo del modello.
- Chiedi aiuto se sei in panne! I modelli sono la parte principale di 🤗 Transformers, perciò qui a Hugging Face siamo più che contenti di aiutarti in ogni passo per aggiungere il tuo modello. Non esitare a chiedere se vedi che non riesci a progredire.
Di seguito, diamo una ricetta generale per aiutare a portare un modello in 🤗 Transformers.
La lista seguente é un sommario di tutto quello che é stato fatto per aggiungere un modello, e può essere usata come To-Do List:
- 1. ☐ (Opzionale) Capire gli aspetti teorici del modello
- 2. ☐ Preparare l'ambiente dev per transformers
- 3. ☐ Preparare l'ambiente debugging della repository originale
- 4. ☐ Create uno script che gestisca con successo il forward pass usando la repository originale e checkpoint
- 5. ☐ Aggiungere con successo lo scheletro del modello a Transformers
- 6. ☐ Convertire i checkpoint original a Transformers checkpoint
- 7. ☐ Effettuare con successo la forward pass in Transformers, di modo che dia un output identico al checkpoint originale
- 8. ☐ Finire i tests per il modello in Transformers
- 9. ☐ Aggiungere con successo Tokenizer in Transformers
- 10. ☐ Testare e provare gli integration tests da capo a fine
- 11. ☐ Completare i docs
- 12. ☐ Caricare i moedl weights all'hub
- 13. ☐ Sottomettere una pull request
- 14. ☐ (Opzionale) Aggiungere un notebook con una demo
Per cominciare di solito consigliamo `BrandNewBert`, partendo dalla teoria, di modo da avere una buona comprensione della teoria generale. TUttavia, se preferisci imparare l'aspetto teorico del modello mentre *lavori* sul modello é ok immergersi direttamente nel codice di `BrandNewBert`. Questa opzione puó essere buona se le tue skills ingegneristiche sono meglio che quelle teoriche, o se il paper `BrandNewBert` ti dá problemi, o se semplicemente ti piace programmare piú che leggere articoli scientifici.
### 1. (Opzionale) Aspetti teorici di BrandNewBert
Allora con calma, prendi un po' di tempo per leggere l'articolo su *BrandNewBert* . Sicuramente, alcune sezioni dell'articolo sono molto complesse, ma non preoccuparti! L'obiettivo non é avere una compresione immensa della teoria alla base, ma estrarre le informazioni necessarie per re-implementare con successo il modello in 🤗 Transformers. Quindi, non impazzire sugli aspetti teorici, ma piuttosto focalizzati su quelli pratici, ossia:
- Che tipo di modello é *brand_new_bert*? É solo un encoder in stile BERT? O tipo decoder come GPT2? O encoder e decoder stile BART? Dai un'occhiata a [model_summary](model_summary) se non sei famigliare con le differenze tra questi modelli
- Quali sono le applicazioni di *brand_new_bert*? Classificazione di testo? Generazione di testo? O per tasks del genere seq2seq?
- Quali sono le nuove aggiunte al modello che lo rendono diverso da BERT/GPT-2/BART?
- Quali modelli estistenti in [🤗 Transformers models](https://huggingface.co/transformers/#contents) sono molto simili a *brand_new_bert*?
- Che tipo di tokenizer si usa in questo caso? Un sentencepiece tokenizer? O un word piece tokenizer? Il tokenizer é lo stesso di BERT o BART?
Una volta che senti che hai avuto una bella overview dell'architettura del modello, puoi scrivere senza problemi al team di Hugging Face per ogni domanda che tu hai. Questo puó includere domande sull'architettura del modello, o sull'attention layer, etc. Saremo molto felici di aiutarti :)
### 2. Prepare il tuo ambiente
1. Forka la [repository](https://github.com/huggingface/transformers) cliccando sul tasto ‘Fork' nella pagina della repository. Questo crea una copia del codice nel tuo account GitHub
2. Clona il tuo fork `transfomers` sul tuo dico locale, e aggiungi la repository base come remota:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Crea un ambiente di sviluppo, per esempio tramite questo comando:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
quindi torna alla directory principale:
```bash
cd ..
```
4. Attenzione, raccomandiamo di aggiungere la versione di PyTorch di *brand_new_bert* a Transfomers. Per installare PyTorch, basta seguire queste istruzioni https://pytorch.org/get-started/locally/.
**Nota bene:** Non c'é bisogno di installare o avere installato CUDA. Il nuovo modello può funzionare senza problemi su una CPU.
5. Per trasferire *brand_new_bert* To port *brand_new_bert* avrai bisogno anche accesso alla sua repository originale:
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
Ok, ora hai un ambiente di sviluppo per portare *brand_new_bert* in 🤗 Transformers.
### 3.-4. Provare un pretrained checkpoint usando la repo originale
Per cominciare, comincerai a lavorare sulla repo originale di *brand_new_bert*. Come spesso accade, l'implementazione originale é molto sullo stile "ricerca". Questo significa che a volte la documentazione non é al top, magari manca qualche cosa e il codice puó essere difficile da capire. Tuttavia, questa é e dev'essere la motivazione per reimplementare *brand_new_bert*. In Hugging Face, uno degli obiettivi principali é di *mettere le persone sulle spalle dei giganti*, il che si traduce, in questo contesto, di prendere un modello funzionante e riscriverlo e renderlo il piú possibile **accessibile, user-friendly, e leggibile**. Questa é la top motivazione per re-implementare modelli in 🤗 Transformers - cercare di creare nuove complesse tecnologie NLP accessibili a **chiunque**.
Riuscire a far girare il modello pretrained originale dalla repository ufficiale é spesso il passo **piu arduo**. Dalla nostra esperienza, é molto importante spendere un p' di tempo per diventare familiari con il codice base originale. Come test, prova a capire i seguenti punti:
- Dove si trovano i pretrained weights?
- Come caricare i pretrained weights nel modello corrispondente?
- Come girare un tokenizer independentemente dal modello?
- Prova a tracciare un singolo forward pass, cosicché potrai sapere che classi e funzioni sono richieste per un semplice forward pass. Di solito, dovrai reimplementare queste funzioni e basta
- Prova a localizzare i componenti importanti del modello: Dove si trova la classe del modello? Ci sono sotto classi nel modello *per esempio* EngoderModel, DecoderMOdel? Dove si trova il self-attention layer? Ci sono molteplici differenti layer di attention, *per esempio * *self-attention*, *cross-attention*...?
- Come puoi fare debug sul modello nell'ambiente originale della repo? Devi aggiungere dei *print* o puoi usare *ipdb* come debugger interattivo, o vabene anche un IDE efficiente per debug come PyCharm?
É molto importante che prima di cominciare a trasferire il modello nuovo tu spenda tempo a fare debug del codice originale in maniera **efficiente**! Inoltre, ricorda che tutta la library é open-soruce, quindi non temere di aprire issue o fare una pull request nella repo originale. Tutti coloro che mantengono la repository saranno piú che felici di avere qualcuno che guarda e gioca con i loro codici!
A questo punto, sta a te decidere quale ambiente per debug vuoi usare. Noi consilgiamo di evitare setup con GPU, che potrebbero costare assai, lavorare su una CPU puó essere un ottimo punto di partenza per indagare la repository originale e per cominciare a scrivere il codice per 🤗 Transformers. Solo alla fine, quando il modello é stato portato con successo in 🤗 Transformers, allora si potrá verificare il suo funzionamento su GPU.
In generale ci sono due possibili ambienti di debug per il testare il modello originale:
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Scripts locali in Python
Il vantaggio dei Jupyter notebooks é la possibilità di eseguire cella per cella, il che può essere utile per decomporre tutte le componenti logiche, cosi da a vere un ciclo di debug più rapido, siccome si possono salvare i risultati da steps intermedi. Inoltre, i notebooks spesso sono molto facili da condividere con altri contributors, il che può essere molto utile se vuoi chiedere aiuto al team di Hugging Face. Se sei famigliare con Jupyter notebooks allora racommandiamo di lavorare in questa maniera.
Ovviamente se non siete abituati a lavorare con i notebook, questo può essere uno svantaggio nell'usare questa tecnologia, sprecando un sacco di tempo per setup e portare tutto al nuovo ambiente, siccome non potreste neanche usare dei tools di debug come `ipdb`.
Per ogni pratica code-base, é sempre meglio come primo step caricare un **piccolo** checkpoint pretrained e cercare di riprodurre un singolo forward pass usando un vettore fittizio di IDs fatti da numeri interi. Un esempio per uno script simile, in pseudocodice é:
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Per quanto riguarda la strategia di debugging, si può scegliere tra:
- Decomporre il modello originario in piccole componenenti e testare ognuna di esse
- Decomporre il modello originario nel *tokenizer* originale e nel *modello* originale, testare un forward pass su questi,
e usare dei print statement o breakpoints intermedi per verificare
Ancora una volta, siete liberi di scegliere quale strategia sia ottimale per voi. Spesso una strategia é piu
avvantaggiosa di un'altra, ma tutto dipende dall'code-base originario.
Se il code-base vi permette di decomporre il modello in piccole sub-componenenti, *per esempio* se il code-base
originario può essere facilmente testato in eager mode, allora vale la pena effettuare un debugging di questo genere.
Ricordate che ci sono dei vantaggi nel decidere di prendere la strada piu impegnativa sin da subito:
- negli stage piu finali, quando bisognerà comparare il modello originario all'implementazione in Hugging Face, potrete verificare
automaticamente ogni componente, individualmente, di modo che ci sia una corrispondenza 1:1
- avrete l'opportunità di decomporre un problema molto grande in piccoli passi, così da strutturare meglio il vostro lavoro
- separare il modello in componenti logiche vi aiuterà ad avere un'ottima overview sul design del modello, quindi una migliore
comprensione del modello stesso
- verso gli stage finali i test fatti componente per componente vi aiuterà ad essere sicuri di non andare avanti e indietro
nell'implementazione, così da continuare la modifica del codice senza interruzione
Un ottimo esempio di come questo può essere fatto é dato da [Lysandre](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
per il modello ELECTRA
Tuttavia, se il code-base originale é molto complesso o le componenti intermedie possono essere testate solo in tramite
compilazione, potrebbe richiedere parecchio tempo o addirittura essere impossibile separare il modello in piccole sotto-componenti.
Un buon esempio é [MeshTensorFlow di T5](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow). Questa libreria
é molto complessa e non offre un metodo semplice di decomposizione in sotto-componenti. Per simili librerie, potrete fare
affidamento ai print statements.
In ogni caso, indipendentemente da quale strategia scegliete, la procedura raccomandata é di cominciare a fare debug dal
primo layer al layer finale.
É consigliato recuperare gli output dai layers, tramite print o sotto-componenti, nel seguente ordine:
1. Recuperare gli IDs di input dati al modello
2. Recuperare i word embeddings
3. Recuperare l'input del primo Transformer layer
4. Recuperare l'output del primo Transformer layer
5. Recuperare l'output dei seguenti `n - 1` Transformer layers
6. Recuperare l'output dell'intero BrandNewBert Model
Gli IDs in input dovrebbero essere un arrary di interi, *per esempio* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
Gli output dei seguenti layer di solito dovrebbero essere degli array di float multi-dimensionali come questo:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
Ci aspettiamo che ogni modello aggiunto a 🤗 Transformers passi con successo un paio di test d'integrazione. Questo
significa che il modello originale e la sua implementazione in 🤗 Transformers abbiano lo stesso output con una precisione
di 0.001! Siccome é normale che lo stesso esatto modello, scritto in librerie diverse, possa dare output leggermente
diversi, la tolleranza accettata é 1e-3 (0.001). Ricordate che i due modelli devono dare output quasi identici. Dunque,
é molto conveniente comparare gli output intermedi di 🤗 Transformers molteplici volte con gli output intermedi del
modello originale di *brand_new_bert*. Di seguito vi diamo alcuni consigli per avere un ambiente di debug il piu efficiente
possibile:
- Trovate la migliore strategia per fare debug dei risultati intermedi. Per esempio, é la repository originale scritta in PyTorch?
Se si, molto probabilmente dovrete dedicare un po' di tempo per scrivere degli script piu lunghi, così da decomporre il
modello originale in piccole sotto-componenti, in modo da poter recuperare i valori intermedi. Oppure, la repo originale
é scritta in Tensorflow 1? Se é così dovrete fare affidamento ai print di Tensorflow [tf.print](https://www.tensorflow.org/api_docs/python/tf/print)
per avere i valori intermedi. Altro caso, la repo é scritta in Jax? Allora assicuratevi che il modello non sia in **jit**
quanto testate il foward pass, *per esempio* controllate [questo link](https://github.com/google/jax/issues/196).
- Usate i più piccoli pretrained checkpoint che potete trovare. Piu piccolo é il checkpoint, piu velocemente sarà il vostro
ciclo di debug. Non é efficiente avere un pretrained model così gigante che per il forward pass impieghi piu di 10 secondi.
Nel caso in cui i checkpoints siano molto grandi, e non si possa trovare di meglio, allora é buona consuetudine ricorrere
a fare un dummy model nel nuovo ambiente, con weights inizializzati random e salvare quei weights per comprare la versione 🤗 Transformers
con il vostro modello
- Accertatevi di usare la via piu semplice per chiamare il forward pass nella repo originale. Sarebbe opportuno trovare
la funzione originaria che chiami **solo** un singolo forward pass, *per esempio* questa funzione spesso viene chiamata
`predict`, `evaluate`, `forward` o `__call__`. Siate sicuri di non fare debug su una funzione che chiami `forward` molteplici
volte, *per esempio* per generare testo, come `autoregressive_sample`, `generate`.
- Cercate di separare la tokenization dal forward pass del modello. Se la repo originaria mostra esempio dove potete dare
come input una stringa, provate a cercare dove nella forward call la stringa viene cambiata in input ids e cominciate il
debug da questo punto. Questo vi garantisce un ottimo punto di partenza per scrivere un piccolo script personale dove dare
gli input al modello, anziche delle stringhe in input.
- Assicuratevi che il debugging **non** sia in training mode. Spesso questo potra il modello a dare degli output random, per
via dei molteplici dropout layers. Assicuratevi che il forward pass nell'ambiente di debug sia **deterministico**, cosicche
i dropout non siano usati. Alternativamente, potete usare *transformers.utils.set_seed* se la vecchia e nuova implementazione
sono nello stesso framework.
La seguente sezione vi da ulteriori dettagli e accorgimenti su come potete fare tutto questo per *brand_new_bert*.
### 5.-14. Trasferire BrandNewBert in 🤗 Transformers
Allora cominciamo ad aggiungere un nuovo codice in 🤗 Transformers. Andate nel vostro fork clone di 🤗 Transformers:
```bash
cd transformers
```
Nel caso speciale in cui stiate aggiungendo un modello, la cui architettura sia identica a una di un modello già esistente,
dovrete solo aggiugnere uno script di conversione, come descritto [qui](#write-a-conversion-script).
In questo caso, potete riutilizzare l'intera architettura del modello gia esistente.
Se questo non é il caso, cominciamo con il generare un nuovo modello. Avrete due opzioni:
- `transformers-cli add-new-model-like` per aggiungere un nuovo modello come uno che gia esiste
- `transformers-cli add-new-model` per aggiungere un nuovo modello da un nostro template (questo assomigliera a BERT o Bart, in base al modello che selezionerete)
In entrambi i casi, l'output vi darà un questionario da riempire con informazioni basi sul modello. Il secondo comando richiede di installare
un `cookiecutter` - maggiori informazioni [qui](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model).
**Aprire una Pull Request in main huggingface/transformers repo**
Prime di cominciare ad adattare il codice automaticamente generato, aprite una nuova PR come "Work in progress (WIP)",
*per esempio* "[WIP] Aggiungere *brand_new_bert*", cosicché il team di Hugging Face possa lavorare al vostro fianco nell'
integrare il modello in 🤗 Transformers.
Questi sarebbero gli step generali da seguire:
1. Creare un branch dal main branch con un nome descrittivo
```bash
git checkout -b add_brand_new_bert
```
2. Commit del codice automaticamente generato
```bash
git add .
git commit
```
3. Fare fetch e rebase del main esistente
```bash
git fetch upstream
git rebase upstream/main
```
4. Push dei cambiamenti al proprio account:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. Una volte che siete soddisfatti dei nuovi cambiamenti, andate sulla webpage del vostro fork su GitHub. Cliccate "Pull request".
Assiuratevi di aggiungere alcuni membri di Hugging Face come reviewers, nel riguardo alla destra della pagina della PR, cosicche il team
Hugging Face verrà notificato anche per i futuri cambiamenti.
6. Cambiare la PR a draft, cliccando su "Convert to draft" alla destra della pagina della PR
Da quel punto in poi, ricordate di fare commit di ogni progresso e cambiamento, cosicche venga mostrato nella PR. Inoltre,
ricordatevi di tenere aggiornato il vostro lavoro con il main esistente:
```bash
git fetch upstream
git merge upstream/main
```
In generale, tutte le domande che avrete riguardo al modello o l'implementazione dovranno essere fatte nella vostra PR
e discusse/risolte nella PR stessa. In questa maniera, il team di Hugging Face sarà sempre notificato quando farete commit
di un nuovo codice o se avrete qualche domanda. É molto utile indicare al team di Hugging Face il codice a cui fate riferimento
nella domanda, cosicche il team potra facilmente capire il problema o la domanda.
Per fare questo andate sulla tab "Files changed", dove potrete vedere tutti i vostri cambiamenti al codice, andate sulla linea
dove volete chiedere una domanda, e cliccate sul simbolo "+" per aggiungere un commento. Ogni volta che una domanda o problema
é stato risolto, cliccate sul bottone "Resolve".
In questa stessa maniera, Hugging Face aprirà domande o commenti nel rivedere il vostro codice. Mi raccomando, chiedete più
domande possibili nella pagina della vostra PR. Se avete domande molto generali, non molto utili per il pubblico, siete liberi
di chiedere al team Hugging Face direttamente su slack o email.
**5. Adattare i codici per brand_new_bert**
Per prima cosa, ci focalizzeremo sul modello e non sui tokenizer. Tutto il codice relative dovrebbe trovarsi in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` e
`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
Ora potete finalmente cominciare il codice :). Il codice generato in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` avrà sia la stessa architettura di BERT se é un
modello encoder-only o BART se é encoder-decoder. A questo punto, ricordatevi cio che avete imparato all'inizio, riguardo
agli aspetti teorici del modello: *In che maniera il modello che sto implmementando é diverso da BERT o BART?*. Implementare
questi cambi spesso vuol dire cambiare il layer *self-attention*, l'ordine dei layer di normalizzazione e così via...
Ancora una volta ripetiamo, é molto utile vedere architetture simili di modelli gia esistenti in Transformers per avere
un'idea migliore su come implementare il modello.
**Notate** che a questo punto non dovete avere subito un codice tutto corretto o pulito. Piuttosto, é consigliato cominciare con un
codice poco pulito, con copia-incolla del codice originale in `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`
fino a che non avrete tutto il codice necessario. In base alla nostra esperienza, é molto meglio aggiungere una prima bozza
del codice richiesto e poi correggere e migliorare iterativamente. L'unica cosa essenziale che deve funzionare qui é la seguente
instanza:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
Questo comando creerà un modello con i parametri di default definiti in `BrandNewBergConfig()` e weights random. Questo garantisce
che `init()` di tutte le componenti funzioni correttamente.
