
CSMT
Collection
China Sound and Music Technology Database
•
5 items
•
Updated
•
9
The dataset is initially created by [1]. It is then expanded and used for automatic Chinese national pentatonic mode recognition by [2], to which readers can refer for more details along with a brief introduction to the modern theory of Chinese pentatonic mode. This includes the definition of "system", "tonic", "pattern", and "type," which will be included in one unified table during our integration process as described below. The original dataset includes audio recordings and annotations of five modes of Chinese music, encompassing the Gong (宫), Shang (商), Jue (角), Zhi (徵), and Yu (羽) modes. The total recording number is 287.
Similar to the Guzheng Tech99 dataset in Section 1, the labels in this dataset were initially stored in a separate CSV file, which led to certain usability issues. Through our integration, labels are integrated with audio data into a single dictionary. After the integration, the data structure consists of seven columns: the first and second columns denote the audio recording (sampled at 44,100 Hz) and mel spectrogram. The subsequent columns represent the system, tonic, pattern, and type of the musical piece, respectively. The final column contains an additional Chinese name of the mode. The total recording number remains at 287, and the total duration is 858.63 minutes. The average duration is 179.51 seconds.
We have constructed the default subset of this integrated version of the dataset, and its data structure can be viewed in the viewer. As this dataset has been cited and used in published articles, no further eval subset needs to be constructed for evaluation. Because the default subset is multi-labelled, it is difficult to maintain the integrity of labels in the split for all label columns, hence only a single split for the training set is provided. Users can perform their own splits on specified columns according to their specific downstream tasks. Building on the default subset, we segmented the audio into 20-second slices and used zero padding to complete segments shorter than 20 seconds. The audio was then converted into mel, CQT, and chroma spectrograms. This process resulted in the construction of the eval subset for dataset evaluation experiments.
In this part, we provide statistics for the "pattern" in the dataset, which includes five categories: Gong, Shang, Jue, Zhi, and Yu. Our evaluation is also conducted on "pattern." In a Western context, identifying these patterns is analogous to identifying a musical mode, such as determining whether a piece of music is in the Dorian mode or Lydian mode. These patterns form the core of modern Chinese pentatonic mode theory.
 |
 |
 |
|---|---|---|
| Fig. 1 | Fig. 2 | Fig. 3 |
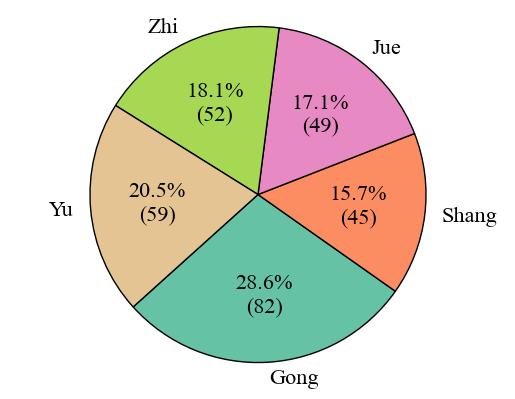
To begin with, Fig. 1 presents the number of audio clips by category. Gong accounts for the largest proportion among all modes, making up 28.6% of the dataset with 82 audio clips. The second-largest mode is Yu, accounting for 20.6% with 59 audio clips. The smallest mode is Shang, which accounts for 15.7% with only 45 audio clips. The difference in proportion between the largest and smallest modes is 12.9%.