**6. Scrivere uno script di conversione**
Il prossimo step é scrivere uno script per convertire il checkpoint che avete usato per fare debug su *brand_new_berts* nella
repo originale in un checkpoint per la nuova implementazione di *brand_new_bert* in 🤗 Transformers. Non é consigliato scrivere
lo script di conversione da zero, ma piuttosto cercate e guardate script gia esistenti in 🤗 Transformers, così da trovarne
uno simile al vostro modello. Di solito basta fare una copia di uno script gia esistente e adattarlo al vostro caso.
Non esistate a chiedre al team di Hugging Face a riguardo.
- Se state convertendo un modello da TensorFlow a PyTorch, un ottimo inizio é vedere [questo script di conversione per BERT](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- Se state convertendo un modello da PyTorch a PyTorch, [lo script di conversione di BART può esservi utile](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
Qui di seguito spiegheremo come i modelli PyTorch salvano i weights per ogni layer e come i nomi dei layer sono definiti. In PyTorch,
il nomde del layer é definito dal nome della class attribute che date al layer. Definiamo un modello dummy in PyTorch,
chiamato `SimpleModel`:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Ora possiamo creare un'instanza di questa definizione di modo da inizializzare a random weights: `dense`, `intermediate`, `layer_norm`.
Possiamo usare print per vedere l'architettura del modello:
```python
model = SimpleModel()
print(model)
```
Da cui si ottiene:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
Si può vedere come i nomi dei layers siano definiti dal nome della class attribute in PyTorch. I valori dei weights di uno
specifico layer possono essere visualizzati:
```python
print(model.dense.weight.data)
```
ad esempio:
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
Nello script di conversione, dovreste riempire quei valori di inizializzazione random con gli stessi weights del corrispondente
layer nel checkpoint. *Per esempio*
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
Così facendo, dovete verificare che ogni inizializzazione random di un peso del modello PyTorch e il suo corrispondente peso nel pretrained checkpoint
siano esattamente gli stessi e uguali in **dimensione/shape e nome**. Per fare questo, é **necessario** aggiungere un `assert`
per la dimensione/shape e nome:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Inoltre, dovrete fare il print sia dei nomi che dei weights per essere sicuri che siano gli stessi:
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
Se la dimensione o il nome non sono uguali, probabilmente avete sbagliato ad assegnare il peso nel checkpoint o nel layer costrutture di
🤗 Transformers.
Una dimensione sbagliata può essere dovuta ad un errore nei parameteri in `BrandNewBertConfig()`. Tuttavia, può essere anche
che l'implementazione del layer in PyTorch richieda di fare una transposizione della matrice dei weights.
Infine, controllate **tutti** che tutti i weights inizializzati e fate print di tutti i weights del checkpoint che non sono stati
usati per l'inizializzazione, di modo da essere sicuri che il modello sia correttamente convertito. É normale che ci siano
errori nel test di conversione, fai per un errore in `BrandNewBertConfig()`, o un errore nell'architettura in 🤗 Transformers,
o un bug in `init()`.
Questo step dev'essere fatto tramite iterazioni fino a che non si raggiungano gli stessi valori per i weights. Una volta che
il checkpoint é stato correttamente caricato in 🤗 Transformers, potete salvare il modello in una cartella di vostra scelta
`/path/to/converted/checkpoint/folder` che contenga sia
`pytorch_model.bin` che `config.json`:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implementare il forward pass**
Una volta che i weights pretrained sono stati correttamente caricati in 🤗 Transformers, dovrete assicurarvi che il forward pass
sia correttamente implementato. [Qui](#provare-un-pretrained-checkpoint-usando-la-repo-originale), avete give creato e provato
uno script che testi il forward pass del modello usando la repo originaria. Ora dovrete fare lo stesso con uno script analogo
usando l'implementazione in 🤗 Transformers anziché l'originale. Piu o meno lo script dovrebbe essere:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
Di solito l'output da 🤗 Transformers non é uguale uguale all'output originario, sopratto la prima volta. Non vi abbattete -
é normale! Prima di tutto assicuratevi che non ci siano errori o che non vengano segnalati degli errori nella forward pass.
Spesso capita che ci siano dimensioni sbagliate o data type sbagliati, *ad esempio* `torch.long` anziche `torch.float32`.
Non esistate a chiedere al team Hugging Face!
Nella parte finale assicuratevi che l'implementazione 🤗 Transformers funzioni correttamente cosi da testare che gli output
siano equivalenti a una precisione di `1e-3`. Controllate che `outputs.shape` siano le stesse tra 🤗 Transformers e l'implementazione
originaria. Poi, controllate che i valori in output siano identici. Questa é sicuramente la parte più difficile, qui una serie
di errori comuni quando gli output non sono uguali:
- Alcuni layers non sono stati aggiunti, *ad esempio* un *activation* layer non é stato aggiunto, o ci si é scordati di una connessione
- La matrice del word embedding non é stata ripareggiata
- Ci sono degli embeddings posizionali sbagliati perché l'implementazione originaria ha un offset
- Il dropout é in azione durante il forward pass. Per sistemare questo errore controllate che *model.training = False* e che
il dropout non sia stato attivato nel forward pass, * per esempio * passate *self.training* a [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
La miglior maniera per sistemare il problema é di vedere all'implementazione originaria del forward pass e in 🤗 Transformers
fianco a fianco e vedere se ci sono delle differenze. In teoria, con debug e print degli output intermedie di entrambe le
implementazioni nel forward pass nell'esatta posizione del network dovrebbe aiutarvi a vedere dove ci sono differenze tra
i due frameworks. Come prima mossa controllate che `input_ids` siano identici in entrambi gli scripts. Da lì andate fino
all'ultimo layer. Potrete notare una differenza tra le due implementazioni a quel punto.
Una volta che lo stesso output é stato ragguingi, verificate gli output con `torch.allclose(original_output, output, atol=1e-3)`.
A questo punto se é tutto a posto: complimenti! Le parti seguenti saranno una passeggiata 😊.
**8. Aggiungere i test necessari per il modello**
A questo punto avete aggiunto con successo il vostro nuovo modello. Tuttavia, é molto probabile che il modello non sia
del tutto ok con il design richiesto. Per essere sicuri che l'implementazione sia consona e compatibile con 🤗 Transformers é
necessario implementare dei tests. Il Cookiecutter dovrebbe fornire automaticamente dei file per test per il vostro modello,
di solito nella folder `tests/test_modeling_brand_new_bert.py`. Provate questo per verificare l'ok nei test piu comuni:
```bash
pytest tests/test_modeling_brand_new_bert.py
```
Una volta sistemati i test comuni, bisogna assicurarsi che il vostro lavoro sia correttamente testato cosicchè:
- a) La community puo capire in maniera semplice il vostro lavoro controllando tests specifici del modello *brand_new_bert*,
- b) Implementazioni future del vostro modello non rompano alcune feature importante del modello.
Per prima cosa agguingete dei test d'integrazione. Questi sono essenziali perche fanno la stessa funzione degli scripts di
debug usati precedentemente. Un template per questi tests esiste gia nel Cookiecutter ed é sotto il nome di `BrandNewBertModelIntegrationTests`,
voi dovrete solo completarlo. Una volta che questi tests sono OK, provate:
```bash
RUN_SLOW=1 pytest -sv tests/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
<Tip>
Nel caso siate su Windows, sostituite `RUN_SLOW=1` con `SET RUN_SLOW=1`
</Tip>
Di seguito, tutte le features che sono utili e necessarire per *brand_new_bert* devono essere testate in test separati,
contenuti in `BrandNewBertModelTester`/ `BrandNewBertModelTest`. spesso la gente si scorda questi test, ma ricordate che sono utili per:
- Aiuta gli utenti a capire il vostro codice meglio, richiamando l'attenzione su queste nuove features
- Developers e contributors futuri potranno velocemente testare nuove implementazioni del modello testanto questi casi speciali.
**9. Implementare il tokenizer**
A questo punto avremo bisogno un tokenizer per *brand_new_bert*. Di solito il tokenizer é uguale ad altri modelli in 🤗 Transformers.
É importante che troviate il file con il tokenizer originale e che lo carichiate in 🤗 Transformers.
Per controllare che il tokenizer funzioni in modo corretto, create uno script nella repo originaria che riceva come input
una stringa e ritorni gli `input_ids`. Piu o meno questo potrebbe essere il codice:
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
Potrebbe richiedere un po' di tempo, ma guardate ancora alla repo originaria per trovare la funzione corretta del tokenizer.
A volte capita di dover riscrivere il tokenizer nella repo originaria, di modo da avere come output gli `input_ids`.
A quel punto uno script analogo é necessario in 🤗 Transformers:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
Una volta che `input_ids` sono uguali, bisogna aggiungere un test per il tokenizer.
Il file test per tokenizer di *brand_new_brand* dovrebbe avere un paio di hard-coded test d'integrazione.
**10. Test end-to-end**
Ora che avete il tokenizer, dovrete aggiungere dei test d'integrazione per l'intero workflow in `tests/test_modeling_brand_new_bert.py` in 🤗 Transformer.
Questi test devono mostrare che un significante campione text-to-text funzioni come ci si aspetta nell'implementazione di 🤗 Transformers.
*Per esempio* potreste usare dei source-to-target-translation, o un sommario di un articolo, o un domanda-risposta e cosi via.
Se nessuno dei checkpoints é stato ultra parametrizzato per task simili, allora i tests per il modello sono piu che sufficienti.
Nello step finale dovete assicurarvi che il modello sia totalmente funzionale, e consigliamo anche di provare a testare su GPU.
Puo succedere che ci si scordi un `.to(self.device)` ad esempio. Se non avete accesso a GPU, il team Hugging Face puo provvedere
a testare questo aspetto per voi.
**11. Aggiungere una Docstring**
Siete quasi alla fine! L'ultima cosa rimasta é avere una bella docstring e una pagina doc. Il Cookiecutter dovrebbe provvedere già
un template chiamato `docs/source/model_doc/brand_new_bert.rst`, che dovrete compilare. La prima cosa che un utente farà
per usare il vostro modello sarà dare una bella lettura al doc. Quindi proponete una documentazione chiara e concisa. É molto
utile per la community avere anche delle *Tips* per mostrare come il modello puo' essere usato. Non esitate a chiedere a Hugging Face
riguardo alle docstirng.
Quindi, assicuratevi che la docstring sia stata aggiunta a `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`.
Assicuratevi che la docstring sia corretta e che includa tutti i necessari input e output. Abbiamo una guida dettagliata per
scrivere la documentazione e docstring.
**Rifattorizzare il codice**
Perfetto! Ora che abbiamo tutto per *brand_new_bert* controllate che lo stile del codice sia ok:
```bash
make style
```
E che il codice passi i quality check:
```bash
make quality
```
A volte capita che manchino delle informazioninella docstring o alcuni nomi sbagliati, questo farà fallire i tests sopra.
Ripetiamo: chiedete pure a Hugging Face, saremo lieti di aiutarvi.
Per ultimo, fare del refactoring del codice una volta che é stato creato.
Avete finito con il codice, congratulazioni! 🎉 Siete fantasticiiiiiii! 😎
**12. Caricare il modello sul model hub**
In questa ultima parte dovrete convertire e caricare il modello, con tutti i checkpoints, nel model hub e aggiungere una
model card per ogni checkpoint caricato. Leggete la nostra guida [Model sharing and uploading Page](model_sharing) per
avere familiarità con l'hub. Di solito in questa parte lavorate a fianco di Hugging face per decidere un nome che sia ok
per ogni checkpoint, per ottenere i permessi necessari per caricare il modello nell'organizzazione dell'autore di *brand_new_bert*.
Il metodo `push_to_hub`, presente in tutti i modelli `transformers`, é una maniera rapida e indolore per caricare il vostro checkpoint sull'hub:
```python
brand_new_bert.push_to_hub(
repo_path_or_name="brand_new_bert",
# Uncomment the following line to push to an organization
# organization="<ORGANIZATION>",
commit_message="Add model",
use_temp_dir=True,
)
```
Vale la pena spendere un po' di tempo per creare una model card ad-hoc per ogni checkpoint. Le model cards dovrebbero
suggerire le caratteristiche specifiche del checkpoint, *per esempio* su che dataset il checkpoint é stato pretrained o fine-tuned.
O che su che genere di task il modello lavoro? E anche buona pratica includere del codice su come usare il modello correttamente.
**13. (Opzionale) Aggiungere un notebook**
É molto utile aggiungere un notebook, che dimostri in dettaglio come *brand_new_bert* si utilizzi per fare inferenza e/o
fine-tuned su specifiche task. Non é una cosa obbligatoria da avere nella vostra PR, ma é molto utile per la community.
**14. Sottomettere la PR**
L'ultimissimo step! Ovvero il merge della PR nel main. Di solito il team Hugging face a questo punto vi avrà gia aiutato,
ma é ok prendere un po' di tempo per pulire la descirzione e commenti nel codice.
### Condividete il vostro lavoro!!
É ora tempo di prendere un po' di credito dalla communità per il vostro lavoro! Caricare e implementare un nuovo modello
é un grandissimo contributo per Transformers e l'intera community NLP. Il codice e la conversione dei modelli pre-trained sara
sicuramente utilizzato da centinaia o migliaia di sviluppatori e ricercatori. Siate fieri e orgogliosi di condividere il vostro
traguardo con l'intera community :)
** Avete create un altro modello che é super facile da usare per tutti quanti nella community! 🤯**
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/pr_checks.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Controlli su una Pull Request
Quando apri una pull request sui 🤗 Transformers, vengono eseguiti un discreto numero di controlli per assicurarsi che la patch che stai aggiungendo non stia rompendo qualcosa di esistente. Questi controlli sono di quattro tipi:
- test regolari
- costruzione della documentazione
- stile del codice e della documentazione
- coerenza generale del repository
In questo documento, cercheremo di spiegare quali sono i vari controlli e le loro ragioni, oltre a spiegare come eseguire il debug locale se uno di essi fallisce sulla tua PR.
Nota che tutti richiedono un'installazione dev:
```bash
pip install transformers[dev]
```
o un'installazione modificabile:
```bash
pip install -e .[dev]
```
all'interno del repo Transformers.
## Tests
Tutti i job che iniziano con `ci/circleci: run_tests_` eseguono parti della suite di test dei Transformers. Ognuno di questi job si concentra su una parte della libreria in un determinato ambiente: per esempio `ci/circleci: run_tests_pipelines_tf` esegue il test delle pipeline in un ambiente in cui è installato solo TensorFlow.
Nota che per evitare di eseguire i test quando non ci sono cambiamenti reali nei moduli che si stanno testando, ogni volta viene eseguita solo una parte della suite di test: viene eseguita una utility per determinare le differenze nella libreria tra prima e dopo la PR (ciò che GitHub mostra nella scheda "Files changes") e sceglie i test che sono stati impattati dalla diff. Questa utility può essere eseguita localmente con:
```bash
python utils/tests_fetcher.py
```
dalla root del repo Transformers. Di seguito ciò che farà:
1. Controlla per ogni file nel diff se le modifiche sono nel codice o solo nei commenti o nelle docstrings. Vengono mantenuti solo i file con modifiche reali al codice.
2. Costruisce una mappa interna che fornisce per ogni file del codice sorgente della libreria tutti i file su cui ha un impatto ricorsivo. Si dice che il modulo A ha un impatto sul modulo B se il modulo B importa il modulo A. Per l'impatto ricorsivo, abbiamo bisogno di una catena di moduli che va dal modulo A al modulo B in cui ogni modulo importa il precedente.
3. Applica questa mappa ai file raccolti nel passaggio 1, si ottiene l'elenco dei file del modello interessati dalla PR.
4. Mappa ciascuno di questi file con i corrispondenti file di test e ottiene l'elenco dei test da eseguire.
Quando esegui lo script in locale, dovresti ottenere la stampa dei risultati dei passi 1, 3 e 4 e quindi sapere quali test sono stati eseguiti. Lo script creerà anche un file chiamato `test_list.txt` che contiene l'elenco dei test da eseguire e che puoi eseguire localmente con il seguente comando:
```bash
python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
```
Nel caso in cui qualcosa sia sfuggito, l'intera suite di test viene eseguita quotidianamente.
## Build della documentazione
Il job `ci/circleci: build_doc` esegue una build della documentazione per assicurarsi che tutto sia a posto una volta che la PR è stata unita. Se questo passaggio fallisce, puoi controllare localmente entrando nella cartella `docs` del repo Transformers e digitare
```bash
make html
```
Sphinx non è noto per i suoi messaggi di errore chiari, quindi potrebbe essere necessario che provi alcune cose per trovare davvero la fonte dell'errore.
## Stile del codice e della documentazione
La formattazione del codice viene applicata a tutti i file sorgenti, agli esempi e ai test usando `black` e `isort`. Abbiamo anche uno strumento personalizzato che si occupa della formattazione delle docstring e dei file `rst` (`utils/style_doc.py`), così come dell'ordine dei lazy imports eseguiti nei file `__init__.py` dei Transformers (`utils/custom_init_isort.py`). Tutto questo può essere lanciato eseguendo
```bash
make style
```
I controlli della CI sono applicati all'interno del controllo `ci/circleci: check_code_quality`. Esegue anche `flake8`, che dà un'occhiata di base al codice e si lamenta se trova una variabile non definita o non utilizzata. Per eseguire questo controllo localmente, usare
```bash
make quality
```
Questa operazione può richiedere molto tempo, quindi per eseguire la stessa operazione solo sui file modificati nel branch corrente, eseguire
```bash
make fixup
```
Quest'ultimo comando eseguirà anche tutti i controlli aggiuntivi per la consistenza del repository. Diamogli un'occhiata.
## Coerenza del repository
All'interno sono raggruppati tutti i test per assicurarsi che la tua PR lasci il repository in un buono stato ed è eseguito dal controllo `ci/circleci: check_repository_consistency`. Puoi eseguire localmente questo controllo eseguendo quanto segue:
```bash
make repo-consistency
```
Questo verifica che:
- Tutti gli oggetti aggiunti all'init sono documentati (eseguito da `utils/check_repo.py`)
- Tutti i file `__init__.py` hanno lo stesso contenuto nelle loro due sezioni (eseguito da `utils/check_inits.py`)
- Tutto il codice identificato come copia da un altro modulo è coerente con l'originale (eseguito da `utils/check_copies.py`)
- Le traduzioni dei README e l'indice della documentazione hanno lo stesso elenco di modelli del README principale (eseguito da `utils/check_copies.py`)
- Le tabelle autogenerate nella documentazione sono aggiornate (eseguito da `utils/check_table.py`)
- La libreria ha tutti gli oggetti disponibili anche se non tutte le dipendenze opzionali sono installate (eseguito da `utils/check_dummies.py`)
Se questo controllo fallisce, le prime due voci richiedono una correzione manuale, mentre le ultime quattro possono essere corrette automaticamente per te eseguendo il comando
```bash
make fix-copies
```
Ulteriori controlli riguardano le PR che aggiungono nuovi modelli, principalmente che:
- Tutti i modelli aggiunti sono in un Auto-mapping (eseguita da `utils/check_repo.py`)
<!-- TODO Sylvain, add a check that makes sure the common tests are implemented.-->
- Tutti i modelli sono testati correttamente (eseguito da `utils/check_repo.py`)
<!-- TODO Sylvain, add the following
- All models are added to the main README, inside the main doc
- All checkpoints used actually exist on the Hub
-->
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/autoclass_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Carica istanze pre-allenate con AutoClass
Con così tante architetture Transformer differenti, può essere sfidante crearne una per il tuo checkpoint. Come parte della filosofia centrale di 🤗 Transformers per rendere la libreria facile, semplice e flessibile da utilizzare, una `AutoClass` inferisce e carica automaticamente l'architettura corretta da un dato checkpoint. Il metodo `from_pretrained` ti permette di caricare velocemente un modello pre-allenato per qualsiasi architettura, così non devi utilizzare tempo e risorse per allenare un modello da zero. Produrre questo codice agnostico ai checkpoint significa che se il tuo codice funziona per un checkpoint, funzionerà anche per un altro checkpoint, purché sia stato allenato per un compito simile, anche se l'architettura è differente.
<Tip>
Ricorda, con architettura ci si riferisce allo scheletro del modello e con checkpoint ai pesi di una determinata architettura. Per esempio, [BERT](https://huggingface.co/bert-base-uncased) è un'architettura, mentre `bert-base-uncased` è un checkpoint. Modello è un termine generale che può significare sia architettura che checkpoint.
</Tip>
In questo tutorial, imparerai a:
* Caricare un tokenizer pre-allenato.
* Caricare un estrattore di caratteristiche (feature extractor, in inglese) pre-allenato.
* Caricare un processore pre-allenato.
* Caricare un modello pre-allenato.
## AutoTokenizer
Quasi tutti i compiti di NLP iniziano con un tokenizer. Un tokenizer converte il tuo input in un formato che possa essere elaborato dal modello.
Carica un tokenizer con [`AutoTokenizer.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-base")
```
Poi tokenizza il tuo input come mostrato in seguito:
```py
>>> sequenza = "In un buco nel terreno viveva uno Hobbit."
>>> print(tokenizer(sequenza))
{'input_ids': [0, 360, 51, 373, 587, 1718, 54644, 22597, 330, 3269, 2291, 22155, 18, 5, 2],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoFeatureExtractor
Per compiti inerenti a audio e video, un feature extractor processa il segnale audio o l'immagine nel formato di input corretto.
Carica un feature extractor con [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
Compiti multimodali richiedono un processore che combini i due tipi di strumenti di elaborazione. Per esempio, il modello [LayoutLMV2](model_doc/layoutlmv2) richiede un feature extractor per gestire le immagine e un tokenizer per gestire il testo; un processore li combina entrambi.
Carica un processore con [`AutoProcessor.from_pretrained`]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
Infine, le classi `AutoModelFor` ti permettono di caricare un modello pre-allenato per un determinato compito (guarda [qui](model_doc/auto) per una lista completa di compiti presenti). Per esempio, carica un modello per la classificazione di sequenze con [`AutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Semplicemente utilizza lo stesso checkpoint per caricare un'architettura per un task differente:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
Generalmente, raccomandiamo di utilizzare la classe `AutoTokenizer` e la classe `AutoModelFor` per caricare istanze pre-allenate dei modelli. Questo ti assicurerà di aver caricato la corretta architettura ogni volta. Nel prossimo [tutorial](preprocessing), imparerai come utilizzare il tokenizer, il feature extractor e il processore per elaborare un dataset per il fine-tuning.
</pt>
<tf>
Infine, le classi `TFAutoModelFor` ti permettono di caricare un modello pre-allenato per un determinato compito (guarda [qui](model_doc/auto) per una lista completa di compiti presenti). Per esempio, carica un modello per la classificazione di sequenze con [`TFAutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Semplicemente utilizza lo stesso checkpoint per caricare un'architettura per un task differente:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
Generalmente, raccomandiamo di utilizzare la classe `AutoTokenizer` e la classe `TFAutoModelFor` per caricare istanze pre-allenate dei modelli. Questo ti assicurerà di aver caricato la corretta architettura ogni volta. Nel prossimo [tutorial](preprocessing), imparerai come utilizzare il tokenizer, il feature extractor e il processore per elaborare un dataset per il fine-tuning.
</tf>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: Tour rapido
- local: installation
title: Installazione
title: Iniziare
- sections:
- local: pipeline_tutorial
title: Pipeline per l'inferenza
- local: autoclass_tutorial
title: Carica istanze pre-allenate con AutoClass
- local: preprocessing
title: Preprocess
- local: training
title: Fine-tuning di un modello pre-addestrato
- local: accelerate
title: Allenamento distribuito con 🤗 Accelerate
- local: model_sharing
title: Condividere un modello
title: Esercitazione
- sections:
- local: create_a_model
title: Crea un'architettura personalizzata
- local: custom_models
title: Condividere modelli personalizzati
- local: run_scripts
title: Addestramento con script
- local: multilingual
title: Modelli multilingua per l'inferenza
- local: converting_tensorflow_models
title: Convertire modelli tensorflow
- local: serialization
title: Esporta modelli Transformers
- local: perf_train_cpu
title: Addestramento efficiente su CPU
- local: perf_train_cpu_many
title: Addestramento efficiente su multiple CPU
- local: perf_train_tpu
title: Addestramento su TPU
- local: perf_train_special
title: Addestramento su Hardware Specializzato
- local: perf_infer_cpu
title: Inferenza Efficiente su CPU
- local: perf_infer_gpu_one
title: Inferenza su una GPU
- local: perf_infer_gpu_many
title: Inferenza Efficiente su GPU Multiple
- local: perf_infer_special
title: Inferenza su Hardware Specializzato
- local: big_models
title: Istanziare un big model
- local: migration
title: Passaggio da pacchetti precedenti
- local: debugging
title: Debugging
title: Guide pratiche
- sections:
- local: add_new_pipeline
title: Come aggiungere una pipeline a 🤗 Transformers?
- local: add_new_model
title: Come aggiungere un modello a 🤗 Transformers?
- local: perf_hardware
title: Hardware ottimizzato per l'addestramento
- local: community
title: Risorse della comunità
- local: pr_checks
title: Controlli su una Pull Request
title: Guide How-to
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_infer_special.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Inferenza su Hardware Specializzato
Questo documento sarà completato a breve con la documentazione per l'inferenza su hardware specializzato. Nel frattempo puoi controllare [la guida per fare inferenza sulle CPU](perf_infer_cpu).
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_train_cpu.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Addestramento efficiente su CPU
Questa guida si concentra su come addestrare in maniera efficiente grandi modelli su CPU.
## Mixed precision con IPEX
IPEX è ottimizzato per CPU con AVX-512 o superiore, e funziona per le CPU con solo AVX2. Pertanto, si prevede che le prestazioni saranno più vantaggiose per le le CPU Intel con AVX-512 o superiori, mentre le CPU con solo AVX2 (ad esempio, le CPU AMD o le CPU Intel più vecchie) potrebbero ottenere prestazioni migliori con IPEX, ma non sono garantite. IPEX offre ottimizzazioni delle prestazioni per l'addestramento della CPU sia con Float32 che con BFloat16. L'uso di BFloat16 è l'argomento principale delle seguenti sezioni.
Il tipo di dati a bassa precisione BFloat16 è stato supportato in modo nativo su 3rd Generation Xeon® Scalable Processors (aka Cooper Lake) con AVX512 e sarà supportata dalla prossima generazione di Intel® Xeon® Scalable Processors con Intel® Advanced Matrix Extensions (Intel® AMX) instruction set con prestazioni ulteriormente migliorate. L'Auto Mixed Precision per il backende della CPU è stato abilitato da PyTorch-1.10. allo stesso tempo, il supporto di Auto Mixed Precision con BFloat16 per CPU e l'ottimizzazione degli operatori BFloat16 è stata abilitata in modo massiccio in Intel® Extension per PyTorch, and parzialmente aggiornato al branch master di PyTorch. Gli utenti possono ottenere prestazioni migliori ed users experience con IPEX Auto Mixed Precision..
Vedi informazioni più dettagliate su [Auto Mixed Precision](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html).
### Installazione di IPEX:
Il rilascio di IPEX segue quello di PyTorch, da installare via pip:
| PyTorch Version | IPEX version |
| :---------------: | :----------: |
| 1.13 | 1.13.0+cpu |
| 1.12 | 1.12.300+cpu |
| 1.11 | 1.11.200+cpu |
| 1.10 | 1.10.100+cpu |
```bash
pip install intel_extension_for_pytorch==<version_name> -f https://developer.intel.com/ipex-whl-stable-cpu
```
Vedi altri approcci per [IPEX installation](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html).
### Utilizzo nel Trainer
Per abilitare la auto mixed precision con IPEX in Trainer, l'utende dovrebbe aggiungere `use_ipex`, `bf16` e `no_cuda` negli argomenti del comando di addestramento.
Vedi un sempio di un caso d'uso [Transformers question-answering](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
- Training with IPEX using BF16 auto mixed precision on CPU:
<pre> python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
<b>--use_ipex \</b>
<b>--bf16 --no_cuda</b></pre>
### Esempi pratici
Blog: [Accelerating PyTorch Transformers with Intel Sapphire Rapids](https://huggingface.co/blog/intel-sapphire-rapids)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/accelerate.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Allenamento distribuito con 🤗 Accelerate
La parallelizzazione è emersa come strategia per allenare modelli sempre più grandi su hardware limitato e accelerarne la velocità di allenamento di diversi ordini di magnitudine. In Hugging Face, abbiamo creato la libreria [🤗 Accelerate](https://huggingface.co/docs/accelerate) per aiutarti ad allenare in modo semplice un modello 🤗 Transformers su qualsiasi tipo di configurazione distribuita, sia che si tratti di più GPU su una sola macchina o di più GPU su più macchine. In questo tutorial, imparerai come personalizzare il training loop nativo di PyTorch per consentire l'addestramento in un ambiente distribuito.
## Configurazione
Inizia installando 🤗 Accelerate:
```bash
pip install accelerate
```
Poi importa e crea un oggetto [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator). `Accelerator` rileverà automaticamente il tuo setup distribuito e inizializzerà tutte le componenti necessarie per l'allenamento. Non dovrai allocare esplicitamente il tuo modello su un device.
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## Preparati ad accelerare
Il prossimo passo è quello di passare tutti gli oggetti rilevanti per l'allenamento al metodo [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare). Questo include i tuoi DataLoaders per l'allenamento e per la valutazione, un modello e un ottimizzatore:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## Backward
Infine, sostituisci il tipico metodo `loss.backward()` nel tuo loop di allenamento con il metodo [`backward`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.backward) di 🤗 Accelerate:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
Come puoi vedere nel seguente codice, hai solo bisogno di aggiungere quattro righe in più di codice al tuo training loop per abilitare l'allenamento distribuito!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## Allenamento
Una volta che hai aggiunto le righe di codice rilevanti, lancia il tuo allenamento in uno script o in un notebook come Colaboratory.
### Allenamento con uno script
Se stai eseguendo il tuo allenamento da uno script, esegui il comando seguente per creare e salvare un file di configurazione:
```bash
accelerate config
```
Poi lancia il tuo allenamento con:
```bash
accelerate launch train.py
```
### Allenamento con un notebook
La libreria 🤗 Accelerate può anche essere utilizzata in un notebook se stai pianificando di utilizzare le TPU di Colaboratory. Inserisci tutto il codice legato all'allenamento in una funzione, e passala al `notebook_launcher`:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
Per maggiori informazioni relative a 🤗 Accelerate e le sue numerose funzionalità, fai riferimento alla [documentazione](https://huggingface.co/docs/accelerate).
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_train_special.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Addestramento su Hardware Specializzato
<Tip>
Nota: Molte delle strategie introdotte nella [sezione sulla GPU singola](perf_train_gpu_one) (come mixed precision training o gradient accumulation) e [sezione multi-GPU](perf_train_gpu_many) sono generiche e applicabili all'addestramento di modelli in generale quindi assicurati di dargli un'occhiata prima di immergerti in questa sezione.
</Tip>
Questo documento sarà presto completato con informazioni su come effettuare la formazione su hardware specializzato.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/it/perf_infer_gpu_one.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Inferenza efficiente su GPU singola
Questo documento sarà presto completato con informazioni su come effetture l'inferenza su una singola GPU. Nel frattempo è possibile consultare [la guida per l'addestramento su una singola GPU](perf_train_gpu_one) e [la guida per l'inferenza su CPU](perf_infer_cpu).
## `BetterTransformer` per l'inferenza più veloce
Abbiamo recentemente integrato `BetterTransformer` per velocizzare l'inferenza su GPU per modelli di testo, immagini e audio. Per maggiori dettagli, consultare la documentazione su questa integrazione [qui](https://huggingface.co/docs/optimum/bettertransformer/overview).
## Integrazione di `bitsandbytes` per Int8 mixed-precision matrix decomposition
<Tip>
Nota che questa funzione può essere utilizzata anche nelle configurazioni multi GPU.
</Tip>
Dal paper [`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339), noi supportiamo l'integrazione di Hugging Face per tutti i modelli dell'Hub con poche righe di codice.
Il metodo `nn.Linear` riduce la dimensione di 2 per i pesi `float16` e `bfloat16` e di 4 per i pesi `float32`, con un impatto quasi nullo sulla qualità, operando sugli outlier in half-precision.

Il metodo Int8 mixed-precision matrix decomposition funziona separando la moltiplicazione tra matrici in due flussi: (1) una matrice di flusso di outlier di caratteristiche sistematiche moltiplicata in fp16, (2) in flusso regolare di moltiplicazione di matrici int8 (99,9%). Con questo metodo, è possibile effettutare inferenza int8 per modelli molto grandi senza degrado predittivo.
Per maggiori dettagli sul metodo, consultare il [paper](https://arxiv.org/abs/2208.07339) o il nostro [blogpost sull'integrazione](https://huggingface.co/blog/hf-bitsandbytes-integration).

Nota che è necessaria una GPU per eseguire modelli di tipo mixed-8bit, poiché i kernel sono stati compilati solo per le GPU. Prima di utilizzare questa funzione, assicurarsi di disporre di memoria sufficiente sulla GPU per memorizzare un quarto del modello (o la metà se i pesi del modello sono in mezza precisione).
Di seguito sono riportate alcune note per aiutarvi a utilizzare questo modulo, oppure seguite le dimostrazioni su [Google colab](#colab-demos).
### Requisiti
- Se si dispone di `bitsandbytes<0.37.0`, assicurarsi di eseguire su GPU NVIDIA che supportano tensor cores a 8 bit (Turing, Ampere o architetture più recenti - ad esempio T4, RTX20s RTX30s, A40-A100). Per `bitsandbytes>=0.37.0`, tutte le GPU dovrebbero essere supportate.
- Installare la versione corretta di `bitsandbytes` eseguendo:
`pip install bitsandbytes>=0.31.5`.
- Installare `accelerate`
`pip install accelerate>=0.12.0`
### Esecuzione di modelli mixed-Int8 - configurazione per singola GPU
Dopo aver installato le librerie necessarie, per caricare il tuo modello mixed 8-bit è il seguente:
```py
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
```
Per la generazione di testo, si consiglia di:
* utilizzare il metodo `generate()` del modello invece della funzione `pipeline()`. Sebbene l'inferenza sia possibile con la funzione `pipeline()`, essa non è ottimizzata per i modelli mixed-8bit e sarà più lenta rispetto all'uso del metodo `generate()`. Inoltre, alcune strategie di campionamento, come il campionamento nucleaus, non sono supportate dalla funzione `pipeline()` per i modelli mixed-8bit.
* collocare tutti gli ingressi sullo stesso dispositivo del modello.
Ecco un semplice esempio:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
text = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
```
### Esecuzione di modelli mixed-8bit - configurazione multi GPU
Usare il seguente modo caricare il modello mixed-8bit su più GPU (stesso comando della configurazione a GPU singola):
```py
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
```
Puoi controllare la RAM della GPU che si vuole allocare su ogni GPU usando `accelerate`. Utilizzare l'argomento `max_memory` come segue:
```py
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)
```
In questo esempio, la prima GPU utilizzerà 1 GB di memoria e la seconda 2 GB.
### Colab demos
Con questo metodo è possibile inferire modelli che prima non era possibile inferire su Google Colab.
Guardate la demo per l'esecuzione di T5-11b (42GB in fp32)! Utilizzo la quantizzazione a 8 bit su Google Colab:
[](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing)
Oppure questa demo di BLOOM-3B:
[](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/te/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
[పైటోర్చ్](https://pytorch.org/), [టెన్సర్ఫ్లో](https://www.tensorflow.org/), మరియు [జాక్స్](https://jax.readthedocs.io/en/latest/) కోసం స్థితి-కలాన యంత్ర అభ్యాసం.
🤗 ట్రాన్స్ఫార్మర్స్ అభివృద్ధిస్తున్నది API మరియు ఉపకరణాలు, పూర్వ-చేతన మోడల్లను సులభంగా డౌన్లోడ్ మరియు శిక్షణ చేయడానికి అవసరమైన సమయం, వనరులు, మరియు వస్తువులను నుంచి మోడల్ను శీర్షికం నుంచి ప్రశిక్షించడం వరకు దేవాయనం చేస్తుంది. ఈ మోడల్లు విభిన్న మోడాలిటీలలో సాధారణ పనులకు మద్దతు చేస్తాయి, వంటివి:
📝 **ప్రాకృతిక భాష ప్రక్రియ**: వచన వర్గీకరణ, పేరుల యొక్క యెంటిటీ గుర్తువు, ప్రశ్న సంవాద, భాషా రచన, సంక్షేపణ, అనువాదం, అనేక ప్రకారాలు, మరియు వచన సృష్టి.<br>
🖼️ **కంప్యూటర్ విషయం**: చిత్రం వర్గీకరణ, వస్త్రం గుర్తువు, మరియు విభజన.<br>
🗣️ **ఆడియో**: స్వయంచలన ప్రసంగాన్ని గుర్తుచేసేందుకు, ఆడియో వర్గీకరణ.<br>
🐙 **బహుమూలిక**: పట్టి ప్రశ్న సంవాద, ఆప్టికల్ సిఫర్ గుర్తువు, డాక్యుమెంట్లు స్క్యాన్ చేసినంతగా సమాచార పొందడం, వీడియో వర్గీకరణ, మరియు దృశ్య ప్రశ్న సంవాద.
🤗 ట్రాన్స్ఫార్మర్స్ పైన మద్దతు చేస్తుంది పైన తొలగించడానికి పైన పైన పైన ప్రోగ్రామ్లో మోడల్ను శిక్షించండి, మరియు అన్ని ప్రాథమిక యొక్కడా ఇన్ఫరెన్స్ కోసం లోడ్ చేయండి. మో
డల్లు కూడా ప్రొడక్షన్ వాతావరణాలలో వాడుకోవడానికి ONNX మరియు TorchScript వంటి ఆకృతులకు ఎగుమతి చేయవచ్చు.