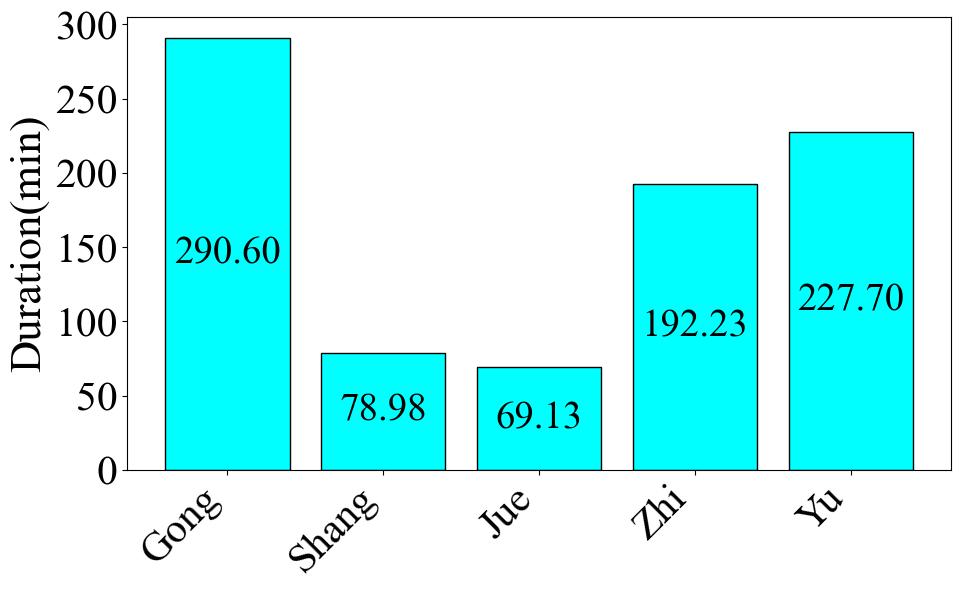
Moving on to Fig. 2, it displays the total audio duration by category. The total duration of Gong audio is significantly longer than that of other modes, at 290.6 minutes. The second-longest mode is Yu, with a total duration of 227.7 minutes, consistent with the proportions shown in the pie chart. However, the shortest mode is not Shang, which has the smallest proportion in the pie chart, but rather Jue, with a total duration of only 69.13 minutes. The difference in duration between the longest and shortest modes is 221.47 minutes.
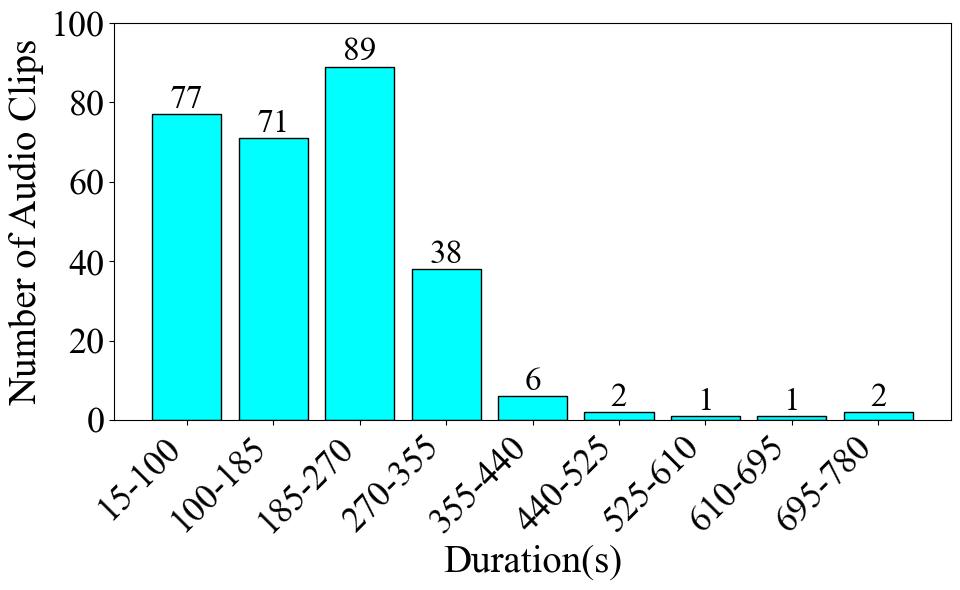
When we consider the pie chart and the duration statistics together, they clearly expose a data imbalance problem within the dataset. Finally, Fig. 3 depicts the number of audio clips across various duration intervals. The time interval with the highest concentration of audio clips is 185-270 seconds, closely followed by 15-100 seconds. However, once we go beyond 355 seconds, the number of audio clips experiences a sharp decline, with only single-digit counts in these longer intervals.