ఈరువులకు [హబ్](https://huggingface.co/models), [ఫోరం](https://discuss.huggingface.co/), లేదా [డిస్కార్డ్](https://discord.com/invite/JfAtkvEtRb) లో ఈ పెద్ద సముదాయంలో చేరండి!
## మీరు హగ్గింగ్ ఫేస్ టీమ్ నుండి అనుకూల మద్దతు కోసం చూస్తున్నట్లయితే
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## విషయాలు
డాక్యుమెంటేషన్ ఐదు విభాగాలుగా నిర్వహించబడింది:
- **ప్రారంభించండి** లైబ్రరీ యొక్క శీఘ్ర పర్యటన మరియు రన్నింగ్ కోసం ఇన్స్టాలేషన్ సూచనలను అందిస్తుంది.
- **ట్యుటోరియల్స్** మీరు అనుభవశూన్యుడు అయితే ప్రారంభించడానికి గొప్ప ప్రదేశం. మీరు లైబ్రరీని ఉపయోగించడం ప్రారంభించడానికి అవసరమైన ప్రాథమిక నైపుణ్యాలను పొందడానికి ఈ విభాగం మీకు సహాయం చేస్తుంది.
- **హౌ-టు-గైడ్లు** లాంగ్వేజ్ మోడలింగ్ కోసం ప్రిట్రైన్డ్ మోడల్ని ఫైన్ట్యూన్ చేయడం లేదా కస్టమ్ మోడల్ను ఎలా వ్రాయాలి మరియు షేర్ చేయాలి వంటి నిర్దిష్ట లక్ష్యాన్ని ఎలా సాధించాలో మీకు చూపుతాయి.
- **కాన్సెప్చువల్ గైడ్స్** మోడల్లు, టాస్క్లు మరియు 🤗 ట్రాన్స్ఫార్మర్ల డిజైన్ ఫిలాసఫీ వెనుక ఉన్న అంతర్లీన భావనలు మరియు ఆలోచనల గురించి మరింత చర్చ మరియు వివరణను అందిస్తుంది.
- **API** అన్ని తరగతులు మరియు విధులను వివరిస్తుంది:
- **ప్రధాన తరగతులు** కాన్ఫిగరేషన్, మోడల్, టోకెనైజర్ మరియు పైప్లైన్ వంటి అత్యంత ముఖ్యమైన తరగతులను వివరిస్తుంది.
- **మోడల్స్** లైబ్రరీలో అమలు చేయబడిన ప్రతి మోడల్కు సంబంధించిన తరగతులు మరియు విధులను వివరిస్తుంది.
- **అంతర్గత సహాయకులు** అంతర్గతంగా ఉపయోగించే యుటిలిటీ క్లాస్లు మరియు ఫంక్షన్ల వివరాలు.
## మద్దతు ఉన్న నమూనాలు మరియు ఫ్రేమ్వర్క్లు
దిగువన ఉన్న పట్టిక ఆ ప్రతి మోడల్కు పైథాన్ కలిగి ఉన్నా లైబ్రరీలో ప్రస్తుత మద్దతును సూచిస్తుంది
టోకెనైజర్ ("నెమ్మదిగా" అని పిలుస్తారు). Jax (ద్వారా
ఫ్లాక్స్), పైటార్చ్ మరియు/లేదా టెన్సర్ఫ్లో.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | PyTorch support | TensorFlow support | Flax Support |
|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
| [LED](model_doc/led) | ✅ | ✅ | ❌ |
| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
<!-- End table-->
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/te/quicktour.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# శీఘ్ర పర్యటన
[[ఓపెన్-ఇన్-కోలాబ్]]
🤗 ట్రాన్స్ఫార్మర్లతో లేచి పరుగెత్తండి! మీరు డెవలపర్ అయినా లేదా రోజువారీ వినియోగదారు అయినా, ఈ శీఘ్ర పర్యటన మీకు ప్రారంభించడానికి సహాయం చేస్తుంది మరియు [`pipeline`] అనుమితి కోసం ఎలా ఉపయోగించాలో మీకు చూపుతుంది, [AutoClass](./model_doc/auto) తో ప్రీట్రైన్డ్ మోడల్ మరియు ప్రిప్రాసెసర్/ ఆటో, మరియు PyTorch లేదా TensorFlowతో మోడల్కు త్వరగా శిక్షణ ఇవ్వండి. మీరు ఒక అనుభవశూన్యుడు అయితే, ఇక్కడ పరిచయం చేయబడిన భావనల గురించి మరింత లోతైన వివరణల కోసం మా ట్యుటోరియల్స్ లేదా [course](https://huggingface.co/course/chapter1/1)ని తనిఖీ చేయమని మేము సిఫార్సు చేస్తున్నాము.
మీరు ప్రారంభించడానికి ముందు, మీరు అవసరమైన అన్ని లైబ్రరీలను ఇన్స్టాల్ చేశారని నిర్ధారించుకోండి:
```bash
!pip install transformers datasets
```
మీరు మీ ప్రాధాన్య యంత్ర అభ్యాస ఫ్రేమ్వర్క్ను కూడా ఇన్స్టాల్ చేయాలి:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## పైప్లైన్
<Youtube id="tiZFewofSLM"/>
[`pipeline`] అనుమితి కోసం ముందుగా శిక్షణ పొందిన నమూనాను ఉపయోగించడానికి సులభమైన మరియు వేగవంతమైన మార్గం. మీరు వివిధ పద్ధతులలో అనేక పనుల కోసం [`pipeline`] వెలుపల ఉపయోగించవచ్చు, వాటిలో కొన్ని క్రింది పట్టికలో చూపబడ్డాయి:
<Tip>
అందుబాటులో ఉన్న పనుల పూర్తి జాబితా కోసం, [పైప్లైన్ API సూచన](./main_classes/pipelines)ని తనిఖీ చేయండి.
</Tip>
Here is the translation in Telugu:
| **పని** | **వివరణ** | **మోడాలిటీ** | **పైప్లైన్ ఐడెంటిఫైయర్** |
|------------------------------|--------------------------------------------------------------------------------------------------------|-----------------|------------------------------------------|
| వచన వర్గీకరణు | కొన్ని వచనాల అంతా ఒక లేబుల్ను కొడి | NLP | pipeline(task=“sentiment-analysis”) |
| వచన సృష్టి | ప్రమ్పుటం కలిగినంత వచనం సృష్టించండి | NLP | pipeline(task=“text-generation”) |
| సంక్షేపణ | వచనం లేదా పత్రం కొరకు సంక్షేపణ తయారుచేసండి | NLP | pipeline(task=“summarization”) |
| చిత్రం వర్గీకరణు | చిత్రంలో ఒక లేబుల్ను కొడి | కంప్యూటర్ విషయం | pipeline(task=“image-classification”) |
| చిత్రం విభజన | ఒక చిత్రంలో ప్రతి వ్యక్తిగత పిక్సల్ను ఒక లేబుల్గా నమోదు చేయండి (సెమాంటిక్, పానొప్టిక్, మరియు ఇన్స్టన్స్ విభజనలను మద్దతు చేస్తుంది) | కంప్యూటర్ విషయం | pipeline(task=“image-segmentation”) |
| వస్త్రం గుర్తువు | ఒక చిత్రంలో పదాల యొక్క బౌండింగ్ బాక్స్లను మరియు వస్త్రాల వర్గాలను అంచనా చేయండి | కంప్యూటర్ విషయం | pipeline(task=“object-detection”) |
| ఆడియో గుర్తువు | కొన్ని ఆడియో డేటానికి ఒక లేబుల్ను కొడి | ఆడియో | pipeline(task=“audio-classification”) |
| స్వయంచలన ప్రసంగ గుర్తువు | ప్రసంగాన్ని వచనంగా వర్ణించండి | ఆడియో | pipeline(task=“automatic-speech-recognition”) |
| దృశ్య ప్రశ్న సంవాదం | వచనం మరియు ప్రశ్నను నమోదు చేసిన చిత్రంతో ప్రశ్నకు సమాధానం ఇవ్వండి | బహుమూలిక | pipeline(task=“vqa”) |
| పత్రం ప్రశ్న సంవాదం | ప్రశ్నను పత్రం లేదా డాక్యుమెంట్తో సమాధానం ఇవ్వండి | బహుమూలిక | pipeline(task="document-question-answering") |
| చిత్రం వ్రాసాయింగ్ | కొన్ని చిత్రానికి పిటియార్లను సృష్టించండి | బహుమూలిక | pipeline(task="image-to-text") |
[`pipeline`] యొక్క ఉదాహరణను సృష్టించడం ద్వారా మరియు మీరు దానిని ఉపయోగించాలనుకుంటున్న పనిని పేర్కొనడం ద్వారా ప్రారంభించండి. ఈ గైడ్లో, మీరు సెంటిమెంట్ విశ్లేషణ కోసం [`pipeline`]ని ఉదాహరణగా ఉపయోగిస్తారు:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
సెంటిమెంట్ విశ్లేషణ కోసం [`pipeline`] డిఫాల్ట్ [ప్రీట్రైన్డ్ మోడల్](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) మరియు టోకెనైజర్ని డౌన్లోడ్ చేస్తుంది మరియు కాష్ చేస్తుంది. ఇప్పుడు మీరు మీ లక్ష్య వచనంలో `classifier`ని ఉపయోగించవచ్చు:
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
మీరు ఒకటి కంటే ఎక్కువ ఇన్పుట్లను కలిగి ఉంటే, నిఘంటువుల జాబితాను అందించడానికి మీ ఇన్పుట్లను జాబితాగా [`pipeline`]కి పంపండి:
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
```
[`pipeline`] మీకు నచ్చిన ఏదైనా పని కోసం మొత్తం డేటాసెట్ను కూడా పునరావృతం చేయగలదు. ఈ ఉదాహరణ కోసం, స్వయంచాలక ప్రసంగ గుర్తింపును మన పనిగా ఎంచుకుందాం:
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
మీరు మళ్లీ మళ్లీ చెప్పాలనుకుంటున్న ఆడియో డేటాసెట్ను లోడ్ చేయండి (మరిన్ని వివరాల కోసం 🤗 డేటాసెట్లు [త్వరిత ప్రారంభం](https://huggingface.co/docs/datasets/quickstart#audio) చూడండి. ఉదాహరణకు, [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) డేటాసెట్ను లోడ్ చేయండి:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
డేటాసెట్ యొక్క నమూనా రేటు నమూనాతో సరిపోలుతుందని మీరు నిర్ధారించుకోవాలి
రేటు [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) దీనిపై శిక్షణ పొందింది:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
`"ఆడియో"` కాలమ్కి కాల్ చేస్తున్నప్పుడు ఆడియో ఫైల్లు స్వయంచాలకంగా లోడ్ చేయబడతాయి మరియు మళ్లీ నమూనా చేయబడతాయి.
మొదటి 4 నమూనాల నుండి ముడి వేవ్ఫార్మ్ శ్రేణులను సంగ్రహించి, పైప్లైన్కు జాబితాగా పాస్ చేయండి:
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
```
ఇన్పుట్లు పెద్దగా ఉన్న పెద్ద డేటాసెట్ల కోసం (స్పీచ్ లేదా విజన్ వంటివి), మెమరీలోని అన్ని ఇన్పుట్లను లోడ్ చేయడానికి మీరు జాబితాకు బదులుగా జెనరేటర్ను పాస్ చేయాలనుకుంటున్నారు. మరింత సమాచారం కోసం [పైప్లైన్ API సూచన](./main_classes/pipelines)ని చూడండి.
### పైప్లైన్లో మరొక మోడల్ మరియు టోకెనైజర్ని ఉపయోగించండి
[`pipeline`] [Hub](https://huggingface.co/models) నుండి ఏదైనా మోడల్ను కలిగి ఉంటుంది, దీని వలన ఇతర వినియోగ-కేసుల కోసం [`pipeline`]ని సులభంగా స్వీకరించవచ్చు. ఉదాహరణకు, మీరు ఫ్రెంచ్ టెక్స్ట్ను హ్యాండిల్ చేయగల మోడల్ కావాలనుకుంటే, తగిన మోడల్ కోసం ఫిల్టర్ చేయడానికి హబ్లోని ట్యాగ్లను ఉపయోగించండి. అగ్ర ఫిల్టర్ చేసిన ఫలితం మీరు ఫ్రెంచ్ టెక్స్ట్ కోసం ఉపయోగించగల సెంటిమెంట్ విశ్లేషణ కోసం ఫైన్ట్యూన్ చేయబడిన బహుభాషా [BERT మోడల్](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment)ని అందిస్తుంది:
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `AutoClass`పై మరిన్ని):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`TFAutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `TFAutoClass`పై మరిన్ని):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
[`pipeline`]లో మోడల్ మరియు టోకెనైజర్ను పేర్కొనండి మరియు ఇప్పుడు మీరు ఫ్రెంచ్ టెక్స్ట్పై `క్లాసిఫైయర్`ని వర్తింపజేయవచ్చు:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
మీరు మీ వినియోగ-కేస్ కోసం మోడల్ను కనుగొనలేకపోతే, మీరు మీ డేటాపై ముందుగా శిక్షణ పొందిన మోడల్ను చక్కగా మార్చాలి. ఎలాగో తెలుసుకోవడానికి మా [ఫైన్ట్యూనింగ్ ట్యుటోరియల్](./training)ని చూడండి. చివరగా, మీరు మీ ప్రీట్రైన్డ్ మోడల్ని ఫైన్ట్యూన్ చేసిన తర్వాత, దయచేసి అందరి కోసం మెషిన్ లెర్నింగ్ని డెమోక్రటైజ్ చేయడానికి హబ్లోని సంఘంతో మోడల్ను [షేరింగ్](./model_sharing) పరిగణించండి! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
హుడ్ కింద, మీరు పైన ఉపయోగించిన [`pipeline`]కి శక్తిని అందించడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`] తరగతులు కలిసి పని చేస్తాయి. ఒక [AutoClass](./model_doc/auto) అనేది ముందుగా శిక్షణ పొందిన మోడల్ యొక్క ఆర్కిటెక్చర్ను దాని పేరు లేదా మార్గం నుండి స్వయంచాలకంగా తిరిగి పొందే సత్వరమార్గం. మీరు మీ టాస్క్ కోసం తగిన `ఆటోక్లాస్`ని మాత్రమే ఎంచుకోవాలి మరియు ఇది అనుబంధిత ప్రీప్రాసెసింగ్ క్లాస్.
మునుపటి విభాగం నుండి ఉదాహరణకి తిరిగి వెళ్లి, [`pipeline`] ఫలితాలను ప్రతిబింబించడానికి మీరు `ఆటోక్లాస్`ని ఎలా ఉపయోగించవచ్చో చూద్దాం.
### AutoTokenizer
ఒక మోడల్కు ఇన్పుట్లుగా సంఖ్యల శ్రేణిలో వచనాన్ని ప్రీప్రాసెసింగ్ చేయడానికి టోకెనైజర్ బాధ్యత వహిస్తుంది. పదాన్ని ఎలా విభజించాలి మరియు ఏ స్థాయిలో పదాలను విభజించాలి ([tokenizer సారాంశం](./tokenizer_summary)లో టోకనైజేషన్ గురించి మరింత తెలుసుకోండి) సహా టోకనైజేషన్ ప్రక్రియను నియంత్రించే అనేక నియమాలు ఉన్నాయి. గుర్తుంచుకోవలసిన ముఖ్యమైన విషయం ఏమిటంటే, మీరు మోడల్కు ముందే శిక్షణ పొందిన అదే టోకనైజేషన్ నియమాలను ఉపయోగిస్తున్నారని నిర్ధారించుకోవడానికి మీరు అదే మోడల్ పేరుతో టోకెనైజర్ను తక్షణం చేయాలి.
[`AutoTokenizer`]తో టోకెనైజర్ను లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
మీ వచనాన్ని టోకెనైజర్కు పంపండి:
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
టోకెనైజర్ వీటిని కలిగి ఉన్న నిఘంటువుని అందిస్తుంది:
* [input_ids](./glossary#input-ids): మీ టోకెన్ల సంఖ్యాపరమైన ప్రాతినిధ్యం.
* [అటెన్షన్_మాస్క్](./glossary#attention-mask): ఏ టోకెన్లకు హాజరు కావాలో సూచిస్తుంది.
ఒక టోకెనైజర్ ఇన్పుట్ల జాబితాను కూడా ఆమోదించగలదు మరియు ఏకరీతి పొడవుతో బ్యాచ్ను తిరిగి ఇవ్వడానికి టెక్స్ట్ను ప్యాడ్ చేసి కత్తిరించవచ్చు:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
<Tip>
టోకనైజేషన్ గురించి మరిన్ని వివరాల కోసం [ప్రీప్రాసెస్](./preprocessing) ట్యుటోరియల్ని చూడండి మరియు ఇమేజ్, ఆడియో మరియు మల్టీమోడల్ ఇన్పుట్లను ప్రీప్రాసెస్ చేయడానికి [`AutoImageProcessor`], [`AutoFeatureExtractor`] మరియు [`AutoProcessor`] ఎలా ఉపయోగించాలి.
</Tip>
### AutoModel
<frameworkcontent>
<pt>
🤗 ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ ఇన్స్టాన్స్లను లోడ్ చేయడానికి సులభమైన మరియు ఏకీకృత మార్గాన్ని అందిస్తాయి. దీని అర్థం మీరు [`AutoTokenizer`]ని లోడ్ చేసినట్లుగా [`AutoModel`]ని లోడ్ చేయవచ్చు. టాస్క్ కోసం సరైన [`AutoModel`]ని ఎంచుకోవడం మాత్రమే తేడా. టెక్స్ట్ (లేదా సీక్వెన్స్) వర్గీకరణ కోసం, మీరు [`AutoModelForSequenceClassification`]ని లోడ్ చేయాలి:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
[`AutoModel`] క్లాస్ ద్వారా సపోర్ట్ చేసే టాస్క్ల కోసం [టాస్క్ సారాంశం](./task_summary)ని చూడండి.
</Tip>
ఇప్పుడు మీ ప్రీప్రాసెస్ చేయబడిన బ్యాచ్ ఇన్పుట్లను నేరుగా మోడల్కి పంపండి. మీరు `**`ని జోడించడం ద్వారా నిఘంటువుని అన్ప్యాక్ చేయాలి:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
మోడల్ తుది యాక్టివేషన్లను `logits` లక్షణంలో అవుట్పుట్ చేస్తుంది. సంభావ్యతలను తిరిగి పొందడానికి సాఫ్ట్మాక్స్ ఫంక్షన్ను `logits` కు వర్తింపజేయండి:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ ఇన్స్టాన్స్లను లోడ్ చేయడానికి సులభమైన మరియు ఏకీకృత మార్గాన్ని అందిస్తాయి. మీరు [`AutoTokenizer`]ని లోడ్ చేసినట్లుగా మీరు [`TFAutoModel`]ని లోడ్ చేయవచ్చని దీని అర్థం. టాస్క్ కోసం సరైన [`TFAutoModel`]ని ఎంచుకోవడం మాత్రమే తేడా. టెక్స్ట్ (లేదా సీక్వెన్స్) వర్గీకరణ కోసం, మీరు [`TFAutoModelForSequenceClassification`]ని లోడ్ చేయాలి:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
[`AutoModel`] క్లాస్ ద్వారా సపోర్ట్ చేసే టాస్క్ల కోసం [టాస్క్ సారాంశం](./task_summary)ని చూడండి.
</Tip>
ఇప్పుడు మీ ప్రీప్రాసెస్ చేయబడిన బ్యాచ్ ఇన్పుట్లను నేరుగా మోడల్కి పంపండి. మీరు టెన్సర్లను ఇలా పాస్ చేయవచ్చు:
```py
>>> tf_outputs = tf_model(tf_batch)
```
మోడల్ తుది యాక్టివేషన్లను `logits` లక్షణంలో అవుట్పుట్ చేస్తుంది. సంభావ్యతలను తిరిగి పొందడానికి సాఫ్ట్మాక్స్ ఫంక్షన్ను `logits`కు వర్తింపజేయండి:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
అన్ని 🤗 ట్రాన్స్ఫార్మర్స్ మోడల్లు (PyTorch లేదా TensorFlow) తుది యాక్టివేషన్కు *ముందు* టెన్సర్లను అవుట్పుట్ చేస్తాయి
ఫంక్షన్ (softmax వంటిది) ఎందుకంటే చివరి యాక్టివేషన్ ఫంక్షన్ తరచుగా నష్టంతో కలిసిపోతుంది. మోడల్ అవుట్పుట్లు ప్రత్యేక డేటాక్లాస్లు కాబట్టి వాటి లక్షణాలు IDEలో స్వయంచాలకంగా పూర్తి చేయబడతాయి. మోడల్ అవుట్పుట్లు టుపుల్ లేదా డిక్షనరీ లాగా ప్రవర్తిస్తాయి (మీరు పూర్ణాంకం, స్లైస్ లేదా స్ట్రింగ్తో ఇండెక్స్ చేయవచ్చు) ఈ సందర్భంలో, ఏదీ లేని గుణాలు విస్మరించబడతాయి.
</Tip>
### మోడల్ను సేవ్ చేయండి
<frameworkcontent>
<pt>
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`PreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
మీరు మోడల్ని మళ్లీ ఉపయోగించడానికి సిద్ధంగా ఉన్నప్పుడు, దాన్ని [`PreTrainedModel.from_pretrained`]తో రీలోడ్ చేయండి:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`TFPreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
మీరు మోడల్ని మళ్లీ ఉపయోగించడానికి సిద్ధంగా ఉన్నప్పుడు, దాన్ని [`TFPreTrainedModel.from_pretrained`]తో రీలోడ్ చేయండి:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
ఒక ప్రత్యేకించి అద్భుతమైన 🤗 ట్రాన్స్ఫార్మర్స్ ఫీచర్ మోడల్ను సేవ్ చేయగల సామర్థ్యం మరియు దానిని PyTorch లేదా TensorFlow మోడల్గా రీలోడ్ చేయగలదు. `from_pt` లేదా `from_tf` పరామితి మోడల్ను ఒక ఫ్రేమ్వర్క్ నుండి మరొక ఫ్రేమ్వర్క్కి మార్చగలదు:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
## కస్టమ్ మోడల్ బిల్డ్స్
మోడల్ ఎలా నిర్మించబడుతుందో మార్చడానికి మీరు మోడల్ కాన్ఫిగరేషన్ క్లాస్ని సవరించవచ్చు. దాచిన లేయర్లు లేదా అటెన్షన్ హెడ్ల సంఖ్య వంటి మోడల్ లక్షణాలను కాన్ఫిగరేషన్ నిర్దేశిస్తుంది. మీరు కస్టమ్ కాన్ఫిగరేషన్ క్లాస్ నుండి మోడల్ను ప్రారంభించినప్పుడు మీరు మొదటి నుండి ప్రారంభిస్తారు. మోడల్ అట్రిబ్యూట్లు యాదృచ్ఛికంగా ప్రారంభించబడ్డాయి మరియు అర్థవంతమైన ఫలితాలను పొందడానికి మీరు మోడల్ను ఉపయోగించే ముందు దానికి శిక్షణ ఇవ్వాలి.
[`AutoConfig`]ని దిగుమతి చేయడం ద్వారా ప్రారంభించండి, ఆపై మీరు సవరించాలనుకుంటున్న ప్రీట్రైన్డ్ మోడల్ను లోడ్ చేయండి. [`AutoConfig.from_pretrained`]లో, మీరు అటెన్షన్ హెడ్ల సంఖ్య వంటి మీరు మార్చాలనుకుంటున్న లక్షణాన్ని పేర్కొనవచ్చు:
```py
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
```
<frameworkcontent>
<pt>
[`AutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
```py
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
```
</pt>
<tf>
[`TFAutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
```py
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
```
</tf>
</frameworkcontent>
అనుకూల కాన్ఫిగరేషన్లను రూపొందించడం గురించి మరింత సమాచారం కోసం [కస్టమ్ ఆర్కిటెక్చర్ని సృష్టించండి](./create_a_model) గైడ్ను చూడండి.
## శిక్షకుడు - పైటార్చ్ ఆప్టిమైజ్ చేసిన శిక్షణ లూప్
అన్ని మోడల్లు ప్రామాణికమైన [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) కాబట్టి మీరు వాటిని ఏదైనా సాధారణ శిక్షణ లూప్లో ఉపయోగించవచ్చు. మీరు మీ స్వంత శిక్షణ లూప్ను వ్రాయగలిగినప్పటికీ, 🤗 ట్రాన్స్ఫార్మర్లు PyTorch కోసం [`ట్రైనర్`] తరగతిని అందజేస్తాయి, ఇందులో ప్రాథమిక శిక్షణ లూప్ ఉంటుంది మరియు పంపిణీ చేయబడిన శిక్షణ, మిశ్రమ ఖచ్చితత్వం మరియు మరిన్ని వంటి ఫీచర్ల కోసం అదనపు కార్యాచరణను జోడిస్తుంది.
మీ విధిని బట్టి, మీరు సాధారణంగా కింది పారామితులను [`ట్రైనర్`]కి పంపుతారు:
1. మీరు [`PreTrainedModel`] లేదా [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)తో ప్రారంభిస్తారు:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. [`TrainingArguments`] మీరు నేర్చుకునే రేటు, బ్యాచ్ పరిమాణం మరియు శిక్షణ పొందవలసిన యుగాల సంఖ్య వంటి మార్చగల మోడల్ హైపర్పారామీటర్లను కలిగి ఉంది. మీరు ఎలాంటి శిక్షణా వాదనలను పేర్కొనకుంటే డిఫాల్ట్ విలువలు ఉపయోగించబడతాయి:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="path/to/save/folder/",
... learning_rate=2e-5,
... per_device_train_batch_size=8,
... per_device_eval_batch_size=8,
... num_train_epochs=2,
... )
```
3. టోకెనైజర్, ఇమేజ్ ప్రాసెసర్, ఫీచర్ ఎక్స్ట్రాక్టర్ లేదా ప్రాసెసర్ వంటి ప్రీప్రాసెసింగ్ క్లాస్ని లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
4. డేటాసెట్ను లోడ్ చేయండి:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
```
5. డేటాసెట్ను టోకనైజ్ చేయడానికి ఒక ఫంక్షన్ను సృష్టించండి:
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"])
```
ఆపై దానిని [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్లో వర్తింపజేయండి:
```py
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
6. మీ డేటాసెట్ నుండి ఉదాహరణల సమూహాన్ని సృష్టించడానికి [`DataCollatorWithPadding`]:
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
ఇప్పుడు ఈ తరగతులన్నింటినీ [`Trainer`]లో సేకరించండి:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
మీరు సిద్ధంగా ఉన్నప్పుడు, శిక్షణను ప్రారంభించడానికి [`~Trainer.train`]కి కాల్ చేయండి:
```py
>>> trainer.train() # doctest: +SKIP
```
<Tip>
సీక్వెన్స్-టు-సీక్వెన్స్ మోడల్ని ఉపయోగించే - అనువాదం లేదా సారాంశం వంటి పనుల కోసం, బదులుగా [`Seq2SeqTrainer`] మరియు [`Seq2SeqTrainingArguments`] తరగతులను ఉపయోగించండి.
</Tip>
మీరు [`Trainer`] లోపల ఉన్న పద్ధతులను ఉపవర్గీకరించడం ద్వారా శిక్షణ లూప్ ప్రవర్తనను అనుకూలీకరించవచ్చు. ఇది లాస్ ఫంక్షన్, ఆప్టిమైజర్ మరియు షెడ్యూలర్ వంటి లక్షణాలను అనుకూలీకరించడానికి మిమ్మల్ని అనుమతిస్తుంది. ఉపవర్గీకరించబడే పద్ధతుల కోసం [`Trainer`] సూచనను పరిశీలించండి.
శిక్షణ లూప్ను అనుకూలీకరించడానికి మరొక మార్గం [కాల్బ్యాక్లు](./main_classes/callbacks). మీరు ఇతర లైబ్రరీలతో అనుసంధానం చేయడానికి కాల్బ్యాక్లను ఉపయోగించవచ్చు మరియు పురోగతిపై నివేదించడానికి శిక్షణ లూప్ను తనిఖీ చేయవచ్చు లేదా శిక్షణను ముందుగానే ఆపవచ్చు. శిక్షణ లూప్లోనే కాల్బ్యాక్లు దేనినీ సవరించవు. లాస్ ఫంక్షన్ వంటివాటిని అనుకూలీకరించడానికి, మీరు బదులుగా [`Trainer`]ని ఉపవర్గం చేయాలి.
## TensorFlowతో శిక్షణ పొందండి
అన్ని మోడల్లు ప్రామాణికమైన [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) కాబట్టి వాటిని [Keras]తో TensorFlowలో శిక్షణ పొందవచ్చు(https: //keras.io/) API. 🤗 ట్రాన్స్ఫార్మర్లు మీ డేటాసెట్ని సులభంగా `tf.data.Dataset`గా లోడ్ చేయడానికి [`~TFPreTrainedModel.prepare_tf_dataset`] పద్ధతిని అందజేస్తుంది కాబట్టి మీరు వెంటనే Keras' [`compile`](https://keras.io /api/models/model_training_apis/#compile-method) మరియు [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) పద్ధతులు.
1. మీరు [`TFPreTrainedModel`] లేదా [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)తో ప్రారంభిస్తారు:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. టోకెనైజర్, ఇమేజ్ ప్రాసెసర్, ఫీచర్ ఎక్స్ట్రాక్టర్ లేదా ప్రాసెసర్ వంటి ప్రీప్రాసెసింగ్ క్లాస్ని లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
3. డేటాసెట్ను టోకనైజ్ చేయడానికి ఒక ఫంక్షన్ను సృష్టించండి:
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"]) # doctest: +SKIP
```
4. [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్పై టోకెనైజర్ని వర్తింపజేయి, ఆపై డేటాసెట్ మరియు టోకెనైజర్ను [`~TFPreTrainedModel.prepare_tf_dataset`]కి పంపండి. మీరు కావాలనుకుంటే బ్యాచ్ పరిమాణాన్ని కూడా మార్చవచ్చు మరియు డేటాసెట్ను ఇక్కడ షఫుల్ చేయవచ్చు:
```py
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
... dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer
... ) # doctest: +SKIP
```
5. మీరు సిద్ధంగా ఉన్నప్పుడు, శిక్షణను ప్రారంభించడానికి మీరు `కంపైల్` మరియు `ఫిట్`కి కాల్ చేయవచ్చు. ట్రాన్స్ఫార్మర్స్ మోడల్స్ అన్నీ డిఫాల్ట్ టాస్క్-సంబంధిత లాస్ ఫంక్షన్ని కలిగి ఉన్నాయని గుర్తుంచుకోండి, కాబట్టి మీరు కోరుకునే వరకు మీరు ఒకదానిని పేర్కొనవలసిన అవసరం లేదు:
```py
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5)) # No loss argument!
>>> model.fit(tf_dataset) # doctest: +SKIP
```
## తరవాత ఏంటి?
ఇప్పుడు మీరు 🤗 ట్రాన్స్ఫార్మర్స్ త్వరిత పర్యటనను పూర్తి చేసారు, మా గైడ్లను తనిఖీ చేయండి మరియు అనుకూల మోడల్ను వ్రాయడం, టాస్క్ కోసం మోడల్ను చక్కగా తీర్చిదిద్దడం మరియు స్క్రిప్ట్తో మోడల్కు శిక్షణ ఇవ్వడం వంటి మరింత నిర్దిష్టమైన పనులను ఎలా చేయాలో తెలుసుకోండి. 🤗 ట్రాన్స్ఫార్మర్స్ కోర్ కాన్సెప్ట్ల గురించి మరింత తెలుసుకోవడానికి మీకు ఆసక్తి ఉంటే, ఒక కప్పు కాఫీ తాగి, మా కాన్సెప్టువల్ గైడ్లను చూడండి!
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/te/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: త్వరిత పర్యటన
title: ప్రారంభించడానికి
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/fast_tokenizers.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Usando os Tokenizers do 🤗 Tokenizers
O [`PreTrainedTokenizerFast`] depende da biblioteca [🤗 Tokenizers](https://huggingface.co/docs/tokenizers). O Tokenizer obtido da biblioteca 🤗 Tokenizers pode ser carregado facilmente pelo 🤗 Transformers.
Antes de entrar nos detalhes, vamos começar criando um tokenizer fictício em algumas linhas:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
Agora temos um tokenizer treinado nos arquivos que foram definidos. Nós podemos continuar usando nessa execução ou salvar em um arquivo JSON para re-utilizar no futuro.
## Carregando diretamente de um objeto tokenizer
Vamos ver como aproveitar esse objeto tokenizer na biblioteca 🤗 Transformers. A classe [`PreTrainedTokenizerFast`] permite uma instanciação fácil, aceitando o objeto *tokenizer* instanciado como um argumento:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
Esse objeto pode ser utilizado com todos os métodos compartilhados pelos tokenizers dos 🤗 Transformers! Vá para [a página do tokenizer](main_classes/tokenizer) para mais informações.
## Carregando de um arquivo JSON
Para carregar um tokenizer de um arquivo JSON vamos primeiro começar salvando nosso tokenizer:
```python
>>> tokenizer.save("tokenizer.json")
```
A pasta para qual salvamos esse arquivo pode ser passada para o método de inicialização do [`PreTrainedTokenizerFast`] usando o `tokenizer_file` parâmetro:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
Esse objeto pode ser utilizado com todos os métodos compartilhados pelos tokenizers dos 🤗 Transformers! Vá para [a página do tokenizer](main_classes/tokenizer) para mais informações.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers
Estado da Arte para Aprendizado de Máquina em PyTorch, TensorFlow e JAX.
O 🤗 Transformers disponibiliza APIs para facilmente baixar e treinar modelos pré-treinados de última geração.
O uso de modelos pré-treinados pode diminuir os seus custos de computação, a sua pegada de carbono, além de economizar o
tempo necessário para se treinar um modelo do zero. Os modelos podem ser usados para diversas tarefas:
* 📝 Textos: classificação, extração de informações, perguntas e respostas, resumir, traduzir e gerar textos em mais de 100 idiomas.
* 🖼 Imagens: classificação, deteção de objetos, e segmentação.
* 🗣 Audio: reconhecimento de fala e classificação de áudio.
* 🐙 Multimodal: perguntas tabeladas e respsostas, reconhecimento ótico de charactéres, extração de informação de
documentos escaneados, classificação de vídeo, perguntas e respostas visuais.
Nossa biblioteca aceita integração contínua entre três das bibliotecas mais populares de aprendizado profundo:
Our library supports seamless integration between three of the most popular deep learning libraries:
[PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) e [JAX](https://jax.readthedocs.io/en/latest/).
Treine seu modelo em três linhas de código em um framework, e carregue-o para execução em outro.
Cada arquitetura 🤗 Transformers é definida em um módulo individual do Python, para que seja facilmente customizável para pesquisa e experimentos.
## Se você estiver procurando suporte do time da Hugging Face, acesse
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://huggingface.co/front/thumbnails/support.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## Conteúdo
A documentação é dividida em cinco partes:
- **INÍCIO** contém um tour rápido de instalação e instruções para te dar um empurrão inicial com os 🤗 Transformers.
- **TUTORIAIS** são perfeitos para começar a aprender sobre a nossa biblioteca. Essa seção irá te ajudar a desenvolver
habilidades básicas necessárias para usar o 🤗 Transformers.
- **GUIAS PRÁTICOS** irão te mostrar como alcançar um certo objetivo, como o fine-tuning de um modelo pré-treinado
para modelamento de idioma, ou como criar um cabeçalho personalizado para um modelo.
- **GUIAS CONCEITUAIS** te darão mais discussões e explicações dos conceitos fundamentais e idéias por trás dos modelos,
tarefas e da filosofia de design por trás do 🤗 Transformers.
- **API** descreve o funcionamento de cada classe e função, agrupada em:
- **CLASSES PRINCIPAIS** para as classes que expõe as APIs importantes da biblioteca.
- **MODELOS** para as classes e funções relacionadas à cada modelo implementado na biblioteca.
- **AUXILIARES INTERNOS** para as classes e funções usadas internamente.
Atualmente a biblioteca contém implementações do PyTorch, TensorFlow e JAX, pesos para modelos pré-treinados e scripts de uso e conversão de utilidades para os seguintes modelos:
### Modelos atuais
<!--This list is updated automatically from the README with _make fix-copies_. Do not update manually! -->
1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MBart](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[MBart-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBert](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Frameworks aceitos
A tabela abaixo representa a lista de suporte na biblioteca para cada um dos seguintes modelos, caso tenham um tokenizer
do Python (chamado de "slow"), ou um tokenizer construído em cima da biblioteca 🤗 Tokenizers (chamado de "fast"). Além
disso, são diferenciados pelo suporte em diferentes frameworks: JAX (por meio do Flax); PyTorch; e/ou Tensorflow.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecVision | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| MegatronBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| mT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Nystromformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| Realm | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ❌ | ✅ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| SegFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| TAPEX | ✅ | ✅ | ✅ | ✅ | ✅ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| VisualBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- End table-->
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/run_scripts.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Treinamento a partir de um script
Junto com os 🤗 Transformers [notebooks](./noteboks/README), também há scripts de exemplo demonstrando como treinar um modelo para uma tarefa com [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow) ou [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
Você também encontrará scripts que usamos em nossos [projetos de pesquisa](https://github.com/huggingface/transformers/tree/main/examples/research_projects) e [exemplos legados](https://github.com/huggingface/transformers/tree/main/examples/legacy) que são principalmente contribuições da comunidade. Esses scripts não são mantidos ativamente e exigem uma versão específica de 🤗 Transformers que provavelmente será incompatível com a versão mais recente da biblioteca.
Não se espera que os scripts de exemplo funcionem imediatamente em todos os problemas, você pode precisar adaptar o script ao problema que está tentando resolver. Para ajudá-lo com isso, a maioria dos scripts expõe totalmente como os dados são pré-processados, permitindo que você os edite conforme necessário para seu caso de uso.