| Statistical items | Values |
|---|---|
| Total count | 287 |
| Total duration(s) | 51517.97027494332 |
| Mean duration(s) | 179.50512290921014 |
| Min duration(s) | 15.413333333333334 |
| Max duration(s) | 778.0065306122449 |
| Classes with max durs | Jue, Zhi |
| audio | mel | system | tonic | pattern | type | mode_name | length |
| .wav, 44100Hz | .jpg, 44100Hz | 12-class | 12-class | 5-class | 6-class | string | string |
.zip(.wav), .csv
Mode type, Name, Performer, Album Name, National Mode Name, Tonggong System, Audio Links
train / validation / test
| TongGong System | Label |
|---|---|
| C | 0 |
| #C/bD | 1 |
| D | 2 |
| #D/bE | 3 |
| E | 4 |
| F | 5 |
| #F/bG | 6 |
| G | 7 |
| #G/bA | 8 |
| A | 9 |
| #A/bB | 10 |
| B | 11 |
Pitch of Tonic (The rules are the same as the TongGong system)
| Mode Pattern | Label |
|---|---|
| Gong | 0 |
| Shang | 1 |
| Jue | 2 |
| Zhi | 3 |
| Yu | 4 |
| Mode Type | Label |
|---|---|
| Pentatonic | 0 |
| Hexatonic (Qingjue) | 1 |
| Hexatonic (Biangong) | 2 |
| Heptatonic Yayue | 3 |
| Heptatonic Qingyue | 4 |
| Heptatonic Yanyue | 5 |
The expanded dataset is integrated into our database, and each data entry consists of seven columns: the first column denotes the audio recording in .wav format, sampled at 22,050 Hz. The second and third presents the name of the piece and artist. The subsequent columns represent the system, tonic, pattern, and type of the musical piece, respectively. The eighth column contains an additional Chinese name of the mode, while the final column indicates the duration of the audio in seconds.
MIR, audio classification
Chinese, English
from datasets import load_dataset
ds = load_dataset("ccmusic-dabase/CNPM", split="train")
for data in ds:
print(data)
from datasets import load_dataset
ds = load_dataset("ccmusic-database/CNPM", subset_name="eval")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
git clone [email protected]:datasets/ccmusic-database/CNPM
cd CNPM
Lack of a dataset for Chinese National Pentatonic Mode
Weixin Ren, Mingjin Che, Zhaowen Wang, Qinyu Li, Jiaye Hu, Fan Xia, Wei Li, Monan Zhou
Teachers & students from FD-LAMT, CCOM, SCCM
Based on the working idea of combining manual labeling with a computer in the construction of the World Music Database, this database collects and labels the audio of five modes (including five tones, six tones and seven tones) of "Gong, Shang, Jue, Zhi and Yu". At the same time, it makes a detailed analysis of the judgment of Chinese national pentatonic modes and finds application scenarios and technical models, which can provide raw data for the analysis and retrieval of Chinese national music characteristics.
Teachers & students from FD-LAMT, CCOM, SCCM
Promoting the development of the music AI industry
Only for Traditional Chinese Instruments
Only for Pentatonic Mode
Weixin Ren, Mingjin Che, Zhaowen Wang, Qinyu Li, Jiaye Hu, Fan Xia, Wei Li.
[1] Wang, Z., Che, M., Yang, Y., Meng, W., Li, Q., Xia, F., and Li, W. (2022b). Automatic chinese national pentatonic modes recognition using convolutional neural network. In Proc. Int. Society Music Information Retrieval (ISMIR).
[2] Ren, W., Che, M., Wang, Z., Meng, W., Li, Q., Hu, J., Xia, F., and Li, W. (2022). Cnpm database: A chinese national pentatonic modulation database for computational musicology. Journal of Fudan University(Natural Science), 61(5):9.
[3] https://huggingface.co/ccmusic-database/CNPM
@dataset{zhaorui_liu_2021_5676893,
author = {Monan Zhou, Shenyang Xu, Zhaorui Liu, Zhaowen Wang, Feng Yu, Wei Li and Baoqiang Han},
title = {CCMusic: an Open and Diverse Database for Chinese Music Information Retrieval Research},
month = {mar},
year = {2024},
publisher = {HuggingFace},
version = {1.2},
url = {https://huggingface.co/ccmusic-database}
}
Provide a dataset for the Chinese National Pentatonic Mode