Para qualquer recurso que você gostaria de implementar em um script de exemplo, discuta-o no [fórum](https://discuss.huggingface.co/) ou em uma [issue](https://github.com/huggingface/transformers/issues) antes de enviar um Pull Request. Embora recebamos correções de bugs, é improvável que mesclaremos um Pull Request que adicione mais funcionalidades ao custo de legibilidade.
Este guia mostrará como executar um exemplo de script de treinamento de sumarização em [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) e [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). Espera-se que todos os exemplos funcionem com ambas as estruturas, a menos que especificado de outra forma.
## Configuração
Para executar com êxito a versão mais recente dos scripts de exemplo, você precisa **instalar o 🤗 Transformers da fonte** em um novo ambiente virtual:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
Para versões mais antigas dos scripts de exemplo, clique no botão abaixo:
<details>
<summary>Exemplos para versões antigas dos 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Em seguida, mude seu clone atual dos 🤗 Transformers para uma versão específica, como v3.5.1, por exemplo:
```bash
git checkout tags/v3.5.1
```
Depois de configurar a versão correta da biblioteca, navegue até a pasta de exemplo de sua escolha e instale os requisitos específicos do exemplo:
```bash
pip install -r requirements.txt
```
## Executando um script
<frameworkcontent>
<pt>
O script de exemplo baixa e pré-processa um conjunto de dados da biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Em seguida, o script ajusta um conjunto de dados com o [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) em uma arquitetura que oferece suporte à sumarização. O exemplo a seguir mostra como ajustar [T5-small](https://huggingface.co/t5-small) no conjunto de dados [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). O modelo T5 requer um argumento `source_prefix` adicional devido à forma como foi treinado. Este prompt informa ao T5 que esta é uma tarefa de sumarização.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Este outro script de exemplo baixa e pré-processa um conjunto de dados da biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Em seguida, o script ajusta um conjunto de dados usando Keras em uma arquitetura que oferece suporte à sumarização. O exemplo a seguir mostra como ajustar [T5-small](https://huggingface.co/t5-small) no conjunto de dados [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). O modelo T5 requer um argumento `source_prefix` adicional devido à forma como foi treinado. Este prompt informa ao T5 que esta é uma tarefa de sumarização.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Treinamento distribuído e precisão mista
O [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) oferece suporte a treinamento distribuído e precisão mista, o que significa que você também pode usá-lo em um script. Para habilitar esses dois recursos:
- Adicione o argumento `fp16` para habilitar a precisão mista.
- Defina o número de GPUs a serem usadas com o argumento `nproc_per_node`.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Os scripts do TensorFlow utilizam um [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) para treinamento distribuído, e você não precisa adicionar argumentos adicionais ao script de treinamento. O script do TensorFlow usará várias GPUs por padrão, se estiverem disponíveis.
## Executando um script em uma TPU
<frameworkcontent>
<pt>
As Unidades de Processamento de Tensor (TPUs) são projetadas especificamente para acelerar o desempenho. O PyTorch oferece suporte a TPUs com o compilador de aprendizado profundo [XLA](https://www.tensorflow.org/xla) (consulte [aqui](https://github.com/pytorch/xla/blob/master/README.md) para mais detalhes). Para usar uma TPU, inicie o script `xla_spawn.py` e use o argumento `num_cores` para definir o número de núcleos de TPU que você deseja usar.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
As Unidades de Processamento de Tensor (TPUs) são projetadas especificamente para acelerar o desempenho. Os scripts do TensorFlow utilizam uma [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) para treinamento em TPUs. Para usar uma TPU, passe o nome do recurso TPU para o argumento `tpu`.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Execute um script com 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) é uma biblioteca somente do PyTorch que oferece um método unificado para treinar um modelo em vários tipos de configurações (CPU, multiplas GPUs, TPUs), mantendo visibilidade no loop de treinamento do PyTorch. Certifique-se de ter o 🤗 Accelerate instalado se ainda não o tiver:
> Nota: Como o Accelerate está se desenvolvendo rapidamente, a versão git do Accelerate deve ser instalada para executar os scripts
```bash
pip install git+https://github.com/huggingface/accelerate
```
Em vez do script `run_summarization.py`, você precisa usar o script `run_summarization_no_trainer.py`. Os scripts suportados pelo 🤗 Accelerate terão um arquivo `task_no_trainer.py` na pasta. Comece executando o seguinte comando para criar e salvar um arquivo de configuração:
```bash
accelerate config
```
Teste sua configuração para garantir que ela esteja corretamente configurada :
```bash
accelerate test
```
Agora você está pronto para iniciar o treinamento:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Usando um conjunto de dados personalizado
O script de resumo oferece suporte a conjuntos de dados personalizados, desde que sejam um arquivo CSV ou JSON. Ao usar seu próprio conjunto de dados, você precisa especificar vários argumentos adicionais:
- `train_file` e `validation_file` especificam o caminho para seus arquivos de treinamento e validação respectivamente.
- `text_column` é o texto de entrada para sumarização.
- `summary_column` é o texto de destino para saída.
Um script para sumarização usando um conjunto de dados customizado ficaria assim:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Testando um script
Geralmente, é uma boa ideia executar seu script em um número menor de exemplos de conjuntos de dados para garantir que tudo funcione conforme o esperado antes de se comprometer com um conjunto de dados inteiro, que pode levar horas para ser concluído. Use os seguintes argumentos para truncar o conjunto de dados para um número máximo de amostras:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Nem todos os scripts de exemplo suportam o argumento `max_predict_samples`. Se você não tiver certeza se seu script suporta este argumento, adicione o argumento `-h` para verificar:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Retomar o treinamento a partir de um checkpoint
Outra opção útil para habilitar é retomar o treinamento de um checkpoint anterior. Isso garantirá que você possa continuar de onde parou sem recomeçar se o seu treinamento for interrompido. Existem dois métodos para retomar o treinamento a partir de um checkpoint.
O primeiro método usa o argumento `output_dir previous_output_dir` para retomar o treinamento do último checkpoint armazenado em `output_dir`. Neste caso, você deve remover `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
O segundo método usa o argumento `resume_from_checkpoint path_to_specific_checkpoint` para retomar o treinamento de uma pasta de checkpoint específica.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Compartilhando seu modelo
Todos os scripts podem enviar seu modelo final para o [Model Hub](https://huggingface.co/models). Certifique-se de estar conectado ao Hugging Face antes de começar:
```bash
huggingface-cli login
```
Em seguida, adicione o argumento `push_to_hub` ao script. Este argumento criará um repositório com seu nome de usuário do Hugging Face e o nome da pasta especificado em `output_dir`.
Para dar um nome específico ao seu repositório, use o argumento `push_to_hub_model_id` para adicioná-lo. O repositório será listado automaticamente em seu namespace.
O exemplo a seguir mostra como fazer upload de um modelo com um nome de repositório específico:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/multilingual.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Modelos multilinguísticos para inferência
[[open-in-colab]]
Existem vários modelos multilinguísticos no 🤗 Transformers e seus usos para inferência diferem dos modelos monolíngues.
No entanto, nem *todos* os usos dos modelos multilíngues são tão diferentes.
Alguns modelos, como o [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased),
podem ser usados como se fossem monolíngues. Este guia irá te ajudar a usar modelos multilíngues cujo uso difere
para o propósito de inferência.
## XLM
O XLM tem dez checkpoints diferentes dos quais apenas um é monolíngue.
Os nove checkpoints restantes do modelo são subdivididos em duas categorias:
checkpoints que usam de language embeddings e os que não.
### XLM com language embeddings
Os seguintes modelos de XLM usam language embeddings para especificar a linguagem utilizada para a inferência.
- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
- `xlm-clm-ende-1024` (Causal language modeling, English-German)
Os language embeddings são representados por um tensor de mesma dimensão que os `input_ids` passados ao modelo.
Os valores destes tensores dependem do idioma utilizado e se identificam pelos atributos `lang2id` e `id2lang` do tokenizador.
Neste exemplo, carregamos o checkpoint `xlm-clm-enfr-1024`(Causal language modeling, English-French):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
O atributo `lang2id` do tokenizador mostra os idiomas deste modelo e seus ids:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
Em seguida, cria-se um input de exemplo:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
```
Estabelece-se o id do idioma, por exemplo `"en"`, e utiliza-se o mesmo para definir a language embedding.
A language embedding é um tensor preenchido com `0`, que é o id de idioma para o inglês.
Este tensor deve ser do mesmo tamanho que os `input_ids`.
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
```
Agora você pode passar os `input_ids` e a language embedding ao modelo:
```py
>>> outputs = model(input_ids, langs=langs)
```
O script [run_generation.py](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-generation/run_generation.py) pode gerar um texto com language embeddings utilizando os checkpoints `xlm-clm`.
### XLM sem language embeddings
Os seguintes modelos XLM não requerem o uso de language embeddings durante a inferência:
- `xlm-mlm-17-1280` (Modelagem de linguagem com máscara, 17 idiomas)
- `xlm-mlm-100-1280` (Modelagem de linguagem com máscara, 100 idiomas)
Estes modelos são utilizados para representações genéricas de frase diferentemente dos checkpoints XLM anteriores.
## BERT
Os seguintes modelos do BERT podem ser utilizados para tarefas multilinguísticas:
- `bert-base-multilingual-uncased` (Modelagem de linguagem com máscara + Previsão de frases, 102 idiomas)
- `bert-base-multilingual-cased` (Modelagem de linguagem com máscara + Previsão de frases, 104 idiomas)
Estes modelos não requerem language embeddings durante a inferência. Devem identificar a linguagem a partir
do contexto e realizar a inferência em sequência.
## XLM-RoBERTa
Os seguintes modelos do XLM-RoBERTa podem ser utilizados para tarefas multilinguísticas:
- `xlm-roberta-base` (Modelagem de linguagem com máscara, 100 idiomas)
- `xlm-roberta-large` Modelagem de linguagem com máscara, 100 idiomas)
O XLM-RoBERTa foi treinado com 2,5 TB de dados do CommonCrawl recém-criados e testados em 100 idiomas.
Proporciona fortes vantagens sobre os modelos multilinguísticos publicados anteriormente como o mBERT e o XLM em tarefas
subsequentes como a classificação, a rotulagem de sequências e à respostas a perguntas.
## M2M100
Os seguintes modelos de M2M100 podem ser utilizados para traduções multilinguísticas:
- `facebook/m2m100_418M` (Tradução)
- `facebook/m2m100_1.2B` (Tradução)
Neste exemplo, o checkpoint `facebook/m2m100_418M` é carregado para traduzir do mandarim ao inglês. É possível
estabelecer o idioma de origem no tokenizador:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
Tokenização do texto:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
O M2M100 força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
Os seguintes modelos do MBart podem ser utilizados para tradução multilinguística:
- `facebook/mbart-large-50-one-to-many-mmt` (Tradução automática multilinguística de um a vários, 50 idiomas)
- `facebook/mbart-large-50-many-to-many-mmt` (Tradução automática multilinguística de vários a vários, 50 idiomas)
- `facebook/mbart-large-50-many-to-one-mmt` (Tradução automática multilinguística vários a um, 50 idiomas)
- `facebook/mbart-large-50` (Tradução multilinguística, 50 idiomas)
- `facebook/mbart-large-cc25`
Neste exemplo, carrega-se o checkpoint `facebook/mbart-large-50-many-to-many-mmt` para traduzir do finlandês ao inglês.
Pode-se definir o idioma de origem no tokenizador:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
Tokenizando o texto:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
O MBart força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
Se estiver usando o checkpoint `facebook/mbart-large-50-many-to-one-mmt` não será necessário forçar o id do idioma de destino
como sendo o primeiro token generado, caso contrário a usagem é a mesma.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/pipeline_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines para inferência
Um [pipeline] simplifica o uso dos modelos no [Model Hub](https://huggingface.co/models) para a inferência de uma diversidade de tarefas,
como a geração de texto, a segmentação de imagens e a classificação de áudio.
Inclusive, se não tem experiência com alguma modalidade específica ou não compreende o código que forma os modelos,
pode usar eles mesmo assim com o [pipeline]! Este tutorial te ensinará a:
* Utilizar um [`pipeline`] para inferência.
* Utilizar um tokenizador ou model específico.
* Utilizar um [`pipeline`] para tarefas de áudio e visão computacional.
<Tip>
Acesse a documentação do [`pipeline`] para obter uma lista completa de tarefas possíveis.
</Tip>
## Uso do pipeline
Mesmo que cada tarefa tenha um [`pipeline`] associado, é mais simples usar a abstração geral do [`pipeline`] que
contém todos os pipelines das tarefas mais específicas.
O [`pipeline`] carrega automaticamenta um modelo predeterminado e um tokenizador com capacidade de inferência para sua
tarefa.
1. Comece carregando um [`pipeline`] e especifique uma tarefa de inferência:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation")
```
2. Passe seu dado de entrada, no caso um texto, ao [`pipeline`]:
```py
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
```
Se tiver mais de uma entrada, passe-a como uma lista:
```py
>>> generator(
... [
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
... ]
... )
```
Qualquer parâmetro adicional para a sua tarefa também pode ser incluído no [`pipeline`]. A tarefa `text-generation` tem um método
[`~generation.GenerationMixin.generate`] com vários parâmetros para controlar a saída.
Por exemplo, se quiser gerar mais de uma saída, defina-a no parâmetro `num_return_sequences`:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... num_return_sequences=2,
... )
```
### Selecionando um modelo e um tokenizador
O [`pipeline`] aceita qualquer modelo do [Model Hub](https://huggingface.co/models). Há rótulos adicionais no Model Hub
que te permitem filtrar pelo modelo que gostaria de usar para sua tarefa. Uma vez que tiver escolhido o modelo apropriado,
carregue-o com as classes `AutoModelFor` e [`AutoTokenizer'] correspondentes. Por exemplo, carregue a classe [`AutoModelForCausalLM`]
para uma tarefa de modelagem de linguagem causal:
```py
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
```
Crie uma [`pipeline`] para a sua tarefa e especifíque o modelo e o tokenizador que foram carregados:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
```
Passe seu texto de entrada ao [`pipeline`] para gerar algum texto:
```py
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
```
## Pipeline de audio
A flexibilidade do [`pipeline`] significa que também pode-se extender às tarefas de áudio.
La flexibilidad de [`pipeline`] significa que también se puede extender a tareas de audio.
Por exemplo, classifiquemos a emoção de um breve fragmento do famoso discurso de John F. Kennedy /home/rzimmerdev/dev/transformers/docs/source/pt/pipeline_tutorial.md
Encontre um modelo de [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) para
reconhecimento de emoções no Model Hub e carregue-o usando o [`pipeline`]:
```py
>>> from transformers import pipeline
>>> audio_classifier = pipeline(
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
Passe o arquivo de áudio ao [`pipeline`]:
```py
>>> audio_classifier("jfk_moon_speech.wav")
[{'label': 'calm', 'score': 0.13856211304664612},
{'label': 'disgust', 'score': 0.13148026168346405},
{'label': 'happy', 'score': 0.12635163962841034},
{'label': 'angry', 'score': 0.12439591437578201},
{'label': 'fearful', 'score': 0.12404385954141617}]
```
## Pipeline de visão computacional
Finalmente, utilizar um [`pipeline`] para tarefas de visão é praticamente a mesma coisa.
Especifique a sua tarefa de visão e passe a sua imagem ao classificador.
A imagem pode ser um link ou uma rota local à imagem. Por exemplo, que espécie de gato está presente na imagem?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(task="image-classification")
>>> vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
[{'label': 'lynx, catamount', 'score': 0.4403027892112732},
{'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
'score': 0.03433405980467796},
{'label': 'snow leopard, ounce, Panthera uncia',
'score': 0.032148055732250214},
{'label': 'Egyptian cat', 'score': 0.02353910356760025},
{'label': 'tiger cat', 'score': 0.023034192621707916}]
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/quicktour.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tour rápido
[[open-in-colab]]
Comece a trabalhar com 🤗 Transformers! Comece usando [`pipeline`] para rápida inferência e facilmente carregue um modelo pré-treinado e um tokenizer com [AutoClass](./model_doc/auto) para resolver tarefas de texto, visão ou áudio.
<Tip>
Todos os exemplos de código apresentados na documentação têm um botão no canto superior direito para escolher se você deseja ocultar ou mostrar o código no Pytorch ou no TensorFlow. Caso contrário, é esperado que funcione para ambos back-ends sem nenhuma alteração.
</Tip>
## Pipeline
[`pipeline`] é a maneira mais fácil de usar um modelo pré-treinado para uma dada tarefa.
<Youtube id="tiZFewofSLM"/>
A [`pipeline`] apoia diversas tarefas fora da caixa:
**Texto**:
* Análise sentimental: classifica a polaridade de um texto.
* Geração de texto (em Inglês): gera texto a partir de uma entrada.
* Reconhecimento de entidade mencionada: legenda cada palavra com uma classe que a representa (pessoa, data, local, etc...)
* Respostas: extrai uma resposta dado algum contexto e uma questão
* Máscara de preenchimento: preenche o espaço, dado um texto com máscaras de palavras.
* Sumarização: gera o resumo de um texto longo ou documento.
* Tradução: traduz texto para outra língua.
* Extração de características: cria um tensor que representa o texto.
**Imagem**:
* Classificação de imagens: classifica uma imagem.
* Segmentação de imagem: classifica cada pixel da imagem.
* Detecção de objetos: detecta objetos em uma imagem.
**Audio**:
* Classficação de áudio: legenda um trecho de áudio fornecido.
* Reconhecimento de fala automático: transcreve audio em texto.
<Tip>
Para mais detalhes sobre a [`pipeline`] e tarefas associadas, siga a documentação [aqui](./main_classes/pipelines).
</Tip>
### Uso da pipeline
No exemplo a seguir, você usará [`pipeline`] para análise sentimental.
Instale as seguintes dependências se você ainda não o fez:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
Importe [`pipeline`] e especifique a tarefa que deseja completar:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
A pipeline baixa and armazena um [modelo pré-treinado](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) padrão e tokenizer para análise sentimental. Agora você pode usar `classifier` no texto alvo:
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
Para mais de uma sentença, passe uma lista para a [`pipeline`], a qual retornará uma lista de dicionários:
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
```
A [`pipeline`] também pode iterar sobre um Dataset inteiro. Comece instalando a biblioteca de [🤗 Datasets](https://huggingface.co/docs/datasets/):
```bash
pip install datasets
```
Crie uma [`pipeline`] com a tarefa que deseja resolver e o modelo que deseja usar.
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
A seguir, carregue uma base de dados (confira a 🤗 [Iniciação em Datasets](https://huggingface.co/docs/datasets/quickstart) para mais detalhes) que você gostaria de iterar sobre. Por exemplo, vamos carregar o dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
Precisamos garantir que a taxa de amostragem do conjunto de dados corresponda à taxa de amostragem em que o facebook/wav2vec2-base-960h foi treinado.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
Os arquivos de áudio são carregados e re-amostrados automaticamente ao chamar a coluna `"audio"`.
Vamos extrair as arrays de formas de onda originais das primeiras 4 amostras e passá-las como uma lista para o pipeline:
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I TURN A JOIN A COUNT']
```
Para um conjunto de dados maior onde as entradas são maiores (como em fala ou visão), será necessário passar um gerador em vez de uma lista que carregue todas as entradas na memória. Consulte a [documentação do pipeline](./main_classes/pipelines) para mais informações.
### Use outro modelo e tokenizer na pipeline
A [`pipeline`] pode acomodar qualquer modelo do [Model Hub](https://huggingface.co/models), facilitando sua adaptação para outros casos de uso. Por exemplo, se você quiser um modelo capaz de lidar com texto em francês, use as tags no Model Hub para filtrar um modelo apropriado. O principal resultado filtrado retorna um [modelo BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) bilíngue ajustado para análise de sentimentos. Ótimo, vamos usar este modelo!
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Use o [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] para carregar o modelo pré-treinado e seu tokenizer associado (mais em `AutoClass` abaixo):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Use o [`TFAutoModelForSequenceClassification`] and [`AutoTokenizer`] para carregar o modelo pré-treinado e o tokenizer associado (mais em `TFAutoClass` abaixo):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Então você pode especificar o modelo e o tokenizador na [`pipeline`] e aplicar o `classifier` no seu texto alvo:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Se você não conseguir achar um modelo para o seu caso de uso, precisará usar fine-tune em um modelo pré-treinado nos seus dados. Veja nosso [tutorial de fine-tuning](./training) para descobrir como. Finalmente, depois que você tiver usado esse processo em seu modelo, considere compartilhá-lo conosco (veja o tutorial [aqui](./model_sharing)) na plataforma Model Hub afim de democratizar NLP! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Por baixo dos panos, as classes [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] trabalham juntas para fortificar o [`pipeline`]. Um [AutoClass](./model_doc/auto) é um atalho que automaticamente recupera a arquitetura de um modelo pré-treinado a partir de seu nome ou caminho. Basta selecionar a `AutoClass` apropriada para sua tarefa e seu tokenizer associado com [`AutoTokenizer`].
Vamos voltar ao nosso exemplo e ver como você pode usar a `AutoClass` para replicar os resultados do [`pipeline`].
### AutoTokenizer
Um tokenizer é responsável por pré-processar o texto em um formato que seja compreensível para o modelo. Primeiro, o tokenizer dividirá o texto em palavras chamadas *tokens*. Existem várias regras que regem o processo de tokenização, incluindo como dividir uma palavra e em que nível (saiba mais sobre tokenização [aqui](./tokenizer_summary)). A coisa mais importante a lembrar, porém, é que você precisa instanciar o tokenizer com o mesmo nome do modelo para garantir que está usando as mesmas regras de tokenização com as quais um modelo foi pré-treinado.
Carregue um tokenizer com [`AutoTokenizer`]:
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
Em seguida, o tokenizer converte os tokens em números para construir um tensor como entrada para o modelo. Isso é conhecido como o *vocabulário* do modelo.
Passe o texto para o tokenizer:
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
O tokenizer retornará um dicionário contendo:
* [input_ids](./glossary#input-ids): representações numéricas de seus tokens.
* [atttention_mask](.glossary#attention-mask): indica quais tokens devem ser atendidos.
Assim como o [`pipeline`], o tokenizer aceitará uma lista de entradas. Além disso, o tokenizer também pode preencher e truncar o texto para retornar um lote com comprimento uniforme:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
Leia o tutorial de [pré-processamento](./pré-processamento) para obter mais detalhes sobre tokenização.
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers fornecem uma maneira simples e unificada de carregar instâncias pré-treinadas. Isso significa que você pode carregar um [`AutoModel`] como carregaria um [`AutoTokenizer`]. A única diferença é selecionar o [`AutoModel`] correto para a tarefa. Como você está fazendo classificação de texto ou sequência, carregue [`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Veja o [sumário de tarefas](./task_summary) para qual classe de [`AutoModel`] usar para cada tarefa.
</Tip>
Agora você pode passar seu grupo de entradas pré-processadas diretamente para o modelo. Você apenas tem que descompactar o dicionário usando `**`:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
O modelo gera as ativações finais no atributo `logits`. Aplique a função softmax aos `logits` para recuperar as probabilidades:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers fornecem uma maneira simples e unificada de carregar instâncias pré-treinadas. Isso significa que você pode carregar um [`TFAutoModel`] como carregaria um [`AutoTokenizer`]. A única diferença é selecionar o [`TFAutoModel`] correto para a tarefa. Como você está fazendo classificação de texto ou sequência, carregue [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Veja o [sumário de tarefas](./task_summary) para qual classe de [`AutoModel`] usar para cada tarefa.
</Tip>
Agora você pode passar seu grupo de entradas pré-processadas diretamente para o modelo através da passagem de chaves de dicionários ao tensor.
```py
>>> tf_outputs = tf_model(tf_batch)
```
O modelo gera as ativações finais no atributo `logits`. Aplique a função softmax aos `logits` para recuperar as probabilidades:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
Todos os modelos de 🤗 Transformers (PyTorch ou TensorFlow) geram tensores *antes* da função de ativação final (como softmax) pois essa função algumas vezes é fundida com a perda.
</Tip>
Os modelos são um standard [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) ou um [`tf.keras.Model`](https: //www.tensorflow.org/api_docs/python/tf/keras/Model) para que você possa usá-los em seu loop de treinamento habitual. No entanto, para facilitar as coisas, 🤗 Transformers fornece uma classe [`Trainer`] para PyTorch que adiciona funcionalidade para treinamento distribuído, precisão mista e muito mais. Para o TensorFlow, você pode usar o método `fit` de [Keras](https://keras.io/). Consulte o [tutorial de treinamento](./training) para obter mais detalhes.
<Tip>
As saídas do modelo 🤗 Transformers são classes de dados especiais para que seus atributos sejam preenchidos automaticamente em um IDE.
As saídas do modelo também se comportam como uma tupla ou um dicionário (por exemplo, você pode indexar com um inteiro, uma parte ou uma string), caso em que os atributos `None` são ignorados.
</Tip>
### Salvar um modelo
<frameworkcontent>
<pt>
Uma vez que seu modelo estiver afinado, você pode salvá-lo com seu Tokenizer usando [`PreTrainedModel.save_pretrained`]:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Quando você estiver pronto para usá-lo novamente, recarregue com [`PreTrainedModel.from_pretrained`]:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Uma vez que seu modelo estiver afinado, você pode salvá-lo com seu Tokenizer usando [`TFPreTrainedModel.save_pretrained`]:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Quando você estiver pronto para usá-lo novamente, recarregue com [`TFPreTrainedModel.from_pretrained`]
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Um recurso particularmente interessante dos 🤗 Transformers é a capacidade de salvar um modelo e recarregá-lo como um modelo PyTorch ou TensorFlow. Use `from_pt` ou `from_tf` para converter o modelo de um framework para outro:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/converting_tensorflow_models.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convertendo checkpoints do TensorFlow para Pytorch
Uma interface de linha de comando é fornecida para converter os checkpoints originais Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM em modelos
que podem ser carregados usando os métodos `from_pretrained` da biblioteca.
<Tip>
A partir da versão 2.3.0 o script de conversão agora faz parte do transformers CLI (**transformers-cli**) disponível em qualquer instalação
transformers >= 2.3.0.
A documentação abaixo reflete o formato do comando **transformers-cli convert**.
</Tip>
## BERT
Você pode converter qualquer checkpoint do BERT em TensorFlow (em particular [os modelos pré-treinados lançados pelo Google](https://github.com/google-research/bert#pre-trained-models)) em um arquivo PyTorch usando um
[convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py) script.
Esta Interface de Linha de Comando (CLI) recebe como entrada um checkpoint do TensorFlow (três arquivos começando com `bert_model.ckpt`) e o
arquivo de configuração (`bert_config.json`), e então cria um modelo PyTorch para esta configuração, carrega os pesos
do checkpoint do TensorFlow no modelo PyTorch e salva o modelo resultante em um arquivo PyTorch que pode
ser importado usando `from_pretrained()` (veja o exemplo em [quicktour](quicktour) , [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py) ).
Você só precisa executar este script de conversão **uma vez** para obter um modelo PyTorch. Você pode então desconsiderar o checkpoint em
TensorFlow (os três arquivos começando com `bert_model.ckpt`), mas certifique-se de manter o arquivo de configuração (\
`bert_config.json`) e o arquivo de vocabulário (`vocab.txt`), pois eles também são necessários para o modelo PyTorch.
Para executar este script de conversão específico, você precisará ter o TensorFlow e o PyTorch instalados (`pip install tensorflow`). O resto do repositório requer apenas o PyTorch.
Aqui está um exemplo do processo de conversão para um modelo `BERT-Base Uncased` pré-treinado:
```bash
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
transformers-cli convert --model_type bert \
--tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
--config $BERT_BASE_DIR/bert_config.json \
--pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
```
Você pode baixar os modelos pré-treinados do Google para a conversão [aqui](https://github.com/google-research/bert#pre-trained-models).
## ALBERT
Converta os checkpoints do modelo ALBERT em TensorFlow para PyTorch usando o
[convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py) script.
A Interface de Linha de Comando (CLI) recebe como entrada um checkpoint do TensorFlow (três arquivos começando com `model.ckpt-best`) e o
arquivo de configuração (`albert_config.json`), então cria e salva um modelo PyTorch. Para executar esta conversão, você
precisa ter o TensorFlow e o PyTorch instalados.
Aqui está um exemplo do processo de conversão para o modelo `ALBERT Base` pré-treinado:
```bash
export ALBERT_BASE_DIR=/path/to/albert/albert_base
transformers-cli convert --model_type albert \
--tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
--config $ALBERT_BASE_DIR/albert_config.json \
--pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
```
Você pode baixar os modelos pré-treinados do Google para a conversão [aqui](https://github.com/google-research/albert#pre-trained-models).
## OpenAI GPT
Aqui está um exemplo do processo de conversão para um modelo OpenAI GPT pré-treinado, supondo que seu checkpoint NumPy
foi salvo com o mesmo formato do modelo pré-treinado OpenAI (veja [aqui](https://github.com/openai/finetune-transformer-lm)\
)
```bash
export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
transformers-cli convert --model_type gpt \
--tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT_CONFIG] \
[--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
```
## OpenAI GPT-2
Aqui está um exemplo do processo de conversão para um modelo OpenAI GPT-2 pré-treinado (consulte [aqui](https://github.com/openai/gpt-2))
```bash
export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/gpt2/pretrained/weights
transformers-cli convert --model_type gpt2 \
--tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT2_CONFIG] \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
## XLNet
Aqui está um exemplo do processo de conversão para um modelo XLNet pré-treinado:
```bash
export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
transformers-cli convert --model_type xlnet \
--tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
--config $TRANSFO_XL_CONFIG_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--finetuning_task_name XLNET_FINETUNED_TASK] \
```
## XLM
Aqui está um exemplo do processo de conversão para um modelo XLM pré-treinado:
```bash
export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
transformers-cli convert --model_type xlm \
--tf_checkpoint $XLM_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT
[--config XML_CONFIG] \
[--finetuning_task_name XML_FINETUNED_TASK]
```
## T5
Aqui está um exemplo do processo de conversão para um modelo T5 pré-treinado:
```bash
export T5=/path/to/t5/uncased_L-12_H-768_A-12
transformers-cli convert --model_type t5 \
--tf_checkpoint $T5/t5_model.ckpt \
--config $T5/t5_config.json \
--pytorch_dump_output $T5/pytorch_model.bin
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/custom_models.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Compartilhando modelos customizados
A biblioteca 🤗 Transformers foi projetada para ser facilmente extensível. Cada modelo é totalmente codificado em uma determinada subpasta
do repositório sem abstração, para que você possa copiar facilmente um arquivo de modelagem e ajustá-lo às suas necessidades.
Se você estiver escrevendo um modelo totalmente novo, pode ser mais fácil começar do zero. Neste tutorial, mostraremos
como escrever um modelo customizado e sua configuração para que possa ser usado com Transformers, e como você pode compartilhá-lo
com a comunidade (com o código em que se baseia) para que qualquer pessoa possa usá-lo, mesmo se não estiver presente na biblioteca 🤗 Transformers.
Ilustraremos tudo isso em um modelo ResNet, envolvendo a classe ResNet do
[biblioteca timm](https://github.com/rwightman/pytorch-image-models) em um [`PreTrainedModel`].
## Escrevendo uma configuração customizada
Antes de mergulharmos no modelo, vamos primeiro escrever sua configuração. A configuração de um modelo é um objeto que
terá todas as informações necessárias para construir o modelo. Como veremos na próxima seção, o modelo só pode
ter um `config` para ser inicializado, então realmente precisamos que esse objeto seja o mais completo possível.
Em nosso exemplo, pegaremos alguns argumentos da classe ResNet que podemos querer ajustar. Diferentes
configurações nos dará os diferentes tipos de ResNets que são possíveis. Em seguida, apenas armazenamos esses argumentos,
após verificar a validade de alguns deles.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
As três coisas importantes a serem lembradas ao escrever sua própria configuração são:
- você tem que herdar de `PretrainedConfig`,
- o `__init__` do seu `PretrainedConfig` deve aceitar quaisquer kwargs,
- esses `kwargs` precisam ser passados para a superclasse `__init__`.
A herança é para garantir que você obtenha todas as funcionalidades da biblioteca 🤗 Transformers, enquanto as outras duas
restrições vêm do fato de um `PretrainedConfig` ter mais campos do que os que você está configurando. Ao recarregar um
config com o método `from_pretrained`, esses campos precisam ser aceitos pelo seu config e então enviados para a
superclasse.
Definir um `model_type` para sua configuração (aqui `model_type="resnet"`) não é obrigatório, a menos que você queira
registrar seu modelo com as classes automáticas (veja a última seção).
Com isso feito, você pode facilmente criar e salvar sua configuração como faria com qualquer outra configuração de modelo da
biblioteca. Aqui está como podemos criar uma configuração resnet50d e salvá-la:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
Isso salvará um arquivo chamado `config.json` dentro da pasta `custom-resnet`. Você pode então recarregar sua configuração com o
método `from_pretrained`:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
Você também pode usar qualquer outro método da classe [`PretrainedConfig`], como [`~PretrainedConfig.push_to_hub`] para
carregar diretamente sua configuração para o Hub.
## Escrevendo um modelo customizado
Agora que temos nossa configuração ResNet, podemos continuar escrevendo o modelo. Na verdade, escreveremos dois: um que
extrai os recursos ocultos de um lote de imagens (como [`BertModel`]) e um que é adequado para classificação de imagem
(como [`BertForSequenceClassification`]).
Como mencionamos antes, escreveremos apenas um wrapper solto do modelo para mantê-lo simples para este exemplo. A única
coisa que precisamos fazer antes de escrever esta classe é um mapa entre os tipos de bloco e as classes de bloco reais. Então o
modelo é definido a partir da configuração passando tudo para a classe `ResNet`:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
Para o modelo que irá classificar as imagens, vamos apenas alterar o método forward:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
Em ambos os casos, observe como herdamos de `PreTrainedModel` e chamamos a inicialização da superclasse com o `config`
(um pouco parecido quando você escreve um `torch.nn.Module`). A linha que define o `config_class` não é obrigatória, a menos que
você deseje registrar seu modelo com as classes automáticas (consulte a última seção).
<Tip>
Se o seu modelo for muito semelhante a um modelo dentro da biblioteca, você poderá reutilizar a mesma configuração desse modelo.
</Tip>
Você pode fazer com que seu modelo retorne o que você quiser,porém retornando um dicionário como fizemos para
`ResnetModelForImageClassification`, com a função de perda incluída quando os rótulos são passados, vai tornar seu modelo diretamente
utilizável dentro da classe [`Trainer`]. Você pode usar outro formato de saída, desde que esteja planejando usar seu próprio
laço de treinamento ou outra biblioteca para treinamento.
Agora que temos nossa classe do modelo, vamos criar uma:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Novamente, você pode usar qualquer um dos métodos do [`PreTrainedModel`], como [`~PreTrainedModel.save_pretrained`] ou
[`~PreTrainedModel.push_to_hub`]. Usaremos o segundo na próxima seção e veremos como enviar os pesos e
o código do nosso modelo. Mas primeiro, vamos carregar alguns pesos pré-treinados dentro do nosso modelo.
Em seu próprio caso de uso, você provavelmente estará treinando seu modelo customizado em seus próprios dados. Para este tutorial ser rápido,
usaremos a versão pré-treinada do resnet50d. Como nosso modelo é apenas um wrapper em torno dele, será
fácil de transferir esses pesos:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Agora vamos ver como ter certeza de que quando fazemos [`~PreTrainedModel.save_pretrained`] ou [`~PreTrainedModel.push_to_hub`], o
código do modelo é salvo.
## Enviando o código para o Hub
<Tip warning={true}>
Esta API é experimental e pode ter algumas pequenas alterações nas próximas versões.
</Tip>
Primeiro, certifique-se de que seu modelo esteja totalmente definido em um arquivo `.py`. Ele pode contar com importações relativas para alguns outros arquivos
desde que todos os arquivos estejam no mesmo diretório (ainda não suportamos submódulos para este recurso). Para o nosso exemplo,
vamos definir um arquivo `modeling_resnet.py` e um arquivo `configuration_resnet.py` em uma pasta no
diretório de trabalho atual chamado `resnet_model`. O arquivo de configuração contém o código para `ResnetConfig` e o arquivo de modelagem
contém o código do `ResnetModel` e `ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
O `__init__.py` pode estar vazio, apenas está lá para que o Python detecte que o `resnet_model` possa ser usado como um módulo.
<Tip warning={true}>
Se estiver copiando arquivos de modelagem da biblioteca, você precisará substituir todas as importações relativas na parte superior do arquivo
para importar do pacote `transformers`.
</Tip>
Observe que você pode reutilizar (ou subclasse) uma configuração/modelo existente.
Para compartilhar seu modelo com a comunidade, siga estas etapas: primeiro importe o modelo ResNet e a configuração do
arquivos criados:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Então você tem que dizer à biblioteca que deseja copiar os arquivos de código desses objetos ao usar o `save_pretrained`
e registrá-los corretamente com uma determinada classe automáticas (especialmente para modelos), basta executar:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Observe que não há necessidade de especificar uma classe automática para a configuração (há apenas uma classe automática,
[`AutoConfig`]), mas é diferente para os modelos. Seu modelo customizado pode ser adequado para muitas tarefas diferentes, então você
tem que especificar qual das classes automáticas é a correta para o seu modelo.
Em seguida, vamos criar a configuração e os modelos como fizemos antes:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Agora para enviar o modelo para o Hub, certifique-se de estar logado. Ou execute no seu terminal:
```bash
huggingface-cli login
```
ou a partir do notebook:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Você pode então enviar para seu próprio namespace (ou uma organização da qual você é membro) assim:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
Além dos pesos do modelo e da configuração no formato json, isso também copiou o modelo e
configuração `.py` na pasta `custom-resnet50d` e carregou o resultado para o Hub. Você pode conferir o resultado
neste [repositório de modelos](https://huggingface.co/sgugger/custom-resnet50d).
Consulte o [tutorial de compartilhamento](model_sharing) para obter mais informações sobre o método push_to_hub.
## Usando um modelo com código customizado
Você pode usar qualquer configuração, modelo ou tokenizador com arquivos de código customizados em seu repositório com as classes automáticas e
o método `from_pretrained`. Todos os arquivos e códigos carregados no Hub são verificados quanto a malware (consulte a documentação de [Segurança do Hub](https://huggingface.co/docs/hub/security#malware-scanning) para obter mais informações), mas você ainda deve
revisar o código do modelo e o autor para evitar a execução de código malicioso em sua máquina. Defina `trust_remote_code=True` para usar
um modelo com código customizado:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
Também é fortemente recomendado passar um hash de confirmação como uma `revisão` para garantir que o autor dos modelos não
atualize o código com novas linhas maliciosas (a menos que você confie totalmente nos autores dos modelos).
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Observe que ao navegar no histórico de commits do repositório do modelo no Hub, há um botão para copiar facilmente o commit
hash de qualquer commit.
## Registrando um modelo com código customizado para as classes automáticas
Se você estiver escrevendo uma biblioteca que estende 🤗 Transformers, talvez queira estender as classes automáticas para incluir seus próprios
modelos. Isso é diferente de enviar o código para o Hub no sentido de que os usuários precisarão importar sua biblioteca para
obter os modelos customizados (ao contrário de baixar automaticamente o código do modelo do Hub).
Desde que sua configuração tenha um atributo `model_type` diferente dos tipos de modelo existentes e que as classes do seu modelo
tenha os atributos `config_class` corretos, você pode simplesmente adicioná-los às classes automáticas assim:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Observe que o primeiro argumento usado ao registrar sua configuração customizada para [`AutoConfig`] precisa corresponder ao `model_type`
de sua configuração customizada. E o primeiro argumento usado ao registrar seus modelos customizados, para qualquer necessidade de classe de modelo automático
deve corresponder ao `config_class` desses modelos.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/installation.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Guia de Instalação
Neste guia poderá encontrar informações para a instalação do 🤗 Transformers para qualquer biblioteca de
Machine Learning com a qual esteja a trabalhar. Além disso, poderá encontrar informações sobre como gerar cachês e
configurar o 🤗 Transformers para execução em modo offline (opcional).
🤗 Transformers foi testado com Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Para instalar a biblioteca de
deep learning com que deseja trabalhar, siga as instruções correspondentes listadas a seguir:
* [PyTorch](https://pytorch.org/get-started/locally/)
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)
* [Flax](https://flax.readthedocs.io/en/latest/)
## Instalação pelo Pip
É sugerido instalar o 🤗 Transformers num [ambiente virtual](https://docs.python.org/3/library/venv.html). Se precisar
de mais informações sobre ambientes virtuais em Python, consulte este [guia](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
Um ambiente virtual facilitará a manipulação e organização de projetos e evita problemas de compatibilidade entre dependências.
Comece criando um ambiente virtual no diretório do seu projeto:
```bash
python -m venv .env
```
E para ativar o ambiente virtual:
```bash
source .env/bin/activate
```
Agora É possível instalar o 🤗 Transformers com o comando a seguir:
```bash
pip install transformers
```
Somente para a CPU, é possível instalar o 🤗 Transformers e a biblioteca de deep learning respectiva apenas numa linha.
Por exemplo, para instalar o 🤗 Transformers e o PyTorch, digite:
```bash
pip install transformers[torch]
```
🤗 Transformers e TensorFlow 2.0:
```bash
pip install transformers[tf-cpu]
```
🤗 Transformers e Flax:
```bash
pip install transformers[flax]
```
Por último, verifique se o 🤗 Transformers foi instalado com sucesso usando o seguinte comando para baixar um modelo pré-treinado:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Em seguida, imprima um rótulo e sua pontuação:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Instalação usando a fonte
Para instalar o 🤗 Transformers a partir da fonte use o seguinte comando:
```bash
pip install git+https://github.com/huggingface/transformers
```
O comando acima instalará a versão `master` mais atual em vez da última versão estável. A versão `master` é útil para
utilizar os últimos updates contidos em 🤗 Transformers. Por exemplo, um erro recente pode ter sido corrigido somente
após a última versão estável, antes que houvesse um novo lançamento. No entanto, há a possibilidade que a versão `master` não esteja estável.
A equipa trata de mantér a versão `master` operacional e a maioria dos erros são resolvidos em poucas horas ou dias.
Se encontrar quaisquer problemas, por favor abra um [Issue](https://github.com/huggingface/transformers/issues) para que o
mesmo possa ser corrigido o mais rápido possível.
Verifique que o 🤗 Transformers está instalado corretamente usando o seguinte comando:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Instalação editável
Uma instalação editável será necessária caso desejas um dos seguintes:
* Usar a versão `master` do código fonte.
* Contribuir ao 🤗 Transformers e precisa testar mudanças ao código.
Para tal, clone o repositório e instale o 🤗 Transformers com os seguintes comandos:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
Estes comandos vão ligar o diretório para o qual foi clonado o repositório ao caminho de bibliotecas do Python.
O Python agora buscará dentro dos arquivos que foram clonados além dos caminhos normais da biblioteca.
Por exemplo, se os pacotes do Python se encontram instalados no caminho `~/anaconda3/envs/main/lib/python3.7/site-packages/`,
o Python também buscará módulos no diretório onde clonamos o repositório `~/transformers/`.
<Tip warning={true}>
É necessário manter o diretório `transformers` se desejas continuar usando a biblioteca.
</Tip>
Assim, É possível atualizar sua cópia local para com a última versão do 🤗 Transformers com o seguinte comando:
```bash
cd ~/transformers/
git pull
```
O ambiente de Python que foi criado para a instalação do 🤗 Transformers encontrará a versão `master` em execuções seguintes.
## Instalação usando o Conda
É possível instalar o 🤗 Transformers a partir do canal conda `conda-forge` com o seguinte comando:
```bash
conda install conda-forge::transformers
```
## Configuração do Cachê
Os modelos pré-treinados são baixados e armazenados no cachê local, encontrado em `~/.cache/huggingface/transformers/`.
Este é o diretório padrão determinado pela variável `TRANSFORMERS_CACHE` dentro do shell.
No Windows, este diretório pré-definido é dado por `C:\Users\username\.cache\huggingface\transformers`.
É possível mudar as variáveis dentro do shell em ordem de prioridade para especificar um diretório de cachê diferente:
1. Variável de ambiente do shell (por padrão): `TRANSFORMERS_CACHE`.
2. Variável de ambiente do shell:`HF_HOME` + `transformers/`.
3. Variável de ambiente do shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
<Tip>
O 🤗 Transformers usará as variáveis de ambiente do shell `PYTORCH_TRANSFORMERS_CACHE` ou `PYTORCH_PRETRAINED_BERT_CACHE`
se estiver vindo de uma versão anterior da biblioteca que tenha configurado essas variáveis de ambiente, a menos que
você especifique a variável de ambiente do shell `TRANSFORMERS_CACHE`.
</Tip>
## Modo Offline
O 🤗 Transformers também pode ser executado num ambiente de firewall ou fora da rede (offline) usando arquivos locais.
Para tal, configure a variável de ambiente de modo que `TRANSFORMERS_OFFLINE=1`.
<Tip>
Você pode adicionar o [🤗 Datasets](https://huggingface.co/docs/datasets/) ao pipeline de treinamento offline declarando
a variável de ambiente `HF_DATASETS_OFFLINE=1`.
</Tip>
Segue um exemplo de execução do programa numa rede padrão com firewall para instâncias externas, usando o seguinte comando:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Execute esse mesmo programa numa instância offline com o seguinte comando:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
O script agora deve ser executado sem travar ou expirar, pois procurará apenas por arquivos locais.
### Obtendo modelos e tokenizers para uso offline
Outra opção para usar o 🤗 Transformers offline é baixar os arquivos antes e depois apontar para o caminho local onde estão localizados. Existem três maneiras de fazer isso:
* Baixe um arquivo por meio da interface de usuário do [Model Hub](https://huggingface.co/models) clicando no ícone ↓.

* Use o pipeline do [`PreTrainedModel.from_pretrained`] e [`PreTrainedModel.save_pretrained`]:
1. Baixa os arquivos previamente com [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Salve os arquivos em um diretório específico com [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. Quando estiver offline, acesse os arquivos com [`PreTrainedModel.from_pretrained`] do diretório especificado:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* Baixando arquivos programaticamente com a biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
1. Instale a biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) em seu ambiente virtual:
```bash
python -m pip install huggingface_hub
```
2. Utiliza a função [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) para baixar um arquivo para um caminho específico. Por exemplo, o comando a seguir baixará o arquivo `config.json` para o modelo [T0](https://huggingface.co/bigscience/T0_3B) no caminho desejado:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
Depois que o arquivo for baixado e armazenado no cachê local, especifique seu caminho local para carregá-lo e usá-lo:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
Para obter mais detalhes sobre como baixar arquivos armazenados no Hub, consulte a seção [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream).
</Tip>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/pt/create_a_model.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Criar uma arquitetura customizada
Uma [`AutoClass`](model_doc/auto) automaticamente infere a arquitetura do modelo e baixa configurações e pesos pré-treinados. Geralmente, nós recomendamos usar uma `AutoClass` para produzir um código independente de checkpoints. Mas usuários que querem mais contole sobre parâmetros específicos do modelo pode criar um modelo customizado 🤗 Transformers a partir de algumas classes bases. Isso pode ser particulamente útil para alguém que está interessado em estudar, treinar ou fazer experimentos com um modelo 🤗 Transformers. Nesse tutorial, será explicado como criar um modelo customizado sem uma `AutoClass`. Aprenda como:
- Carregar e customizar a configuração de um modelo.
- Criar a arquitetura de um modelo.
- Criar um tokenizer rápido e devagar para textos.
- Criar extrator de features para tarefas envolvendo audio e imagem.
- Criar um processador para tarefas multimodais.
## configuration
A [configuration](main_classes/configuration) refere-se a atributos específicos de um modelo. Cada configuração de modelo tem atributos diferentes; por exemplo, todos modelo de PLN possuem os atributos `hidden_size`, `num_attention_heads`, `num_hidden_layers` e `vocab_size` em comum. Esse atributos especificam o numero de 'attention heads' ou 'hidden layers' para construir um modelo.
Dê uma olhada a mais em [DistilBERT](model_doc/distilbert) acessando [`DistilBertConfig`] para observar esses atributos:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] mostra todos os atributos padrões usados para construir um [`DistilBertModel`] base. Todos atributos são customizáveis, o que cria espaço para experimentos. Por exemplo, você pode customizar um modelo padrão para:
- Tentar uma função de ativação diferente com o parâmetro `activation`.
- Usar uma taxa de desistência maior para as probabilidades de 'attention' com o parâmetro `attention_dropout`.
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
Atributos de um modelo pré-treinado podem ser modificados na função [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Uma vez que você está satisfeito com as configurações do seu modelo, você consegue salvar elas com [`~PretrainedConfig.save_pretrained`]. Seu arquivo de configurações está salvo como um arquivo JSON no diretório especificado:
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
Para reusar o arquivo de configurações, carregue com [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
```
<Tip>
Você pode também salvar seu arquivo de configurações como um dicionário ou até mesmo com a diferença entre as seus atributos de configuração customizados e os atributos de configuração padrões! Olhe a documentação [configuration](main_classes/configuration) para mais detalhes.
</Tip>
## Modelo
O próximo passo é criar um [model](main_classes/models). O modelo - também vagamente referido como arquitetura - define o que cada camada está fazendo e quais operações estão acontecendo. Atributos como `num_hidden_layers` das configurações são utilizados para definir a arquitetura. Todo modelo compartilha a classe base [`PreTrainedModel`] e alguns métodos em comum como redimensionar o tamanho dos embeddings de entrada e podar as 'self-attention heads'. Além disso, todos os modelos também são subclasses de [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) ou [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html). Isso significa que os modelos são compatíveis com cada respectivo uso de framework.
<frameworkcontent>
<pt>
Carregar seus atributos de configuração customizados em um modelo:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> model = DistilBertModel(my_config)
```
Isso cria um modelo com valores aleatórios ao invés de pré-treinar os pesos. Você não irá conseguir usar usar esse modelo para nada útil ainda, até você treinar ele. Treino é um processo caro e demorado. Geralmente é melhor utilizar um modelo pré-treinado para obter melhores resultados mais rápido, enquanto usa apenas uma fração dos recursos necessários para treinar.
Criar um modelo pré-treinado com [`~PreTrainedModel.from_pretrained`]:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
```
Quando você carregar os pesos pré-treinados, a configuração padrão do modelo é automaticamente carregada se o modelo é provido pelo 🤗 Transformers. No entanto, você ainda consegue mudar - alguns ou todos - os atributos padrões de configuração do modelo com os seus próprio atributos, se você preferir:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
Carregar os seus próprios atributos padrões de contiguração no modelo:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
Isso cria um modelo com valores aleatórios ao invés de pré-treinar os pesos. Você não irá conseguir usar usar esse modelo para nada útil ainda, até você treinar ele. Treino é um processo caro e demorado. Geralmente é melhor utilizar um modelo pré-treinado para obter melhores resultados mais rápido, enquanto usa apenas uma fração dos recursos necessários para treinar.
Criar um modelo pré-treinado com [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
```
Quando você carregar os pesos pré-treinados, a configuração padrão do modelo é automaticamente carregada se o modelo é provido pelo 🤗 Transformers. No entanto, você ainda consegue mudar - alguns ou todos - os atributos padrões de configuração do modelo com os seus próprio atributos, se você preferir:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Heads do modelo
Neste ponto, você tem um modelo básico do DistilBERT que gera os *estados ocultos*. Os estados ocultos são passados como entrada para a head do moelo para produzir a saída final. 🤗 Transformers fornece uma head de modelo diferente para cada tarefa desde que o modelo suporte essa tarefa (por exemplo, você não consegue utilizar o modelo DistilBERT para uma tarefa de 'sequence-to-sequence' como tradução).
<frameworkcontent>
<pt>
Por exemplo, [`DistilBertForSequenceClassification`] é um modelo DistilBERT base com uma head de classificação de sequência. A head de calssificação de sequência é uma camada linear no topo das saídas agrupadas.
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Reutilize facilmente esse ponto de parada para outra tarefe mudando para uma head de modelo diferente. Para uma tarefe de responder questões, você usaria a head do modelo [`DistilBertForQuestionAnswering`]. A head de responder questões é similar com a de classificação de sequências exceto o fato de que ela é uma camada no topo dos estados das saídas ocultas.
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</pt>
<tf>
Por exemplo, [`TFDistilBertForSequenceClassification`] é um modelo DistilBERT base com uma head de classificação de sequência. A head de calssificação de sequência é uma camada linear no topo das saídas agrupadas.
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Reutilize facilmente esse ponto de parada para outra tarefe mudando para uma head de modelo diferente. Para uma tarefe de responder questões, você usaria a head do modelo [`TFDistilBertForQuestionAnswering`]. A head de responder questões é similar com a de classificação de sequências exceto o fato de que ela é uma camada no topo dos estados das saídas ocultas.
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
A útlima classe base que você precisa antes de usar um modelo para dados textuais é a [tokenizer](main_classes/tokenizer) para converter textos originais para tensores. Existem dois tipos de tokenizers que você pode usar com 🤗 Transformers:
- [`PreTrainedTokenizer`]: uma implementação em Python de um tokenizer.
- [`PreTrainedTokenizerFast`]: um tokenizer da nossa biblioteca [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) baseada em Rust. Esse tipo de tokenizer é significantemente mais rapido - especialmente durante tokenization de codificação - devido a implementação em Rust. O tokenizer rápido tambem oferece métodos adicionais como *offset mapping* que mapeia tokens para suar palavras ou caracteres originais.
Os dois tokenizers suporta métodos comuns como os de codificar e decodificar, adicionar novos tokens, e gerenciar tokens especiais.
<Tip warning={true}>
Nem todo modelo suporta um 'fast tokenizer'. De uma olhada aqui [table](index#supported-frameworks) pra checar se um modelo suporta 'fast tokenizer'.
</Tip>
Se você treinou seu prórpio tokenizer, você pode criar um a partir do seu arquivo *vocabulary*:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
É importante lembrar que o vocabulário de um tokenizer customizado será diferente de um vocabulário gerado pelo tokenizer de um modelo pré treinado. Você precisa usar o vocabulário de um modelo pré treinado se você estiver usando um modelo pré treinado, caso contrário as entradas não farão sentido. Criando um tokenizer com um vocabulário de um modelo pré treinado com a classe [`DistilBertTokenizer`]:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
```
Criando um 'fast tokenizer' com a classe [`DistilBertTokenizerFast`]:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
```
<Tip>
Pos padrão, [`AutoTokenizer`] tentará carregar um 'fast tokenizer'. Você pode disabilitar esse comportamento colocando `use_fast=False` no `from_pretrained`.
</Tip>
## Extrator de features
Um extrator de features processa entradas de imagem ou áudio. Ele herda da classe base [`~feature_extraction_utils.FeatureExtractionMixin`], e pode também herdar da classe [`ImageFeatureExtractionMixin`] para processamento de features de imagem ou da classe [`SequenceFeatureExtractor`] para processamento de entradas de áudio.
Dependendo do que você está trabalhando em um audio ou uma tarefa de visão, crie um estrator de features associado com o modelo que você está usando. Por exemplo, crie um [`ViTFeatureExtractor`] padrão se você estiver usando [ViT](model_doc/vit) para classificação de imagens:
```py
>>> from transformers import ViTFeatureExtractor
>>> vit_extractor = ViTFeatureExtractor()
>>> print(vit_extractor)
ViTFeatureExtractor {
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
Se você não estiver procurando por nenhuma customização, apenas use o método `from_pretrained` para carregar parâmetros do modelo de extrator de features padrão.
</Tip>
Modifique qualquer parâmetro dentre os [`ViTFeatureExtractor`] para criar seu extrator de features customizado.
```py
>>> from transformers import ViTFeatureExtractor
>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTFeatureExtractor {
"do_normalize": false,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
Para entradas de áutio, você pode criar um [`Wav2Vec2FeatureExtractor`] e customizar os parâmetros de uma forma similar:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
## Processor
Para modelos que suportam tarefas multimodais, 🤗 Transformers oferece uma classe processadora que convenientemente cobre um extrator de features e tokenizer dentro de um único objeto. Por exemplo, vamos usar o [`Wav2Vec2Processor`] para uma tarefa de reconhecimento de fala automática (ASR). ASR transcreve áudio para texto, então você irá precisar de um extrator de um features e um tokenizer.
Crie um extrator de features para lidar com as entradas de áudio.
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
Crie um tokenizer para lidar com a entrada de textos:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
Combine o extrator de features e o tokenizer no [`Wav2Vec2Processor`]:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Com duas classes básicas - configuração e modelo - e um preprocessamento de classe adicional (tokenizer, extrator de features, ou processador), você pode criar qualquer modelo que suportado por 🤗 Transformers. Qualquer uma dessas classes base são configuráveis, te permitindo usar os atributos específicos que você queira. Você pode facilmente preparar um modelo para treinamento ou modificar um modelo pré-treinado com poucas mudanças.
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.